- 投稿日:2019-12-24T16:38:51+09:00
(失敗)Flaskで作ったwebアプリをherokuでデプロイする
Flaskのアプリをherokuとgithubを使ってデプロイしてみます。
メモのために書きます。と思ってやってたんですが、デプロイしたページを見ようとするとエラーが出てします。前はできたんだけど、、、まずプログラムを入れるファイルを作ります。
(base) PS C:\working\web_app> python -m venv 新しく作るファイル名(今回はmessage_app)仮想環境を設定する。
下のコマンドを打つと仮想環境が稼働します。(base) PS C:\working\web_app\message_app>Scripts\activate次にライブラリを仮想環境にインストールします。
(message_app) PS C:\working\web_app\message_app>pip install 使うライブラリ名(今回はflaskとrequestとgunicorn) pip install -r requirements.txt(requirements.txtを使ってインストールもできる)Procfileという名前のファイルを作るってエディタでファイルに以下の文を書いておく
web: gunicorn app:app --log-file=-requirements.txtを作って中にしたのコマンドで出てきたインストールされてるライブラリの情報をコピペする
pip freeze以下のコマンドを実行する
git initgit add .addと.の間に半角スペースがあるのに注意
git commit -m “コメント”heroku loginheroku creategit push heroku masterってやってみたけど、できなかった ><
- 投稿日:2019-12-24T15:31:19+09:00
Kendra 試してみたよ。
こんにちは。Da Vinci Studio の bbz です。
社内ドキュメントとかから欲しい情報を探すのって結構めんどくさいですよね。
キーワード検索だとあれこれヒットするし。
ペロッと欲しい情報が探せないかなということで先日発表された AWS Kendra 試してみました。Kendra
Kendra とは
機械学習を原動力とする高精度のエンタープライズ検索サービスです。
https://aws.amazon.com/jp/kendra/
ということで自然言語で問い合わせたらいい感じに答えてくれそうな検索サービスですね。
(まだ Preview 段階ですが)セットアップ
管理コンソールから手軽に使えます。
(まだ東京 Region にはありませんのでバージニアとか選んでください。)
最初は index を作成。
結構時間かかります。(30分くらい)
つづいて Data Source の追加
たくさんの Source を追加できるようになるみたいですが、今のところは3つだけ。Amazon Kendra は、ファイルシステム、ウェブサイト、Box、DropBox、Salesforce、SharePoint、リレーショナルデータベース、および Amazon S3 などの人気のデータソースに対する幅広いネイティブなクラウドコネクタとオンプレミスコネクタを提供することにより、検索アプリケーションの構築に伴う困難な作業を排除します。
プレビューでご利用いただけるコネクタは、SharePoint Online、JDBC、および S3 のみとなります。
Data Source 追加したら後はドキュメントなりを突っ込んで検索するだけ!!
なのですが、現在はデータもクエリも英語だけの対応なのであった

無理やり日本語で検索する
英語で使えばいいのですが、どうせなら日本語のキーワードで検索(入力)したいので ↓ の感じにしてみました。
- Slack で日本語入力 -> Slackbot に飛ぶ
- AWS Translate で問い合わせを英語に翻訳
- 翻訳されたクエリで Kendra に問い合わせ
- 結果を AWS Translate で日本語に翻訳
- Slack に表示
(データは英語に翻訳して S3 に置いておく。)
で、使ってみるとこんな感じ。(表示しているのは一部のレスポンスだけ)
ちゃんと日本語で検索してる風に見えますね。
料金
すごく手軽に使える Kendra ですが料金は結構お高い。
https://aws.amazon.com/jp/kendra/pricing/今は Enterprise Edition しか使えないというのもありますが
$7/hourもしちゃいます。
ざっくり$7 x 720 hours/month = $5,040ですね
(Developer Edition が出てくれば$2.5 x 720 hours/month = $1,800と少し利用しやすくはなりそうですが。)使ってみて
Index 作ってデータ連携させるだけで使えてとっても簡単。検索は楽ちんになりますね。
ただ関連のあるデータはちゃんと返してくれるものの、すごい検索精度だ!!とはなりませんでした。
(今回は途中で翻訳とか挟んでるし。)
データ量が増えてクエリがもうちょい複雑になると違ってくるかもですが。良くある質問と回答を事前に登録したり Kendra の結果を評価して育てていく必要はありそうですね。
事前登録するとこんな感じででてくる。
まだ Preview なので本番利用はできないですが、GA になって日本語対応もしてくれたら使い所はありそうだなーという感じでした!







- 投稿日:2019-12-24T15:22:56+09:00
本日はクリスマス・イブということであのお菓子の分類をML初心者がAmazon Rekognition Custom Labelsを使って挑戦してみた
はじめに
今回は、先日公開がされたこちらの記事https://qiita.com/KC_NN/items/d265eddcbdc8a47ed88c
をML初心者の私が見ながらでもできるものなのかを試してみた記事になります。その為新技術などの情報はないですが、そこはご容赦ください。今回の背景
今日(投稿日)がクリスマス・イブということで、せっかくだからクリスマスにちなんだ記事にしようと思いました。そこで、クリスマスのお菓子で定番のあのお菓子を画像分類してみようと思いました。
そう!あの「ジンジャーマンクッキー」です!
ラベル付けの際にジンジャーマンクッキーに名前を付けて名前による分類ができるんじゃないか。この企画ならいける!と思い、早速ジンジャーマンクッキーを購入しようと思いました。が、みんな見た目一緒じゃないか…↓私の中のイメージ
↓現実
これじゃあ分類ができない!いっそ自分で作るかとも少しだけ思いましたが料理を普段しない私にはできるはずもなく…
そこで、形が違って、クッキーっぽいものはないかと探したところ。このお菓子にたどり着きました!
これなら要望を満たせる!ということで、たべっ子どうぶつビスケットの画像分類をML初心者の私が、先日公開された記事を見ながらAWSのRekognition Custom Labelsで挑戦してみました。
いざ実践!
まず、記事の手順通りに素材を集めるところからということで素材写真をiphoneで撮影しました。今回は、全体画像の角度を変えたものを7枚ほど撮影しました。
こんな感じで7枚ほど撮影
記事の手順通りに、「プロジェクト名作成、S3バケット作成、画像をS3に保存」を実施していきます。
次に、保存した画像にラベリングをしていきます。
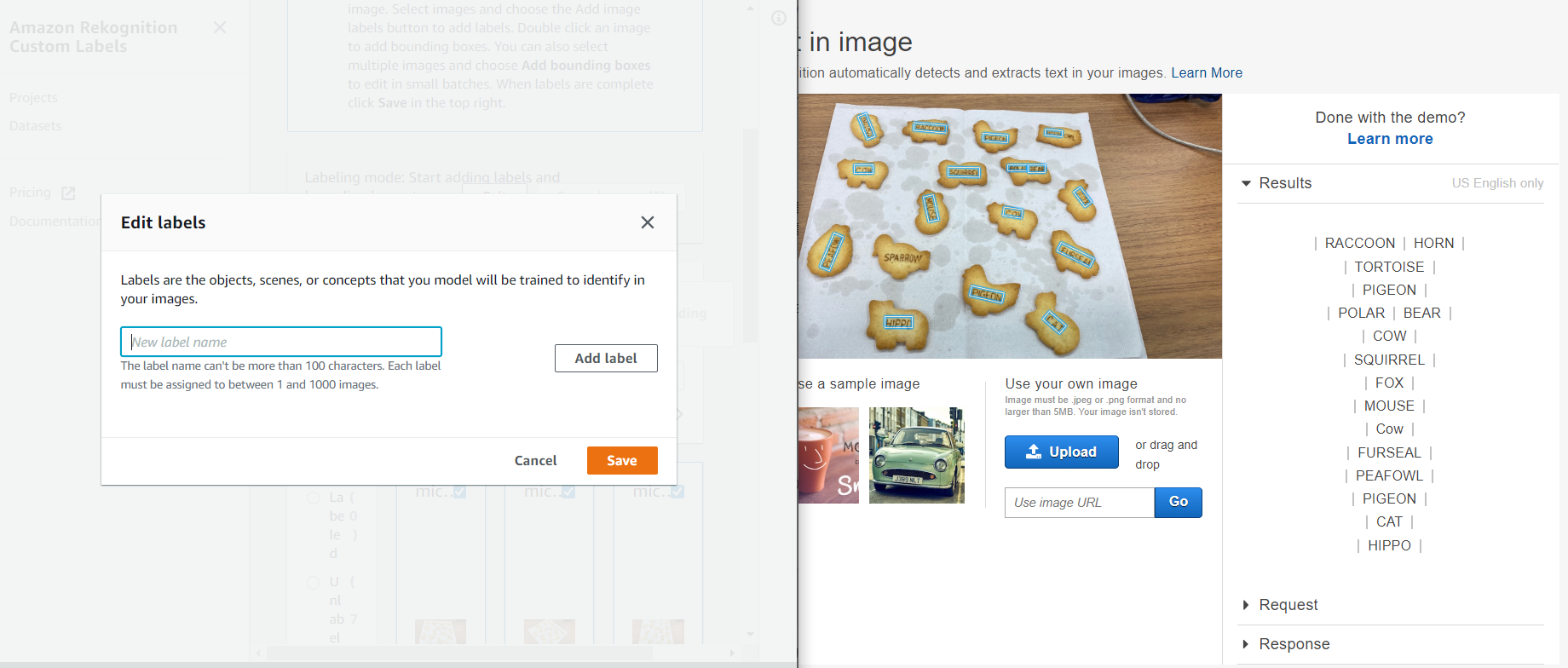
ラベリングは、自分で入力をしていくのですが、この数は結構めんどいなーと思ったので、OCR(Amazon Rekognition text in image)を使って画像内のテキストを抽出し、こんな感じに2画面にし、抽出したテキストをコピペして作業を簡略化してみました。(下記画像の左がCustom labels、右がtext in imageの画面です。)
ラベリング名の登録も済んだので、実際に写真にラベル付けをしていきたいと思います。
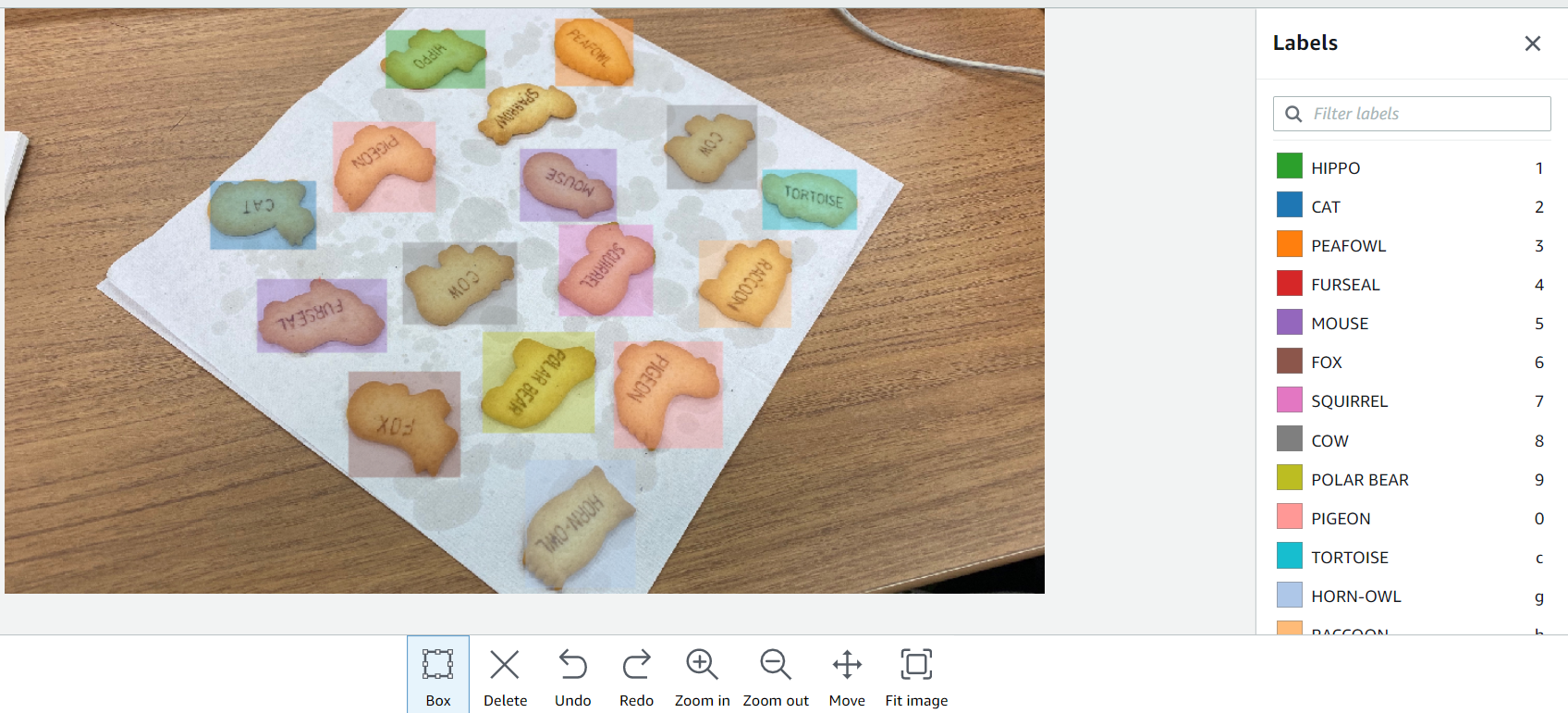
ラベル付けも記事の手順通りに、ラベル付けしたい画像を選んで、画像内のオブジェクトに対してラベル名のついたドローイングボックスをただひたすらにこんな感じで囲っていきます。
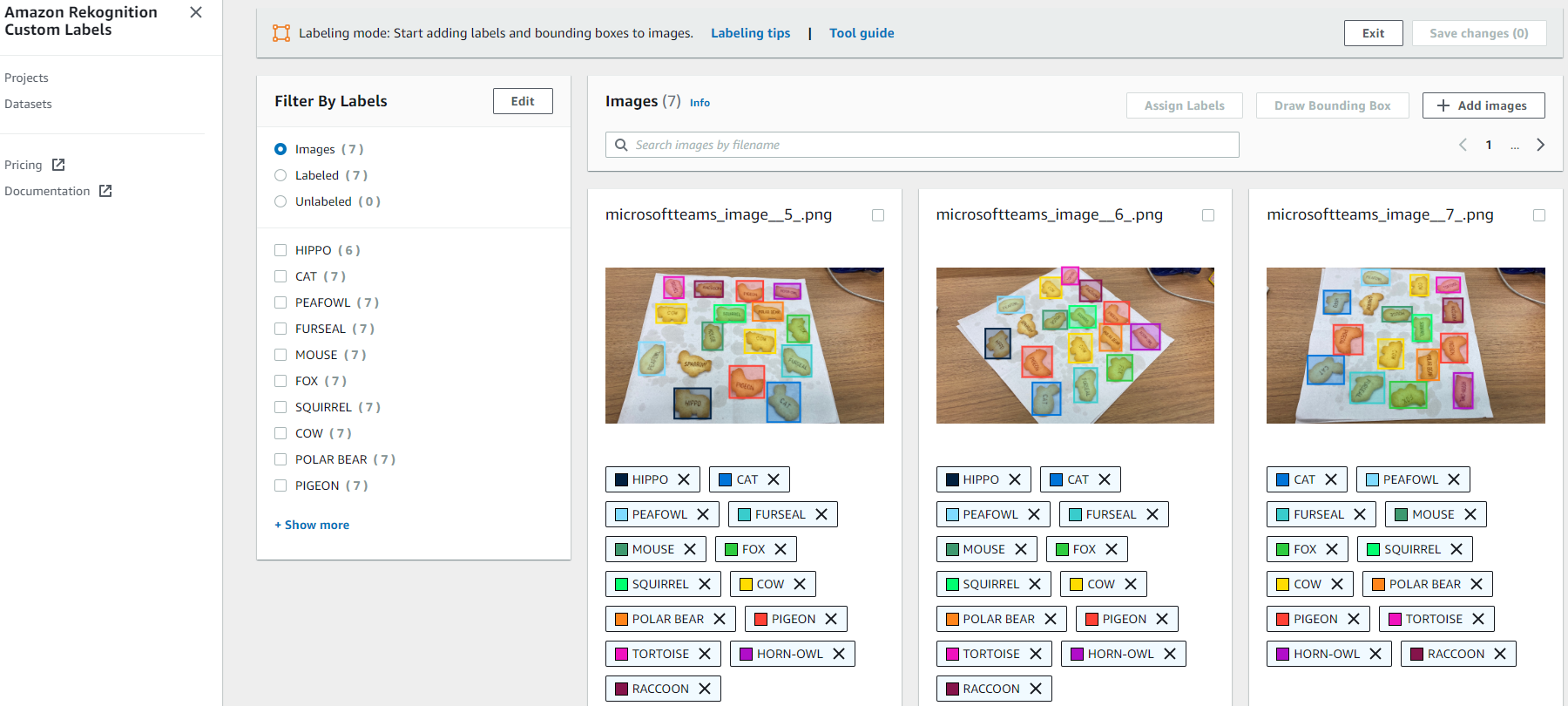
こうして撮影した全部で7枚の写真にラベルを付けていきます。
ここまでだいたい30分前後で作業は終わりました。(画像のアップロードから数えて)作業が終わるとダッシュボードがカラフルになります。
記事では、ラベル付けをした後に、「save change」を選択後「Train model」を選択するとありましたが、
実際は、「save change」を選択した後に隣の「Exit」を選択しないと「Train model」のボタンがに切り替わらないので、ご注意を。
ここまで簡単に画像認識のモデルを作れるとは思いませんでした。技術的にあまり詳しくない私でもこんなに簡単にできるとは、AWSはすごいですね!
あとは、推論するだけ。ってここにきてまさかのCLI!
CLIでモデルを使って推論した結果こんな感じになりました。
"CustomLabels": [ { "Name": "HORN-OWL", "Confidence": 100.0, "Geometry": { "BoundingBox": { "Width": 0.8662499785423279, "Height": 0.2805599868297577, "Left": 0.05463000014424324, "Top": 0.31387001276016235 } } } ]
HORN-OWLを判定しているみたいですが、今回用意したデータセットが少ないせいか信頼スコア(Confidence)がかなり高いように見えます。もう少しデータセットを増やすべきでしたね…
結果を視覚的に見せるのには、結果コードと画像を使ってプログラムを書く必要があるとのことなので、ここだけは社内のメンバーに手伝ってもらいました。まとめ
トータル的に見て、ほとんど技術を知らない人でも簡単に画像認識の予測モデルができて推論までできてしまうすごいサービスがリリースされたなーと感じずにはいられません。
こんなに簡単にライトにできるのであれば、もっといろんな画像分析を試してみたいと思いました。
最後まで、読んでいただきありがとうございました!メリークリスマス!








