- 投稿日:2019-12-14T23:49:11+09:00
Amazon Rekognition を使ってみた
この記事は YAMAP エンジニア Advent Calendar 2019の14日目の記事です。
はじめに
おかげさまで、 YAMAP には毎日大量の写真がアップロードされております。
その中で自分が写っている写真をシュッと検索できたらな〜と思い立ち、まずはお手軽な Amazon Rekognition で試してみました。手順
Amazon Rekognition には顔コレクションというものがあり、下記の手順で自分が写っている写真を検索できます。今回はAWS CLIで実施しましたので、コマンドと結果と共に手順を記載します。
1. 顔コレクションを作成する。
まずは、顔の情報を保存するコレクションを作ります。
aws rekognition create-collection \ --collection-id "sampleCollection"正常に作成できました。
{ "CollectionArn": "aws:rekognition:ap-northeast-1:270040163539:collection/sampleCollection", "FaceModelVersion": "4.0", "StatusCode": 200 }作成されたコレクションの一覧を確認します。
aws rekognition list-collections問題なさそうです。
{ "FaceModelVersions": [ "4.0" ], "CollectionIds": [ "sampleCollection" ] }2. 写真から顔コレクションに追加する
読み込むファイルは全てS3にアップロードして実施しました。
自分が写っている写真をコレクションに追加しました。
aws rekognition index-faces \ --image '{"S3Object":{"Bucket":"rekognition.yamap.com","Name":"sample.jpg"}}' \ --collection-id "sampleCollection" \ --max-faces 1 \ --quality-filter "AUTO" \ --detection-attributes "ALL" \ --external-image-id "sample.jpg"長いので途中省略しますが、問題なく登録されました。
{ "FaceRecords": [ { "FaceDetail": { "Confidence": 100.0, "Eyeglasses": { "Confidence": 99.3648910522461, "Value": false }, "Sunglasses": { "Confidence": 99.69197082519531, "Value": false }, "Gender": { "Confidence": 99.35709381103516, "Value": "Male" }, "Landmarks": [ { "Y": 0.2901921272277832, "X": 0.5219544768333435, "Type": "eyeLeft" }, 〜中略〜 { "Confidence": 0.030570564791560173, "Type": "SURPRISED" } ], "AgeRange": { "High": 30, "Low": 18 }, "EyesOpen": { "Confidence": 99.95922088623047, "Value": true }, "BoundingBox": { "Width": 0.12911078333854675, "Top": 0.20607025921344757, "Left": 0.4941314160823822, "Height": 0.1995418518781662 }, "Smile": { "Confidence": 98.78253173828125, "Value": true }, "MouthOpen": { "Confidence": 99.3538818359375, "Value": true }, "Quality": { "Sharpness": 98.08562469482422, "Brightness": 78.78662109375 }, "Mustache": { "Confidence": 99.59739685058594, "Value": false }, "Beard": { "Confidence": 87.28791809082031, "Value": false } }, "Face": { "BoundingBox": { "Width": 0.12911078333854675, "Top": 0.20607025921344757, "Left": 0.4941314160823822, "Height": 0.1995418518781662 }, "FaceId": "ad1e894b-2343-4a0f-8a2a-47a412ee6971", "ExternalImageId": "sample.jpg", "Confidence": 100.0, "ImageId": "afd351f4-a1df-32e6-83e7-a0bd38fbbe89" } } ], "UnindexedFaces": [], "FaceModelVersion": "4.0" }他にも、自分が写ってない写真をたくさんコレクションに追加しました。
3. 自分の写真をアップして、他の写真を検索する
最後に自分が写っている別の写真を持ってきて、他に自分が写っている写真を検索しました。
aws rekognition search-faces-by-image \ --image '{"S3Object":{"Bucket":"rekognition.yamap.com","Name":"me.jpg"}}' \ --collection-id "sampleCollection"結果、確かに自分が写っている写真が返ってきました。(当たり前)
{ "FaceModelVersion": "4.0", "Faces": [ { "BoundingBox": { "Width": 0.12911100685596466, "Top": 0.20607000589370728, "Left": 0.4941309988498688, "Height": 0.19954200088977814 }, "FaceId": "ad1e894b-2343-4a0f-8a2a-47a412ee6971", "ExternalImageId": "sample.jpg", "Confidence": 100.0, "ImageId": "afd351f4-a1df-32e6-83e7-a0bd38fbbe89" } ] }まとめ
かなりお手軽に自分が写っている写真を検索できました。
細かな精度についてはもっとたくさんの写真を投入して試す必要がありますが、使い方が簡単であることはわかりました。
もう少し掘り下げて使ってみて、また報告できたらなと思います。ここまで書いて気づいたのですが、いろんな人の顔が写った写真を公開するのはハードルが高いので、このネタはブログ向きじゃないな〜と反省しております。
おまけ
実際にサービスに導入するとなるとコスト面も気にしておかないといけません。
Rekognition は コマンド実行回数で課金されますので、人物の顔が写ってない写真は事前にフィルタして対象外にしたいものです。そこで OpenCV を使って顔が写っている写真だけをピックアップして Rekognition に投入するよう作っていたのですが、いかんせん誤判定が多くて今回は成果を掲載できませんでした。。
もう少しブラッシュアップして公開できたらと思います。
- 投稿日:2019-12-14T23:40:25+09:00
[小ネタ]VSCodeからSAMによるLambdaのローカル実行で「Error with child process: Building resource 'awsToolkitSamLocalResource'」がでて動かない場合の対処
要約
SAMの内部にあるpipのversionとローカルのpipのversionが合わないと動かない時があるので、ローカルのpipのversionを修正する必要がある。
実行環境
項目名 バージョン OS MacOS High Sierra 10.13.6 VSCode 1.40.2 SAM 0.37.0 Python 3.7.3 pip 19.3.1(記事内で19.2.3に変更) 問題
VSCodeの「Run Locally」からAWS Toolkitを使用してローカル環境で試験したい時に動かない場合があります。例えば以下のようなエラーです。
Local invoke of SAM Application has ended. Preparing to run app.lambda_handler locally... Building SAM Application... An error occurred trying to run SAM Application locally: Error with child process: Building resource 'awsToolkitSamLocalResource' ,Running PythonPipBuilder:ResolveDependencies ,Error: PythonPipBuilder:ResolveDependencies - Traceback (most recent call last): File "<string>", line 1, in <module> TypeError: 'module' object is not callable原因(おそらく)
SAMの方で起きていたIssueがVSCodeのAWS Toolkitではまだ解決していないみたいです。
GitHub : sam build fails for python3.7 functions with pip==19.3 installed
試しに同じ設定で、ターミナルから以下のコマンドで実行した場合はSAMとpipのverisonは同じでも問題ありませんでした。$ sam local invoke HelloWorldFunction --event events/event.json対処
一時的な対処とはなりますが、pipのversionを以下に修正するとVSCodeからでも正常に実行することが可能になります
$ pip install pip==19.2.3pipのversion変更後にVSCodeから「Run Locally」したログ
Fetching lambci/lambda:python3.7 Docker container image...... Mounting /tmp/aws-toolkit-vscode/vsctkytL1AY/output/awsToolkitSamLocalResource as /var/task:ro,delegated inside runtime container ...(中略)... {"statusCode":200,"body":"{\"message\": \"hello worldXXX\"}"}
- 投稿日:2019-12-14T23:24:50+09:00
EKS for Fargate the Hard Way 〜 EKS for Fargateをeksctlに頼らず構築する
TL:DR
eksctlに頼らず、EKS for Fargateクラスタを構築する際は以下を確認!
- プライベートサブネットにアタッチするルートテーブルにはNAT GWへのルートを!
- VPCのDNSホスト名を有効にしているか確認!
- PodテンプレートのAnnotationに
eks.amazonaws.com/compute-type: fargateをつけよう!EKS for Fargate the Hard Way
2019/12/5にAWS Re:InventにてGAとなったEKS for Fargate。皆様もう試してみたでしょうか?? 私もただいまECS for Fargateと比較して、何ができて何ができないのか、絶賛検証中でございます!
さて、EKS for FargateのGAの記事を見ると、
eksctlコマンドを使ってEKS for Fargateクラスタを構築する例が上がっております。しかし、私はブラックボックス化されたものの中身を理解したい性分なもので、EKS for Fargateを手動で構築してみることにいたしました。言ってみれば、「EKS for Fargate the Hard Way」です! 本記事ではそんなハードな手順と共に、EKS for Fargateのハマりどころを紹介していきたいと思いますHard Way手順
EKS for FargateクラスタでPodが実行されるためには以下の手順を実施しましょう!
VPC作成
まずはEKSクラスタが所属するVPCを作成します。このとき重要なことはDNSホスト名の値を有効に設定することです。
パブリックサブネット、プライベートサブネットを切る
どちらもガチガチに可用性を固めたいなら3つずつ切ります。EIPおよびNAT GWを切る
NAT GWは当然パブリックサブネットに切ります。こちらもガチガチに可用性を高めたいなら3つずつ切ります。パブリックサブネット用のルートテーブルを切る
Internet GWへのルートを持つルートテーブルを切り、パブリックサブネットにアタッチします。プライベートサブネット用のルートテーブルを切る
NAT GWへのルートを持つルートテーブルを切り、NAT GWの所属するAZにあるプライベートサブネットにアタッチします。もちろん、NAT GWを一つしか切らない場合は、作ったルートテーブルを全てのプライベートサブネットにアタッチします。EKSクラスタ用デプロイ用IAMロールを切る
こちらはマネジメントコンソール上から作るのが簡単です。IAMのマネジメントコンソールから「ロールを作成」を選択し、AWSサービスとしてEKS(EKS - Nodegroupではない)を選択すれば必要な管理ポリシーが選択されます。EKS Fargate Pod実行用IAMロールを切る
こちらもマネジメントコンソールから作れます。IAMのマネジメントコンソールから「ロールを作成」を選択し、AWSサービスとしてEC2を選択します。表示された管理ポリシーの内、AmazonEKSFargatePodExecutionRolePolicyを選択しロールを作成します。その後、できたロールの信頼関係を以下のように修正します。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "eks-fargate-pods.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }EKSクラスタを作る
今まで作ったリソースを使って、EKSクラスタを作ります。Fargateプロファイル作る
最低限、kube-system名前空間に対するFargateプロファイルをEKSマネジメントコンソールから作ります。CoreDNSのyamlファイルを編集する
ここまで作業すると、とうとうkube-system名前空間内でFargate上にPodを浮かべることができるようになります。そのためにはmanifestのPodテンプレートにおいて、Annotationにeks.amazonaws.com/compute-type: fargateを加えます。既存のCoreDNSのDeploymentには、eks.amazonaws.com/compute-type: ec2が指定されているので、こちらを書き換えます。最終的にCoreDNSのPodが以下のように浮かび、Podの数だけWorkerノードを確認することができるはずです。
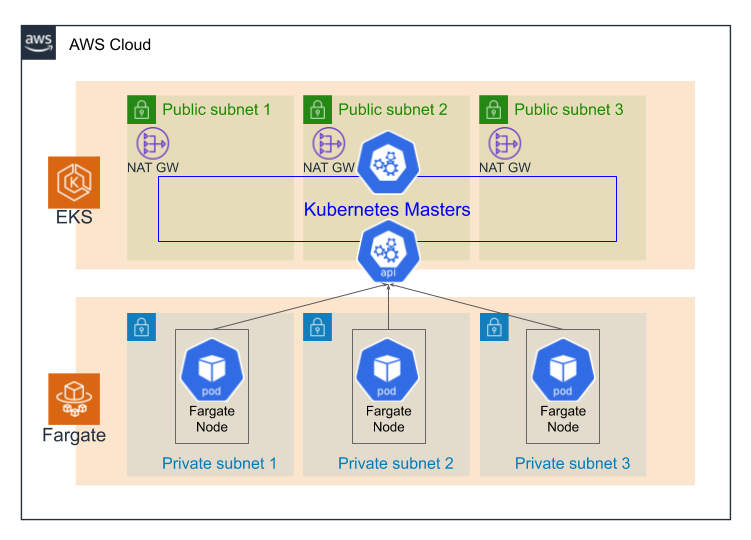
tatsunori@neptune-surface:~$ kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE coredns-6d75bbbf58-77hks 1/1 Running 0 2m24s coredns-6d75bbbf58-v5d7v 1/1 Running 0 2m24s tatsunori@neptune-surface:~$ kubectl get node NAME STATUS ROLES AGE VERSION fargate-ip-10-100-101-85.ap-northeast-1.compute.internal Ready <none> 3m38s v1.14.8-eks fargate-ip-10-100-103-157.ap-northeast-1.compute.internal Ready <none> 3m47s v1.14.8-eks最終的にできた構成
ガチガチに3AZで構成した場合は、以下のような構成でEKSクラスタが作成されます!
まとめ(注意点)
NAT Gatewayの作成を忘れない
Fargateプロファイルで指定できるサブネットはプライベートサブネットのみです。つまり、Podはプライベートサブネットで起動します。このためプライベートサブネット上から
docker pullによってコンテナイメージをインターネット上からダウンロードできる必要があります。NAT Gatewayが作成され、それにルーティングされるルートテーブルがプライベートサブネットにアタッチされていないと
docker pullできませんので注意が必要です。VPCのDNSホスト名を必ず有効化する
Fargate Podが起動するノードのノード名は
fargate-<VPC DNSホスト名>となります。このため、VPCのDNSホスト名が有効化されていないとノード名は全てfargate-nullとなります。この場合登録ノード名が重複するため、最高1Podしかクラスタ上にPodが起動できない状態になってしまいます。。。Pod TemplateのAnnotationに
eks.amazonaws.com/compute-type: fargateをつけるEKSクラスタを作成するとデフォルトでCoreDNSのDeploymentが作成されていますが、こちらのPod TemplateにはAnnotation
eks.amazonaws.com/compute-type: ec2が指定されているため、いつまで経ってもFargate上にPodは起動してきません。eks.amazonaws.com/compute-type: fargateに変更するのを忘れないように。

- 投稿日:2019-12-14T23:15:19+09:00
InCaaaan:印鑑マシーンの作り方 上司ツール編
InCaaaanとは?
InCaaaan:印鑑マシーンの作り方 超概要編に、全体的な構成と動画を置いてますので、ご確認ください。
では、早速作り方を!!!!InCaaaanの中核は、IBM CloudのNode-RED
主に以下の制御を行っている。
- 部下用の申請Webコンテンツの表示(LINE ID、LINE名取得もする)
- Kintoneに申請データを保存する
- AWSからKintoneのレコードが無事に追加されたことを受ける
- レコードが追加されたことをトリガーにTwillioに自動音声の電話を要求(今回は説明対象外)
- 電子型押印にKintoneのレコード IDとLINE名と金額をMQTTで送る
- 電子型押印からの承認要求を受けて、承認データを生成してKintoneに送信
- Obnizのサーボを動作
Kintoneの環境を準備する
帳票を作成する
Kintoneは非常に使い勝手の良いサービスだけではなく、ユーザガイドも充実してますので、ここであえて解説は必要ないと思います。
デベロッパーに登録すると、無料でかなり楽しめる・・・間違えたかなり試せるので、デベロッパー登録は忘れずに!
登録は、kintone 開発者ライセンスこちらからできます。InCaaaanの申請・承認を保管する帳票の作成
帳票には以下の項目を配置した。括弧の中は変数名です。
- レコード番号(recordId)
- 承認キー(Approval)
- LINE ID(LINE_ID)
- 氏名(LINE_NAME)
- LINE プロファイル(LINE_PROFILE)
- 書類名(FileName)
- 金額(currency)
- 申請理由(Reason)
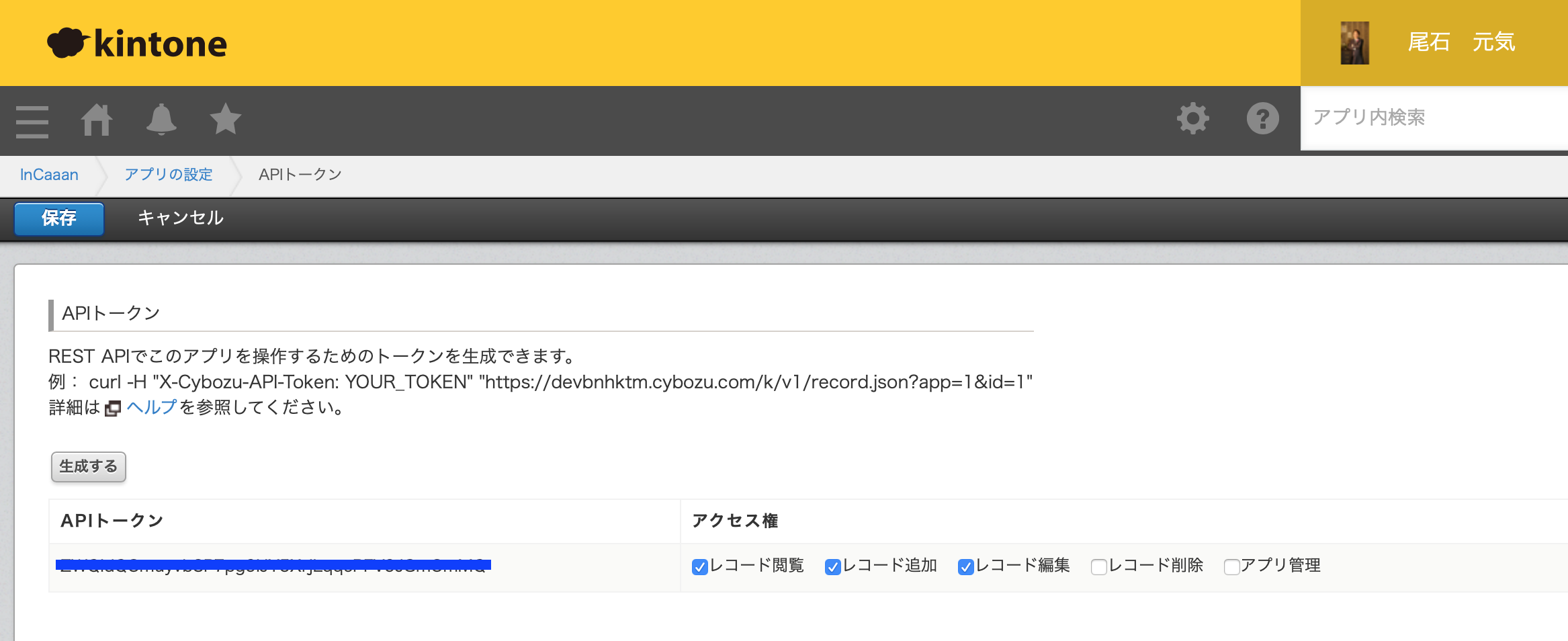
APIトークンを設定する
設定にある「APIトークン」をクリックします。
APIは、レコード閲覧、レコード追加、レコード編集にチェックをしておく。なんと!これだけで終わり!
