- 投稿日:2019-12-24T19:32:05+09:00
【ポケモン剣盾】御三家分類を例に深層学習の判断根拠を可視化してみた
はじめに
みなさん、ポケモンやってますか?私は10年振りくらいに
買いましたサンタさんにもらいました。
ガチ勢目指して、年末年始は家に引きこもって厳選予定です。
AdventCalendarはポケモンネタで何かできないかなーと思っていたので、最近気になっている深層学習モデルの判断根拠を示す手法を、ポケモン御三家分類を例に試してみました。※手法の説明やデータセットの準備も含めて記載していくので、結果だけ知りたい方は結果まで飛ばしてください
深層学習モデルの判断根拠を示す手法:TCAVとは
深層学習は様々な分野で社会実装が進み始めていますが、モデルが何を根拠に判断しているのかはブラックボックスになりがちです。
近年、モデルの「説明性」「解釈性」に関する研究が進められています。そこで今回は、ICML2018に採択されたQuantitative Testing with Concept Activation Vectors (TCAV) という手法を試してみたいと思います。
論文概要
- ニューラルネットワークモデルの判断根拠を示す手法
- 従来のピクセルごとに重要度を算出するような手法ではなく、予測クラスの概念(色、性別、人種など)の重要度を示す
- 各画像に対する説明(≒ローカル)ではなく、各クラスに対する説明(≒グローバル)を生成するので、人間にわかりやすい説明性を持つ
- MLモデルの専門知識がなくても説明を理解することができる
- 解釈したい既存モデルに対して、再学習や変更の必要はない
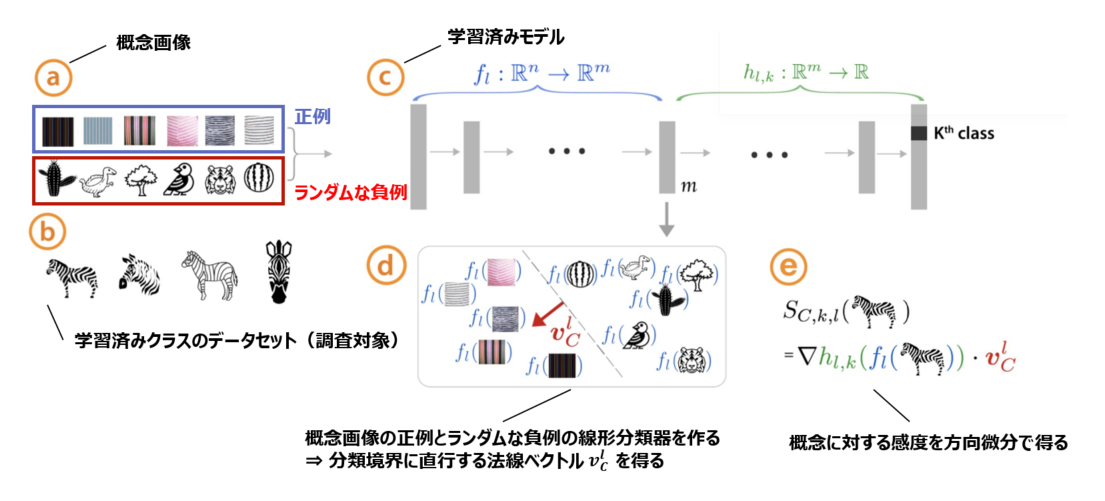
Concept Activation Vectors (CAV)の概念
概念画像とランダムな反例の間で線形分類器をトレーニングし、決定境界に直交するベクトルを取得することにより、CAVを導出します。
(下の図見た方が早い)。
※より詳細な論文メモはこちらに置いてありますので、ご興味ある方はご覧ください
何がわかる?
