- 投稿日:2019-12-24T23:39:06+09:00
データ分析初心者におくるデータ分析ツールの使い分け
この記事の目的・対象読者
データ分析用のツールはたくさんあります。
ここでは、データ分析ツールとは、Excelやプログラミング、ダッシュボードツール、BIツールなどを含みます。この記事では、データ分析初心者やこれからデータ分析をしようとする人に向けて、どのような場面にどのような分析ツールを使うのがいいかを解説します。
どのような場面にどのような分析ツールを使うのかが重要な1番の理由は、適切なツールを使うことでデータ分析を効率的に行えるからです。
プログラミングが必要のないところでは、無理して使う必要がないかもしれませんし、
場面によっては、便利なBIツールは役に立たず、どうしてもプログラミングやSQLの知識が必要かもしれません。また、これからデータ分析をしていこうとする人は、自分がしたい(あるいは任された)分析のために、どの程度の知識を身に着けておくべきかという疑問にぶち当たります。
その際に、どのような場面にどのような分析ツールを使うのかをなんとなく分かっていれば、どの程度の知識が必要か予想することができるでしょう。この記事が分析ツールの対象とする分析ツールとそれぞれの特徴
データ分析の分類
データ分析には、大きく分けて、「アドホック分析」と「定期的な分析」の2種類があります。
データ分析の基盤が整っておらず、自動化されていない会社や研究では、必要なタイミングでその都度、手作業でデータを分析することになります。
これをその場限りな分析という意味でアドホック分析と呼びます。アドホック分析では、クエリやデータの変形・集計処理を実行してすぐに結果を確認できるような対話型の分析ツールが用いられます。
一方、手作業で都度分析するのではなく、定期的なレポーティングなどを求められる場合には、ある程度自動的にデータを集計して表示するダッシュボードツールが使われます。
ここでは、
・Excel
・プログラミング言語
・BIツール
・ダッシュボードツールのそれぞれの特徴や具体的な製品などを見ていき、どのような場面でどのようなツールが使われるのかを見ていきましょう。
Excel
まずは、誰でもご存知のExcel先生です!
私自身は、Excelを使わずにプログラミングでデータ分析をしようという教育を受けて育ったので、実はPythonよりもExcelの方が苦手だったりします……実際は、簡単な分析ならExcelでも十分です。
ピポッドテーブル
まずは、ピポッドテーブルの使い方を覚えましょう。
これは、ピポッドテーブルによるクロス集計はあらゆるデータ分析の基本です。
クロス集計の考え方そのものはExcelであろうとプログラミングであろうと共通なので、この考え方が見についていなければお話にはなりません。
Excelの苦手なこと
Excelは大変便利なツールですが、データの統合には限界があります。
横方向に列を増やしていくことはExcelらしい処理ですが、縦方向のデータの統合は苦手だったりします。例えば、センサーの時系列データを扱う場合を考えます。
(抽象化すると、Google Analyticsなどもセンサーみたいなものですよね?笑)センサー①は1秒ごとにデータを記録していて、センサー②は10秒ごとにデータを記録しているとします。
それらのデータを集計して統合する場合、センサー①のデータを10秒ごとに平均するなり、代表値を取ってくるなりして、合体させなければなりません。これらの処理をExcelで行うのはひと手間ですし、そもそもデータの数が何十万行、何百万行にもなると、Excelでは計算が遅くなってしまいます。
とはいえ、
例えば、経営の指標を扱うような場合には、Excelで十分でしょう。
せいぜい、週や月ごとの集計結果をみて議論する程度ですからね。
そのため、コンサルティング会社や会計事務所などでは、今でもExcelをゴリゴリ使えることが1つの重要なスキルとして認識されているわけです。プログラミング言語(Python)
ここでは、プログラミング言語としてPythonを取り上げます。
近年データ分析用のプログラミング言語として世界を支配したと言っても過言ではないPythonは、データ分析用のライブラリーも豊富ですし、なんといっても後述する対話型ツールのJupyter Notebookが人気です。Jupyter Notebook
(公式ホームページより)Jupyter Notebookとは、オープンソースの対話型スクリプト実行ツールです。
Python以外にも、RubyやRなどのプログラミング言語も実行可能です。一つ一つの処理工程ごとにの結果を可視化することができます。
Markdown形式で説明文などを書くこともできるため、他人に見せるレポートとしても十分に機能します。Pythonでグラフを作るのに最も有名なのが、matplotlibというライブラリーです。
上記の公式ホームページから取ってきた写真のようなオシャレなグラフを作ることが可能です。Pythonを使ったデータ分析および可視化には下記の本が参考になります。
Pythonの限界
当然ながら、データ分析のためにPythonを使いこなすのは簡単ではありません。
プログラミング初心者からすれば、学習コストはかかります。ですから、エンジニアでない人たちがデータ分析できないという意味では、データが本当に民主化されたとは言えません。
BIツール
そこで、近年データ分析ツールとして人気が出ているのがBIツールです。
Tableauというツールの名前は聞いたことがある人が多いでしょう。近年は、コンサルティング会社などでもTableauを使って分析をすることが増えていると聞きます。
私もコンサルティング会社に勤めていた頃にはExcelよりもTableauの方がナウでヤングでトレンディーだよねという空気がありました。
(Tableau公式ホームページより)
グラフを作ったりしながら、チームメンバーで分析を進めていくのに向いています。
使う場面としては、後述するダッシュボードツールは、分析を自動化しようという方向を向いているのに対して、BIツールはより探索的なデータ分析のために用います。BIツールにできないこと
BIツールは素晴らしく、データの民主化を進めてくれるものとして、非常に価値のあるものです。
ですが、BIツールも統合されたデータを扱うことにはできても、統合作業そのものは苦手(できるはできる)です。
BIツールを使う前の、データ集計や統合のSQLのクエリは自分たちで書かなければなりません。つまり、結局は、意味のある分析をするためには、データを統合してBIツールが読み込みやすいようにするデータ前処理班が必要なのです。
ダッシュボードツール
アドホック分析とは対照的に、定期的にクエリを実行してレポートを作成したり、グラフを表示したりする目的のために使われるのがダッシュボードツールです。
有名なのには、Redashなどがあります。
AWS EC2にdockerベースのredashを一から設定して起動するまで
ダッシュボードツールはデータの分析を自動化して、定期的に確認することができることに主眼が置かれています。
しかし、BIツールのように対話的なダッシュボードを作ることに対応していないダッシュボードツールも多いです。
あくまで、定期的に最新の情報を可視化することに最適化されています。ダッシュボードツールの限界
ダッシュボードの使用するためには、プログラミング言語やSQLを実行する必要があります。
(当然前処理も別途必要です。)実際、高度なことができるとうたっている可視化ツールは、その実は、「内部でPythonコードを書いて実行できますよ」ということだったりします。
メルカリのデータサイエンスチームと分析エコシステムのはなし
この記事によると、メルカリでは非アナリスト職でもSQLを書いて、簡易な分析は自分で出来る人が多いですね。
最近は財務部、経理部、法務部、デザイナーまで勉強中という噂もあります。(事実です)とのこと。
分析するためにSQLを実行する必要があるから、みんながんばって勉強しているのですね。普通の会社であれば、SQLを誰が書くんだという問題が発生しますね。
業務の改善フローが決まっていて、追うべき指標がもうずっと一定の会社などは、それなりのお金をかけてデータ分析基盤を整え、ダッシュボードツールを導入するのもいいでしょう。
しかし、普通は、見たい指標やデータはどんどん変わっていくものなので、SQLもどんどん新しく変えていかなければなりません。
まとめ
データ分析基盤がしっかり整っていて、きちんとデータの集計・統合をする余裕のある会社では、BIツールや可視化ツールの導入をするとよいでしょう。
エンジニア以外のメンバーもデータ分析をして日々の議論に活かしたい場合は、BIツールや可視化ツールを導入するしかありません。ただ、見たいKPIが定まってなかったり、考察することもきちんと定まっていない場合には、BIツールを使って都度みんなで議論していくのがいいでしょう。
データ分析から考察の流れがすでに定型化されている会社の場合は、可視化ツールを使って分析の自動化をするとよいと思います。
まだまだデータ分析基盤が整っておらず、データをとりあえず貯めているだけのような場合は、プログラミング言語を使ってアドホック分析をして
ここできちんとアドホックな分析をすることで、その会社にとって重要なKPIはなんなのか、データを使って何を考察したいのかが明らかになっていきます。
非常に重要な手順です。急に分析を自動化していっても、結局その分析は使われなくなるものかもしれません。
データ分析基盤を整えるのにも手間もお金もかかるので、深く考えずに分析基盤を作り始めるのは絶対によくないことです。最後に
この記事は、私が友人たちと何年間もやっているStudyCoという勉強会のアドベントカレンダーの24日目の記事として書いています。
これまで私が書いた別の記事も是非参考にしていただけると嬉しいです!
- これからのデータ分析担当者に求められる知識と勉強方法
- 機械学習・ディープラーニング初心者のためのおすすめ勉強順序
- 統計初心者がベイズ統計学に入門するまでの勉強法これからデータ分析に取り組もうとするみなさんへのクリスマスプレゼントになればいいと思います!
聖夜もデータで語らナイト!メリークリスマス!
参考




- 投稿日:2019-12-24T23:28:17+09:00
線形モデルによる回帰
皆さんこんにちは。
私は今Pythonで始める機械学習で勉強中です。線形回帰という面白い概念が出てきたので少しまとめよーかなと思います。
そもそも回帰とは?
回帰(かいき、英: regression)とは、統計学において、Y が連続値の時にデータに Y = f(X) というモデルを当てはめる事。別の言い方では、連続尺度の従属変数(目的変数)Yと独立変数(説明変数)Xの間にモデルを当てはめること。X が1次元ならば単回帰、X が2次元以上ならば重回帰と言う。Wikipedia
つまり、回帰の目的は連続値の予測に着地する。
例えば・・・・
ある人の年収(目的変数)を、学歴と年齢と住所(説明変数)から予測する事。
トウモロコシ農家の収穫量(目的変数)を、前年の収穫量、天候、従業員数(説明変数)から予測する事。では、線形モデルによる回帰とは
線形モデルによる回帰とは文字通り、線形関数を用いて目的変数を予測するものです。
回帰問題での線形モデルによる一般的な予測式は、
y = w[0] \times x[0] + w[1] \times x[1] + \dots + w[p] \times x[p] + bと表せます。
ここでx[0]・・・x[p]は1データポイントの特徴量を示し、w, bは学習されたモデルのパラメータであり、yはモデルからの予測である。
つまり訓練データから最適化されたw, bを求め(学習し),新しいx[0]・・・x[p]を入れられたときに、
出来るだけ正確なyを出力することに帰着する。ここで線形モデルを用いた回帰には様々なアルゴリズムが存在する。
それらのモデルの相違点は、w, bを求める(学習する)方法とモデルの複雑さを生業する方法に存在する。今日は最も単純で古典的な線形回帰手法である通常最小二乗法(OLS)について触れたいと思う。
通常最小二乗法(OLS)
それでは簡単にするために、1つの説明変数で考えましょう。
つまり数式はy = wx + bこの線形回帰では訓練データにおいて、yと予測値の平均二乗誤差が最小になるようにw, bを求める。
文章じゃわかりづらいので画像で考えると下記です。
つまり青い線が出来るだけ短くなるようにwとbを求めて、その結果が赤い直線となります。数式で書くならば
平均二乗誤差=\frac{1}{n}\sum_{i=1}^{n} y_i - y'_i (y_i:i番目の訓練データでの値, y'_i: i番目の予測値)この平均二乗誤差が小さくなるように、w, bを選んでいきます。
これがOLSです。簡単で美しいですね。サンプルコード
from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression import mglearn X, y =mglearn.datasets.make_wave(n_samples=60) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) lr = LinearRegression().fit(X_train, y_train) print("lr.coef_(傾きOR重み) : {}".format(lr.coef_)) print("lr.intercept_(切片) : {}".format(lr.intercept_)) print("Training set score: {:.2f}".format(lr.score(X_train, y_train))) print("test set score: {:.2f}".format(lr.score(X_test, y_test)))結果はこちら
lr.coef_(傾きOR重み) : [0.39390555] lr.intercept_(切片) : -0.031804343026759746 Training set score: 0.67 test set score: 0.66この直線をプロットしてみる。
しかし、予測が66%とはあまり良くありませんね。
おそらくこれは適合不足(underfitting)だと考えられます。次回は別の回帰モデルであるRidgeとLassoについてです。
皆さん、いい夜をお過ごしください。
おやすみなさい。


- 投稿日:2019-12-24T23:22:38+09:00
いい感じなgitignoreエディタ作れないかなと思ったので、とりあえずMVPっぽいのを作ってみた
起:
.gitignoreのちょっとした悩みことの発端
プロジェクトを
Initial commitした後におもむろにやる作業として、「gitignore.ioから良さげな.gitignoreを作る」というのがありますよね? 1 2ありますよね?
時間経過で.gitignoreは変化する...こともある
最初のまま運用できれば問題ないのですが、
- あ、この環境用のignoreもつけたい
- ちょっと特殊なignoreが必要になりそう
ということが出てきたりします。
出てきたりします。
(1)のケースだと、もう一回gitignore.ioに行って再生成しないといけなかったりします。
(2)のケースだと、テンプレ生成した
.gitignoreのどこかに記述しないといけなくなるのですが、
こうなってくると(1)の対応のたびに若干の手間を感じてしまったりします。多分承:雑な思いつきと、MVPっぽいの
思いつき
そこで「
.gitignore編集時にいい感じに『言語名』と『言語のignore』をいい感じに連携しつつ簡素に書くエディタ」とか作れないかなと考えてみました。lazygitみたいなUIかっこいいじゃないですか
- キーワードを入れると、「そのキーワードを含む言語・環境の候補」が出る
- Tabで候補に移動して右とか押したら、、言語として反映
- 候補がない中でキーワードを選択して右を押したら、パターンとして反映
- 保存時に、勝手にAPIコールしてgitignore.io+パターンで構築
とかできると、派生でignoreしたいパターンなどをまとめて放り込めて便利かなーなんて。
とはいえ、こういう形式でのエディタを作成する能力は今の所ありません。
手間を掛けずにそれっぽいの(=MVP?)を作ってみる
超雑に、MVPっぽい超簡易実装を試してみました。
こちら => vigi = vi gitignore
vigiコマンドを実行すると、# ~~~~~~こんな感じのファイルを
vimで開き、.idea # ~~~~~~ python virtualenvこんな感じで編集して
vimを終了すると、.idea # ~~~~~~ # https://www.gitignore.io/api/python,virtualenv の中身みたいな状態の
.gitignoreを作ってくれます。ちなみに、この状態で
vigiコマンドを実行すると、gitignore.io部分はちゃんと言語のみの情報になります。編集がしやすい……かなと思います。転:中身はこんな感じ
.giという名で仮ファイルを作って編集し、保存されたらそれを.gitignoreに変換するスタイルimport subprocess from pathlib import Path from subprocess import CalledProcessError, PIPE def main(): gi_path = Path.cwd() / '.gi' gitignore_path = Path.cwd() / '.gitignore' try: # Convert from ``.gitignore`` to ``.gi`` if gitignore_path.exists(): encode_gitignore(gitignore_path, gi_path) else: with gi_path.open('w') as fp: fp.write(dedent(gi_template).strip()) # Spawn vim vim_args = ['/usr/bin/vim', str(gi_path)] vim_proc = subprocess.run(vim_args, check=True) # Convert from ``.gi`` to ``.gitignore`` decode_gitignore(gi_path, gitignore_path) except CalledProcessError: pass finally: # Remove ``.gi`` gi_path.unlink()vimを呼ぶ
subprocess.runでvimを呼出し、CalledProcessError例外がなければOKというざっくりスタイル。楽で良いですね。
.giは残さない
try〜finallyを使って、最終的に.giファイルは捨てちゃってます。エラーなら.gitignoreの編集もしないので環境に配慮されていますね。素材をもとに
.gitignoreを作る
.giファイルはこの時点でファイルシステム上に普通にあるので、普通にファイルとして開く感じです。
そして、言語側の情報をまとめてgitignore.ioにパス。
HTTPステータスが404の時に限り、通常と同じようにレスポンスを保存してますが、
これは「マスターに存在しない情報を含む」ケースが全て404になるっぽいためです。
唯一と言っていい、ちょっとした工夫点ですね。def decode_gitignore(src, dest): custom = [] online = [] with src.open() as fp: # .giファイルを開いて、デリミタの前後を分けるなど if online: url = f'https://www.gitignore.io/api/{",".join(online)}' req = Request(url, None, headers={'User-Agent': 'vigi'}) try: resp = urlopen(req) custom.append(resp.read().decode()) except HTTPError as err: if err.code == 404: custom.append(resp.read().decode()) raise err with dest.open('w') as fp: fp.write('\n'.join(custom))結:使用感とか
一応、
vigiプロジェクト内にある.gitignoreはこのコマンドベースで作りました。編集時点で表示される行数が格段に減るのはメリットではあるかなと思います。
そういう意味ではMVPとしての仕事はきちんと全うしてくれました。ただ、言語マスターにどんなパターンが含まれているかが、
.gitignoreへの変換を終えないとわからないので、
仮にもうちょっと開発してみようと思ったら、きちんとパターン候補から言語マスターを引っ張り出すようにしないと、
本当に良いものなのかはわからないですね。何かの言語のトレーニングには向いてるかも?

