- 投稿日:2020-01-10T23:17:48+09:00
特定のS3バケットのみ一覧表示と読み書きを許可するIAMポリシーの例
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation", "s3:PutObject", "s3:GetObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::<バケット名>", "arn:aws:s3:::<バケット名>/*" ] } ] }
- 投稿日:2020-01-10T21:58:18+09:00
はじめてAWSでデプロイする方法③(AWSセキュリティグループの設定)
これまでの記事
はじめてAWSでデプロイする方法①(インスタンスの作成)
はじめてAWSでデプロイする方法②(Elastic IPの作成と紐付け)前回までの流れ
作成したEC2インスタンスとElastic IPを紐付けして、パブリックIPを固定にした。
今回の流れ
現状
現時点において、HTTP(www.サイトURL)で接続することはできない。
(ターミナルでEC2とSSH接続は可能。)つまり、一般ユーザーは閲覧することはできない状態である。
なので、今回はHTTP接続(www.)を解放して、URLでサイトを閲覧できるようにしていく。ポート(入り口)の解放
このHTTP接続(www.)の入り口となるのが、「ポート」(扉)と呼ばれます。IPアドレスが住所「家」であれば、ポートは外に出る・外から入る「扉(ドア)」に該当します。
ポートの設定をするためには、「セキュリティグループ」という設定を変更していきましょう
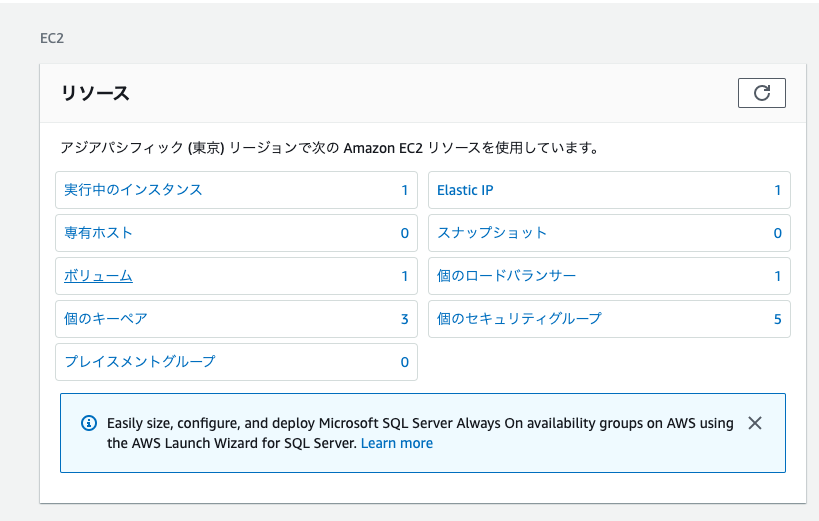
本題、セキュリティグループの設定
セキュリティグループとは、AWSのファイアウォール機能の一つ。
プロトコル、ポート範囲、送信元/送信先IPアドレスによるパケットフィルターが可能。
インスタンス単位に適用することができる。手順
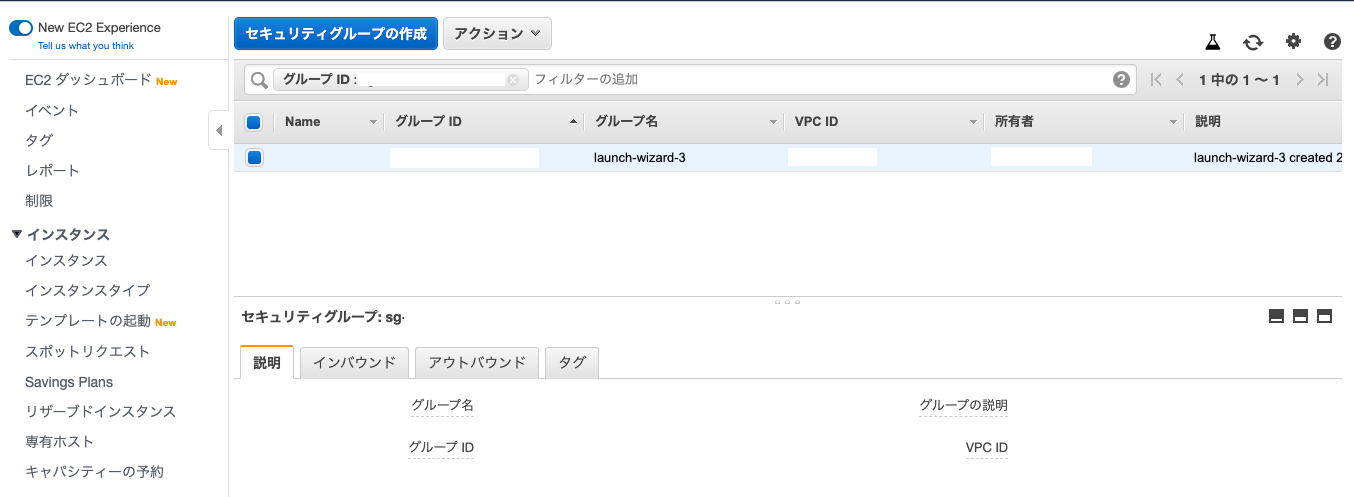
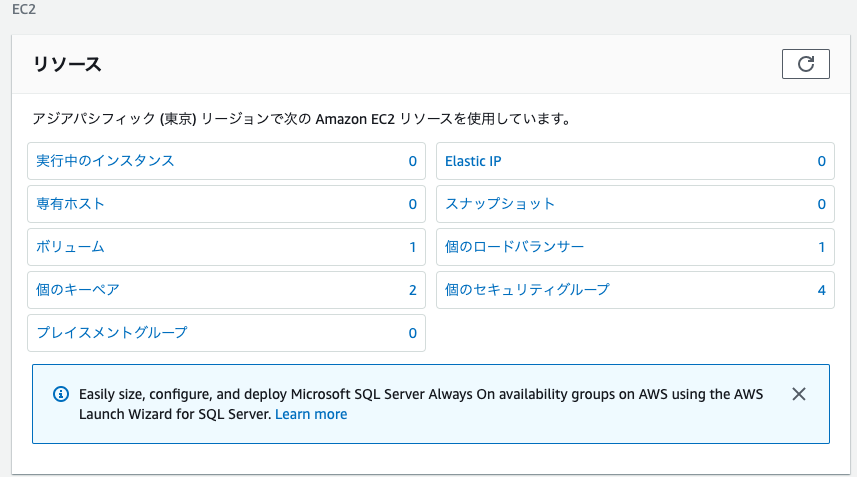
- AWSのEC2ダッシュボードを開く

- 『実行中のインスタンス』をクリック

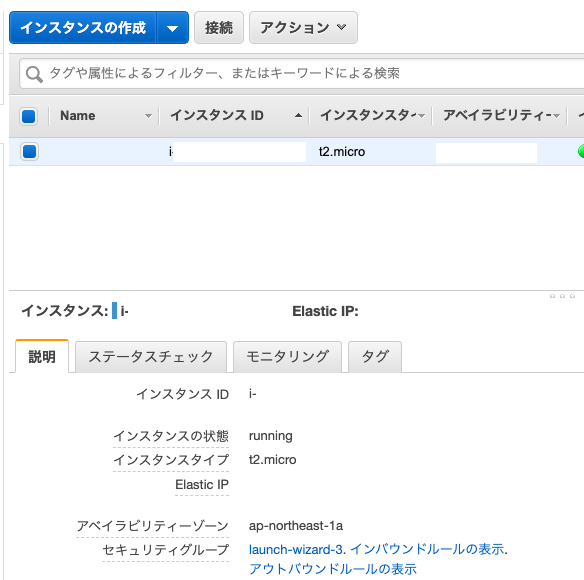
インスタンスを選択
セキュリティグループの『launch-wizard-3』をクリック
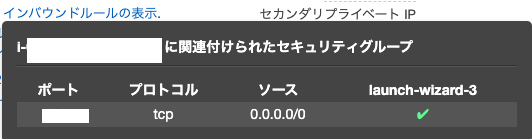
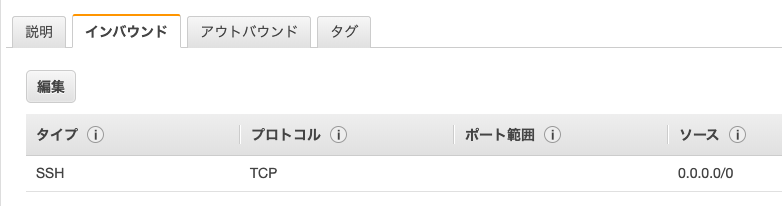
補足: インバウンドルール(この後追加します)
そのセキュリティグループに関連付けられたインスタンスにアクセスできるトラフィックを規制する。『インバウンドルールの表示』をクリックすると下記が表示される。
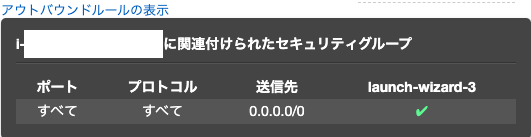
補足: アウトバウンドルール(この後追加します)
そのセキュリティグループに関連付けられたインスタンスからどの送信先にトラフィックを送信できるか(トラフィックの送信先と送信先ポート)を制御するルール
『アウトバウンドルールの表示』をクリックすると下記が表示される。
(ここから、セキュリティグループの『launch-wizard-3』をクリック後に続く)
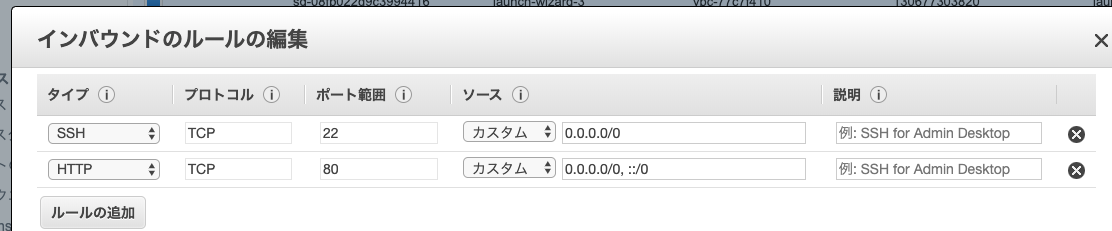
5. 下記の画面が表示される
6.『 インバウンド 』を選択
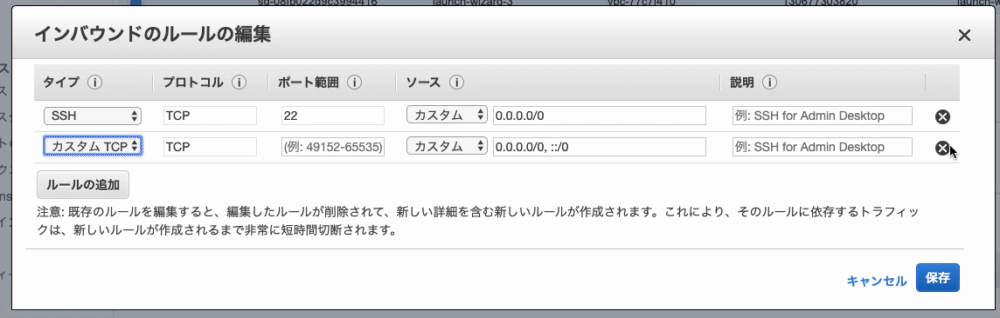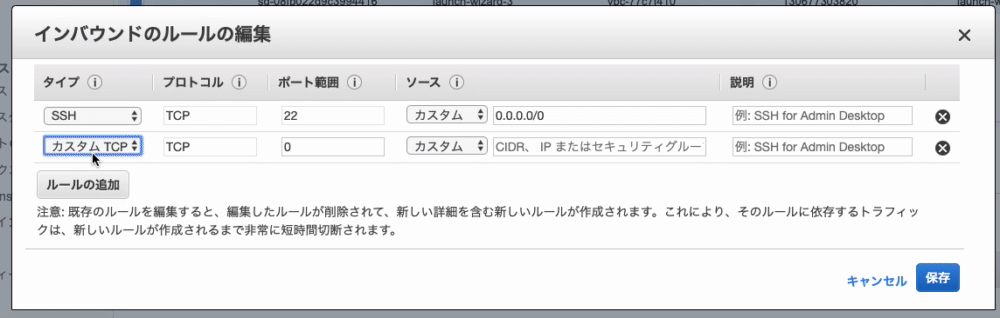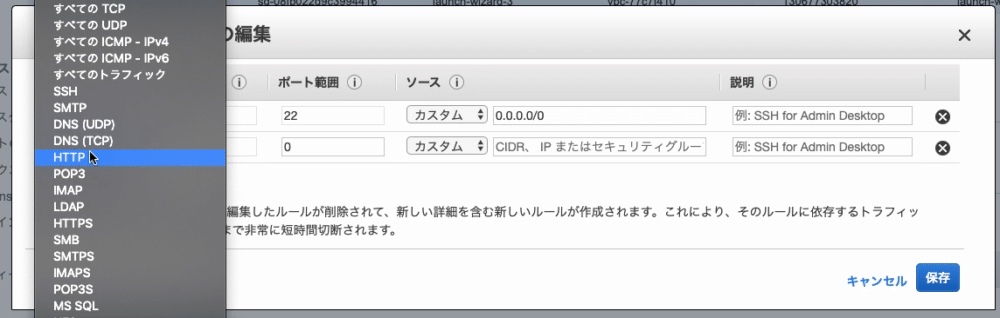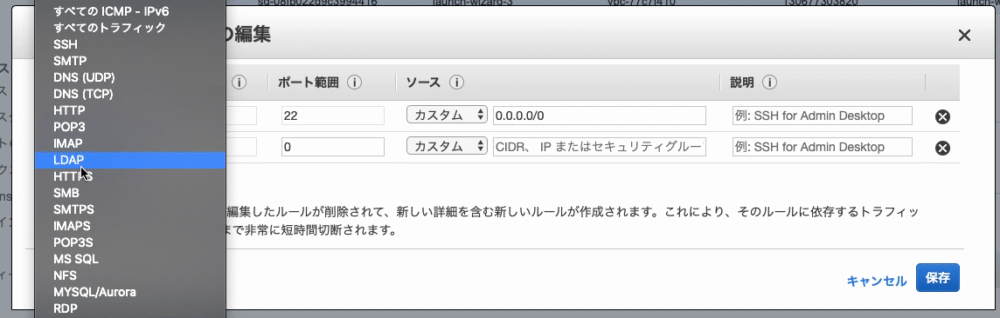
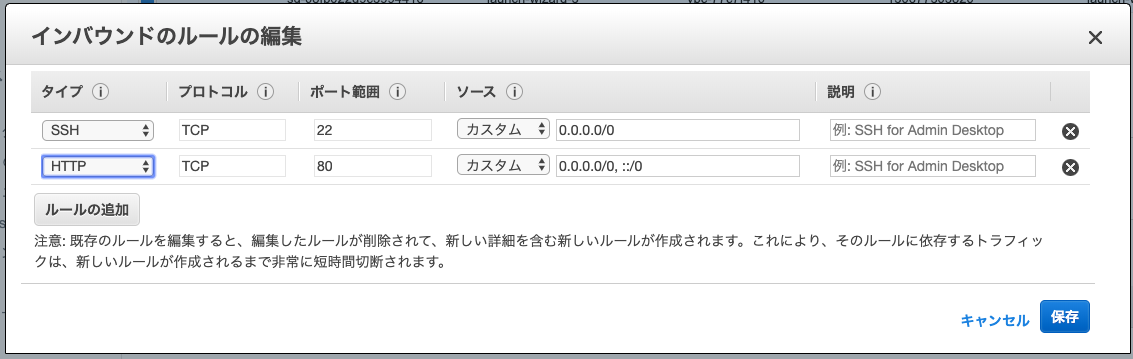
7. 『 編集 』をクリック
8. 左下の『ルールの追加』をクリック
9. タイプ:『 HTTP 』を選択
10. 画面左下の『 保存 』をクリック
11. 完了
これでIPアドレス、WWW.やドメインでのWEB閲覧が可能となります。次はEC2にSSHログインしていきましょう!
ここまで、お疲れ様でした。
なかなか慣れない作業で疲れたのではないでしょうか?セキュリティグループについては、下記記載のAWSのセキュリティグループリファレンスを参照してみるといいかもしれません。
次回は自身で作成したWEBアプリとEC2サーバーを紐づけていくために、SSHログインしましょう
次回の記事はこちら!
はじめてAWSでデプロイする方法④(EC2にSSHログイン)参考


- 投稿日:2020-01-10T20:17:18+09:00
EKSでPrivate IPが足りなくなった場合の対処
はじめに
ある日、EKSで新しいServiceを作ろうとしたところ、Subnet内に利用可能なPrivateIPが足りずに失敗した。
Warning CreatingLoadBalancerFailed 7m12s service-controller Error creating load balancer (will retry): failed to ensure load balancer for service xxxxx: InvalidSubnet: Not enough IP space available in subnet-xxxxx. ELB requires at least 8 free IP addresses in each subnet.このSubnetのサブネットマスクは255.255.255.0なので、256弱のPrivateIPが使えるはずであるが、各Node(m5.xlarge)に30のPrivateIPが割り当ていることが原因でPrivateIPが枯渇していた。
ENIの割り当て
ENIの割り当て方法については詳しくは以下を参照。
https://github.com/aws/amazon-vpc-cni-k8s#eni-allocation
要は、NodeがClusterに追加された時にENIが一つ、その後ipamDがもう一つENIをアタッチする。今回のNodeはm5.xlargeなので、1ENI辺り15のIPを割り当てられるので、計30個のIPが割り当てられていた。
解決方法
WARM_ENI_TARGETとWARM_IP_TARGETの適宜修正することで、事前に割り当てるPrivateIPの数を調整できる。詳しくは以下を参照。https://docs.aws.amazon.com/eks/latest/userguide/cni-env-vars.html
WARM_ENI_TARGETは使っていない事前に確保しておくENIの数。WARM_IP_TARGETは使っていない事前に確保しておくIPの数。更新方法
まず以下のようなファイルを生成する。ここでは仮にtmp.yamlとする。
WARM_IP_TARGETには設定したい値に変えてください。spec: template: spec: containers: - name: aws-node env: - name: WARM_IP_TARGET value: "5"以下のコマンドを実行。
$ kubectl patch daemonset -n kube-system aws-node --patch "$(cat tmp.yaml)"参考
- 投稿日:2020-01-10T17:43:21+09:00
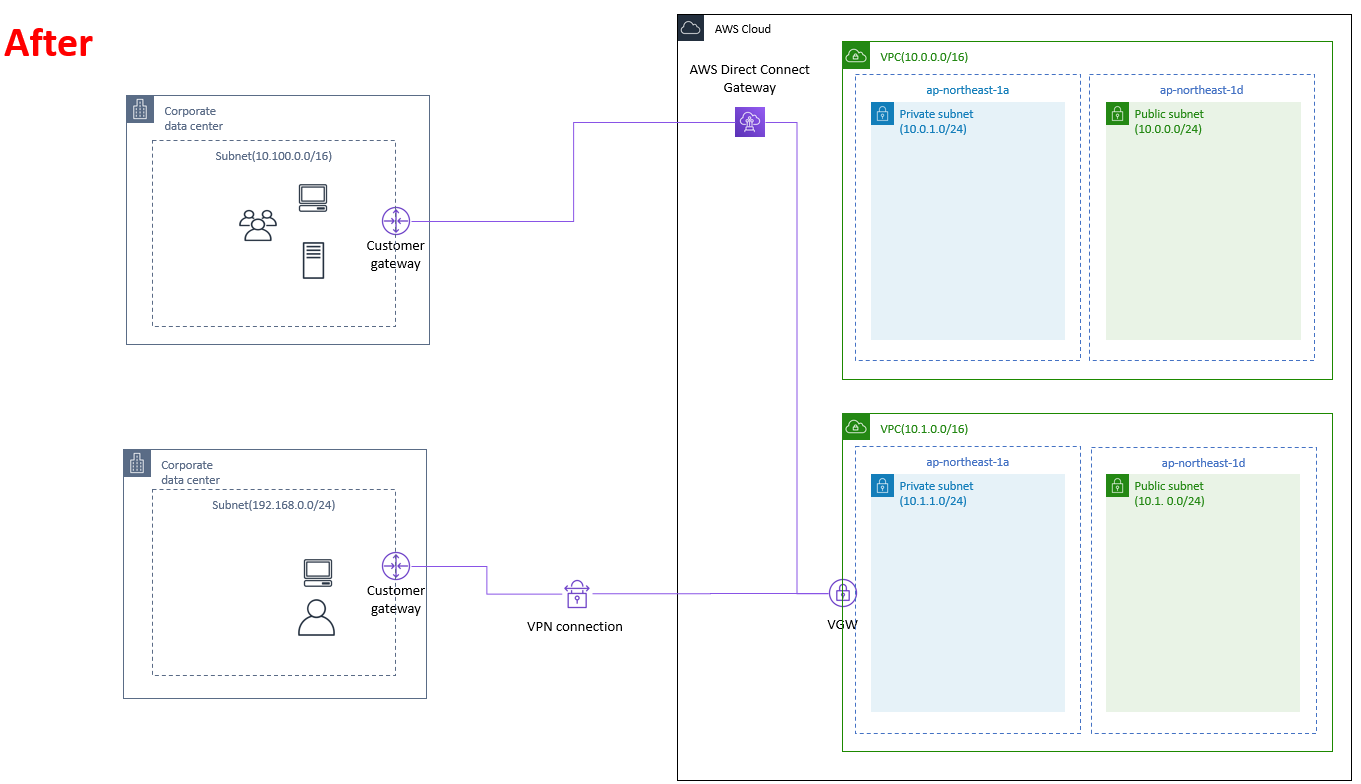
VPC再構築に伴うDirect Connectとサイト間VPN接続の移行について
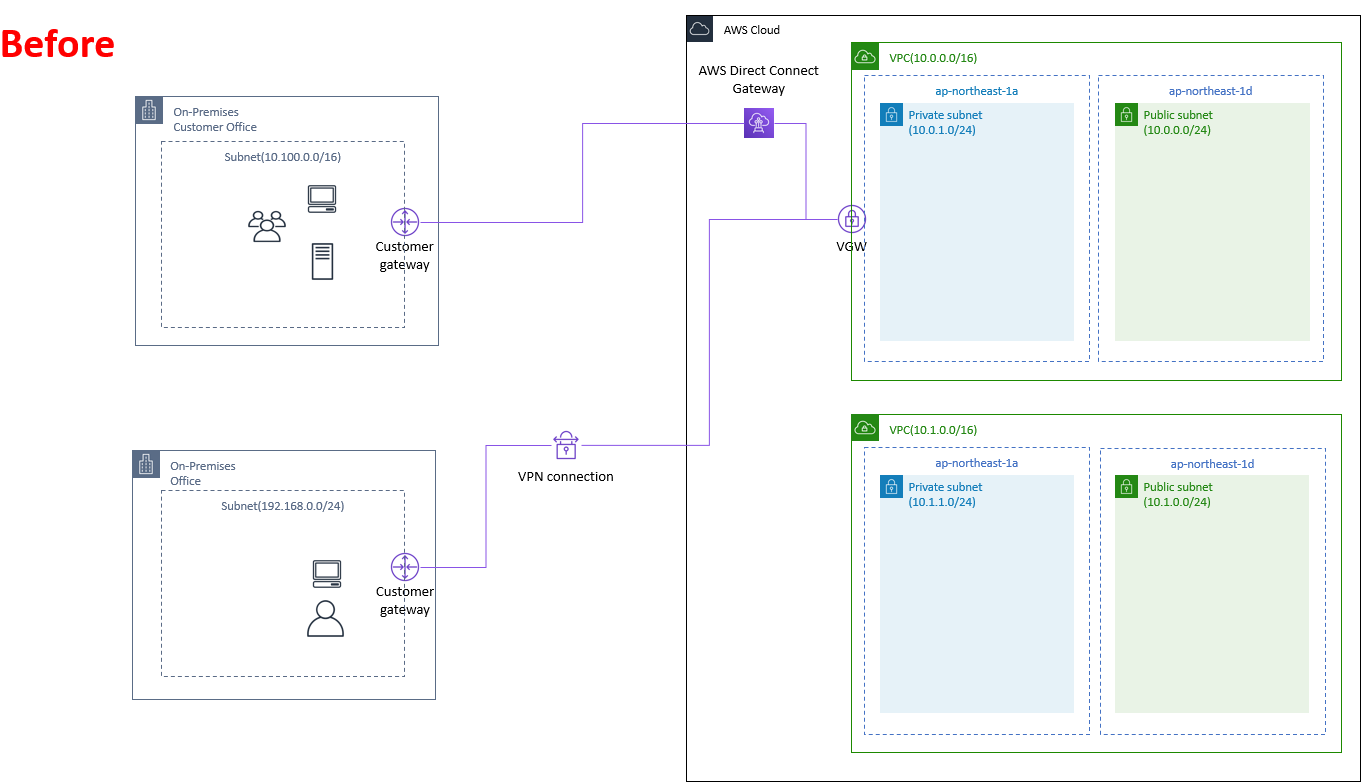
とあるAWS環境でDirect Connectでの接続と、VPN接続を両方行っているVPCの再構築を行うことになりました。
当初は「うわ、ルータ設定とか全部やり直しになんの!?」って思っていましたが、調べてみたら全然簡単でした。だいぶ端折っていますが、環境はこんな感じ。
AWS側
- 現行VPC(10.0.0.0/16)
- 新規構築VPC(新しいCIDRで再構築 10.1.0.0/16)
- VGW(これが無いと始まらない)
- Direct Connect Gateway(VGWを関連付け)
- カスタマーゲートウェイ(サイト間VPN用設定に必要)
オンプレミス(顧客)側
- サブネット(10.100.0.0/16)
オンプレミス(オフィス)側
- サブネット(192.168.0.0/24)
で、実際に行う作業はこれだけ。
作業内容
- 再構築前のVPCからVGWをデタッチ
(※デタッチしたことでVGWとDirect Connect Gatewayとの関連付けもなくなるので注意!)- 新たに構築したVPCへVGWをアタッチ
- VGWをアタッチしたVPCに紐づくルートテーブルで「Route Propagation(ルート伝播)」を有効化(※1)
- VPCにアタッチしたVGWをDirect Connect Gatewayに再度関連付け実施
その際に「許可されたプレフィックス(Allowed prefixes)」を新しいVPCのCIDRで設定(※2)
----------
※1 ルート伝搬を有効化する前に通信に必要なルーティングを追加しておくようにする
※2 オンプレ側に許可してもらうための広告を実施するので、通信に必要なサイズのCIDRでもOK
----------そうするとこんなふうになります。
注意しなければいけないのが、セキュリティグループの設定。
新規に作る場合は良いのですが、既存の設定をコピーして作成する時にインバウンド/アウトバウンドのソースIPの書き換えを忘れがちです。
これを忘れると、後で「え?何?なんで通信できないの? BGPのステータスもUPになってるし、VPNも利用可能なのに..」と言った感じで、途方に暮れた挙げ句、全然関係ないルートテーブルをいじったりする羽目になります(私です)。今回はVGWの付け替えでの対応だったのですが、どうせならばTransit Gatewayでの設定にすればよかったなぁと思っています。
が、何分自分の環境ではないため、思いきれなかったのは事実です。今度、自分の検証環境でVPN接続をTransit Gateway経由に変更してみようかなと思います。
今回の記事も誰かのお役に立てれば幸いです。
- 投稿日:2020-01-10T17:43:16+09:00
ローカル端末からEC2へホスト名でSSH接続する
やりたいこと
AWS上に構築したEC2へローカル端末からホスト名でSSH接続できるようにしたい。
構成
AWSの設定
■セキュリティグループ
・test-aに対するインバウンド
- TCPの22番ポートを許可
- ソース:マイIP
・test-bに対するインバウンド
- TCPの22番ポートを許可
- ソース:10.0.1.0/24test-aの設定
[/etc/hosts]にtest-aとtest-bの情報を記載
10.0.1.100 test-a 10.0.2.100 test-bローカル端末の設定
①[~/.ssh]配下に鍵ファイルを格納
②[~/.ssh]配下に[config]ファイルを作成し、以下を記載
Host test-a Hostname xxx.xxx.xxx.xxx #test-aのグローバルIPアドレス User ubuntu port 22 IdentityFile ~/.ssh/xxx #鍵ファイル名 Host test-b User ubuntu Port 22 IdentityFile ~/.ssh/xxx #鍵ファイル名 ProxyCommand ssh -W %h:%p test-aローカル端末から接続確認
①test-aへの接続
ubuntu_root@xxx:~/.ssh$ ssh test-a Welcome to Ubuntu 16.04.6 LTS (GNU/Linux 4.4.0-1100-aws x86_64) ubuntu@test-a:~$②test-bへの接続
ubuntu_root@xxx:~/.ssh$ ssh test-b Welcome to Ubuntu 16.04.6 LTS (GNU/Linux 4.4.0-1100-aws x86_64) ubuntu@test-b:~$

- 投稿日:2020-01-10T15:59:58+09:00
ServerlessFramework+Slackで運行遅延情報をお知らせする
はじめに
AWSLambdaで運行遅延情報をslackに通知するbotを作りました。
運行遅延APIを利用して、遅延が発生して入れば運行会社のWEBから遅延内容をスクレイピングしてSlackにお知らせします。
何番煎じか分かりませんが、lambdaとnodejsで書かれた記事が見当たらなかったので紹介します。作ったもの
GitHub
https://github.com/t-yasukawa/incoming-webhook環境
- macOS Catalina 10.15.2
- VSCode 1.41.1
- AWS(Lambda, CloudFormation)
- ServerlessFramework 1.60
- Node.js 12.14.1
- puppeteer 2.0.0
- chrome-aws-lambda 2.0.0
事前準備
- AWSアカウント
- SlackのWebhook URLの取得
- AWSCLIの導入 【真っさらな状態のMACにAWSCLIをインストールするまで】
- Node.jsの導入(nodebrewが便利)
1. ServerlessFrameworkの導入
まずはバージョン確認
$ npm ls --depth=0 -g /Users/t-yasukawa/.nodebrew/node/v12.14.1/lib └── npm@6.13.4ServerlessFrameworkを入れます。
npm i serverless -gでも良いのですが、他のプロジェクトでも使っているので今回はプロジェクト直下におきます。
npm initで生成されるpackage.jsonの初期値は適当に埋めてください。$ mkdir incoming-webhook $ cd incoming-webhook $ npm init package name: (incoming-webhook) version: (1.0.0) description: entry point: (index.js) test command: git repository: keywords: author: license: (ISC) $ npm i serverless $ npm ls --depth=0 incoming-webhook@1.0.0 /Users/t-yasukawa/git/incoming-webhook └── serverless@1.60.5無事インストールできました。
しかしこのままでは./node_modules/.bin/slsと毎回打たないといけないので面倒です。
方法は色々ありますが、安直にパスを追加します。$ echo 'export PATH=node_modules/.bin:$PATH' >> ~/.bash_profile $ source ~/.bash_profile $ sls -v Framework Core: 1.60.5 Plugin: 3.2.7 SDK: 2.2.1 Components Core: 1.1.2 Components CLI: 1.4.0これでOKです。
早速プロジェクトファイルをテンプレートから作成します。$ sls create --template aws-nodejs --path ./ Serverless: Generating boilerplate... Serverless Error --------------------------------------- The directory "/Users/t-yasukawa/git/incoming-webhook/" already exists, and serverless will not overwrite it. Rename or move the directory and try again if you want serverless to create it"はい、怒られました。
プロジェクトディレクトリはこのタイミングで作らないといけないようです。
serverlessをグローバルにしなかったせいですね。仕方ないので一旦パスを変えます。$ sls create --template aws-nodejs --path ./src/models/lambda Serverless: Generating boilerplate... Serverless: Generating boilerplate in "/Users/t-yasukawa/git/test/src/models/lambda" _______ __ | _ .-----.----.--.--.-----.----| .-----.-----.-----. | |___| -__| _| | | -__| _| | -__|__ --|__ --| |____ |_____|__| \___/|_____|__| |__|_____|_____|_____| | | | The Serverless Application Framework | | serverless.com, v1.60.5 -------' Serverless: Successfully generated boilerplate for template: "aws-nodejs"生成されたファイルを変更します。
$ mv src/models/lambda/serverless.yml ./ $ mv src/models/lambda/.gitignore ./ $ tree -a -L 1 . ├── .gitignore ├── node_modules ├── package-lock.json ├── package.json ├── serverless.yml └── src2.puppeteer導入
スクレイピング処理に
puppeteerを利用しますが、このままローカルで利用することができたのですが、
いざLambda上にデプロイしようとした時にLambdaの上限250MBを超えてしまう問題が発生しました。
An error occurred: SessionLambdaFunction - Unzipped size must be smaller than 262144000 bytes.そこで、軽量版の
puppeteer-coreとAWS上でchromiumが動くchrome-aws-lambdaを入れることでこれを回避します。
(ついでにAPI取得用のaxiosも入れます。)
※versionを揃えないと実行時にエラーとなるので注意
Error: Chromium revision is not downloaded. Run "npm install" or "yarn install"$ npm i chrome-aws-lambda puppeteer-core axios $ npm ls --depth=0 incoming-webhook@1.0.0 incoming-webhook ├── axios@0.19.1 ├── chrome-aws-lambda@2.0.0 ├── puppeteer-core@2.0.0 └── serverless@1.60.53.実装
- 遅延情報APIで遅延情報を取得
- お知らせしたい路線を検出
- 検出できたらWebに飛んでスクレイピング
- Slackに送信
handler.js'use strict' const axios = require("axios") const chromium = require("chrome-aws-lambda"); // 取得したい路線情報 const CHECK_LIST = [ { 'name': '常磐線', 'company': 'JR東日本', 'website': 'https://traininfo.jreast.co.jp/train_info/tohoku.aspx', 'selector': async (page) => await selectorForJrEast(page, '常磐線') }, { 'name': '東北本線', 'company': 'JR東日本', 'website': 'https://traininfo.jreast.co.jp/train_info/tohoku.aspx', 'selector': async (page) => await selectorForJrEast(page, '東北本線') }, { 'name': '仙台市営地下鉄', 'company': '仙台市交通局', 'website': 'https://www.kotsu.city.sendai.jp/unkou/', 'selector': async (page) => await selectorForSendaiSubway(page) }, ] module.exports.sendToSlack = async () => { // 鉄道運行遅延の情報を取得 const notifyDelays = await getNotifyDelays() if (notifyDelays.length == 0) { console.log('遅延情報はありませんでした。') return; } console.log('遅延情報が見つかりました。') // 遅延内容を取得 const messages = await getDelayMessage(notifyDelays) console.log(messages.join('\n')) // Sclackに送信 await postSlack(messages.join('\n')) } /** * 遅延情報を取得 */ async function getNotifyDelays() { const delay_url = process.env['TRAIN_DELAY_JSON_URL'] const notifyDelays = [] try { // 運行遅延情報を取得 const res = await axios.get(delay_url) // res = [{ // "name":"東北本線", // "company":"JR東日本", // "lastupdate_gmt":1578638905, // "source":"鉄道com RSS" // }] // 通知する路線のみ抽出 res.data.forEach(delayItem => { CHECK_LIST.forEach(checkItem => { if (delayItem.name == checkItem.name && delayItem.company == checkItem.company) { notifyDelays.push(checkItem) } }) }) } catch (error) { console.error(error) } return notifyDelays } /** * 遅延メッセージを取得 * * @param {Array} delays */ async function getDelayMessage(delays) { const messages = []; let browser = null try { browser = await chromium.puppeteer.launch({ args: chromium.args, defaultViewport: chromium.defaultViewport, executablePath: await chromium.executablePath, headless: chromium.headless }) const page = await browser.newPage() for(const i of delays) { // websiteから遅延情報をスクレイピング await page.goto(i.website) const detail = await i.selector(page) const message = `*・${i.company} \<${i.name}\>* (<${i.website}|jump>)\n ${detail}\n` messages.push(message) } } catch(e) { console.warn(e) } finally { if (browser !== null) { await browser.close() } } return messages; } /** * JR東日本(東北エリア)の遅延内容をスクレイピング * * @param {Page} page Page * @param {string} target 路線名 */ async function selectorForJrEast(page, target) { const selector = '#wrapper > div.main_con02 > div.table_access > table > tbody > tr' const messages = [] try { for (const item of await page.$$(selector)) { const lineName = await getTextContext(item, '.line_name') if (lineName == target) { const message = await getTextContext(item, '.status_text') messages.push(message) } } } catch (error) { console.error(error) return `:warning: ノードの取得に失敗しました。DOMが変更されている可能性があります。\n \`${selector}\` ` } return messages.join('\n') } /** * 仙台市地下鉄(南北・東西)の遅延内容をスクレイピング * * @param {Page} page Page */ async function selectorForSendaiSubway(page) { const selector = '#unkou_detail' try { const item = await page.$(selector) const text = await getTextContext(item) if (text == null) { return `:warning: ノードの取得に失敗しました。DOMが変更されている可能性があります。\n \`${selector}'\` ` } } catch (error) { console.error(error) return `:warning: ノードの取得に失敗しました。DOMが変更されている可能性があります。\n \`${selector}'\` ` } return text } /** * textContent取得 * * @param {ElementHandle} elementHandle * @param {string} target */ async function getTextContext(elementHandle, target) { const tag = await elementHandle.$(target) const prop = await tag.getProperty('textContent') const text = await prop.jsonValue() return text } /** * Slackへ送信 * * @param {string} message */ async function postSlack(message) { const slack_url = process.env['SLACK_WEBHOOK_URL'] const payload = { 'username': '運行遅延お知らせbot', 'icon_emoji': ':train:', 'attachments': [ { 'fallback': message, 'color': '#36a64f', 'pretext': '<!channel> 電車の遅延があります。', 'text': message, "mrkdwn_in": [ "text" ], 'channel': '#列車運行情報' } ] } const res = await axios.post(slack_url, payload) console.log(res) }serverless.ymlservice: incoming-webhook provider: name: aws runtime: nodejs12.x timeout: 300 profile: ${self:custom.profiles.${self:provider.stage}} region: ${opt:region, self:custom.defaultRegion} custom: defaultRegion: ap-northeast-1 profiles: dev: default package: exclude: - node_modules/serverless/** - node_modules/chrome-aws-lambda/** - chrome-aws-lambda/** functions: sendTrainDelayToSlack: handler: src/models/lambda/handler.sendToSlack events: - schedule: rate: cron(15 9,22,23 ? * MON-FRI *) ## 7:15,8:15,18:15 月~金 layers: - {Ref: ChromeLambdaLayer} environment: TRAIN_DELAY_JSON_URL: 'https://tetsudo.rti-giken.jp/free/delay.json' SLACK_WEBHOOK_URL: 'https://hooks.slack.com/services/****************' layers: chrome: package: artifact: ./chrome-aws-lambda/chrome_aws_lambda.zip4. 動作確認(問題発生)
動作確認のためにローカルでLambdaを実行するとchromiumが起動できないとエラーになりました。
 $ sls invoke local --function sendTrainDelayToSlack 遅延情報が見つかりました。 Error: Failed to launch chrome! /var/folders/v8/ydzbmvkj6_zbm8msr6x730nr0000gn/T/chromium: /var/folders/v8/ydzbmvkj6_zbm8msr6x730nr0000gn/T/chromium: cannot execute binary file TROUBLESHOOTING: https://github.com/GoogleChrome/puppeteer/blob/master/docs/troubleshooting.md
$ sls invoke local --function sendTrainDelayToSlack 遅延情報が見つかりました。 Error: Failed to launch chrome! /var/folders/v8/ydzbmvkj6_zbm8msr6x730nr0000gn/T/chromium: /var/folders/v8/ydzbmvkj6_zbm8msr6x730nr0000gn/T/chromium: cannot execute binary file TROUBLESHOOTING: https://github.com/GoogleChrome/puppeteer/blob/master/docs/troubleshooting.mdMac環境でデバッグしようとするとPC内のChromeアプリのバイナリを利用しようとするのですが、
バイナリファイルのchromiumを実行することができませんでした。Chromeとモジュールのバージョンがリビジョン単位で違うけど、そのせい?よくわからず。。
Chromeバージョン:79.0.3945.117(2020/01/10時点)
puppeteer Version chrome-aws-lambda Version Chromium Revision 2.0.* npm i chrome-aws-lambda@~2.0.2 705776 (79.0.3945.0) 参照: https://github.com/alixaxel/chrome-aws-lambda
解決策
ローカルでは容量が大きいけど
puppeteerでchroniumのバイナリファイルをDLして利用し、
AWS上ではpuppeteer-coreとchrome-aws-lambdaを使うことにしました。$ npm i --save-prod chrome-aws-lambda puppeteer-core $ npm i --save-dev puppeteer Downloading Chromium r706915 - 111.8 Mb [====================] 100% 0.0s Chromium downloaded to /Users/t-yasukawa/git/incoming-webhook/node_modules/puppeteer/.local-chromium/mac-706915ただ、これだけではローカルで動かないのでデバッグ中だけ
executablePathを変える必要があります。browser = await chromium.puppeteer.launch({ args: chromium.args, defaultViewport: chromium.defaultViewport, - executablePath: await chromium.executablePath, + executablePath: null, headless: chromium.headless })もしくは上記でDLしたchromiumのパスでも行けると思います。
executablePath: `${process.cwd()}/node_modules/puppeteer/.local-chromium/mac-706915/chrome-mac/Chromium.app/Contents/MacOS/Chromium`5.動作確認(解決)
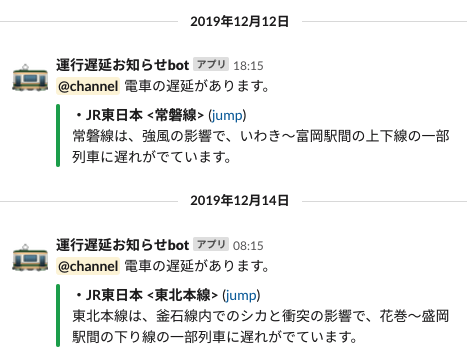
$ sls invoke local --function sendTrainDelayToSlack 遅延情報が見つかりました。 *・JR東日本 <東北本線>* (<https://traininfo.jreast.co.jp/train_info/tohoku.aspx|jump>) 東北本線は、釜石線内でのシカと衝突の影響で、盛岡~花巻駅間の上下線で一部列車が運休となっています。無事スクレイピングできました。・・・シカさん

6.解説
API関連は
axiosを使いました。とてもシンプルで使いやすい!const res = await axios.get(delay_url) const res = await axios.post(slack_url, payload)遅延情報はJR東日本と仙台市地下鉄の2サイトからスクレイピングしました。
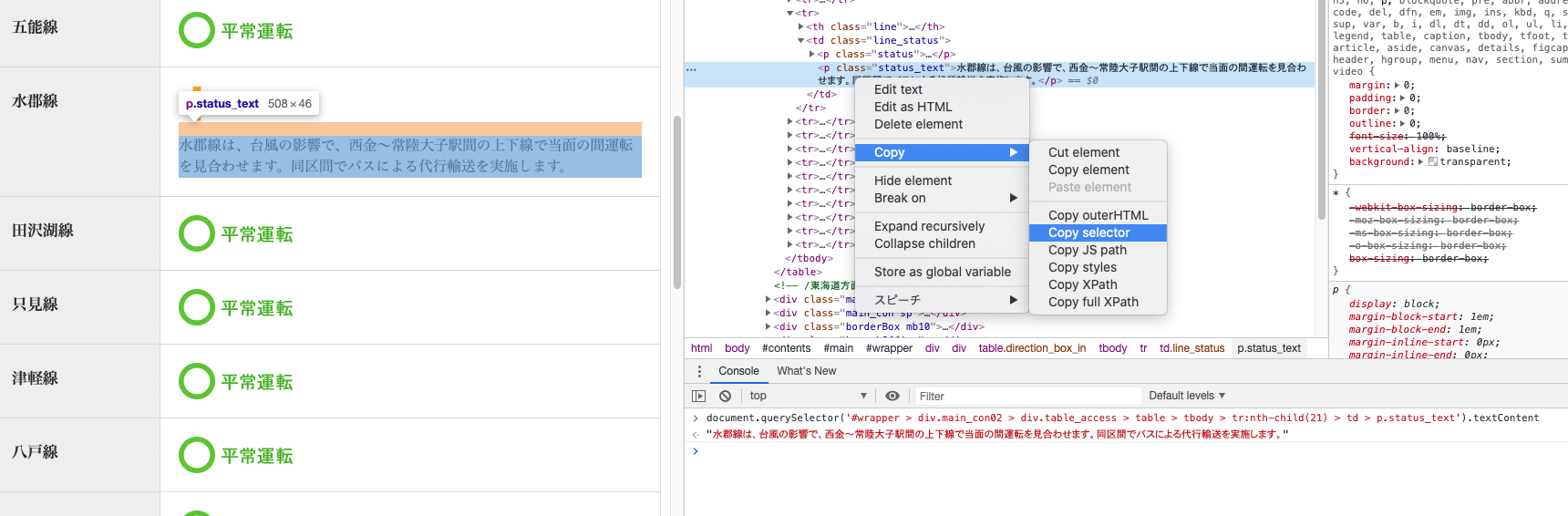
地下鉄はノード指定ですんなり取得できましたが、JRの方はノード取得に癖があったので力技でした。スクレイピングのやり方ですが簡単に取得できます。(chromeの場合)
デベロッパーツールを開く(検証モード) → 指定ノードの箇所で右クリック → Copy → Copy selector
コンソール上で以下を入力することでも確認できます。
document.querySelector('{copyしたノード}').textContentjsなのでそのままコードで使えますが、今回は
puppeteerの用意したものを使います。const browser = await chromium.puppeteer.launch() const page = await browser.newPage() await page.goto({webUrl}) const tag = await page.$('#wrapper > div.main_con02 > div.table_access > table > tbody > tr:nth-child(21) > td > p.status_text') const prop = await tag.getProperty('textContent') const text = await prop.jsonValue() console.log(text) // 水郡線は、台風の影響で、西金~常陸大子駅間の上下線で当面の間運転を見合わせます。同区間でバスによる代行輸送を実施します。それにしても長い。。。
7.AWSへデプロイ
さぁ、最後はAWSへデプロイしてCloudWatchを使って定時実行させれば完成です。
Lambdaの容量をなるべく節約して使うため不要なモジュールたちを削除します。
ローカルで使っていたpuppeteerを除いた状態で再インストールします。
serverlessもLambdaには必要ないのですがデプロイコマンドで必要なのでproductionに含めます。$ rm -rf node_modules $ npm i --production
chrome-aws-lambdaもそこそこの容量なのでそのまま入れずzipに固めてLambda Layerに格納させます。
他のLambdaでスクレイピングしたい時はこのLayerが汎用的に使えて便利です。
READMEにしたがってzipに圧縮します。
パーミッションも変えないとデプロイできなかったので適宜変えてください。$ git clone --depth=1 https://github.com/alixaxel/chrome-aws-lambda.git $ cd chrome-aws-lambda $ make chrome_aws_lambda.zip $ chmod 777 chrome_aws_lambda.zipLambdaアプリをzipで固める前にさらに不要なファイルを除外します。
serverless.ymlpackage: exclude: - node_modules/serverless/** - node_modules/chrome-aws-lambda/** - chrome-aws-lambda/** layers: chrome: package: artifact: ./chrome-aws-lambda/chrome_aws_lambda.zip最後にデプロイして終了!