モデルが学習している「概念」を人間が解釈可能な形で定量化できる
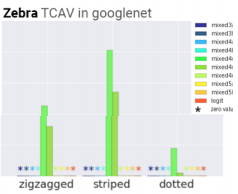
例:「シマウマ」分類において「ドット柄」より「ストライプ柄」を学習している
また、任意の層での学習を見ることもできるので、浅い層/深い層でどの程度粗い/細かい特徴を捉えているかも見ることができます。
データセットのバイアスがわかる
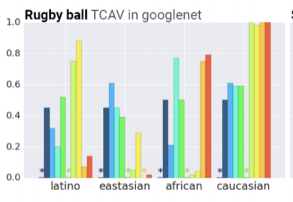
例:「エプロン」クラスにおいて、「女性」の概念が関連している、「ラグビーボール」クラスにおいて、「白人」の概念が関連している
画像ソーターとして使える(概念画像との類似性に基づいて並び替えができる)
まず適当な分類器を作る
今回はTCAVを動かしてみるのが目標なので、簡単なタスクにしました。
ポケモン御三家分類器を作ります。データセットの準備
①クローリング
icrawlerを使って下記の画像を収集しました。
コード貼っておきます。import os from icrawler.builtin import GoogleImageCrawler save_dir = '../datasets/hibany' os.makedirs(save_dir, exist_ok=True) query = 'ヒバニー' max_num = 200 google_crawler = GoogleImageCrawler(storage={'root_dir': save_dir}) google_crawler.crawl(keyword=query, max_num=max_num)②前処理
最低限の処理だけです。
- ①クローリングで取得した画像を手動で正方形にクロップ
- 256×256にリサイズ
- train/val/testに分割
御三家画像サンプル
こんな感じで画像が集まりました。
(ちなみに私はヒバニー即決でした。炎タイプ大好き)
ヒバニー メッソン サルノリ 156枚 147枚 182枚 以下のような御三家以外のポケモンや、キャラクターの画像、デフォルメされすぎているイラストなども紛れていたので目検で除外しています。
キバナサンカッコイイ

分類器作成
シンプルなCNNです。
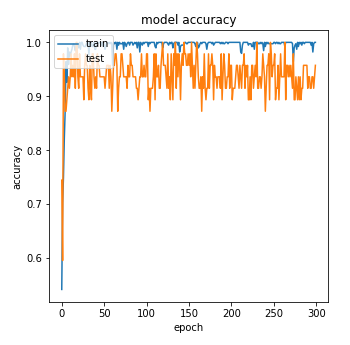
テストデータの画像が少ない(15枚程度)のでテストデータのAccuracyはバタついていますが、TCAVの検証には十分であろう精度の分類モデルができました。
CAVの計算に.pbファイルが必要になるので、.pbでモデルを保存します。
次に、モデルが何を学習しているのか見るための準備をします。TCAVの実行準備
下記ステップに沿って準備していきます。
(今回使ったコードはこちらに置いてあります。あとでちゃんとREADME書きます。。。)Step1:概念画像(正例と負例)の準備
正例画像に用意したのは下記の画像です。
色を見て御三家を分類するのでは、という仮説のもと数色準備しました。
(10~20枚でも動きはしますが、50~200枚くらいあった方がよいとのことです)正例画像サンプル
白 赤 青 黄 緑 黒 22枚 20枚 15枚 18枚 21枚 17枚 こういう複数カラーが混ざりすぎているものは除外しています
負例画像サンプル
上記のどの正例にも該当しないものが望ましいです。(今回の場合、どの色にも該当しないというのは難しいですが。。)
今回はCaltech256からランダムに画像を取ってきました。ここまでに集めた画像たちのディレクトリ構成は下記のようになります。
概念画像のセットは全てサブディレクトリにする必要があります。├── datasets │ ├── for_tcav # TCAV用のデータセット │ │ ├── black │ │ ├── blue │ │ ├── green │ │ ├── hibany │ │ ├── messon │ │ ├── random500_0 │ │ ├── random500_1 │ │ ├── random500_2 │ │ ├── random500_3 │ │ ├── random500_4 │ │ ├── random500_5 │ │ ├── red │ │ ├── sarunori │ │ ├── white │ │ └── yellow │ └── splited # 画像分類モデル作成用データセット │ ├── test │ │ ├── hibany │ │ ├── messon │ │ └── sarunori │ ├── train │ │ ├── hibany │ │ ├── messon │ │ └── sarunori │ └── validation │ ├── hibany │ ├── messon │ └── sarunoriStep2:モデルラッパーを実装する
まずクローンしてきます。
git clone git@github.com:tensorflow/tcav.gitここでは、モデルの情報をTCAVに伝えるためのラッパーを作ります。
このクラスを tcav/model.py に追記します。class SimepleCNNWrapper_public(PublicImageModelWrapper): def __init__(self, sess, model_saved_path, labels_path): self.image_value_range = (0, 1) image_shape_v3 = [256, 256, 3] endpoints_v3 = dict( input='conv2d_1_input:0', logit='activation_6/Softmax:0', prediction='activation_6/Softmax:0', pre_avgpool='max_pooling2d_3/MaxPool:0', logit_weight='activation_6/Softmax:0', logit_bias='dense_1/bias:0', ) self.sess = sess super(SimepleCNNWrapper_public, self).__init__(sess, model_saved_path, labels_path, image_shape_v3, endpoints_v3, scope='import') self.model_name = 'SimepleCNNWrapper_public'これで準備が完了します。早速結果を見てみます。
結果
各クラスで重要視している概念(今回は色)を見てみます。
*印がついていない概念が重要視しているものです。
ヒバニークラス メッソンクラス サルノリクラス 赤・黄色・白
赤 (!?)