- 投稿日:2019-12-24T23:19:10+09:00
学習記録 その11(15日目) Kaggle参加
学習記録(15日目)
勉強開始:12/7(土)〜
教材等:
・大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年):12/19(木)読了
・Progate Python講座(全5コース):12/21(土)終了
・Andreas C. Müller、Sarah Guido『(邦題)Pythonではじめる機械学習』(オライリージャパン、2017年):12月23日(土)読了Kaggle初参加
参加コンペ:Real or Not? NLP with Disaster Tweets 12/24(火)〜
ツイートのうち、災害に関する情報を示したものとそうでないものを仕分けするという問題です。
分野としては自然言語処理に当たります。開催期間は来年の3月までですが、遅くとも本日から約2週間後の1月10日(金)までを目安として一度submitしたいと考えています。
今お世話になっている某大学の研究室の方々と幸運にもチームを組むことができたため、非常に心強い状況ではありますが、頼りきりにならないようしっかりとアウトプットしていきます。
データ前処理
・head(), shape, describe() でデータの概要を把握
・訓練データの欠損値及びその数を把握
・drop('データラベル名', axis=1) で不必要(と思われる)箇所をカット
・df["データラベル名"] で該当するテキスト部分を抽出し、tolist() でリスト化データ抽出・コーパス作成
・ストップワードを定義し(and や or)、split() で分割
・lower() で全て小文字に、さらに for構文でsplitを使用し単語に分割
・pprint()で出力(pprintだと要素毎に改行が入り見やすくなる。)
・単語の出現回数をカウントし、指定回数以下のものを除外
・完成した単語列を gensimのcorpora.dictionary()を用いて辞書化(コーパス完成)
・LDAモデルに変換ここまででベクトル化には成功したものの、ただ変換しただけなので次元数が数千に至っており、かつ、災害に関する情報かそうでないかを示すtargetと抜き出した情報が結びついていないことに気が付きました。
今の所、結びつける方法について検討も付きませんが、また明日引き続き挑戦します。
- 投稿日:2019-12-24T22:09:17+09:00
PyCharm環境が壊れたと思ったらファイル名のせいだった話
はじめに
これはFatal Python errorが出てPyCharm環境が壊れたと思ったら.pyファイル名のせいだったという話です。
初心者あるあるだと思いたい。環境
Windows10 + Anacondaでpython 3.7の仮想環境を作りPyCharmで実行
この組み合わせにたどり着くまでに幾度も苦難があったため、既にpythonに恐れを抱いている人間がこの記事を書いています。エラー発生までの経緯
Python3エンジニア試験の勉強中に出てきたreprlibについて、動作確認しようと思い以下のコードを書いて.pyファイルを作成しました。
import reprlib reprlib.repr(set('abcdefg'))2行なので超気楽に実行するとまさかのエラー。。。
Fatal Python error: initsite: Failed to import the site module Traceback (most recent call last): File "C:\XXXXXXXX\Anaconda3\envs\py37\lib\site.py", line 168, in addpackage exec(line) # (中略) File "<プロジェクトフォルダ>\reprlib.py", line 2, in <module> reprlib.repr(set('abcdefg')) AttributeError: module 'reprlib' has no attribute 'repr'※エラーメッセージに既に答えが出ていますが、初心者は気付かないのが常です。
エラー解消までの流れ
今まで動いていたプログラムの確認
試験の例題通りのプログラムなのでプログラムのせいではない、と考え、前回PyCharmを使ってからの間で何か環境が変わってしまったのではないか、と予想しました。
そこでとりあえず今まで動いていたpythonプログラムが動くか確認しようと実行。a = 100 b = 50 c = a + b print(c)ただの足し算ですが、
Fatal Python error: initsite: Failed to import the site module # (中略) File "<プロジェクトフォルダ>\reprlib.py", line 2, in <module> reprlib.repr(set('abcdefg')) AttributeError: module 'reprlib' has no attribute 'repr'reprlibを使っていないのにさっきと全く同じエラーが発生。
⇒PyCharmがプログラムを読み込めていない…?Google先生に聞いてみる
"Failed to import the site module"で検索すると、pythonのバージョンが異なるとかpathが間違ってるとかモジュール名が間違ってるとかが出てきました。
PyCharmがプログラムを読めていなさそうだということもあり、Anaconda Navigatorから以下を確認。
- Environmentsで仮想環境がActiveにできる
- ターミナルでpythonが打てる
- ターミナルでimport reprlibを打ってもエラーにならない
⇒Anacondaは問題なさそう。やはりPyCharmの設定がおかしくなった…?PyCharm再インストール
自分の手で設定を変更した記憶はない、となるととりあえず再インストールを試すのが早いと判断。
PyCharmをアンインストール→再インストール後、再度足し算プログラムを実行。Fatal Python error: initsite: Failed to import the site module # (中略) File "<プロジェクトフォルダ>\reprlib.py", line 2, in <module> reprlib.repr(set('abcdefg')) AttributeError: module 'reprlib' has no attribute 'repr'な゛ん゛て゛か゛わ゛ら゛な゛い゛の゛
仮想環境作り直し
PyCharmと仮想環境の連結がおかしいのかも?と思って
やけくそで仮想環境を別名で作り直し→PyCharmからインタプリタを再設定し足し算プログラム実行。Fatal Python error: initsite: Failed to import the site module # (中略) File "<プロジェクトフォルダ>\reprlib.py", line 2, in <module> reprlib.repr(set('abcdefg')) AttributeError: module 'reprlib' has no attribute 'repr'そろそろ見飽きた。
キャッシュを疑う
PyCharmを再インストールしたものの、アンインストール時に消されていない何かがあるのでは??そういえば再インストールするときなんかConfig読みに行ってたし。と思いPyCharmのプロジェクトフォルダ内を確認。
すると__pycache__とかいう怪しいフォルダを発見!!
これだ!!PyCharm再々インストール
__pycache__フォルダを削除し、本日2度目のPyCharm再インストール。
今度こそ綺麗な環境になったのできっと動くでしょう、と祈り、足し算プログラム実行。150 Process finished with exit code 0ほらねーー!!
そしてreprlibプログラム実行!!Fatal Python error: initsite: Failed to import the site module # (中略) File "<プロジェクトフォルダ>\reprlib.py", line 2, in <module> reprlib.repr(set('abcdefg')) AttributeError: module 'reprlib' has no attribute 'repr'神よ。。。
天啓を得る
まだ何かが残っているのは間違いないと思い、プロジェクトフォルダを再度確認すると、また__pycache__フォルダができていました。
そういえば何が入ってるんだろう、と思い中を確認。reprlib.cpython-37.pyc
ん゛?
何が起こったのか
拡張子pycはpythonがコンパイルされたときに作成されるファイルです。
作成タイミング:
1. モジュールのインポート初回
2. モジュールのインポート2回目以降で、既にpycファイルが存在するが、pyファイルと比較しタイムスタンプが古い場合
参考:https://techacademy.jp/magazine/19131エラーメッセージに出ていますが、今回import reprlibをする.pyファイル名をreprlib.pyとしていました。
これが実行されると、import対象モジュールと同名でプロジェクトフォルダの下に新しくreprlibがコンパイルされてしまうため、その新しい方をpythonが実行しにいってしまい、正しいreprlibを呼び出すことができなかったと思われます。(不具合のある自作モジュールを作ったと同義)
reprlibをimportしていない足し算プログラムも動かなかった理由についてはよく分かりません。。。推測ですが、プロジェクトフォルダ内の.pyc検索が.pyよりも先に実行されているのかも。解決策
import reprlibをする.pyファイル名をreprlib.pyから別の適当な名前に変更したら、あっさり実行できました。
なお、通常の__pycache__はAnacondaの場合 ~\Anaconda3\envs\<仮想環境名>\Libの下にあります。自作モジュールを作っていないのにプロジェクトフォルダの下にある場合は疑った方がいいです。教訓
- .pyファイル名は既存のモジュール名と別の名前にする。
- もう少しpythonについて調べてから動く。(pycacheが何か調べていればPyCharm再々インストールは不要だった)
お粗末様でした。
- 投稿日:2019-12-24T21:34:01+09:00
クリスマスなのでFPGAでクリスマスツリーを実装する
はじめに
何が楽しくて聖夜の夜にFPGAをいじってるのかわかりませんが、何故かクリスマスツリーを作ってみました。
やってることはとても簡単で、FPGAでLチカさせて、100均のツリーに飾りました。
また、今回はあえてハードウェア記述言語に触らず、Pythonによる高位合成(Polyphony)のみでやってみました。
環境
FPGAボード
- DE2-115
言語・ライブラリ等
- Python3.6
- Polyphony(0.3.6)
その他
- ちょっと広めの机
- (電気を消しても怒られない環境)
実装
Lチカ
LEDをチカチカさせること。通称Lチカ。
このLチカをPolyphonyの公式チュートリアルに沿って実装します。
参考: Python で FPGA これが Lチカだというか、Polyphonyの開発者が「これが"Lチカ"だ」とおっしゃっていたので、これが"Lチカ"です。
恐れ多いですが、このコードを少しいじって、個人的に好きな書き方(や変数名)にしていきます。blink.pyfrom polyphony import testbench, module, is_worker_running from polyphony.io import Port from polyphony.typing import bit # onとoffの数字に名前付け ON = 1 def wait_1_clock(): """ for文中で 1 clock 何もしない """ pass @module class Blink: """ FPGAボードに乗っているLEDを光らせる """ def __init__(self, interval): self.led = Port(bit, 'out') self.interval = interval self.append_worker(self.main) def main(self): # 初期化 led_bit:bit = ON # waitの間隔でチカチカ光らせるループ while is_worker_running(): self.led(led_bit) led_bit = ~led_bit # OFF->ON, ON->OFF self._wait() def _wait(self): for _ in range(self.interval // 2): wait_1_clock() blink = Blink(10)
self.append_worker(self.main)でIDEと自分の脳が?みたいな警告してきますが、無視して大丈夫です。1bitの値の反転に
b=1-bのような書き方をすることに違和感があったので、b=~bに書き換えました。
for i in range(x):の書き方もiを使ってないので_にしました。
for文の中もpassのみで見た目が悪かったので、無理やりpassにwait_1_clock()と名付けました。コンパイルすると、Lチカするハードウェア記述言語のファイルが生成されます。
$ polyphony blink.pyPolyphonyの動作確認
そんなこんなで作ったLチカですが、本当にPythonでFPGAが動くのか?と不安があるのでテストをしてみました。
これを見た感じでは、LEDがチカチカするのできているようですが、1回チカチカさせるのに少しの遅延があり、
1 interval + 4 clockありそうです。
これにより、Pythonのプログラム中でinterval = interval - 4ををすることで、正確な時間でチカチカさせる事ができます。複数Lチカ
イメージではこんなものを作りたい。
1秒毎にチカチカするLEDを0.5秒ずらして並べればできそうなので、先程のコードに継ぎ足していきます。
blinks.pyfrom polyphony import testbench, module, is_worker_running from polyphony.io import Port from polyphony.typing import bit # onとoffの数字に名前付け OFF = 0 ON = 1 def wait_1_clock(): """ for文中で 1 clock 何もしない """ pass @module class Blinks: """ FPGAボードに乗っているLEDを光らせる """ def __init__(self, interval): # 全18個分のLED self.led00 = Port(bit, 'out') self.led01 = Port(bit, 'out') self.led02 = Port(bit, 'out') self.led03 = Port(bit, 'out') self.led04 = Port(bit, 'out') self.led05 = Port(bit, 'out') self.led06 = Port(bit, 'out') self.led07 = Port(bit, 'out') self.led08 = Port(bit, 'out') self.led09 = Port(bit, 'out') self.led10 = Port(bit, 'out') self.led11 = Port(bit, 'out') self.led12 = Port(bit, 'out') self.led13 = Port(bit, 'out') self.led14 = Port(bit, 'out') self.led15 = Port(bit, 'out') self.led16 = Port(bit, 'out') self.led17 = Port(bit, 'out') self.led20 = Port(bit, 'out') self.led21 = Port(bit, 'out') self.led22 = Port(bit, 'out') self.led23 = Port(bit, 'out') self.led24 = Port(bit, 'out') self.led25 = Port(bit, 'out') self.led26 = Port(bit, 'out') self.led27 = Port(bit, 'out') self.interval = interval self.append_worker(self.main) def main(self): # 初期化 led_bit_ptn0:bit = OFF led_bit_ptn1:bit = ON # waitの間隔でチカチカ光らせるループ while is_worker_running(): self.led00(led_bit_ptn0) self.led01(led_bit_ptn1) self.led02(led_bit_ptn0) self.led03(led_bit_ptn1) self.led04(led_bit_ptn0) self.led05(led_bit_ptn1) self.led06(led_bit_ptn0) self.led07(led_bit_ptn1) self.led08(led_bit_ptn0) self.led09(led_bit_ptn1) self.led10(led_bit_ptn0) self.led11(led_bit_ptn1) self.led12(led_bit_ptn0) self.led13(led_bit_ptn1) self.led14(led_bit_ptn0) self.led15(led_bit_ptn1) self.led16(led_bit_ptn0) self.led17(led_bit_ptn1) self.led20(led_bit_ptn0) self.led21(led_bit_ptn1) self.led22(led_bit_ptn0) self.led23(led_bit_ptn1) self.led24(led_bit_ptn0) self.led25(led_bit_ptn1) self.led26(led_bit_ptn0) self.led27(led_bit_ptn1) led_bit_ptn0 = ~led_bit_ptn0 # OFF->ON, ON->OFF led_bit_ptn1 = ~led_bit_ptn1 # OFF->ON, ON->OFF self._wait() def _wait(self): for _ in range(self.interval): wait_1_clock() # 1 interval = 1 clock = 50 MHz = 20 ns # 1 s = 50,000,000*20 ns = 50,000,000 interval # 4 clockの遅延を考慮 blink = Blink(49999996)単純にLED(Portのインスタンス)を増やして、メインループもそれに対応させ、1秒のインターバルになるようにしました。
この後はPolyphonyでコンパイルして生成されたverilogコードをFPGA用のソフトウェアでコンパイルして、ピンを配置して、FPGAに書き込みして、などなどの作業がありますが、FPGAの知識が無いと少し難しいので省略します。
物理
最後にツリーの実装です。こちらもとてもかんたんで、ツリーにFPGAボードを乗せるだけです!
ただ、FPGAボードは重たいので、そのまま木の枝に乗せると落ちてしまいます。
なので、今回は「本」で主に支えて「プラスチックコップ」でバランスを保ち、木の枝を間から出す作戦を取りました。イメージ図
あとは、それっぽい角度から写真を撮れれば完成です。
完成物
明るいところver
暗いところver
マウスとかVGAケーブルとか飾ってみたver
後ろのディスプレイにクリスマスっぽい画像を写すのがポイントです。
ソースコード







- 投稿日:2019-12-24T21:33:58+09:00
SIGNATE『【練習問題】レンタル自転車の利用者数予測』をやってみた
はじめに
今回、SIGNATEの『【練習問題】レンタル自転車の利用者予測』に取り組みました。機械学習については、学びたてでまだ多くのことができていない状況ですが、コンペなどを通じて少しずつ成長していければなぁと思っています。
コンペの内容
下記の練習問題に取り組みました。
【練習問題】レンタル自転車の利用者数予測
2年間の季節情報や気象情報から、各日の1時間ごとのレンタル自転車の利用者数を予測するこのモデルを作成していただきます
実際のコード
1.データの読み込み
# ライブラリのインポート import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline# ファイルの読み込み・表示 train = pd.read_csv('train.tsv',sep='\t') test = pd.read_csv('test.tsv',sep='\t') train.head()
2.データ内容の把握
# 利用状況をプロットしてみる plt.figure(figsize=(12,5)) plt.plot(train['id'],train['cnt'])
# 試しにとある1週間の利用状況をプロット # 1.日付ごとに変数に格納 _day0703 = train.query('dteday == "2011-07-03"')# 日 _day0704 = train.query('dteday == "2011-07-04"')# 月 _day0705 = train.query('dteday == "2011-07-05"')# 火 _day0706 = train.query('dteday == "2011-07-06"')# 水 _day0707 = train.query('dteday == "2011-07-07"')# 木 _day0708 = train.query('dteday == "2011-07-08"')# 金 _day0709 = train.query('dteday == "2011-07-09"')# 土# 2.各日付をグラフ表示 plt.figure(figsize=(12,5)) plt.plot(_day0703['hr'],_day0703['cnt'],label='Sun') plt.plot(_day0704['hr'],_day0704['cnt'],label='Mon') plt.plot(_day0705['hr'],_day0705['cnt'],label='Tue') plt.plot(_day0706['hr'],_day0706['cnt'],label='Wed') plt.plot(_day0707['hr'],_day0707['cnt'],label='Thu') plt.plot(_day0708['hr'],_day0708['cnt'],label='Fri') plt.plot(_day0709['hr'],_day0709['cnt'],label='Sat') plt.legend() plt.grid()
・休日と平日で利用状況が異なるらしい。
・平日では、午前6~10時、午後16~21時が多く利用されているため、通勤・通学などに用いられてそう。休日、また時間帯によって利用状況が変化するため、線形回帰は不向きと考えXGBoostを選択。
3.XGBoostを使った学習
# XGBoostのライブラリのインポート import xgboost as xgb from sklearn.model_selection import GridSearchCV from sklearn.metrics import mean_squared_error# xgboostモデルの作成 reg = xgb.XGBRegressor()# id2500以前は、傾向が違うため、カット(運用開始など?) train = train[train['id'] > 2500]# 説明変数、目的変数を格納 X_train = train.drop(['id','dteday','cnt'], axis=1) y_train = train['cnt'] X_test = test.drop(['id','dteday'], axis=1)# ハイパーパラメータ探索 reg_cv = GridSearchCV(reg, {'max_depth': [2,4,6], 'n_estimators': [50,100,200]}, verbose=1) reg_cv.fit(X_train, y_train) print(reg_cv.best_params_, reg_cv.best_score_)# 改めて最適パラメータで学習 reg = xgb.XGBRegressor(**reg_cv.best_params_) reg.fit(X_train, y_train)4.モデルの確認
# 学習データを使って予測 pred_train = reg.predict(X_train)# 予測値が妥当か確認 train_value = y_train.values _df = pd.DataFrame({'actual':train_value,'pred':pred_train}) _df.plot(figsize=(12,5))
おおむね、正しく予測できていそう。
5.評特徴量の重要度を確認
# feature importance のプロット importances = pd.Series(reg.feature_importances_, index = X_train.columns) importances = importances.sort_values() importances.plot(kind = "barh") plt.title("imporance in the xgboost Model") plt.show()
6.提出ファイルの作成
# テストデータに対し予測値の算出 pred_test = reg.predict(X_test)# 結果を張り付け、ファイル出力 sample = pd.read_csv("sample_submit.csv",header=None) sample[1] = pred_test sample.to_csv("submit01.csv",index=None,header=None)結果&まとめ
209人中29位でした。
今回は、単純にXGBoostに入れただけなので、他にも特徴量を作り上げたり、別の学習モデルやアンサンブル学習など、いろいろ工夫する余地がありそうです。
また再チャレンジできたらと思っているので、その時にはまた記事にしたいと思います。