ちょっとしたアプリですがモジュールを入れるとそこそこのサイズになりますね。
incoming-webhook.zip file to S3 (25.49 MB)
chrome_aws_lambda.zip file to S3 (41.63 MB)$ sls deploy --verbose --profile dev Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service incoming-webhook.zip file to S3 (25.49 MB)... Serverless: Uploading service chrome_aws_lambda.zip file to S3 (41.63 MB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... CloudFormation - UPDATE_IN_PROGRESS - AWS::CloudFormation::Stack - incoming-webhook-dev CloudFormation - UPDATE_IN_PROGRESS - AWS::Lambda::LayerVersion - ChromeLambdaLayer CloudFormation - UPDATE_IN_PROGRESS - AWS::Lambda::LayerVersion - ChromeLambdaLayer CloudFormation - UPDATE_COMPLETE - AWS::Lambda::LayerVersion - ChromeLambdaLayer CloudFormation - UPDATE_IN_PROGRESS - AWS::Lambda::Function - SendTrainDelayToSlackLambdaFunction CloudFormation - UPDATE_COMPLETE - AWS::Lambda::Function - SendTrainDelayToSlackLambdaFunction CloudFormation - UPDATE_COMPLETE_CLEANUP_IN_PROGRESS - AWS::CloudFormation::Stack - incoming-webhook-dev CloudFormation - DELETE_IN_PROGRESS - AWS::Lambda::LayerVersion - ChromeLambdaLayer CloudFormation - DELETE_COMPLETE - AWS::Lambda::LayerVersion - ChromeLambdaLayer CloudFormation - UPDATE_COMPLETE - AWS::CloudFormation::Stack - incoming-webhook-dev Serverless: Stack update finished... Service Information service: incoming-webhook stage: dev region: ap-northeast-1 stack: incoming-webhook-dev resources: 7 api keys: None endpoints: None functions: sendTrainDelayToSlack: incoming-webhook-dev-sendTrainDelayToSlack layers: chrome: arn:aws:lambda:ap-northeast-1:*:layer:chrome:9 Stack Outputs SendTrainDelayToSlackLambdaFunctionQualifiedArn: arn:aws:lambda:ap-northeast-1:*:function:incoming-webhook-dev-sendTrainDelayToSlack:17 ChromeLambdaLayerQualifiedArn: arn:aws:lambda:ap-northeast-1:*:layer:chrome:9 ServerlessDeploymentBucketName: incoming-webhook-dev-serverlessdeploymentbucket-* Serverless: Removing old service artifacts from S3... Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.参考
- 投稿日:2020-01-10T15:51:48+09:00
はじめてAWSでデプロイする方法②(Elastic IPの作成と紐付け)
前回の記事
はじめてAWSでデプロイする方法①(インスタンスの作成)の続きになります。
インスタンスの作成などを知りたい場合は、この記事を参照してください。今回実施していくこと
作成したEC2インスタンスには、作成時にIPアドレスが""自動""で割り振られています。
これをパブリックIP(一般公開用のID)と言います。
しかし、""サーバーを再起動させるたびにこのパブリックIPが変わってしまうという欠点""を持っています。そのため、パブリックIDを固定して、いちいち更新しないようにします。
この固定化したパブリックIDを『 Elastic IP 』と呼びます。今回はその欠点を改善するために、『 EC2インスンタンスとElastic IP紐付け 』をしていきましょう。
Elastic IPの作成
EC2インスタンスのパブリックIPアドレスをElastic IPに固定する。
Elastic IPとは、AWSから割り振られた固定したパブリックIPアドレス。
このパブリックIPアドレスをEC2インスタンスに紐付けることで、インスタンスの起動、停止に関わらず常に同じIPアドレスで通信をすることが可能になります手順
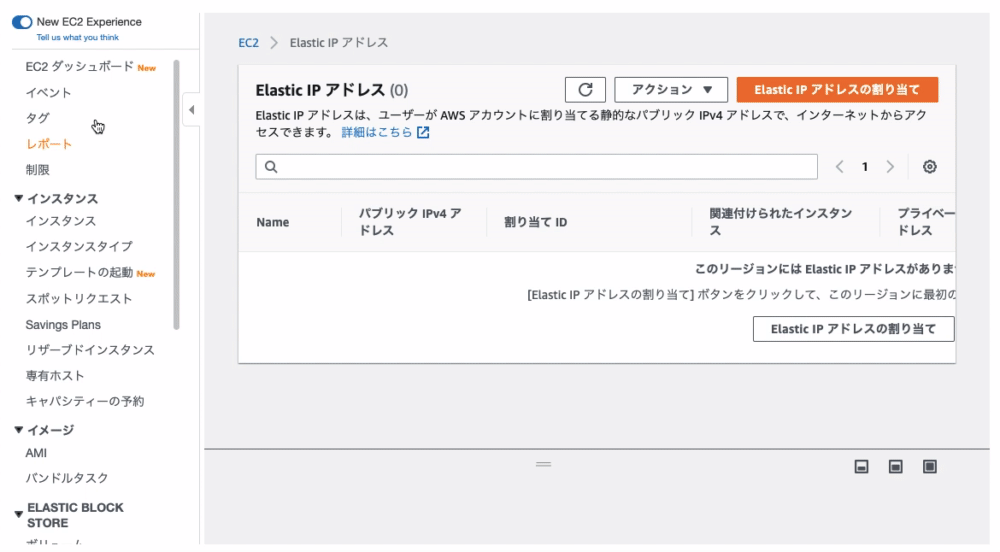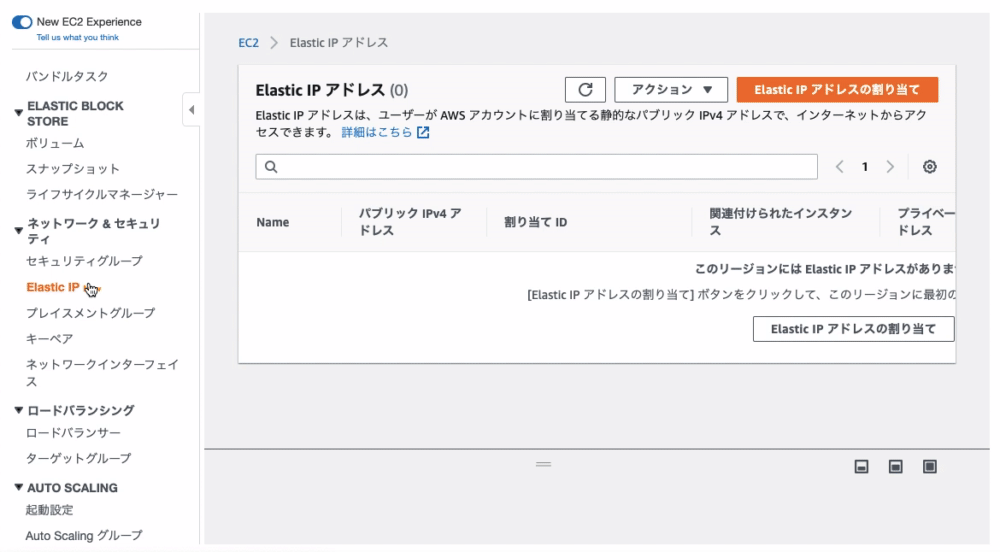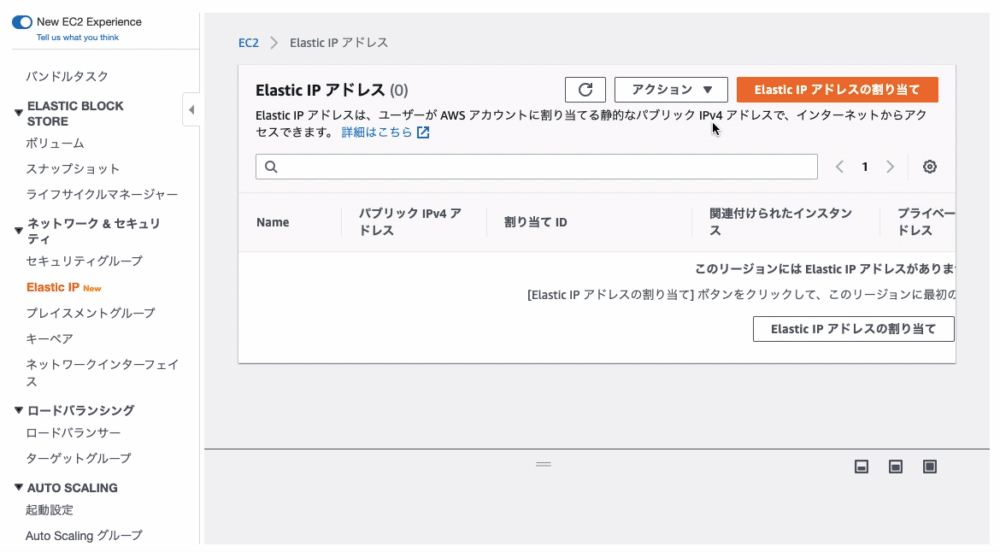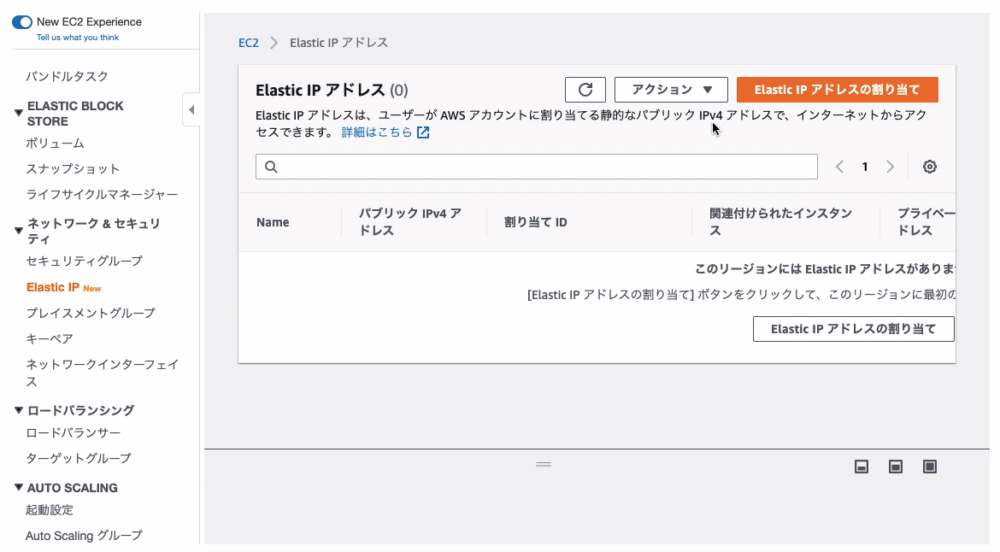
AWSのサイドナビにある、『Elastic IP』をクリック。こちらからでも進めます
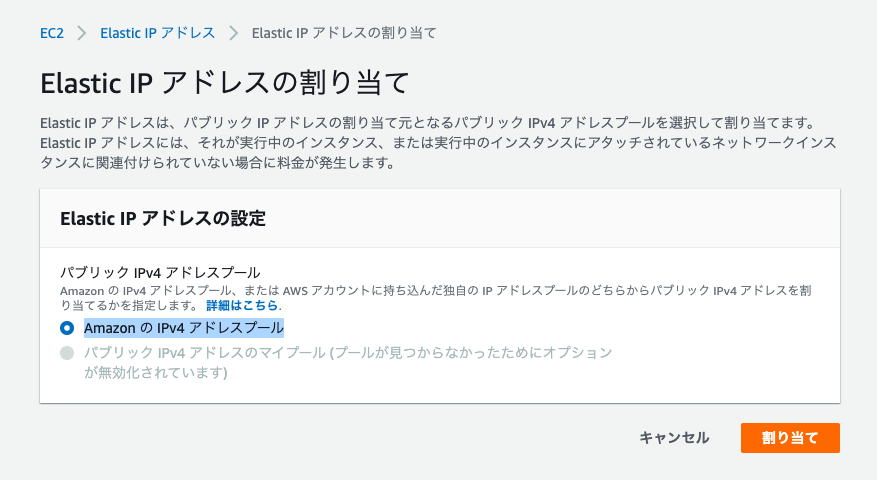
『 Elastic IP アドレスの割り当て 』をクリック
画面右下の『 割り当て 』をクリック
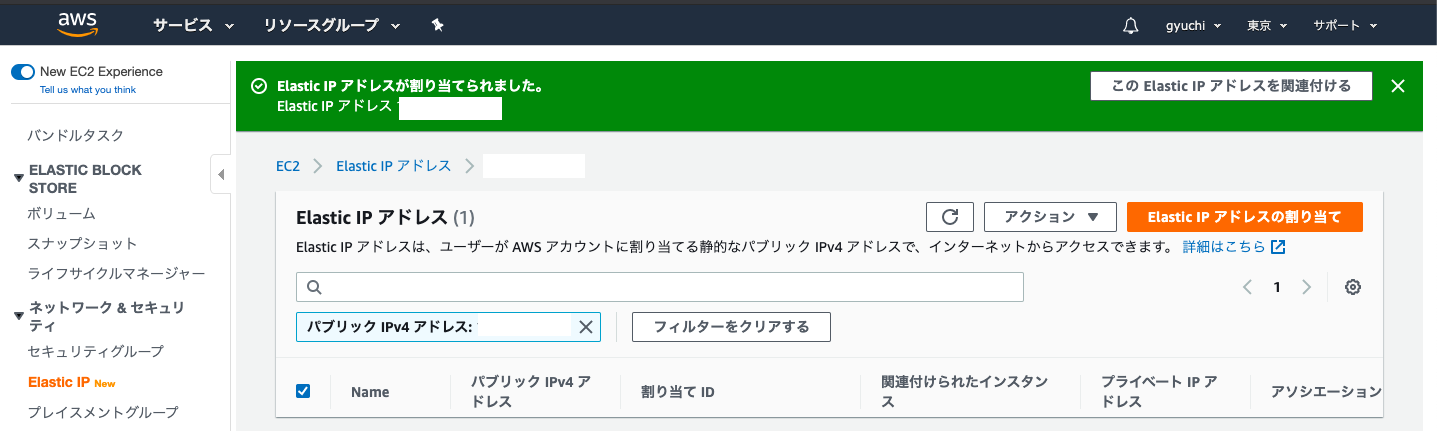
Elastic IPの作成完了(緑の帯に作成されたElastic IPアドレスが記載されています。)
Elastic IPアドレスは、パブリック IPv4 アドレスの項目にも記載されています(公開するわけにはいかないので伏せています)
Elastic IPアドレスとEC2インスタンスと紐付け
ここからEC2インスタンスとElastic IPアドレスを紐付けします。
紐付けが完了すれば、EC2インスタンスのパブリックIPは、Elastic IPアドレスで固定されます手順
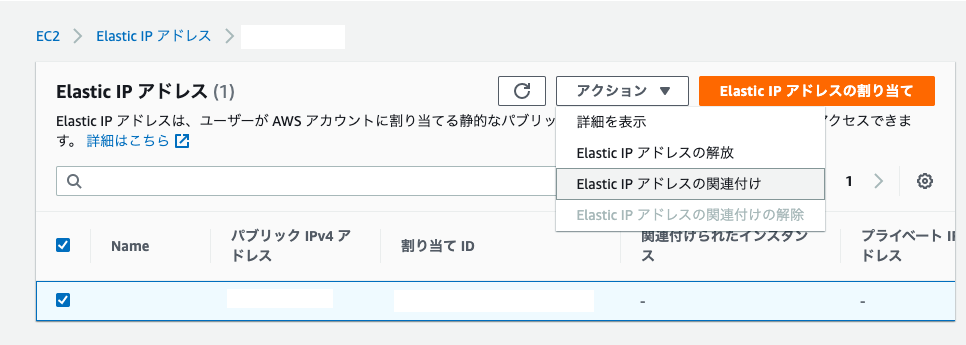
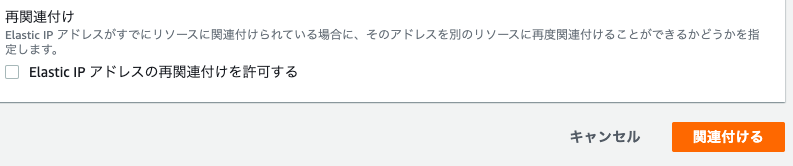
- Elastic IPアドレスを選択✅
アクション 『Elastic IPアドレスの関連付け』をクリック
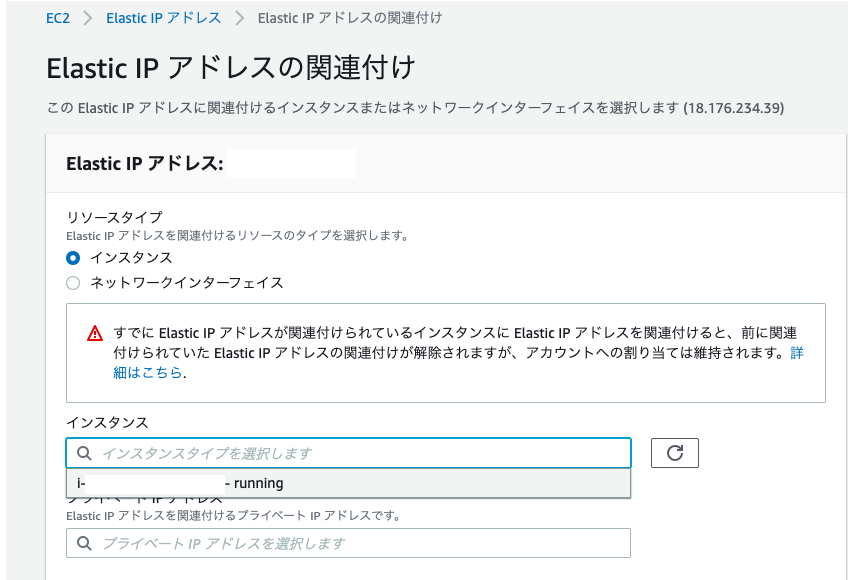
作成したEC2インスタンスを選択
補足:上の画像のようにインスタンスを選択すると、その下にあるプライベートIPアドレスが自動で選択されます。なのでプライベートIPアドレスは空白で大丈夫です4.画面右下の『関連付ける』をクリック
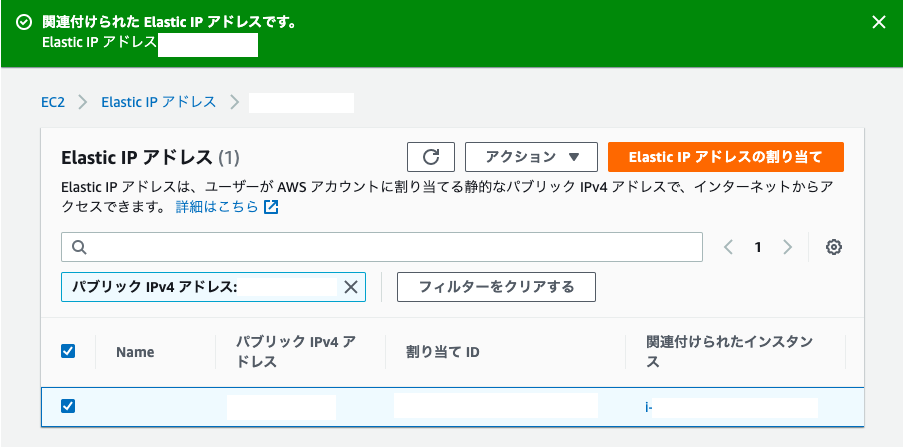
5.紐付け完了
無事に関連づけられたインスタンスに『i- (EC2インスタンスID)』が表示されています
次は AWS セキュリティグループの設定
みなさん、ここまでお疲れ様です。
慣れていないとここまででも大変かと思います。立ち上げたばかりのEC2インスタンスはSSHでアクセスすることはできますが、HTTPなどの他の接続は一切つながらないようになっています。そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放する必要があります
次回はポート解放の操作をお伝えしていきたいと思います。
長くなってきたので、次の記事で案内したいと思います。
はじめてAWSでデプロイする方法③(AWSセキュリティグループの設定)いいね!とフォローをして、有料級記事を見逃すな

- 投稿日:2020-01-10T15:33:32+09:00
IoT@Loft ハンズオン #2 - Amazon FreeRTOSを用いた量産向けIoTマイコンデバイス開発プロトタイピング(2020年1月8日実施)を受講したよ
2020年1月8日 IoT@Loft ハンズオン #2- Amazon FreeRTOSを用いた量産向けIoTマイコンデバイス開発プロトタイピングが実施されました。
https://iotlofthandson2020jan.splashthat.com/第1回AWS IoT@Loft スマートファクトリー IoT基盤構築プロトタイピングの2回目になります。
今回はSTM32を使用しAmazonFreeRTOSを触るハンズオンになります。
https://qiita.com/usashirou/items/426c2e96e7568b708ade使用機材:STM32L4 Discovery kit IoT node
https://www.stmcu.jp/design/hwdevelop/discovery/51734/
AmazonFreeRTOSは、STM32L4 Discovery kit IoT node用が用意されています。
今回は、下記ハンズオン資料を基に進めます
https://awsj-iot-handson.s3-ap-northeast-1.amazonaws.com/Amazon_FreeRTOS_V2/st/AmazonFreeRTOS_Handson-2020.pdfIoT@Loftのご紹介ハンズオンで構築するサービスの概要説明
アマゾン ウェブ サービス ジャパン株式会社
飯田 起弘さん
使用するハードウェアのご紹介
STマイクロエレクトロニクス株式会社
原 文雄さん
ハンズオン
環境構築
AmazonFreeRTOSのセッティング
シャドウ
センサーデータの可視化
Elasticsearch Service
Lambda
今回は、System Workbench for STM32を使用して行いました、
WiFiの混雑もありながら、多くの人が時間内に終わったようです。AmazonFreeRTOSをセッティングし、AWSにつなぐまではAzureよりも簡単に行えていると思います。
(認証情報などが使いやすいと思います)注意:終わった人はElasticSearch Service の削除を必ずしてください。
AWSのサービスとマイコンボードを一元的に触ることが出来る有意義なハンズオンでした。



- 投稿日:2020-01-10T14:55:59+09:00
はじめてAWSでデプロイする方法①(インスタンスの作成)
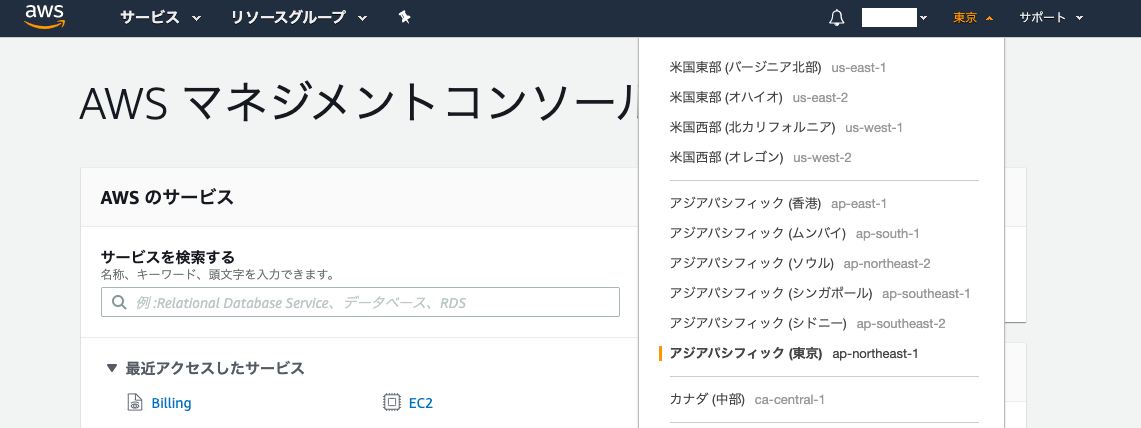
AWSアカウントのリージョン設定をしよう
リージョンとは、AWSの物理的なサーバの場所を指定するものです。リージョンは世界各地に10箇所以上存在し、そのうちの一つは東京にあります。
リージョンを東京に設定していきましょう手順
画面右上にある『 国 』を『アジアパシフィック(東京)を選択』
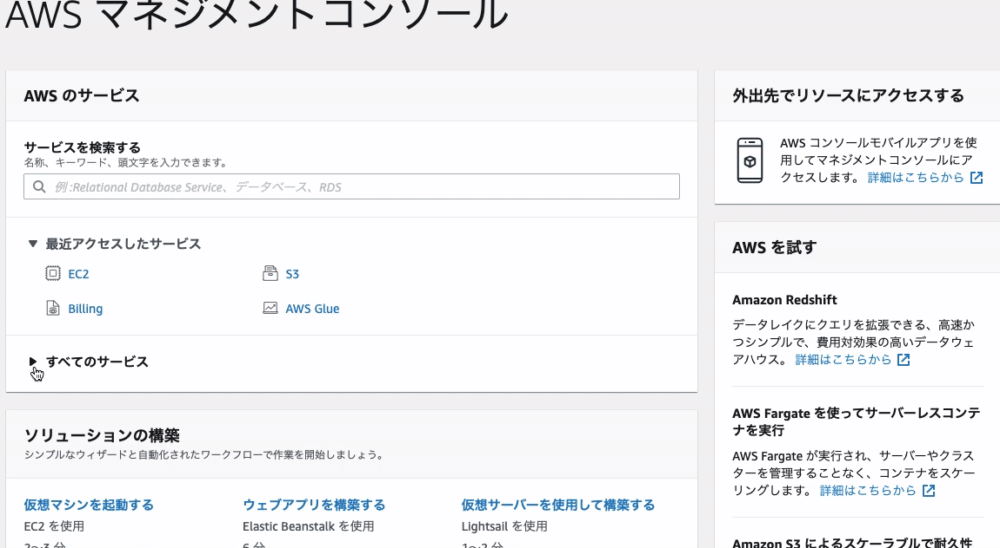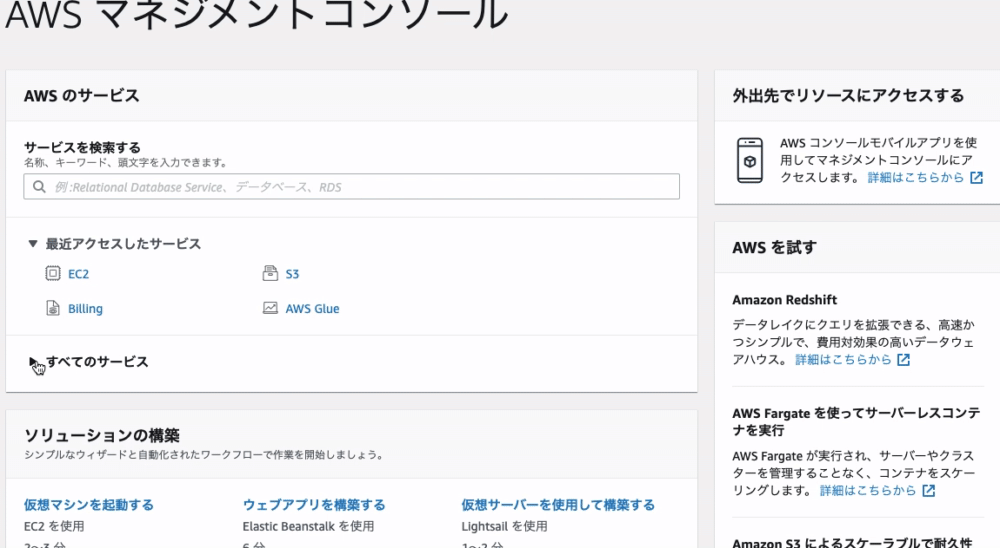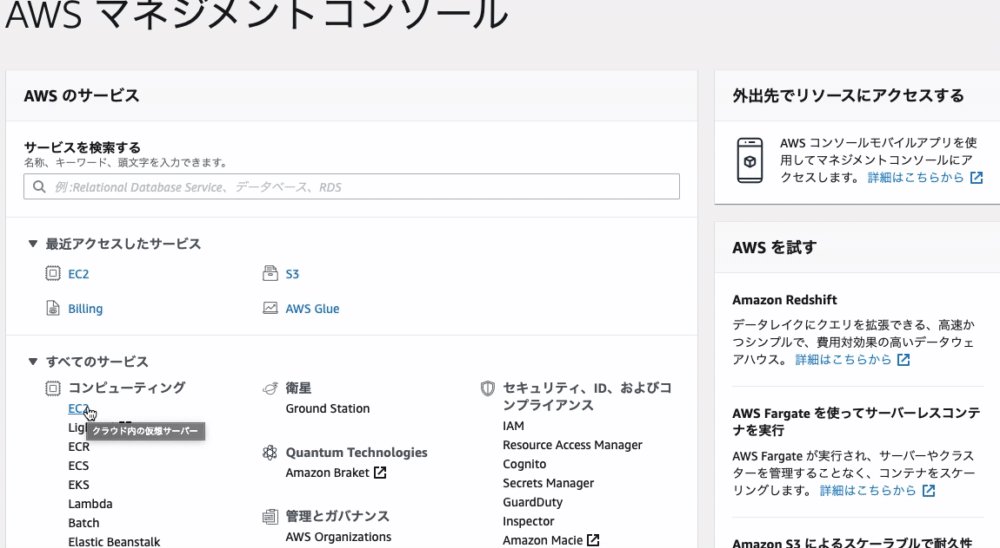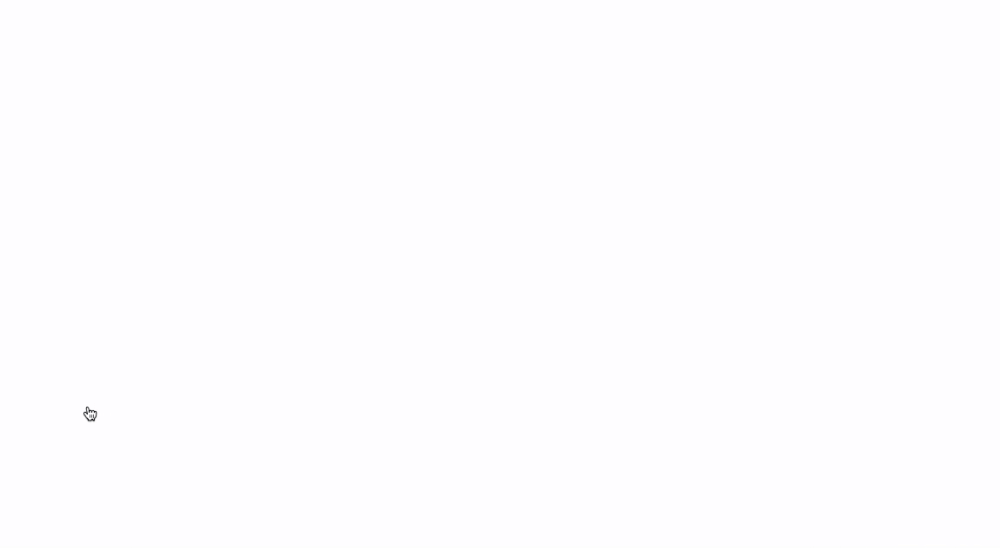
EC2インスタンスを作成
「サーバーを生成する」といっても、AWSが全てのサーバを物理的に用意しているわけではなく、実際には「仮想マシン」と呼ばれるソフトウェアを利用しています。
この「仮想マシン」のことをAWSでは「EC2インスタンス」と呼んでいます。手順
AWSにアクセス
EC2を選択する
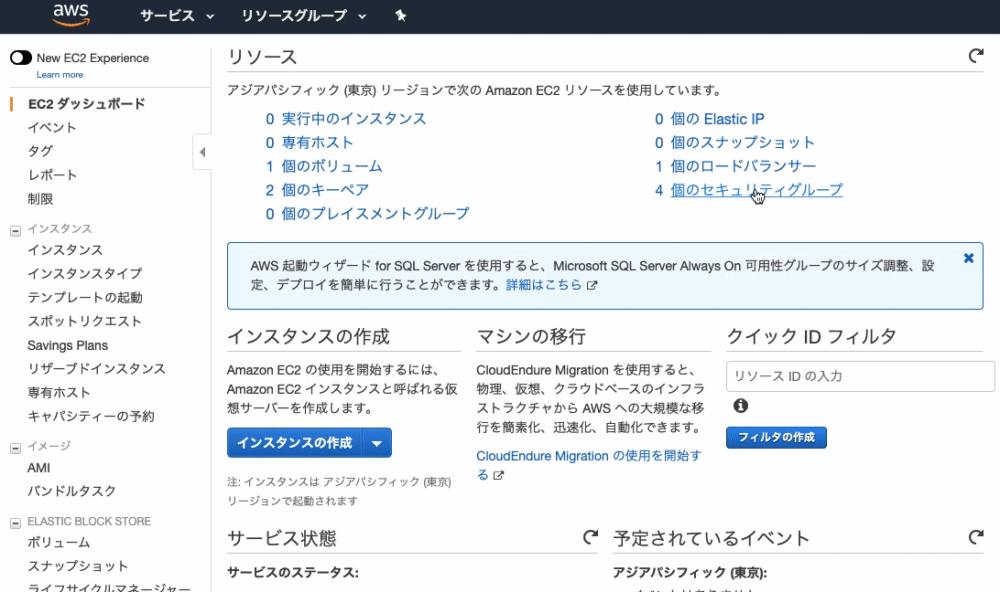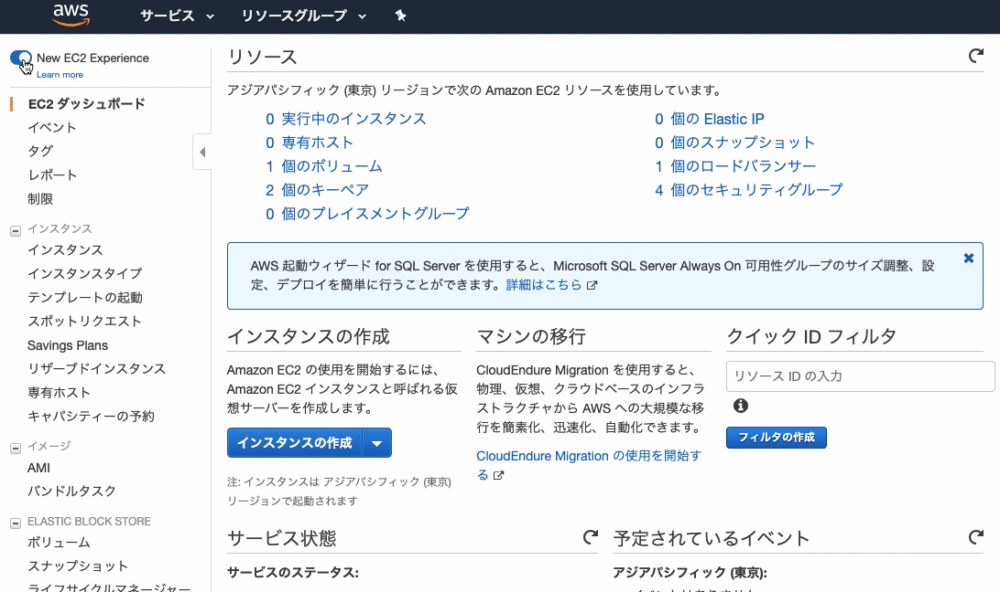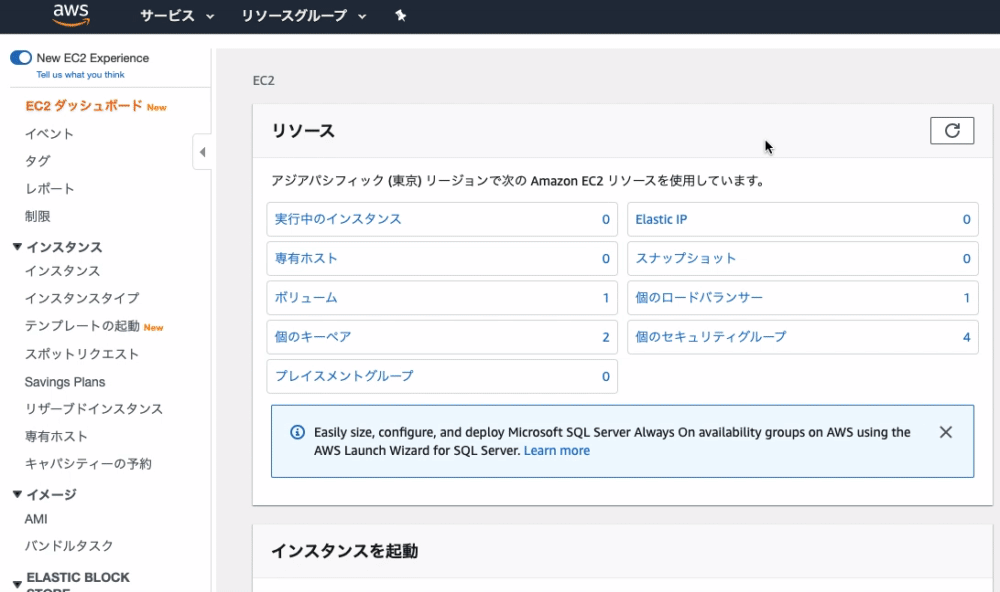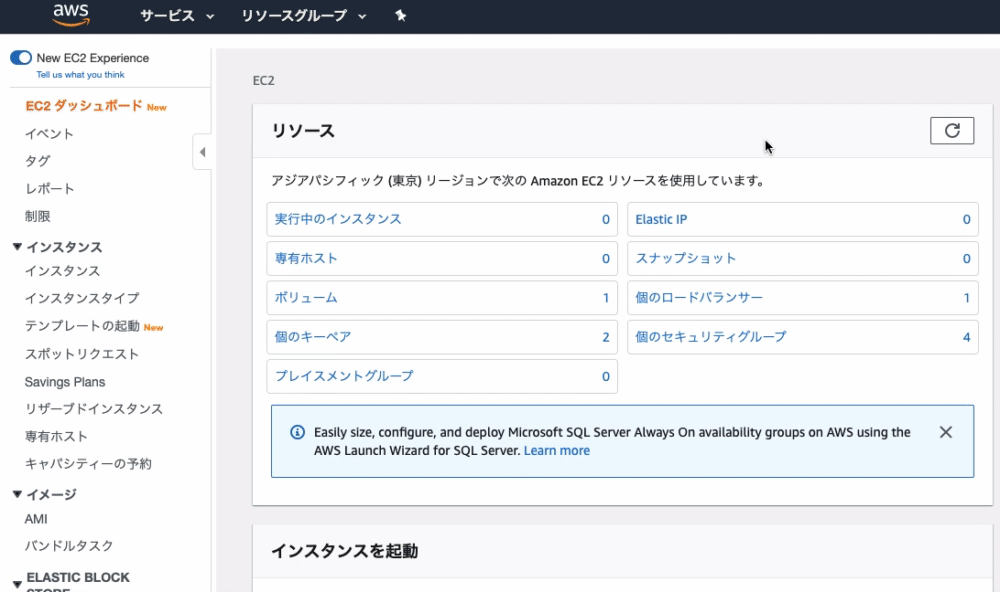
画面右上にある、『New EC2 Experience』をオン
※アンケートは『 キャンセル 』 しましょう。
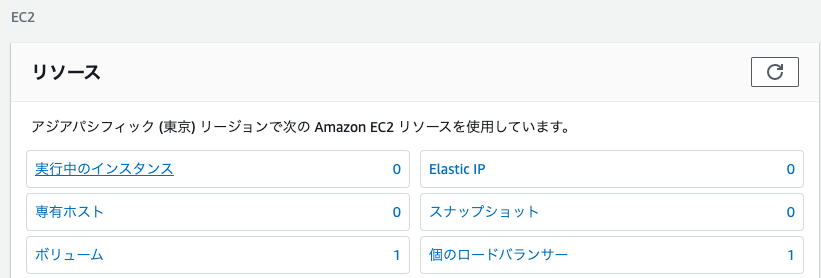
『実行中のインスタンス』をクリック
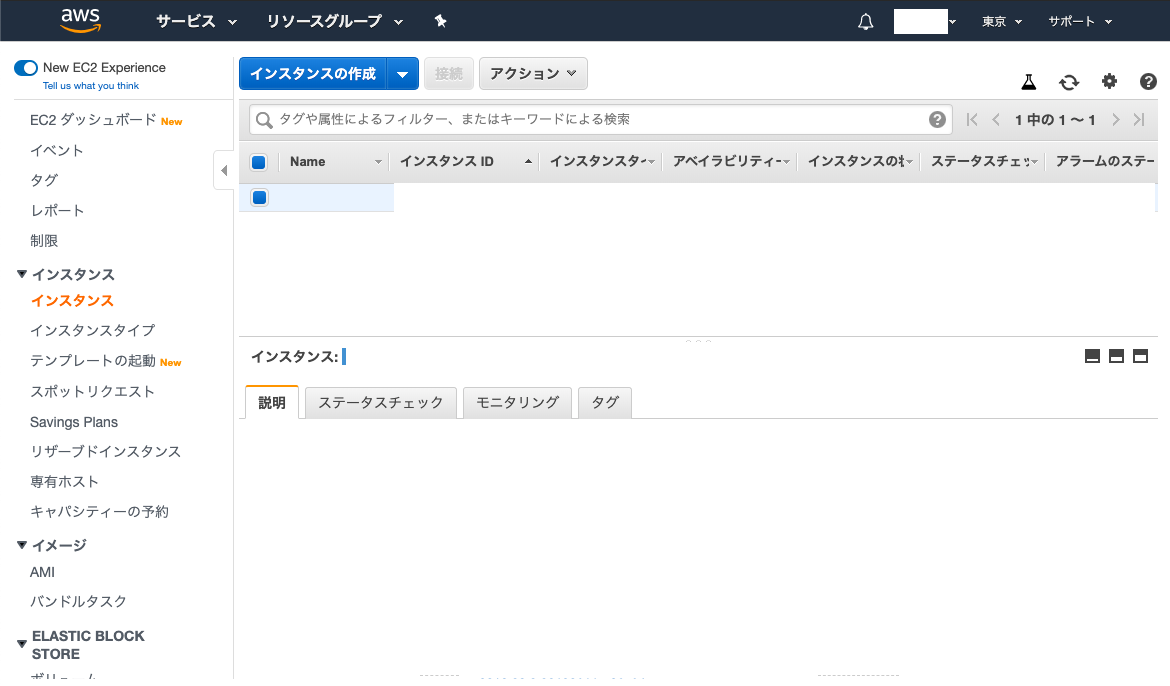
インスタンスの画面が開かれたら、画面右上の 『インスタンスの作成』 をクリック
「 Amazon Linux2 AMI 」ではなく、「 Amazon Linux AMI 」を選択してください。
(上から2番目にあります)
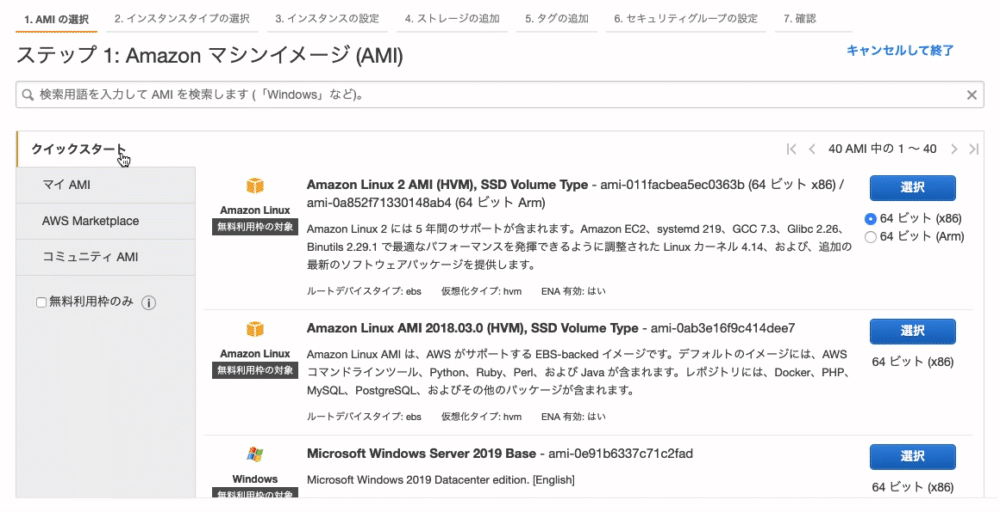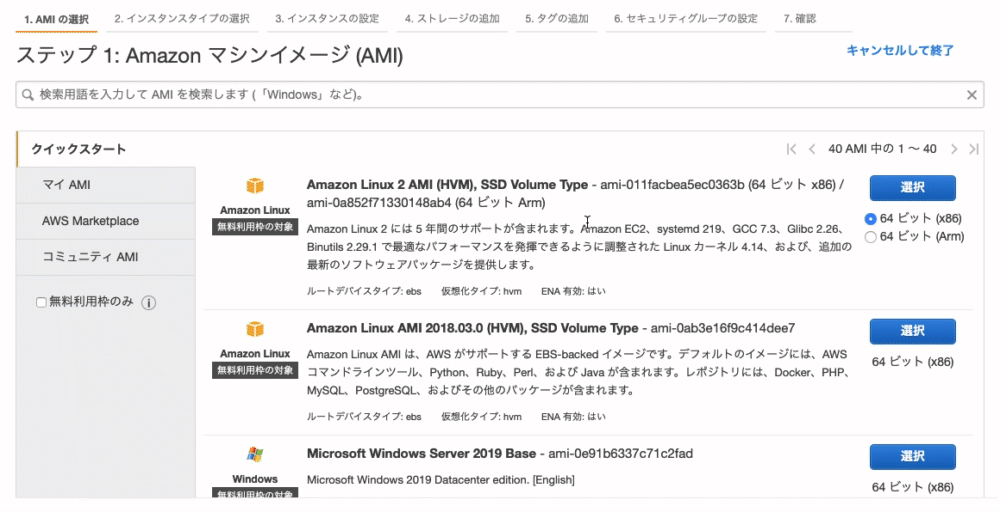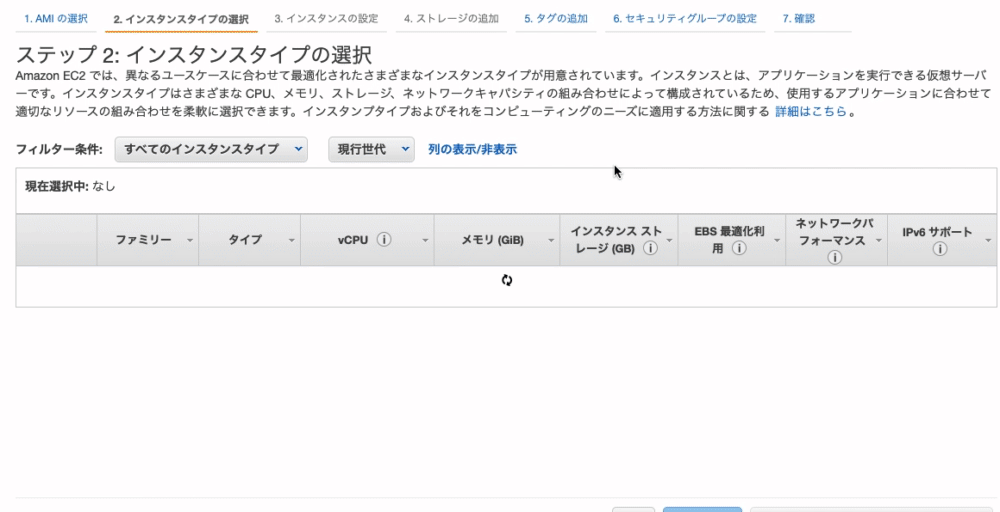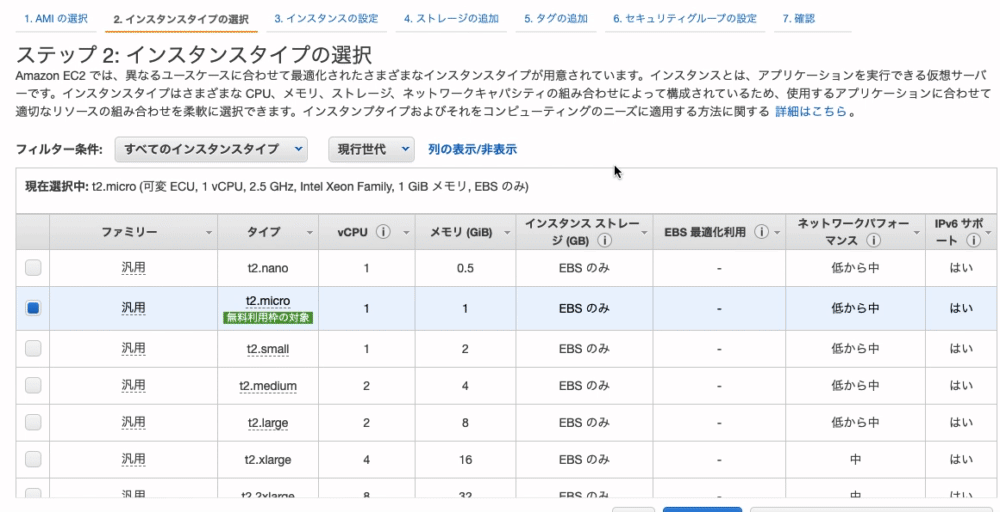
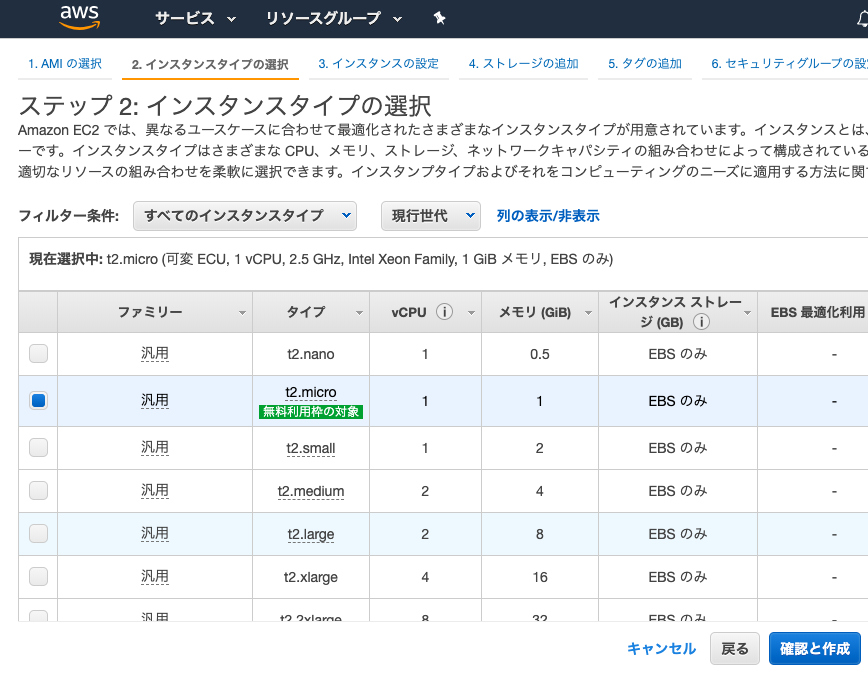
無料枠で利用できる「t2.micro」を選択し、画面右下の 『確認と作成』 をクリック
( EC2インスタンスのタイプを選択します。EC2ではさまざまなインスタンスタイプが用意されており、CPUやメモリなどのスペックを柔軟に指定することができます。)画面右下の『起動』をクリック
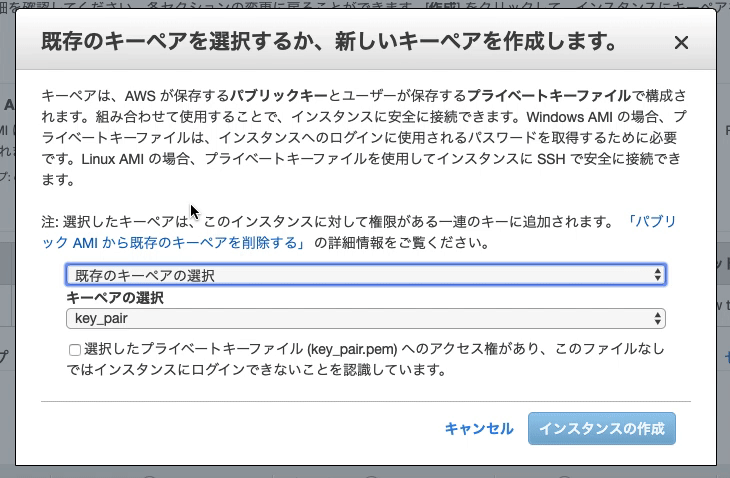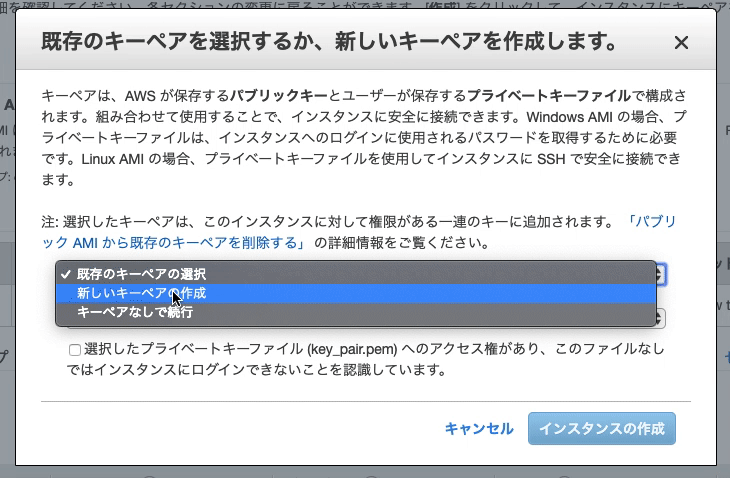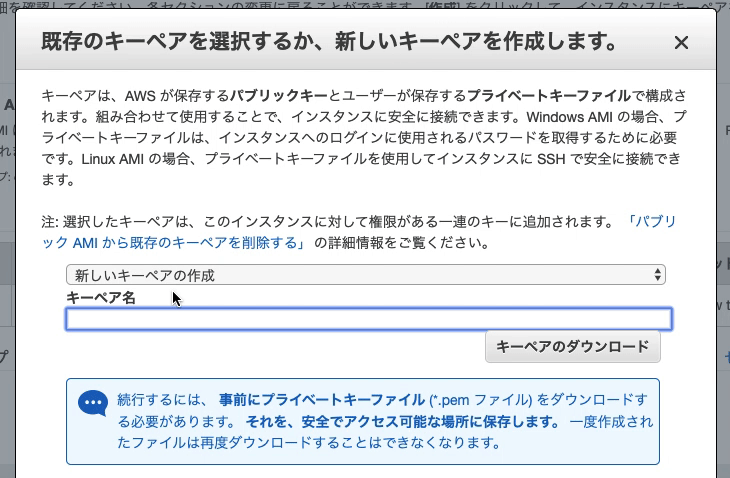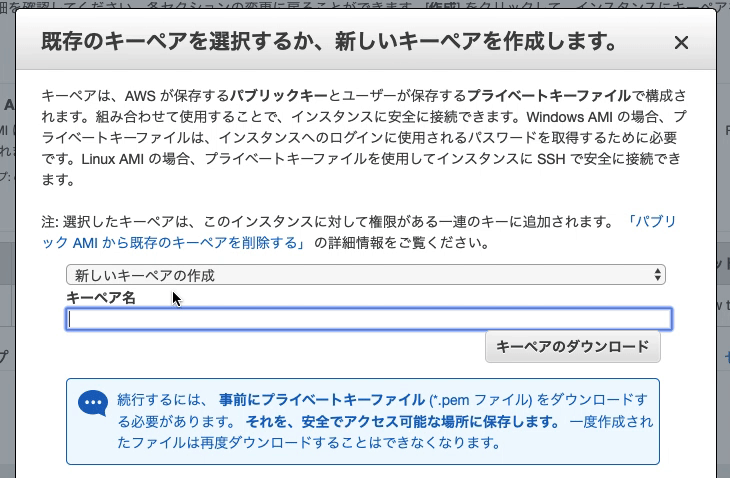
『新しいキーペアの作成』を選択
キーペア名を入力(空白NG)
キーペアのダウンロード(ファイル名.pem)
