- 投稿日:2019-12-23T23:07:33+09:00
AWS Ampliy の DataStore を使ったら AppSync のデータアクセスがめちゃくちゃ楽になった
概要
AWS Amplify Advent Calendar 2019、23日目は 今年のre:Inventで発表されたAmplifyのDataStoreについてです。本記事ではサンプルコードの実装にReactを用いていますが、基本的な考え方はVueなどの他のフレームワークでも同じです。
想定読者
- Amplify 使ったことがある
- AppSync 使ったことがある
Amplify DataStore の概要
まずは簡単に DataStore についておさらいします。DataStore は AWS AppSync に接続するための新たなインターフェースです。DataStore は以下のような特徴を持ちます。
1. クラウドへのデータ同期、及び競合検知
端末のネットワーク状況(オンライン or オフライン)を検知して、端末がオンラインになったら自動的にローカルデータをクラウドに同期し、データの競合をいい感じに解決してくれます。
2. デベロッパーフレンドリーなインターフェース
デベロッパーフレンドリーなインターフェースでGraphQLに詳しくなくてもAppSyncからデータを操作できます。GraphQLの操作を抽象化した関数を組み合わせることでAppSyncに対してクエリを発行できるようになりました。
クラウドへのデータ同期、及び競合検知
DataStoreを用いることで、オフライン時のアプリの開発を簡素化することができます。
DataStoreはローカルストレージとクラウドの両方にデータの書き込みを試みます。端末がオフラインの場合、リクエストを失敗させることなく、ローカルストレージにのみデータ書き込みを行い、オンライン復旧後にクラウドへのデータ同期を行います。オフライン期間にクラウド上のデータとローカルストレージのデータで差分が発生した場合は、データのマージ、データの競合検知を自動的に行います。そしてこれらの挙動は全て隠蔽されており、開発者はこれらの挙動について、意識をする必要はありません!!
DataStoreでは、データの競合時の動作を以下の3つから選択できるようになっています。
- Auto Merge (デフォルト)
- Optimistic Concurrency
- Custom Lambda
データの競合が起こった時の挙動1(Auto Merge)
データの競合が起こった際の挙動はデフォルトではAutomergeが選択されています。
以下の例ではClienrt A、Client Bがオフライン中に同時にデータの更新を行った場合を想定します。DataStoreは互いの更新内容を確認し、自動でデータをマージしクラウド上のデータと各クライアントのローカルストレージ上のデータに対し更新を行います。// 元のデータ { id: 'id_001', name: 'Andy', hobby: [], _version: 1, _lastChangedAt: 1577001382093, _deleted: false }// Client A がオフライン中にローカルで変更したデータ { id: 'id_001', name: 'Andy', hobby: [baseball], // Client A が hobbyに baseballを追加 _version: 2, _lastChangedAt: 1577001382094, _deleted: false }// Client B がオフライン中にローカルで変更したデータ { id: 'id_001', name: 'Jeff', // Client B が nameを Jeffに変更 hobby: [tennis], // Client B が hobbyに tennisを追加 _version: 2, _lastChangedAt: 1577001382095, _deleted: false }この場合、Client A と Client Bの更新は矛盾なく実施することができるため、以下のようなデータにマージされます。
{ id: 'id_001', name: 'Jeff', // Client B の変更が反映 hobby: [baseball, tennis], // Client A,B の変更を反映 _version: 2, _lastChangedAt: 1577001382524, _deleted: false }データの競合が起こった時の挙動2(Optimistic Concurrency)
Optimistic Concurrencyでは、データの競合を検知した際に、単純にクライアントからのリクエストを拒否します。クライアントは、再度、クラウド上のデータを正としてデータの更新処理を行う必要があります。
データの競合が起こった時の挙動3(Custom Lambda)
Custom Lambdaでは競合が起こった際に、独自に定義したLambda関数を起動させることができます。Custom Lambdaを用いることで、より柔軟なデータ競合時の処理を実装することが可能です。
データの競合戦略の変更はAmplify CLIから行うことができます。特に指定がなければAuto Mergeを選択するのが良いかと思われます。
デベロッパーフレンドリーなインターフェース
DataStoreを用いたAppSyncのデータアクセス方法
先ほども言及したように、DataStoreの登場で、デベロッパーはGraphQLを記述しなくてもAppSync経由でデータストアにアクセスできるようになりました。
例えば、以下のようなスキーマがあった場合に、
enum PostStatus { ACTIVE INACTIVE } type Post @model { id: ID! title: String! rating: Int! status: PostStatus! }評価(rating)が4以上の投稿を抽出するには以下のように記述することができます。
import { Post } from "./models"; const posts = await DataStore.query(Post, c => c.rating("gt", 4));第一引数には、取得する対象のデータモデルのClassを指定し、第二引数には取得するデータの検索条件を指定します。
さらに複雑な条件を記述することもできます。たとえば、以下の例では、「ratingが4以上、もしくは、ステータスがACTIVEな投稿」を取得しています。import { Post } from "./models"; const posts = await DataStore.query(Post, c => c.or( c => c.rating("gt", 4).status("eq", PostStatus.ACTIVE) ));ちなみにこれと同じクエリをGraphQLで発行すると以下のようになります。
const posts = await API.graphql(graphqlOperation(` query listPosts { listPosts( filter: { or: { rating: { gt: 4 } status: { eq: ACTIVE } } } ) { items { id title rating } } } `));どうでしょうか。このようにGraphQLに精通していなくてもAppSyncに対しクエリを発行することができます。
静的型付け言語の恩恵
関数でクエリの操作を行えるようになったことで、TypeScriptやKotlin、Swiftといった静的型付け言語の恩恵を受けやすくなります。今まではGraphQLのクエリを文字列で記述していたのに対し、DataStoreでは関数でクエリを組み立てていくため、IDEの補完機能を用いながら実装を行うことができるようになります。
Amplify CLI の
codegenというコマンドを実行することで、作成したモデル定義からAppSyncへのデータアクセスの実装に必要なソースコードを自動で生成してくれます。このコマンドを用いることで、静的型付けに必要なコードも自動で出力してくれます。先ほどのモデルを定義した状態で、
codegenコマンドを発行すると、以下のようなコードが出力されます。import { ModelInit, MutableModel, PersistentModelConstructor } from "@aws-amplify/datastore"; export enum PostStatus { ACTIVE = "ACTIVE", INACTIVE = "INACTIVE" } export declare class Post { readonly id: string; readonly title: string; readonly rating: number; readonly status: PostStatus | keyof typeof PostStatus; constructor(init: ModelInit<Post>); static copyOf(source: Post, mutator: (draft: MutableModel<Post>) => MutableModel<Post> | void): Post; }型定義されたClassをimportすることで、先ほどのようにIDEの機能を活用しながら実装を進めることが可能です。
上記のソースはTypeScriptを用いることを前提としています。TypeScriptを用いない場合であってもある程度補完は効きますが、やはりTypeScriptの方が補完は強力です。
まとめ
いかがでしょうか。DataStoreを用いればオフライン時のアプリの実装が非常に簡単になります。また、AppSyncへのデータ操作が関数で記述できることにより、非常に効率的に開発を行うことができるようになりました。Amplifyを使って開発をされている方は、是非DataStoreの導入も検討いただけると良いと思います!
おわり





- 投稿日:2019-12-23T22:40:11+09:00
インフラ未経験者がAWSソリューションアーキテクト アソシエイトに2ヶ月で合格するまでのロードマップ
はじめに
先日、AWS認定ソリューションアーキテクト アソシエイトに合格しました。
AWS ソリューションアーキテクト アソシエイト受かったあああああああああ!!!!!!!! pic.twitter.com/CyJn0d9IQ5
— たから (@takara1356) December 22, 2019業務未経験からRailsなどのフレームワークを学び、クラウドに興味を持って受験される方も多いと思うので、ぜひ参考にしていただければと思います。
正確に数えていませんが、勉強時間は毎日1.5~3時間位×2ヶ月でトータル60~90hくらいだと思います。
学習を始める前のスキル
スクール卒業後、Rails、Nuxtを触ってたくらいで、インフラの知識はほぼありませんでした。
あとは新人研修でTCP/IPなどのネットワーク周りの基礎的な知識を教わったり、EC2でサーバー立てたり、S3バケットにデータ格納したくらいです。
立てたサーバーを使ってあれこれとかは一切しておらず、ただただEC2インスタンスがrunnningになったりpendingになったりしてるのを見ておーすげーとか言ってるレベルでした。Step.1 ハンズオンで学ぶ
まずはAWSの基礎を抑えるために、Udemyで販売されているこちらの教材から始めました。
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(初心者向け21時間完全コース)
(頻繁にセールがあり、1200円とかになったりするのでその時に買うのがオススメ!)良かった点を挙げていきます。
ハンズオン形式で学べる
AWSの各サービスを動画で丁寧に教えてくれるので、前知識がなくてもスムーズに学べます。
常に手を動かし続けるので退屈しません。まずはこちらから始めるといいかと。インフラの基礎も教えてくれる
SSH接続から教えてくれる上、Linux上のコマンドも逐一指示してくれるので、後半では多少Linuxにも慣れてきます。
試験に出てくるサービスが大体触れる
EC2、S3といった主要なサービス、VPCの基本的な設計パターンに加え、CloudFormationやKinesis、SQSなどの触ってみたくても初心者にはどう試していいか分からないようなサービスまで教えてくれるので非常に助かります。
模試がついてくる
本番に近い内容の模試が3つも付属します。後述しますがめっちゃ役に立った。
ガッツリ試験対策というよりは、まずはAWSをざっくりと理解する、といった感じです。
急に試験問題を解き始めるより、これから学ぶサービスをとりあえず触ってみて感覚を養うほうが、後々スムーズに理解できるかと!Step.2 参考書を買う
徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
購入した参考書はこちらのみです。通称「黒本」。
私は問題を解きながら覚えるタイプだったので、通して読む、というよりは知らなかったサービスを調べるためのリファレンス的な感じで使ってました。Step.3 無料問題集を解く
一通りのサービスを触ったら、次はこちらのサイトの問題集をひたすら解きました。
Amazon AWS 資格取得のための演習問題集(完全無料、オリジナル)
一番最初の問題から徐々に進めていきました。
本番よりシンプルな問題が多いので、まずはこちらで慣れていくといいかと思います。
そして何より無料なのがありがたい...問題を解く→間違える→間違えたサービスをググる→QiitaやDevelopers.IOの解説記事を眺める
といった風に勉強してました。
公式の解説は、初心者には少々敷居が高い気がしたので、なるべくシンプルに伝えてくれているサイトを探すのがコツかと。Step.4 有料問題集を解く
無料問題集を解き終えたら、次はこちらのサイトの問題集を購入しました。(ゴールドプラン、4千円ちょい)
AWS WEB問題集で学習しよう最初は少し値段に怯みましたが、納得いく問題数とクオリティでした。
こちらの問題集の難易度が本番に一番近いと思います。
僕は全部解いたわけでなく、SAA#50以降から始めていきました。
AWSのサービスが新しくなるにつれ、問題集もアップデートされています。
特にSAA#100以降の問題は確実に抑えておいたほうがいいと思います!Step.5 ポートフォリオに組み込む
試験対策と並行してポートフォリオを作っていたポートフォリオに、AWSのハンズオンで学んだVPC設計を組み込んでいきました。
ネットワーク構成をを自分で一から考え構築したので知識がより定着しました。
詳しくはこちら。
未経験がNuxt + Rails(API Mode) + AWS でプチ疎結合なポートフォリオを作って得たものStep.6 模試を解きまくる
ここまでくると基本的なサービスの役割はなんとなく理解できているかと思います。
あとはテスト形式の問題をひたすら解きまくり、合格点まで自分がどのくらいの距離にいるのか測りつつ学習を進めます。
主に使用したのは、Step1で使用した講座に付いてくる模試×3と、以下の講座です。
AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(5回分325問)5回分とありますが、内1つはハンズオンに付いてくる模試と内容が同じなので実質4つです。
こちらは特に難易度が高いので、全然解けなくても気にせず進めましょう。参考までに。この段階で私の点数を載せておきます。
Step1のハンズオンに付属の模試×2(70%以上で合格)
演習テスト1: 63%
演習テスト2: 60%模擬問題集
演習テスト1: 41%
演習テスト2: 46%
演習テスト3: 55%
演習テスト4: 66%
演習テスト5: 50%1周目の時点ではボロボロで挫けそうになりました。笑
こちらで分からなかったサービスをブラックベルト(公式のサービス説明スライド&動画)を使って勉強し直したり、Step4の問題集を解き直し、再度チャレンジすることで2周目はだいぶ点数が上がりました。2週目の点数
Step1のハンズオンに付属の模試×2(70%以上で合格)
演習テスト1: 78%
演習テスト2: 80%模擬問題集
演習テスト1: 55%
演習テスト2: 80%
演習テスト3: 73%
演習テスト4: 81%
演習テスト5: 86%2周目、3周目でコンスタントに80%を取れるようになってきたあたりで、試験の予約を入れました。
試験日まではひたすら模試と有料問題集を解き直してました。実際の試験で思ったこと
微妙なニュアンスが結構多い
ネットで言われているほど分かりにくい日本語ではなかったのですが、上記で使ってきた問題集と違う表現のものあり一瞬戸惑いました。(インスタンスストア→インスタンスストレージとか)
やはり難しい
問題文は言われてるほど長いと思いませんでした。(Udemy模試の3分の2くらい?)