- 投稿日:2019-12-24T21:33:35+09:00
UbuntuServer18.04 + Apache2でPythonCGIを動かすまで
経緯
- デスクトップのWindows10がぶっとんだ
- Djangoが使えなかった
- でもでもWebアプリっぽいの作りたい!
そうだ!CGIにしよう!
というなんとも情けない経緯で始めることになりました。
実際にやってみると微妙なところで結構詰まったりしたのでこの通りにすればとりあえずは動くはずと言うのを紹介していきます。前準備
- サーバに固定IPアドレスを割り当てる
- 自宅であればルーター設定から割り当てられるはず
- 携帯とか会社はわかんない
- ネットワークをDDNSと紐付ける(MyDNS.JPの説明)
- 117.125.xxx.xxxとかでアクセスするのダサい
- グローバルIPアドレスを晒すことになり非常に危険
- なんかそれっぽくなる
- Python3をインストール済み
Apache2の準備
インストール
sudo apt install apache2これ一行で問題なし。
UbuntuServerの導入時に「LAMP Server」を選択していればインストールはすでに終わっているので無視して構わない。cgiモジュールの有効化
user@hostname:~# sudo a2enmod cgid Enabling module cgid. To activate the new configuration, you need to run: systemctl restart apache2 user@hostname:~# sudo systemctl restart apache2有効化が正常に完了していれば
/usr/lib/cgi-binがドCGIのドキュメントルートとして認識されます。
このままでは通常のドキュメントルート/var/www/htmlと場所が違いすぎて面倒なのでドキュメントルートの変更を行う。ドキュメントルートの変更 #任意
新規ファイルを作成する。
user@hostname:~# sudo vi /etc/apache2/conf-available/cgi-bin.conf内容は
/etc/apache2/conf-available/cgi-bin.conf<Directory "/var/www/cgi-bin"> Options +ExecCGI AddHandler cgi-script .cgi .py </Directory>作成できたら設定ファイルをApache2に認識させる必要がある。
user@hostname:~# mkdir /var/www/cgi-bin user@hostname:~# sudo a2enconf cgi-bin Enabling conf cgi-bin. To activate the new configuration, you need to run: service apache2 reload user@hostname:~# sudo systemctl restart apache2コーディングの注意点
- Shebangの記入は必須
- ないと正常に認識されない
- 開発環境とサーバで環境が変わる場合はShebangの変更を忘れない
もしもエラーが出たら
403 Forbidden(権限エラー)
該当のファイルの権限が間違っている可能性がある。
ターミナルでファイルの場所を開き権限を設定する。user@hostname:~# sudo chmod 755 xxx.cgi500 Internal Server Error(スクリプトエラー)
多分一番わかりにくいエラーコード。
エラーログを見るのが一番だけどありがちなのを2つ紹介する。1. Pythonモジュールがインストールされていない
ModuleNotFoundError: No module named 'hoge'が表示されたらとりあえずpip install hogeでOK。
pipコマンドでインストールできなければGithubから探してくるのも一つの手段。2. 日本語が入るとエラーになる
実際に遭遇した例だと半角文字のみの場合は問題なく表示されるが全角文字が含まれるとエラーになったことがあった。
どんな手を使ってもファイルを読み出す時点で文字化けしていたのではさすがにスクリプト内で対処するのは難しい。
そこでApache2の設定を変更する。/etc/apache2/conf-available/charset.conf# 一行追記 AddDefaultCharset UTF-8筆者の場合はこれで解消された。
502 Bad Gateway(応答なし)
- ルーターのポート開放はできているか
- ファイアーウォールの設定を解除できているか
sudo ufw allow 80- Apacheは起動しているか
これらの可能性をもう一度洗い直してみよう。
- 投稿日:2019-12-24T21:30:47+09:00
可視化ウェブフレームワークDashでAltairやmatplotlibを使う
クリスマスイブにこの記事を書いています。こんばんは。
この記事はPythonその4アドベントカレンダーの24日目の記事です。
本日は色々なグラフモジュールを使用できる、Dashのモジュールdash_alternative_vizをご紹介します。実はこれを主役にしようと思っていたのですが、Altairの絵文字可視化が凄いので、そっちが主役な感じの記事になったかもしれません。
開発環境は以下のようになっています。
- Windows10 Pro WSL
- dash 1.7.0
- dash_core_components 1.6.0
- dash_html_components 1.0.2
- dash_alternative_viz 0.0.1
- plotly 4.4.1
- altair 4.0.0
- holoviews 1.12.7
- matplotlib 3.1.2
- seaborn 0.9.0
- pandas 0.25.3
Dashとは
その前に一先ず、Dashとは何かというご紹介から。
DashとはPlotly社が作成する、OSSのウェブフレームワークです。Plotly.js、React.js、Flaskを組み合わせて作成されており、インタラクティブにデータが可視化できるのと、それをウェブアプリケーションとして共有できるのが特徴です。
ドキュメントも充実しており、これを読みながら作ると簡単にアプリケーションが作れるようになります。
こんな感じで動くチャートを作れるのでDash凄い!!ってなっていたわけですが、可視化をするのにエクスタシーを感じる我々としては、徐々にこの種類のグラフはseabornの方がいいよなぁとか、Altairの方が良いよなぁとか思い始めます。
少し前にPanelというDashによく似たコンセプトで作成されたうえに、色々なグラフモジュールが使えるものが出たのですが、ちょっと使い方が素人の私には難しくどうしたもんかなぁと思っていました。
dash_alternative_viz
そして最近見つけたのがdash_alternative_vizです。
https://github.com/plotly/dash-alternative-viz
これはDashのコンポーネントとしてテスト的に作られているようですが、Dashアップリケーションのコンポーネントとして、Matplotlibやseaborn、bokehにAltairのグラフが使えるというモジュールになっています。
Dashの簡単さで色々なグラフモジュールが使えるなんてすごい。ということで早速実際に見てみましょう。まずは、githubにあるusage.pyを実行します。
ちなみに左上がplotly.express、右上がseaborn、左下がAltair、右下がholoviews(bokeh)で作成したグラフです。上のスライダの動きに反応して、全てのチャートが動いていますね。
先ほどのものをスライダからドロップダウンにするとまた違ったアプリケーションになり、これはこれで趣があります。
こんな感じで今のところ、Pythonを代表する4つの可視化ライブラリが使えるdash_alternative_viz、かなり使い勝手が良いと思います。
ちなみにdashのインストールは
pip install dashでdash、dash_html_components、dash_html_components、dash_tableという基本的なツールはインストールできます。dash_alternative_vizのインストールは、
pip install git+https://github.com/plotly/dash-alternative-vizで完了です。本来はこれをもっと、使いまわそうかと思ったのですが、トンデモナイ機能がAltairにあったので、そちらの紹介をして終わります。
Altairの絵文字表示vizが凄い
dash_alternative_vizを紹介するにあたり、各ライブラリの使い方なんかを見ていました。holoviewsはめちゃ難しいなと思いました。
そうして、Altairのドキュメントを見る番になりました。実は以前このツールをお勧めされて、結構気に入って使っていたのですが、最近はDashを使うようになってしまいあまり使わなくなっていました。だがしかし、これを見て虜になりました。
https://altair-viz.github.io/gallery/isotype_emoji.html
なんとAltairでは絵文字が可視化できるのです!!!
インフォグラフィック系の本を読んで面白そうだなぁと思ったことがあるのですが、何か自分で作ったりしないとできないしなぁという感じで諦めていました。しかし、Altairならそのような可視化もできるのです。
おおおおおお!!!!
というわけで、この記事で言いたいことは以下の2点です。
- dash_alternative_vizはまだ本格的に作成されるのか分からないけど、凄いよ!
- Altairの絵文字可視化は革命的!
ちなみにこのアプリケーションのスクリプトは以下に掲載します。
import dash from dash.dependencies import Input, Output import dash_html_components as html import dash_core_components as dcc import dash_alternative_viz as dav import pandas as pd import altair as alt source = pd.DataFrame([ {'country': 'Great Britain', 'animal': 'gold'}, {'country': 'Great Britain', 'animal': 'gold'}, {'country': 'Great Britain', 'animal': 'gold'}, {'country': 'Great Britain', 'animal': 'silver'}, {'country': 'Great Britain', 'animal': 'silver'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'Great Britain', 'animal': 'bronze'}, {'country': 'United States', 'animal': 'gold'}, {'country': 'United States', 'animal': 'gold'}, {'country': 'United States', 'animal': 'gold'}, {'country': 'United States', 'animal': 'gold'}, {'country': 'United States', 'animal': 'gold'}, {'country': 'United States', 'animal': 'gold'}, {'country': 'United States', 'animal': 'gold'}, {'country': 'United States', 'animal': 'gold'}, {'country': 'United States', 'animal': 'gold'}, {'country': 'United States', 'animal': 'silver'}, {'country': 'United States', 'animal': 'silver'}, {'country': 'United States', 'animal': 'silver'}, {'country': 'United States', 'animal': 'silver'}, {'country': 'United States', 'animal': 'silver'}, {'country': 'United States', 'animal': 'silver'}, {'country': 'United States', 'animal': 'bronze'}, {'country': 'United States', 'animal': 'bronze'}, {'country': 'United States', 'animal': 'bronze'}, {'country': 'United States', 'animal': 'bronze'}, {'country': 'United States', 'animal': 'bronze'}, {'country': 'United States', 'animal': 'bronze'}, {'country': 'United States', 'animal': 'bronze'}, {'country': 'Germany', 'animal': 'gold'}, {'country': 'Germany', 'animal': 'gold'}, {'country': 'Germany', 'animal': 'gold'}, {'country': 'Germany', 'animal': 'gold'}, {'country': 'Germany', 'animal': 'silver'}, {'country': 'Germany', 'animal': 'silver'}, {'country': 'Germany', 'animal': 'silver'}, {'country': 'Germany', 'animal': 'silver'}, {'country': 'Germany', 'animal': 'silver'}, {'country': 'Germany', 'animal': 'silver'}, {'country': 'Germany', 'animal': 'bronze'}, {'country': 'Germany', 'animal': 'bronze'}, {'country': 'Germany', 'animal': 'bronze'}, {'country': 'Germany', 'animal': 'bronze'}, {'country': 'Germany', 'animal': 'bronze'}, {'country': 'Germany', 'animal': 'bronze'}, {'country': 'Germany', 'animal': 'bronze'} ]) app = dash.Dash(__name__) app.layout = html.Div([ html.H1("各国のメダル獲得数"), dav.VegaLite(spec=alt.Chart(source).mark_text(size=45, baseline='middle').encode( alt.X('x:O', axis=None), alt.Y('animal:O', axis=None), alt.Row('country:N', header=alt.Header(title='')), alt.Text('emoji:N') ).transform_calculate( emoji="{'gold': '?', 'silver': '?', 'bronze': '?'}[datum.animal]" ).transform_window( x='rank()', groupby=['country', 'animal'] ).properties(width=700, height=200).to_dict()) ]) if __name__ == "__main__": app.run_server(debug=True)




- 投稿日:2019-12-24T20:38:51+09:00
ハッカソンは開催者のお気持ちを汲み取ることが何よりも大切だという経験談
はじめに
こんにちは。
社会性を気にせずただ作りたいものを作っている者です。
(もちろん気にするときもあります)もうこのWeekend Engineer Advent Calendar 2019に投稿するのもこれで3日目となります。
週1で自分で作ったものをQiitaで投稿しているわけですね。どんどん内容が雑になってるような気がする
もう少し評価されたいものです。さて今回作ったものは、「スパルタルーム」です。
これは、12月頭にあったKDDIさんの学生向けハッカソン KDGHACKSにてチームで開発したものになります。対象者
- IoTネタを探している人
- 最近のハッカソンに対して悶々とした気持ちがある人
- タイトルに対し面白そうだなあと感じた人
何を作ったか
スパルタルームは、こんな風にスマホやPCから家電を操作することができるプロダクトです。
ただし、家電を操作しようとすると、プログラミングや数学や英語の問題が表示されます。
それらの問題を解くことで、ようやく操作が赤外線リモコンに送られ、家電が動くわけです。これで、電気をつけるとき、エアコンをつけるとき、TVをつけるときなど、日常的な生活を行うためには強制的に勉強をさせられる超ストイックな部屋が完成するわけです。
動機
「最強のエンジニアになりたい!」
そのためには、毎日プログラミング問題を解いて、毎日英語の勉強をして、あとは多分数学の勉強もすれば良さそう!!
でも、そんなの自分だけじゃ続けられない。。怠けちゃう。。。どうしよう。。。
そういった悩みをもつ全てのエンジニアの課題を解決するために本プロダクトのアイデアを思いつきました。もちろん本番のハッカソンでは、他にもアイデアが出たのですが、1番(エンジニアとして)身近に感じている課題であり、アイデアとしてユニークなのではないか、という理由からこれが選ばれました。
加えて、何より過去の優勝者の方の作品がかなり独創性重視のものだったので、きっとこのハッカソンは数ある評価軸の中でも独創性の重みが高いんだろう!という仮説がありました。
技術的な説明
アプリはFlaskでできており、Herokuにデプロイされています。
アプリ内では、操作した家電に合わせて、それぞれ問題の種類が設定されており、毎回外部からランダムに問題を表示するようにしています。(現段階では決まった問題しか表示されません)
それを解くことで、専用の赤外線リモコンに通信が送られ、実際に家電が動くわけです。なぜ評価されなかったのか
結論から言うと、入賞できませんでした。
以下、今後ハッカソンに出る人に向けて自分の考察を載せます。評価軸は満たしていた(はず)
本ハッカソンの評価軸は以下の通りでした。
- アイデアに独創性、夢があること
- 情熱を持って取り組めたか
- 持ち前の技術力を発揮できたか
- 生活が便利になるか、豊かになるか
- 会場の参加者に共感が得られたか
- 動くデモがあること
これらを総合的に評価するとのことでした。
*本プロダクトでいうと、「生活が便利になるか、豊かになるか」という点を除けばかなり相対的に見ても高評価のように思えました。 *開催者のお気持ちを汲み取れなかった
実は本ハッカソンは「IoTでワクワクする空間をデザインしよう」というテーマだったのですが、本プロダクトでIoTっぽいことといえば、赤外線センサーへの通信のみでした。
1位のチームや他のどの入賞チームを見ても、みんなセンサーっぽいものを使用していました。
正直それ、PCの内臓カメラでよくね?実用的に考えてそこセンサーいらなくね?という場面でも、〇〇センサーみたいなものを出来るだけ使っている印象でした。個人的な感想ですが、実用性や独創性といった評価軸よりも、開催者の気持ちにどれだけ寄せられているかをもっと重視すればよかったように思えます
今回のハッカソンでいうと、開催者はKDDI社をはじめセンサー系の製品を売っている会社様ばかりでした。
彼らがわざわざ休日を潰し、スポンサー費用等でお金をかけ、(プロに比べればそんなに技術力もない)学生を集めて、実質開発期間が1日もないイベントを開催している、という状況から、はなから実用的なものは求めていないと言う点や、会社の製品を出来るだけ実際に使ってもらいたいというお気持ちを察することが重要だったようです。(今回のハッカソンにかかわらず、休日で行われるような短いハッカソンにおいて実用性はほとんど期待されていないように感じます)
社会性という虚像
加えて、「社会性」という言葉が審査員フィードバックコメントの中で何度か出てきました。
評価軸に直接そのような項目はなかったのですが、社会性が入賞に影響を与えたようです。終わりに
ハッカソンは新しい仲間に出会えたり、普段1人では絶対に作らないようなくだらないプロダクトをつくる機会として個人的にとても好きです。
しかし、一方で、最近はただ面白いものを作ったりするよりも、開催企業の気持ちに寄せたり、社会性のありそうなものばかりが評価されているように感じます。
至極当たり前のようにも感じますが、この形式のハッカソンでは平日の仕事や研究となんら変わらないし、(社会性やマーケットサイズから逆算的に形式的にアイデアを組み立て、賞をとったら結局何も実行しない)ビジコンとなんら変わらないようなものにも感じています。
もっと、ただ自分の作りたいものを作り、面白いかどうかという軸だけでオーディエンスが優勝者を決めるハッカソンが増えたら個人的に嬉しいなとも感じています。
ので、自分で開催してみることにしました!こちらにコンパスのページをとりあえず作りました!まだ日程以外全然詳細は決まっていないですが、少しでも興味のある方いれば参加予定だけしておいてもらえると、詳細決まり次第連絡できますので、どうかよろしくお願いいたします!
最後まで読んでいただきありがとうございました。
Twitterで個人開発したもの発信しているので、興味がある方フォローや連絡ください!では。