?注意:こちらはインスタンスにSSHでログインする際に必要となる「秘密鍵」です。これがないとEC2インスタンスにログインできないので、必ずダウンロードしてパソコンに保存しておきましょう。また、間違って他人に渡さないよう気をつけてください。
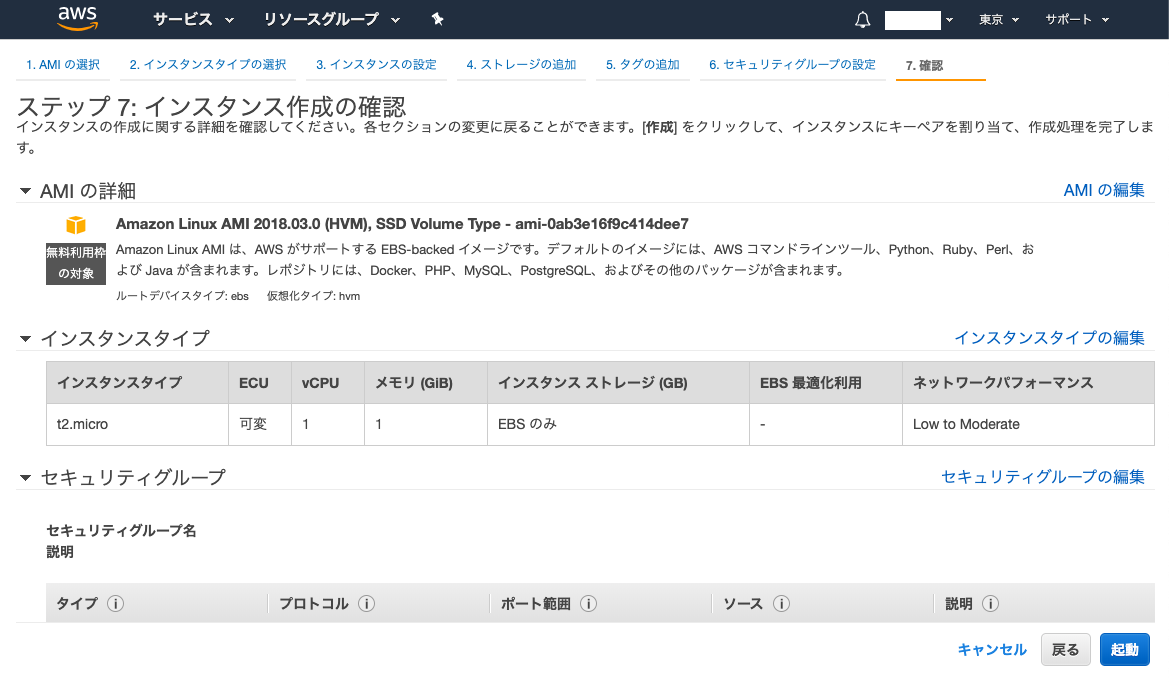
ダウンロードしたpemキー(ファイル名.pem)のsshフォルダに移行する$ cd ~ #ターミナルをスタート地点に戻す $ mkdir ~/.ssh #.sshというディレクトリを作成 # エラー『 mkdir: /Users/owner/.ssh: File exists 』と表示の場合、すでに存在します $ mv Downloads/ファイル名.pem .ssh/ # mvコマンドで、移動させたい対象(ファイル名.pem) → .sshディレクトリに移動します。 $ cd .ssh/ $ ls # pemファイルが存在するか確認します12.画面右下の『インスタンスの作成』をクリック
13. 作成完了(反映に時間がかかる場合があります)
14.次のインスタンスの作成がされました: 『 i- 』のインスタンスIDをクリック
15. 作成したインスタンスがrunningと表示されて、稼働している
完了
次は『 Elastic IPの作成と紐付け 』をしよう
ここまで、お疲れ様です。
初めてだとかなり、疲れたと思います。先ほど作成したEC2インスタンスには、作成時にIPアドレスが自動で割り振られています。これをパブリックIPと言います。しかし、サーバーを再起動させるたびにこのパブリックIPが変わってしまうという欠点を持っています。
次回はその欠点を改善するために、『 Elastic IPの作成と紐付け 』をしていきましょう。
長くなったので、次の記事で続きを記載します
はじめてAWSでデプロイする方法②(Elastic IPの作成と紐付け)

- 投稿日:2020-01-10T14:24:46+09:00
AWSに構築したWordPressをhttps対応してみた
はじめに
「AWSにWordPressを構築してみた」
「AWSに構築したWordPressに独自ドメインを割り当ててみた」
の続き。
WordPressを構築して独自ドメインを割り当ててSSL対応したところまで終わった。
が、WordPress側がhttpsに対応してないのでデザイン崩れが発生しているのと
httpでのアクセスがまだできる状態なのでその2つを対応していく。https対応設定
現状、こんな感じ。
httpsのページからhttpのコンテンツを参照しようとするとセキュリティレベルの問題でブラウザが読み込みを止めるのでこういう現象が起こる。
<link rel='stylesheet' id='dashicons-css' href='http://olafblog.org/wp-includes/css/dashicons.min.css?ver=4.7.2' type='text/css' media='all' />こういうの。ってことでコンテンツの読み込みもhttpsでするようにしていく。
WordPress側での設定
ちょっと調べたらWordPressのプラグインで一発で対応できそうなのでそのプラグインを試してみる。
http://xxx.xxx.xxx.xxx/wp-login.php
で管理ツールにログイン。[プラグイン]>[新規追加]で画面を開いて
「Really Simple SSL」
を検索してインストールして、有効化!はい、完成。
でログイン。・・・あれ崩れたまま?
管理画面に入って原因ch・・・リダイレクトループ?ぐぐるとどうやらサーバー側での設定が必要みたい。
サーバー側での設定
サーバー側にログインして設定を追加していく。
$ cd /var/www/html # 管理画面から設定が変えれるように権限変更しておく $ chmod 660 wp-config.php # 下記設定を # require_once(ABSPATH . 'wp-settings.php'); # の上部に追加 $ vi wp-config.php _/_/_/_/_/_/_/_/_/_/_/_/_/_/ $_SERVER['HTTPS']='on'; define('FORCE_SSL_LOGIN', true); define('FORCE_SSL_ADMIN', true); _/_/_/_/_/_/_/_/_/_/_/_/_/_/再度アクセス。・・・うん。管理画面に入れるようになった。
再度、WordPress側ので設定
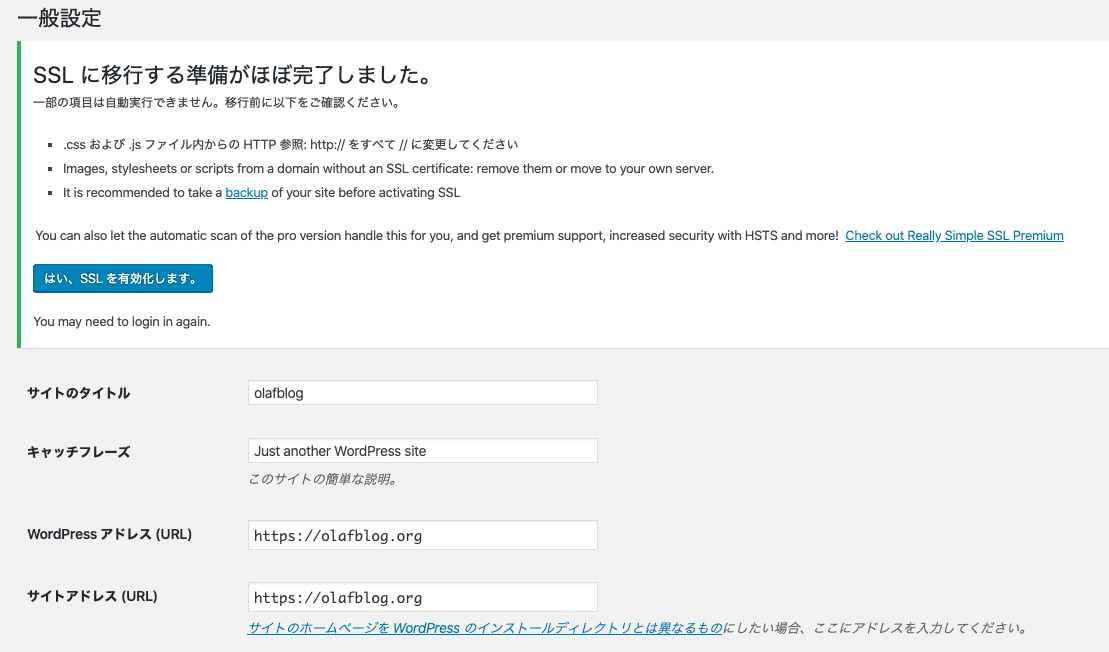
[設定]の「WordPressアドレス(URL)」と「サイトアドレス(URL)」をhttpsに変更。
あとなんか上の方にボタンが出てたのでSSL有効ボタンをポチる。
さて、トップページにアクセス。
お、できた。余裕ですねぇ。
http->httpsリダイレクト設定
最後にhttpアクセスをhttpsリダイレクトするように設定していく。
# server_nameを正規ルートのみ許可するように不要な記述を削除 # httpアクセスに対して301リダイレクトするよう設定を追加 $ sudo vi /etc/nginx/conf.d/wordpres.conf _/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/ server { listen 80; server_name olafblog.org; location / { if ($http_x_forwarded_proto = 'http'){ return 301 https://$host$request_uri; } root /var/www/html; index index.php index.html; } location ~ \.php$ { root /var/www/html; fastcgi_pass 127.0.0.1:9000; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } } # 再起動だとうまく設定が反映されなかったので再起動 $ sudo nginx -s stop $ sudo nginx _/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/_/オッケー。設定完了したのでhttpでアクセス。
httpsにリダイレクトされることを確認。
簡単ですねぇ。お疲れ様でした。
- 投稿日:2020-01-10T13:32:06+09:00
LambdaでCognito認証(ユーザー認証)
はじめに
SDKをローカルに持ってきてゴニョるサンプルは検索に引っかかるのですが、
クラウド側(Lambda関数内部)で完結するサンプルが見つからない...
よし、ならば投稿してしまえ。トップ
├ユーザー作成
├ユーザー確認
└ユーザー認証 ←イマココユーザー認証 (InitiateAuth)
概要
通知されたIDとパスワードの組み合わせが正しいかを検証します。
登録された情報と一致した場合、ユーザー認証に必要なIDトークンを発行します。ドキュメント
ソースコード
'use strict'; const AWS = require('aws-sdk'); const cognito = new AWS.CognitoIdentityServiceProvider(); /** * initiateAuthする * params {string} userId 登録者のメールアドレスor電話番号 * params {string} userPassword 登録者のパスワード * returns {Promise<HTTPResponse>} 200 OK */ module.exports = async (userId, userPassword) => { // ConfirmSignUpのパラメーター const params = { AuthFlow: 'USER_PASSWORD_AUTH', // ユーザープールの 全般設定>アプリクライアント>認証フローの設定 で指定した認証方法 ClientId: '{アプリクライアントID}', // ユーザープールの 全般設定>アプリクライアント で確認する AuthParameters: { 'USERNAME': userId, 'PASSWORD': userPassword, }, }; // initiateAuth実行 const result = await cognito.initiateAuth(params).promise().catch(error => { // 必要に応じて例外処理を追加する。 // パスワード不一致の例外は→「error.code == 'NotAuthorizedException'」 throw error; }); // HTTPレスポンス 必要に応じて編集する。 // 例えば、IDトークンをcookieに設定したい場合は、headersに↓これを追加する。 // 'Set-Cookie': `IdToken=${result.AuthenticationResult.IdToken}; Max-Age=${result.AuthenticationResult.ExpiresIn}` return { statusCode: 200, headers: { 'Content-Type': 'application/json; charset=utf-8', }, body: JSON.stringify({ IdToken: result.AuthenticationResult.IdToken, }), }; };
- 投稿日:2020-01-10T13:31:42+09:00
LambdaでCognito認証(ユーザー確認)
はじめに
SDKをローカルに持ってきてゴニョるサンプルは検索に引っかかるのですが、
クラウド側(Lambda関数内部)で完結するサンプルが見つからない...
よし、ならば投稿してしまえ。トップ
├ユーザー作成
├ユーザー確認 ←イマココ
└ユーザー認証ユーザー確認 (ConfirmSignUp)
概要
作成したユーザーの連絡手段(メールアドレスor電話番号)が有効か確認します。
通知された確認コードが正しければ、ユーザーのアカウントステータスを「CONFIRMED」にします。ドキュメント
ソースコード
'use strict'; const AWS = require('aws-sdk'); const cognito = new AWS.CognitoIdentityServiceProvider(); /** * ConfirmSingUpする * params {string} userId 登録者のメールアドレスor電話番号 * params {string} confCode 登録者に通知された確認コード * returns {Promise<HTTPResponse>} 200 OK */ module.exports = async (userId, confCode) => { // ConfirmSignUpのパラメーター const params = { ClientId: '{アプリクライアントID}', // ユーザープールの 全般設定>アプリクライアント で確認する Username: userId, ConfirmationCode: confCode, }; // ConfirmSignUp実行 const result = await cognito.confirmSignUp(params).promise().catch(error => { // 必要に応じて例外処理を追加する。 // 例えば、確認コード不一致の例外は→「error.code == 'CodeMismatchException'」 throw error; }); // HTTPレスポンス 必要に応じて編集する。 return { statusCode: 200, }; };
- 投稿日:2020-01-10T13:31:26+09:00
LambdaでCognito認証(ユーザー作成)
はじめに
SDKをローカルに持ってきてゴニョるサンプルは検索に引っかかるのですが、
クラウド側(Lambda関数内部)で完結するサンプルが見つからない...
よし、ならば投稿してしまえ。トップ
├ユーザー作成 ←イマココ
├ユーザー確認
└ユーザー認証ユーザー作成 (SignUp)
概要
通知されたIDとパスワード(とその他の情報)でユーザーアカウントを作成します。
続けて、登録したメールアドレスor電話番号に確認コードを通知します。ドキュメント
ソースコード
'use strict'; const AWS = require('aws-sdk'); const cognito = new AWS.CognitoIdentityServiceProvider(); /** * SingUpする * params {string} userId ユーザーのメールアドレスor電話番号 * params {string} userPassword ユーザーのパスワード * returns {Promise<HTTPResponse>} 200 OK */ module.exports = async (userId, userPassword) => { // SignUpのパラメーター const params = { ClientId: '{アプリクライアントID}', // ユーザープールの 全般設定>アプリクライアント で確認する Username: userId, Password: userPassword, UserAttributes: [ {Name: '{属性名1}', Value: '{属性値1}'}, // 必要に応じて増減する。 {Name: '{属性名2}', Value: '{属性値2}'}, // ユーザープールの 全般設定>属性 の {Name: '{属性名3}', Value: '{属性値3}'}, // 標準属性とカスタム属性が該当する。 {Name: '{属性名4}', Value: '{属性値4}'}, // 必須指定したものは、もちろん必須。 ], }; // SignUp実行 const result = await cognito.signUp(params).promise().catch(error => { // 必要に応じて例外処理を追加する。 // 例えば、IDが重複したときの例外は→「error.code == 'UsernameExistsException'」 throw error; }); // HTTPレスポンス 必要に応じて編集する。 return { statusCode: 200, }; };
- 投稿日:2020-01-10T13:31:09+09:00
LambdaでCognito認証
はじめに
SDKをローカルに持ってきてゴニョるサンプルは検索に引っかかるのですが、
クラウド側(Lambda関数内部)で完結するサンプルが見つからない...
