- 投稿日:2019-12-23T23:52:46+09:00
10. 行数のカウント
10. 行数のカウント
行数をカウントせよ.確認にはwcコマンドを用いよ.
Go
package main import ( "bufio" "fmt" "os" ) func main() { // 読み込みファイルを指定 name := "../hightemp.txt" line := 0 // 読み込むファイルを開く fp, err := os.Open(name) if err != nil { fmt.Printf("os.Open: %#v\n",err) return } defer fp.Close() // 終了時にクリーズ // スキャナライブラリを作成 scanner := bufio.NewScanner(fp) // データを1行読み込み for scanner.Scan() { line++; } // エラーが有ったかチェック if err = scanner.Err(); err != nil { fmt.Printf("scanner.Err: %#v\n",err) return } // 行数を表示 fmt.Println("Line",line) }python
line = 0 # ファイルを開く fp = open("../hightemp.txt", "r") # 一行ずつ読み込む for data in fp: # 行数を加算 line += 1 # ファイルをクローズ fp.close() # 行数を表示 print("Line",line)Javascript
// モジュールの読み込み var fs = require("fs"); var readline = require("readline"); var line = 0; // ストリームを作成 var stream = fs.createReadStream("../hightemp.txt", "utf8"); // readlineにStreamを渡す var reader = readline.createInterface({ input: stream }); // 行読み込みコールバック reader.on("line", (data) => { line = line + 1 }); // クローズコールバック reader.on("close", function () { console.log("Line",line); });まとめ
やっと 「第2章: UNIXコマンドの基礎」 へ突入!!。
2章に入ったとのことで、Pythonのバージョン設定をやっと 3.7 へ変更しました。
IDEの設定だけですけど・・・。設定がどこにあるか探すのが・・・。と言い訳。ファイルの読み込みをそれぞれの言語調べながら。
Go,Python はそれほど困らなかったが、
Javascirpt は。おぉおぉ。なんか面白い。非同期との事もあり考え方は注意が必要か。補足
Go 言語で変数名を fname としていたが、IDE(Golang) が typo? と言ってくる。
有り難いのかなぁ。とりあえず name へ変更し回避。
- 投稿日:2019-12-23T23:44:51+09:00
Yahoo! Hack Day 2019 で感じた、ハッカソン前に準備しておいたら開発しやすくなったもの
はじめに
初めて Yahoo! Hack Day 2019 に参加してきました。
流石に24時間ぶっ続けでの開発はしんどかったけど、
あのわくわくさんからwakuwaku賞(審査員特別賞)をいただけて、いい思い出になりました。Hack Day 2019 で作ったもの
MOGbee
スマホ依存症の現代人からスマホを引き剥がし、家族団欒の邪魔を通知するかわいい充電器、MOGbee を作りました。
90秒プレゼンの動画はこちら
MOGbeeの構成図
MOGbeeは、スマホがwifiを介してラズパイにつながることで、LEDやサーボモータが動作する仕組みになっています。
この記事は、ハッカソンでラズパイ工作をしようと思っている方(と未来の僕)に向けて、ハッカソンに行く前に準備して良かったことと、今後準備したほうがいいものについてまとめました。
⭐ 準備しておいて良かったと思ったもの
タコ足コンセント
ラズパイ工作には電気が必要。一人でも 6台 (Mac, ラズパイ, スマホ×2, wifi, ディスプレイ)の電源が必要だったので、多いに越したことはなさそう。
今回はタコ足コンセントに加えて最近買ったUSB電源分配器も持っていったので、盤石だった。
wifiルータ
ハッカソンではwifiが用意されている場合が多いが、参加者が多いと繋がりにくいし、最悪自分の端末が複数のネットワークに別れてしまいうことも・・・
特にラズパイを使う人にとっては ssh で繋げないことは死活問題になってしまうため、確実につながるルータがあることは通信的にも精神的にも非常に安心できた。
最近契約した どんなときもwifi が思わぬところで活躍してくれました。(ステマじゃないよ)
☔ 準備しておけば良かったと反省したもの
PCからラズパイへのリモートデバッグ環境
GPIOを使ってLEDを光らせるのはラズパイ上で動かさないとできない。しかし、開発はいつものなれたPCでIDE使いながらやったほうが圧倒的に効率が良い。
今回は、PCで開発→GitHubにpush→ラズパイの前まで移動→ラズパイでpullコマンドを打つ、という無駄極まりない方法で開発してしまった・・・ってことで、visual studio code のremote Developmentの設定をしとけばよかったと反省。(愛用しているpycharmにはお布施してないので、remote developできない orz)
もしくは、sshがつながらないことを考えて、ラズパイが自動的にpullしてくれるツールを作っときたいな、と思った。年末暇なら、オープンソースを作ろうかな〜?定期的なラズパイのimgバックアップ
24時間の開発時間は長く疲労が貯まるものだった。そんな中、残り4時間でラズパイの中身をぶっ壊すと、チームメイトが頑張ってきた時間と、返上した睡眠時間がすべて水の泡になります。どのタイミングでバックアップと取るかは、予め計画を立てといたほうが良いと思いました。
サーバを自動起動させたいと思って、開発終了直前に /etc/rc.local にコマンド書いて再起動したときのヒヤヒヤ感は精神安定上よろしくなかった。
さいごに
Hack Dayに参加できて、すごく良かった!
70組以上の参加者がいたにもかかわらず、アイディアがかぶらない独創的なハッカー達が作り上げる発表を聞いているだけで、楽しくなれました。特に、Happy Hacking賞をとった「ポピポポピピプピリロピロリププププピーポ」さんのプレゼンはめっちゃ笑えて印象に残りました。僕も理系ギャグを入れたプレゼンをいつかやってみたいです。
「とりそば弁当」さんのブースに伺った時には、人の顔にジャガイモが追従する精度へのこだわりを全力で語っていただきました。最高にハッカソンやってるなーって感じて、嬉しくなりました。また来年も参加したいな!!



- 投稿日:2019-12-23T23:34:35+09:00
Django-SESとAmazon SESでメール運用しようとした時に詰みまくった話(最速の運用手順も紹介)
はじめに
これはDjango Advent Calendar 2019 24日目の記事になります。
クリスマスイブでもDjangoについて考えている自分に誇りを持って、記事を書きました。笑まだまだ初心者の身ですが、Djangoを勉強していて、ある点で何時間も詰まりました(少し新しい詰まり方?)。参考文献が英語にしてもジャストな記事が無かったので、『他の方がここで躓いて欲しくない』という気持ちで、この記事を書くに至りました。
今回の記事の構成
最初は読者層を広げるためにDjango-sesとAmazon-SESをつかってメール配信を行える最速の手順をご紹介します(。・_・。)
その次に、一応今回の本題である詰まった部分を紹介したいと考えています!対象読者
タイトル通りなのですが、『django-sesとAmazon SES(Amazon Simple Email Service)を利用して、メールを配信しようと思っている方』へ向けての記事です。
開発環境
- Python:3.8.0
- Django:2.2.9(※Django:3.0で環境構築すると詰まります。記事下へジャンプ)
- Django-ses:0.8.13
- boto3:1.10.44
今回の目標を確認
今回は『AmazonSESとDjango-SESを用いてsend_mail出来れば目標達成!』ということにします。
※環境を構築するのが目標以前に難しすぎるので、環境構築にDockerを使用することをお許しください。プログラムの完成形(AmazonSESのKEY設定でsettingsをイジる必要アリ)はコチラのGitHubにあげておきました。
プログラムを作成していく
Docker系のファイル
まずはサラッとDocker系のファイルを載せておきます。
以下のファイルをdocker-ses-sampleディレクトリ下に作成してください。dockerfileFROM python:3 ENV PYTHONUNBUFFERED 1 RUN mkdir /code WORKDIR /code COPY requirements.txt /code/ RUN pip install -r requirements.txt COPY . /code/docker-compose.ymlversion: "3" services: django-ses-sample: build: . volumes: - .:/code ports: - "8000:8000" command: python manage.py runserver 0.0.0.0:8000次にインストールするパッケージ達一覧です。
requirements.txtDjango==2.2.9 boto3==1.10.44 django-ses==0.8.13↓現在のディレクトリこんな感じ↓
作業ディレクトリdjango-ses-sample ├ dockerfile ├ docker-compose.yml └ requirements.txtここから一気にstartprojectまでしてしまします。
まずdockerをいじれるCLIを開いてください。(僕はUbuntu18.04LTSのCLI使ってます)次に作業ディレクトリまで移動します。
dockerがイジれるCLI~/$ cd django-ses-sample ~/django-ses-sample$ docker-compose run --rm django-ses-sample django-admin startproject config .これによってビルドついでにstartprojectまでいけるので、楽です。
そしてこんな表示が来たら成功です。dockerがイジれるCLISuccessfully tagged djangosessample_django-ses-sample:latestそしてdjango-ses-sample下にstartprojectされているのが確認できたら、次へ進みましょう!
Django系のファイル
つぎにstartprojectによって作成されたconfig内のsettings.pyをいじっていきます。
settings.py内にINSTALLED_APPSという欄があるので、コチラにdjango_sesを追加していきます。settings.py: INSTALLED_APPS = [ : 'django_ses', #追加した ]次に一番下までスクロールして、新たに以下のプログラムを追加してください。
settings.py: # AWS settings AWS_ACCESS_KEY_ID = 'AKI***********' # アクセスキーID AWS_SECRET_ACCESS_KEY = '****************************' # シークレットアクセスキー # Email settings EMAIL_BACKEND = 'django_ses.SESBackend' # これは必須 DEFAULT_FROM_EMAIL = SERVER_EMAIL = '**** <****@******>' #送信元のユーザ名とメールアドレス(例:'飛鳥 <asuka@nogi.com>')このようにアクセスキーIDとシークレットアクセスキーを設定する必要があります。これは次の章でAWSにて作成するので今は空欄でOKです。
またEMAIL_BACKENDにてメール配信の設定をしています。ここでDjango-SESを使うことを宣言しています。
最後の行は送信側の情報を置いておきます。この時点でのプログラムはコチラのGitHubにて置いておきました。
AWSへ色々と設定しに行く
Amazon SESの登録手順
*制限解除を行っていないアカウント にて、AmazonSESを使用するには送信するメールアドレスと受け取るメールアドレスを登録しておく必要があります。
*1 Amazon SES Documentaition
まずAWSのアカウントを用意してください。
そしてサインインができたら、サービスにてSES(Simple Email Service)を入力してそのページへ飛んでください。
ここで恐らく標準のリージョンを東京としていた人は、リージョンの選択をさせられるので、必ず米国東部(バージニア北部):us-east-1を選択してください。(※ここで僕は詰まりました。記事下へジャンプ)
左の欄にEmail Addressesが出て来るので、選択してください。
【Varify a New mail adress】にてを選択して受信可能なメールアドレスを登録してください。
ここで【Varify a New mail adress】でもう一つ受信可能なメールアドレスを登録してください。
次に5,6で登録したメールアドレスにAWSからメールが来るので、そのURLにアクセスして、メールアドレスを認証してください。
これで完了
IAMの登録
AmazonSESを使うには、先ほど紹介したアクセスキーIDとシークレットアクセスキーを生成する必要があります。
- サービスにてIAMページを検索して飛ぶ
- 左の欄にてユーザーを選択
- [ユーザーを追加]を選択
- ユーザ名は好きに入力
- プログラムによるアクセスにチェックを入れる
- 下の[次のステップ]を選択
- 既存のポリシーを直接アタッチを選択
- SESと検索して、AmazonSESFullAccessを選択
- あとはスルーしてユーザーの作成してください
- 作成した時にcsvがダウンロードできるので、ダウンロード
- アクセスキーIDとシークレットアクセスキーをcsvにて確認
- これで完了
最後にconfig/settings.pyにてアクセスキーIDとシークレットアクセスキーを入力してください!!
SESがDjangoで機能するかどうかを確認
確認方法は今回の目標であった『AmazonSESとDjango-SESを用いてsend_mail出来れば目標達成!』であるsend_mailの使用なので、pythonのshellにてインポートして、実行していきます。
CLI~/django-ses-sample$ docker-compose run --rm django-ses-sample python3 manage.py shell >>> from django.core.mail import send_mail >>> title = '齋藤飛鳥です。' >>> content = '明日のクリスマス空いてない?' >>> host_email = 'SESで登録したメールアドレス①' # 例:asuka@nogi.com >>> rece_email = ['SESで登録したメールアドレス②'] # 例:['hirochon@bocchi.com'] >>> send_mail(title,content,host_email,rece_email)これでメールが届くはずです(泣)
今回の記事の本題に入ります!!!(詰みまくった話)
ついでにという感じで見てやってください。笑
どこで躓いたのかを先に紹介しておきます!
- Django3.0で環境を構築したこと
- Regionをアジアパシフィックのムンバイに設定したこと
①Django3.0で環境を構築した件について
正式にリリースされると使いたくなりますよね…笑
ですがDjango3.0にて環境を構築すると、botoかdjango-sesのファイル関係でこんなエラーが出てきます。
CLIImportError: cannot import name 'python_2_unicode_compatible' from 'django.utils.encodingこれはどうやらDjango3.0にてPython2の互換性APIを廃止したことによってエラーを吐くようになったみたいです。
*2 Django公式Documentation
*3 GitHubのissueどうやらファイルをいじったら治るみたいなのですが、Dockerコンテナ内(元はPostgreSQLで開発してた)のDBでファイルが見つからず、Django2.2系を使用することによってエラーを吐かなくなりました。
②Regionをアジアパシフィックのムンバイに設定した件について
ちらほら目にする『自分の地域と近いリージョンのほうがレスポンス早くなるよ』という情報に体がつい動いてしまいました…
コチラの問題点は色々と文献を探してみたのですが、しっくり来るものはなかったんです。
なので今回は書こうと決断したわけでございます。ですが恐らく専門家の方たちから指摘が来そうなので先にコチラを書いておきます。
settings.pyに設定を書いても無理でした
AWS_SES_REGION_NAMEとAWS_SES_REGION_ENDPOINTを設定することによって「米国東部(バージニア北部)」(us-east-1)以外のリージョン設定が可能なのです。
例えば「米国西部(オレゴン)」(us-west-2)だとAmazon SESでメールアドレスを認証した後に、settings.pyにこのように書くとメールを送ることができます。
settings.pyAWS_ACCESS_KEY_ID = 'AKI***********' # アクセスキーID AWS_SECRET_ACCESS_KEY = '**************************' # シークレットアクセスキー AWS_SES_REGION_NAME = 'us-west-2' # 追加した AWS_SES_REGION_ENDPOINT = 'email.us-west-2.amazonaws.com' # 追加したですが!!!「アジアパシフィック(ムンバイ)」(ap-south-1)だとこのように設定してもメールを送ることができないのです!!
settings.pyAWS_ACCESS_KEY_ID = 'AKI***********' # アクセスキーID AWS_SECRET_ACCESS_KEY = '**************************' # シークレットアクセスキー AWS_SES_REGION_NAME = 'ap-south-1' # 追加した AWS_SES_REGION_ENDPOINT = 'email.ap-south-1.amazonaws.com' # 追加したじゃあ結局何がだめだったの??
僕の結論としては、AWSにはリージョンごとに実装されているサービスとされていないサービスが存在いることから、まだアジアパシフィック(オレゴン)にはそのサービスが実装されていなかったのではないかと推測しています。
実際オレゴンがSESサービスに追加されたのは最近だそうで、『これからのアップデートで恐らく使えるようになるのではないかな〜』と思っています(/・ω・)/
さいごに
最後まで読んでいただきありがとうございました。
今回作ったプログラムにallauthパッケージなどを追加していくとしっかりとしたメール機能を実装できるようになるので、是非最速手順を活用していってください。
また間違っている点や感想などでもございましたら、お気軽にコメントください!!DjangoやAWS,Dockerなどのバックエンドを勉強していたり、機械学習にも少し手を出している姿を発信している僕のTwitterをフォローして頂ければ喜びます!!@heacet43
参考文献
*1 Amazon SES における制限(AmazonSES Doccumentation 開発者ガイド)[https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/limits.html]
*2 Django 3.0 release notes (Django documentation) [https://docs.djangoproject.com/en/dev/releases/3.0/#removed-private-python-2-compatibility-apis]
*3 Django3 support·Issue #598·treyhunner/django-simple-history(GitHub) [https://github.com/treyhunner/django-simple-history/issues/598]
- 投稿日:2019-12-23T23:23:48+09:00
jupyterを支える技術:traitlets(の解読を試みようとした話)
Python Advent Calendar 2019 23日目の記事です。
はじめに
皆さんは、traitletsというライブラリをご存知でしょうか?
私も少し前にjupyter notebookの実装を眺めていて、存在を知りました。元々IPythonの開発から生まれて切り離されたライブラリのようです。なので、IPythonやjupyter notebookを使用されている方はお世話になっていますし、なんなら知らない内に使っていたりします。というのも、jupyter notebookやIPythonの設定ファイルは、traitletsを使って読み込まれているからです例えば
jupyter_notebook_config.py1やipython_config.py2を編集して# 基本コメントアウトされています c.Application.log_datefmt = '%Y-%m-%d %H:%M:%S'みたいな記述を見たor編集した経験のある方もおられるかもしれません。
実はここで出てくる、謎の
cは、traitletsのConfigクラスのインスタンスとなっています。そして、c.Application.log_datefmt = ...と書いた時、これはこの記述が書かれた設定ファイルを読み込むConfigurableクラス(実際は、それらを束ねるApplicationクラス?)が管理するApplicationクラスのlog_datefmtというメンバ変数に...の値が割り当てられます。実際、jupyter notebookのコアクラスとも言えるNotebookAppクラス(定義)は、jupyter_coreモジュールのJupyterAppクラス(定義)を継承していますが、このJupyterAppクラスは、traitletsのApplicationクラスを継承(ここ)しています。
本記事は、このtraitletsがどういうライブラリか、ちょっと調べてみたけど、ドキュメントが雑で結局ちゃんと理解できなかったから、とりあえず存在だけ広めておく、という目的で書きました。
そして以下は、使い方の翻訳+内容希釈した文書となります。
Traitletsの使い方
pythonは、いわゆる"型"が動的に決まるため、明示的に書かない限り、クラスの属性(メンバ変数)に、好き勝手な値を割り当てる事が可能です。このクラスの属性の型をきちんと定めて、さらに細かいチェック機能を簡単に呼び出せるようにしておこう、というのがtraitletsの提供する役割の1つだと理解しています。実際はjupyterやipython実装でも用いられている設定ファイルの読み込みのほうが、主役な機能である気もしますが...
型チェック機能
HasTraitsのサブクラスFooを次のように定義します:
from traitlets import HasTraits, Int class Foo(HasTraits): bar = Int()これは、通常のクラスと同様に、Fooというクラスにbarという属性(attribute)を持たせています。ただし通常のクラス変数と違い、これはtraitと呼ばれる特殊な属性になっています。
特に、このbarはintと呼ばれるタイプのtraitになっており、名前から分かるように整数値を格納するtraitです。実際にインスタンスを生成してみましょう:
> foo = Foo(bar=3) > print(foo.bar) 3 > foo.bar = 6 > print(foo.bar) 6でfooは整数値"型"のbarという属性を持っており、値を変更することも可能です。
一方で、文字列を与えてみるとどうでしょうか?
> foo = Foo(bar="3") TraitError: The 'bar' trait of a Foo instance must be an int, but a value of '3' <class 'str'> was specified.このような型の割り当てが間違っている旨のエラーメッセージが出るはずです。これにより、
__setattr__などを用いて、型チェックを自分で実装する必要がなくなります。ここでInt型しか紹介していませんが、Listなどのコンテナ型含め、幾らか用意されていますし、自分で定義する事も可能です。詳しくはドキュメントを参照してください。
デフォルト値設定
traitletでは、デフォルト値を、インスタンス生成時に動的に指定できます。ちなみに先の
Intというtraitタイプでは、何も指定しないとデフォルト値として0がセットされます:> foo = Foo() > print(foo.bar) 0次の例では、todayというtraitに、今日の日付を格納しています。
from traitlets import Tuple class Foo(HasTraits): today = Tuple(Int(), Int(), Int()) @default("today") def default_today(self): import datetime today_ = datetime.datetime.today() return (today_.year, today_.month, today_.day) > foo = Foo() > foo.today (2019, 12, 22)ちなみにコードを見れば一目瞭然ですが、todayのtraitタイプは、整数値3つから成るtupleです。
Tupleのデフォルト値は、()なので、デフォルト値を明示しなかったり、インスタンス生成時に値を指定したりしないと、型が違うので、割り当てエラーが発生する事に注意してください。なお、これは次のように書くのとおそらく等価だと思いますが、ロジックの切り分け、という観点からは前者の方が明らかに読みやすいですね:
class Foo(HasTraits): today = Tuple(Int(), Int(), Int()) def __init__(self): import datetime today_ = datetime.datetime.today() self.today = (today_.year, today_.month, today_.day)値の検証
次に紹介するのは、値割り当ての検証機能です。型チェックができるようになっても、その値が適切かどうかは分かりません。例えば、あるtrait(何かの個数を表すとしましょう)が非負整数である事が要求される場合に、
Intだけでは不十分です。もっと言えば、この制限が、別のtraitに依存している可能性もあります。例えば、月を格納したmonthと、日を格納したdayがある場合に、monthの値によって許されるdayの範囲が変わります。こういったチェックを行うのが、
validateです。ここでは、11月と12月だけ実装してみます。
from traitlets import validate class Foo(HasTraits): today = Tuple(Int(), Int(), Int()) @validate('today') def _valid_month_day(self, proposal): year, month, day = proposal['value'] if month not in [11,12]: raise TraitError('invalid month') if month == 11 and day not in range(1,31): raise TraitError('invalid day') elif month == 12 and day not in range(1,32): raise TraitError('invalid day') return proposal['value'] > foo = Foo(today=(2000,12,1)) > foo.today (2000, 12, 1) > foo.today = (2000,13,1) TraitError: invalid month > foo.today = (2000,12,31) > foo.today = (2000,12,32) TraitError: invalid dayなお、複数のtrait変数が相互参照している場合、1つ値を変更していくと、途中で検証エラーに引っかかる可能性があります。このような場合、全てのtraitが変更されまで検証をスキップする必要があります。これは
hold_trait_notificationsスコープ内で実現できます。以下の例を見てましょう:class Foo(HasTraits): a, b = Int(), Int() @validate('a') def _valid_a(self, proposal): if proposal['value'] * self.b <= 0: raise TraitError("invalid a") return proposal['value'] @validate('b') def _valid_b(self, proposal): if proposal['value'] * self.a <= 0: raise TraitError("invalid b") return proposal['value'] > foo = Foo(a=1,b=1) > foo.a = -1 > foo.b = -1 TraitError: invalid a > with foo.hold_trait_notifications(): > foo.a = -1 > foo.b = -1 > print(foo.a, foo.b) -1 -1この例では、a,bという2つのtraitが定義されていますが、それらの積は非負である事が要求されるとします。すると、両方の値を負にしても、この検証は通りますが、片方だけ変更すると、検証エラーが発生してしまいます。一方、
hold_trait_notifications内でa, b両traitの値を変更すると、このスコープ終了時に遅延検証されるので、そのような心配がなくなります。変更通知
最後に紹介するのは、traitにobserverパターンを実装する機能です。これは、指定したtraitの値が書き換わった時に(イベント発生)、何か処理を行うことができます。
class Foo(HasTraits): bar = Int() @observe('bar') def _observe_bar(self, change): ...は、もはや完全なコードではないですが、barというtraitの値が変更された際に、_observe_barという関数が実行されます。
以上、めちゃくちゃ内容が薄いですが、初めてのプログラミング言語系の投稿、という事でこれでお許しを。また、traitlets詳しい方いたら、寂しすぎるドキュメントやexamplesを充実させてください...
- 投稿日:2019-12-23T22:09:53+09:00
今日のAnsibleモジュールをツイートするTwitter botを作った話
こちらの記事は Ansible 3 Advent Calendar 2019 25日目の記事になります。
今回は定期的にAnsibleのモジュール名をTweetするボットを作成したので紹介します。
Ansibleモジュール紹介
— matsumuratomonori (@ma2muratomonori) December 23, 2019
azure_rm_publicipaddress
Manage Azure Public IP Addresses
supported_by: community
version_added: 2.1https://t.co/f7XpVAYtBgAnsibleモジュール紹介
— matsumuratomonori (@ma2muratomonori) December 22, 2019
win_psmodule
Adds or removes a Windows PowerShell module
supported_by: community
version_added: 2.4https://t.co/Vc6w6j844nAnsibleモジュール紹介
— matsumuratomonori (@ma2muratomonori) December 22, 2019
oneview_ethernet_network_info
Retrieve the information about one or more of the OneView Ethernet Networks
supported_by: community
version_added: 2.4https://t.co/5fJNdRZaaqAnsibleモジュール紹介
— matsumuratomonori (@ma2muratomonori) December 22, 2019
win_route
Add or remove a static route
supported_by: community
version_added: 2.4https://t.co/9BkqMLPdlQAnsibleモジュール紹介
— matsumuratomonori (@ma2muratomonori) December 22, 2019
script
Runs a local script on a remote node after transferring it
supported_by: core
version_added: 0.9https://t.co/TtWFWP07O0元ネタ
今日のラッキーAnsibleモジュール
— よこち(yokochi) (@akira6592) December 2, 2019そんなことないぽて〜 今日のモジュール紹介したいぽて〜
— 怒れるじゃがいも@Ansible AWX リリース早め (@angrypotato_jp) December 19, 2019リポジトリ
python-tomo/twitter-ansible-bot | GitHub
開発環境を構築するためのDockerfileが含まれていますが実際のプログラム部分は赤枠のファイル のみです。
使い方
- Twitter APIへ登録しアプリケーションキーを発行する
- CircleCIとリポジトリを連携させる
- CircleCIへアプリケーションキーを登録する
- GitHubリポジトリでcronの設定を行う
1. Twitter APIへ登録しアプリケーションキーを発行する
登録方法は こちらのサイト の情報を参考にします
2. CircleCIとリポジトリを連携させる
3. CircleCIへアプリケーションキーを登録する
4. GitHubリポジトリでcronの設定を行う
twitter-ansible-bot/.circleci/config.yml でcronの設定を行います。赤枠の部分はそれぞれcronの設定とコードを配置するブランチになります。
初期設定だと毎時間25分になったらtestブランチに置かれたスクリプトが実行されます。
初期設定はmasterブランチしかないので以下のようなコマンドでtestブランチをGitHubリポジトリに作成します。
testブランチが作成された時点でcronが有効になります。
.circleci/config.ymlcd twitter-ansible-bot git branch test Git checkout test git push origin test
また下の画像の部分の赤枠の部分でリポジトリにpushがあった時点で処理が走る設定になっています。testブランチにpushした瞬間にTweetが実行されれば設定は成功です。
改善点
エラー処理が甘い
モジュール情報を取得する処理を以下のように書いてますがモジュール情報が取得できない場合のエラー処理が書いてない
ansible-doc -l | awk '{print $1}' > list.txt # Get total number of modules total_number=$(cat list.txt | wc -l) echo ${total_number} # Set module number module_number=$(echo $(($RANDOM % ${total_number}))) echo ${module_number} # Set module name by random number module=$(sed -n ${module_number}p list.txt) echo ${module} # Get module name ansible-doc ${module} -j | jq ".${module}.doc.module" > module.txt # Get short_description ansible-doc ${module} -j | jq ".${module}.doc.short_description" > short_description.txt # Get supported_by ansible-doc ${module} -j | jq ".${module}.metadata.supported_by" > supported_by.txt # Get version_added ansible-doc ${module} -j | jq ".${module}.doc.version_added" > version_added.txtbashの部分をPython3にしたい
作成者のPython力が低いので部分的にbashが使われています。これらをPython3に置き換えたい。
将来的にはAWS Lambdaに置き換えたい
作成者のPython力が低くbashが扱えるCircleCI上で動いてますが将来的にはAWS Lambdaに置き換えたい
参考リンク
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ ※2019年8月時点の情報 | Qiita






- 投稿日:2019-12-23T22:06:06+09:00
pythonでスクレイピングした表をcsvに保存する方法
この記事について
研究でWebページ上にある表をスクレイピングする必要があったので,そのときに使用したpythonのプログラムを紹介します.ちなみに,自分はスクレイピング歴0だったので色々調べながら作っていったのですが,Webページ上の表をHTML化した後にHTMLの表部分をcsv化する方法まで説明しているものがほとんどなかったのでこの記事を書きました.
はじめに
スクレイピングについての注意点は,下記URLから御覧ください
https://qiita.com/Azunyan1111/items/b161b998790b1db2ff7aPythonでスクレイピング
プログラム全体はこちらに置いてあります.
import
import csv import urllib from bs4 import BeautifulSoupimportしたライブラリの説明
・csvは,Pythonの標準ライブラリで今回はCSVファイルの書き込みで使用
・urllibは,web上のデータ(HTML)にアクセス&取得するために使用
・BeautifulSoupは,HTMLから狙ったデータを抽出するために使用HTMLを取得
url = "https://en.wikipedia.org/wiki/List_of_cities_in_Japan" html = urllib.request.urlopen(url) soup = BeautifulSoup(html, 'html.parser') # HTMLから表(tableタグ)の部分を全て取得する table = soup.find_all("table")今回は,日本の都市についてまとめてあるwikipediaの表をスクレイピングしてみます.
プログラムのurllib.request.urlopenは,指定したurlのHTMLを取得します.その後,Beautiful Soupを使って扱いやすいように整形し,更に,HTMLから表がある部分(table タグで囲われてある部分)を全てsoup.find_all("table")で取得すれば準備完了です.
取得したいTABLEタグの名前を調べる
chromeブラウザを使用している方は,F12(macだとcommand+option+I)を押すことで開発者ツール(スクリーンショットの黒い画面)に入ることができます.その後,ElementsからHTMLのソースコードを見ることができるので,その中からスクレイピングしたいtableタグを探します.今回は,青く選択されている表を取得してみたいと思います.実はこれは単純に,全てのtableタグからclassNameが"wikitable"のものを選択することで取得できます.
for tab in table: table_className = tab.get("class") print(table_className) if table_className[0] == "wikitable": break # break文がないときの出力結果 # ['vertical-navbox', 'nowraplinks', 'hlist'] # ['wikitable'] <- ここで,break文を使って抜ける # ['wikitable', 'sortable'] # ['wikitable', 'sortable'] # ['wikitable'] # ['nowraplinks', 'mw-collapsible', 'autocollapse', 'navbox-inner']・table_className[0]としているのは,classNameの先頭にwikitableが来ているためです.
・また,今回の場合,HTML上で他にもwikitableと同じ名前の表が複数存在していますが,今回欲しい表は常に一番目のwikitableなので初めてif文を通過した後,すぐにbreak文を使ってループを抜ける処理を入れてます.目的の表を取り出せたら,CSVに変換して保存する
最後に,上のプログラムにCSV保存機能をつけます.
for tab in table: table_className = tab.get("class") if table_className[0] == "wikitable": # CSV保存部分 with open("test.csv", "w", encoding='utf-8') as file: writer = csv.writer(file) rows = tab.find_all("tr") for row in rows: csvRow = [] for cell in row.findAll(['td', 'th']): csvRow.append(cell.get_text()) writer.writerow(csvRow) breakCSV保存機能の部分は,tableタグを行方向("tr")に抜き出して更に列方向("td", "th")に取り出し,list形式にappendしてCSVで保存するというものです(tableタグまで抜き出せたら,ここはコピペで使用していいと思う).
確認のため,pandasを使ってCSVを表示してみる
import pandas as pd pd.read_csv("test.csv")
無事,csv保存したものがpandasによって表示することができました!
まとめ
スクレイピングしたいサイトにもよりますが,大体この流れで表をCSVで取得できると思います!ここまでご覧頂きありがとうございました〜!
参考文献