- 投稿日:2019-12-24T15:02:21+09:00
閉域 de EKS
※1 閉域:インターネット接続なし、と読み替えてください。英語だとoff-lineだそう(ググる時捗ります)
※2 kubernetes v1.13 を利用ドコモではRedshiftを中核にした分析基盤の前段に、こんな形の前処理システムの運用をしています。
オンプレミスで構築された各システムからのデータをDirectConnect経由で受け取り、整形し、DWHへ格納する、よくあるNW構成のシステムです。
このようなシステムの常として、主にセキュリティの観点から、
- インターネット接続不可、もしくはプロキシ経由でのみ可能
という制約が付いて回ります( 閉域 と私たちは良く呼びます)。
このような制限下でのシステム開発、ダミーデータや検証環境をしっかり用意できれば良いのですが、なんだかんだ理想通りにはいかず……
- 検証環境下で開発、ビルド
- インターネット疎通経路のない本番環境へと転送、デプロイ
- エラーなどログの調査、改善点の洗い出し
といったサイクルを回しながら進めることになるものの、
- ネットワーク的に断絶されているがゆえ、1サイクルを回すのに時間かかる
- 本番環境内での作業が増え、検証環境との解離が起きがち
と、開発自体が複雑/高負荷になりがちでした。また当初は予定通りの動作であったとしても、その後の変更への対応の負担が大きく、対向システムの変化の速さ に追従しきれないことも…
そのため現在、このようなアーキテクチャの前処理システムの開発・運用を一部で進めています。
EKSを中核に1
- コンテナの可搬性を活かし、制限環境下でも迅速な開発を可能にする
- Kubernetesにより、水平スケーリングをシンプルに行えるようにする
のが狙いのアーキテクチャ、です。色々大変な想いもしましたが、上記のメリットはそれを補いあまりあるものを得られているな、と感じています。
せっかくのアドベントカレンダーの機会をいただけたので、この 閉域環境でのEKSの利用 について少し内部に踏み込みつつ、まとめていこうと思います。
模擬環境の構築
要点
- EKSのプライベートアクセスオプションをによりControlPlaneへの経路作成、VPC内からのアクセスを可能に。
- VPC Endpointを利用し経路確保。必要なのはECR、S3、EC2。
- AMI起動時に明示的に認証パラメータを注入し、ControlPlane側にノードとして認識させる。
勘所を押さえれば、全てAWSが提供する手段で完結するので、さした手間なしに作成できます。
Kubernetesの構成要素とEKSの職掌範囲
勘所を押さえるのに簡単に内部構造から。
kubernetes blogより引用Kubernetesは上図のようにいくつかのコンポーネントから成り立っており、ユーザとのインターフェースや全体管理を行うMaster (Cotrol Plane、CPlaneとも)と、実際にアプリケーションコンテナが動作するNodeの部分へと大別されます。
EKSはこれらのうち、主にMasterの部分を提供するサービスです。2
Running Kubernetes at Amazon scale using Amazon EKS re:Invent 2019セッション資料より引用Nodeの部分はベースとなるAMIからEC2を起動し、Masterへと登録/認識させる、という割と下回りを意識する流れになります(CloudFormationが提供されているので操作自体は簡素ではあります)。
この操作を行う際、Node内の構成要素(kubelet, コンテナランタイム、ネットワーキング)について、全て動作可能な状態となるように必要なコンポーネントのダウンロードや認証等の通信が発生します。
これらについて、なにかしらの経路で通信できるようにするか、事前に入れ込んでおけば、閉域内でもクラスタ構築が可能になる、と言ったかたちとなります。EKS-Optimized AMI
それではどのようにこれら要素を整えれば良いのか、NodeのもとになるAMI(EKS-Optimized AMI)について踏み込んでみましょう。AWSが配布しているAMIの、ビルドに使用されるスクリプトがGitHubで公開されています。
ビルドにはPackerが利用されています。利用したことがないと最初は??となるかもしれませんが、EC2上でシェルスクリプト走らせたり、設定ファイルを配置したりして後AMIを作り上げているものだと思っておけば大丈夫です。
eks-worker-al2.jsonで各種パラメータ定義
- amzn2-ami-minimal-hvm(最低限のライブラリのみが入ったAmazon Linux 2のAMI)をベースAMIとして指定
files`下の設定ファイルを転送install-worker.sh起動 といった流れとなっています(実際に自分でAMIを焼きたければ、Makefileがあるのでmakeを使うのが簡便です)。このうち
install-worker.shに前述の必要なコンポーネントの導入が記述されています。コンテナランタイム
こちらの通り、Dockerがランタイムとしてインストールされます。device-mapperやlvmもこちらでインストールされています。
kubelet
こちらで、AWSの用意したバイナリをS3から取得、設定がされるようになっています。
aws s3 ls amazon-eks/1.14.7/2019-09-27/bin/linux/amd64/を打つとバイナリの配置されているS3が見られます(バージョンや日付、OSなどは適宜読み替えてください)。このamazon-eksバケットに、kubelet以外のEKS動作に必要なファイル類(IAMと連携するためのaws-iam-authenticatorなど)が収められています。ネットワーキング
ここまでは予めAMIの内部に収められるのですが、ネットワーキングについては少々異なります。
EKS(※v1.11以降)では
kube-proxy: Podの通信先を制御。EKSだとデフォルトでNodeのiptablesを制御するモードで動作coredns: Service(Kubernetesの外部への公開点の概念)にDNSを付与aws-nodes: kubeletと連携してPodに対しVPC内でWorkするPrivateIPアドレスを付与の3つがコンテナとして起動され、動作するのですが、これらに関してはAMIの中には収めらない状態です。
つまり起動した際、AWSのコンテナレジストリサービス(ECR)からPullしてくることで、NodeとしてWorkするような仕組みとなっています(EKSでKubernetes 1.13が公開される前は、この辺をユーザーがゴニョゴニョすることで無理矢理off-lineで動作させるしんどい状況だったりしました)。これらについては、ECRとS3のVPCエンドポイントを付与することで、v1.13より解決が可能です。ポイントとしては
- ECRのVPCエンドポイントは2種類。dkr.ecr...(コンテナ本体のPull元)だけでなくapi.ecr...もつける(認証に必要なため)
- S3のエンドポイントも必要(ECRのストレージがS3のため)。最小の権限はこちら。
EKSからのNodeの認識
Nodeを起動した際、EKS側から認識させる必要があります。通常CloudFormationからNodeを起動すると、自動でEKS側の情報をEKSのAPIを利用し取得してくれるのですが、EKSそのものについてはPrivateLinkが現在存在しないため、そのままでは認識がされません。
そのため、AMIの起動時にパラメータとして予め渡してあげることで、EKSへのAPIコールを回避しNodeとして認識させることが可能です。
先ほど触れたAMI内部に転送されているファイルのなかにある、bootstrap.shが起動時に実行されるスクリプトになります。これに
- EKSのKubernetesのMasterとしてのエンドポイント(ややこしいですが...
kube-apiserverへのエンドポイントと読み替え他方がわかりやすいかもしれません。)- その認証情報
の2点を、CloudFormationから渡すと、Nodeとして認識がされます。
EKSのPrivateAccess
このオプションをEnableにすると、Masterエンドポイントに対するPrivate IPが払い出され、EKSが対象としたVPC内部からはDNSでの名前解決も可能となります。
これをEnableの状態で、PublicAccessの方をDisableにすると、対象のVPC内からのみkubectlを用いてKubernetesの操作が可能な状態となります(※ 正確には、Enabling DNS resolution for Amazon EKS cluster endpoints | AWS Compute Blog工夫すればピアリングした隣のVPCからもエンドポイントへの名前解決が可能です)。
EKSとkubectlとIAMの関係
EKSでは、kubectlが打たれた際、クライアントのIAMを認証として利用します。
Masterを作成した時点では、その作成者がAdminとされるため、閉域内からkubectlを叩いて利用するためには作成者のIAMキーを渡すか、作成後に他のIAMユーザーかロールをAdminとして追加する必要がでます。環境構築
長くなってしまいましたが、それでは閉域を模擬した環境で、EKSを使用してみます。
(CloudFormationや構築スクリプトを付しておきますが、参考程度に。)1 NW+関連サービス
Direct Connectを用意はできないので、まずVPC Peeringを越えてインターネットへは出ていけないことを利用して閉域を模擬した環境を作ります。(今だったらSSM Session Managerを利用するのが良いかもしれません)
EKS自身が2以上のサブネットを必要とするのでそれについても作成(今回利用はしません)。
また、EKS自身が利用するためのIAMロールや、kubectlを打つためにEC2へ付与するロールも、ここで作成しています。(VPCFlowLogsつけたり色々してますが無視してください、開発環境でもなるべくつけるようにしようという弊社ポリシーです)
1-infrastructure.yaml1-infrastructure.yamlAWSTemplateFormatVersion: '2010-09-09' Parameters: EnvName: Type: String Default: yoda-close-nw Description: Component application identifier used by this sequential deployment AZ1: Type: String Default: ap-northeast-1a Description: Main AZ AZ2: Type: String Default: ap-northeast-1c Description: Second AZ (Just for EKS K8s endpoints) BastionVPCCIDR: Type: String Default: 172.24.0.0/24 Description: Bastion VPC CIDR block BastionPublicSubnetCIDR: Type: String Default: 172.24.0.0/25 Description: Public Subnet in Bastion VPC CIDR block (For bastion, natgw) K8sVPCCIDR: Type: String Default: 172.25.0.0/16 Description: K8s VPC CIDR block K8sWorkerSubnet1CIDR: Type: String Default: 172.25.0.0/17 Description: K8s Worker Subnet in AZ1 CIDR block K8sWorkerSubnet2CIDR: Type: String Default: 172.25.128.0/18 Description: K8s Worker Subnet in AZ2 CIDR block K8sOperatorSubnetCIDR: Type: String Default: 172.25.192.0/18 Description: kubectl instance located subnet CIDER YourComputerIPAddress: Type: String Default: 121.118.77.48 Description: Access point IP address InstanceType: Description: Server EC2 instance type Type: String Default: t3.nano ConstraintDescription: must be a valid EC2 instance type. RootVolumeSize: Default: 8 Type: String RootVolumePath: Description: Amazon Linux=>/dev/xvda, Ubuntu=>/dev/sda1 Default: /dev/xvda Type: String KeyName: Description: Name of an existing EC2 KeyPair to enable SSH access to the instance Type: AWS::EC2::KeyPair::KeyName ConstraintDescription: must be the name of an existing EC2 KeyPair. AmiId: Description: kubectl installed ami Type: String Resources: ################################################################################ ### VPC ######################################################################## ################################################################################ BastionVPC: Type: 'AWS::EC2::VPC' Properties: CidrBlock: !Sub ${BastionVPCCIDR} EnableDnsSupport: 'true' EnableDnsHostnames: 'true' Tags: - Key: Name Value: !Sub ${EnvName}-bastion-vpc K8sVPC: Type: 'AWS::EC2::VPC' Properties: CidrBlock: !Sub ${K8sVPCCIDR} EnableDnsSupport: 'true' EnableDnsHostnames: 'true' Tags: - Key: Name Value: !Sub ${EnvName}-k8s-vpc ### VPC Peering ### VPCPeering: Type: AWS::EC2::VPCPeeringConnection Properties: PeerVpcId: !Ref BastionVPC # Accepter Tags: - Key: Name Value: !Sub ${EnvName}-vpcpeering VpcId: !Ref K8sVPC # Requester ################################################################################ ### Subnet ##################################################################### ################################################################################ BastionPublicSubnet: Type: AWS::EC2::Subnet Properties: AvailabilityZone: !Ref AZ1 CidrBlock: !Ref BastionPublicSubnetCIDR VpcId: !Ref BastionVPC Tags: - Key: Name Value: !Sub ${EnvName}-bastion-public-subnet K8sOperatorSubnet: Type: AWS::EC2::Subnet Properties: AvailabilityZone: !Ref AZ1 CidrBlock: !Sub ${K8sOperatorSubnetCIDR} VpcId: !Ref K8sVPC Tags: - Key: Name Value: !Sub ${EnvName}-k8s-operator-subnet K8sWorkerSubnet1: Type: AWS::EC2::Subnet Properties: AvailabilityZone: !Ref AZ1 CidrBlock: !Sub ${K8sWorkerSubnet1CIDR} VpcId: !Ref K8sVPC Tags: - Key: Name Value: !Sub ${EnvName}-k8s-worker-subnet-1 K8sWorkerSubnet2: Type: AWS::EC2::Subnet Properties: AvailabilityZone: !Ref AZ2 CidrBlock: !Sub ${K8sWorkerSubnet2CIDR} VpcId: !Ref K8sVPC Tags: - Key: Name Value: !Sub ${EnvName}-k8s-worker-subnet-2 ################################################################################ ### Internet Gateway ########################################################### ################################################################################ BastionInternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: Name Value: !Sub ${EnvName} AttachBastionInternetGateway: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !Ref BastionVPC InternetGatewayId: Ref: BastionInternetGateway ################################################################################ ### Route Table & Rule ######################################################### ################################################################################ # Route Table BastionPublicSubnetRouteTable: # RTB for ops public subet Type: AWS::EC2::RouteTable Properties: VpcId: !Ref BastionVPC Tags: - Key: Name Value: !Sub ${EnvName}-bastion-public-subnet-rtb K8sWorkerRouteTable: # For master & worker subet Type: AWS::EC2::RouteTable Properties: VpcId: !Ref K8sVPC Tags: - Key: Name Value: !Sub ${EnvName}-k8s-worker-subnet-rtb K8sOperatorRouteTable: # For master & worker subet Type: AWS::EC2::RouteTable Properties: VpcId: !Ref K8sVPC Tags: - Key: Name Value: !Sub ${EnvName}-k8s-operator-subnet-rtb # Association BastionPublicRtbAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref BastionPublicSubnet RouteTableId: !Ref BastionPublicSubnetRouteTable K8sOperatorRtbAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref K8sOperatorSubnet RouteTableId: !Ref K8sOperatorRouteTable K8sWorkerAZ1RtbAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref K8sWorkerSubnet1 RouteTableId: !Ref K8sWorkerRouteTable K8sWorkerAZ2RtbAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref K8sWorkerSubnet2 RouteTableId: !Ref K8sWorkerRouteTable # Route BastionPublicToIGWRoute: Type: AWS::EC2::Route Properties: DestinationCidrBlock: '0.0.0.0/0' RouteTableId: !Ref BastionPublicSubnetRouteTable GatewayId: !Ref BastionInternetGateway DependsOn: AttachBastionInternetGateway BastionPublicToK8sOperatorRoute: Type: AWS::EC2::Route Properties: DestinationCidrBlock: !Ref K8sOperatorSubnetCIDR RouteTableId: !Ref BastionPublicSubnetRouteTable VpcPeeringConnectionId: !Ref VPCPeering K8sOperatorToBastionRoute: Type: AWS::EC2::Route Properties: DestinationCidrBlock: !Ref BastionVPCCIDR RouteTableId: !Ref K8sOperatorRouteTable VpcPeeringConnectionId: !Ref VPCPeering ################################################################################ ### Security Group & Rule ###################################################### ################################################################################ ##### Bastion Public SG ##### BastionPublicSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupName: !Sub ${EnvName}-bastion-public-sg GroupDescription: SG for public subnet instance Tags: - Key: Name Value: !Sub ${EnvName}-bastion-public-sg VpcId: !Ref BastionVPC BastionPublicIngressFromYourComputerSSH: Type: AWS::EC2::SecurityGroupIngress Properties: Description: From Your Computer to Public GroupId: !GetAtt BastionPublicSecurityGroup.GroupId FromPort: 22 ToPort: 22 IpProtocol: tcp CidrIp: !Sub ${YourComputerIPAddress}/32 DependsOn: BastionPublicSecurityGroup BastionPublicIngressFromYourComputerRDP: Type: AWS::EC2::SecurityGroupIngress Properties: Description: From Your Computer to Public GroupId: !GetAtt BastionPublicSecurityGroup.GroupId FromPort: 3389 ToPort: 3389 IpProtocol: tcp CidrIp: !Sub ${YourComputerIPAddress}/32 DependsOn: BastionPublicSecurityGroup BastionPublicIngressFromK8sOperator: Type: AWS::EC2::SecurityGroupIngress Properties: Description: From K8s Operator to Bastion Public GroupId: !GetAtt BastionPublicSecurityGroup.GroupId FromPort: -1 # All port ToPort: -1 IpProtocol: -1 # All traffic CidrIp: !Ref K8sOperatorSubnetCIDR DependsOn: BastionPublicSecurityGroup #### K8s Operator SG ##### K8sOperatorSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupName: !Sub ${EnvName}-k8s-operator-sg GroupDescription: SG for K8s operator Tags: - Key: Name Value: !Sub ${EnvName}-k8s-operator-sg VpcId: !Ref K8sVPC K8sOperatorIngressFromK8s: Type: AWS::EC2::SecurityGroupIngress Properties: Description: From K8sVPC to Control GroupId: !GetAtt K8sOperatorSecurityGroup.GroupId FromPort: -1 # All port ToPort: -1 IpProtocol: -1 # All traffic CidrIp: !Ref K8sVPCCIDR DependsOn: K8sOperatorSecurityGroup K8sOperatorIngressFromBastion: Type: AWS::EC2::SecurityGroupIngress Properties: Description: From Closed to Worker GroupId: !GetAtt K8sOperatorSecurityGroup.GroupId FromPort: -1 # All port ToPort: -1 IpProtocol: -1 # All traffic CidrIp: !Ref BastionVPCCIDR DependsOn: K8sOperatorSecurityGroup ################################################################################ ### VPC Endpoint ############################################################### ################################################################################ # VPC Endpoints Security Group for K8s VPCs VPCEndpointSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: !Sub ${EnvName}-vpce-sg GroupDescription: SG for VPC endpoints Tags: - Key: Name Value: !Sub ${EnvName}-vpce-sg VpcId: !Ref K8sVPC VPCEndpointSGRules: Type: AWS::EC2::SecurityGroupIngress Properties: Description: From k8s vpc to private links GroupId: !GetAtt VPCEndpointSG.GroupId IpProtocol: tcp FromPort: 443 ToPort: 443 CidrIp: !Ref K8sVPCCIDR DependsOn: VPCEndpointSG S3Endpoint: Type: AWS::EC2::VPCEndpoint Properties: ServiceName: !Sub com.amazonaws.${AWS::Region}.s3 VpcEndpointType: Gateway VpcId: !Ref K8sVPC RouteTableIds: - !Ref K8sWorkerRouteTable PolicyDocument: Version: 2012-10-17 Statement: - Sid: AmazonLinuxYumUpdatePolicy Effect: Allow Principal: '*' Action: - s3:Get* Resource: - !Sub arn:aws:s3:::packages.${AWS::Region}.amazonaws.com/* - !Sub arn:aws:s3:::repo.${AWS::Region}.amazonaws.com/* - !Sub arn:aws:s3:::amazonlinux.${AWS::Region}.amazonaws.com/* - Sid: AllowPullFromECRPolicy Effect: Allow Principal: '*' Action: - s3:Get* Resource: - !Sub arn:aws:s3:::prod-${AWS::Region}-starport-layer-bucket/* EC2Endpoint: # Kubelet with aws cloud provider requires ec2 endpoint access Type: AWS::EC2::VPCEndpoint Properties: ServiceName: !Sub com.amazonaws.${AWS::Region}.ec2 VpcEndpointType: Interface # Private Link VpcId: !Ref K8sVPC SubnetIds: - !Ref K8sWorkerSubnet1 SecurityGroupIds: - !Ref VPCEndpointSG PrivateDnsEnabled: True ECRDKREndpoint: # WorkerNodes requires pull containers from ECR Type: AWS::EC2::VPCEndpoint Properties: ServiceName: !Sub com.amazonaws.${AWS::Region}.ecr.dkr # Image Endpoisnt VpcEndpointType: Interface # Private Link VpcId: !Ref K8sVPC SubnetIds: - !Ref K8sWorkerSubnet1 SecurityGroupIds: - !Ref VPCEndpointSG PrivateDnsEnabled: True ECRAPIEndpoint: # WorkerNodes requires pull containers from ECR Type: AWS::EC2::VPCEndpoint Properties: ServiceName: !Sub com.amazonaws.${AWS::Region}.ecr.api # Control Endpoint VpcEndpointType: Interface # Private Link VpcId: !Ref K8sVPC SubnetIds: - !Ref K8sWorkerSubnet1 SecurityGroupIds: - !Ref VPCEndpointSG PrivateDnsEnabled: True ################################################################################ ### IAM ######################################################################## ################################################################################ # Role for EKS # This Role should be created for each cluster, # however aws doesn't allow custom policy for eks role. # so, to simplify, create 1 role managing multiple clustors AWSServiceRoleForAmazonEKS: Type: AWS::IAM::Role Properties: RoleName: !Sub ${EnvName}-eks-service-role AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - eks.amazonaws.com Action: - sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/AmazonEKSServicePolicy # EKS requires aws managed policy... - arn:aws:iam::aws:policy/AmazonEKSClusterPolicy # EKS requires aws managed policy... # K8s operator role K8sAdminRole: Type: AWS::IAM::Role Properties: RoleName: !Sub ${EnvName}-admin-role AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - ec2.amazonaws.com Action: - sts:AssumeRole K8sAdminInstanceProfile: Type: AWS::IAM::InstanceProfile Properties: Path: /Minaden/DataProcessing/ Roles: - Ref: K8sAdminRole InstanceProfileName: !Sub ${EnvName}-k8s-admin-instance-profile # Limitation in length ################################################################################ ### EC2 Instance ############################################################### ################################################################################ BastionEIP: Type: AWS::EC2::EIP Properties: Domain: vpc BastionEIPAssociate: Type: AWS::EC2::EIPAssociation Properties: AllocationId: !GetAtt BastionEIP.AllocationId InstanceId: !Ref Bastion Bastion: Type: AWS::EC2::Instance Properties: ImageId: !Ref AmiId InstanceType: !Ref InstanceType BlockDeviceMappings: - DeviceName: !Ref RootVolumePath Ebs: VolumeSize: !Ref RootVolumeSize Encrypted: true DeleteOnTermination: true KeyName: !Ref KeyName SecurityGroupIds: - !GetAtt BastionPublicSecurityGroup.GroupId Tags: - Key: Name Value: !Sub ${EnvName}-bastion SubnetId: !Ref BastionPublicSubnet CreditSpecification: CPUCredits: standard # Disable T2/3 Unlimited IamInstanceProfile: !Ref K8sAdminInstanceProfile Operator: Type: AWS::EC2::Instance Properties: ImageId: !Ref AmiId InstanceType: !Ref InstanceType BlockDeviceMappings: - DeviceName: !Ref RootVolumePath Ebs: VolumeSize: !Ref RootVolumeSize Encrypted: true DeleteOnTermination: true KeyName: !Ref KeyName SecurityGroupIds: - !GetAtt K8sOperatorSecurityGroup.GroupId Tags: - Key: Name Value: !Sub ${EnvName}-operator SubnetId: !Ref K8sOperatorSubnet CreditSpecification: CPUCredits: standard # Disable T2/3 Unlimited IamInstanceProfile: !Ref K8sAdminInstanceProfile Outputs: K8sVPCID: Description: The ID of K8s VPC Value: !Ref K8sVPC K8sWorkerSubnet1: Description: The ID of K8s worker subnet for main use Value: !Ref K8sWorkerSubnet1 K8sWorkerSubnet2: Description: The ID of K8s worker subnet for sub use Value: !Ref K8sWorkerSubnet2 K8sOperatorSubnet: Description: The ID of K8s operator subnet Value: !Ref K8sOperatorSubnet K8sOperatorSecurityGroup: Description: SG for K8s Operator Value: !Ref K8sOperatorSecurityGroup RoleArn: Description: The role that EKS will use to create AWS resources for Kubernetes clusters Value: !GetAtt AWSServiceRoleForAmazonEKS.Arn2-1 Control Plane SG
1に統合してもいいのですが、クラスターセキュリティグループの考慮事項 - Amazon EKSによるとクラスタごとにSGは分けた方がいいと記述されています。今回は1つのみですが、複数クラスタを作成することを考慮し分けています。
(実際のうちの環境では、コンポーネントごとにEKSクラスタを分離しています。)
2-1-controlplane-sg.yaml
```yaml:2-1-controlplane-sg.yamlAWSTemplateFormatVersion: '2010-09-09'
Parameters:
EnvName:
Type: String
Default: yoda-close-nw
Description: Component application identifier used by this sequential deployment
ClusterName:
Type: String
Default: yoda-closed-cluster-1
Description: K8s cluster name
K8sVpcId:
Type: String
Description: K8s cluster VPCID
OperatorSgId:
Type: String
Description: Operator security group id
Resources:
##### K8s Cluster ControlPlane SG #####
ClusterControlPlaneSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupName: !Sub ${EnvName}-${ClusterName}-controlplane-sg
GroupDescription: SG for control plane (k8s endpoint)
Tags:
- Key: Name
Value: !Sub ${EnvName}-${ClusterName}-controlplane-sg
VpcId: !Ref K8sVpcId
ClusterControlPlaneSecurityGroupIngressFromOperator:
Type: AWS::EC2::SecurityGroupIngress
Properties:
Description: Allow operator to communicate with the cluster API Server
GroupId: !Ref ClusterControlPlaneSecurityGroup
SourceSecurityGroupId: !Ref OperatorSgId
IpProtocol: tcp
ToPort: 443
FromPort: 443
```
2-2 EKS
CloudFormationでは現在、Private AccessをEnableにできないのでCLIで作成します。 3
2-3 Worker Nodes
AWS提供のテンプレートをいくつか改修してあります(PublicIPを削除する、EBS暗号化入れるなど)
UserDataのセクションでbootstrap.shを起動しているのが見えるかと思います。
2-3-workers.yaml2-3-workers.yaml# Based on https://github.com/awslabs/amazon-eks-ami/blob/master/amazon-eks-nodegroup.yaml # Add # - Default Value for NodeImageId # - Parameter for EnvName # - Name tag for worker sg # - Name for worker IAM role # - Parameter for operator sg # - SG rule from operator # - EBS encryption enable # Change # - Default Value for AutoScalingCapacities (to be single nodes) # - Disable Public IP for workers --- AWSTemplateFormatVersion: 2010-09-09 Description: Amazon EKS - Node Group Parameters: KeyName: Description: The EC2 Key Pair to allow SSH access to the instances Type: AWS::EC2::KeyPair::KeyName NodeImageId: Description: AMI id for the node instances. Type: AWS::EC2::Image::Id Default: ami-04c0f02f5e148c80a NodeInstanceType: Description: EC2 instance type for the node instances Type: String Default: t3.medium ConstraintDescription: Must be a valid EC2 instance type AllowedValues: - a1.medium - a1.large - a1.xlarge - a1.2xlarge - a1.4xlarge - c1.medium - c1.xlarge - c3.large - c3.xlarge - c3.2xlarge - c3.4xlarge - c3.8xlarge - c4.large - c4.xlarge - c4.2xlarge - c4.4xlarge - c4.8xlarge - c5.large - c5.xlarge - c5.2xlarge - c5.4xlarge - c5.9xlarge - c5.18xlarge - c5d.large - c5d.xlarge - c5d.2xlarge - c5d.4xlarge - c5d.9xlarge - c5d.18xlarge - c5n.large - c5n.xlarge - c5n.2xlarge - c5n.4xlarge - c5n.9xlarge - c5n.18xlarge - cc2.8xlarge - cr1.8xlarge - d2.xlarge - d2.2xlarge - d2.4xlarge - d2.8xlarge - f1.2xlarge - f1.4xlarge - f1.16xlarge - g2.2xlarge - g2.8xlarge - g3s.xlarge - g3.4xlarge - g3.8xlarge - g3.16xlarge - h1.2xlarge - h1.4xlarge - h1.8xlarge - h1.16xlarge - hs1.8xlarge - i2.xlarge - i2.2xlarge - i2.4xlarge - i2.8xlarge - i3.large - i3.xlarge - i3.2xlarge - i3.4xlarge - i3.8xlarge - i3.16xlarge - i3.metal - i3en.large - i3en.xlarge - i3en.2xlarge - i3en.3xlarge - i3en.6xlarge - i3en.12xlarge - i3en.24xlarge - m1.small - m1.medium - m1.large - m1.xlarge - m2.xlarge - m2.2xlarge - m2.4xlarge - m3.medium - m3.large - m3.xlarge - m3.2xlarge - m4.large - m4.xlarge - m4.2xlarge - m4.4xlarge - m4.10xlarge - m4.16xlarge - m5.large - m5.xlarge - m5.2xlarge - m5.4xlarge - m5.12xlarge - m5.24xlarge - m5a.large - m5a.xlarge - m5a.2xlarge - m5a.4xlarge - m5a.12xlarge - m5a.24xlarge - m5ad.large - m5ad.xlarge - m5ad.2xlarge - m5ad.4xlarge - m5ad.12xlarge - m5ad.24xlarge - m5d.large - m5d.xlarge - m5d.2xlarge - m5d.4xlarge - m5d.12xlarge - m5d.24xlarge - p2.xlarge - p2.8xlarge - p2.16xlarge - p3.2xlarge - p3.8xlarge - p3.16xlarge - p3dn.24xlarge - r3.large - r3.xlarge - r3.2xlarge - r3.4xlarge - r3.8xlarge - r4.large - r4.xlarge - r4.2xlarge - r4.4xlarge - r4.8xlarge - r4.16xlarge - r5.large - r5.xlarge - r5.2xlarge - r5.4xlarge - r5.12xlarge - r5.24xlarge - r5a.large - r5a.xlarge - r5a.2xlarge - r5a.4xlarge - r5a.12xlarge - r5a.24xlarge - r5ad.large - r5ad.xlarge - r5ad.2xlarge - r5ad.4xlarge - r5ad.12xlarge - r5ad.24xlarge - r5d.large - r5d.xlarge - r5d.2xlarge - r5d.4xlarge - r5d.12xlarge - r5d.24xlarge - t1.micro - t2.nano - t2.micro - t2.small - t2.medium - t2.large - t2.xlarge - t2.2xlarge - t3.nano - t3.micro - t3.small - t3.medium - t3.large - t3.xlarge - t3.2xlarge - t3a.nano - t3a.micro - t3a.small - t3a.medium - t3a.large - t3a.xlarge - t3a.2xlarge - x1.16xlarge - x1.32xlarge - x1e.xlarge - x1e.2xlarge - x1e.4xlarge - x1e.8xlarge - x1e.16xlarge - x1e.32xlarge - z1d.large - z1d.xlarge - z1d.2xlarge - z1d.3xlarge - z1d.6xlarge - z1d.12xlarge NodeAutoScalingGroupMinSize: Description: Minimum size of Node Group ASG. Type: Number Default: 1 NodeAutoScalingGroupMaxSize: Description: Maximum size of Node Group ASG. Set to at least 1 greater than NodeAutoScalingGroupDesiredCapacity. Type: Number Default: 1 NodeAutoScalingGroupDesiredCapacity: Description: Desired capacity of Node Group ASG. Type: Number Default: 1 NodeVolumeSize: Description: Node volume size Type: Number Default: 20 ClusterName: Description: The cluster name provided when the cluster was created. If it is incorrect, nodes will not be able to join the cluster. Type: String BootstrapArguments: Description: Arguments to pass to the bootstrap script. See files/bootstrap.sh in https://github.com/awslabs/amazon-eks-ami Type: String Default: "" NodeGroupName: Description: Unique identifier for the Node Group. Type: String ClusterControlPlaneSecurityGroup: Description: The security group of the cluster control plane. Type: AWS::EC2::SecurityGroup::Id VpcId: Description: The VPC of the worker instances Type: AWS::EC2::VPC::Id Subnets: Description: The subnets where workers can be created. Type: List<AWS::EC2::Subnet::Id> EnvName: Type: String Default: yoda-close-nw Description: Component application identifier used by this sequential deployment OperatorSgId: Description: Operator security group id Type: String Metadata: AWS::CloudFormation::Interface: ParameterGroups: - Label: default: EKS Cluster Parameters: - ClusterName - ClusterControlPlaneSecurityGroup - Label: default: Worker Node Configuration Parameters: - NodeGroupName - NodeAutoScalingGroupMinSize - NodeAutoScalingGroupDesiredCapacity - NodeAutoScalingGroupMaxSize - NodeInstanceType - NodeImageId - NodeVolumeSize - KeyName - BootstrapArguments - Label: default: Worker Network Configuration Parameters: - VpcId - Subnets Resources: NodeInstanceProfile: Type: AWS::IAM::InstanceProfile Properties: Path: "/" Roles: - !Ref NodeInstanceRole NodeInstanceRole: Type: AWS::IAM::Role Properties: RoleName: !Sub ${EnvName}-${ClusterName}-worker-role AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: ec2.amazonaws.com Action: sts:AssumeRole Path: "/" ManagedPolicyArns: - arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy - arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy - arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly NodeSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Security group for all nodes in the cluster VpcId: !Ref VpcId Tags: - Key: !Sub kubernetes.io/cluster/${ClusterName} Value: owned - Key: Name Value: !Sub ${EnvName}-${ClusterName}-worker-sg NodeSecurityGroupIngress: Type: AWS::EC2::SecurityGroupIngress DependsOn: NodeSecurityGroup Properties: Description: Allow node to communicate with each other GroupId: !Ref NodeSecurityGroup SourceSecurityGroupId: !Ref NodeSecurityGroup IpProtocol: -1 FromPort: 0 ToPort: 65535 NodeSecurityGroupFromControlPlaneIngress: Type: AWS::EC2::SecurityGroupIngress DependsOn: NodeSecurityGroup Properties: Description: Allow worker Kubelets and pods to receive communication from the cluster control plane GroupId: !Ref NodeSecurityGroup SourceSecurityGroupId: !Ref ClusterControlPlaneSecurityGroup IpProtocol: tcp FromPort: 1025 ToPort: 65535 ControlPlaneEgressToNodeSecurityGroup: Type: AWS::EC2::SecurityGroupEgress DependsOn: NodeSecurityGroup Properties: Description: Allow the cluster control plane to communicate with worker Kubelet and pods GroupId: !Ref ClusterControlPlaneSecurityGroup DestinationSecurityGroupId: !Ref NodeSecurityGroup IpProtocol: tcp FromPort: 1025 ToPort: 65535 NodeSecurityGroupFromControlPlaneOn443Ingress: Type: AWS::EC2::SecurityGroupIngress DependsOn: NodeSecurityGroup Properties: Description: Allow pods running extension API servers on port 443 to receive communication from cluster control plane GroupId: !Ref NodeSecurityGroup SourceSecurityGroupId: !Ref ClusterControlPlaneSecurityGroup IpProtocol: tcp FromPort: 443 ToPort: 443 NodeSecurityGroupFromOperatorOn22Ingress: Type: AWS::EC2::SecurityGroupIngress DependsOn: NodeSecurityGroup Properties: Description: Allow nodes to communicate with the operator on SSH GroupId: !Ref NodeSecurityGroup SourceSecurityGroupId: !Ref OperatorSgId IpProtocol: tcp FromPort: 22 ToPort: 22 NodeSecurityGroupFromOperatorOn80Ingress: Type: AWS::EC2::SecurityGroupIngress DependsOn: NodeSecurityGroup Properties: Description: Allow nodes to communicate with the operator on HTTP GroupId: !Ref NodeSecurityGroup SourceSecurityGroupId: !Ref OperatorSgId IpProtocol: tcp FromPort: 80 ToPort: 80 ControlPlaneEgressToNodeSecurityGroupOn443: Type: AWS::EC2::SecurityGroupEgress DependsOn: NodeSecurityGroup Properties: Description: Allow the cluster control plane to communicate with pods running extension API servers on port 443 GroupId: !Ref ClusterControlPlaneSecurityGroup DestinationSecurityGroupId: !Ref NodeSecurityGroup IpProtocol: tcp FromPort: 443 ToPort: 443 ClusterControlPlaneSecurityGroupIngress: Type: AWS::EC2::SecurityGroupIngress DependsOn: NodeSecurityGroup Properties: Description: Allow pods to communicate with the cluster API Server GroupId: !Ref ClusterControlPlaneSecurityGroup SourceSecurityGroupId: !Ref NodeSecurityGroup IpProtocol: tcp ToPort: 443 FromPort: 443 NodeGroup: Type: AWS::AutoScaling::AutoScalingGroup Properties: DesiredCapacity: !Ref NodeAutoScalingGroupDesiredCapacity LaunchConfigurationName: !Ref NodeLaunchConfig MinSize: !Ref NodeAutoScalingGroupMinSize MaxSize: !Ref NodeAutoScalingGroupMaxSize VPCZoneIdentifier: !Ref Subnets Tags: - Key: Name Value: !Sub ${ClusterName}-${NodeGroupName}-Node PropagateAtLaunch: true - Key: !Sub kubernetes.io/cluster/${ClusterName} Value: owned PropagateAtLaunch: true UpdatePolicy: AutoScalingRollingUpdate: MaxBatchSize: 1 MinInstancesInService: !Ref NodeAutoScalingGroupDesiredCapacity PauseTime: PT5M NodeLaunchConfig: Type: AWS::AutoScaling::LaunchConfiguration Properties: AssociatePublicIpAddress: false IamInstanceProfile: !Ref NodeInstanceProfile ImageId: !Ref NodeImageId InstanceType: !Ref NodeInstanceType KeyName: !Ref KeyName SecurityGroups: - !Ref NodeSecurityGroup BlockDeviceMappings: - DeviceName: /dev/xvda Ebs: VolumeSize: !Ref NodeVolumeSize VolumeType: gp2 DeleteOnTermination: true Encrypted: true UserData: Fn::Base64: !Sub | #!/bin/bash set -o xtrace /etc/eks/bootstrap.sh ${ClusterName} ${BootstrapArguments} /opt/aws/bin/cfn-signal --exit-code $? \ --stack ${AWS::StackName} \ --resource NodeGroup \ --region ${AWS::Region} Outputs: NodeInstanceRole: Description: The node instance role Value: !GetAtt NodeInstanceRole.Arn NodeSecurityGroup: Description: The security group for the node group Value: !Ref NodeSecurityGroup起動後のセットアップ
Worker Nodeを起動しただけでは、EKSからはNodeとして認識されるものの
NotReadyの状態となります。
そのためaws-authというConfigMap(Kubernetesにおける設定ファイルのような概念)を作成・適用する必要があります。
また、VPC内にのOperatorからkubectlを打てるように、Operatorへ紐付けたIAMロールもaws-authに追加する必要があります。さらに環境変数等設定せずにkubectlを打つためには、
${HOME}/.kube/config以下に設定が記載されたファイルを保持する必要があります。
参考スクリプトでは、scpでクライアントPCから転送します。クライアントのssh_configへと追記を行うようにしていますが、こいじるのが嫌な場合は適宜修正してください。
create_cluster.sh#!/usr/bin/env bash set -o pipefail # Stop pipe when error occurred set -o nounset # Check undefined variables set -o errexit # Exit when error occurred set -o xtrace # Print debug information ################################################################################ ### Variables ################################################################## ################################################################################ ENV_NAME=${ENV_NAME:-"yoda-eks-closed"} STACK_NAME_BASE=${STACK_NAME_BASE:-$ENV_NAME} CLUSTER_NAME=${CLUSTER_NAME:-"yoda-k8s-1"} K8S_VERSION=${K8S_VERSION:-"1.13"} KEY_NAME=${KEY_NAME:-"yoda-key"} NODE_INSTANCE_TYPE=${NODE_INSTANCE_TYPE:-"t3.small"} OPERATOR_AMI_ID=${OPERATOR_AMI_ID:-"ami-03dc8213c70f79358"} YOUR_COMPUTER_IPADDR=${YOUR_COMPUTER_IPADDR:-$(curl inet-ip.info)} ################################################################################ ### 1 Infrastructure ########################################################### ################################################################################ STACK_NAME=${STACK_NAME_BASE}-infrastructure TEMPLATE=${TEMPLATE_1:-"file://templates/1-infrastructure.yaml"} aws cloudformation create-stack \ --stack-name ${STACK_NAME} \ --template-body ${TEMPLATE} \ --parameters \ ParameterKey=EnvName,ParameterValue=${ENV_NAME} \ ParameterKey=YourComputerIPAddress,ParameterValue=${YOUR_COMPUTER_IPADDR} \ ParameterKey=KeyName,ParameterValue=${KEY_NAME} \ ParameterKey=AmiId,ParameterValue=${OPERATOR_AMI_ID} \ --capabilities CAPABILITY_NAMED_IAM aws cloudformation wait stack-create-complete --stack-name ${STACK_NAME} ################################################################################ ### 2-1 Control Plane SG ####################################################### ################################################################################ STACK_NAME=${STACK_NAME_BASE}-${CLUSTER_NAME}-cplane-sg TEMPLATE=${TEMPLATE_2_1:-"file://templates/2-1-controlplane-sg.yaml"} K8S_VPC_ID=$(aws ec2 describe-vpcs \ --filters Name=tag:Name,Values=${ENV_NAME}-k8s-vpc \ --query "Vpcs[*].VpcId" \ --output text) OPERATOR_SG_ID=$(aws ec2 describe-security-groups \ --filter Name=group-name,Values=${ENV_NAME}-k8s-operator-sg \ --query "SecurityGroups[*].GroupId" \ --output text) aws cloudformation create-stack \ --stack-name ${STACK_NAME} \ --template-body ${TEMPLATE} \ --parameters \ ParameterKey=EnvName,ParameterValue=${ENV_NAME} \ ParameterKey=ClusterName,ParameterValue=${CLUSTER_NAME} \ ParameterKey=K8sVpcId,ParameterValue=${K8S_VPC_ID} \ ParameterKey=OperatorSgId,ParameterValue=${OPERATOR_SG_ID} aws cloudformation wait stack-create-complete --stack-name ${STACK_NAME} ################################################################################ ### 2-2 EKS #################################################################### ################################################################################ EKS_SERVICE_ROLE_ARN=$(aws iam get-role \ --role-name ${ENV_NAME}-eks-service-role \ --query "Role.Arn" \ --output text) SUBNET_IDS=$(aws ec2 describe-subnets \ --filter "Name=tag:Name,Values=${ENV_NAME}-k8s-worker*" \ --query "Subnets[*].SubnetId" \ --output text | tr '\t' ',') CPLANE_SG_ID=$(aws ec2 describe-security-groups \ --filter Name=group-name,Values=${ENV_NAME}-${CLUSTER_NAME}-controlplane-sg \ --query "SecurityGroups[*].GroupId" \ --output text) aws eks create-cluster \ --name ${CLUSTER_NAME} \ --role-arn ${EKS_SERVICE_ROLE_ARN} \ --resources-vpc-config \ subnetIds=${SUBNET_IDS},securityGroupIds=${CPLANE_SG_ID},endpointPublicAccess=true,endpointPrivateAccess=true \ --kubernetes-version=${K8S_VERSION} aws eks wait cluster-active --name ${CLUSTER_NAME} # Download kubeconfig to /root/.kube aws eks update-kubeconfig --name ${CLUSTER_NAME} kubectl get svc # Check Auth ################################################################################ ### 2-3 Worker Nodes ########################################################### ################################################################################ STACK_NAME=${STACK_NAME_BASE}-${CLUSTER_NAME}-workers TEMPLATE=${TEMPLATE_2_3:-"file://templates/2-3-workers.yaml"} K8S_ENDPOINT=$(aws eks describe-cluster \ --name ${CLUSTER_NAME} \ --query "cluster.endpoint" \ --output text) K8S_CA=$(aws eks describe-cluster \ --name ${CLUSTER_NAME} \ --query "cluster.certificateAuthority.data" \ --output text) MAIN_SUBNET_ID=$(aws ec2 describe-subnets \ --filter "Name=tag:Name,Values=${ENV_NAME}-k8s-worker-subnet-1" \ --query "Subnets[*].SubnetId" \ --output text) aws cloudformation create-stack \ --stack-name ${STACK_NAME} \ --template-body ${TEMPLATE} \ --parameters \ ParameterKey=KeyName,ParameterValue=${KEY_NAME} \ ParameterKey=NodeInstanceType,ParameterValue=${NODE_INSTANCE_TYPE} \ ParameterKey=ClusterName,ParameterValue=${CLUSTER_NAME} \ ParameterKey=BootstrapArguments,ParameterValue="--apiserver-endpoint ${K8S_ENDPOINT} --b64-cluster-ca ${K8S_CA}" \ ParameterKey=NodeGroupName,ParameterValue=${CLUSTER_NAME}-worker \ ParameterKey=ClusterControlPlaneSecurityGroup,ParameterValue=${CPLANE_SG_ID} \ ParameterKey=VpcId,ParameterValue=${K8S_VPC_ID} \ ParameterKey=Subnets,ParameterValue=${MAIN_SUBNET_ID} \ ParameterKey=EnvName,ParameterValue=${ENV_NAME} \ ParameterKey=OperatorSgId,ParameterValue=${OPERATOR_SG_ID} \ --capabilities CAPABILITY_NAMED_IAM aws cloudformation wait stack-create-complete --stack-name ${STACK_NAME} # Apply AWS Authenticator ConfigMap WORKER_ROLE_ARN=$(aws iam get-role \ --role-name ${ENV_NAME}-${CLUSTER_NAME}-worker-role \ --query "Role.Arn" \ --output text) K8S_ADMIN_ROLE_ARN=$(aws iam get-role \ --role-name ${ENV_NAME}-admin-role \ --query "Role.Arn" \ --output text) cat <<EOF | kubectl apply -f - apiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: ${WORKER_ROLE_ARN} username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes - rolearn: ${K8S_ADMIN_ROLE_ARN} username: system:node:{{EC2PrivateDNSName}} groups: - system:masters EOF ################################################################################ ### 3 Configuration ############################################################ ################################################################################ # Assemble .ssh/config BASTION_IP=$(aws ec2 describe-instances \ --filter Name=tag:Name,Values=${ENV_NAME}-bastion \ --query "Reservations[*].Instances[*].PublicIpAddress" \ --output text) OPERATOR_IP=$(aws ec2 describe-instances \ --filter Name=tag:Name,Values=${ENV_NAME}-operator \ --query "Reservations[*].Instances[*].PrivateIpAddress" \ --output text) cat <<EOF > ~/.ssh/config Host * IdentitiesOnly yes ServerAliveInterval 120 ServerAliveCountMax 10 ForwardAgent yes User ec2-user IdentityFile ~/.ssh/${KEY_NAME}.pem TCPKeepAlive yes Host bastion HostName ${BASTION_IP} Host operator HostName ${OPERATOR_IP} Localforward 0.0.0.0:8765 localhost:8765 ProxyCommand ssh -W %h:%p bastion EOF # Create .kube and transport config file to bastion ssh -oStrictHostKeyChecking=no bastion \ mkdir /home/ec2-user/.kube scp -oStrictHostKeyChecking=no ~/.kube/config bastion:/home/ec2-user/.kube/ # Create .kube and transport config file to operator ssh -oStrictHostKeyChecking=no operator \ mkdir /home/ec2-user/.kube scp -oStrictHostKeyChecking=no ~/.kube/config operator:/home/ec2-user/.kube/ # Enable SSH Agent (To log-in to worker nodes from this container) eval `ssh-agent` ssh-add ~/.ssh/${KEY_NAME}.pem echo "Creation Completed."先にあげたテンプレートを作業ディレクトリ(仮に
/templetesとします)に
1-infrastructure.yaml2-1-controlplane-sg.yaml2-3-workers.yamlと配置して、スクリプトを走らせると通しで環境作成がされます(
Variablesは適宜変更ください)。運用について
VPCエンドポイントについて
構築時に必要になるVPCエンドポイントですが、それ以降は必要にならないので、セキュリティ面で気になる場合は外してしまっても問題ありません。
ただし、AutoScalingが組まれるので、VPCエンドポイントをそのままにしておけば
- AutoScalingの値を調整するだけでノード増減が可能
- EC2の障害発生時も自動で新しいノードに挿しかわる
ため、つけておくと何かと便利です。
またS3, ECRはVPCエンドポイントポリシーとリソースのポリシーの両方を持ち合わせているため、内部からの流出経路となりうるバケットやリポジトリに対し、強固な制限 が可能です(e.g. 他のアカウントのアクセスキーを持ち込まれてもエンドポイントポリシーで拒否する、リソースのポリシーで特定VPCエンドポイントからの操作のみ受け付けるようにする、など)。コンテナの持ち込み
いくつか手段がありますが、
- ECRに直接Push
docer exportを利用し、tarで固めたイメージをS3経由で転送が簡便です。双方上述の通りリソースポリシー、VPCエンドポイントポリシーを持つので持ち込み限定のリポジトリやバケットの作成が可能です。
前者が簡便ですが、後者の方がログや他の資材の持ち込みも可能、と言った長短があります。EKSの困ったところ
自動アップデート
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/platform-versions.html
にあるように、EKSの対応するkubernetesの、マイナーバージョンがアップデートが行われた場合自動でアップデートされます。そのため EKSの上でSparkアプリケーションをを動かしていたのですがある日突然停止 するなんてことも……
(こちらの事象だったので一部jarを差し替えてことなきを得ました)
レアケースだとは思いますが、気をつけておいた方がいいポイントです。PodとPrivate IPの1:1対応
こちらはよく言われていることですが、EKSではPodに対しVPC内でワークするPrivateIPを割り当てます。そのため
- VPCのレンジを広めに
- NodeのEC2のサイズは大きめ(EC2に割り当て可能なENIの上限はインスタンスサイズで決まるため、それぞれの上限数はこちら)
にしておかないと追加で新しいPrivate IPが払い出せない=新しいPodの追加ができない、ことになるため難儀します。
慣れるまでは大変でしたが、現在はコンテナの便利さを十分に受けれてるんでないかなーと。KubernetesやEKSユーザーの助けになれば幸いです。
1月の第三者認証対応や、6月のECR VPCEndpoint対応など、一気にEKSが利用しやすい環境が整った2019年でした! ↩
今年のKubeConでManaged Nodeが発表されたため、正確には全てを管理するサービスとなっています。 ↩
Cloud Formation Roadmapによると現在検討中らしい。。。 ↩