ただ、サービスの細かい仕様を聞かれる問題が結構多く、半分近く見直しフラグを立てました。
単に問題=答えで結びつけて覚えるのではなく、細かな仕様やユースケースまで学ぶことで、消去法で正解率を上げることに繋がると思います。全問解き終わったあとの確信度はだいたいこんな感じです。
50%以下: 3割
50〜80%: 5割
80%以上: 2割確信をもって答えられたのが半分以下だったので、かなり不安を感じましたが、852点というそこそこの点数で合格することができました。(合格ラインは720点)
先述の通り、確信が持てなくても消去法で正解率を挙げられたことが合格に繋がったと思います。
できる限りピアソンで受けろ
試験方式はPSIとピアソンの2種類があります。
PSIは監視が厳しいという噂を聞いていたのですが、実際その通りでした。(日程の都合上PSIで受けた)
カメラで海外のスタッフが監視しており、逐一チャットで指示を出してきます。
免許証とクレカをこっちに見せて!と言われましたが、カメラが2台、スキャナが1台あり、どれを使うんだ!!??と隣の受験者の方と混乱してました。
テストセンターのスタッフも慣れていなかったようで、どうにか自分たちで手探りで試験を始めることができました。
英語に苦手意識のある方だとこの時点でパニックになりかねないです。(日本語にもできましたが、ザ・翻訳という感じの文章だった)
また、「顔を下げないで」「両手は机の上に出しておいて」などの指示があり、窮屈さを感じました(流石に頭や膝を掻くくらいなら何も言われなかった。)もしかしたら自分の訳が間違ってるかもですが。疲れ果てた試験後、ガラス越しにピアソンでAWSの資格を受けている人たちが見えました。(試験中に受付の声が聞こえてきた)
そちらは特に監視カメラはないようで、スタッフに聞いてみると、ピアソンの場合は会場のスタッフが代わりに監視する、という仕組みになっているそうでした。
絶対にそっちがいいやん。会場によって差はあると思いますが、都合が合う限りピアソンでいいんじゃないかなーと思います。
まとめ
Railsなどのアプリケーション側の知識があった状態で、2ヶ月の勉強期間でした。
インフラ周りの経験があればもっと早く取れるでしょう。
合格体験記を漁ると、2週間で合格!!とか3日で合格!!といった記事も結構見かけます。
ですが、クラウドやサーバの詳しくない人、アプリ開発の実務経験がない人が取ろうとすると、1~3ヶ月、もしくはそれ以上普通にかかると思うので、焦らず自分のペースでじっくり取り組みましょう。私は個人的な事情により少し急いでいたため、公式の模試、参考書に付属の模試は受けていませんが、当然受けておくに越したことはないです。
参考になった記事
【AWS】AWS認定『ソリューションアーキテクト- アソシエイト』(SAA)に未経験から合格した話:これから挑戦する方へ
後半のAWS最強理論、勉強を進めたあとに読むと、めっちゃ分かる〜!ってなる。
RDBMSのスペックがボトルネックになってる問題、大体Auroraが正解あるあるとか。10ヶ月勉強してもAWS認定ソリューションアーキテクト-アソシエイト-に合格できないので、勉強方法を振り返る
○日で受かったぜヒャッハー!という記事よりも、落ちた上で自分に足りないものを分析されている記事の方が、試験に合格するために大切なものが見えてくる気がします。

- 投稿日:2019-12-23T21:52:03+09:00
CodeStarでDjangoやーる(Python3.6.8、Django2.2.9)
CodeStarでDjangoアプリを作成し、CodePiplineによってCI/CDしていきましょう。
開発環境
ローカルマシン
- git for windows
- anaconda 2019
- python 3.6.9
- Django 1.11.18 / 2.2.9
AWS EC2
- python 3.6.8
- Django 1.11.18 / 2.2.9
プロジェクトの作成
1.aws consoleにログイン、CodeStarを開く(の前にIAMユーザーにAWSCloudFormationFullAccessが必要だったかも)
2.新規プロジェクトの作成をクリック
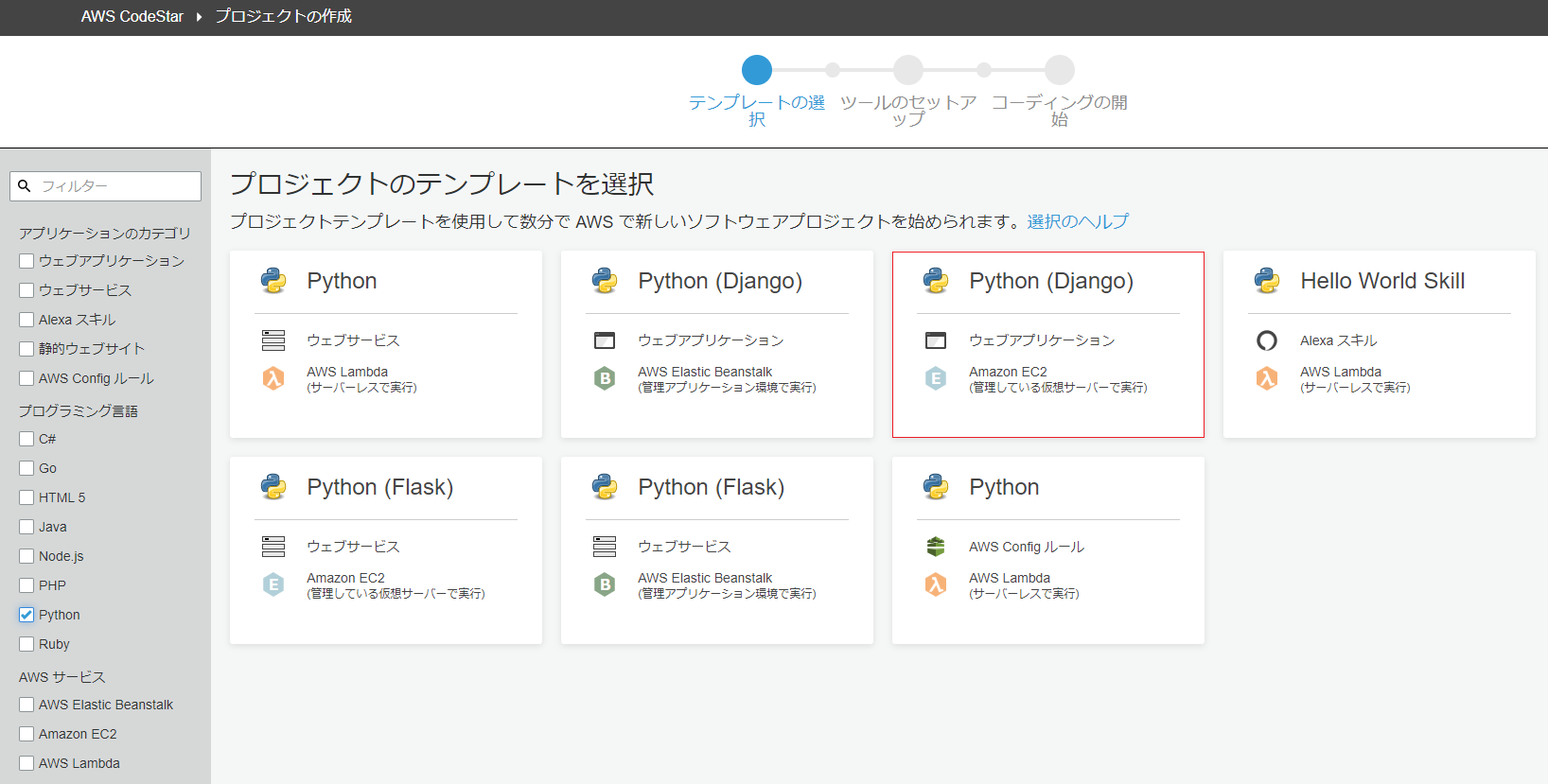
3.Python(Django)、Amazon EC2を選択
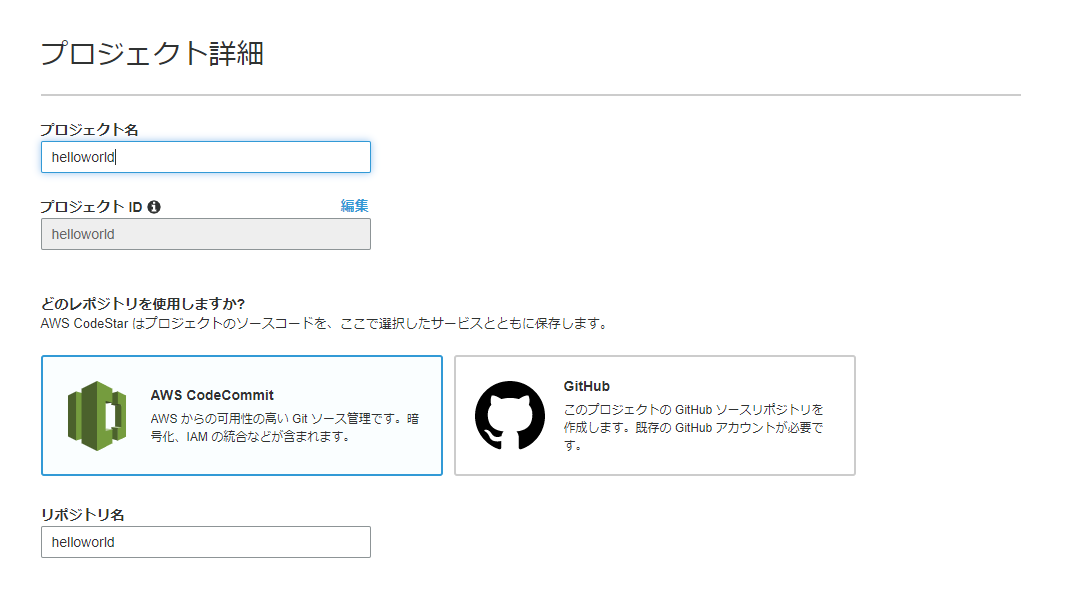
4.プロジェクト名(例:helloworld)を入力し、次へをクリック
5.プロジェクトの詳細を確認したら、プロジェクトを作成するをクリック
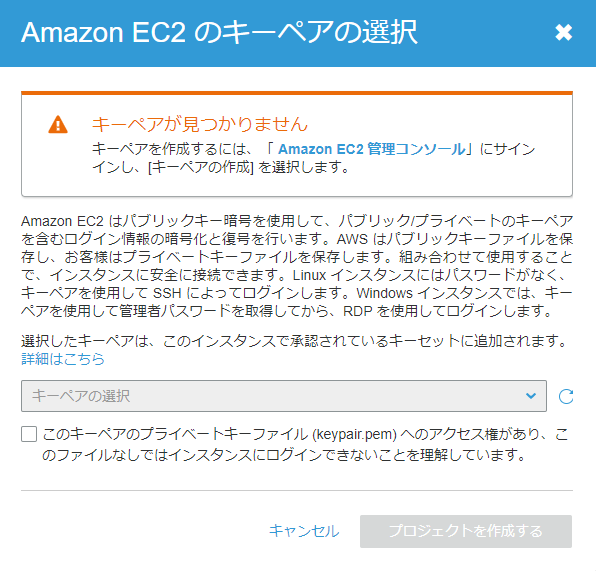
6.Amazon EC2 管理コンソールを新しいタブで開き
7.キーペアを作成
8.helloworld.pemを保管しておく
9.作成したキーペアを選択し、プロジェクトを作成するをクリック
10.スキップ(オレゴンリージョンにはAWS Cloud9があった)
11.CodeStarのダッシュボードが表示される
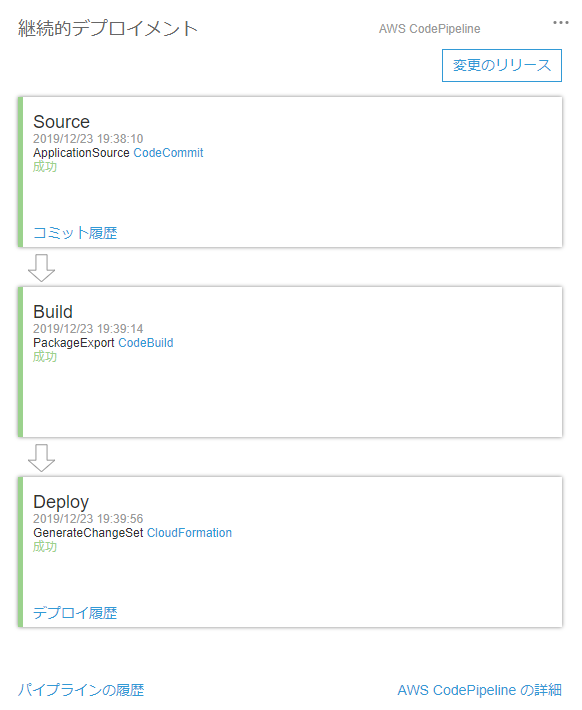
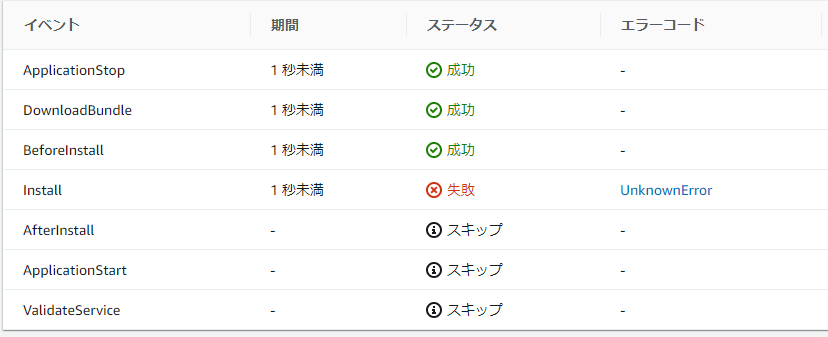
12.CodePiplineのSource→Build→Deployが完了するまで待つ
※オレゴンリージョンだとエラーが出た
Your requested instance type (t2.micro) is not supported in your requested Availability Zone (us-west-2d). Please retry your request by not specifying an Availability Zone or choosing us-west-2a, us-west-2b, us-west-2c. (Service: AmazonEC2; Status Code: 400; Error Code: Unsupported; Request ID: 7ee63da9-fc85-4e2a-999c-629fe3997dbe)13.Deployが完了したら、アプリケーションのエンドポイントを開く
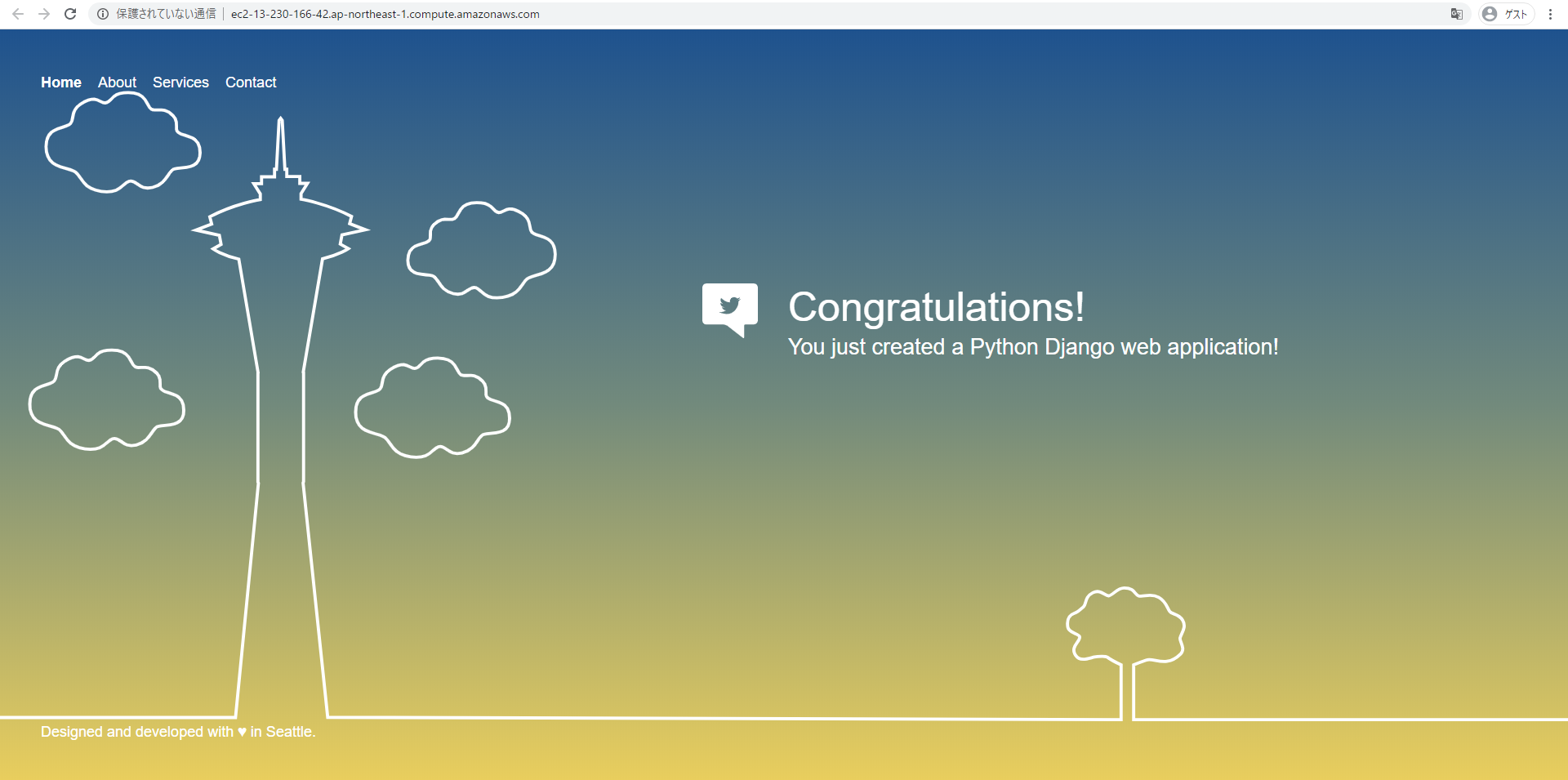
14.ページが見えればOK
※EC2を停止/起動するとページが見えなくなるので、起動時にDjangoアプリも起動するようにスクリプトを設定する必要がある。後述。
プロジェクトの編集(CodeCommitの練習)
1.CodeStarのダッシュボードからコードをクリックするとCodeCommitへ遷移
2.URLのクローンからURLをコピー
3.git for Windowsをインストール
4.anaconda promptを開く
5.django1とdjango2の仮想環境を作っておく
conda create -n django1 python=3.6 conda create -n django2 python=3.66.IAMのCodeCommitの設定
IAMグループのアクセス許可は下記のような感じ。
AmazonEC2FullAccess AWSCodeCommitFullAccess AWSLambdaFullAccess AmazonS3FullAccess AmazonDynamoDBFullAccess AmazonSageMakerFullAccess AmazonSageMaker-ExecutionPolicy-20191208Txxxxxx AWSCloudFormationFullAccessIAMユーザーの認証情報から認証情報を生成
※このユーザー名とパスワードはgit cloneする際に必要なのでメモっておくこと
※パスワードを変更したら、git for Windowsを使用していて認証情報をリセットする方法
7.django1環境をactivateし、プロジェクトをクローン。設定したユーザー名とパスワードを聞かれる。あとはgit configure。
(base) $ conda activate django1 (django1) $ git config --global user.email "s-fujimoto@knowledgecommunication.jp" (django1) $ git config --global user.name "s-fujimoto" (django1) $ git clone https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/helloworld (django1) $ cd helloworld8.developブランチを切る ※masterに直接コミットしない。プロジェクト作成したらすぐにdevelopブランチを切る。
(django1) $ git branch develop (django1) $ git checkout develop Switched to branch 'develop'9.featureブランチを切る ※developに直接コミットしない。新機能の追加や変更を行うたびにfeatureブランチを切る。
(django1) $ git branch feature (django1) $ git checkout feature Switched to branch 'feature'10.プロジェクトに必要なライブラリをインストール
(django1) $ pip install -r requirements/dev.txt Collecting Django==1.11.18 Using cached https://files.pythonhosted.org/packages/e0/eb/6dc122c6d0a82263bd26bebae3cdbafeb99a7281aa1dae57ca1f645a9872/Django-1.11.18-py2.py3-none-any.whl Collecting pytz Using cached https://files.pythonhosted.org/packages/e7/f9/f0b53f88060247251bf481fa6ea62cd0d25bf1b11a87888e53ce5b7c8ad2/pytz-2019.3-py2.py3-none-any.whl Installing collected packages: pytz, Django Successfully installed Django-1.11.18 pytz-2019.3Django 1.11.18がインストールされる
11.Djangoをローカルで起動
(django1) $ python manage.py runserver Performing system checks... System check identified no issues (0 silenced). You have 13 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. December 23, 2019 - 18:15:46 Django version 1.11.18, using settings 'ec2django.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CTRL-BREAK. [23/Dec/2019 18:15:54] "GET / HTTP/1.1" 200 6652 [23/Dec/2019 18:15:54] "GET /static/helloworld/css/styles.css HTTP/1.1" 200 2690 [23/Dec/2019 18:15:54] "GET /static/helloworld/js/set-background.js HTTP/1.1" 200 137 [23/Dec/2019 18:15:54] "GET /static/helloworld/css/gradients.css HTTP/1.1" 200 2133 [23/Dec/2019 18:15:54] "GET /static/helloworld/img/tweet.svg HTTP/1.1" 200 1418 [23/Dec/2019 18:15:54] "GET /favicon.ico HTTP/1.1" 404 7712.ブラウザから http://127.0.0.1:8000/ にアクセスして同じページが見えればOK
13.git statusでプログラムの変更を見る
(django1) $ git status On branch feature Untracked files: (use "git add <file>..." to include in what will be committed) db.sqlite3 ec2django/__pycache__/ helloworld/__pycache__/ helloworld/migrations/__pycache__/ nothing added to commit but untracked files present (use "git add" to track)14.pycacheがあるとCodePiplineのデプロイに失敗するので不要、下記.gitignoreファイルを追加(db.sqlite3は任意)
# Byte-compiled / optimized / DLL files __pycache__/ *.py[cod] *$py.class # C extensions *.so # Distribution / packaging .Python env/ build/ develop-eggs/ dist/ downloads/ eggs/ .eggs/ lib/ lib64/ parts/ sdist/ var/ wheels/ *.egg-info/ .installed.cfg *.egg # PyInstaller # Usually these files are written by a python script from a template # before PyInstaller builds the exe, so as to inject date/other infos into it. *.manifest *.spec # Installer logs pip-log.txt pip-delete-this-directory.txt # Unit test / coverage reports htmlcov/ .tox/ .coverage .coverage.* .cache nosetests.xml coverage.xml *.cover .hypothesis/ # Translations *.mo *.pot # Django stuff: *.log local_settings.py # Flask stuff: instance/ .webassets-cache # Scrapy stuff: .scrapy # Sphinx documentation docs/_build/ # PyBuilder target/ # Jupyter Notebook .ipynb_checkpoints # pyenv .python-version # celery beat schedule file celerybeat-schedule # SageMath parsed files *.sage.py # dotenv .env # virtualenv .venv venv/ ENV/ # Spyder project settings .spyderproject .spyproject # Rope project settings .ropeproject # mkdocs documentation /site # mypy .mypy_cache/ .idea/ db.sqlite3 migrations/15.featureへコミット
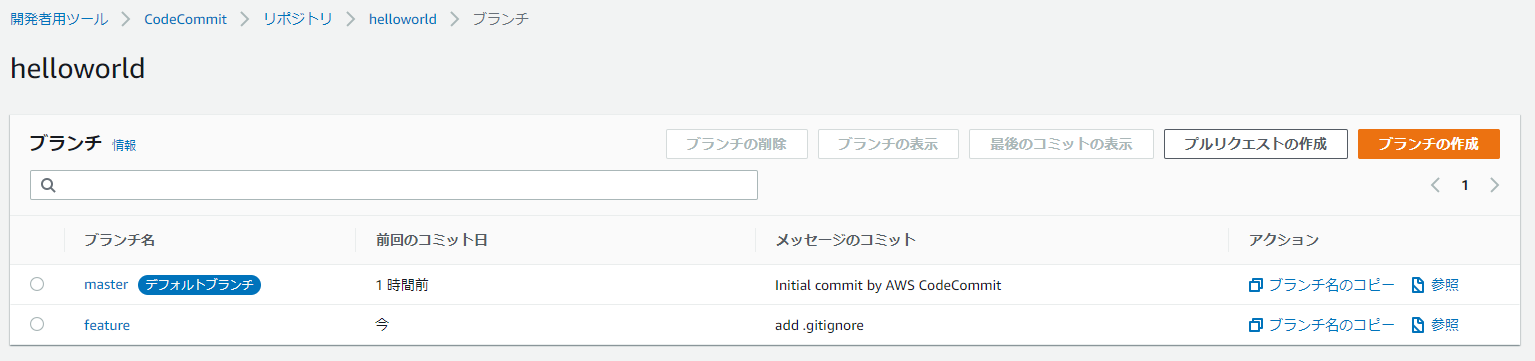
