- 投稿日:2019-12-24T23:41:56+09:00
MySQL innodbの領域最適化
この記事はMySQL Advent Calendar 2019の25日目の記事です。
MySQLのinnodbの領域最適化について最近確認し直したことをまとめたいと思います.
本エントリの内容
本エントリでは下記の2点をランダムInsertにより格納効率が悪くなったデータを最適化するサンプルにそって確認します.
ページ分割が発生しディスク上の格納効率が悪くなった際の次の確認方法
- 特定テーブルスペースのディスク上の配置
- 特定テーブルのbuffer_pool上のデータ格納状況
innodb_fill_factorの設定による動作
物理配置の詳細については本エントリではとりあげませんので下記を参照してください.
https://blog.jcole.us/innodb/検証条件
- MySQL: 5.7.28
- テストデータ: 主キーがランダム,セカンダリインデックスとして追記(created), ランダム(id)の列をそれぞれ用意
create table users( uuid varchar(36) NOT NULL PRIMARY KEY, id varchar(36), created TIMESTAMP DEFAULT CURRENT_TIMESTAMP, INDEX (id), INDEX (created) );テストデータ作成は下記にて
for i in {1..100000}; do mysql -u root -e "INSERT INTO test.users set uuid=uuid(), id=uuid();"; done
- その他: innodb_buffer_pool_instances: 1 (単純化のため)
最適化の動作確認
次の順に操作を行い最適化/断片化の様子を確認します.
- ランダムInsert
- mysqldump
- optimize
ランダムInsert
MySQLが苦手とされるランダムInsertを領域管理の面から確認して行きたいと思います.
ランダムInsert後の初期状態のディスク容量およびbuffer poolの状態を確認します.$ sudo ls -lah /var/lib/mysql/test/users.ibd -rw-r-----. 1 mysql mysql 44M 12月 23 16:52 /var/lib/mysql/test/users.ibd mysql> select * from sys.schema_table_statistics_with_buffer where table_name='users'\G *************************** 1. row *************************** table_schema: test table_name: users rows_fetched: 0 fetch_latency: 0 ps rows_inserted: 100000 insert_latency: 3.05 s rows_updated: 0 update_latency: 0 ps rows_deleted: 0 delete_latency: 0 ps io_read_requests: 14 io_read: 1.35 KiB io_read_latency: 20.28 us io_write_requests: 2407 io_write: 37.27 MiB io_write_latency: 26.62 ms io_misc_requests: 510 io_misc_latency: 680.80 ms innodb_buffer_allocated: 29.03 MiB innodb_buffer_data: 21.38 MiB innodb_buffer_free: 7.65 MiB innodb_buffer_pages: 1858 innodb_buffer_pages_hashed: 289 innodb_buffer_pages_old: 0 innodb_buffer_rows_cached: 100637 1 row in set (0.04 sec)※クエリは一定の負荷が発生します.
続いて、Jerami Cole氏のinnodb_rubyを利用してibdファイルの物理配置を確認します.
uuidを代表とするランダムinsertではページ分割の発生によりfree_spaceが増え、データの充填率が低くなりますがこれを実際に確認します.充填率/レイアウトの確認にはデータが少量の際は、
space-extents-illustrate量が多い場合や実際の充填率分布を細かくみたい場合は、space-index-pages-free-plotが有用です.$ innodb_space -f ../users.ibd space-extents-illustrate ```せ 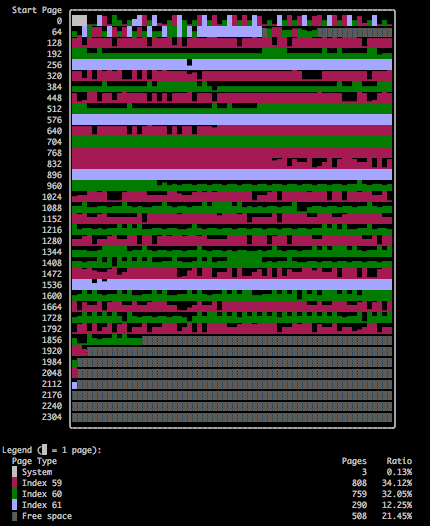 指定のテーブルスペースに対する物理配置を表しています. Index 59が主キーのuuid, Index 69がid, Index 61がcreatedで、ランダム挿入となっている主キーおよびcreatedに対して隙間がある様子が観測できます. 一方でcreatedは追記となるためこちらは断片化せず容量が増加します. > If the insertions into an index are always ascending and records are deleted only from the end, the InnoDB filespace management algorithm guarantees that fragmentation in the index does not occur. 同一行に連続して配置されて、領域確保の単位であるエクステントが専有エクステントとして各セグメント毎にエクステントで領域確保される様子が合わせて確認できます.$ innodb_space -f ../users.ibd space-index-pages-free-plot
```
横軸はページ数,縦軸は空きスペースを示します。innodb_page_sizeが16Kですので、この例では主キーに対して最大約50%程度の空きスペースが発生していることが読み取れます.
