- 投稿日:2019-12-23T23:26:10+09:00
java 配列変数
今回は配列変数について書きます。
配列変数とは
配列が複数の値がまとまったものですが。
配列変数はそれを変数に入れて使用する方式です。例はこちら
配列変数の例public class Sample { public static void main(String[] args) { double[] d = new double[3]; double sum,avg; // 合計値、平均値を入れる変数 // 値を代入 d[0] = 1.2; d[1] = 3.7; d[2] = 4.1; sum = 0.0; for(int i = 0; i < d.length; i++){ System.out.print(d[i] + " "); sum += d[i]; //繰り返し構文で値を総ていれる。 } System.out.println(); avg = sum / 3.0; System.out.println("合計値:" + sum); System.out.println("平均値:" + avg); } }実行結果は
1.2 3.7 4.1
合計値:9.0
平均値:3.0
とで出てきます。では詳細を進めて行きます。
配列の宣言
まず配列の宣言を行います。
配列の宣言(変数の型名) (変数名)[] = new (変数の型名)[配列の数]; または (変数の型名) [](変数名) = new (変数の型名)[配列の数];一番最初はこうした形で宣言しました。
一部抜粋public static void main(String[] args) { double[] d = new double[3]; //ここで宣言しています。変数dにdoubleの型,配列の数は3です。 double sum,avg;
- 投稿日:2019-12-23T20:35:15+09:00
レガシーコードの改善をし続けるPHPエンジニアがオブジェクト指向について勉強してみた
この記事を書こうとと思ったきっかけ
レガシーコードを日々改善し続けているのですが、あまりにもレガシーコードの改善しか仕事がないので、オブジェクト指向について学んでみたいと思いこの記事をアウトプットします。
オブジェクト指向とは
システムを実現するために必要な処理を部品化し、それを組み合わせること
なぜオブジェクト思考が必要か
- コードを書く上での問題
処理が長くなりすぎて人間の頭では何をしているかわからないものになっていく。
一旦、動くものを作ることができてもできても保守等をするときに
読み返したとき、何をどこで行なっているかわからない処理になってしまう。
→開発の一番のボトルネックオブジェクト指向のプログラミングの考え方
- どこに何の機能を持たせるか
- その機能を組み合わせてどういう風にシステムを作っていくか
オブジェクト指向の定義
ソフトウェアを開発するプロセスを部品化し組み立てていく考え方
例えば、電車というモノ(オブジェクト)があったときに、
どのような動きをするものが電車であるかを考える。
- 電車が動く
- 電車が止まる
- 電車の扉が開く
- 電車の扉が閉じる
上記のように、電車というモノを作ると考えた時に
どういった処理をすることで電車として構成されているのかを考えるオブジェクト思考で大切な3大要素
- カプセル化
- 継承
- 多態性(ポリモーフィズム)
プログラムの一行一行が何をしているかではなく、オブジェクト(処理)をどう作り、どのように連携させていくかを軸に考えるために上記の3大要素を活用していく
3大要素をそれぞれ解説していく。
カプセル化
以下のようなVehicleクラスがあるとしてmoveOnというメソッドが用意されている。
- 呼び出し元はmoveOnというメソッドを呼んでいることしか分からない
- メソッド内で使用しているisMoveは外部から隠蔽されていると言える。
このような作りをカプセル化という。
Vehicle.javapublic class Vehicle { private Boolean isMove = false; public void moveOn() { this.isMove = true; System.out.println("乗り物が動きます"); } public void stop() { this.isMove = false; System.out.println("乗り物が停まります"); } }カプセル化は、フィールドへの読み書きやメソッドへの呼び出しを制限して、実装をするため、オブジェクト内部の変更が外部に対して予期しない干渉・影響を与えて壊れにくくなる。
アクセス制御は以下の4段階がある。
制限の強さ(黒星が多いほど厳しい) 名前 記載方法 アクセス許可範囲 ★★★★ private privateと記載 自分自身のクラスのみ ★★★☆ package private 何も書かない 自分と同じパッケージに属するクラス ★★☆☆ protected protectedと記載 自分と同じパッケージに属するか、自分を継承した子クラス ★☆☆☆ public publicと記載 すべてのクラス 継承とはなにか
以下のようにVehicleクラスとそれを継承したTrainクラスがある。
この場合、次のように呼称することがある。
- Vehicle: 親クラス、スーパークラス
- Train: 子クラス、サブクラス
ざっくりいうと、親クラスを引き継ぐ(extends)ことを継承という。
下記のTrainはmoveOnはOverrideして独自に実装しているが、stopは親クラスのメソッドを使用している。
Vehicle.javapublic class Vehicle { protected Boolean isMove = false; public void moveOn() { this.isMove = true; System.out.println("乗り物が動きます"); } public void stop() { this.isMove = false; System.out.println("乗り物が停まります"); } public void setIsMove(Boolean isMove) { this.isMove = isMove; } public void info() { System.out.println("乗り物(Vehicle)です"); } }Train.javapublic class Train extends Vehicle { private Boolean isOpenDoor; @Override public void moveOn() { if (this.isOpenDoor) { throw new RuntimeException("例外エラーです"); } super.moveOn(); } public void closeDoor() { this.isOpenDoor = false; } public void openDoor() { if (super.isMove) { throw new RuntimeException("例外エラーです"); } System.out.println("扉を開けました"); } public void info() { System.out.println("電車(Train)です"); } }実際に動かしてみる。
Main.javapublic class Main { public static void main(String[] args) { Train train = new Train(); train.closeDoor(); train.moveOn(); train.stop(); } }【結果】
Vehicleを継承しているため、stopも問題なく呼び出せていることがわかる。
乗り物が動きます 乗り物が停まります Process finished with exit code 0多態性(Polymorphism)とは何か
多態性とは、物事を大きく捉えることにより、違うものを同じように扱うこと。
簡単に言うと、これまで登場したTrainをVehicleとして扱うこと。新たにCarクラスを作成し、Vehicleとして扱ってみる。(※継承の時に利用したTrainとVehicleを再利用して...)
Car.javapublic class Car extends Vehicle { private Boolean isStartEngine = false; private String gearMode = "NEUTRAL"; @Override public void moveOn() { if (!isStartEngine) { throw new RuntimeException("エンジンがかかっていません"); } if (gearMode.equals("NEUTRAL")) { throw new RuntimeException("ニュートラルでは進めません"); } super.moveOn(); } public void setGear(String mode) { switch (mode) { case "NEUTRAL": case "DRIVE": case "BACK": gearMode = mode; default: throw new RuntimeException("指定されたモードが存在しません"); } } public void info () { System.out.println("車(Car)です"); } }Main.javapublic class Main { public static void main(String[] args) { Vehicle vehicle = new Vehicle(); Vehicle vehicleCar = new Car(); Vehicle vehicleTrain = new Train(); vehicle.info(); vehicleCar.info(); vehicleTrain.info(); } }【結果】 Vehicleを親クラスとしているのでCar・TrainはVehicleとして扱えており、多態性を満たしていると言える。
オブジェクト指向のメリット
- ブログラムを容易に変更しやすくなる
- プログラムの一部を簡単に転用できる
手続き型プログラミングとオブジェクト指向のプログラミングの違い
- プログラムの先頭から順番に命令として記述していくのが手続き型
- 実現しようとするプログラムを部品で考え、処理を分け組み合わせるのがオブジェクト指向
感想
使われ続けていくシステムを作るために、見やすく、わかりやすく、安全性の高いコードを書くためにオブジェクト指向の基本的なことを知ることはとても大切だと感じた。
概要を難しい言葉を使わずに記載しましたが、実際にソースコードを書く際はそれぞれの機能にもルールがあるのでそれを確認しながら活用していきたい。
- 投稿日:2019-12-23T18:22:43+09:00
オブジェクト指向の申し子!?JavaでDeep Learningをやってみた(お試し編)
FUJITSU Advent Calendar 2019 23日目の記事です。
オブジェクト指向の申し子的言語と言えばJavaなのではないでしょうか?歴史的にはC++やSmalltalkが先に世に出た様ですが、Cとの互換性を考慮して開発されたC++はオブジェクト指向による実装を強制しません。Smalltalkに至っては筆者は寡聞にしてその存在を知りませんでした。。。以前ある書籍で「再利用性を考慮したプログラムを比較的簡単に実装できる開発思想=オブジェクト指向」を代表する言語はJavaと読んだ記憶が有りますが、あながち間違っていないのではないかと思います。人気プログラミング言語の変遷、1965~2019年(Python視点)からも分かりますが、ソフトウェア開発でも広く利用されて来た言語です。因みに社内のソフトウェア開発では現在でも圧倒的なシェア!?を握っている様です。(俗説で統計データは有りません
やりたいこと
前置きがとても長くなりましたが、要はJavaでDeep Learningをやってみると言うのが本記事の内容です。
なぜJavaなのか?
競技プログラミングが三度の飯より好きな友人が、以前はJavaでプログラミングをやっていたのが、最近Rustに乗り換えたと言っていました。何でも流行の言語をやってみたかったとのこと。前掲の人気プログラミング言語の変遷からも分かる様にどうも他の言語に押され気味のJava。。。古い言語という様な表現する人も居たりと散々の扱い。。。オブジェクト指向の申し子がまだまだ現役で戦えるということを証明するには昨今流行のDeep Learningをやってのけるぐらいのことをやらなければと思いやってみました。但し、今回は表題にも有る通りお試し編です。
The Last Java Samurai1
因みに筆者は非情報系の出身で、学生時代にJavaを勉強しようとして挫折し、入社後勉強してJavaの良さが初めて分かりました。
Java ∩ Deep Learning ∩ OSSが実は存在する
Deep Learningを含む機械学習の世界ではPythonが圧倒的なシェアを握り、大半のOSS機会学習用ライブラリもPythonで実装されていますが、以前からJavaでDeep Learningのモデルを用いて学習や推論が可能なOSS2は有りました。しかし、今回は2019年12月3日に新しくリリースされたOSS「Deep Java Library (以下DJL)3」を使ってみようと思います。
Deep Java Library (DJL) でDeep Learning (漸く本題)
記事が長くなってしまっていますが漸く本題です。現在の所、頼れる情報は公式サイトや参考記事だけの様です。

環境構築
参考記事ではGradleを用いた方法でAWS上で環境構築を行っていましたが、今回はローカル環境でDocker + Jupyter Notebookを用いてコンテナ上で実行する方法を採用したいと思います。Jupyter NotebookはPython用の可視化ツールというイメージが有りますが、最近は多言語対応が進んでおり、益々便利になっています。
実行環境
macOS Mojave 10.14.6(CPU:Corei5-8210Y 1.6GHz, DRAM:16GB)4
Docker 19.03.5ソースのクローン
GitHubからリポジトリをクローンします。
git clone https://github.com/awslabs/djl.git
djlディレクトリ配下のjupyterディレクトリに移動cd djl/jupyter/コンテナの起動
docker container run -itd -p 127.0.0.1:8888:8888 -v $PWD:/home/jupyter deepjavalibrary/jupyterDockerfileを編集してイメージをビルドすることも出来ますが、今回はデフォルトのまま起動しました。
コンテナの起動確認
$ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 03791a7b1641 deepjavalibrary/jupyter "jupyter notebook --…" 4 minutes ago Up 4 minutes 127.0.0.1:8888->8888/tcp suspicious_brattainJupyterを起動
http://localhost:8888にアクセスして以下のページが表示されれば成功です。
よく見るとチュートリアルが各々のノートブックとして既に格納済です。Javaでやると豪語しつつJupyter Notebookのお手軽さに屈してしまいました。。。
Multi Layer Perceptron (MLP) の実行
train_your_first_model.ipynbを起動します。MLPを用いた手書き文字認識(MNIST)のサンプルです。学習の実行はShit + Enterで順にセル上のコマンドを実行していくだけです。とてもお手軽に実行出来ます。main関数やclassの記述も不要なのには最初驚きました。
モデル保存時に以下のメッセージが出力されました。正答率が約97%ですが、これはあくまで学習時の評価用データでの数値で、今回テストデータによる正答率は測定していません。。。。
Model ( Name: mlp Model location: /home/jupyter/build/mlp Data Type: float32 Accuracy: 0.96991664 Epoch: 2 )Model Zoo(Deep Learning)で推論を実行
今回はオブジェクト認識のサンプルを実行してみます。
object_detection_with_model_zoo.ipynbを起動します。前掲の参考記事でModel Zooを試していたため、別のサンプルを試そうと思ったのですが、ライブラリの詳細な使い方をまだ理解出来ていないのと、学習には矢張りGPU環境が必須であるため(CPUではMLPの学習でも時間が。。。)今回は学習済モデル(SSD:Single Shot MultiBox Detector)によるオブジェクト認識(推論)を試しました。
オブジェクト認識を以下の画像で試します。犬、自転車、車が写っている写真です。
推論結果
実行結果を以下に示します。正しくオブジェクト(犬、自転車、車)を認識出来ています。
推論結果(数値)を以下に示します。各々のオブジェクトが高い確度で認識されていることが分かります。
[ class: "car", probability: 0.99991, bounds: [x=0.612, y=0.137, width=0.293, height=0.160] class: "bicycle", probability: 0.95365, bounds: [x=0.162, y=0.207, width=0.594, height=0.590] class: "dog", probability: 0.93471, bounds: [x=0.168, y=0.350, width=0.274, height=0.594] ]まとめと今後の課題
JavaでDeep Learningが実行可能なJDLを試しました。AWS上での実行を想定している様ですが、ローカル環境上のDockerでも問題無く動作しました。今回はお試し編でしたが、今後調査を進めてもう少し高度なことに挑戦したいと思います。最後に今後の課題を以下に記載します。
- GPU環境への導入(まずはGPUマシーンの構築から)
- 各種APIやモジュールの使い方を調査して自分で実装したモデルの学習、評価等まで実行
以上、オブジェクト指向の申し子によるDeep Learningの実行お試し編でした。来年も頑張って記事の投稿を続けていきたいと思います。
https://blog.heroku.com/samurai-duke-and-the-legend-of-openjdk ↩
Deeplearning4jです。日本語の書籍として「Deep Learning Javaプログラミング 深層学習の理論と実装 (巣籠 悠輔著; インプレス; 2016年)」が出版されています。 ↩
今回はDJLを試してみることを目標としているため、GPU+CUDAが動作する環境ではなく、CPU上で実行します。故に、今回の検証はMulti Layer Perceptronの学習やDeep Learningの学習済モデルを用いた推論を試すことに留めます。GPU上での動作は後日試してみることにします。 ↩







- 投稿日:2019-12-23T17:33:14+09:00
LiferayのREST Builderを使用した独自ヘッドレスAPIの作成方法(パート4)
※この記事はLiferayコミュニティブログに投稿された、Creating Headless APIs (Part 4)を翻訳したものです。
はじめに
LiferayのREST Builderツールを使用して独自のヘッドレスAPIを生成することを目的とした当ブログシリーズも、いよいよ大詰めです!