よし、ならば投稿してしまえ。トップ ←イマココ
├ユーザー作成
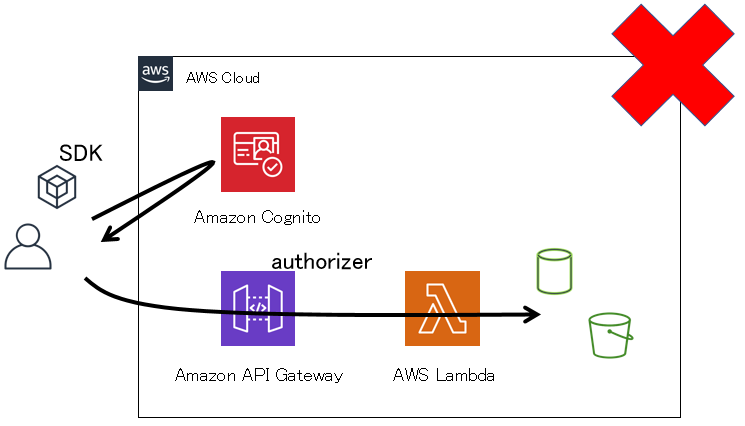
├ユーザー確認
└ユーザー認証 ※なお、続く認可はAPI Gatewayのオーソライザーにお任せします。※メインはLambda関数のコードの紹介です。付随する情報は簡潔に記します。
概要
ローカルにダウンロードしたSDKを使うのではなく、
クラウド側で用意されているSDKを使ってCognito認証しよう。
というのが今回のコンセプトです。↓こちらを使います。
https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/CognitoIdentityServiceProvider.html
Cognito
- ユーザープールを作成する。
※必須属性は任意。- 全般設定>アプリクライアント からアプリクライアントを作成する。
※認証フローは"ALLOW_USER_PASSWORD_AUTH"を選択する。Lambda
- Lambda関数を作成する。
※ランタイムはNode.jsの最新版を選択する。- Cognitoのポリシーをアタッチする。
※とりあえずは「AmazonCognitoPowerUser」だけでOK。必要に応じて取捨選択を。- 関数コードを書く。詳細は各ページにて。
API Gateway
- "REST API" または "HTTP API"を作成する。
※REST APIの場合は、Lambdaプロキシ統合を使用する。- 先に作成したLambda関数を、統合先に指定する。
※REST APIの場合は、デプロイを忘れずに。

- 投稿日:2020-01-10T12:28:24+09:00
2回目以降のAWSを無料で利用する方法(請求かからないようにする)
Amazon EC2の無料条件
- 750時間/月 (t2.microインスタンスの使用もこれに含む)まで
- Amazon S3: 5GBの標準ストレージ、20,000件のGETリクエスト、2,000件のPUTリクエスト
- Elastic IPアドレス 実行中のインスタンスに関連づけられたElastic IPアドレスを1つだけ インスタンスに紐付いていないElastic IPアドレスは全て課金対象
- IAM: IAMユーザーの一時的なセキュリティ認証情報を使用して他のAWSサービスにアクセスするときのみ料金が発生
2回目以降で実施する場合
- Elastic IPアドレスを解放する (すでに作成済みで、これ以上必要の無い場合)
- 紐付いているS3バケットを削除する
- インスタンスを削除する
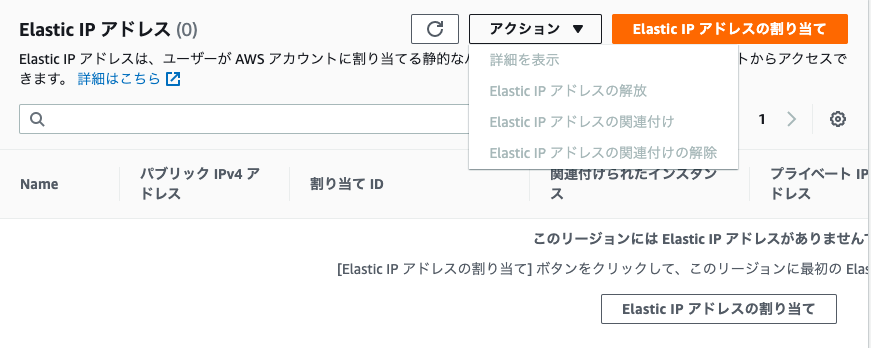
Elastic IPアドレスを解放する
Elastic IPアドレスは、停止しているインスタンスに関連づけられている場合に時間ごとに料金が発生します。そのため、インスタンスを停止するときにElastic IPアドレスを解放する必要があります。
手順
(https://console.aws.amazon.com/ec2/) にある Amazon EC2 コンソールを開きます。
[Elastic IP] を選択します。
Elastic IP アドレスを選択✅し、[アクション]>[Elastic IPアドレスの解放]>[解放] の順に選択します。
参考URL: Elastic IPアドレスを解放する方法
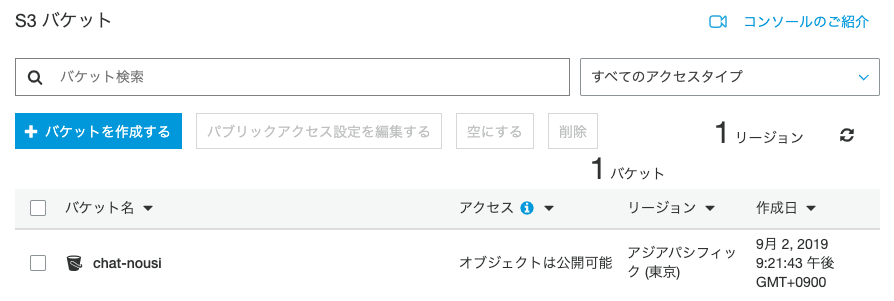
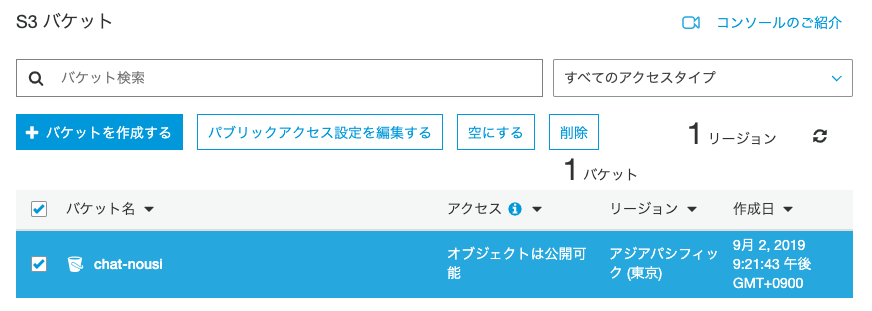
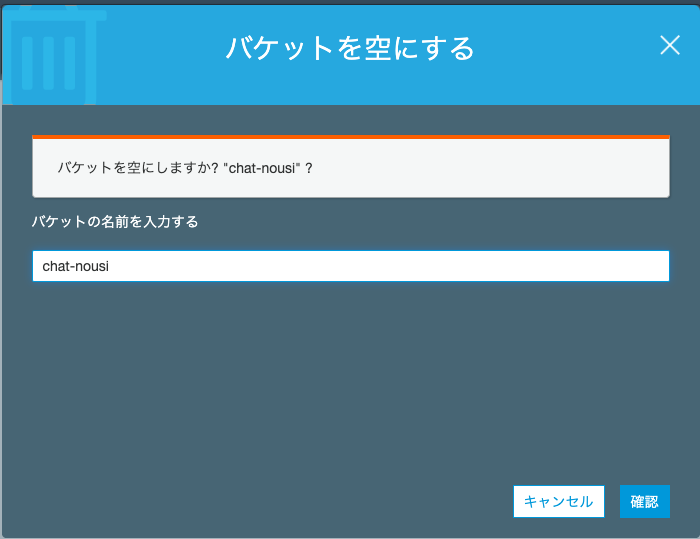
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/elastic-ip-addresses-eip.html#using-instance-addressing-eips-releasingS3バケットを削除しよう
不要なバケットである場合、以下の手順で削除することができます。(ただし、同じバケット名を別のサービス等で使いたい場合は、バケットの中身を空にするようにしてください。)
手順
AWS マネジメントコンソール にサインインし、Amazon S3 コンソール (https://console.aws.amazon.com/s3/) を開きます。
[バケット名] リストで、削除するバケットの名前の横にあるバケットアイコンを選択✅
[バケットを削除する] を選択します。(または空にする)
[バケットを削除する] ダイアログボックスで、削除するバケットの名前を確認のために入力し、[確認] を選択します。
EC2インスタンスの停止させましょう
インスタンスを停止するとEIastic IPアドレスは関連づけられなくなるので、あらかじめEIastic IPアドレスを解放し課金されないように気をつけましょう。
手順
(https://console.aws.amazon.com/ec2/) にある Amazon EC2 コンソールを開きます。
EC2コンソールで [実行中インスタンス] を選択し、インスタンスを選択します
停止したいインスタンスを選択✅
[アクション] を選択
[インスタンスの状態] >[停止] を選択します。
[停止] が無効になっている場合は、インスタンスが既に停止しているか、またはルートボリュームがインスタンスストアボリュームです。(インスタンスを停止すると、インスタンスストアボリューム上のデータは消去されます。インスタンスストアボリュームのデータを保持するには、このデータを永続的ストレージに必ずバックアップしてください。)参考URL: インスタンスの停止と起動
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/Stop_Start.html費用はこまめに確認する
発生している料金については、AWSの請求ダッシュボードからいつでも確認することができます。気になる場合は、こまめに確認するようにしましょう。
手順
画面右上にある 『アカウント名』 を選択し、 『注文と請求書』 を選択
画面右にあるサイドナビの『請求書』を選択。請求金額の確認が可能
不明な課金がされている場合
その他にも数十円の料金が発生していたり、不明な料金が発生していることがあったら以下のような対応を取りましょう。
- AWSのカスタマーサポートに問い合わせてみる (https://aws.amazon.com/jp/contact-us/?nc2=h_header)
- 解決しない場合は、AWSのアカウントごと消去する
高度な設定
費用発生を最小限に留めるために、EC2を自動でシャットダウンされるように設定したり、無料利用枠を超えないようにS3でオブジェクトの有効期限を設定できたりします。以下のリンクを参考にしてください。
無駄なコストを省こう!AWSで消し忘れを防止するためにチェックすべき7つのポイント
(https://dev.classmethod.jp/cloud/aws/cost-check-point/)



- 投稿日:2020-01-10T12:28:24+09:00
2回目以降のAWSを無料で利用する方法(請求かからないようにインスタントの削除)
Amazon EC2の無料条件
- 750時間/月 (t2.microインスタンスの使用もこれに含む)まで
- Amazon S3: 5GBの標準ストレージ、20,000件のGETリクエスト、2,000件のPUTリクエスト
- Elastic IPアドレス 実行中のインスタンスに関連づけられたElastic IPアドレスを1つだけ インスタンスに紐付いていないElastic IPアドレスは全て課金対象
- IAM: IAMユーザーの一時的なセキュリティ認証情報を使用して他のAWSサービスにアクセスするときのみ料金が発生
2回目以降で実施する場合
- Elastic IPアドレスを解放する (すでに作成済みで、これ以上必要の無い場合)
- 紐付いているS3バケットを削除する
- インスタンスを削除する
Elastic IPアドレスを解放する
Elastic IPアドレスは、停止しているインスタンスに関連づけられている場合に時間ごとに料金が発生します。そのため、インスタンスを停止するときにElastic IPアドレスを解放する必要があります。
手順
(https://console.aws.amazon.com/ec2/) にある Amazon EC2 コンソールを開きます。
[Elastic IP] を選択します。
Elastic IP アドレスを選択✅し、[アクション]>[Elastic IPアドレスの解放]>[解放] の順に選択します。
参考URL: Elastic IPアドレスを解放する方法
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/elastic-ip-addresses-eip.html#using-instance-addressing-eips-releasingS3バケットを削除しよう
不要なバケットである場合、以下の手順で削除することができます。(ただし、同じバケット名を別のサービス等で使いたい場合は、バケットの中身を空にするようにしてください。)
手順
AWS マネジメントコンソール にサインインし、Amazon S3 コンソール (https://console.aws.amazon.com/s3/) を開きます。
[バケット名] リストで、削除するバケットの名前の横にあるバケットアイコンを選択✅
[バケットを削除する] を選択します。(または空にする)
[バケットを削除する] ダイアログボックスで、削除するバケットの名前を確認のために入力し、[確認] を選択します。
EC2インスタンスの停止させましょう
インスタンスを停止するとEIastic IPアドレスは関連づけられなくなるので、あらかじめEIastic IPアドレスを解放し課金されないように気をつけましょう。
手順
(https://console.aws.amazon.com/ec2/) にある Amazon EC2 コンソールを開きます。
EC2コンソールで [実行中インスタンス] を選択し、インスタンスを選択します
停止したいインスタンスを選択✅
[アクション] を選択
[インスタンスの状態] >[停止] を選択します。
[停止] が無効になっている場合は、インスタンスが既に停止しているか、またはルートボリュームがインスタンスストアボリュームです。(インスタンスを停止すると、インスタンスストアボリューム上のデータは消去されます。インスタンスストアボリュームのデータを保持するには、このデータを永続的ストレージに必ずバックアップしてください。)参考URL: インスタンスの停止と起動
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/Stop_Start.html費用はこまめに確認する
発生している料金については、AWSの請求ダッシュボードからいつでも確認することができます。気になる場合は、こまめに確認するようにしましょう。
手順
画面右上にある 『アカウント名』 を選択し、 『注文と請求書』 を選択
画面右にあるサイドナビの『請求書』を選択。請求金額の確認が可能
不明な課金がされている場合
その他にも数十円の料金が発生していたり、不明な料金が発生していることがあったら以下のような対応を取りましょう。
- AWSのカスタマーサポートに問い合わせてみる (https://aws.amazon.com/jp/contact-us/?nc2=h_header)
- 解決しない場合は、AWSのアカウントごと消去する
高度な設定
費用発生を最小限に留めるために、EC2を自動でシャットダウンされるように設定したり、無料利用枠を超えないようにS3でオブジェクトの有効期限を設定できたりします。以下のリンクを参考にしてください。
無駄なコストを省こう!AWSで消し忘れを防止するためにチェックすべき7つのポイント
(https://dev.classmethod.jp/cloud/aws/cost-check-point/)
- 投稿日:2020-01-10T12:03:34+09:00
AWSでサーバレスの自己紹介サイトを作って各種設定を行ってみた~当初簡単だと思ったら意外と面倒だった話~
目的
最近業務でアドバイスを行う機会が増えている一方、実際に自分で手を動かしアウトプットする機会が減ってしまっていることに危機感を覚えました。とりあえず自分のWebサイトを再作成します。
以前WordPressでサイトを作ったことがあるのですが、ブログ形式は更新が滞ってしまうので、静的サイトを作ってそこに各種リンクを貼る形式にしました。
昔一度やったことがあるので簡単だと思っていましたが、ドメイン設定やSSL証明書の作成など、日常業務であまりやらないことに手間取りましたので、その点を共有できればと思います。
想定した流れ
1.HTMLとCSSで紹介ページの作成
2.S3へアップロード
3.CloudFrontでURL公開
4.ムームドメインで独自ドメインを取得
5.Route53でドメインを設定実際の手順
1.HTMLとCSSで紹介ページの作成とドメイン取得
2.S3へアップロード
3.S3へアップロードしたところ、ログファイルの出力先など検討しなければならないことに気づき手間取る
4.Cloudfrontで公開しようとするが、SSL証明書のインポート、Route53の認証、お名前ドットコムの設定などで手間取る
5.Route53のムームードメインを設定結論
公開したWebページはこちらになります。
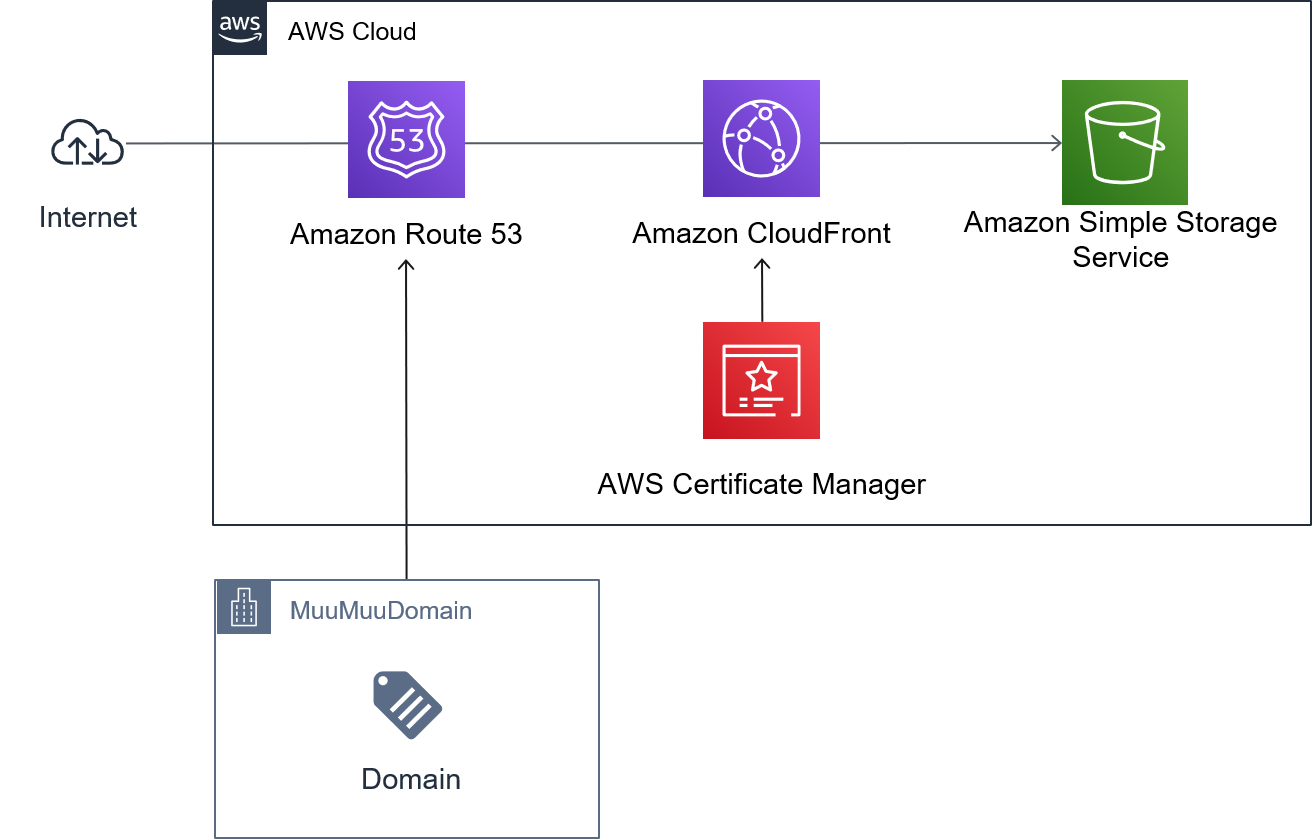
https://www.hanzohattori-arch.com/構成図
1.HTMLとCSSで紹介ページの作成
まずは静的サイトとなるhtmlを作成しました。
久しぶりにhtmlとCSSを書いたので、LIGさまのブログを参考に自己紹介の内容検討10分、サイトデザイン20分ほどでさくっと作成しました。
https://liginc.co.jp/2303452.S3へアップロード
下記の設定を行ない、アップロードしました。
下記の資料を参考にしました。ありがとうクラスメソッドさま。
https://dev.classmethod.jp/cloud/aws/cloudfront-s3-web/3.S3へアップロードしたところ、ログファイルの出力先など検討しなければならないことに気づき手間取る
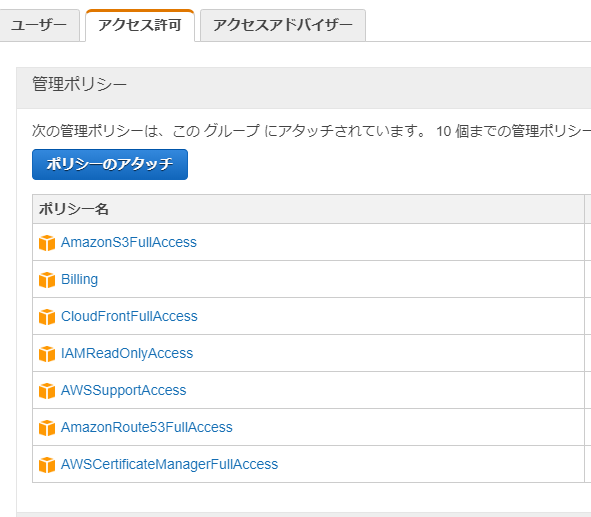
クラメソさまの記事では、コンテンツ管理者とサービスの管理者が別という想定で作られているため、斜め読みした際に混乱してしまいました。
読解力が低いことがばれる。最終的にはIAM以外は記事通りの設定を行いました。
IAMは権限をグループで持ちました。(BillingとSupportは作業用につけました)
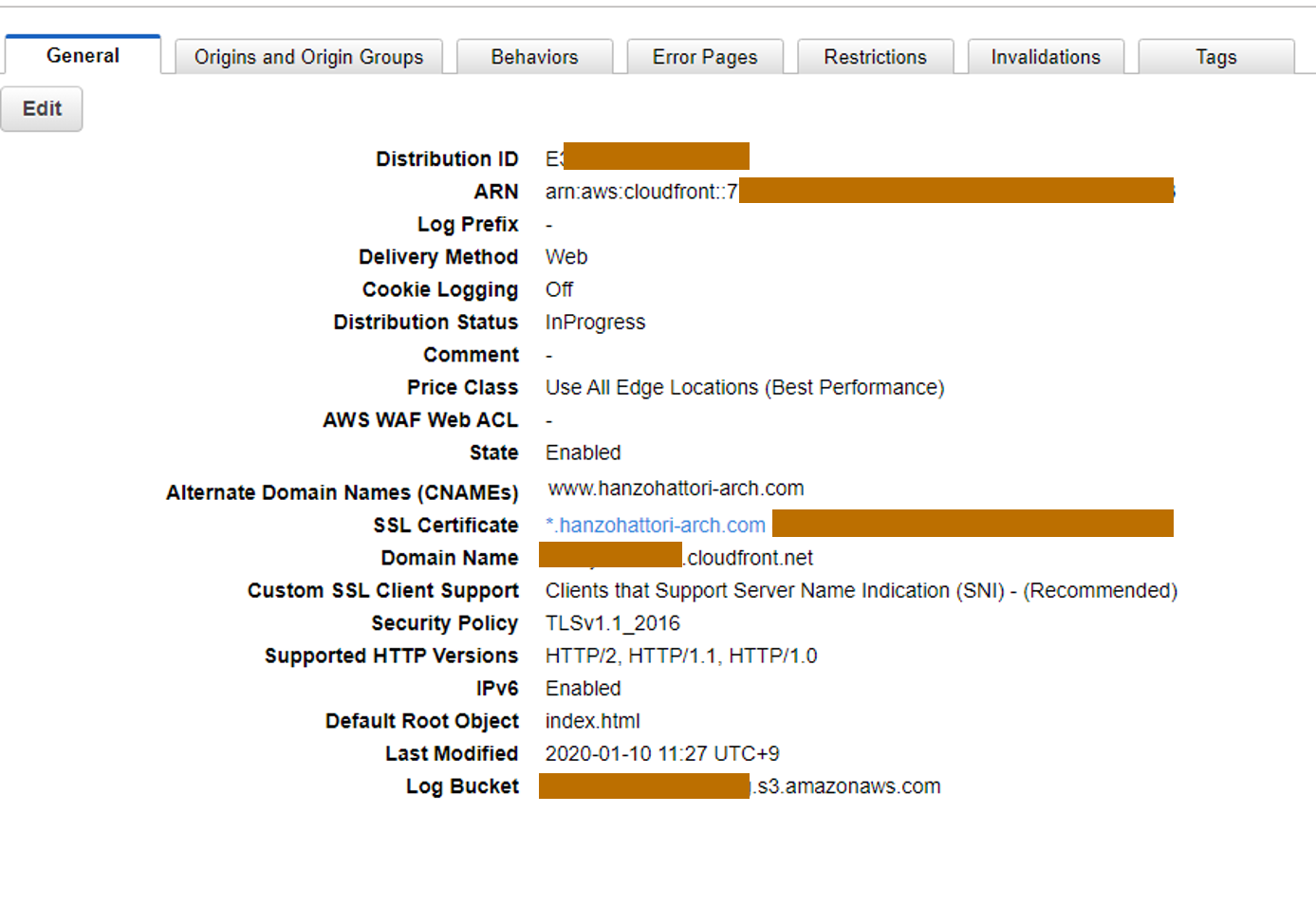
4.Cloudfrontで公開しようとするが、SSL証明書のインポート、
CloudFrontの設定が久しぶりすぎてちょっと困りました。
最終的にはACMで証明書発行、Route53でDNS設定を行いました。
正しいかどうかDeployされるまで30分ほど待機時間が発生してしまい。ちょっと困りました。
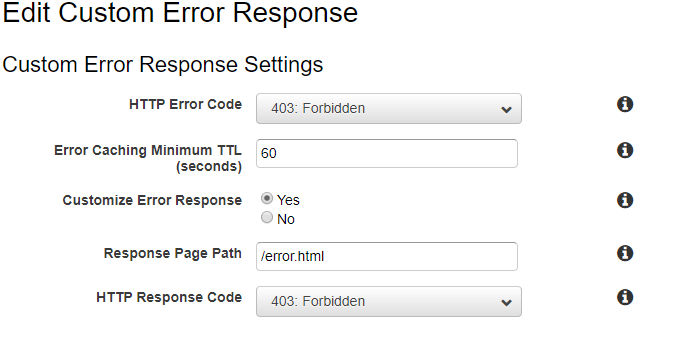
エラーページもCloudfrontで設定してます。
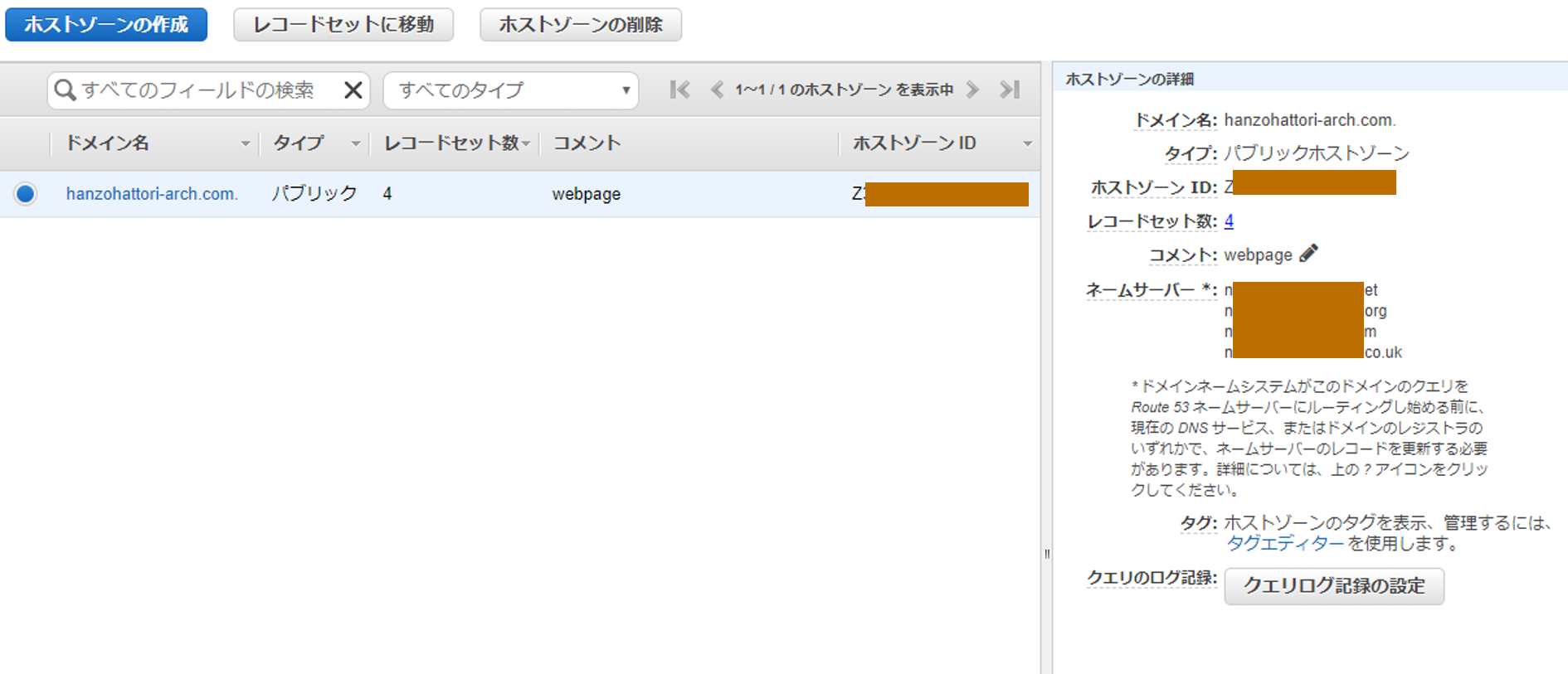
5.Route53でドメインを設定
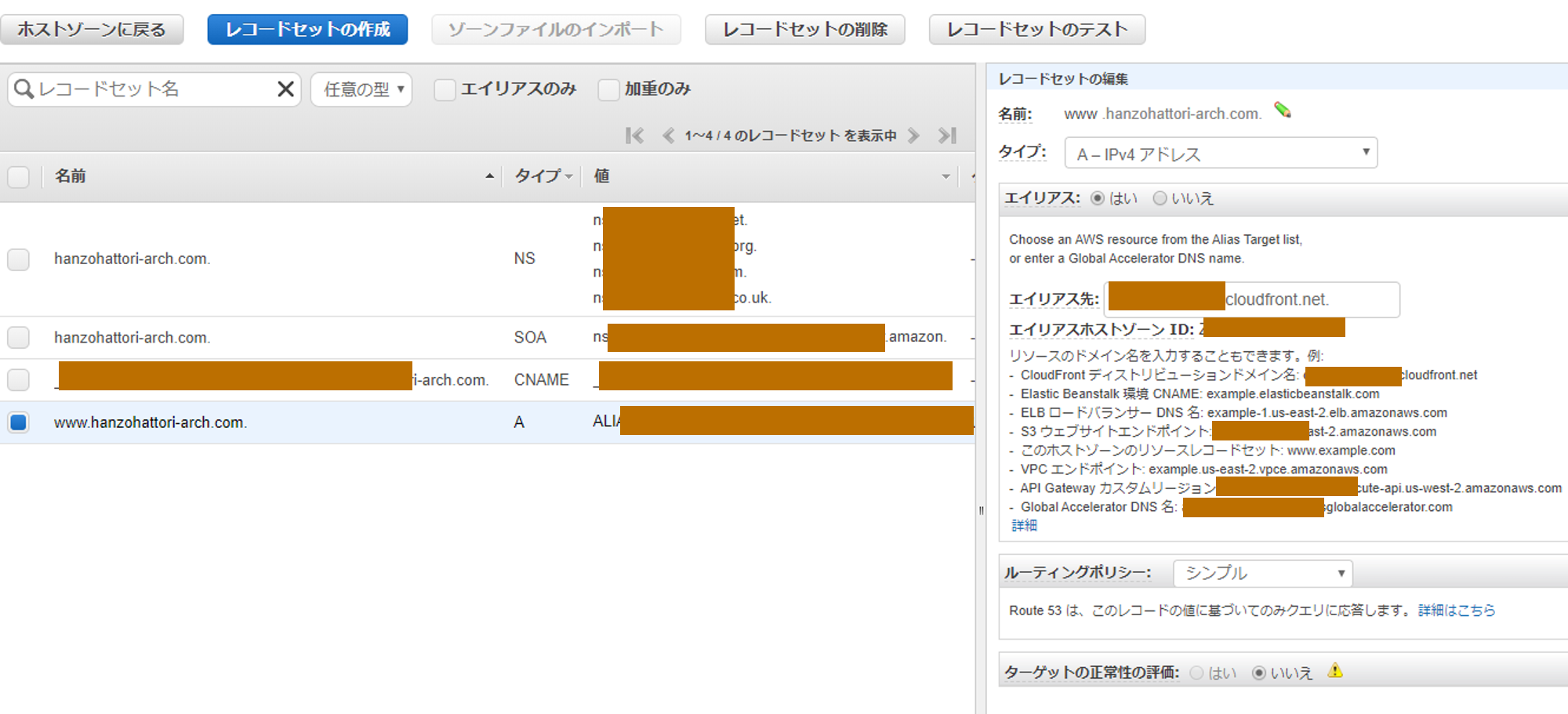
Route53でホストゾーンを作成した後、Aレコードを追加しました。
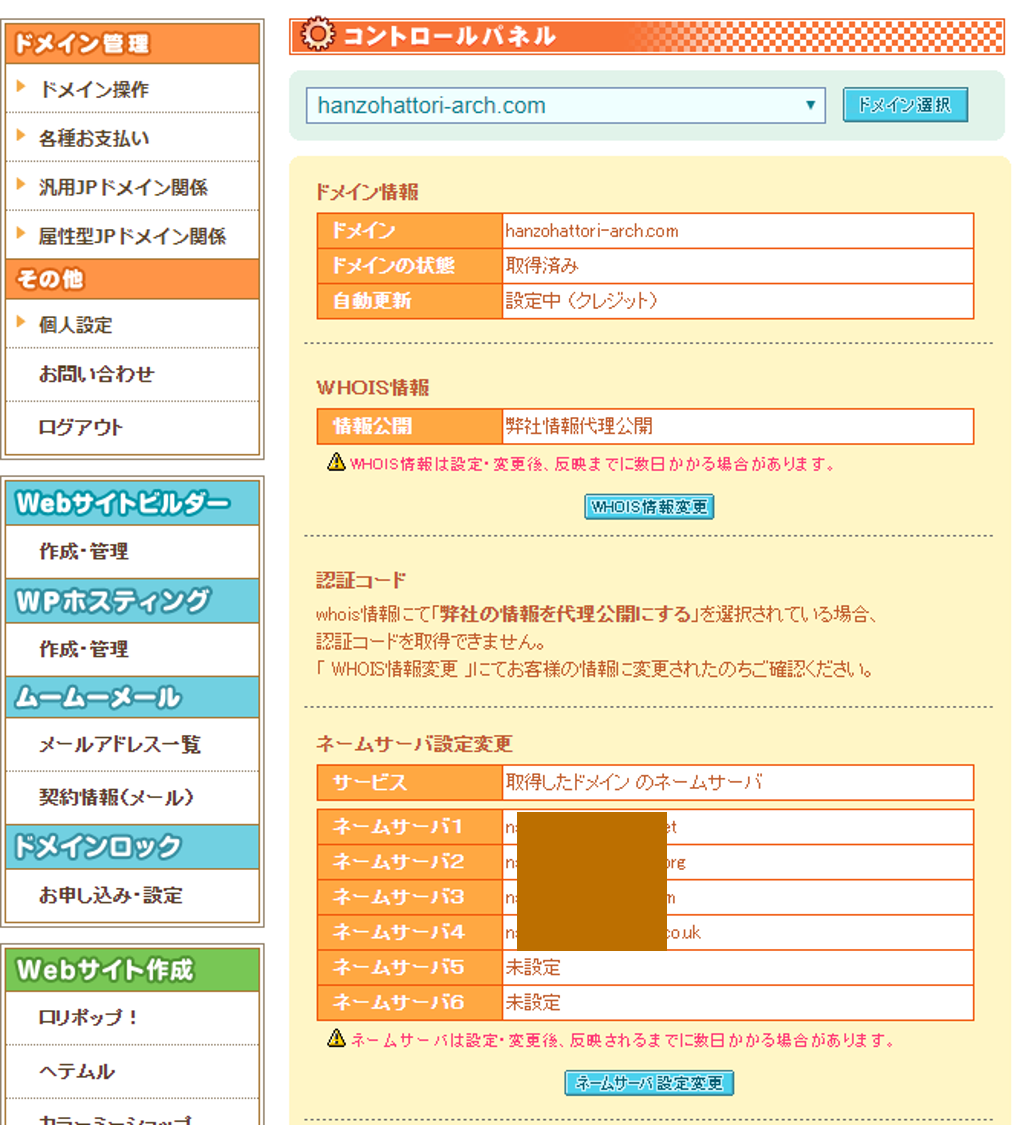
ムームードメイン側の設定はRoute53のNS側の設定を移してます。
参考資料
SORACOM エンジニアブログ 初めての「技術ブログ」書き方のご紹介
Developers.IO CloudFrontを使用してS3静的ウェブサイトを提供する手順
LIG CSSをつかい、要素の中央寄せ&文字色と背景色を変更してみよう
- 投稿日:2020-01-10T11:16:23+09:00
【AWS】AWSの勉強
勉強した事をつらつらと書いています。
AWSのネットワークについて
リージョンという考え方
AWSの各サービスが提供されている地域の事
アベーラビリティーゾーン
独立したデータセンターの事
東京リージョンでは、100Kmほど離れた場所にデータセンターがある。VPCとは
Virtual Private Cloud
AWS上に仮想ネットワークを作成できるサービスVPCはリージョンを跨いで構築することはできない
サブネット
VPCを細かく区切ったネットワーク
ネットワークを区切りたい時に利用する。
複数のアベイラビリティーゾーンを利用し、冗長性を確保することがベストプラクティスとして紹介されている。ネットワークのIPアドレスについて
IPアドレスとは
ネットワーク上の機器を識別するためのインターネット上の住所
特徴
- ネットワーク上で重複しない番号
- 32ビットの整数値
- 読みにくいので、8ビットずつ4つの組みに分け、ピリオドを入れて10進数で表現する
- 0.0.0.0〜255.255.255.255 まで
パブリックIPアドレス
インターネットに接続する際に使用するIPアドレス
重複すると正しく通信できなくなるのでICANNという団体が管理している
プロバイダーやサービス事業者から貸し出される(AWS上では、AWSから借りる)プライベートIPアドレス
インターネットで使用されないIPアドレス
下記の範囲内でアドレスを自由に使用することができる
利用できるIPアドレスの範囲 10.0.0.0 〜10.255.255.255 172.16.0.0 〜172.31.255.255 192.168.0.0 〜192.168.255.255 社内LANの構築やネットワークの実験時はプライベートIPアドレスを使用する
ネットワーク部とホスト部について
IPアドレスのは「ネットワーク部」と「ホスト部」がある
ネットワーク部とホスト部を表現するための表記方法CIDR表記(サイダー表記)
IPアドレスの後ろに「/」を書き、その後ろにネットワーク部が先頭から何ビット目までなのか記載する
例)
192.168.128.0/24サブネットマスク表記
IPアドレスの後ろに「/」を書き、ネットワーク部を表すビットと同じ部分を1に、ホスト部を表すビットを0にする
例)
192.168.128.0/255.255.255.0VPCの作成
流れ
- VPCを作成
- サブネットを作成する
- ルーティングを設定する
VPCの作成
AWSはデフォルトで1つ作成済みだが、基本的には、新しく作成して利用する
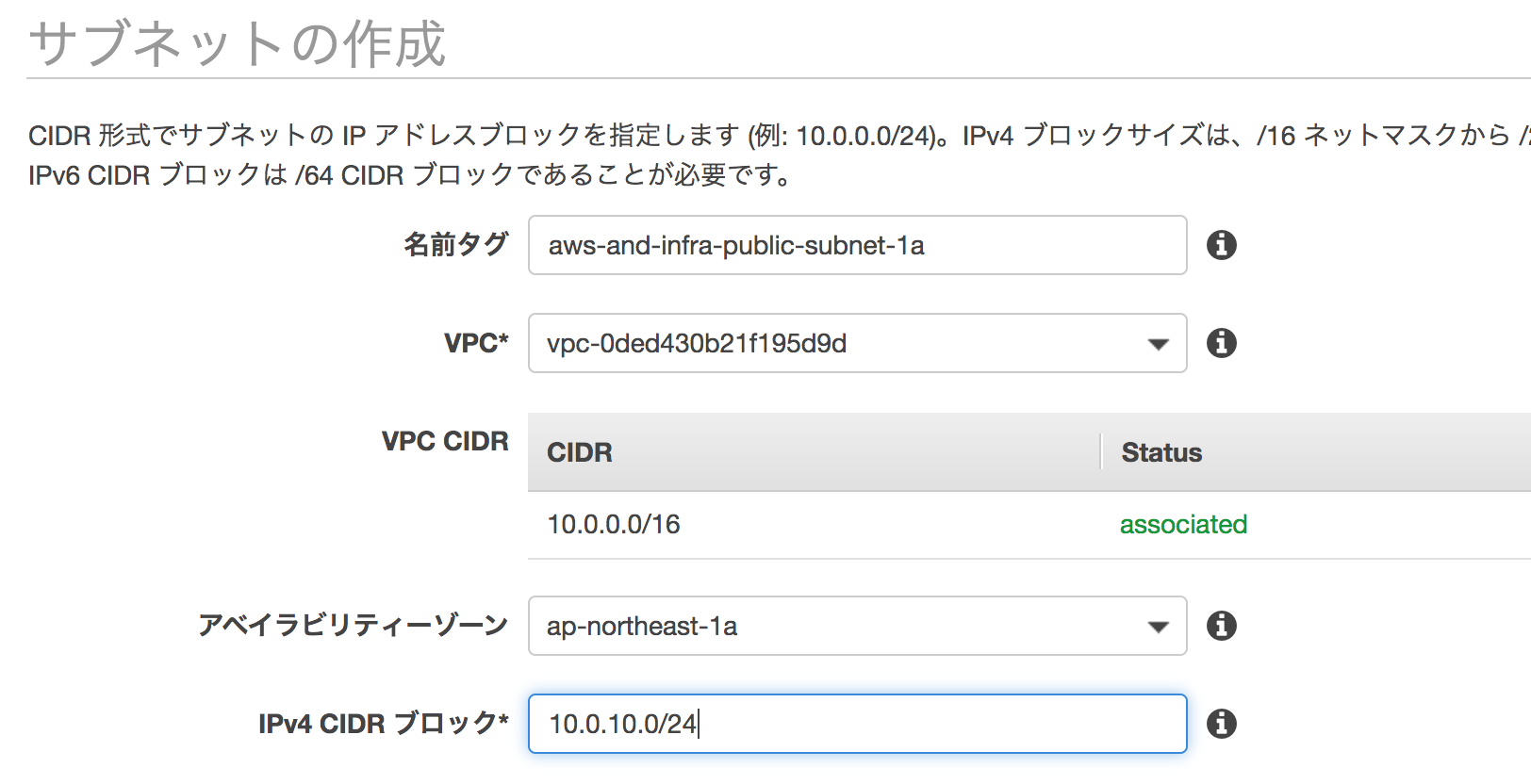
10.0.0.0/16を指定し、作成するサブネットの作成
IPアドレスの範囲を分割して使いやすくする
▪️特徴
- アベイラビリティーゾーン別でサブネットを構築し、物理的に離すことで対障害性を確保できる
- あるサーバのみインターネットに配置したくない場合に、利用できるパブリックサブネット
プライベートサブネットは上記と同様に作成する
名前aws-and-infra-private-subnet-1a
CIDR表記10.0.20.0/24ルーティングの説明
インターネットでは、ルーターがIPアドレスの行き先を管理しているため、ネットワークとネットワークがIPアドレスを通じて接続することができる。
ルートテーブルとは、「宛先のIPアドレス」と「次のルーター(AWSでは「ターゲット」という)」という形式で設定する。▪️ 初期のルーティングテーブルについて
送信先 ターゲット 10.0.0.0/16 local ▪️作成するルーティングテーブル
送信先 ターゲット 10.0.0.0/16 local 0.0.0.0/0 インターネットゲートウェイ インターネットに向けるために10.0.0.0/16以外の通信は、インターネットゲートウェイに対応させる
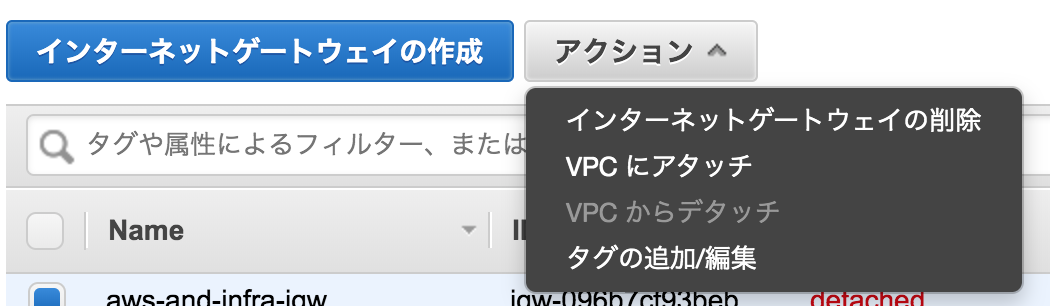
インターネットゲートウェイの設定
名前
aws-and-infra-igw
でインターネットゲートウェイを作成する作成後、まだVPCにアタッチされていない状態なので、作成したインターネットゲートウェイを選択し、アクションから、VPCにアタッチを選択する。
先ほど作成したVPCを設定する。ルートテーブルの設定
VPC設計のポイント
- 作成後は変更できないので、大きめに設定しておいた方が良い(大きさは/16を推奨)
- オンプレミスや他のVPCのレンジと重複しないように気をつける(相互接続する可能性がある場合は、重複厳禁)
VPCを分割するか?アカウントを分けるか?