- 投稿日:2019-12-24T13:28:40+09:00
Webシステム構築(超基礎)①:Webサーバ構築と基本動作
目的
Webシステム構築を目的として、まずは超基礎的なWebサーバの構築と動作を確認する。
環境条件
- Webサーバ
- EC2:t2.micro
- OS:Red Hat Enterprise Linux 8 (HVM), SSD Volume Type
- Disk:汎用SSD(GP2) 10GB
セキュリティグループの設定等はいい感じに。
構築手順
ec2-userでログイン rootユーザにスイッチ $ sudo su - httpパッケージの存在確認 # yum info httpd httpパッケージのインストール # yum install -y httpd Complete!の出力を確認する。 httpdサービスの停止を確認 # service httpd status Active: inactive (dead)の出力を確認する。 httpdサービスを起動する # service httpd start Redirecting to /bin/systemctl start httpd.service 再度httpdサービスのステータスを確認する # service httpd status Active: active (running)の出力を確認する。 ブラウザからWebサーバの「パブリックDNS:80」に接続し、 Red Hat Enterprise Linux Test Pageが表示されることを確認する。Webサーバの基本動作
以下2点ほど確認しておく。
1. DocumentRootとコンテンツの配置
2. 別ポートでのWebサーバ起動1. DocumentRootとコンテンツの配置
DocumentRoot
DocumentRootとはざっくりいうと、自分で作ったコンテンツを
Apache HTTP ServerでWebサービスとして提供するための置き場所。
デフォルトは、以下となっている。
/var/www/html
DocumentRootの変更や設定の確認については、
以下ファイルによって可能。
/etc/httpd/conf/httpd.conf
httpd.conf(:set numberを実行の上、一部抜粋) 117 # 118 # DocumentRoot: The directory out of which you will serve your 119 # documents. By default, all requests are taken from this directory, but 120 # symbolic links and aliases may be used to point to other locations. 121 # 122 DocumentRoot "/var/www/html" #←ここを変更することでDocumentRootが変更可能コンテンツの配置
まずは、DocumentRootにindex.htmlファイルを配置してみる。
index.html(中身はなんでもいい。) index.htmlこの状態で、ブラウザからWebサーバの「パブリックDNS:80」に接続すると、
Red Hat Enterprise Linux Test Pageが表示されなくなり、
index.htmlの中に記載した内容が表示される。
DocumentRootにindex.が存在しない場合、
Testページを表示するが、存在する場合、index.を表示する。次に、DocumentRootにtest.htmlファイルを配置してみる。
test.html(中身はなんでもいい。) test.htmlこの状態で、ブラウザからWebサーバの「パブリックDNS:80/test.html」に接続すると、
test.htmlを表示することができる。2. 別ポートでのWebサーバ起動
80番ポート以外でのWebサーバの起動が必要な場合に、DocumentRootと同じく、
以下ファイルを変更することで対応することが可能。httpd.conf(:set numberを実行の上、一部抜粋) 37 # Listen: Allows you to bind Apache to specific IP addresses and/or 38 # ports, instead of the default. See also the <VirtualHost> 39 # directive. 40 # 41 # Change this to Listen on specific IP addresses as shown below to 42 # prevent Apache from glomming onto all bound IP addresses. 43 # 44 #Listen 12.34.56.78:80 45 Listen 8045行目のListen 80を Listen 10000等に変更し、プロセスを再起動することで、
10000ポートでのWebサーバの起動が可能になる。次回は、
Webシステム構築(超基礎)②:APサーバ構築と基本動作
です。
- 投稿日:2019-12-24T13:17:02+09:00
AmplifyでCognitoユーザプールの認証を行いトークン(ID、アクセス)取得後、トークンの有効期限を取得する
- 投稿日:2019-12-24T13:11:54+09:00
AWS re:invent2019に行った感想(次行く人のためにメモ)
はじめに
12/1~12/6に開催されるAWS re:invent2019に会社名義で参加してきました。
雰囲気や今後行く人のために参考になればと残しておきます。
画像とか追加であげます。AWSの認定資格を取得する
懇親会の際に知識共有がしやすい
AWSの社員経由でre:inventに参加したので、日本企業で行く人たちが集まる事前懇親会がAWS目黒本社に招待されました。多くのAWSを使用した企業と交流するにあたり幅広く知識を持っていると、自分が担当しているサービス以外でも吸収できる部分が多くなります。
(現地で首に下げるIDバッジに認定者シールが貼られるので、胸を張れる部分もあります)認定者限定のスペース・ノベルティがある
イベント会場でも認定者資格を持っている人は休憩スペースに入れたり、
特別なノベルティがもらえます。2019年はスポーツウェア・靴下・バッジでした。
正直、休憩スペースは狭くて席が埋まっているのでそんなにうまみは感じませんでした。
ドリンクとか軽食がもらえますとre:invent関連の記事にありますが、ドリンクと軽食は認定者ラウンジ以外でももらえます。取るならSAA(ソリューションアーキテクト)が全体的なことを知れて良いかなと思いました。
セッションの種類について
re:inventでは5日間で4000以上のセッションがあり、それぞれ形式が異なるセッションが行われています。
自分が参加したものだけ参考に書いていきます。現地でしかできないことをやる
まず事前懇親会でも言われたのが「現地でしかできないことをやる」です。
講義形式のセッションは後に動画配信されるので、見逃してしまっても興味があれば後からでも見ることができます。
とはいえ現場の温度感などしっかり味わえるし、セッション取ってもいいと思います。予約時はSessionは後回しでもいい
セッションはよっぽど人気でない限り、当日でも余裕で入れると思います。
当日から20分前くらいに並べば入れるので、予約の際はセッション以外を優先的に取るようにするといいです。
→10分前には待機列が解放されるので、予約をしていても早めに来ていないと受けられなくなる可能性もあります。Workshopをたくさん取るようにするといい
手を動かす方が英語を使わないので英語ができない人はWorkshopオススメです。
→でもわからないことがあると聞く必要はある(画面見せれば色々喋りながらサポートしてくれます)
ワークショップは人気なので後からはなかなか取れない。予約の際にとっておくといいと思います。また、予約枠以外で当日並ぶ場合、開始1時間前に並べばほぼ入れる(30~45分だと入れたり入れなかったり、30分)
→当日ノベルティがもらえるワークショップは2~3時間前くらいから並ばないと取れないです(去年ならdeepcomposer/一昨年ならdeepracer)Chalk Talk
20分程度のセッションから残り40分は質疑応答になります。
自分が参加したものはボード一切使いませんでした。
スライドなどがないので、英語のリスニングがある程度できる前提で取った方がいいと思います。
→ただ話さなくてもいいので、話すことが苦手でも大丈夫です。
スピーキングができるとより価値があるセッションだと思います。SpotLight Lab
ハンズオンのトレーニングを現場でできます。
無料で提供されているハンズオンではないものなど実践できるし、
実際に手を動かすのでインプットが多いと思います。基調講演は一度は必ず参加すると良い
フェスのようなどでかい会場で講演があります。前座でバンドとかDJが演奏しているし、
先着1000名にはノベルティのTシャツがもらえます。(1時間前くらいに会場入りすればもらえる)
日本語訳が同時通訳にあるので理解しやすいです。温度感だけでも1度は必ず現場で体験してみて、そのあとは中継でもどちらでも良いかなと思いました。
その他イベントについて
朝食&昼食&軽食&ドリンク
全て会場内で無料なので有効活用すると良いです。
缶ジュースとか持って帰ってホテルとかで飲むのも良いです。re:play
木曜日にバスでどこだかわからないところに連れて行かれます。
フェスみたいな会場、いろんなことに力が入っていて楽しいです。EXPO
AWSのスポンサーがブースを開いており、小規模なセッションをやっていたりサービスを試せたりする。
英会話の練習でこのサービスは何なのかとか色々聞いてみるといいかも。
ノベルティをたくさん配っており、プリーズって言えばとりあえず貰える。Tシャツとか頑張れば10着くらい貰える。
曜日によりスポンサーが異なっており、毎日空き時間にいくといいと思う。
シャツやパーカーのサイズはいつも自分が来ている1サイズ小さめのものをお願いすると良い。英語について
スピーキングよりリスニングが重要な印象を受けました。
行く前はリスニングに注力して勉強するといいと思います。
海外の人はみんなフランクで昼食バイキング中やセッションの待ち時間に普通に声をかけてきます。
・どこから来たの?
・fargateを自社サービスに導入していますか?課題はありますか?
・その背中の大きい荷物は何ですか?
とか聞かれたりしました。
話せると自分から列の待ち時間で周りの人にヒアリングできてより充実してイベントに参加できると思います。
- 投稿日:2019-12-24T12:39:16+09:00
Elasticsearch によるログ収集と可視化
Elasticsearch によるログ収集と可視化について、全三回に渡って記事を掲載しています。
第一回から第三回まで順を追ってご覧頂ければ幸いです。・Elasticsearch によるログ収集と可視化(第一回)
Elasticsearch の概要とデータ構造について・Elasticsearch によるログ収集と可視化(第二回)
データの流れと AWS 上での環境構築について・Elasticsearch によるログ収集と可視化(第三回)
各ツールの設定内容と可視化について
- 投稿日:2019-12-24T12:11:57+09:00
mockmockで簡単なIoTシステムを開発してみよう
この記事はmockmockアドベントカレンダー24日目の記事です。
クリスマスイブの今日はmockmockを使って簡単なIoTシステムを開発します。ただし、mockmockのアドバンスドオプションの一つである「DataRecorder」を使って、
デバイスから送信されたデータの確認・クラウドへの再送を行い、スマートに開発していく点に注目です。開発するシステム
システム名
システム名は「Suwarin」とします。
某子供向け番組のキャラクターをリスペクトして名付けました。仕様
自分自身の着席状況をSlackへ通知するIoTシステムです。
自分が着席したら「着席しました」、離席したら「離席しました」とメッセージを送信します。システム構成
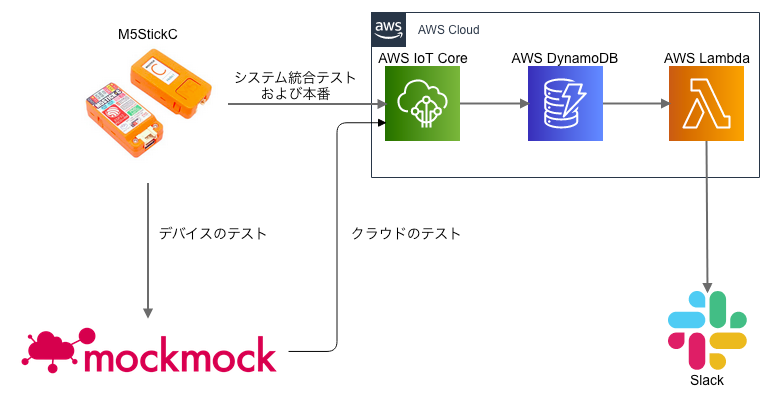
今回、デバイスにはM5StickCを使用します。クラウドはAWSでIoT Core, DynamoDB(Stream), Lambdaを使用します。
肝心のセンサーですがたまたま手元にあった「Seed社 Grove-Ultrasonic Ranger」を使用します。
検出した距離が近いときは「着席中」、遠いとき(未検出時の値)のときは「離席中」と判定します。
[デバイスの開発・テスト]M5StickC→mockmockにデータを送る
まずはM5StickCでプログラムを起動して、mockmockにデータを送ります。
mockmock DataRecorderの設定
エンドポイントの作成
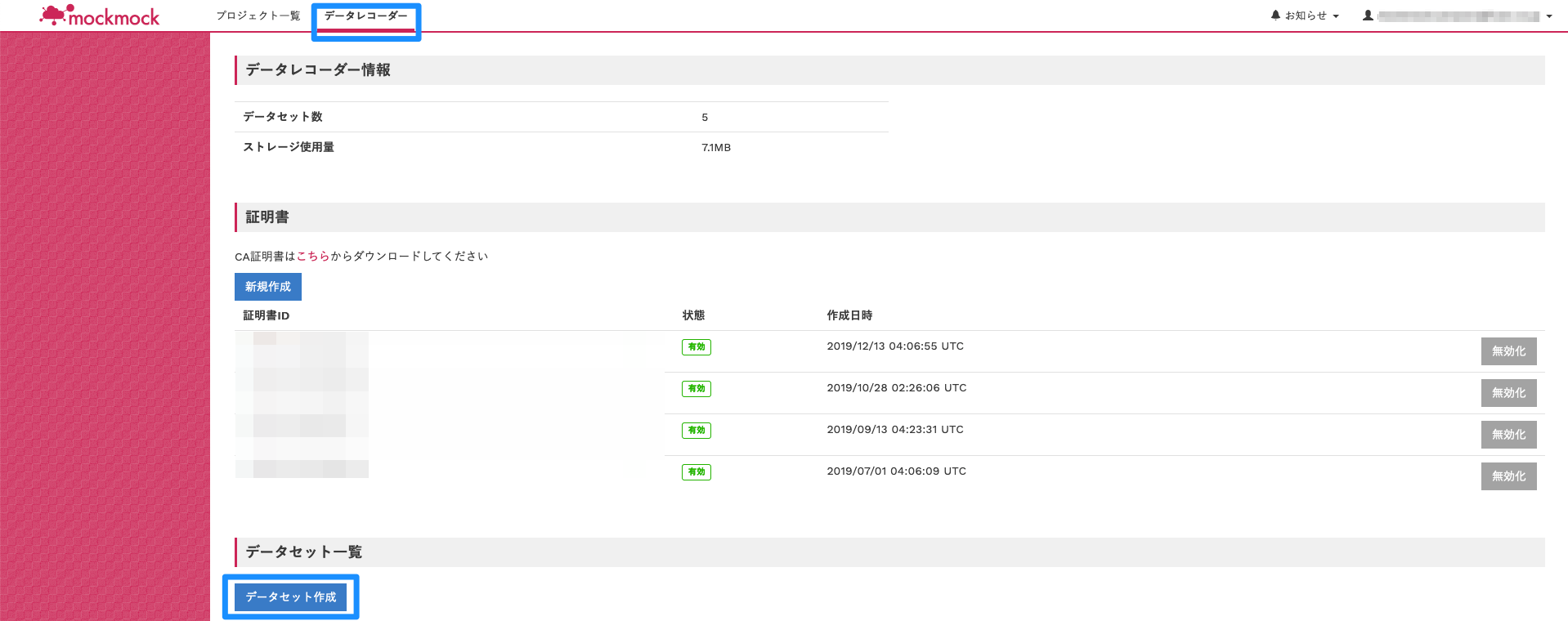
mockmockのログインページからログイン後、「データレコーダー」→「データセット作成」の順でクリックしてください。
「データセット新規作成」フォームが表示されるので、任意の名称と説明を入力後、「登録」をクリックしてください。
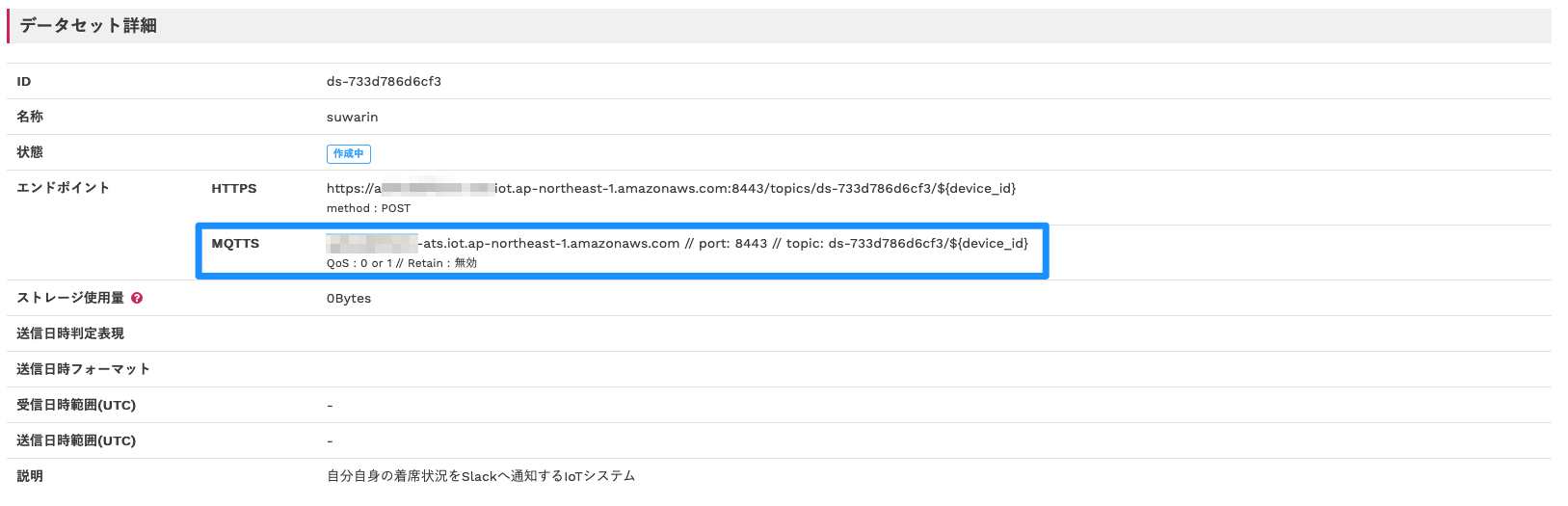
「データセット一覧」に作成したデータセットが表示されたら「詳細」をクリックしてください。
「エンドポイント」の「MQTTS」の内容をメモしておいてください。後ほど使用します。
証明書の作成
「データレコーダー」→「証明書:新規作成」の順でクリックしてください。
証明書ファイルのダウンロードがはじまりますので任意の場所に保存してください。後ほど使用します。
作成した証明書が表示されたら「有効化」をクリックしてください。
デバイス側の実装
以下ソースコードをビルドして、M5StickCへ書き込んでください。
{{ }}で囲まれた文字列はmockmockの設定やご使用のWi-Fiアクセスポイントに合わせて書き換える必要があります。
Root CAはこちらを参照。suwarin#include <M5StickC.h> #include "Ultrasonic.h" #include "cloud.h" #define FILTER_RATE 0.95 Ultrasonic ultrasonic(33); float filtered_value = 0; void setup_lcd() { M5.Lcd.fillScreen(BLACK); M5.Lcd.setTextSize(1); M5.Lcd.setRotation(1); M5.Lcd.setCursor(0, 0); } void setup_serial() { Serial.begin(9600); } void setup() { M5.begin(); setup_lcd(); setup_serial(); setup_mqtt(); } float rc_filter(float raw_value) { filtered_value = (1 - FILTER_RATE) * raw_value + FILTER_RATE * filtered_value; return filtered_value; } void loop() { mqtt_connect(); for(int i = 0 ; i < 10 ; i++) { M5.Lcd.setCursor(0, 30); M5.Lcd.printf("%d cm ", ultrasonic.MeasureInCentimeters()); M5.Lcd.println(""); delay(100); } mqtt_publish_measure(rc_filter(ultrasonic.MeasureInCentimeters())); }cloud.h#define WIFI_SSID "{{Wi-FiのSSID}}" #define WIFI_PASSWORD "{{Wi-Fiのパスワード}}" #define CLOUD_ENDPOINT "<実際のエンドポイントに置き換えてください>.iot.ap-northeast-1.amazonaws.com" #define CLOUD_PORT 8883 #define CLOUD_TOPIC "{{DataRecorderが表示するtopic名に置き換えてください}}" // {{実際の証明書に置き換えてください}} #define ROOT_CA "-----BEGIN CERTIFICATE-----\n"\ "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\n"\ "xxxxxxxxxxxxxxxxxxxxxxxxxxxx\n"\ "-----END CERTIFICATE-----\n" #define CERTIFICATE "-----BEGIN CERTIFICATE-----\n"\ "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\n"\ "xxxxxxxxxxxxxxxxxxxxxxxxxxxx\n"\ "-----END CERTIFICATE-----\n" #define PRIVATE_KEY "-----BEGIN RSA PRIVATE KEY-----\n"\ "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\n"\ "xxxxxxxxxxxxxxxxxxxxxxxxxxxx\n"\ "-----END RSA PRIVATE KEY-----\n"\ void setup_wifi(); void setup_mqtt(); void mqtt_connect(); void mqtt_publish_measure(int centimeters);cloud#include <M5StickC.h> #include <WiFi.h> #include <WiFiClientSecure.h> #include <PubSubClient.h> #include "cloud.h" WiFiClientSecure https_client; PubSubClient mqtt_client(https_client); char pub_message[256]; void mqtt_callback (char* topic, byte* payload, unsigned int length) { } void setup_mqtt() { WiFi.begin(WIFI_SSID, WIFI_PASSWORD); while (WiFi.status() != WL_CONNECTED) { delay(500); M5.Lcd.printf("."); } M5.Lcd.println(""); M5.Lcd.println("WiFi connected"); M5.Lcd.printf("IP address: "); M5.Lcd.println(WiFi.localIP()); https_client.setCACert(ROOT_CA); https_client.setCertificate(CERTIFICATE); https_client.setPrivateKey(PRIVATE_KEY); mqtt_client.setServer(CLOUD_ENDPOINT, CLOUD_PORT); mqtt_client.setCallback(mqtt_callback); } void mqtt_connect() { if (!mqtt_client.connected()) { while (!mqtt_client.connected()) { String clientId = "1"; if (!(mqtt_client.connect(clientId.c_str()))) { Serial.println(mqtt_client.state()); delay(5000); } } M5.Lcd.println("MQTT Connected!"); } mqtt_client.loop(); } void mqtt_publish_measure(int centimeters) { memset(pub_message, 0x0, sizeof(pub_message)); sprintf(pub_message, "{\"centimeters\":%d}", centimeters); mqtt_client.publish(CLOUD_TOPIC, pub_message); M5.Lcd.println("MQTT Published!"); }テスト
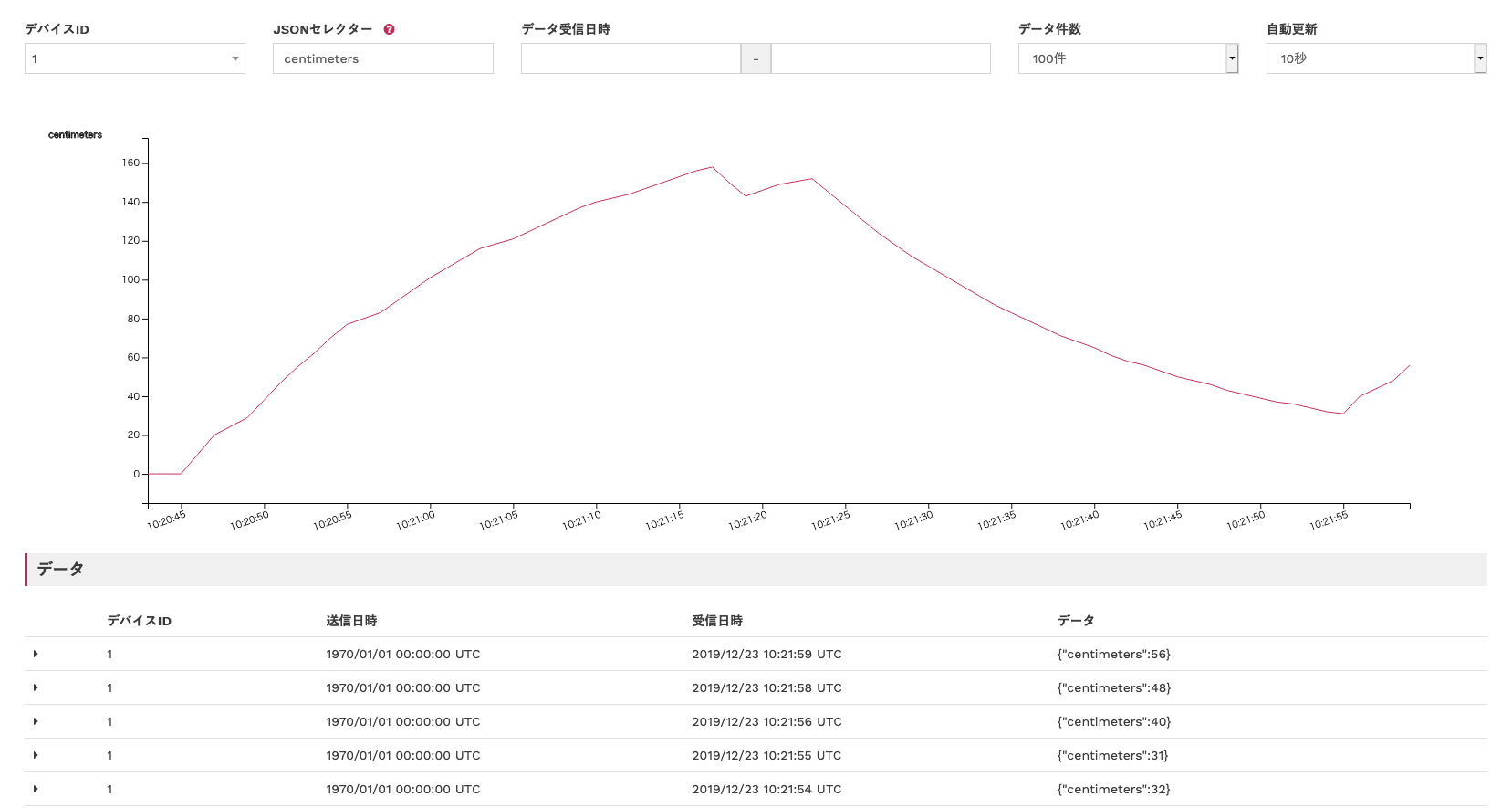
M5StickCの電源をONしてください。
次に「データレコーダー」→「証明書:新規作成」の順でクリックすると、デバイスから送信されたデータを確認できます。
[クラウドの開発・テスト]mockmock→AWS IoTにデータを送る
AWSの設定
以下の記事の「IoT Coreの証明書を作成する」〜「AWS IoT Coreのエンドポイントの確認」までの手順を実施ください。
mockmockでAWS IoT Coreにデータを送るプロジェクトを作成するmockmockの設定
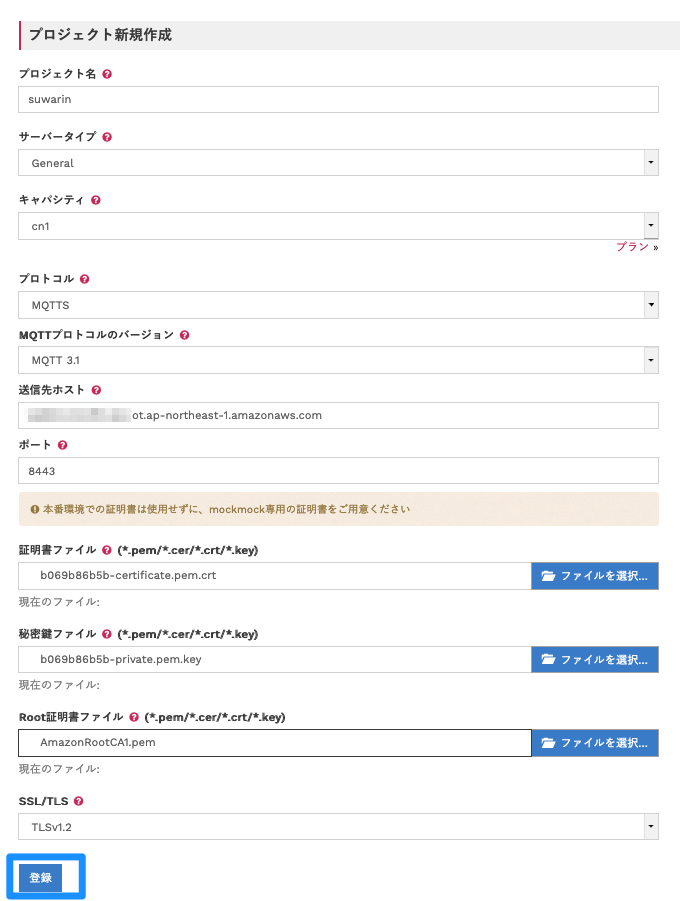
「プロジェクト一覧」→「プロジェクト作成」の順にクリックしてください。
フォームに以下の通り入力して、「登録」をクリックしてください。
「送信先ホスト」や「各種証明書ファイル」は先の手順で確認した内容・ファイルに変更ください。
「リプレイヤー」を作成します。
「リプレイヤーの右側の+ボタン」をクリック後、フォームを以下の通り入力して、「登録」をクリックしてください。
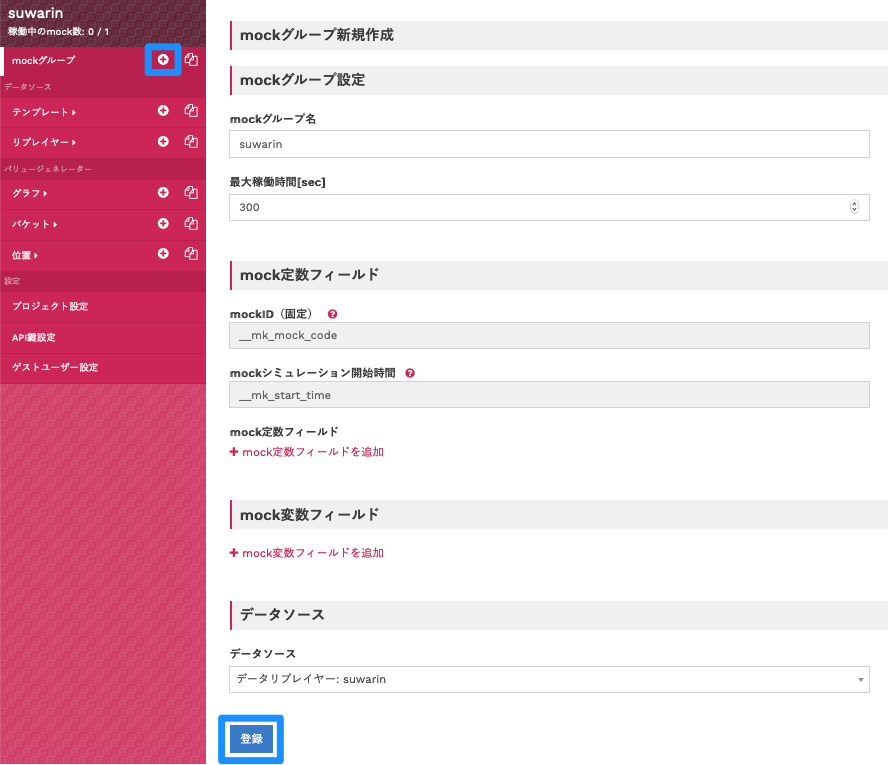
「mockグループ」を作成します。
「mockグループの右側の+ボタン」をクリック後、フォームを以下の通り入力して、「登録」をクリックしてください。
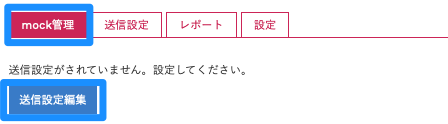
「送信設定」を作成します。
「mock管理」→「送信設定編集」の順にクリックしてください。
以下の通り入力して「登録」をクリックしてください。
「Topic」はデータレコーダーで使用していたエンドポイントに合わせておくと、後々楽に作業を進められます。
テスト
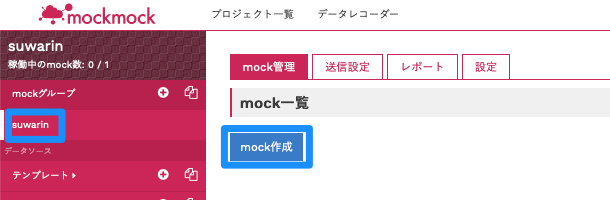
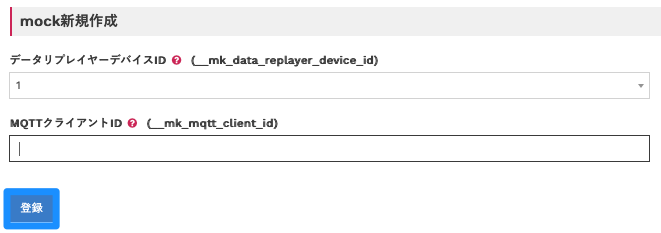
「mockグループ:suwarin」→「mock作成」の順にクリックしてください。
以下の通り入力して「登録」をクリックしてください。
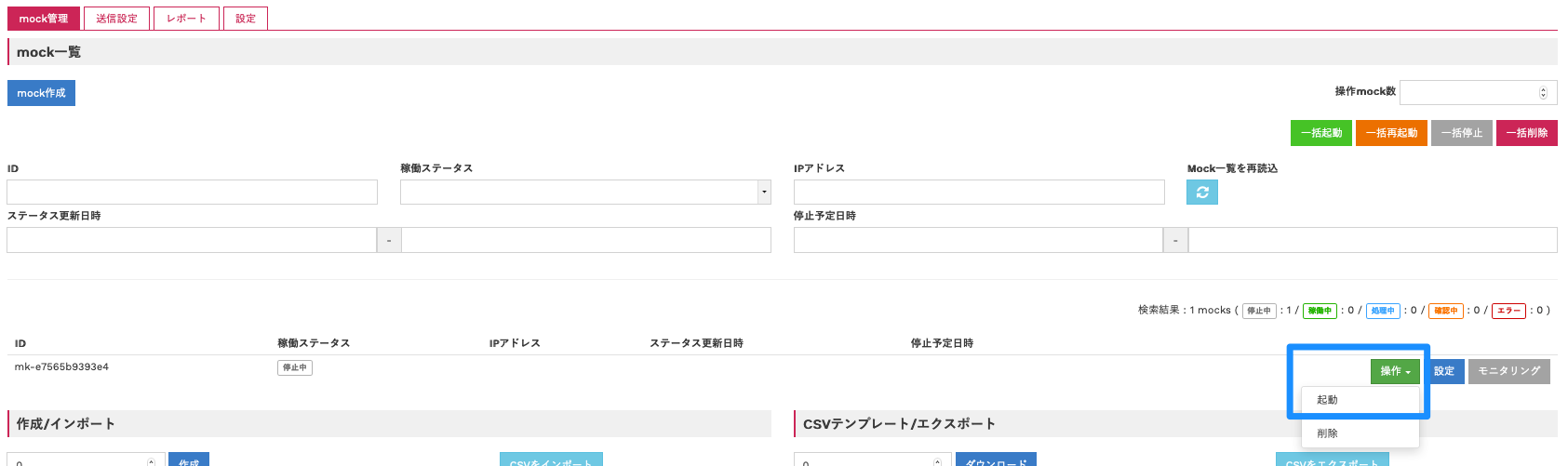
表示されたmockの「操作」→「起動」をクリックします。
AWS IoT Coreの「テスト」をクリックし、以下の通り入力して「トピックへのサブスクライブ」をクリックしてください。
mockが起動すると、データレコーダ内のデータが送信されます。
[クラウドの開発・テスト]DynamoDB, Lambdaの動作確認をする
この手順に関しては本記事のメインの部分から外れるので、簡単に紹介します。
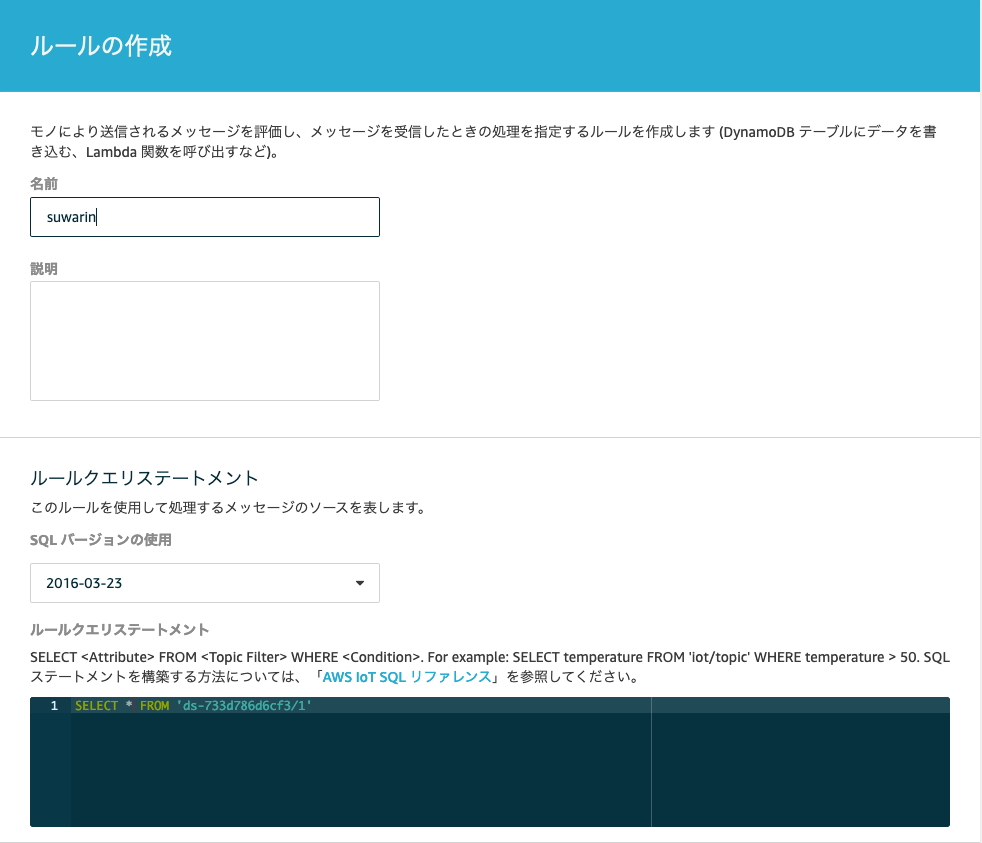
まずAWS IoT Coreのルールを以下の通り作成します。
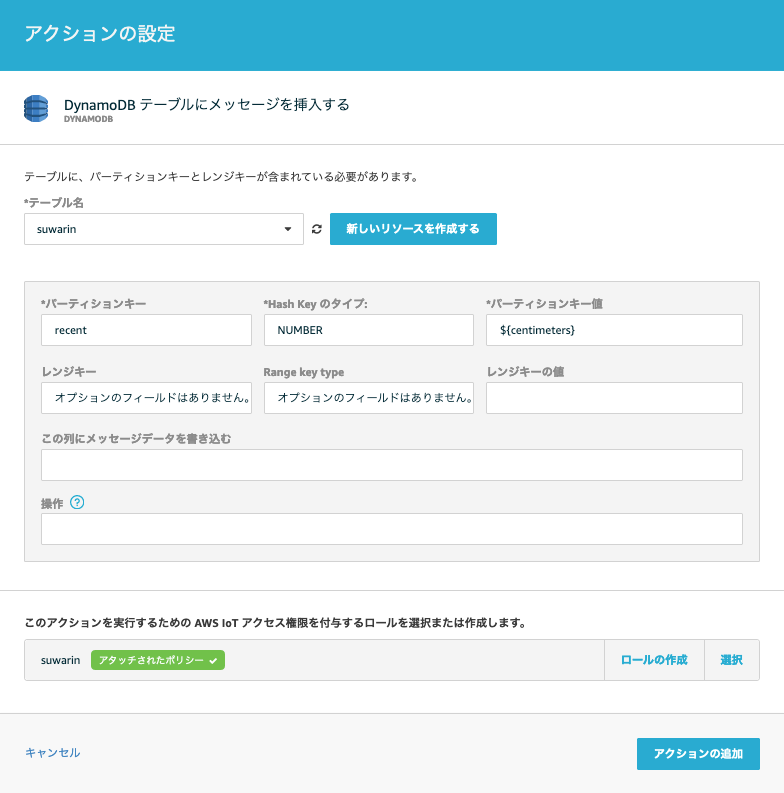
アクションは以下の通りDynamoDBへ値を書き込むこととします。
DynamoDBのコンソールにてストリームを有効にしておきます。
DynamoDBのストリームをトリガーとするLambdaを作成します。
lambda_function.rbrequire 'json' require 'slack-notifier' def lambda_handler(event:, context:) event['Records'].each do |record| next unless record['eventName'] == 'MODIFY' old = record['dynamodb']['OldImage']['payload']['M']['centimeters']['N'].to_f new = record['dynamodb']['NewImage']['payload']['M']['centimeters']['N'].to_f next if sit_down?(old) == sit_down?(new) notifier = Slack::Notifier.new('<WEBHOOK_URLに置き換えてください>') if sit_down?(new) notifier.ping('着席しました') else notifier.ping('離席しました') end end end def sit_down?(centimeters) centimeters.to_f < 100.0 end以上の設定・実装を終えた後、mockmockデータを送信してみます。
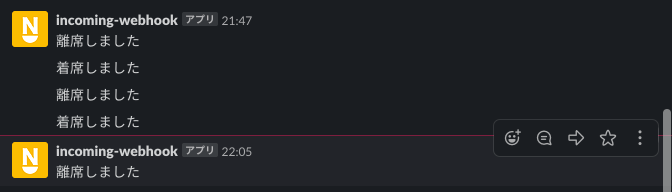
数値が100を超えたタイミング、100を下回ったタイミングでSlackに通知が飛ぶことが確認できます。
[システム統合テスト]M5StickC→AWS IoTにデータを送る
M5StickCのソースコードを変更し、証明書およびエンドポイントをAWS IoT Coreのものに変更すれば
無事IoTシステムが完成です。まとめ
mockmockのDataRecorderを使うことで、クラウドなしでデバイスの動作確認、デバイスなしでクラウドの動作確認を行った上で、システム全体をテストすることができました。
IoT開発においてデバイス・クラウドのテストが不十分な状態で、システム統合テストに突入すると不具合の原因調査に膨大な工数がかかるケースが多いです。
mockmockを活用し段階を踏んでテストすると、早い段階で不具合を検出し原因の特定に要する時間を短縮化できるため、開発工数を大幅に削減することが可能です。ぜひお試しください!