なぜレコードの追加を受けるか、というと、部下用のUIとしてLINE Front-end Frameworkを使って表示しているWebサイトを入力元にしたいと考えたからである。
当初、ブラウザからKintoneにログインして・・・という考えもあったが、若い人がいつも使い慣れているインターフェースを入り口にして、いつか認証の連携もLINEと行えば、LINE IDで様々なことができるのではないか?と考えたからです(ただし、ヒーローズリーグでは実装できてなかった)
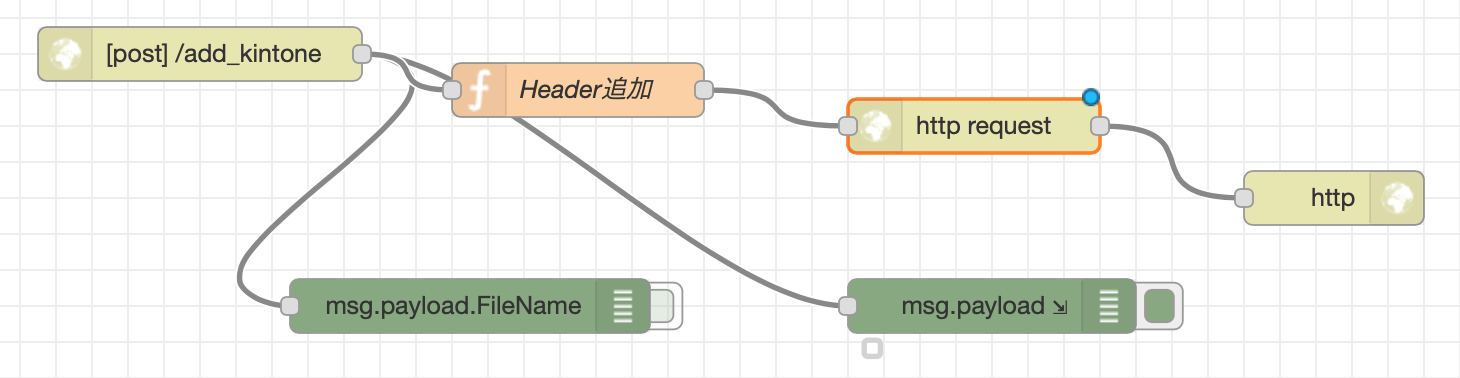
部下からの申請をNode-REDで受信する
部下がLINE上で入力したデータを受信する仕組みです。
構造は至ってシンプルで、POSTされたデータをKintone APIを使ってKintoneにレコード追加するのみとなります。
「Headerを追加」というファンクションでKintone APIを呼ぶ前の準備をしています。
構造は至ってシンプルで、APIキーをセットして、部下からPOSTされてきたデータをKintoneのお作法にならってJSON形式に整形してあげるだけです。KintoneAPIを呼ぶ前の準備var api_key = 'KintoneのAPIキー'; msg.headers = { 'X-Cybozu-API-Token': api_key, 'Content-Type': 'application/json', 'Authorization': 'Basic ' + api_key //"X-HTTP-Method-Override": "GET" }; msg.payload = { app: 1, record: { 'LINE_ID': { value: msg.payload.LINE_ID }, 'LINE_NAME': { value: msg.payload.LINE_NAME }, 'LINE_PROFILE': { value: msg.payload.LINE_PROFILE }, 'FileName': { value: msg.payload.FileName }, 'currency': { value: msg.payload.currency }, 'Reason': { value: msg.payload.Reason } } } return msg;レコードが追加された場合に動作するWebhookを設定する
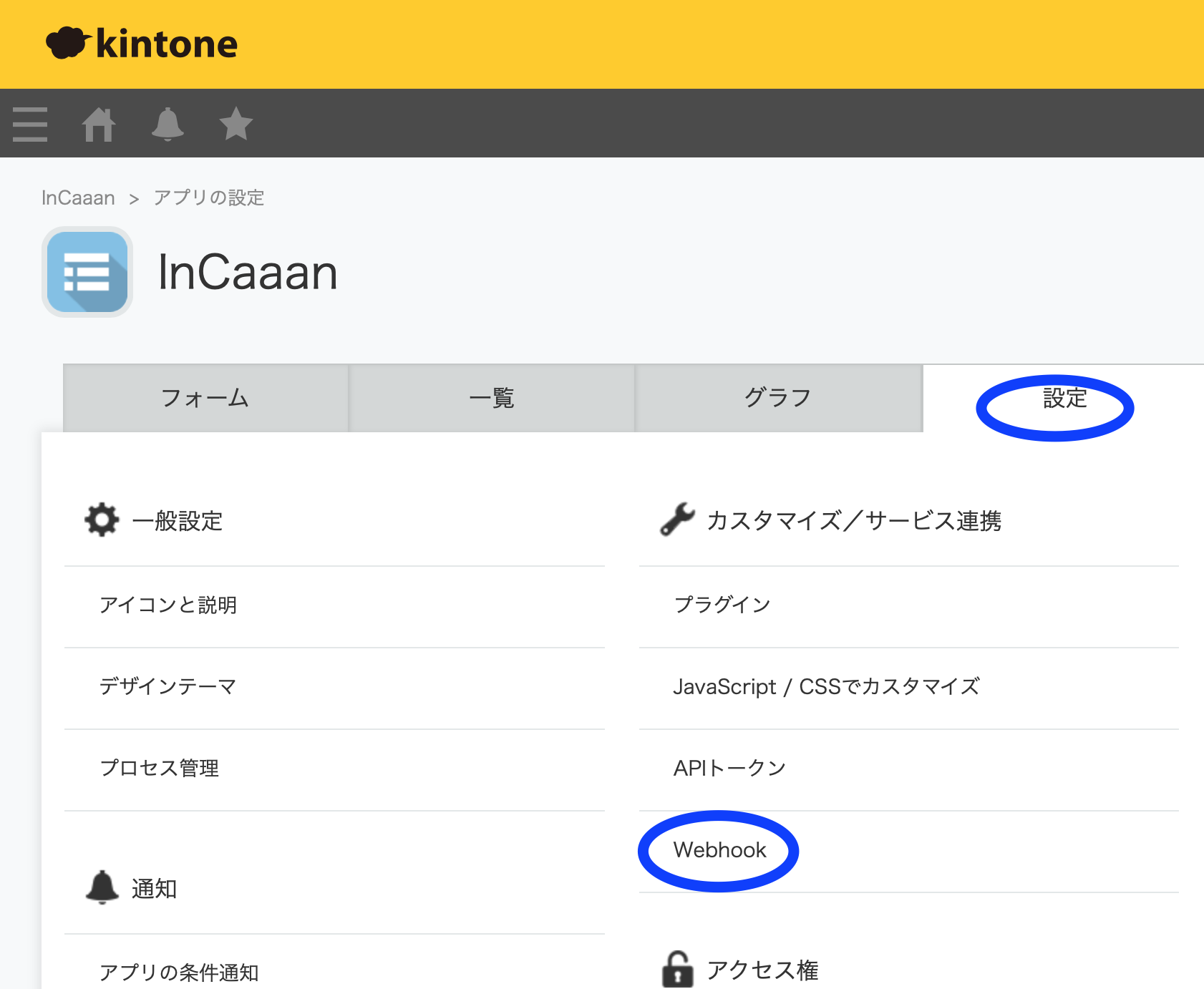
別のインターフェースを用いたことにより、KintoneにAPIの追加が完了して、次の承認要求のプロセスを動作させる為に、Webhookを利用した。
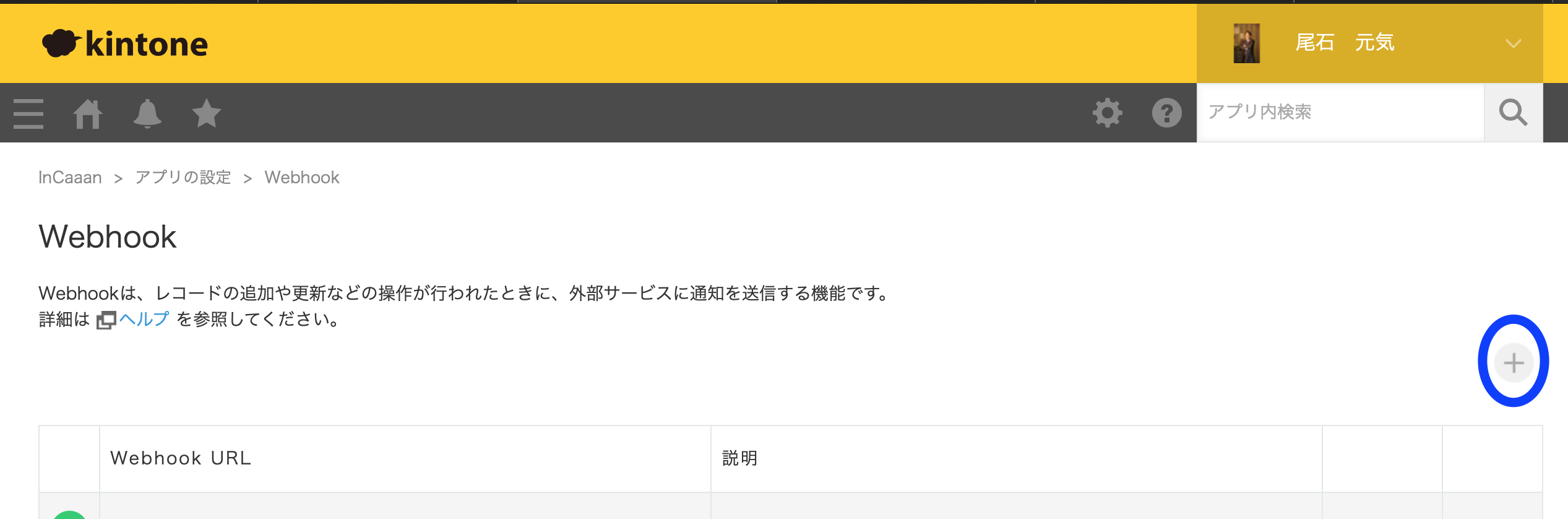
アプリの設定のWebhookを選択する。
Webhookの画面の+ボタンを選択します。
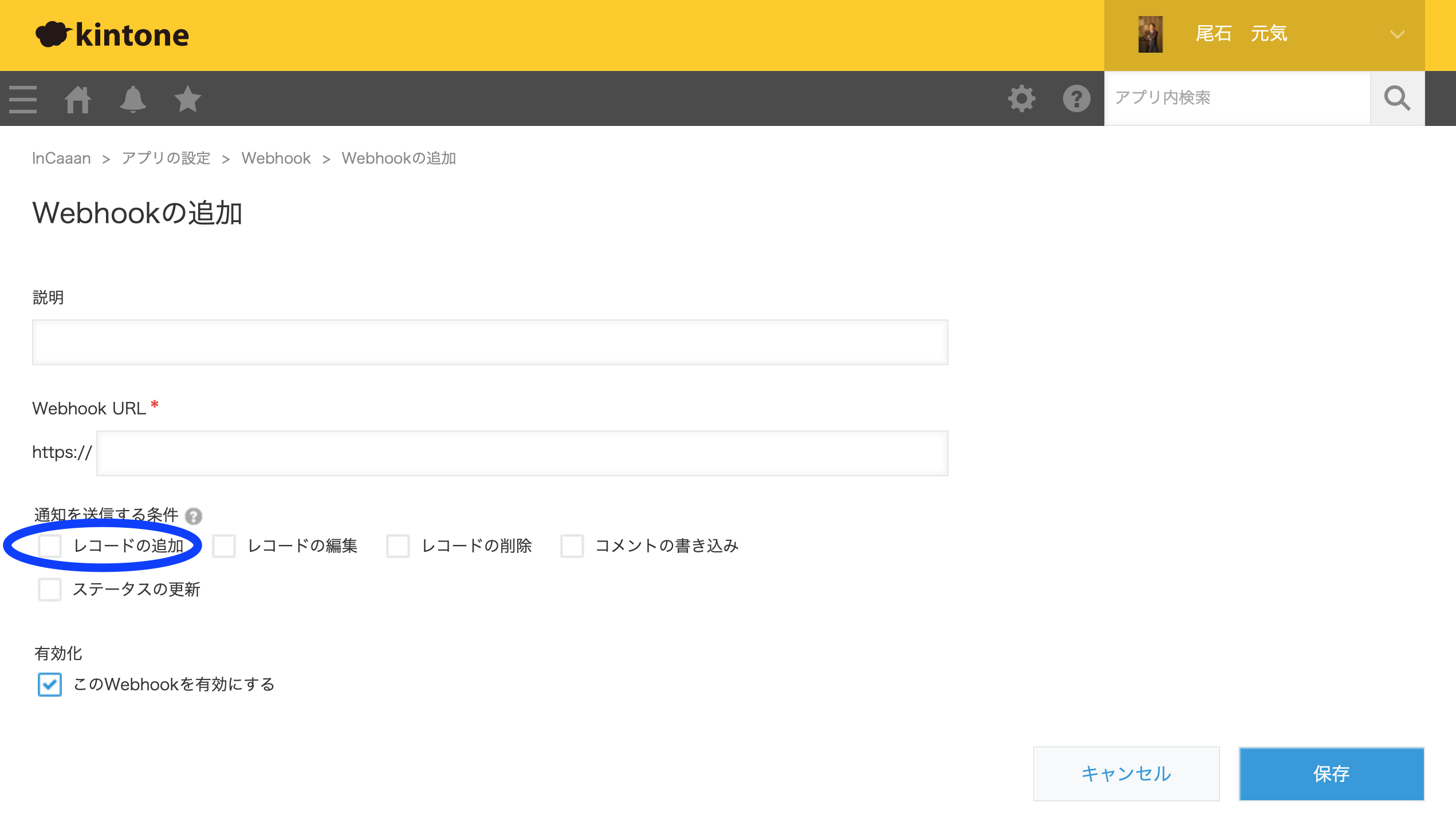
ここでは、URLと通知を送信する条件として「レコードの追加」を選択して保存するだけとなる。
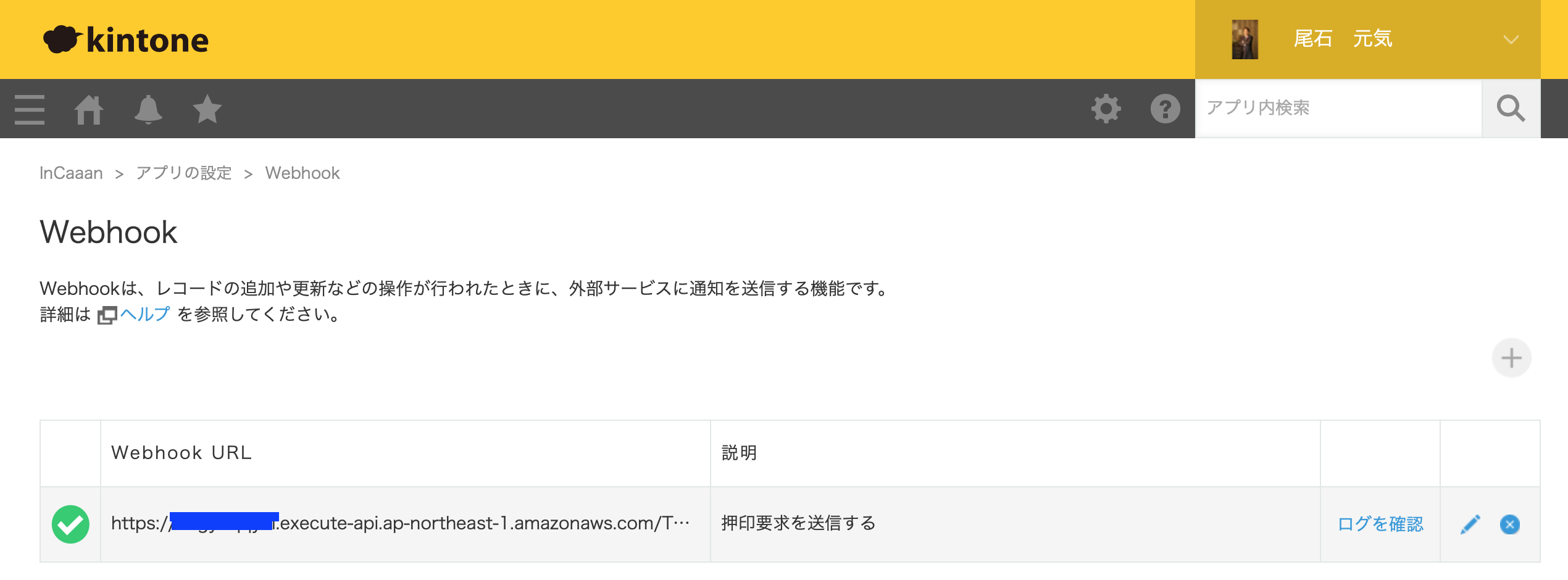
追加が完了すると、以下のように追加されている。緑のチェックアイコンは正常に接続された場合なので、ここが赤いXマークだとWebhookが動作してないのでご注意を。
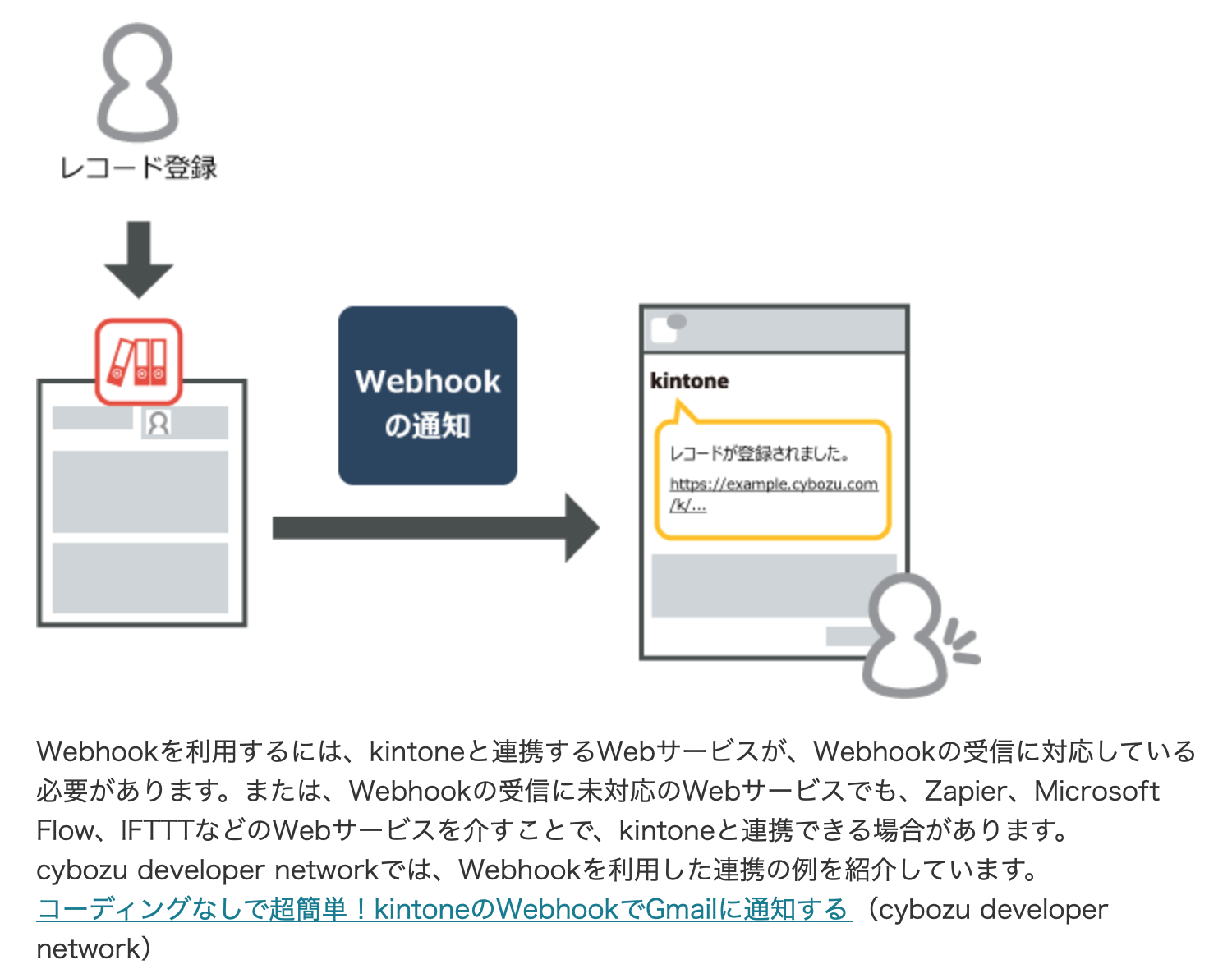
AWSの環境(KintoneからWebhookを受ける)を整える
KintoneからWebhookの通知を送る方法を確認したところ、以下公式ページから拝借した図では、Zapier、Microsoft Flow、IFTTTなどの紹介があった。しかし、これらは何か追加された、削除された、というような簡単なリクエストを受ける場合には有益なサービスであるが、部下からの入力データを使い回したいのニーズに適用できなかった。
その為、AWSで自作することにした。というか、AWSで作る方が早いと思った。
Lambdaファンクションを作る
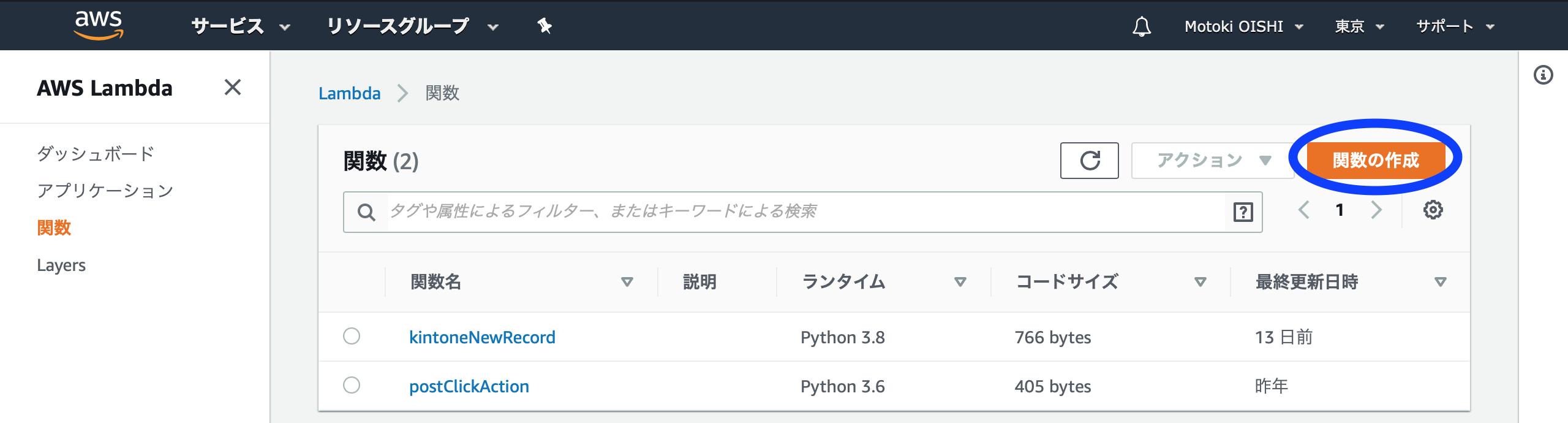
AWSと言っても沢山のサービスがある。AWSマネジメントコンソールの「サービスを検索する」の部分に「Lambda」と入力する
AWS Lambdaの画面に遷移するので、早速「関数の作成」を選択する
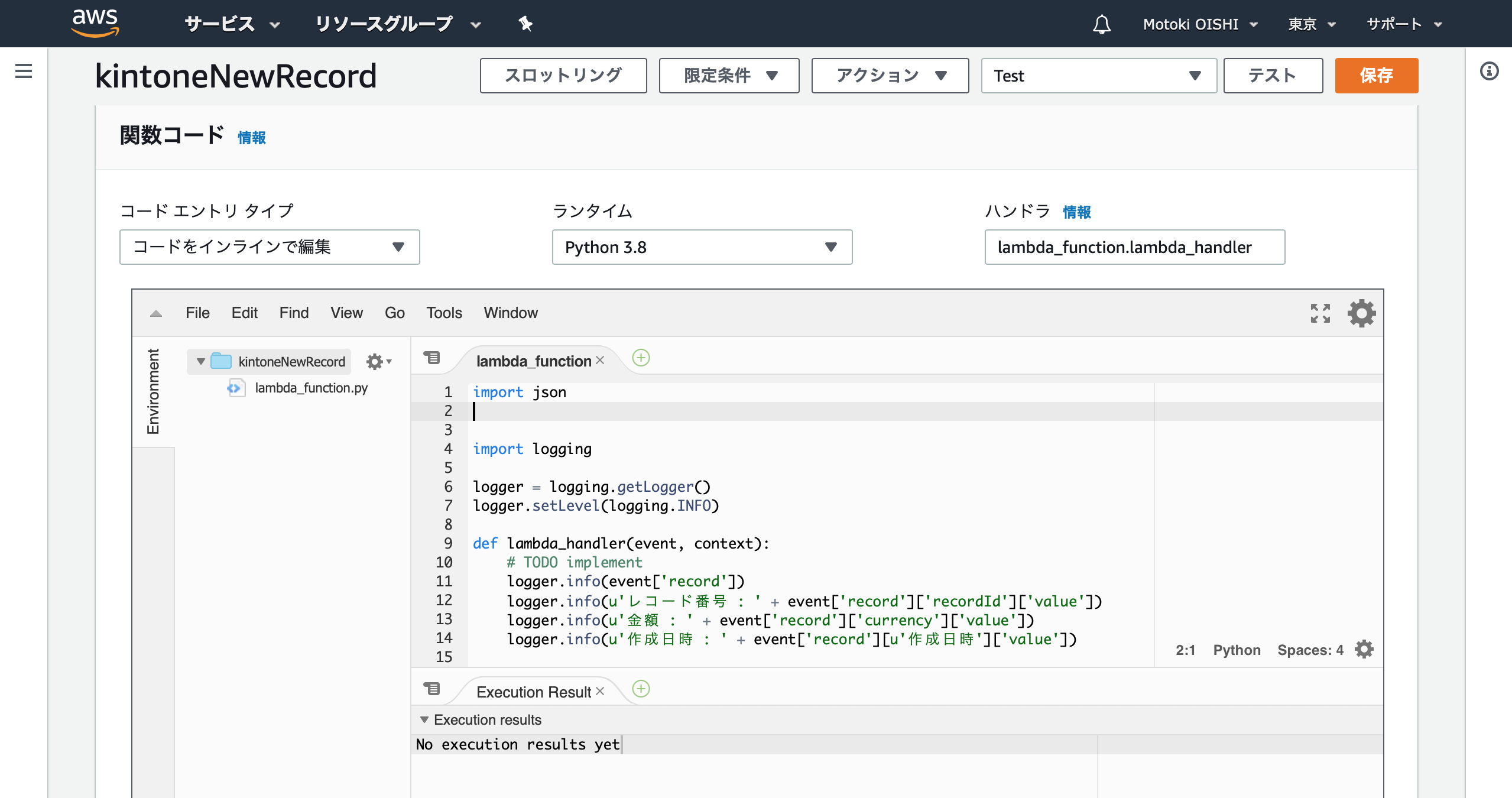
「一から作成」を選択し、ランタイムは「Python 3.8」を選択して作成する
「関数コード」の部分に以下のコードを入力する
プログラムはものすごく単純で、KintoneのWebhookで通知されてきたリクエストに格納されているデータを抽出し、IBM CloudにPOSTしている
lambda_function.pyimport json import logging logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): logger.info(event['record']) logger.info(u'レコード番号 : ' + event['record']['recordId']['value']) logger.info(u'金額 : ' + event['record']['currency']['value']) logger.info(u'作成日時 : ' + event['record'][u'作成日時']['value']) import urllib.request url = 'IBM CloudのNode-REDのポスト先:電子型押印に通知' params = { 'recordId': event['record']['recordId']['value'], 'LINE_ID': event['record']['LINE_ID']['value'], 'LINE_NAME': event['record']['LINE_NAME']['value'], 'LINE_PROFILE': event['record']['LINE_PROFILE']['value'], 'FileName': event['record']['FileName']['value'], 'currency': event['record']['currency']['value'], 'Reason': event['record']['Reason']['value'], 'date':event['record'][u'作成日時']['value'] } req = urllib.request.Request('{}?{}'.format(url, urllib.parse.urlencode(params))) with urllib.request.urlopen(req) as res: body = res.read()API Gatewayを設定する
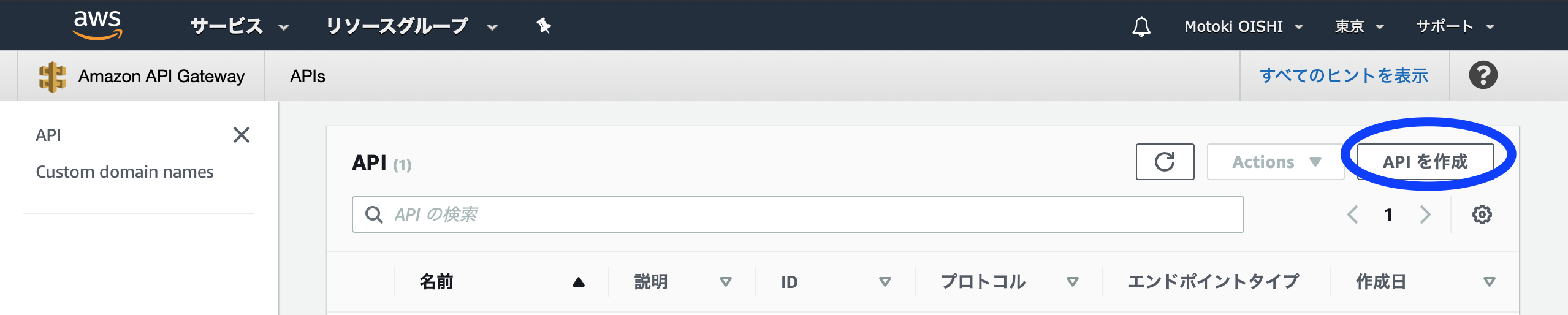
AWSマネジメントコンソールの「サービスを検索する」の部分に「API Gateway」と入力する
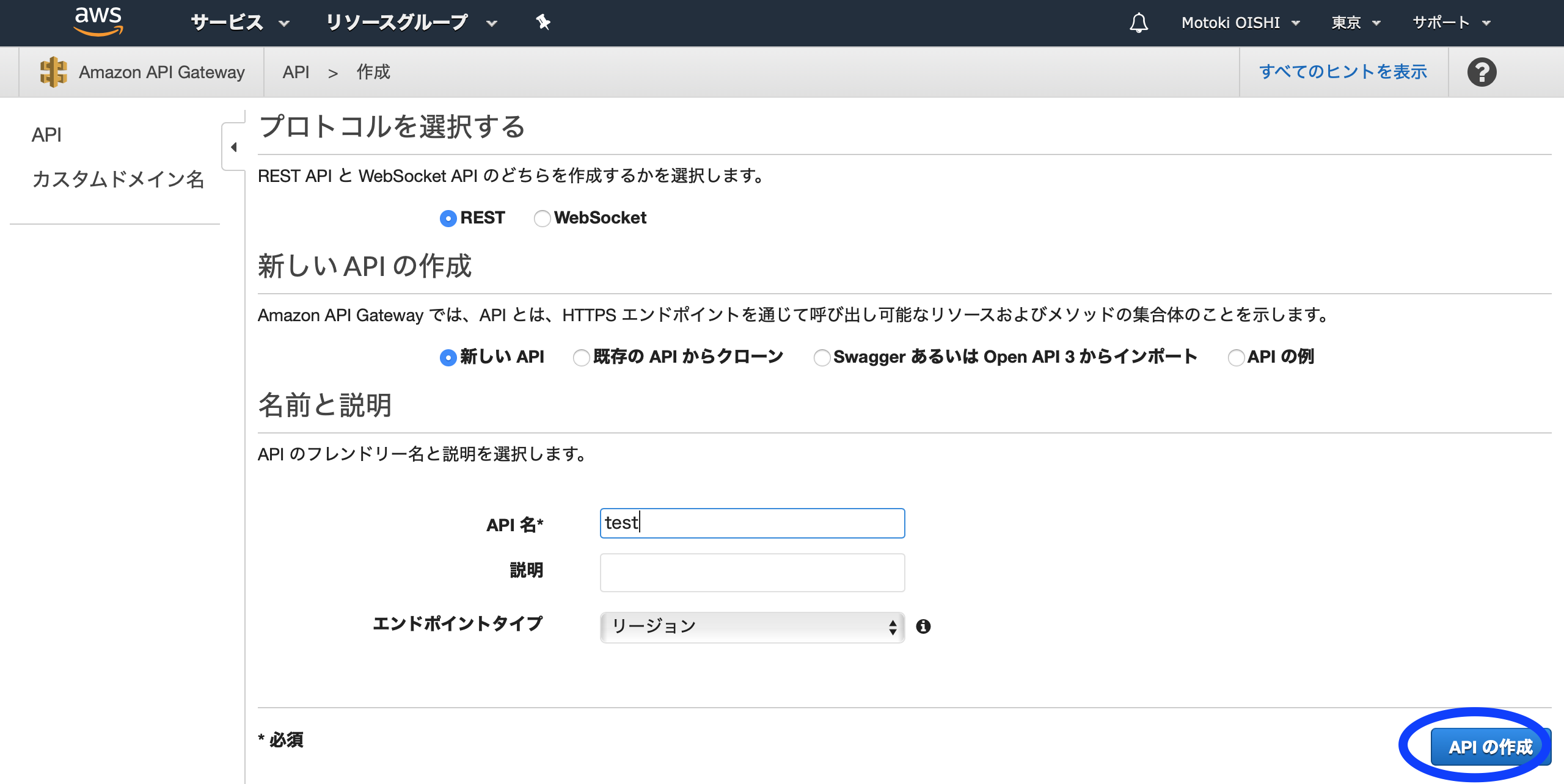
Amazon API Gatewayの画面が表示されたら、さっそく「APIを作成」をクリックする
REST APIの「構築」を選択します。
API名を入力して、「APIの作成」を選択しましょう
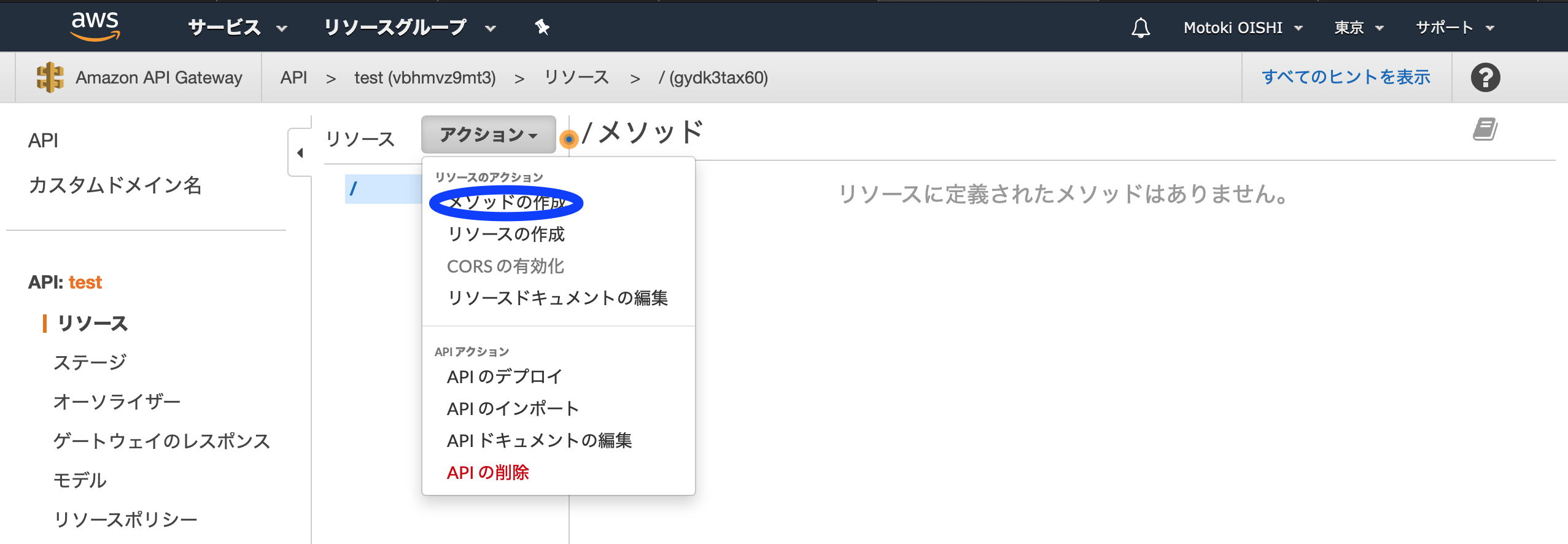
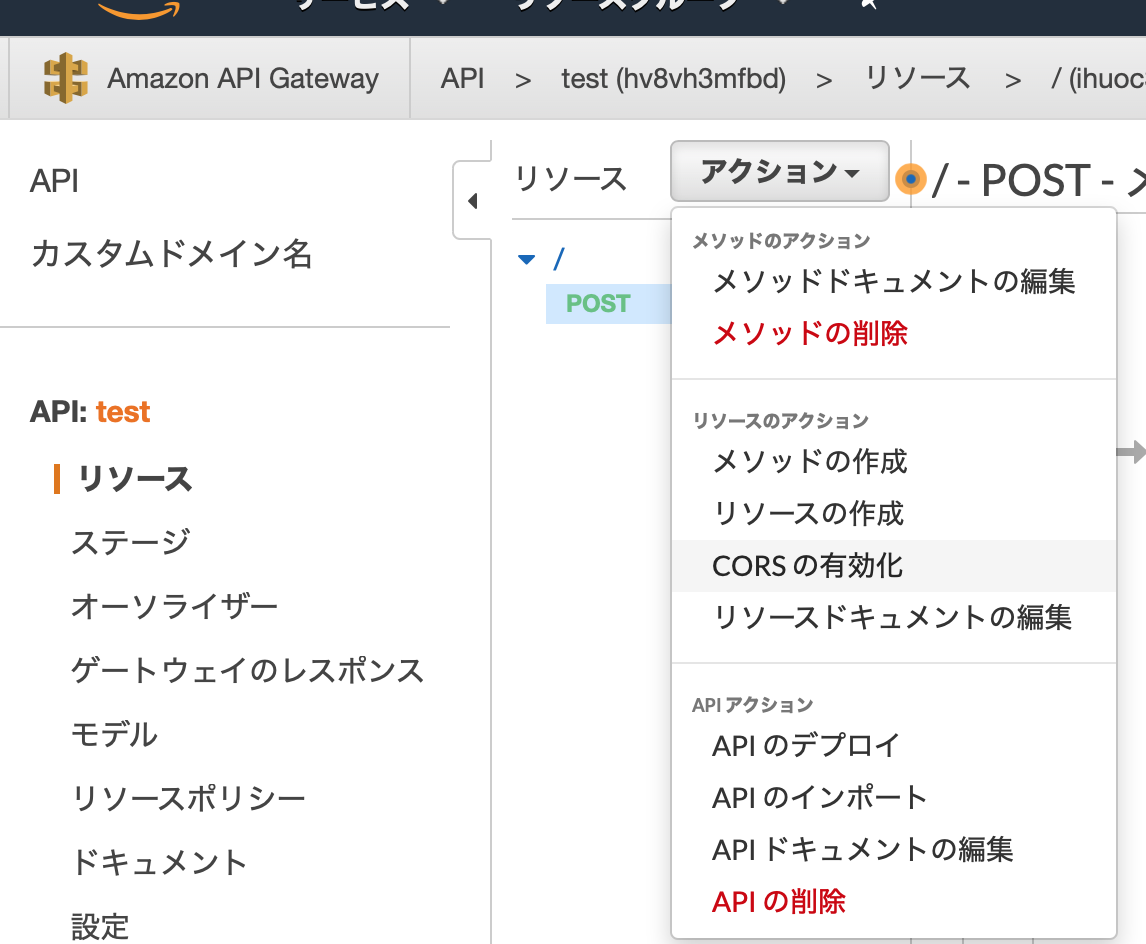
「アクション」というタブの中に、「メソッドの作成」があるので選択してください。
HTTPのコマンドが表示されるので「POST」を選択します。
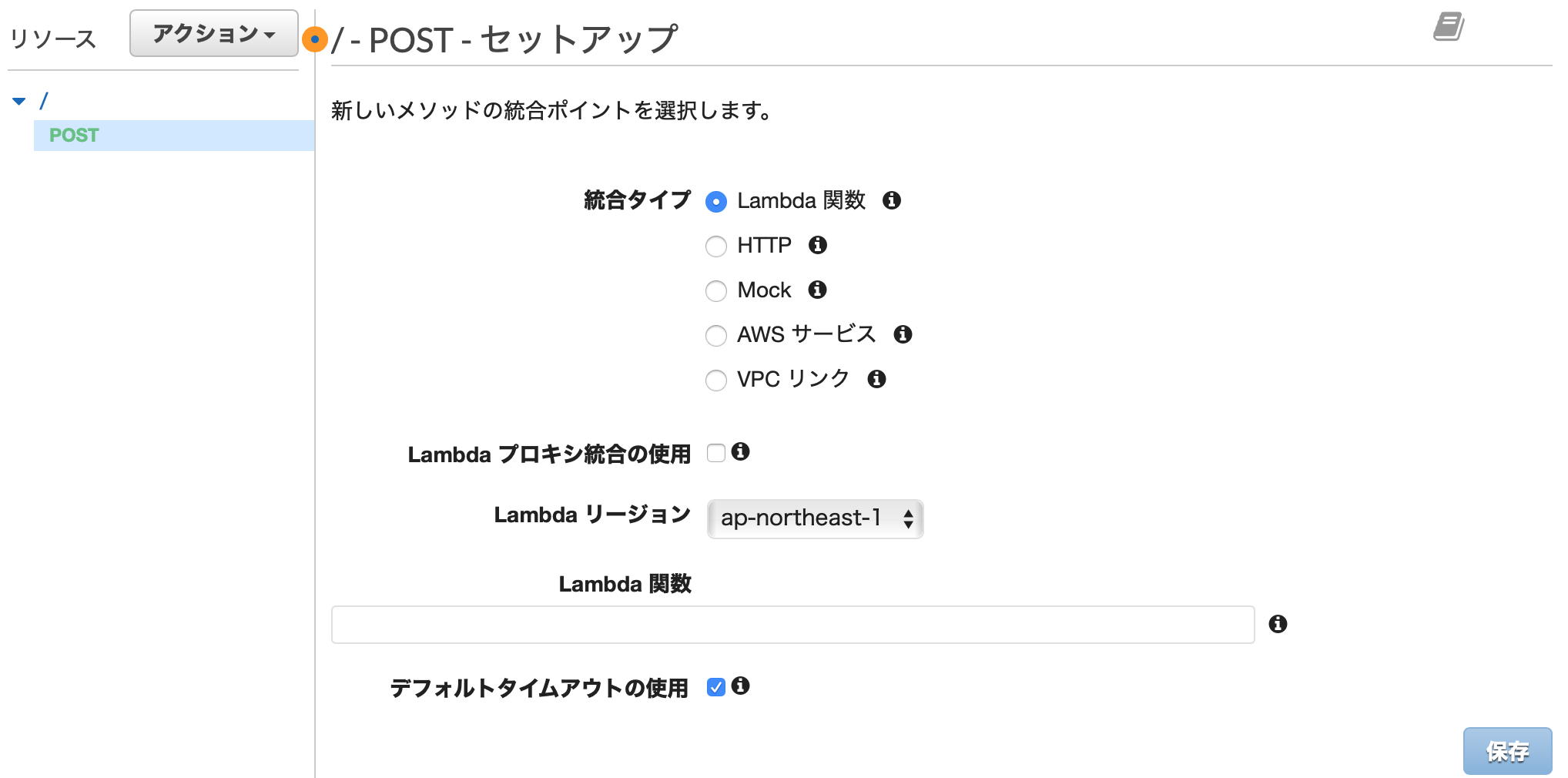
POSTのセットアップ画面が表示されるので、作成したLambda関数を入力しましょう
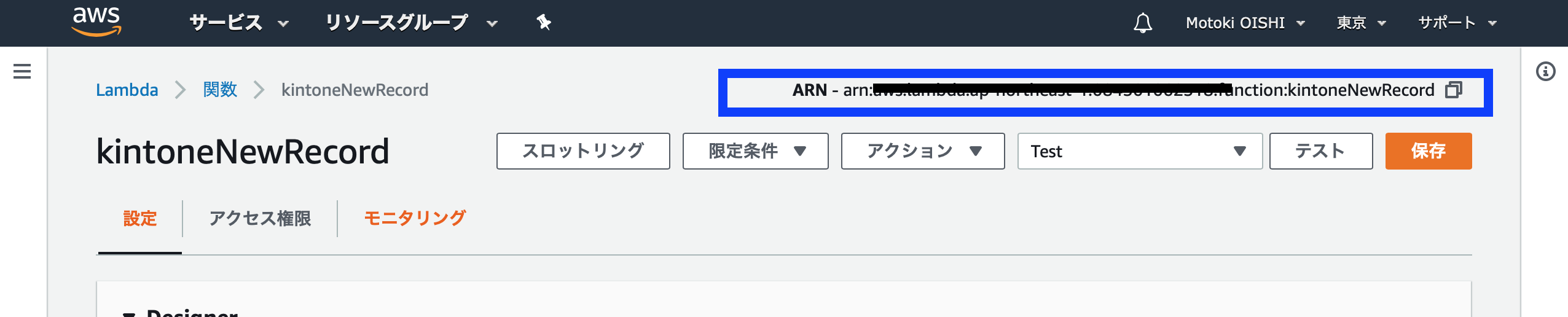
といっても、なんのこっちゃ、という話になるので、Lambda関数の部分には、Lambda関数を作成していた画面の右上に表示されている「ARN」の部分(以下の図)の文字の羅列をコピーして貼り付けると良いです。そして保存しておしまいです。
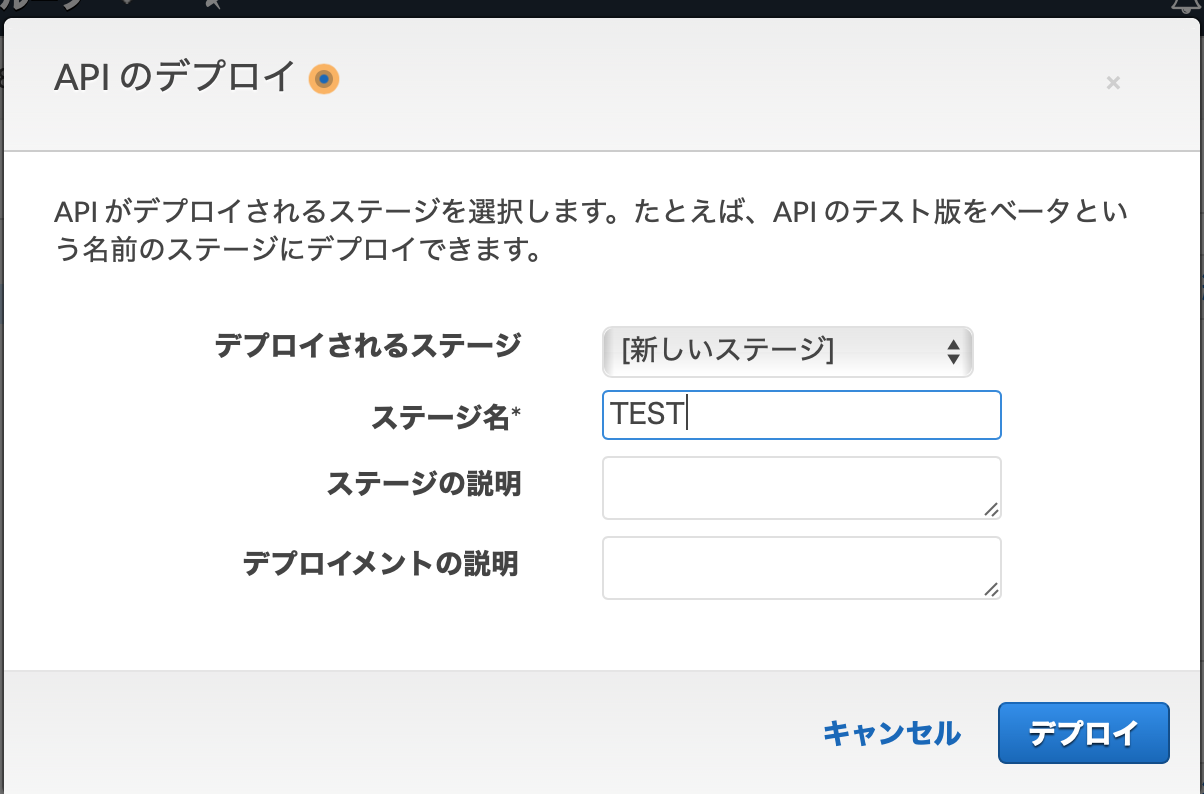
次に、「ステージ」を作成します。と、いいつつ、「APIのデプロイ」を行います。
APIのデプロイを選択すると、新しいステージが作れるので、新しいステージを選択して、ステージ名を入力後、「デプロイ」を選択する。
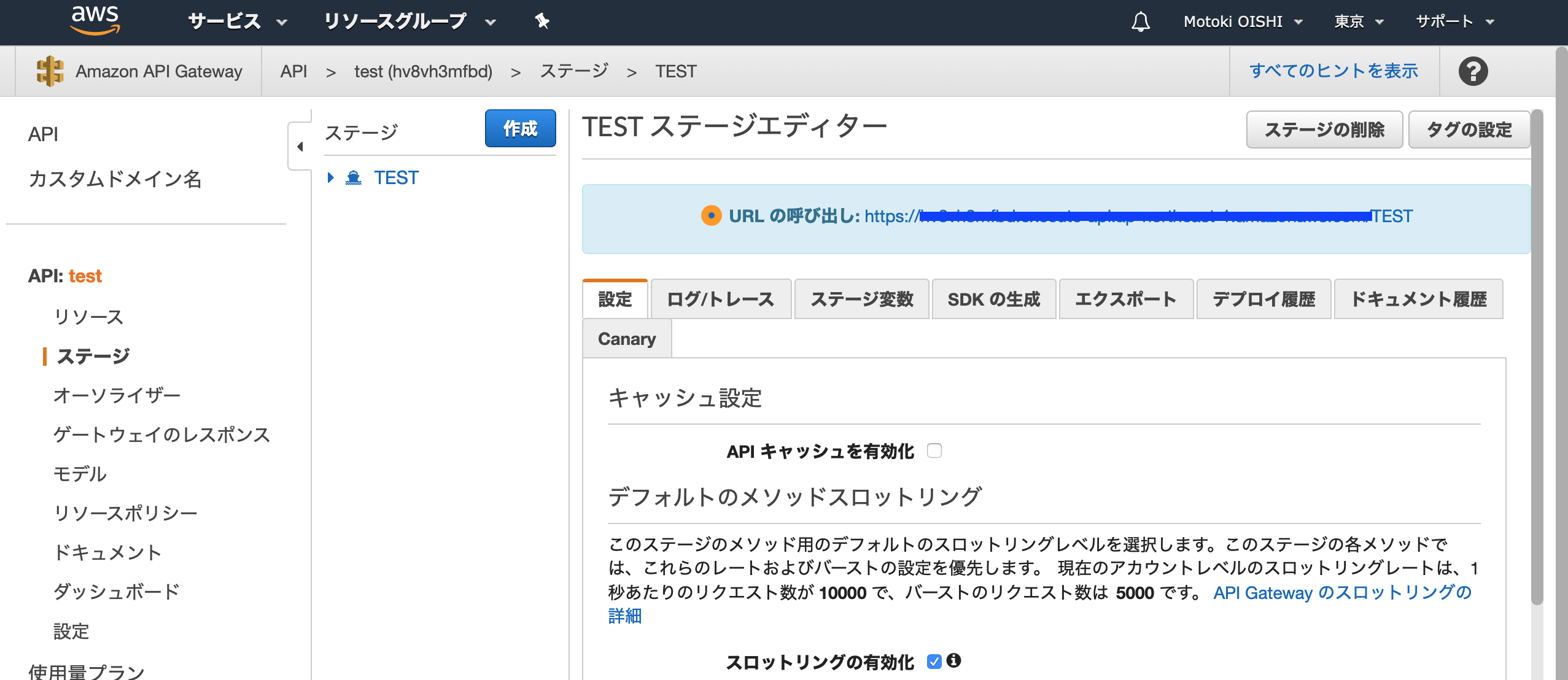
なんと、これで呼び出し可能なURLが発行されました。
本来は、APIキーの発行だ、とか、VPCリンクだ、とかセキュリティを担保する設定も必要だが、今回はプロトタイプということで設定を省略しています。
このURLをKintoneのWebhookの追加に出てきたURLに設定するだけで、Kintoneにレコードが追加されるたびに、AWSに送信される仕組みとなる
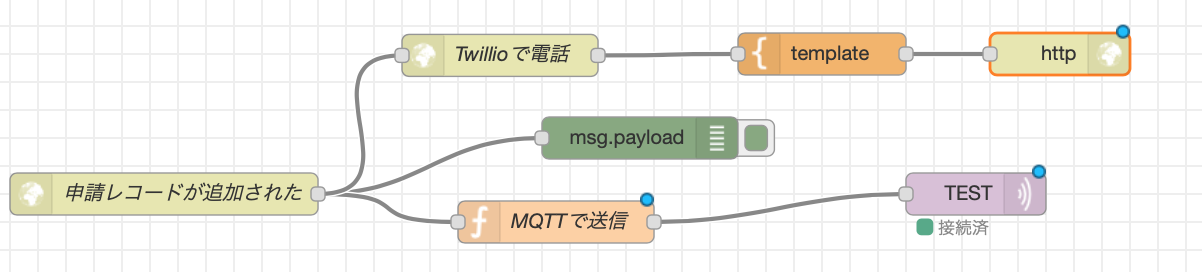
AWSからPOSTを受けるIBM Cloud Node-REDで受信後、MQTTのメッセージをパブリッシュする
ここは、HTTPのPOSTを受信し、MQTTでメッセージをパブリッシュするというシンプルな説明となる。
ここでは、「MQTTで送信」というファンクションが肝になる。
記載しているプログラムはシンプルで、AWSからPOSTされたデータ(KintoneレコードID、LINE名、金額)を、アンダーバーで連結して、新しいmsg2.payloadという変数に格納しなおしているだけとなる。MQTTで送信var msg2 = {}; msg2.topic='TEST' msg2.payload=msg.payload.recordId + "_" +msg.payload.LINE_NAME + "_" + msg.payload.currency; return msg2;以下にNode-REDでインポート可能なものを置いておきます。
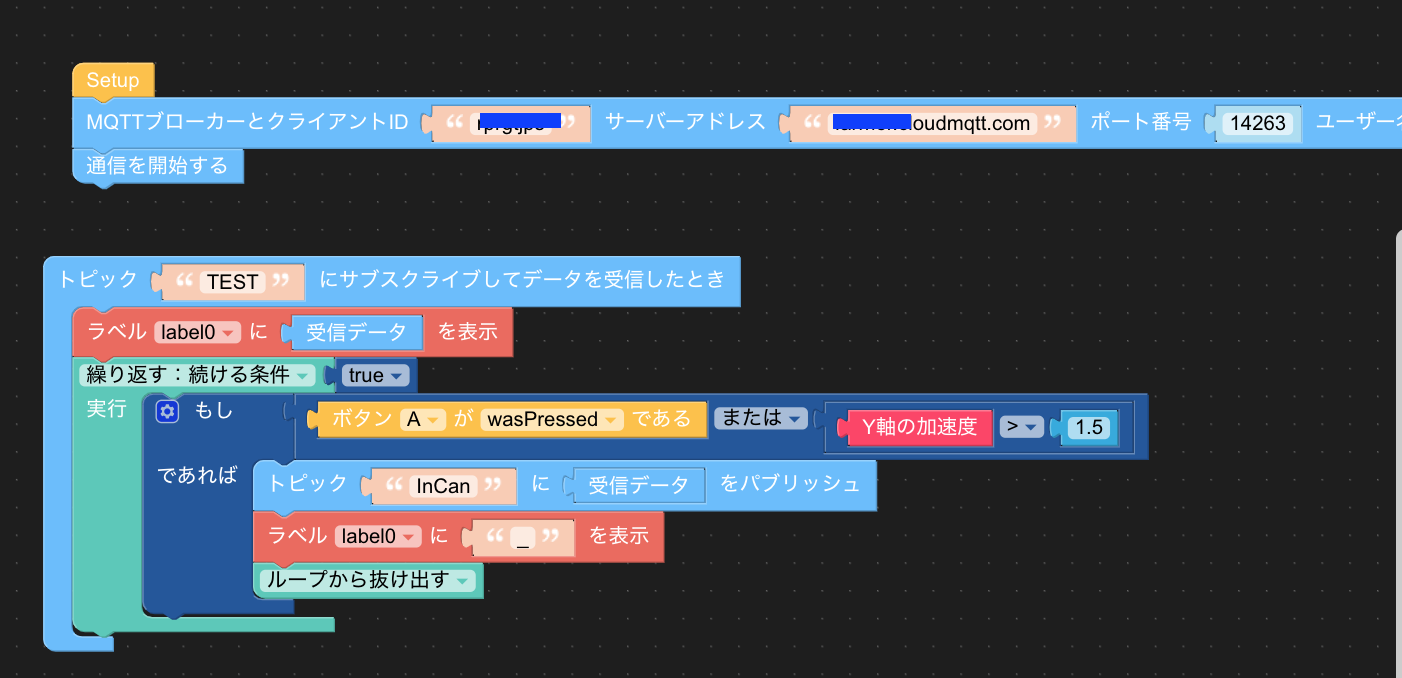
MQTTはCloudMQTTを使用しています(フリーの範囲で十分使える)関連するNode-RED[{"id":"f50b99c1.829b18","type":"http in","z":"38dd45d0.ae9242","name":"申請レコードが追加された","url":"/kintoneData","method":"get","upload":false,"swaggerDoc":"","x":130,"y":800,"wires":[["a7540857.d977d","4c688ee7.9e7a08","11a5ece2.3aa2fb"]]},{"id":"a7540857.d977d","type":"debug","z":"38dd45d0.ae9242","name":"","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","x":470,"y":760,"wires":[]},{"id":"15081bde.4256d4","type":"mqtt out","z":"38dd45d0.ae9242","name":"","topic":"TEST","qos":"2","retain":"false","broker":"33535a31.0e74ee","x":710,"y":800,"wires":[]},{"id":"4c688ee7.9e7a08","type":"function","z":"38dd45d0.ae9242","name":"MQTTで送信","func":"var msg2 = {};\nmsg2.topic='TEST'\nmsg2.payload=msg.payload.recordId + \"_\" +msg.payload.LINE_NAME + \"_\" + msg.payload.currency;\nreturn msg2;","outputs":1,"noerr":0,"x":410,"y":820,"wires":[["15081bde.4256d4"]]},{"id":"33535a31.0e74ee","type":"mqtt-broker","z":"","name":"","broker":"xxx.cloudmqtt.com","port":"14263","clientid":"","usetls":false,"compatmode":true,"keepalive":"15000","cleansession":true,"birthTopic":"","birthQos":"0","birthRetain":"false","birthPayload":"","closeTopic":"","closeQos":"0","closeRetain":"false","closePayload":"","willTopic":"","willQos":"0","willRetain":"false","willPayload":""}]電子型押印(M5StickC)の準備
電子型押印は、MQTTでメッセージを受ける仕組みしています。
受けたメッセージを、LCDに表示し、LCDにメッセージが表示された状態で、Y軸方向に1.5Gの重力を加えれば承認された、解釈してMQTTメッセージをパブリッシュします。ほとんど、ヒーローズリーグ直前で作ったので、スピード重視にUI Flowを使いました。
すごくシンプルで、MQTTブローカーと接続した後、TESTというトピックをサブスクライブした時に、
- 受信データをLCDに表示する
- Y軸の加速度1.5Gが来るまでループする
- Y軸の加速度1.5Gがきたら、トピック"InCan"にメッセージにTESTトピックで受信したデータをパブリッシュ
- Y軸の加速度1.5Gがきたら、LCDに_表示を設定
- ループを抜け出す(また、TESTトピックが来るまで待機)
という流れである。めっちゃシンプル!
電子型押印の承認モーションをNode-REDで受信する
M5StickCからパブリッシュされたInCanというメッセージを受信して処理を開始します。
やることは、2つで
- 承認した対象のレコードを更新する為、Kintone APIを起動する
- ObnizのWebhookを呼び出す
のみです。
Kintone更新var newPayload = msg.payload; //M5StickCに表示されているものは、_で連結されているので、分割 var result = newPayload.split('_'); var api_key = 'KintoneのAPI Keyを書く'; msg.headers = { 'X-Cybozu-API-Token': api_key, 'Content-Type': 'application/json', 'Authorization': 'Basic ' + api_key //"X-HTTP-Method-Override": "GET" }; //更新対象のレコードIDを設定し、承認レコードを更新する msg.payload = { app: 1, id: result[0], record: { 'Approval': { value: getBlockchainID() } } } return msg;ObnizのWebhookを設定する
Obnizも開発者ドキュメントが充実している為、かなり説明は省略します。
サーバレスイベントに、サーボを動かすプログラムを設定するのみとなります。
サーボでキレイに押印するのは、割と苦労したので、ここでは伏せておきます。
今回、ヒーローズリーグに向かう道中に輸送している最中にサーボが死ぬ(電源入れてもトルクが全くない状態)、会場で大手術をするというハプニングがありました。
まあ、本番前には無事に治ったんですが、
正直なところ今回は物理押印をキレイに押す、という難しさを克服する為、
- 木を加工してサーボとObnizを取り付ける
- 取り付けた場所の距離を考えて、スポンジ、印鑑台を設定
- スポンジとサーボを動かす角度を調整する
というのが、一番作るのが苦労した部分だった・・・
手が痛くなるくらい、木を削り、角度を測り、何度も何度もテストしてレッドハッカソンよりも進化させたという・・・・






- 投稿日:2019-12-14T22:51:01+09:00
AWSの講義を受けて書いたメモ
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得を受けた。出てくる語句をメモ。
どんな講義?
講義の流れはこんな感じ。