緑
ヒバニーとサルノリはそれっぽい結果かなと思います。
メッソンに関しては謎なので要考察です。
実験中に、試行回数や概念画像・ターゲット画像の枚数を変えると結構結果が変わるので、もう少し考察が必要かなと思っています。
概念画像の選び方によっても変わりそうなので、色々試し甲斐がありそうです。まとめ
ニューラルネットワークモデルの判断根拠を示す手法を試してみました。
人間が解釈しやすく、"直観的にそれっぽい"結果が得られました。
今回は御三家分類ということで概念画像として色を選びましたが、概念画像を準備するのが大変ですね。。
諸々準備は必要ですが、モデルを学習しなおす必要はないし、一連の流れを一回試して慣れちゃえば楽に使えると思います。
是非試してみてください!














- 投稿日:2019-12-24T14:09:15+09:00
tf.kerasで学習中の進捗表示をカスタマイズする (GoogleColaboratoryのセルあふれ対策)
【内容】
同僚がKeras(tf.keras)を使ってGoogleColaboratory上で数万Epochの学習をしていたら、ブラウザは重くなるし、挙句の果てに表示が更新されなくなってしまったと嘆いていました。
原因はmodel.fit中にverbose=1を指定して進捗ログを表示していたのですが、そのログが肥大化して重くなり、ある閾値(?)に達すると表示が更新されなくなってしまいました。(動作は継続している)
verbose=0でログを止めて回せば事足りますが、それでは進捗状況が確認できなくなってしまいます。そういえば自分も過去に同じ現象に悩んだ挙げ句、Callback関数を使って解決したこと思い出したので共有したいと思います。
【tf.kerasのCallback関数について】
model.fitの引数callbacksにtf.keras.callbacks.Callbackクラスを継承したクラスを指定することで、学習中の振舞いをカスタマイズできます。
詳細は公式のドキュメントを確認してください。
【tf.keras.callbacks.Callback - TensorFlow】
【コールバック - Keras Documentation】
tf.keras.callbacks.Callbackにはメソッドがいくつか用意されていますが、それらはあるタイミングで呼び出されるようになっています。
これらのメソッドをオーバライドすることで、学習時の振る舞いを変更できます。
今回は以下のメソッドをオーバライドしました。
メソッド 呼び出されるタイミング on_train_begin 学習開始時 on_train_end 学習終了時 on_batch_begin Batch開始時 on_batch_end Batch終了時 on_epoch_begin Epoch開始時 on_epoch_end Epoch終了時 上記以外にも推論時やテスト時などに呼び出されるメソッドが用意されています。
【方針】
学習中の進捗表示を改行せずに同一行に上書きし続けることで、出力セルが肥大化してあふれないようにします。
同一行で上書きし続けるためには以下のコードを使います。print('\rTest Print', end='')上記コードの
\rはCarriage Return(CR)を意味していて、カーソルを行の先頭に移動することが出来ます。
これにより表示済みの行の上書きが可能になります。ただし、このままだとprint文を実行するたびに改行されてしまします。
そこでprint文の引数としてend=''を指定します。
要は第一引数を出力後になにも出力しないように指定することで、改行を抑止します。
なお、print文はデフォルトでend='\n'が指定されています。
\nはLine Feed(LF)を意味して、カーソルを新しい行に送ります (つまり改行されます)。試しに下記のコードを実行すると 0 ~ 9 を上書きし続け、カウントアップしているように表現できます。
上書きサンプルfrom time import sleep for i in range(10): print('\r%d' % i, end='') sleep(1)ここで、ふと思います。
わざわざ'\r'をプリントするのではなくend='\r'にすれば良いようにも感じます。しかし、この試みはうまくいきません。
なぜならPythonでは'\r'が出力される際に、それまで出力された内容がクリアされてしまうようです。
例えばprint('Test Print', end='\r')を実行すると見かけ上はなにも表示されず、今回の用途では都合が悪いです。
なので、文字出力直前に'\r'を出力した後に、出力したい文字列を出力する方法で行くしかありません。というわけで、上記の手法を使って以下の方針でコーディングします。
学習開始/終了時
開始/終了を表示するとともに、実行された時間を表示します。
ここは普通に改行します。Batch完了時 および Epoch完了時
Epoch数や処理したデータ数、accやlossを表示します。
この表示は改行せずに上書きすることによって、出力セルのサイズを抑制します。【コーディング】
上記の方針をもとに、実装します。
モデル部分はTensorFlowのチュートリアがベースになっています。