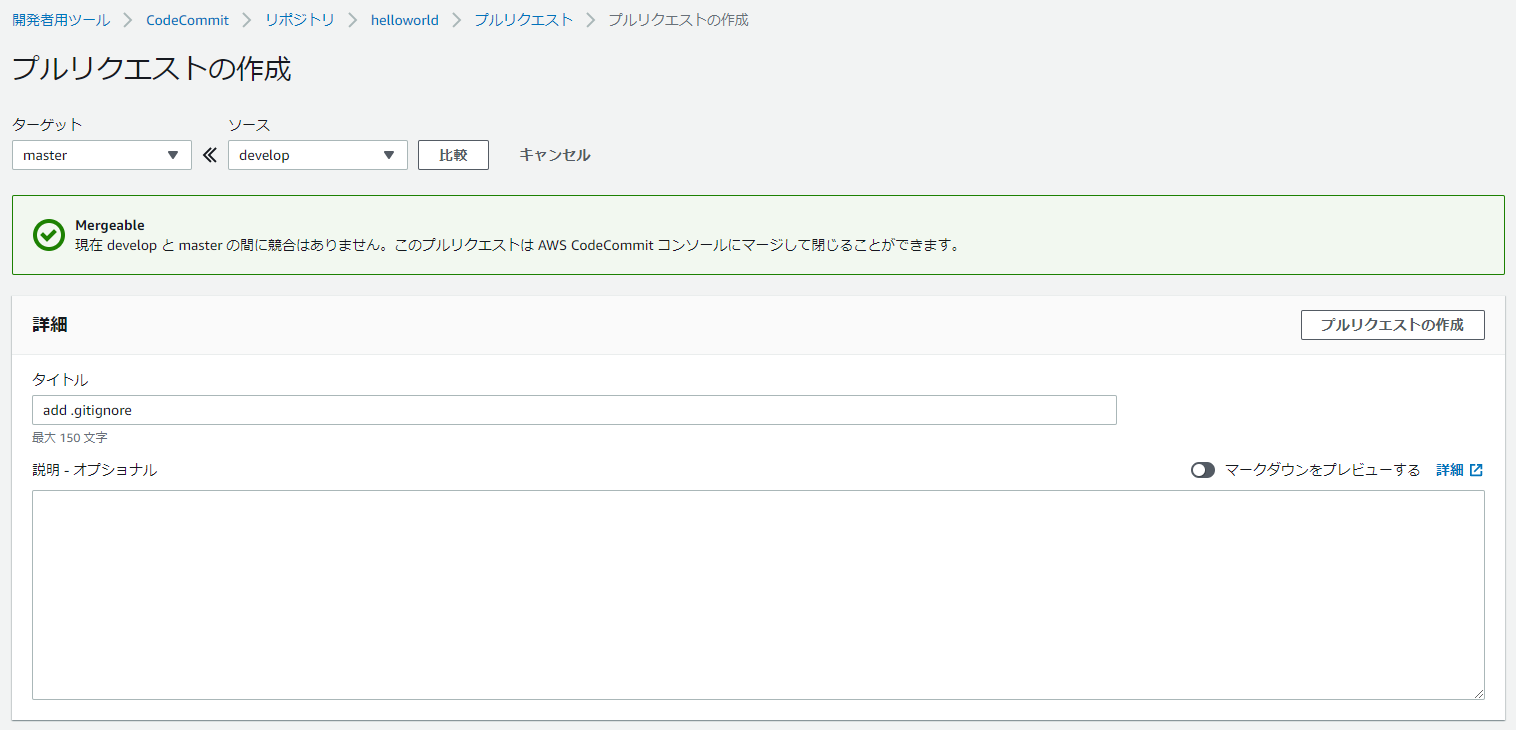
(django1) $ git add . (django1) $ git commit -m "add .gitignore" [feature 6d9a594] add .gitignore 1 file changed, 106 insertions(+) create mode 100644 .gitignore (django1) $ git push origin feature Enumerating objects: 4, done. Counting objects: 100% (4/4), done. Delta compression using up to 8 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 939 bytes | 939.00 KiB/s, done. Total 3 (delta 1), reused 0 (delta 0) To https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/helloworld * [new branch] feature -> feature16.CodeCommitを確認すると、featureブランチが作成されている
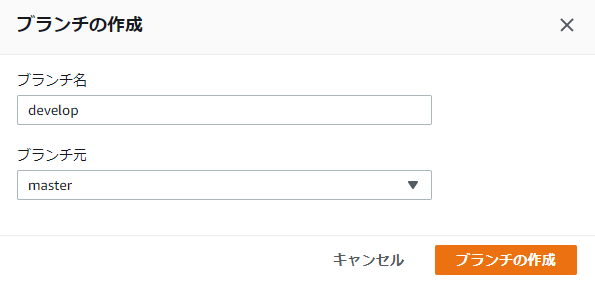
17.developブランチを作成
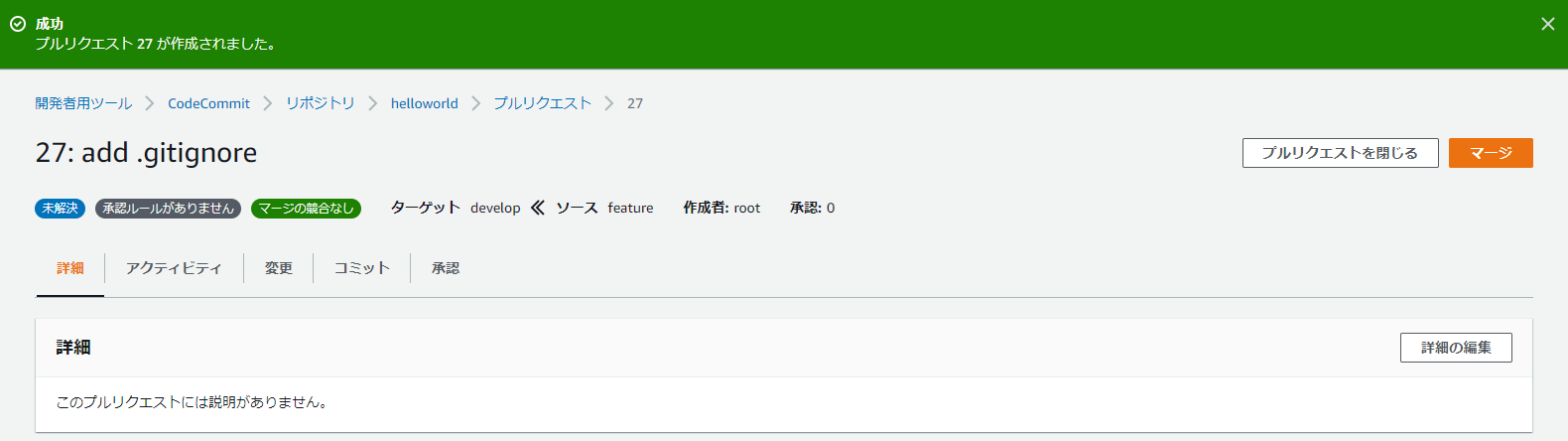
18.プルリクエストの作成
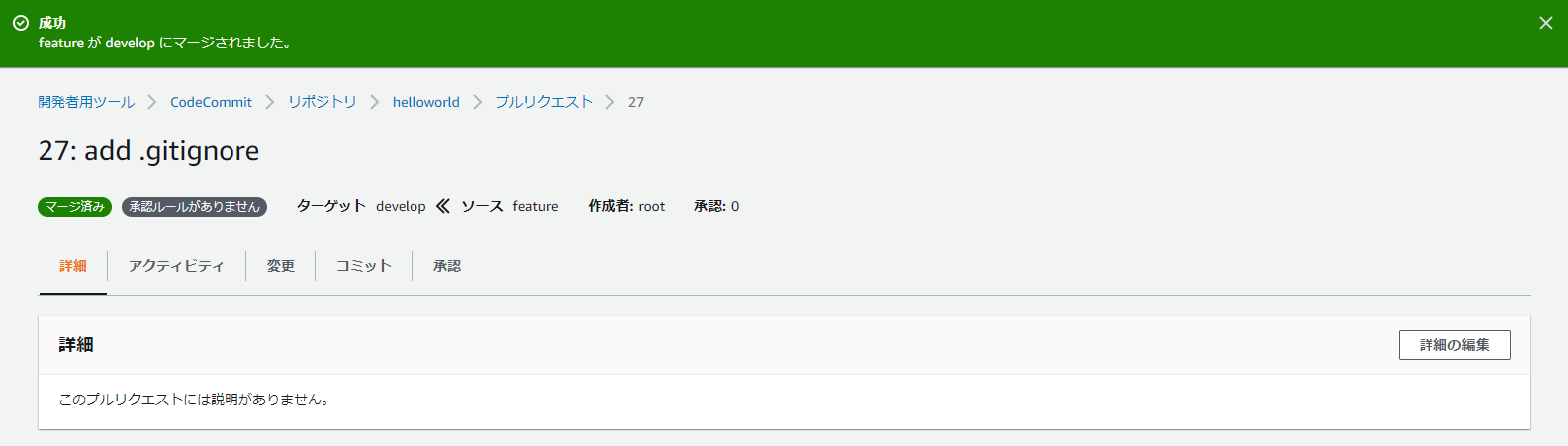
19.featureからdevelopへマージする
20.マージしたらfeatureは消す。(けどまた新機能の追加や変更をするときはfeatureブランチを切る。ローカルにはfeatureブランチが残るのでそのまま使う。)
21.マージ成功
22.同様にdevelopからmasterへマージする
23.developブランチは消さない
24.masterへマージされるとCodePiplineが起動
25.ページが見えていることを確認
プロジェクトの編集(Django1からDjango2へ更新)
1.django1環境から抜けて、django2環境へactivate
(django1) $ conda deactivate (base) $ conda activate django2 (django2) $2.requirements/common.txtを編集
変更前# dependencies common to all environments Django==1.11.18変更後
# dependencies common to all environments Django==2.2.92.ライブラリのインストール
(django2) $ pip install -r requirements/dev.txt Collecting Django==2.2.9 Using cached https://files.pythonhosted.org/packages/cb/c9/ef1e25bdd092749dae74c95c2707dff892fde36e4053c4a2354b2303be10/Django-2.2.9-py3-none-any.whl Collecting pytz Using cached https://files.pythonhosted.org/packages/e7/f9/f0b53f88060247251bf481fa6ea62cd0d25bf1b11a87888e53ce5b7c8ad2/pytz-2019.3-py2.py3-none-any.whl Collecting sqlparse Using cached https://files.pythonhosted.org/packages/ef/53/900f7d2a54557c6a37886585a91336520e5539e3ae2423ff1102daf4f3a7/sqlparse-0.3.0-py2.py3-none-any.whl Installing collected packages: pytz, sqlparse, Django Successfully installed Django-2.2.9 pytz-2019.3 sqlparse-0.3.0Django==2.2.9がインストールされる
3.ec2django/setting.pyを編集
変更前MIDDLEWARE_CLASSES = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.auth.middleware.SessionAuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] LANGUAGE_CODE = 'en-us' TIME_ZONE = 'UTC' USE_I18N = True USE_L10N = True USE_TZ = True変更後
MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo' USE_I18N = True USE_L10N = True USE_TZ = True4.ec2django/urls.pyを編集
変更前
from django.conf import settings from django.conf.urls.static import static from django.conf.urls import include, url from django.contrib import admin from django.contrib.staticfiles.urls import staticfiles_urlpatterns urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^', include('helloworld.urls')), ] + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)変更後
from django.conf import settings from django.conf.urls.static import static from django.conf.urls import include, url from django.contrib import admin from django.contrib.staticfiles.urls import staticfiles_urlpatterns from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('helloworld.urls')), ] + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)5.helloworld/templates/index.htmlをhelloworld/templates/helloworld/index.htmlに移動
6.helloworld/urls.py
変更前
# helloworld/urls.py from django.conf.urls import url from django.conf.urls.static import static from helloworld import views urlpatterns = [ url(r'^$', views.HomePageView.as_view()), ]変更後
# helloworld/urls.py from django.urls import path from django.conf.urls import url from django.conf.urls.static import static from helloworld import views urlpatterns = [ path('', views.HomePageView.as_view(), name='index'), ]7.helloworld/views.py
変更前
# helloworld/views.py from django.shortcuts import render from django.views.generic import TemplateView # Create your views here. class HomePageView(TemplateView): def get(self, request, **kwargs): return render(request, 'index.html', context=None)変更後
# helloworld/views.py from django.shortcuts import render from django.views.generic import TemplateView from django.views import generic # Create your views here. class HomePageView(generic.TemplateView): template_name = 'helloworld/index.html'8.Djangoをローカルで起動し、ブラウザから http://127.0.0.1:8000/ にアクセスして同じページが見えればOK
(django2) $ python manage.py runserver Performing system checks... System check identified no issues (0 silenced). You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. December 23, 2019 - 19:27:46 Django version 2.2.9, using settings 'ec2django.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CTRL-BREAK. [23/Dec/2019 19:27:49] "GET / HTTP/1.1" 200 6652 [23/Dec/2019 19:27:49] "GET /static/helloworld/js/set-background.js HTTP/1.1" 200 137 [23/Dec/2019 19:27:49] "GET /static/helloworld/css/gradients.css HTTP/1.1" 200 2133 [23/Dec/2019 19:27:49] "GET /static/helloworld/css/styles.css HTTP/1.1" 200 2690 [23/Dec/2019 19:27:49] "GET /static/helloworld/img/tweet.svg HTTP/1.1" 200 14189.featureへコミットして、developにマージ、developからmasterにマージする
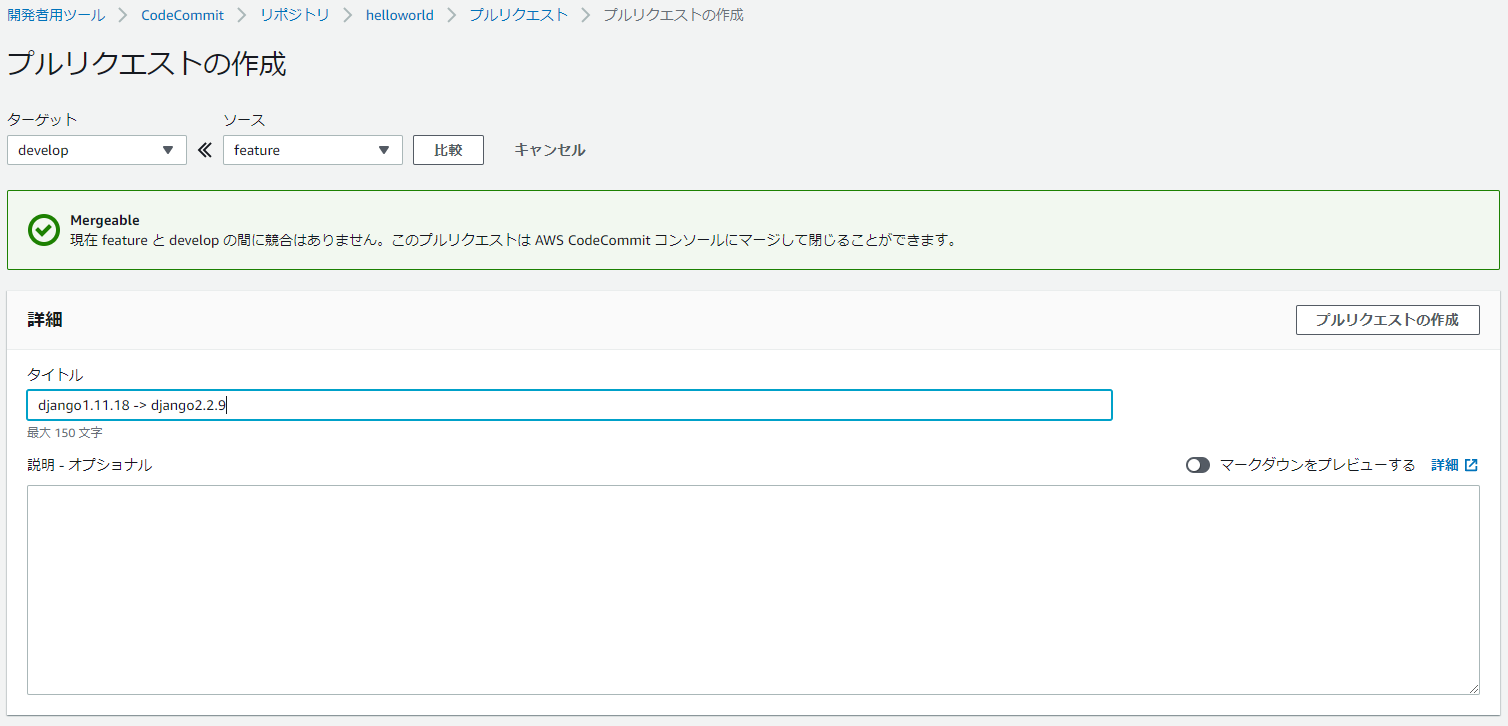
(django2) $ git status On branch feature Changes not staged for commit: (use "git add/rm <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: ec2django/settings.py modified: ec2django/urls.py deleted: helloworld/templates/index.html modified: helloworld/urls.py modified: helloworld/views.py modified: requirements/common.txt Untracked files: (use "git add <file>..." to include in what will be committed) helloworld/templates/helloworld/ no changes added to commit (use "git add" and/or "git commit -a") (django2) $ git add . (django2) $ git commit -m "django1.11.18 -> django2.2.9" [feature 2226d88] django1.11.18 -> django2.2.9 6 files changed, 12 insertions(+), 12 deletions(-) rename helloworld/templates/{ => helloworld}/index.html (100%) (django2) $ git push origin feature Enumerating objects: 21, done. Counting objects: 100% (21/21), done. Delta compression using up to 8 threads Compressing objects: 100% (10/10), done. Writing objects: 100% (11/11), 1.27 KiB | 648.00 KiB/s, done. Total 11 (delta 5), reused 0 (delta 0) To https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/helloworld * [new branch] feature -> feature
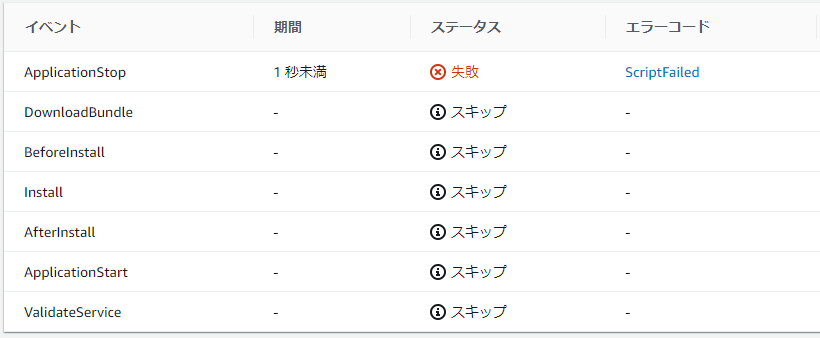
10.CodePiplineが完了したら、ページを確認
11.サイトにアクセスできなくなっている
12.EC2を開く
13.TeraTermを用いて、EC2へSSH接続(PuTTYならPuTTY genを用いてキーペア.pemを.ppkに変換してから接続する)
14.セキュリティ警告は続行をクリック
15.ユーザー名にec2-user, キーペアを指定
16.接続
17.Djangoを起動