- 投稿日:2019-12-24T11:48:20+09:00
AWSの利用料金をChatworkに通知してくれるバッチをGoで作った
はじめに
AWSの料金を毎日確認しにログインしてコンソールを開くのは面倒…。でも、気がついたら設定が間違っててすごい料金を請求されるなーんてことも。
そんなことが起こる前に、毎日使用料金を通知して把握しておこう!
ということで、Cost ExplorerのSDKを使ってGoでバッチを作成してみました。
AWSの構成
当記事はLambdaにアップするバッチにフォーカスしてます。
実装
通知したいこと
- 昨日の利用料金
- 今月の利用料金(今月1日から昨日までの合計金額) or 今日が1日のときは先月の利用料金
必要なもの
- Chatworkのルームid(トークルームURL:chatwork.com/#!rid********* ←9桁の数字)
- ChatworkのAPIトークン(画面右上の自分の名前 → API設定で発行できます)
気をつけるところ
料金を知るのにもお金がかかります。
Cost Explorerに対して1リクエストあたり 0.01USD かかります。ソースコード
package main import ( "bytes" "fmt" "github.com/pkg/errors" "io/ioutil" "log" "net/http" "net/url" "os" "time" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/costexplorer" "github.com/aws/aws-sdk-go/service/costexplorer/costexploreriface" ) var chatworkClient = ChatworkClient{ APIURL: "https://api.chatwork.com/", Resource: "/v2/rooms/<ルームid>/messages", } // ChatworkClient はチャットワークへ通知するためのクライアントに相当する構造体 type ChatworkClient struct { APIURL string Resource string } // メッセージの通知 func (chatwork ChatworkClient) postMessage(msg string) error { u, _ := url.ParseRequestURI(chatwork.APIURL) u.Path = chatwork.Resource urlStr := fmt.Sprintf("%v", u) data := url.Values{} data.Set("body", msg) fmt.Printf(data.Encode()) client := &http.Client{} r, err := http.NewRequest("POST", urlStr, bytes.NewBufferString(data.Encode())) if err != nil { fmt.Println("HTTPリクエストの生成に失敗しました。date:" + fmt.Sprint(data) + ", urlStr:" + urlStr + ", err:" + fmt.Sprint(err)) return errors.WithStack(err) } r.Header.Add("X-ChatWorkToken", "<APIトークン>") r.Header.Add("Content-Type", "application/x-www-form-urlencoded") resp, err := client.Do(r) if err != nil { fmt.Println("HTTPリクエストに失敗しました。date:" + fmt.Sprint(data) + ", urlStr:" + urlStr + ", err:" + fmt.Sprint(err)) return errors.WithStack(err) } defer resp.Body.Close() contents, _ := ioutil.ReadAll(resp.Body) fmt.Printf("Http Status:%s, result: %s\n", resp.Status, contents) return nil } // コストの取得 func GetCost(svc costexploreriface.CostExplorerAPI, period string) (result *costexplorer.GetCostAndUsageOutput) { // 現在時刻の取得 jst, _ := time.LoadLocation("Asia/Tokyo") now := time.Now().UTC().In(jst) dayBefore := now.AddDate(0, 0, -1) first := time.Date(now.Year(), now.Month(), 1, 0, 0, 0, 0, jst) if now.Day() == 1 { // 月初のときは先月分 first = first.AddDate(0, -1, 0) } nowDate := now.Format("2006-01-02") nowDateP := &nowDate dateBefore := dayBefore.Format("2006-01-02") dateBeforeP := &dateBefore firstDate := first.Format("2006-01-02") firstDateP := &firstDate start := dateBeforeP if period == "Monthly" { start = firstDateP } granularity := aws.String("DAILY") if period == "Monthly" { granularity = aws.String("MONTHLY") } metric := "NetUnblendedCost" // 非ブレンド純コスト metrics := []*string{&metric} timePeriod := costexplorer.DateInterval{ Start: start, End: nowDateP, } // Inputの作成 input := &costexplorer.GetCostAndUsageInput{ Granularity: granularity, Metrics: metrics, TimePeriod: &timePeriod, } // 処理実行 result, err := svc.GetCostAndUsage(input) if err != nil { log.Println(err.Error()) } // 処理結果を出力 log.Println(result) return result } // 処理実行 func run() error { log.Println("--- コスト取得バッチ 開始") log.Println("----- セッション作成") svc := costexplorer.New(session.Must(session.NewSession())) log.Println("----- コスト取得 実行") costDaily := GetCost(svc, "Daily") costMonthly := GetCost(svc, "Monthly") log.Println("----- コスト取得 完了") log.Printf("----- メッセージの通知 実行") err := chatworkClient.postMessage(costDaily.String()) if err != nil{ fmt.Printf("%+v\n", err) return err } err = chatworkClient.postMessage(costMonthly.String()) if err != nil{ fmt.Printf("%+v\n", err) return err } log.Println("--- コスト取得バッチ 完了") return nil } // メイン func main() { lambda.Start(run) }実行結果
2019/12/16に実行してみました。
こちらが1日前(12/15)の利用料金を取得した結果です。期間(TimePeriod)を2019/12/15から2019/12/16で指定しています。料金はTotalの中にあるAmountで、今回だと約0.06USDとなっています。
こちらは当月(2019/12/01~2019/12/15)の合計金額です。指定した期間は2019/12/01から2019/12/16で、費用は約1.35USDという結果が得られました。
解説
コストの取得
今回は、API「GetCostAndUsage」のInputを構成する要素として以下の3つを使用しています。
- Granularity
- Metrics
- TimePeriod
Granularity
Granularityは「粒度」という意味で、どの粒度の期間で取得するのか指定できます。選択肢は以下の3つがあります。
- MONTHLY
- DAILY
- HOURLY
今回はMONTHLYとDAILYを使いました。
Metrics
Metricsは「指標」という意味で、コストをどう計算するかを指定できます。選択肢は以下の7つがあります。
- AmortizedCost
- BlendedCost
- NetAmortizedCost
- NetUnblendedCost
- NormalizedUsageAmount
- UnblendedCost
- UsageQuantity
それぞれのメトリクスの内容はこの記事を参考にしました。
AWS Cost Explorerに渡す、Metricsの値の意味今回は「NetUnblendedCost = ディスカウント適用後(EDP割引等)のコスト」を使っています。
ちなみに、コンソール上で見る場合は、Cost Explorer: コストと使用状況のページの右下、詳細オプション → コストの表示方法 → 非ブレンド純コスト と同額になります。
TimePeriod
Start(集計開始日時)とEnd(集計終了日時)を指定します。
フォーマットは " YYYY-MM-DD "です。なお、Endに指定した日の利用料金は加算されません。
例えば、
Start : 2019-12-01
End : 2019-12-16
とした場合は1日から15日までの料金を取得することになります。通知するベスト時間
最初、朝9時に前日の利用料金を通知するようにしていましたが、ある日、コスト通知用のトークルームを見ると「$ 0」。
昨日は無料キャンペーンだったのかなあ(わくわく)という話になりましたが、そんなことは…なかったです。
明確なコストエクスプローラーの更新時間は書かれていませんが、公式ページでは、「24 時間ごとに少なくとも一度コストデータを更新します。」とのことだったので、夜に通知するほうが正確な金額になると思われます。
ちなみに、私は朝9時に一昨日の利用料金を取得するようにしています。今のところ、それ以降の料金更新はないっぽいです。
おまけ
かわいく通知してみた
上記のままだと取得してきたJSONのまま表示されるので、お花をつけてかわいく整えてみました?
func MakeMassage(costMonthly, costDaily *costexplorer.GetCostAndUsageOutput) string { var msg bytes.Buffer msg.WriteString("(F)" + "AWS使用料金" + "(F)" + "\n\n") msg.WriteString("◆MONTHLY") msg.WriteString(" (" + *costMonthly.ResultsByTime[0].TimePeriod.Start + "~" + *costDaily.ResultsByTime[0].TimePeriod.Start + ")\n") msg.WriteString(" $ " + *costMonthly.ResultsByTime[0].Total["NetUnblendedCost"].Amount + "\n\n") msg.WriteString("◆DAILY") msg.WriteString(" (" + *costDaily.ResultsByTime[0].TimePeriod.Start + ")\n") msg.WriteString(" $ " + *costDaily.ResultsByTime[0].Total["NetUnblendedCost"].Amount + "\n") return msg.String() }処理実行箇所にメッセージ作成を追加し、実行コードを少し変更
log.Println("----- メッセージの作成 実行") msg := MakeMassage(costMonthly, costDaily) log.Println("----- メッセージの作成 完了") log.Printf("----- メッセージの通知 実行") err := chatworkClient.postMessage(msg)実行結果
かわいくなりました?
おわりに
コンソール上だと下2桁しか表示されないですけど、Cost Explorer APIで取得すると下10桁まで表示されるので、コンソール上では0.00USD。でも実際は0.0012345678USDってことも分かるのでいいですよね。
大変だったとこととしては、はじめましてのGo。C言語を昔授業でちょっとやっていたけどポインタから逃げたので、今となってポインタに苦しめられました。
あとは、AWSのSDKを使う時に公式ドキュメントを読んでコードを書くことが大変でした。あまりGoでCostExplorerを使っている記事がなくて、自力では完成させることができず…。SDKの使い方、Goの書き方、とても勉強になりました。
次は藤原さんのQiitaの記事を見ながら、slackに通知できるようにしてみようと思っています!