- 異なるシステムの場合は、アカウントを分ける
- 同一システムの各環境は、VPCとアカウントのどちらを分けるか?
- 環境が違う場合は同一の物を使用するのはダメ
- アカウントをわけると、他の環境のリソースが見えず、作業しやすい。環境ごとにIAMの設定が必要
- VPCをわけると、IAMの設定が一度で良い。各環境のリソースが見えてしまい事故に繋がる。
サブネットのポイント
サブネットの分割はアベーラビリティーゾーンを基準に行う
- サブネットに割り当てられるルートテーブルは1つ
- インターネットアクセスの有無、拠点アクセスの有無などのルーティングポリシーに応じて分割する
- 高可用性のために、2つ以上のアベイラビリティーゾーンを利用するEC2を構築する
パブリックサブネットにサーバーを設置し、Apacheをインストールする。
EC2インスタンスを設置しよう
EC2はElastic Compute Cloudの略
特徴
- 数分で起動し、1時間または秒数で従量課金
- サーバーの追加・削除、マシンスペックの変更も数分で可能
- OSより上のレイヤについては自由に設定できる
作成手順
- AMIの設定
- インスタンスタイプの設定
- ストレージの追加
- セキュリティーグループの設定
- SSHキーペアの設定
AMIとは
Amazon Machine Imageの略
OSのイメージ。サーバーのテンプレートのような物インスタンスタイプについて
サーバーのスペックを定義したもの
例)
m5.xlarge
「m」:インスタンスファミリー
「5」:インスタンス世代
「xlarge」:インスタンスサイズストレージとは
サーバーにくっつけるデータの保存場所
EC2のストレージは2種類ある
- EBS (Elastic Block Store)
高い可用性と耐用性を持つストレージ
Snapshotを取得し、S3に保存可能
別途料金が発生
- インスタンスストア
インスタンス上に保存する方法
Stopするとデータが消えるEC2インスタンスの設定
- EC2インスタンスを設置
- Apacheをインストール
- ファイアウォールを設定
SSHとは
サーバーと自分のパソコンをセキュアにつなぐサービスの事
公開鍵認証
サーバーに本人だけがログインできるようにする物
EC2ではSSHログイン時に公開鍵認証を行っている公開鍵で暗号化して、秘密鍵で復号化する
- 自分⇨サーバー:自分のコンピュータにログインさせて
- サーバー⇨自分:適当なデータを公開鍵で暗号化して送る
- 自分⇨サーバー:秘密鍵で復号化したデータを送る
- サーバー⇨自分:元のデータと合っていたからログインしていいよ
ポート番号とは
プログラムのアドレス
同一コンピュータ内で通信を行うプログラムを識別するために利用するポート番号の決め方
- 標準で決めれらている番号 ウェルノウンポート番号(0〜1023まで)
- 動的に決まる番号 動的に割り当てる番号は49142〜65535までのいずれかの整数値をとる
ファイアウォール
AWSでは、セキュリティーグループがファイアウォールの役割を担っている
インターネットからサーバーに入ってくる通信 ⇨ インバウンド
サーバーから出て行く通信 ⇨ アウトバウンドElastic IPアドレス
EC2インスタンスのパブリックIPは、起動・停止すると別のIPアドレスが割り当てられる。
EC2インスタンスが起動している場合は、無料
EC2インスタンスを停止している場合は、有料後片付け
Elastic IPの関連付けの解除及び解放
EC2インスタンスを停止させるドメインを登録(Route53)
注意点(実際にドメインを購入するため、お金がかかる)
ドメインとは
IPアドレスは数字の列なので、人にとっては覚えづらい。
ドメイン名を用いてWebサイトにアクセスするようにするwww.example.co.jp
「www」:第4レベルドメイン
「example」:第3レベルドメイン
「co」:第2レベルドメイン
「jp」:トップレベルドメインICANN : ドメイン全体を管理
⬇︎
レジストリ : トップレベルドメインを管理し、レジストラに卸す
⬇︎
レジストラ : 一般消費者に販売しつつ、リセラに卸す
⬇︎
リセラ : 一般消費者に販売DNSとは
ドメインとサーバー(IPアドレス)をDNSで紐付ける必要がある
Domain Name System
- ネームサーバー
ドメインメ名とそれと紐付くIPアドレスが登録されているサーバー
ドメインの階層ごとにネームサーバーが配置され、そのネームサーバーが配置された階層のドメインに関する情報を管理する- フルリゾルバ
色々なネームサーバーに聞いてIPアドレスを調べて教えてくれるサーバーリソースレコード
DNSは様々な情報を管理している。
「ドメイン名とIPアドレスの紐付け」1つ1つの事をリソースレコードと呼ぶAレコード:ドメインに紐付くIPアドレス
NSレコード:ドメインのゾーンを管理するネームサーバー
MXレコード:ドメインに紐付くメール受信サーバー
CNAME:ドメインの別名でリソースのレコード参照先
SOA:ドメインのゾーンの管理情報Route 53
AWSのDNSサービス。ネームサーバーの役割を果たす
特徴
高可用性。SLA 100%
高速
フルマネージドサービス。DNSサーバーの設計・構築・維持管理が不要重要な概念
- ホストゾーン
DNSのリソースレコードの集合- レコードセット
リソースレコードのこと- ルーティングポリシー
Route 53がRoute Setに対してどのようにルーティングを行うか決める- ヘルスチェック
サーバーの稼働状況をチェックルーティングポリシー
- シンプル
- 加重
ABテスト時に使用する- レイテンシー
- 位置情報
地域限定配信時に使用できる- フェイルオーバー
コマンドでネームサーバー等を確認する
dig ドメイン名 NS +short【RDS】DBサーバーを構築しよう
EC2を借りてDBを構築することも可能だが、今回は、RDSを利用する
複数のアベイラビリティーゾーンに作れるように、プライベートサブネットを2つ作る必要がある。
RDSとは
フルマネージドなリレーショナルデータベースのサービス
- 構築の手間の軽減
- 運用の手間の軽減
- AWSエンジニアによるデータベース設計のベストプラクティスを適用
⇒コア機能の開発に注力できる各種設定グループ
- DBパラメータグループ:DB設定値を制御
- DBオプショングループ:RDSへの機能追加を制御
- DBサブネットグループ:RDSを起動させるサブネットを制御
RDSの特徴
■可用性の向上
⇒マルチAZ(アベイラビリティーゾーン)を簡単に構築
■パフォーマンスの向上
⇒リードレプリカを簡単に構築
■運用負荷の軽減
⇒自動的なバックアップ
⇒自動的なソフトウェアメンテナンス
⇒監視プライベートサブネットの追加作成
RDSを作成する際に、マルチAZに対応できるように複数のAZにプライベートサブネットを構築する必要がある
RDSの作成準備
以下の手順で作成を行っていく
1. セキュリティーグループの作成(EC2)
1. DBサブネットグループの作成
1. DBパラメータグループの作成
1. DBオプショングループの作成RDSのセキュリティーグループもEC2の設定を使う
今回は、「MySQL」を利用する。
セキュリティーグループの作成
今回は、
aws-and-infra-subnet-groupのセキュリティーグループを作成する。
パブリックサブネット上のEC2のIPアドレスで指定することも可能だが、AWSのセキュリティーグループも指定可能なので、今回は、AWSセキュリティーグループを指定する。DBサブネットグループの作成
Amazon RDSのサービスページに移動し、「サブネットグループ」を作成するページに移動する
RDSを構築する前にマルチAZを構成するために、サブネットグループを作成する必要があります。
今回は、1aと1cのプライベートサブネットを指定します。DBパラメータグループ
DBの設定を行うパラメータ
数がとても多いため、今回は、ポイントになるパラメータのみ確認を行うオプショングループ
プラグインを使いたい等の設定が可能
オプショングループを作成すると、デフォルトの物も作成されるが、今回は、自身で作成したグループを利用していく。RDSの作成
以下の手順で作成を行っていく
1. DBエンジン
2. 本番環境
3. DB詳細の指定
4. [詳細設定]の設定RDSの構築
今回は、MySQLの
8.0.15を選択する。
テンプレートという項目は、無料を選択する。RDSの停止は注意が必要
RDSの起動時にリソースが余っていないと停止できない事が有る。WebサーバーからRDSへ接続
MySQLのインストールを行う
sudo yum -y install mysqlを実行する
mysql -h エンドポイント -u ユーザー名 -pコマンドを打ち、パスワードを入力する。WordPressの構築について
WordPress用のデータベースの作成
- データベースの作成
- ユーザー作成
- ユーザーに権限付与
CREATE DATABASE aws_and_infra DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE USER 'saito_ryota'@'%' IDENTIFIED BY 'ryouta3110';
%で接続元はどこでもOKとしている。
GRANT ALL ON aws_and_infra.* TO 'saito_ryota'@'%';変更内容を更新
FLUSH PRIVILEGES;ユーザーの登録内容を確認
下記のコマンドでユーザーが正しく追加されているかを確認する。
SELECT user , host FROM mysql.user;
hostの部分は%となり、どこからでも接続できるようになっている。MysqlやEC2はコマンドの誤操作が発生すると困るため、接続はすぐに解除するようにする。
WordPressのインストール
- ライブラリのインストール
- WordPressのダウンロード
- WordPressの解凍
- WordPressのプログラムをApacheから見える場所に配置
- WordPressファイルの所有者・グループを変更
- Apacheの再起動
WordPressを動作させる為に、phpの最新版を取得する。
yumでinstallすると、最新バージョンを手に入れられないので、下記のコマンドでインストールする。
sudo amazon-linux-extras install -y php7.3
amazon-linux-extrasは、パッケージが集まっている場所下記のコマンドでインストールされているphpにあった依存関係等を構築してくれる。
sudo yum install -y php php-mbstring
cd ~でルートディレクトリに移動する。
下記のコマンドでWordPressの最新版をダウンロードする
wget https://ja.wordpress.org/latest-ja.tar.gz
ダウンロードしたファイルは圧縮されているので、解凍する必要が有る。
tar xzvf latest-ja.tar.gz解凍が完了したら、Apacheから見える所にファイルを配置する必要が有る為、
cd wordpress/でWordPressのディレクトリに移動する。
その後、下記のコマンドでファイルを移動する。
sudo cp -r * /var/www/html/
「/var/www/html/」はApacheが参照しているディレクトリ!
外部からアクセスされたら、ここのフォルダのデータが表示される。下記のコマンドで、ファイルのアクセス権を変更する。
sudo chown apache:apache /var/www/html/ -R
すべてのファイルの権限をApacheにした。下記のコマンドでApacheの実行状況を確認する。
sudo systemctl status httpd.service
現在、「実行中」なので、一旦再起動を行う。もしも、起動していない場合は、下記のコマンドで起動する。
sudo systemctl start httpd.service実行中だった場合は、下記のコマンドで再起動する。
sudo systemctl restart httpd.serviceWordPressの設定
- ドメイン名にアクセス
- WordPressの設定
設定
wp-config.php ファイルを作成していく。
Webページで作成する。TCP/IPプロトコルについて
プロトコルとは?
コンピュータ同士がネットワークを利用して通信するために決められた約束事
TCP/IPとは
インターネットを構築する上で必要なプロトコル群の総称
例)
アプリケーションプロトコル:HTTP,SMTP,FTP
トランスポートプロトコル:TCP,UDP
経路制御プロトコル:RIP,OSPF,BGP
インターネットプロトコル:IP,ICMP,ARPTCP/IPの階層モデル
階層 役割 プロトコル例 アプリケーション層 アプリケーション同士が会話する HTTP, DNS, SSH, SMTP トランスポート層 データの転送を制御する TCP, UDP ネットワーク層 IPアドレスを管理し、経路選択する IP, ICMA, ARP ネットワークインターフェイス層 直接接続された機器同士で通信する Ethernet, PPP HTTPについて
HyperText Transfer Protocol
インターネットでHTMLなどのコンテンツの送受信に用いられる通信の約束事
◼️クライアントがHTTPレスポンスを送り、
サーバーがHTTPレスポンスを返す。HTTPリクエストの中身
- リクエストライン
- ヘッダー
- ボディー から構成される
HTTPレスポンス
- ステータスライン
- ヘッダー
- ボディー から構成される
Chromeで確認してみる
見たいページで右クリックし、検証ページを開く
「Network」タブで見ると通信の中身が分かるTCPとUDPについて
トランスポート層とは
アプリケーショん間のコネクション確立や切断を担うTCP
Transmission Contorol Protocol
信頼性を保つために、送信するパケットの順序制御や再送制御を行う
信頼性のある通信を実現する必要が有る場合に使用する
◼️データの到達確認
送信したデータが届いたかを確認する
届いていれば再送する
確認応答とシーケンス番号を使用することで、再送制御などを行う
◼️コネクション管理
通信相手との間で通信を始める準備をしてから通信を行う。UDP
User Datagram Protocol
信頼性のない通信
高速性やリアルタイム性を重視する通信で使用するコネクションレスな通信サービス
◼️特徴
アプリケーションから送信要求のあったデータをそのままネットワークに流す
コネクションレスなのでいつでもデータを送信できる
プロトコルの処理も簡単なので高速
◼️向いている用途
動画や電話など即時性が必要な通信
総パケット数が少ない通信(DNS)
特定ネットワークに限定したアプリケーションの通信IPについて
ネットワーク層の役割は、最終的な宛先のコンピュータに届けること
- ルーティング 終点コンピュータまでのパケット配送
- パケットの分割
- 再構築処理
IPヘッダーに、送信元IPアドレスと宛先IPアドレスが含まれる
画像を配信する
インフラ設計における重要なポイント
観点 内容 具体的指標 可用性 サービスを継続的に利用できるか 稼働率・目標復旧時間・災害対策 性能・拡張性 システムの性能が充分で、将来においても拡張しやすいか 性能目標・拡張性 運用・保守 運用と保守がしやすいか 運用時間・バックアップ・運用監視・メンテナンス セキュリティー 情報が安全に守られているか 資産の公開範囲・ガイドライン・情報漏えい対策 移行性 現行システムの他のシステムに移行しやすくなっているか 移行方式の規定・設備やデータ・移行スケジュール 可用性が重要!
画像の保存場所をWebサーバーではなくS3にする理由
Webサーバーのストレージの画像で一杯になるのを防ぐ
HTMLへのアクセスと画像へのアクセスを分けることで負荷分散する
サーバーの台数を増やしやすくする
- 画像の保存場所は分離されていたほうがWebサーバーの台数を簡単に増やす事ができる。
コンテンツ配信サービスから配信することで、画像配信を高速化できるS3について
■特徴
安価で耐久性の高いAWSクラウドストレージサービス
0.023USD/GB・月 ⇒ 1GB約3円/月
容量無制限。1ファイル最大5TBまで■重要概念
バケット
- オブジェクトの保存場所。名前はグローバルなユニークである必要が有る
オブジェクト
- データ本体。URLが付与される
- バケット内オブジェクトは無制限
キー
- オブジェクトの格納URLパスS3の良く有る利用シーン
- 静的コンテンツの配信
- バッチ連携用のファイル置き場
- ログなどの出力先
- 静的ウェブホスティング
S3バケットの作成
パブリックアクセスをブロックしないを選択する。
⇒オブジェクトは公開可能となっているかを確認IAMの追加を行う
最後の確認画面のcsvは重要なので必ず保存する。
WordPressの設定
以下の手順で進めます
1. プラグインのインストール
2. 必要なライブラリをEC2にインストール
3. プラグインの設定WordPressの管理画面でプラグインの新規追加を行う
「WP Offload Media Lite for Amazon S3, DigitalOcean Spaces, and Google Cloud Storage」を選択する。上記のプラグインを動作させるためのライブラリをEC2にインストールする。
sudo yum install -y php-xml
でライブラリをインストールする。
sudo systemctl restart httpd.service
でサービスを再起動し、ライブラリを読み込むようにする。WordPressの設定画面で、「Offload Media」という物を選択し、S3へのアクセス設定例をコピーして、「wp-config.php」ファイルに追記する。
