- 投稿日:2019-12-14T22:43:43+09:00
Apache Kafkaを触った
MDC Advent Calendar 2019 の15日目です。
Kafkaとは何か
LinkedInが作ったOSSの分散メッセージングシステム(メッセージングキュー)。
高スループット、高スケーラビリティ。
Java(Scala)で書かれている。Producer、Broker、Consumerの3つのコンポーネントで構成される。
ProducerからストリーミングされたデータをConsumerへ中継する。対障害のためにデータの永続化もする。送達保証も実現。
・ Producer: メッセージを配信する
・ Broker: ProducerからConsumerへメッセージの受け渡しをする
・ Consumer: メッセージを受け取る※仔細な仕組みやアーキテクチャ等については以下が参考になります。
・Apache Kafkaの概要とアーキテクチャ
・Apache Kafkaに入門した何に使うのか
ユースケースとしては以下のようなものが挙げられます。
- システムがサイロ化するのを防ぐためにデータハブとしてアーキテクチャに組み込む(マイクロサービスとかで)
- Fluentdなどと連携してログ収集に使う
- Webサイトのユーザのページ移動とかを収集してWebアクティビティ分析に使う
- IoTデバイスのセンサーの値を集約し、可視化や分析、他のデバイスの制御などに使う
- ビッグデータ、機械学習、etc
具体的なところだと以下。
・LINEの大規模データパイプライン
・Yahooリアルタイム検索
・大手ヘルスケアIT企業 Cerner社のKafka活用事例動かしてみる
簡単なサンプルを作って試してみます。
今回はKafka本体はKafka-dockerを使って環境構築をして、ProducerとConsumerのクライアント側はkafka-pythonを使いました。Kafka-dockerのインストール・起動
公式にあるとおり、kafka-dockerをダウンロードして、docker-compose.ymlの
KAFKA_ADVERTISED_HOST_NAMEにdocker hostのIPアドレスを書いたあと、docker-compose up -dすればOKです。
Producerを実装する
ほんとうはTwitter Striming APIみたいなデータをとってきたり、IoTのセンサーの値を取得したかったですが、今回は用意がないので一旦適当に数値を取れるものを、ということでマウスのx座標を取得して1秒おきにKafkaに送付するスクリプトを書きました。
KafkaProducerの引数bootstrap_serverに渡す値は、docker-compose.ymlにも書いたdocker hostのIPアドレスと、kafkaのコンテナに割り当てられたPort番号を指定します。
割り当てられてるPort番号はdocker psで確認できます。
上の場合は32783がそれです。
以下が作成したProducer側のソースコードです。
procuer.send(でtestというTopicに現在のマウスのx座標を投げています。from kafka import KafkaProducer import pyautogui import time def main(): producer = KafkaProducer(bootstrap_servers='{Docker HostのIPアドレス}:{Port}') while True: result = producer.send('test', str(pyautogui.position().x).encode()).get(timeout=60) print(result) time.sleep(1) if __name__ == '__main__': main()Consumerを実装する
次にConsumer側の実装です。同様にKafkaのIPアドレスとPortを指定します。
for message in consumer:でKafkaからデータを逐次pullしてきてくれます。from kafka import KafkaConsumer def main(): consumer = KafkaConsumer( 'test', bootstrap_servers=['{Docker HostのIPアドレス}:{Port}']) for message in consumer: print("x = " + message.value.decode()) if __name__ == '__main__': main()実行
下の左側でProducer側、右側でConsumerを実行しています。
Producer側からKafkaに送った値(マウスのx座標)をConsumer側でKafkaから取得して表示できているのが確認できます。
今後やりたいこと
・ラズパイ、Arduinoとか使ってセンサーの値を組み込む。
・取得したデータをグラフにしたり、解析したりする。


- 投稿日:2019-12-14T21:52:00+09:00
AWSを触ってみる
はじめに
AWSを触り始めてみた。
アカウント登録から10分間チュートリアルをいくつか試してみたときのメモを残す。アカウント登録
- 氏名、住所、連絡先
- クレジットカード情報
- SMSまたは電話認証
よくある通常のアカウント登録に加え、住所詳細や支払情報(クレカ登録)が必須となっている。また、SMS or 電話認証も必要で、IBM Cloudと比べると手間なように感じる。
何よりも、クレカ登録することで想定外の利用料が発生する可能性がある、という点はイマイチ(それも狙いのひとつなのだろうが)。クレジットコードの登録方法
- プロモーション等によりクレジットコード(AWSで使える有料枠)をもらえることがある。
- 登録は、マイ請求ダッシュボード>Billing:クレジット から入力すればOK。
支払通貨について
- デフォルトはUSDで、日本円に変更可能。
- 変更はマイアカウントから行う。
- USDの場合はクレジットカード会社の為替レートが適用され、一般的にコスト高のため、日本円に切り替えておいた方が無難。
- 但し、必ずしもすべての利用料が日本円になるわけではない点、認識しておく必要あり。
<参考>
https://qiita.com/takachan/items/5d56b2ada63b896628bb
https://www.publickey1.jp/blog/15/amazonvisamastercard.html10分間チュートリアル
- 無料枠、有料枠利用など、10分程度で実行できるチュートリアルがある。
- TOP > 学習 > AWSの開始方法 > 10分間チュートリアル からメニューが確認できる。
- いくつか試してみたので、ポイントを書いておく。
その1:AWSコストの管理
- https://aws.amazon.com/jp/getting-started/tutorials/control-your-costs-free-tier-budgets/
- AWSは有料サービスが含まれるためコスト管理が必要。
- モニタリングには 「AWS Budgets」 を使う。
- 無料サービスには「無制限」と「12か月間」(初期登録者用)、「トライアル」(指定の期間無料)がある。
- 有料サービスの利用状況はは、アカウントの「マイ請求ダッシュボード」から確認できる。
AWS Budgets
- 設定した予算を超過するとアラートを出すサービス。
- アカウントごとに月間総コスト予算を作成するとよい。
無料利用枠のEメールアラートの設定
- マイ請求ダッシュボード > 設定:Billingの設定 > 無料利用枠の使用のアラートの受信 にチェック。
- 通常は85%の利用でアラートが出る。
AWS Budgetsのアラートの作り方
- マイ請求ダッシュボード > ホーム:Budgets > Create a Budget でアラート作成。
- コストで計測する場合はコスト予算を選択して進める。
所感
有料サービスはモニタリングが面倒だが、アラート設定は必須!
(でも正しく設定できているのか不安になりがち・・・)その2:サーバーレスアプリケーションを構築する
https://aws.amazon.com/jp/getting-started/tutorials/build-serverless-app-codestar-cloud9
サーバーレスアプリケーションを作る
「AWS Lambda」ベースの新しい Node.js サーバーレスウェブアプリケーションを構築する。
ソース管理には 「AWS CodeCommit」 、リリースプロセスの自動化には 「AWS CodePipeline」 を使用する。AWS CodeStar
継続的デリバリーのツールチェーンで、全体を数分でセットアップできる。
AWS で迅速にアプリケーションを開発、構築、デプロイできるようにするソフトウェア開発ツールである。
CodeCommit、CodePipelineが含まれる。AWS Cloud9
クラウドベースの IDE(統合開発環境)。
JavaScript、Python、PHP などのツールを内包しているのですぐ使えるのがよい。所感
手順通りにやれば、アプリ構築は非常に簡単だと感じる。
サーバレスをちょっと試してみたいという時には良いサービスだが、git操作が少々面倒。その3:Docker コンテナのデプロイ
Amazon ECS(Elastic Container Service)
Docker アプリケーションをスケーラブルなクラスターで実行できるサービス。
タスク定義
アプリケーションの設計図のようなもの。以下の事項をECSに知らせる。
・使用する Dockerイメージ
・タスクで使用するコンテナ数
・各コンテナへのリソース割り当て所感
説明と実際の画面が違うところがあり、わかりづらいところがあった。
また、有償/無償の線引きがわかりづらいと感じる。(IBM Cloudの場合は、サービス立ち上げ時に無料メニューを選択するようになっているため安心して使える)その4:ファイルの保存と取得
https://aws.amazon.com/jp/getting-started/tutorials/backup-files-to-amazon-s3/
Amazon S3 バケットの作成、ファイルのアップロード、ファイルの取得、ファイルの削除を行う。
Amazon S3(Simple Storage Solution)
ユーザのデータ (オブジェクトと呼ぶ) を大規模に保存できるようにするサービス。
所管
サービス作ってアップロードしてダウンロードしてパケット削除して・・・と、やっていることは簡単。
しかし、最初にコンソール開いたとき、身に覚えのないパケットが既に3つあった。
どうやら、ここまでのチュートリアルで自動的に作られていたようだ。全体所感
UIは少々扱いづらく、慣れが必要だと感じる。
ある程度前提知識をもって使い始めるべきだが、そもそも触らないとわからないというジレンマ。(どのクラウドサービスでも同じだが)
コツコツやるしかない、と改めて感じた。
- 投稿日:2019-12-14T21:35:33+09:00
DockerをProxy環境下&root権限なしでUbuntuに導入する (RootlessのDockerにProxy設定がメイン)
前書き
- root権限が無いからUbuntuの環境構築はかどらない!
- なんかroot権限が必要ないDockerがあるらしいぞ!
- 導入したがProxy設定わかんねー!
- あと記事書くの初めてなので優しくしてください
Root権限が必要ないRootlessモードのDocker
Docker19.03にて、root権限がなくても実行できるRootlessモードが実装されました1。
root権限を持たない身としてはありがたいお話です。RootlessモードのDockerインストール
(インストールについては先人の方々の記事or公式ページ1を参考にしていただければ...)