- 投稿日:2019-12-24T19:55:09+09:00
Wagtailを触ってみた(2)。django-extensionsの導入。
はじめに
こんにちは。
Wagtailを使って開発を進めていきたいところですが、現状ではデバッグ等に必要なライブラリが何もインストールされていません。
デバッグで使えるDjangoのライブラリといえば、django-extensionsかdjango-debug-toolbarなどが挙げられますね。それしか知らないらしいそこで今回は、django-extensionsを導入したので、その流れをまとめました。Djangoのライブラリについても調査してみたいと思います。
django-extensionsの導入
django-extensionsの導入の流れについて書いておきます。
僕はmacでやりました。まず、下記コマンドを実行します。
pip install django-extensions次に、mysite/settings/base.pyのINSTALLED_APPSにdjango-extensionsを追記します。
これだけで基本機能は使えますが、一部使えないものがあります。
モデルのER図(後述)が生成できるコマンドがありますが、それにはいくつかの手順が必要でした。brew install Graphviz pip install pygraphvizエラーが出てうまくいかなかったですが、このISSUEを見れば解決できました。
参考:Cannot install pygraphviz on Mac OS 10.11.6
django-extensionsを試す
□show_urls
django-extensionsの機能はなかなか便利ですよ。
一つ目に紹介するものは、show_urlsです。python manage.py show_urlsDjangoのプロジェクトに設定されているURLの「View」や「template」における関係が一覧となって表示されます。
この表現だとわかりにくいと思うので、まずは実行ログをみてみましょう。(一部抜粋)/django-admin/login/ django.contrib.admin.sites.login admin:login /django-admin/logout/ django.contrib.admin.sites.logout admin:logout /django-admin/password_change/ django.contrib.admin.sites.password_change admin:password_change /django-admin/password_change/done/ django.contrib.admin.sites.password_change_done admin:password_change_done左側の/django-admin/login/などは、
http://localhost:8000/
の後に続くパス(URLパターン)を表しています。中央のdjango.contrib.admin.sites.loginなどは、view関数の所在を表しています。
djangoのGithubでdjango.contirib.admin.sitesを見てみましょう。login関数があることが分かりますね。右側のadmin:loginなどはパスの名前を表しています。
url_patternsにURLを設定する時に、第三引数にname="hogehoge"のように書きますよね。そのnameがこれに当たります。
試しに、一つview関数を追加して、それをshow_urlsを使って調べてみたいと思います。
参考サイトを元に、コードを書いていきます。
参考:【Django入門】viewsを使ってページを表示させよう追加したコードは下記の通りです。
home/views.pyfrom django.http import HttpResponse def index(request): return HttpResponse("Hello, world.")home/urls.pyfrom django.conf.urls import url from . import views urlpatterns = [ url(r'^$', views.index, name='index'), ]mysite/urls.pyfrom home import views as home_views # 上部に追記 url(r'^home/', include('home.urls')) # urlpatternsのリスト内に追記ここをクリックしてHello, world.が表示されたらOKです。
では、下記のコマンドを実行してみましょう。
python manage.py show_urls | grep home/home/ home.views.index index表示されましたね。
viewをインポートするときやテンプレートにURLを記入するときなどで重宝します。
参考:DjangoアプリのURLリンクの貼り方とメリット□ER図
参考:ER図(Entity Relationship Diagram)
django-extensionsではコマンド一つでプロジェクトのER図をpngで生成できます。
データベース設計の時に使える優れものです。
では、コマンドを実行して確認してみましょう。python manage.py graph_models -a -o mysite_er.png同ディレクトリ上にmysite_er.pngが生成されていると思います。
ER図□runserver_plus
今回はもう一つ紹介しておきます。
デバッグをWebブラウザ上で実行できる優れものです。
早速コマンドを実行してみましょう。python manage.py runserver_plusすると、、
CommandError: Werkzeug is required to use runserver_plus. Please visit http://werkzeug.pocoo.org/ or install via pip. (pip install Werkzeug)言われるがままにWekzeugをインストールして再挑戦です。
普通のrunserverとなんか違いますね。
ログの最終行にこのようなものがあります。
これを後から使うのでメモしておきましょう。* Debugger PIN: xxx-xxx-xxxでは、下記のようにコードを編集してみましょう。
home/views.pyreturn HttpReesponse("Hello, world.") # わざと間違える
エラー画面
エラー画面下部右側にターミナルのようなボタンがあります。
そこをクリックして、先ほどメモしたPINコードを記入すればデバッグが可能です。
Pythonのコードが対話的に実行できるので、変数などのオブジェクトの値が調べられますね。
さいごに
今回は、django-extensionsをプロジェクトに導入してみました。
次こそはWagtailを触っていきたいと思います。



- 投稿日:2019-12-24T19:50:46+09:00
日向坂のブログ画像のスクレイピング
はじめに
日向坂のブログのスクレイピングです
今回は画像のダウンロードのみにフォーカスしています開発環境
Python:3.7
beautifulsoup4:4.8.1コード
改善点、ツッコミ等ありましたらコメント or Twitter(@Azumi_cpa)にお願いします
from bs4 import BeautifulSoup import requests import time def get_picture_url(url): pic_urls = [] page_number = 0 # 記事が表示されなくなるまで各ページの画像のurlを取得 while True: print(url + "&page=" + str(page_number)) response = requests.get(url + "&page=" + str(page_number)) soup = BeautifulSoup(response.text, 'lxml') a = soup.find_all('div', class_='p-blog-article') # ここもっときれいに書けそう if a != []: for b in a: for c in b.find_all('img'): pic_urls.append(c["src"]) print(page_number) page_number += 1 time.sleep(3) else: break return pic_urls def save_pictures(name, url): # 画像のurl取得 pic_urls = get_picture_url(url) # 保存開始 for i, url in enumerate(pic_urls): try: response = requests.get(url) image = response.content # メンバー名/番号.jpg file_name = name + "/" + str(i) + ".jpg" with open(file_name, "wb") as aaa: aaa.write(image) time.sleep(3) except: print("エラー") def get_members(): member_list = {} response = requests.get('https://www.hinatazaka46.com/s/official/diary/member?ima=0000') soup = BeautifulSoup(response.text, 'lxml') members = soup.find_all("a", class_="p-blog-face__list") for member in members: # スペースと改行を削除 member_name = member.text.replace(" ", "") member_name = member_name.replace("\n", "") # ブログの0ページ目のurlも取得(1ページ以降はこれに"&page=n"を追加 member_list[member_name] = "https://www.hinatazaka46.com" + member.attrs["href"] return member_list def main(): # メンバーリスト作成 members_list = get_members() for name, url in members_list.items(): print(name + "開始") save_pictures(name, url) main()今後やること
- 保存するとき、メンバー名/ブログ日付_n.jpgにする
- 前回保存分~実行時までの差分のみを保存するようにする
- 投稿日:2019-12-24T19:32:05+09:00
【ポケモン剣盾】御三家分類を例に深層学習の判断根拠を可視化してみた
はじめに
みなさん、ポケモンやってますか?私は10年振りくらいに
買いましたサンタさんにもらいました。
ガチ勢目指して、年末年始は家に引きこもって厳選予定です。
AdventCalendarはポケモンネタで何かできないかなーと思っていたので、最近気になっている深層学習モデルの判断根拠を示す手法を、ポケモン御三家分類を例に試してみました。※手法の説明やデータセットの準備も含めて記載していくので、結果だけ知りたい方は結果まで飛ばしてください
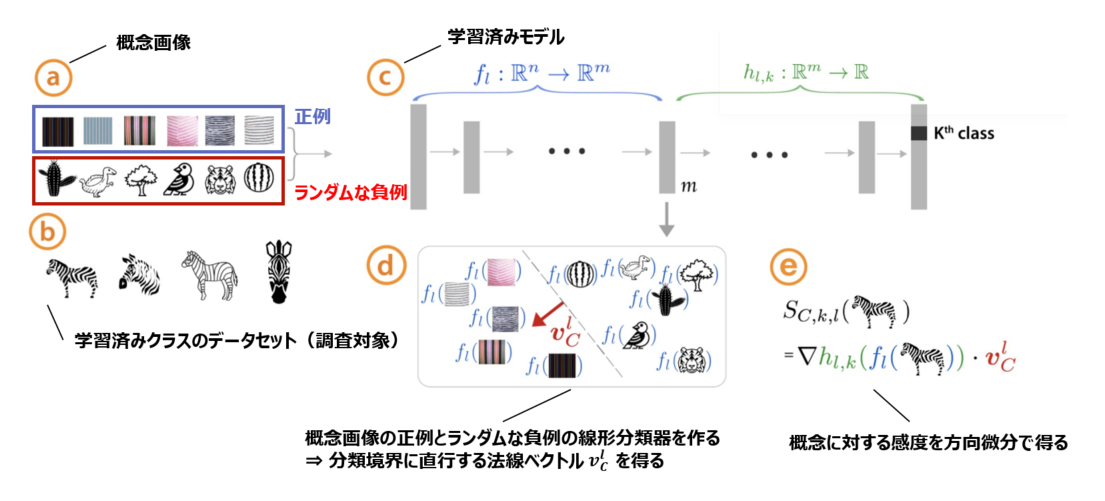
深層学習モデルの判断根拠を示す手法:TCAVとは
深層学習は様々な分野で社会実装が進み始めていますが、モデルが何を根拠に判断しているのかはブラックボックスになりがちです。
近年、モデルの「説明性」「解釈性」に関する研究が進められています。そこで今回は、ICML2018に採択されたQuantitative Testing with Concept Activation Vectors (TCAV) という手法を試してみたいと思います。
論文概要
- ニューラルネットワークモデルの判断根拠を示す手法
- 従来のピクセルごとに重要度を算出するような手法ではなく、予測クラスの概念(色、性別、人種など)の重要度を示す
- 各画像に対する説明(≒ローカル)ではなく、各クラスに対する説明(≒グローバル)を生成するので、人間にわかりやすい説明性を持つ
- MLモデルの専門知識がなくても説明を理解することができる
- 解釈したい既存モデルに対して、再学習や変更の必要はない
Concept Activation Vectors (CAV)の概念
概念画像とランダムな反例の間で線形分類器をトレーニングし、決定境界に直交するベクトルを取得することにより、CAVを導出します。
(下の図見た方が早い)。
※より詳細な論文メモはこちらに置いてありますので、ご興味ある方はご覧ください
何がわかる?
モデルが学習している「概念」を人間が解釈可能な形で定量化できる
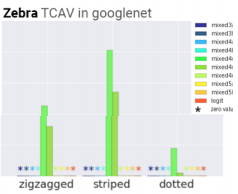
例:「シマウマ」分類において「ドット柄」より「ストライプ柄」を学習している
また、任意の層での学習を見ることもできるので、浅い層/深い層でどの程度粗い/細かい特徴を捉えているかも見ることができます。
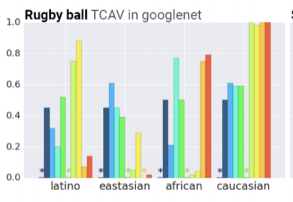
データセットのバイアスがわかる
例:「エプロン」クラスにおいて、「女性」の概念が関連している、「ラグビーボール」クラスにおいて、「白人」の概念が関連している
画像ソーターとして使える(概念画像との類似性に基づいて並び替えができる)
まず適当な分類器を作る
今回はTCAVを動かしてみるのが目標なので、簡単なタスクにしました。
ポケモン御三家分類器を作ります。データセットの準備
①クローリング
icrawlerを使って下記の画像を収集しました。
コード貼っておきます。import os from icrawler.builtin import GoogleImageCrawler save_dir = '../datasets/hibany' os.makedirs(save_dir, exist_ok=True) query = 'ヒバニー' max_num = 200 google_crawler = GoogleImageCrawler(storage={'root_dir': save_dir}) google_crawler.crawl(keyword=query, max_num=max_num)②前処理
最低限の処理だけです。
- ①クローリングで取得した画像を手動で正方形にクロップ
- 256×256にリサイズ
- train/val/testに分割
御三家画像サンプル
こんな感じで画像が集まりました。
(ちなみに私はヒバニー即決でした。炎タイプ大好き)
ヒバニー メッソン サルノリ 156枚 147枚 182枚 以下のような御三家以外のポケモンや、キャラクターの画像、デフォルメされすぎているイラストなども紛れていたので目検で除外しています。
キバナサンカッコイイ

分類器作成
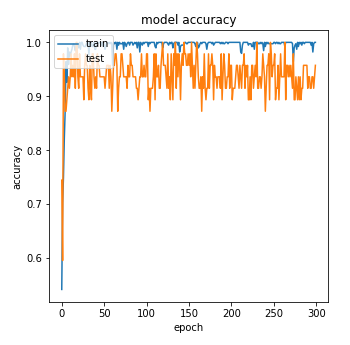
シンプルなCNNです。
テストデータの画像が少ない(15枚程度)のでテストデータのAccuracyはバタついていますが、TCAVの検証には十分であろう精度の分類モデルができました。
CAVの計算に.pbファイルが必要になるので、.pbでモデルを保存します。
次に、モデルが何を学習しているのか見るための準備をします。TCAVの実行準備
下記ステップに沿って準備していきます。
(今回使ったコードはこちらに置いてあります。あとでちゃんとREADME書きます。。。)Step1:概念画像(正例と負例)の準備
正例画像に用意したのは下記の画像です。
色を見て御三家を分類するのでは、という仮説のもと数色準備しました。
(10~20枚でも動きはしますが、50~200枚くらいあった方がよいとのことです)正例画像サンプル
白 赤 青 黄 緑 黒 22枚 20枚 15枚 18枚 21枚 17枚 こういう複数カラーが混ざりすぎているものは除外しています
負例画像サンプル
上記のどの正例にも該当しないものが望ましいです。(今回の場合、どの色にも該当しないというのは難しいですが。。)
今回はCaltech256からランダムに画像を取ってきました。ここまでに集めた画像たちのディレクトリ構成は下記のようになります。
概念画像のセットは全てサブディレクトリにする必要があります。├── datasets │ ├── for_tcav # TCAV用のデータセット │ │ ├── black │ │ ├── blue │ │ ├── green │ │ ├── hibany │ │ ├── messon │ │ ├── random500_0 │ │ ├── random500_1 │ │ ├── random500_2 │ │ ├── random500_3 │ │ ├── random500_4 │ │ ├── random500_5 │ │ ├── red │ │ ├── sarunori │ │ ├── white │ │ └── yellow │ └── splited # 画像分類モデル作成用データセット │ ├── test │ │ ├── hibany │ │ ├── messon │ │ └── sarunori │ ├── train │ │ ├── hibany │ │ ├── messon │ │ └── sarunori │ └── validation │ ├── hibany │ ├── messon │ └── sarunoriStep2:モデルラッパーを実装する
まずクローンしてきます。
git clone git@github.com:tensorflow/tcav.gitここでは、モデルの情報をTCAVに伝えるためのラッパーを作ります。
このクラスを tcav/model.py に追記します。class SimepleCNNWrapper_public(PublicImageModelWrapper): def __init__(self, sess, model_saved_path, labels_path): self.image_value_range = (0, 1) image_shape_v3 = [256, 256, 3] endpoints_v3 = dict( input='conv2d_1_input:0', logit='activation_6/Softmax:0', prediction='activation_6/Softmax:0', pre_avgpool='max_pooling2d_3/MaxPool:0', logit_weight='activation_6/Softmax:0', logit_bias='dense_1/bias:0', ) self.sess = sess super(SimepleCNNWrapper_public, self).__init__(sess, model_saved_path, labels_path, image_shape_v3, endpoints_v3, scope='import') self.model_name = 'SimepleCNNWrapper_public'これで準備が完了します。早速結果を見てみます。
結果
各クラスで重要視している概念(今回は色)を見てみます。
*印がついていない概念が重要視しているものです。
ヒバニークラス メッソンクラス サルノリクラス 赤・黄色・白
赤 (!?)
緑
ヒバニーとサルノリはそれっぽい結果かなと思います。
メッソンに関しては謎なので要考察です。
実験中に、試行回数や概念画像・ターゲット画像の枚数を変えると結構結果が変わるので、もう少し考察が必要かなと思っています。
概念画像の選び方によっても変わりそうなので、色々試し甲斐がありそうです。まとめ
ニューラルネットワークモデルの判断根拠を示す手法を試してみました。
人間が解釈しやすく、"直観的にそれっぽい"結果が得られました。
今回は御三家分類ということで概念画像として色を選びましたが、概念画像を準備するのが大変ですね。。
諸々準備は必要ですが、モデルを学習しなおす必要はないし、一連の流れを一回試して慣れちゃえば楽に使えると思います。
是非試してみてください!