セクション AWS インフラ 内容 1 概要 概要 AWSでネットワーク・サーバを構築しよう 2 サインアップ、CloudWatch、IAM、CloudTrail - AWSを始めよう 3 VPC IPアドレス、ルーティング ネットワークの構築しよう 4 EC2 SSH、公開鍵認証、ポート番号、ファイアウォール Webサーバーを構築しよう 5 Route53 ドメイン、DNS ドメインを登録しよう 6 RDS - DBサーバーを構築しよう 7 EC2 HTTP、TCP、UDP、IP WordPressを構築しよう 8 S3、CloudFront 画像配信、キャッシュ 画像を配信しよう 9 ELB Webレイヤ冗長化 Webレイヤを冗長化しよう 10 RDS DBレイヤ冗長化 DBレイヤを冗長化しよう 11 CloudWatch 監視 システムを監視しよう 12 IAM 権限管理 アクセス権限を管理しよう セクション1-7の基礎編(構築編)と8-12の発展編(運用編)に分かれている。AWSの各サービスおよびそれに付随するインフラについて、実際に手を動かしながら学ぶのが特徴。
- はじめてAWSを学ぶ人
- インフラにあまり詳しくない人
- AWSを使用してネットワーク・サーバを構築したいアプリケーションエンジニア
を対象とした講義。
講義を受けることで、下図のようなシステムを構築することができるようになる。
VPCの中にパブリックサブネットとプライベートサブネットがある。
パブリックサブネットはインターネットゲートウェイと繋がっていて、インターネットにアクセス出来る。一方、プライベートサブネットはインターネットゲートウェイと繋がっていないので、インターネットからは接続できない。
パブリックサブネットの中に、EC2のWebサーバーがあって、ApacheとWordPressがインストールされている。
プライベートサブネットの中には、RDSのDBサーバーがあって、MySQLがインストールされていて、WordPressからMySQLに接続できるようになっている。VPCの外にはRoute53があり、ドメイン名で問い合わせがあった時に、名前解決できるようになっている。以上が講義の簡単な説明。
以下が出てくる語句のまとめ。
AWS
Amazon Web Services
Amazon社が提供する クラウドサービス
- サービスが豊富
- クラウドサービスとして 世界最大規模
- EC2やRDS等、100以上のサービスが存在
- 高負荷に耐えられる、信頼性の高いシステムを少ない手間で運用できる
- リソースが柔軟
- リソースを、必要なときに必要な分だけ調達できる
- 従量課金
- 使った分だけ支払う
- 不必要なときは使う必要がなく、費用対効果に優れている
インフラ
Infrastracture: 基盤
システムやサービスの基盤となる設備 = サーバーやネットワークのこと。サーバー
クライアントに対してサービスを提供するコンピューター
ネットワーク
複数のコンピューターをつないで、データを送受信できるようにするもの。
クラウド
クラウドコンピューティング
ネットワークを利用してコンピュータリソースを利用する形態
- オンプレミス(インフラを時前で用意し、自社で所有・管理すること)と比べ、初期コストが少ない
- すぐに始められる
- サーバーの増減が自由
- 費用の予測が付きづらい
- クラウド全体で障害が起こると対応できない
【VPC】ネットワークの構築しよう
リージョン
AWSの各サービスが提供されている地域
東京リージョンなどアベイラビリティゾーン
独立したデータセンター
ap-northeast-1aなどVPC(Virtual Private Cloud)
AWS上に仮想ネットワークを作成できるサービス
この講義では、VPCのIPアドレスを
10.0.0.0/16に設定する。サブネット
VPCを細かく区切ったネットワーク
パブリックサブネット
講義では、パブリックサブネットのIPアドレスを
10.0.10.0/24に設定する。プライベートサブネット
講義では、IPアドレスを
10.0.20.0/24に設定する。IPアドレス
インターネット上の住所
ネットワーク上で重複しない番号
- 32ビットの整数値で構成
- 32ビットのIPアドレスを8ビットずつ4つの組に分け、
.を入れて10進数で表現- 0.0.0.0 - 255.255.255.255
- パブリックIPアドレスとプライベートIPアドレスがある
- ネットワーク部とホスト部に区分けする
パブリックIPアドレス
インターネットに接続する際に使用するIPアドレス
- ICANN(Internet Corporation for Assigned Names and Numbers)が、重複しないように管理
- プロバイダーやサーバー事業者から貸し出される
プライベートIPアドレス
インターネットで使用されないIPアドレス
- 社内LANの構築やネットワークの実験時はプライベートIPアドレスを使用する
- 下記範囲内のアドレスで自由に使用できる
プライベートIPアドレスの範囲 10.0.0.0 - 10.255.255.255 172.16.0.0 - 172.31.255.255 192.168.0.0 - 192.168.255.255 ネットワーク部
IPアドレスが属しているネットワークを識別するための部分
ホスト部
ネットワーク内のコンピュータを識別するための部分
CIDR(サイダー)表記 (Classless Inter-Domain Routing)
IPアドレスのネットワーク部とホスト部の境目を
/の後に続くビット数で指定する方法例えば、
192.168.128.0-192.168.128.255の256個のIPアドレスは、192.168.128.0/24と表される。この場合、IPアドレスの先頭から24ビットがネットワーク部、残りの8ビットがホスト部。サブネットマスク表記
IPアドレスとサブネットマスクを
/で区切って並べた表記例えば、
192.168.128.0-192.168.128.255の256個のIPアドレスは、192.168.128.0/255.255.255.0と表される。2進数
各桁を0か1で表す。コンピュータは2進数で計算を行う。
ビット
2進数の1桁(0か1)。コンピュータデータの最小単位。
バイト
1バイト = 8ビット
10進数
0-9の10種類で数値を表す。
【EC2】Webサーバーを構築しよう
EC2(Elastic Compute Cloud)
AWSクラウド上の仮想サーバー
- 数分で起動し、1時間または秒単位従量課金
- サーバー(EC2インスタンス)の追加・削除、マシンスペック変更も数分で可能
- OSより上のレイヤは自由に設定できる
AMI(Amazon Machine Image)
インスタンス起動に必要な情報が入った、OSのイメージ
サーバーのテンプレートのようなもの
- AWSやサードパーティが提供
- 自前のカスタムAMIも作成可能
- カスタムAMIから何台でもEC2インスタンスを起動可能
インスタンスタイプ
サーバーのスペックを定義したもの
- インスタンスタイプにより、CPU、メモリ、ストレージ、ネットワーク帯域が異なる
- インスタンスタイプにより、料金が異なる。
- アクセス数等に応じて必要なスペックのあるインスタンスタイプを選択する
- 例えば、
m5.xlargeの場合、mは、インスタンスファミリー 、5は、インスタンス世代、xlargeは、インスタンスサイズと言う。ストレージ
サーバーにつける、データの保存場所
EBS(Elastic Block Store)
高い可用性と耐久性を持つストレージ
- 他のインスタンスに付け替え可能
- EC2インスタンスをStop/TerminateしてもEBSは保持可能
- Snapshotを取得してS3に保存可能
- 費用が別途発生
- OS、DB等、永続性、耐久性が必要なデータを置く
インスタンスストア
インスタンス専用の一時的なストレージ
- 他のインスタンスに付け替えることができない
- EC2インスタンスをStop/Terminateするとクリアされる
- 無料
- 無くなってはいけないデータは置かない
- 一時ファイル、キャッシュ等、失われても問題ないデータを置く
SSH
サーバーとパソコンをセキュアにつなぐサービス
通信内容が暗号化された遠隔ログインシステム
- SSHクライアント
- SSHサーバー
- EC2ではSSHログインじに公開鍵認証を行なっている
公開鍵認証
サーバーへのログイン時に認証を行う仕組み
- ユーザー名とパスワードをしようした認証と比べ、よりセキュリティが高い
- 公開鍵暗号(秘密鍵と公開鍵)を用いて認証を行う
- 公開鍵はサーバーが保有
- 秘密鍵を持っているユーザーのみログイン可能
ポート番号
プログラムのアドレス
- 同一コンピュータ内で通信を行うプログラムを識別するときに利用される
ポート番号を決める方法
ウェルノウンポート番号
- 代表的なプログラムが使うポート番号は予め決められている
- 0 - 1023までの整数値
- ex) SSH: 22番, SMTP: 25番, HTTP: 80番, HTTPS: 443番
- クライアントが接続先のポート番号を省略した場合はウェルノウンポート番号が使用される
動的に決まる番号
- サーバーはポート番号が決まっている必要があるが、クライアントのポート番号は決まっていなくてもよい
- クライアントのポート番号は、OSが他のポート番号と被らないよう、ランダムに決める
- 49142 - 65535の整数値
ファイアウォール
ネットワークを不正アクセスから守るために、通してよい通信のみ通し、それ以外は通さない機能の総称
- AWSではセキュリティグループが担う
Elastic IPアドレス
インターネット経由でアクセス可能な固定グローバルIPアドレスを取得でき、インスタンスに付与できるサービス
- インスタンスを削除するまで同じIPアドレスを使用することができる
- EC2インスタンスに関連づけられており、インスタンスが起動中であれば無料。起動していないと課金される
【Route53】ドメインを登録しよう
ドメイン
覚えにくいIPアドレスの代わりに、Webサイトにアクセスできる、任意でつけられる文字列の名前
- ピリオドで区切られた構造
- 例えば、
www.example.co.jpの場合、
- トップレベルドメイン:
jp- 第2レベルドメイン:
co- 第3レベルドメイン:
example- 第4レベルドメイン:
www- ICANNがドメイン全体を管理
- レジストリがトップレベルドメインを管理、レジストラに卸す
- レジストラがリセらに卸す、一般消費者に販売
- リセラが一般消費者に販売
DNS(Domain Name System)
ドメイン名をIPアドレスに変換する、ドメイン名管理システム
ネームサーバー と フルリゾルバ の2つから構成
ネームサーバー
ドメイン名とそれに紐づくIPアドレスが登録されているサーバー
ドメインの階層ごとに配置され、配置された階層のドメインに関する情報を管理
フルリゾルバ
どのドメインに紐づくIPアドレスを問い合わせると、様々なネームサーバーに聞いてIPアドレスを調べて教えてくれるサーバー
リソースレコード
DNSの、ドメイン名とIPアドレスの一つひとつの紐付けのこと
リソースレコードのタイプ 内容 Aレコード ドメインに基づくIPアドレス NSレコード ドメインのゾーンを管理するネームサーバー MXレコード ドメインに紐付くメール受信サーバー CNAME ドメインの別名でリソースレコードの参照先 SOA ドメインのゾーンの管理情報 Route53
AWSのDNSサービス
ネームサーバーの役割
- 高可用性
- SLA(Service Level Agreement) 100%
- 高速
- フルマネージドシステム
ホストゾーン
DNSのリソースレコードの集合
レコードセット
リソースレコード
ルーティングポリシー
Route53がレコードセットに対してどのようにルーティングを行うかを決める
シンプルルーティング
- レコードセットで事前に設定された値に基づいて、ドメインへの問い合わせに応答
加重ルーティング
- 複数エンドポイント毎に設定された重みづけに基づいて、ドメインへの問い合わせに応答する
- 提供リソースに差がある場合に使用
- ABテスト時に使用
レイテンシールーティング
- リージョン間の遅延が少ない方のリソースへルーティングする
- マルチリージョンにリソースが存在する場合に使用
位置情報ルーティング
- クライアントの位置情報に基づいて、ドメインへの問い合わせに応答する
- コンテンツのローカライズに使用
- 地域限定配信時に使用
フェイルオーバールーティング
- ヘルスチェックの結果に基づいて、利用可能なリソースへルーティングする
- 障害発生時にSorryサーバーに簡単に切り替えられる
ヘルスチェック
サーバーの稼働状況をチェック
【RDS】DBサーバーを構築しよう
RDS
フルマネージドなリレーショナルデータベースのサービス
構築の手間の軽減
- 物理サーバー設置
- OSインストール
運用の手間の軽減
- アップデート
- バックアップ
- スケーリング
AWSエンジニアによるデータベース設計のベストプラクティスを適用
これらにより、コア機能の開発(アプリ最適化)に注力できる。
- 設定できる項目には制限がある
- 利用可能なエンジン
- MySQL
- PostgreSQL
- Oracle
- Microsoft SQL Server
- Amazon Aurora
- MariaDB
- 各種設定グループ
- DBパラメータグループ: DB設定値を制御
- DBオプショングループ: RDSへの機能追加を制御
- DBサブネットグループ: RDSを起動させるサブネットを制御
- 可用性の向上
- マルチAZ(マスタースレーブ方式: DBの冗長化)を簡単に構築
- パフォーマンスの向上
- リードレプリカを簡単に構築
- 運用負荷の軽減
- 自動的なバックアップ
- スナップショットと呼ばれるバックアップを1日1回自動取得
- スナップショットを基にDBインスタンスを作成(リストア)
- 自動的なソフトウェアメンテナンス
- メンテナンスウィンドウで指定した曜日・時間帯にアップデートを自動実施
- 監視
- 各種メトリクスを60秒間隔で取得・確認可能
【EC2】WordPressを構築しよう
プロトコル
コンピュータ同士がネットワークを利用して通信するために決められた約束事
- プロトコルの例
- HTTP
- TCP
- UDP
- IP
- SMTP
- IPX など
- メーカーやOSが違うコンピュータ同士が通信するためには、同じ仕様でやりとりする必要がある
- 同じプロトコルを使用するという同意があるため、様々なコンピュータ同士が通信できる
TCP/IP
TCP・IPを中心として、インターネットを構築する上で必要なプロトコル群の総称。インターネットを運用するために開発された。
TCP/IPプロトコル群
アプリケーションプロトコル トランスポートプロトコル HTTP、SMTP、FTP TCP、UDP
経路制御プロトコル インターネットプロトコル RIP、OSPF、BGP IP、ICMP、ARP TCP/IPの階層モデル
インターネットでコンピュータ同士が通信する一連の処理を4階層で表現したもの
役割 プロトコル例 アプリケーション層 アプリケーション同士が会話 HTTP、DNS、SSH、SMTP トランスポート層 データの転送を制御 TCP、UDP ネットワーク層 IPアドレスを管理、経路選択 IP、ICMP、ARP ネットワークインターフェース層 直接接続された機器同士で通信 Ethernet、PPP HTTP(Hyper Text Protocol)
HTML等のコンテンツの送受信に用いられる通信の約束事
- クライアントがHTTPリクエストを送り、サーバーがHTTPレスポンスを返す
- リクエストライン、ヘッダー、ボディから構成される
HTTPリクエスト
リクエストライン
GET /HTTP/1.1ヘッダー
Host: example.com User-Agent: Mozila/5.0 Accept-Encoding: gzip, deflate Connection: keep-aliveボディ
オプションでつけられる
HTTPレスポンス
ステータスライン
HTTP/1.1 200 OKのようなものヘッダー
Data: Fri, 28 Jun 2019 01:09:23 GMT Content-Type: text/html; charset=utf-8 Cache-Control: max-age=604800 Last-Modified: Fri, 09 Aug 2013 23:54:35 GMTボディ
<!doctype> <html> ... </html>TCP(Trnsmission Control Protocol)
通信を制御するプロトコル。データの到着確認や、コネクション管理を行う
- 信頼性のある通信を提供
- 信頼性を保つために、送信するパケットの順序制御や再送制御を行う