[ec2-user@ip-172-31-14-214 ~]$ sudo su [root@ip-172-31-14-214 ec2-user]# source /home/ec2-user/environment/bin/activate (environment) [root@ip-172-31-14-214 ec2-user]# /usr/local/bin/supervisord -c /home/ec2-user/supervisord.conf Error: Another program is already listening on a port that one of our HTTP servers is configured to use. Shut this program down first before starting supervisord. For help, use /usr/local/bin/supervisord -h (environment) [root@ip-172-31-14-214 ec2-user]# pkill supervisord (environment) [root@ip-172-31-14-214 ec2-user]# /usr/local/bin/supervisord -c /home/ec2-user/supervisord.conf18.ページは見れないままなので、ログを確認する
(environment) [root@ip-172-31-14-214 ec2-user]# cat /var/log/django-application-stderr.log ・・・ File "/home/ec2-user/environment/local/lib/python3.6/site-packages/django/db/backends/sqlite3/base.py", line 63, in check_sqlite_version raise ImproperlyConfigured('SQLite 3.8.3 or later is required (found %s).' % Database.sqlite_version) django.core.exceptions.ImproperlyConfigured: SQLite 3.8.3 or later is required (found 3.7.17). [2019-12-23 19:54:59 +0900] [25438] [INFO] Worker exiting (pid: 25438) [2019-12-23 10:54:59 +0000] [25435] [INFO] Shutting down: Master [2019-12-23 10:54:59 +0000] [25435] [INFO] Reason: Worker failed to boot.Django2に更新したためSQLite3のバージョンを更新する必要がある。
19.SQLite3の更新
下記の記事を参考
Django2.2で開発サーバー起動時にSQLite3のエラーが出た場合の対応(environment) [root@ip-172-31-14-214 ec2-user]# wget https://www.sqlite.org/2019/sqlite-autoconf-3280000.tar.gz (environment) [root@ip-172-31-14-214 ec2-user]# tar xvfz sqlite-autoconf-3280000.tar.gz (environment) [root@ip-172-31-14-214 ec2-user]# cd sqlite-autoconf-3280000 (environment) [root@ip-172-31-14-214 ec2-user]# ./configure --prefix=/usr/local (environment) [root@ip-172-31-14-214 ec2-user]# make (environment) [root@ip-172-31-14-214 ec2-user]# sudo make install (environment) [root@ip-172-31-14-214 ec2-user]# sudo find /usr/ -name sqlite3 (environment) [root@ip-172-31-14-214 ec2-user]# cd ../ (environment) [root@ip-172-31-14-214 ec2-user]# rm sqlite-autoconf-3280000.tar.gz (environment) [root@ip-172-31-14-214 ec2-user]# rm -rf ./sqlite-autoconf-3280000 (environment) [root@ip-172-31-14-214 ec2-user]# /usr/local/bin/sqlite3 --version 3.28.0 2019-04-16 19:49:53 884b4b7e502b4e991677b53971277adfaf0a04a284f8e483e2553d0f83156b50 (environment) [root@ip-172-31-14-214 ec2-user]# /usr/bin/sqlite3 --version 3.7.17 2013-05-20 00:56:22 118a3b35693b134d56ebd780123b7fd6f1497668 (environment) [root@ip-172-31-14-214 ec2-user]# sqlite3 --version 3.7.17 2013-05-20 00:56:22 118a3b35693b134d56ebd780123b7fd6f1497668 (environment) [root@ip-172-31-14-214 ec2-user]# sudo mv /usr/bin/sqlite3 /usr/bin/sqlite3_old (environment) [root@ip-172-31-14-214 ec2-user]# sudo ln -s /usr/local/bin/sqlite3 /usr/bin/sqlite3 (environment) [root@ip-172-31-14-214 ec2-user]# export LD_LIBRARY_PATH="/usr/local/lib" (environment) [root@ip-172-31-14-214 ec2-user]# python Python 3.6.8 (default, Oct 14 2019, 21:22:53) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sqlite3 >>> sqlite3.sqlite_version '3.28.0' >>> exit() (environment) [root@ip-172-31-14-214 ec2-user]#Djangoを起動しページが見れればOK
(environment) [root@ip-172-31-14-214 ec2-user]# pkill supervisord (environment) [root@ip-172-31-14-214 ec2-user]# /usr/local/bin/supervisord -c /home/ec2-user/supervisord.confEC2再起動時にDjangoを起動するように設定
1.supervisord.confを修正(ローカルも編集してあとでmasterへマージする)
変更前[program:djangoproject] command = environment/bin/gunicorn -b 0.0.0.0:80 ec2django.wsgi変更後
[program:djangoproject] command = /home/ec2-user/environment/bin/gunicorn -b 0.0.0.0:80 ec2django.wsgi2.サービスの登録
(environment) [root@ip-172-31-14-214 ec2-user]# vi /etc/init.d/helloworld#!/bin/sh # chkconfig: 2345 99 10 # description: start helloworld # processname: helloworld start() { echo "start" source /home/ec2-user/environment/bin/activate export LD_LIBRARY_PATH="/usr/local/lib" /usr/local/bin/supervisord -c /home/ec2-user/supervisord.conf } stop() { echo "stop" pkill supervisord } case "$1" in start) start ;; stop) stop ;; restart) stop start ;; esac exit 0(environment) [root@ip-172-31-14-214 ec2-user]# chkconfig --add helloworld (environment) [root@ip-172-31-14-214 ec2-user]# chkconfig helloworld on (environment) [root@ip-172-31-14-214 ec2-user]# chmod u+x /etc/init.d/helloworld (environment) [root@ip-172-31-14-214 ec2-user]# service helloworld restart3.再起動してもページが見えればOK(EC2の停止・起動でもDjangoは起動)
(environment) [root@ip-172-31-14-214 ec2-user]# sudo reboot※EC2を停止・起動するとIP変わるので注意
4.featureのsupervisord.confを修正しコミット、featureからdevelopへマージ、developからmasterへマージする
(django2) $ git status On branch feature Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: supervisord.conf no changes added to commit (use "git add" and/or "git commit -a") (django2) $ git add . (django2) D:\Users\s-fujimoto\CodeStar\helloworld>git commit -m "modified supervisord.conf" [feature 38c0e8c] modified supervisord.conf 1 file changed, 1 insertion(+), 1 deletion(-) (django2) D:\Users\s-fujimoto\CodeStar\helloworld>git push origin feature Enumerating objects: 5, done. Counting objects: 100% (5/5), done. Delta compression using up to 8 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 325 bytes | 325.00 KiB/s, done. Total 3 (delta 2), reused 0 (delta 0) To https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/helloworld * [new branch] feature -> feature5.CodePiplineが完了し、ページが見えればOK
(6.見えないときはEC2を再起動するか、SSHで接続しログの確認とサービスを再起動する)
(environment) [root@ip-172-31-14-214 ec2-user]# cat /var/log/django-application-stderr.log (environment) [root@ip-172-31-14-214 ec2-user]# cat /var/log/django-application-stdout.log (environment) [root@ip-172-31-14-214 ec2-user]# service helloworld restart強行デプロイ
.gitignoreの設定を忘れてマージしたら、pycacheがもうあるよと怒られデプロイ失敗
EC2の停止中にマージしたら、デプロイ失敗。失敗後にEC2を起動して再試行しても失敗。
一度デプロイ失敗してる状態から再試行してもまた失敗する。なので強行デプロイしてから、masterへマージすると成功する。
appspec.ymlとbuildspec.ymlにfileを追記しなかったために,沼にハマった話
1.CodeDeployのアプリケーションから対象を選択
2.失敗したリビジョンの場所を指定
3.デプロイを失敗させないにチェックし、コンテンツの上書きを選択、デプロイの作成からデプロイ
カスタムユーザーモデルを使用する(割愛)
db.sqlite3は.gitignoreされるので、Tera Termで送信
AWS EC2(Linux系)の接続方法とファイル転送方法DBの更新が必要
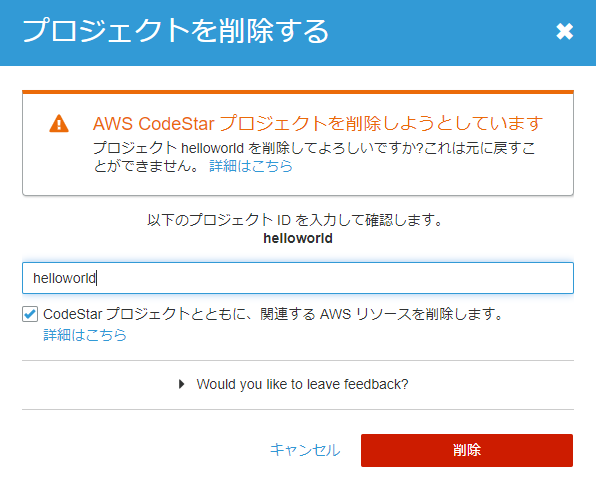
python manage.py makemigrations helloworld python manage.py migrateプロジェクトの削除
1.CodeStarのプロジェクト一覧から削除
2.プロジェクト名を入力し削除
まとめ
Djangoアプリ開発がかなり楽になった気がする。CICDがんばろー。


















- 投稿日:2019-12-23T21:34:10+09:00
AWS S3バケットのオブジェクトがずっと削除されてた話
バケットのオブジェクトがずっと削除されてた話
ある日、動作テストしてくれてる先輩から、「ステージングのデータが何か消えてるらしいよほげ」と言われました。
そのデータは実行履歴のデータでシステムを使うとデータがAWS S3に溜まって来て、AWS Athenaを利用してデータをクエリしてるのがざっくりの仕組みでした。
オブジェクトを削除してるコードは一切ない、
毎日ちゃんと溜まってる、
他の環境では何ヶ月間ちゃんと溜まってる、
ライフサイクルも必要な特定ディレクトリだけ指定して置いただけでした。最初はAthenaのTableやDBが削除されると消える?とAthenaを疑ったり、
Terraformの処理のせい?と会社のTerraformマスターを疑ったり、
酔っ払ってやっちゃった?と自分をを疑ってました。原因
しかし、見つかった原因は、
ライフサイクル設定ルールを間違ってルール名に書いてしまったことが恥ずかしい原因でした。
先輩、すみません!まとめ
こんなアホみたいなミスは誰もしない珍しい話でしたが、ルールを指定しないとS3バケット全体が対象になりますので、お気をつけてください!