# curlのproxy設定してない場合はcurlrcファイルにproxy設定を書き込む vi ~/.curlrc #以下を書き込む proxy=http://proxy.url:port # Rootless mode Dockerをlocal環境にインストール $ curl -fsSL https://get.docker.com/rootless | sh # インストーラ終了時に追加すべきPATHを指示してくれるため、指示されたコマンドを実行する $ export PATH=/home/testuser:/bin:$PATH $ export PATH=$PATH:/sbin $ export DOCKER_HOST=unix:///run/user/1001/docker.sockHello Worldで動作確認
恐らくProxyが原因でTimeoutが発生
$ docker run docker/whalesay cowsay Hello World $ systemctl --user start docker: Error response from daemon: Get https://registry-1.docker.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers).Docker daemonにProxy設定
詰まった所
本来Docker daemonにproxy設定を行う際は
/etc/systemd/system/docker.service.d/http-proxy.confに設定を書く必要があります2。
(するとdocker.servicの設定に継承される形で適用される...多分)
これがRootlessモードの時にどう設定するかわからないという状況で2日かかりました。解法
結論としては、
~/.config/systemd/system/docker.service.d/http-proxy.conf
に設定することで解決しました。$ mkdir -p ~/.config/systemd/system/docker.service.d $ vi ~/.config/systemd/system/docker.service.d/http-proxy.conf # 以下2行を書き込み [Service] Environment="HTTP_PROXY=http://proxy.url:port" $ systemctl --user daemon-reload $ systemctl --user restart docker再度Hello World
$ docker run docker/whalesay cowsay Hello World _____________ < Hello World > ------------- \ \ \ ## . ## ## ## == ## ## ## ## === /""""""""""""""""___/ === ~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~ \______ o __/ \ \ __/ \____\______/反省
公式ページにdaemon configディレクトリのパス
~/.config/dockerが記載されており3、
~/.config/systemdも生成されていた為、冷静に見れはもう少し早くわかったなと反省。
- 投稿日:2019-12-14T21:06:39+09:00
MacでRaspberry Piにraspbianをインストールする
放置していたRaspberry Piを動かしてpythonを実行するリモートサーバにしたので、メモとしてまとめておく。また、開発・実行環境はかっこよくDockerを用いることにした。今回はOSのインストールから簡易な設定まで
Raspberry PiにRaspbianをインストール
ssh接続を用いればOSのインストールから設定までマウスもキーボードもスクリーンも必要ないらしい。
イメージを焼く〜簡易な設定まではこちらとこちらを参考にした。
まずRaspbianのOSのイメージをダウロードしてくる。デスクトップ+recommended software, デスクトップ, Liteの三種類が存在するが、今回はサーバとして動かす目的でデスクトップは必要ないと思われるので、Liteを選んだ。
SDカードを差し込んだのち、以下のコマンドを実行してSDカードがどこに認識されているかを調べる。$ diskutil list /dev/disk0 (internal): #: TYPE NAME SIZE IDENTIFIER 0: GUID_partition_scheme 251.0 GB disk0 1: EFI EFI 314.6 MB disk0s1 2: Apple_APFS Container disk1 250.7 GB disk0s2 /dev/disk1 (synthesized): #: TYPE NAME SIZE IDENTIFIER 0: APFS Container Scheme - +250.7 GB disk1 Physical Store disk0s2 1: APFS Volume Macintosh HD 234.8 GB disk1s1 2: APFS Volume Preboot 45.5 MB disk1s2 3: APFS Volume Recovery 528.0 MB disk1s3 4: APFS Volume VM 3.2 GB disk1s4SDカードを差し込む前後で表示される内容に差があるので、その新しく追加されたマウントがSDカードである。
/dev/disk2にSDカードがマウントされていることがわかったので、フォーマットする。$ diskutil unMountDisk /dev/disk2 $ diskutil eraseDisk FAT32 [デバイス名] /dev/disk2デバイス名は適当に。
ダウロードしてきたイメージを焼く。$ diskutil unMountDisk /dev/disk2 $ sudo dd bs=1m if=2019-09-26-raspbian-buster-lite.img of=/dev/rdisk2 conv=syncこのあと焼いたSDカードに空のファイル
/Volume/boot/sshを作成する。このファイルを作っておくことで、デフォルトでRaspberry PiにSSHデーモンが立ち上がり、ssh接続ができるようになるらしい。$ touch /Volume/boot/sshssh接続と初期設定
ssh接続するためには、IPアドレスを確認しなければならない。デフォルトでは、DHCP(IPアドレスが動的に割り当てられる方式)でIPアドレスが設定されるので、すぐにはわからない。今回は、たまたまルータの設定アプリからIPアドレスを確認できた。デフォルト
username: pi,password: raspberryでログインすることができる。$ ssh pi@[IPアドレス] $ pi@[IPアドレス]’s password: $ pi@raspberrypi ~今回は固定IPアドレスを追加しなかったが、追加したい場合は参考URLから。
パスワードの設定
$ sudo passwd roothoge ユーザの追加
$ sudo adduser hogehogeユーザにsudo権限
$ sudo gpasswd -a hoge sudopiユーザをsudoから外す
$ sudo gpasswd -d pi sudo今回はここまで、この後Dockerのインストールへと続く
- 投稿日:2019-12-14T19:12:18+09:00
ホスト側の保存先を指定せずに作ったdata volumeを、望みの保存先に変更したい
dockerコンテナ内の/var/www/htmlがマウントしているホスト側のディレクトリを変更したいのだが、一度コンテナをrunした後は変更はできなくなってしまうらしい。
したがって移動の手順はこのようになる。
- ホスト側のvolumeの内容を望みの保存先にコピーする
- コンテナを破棄する
- docker-compose.ymlのvolumesの設定を望みの保存先に変更する
- コンテナを新規に起動する
ホスト側のvolumeの内容を望みの保存先にコピーする
docker-compose.yamlのあるディレクトリにhtmlディレクトリを作成し、そこにvolumeの内容をコピー
mkdir html cd html docker run --rm --volumes-from wordpress-study_wordpress_1 -v $(pwd):/html busybox cp -rp /var/www/html /コンテナを破棄する
docker-compose downdocker-compose.ymlのvolumesの設定を望みの保存先に変更する
volumes: - ./html:/var/www/htmlコンテナを新規に起動する
docker-compose up -d
- 投稿日:2019-12-14T14:28:26+09:00
ScalatraのAPIをDockerで動かす
ぷりぷりあぷりけーしょんずインフラ担当による ぷりぷりあぷりけーしょんず Advent Calendar 2019 の19日目
概要
普段クラウドエンジニアとして、パブリッククラウドを利用してアプリケーションサーバの構築といったインフラ寄りの仕事しています。
ただ個人学習としてミドルウェアをインストールしたり、NWの設定をしたりしてサーバを構築することは楽しいですが、サーバに乗っかっているアプリケーションが出来合いのものだと愛着が湧かないというのが不満でした。
ぷりぷりあぷりけーしょんずは名前の通りアプリケーションエンジニアが多数在籍(9割くらい?)しているサークルなので、サークル活動ではアプリケーションの話を聞くこともあったため、せっかくだし興味のあったScalaで
業務でアプリ開発をしたことないけどなんとなくで自作してみたというお話です。作ったもの
リクエストで投げるとJsonを返してくるという単純なAPIです。
e.g. ユーザ登録
curl http://localhost:8080/user -X POST -H "Content-Type: application/json" -d '{"name": "MSHR-Dec", "pswd": "mshr-dec"}'e.g サイト登録
curl http://localhost:8080/site/MSHR-Dec -X POST -H "Content-Type: application/json" -d '{"name": "puri", "pswd": "puripuri"}'e.g. 参照
curl http://localhost:8080/user
curl http://localhost:8080/user/MSHR-Dec
curl http://localhost:8080/site/MSHR-Decテーマはなんでも良いのですが、わかりやすいようにユーザの名前とパスワード、サイトの名前とパスワードを管理するという設定のAPIを、それぞれ別のプロジェクトで作成して、それらを連携させようというものになっています。
ユーザ側のプロジェクトを作成してしまえば、サイト側の実装はユーザの実装とほとんど同様なので省きます。Scalatra
http://scalatra.org/
Sinatraを意識したフレームワークらしいです。PythonだとDjangoのような規約の多いフレームワークと逆のFlaskのような存在です。
ディレクトリレイアウト
ディレクトリで終わっているものは基本デフォルトです。
ファイルについては今回編集または新規作成しています。. ├── Dockerfile ├── README.md ├── build.sbt ├── project/ │ ├── assembly.sbt │ ├── build.properties // デフォルト │ ├── plugins.sbt // デフォルト │ ├── project/ │ └── target/ ├── src/ │ └── main/ │ ├── resources/ │ │ ├── application.conf │ │ └── logback.xml // デフォルト │ ├── scala/ │ │ ├── ScalatraBootstrap.scala │ │ └── com/ │ │ └── hoge/ │ │ ├── app/ │ │ │ └── Launcher.scala │ │ ├── controller/ │ │ │ ├── HealthCheck.scala │ │ │ ├── SiteController.scala │ │ │ └── UserController.scala │ │ ├── mysql/ │ │ │ ├── Initialize.scala │ │ │ ├── Mysql.scala │ │ │ └── MysqlBase.scala │ │ ├── model/ │ │ │ └── User.scala │ │ └── utils/ │ │ └── HttpClient.scala │ ├── twirl/ │ └── webapp/ └── target/ ├── scala-2.12/ │ ├── classes/ │ ├── resolution-cache/ │ ├── test-classes/ │ ├── ppap.jar │ └── twirl/ ├── streams/ └── test-reports/インストール
http://scalatra.org/getting-started/first-project.html
SBTを利用できる環境さえ用意してあれば、上記サイトを参考にしてScalatraの環境構築を行うことができます。scala_version [2.12.3]: 2.12.6 sbt_version [1.0.2]: 1.2.1 scalatra_version [2.5.3]: 2.6.5バージョンは上記の設定です。
ライブラリの追加
build.sbtの
libraryDependenciesを書き換えます。
MySQLへの接続やHTTPクライアントを利用する際に必要となるものを定義します。build.sbtlibraryDependencies ++= Seq( "org.scalatra" %% "scalatra" % ScalatraVersion, "org.scalatra" %% "scalatra-scalatest" % ScalatraVersion % "test", "ch.qos.logback" % "logback-classic" % "1.2.3" % "runtime", "org.eclipse.jetty" % "jetty-webapp" % "9.4.19.v20190610" % "container", "javax.servlet" % "javax.servlet-api" % "3.1.0" % "provided", "org.scalatra" %% "scalatra-json" % ScalatraVersion, "org.json4s" %% "json4s-jackson" % "3.5.2", "org.scalikejdbc" %% "scalikejdbc" % "3.3.5", "org.scalikejdbc" %% "scalikejdbc-config" % "3.3.5", "mysql" % "mysql-connector-java" % "8.0.11", "org.eclipse.jetty" % "jetty-webapp" % "9.4.20.v20190813", "org.scalaj" %% "scalaj-http" % "2.4.2" )Scalatraサーバ起動の設定
Scalatraで作成したAPIのDockerイメージ