- 投稿日:2019-12-23T21:52:03+09:00
CodeStarでDjangoやーる(Python3.6.8、Django2.2.9)
CodeStarでDjangoアプリを作成し、CodePiplineによってCI/CDしていきましょう。
開発環境
ローカルマシン
- git for windows
- anaconda 2019
- python 3.6.9
- Django 1.11.18 / 2.2.9
AWS EC2
- python 3.6.8
- Django 1.11.18 / 2.2.9
プロジェクトの作成
1.aws consoleにログイン、CodeStarを開く(の前にIAMユーザーにAWSCloudFormationFullAccessが必要だったかも)
2.新規プロジェクトの作成をクリック
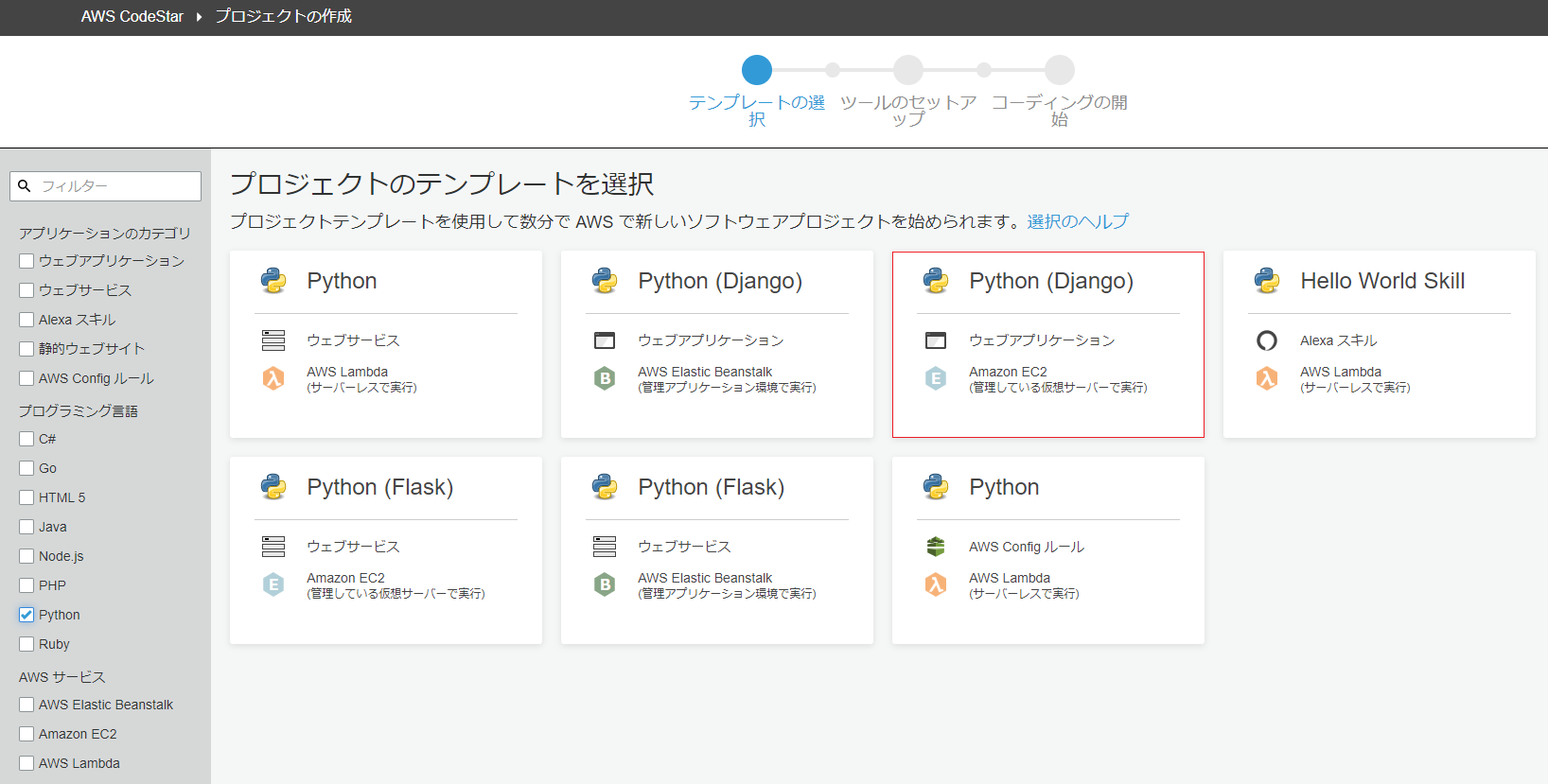
3.Python(Django)、Amazon EC2を選択
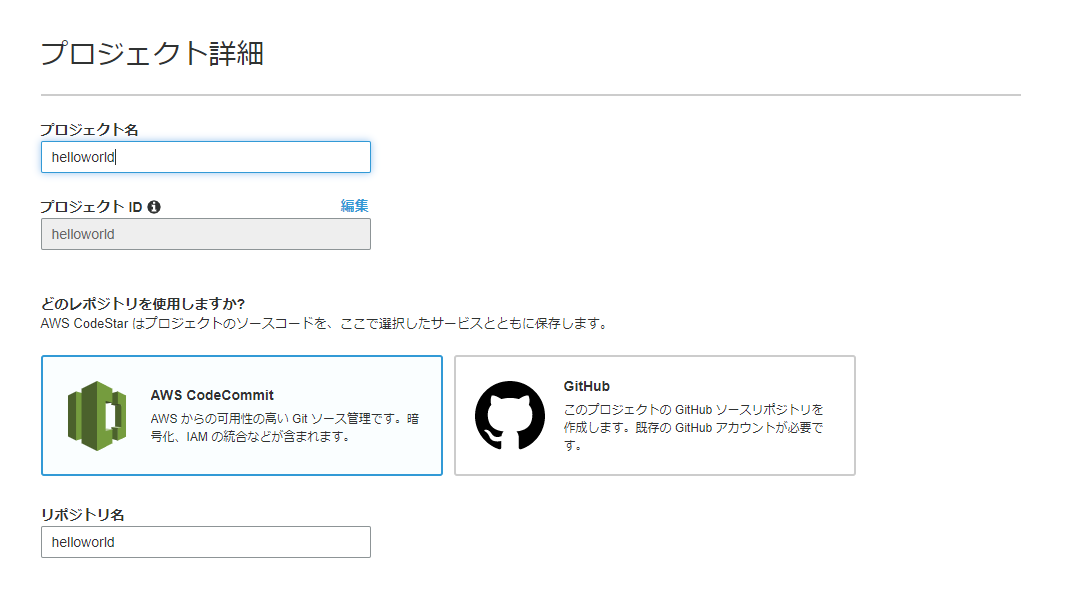
4.プロジェクト名(例:helloworld)を入力し、次へをクリック
5.プロジェクトの詳細を確認したら、プロジェクトを作成するをクリック
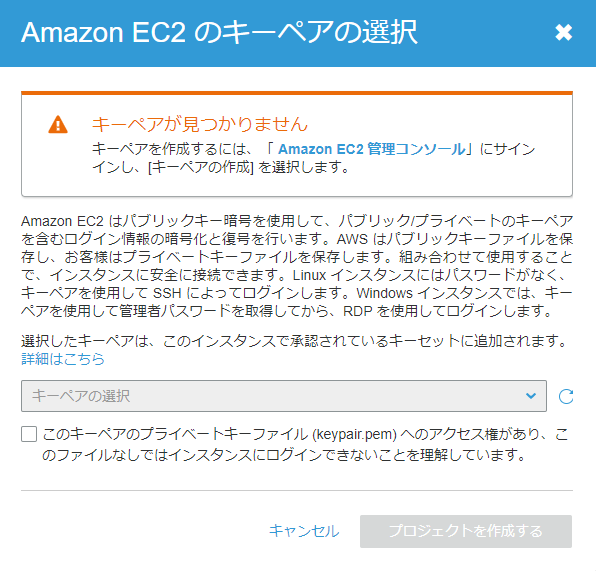
6.Amazon EC2 管理コンソールを新しいタブで開き
7.キーペアを作成
8.helloworld.pemを保管しておく
9.作成したキーペアを選択し、プロジェクトを作成するをクリック
10.スキップ(オレゴンリージョンにはAWS Cloud9があった)
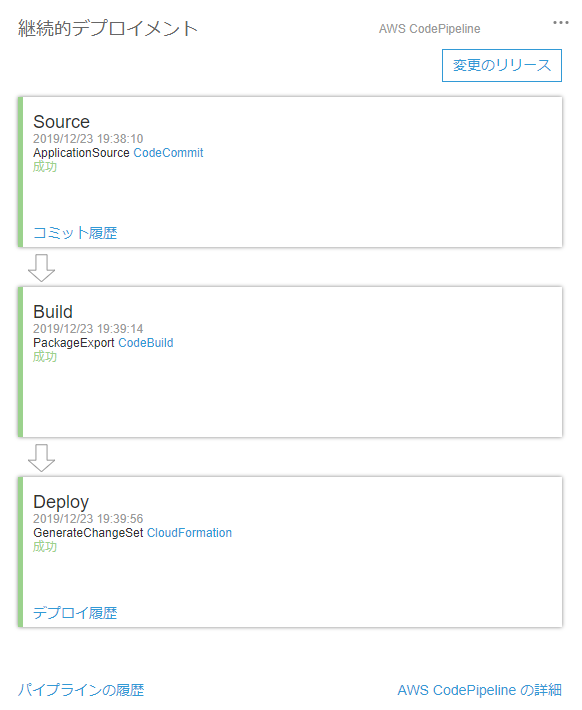
11.CodeStarのダッシュボードが表示される
12.CodePiplineのSource→Build→Deployが完了するまで待つ
※オレゴンリージョンだとエラーが出た
Your requested instance type (t2.micro) is not supported in your requested Availability Zone (us-west-2d). Please retry your request by not specifying an Availability Zone or choosing us-west-2a, us-west-2b, us-west-2c. (Service: AmazonEC2; Status Code: 400; Error Code: Unsupported; Request ID: 7ee63da9-fc85-4e2a-999c-629fe3997dbe)13.Deployが完了したら、アプリケーションのエンドポイントを開く
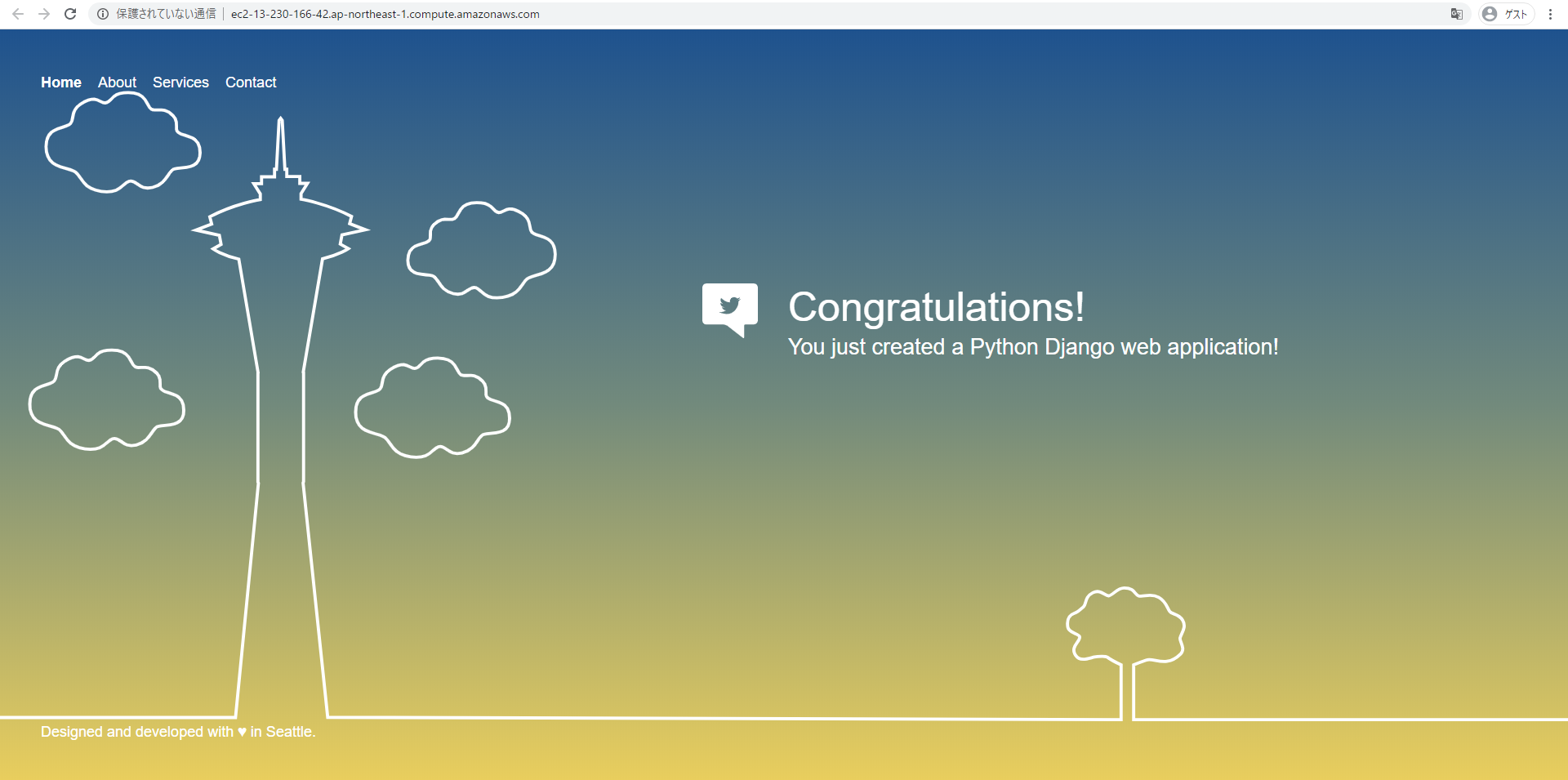
14.ページが見えればOK
※EC2を停止/起動するとページが見えなくなるので、起動時にDjangoアプリも起動するようにスクリプトを設定する必要がある。後述。
プロジェクトの編集(CodeCommitの練習)
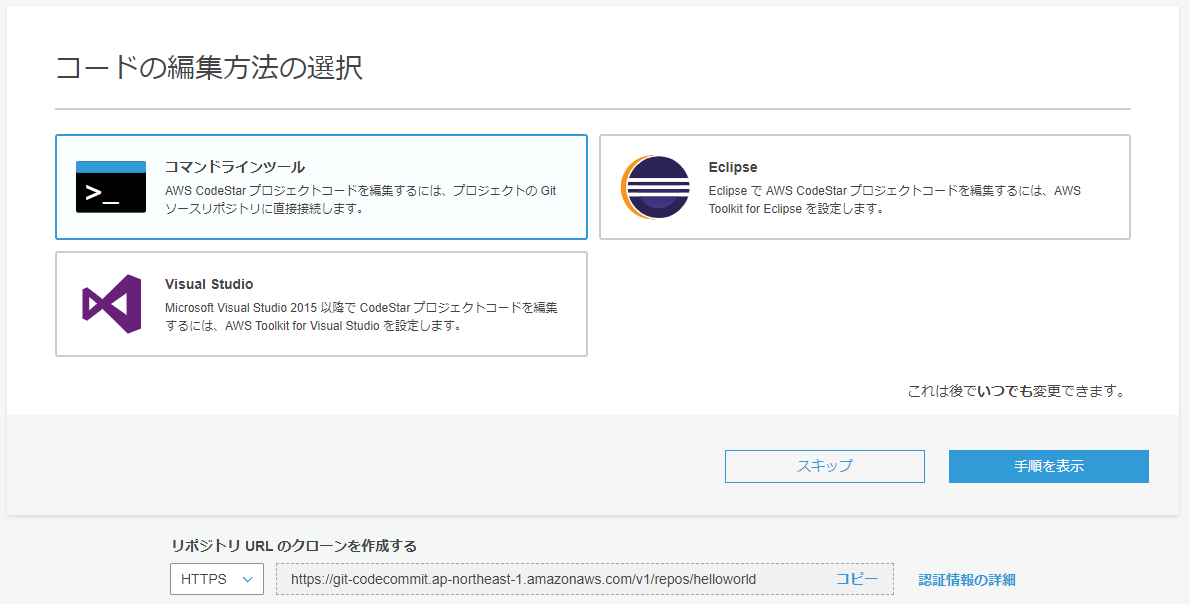
1.CodeStarのダッシュボードからコードをクリックするとCodeCommitへ遷移
2.URLのクローンからURLをコピー
3.git for Windowsをインストール
4.anaconda promptを開く
5.django1とdjango2の仮想環境を作っておく
conda create -n django1 python=3.6 conda create -n django2 python=3.66.IAMのCodeCommitの設定
IAMグループのアクセス許可は下記のような感じ。
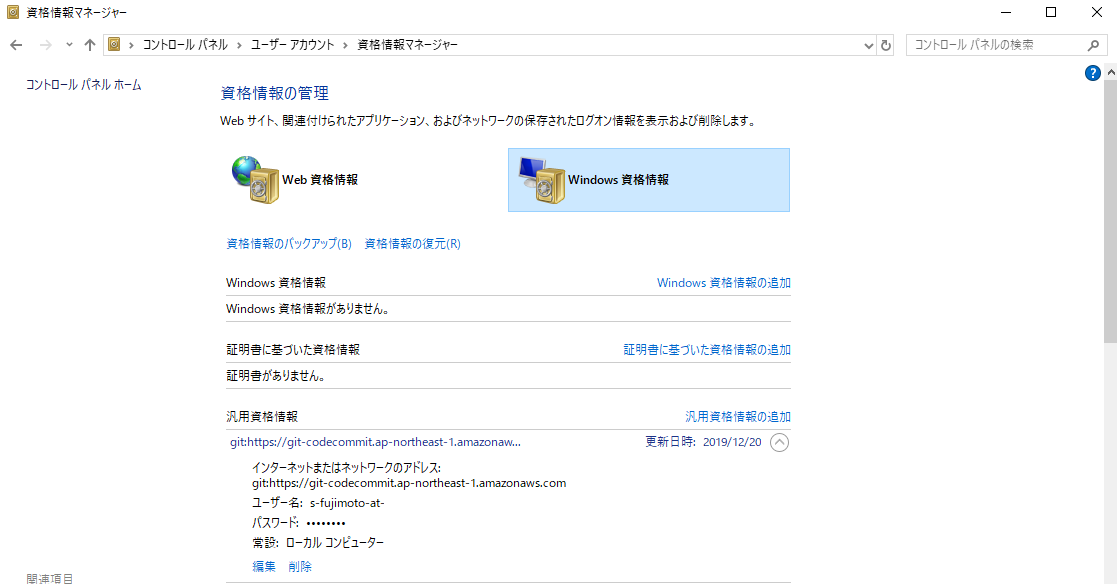
AmazonEC2FullAccess AWSCodeCommitFullAccess AWSLambdaFullAccess AmazonS3FullAccess AmazonDynamoDBFullAccess AmazonSageMakerFullAccess AmazonSageMaker-ExecutionPolicy-20191208Txxxxxx AWSCloudFormationFullAccessIAMユーザーの認証情報から認証情報を生成
※このユーザー名とパスワードはgit cloneする際に必要なのでメモっておくこと
※パスワードを変更したら、git for Windowsを使用していて認証情報をリセットする方法
7.django1環境をactivateし、プロジェクトをクローン。設定したユーザー名とパスワードを聞かれる。あとはgit configure。
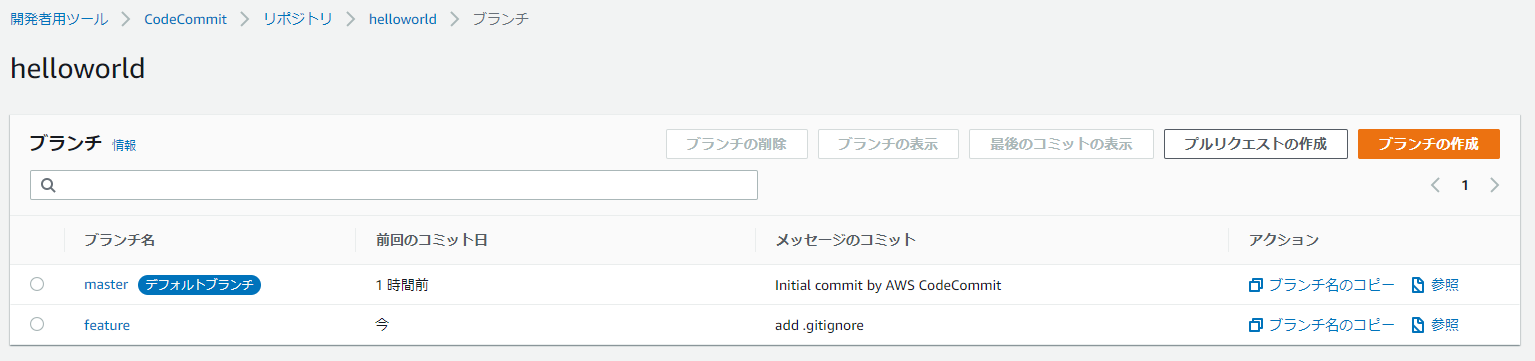
(base) $ conda activate django1 (django1) $ git config --global user.email "s-fujimoto@knowledgecommunication.jp" (django1) $ git config --global user.name "s-fujimoto" (django1) $ git clone https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/helloworld (django1) $ cd helloworld8.developブランチを切る ※masterに直接コミットしない。プロジェクト作成したらすぐにdevelopブランチを切る。
(django1) $ git branch develop (django1) $ git checkout develop Switched to branch 'develop'9.featureブランチを切る ※developに直接コミットしない。新機能の追加や変更を行うたびにfeatureブランチを切る。
(django1) $ git branch feature (django1) $ git checkout feature Switched to branch 'feature'10.プロジェクトに必要なライブラリをインストール
(django1) $ pip install -r requirements/dev.txt Collecting Django==1.11.18 Using cached https://files.pythonhosted.org/packages/e0/eb/6dc122c6d0a82263bd26bebae3cdbafeb99a7281aa1dae57ca1f645a9872/Django-1.11.18-py2.py3-none-any.whl Collecting pytz Using cached https://files.pythonhosted.org/packages/e7/f9/f0b53f88060247251bf481fa6ea62cd0d25bf1b11a87888e53ce5b7c8ad2/pytz-2019.3-py2.py3-none-any.whl Installing collected packages: pytz, Django Successfully installed Django-1.11.18 pytz-2019.3Django 1.11.18がインストールされる
11.Djangoをローカルで起動
(django1) $ python manage.py runserver Performing system checks... System check identified no issues (0 silenced). You have 13 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. December 23, 2019 - 18:15:46 Django version 1.11.18, using settings 'ec2django.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CTRL-BREAK. [23/Dec/2019 18:15:54] "GET / HTTP/1.1" 200 6652 [23/Dec/2019 18:15:54] "GET /static/helloworld/css/styles.css HTTP/1.1" 200 2690 [23/Dec/2019 18:15:54] "GET /static/helloworld/js/set-background.js HTTP/1.1" 200 137 [23/Dec/2019 18:15:54] "GET /static/helloworld/css/gradients.css HTTP/1.1" 200 2133 [23/Dec/2019 18:15:54] "GET /static/helloworld/img/tweet.svg HTTP/1.1" 200 1418 [23/Dec/2019 18:15:54] "GET /favicon.ico HTTP/1.1" 404 7712.ブラウザから http://127.0.0.1:8000/ にアクセスして同じページが見えればOK
13.git statusでプログラムの変更を見る
(django1) $ git status On branch feature Untracked files: (use "git add <file>..." to include in what will be committed) db.sqlite3 ec2django/__pycache__/ helloworld/__pycache__/ helloworld/migrations/__pycache__/ nothing added to commit but untracked files present (use "git add" to track)14.pycacheがあるとCodePiplineのデプロイに失敗するので不要、下記.gitignoreファイルを追加(db.sqlite3は任意)
# Byte-compiled / optimized / DLL files __pycache__/ *.py[cod] *$py.class # C extensions *.so # Distribution / packaging .Python env/ build/ develop-eggs/ dist/ downloads/ eggs/ .eggs/ lib/ lib64/ parts/ sdist/ var/ wheels/ *.egg-info/ .installed.cfg *.egg # PyInstaller # Usually these files are written by a python script from a template # before PyInstaller builds the exe, so as to inject date/other infos into it. *.manifest *.spec # Installer logs pip-log.txt pip-delete-this-directory.txt # Unit test / coverage reports htmlcov/ .tox/ .coverage .coverage.* .cache nosetests.xml coverage.xml *.cover .hypothesis/ # Translations *.mo *.pot # Django stuff: *.log local_settings.py # Flask stuff: instance/ .webassets-cache # Scrapy stuff: .scrapy # Sphinx documentation docs/_build/ # PyBuilder target/ # Jupyter Notebook .ipynb_checkpoints # pyenv .python-version # celery beat schedule file celerybeat-schedule # SageMath parsed files *.sage.py # dotenv .env # virtualenv .venv venv/ ENV/ # Spyder project settings .spyderproject .spyproject # Rope project settings .ropeproject # mkdocs documentation /site # mypy .mypy_cache/ .idea/ db.sqlite3 migrations/15.featureへコミット
(django1) $ git add . (django1) $ git commit -m "add .gitignore" [feature 6d9a594] add .gitignore 1 file changed, 106 insertions(+) create mode 100644 .gitignore (django1) $ git push origin feature Enumerating objects: 4, done. Counting objects: 100% (4/4), done. Delta compression using up to 8 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 939 bytes | 939.00 KiB/s, done. Total 3 (delta 1), reused 0 (delta 0) To https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/helloworld * [new branch] feature -> feature16.CodeCommitを確認すると、featureブランチが作成されている
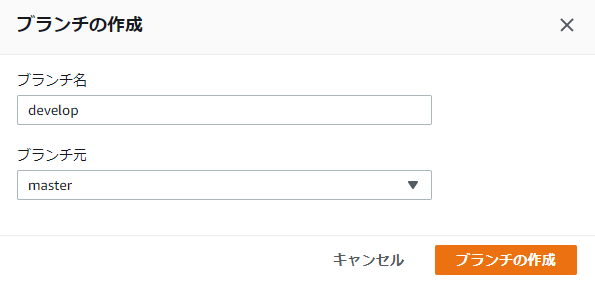
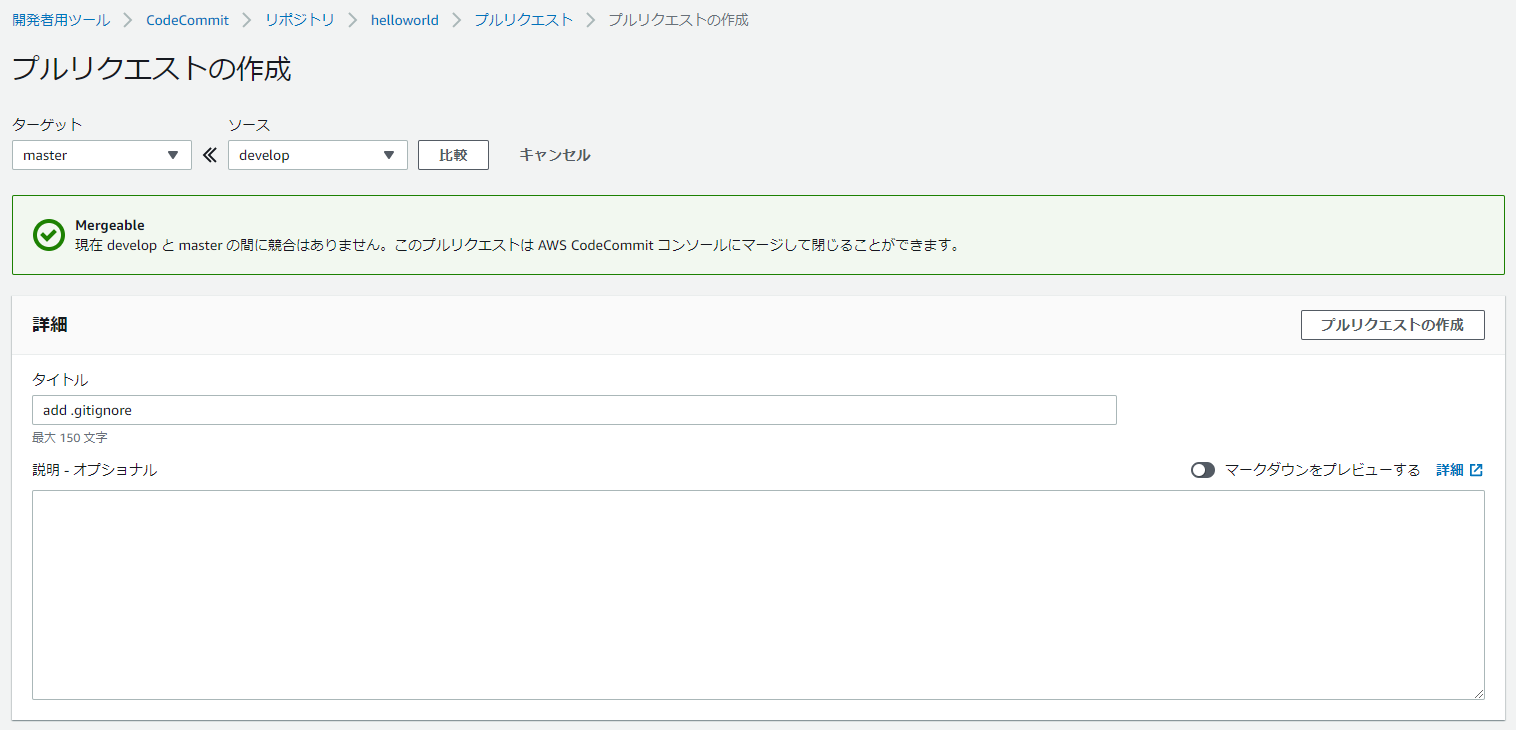
17.developブランチを作成
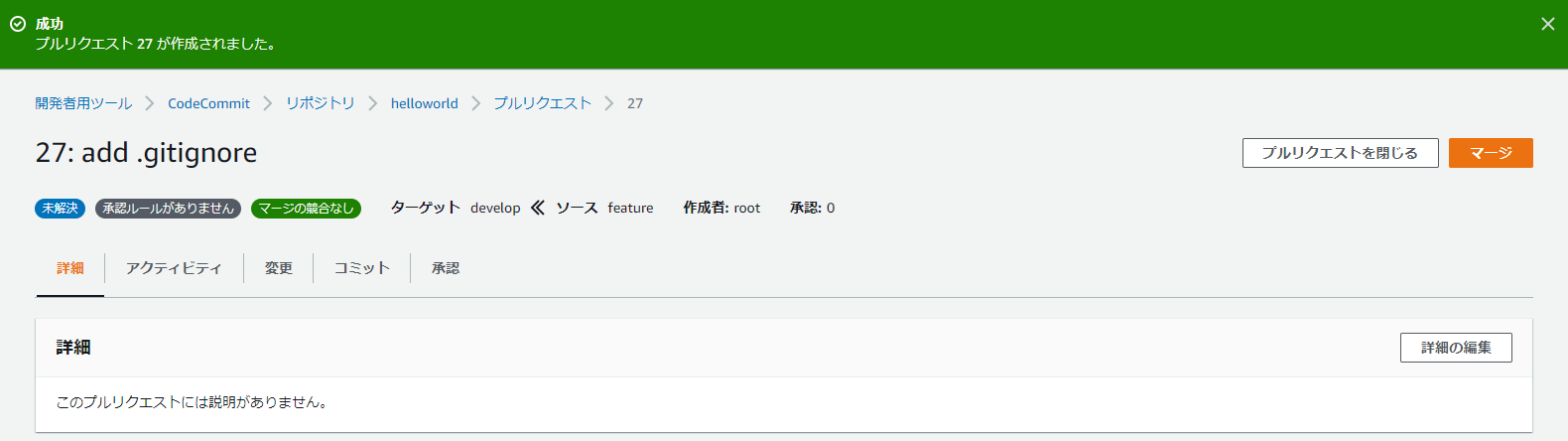
18.プルリクエストの作成
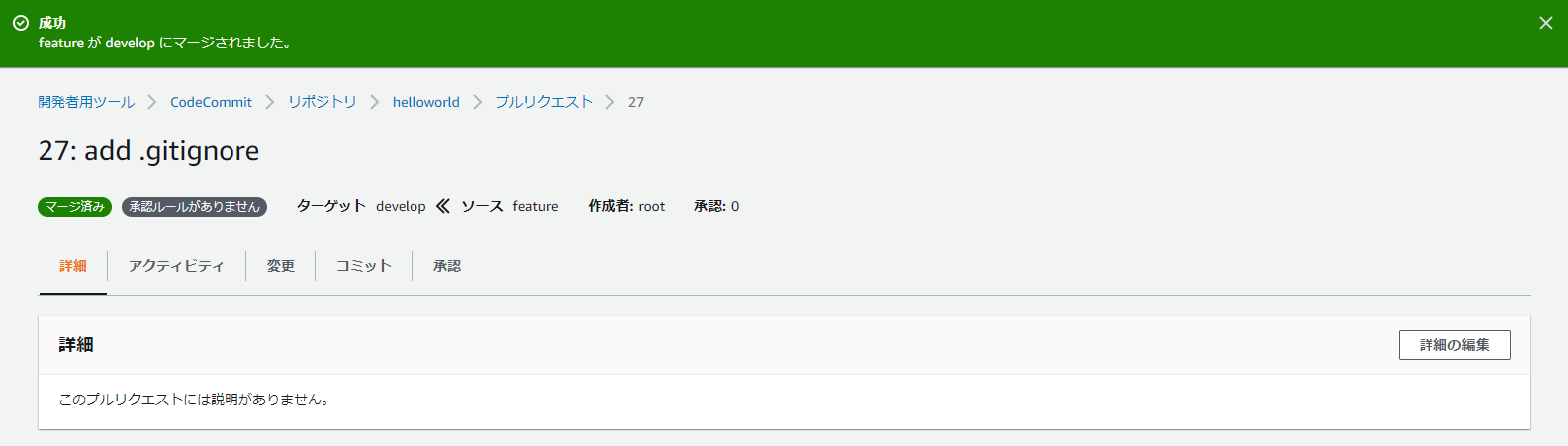
19.featureからdevelopへマージする
20.マージしたらfeatureは消す。(けどまた新機能の追加や変更をするときはfeatureブランチを切る。ローカルにはfeatureブランチが残るのでそのまま使う。)
21.マージ成功
22.同様にdevelopからmasterへマージする
23.developブランチは消さない
24.masterへマージされるとCodePiplineが起動
25.ページが見えていることを確認
プロジェクトの編集(Django1からDjango2へ更新)
1.django1環境から抜けて、django2環境へactivate
(django1) $ conda deactivate (base) $ conda activate django2 (django2) $2.requirements/common.txtを編集
変更前# dependencies common to all environments Django==1.11.18変更後
# dependencies common to all environments Django==2.2.92.ライブラリのインストール
(django2) $ pip install -r requirements/dev.txt Collecting Django==2.2.9 Using cached https://files.pythonhosted.org/packages/cb/c9/ef1e25bdd092749dae74c95c2707dff892fde36e4053c4a2354b2303be10/Django-2.2.9-py3-none-any.whl Collecting pytz Using cached https://files.pythonhosted.org/packages/e7/f9/f0b53f88060247251bf481fa6ea62cd0d25bf1b11a87888e53ce5b7c8ad2/pytz-2019.3-py2.py3-none-any.whl Collecting sqlparse Using cached https://files.pythonhosted.org/packages/ef/53/900f7d2a54557c6a37886585a91336520e5539e3ae2423ff1102daf4f3a7/sqlparse-0.3.0-py2.py3-none-any.whl Installing collected packages: pytz, sqlparse, Django Successfully installed Django-2.2.9 pytz-2019.3 sqlparse-0.3.0Django==2.2.9がインストールされる
3.ec2django/setting.pyを編集
変更前MIDDLEWARE_CLASSES = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.auth.middleware.SessionAuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] LANGUAGE_CODE = 'en-us' TIME_ZONE = 'UTC' USE_I18N = True USE_L10N = True USE_TZ = True変更後
MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo' USE_I18N = True USE_L10N = True USE_TZ = True4.ec2django/urls.pyを編集
変更前
from django.conf import settings from django.conf.urls.static import static from django.conf.urls import include, url from django.contrib import admin from django.contrib.staticfiles.urls import staticfiles_urlpatterns urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^', include('helloworld.urls')), ] + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)変更後
from django.conf import settings from django.conf.urls.static import static from django.conf.urls import include, url from django.contrib import admin from django.contrib.staticfiles.urls import staticfiles_urlpatterns from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('helloworld.urls')), ] + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)5.helloworld/templates/index.htmlをhelloworld/templates/helloworld/index.htmlに移動
6.helloworld/urls.py
変更前
# helloworld/urls.py from django.conf.urls import url from django.conf.urls.static import static from helloworld import views urlpatterns = [ url(r'^$', views.HomePageView.as_view()), ]変更後
# helloworld/urls.py from django.urls import path from django.conf.urls import url from django.conf.urls.static import static from helloworld import views urlpatterns = [ path('', views.HomePageView.as_view(), name='index'), ]7.helloworld/views.py
変更前
# helloworld/views.py from django.shortcuts import render from django.views.generic import TemplateView # Create your views here. class HomePageView(TemplateView): def get(self, request, **kwargs): return render(request, 'index.html', context=None)変更後
# helloworld/views.py from django.shortcuts import render from django.views.generic import TemplateView from django.views import generic # Create your views here. class HomePageView(generic.TemplateView): template_name = 'helloworld/index.html'8.Djangoをローカルで起動し、ブラウザから http://127.0.0.1:8000/ にアクセスして同じページが見えればOK
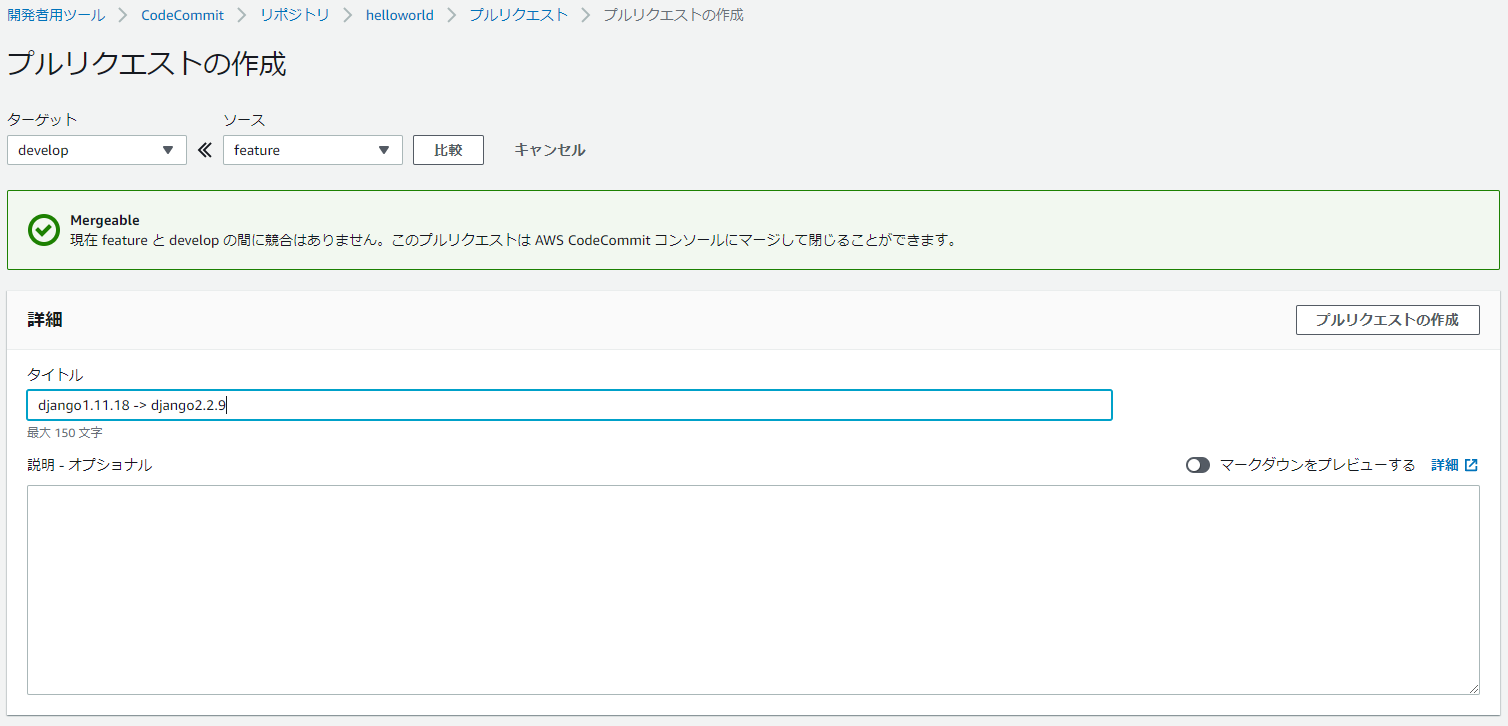
(django2) $ python manage.py runserver Performing system checks... System check identified no issues (0 silenced). You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. December 23, 2019 - 19:27:46 Django version 2.2.9, using settings 'ec2django.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CTRL-BREAK. [23/Dec/2019 19:27:49] "GET / HTTP/1.1" 200 6652 [23/Dec/2019 19:27:49] "GET /static/helloworld/js/set-background.js HTTP/1.1" 200 137 [23/Dec/2019 19:27:49] "GET /static/helloworld/css/gradients.css HTTP/1.1" 200 2133 [23/Dec/2019 19:27:49] "GET /static/helloworld/css/styles.css HTTP/1.1" 200 2690 [23/Dec/2019 19:27:49] "GET /static/helloworld/img/tweet.svg HTTP/1.1" 200 14189.featureへコミットして、developにマージ、developからmasterにマージする
(django2) $ git status On branch feature Changes not staged for commit: (use "git add/rm <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: ec2django/settings.py modified: ec2django/urls.py deleted: helloworld/templates/index.html modified: helloworld/urls.py modified: helloworld/views.py modified: requirements/common.txt Untracked files: (use "git add <file>..." to include in what will be committed) helloworld/templates/helloworld/ no changes added to commit (use "git add" and/or "git commit -a") (django2) $ git add . (django2) $ git commit -m "django1.11.18 -> django2.2.9" [feature 2226d88] django1.11.18 -> django2.2.9 6 files changed, 12 insertions(+), 12 deletions(-) rename helloworld/templates/{ => helloworld}/index.html (100%) (django2) $ git push origin feature Enumerating objects: 21, done. Counting objects: 100% (21/21), done. Delta compression using up to 8 threads Compressing objects: 100% (10/10), done. Writing objects: 100% (11/11), 1.27 KiB | 648.00 KiB/s, done. Total 11 (delta 5), reused 0 (delta 0) To https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/helloworld * [new branch] feature -> feature
10.CodePiplineが完了したら、ページを確認
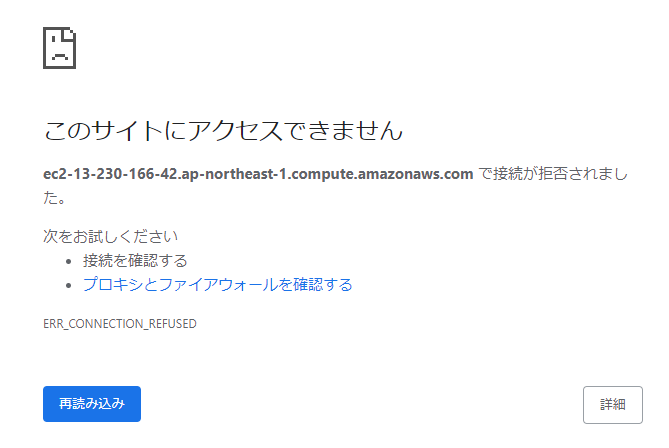
11.サイトにアクセスできなくなっている
12.EC2を開く
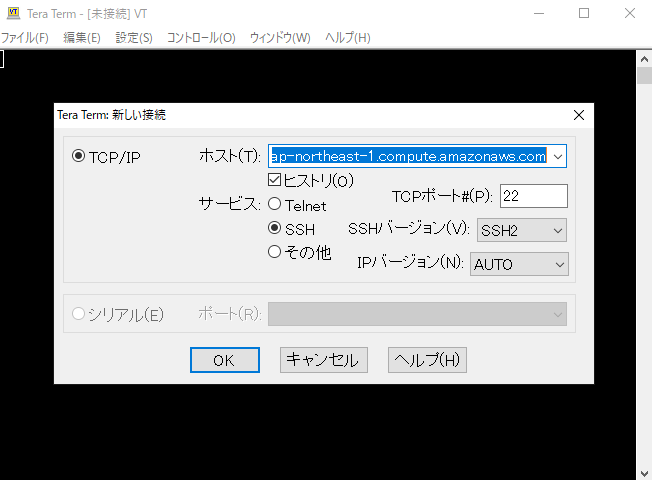
13.TeraTermを用いて、EC2へSSH接続(PuTTYならPuTTY genを用いてキーペア.pemを.ppkに変換してから接続する)
14.セキュリティ警告は続行をクリック
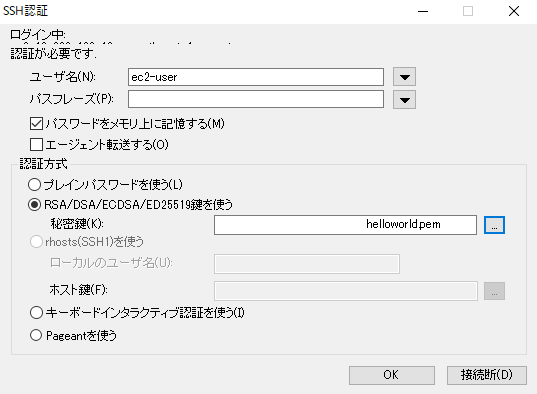
15.ユーザー名にec2-user, キーペアを指定
16.接続
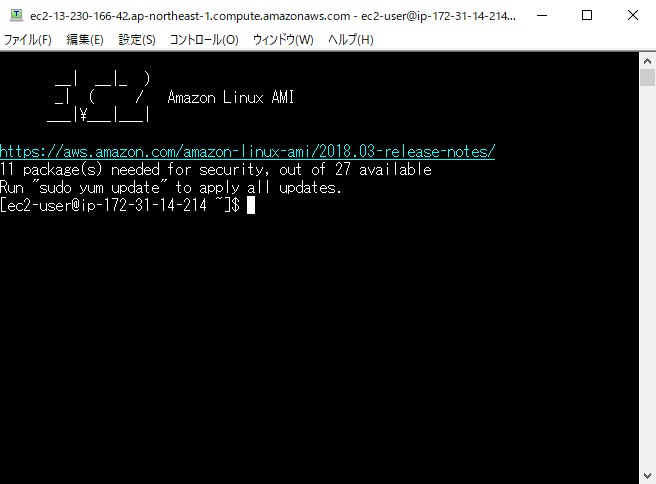
17.Djangoを起動
[ec2-user@ip-172-31-14-214 ~]$ sudo su [root@ip-172-31-14-214 ec2-user]# source /home/ec2-user/environment/bin/activate (environment) [root@ip-172-31-14-214 ec2-user]# /usr/local/bin/supervisord -c /home/ec2-user/supervisord.conf Error: Another program is already listening on a port that one of our HTTP servers is configured to use. Shut this program down first before starting supervisord. For help, use /usr/local/bin/supervisord -h (environment) [root@ip-172-31-14-214 ec2-user]# pkill supervisord (environment) [root@ip-172-31-14-214 ec2-user]# /usr/local/bin/supervisord -c /home/ec2-user/supervisord.conf18.ページは見れないままなので、ログを確認する
(environment) [root@ip-172-31-14-214 ec2-user]# cat /var/log/django-application-stderr.log ・・・ File "/home/ec2-user/environment/local/lib/python3.6/site-packages/django/db/backends/sqlite3/base.py", line 63, in check_sqlite_version raise ImproperlyConfigured('SQLite 3.8.3 or later is required (found %s).' % Database.sqlite_version) django.core.exceptions.ImproperlyConfigured: SQLite 3.8.3 or later is required (found 3.7.17). [2019-12-23 19:54:59 +0900] [25438] [INFO] Worker exiting (pid: 25438) [2019-12-23 10:54:59 +0000] [25435] [INFO] Shutting down: Master [2019-12-23 10:54:59 +0000] [25435] [INFO] Reason: Worker failed to boot.Django2に更新したためSQLite3のバージョンを更新する必要がある。
19.SQLite3の更新
下記の記事を参考
Django2.2で開発サーバー起動時にSQLite3のエラーが出た場合の対応(environment) [root@ip-172-31-14-214 ec2-user]# wget https://www.sqlite.org/2019/sqlite-autoconf-3280000.tar.gz (environment) [root@ip-172-31-14-214 ec2-user]# tar xvfz sqlite-autoconf-3280000.tar.gz (environment) [root@ip-172-31-14-214 ec2-user]# cd sqlite-autoconf-3280000 (environment) [root@ip-172-31-14-214 ec2-user]# ./configure --prefix=/usr/local (environment) [root@ip-172-31-14-214 ec2-user]# make (environment) [root@ip-172-31-14-214 ec2-user]# sudo make install (environment) [root@ip-172-31-14-214 ec2-user]# sudo find /usr/ -name sqlite3 (environment) [root@ip-172-31-14-214 ec2-user]# cd ../ (environment) [root@ip-172-31-14-214 ec2-user]# rm sqlite-autoconf-3280000.tar.gz (environment) [root@ip-172-31-14-214 ec2-user]# rm -rf ./sqlite-autoconf-3280000 (environment) [root@ip-172-31-14-214 ec2-user]# /usr/local/bin/sqlite3 --version 3.28.0 2019-04-16 19:49:53 884b4b7e502b4e991677b53971277adfaf0a04a284f8e483e2553d0f83156b50 (environment) [root@ip-172-31-14-214 ec2-user]# /usr/bin/sqlite3 --version 3.7.17 2013-05-20 00:56:22 118a3b35693b134d56ebd780123b7fd6f1497668 (environment) [root@ip-172-31-14-214 ec2-user]# sqlite3 --version 3.7.17 2013-05-20 00:56:22 118a3b35693b134d56ebd780123b7fd6f1497668 (environment) [root@ip-172-31-14-214 ec2-user]# sudo mv /usr/bin/sqlite3 /usr/bin/sqlite3_old (environment) [root@ip-172-31-14-214 ec2-user]# sudo ln -s /usr/local/bin/sqlite3 /usr/bin/sqlite3 (environment) [root@ip-172-31-14-214 ec2-user]# export LD_LIBRARY_PATH="/usr/local/lib" (environment) [root@ip-172-31-14-214 ec2-user]# python Python 3.6.8 (default, Oct 14 2019, 21:22:53) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sqlite3 >>> sqlite3.sqlite_version '3.28.0' >>> exit() (environment) [root@ip-172-31-14-214 ec2-user]#Djangoを起動しページが見れればOK
(environment) [root@ip-172-31-14-214 ec2-user]# pkill supervisord (environment) [root@ip-172-31-14-214 ec2-user]# /usr/local/bin/supervisord -c /home/ec2-user/supervisord.confEC2再起動時にDjangoを起動するように設定
1.supervisord.confを修正(ローカルも編集してあとでmasterへマージする)
変更前[program:djangoproject] command = environment/bin/gunicorn -b 0.0.0.0:80 ec2django.wsgi変更後
[program:djangoproject] command = /home/ec2-user/environment/bin/gunicorn -b 0.0.0.0:80 ec2django.wsgi2.サービスの登録
(environment) [root@ip-172-31-14-214 ec2-user]# vi /etc/init.d/helloworld#!/bin/sh # chkconfig: 2345 99 10 # description: start helloworld # processname: helloworld start() { echo "start" source /home/ec2-user/environment/bin/activate export LD_LIBRARY_PATH="/usr/local/lib" /usr/local/bin/supervisord -c /home/ec2-user/supervisord.conf } stop() { echo "stop" pkill supervisord } case "$1" in start) start ;; stop) stop ;; restart) stop start ;; esac exit 0(environment) [root@ip-172-31-14-214 ec2-user]# chkconfig --add helloworld (environment) [root@ip-172-31-14-214 ec2-user]# chkconfig helloworld on (environment) [root@ip-172-31-14-214 ec2-user]# chmod u+x /etc/init.d/helloworld (environment) [root@ip-172-31-14-214 ec2-user]# service helloworld restart3.再起動してもページが見えればOK(EC2の停止・起動でもDjangoは起動)
(environment) [root@ip-172-31-14-214 ec2-user]# sudo reboot※EC2を停止・起動するとIP変わるので注意
4.featureのsupervisord.confを修正しコミット、featureからdevelopへマージ、developからmasterへマージする
(django2) $ git status On branch feature Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: supervisord.conf no changes added to commit (use "git add" and/or "git commit -a") (django2) $ git add . (django2) D:\Users\s-fujimoto\CodeStar\helloworld>git commit -m "modified supervisord.conf" [feature 38c0e8c] modified supervisord.conf 1 file changed, 1 insertion(+), 1 deletion(-) (django2) D:\Users\s-fujimoto\CodeStar\helloworld>git push origin feature Enumerating objects: 5, done. Counting objects: 100% (5/5), done. Delta compression using up to 8 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 325 bytes | 325.00 KiB/s, done. Total 3 (delta 2), reused 0 (delta 0) To https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/helloworld * [new branch] feature -> feature5.CodePiplineが完了し、ページが見えればOK
(6.見えないときはEC2を再起動するか、SSHで接続しログの確認とサービスを再起動する)
(environment) [root@ip-172-31-14-214 ec2-user]# cat /var/log/django-application-stderr.log (environment) [root@ip-172-31-14-214 ec2-user]# cat /var/log/django-application-stdout.log (environment) [root@ip-172-31-14-214 ec2-user]# service helloworld restart強行デプロイ
.gitignoreの設定を忘れてマージしたら、pycacheがもうあるよと怒られデプロイ失敗
EC2の停止中にマージしたら、デプロイ失敗。失敗後にEC2を起動して再試行しても失敗。
一度デプロイ失敗してる状態から再試行してもまた失敗する。なので強行デプロイしてから、masterへマージすると成功する。
appspec.ymlとbuildspec.ymlにfileを追記しなかったために,沼にハマった話
1.CodeDeployのアプリケーションから対象を選択
2.失敗したリビジョンの場所を指定
3.デプロイを失敗させないにチェックし、コンテンツの上書きを選択、デプロイの作成からデプロイ
カスタムユーザーモデルを使用する(割愛)
db.sqlite3は.gitignoreされるので、Tera Termで送信
AWS EC2(Linux系)の接続方法とファイル転送方法DBの更新が必要
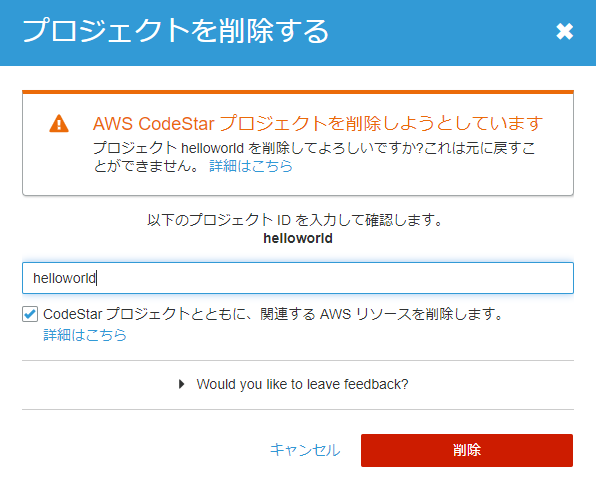
python manage.py makemigrations helloworld python manage.py migrateプロジェクトの削除
1.CodeStarのプロジェクト一覧から削除
2.プロジェクト名を入力し削除
まとめ
Djangoアプリ開発がかなり楽になった気がする。CICDがんばろー。