- 投稿日:2019-12-24T19:30:24+09:00
SinGANで食べ物を動かしてみた
はじめに
物工/計数 Advent Calendar 2019の空き枠にお邪魔させていただきました.
最近, 「SinGAN」でいろいろと遊んでいたので, その結果を雑にまとめてみようと思います.
SinGANは, ICCV 2019でベストペーパーに選ばれたことで話題になった論文です.
たった1枚の画像で学習して, 同じ特徴を持った任意のサイズの画像を生成するほか, こんなこともできる優れものです.
論文: https://arxiv.org/abs/1905.01164
コード: https://github.com/tamarott/SinGAN
動画: https://youtu.be/xk8bWLZk4DUしかも, 画像1枚・GPU1台で手軽に試せるところも嬉しいポイントです. GPU1台だと, 私の環境では毎回の学習に数時間かかりました.
論文の内容については,
早く修論を書かなければならないので既に他に解説してくださっている方がいるので, ここでは割愛します.
Qiitaだけでも数件見つかりました.
- 【SinGAN】たった1枚の画像から多様な画像生成タスクが可能に
- 【論文解説】SinGAN: Learning a Generative Model from a Single Natural Image
- ICCV2019 Best Paper "SinGAN"さらっと読んで簡単にまとめてみた
さて, 本記事では, SinGANのREADMEにしたがっていろいろな機能(主にAnimation)を試してみます. 再現したい方はレポジトリをクローンしておいてください.
なお, SinGANで遊んでみた結果は適宜#SinGANで細々とツイートしています. みなさんもぜひ.
Animation
静止画から動画を作るのは, こちらのコマンドで一発です.
$ python animation.py --input_name <input_file_name>ラーメン
まずは定番のラーメンから.
こちらの美味しそうなラーメンが…
この通り. 活きが良くて美味しそうですね!
二郎系のラーメンはどうなるでしょうか?
こちらの冷やし中華が…
この通り. 活きが良くて美味しそうですね!
ピザ
こちらのピザが…
この通り. できたての熱々ですね!
海鮮丼
こちらの海鮮丼が…
この通り. 新鮮ですね!
ラテアート
こちらのカフェラテが…
この通り. 活きが良くて美味しそうですね!
『叫び』
Munchの『叫び』が…
この通り. 自我が崩壊していますね!
青の洞窟(渋谷の方)
渋谷のイルミネーションが…
この通り. これが最も正しい使い方だった気がします.
Harmonization
コラージュを自然にするには, まずモデルの学習が必要です. 背景となる画像を指定してください.
$ python main_train.py --input_name <input_file_name>2つめのコマンドで, 切り貼りした画像とマスク画像を指定してharmonizeします. こちらはすぐに完了します.
$ python harmonization.py --input_name <training_image_file_name> --ref_name <naively_pasted_reference_image_file_name> --harmonization_start_scale <scale to inject>マスク画像の作成にはこちらを参考にしました.
Gimpで特定領域の白黒マスク画像を作成する – Urusu Lambda Webさて, 今回はMonetの『睡蓮』にサンタクロースを合成したいと思います. こちらの切り貼りした画像が…
このようになりました. 小さくて見えづらいですね.
Super Resolution
SinGANは超解像もできるので, 先ほどの画像を大きくしてみましょう.
こちらのコマンドで一発です. 何も指定しないと縦横が4倍になります.$ python SR.py --input_name <LR_image_file_name>
メリークリスマス!よいお年を!


















- 投稿日:2019-12-24T19:17:59+09:00
リファレンスが切れているシーンをスクリプトで開くときのTips
Mayaではリファレンスが切れていると、接続しなおすかそのままにするか毎回指定する必要があります。
このダイアログをスキップする小技のご紹介です。
fileオープン処理を次のように書いてみましょう。
import maya.cmds as cmds _show_dialog = cmds.file(q=True, prompt=True) cmds.file(prompt=False) cmds.file( "hoge.ma", f=True, options="v=0;", ignoreVersion=True, typ="mayaAscii", o=True) cmds.file(prompt=_show_dialog)この書き方をすることによって、ダイアログを表示せずにデータを開くことが可能になります。

- 投稿日:2019-12-24T19:03:08+09:00
kivyを使ってGUIプログラミング ~その2 プログレスバー編~
はじめに
前回の導入編では、その名の通りKivyについての説明と環境構築やサンプルプログラムの実行を行いました。
今回は、何か処理を行なっている時のプログレスバーに関して紹介したいと思います。
タイトル詐欺みたいな感じのちょっとニッチな記事になりそうですがご容赦ください。
次回からもこんな感じの記事になると思いますwプログレスバーとは
皆様ご存知とは思いますが、wikipediaから概要を引用いたします。
プログレスバー(英: Progress Bar)とは、長時間かかるタスクの進捗状況がどの程度完了したのかを視覚的・直感的に表示するもので、グラフィカルユーザインタフェースの要素(ウィジェット)の一つである。しばしば、ダウンロードやファイル転送のようにパーセント形式で表示される際に使われる。プログレスメーター (英: Progress Meters)とも呼ばれる。
こんなやつですね。(こちらのイメージもwikipediaから)
kivyで何か時間のかかる動作を実装した時に、プログレスバーが欲しいなと思ったところ、
Kivyのリファレンスには、ほとんど解説がなく、ネットをさまようことになりました。。。kivyでのプログレスバーの使い方
こんな感じで動きます。
ソースは以下の通りです。
from kivy.app import App from kivy.clock import Clock from kivy.uix.boxlayout import BoxLayout from kivy.uix.button import Button from kivy.uix.progressbar import ProgressBar class ProgressTest(BoxLayout): def __init__(self, **kwargs): super(ProgressTest, self).__init__(**kwargs) #プログレスバーのウィジェット self.pb = ProgressBar() self.add_widget(self.pb) #処理開始ボタンのウィジェット button_pb = Button(text='progress') # ボタンに処理を紐づける button_pb.bind(on_press=self.test_progress) self.add_widget(button_pb) #一定時間ごとに処理を繰り返す def pb_clock(self,dt): #プログレスバーの最大値になった時、クロックを停止する if self.pb.value == 100: return False #プログレスバーの値を増やす self.pb.value += 1 def test_progress(self, *args): self.pb.value = 0 #クロック始動 Clock.schedule_interval(self.pb_clock, 1/60) class TestProgress(App): def build(self): return ProgressTest() if __name__ == '__main__': TestProgress().run()肝に当たるのが、Clockの処理です。プログレスバーのvalueにfor文で値を更新しても、value自体の値は更新されても、画面のプログレスバーはforの処理が終わるまで変化がありません。
そこで、kivyの時間ごとに逐次的に呼び出され画面描画を行なってくれる、Clockを使います。使い方として、上記のソースを記述しましたが、実際にプログレスバーが使われているところを考えると、ポップアップか何かに組み込まれていることが多いような気がします。
また、上記プログラムでは、行いたい処理をClock処理内に書く必要があり、
既存のクラスの繰り返し処理の進捗状況を可視化するには、for文をClock用に書き直す必要があると思います。そこで、ポップアップ上でさらに外部クラスからの処理の進捗状況を可視化できるようカスタマイズしていきます。
作りたいもの
今回はポップアップ上でプログレスバーを2本同時に動作させる処理を実装したいと思います。
イメージは下図のような感じです。
別のクラスの関数をサブの処理として、サブの処理が終わるごとにメインの
プログレスバーが進むよう処理を想定しています。使い方の章でも触れたように、別のクラスでfor文のちょっと長めの処理を行うと画面が暗くなり操作が効かなくなります。
公式にもこんな感じで記述があります。2本目のプログラレスバーを動かそうとすると、処理自体は動いていても画面描画は受け付けておらず、GUIだけでは動作しているかわからない状態になっています。
そこで、無理やり画面描画をさせるために、Pythonのthreadingモジュールを用いて、処理を行いつつ、画面描画も行えるようにしています。
(正攻法なのかはわかりませんが、問題なく動作します。)ソースコード
sample.pyfrom kivy.uix.progressbar import ProgressBar from kivy.uix.popup import Popup from kivy.app import App from kivy.clock import Clock from kivy.uix.boxlayout import BoxLayout from kivy.uix.button import Button import time import threading #重い処理を想定したクラス from NagaiSyori import longProc class ProgressPop(BoxLayout): def __init__(self, **kwargs): super(ProgressPop, self).__init__(**kwargs) #ポップアップを出すボタン button_pb = Button(text='thread pop!!') button_pb.bind(on_press=self.open_pupup) self.add_widget(button_pb) #self.tmp = 0 #外部の重い処理をするクラス self.sub_process = longProc() #スレッド処理を終了するフラグ self.thread_flag = False #ポップアップの画面とその処理 def open_pupup(self, btn): #ポップアップ画面の基盤 content = BoxLayout(orientation='vertical') self.pb = ProgressBar() content.add_widget(self.pb) self.sub_pb= ProgressBar() content.add_widget(self.sub_pb) self._close = Button(text="close", on_press=self.dissmiss) content.add_widget(self._close) #ポップアップのウィジェット self._pup = Popup(title="Popup Test", content=content, size_hint=(0.5,0.5)) #ポップアップを開く self._pup.open() #スレッド処理の準備 self.thread_flag = True self.ev = threading.Event() #スレッド処理開始 self.thed = threading.Thread(target=self.test_progress) self.thed.start() #ポップアップを閉じる時の処理 def dissmiss(self, *args): self.ev.clear() self.thread_flag = False self._pup.dismiss() #メインのプログレスバーの値を更新 def main_clock(self, *args): #プログレスバーの値が最大になった場合にクロックを停止する if self.tmp >= 100: Clock.unschedule(self.main_clock) self.pb.value = self.tmp #サブのプログレスバーの値を更新 def sub_clock(self, *args): # プログレスバーの値が最大になった場合にクロックを停止する if self.sub_process.num >= 100: Clock.unschedule(self.sub_clock) self.sub_pb.value = self.sub_process.num #処理 def test_progress(self): #プログレスバーに値を渡すための変数 self.tmp = 0 #プログレスバーに値を更新するクロック始動 Clock.schedule_interval(self.main_clock, 1 / 60) for i in range(20): #すべの処理が終わっていなければ if self.thread_flag: time.sleep(1/60) #サブのプログレスバーの値を更新するクロック Clock.schedule_interval(self.sub_clock, 1 / 60) #重い処理 self.sub_process.process() self.tmp = i*5 + 5 print(self.tmp) #処理が全て終わった時のスレッド終了処理 self.ev.clear() self.thread_flag = False class TestPopupProgressApp(App): def build(self): return ProgressPop() if __name__ == '__main__': TestPopupProgressApp().run()NagaiSyori.pyimport time class longProc: def __init__(self): #プログレスバーに値を受け渡すための変数 self.num = 0 #重い処理 def process(self): self.num = 0 for i in range(100): time.sleep(1/600) self.num = i + 1
実行するとこんな感じで動くと思います。
スレッド処理を加えたことにより、Clock内で繰り返し処理を書かずに済みます。
またに外部のクラスの処理状況も可視化することができるようになりました!!!参考記事
大変参考になりました。本当にありがとうございます。




- 投稿日:2019-12-24T18:58:31+09:00
Pandasのapply()をなぜ使うべきか
TL;DR
Pandasでデータの前処理をする場合はapply()を使っていこうという話をまとめます。
Pandasとは
http://pandas.pydata.org/pandas-docs/stable/
pandasは、Pythonにおいて、データ解析に必要なメソッドを用意したライブラリです。時系列データから、テーブルのようなデータ系列まで幅広く対応でき、かつ高速に集計できるようになっています。今のご時世ではPythonでデータ分析するというのはよく耳にするかと思います。会社でのデータ分析業務
Moff社内ではデータ分析業務をする際、事前データを抽出して後、スポットで分析する場合はデータを加工することをよくやります。最終的に作りたいデータテーブルを描いた上で、それまでに前処理をいくつか走らせることになります。
初学者でなされたこと。
例えば下記のようなデータセットがあったとします。
その上で、「nameの文字数を新しくcolumnに追加したい」という前処理をするとしましょう。
その時に、プログラミングを初めたばかりのインターン生に特に散見されましたが、前処理上でよく見かけるのが下記の前処理コードでした。
data['len'] = 0 for k, d in data['name'].iteritems(): data['len'][k] = len(d)確かに出力結果はこれ事足りますし、数行程度のデータでは確かにそこまで時間を消費するものにはならないかと思います。
apply()で対処してみる。
では今度は、apply()で対処してみようと思います。
apply()とはDataFrame, Series型に備わっているメソッドの一つでDataFrame, Seriesも式はgroupbyされたDataFrameにおける各々のvalueを引数として、apply()の引数に与えられた関数のreturn値のSeries、DataFrame、もしくはスカラー値を返すことができます。https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.apply.html先ほどの例だと、lenを返す関数を作ればこういう形になります。
def return_len(x) return len(x) data['len'] = data['name'].apply(return_len)lambda式(無名関数)を知っていれば、下記ようなこともできます。
data['len'] = data['name'].apply(lambda x: len(x))と記述的には比較的シンプルにはなると思います。
気づいた方もいるかもしれませんが、今回はlen()の結果を返す関数をわざわざ関数を挟んで紹介しました。よくよく考えればlen()自体も関数なので、こういう風にもできます。
data['len'] = data['name'].apply(len)単純な処理であればforループでも解決はできるかもしれませんが、より複雑な前処理を検討する場合は、前述よりかは関数化してapply()で適用させる方が、間違い等には気づき安くなるんではないかと思います。
処理速度はどうなのか
上記の例ではデータが少量なので対して、処理速度においては差分はないかと思うので、ランダムな文字列データに対してな長さを出力する処理を適用してみた結果を示してみます。
検証環境は下記になります。
- MacBook Pro (13-inch, 2016, Four Thunderbolt 3 Ports)
- macOS Mojave 10.14.5
- プロセッサ 2.9GHz Intel Core i5
- メモリ 8GB 2133 MHz LPDR3
- 文字列データに対して新しく文字列の長さを値にいれた行を追加する処理(つまり上記のような処理)を実行完了するまでの時間を計測
# of data for loop pandas.DataFrame.apply() 100 3.907sec 0.079sec 10000 415.032sec 0.231sec apply()が何をしているのか。実体は?
例えばDataFrameのapplyの本体はこちら
https://github.com/pandas-dev/pandas/blob/5a7b5c958c6f004c395136f9438a1ed6c04861dd/pandas/core/frame.py#L6440frame_apply()を追跡してみると
FrameApplyというクラスにどうも何かしら書いてる模様。
frame_apply()上にてget_result()をコールしているのでその処理を追跡します。
パラメータによっては分岐もありますが、特にOptionalな引数を与えなければ、下記が呼ばれている模様です。
apply_standard()内でlibreduction.compute_reduction()が計算本体をやっているようです。そのあとに、apply_series_generator()、wrap_results()で結果をしているようですね。
libreductionが/_lib/reduction.pyxにあるみたいです。https://github.com/pandas-dev/pandas/blob/master/pandas/_libs/reduction.pyx
どうも、Reducer内にてデータをnumpy.ndarray.shapeで行列データを分割して扱うような挙動をしているようです、
for i in range(self.nresults):から諸々やっている模様。ここからNumpy上での話になりそうです。上記のコードを閲覧してみてもどうもPandas
上では計算で工夫されているポイントはなさそうに見えるのでNumpy上で処理の工夫をしているように思えます。というのも、最終的に上記のReducer上でres = self.f(chunk)とあり、Numpyのndarrayに対して関数を適用する処理以降で特に特徴的に計算処理で工夫している点が見当たらなかったからです。一応Chunk分けして処理しているような記述がありましたが、関数適用のres = self.f(chunk)の時点で実処理の詳細がこの時点では不明瞭で、以降Numpy側の処理で完結されているようにみえます。Numpyにおける計算処理が純Pythonのみでの計算処理に比べて高速なところを加味すると、納得いきます。もう少し知りたいところですが、これ以上書くとボリューミーなので、Numpyにおける処理特定は別の機会にします。ともあれ、少なくてもPandas上ではないことは確定しました。(言語性能に依存しているのか計算処理で工夫しているかはいまだに不明ですが)
map, apply, applymapなどに関してその他
違いがまとまったStackOverFlowの回答なんかはよくまとまっています。
https://stackoverflow.com/a/56300992/7649377要点だけ抑えると、
- DataFrame, Series共にapply()が使用可能、applymapはDataFrame、mapはSeriesにのみ使える。
- Seriresのmapではdict, Seriresを引数として渡すとその引数のキーに応じて適用する関数を設定することができる
- apply()に関してはgroupby等の集計系処理にできたDaraFrame, Seriesでも使える
というのがポイントでしょうか。
まとめ
- applyの使い方に慣れるだけで、前処理作業は格段に早い処理にすることができます。
- applyが何をやっているかはそれこそPandasの中身を追ってみる。追ってみた結果Numpyにおける配列処理に帰結しているため、Numpy上のコードリーディングが必要。
次このネタで記事描くときはNumpyを読み漁ろうと思います。
ありがとうございました。

- 投稿日:2019-12-24T18:08:34+09:00
GCPのComputeEngine上にPython3系+flask環境を構築する
はじめに
GCPのロードバランサーの動作を確認したく、ComputeEngineでウェブアプリを立てることにしました。
もともとはロードバランサーの検証作業が目的だったのですが、その過程の作業もちゃんと記録しておいた方がいいなと思い、今回これを記事にすることにしました。内容としてはタイトルの通りで「ComputeEngineを使ってPython3系+flask環境でウェブアプリを構築する」というものです。
GCP初心者の方は参考になるかと思いますので、よかったら読ん進めてみてくださいComputeEngine構築
ComputeEngineの環境構築は簡単ですね。
ボタンをポチポチすれば簡単にLinuxサーバが立っちゃいます。1. VMインスタンス作成
GCPコンソールのここからComputeEngineのVMマシンを作ります。
こちら↓はインスタンス設定の参考例です。
ポイントは『HTTPトラフィックを許可する』にチェックをいれることですね。
Webサーバ(flask)を立てるので、これをチェックしないと外からの動作確認ができません。
後は『作成』ボタンを押して数分待てばVMが起動します。
2. 動作確認(VMインスタンス起動)
ちゃんと起動したかどうかSSHしてみましょう。
はい、無事に起動しました
Python3系の準備
VMが無事立ち上がったので、次はPython環境を整えていきます。
1. aptアップデート
まずはaptのアップデートを。
※これはやらなくてもいい場合がほとんどですが、まぁ「最新状態を保っておいた方が良いだろう…」ということでやっておきます。sudo apt update
立てたVMはデフォルトでPython2系がインストールされています。
今回のDebian9パッケージではPython3系もインストールされています。
ただpip3はインストールされていないので、こちらを準備する必要があります。
2. pip3のインストール
次のコマンドでpip3が使えるようにします。
sudo apt install python3-pip
これでpip3が使えるようになりました。
次はpip3でflaskをインストールしていきます。flaskインストール
pip3を使ったflaskをインストールします。簡単です。
これでflaskが使えるようになりました。
動作確認してみましょう。動作確認
動作確認のためのflaskを使ったPythonスクリプトを用意しましょう。
1. Pythonスクリプト作成
まず、下記のコマンドからnano(テキストエディタ)でファイルを作成します。
nano main.pyエディタが開いたら、下記のスクリプトをコピペします。
from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello, Flask World!!' if __name__ == '__main__': app.run(debug=False, host='127.0.0.1', port=5000)
コピペできたら、
- Control+O
- Enter
- Control+X
の順に打ってnanoエディタを終了します。
2. flask動作確認
作成したスクリプトを起動します。
python3 main.py下記のような画面になっていればOKです。
flaskが動作しています。
ここまでで一応動作確認はできていますが、念の為curlコマンドでウェブアプリの応答を確認してみましょう。
curl 127.0.0.1:5000ポート番号は5000で作っていますので、上記のコマンドでcurlを打ちます。
ちゃんと「Hello world」と言う文字列が応答されましたので、ウェブアプリが動作していることが確認できます。
おわりに
いかがでしたでしょうか?
いずれの作業もさほど難しくありませんので、慣れてしまえばComputeEngineの立ち上げからflaskウェブアプリケーションの起動まで、数分でできちゃいます!
よかったら挑戦してみてください