docker runで起動した際に、コンテナに8080番ポートでアクセスできるようにします。project-root/src/main/scala/com/ppap/app/Launcher.scalapackage com.ppap.app import org.eclipse.jetty.server.Server import org.eclipse.jetty.servlet.{DefaultServlet, ServletContextHandler} import org.eclipse.jetty.webapp.WebAppContext import org.scalatra.servlet.ScalatraListener object Launcher extends App { val port = if(System.getenv("PORT") != null) System.getenv("PORT").toInt else 8080 val server = new Server(port) val context = new WebAppContext() context setContextPath "/" context.setResourceBase("src/main/webapp") context.addEventListener(new ScalatraListener) context.addServlet(classOf[DefaultServlet], "/") server.setHandler(context) server.start server.join }MySQLとの接続設定
- DBのフィールドの型を定義
project-root/src/main/scala/com/ppap/User.scalapackage com.ppap.model case class User(id: Int, name: String, pswd: String)
- テーブルの初期設定やCRUDの定義
project-root/src/main/scala/com/ppap/mysql以下に下記のファイルを追加していきます。MysqlBase.scalapackage com.ppap.mysql import scalikejdbc.config.DBs import com.ppap.model._ import scalikejdbc.WrappedResultSet trait MysqlBase { DBs.setupAll() protected val allColumns = (rs: WrappedResultSet) => User( id = rs.int("id"), name = rs.string("name"), pswd = rs.string("pswd") ) }Initialize.scalapackage com.ppap.mysql import scalikejdbc._ import scalikejdbc.config._ class Initialize { DBs.setupAll() def createTable(): Unit = { val value = "admin" DB autoCommit { implicit session => SQL(""" CREATE TABLE IF NOT EXISTS `users` ( `id` INT NOT NULL AUTO_INCREMENT, `name` VARCHAR(32) BINARY UNIQUE, `pswd` VARCHAR(32), PRIMARY KEY (`id`) ) """).execute.apply() } DB autoCommit { implicit session => SQL("insert into users (name, pswd) values (?, ?) on duplicate key update name = ?").bind(value, value, value).update.apply() } } }Mysql.scalapackage com.ppap.mysql import scalikejdbc._ import com.ppap.model._ class Mysql extends MysqlBase { def insert(name: String, pswd: String): Unit = { DB localTx { implicit session => SQL("insert into users (name, pswd) values (?, ?)").bind(name, pswd).update.apply() } } def update(name: String, pswd: String): Unit = { DB localTx { implicit session => SQL("update users set pswd = ? where name = ?").bind(pswd, name).update.apply() } } def delete(name: String): Unit = { DB localTx { implicit session => SQL("delete from users where name = ?").bind(name).update.apply() } } def select(name: String):Option[User] = { DB readOnly { implicit session => SQL("select * from users where name = ?").bind(name).map(allColumns).single.apply() } } def getAll(): List[User] = { DB readOnly { implicit session => SQL("select * from users").map(allColumns).list.apply() } } }
- DBの接続情報を定義
project-root/src/main/resources/application.conf# JDBC settings db.default.driver="com.mysql.cj.jdbc.Driver" # jdbc:mysql://DBのIPorドメイン:ポート/Database名?characterEncoding=UTF-8 db.default.url="xxx.xxx.xxx.xxx:3306/ppap?characterEncoding=UTF-8" db.default.user="MSHR-Dec" db.default.password="mshr-dec"サイト管理プロジェクトとHTTPで接続
HTTPクライアントを作成します。
curl http://localhost:8080/site/MSHR-Decのユーザ名をDBのidに変更して、URIに指定する形でリクエストを投げています。project-root/src/main/scala/com/ppap/utils/HttpClient.scalapackage com.ppap.utils import scalaj.http.Http class HttpClient { def getAllSite(userId: Int) = { // サイト管理プロジェクトのIPを指定 // DockerやK8sであればサービス名を指定 val getUrl = s"http://fuga:8000/$userId" Http(getUrl). asString } def postSite(name: String, pswd: String, userId: Int): Unit = { // サイト管理プロジェクトのIPを指定 // DockerやK8sであればサービス名を指定 val postUrl = s"http://fuga:8000/$userId" val data =s"""{"name": "$name", "pswd": "$pswd"}""" Http(postUrl). postData(data). header("content-type", "application/json"). asString } }エンドポイントの定義
project-root/src/main/scala/com/controller以下にAPIのエンドポイントの定義をします。
K8sのReadinessProbeなどのためにHealthcheck用のエンドポイントも作成すると良いです。getリクエストのパラメータをJSONに変換して、その値をMySQLの操作をするオブジェクトに引数で渡しています。
UserController.scalapackage com.ppap.controller import org.scalatra._ import org.json4s._ import org.scalatra.json.JacksonJsonSupport import org.json4s.jackson.Serialization import org.json4s.jackson.Serialization.{read, write} import com.ppap.mysql._ case class User(name: String, pswd: String) class UserController extends ScalatraServlet with JacksonJsonSupport with MethodOverride { protected implicit lazy val jsonFormats: Formats = DefaultFormats get("/:name") { implicit val formats = Serialization.formats(NoTypeHints) val mysql = new Mysql() write(mysql.select(params("name"))) } }サイト管理プロジェクトへ接続する必要があるため
HttpClientを呼び出しています。SiteController.scalapackage com.ppap.controller import org.scalatra._ import org.json4s._ import org.scalatra.json.JacksonJsonSupport import org.json4s.jackson.Serialization import org.json4s.jackson.Serialization.{read, write} import com.ppap.mysql._ import com.ppap.model._ import com.ppap.utils._ case class Site(name: String, pswd: String) class SiteController extends ScalatraServlet with JacksonJsonSupport with MethodOverride { protected implicit lazy val jsonFormats: Formats = DefaultFormats get("/:user") { val mysql = new Mysql val id = mysql.select(params("user")).get.id val httpClient = new HttpClient httpClient.getAllSite(id) } }HealthCheck.scalapackage com.ppap.controller import org.scalatra.ScalatraServlet class HealthCheck extends ScalatraServlet { get("/") { views.html.hello() } }Postリクエストなども以下のようにすることで定義できます。
post("/") { val user = parsedBody.extract[User] val mysql = new Mysql() mysql.insert(user.name, user.pswd) }post("/:user") { val site = parsedBody.extract[Site] val mysql = new Mysql val id = mysql.select(params("user")).get.id val httpClient = new HttpClient httpClient.postSite(site.name, site.pswd, id) }Scalatraの初期化を
project-root/src/main/scala/ScalatraBootstrap.scalaで行います。import org.scalatra._ import javax.servlet.ServletContext import com.ppap.controller._ import com.ppap.mysql._ class ScalatraBootstrap extends LifeCycle { val table = new Initialize table.createTable() override def init(context: ServletContext) { context.mount(new HealthCheck, "/healthcheck") context.mount(new UserController, "/user") context.mount(new SiteController, "/site") } }Dockerイメージの作成
jarファイルの作成
build.sbtに下記を追加します。
build.sbtresolvers += Classpaths.typesafeReleases mainClass in assembly := Some("com.ppap.app.Launcher") assemblyJarName in assembly := "ppap.jar"また下記ファイルを追加します。
project-root/project/assembly.sbtaddSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.9")ここまででjarファイル作成の準備ができたので、下記コマンドを実行してjarファイルを作成します。
$ sbt assembly
これでtarget/scala-2.12/ppap.jarというjarファイルが作成されます。
このファイルは$ java -jar target/scala-2.12/ppap.jarで実行することが可能です。Dockerfileの作成
シンプルにjarファイルを実行するだけです。
FROM openjdk:8 ADD /target/scala-2.12/ppap.jar /root/ppap.jar EXPOSE 8080 ENTRYPOINT ["java", "-jar", "/root/ppap.jar"]あとはDockerfileを元にDockerイメージを作成し、コンテナを実行すればScalatraのAPIを利用することが可能になります。
まとめ
PythonについてはLambdaやFlaskでのAPI作成をしたことがありますが、Scalaでの開発は初めてでした。
ただScalatraは制約が少なく、割とそれっぽい書き方をしただけですが、APIの作成をすることができました(コードの質はさておき...)。Scalaはオブジェクト指向と関数型のマルチパラダイムですが、どちらもしっかりと学習したことがないので今回はどちらも生かせていないコードではありますが、今後はもう少し勉強してより見栄えの良いものを投稿できるように精進したいところです!
おまけ
k8s環境でこのAPIを利用する手順
DockerHubにイメージをPush
$ docker build -t ユーザ名/ppap-scala:1.0 .
$ docker push ユーザ名/ppap-scala:1.0Secretの作成
$ docker login
$ kubectl create secret docker-registry regcred --docker-server=DockerhubのURL --docker-username=ユーザ名 --docker-password=パスワード
--docker-serverの値は~/.docker/config.json内にあります。ポッドでDockerイメージを利用
Deploymentの
spec.template.specに下記を記入します。imagePullSecrets: - name: regcredこれでk8sに作成したDockerイメージを利用したポッドをデプロイできます!