アクセスキーやシークレットキーは前述の手順でダウンロードしたcsvファイルの内容を利用する。
設定が完了し、再読み込みをするとWordPressの設定「Offload Media」のページが変更されている。今回は、サーバーにファイルを残したくないので、「ADVANCED OPTIONS」の「Remove Files From Server」を有効にする。
CloudFrontによる高速化について
CloudFrontとはどういう物なのか?
高速にコンテンツを配信するサービス(CDNのサービス)
■ 概要
- CDN:Contents Delivery Network
- オリジンサーバー上にあるコンテンツを、世界中に100箇所以上有るエッジロケーションから配信
■ 特徴
- 高速:ユーザーから最も近いエッジサーバーから画像を配信する
- 効率的:オリジンサーバーに付加をかけずに配信できるCloudFrontが有ることで、高速化され、S3の負荷が軽減される。
CloudFrontから配信する
以下の順序で作業を行います。
1. ディストリビューションの作成「Origin Domain Name」にS3のバケット名を記載する
「Origin Path」はバケット内のフォルダ等を指定する項目だが、今回は、指定しない。
CloudFrontからのみアクセスしたい場合は「Restrict Bucket Access」にチェックを入れる。
(今回は、S3との違いを比較する為に、Noのままを入れない)Locationsは「Use All Edge Locations」にする。
独自ドメインから配信する
以下の順序で作業を行います。
1. Certificate ManagerでSSLサーバー証明書の発行
2. CloudFrontのディストリビューションに独自ドメインを登録
3. Route 53で独自ドメインとClooudFrontドメインのCNAMEレコードを作成する
4. Officed Mediaで独自ドメインを登録するSSL証明書を取得する
作成したCloudFrontのIDを選択し、Editボタンをクリックする。
「Request or Import a Certificate with ACM」をクリックして証明書を発行する。
ドメイン名の部分に「*.starbucksblog.tokyo」と指定し、全てのサブドメインに証明書を発行する。
「starbucksblog.tokyo」も下に追加します。(追加しないと、ドメイン本体に証明書が発行されない。)続行をクリックすると、検証ページに移行し、DNSの設定を行う必要がある。
2つのドメイン共に一緒の値になっているはずなので、片方の設定を行う。Route 53での設定ボタンを押す
続行を押す
AWSが検証を完了させるまで、待機します。CloudFrontの独自ドメイン 設定
作成したCloudFrontのIDを選択し、Editボタンをクリックする。
そこの「Alternate Domain Names」に配信したいドメイン名を記載する。
今回は、「static.starbucks.tokyo」を指定する。SSL Certificateを「Custom SSL Certificate」を選択し、発行したSSL証明書を選択する。
その他はそのままで作成をクリックする。
Route 53でCloud Frontのドメイン名を登録する
レコードの作成を選択し、作成する。
名前:「static.starbucksblog.tokyo.」
タイプ:「CNAME」
ルーティングポリシー:「シンプル」Offload Mediaの設定を行う
Word Pressの設定でOffload Mediaの設定画面を開く
下の方に「Custom Domain (CNAME)」という項目が存在するので、ONに変更し、「static.starbucksblog.tokyo」を入力し、設定を保存する。Webレイヤを冗長化しよう
Webサーバーを2台にしてELBを用いて冗長化する。
稼働率を上げる方法
■稼働率とは
障害発生間隔と平均復旧時間で構成されている。稼働率を上げるためには、
- 障害発生間隔を長くする
- 平均復旧時間を短くするそのための手法として、「冗長化」する必要がある。
単一障害点(SPOF)を無くすSPOF:Single Point Of Failure
要素を組み合わせて全体の稼働率を高くする
◼️冗長化構成
Active-Active:冗長化した両方が利用可能
Active-Standby:冗長化した片方は利用可能
- Hot Standby:スタンバイ側は普段起動しすぐに利用可能
- Warm Standby:スタンバイ側は普段起動しているが、利用するのに準備が必要
- Cold Standby:スタンバイ側は普段停止している負荷を適切なプロビジョニングで回避する
アクセス数などを予測し、適切にリソースを準備(プロビジョニング)ことで、負荷を捌けるようにする
- スケールアップ
個々の要素の性能を向上させる
ある程度の規模まではスケールアップがコストパフォーマンス的に良いが、一定範囲を超えると悪くなる
- スケールアウト
個々の要素の数を増やす
ある程度の規模を超えそうであれば、スケールアウトで対応する
最低限用意しておくべきなのがN +1構成、安全なのはN +2構成ロードバランサとは何か?
各サーバーにアクセスを振り分ける
ELB(Elastic Load Balancing)とは何か?
ELBは、AWSクラウド上のロードバランサー
◼️特徴
- スケーラブル:ELB自体にも負荷に応じて自動でスケールアウト・スケールインする。
- アベイラビリティゾーンをまたがる構成:ELBを利用する場合、一つのリージョンを選び、そのリージョン内のアベイラビリティゾーンにまたがるように構成できる
- 名前解決:ELBにはDNS名が割り当てられる。ELBへの接続ポイントへのアクセスにはDNSを使用する(IPアドレスを使用すると自動でスケールできなくなる)
- 安価な従量課金:従量課金で利用可能
- マネージドサービス:運用が楽AMIからEC2を作成
以下の手順で行います
1. パブリックサブネットの作成
2. AMIの作成
3. AMIからEC2を作成パブリックサブネットの作成
VPCのサブネットの作成からパブリックサブネットの作成を行う
名前:aws-and-infra-public-subnet-1c
CIDR:10.0.11.0/24
サブネットの作成を行ったら、作成したサブネットを選択し、「ルートテーブル」のタブで「ルートテーブル関連付け」を選択「aws-and-infra-public-route」を選択する。
AMIの作成
EC2のページの「アクション」から、「イメージの作成」を選択する
名前を指定して、イメージの保存を行う。AMIの作成が完成したら、「起動」ボタンを押す
インスタンスタイプは「t2.micro」を選択する。
その後、「次の手順」ボタンを押し、更に設定を行う。ネットワーク:「aws-and-infra-vpc」
サブネット:「aws-and-infra-public-1c」
自動割り当てパブリックIP:「有効」
キャパシティーの予約:「なし」
プライマリIP:「10.0.11.10」
「次のステップ」へ
ストレージの設定はそのままで大丈夫セキュリティグループの設定へ
「既存のセキュリティグループの利用」をチェックし、「aws-and-infra-web」を選択する。「起動」ボタンを押下すると、セキュリティキーの設定が必要なため、「既存のキーペアの選択」を選択し、以前発行したsshキーを指定する。
ELBで負荷を分散しよう
EC2のロードバランサーから作成する。
今回は、「Application Load Balancer」を選択する。
名前:「aws-and-infra-alb」
スキーム:「インターネット向け」■アベイラビリティーゾーン
VPC:aws-and-infra-vpc
アベイラビリティーゾーン:1aと1cのそれぞれのPublicサブネットを指定するセキュリティーグループの設定は以下の設定にする
次のルーティングの設定を下記の設定にする。
ターゲットの登録に、起動中の2台を指定する。
独自ドメインにアクセスが来た場合にELBへアクセスするように変更する
Route53の設定を変更する。
Route53のコンソールにアクセスし、ホットゾーンの設定に行く
今はAレコードにEC2のパブリックIPが選択されている。
Aレコードの内容を編集していく
エイリアスを「はい」に変更する
指定する欄でalbを指定する。変更を行う
ELBを運用する際のポイント
- サーバーをアベイラビリティゾーンにまたがって配置する
- Webサーバーをステートレスに構築する
状態を持たないように構築する【RDS】DBレイヤの冗長化
可用性の部分をここで扱う
DBサーバーをマスタースレーブ方式にする事で、DBの冗長化を行うマスタースレーブの入れ替わりが発生した場合も、同じエンドポイントで接続できる為、操作を行う必要は無い。
RDSの設定を変更するだけで、変更が可能になる
2台分のRDSの料金が発生する。【Cloud Watch】システムを監視しよう
「運用・保守性」の部分
監視して、通知しなければならない。EC2のCPU使用率が60%を超えた場合、CloudWatchでアラームを出し、SNSで通知する構成を作る。
システム監視について
システムを正常な状態に保てるように、稼働状況やリソースを監視すること
■ 目的
- すぐに障害発生を確認できるようにする
- 復旧にすぐに取りかかれるようにする
■ 中身
1. 「正常な状態」を監視項目+正常な結果の形で定義する
2. 「正常な状態」でなくなった際の対応方法を監視項目ごとに定義する
3. 「正常な状態」であることを継続的に確認する
4. 「正常な状態」でなくなった場合には通知が来るようにし、すぐ「正常な状態」に復旧させる■ 監視の種類
- 死活監視
正常にシステムが動作しているかを確認
- メトリクス監視
パフォーマンスを定量的に確認
指標を決め、指標が閾値以上・以下となっているかを把握■ 監視のポイント
1. システムや利用状況は変わるので、足りない監視を都度足していく
2. 最初は基本的な要素でOK
※注意点:CloudWatchだとメモリの監視ができないCloudWatchについて
AWSサービスの監視モニタリングができるサービス
■ 概要
AWSサービスのメトリクス(リソースの状況)を監視する
メトリクスに対して閾値を登録し、その条件を満たしたら通知するCloudWatchの設定
以下の流れで設定します。
1. CloudWatchのアラームを作成
2. アラートを確認IAMについて
セキュリティーの部分
AWSのサービスを利用するユーザー権限を管理するサービス
■ 概要
- AWSリソースをセキュアに操作するために、認証・認可の仕組みを提供する
- 各AWSリソースに対して別々のアクセス権限をユーザー毎に付与できる
- AWS IAMの利用料は無料■ 用語
- ポリシー
アクセス許可の定義
- ユーザー
個々のアカウントのユーザー
- グループ
IAMユーザーの集合体。
複数のユーザーにアクセス許可を付与する作業を簡素化
- ロール
一時的にアクセス許可したアカウントを発行できる。
EC2やLambdaなどのAWSリソースに権限を付与する為に使用 → AWSのサービスに権限を付与するときに利用するIAMのベストプラクティス
- 個々人にIAMユーザーを作成する
- ユーザーをグループに所属させ、グループ権限を割り当てる
- 権限は最小限にする
必要に応じて足していく- EC2インスタンスから実行するアプリケーションには、ロールを使用する
- 定期的に不要な認証情報を削除する
今後に向けて

- 投稿日:2020-01-10T10:45:29+09:00
【クラウド初心者向け】お客様の選択による分岐と外線転送
概要
- お客様の選択した数字により処理が分岐します。
- 繰り返しは3回とします。
- あらかじめ指定した番号の外線に発信します。
使用ユーザー
- IAMユーザー
手順
AWSにサインインします。
- アカウント、ユーザー名、パスワードを入力してサインインします。
アカウント内(IAM)で作成したユーザーを使用してコンソールにサインインする『AWSマネジメントコンソール』画面の右上にある《リージョン名》をクリックし、ドロップダウンます。
『AWSマネジメントコンソール』画面にある「サービスを検索」にConnectと入力し、検索結果から《Amazon Connect》をクリックし、Amazon Connect コンソール(https://console.aws.amazon.com/connect/)を開きます。
Amazon Connectのインスタンス一覧が表示されるので、該当のインスタンスをクリックします。
インスタンスの概要が表示されるので《管理者としてログイン》をクリックします。
左側のメニューから《問い合わせフロー》をクリックします。
Amazon Connectの案内音声を人間の音声に変更で作成した問い合わせフローをクリックします。
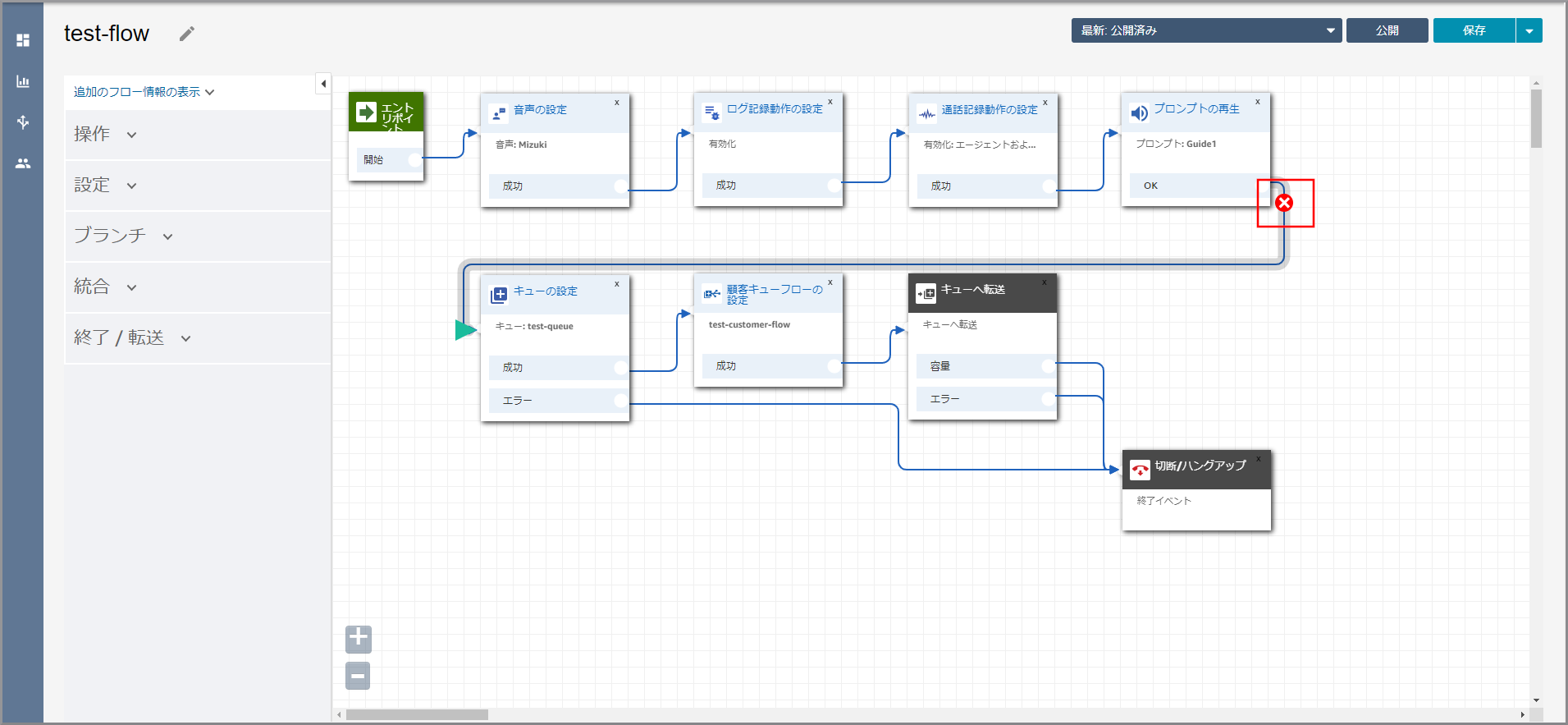
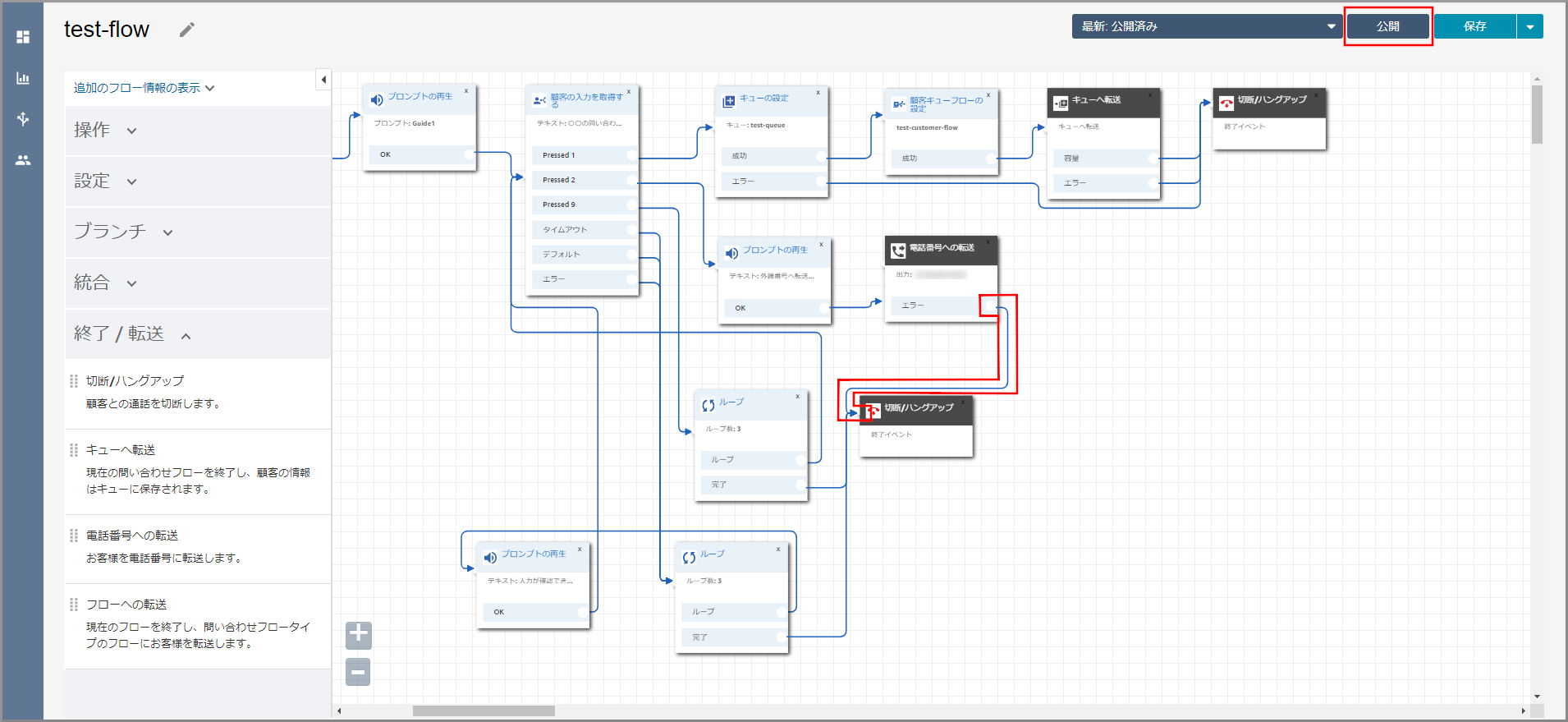
《プロンプトの再生》から出ている矢印にカーソルを合わせて『×』ボタンをクリックして矢印を消します。
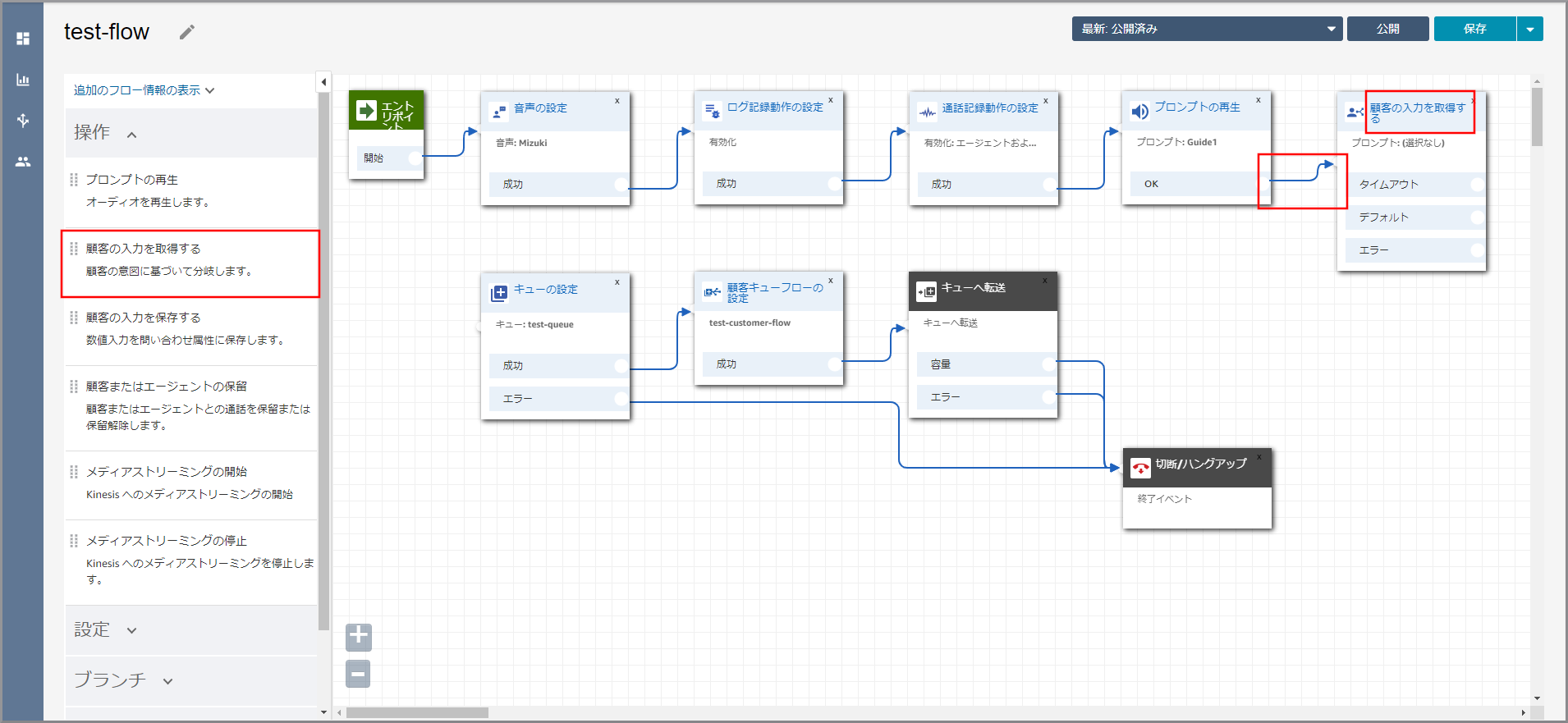
左側メニューの「操作」から《顧客の入力を取得する》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《顧客の入力を取得する》のタイトル部分をクリックします。
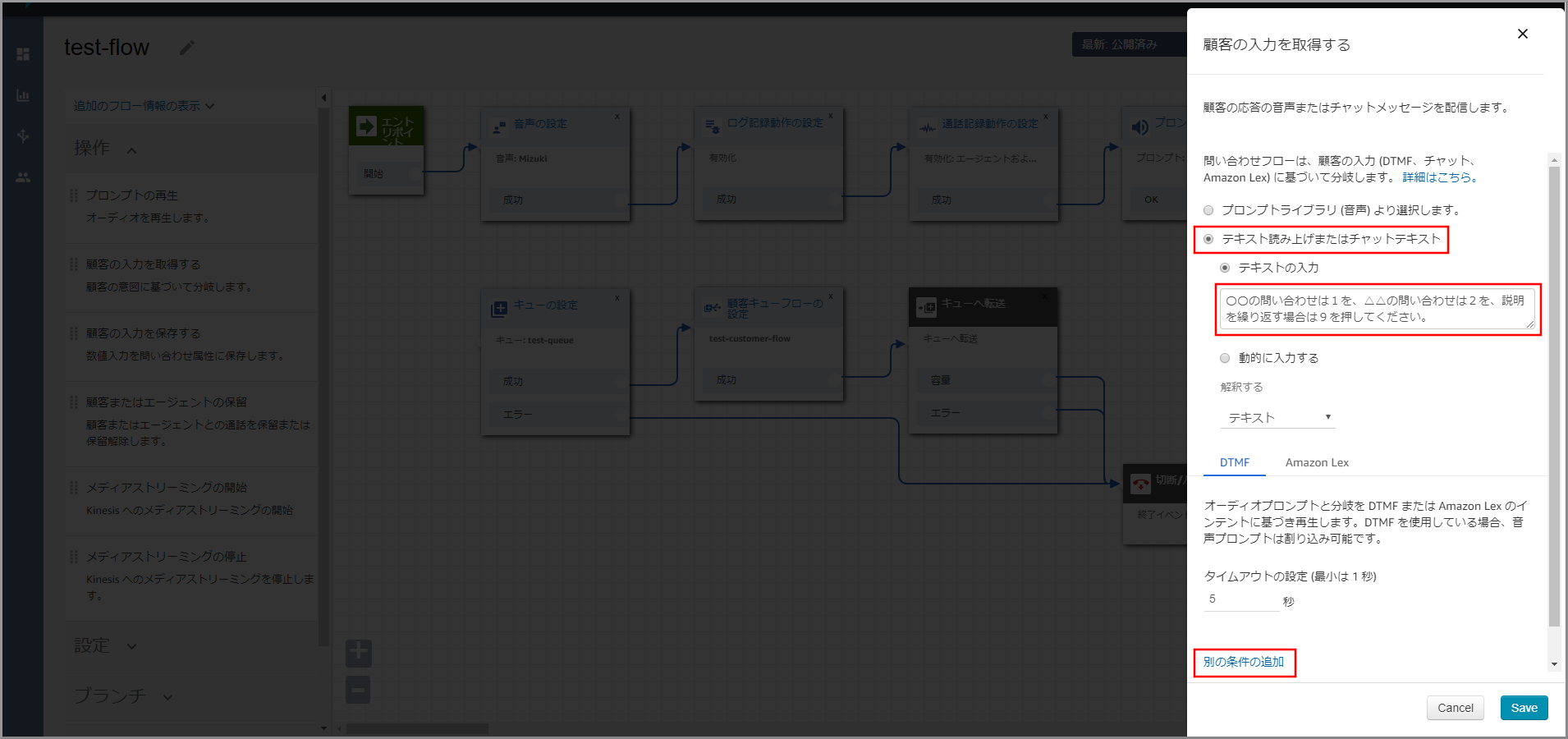
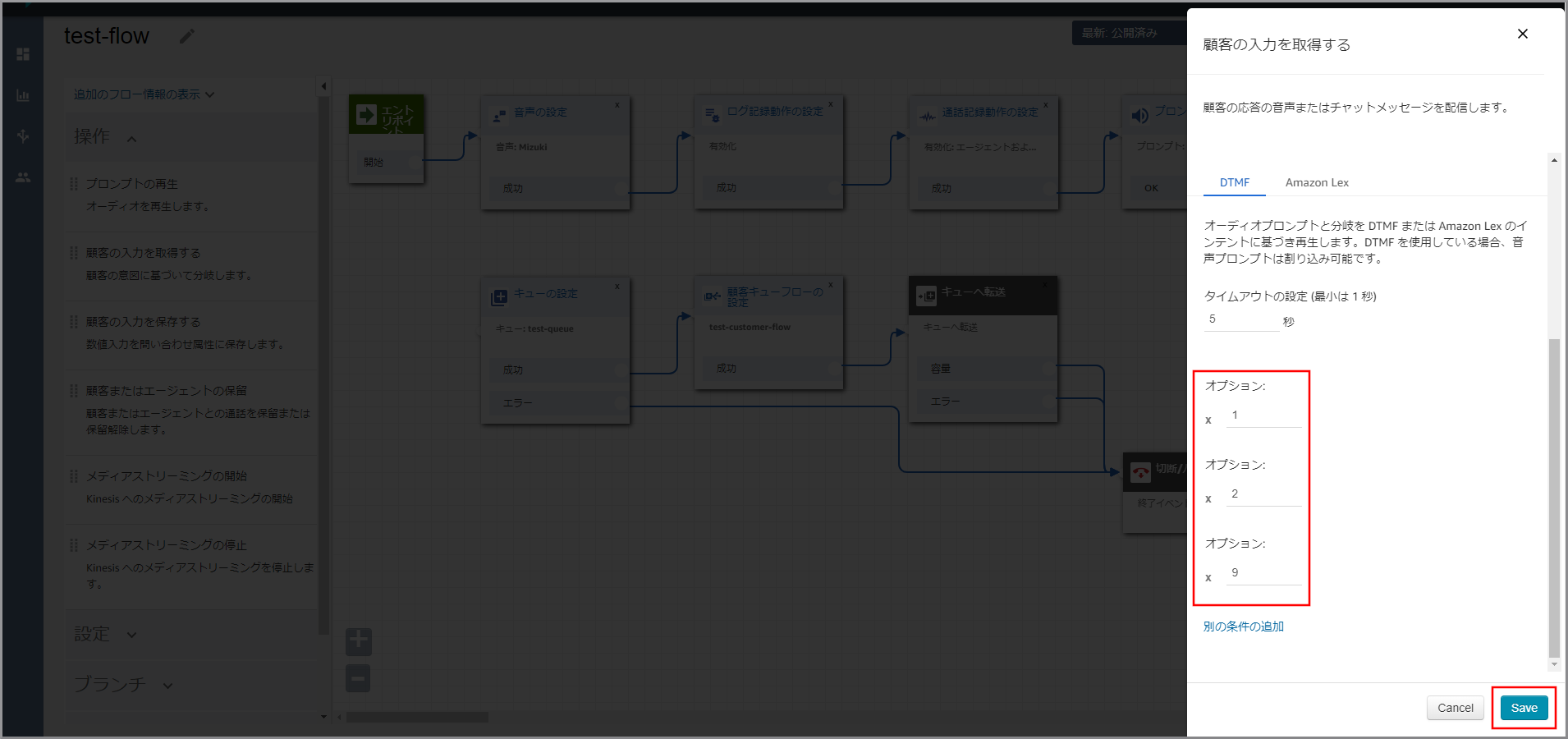
右側に「顧客の入力を取得する」画面が表示されるので、以下の項目を選択、入力して《別の条件の追加》を3回クリックします。
- テキスト読み上げまたはチャットテキスト:選択します。
- テキストの入力:選択し、音声案内する文言を入力します。
「オプション」が3個表示されるので、それぞれ1、2、9と入力して《Save》をクリックします。
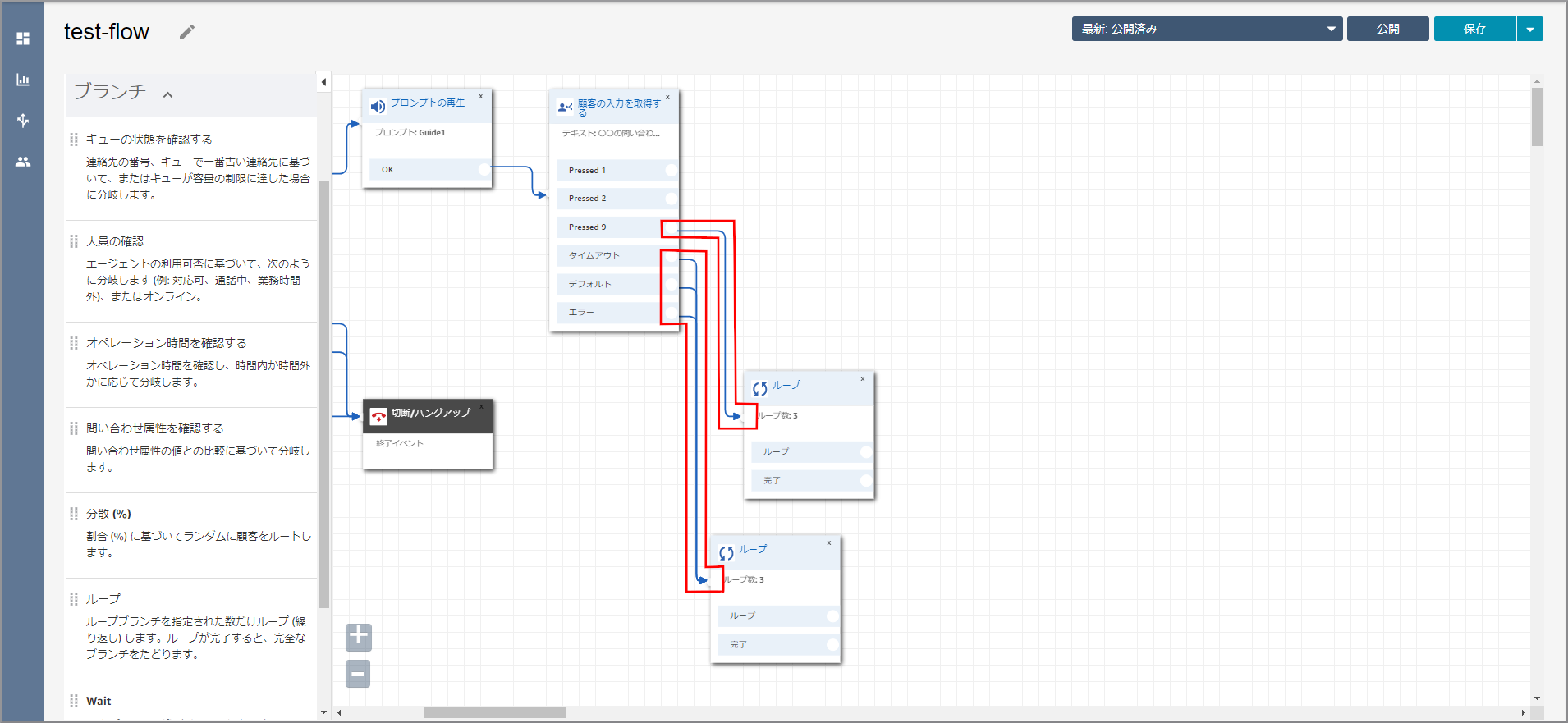
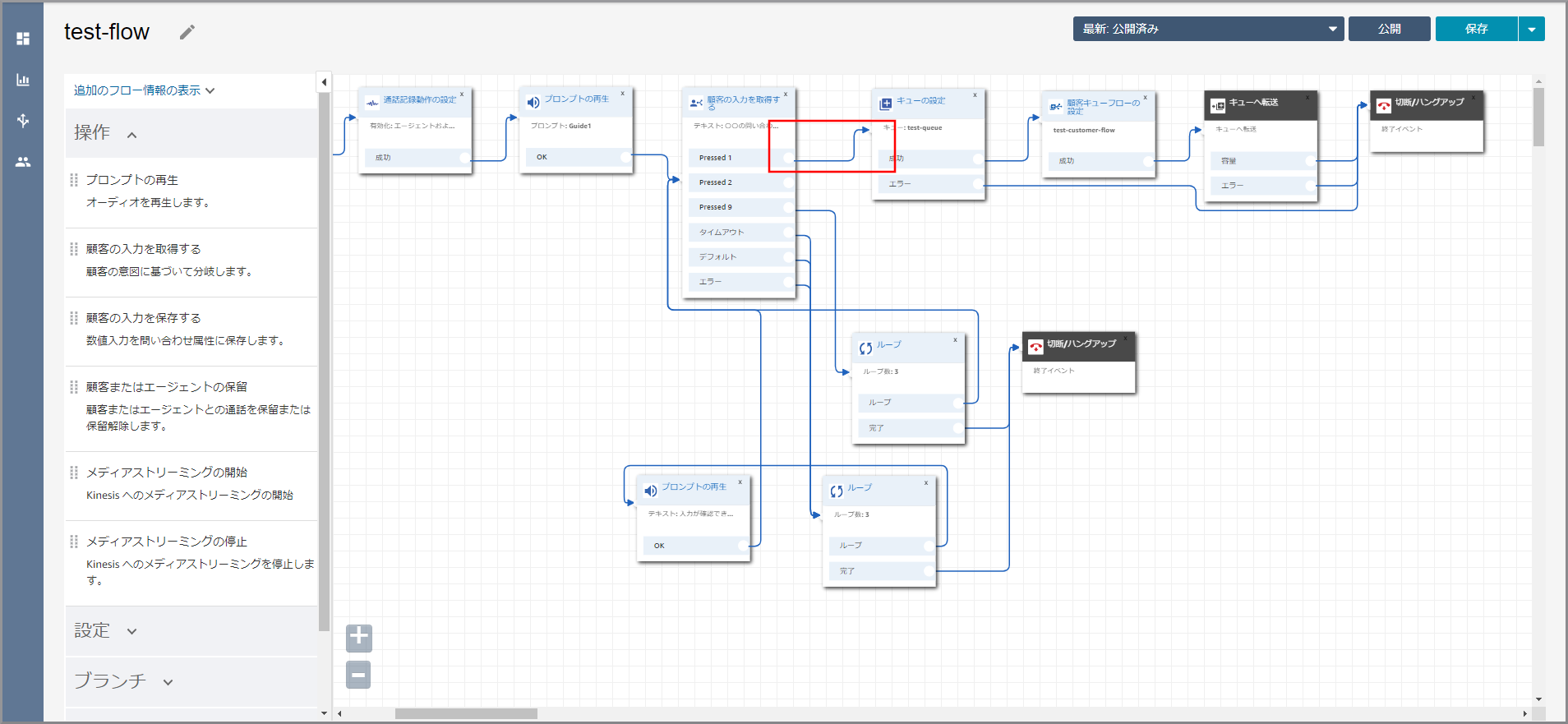
左側メニューの「ブランチ」から《ループ》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続します。
顧客の入力を取得するの説明 タイムアウト 入力しない時間がタイムアウトの設定に設定した秒数経過した場合に発生します。 デフォルト 入力値(オプション)として想定していない番号が入力された場合に発生します。
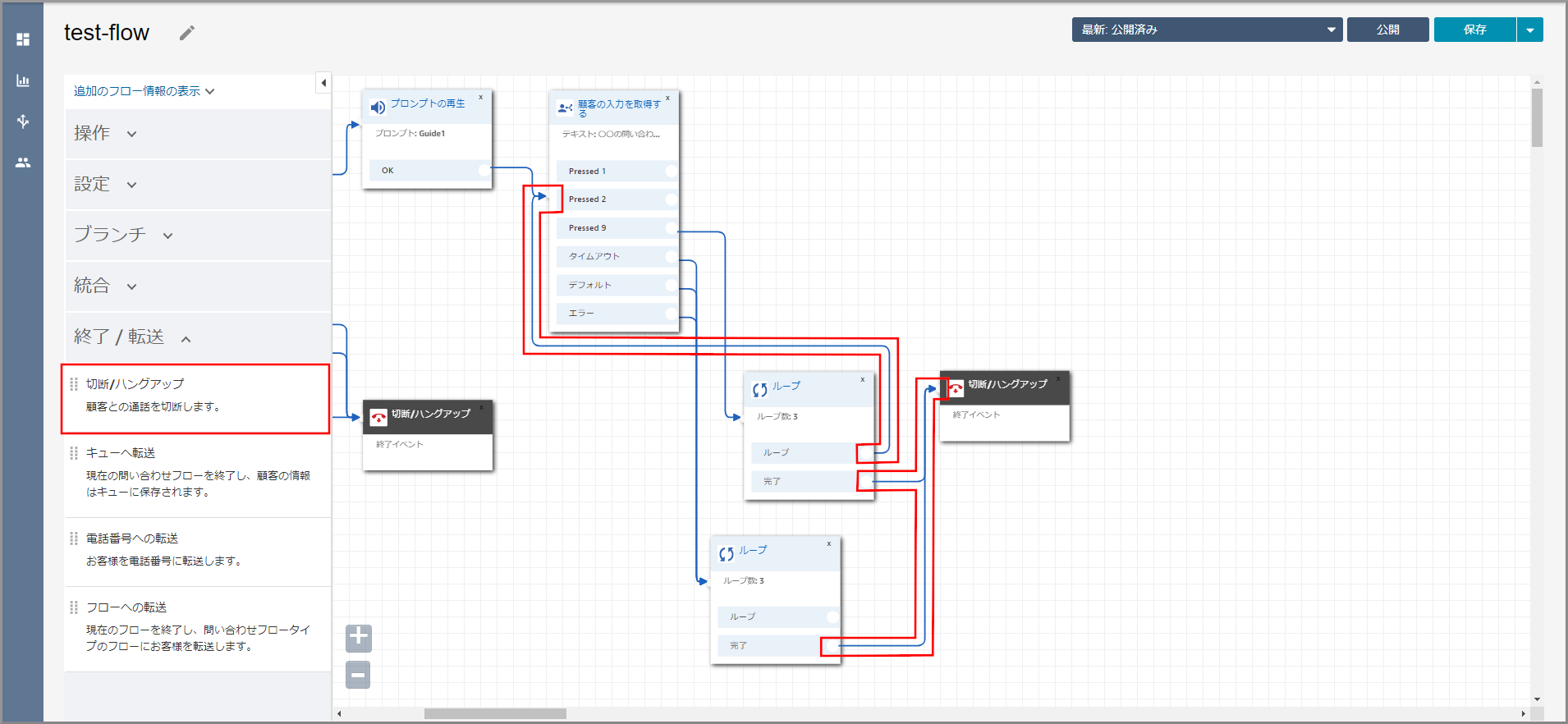
左側メニューの「終了/ハングアップ」から《切断/ハングアップ》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続します。
左側メニューの「操作」から《プロンプトの再生》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《顧客の入力を取得する》のタイトル部分をクリックします。
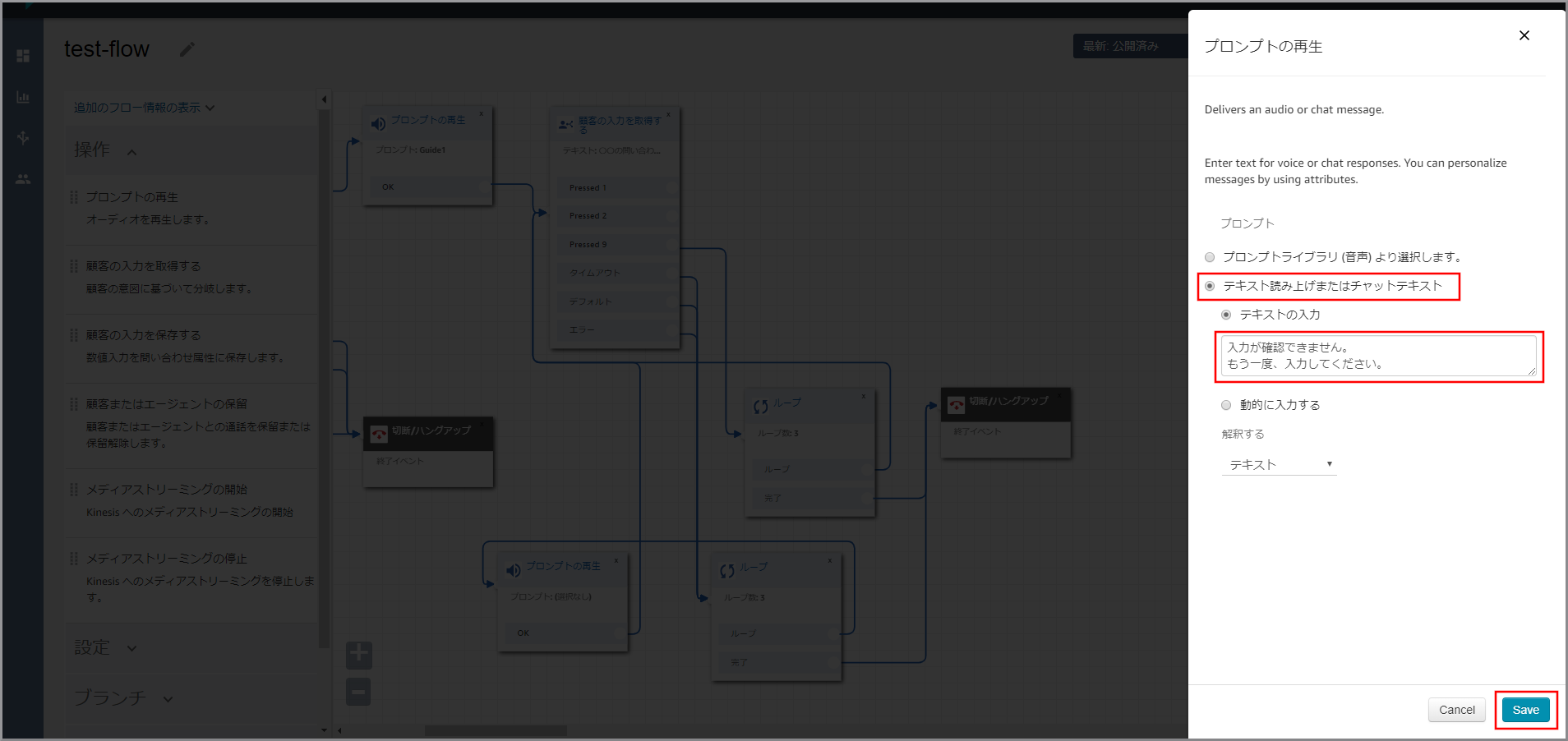
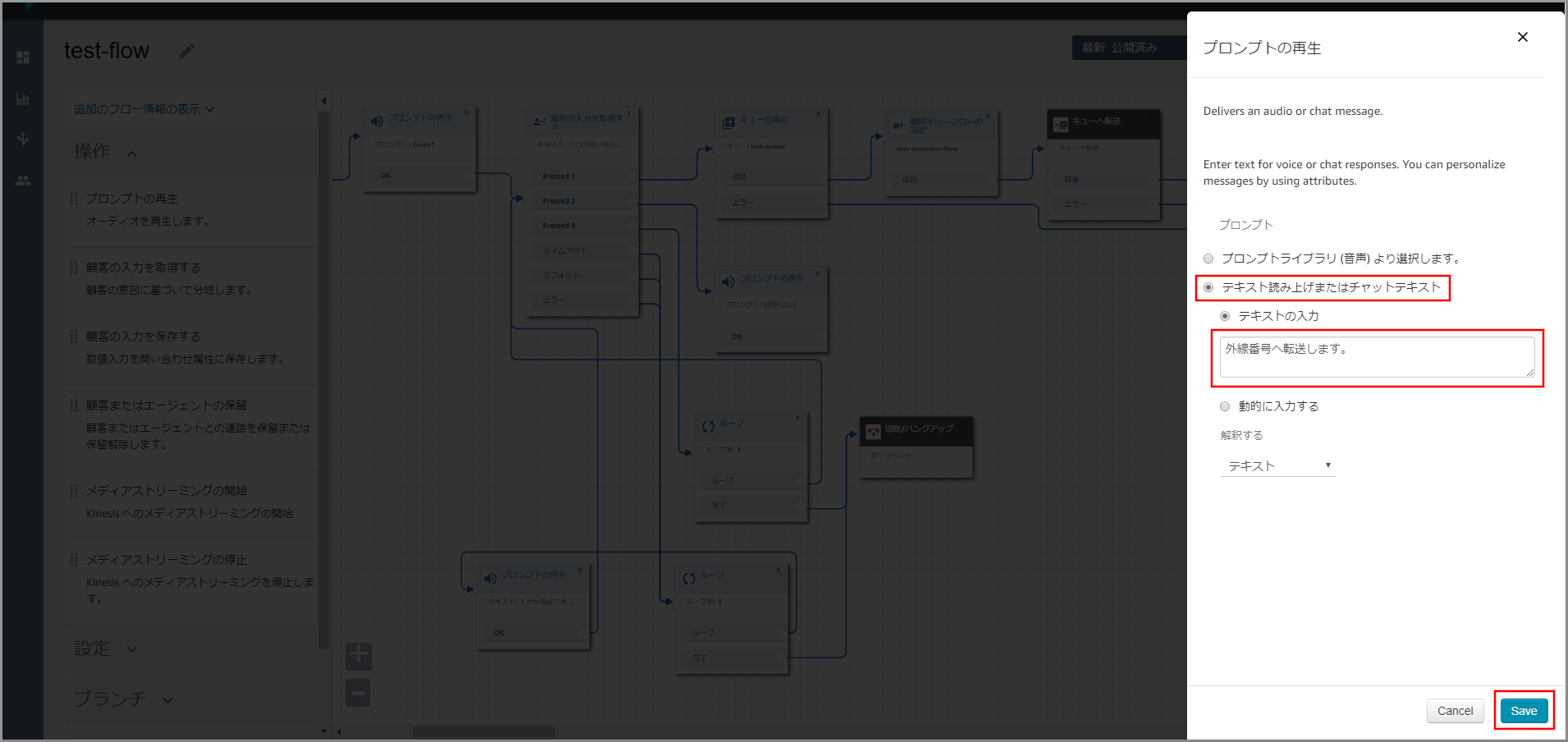
右側に「プロンプトの再生」画面が表示されるので、以下の項目を選択、入力して《Save》をクリックします。
- テキスト読み上げまたはチャットテキスト:選択します。
- テキストの入力:選択し、音声案内する文言を入力します。
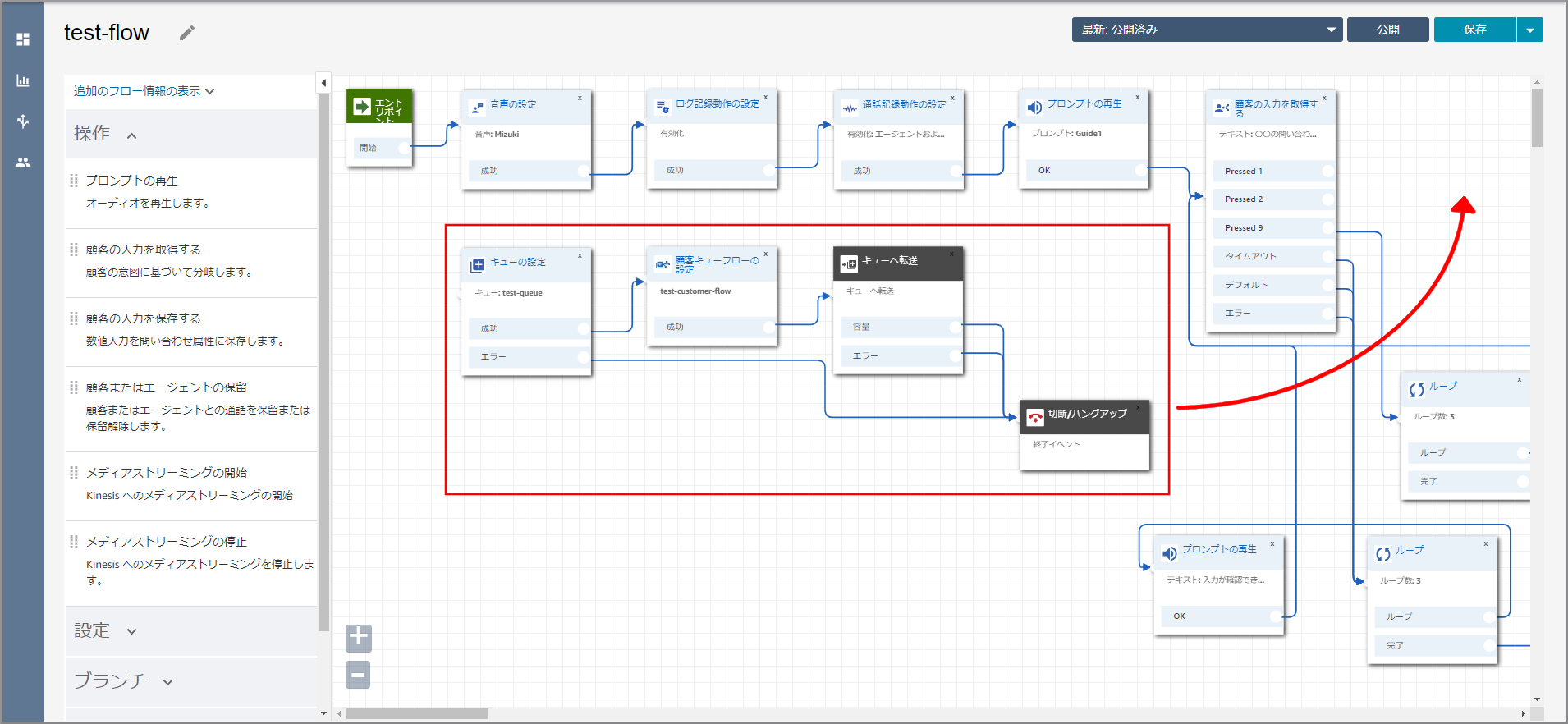
《キューの設定》~《切断/ハングアップ》を《顧客の入力を取得する》の後ろに移動します。
《顧客の入力を取得する》と《キューの設定》を矢印で接続します。
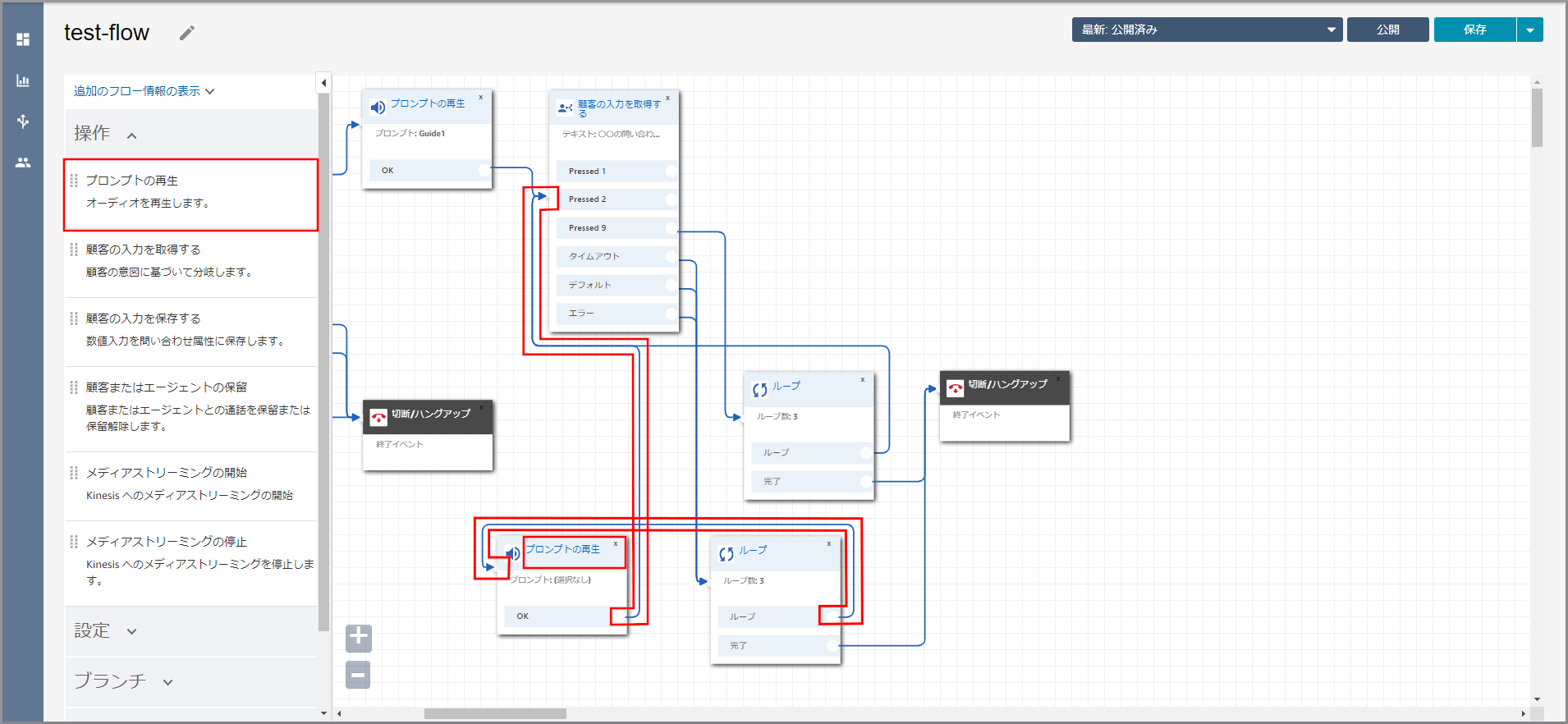
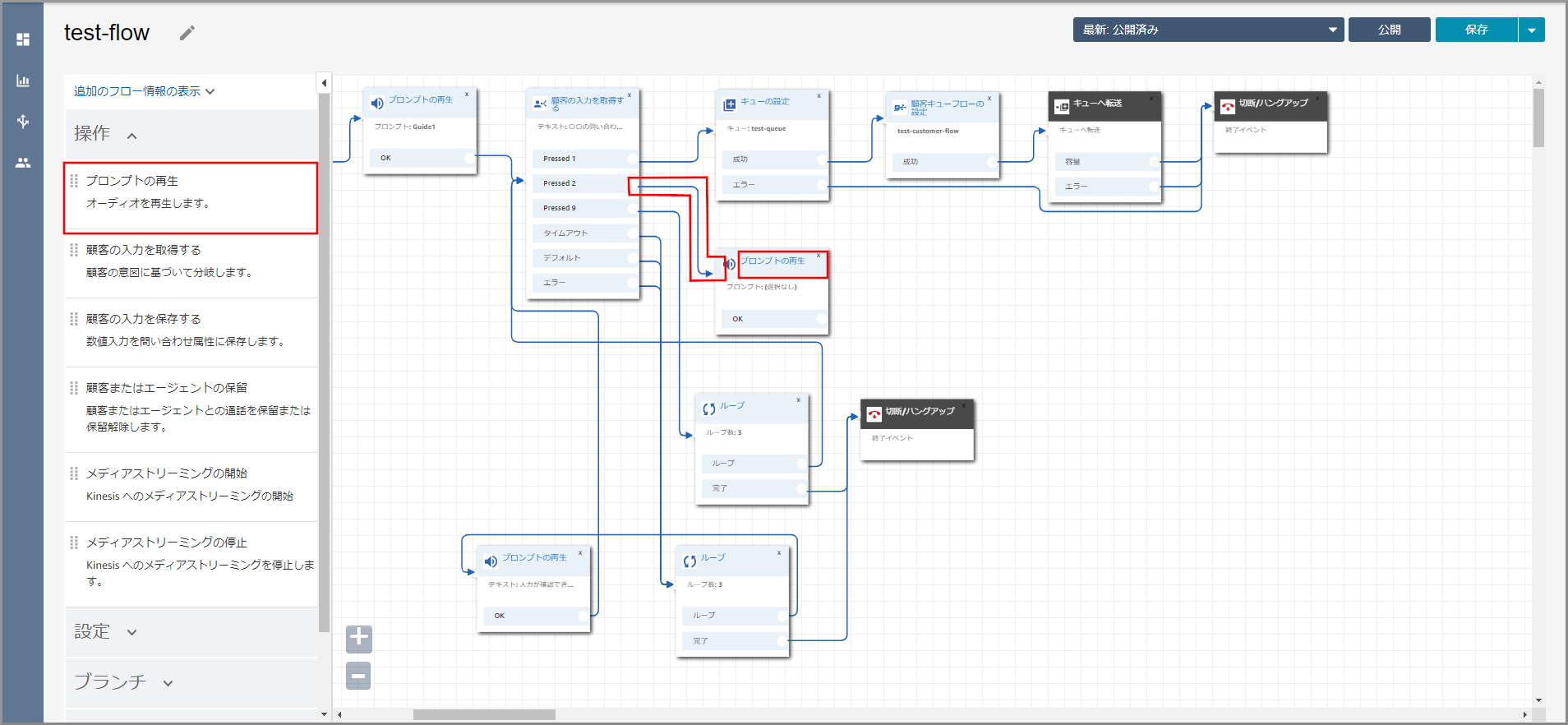
左側メニューの「操作」から《プロンプトの再生》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《プロンプトの再生》のタイトル部分をクリックします。
右側に「プロンプトの再生」画面が表示されるので、以下の項目を選択、入力して《Save》をクリックします。
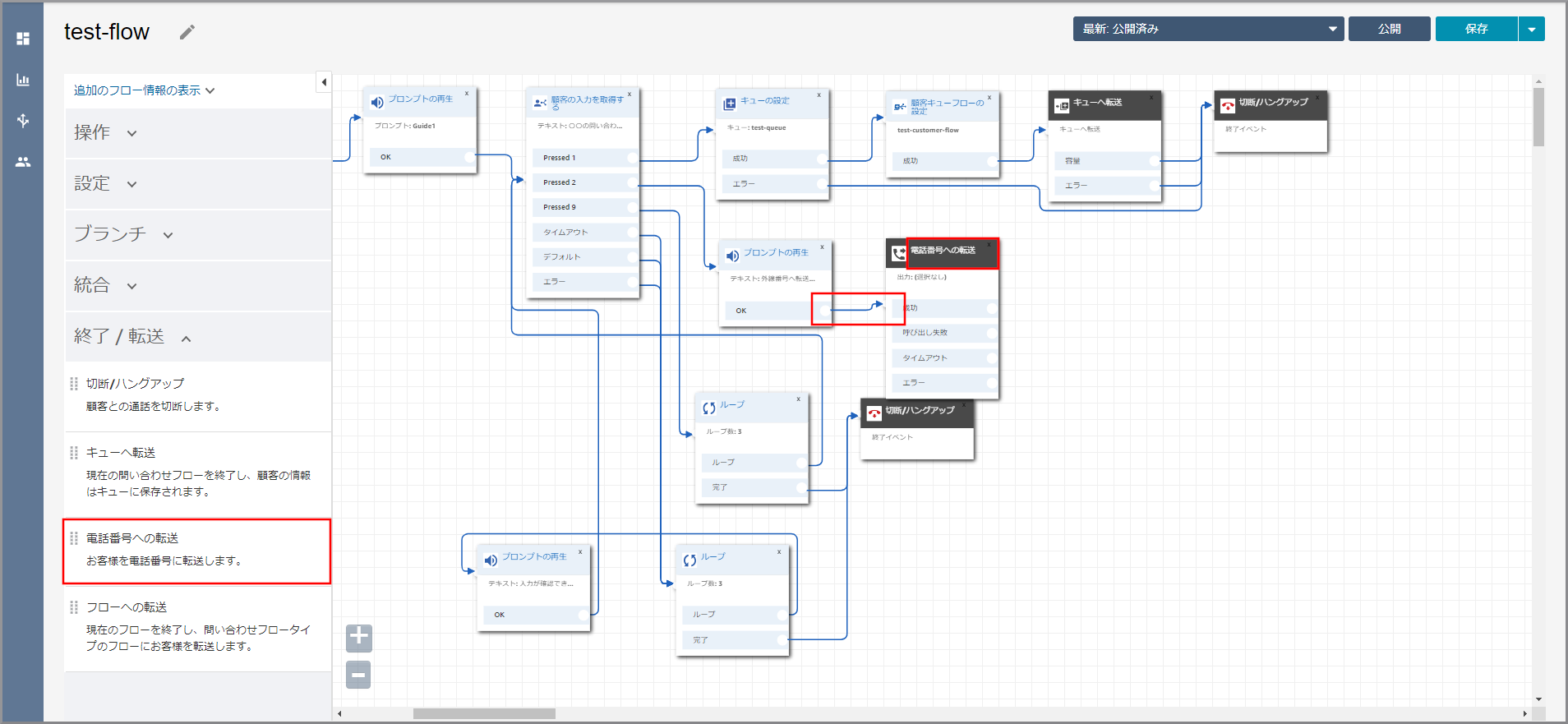
左側メニューの「終了/転送」から《電話番号への転送》をフロー部分にドラッグ&ドロップし、オブジェクト同志を矢印で接続後に《電話番号への転送》のタイトル部分をクリックします。
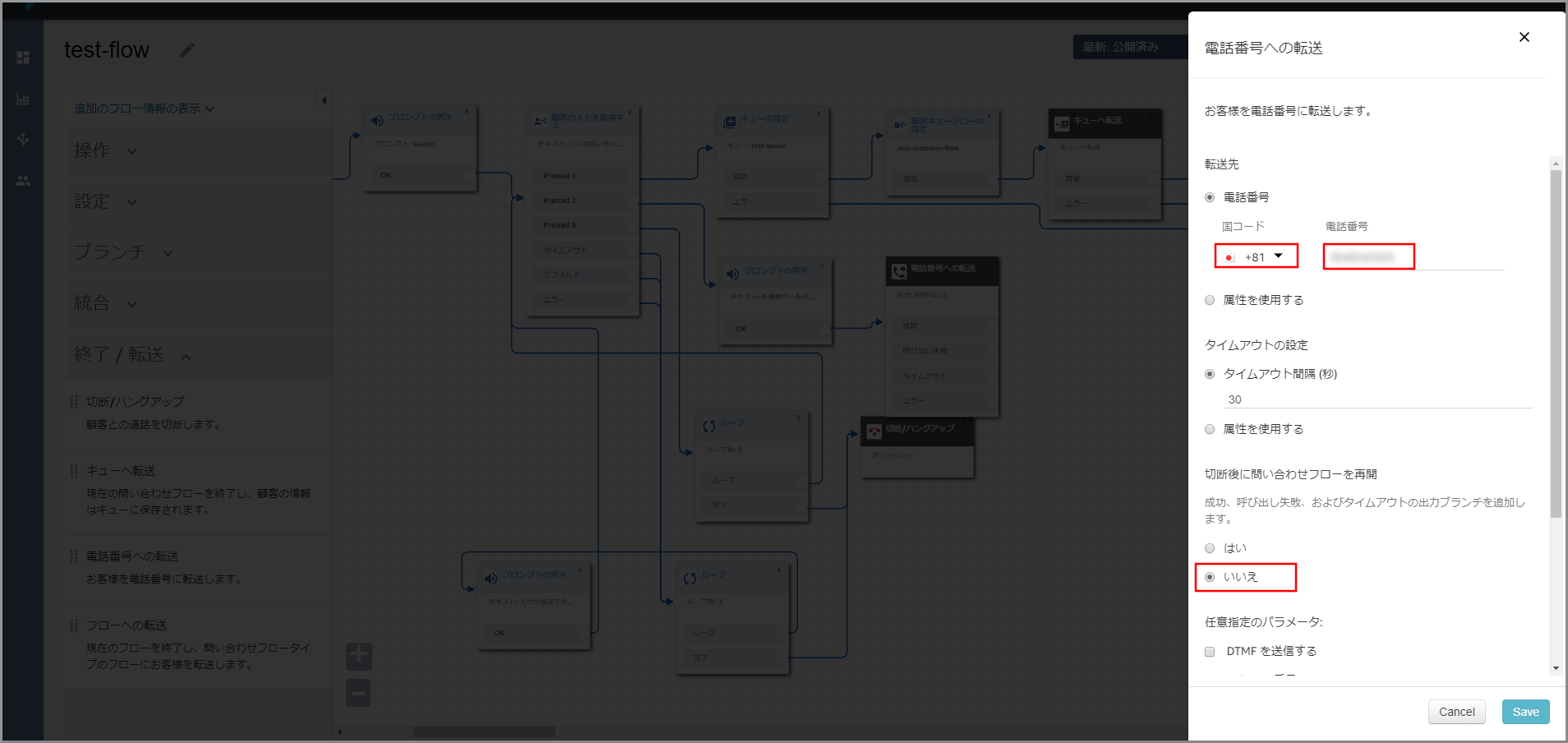
右側に「電話番号への転送」画面が表示されるので、以下の項目を選択、入力します。
- 国コード:転送先の国コード
- 電話番号:頭の0を除いた転送先の電話番号
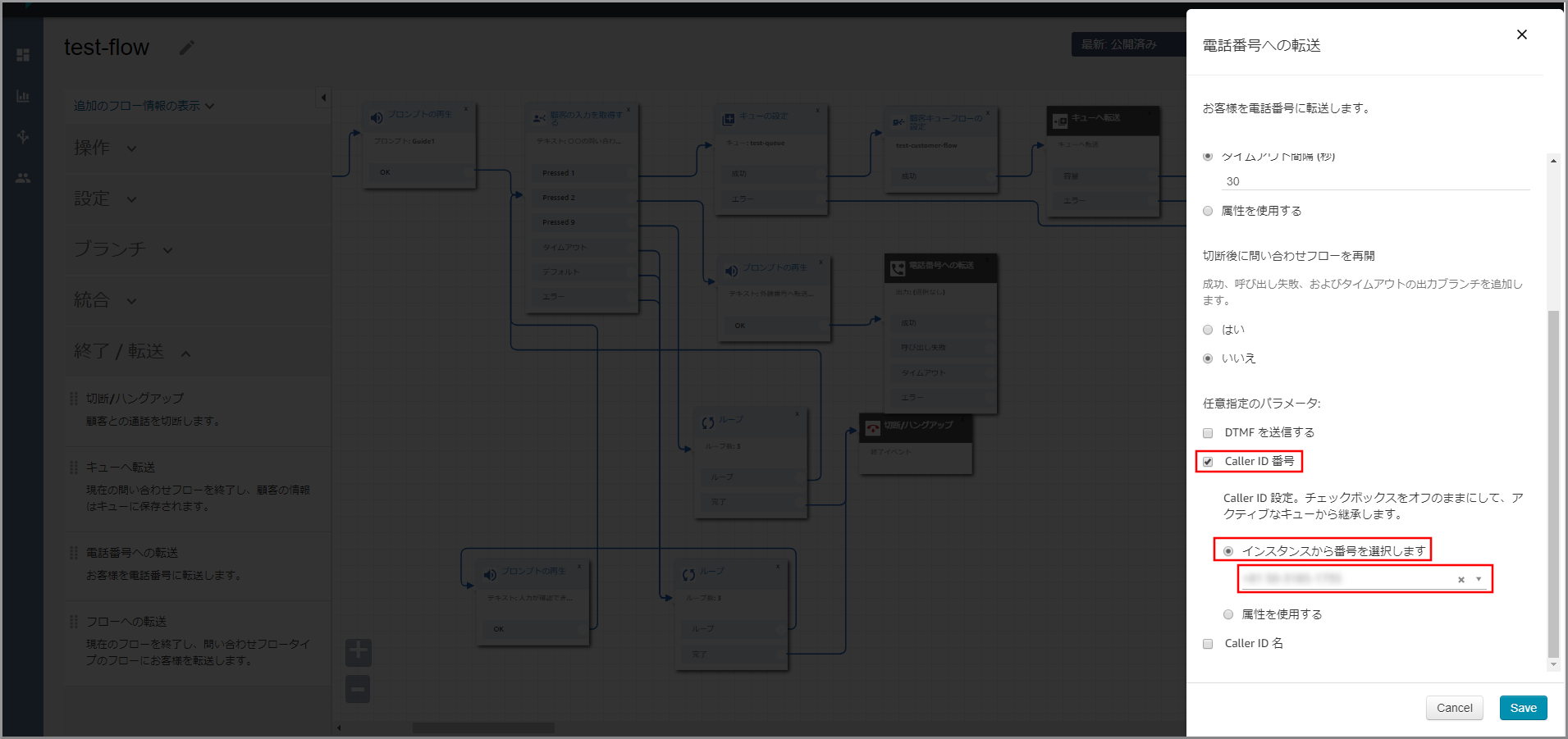
下にスクロールして、以下の項目を選択して《Save》をクリックします。
- 「Caller ID番号」を選択
- 「インスタンスから番号」を選択しますを選択
- ダイアログボックスをクリックして番号を選択
《電話番号への転送》と《切断/ハングアップ》を矢印で接続し、右上の《公開》をクリックします。
《公開》をクリックします。
目次に戻る


- 投稿日:2020-01-10T10:36:00+09:00
AWS Elemental MediaConvert と Amazon ElasticTranscoderの違いってなに?