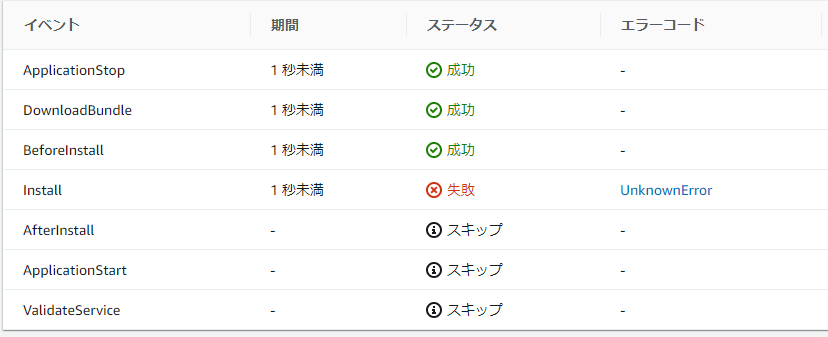
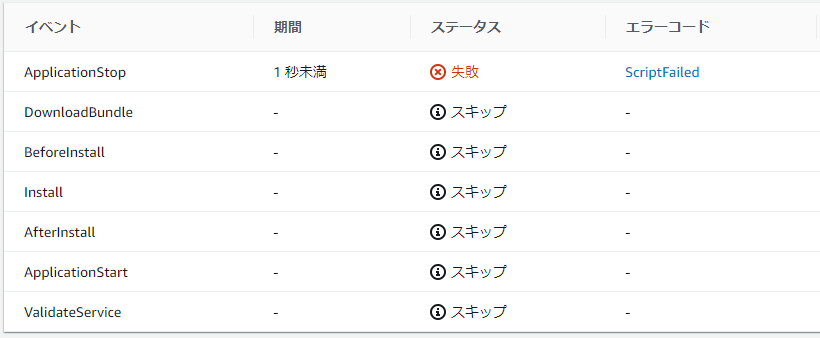