ページ分割が期待通りに発生しています.mysqldumpでデータを入れ直す
--order-by-primary を付与してmysqldumpしたものを入れ直し、同様にデータの最適化状態を確認します.
$ sudo ls -lah /var/lib/mysql/test/users.ibd -rw-r-----. 1 mysql mysql 32M 12月 23 23:44 /var/lib/mysql/test/users.ibdmysql> select * from sys.schema_table_statistics_with_buffer where table_name='users'\G *************************** 1. row *************************** table_schema: test table_name: users rows_fetched: 0 fetch_latency: 0 ps rows_inserted: 100000 insert_latency: 901.03 ms rows_updated: 0 update_latency: 0 ps rows_deleted: 0 delete_latency: 0 ps io_read_requests: 19 io_read: 1.81 KiB io_read_latency: 16.79 us io_write_requests: 1480 io_write: 22.79 MiB io_write_latency: 15.63 ms io_misc_requests: 132 io_misc_latency: 224.42 ms innodb_buffer_allocated: 22.52 MiB innodb_buffer_data: 21.35 MiB innodb_buffer_free: 1.17 MiB innodb_buffer_pages: 1441 innodb_buffer_pages_hashed: 290 innodb_buffer_pages_old: 0 innodb_buffer_rows_cached: 100479 1 row in set (0.04 sec)ディスク上の領域が最適化され、合わせて次のようにbuffer_pool上の領域が削減されています. buffer pool上の最適化によりいままでbuffer_pool上にのらなかった他のデータをキャッシュヒットさせることが可能となり場合によっては性能上大きな改善が期待できます.
- innodb_buffer_pages: 1858 > 1441
- innodb_buffer_allocated: 29.03 MiB > 22.52 MiB
$ innodb_space -f ../users.ibd space-extents-illustrate
$ innodb_space -f ../users.ibd space-index-pages-free-plot
こちらのグラフを見ると主キーについては1/16の空きスペースを計画的に確保しているのに対し、セカンダリインデックスは同じ空きスペースは確保せず隙間を空けずに最適化されていることが観測できます.
これは下記のデフォルトのinnodb_fill_factor 0 の動作と整合性がありますhttps://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_fill_factor
An innodb_fill_factor setting of 100 leaves 1/16 of the space in clustered index pages free for future index growth.
短期的には容量が節約されますがセカンダリインデックスに空きスペースがないため断片化が発生しやすい状態となります.
optimizeを実施
MySQL 5.6.17以降は通常またはpartitioningされたInnoDBについてはonlineでoptimizeが実行できます.
mysql> alter table users ENGINE=innodb; Query OK, 0 rows affected (2.01 sec) Records: 0 Duplicates: 0 Warnings: 0mysql> select * from sys.schema_table_statistics_with_buffer where table_name='users'\G *************************** 1. row *************************** table_schema: test table_name: users rows_fetched: 100000 fetch_latency: 13.99 ms rows_inserted: 100000 insert_latency: 901.03 ms rows_updated: 0 update_latency: 0 ps rows_deleted: 0 delete_latency: 0 ps io_read_requests: 64 io_read: 6.09 KiB io_read_latency: 64.88 us io_write_requests: 1467 io_write: 22.58 MiB io_write_latency: 17.58 ms io_misc_requests: 142 io_misc_latency: 173.55 ms innodb_buffer_allocated: 22.45 MiB innodb_buffer_data: 21.36 MiB innodb_buffer_free: 1.09 MiB innodb_buffer_pages: 1437 innodb_buffer_pages_hashed: 0 innodb_buffer_pages_old: 0 innodb_buffer_rows_cached: 100573 1 row in set (0.04 sec)
各セグメントが連続領域として配置されセグメントの末尾に空きスペースが配置されます.
innodb_fill_factorの影響を確認する
無駄な容量は減らしたいものの最適化後に急に容量が増えない方が望ましいケースがあるかもしれません. これを制御するパラメータの動作を確認します.