参考URL
- 投稿日:2019-12-14T11:51:31+09:00
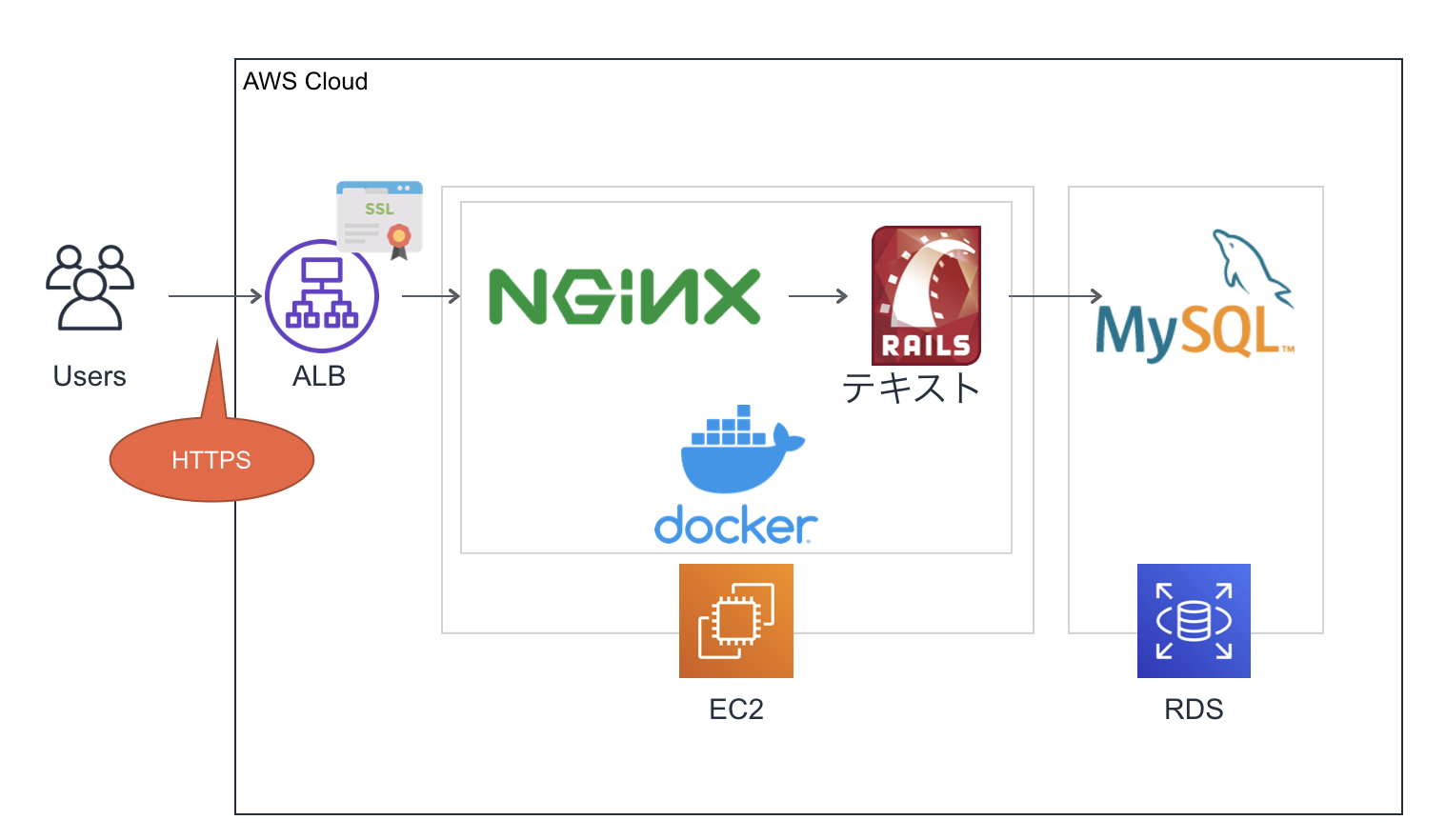
ハンズオン!dockerとAWS(EC2+ALB+RDS)を触ってみて学んだこと
この記事はエイチーム引越し侍 / エイチームコネクト Advent Calendar 2019 14日目の記事です。本日はエイチーム引越し侍に入社してWEBエンジニア歴4ヶ月目に突入した@halktが担当します!
なぜこれをやろうと思ったのか?
一言で言うと、自分の力でWEBサービスをデプロイする経験をしてみたかったからです。
WEBエンジニアになる前は、社内サービスの維持運用を主として行なっていたため、物理的なサーバを建てたり、仮想マシンを作成したりということはしておりましたが、インフラなどはすでに構成された社内ネットワークの中でしか触ったことはありませんでした。
そのため、Webサービスを外部に公開する上での考慮事項や外からサービスに接続するための知識は特に足りていないと感じていたので、このテーマにまずは挑戦しようと思いました!!
兎にも角にもまずは触ってみなきゃ始まらん!と思い、下記の構成を目指し、タイトル通りハンズオン形式で学んだ内容をまとめてみたいと思います!
ゴールのイメージ
Railsなのは特にこだわりがあるわけでなく、たまたまあるアプリを使っただけです。最近だとECSやFargateを使った構成が多いと知りましたので別途挑戦したいと思います・・・!?docker/docker-compose編
最初にローカルで作成していた既存のRailsアプリをdockerにのせました。dockerの勉強したいから、という理由がきっかけですが、コンテナをデプロイできるようになれば、他のアプリでデプロイをしたいときに応用が効くことを期待してdocker化から初めました。
実施内容
細かな作業内容などは割愛しますが、ざっくり下記のようなことをやりました。
- Dockerfile(Railsやnginx)の作成
- pumaとnginxのソケット通信の設定
- nginxの設定ファイルの修正
- docker-compose.ymlの作成
- buildしてアプリケーションを実行しアクセスする
- githubにpushしておく
docker-compose.ymlの作成
docker-composeは、複数コンテナ群の構成や動きを管理することができます。所謂インフラ構成のコード化が実現できます。
version: '3' services: app: build: context: . environment: MYSQL_ROOT_PASSWORD: XXX MYSQL_DATABASE: XXX command: bundle exec puma -C config/puma.rb volumes: - .:/app - public-data:/app/public - tmp-data:/app/tmp - log-data:/app/log depends_on: - db db: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: XXX MYSQL_DATABASE: XXX ports: - "3306:3306" web: build: context: containers/nginx volumes: - public-data:/app/public - tmp-data:/app/tmp ports: - 80:80 depends_on: - app volumes: public-data: tmp-data: log-data: db-data:docker-composeコマンドを使ってbuildしてアクセス!
ここまで準備が整えば、あとはbuildするだけで環境の作成ができます。便利なのは、このファイル群を使えば同じインフラが一発で再現ができるようになった点ですね〜本当にいい時代だ。。。(しみじみ)
# コンテナを起動する $ docker-compose build # コンテナをビルド $ docker-compose up -d # コンテナの一斉起動 # railsの設定 $ docker-compose run --rm app rails db:create $ docker-compose run --rm app rails db:migrateここまでするとnginx経由でアクセスができるようなりました!
ここで学んだこと
頭では理解していたつもりでしたが、もともと普通に構築したアプリをdocker化することでその良さをより知ることができたと思います!
それまでミドルウェアのインストールから設定からまでやっていた環境構築が数回のコマンドで再現できるのは感動的???
今後はガシガシコンテナを使って色々と構築していき、理解を深めていきたいと思います!!
?AWS編
コンテナ化までできたので、デプロイそのもののハードルはほぼなくなりました。ここからは、本丸に挑戦・・・!
実施した内容
- VPCの作成
- RDSインスタンスの構築と接続設定
- EC2インスタンスの作成
- ALBの作成
- ドメインの取得
- ACMによる証明書の作成
- HTTPS化
RDSインスタンスの構築と接続設定
RDSは、DBエンジンを提供するサービスでDBサーバーとして利用することができます。こちらの生成は正直そこまで難しいことはありませんが、RailsアプリからこちらのDBに接続する設定を直接書き出してしまうのは危険なため、credentialを使って隠蔽する設定を行いました。
# credentialsの設定 $ docker-compose run -e EDITOR="vim" app rails credentials:edit# credentialsの中身 # ここに書いた内容は外から見ることはできません rds: host: RDSのエンドポイント database: RDSの「データベースの名前」 username: RDSの「マスターユーザの名前」 password: RDSの「マスターパスワード」
- config/database.yml
production: <<: *default host: <%= Rails.application.credentials.rds[:host] %> database: <%= Rails.application.credentials.rds[:database] %> username: <%= Rails.application.credentials.rds[:username] %> password: <%= Rails.application.credentials.rds[:password] %>こうすることで、本番環境の接続DBをRDSに設定することができました。
EC2インスタンスの作成
EC2インスタンスはssh接続できるように設定し、コンテナを動かすためにdockerやdocker-composeのインストールを行いました。
その後、?docker編で作成したアプリのgithubからリポジトリごとcloneしてきます。また、githubには存在しない
master.keyを個別にconfigファイルにコピーしていきます。これをしないと、先ほどcredentialsに設定した内容を参照できないのでご注意を。$ scp -i ~/.ssh/myapp.pem ~/myapp/config/master.keyここまできたらdockerを起動してアプリを起動・・・!
$ docker-compose build $ docker-compose run app rails db:create $ docker-compose run app rails db:migrate $ docker-compose run app rails assets:precompile # nginxとpumaのソケット通信 $ mkdir tmp/sockets $ touch tmp/sockets/puma.sock # コンテナ起動 $ docker-compose upIPアドレス経由ですが、Webアプリケーションにアクセスができるようになりました!!!
HTTPS化
最後に、EC2+RDSで構成されたアプリにALB経由で接続するようにします。また、ACMで証明書を作成してALBに設定することで、外部→ALBの通信をHTTPS化(暗号化)します。※ALBとnginx間は同一ネットワーク内なのでHTTP通信になります。
これにより、特定のドメインでHTTPS化した状態でWebアプリにアクセスできるようになりましたーーー!!!
ここで学んだこと
今回、ほぼ無料枠のみでWebアプリケーションをSSL化してインターネット上に公開することができました!!
インスタンスの生成やロードバランサーがこんなにサクッとできるのはやはりすごいですね。今回は1台構成ですが、冗長構成なども容易にできそうな実感を得られました。
また、デプロイは単純にEC2上にリポジトリをコピーしただけだったので、今後はCIできるようにしたり、Githubと連携させたり、なかなかコストはかかりそうですが色々やりたいことも見えてきたので、他のサービスの利点を知るためにも継続的に触っていきたいと思います。
まとめ
目的だった自分の力でWEBサービスをデプロイする経験することができ、知らなかったサービスやインフラの基礎的な部分を効率よく学ぶことができたのはGOODでした!