【TensorFlow 2 quickstart for beginners】import tensorflow as tf# カスタム進捗表示用のCallback関数定義 """ 進捗表示用のCallback関数です。 Batch終了時とEpoch終了時にデータを収集して、表示しています。 ポイントとしては print 出力時に /r で行先頭にカーソルを戻しつつ、引数 end='' で改行を抑制している点です。 """ import datetime class DisplayCallBack(tf.keras.callbacks.Callback): # コンストラクタ def __init__(self): self.last_acc, self.last_loss, self.last_val_acc, self.last_val_loss = None, None, None, None self.now_batch, self.now_epoch = None, None self.epochs, self.samples, self.batch_size = None, None, None # カスタム進捗表示 (表示部本体) def print_progress(self): epoch = self.now_epoch batch = self.now_batch epochs = self.epochs samples = self.samples batch_size = self.batch_size sample = batch_size*(batch) # '\r' と end='' を使って改行しないようにする if self.last_val_acc and self.last_val_loss: # val_acc/val_loss が表示可能 print("\rEpoch %d/%d (%d/%d) -- acc: %f loss: %f - val_acc: %f val_loss: %f" % (epoch+1, epochs, sample, samples, self.last_acc, self.last_loss, self.last_val_acc, self.last_val_loss), end='') else: # val_acc/val_loss が表示不可 print("\rEpoch %d/%d (%d/%d) -- acc: %f loss: %f" % (epoch+1, epochs, sample, samples, self.last_acc, self.last_loss), end='') # fit開始時 def on_train_begin(self, logs={}): print('\n##### Train Start ##### ' + str(datetime.datetime.now())) # パラメータの取得 self.epochs = self.params['epochs'] self.samples = self.params['samples'] self.batch_size = self.params['batch_size'] # 標準の進捗表示をしないようにする self.params['verbose'] = 0 # batch開始時 def on_batch_begin(self, batch, logs={}): self.now_batch = batch # batch完了時 (進捗表示) def on_batch_end(self, batch, logs={}): # 最新情報の更新 self.last_acc = logs.get('acc') if logs.get('acc') else 0.0 self.last_loss = logs.get('loss') if logs.get('loss') else 0.0 # 進捗表示 self.print_progress() # epoch開始時 def on_epoch_begin(self, epoch, log={}): self.now_epoch = epoch # epoch完了時 (進捗表示) def on_epoch_end(self, epoch, logs={}): # 最新情報の更新 self.last_val_acc = logs.get('val_acc') if logs.get('val_acc') else 0.0 self.last_val_loss = logs.get('val_loss') if logs.get('val_loss') else 0.0 # 進捗表示 self.print_progress() # fit完了時 def on_train_end(self, logs={}): print('\n##### Train Complete ##### ' + str(datetime.datetime.now()))# コールバック関数用のインスタンス生成 cbDisplay = DisplayCallBack()# MNISTデータセットを読み込み正規化 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0# tf.keras.Sequential モデルの構築 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# モデルの学習 # ここでコールバック関数を使います history = model.fit(x_train, y_train, validation_data = (x_test, y_test), batch_size=128, epochs=5, verbose=1, # 標準の進捗表示はコールバック関数内で無視するようにしている callbacks=[cbDisplay]) # コールバック関数としてカスタム進捗表示をセット# モデル評価 import pandas as pd results = pd.DataFrame(history.history) results.plot();【出力例】
上記を実行すると何Epoch回しても、下記の3行しか表示されません。
2行目がBatch終了時とEpoch終了時に最新の情報に書き換わり、学習が完了すると最後の行が出力されます。##### Train Start ##### 2019-12-24 02:17:27.484038 Epoch 5/5 (59904/60000) -- acc: 0.970283 loss: 0.066101 - val_acc: 0.973900 val_loss: 0.087803 ##### Train Complete ##### 2019-12-24 02:17:34.443442