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_fill_factor
mysql> show variables like 'innodb_fill_factor'; mysql> set global innodb_fill_factor=95; mysql> alter table users ENGINE=innodb; Query OK, 0 rows affected (2.01 sec) Records: 0 Duplicates: 0 Warnings: 0この状態で先程のspace-index-pages-free-plotを確認します.
セカンダリインデックスの空きスペースもコントロールされました.
An innodb_fill_factor setting of 100 leaves 1/16 of the space in clustered index pages free for future index growth.
この例だと現実的には追記のみ発生し空きスペースが必要ないcreatedカラムにも一定の空きスペースが確保されることになるため全体でのトレードオフを考慮して運用する必要がありそうです.
まとめ
ランダム挿入されたデータがoptimizeによってディスク上のスペースおよびbuffer_pool上のサイズが最適化されることを確認しました
バッファプール上のサイズは、sys.schema_table_statistics_with_bufferで、ディスク上でデータがどのように分割されているかはinnodb_spaceのspace-extents-illustrateやspace-index-pages-free-plotで確認しました.セカンダリインデックスがランダム挿入の場合と追記の場合のデータの充填の様子を確認しました.
本記事では扱わなかったデータが削除大量にされているときはもちろん、ランダム挿入されるインデックスが多い場合、特に最適化をしたときの効果が期待されます.
innodb_fill_factorの動作: デフォルトでクラスタインデックスのみ1/16の空きを確保、その他の値に設定した際はセカンダリインデックスも含め空きスペースを作る挙動を確認しました.
参考
関連するページヘのリンクを記載します.
領域最適化
- https://dev.mysql.com/doc/refman/5.7/en/optimize-table.html
- https://dev.mysql.com/doc/refman/5.7/en/sorted-index-builds.html
- https://dev.mysql.com/doc/refman/5.7/en/innodb-file-defragmenting.html
- http://gihyo.jp/dev/serial/01/mysql-road-construction-news/0035
- https://mysqlserverteam.com/mysql-5-6-17-improved-online-optimize-table-for-innodb-and-partitioned-innodb-tables/
領域管理
uuid on MySQL (uuidの容量効率や性能をあげる議論など):
- https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/
- https://www.percona.com/blog/2015/04/03/illustrating-primary-key-models-in-innodb-and-their-impact-on-disk-usage/
- https://www.percona.com/blog/2017/05/03/uuid-generated-columns/
- https://mysqlserverteam.com/storing-uuid-values-in-mysql-tables/
その他






- 投稿日:2019-12-24T23:41:56+09:00
MySQL InnoDBの領域最適化
この記事はMySQL Advent Calendar 2019の25日目の記事です。
MySQLのInnoDBの領域最適化について最近確認し直したことをまとめたいと思います.
本エントリの内容
本エントリでは下記の2点をランダムInsertにより格納効率が悪くなったデータを最適化するサンプルにそって確認します.
ページ分割が発生しディスク上の格納効率が悪くなった際の次の確認方法
- 特定テーブルスペースのディスク上の配置
- 特定テーブルのbuffer_pool上のデータ格納状況
innodb_fill_factorの設定による動作
物理配置の詳細については本エントリではとりあげませんので下記を参照してください.
https://blog.jcole.us/innodb/検証条件
- MySQL: 5.7.28
- テストデータ: 主キーがランダム,セカンダリインデックスとして追記(created), ランダム(id)の列をそれぞれ用意
create table users( uuid varchar(36) NOT NULL PRIMARY KEY, id varchar(36), created TIMESTAMP DEFAULT CURRENT_TIMESTAMP, INDEX (id), INDEX (created) );テストデータ作成は下記にて
for i in {1..100000}; do mysql -u root -e "INSERT INTO test.users set uuid=uuid(), id=uuid();"; done
- その他: innodb_buffer_pool_instances: 1 (単純化のため)
最適化の動作確認
次の順に操作を行い最適化/断片化の様子を確認します.
- ランダムInsert
- mysqldump
- optimize
ランダムInsert
MySQLが苦手とされるランダムInsertを領域管理の面から確認して行きたいと思います.