パート1では、新規プロジェクトとモジュールを作成し、再利用可能なコンポーネントの説明を経てヘッドレスサービスを定義するOpenAPI Yamlファイルの作成を開始しました。
パート2では、パスの追加とREST Builderで生成されたコードにまつわる一般的な問題とそれらへの対処方法を経て、OpenAPI Yamlファイルを完成させました。
パート3では、生成されたすべてのコードをレビューし、構築を理解し、実装コードをどこへ追加するのかを学びました。シリーズラストとなる本章では、値の永続化に必要な
ServiceBuilder(SB)レイヤーを作成し、ヘッドレスAPIのサポートにあたり、特に実装の必要がある部分に細心の注意を払います。注:Service Builderの使用は必須ではありません。永続性担保については任意の手法を採ることができます(どの方法であれ、永続性の担保は必要です)。また、独自実装の負荷が高いもの(ページリストのreturn、検索/フィルタ/ソートの適用など)もあります。
ServiceBuilderを利用する場合、それらの面倒事をスキップし、独自サービスの設計に時間を割くことができます。Service Builderレイヤーの作成
永続化レイヤーにService Builderを使用します。この工程の詳細すべてには触れませんが、ヘッドレスAPIの利便性を向上させるにあたり追加する箇所に、重点的に触れていきます。
サービス部分の最も複雑な側面は、すべての「ビタミン成分」を取得する
/vitaminsパスで、一見すると最も容易に感じられる箇所です。なぜとても難しいのか?私たちはLiferayモデルに則り、下記の点を考慮する必要があるためです:
- 検索のサポート。これはインデックスを介して行われるため、SBエンティティのインデックスを生成する必要があります。
- パーミッションのサポート。新しい検索の実装はデフォルトでパーミッションに対応しているため、これをサポートする必要があります。
- 呼び出し元で決定された結果のソートのサポート。
- 特殊文字を使用した検索結果のフィルタリング
- 検索結果のページネーションのサポート。ページ数は呼び出し元によって決定されます。
- Remote Services。適切なタイミングで権限チェッカーを呼び出します。
これらすべてを実現するには、エンティティにインデックスが付与されていることを確認する必要があります。確認方法はこちらをご覧ください。
新しいインデックスはデフォルトでパーミッションに対応しているため、エンティティにパーミッションを追加する必要があります。参考記事:https://portal.liferay.dev/docs/7-2/frameworks/-/knowledge_base/f/defining-application-permissions
私はコンポーネント名を「Vitamin」と名付けたため、Service BuilderでVitaminを使用しないようにしました。そうしないと、どこにでもパッケージを含める必要があるためです。代わりにエンティティ
PersistedVitaminを呼び出すことにしました。これにより、Headlessが使用しているDTOクラスと、Service Builderによって管理される、実際の永続化されたエンティティを区別できます。リストフィルタ、検索、ソートのサポート
このセクションの残りの部分では、Liferayがサポートするメカニズムを使用したリストフィルタリング、検索、ソートのサポートの追加について説明します。リストのフィルタリング、検索、ソートをサポートしない場合、またはいずれかのみのサポートが必要で、Liferayの手法を採らない場合、このセクションは当てはまらない場合があります。
/v1.0/message-board-threads/{messageBoardThreadId}/message-board-messagesなどのLiferayのリストメソッドの多くには、検索、フィルタ、ソート、ページングおよびフィールドの制限をサポートするための、クエリで提供可能な追加の属性があります。これらの詳細に関するLiferayの全ドキュメント:
- https://portal.liferay.dev/docs/7-2/frameworks/-/knowledge_base/f/pagination
- https://portal.liferay.dev/docs/7-2/frameworks/-/knowledge_base/f/filter-sort-and-search
- https://portal.liferay.dev/docs/7-2/frameworks/-/knowledge_base/f/restrict-properties
上記ドキュメントで触れられていないポイントとして、エンティティの検索インデックスを使用する必要があるフィルタ、ソート、検索が挙げられます。
例えば検索は、1つ以上のキーワードをクエリに追加することによって実行されます。これらはインデックスクエリに入力され、エンティティの一致を検索します。
フィルタリングは、インデックス検索クエリを調整することによっても管理されます。コンポーネント内の1つ以上のフィールドにフィルタを適用するには、それらのフィールドが検索インデックス内にある必要があります。さらに、以降の別のセクションで説明するフィールドには
OData EntityModelが必要です。ソートは、インデックス検索クエリを調整することによっても管理されます。コンポーネント内の1つまたは複数のフィールドを基準にソートするには、それらフィールドが検索インデックス内にある必要があります。さらに、
com.liferay.portal.kernel.search.DocumentインタフェースのaddKeywordSortable()メソッドを使用してインデックスを作成する必要があり、ソート可能なフィールドも、後に触れるOData EntityModel実装に追加する必要があります。上記を念頭に置き、カスタムエンティティの検索定義に特に注意を払う必要があります:
ModelDocumentContributorを使用して、重要なテキストやキーワードを追加し、適切な検索ヒットを取得します。ModelDocumentContributorを使用して、フィルタリングをサポートするフィールドを追加します。ModelDocumentContributorを使用して、ソート可能なキーワードフィールドを追加します。VitaminResourceImplメソッドの実装
Service Builderレイヤーを作成し、
headless-vitamins-implの依存関係を修正したら、次のステップでは実際にメソッドの実装を開始します。
deleteVitamin()の実装簡単な
deleteVitamin()メソッドから始めましょう。VitaminResourceImplでは、基本クラス(すべてのアノテーションを持つもの)からメソッドを拡張し、サービスレイヤーを呼び出します:@Override public void deleteVitamin(@NotNull String vitaminId) throws Exception { // super easy case, just pass through to the service layer. _persistedVitaminService.deletePersistedVitamin(vitaminId); }ローカルサービスではなくリモートサービスのみを使用してエンティティの永続化を処理することをおすすめします。なぜか?ユーザーが「ビタミン」の記録を削除するなどの許可を得ているかどうかを確認するのは、まさにあなたの最後の防衛線です。
OAuth2スコープを使用して制御を実行し、アクティビティをブロックできますが、管理者がOAuth2スコープの構成を正しく行うことは難しく、私自身が管理者であっても、毎回スコープを正しく取得できるとは思えません。
アクセス権限チェック付きのリモートサービスを使用することにより、スコープの整合性を心配する必要がなくなります。管理者(私)がOAuth2スコープを無効にしても、ユーザーに適切な権限がない限り、リモートサービスは操作をブロックします。
変換処理
実装メソッドのいくつかをさらに詳しく説明する前に、バックエンドの
ServiceBuilderエンティティから返されるヘッドレスコンポーネントへの変換について説明しておく必要があります。現時点では、Liferayはエンティティからコンポーネントへの変換を処理するための標準を確立していません。 Liferayソースの
headless-delivery-implモジュールは一方向に変換を行いますが、headless-admin-user-implモジュールは変換を別の方法で処理します。便宜上、ここでは
headless-admin-user-implテクニックに基づく手法を紹介します。これとは異なる、より効果的な手法がある場合や、headless-delivery-impl方式を好む場合もあります。また、Liferayは次のリリースで変換をサポートするための標準的な方法を考え出すかもしれません。「変換処理の必要がある」と書いてはいますが、特定の方法に縛られているわけではありません。 Liferayはより善いものを出すかもしれませんが、新しい方法に適応するか、自分流の方法を採るかはあなた次第です。
したがって、ヘッドレスAPI定義の一部として返すには、
PersistedVitaminからVitaminコンポーネントへ変換できる必要があります。クラスVitaminResourceImplに、メソッド_toVitamin()を作成します:protected Vitamin _toVitamin(PersistedVitamin pv) throws Exception { return new Vitamin() {{ creator = CreatorUtil.toCreator(_portal, _userLocalService.getUser(pv.getUserId())); articleId = pv.getArticleId(); group = pv.getGroupName(); description = pv.getDescription(); id = pv.getSurrogateId(); name = pv.getName(); type = _toVitaminType(pv.getType()); attributes = ListUtil.toArray(pv.getAttributes(), VALUE_ACCESSOR); chemicalNames = ListUtil.toArray(pv.getChemicalNames(), VALUE_ACCESSOR); properties = ListUtil.toArray(pv.getProperties(), VALUE_ACCESSOR); risks = ListUtil.toArray(pv.getRisks(), VALUE_ACCESSOR); symptoms = ListUtil.toArray(pv.getSymptoms(), VALUE_ACCESSOR); }}; }はじめに、ダブルブレースのインスタンス化を使用したことを謝らなければなりません...。私もアンチパターンだと認識しています。しかし私の目標は、
headless-admin-user-implモジュールでレイアウトされている「Liferayの手法」に従うことであり、それがLiferayの使用するパターンでした。LiferayはBuilderパターンを頻繁に使用していないことから、ダブルブレースのインスタンス化が代わりに使用されていると思います。私自身の好みを考えると、オブジェクトの生成を単純化するためにBuilderパターンやFluentパターンにも従います。結局のところ、Intellijは私のためにBuilderクラスを簡単に作成してくれます。
このメソッドは、外部の
CreatorUtilクラス(Liferayのコードからコピー)、内部の整数コードをコンポーネントの列挙型に変換する_toVitaminType()メソッド、ListUtilのtoArray()メソッドによって実装の詳細の一部である内部オブジェクトをString配列に処理するVALUE_ACCESSORを使用します。要するに、このメソッドは実際のメソッド実装で実行する必要がある変換を処理できます。
getVitamin()の実装別の簡単な
getVitamin()メソッドを見てみましょう。このメソッドは、vitaminIdを指定すると単一のエンティティを返します。@Override public Vitamin getVitamin(@NotNull String vitaminId) throws Exception { // fetch the entity class... PersistedVitamin pv = _persistedVitaminService.getPersistedVitamin(vitaminId); return _toVitamin(pv); }ここでは、サービスレイヤーから
PersistedVitaminインスタンスを取得しますが、取得したオブジェクトを_toVitamin()メソッドに渡して変換します。
postVitamin()、patchVitamin()、およびputVitamin()の実装パターンはすでに見飽きていると思いますので、ひとまとめに見てみましょう。
postVitamin()は/vitaminsに対するPOSTメソッドであり、エンティティの新規作成を表します。
patchVitamin()は、/vitamins/{vitaminId}のPATCHメソッドであり、既存のエンティティへのパッチ適用を表します(他の既存のプロパティはそのままにして、入力オブジェクトに指定された値のみを変更する)。
putVitamin()は/vitamins/{vitaminId}のPUTメソッドであり、既存エンティティの置換を表し、フィールドがnullや空の場合でも、すべての永続値を渡された値で置換します。ServiceBuilderレイヤーを作成し、これらのエントリポイント用にカスタマイズしたため、
VitaminResourceImplクラスでの実装は非常に軽量に見えます。@Override public Vitamin postVitamin(Vitamin v) throws Exception { PersistedVitamin pv = _persistedVitaminService.addPersistedVitamin( v.getId(), v.getName(), v.getGroup(), v.getDescription(), _toTypeCode(v.getType()), v.getArticleId(), v.getChemicalNames(), v.getProperties(), v.getAttributes(), v.getSymptoms(), v.getRisks(), _getServiceContext()); return _toVitamin(pv); } @Override public Vitamin patchVitamin(@NotNull String vitaminId, Vitamin v) throws Exception { PersistedVitamin pv = _persistedVitaminService.patchPersistedVitamin(vitaminId, v.getId(), v.getName(), v.getGroup(), v.getDescription(), _toTypeCode(v.getType()), v.getArticleId(), v.getChemicalNames(), v.getProperties(), v.getAttributes(), v.getSymptoms(), v.getRisks(), _getServiceContext()); return _toVitamin(pv); } @Override public Vitamin putVitamin(@NotNull String vitaminId, Vitamin v) throws Exception { PersistedVitamin pv = _persistedVitaminService.updatePersistedVitamin(vitaminId, v.getId(), v.getName(), v.getGroup(), v.getDescription(), _toTypeCode(v.getType()), v.getArticleId(), v.getChemicalNames(), v.getProperties(), v.getAttributes(), v.getSymptoms(), v.getRisks(), _getServiceContext()); return _toVitamin(pv); }このとおり、非常に軽量です。
サービスレイヤーに移動するため、
ServiceContextが必要です。 Liferayはcom.liferay.headless.common.spi.service.context.ServiceContextUtilを提供します。これには、ServiceContextを作成するのに必要なメソッドだけがあります。これはコンテキストを開始するもので、企業IDや現在のユーザーIDなどの追加情報を加えるだけです。そこで、このすべてを_getServiceContext()メソッドにラップしました。REST Builderの将来のバージョンでは、有効なServiceContextをより簡単に取得できるように、新しいコンテキスト変数を取得する予定です。私のServiceBuilderメソッドはすべて、ServiceBuilderに関する誰もが知る、展開されたパラメーターを渡して使用します。メソッド呼び出しから返された
PersistedValueインスタンスは、変換のために_toVitamin()に渡され、それが戻されます。以上が簡単な対処方法です。
getVitaminsPage()メソッドについても説明する必要がありますが、その前にEntityModelsについて説明する必要があります。EntityModels
先ほど、Liferayが検索インデックスを使用してリストのフィルタリング、検索、ソートをサポートする方法について説明しました。また、フィルタリングやソートに使用できるフィールドがコンポーネントの
EntityModel定義の一部である必要があることについても説明しました。EntityModelの一部ではないコンポーネントのフィールドは、フィルタリングもソートもできません。追加の副作用として、
EntityModelはフィルタリングとソートのために検索インデックスからこれらのフィールドを公開するため、これらのフィールドをコンポーネントフィールドに接続する必要はありません。例えば
EntityModel定義では、検索インデックスのユーザーIDへのフィルタとなるcreatorIdのエントリを追加できます。コンポーネント定義には、creatorIdフィールドではなくCreatorフィールドが含まれる場合がありますが、creatorIdはEntityModelの一部であるため、フィルタリングやソートの両方で使用できます。そのため、フィルタリングとソートの両方をサポートするフィールドを定義する
EntityModelを構築する必要があります。既存のLiferayユーティリティを使用して、EntityModelクラスをまとめます:public class VitaminEntityModel implements EntityModel { public VitaminEntityModel() { _entityFieldsMap = Stream.of( // chemicalNames is a string array of the chemical names of the vitamins/minerals new CollectionEntityField( new StringEntityField( "chemicalNames", locale -> Field.getSortableFieldName("chemicalNames"))), // we'll support filtering based upon user creator id. new IntegerEntityField("creatorId", locale -> Field.USER_ID), // sorting/filtering on name is okay too new StringEntityField( "name", locale -> Field.getSortableFieldName(Field.NAME)), // as is sorting/filtering on the vitamin group new StringEntityField( "group", locale -> Field.getSortableFieldName("vitaminGroup")), // and the type (vitamin, mineral, other). new StringEntityField( "type", locale -> Field.getSortableFieldName("vType")) ).collect( Collectors.toMap(EntityField::getName, Function.identity()) ); } @Override public Map<String, EntityField> getEntityFieldsMap() { return _entityFieldsMap; } private final Map<String, EntityField> _entityFieldsMap; }フィールド名は、フィールド値を追加するためにサービスレイヤーの
PersistedVitaminModelDocumentContributorクラスで使用した名前に由来します。検索インデックスから、
chemicalNames、Field.USER_ID、Field.NAME、vitaminGroup、vType Fieldsの定義を含めました。定義のうち、フィルタが使用するcreatorIdフィールドは、ビタミンコンポーネント定義のフィールドとしては存在しません。Vitaminコンポーネントの一部である他のフィールドは、残りのソートまたはフィルタリングを許可する必要がないように感じます。この種の決定は、通常要件によって決定されます。
Liferayはこれらのクラスを内部パッケージである
odata.entity.v1_0パッケージに保存するため、私のケースで配置するファイルとして、com.dnebinger.headless.delivery.internal.odata.entity.v1_0を持っています。クラスの準備が整ったので、
EntityModelを提供できることを正しく確認するために、VitaminResourceImplクラスも装飾する必要があります。必要な変更は次のとおりです:
<Component>ResourceImplクラスは、com.liferay.portal.vulcan.resource.EntityModelResourceインターフェースの実装。- クラスで
EntityModelインスタンスを返すgetEntityModel()メソッドの実装。私の
VitaminEntityModelは非常に単純であまり動的ではないため、実装は次のようになります:public class VitaminResourceImpl extends BaseVitaminResourceImpl implements EntityModelResource { private VitaminEntityModel _vitaminEntityModel = new VitaminEntityModel(); @Override public EntityModel getEntityModel(MultivaluedMap multivaluedMap) throws Exception { return _vitaminEntityModel; }これは一般的な実装ではないことに注意してください。 Liferayのコンポーネントリソース実装クラスには、はるかに複雑で動的な
EntityModel生成がありますが、これは、関連するエンティティの複雑さによるものです(例えばStructuredContentはJournalArticle、DDMストラクチャ、テンプレートの寄せ集めです)。したがって、ただ単にメソッドをコピーして実行しないでください。あなたの場合はうまくいくかもしれませんが、他のケースではうまくいかないかもしれません。より複雑なシナリオについては、
EntityModelクラスのLiferay実装と、コンポーネントリソース実装のgetEntityModel()メソッドを確認してください。
getVitaminsPage()の実装これはおそらく最も複雑な実装方法です。それ自体が困難なのではなく、他の多くのものに依存しているという点でです。
ここでのLiferayリスト処理機能は、データベースではなく検索インデックスから取得されます。したがって、エンティティにはインデックスが付けられている必要があります。
これは、フィルタ、検索、ソートのパラメーターをサポートするメソッドでもあり、エンティティにインデックスを付ける必要があります。そして先ほど見たように、フィルタとソートも
EntityModelクラスに依存しています。最後に、Liferayメソッドを呼び出しているため、実装自体はかなり不透明で、制御できません。
最終的には次のようになります:public Page<Vitamin> getVitaminsPage(String search, Filter filter, Pagination pagination, Sort[] sorts) throws Exception { return SearchUtil.search( booleanQuery -> { // does nothing, we just need the UnsafeConsumer<BooleanQuery, Exception> method }, filter, PersistedVitamin.class, search, pagination, queryConfig -> queryConfig.setSelectedFieldNames( Field.ENTRY_CLASS_PK), searchContext -> searchContext.setCompanyId(contextCompany.getCompanyId()), document -> _toVitamin( _persistedVitaminService.getPersistedVitamin( GetterUtil.getLong(document.get(Field.ENTRY_CLASS_PK)))), sorts); }私たちは、すべての処理方法を知っている
SearchUtil.search()メソッドを使用しています。最初の引数は
UnsafeConsumerクラスで、基本的にはエンティティの必要に応じてbooleanQueryを微調整することを担います。ここでは必要ありませんでしたが、Liferayのヘッドレスデリバリモジュールに例があります。サイトIDで記事を検索するStructuredContentのバージョンは、クエリ引数としてサイトIDを追加します。flattenパラメータは、特定のフィルタ、これらの種類のものを検索するためにクエリを微調整します。ヘッドレスレイヤーから取得したフィルタ、検索、およびページネーションの引数はそのまま渡されます。結果はブーリアンクエリに適用され、結果のフィルタリングと検索が行われ、ページネーションによりページに相当する結果が得られます。
queryConfigは主キー値のみを返し、他のフィールドデータは要求しません。検索インデックスDocumentから変換するわけではないので、ServiceBuilderエンティティが必要になります。最後から2番目の引数は、ドキュメントからコンポーネントタイプへの変換の適用をする別の
UnsafeFunctionです。この実装では、Documentから抽出されたプライマリ・キー値を使用してPersistedVitaminインスタンスをフェッチし、PersistedVitaminが_toVitamin()に渡されて最終的な変換を処理します。残作業
これで、すべてのコーディングを終えましたが、完了はしていません。
buildRESTコマンドを再実行します。メソッドをVitaminResourceImplメソッドへ追加したので、それらに適用できるテストケースを用意しておきたいと思います。次にモジュールをビルドおよびデプロイし、未解決の参照やデプロイメントの問題などをクリーンアップする必要があります。ServiceBuilder層には