- 投稿日:2019-12-24T09:06:29+09:00
Windows10でTensorFlow2.0,Keras,MNISTメモ
動作環境
Windows10 Home
RTX2080Anacondaのインストール
CUDA
https://developer.nvidia.com/cuda-toolkit-archive
cuDNN
https://developer.nvidia.com/rdp/cudnn-download
Anacondapromptを起動
conda create -n [仮想環境名] python=3.7 jupyter
activate [仮想環境名]tensorflowをインストール
pip install tensorflow-gpu
バージョン確認import tensorflow as tf tf.__version__ '2.0.0'kerasをインストール
pip install keras
バージョン確認import keras Using TensorFlow backend. keras.__version__ '2.3.1'MNISTで動作確認
mnist.pyimport tensorflow as tf #MNIST データセットをロードして準備します。サンプルを整数から浮動小数点数に変換します。 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 #層を積み重ねてtf.keras.Sequentialモデルを構築します。訓練のためにオプティマイザと損失関数を選びます。 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) #モデルを訓練してから評価します。 model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test, verbose=2)その他必要なものをインストール
pip install Protobuf Pillow lxml
pip install Jupyter
pip install Matplotlib
- 投稿日:2019-12-24T03:14:32+09:00
Hikey970 で Debian Pre-built Tensorflow が動くように mac でセットアップする(途中)
準備
公式ページには Linux で fastboot を使ってインストールする方法が書かれているので、mac でもできるだろうということで無計画に始めてみる。
物理的な準備
- Hikey970
- mac
- USB-Cケーブル
- ACアダプタ 12V/2A EIAJ-3 内径1.7mm/外形4.75mm
Hikey970 は、今は amazon とかスイッチサイエンスで購入できるもよう。手に入れたものは AC アダプタが米国仕様のもので、変換プラグが必要だった。秋月で購入した 12V/2A の AC アダプタに、付属の 2.1mm -> 1.7mm 変換ケーブルを付けて対処することに。
- スイッチサイエンス: https://www.switch-science.com/catalog/3775/
- 秋月の 12V/2A AC アダプタ: http://akizukidenshi.com/catalog/g/gM-06239/
mac の準備
Android SDK をインストールして、下記にパスを通しておく。
/Users/<ユーザ名>/Library/Android/sdk/platform-tools/Debian Pre-built Tensorflow for Hikey970
下記URLからダウンロードできる。
- http://www.lemaker.org/product-hikey970-download-86.htmlインストール
手順は下記に書かれれているので、基本この通りに進めていく。
https://www.96boards.org/documentation/consumer/hikey/hikey970/installation/linux-fastboot.md.html
- 投稿日:2019-12-24T03:14:32+09:00
Hikey970 で Debian Pre-built Tensorflow が動くように mac でセットアップする
準備
公式ページには Linux で fastboot を使ってインストールする方法が書かれているので、mac でもできるだろうということで無計画に始めてみる。(画像は公式のものです)
物理的な準備
- Hikey970
- mac
- USB-Cケーブル
- ACアダプタ 12V/2A EIAJ-3 内径1.7mm/外形4.75mm
- 起動後: HDMI ケーブル
- 起動後: USB キーボード
- 起動後: USB マウス
Hikey970 は、今は amazon とかスイッチサイエンスで購入できるようだ。私が手に入れたものは AC アダプタが米国仕様のもので、変換プラグが必要だった。とりあえず、秋月で購入した 12V/2A の AC アダプタに、付属の 2.1mm -> 1.7mm 変換ケーブルを付けて対処した。
- スイッチサイエンス: https://www.switch-science.com/catalog/3775/
- 秋月の 12V/2A AC アダプタ: http://akizukidenshi.com/catalog/g/gM-06239/
mac の準備
fastboot が必要なので、Android SDK をインストールして、下記にパスを通しておく。
/Users/<username>/Library/Android/sdk/platform-tools/Debian Pre-built Tensorflow for Hikey970
下記URLからダウンロードできる。