ランダムInsert後の初期状態のディスク容量およびbuffer poolの状態を確認します.$ sudo ls -lah /var/lib/mysql/test/users.ibd -rw-r-----. 1 mysql mysql 44M 12月 23 16:52 /var/lib/mysql/test/users.ibd mysql> select * from sys.schema_table_statistics_with_buffer where table_name='users'\G *************************** 1. row *************************** table_schema: test table_name: users rows_fetched: 0 fetch_latency: 0 ps rows_inserted: 100000 insert_latency: 3.05 s rows_updated: 0 update_latency: 0 ps rows_deleted: 0 delete_latency: 0 ps io_read_requests: 14 io_read: 1.35 KiB io_read_latency: 20.28 us io_write_requests: 2407 io_write: 37.27 MiB io_write_latency: 26.62 ms io_misc_requests: 510 io_misc_latency: 680.80 ms innodb_buffer_allocated: 29.03 MiB innodb_buffer_data: 21.38 MiB innodb_buffer_free: 7.65 MiB innodb_buffer_pages: 1858 innodb_buffer_pages_hashed: 289 innodb_buffer_pages_old: 0 innodb_buffer_rows_cached: 100637 1 row in set (0.04 sec)※クエリは一定の負荷が発生します.
続いて、Jeremy Cole氏のinnodb_rubyを利用してibdファイルの物理配置を確認します.
uuidを代表とするランダムinsertではページ分割の発生によりfree_spaceが増え、データの充填率が低くなりますがこれを実際に確認します.充填率/レイアウトの確認にはデータが少量の際は、
space-extents-illustrate量が多い場合や実際の充填率分布を細かくみたい場合は、space-index-pages-free-plotが有用です.$ innodb_space -f ../users.ibd space-extents-illustrate
指定のテーブルスペースに対する物理配置を表しています.
Index 59が主キーのuuid, Index 69がid, Index 61がcreatedで、ランダム挿入となっている主キーおよびcreatedに対して隙間がある様子が観測できます.
一方でcreatedは追記となるためこちらは断片化せず容量が増加します.If the insertions into an index are always ascending and records are deleted only from the end, the InnoDB filespace management algorithm guarantees that fragmentation in the index does not occur.
同一行に連続して配置されて、領域確保の単位であるエクステントが専有エクステントとして各セグメント毎にエクステントで領域確保される様子が合わせて確認できます.
$ innodb_space -f ../users.ibd space-index-pages-free-plot
横軸はページ数,縦軸は空きスペースを示します。innodb_page_sizeが16Kですので、この例では主キーに対して最大約50%程度の空きスペースが発生していることが読み取れます.
ページ分割が期待通りに発生しています.mysqldumpでデータを入れ直す
--order-by-primary を付与してmysqldumpしたものを入れ直し、同様にデータの最適化状態を確認します.
$ sudo ls -lah /var/lib/mysql/test/users.ibd -rw-r-----. 1 mysql mysql 32M 12月 23 23:44 /var/lib/mysql/test/users.ibdmysql> select * from sys.schema_table_statistics_with_buffer where table_name='users'\G *************************** 1. row *************************** table_schema: test table_name: users rows_fetched: 0 fetch_latency: 0 ps rows_inserted: 100000 insert_latency: 901.03 ms rows_updated: 0 update_latency: 0 ps rows_deleted: 0 delete_latency: 0 ps io_read_requests: 19 io_read: 1.81 KiB io_read_latency: 16.79 us io_write_requests: 1480 io_write: 22.79 MiB io_write_latency: 15.63 ms io_misc_requests: 132 io_misc_latency: 224.42 ms innodb_buffer_allocated: 22.52 MiB innodb_buffer_data: 21.35 MiB innodb_buffer_free: 1.17 MiB innodb_buffer_pages: 1441 innodb_buffer_pages_hashed: 290 innodb_buffer_pages_old: 0 innodb_buffer_rows_cached: 100479 1 row in set (0.04 sec)ディスク上の領域が最適化され、合わせて次のようにbuffer_pool上の領域が削減されています. buffer pool上の最適化によりいままでbuffer_pool上にのらなかった他のデータをキャッシュヒットさせることが可能となり場合によっては性能上大きな改善が期待できます.
- innodb_buffer_pages: 1858 > 1441
- innodb_buffer_allocated: 29.03 MiB > 22.52 MiB
$ innodb_space -f ../users.ibd space-extents-illustrate
$ innodb_space -f ../users.ibd space-index-pages-free-plot
こちらのグラフを見ると主キーについては1/16の空きスペースを計画的に確保しているのに対し、セカンダリインデックスは同じ空きスペースは確保せず隙間を空けずに最適化されていることが観測できます.
これは下記のデフォルトのinnodb_fill_factor 0 の動作と整合性がありますhttps://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_fill_factor
An innodb_fill_factor setting of 100 leaves 1/16 of the space in clustered index pages free for future index growth.