- 信頼性のある通信を実現する必要がある場合に使用
データの到達確認
- 送信したデータが届いたかを確認する
- 届いていなければ再送する
- 確認応答とシーケンス番号を使用することで、再送制御などを行う
コネクション管理
- 通信相手との間で通信を始める準備をしてから通信を行う
- コネクション指向の通信を提供する
ヘッダーのフォーマット
- 送信元ポート番号
- 宛先ポート番号
- シーケンス番号
- チェックサム
- データオフセット
- 予約
- コントロールフラグ
- ウィンドウサイズ
- 確認応答番号
- 緊急ポインタ
- オプション
- パディング
UDP(User Datagram Protocol)
コネクションレスな通信サービス
- 信頼性のない通信
- 送信するだけで、パケットが届いたかは保証しない
- 高速性やリアルタイム性を重視する通信で使用
- アプリケーションからの送信要求のあったデータをそのままネットワークに流す
- パケットが届かなくても再送制御はせず、パケットの到着順序が入れ替わっても直せない
- コネクションレスなのでいつでもデータを送信できる
- プロトコルの処理も簡単なので高速
- 動画、電話等、即時性が必要な通信
- 総パケット数が少ない通信(DNS等)
- 特定ネットワークに限定したアプリケーションの通信
ヘッダーのフォーマット
- 送信元ポート番号
- 宛先ポート番号
- パケット長
- チェックサム
IP(Internet Protocol)
IPアドレス
- ネットワーク上で、通信を行う宛先を識別するのに使われる
- IPアドレスを基にしてパケットが配送される
ルーティング
- 宛先IPアドレスのコンピュータまでパケットを届ける
- それぞれの区間ごとにルーターがIPパケットを転送し、それを繰り返して最終的な宛先コンピュータまでパケットが辿り着く
パケットの分割・再構築処理
- ネットワークインターフェース層のプロトコルによって、最大転送単位が異なる。
- IPでは、各ネットワークインターフェースの最大転送単位より小さくなるようにパケットを分割して送信し、終点コンピュータで再構築する
IPv4のヘッダーのフォーマット
- 送信元IPアドレス
- 宛先IPアドレス
- バージョン
- ヘッダ長
- サービスタイプ
- パケット長
- 識別子
- フラグ
- フラグメントオフセット
- 生存時間
- プロトコル
- ヘッダチェックサム
- オプション
- パディング
【S3/CloudFront】画像を配信しよう
インフラ設計における重要な観点
観点 内容 具体的指標例 可用性 サービスを継続的に利用できるか 稼働率、目標復旧時間、災害対策 性能・拡張性 システムの性能が十分で、将来的においても拡張しやすいか 性能目標、拡張性 運用・保守性 運用と捕手がしやすいか 運用時間、バックアップ、運用監視、メンテナンス セキュリティ 情報が安全に守られているか 資産の公開範囲、ガイドライン、情報漏洩対策 移行性 現行のシステムを他のシステムに移行しやすくなっているか 移行方式の規定、設備・データ、移行スケジュール 画像の保存場所をWebサーバーではなくS3にする理由
- Webサーバーのストレージが画像で一杯になるのを防ぐ
- HTMLへのアクセスと画像へのアクセスを分けることで負荷分散する
- サーバーの台数を増やしやすくする
- Webサーバー上に画像が保存されていると、Webサーバーの台数を増やした時に、画像を同期する必要があり、スケールアウトが難しい
- 画像の保存場所は分離されていた方がWebサーバーの台数を簡単に増やすことができる
- コンテンツ配信サービスから配信することで、画像配信を高速化できる
S3(Simple Storage Service)
安価で耐久性の高いAWSのクラウドストレージサービス
- 0.023USD/GB・月と、安価。1GB約3円/月
- 99.99999999999%の高い耐久性
- 容量無制限。1ファイル最大5TBまで
- パケットやオブジェクトに対してアクセス制限を設定できる
利用シーン
- 静的コンテンツの配信
- 画像はS3から配信
- バッチ連携用のファイル置き場
- S3にファイルを置き、バッチでそのファイルをサンス用して処理を行う
- ログなどの出力先
- 定期的にS3にログを送る
- 静的ウェブホスティング
- 静的なウェブサイト(LPなど)をS3から公開
バケット
オブジェクトの保存場所
- 名前はグローバルでユニークな必要あり
オブジェクト
データ本体
- S3に格納されるファイルで、URLが付与される
- パケット内オブジェクト数は無制限
キー
オブジェクトの格納URLパス
CloudFront
高速にコンテンツを配信するCDN(Content Delivery Network)のサービス
- オリジンサーバー上にあるコンテンツを、世界中100箇所以上にあるエッジロケーションにコピーし、そこから配信を行う
- 高速
- ユーザーから最も近いエッジサーバーから画像を配信する
- 効率的
- エッジサーバーでコンテンツのキャッシングを行うので、オリジンサーバーに負荷をかけずに配信できる
【ELB】Webレイヤを冗長化しよう
稼働率を高くするための考え方
- 障害発生間隔を長くする
- 平均復旧期間を短くする
冗長化
システムの構成要素を多重化すること
ある構成要素で障害が発生しても処理を引き継げるようにすることで稼働率を高める。
↓
単一障害点(SPOF: Single Point Of Failure)をなくす。
- 要素単体の稼働率を高くする
要素を組み合わせて、全体の稼働率を高くする
冗長化構成 | - Active-Active 冗長化した両方が利用可能 | - Active-Standby 冗長化した片方は利用不可能 | - Hot Standby スタンバイ側は普段起動し、すぐに利用可能 | - Warm Standby スタンバイ側は普段起動しているが、利用するのに準備が必要 | - Cold Standby スタンバイ側は普段停止している負荷を適切なプロビジョニングで回避する
プロビジョニング
アクセス数を予測し適切にリソースを準備すること
- スケールアップ
- 個々の要素の性能を向上させる
- ある程度の規模まではコストパフォーマンスが良いが、一定を超えると悪くなる
- スケールアウト
- ここの要素の数を増やす
- ある程度の規模を超えそうであれば、スケールアウトで対応
- 最低限N+1構成で、N+2構成がベター
サーバー構成のベストプラクティス
- パターン1
- Webサーバー 1 + DBサーバー1
- パターン2
- Webサーバー 2 + DBサーバー1
- パターン3
- Webサーバー 2 + DBサーバー2
ロードバランサー
各サーバーにアクセスを振り分け、負荷を分散する装置
ELB(Elastic Load Balancing)
AWS上のロードバランサー
- 複数のEC2インスタンスに負荷分散する
- 複数のアベイラビリティゾーンにある複数のEC2インスタンスの中から正常なターゲットにのみ振り分ける(ヘルスチェック)
- スケーラブル
- アベイラビリティゾーンをまたがる構成
- 名前解決
- 安価な従量課金
- マネージドサービス
【RDS】DBレイヤを冗長化しよう
RDSでは、マルチAZの機能を使えばマスタースレーブ構成を構築できる。
【CloudWatch】システムを監視しよう
システム監視
システムを正常な状態に保てるよう、稼働状況やリソースを監視すること
【IAM】アクセス権限を管理しよう
IAM
AWSのサービスを利用するユーザー権限を管理するサービス
- AWSリソースをセキュアに操作するために、認証・認可の仕組みを提供する
- 各AWSリソースに対して別々のアクセス権限をユーザーごとに付与できる
- AWS IAM自体の利用は無料
ポリシー
アクセス許可の定義
どのAWSサービスの、どのリソースに対して、どんな操作を、許可する(しない)を定義ユーザー
ここのアカウントのユーザー
グループ
IAMユーザーの集合。複数のユーザーにアクセス許可を付与する作業を簡素化
ロール
一時的にアクセスを許可したアカウントを発行できる。EC2やLambadaなどのAWSリソースに権限を付与するために使用
IAMのベストプラクティス
- 個々人にIAMユーザーを作成する
- rootユーザーは使わない
- 誰が何の操作をしたか記録される
- ユーザーをグループに所属させ、グループに権限を割り当てる
- 権限は最小限にする
- EC2インスタンスから実行するアプリケーションには、ロールを使用する
- 定期的に不要な認証情報を削除する
おわりに
以上、備忘録としての語句のメモ。
参考


- 投稿日:2019-12-14T22:38:48+09:00
AWS SDK for Python(Boto3)ではClient APIよりResource APIを使おう
はじめに
この記事はAWS初心者 Advent Calendar 2019
の14日目の記事です。
もし誤りがあれば指摘してもらえると幸いです。要約
Boto3の中ではサービスによってリソースAPI(boto3.reosurce('サービス名')で呼び出すもの)があります。リソースAPIの方がクライアントAPIより抽象化されていて不要な情報を書かずに実装できるので、それぞれのAPIで同じことができる場合はリソースAPIを優先して使用した方が良いです。
記事全体の構成
まずBoto3、クライアントAPI、リソースAPIとは何だったのかを再確認します。
その後に両方のAPIを使用した場合にSQS、S3、DynamoDBの使用パターンを1ケースずつとりあげて比較してどう違うのかを具体的に見てみます。
最後に現在リソースAPIが提供されているサービスの一覧と所感を書いてます。Boto3とは
Pythonに提供されているAWSのSDKで、コードからAWSの各種サービス(EC2やDynamoDB、S3など)に接続する場合に使用します。
APIのリファレンスは以下の資料に書かれています。
Boto 3 DocumentationAPIには主に低レベルなAPIであるクライアントAPIと高レベルなAPIであるリソースAPIがあります。具体的には以下のような記述で呼び出されます。
# Client API boto3.client('sqs') # Resource API boto3.resource('sqs')次にそれぞれのAPIにどんな特性があるか確認します。
クライアントAPI(低レベルAPI)
AWSのサービスで提供しているHTTP APIと1対1に対応するメソッドです。HTTP API
と完全にマッピングしているので、APIで可能な操作はすべてできるようになっています。ただ汎用的な設定になっているので、APIに設定するパラメータをメソッドに直接する必要があります。
以下はSQSのsend_messageを実行する例です。APIで使用するQueueUrlなどを指定しています。import boto3 # SQS クライアントAPI版 sqs = boto3.client('sqs') response = sqs.send_message(QueueUrl='https://sqs.us-east-2.amazonaws.com/123456789012/MyQueue', MessageBody='...')参考元:Boto3のClient APIドキュメント(send_message)
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sqs.html#SQS.Client.send_message
※「QueueUrl='...'」の部分はURLの記述を追加リソースAPI(高レベルAPI)
クライアントAPIと比べて高レベルで抽象化したAPIです。APIとの直接マッピングではなく、抽象化したクラスを間に挟むことでより開発者にとって扱いやすくなっています。
ここでは例として、クライアントAPIと同じようにリソースAPIでsend_messageを行う例を記載します。queueName='target-queue-name' # SQS リソースAPI版 sqs = boto3.resource('sqs') response = sqs.get_queue_by_name QueueName = queueName ).send_message( MessageBody = '...' )参考元:「Boto3(Python)で"Service Resource"を使ってみた(Lambda)」
https://cloudpack.media/16114クライアントAPIと比較するとコード内にSQSのURLを記載せず、queue名の問い合わせからメッセージの送信が書けます。いちいちキューのURLを意識する必要がなくなるので開発者はキューの名前さえ記述すればよくなります。
クライアントAPIとリソースAPIの比較(S3)
次にS3のクライアントAPIとリソースAPIを比較します。
例としてバケットからファイル名を取得するコードを記述します。# 共通定数(バケットとS3内ファイルのプレフィックス) BUCKET_NAME= "xxx-bucket" S3_PREFIX = "image-file-done/"# S3 クライアントAPI版 s3_client = boto3.client('s3') # 戻り値の型:<class 'dict'> s3_objects = s3_client.list_objects_v2(Bucket=BUCKET_NAME, Prefix=S3_PREFIX) for filename in s3_objects['Contents']: print('client:'+filename['Key'])# S3 リソースAPI版 s3_resource = boto3.resource('s3') # 戻り値の型:<class 'boto3.resources.collection.s3.Bucket.objectsCollection'> s3_objects = s3_resource.Bucket(BUCKET_NAME).objects.filter(Prefix=S3_PREFIX) for filename in s3_objects: print('resource:'+filename.key)呼び出しまではほとんど変わりませんが、呼び出し後の型が異なります。
クライアントAPIで呼び出した場合は、辞書型で返ってくるので実装のたびに返却される辞書型の形式を意識したデータの取り出しが必要になります。リソースAPIであればboto3用のオブジェクトになっているので、他のサービスでリソースAPIを使用する場合でも似たような記述でコードが書けます。クライアントAPIとリソースAPIの比較(DynamoDB)
最後にDynamoDBのクライアントAPIとリソースAPIを比較します。
こちらは特にBoto3のドキュメントがよく分からなくて、他の記述を参考にして間違ってコピーしてしまうことが多そうです。(昔の自分のことです…)# 共通定数(テーブル名とハッシュキー名、ソートキー名) TABLE_NAME='XXXXX_IFO' HASH_KEY_NAME='XXXXX_CODE' SORT_KEY_NAME='DATE_TIME'# DynamoDB クライアント版 dynamodb_client = boto3.client('dynamodb') # 戻り値の型: <class 'dict'> response = dynamodb_client.get_item( TableName=TABLE_NAME, Key={ HASH_KEY_NAME:{ 'S': '54620100' }, SORT_KEY_NAME:{ 'S': '2019050621' } } )# DynamoDB リソース API dynamodb_resource = boto3.resource('dynamodb') table = dynamodb_resource.Table(TABLE_NAME) # 戻り値の型: <class 'dict'> response = table.get_item( Key={ HASH_KEY_NAME: '54620100', SORT_KEY_NAME: '2019050621' } )久々にクライアントAPIで書きましたがパラメータをCLIと同じ形式で書くので少ししんどいです。戻り値の型自体はどちらも辞書型ですが、テーブル内部の操作をTableオブジェクトからでき、Key項目の記述は型情報を逐一書かなくて済むのでかなり楽になってます。
リソースAPIが提供されているサービス(2019/12/14時点)
リソースAPIは提供されているサービスが限られています。具体的には以下のサービスが対応しています。
- CloudFormation
- Cloud Watch
- DynamoDB
- EC2
- Glacier
- IAM
- OpsWorks
- S3
- SNS