ちなみに、今回の事故で何があっても消さない実行履歴のデータだと気づき、Amazon S3 オブジェクトロックを使うことになりました!
?S3オブジェクトのロック(なにをどうやっても改竄削除が不可)がリリースされました!


- 投稿日:2019-12-23T18:58:32+09:00
Slack ワークフロービルダーとAWS Chatbotで負荷試験環境の構築を楽にする
本記事は、サムザップ Advent Calendar 2019 #1 の12/23の記事です。
はじめに
2019年11月25日にAWS ChatbotがSlack からのコマンドの実行をサポートするようになりました(ベータ版)。
AWSコマンドラインインターフェイス構文を使用したコマンドがサポートされており、馴染みのあるシンタックスでコマンドを記述できます。
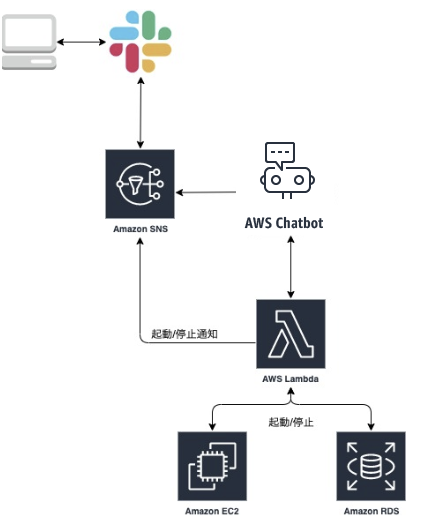
この記事ではAWS Chatbot , Slack ワークフロービルダーを用いて負荷試験環境の起動・停止を簡単にする手順を説明します。前提
負荷試験環境はEC2インスタンスやRDBなど複数のサービスにまたがるため、
普段は使わないので停止させておきたい、使いたいときに起動したいと思っても手順が煩雑になることがあります。
そこでAWS Lambdaを用いて一度に必要なサービスを立ち上げられるようにし、運用しています。
今回はSlack ワークフローの作成からAWS ChatbotとSlackの連携、作成済みのAWS Lambdaを実行するまでの手順を説明します。
手順
ワークフローの作成
Slackの左上のメニューからワークフロービルダーをクリックします。
すると自分が作成・共有されたワークフローの一覧ページが表示されます。
右上の作成をクリックし、ワークフローの名前を入力し、次へをクリックします。
Chatbotが有効になるチャンネルを選択し、短い名前(これがチャンネル上部のワークフローの一覧に表示されます)を記入、保存するをクリックします。
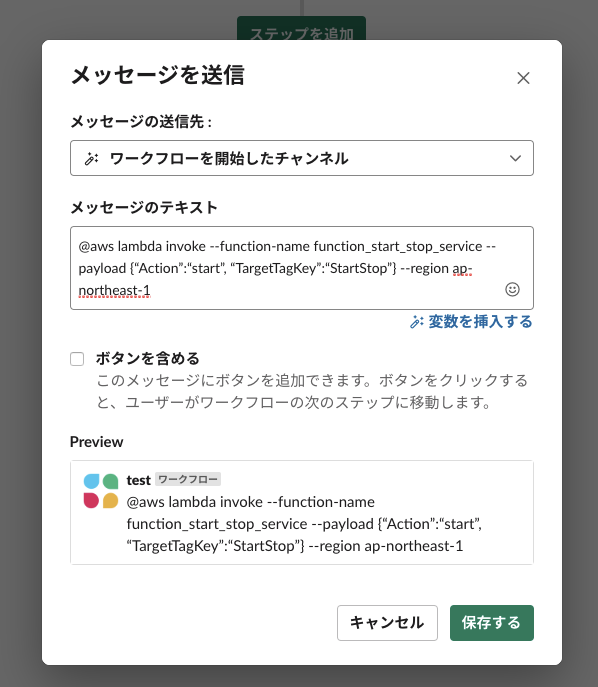
ステップを追加をクリックし、
メッセージの送信先、メッセージのテキストを入力し保存するをクリックします。
メッセージの送信先は「ワークフローを開始したチャンネル」、メッセージのテキストにはAWS CLIによく似たAWS Lambadaを発火させるコマンドを記入します。
ここではAWS Lambda関数function_start_stop_serviceを入力{"Action":"stop", "TargetTagKey":"StartStop"}、リージョンap-northeast-1で実行するものとします。@aws lambda invoke --function-name function_start_stop_service --payload {"Action":"start", "TargetTagKey":"StartStop"} --region ap-northeast-1
6. invite
SlackでAWS Chastbotアプリをインストールし使いたいチャンネルからinviteします。/invite @awsAWS Chatbotの設定
- AWS側でChatbotの設定を行います。 AWS マネジメントコンソールからAWS Chatbotに移動します。
- Configure new clientをクリックし、Slackを選択、Configureをクリックします。
するとSlack側から許可が求められます。
許可をすると作成したclientが現れるので、クリックします。
Configure new channelをクリックします。
Slack channelの設定を記入します。
今回はprivate channelなのでPrivateを選択し、channel IDを記入します。最初に指定したチャンネルのIDです。IDが分からない場合はSlackの部屋名を右クリックし、リンクをコピーすると表示されます。Permissionsの設定を記入します。
IAM RoleはCreate an IAM role using templateを選択、Role nameを記入、Pollicy templatesはLambda-invoke command permissionsを選択します。
Notificationsの設定をします。Topicは予め作成しておき、そちらを選択しConfigureをクリックします。
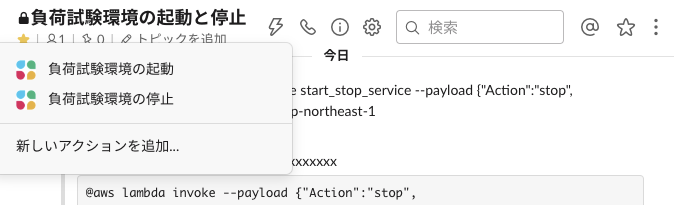
実行
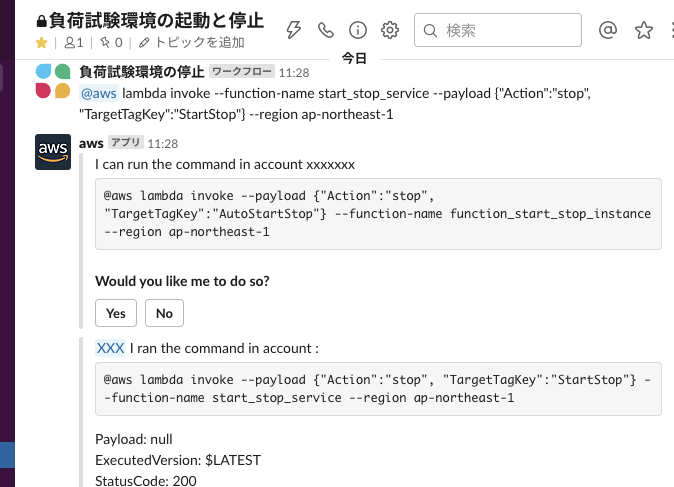
作成したチャンネルの上部にある⚡マークをクリックすると、先程作成したアクションが表示されるので選択します。
yes/noで確認があるのでyesを選択するとAWS Lambdaが実行され結果が返ってきます。
まとめ
以上AWS Chatbot, Slack ワークフロービルダー, AWS Lambdaを用いてアクションを作成しました。
まだベータ版ではありますが、Chatbotを利用すると作業をより簡単にできそうです。明日は@ohbashunsukeさんの記事です。







- 投稿日:2019-12-23T18:33:32+09:00
LambdaをVPC内に作ってちょっとだけハッピーになった話
前提
- LambdaについてはServerlessFrameworkを使用
- IP制限の掛かったサービスにWebhook的にLambdaから通知を送りたかった
- SESのバウンス通知
- 動画変換完了後の通知など(うちの会社ではよくあるパターン)
課題
- これまではどうしていたかというと
- IP制限の掛かっていないCloudFrontディストリビューションを作成
- 上記のディストリビューションに対してドメインを振る(
webhook.xx.com等)- アプリケーション側の該当のパス以下(
/webhooks/hoge等)にベーシック認証を設定- Lambdaから上記のパスに通知
ペイン(辛み)
- (ベーシック認証は掛けるものの)野ざらしになったWebhookディストリビューションを作ることになること
- ドメインも別途発行する必要があること
- クライアントによっては発行まで色々やり取り発生するし時間かかるしめんどくさい
- 同時にSSLの設定等も増えるのでとにかくめんどくさい
解決策
- 今回下記の流れで面倒くささが解消されました
- LambdaをVPC内に作っちゃう
- Lambdaを配置したPrivateサブネットに繋がったNATゲートウェイのIPをWAFに追加する
- LambdaからメインのCloudFrontのURLを叩けるように書き換える
ゲイン(ハッピーになったこと)
- IP制限を掛けている範囲内でアプリケーションが完結したこと
- クライアントにドメインの追加申請をするという申し訳ない事態を防げたこと
- VPC内にLambdaを作成するという新たな知見を得ることができたこと
- 他にも同様の構成で悩んでいた人たちのちょっとした悩みを解消できたこと
解決策(解説)
LambdaをVPC内に作っちゃう
ServerlessFrameworkを使うとめちゃ簡単にできちゃいます。下記の通り
serverless.ymlのproviderに設置するサブネットとセキュリティグループを設定するだけ。# serverless.yml provider: name: aws runtime: ruby2.5 region: ap-northeast-1 stage: ${opt:stage, 'development'} # 以下を追加 vpc: securityGroupIds: - sg-xxxxxx subnetIds: - subnet-yyyyyy - subnet-zzzzzzちなみに私の場合は、複数の環境にまたいで管理をしているので実際はこんな感じで設定しています。
# serverless.yml provider: name: aws runtime: ruby2.5 region: ap-northeast-1 stage: ${opt:stage, 'development'} vpc: ${self:custom.vpc.${self:provider.stage}} custom: vpc: ${file(./vpc.yml)}# vpc.yml development: securityGroupIds: - sg-xxxxxx subnetIds: - subnet-yyyyyy - subnet-zzzzzz staging: securityGroupIds: - sg-aaaaaa subnetIds: - subnet-bbbbbb - subnet-cccccc production: securityGroupIds: - sg-dddddd subnetIds: - subnet-eeeeee - subnet-ffffff微妙なハマリポイント
ちなみに一見、下記のようにVPC内でLambdaを実行するためのポリシーを設定しないとだめなように思いますが、むしろ下記を設定するとエラーが発生します。
# serverless.yml provider: name: aws runtime: ruby2.5 region: ap-northeast-1 stage: ${opt:stage, 'development'} vpc: securityGroupIds: - sg-xxxxxx subnetIds: - subnet-yyyyyy - subnet-zzzzzz # 下記を追加すると動かない iamManagedPolicies: - arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRoleServerless Error --------------------------------------- An error occurred: IamRoleLambdaExecution - Property ManagedPolicyArns contains duplicate values.. Get Support --------------------------------------------どうやら
serverless.ymlにvpcの設定を行ったことでServerlessFramework自身がよしなにAWSLambdaVPCAccessExecutionRole相当のポリシーを実行ロールに付与してくれるようで(実際に追加されてました)、「それと同じポリシーは追加できないよー」的な感じで怒っているようです。よしな力高いのは良いけど分かりづらいwということで、これによりLambdaをVPC内に作成することができました。あとはプロジェクトによって方針はまちまちだと思うので、うまい具合にやってもらえたらと思います。
以上、LambdaをVPC内に作ってハッピーになった話、でした。
- 投稿日:2019-12-23T15:06:38+09:00
AWS Lambdaで動的サイトのwebスクレイピングをしてtwitterに投稿するbotを作った(続)
2018/10に作ったtwitterのbotをリファクタリングしました。理由としては
- python2.7で実行していた。
- Lambda Layer実装以前だったため、ソースコードのサイズが大きすぎてコンソールからは確認・修正できなかった。
- Serverless Framework/Lambda Layerを使ってみたかった。
などもあり、AWSの一年間の無料期間が終わるのでアカウントを作り直すついでに作り直しました。
ソースコードはこちら。
レポジトリの構成の概要は以下の通りです。. ├── lambda (Lambda本体) │ ├── includeするmoduleたち │ ├── lambdafunction.py │ └── serverless.yml │ └── selenium-layer (Lambda Layer用) ├── chrome-driver ├── selenium └── serverless.ymlServerless Frameworkが簡単すぎて感動しました。
前提条件
serverlessインストール済み(node.js v4以上必須)
AWSアカウント取得済み
aws-cliインストール・設定済み使い方
先にソースコード肥大化の原因のselenium+chromiumたちをLambda Layerにアップロードします。
$ cd selenium-layer $ sls deployそのあとはLambda本体をアップロード
$ cd ../lambda $ sls deployこれで終わりです。
- 投稿日:2019-12-23T14:58:05+09:00
eksctlでAWS EKSのNodegroupのインスタンス数をscaleする方法
AWS EKSで使うNodegroupをコマンドで操作する時はeksctlを使うので、NodegroupのEC2インスタンス数をscaleする時もeksctlを使います。
- まず、nodegroupのDESIRED CAPACITY数を確認します。
eksctl get nodegroup --cluster=[Cluster Name] CLUSTER NODEGROUP CREATED MIN SIZE MAX SIZE DESIRED CAPACITY INSTANCE TYPE IMAGE ID [Custer Name] [Nodegroup Name] 2019-12-19T03:38:35Z 1 6 1 t3.medium ami-[ID]DESIRED CAPACITY 1なので、1つのインスタンスが上がっていることが確認できます。
- nodeの数を1から2に増やします。
eksctl scale nodegroup --cluster=[Cluster Name] --nodes=2 --name=[Nodegroup Name] [?] scaling nodegroup, desired capacity from 1 to 2
- 再度nodegroupのDESIRED CAPACITY数を確認しすると、2に変わっていて2つのインスタンスが上がっていることが確認できます。
eksctl get nodegroup --cluster=[Cluster Name] CLUSTER NODEGROUP CREATED MIN SIZE MAX SIZE DESIRED CAPACITY INSTANCE TYPE IMAGE ID [Custer Name] [Nodegroup Name] 2019-12-19T03:38:35Z 1 6 2 t3.medium ami-[ID]もちろん、インスタンスの数はAWSのWebコンソル上でも確認できます。
年末年始に不要なインスタンスをたくさん上げたままにすると、請求金額が高くなるので、これで必要最低限に押さえることができます。
- 投稿日:2019-12-23T10:44:53+09:00
インフラ問題: CORSを使わずにSPAアプリをAWSにホスティングする
久々にインフラ周りの作業を行ったので備忘を兼ねて、やったことのメモを残しておきます。
インフラエンジニア向けの課題として、そこそこ面白い内容だと思うのでそれっぽい形式で書いてみます。命題
APIサーバと連携するSPAアプリケーションをAWSでホスティングしたい。
そのために必要な設定を行いなさい。アプリケーション条件
- この文書内ではアプリケーションのドメインは
hoge.comとする- アプリケーションは顧客企業毎にサブドメインを割り当てる仕組み
aaa.hoge.comとかbbb.hoge.comなど複数のドメインがある- SPAはルートにindex.htmlがあり、そこから参照されるJS, CSS, 画像などがサブディレクトリにある
- SPAのルーティングはHistory(ブラウザのパスが切り替わる)
- APIサーバはすでにELBを構成済み。APIサーバのエンドポイントは
api.hoge.com- APIサーバのエンドポイントはすべて
/api/で始まる- APIサーバはSPA以外からも単独で使用されることがある(かもしれないので想定しておく)
- SSL必須
- CORSは使えない
- SPAからのAPIリクエストは
/api/hogeのようにホスト名を含まない形で行われる- APIサーバ側でもCORSの設定はない
正直CORSを使えないという条件は無理ゲーなんじゃないかと途中から思ってましたけど、今回任されている役割はインフラなのでそれでできるところまでやってみることにしました。
結果、一応動くところまでは持っていけましたけど色々と問題もあるのでおいおいCORS対応して、インフラも構成し直すと思います。
解答例
以下の内容は今回自分が行った設定に過ぎず、もちろん唯一解ではないです。(むしろ他の方法があるなら知りたい)
基本方針はCloudfrontを使ってAPIとコンテンツのリクエストを振り分けるやり方をとってますが、各種設定の細かいところには触れておらずポイントのみを示しています。
ここから文体変わります
ACM
CloudfrontとAPIサーバに証明書が必要なので、
*.hoge.comの証明書を発行する。
Cloudfrontは何故かバージニアの証明書しか使えないので、東京都バージニアの両方で同じ証明書を発行する必要がある。Route53
api.hoge.com-> ELB*.hoge.com-> CloudfrontのAレコードをエイリアスを使って登録する。
S3
新しいBucketを作ってSPAの各種ファイルの置き場所とする。
ルートにindex.htmlを置き、各種サブフォルダもアプリの構成に従って配置。
ACLはpublic-readとする。またStatic Website Hostingを有効にして、インデックスドキュメント、エラードキュメントの両方を
index.htmlにする。Static Website Hostingとは?