- 投稿日:2019-12-24T17:54:34+09:00
サウンドフォントマッピング問題
この記事は音楽ツール・ライブラリ・技術 Advent Calendar 2019 12/24の記事です。
(今回は急いで用意したので若干趣旨に合ってないかもです。来年は自作音源とか音声圧縮とかをやりたいところです。
はじめに
DTMを初めて早10年、10年前に導入したMusic Studio Producer と8年前に導入したTimidity++とSoundFontの組み合わせで長々と使ってきましたが、更新されていないTimidityのMIDIドライバーとWindows10の相性問題を踏み、ついにTimidityを廃止することに...
10年前は手動でマッピングファイルを作っていたのですが、この10年でプログラミングに対応したため今回はプログラムの力で楽をして快適なDTM環境を手に入れようという、そういうお話です。
サウンドフォントのマッピング
MIDIしか扱えないDAWでサウンドフォントを使う場合、TimidityのようなサウンドフォントをMIDI音源として使える仮想音源を利用します。サウンドフォントの音色は バンク番号とプリセット番号の二つ を組み合わせることで指定でき、MIDIの バンクセレクト、プログラムチェンジと対応 するためMIDIメッセージでサウンドフォント中の任意の音色を選択することができます。
ただし、サウンドフォントを複数同時に使用するとバンクやプリセット番号が衝突したり、サウンドフォントによってはMIDIで規定されている音色の配置と大幅に異なる場合があり、不便なためマッピングを行います。
幸いTimidityにはこの機能があり、使いやすいように配置しました。
(なお、当時はユーザーとして使っていたので、サウンドフォントのファイルフォーマットはもちろん知らないですし、MIDIについても詳しくありませんでした。)256*256の空間にExcel上で音色を配置し、対応するようにTimidityの設定ファイルとDAWの音色ファイル(楽器名とプログラム番号、バンク番号の対応表です。設定するとDAWのGUIで楽器名が表示されるので作成していました。)を手で書いていました。
追加したいサウンドフォントはたくさんありましたが、Excelで割り当てて、設定ファイルを手で追加する...めんどくさいですね
TimidityからVirtualMIDISynth
今年の夏くらいにWin10をメジャーアップデートしたらついにTimidity++が動かなくなりました。そもそもTimidity++は署名がないドライバーで動いており、更新もされていないのでそろそろ限界かと思い乗り換えへ
乗り換え先の仮想MIDI音源としてVirtualMIDISynthを導入しました。
ところがサウンドフォントのマッピング機能がないのです。複数ファイルのサウンドフォントを読み込むことはできますが、衝突した場合優先度の高いサウンドフォントファイルの音色が利用されるようです。これは困りました。
ということでサウンドフォントファイルを書き換えて衝突が起きないようにし、ついでに音色マップまで自動で生成してしまおうという話です<前置きが長い
仕様
- サウンドフォントファイルのバンクとプリセットを衝突しないように再配置する
- サウンドフォントに対応するMusic Studio Producer用の音色マップを生成する
- VirtualMIDISynth用の設定ファイルを生成する
- 削除する音色・音色名の省略などの指定ができるようにする
音色の削除はサウンドフォントファイルにゴミ音色データが入っているものが見られたため、音色名の省略は音色名が長すぎてDAWの表示がおかしくなるため追加しました。
なお、Music Studio ProducerとVirtualMIDISynthの設定ファイルの説明はここでは行いません。
サウンドフォントのファイル構造
仕様書:http://freepats.zenvoid.org/sf2/sfspec24.pdf
サウンドフォントはRIFF形式で格納されています。RIFFはチャンクと呼ばれる単位でデータが格納されており、チャンクはIDとサイズとデータで構成されています。
RIFFの構造
チャンクの基本構造
項目 サイズ 備考 チャンクID 4byte チャンクの識別子(RIFF/LISTなど) データサイズ 4byte データのサイズ(リトルエンディアン) データ Nbyte また、先頭のチャンクであるRIFFチャンク、複数のチャンクをまとめるLISTチャンクの2つは特別なチャンクとして用意されています。(なお、RIFFとLIST以外のチャンクにはチャンクを含めることはできません。)
RIFFチャンクの構造
項目 サイズ 備考 チャンクID 4byte RIFF データサイズ 4byte N+4 ファイル識別子 4byte RIFFファイルに格納しているデータの識別子 (サウンドフォントの場合sfbk) データ Nbyte チャンクやLISTチャンクが入る LISTチャンクの構造
項目 サイズ 備考 チャンクID 4byte LIST データサイズ 4byte N+4 リスト識別子 4byte リストに格納しているデータの識別子 (INFO/dataなど) データ Nbyte チャンクやLISTチャンクが入る RIFFファイルはこれらのチャンクを利用し入れ子構造データを表記できます。
すべてのチャンクはデータ部のサイズが先頭に書かれているため、不要なチャンクは読み飛ばしてしまうこともできます。そのため、サウンドフォントのチャンクのうちバンク番号とプリセット番号に関するチャンクだけを処理し後のチャンクはそのまま読み飛ばすだけという実装で目的は達成できます。
サウンドファイルのRIFF構造
サウンドフォントのRIFF構造は以下のようになります。このうちpdta以下に入っているチャンクに楽器名やプリセット番号などが入っています。
pdtaにはプリセット、インストゥルメント、サンプルに関するサブチャンクが含まれています。このうちインストゥルメントは複数のサンプルをまとめた単位でサウンドフォントの内部で利用される単位となり、プリセットは複数のインストゥルメントをまとめユーザーが利用できる単位となります。
そのため、今回はプリセット関係のサブチャンクのみ利用します。なお、サブチャンクは構造体の配列として格納されており、末尾の値は終端を示す特別な値となります。また、サイズはsizeof(構造体)の整数倍となります。
phdrサブチャンク
phdrサブチャンクはヘッダー情報(プリセットの楽器名やバンク、プリセット番号など)が格納されています。
struct phdr { char achPresetName[20]; // プリセット名 null終端ascii WORD wPreset; // プリセット番号 WORD wBank; // バンク番号 0~127は楽器用 128はパーカッション用 WORD wPresetBagNdx; // pbagの先頭のindex DWORD dwLibrary; // 予約 0 DWORD dwGenre; // 予約 0 DWORD dwMorphology; // 予約 0 }なお、wPresetBagNdxはphdrの先頭から順に増加する必要があります。
当初この仕様を見落としており、phdrだけ書き換えて不要なものは消せばOKだと思い、実装した結果音が違う音が鳴るようになってしまいました。
この仕様を満たすため、pbag, pmod, pgenサブチャンクも編集する必要があります。phdrの末尾(EOP)の値は以下のようにします。
変数名 値 achPresetName EOP wPreset 0 wBank 0 wPresetBagNdx pbagの末尾のindex dwLibrary 0 dwGenre 0 dwMorphology 0 pbagサブチャンク
pbagサブチャンクはどのモジュレーション(pmod)とジェネレーター(pgen)をプリセットで利用するかを示す情報が格納されています。
プリセットとpbagの関連付けはあるプリセットのwPresetBagNdxが指すpbagから次のプリセットのwPresetBagNdx-1のpbagまでが関連付けられます。
(そのため1つのプリセットに複数のpbagを関連付けることも可能です)struct pbag { WORD wGenNdx; // pgenの先頭のindex WORD wModNdx; // pmodの先頭のindex }phdr同様wGenNdxとwModNdxはpbagの先頭から順に増加する必要があります。
pbagの末尾の値は以下のようにします。
変数名 値 wGenNdx pgenの末尾のindex wModNdx pmodの末尾のindex pgenサブチャンク
pgenサブチャンクはプリセットと関連付けるインストゥルメントや音量、フィルターといったパラメータ情報(ジェネレーター)が格納されます。
中身はパラメーターの種類と値というキーバリュー形式となっています。
struct pgen { WORD sfGenOper; // パラメーターの種類 WORD genAmount; // パラメーターの値 }なおgenAmountはパラメーターの種類に応じて2つのbyte、short、もしくはword型の値が入ます。(サイズはword固定です。)
pbagの末尾の値は以下のようにします。
変数名 値 sfGenOper 0 genAmount 0 pmodサブチャンク
pmodサブチャンクはMIDIのコントロールチェンジやベロシティといった動的なパラメーターから音をどのように変化させるか(音量を変えたりフィルターを掛けたり)を対応付ける情報が格納されています。
struct pmod { WORD sfModSrcOper; // モジュレーション元のパラメーターの種類(CCやベロシティなど WORD sfModDestOper; // 操作するパラメーターの種類(音量やフィルターの強さなど) SHORT modAmount; // 操作量 WORD sfModAmtSrcOper; // モジュレーションの操作量を変化させるモジュレーション元のパラメーターの種類 WORD sfModTransOper; // 入力された操作量を変換する(線形、曲線) }pmodの末尾の値は以下のようにします。
変数名 値 sfModSrcOper 0 sfModDestOper 0 modAmount 0 sfModAmtSrcOper 0 sfModTransOper 0 サブチャンクの関係
各サブチャンクの関係を見るとこのようになります。
例えばこの図の例だとプリセット0はbag0とbag1が関連付けれれており、bag0はgen0,gen1とmod0が、bag1はgen2とmod1, mod2が関連付けられているのでプリセットで利用されるジェネレーターはgen0~gen2、モジュレーションはmod0~mod2というイメージになります。
(仕様書を読み込んでないので正しくないかもしれませんが、bag単位でジェネレーターとモジュレーションは関連付けられて音が鳴ると思われますが、ファイルを触る範囲ではあまり気にしなくていいと思います。)
サウンドフォントパーサー
ソースコード:https://github.com/mmitti/sf2conv/blob/master/riff.py
RIFFとサウンドフォントの構造(の一部)をパースできるスクリプトをPythonとstructモジュールを利用して作成しました。
RIFFチャンク、LISTチャンク、phdr、pbag、pmod、pgenサブチャンクの読み書きに対応しています。また、それ以外のチャンクは編集しないため読み出したものをそのまま書き込むようにしています。
phdrを削除する際にpbag, pmod, pgenも対応するものを削除する必要がありますので、書き込み時に更新処理をしています。
(夏休み中自動車学校の待ち時間に実装していたのですが、今見ると汚いですね。RiffRootとかElementとか何という
サウンドフォントのマッピングを行うプログラム
ソースコード:https://github.com/mmitti/sf2conv/blob/master/main.py
上のRiffパーサー(というかサウンドフォントパーサー)を利用してサウンドフォントを変換しMusicStudioProducerの音色マップとVirtualMIDISynthの設定ファイルを吐くスクリプトを作りました。
jsonファイルに入力するサウンドフォントや除外する音色、音色名の置換ルールなどを書いておき、これを利用してサウンドフォントファイルを書き換え、音色名とバンク、プログラム番号を音色マップに吐くだけの簡単なスクリプトとなっています。
地味に変な名前の音色(------とか)や管楽器系がピアノのプログラム番号に割り当てられているサウンドフォントがあったりして、設定できるルールを増やしていた結果設定項目は増えてしまいましたが、設定ファイルを書いてしまえばあとは空いている部分に音色が割り当てられてDAWの音色リストに追加されるので新しいサウンドフォントの追加は楽になりました。
おわりに
今回はDTM環境が破損したことからサウンドフォントの中身をのぞくこととなり、多少は理解が深まりました。
スクリプトでサウンドフォントの追加作業が簡単になりましたので、さっそく使ってみたかったsinfonを導入して1曲打ち込んでみました。
今作っているFPGA USB MIDIデバイスが完成した後はサウンドフォントを読み込む方式のMIDI音源も作ってみたいと思っているのでまた、そのうちサウンドフォントについて調べて書くかもしれません。
それではまた




- 投稿日:2019-12-24T17:40:43+09:00
Serverless FrameworkでAPIに対してProtocol Bufferを適用して作ってみる。
TL;DR
Serverless Frameworkでもう少しAPI周りをなんとか扱いたい気持ちがあり、Protocol Bufferでお試ししたことがあったのでそれを共有します。
Protocol Bufferとは
https://developers.google.com/protocol-buffers
そんなに新しい技術ではないんですが、インタフェース記述言語(IDL)です。Googleにて開発され、元はXMLよりも高速になるようデザインされたようです。
よくProtobufと略して記載されていたりします。
Protocol Bufferに関してはこちらの記事でよくわかりやすくサマらているのでご参考までに。
https://qiita.com/yugui/items/160737021d25d761b353なぜServerless FrameworkにProtocol Bufferを使う?
もともとServerless Frameworkを主体にサービスを構築して管理していたため、クライアント側がマルチに存在する場合に使用を共有できるようにしたいのが最初のモチベーションで、同じAPIをWeb,Native Appからアクセスすることが予想されるサービスや、センサーデータをまとめて送るにしても、通信量が大きいのでなんとかデータを圧縮できないかと考えていたので、検討しました。
サンプル
https://github.com/hisato-kawaji/protocol-buffer-with-serverless-sample
やること
LambdaのコードをPythonを前提としてAPI Gateway + Lambdaだけのサービスをやってみました。
(Serverless Frameworkの基礎的な内容は割愛して、Protocol Bufferにまつわるところに絞った話を記載します。)pluginの追加
pluginに
serverless-python-requirementsとserverless-apigw-binaryを追加します。sls plugin install --name serverless-python-requirements sls plugin install --name serverless-apigw-binary
serverless.ymlにも記載しておきます。plugins: - serverless-python-requirements - serverless-apigw-binarycustom: . . . apigwBinary: types: - 'application/x-protobuf'requierement.txt
Lambda上でProtoBufを扱うので、protobufをimportする必要があります。
というわけで、requirement.txtを作ります。protobuf==3.5.1 six==1.11.0スキーマ作成
事前にprotobufをインストールしておきます。
git clone git://github.com/openx/python3-protobuf.git cd python3-protobuf ./autogen.sh ./configure --prefix=$PREFIX # protobuf インストール先を指定 make make check sudo make install cd python # Python バインディング python setup.py build python setup.py test sudo python setup.py install
.protoファイルを作って、スキーマを定義していきます。sample.protosyntax = "proto3"; message Test { string test_id = 1; string hoge = 2; }スキーマを作成したら、ビルドです。
protoc -I=. --python_out=. sample.protoコマンド実行後、
sample_pb2.pyが生成されます。Lambda Functionの実装
serverless.ymlに関数を記載します。functions: Get: handler: handler.get package: include: sample_pb2.py exclude: - serverless.yml events: - http: path: get method: post cors: true private: true
handler.pyを用意して実際にProtoBufを組み込んでいきます。bodyにProtocolBufferでSerializeされたデータを与えて、LambdaにてParseすれば扱えるようになります。
Responseで返す場合はSerializeしてstringで扱ってあげればレスポンスできます。mport json import sample_pb2 import base64 def get(event, context): obj = sample_pb2.Test() obj.ParseFromString(base64.b64decode(event['body'])) obj.test_id = 'bbb' response = { 'statusCode': 200, 'headers': { "Access-Control-Allow-Origin": "*", 'Content-Type': 'application/x-protobuf' }, 'body': obj.SerializeToString().decode('utf-8'), 'isBase64Encoded': True } return responseあれ?簡単?
Protocol Bufferの扱いに慣れるのには苦労しましたが、組み込み自体はさほど時間がかかりませんでした。どちらかというとスキーマ定義した後にPython上で扱う際Lambdaでデバッグする作業がなかなか苦痛でした。
まとめ・展望
- ProtoBufをServerless Frameworkで実現できるようにしてみました。
ありがとうございました。
- 投稿日:2019-12-24T17:31:05+09:00
Google Colaboratory上でCaffeモデルを動かして世界のスーパーモデルの年齢と性別を予測する
オープンソースのディープラーニングライブラリ Caffe を Google Colaboratory 上で動かしてみました。 Google Colab 上に Caffe はないようなので、次のようにしてインストールします。
!apt install caffe-cpu計算済みの Caffe モデルを選ぶにあたって、説明の詳しかった AgeGenderDeepLearning を選びました。 Google Colaboratory 上に git clone します。
!git clone https://github.com/GilLevi/AgeGenderDeepLearningこれは写真に映った人物の年齢と性別を予測するモデルです。このモデルを使って、世界のスーパーモデルの年齢と性別を予測したいと思います。
スーパーモデルの写真はこちらから取得しました。
# https://github.com/GilLevi/AgeGenderDeepLearning のコードそのまま import os import numpy as np import matplotlib.pyplot as plt %matplotlib inline caffe_root = './caffe/' import sys sys.path.insert(0, caffe_root + 'python') import caffe plt.rcParams['figure.figsize'] = (10, 10) plt.rcParams['image.interpolation'] = 'nearest' plt.rcParams['image.cmap'] = 'gray'mean_filename='./AgeGenderDeepLearning/models/mean.binaryproto' # 変更箇所 proto_data = open(mean_filename, "rb").read() a = caffe.io.caffe_pb2.BlobProto.FromString(proto_data) mean = caffe.io.blobproto_to_array(a)[0]age_net_pretrained='./AgeGenderDeepLearning/models/age_net.caffemodel' # 変更箇所 age_net_model_file='./AgeGenderDeepLearning/age_net_definitions/deploy.prototxt' # 変更箇所 age_net = caffe.Classifier(age_net_model_file, age_net_pretrained, mean=mean, channel_swap=(2,1,0), raw_scale=255, image_dims=(256, 256))gender_net_pretrained='./AgeGenderDeepLearning/models/gender_net.caffemodel' # 変更箇所 gender_net_model_file='./AgeGenderDeepLearning/gender_net_definitions/deploy.prototxt' # 変更箇所 gender_net = caffe.Classifier(gender_net_model_file, gender_net_pretrained, mean=mean, channel_swap=(2,1,0), raw_scale=255, image_dims=(256, 256))# https://github.com/GilLevi/AgeGenderDeepLearning のコードそのまま age_list=['(0, 2)','(4, 6)','(8, 12)','(15, 20)','(25, 32)','(38, 43)','(48, 53)','(60, 100)'] gender_list=['Male','Female']https://ja.wikipedia.org/wiki/%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E3%83%A2%E3%83%87%E3%83%AB
# URL によるリソースへのアクセスを提供するライブラリをインポートする。 import urllib.request # ウェブ上のリソースを指定する url = 'https://upload.wikimedia.org/wikipedia/commons/thumb/7/73/Gisele_B_edit.jpg/300px-Gisele_B_edit.jpg' # 指定したURLからリソースをダウンロードし、名前をつける。 urllib.request.urlretrieve(url, 'model1.jpg')('model1.jpg', <http.client.HTTPMessage at 0x7f7d928eea58>)example_image = 'model1.jpg' input_image = caffe.io.load_image(example_image) _ = plt.imshow(input_image)/usr/local/lib/python3.6/dist-packages/skimage/io/_io.py:48: UserWarning: `as_grey` has been deprecated in favor of `as_gray` warn('`as_grey` has been deprecated in favor of `as_gray`')
(著作権的に問題になる気がするので、この写真は見せません。)
# https://github.com/GilLevi/AgeGenderDeepLearning のコードそのまま prediction = age_net.predict([input_image]) print ('predicted age:', age_list[prediction[0].argmax()])predicted age: (15, 20)なるほど。
# https://github.com/GilLevi/AgeGenderDeepLearning のコードそのまま prediction = gender_net.predict([input_image]) print ('predicted gender:', gender_list[prediction[0].argmax()])predicted gender: Femaleなるほど。
# URL によるリソースへのアクセスを提供するライブラリをインポートする。 import urllib.request # ウェブ上のリソースを指定する url = 'https://upload.wikimedia.org/wikipedia/commons/f/f3/LindaEvangelista.jpg' # 指定したURLからリソースをダウンロードし、名前をつける。 urllib.request.urlretrieve(url, 'model2.jpg')('model2.jpg', <http.client.HTTPMessage at 0x7f7d925944a8>)example_image = 'model2.jpg' input_image = caffe.io.load_image(example_image) _ = plt.imshow(input_image)/usr/local/lib/python3.6/dist-packages/skimage/io/_io.py:48: UserWarning: `as_grey` has been deprecated in favor of `as_gray` warn('`as_grey` has been deprecated in favor of `as_gray`')
(著作権的に問題になる気がするので、この写真は見せません。)
# https://github.com/GilLevi/AgeGenderDeepLearning のコードそのまま prediction = age_net.predict([input_image]) print ('predicted age:', age_list[prediction[0].argmax()])predicted age: (60, 100)なるほど?
# https://github.com/GilLevi/AgeGenderDeepLearning のコードそのまま prediction = gender_net.predict([input_image]) print ('predicted gender:', gender_list[prediction[0].argmax()])predicted gender: Maleふーむ?