- 投稿日:2019-12-23T21:35:41+09:00
【jinja2】ハイフンの位置による改行の変化
はじめに
<バージョン>
Python: 3.7.4
jinja2: 2.7.2jinja2テンプレートでfor/if文を書く際に、ハイフンの有無や位置で改行のされ方が変わります。
for文を書くときにいつも迷うのでまとめます。
以下の出力を得るにはどう書けばよいのでしょう?出力start apple0 orange0 apple1 orange1 endパターン1:全てにハイフンを入れる
以下のテンプレートが今回の基準になります。
for文の開始位置、終了位置の前後それぞれにハイフンを入れますjinja_test1.j2start {%- for i in range(2) -%} apple{{ i }} orange{{ i }} {%- endfor -%} endパターン1:実行結果
appleとorangeの間だけ改行が入ります。
for文の中に書いてある内容は勝手に改行してくれるようです。出力startapple0 orange0apple1 orange1endパターン2:for文開始位置の手前のハイフンを消す
jinja_test2.j2start {% for i in range(2) -%} apple{{ i }} orange{{ i }} {%- endfor -%} endパターン2:実行結果
startとapple0の間が改行されました。
for文開始位置の手前は、for文の開始時に1回だけ改行します。出力start apple0 orange0apple1 orange1endパターン3:for文開始位置の後ろのハイフンを消す
jinja_test3.j2start {%- for i in range(2) %} apple{{ i }} orange{{ i }} {%- endfor -%} endパターン3:実行結果
apple0とapple1の手前に改行が入りました。
for文開始位置の後ろは、for文内の開始位置で毎回改行します。出力start apple0 orange0 apple1 orange1endパターン4:for文終了位置の手前のハイフンを消す
jinja_test4.j2start {%- for i in range(2) -%} apple{{ i }} orange{{ i }} {% endfor -%} endパターン4:実行結果
orange0とorange1の後ろに改行が入るようになりました。
for文終了位置の手前は、for文内の最終行で毎回改行します。出力startapple0 orange0 apple1 orange1 endパターン5:for文終了位置の後ろのハイフンを消す
jinja_test5.j2start {%- for i in range(2) -%} apple{{ i }} orange{{ i }} {%- endfor %} endパターン5:実行結果
orange1の後ろに改行が入るようになりました。
for文終了位置の後ろは、for文を出るときに1回だけ改行するようです。出力startapple0 orange0apple1 orange1 endまとめ
今までの内容を踏まえると以下のようになります。
ハイフンを消す位置 改行の仕方 for文開始位置の手前 for文開始時に1回だけ改行 for文開始位置の後ろ ループの先頭で毎回改行 for文終了位置の手前 ループの末端で毎回改行 for文終了位置の後ろ for文終了時に1回だけ改行 つまり、最初の出力を得るには、
・startとapple0の間で2回改行している
→for文開始位置の前後のハイフンは不要
・orange1とendの間で2回改行する必要がある
→for文終了位置の前後のハイフンは不要
ということで、「全てのハイフンを消す」が正解となり、以下のようになります。jinja_test6.j2start {% for i in range(2) %} apple{{ i }} orange{{ i }} {% endfor %} end
- 投稿日:2019-12-23T19:13:16+09:00
【Ubuntu18.04】Tensorflow2.0.0-GPU環境構築
はじめに
Tensorflow 2.0.0がリリースされkerasと統合されるなど、ますます便利になった。
そこで、Ubuntu18.04LTSにGPU版のTensorflow 2.0.0を導入するために必要な、GPUドライバのインストールからCUDA、cuDNNのインストール、Tensorflow 2.0.0-gpuのインストールまでの手順を書いていく。環境
OS:Ubuntu 18.04 LTS
GPU:nvidia Geforce GTX1660GPUドライバのインストール
・パッケージ情報を更新する
パッケージのリポジトリから、パッケージ名、バージョン、依存関係を取得する。$ sudo apt update・パッケージの更新
念の為、パッケージを更新しておく。$ sudo apt upgrade・利用可能なドライバ一覧を表示
$ ubuntu-drivers deviceseGTX1660では以下のような結果が表示された。
== /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 == modalias : pci:v000010DEd00002184sv00001462sd00008D91bc03sc00i00 vendor : NVIDIA Corporation driver : nvidia-driver-435 - distro non-free recommended driver : nvidia-driver-430 - distro non-free driver : xserver-xorg-video-nouveau - distro free builtin推奨ドライバであるnvidia-driver-435をインストールする。
・ドライバのインストール
$ sudo apt install nvidia-driver-435・再起動
$ sudo reboot再起動することでインストールしたドライバを有効化させる。
CUDAのインストール
Tensorflow2.0.0が対応しているCUDA-10.0をインストールする。
・CUDA Toolkitのダウンロード
下のnvidiaのページからCUDA Toolkit 10.0の.runファイルをダウンロードする。
CUDA Toolkit 10.0 Archive
https://developer.nvidia.com/cuda-10.0-download-archive
・CUDA Toolkitのインストール
Base InstallerとPatchの両方をダウンロードした後、CUDAを保存したディレクトリに移動する。$ cd CUDAを保存したディレクトリまずBase Installerを実行する。
/CUDAを保存したディレクトリ$ sudo sh cuda_10.0.130_410.48_linux.runDキーを押して先に進み、質問に答える。今回はドライバは先にインストールしているため、ドライバはインストールしていない。CUDAのサンプルが必要であれば最後の質問をyesにする。
----------------- Do you accept the previously read EULA? accept/decline/quit: accept Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 410.48? (y)es/(n)o/(q)uit: n Install the CUDA 10.0 Toolkit? (y)es/(n)o/(q)uit: y Enter Toolkit Location [ default is /usr/local/cuda-10.0 ]: /usr/local/cuda-10.0 Do you want to install a symbolic link at /usr/local/cuda? (y)es/(n)o/(q)uit: y Install the CUDA 10.0 Samples? (y)es/(n)o/(q)uit: n =========== = Summary = =========== Driver: Not Selected Toolkit: Installed in /usr/local/cuda-10.0 Samples: Not Selected次にPatchをインストールする。
/CUDAを保存したディレクトリ$ sudo sh cuda_10.0.130.1_linux.runこちらも先程と同様、Dキーを押して先に進み、質問に答える。
Do you accept the previously read EULA? accept/decline/quit: accept Enter CUDA Toolkit installation directory [ default is /usr/local/cuda-10.0 ]: /usr/local/cuda-10.0 Installation complete! Installation directory: /usr/local/cuda-10.0・CUDAのPATHを通す
以下のコマンドを入力する。$ echo -e "\n## CUDA and cuDNN PATHS" >> ~/.bashrc $ echo "export PATH=/usr/local/cuda-10.0/bin:${PATH}" >> ~/.bashrc $ echo "export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64:${LD_LIBRARY_PATH}" >> ~/.bashrc $ source ~/.bashrc・CUDAインストールの確認
以下のコマンドのCUDAが正しくインストールされたか確認する。$ nvcc -V結果
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2018 NVIDIA Corporation Built on Sat_Aug_25_21:08:01_CDT_2018 Cuda compilation tools, release 10.0, V10.0.130CUDA10.0がインストールできていることが確認できる。
cuDNNのインストール
Tensorflow2.0.0が対応しているcuDNN7.6をインストールする。
・cuDNNのインストール
下のnvidiaのページからcuDNN7.6の.debファイルをダウンロードする。なおダウンロードには会員登録が必要。
Download cuDNN v7.6.0 (May 20, 2019), for CUDA 10.0
https://developer.nvidia.com/rdp/cudnn-archive
cuDNN Runtime Library for Ubuntu18.04 (Deb)と、cuDNN Developer Library for Ubuntu18.04 (Deb)の両方をダウンロードした後、保存したディレクトリに移動する。$ cd cuDNNを保存したディレクトリまずランタイムライブラリをインストールする。
/cuDNNを保存したディレクトリ$ sudo dpkg -i libcudnn7_7.6.0.64-1+cuda10.0_amd64.deb次にディベロッパーライブラリをインストールする。
/cuDNNを保存したディレクトリ$ sudo dpkg -i libcudnn7-dev_7.6.0.64-1+cuda10.0_amd64.deb・cuDNNインストールの確認
次のコマンドを入力する$ cat /usr/include/cudnn.h | grep CUDNN_MAJOR -A 2結果
#define CUDNN_MAJOR 7 #define CUDNN_MINOR 6 #define CUDNN_PATCHLEVEL 0 -- #define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL) #include "driver_types.h"上のように表示されればcuDNNは正常にインストールされている。
Tensorflowのインストール
Tensorflowをインストールするためにpipを導入する。最新版のpipがすでにインストールされている環境の場合、curlとpipのインストールは飛ばしてよい。
・curlコマンドのインストール
URLを指定してWEB上のファイルをインストールできるcurlコマンドをインストールする。$ sudo apt install curl・pipのインストール
Pythonのパッケージ管理ツールpipをインストールする。Ubuntu18.04LTSを最小構成でインストールしていた場合は、Python2系はインストールされていないためpip3を導入する必要がない。Tensorflow2.0.0をインストールするためにはpipが最新のバージョンである必要があるのだが、Python2の環境がPython3の環境と共存していると、aptでインストールしたpip3をpip3でアップデートした後にエラーが起こるため、Python3のみの環境でTensorflowのインストールをしたほうが手軽。
以下のコマンドでpipをインストールするためのPythonコードをダウンロードし、プログラムを実行する。$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py $ sudo python3 get-pip.pyこれでpipのインストールは完了。下のコマンドでpipのバージョンを確認できる。
$ pip -V pip 19.3.1 from /usr/local/lib/python3.6/dist-packages/pip (python 3.6)pipのバージョンが19.0未満の場合以下のコマンドを入力する。
$ pip install --upgrade pip・setuptoolsのアップグレード
下のコマンドでsetuptoolsをアップグレードする。$ pip install setuptools --upgrade・Tensorflow2.0.0-GPUのインストール
Tensorflow2.0.0-GPUをインストールする。
下記のコマンドを入力。$ pip install tensorflow-gpu==2.0.0以上でtensorflow-gpu==2.0.0のインストールが完了する。
おつかれさまでした!!



- 投稿日:2019-12-23T18:47:10+09:00
学習記録 その10(14日目)
学習記録(14日目)
勉強開始:12/7(土)〜
教材等:
・大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年):12/19(木)読了
・Progate Python講座(全5コース):12/21(土)終了
・Andreas C. Müller、Sarah Guido『(邦題)Pythonではじめる機械学習』(オライリージャパン、2017年):12月23日(土)読了第3章 教師なし学習と前処理(Unsupervised Learning and Preprocessing)
・教師なし変換(Unsupervised Transformation):人間や他の機械学習アルゴリズムにとってよりわかりやすいデータ表現を作る。最も一般的なのは次元削減。または文書データの集合からのトピック抽出。後者はソーシャルメディア上の話題を解析するのに有用。
・クラスタリングアルゴリズム(Clustering Algorithms):データを似たような要素から構成されるグループに分ける。SNSサイトなどの写真を人物別に分ける仕組みなどが該当する。
・教師情報がない場合にデータから意味を見出す唯一の手法である。教師なし学習の難しさ
・教師なし学習はラベル情報がまったく含まれていないデータが与えられるため、結果を評価するには人間が確かめるしかない場合が多い。
・そのため、データをよりよく理解するために探索的に用いられる場合が多い。前処理とスケール変換
・教師あり学習のニューラルネットワークやSVMはスケール変換に非常に敏感
・Standard Scaler:特徴量の平均が0で分散が1になるように変換する。
・Robust Scaler:平均値の分散の代わりに中央値と四分位数を用いる。外れ値(outliner)を無視する。
・MinMax Scaler:データがちょうど0〜1の間に入るよう変換する。
・Normalizer:データポイントを半径1の円に投射する。特徴ベクトルの長さではなく方向または角度だけが問題となる場合に用いる。
・テストセットと訓練セットは同じように変換すること。
・前処理してから学習、スコア計算する。次元作劇、特徴量抽出、多様体学習
・動機:可視化、データ圧縮、以降の処理に適した表現の発見など。
主成分分析(Principal component analysis:PCA)
・上記すべての動機に対し最も多く用いられるアルゴリズム
・特徴量を、相互に統計的に関連しないように回転する手法
・StandardScalerで分散を1に → PCAを適用
・labeled faces in the wildを用いた特徴量抽出の説明非負値行列因子分解(Non-negative matrix factorization:NMF)
・PCAと同様に有用な特徴量を抽出することを目的とする教師なし学習
・データを非負の重み付き和に分解するこの方法は複数の人が話している音声データといった、いくつもの独立した発生源から得られたデータを重ね合わせて作られるようなデータに特に有効t-SNEアルゴリズム
・多様体学習アルゴリズム(manifold learning algorithms)と呼ばれる。
・よい可視化を実現でき、複雑なマッピングも行うことができるものの、新しいデータを変換することはできず、訓練に使ったデータしか変換することはできない。
探索的なデータ解析に有用であるものの、最終的な目標が教師あり学習の場合はほとんど用いられない。クラスタリング(Clustering)
・データセットをクラスタと呼ばれるグループに分割する。
k-means クラスタリング
・最も単純で広く用いられているクラスタリングアルゴリズム
・データのある領域を代表するようなクラスタ重心を見つけ、データポイントを割り当てる。そして引き続き個々のクラスタ重心を、データポイントの平均に設定する。これを繰り返し、変化がなくなったところでアルゴリズムを終了する。
・上記のとおり分割されたデータにラベルはないので、アルゴリズムからわかるのは指定したクラスタ数の分だけ似ている画像が並ぶということのみ。
・ベクトル量子化(vector quantization)凝集型クラスタリング(agglomerative clustering)
・個々のデータポイントを個別のクラスタとして開始し、似たクラスタを併合しつつ、指定したクラスタ数になるまで繰り返し処理を実施する。
・scikit-learnにはward, average, completeの3つが実装されているが、大抵wardで十分
・デンドログラム(dendrogram)で可視化できる。SciPyで描画できる。DBSCAN(密度に基づくノイズあり空間クラスタリング)
・density-based spatial clustering of applications with noise の略
・特徴空間における高密度領域の点を見つける。
・過程でノイズが生ずるので、得られたクラスタリング結果の扱いには注意を要する。第4章 データの表現と特徴量エンジニアリング
・特定のアプリケーションに対し、最良のデータ表現を模索することを特徴量エンジニアリングと呼ぶ。
・どのような特徴量を用いるか、また必要に応じて追加や組み合わせるかということが、機械学習応用がうまくいくかどうかを決定する最も重要な要素である。ワンホットエンコーディング(one-hot-encoding)
・ダミー変数と呼ばれることもある。カテゴリ変数を1つ以上の0と1の値を持つ新しい特徴量で置き換える。scikit-learnが扱える形に変換する。
ビニング、離散化(binning, discretization)
・線形モデルを連続データに対してより強力にする。
交互作用と多項式(interaction feature and polynomial feature)
・線形モデルに有効、もとの特徴量同士を組み合わせる。
第5章 モデルの評価と改良
・交差検証(cross-validation):任意のk(大体の場合5〜10)の分、データを分割(fold)し、訓練セットとテストセットとして使用する。シャッフル分割やグループ付き分割がある。
・グリッドサーチ(grid search):パラメータのすべての組み合わせを検証する。
・実際に機械学習を利用する場合は、正確な予測のみに興味があるわけではなく、より大きな意思決定の過程の中でその予測を用いる場合が多い。
基準にあるモデルと別のモデルを比較し、ビジネスインパクトをしっかりと考慮する必要がある。
・スレッショルド(threshold):しきい値のこと。第6章 アルゴリズムチェーンとパイプライン
・pipelineクラスで複数の処理ステップを糊付けし、1つのestimator(推定器)にできる。
・実世界における機械学習アプリは独立モデルを単独で用いることはほとんどない。pipelineモデルで糊付けしておくことで、変換を適用することを忘れたり順番を間違えたりといったミスを減らせる。第7章 テキストデータの処理
・自然言語処理(natural language processing:NLP)、情報検索(information retrieval:IR)
・テキスト解析におけるデータセットをコーパス(corpus)と呼び、1つのテキストとして表現される個々のデータポイントを文書(document)と呼ぶ。
・テキストデータはそのままだと機械学習に適用できないので、アルゴリズムを扱えるような数値表現に変換する必要がある。
最も単純で効率がよく、広く用いられてる表現がBoW(bag-of-words)表現である。構造を捨て単語の現れる数だけを数える。
・BoW表現を計算する3ステップ
(1)トークン分割(Tokenization):スペースや句読点を目安として個々の文章を単語に分割する。
(2)ボキャブラリ構築(Vocabulary building):すべての文章に現れる単語をボキャブラリとして集め、番号を付ける。(例えばアルファベット順など)
(3)エンコード(encord):ボキャブラリの単語が現れる数を数える。
・sparse matrix(疎行列)、compressed s.m.:CSR(圧縮疎行列)、SciPyで使える。
・tf-idf(term frequency-inverse document frequency):ストップリストのように重要でなさそうな特徴量を落とすのではなく、特徴量の情報の重みに応じてスケール変換する手法。
・BoWの問題→順番が失われるため、正反対の意味を持つ一部の文章がまったく同じ意味になってしまう。(it's bad, not good at allとit's good,not bad at allなど)
ただし、トークンを単独でなく、2つないし3つの連続するものとして扱うことで回避できる。それぞれバイグラム(bigram)、トリグラム(trigram)と呼ぶ。難点として、特徴量が激増する。
単語1つでも相当な意味を持つ場合が多いため、ほとんどの場合は最小長を1としたほうがよい。
・語幹処理(stemming)や見出し語化(lemmatization)は正規化(normalization)の1つ。
『(邦題)Pythonではじめる機械学習』 読了
- 投稿日:2019-12-23T18:35:19+09:00
Wagtailを触ってみた(1)、saveメソッドをオーバーライドしよう。
はじめに
こんにちは
少し前にWagtailを使って開発をしていました。Wagtailの日本語の文献はあまり多くないので、英語の文献を読むことが求められます。
エンジニアとしては英語の文献を読む力は非常に重要ではありますが、
日本語で書かれた文献があればなぁ
と多くの方が思うはずではないでしょうか。僕は思いますというわけで、Wagtailを使ってコードを書いて、それをアウトプットしていきたいと思います。
今回はそれの第一弾です。
Wagtailについて
そもそもWagtailって何って思われる方もいると思います。
WagtailはDjangoベースで開発されたCMSのOSSです。WordPressがPHPで動いているのに対して、WagtailはPythonで動いています。リリースノートを見れば分かるように、開発が結構盛んに行われていますね。
ちなみに、Wagtailは日本語ではセキレイにあたる言葉です。Wagtailのロゴもセキレイをモチーフにして作られていますね。
環境を整えよう
早速触っていきましょう。
僕はmacでやってます。環境構築に関しては下記サイトを参考にしました。参考:Wagtailのすすめ(1) DjangoベースのCMSを比較・検討してWagtailを選択した話
本文を書き込めるようにしよう
localhostからCMSにアクセスして、「Pageボタン」をクリックしましょう。次に、画面上部にある「ADD CHILD PAGE」をクリックします。ここではブログの編集ができます。
コードを何も編集していない状態であれば、タイトルしか記入できません。下記の参考サイトを参考にして、本文を書き込めるように設定します。
home/models.py1 from django.db import models 2 3 from wagtail.core.models import Page 4 from wagtail.core.fields import RichTextField 5 from wagtail.admin.edit_handlers import FieldPanel 6 7 8 class HomePage(Page): 9 """ 10 Pageのモデル 11 """ 12 body = RichTextField(blank=True) 13 content_panels = Page.content_panels + [FieldPanel("body", classname="full"),]コードを見てみましょう。このモデルのコードには、Pageモデルを継承したHomePageモデルが書かれていますね。RichTextFieldとしてのbody、つまり本文のモデルを追加しました。FieldPanelの追記を忘れないようにしましょう。
忘れた人がここにいますマイグレーションもしておきましょう。
python manage.py makemigrations python manage.py migrate表示画面はこんな感じになってると思います。
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
タイトル、本文保存時の動作を書いてみよう
タイトルや本文を記入したら、画面下部にあるタブをクリックしてコンテンツを保存できます。その際の処理として、タイトルや本文にバリデーションをかけてみます。今回は文字数に制限をかけてみます。
テストのために、タイトルと本文を保存しておきましょうhome/models.py1 from django.db import models 2 3 from wagtail.core.models import Page 4 from wagtail.core.fields import RichTextField 5 from wagtail.admin.edit_handlers import FieldPanel 6 7 8 class HomePage(Page): 9 """ 10 Pageのモデル 11 """ 12 body = RichTextField(blank=True) 13 content_panels = Page.content_panels + [FieldPanel("body", classname="fu ll"),] 14 15 def save(self, *args, **kwargs): 16 """save関数""" 17 print("save関数に入りました") 18 breakpoint()breakpoint()これはPythonで使えるデバッガPDBを呼び出す関数です。早速実行してみましょう。
1. ローカルサーバを起動する
2. breakpoint()を任意の場所に記述する
3. 編集したファイルを保存する
4. 任意のコマンドを実行する
これで下記のようなログが出力されました。save関数に入りました --Return-- > /Users/Username/mysite/home/models.py(18)save()->None -> breakpoint() (Pdb) HomePage <class 'home.models.HomePage'> (Pdb) HomePage.objects <django.db.models.manager.BasePageManagerFromPageQuerySet object at 0x10ebee410> (Pdb) HomePage.objects.all() <PageQuerySet [<HomePage: Home>, <HomePage: title>]> (Pdb) instance = HomePage.objects.all() (Pdb) instance <PageQuerySet [<HomePage: Home>, <HomePage: title>]> (Pdb) instance[1] <HomePage: title> (Pdb) instance[1].title 'title' (Pdb) len(instance[1].title) 5len関数を使えば文字列の長さが分かりますね。
DjangoやWagtailで開発をする場合、僕はこんな感じでデバッガを起動してオブジェクトの中身を確認します。あとは条件式を書けば、タイトルの文字数のバリデーションがかけれそうですね。
このサイト「Google SEOで効果的なタイトルの文字数とは」によれば、タイトル文字は32文字ぐらいまでがちょうどいいみたいですね。今回は33文字を超えないように処理したいと思います。
home/models.py16 def save(self, *args, **kwargs): 17 """save関数""" 18 print("save関数に入りました") 19 breakpoint() 20 instance = HomePage.objects.all() 21 titleCharCount = len(self.title) 22 if ((titleCharCount < 0) | (titleCharCount > 32)): 23 #バリデーションが通っていない 24 return 25 else: 26 #バリデーションが通った 27 return super(HomePage, self).save()24行目ではオブジェクトは保存されません。27行目で保存されます。デバッガを使って確認してみましょう。同じような処理を書けば、本文にもバリデーションがかけられるでしょう。
さいごに
オブジェクトが保存できない時に画面上部に表示されるエラーメッセージが実装できていませんね。
次回はそれのアウトプットを書きたいと思います。
- 投稿日:2019-12-23T18:27:04+09:00
2019年度版 : 不正アクセスの傾向分析 (クラウド上の汎用的サーバの例)
はじめに
この記事はシスコの同志による Cisco Systems Japan Advent Calendar 2018 の 23 日目として投稿しました。
2017年版: https://qiita.com/advent-calendar/2017/cisco
2018年版: https://qiita.com/advent-calendar/2018/cisco
2019年版: https://qiita.com/advent-calendar/2019/ciscoネットワーク/インフラ/サーバ系エンジニアの方で自宅ラボを構築されている方も多いと思います。私も数年そのような形で自宅に実機を持っていましたが、約1年半前に自宅に機材を持つことをやめ、複数のクラウドサービスに移行しました。サーバの要塞化をするためのソフトウェアと管理系ツールをいくつか試し、設定変更を繰り返しながらようやく手放し運転をしてほぼ1年が経過しましたので、その一台のサーバへの直近一年間の不正アクセスの傾向をまとめてみたいと思います。
このエントリで取り上げるテーマは
「2019年度版 : 不正アクセスの傾向分析 (クラウド上の汎用的サーバの例)」です。この中では、
- 年間不正アクセス統計
- 環境の前提とfail2banのチューニング例
- 不正アクセス接続元の悪性スコア調査Tips (Umbrella Investigate API)
の主に3項目をまとめてみます。2018年度のAdvent Calender投稿から時間が経過するに連れ、いつかネタとしてまとめてみたいと思っていたテーマでした。
年間不正アクセス統計
- 期間
- 2019/01/01 ~ 2019/11/31
- 項目
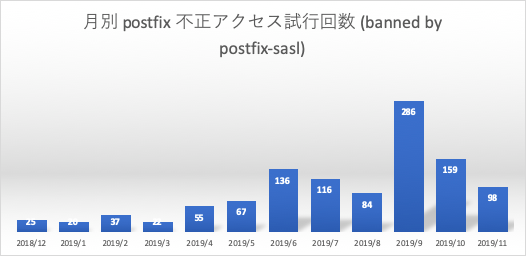
- 月別 ssh 不正アクセス試行回数 (banned by ssh-sasl)
- 月別 ssh root ログイン試行回数 (root login fail)
- 月別 postfix 不正アクセス試行回数 (banned by postfix-sasl)
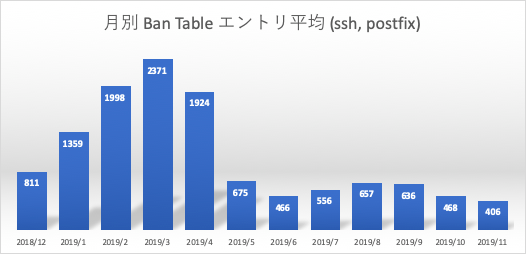
- 月別 Ban Table エントリ平均 (ssh, postfix)
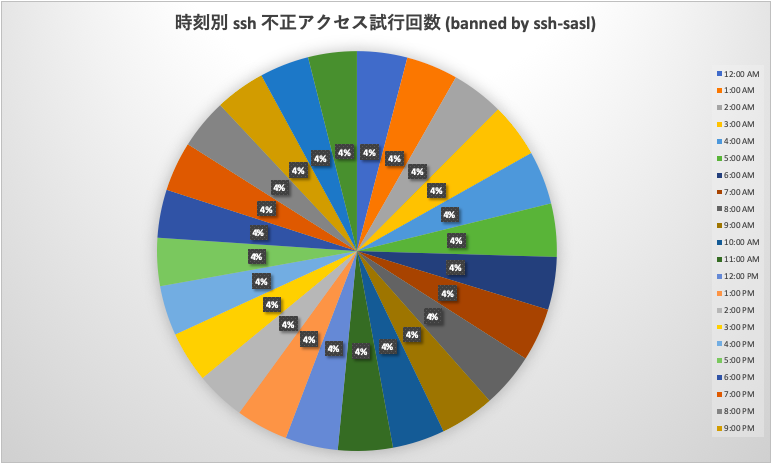
- 時刻別 ssh 不正アクセス試行回数 (banned by ssh-sasl)
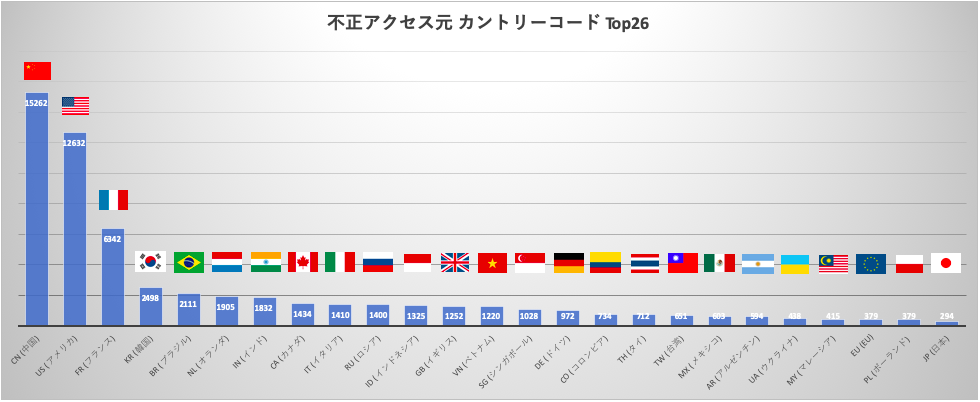
- 不正アクセス元カントリーコード Top26
- 月別不正アクセスソースIPアドレスドメイン逆引き可否
- ssh アカウント Top20
- dovecot アカウント Top14
- 不正アクセスソース RiskScore (全体)
- 不正アクセスソース RiskScore (日本)
- postfix RBL アクセス違反統計
- 統計元データ&Tool
- fail2ban にて送信されるaction mail (ban時にactionで送信されるメール)
- logwatch にて送信される統計レポート (
/vat/log/maillog,/var/log/secure,/var/log/messages,/var/log/dovecot/dovecot.log)- Cisco Umbrella Investigate (不正アクセスソース悪性スコア(RiskScore)調査用)
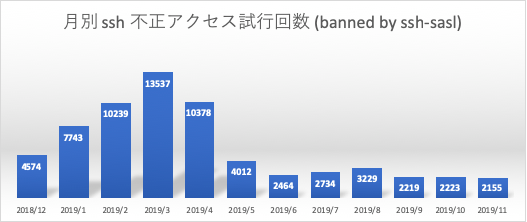
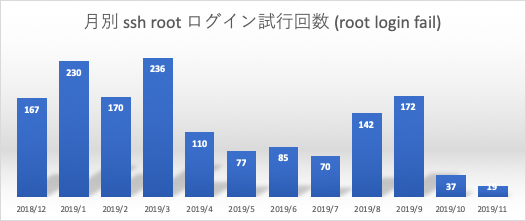
月別 ssh 不正アクセス試行回数 (banned by ssh-sasl), 月別 ssh root ログイン試行回数 (root login fail)
期間内12ヶ月における月別の ssh 不正アクセス試行回数と月別 ssh root アカウントの試行回数推移です。fail2ban/iptablesの設定により、1800秒以内に3回失敗した接続元IPアドレスは少なくとも36000秒 (10日間) は再接続ができません。このグラフの不正アクセス試行回数はほぼ自動的に総当たり攻撃が実行される1回目, 2回目のアクセス数の記録です。通常このようなアクセス制御がされていないシステムにおいては、桁の異なる更に膨大なアクセスが行われていると考えられます。
2018年12月以前は、環境整備のため頻繁にpower offをしており、本格連続稼働は2018/11ころよりスタートしていました。その後にsshのアクセス試行回数が伸びていますが、2019年5月以降は一気にアクセス数が減ってきています。
月別 postfix 不正アクセス試行回数 (banned by postfix-sasl), 月別 Ban Table エントリ平均 (ssh, postfix)
期間内12ヶ月における月別の Postfix 認証不正アクセス試行回数と、月別のActive Ban Tableの平均値です。今回の対象システムでは Postfix によるメール送信時に3rd Party リレー対策の一貫としてSMTP-AUTHを有効にしています。maillogよりこの SMTP-AUTH の試行が失敗した回数をカウントしています。ssh と同様に5400秒以内に2回失敗した接続元IPアドレスはiptablesにエントリされるため、初期接続時での認証失敗が対象になります。
sshに比べ総数はかなり少なくなっていますが、ssh へのアクセスが減る時期より徐々に増えていることが確認できます。Ban Tableエントリは、logwatch にて報告される(午前3時)ssh と postfix の Active Banned Table エントリの合計数を定点観測した結果となります。ssh アクセス数に比例していることが確認できます。
時刻別 ssh 不正アクセス試行回数 (banned by ssh-sasl)
期間内12ヶ月における ssh 不正アクセスイベントの日本時刻別での発生比率です。メールサービスへの不正アクセスはカウントしていません。日本時刻別でのアクセス数の偏りは全くありません。全世界のアクセス元からほぼ機械的に実行されていると考えられます。
不正アクセス元カントリーコード Top26
期間内12ヶ月における ssh 不正アクセスイベントの接続元の国別トップ26(日本がランクインするまで)です。メールサービスへの不正アクセスはカウントしていません。圧倒的に中国、アメリカの二カ国、次いでフランスからのアクセスが多いことが確認できます。
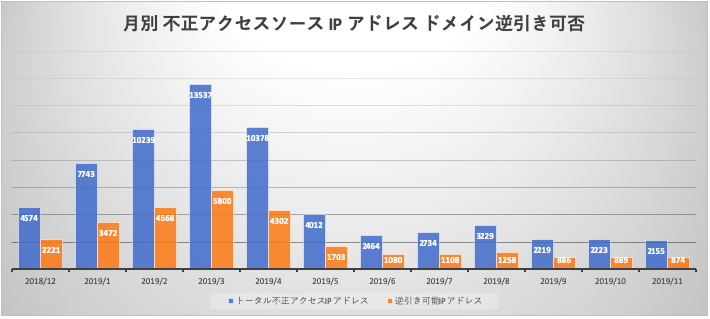
月別不正アクセスソースIPアドレスドメイン逆引き可否
期間内12ヶ月における月別の ssh 不正アクセス試行回数(青縦線は前の '月別 ssh 不正アクセス試行回数' グラフと同じ)とその接続元IP アドレスからホストドメイン逆引きが可能だったIPアドレスとの比較です。ssh 全不正アクセス試行回数 65507 回において、その接続元 IP アドレスが登録された FQDN を持っている比率は43%でした。月別での比率も大きく開きはありません。(39%~43%)
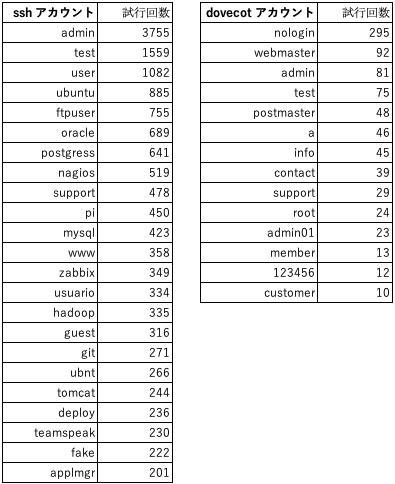
ssh アカウント Top20, dovecot アカウント Top14
期間内12ヶ月における ssh, メールサービスへの不正アクセス施行に利用された root 以外のアカウントの利用率上位の表です。ssh は簡易的に作成されてしまうと想像し得るアカウントが多く回数の偏りがあります。dovecot, postfix において偏りが少なくグラフ内にない利用回数がさらに少ない個別のアカウントにて多くのアクセスが確認できています。
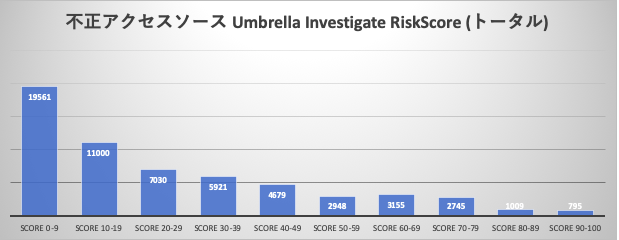
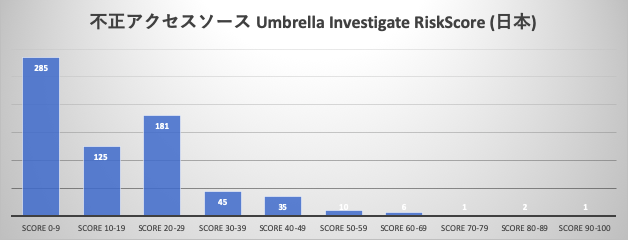
不正アクセスソース RiskScore (全体), 不正アクセスソース RiskScore (日本)
期間内12ヶ月における ssh 不正アクセス接続元 の Cisco Umbrella Investigate による予測的な悪性度評価 (RiskScore) の分布です。不正アクティビティを行う接続元のレピュテーション情報としてUmbrella Investigateより抽出してみました。スコアは 0 - 100、100は最も悪性度が高いスコアとなります。大半が比較的良性なスコアを持つ接続元であることが確認できます。
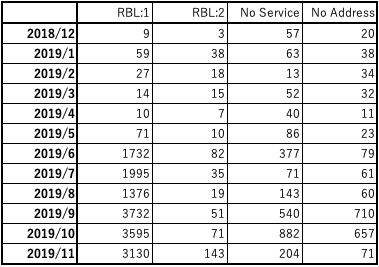
postfix RBL アクセス違反統計
期間内12ヶ月における RBLルールによる postfix 接続違反統計です。
- RBL:1 : zen.spamhaus.org によるレピュテーションチェック
- RBL:2 : bl.spamcop.net によるレピュテーションチェック
- No Service : Name or service not known
- No Address : Address not listed for hostname
迷惑メール送信元レピュテーションブラックリスト RBL (Realtime Blackhole List) のとして zen.spamhaus.org , bl.spamcop.net を設定しており、これによりMTA接続時にこのリストをチェックしリストに該当した接続元を拒否します。zen.spamhaus.org のヒット数が 2019/6, 2019/10にそれぞれスパイクしています。
環境の前提とfail2banのチューニング例
年間不正アクセス統計の前提条件です。不正アクセス統計のグラフで表示されるカウントそのものがすべてのアクセス試行回数ではなく、利用しているツールにより十分にフィルタされた上での分析結果となっています。その条件をいくつか整理します。
今回の分析対象のシステム上ではsshの他にXRDP+GNOMEによるリモートデスクトップ環境、postfix+dovecotによるメールサービスを構築しています。その他Webサーバ等のサービスは利用していません。オープンポートは22/tcp (ssh), 25/tcp (SMTP), 993/tcp (imaps), 995/tcp (pop3s), 3389/tcp (RDP)です。
シンプルにリモートデスクトップサービスは接続元を固定する静的なiptablesで保護し、sshとメールサービスはfail2banを用い、指定したルールに従ってダイナミックなiptablesエントリを登録し保護します。fail2banによるbanned tableエントリ時にその結果を都度メールに送信、24間置きのセキュリティイベント分析し結果をlogwatchで送信しています。
各サービスは定期アップデートを実施することを前提で、脆弱性に対応するIPS/IDS等の高度なツールは利用していません。今回は主にこの伝統的なfail2banで遮断された情報を元に不正アクセスの傾向を出力することを目的としています。fail2ban
fail2ban は新しいツールでは全くありません。リアルタイムに
/var/log/apache/error_log等、サービスへの不正アクセスがレポートされる設定によって指定されたログファイルをリアルタイムでスキャンし、ログファイルの中の悪意あるサインを元に接続元IPアドレスを指定された時間においてBan (iptablesへの自動追加・アップデート) することで、ログインパスワードの失敗, Exploit利用からシステムを保護します。fail2banはbrutefoce攻撃のように繰り返し試行されるログインのレートを軽減することには有効に働きますが、脆弱な認証へのアクセスそのもを軽減するわけではありません。jail.local
sshの場合、なるべく同一のIPアドレスから連続した 'Failed password' が
/var/log/secureに出力されないようにする、postfixの場合、なるべく同一のIPアドレスから連続した 'LOGIN authentication failed' が/var/log/mail/maillogから出力されないようにするための調整をしばらく続け、最終的にそれぞれ、findtime=1800/maxentry=3,findtime=5400/maxentry=2がベストであるという結論に行き着きました。つまりpostfixの場合、90分以内に3回同一接続元からログイン失敗があればBanするという設定です。多くの場合同一接続元から17~18分以内に再アクセスを試みていました。jail.local[DEFAULT] ignoreip = x.x.x.0/24 backend = polling bantime = 360000 maxretry= 3 usedns = yes [ssh-iptables] enabled = true filter = sshd action = iptables[name=SSH, port=ssh, protocol=tcp] sendmail-whois[name=ssh-sasl, dest=root, sender=fail2ban@sample.org] logpath = /var/log/secure findtime = 1800 [sasl-iptables] enabled = true filter = postfix-sasl action = iptables-multiport[name=postfix-sasl, port="smtp,smtps", protocol=tcp] sendmail-whois[name=postfix-sasl, dest=root, sender=fail2ban@sample.org] logpath = /var/log/mail/maillog maxretry= 2 findtime = 5400不正アクセス接続元の悪性スコア調査Tips (Umbrella Investigate API)
Cisco Umbrella Investigate
Umbrella は Public Recursive DNS として1日辺り1800億以上のリクエストから自動解析された潜在的な悪性ドメイン, IPアドレスを予測的指標としてスコアリングしています。これらのDNS, IPアドレスに対するセキュリティ統計分析は Umbrella Investigate の機能として数多くの視点からスコア情報を取得できます。この特定のドメイン, IPアドレスに対して生成されたスコアは、主に予測分析を支援、疑わしいと見なされるネットワークアクティビティ情報を見つけるため、高度なセキュリティオペレーション担当者、セキュリティ研究者向けに利用することが可能です。
Umbrella Investigate Risk Score
Umbrella Investigate Risk Score はドメイン名の字句特性 (構成文字列), とUmbrellaインフラへのドメインクエリ, リクエストパターン分析に基づき、0 - 100の範囲の予測的な潜在性スコアです。この数値は必ずしも調査対象の過去の不正活動による悪性度裁定に直結するわけでは無くあくまでも予測されるリスク値という位置づけです。この情報は調査対象に関する過去のBotnet、フィッシングドメイン、マルバタイジング、ランサムウェアとの関連性にもひも付きスコアリングされています。
pyinvestigate (Umbrella Investigate API python モジュール)
不正アクセス情報統計のリスクスコア分布の情報として、Umbrella Investigate を利用しました。Umbrella Investigate は Web UI だけでなく REST API により Query することが可能です。65000 以上の取得された不正アクセス元IPアドレス, ホストFQDNから RiskScore をREST API から一括取得するため、Umbrella Investigate 用 python module である pyinvestigate を利用しました。
1. pyinvestigate インストール
# pip3 install investigate # pip3 install pytest # pip3 install pytest-django # pip3 install pytest-pythonpath2. investigate API キーの取得
https://dashboard.umbrella.com/へログイン- Investigate > Investigate API Access へナビゲート
- CREATE NEW TOKEN
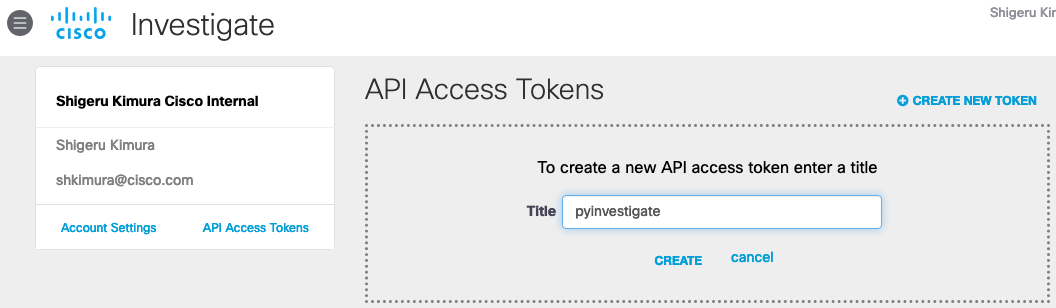
作成したTokenを参照し、コピー
3. pyinvestigate 実行
pyinvestigate は pythonインタープリタから実行できます。
コピーしたAPI Keyを指定し、調査IPアドレス/ドメインをクエリします。
不正アクセス調査用には別途スクリプトを作成し、一括取得しています。# python36Python 3.6.8 (default, Aug 10 2019, 06:52:10) [GCC 4.4.7 20120313 (Red Hat 4.4.7-23)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> >>> import investigate >>> import datetime >>> api_key = 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx' >>> inv = investigate.Investigate(api_key) >>> >>> inv.risk_score('xxx.com') {'features': [{'feature': 'Geo Popularity Score', 'normalizedScore': 50, 'score': 0}, {'feature': 'Keyword Score', 'normalizedScore': 26, 'score': 0.26108091120959626}, {'feature': 'Lexical', 'normalizedScore': 89, 'score': 0.898}, {'feature': 'Popularity 1 Day', 'normalizedScore': None, 'score': None}, {'feature': 'Popularity 30 Day', 'normalizedScore': None, 'score': None}, {'feature': 'Popularity 7 Day', 'normalizedScore': None, 'score': None}, {'feature': 'Popularity 90 Day', 'normalizedScore': None, 'score': None}, {'feature': 'TLD Rank Score', 'normalizedScore': 0, 'score': 0.007835250367488503}, {'feature': 'Umbrella Block Status', 'normalizedScore': 0, 'score': False}], 'riskScore': 71} >>>{'features': [{'feature': 'Geo Popularity Score', 'normalizedScore': 3, 'score': -3.1797661699999997}, {'feature': 'Keyword Score', 'normalizedScore': 0, 'score': 0.005737760395203566}, {'feature': 'Lexical', 'normalizedScore': 50, 'score': 0.504}, {'feature': 'Popularity 1 Day', 'normalizedScore': 95, 'score': 95.59}, {'feature': 'Popularity 30 Day', 'normalizedScore': 96, 'score': 96.94}, {'feature': 'Popularity 7 Day', 'normalizedScore': 96, 'score': 96.26}, {'feature': 'Popularity 90 Day', 'normalizedScore': 96, 'score': 96.41}, {'feature': 'TLD Rank Score', 'normalizedScore': 0, 'score': 0.00562125007281412}, {'feature': 'Umbrella Block Status', 'normalizedScore': 0, 'score': False}], 'riskScore': 1} {'features': [{'feature': 'Geo Popularity Score', 'normalizedScore': 84, 'score': 1.68891283}, {'feature': 'Keyword Score', 'normalizedScore': 50, 'score': 0.5030948281811238}, {'feature': 'Lexical', 'normalizedScore': 75, 'score': 0.751}, {'feature': 'Popularity 1 Day', 'normalizedScore': 11, 'score': 11.45}, {'feature': 'Popularity 30 Day', 'normalizedScore': 8, 'score': 8.72}, {'feature': 'Popularity 7 Day', 'normalizedScore': 9, 'score': 9.59}, {'feature': 'Popularity 90 Day', 'normalizedScore': 10, 'score': 10.8}, {'feature': 'TLD Rank Score', 'normalizedScore': 28, 'score': 0.28834641075042694}, {'feature': 'Umbrella Block Status', 'normalizedScore': 0, 'score': False}], 'riskScore': 29} {'features': [{'feature': 'Geo Popularity Score', 'normalizedScore': 86, 'score': 1.8171738299999998}, {'feature': 'Keyword Score', 'normalizedScore': 50, 'score': 0.5030948281811238}, {'feature': 'Lexical', 'normalizedScore': 99, 'score': 0.991}, {'feature': 'Popularity 1 Day', 'normalizedScore': None, 'score': None}, {'feature': 'Popularity 30 Day', 'normalizedScore': None, 'score': None}, {'feature': 'Popularity 7 Day', 'normalizedScore': None, 'score': None}, {'feature': 'Popularity 90 Day', 'normalizedScore': None, 'score': None}, {'feature': 'TLD Rank Score', 'normalizedScore': 28, 'score': 0.28834641075042694}, {'feature': 'Umbrella Block Status', 'normalizedScore': 0, 'score': False}], 'riskScore': 94}参照
[1] fail2ban
https://www.fail2ban.org/wiki/index.php/Main_Page
[2] Umbrella Investigate REST API - Security Information for a Domain
https://docs.umbrella.com/investigate-api/docs/security-information-for-a-domain-1#section-risk-score-for-a-domain
[3] pyinvestigate
https://github.com/opendns/pyinvestigate
- 投稿日:2019-12-23T17:26:16+09:00
ポモドーロできるメモ帖作ってみたが反省会
ログをメモに残しつつポモドーロがしたい
ポモドーロテクニックとは25分の集中と5分の短時間休憩もしくは15分の長時間休憩を繰り返し、
仕事を集中的に行う時間管理術です。
自分はいつも使っているわけではないですが、
集中できない時にメリハリをつけるために使っています。FirefoxのTomato Clockというポモドーロアドオンがあるので、
自分はそれをタイマー代わりに使っていました。非常に使いやすいのですがブラウザ上で稼働してるので、
後で何をしたかを振り返るためにポモロードのサイクル結果を
具体的に行動ログを残す場合は
別口でメモ帖等に書かねばなりませんでした。丁度昔、tkinterの練習用にその日の行動ログを残しつつテキスト編集してくれるアプリを作ったので、
それを改造してポモロード用のタイマー機能を追加することにしました。要はポモロードのタイマーがついたメモ帖です。
完成(?)物
配布用Exe版
https://github.com/rabbitbeef/KetchupEXEソース
https://github.com/rabbitbeef/ketchup
設計や細かな仕様はともかくとりあえず自分の使う分には満足いくものができました。
画像のログは実験用ですが、
tomatoや休憩をしていた時間は
[11:0][tomato]
[11:25][tomato:End]
や
[10:55][ShortBreak]
[11:0][ShortBreak:End]
という感じで開始と終了の時刻を残してくれます。
また何をしたか等のログを直接メモに書き込むことができます。反省
上でも書きましたが設計が雑です。
特にViewが分離していないです。
下
全部のクラスがtkinternに依存しています。
もともとtkinterで作った物を拡張して作る気でおり、
そのまま何も考えずに拡張してしまったのが原因です。
もし後でtkinterではなくKivy等の他のguiライブラリを用いたくなった場合、
改修箇所が多くなりです。
(それでも元のソースもそんなに長くないですが。)もし自分が現状から変更するならですが、以下の図のような構成にします。
interfaceが増えましたが、
どうしてもtkinterが必要な、表示や書き込みに関係する部分はinterfaceを継承して作り、
それらはTkinterのパーツを使用します。これならば、Tkinter以外のguiライブラリに変更する際にも、
前の設計に比べて影響や改修を少なくすることができそうです。
タイマー以外の機能を拡張も改修しやすく作ることができます。機能を拡張するなら
ソースの方にはちょっと跡を残していますが、
タイマーやスタンプの設定をconfigで自由に変更可能にするとか
他のポモドーロ系アプリにも多いログから行動を集計する機能を作成するなど
あったら利便性高いかなという機能はありますが、
現状はメインの機能が取り合えず稼働して満足なので、
気が向いたら改修するかもしれません。最後に
実は作成物を公開して上げるのは初めてなので、
もし使って頂けたなら、使用感やこういうのあると便利など、
レビューがあると嬉しいです。駄文の反省ですが、
ここまで読んでいただきありがとうございます。