vitamins-apiおよびvitamins-serviceを、Headless層にはvitamins-headless-apiおよびvitamins-headless-implモジュールをデプロイします。それらの準備ができたら、
headless-vitamins-testモジュールにドロップして、すべてのテストケースを実行する必要があります(不足がある場合は、それらも再作成できます)。すべて準備できたら、Headless APIをSwaggerHubに公開して他の人が使用できるようにしたいと思うかもしれません。
REST Builder用に作成したYamlファイルは使用しません。代わりに、ブラウザでhttp://localhost:8080/o/headless-vitamins/v1.0/openapi.yamlを指定し、そのファイルを送信に使用します。必要なすべてのパーツが配置され、
PageVitaminタイプなどの追加コンポーネントが追加されます。まとめ
パート1で新しいヘッドレス検証用のワークスペースとモジュールを作成し、REST Builderが最終的にコードを生成するのに使用するOpenAPI Yamlファイルに着手しました。
パート2ではパス定義を追加し、REST BuilderのOpenAPI Yamlファイルを完成させました。 REST Builderのビルドエラーに直面しつつも、ビルドエラーを引き起こす可能性のある一般的なフォーマットエラーの一部を理解し、それらを修正し、REST Builderを使用してコードを正常に生成しました。
パート3では、全モジュールで生成すべてのコードをレビューして、どこで変更が行われるのかを示しました。
パート4(本章)では、Service Builderレイヤーを作成し、リソースのアクセス許可(リモートサービスでのアクセス許可チェック用)とエンティティのインデックス作成(Liferayのヘッドレスインフラストラクチャのリストフィルタ/検索/ソート機能をサポートするため)を含めました。次に、
VitaminResourceImplメソッドをフラッシュし、エンティティからコンポーネントへの変換の処理方法、およびフィルタとソートを容易にするために必要なEntityModelクラスについて説明しました。私たちはすべてをテストし、おそらくはAPIをSwaggerHubに公開し、みんなが楽しめるようにしました。長い道のりでしたが、私にとっては実に興味深いものでした。楽しんでいただけたら嬉しいです。
今一度、本ブログシリーズのリポジトリを示します:https://github.com/dnebing/vitamins
- 投稿日:2019-12-23T17:30:16+09:00
LiferayのREST Builderを使用した独自ヘッドレスAPIの作成方法(パート3)
※この記事はLiferayコミュニティブログに投稿された、Creating Headless APIs (Part 3)を翻訳したものです。
はじめに
このシリーズのパート1では、ヘッドレスAPIを生成するためにLiferayの新しいREST Builderツールを活用するプロジェクトを開始しました。Reusable Components (再利用可能なコンポーネント)セクションで、リクエストとレスポンスのオブジェクトの定義、すなわちビタミンコンポーネントとLiferayのCreatorコンポーネントのコピーを定義しました。
シリーズのパート2では、Paths(エンドポイント)を定義することでOpenAPI Yamlファイルを完成させ、一般的な問題に遭遇しつつも無事コード生成に成功しました。
このパートでは、生成されたコードの適切な場所に実装コードを追加する方法を見ていきます。
生成されたコードに目を通す
コードが生成されたモジュールは、
headless-vitamin-api、headless-vitamin-client、headless-vitamin-impl、headless-vitamin-testの4つです。REST Builderはコードを生成しますが、
build.gradleとbnd.bndのいずれも変更しません。依存関係を追加してパッケージをエクスポートするかどうかはあなた次第です。以降のセクションでは私が使用した設定を共有しますが、実装に必要なセットは都度調整が必要です。各モジュールを個別に見てみましょう。
headless-vitamins-api
APIモジュールの概念はService Builder APIモジュールに似ており、リソース(サービス)のインターフェイスが含まれています。また、コンポーネントタイプ(VitaminおよびCreator)の具体的なPOJOクラスも含まれています。それらは単なるPOJOだけではなく、コンポーネントタイプクラスには、オブジェクトをデシリアライズするときにフレームワークによって呼び出される追加のセッターがあります。 Creatorコンポーネントタイプの1つを見てみましょう。
@JsonIgnore public void setAdditionalName( UnsafeSupplier additionalNameUnsafeSupplier) { try { additionalName = additionalNameUnsafeSupplier.get(); } catch (RuntimeException re) { throw re; } catch (Exception e) { throw new RuntimeException(e); } }生成された上記コードはとても単純なものですが、心配はいりません。
VitaminResourceはリソース(サービス)のインターフェイスで、OpenAPI Yamlファイルで定義されたパスから取得されます。REST Builderを呼び出したあと、yamlファイルのoperationIdの各パスに新しい属性が追加され、これらの値がインターフェイスのメソッドと正確に一致することに気付くかもしれません。生成されたコードだけではメソッドが少なすぎるため、ここでインターフェイスを共有します。
@Generated("") public interface VitaminResource { public Page getVitaminsPage( String search, Filter filter, Pagination pagination, Sort[] sorts) throws Exception; public Vitamin postVitamin(Vitamin vitamin) throws Exception; public void deleteVitamin(String vitaminId) throws Exception; public Vitamin getVitamin(String vitaminId) throws Exception; public Vitamin patchVitamin(String vitaminId, Vitamin vitamin) throws Exception; public Vitamin putVitamin(String vitaminId, Vitamin vitamin) throws Exception; public void setContextCompany(Company contextCompany); }ビタミンオブジェクトの配列を返すパスである
/vitaminsが、最初のメソッドであるgetVitaminsPage()です。独自のYamlファイルはPageVitaminコンポーネントを宣言しませんが、エクスポートされたYamlファイルには1つ挿入されます。リソースインターフェースの他のメソッドは、Yamlファイルで定義されている他のパスと一致します。次に、APIモジュールのbuild.gradleファイルにいくつかの依存関係を追加する必要がありました:
dependencies { compileOnly group: "com.fasterxml.jackson.core", name: "jackson-annotations", version: "2.9.9" compileOnly group: "com.liferay", name: "com.liferay.petra.function" compileOnly group: "com.liferay", name: "com.liferay.petra.string" compileOnly group: "com.liferay", name: "com.liferay.portal.vulcan.api" compileOnly group: "com.liferay.portal", name: "com.liferay.portal.kernel" compileOnly group: "io.swagger.core.v3", name: "swagger-annotations", version: "2.0.5" compileOnly group: "javax.servlet", name: "javax.servlet-api" compileOnly group: "javax.validation", name: "validation-api", version: "2.0.1.Final" compileOnly group: "javax.ws.rs", name: "javax.ws.rs-api" compileOnly group: "org.osgi", name: "org.osgi.annotation.versioning" }コンポーネントとリソースインターフェイスを公開するために、
bnd.bndファイルにもわずかな変更を加えました:Export-Package: com.dnebinger.headless.vitamins.dto.v1_0, \ com.dnebinger.headless.vitamins.resource.v1_0headless-vitamins-client
このモジュールのコードは、ヘッドレスAPIを呼び出すためのJavaベースのクライアントを構築します。
クライアントエントリポイントは、
<パッケージの接頭辞>.client.resource.v1_0<Component>Resourceクラスにあります。私のケースでは、com.dnebinger.headless.vitamins.client.resource.v1_0.VitaminResourceクラスが該当します。各パスには静的メソッドがあり、各メソッドは同じ引数を取り、同じオブジェクトを返します。裏では各メソッドは
HttpInvokerインスタンスを使用して、test@liferay.comとテスト用ログイン情報を使用してlocalhost:8080のWebサービスを呼び出します。リモートサービスをテストする場合や異なるログイン情報を使用する場合は、<Component>Resourceクラスを適宜編集して、異なる値を使用する必要があります。クライアントコードを呼び出すための主要クラスやその他のコードを作成するかどうかは設計者次第ですが、テスト用の完全なクライアントライブラリを用意することは素晴らしい第一歩です!
注:生成された
headless-vitamins-testモジュールは、サービス層のテストに際しheadless-vitamins-clientモジュールに依存します。
headless-vitamins-clientモジュールには外部依存関係はありませんが、bnd.bndファイルのパッケージをエクスポートする必要があります。Export-Package: com.dnebinger.headless.vitamins.client.dto.v1_0, \ com.dnebinger.headless.vitamins.client.resource.v1_0headless-vitamins-test
headless-vitamins-implモジュールをスキップして、headless-vitamins-testについて簡単に説明します。ここで生成されたコードは、サービスモジュールのすべての統合テストを提供し、クライアントモジュールを利用して、リモートAPIを呼び出します。
このモジュールでは、Base<Component>ResourceTestCaseと<Component>ResourceTestCaseの2つのクラスを取得するため、BaseVitaminResourceTestCaseとVitaminResourceTestがあります。
VitaminResourceTestクラスは、Baseクラスがまだ実装していないテストを追加する場所です。他のモジュールを活用するための大規模なテストであり、重複した主キーの追加や存在しないオブジェクトを削除しようとしたときのエラー検証に利用されます。基本的に、素のリソースメソッドの単純な呼び出しでは個別にカバーできないテストがこれに該当します。このモジュールの
build.gradleファイルには、多くの追加が必要でした:dependencies { testIntegrationCompile group: "com.fasterxml.jackson.core", name: "jackson-annotations", version: "2.9.9" testIntegrationCompile group: "com.fasterxml.jackson.core", name: "jackson-core", version: "2.9.9" testIntegrationCompile group: "com.fasterxml.jackson.core", name: "jackson-databind", version: "2.9.9.1" testIntegrationCompile group: "com.liferay", name: "com.liferay.arquillian.extension.junit.bridge", version: "1.0.19" testIntegrationCompile group: "com.liferay.portal", name: "com.liferay.portal.kernel" testIntegrationCompile project(":modules:headless-vitamins:headless-vitamins-api") testIntegrationCompile project(":modules:headless-vitamins:headless-vitamins-client") testIntegrationCompile group: "com.liferay", name: "com.liferay.portal.odata.api" testIntegrationCompile group: "com.liferay", name: "com.liferay.portal.vulcan.api" testIntegrationCompile group: "com.liferay", name: "com.liferay.petra.function" testIntegrationCompile group: "com.liferay", name: "com.liferay.petra.string" testIntegrationCompile group: "javax.validation", name: "validation-api", version: "2.0.1.Final" testIntegrationCompile group: "commons-beanutils", name: "commons-beanutils" testIntegrationCompile group: "commons-lang", name: "commons-lang" testIntegrationCompile group: "javax.ws.rs", name: "javax.ws.rs-api" testIntegrationCompile group: "junit", name: "junit" testIntegrationCompile group: "com.liferay.portal", name: "com.liferay.portal.test" testIntegrationCompile group: "com.liferay.portal", name: "com.liferay.portal.test.integration" }これら依存関係の一部は、クラス(junitおよびliferayテストモジュール)にのみ必要なデフォルトであり、他の依存関係はプロジェクト(クライアントモジュールとapiモジュール、場合により他のモジュール)に依存します。要件を満たすリストを取得するために、いくらかの試行錯誤が必要になるかもしれません。
このモジュールの
bnd.bndファイルはクラスまたはパッケージをエクスポートしないため、変更の必要はありませんでした。headless-vitamins-impl
ようやく面白くなってきました。これは、実装コードが格納されているモジュールです。 REST Builderは、たくさんのスターターコードを生成してくれました。どんなものか見てみましょう。
com.dnebinger.headless.vitamins.internal.graphql、GraphQLの登場です!ヘッドレス実装には、定義したパスに基づきクエリとミューテーションを公開するGraphQLのエンドポイントが含まれます。 GraphQLは、この種の混合でよく見られるREST実装への呼び出しを単にプロキシするのではなく、<Component>Resourceを直接呼び出して、クエリとミューテーションの変更を処理することに注意してください。したがって、REST Builderを使用するだけでGraphQLも自動的に取得できるのです。
com.dnebinger.headless.vitamins.internal.jaxrs.application、これはJAX-RS Applicationクラスが格納されている場所です。特段面白いものが含まれているわけではありませんが、LiferayのOSGiコンテナへアプリケーションを登録します。
com.dnebinger.headless.vitamins.internal.resource.v1_0、これは、コード修正を施す場所です。
OpenAPIResourceImpl.javaクラスは、例えばSwagger HubにロードするOpenAPI yamlファイルを返すためのパスです。各<Component>Resourceインターフェースごとに、抽象基本クラスBase<Component>ResourceImplと、作業を行うためのコンクリートクラス<Component>ResourceImplを取得します。ゆえに、BaseVitaminResourceImplとVitaminResourceImplの2つのクラスがあります。基本クラスのメソッドを見てみると、SwaggerとJAX-RSのアノテーションで多量に装飾されていることがわかります。
/vitaminsに格納されているVitaminコンポーネントの配列を返すのに使用される、getVitaminsPage()メソッドの1つを見てみましょう:@Override @GET @Operation( description = "Retrieves the list of vitamins and minerals. Results can be paginated, filtered, searched, and sorted." ) @Parameters( value = { @Parameter(in = ParameterIn.QUERY, name = "search"), @Parameter(in = ParameterIn.QUERY, name = "filter"), @Parameter(in = ParameterIn.QUERY, name = "page"), @Parameter(in = ParameterIn.QUERY, name = "pageSize"), @Parameter(in = ParameterIn.QUERY, name = "sort") } ) @Path("/vitamins") @Produces({"application/json", "application/xml"}) @Tags(value = {@Tag(name = "Vitamin")}) public Page<Vitamin> getVitaminsPage( @Parameter(hidden = true) @QueryParam("search") String search, @Context Filter filter, @Context Pagination pagination, @Context Sort[] sorts) throws Exception { return Page.of(Collections.emptyList()); }どうでしょう?
これはREST Builderが私たちにもたらす利点の1つです。すべてのアノテーションは基本クラスで定義されているため、それらについて心配する必要はないのです。
Page.of(Collections.emptyList())を渡しているreturnステートメントを見てみましょう。これが基本クラスが提供するスタブメソッドです。価値のある実装を提供するわけではありませんが、実装しない場合に確実に値が返されるようにします。このメソッドを実装する準備ができたら、
VitaminResourceImplクラス(現在は空)に次のメソッドを追加します:@Override public Page<Vitamin> getVitaminsPage(String search, Filter filter, Pagination pagination, Sort[] sorts) throws Exception { List<Vitamin> vitamins = new ArrayList<Vitamin>(); long totalVitaminsCount = ...; // write code here, should add to the list of Vitamin objects return Page.of(vitamins, Pagination.of(0, pagination.getPageSize()), totalVitaminsCount); }アノテーションが一切無いことに注目してください。
先述したとおり、全アノテーションはオーバーライドしているメソッドに含まれているため、すべての構成の準備が整っているのです!そのため、Service Builderで生成されたコードとは異なり、「このファイルは生成されていますが、このファイルを変更しないでください」という旨のコメントはどこにも表示されません。 REST Builderを再度実行すると(再)生成されるすべてのクラスに
@Generated("")アノテーションが表示されます。
Base<Component>ResourceImplクラスには、このようにアノテーションされています。これは、REST Builderを実行するたびに再生成されるファイルです。したがって、このファイルのアノテーションやメソッドの実装に手を加えないでください。すべての変更は<Component>ResourceImplクラスに対して行ってください。アノテーションを変更する必要がある場合(推奨しません)、
<Component>ResourceImplクラスでこれを行うことができ、基本クラスからのアノテーションをオーバーライドする必要があります。したがって、build.gradleファイルにはいくつかの依存関係を追加する必要があります。私のファイルは次のようになりました:buildscript { dependencies { classpath group: "com.liferay", name: "com.liferay.gradle.plugins.rest.builder", version: "1.0.21" } repositories { maven { url "https://repository-cdn.liferay.com/nexus/content/groups/public" } } } apply plugin: "com.liferay.portal.tools.rest.builder" dependencies { compileOnly group: "com.fasterxml.jackson.core", name: "jackson-annotations", version: "2.9.9" compileOnly group: "com.liferay", name: "com.liferay.adaptive.media.api" compileOnly group: "com.liferay", name: "com.liferay.adaptive.media.image.api" compileOnly group: "com.liferay", name: "com.liferay.headless.common.spi" compileOnly group: "com.liferay", name: "com.liferay.headless.delivery.api" compileOnly group: "com.liferay", name: "com.liferay.osgi.service.tracker.collections" compileOnly group: "com.liferay", name: "com.liferay.petra.function" compileOnly group: "com.liferay", name: "com.liferay.petra.string" compileOnly group: "com.liferay", name: "com.liferay.portal.odata.api" compileOnly group: "com.liferay", name: "com.liferay.portal.vulcan.api" compileOnly group: "com.liferay", name: "com.liferay.segments.api" compileOnly group: "com.liferay.portal", name: "com.liferay.portal.impl" compileOnly group: "com.liferay.portal", name: "com.liferay.portal.kernel" compileOnly group: "io.swagger.core.v3", name: "swagger-annotations", version: "2.0.5" compileOnly group: "javax.portlet", name: "portlet-api" compileOnly group: "javax.servlet", name: "javax.servlet-api" compileOnly group: "javax.validation", name: "validation-api", version: "2.0.1.Final" compileOnly group: "javax.ws.rs", name: "javax.ws.rs-api" compileOnly group: "org.osgi", name: "org.osgi.service.component", version: "1.3.0" compileOnly group: "org.osgi", name: "org.osgi.service.component.annotations" compileOnly group: "org.osgi", name: "org.osgi.core" compileOnly project(":modules:headless-vitamins:headless-vitamins-api") }パッケージはすべて内部にあるため、bnd.bndファイルには何も加える必要はありません。
まとめ
実装の構築を開始できる段階まで進みました!切りよく今回はここまでとします。
パート1では、プロジェクトを作成し、再利用可能なコンポーネントを定義してOpenAPI Yamlに触れました。
パート2では、OpenAPIサービスのすべてのパス定義を追加し、REST Builderを使用してコードを生成しました。
パート3(本記事)では、生成されたすべてのコードを確認し、コードの変更箇所や、実装コードのアノテーションについて心配する必要がないことを理解しました。いよいよ最後となる次のパートでは、データストレージ用のプロジェクトにService Builderモジュールを追加し、すべてのリソースメソッドを実装して
ServiceBuilderコードを利用します。それではまた!