- 投稿日:2019-12-24T11:40:06+09:00
AWS Lambda/PythonでJSON形式でログを出すベストプラクティス
Lambdaはログを CloudWatch Logs に自動保存しますが、CloudWatch Logs にはJSON形式のログを自動でパースして整形表示したり検索したりする機能があります。是非とも、ログをJSON形式にしたいところです。
しかし、「python lambda logging json」でググって見つかる記事は、いずれも内容に不備があるようでしたので、自分がベストだと思う方法を紹介するのがこの記事です。
お断り
Pythonのログ出力は標準ライブラリの
loggingがスタンダードなので、この記事ではloggingを前提にしています。printを使うべきではない理由・logging の正しい使い方については「ログ出力のための print と import logging はやめてほしい 」という記事が分かりやすいです(文体は辛辣ですけど)
これが(きっと)ベストプラクティスだ!
import logging import json # 冒頭に、独自のフォーマッタの定義と、ルートロガーの設定を書く class JsonFormatter: def format(self, record): return json.dumps(vars(record)) # ルートロガーの設定 logging.basicConfig() # 標準エラーに出力するハンドラーをセット logging.getLogger().handlers[0].setFormatter(JsonFormatter()) # ハンドラーの出力フォーマットを自作のものに変更 # 以降は普通にloggerを取得して処理を関数を書く logger = logging.getLogger(__name__) logger.setLevel(os.environ.get('LOG_LEVEL', 'INFO')) # 余談: 環境変数でログレベルを変更可能にしとくと便利 def lambda_handler(event: dict, context): # ログに付加情報をもたせたいときは、`extra=` に dict を渡す。 # もちろん、 dict は2要素以上でもOK logger.info("sample", extra={"foo": 12, "bar": "Hello World!"})CloudWatch Logsに保存されるログ:
logger.infoの出力がJSONになっています。なお、START RequestId:...などのログはAWS Lambda自体が出しているものなので変更できません。START RequestId: 3ba9c9dd-0758-482e-8aa4-f5496fa49f04 Version: $LATEST { "name": "lambda_function", "msg": "sample", "args": [], "levelname": "INFO", "levelno": 20, "pathname": "/var/task/lambda_function.py", "filename": "lambda_function.py", "module": "lambda_function", "exc_info": null, "exc_text": null, "stack_info": null, "lineno": 23, "funcName": "lambda_handler", "created": 1577152740.1250498, "msecs": 125.04982948303223, "relativeCreated": 64.58139419555664, "thread": 140315591210816, "threadName": "MainThread", "processName": "MainProcess", "process": 7, "foo": 12, "bar": "Hello World!", "aws_request_id": "3ba9c9dd-0758-482e-8aa4-f5496fa49f04" } END RequestId: 3ba9c9dd-0758-482e-8aa4-f5496fa49f04 REPORT RequestId: 3ba9c9dd-0758-482e-8aa4-f5496fa49f04 Duration: 1.76 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 55 MB Init Duration: 113.06 ms一応の解説
(詳しくは公式ドキュメントを参照)
logging.Loggerは階層構造になっているので、全体のフォーマットを変えたいならルートロガー(logging.getLogger())を変更すればOK。logging.basicConfig()でルートロガーにハンドラーがセットされるので、あとは.setFormatter()で独自のフォーマッタをセットします。
.format(record)にはlogging.LogRecordが渡されます。このオブジェクトは諸々の情報を属性として持っているので、vars(record)で取得して、JSONに変換しています。
logger.infoのextra=で渡した値は、LogRecordの属性としてセットされます。ここで、msg,funcNameなどのキーを使うと、本来の値を上書きしてしまいます。
どうしても上書きを避けたい場合は、.makeRecordをオーバーライドした独自のロガーを定義することもできます。
ただ、私はコードが複雑になるので気が進みません。ね、簡単でしょ?
ライブラリを使うべき?
ところで、GithubにはログをJSONにフォーマットするライブラリがいくつも転がっています。
しかし、私はそういったライブラリを使うのはオススメしません。ライブラリを導入すると依存関係が生じ、バージョンアップの手間やセキュリティ上のリスクが生じるからです(2016年の left-pad を思い出せ!)。
上述のように
JsonFormatterはたった3行で書けるので、コードをコピペするのが結局ベストではないかと思います。どっとはらい。
- 投稿日:2019-12-24T11:25:22+09:00
GitLab on Amazon EC2な構成で始めるTerraform × Ansibleハンズオン
はじめに
TerraformとAnsibleを使ってAWSにGitLabを構築してみました。これからTerraform/Ansibleを始めよう思っている方の参考になれば幸いです。前提条件として、AWSのアカウントを持っていてEC2・IAM・VPC等の基本的なAWSリソースの使い方を理解していればスムーズに進めれるかと思います。
目次
- 実行環境
- 実際のコード
- 実行のイメージ
- 環境構築
- Terraformを動かしてみる
- Terraformで実践的なインフラリソースを構築してみる
- Ansibleを動かしてみる
- AnsibleでGitLabを構築する
- リソースのクリーンアップ
- 参考資料
実行環境
macOS Mojave v10.14.5 Terraform v0.11.14 ansible v2.9.2 virtualenv v16.6.2 pip3 v19.1.1 Amazon Linux 2 t2.medium(GitLab環境)実際のコード
GitHubに置いておきます。参考までに。
実行のイメージ
実行のイメージです。ローカルPCにTerraformとAnsibleをインストールしています。TerraformでEC2・VPC等のリソースを構築し、AnsibleでGitLabとそれに必要なモジュールをインストールしています。
環境構築
Terraformのインストール
公式サイトを参考に自分のマシンにあったインストールを行ってください。
Ansibleのインストール
Ansibleは色々なインストール方法があるのですが、今回はvirtualenv上でpip経由でインストールしました。virtuaenvをインスとーしてない方は以下の方法でダウンロードし、virtualenvを有効にしてください。
$ pip3 install virtualenv $ mkdir sample $ cd sample $ virtualenv --no-site-packages ansible $ source ansible/bin/activate # virtualenvが有効になる $ (ansible) ← 有効化された $ pip3 install ansible # インストール $ ansible --version # version確認AWS側でIAMユーザーを作成する
Terraformの実行にはIAMユーザーとそのシークレットキーとアクセスキーが必要になります。ここでは
terraform-userというIAMユーザーを作成しました。また、シークレットキーとアクセスキーも控えておきましょう。(シークレットキーとアクセスキーの取り扱いには気をつけてください。)Terraformを動かしてみる
まず、Terraformから動かしてみようと思います。プロジェクトディレクトリに
terraform.tfvarsというファイルを作成し、IAMユーザーのシークレットキーとアクセスキーを記述します。(Gitなどのバージョン管理システムのの管理対象からは必ず外してください。)terraform.tfvarsaccess_key = "xxxxxxxxxxxx" secret_key = "xxxxxxxxxxxx"次に
variables.tfというファイルを作成し、terraform.tfvarsで定義した情報を変数として定義し、Terraformの実行ファイルから変数を参照できるようにします。variables.tfvariable "access_key" {} variable "secret_key" {}それではいよいよTerraformの実行ファイルを作成し、動かしていきたいと思います。
main.tfを作成し、次のように記述します。regionとamiは任意の値に置き換えてください。main.tfprovider "aws" { profile = "default" region = "ap-northeast-1" access_key = "${var.access_key}" secret_key = "${var.secret_key}" } resource "aws_instance" "example" { ami = "ami-xxxx" instance_type = "t2.micro" }最後に実行していきます。
-auto-approveオプションを入力することで実行前の確認をスキップできます。コマンド実行後AWSのコンソールを確認すると、新しいEC2インスタンスが作成されているはずです。$ terraform init # 初期化 $ terraform apply -auto-approve# 実行EC2が作成されたのが確認できたらリソースを削除していきます。削除コマンドは以下の通りです。
$ terraform destroy -auto-approve Destroy complete! Resources: 1 destroyed.Terraformで実践的なインフラリソースを構築してみる
前のセクションではTerraformを使ってEC2インスタンスを起動しましたが、VPCやセキュリティグループはデフォルトのものを利用しており、キーペアも作成されていないのでSSHログインすることができません。このセクションではより実践的なインフラを構築していきます。
EC2にSSHするための鍵を生成する
EC2はAWS側で作成したキーペアでSSH接続することが多いのですが、ここではキーペアをローカルPCで作成し、その公開鍵を元にEC2を作成していきます。
$ ssh-keygen # 公開認証方式に必要なキーペアを作成 Enter file in which to save the key (/Users/user-name/.ssh/id_rsa): # Enterで省略 Enter passphrase (empty for no passphrase): # Enterで省略 Enter same passphrase again: # Enterで省略ここで作られた公開鍵を元にAWS側でキーペアを作成していきます。公開鍵の内容が必要になるのでcatコマンドでファイルの中身を表示し、控えておきます。
$ cat ~/.ssh/id_rsa.pub ssh-rsa ・・・・・・・・省略次にAWSのコンソール画面でキーペアを作成します。キーペアのインポートから先ほどcatコマンドで出力した公開鍵の中身をコピペします。
これで準備が完了しました。次にTerraformの実行ファイルを作成していきます。この例ではインスタンスサイズに
t2.mediumを使用しています。t2.microインスタンスだとGitLabのインストール要件を満たさずインストールに失敗するからです。main.tfprovider "aws" { profile = "default" region = "ap-northeast-1" access_key = "${var.access_key}" secret_key = "${var.secret_key}" } # VPC resource "aws_vpc" "tf-vpc" { cidr_block = "10.0.0.0/16" instance_tenancy = "default" enable_dns_support = "true" enable_dns_hostnames = "true" tags = { Name = "tf-vpc" } } # internet gateway resource "aws_internet_gateway" "tf-gw" { vpc_id = "${aws_vpc.tf-vpc.id}" } # piblic subnet resource "aws_subnet" "tf-public-subnet" { vpc_id = "${aws_vpc.tf-vpc.id}" cidr_block = "10.0.10.0/24" availability_zone = "ap-northeast-1a" } # route table resource "aws_route_table" "tf-pub-rt" { vpc_id = "${aws_vpc.tf-vpc.id}" route = { cidr_block = "0.0.0.0/0" gateway_id = "${aws_internet_gateway.tf-gw.id}" } } # An association between a route table and a subnet. resource "aws_route_table_association" "tf-public_subnet" { subnet_id = "${aws_subnet.tf-public-subnet.id}" route_table_id = "${aws_route_table.tf-pub-rt.id}" } # EC2 instance resource "aws_instance" "tf-ec2" { ami = "ami-068a6cefc24c301d2" # Amazon linux2 instance_type = "t2.medium" key_name = "${aws_key_pair.tf-sample-key.id}" vpc_security_group_ids = ["${aws_security_group.tf-sg.id}"] subnet_id = "${aws_subnet.tf-public-subnet.id}" associate_public_ip_address = "true" tags = { Name = "tf-ec2" } } # key-pair resource "aws_key_pair" "tf-sample-key" { key_name = "${var.key_name}" public_key = "${file(var.public_key_path)}" } # security group resource "aws_security_group" "tf-sg" { name = "tf-sg" description = "tf test" vpc_id = "${aws_vpc.tf-vpc.id}" ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } }
terraform.tfvarsとvariables.tfにキーペアの名前とローカルにおいてある公開鍵のパス情報を追記します。terraform.tfvars~省略~ key_name = "tf-sample-key" public_key_path = "~/.ssh/id_rsa.pub"variables.tf~省略~ variable "key_name" {} variable "public_key_path" {}それではいよいよ動かしていきます。完了まで数分かかります。
$ terraform applyリソースが作成されたら、試しにEC2インスタンスにssh接続してみてください。
$ ssh -i .ssh/id_rsa ec2-user@<your-ec2-ip> [ec2-user@ip-10-0-10-157 ~]$ここで一点、修正を加えたいと思います。現在作成されているセキュリティグループでは22番ポートのみ解放していますが、あとでブラウザから表示する必要があるので80番ポートを解放したいと思います。また、既存のルールだとアウトバウンドのルールが記載されておらず、Ansibleが外部リポジトリを参照できないので
main.tfの一部を変更します。aws_security_groupのブロックに直接ルールを記載せず、aws_security_group_ruleに外出ししてsecurity_group_id = "${aws_security_group.tf-sg.id}"で紐付けを行っています。また、22番ポートを解放するインバウンドルールは明示的に記述していません。デフォルトで作成されるので明示的に22番ポートを解放するルールを作成してしまうと、エラーになります。なので、ここでは80番ポートの解放ルールのみ記述します。main.tfの一部~省略~ resource "aws_security_group" "tf-sg" { name = "tf-sg" description = "tf test" vpc_id = "${aws_vpc.tf-vpc.id}" } resource "aws_security_group_rule" "http-port" { type = "ingress" from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] security_group_id = "${aws_security_group.tf-sg.id}" } resource "aws_security_group_rule" "out-bound" { type = "egress" from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] security_group_id = "${aws_security_group.tf-sg.id}" }再度コマンドを実行します。
$ terraform applyマネジメントコンソール画面からセキュリティグループのインバウンドルールが変更されていることを確認します。
Ansibleを動かしてみる
Terraformを使ってリソースを作成することができたので次はAnsibleでEC2にGitLabを構築していきます。
まずはカレントディレクトリにansible関連のファイルを保存するansible-projectディレクトリを作成します。$ mkdir ansible-project $ cd ansible-projectAnsibleはコントロールノードからターゲットノードに対してplaybookを実行する際、SSHを利用します。なので、まずはSSHの接続情報が書かれた
ssh_configファイルを作成し、以下を記述します。HostNameは任意の値に書き換えてください。ssh_configHost * StrictHostKeyChecking no UserKnownHostsFile /dev/null Host gitlab HostName ec2-<your ec2 instance>.ap-northeast-1.compute.amazonaws.com User ec2-user IdentityFile ~/.ssh/id_rsa以下のコマンドでファイルを利用してssh接続できます。
$ ssh -F ssh_config ec2-user@ec2-<your-ec2-ip>.ap-northeast-1.compute.amazonaws.comまずはいきなりGitLabを構築せず、Apacheをインストールし、起動するところから始めたいと思います。次のplaybookを用意します。
test.yml- hosts: gitlab become: yes become_user: root tasks: - name: Install http server yum: name: httpd - name: Start http server service: name: httpd state: started enabled: yes同ディレクトリに
hostsファイルを用意し、ターゲット情報を記載します。hosts[gitlab] gitlab次のコマンドでplaybookを実行していきます。
$ ansible-playbook -i hosts test.ymlすると。。。失敗しました。
fatal: [gitlab]: UNREACHABLE! => {"changed": false, "msg": "Failed to connect to the host via ssh: ssh: Could not resolve hostname gitlab: nodename nor servname provided, or not known", "unreachable": true}Ansibleがターゲットノードに接続しようとしていますが、sshコマンドのオプションが明示されておらず失敗しています。
playbook.ymlと同じディレクトリにansible.cfgを作成し、以下の設定を記載します。ansible.cfg[defaults] inventory = hosts retry_files_enabled = False [privilege_escalation] become = True [ssh_connection] control_path = %(directory)s/%%h-%%r ssh_args = -o ControlPersist=15m -F ssh_config -q scp_if_ssh = True気を取り直してもう一度実行してみます。
$ ansible-playbook -i hosts test.yml ~省略~ ok: [gitlab] ____________________________ < TASK [Install http server] > ---------------------------- \ ^__^ \ (oo)\_______ (__)\ )\/\ ||----w | || || ~省略 gitlab : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0確認のためにブラウザにEC2インスタンスのIPアドレスを入力します。以下のように表示されていれば成功です。
AnsibleでGitLabを構築する
それではいよいよ、AnsibleでGitLabを構築していきたいと思います。
playbook.ymlを作成し、以下を記述します。GitLabのインストールの詳細が知りたい方はこちらをご覧ください。playbook.yml- name: Install GitLab hosts: gitlab tasks: - name: Upgrade all packages yum: name: '*' state: latest - name: Install a list of packages yum: name: - curl - golang - policycoreutils - openssh-server - openssh-clients - postfix - vim - wget - "@Development tools" state: latest - name: systemctl enabled sshd & systemctl start sshd systemd: name: sshd state: started enabled: yes - name: systemctl enabled postfix & systemctl start postfix systemd: name: postfix state: started enabled: yes - name: Download gitlab-ce get_url: url: https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.rpm.sh dest: /usr/local/src mode: '0755' become: yes become_user: root - name: Run script.rpm.sh shell: ./script.rpm.sh args: chdir: /usr/local/src become: yes become_user: root - name: Install gitlab-ce yum: name: gitlab-ce state: latest - name: gitlab-ctl reconfigure shell: gitlab-ctl reconfigure become: yes become_user: root実行してみます。実行には数分かかります。また、サーバー上
sudo systemctl status httpdを実行しApacheのプロセス停止させておいてください。新しい、playbookを実行したらApcheのプロセスが停止するのかと思ったのですが、実行状態のままでGitLabにアクセスすることができませんでした。(泣))$ ansible-playbook -i hosts playbook.ymlブラウザからアクセスし、GitLabのトップページが表示されていれば成功です。
リソースのクリーンアップ
EC2のt2.mediumインスタンスは無料枠の対象外なので削除しておきます。また、このハンズオンで利用したTerraform用のIAMユーザーも念の為消しておきましょう。
$ terraform destroy参考資料