- http://www.lemaker.org/product-hikey970-download-86.htmlインストール
手順は下記に書かれれているので、基本この通りに進めていく。
https://www.96boards.org/documentation/consumer/hikey/hikey970/installation/linux-fastboot.md.htmlmac と接続
ボード上の DIP スイッチを 1:on, 2:off, 3:on としておく。初期状態では 3 が off になっていた。次に usb-c ケーブルで mac とつないで、AC アダプタをつないでから fastboot でデバイスが認識されているかを調べてみる。Type C ボードにある Type-C のコネクタのうち、HDMI コネクタの隣りにあるほうにつなぐ。
fastboot devicesこれでデバイスの ID が表示されたら成功なのだけど、この時点では何もでなかった。おそらく UART のドライバが mac に入ってない気がしたので、ドキュメントを調べてみると FT230X を使っているとあったので、mac 用の FTDI のドライバを下記から入れてみた。
これで、ボード側の電源を入れなおしたら fastboot で認識してくれるようになった。
$ fastboot devices 2D67419D028CE119 fastbootこんな感じ。
OSイメージの書き込み
先にダウンロードした hikey970-lebian-9.tar.gz を展開して、flash-all-binaries.sh を実行する。
$ tar xzvf hikey970-lebian-9.tar.gz $ cd hikey970-lebian-9 $ bash flash-all-binaries.shデバイスが認識できていれば、書き込みが始まって下記のようなメッセージが出る(はず)。
Flashing ptable Sending 'ptable' (24 KB) OKAY [ 0.001s] Writing 'ptable' OKAY [ 0.004s] Finished. Total time: 0.007s Sending 'xloader' (164 KB) OKAY [ 0.005s] Writing 'xloader' OKAY [ 0.003s] Finished. Total time: 0.010s Sending 'fastboot' (1152 KB) OKAY [ 0.034s] Writing 'fastboot' OKAY [ 0.061s] Finished. Total time: 0.097s Sending 'fip' (1224 KB) OKAY [ 0.037s] Writing 'fip' OKAY [ 0.057s] Finished. Total time: 0.095s Sending 'boot' (65536 KB) OKAY [ 1.913s] Writing 'boot' OKAY [ 0.231s] Finished. Total time: 2.145s Please be patient... Sending sparse 'userdata' 1/21 (131068 KB) OKAY [ 3.856s] Writing 'userdata' OKAY [ 0.335s] Sending sparse 'userdata' 2/21 (131068 KB) OKAY [ 3.774s] Writing 'userdata' OKAY [ 0.576s] (中略) Sending sparse 'userdata' 21/21 (113218 KB) OKAY [ 3.850s] Writing 'userdata' OKAY [ 0.817s] Finished. Total time: 100.527sこれで書き込み終了。
リブート
電源ケーブルと USB-C ケーブルを抜いてから、dip スイッチの 3 番を off にして、再度電源ケーブルを差せば Hikey970 が起動する。
最初に Hikey970 を操作するためには、USB にマウスとキーボードをつないで、HDMI ケーブルでディスプレイにつないでおく必要がある。ネットワークと ssh の設定をしたら、以降は電源だけさせばいいはず。

- 投稿日:2019-12-24T03:14:32+09:00
Hikey970 で Debian Pre-built Tensorflow が動くように mac で設定する
準備
公式ページには Linux で fastboot を使ってインストールする方法が書かれているので、mac でもできるだろうということで無計画に始めてみた。結果的にはうまくいった。(画像は公式のものです)
物理的な準備
- Hikey970
- mac
- USB-Cケーブル
- ACアダプタ 12V/2A EIAJ-3 内径1.7mm/外形4.75mm
- 起動後: HDMI ケーブル
- 起動後: USB キーボード
- 起動後: USB マウス
Hikey970 は、今は amazon とかスイッチサイエンスで購入できるようだ。私が手に入れたものは AC アダプタが米国仕様のもので、変換プラグが必要だった。とりあえず、秋月で購入した 12V/2A の AC アダプタに、付属の 2.1mm -> 1.7mm 変換ケーブルを付けて対処した。
- スイッチサイエンス: https://www.switch-science.com/catalog/3775/
- 秋月の 12V/2A AC アダプタ: http://akizukidenshi.com/catalog/g/gM-06239/
mac の準備
fastboot が必要なので、Android SDK をインストールして、下記にパスを通しておく。
/Users/<username>/Library/Android/sdk/platform-tools/Debian Pre-built Tensorflow for Hikey970