- 投稿日:2019-12-23T17:28:29+09:00
LiferayのREST Builderを使用した独自ヘッドレスAPIの作成方法(パート2)
※この記事はLiferayコミュニティブログに投稿された、Creating Headless APIs (Part 2)を翻訳したものです。
はじめに
このシリーズのパート1では、LiferayのREST Builderツールを使用して独自のカスタムヘッドレスAPIを構築するプロジェクトを開始しました。プロジェクトを開始し、4つのモジュールが作成され、OpenAPI YamlファイルのMetaセクションとReusable Componentsセクションについて紹介しました。
前回の続きとなる本記事では、Paths(エンドポイント)セクションに進み、コードの生成に入ります。
パスの定義
パスはAPIのRESTエンドポイントです。これらの定義はRESTエンドポイントを作成するうえで重要な部分です。この工程に誤りがあると、リファクタリングや将来的に破壊的な変更の原因となり、サービス利用者に不便を強いてしまう可能性が生じます。実際、RESTエンドポイントは適切でない定義になりがちです。REST実装例のバッドプラクティスは非常にたくさんあふれているため、正しいものを見つけたときは驚かされます。
リソース用に選択されたパスには、次の2つの形式があります。
- /v1.0/vitamins
- /v1.0/vitamins/{vitaminId}
1番目の形式はコレクションの取得または新規レコードの作成(使用するHTTPメソッドに準ずる)で、2番目の形式は主キーが指定された特定レコードの取得、更新および削除です。
以下の定義では、レスポンスはすべてハッピーパスレスポンスを指します。そのため
getVitaminは、Vitaminオブジェクトでの成功したレスポンスのみを提供します。 OpenAPI、とりわけLiferayフレームワークをすべてのパスで活用しているため、エラーや例外を含む可能性のある応答のセットが大きくなることに留意しておく必要があります。フレームワークがそれらすべてを処理するため、成功した応答にのみ関心を払う必要があります。すべてのビタミンのリスト
したがって最初のパスは、ビタミン/ミネラルのリストの取得に使用されるパスであり、一度にリスト全体を返すのではなく、ページングを使用します。
paths: "/vitamins": get: tags: ["Vitamin"] description: Retrieves the list of vitamins and minerals. Results can be paginated, filtered, searched, and sorted. parameters: - in: query name: filter schema: type: string - in: query name: page schema: type: integer - in: query name: pageSize schema: type: integer - in: query name: search schema: type: string - in: query name: sort schema: type: string responses: 200: description: "" content: application/json: schema: items: $ref: "#/components/schemas/Vitamin" type: array application/xml: schema: items: $ref: "#/components/schemas/Vitamin" type: array
/vitaminsに対するGETリクエストは、Vitaminオブジェクトの配列を返します。 Swagger側では、必要なページングの詳細で配列をラップするPageVitaminという別のコンポーネントタイプが実際に表示されます。注:ここでのtags属性は重要です。この値は、パスが動作するコンポーネントタイプまたは返されるコンポーネントタイプに一致します。私の方法はすべてVitaminコンポーネントを扱うため、すべてのタグの値は同じ
["Vitamin"]となります。これは、コード生成に絶対に必要です。多くのLiferay Headless APIと同様に、検索、フィルター、ページングの制御および項目の並べ替えもサポートします。
ビタミンの作成
同じパスにPOSTメソッドを用いて、新しいビタミン/ミネラルオブジェクトを作成できます。
post: tags: ["Vitamin"] description: Create a new vitamin/mineral. requestBody: content: application/json: schema: $ref: "#/components/schemas/Vitamin" application/xml: schema: $ref: "#/components/schemas/Vitamin" responses: 200: description: "" content: application/json: schema: $ref: "#/components/schemas/Vitamin" application/xml: schema: $ref: "#/components/schemas/Vitamin"リクエストのボディは作成されるビタミンオブジェクトになり、レスポンスは新たに作成されたインスタンスになります。
ビタミンの取得
2番目のURLフォームは、単一レコードに対して機能します。最初の例では、GETリクエストは指定された
vitaminIdを持つ単一のVitaminオブジェクトを取得します。"/vitamins/{vitaminId}": get: tags: ["Vitamin"] description: Retrieves the vitamin/mineral via its ID. parameters: - name: vitaminId in: path required: true schema: type: string responses: 200: description: "" content: application/json: schema: $ref: "#/components/schemas/Vitamin" application/xml: schema: $ref: "#/components/schemas/Vitamin"ビタミンの交換
PUTリクエストを使用して現在のビタミンオブジェクトをリクエストボディに含まれるオブジェクトに置き換えることができます。リクエストに含まれていないフィールドは、置換されるレコードの空白または
nullにする必要があります。put: tags: ["Vitamin"] description: Replaces the vitamin/mineral with the information sent in the request body. Any missing fields are deleted, unless they are required. parameters: - name: vitaminId in: path required: true schema: type: string requestBody: content: application/json: schema: $ref: "#/components/schemas/Vitamin" application/xml: schema: $ref: "#/components/schemas/Vitamin" responses: 200: description: Default Response content: application/json: schema: $ref: "#/components/schemas/Vitamin" application/xml: schema: $ref: "#/components/schemas/Vitamin"リクエストには既存のものと置き換えるビタミンが含まれ、レスポンスは新しいビタミンオブジェクトとなります。
ビタミンの更新
PATCHリクエストを使用して現在のビタミンを更新することもできます。提供されないフィールドを空白にするPUTとは異なり、PATCHではリクエストの一部でないフィールドは、該当オブジェクトでは変更されません。
patch: tags: ["Vitamin"] description: Replaces the vitamin/mineral with the information sent in the request body. Any missing fields are deleted, unless they are required. parameters: - name: vitaminId in: path required: true schema: type: string requestBody: content: application/json: schema: $ref: "#/components/schemas/Vitamin" application/xml: schema: $ref: "#/components/schemas/Vitamin" responses: 200: description: "" content: application/json: schema: $ref: "#/components/schemas/Vitamin" application/xml: schema: $ref: "#/components/schemas/Vitamin"リクエストには更新するビタミンのフィールドが含まれ、レスポンスは更新されたビタミンオブジェクトとなります。
ビタミンを削除する
最後は、DELETEリクエストを使用してビタミンを削除するパスです。
delete: tags: ["Vitamin"] description: Deletes the vitamin/mineral and returns a 204 if the operation succeeds. parameters: - name: vitaminId in: path required: true schema: type: string responses: 204: description: "" content: application/json: {}このパスにはリクエストボディもレスポンスボディもありません。
結果の確認
Swagger Editorを使用してAPIを定義すると、サービスがどのように機能しているかをわかりやすくレビューできます。
上の図のように、視覚的に理解しやすいです!
Yamlファイルの作成に際しては、エディタ自体にコンテキスト依存ヘルプ、構文エラーに対する即時フィードバックなどの優れた機能が用意されており、APIの構成を理解するのに非常に役立ちます。
Swagger Editorを使用する場合は、YamlファイルをIDEへ移すことをお忘れなく。
Swagger Hubで「Resolved Yaml」オプションを使用してエクスポートすると、Yamlエクスポートの最良の結果が得られます。
コード生成試行その1
新しいREST Builderを呼び出す準備が整いました。
headless-vitamins-implディレクトリで次のコマンドを実行します。$ ../../../gradlew buildREST私と同様、あなたも失敗に終わったかもしれません。
buildRESTを初めて実行したときの出力の一部を次に示します。Exception in thread "main" Cannot create property=paths for JavaBean=com.liferay.portal.vulcan.yaml.openapi.OpenAPIYAML@1e730495 in 'string', line 1, column 1: openapi: 3.0.1 ^ Cannot create property=get for JavaBean=com.liferay.portal.vulcan.yaml.openapi.PathItem@23f7d05d in 'string', line 8, column 5: get: ^ Cannot create property=responses for JavaBean=com.liferay.portal.vulcan.yaml.openapi.Get@23986957 in 'string', line 9, column 7: tags: ^ For input string: "default" in 'string', line 36, column 9: default: ^ [...省略...] > Task :modules:headless-vitamins-impl:buildREST FAILED失敗したのはなぜでしょう?メッセージは具体性に欠けており、正確に原因を把握できません。
OpenAPI Yamlファイルを今一度見てみましょう。 Swagger Editorでは問題なく表示されることから、コンテンツの問題ではなさそうです。
次に、このファイルをLiferayがヘッドレスモジュールに使っているものと比較してみたところ、多くの相違点がありました。既にブログを修正したため、当該のエラーは見られません。平たく言えば、単純なYaml形式では、Swagger Editorの形式であっても
buildRESTコマンドで期待する結果を得ることはできません。以下に、その違いを簡単に紹介します:
Yaml for Liferayのheadless-delivery APIでは、多くのレスポンスが「デフォルト」として使用されますが、これはREST Builderでは受け入れられず、実際のレスポンスコードを使用する必要があります。 Github上のLiferay Yamlファイルは、実際のレスポンスコードを使用します。
コンポーネントセクションの説明は引用符で括る必要はありませんが、パスセクションではそうする必要があります。
- DescriptionなどはオンラインYamlでラップできますが、REST Builderはすべてを1行まとめようとします。
- パスはクオーテーションで囲む必要があります。
- タグは異なる形式でフォーマットされます。REST Builderはオンラインバージョンではなく、
tags: ["Vitamins"]などの形式を想定しています。- Swaggerに表示されるURLの
/v1.0部分は、パス定義に含めるべきではありません。他にも私が気づいていない差異があるかもしれません。先述のようなエラーが発生する場合は、ファイルをLiferay公式のものと比較し、クオーテーションの使い方や同様のフォーマットに準じているかチェックしてみるといいでしょう。
コード生成試行その2
注:私はれを2番目の試みとしていますが、おそらくここにたどり着くまでにより多くの試みをしています。 REST Builderで何らかのエラーが発生した際には、自分ファイルをLiferayのファイルと比較し、僅かな差異があれば微調整を繰り返し、REST Builderを再度実行し、最終的にビルドエラーはなくなりました。私はこれを2番目の試みと結論づけました。
この試行錯誤の末、私のYamlファイルはLiferayのものに倣ったフォーマットとなり、無事コード生成に成功しました。
$ ../../../gradlew buildREST成功した場合の結果:
> Task :modules:headless-vitamins-impl:buildREST Writing vitamins/modules/headless-vitamins/headless-vitamins-impl/src/main/java/com/dnebinger/headless/vitamins/internal/jaxrs/application/HeadlessVitaminsApplication.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/json/BaseJSONParser.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/http/HttpInvoker.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/pagination/Page.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/pagination/Pagination.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/function/UnsafeSupplier.java Writing vitamins/modules/headless-vitamins/headless-vitamins-impl/rest-openapi.yaml Writing vitamins/modules/headless-vitamins/headless-vitamins-impl/src/main/java/com/dnebinger/headless/vitamins/internal/graphql/mutation/v1_0/Mutation.java Writing vitamins/modules/headless-vitamins/headless-vitamins-impl/src/main/java/com/dnebinger/headless/vitamins/internal/graphql/query/v1_0/Query.java Writing vitamins/modules/headless-vitamins/headless-vitamins-impl/src/main/java/com/dnebinger/headless/vitamins/internal/graphql/servlet/v1_0/ServletDataImpl.java Writing vitamins/modules/headless-vitamins/headless-vitamins-impl/src/main/java/com/dnebinger/headless/vitamins/internal/resource/v1_0/OpenAPIResourceImpl.java Writing vitamins/modules/headless-vitamins/headless-vitamins-api/src/main/java/com/dnebinger/headless/vitamins/dto/v1_0/Vitamin.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/dto/v1_0/Vitamin.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/serdes/v1_0/VitaminSerDes.java Writing vitamins/modules/headless-vitamins/headless-vitamins-api/src/main/java/com/dnebinger/headless/vitamins/dto/v1_0/Creator.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/dto/v1_0/Creator.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/serdes/v1_0/CreatorSerDes.java Writing vitamins/modules/headless-vitamins/headless-vitamins-impl/src/main/java/com/dnebinger/headless/vitamins/internal/resource/v1_0/BaseVitaminResourceImpl.java Writing vitamins/modules/headless-vitamins/headless-vitamins-impl/src/main/resources/OSGI-INF/liferay/rest/v1_0/vitamin.properties Writing vitamins/modules/headless-vitamins/headless-vitamins-api/src/main/java/com/dnebinger/headless/vitamins/resource/v1_0/VitaminResource.java Writing vitamins/modules/headless-vitamins/headless-vitamins-impl/src/main/java/com/dnebinger/headless/vitamins/internal/resource/v1_0/VitaminResourceImpl.java Writing vitamins/modules/headless-vitamins/headless-vitamins-client/src/main/java/com/dnebinger/headless/vitamins/client/resource/v1_0/VitaminResource.java Writing vitamins/modules/headless-vitamins/headless-vitamins-test/src/testIntegration/java/com/dnebinger/headless/vitamins/resource/v1_0/test/BaseVitaminResourceTestCase.java Writing vitamins/modules/headless-vitamins/headless-vitamins-test/src/testIntegration/java/com/dnebinger/headless/vitamins/resource/v1_0/test/VitaminResourceTest.java BUILD SUCCESSFUL in 2s 1 actionable task: 1 executedしたがって、ここで当ブログシリーズのパート2の終わりとします。
まとめ
ブログシリーズのパート1では、新しいヘッドレスAPIのプロジェクトの作成、設定用yamlファイルの作成、オブジェクトタイプの定義およびOpenAPI yamlファイルに取り組みました。
当パートではその続きとして、RESTアプリケーションのすべてのパス(エンドポイント)を追加しました。 OpenAPI yamlファイルの作成にあたり直面するであろう一般的なポイントに触れ、
buildRESTタスクエラーが発生した場合にLiferayのファイルを例として比較する方法に触れました。そして、
buildRESTを正常に呼び出して、新しいヘッドレスAPIのコードを生成することで、このパートを終了しました。次回のパートでは、生成されたコードを掘り下げ、ロジックの追加をどこから開始する必要があるかを確認します。
それではまた!
https://github.com/dnebing/vitamins

- 投稿日:2019-12-23T17:27:14+09:00
LiferayのREST Builderを使用した独自ヘッドレスAPIの作成方法(パート1)
※この記事はLiferayコミュニティブログに投稿された、Creating Headless APIs (Part 1)を翻訳したものです。
はじめに
最近私は、Liferayの新しいヘッドレスAPIを用いた開発を試みています。私は新たなヘッドレス・デリバリーとヘッドレス・ユーザー管理モジュールを活用したReactベースのSAPを持っています。いくつかの箇所は準備段階ですが、最終的にはすべてのリリースを予定しています。最初のパーツは準備が完了しており、新しいREST Builderツールを使用して独自のヘッドレスAPIを作成しています。
ここで次のような疑問を抱くかも知れません。
「なぜ伝統的なJAX-RSに基づく独自のRESTではなく、REST Builderを使用するのか?」
これはとても重要かつ自然な疑問です。LiferayのREST Builderは、単にエンドポイントを公開するアプリケーションをビルドするわけではありません。それらに加え、次のような追加要素があります:
- Liferayの認証パイプラインとの統合
- LiferayのCORSの扱いとの統合
- Liferayの検索、フィルタリング、ページングなどとの統合をサポートするためのヘッドレスファシリティ
- 呼び出し側リクエストに対するJSONまたはXMLの生成機能
- 近くリリースされる LiferayのGraphQLエンドポイントとの統合により、REST Builder APIのカスタマイズなしでのGraphQLを経由した利用
- モバイルおよびSPAアプリケーション開発者への一貫性の担保。
これらはプロジェクト要件に適用されないかつこれら分野に精通している場合は、場合は、適材適所で親しみのある手段を採ることをおすすめします。これらがプロジェクトに適している場合、あなたはこのブログシリーズを気に入ってくれるでしょう!