- SQS参考元:「Boto 3 Documentation」
https://boto3.amazonaws.com/v1/documentation/api/latest/index.html上記サービスを利用する場合は、クライアントAPIの利用よりも先にまずリソースAPIの検討を行う必要がありそうです。Boto3のCodeExamples(サンプルドキュメント)でDynamoDBはresourceになっていますが、他のEC2やCloudWatchはclientなのでCodeExamplesだけでなくAvailable Servicesを見る必要がありそうです。
所感
今までクライアントAPIやリソースAPIなどをあまり意識せずに使用していたため反省もかねて色々調べた結果をまとめました。SQSの例でもわかるようにコード部分に不要な情報を書く必要がなくなるので、今後自分もまずはリソースAPIの提供があるサービスか確認し、提供されているならうまく使用できないか考えてからクライアントAPIを使いたいと思います。
QiitaやネットにはクライアントAPIで書かれた実装が多々あるようなので、今後自分が記事を書くことでリソースAPIの情報を増やしたいと思います。
- 投稿日:2019-12-14T21:54:49+09:00
主要クラウドサービスのパブリック IP アドレスレンジ(AWS/Azure/GCP/OracleCloud)
はじめに
ネットワーク制限が厳しい環境などで明示的に通信許可を設定する場合などに、主要なクラウドサービスが所有しているパブリック IP アドレスの範囲を確認したい時があります。
そこで、主要なクラウドサービスが保持する IP アドレスリストを取得する方法について調査し整理しておきます。Amazon Web Service(AWS)
AWS では、JSON 形式でリストを公開しています。
AWS IP アドレスの範囲
https://docs.aws.amazon.com/ja_jp/general/latest/gr/aws-ip-ranges.html次のエンドポイントで最新の IP アドレスリストを取得することができるため、定期的に参照するのが良いと思われます。
AWS ip-ranges.json
https://ip-ranges.amazonaws.com/ip-ranges.jsonなお、createDate の項目が更新日時のため、プログラムなどで自動参照する際は、更新時に最新を取り込むようにするのが良いでしょう。
{ "syncToken": "1576148589", "createDate": "2019-12-12-11-03-09", "prefixes": [ { "ip_prefix": "13.248.118.0/24", "region": "eu-west-1", "service": "AMAZON" }, { "ip_prefix": "18.208.0.0/13", "region": "us-east-1", "service": "AMAZON" }, ~以下略〜Microsoft Azure
Microsoft Azure も JSON 形式で IP アドレスのリストを提供しています。リストのファイルは以下からダウンロードすることができます。
Azure IP Ranges and Service Tags – Public Cloud
https://www.microsoft.com/en-us/download/details.aspx?id=56519ファイルのダウンロード URL は更新ごとに変わるためプログラムなどから参照する場合は、URL 固定の RESTエンドポイントが別に存在しています。サンプルコマンドは以下で説明されていますが、POST でリストを取得することができます。
Azure: Get Datacenter IP address ranges via API
https://social.technet.microsoft.com/wiki/contents/articles/50886.azure-get-datacenter-ip-address-ranges-via-api.aspx$body = @{"region"="all";"request"="dcip"} | ConvertTo-Json $webrequest= Invoke-WebRequest -Method “POST” -uri `https://azuredcip.azurewebsites.net/api/azuredcipranges -Body $bodyしかし、上記のエンドポイントでは、リージョン毎のIPレンジはわかりますが、VM、ストレージなどのサービス毎のレンジはわかりません。それは別になっているようで、次の API で参照できます。
Service Tags - List
https://docs.microsoft.com/en-us/rest/api/virtualnetwork/servicetags/listGoogle Cloud Platform(GCP)
GCPでは、パブリック IP アドレスのリストは _cloud-netblocks.googleusercontent.com の SPF レコードとして公開されています。
$ dig @8.8.8.8 -t TXT _cloud-netblocks.googleusercontent.com ; <<>> DiG 9.10.6 <<>> @8.8.8.8 -t TXT _cloud-netblocks.googleusercontent.com ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 5516 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;_cloud-netblocks.googleusercontent.com. IN TXT ;; ANSWER SECTION: _cloud-netblocks.googleusercontent.com. 3599 IN TXT "v=spf1 include:_cloud-netblocks1.googleusercontent.com include:_cloud-netblocks2.googleusercontent.com include:_cloud-netblocks3.googleusercontent.com include:_cloud-netblocks4.googleusercontent.com include:_cloud-netblocks5.googleusercontent.com ?all" ;; Query time: 46 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Sat Dec 14 21:27:37 JST 2019 ;; MSG SIZE rcvd: 331上記で応答されたドメイン(cloud-netblocks1.googleusercontent.com、_cloud-netblocks2.googleusercontent.com、_cloud-netblocks3.googleusercontent.com、cloud-netblocks4.googleusercontent.com、_cloud-netblocks5.googleusercontent.com)のTXTレコードを取得します。
$ dig @8.8.8.8 -t TXT _cloud-netblocks1.googleusercontent.com ; <<>> DiG 9.10.6 <<>> @8.8.8.8 -t TXT _cloud-netblocks1.googleusercontent.com ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31299 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;_cloud-netblocks1.googleusercontent.com. IN TXT ;; ANSWER SECTION: _cloud-netblocks1.googleusercontent.com. 3599 IN TXT "v=spf1 include:_cloud-netblocks6.googleusercontent.com include:_cloud-netblocks7.googleusercontent.com ip4:8.34.208.0/20 ip4:8.35.192.0/21 ip4:8.35.200.0/23 ip4:108.59.80.0/20 ip4:108.170.192.0/20 ip4:108.170.208.0/21 ?all" ;; Query time: 40 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Sat Dec 14 21:29:06 JST 2019 ;; MSG SIZE rcvd: 303次のように、その時点の IP レンジが応答されます。
ip4:8.34.208.0/20 ip4:8.35.192.0/21 ip4:8.35.200.0/23 ip4:108.59.80.0/20 ip4:108.170.192.0/20 ip4:108.170.208.0/21 ?all"今現在(2019/12)では、次の範囲が含まれているようです。
104.154.0.0/15 104.196.0.0/14 107.167.160.0/19 107.178.192.0/18 108.170.192.0/20 108.170.208.0/21 108.170.216.0/22 108.170.220.0/23 108.170.222.0/24 108.59.80.0/20 130.211.128.0/17 130.211.16.0/20 130.211.32.0/19 130.211.4.0/22 130.211.64.0/18 130.211.8.0/21 146.148.16.0/20 146.148.2.0/23 146.148.32.0/19 146.148.4.0/22 146.148.64.0/18 146.148.8.0/21 162.216.148.0/22 162.222.176.0/21 173.255.112.0/20 192.158.28.0/22 199.192.112.0/22 199.223.232.0/22 199.223.236.0/23 208.68.108.0/23 23.236.48.0/20 23.251.128.0/19 34.100.0.0/16 34.102.0.0/15 34.104.0.0/14 34.124.0.0/18 34.64.0.0/11 34.96.0.0/14 35.184.0.0/14 35.188.0.0/15 35.190.0.0/17 35.190.128.0/18 35.190.192.0/19 35.190.224.0/20 35.190.240.0/22 35.192.0.0/14 35.196.0.0/15 35.198.0.0/16 35.199.0.0/17 35.199.128.0/18 35.200.0.0/13 35.208.0.0/13 35.216.0.0/15 35.220.0.0/14 35.224.0.0/13 35.232.0.0/15 35.234.0.0/16 35.235.0.0/17 35.235.192.0/20 35.235.216.0/21 35.235.224.0/20 35.236.0.0/14 35.240.0.0/13 8.34.208.0/20 8.35.192.0/21 8.35.200.0/23RESTなどのエンドポイントは提供されていないようなので、プログラムから参照する際は、DNSクエリを再帰的に呼び出す必要がありちょっと手間な気がします。
Compute Engine の IP 範囲はどこで確認できますか?
https://cloud.google.com/compute/docs/faq#find_ip_rangeOracle Cloud
Oracle Cloud でも JSON 形式でリストを公開しています。
Oracle Cloud - IP Address Ranges
https://docs.cloud.oracle.com/iaas/Content/General/Concepts/addressranges.htm次のエンドポイントで最新の IP アドレスリストを取得することができるため、定期的に参照するのが良いと思われます。
https://docs.cloud.oracle.com/iaas/tools/public_ip_ranges.json
また、last_updated_timestamp がリストの最終更新日時のため、この値が更新されているかを確認すると良いでしょう。
{ "last_updated_timestamp": "2019-12-05T17:08:50.165960", "regions": [ { "region": "us-phoenix-1", "cidrs": [ { "cidr": "129.146.0.0/21", "tags": [ "OCI" ] ~以下略〜Github
パブリッククラウドではないですが、Github も IPアドレスを公開しています。
GitHubのIPアドレスについて
https://help.github.com/ja/github/authenticating-to-github/about-githubs-ip-addresses次のエンドポイントで最新の IP アドレスリストを取得することができます。
https://api.github.com/meta
- 投稿日:2019-12-14T21:54:49+09:00
主要クラウドサービスの公開 IP アドレスレンジ(AWS/Azure/GCP/OracleCloud)
はじめに
ネットワーク制限が厳しい環境などで明示的に通信許可を設定する場合などに、主要なクラウドサービスが所有しているパブリック IP アドレスの範囲を確認したい時があります。
そこで、主要なクラウドサービスが保持する IP アドレスリストを取得する方法について調査し整理しておきます。Amazon Web Service(AWS)
AWS では、JSON 形式でリストを公開しています。
AWS IP アドレスの範囲
https://docs.aws.amazon.com/ja_jp/general/latest/gr/aws-ip-ranges.html次のエンドポイントで最新の IP アドレスリストを取得することができるため、定期的に参照するのが良いと思われます。
AWS ip-ranges.json
https://ip-ranges.amazonaws.com/ip-ranges.jsonなお、createDate の項目が更新日時のため、プログラムなどで自動参照する際は、更新時に最新を取り込むようにするのが良いでしょう。
{ "syncToken": "1576148589", "createDate": "2019-12-12-11-03-09", "prefixes": [ { "ip_prefix": "13.248.118.0/24", "region": "eu-west-1", "service": "AMAZON" }, { "ip_prefix": "18.208.0.0/13", "region": "us-east-1", "service": "AMAZON" }, ~以下略〜Microsoft Azure
Microsoft Azure も JSON 形式で IP アドレスのリストを提供しています。リストのファイルは以下からダウンロードすることができます。
Azure IP Ranges and Service Tags – Public Cloud
https://www.microsoft.com/en-us/download/details.aspx?id=56519ファイルのダウンロード URL は更新ごとに変わるためプログラムなどから参照する場合は、URL 固定の RESTエンドポイントが別に存在しています。サンプルコマンドは以下で説明されていますが、POST でリストを取得することができます。
Azure: Get Datacenter IP address ranges via API