S3はそのままでも、staticなコンテンツサーバとして機能するが、それにちょっとだけ便利な機能を追加したものと理解すると良い。
Static Website Hosting向けには
BUCKETNAME.s3-website-ap-northeast-1.amazonaws.comのようにS3とは別のエンドポイントが発行される。今回使った機能としては以下がある。
- インデックスドキュメント - ホストの
/にアクセスした時に表示するコンテンツ- エラードキュメント - 存在しないパスにアクセスした時に表示するコンテンツ
他にもカスタムリダイレクトルールを定義できたりするが、今回は使用していない。
ここでのポイントはエラードキュメントに
index.htmlを指定していること。
SPAでは画面遷移した後にリロードすると存在しないパスに対してリクエストが発行されることになるが、その場合でもindex.htmlを返すことでリロードにも対応できるようにしている。
(残念ながらStatusコードは403のままとなるがここで返したHTMLはブラウザで解釈されるので、動作自体には問題はない。)Cloudfront
Generalの設定でポイントとなる項目は以下
- Aternative Domain Names ->
*.hoge.com- SSL Certificate -> CustomでACMで作成した証明書を選択
- バージニアで作成したものしか選べない
- Default Root Object -> index.html
- ルートにアクセスした時にindex.htmlが表示されるようにする
- S3側でも設定しているので不要な気もするがまぁ一応
ログ等は必要に応じてよしなに。
次にS3向けのオリジンとELB向けのオリジンの2つを作成する。
WebConsole上ではOrigin Domain Nameの項目はドロップダウンから既存のS3 BucketやELBを選択することができるが、どちらもそこから選択してはいけない。
- S3 -> Static Website Hostingで発行されたエンドポイントを手入力する
- こうしないとインデックスドキュメントやエラードキュメントの設定が有効にならない
- ELB ->
api.hoge.comを手入力する
- こうしないと証明書不一致でアクセスできない
- (APIサーバはSPA以外からも使用されるので、ELBには
*.hoge.comの証明書が設定されている)Terraformで作成する場合は
origin_protocol_policyを
- S3 ->
http-only- ELB ->
https-onlyとする。
WebConsole上ではS3のStatic Website Hosting URLを指定した場合、origin_protocol_policyは表示されないがTerraformからは設定できるっぽい。
(Static Website HostingにはSSLはないのでhttps-onlyにしているとエラーとなる)最後にBehaviorの設定を行う
Behavior - S3側(Default)
- Origin -> S3
- Viewer Protocol Policy -> Redirect HTTP to HTTPS
http://でアクセスしてきた時に自動的にhttps://にリダイレクト- Allowed HTTP Methods -> GET, HEAD
- S3に対するリクエストではPOSTやDELETEはない
Behavior - ELB側
- Origin -> ELB
- Path Pattern -> /api/*
/api/*へのリクエストはELBに流す- Viewer Protocol Policy -> HTTPS Only
- Redirectでも良いけど
- Allowed HTTP Methods -> GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE
- Forward Cookies -> All
- NoneだとCookieが送られなくてセッションが維持されない
- Query String Forwarding and Caching -> All
- APIサーバではGET時のquery文字列はもちろん必要
キャッシュ周りの設定はどう設定するのが適切なのか検証しきれてないので割愛。
まぁ、APIサーバ側は一切キャッシュしなくても良いと思う。
総評
以上、ここまでの設定で一応当初の命題/条件はクリアしていると思います。
しかし、いくつか問題もあるのでここではそれらを列挙します。リロード時のStatusコードが403
これが一番気になるところです。
今回の設定は色々と試行錯誤の末にたどり着いたものですが、SPAのリロード周りを考慮するのが一番厄介でした。ちなみにネット上ではCloudfront側のError Pagesの設定で、404エラー時にindex.htmlを200で返す設定が紹介されてたりいますが、この方法はうまく行きません。
何故なら、この設定はAPIサーバ側にも効いてしまうので、APIサーバが404を返した時にも200 with index.htmlに書き換えられてしまうから。。。(--
Static Website Hostingのエンドポイントでコンテンツが公開されている
*.hoge.comではなく、BUCKETNAME.s3-website-ap-northeast-1.amazonaws.comにアクセスした場合にもSPAのコンテンツにアクセスできてしまいます。APIはコールできないのでアプリ自体が動作するわけではないですが気にはなります。
先のError Pagesの設定がBehavior毎に行えるものであれば、Static Websit Hosting(のエラードキュメント機能)を使う必要がなくなるので、Cloudfront経由以外のコンテンツアクセスを完全に禁止できて幸せになれそうな気がしますが。。。。
AWSさん、是非機能拡張を。
APIサーバへのSSLアクセスが中間で一度解かれる
CloudfrontはリージョンをまたがるのでそこからELBへのアクセスはインターネットを経由するという理解です。
なので、SSLは必須。しかし、この場合Cloudfront側で一度SSLが解かれて、再度APIサーバにSSLアクセスしているはず。
そのコストが若干気になります。まぁ、世のプロキシーサーバはだいたい同じことしてると思うのであんまり気にしなくてもよいのかもしれませんが。
結論
今回インフラ技術だけで問題を解決しようと色々と試行錯誤してみましたが、リロード403問題だけはクリアできませんでした。
Lambdaを使うことも考えましたが、Cloudfrontでやる方が素直な気がするので試してません。この構成で一応動作はするもののもちろんこのままで本番適用するわけにはいかず、対応としては、まぁ素直にアプリ側でCORS対応するのかなと思ってます。
その場合の構成変更及びメリットは以下のようになると思われます。
- S3ではStatic Website Hosting不要
- Cloudfront経由以外のコンテンツアクセスを不可にできる
- CloudfrontのオリジンはS3のみでとてもシンプル
- SPA対応はError Pagesで404を200 with index.htmlに設定すれば良いだけ
- APIサーバへのアクセスはProxyを経由しない直接アクセスになるので高速化
技術課題としてはとても面白かったです。
誰かリロード403問題をクリアする方法を知ってれば教えて下さい。
- 投稿日:2019-12-23T01:56:03+09:00
ランキングデータを作ったときのAWSサービス選定について
zomです。
この記事はLIFULL Advent Calendar その1の23日目の記事です。
いつもはアドベントカレンダーの日に向けて、前々から興味があったテーマについて調査検証した内容を書いたりしているのですが、今回は年の瀬ということもありますので今年担当したWebアプリケーションについて書いてみます。
Webアプリケーションにおける技術選定という工程は、そのときの要件、リソース(時間や人、金)、会社・組織・あるいはレガシーなシステムとのしがらみといった変数によって大きく変化します。
そのためQiitaなどで検索してもなかなか参考になる記事や考え方が見つからず、どうしたものかなぁと思ったので、このときの設計や技術選定の過程について書いてみようと思います。初めてこういったことをする人の参考になればいいな、と思います
なお、このプロダクトの作成時期は2019年の3月頃です。
また私の部署ではAWSを利用した環境が主なのでAWSのサービスで考えました。要件
- 駅/市区町村のランキングを表示する
- 駅数は2018年4月1日時点で9516駅(5/29(火)日本中の駅の数、全部でいくつ? 【駅DB2018年度、整備完了いたしました!】 | ナビットブログ調べ)
- 市区町村数は2019年時点で1724市区町村(市区町村数を調べる | 政府統計の総合窓口調べ)
- つまり合計1万超のデータを用意する
- もちろん本当は弊社所有のデータで計算していますが、Qiitaに載せていいのか分からないので参考値として↑を挙げさせていただきました

- ランキングの元データは3ヶ月分のデータを利用すること
- 具体的に3ヶ月分の何なのか、はロジックに関するので非公開とさせてください
前提条件(裏目標)
- 技術選定は自由
- その代わりに使い慣れたレガシーなシステムをなるべく使わないようにすること
- 古いレールに乗らない、次のレールを作るつもりでやること
- 人員は1人、納期はなる早であること
この前提は特に要件にはなかったのですが、当時の上司(に近い人)からのオーダーでした。
自由にやっていいので後輩の手本になるようなやり方をしてくれ、というものです。
実際にはもっと柔らかいニュアンスのオーダーですが、対外的に書くとこうなります
最初に考えたこと
前提条件を抜きに一旦考えてみます。
データストアを何にするか
- S3?
- RDB(RDS)?
- KVS(ElastiCache or DynamoDB)?
データをどう集めるか
- 既存のログを集計する?
- 新規に専用のデータを取り始める?
データを集計処理をどうやるか
- EC2でcron?
- Lambda?
- AWS Batch?
- AWS ECS?