ブログシリーズの初回を飾る当記事では、新しいREST Builderを使用するためのプロジェクトをセットアップし、エントリポイントを定義するYAMLファイルの主要箇所を紹介します。当記事は長くなるため、いくつかのパートに別け、まずはサービスパス(エントリポイント)の定義から始め、サービスビルディングへ続いていきます。
事前作業
作業を始める前に、REST Builderの使い方に関するLiferayの公式ドキュメントに目を通してください。記事を読むのにはそれほど時間はかかりませんので、読み終えたらまた当記事へ戻ってきてください。
プロジェクトの開始
次のコマンドを実行して作業用プロジェクトを作成します:
blade init -v 7.2 vitamins今回はプロジェクトの構成をイメージしやすくするため、プロジェクトを「ビタミン」と名付けました。このプロジェクトはビタミンとミネラルで構成され、それらはWebコンテンツよりも多くのビタミンとミネラルを保持している必要があります。そのためヘッドレスREST層(REST Builder)と併せて、カスタムサービス層(Service Builder)が必要になります。
注:この先、gradle.propertiesでターゲットプラットフォームが有効になっているものとします。すでに設定が済んでいる場合は問題なく次へ読み進めてください。私はターゲットプラットフォームを使用しているため、build.gradleファイル内にバージョンを含めません。
次にプロジェクトをIDEにロードし、次の手順に従ってheadless-vitamins-implモジュール(後に説明)でbuild.gradleファイルを編集します:https://portal.liferay.dev/docs/7-2/reference/-/knowledge_base/r/rest-builder-gradle-plugin
注:参照記事に明記されていない注意点として、Liferay Gradle Workspaceを使用している場合、該当ワークスペースが生成するビルドスクリプトは
headress-<名前>-implモジュール内のbuild.gradleファイルに入り、settings.gradleファイルまたはルートレベルのbuild.gradleファイルには入りません。このケースでビルドスクリプトをsettings.gradleファイルへ置こうとすると、org.gradle.initialization.DefaultSettings_Decorated cannot be cast to org.gradle.api.Projectといった予期せぬエラーが発生します。もしこれが発生した場合は、あなたのREST Builderプラグインが正しくないファイルにリストされていることを意味します。
headless-vitamins-implモジュール内で./gradlew tasksコマンドを実行することで、実際にREST Builderが利用可能であることを確認できます:$ ./gradlew tasks > Task :tasks ------------------------------------------------------------ All tasks runnable from root project ------------------------------------------------------------ Build tasks ----------- assemble - Assembles the outputs of this project. build - Assembles and tests this project. buildCSS - Build CSS files. buildDependents - Assembles and tests this project and all projects that depend on it. buildLang - Runs Liferay Lang Builder to translate language property files. buildNeeded - Assembles and tests this project and all projects it depends on. buildREST - Runs Liferay REST Builder. ...省略...モジュール一式が必要となるため、ワークスペースの
modules/headless-vitaminsフォルダ(ヘッドレスモジュールを一緒にまとめるためにこのサブディレクトリを作成しました)にheadless-vitamins-api、headless-vitamins-impl、headless-vitamins-client、およびheadless-vitamins-testを作成します。参照ドキュメンテーションではこれら追加モジュールの作成には触れていませんが、後に示す通り、これらは必要になってきます。$ cd modules/headless-vitamins $ blade create -t api -v 7.2 -p com.dnebinger.headless.vitamins headless-vitamins-api Successfully created project headless-vitamins-api in vitamins/modules/headless-vitamins $ blade create -t api -v 7.2 -p com.dnebinger.headless.vitamins headless-vitamins-impl Successfully created project headless-vitamins-impl in vitamins/modules/headless-vitamins $ blade create -t api -v 7.2 -p com.dnebinger.headless.vitamins headless-vitamins-client Successfully created project headless-vitamins-client in vitamins/modules/headless-vitamins $ blade create -t api -v 7.2 -p com.dnebinger.headless.vitamins headless-vitamins-test Successfully created project headless-vitamins-test in vitamins/modules/headless-vitamins上記コマンドでモジュールを作成する際に、タイプとして
apiを指定したため、いくつかの不要なパッケージやjavaファイルも生成されます。これらをクリーンアップするには、少々時間を要します。また、headless-vitamins-testディレクトリのsrc/maiディレクトリをsrc/testIntegrationへリネームする必要があります。このプロジェクトはREST Builderがいくつかの統合テストケースを生成しますが、それを機能させるには適切なディレクトリが必要です。
Liferayのバンドルの標準命名規則に従うため、bnd.bndファイルはcom.dnebinger.headless.vitamins.apiおよびcom.dnebinger.headless.vitamins.implシンボリック名などで更新されます。build.gradleファイルには多くの追加が必要になりますが、もうひと息です。サービスの定義
ここから徐々に楽しくなってきます。サービスエンドポイントを定義するためのYAMLファイルを作成しましょう。この作業が初めての場合、気が遠くなると感じるかもしれません。
まずは単純な作業として。
headless-vitamins-impl内にrest-config.yamlファイルを追加する必要があります。apiDir: "../headless-vitamins-api/src/main/java" apiPackagePath: "com.dnebinger.headless.vitamins" application: baseURI: "/headless-vitamins" className: "HeadlessVitaminsApplication" name: "dnebinger.Headless.Vitamins" author: "Dave Nebinger" clientDir: "../headless-vitamins-client/src/main/java" testDir: "../headless-vitamins-test/src/testIntegration/java"これはLiferayのヘッドレスが機能するのに必要な、あなたの作成した要素群を一つに構成したものです。最後の2つのエントリでクライアントとテストを指します。したがって、この作業は先に終わらせます。
次に
rest-openapi.yamlファイルを扱います。このファイルもheadless-vitamins-implモジュール内に作成されるものです。一度にすべてを捨てるのではなく、ここでは順を追って詳細を理解していきます。すべてのファイル構成はこのリポジトリで確認できます。各OpenAPI YAMLファイルはMeta、Paths(エンドポイント)およびReusable Components(型定義)の3つのセクションから成り、今回作成したものと違いはありません。
私のメタセクションは次の通りです:
openapi: 3.0.1 info: title: "Headless Vitamins" version: v1.0 description: "API for accessing Vitamin details."ここまで順調に進んでいます。
注:単純なテキストエディタはYAMLファイルの編集に向きません。特に、行の折り返しにおける適切なインデント処理に難があります。もし使い慣れたエディタをお持ちでなければ、https://editor.swagger.io/で入手可能なSwaggerのアウトラインツールがおすすめです。このツールは適切なインデント処理だけでなく、OpenAPI YAML形式のファイルを扱う際に非常に役立つコード補完機能も有しています。
型の定義
次に、今回作成した再利用可能なコンポーネントを共有します。これらは単体で機能するものではありませんが、後にPathsをカバーする際の負担を軽くします。
私の主要型と「ビタミン」の型:
components: schemas: Vitamin: description: Contains all of the data for a single vitamin or mineral. properties: name: description: The vitamin or mineral name. type: string id: description: The vitamin or mineral internal ID. type: string chemicalNames: description: The chemical names of the vitamin or mineral if it has some. items: type: string type: array properties: description: The chemical properties of the vitamin or mineral if it has some. items: type: string type: array group: description: The group the vitamin or mineral belongs to, i.e. the B group or A group. type: string description: description: The description of the vitamin or mineral. type: string articleId: description: A journal articleId if there is a web content article for this vitamin. type: string type: description: The type of the vitamin or mineral. enum: [Vitamin, Mineral, Other] type: string attributes: description: Health properties attributed to the vitamin or mineral. items: type: string type: array risks: description: Risks associated with the vitamin or mineral. items: type: string type: array symptoms: description: Symptoms associated with the vitamin or mineral deficiency. items: type: string type: array creator: $ref: "#/components/schemas/Creator" type: object上記はYAMLの書式です。インデントは階層を表し、より深いインデントの行がその子となり、同階層の行は兄弟を意味します。
「ビタミン」の型は多くのプロパティを持ちます。プロパティは name や id といった単純なものから、より複雑なものまでさまざまです。型プロパティは
Stringですが、可能な値の列挙によって制限されます。クリエイターはこのファイル内における別オブジェクト($refがこれに当たります)への参照です。同一ファイル内に
$refがある場合、参照を含める必要があることを意味します。Liferayのheadless-deliveryファイルからコピーした「ビタミン」のクリエイター型は次のとおりです:Creator: description: Represents the user account of the content's creator/author. Properties follow the [creator](https://schema.org/creator) specification. properties: additionalName: description: The author's additional name (e.g., middle name). readOnly: true type: string familyName: description: The author's surname. readOnly: true type: string givenName: description: The author's first name. readOnly: true type: string id: description: The author's ID. format: int64 readOnly: true type: integer image: description: A relative URL to the author's profile image. format: uri readOnly: true type: string name: description: The author's full name. readOnly: true type: string profileURL: description: A relative URL to the author's user profile. format: uri readOnly: true type: string type: object型の説明は以上です。
まとめ
まとめるには早すぎますか?確かにまだ作業は未完了ですね!次のパートはすでに記事にしてあるのでご安心ください。
このパートでは、カスタムヘッドレスサービスと必要なモジュール群を備えた、新しい Liferay Gradle Workspace の作成方法を紹介しました。
また、OpenAPIのYAMLファイルをはじめ、再利用可能なコンポーネントについて理解を深めるために、Pathセクションを飛ばしつつMetaセクションに触れ、「ビタミン」プロジェクトとクリエイターオブジェクトを定義しました。次回はPaths(エントリポイント)を洗い出していきます
それではまた次のパートでお会いしましょう!
- 投稿日:2019-12-23T16:42:36+09:00
[検証]SpringBoot vs Micronaut 起動速度の比較
Java Advent Calendar 2019 24日目の記事です。
クリスマス前にも関わらず暇なので
JVM言語ベースのフレームワークであるSpringBootとMicronautの単純起動速度を比較してみたSpringは知る人ぞ知るフレームワークなので紹介は省きます
Mirconautとは
- OCI社が開発したマイクロサービス向けフレームワーク
- JVMベース
- 2018年10月に1.0GAリリース
公式サイト
https://micronaut.io/特徴
- プログラム言語にJava/Groovy/Kotlinが使える
- Compile Time DI&AOPを採用している
- GraalVM、NativeImageも使える
- CLIが提供されている
- 起動が早い
- メモリフットプリントが小さい
検証
環境
MacBook Pro
SpringBoot v2.2.2.RELEASE
Micronaut 1.2.7
実行環境
- AdoptOpenJDK 11.0.4
- AdoptOpenJDK 8.0.232
- GraalVM 19.2.1
- JIT
- AOT(NativeImage)
方法
- シンプルなREST APIを1つ実装する
- jarにパッケージして起動する(java -jar xxx.jar)
- 各実行環境で10回起動して、その平均値を取る
- SpringBootはTomcatとJettyの両方で起動速度を計測する
実装
SpringBoot
@RestController public class HelloController { @RequestMapping(value="/hello", method=RequestMethod.GET) public String hello() { return "Hello Spring"; } }Tomcat起動
. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.2.2.RELEASE) 2019-12-23 14:29:46.247 INFO 73041 --- [ main] com.example.sphelloapp.DemoApplication : Starting DemoApplication 2019-12-23 14:29:46.250 INFO 73041 --- [ main] com.example.sphelloapp.DemoApplication : No active profile set, falling back to default profiles: default 2019-12-23 14:29:46.925 INFO 73041 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http) 2019-12-23 14:29:46.935 INFO 73041 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2019-12-23 14:29:46.935 INFO 73041 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.29] 2019-12-23 14:29:46.984 INFO 73041 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2019-12-23 14:29:46.984 INFO 73041 --- [ main] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 695 ms 2019-12-23 14:29:47.105 INFO 73041 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor' 2019-12-23 14:29:47.214 INFO 73041 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2019-12-23 14:29:47.216 INFO 73041 --- [ main] com.example.sphelloapp.DemoApplication : Started DemoApplication in 1.233 seconds (JVM running for 1.556)Jetty起動
. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.2.2.RELEASE) 2019-12-23 14:22:39.036 INFO 72942 --- [ main] c.e.sphelloappjetty.DemoApplication : Starting DemoApplication 2019-12-23 14:22:39.038 INFO 72942 --- [ main] c.e.sphelloappjetty.DemoApplication : No active profile set, falling back to default profiles: default 2019-12-23 14:22:39.651 INFO 72942 --- [ main] org.eclipse.jetty.util.log : Logging initialized @1229ms to org.eclipse.jetty.util.log.Slf4jLog 2019-12-23 14:22:39.713 INFO 72942 --- [ main] o.s.b.w.e.j.JettyServletWebServerFactory : Server initialized with port: 8080 2019-12-23 14:22:39.716 INFO 72942 --- [ main] org.eclipse.jetty.server.Server : jetty-9.4.24.v20191120; built: 2019-11-20T21:37:49.771Z; git: 363d5f2df3a8a28de40604320230664b9c793c16; jvm 1.8.0_232-20191009173705.graal.jdk8u-src-tar-gz-b07 2019-12-23 14:22:39.738 INFO 72942 --- [ main] o.e.j.s.h.ContextHandler.application : Initializing Spring embedded WebApplicationContext 2019-12-23 14:22:39.739 INFO 72942 --- [ main] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 664 ms 2019-12-23 14:22:39.815 INFO 72942 --- [ main] org.eclipse.jetty.server.session : DefaultSessionIdManager workerName=node0 2019-12-23 14:22:39.815 INFO 72942 --- [ main] org.eclipse.jetty.server.session : No SessionScavenger set, using defaults 2019-12-23 14:22:39.816 INFO 72942 --- [ main] org.eclipse.jetty.server.session : node0 Scavenging every 660000ms 2019-12-23 14:22:39.821 INFO 72942 --- [ main] o.e.jetty.server.handler.ContextHandler : Started o.s.b.w.e.j.JettyEmbeddedWebAppContext@45f45fa1{application,/,[file:///private/var/folders/xk/q20_p4gd2xz1sfmtmngwjg380000gp/T/jetty-docbase.146795275059491819.8080/],AVAILABLE} 2019-12-23 14:22:39.822 INFO 72942 --- [ main] org.eclipse.jetty.server.Server : Started @1400ms 2019-12-23 14:22:39.922 INFO 72942 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor' 2019-12-23 14:22:40.036 INFO 72942 --- [ main] o.e.j.s.h.ContextHandler.application : Initializing Spring DispatcherServlet 'dispatcherServlet' 2019-12-23 14:22:40.036 INFO 72942 --- [ main] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet' 2019-12-23 14:22:40.040 INFO 72942 --- [ main] o.s.web.servlet.DispatcherServlet : Completed initialization in 4 ms 2019-12-23 14:22:40.060 INFO 72942 --- [ main] o.e.jetty.server.AbstractConnector : Started ServerConnector@37574691{HTTP/1.1,[http/1.1]}{0.0.0.0:8080} 2019-12-23 14:22:40.062 INFO 72942 --- [ main] o.s.b.web.embedded.jetty.JettyWebServer : Jetty started on port(s) 8080 (http/1.1) with context path '/' 2019-12-23 14:22:40.064 INFO 72942 --- [ main] c.e.sphelloappjetty.DemoApplication : Started DemoApplication in 1.299 seconds (JVM running for 1.643)(参考)
jetty起動にする場合の設定(gradle)build.gradledependencies { compile('org.springframework.boot:spring-boot-starter-web') { exclude module: 'spring-boot-starter-tomcat' } compile('org.springframework.boot:spring-boot-starter-jetty') }NativeImage起動
Springはまだ正式にはNativeImageに対応していない(2020年2Qに対応予定)
実験版がgithubにあるので、これで検証する(TomcatのみでJettyはない)
https://github.com/spring-projects-experimental/spring-graal-native手順
1. GitHubのspring-graal-nativeをclone
2../build-feature.shを実行
3.spring-graal-native-samples/springmvc-tomcatに移動
4../compile.shを実行 (1〜2分)
5.targetフォルダに移動し、springmvc-tomcatが生成されていることを確認
6../springmvc-tomcatで実行これでspring側の準備は完了
Micronaut
HelloController.java@Controller public class HelloController{ @Get(value="/hello", produces = MediaType.TEXT_PLAIN) public String index(){ return "Hello Micronaut"; } }起動
14:37:49.383 [main] INFO io.micronaut.runtime.Micronaut - Startup completed in 985ms. Server Running: http://localhost:8080NativeImage起動
Micronautは標準でNativeImageに対応しているが、NativeImage専用のプロジェクトを作ると楽できる
※前提としてMicronautCLIがインストールされていること
Micronautインストール手順はここを参照
手順
1.$mn create-app hello-graal --features graal-native-image
2.HelloController.javaを実装
3../gradlew buildを実行
4.$native-image --no-server -cp build/libs/hello-graal-0.1-all.jarを実行 (1〜2分)
5../hello-graalを実行これでMicronaut側の準備は完了
結果
考察
- JDK(11, 8, GraalVM JIT)では差はほぼない。
- フレームワーク同士では約300msの差はあるが、これを大きいと捉えるか小さいと捉えるかは個人の考えやケースによる。筆者の場合は特に気にならない差である。
- GraalVM AOT(NativeImage)は圧倒的に早い。
- JVM上で動作させることの利点を捨ててまでNativeImageにする恩恵があるかと言われれば疑問も残る。 (JVMも1秒前後で起動するからいいんじゃないか)
- ただし、今回は超シンプルなアプリだった結果であるため、たくさんクラスロードがあるようなアプリだと起動時間においてはAOTの恩恵をさらに感じるかもしれない。
最後に
今回は単純なアプリでの検証のため、実際の複雑なアプリでは異なる結果になるかもしれないので、あくまで参考として見ていただけると幸いです。
機会があればhelidonとかQuarkusといったフレームワークも検証してみます。




- 投稿日:2019-12-23T14:14:40+09:00
tomcatでjsp/servlet/struts2
tomcatでservlet HelloWorld
Javaとjsp/servletを学習して、Eclipseを使用して開発をしていたが、
Eclipseを使わず開発をするために以下やったことをまとめる環境
・macOS Catalina 10.15.2
・Tomcat 9.0.30
・Java 13参考にしたサイト
■さとうきびの初心者プログラミング日記>Tomcat -ServletでHelloWorldしてみる(Mac)
http://satoukibi.hatenablog.com/entry/2017/02/24/Tomcat_-Servlet%E3%81%A7HelloWorld%E3%81%97%E3%81%A6%E3%81%BF%E3%82%8B%28Mac%29■soracane>Struts2について>03.Struts2の設計と設定のルール
https://sites.google.com/site/soracane/home/struts2nitsuite/struts2no-she-jito-she-dingnorurubrewにtomcatがあるか調べる
$ brew search tomcat ==> Formulae tomcat tomcat-native tomcat@6 tomcat@7 tomcat@8tomcatインストール
$ brew install tomcat ・・・ ==> Downloading https://www.apache.org/dyn/closer.cgi?path=/tomcat/tomcat-9/v9.0 ==> Downloading from https://www-eu.apache.org/dist/tomcat/tomcat-9/v9.0.30/bin/ ######################################################################## 100.0% ? /usr/local/Cellar/tomcat/9.0.30: 641 files, 14.8MB, built in 27 seconds/usr/local/Cellar/tomcat/9.0.30にインストールされた
tomcatの起動
$ /usr/local/Cellar/tomcat/9.0.30/bin/catalina start Using CATALINA_BASE: /usr/local/Cellar/tomcat/9.0.30/libexec Using CATALINA_HOME: /usr/local/Cellar/tomcat/9.0.30/libexec Using CATALINA_TMPDIR: /usr/local/Cellar/tomcat/9.0.30/libexec/temp Using JRE_HOME: /Library/Java/JavaVirtualMachines/jdk-13.jdk/Contents/Home Using CLASSPATH: /usr/local/Cellar/tomcat/9.0.30/libexec/bin/bootstrap.jar:/usr/local/Cellar/tomcat/9.0.30/libexec/bin/tomcat-juli.jar Tomcat started.http//localhost:8080でtomcatの画面が表示されていたら起動成功
終了するには以下
$ /usr/local/Cellar/tomcat/9.0.30/bin/catalina stopHelloWorld.javaの作成
HelloWorld.javaimport java.io.*; import javax.servlet.*; import javax.servlet.http.*; public class HelloWorld extends HttpServlet { public void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException, ServletException{ response.setContentType("text/html"); PrintWriter out = response.getWriter(); out.println("<html>"); out.println("<head>"); out.println("<title>Hello World!</title>"); out.println("</head>"); out.println("<body>"); out.println("<h1>Hello World!</h1>"); out.println("</body>"); out.println("</html>"); } }web.xmlの作成
web.xml<?xml version="1.0" encoding="ISO-8859-1"?> <web-app xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd" version="2.4"> <servlet> <servlet-name>HelloWorldName</servlet-name> <servlet-class>HelloWorld</servlet-class> </servlet> <servlet-mapping> <servlet-name>HelloWorldName</servlet-name> <url-pattern>/HelloWorldPage</url-pattern> </servlet-mapping> </web-app>コンパイル
$ javac -classpath "/usr/local/Cellar/tomcat/9.0.30/libexec/lib/servlet-api.jar" HelloWorld.javatomcatのディレクトリ構成
/usr/local/Cellar/tomcat/バージョン/libexec/webapps/
webapps配下にwebアプリケーションを配置するwebアプリのディレクトリ構成
webapps/ └--webアプリのルートディレクトリ/ └--WEB-INF/ |--web.xml └--classes/ └HelloWorld.classhttp://localhost:8080/test/HelloWorldPageにアクセス
できた
tomcatでstruts2を利用したwebアプリを動かす
・ホームページ表示(index.jsp)
・ボタンクリックでHelloStrutsと表示するページ表示(hello.jsp)
・ボタンクリックで名前を入力するページ表示(welcome.jsp)
→名前入力後、送信ボタンクリックでPOST通信で送られた名前を表示するページ表示(login.jsp)
struts2のディレクトリ構成webapps/ └--HelloStruts/ |--index.jsp |--hello.jsp |--welcome.jsp |--login.jsp |--src/ | └--action/ | └--com/ | └--action/ | |--HelloStrutsAction.java | |--WelcomeAction.java | └--Login.Action.java └--WEB-INF/ |--web.xml |--lib/ ※ライブラリ | |--commons-fileupload-1.4.jar | |--commons-io-2.2.jar | |--commons-lang3-3.2.jar | |--commons-logging-1.1.3.jar | |--freemarker-2.3.28.jar | |--javassist-3.11.0.GA.jar | |--ogni-3.0.21.jar | |--struts2-core-2.3.37.jar | └--xwork-core-2.3.37.jar └--classes/ |--struts.xml └--com/ └--action/ |--HelloStrutsAction.class |--WelcomeAction.class └--Login.Action.classjavaファイルがあるディレクトリに移動
cd /usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/src/com/actionコンパイル&ライブラリのパスを通す
※ライブラリの間は「:」でつないでいる$ javac -classpath "/usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/WEB-INF/lib/commons-fileupload-1.4.jar: /usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/WEB-INF/lib/commons-io-2.2.jar: /usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/WEB-INF/lib/commons-lang3-3.2.jar: /usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/WEB-INF/lib/commons-logging-1.1.3.jar: /usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/WEB-INF/lib/freemarker-2.3.28.jar: /usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/WEB-INF/lib/javassist-3.11.0.GA.jar: /usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/WEB-INF/lib/ognl-3.0.21.jar: /usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/WEB-INF/lib/struts2-core-2.3.37.jar: /usr/local/Cellar/tomcat/9.0.30/libexec/webapps/HelloStruts/WEB-INF/lib/xwork-core-2.3.37.jar" HelloStrutsAction.java LoginAction.java WelcomeAction.javajavaファイルの下にそれぞれの.classファイルができているので、
それを/HelloStruts/WEB-INF/classes/classes/配下に移動して
http://localhost:8080/HelloStruts/
にアクセス
ホームページ表示
↓↓↓
HelloStrutsボタンをクリック
HelloStrutsと表示できた!ホームページに戻る
Welcomeボタンをクリック
↓↓↓
入力するページを表示できた!