- 投稿日:2019-12-24T17:21:59+09:00
items()を使った辞書型の処理
items()をつかって、forループでひとつずつ取り出す。
sample.pydict = { "A": 1, "B": 2, "C": 3 } for dict_str, dict_num in dict.items(): print(dict_str,dict_num,sep="→") # 出力結果 # A→1 # B→2 # C→3中身を見てみるとリストの中にタプルが入っている。
sample.pyprint(dict.items()) # 出力結果 # dict_items([('A', 1), ('B', 2), ('C', 3)])これらのタプルがアンパックされて
A → dict_str
1 → dict_numへと入っていることが読み取れる。
- 投稿日:2019-12-24T17:01:53+09:00
Jupyter NotebookでModuleNotFoundError: No module named XXXを解消する方法
この記事について
pip3でSeleniumを落としたのにJupyter Notebookを開くと以下のようなエラーがあってハマったので、対処法を記事にしました。
参考
pythonのパッケージの保存場所で、なんとなくパッケージの場所のPATHが通っていないんだと悟りました。
MacでPATHを通すでパスを通してみましたが、動きませんでした。よって今回は自力で解決したので、以下にそのやり方を説明します。
原因調査
まず、コンソールで、
pip3 show [Package Name]のコマンドを叩き、Seleniumがどこに落ちているのかを確認しました。
Location:の箇所がSeleniumが落ちている場所です。自分の場合は/usr/local/lib/python3.7/site-packagesにあるようです。次に、Jupyter Notebookを開き、通っているPATHを以下のコマンドで確認しました。(自分のユーザー名には一応モザイクかけてます。)
これをみて、
/usr/local/lib/python3.7/site-packagesがない事がわかります。解決策
MacでPATHを通すを参考に、PATHを指定してみましたが、うまくいかなかったので、以下のコマンドをJupyter Notebook内で実行しました。
これで、
import seleniumがエラーなく実行されました。最後に
以上、Jupyter NotebookでModuleNotFoundError: No module named XXXを解消する方法でした。




- 投稿日:2019-12-24T16:38:51+09:00
(失敗)Flaskで作ったwebアプリをherokuでデプロイする
Flaskのアプリをherokuとgithubを使ってデプロイしてみます。
メモのために書きます。と思ってやってたんですが、デプロイしたページを見ようとするとエラーが出てします。前はできたんだけど、、、まずプログラムを入れるファイルを作ります。
(base) PS C:\working\web_app> python -m venv 新しく作るファイル名(今回はmessage_app)仮想環境を設定する。
下のコマンドを打つと仮想環境が稼働します。(base) PS C:\working\web_app\message_app>Scripts\activate次にライブラリを仮想環境にインストールします。
(message_app) PS C:\working\web_app\message_app>pip install 使うライブラリ名(今回はflaskとrequestとgunicorn) pip install -r requirements.txt(requirements.txtを使ってインストールもできる)Procfileという名前のファイルを作るってエディタでファイルに以下の文を書いておく
web: gunicorn app:app --log-file=-requirements.txtを作って中にしたのコマンドで出てきたインストールされてるライブラリの情報をコピペする
pip freeze以下のコマンドを実行する
git initgit add .addと.の間に半角スペースがあるのに注意
git commit -m “コメント”heroku loginheroku creategit push heroku masterってやってみたけど、できなかった ><
- 投稿日:2019-12-24T16:12:01+09:00
Lazy advent calendar 2019
OCRの自己満足実装
Plans
個々の文字をまず認識する。(Using haar or YOLO?)
Rectangleで個々の文字を覆い、以下の処理を施す。
Rectangleで囲まれた領域において、輝度値を3D-plotしたものに対して、これを3D-modelingして、回転させた際の写像をもとに個々の文字を正確に認識させる。
# Modules from pathlib import Path from skimage import io import matplotlib.pyplot as plt import cv2 import numpy as np # Putting some image files of any documents under dataset p = Path("../dataset") paths = list(p.glob("**/*.jpg")) data1 = io.imread(paths[0]) # Using tile strategy to evaluate the recognition accuracy. mini = data1[1200:1400, 800:1000, 0] plt.imshow(mini) print("Showing data to be processed...") plt.show()Switch1
- 紙全体の領域をAffine変換などで切り取った上で、一文字のpixel-widthを推定する。
# Highlighting the target ## Lazy normalization if mini.max() > 256: subject = np.true_divide(mini, 256).astype("uint8") else: subject = mini.astype("uint8") ## Creating a mask to remove noise. mask = (subject < 200) masked = mask * subject ## Distance transform distmap = cv2.distanceTransform(masked,1,3) ## Creating all zero matrix, which size equal to data featuremap = distmap*0 ## Deciding kernel size to convolve. ksize = 20 ## Detecting edge with convolution... for x in range(ksize,distmap.shape[0]-ksize*2): for y in range(ksize,distmap.shape[1]-ksize*2): ### Kernel内で最大の値を持つ座標をfeaturemap内に1として出力している... ### max-poolingと処理は近い。Max-poolingと標準化を同時に実施している。 if distmap[x,y]>0 and distmap[x,y]==np.max(distmap[x-ksize:x+ksize,y-ksize:y+ksize]): featuremap[x,y]=1 ### defining feature_dilated for imshow feature_dilated = cv2.dilate(featuremap, (50, 50)) print("Masked image is ... : ") plt.imshow(masked) plt.show() plt.imshow(feature_dilated) print("Feature shape is ... : " + str(feature_dilated.shape)) plt.show() Feature_mask = (feature_dilated > 0) Cropped = masked * Feature_mask plt.imshow(Cropped) plt.show()Switch2
Tile-strategyにおいて切り取った画像ファイルをPublic-OCR-serverに処理させる。
切り取った画像ファイルを自作した1文字認識のためのMNISTのようなサーバーに処理させる。(One-hotベクトル化を行ったのちに、その座標から1文字だけをcropする。)
今後の課題
- 今はやりの(?)Spiking neural networkでYOLOを実装し、解釈性ゴリゴリの1文字cropping processを完成させる。
- 3次元データの識別に有効な射影行列に関する研究(勉強)をする。
- フルスクラッチ次元削減
参考
- 投稿日:2019-12-24T16:07:28+09:00
僕とNERとFlairと
この記事はMYJLabアドベントカレンダー23日目です。
はじめに
こんにちは。MYJLab m1のmarutakuです。今回は、固有表現抽出と呼ばれる技術を使う機会があったので、その時に使ったライブラリの紹介をしようと思います。
固有表現抽出(NER)について
固有表現抽出(Named Entity Recognition)とは、企業名や地名などの固有名詞を企業・地名などのラベル付きで取得してくる技術です。
例として、米航空機大手ボーイングは23日、ミュイレンバーグ最高経営責任者(CEO)の即時辞任を発表した。 2度の墜落事故を起こして運航停止中の最新鋭機「737MAX」の問題の責任を取ったとみられる。 カルフーン会長が来年1月13日付でCEO職に就くという。https://news.yahoo.co.jp/pickup/6346205
この時、人名はミュイレンバーグ, カルフーンであり、組織名はボーイングということがわかります。このように、文章の中に存在する固有名詞を取得するのが固有表現抽出のタスクです。データセット
このリポジトリにまとまってます。よく使われるのはCoNLL2003とOntonotes v5だと思っています。他にも、医療系のデータやwikipedhiaのアノテーション済みデータなどがあります。
日本語のデータセットはあまり公開されていませんが、売ってはいるようです。固有表現抽出の難しいところ
最近の固有表現抽出の論文は、実装するのが大変難しいです。Paper With Codeをみてもらえればわかると思いますが、大量のモデルをスタックさせて使用したり、複数の事前学習済みモデルの単語表現を使用したいりしているので大変面倒です。
LSTM-CRF+ELMo+BERT+Flairとかモウナニイッテルノカワカラナイ。
そんな時に、NERのState of the artを達成したモデルを簡単に実装できるFlairというライブラリに出会いました。Flairとは
Flairは、簡単にState of the artのモデルを実装できるようにと作られた自然言語処理用のライブラリです。学習済みのモデルが豊富に用意されており、過去のSoTAモデルをすぐに自分のシステムに組み込むことができます。
チュートリアルにも書いてありますが、Flairで学習済みの固有表現抽出モデルを試す時は以下のコードだけで実現できますfrom flair.data import Sentence from flair.models import SequenceTagger # make a sentence sentence = Sentence('I love Berlin .') # load the NER tagger tagger = SequenceTagger.load('ner') # run NER over sentence tagger.predict(sentence)ここで用いられている
nerというモデルの他にも、CPUでも高速に動作するner-fastというモデルなど多様なモデルが存在しています。Flairを用いた自作モデル
Flairは学習済みモデルの実行だけではなく、自作のモデルを作成することも可能です。
Flairは学習済みモデルだけでなく、有名なモデルの埋め込み表現も簡単に扱えるようにしています。(https://github.com/flairNLP/flair/blob/master/resources/docs/TUTORIAL_4_ELMO_BERT_FLAIR_EMBEDDING.md)
自作のモデルの例を以下に示します。from flair.data import Corpus from flair.datasets import WNUT_17 from flair.embeddings import TokenEmbeddings, WordEmbeddings, StackedEmbeddings from typing import List # 1. get the corpus corpus: Corpus = WNUT_17().downsample(0.1) print(corpus) # 2. what tag do we want to predict? tag_type = 'ner' # 3. make the tag dictionary from the corpus tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type) print(tag_dictionary.idx2item) # 4. initialize embeddings embedding_types: List[TokenEmbeddings] = [ WordEmbeddings('glove'), # comment in this line to use character embeddings # CharacterEmbeddings(), # comment in these lines to use flair embeddings # FlairEmbeddings('news-forward'), # FlairEmbeddings('news-backward'), ] embeddings: StackedEmbeddings = StackedEmbeddings(embeddings=embedding_types) # 5. initialize sequence tagger from flair.models import SequenceTagger tagger: SequenceTagger = SequenceTagger(hidden_size=256, embeddings=embeddings, tag_dictionary=tag_dictionary, tag_type=tag_type, use_crf=True) # 6. initialize trainer from flair.trainers import ModelTrainer trainer: ModelTrainer = ModelTrainer(tagger, corpus) # 7. start training trainer.train('resources/taggers/example-ner', learning_rate=0.1, mini_batch_size=32, max_epochs=150) # 8. plot weight traces (optional) from flair.visual.training_curves import Plotter plotter = Plotter() plotter.plot_weights('resources/taggers/example-ner/weights.txt')上のモデルは
gloveというモデルの埋め込み表現をモデル内部で使用していますが、これを増やすことで複数の単語埋め込み表現を利用することができます。
まだ試してはいないですが、埋め込み表現のファインチューニングもできるみたいです。終わりに
今回は、NERの話とFlairの話をしました。FlairはNERの他にもネガポジ判定やテキスト分類などのタスクに応用が可能です。自然言語処理使いたいけど難しそう…と思っている方はぜひ使ってみてください。
参考文献
- 投稿日:2019-12-24T15:50:26+09:00
Kaggleのハローワールド、タイタニック号の生存者をロジスティック回帰で予測してみるー予測・評価編ー
0. はじめに
- 前提:大した記事でもないのに分けてしまいましたが、モデリング編の続きです。
- 主旨:テストデータを使って予測し、モデルの検証までのプロセスを紹介します。数学的な細かいところなどはすっ飛ばします。(Kaggle上で検証することが大前提)
- 環境:Kaggle Kernel Notebook
4. 予測する
前回の記事で作成したモデルで、テストデータを使って生存したかどうかを予測します。
4.1. テストデータ準備
まずは、テストデータを準備します。
実際のデータ解析時には、元のデータから訓練データとテストデータを分ける必要がありますが、
Kaggleでは分けてくれているので、Competitionページからテストデータ(test.csv)をダウンロードします。test_csv = pd.read_csv('../input/titanic/test.csv', sep=',') test_csv.head()念のため、テストデータの概要も確認しておきます。
# 次元の確認 test_csv.shape # 出力結果 (418, 11) # 欠損データ数の確認 test_csv.isnull().sum() # 出力結果 PassengerId 0 Pclass 0 Name 0 Sex 0 Age 86 SibSp 0 Parch 0 Ticket 0 Fare 1 Cabin 327 Embarked 0 dtype: int64訓練データではFareの欠損値はありませんでしが、テストデータでは1件だけあるようです。
モデリング時のAgeと同様に、欠損値は平均値で埋めることにします。テストデータに対しても、訓練データ同様にデータ整形をしていきます。
# 不要な列を取り除く test = test_csv.drop(['Name', 'SibSp', 'Ticket', 'Cabin'] , axis=1) # 女性ダミーを作る test['Female'] = test['Sex'].map(lambda x: 0 if x == 'male' else 1 ).astype(int) # Parchが0とそれ以上でダミーを作る test['Parch_d'] = test['Parch'].map(lambda x: 0 if x == 0 else 1).astype(int) # EmbarkedがSとそれ以外でダミーを作る test['Embarked_S'] = test['Embarked'].map(lambda x: 1 if x == 'S' else 0).astype(int) # Ageの欠損値を埋める test['Age'].fillna(test['Age'].mean(), inplace=True) # Fareの欠損値を埋める test['Fare'].fillna(test['Fare'].mean(), inplace=True)4.2. 予測する
それでは、前回作成したモデルを使って予測していきましょう。
# 予測する predict = model.predict(test_x) predict[:10] # 出力結果 array([0, 0, 0, 0, 1, 0, 1, 0, 1, 0])出力はNumpy配列のarrayで返ってくることに注意してください。
5. 評価
5.1. 予測結果データの提出
それでは、作成したモデルがどのくらいいいのかを検証していきたいと思います。
Kaggle上では、予測した結果を提出するとScoreが返ってきて、その値によって評価します。
そのため、提出用のデータを作成します。submit_csv = pd.concat([test['PassengerId'], pd.Series(predict)], axis=1) submit_csv.columns = ['PassengerId', 'Survived'] submit_csv.to_csv('./submition.csv', index=False)
こんな感じのデータを作って、Competitionのページから提出します。
結果は、こんな感じでした。
5.2. 予測結果の評価
Kaggleでは正解データを入手できなかったので、正解データがあった場合の評価としてAccuracyを紹介します。
Accuracyは予測結果がどのくらい実際のデータと合っていたのかを示します。
Accuracy = (正しく予測できたサンプル数)/(全体のサンプル数)
として計算されます。このうち、正しく予測できたサンプル数とは、1のサンプルは1、0のサンプルは0と予測できたものです。
仮に、先ほどのsubmit_csvに'Survived_test'という実際に生存したかどうかのデータが入っているとします。pd.crosstab(submit_csv['Survived'], submit_csv['Survived_test']) # 出力結果(想定) Survived_test 0 1 Survived 0 a b 1 c d上記のような出力結果になるはずですので、
Accuracy = a + d / (a + b + c + d)
で求められます。モデルの評価指標は他にもあって、モデルの用途などによって使い分けていきます。
6. 終わりに
- 途中でミスってEmbarked_Sを抜きでモデリング・評価していたのですが、そちらの方が結果は良かったです
- 今回はお試しなので直感的にではありますが、仮説を持ってモデリングしていきました
- 次回はロジスティック回帰の解説をしたいと思います