ハンズオン形式で触りながら学ぶことで、技術の恩恵をより実感することができました。一度触ることで、学びたいサービスや領域が広がったのもいい収穫だったと思います。まだまだいろんなサービスがあるので、どんどん触れてみてITで解決できることの幅を増やしていきたいと思います!
まだまだ勉強不足で毎日学ぶことの連続ですが、着実に力をつけていきたいと思います!!
参考にさせていただいた記事
これを実施するために下記の記事を参考にさせていただきました。
docker-compose(公式)
知識0から、AWSのEC2でウェブサーバーを構築するまで
丁寧すぎるDocker-composeによるrails5 + MySQL on Dockerの環境構築(Docker for Mac)
Docker導入のための、コンテナの利点を解説した説得資料
Nginx + Rails (Puma) on Docker のいくつかの実用パターン
無料!かつ最短?で Ruby on Rails on Docker on AWS のアプリを公開するぞ。お知らせ
エイチームグループでは一緒に活躍してくれる優秀な人材を募集中です。
興味のある方はぜひともエイチームグループ採用ページよりご応募ください。
WEBエンジニア詳細ページよりお問い合わせ下さい。明日
明日は@2boさんの記事です!
どんな内容か楽しみです、それではお楽しみに〜〜
- 投稿日:2019-12-14T03:44:44+09:00
【Docker】error Couldn't find the binary gitが出た時の対処法
error Couldn't find the binary gitが出たDockerfileのソースコード
Nuxt.jsで開発したアプリから、Dockerのイメージを作成した時に「error Couldn't find the binary git」というエラーが起きました。
実際にエラーが起きたDockerfileのソースコードは以下です。
FROM node:10.15.1-alpine as builder WORKDIR /app COPY . /app RUN yarn install --production RUN yarn build FROM node:10.15.1-alpine WORKDIR /app COPY --from=builder /app /app CMD ["yarn", "start"]※Dockerfileの作成方法もまとめているので参考にしてもらえると嬉しいです。
参考:https://qiita.com/arthur_foreign/items/fca369c1d9bde1701e38
Dockerイメージ作成時のエラーログ
エラーログは以下のような感じです。(GCRにイメージをPUSHする想定でした)
$ docker build -t gcr.io/${PROJECT_ID}/app_name:v1 . Sending build context to Docker daemon 157.9MB Step 1/9 : FROM node:10.15.1-alpine as builder ---> xxxxxxxxxx Step 2/9 : WORKDIR /app ---> Running in xxxxxxxxxx Removing intermediate container 0eb38e4dfdc1 ---> xxxxxxxxxx Step 3/9 : COPY . /app ---> xxxxxxxxxx Step 4/9 : RUN yarn install --production ---> Running in xxxxxxxxxx yarn install v1.13.0 [1/4] Resolving packages... [2/4] Fetching packages... error Couldn't find the binary git info Visit https://yarnpkg.com/en/docs/cli/install for documentation about this command. The command '/bin/sh -c yarn install --production' returned a non-zero code: 1タイトルや見出しにも書いてる通り、
error Couldn't find the binary gitというエラーが発生していますね。error Couldn't find the binary gitの原因
ちょうど同じエラーがteratailに掲載されていました。
参考:https://teratail.com/questions/179483
teratailのベストアンサーや解決の報告を見るにGitでこけているようですね。
error Couldn't find the binary gitの解決方法
おそらく、teratailはローカルの操作なのでDockerfileにも合わせていきましょう。
Dockerでうまくいかないということは、
alpineのパッケージマネージャであるapkにGitを入れる必要があります。そのため、Dockerfileを以下のようにしましょう。
FROM node:10.15.1-alpine as builder WORKDIR /app COPY . /app RUN apk update && \ apk add git RUN yarn install --production RUN yarn build FROM node:10.15.1-alpine WORKDIR /app COPY --from=builder /app /app CMD ["yarn", "start"]すると、Dockerイメージの作成に成功します。
Successfully built xxxxxxxxxxxx Successfully tagged gcr.io/gke_project_name/app_name:v1
- 投稿日:2019-12-14T02:34:43+09:00
Linux mint 19.2にdockerをインストールするときにはまったこと
Linux mintにdockerをインストールする
dockerについて少し勉強したいと思ったので、VM上のLinux mintにdockerをインストールする
環境
- OS:Linux mint 19.2
- VM:Oracle VM VirtualBox 6.0.14
https://docs.docker.com/install/linux/docker-ce/ubuntu/
上記リンクを参考に手順通り行っていく。
1.apt-get update
$ sudo apt-get update2.必要なソフトのインストール
$ sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common3.dockerのGPG公開鍵を追加
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -上記を実行後、以下のコマンドで確認をする
$ sudo apt-key fingerprint 0EBFCD88 pub rsa4096 2017-02-22 [SCEA] 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 uid [ unknown] Docker Release (CE deb) <docker@docker.com> sub rsa4096 2017-02-22 [S]ここまでは、とても順調に進んでいた。
4.リポジトリの設定
ここから問題がおきる・・・
$ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable"
Malformed input, repository not added.というエラーが表示されてしまった。
参考サイトを見ると注意書きがあった。注:以下のlsb_release -csサブコマンドは、Ubuntuディストリビューションの名前(など)を返しますxenial。Linux Mintなどのディストリビューションで$(lsb_release -cs) は、親のUbuntuディストリビューションに変更する必要がある場合があります。たとえば、を使用している場合 Linux Mint Tessa、を使用できますbionic。Dockerは、テストされていない、サポートされていないUbuntuディストリビューションについては保証しません。(翻訳)
Ubuntuでは上記のコマンドで大丈夫みたいだが、Linux mintだとエラーが起きてしまうみたい。
調べてみると、全く同じことで困っているひとがいた。https://stackoverflow.com/questions/57402923/docker-installation-on-linux-mint-19-2-doesnt-work
上記の回答を実際にやってみた。
sudo vim /etc/apt/sources.list.d/additional-repositories.list
deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable上記を記入してファイルを保存して終了。
$ sudo apt-get updateこれでdockerをインストールすることが出来るようになる。
質問していた方、回答していた方本当に助かりました!!!
5.dockerのインストール
$ sudo apt-get install docker-ce docker-ce-cli containerd.ioインストール後、dockerのバージョンを確認する。
$ docker version Client: Docker Engine - Community Version: 19.03.5 API version: 1.40 Go version: go1.12.12 Git commit: 633a0ea838 Built: Wed Nov 13 07:29:52 2019 OS/Arch: linux/amd64 Experimental: false Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.40/version: dial unix /var/run/docker.sock: connect: permission deniedデフォルトではrootユーザーのみdocekrコマンド使用可能なためdockerグループにユーザーを追加するのを忘れないように・・・
$ sudo gpasswd -a USER_NAME dockerこれでようやくdockerを使うことが出来ます。
はてなブログにも投稿しています。
- 投稿日:2019-12-14T01:57:31+09:00
EC-CUBE4の快適な開発環境をDocker Composeで整える for Windows
12/13(金) EC-CUBE4ハンズオンセミナーに参加したところ、EC-CUBE AdventCalender 2019の5日目が空いているということだったので、ちょっと書いてみました。
口調も内容も統一されていない気がしますが、勢いで書いたのでよろしくお願いします
EC-CUBE4は基本的にMac/Linux環境での開発が推奨されている。
1日目 phpbrew で EC-CUBE の開発環境を構築する @nanasess さんどうやら基盤となるSymfonyとWindowsのファイルシステムの相性が悪く遅いらしい。
また、Shellで記述されているスクリプトもあるため、Windows環境では使用できないコマンドが出てくる。ところが世の中にはWindowsユーザーは多い。林檎は贅沢品である。
Ubuntuデスクトップ使えばいいかもしれないそんな筆者を含むWindowsユーザーがDockerを用いてEC-CUBE4の開発環境を整えるための方法を紹介する。
一応この内容(前半部分)についてはPull Requestを出したところ採用いただけたため、開発ドキュメントにも手順は記載されている。Dockerを使用した構築手順自体は以前より確立されており、筆者はそれをDocker Composeで少々工夫を加えてまとめた形に過ぎないが、
本記事にて、Windows開発者向けに構築方法を紹介及び、構築の過程で得た知見、そして自分が使っている環境について共有したいと思う。Dockerを使用して環境を整える
まず先述のように、EC-CUBE4(Symfony)とWindows環境は色々と相性が良くないので、まず何かしらの手段でLinux環境を用意する必要がある。
- Dockerを使用する
- Vagrantを使用する
- WSL(Windows Subsystem for Linix)を使用する。
いくつか方法はあるが、ここではローカルと切り離して軽量にLinux環境を用意できるDockerを使用した方法を紹介する。
動作環境
- ホストOS: Windows 10 Pro
- Docker Desktop for Windows
- (WindowsのエディションがHomeの場合はDocker Toolboxで代用)
- Docker 19.03.5
- Docker Compose 1.24.1
Docker Desktop for Windowsのインストールについては公式や以下の記事を参照していただくのが良いと思う。
https://qiita.com/gahoh/items/7b21377b5c9e3ffddf4aHomeエディションの場合はDocker Desktop for Windowsの動作に必要なHyper-Vが使用できないため、
VirtualBoxベースで動作するDocker Toolboxを使用することになる。Docker ComposeでEC-CUBE4動作環境を立ち上げる
基本的には開発ドキュメントのdocker-composeを使用してインストールするに記載している通りである。
# GitリポジトリからEC-CUBE4を取得 git clone https://github.com/EC-CUBE/ec-cube.git cd ec-cube # .envファイルのコピー cp .env-dist .env # ビルド&起動 docker-compose up -d # 初回はインストールスクリプトを実行 # DBスキーマ作成・初期データ投入・キャッシュ作成 等 docker-compose exec ec-cube bin/console eccube:install以上でEC-CUBE4が動作する基本的な環境は完成である。
特にdocker-compose.ymlを編集していない場合は、8080ポートでEC-CUBEが表示できるDockerは本当に便利。
構築のポイント
ここからは、DockerComposeに関するPull Requestを作成するにあたり、ポイントとなった箇所について記述する。
課題1. ローカルファイルを全てマウントすると激烈に重い