短期的には容量が節約されますがセカンダリインデックスに空きスペースがないため断片化が発生しやすい状態となります.
optimizeを実施
MySQL 5.6.17以降は通常またはpartitioningされたInnoDBについてはonlineでoptimizeが実行できます.
mysql> alter table users ENGINE=innodb; Query OK, 0 rows affected (2.01 sec) Records: 0 Duplicates: 0 Warnings: 0mysql> select * from sys.schema_table_statistics_with_buffer where table_name='users'\G *************************** 1. row *************************** table_schema: test table_name: users rows_fetched: 100000 fetch_latency: 13.99 ms rows_inserted: 100000 insert_latency: 901.03 ms rows_updated: 0 update_latency: 0 ps rows_deleted: 0 delete_latency: 0 ps io_read_requests: 64 io_read: 6.09 KiB io_read_latency: 64.88 us io_write_requests: 1467 io_write: 22.58 MiB io_write_latency: 17.58 ms io_misc_requests: 142 io_misc_latency: 173.55 ms innodb_buffer_allocated: 22.45 MiB innodb_buffer_data: 21.36 MiB innodb_buffer_free: 1.09 MiB innodb_buffer_pages: 1437 innodb_buffer_pages_hashed: 0 innodb_buffer_pages_old: 0 innodb_buffer_rows_cached: 100573 1 row in set (0.04 sec)
各セグメントが連続領域として配置されセグメントの末尾に空きスペースが配置されます.
innodb_fill_factorの影響を確認する
無駄な容量は減らしたいものの最適化後に急に容量が増えない方が望ましいケースがあるかもしれません. これを制御するパラメータの動作を確認します.
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_fill_factor
mysql> show variables like 'innodb_fill_factor'; mysql> set global innodb_fill_factor=95; mysql> alter table users ENGINE=innodb; Query OK, 0 rows affected (2.01 sec) Records: 0 Duplicates: 0 Warnings: 0この状態で先程のspace-index-pages-free-plotを確認します.
セカンダリインデックスの空きスペースもコントロールされました.
An innodb_fill_factor setting of 100 leaves 1/16 of the space in clustered index pages free for future index growth.
この例だと現実的には追記のみ発生し空きスペースが必要ないcreatedカラムにも一定の空きスペースが確保されることになるため全体でのトレードオフを考慮して運用する必要がありそうです.
まとめ
ランダム挿入されたデータがoptimizeによってディスク上のスペースおよびbuffer_pool上のサイズが最適化されることを確認しました
バッファプール上のサイズは、sys.schema_table_statistics_with_bufferで、ディスク上でデータがどのように分割されているかはinnodb_spaceのspace-extents-illustrateやspace-index-pages-free-plotで確認しました.セカンダリインデックスがランダム挿入の場合と追記の場合のデータの充填の様子を確認しました.
本記事では扱わなかったデータが削除大量にされているときはもちろん、ランダム挿入されるインデックスが多い場合、特に最適化をしたときの効果が期待されます.
innodb_fill_factorの動作: デフォルトでクラスタインデックスのみ1/16の空きを確保、その他の値に設定した際はセカンダリインデックスも含め空きスペースを作る挙動を確認しました.
参考
関連するページヘのリンクを記載します.
領域最適化
- https://dev.mysql.com/doc/refman/5.7/en/optimize-table.html
- https://dev.mysql.com/doc/refman/5.7/en/sorted-index-builds.html
- https://dev.mysql.com/doc/refman/5.7/en/innodb-file-defragmenting.html
- http://gihyo.jp/dev/serial/01/mysql-road-construction-news/0035
- https://mysqlserverteam.com/mysql-5-6-17-improved-online-optimize-table-for-innodb-and-partitioned-innodb-tables/
領域管理
uuid on MySQL (uuidの容量効率や性能をあげる議論など):
- https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/
- https://www.percona.com/blog/2015/04/03/illustrating-primary-key-models-in-innodb-and-their-impact-on-disk-usage/
- https://www.percona.com/blog/2017/05/03/uuid-generated-columns/
- https://mysqlserverteam.com/storing-uuid-values-in-mysql-tables/
その他

- 投稿日:2019-12-24T23:37:24+09:00
Ha4go運用の実績と課題 2019
Ha4go の開発と運用をやっている @PharaohKJ です。この記事はチームの総意だとかそういうのじゃなく、あくまでも開発と運用を担当している私の考えていることです。いわゆるシビックテック発のプロダクトを開発・運営する現場について少しでも感じる、伝わればと思っています。
Ha4go とは
Ha4go by codeforkanazawa-org を参照してください。一応、Code for Kanazawa にリポジトリがあって開発されています。
CfKのメンバーだけではなく、 Code for Okinawa の kimihito (kimihito) さん、Code for Japan の halsk (Hal Seki) さんにもコードのコミットをいただいて共同開発しています。
大きな役割は3つだと考えています.