RDBのORDER BYなどでリアルタイムに計算すれば処理は不要、データストアで完結するというやり方もあるかと思います。
上記のようなことが頭の中をよぎります。
他にもあるかもしれませんが、当時の自分が最初に思い浮かんだ選択肢はこんなところです。
ここからサイトでのレスポンス速度、既存の構成との兼ね合い、納期、拡張性(他のページでの利用しやすさ)、保守性(運用の楽さ)、前提条件などから最適解を見つけます。選定
自由とはいえ、やはり金・納期のことは無視できません。
そのためいくつかが選択肢から外れます。
- 新規に専用のデータを取り始める
- ランキングの元データは3ヶ月分のデータを利用すること
正直、自由にやっていいというところでログ設計から自分でできるチャンス!と思ったのですが、3ヶ月分のデータを表示するということから、リリースしてからランキングが表示されるまでさらに3ヶ月待たせてしまうことになります。
これでは前提条件の「なる早」にも反してますので却下となります。
- RDB
RDBは人によっては全然選択肢に入っていい内容かと思います。
ただ、RDBのRelationalな部分をそこまで活かすこともなく、KVSで十分なのでは?と考えたことや、すでに使っているデータベース上に(社内事情的な制約で)新規にテーブルを作る積極的な理由が見つかりませんでした。
- EC2でcron
これは社内では実績がある作り、バッチ用インスタンスなるものが存在します。なのでそこで開発すればリリース速度はおそらく一番早く、納期重視だったらこの選択肢を選んでいたことでしょう。
しかしレールが古く私自身にとっても学びが少ない作り方になってしまうので採用しませんでした。
- Lambda
ランキングの集計処理に関して言うと、真っ先に思い浮かんだのはLambdaでした。
そのつもりでデータ設計などをして試しにデータを集計する処理などを書いたりして検証を始めたのですが、3ヶ月という膨大なデータ量がLambdaの制限である15分の壁をクリアできないということが発覚しました。
たしか1ヶ月分のデータでも15分の壁を突破できなかったと記憶しています。
検証はしていませんがメモリ量(CPU)を多く割り当てれば行けた可能性はあります。ただ、メモリ量を増やしたところでデータ量次第でさらにメモリを必要とする、安定稼働しないリスクがあるということになりますので別の方法を考えておくべきだと考えました。※データ量がネックになっているので、あれば例えば10日分のデータなど細かい単位で実行し、中間データみたいなものを作るという手法も検討しました。
ただそうなると中間データを生成するバッチ処理と最終的なデータを生成するバッチ処理の2つが必要になります。
この場合前後関係ができてしまい、順番を考慮する必要があるなど要件に対して管理コストが高くなってしまうのでは?ということで却下しました。
- AWS Batch
Lambdaが選択肢から外れかけたので使ったことのないAWS Batchも視野に入れてみましたが、やりたいことに対して機能が過剰な気がしました。
当時参考にさせていただいた記事はAWS Batch とは何か@pottavaです。これがマネージドされると僕らは何がうれしいのか
- 本来やりたい、ジョブの実行依頼(submit)と実処理だけを考えればよくなる
- クラスタ全体で利用可能なリソースの把握、過不足に応じたその調整が不要3に
- 前処理、集約処理、後処理といった流れのある処理も基盤側に制御を移譲できる
- 依頼者や状況に応じた優先的リソース配分が容易に実現できる
- CPU / GPU でそれぞれクラスタを作り、前処理 CPU、本処理 GPU なども簡単
- クラスタごとに可用性、パフォーマンス、コストのバランスが定義しやすい
- Docker イメージにさえしてしまえばどんな処理も AWS Batch に乗せられる
- すでにデータ分析パイプラインの定義があれば移行しやすい(かもしれない)
上記記事より一部引用
3ヶ月分のデータがサクッと集計できるのであれば 前処理、集約処理、後処理といった流れのある処理 も不要ですし、 状況に応じた優先的リソース配分 や CPU / GPU でそれぞれクラスタを作り、前処理 CPU、本処理 GPU なども簡単 といった、そんなことをせずに済むのです。
ということでAWS Batchも選択肢から外れました。
採用したもの
- 既存のログを
- AWS ECSで集計し
- KVS(Redis(ElastiCache)のSortedSets)に入れる
という構成です。
ここからは今まで以上に既存のシステム構成によるので汎用性のない話になります。
既存のログ
既存のログというのがS3上に格納されていました。
S3上にあるデータを集計するといえばAWS Athenaですね!これをAWS ECSで集計します。
AWS ECS
ECSはDockerコンテナアプリケーションをAWS上で実行できるサービスです。またFargateを使えばサーバレスで実行できるのでサーバの管理コストも減らせます。
プログラムは個人的に好きなRubyで書きAWS SDKを使ってAthenaの実行をしました。データベースの作成からテーブルの作成など、すべてSQLライクに書けるので多くのエンジニアでもとっつきやすいのではないかと思います。
が、S3のログの内容からデータ型の設定がうまく行かないとか、思ったよりいろんなポリシーを必要としてIAM周りをバコッと食わせる必要があるとか、サービス間の連携の部分でのハマり事はあるかもしれません。プログラムからRedisに接続する際の接続情報をセキュアに管理したほうが良いよね、となったときはParameterStoreを使うことで難なく実現できました。便利。
肝心の定期実行はCloudWatchEventsのcron式で実現可能です。
ハマりどころとしては、UTCの時間であることや、通常のLinuxのcronとちょっとだけ構文が異なったり、CloudWatchEvents独自の記法があるのが少しだけある程度です。RedisのSortedSets
これもドチャクソ便利でした。
過去にMemcacheの利用からRedisに移り変わるときにソート済みセット型 — redis 2.0.3 documentationを目にしていて「いつかこれ使うぞ〜〜〜」という気持ちだったので、ついに使う時が来たという気持ちでいっぱいでした。
上記の日本語ドキュメントは2.0.3時点のものなので存在していませんが、
zrevrangebyscoreが今回最高に使えました。
スコアの高い順にソートして返してくれる、上限下限も設定できるのでスコアによる足切りもできちゃうし、offsetとcountがあるのでランキングのページング機能もお手の物。スコアも返せちゃうので同点だったときにちょっと入れ替えようか、なんてときもアプリケーションで制御可能です。(同点だったときのデフォルトはmemberのASCIIコード順になるはず)最終的に利用したAWSのサービス
- ログ置き場としてS3
- 集計のメイン処理としてAthena
- 実行環境としてECS
- コンテナイメージ管理としてECR
- ECS起動&ログ出力のためにCloudWatch(Events)
- データの保存先としてElastiCache
このようになりました。
結びに
今回は様々な事情からこのような構成になりましたが、LambdaやAWS Batchを使う可能性も全然ありえたとは思います。例えばLambdaのところで触れた中間データも、他のアプリケーションで使い回すことがあるなどの要件や展望があれば採用されていたと思います。