明けましておめでとうございます
今年はねずみ年ですね!
年女Risakoの新年一発目は、AWS Elemental MediaConvert と Amazon ElasticTranscoderを比較してみたいと思います!
少しでも参考になれば幸いですAWS Elemental MediaConvertとは
特徴
ビデオオンデマンドコンテンツのブロードキャスト機能
AWS Elementalのテクノロジーで構成されている。
グラフィックオーバーレイ、コンテンツ保護、多言語音声、クローズドキャプションのサポート包括的な入出力サポート
ブロードキャスト用やインターネット配信用など幅広い動画の入出力形式をサポート
MPEG-2,AVC,Apple ProRes,HEVC の圧縮規格、高度なカラーサンプリングをサポート
CMAF、Apple HLS、DASH ISO、Microsoft Smooth Streaming などの幅広いアダプティブビットレートパッケージング形式をサポート
4K解像度およびハイダイナミックレンジ(HDR)の動画コンテンツの処理および変換もサポートリソースの自動プロビジョニング
動画インフラストラクチャの作成および管理作業を自動化する
ワークロードのプロビジョニングと管理の主な作業を自動化することで、動画処理のインフラストラクチャを管理する負担が減る。
リソースのプロビジョニングおよび最適化、サービスオーケストレーション、スケーリング、修復、回復性の高いフェイルオーバー、モニタリング、レポートなどが処理される。
ブロードキャスト用やインターネット配信など、幅広い動画の入出力形式をサポート固有の信頼性
ビデオオンデマンドワークフローの冗長性と自動スケーラビリティ
動画コンテンツの需要に合わせて適切なコンピューティングリソースが自動的にプロビジョニングされ、応答時間やパフォーマンスを下げることなくピークのワークロードに合わせて伸縮自在にスケールされる。エラー処理といった組み込み機能は簡単に使用でき、メディアワークフロー全体をモニタリングして通知の発信などのアクションをリアルタイムで実行できる。AWS Elemental ElasticTranscoderとは
特徴
動画ファイルの変換
サイズが大きい高品質のデジタルメディアファイルを、モバイルデバイス・タブレット・Webブラウザなどで再生できる動画ファイルに変換することが可能。ウォータマークの挿入
ウォータマーク(画像や文字のすかし)を動画内に挿入することが可能。サムネイルの自動生成
変換が終了すると、S3に自動でサムネイル(キャプチャ)が作成されています。MediaConvert と ElasticTranscoder比較
MediaConvert できること
動画の結合ができる
JOB作成時に指定するINPUTの動画を複数にするのみ。
また、複数の動画の一部を切り取って結合することも可能別の動画の音に差し替える
既存の動画の映像と音声を必要な部分だけ選んで新しい動画を作成することができる。
S3の動画を指定することができるため、映像と音声で違う動画を使うことも可能。
この動画形式で、複数言語対応の動画の作成も可能になる。動画のノイズを軽減することができる
出力設定に[Noise reducer] というものを選択し、設定することでノイズ軽減できる。MediaConvert できないこと
動画ファイルの暗号化のキーにKMSを利用できない
WebM動画の作成
アニメーションGIFの作成
Elastic Transcoder できること
主なユースケースは、
・iphoneなどで撮影した動画をPCなどのマルチデバイスで見れる動画ファイルに変換
・動画変換時に動画に写し込まれる小さな図案や文字の挿入
・サムネイル画像の自動再生Elastic Transcoder できないこと
動画結合などの高度な編集
H.265に対応していない
→H.265とは、従来のH.264と比べて圧縮率が2倍になっているので動画ファイルのサイズが大幅に削減され、8Kにも対応しているエンコード結果はSNSにしか送れない
結果
今回比較してみて、必ずしもどちらがいいとは言えない結果となりました。
WebM出力・MP3オーディオのみの出力・アニメーションGIF出力などを使う場合は、 ElasticTranscoder。
それ以外の場合は、コストメリット・最先端フォーマットへの対応などの利点から MediaConvert など、必要な機能やコストなどそれぞれの特徴を踏まえて利用するのが良さそうです!最後までありがとうございました
参考サイト
・https://docs.aws.amazon.com/ja_jp/mediaconvert/latest/ug/more-about-audio-tracks-selectors.html
・https://aws.amazon.com/jp/mediaconvert/
・https://aws.amazon.com/jp/elastictranscoder/faqs/
・https://qiita.com/ryotax/items/445ec80b18af30b85054
- 投稿日:2020-01-10T10:29:35+09:00
AWS re:Invent2019参加レポート
AI.RL.LYsのcursheyです。
今回はAWS re:Invent2019に参加してきましたので、そのレポートを記事にしました。ここではAI・機械学習の新サービスや新機能について私が特に興味を持ったものについて書いていきたいと思います。re:Inventって何?
Amazon Web Serviceがラスベガスで開催する学び放題、遊び放題のお祭りです。新サービスの発表が最も大きなイベントなのですが、それ以外にもセッションやワークショップなどによる学びや、音楽ライブ、Tatonkaというチキン大食い競争やスポーツなどの遊び場が提供されます。
AWS Inferentia
低コスト高パフォーマンスを実現する機械学習推論チップで、TensorFlow、Apache MXNet、PyTorchのような深層学習フレームに対応した基盤です。この基盤に新しくinf1インスタンスが使えるようになりました。このインスタンスは、G4インスタンスと比べて40%近くのコストダウンができ、また、低レイテンシー、3倍のスループットを実現しています。これにより、深層学習にかかる時間を大きく削減できそうです。また、ECS、EKSにも使うことができます。
データレイク
ビッグデータがより大きくなっていくにつれて、ストージコスト増加、セキュリティの懸念、社内データ探索の負荷がどんどん大きくなっていきます。それに対応する手段として、データレイクという基盤構築が考えられました。AWSのサービスでデータレイクを構築するにはS3が利用されますが、そのS3に新機能が追加されました。S3の1つのバケットに数百のアクセスポイントが作られるようになりました。これにより、複数のアプリケーションで、それぞれに対応したアクセス権限のルールをカスタマイズができるようになりました。この機能はVPCの制限もできます。これによりデータ分析基盤の構築が簡単になりそうです。
Amazon Fraud Detector
Personalize、Forecastに続く新しいAIサービスとして、Amazon Fraud Detector が発表されました。これは不正なアクセスや支払いを検知することができる不正検知で、Amazonが20年以上に渡る不正検知のノウハウを駆使して作られたサービスです。コンソール画面で数回のクリックだけで不正検出モデルを作ることができます。機械学習やAIの経験がなくてもできてしまうので、多くの人に使われるサービスになるのではないかと思います。
他にもコードレビューを機械学習が行ってくれるAmazon CodeGuru や、AWSサービス上のデータやdropboxのドキュメントをAIを用いた検索エンジンで探すことができるAmazon Kendraが発表されました。DeepComposer
DeepLens、DeepRacerに続く機械学習の教育用デバイスとして、新しくDeepComposerが発表されました。これは機械学習を使って新しい音楽を作り出すことができるサービスです。元の曲にDeepComposerのキーボードから打ち込んだ音を混ぜ合わせた新しい曲を作ることができます。なお、他の MIDIキーボードでも作曲することはできます。また、出来上がる曲のジャンルも指定することもでき、新しいジャンルも後から追加することも可能です。作った曲はSoundCloudにアップロードすることもできます。
DeepComposerのように、創造的な作品を作り出すことのできるAIをGenerative AIと呼ばれています。DeepComposerの裏側は敵対的生成ネットワーク(Generative Adversarial Networks)モデルが使われています。これはAlphaGoでも使われており、教育者はDeepComposerを通してこのモデルの教育をすることができます。Amazon SageMaker With RL and Bandit
Amazon SageMakerは機械学習向けのjupyter環境で、様々なアルゴリズムの開発をすることができますが、強化学習という一大分野の開発もすることができます。その強化学習で、コンテンツ配信で実際に応用されている多腕バンディット問題をSageMakerで開発をするというワークショップに参加しました。多腕バンディット問題は強化学習で最もシンプルな問題設定で、よくABテストと比較されます。
ABテストのデメリットとして、人力で配信比率の調整と選定が必要になるため、運用負荷が大きく、効果を確認できるまで時間がかかってしまいます。一方で、多腕バンディット問題は探索と活用のバランスを取ることができるので、運用負荷が小さく、また自動的に最適なコンテンツ配信をすることができます。
SageMakerでの多腕バンディット問題はバッチ学習ではなく、オンライン学習を対象にしています。また、オフライン評価としてDR(Doubly Robust)、IPS(Inverse Propensity Score)が使えます。
多腕バンディット問題を動かすコンテナはVowpal Wabbitというオンライン学習を対象とした機械学習ライブラリで構築されています。このライブラリでは様々なアルゴリズムが用意されていますが、SageMakerではepsilon-greedy、bagging、coverの3種類が選択できます。詳細はこちらです。
上で紹介したAIサービスやDeepComposerなどとは違い、SageMakerは全くの初心者が動かすことは難しいです。特にバンディット問題は数学的知識が必要になるため、このコンテナを扱いこなすのは容易ではないと思います。しかし、自分でコードを組むよりは簡単で、オフライン評価による性能評価もサポートされていますので、開発が大きく簡単になっていると思います。
また、今回のワークショップほどの内容はではありませんが、チュートリアルがありますので、そちらを試してみるといいと思います。オフライン評価(補足)
強化学習において行動はポリシーによって決定されます。例えば開発者がすでに実施している既存のポリシーAから、新しく考えたポリシーBに切り替えたい場合、既存のポリシーAより良い性能を出せないと意味がありません。
新しいポリシーBの性能を現実に近い形で評価するには、既存のポリシーAで生成された行動履歴でシミュレートを行うことが考えられます。しかし、ある状態で新しいポリシーBが既存のポリシーAと違う行動を取ることがあります。同じ行動であれば観測された行動履歴から性能評価はできますが、違う場合、性能評価を行動履歴から評価することはできません。この問題設定をオフライン評価と呼び、DR、IPSはオフライン評価に対する評価手法になります。Amazon SageMakerバージョンアップ
re:Invent2019では多くの機械学習関連のサービス、バージョンアップが発表されましたが、特に多かったのがAmazon SageMakerのバージョンアップです。ここからそのバージョンアップについて紹介したいと思います。一覧にすると、以下のようになります。
- Amazon SageMaker Studio
- Amazon SageMaker Notebooks
- Amazon SageMaker Experiments
- Amazon SageMaker Debugger
- Amazon SageMaker Model Monitor
- Amazon SageMaker Autopilot
- Amazon SageMaker Processing
- Amazon SageMaker Deep Graph Library
Amazon SageMaker Studio
機械学習初のIDEです。多機能で情報の多いSageMakerを、このIDEで完結させることができます。これにより、性能の比較やデバッグ情報などを簡単に確認することができます。
Amazon SageMaker Notebooks
実際にSageMakerを動かしますと、jupyter notebookを起動するには数分かかっていました。今回のバージョンアップでマネージドとなり、数秒で立ち上がり、インスタンスのプロビジョニングも不要となりました。また、jupyter notebookは一人で使うことが想定されており、共有するのに工夫が入りましたが、このバージョンアップでワンクリックで共有できるようになりました。
Amazon SageMaker Experiments
機械学習には多くの回数の実験が必要になりますが、その実験サイクルを簡単に回せるようになりました。実験に使ったデータセットやアルゴリズム、ハイパーパラメーターなどの入力/出力をキャプチャして管理できるようになり、多くのジョブを効率的に比較検証できるようになりました。
Amazon SageMaker Autopilot
Auto MLを実現させるための新機能で、前処理、アルゴリズム選択、チューニングなどの機械学習の処理を自動化できるようになりました。
Amazon SageMaker Processing
泥臭いデータ処理や性能評価を簡単にできるようになりました。Python SDKにより、ジョブを実行でき、また独自コンテナを作ることも可能で、特殊な処理もできるようになりました。
Amazon SageMaker Deep Graph Library
グラフニューラルネットワーク(GNN)のためのオープンソースライブラリDeep Graph Library(DGL)がSageMakerで利用可能になりました。これにより、SageMakerでもグラフ構造を取り扱うことができるようになりました。
Amazon SageMaker Debugger
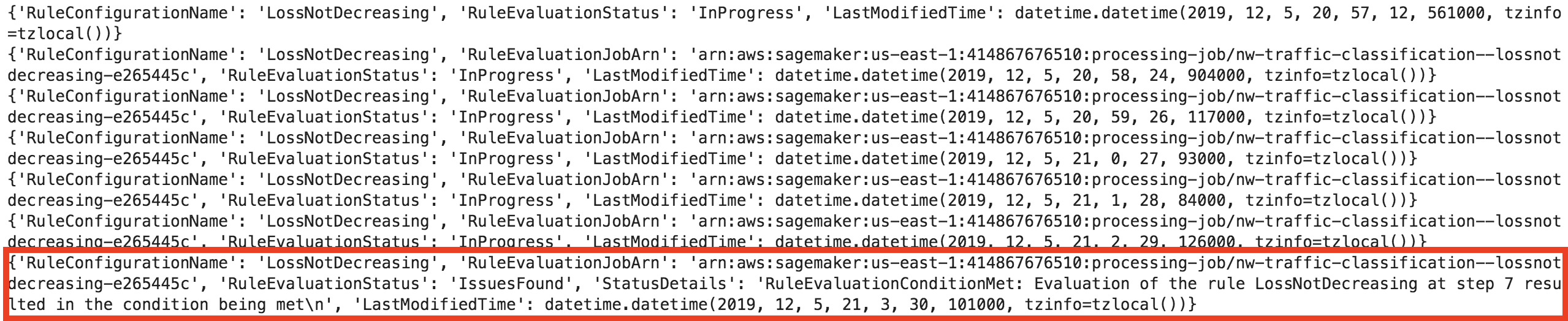
この機能についてワークショップを受けることができましたので、そこで学んだことも含めて説明します。この機能ではTensorFlow、Keras、Apache MXNetなどを使った学習のデバッグをすることができます。このデバッグ機能では勾配の減少や、混同行列の遷移など学習に対するものになっています。学習に失敗した場合、今までは開発者は勘とトライアンドエラーで解決していました。このデバッグで、深層学習でブラックボックスになっていたのを可視化することができ、なぜ学習しなかったを解決する手がかりを掴めるようになりました。
上記の画像はワークショップで実際にデバッグをした時のメッセージです。Amazon SageMaker Debuggerは学習に失敗した場合、その時点でストップされます。必要な場合はそのまま継続させることもできます。今回は赤枠部分でRuleEvaluationStatusでIssuesFoundと表示され、RuleEvaluationConditionMetを確認しますと、7ステップ目で勾配が減少しなくなったことが確認できます。開発者はこのステップで何が起こったかを推論することができるようになります。
以下のURLにデバッグ例がありますので、参考になると思います。また、ルール一覧も公開されています。
- デバッグ例: https://aws.amazon.com/jp/blogs/news/amazon-sagemaker-debugger-debug-your-machine-learning-models/
- ルール一覧: https://docs.aws.amazon.com/sagemaker/latest/dg/debugger-built-in-rules.html
Amazon SageMaker Model Monitor
この機能についてもワークショップを受けることができましたので、それも含めて説明します。この機能はDeploy後の推論モデルの監視ができるようになります。これにより、環境の変化によるモデルの性能変化を監視できるようになりました。環境の変化とはサイトのリニューアル、流行の変化、DDoSなどの攻撃などを指します。この変化により、推論モデルの性能が設定したベースラインを下回ればアラートを出すことができ、開発者はその変化を知ることができます。
上記の画像はワークショップでモデル監視をした時のログで、アラートがあったものに絞り込んで表示をしています。これは違反しているデータタイプの監視をしています。constraint_check_typeはどのような違反があり、feature_nameはどの特徴量で違反が起こったかを確認することができます。descriptionは違反の詳細です。事前にベースラインを設定すれば、性能監視やより高度な違反監視もすることができます。
所感
AWSは今後もAIの民主化を継続する意思を感じました。簡単で使いやすいAIサービスをどんどん作っていて、今後もリリースする意欲を感じました
機械学習の開発者のサポートも強化していました。SageMakerの大幅なバージョンアップは開発者の負担を大きく軽減でき、深層学習にかかる時間を大幅に短縮できたのは、実験サイクルもより早く回せるようになりました。また、Auto MLへの意欲も強く感じました。
また、機械学習系の発表は最多の20個で、AWSの機械学習へ力の入れようが感じられると思います。


- 投稿日:2020-01-10T10:09:22+09:00
Serverless Framework for AWS Lambda Development
0 .Intro
The complete solution for building & operating serverless applications.
就自己這陣子的使用經驗上來看,我覺得這樣的敘述還算名符其實。
目前最主要會用場景為開發在自己的MBPR 上利用Golang 開發AWS Lambda,利用Serverless Framework CLI所提供的功能來開發,部署以及在本機做測試,整體的流暢度滿高的。 雖然Serverless還有提供其他Monorting, integration或policy目前還沒有使用到,但是整理的使用經驗大勝SAM CLI,特別是早期被SAM對於Golang的支援踩到太多的坑了。
除了AWS之外,其他serverless的部署對象目前有都有支援。更多完整可以參考Serverless Framework
真的要說目前Serverless Framework有什麼缺點,我覺得是名字取得不好XD 造成要SEO/search的結果不佳。
1. Perquisite & Installation
在開始之前,要先確認你的電腦椅已經設定好AWS CLI相關的configuration,確認沒有問題後,我們就可以來安裝Serverless Framework。
# install serverless cli curl -o- -L https://slss.io/install | bash # testing sls --version # upgrade to latest version sls upgrade2. Create New Lambda Service
接著,我們可以透過 Serverless framework 提供的 template 來完成,
-t參數代表template,目前這邊我們選用的是採用 go mod 的 template,如果你的專用目前是用go dep來管理的話,你也可以選用 aws-go-dep 這個template來建立 hello world。
-p代表的是Path,command執行完成後,Serverless framework會幫我們將產生的檔案放在新建立的myService資料夾中。sls create -t aws-go -p myService cd myService切換到myService下後,你可以看到我們從template產生的兩個lambda的範例,一個hello一個world分別放在不同的資料夾中,並且可以稍微瀏覽一下兩隻lambda裡面的code,分別會回傳不同的hello world訊息。
3. Build & Deploy
Serverless Framework很貼心的已經幫我們處理好Makefile,因此我們需要先init go mod,接著透過make build的command來幫我們產生binary。
#/myService go mod init helloworld make build確認
/bin資料夾中有成功產生hello跟world兩個檔案後,在deploy之前有個小小需要注意的地方,如果你目前的aws config中的region不是us-east-1的話,記得要修改serverless.yml中region的設定。# serverless.yml region: <YOUR AWS CONFIG REGION> sls deploy4. Testing Your Lambda
部署完成後,我們可以分別來測試這兩隻不同的lambda,
-f代表要執行的function。
- lambda hello
sls invoke -f hello { "message": "Go Serverless v1.0! Your function executed successfully!" }
- lambda world
sls invoke -f world { "message": "Okay so your other function also executed successfully!" }有興趣的人可以進一步登入到AWS web console中,便可以發現Serverless Framwork在剛剛一行command中,已經幫我們部署了API Gateway+lambda,而且這些設定指示在serverless.yml中functions > hello > events > http的config便可以完成,其他我們在lambda中常用的Trigger,在被註解掉的event sample中也都已經給了範例。
Hello World的介紹屆先到這邊,之後的篇章再來分享透過Serverless Framework實作的其他lambda。
- 投稿日:2020-01-10T09:19:44+09:00
Amazon API GatewayにBasic認証をかける方法
はじめに
ちょっとしたテスト用のAPIをAmazon API Gatewayで作ったのですが、あんまり外部公開はしたくない…でもガッチガチなセキュリティが必要なほど重要なものでもない…
というわけでBasic認証をかける方法を調べたメモです。
いくつかハマリポイントがありました。大まかな流れ
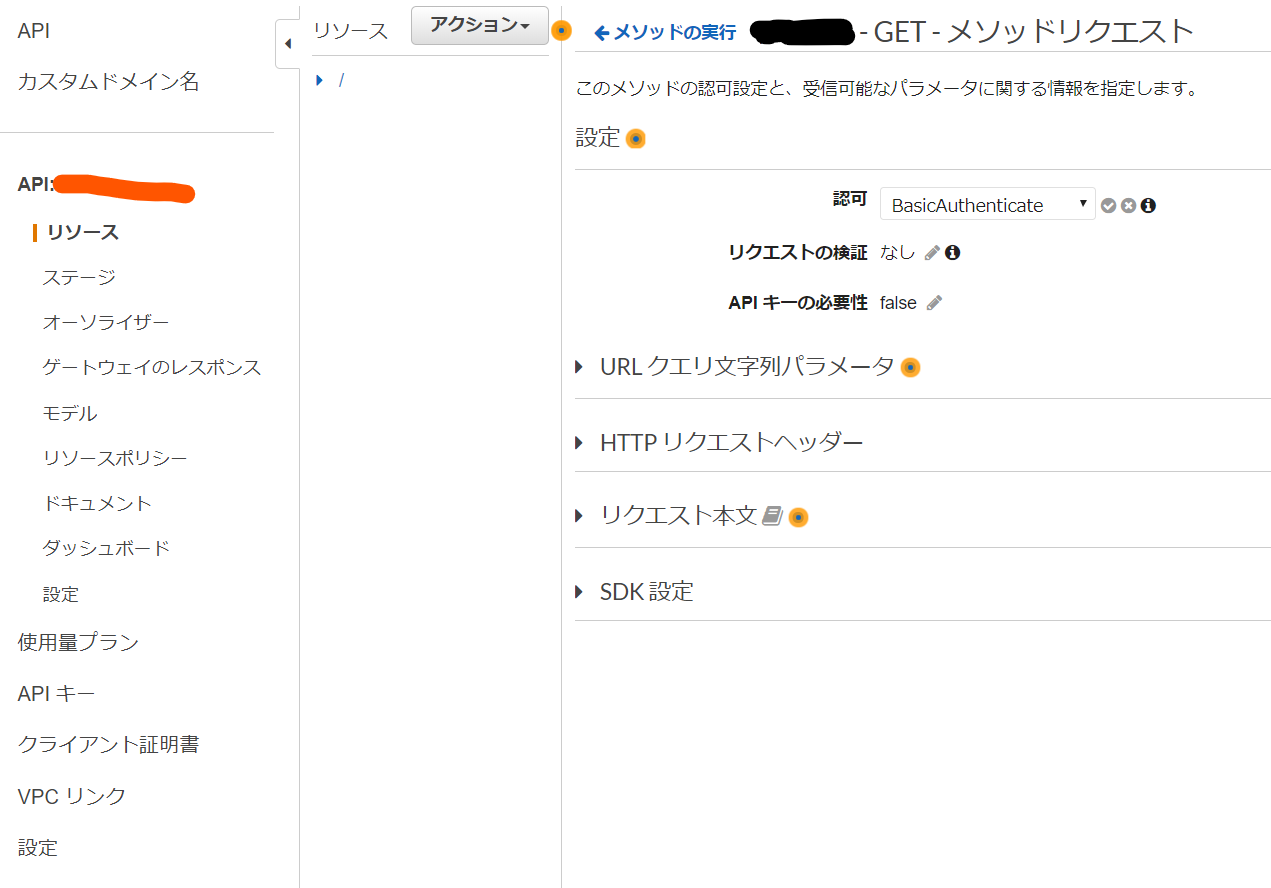
API GatewayでBasic認証する大まかな流れ。
- API Gatewayのオーソライザーに認証をするLambda関数を指定する。
- オーソライザーのIDソースにauthorization (header)を設定する。
- API Gatewayの「ゲートウェイのレスポンス」の401レスポンスにWWW-Authenticateヘッダーを追加する。
- メソッドリクエストの設定でオーソライザーを指定する。
Lambda関数の作成
AWS Lambdaのダッシュボードから関数を作成します。Rubyが好きなのでここではRubyを選択しています。
名前は適当に、実行ロールは「基本的な Lambda アクセス権限で新しいロールを作成」でOKです。
lambda-authorizer-basic-authrequire 'aws-sdk-kms' require 'base64' def lambda_handler(event:, context:) if basic_auth(event) # Basic認証で認可する場合は次のようなIAMポリシーを返す { 'principalId': 'user', 'policyDocument': { 'Version': '2012-10-17', 'Statement': [ { 'Action': 'execute-api:Invoke', 'Effect': 'Allow', 'Resource': event['methodArn'] } ] } } else # 認可しない場合は例外を送出する raise 'Unauthorized' end end # Basic認証する適当メソッド def basic_auth(event) # ユーザー名とパスワードはLambdaの環境変数に暗号化して保存してある。 user = Aws::KMS::Client.new.decrypt({ ciphertext_blob: Base64.decode64(ENV['user']) }).plaintext password = Aws::KMS::Client.new.decrypt({ ciphertext_blob: Base64.decode64(ENV['password']) }).plaintext # event['headers']['authorization']にBasic認証の認証情報が入っている auth_header = event['headers']['authorization'] # 適当に認可 auth_str = 'Basic ' + Base64.strict_encode64("#{user}:#{password}") auth_header == auth_str endオーソライザーのドキュメントはこちらにあります。