https://social.technet.microsoft.com/wiki/contents/articles/50886.azure-get-datacenter-ip-address-ranges-via-api.aspx$body = @{"region"="all";"request"="dcip"} | ConvertTo-Json $webrequest= Invoke-WebRequest -Method “POST” -uri `https://azuredcip.azurewebsites.net/api/azuredcipranges -Body $bodyしかし、上記のエンドポイントでは、リージョン毎のIPレンジはわかりますが、VM、ストレージなどのサービス毎のレンジはわかりません。それは別になっているようで、次の API で参照できます。
Service Tags - List
https://docs.microsoft.com/en-us/rest/api/virtualnetwork/servicetags/listGoogle Cloud Platform(GCP)
GCPでは、パブリック IP アドレスのリストは _cloud-netblocks.googleusercontent.com の SPF レコードとして公開されています。
$ dig @8.8.8.8 -t TXT _cloud-netblocks.googleusercontent.com ; <<>> DiG 9.10.6 <<>> @8.8.8.8 -t TXT _cloud-netblocks.googleusercontent.com ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 5516 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;_cloud-netblocks.googleusercontent.com. IN TXT ;; ANSWER SECTION: _cloud-netblocks.googleusercontent.com. 3599 IN TXT "v=spf1 include:_cloud-netblocks1.googleusercontent.com include:_cloud-netblocks2.googleusercontent.com include:_cloud-netblocks3.googleusercontent.com include:_cloud-netblocks4.googleusercontent.com include:_cloud-netblocks5.googleusercontent.com ?all" ;; Query time: 46 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Sat Dec 14 21:27:37 JST 2019 ;; MSG SIZE rcvd: 331上記で応答されたドメイン(cloud-netblocks1.googleusercontent.com、_cloud-netblocks2.googleusercontent.com、_cloud-netblocks3.googleusercontent.com、cloud-netblocks4.googleusercontent.com、_cloud-netblocks5.googleusercontent.com)のTXTレコードを取得します。
$ dig @8.8.8.8 -t TXT _cloud-netblocks1.googleusercontent.com ; <<>> DiG 9.10.6 <<>> @8.8.8.8 -t TXT _cloud-netblocks1.googleusercontent.com ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31299 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;_cloud-netblocks1.googleusercontent.com. IN TXT ;; ANSWER SECTION: _cloud-netblocks1.googleusercontent.com. 3599 IN TXT "v=spf1 include:_cloud-netblocks6.googleusercontent.com include:_cloud-netblocks7.googleusercontent.com ip4:8.34.208.0/20 ip4:8.35.192.0/21 ip4:8.35.200.0/23 ip4:108.59.80.0/20 ip4:108.170.192.0/20 ip4:108.170.208.0/21 ?all" ;; Query time: 40 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Sat Dec 14 21:29:06 JST 2019 ;; MSG SIZE rcvd: 303次のように、その時点の IP レンジが応答されます。
ip4:8.34.208.0/20 ip4:8.35.192.0/21 ip4:8.35.200.0/23 ip4:108.59.80.0/20 ip4:108.170.192.0/20 ip4:108.170.208.0/21 ?all"今現在(2019/12)では、次の範囲が含まれているようです。
104.154.0.0/15 104.196.0.0/14 107.167.160.0/19 107.178.192.0/18 108.170.192.0/20 108.170.208.0/21 108.170.216.0/22 108.170.220.0/23 108.170.222.0/24 108.59.80.0/20 130.211.128.0/17 130.211.16.0/20 130.211.32.0/19 130.211.4.0/22 130.211.64.0/18 130.211.8.0/21 146.148.16.0/20 146.148.2.0/23 146.148.32.0/19 146.148.4.0/22 146.148.64.0/18 146.148.8.0/21 162.216.148.0/22 162.222.176.0/21 173.255.112.0/20 192.158.28.0/22 199.192.112.0/22 199.223.232.0/22 199.223.236.0/23 208.68.108.0/23 23.236.48.0/20 23.251.128.0/19 34.100.0.0/16 34.102.0.0/15 34.104.0.0/14 34.124.0.0/18 34.64.0.0/11 34.96.0.0/14 35.184.0.0/14 35.188.0.0/15 35.190.0.0/17 35.190.128.0/18 35.190.192.0/19 35.190.224.0/20 35.190.240.0/22 35.192.0.0/14 35.196.0.0/15 35.198.0.0/16 35.199.0.0/17 35.199.128.0/18 35.200.0.0/13 35.208.0.0/13 35.216.0.0/15 35.220.0.0/14 35.224.0.0/13 35.232.0.0/15 35.234.0.0/16 35.235.0.0/17 35.235.192.0/20 35.235.216.0/21 35.235.224.0/20 35.236.0.0/14 35.240.0.0/13 8.34.208.0/20 8.35.192.0/21 8.35.200.0/23RESTなどのエンドポイントは提供されていないようなので、プログラムから参照する際は、DNSクエリを再帰的に呼び出す必要がありちょっと手間な気がします。
Compute Engine の IP 範囲はどこで確認できますか?
https://cloud.google.com/compute/docs/faq#find_ip_rangeOracle Cloud
Oracle Cloud でも JSON 形式でリストを公開しています。
Oracle Cloud - IP Address Ranges
https://docs.cloud.oracle.com/iaas/Content/General/Concepts/addressranges.htm次のエンドポイントで最新の IP アドレスリストを取得することができるため、定期的に参照するのが良いと思われます。
https://docs.cloud.oracle.com/iaas/tools/public_ip_ranges.json
また、last_updated_timestamp がリストの最終更新日時のため、この値が更新されているかを確認すると良いでしょう。
{ "last_updated_timestamp": "2019-12-05T17:08:50.165960", "regions": [ { "region": "us-phoenix-1", "cidrs": [ { "cidr": "129.146.0.0/21", "tags": [ "OCI" ] ~以下略〜Github
パブリッククラウドではないですが、Github も IPアドレスを公開しています。
GitHubのIPアドレスについて
https://help.github.com/ja/github/authenticating-to-github/about-githubs-ip-addresses次のエンドポイントで最新の IP アドレスリストを取得することができます。
https://api.github.com/meta
- 投稿日:2019-12-14T21:52:00+09:00
AWSを触ってみる
はじめに
AWSを触り始めたので、アカウント登録と10分間チュートリアルを触ってみたときのメモと所感。
アカウント登録
通常のアカウント登録に加え、住所等の詳細や支払いのためのクレカ登録が必須となっている。
また、SMSまたは電話認証も必須となっており、IBM Cloudなどと比べると手間がかかるように感じる。
- 氏名、住所、連絡先
- クレジットカード情報
- SMSまたは電話認証
クレジットコードの登録方法
- プロモーション等でAWSからクレジットコード(一定の有料枠)をもらえることがある。
- マイ請求ダッシュボード>Billing:クレジット から入力すればOK。
支払い通貨について
- デフォルトはUSD。日本円に変更可能。
- 変更はマイアカウントから行う。
- USDの場合はクレジットカード会社の為替レートが適用され、一般的にコスト高である。
- 日本円に切り替えておいた方が無難。
- しかし、必ずしもすべての利用料が日本円になるわけではない点、認識しておく必要あり。
<参考>
https://qiita.com/takachan/items/5d56b2ada63b896628bb
https://www.publickey1.jp/blog/15/amazonvisamastercard.html10分間チュートリアル
- 無料枠、有料枠利用を含め、概ね10分間で勧められるチュートリアルがある。
- TOP > 学習 > AWSの開始方法 > 10分間チュートリアル
試したコースその1:AWSコストの管理
https://aws.amazon.com/jp/getting-started/tutorials/control-your-costs-free-tier-budgets/
- 有料サービスが含まれるため、当然ながらコスト管理が必要。
- モニタリングに AWS Budgets を使うことで、設定した閾値でアラートが出せる。
- アカウントごとに月間総コスト予算を作成するとよい。
- 無料サービスには無制限と12か月間(初期登録者用)、トライアル(指定の期間無料)がある。
- 有料サービスの利用状況はは、アカウントの「マイ請求ダッシュボード」から確認できる。
無料利用枠のEメールアラートの設定
- マイ請求ダッシュボード>設定:Billingの設定>無料利用枠の使用のアラートの受信 にチェック
- 通常は85%の利用でアラートが出る。
AWS Budgetsのアラートの作り方
- マイ請求ダッシュボード>ホーム:Budgets>Create a Budget でアラート作成。
- コストで計測する場合はコスト予算を選択して進める。
所感
有料サービスはモニタリングがめんどくさいが、アラートをあげてくれるのはよい。
でも正しく設定できているのか不安になりがち。試したコースその2:サーバーレスアプリケーションを構築する
https://aws.amazon.com/jp/getting-started/tutorials/build-serverless-app-codestar-cloud9
いくつかのサービスを使って、サーバーレスアプリケーションを作る。
AWS Lambda ベースの新しい Node.js サーバーレスウェブアプリケーションを構築する。
ソース管理には AWS CodeCommit 、リリースプロセスの自動化には AWS CodePipeline を使用する。AWS CodeStar
継続的デリバリーのツールチェーンで、全体を数分でセットアップできる。
AWS で迅速にアプリケーションを開発、構築、デプロイできるようにするソフトウェア開発ツールである。AWS Cloud9
クラウドベースの IDE(コーディング、実行、デバッグなど)。
JavaScript、Python、PHP などのツールを内包しているのですぐ使える。所感
手順通りにやればアプリ構築は非常に簡単。
サーバレスをちょっと試してみたいという時にはいいサービスだが、git操作がめんどくさい。試したコースその3:Docker コンテナのデプロイ
https://aws.amazon.com/jp/getting-started/tutorials/deploy-docker-containers/
Amazon ECS(Elastic Container Service)
Docker アプリケーションをスケーラブルなクラスターで実行できるサービス。タスク定義
アプリケーションの設計図のようなもの。
以下の事項をECSに知らせる。
・使用する Dockerイメージ
・タスクで使用するコンテナ数
・各コンテナへのリソース割り当て・・・など
所感
わかりづらい。
説明と実際の画面が違うので、よくわからないところが多かった。
有償/無償の線引きもわかりづらい。試したコースその4:ファイルの保存と取得
https://aws.amazon.com/jp/getting-started/tutorials/backup-files-to-amazon-s3/
Amazon S3(Simple Storage Solution)
ユーザのデータ (オブジェクトと呼ぶ) を大規模に保存できるようにするサービス。Amazon S3 バケットの作成、ファイルのアップロード、ファイルの取得、ファイルの削除を行う。
所管
作ってアップロードしてダウンロードしてパケット削除、やっていることは簡単。
しかし、最初にコンソール開いたとき、身に覚えのないパケットが既に3つ・・・!
ここまでのチュートリアルで自動的に作られていたようだ。
削除プロセスは各チュートリアルにあったはずなのに・・・今使っているサービスの全体を見渡すにはどうしたらいいの・・・?全体所感
UIは扱いずらい。どこに何があるのかわからないし、導線もよくわからない。(すぐに慣れるのだろうけど)
ある程度前提知識をもって使い始めるべきだけど、触らないとそれもわからない。
コツコツやるしかないのね。。。
- 投稿日:2019-12-14T21:51:10+09:00
AWS IoT ShadowとROSのDynamic Reconfigureを同期するノードを作った
この記事はROSアドベントカレンダー 14日目の記事です。
こんにちは、WHILLの杉浦です。今年もアドベントカレンダーの時期がやってきましたね。
以前、ROSCon JP 2019で発表させていただいたのですが、AWS IoTのThingShadowとDynamic Reconfigureのパラメータを同期するノードを作りました。もっと早く公開する予定だったのですが、いい機会なのでROSアドベントカレンダーのネタにさせてください。このノードは、他ノードのDynamic Reconfigureインターフェースにアクセスして、AWSIoT ThingShadowとパラメータを同期してくれるものです。
この仕組みを使うと、既にDynamic Reconfigureインターフェースを実装しているノードをすぐにクラウド対応することができます。今年1月にラスベガスで開催されたCES 2019で発表した仕組みも、この仕組みを使ってクラウドと連携しています。— Hikaru Sugiura (@aquahika) December 14, 2019フル動画はこちら http://www.youtube.com/watch?v=JVf-OTqWyKM
AWS IoT ThingShadowとは?