- みんなで見つけた・考えた課題の投稿
- 課題を解決するための何かを提供できる人の登録
- 課題の欲していることからの課題と人のマッチング
実績(現状)
今年は、全国対応版としてバージョンアップすることを宣言しましたが、実質とりかかれていません。なんかまぁ下げ止まってるのか、ユーザー数にあまり変化はありません。
UU・PV
登録されてる課題と増えた量
去年は5件、今年1件でした。CfK Civic Hack Nightに集まってくる人も減ってきてますし、後述する「権利的な課題」が噴出したこともあってなかなか件数が増えません。要全国版ですね!
subject created_at ネット犯罪に巻き込まれるのを防ぎたい 2019-02-24 21:35:12 mysql> select year(created_at), month(created_at), count(id) from projects group by year(created_at), month(created_at); +------------------+-------------------+-----------+ | year(created_at) | month(created_at) | count(id) | +------------------+-------------------+-----------+ | 2016 | 3 | 1 | | 2016 | 4 | 2 | | 2016 | 5 | 1 | | 2016 | 7 | 5 | | 2016 | 8 | 1 | | 2016 | 9 | 1 | | 2016 | 10 | 3 | | 2016 | 11 | 1 | | 2016 | 12 | 1 | | 2017 | 5 | 2 | | 2017 | 6 | 1 | | 2017 | 8 | 1 | | 2017 | 10 | 1 | | 2018 | 1 | 1 | | 2018 | 3 | 1 | | 2018 | 5 | 1 | | 2018 | 6 | 1 | | 2018 | 9 | 1 | | 2019 | 2 | 1 | +------------------+-------------------+-----------+運用
ソースコード、issue
前述のとおり、CfKのGitHubにリポジトリなど一式用意されています。 → codeforkanazawa-org/ha4go: ha4go
ウェブ上のインフラ
今年は全国版に移植する、、、と宣言したのですが、特にかわっていません。これまでは金沢の課題は
kanazawa.ha4go.netに集め、他の課題はxxx.ha4go.netといったようにxxxを地域名にして運用しようと当初考えていましたが、今後は全国版にしていこうと考えています。ドメイン名はCfKにとっていただいてます。
ウェブページ( http://ha4go.net )は上記リポジトリの GitHub Pages を使って運用しています。
ウェブアプリは さくらインターネット様のご厚意で、IaaSであるさくらクラウドをご提供いただきました。この上に以下のような構成とミドルウェアを使っています。
- Ruby on Rails のウェブアプリ用インスタンス1
- nginx
- Let's Encrypt
- docker (Ruby on Rails アプリ)
- MySQL 用インスタンス1
- docker (MySQL)
- メンテ用踏み台1
- munin
- cron
- DBデイリーバックアップ
- Let's Encrypt 証明書更新(マンスリー)
通知メール配信はさくらのメールボックスを使わせてもらってます(これは有料でもともとCfKが契約していたものです)。
開発のコミュニケーションは 一連の業務の拠点となるデジタルワークスペース | Slack の無料プランで行っています。GitHubとの連携や、さくらインターネットさんの障害情報のRSSをここに通知させたりしています。
課題と今後
技術的課題
去年と全くかわっていません。セキュリティアラートはGitHubから飛んでくるので、把握はしやすくなりましたが、デプロイはオオゴトです。また、Railsも6がリリースされて、そちらに以降したいと考えています。幸いなことに、JavaScriptがたくさんあったりはしないので移行は簡単、、、なはずと考えています。
権利的な課題
今年増えた課題「ネット犯罪に巻き込まれるのを防ぎたい」において、プロダクト作成にまで進んでいたのですが、いろいろあって特に権利問題、、、つまり「CfKでやったものについてはCfKに帰属する」というところがご納得いただけず、プロジェクトは解散になってしまいました。
アイデアソンやハッカソンなどやるのはいいのですが、なかなかどうしてこういった権利関係は複雑になりがちで、それ故に「権利はすべて主催者側に帰属する」とざっくりと決めざるを得ないことが多いと思います。しかしながら、この方式だと人が集まってくる・やろうとする限界があるんじゃないかなあとも考え始めています。
「これが飲めないんだったら、発言も手を動かすもやめてください」ってのはさすがにキツすぎませんか?何か新しいライセンスや権利など、提案できたらなと考えています。そうじゃないと「ha4goに課題を書いたら損」「会に参加して思いついたことを話したら損」なんて状況になるのはちょっと加藤が望む状況ではありません。
今後
来年こそは
- ha4goを全国版対応
- Rails 6 対応
- 発言や書き込みへの ha4go ライセンスについて提案
したいと考えています。よろしくおねがいします。

- 投稿日:2019-12-24T22:51:20+09:00
Railsアプリ、EC2の本番環境でMySQLを直接いじる方法
自分の作ったアプリを本番環境で起動させた時に、エラーが出てしまうことはあると思います。
currentフォルダ内のlogを見て、エラーを発見したとしても、それがMySQLのエラーだと直接コマンド打たないと行けないので、修正が結構めんどくさいんですよね!そこで、よく使うMySQLのコマンドをまとめました!