- 投稿日:2019-12-23T17:26:16+09:00
ポモドーロできるメモアプリ作ってみたが反省録
ログをメモに残しつつポモドーロがしたい
ポモドーロテクニックとは25分の集中と5分の短時間休憩もしくは15分の長時間休憩を繰り返し、
仕事を集中的に行う時間管理術です。
自分はいつも使っているわけではないですが、
集中できない時にメリハリをつけるために使っています。FirefoxのTomato Clockというポモドーロアドオンがあるので、
自分はそれをタイマー代わりに使っていました。非常に使いやすいのですがブラウザ上で稼働してるので、
後で何をしたかを振り返るためにポモロードのサイクル結果を
具体的に行動ログを残す場合は
別口でメモ帖等に書かねばなりませんでした。丁度昔、tkinterの練習用にその日の行動ログを残しつつテキスト編集してくれるアプリを作ったので、
それを改造してポモロード用のタイマー機能を追加することにしました。要はポモロードのタイマーがついたメモ帖です。
完成(?)物
配布用Exe版
https://github.com/rabbitbeef/KetchupEXEソース
https://github.com/rabbitbeef/ketchup
設計や細かな仕様はともかくとりあえず自分の使う分には満足いくものができました。
画像のログは実験用ですが、
tomatoや休憩をしていた時間は
[11:0][tomato]
[11:25][tomato:End]
や
[10:55][ShortBreak]
[11:0][ShortBreak:End]
という感じで開始と終了の時刻を残してくれます。
また何をしたか等のログを直接メモに書き込むことができます。反省
上でも書きましたが設計が雑です。
特にViewが分離していないです。
下
全部のクラスがtkinternに依存しています。
もともとtkinterで作った物を拡張して作る気でおり、
そのまま何も考えずに拡張してしまったのが原因です。
もし後でtkinterではなくKivy等の他のguiライブラリを用いたくなった場合、
改修箇所が多くなりです。
(それでも元のソースもそんなに長くないですが。)もし自分が現状から変更するならですが、以下の図のような構成にします。
interfaceが増えましたが、
どうしてもtkinterが必要な、表示や書き込みに関係する部分はinterfaceを継承して作り、
それらはTkinterのパーツを使用します。これならば、Tkinter以外のguiライブラリに変更する際にも、
前の設計に比べて影響や改修を少なくすることができそうです。
タイマー以外の機能を拡張も改修しやすく作ることができます。機能を拡張するなら
ソースの方にはちょっと跡を残していますが、
タイマーやスタンプの設定をconfigで自由に変更可能にするとか
他のポモドーロ系アプリにも多いログから行動を集計する機能を作成するなど
あったら利便性高いかなという機能はありますが、
現状はメインの機能が取り合えず稼働して満足なので、
気が向いたら改修するかもしれません。最後に
実は作成物を公開して上げるのは初めてなので、
もし使って頂けたなら、使用感やこういうのあると便利など、
レビューがあると嬉しいです。駄文の反省ですが、
ここまで読んでいただきありがとうございます。
- 投稿日:2019-12-23T17:19:38+09:00
sklearn.metrics.f1_scoreのaverageオプションについて
f1 scoreとは
$$ f1 = \frac{2 \times Recall \times Precision}{Recall + Precision} = \frac{1}{\frac{1}{Recall} \times \frac{1}{Precison}} = \frac{2 \times TP}{2 \times TP + FP + FN}$$
で示されるRecall(再現率、感度)とPrecision(適合度、精度)の兼ね合いの指標である。
調和平均であるのでどちらかが極端に低い場合にはスコアが低くなる。多クラス分類
簡略化のため、3クラス分類とする(4クラス以上でも同じ考えで行ける)
予想クラス a b c a 10 3 5 正解のクラス b 4 20 3 c 4 3 15 こんな感じの混同行列があったとき、TP、FP、FNを以下のように定義する。
クラス TP FP FN a 10 8 8 b 20 6 7 c 15 8 7 FPは縦、FNは横の対角要素以外の和である。
sklearn.metrics.f1_score
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.htmlをみるとオプションに
"binary","micro","macro","weighted","samples"が存在する。(recall_score, precision_scoreも同様)
"binary"は2値分類で用いるものである。
その他について以下に記す。
"micro"
全体でTP,FP,FNを計算する。
TP FP FN 45 22 22 求めたTP,FP.FNで計算する
$$f1 = \frac{2 \times TP}{2 \times TP + FP + FN} = \frac{90}{90+22+22} = 0.67164179104\dots$$
"macro"
個々のクラスでRecallとPrecisionを算出する
クラス Recall Precision a $\frac{10}{18}$ $\frac{10}{18}$ b $\frac{20}{27}$ $\frac{20}{26}$ c $\frac{15}{22}$ $\frac{15}{23}$ 平均のRecallとPrecisionを算出する
Recall Precision $\frac{1}{3}\sum{Recall}$ $\frac{1}{3}\sum{Precision}$ 求めた平均でf1を計算する
$$ \frac{1}{\frac{1}{\frac{1}{3}\sum{Recall}} \times \frac{1}{\frac{1}{3}\sum{Precision}}} $$
(計算は面倒なので省略)
"weighted"
各クラスのデータ数を個々のRecall, Precisionに乗算する
クラス Recall Precision a $\frac{10}{18} \times 18$ $\frac{10}{18}\times 18$ b $\frac{20}{27}\times 18$ $\frac{20}{26}\times 18$ c $\frac{15}{22}\times 18$ $\frac{15}{23}\times 18$ Recall,Precisionの総和をデータ総数で割る
Recall Precision $\frac{1}{67}\sum{Recall}$ $\frac{1}{67}\sum{Precision}$ 求めた平均でf1を計算する
$$ \frac{1}{\frac{1}{\frac{1}{67}\sum{Recall}} \times \frac{1}{\frac{1}{67}\sum{Precision}}} $$
(計算は面倒なので省略)
"samples"よくわかってないので分かり次第加筆予定
- 投稿日:2019-12-23T17:04:22+09:00
データハンドリング
NumPyとは
numpyは,Python言語で数値計算を効率的に行うためのライブラリである。
numpyには以下のような利点がある。
- ベクトル化記法による高速な計算
- 効率的な記述統計的データ操作
- 拝謁内での条件記述ndarray:多次元配置オブジェクト
ndarrayではベクトル化記法により配列に対する高速な一括計算が可能になる。
ndarrayオブジェクトの生成
↓↓↓↓↓↓↓ あなたの記事の内容
ndarray.pyPython:ndarray1.py
───────
↑↑↑↑↑↑↑ 編集リクエストの内容
import numpy as np
ndarray1 = np.array([1,2,3,4,5])
↓↓↓↓↓↓↓ あなたの記事の内容
print(ndarray)出力結果 [1 2 3 4 5]
───────
print(ndarray1)
```
↑↑↑↑↑↑↑ 編集リクエストの内容↓↓↓↓↓↓↓ あなたの記事の内容
ndarray2 = np.arrange(1,6,1)
───────
text:出力結果
[1 2 3 4 5]
ndarray2.pyndarray2 = np.arrange(1,6,1) ↑↑↑↑↑↑↑ 編集リクエストの内容 print(ndarray2) ↓↓↓↓↓↓↓ あなたの記事の内容 #出力結果 [1 2 3 4 5] print(np.ones(5)) #出力結果 [1 1 1 1 1]np.array関数は,多次元のリストを渡すことができる。
ndarry2.pyndarray4 = np.array([[1,2,3],[4,5,6]]) print(ndarray4) #出力結果 [[1 2 3] [4 5 6]]
- shape → 配列の形状
- size → 配列の全要素数
- ndim → 配列の次元数
ndarray3.pyndarray = np.array([[1, 2, 3], [4, 5, 6]]) print(ndarray.shape) print(ndarray.size) print(ndarray.ndim) #出力結果 (2,3) #出力結果 6 #出力結果 2───────
```出力結果[1 2 3 4 5]↑↑↑↑↑↑↑ 編集リクエストの内容
- 投稿日:2019-12-23T17:00:17+09:00
PythonでWiFiの速度計測をする
この記事は JSL (日本システム技研) Advent Calendar 2019 の13日目の記事です。
最近、社内のWiFiが遅くなるタイミングがあるような気がしていて、とはいえどの程度遅くなっているか定量的に分からなかったため、スピードテストを定期実行するスクリプトを書いてみました。
最初にまとめ
- Speedtest CLI - Internet connection measurement for developers を使って社内WiFiの速度計測するプログラムをPythonで書いた
- CUIからスピードテスト実行できると便利
CUIからスピードテスト
まず、cron等で定期的に実行したかったためCUIでスピードテストを実行することを考えました
私のイメージではスピードテストといえば以下のように検索→実行…のようにして計測するものでした。
Linux上でネットワーク回線速度を計測する手段について整理してみた | Developers.IO) の記事などをみつつ調査したところ
speedtest.netがCLIを提供しているようでしたまた、Speedtest CLIはPython packageも提供しており、
- pipでbinaryをinstallすることが可能
- brewで管理しなくても仮想環境化でspeedtestコマンドが使えそう
- Python上でimportすることもできそう
なことがわかりました
speedtest実行環境の構築
pipenvを使って環境構築しました
$ mkdir wifi_speedtest $ cd $_ # pipenv 未インストールの場合 # brew install pipenv # 仮想環境作成 $ pipenv --python 3.7 # パッケージのインストール $ pipenv install speedtest-cli # 仮想環境の有効化 $ pipenv shell # speedtestコマンドのテスト (.venv) $ speedtest --version speedtest-cli 2.1.2 Python 3.7.4 (default, Oct 12 2019, 18:55:28) [Clang 11.0.0 (clang-1100.0.33.8)]CUI上でSpeedtestを実行してみる
speedtest --listで有志が提供している接続先サーバの一覧が取れるのでいずれかに決めて番号を控えておきます。(.venv) $ speedtest --list | grep Tokyo 15047) OPEN Project (via 20G SINET) (Tokyo, Japan) [6.34 km] 24333) Rakuten Mobile , Inc (Tokyo, Japan) [6.34 km] 28910) fdcservers.net (Tokyo, Japan) [6.34 km] 18516) GIAM PING VIETPN.COM (Tokyo, Japan) [6.34 km] 22247) Tokyonet (Castro, Brazil) [18486.74 km]以下のように指定すると常に指定したサーバでスピードテストを実行します。例えば、
Rakuten Mobile , Inc提供のサーバの場合、番号は24333となります。# スピードテストを実行 (.venv) $ speedtest --server 24333 Retrieving speedtest.net configuration... Testing from XXX (xx.xx.xx.xx)... Retrieving speedtest.net server list... Retrieving information for the selected server... Hosted by Rakuten Mobile , Inc (Tokyo) [6.34 km]: 200.123 ms Testing download speed................................................................................ Download: 16.08 Mbit/s Testing upload speed...................................................................................................... Upload: 31.96 Mbit/s無事計測できました(クライアント情報は一部隠しています)
- Download: 16.08 Mbit/s
- Upload: 31.96 Mbit/s
ただ、これだとプログラム上で扱いづらいので
--jsonを付与して json 形式で結果を取得してみます(.venv) $ speedtest --server 24333 --json結果{"download": 20208058.464686207, "upload": 54426180.687909536, "ping": 48.215, "server": {"url": "http://ookla.mbspeed.net:8080/speedtest/upload.php", "lat": "35.6833", "lon": "139.6833", "name": "Tokyo", "country": "Japan", "cc": "JP", "sponsor": "Rakuten Mobile , Inc", "id": "24333", "host": "ookla.mbspeed.net:8080", "d": 6.336536019993832, "latency": 48.215}, "timestamp": "2019-12-23T07:23:16.316637Z", "bytes_sent": 68534272, "bytes_received": 25353712, "share": null, "client": {"ip": "xx.xx.xx.xx", "lat": "xx.xxxx", "lon": "xxx.xxxx", "isp": "XXX", "isprating": "3.7", "rating": "0", "ispdlavg": "0", "ispulavg": "0", "loggedin": "0", "country": "JP"}}これをPython上で扱うことを考えます
PythonでSpeedtestを実行する
せっかくPython Packageとして提供しているので、Pythonの中でプラグラマブルにスピードテストを実行することも考えましたが、今回はCUIでの実行結果をそのまま扱うことを考えたので
subprocessモジュールでspeedtestコマンドを実行することにしましたsubprocess --- サブプロセス管理 — Python 3.8.1 ドキュメント
wifi_speedtest.pydef get_speedtest_result(): process = subprocess.run(['speedtest', '--server', '24333', '--json'], capture_output=True) return json.loads(process.stdout) def bit_to_mbit(bit): """ 誤差とかは気にしない感じの作り """ return bit / 1024 / 1024 result = get_speedtest_result() print(bit_to_mbit(result["download"]), bit_to_mbit(result["upload"]))結果13.46394215 50.48002296
subprocessでコマンド実行する方法はいくつかありますが、今回は公式で使用例に載っているrun()+capture_output=Trueで標準出力を取得しました今回はSpreadSheetのAPIを叩いて記録するようにしました(詳細は割愛 以下を大いに参考にさせていただきました)。
Slackに飛ばすなり好きな方法で記録すると良いと思います。
余談ですが、Pipenvのscriptsを活用すると、cronから実行するときの仮想環境の有効化などが不要で便利でした(pipenv run経由で実行したプロセスは仮想環境化での実行と同じ扱いになる)
Pipfile[scripts] dev = 'python wifi_speedtest.py'