↓↓↓
ユーザー名を入力して送信ボタンをクリック
実行できた!javaファイルやライブラリが大きくなるとコンパイルするコマンドがどんどん長くなってしまうし大変なので
今後はそこを改善してみたいと思う。







- 投稿日:2019-12-23T14:00:58+09:00
iOSでのATDD開発(基礎編)
以下の続きです。
システムアーキテクチャ
前記事に記載してますが、再掲。
プロジェクトの構成
├─ src ├─ test ├─ java | └─ jp.co.hoge.Project.E2ETest | ├─ pageobject | └─ steps | └─ utils └─ resources └─ jp.co.hoge.Project.E2ETest └─ feature files
- pagobject - 後述
- steps - 実際のテストを記述するファイルとなります。Gherkinで書かれた自然言語とコードの紐付けが行われます。
- utils - ユーティリティクラス群です。appiumサーバ作成用のクラスなどがあります。
- feature files - Gherkinでかかれたフィーチャーファイル群です。
PageObject
PageObjectは(テストとは関係なく)ページとユーザの関係を表したオブジェクトのことです。
以下条件を満たします。
- publicなメソッドはそのページが提供する論理的な処理を表す
- ページ内部の情報は公開しない
- テストで使用するアサーションはPageObject内に含まない
- メソッドはPageObjectを返す
- ページ全体を表す必要はない
- 同じアクションでも結果が異なる場合は異なるメソッドとして定義する
PageObjectサンプル
PageObjectは基本的に上記要件を満たしたものを言うのですが、開発の都合上完全に準拠する形にはしませんでした。
例えば今回PageObjectの基底クラスとしてBasePageというPageObjectを用意しています。
基本的に新たにPageObjectを作る際にはこのクラスを継承しています。
このBasePageには要素の存在確認用のpublicメソッドが実装されていますが、上の原則でいうメソッドはPageObjectsを返すに反してはいますが、便宜上存在確認は各PageObjectに実装することにしました。/// PageObjectのExample public class SearchPage extends BasePage { public SearchPage(IOSDriver driver) { super(driver); } @iOSXCUITFindBy(xpath = "//*[@name=\"検索\"]") private IOSElement navigationBar; @iOSXCUITFindBy(xpath = "//*[@name=\"アーティストをさがす\"]") private IOSElement textSearchField; @iOSXCUITFindBy(accessibility = "ランキング") private IOSElement ranking; ... public SearchResultPage searchText(String keyword) { textSearchField.setValue(keyword); driver.hideKeyboard(); return new SearchResultPage(driver); } public SearchSuggestPage showSuggest(String keyword) { textSearchField.setValue(keyword); return new SearchSuggestPage(driver); } public Boolean existsNavigationBar() { return checkVisibilityOfElement(navigationBar); } ...Feature
シナリオを平文で書いたものです。ここで登場するのがGherkinと呼ばれる構文規則です。
Sample
Feature: 探すページを表示する Scenario: 探すタブを押下する Given アプリを起動し、さがす画面に遷移 Then さがす画面で、ヘッダに「さがす」と表示されるSteps Keyword
各ステップにはGiven, When, Then, And or Butというキーワードをつかうことができます。
ただし、これらはステップ定義を探す際に考慮されません。Steps Argument
ステップ定義に引数を渡すことができます。ただし、使える型には制限があります。
https://cucumber.io/docs/cucumber/cucumber-expressions/#parameter-types// example feature Scenario: 音楽再生時のコントロールパネルを表示する Given さがすタブをタップする And テキスト検索から"米津玄師"を入力する ...// example steps definision @Given("テキスト検索から{string}を入力する") public void テキスト検索から米津玄師を表示する(String keyword) { searchResultPage = searchPage.searchText(keyword); }Skip Test
開発途中のステップなど、まだCI上でテストを実行して欲しくないFeatureがある際にignoreアノテーションをつけることによって該当テストの実行をスキップできます。
@ignore Feature: 広告表示

- 投稿日:2019-12-23T12:31:12+09:00
[Java] 内部イテレータのメモ
はじめに
StreamやforEachについて勉強していたときに、内部イテレータという知らない単語に出会ったので、そのときのメモ。
あくまで自分なりに理解しただけだから、たぶん適当なことが書いてある。イテレータに内部と外部があるの?
内部イテレータという単語を知ったときに驚いたのが、イテレータには内部イテレータと外部イテレータの2種類があること。
じゃあ俺が知っているイテレータは何なんだと思い、まずはイテレータについて調べた。イテレータ(英語: iterator)とは、プログラミング言語において配列やそれに類似する集合的データ構造(コレクションあるいはコンテナ)の各要素に対する繰り返し処理の抽象化である。実際のプログラミング言語では、オブジェクトまたは文法などとして現れる。JISでは反復子(はんぷくし)と翻訳されている[1][2]。
繰り返し処理の抽象化か。これはなんとなく理解していた気がする。
この抽象化の仕方に外部と内部の2種類があるってことだな。
じゃあ次はその2つの違いについて調べる。外部イテレータ
Javaでは、java.util.Iteratorインターフェイス族を実装するオブジェクトが外部イテレータとなる。Java 1.5以降のIteratorはジェネリクスに対応している。
つまり俺がイテレータと認識していたものは外部イテレータだった。
で、外部イテレータの実装はこんな感じになる。外部イテレータIterator<ほげ> iterator = Iterableを実装しているやつ.iterator() while (iterator.hasNext()) { // iterator.next()になんかの処理 }めっちゃ適当に書いたけど、Iterableというインターフェースを実装し、Iteratorを持たせることで繰り返しの処理を抽象化することができる。
繰り返しをしているところ(while)が外部に剥き出しだから、外部イテレータって呼ばれるのかな?内部イテレータ
Rubyのブロックのような個々の要素ごとの処理を表現するものをコンテナ・オブジェクトのメソッドに渡し,メソッドが要素ごとの処理を呼び返すタイプの繰り返し方法を「内部イテレータ」と呼びます。
内部イテレータは余分なクラスを作らず,使うのも作るのも簡単です。しかし,言語がクロージャをサポートしていないとループ本体と外側とで情報を共有するために工夫が必要になり,C言語の例で見たようにループとしての使い勝手が悪くなります。このため,クロージャを持たないC++やJavaでは外部イテレータが採用されているのです。
よくわからないので実装をみる。
内部イテレータList<Integer> list = なんかのリスト; list.forEach(n -> n + 1); // 想像上のforEach forEach(処理) { for (繰り返し) { // 処理を呼ぶ; } }つまり繰り返しは内側にあって、やって欲しい処理を渡す。だから内部イテレータって呼ぶのかな。
Javaの場合、第一級関数はないので関数型インターフェースを渡す。で、ここでよくわからないのが、クロージャをサポートしていないと内部イテレータを実装しにくいということ。
なんでクロージャが必要なの?クロージャ
そもそもクロージャもあまり詳しくないので調べた。
関数が関数内部以外の変数をスコープとして保持することだと理解した。
ここもいろいろ調べたので、別の記事にしたい。クロージャfunction createCounter() { let count = 0; return function() { count++; console.log(count); }; } let counter = createCounter(); counter(); // 1 counter(); // 2JSだとこんな感じになる。
内部イテレータにクロージャが必要な理由
最初はなんで必要なのか全然分からなかった。
クロージャについて調べていくうちになんとなく理解。
とりあえずJavaのサンプルコード。内部イテレータとクロージャfinal List<Integer> list = なんかのリスト final Integer n = なんかの数字; list.forEach(value -> value + n); // 想像上のforEach forEach(処理) { for (繰り返し) { // 処理を呼ぶ; } }このときnがクロージャの仕組みによって、forEachに渡している処理でもスコープに入り、使えることができる。
もしクロージャがないと、引数を渡す仕組みを用意するか、繰り返しの対象のフィールドとして持たせる必要がある。
つまりはクロージャによって実装が楽になるということかな。まとめ
イテレータには外部イテレータと内部イテレータがある。
内部イテレータの方が個人的にスマートに見える。
しかしクロージャがないと内部イテレータの実装はめんどくさい。余談
普段から勉強するときに、メモを取っているので、それを元に記事を書いた。人に見られる以上は適当なことを書けないし、引用元に関しても本当にあっているか?とか考える必要がある。まぁ、今回はお試しに書いたから適当なところがあると思うけど、今度何か書くときはもっと時間を取りたい。
あと、Java中心に書いたけど、Javaにおけるクロージャは、他の関数型言語と少し違うらしい。
「Java8のlambdaはクロージャーではないけど、クロージャーでやりたいことはできるし、やってはいけないことができないようになっているので、特に問題はない」という記事を見かけた。
これがよくわかっていないのでもっと調べる。
- 投稿日:2019-12-23T06:16:52+09:00
GraphQL Javaでのスキーマ定義ファイルのコメントの書き方とGraphiQLやGraphQL Playgroundへの反映
初めてのGraphQL Webサービスを作って学ぶ新世代APIによると、スキーマ定義ファイルにて各スキーマにコメントをする場合は、以下のようにダブルクォーテーション3つで囲むということになっています。
scheme.graphqls"""本""" type Book { """ID""" id: ID """名前""" name: String """ページ数""" pageCount: Int """著者""" author: Author }上記のように書くことで、GraphiQLやGraphQL PlaygroundのDescriptionにもダブルクォーテーション3つで囲ったコメントが表示されるようになるとのことでした。
ただ、当方Java + Spring BootでGraphQLを軽く書いている中で、上記の書きっぷりだとGraphiQLやGraphQL Playgroundへは反映されず、No Descriptionとなってしまうことに気付きました。そのため、以下のように先頭に#を置く書くことで解決しました。
scheme.graphqls# 本 type Book { # ID id: ID # 名前 name: String # ページ数 pageCount: Int # 著者 author: Author }GraphiQLとGraphQL Playgroundで確認すると以下の通り表示されるようになりました。
以上です。

- 投稿日:2019-12-23T06:14:14+09:00
Spring BootでGraphQLを実装する
GraphQLとは
RESTの課題とGraphQLを参照していただけたらと思います。
環境
- Windows10
- Java8
- Spring Boot 2.2.1.RELEASE
- Maven 3.2.5
依存ライブラリの追加
以下を追加します。
- GraphQL Java
- GraphQL Spring Boot Starter
- GraphQL Java Tools
pom.xml<!-- https://mvnrepository.com/artifact/com.graphql-java/graphql-java --> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java</artifactId> <version>11.0</version> </dependency> <!-- https://mvnrepository.com/artifact/com.graphql-java/graphql-spring-boot-starter --> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <!-- https://mvnrepository.com/artifact/com.graphql-java/graphql-java-tools --> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java-tools</artifactId> <version>5.2.4</version> </dependency>※バージョンは2019年12月時点の最新を利用しています
Schema(スキーマ)定義
スキーマや型については、GraphQLのスキーマと型定義を参照していただけたらと思います。
schema.graphqlstype Book { id: ID name: String pageCount: Int author: Author } type Author { id: ID firstName: String lastName: String } type Query { bookById(id: ID): Book }Typeクラスの作成
スキーマ定義で定義したtypeに該当するJavaクラス(何らかのデータソースから取得したデータを保持するクラス)を作成します。
Book.javapublic class Book { private String id; private String name; private int pageCount; private Author author; public void setId(String id) { this.id = id; } public void setName(String name) { this.name = name; } public void setPageCount(int pageCount) { this.pageCount = pageCount; } public void setAuthor(Author author) { this.author = author; } }Author.javapublic class Author { private String id; private String firstName; private String lastName; public void setId(String id) { this.id = id; } public void setFirstName(String firstName) { this.firstName = firstName; } public void setLastName(String lastName) { this.lastName = lastName; } }リゾルバ(Resolver)の作成