ドキュメントの例がNode.jsだったので、Rubyの場合は認可しない場合に何を返せばいいのかわからず悩んだのですが、raiseしてエラーを送出すれば良いようです。
(Node.jsのcallbackの引数をちゃんと調べればわかることでした)オーソライザーの設定
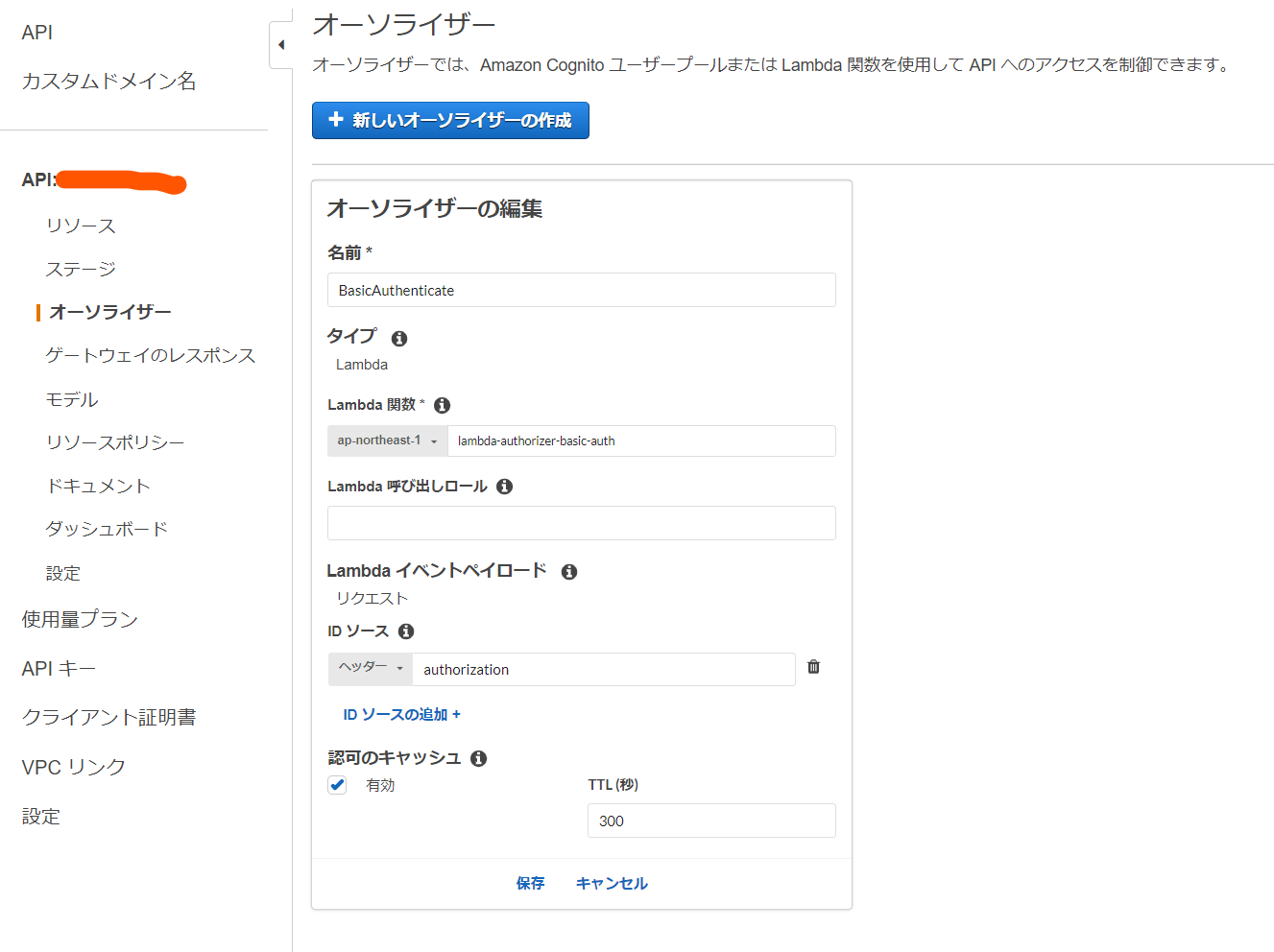
API Gatewayのダッシュボードから次のようにオーソライザーを設定します。
ポイントはIDソースに
authorizationヘッダーを設定することです。これによりブラウザなどからのBasic認証を伴うリクエストをLambda関数に渡すことができます。
401レスポンスの設定
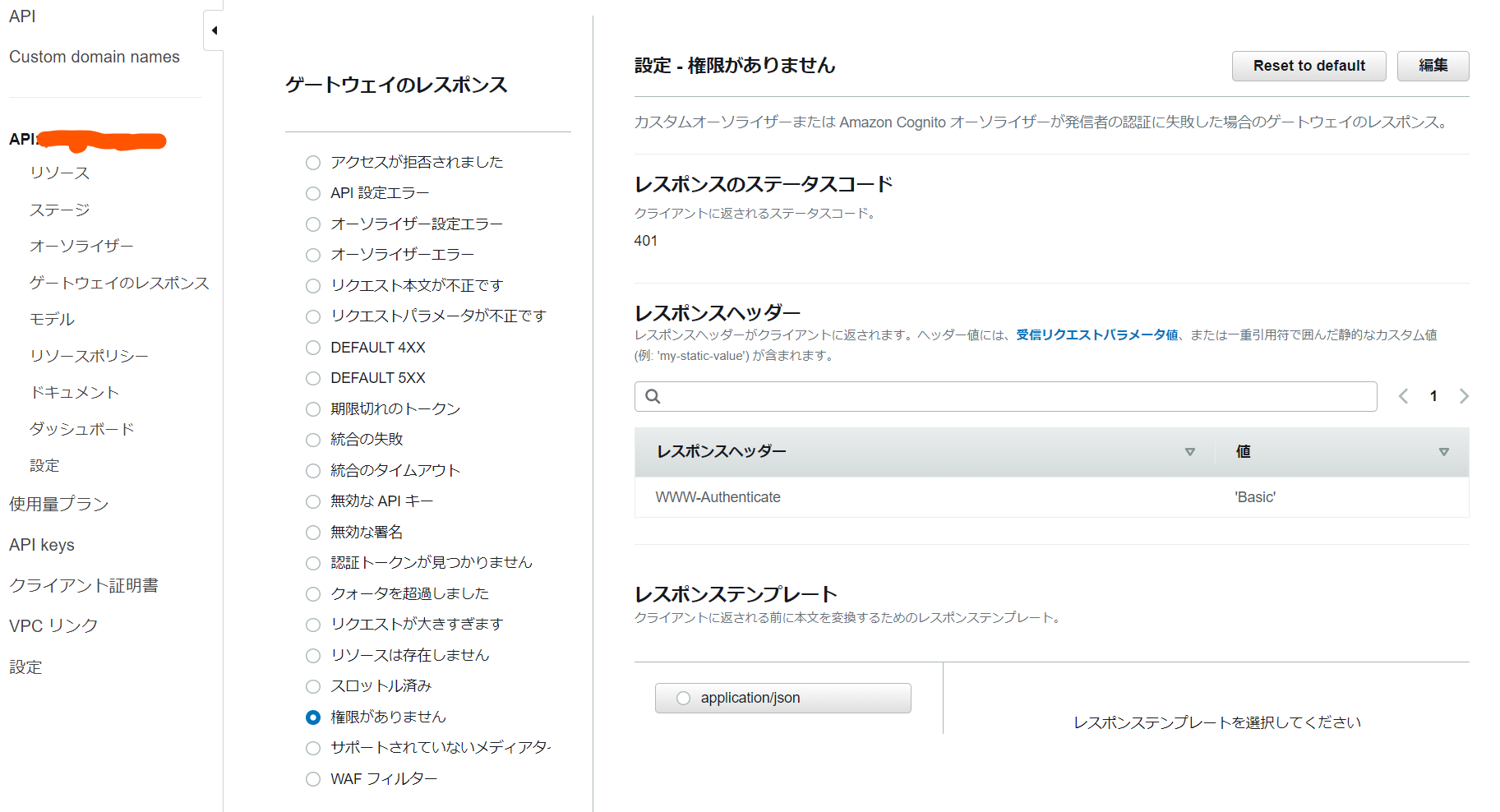
Basic認証なしでAPIにアクセスした場合に401エラーを返しますが、そのときにBasic認証が必要であることをブラウザなどに伝える必要があります。これがないと、ブラウザのBasic認証ダイアログなどが出ないので困ります。
「ゲートウェイのレスポンス」→「権限がありません」→レスポンスヘッダーに
WWW-Authenticate、値に'Basic'を追加します。静的な値の場合は''で囲む必要があります。
メソッドの設定
あとはBasic認証をかけたいAPIメソッドの設定で、認可の方法に先のオーソライザーを指定するだけです。
その他
オーソライザーやレスポンス、メソッドの設定を変えた後はデプロイしないとAPIに反映されないので気をつけましょう(n敗)
おわりに
AWS勉強中なのですが色々わからない概念が多くてつらいです。
記事のコード中のコメントにIAMロールを返すとかもっともらしく書いてありますが、それが何かはよくわかっていない模様。今回はブラウザからAPIにアクセスする必要があったのでBasic認証にしましたが、アプリケーションなどからアクセスする場合はAPIキー使ったほうが楽だと思います。
- 投稿日:2020-01-10T09:17:12+09:00
AWSに構築したWordPressに独自ドメインを割り当ててみた
はじめに
前記事「AWSにWordPressを構築してみた」の続き
実際に使えるサイトにしていきたいので下記の要件を満たす。
- 独自ドメインを割り当てる
- SSL対応する
ってことでチャッチャと作っていく。
設定
お名前コムでドメインを取得する
ドメインの管理は全てお名前コムで行っているので今回もお名前コムでドメインを取得してAWS側に紐付けていく。
ってことで取得。
route53を設定する
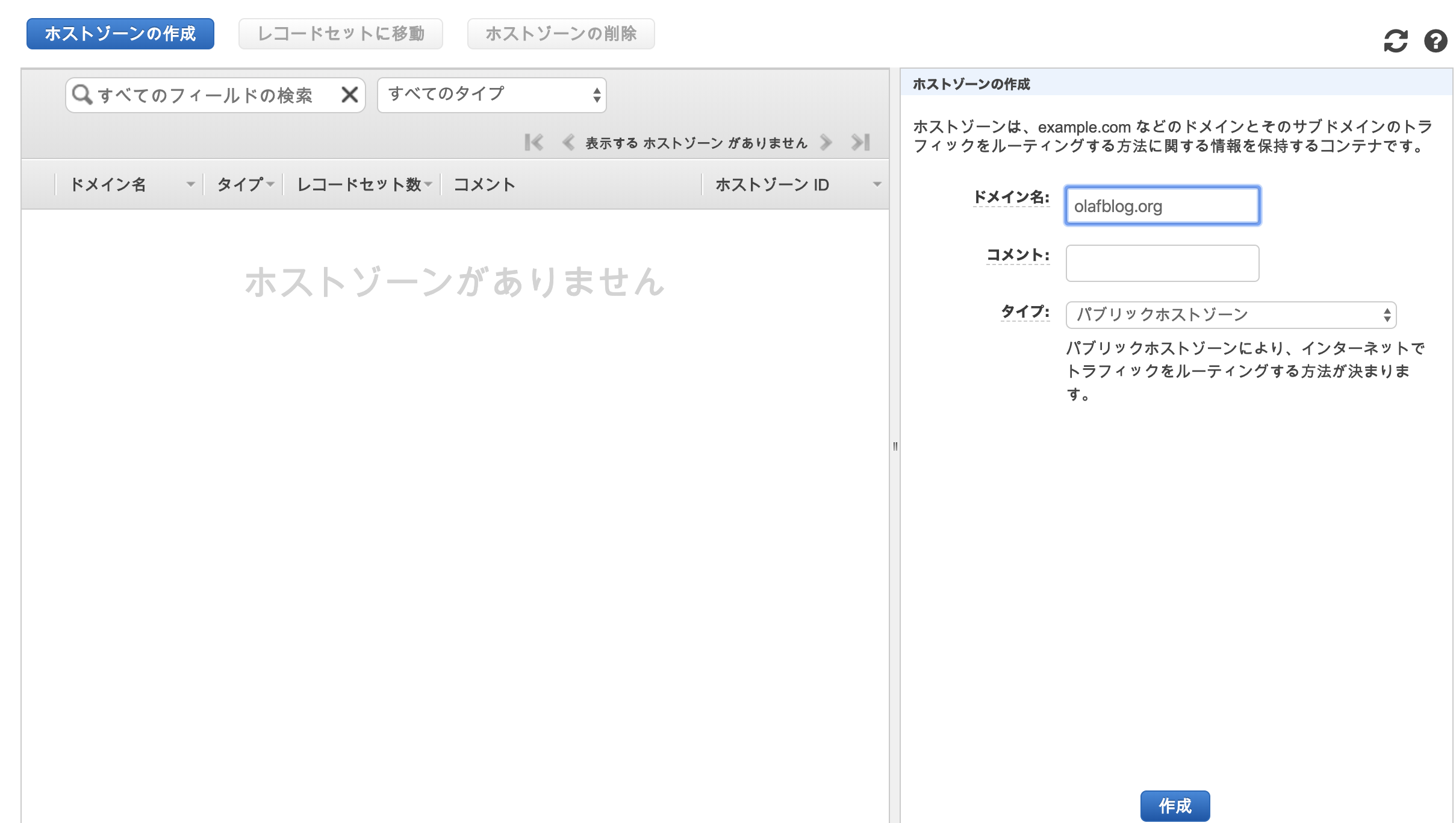
AWSのroute53で先ほど取得したドメインのホストゾーンを作成する。
とりあえず今はホストゾーンを作るだけで終了。
NSのValueをメモしておく。
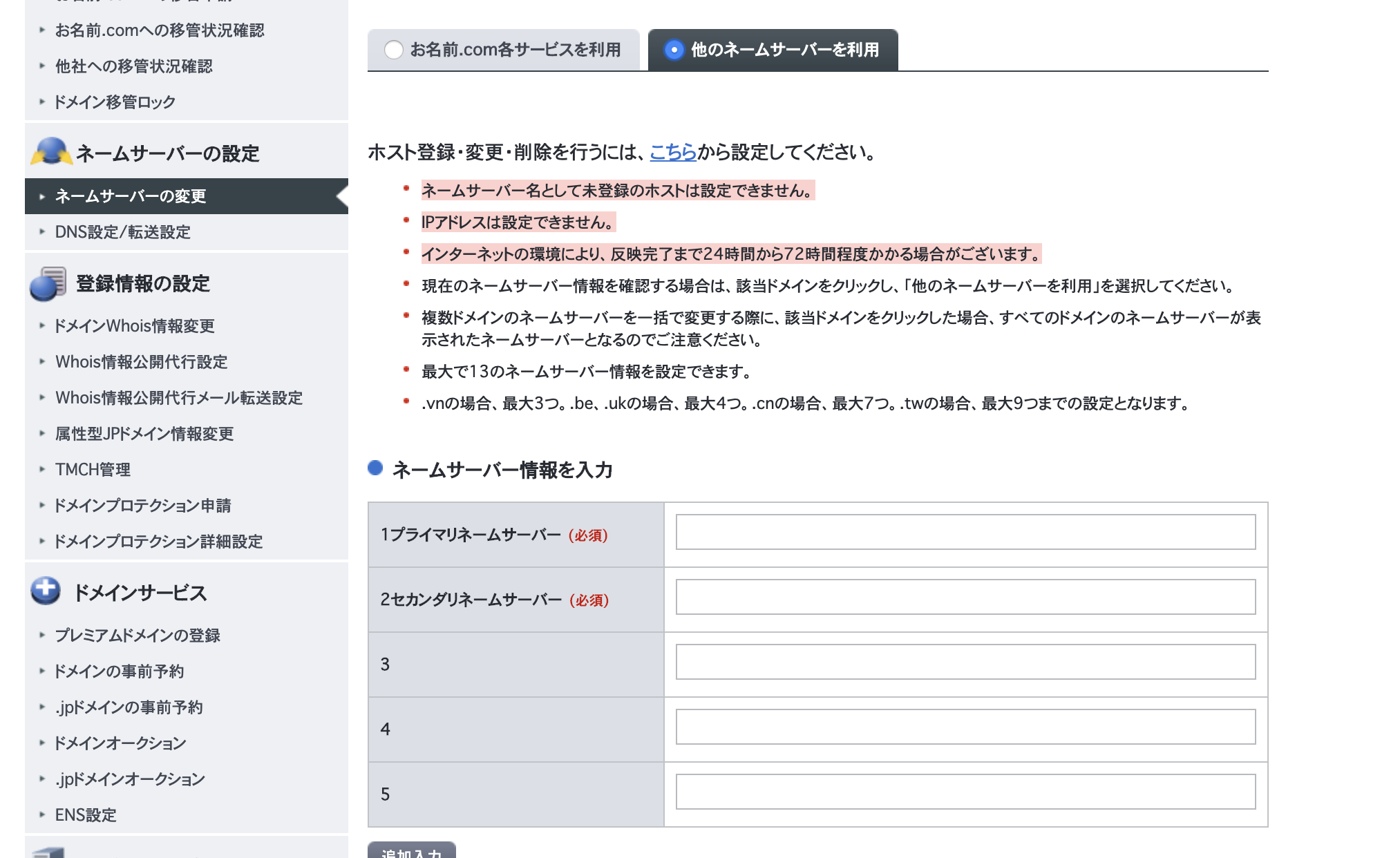
お名前コムに設定をいれる
お名前コムの管理ページ「ドメイン設定」>「他のネームサーバーを利用」で先ほどメモしたNSのValueを入力する。
これで先ほど作ったホストゾーンにアクセスが流れるようになる。
SSL証明書を発行する
AWSの「Certificate Manager」で取得する。
「証明書のプロビジョニング」>「パブリック証明書のリクエスト」でドメインは取得したドメインを入力。
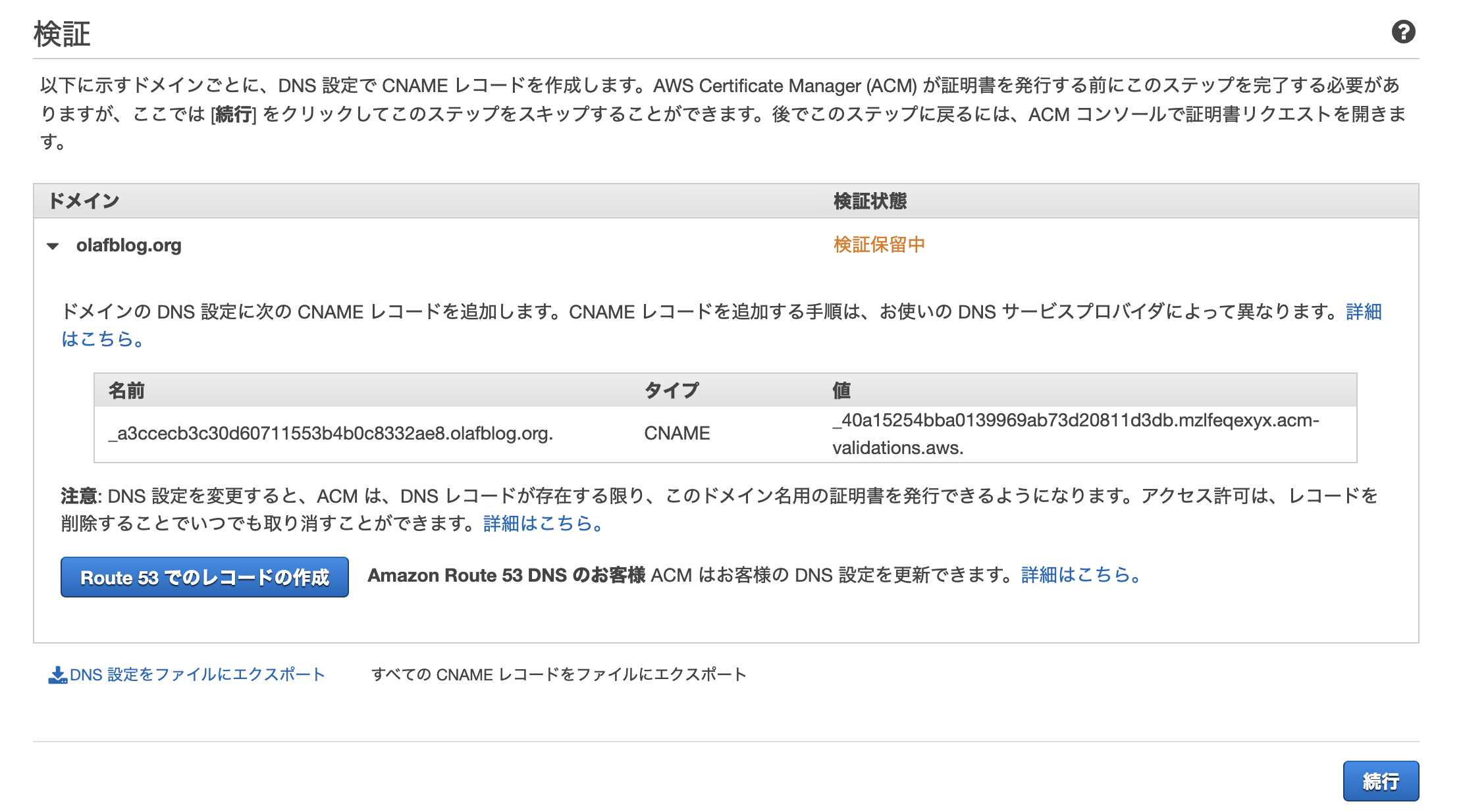
そいで「DNSの検証」を選択して残りは「次へ」を連打。
そーすると検証保留中のレコードができるので「Route53でのレコードを作成」を押下。
あとはステータスが変わるまで30分程度待つ。
ターゲットグループを作成する
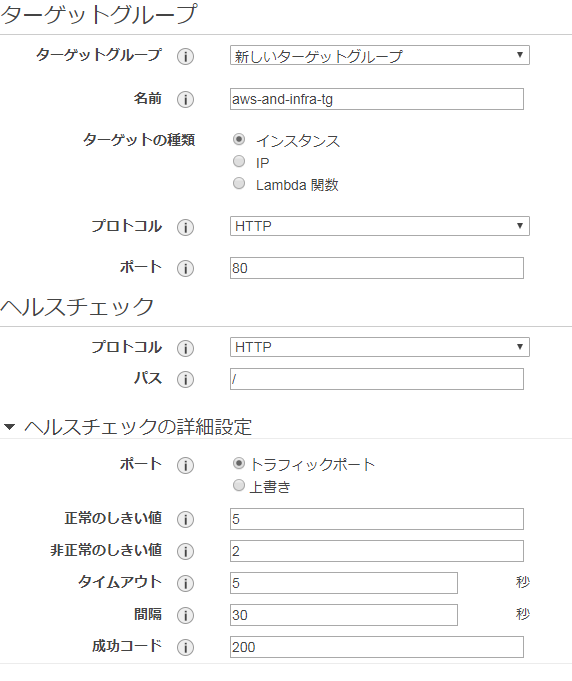
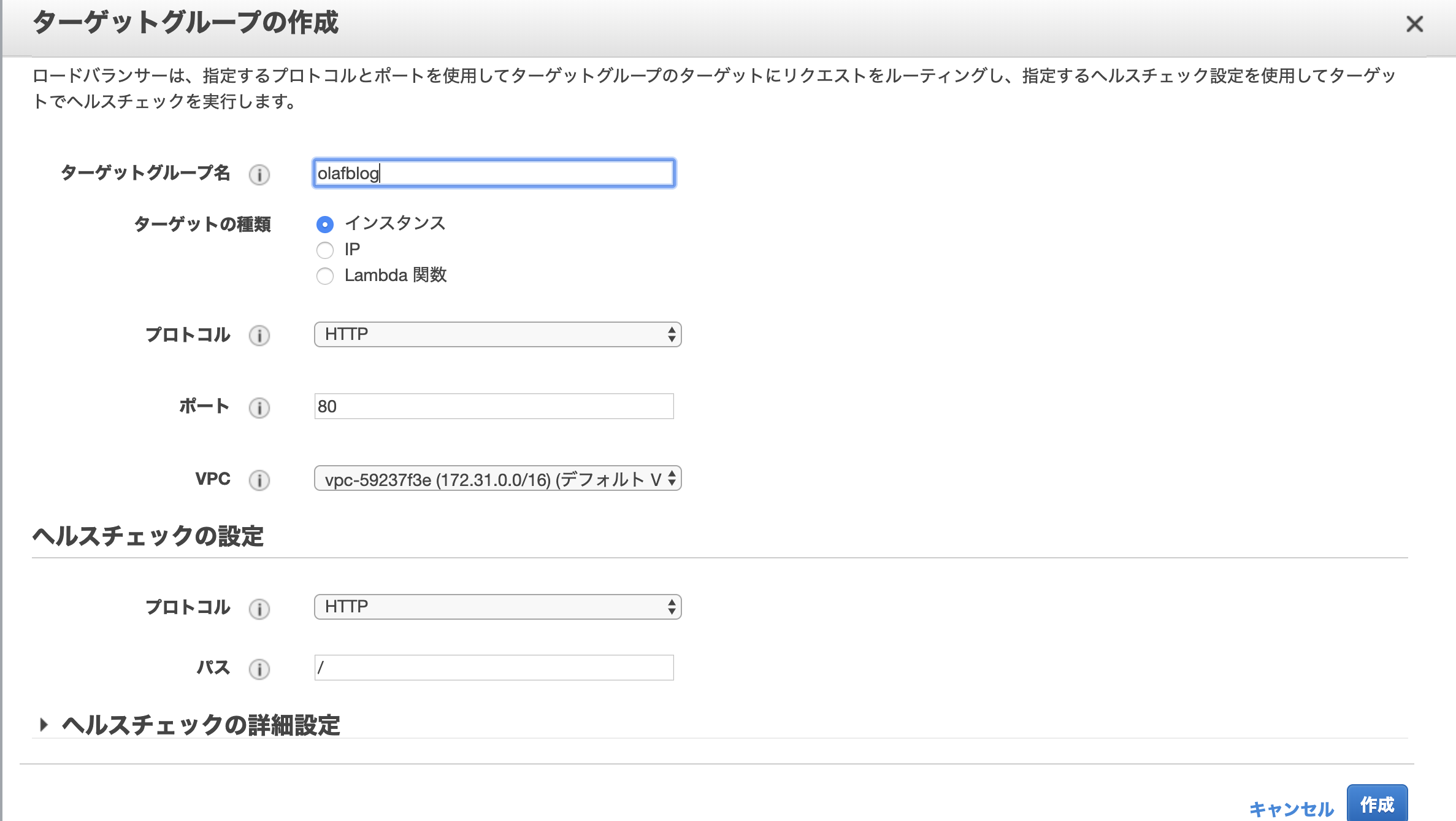
ロードバランサー作成の事前作業のためにターゲットグループの作成をしておく。
「EC2」>「ターゲットグループ」から「ターゲットグループの作成」をポチッ。
名前を入力、それ以外は特に変更なし。
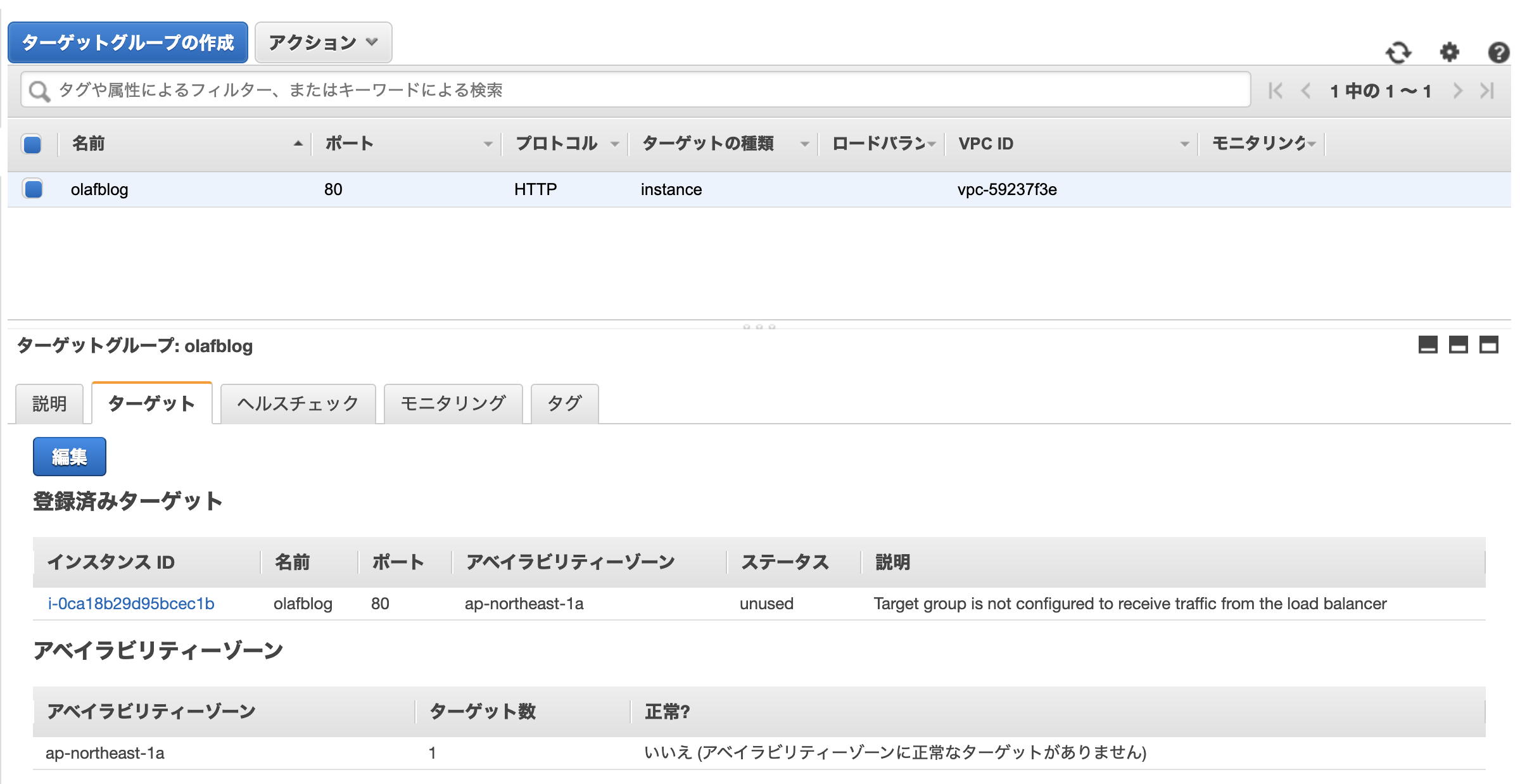
作成したターゲットグループを選択し、ターゲットタブから「編集」をポチッ。
アクセスを流したいインスタンスを選択し「保存」。
ロードバランサーを作成する
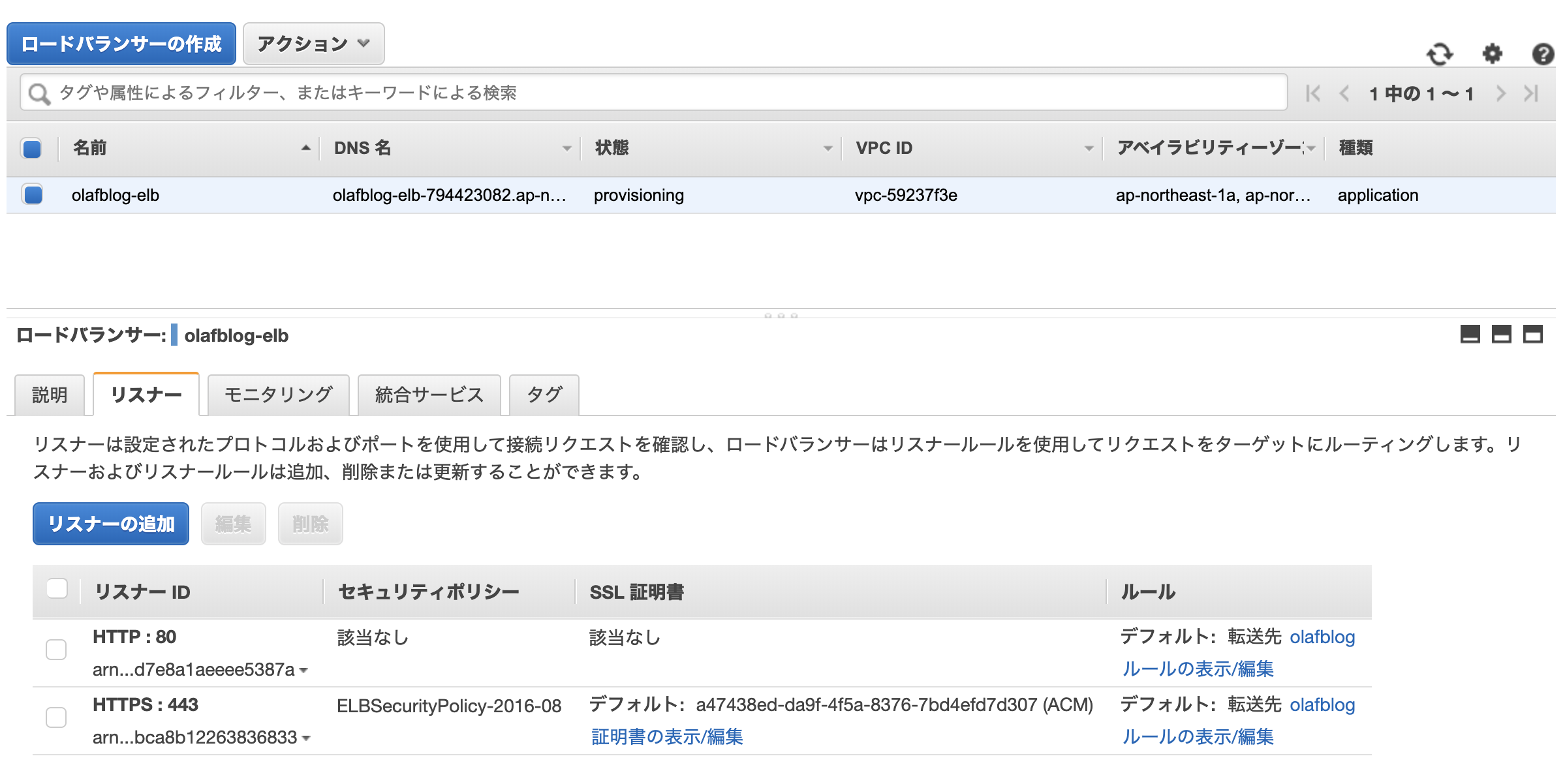
先ほど作成したSSL証明書を利用するためにロードバランサーを作成してSSL証明書を紐づけていく。
「EC2」>「ロードバランサー」から「ロードバランサーの作成」をポチッ。
「HTTP/HTTPS」を選択。
名前を適当に決めてプロトコルに「HTTPS」を追加。
アベイラビリティゾーンに全件チェックを入れて「次へ」。
「ACMから証明書を選択する」から先ほど作成した証明書を選択して「次へ」。
「既存のターゲットグループ」から先ほど作成したターゲットグループを選択して「次へ」。
残りは「次へ」を連打。出来上がりはこんな感じ。
ホストゾーンにロードバランサーを設定する
最初に作成したホストゾーンに先ほど作成したロードバランサーを設定していく。
「Route53」で作成したホストゾーンを選択。
「レコードセットの作成」をポチッ。
エイリアスを「はい」にしてエイリアス先を先ほど作成したロードバランサーを選択し「作成」をポチッ。はい、完成。
ってことでドメイン経由でアクセスしてみまっしょい。
あん?nginxのデフォルトページ?
ってことでサーバに入ってnginxの設定を確認してみる。$ cat /etc/nginx/conf.d/wordpres.conf server { listen 80; server_name *.amazonaws.com; server_name ~^\d+\.\d+\.\d+\.\d+$; location / { root /var/www/html; index index.php index.html; } location ~ \.php$ { root /var/www/html; fastcgi_pass 127.0.0.1:9000; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } }なるほど。server_nameで「*.amazonaws.com」とIPアドレス直打ちのみルーティングするように設定されてるのね。
ってことで修正。server { listen 80; server_name olafblog.org; server_name *.amazonaws.com; server_name ~^\d+\.\d+\.\d+\.\d+$; location / { root /var/www/html; index index.php index.html; } location ~ \.php$ { root /var/www/html; fastcgi_pass 127.0.0.1:9000; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } }server_nameを追加してnginxを再起動。
$ sudo nginx -s reload設定できたので再度アクセス!
おぉ、表示できた!
まぁhttpsのページからhttpでスタイルシート等を読み込みにいってるのでスタイルが崩れるのは想定の範囲内。
一旦独自ドメインとSSL対応は完了したので今回は満足。
次回はhttp->httpsリダイレクトとスタイルが崩れないように対応していく。
続きはこちら->「AWSに構築したWordPressをhttps対応してみた」
- 投稿日:2020-01-10T09:00:17+09:00
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #20 (ゲーム開発)
Amazon Web Services (AWS)のサービスで正式名称や略称はともかく、読み方がわからずに困ることがよくあるのでまとめてみました。
Amazon Web Services (AWS) - Cloud Computing Services
https://aws.amazon.com/全サービスを並べたチートシートもあるよ!
Amazon Web Services (AWS)サービスの正式名称・略称・読み方チートシート - Qiita
https://qiita.com/kai_kou/items/cb29d261c8acc49fd22aまとめルールについては下記を参考ください。
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #1 (コンピューティング) - Qiita
https://qiita.com/kai_kou/items/a6795dbab7e707b0d1a6間違いや、こんな呼び方あるよーなどありましたらコメントお願いします!
Game Development - ゲーム開発
Amazon GameLift
- 正式名称: Amazon GameLift
- https://docs.aws.amazon.com/gamelift/?id=docs_gateway
- 読み方: ゲームリフト
- 略称: なし
- 俗称: なし
Amazon Lumberyard
- 正式名称: Amazon Lumberyard
- https://docs.aws.amazon.com/lumberyard/?id=docs_gateway
- 読み方: ランバーヤード
- 略称: なし
- 俗称: なし
他のまとめ
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #1 (コンピューティング) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #2 (ストレージ) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #3 (データベース) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #4 (開発者用ツール) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #5 (セキュリティ、アイデンティティ、コンプライアンス) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #6 (暗号化と PKI) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #7 (機械学習) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #8 (マネジメントとガバナンス) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #9 (移行と転送) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #10 (モバイル) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #11 (ネットワーキングとコンテンツ配信) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #12 (メディアサービス) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #13 (エンドユーザーコンピューティング) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #14 (分析) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #15 (アプリケーション統合) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #16 (ビジネスアプリケーション) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #17 (サテライト) - Qiita
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #18 (ロボット工学) - Qiita
- 投稿日:2020-01-10T00:35:05+09:00
AWS ECRにk8sで必要なイメージを持っていくの楽にする
AWSでKubernetesを運用する
少し前はEC2とかと、kubernetes構成管理ツール(kopsやらkubeadm)とかを使って構築していましたが最近ではEKS + ECRがデファクトスタンダードになってきたかなと思います。
またEKS + ECR構成にしたときは、Docker Imageは全てECRからpullしてきて、DockerHubからはpullしないようにするとかはよくあるかと思います。
これで運用しているときに地味に辛いのが、自分たちで作成していないimageやmanifestをデプロイする時だと思います。(kubernetes dashboard, prometheus, metric-server, etc...)
これらをデプロイしようとする場合は以下の手順を踏む必要があります。
- デプロイ用のマニフェストからimageの箇所を全て抜き出して, 外通できる場所でdocker pullする
- pullしたimageにecr用のtagをつける
- ecrにrepositoryを作成する
- tag付けしたimageをecrへpushする
- 元のマニフェストのimage箇所を書き換えてecrのimage pathに変更する
- manifestをapplyする
地味にめんどいです、2~4あたりを自動化するshellとかを作っていたのですが、1,5の作業もだいぶ辛くなってきた
これらの作業をまとめるツールを作ってみた
https://github.com/esakat/trimg
このあたりを楽にするCLIを作ってみました。
homebrewでインストールできます
$ brew install esakat/trimg/trimg使い方
最初にあげた6つの手順のうち、1~4を実施するサブコマンドと、5を実施するサブコマンドを用意しました。
マニフェストからイメージ情報を抜き出して、docker pullして、tag付けして、ecrにリポジトリ作って、pushする
$ trimg transfer -f testfiles/input/replicaset.yml [gcr.io/google_samples/gb-frontend:v3] [==============================================================================] 100 % 1: gcr.io/google_samples/gb-frontend:v3 transfer to <YourAccountId>.dkr.ecr.<YourDefaultRegion>.amazonaws.com/gcr.io/google_samples/gb-frontend:v3ベースのマニフェストはこちらです
実行すると、見出しの通りのことをしてくれます
ECRにpushされています$ aws ecr list-images --repository-name gcr.io/google_samples/gb-frontend { "imageIds": [ { "imageDigest": "sha256:60049e8aa1bb97242ce1a5fc5f9d86478d3f3407c2643edb054c717ac12c14bb", "imageTag": "v3" } ] }マニフェストからイメージ情報を抜き出して、ecrのpathに書き換える
$ trimg replace testfiles/input/replicaset.yml > replacedManifest.ymlコメント情報消えたり、keyの順番が少し変わったりするのでdiffでみてないです.
$ cat testfiles/input/replicaset.yml | grep image: image: gcr.io/google_samples/gb-frontend:v3 $ cat replacedManifest.yml | grep image: image: <YourAccountId>.dkr.ecr.<YourDefaultRegion>.amazonaws.com/gcr.io/google_samples/gb-frontend:v3kubectlと組み合わせる
trimgでmanifestを書き換え、必要なイメージをecrへ送ります
$ trimg transfer -f testfiles/input/replicaset.yml $ trimg replace testfiles/input/replicaset.yml > replacedManifest.ymlEKSを用意しています
$ kubectl cluster-info | grep master Kubernetes master is running at https://......eks.amazonaws.com書き換えられたマニフェストをdeployします
$ kubectl apply -f replacedManifest.yml replicaset.apps/frontend created正常に起動して、ecrのimageを使って動いています
$ kubectl get replicaset NAME DESIRED CURRENT READY AGE frontend 3 3 3 97s $ kubectl get replicaset frontend -ojson | jq .spec.template.spec.containers[0].image "<YourAccountId>.dkr.ecr.<YourDefaultRegion>.amazonaws.com/gcr.io/google_samples/gb-frontend:v3"シンプルなものですが、よかったら使ってもらえると嬉しいです
内部的なもの
これだけだと宣伝なので、内部でちょっとハマった箇所とかをまとめておきます。
DockerHubからのpullがgoでうまくできない
https://github.com/docker/docker を使ってgoのプログラムでdocker pullなどをやっていたのですが、なぜかDockerHubからのimage pullができませんでした(
k8s.gcr.ioとかからはできた)理由としては、DockerHubのイメージパスはデフォで省略されているようだった
docker pull nginx:latest -> docker pull docker.io/library/nginx:latest
docker.ioが省略されており、さらにDockerHub公式のイメージの場合はさらにlibraryを付与する必要があります。以下で対応しています。
https://github.com/esakat/trimg/blob/master/pkg/image_transfer.go#L68-L84この省略で拾えない場合は決まったエラーが返ってくるので
とりあえず元のイメージ名でpull, 省略で拾えないエラーだったら、省略されている文字を追加してあげてます。Manifestからimageの箇所を抜き出す。
かなりごり押してます
まずmanifestを読み込むところですが、kubernetesの場合は1つのファイルに複数マニフェストが含まれるのはよくあります。
(これは別の記事で書いてます)複数マニフェストを読み込んで
[]map[interface{}]interface{}型の変数を得ます最初は
manifest["kind"],manifest["apiVersion"]だけ読み込んで、対応する構造体(kubernetesリポジトリが提供している)にマッピングしようとしましたがうまくいきませんでした。というのもkubernetesリポジトリが提供している構造体は全ての情報を含んでいるので(例えばcreationTimeとか)マッピングしたら余分な情報が初期値で作られてしまいます。
今回のアプリでは、image名だけ変えて、あとはそのままというのにする必要があったので、この方法は諦めて,以下のようにゴリ押しをしています。
manifest["spec"].(map[interface{}]interface{})["template"].(map[interface{}]interface{})....これで掘っていくと、ネストがとても深くなります
一番長いCronJobだと以下のようになりますmanifest["spec"].(map[interface{}]interface{})["template"].(map[interface{}]interface{})["spec"].(map[interface{}]interface{})["containers"].([]interface{})[i].(map[interface{}]interface{})["image"]これを1つのkey毎に存在チェックしてあれば、次の処理へってネストするとコードのインデントが半端なくなります。
このあたりはutil化して再帰的にやるようにしています。
ここだけ抜き出したリポジトリがこちらです関数型っぽい感じですが、head/tailみたいな感じの関数になっています
func DigYaml(y interface{}, keys ...interface{}) (interface{}, error) { head := keys[0] // y[head]を取得する処理 .. value := y[head] // y[head]の中身と可変長引数のtailを再帰する return DigYaml(value, keys[1:]...) }
key1, err := dig_yaml.DigYaml(y, "hoge", 0, "key1")こんな感じで呼べます、これは次と同義ですyamlDoc["hoge"].([]interface{})[0].(map[interface{}]interface{})["key1"]可変長引数はstringかintだけ受け付けて、stringならyamlのkeyとして判定, intの場合は配列のインデックスとして認識するようにしています
(数値型, 真偽型のkey含んでたらうまく動かないです..)
また対象のmanifestですが、image(PodTemplateSpec)を含むリソースが対象で、そのpod spec内のcontainers, initContainers配列で使われているimageが対象になります
リソースとかの仕様はAPI Documentで
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.17/MultiProgressbarを使いたい
マニフェストからイメージ情報を抜き出して、docker pullして、tag付けして、ecrにリポジトリ作って、pushする という処理は全部やるとそこそこ時間かかります(でかいイメージだと2,3分かかったり)その間画面動かないのも嫌なのでプログレスバーを用意しようとしました。
go progress barで検索するといくつか候補がありますが
- マルチプログレスバー対応
- 今でも開発が続いている
- Githubのstar数
から https://github.com/vbauerster/mpb を使うようにしました
[gcr.io/google_samples/gb-frontend:v3] [==============================================================================] 100 %
[gcr.io/google_samples/gb-frontend:v3]の右とかに,今やってるtask(docker pull中なのか, ecrへpush中なのか)を表示したいけど、一度progressbarを作っちゃうと、パーセンテージとか以外の情報は変えづらいのが少しだけ辛いとこですが、それ以外はとても使いやすいいいライブラリです。