- 投稿日:2019-12-24T11:16:10+09:00
AWS IAMユーザにMFA必須ポリシーを当てる
当記事はAWS初心者 Advent Calendar 2019の25日目の記事です。
はじめに
みなさん、コンソールログイン出来る AWS IAMユーザにMFAを当てていますか?
勿論皆さん当てていると思いますが、そのアカウントにいる他のユーザはどうですか?MFAを有効化していないユーザはいましたか? いなかったですか。それなら良かったです。え? 貴方は……そうですか。いましたか。
困りましたね。あ、早速注意しに行くのですね。ふむふむ、素直にMFAを設定してくれましたか。それは良かった。後は……それはお客様のIAMユーザですね。slackでお願いしますか? でも10人全員に説明するのは大変だし。あ、その人は中々連絡が付かない人ですね。
お久しぶりです。あの後、無事全員のMFAを設定出来ましたか? 全員設定してくれたけど、またMFA設定されてないユーザが作成された? 困りましたね。hereをつけて注意喚起でもしてみますか?MFAを設定しないと何も操作出来ないようにする
ちょっと待ってください。そんなに胃をキリキリさせて周囲のモラルを恨まなくても済む方法がありますよ。
試しに、テストユーザを作成して、admin権限と以下のポリシーをアタッチしてみてください。テストユーザは[AWS マネジメントコンソールへのアクセス]にチェックを付けてください。
ユーザ>アクセス権限>インラインポリシーの追加>JSONタブforce_mfa_policy.json{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:EnableMFADevice", "iam:ResyncMFADevice", "iam:CreateVirtualMFADevice", "iam:ListMFADevices", "iam:GetUser", "iam:ChangePassword", "iam:DeleteVirtualMFADevice" ], "Resource": [ "arn:aws:iam::*:user/${aws:username}", "arn:aws:iam::*:mfa/*" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "iam:ListUsers", "iam:ListVirtualMFADevices", "iam:GetAccountPasswordPolicy" ], "Resource": "*" }, { "Effect": "Deny", "NotAction": [ "iam:ListUsers", "iam:ListVirtualMFADevices", "iam:ListMFADevices", "iam:EnableMFADevice", "iam:ResyncMFADevice", "iam:DeleteVirtualMFADevice", "iam:CreateVirtualMFADevice", "iam:DeactivateMFADevice", "iam:ChangePassword", "iam:CreateLoginProfile", "iam:DeleteLoginProfile", "iam:GetLoginProfile", "iam:UpdateLoginProfile" ], "Resource": "*", "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } } }, { "Effect": "Deny", "Action": [ "iam:EnableMFADevice", "iam:ResyncMFADevice", "iam:DeleteVirtualMFADevice", "iam:CreateVirtualMFADevice", "iam:DeactivateMFADevice", "iam:ChangePassword", "iam:CreateLoginProfile", "iam:DeleteLoginProfile", "iam:GetLoginProfile", "iam:UpdateLoginProfile" ], "NotResource": [ "arn:aws:iam::*:mfa/${aws:username}", "arn:aws:iam::*:user/${aws:username}" ], "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } } } ] }次に、このテストユーザでログインしてみてください。とりあえず、Lambdaでも触ってみましょうか。
Lambda>関数
アクセスがブロックされましたね。これは許可よりも明示的な拒否が優先されるというIAMの特性の為です(詳細はこちら(公式ドキュメントに飛びます))
次に、IAMユーザコンソールにアクセスしてみてください。テストユーザ名を選択し、MFAの設定を行ってみましょう。MFAの設定は許可されている筈です。
IAM>ユーザー>テストユーザ>認証情報>MFAデバイスの割り当て>管理>仮想MFAデバイス
エラーが出ますが、気にせず進みます。
作成したテストユーザの概要でもエラーが出ますが、MFAの設定は出来ますので、MFAを設定しましょう。
ちなみに、他のユーザのMFAを設定しようとすると、以下のようなエラーが出力されます。これは、自分のMFAのみ設定出来るようにポリシーで制限している為です。
設定出来ましたか? それでは一度ログアウトし、再ログインしてください。ではもう一度Lambdaを触ってみましょう。
無事に出来ましたね。
これは、MFAを設定したかどうかではなく、"MFAを使ってログインしたかどうか"を判定している為です。
MFA強制ポリシーとCLI
やりましたね! このポリシーでグループを作り、全員を追加すればもう安心です!
……あれ? どこからか悲鳴が聞こえてきました。CLIが叩けない???$ aws s3 ls --profile mfa_test An error occurred (AccessDenied) when calling the ListBuckets operation: Access Deniedこのポリシーを適用すると、CLIを叩くときにもMFAを使わないといけなくなってしまいます。なので、トークンを取得し、それをつけてCLIを叩かないといけないので、気をつけてください。
試しにインラインポリシーで設定したMFA強制ポリシーを削除してみましょう。
無事にバケット一覧が出力されましたね。なので、このMFA必須ポリシーを使用するときは、コンソールログインとCLI用のアカウントを分けるか、CLIを叩くときにトークンを取得し使用する必要がありますので気をつけてください。
CLIを叩くときにトークンを取得し使用する方法も教えてください

要望があったので公式ドキュメントのリンクを貼っておきます(手抜き)
https://aws.amazon.com/jp/premiumsupport/knowledge-center/authenticate-mfa-cli/参考
当記事を書くにあたって参考にさせていただきました。ありがとうございます。
http://blog.serverworks.co.jp/tech/2019/04/02/mysecuritycredentials/
https://qiita.com/n-ishida/items/8198da745a957e8ebdaa
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/tutorial_users-self-manage-mfa-and-creds.html#tutorial_mfa_step1






- 投稿日:2019-12-24T10:41:09+09:00
Visual Studio Code でAWS上のコード開発
概要
社内からAWSの踏み台EC2インスタンスを経由しデプロイ先のEC2インスタンスに接続するような環境で開発を行っています。社内の開発マシン上のVisual Studio Code でデプロイ先のEC2インスタンスを直接触ることができたので、備忘録として残します。
環境
開発マシン(社内のプロキシ環境下):Windows10
踏み台EC2インスタンス:Linux
デプロイ先EC2インスタンス:Linux手順
- 開発マシンにVisual Studio Code のインストール
https://code.visualstudio.com/download
- Remote - Development(SSH) プラグインのインストール
https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.vscode-remote-extensionpack
- 開発マシンでユーザー環境変数の設定
HTTP_PROXY_USER 社内プロキシの認証ユーザー名
HTTP_PROXY_PASSWORD 社内プロキシの認証パスワード
- .ssh/configを開発マシンの任意の場所に作成
Host 踏み台EC2インスタンスの名前(任意) HostName インスタンスのIPアドレス User ec2-user Port 22 IdentityFile パス/pemキー(開発マシンのどこかに置いておく) # 社内プロキシを経由 ProxyCommand C:/Program Files/Git/mingw64/bin/connect.exe -H proxy.example.com:port %h %p Host デプロイ先EC2インスタンスの名前(任意) HostName インスタンスのIPアドレス User ec2-user Port 22 IdentityFile パス/pemキー(開発マシンのどこかに置いておく) ProxyCommand ssh -W %h:%p 踏み台インスタンスの名前- VSCode から接続
作成した.ssh/configを選択して接続する。途中で、"Continue"のポップアップが出たら、Continueを選択して進める。

接続できた。
これでデプロイ先インスタンスのファイルを直接編集できるようになりました。

- 投稿日:2019-12-24T10:15:03+09:00
AWS re:Invent 2019 – Healthcare and life sciences industry recap 和訳してみた
はじめに
2019年12月19日に、David Niewolny 氏と Kelli Jonakin 氏が掲載した 「AWS re:Invent 2019 – Healthcare and life sciences industry recap」の記事を翻訳し、まとめてみました。
■本記事リンク
AWS re:Invent 2019 – Healthcare and life sciences industry recap
HCL に関する新情報トップ5
AWS における HCL(Healthcare and life sciences)関連の新情報トップ5を紹介していきたいと思います。
1. Amazon Transcribe Medical
- 医療スピーチをテキストに翻訳
- 医師が効率的に臨床文書を作成可能
- 患者へのフィードバックがより効率的に
2. AWS Data Exchange
- クラウド内にあるサードパーティのデータ検索や利用が簡単に実現可能
- 製薬会社、医療提供者、そして健康保険会社は臨床試験の計画や保険制度の構築が簡単に実現可能
3. Amazon SageMaker
Amazon SageMaker では HCLS 関連で以下の3つの情報が発表されました。
Amazon SageMaker Studio
- 機械学習用の完全に統合された開発環境
- モデルの構築、トレーニング、デバッグ、トラッキングをプログラム化
Amazon SageMaker Notebooks
- 数秒で機会学習ノートブックを立ち上げ可能
- ワンクリックでノートブックの共有も可能
Amazon SageMaker Debugger
- リアルタイムで機械学習モデルの解析とデバックが可能
- トレーニングモデルにおける複雑な問題を自動的に判別可能
4. AWS Outposts
- フルマネージドサービス
- AWS のインフラストラクチャとサービスをオンプレミスで実行可能なハイブリッドエクスペリエンスを実現
- オンプレ環境で解析や機械学習 AWS サービスをヘルスマネジメントシステムに利用可能
5. Amazon Kendra
- 非常に正確で簡単に使用できるエンタープライズ
- 強力な自然言語の検索機能を駆使して、膨大な情報の中から必要な情報を見つけることが可能
HCLS に関連する重要サービスの情報
Amazon EC2 Inf1 Instances
- 機械学習推論アプリケーションをサポートするために新規に構築された新しいインスタンス
- Amazon EC2 G4インスタンスよりも、推論あたり最大3倍高いスループットと最大40%低いコストを提供
Amazon Braket
- フルマネージドサービスで、一箇所にある複数の量子ハードウェアプロバイダをコンピュータを使って実験が可能
- 将来の計画に向け、量子コンピューティングハードウェアを探索、評価、および実験することで経験をつむことが可能
Amazon Connect & Contact Lens for Connect
- Amazon Connect は低価格で顧客にサービスを提供することができるオムニチャネルクラウドコンタクトセンター
- Contact Lens for Amazon Connect は ML 解析機能を統合することでAmazon Connect の機能を拡大
AWS Nitro Enclaves
- 隔離されたコンピュータ環境を構築可能
- ヘルスケアやバイオファーマ、ゲノミクスにおける個人を特定できる情報(PII)などのデータをセキュアに保護
AQUA for Amazon Redshift
- 新しい分散型ハードウェア
- Redshift を他のクラウドデータウェアハウスよりも最大10倍高速で実行可能
AWS Identity and Access Management Access Analyzer
- AWSアカウントの外部からアクセスできるリソースを識別可能な包括的な結果を生成
- 最高レベルのセキュリティ保証と継続的な監視を提供
- 重要なヘルスケア、およびライフサイエンスデータに不適切にアクセスされないようユーザで権限を調整
関連動画
ライフサイエンス関連の動画
- Leadership Session: Transforming the Pharma Value Chain
- Digital Therapeutics and Patient Personalization
- Enhancing Clinical Trials with Machine Learning
- Data Lakes Reimagined: Efficiency and Innovation at Bristol-Myers Squibb
- Labs of the Future in Life Sciences
- Modernizing Pharma Manufacturing with IoT and AI/ML
- Merck Drives Innovation with a ‘real-world data exchange’ on AWS
- Creating Life at Scale with AWS: How Ginkgo Bioworks Makes Organisms
- Learn How Genomics Medicine Ireland Achieves High Performance in its Databases
ヘルスケア関連の動画
おわりに
AWS re:Invent 2019 – Healthcare and life sciences industry recap の翻訳まとめは以上となります。
ヘルスケア関連で AWS サービスの利用を考えている方、ぜひこちらの本記事で紹介されているサービスを利用してみて下さい。

- 投稿日:2019-12-24T09:21:32+09:00
S3のパブリック公開はパブリックじゃない時もあるから気をつけろ!
この投稿はGlobal Mobility Serviceのアドベントカレンダーの25日目です。
AWSでの今年の失敗を振り返りたいと思います。
S3のパブリック公開でやらかしました。要約
S3のバケットポリシーによるパブリック公開はオブジェクトの権限によってパブリックじゃない時もあるので気をつけよう
失敗について
失敗までの経緯
S3のパブリック公開を調べてみると公式ドキュメントで以下の内容が見つかります。
匿名ユーザーへの読み取り専用アクセス許可の付与
次のポリシー例では、任意のパブリック匿名ユーザーに s3:GetObject アクセス許可を付与します。(これによって許可されるアクセスとオペレーションの一覧については、「ポリシーでのアクセス許可の指定」を参照してください。) このアクセス許可はオブジェクトデータを誰でも読み取り可能にするので、バケットをウェブサイトとして設定し、バケット内のオブジェクトをすべての人が読み取れるようにする場合に便利です。
これを見て、以下のようなバケットポリシーをパブリック公開したいバケットに設定しておけば大丈夫と思ってしまいました。
パブリック公開のバケットポリシー例{ "Version":"2012-10-17", "Statement":[ { "Sid":"PublicRead", "Effect":"Allow", "Principal": "*", "Action":["s3:GetObject"], "Resource":["arn:aws:s3:::examplebucket/*"] } ] }ちなみに、このバケットポリシーを設定するとAWSコンソール上でパブリックであることがアピールされるので、なんとなくこれで大丈夫だと思ってしまいます。
失敗したケース
普段利用しているAWS環境はマルチアカウントになっています。
本ケースでは、以下のように別アカウント間でS3にオブジェクトを配置するという流れでした。
BアカウントからAアカウントのバケットにPutObjectするのに、以下のようなバケットポリシーを適用しました。
特定のロールにPutObjectを許可するポリシーです。パブリック公開と別アカウントからPutObjectを許可するバケットポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::hi1280-public/*" }, { "Sid": "", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::012345678901:role/AAccountAccessRole" }, "Action": "s3:PutObject", "Resource": "arn:aws:s3:::hi1280-public/*" } ] }あとは、Bアカウントの環境からAWS CLIを使ってPutObjectをするだけの簡単なお仕事だと思って、オブジェクトを配置して安心していました。
が、のちに公開したはずのオブジェクトが見れないという連絡が来て焦りました。実はこのようなケースの場合、PutObjectでオブジェクトを置いてもパブリック公開されません。
その当時は全く見ていなかったのですが、公式ドキュメントにちゃんと書かれていました。注記
バケットとオブジェクトの所有者が同じ場合、オブジェクトへのアクセスは、バケットコンテキストで評価されるバケットポリシーで許可することができます。つまり、バケットポリシーのみでパブリック公開できるのは、バケットが存在するAWSのアカウントと同じユーザやロールがオブジェクトを配置した時のみでした。
どうすれば良いのか
さらにこのような記述があります。
所有者が異なる場合、オブジェクトの所有者はオブジェクト ACL を使用してアクセス許可を付与する必要があります。
AWSのアカウントが異なる場合は、オブジェクトを配置したユーザやロールがACLでオブジェクトに対してアクセス権限を付与しなければいけなかったのです。
AWS CLIを使う場合、以下のコマンドです。
$ aws s3api put-object-acl --bucket bucket-name --key my_object --acl public-readこれで無事にオブジェクトをパブリック公開することができます。
まとめ
油断大敵。確認を怠らないようにしなければと思いました。
皆様におかれましては、このような失敗が起きないようにS3におけるアクセス権限には十分にお気をつけください。おわりに
AWSはやっぱりよく分からないので色々学びあえるエンジニアを募集しています。


- 投稿日:2019-12-24T07:37:52+09:00
PostgreSQLパーティショニングのTableau、DBeaver、Glue Crawlerでの対応状況調査
PostgreSQLの2種類のパーティショニングについて、AWSのRDSで作成し、ツールで接続してみて対応状況を調べました。
2種類のパーティショニング
- テーブル継承によるパーティショニング
- 宣言的パーティショニング
試したツール
- Tableau
- DBeaver
- AWS Glue Crawler
- AWS Redshift Federated Query
PostgreSQLのバージョンは11.4です。最新でない11.4を選んだのは、試した時点でRedshift Federated Queryが対応していた最新バージョンがそれだったためです。
2種類のパーティショニング
テーブル継承によるパーティショニングは、バージョン8.1からのもので、文字通りテーブルの継承を使って無理やりパーティショニングを実現するイメージです。レコード挿入時のパーティション振り分けは、トリガ関数を手動で定義することで実現します。
宣言的パーティショニングは、バージョン10からのもので、パーティションの振り分けルールを宣言的に書けるので、テーブル継承よりは運用が楽です。
継承による柔軟性を活用したい場合はテーブル継承しかありませんが、そうでない限りは宣言的なパーティショニングのほうがよさそうです。
テーブルのパーティショニング - PostgreSQL 11.5文書
まずはパーティショニングされたテーブルを作成します。
宣言的パーティショニング
テーブル作成手順
- 親テーブルを
CREATE TABLEにPARTITION BY句を付与して作成- 子テーブルを
CREATE TABLEにPARTITION OF句を付与して作成create table sample3 ( timestamp timestamp, data text ) partition by range(timestamp); create index on sample3 (timestamp); create table sample3_201911 partition of sample3 for values from ('2019-11-01') to ('2019-12-01'); create table sample3_201912 partition of sample3 for values from ('2019-12-01') to ('2020-01-01'); insert into sample3 (timestamp, data) values ('2019-11-16 00:00:00', 'aaa'); insert into sample3 (timestamp, data) values ('2019-12-16 00:00:00', 'bbb');継承によりパーティショニング
テーブル作成手順(宣言的パーティショニングより手順が多いです)
- 親テーブルを作成
- 子テーブルを
CREATE TABLEにINHERITS句を付与して作成- レコードをパーティションに振り分けるトリガー関数を
CREATE FUNCTIONで定義- 親テーブルに上記トリガー関数をトリガーとして
CREATE TRIGGERで設定create table sample4 ( timestamp timestamp, data text ); create table sample4_201911 ( check (timestamp >= '2019-11-01' and timestamp < '2019-12-01') ) inherits(sample4); create index on sample4_201911 (timestamp); create table sample4_201912 ( check (timestamp >= '2019-12-01' and timestamp < '2020-01-01') ) inherits(sample4); create index on sample4_201912 (timestamp); CREATE OR REPLACE FUNCTION sample4_insert_trigger() RETURNS TRIGGER AS $$ BEGIN IF ( NEW.timestamp >= DATE '2019-11-01' AND NEW.timestamp < DATE '2019-12-01' ) THEN INSERT INTO sample4_201911 VALUES (NEW.*); ELSIF ( NEW.timestamp >= DATE '2019-12-01' AND NEW.timestamp < DATE '2020-01-01' ) THEN INSERT INTO sample4_201912 VALUES (NEW.*); ELSE RAISE EXCEPTION 'Date out of range. Fix the sample4_insert_trigger() function!'; END IF; RETURN NULL; END; $$ LANGUAGE plpgsql; CREATE TRIGGER insert_sample4_trigger BEFORE INSERT ON sample4 FOR EACH ROW EXECUTE FUNCTION sample4_insert_trigger(); insert into sample4 (timestamp, data) values ('2019-11-16 00:00:00', 'aaa'); insert into sample4 (timestamp, data) values ('2019-12-16 00:00:00', 'bbb');Tableau
TableauをPostgreSQLに接続してみます。
Tableauの画面では、Table一覧には宣言的パーティショニング(sample3)の親テーブルが見えず、子テーブルが見えます。継承によるパーティショニング(sample4)は親も子も見えています。
宣言的パーティショニング(sample3)もCustom SQLを書けば親テーブルをデータソースとして指定することは可能でした。
バージョンは
Tableau Desktop Professional Edition 2019.4.0
です。DBeaver
DBeaverはデータベースに接続してクエリを投げれるデスクトップアプリです。DBeaverをPostgreSQLに接続してみます。
DBeaverでは宣言的パーティショニング(sample3)は親テーブルのみが見えます。継承によるパーティショニング(sample4)は親も子も見えています。
継承はパーティショニング以外の目的でも使われる可能性があると考えると、親と子の両方が出てくるのは合理的で、一方宣言的パーティショニングはパーティショニングだけが目的なので、親が一覧に出てこれば十分なケースが多く、DBeaverのパーティショニングの対応状況はよさそうに見えます。
バージョンは
DBeaver 6.3.0
です。AWS Glue Crawler
AWSのGlue CrawlerでPostgreSQLに接続してData Catalogを作成してみました。
作成されたData Catalogのテーブルはこちらです。Tableauと同じ状況で、宣言的パーティショニングの親テーブルはクロールできませんでした。
2019/12/21時点です。
Amazon Redshift Federated Query
AWSのRedshiftのFederated QueryはRedshiftに外部スキーマを定義することでPostgreSQLに存在するデータに対してもRedshiftにクエリを投げれるようになる機能です。
Federated QueryとPostgreSQLのパーティショニングの組み合わせを試しましたが、Federated QueryはまだAWSのプレビュー機能でブログ等には書いちゃいけないらしいので、伏せておきます。早く使いたいですね。