- 投稿日:2019-12-23T16:47:40+09:00
基礎から始める Revit Dynamo 超入門 ~基礎知識・環境編~
はじめに
本記事はAutodesk Revit用のVPLであるDynamoについて、私が個人的に取り組んでいる内容及び社内で取り組んでいる内容の一部または抽象化したものについて、備忘録として、また建築業界のICT技術活用の発展に寄与することを願って執筆するものです。
特に入門的な内容を扱うシリーズとして作成しますが、たまに難しいことをし始めるかもしれないので、その際はご指摘、ご質問いただければと思います。また本記事をご覧になっている皆様は、おそらく建築に関わるお仕事をなさっている方ではないでしょうか。
- 会社からやれと急に言われた
- 自動化できると聞いて興味を持った
- RhinocerosのGrasshopperが得意でやってみようと思った
など、モチベーションは様々かと思います。
ここでは、まったくビジュアルプログラミングをやったことがない人向けに基礎的な話から説明させていただきます。Revit Dynamoについて
まずは本記事で扱うRevit Dynamoとは何かについてざっくりご説明いたします。
公式からの文言ですが、
"Dynamoは、建物情報ワークフローのカスタマイズを可能にするグラフィカルなプログラミングインターフェースです。"
すごくざっくり説明するなら、「BIMの情報を利用して手作業ではしたくないような操作をコンピュータにやってもらうためのツール」だと今は思っておいて下さい。できることとしては、繰り返し行われるタスクを自動化したり、法規などのルールにかかる問題がある際に警告を出したりと、様々なことがあります。
基礎的な説明に時間をかけても仕方がないのでどんどん行きましょう(詳しく知りたい方はこちらなどを参照して頂ければと思います)。
Dynamoの起動
Dynamoは、Autodesk Revitをインストールすると併せてインストールされますので、特に個別でのインストール作業などを行う必要はありません。
起動する際は
「管理」タブ>「ビジュアルプログラミング」パネル>「Dynamo」をクリックします。
するとDynamoが起動しホーム画面が表示されますので、新規作成で新たなDynamoプロジェクトを作成しましょう。
Dynamoのインターフェース
新規プロジェクトを作成すると、以下のような画面が立ち上がります(色はついていませんが……)。
非常に簡潔なUIですね。分かりやすくていいことです。
注目すべきは以下の2つです。②ライブラリ:ノードと呼ばれる機能の塊が格納されています。
③ワークスペース:ノードを配置してプログラムのフローを作成する場所です。少し整理してみると、以下の図のような感じでしょうか。ワークスペースという名のキャンバスにノードという絵の具を使って絵を描いていくイメージです。
(ライブラリはパレットなのかというのが微妙なところですが、市販の絵の具のうち、利用したいものを購入して使うという点を考慮するとこれでいいかもしれないですね。)
Dynamoのバージョン
次にDynamoのバージョンについてですが、現在、自身が利用しているDynamoのバージョンを確認する場合は、
「メニューバー」>「ヘルプ」>「バージョン情報」から確認することができます。
Dynamoは最近(2019年12月現在)でこそ仕様変更が落ち着いてきた様子ですが、以前は作ったプログラムが変更ですぐに動かなくなってしまうなどがよくありました。
この記事執筆以降に取り組み始めた方々はあまり気にする必要はないかもしれませんが、一応ご使用のバージョンは確認するようにしてください(私の環境におけるバージョンは上図の通りです)。次回
内容的には薄いですが、この先は長くなりそうですので次回に譲ろうと思います。
次回からは実際に簡単なプログラムを作成しながら解説を行っていこうと思います。






- 投稿日:2019-12-23T16:30:41+09:00
3Dマークアップ言語でWebサービス的なやつを作ってみる
目的
前回までの、3Dマークアップ言語を動的に出力するWebシステムを作る。
道具立て
比較的慣れてるので、PythonでFlaskを使ってサクッと作ってみる。
時計を作る
データベースとかアクセスしたりAPI使うのも大がかりなので、PoCとして最低限として、アクセス時刻の表示をする時計を作ってみる。
以下、時分秒に対応する球を表示するプログラム。時刻の経過に合わせて動くわけではない。app.pyfrom flask import Flask import datetime import math app = Flask(__name__) @app.route('/') def clock(): dt_now = datetime.datetime.now() hour = dt_now.hour % 12 minute = dt_now.minute sec = dt_now.second yh = 0.2 * math.cos(hour * 2 * 3.141592 / 12) xh = 0.2 * math.sin(hour * 2 * 3.141592 / 12) ym = 0.4 * math.cos(minute * 2 * 3.141592 / 60) xm = 0.4 * math.sin(minute * 2 * 3.141592 / 60) ys = 0.35 * math.cos(sec * 2 * 3.141592 / 60) xs = 0.35 * math.sin(sec * 2 * 3.141592 / 60) homl = '''<homl><head><title>CLOCK</title></head> <body><a-scene wx=0.2 wy=0.2 wz=0.2> <a-sphere r=0.05 x=0 y=0 z=0 color=white /> <a-sphere r=0.05 x={xh} y={yh} z=0 color=red /> <a-sphere r=0.03 x={xm} y={ym} z=0 color=green /> <a-sphere r=0.01 x={xs} y={ys} z=0 color=blue /> </a-scene></body></homl> '''.format(xh=xh,yh=yh,xm=xm,ym=ym,xs=xs,ys=ys) return homl if __name__ == '__main__': app.run()結果
それっぽくなった。
これで、インターネットの世界とXRの世界が簡単につながるようになった。

- 投稿日:2019-12-23T16:26:08+09:00
[python]DataFrameを用いて任意の変数や配列をまとめてラベル付してcsvに保存[pandas]再UP
変数をまとめてラクに保存したいなーって思ったのでそういうプログラムを作りました。
2次元配列も応用すれば保存できます。[python]DataFrameを用いて任意の変数や配列をまとめてラベル付してcsvに保存[pandas]でやってたんですけど
テストプログラムでなく本番でプログラムの中に組み込んだら
名前が全部"data"で保存されてしまうバグが発生していたのでその対処法を書きます。
原因は不明ですが細かい症状は こちらにまとめておきました。上記だと
forの部分でデータをfor data in datas:としてしまったため
名前が全部"data"で保存されてしまったよう。
なのでdatas[i]の形で指定してあげればOK
なぜテストコードだと出来て、本番では出来ていないのかは謎です。関数のなかだから??大した書き換えじゃないのでソースコードだけ置いておきます
import pandas as pd # --- テスト用に変数を定義 --- a ,b,c,d = 1,2,3,4 xx = [3,6,8] yy = [5,8,2] zz = [8,2,8] # --- 変数をまとめてdataframeにしてcsv保存 --- def getName(obj): return [k for k, v in globals().items() if id(obj) == id(v)][0] # 変数名をstrでreturn df = pd.DataFrame() datas = [xx,yy,zz] # 変数名をヘッダーにしながら、1次元配列をまとめてdataframe化 for i in range(len(datas)): df = pd.concat([df, pd.DataFrame({getName(datas[i]):datas[i]})],axis=1) # {}集合を使ってdataframeをconcatで追加 datas = [a,b,c,d]# 変数名をヘッダーにしながら、変数をまとめてdataframe化 for i in range(len(datas)): df = pd.concat([df, pd.DataFrame({getName(datas[i]):[datas[i]]})],axis=1)# {}集合を使ってdataframeをconcatで追加 df.to_csv('test.csv') print(df) del dfoutput
xx yy zz a b c d 0 3 5 8 1.0 2.0 3.0 4.0 1 6 8 2 NaN NaN NaN NaN 2 8 2 8 NaN NaN NaN NaNバグの内容解析
元のプログラムを回したあと、変数名を変えてから再度回すと何故か上記エラーが発生した。
import pandas as pd # --- テスト用に変数を定義 --- a ,b,c,d = 1,2,3,4 xx = [3,6,8] yy = [5,8,2] zz = [8,2,8] # --- 変数をまとめてdataframeにしてcsv保存 --- def getName(obj): return [k for k, v in globals().items() if id(obj) == id(v)][0] # 変数名をstrでreturn df = pd.DataFrame() datas1 = [xx,yy,zz] # 変数名をヘッダーにしながら、1次元配列をまとめてdataframe化 for data in datas1: df = pd.concat([df, pd.DataFrame({getName(data):data})],axis=1) # {}集合を使ってdataframeをconcatで追加 datas2 = [a,b,c,d]# 変数名をヘッダーにしながら、変数をまとめてdataframe化 for data in datas2: df = pd.concat([df, pd.DataFrame({getName(data):[data]})],axis=1)# {}集合を使ってdataframeをconcatで追加 df.to_csv('test.csv') print(df) del dfoutput
xx yy zz a b c d 0 3 5 8 1.0 2.0 3.0 4.0 1 6 8 2 NaN NaN NaN NaN 2 8 2 8 NaN NaN NaN NaNこのように1度目は成功するのですが
この状態のまま再度変数名を変えて回すとimport pandas as pd # --- テスト用に変数を定義 --- a ,b,c,d = 1,2,3,4 xxx= [3,6,8] ###これを変更 yyy= [5,8,2] ###これを変更 zz= [8,2,8] # --- 変数をまとめてdataframeにしてcsv保存 --- def getName(obj): return [k for k, v in globals().items() if id(obj) == id(v)][0] # 変数名をstrでreturn df = pd.DataFrame() ###ここを変更 datas1 = [xxx,yyy,zz] # 変数名をヘッダーにしながら、1次元配列をまとめてdataframe化 for data in datas1: df = pd.concat([df, pd.DataFrame({getName(data):data})],axis=1) # {}集合を使ってdataframeをconcatで追加 datas2 = [a,b,c,d]# 変数名をヘッダーにしながら、変数をまとめてdataframe化 for data in datas2: df = pd.concat([df, pd.DataFrame({getName(data):[data]})],axis=1)# {}集合を使ってdataframeをconcatで追加 df.to_csv('test.csv') print(df) del dfoutput
data data zz a b c d 0 3 5 8 1.0 2.0 3.0 4.0 1 6 8 2 NaN NaN NaN NaN 2 8 2 8 NaN NaN NaN NaNこのように名前がdataになってしまいます
- 投稿日:2019-12-23T16:05:41+09:00
機械学習で学習中にログをぼーっと見てしまうあなたに 〜 LightGBMで筋トレする 〜
皆さん、機械学習でモデルの学習時、何していますか?
ぼーっとコンソールに出力されるログを眺めていませんか?
「お、思ったより下がった!」「あれ、精度悪くなってる、頑張れ!!」
と思いながら、見るのは意外と楽しいですよね。でも応援したところで、モデルがその分頑張ってくれるわけでもないし、ドラマチックな展開があるわけでもないので、見てても時間の無駄なんですよね。
そんなことを考えてるときに気付いてしまいました。「あれ、この時間筋トレしたらよくね?」
そんなわけで、機械学習の合間に筋トレできるような環境を考えました。
NTTドコモの服部です。
こちらはNTTドコモサービスイノベーション部 AdventCalender2019 23日目の記事です。この記事の対象者
- 筋トレ好き
- 運動不足な機械学習界隈の人
- kagglerなどLightGBMをよく使う人
なんで筋トレするの?
モデルの精度向上のためには、何度も仮説・検証を繰り返す必要があります。
しかし、全然精度が上がらない時には、やる気が低下することもあると思います。
そんな時には筋トレが有効です。
筋トレをすると、「テストステロン」というホルモンの分泌が活性化します。
テストステロンは脳のやる気をつかさどるホルモンであり、これを分泌させることで
精度が上がらなくて落ち込むときも「よし!もう一回!」
と考えられるようになり、精度向上まったなしです。
また、世の中的にも筋トレが最近流行ってきているように感じます。
女子高生が筋トレするアニメが放映されたり、山手線で筋トレするアプリが出たり。やはり筋トレの需要は高そうです。山手線の車内で筋トレ…JR東日本が導入した“電車専用アプリ”。 でも、周囲の目は気にならないの?
方向性
筋トレの強制まではさすがに出来ないので、
- 「筋トレしなきゃ!」と思わせる状況を作る →筋トレのメニュー・始める合図、リズム等の音を再生
- 筋トレのモチベーションを上げる →学習状況(精度)によって、筋トレの回数などを変化させてゲーム性を持たす
といったところにフォーカスします。
また、実装対象のモデルとしては、LightGBMを対象とします。
※「深層学習」系のモデルは学習時間が長い傾向があり、試すにも筋トレし続けるのがきついので、断念しました...orz
LightGBMとは
LightGBMはMicrosoftが開発した勾配ブースティングのライブラリです。
Kaggle1のでもよく使われており、高精度かつ学習速度も早いのが魅力です。
XGBoostも有名ですが、最近はLightGBMのほうが使われている印象があります。LightGBMについては、下記の記事がわかりやすいです。
LightGBM公式ドキュメント(English)
「初手LightGBM」をする7つの理由
LightGBM 徹底入門 – LightGBMの使い方や仕組み、XGBoostとの違いについてLightGBMのCallback関数
今回はLightGBMのCallback関数を主に使って実装します。
LightGBMのCallback関数は、学習時に自分で定義したCallback関数を渡すことで、学習時に実行されます。基本的に、多くの機械学習ライブラリ(NNフレームワークを除く)では、学習はライブラリ側で実行されるため、学習途中については使う側がカスタマイズしにくいのですが、callback関数により様々なカスタマイズが可能になります。
例えば
- 学習経過をloggerに送る(さらにはSlack/LINEに送る)
- 独自のEarlyStoppingの実装
- ハイパーパラメータを動的に変更する
などの使いみちがあり、ヘビーユーザーからは重宝されています。
Callback関数の仕組み
Callback関数は、namedtuple型の引数を受け取れるよう定義します(下のサンプルコードでいうenv)。
その中に学習状況を含んだ変数が含まれているので、それを使った処理を定義します。
受け取れるものは、
- ハイパーパラメータ
- 現在のiteration回数
- 現在のiterationでのtrain/validのスコア
- 学習中のモデル(Boosterクラス)
などです。
定義したcallback関数を、
lgb.train()やlgb.fit()など学習実行するときに、callbacksという引数名でリスト形式で渡します。
以下、簡単なサンプルコードです。import lightgbm as lgb .... def callback_func(env): """ 自分で定義するCallback関数 引数のenv(namedtuple)から学習の状況を取得できる """ if env.iteration + 1 % 100 == 0: print(f"今、{env.iteration + 1}イテレーション終わったよ") lgb.train( lgb_param, ..... callbacks=[callback_func] #callbacksに定義した関数をリスト形式で渡す )下記のリンクを見ると、より詳しい中身や他の使いみちが理解できるかと思います。
LightGBM/callback.py at master · Microsoft/LightGBM · GitHub
細かすぎて伝わらないLightGBM活用法 (callback関数)
LightGBMのcallbackを利用して学習履歴をロガー経由で出力する実装した機能
学習時に筋トレガイダンスを出す
- 学習開始時: 筋トレメニュー開始の案内
- 例:「腹筋30回スタート」
- 一定間隔で、メトロノーム音(ポーン音)を出す
- 例:5秒毎にポーン
- 学習終了/最大回数終了時に、終了の案内
- 例:「お疲れさまでした。」「よく頑張りました。」
筋トレには大きく
- 時間が決まっているもの(例:プランク30秒)
- 回数が決まっているもの(例:腹筋30回)
の2つがあり、メトロノーム音についてはどちらの種類かで出すべきタイミングが変わります。
時間が決まっているもの
目標時間になるまで一定の間隔で音を出します。
ただし、普通の時間にするのではなく、「学習時くらいLightGBMと同じ時間軸で頑張ってほしい」という思いから、目標時間も音を鳴らす間隔も機械学習のiterationで設定することにしました。「30秒プランク」よりも 「300iterationプランク」 のほうがモデルとも仲良くなれる気がします。
回数が決まっているもの
回数が決まっているものはペースが重要なため、iteration回数に合わせるのは難しいので、秒数で設定します。
最初の数イテレーションで、指定した秒数分のiteration回数を計算し、以降はその回数毎にメトロノーム音を出します。筋トレメニューは指定 or ランダム
同じトレーニングばかりするのもよくないので、自分で指定もしくはランダム設定ができるようにしました。
オススメはランダム設定で、何のトレーニングをするかも含めて楽しむことです。精度が前回より良かったら、メトロノーム音が変わる
辛い筋トレ中に、「お、精度上がった!」と分かれば、筋トレのモチベーションもあがりますよね。
また、学習途中に精度が気になって筋トレに集中できないみたいなことを防げます。これを実装するために、毎回学習ログをログファイルに出力し、
前回の学習ログを読み込み比較するよう実装しました。精度が前回より悪かったら、ペナルティ(筋トレ追加)
ゲーム性をもたせる意味でも、モデルの精度は筋トレにも影響します。
こちらも前回学習ログとの比較で対応できます。途中で学習を打ち切ってもペナルティ(筋トレ追加)
途中で学習を打ち切る≒精度が上がらなかった
みたいなものなので、その場合はペナルティの筋トレです。
Keyboard Interrupt ExceptionをCatchすることで対応します。「Ctrl + C」で抜け駆けなんて許しません。
実装
実行環境/用意
- MacOS 10.14.5
- Python 3.6.8
- lightgbm 2.3.0
- VLC media player 3.0.8
インストール
# VLCのインストール brew cask install vlc # Python-VLCのインストール pip install python-vlc # LightGBMのインストール pip install lightgbm音源準備
音源の用意が必要です。
音声についてはMacOS標準の音声読み上げ機能2で作成し、
その他効果音についてはフリーの音源サイト3から用意しました。音声は、自分好みのものを用意することで、よりやる気が上がるかもしれません。
ソースコード
事前に定義しておくconfig
筋トレのメニューや種類、実行回数、音源のパスなどを設定します。
本質的でないところなので、折りたたんでおきます。
筋トレのメニュー用Configコード
train_config = { "planc":{ "train_menu": "planc", "train_type": "duration", "total_iteration": 500, }, "abs":{ "train_menu": "abs", "train_type": "iter", "total_times": 50, "seconds_1time": 3 }, "pushup":{ "train_menu": "pushup", "train_type": "iter", "total_times": 50, "seconds_1time": 2 }, "squat":{ "train_menu": "squat", "train_type": "iter", "total_times": 50, "seconds_1time": 2 }, } def make_sound_dict(config): sound_dict = { "iteration_10":[ 'sound/iter_sound_1.mp3' ], "iteration_100":[ 'sound/iter_sound_2.mp3' ], "iteration_100_better":[ 'sound/iter_sound_3.mp3' ], "train_finish":[ 'sound/finish.mp3' ] } if config["train_type"] == "duration": sound_dict["train_start"] = [ f"sound/{config['total_iteration']}iter.mp3", # Nイテレーション f"sound/{config['train_menu']}_train.mp3", "sound/start.mp3" ] elif config["train_type"] == "iter": sound_dict["train_start"] = [ f"sound/{config['train_menu']}_train.mp3", # 筋トレ名(ex: 腕立て伏せ、腹筋、。。。) f"sound/{config['total_times']}times.mp3", # Nイテレーション "sound/start.mp3" # スタート ] return sound_dictCallback関数を含んだ筋トレ用クラス
少し長いですが、メインのところなのでそのまま載せます。
class MuscleSound(): """ LightGBMで筋トレするためのCallback """ def __init__(self, train_config, train_menu="planc"): if train_menu == "random": # randomの場合はメニューからランダムで設定 train_menu = random.choice(train_config.keys()) assert(train_menu in train_config.keys()) self.train_menu = train_menu self.config = train_config[train_menu] self.sound_dict = make_sound_dict(self.config) self.log_dir = "./muscle" self.start_time = None self.n_iter_1time = None # setup os.makedirs(self.log_dir, exist_ok=True) self._setup_prev_log() self._load_prev_log() def media_play(self, media_list): """ 指定されたmedia_listの音声ファイルを順番に再生 """ p = vlc.MediaListPlayer() vlc_media_list = vlc.MediaList(media_list) p.set_media_list(vlc_media_list) p.play() def _setup_prev_log(self): """ 前回の学習ログがcurr.logになっているのを prev.logにrename """ log_filepath = os.path.join(self.log_dir, "curr.log") if os.path.exists(log_filepath): os.rename( log_filepath, os.path.join(self.log_dir, "prev.log") ) def _load_prev_log(self, log_filepath="muscle/prev.log"): """ 前回学習時のログを読み込む """ if os.path.exists(log_filepath): self.prev_log = pd.read_csv( log_filepath, names=["iter","score"] ).set_index("iter")["score"] else: self.prev_log = None def _check_score(self, env): """ スコアの比較及び、ログの保存 """ n_iter = env.iteration + 1 is_better_score = False # Validationスコアを抽出 # valid_setsの最後のdatasetのスコアを使う curr_score = env.evaluation_result_list[-1][2] # 数値が上がるほど良いスコアになるかどうか is_upper_metric = env.evaluation_result_list[-1][3] # 前回のログに同じiterationのスコアがあれば比較 if self.prev_log is not None and n_iter in self.prev_log.index: prev_score = self.prev_log.loc[n_iter] is_better_score = curr_score > prev_score \ if is_upper_metric else curr_score < prev_score # ログを保存 with open(os.path.join(self.log_dir, "curr.log"), "a") as f: f.write(f"{n_iter},{curr_score}\n") return is_better_score def play_train_start(self, train_menu): """ 学習スタート時の音再生 """ self.play_media_list(self.sound_dict["train_start"]) # 読み終わる前に学習(筋トレ)が始まらないよう少しsleep time.sleep(5) def duration_sound(self, env): """ 時間が決まっている筋トレ向け 一定のイテレーション回数毎のときに音を出す """ if (env.iteration + 1) > self.config["total_iteration"]: # 筋トレする最大イテレーション数を超えたら何もしない return elif env.iteration + 1 == self.config["total_iteration"]: # 終了回数に達したため、合図 self.media_play(self.sound_dict["train_finish"]) elif (env.iteration + 1) % 100 == 0: # 100回毎の音 is_better_score = self._check_score(env) if is_better_score: self.media_play(self.sound_dict["iteration_100_better"]) else: self.media_play(self.sound_dict["iteration_100"]) elif (env.iteration + 1) % 10 == 0: # 10回毎の音 self.media_play(self.sound_dict["iteration_10"]) def iter_sound(self, env): """ 時間に合わせた音再生(回数が決まっている筋トレ向け) 一定の秒数毎に音を出す """ if self.n_iter_1time is None: return if (env.iteration + 1) > self.config["total_times"]*self.n_iter_1time: # 筋トレする最大回数数を超えたら何もしない return if (env.iteration + 1) == self.config["total_times"]*self.n_iter_1time: # 最大回数に達したら終了の案内を出す self.media_play(self.sound_dict["train_finish"]) if (env.iteration + 1)%self.n_iter_1time != 0: # 1回あたりのイテレーション数で割り切れない場合は何もしない return if ((env.iteration + 1)//self.n_iter_1time) % 10 == 0: # 100回毎の音 self.media_play(self.sound_dict["iteration_100"]) else: # 10回毎の音 self.media_play(self.sound_dict["iteration_10"]) def __call__(self, env): if env.iteration == 0: # 学習開始時 self.media_play(self.sound_dict["train_start"]) if self.config["train_type"] == "times": # 1回あたりの適切なiteration数を設定 if env.iteration == 1: self.start_time = time.time() elif env.iteration == 11: time_10iter = time.time() - self.start_time self.n_iter_1time = int(self.config["seconds_1time"] / time_10iter * 10) print("1回あたりのiteration数", self.n_iter_1time) if not env.evaluation_result_list: return # 筋トレタイプに合わせたメトロノーム音再生 if self.config["train_type"] == "iter": self.iter_sound(env) elif self.config["train_type"] == "duration": self.duration_sound(env)中断時のペナルティ処理
学習を途中で止めてしまった場合にペナルティを課すための処理です。
こちらはCallback関数ではなく、KeyboardInterruptのExceptionをCatchして、処理をしています。
また学習時に簡単に書けるようデコレータとして使えるようにしてます。
def penalty_muscle(func): def play_media_list(media_list): """ 指定されたmedia_listの音声ファイルを順番に再生 """ p = vlc.MediaListPlayer() vlc_media_list = vlc.MediaList(media_list) p.set_media_list(vlc_media_list) p.play() def wrapper_func(*args, **kwargs): try: func(*args, **kwargs) except KeyboardInterrupt: interrupt_list = [ 'sound/keyboard_interrupt.mp3', 'sound/1000iter.mp3', 'sound/planc_train.mp3', 'sound/add.mp3' ] print("Ctrl+Cしたので筋トレ追加!!!") play_media_list(interrupt_list) time.sleep(5) for i in range(100): if i % 10 == 0 and i > 0: play_media_list([ 'sound/iter_sound_2.mp3']) else: play_media_list([ 'sound/iter_sound_1.mp3']) time.sleep(1) raise Exception(KeyboardInterrupt) return wrapper_funcCallback関数を使った学習コード例
通常のLightGBMの学習に対して、
- 学習させる関数にpenalty_muscleのデコレータをつける
- MuscleSoundクラスのインスタンスを生成して、callbacksに渡す
だけです。
デコレータはKeyboardInterruptのCatchをしているだけなので、関数内でLightGBMの学習をしていれば、どんな関数でも良いです。
これでいつでも簡単に筋トレ版LightGBMが作れちゃいます。@penalty_muscle # 学習を行う関数にデコレータをつける def train_muscle_lgb(train_df, target_col, use_cols): folds = KFold(n_splits=2, shuffle=True, random_state=2019) for i, (trn_, val_) in enumerate(folds.split(train_df, train_df[target_col])): print(f"============fold{i}============") trn_data = lgb.Dataset( train_df.loc[trn_, use_cols], label=train_df.loc[trn_, target_col] ) val_data = lgb.Dataset( train_df.loc[val_, use_cols], label=train_df.loc[val_, target_col] ) lgb_param = { "objective": "binary", "metric": "auc", "learning_rate": 0.01, "verbosity": -1, } # MuscleSoundクラスのインスタンス生成(実質Callback関数) callback_func = MuscleSound(train_config, train_menu="random") model = lgb.train( lgb_param, trn_data, num_boost_round=10000, valid_sets=[trn_data, val_data], verbose_eval=100, early_stopping_rounds=500, callbacks=[callback_func] #callback関数を指定 )実際にやってみた
諸事情によりアニメーションGIFです。
本当は字幕に書いてある声・音がするので、脳内再生してください。
実際にやってみて感じた課題
実際に自分で筋トレしてみた結果、まだまだ課題はありました。
サボってしまう
いくら音が聞こえたって、何回もやるとサボりたくなります。にんげんだもの。
- あまりに何回もやると飽きるので、1日の筋トレ上限回数を決めておく
- IoT機器で筋トレやっていることを感知する。その結果をtwitterなどにあげる
などの対処が必要そうです。
後者はハードルが高そうですが、ここまでやれば皆使うかも?学習時間が短すぎて筋トレにならない
学習データが少ないと筋トレする間もなかったです。数十万件くらいは欲しいですね。
そしてLightGBMやっぱり速いです。対策は難しいですが、学習率を下げるか、特徴量作りまくるしかないですね。
(あれ?筋トレするためにLightGBM使う状況になってる?)そもそも筋トレはペナルティなのか?
私はそんなに筋トレ好きではないのですが、筋トレ好きにとっては、筋トレ回数増やすことはペナルティではないのでは。。?あえて精度を上げなかったり、Ctrl+Cする人が出てくるかも。。?
筋トレとは、好きでやるものなのかペナルティでやるものなのか、奥が深いです。
まとめ
みなさんもモデルの学習中は筋トレして有意義な時間を過ごしましょう!!
世界で最も有名なデータ分析プラットフォーム(https://www.kaggle.com/) ↩


- 投稿日:2019-12-23T15:54:49+09:00
python3でtkinter を使って入出力画面の基礎の基礎
やりたかったこと
pythonを使い始めて、いろいろなことができることがわかってたレベルです。コマンドプロンプトから使ってきましたが、GUIで入出力をするツールもできるんじゃない?と思ってまずは自分向けのサンプルを作りました。
なぜシンプルなサンプルを書いたか
「tkinter」「GUI」「テキストボックス」で検索していくつかのサイトがヒットしますが、いきなり電卓が動いていたり、tkinterを初めて使う身としては説明が一部しかなかったり、入力のみ・出力のみだったり、でしたので、基礎の基礎である、入力して表示する部分のみを書きました
まずは動いたので、自分用の備忘録として記録します
早急に説明を追記する予定です
ここまでできれば、あとはCUIで書いていたものを追加すれば、検索キーを入力して、その結果をGUIで表示することもいつもの手順でできるので、一安心です。イメージ
まずは動いたソース
Enterキーを押すか、ボタンのクリックどちらでも、入力した文字が出力用のラベル(初期値で"OutputData"と表示している部分)に表示されます。
実際に使うときは、funcとcalcどちらかだけになると思いますimport os, tkinter def func(): # Etnerキー押下時の動作 getvalue = textBox1.get() print("in the function =",getvalue) textBox1.delete(0,tkinter.END) label2["text"] = getvalue def calc(event): # ボタン押下時の動作 getvalue = textBox1.get() print("in the function =",getvalue) textBox1.delete(0,tkinter.END) label2["text"] = getvalue # ウインドウ root = tkinter.Tk() # Tkクラス生成 root.title(u"ウインドウタイトル") # 画面タイトル root.geometry("350x150") # 画面サイズ # 入出力エリア label1 = tkinter.Label(text='InputData') # 入力用ラベル label1.place(x=5,y=5) # ラベルの表示位置 textBox1 = tkinter.Entry(width=5) # 入力用テキストボックス textBox1.place(x=100, y=5) # テキストボックス位置指定 label2 = tkinter.Label(text='OutputData') # 出力用ラベル label2.place(x=100,y=50) # ラベル位置 textBox1.focus_set() # テキストボックスにフォーカス指定 btn = tkinter.Button(text='Go', command=func) # ボタン作成 btn.pack() textBox1.bind('<Return>', calc) # Enterキーが押されイベント設定 root.mainloop() # 画面を表示