AWS IoTの機能です。自身でサーバーを用意しなくてもJSON形式でIoT機器のパラメータの保持および状態の管理を行ってくれます。またパラメータの先祖返りを防ぐ機能なども持っています。
AWSの他サービスとの連携が取りやすく、ThingShadowのパラメータによってLambdaを起動したりもできます。仕組み
(ROSConJPで発表した内容とは微妙に異なります)
今回作ったdyn_reconf_shadowノードは設定ファイルに基づき、他ノードのdynamic reconfigureサーバーの要素をThingShadowと同期してくれます。
設定ファイルはYamlで記述します。設定ファイルではDynamic reconfigureのサーバー名と、どの項目を同期するかを指定できます。動かしてみる
あらかじめ、AWS IoTでThingを作っておきます。Thing名は
specialdeviceとします。
AWS IoTでポリシーを作成した時に発行される証明書をダウンロードし、次の名前に変更して~/.awsiot以下に配置します。
- 公開鍵:certificate.pem.crt
- 秘密鍵:private.pem.key
- ルート証明書:AmazonRootCA1.pemまた、以下のような設定ファイルを適当な場所に作っておきましょう
config.yamldyn_reconfigures: /sample_dyn_server/testServer1: - int_param - str_param - double_param /sample_dyn_server/testServer2: - double_paramテスト用のDynamic reconfigureサーバーを起動します。
roscoreは別ウィンドウで立ち上げておいてください。$ rosrun dyn_reconf_shadow dyn_server_for_test.pyこれを立ち上げると、それぞれ
int_param,str_param,double_param,bool_param,sizeというパラメータを持ったdynamic reconfigureサーバー/sample_dyn_server/testServer1と/sample_dyn_server/testServer2が起動します。本体を立ち上げます
$ rosrun dyn_reconf_shadow sync.py _host:=<Your AWS IoT Hostname> _thingName:=specialdevice _dyn_reconf_args:=./config.yamlはAWS IoTのコンソールのモノ、"specialdevice"画面にある"操作"から確認できます。おそらく、
XXXXXXXXXX-ats.iot.ap-northeast-1.amazonaws.comのような形式になっているはずです。rqt_reconfigureでDynamic reconfigureをGUIで見られるようにしましょう。
$ rosrun rqt_reconfigure rqt_reconfigureを開きましょう。また、ブラウザでAWS IoTコンソールから、
specialdeviceのShadowを開きましょう。AWS IoTとDynamic reconfigureの連携デモ: rqt_reconfigureで値を変更するとThing Shadowにも反映される pic.twitter.com/iYrgLOaBuk
— Hikaru Sugiura (@aquahika) December 14, 2019AWS IoTとDynamic reconfigureの連携デモ2: ThingShadow上で値を変更するとDynamic Reconfigure上の値が変更される pic.twitter.com/OER24vy0bc
— Hikaru Sugiura (@aquahika) December 14, 2019パッケージはこちら
GitHubから落として
catkin_makeしてください。
rosdep installも必要です。
ros_dyn_reconf_shadow
https://github.com/WHILL/ros_dyn_reconf_shadow/リクルーティングPR
現在WHILLでは 自動運転・障害物回避などの機能をもったパーソナルモビリティを用いたMaaSサービスを開発しています。
現在、MaaSアプリケーションとして空港利用者向けの移動サービスを世界各地の空港で展開する準備をしています。
このような形で羽田空港での自動運転は動いています。ユーザーからのフィードバックがなかなか嬉しい。さらに改善を進めています https://t.co/M42NCyuuAF
— Sugie @ WHILL Inc (@sugix_02) November 19, 2019インターネットが繋がった移動体をクラウドから操作してサービスを提供できる事ってなんだかワクワクしませんか?
このワクワクを一緒に共有できるクラウドエンジニア、アプリエンジニアを大募集中です。ぜひ一緒に働きましょう!お気軽にTwitter:@aquahikaまでリプライしてください。


- 投稿日:2019-12-14T21:29:20+09:00
[AWS] LINEWORKSでリマインダBOTを作ってみた(実装編)
LINEWORKS Advent Calendar 14日目です。
今回は、LINEWORKS Advent Calendar 7日目 で紹介したリマインダBOT の実装について紹介します。
[再掲]BOTの画面と全体構成
リマインダBOTは3つのLambdaで構成されており、Python3.7 で実装してます。
①. LINEWORKSから送信されるメッセージの処理およびSQSへの通知
②. テーブル内に保存されたイベントをポーリングおよびSQSへの通知
③. SQSから受信したメッセージをLINEWORKSサーバに通知今回は、①に焦点を当てて紹介します。
状態遷移表とメッセージリスト
ユーザとのBOTのやり取りを状態遷移表で表現しました。リマインダBOTは、以下の4つのイベントを扱います。
- ユーザ参加
- ユーザがBOTを追加時に発生
- テキスト入力
- ユーザがBOTに対して任意のテキスト入力
- イベント入力ボタン押下
- BOT内のメニューに表示される「イベント登録」を押下
- イベント出力ボタン押下
- BOT内のメニューに表示される「イベント参照」を押下
それぞれのユーザイベントに対して4つの状態を管理します。
BOTは、ユーザイベントとBOTの状態に対応するメッセージをユーザに返答します。
メッセージの内容は、メッセージリストとして定義しておきます。Lambdaの実装
では、本題のLambdaの実装です。
まずは、Lambda関数の全体の処理です。
リクエストボディの検証とメッセージのメインの処理を担う自作のon_event関数を呼び出します。
リクエストボディの検証は、ヘッダーのx-works-signatureの値に基づいて処理します。""" index.py """ import os import json from base64 import b64encode, b64decode import hashlib import hmac import reminderbot API_ID = os.environ.get("API_ID") def validate(payload, signature): """ x-works-signatureの検証 """ key = API_ID.encode("utf-8") payload = payload.encode("utf-8") encoded_body = hmac.new(key, payload, hashlib.sha256).digest() encoded_base64_body = b64encode(encoded_body).decode() return encoded_base64_body == signature def handler(event, context): """ main関数 """ # リクエストボディの検証 if not validate(event["body"], event["headers"].get("x-works-signature")): return { "statusCode": 400, "body": "Bad Request", "headers": { "Content-Type": "application/json" } } body = json.loads(event["body"]) # メッセージのメイン処理 reminderbot.on_event(body) return { "statusCode": 200, "body": "OK", "headers": {"Content-Type": "application/json"} }続いて、on_event関数についてです。
今回事前に定めた、4つの状態、4つのユーザイベント、メッセージリストを定数で定義しておきます。""" reminderbot.py """ import os import json import datetime import dateutil.parser from dateutil.relativedelta import relativedelta import boto3 from boto3.dynamodb.conditions import Key, Attr # 状態遷移表に基づき4つの状態を定義 STATUS_NO_USER = "no_user" STATUS_WATING_FOR_BUTTON_PUSH = "status_waiting_for_button_push" STATUS_WATING_FOR_NAME_INPUT = "status_waiting_for_name_input" STATUS_WATING_FOR_TIME_INPUT = "status_waiting_for_time_input" # メッセージリストに基づき定義 MESSAGE_LIST = [ "こんにちは、リマインドボットだよ。メニューボタンを押してね。", "イベント名を入力してね", "メニューボタンを押してね。", "イベントの内容はこちら!", "イベント時間を入力してね。", "登録完了!", "エラーだよ。もう一度入力してね。", ] # ユーザのイベントをpostbackイベントとして定義 # BOTのメニュー登録時は、以下のpostbackイベントの値と同じにすること POSTBACK_START = "start" POSTBACK_MESSAGE = "message" POSTBACK_PUSH_PUT_EVENT_BUTTON = "push_put_event_button" POSTBACK_PUSH_GET_EVENT_BUTTON = "push_get_event_button" # ステータスを管理するテーブル dynamodb = boto3.resource("dynamodb") table = dynamodb.Table("lineworks-sample-table") def on_event(event): """ botの全体のイベントの処理 """ account_id = event["source"]["accountId"] content = event["content"] postback = content.get("postback") or "message" # ユーザの今の状態を確認 response = table.get_item( Key={ "Hash": "status_" + account_id, "Range": "-" } ) status = STATUS_NO_USER message = None if response.get("Item") is not None: status = response.get("Item")["Status"] # 各ユーザイベント(postback)毎の分岐処理 try: if postback == POSTBACK_START: message = on_join(account_id, status) elif postback == POSTBACK_MESSAGE: text = content["text"] message = on_message(account_id, status, text) elif postback == POSTBACK_PUSH_PUT_EVENT_BUTTON: message = on_pushed_put_event_button(account_id, status) elif postback == POSTBACK_PUSH_GET_EVENT_BUTTON: message = on_pushed_get_event_button(account_id, status) except Exception as e: print(e) message = MESSAGE_LIST[6] # SQSにメッセージ内容を通知 sqs = boto3.resource("sqs") queue = sqs.get_queue_by_name(QueueName="lineworks-message-queue") queue.send_message( MessageBody=json.dumps( { "content": { "type": "text", "text": message, }, "account_id": account_id, } ), ) return True最後に、各イベントごとの処理の実装です。
それぞれのイベントの中で、各状態ごとの分岐処理を状態遷移表に基づいて実装しています。
重複する処理はまとめています。def on_join(account_id, status): """ bot追加時のイベントの処理 """ # ステータスに応じた分岐処理 if status == STATUS_NO_USER: table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_BUTTON_PUSH, } ) return MESSAGE_LIST[0] else: table.delete_item( Key={ "Hash": "status_" + account_id, "Range": "-" } ) table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_BUTTON_PUSH, } ) return MESSAGE_LIST[0] def on_message(account_id, status, text): """ テキスト入力時のイベントの処理 """ if status == STATUS_WATING_FOR_BUTTON_PUSH: table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_BUTTON_PUSH, } ) return MESSAGE_LIST[2] elif status == STATUS_WATING_FOR_NAME_INPUT: table.update_item( Key={ "Hash": "status_" + account_id, "Range": "-", }, UpdateExpression="set #st = :s, Title = :t", ExpressionAttributeNames = { "#st": "Status" # Statusは予約語なので#stに置き換える }, ExpressionAttributeValues={ ":s": STATUS_WATING_FOR_TIME_INPUT, ":t": text, }, ) return MESSAGE_LIST[4] elif status == STATUS_WATING_FOR_TIME_INPUT: # dateutil.parserで日付は変換 time_dt = dateutil.parser.parse(text) time = time_dt.strftime("%Y/%m/%d %H:%M:%S") response = table.get_item( Key={ "Hash": "status_" + account_id, "Range": "-", } ) table.put_item( Item={ "Hash": "event_" + account_id, "Range": time, "Title": response["Item"]["Title"], # utc -> 日本時間変換のため、9時間の差分をとる # utc -> 当初の予定 + 1h後に削除するように設定 "ExpireTime": int((time_dt - relativedelta(hours=9) + relativedelta(hours=1)).timestamp()), "SentFlag": False } ), table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_BUTTON_PUSH, } ) return MESSAGE_LIST[5] def on_pushed_put_event_button(account_id, status): """ 「イベント登録」ボタン押下時のイベントの処理 """ if status == STATUS_WATING_FOR_BUTTON_PUSH: table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_NAME_INPUT, } ) return MESSAGE_LIST[1] elif status == STATUS_WATING_FOR_NAME_INPUT: return MESSAGE_LIST[1] elif status == STATUS_WATING_FOR_TIME_INPUT: table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_NAME_INPUT, } ) return MESSAGE_LIST[1] def on_pushed_get_event_button(account_id, status): """ 「イベント参照」ボタン押下時のイベントの処理 """ current_jst_time = (datetime.datetime.utcnow() + relativedelta(hours=9)).strftime("%Y/%m/%d %H:%M:%S") # event取得処理 response = table.query( KeyConditionExpression=Key("Hash").eq("event_" + account_id) & Key("Range").gt(current_jst_time) ) items = response["Items"] or [] message = MESSAGE_LIST[3] if len(items) == 0: message += "\n-----" message += "\nなし" message += "\n-----" for item in items: message += "\n-----" message += "\n タイトル: {title}".format(title=item["Title"]) message += "\n 日時: {time}".format(time=item["Range"]) message += "\n-----" return messageまとめ
状態遷移表を作成することで、各イベント時にどのような処理を実装すべきか、
どのメッセージを返すべきか、が明確になるので迷いなく実装することができました。今回は、シンプルなアプリだったので状態やイベントの数も少ないですが、
より複雑な処理をBOTにさせようとすると状態遷移表がより役に立ってくるかと思います。


- 投稿日:2019-12-14T21:18:37+09:00
Sagemakerのアップデートで機械学習を完全に理解…したかった
先日のre:Inventで多くのアップデートが発表された中、Sagemakerにかなり多くのアップデートが発表されました。
参考
https://dev.classmethod.jp/cloud/aws/reinvent2019-summary-sagemaker/
https://aws-seminar.smktg.jp/public/seminar/view/892AWSとして機械学習に力を入れてるなあというのがはっきり見て取れますね。
また、おそらくAWS自身が機械学習を使って自分たちのサービスに組み込んでいるだろうと思われる機能追加も出てきています。re:Inventの前ですけど、アノマリーディテクションとかは完全にそれですね。
さて、せっかく色々出たので「ここらで一つ触ってみよう」というエントリです。
既に知ってる人には特に得るものはないと思いますw筆者の現在のレベルとしては
- 機械学習に触れたことがない(聞いたことはありますが)
- Sagemakerに触れたことがない
というわけで、ほぼ素人です。
色々参考にしながらやっていきます。※なお、「完全に理解した」の定義についてはこちらを参考にしてください。
https://togetter.com/li/1268851ノートブックインスタンスの作成
まずはコンソールに従ってノートブックインスタンスを作成します…と言いたいとこですが、どうやらその前にS3バケットが必要らしいので適当な名前で作っておきます。
ただし、名前に「sagemaker」を含める必要があるようです。
※今回は設定はすべてデフォルトで作成しています。
ここで作ったバケットは、IAMロールを作成するときに指定します。
今回は初めてノートブックインスタンスを作成するので、過去に作成したIAMロールはもちろんありません。
なのでインスタンス作成時に合わせて作成することとします。
それ以外の設定はデフォルトのまま作ります。
作成には少し時間がかかりますが、ボタンを押してしばらく待っているとインスタンスが利用可能になります。
Jupyter Notebookについての説明は(あまり詳しくできないというのもありますが)このへんの記事を参照
https://deepage.net/machine_learning/2016/12/13/jupyter_notebook.htmlPythonを実行するための環境と思い込んでたんですが、いろんな言語に対応してるんですね。
トレーニングしてみる
AWSの公式ドキュメントにGetting Started的なものがあるのでそれに従います。
今回は
Conda_Python3の環境を利用します。
やることはぶっちゃけるとドキュメントに従ってコードを貼り付けて実行するだけです。
それぞれのコードで何やってるかはドキュメント内で解説されてるのでここでは割愛します。最初に下記を貼り付けてRunを押します。
元のコードはこちら
バケット名は今回作成したものにしています。
※実はこれを最初にしていなかったがために後でエラーになったのでやり直しています。
なのでスクショの順番が少し変わっているところがあります。import os import boto3 import re import copy import time from time import gmtime, strftime from sagemaker import get_execution_role role = get_execution_role() region = boto3.Session().region_name bucket='sagemaker-completely-understood' # Replace with your s3 bucket name prefix = 'sagemaker/xgboost-mnist' # Used as part of the path in the bucket where you store data bucket_path = 'https://s3-{}.amazonaws.com/{}'.format(region,bucket) # The URL to access the bucketまずはデータセットをダウンロードします。
上記のドキュメントのコードを貼り付け、「Run」を押します。
すると、データセットがダウンロードされます。
次にデータセットを変換しS3にアップロードします。
うまくいくとこんな感じになるはずです。
次はステップ5、モデルのトレーニングをします。
今回は流れに従ってXGBoostアルゴリズムを使うことにします。
そのまま実行しようとしたら下記のようなWARNINGが出てしまったので、少し貼り付けるコードを改変しました。
import sagemaker from sagemaker.amazon.amazon_estimator import get_image_uri container = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1')このステップはこんな感じ
コンソールに戻ってトレーニングジョブを見ると動いているのがわかりますね。
最大15分ほどかかるそうなので待ちます。(自分は4分で終わりました。)
さすがに貼ったコードの意味を何も理解していないのはまずいので待っている間にコードを見返すのもいいでしょう。次にステップ6のモデルのデプロイですが、今回はステップ 6.1: Amazon SageMaker ホスティングサービスにモデルをデプロイするに従います。
どうやらdeployメソッド一発で行えるようです。
6.1を選んだのでそのままステップ7.1: Amazon SageMaker ホスティングサービスにデプロイされるモデルの検証に進みます。そのまま検証に進んだんですが、最後の検証でエラーになってしまいました。
ちょっと解消できそうにないのでここで断念。
うーん、でも大まかなここまでの流れはつかめたので今度やり直します。完全に理解…できなかったよ…
AutoPilot
これだけだとあんまりなので、先日のre:Inventで発表されたAutoPilotを試してみます。
書こうと思った内容がほぼこちらの記事に書いてあったので、詳細はこちらを見てください(手抜き)
AutoPilotのサンプルはここにあります。
useを選択して保存するとここに保存されます。
こちら
に従ってやっていきます。
サンプルに文章も細かく書いてあるので、そのまま実行していきます。途中でMLを実行してステータスを表示します。
ここでかなり待ちます。
終わるとこんな感じになります。
ここまで数時間ぐらいかかりました。
こんな感じでモデルががっつりできています。
最終的にバッチ変換ジョブを実行して結果を見るとこんな感じになりました。
なんとなくそれっぽい?