ログイン
$ mysql -u root -p Enter password: パスワードを入力(実際に文字は見えません)データベースの確認
show databases;以下のように出てきます
+----------------------------------+ | Database | +----------------------------------+ | information_schema | | xxxxxxxxxxxxxxxxxx| | mysql | | performance_schema | +----------------------------------+いじるデータベースの選択
上のコマンドで確認したものの中から選びます
use データベース名;これが出ればOKです
Database changedテーブル一覧表示
show tables;データの検索
とりあえずテーブルの中身を全部見たい場合は
SELECT * FROM テーブル名;データの削除
僕がよく使うのはこれ、とりあえずエラー引き起こすデータは消してしまえ精神
DELETE FROM テーブル名 WHERE id = 数字;補足
この方法はあくまで、直接いじらないと直せないエラーなどを解決する方法です!
Railsの場合は、カラムの追加やテーブルの新規作成などは
マイグレーションファイルを使っていつものようにやれば大丈夫です。
- 投稿日:2019-12-24T20:51:28+09:00
Dockerで使い捨てのMySQL環境を用意する
ローカルで使い捨てのデータベースが立てられると個人で何かと試したいときなどに便利なので、DockerのMySQLイメージを使ったやり方を残しておきます。
1.MySQLのDockerコンテナを起動
Dockerの公式イメージに記載の通り、コンテナを起動します。
docker run --name {適当なコンテナ名} -e MYSQL_ROOT_PASSWORD={適当なパスワード} -d -p 3307:3306 mysql:5.7
- ここではホスト(Mac)側 port 3307とコンテナのport 3306をマッピングしています。
2.アプリケーションから接続
- CakePHP2.9から接続しています。
- "localhost"ではなく127.0.0.1で繋いでください。
app/Config/database.phppublic $default = array( 'datasource'=>'Database/Mysql', 'persistent'=>false, 'host'=>'127.0.0.1:3307', //ホスト側のportを記載 'login'=>'root', 'password'=>'{パスワード}', 'database'=>'{データベース名}', 'prefix'=>'', 'encoding'=>'utf8', );3.SequelProからつなぐ
- GUIツールからも普通に繋げます。ここでもホスト名は127.0.0.1です。

- 投稿日:2019-12-24T20:07:20+09:00
xamppを使ってMySQLに接続
xampp とは
xamppとは無料でMariaDBやPHPとかをインストールできるすごいやつ。
※今回はもうインストールとか初期設定を終えたところから話が進みます。今回は実際に使ったコマンド等をざっくりまとめていきます。
まぁいつもの感じで
URL系
- テストページ的なの
[[[ http://localhost/ ]]]- mysqlのページ
[[[ http://localhost/phpmyadmin/index.php?lang=ja ]]]- phpを実行するときは
[[[ http://localhost/名前 ]]]をブラウザで実行
コマンドプロンプトで使うコマンド
mysqlに接続、切断
C:\xampp\mysql\bin> mysql -u root -p //mysqlのあるディレクトリ内で実行 MariaDB [(none)]> //このようになればOK MariaDB [(none)]> exit //mysqlから切断ステータス確認
MariaDB [(none)]> status; //いろんな情報が出てきます()データベース確認
MariaDB [(none)]> show databases; +--------------------+ | Database | +--------------------+ | example | | information_schema | | mysql | | performance_schema | | phpmyadmin | | test | +--------------------+データベースの作成、確認
MariaDB [(none)]> create database データベース名; MariaDB [(none)]> show databases;MariaDB [(none)]> create database test2; Query OK, 1 row affected (0.002 sec) MariaDB [(none)]> show databases; +--------------------+ | Database | +--------------------+ | example | | information_schema | | mysql | | performance_schema | | phpmyadmin | | test | | test2 | //追加されていれば成功 +--------------------+使用するデータベースの指定
MariaDB [(none)]> use データベース名;MariaDB [(none)]> use test2; Database changed MariaDB [test2]> //[]のなかが変更されていれば成功テーブルの作成、確認