開発ドキュメント Dockerを使用してインストールするに、以下の通り記述があった
## ローカルディレクトリをマウントする場合 # var 以下をマウントすると強烈に遅くなるため、 src, html, app 以下のみをマウントする docker run --name ec-cube -p "8080:80" -p "4430:443" -v "$PWD/html:/var/www/html/html:cached" -v "$PWD/src:/var/www/html/src:cached" -v "$PWD/app:/var/www/html/app:cached" eccube4-php-apacheこれは、ホスト上のフォルダとコンテナ上のフォルダをマウントした場合、当然ながら同期にコストがかかるためである。
(同様の問題はSymfonyやLaravel等でもあるらしい)対応
ここで開発ドキュメントより、EC-CUBE4のフォルダ構成について確認してみる
app/ 設定ファイルやプラグイン、EC-CUBEをカスタマイズするPHPコードなど、アプリケーションごとに変更されるファイルを配置 bin/ bin/consoleなど、開発に使用する実行ファイルを配置 html/ リソースファイル(jsやcssや画像ファイル)を配置 src/ EC-CUBE本体となり、phpファイルやTwigファイルを配置 tests/ テストコードを配置 var/ キャッシュやログファイルなど、実行時に生成されるファイルを配置 vendor/ サードパーティの依存ライブラリを配置基本的にカスタマイズではapp, html, src しか編集する機会はないはずなので、Dockerのイメージビルドの段階でソースコード全体をイメージ内にコピーし、その後は編集の可能性があるapp, html, srcのみローカルと同期するという形をとっていた。
ただしこれにも一つ落とし穴(ドキュメントにはしっかり記載されているが)があり、プロジェクトフォルダ直下のファイル(.env)等がホストと共有されないのである。
.envが代表的だが、直下のファイルを編集したくなることもあるため、出来ればパフォーマンスに影響しない範囲で広く同期をしたい。パフォーマンス低下の原因となるのは、主にキャッシュが作成されるvarフォルダ、それと
composer updateを行った際に露骨に遅くなるvendorの2つである。これら2フォルダについてのみ何とかしたい。DockerのVolumeやマウントはSFTPやGitのignore指定のように、一部のフォルダだけ同期しないような設定をすることは基本的にはないらしいが、以下の記事にて一部を除外する方法があることが判明
DockerでVolumeをマウントするとき一部を除外する方法問題のサブフォルダをホストではなく別途Volumeにマウントすることで、同期コストの高い部分を避けて全体をマウントできるようになった。
# docker-compose.yml version: "3" volumes: ### ignore folder volume ##### var: driver: local vender: driver: local services: ### ECCube4 ################################## ec-cube: # === 略 ===================== volumes: - ".:/var/www/html:cached" ### 同期対象からコストの重いフォルダを除外 ##################### - "var:/var/www/html/var" - "vender:/var/www/html/vendor" # ※ この記事を書いているときにvendorがvenderにタイポしていることに気が付きましたvarやvendorに関してはDocker Volumeを用いて同期よりも低コストで永続化される形になるため、これでパフォーマンス低下を避けてEC-CUBE4をDocker環境で構築出来るようになった。
さらなる環境を目指して
課題2 XDebug使えない問題発生
ここからの話は執筆時点(2019/12/13)でリポジトリに取り込まれておらず、取り込んでいただくのとも違う内容の気がするため、必要であれば記事を開発環境の参考にしていただけたらと思う。
PHPの開発においてはXDebugを用いてデバッグを行うことは一般的であるが、ここで新たな問題が発生する。
課題1を対応したことでホストのvarやvendorはコンテナと同期されなくなるため、XDebugを使用した際にエラーが出るようになった。
XDebugはコンテナとホストのソースを対応させてエディタ上で表示させるため、ホストにもvarやvendorの中身が適切に存在しないとマッピングできずにエラーとなる。一応コンテナのvar, vendorからホストにコピーすることで動作可能となったりはするが、varの中身などはキャッシュなので流動的(ここはあまり理解していません)だったりしそうなので、個人的にはこの方法はあまりやりたくない。
対応 VSCode Remote Developmentを使う
Visual Studio CodeにはRemote Developmentという機能が実装されている。
Insider Previewでないと使えないという情報も多いが、2019年5月より安定版のVSCodeでも提供されるようになった。VS Code Remote Development
VSCodeのRemote Development機能が革命的な話。これは大変に便利で、「リモートのフォルダを最初から開けて直接弄れる」とかだけではなく、「VSCodeの拡張機能自体もリモート上のリソースで動く」というところが素晴らしい。
つまり、Remote Development でコンテナに接続してXDebugを実行した場合、コンテナ上にvar, vendorフォルダさえあれば良い状態となるため、パフォーマンスを保ったままデバッグを行えるようになる。また、Windows上にPHPをインストールする必要もなくなる。強い。導入方法
VSCodeの拡張機能にて[Remote Development]をインストール
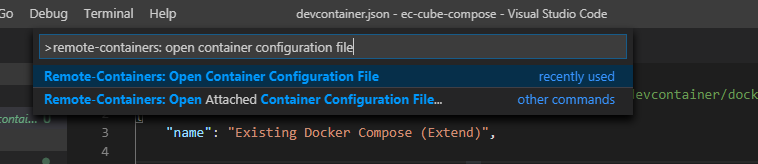
EC-CUBE4のプロジェクトフォルダを開き、コマンドパレットより[Remote-Containers: Open Configure]を実行
[From 'docker-compose.yml']
[ec-cube]
.devcontainerフォルダ以下にファイルが生成されるため、以下の通り編集する
【.devcontainer/docker-compose.yml】
# .devcontainer/docker-compose.yml # 通常のdocker-compose.ymlに対する差分ファイルになります # 今回は通常のdocker-compose.ymlにて必要なマウントは行っているため、ほぼ設定する内容がありません #------------------------------------------------------------------------------------------------------------- # Copyright (c) Microsoft Corporation. All rights reserved. # Licensed under the MIT License. See https://go.microsoft.com/fwlink/?linkid=2090316 for license information. #------------------------------------------------------------------------------------------------------------- version: '3' services: # Update this to the name of the service you want to work with in your docker-compose.yml file ec-cube: # You may want to add a non-root user to your Dockerfile. On Linux, this will prevent # new files getting created as root. See https://aka.ms/vscode-remote/containers/non-root-user # for the needed Dockerfile updates and then uncomment the next line. # user: vscode # Uncomment if you want to add a different Dockerfile in the .devcontainer folder # build: # context: . # dockerfile: Dockerfile # Uncomment if you want to expose any additional ports. The snippet below exposes port 3000. # ports: # - 3000:3000 ### コメントアウトする # volumes: # # Update this to wherever you want VS Code to mount the folder of your project # - .:/workspace ### # Uncomment the next line to use Docker from inside the container. See https://aka.ms/vscode-remote/samples/docker-in-docker-compose for details. # - /var/run/docker.sock:/var/run/docker.sock # Uncomment the next four lines if you will use a ptrace-based debugger like C++, Go, and Rust. # cap_add: # - SYS_PTRACE # security_opt: # - seccomp:unconfined # Overrides default command so things don't shut down after the process ends. ### コメントアウトする。 # command: /bin/sh -c "while sleep 1000; do :; done"【.devcontainer/devcontainer.json】
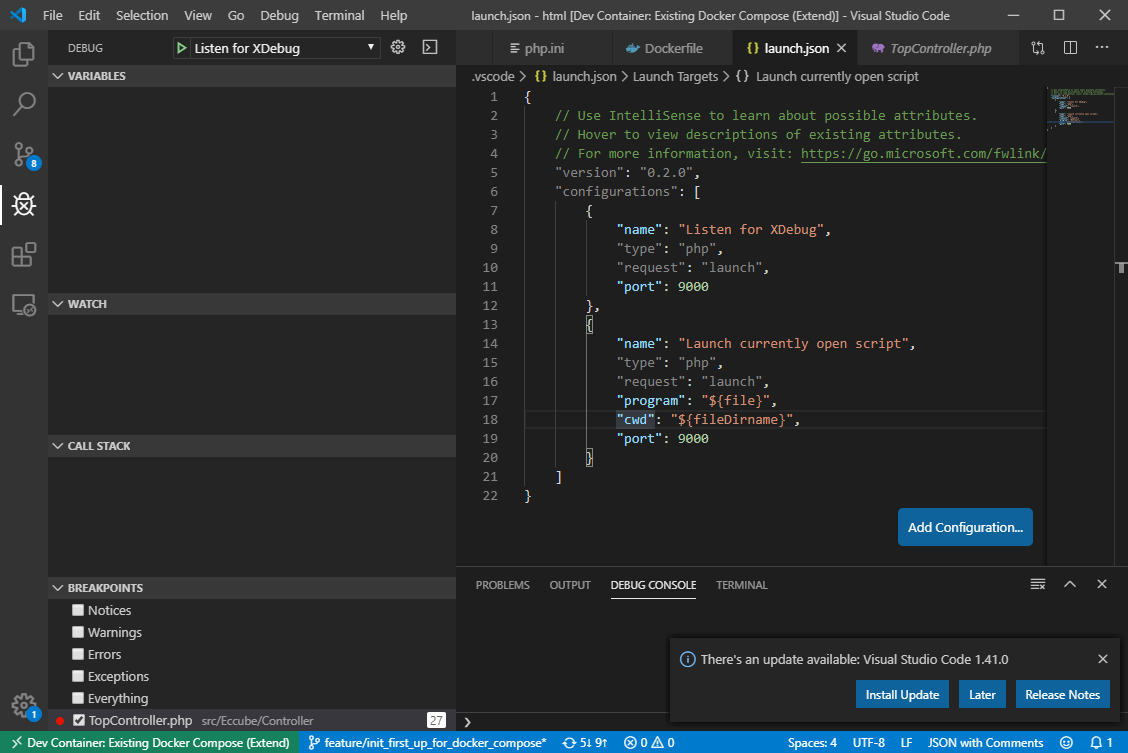
// If you want to run as a non-root user in the container, see .devcontainer/docker-compose.yml. { "name": "Existing Docker Compose (Extend)", // Update the 'dockerComposeFile' list if you have more compose files or use different names. // The .devcontainer/docker-compose.yml file contains any overrides you need/want to make. "dockerComposeFile": [ "..\\docker-compose.yml", "docker-compose.yml" ], // The 'service' property is the name of the service for the container that VS Code should // use. Update this value and .devcontainer/docker-compose.yml to the real service name. "service": "ec-cube", // The optional 'workspaceFolder' property is the path VS Code should open by default when // connected. This is typically a file mount in .devcontainer/docker-compose.yml // "workspaceFolder": "/workspace", "workspaceFolder": "/var/www/html", // ドキュメントルート(ファイルがマウントされている場所)を指定する // Use 'settings' to set *default* container specific settings.json values on container create. // You can edit these settings after create using File > Preferences > Settings > Remote. "settings": { // This will ignore your local shell user setting for Linux since shells like zsh are typically // not in base container images. You can also update this to an specific shell to ensure VS Code // uses the right one for terminals and tasks. For example, /bin/bash (or /bin/ash for Alpine). "terminal.integrated.shell.linux": null }, // Uncomment the next line if you want start specific services in your Docker Compose config. // "runServices": [], // Uncomment the next line if you want to keep your containers running after VS Code shuts down. // "shutdownAction": "none", // Uncomment the next line to run commands after the container is created - for example installing git. // "postCreateCommand": "apt-get update && apt-get install -y git", // Add the IDs of extensions you want installed when the container is created in the array below. "extensions": [] // 使いたい拡張機能があれば書いておくと自動インストールされる }この状態で[Remote-Containers: ReOpen in Container]を実行すると、コンテナ起動&接続が行われる。