下記URLからダウンロードできる。
- http://www.lemaker.org/product-hikey970-download-86.htmlインストール
手順は下記に書かれれているので、基本この通りに進めていく。
https://www.96boards.org/documentation/consumer/hikey/hikey970/installation/linux-fastboot.md.htmlmac と接続
ボード上の DIP スイッチを 1:on, 2:off, 3:on としておく。初期状態では 3 が off になっていた。次に usb-c ケーブルで mac とつないで、AC アダプタをつないでから fastboot でデバイスが認識されているかを調べてみる。Type C ボードにある Type-C のコネクタのうち、HDMI コネクタの隣りにあるほうにつなぐ。
fastboot devicesこれでデバイスの ID が表示されたら成功なのだけど、この時点では何もでなかった。おそらく UART のドライバが mac に入ってない気がしたので、ドキュメントを調べてみると FT230X を使っているとあったので、mac 用の FTDI のドライバを下記から入れてみた。
これで、ボード側の電源を入れなおしたら fastboot で認識してくれるようになった。
$ fastboot devices 2D67419D028CE119 fastbootこんな感じ。
OSイメージの書き込み
先にダウンロードした hikey970-lebian-9.tar.gz を展開して、flash-all-binaries.sh を実行する。
$ tar xzvf hikey970-lebian-9.tar.gz $ cd hikey970-lebian-9 $ bash flash-all-binaries.shデバイスが認識できていれば、書き込みが始まって下記のようなメッセージが出る(はず)。
Flashing ptable Sending 'ptable' (24 KB) OKAY [ 0.001s] Writing 'ptable' OKAY [ 0.004s] Finished. Total time: 0.007s Sending 'xloader' (164 KB) OKAY [ 0.005s] Writing 'xloader' OKAY [ 0.003s] Finished. Total time: 0.010s Sending 'fastboot' (1152 KB) OKAY [ 0.034s] Writing 'fastboot' OKAY [ 0.061s] Finished. Total time: 0.097s Sending 'fip' (1224 KB) OKAY [ 0.037s] Writing 'fip' OKAY [ 0.057s] Finished. Total time: 0.095s Sending 'boot' (65536 KB) OKAY [ 1.913s] Writing 'boot' OKAY [ 0.231s] Finished. Total time: 2.145s Please be patient... Sending sparse 'userdata' 1/21 (131068 KB) OKAY [ 3.856s] Writing 'userdata' OKAY [ 0.335s] Sending sparse 'userdata' 2/21 (131068 KB) OKAY [ 3.774s] Writing 'userdata' OKAY [ 0.576s] (中略) Sending sparse 'userdata' 21/21 (113218 KB) OKAY [ 3.850s] Writing 'userdata' OKAY [ 0.817s] Finished. Total time: 100.527sこれで書き込み終了。
リブート
電源ケーブルと USB-C ケーブルを抜いてから、dip スイッチの 3 番を off にして、再度電源ケーブルを差せば Hikey970 が起動する。
最初に Hikey970 を操作するためには、USB にマウスとキーボードをつないで、HDMI ケーブルでディスプレイにつないでおく必要がある。ネットワークと ssh の設定をしたら、以降は電源だけさせばいいはず。
- 投稿日:2019-12-24T00:52:10+09:00
GPUのメモリ使い果たし対策(tensorflow version2.0)
GPUのメモリ節約法(tensorflow)
こんにちは、にわかです。
普段は、低レイヤの記事を書いていますが、今回は機械学習関連の記事を書きたいと思います。
テーマは、タイトル通りなのですが、GPUのメモリ(VRAM)使い果たし対策です。
初期化時のGPUのメモリ確保を制限する。
gpus = tf.config.experimental.list_physical_devices('GPU') if gpus: try: for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True) except RuntimeError as e: print(e)バッチサイズを1つにしたのに、画像の縦横の大きさを小さくしたのに、メモリの使い果たしをした人は上の方法で解決できるはずです。
※プログラムの開始時に、GPUのメモリを確保できるだけ確保するため(何かしらのプロセス用に)、後から学習データをGPUにロードする際にメモリの使い果たしで、ランタイムエラーを起こす場合があります。上のコードを書けば、必要になった分だけGPUのメモリ確保を行います。
ちなみに、CPUには上のコード使えないので注意してください。
これだけの記事なのです。。。
しかし、自分の周りでは、上のコードを書かずにメモリの使い果たしエラーを引き起こしています。
意外と役に立つ記事になると信じておるのじゃ