- 投稿日:2019-12-24T15:48:24+09:00
DjangoのMVT-モデルとモジュールの関係-
目的
Djangoを使うときのMVTパターンと各パターンに対応するモジュールをまとめてみます。
ちなみに、モジュールとは「~.py」のソースファイルのこと。パッケージとはソースファイルを管理するためのフォルダのことです。(Pythonの方言と思ってもらえばOK)背景
MVTパターンはよく聞く、Djangoのフレームワークの記事はよく見かける。でもその2つの対応付けがイメージしにくいなと思ったので備忘録としてまとめてみます。
もっと詳しく書いて欲しいところや間違っているところがあればコメントお願いします。MVTパターンって?
説明 Model データ管理 View 呼び出し制御 Template ユーザーインタフェース シンプルに書くとこんな感じでしょうか。
その他にもDjangoフォームという入力データ制御用クラスが使える機能があったりとか、大規模なアプリを作るのであればもう少しアーキテクチャのことを考えて、サービス層とドメイン層わけてとか考えられますが、それはまたいつか細かいバージョンでまとめてみようと思います。まずはDjangoプロジェクトの構成
例えば「sample_project」というプロジェクトを作成し、その中に「sample_app」というアプリケーションを作成した場合の基本的な構成を紹介します。
(Djangoプロジェクト作成時にデフォルトでは作られず、自身で追加が必要なフォルダやモジュールには、名前の前に☆をつけます)
(パッケージまたはフォルダの場合、名前の後ろに*をつけます)sample_project* | - sample_project* | - settings.py | - urls.py | - wsgi.py | - sample_app* | - migrations* | - ☆templates* | - ☆static* | - ☆sample_app* | - models.py | - views.py | - ☆urls.py | - manage.py今回紹介する焦点がMVTなので、関連しないパッケージやモジュールは省略します。
それぞれの層ごとに対応するモジュールは?
実際に各層ごとに対応するモジュールを紹介していきます。
Model
Modelに関連するものはこれ
sample_project* | - sample_project* | - settings.py・・・A | - sample_app* | - migrations*・・・B | - models.py・・・CA.プロジェクト全体の設定用モジュール
Modelだけで利用するモジュールではないですけど、データベースの設定情報などはここに書きます。B.migrationsパッケージ
コードベースでデータベースを構築しようとしたときに、makemigrationsコマンドにより生成されるソースファイルが格納されます。
migrateコマンドでここの内容がデータベースに適用されます。C.各Modelクラスの定義用モジュール
ここに独自のModelクラスを定義していくことになります。
Modelクラスの作り方View
Viewに関連するものはこれ
Viewでは呼び出し後の制御のためのView関数の定義だけでなく、どのView関数を呼び出すかというURLディスパッチャの設定が必要になることをしっかり覚えておくことが大事です。sample_project* | - sample_project* | - urls.py・・・A | - sample_app* | - views.py・・・B | - ☆urls.py・・・CA.プロジェクトパッケージ内のurls.py
URLをもとにView関数を呼び出すためのディスパッチャ情報を記載します。
ただし、このモジュールではDjangoプロジェクト内の各アプリケーションを分割するためのURLディスパッチャを記載します。
今回の例ではhttp://~~~~~/sample_project/sample_app/のように
ホスト名以降のアプリケーションの分割までのURLディスパッチャを登録します。B.各View関数定義用モジュール
ここに独自のView関数を定義します。C.アプリケーションパッケージ内のurls.py
アプリケーション内の各URLディスパッチャ情報を記載します。このモジュールは自身で追加する必要があります。
上記A.によりアプリケーションごとに分割されたURLの続きのURLディスパッチャを登録することになります。
今回の例ではhttp://~~~~~/sample_project/sample_app/homeとかhttp://~~~~~/sample_project/sample_app/editのようなURLが指定できるようにsample_app/の後ろの部分を登録します。Template
Templateに関連するものはこれ
sample_project* | - sample_app* | - ☆templates* | - ☆static*・・・A | - ☆sample_app*・・・BA.レンダリング用ファイル(cssファイルやJSファイル)格納用パッケージ
HTML以外に画面の構成に必要なファイルはここに置きます。B.Templateファイル格納用パッケージ
HTMLファイルはここに置きます。まとめ
フレームワーク使うなら、どこに何書けばいいのかを整理することが結構大事です!
今回はひとまずシンプルな構成にしてMVTそれぞれでまずはここを見ないといけないというフォルダやファイルに絞って紹介しました。
- 投稿日:2019-12-24T15:24:36+09:00
Model Complexity and Over-fitting
モデルの複雑さと、データに軽いノイズを乗っけたときのモデル精度の悪化を検証
モデル構築に用いたデータは、過去起こり得た事象(population)の一つのサンプルであったという発想を持ちがちな私として、ただ一つの過去に見えたサンプルが多少ぶれうる事象であったことも気にかけたくなるもの。「サンプルが多少ぶれることを考えること」=「目に見えたサンプルににノイズを足す」とすれば、自分の作るモデルの頑健性(データへの依存度)を確認する一つの方法として使えるのはないかと思い、作成
ざっくり言うと
テストデータ、学習データに分けるののではなく、これだ!!というモデルを作り、本当はちょっとデータ違い得るです。というときにモデルは精度がどれだけ悪化するか
という現象を確認したかったというのが動機
- 予測対象:USDJPYの翌週リターン
- 予測の用いるデータ:過去4週分のリターン
- 予測方法:PolynomialFeatures & LinearRegression
- 複雑さとして、PolynomialFeaturesに用いるdegreeを1~6と設定
- 足すノイズ:元データの0.3倍のvolatilityを持つ正規分布乱数
モデルシンプルで、ノイズもシンプルなものなら、数式を用いて予測精度の劣化は計算できると思うが、Simulationベースにすることで、多様なモデル、i.i.dでも正規分布でもないノイズにでも対応できるのではないかと
Import など
import numpy as np import pandas as pd import matplotlib.pyplot as plt # import statsmodels.api as sm # from statsmodels.tsa.arima_model import ARIMA import pandas_datareader.data as web import yfinance as yf from numpy.random import * from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression # from pandas.plotting import table # from scipy.optimize import minimize import seaborn as sns import warnings import sys warnings.filterwarnings('ignore') plt.style.use('seaborn-darkgrid') plt.rcParams['axes.xmargin'] = 0.01 plt.rcParams['axes.ymargin'] = 0.01yfinanceから、'USDJPY'を取得し、週次リターン作成
ReadDF = yf.download('JPY=X', start="1995-01-01", end="2019-10-30") ReadDF.index = pd.to_datetime(ReadDF.index) IndexValueReadDF_rsmpl = ReadDF.resample('W').last()['Adj Close'] ReadDF = IndexValueReadDF_rsmpl / IndexValueReadDF_rsmpl.shift(1) - 1説明変数(X)、被説明変数(y)データ作成
ret_df = pd.DataFrame() ret_df[mkt] = ReadDF test = pd.DataFrame(ret_df[mkt]) for i in range(1, 5): test['i_' + str(i)] = test['USDJPY'].shift(1 * i) test = test.dropna(axis=0) X = test.ix[:, 1:] y = test[mkt]モデルの作成(実サンプル&ノイズを乗っけたもの)
m_ = 3 # 0.3倍のvolatilityを持たせるための掛け目 output_degree = {} for k in range(1, 7): polynomial_features = PolynomialFeatures(degree=k, include_bias=False) linear_regression = LinearRegression() pipeline = Pipeline([("polynomial_features", polynomial_features), ("linear_regression", linear_regression)]) pipeline.fit(X, y) k_sample = pd.DataFrame() for l in range(0, 300): # 正規乱数発生 eps_0 = pd.DataFrame(randn(X.shape[0], X.shape[1])) eps_1 = eps_0.apply(lambda x: x * list(X.std()), axis=1) eps_1.columns = X.columns eps_1.index = X.index # 元データに足す X_r = X + m_/10 * eps_1 signal = pd.DataFrame() signal[mkt] = np.sign(pd.DataFrame(pipeline.predict(X_r)))[0] signal.index = y.index k_sample['s_' + str(l)] = (pd.DataFrame(signal[mkt]) * pd.DataFrame(y)).ix[:, 0] signal_IS = pd.DataFrame() # signal_IS[mkt] = np.sign(pd.DataFrame(pipeline.predict(X.ix[:, 0][:, np.newaxis])))[0] signal_IS[mkt] = np.sign(pd.DataFrame(pipeline.predict(X)))[0] signal_IS.index = y.index k_sample['IS'] = (pd.DataFrame(signal_IS[mkt])*pd.DataFrame(y)).ix[:, 0] k_sample[mkt] = pd.DataFrame(y).ix[:, 0] output_degree['degree_' + str(k)] = k_sampleアウトプットヒストグラム(degree N毎)
- グレー線:元データ(USDJPY)のリターン/リスク
- 赤線:元サンプルへモデル適用した戦略のリターン/リスク
- 青線:ノイズを乗っけたサンプルへモデル適用した戦略の平均リターン/リスク
- ヒストグラム:青線の元データ
- グレー線:
Performance_sim = pd.DataFrame() fig = plt.figure(figsize=(15, 7), dpi=80) for k in range(1, 7): ax = fig.add_subplot(2, 3, k) for_stats = output_degree['degree_' + str(k)] Performance = pd.DataFrame(for_stats.mean()*50 / (for_stats.std()*np.sqrt(50))).T Performance_tmp = Performance.ix[:, 1:].T ax.hist(Performance.drop(['IS', mkt], axis=1), bins=30, color="dodgerblue", alpha=0.8) ax.axvline(x=float(Performance.drop(['IS', mkt], axis=1).mean(axis=1)), color="b") ax.axvline(x=float(Performance['IS']), color="tomato") ax.axvline(x=float(Performance[mkt]), color="gray") ax.set_ylim([0, 40]) ax.set_xlim([-0.3, 2.5]) ax.set_title('degree-N polynomial: ' + str(m_)) fig.show()
- 同然インサンプルでも、週次リターンの簡単なモデルではUSDJPYは予測できない→外れてもパフォーマンスそんなかわらない(もともと良くないから)
- インサンプルで複雑なモデルは当然当てはまるものを見つけられるが、激しく元データに依存
シンプルなデータだと当然な結果だが、自分がモデルを作った際の検証には役立ちそう

- 投稿日:2019-12-24T14:35:12+09:00
iTunesで再生中の曲の歌詞をPythonで自動表示させよう
はじめに
iTunes(Catalina からはミュージックに名前が変わりましたが)で曲を再生しながら歌詞を表示させたいことってありますよね。しかし曲が変わるたびに手動で検索して歌詞を表示させるのは面倒です。面倒なことは Python にやらせましょう。
やりたいこと
Mac 標準アプリの「ミュージック」で曲を再生して、曲が切り替わるたびに自動で歌詞サイトの歌詞を表示させる。
環境
OS: macOS Catalina バージョン 10.15
言語: Python 3.6
使用ライブラリ: appscript, urllib, BeautifulSoup, selenium
各ライブラリのインストールは PyCharm で行いました。それぞれ pip でもインストールできると思います。曲名の取得
まずはミュージックアプリから曲情報を取得します。ここでは appscript を使います。詳しいことはよくわかりませんが、AppleScript を Python で操作できるらしいです。appscript サイトURL
まずはアプリにアクセスします。今回はミュージックなので Music になります(Catalina 以前を使用してる場合は iTunes になります)。
music = appscript.app("Music")次に再生中の曲情報を取得します。
name = music.current_track.name.get() # 曲名 artist = music.current_track.artist.get() # アーティスト名 album = music.current_track.album.get() # アルバム名 music_time = music.current_track.time.get() # 曲の長さ("分:秒"の文字列です)曲の長さが文字列のままだと面倒なので、秒の数値に直しておきます。曲の長さは曲の切り替わりを判定するのに使います。
music_time = music_time.split(":") music_time = int(music_time[0]) * 60 + int(music_time[1])歌詞の表示
歌詞ページを探す
曲情報が取得できたら、今度はそれを使って歌詞サイトにアクセスしましょう。今回歌詞サイトは Uta-Net を使用します。また、サイトへのアクセスにはスクレイピング用ライブラリの BeautifulSoup を使います。Beautiful Soup を用いたスクレイピングの詳細は「PythonとBeautiful Soupでスクレイピング」がわかりやすいです。
まず、サイトにある曲名検索機能を使って検索結果の画面に飛びます。日本語の曲名を検索するためにパーセントエンコーディングを行います。
name = parse.quote(name) # パーセントエンコーディング url = "https://www.uta-net.com/search/?Aselect=2&Keyword=" + name + "&Bselect=4&x=0&y=0" html = request.urlopen(url) soup = BeautifulSoup(html, "html.parser")検索結果に飛ぶと、同名の曲が一覧として出てきます。HTML を見てみると tr タグ内の a タグで曲名と歌手名が一覧になっているため、その中から目当ての歌手を探します。一致するものが見つかれば次の段階に進みます。
tr = soup.find_all("tr") name_url = "" # 目当ての曲の URL を入れる flag = False for tag_tr in tr: a = tag_tr.find_all("a") # 曲名、歌手名、作詞、作曲の順番で格納されている for i, tag_a in enumerate(a): if i == 0: # 曲名 name_url = tag_a.get("href") elif i == 1: # 歌手名 if tag_a.string == artist: flag = True break if flag: break歌詞ページの表示
今回は自動で歌詞ページを開くだけではなく、次の曲に切り替わったら前のページを閉じる必要があります。そのためにブラウザ上の操作を自動化できる selenium を使います。selenium については「PythonでSelenium」がわかりやすいです。
まず先ほど取得した URL にアクセスしましょう。全体としては以下のループになります。
1. 曲が変わる
↓
2. 新しいタブを開いて歌詞ページにアクセス
↓
3. 前回のタブを閉じる
↓
4. 1 に戻るまずはループの前にブラウザを開いておきます。
# Chrome を開く driver = webdriver.Chrome(executable_path="chromedriver") # ループの起点の初期タブ driver.get("https://www.google.com/")次にループ内の 2 ~ 3 を行います。その際歌詞ページの上の余白が邪魔なのでページをスクロールしておきます。
# 新しいタブを開いて移動 driver.execute_script("window.open()") driver.switch_to.window(driver.window_handles[1]) # 移動先で指定 URL にアクセス driver.get("https://www.uta-net.com/" + name_url) # 歌詞の位置までスクロール driver.execute_script("window.scrollTo(0, 380);")完成
これで現在再生している曲の歌詞を表示することができました。あとはこれをループするだけです。以下全体のコードです。
import appscript from urllib import request, parse from bs4 import BeautifulSoup from selenium import webdriver import time driver = webdriver.Chrome(executable_path="chromedriver") driver.get("https://www.google.com/") # 初期タブ music_time = 0 while True: start = time.time() # ---- 曲名取得 ---- # Music アプリにアクセスする music = appscript.app("Music") # 再生中の曲名、アルバム名、アーティスト名、曲の長さ name = music.current_track.name.get() artist = music.current_track.artist.get() album = music.current_track.album.get() music_time = music.current_track.time.get() # m:s の str print(name, artist, album, music_time) # music_time を秒数に直す music_time = music_time.split(":") music_time = int(music_time[0]) * 60 + int(music_time[1]) # ---- 歌詞サイトにアクセス ---- name = parse.quote(name) # パーセントエンコーディング url = "https://www.uta-net.com/search/?Aselect=2&Keyword=" + name + "&Bselect=4&x=0&y=0" try: html = request.urlopen(url) soup = BeautifulSoup(html, "html.parser") tr = soup.find_all("tr") name_url = "" flag = False for tag_tr in tr: a = tag_tr.find_all("a") for i, tag_a in enumerate(a): if i == 0: # 曲名 name_url = tag_a.get("href") elif i == 1: # 歌手名 if tag_a.string == artist: flag = True break if flag: break # 新しいタブで開く driver.execute_script("window.open()") driver.switch_to.window(driver.window_handles[1]) driver.get("https://www.uta-net.com/" + name_url) driver.execute_script("window.scrollTo(0, 380);") # 歌詞の位置までスクロール # 前のタブを閉じる driver.switch_to.window(driver.window_handles[0]) driver.close() driver.switch_to.window(driver.window_handles[0]) except: pass print("now browsing") print() # 曲の時間待つ time.sleep(music_time - (time.time() - start))おわりに
この記事を書いてる間も無事歌詞ページを表示し続けてくれています。が、不十分な点がいくつかありました。
- 曲名に記号や空白が入っていると対応できない
- そもそも歌詞サイトに載っていないと使えない
- ページを開くたびに歌詞を表示してるウィンドウがアクティブになるため、作業が一瞬(2 秒ほど)止まる
上二つについては try-except によって無視しています(たまに表示できなくてもさほど困らないため)。最後に関しては歌詞を表示する以上しょうがないです。