- 投稿日:2019-12-24T06:22:39+09:00
GKEとEKSをいじってみる【Kubernetes】
この記事はうるる Advent Calendar 2019 24日目の記事です。
TL; DR
Kubernetesはコンテナオーケストレーションツールとして有名なミドルウェアですが、マネージド型のKubernetesってどこで使うのがいいんだろうか?とお悩みの方へ参考になれば幸いです。
ちなみに筆者はEKSでAPIをガッと集めたものを本番化したことが1度だけある程度のレベル感です。
運用自体は1ヶ月ほどだったので世の皆様ほどつらみなどは理解しておりません。
GKEに関しては完全に個人で遊ぶレベルなのでお察しです。それらを踏まえた上で生暖かく見守りつつ読んでいただければと思います。Kubernetesとは
この辺りはもう既に素晴らしい記事がQiita上にいっぱいあるので、特に詳しくは説明しません。
要はコンテナをよしなにしてくれる素敵なツールであるということを理解してもらえば十分です。余談としては今はCNCFが管理していますが、元々Googleが社内で利用していたBorgというクラスターマネージャーを元に開発されたものです。
興味ある方はBorgについての論文があるので見てみると面白いと思います。
https://research.google/pubs/pub43438/この時点で既にGKEのがいいんじゃないか臭がしてくるのはお約束です。
EKSとは
Amazon Elastic Kubernetes Service (Amazon EKS) は、独自の Kubernetes コントロールプレーンを立ち上げたり維持したりすることなく、AWS で Kubernetes を簡単に実行できるようにするマネージド型サービスです。
公式リファレンス : https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/what-is-eks.html
要はAWSのマネージドなKubernetesサービスのことです。
マネージドサービスのお約束なのですが、制限が多かったりブラックボックスな部分が多かったりで中々ワガママなやつです。
Kubernetes自体学習コストが高いのですが、そこにAWS独自のものが入ってくるので中々大変にです。
またECSとの住み分けも判断に迷うことが多いです。メリット
- 既にAWS上でサービスを展開している場合は導入がしやすい
- Infrastructure as Codeが進んでいる場合は周辺リソース含めて管理が容易
デメリット
- 学習コストが高い
- ECSとの住み分けが難しい
GKEとは
Kubernetes Engine(GKE)は、コンテナ化されたアプリケーションをデプロイするための、本番環境に対応したマネージド型環境です。
公式リファレンス : https://cloud.google.com/kubernetes-engine/?hl=ja
こちらもEKS同様GCPのマネージドなKubernetesサービスです。
前述の通り、コンテナ技術自体Googleが長年培ってきたものなので、入門はしやすいと思います。
反面ネットワーク周りなどブラックボックスが多く、インフラ寄りの方はお任せするのは物足りないと思います。
マネージドも割と充実している印象なのですが、やはり学習コストは高いと思います。メリット
- サポートが手厚い
- Stackdriverがネイティブで使える
デメリット
- 学習コストが高い
- Cloud Runとの住み分けに迷う
EKSへのデプロイ
先日のre:Invent 2019にてEKS on FargateがGAとなりましたが、今回は通常のEC2にデプロイしていきます。
公式にもあるゲストプックアプリケーションのデプロイをしていきます。リポジトリ : https://github.com/uluru-kinoshitat/advent-calendar-2019-2
リソース作成
今回はGKEにもデプロイをするのでTerraformでコードを書いていきます。
eks.tf// EKS Cluster cofigure resource "aws_eks_cluster" "advent" { name = "${var.service_name}-${var.env}-k8s" role_arn = aws_iam_role.eks_assume_role.arn vpc_config { subnet_ids = [for subnets in aws_subnet.advent_public : subnets.id] security_group_ids = [aws_security_group.advent_eks.id] } tags = { Name = "${var.service_name}-${var.env}-igw" Service = var.service_name ENV = var.env } } // Security Group configure for EKS Cluster resource "aws_security_group" "advent_eks" { name = "${var.service_name}-${var.env}-eks" description = "${var.service_name} ${var.env} eks security group" vpc_id = aws_vpc.advent_eks.id tags = { Name = "${var.service_name}-${var.env}-eks-sg" Service = var.service_name ENV = var.env } } resource "aws_security_group_rule" "advent_eks_local" { type = "ingress" from_port = 443 to_port = 443 protocol = "tcp" security_group_id = aws_security_group.advent_eks.id cidr_blocks = var.own_ip } resource "aws_security_group_rule" "advent_eks_ingress" { type = "ingress" from_port = 1025 to_port = 65535 protocol = "tcp" security_group_id = aws_security_group.advent_eks.id source_security_group_id = aws_security_group.k8s_node.id } resource "aws_security_group_rule" "eks_2node_ingress_443" { type = "ingress" from_port = 443 to_port = 443 protocol = "tcp" security_group_id = aws_security_group.advent_eks.id source_security_group_id = aws_security_group.k8s_node.id } resource "aws_security_group_rule" "eks_default_egress" { type = "egress" from_port = 0 to_port = 0 protocol = "-1" security_group_id = aws_security_group.advent_eks.id cidr_blocks = ["0.0.0.0/0"] } resource "aws_security_group_rule" "eks_2node_egress" { type = "egress" from_port = 1025 to_port = 65535 protocol = "tcp" security_group_id = aws_security_group.advent_eks.id source_security_group_id = aws_security_group.k8s_node.id } resource "aws_security_group_rule" "eks_2node_egress_443" { type = "egress" from_port = 443 to_port = 443 protocol = "tcp" security_group_id = aws_security_group.advent_eks.id source_security_group_id = aws_security_group.k8s_node.id }worker.tf// EKS Node cofigure resource "aws_eks_node_group" "k8s_node" { cluster_name = aws_eks_cluster.advent.name node_group_name = "advent-k8s" node_role_arn = aws_iam_role.k8s_node.arn subnet_ids = [for subnets in aws_subnet.advent_public : subnets.id] scaling_config { desired_size = 1 max_size = 3 min_size = 1 } disk_size = 20 instance_types = ["t2.small"] depends_on = [ aws_iam_role_policy_attachment.managed_AmazonEKSWorkerNodePolicy, aws_iam_role_policy_attachment.managed_AmazonEKS_CNI_Policy, aws_iam_role_policy_attachment.managed_AmazonEC2ContainerRegistryReadOnly, ] tags = { Name = "${var.service_name}-${var.env}-k8s-node" Service = var.service_name ENV = var.env } } // Security Group configure for EKS Node resource "aws_security_group" "k8s_node" { name = "${var.service_name}-${var.env}-k8s-node" description = "${var.service_name} ${var.env} k8s node security group" vpc_id = aws_vpc.advent_eks.id tags = { Name = "${var.service_name}-${var.env}-k8s-node-sg" Service = var.service_name ENV = var.env } } resource "aws_security_group_rule" "k8s_node_ingress" { type = "ingress" from_port = 0 to_port = 65535 protocol = "-1" self = true security_group_id = aws_security_group.k8s_node.id } resource "aws_security_group_rule" "control_plane_ingress" { type = "ingress" from_port = 1025 to_port = 65535 protocol = "tcp" security_group_id = aws_security_group.k8s_node.id source_security_group_id = aws_security_group.advent_eks.id } resource "aws_security_group_rule" "control_plane_ingress_443" { type = "ingress" from_port = 443 to_port = 443 protocol = "tcp" security_group_id = aws_security_group.k8s_node.id source_security_group_id = aws_security_group.advent_eks.id } resource "aws_security_group_rule" "k8s_node_egress" { type = "egress" from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] security_group_id = aws_security_group.k8s_node.id }VPCなどはリポジトリに用意してありますので割愛します。
ポイントはcontrol planeとワーカーノードから相互に疎通できるよう必要なポートを開けてあげる必要があるところです。ConfigMap
ざっとリソースができたら下記コマンドにてEKS用に
kubeconfigを作成します。$ aws eks --region us-east-1 update-kubeconfig --name advent-k8s-sand-k8s Added new context arn:aws:eks:us-east-1:123456789012:cluster/advent-k8s-sand-k8s to /Users/user/.kube/config手動で作ることももちろん可能ですが、パスを指定したりのちょっとめんどくさいので今回は普通にやりました。
outputにて出力したconfig_map_aws_authを適当なyamlファイルに吐き出します。config_map_aws_auth.yamlapiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: arn:aws:iam::123456789012:role/advent-k8s-sand-k8s-nodes username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodeskubectlコマンドにてAWSの作成済みリソースと連携します。
$ kubectl apply -f config_map_aws_auth.yaml configmap/aws-auth createdここまで実施するとkubectlにてリソース状態を確認できます。
$ kubectl get nodes --watch NAME STATUS ROLES AGE VERSION ip-192-168-179-153.ec2.internal NotReady <none> 8s v1.14.8-eks-b8860f ip-192-168-73-176.ec2.internal NotReady <none> 11s v1.14.8-eks-b8860f NAME AGE ip-192-168-73-176.ec2.internal 20s ip-192-168-73-176.ec2.internal 20s ip-192-168-179-153.ec2.internal 20s ip-192-168-179-153.ec2.internal 20s ip-192-168-179-153.ec2.internal 30s ip-192-168-73-176.ec2.internal 50s ip-192-168-179-153.ec2.internal 90s ip-192-168-73-176.ec2.internal 110s ip-192-168-179-153.ec2.internal 2m30s $ $ kubectl get nodes NAME STATUS ROLES AGE VERSION ip-192-168-179-153.ec2.internal Ready <none> 2m39s v1.14.8-eks-b8860f ip-192-168-73-176.ec2.internal Ready <none> 2m42s v1.14.8-eks-b8860fkubectl apply
ここから先はGCPでも同じですがゲストブックのマニュフェストを反映していきます。
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-master-controller.json replicationcontroller/redis-master created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-master-service.json service/redis-master created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-slave-controller.json replicationcontroller/redis-slave created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-slave-service.json service/redis-slave created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/guestbook-controller.json replicationcontroller/guestbook created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/guestbook-service.json service/guestbook created $ $ kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE guestbook LoadBalancer 10.100.87.103 a55fb3b2225bb11ea8ecd0aa3c594265-989118657.us-east-1.elb.amazonaws.com 3000:31524/TCP 6s kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 48m redis-master ClusterIP 10.100.87.66 <none> 6379/TCP 57s redis-slave ClusterIP 10.100.107.22 <none> 6379/TCP 22sあとはLBの
EXTERNAL-IPにアクセスしてあげればゲストブックが見えます。
GKEへのデプロイ
こちらも同様Terraformでリソースを作成して、kubectlにてゲストブックマニュフェストを反映していきます。
リソース作成
Terraformのコードはマネージドが優秀なのでめちゃくちゃ短いです。
gke.tfresource "google_container_cluster" "advent_gke" { name = "${var.service_name}-${var.env}-gke" location = var.location remove_default_node_pool = true initial_node_count = 2 master_auth { username = var.user_name password = var.user_passwd client_certificate_config { issue_client_certificate = false } } } resource "google_container_node_pool" "advent_k8s_node" { name = "${var.service_name}-${var.env}-k8s-node" location = var.location cluster = google_container_cluster.advent_gke.name node_count = 2 node_config { preemptible = true machine_type = var.machine metadata = { disable-legacy-endpoints = "true" } oauth_scopes = [ "https://www.googleapis.com/auth/logging.write", "https://www.googleapis.com/auth/monitoring", ] } }
サクッとできました。
Cloud Shell
GCPはコンソール上で簡単にCLIを叩くことができます。せっかくなので利用してみます。
画面上部の赤枠を押すと下部に表示されます。
ではこのままコマンドを打ち込んでいきます。
aws cliを使って実施したようにgcloudコマンドを利用してkubeconfigを作成します。
$ gcloud container clusters get-credentials advent-k8s-sand-gke --zone us-east1-b Fetching cluster endpoint and auth data. kubeconfig entry generated for advent-k8s-sand-gke. $ $ kubectl get node NAME STATUS ROLES AGE VERSION gke-advent-k8s-sand--advent-k8s-sand--7921968e-j0s6 Ready <none> 41m v1.13.11-gke.14 gke-advent-k8s-sand--advent-k8s-sand--7921968e-s5cm Ready <none> 41m v1.13.11-gke.14 $ kubectl get node --watch NAME STATUS ROLES AGE VERSION gke-advent-k8s-sand--advent-k8s-sand--7921968e-j0s6 Ready <none> 41m v1.13.11-gke.14 gke-advent-k8s-sand--advent-k8s-sand--7921968e-s5cm Ready <none> 41m v1.13.11-gke.14 gke-advent-k8s-sand--advent-k8s-sand--7921968e-s5cm Ready <none> 41m v1.13.11-gke.14無事に確認できました。
kubectl
あとは同様にgithubからマニュフェストを引っ張ってくるだけです。
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-master-controlle r.json replicationcontroller/redis-master created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-master-service.j son service/redis-master created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-slave-controller .json replicationcontroller/redis-slave created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/redis-slave-service.js on service/redis-slave created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/guestbook-controller.j son replicationcontroller/guestbook created $ $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/examples/master/guestbook-go/guestbook-service.json service/guestbook created $ $ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE guestbook LoadBalancer 10.23.241.207 35.231.230.228 3000:32602/TCP 112s kubernetes ClusterIP 10.23.240.1 <none> 443/TCP 47m redis-master ClusterIP 10.23.247.54 <none> 6379/TCP 2m20s redis-slave ClusterIP 10.23.241.61 <none> 6379/TCP 2m4s
まとめ
どちらもkubectlでのマニュフェスト反映は同じようにできますが、それをデプロイするための環境を整えるまでの道のりが違います。
AWSはやはりSecurityGroup周りなどから用意してあげる必要があり、使い出すまでに手間がかかるかなと思います。
反面GCPは簡単にできるけど、内部の通信がどうなっているかがわからなくて微妙な気持ちも起きると思います。
初めて触る分にはGCPの方が入門しやすいと思いますが、自分の環境や習熟度によって使い分ける必要があると思います。
とりあえずどちらでも面白いのでこれを機にぜひ触れてみていただければと思います!明日はアドベントカレンダーを締めくくるhokutohagiさんの記事です!




- 投稿日:2019-12-24T05:27:47+09:00
EKS on Fargateでguestbookアプリをデプロイする
この記事は、Amazon EKS Advent Calendar 2019 24日目の記事です。
先日のre:Invent 2019で、待望のEKS on Fargateがリリースされました。
すでにAdventCalenderにもいくつか記事が出てきていますが、
本記事では、拙記事「わりとゴツいKubernetesハンズオン」にて各環境の第一歩としてやっているguestbookアプリのデプロイを行います。
これができればあとはわりとどうにでもなる気がする!クラスタを作成する
eksctlで作ります。
ちなみにeksctlは2019/7/23にEKSの公式CLIになりました。各ツールのバージョンはこちら
$ eksctl version [ℹ] version.Info{BuiltAt:"", GitCommit:"", GitTag:"0.11.1"} $ aws --version aws-cli/1.16.305 Python/3.7.3 Darwin/19.2.0 botocore/1.13.41 $ kubectl version --client --short Client Version: v1.17.0
--fargateフラグをつけるだけで、EKS on Fargateのクラスタができます。
EC2が立たない分早くできそうな期待がありましたが、
Fargate profileを作るからか、20分程度かかります…とてもつらい$ eksctl create cluster --name guestbook --fargate [ℹ] eksctl version 0.11.1 [ℹ] using region ap-northeast-1 [ℹ] setting availability zones to [ap-northeast-1d ap-northeast-1a ap-northeast-1c] [ℹ] subnets for ap-northeast-1d - public:192.168.0.0/19 private:192.168.96.0/19 [ℹ] subnets for ap-northeast-1a - public:192.168.32.0/19 private:192.168.128.0/19 [ℹ] subnets for ap-northeast-1c - public:192.168.64.0/19 private:192.168.160.0/19 [ℹ] using Kubernetes version 1.14 [ℹ] creating EKS cluster "guestbook" in "ap-northeast-1" region with Fargate profile [ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=ap-northeast-1 --cluster=guestbook' [ℹ] CloudWatch logging will not be enabled for cluster "guestbook" in "ap-northeast-1" [ℹ] you can enable it with 'eksctl utils update-cluster-logging --region=ap-northeast-1 --cluster=guestbook' [ℹ] Kubernetes API endpoint access will use default of {publicAccess=true, privateAccess=false} for cluster "guestbook" in "ap-northeast-1" [ℹ] 1 task: { create cluster control plane "guestbook" } [ℹ] building cluster stack "eksctl-guestbook-cluster" [ℹ] deploying stack "eksctl-guestbook-cluster" [✔] all EKS cluster resources for "guestbook" have been created [✔] saved kubeconfig as "/Users/kta-m/.kube/config" [ℹ] creating Fargate profile "fp-default" on EKS cluster "guestbook" [ℹ] created Fargate profile "fp-default" on EKS cluster "guestbook" [ℹ] "coredns" is now schedulable onto Fargate [ℹ] "coredns" is now scheduled onto Fargate [ℹ] "coredns" pods are now scheduled onto Fargate [ℹ] kubectl command should work with "/Users/kta-m/.kube/config", try 'kubectl get nodes' [✔] EKS cluster "guestbook" in "ap-northeast-1" region is readyFargate profileの主な役割はPodセレクターです。
Podセレクターで指定したNamespaceに属するPodしか起動しないようになっています。デフォルトで作られるFargate profile
fp-defaultでは、kube-systemとdefaultのみが指定されています。
ほかのNamespaceでPodを起動させようとする場合は、Fargate profileの追加が必要です。ALB Ingress Controllerを作る
わりとゴツいKubernetesハンズオンでEC2を使ったEKSクラスタを立てたときは、Serviceのタイプを
LoadBalancerにすればいい感じにELBができるのでそれを使っていました。
しかし、EKS on Fargateではその手が使えません。EKSには、Ingressを使って柔軟にアクセス制御をする方法として、ALB Ingress Controllerなるものがあります。
Fargateでクラスタを外部公開する場合はこれを利用します。
とはいえ、こちらのドキュメントは(今のところ)EC2ノードのクラスタ前提で書かれているので、IAMロールの扱いの部分がこのままではうまくいきません。
Fargateの場合はPodを操作するサービスアカウントにIAMロールを渡す必要があります。
Introducing fine-grained IAM roles for service accounts の記事を参考にしてやっていきます。サービスアカウントの作成
まず、サービスアカウントがIAMロールを持てるよう、クラスタにIAM Open ID Connect providerを作成します。
$ eksctl utils associate-iam-oidc-provider --region=ap-northeast-1 --cluster=guestbook --approve [ℹ] eksctl version 0.11.1 [ℹ] using region ap-northeast-1 [ℹ] will create IAM Open ID Connect provider for cluster "guestbook" in "ap-northeast-1" [✔] created IAM Open ID Connect provider for cluster "guestbook" in "ap-northeast-1" curl -O https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/iam-policy.json次に、サービスアカウントを作成します。
$ policyArn=$(aws iam create-policy \ --policy-name ALBIngressControllerIAMPolicy \ --policy-document file://iam-policy.json | jq -r .Policy.Arn) $ rm iam-policy.json $ eksctl create iamserviceaccount --name alb-ingress-controller \ --namespace kube-system \ --cluster guestbook \ --attach-policy-arn ${policyArn} \ --approve --override-existing-serviceaccounts [ℹ] eksctl version 0.11.1 [ℹ] using region ap-northeast-1 [ℹ] 1 iamserviceaccount (kube-system/alb-ingress-controller) was included (based on the include/exclude rules) [!] metadata of serviceaccounts that exist in Kubernetes will be updated, as --override-existing-serviceaccounts was set [ℹ] 1 task: { 2 sequential sub-tasks: { create IAM role for serviceaccount "kube-system/alb-ingress-controller", create serviceaccount "kube-system/alb-ingress-controller" } } [ℹ] building iamserviceaccount stack "eksctl-guestbook-addon-iamserviceaccount-kube-system-alb-ingress-controller" [ℹ] deploying stack "eksctl-guestbook-addon-iamserviceaccount-kube-system-alb-ingress-controller" [ℹ] created serviceaccount "kube-system/alb-ingress-controller"成功すれば、以下のようにサービスアカウントに紐付いたIAMロールのARNが確認できます。
$ kubectl get sa -n kube-system alb-ingress-controller -o jsonpath="{.metadata.annotations['eks\.amazonaws\.com/role-arn']}" arn:aws:iam::XXXXXXXXXXXX:role/eksctl-guestbook-addon-iamserviceaccount-kub-Role1-XXXXXXXXXXXXRole-Based Access Control (RBAC)の設定
サービスアカウントを使うのでRBACも設定しておきましょう。
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/rbac-role.yamlALB Ingress Controllerのデプロイ
マニフェストファイルを以下のように作成します。
alb-ingress-controller.yaml--- apiVersion: apps/v1 kind: Deployment metadata: labels: app.kubernetes.io/name: alb-ingress-controller name: alb-ingress-controller namespace: kube-system spec: selector: matchLabels: app.kubernetes.io/name: alb-ingress-controller template: metadata: labels: app.kubernetes.io/name: alb-ingress-controller spec: serviceAccountName: alb-ingress-controller containers: - name: alb-ingress-controller image: docker.io/amazon/aws-alb-ingress-controller:v1.1.4 args: - --ingress-class=alb - --cluster-name=guestbook # クラスタ名 - --aws-region=ap-northeast-1 - --aws-vpc-id=vpc-xxxx # eksctlで作成されたVPCのid resources: {}そしてデプロイ!
$ kubectl apply -f alb-ingress-controller.yamlguestbookアプリのデプロイ
guestbookアプリののマニフェストファイルを取ってきます。
$ git clone git@github.com:kubernetes/examples.gitServiceのタイプを
ClusterIPにします。examples/guestbook/frontend-service.yamlapiVersion: v1 kind: Service metadata: name: frontend labels: app: guestbook tier: frontend spec: # comment or delete the following line if you want to use a LoadBalancer # type: NodePort # if your cluster supports it, uncomment the following to automatically create # an external load-balanced IP for the frontend service. # type: LoadBalancer type: ClusterIP ports: - port: 80 selector: app: guestbook tier: frontendそしてデプロイ!
$ kubectl apply -f examples/guestbook/Ingressのデプロイ
マニフェストファイルを以下のように作成します。
alb.ingress.kubernetes.io/target-type: ipが重要らしい。nginx.yaml--- apiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: nginx annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip spec: rules: - http: paths: - path: /* backend: serviceName: frontend servicePort: 80そしてデプロイ!
$ kubectl apply -f nginx.yamlうまくいけば以下のようなログが出てくるはず。
$ kubectl logs -n kube-system $(kubectl get po -n kube-system -o name | grep alb | cut -d/ -f2) -f ------------------------------------------------------------------------------- AWS ALB Ingress controller Release: v1.1.3 Build: git-0db46039 Repository: https://github.com/kubernetes-sigs/aws-alb-ingress-controller.git ------------------------------------------------------------------------------- W1221 20:44:59.754825 1 client_config.go:549] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work. I1221 20:44:59.820425 1 controller.go:121] kubebuilder/controller "level"=0 "msg"="Starting EventSource" "controller"="alb-ingress-controller" "source"={"Type":{"metadata":{"creationTimestamp":null}}} I1221 20:44:59.820694 1 controller.go:121] kubebuilder/controller "level"=0 "msg"="Starting EventSource" "controller"="alb-ingress-controller" "source"={"Type":{"metadata":{"creationTimestamp":null},"spec":{},"status":{"loadBalancer":{}}}} I1221 20:44:59.820752 1 controller.go:121] kubebuilder/controller "level"=0 "msg"="Starting EventSource" "controller"="alb-ingress-controller" "source"= I1221 20:44:59.820903 1 controller.go:121] kubebuilder/controller "level"=0 "msg"="Starting EventSource" "controller"="alb-ingress-controller" "source"={"Type":{"metadata":{"creationTimestamp":null},"spec":{},"status":{"loadBalancer":{}}}} I1221 20:44:59.820937 1 controller.go:121] kubebuilder/controller "level"=0 "msg"="Starting EventSource" "controller"="alb-ingress-controller" "source"= I1221 20:44:59.821045 1 controller.go:121] kubebuilder/controller "level"=0 "msg"="Starting EventSource" "controller"="alb-ingress-controller" "source"={"Type":{"metadata":{"creationTimestamp":null}}} I1221 20:44:59.821307 1 controller.go:121] kubebuilder/controller "level"=0 "msg"="Starting EventSource" "controller"="alb-ingress-controller" "source"={"Type":{"metadata":{"creationTimestamp":null},"spec":{},"status":{"daemonEndpoints":{"kubeletEndpoint":{"Port":0}},"nodeInfo":{"machineID":"","systemUUID":"","bootID":"","kernelVersion":"","osImage":"","containerRuntimeVersion":"","kubeletVersion":"","kubeProxyVersion":"","operatingSystem":"","architecture":""}}}} I1221 20:44:59.821624 1 leaderelection.go:205] attempting to acquire leader lease kube-system/ingress-controller-leader-alb... I1221 20:45:16.071715 1 leaderelection.go:214] successfully acquired lease kube-system/ingress-controller-leader-alb I1221 20:45:16.172899 1 controller.go:134] kubebuilder/controller "level"=0 "msg"="Starting Controller" "controller"="alb-ingress-controller" I1221 20:45:16.273136 1 controller.go:154] kubebuilder/controller "level"=0 "msg"="Starting workers" "controller"="alb-ingress-controller" "worker count"=1 E1221 20:46:06.292652 1 controller.go:217] kubebuilder/controller "msg"="Reconciler error" "error"="no object matching key \"default/nginx\" in local store" "controller"="alb-ingress-controller" "request"={"Namespace":"default","Name":"nginx"} I1221 20:46:09.386726 1 security_group.go:36] default/nginx: creating securityGroup 88704138-default-nginx-ef8b:managed LoadBalancer securityGroup by ALB Ingress Controller I1221 20:46:09.472251 1 tags.go:69] default/nginx: modifying tags { ingress.k8s.aws/resource: "ManagedLBSecurityGroup", kubernetes.io/cluster-name: "guestbook", kubernetes.io/namespace: "default", kubernetes.io/ingress-name: "nginx", ingress.k8s.aws/cluster: "guestbook", ingress.k8s.aws/stack: "default/nginx"} on sg-00644bf833d3e22af I1221 20:46:09.597685 1 security_group.go:75] default/nginx: granting inbound permissions to securityGroup sg-00644bf833d3e22af: [{ FromPort: 80, IpProtocol: "tcp", IpRanges: [{ CidrIp: "0.0.0.0/0", Description: "Allow ingress on port 80 from 0.0.0.0/0" }], ToPort: 80 }] I1221 20:46:09.797729 1 loadbalancer.go:191] default/nginx: creating LoadBalancer 88704138-default-nginx-ef8b I1221 20:46:10.720829 1 loadbalancer.go:208] default/nginx: LoadBalancer 88704138-default-nginx-ef8b created, ARN: arn:aws:elasticloadbalancing:ap-northeast-1:XXXXXXXXXXXX:loadbalancer/app/88704138-default-nginx-ef8b/f38fd5222d13eed9 I1221 20:46:10.866826 1 targetgroup.go:119] default/nginx: creating target group 88704138-3fcc75cb1898279c122 I1221 20:46:11.034105 1 targetgroup.go:138] default/nginx: target group 88704138-3fcc75cb1898279c122 created: arn:aws:elasticloadbalancing:ap-northeast-1:XXXXXXXXXXXX:targetgroup/88704138-3fcc75cb1898279c122/6c3561d5fe7832b4 I1221 20:46:11.054416 1 tags.go:43] default/nginx: modifying tags { ingress.k8s.aws/resource: "default/nginx-frontend:80", kubernetes.io/cluster/guestbook: "owned", kubernetes.io/namespace: "default", kubernetes.io/ingress-name: "nginx", ingress.k8s.aws/cluster: "guestbook", ingress.k8s.aws/stack: "default/nginx", kubernetes.io/service-name: "frontend", kubernetes.io/service-port: "80"} on arn:aws:elasticloadbalancing:ap-northeast-1:XXXXXXXXXXXX:targetgroup/88704138-3fcc75cb1898279c122/6c3561d5fe7832b4 I1221 20:46:11.160612 1 targets.go:80] default/nginx: Adding targets to arn:aws:elasticloadbalancing:ap-northeast-1:XXXXXXXXXXXX:targetgroup/88704138-3fcc75cb1898279c122/6c3561d5fe7832b4: 192.168.133.249:80 I1221 20:46:11.416142 1 listener.go:110] default/nginx: creating listener 80 I1221 20:46:11.453183 1 rules.go:60] default/nginx: creating rule 1 on arn:aws:elasticloadbalancing:ap-northeast-1:XXXXXXXXXXXX:listener/app/88704138-default-nginx-ef8b/f38fd5222d13eed9/969acd682c64ffe0 I1221 20:46:11.480280 1 rules.go:77] default/nginx: rule 1 created with conditions [{ Field: "path-pattern", Values: ["/*"] }] I1221 20:46:11.952942 1 instance_attachment_v2.go:192] default/nginx: granting inbound permissions to securityGroup sg-09e10020509367f5f: [{ FromPort: 0, IpProtocol: "tcp", ToPort: 65535, UserIdGroupPairs: [{ GroupId: "sg-00644bf833d3e22af" }] }] I1221 20:46:13.116078 1 rules.go:82] default/nginx: modifying rule 1 on arn:aws:elasticloadbalancing:ap-northeast-1:XXXXXXXXXXXX:listener/app/88704138-default-nginx-ef8b/f38fd5222d13eed9/969acd682c64ffe0 I1221 20:46:13.137496 1 rules.go:98] default/nginx: rule 1 modified with conditions [{ Field: "path-pattern", Values: ["/*"] }]Ingressを確認するとELBのホスト名が出ているはずなので、アクセスしてみましょう。
ELBのヘルスチェックが通るまで少し時間がかかるので、数分待ちます。$ kubectl get ing NAME HOSTS ADDRESS PORTS AGE nginx * 88704138-default-nginx-ef8b-617276039.ap-northeast-1.elb.amazonaws.com 80 24s出ました!
ターゲットグループを見てみるとこんな感じ。
Fargateへのロードバランシングなので、EC2インスタンスではなくIPアドレスがターゲットになっていますね。
お片付け
eksctlでクラスタの削除コマンドを実行してもリソースが残ることが多いです。
成功したようなメッセージが出ますが、CloudFormationの削除処理が走り始めたところまでしか見ていないので、コンソールで本当に削除されたか確認しておきましょう。
EKSクラスタが削除されずに残っていたら費用が発生し続けるので大変です。$ kubectl delete -f nginx.yaml $ kubectl delete -f examples/guestbook/ $ kubectl delete -f alb-ingress-controller.yaml $ kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/rbac-role.yaml $ eksctl delete iamserviceaccount --name alb-ingress-controller \ --namespace kube-system \ --cluster guestbook $ eksctl delete cluster --name guestbookまとめ
今回はguestbookアプリをデプロイするだけだったので、あまりFargateのありがたみが見えない(というかむしろめんどくさそうな)記事になりましたが、EC2ノードから開放されるのはうれしいはず!
参考

https://839.hateblo.jp/entry/2019/12/08/172020
https://dev.classmethod.jp/cloud/aws/eksctl-usage-for-eks-fargate/