GraphQLのスキーマと型定義でも触れたとおり、スキーマ定義にてクライアントが操作できるクエリや様々な型を定義しています。ただし、スキーマはあくまで定義のみで実際のデータ操作は行いません。実際のデータ操作を行うのがリゾルバというものになります。
BookResolver.java@Component public class BookResolver implements GraphQLQueryResolver { public Book bookById(String bookId) { // 実際は何らかのデータストアからデータを読み込み返却するケースがほとんどだが、ここではダミー値を返却 Book book = new Book(); book.setId(bookId); book.setName("bookName"); book.setPageCount(900); Author author = new Author(); author.setId("0001"); author.setFirstName("fName"); author.setLastName("lName"); book.setAuthor(author); return book; } }実行
GraphQLを実行するには、GraphQLの便利なツールでも紹介した通り、GraphiQLとGraphQL Playground等のツールを利用します。今回は、GraphQL Playgroundのデスクトップ版を利用します。
※ダウンロード、インストールはGraphQLの便利なツールを参照ください。
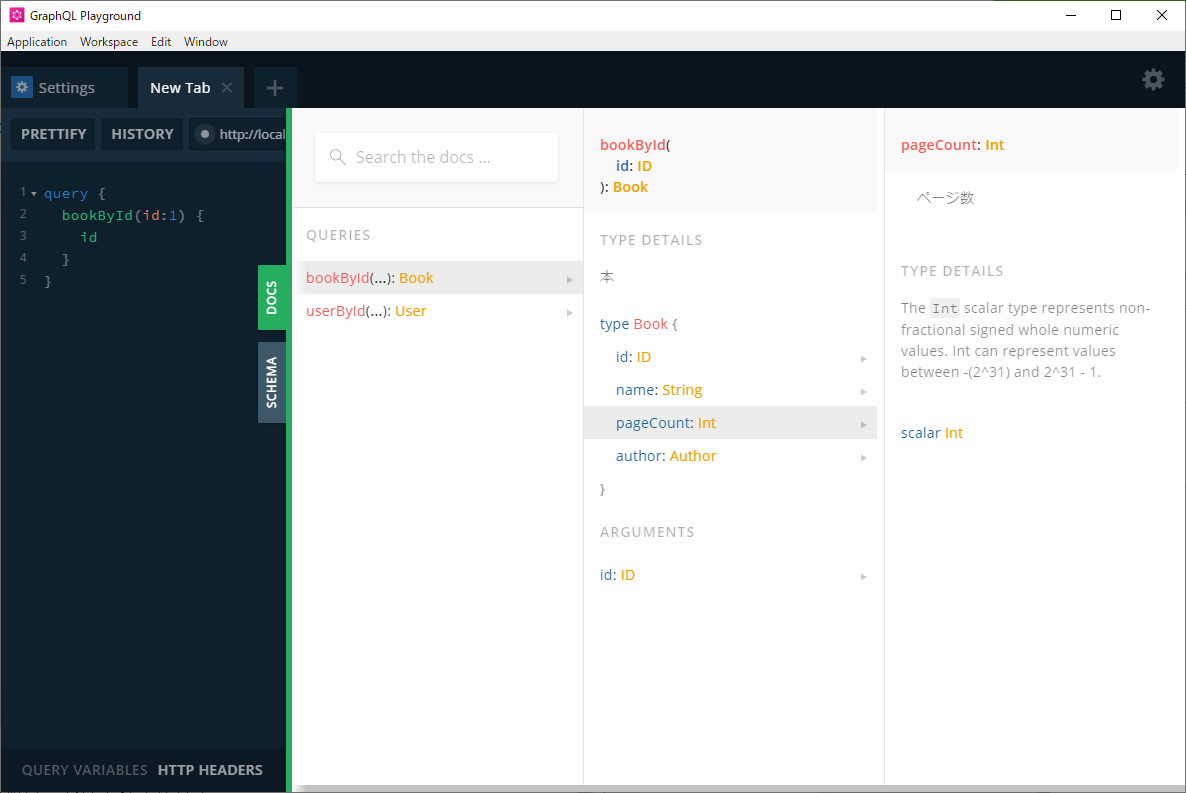
Spring Bootを起動したら、インストールしたGraphQL Playgroundを立ち上げます。「URL ENDPOINT」を選択し、http://localhost:8080/graphql を入力しOPENをクリックします。立ち上がったら、左ペインに以下のクエリを書いて再生ボタンを押してみます。query { bookById(id:1) { id name } }以下のようなレスポンスが返ってくれば成功です。
{ "data": { "bookById": { "id": "1", "name": "bookName" } } }取得項目を増やしてみましょう。今度は以下のクエリを書いて再生ボタンを押してみます。
query { bookById(id:1) { id name author { id firstName lastName } } }以下のようなレスポンスが返ってくれば成功です。ソースを変更せずに取得したい項目が動的に変えることが可能となります。
{ "data": { "bookById": { "id": "1", "name": "bookName", "author": { "id": "0001", "firstName": "fName", "lastName": "lName" } } } }以上です。
参考
- 投稿日:2019-12-23T03:49:45+09:00
STS, SpringBootで手軽にWebアプリ開発。10分で。
タイトルのお手軽手順を紹介します。
要素
- STS
- Spring Boot
- Thymeleaf
手順
STSインストール
こちらから STSの最新版をダウンロードし、インストール。
https://spring.io/toolsStarter Project 作成
Create new Spring Starter Project をクリックし、"Type" は "Gradle (Buildship 3.x) を指定して Next。
以下を選択。
- AWS Core
- AWS RDS
- Spring Boot DevTools
- Spring 開発環境を強化
- Lombok
- アノテーションで getter, setter 等を自動生成
- Spring Configuration Processor
- Spring 開発環境を強化
- MyBatis Framework
- ORM
- MySQL Driver
- Spring Security
- 認証, 認可, CSRF対策, IP制限等のフレームワーク
- Thymeleaf
- 最もシェアのあるテンプレートエンジン
- Spring Web
- MVC
(今回使用しないものもあるが、いつも使っているものをチェックしている)
Finish。実装
コントローラを作成。
Package Explorer で、src/main/java の下の com.example.demo を右クリックして New>Classをクリックし、Nameは "TopController" で Finish。
ビューを作成。
Package Explorer で、src/main/resources の下の templates を右クリックして New>Fileをクリックし、Nameは "top.html" で Finish。
起動、表示確認
簡単のため、build.gradle を開き、今回使用せず、設定の必要な依存関係をコメントアウト。
忘れずに プロジェクトを右クリックし、Reflesh Gradle Project し、起動。
おわりに
近年、プログラミング言語も流行り廃りが起きていますが、Java は静的型付け言語であるためリファクタリングもしやすく、大規模開発向きで(初期開発から10年以上小規模メンテのみで現役のシステムなんてザラ)、Android向けにKotlinも登場したりと、世界中で未だに根強い人気を誇っています。
一方でなかなか Javaを使うことに踏み切れず、厳格・冗長故に苦手意識のある人も多いと思いますが、これについては Lombok の様なライブラリや、Spring Boot の様な FW を使って解決できる事が殆どです。
本記事では、Java 界のスタンダードと言ってもいい Spring Boot のシンプルな開発環境構築を簡単に紹介しました。この機会に触れてみるきっかけとなれば幸いです。
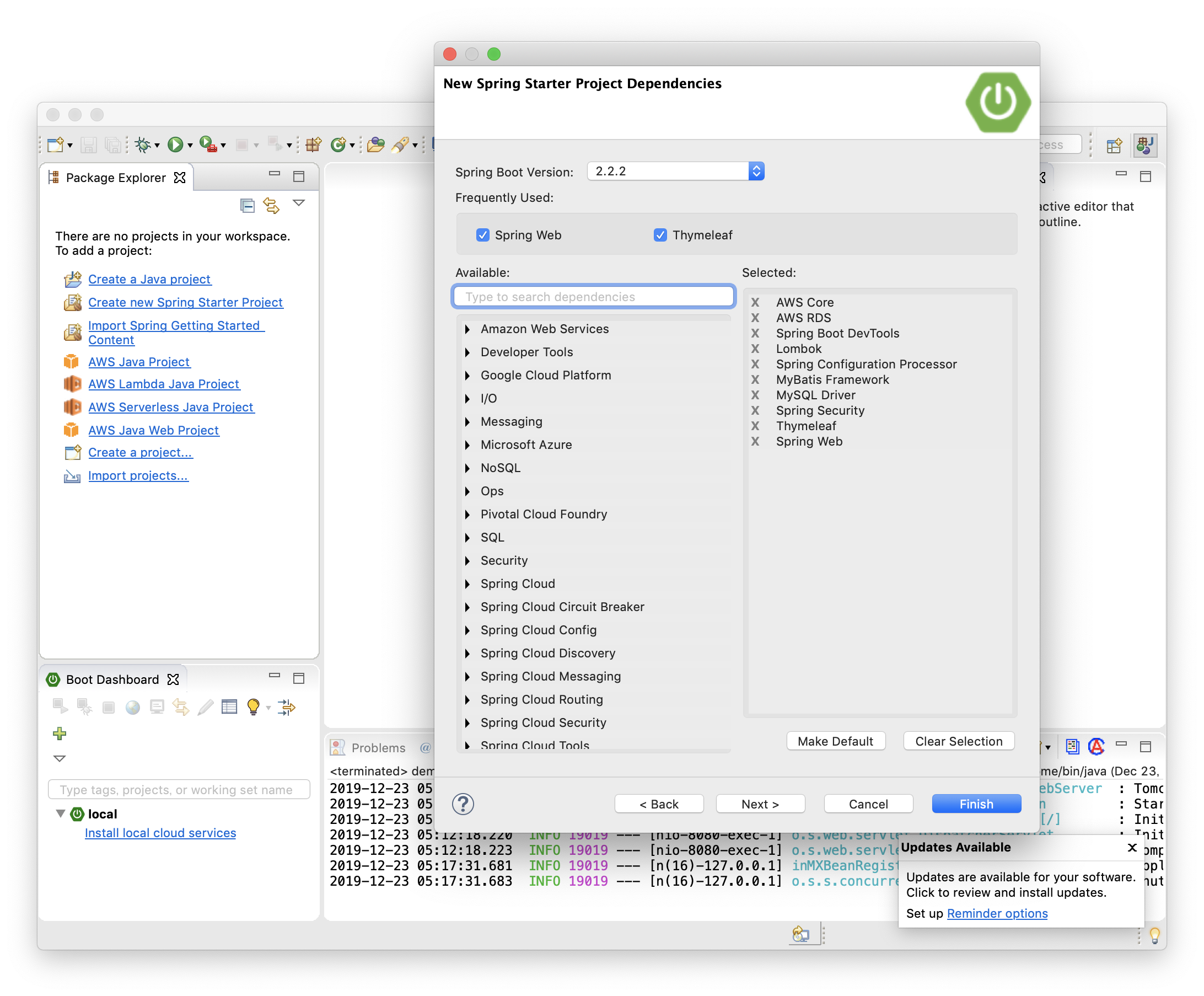
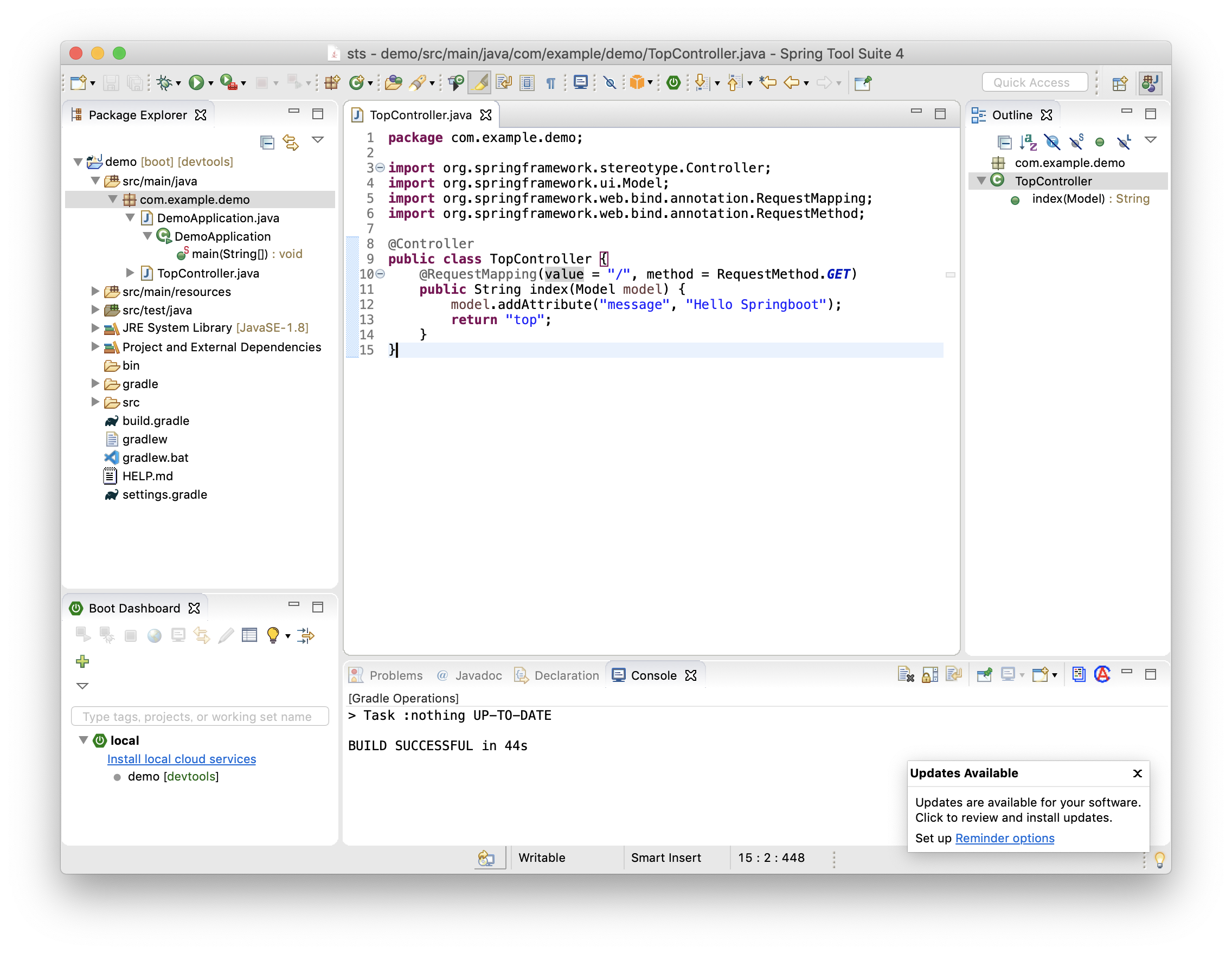
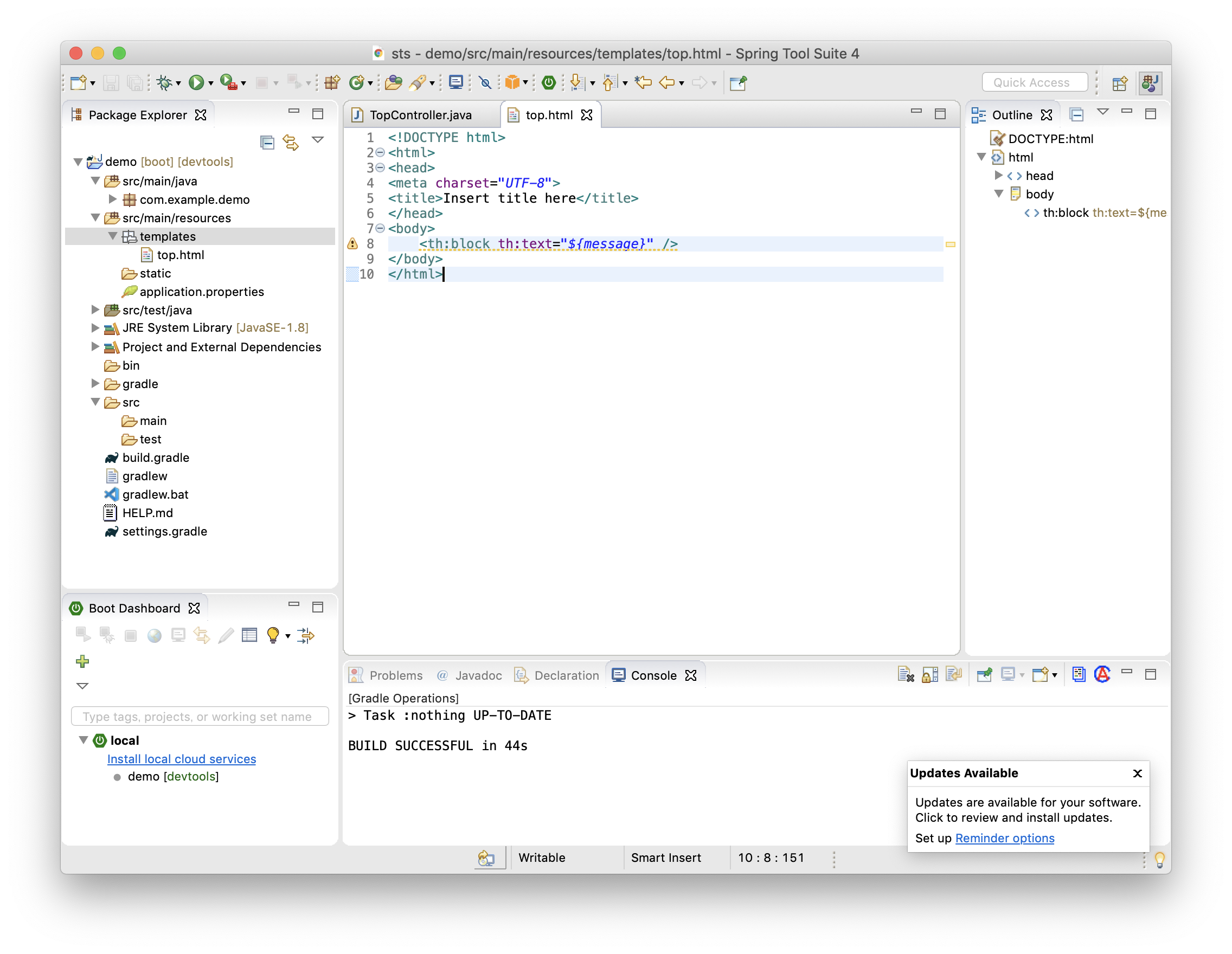
- 投稿日:2019-12-23T03:49:45+09:00
Spring Tool Suite で SpringBoot �のウェブアプリケーションを構築し、Elastic Beanstalk にデプロイする。
はじめに
近年、AIやIoT機器を活用したシステムの開発が増えたり、分析システムの必要性が高まるなど、
開発対象となるシステムは多様化しています。
そんな中、プログラミング言語も流行り廃りが起きていますが、Java は堅牢で信頼性が高く、世界中で未だに根強い人気を誇っています。
が、一方でなかなか Javaを使うことに踏み切れない方も少なくありません。本記事では、Java について簡単に紹介し、SpringBoot フレームワークのシンプルな開発環境構築と AWS ElasticBeanstalk へのデプロイ方法をお見せしますので、この機会に興味をもって触れてみるきっかけとなれば幸いです。
Javaは難しいという声
改めて言うまでもありませんが、Javaは静的型付け言語です。
「Write once, run anywhere」と宣伝されていたとおり、プラットフォームに依存しないため、環境毎のコンパイルは不要です。Javaプログラミングは若干古臭い部分はありますが、他言語同様フレームワークにより開発効率、保守性は格段に上がり、Androidのネイティブ言語としてはJavaを簡潔に書けるようにKotlinが登場したりと、歴史は長いですが、未だに最前線で使われている言語と言えます。
Javaに対する印象として、厳格すぎる・冗長であることが挙がります。
例えば、classにgetter , setter , toString , equals 等を一々書く必要があること。
確かに通常、クラスにはそれらのメソッドを用意する必要があります。しかし、こういった定形的コードは Lombokというライブラリを使えば、アノテーションをつけるだけでコンパイル時に自動生成してくれるようになります。上記は一例ですが、Javaの歴史は長く、ユーザーも圧倒的に多いため、難しい印象の要因はほぼ簡単に解決することができます。
Springフレームワークについて
2004年に登場して以来、存在感が増していき、今もJavaのフレームワークとしてトップシェアを誇っています。
Eclipse ベースの IDE もあり、開発効率は抜群。
https://spring.io/tools今回は、SpringBoot というフレームワークと Gradle というビルドシステムを使って、Webアプリのデモを構築し、AWS ElasticBeanstalk へデプロイするまでの、手順を簡単に記載します。
手順
プロジェクト作成
以下、後日(数日以内に)記載予定です。
- 投稿日:2019-12-23T03:49:45+09:00
STS, SpringBootで手軽にウェブアプリをBeanstalkにデプロイ。10分で。
タイトルのお手軽手順を紹介します。
要素
- STS
- Spring Boot
- Thymeleaf
- Beanstalk
手順
STSインストール
こちらから STSの最新版をダウンロードし、インストール。
https://spring.io/toolsStarter Project 作成
Create new Spring Starter Project をクリックし、"Type" は "Gradle (Buildship 3.x) を指定して Next。
以下を選択。
- AWS Core
- AWS RDS
- Spring Boot DevTools
- Spring 開発環境を強化
- Lombok
- アノテーションで getter, setter 等を自動生成
- Spring Configuration Processor
- Spring 開発環境を強化
- MyBatis Framework
- ORM
- MySQL Driver
- Spring Security
- 認証, 認可, CSRF対策, IP制限等のフレームワーク
- Thymeleaf
- 最もシェアのあるテンプレートエンジン
- Spring Web
- MVC
(今回使用しないものもあるが、いつも使っているものをチェックしている)
Finish。コントローラを作成します。
Package Explorer で、src/main/java の下の com.example.demo を右クリックして New>Classをクリックし、Nameは "TopController" で Finish。
ビューを作成します。
Package Explorer で、src/main/resources の下の templates を右クリックして New>Fileをクリックし、Nameは "top.html" で Finish。
application.properties 右クリック、"Convert .properties to .yml"。
簡単のため、build.gradle を開き、今回使用せず、設定の必要な依存関係をコメントアウトします。
忘れずに プロジェクトを右クリックし、Reflesh Gradle Project。ローカルで実行
表示されました。Beanstalk へのデプロイ
後日(数日以内に)記載予定です。
- 投稿日:2019-12-23T03:49:45+09:00
STS, SpringBootで手軽にウェブアプリをローカルにデプロイ。10分で。
タイトルのお手軽手順を紹介します。
要素
- STS
- Spring Boot
- Thymeleaf
手順
STSインストール
こちらから STSの最新版をダウンロードし、インストール。
https://spring.io/toolsStarter Project 作成
Create new Spring Starter Project をクリックし、"Type" は "Gradle (Buildship 3.x) を指定して Next。
以下を選択。
- AWS Core
- AWS RDS
- Spring Boot DevTools
- Spring 開発環境を強化
- Lombok
- アノテーションで getter, setter 等を自動生成
- Spring Configuration Processor
- Spring 開発環境を強化
- MyBatis Framework
- ORM
- MySQL Driver
- Spring Security
- 認証, 認可, CSRF対策, IP制限等のフレームワーク
- Thymeleaf
- 最もシェアのあるテンプレートエンジン
- Spring Web
- MVC
(今回使用しないものもあるが、いつも使っているものをチェックしている)
Finish。コントローラを作成します。
Package Explorer で、src/main/java の下の com.example.demo を右クリックして New>Classをクリックし、Nameは "TopController" で Finish。
ビューを作成します。
Package Explorer で、src/main/resources の下の templates を右クリックして New>Fileをクリックし、Nameは "top.html" で Finish。
application.properties 右クリック、"Convert .properties to .yml"。
簡単のため、build.gradle を開き、今回使用せず、設定の必要な依存関係をコメントアウトします。
忘れずに プロジェクトを右クリックし、Reflesh Gradle Project。ローカルで実行
表示されました。
- 投稿日:2019-12-23T00:34:04+09:00
Spring Cloud Gatewayで独自認証をした上でバックエンドにリクエストを流す
目的
Locustなどの特にユーザー認証の必要がなく使える諸々のWebUIツールに対して、
独自の認証を挟んだ上で利用するようにしたかったのですが、
ツールの種類が増えるたびに個々のツールに認証機能を実装していくのも面倒かなと思いました。そこで各ツールの前段にSpring Cloud Gatewayのアプリケーションを配置して
ここで各ツールに対するリクエストを全て受け付けて独自認証を行い、
認証がOKであればバックエンドのツールにリクエストを流すようにしてみました。プロジェクトのセットアップ
Spring initializrでDependenciesに"Gateway"を追加した上で雛形を作成してダウンロードします。
実装1: まずは認証無しでリクエストの振り分け
まずは認証機能無しで、単純にSprin Cloud Gatewayでリクエストを受け付けて、
バックエンドのツールにリクエストを振り分けるところまでやってみます。ここまではJavaクラスの実装は必要なく、application.yamlの設定だけで実現できます。
今回はSpring Cloud Gatewayのアプリケーションは8080ポートでリッスンし、
http://localhost:8080
でアクセスできるようにしておきます。バックエンドのWebUIツールのURLは
http://localhost:9001
および
http://localhost:9002
とします。application.yaml
# Spring Cloud Gatewayのポート番号の設定(なくても良い) server: port: 8080 # Spring Cloud Gatewayのメインの設定 spring: cloud: gateway: routes: # ----------------------------------------------------- # http://localhost:8080/tool1/hoge/fuga/...のリクエストを # http://localhost:9001/hoge/fuga/...に流す # ----------------------------------------------------- - id: tool1 # プロキシ先 uri: http://localhost:9001 # ルーティング predicates: - Path=/tool1/** # フィルタ(パスの書き換えや独自処理を挟み込む) filters: - StripPrefix=1 # パスの先頭部分を切り取る。今回の場合"/tool1"を取り除く # ----------------------------------------------------- # http://localhost:8080/tool2/hoge/fuga/...のリクエストを # http://localhost:9002/hoge/fuga/...に流す # ----------------------------------------------------- - id: tool2 # プロキシ先 uri: http://localhost:9002 # ルーティング predicates: - Path=/tool2/** # フィルタ(パスの書き換えや独自処理を挟み込む) filters: - StripPrefix=1 # パスの先頭部分を切り取る。今回の場合"/tool2"を取り除く重要なのはspring.cloud.gateway.routesで、各項目の概要は以下の通り
項目 内容 id 任意のIDを設定する uri リクエストを送る先(バックエンド)を設定する predicates Spring Cloud Gatewayに対してどういうリクエストがきたら、このルーティングルールに適用させるかを定義する。 filters バックエンドにリクエストを送る前や後に処理を挟み込む時に指定する。自作のフィルタクラスを利用することも可能(後述) 組み込みのpredicatesとfiltersにどういう物があるかは、Spring Cloud Gatewayの公式ドキュメントを参考にしてみると良いと思います。