MariaDB [test2]> create table テーブル名( -> テーブルのフィールド情報を入力 ->); MariaDB [test2]> show tables; MariaDB [test2]> describe テーブル名;MariaDB [test2]> create table students( -> id int; -> first_name varcharset(60); -> last_name varcharset(60); ->); MariaDB [test2]> show tables; +----------------+ | Tables_in_test | +----------------+ | students | +----------------+ MariaDB [test2]> describe students; +------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | first_name | varchar(60) | YES | | NULL | | | last_name | varchar(60) | YES | | NULL | | +------------+-------------+------+-----+---------+-------+こんなもんですかね。
実際xamppさんはかなり強い雰囲気を漂わせていて、上に記したMySQLのページに行くとデータベースなり、テーブルがGUIで作れたり、テーブルの中身見れたりと結構便利な感じがします。あとはPHP書いてそこに作ったデータベースの情報を書いて終わり!!!
- 投稿日:2019-12-24T16:08:30+09:00
MySQLでランダムな携帯電話の番号を作成する方法
070080090のランダムな携帯番号を生成しますSELECT CONCAT('0', 9 - FLOOR(RAND() * 3), 0, FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10));
- 投稿日:2019-12-24T16:08:30+09:00
MySQLでランダムの電話番号を作成する方法
070080090のランダムな携帯番号を生成しますSELECT CONCAT('0', 9 - FLOOR(RAND() * 3), 0, FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10), FLOOR(RAND() * 10));
- 投稿日:2019-12-24T08:04:24+09:00
データベースの重複をなくす
環境
MySQL
MacOSやりたいこと
データベース上に特定の組み合わせのカラムが複数できてしまったレコードをユニーク(一意)にする。
コード
// 重複の組み合わせはGROUP BYの後ろで調整 > DELETE FROM target_table WHERE id NOT IN (SELECT MIN(id) min_id FROM target_table GROUP BY column1,column2,column3);解説
SQLのコードを見るときは、一番内側にあるSQLから見ていくと理解が早いです。
1.削除しないIDのリストを作成する
一番内側のSQLはカッコの中に入っている、
> SELECT MIN(id) min_id FROM target_table GROUP BY column1,column2,column3;ですね。
これは、特定のカラムが同じレコードを一つにまとめて、その中でidが古い(数字が小さい)ものを出力しています。
2.上記で作成したID以外のレコードを削除する
そして、それをNOT IN区で使ってあげることで、作ったIDのリスト以外のデータをすべて削除します。
> DELETE FROM target_table WHERE id NOT IN (SELECT MIN(id) min_id FROM target_table GROUP BY column1,column2,column3);メリットとデメリット
メリット
・一発で削除することができる
・GROUP BYを変更すれば様々なパターンに対応できるデメリット
・どれを削除したかわからない
・若干SQLが長いただ、デメリットのどれを削除したかわからない(ログが残らない)ということに関しては、一度DELETE文ではなくてSELECT文に変更して流すとか、削除しないIDのリストだけ作って、それを置換してSQLを作って上げればいい感じにできます。
// 例 // IDのリストを作成 $ echo "SELECT id FROM target_table WHERE id NOT IN (SELECT MIN(id) min_id FROM target_table GROUP BY column1,column2,column3);" | mysql -u root | tee id_list.tsv $ cat id_list.tsv id 1 3 5 7 ... // 先頭と行末を置換してSQLを作成(もちろんエディタを使っても良い) $ cat id_list.tsv | sed 's/^/DELETE FROM target_table WHERE id = /g' | sed 's/$/;/g' DELETE FROM target_table WHERE id = 1; DELETE FROM target_table WHERE id = 2; DELETE FROM target_table WHERE id = 3; DELETE FROM target_table WHERE id = 4; DELETE FROM target_table WHERE id = 5; DELETE FROM target_table WHERE id = 6; ... → コピーしてmysqlに流す or シェル芸でmysqlに渡してあげる最後に
DELETE文って怖いですよね笑
書いてもいいけど、エンターは誰かに押してほしい。