開かれたWindowは、コンテナ上を参照している
[Remote-Containers: Reopen Locally]でローカル環境に戻れる
DockerイメージにXDebugを追加
php.iniにXdebugの設定を追加。
# dockerbuild/php.ini # 以下を追記 [xdebug] zend_extension="xdebug.so" xdebug.remote_host=127.0.0.1 xdebug.remote_autostart=1 xdebug.remote_enable=1 xdebug.remote_port=9000# 最後あたりにXDebugインストール追記 # dockerbuild/Dockerfile # ------------95行目? 適当な場所に追加 -------------- RUN pecl install xdebug \ && docker-php-ext-enable xdebugコンテナイメージを再度ビルド
これでコンテナの準備は完了VSCodeにPHP Debug拡張をインストール(Install in Dev Container)
左メニューからデバッグを選択し、歯車にてPHPを追加
src/Eccube/Controller/TopController等にブレークポイントを設定し、
[Listen for XDebug]を実行する。
http://localhost:8080 にアクセスしたときにデバッガが反応すれば設定完了
たぶんこれが一番快適だと思います
何だか後半、VSCode Remote Developmentいいよ!!って話になってしまいました。
快適な開発環境をいい感じに共有するというのは一つのテーマだと思いますので、色々と共有できるといいなと思っています。Docker Composeを用いて環境を作成し、VSCode Remote Developmentで接続して開発を行う、
今のところWindows環境でEC-CUBE開発をやるならこれがいいかなと個人的には思っています。とはいえEC-CUBE4歴1ヶ月なので、正直色々見えない部分は多いです。
もっと良さげな環境があればぜひご教示いただきたいです







- 投稿日:2019-12-14T00:58:30+09:00
BERTをお手軽に試すための環境
はじめに
いつも参考にさせていただいているDevelopers.IOさんのサイトに掲載されている記事BERTの日本語事前学習済みモデルでテキスト埋め込みをやってみるを見ると、いつものように試したくなるのが人情というもの。そして、色々とつまづいた点もあり、ちょっと修正しなければならなかったり、環境を揃えなければいけない点もありました。これらをできるだけ簡単に揃えて試すところまでできたので紹介します。
ベースイメージ
やっぱりお手軽に試すには、サイズは小さい方が正義ということで、alpineベースにしようとしたけれど、そもそもtensorflowが対応していなかった(←
)。ということで、tensorflowと親和性が良いUbuntuベースにpython環境があるものを利用する方針。
ただ、python公式を探しても基本debianベースのイメージしかなかったため、3.7.5-slim-busterを参考にubuntuベースのイメージを用意して利用することとした。サイズ的にはまぁまぁな感じです。0bara/python 3.7.5-ubuntu18.04 167MB python 3.7.5-slim-buster 178MBjuman++ & tensorflow
ただ、ベースイメージを小さくしても、結局形態素解析(とその辞書)やtensorflow動作環境を入れると大きくなってしまいます。
# docker/Dockerfile FROM 0bara/python:3.7.5-ubuntu18.04 MAINTAINER t.obara RUN apt update -y && apt upgrade -y && \ apt install -y --no-install-recommends \ build-essential cmake git curl WORKDIR /opt COPY requirements.txt /opt COPY bin /opt/bin RUN curl -L https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc3/jumanpp-2.0.0-rc3.tar.xz -o /tmp/j.txz \ && cd /tmp && tar xJfv j.txz \ && cd jumanpp-2.0.0-rc3 \ && mkdir build && cd build \ && cmake .. -DCMAKE_BUILD_TYPE=Release \ && make install \ && cd /opt \ && git clone https://github.com/0bara/bert.git \ && pip install -r requirements.txt \ && rm -rf /tmp/* \ && apt autoremove -y build-essential cmake git curl \ && apt -y clean \ && rm -rf /var/cache/* \ && rm -rf /var/lib/apt/lists/* CMD ["/bin/bash"]これでサイズが1.5G近く
bert_env latest 1.51GBちなみに、元のBERTコードは、TensorFlow1.11.0で確認したとのことで、新しいTensorFlowだとエラーやワーニングが出てきます。既にdeprecatedなメソッドなどがエラー、もうすぐでdeprecatedだよというワーニングがある。基本的には
import tensorflow as tfを、import tensorflow.compat.v1 as tfとするとかなりの軽減される。ワーニングも全て解消したいとは思ったのだけれど、それなりにあるLayerをEager modeに変換するのは厄介なので、その部分のワーニングは放置したけど、それなりに動くようにしたコードを置いたので、Docker Image内で取り込むようにしている。修正するのであれば、「Migrate your TensorFlow 1 code to TensorFlow 2」とか、「Writing custom layers and models with Keras」を読むのが良さそうです。
あ、肝心な事を忘れていましたが、Juman++を利用して日本語をトークン化する部分も同時に追加しています。この部分は元のページに詳しく記述されているので、ここでは特に触れない。事前学習モデル
さらに事前学習モデルがあるともっと大きくなるのですが、このモデル自体は色々と出てくるでしょうし、ここに入れてより簡単にするか手間を増やすか考えたのですが、複数のモデルを同時に利用することもないだろうということから、利用したいモデルを選んで(自分でダウンロードして)利用していただく方法とした。(比較したい人は同梱の方が楽でしょうけど。)
一応、ダウンロードして動く事を確認したのは以下3つのモデルです。1、2は同じサイトで、それぞれtensorflow用のzipファイルをダウンロードし、所定の場所に配置してください。3については「ダウンロードリンク」が示されているので、そこを辿り、GoogleDriveにあるtensorflow版に個々のファイルがあるので、それぞれダウンロードして所定の場所においてください。所定の場所については、以降に記載する手順の中にあります。
環境構築準備
それほど難しい作業ではないけれど、手軽と言いつつ、それなりに面倒かもしれない。
以下に手順を示す。# 作成したファイルのダウンロード $ git clone https://github.com/0bara/bert_env.git $ cd bert_env # Dockerイメージの作成 $ docker-compose build # extract_features.pyを実行する際に入力するテキストをinput.txtを配置する場所としてworkディレクトリを用意する。ここには実行結果(output.jsonlと、output.tsv)が出力される。binディレクトリに入力例のテキストを配置しているので、binをworkにシンボリックリンクしている。自分で入力テキストを用意するのであれば、workディレクトリを作成するだけで良い。 $ ln -s docker/bin work $ cd work $ ln -s input_ex1.txt input.txt $ cd .. # モデルデータを用意する $ mkdir model # このディレクトリにダウンロードしたファイルを配置する $ curl http://nlp.ist.i.kyoto-u.ac.jp/nl-resource/JapaneseBertPretrainedModel/Japanese_L-12_H-768_A-12_E-30_BPE.zip -o model/Japanese_L-12_H-768_A-12_E-30_BPE.zip $ cd model $ unzip Japanese_L-12_H-768_A-12_E-30_BPE.zip $ cd ..上記の作業により、以下のようなファイル構成となっていれば良い。
$ tree . ├── README.md ├── docker │ ├── Dockerfile │ ├── bin │ │ ├── btest.sh │ │ ├── conv_tsv.py │ │ ├── elmo.env │ │ ├── input.txt -> input_ex1.txt │ │ ├── input_ex1.txt │ │ ├── input_ex2.txt │ │ ├── norm.env │ │ ├── output.jsonl │ │ ├── output.tsv │ │ └── wwm.env │ ├── jumanpp-2.0.0-rc3.tar.xz │ └── requirements.txt ├── docker-compose.yml ├── model │ ├── Japanese_L-12_H-768_A-12_E-30_BPE │ │ ├── README.txt │ │ ├── bert_config.json │ │ ├── bert_model.ckpt.data-00000-of-00001 │ │ ├── bert_model.ckpt.index │ │ ├── bert_model.ckpt.meta │ │ └── vocab.txt │ └── Japanese_L-12_H-768_A-12_E-30_BPE.zip └── work -> docker/bin実行してみる
$ docker-compose upこれを行うと、workディレクトリにoutput.jsonlとoutput.tsvが出力される。
可視化
これも元のページと同じなので軽く
Embedding Projectorを利用して可視化できるようにしています。利用するのは、入力で利用したinput.txtと出力されたoutput.tsvです。
- 上記Embedding Projectorを開く
- 左側ペインにあるLoadボタンを押すとダイヤログが開く
- 上部[Step 1: Load a TSV file of vectors]に対してoutput.tsvを指定
- 下部[Step 2 (optional): Load a TSV file of metadata]にinput.txtを指定 ダイヤログ以外をクリックすると結果が表示される
別のモデルを利用する場合
Whole Word Masking model
tensorflow版のJapanese_L-12_H-768_A-12_E-30_BPE_WWM.zip をダウンロードし、modelディレクトリに置いてunzipする
以下のような配置になれば良いかと。├── model │ ├── Japanese_L-12_H-768_A-12_E-30_BPE_WWMそして、以下のコマンドで実行する
$ docker-compose run bert /bin/sh bin/btest.sh bin/wwm.envちなみに、bin/wwm.envファイルは環境変数を設定しているファイルで、各モデルがあるディレクトリに応じて変更すれば良いが、上記の配置にしておけば、そのまま修正する必要はない。
これは次のモデルでも同様である。日本語ビジネスニュース記事(300万記事)
modelディレクトリ直下にELMoディレクトリを作成し、ダウンロードリンクからダウンロードした各ファイルを配置する。
├── ELMo │ ├── bert_config.json │ ├── output_model.ckpt.data-00000-of-00001 │ ├── output_model.ckpt.index │ ├── output_model.ckpt.meta │ └── vocab.txtそして、以下のコマンドで実行する
$ docker-compose run bert /bin/sh bin/btest.sh bin/elmo.env参考ページ
- https://dev.classmethod.jp/machine-learning/bert-text-embedding/
- http://nlp.ist.i.kyoto-u.ac.jp/index.php?BERT%E6%97%A5%E6%9C%AC%E8%AA%9EPretrained%E3%83%A2%E3%83%87%E3%83%AB
- https://qiita.com/mkt3/items/3c1278339ff1bcc0187f
最後に
本当はGPUを利用した場合も試したかったのだけれど、すぐ使えるモノがなかったのと、AWSで試そうかと調べたんだけど、そこまでの元気がありませんでした。。
また、「機械学習ツールを掘り下げる」のAdventCalendarに参加している割に、機械学習という単語がタイトルにもタグも入れないという記事ですが、生暖かい感じで流し読みいただけたら幸いです。
- 投稿日:2019-12-14T00:20:28+09:00
Docker+VSCodeで保存時に自動でコンパイルされるLatex環境を作る話
概要
この記事は環境の設定が面倒なLatex環境作成をLatex+Dockerでサクッと作っちゃおうという記事です.