また今回は自分の想定の中にありませんでしたが、多くのWebサービスでも使われているであろうGoogleAnalyticsから集計するという手法もあったのではないかと思います。AWSのサービスを使い倒して手軽に、安全で、安定した価値提供を行っていきたいですね。
- 投稿日:2019-12-23T00:20:20+09:00
Telegram botをAWS Lambdaでやってみた
Leoです。
この記事は Wanoグループ Advent Calendar 2019 の22日目の記事になります。Telegramのアプリにserverless botの機能を追加しました。
現在僕は複数のメッセンジャを使っています。
Lineにはbotを簡単に追加できますが、今回初めてTelegramのアプリに入れる必要があったので、この記事をメモとしても書きました。Telegramのbotの実装には基本的に4ステップがあります。
- Botの登録
- AWS lambdaの登録
- AWS API Gatewayのendpointを追加
- EndpointをTelegramにwebhookとして登録
Botの登録
Lineと違って、Telegramのbot登録やbotの操作はアプリ内でできます。(Lineの場合、Developerのページでやります)
TelegramのアプリにBotFatherっていうアカウントを検索します。
screen
BotFatherとのチャットに'/newbot'のコマンドで新しいbotを登録します。
登録が始まったら、botの名前とかuser_idを登録します。
登録は完了したらbotのAPIにアクセスする時に必要なtokenが発行されます。secret tokenのため、安全なストレージに保存しましょう。
このチャットでbotの設定の更新もできます。Lambdaの登録
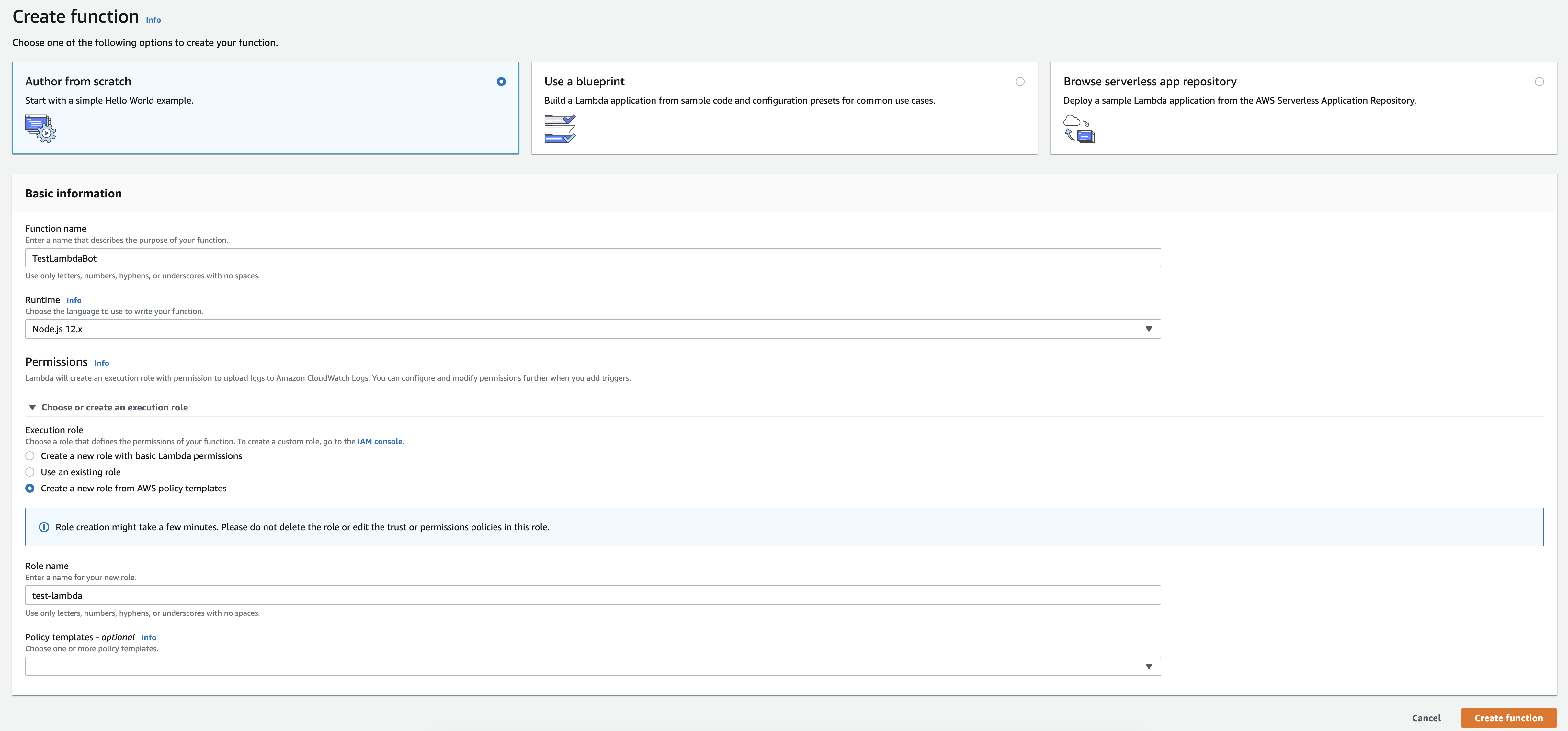
Lambdaを登録します。今日はAWSのコンソールでの登録を説明します。
今回http requestしか使わないのでデフォルトのNodejs環境で実装しますが、GoやPythonなどの環境でも簡単に実装できます。
Lambdaの中に以下のことをやっています。
1. Webhookのイベントを受け取っている
2. Webhookのリクエストのパラメータからmessageのtextを取得している
3. TelegramのAPIを叩いてチャネルに返信してる上の3つの機能が含まれている以下のコードをLambdaのindex.jsに入れる。
const https = require('https'); const BOT_TOKEN = process.env.BOT_TOKEN const URL = "https://api.telegram.org/bot" + BOT_TOKEN + "/sendMessage?"; exports.handler = function(event, context, callback) { let text = 'Echo: ' + event.message.text; let chatId = event.message.chat.id; let replyUrl = URL + 'text=' + text + '&chat_id=' + chatId; https.get(replyUrl, (res) => { console.log("Got response: " + res.statusCode); callback(null, res.statusCode) }).on('error', (e) => { console.log("Got error: " + e.message); callback(Error(e)) }) };Telegramのチャネルにメッセージの送信は単純なGETでできます。
LambdaのEnvironment variableにBOT_TOKENを定義する必要があります。最後に'保存'押して、Lambdaの登録は完了です。
APIの登録
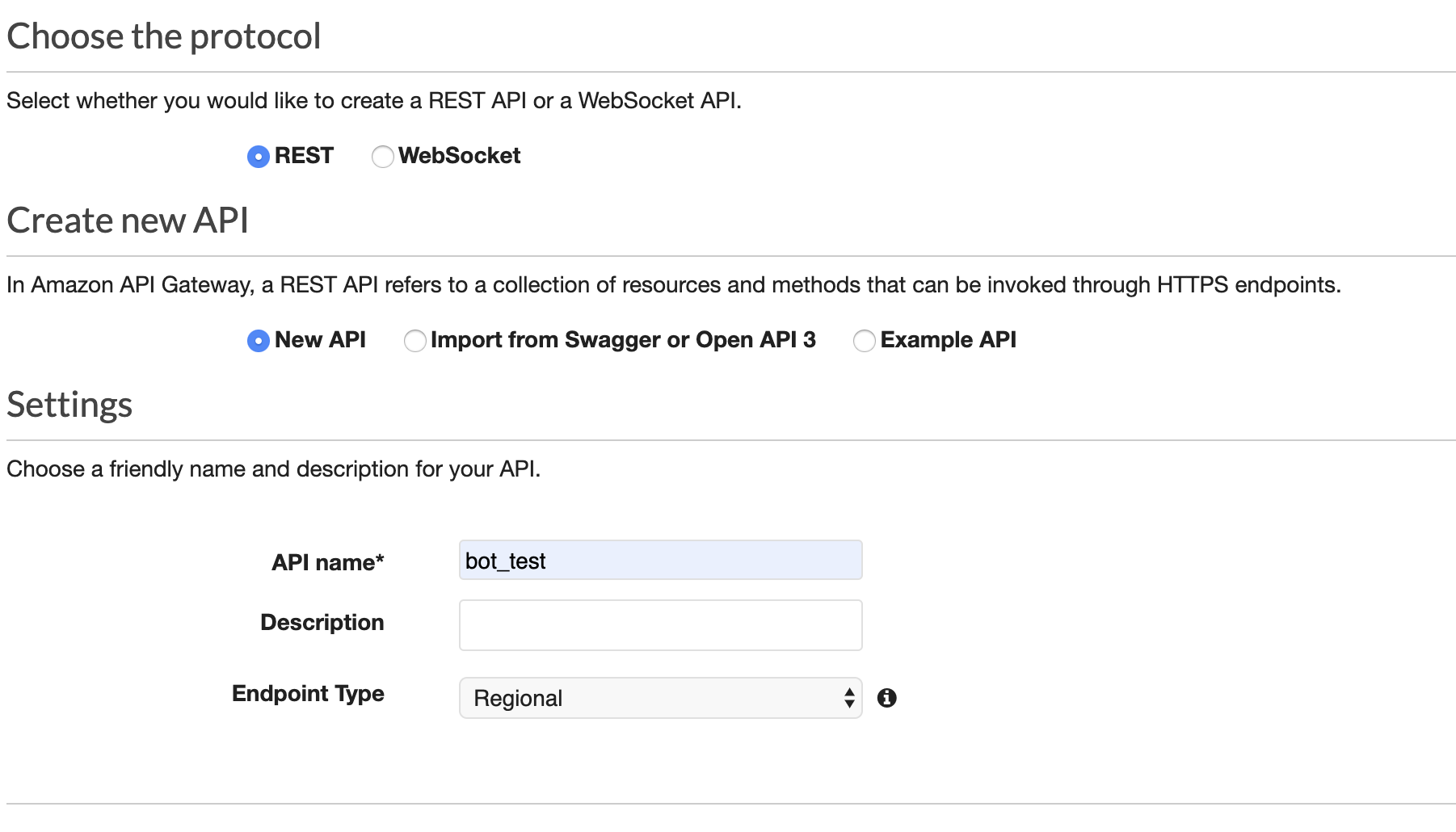
BotのWebhookになるAWS API GatewayのREST APIを登録します。
新しいAPIを登録します。
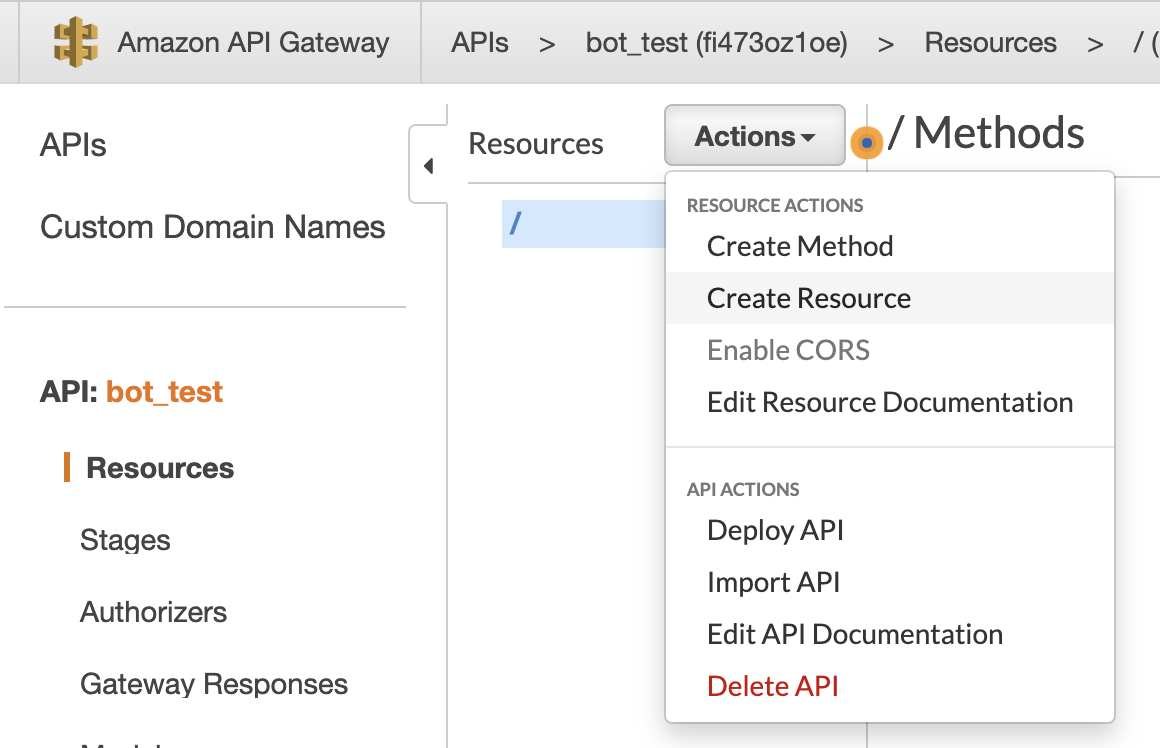
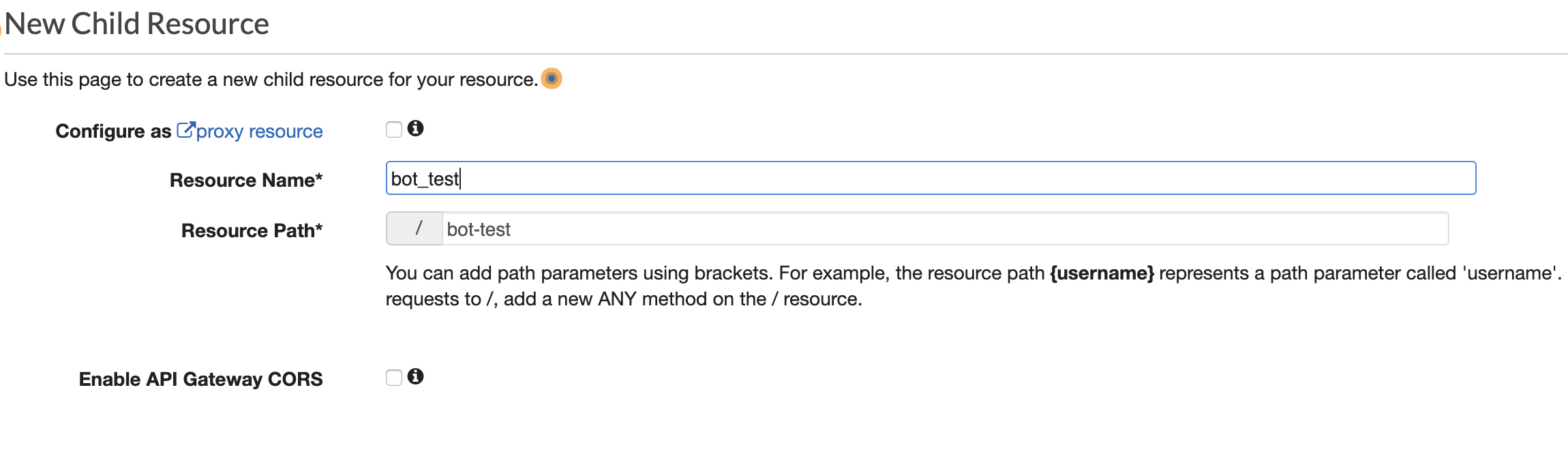
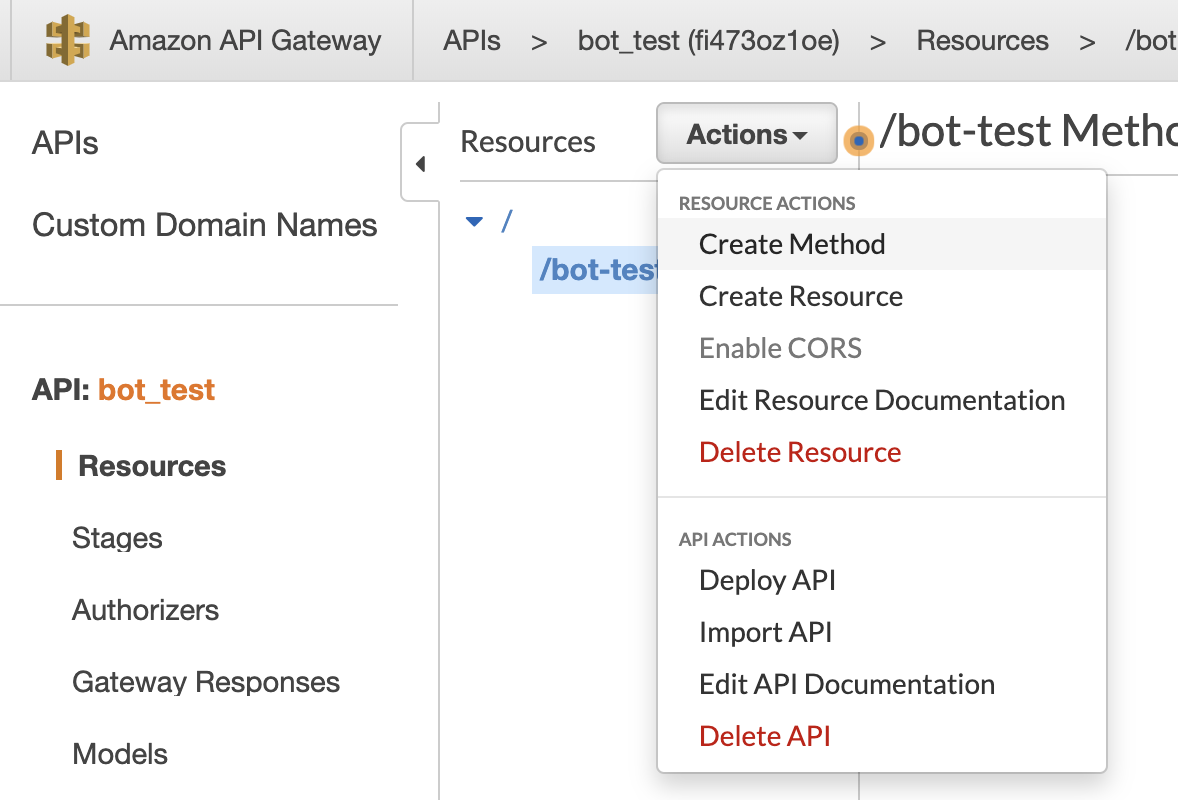
Resource/PathをCreate Resourceで指定します。
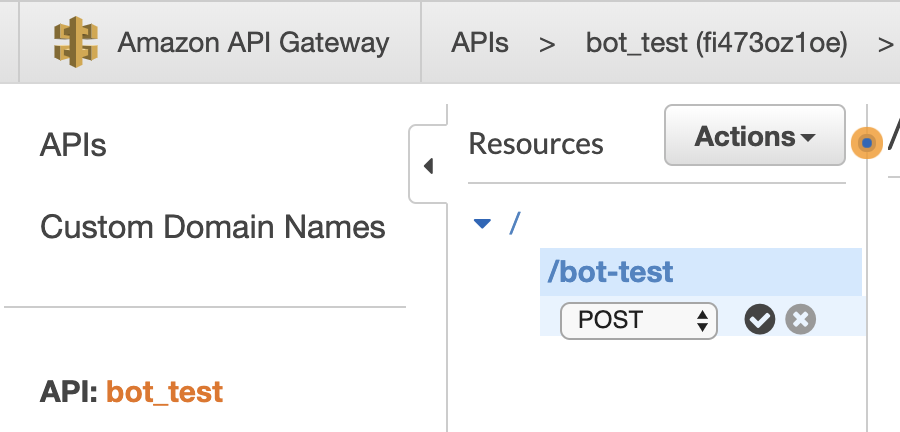
TelegramのWebhookはPOSTで通知するので、Create MethodでPOST指定します。
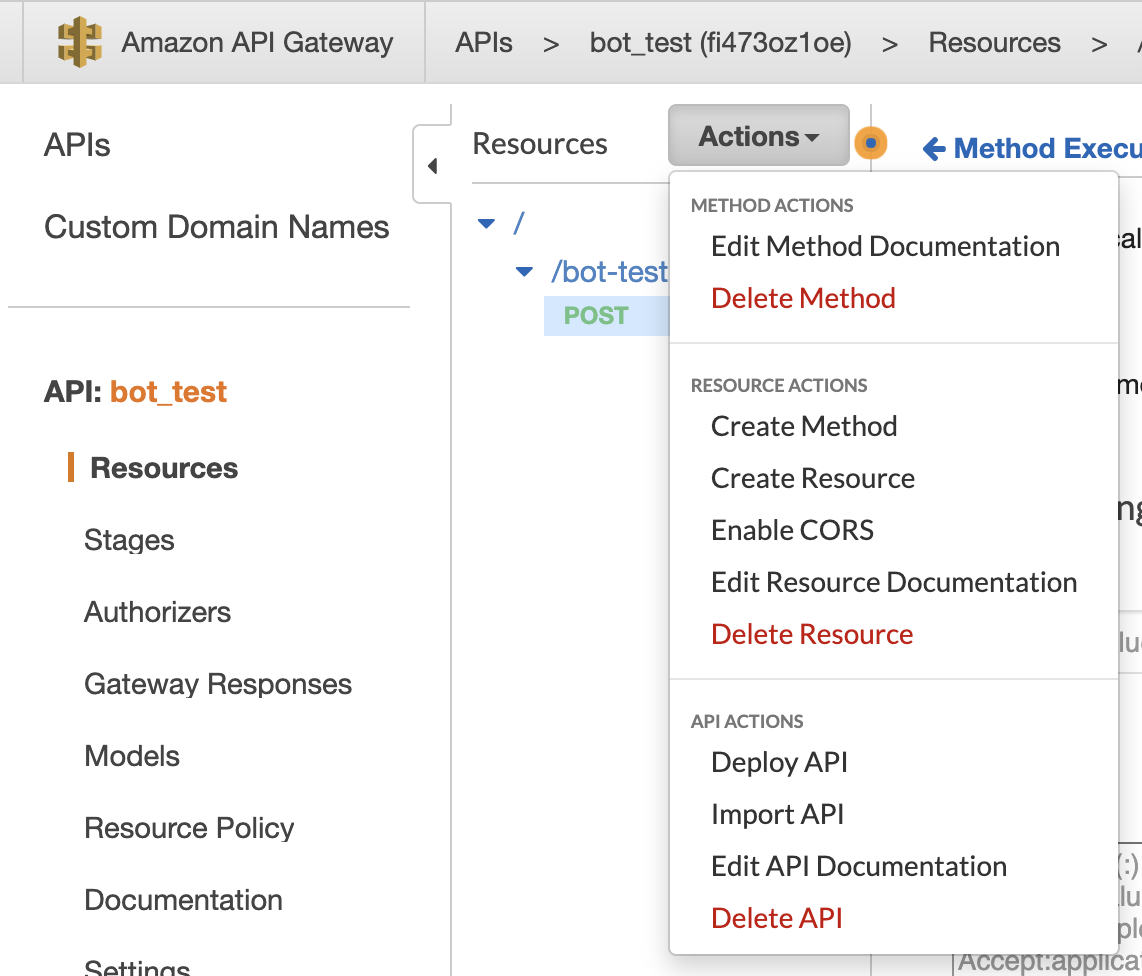
HTTP Methodを指定したら、APIと前に登録したLambdaを結びつくためにIntegrationに用意したLambda名を入れます。そうするとこのAPIはトリガーとして登録されます。
後はステージ名を振ってAPIをデプロイするだけです。
今回はステージ名を'test'にしました。
APIをデプロイしたらページの上に'Invoke API URL'が以下のように表示されます。
https://fiXXXX1oe.execute-api.us-east-2.amazonaws.com/test/これはまだWebhookのURLではありません。最後の'test'はステージ名になります。
このURLの後ろにAPIのpath(今回は'bot-test')を付けるとWebhookのURLになります。https://fiXXXX1oe.execute-api.us-east-2.amazonaws.com/test/bot-testWebhookの登録
最後にAPI Gatewayに登録したURLをTelegramにWebhookとして登録しましょう。
そのために以下のTelegramのAPIを使えます。https://api.telegram.org/bot<BOT_TOKEN>/setWebHook?url=<WEBHOOK_URL><>のところをそれぞれ入れてGETリクエストを叩きます(ブラウザからでもOK)
https://api.telegram.org/bot1001745750:AAFDXkXXXXXXXXXXXXXXXXXXX4kqp0Mto/setWebHook?url=https://fiXXXX1oe.execute-api.us-east-2.amazonaws.com/test/bot-test以下の返信が来ます。
{"ok":true,"result":true,"description":"Webhook was set"}これでBotの基本的な実装は終わりです。
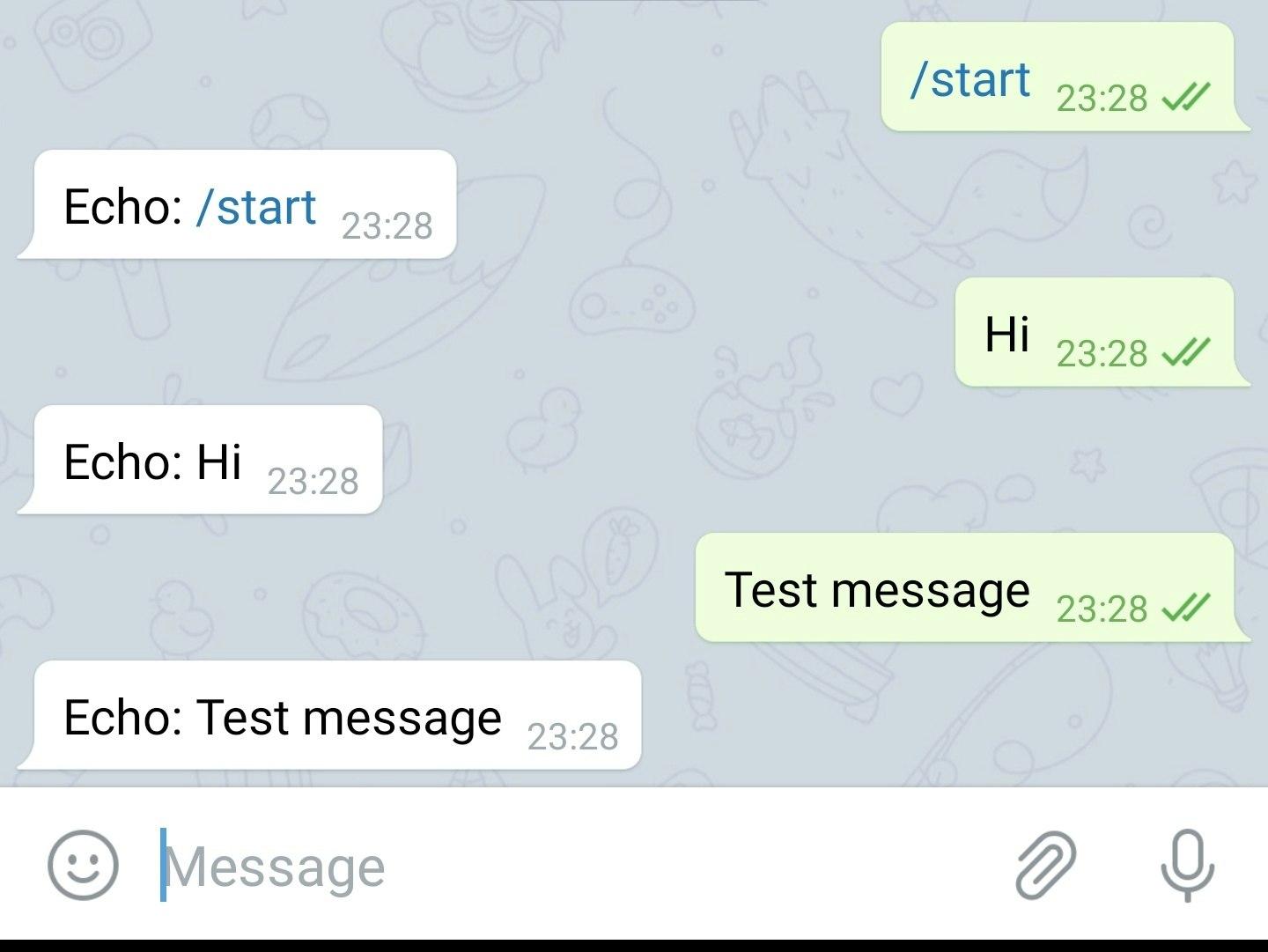
Telegramでbotを検索して、チャネルに書いてみるとEchoされます。
終わりに
もちろんこのbotは例として作りました。LambdaがトリガとしてAWSの色々なサービスに広げることもできます。DBにアクセスやSFNをキックすることなどできます。
Lineのbotと比べてTelegramのbotのAPIはシンプルで、serverlessなbotは誰も作れるって感じでした。