- 投稿日:2019-12-24T02:22:00+09:00
SAMで容量の大きなlambdaのコードをCodeUriで指定する方法
SAMで容量の大きなlambdaのコードをCodeUriで指定する方法についてです。
ローカルにzipにしておいておく。
lambdaはあまりにもでかいコードをあげる場合にはzipにするか、それ以上ではcliからs3にアップし、lambdaからはそのURIを指定する方法をとります。
実際、以前の記事(近くで開催される勉強会を定期的にslackへ流す。)ではdockerコンテナをs3へ置いてlambdaから参照して実行していました。他方で
sam-cliは、template.ymlのCodeUriに指定した相対パスのソースコードをs3へアップします。つまり、zipにまでして相対パスを指定しておけばs3へのアップは
sam packageコマンドの中で同時に行われます。
リファレンスを見るとこのCodeUriにはs3のパスを指定できていることから、一度s3にあげたコードをここで参照させるのかと思っていましたがtemplate.ymlの中ではローカルでのパスを指定するものでした。ただしここには注意が必要で、絶対パスを指定するとSuccessfullyとは出ますがうまくいきません。
template.ymlAWSTemplateFormatVersion : '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: get connpass info Resources: getConnpassSchedule: Type: AWS::Serverless::Function Properties: Handler: index.lambda_handler Runtime: python3.6 # パスを指定 CodeUri: ./deploy_package.zip Description: '' MemorySize: 512 Timeout: 120 # lambdaのバージョンのエイリアスを指定(必須) AutoPublishAlias: prod FunctionName: 'getConnpassSchedule' # IAMロール Role: 'arn:aws:iam::xxxxxxxxxxxx:role/FullAccess' # デプロイ方式 DeploymentPreference: Type: Linear10PercentEvery1Minutes3にzipにしてあげておく。
テンプレートの中の
CodeUriにS3://〜で始まるURIを指定してsam packageを実行すると生成するパッケージのCodeUriにそのまま反映されます。このケースではS3へのアップロードを踏みません。ただ、
sam packageコマンドでs3へ送ってくれるのであれば良いのではないかと思うのですがそこには差があるのでしょうか?(今後使ってみて探索と言ったところですかね)
- 投稿日:2019-12-24T01:27:24+09:00
Amazon SES の配信結果をDynamoDBに保存するLambda関数
この記事は、AWS LambdaとServerless #2 Advent Calendar 2019 の24日目の記事です。
Introduction
システムからのメール配信を行っている場合、BounceやComplaintとなったメールアドレスへの対処が求められます。
Amazon SES の場合、SandboxからProductionで使用する際にどのようなプロセスを実装しているかを申請する必要があります。AWS公式では以下のような知見が紹介されています。
How do I create an AWS Lambda function to store Amazon SNS notification contents for Amazon SES to an Amazon DynamoDB database?概要としては、以下のような処理になります。
1. Eメールのバウンス、苦情、配信などを Amazon SNS で通知するよう設定
2. SNSでの通知を受けて、Lambdaを実行
3. Lambdaの処理でDynamoDBへ保存今回は上の記事をSAMで実装したものを紹介します。
レポジトリ
https://github.com/yyoshiki41/ses-notification-to-ddb
SAM でデプロイ可能なものを上のレポジトリで公開しております。
ランタイムは、Python3.7設定方法
1. 通知に使用するSNSを作成
$ aws sns create-topic --name ses-messages --region us-east-1※このとき、Amazon SES と同じリージョン内でSNSを作成する必要があります。
2. SESの設定で、バウンス、苦情、配信を通知するSNSを設定
bounces, complaints, deliveries に関する通知を受け取るためのSNSとして、
1.で作成したSNSを設定します。
3. 配信結果を保存するDynamoDBを作成
DynamoDBのスキーマを定義したjsonファイルを置いております。
$ aws dynamodb create-table --cli-input-json file://dynamodb_table.json※ 上で作成したDynamoDBのテーブルは簡易的なものです。GSIの設定、READ/WRITE Capacityの設定などは運用に合わせて必要です。
4. Lambda関数をデプロイ
環境変数
S3_BUCKET
SAMデプロイ用のS3バケット
TABLE_SES_NOTIFICATIONS
3.で作成したDynamoDBのテーブル名
SNS_TOPIC_ARNcreated sns topic
2.で作成したSNS ARN各環境変数を設定してデプロイ完了です。
$ S3_BUCKET=sam-app-artifacts \ TABLE_SES_NOTIFICATIONS=SESNotifications \ SNS_TOPIC_ARN=arn:aws:sns:us-east-1:xxx:ses-messages \ make deployメール配信結果
以下のように、送信毎にDynamoDBに保存されます。
あとはこのテーブルを使って、DynamoDB Triggersや別のバッチ処理を書いてそれぞれの処理を行います。
これで Bounce, Complaint などへの対処が可能になりました。Lambda関数での処理
https://github.com/yyoshiki41/ses-notification-to-ddb/blob/master/lambda_function.py
特に手の凝った処理はしていません。
よくあるSNSからの通知内容をパースして保存する形です。Bounce, Complaint といった各シナリオでテストがしたい場合は、以下のアドレスが用意されています。
これを使えばデバッグもスムーズに行なえます。
https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/mailbox-simulator.html


- 投稿日:2019-12-24T01:16:09+09:00
code-server オンライン環境篇 (5) Docker 上で、code-server を立ち上げる
これは、2019年 code-server に Advent Calender の 第15日目の記事です。
前回に続き、EC2 Instance を 立ち上げたいと思います。
目次
ローカル環境篇 1日目
オンライン環境篇 1日目 作業環境を整備する
オンライン環境篇 2日目 仮想ネットワークを作成する
オンライン環境篇 3日目 Boto3 で EC2 インスタンスを立ち上げる
オンライン環境篇 4日目 Code-Serverをクラウドで動かしてみる
オンライン環境篇 5日目 Docker 上で、code-server を立ち上げる
オンライン篇 6日目 自動化してみよう
オンライン篇 7日目 簡単な起動アプリを作成してみよう(オンライン上に)
...
オンライン篇 .. Coomposeファイルで構築
オンライン篇 .. K8Sを試してみる
...
魔改造篇はじめに
前回までで、boto3 x python で EC2 Instance を 立ち上げました。
そして、Code-Server を動かしました。今回は、Docker を利用して、Code-Serverを立ち上げてみましょう。
EC2 Instance を作る
前回のつづきから
$ git clone https://github.com/kyorohiro/advent-2019-code-server.git $ cd advent-2019-code-server/remote_cs04/ $ docker-compose build $ docker-compose up -dブラウザで、
http://127.0.0.1:8443/を開く。
Terminal 上で
Terminal$ pip install -r requirements.txt $ aws configure .. ..EC2Instance を 作成
$ python main.py --createEC2 情報を取得
$ python main.py --get >>>> i-0d1e7775a07bbb326 >>>> >>>> 3.112.18.33 >>>> ip-10-1-0-228.ap-northeast-1.compute.internal >>>> 10.1.0.228 >>>> {'Code': 16, 'Name': 'running'}SSHで中に入る
$ chmod 600 advent-code-server.pem $ ssh -i advent-code-server.pem ubuntu@3.112.18.33Docker を install
Docker 環境を作成していきます
EC2上で
$ sudo apt-get update $ sudo apt-get install -y docker.ioDocker の Hello World
$ sudo docker run hello-world atest: Pulling from library/hello-world 1b930d010525: Pull complete Digest: sha256:4fe721ccc2e8dc7362278a29dc660d833570ec2682f4e4194f4ee23e415e1064 Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly.Code-Server を 起動してみよう
$ mkdir -p ${HOME}/.local/share/code-server/extensions $ sudo docker run -it -p 0.0.0.0:8080:8080 -p0.0.0.0:8443:8443 codercom/code-server:v2 --cert info Server listening on https://0.0.0.0:8080 info - Password is 86821ed9f02ef11d83e980da info - To use your own password, set the PASSWORD environment variable info - To disable use `--auth none` info - Using generated certificate and key for HTTPS
できました!!
削除しよう
# ec2 instance から logout $ exit # local の code-server 上で $ python main.py --deleteなんども使い回したいならば、 ec2 instance を停止するようにしてください
※ 次回か次次回
次回
手動で行っていた作業を、自動化してあげましょう!!
コード
https://github.com/kyorohiro/advent-2019-code-server/tree/master/remote_cs03
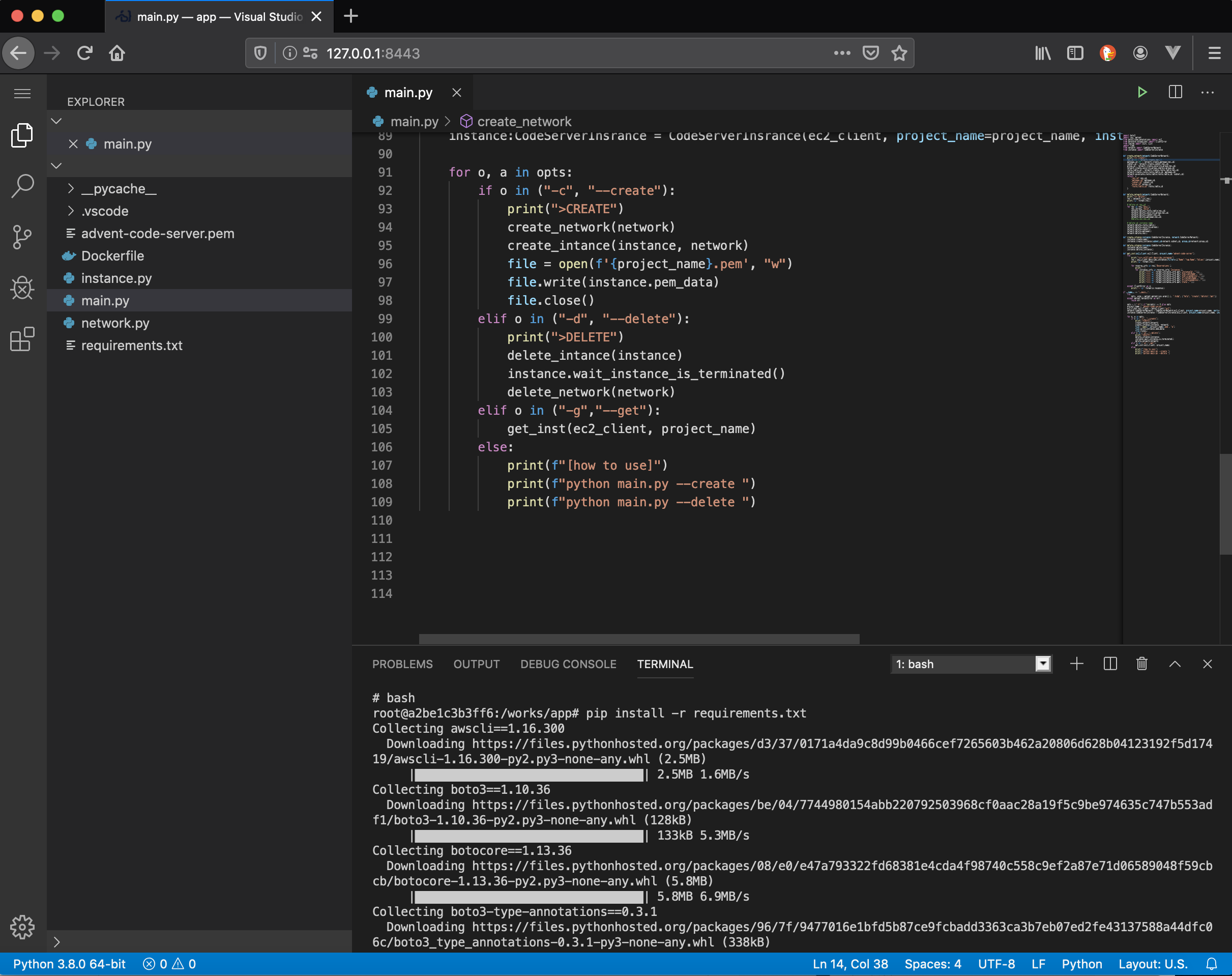
- 投稿日:2019-12-24T00:39:39+09:00
インフラ未経験でAWS認定クラウドプラクティショナーを受けてきたのでレポートします
普段はZOZOTOWNでWebフロントエンドのお仕事をしている佐藤です。
表題のとおり、全くのインフラ未経験ですがAWS認定クラウドプラクティショナー試験を受け、なんとか合格したので、これから受けようと思っている方のために学習記録を共有したいと思います。
本記事は ZOZOテクノロジーズ #5 Advent Calendar 2019 24日目の記事です。
昨日は @RyoU24 さんの「 SQL 文字列結合メモ 」でした。その他の記事はこちらからどうぞ。
ZOZOテクノロジーズ #1 Advent Calendar 2019
ZOZOテクノロジーズ #2 Advent Calendar 2019
ZOZOテクノロジーズ #3 Advent Calendar 2019
ZOZOテクノロジーズ #4 Advent Calendar 2019経緯
インフラやクラウドに興味があって独学であれこれさわってはいたのですが実務で使うことが無いので中々知識が定着しませんでした。
自分は無駄に簿記やFPを持っていて資格のための勉強は得意なので、じゃあAWS認定取れば体系的な知識が効率的に得られるのでは。と思った次第です。
開始したのが11月25日、試験日が12月14日だったので学習期間は19日間、始めた当初はVPC、EC2が(本当の意味で)ちょっとわかるレベルでした。1日目
AWS認定については何かそういうのがあるらしい。くらいの知識だったのでちゃんと調べました。
認定には役割ごとに基礎レベル、アソシエイトレベル、プロフェッショナルレベルの試験が存在し、またそれらとは別に詳細な専門知識を問う試験が用意されています。
- 基礎レベル
- AWS 認定クラウドプラクティショナー
- アソシエイトレベル
- AWS 認定ソリューションアーキテクト アソシエイト
- AWS 認定デベロッパー アソシエイト
- AWS 認定SysOpsアドミニストレーター アソシエイト
- プロフェッショナルレベル
- AWS 認定ソリューションアーキテクト プロフェッショナル
- AWS 認定DevOpsエンジニア プロフェッショナル
- 専門知識認定
- AWS 認定高度なネットワークキング
- AWS 認定ビッグデータ
- AWS 認定セキュリティ
- AWS 認定 機械学習
- AWS 認定 Alexa スキルビルダー
中でも「AWS 認定クラウドプラクティショナー」は、AWSのインフラ、アーキテクチャ、セキュリティ、管理、料金、サポートなどなど…サービス全体を網羅した知識が問われる上に難易度も低いので手っ取り早く全体像を掴むのに良さそうです。
続いて対策本を調べましたが、クラウドプラクティショナーは2018年から始まった試験だそうで書籍も
「 AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー 」
の1冊だけでした。ひとまずこれを購入し学習をはじめることにしました。2日〜10日目の学習方法
参考書は次のような章立てになっています。
第1章 AWS認定資格
第2章 AWSクラウドの概念
第3章 AWSのセキュリティ
第4章 AWSのテクノロジー
第5章 コンピューティングサービス
第6章 ストレージサービス
第7章 ネットワークサービス
第8章 データベースサービス
第9章 管理サービス
第10章 請求と料金ページ数は300弱なので2、3日で読める人もいるかと思います。
個人的な意見なんですが、毎日続けるような学習において大事なのは「頑張らない」と「少しでも進める」だと思ってまして、1日1章、調子良ければ2章、最低でも必ず1ページだけは読み進める、というルールを作り、敢えてのんびりと学習しました。
学習方法は行き帰りの電車の中で参考書を熟読し、帰宅後30分〜1時間ほど実際にAWSを操作して学んだ内容を確認するといった手順です。AWSは本を読んだだけで使いこなせるサービスではないはずなので必ず手を動かしながら学習を進めるべきかと思います。
そうこうして1ページも読まずにサボった日もありつつ予定通り10日間で参考書を読了しました。11日目 模擬試験と本試験の申し込み
参考書を読み終わり何か行けそうな気がしたので、ここに来てやっと試験に申し込みました。
試験は「PSI」と「ピアソン」という会社が運営してまして、個人的にサイトがわかりやすかったピアソンで模擬も本試験も受けることにしました。
模擬試験 本試験 試験時間 35分 90分 問題数 25問 65問 合格ライン - 1000点満点中700点以上 試験方法 オンライン オンラインまたは試験会場で専用端末から受験 料金 2,000円 11,000円 内容は4択または、5つの選択肢から2つ正解を選ぶ形式です。
試験会場は都内であれば新宿、渋谷など18箇所から選ぶことができました。
で、これは模擬試験結果のスクリーンショットです。スコアが96%となっていますが本試験に比べ非常に非常にやさしい問題なのでここで余裕をかますとやられます。
また、分野別の正答率は表示されますが、どの問題を間違えたかは教えてくれません。
必ず問題のスクリーンショットを撮るかコピペをして保存しておき、後で間違えた分野の問題を振り返ることをおすすめします。12日〜15日目 参考書2周目
間違えた問題や頻出する語句をメモにまとめていきました。
下記はその中でも特に重要で、試験を受ける方は必ず抑えるべき項目です。
- 概念
- AWSのメリット6つ
- Design for Failureに備えたアーキテクチャ(弾力性、マイクロサービス)
- AWS Well-Architected フレームワーク
- セキュリティ
- 「責任共有モデル」の各々の責任範囲
- IAMの概要
- セキュリティグループの概要
- コンピューティング
- リージョン、アベイラビリティゾーン、データセンターの関係
- 典型的なEC2、ELB構成
- 垂直スケーリングと水平スケーリング
- Lambdaの特徴
- ストレージ
- EBSの概要
- S3の概要
- ストレージクラス
- リージョン外へのデータ転送時の料金
- ネットワーク
- VPCとサブネットの作成場所
- NATインスタンスやNATゲートウェイの設置場所
- ACLの概要
- オンプレとの接続(VPNゲートウェイ、ダイレクトコネクト)
- エッジロケーション(CloudFront、Route53、AWS Shield)
- DB
- RDSとDynamoDBの概要
- Auroraのメリット
- 管理
- 標準メトリクス、カスタムメトリクスで収集できるものの違い
- CloudWatch、Config、CloudTrailの違い
- Trusted Advisorのレポートカテゴリー
- 請求と料金
- Organizationでできること
- 4つのサポートプランの内容
- TCO計算ツールの設定項目
16日〜19日目 練習問題を繰り返し解く
この期間はちゃんとサボらずに、次の練習問題を繰り返し解いて知識の確認をしました。
- 参考書の確認問題
- コピペしておいた模擬試験
- AWS Cloud Practitioner Essentials (Second Edition) (Japanese): コースの最後の知識の確認
- AWS認定 クラウドプラクティショナー 模擬問題集
3については試験日直前に、そう言えば公式のトレーニングがあったな…と思い出したんですが、時間もなかったので確認問題だけ取り組みました。
4は模擬試験2回分を収録したKindle unlimitedの書籍です。参考書ではあまり触れられていないサービスについての問題もあり知識の補強をすることができました。
難易度としては 4 > 1 > 3 > 2 といった感じです。試験当日
場所は新宿と言いながら渋谷区の 新宿駅前テストセンター で受けてきました。
試験の流れは以下です。
- 受付で試験を受けに来たことを告げる
- 注意事項などが書かれた書類にサインする
- 説明を聞いて身分証明書(2種類)を提出し写真撮影をする
- 荷物を預けポケットが中が空であることを確認する
- メガネのレンズを確認する(メガネにカンニングを仕込む人がいるみたいです)
- 席まで案内され説明を聞いたあと用意ができたら試験開始
外国人の試験官と英語でチャットするとか、試験端末がよく不安定になる。とかいう話も聞いててどうしようかと思っていたんですが、特にそんなこともなく普通でした。PSIを選択していたらもしかしたら状況が違っていたかもしれないです。
内容はもちろん模擬試験よりも難しかったですが、ややこしい問は少なく知っていたら迷わないシンプルな問題が多かったかと思います。また基礎レベルということで最新のサービスに関する問題はありませんでした。結果
合否は試験終了後すぐに出ます。
詳しいスコアは後日メールで案内がお送られてくるので 試験申し込み管理画面 から確認することができます。
結果、887/1000というスコアでした。
一安心ですが、参考書や練習問題では出てこなかった内容もあったので、スコアを伸ばしたい方は忘れずに 公式トレーニング に取り組むと良いかと思います。感想と今後
今回の試験を通しAWSの基本的な概念と代表的なサービスを理解できたので当初の目標は達成できました。
また、資格試験は強制的に毎日の学習時間を捻出することになるので、学習習慣を身につけるために定期的に取り組むと良いかと思います。
来年はさらに上級試験にトライしようと思います。ただ資格を持っていても使いこなせるようになるわけではないので実務に活かせるような取り組みをしていきたいと思いました。
以上です。今年も一年お疲れさまでした。明日の大トリは @Horie1024 さんです。


- 投稿日:2019-12-24T00:33:49+09:00
プライベートサブネット内のEC2 (Amazon Linux 2) 上にAWS Cloud9を構築する
はじめに
Cloud9とは、AWSのマネジメントコンソール上(つまり、ブラウザ上)でコーディングができるソリューションです。
AWSのサーバーレスアーキテクチャとの相性もよく、AWSを利用する上では是非検討したいソリューションです。こういったソリューションが台頭してくる要因として、クラウドを利用する上での「コーディング環境」が挙げられます。
Vimmerならどこであっても実装に困りませんが、普段ローカルPCのIDE等を利用している開発者がいざクラウドを利用しようとすると、この「コーディング環境」という壁にぶち当たることもあるのではないでしょうか?
また、Cloud9のようなクラウド上で使える魅力的なエディターがあっても、会社のプライバシーポリシー的に導入が難しかったりと次々と壁にぶち当たるのも世の常です。本記事では、そういった点を踏まえて、できる限りセキュアにCloud9を使うための構築手順とセキュリティ要件をご紹介します。
なお、Cloud9の使い方はご紹介しませんので、ご注意ください。対象読者
次のようなアーキテクチャでCloud9を利用したい方全員
(Cloud9サーバーはプライベートサブネットに置き、踏み台経由でしかアクセスできない)
セキュリティ要件
上の画像では少し語弊というか間違いがあり、マネジメントコンソールでCloud9を開けばローカルPCからSSHするわけではありません。
マネジメントコンソールからCloud9を開くと、AWSを経由して踏み台サーバーにSSH、踏み台サーバーがCloud9サーバーにSSHするという仕組みになっています。
したがって、踏み台サーバーはAWS側に22番TCPポートを解放しておく必要があります。
AWS Cloud9 のインバウンド SSH IP アドレスの範囲許可するIPは、
https://ip-ranges.amazonaws.com/ip-ranges.json
こちらのjson中のregion: "ap-northeast-1"かつservice: "CLOUD9"のIPアドレスです。Cloud9環境の構築
1. Cloud9用EC2を構築
1-1. EC2の起動
EC2の設定は次の点だけ守っていただければ、後は自由にしていただいて構いません。
設定項目 内容 AMI Amazon Linux 2 サブネット プライベートサブネット PublicIP 無効 セキュリティグループ 踏み台サーバーに設定したセキュリテイグループからのSSH (Port:22) を許可する 1-2. Cloud9用の設定
これから、AWS Cloud9 SSH 開発環境 ホスト要件を参考に設定をしていきます。
まずは、先ほど起動したCloud9用EC2にSSHします。
SSHしたら、yum updateなどの普段行う設定を実施してください。
以下は、あくまでもCloud9に必要な設定のみを記載しています。Pythonのインストール
Python がインストールされている必要があり、バージョンが 2.7 である必要があります。
と記載されているので、Pythonのバージョンを確認します。
$ python --version Python 2.7.16このように2.7系であれば問題ありませんが、もし違えば2.7系を入れてください。
インストール方法は、参考にしているホスト要件内に記載されています。Node.jsのインストール
Node.js がインストールされている必要があり、バージョンが 0.6.16 以降である必要があります。
と記載されているので、Node.jsのバージョンを確認します。
$ node --version -bash: node: コマンドが見つかりません2019年12月23日現在のAmazon Linux 2 AMI (ami-068a6cefc24c301d2)には、標準でNode.jsはインストールされていません。
ここでは、Node.jsのリポジトリをyumリポジトリに追加する方法でインストールを行いたいと思います。まずは、現在設定済みのリポジトリをlistしてみます。
$ ll /etc/yum.repos.d/ 合計 8 -rw-r--r-- 1 root root 985 11月 2 08:45 amzn2-core.repo -rw-r--r-- 1 root root 943 11月 19 07:59 amzn2-extras.repoここに、
nodesource-el7.repoという名前でリポジトリを追加します。$ sudo vim nodesource-el7.repoバージョンは0.6.16以上を指定されているので、基本どのバージョンでもいいですが、今回はバージョン13を指定しています。
pub_13.xの13の箇所がバージョンとなっており、12や11を入れたい場合はその数字を指定すればOKです。
また、el/7は、Red Hat Enterprise Linux 7のことです。nodesource-el7.repo[nodesource] name=Node.js Packages for Enterprise Linux 7 - $basearch baseurl=https://rpm.nodesource.com/pub_13.x/el/7/$basearch failovermethod=priority enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/NODESOURCE-GPG-SIGNING-KEY-EL最終的に、こんな感じになっていればリポジトリの登録完了です。
$ ll /etc/yum.repos.d/ 合計 12 -rw-r--r-- 1 root root 985 11月 2 08:45 amzn2-core.repo -rw-r--r-- 1 root root 943 11月 19 07:59 amzn2-extras.repo -rw-r--r-- 1 root root 235 12月 23 21:01 nodesource-el7.repoそして、
nodesource-el7.repoにgpgkeyを指定したので、これもホストにダウンロードしておく必要があります。
ダウンロードはcurlコマンドを使用して、https://rpm.nodesource.com/pub/el/ から落としてきます。$ cd /etc/pki/rpm-gpg/ $ sudo curl -sSO https://rpm.nodesource.com/pub/el/NODESOURCE-GPG-SIGNING-KEY-ELそれでは準備が整ったので、Node.jsをインストールしましょう
$ sudo yum install nodejsインストールが完了したら、次のコマンドでNode.jsのバージョンが返ってくれば正常にインストールできています。
$ node --version v13.5.0Cloud9起動元ディレクトリのパーミッションを設定
今回は、ec2-userのHOMEディレクトリを指定します。
$ sudo chmod u=rwx,g=rx,o=rx ~ $ ll /home/ 合計 0 drwxr-xr-x 3 ec2-user ec2-user 111 12月 23 21:20 ec2-userAWS Cloud9のインストール
インストーラーを使用してCloud9をインストールしますが、その前に必要な
gccを先にインストールしておきます。$ sudo yum install gccgccのインストールが完了したら、
crulコマンドでCloud9をインストールします(しばらく時間がかかります)。$ curl -L https://raw.githubusercontent.com/c9/install/master/install.sh | bashインストールの最後に
:Done.が表示されればインストール完了です。2. マネジメントコンソールからCloud9環境の作成を行う
2-1. Cloud9の画面を開く
画面を開いたらオレンジ色のボタン
Create environmentをクリックしましょう。
2-2. 環境名と説明を入力
入力したら、
Next stepをクリックします。
2-3. SSHの設定
設定項目 指定内容 Environment type Connect and run in remote server (SSH) SSH server connection User Cloud9サーバーにSSHするユーザー Host Cloud9サーバーのプライベートIP Port SSHに使用するポート Advanced settings Environment path Cloud9ログイン時のディレクトリ(デフォルトはHOMEディレクトリ) Node.js binary path Node.jsのバイナリパス SSH jump host 踏み台サーバーへのSSH時に使用するユーザーとIP(形式はUSER@HOST:PORT) 2-4. 最終ステップ
ここまで入力が完了したら、
Copy key to clipboardをクリックしSSH公開鍵をクリップボードに保存します。
その後、踏み台サーバーとCloud9サーバーの~/.ssh/authorized_keysの両方にコピーします。さらに、SSH 環境を作成するの15番に
Netcat をインストールする必要があります
とある通り、踏み台サーバーにはNetcatをインストールしておく必要があります。
踏み台サーバーもRed Hat系の場合、次のコマンドでインストールできます。$ sudo yum install ncここまで完了すると、
Next stepの実行が正常に行われるはずです。
すると、確認画面が表示されるので、環境の作成をクリックします。
しばらくして、Cloud9のコンソールが開かれれば構築完了です。
まとめ
踏み台サーバーを用いてプライベートサブネット内にCloud9サーバーを構築することができました。
しかしながら、踏み台サーバーにAWSからの22番ポートアクセスを許可する必要があり、この点が会社のセキュリティポリシーに引っかかることが多いような気がします。
Lambdaとの相性も良かったりするそうですので、クラウドサービスの拡大に伴って会社のポリシーも柔軟に変わっていけると良いですね。