- 投稿日:2019-12-23T15:53:01+09:00
Pythonで書くマルコフ連鎖の遷移確率
1. はじめに
マルコフ連鎖の遷移確率についての記事を書きます。
具体的には、時系列データから遷移確率を求め、行列にする関数を紹介します。
マルコフ連鎖の遷移確率行列をどうこうする関数の紹介ではないことに注意してください。「2. マルコフ連鎖とは」から細かい情報を書きますが、
コードだけ知りたいという方は、「3. 遷移確率を求める関数」から参照していただければ十分かなと思います。2. マルコフ連鎖とは
2.1. 遷移確率の定義
下記は、Wikipediaに書いてあるマルコフ連鎖の定義です。
一連の確率変数 X1, X2, X3, ... で、現在の状態が決まっていれば、過去および未来の状態は独立であるものである。
引用元: https://ja.wikipedia.org/wiki/%E3%83%9E%E3%83%AB%E3%82%B3%E3%83%95%E9%80%A3%E9%8E%96
2.2. マルコフ連鎖の遷移確率の式
下記は、Wikipediaに書いてあるマルコフ連鎖の式です。
Pr(X_{n+1}=x | X_n=x_n,..., X_1=x_1,X_0=x_0) = Pr(X_{n+1}=x_{n+1} | X_n=x_n)Xi のとりうる値は、連鎖の状態空間と呼ばれ、可算集合S をなす。マルコフ連鎖は有向グラフで表現され、エッジにはある状態から他の状態へ遷移する確率を表示する。
マルコフ連鎖の一例に有限状態機械がある。これは、時刻n において状態 y にあるとすると、それが時刻n + 1 において状態x に動く確率は、現在の状態にだけ依存し、時刻n には依存しない。引用元: https://ja.wikipedia.org/wiki/%E3%83%9E%E3%83%AB%E3%82%B3%E3%83%95%E9%80%A3%E9%8E%96
下記の式で表される確率を遷移確率と呼びます。
Pr(X_{n+1}| X_n)2.3. 具体例
実際に遷移確率を求めるわけですが、定義や式だけではイメージしづらいかと思います。
ここでは、天気を例に考えてみることにします。S = {晴れ=0, 曇=1, 雨=2}という1か月間の天気の情報があったとします。
tenki = np.array([0, 0, 2, 0, 0, 0, 0, 0, 1, 0, 0, 2, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]) print('晴れた日数:{0}日, 曇の日数:{1}日, 雨の日数:{2}日'.format(np.count_nonzero(data==0), np.count_nonzero(data==1), np.count_nonzero(data==2))))出力晴れた日数:20日, 曇の日数:8日, 雨の日数:2日上記をみるとどうやら晴れが一番多く、次いで曇そして雨が多いということがぱっと見で分かるかと思います。
しかし、目的は“天気がどのように遷移したのか”です。そこで、遷移確率がわかった状態(図1)の行列が欲しいと考えるわけですが、検索しても出てきません。
ということで、関数を作ります。
3. 遷移確率を求める関数
3.1. pythonのバージョン・環境
Python 3.7.1を使用しています。
使用環境はJupyter notebookです。3.2. 関数の作成
3.2.1 必要なライブラリのimport
import numpy as np import copy import itertools import seaborn as snsseabornは関数的には入れなくてもよいですが、後で可視化するので入れてます。
3.2.2 データ
今回は先ほどのtenkiを使用します。
3.2.3 関数とその解説
def tp(transition_probability): data = transition_probability zero = np.zeros((np.max(data)+1,np.max(data)+1)) for i in range(len(data)-1): j = copy.deepcopy(i) j += 1 for x, y in itertools.product(range(np.max(data)+1), range(np.max(data)+1)): if data[i] == x and data[j] == y: zero[x][y] += 1 row_sum = np.sum(zero, axis=1).reshape((np.max(data)+1,1)) prob = zero / row_sum return prob
- zero
- tenkiで使用されている情報は「0~2」の3つです。
- そのため、「np.max(data)+1」をとれば最大値*最大値の0行列が作成できます。
- (3つ以上でも以下でも対応できます。)
forの中の処理
- 「i, j」はそれぞれ Xn* と Xn+1 を表しています。
- 「x, y」はそれぞれ変数「zero」の列と行を表しています。
- forの中の処理によって、変数「zero」に具体的な組み合わせが入るというわけです。
row_sum
- 変数「zero」の中はカウントデータです。
- 各行ごとにカウントの合計を出しています。
prob
- 各行の合計と各行の各個別の値を除算しています。
3.2.3 結果
これにて遷移確率の行列が求められました。
print(tp(data))出力[[0.65 0.25 0.1 ] [0.57142857 0.42857143 0. ] [1. 0. 0. ]]3.2.4 可視化
これだけでは少々物悲しいので、可視化してみます。
sns.heatmap(tp(data), cmap='Blues', vmin=0, vmax=1, center=.5, square=True, cbar_kws={"shrink": .5}, xticklabels = 1, yticklabels = 1)
このヒートマップは左の軸が Xn を表していて、下の軸が Xn+1 を表しています。
4. 最後に
マルコフ連鎖の遷移確率についての関数を書いてみましたが、いかかだったでしょうか。
分かりづらい点や間違っている点があれば、ご指摘いただけると幸いです。参考URL
・マルコフ連鎖(Wikipedia)
https://ja.wikipedia.org/wiki/%E3%83%9E%E3%83%AB%E3%82%B3%E3%83%95%E9%80%A3%E9%8E%96・マルコフ連鎖の基本とコルモゴロフ方程式(高校数学の美しい物語)
https://mathtrain.jp/markovchain


- 投稿日:2019-12-23T15:50:43+09:00
Watson IoT Platform を介してMQTTでデータを送受信する
はじめに
Watson IoT Platform (Internet of Things Platform、以降WIOTP) は、IBM Cloud を基盤とする IoT のためのプラットフォームです。センサー等のデバイスから得られるデータの収集・蓄積・可視化など、様々な機能を提供しています。
デバイスやアプリケーションを接続するための公式のSDKが提供されており、MQTT経由でデータを送受することができます。
本記事ではその方法について解説します。Watson IoT Platform のコンセプト
まずはWIOTPが扱う「モノ」のコンセプトについて説明します。
WIOTPでは、接続する「モノ」の種類として以下の3つを定義しており、それぞれ実装できる機能や接続方法が異なります。
- アプリケーション
- デバイス
- ゲートウェイ
アプリケーション
アプリケーションは、3つモノの中で最も多くの機能を使用することでき、デバイスから送信されたイベントを受信してサービスに活用することも、自らデバイスとしてイベントを送信することもできます。
アプリケーションとして実装するためには、事前にWIOTPコンソールでAPIキーを発行する必要があります。WIOTPに接続する際にAPIキーで認証することで、接続されているアプリケーションをWIOTPで識別することができます。
また、WIOTPでは想定するアプリケーションの種類が定義されており、APIキーごとにアプリケーションの種類を選択することで、使用できる機能を制限することができます。アプリケーションでは、以下の機能を使用することができます。
- デバイスから送信されたイベントを受信する
- デバイスにコマンドを送信する
- デバイスとしてイベントを送信する
- デバイスとしてコマンドを受信するデバイス
センサーなどで得られた周囲の情報をWIOTPに送信するのがデバイスの役割です。
デバイスとして実装するためには、事前にWIOTPコンソールでデバイスタイプ、デバイスIDを設定する必要があり、デバイスIDは1つのデバイスごとにユニークになるように設定します。
WIOTPでは、デバイスIDによって接続要求やデータの送信がどのデバイスによって行われたかを識別することができます。デバイスでは、以下の機能を使用することができます。
- 「人感センサーで人を検知した」のような、イベントをアプリケーションに送信する
- アプリケーションから送信されたコマンドを受信するゲートウェイ
同じ種類・役割の複数のデバイスが存在する場合に、それらとWIOTPの間でデータを中継するのがゲートウェイの役割です。そうすることで、WIOTPは実際には複数のデバイスから送信されたデータを、一つのデバイス(ゲートウェイ)から送信されたものとしてまとめて扱うことができるようになり、データを処理しやすくなります。
ゲートウェイもデバイスと同様に、事前にWIOTPコンソールでデバイスタイプ、デバイスIDを設定する必要があります。WIOTPの中ではデバイスの一つとして扱われます。ゲートウェイでは、以下の機能を使用することができます。
- デバイスから送信されたイベントを受信し、アプリケーションに中継する
- アプリケーションから送信されたコマンドを受信し、デバイスに中継するサンプルの作成
実際に公式のSDKを使用して、WIOTPに定期的にイベントを送受信するサンプルアプリを作成します。今回は送信側をデバイス、受信側をアプリケーションとして作成します。
前提
- IBM Cloud のアカウントを所有していること
- IBM Cloud 上で Watson IoT Platform のインスタンスを作成済みであること
事前準備
WIOTPでのデバイスの設定
デバイスを実装するのに必要なデバイスの登録を行います。
- Watson IoT Platform のインスタンスを開き、画面左のメニューから「デバイス」を開きます。
「デバイスの参照」と書かれたページが表示されるので、右上の「デバイスの追加」ボタンをクリックします。
「デバイス・タイプ」「デバイスID」に任意の値を設定し、「次へ」ボタンをクリックします。
次のページでは、何も入力せずにそのまま「次へ」ボタンをクリックします。
「自動生成認証トークン」のページが表示されます。「認証トークン」は自動で生成することも、任意の値を設定することも可能です。設定したら「次へ」ボタンをクリックします。
要約の画面が表示されるので、「終了」ボタンををクリックします。
「デバイスのドリルダウン」のページが表示されるとデバイスの登録は完了です。ここで表示される情報は後ほど使用するのでメモしておきます。
WIOTPでのAPIキーの発行
アプリケーションを実装するのに必要なAPIキーを発行します。
詳細は以下の記事の「1. APIキーの発行」をご覧ください。
https://qiita.com/Motonaga/items/6304f5f66f63cb566943送信側の実装
送信側のデバイスを実装します。
publish.pyimport wiotp.sdk.application import time import json ## WIOTPで設定した「デバイス」用の各種パラメータをJSON形式の構成情報(options)に埋め込む org_id = "xxxx" # WIOTPの組織ID device_id = "sample_id" # 事前準備で設定した「デバイスID」 device_type = "sample_type" # 事前準備で設定した「デバイスタイプ」 token = "sample-token" # 事前準備で設定した「認証トークン」 event_id = "sample" # 送信するイベントの識別子。任意の値を設定できる。受信側と同じ値にする options = { "identity": { "orgId": org_id, "typeId": device_type, "deviceId": device_id }, "auth": { "token": token } } # SDKを使用して「デバイス」としてWIOTPに接続する client = wiotp.sdk.device.DeviceClient(options, logHandlers=None) client.connect() # 2秒ごとに {count} をインクリメントしてWIOTPに送信する myData = {'message': 'foo', 'count': 0} while True: print("data published: ", json.dumps(myData)) client.publishEvent(event_id, "json", myData) myData['count'] += 1 time.sleep(2)受信側の実装
受信側のアプリケーションを実装します。
subscribe.pyimport wiotp.sdk.application import json import time app_id = "sample_app" # アプリケーションの識別子。任意の値を設定する app_auth_key = "xxxx" # WIOTPで発行したアプリケーションのAPIキー app_auth_token = "xxxx" # WIOTPで発行したアプリケーションの認証トークン # WIOTPで設定した「アプリケーション」用の各種パラメータをJSON形式の構成情報(options)に埋め込む options = { "identity": { "appId": app_id }, "auth": { "key": app_auth_key, "token": app_auth_token } } # SDKを使用して「アプリケーション」としてWIOTPに接続する client = wiotp.sdk.application.ApplicationClient(options, logHandlers=None) client.connect() # イベントを受信した際のコールバック関数を設定。ここでは受信したイベント情報を標準出力に書き出している def event_callback(event): # 受信したデータのbodyはevent.dataで取得できる print("{} event '{}' received from device [{}]: {}".format(event.format, event.eventId, event.device, json.dumps(event.data))) client.deviceEventCallback = event_callback # サブスクライブするデバイスのパラメーター(送信側と同じもの)を設定し、Subscribeを開始 device_id = "sample_id" # 事前準備で設定した「デバイスID」 device_type = "sample_type" # 事前準備で設定した「デバイスタイプ」 event_id = "sample" # 受信するイベントの識別子。任意の値を設定できる。送信側と同じ値にする client.subscribeToDeviceEvents(typeId=device_type, deviceId=device_id, eventId=event_id) # アプリの稼働状態を維持するためにループを回す while True: time.sleep(3)実行結果
送信側と受信側の両方を実行すると、下記のような結果が得られ、期待通りにMQTT経由でデータの送受信ができていることが確認できます。
WIOTPのデバイスのコンソール(送信されたイベントの内容が表示される)
受信側のコンソール
$ python subscribe.py 2019-12-23 15:41:58,308 wiotp.sdk.application.client.ApplicationClient INFO Connected successfully: a:a54k3u:sample_app json event 'sample' received from device [sample_type:sample_id]: {"message": "foo", "count": 0} json event 'sample' received from device [sample_type:sample_id]: {"message": "foo", "count": 1} json event 'sample' received from device [sample_type:sample_id]: {"message": "foo", "count": 2} json event 'sample' received from device [sample_type:sample_id]: {"message": "foo", "count": 3} json event 'sample' received from device [sample_type:sample_id]: {"message": "foo", "count": 4} json event 'sample' received from device [sample_type:sample_id]: {"message": "foo", "count": 5} json event 'sample' received from device [sample_type:sample_id]: {"message": "foo", "count": 6}まとめ
本記事では、Watson IoT Platform と接続する「モノ」のコンセプトの説明と、公式のSDKを使用した接続方法について解説しました。
接続方法については、送信側をデバイス、受信側をアプリケーションとして作成しましたが、実際の現場で使用する際は複数のデバイスをゲートウェイで中継して使用する実装も多くなると思います。参考資料





- 投稿日:2019-12-23T15:06:38+09:00
AWS Lambdaで動的サイトのwebスクレイピングをしてtwitterに投稿するbotを作った(続)
2018/10に作ったtwitterのbotをリファクタリングしました。理由としては
- python2.7で実行していた。
- Lambda Layer実装以前だったため、ソースコードのサイズが大きすぎてコンソールからは確認・修正できなかった。
- Serverless Framework/Lambda Layerを使ってみたかった。
などもあり、AWSの一年間の無料期間が終わるのでアカウントを作り直すついでに作り直しました。
ソースコードはこちら。
レポジトリの構成の概要は以下の通りです。. ├── lambda (Lambda本体) │ ├── includeするmoduleたち │ ├── lambdafunction.py │ └── serverless.yml │ └── selenium-layer (Lambda Layer用) ├── chrome-driver ├── selenium └── serverless.ymlServerless Frameworkが簡単すぎて感動しました。
前提条件
serverlessインストール済み(node.js v4以上必須)
AWSアカウント取得済み
aws-cliインストール・設定済み使い方
先にソースコード肥大化の原因のselenium+chromiumたちをLambda Layerにアップロードします。
$ cd selenium-layer $ sls deployそのあとはLambda本体をアップロード
$ cd ../lambda $ sls deployこれで終わりです。
- 投稿日:2019-12-23T14:55:47+09:00
scatter_matrix(スカッター行列)について
こんにちは〜。
2019/12/23 クリスマス前ですね。
今日はスカッター行列について触れたいと思います。scatter matrix(スカッター行列) ・・・ 各データ間でどんな相関があるかをざっくり見るために使う図
API
pandas.plotting.scatter_matrix(frame, alpha=0.5, figsize=None, ax=None, grid=False, diagonal='hist', marker='.', density_kwds=None, hist_kwds=None, range_padding=0.05, **kwds)
公式ドキュメントパラメータの説明
frame → pd.DataFrame 可視化したいデータをDataFrameクラスでいれる。
c → colorのこと。
alpha → 図上のオブジェクトの透明度。
figsize → 図のサイズ
grid → Trueにセットしたならば、グリッドを表示。
diagonal → カーネル密度推定または対角線上のヒストグラムプロットの「kde」と「hist」を選択。
marker → Matplotlibのmarker。デフォルトは'.'
density_kwds → カーネル密度推定プロットに渡される
hist_kwds → hist関数に渡される(ヒストグラムのbins(棒の数)を指定)
range_padding → (x_max-x_min)または(y_max-y_min)に対するxおよびyの軸範囲の相対的な拡張、デフォルトは0.05サンプルコード
Pythonで始める機械学習から引用。
sample.pyimport pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import mglearn iris = load_iris() X_train, X_test, y_train, y_test = train_test_split( iris['data'], iris['target'], random_state=0 ) fig, ax = plt.subplots() iris_dataframe = pd.DataFrame(X_train, columns=iris.feature_names) grr = pd.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), ax=ax, marker='o', hist_kwds ={'bins': 20}, s = 60, alpha=0.8, cmap=mglearn.cm3) plt.show()
美しいですね。
軽く説明しておくと、基本的にはグラフの行列になっていて、xとyの組み合わせは行列の要素によって変わってくる。
対角部分は個々のヒストグラム(bin : 20)が描写される。scatter_matcixは全ての変数の組み合わせ可能な特徴量の組み合わせをプロットするための関数。
しかしこの方法では全ての特徴量の同時に見ることができないため、データの興味深い側面が見ることができない場合があることに注意。とりあえず、データを検査するためには最良の方法かもしれない。
参考文献