動作確認
実際のWebUIツールの代わりに、ncコマンドで固定の文字列を返すスタブサーバーを立ち上げます。
$ (echo "HTTP/1.1 200 ok"; echo; echo "hello") | nc -l 9001次にSpring Cloud Gatewayに対してcurlリクエストします。
$ curl -v http://localhost:8080/tool1/hoge/fugaSpring Cloud Gatewayの設定内容が正しければ、
localhost:8080/tool1/hoge/fugaのリクエストが
localhost:9001/hoge/fugaに流れるようになるはずです。結果
スタブサーバーにやってきたリクエストの内容は以下の通り。
URLのパスは/tool/hoge/fugaではなく、/hoge/fugaになっていることがわかります。$ (echo "HTTP/1.1 200 ok"; echo; echo "hello") | nc -l 9001 GET /hoge/fuga HTTP/1.1 Host: localhost:8080 User-Agent: curl/7.64.1 Accept: */* Forwarded: proto=http;host="localhost:8080";for="0:0:0:0:0:0:0:1:50024" X-Forwarded-For: 0:0:0:0:0:0:0:1 X-Forwarded-Proto: http X-Forwarded-Prefix: /tool1 X-Forwarded-Port: 8080 X-Forwarded-Host: localhost:8080 content-length: 0curlリクエストの結果は以下の通りで、
Spring Cloud Gatewayから、バックエンドにあるスタブサーバーのレスポンスが返されていることがわかります。$ curl -v http://localhost:8080/tool1/hoge/fuga > GET /tool1/hoge/fuga HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.64.1 > Accept: */* > < HTTP/1.1 200 OK < transfer-encoding: chunked < hello実装2: 独自のフィルタを追加して認証を行う
次に自作の認証フィルタを作って適用してみます。
今回はHTTPリクエストヘッダから"Authorization"キーの値を取り出し、
その値が"xxx"なら認証OKでバックエンドにリクエストを投げ、
それ以外なら認証NGとして401 Unauthorizaedのレスポンスを返すフィルタを作ってみます。※ 実際の認証の機能を作る場合はこんな単純なロジックではNGですが、今回は説明のため、認証のロジックを簡略化して実装コードを書いています。
MyAuthFilter.java
フィルタの実装は以下の通りで、AbstractGatewayFilterFactoryを継承したクラスを実装します。
@Component public class MyAuthFilter extends AbstractGatewayFilterFactory<MyAuthFilter.Config> { public MyAuthFilter() { super(Config.class); } @Override public GatewayFilter apply(Config config) { return (exchange, chain) -> { // Authorization ヘッダの取得 ServerHttpRequest request = exchange.getRequest(); String authorizationHeader = Optional.ofNullable(request.getHeaders().get("Authorization")) .map(h -> {return h.get(0);}).orElse(""); // Authorizationヘッダがxxxなら認証成功でそのままリクエストを流す。 // そうでなければ401 Unauthorizedのレスポンスを返す if(authorizationHeader.equals("xxx")) { return chain.filter(exchange.mutate().request(request).build()); } else { ServerHttpResponse response = exchange.getResponse(); response.setStatusCode(HttpStatus.UNAUTHORIZED); return response.setComplete(); } }; } public static class Config { } }application.yaml
上記のように自作のフィルタクラスを作っただけではまだ反映されません。
自作フィルタを適用したい場合はapplication.yamlのfiltersの項目で、
この独自フィルタのクラス名を書いてあげます。application.yamlの全容は以下の通りで、"[追加]"と書いてある2行だけを追記しています。
# Spring Cloud Gatewayのメインの設定 spring: cloud: gateway: routes: # ----------------------------------------------------- # http://localhost:8080/tool1/hoge/fuga/...のリクエストを # http://localhost:9001/hoge/fuga/...に流す # ----------------------------------------------------- - id: tool1 # プロキシ先 uri: http://localhost:9001 # ルーティング predicates: - Path=/tool1/** # フィルタ(パスの書き換えや独自処理を挟み込む) filters: - MyAuthFilter # [追加]自作の認証フィルタを挟む - StripPrefix=1 # パスの先頭部分を切り取る。今回の場合"/tool1"を取り除く # ----------------------------------------------------- # http://localhost:8080/tool2/hoge/fuga/...のリクエストを # http://localhost:9002/hoge/fuga/...に流す # ----------------------------------------------------- - id: tool2 # プロキシ先 uri: http://localhost:9002 # ルーティング predicates: - Path=/tool2/** # フィルタ(パスの書き換えや独自処理を挟み込む) filters: - MyAuthFilter # [追加]自作の認証フィルタを挟む - StripPrefix=1 # パスの先頭部分を切り取る。今回の場合"/tool2"を取り除く # Spring Cloud Gatewayのポート番号の設定(なくても良い) server: port: 8080動作確認
先ほどと同様に9001番ポートでスタブサーバーを立ち上げ、
以下のようにAuthorizationヘッダ無しでリクエストしたり、
Authorizationヘッダありでcurlリクエストします。$ curl -v http://localhost:8080/tool1/hoge/fuga$ curl -H 'Authorization: xxx' -v http://localhost:8080/tool1/hoge/fuga結果
Authrozationヘッダ無しでリクエストすると、MyAuthFilterで実装した通り、
401 Unauthorizedのレスポンスが返ります。$ curl -v http://localhost:8080/tool1/hoge/fuga > GET /tool1/hoge/fuga HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.64.1 > Accept: */* > < HTTP/1.1 401 Unauthorized < content-length: 0 <また、スタブサーバー側にはリクエストが来ていないこともわかります。
$ (echo "HTTP/1.1 200 ok"; echo; echo "hello") | nc -l 9001 ※ 変化無し次にAuthrozationヘッダにxxxの値をセットしてリクエストすると、
スタブサーバーが返しているhelloの文字列が返ります。$ curl -H 'Authorization: xxx' -v http://localhost:8080/tool1/hoge/fuga > GET /tool1/hoge/fuga HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.64.1 > Accept: */* > Authorization: xxx > < HTTP/1.1 200 OK < transfer-encoding: chunked < helloスタブサーバー側にもリクエストが来ていることが確認できます。
$ (echo "HTTP/1.1 200 ok"; echo; echo "hello") | nc -l 9001 GET /hoge/fuga HTTP/1.1 Host: localhost:8080 User-Agent: curl/7.64.1 Accept: */* Authorization: xxx Forwarded: proto=http;host="localhost:8080";for="0:0:0:0:0:0:0:1:50517" X-Forwarded-For: 0:0:0:0:0:0:0:1 X-Forwarded-Proto: http X-Forwarded-Prefix: /tool1 X-Forwarded-Port: 8080 X-Forwarded-Host: localhost:8080 content-length: 0とりあえず認証OK・NGの判定をしてバックエンドにリクエストを流す・流さないを制御するのは、これで実現できそう。
参考
サイト 概要 Spring Cloud Gatewayで遊ぶ 最初に目を通したページ Spring Cloud Gateway Springの公式ドキュメント。組み込みのPredicatesとFilterの情報に関して色々載ってます。自作Filterに関する説明も少し載っています。 Spring Cloud Gateway - Creating Custom Route Filters (AbstractGatewayFilterFactory) 自作Filterの実装とapplication.yamlでの設定方法は、主にこちらのページを参考にしました。
- 投稿日:2019-12-23T00:09:16+09:00
RecyclerViewとMarkerを対応させる(Kotlin)
作りたいもの
RecyclerViewをスクロールするとそのアイテムに対応するGoogle MapのMarkerに移動し、またMap上でMarkerをタップするとRecyclerViewがアイテムまでスクロールしてくれるやつ。
CardViewとSnaphelperも使用していますがその説明は割愛します。環境
Android Studio
Kotlin
Maps SDK for Android方法
RecyclerView -> Marker
スクロール量でRecyclerView上の順番を判定し、そのアイテムの位置までMapを移動。
//recycler -> marker recyclerView.addOnScrollListener(object :RecyclerView.OnScrollListener(){//スクロールでマーカーに移動 override fun onScrolled(recyclerView: RecyclerView, dx: Int, dy: Int) {//スクロールした量でposition判定 super.onScrolled(recyclerView, dx, dy) val offset = recyclerView.computeHorizontalScrollOffset() val itemWidth = cafeCardRoot.width val edgeMargin = (recyclerView.width - itemWidth)/2 val position = (offset + edgeMargin) / (itemWidth + edgeMargin/2) if (myCafesData[position].latitude == "" || myCafesData[position].longitude == "") { return }else{ val moveLatLng = LatLng(myCafesData[position].latitude.toDouble(),myCafesData[position].longitude.toDouble()) mMap.animateCamera(CameraUpdateFactory.newLatLngZoom(moveLatLng, 16F)) } } })Marker -> RecyclerView
マーカーの順番を判定してそのアイテムまでスクロール。
//marker -> recycler mMap.setOnMarkerClickListener(object : GoogleMap.OnMarkerClickListener{ override fun onMarkerClick(marker: Marker?): Boolean { val markerPosition = marker?.position var selectedMarker = -1 for (i in 0..myCafesData.size-1) { if (myCafesData[i].latitude == "" || myCafesData[i].longitude == "") { continue } else { if (markerPosition?.latitude == myCafesData[i].latitude.toDouble() && markerPosition.longitude == myCafesData[i].longitude.toDouble()) { selectedMarker = i//Markerのposition判定 } } } recyclerView.smoothScrollToPosition(selectedMarker)//scroll return false } })課題
RecyclerViewとMarkerが直接連結してる訳ではないので、Recycler->Markerでマーカーのサイズ変えたりすることができない。
アイテムのデータにRecyclerViewとMarkerの情報を持たせるのですかね?上記の課題の解決方法をご教授いただければ幸いです。お願いいたします!
あとがき
この記事は私のブログからの転載です。
プログラミングの記事等更新していますので是非訪れてみてください。
https://www.imagawahibana.com/