Docker+VSCodeでLatex環境を作る話はネット上に先駆者の方々が書き残してくださった偉大な記事があるのですが,どれも私の環境とは少し違ったような気がしたので,書き残しておこうと思います.被っていたらごめんなさい.
また,間違い等あったらコメントなどでご指摘いただけると幸いです.
事前準備
以下の環境があることを前提に書いていきます.また,筆者の環境はmacOS Catalinaです.Windowsでの動作は確認していませんが,おそらく同様の設定で環境作成ができるかと思います.
- Dockerが使えること
- VSCodeが使えること
Step1 Dockerでイメージをダウンロード
面倒な日本語環境設定などがすでに行われているLatex環境のイメージをローカルに取得します.使用するイメージはこちらのものを使用します.
リポジトリのREADMEにもあるように,以下のコマンドでイメージをダウンロードします.docker pull paperist/alpine-texlive-jaこれでLatexの環境が取得できたわけですが,現状ではいちいちコマンドを打たないといけないので,次にVSCodeの設定を行っていきます.
Step2 VSCodeの拡張(Latex Workshop)を取得
VSCodeの拡張で以下の拡張をインストールします.2019年12月13日現在,Latex Workshopで検索すると一番上に出てきます.
Step3 VSCodeの設定(settings.jsonの編集)
settings.jsonの編集をしていきます.これはVSCodeを起動し,Command+,(Windowsの場合はおそらくCtrl)で編集することができます.このままですとおそらく任意のテキストを編集しづらいと思うので画面右上のアイコンをクリックしてくだい.
ここに以下の設定を付け加えます.
settings.json{ "latex-workshop.latex.recipes": [ { "name": "compile", "tools": [ "ptex2pdf" ] } ], "latex-workshop.latex.tools": [ { "name": "ptex2pdf", "command": "docker", "args": [ "run", "--rm", "-v", "%DIR%:/workdir", "paperist/alpine-texlive-ja", "ptex2pdf", "-l", "%DOC%" ] } ], "latex-workshop.latex.autoBuild.run": "onFileChange", "latex-workshop.docker.enabled": true, "latex-workshop.view.pdf.viewer": "browser", }ざっくり説明すると,texファイルが保存されたことをトリガーにdockerを使用したコンパイルをしてくださいねっていう設定をしています.
付録として最後の方に今回の設定した値の説明を入れておきます.
設定は以上になります.これからはファイル保存時にコンパイルが本当に走るのかテストを行います.Step4 コンパイルのテスト
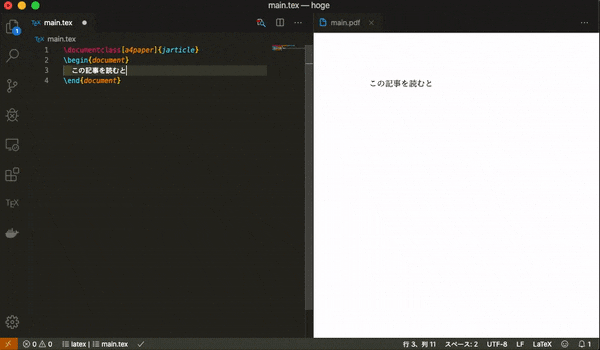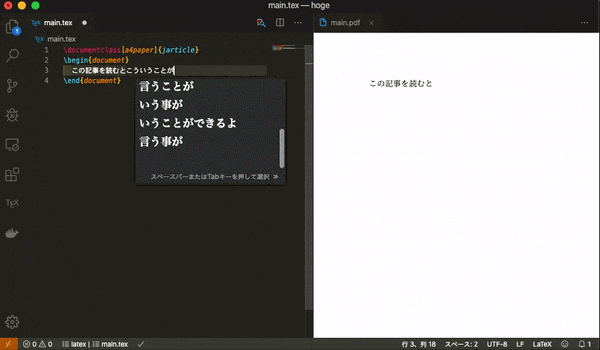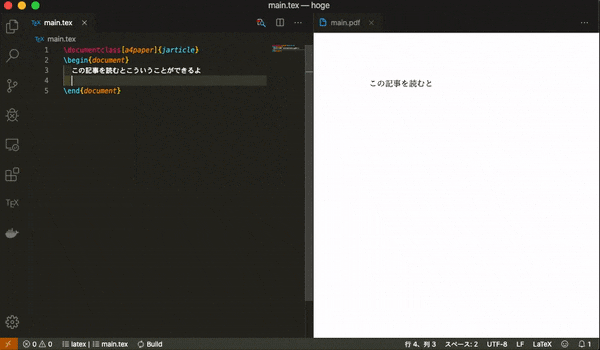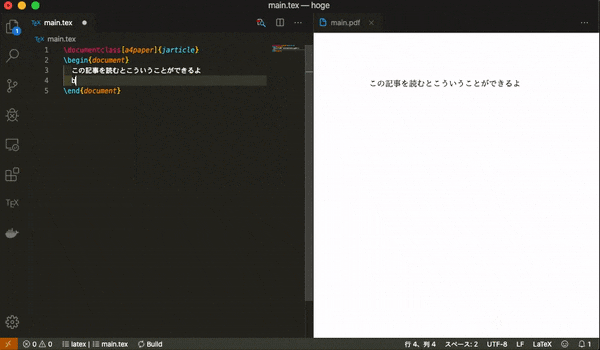
適当なディレクトリを作成し,拡張子が
texのファイルを作成してVSCodeで開いてください.(筆者はmain.texという名前にしています)
そこに以下のLatexの簡単なテンプレートをコピーし,適当に編集をしてファイルを保存してみてください.main.tex\documentclass[a4paper]{jarticle} \begin{document} そろそろ書くの疲れてきた \end{document}同じディレクトリにPDFファイルが作成されていたら成功です.保存をトリガーにしてDockerのコマンドが走り,コンパイルがされています.
既存のPDFのビューアはファイルが開かれた後にファイルが変更された場合に,変更を自動で更新してくれる機能がないものがあります.そのため,Latex Workshopのビューアを開いて編集することをお勧めします.
ビューアは以下のアイコンから開けます.また,このビューアの種類はブラウザとVSCode上の2つから選択でき,付録に示すパラメータで設定できます.
終わりに
Docker+VSCodeを使ってLatex環境を作るというよくある記事でしたが,記事を書くことが初めてだったので,文章に起こすのってこんなに大変なんだなーって思いながら書きました.
間違え等ありましたらご指摘いただけると嬉しいです.付録
settings.jsonで設定したパラーメータ
各値の詳細はこちらを参照してください.
latex-workshop.latex.recipes
Latexファイルをビルドするときのレシピを記載します.今回の記事では
ptex2pdfを使用しているのでtoolsの中身は要素が1つの配列ですが,複数入れることでその順番に実行することができます.latex-workshop.latex.tools
recipesによって指定されたレシピに対応するコマンドを記載します.本記事では,ptex2pdfに対して,dockerを使用してptex2pdfを実行するコマンドを対応させています.
%DIR%や%DOC%はLatex Workshopのプレースホルダーでこちらで確認できます.latex-workshop.latex.autoBuild.run
ビルドを走らせるタイミングについての設定です.
onFileChangeにすると依存関係のあるファイルに変更があった場合に自動でコンパイルが走ります.この設定に加えて,以下のVSCodeの自動保存の設定をしておくと便利だったり鬱陶しかったりします.(書いているTexファイルのサイズが大きくなるほど鬱陶しいと感じました.)setting.json{ "files.autoSave": "onWindowChange", }latex-workshop.docker.enabled
dockerを使用する上で必要な設定のようです.
latex-workshop.view.pdf.viewer
ビューアを何で開くのか設定できます.概要のGIFでは
tabの設定値を開いた場合です.筆者はbrowserを使用しています.