- 投稿日:2019-12-23T14:53:13+09:00
Pythonプログラムが遅い!そんな時は...
Pythonプログラムが遅い!そんな時は...
Pythonで実装したときに、処理時間が長すぎて要件を満たせないことがあります。そんなときにはこの記事で示す4種類の対策があります。
なお、高速化のために何かをすると別の何かを失います。トレードオフの代表例としては、表現の自由度、可読性、依存度、メモリ使用量、CPU使用量でしょうか。用法・容量を守って正しくお使いください。
また、高速化をする前にはスクリプトのどこが遅いのか、プロファイリングツールなどを使って確かめる必要があります。遅くない処理を頑張って高速化しても、全体の実行時間にはほとんど影響を与えません。この記事ではその手順については説明しません。
4種類の高速化手法
この記事では、下記の4種類の高速化手法について紹介します。
- 言語仕様・標準ライブラリの範疇でスクリプトを書き直す
- ライブラリを使う
- ライブラリを作る
- バイトコードを最適化する
言語仕様・標準ライブラリの範疇でスクリプトを書き直す
本来は「ライブラリを使う」や「ライブラリを作る」といったほかの対策も「スクリプトを書き直す」に該当します。ここではPythonの言語仕様と標準ライブラリの範疇でできることとして、下記の手法を紹介します。標準ライブラリの範疇でできることなので、依存はあまり増えません(=Pythonのバージョンには依存することがあります)。
- Pythonスクリプトの書き方を見直す
- アルゴリズムとデータ構造を工夫する
- キャッシュを活用する
- 並列化する
Pythonスクリプトの書き方を見直す
Pythonのインタプリタの最適化はそれほど頑張ってくれません。同じことをするにもいろいろな書き方があるので、より高速な書き方を選んで高速化することができます。
ただし、実際のアプリケーションではここで例を挙げる書き方の違いでそんなに差は出ません。書き方の変換が思いつかない場合や遅い処理はほかの場所にあることが多いはずです。
もちろん、ちりも積もればなんとやらです。例えば、Pythonのみでデータベースの実装をしようと思うと、ここで例を挙げるような処理の遅さが効いてきて、全体としても使い物にならないくらい遅くなってしまいます。
例1: 1からnまでの総和
例えば、1からnまでの整数を足す処理を、「(1)forを使って足していく」「(2)ビルトインのsumを使う」「(3)総和の公式を使う」の3通りで実装して、時間を計ってみると下記のようになります。
In [1]: %%timeit ...: sum = 0 ...: for n in range(1000000): ...: sum += n 87.3 ms ± 492 μs per loop (mean ± std. dev. of 7 runs, 10 loops each) In [2]: %%timeit ...: sum(range(1000000)) 33.3 ms ± 1.47 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) In [3]: %%timeit ...: (1000000)*(1000000+1)/2 12.3 ns ± 0.0888 ns per loop (mean ± std. dev. of 7 runs, 100000000 loops each)この例では、総和公式が高速なのですが、常にこんな変換を思いつくとは限りません。
例2: リストの生成
リストを生成するときに、「(1)リスト内包表記を使う」「(2)forループでappendする」「(3)appendをキャッシュする」「(4)ビルトインのlist関数を使う」の4通りで実装して、時間を計ってみると下記のようになります。
In [1]: %%timeit ...: l = [n for n in range(1000000)] 81.7 ms ± 1.31 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) In [2]: %%timeit ...: l = [] ...: for n in range(1000000): ...: l.append(n) 130 ms ± 2.08 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) In [3]: %%timeit ...: l = [] ...: l_append = l.append ...: for n in range(1000000): ...: l_append(n) 97.9 ms ± 2.01 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) In [4]: %%timeit ...: l = list(range(1000000)) 58.1 ms ± 1.49 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)この例では、リストを生成しているだけですが、一般的にはappendする前にいろいろな処理をするはずです。いろいろな処理のほうが遅いことが多いので、いろいろな処理を高速化したほうが効果があります。
アルゴリズムとデータ構造を工夫する
アルゴリズムとデータ構造は、大昔から研究されている分野です。計算量がオーダー記法で$O(n)$と$O(n^2)$では、実行時間も全然違います。アルゴリズムとデータ構造を自分で実装することもあれば、標準ライブラリにある便利なクラスを使う場合こともあります。
ここでは、標準ライブラリにあるアルゴリズムとデータ構造について例を挙げます。
例3: データの探索
リストに特定の要素が含まれているかを何回も判定するときは、リストを集合(set)に変換してからinで確かめたほうが早いです。1回しか判定しないのであれば、集合に変換する処理時間が効いてくるでしょう。
In [1]: %%timeit ...: l = list(range(10000)) ...: for n in range(10000): ...: n in l 1.04 s ± 19 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) In [2]: %%timeit ...: l = list(range(10000)) ...: s = set(l) ...: for n in range(10000): ...: n in s 1.45 ms ± 14.5 μs per loop (mean ± std. dev. of 7 runs, 1000 loops each)今回は、10000個の要素からなるリストに対して、10000回検索するだけでこの結果となりました。これくらいの量の探索なら、実際のアプリケーションでもよく出てくるのではないでしょうか。
例4: データの操作
リストの先頭に何度も値を追加したい時にはcollections.dequeを使うことができます。
In [1]: from collections import deque In [2]: %%timeit ...: l = [] ...: for n in range(100000): ...: l.insert(0, n) 6.29 s ± 28.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) In [3]: %%timeit ...: dq = deque() ...: for n in range(100000): ...: dq.appendleft(n) 11.7 ms ± 93.1 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)Pythonのリストは、可変長配列のようなものです。配列の中身については、型や順序など何の前提もないので汎用性は高いですが、特定の処理では高速化・効率化の余地があります。collections.dequeのほかにもheapqやbisectなどコレクション(データの集まり)を扱う機能が標準ライブラリに用意されています。
キャッシュを活用する
一度行った計算の結果をメモリ内に格納して再利用したり、データベースからとってきたデータをpickle形式でdumpすることで、高速化することができます。数学的な関数のような引数が一緒ならば常に同じ結果を返すものは、キャッシュすることができます。データベースと通信するよりも、ローカルファイルを読み込んだほうが高速な場合もあります。
例5: 関数のメモ化
Pythonにはfunctools.lru_cacheという関数をメモ化するためのデコレータが標準ライブラリに定義されています。これを使えば一度計算した結果がキャッシュされ、引数が同じであれば再利用されます。
In [1]: from functools import lru_cache In [2]: def fib(n): ...: return n if n <= 1 else fib(n-2) + fib(n-1) In [3]: %%timeit ...: fib(30) 448 ms ± 4.22 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) In [4]: @lru_cache() ...: def fib(n): ...: return n if n <= 1 else fib(n-2) + fib(n-1) In [5]: %%timeit ...: fib(30) 117 ns ± 0.522 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)@lru_cacheデコレータを付ければいいだけなのでお手軽ですね。実際にフィボナッチ数列を計算したいことはあまりないですし、計算したいとしても別の実装にするかもしれません。機械学習で積分を計算したい時などが代表的な応用例でしょうか。
並列化する
標準ライブラリのthreadingやmultiprocessingを使ったり、Python3.2で追加されたconcurrentを使って並列化することで高速化します。CPUがボトルネックでなければthreading、そうでなければmultiprocessingを使います。threadingのほうがデータの共有が簡単ですがGIL(Global Interpreter Lock)によりのCPU100%の壁を越えられないため、マルチコアCPUを使い切りたいのであればmultiprocessingを使うことになります。
例6: concurrentライブラリ
concurrent.futureを使うのが簡単です。ProcessPoolExecutorを使えば、マルチプロセスで並列実行できます。マルチスレッドで実行するThreadPoolExecutorもあります。
from time import sleep from random import uniform def f(x): sleep(uniform(0, 1) * 10) return x from concurrent.futures import ProcessPoolExecutor, Future, wait with ProcessPoolExecutor(max_workers=10) as executor: futures = [executor.submit(f, x) for x in range(10)] done, not_done = wait(futures) results = [future.result() for future in futures]並列化したい処理を関数化して、ワーカー数を指定して呼び出すだけです。定型句として覚えてしまいましょう。
例7: splitコマンド + Pythonスクリプト
マルチプロセスにするのであれば、Pythonではなくshellで頑張ることもできます。前述の関数fをコマンドラインから実行可能にして、shellから並列に呼び出してあげることでマルチプロセスが実現できます。
例えば、入力ファイルが下記(input)だとします。
input0 1 2 3 4 5 6 7 8 9splitコマンドで適当に分割します。
$ split -l 1 input分割したファイルを入力として、Pythonスクリプトを実行します。
$ for file in `ls x*`; do python f.py ${file}&; done分割された実行結果を、結合します。
$ cat x*.result > resultPythonの中で全部実現することもできますが、shellで&を付けるだけで気楽にマルチプロセスにするのも状況によってはありだと思います。
ライブラリを使う
Pythonには標準ライブラリがたくさんありますし、サードパーティのライブラリはもっとたくさんあります。サードパーティのライブラリは、PyPIで公開されており、pipコマンドで簡単にインストールすることができます。
- ライブラリを使う
- ライブラリの環境変数やコンパイル条件を見直す
ライブラリを使う
NumPyのような数値計算に特化したライブラリを使えば高速に数値計算できます。数値計算に限らず、特定の計算に対して最適化されたライブラリがあります。CuPyは、CUDAを使ってGPUによる計算をPythonから簡単に実行できるようにしてくれます。
例8: NumPy
NumPyを使うと行列やベクトルの計算が高速化できます。高速化できるだけでなく、コードが簡略になってわかりやすくなります。ここでは、100×1000の行列をイメージして100000個の要素からなるリストの各要素を足しています。
In [1]: import numpy as np In [2]: %%timeit ...: X = range(100000) ...: Y = range(100000) ...: Z = [x + y for x, y in zip(X, Y)] 13.7 ms ± 140 μs per loop (mean ± std. dev. of 7 runs, 100 loops each) In [3]: %%timeit ...: X = np.arange(100000) ...: Y = np.arange(100000) ...: Z = X + Y 416 μs ± 2.33 μs per loop (mean ± std. dev. of 7 runs, 1000 loops each)NumPyのほうが圧倒的に早いことがわかります。リストでは、要素の型やリストのメソッドが変わってしまうことを考慮しますが、NumPyでは型が固定されているのとBLASなどのライブラリを使えるため高速化できます。
例9: pickleとcPickle
ライブラリが何で実装されているかでも、速度に差ができます。まもなくサポートが終了するPython 2系ではpickle化にはpickleとcPickleという二つのライブラリがありました。どちらを使うかで実行時間に結構な差が出ます。Python 3系では、cPickleは_pickleライブラリという名前に代わってpickleをインポートしたときにcPickleが利用可能であれば内部的に呼び出されるようになりました。
In [1]: import pickle In [2]: import cPickle In [3]: l = range(1000000) In [4]: %%timeit ...: with open("pickle.pkl", "wb") as f: ...: pickle.dump(l, f) 1 loops, best of 3: 3.75 s per loop In [5]: %%timeit ...: with open("cPickle.pkl", "wb") as f: ...: cPickle.dump(l, f) 1 loops, best of 3: 376 ms per loopPython 2系のIPythonなので表示が他と違いますが、10倍くらいの実行時間比ですね。
ライブラリの環境変数やコンパイル条件を見直す
最近のCPUにはいろいろな高速化機能があります。高速化機能自身が有効になっているか、高速化機能をうまく使えるライブラリを呼んでいるかで、実行時間に差ができます。下記のページに解説があります。
ライブラリを作る
すでにPythonライブラリがあればインストールして使うだけでいいのですが、やりたいことに対応するPythonライブラリが必ずしもあるとは限りません。また、Pythonで書いたのではどうしても解消できない無駄な処理も結構あります。それでも高速化したい場合は、下記のいずれかの手法をとることになります。
- C言語で処理を実装し、ctypesで呼び出す
- C言語でPythonライブラリを作る
- Boost.Python(C++のライブラリ)を使う
- Cython を使う
C言語で処理を実装しctypesで呼び出す
Pythonには、WindowsのdllファイルやLinuxのsoファイルからライブラリを読み込んで、ライブラリ内の関数を実行する機能(ctypes)が標準ライブラリあります。Pythonで書くと遅い処理を高速に実行する実装がすでにあるけれど、Pythonから呼び出せるようになっていない場合に使うことができます。
例10: ctypes
Pythonのmathライブラリには、立方根を求めるcbrt関数はありませんが、libmには定義されています。これを呼び出すには下記のようにします。
In [1]: from ctypes import cdll, c_double In [2]: libm = cdll.LoadLibrary("libm.so.6") In [3]: libm.cbrt.restype = c_double In [4]: libm.cbrt.argtypes = (c_double,) In [5]: libm.cbrt(8.0) Out[5]: 2.0この例では嬉しさはわかりませんが、簡単に呼べることだけはおわかりいただけたかと思います。Python側でforを回すと遅いので、forで回す処理も実行してくれるような関数を呼び出せると高速化できます。
C言語でPythonライブラリを作る
PythonのC拡張を使うと、C言語やC++言語を使ってPythonから呼び出せるライブラリを作ることができます。PythonはそもそもC/C++で作られたライブラリのラッパみたいなものなので、ラッパに呼び出される側を作ろうということです。
例11: C言語でPythonから呼び出せる足し算関数を実装する
C拡張で足し算関数を作ってみます。まずは、C言語で下記のソースコードを書きます。
samplemodule.c#include <Python.h> static PyObject * sample_add(PyObject *self, PyObject *args) { int x, y, z; if (!PyArg_ParseTuple(args, "ii", &x, &y)) { return NULL; } z = x + y; return PyLong_FromLong(z); } static PyObject *SampleError; static PyMethodDef SampleMethods[] = { {"add", sample_add, METH_VARARGS, "Sum x and y then return the sum."}, {NULL, NULL, 0, NULL} }; static struct PyModuleDef samplemodule = { PyModuleDef_HEAD_INIT, "sample", NULL, -1, SampleMethods }; PyMODINIT_FUNC PyInit_sample(void) { PyObject *m; m = PyModule_Create(&samplemodule); if (m == NULL) { return NULL; } SampleError = PyErr_NewException("sample.error", NULL, NULL); Py_XINCREF(SampleError); if (PyModule_AddObject(m, "error", SampleError) < 0) { Py_XDECREF(SampleError); Py_CLEAR(SampleError); Py_DECREF(m); return NULL; } return m; }Pythonのヘッダファイルを指定して、gccでコンパイルします。
$ gcc -I`python -c 'from distutils.sysconfig import *; print(get_python_inc())'` -DPIC -shared -fPIC -o sample.so samplemodule.csample.soが出来上がるので、Pythonインタプリタ(IPython)を起動して読み込んでみます。
In [1]: import sample In [2]: sample.add(1, 2) Out[2]: 3Boost.Python(C++のライブラリ)を使う
Boost.Pythonを使うと、少ないコードでPythonライブラリを実装できます。Pythonのバージョン差異もあまり気にしなくてよくなります。その代わり、Boostライブラリに依存してしまうため、Boostライブラリがない環境ではPythonライブラリが読み込みません。Boost.Pythonを使って作られたライブラリは、実装の方法にもよりますがC言語で実装した場合と同じくらい高速です。
例12: BoostでPythonから呼び出せる足し算関数を実装する
Boost.Pythonで足し算関数を作ってみます。まずは、C++言語で下記のソースコードを書きます。たったこれだけです。
#include <boost/python.hpp> int add(int x, int y) { return x + y; } BOOST_PYTHON_MODULE(sample) { using namespace boost::python; def("add", &add); }PythonのヘッダファイルやBoost.Pythonを指定して、g++でコンパイルします。
g++ -I`python -c 'from distutils.sysconfig import *; print(get_python_inc())'` -lboost_python -DPIC -shared -fPIC -o sample.so sample.cppsample.soが出来上がるので、Pythonインタプリタ(IPython)を起動して読み込んでみます。
In [1]: import sample In [2]: sample.add(1, 2) Out[2]: 3C言語で一から書くのに比べてとてもコード量が短くなりました。素敵ですね。
Cythonを使う
Cythonを使えば、Pythonをちょっと改造した言語でソースコードを書いて、C言語で書いたものと同じくらい高速なライブラリを生成することができます。手順は、Pythonライクな言語でpyxファイルを作成し、C言語のソースコードを生成し、それをコンパイルするという流れになります。
例13: Cythonでフィボナッチ関数を実装する
フィボナッチ数列を計算する関数をCythonで作ってみます。まずは、pyxファイルを作成します。ちょっと型の情報があるくらいで、ほぼPythonと同じ文法です。
fib.pyxdef fib(int n): return n if n <= 1 else fib(n-2) + fib(n-1)cythonコマンドでpyxファイルをC言語のソースコードに変換します。そして、gccでコンパイルします。
$ cython fib.pyx $ gcc -I`python -c 'from distutils.sysconfig import *; print(get_python_inc())'` -DPIC -shared -fPIC -o fib.so fib.cfib.soが出来上がるので、Pythonインタプリタ(IPython)を起動して読み込んでみます。
In [1]: import fib.fib In [2]: %%timeit ...: fib(30) 268 ms ± 1.94 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)Pythonですべて書いた場合が、「448 ms ± 4.22 ms」だったので多少は改善されました。
バイトコードを最適化する
ここまでは、C言語でライブラリを作成して高速化していました。ライブラリを作成するにはC言語やCythonによるPythonを拡張した言語の知識が必要で、Python以外の言語を学ぶ必要がありました。しかし、新しい言語を学ぶのはなかなか大変です。ここでは既存のPythonプログラムをできるだけそのままで拡張できる下記の手法を紹介します。
- Numbaを使う
- PyPyを使う
Numbaを使う
NumbaはLLVMを使ってLLRM IRからバイトコードを生成して高速化します。Pythonスクリプトが実行されるまでにできるもの - Qiitaにあるように、PythonはVM型のスクリプト言語で中間命令(バイトコード)を愚直に実行することで処理を実現します。
本家サイトのガイドによると、バイトコードを最適化するだけでなくマシン命令を生成し関数呼び出しを置き換えるようです。すごいですね...。
例14: Numbaのjitデコレータ
In [1]: @jit ...: def fib(n): ...: return n if n <= 1 else fib(n-2) + fib(n-1) In [9]: %%timeit ...: fib(30) 12.6 ms ± 187 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)PyPyを使う
PyPyは、Pythonで書かれたPython処理系です。RPythonという、Pythonより少し機能が制限されていて最適化がしやすいPythonが動作します。Python compatibility - PyPyによるとDjangoやFlaskといった著名なライブラリは動作するとのことですし、PyPy Speedによると実行速度もなかなか優秀なようです。
最後に
この記事では下記の高速化手法を紹介しました。
- 言語仕様・標準ライブラリの範疇でスクリプトを書き直す
- Pythonスクリプトの書き方を見直す
- アルゴリズムとデータ構造を工夫する
- キャッシュを活用する
- 並列化する
- ライブラリを使う
- ライブラリを使う
- ライブラリの環境変数やコンパイル条件を見直す
- ライブラリを作る
- C言語で処理を実装し、ctypesで呼び出す
- C言語でPythonライブラリを作る
- Boost.Python(C++のライブラリ)を使う
- Cython を使う
- バイトコードを最適化する
- Numbaを使う
- PyPyを使う
遅いと感じた処理への対応としてどの手法が適切かは時と場合によります。いろいろな選択肢を考慮したうえで、最適な手法を適用できると素敵ですね。
フィボナッチ数列の例ばかり出していますが、フィボナッチ数列を求めるのがアプリケーションの一般的なタスクではありません。高速化したい処理によってはNumbaよりCythonのほうが早いこともあるでしょう。
今回フィボナッチ数列を求めるのに再起を使っていますが、そもそも再起を除去すればもっと高速になりますね...。皆様のQuality of Python Lifeが素晴らしいものになりますように。
参考
この記事を書くにあたって下記の記事を参考にしました。
なお、私がこれまでPythonを学ぶにあたっては、上記以外の素敵な記事や書籍にお世話になっています。ここで紹介しきれないことを大変申し訳なく思っています。素晴らしい情報を公開・出版してくださり、ありがとうございます。その素晴らしい情報が、これからPythonを学ぶ方々の役に立つと信じています。
- 投稿日:2019-12-23T14:48:51+09:00
【Python】@classmethodとは?
本記事で書くこと
Pythonのクラスで登場する
@classmethodという表記。これが何を意味するのか、どうやって使うのか、何が便利なのかを整理します。@classmethodとは?
- クラスのメソッドをクラスメソッドに変換して、インスタンスを作成しなくても使えるメソッドにしてくれます。
- なお、@classmethodはデコレータ式(シンタックスシュガー)です。
デコレータとは?
デコレータ式を理解するためには、デコレータについて知る必要があります。
デコレータとは、ある関数を受け取り、新たな関数を返す関数のことです。関数の以下の性質を用いて作れらます。
① 関数は変数に割り当てられる
② 関数内で他の関数を定義できる
③ 関数は関数を返すことができる
④ 関数をある関数の引数に渡すことができる上記①~④.が事実かどうか、試してみます↓
①関数は変数に割り当てられる# 関数の定義 def big(word="hello world"): return word.capitalize()+"!" print(big()) # <- Hello world! # 関数はオブジェクトなので、変数に割り当てて使うことができる big2 = big print(big2()) # Hello world!②関数内で他の関数を定義できる# 関数のネスト def tension(): x = 'by neko like man' # low()tenstion()内で定義し、 def low(word='Hello World'): return word + '...' + x # すぐに実行 print(low()) # low()はtension()を呼び出すたびに毎度定義される tension() # <- Hello World...by neko like man # しかし、low()はtenstion()の外側からはアクセスできない try: print(low()) except NameError: print('No low') # <- No low
tension関数の内部でlow関数が定義されています。
又、tension関数で定義されている変数xを、内部関数lowで使うことができます。
この時、low関数をクロージャ、tension関数をエンクロージャといいます。
又、変数xのように、あるコードブロックで使われているけど、そのコードブロックでは定義されていない変数を自由変数(free variable)と呼びます。
(内部関数から変数xの値を変更することは基本的にはできません(nonlocalを使えば可能))③関数は関数を返すことができるdef dragonball(): # 自由変数xとy x = 100 y = 100 # fusiton()では外側の関数(dragonball())で定義されたx, yを保持している # fusion()がクロージャ, dragonball()がエンクロージャ def fusion(left='goku', light='trunks'): # 自由変数の値をクロージャ内から更新したい場合はnonlocal()を使う nonlocal x x = 900 return f'{left}「フュー...」 強さ:{x} \ {light}「フュー....」 強さ:{y} \ {left}, {light}「ジョン!!」 強さ:{x+y}' # dragonball関数内で定義して返す。()は付けず関数オブジェクトを返す。 return fusion x = dragonball() print(x()) # ↑ goku「フュー...」 強さ:900 trunks「フュー....」 強さ:100 goku, trunks「ジョン!!」 強さ:1000 print(x('piccolo','kuririn')) # ↑ piccolo「フュー...」 強さ:900 kuririn「フュー....」 強さ:100 piccolo, kuririn「ジョン!!」 強さ:1000
関数dragonball()は内部で定義された関数fusionを返しています。
()は付けず関数オブジェクトを返すことで、dragonball()の戻り値が渡された変数xはfusion()を使うことができます。④関数をある関数の引数に渡すことができるdef hand_over(func): print('hand over') print(func()) hand_over(dragonball()) # ↑ hand over # goku「フュー...」 強さ:900 trunks「フュー....」 強さ:100 goku, trunks「ジョン!!」 強さ:1000
関数dragonballを関数hand_overの引数に渡すことができます。
関数dragonballは内部関数fusionを含んでおり、関数hand_overには内部関数fusionが渡されます。hand_over()`)は、他の関数が存在することありきなので、単体では動きません。
なお、関数を渡せる関数(今回で言えば、
上記のように、
① 関数は変数に割り当てられる
② 関数内で他の関数を定義できる
③ 関数は関数を返すことができる
④ 関数をある関数の引数に渡すことができる
といった4つの性質を有しています。デコレータは、上記②③④の性質使って定義された関数で、①の性質を用いて利用されます。
つまり、デコレータとは
関数Aを受け取り、機能を追加して、新たな関数A_ver2.0を返す関数です。
関数A_ver2.0は変数に割り当てて使います。デコレータを作る際は、
- デコレータの引数に機能を追加したい関数Aを渡す(④)
- 内部関数で機能を追加(②)する(関数A自体も実行)
- デコレータの戻り値を内部関数のオブジェクト(カッコは付けない)にする(③)
- その戻り値を変数Xに割り当てる(①)
ことで、機能が追加された関数A_ver2.0誕生し、
X()という形で使えるようになります。
(クラスのMixinと似ていると思いました。)デコレータを使ってみる
デコレータの作り方
def デコレータ名(デコレートされる関数の置き場所): # デコレートされる関数の引数がどのようなものでも対応できるように可変長引数にする def デコレータ(*args, **kwargs): # デコレートされる機能を呼び出す(元の機能をそのまま使うか、編集するかは自由) result = func(*args, **kwargs) # デコレートで新たに追加したい機能 return デコレータ # <- デコレートされた機能を含む def デコレートされる関数() 機能デコレータの使い方_1
デコレートされた新たな関数を格納する変数 = デコレータ(デコレートされる関数) デコレートされた新たな関数を格納する変数()実践
買う物をリストに入れて表示する関数があったとします。
関数get_fruitsdef get_fruits(*args): basket = [] for i in args: basket.append(i) print(basket) get_fruits('apple','banana') # <- ['apple', 'banana']これに、心の中のつぶやきをデコレートしてみます。
関数get_fruits_ver2.0# デコレータ def deco(func): #④ def count(*args): #② print('何を買おうかな') func(*args) print('よし、これにしよう') return count #③ def get_fruits(*args): basket = [] for i in args: basket.append(i) print(basket) # get_fruits()をdeco()でデコレートする # デコレータの引数にデコレートしたい関数を入れたものを変数に渡す # その変数に引数を渡して実行すれば、deco + get_fruits な関数(get_fruits_ver2.0)が実行さる deco_get_fruits = deco(get_fruits) #① deco_get_fruits('apple','banana') # ↑ 何を買おうかな # ['apple', 'banana'] # よし、これにしようデコレータを使って作成した関数のオブジェクトを変数(
deco_get_fruits)に入れることで、get_fruitsの機能追加版を使えるようにしています。又、デコレータを使って作成した関数のオブジェクトを、デコレートした関数と同じ名前の変数名に格納することで、デコレートされた関数で上書きできます。get_fruits = deco(get_fruits) get_fruits('apple','banana') # ↑ 何を買おうかな # ['apple', 'banana'] # よし、これにしよう以上のように、デコレータの戻り値を変数に代入することで、関数ver2.0を作っていますが、
デコレータ式を使えばいちいち変数に代入しなくても済み、コードがキレイになります。デコレータの使い方_2 : デコレータ式を使う
@デコレータ名 def デコレートされる関数() 機能 デコレートされた関数()実践
@deco def get_vegetable(*args): basket = [] for i in args: basket.append(i) print(basket) get_vegetable('tomato','carrot') # ↑ 何を買おうかな # ['tomato', 'carrot'] # よし、これにしよう関数定義の前行に
@デコレータの名前と記述することで直下に定義される関数がデコレートされ、その関数と同じ名前の変数名に割り当てられます。つまり、変数の中身が関数ver_2.0に上書きされます。以下のコードと同義です。# デコレートされた関数名と同じ名前の変数 = デコレータ(デコレートされる関数) get_vegitable = deco(get_vegetable)使い方_1よりも、使い方_2のほうが見やすいです。このように、処理内容は同じだけど構文をシンプルにして、見やすくしたものシンタックスシュガーといいます。
以上のように、デコレータ式を使えば、変数への代入を省くことができ、可読性が上がるようです。
本記事の本題である@classmethodも、デコレータ式です。組み込み関数classmethod()を呼び出しています。
classmethod()には、クラス内に定義されたメソッドをクラスメソッドに変換する機能を有しています。classmethod
classmethodは、クラスのインスタンスを作成しなくても使えるメソッドです。
あらかじめクラス内部で処理を行った上で、インスタンスを生成したい時に用いるようです。具体例
例えば、detetimeモジュールでは、dateクラスのtodayメソッドがclassmethodとして定義されており、エポック(1970年1月1日午前0時0分0秒)からの経過時間を現地時間に変換し、必要な情報(年、月、日)を返すようになっています。
datetimeモジュールdateクラスのtodayメソッドclass date: #略 @classmethod def fromtimestamp(cls, t): "Construct a date from a POSIX timestamp (like time.time())." y, m, d, hh, mm, ss, weekday, jday, dst = _time.localtime(t) return cls(y, m, d) @classmethod def today(cls): "Construct a date from time.time()." t = _time.time() return cls.fromtimestamp(t)解説という名の個人的なお勉強
上記のコードを理解するために、改めて文章で整理します。
todayクラスメソッドでは、_timeとして呼び出した
組み込みモジュールtimeのtime関数を使って、エポックからの経過時間(このブログを書いているときは1576760183.8697512という値が返された)を変数tに代入。それをfromtimestampクラスメソッドの引数に渡しています。
fromtimestampクラスメソッドでは、timeモジュールのlocaltime()関数に変数tを入れています。
localtime()を使うと、変数tに入っている数字を月や日、秒などに仕分けをし、タプルに格納してくれるため、わかりやすくて便利。
(localtime()は引数なしで使うと、現地時間を取得してくれる。)time.struct_time(tm_year=2019, tm_mon=12, tm_mday=19, tm_hour=12, tm_min=56, tm_sec=41, tm_wday=3, tm_yday=353, tm_isdst=0)これらをそれぞれ、変数
y, m, d, hh, mm, ss, weekday, jday, dstに格納して、最後にy,m,dだけを返しています。そのため、todayクラスメソッドを実行すると、現在の年
y月m日dを取得できます。何が便利なのだろうか
まだ経験の浅い私には、classmethodのメリットをつかめていませんが、個人的には、「クラスの初期化をしたいけど、コードが煩雑になるため
__init__とは別の場所で初期化をしたい」ような時に用いるのだろうと、整理しました。実用例を見ていると、外部から情報を取得してくる処理をクラスメソッドに定義しているような印象です。@classmethodで遊んでみた。
外部から情報を取得してくるコードを考えていたところ、以前書いたブログで、地元の天気予報の情報を取得してくるコードを書いていたので、再利用してみました。
地元の天気予報を当てるゲームimport requests, xml.etree.ElementTree as ET, os # 今日の降水確率を当てるゲーム class Game(object): ch = [] def __init__(self, am1, am2, pm1, pm2): self.am1 = am1 self.am2 = am2 self.pm1 = pm1 self.pm2 = pm2 @classmethod # 6時間ごとの降水確率をwebから取得 茨城南部 def rain_percent(cls): r = requests.get('https://www.drk7.jp/weather/xml/08.xml') r.encoding = r.apparent_encoding root = ET.fromstring(r.text) area = root.findall(".//area[@id]") #北部と南部 south = area[1] #南部エリアのノード info = south.findall('.//info[@date]') #南部の7日分 today = info[0] #南部の今日の分のノード period = today.findall('.//period[@hour]') cls.ch = [] for percent in period: cls.ch.append(percent.text) return cls.ch def quiz(self): print(f'あなたの回答 -> [{self.am1}-{self.am2}-{self.pm1}-{self.pm2}] : 今日の降水確率 -> {Game.ch}') play1 = Game(10,10,10,10) play1.rain_percent() play1.quiz() # あなたの回答 -> [10-10-10-10] : 今日の降水確率 -> ['0', '10', '40', '50']クラス及びインスタンス両者からアクセス可能です↓
Game.rain_percent() # ['0', '10', '40', '50'] play1.rain_percent() # ['0', '10', '40', '50']クラスメソッドの第一引数は
clsとすることが推奨され、クラス名.クラスメソッド()またはインスタンス名.クラスメソッド()として呼び出された時に、clsにはクラス名またはインスタンスされたクラスが渡されます。まとめ
以上のように、@classmethodとは
- クラスのメソッドをクラスメソッドに変換して、インスタンスを作成しなくても使えるメソッドにしてくれます。
- 又、@classmethodはデコレータ式(シンタックスシュガー)です。
- 投稿日:2019-12-23T14:35:36+09:00
予測 統計(実践編 分類) Python
勉強のアウトプットとして記事を書いているので間違っているところがあるかもしれません。ですので、お気軽にコメントとご意見、ご指摘してください。
今回は以前書いた、予測 統計(実践編 単回帰) Pythonでは回帰について行っていきましたが分類について書いていきます。内容
・機械学習の超概要
・分類についておさらい
・モデリングの流れ
・実践機械学習の超概要
分類について書く前に機械学習について簡単に説明します。
機械学習とは過去のデータからパターンを学習して予測するものです。人が行うデータ分析よりも予測精度が高いためいま世界中で使われています。機械学習では多くのパラメータ(機械学習の世界ではハイパーパラメータという)を必要とし、その数は何万にもなります。さらに、そのパラメータを用いるときにも不要なパラメータがあると過学習が発生してしまうので調整が必要となります。そして、機械学習を勉強するうえで欠かせないのが以下の二つです。
・教師あり学習
・教師なし学習教師あり学習
教師あり学習とは自分が入力したデータが正解となる手法です。実際に自分がデータを入力していき、そのデータをもとにコンピュータが将来のデータを予測していきます。イメージとしては、教師が生徒に勉強を教えていく感じです。
教師なし学習
教師なし学習は実際の正解となるデータを入力せずにデータを予測していくものです。これはデータの本質を見抜くための手法で正解がないので、予測精度は測ることができません。イメージとしては、やりたいことが見つからない就活生みたいな感じです。
今回の実践では教師あり学習の中でも決定木という手法を採用しています。
分類について
以前記事でも書きましたが、分類とはカテゴリに分けるものです。例えば、犬をダックスフンドとチワワに分けたり、ケーキをショートケーキやチョコレートケーキに分けていくことです。この分類で使われる手法が教師あり学習で、犬を分類して場合だとしたらまずダックスフンドとチワワの特徴(パラメータ)を入力していきます。胴が長かったらダックスだとか、目が真ん丸だったらチワワとかを入力していきコンピュータに判定させていきます。パラメータが多ければ分類精度をもちろん上がっていきますが、多すぎると過学習になってしまいます。たとえば、犬の場合だったら尻尾が長さというパラメータを入力した場合、尻尾の長さは個体差があるので判定しづらくなってしまいます。なので、パラメータを決める際は各々独立しているほうが分類精度が上がります。
モデリングの流れ
モデルを作るまでの流れを説明します。
①基礎分析
・データの読み込み
・基礎統計量の確認
・欠損地の確認と修正
・クロス集計
・ビニング
②決定木モデルの作成
・説明変数の選択と決定
・目的変数の選択と決定
・決定木モデルの変数を作成
・決定木モデルの変数にデータを代入
・テストデータを決定木モデルに基づいて予想実践
実際のコードを載せていきます。
①基礎分析
まずは決定木モデルをつくるうえで必要なライブラリをインポートしましょうimport pandas as pd import numpy as np from matplotlib import pyplot as plt %matplotlib inline from sklearn.tree import DecisionTreeClassifier as DT from sklearn.tree import export_graphviz import pydotplus from IPython.display import Imageそして、pandasライブラリをつかってデータを読み込み、基本統計量を調べましょう
train = pd.read_csv("train.csv") #過去データの代入 test = pd.read_csv("test.csv") #予測データの代入 sample = pd.read_csv("submit_sample.csv",header=None) train.describe() #過去データの基本統計量の確認 test.describe() #予測データも確認次に、欠損地の確認をしいきましょう
train.isnull().sum() test.isnull().sum()次は、クロス集計をしていきます。クロス集計はある列のデータに対して、別の列のデータとの数値の関係を示す表です。コードは以下のような感じです。
#crosstab関数でクロス集計ができる、marginsオプションは合計値も出力する pd.crosstab(train["列名"],train["列名"],margins=True)次はビニングです。ビニングとはある区間の数値が何個あるのかを計算します。イメージはヒストグラムの階級と度数の関係みたいなものです。
#第一引数の列データを第二引数の数値で分割します。 bining_data = pd.cut(train["列名"],[1,10,20,30,50,100])②決定木モデルの作成
まずはどのパラメータを使いたいのか決めましょう。そして、そのパラメータを変数に代入していきましょう。複数行、複数列を代入したい場合はiloc関数が便利です。#行すべて、列は0行目から17行目までは抽出します。 trainX = train.iloc[:,0:17] y = train["目的変数"] #copy関数はすべてのカラムを抽出 testX = test.copy()次は、抽出したデータをダミー化していきましょう。
trainX = pd.get_dummies(trainX) testX = pd.get_dummies(testX)そして、決定木モデルを作るための変数を用意しましょう
#第一引数は葉までの深さ、第二引数はサンプルの最小値 clf1 = DT(max_depth=2,min_samples_leaf=500)過去データを代入していきましょう
#必ず説明変数から代入 clf1 = clf1.fit(trainX,y)次に、ジュピター上に表示したいのですが直接表示できなのでdotファイルに書き出してから表示します。
export_graphviz(clf1, out_file="tree.dot", feature_names=trainX.columns, class_names=["0","1"], filled=True, rounded=True) g = pydotplus.graph_from_dot_file(path="tree.dot") Image(g.create_png())さて、いよいよ予測してきます。今回は回帰ではなく分類なのでpredict関数ではなくpredit_proba関数を使います。
pred = clf1.predict_proba(testX)これで、分類を使った分析は終わりです。決定木モデルの表示は特に覚えなくていいのでコピペで大丈夫ですオプションは臨機応変に変えていください。
今回は決定木モデルを使っていきました。しかし、決定木モデルを使う上で葉までの深さと設定する最小値が重要になってきます。葉までの深さが深いほど過学習になりやすいので注意が必要なのです。だから、パラメータのチューニングをすることで過学習しにくくなるモデルを作成することが可能になります。それはまた次回の記事で書いていきます。
- 投稿日:2019-12-23T14:21:32+09:00
データ分析、結局何のためにやるの?
この記事の目標
データ分析に出会うタイミングは人それぞれです。どんな時期に出会ったかによって、自分におけるデータ分析の位置付けは変わってくるでしょう。自分にとってデータ分析とは何で、これからどう関わっていくつもりなのか?
ただの理系学生である僕の一例に触れながら、読んでる人もまた自分に問いかけるきっかけになれば幸いだと思います。記事の全体像
・この記事の目標
・普通の理系学生がデータ分析人材になるまで
・自分にとってデータ分析は何か?
・今後どんなキャリアを考えているか普通の理系学生がデータ分析人材になるまで
僕は特段すごい特技があるわけでもない普通の理系学生です。特定されちゃいそうですが、東大に落ちて後期で東○大に入学した、よくいる「生物に興味のない生物系学生」です。別に数オリや競プロとかその他コンテストに参加したような経験もないです。大学では進級こそしてきましたが、そこに情熱はありませんでした。
理系ならどこでもそうなのかも知れませんが、授業でプログラミングに触れる機会があります。自分の場合、タンパク質の立体構造をpythonで解析したりDNAの塩基配列情報をpythonやRで解析したりでした。ここで初めて触れたデータ分析に、初めて「これをもっと勉強したい!」って思い、自分のキャリアがスタートしました。
実はこのスタートはたった半年くらい前のことで最近なのですが、学習のスピード感を大事にして以下のことをやってきました。
- python,R,SQLなどの技術書を買って独学
- 「データラーニングギルド」というデータ分析に携わる人が集まるオンラインサロンに入る。
- データ分析を業務内容とする短期インターンに申し込みまくる
- データ分析を主な業務とした長期インターンで働く。
今はアプリ事業会社でアクセス解析や分析によるUI/UX改善の提案、マーケティング施策の提案から実行・効果検証などをしています。半年強という短い経験期間ですが、一人で仮説立案から分析・検証・施策提案と展望のプレゼンが出来る程度にはなりました。
学習について、効率を上げるために環境を変えてインターンで働くことを第一目標にして活動してきました。インターンで働くために成果物ベースの勉強をして、最短でインターン採用を狙う。5日間のサマーインターンですが、勉強を初めて二ヶ月で決まりました。今に至っては、データラーニングギルドのオーナーである村上さんの紹介でアプリ事業を進めているベンチャーでデータ分析・マーケターの枠で採用していただきました。5日間の短期インターンでしか分析経験のなかった自分を、学習速度ややる気の観点で評価して推薦していただけて、本当に感謝しています。環境を変えるという意味では、データラーニングギルドに入ったのは大きかったです。実際にデータ分析を活用して独立しているオーナーの村上さんをはじめ、データ分析に関わる多くのエンジニアやコンサルタントなどと繋がれる場は、質問の場としても情報収集の場としても自分にとって大きな存在でした。今もそちらでお世話になっています。自分にとってデータ分析は何か?
僕は小さい頃から人の悩みや心配事などの解決、他人の希望の実現などに楽しみを得てました。もちろん自分の夢を持つこともあったのですが、どうにもハマりきれない。色々な将来の夢を語る人がいる中、自分は早々にプロ野球選手になる夢を諦めて自分に出来ること、身の回りの面白そうなことに手を出すようになっていました。世の中には様々な夢や強い情熱を持った人がいます。しかしその多くは実現されていない。夢を現実に落とし込み、具体的な行動ステップに移すこと、その際に直面する課題を解決することは難しく大変です。
データ分析によって課題解決の力を高めているうちに、僕はこういった強烈な夢や欲望を持っている人の強力な「No.2」として、「右腕」として、その夢と欲望を現実にしていくことに魅力を感じるようになりました。
僕にとってのデータ分析は問題解決の手段です。さらに言うと、理想を現実にするための実現力の核だと思っています。つまり僕にとってデータ分析とは夢や理想、欲望を現実にするための武器であると考えています。
今後どんなキャリアを考えているか
先ほどこう言いました、「データ分析とは夢や理想、欲望を現実にするための武器」だと。
僕はまだまだデータサイエンティストとして経験も技術も知識も浅く、武器としてはまだまだレベルが低いです。
武器の種類は、大別して
- データ理解能力(統計学・ドメイン知識)
- データ加工能力(プログラミングスキル)
- データ解釈能力(論理的思考力)
- コミュニケーション能力(プレゼン力・ヒアリング力・交渉力など)
だと考えています。
この中でどの武器を磨くか、大学では特にデータ理解能力を高めたいと思っています。特に、統計学です。よって、僕の直近の想定キャリアは、大学院にて統計学の専攻をすることです。統計学を大学で学ぶ理由は、その他の能力は実務などアウトプットの機会で身につけられるものだからです。「大学のうちに数理的な理解など理論的なところを理解しておいた方が社会人になった後強い」とは色々なところで聞きます。よって、現在取り組んでいるインターン先での活動をはじめとする実務の場において、他のスキルは磨いていこうと思います。
また、アメリカに留学して英語に慣れつつ海外でデータサイエンティストとしてインターンシップに参加することを考えています。そこでの経験は、いずれ来る就職において就職する国や企業を選ぶ際に選択肢と視野を大きく広げるからです。最終的に僕は、僕が一緒にやりたいと思ったCEOの夢の実現に全力を尽くすCOOであることを望んでいます。とはいえ、これからの長い人生、いつ自分に夢が出来るかもわかりません。その時は、CEOとしての自分の夢を、COOとしての自分の実現力で叶えてやりたいと思います。
まとめ
話がデータ分析から少し逸れましたが、僕にとってのデータ分析は夢を叶える実現力の武器です。
人によっては、データ分析はAIや未知の領域を切り開く夢そのものだと思います。だから、ここでのデータ分析に対する考え方はあくまで「僕にとって」のものです。また、想定しているキャリアはあくまで現時点の僕の知識で考えられるものであり、今後学習を進め、様々な方の話を聞き、どんどん改良していきます。この文章における想定キャリアは曖昧ですが、今後の記事やtwitterで自分の活動記録は残していけたらと思います。
データ分析はその分野自体とても魅力的なので勉強を始める方も多いです。もし勉強をしている方で、データ分析で何をしたいのか明確でない人がいたら、一度考えてみてもらえると、今後の勉強方針の助けにもなると思います。
最後まで読んでくださりありがとうございました。