あとがき
ネタに走ったタイトルですが、いい加減機械学習のほうも少し触らなきゃと思って、その第一歩として手を付けました。
何もしてないと中々仕事で触ることもなくなってしまうので自分でやってみないといけませんね。
というわけで、理解はともかくとして「まず触ってみた」というものでした。
何をやってるか理解していくのはこれからですね、とかいうとタイトルに反してしまうw
環境を自分で用意するのは大変だなと思うので、サクッと実行環境つくれるのはいいかもしれませんね。こんなことやってますが、明日DevOpsの試験を受けるために今日はがっつり対策しようと思ったのにだいぶ時間を取られちゃいました。
頑張ってきます。参考にさせていただいた記事
全然前提知識がなかったので既に触っている記事を参考にさせていただきました。
いつも本当に助かっています。
https://dev.classmethod.jp/machine-learning/getting-started-with-amazon-sagemaker/
https://dev.classmethod.jp/cloud/aws/try-amazon-sagemaker-autopilot/あとはもちろん公式ドキュメントも
https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/gs.html


















- 投稿日:2019-12-14T20:43:16+09:00
AWS CognitoでのauthenticateUser(ログイン)処理で呼ばれる関数を調べてみた。
背景
AWS使ってサーバーレスで自分用の家計簿的なwebサービスを勉強も兼ねて開発中。Cognitoでログイン制御は出来た(前回の記事)。 しかし、どうもすっきりしない部分がある。
すっきりしない部分
新しいパスワード入れた後、以下のエラーがブラウザコンソール出てきた。completeNewPasswordChallenge 関数のcallbackもちゃんと実装必要があるはずだが、今回はスルー。Failしたと思われるが、ユーザーのステータスをAWSコンソールで確認するとCONFIRMEDになっていたし。今後ここらへんもうちょっとちゃんとすることにする。
前提
- MFAは使用しない
- 管理者のみユーザー追加可能。その際は仮パスワード。
- ユーザーにパスワード変更を求める
調べると、同じような事を感じた人がいる様子。
似たケース修正
テストのために、一旦ユーザー削除。※ボタンが表示されず、削除できないのか?と思ったが、一旦 ユーザーを無効化 すると ユーザーを削除 ボタンが出てきた。※ちなみに、ユーザー作成時、E メールを検証済みにしますか? にチェックを入れるとメールが飛んでこない様子。
どんなcallbackが必要なのかちゃんと調べる。VSCodeだと、関数にマウスを合わせると引数の型を表示してくれる。callbackにどんなメソッドが必要かも解る。素晴らしい。
callback関数を指定する引数がthisになっている。これがcallback引数全体を指しているならonFailureもちゃんと実装している。この部分がthisになってるのが関係してる疑惑。サンプルロジックから考えるとどうやらcallbackは再帰呼び出し的に使いまわしするものらしい。callbacksを外に出してみる。
修正したlogin関数部分login (username, password) { const userData = { Username: username, Pool: this.userPool } const cognitoUser = new CognitoUser(userData) const authenticationData = { Username: username, Password: password } const authenticationDetails = new AuthenticationDetails(authenticationData) return new Promise((resolve, reject) => { var callbacks = { onSuccess: (result) => { resolve(result) }, onFailure: (err) => { reject(err) }, newPasswordRequired: (userAttributes, requiredAttributes) => { var newPass = window.prompt('Please input your new Password', 'Your input will not be masked. please make sure there is no other person.') cognitoUser.completeNewPasswordChallenge(newPass, {}, callbacks) } } cognitoUser.authenticateUser(authenticationDetails, callbacks) }) }エラー出なくなった。this参照が意図しない形になっていた様子。onFailureのエラーが出ていたのは、エラー実処理をしようとしていたのではなく、単に参照してる部分があったという事かと思われる。
公式サンプル でもthisは使っているが、今回参考にさせてもらったソースではPromiseの内部で処理してたりするので、thisがずれていたのだと思う。調査
せっかくなので、ちゃんと調べてみる。VSCodeで、cognitoUser.authenticateUser 部分をホバーしてみると、第二引数は callbacks。形式は IAuthenticationCallback という事が分かる。公式ソースの IAuthenticationCallback 部分 を見ると、以下の関数がcallbacksに存在する事が解る。
- onSuccess
- onFailure
- newPasswordRequired
- mfaRequired
- totpRequired
- customChallenge
- mfaSetup
- selectMFAType
同 completeNewPasswordChallengeのcallback部分 を見てみると、callbacksは以下の関数。ほぼ重なるものの、違う。
- onSuccess
- onFailure
- mfaRequired
- customChallenge
- mfaSetup
多分、今までのはただうまく行っていただけと思われる。厳密にいえば再帰的に同じcallbacksを使うのではなくて、ちゃんとそれぞれのcallbacksを用意すべきと思われる。まぁ、当然ですね。認証の各ステップ毎に求められる処理は違うはず。もちろん同じ処理は共通関数にするとして、callbacksまるごと共有にするのは違っていたと思います。onFailureにしても、フェーズによって次の処理が違うと思うし。自分のケースでは、completeNewPasswordChallengeでの成功&失敗が認証全体の成功&失敗だったから問題なかっただけかと。
IAuthenticationCallbackの各関数内ですべき処理をまとめてみる(※実践してないです。調査結果です。間違ってたらごめんなさい。コメントもらえると有り難いです)。
callbacks内関数 呼ばれる時 すべき処理 その処理に使う関数名 参考リンク onSuccess サインイン成功 トークン取得とか アプリによる - onFailure サインイン失敗 エラーメッセージとか アプリによる - newPasswordRequired 仮パスワードログイン成功後 ユーザー入力の新しいパスワード渡す cognitoUser.completeNewPasswordChallenge 参考 mfaRequired サインインに SMS_MFA が必要な場合 ユーザー入力認証コードを送る cognitoUser.sendMFACode 参考 totpRequired サインインに TOTP(ワンタイムパスワード) が必要な場合 ユーザー入力認証コードを送る cognitoUser.sendMFACode 参考 customChallenge 特殊認証追加してる場合 内容による cognitoUser.sendCustomChallengeAnswer - mfaSetup TOTP(ワンタイムパスワード)有効時の初回 associateSecretCodeを含むcallbackを渡し、その中でsecretCodeをユーザーデバイスに登録してもらう。 cognitoUser.associateSoftwareToken、cognitoUser.verifySoftwareToken 参考 selectMFAType MFAの種類が選べる時 SMSかTOTPか指定("SMS_MFA"か"SOFTWARE_TOKEN_MFA") cognitoUser.sendMFASelectionAnswer 参考 今回の件で得た豆知識
- Cognitoユーザープールでは、ユーザーは無効化してからでないと削除できない
- javaScriptの this は取扱注意。特に多人数で扱うソースの場合はどのオブジェクトを指すかすぐには解りにくいと思う。処理位置などを変更すると影響出てきそう。
- VSCodeだと(多分他のプログラム用エディタでも)、javaScript関数にマウスを合わせると引数の型を表示してくれる。
参考にさせてもらったページ

- 投稿日:2019-12-14T19:38:53+09:00
RedshiftのIAM 認証を使用したデータベースユーザー認証情報の生成の制約事項
はじめに
UL Systems Advent Calendar 2019 の16日目です。
データ分析などユーザーがアドホックなクエリを実行する環境では、誰が発行したクエリであるかを把握するために、作業者ごとにデータベースユーザーを作成することがあります。
Redshiftにはデータベースのユーザー認証もIAMで行うことができます。
本機能「IAM 認証を使用したデータベースユーザー認証情報の生成」が導入できるか技術検証を行った際、数点制約事項があることが判明したため、その情報共有となります。パブリックインターネットアクセスが必須
データベースユーザーの認証情報生成API「get-cluster-credentials」にて、HTTPS (ポート443)でredshift.ap-northeast-1.amazonaws.comにアクセスします。
2019年12月現在、RedshiftはVPCエンドポイントに対応していないため、パブリックインターネット経由でのアクセスが必須となります。プライベートサブネット上のEC2などからアクセスする場合、「NAT ゲートウェイ / NAT インスタンス」、「プロキシ」などを利用することになります。
get-cluster-credentialsで生成されたユーザーの権限情報を他ユーザーから参照できない
get-cluster-credentialsで生成されたユーザー(user_a)の権限を、他のユーザー(user_b)が参照することができません。
HAS_TABLE_PRIVILEGEなどの権限確認関数は、実行ユーザーによって結果がかわります。今回の例ではuser_aで実行すればtrue、user_bで実行すればfalseが返ります。その為、user_aが作成したテーブルに対し、あるグループはデフォルトでselectできるようalter default privilegesで権限付与を行いたい場合、user_aでしか行えません。
まとめ
上記のような制約も多いため、導入する前に十分な技術検証期間を設けたほうがよいと思います。
また、公式ドキュメントはあるものの、導入事例の少ない技術でもあるため、問題が発生した場合、自力で解決することになります。
AWSサポートへの問い合わせがなければ解決が難しいことも多いため、ビジネスプラン以上を契約している環境で検証は行いましょう。
- 投稿日:2019-12-14T18:41:57+09:00
AWS RoboMakerのROS2(Beta)版を使ってみる
概要
最近AWS robomakerでROS2がサポートが開始されました!バージョンはbetaですが、2020年の後半くらいにbetaが取れるらしいです。今回は、robotmakerの開発環境でros2を選択し、そこでノードの実行をしてみたいと思います。
また、ros1でのAWS RoboMakerは次の記事がとてもよくまとめられていて助かりました。
https://qiita.com/nmatsui/items/6721c820000cf5115bdc実行手順
今回はros2のチュートリアルとして公開されている"Hello World"を使用してros2のノードを実行してみたいと思います。また、aws robomakerのros2対応のチュートリアルは現在、2つあります。(2019/12/14 現在)他のディストリビューションだと全部で5つあります。今後サポートが続けてられ行くうちに、他のディストリビューションで公開されているチュートリアルもROS2で実行できるようになると思います。
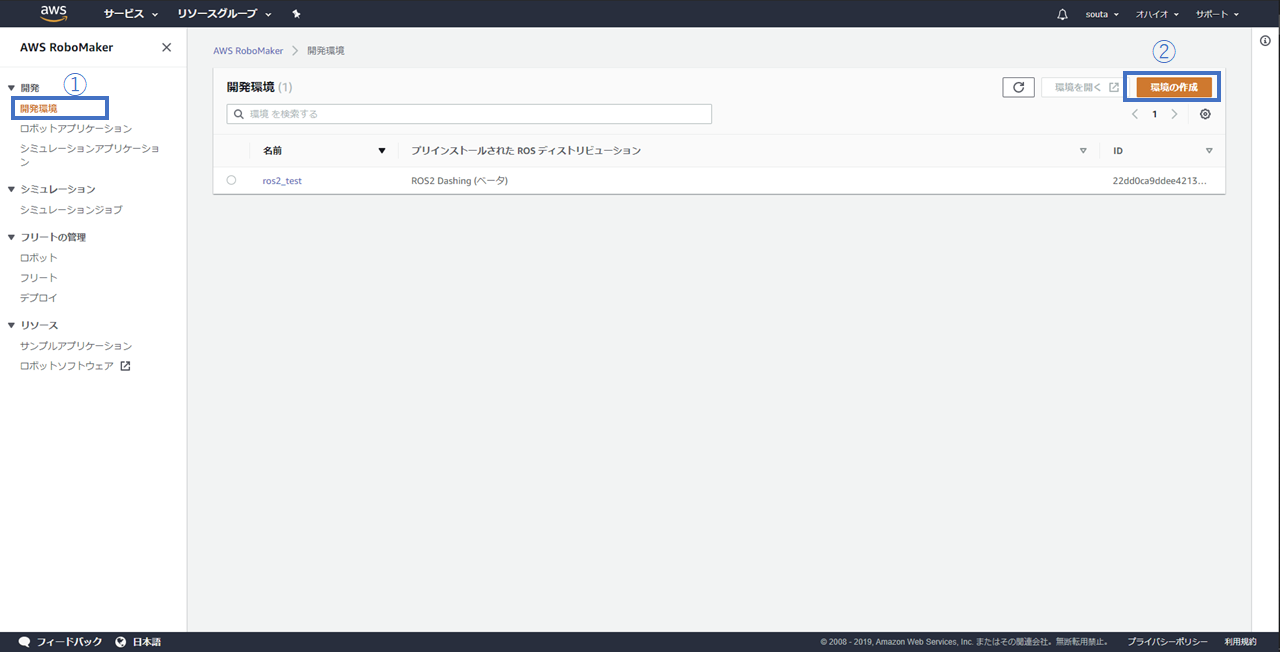
1. AWSコンソールを開き、開発新規->環境の設定を選択する
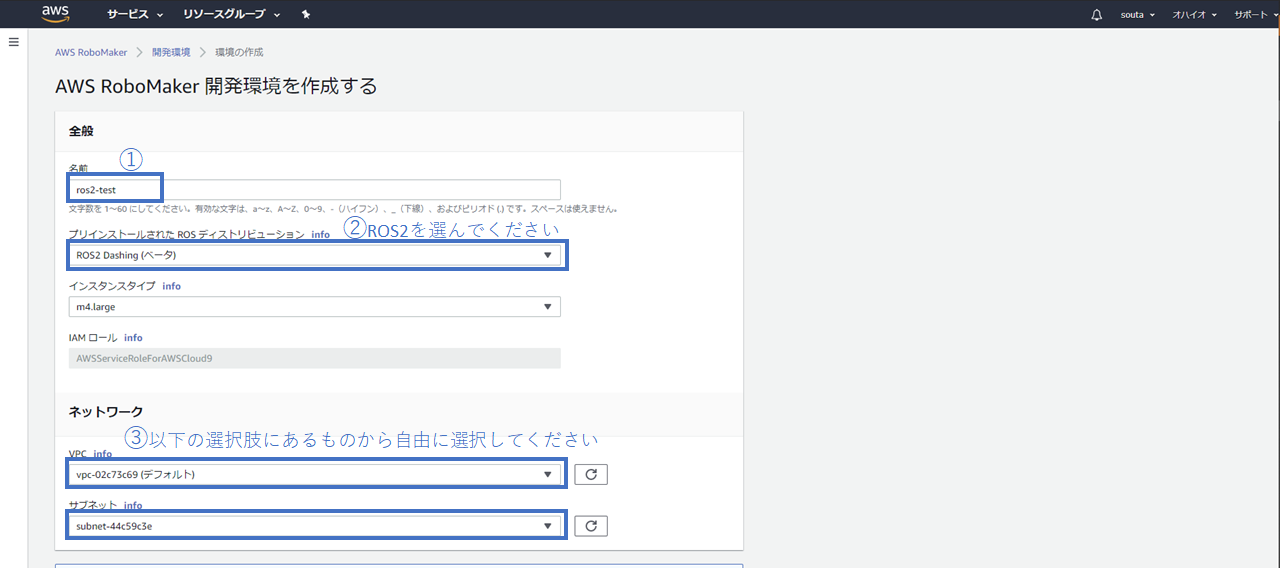
2. ROSディストリビューションをROS2 Dashingに設定する
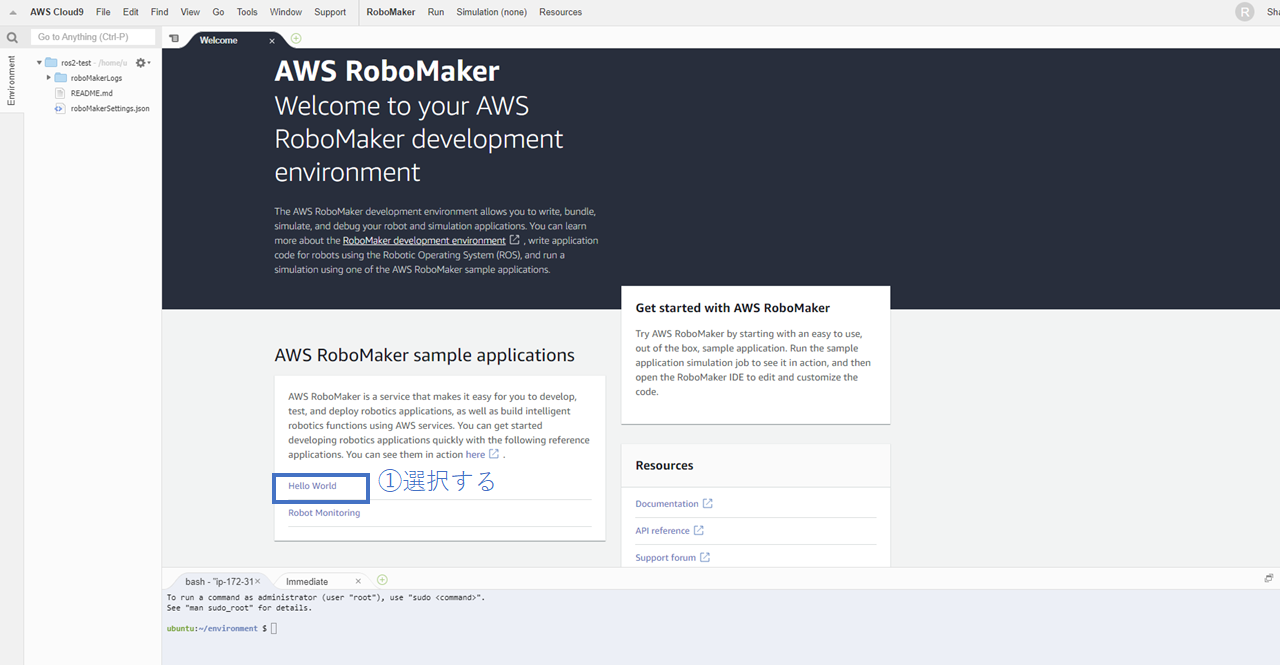
3. Cloud 9が立ち上がったらHello Worldチュートリアルをダウンロードする
ー立ち上がり前
ー立ち上がり後
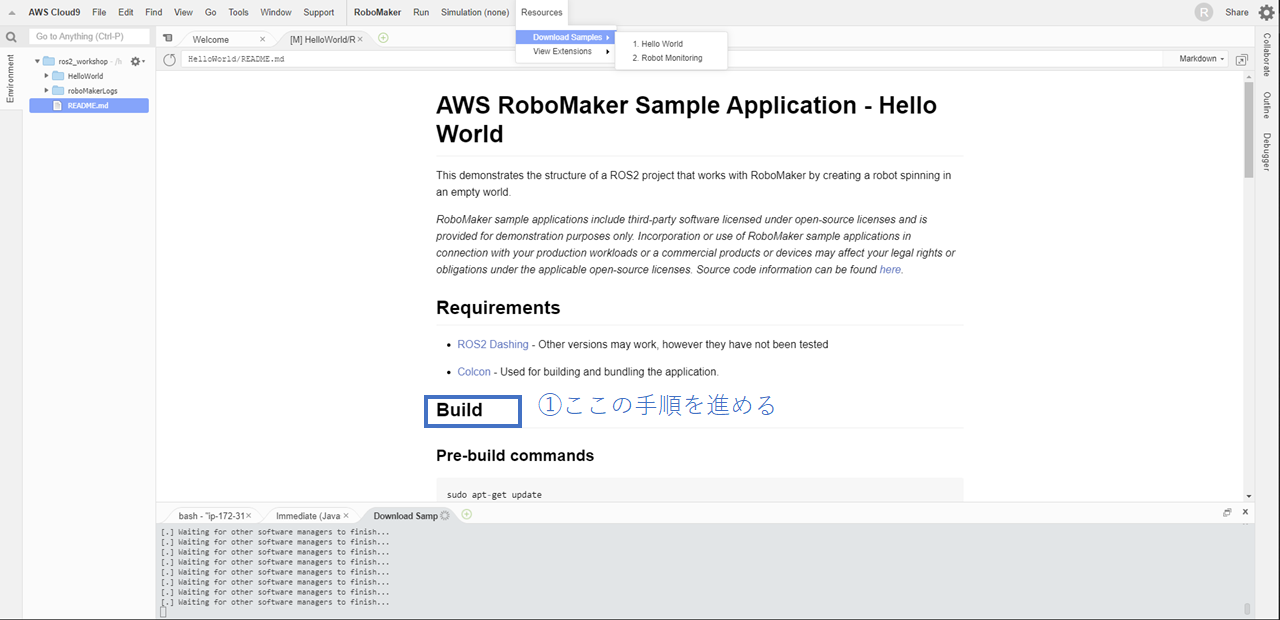
4. Hello Worldチュートリアルのコンフィグレーションを行う
コンフィギュレーションはCloud9の下部にあるbash shellで行ってください.
内容は以下の通りです。
sudo apt-get update rosdep update cd robot_ws rosws update rosdep install --from-paths src --ignore-src -r -y colcon build Simulation cd simulation_ws rosws update rosdep install --from-paths src --ignore-src -r -y colcon build5. /HelloWorld/robot_ws/src/hello_world_robot/srcのrotate.pyを適当に編集する
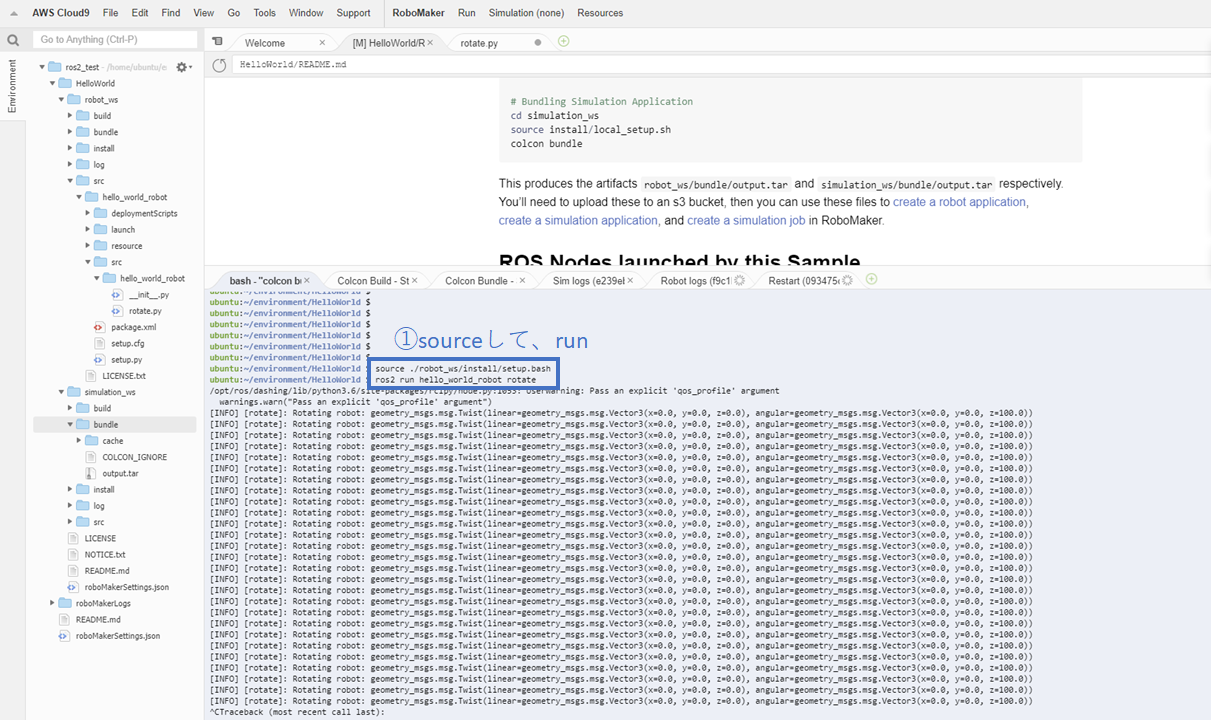
6. ターミナル(Cloud 9上)で実行する
まとめ
今回は実行環境の構築と確認だけ行いましたが、今後はシミュレーションジョブを追加してgazeboとかを試していきたいと思います。すごく簡単にできるのでawsのアカウントを持っている人はぜひ一度試してみて下さい!
- 投稿日:2019-12-14T18:19:13+09:00
Amazon SESのアカウントが止められちゃった話
この記事は本番環境でやらかしちゃった人のアドベントカレンダー14日目の記事です。
多少フェイクを入れているので整合性のおかしい部分があってもご了承ください。
https://qiita.com/advent-calendar/2019/yarakashi-production背景
- モバイル版だけでMAUxx万人のそこそこの規模の多きいサービス。Android/iOS/Webの3プラットフォームで提供。
- 開発元が撤退済みで、運営元から協力を依頼されとりあえずWeb以外の面倒を見ることに。2社にバラバラに頼んでいたようで、なぜか変なところでAWS環境が2つに別れている。
- 色々と設計が荒く、ドキュメントもないのでアプリの追加開発の片手間でアーキテクチャの全容把握と改善計画を練っている途中の状況
- 新規登録時の確認メール、パスワード再発行メールでAWS SESを利用していた。メール利用はそれだけと認識していた。
- なおAWSのサポートプランは無し
事件発生
(一日目)
運用開始時からユーザからの問い合わせに返答していただいている会社の方から連絡あり
運用担当「毎日問い合わせ内容のCSVがメールで届くのですが、今日はきていないようです。確認お願いします。」 私「(そんな運用になっていたのか・・・)調査します」 ...調査結果 問い合わせ内容テーブルから毎日レコードを取り出してCSVにしメール添付送信しているLambdaを発見 試しに実行してみたがメールは飛ばず。定時も過ぎていたので調査は後回しにして取り急ぎSlackに転送するように改修。 私「Slackのほうに転送するように改修しました。送信できなくなっている件については翌日調査します」 一日目 終(二日目)
運用元から連絡あり
運用元「パスワード再発行のメールが届かないと問い合わせが来ているのですが、確認お願いします」 私「(メールの問題が続くな...嫌な予感が...)調査します」 ...数分後 私「Status...SHUTDOWN...?!」 私「メール全停止してます!パスワードリセットどころか新規登録もできません!」 運用元「え、2日後からデカい広告打つんですかど・・・」 私「え?」SESの状況
bounce管理一切されてなかった。
SESにおけるbounce管理の重要性については他の方の記事をご参考ください。
https://qiita.com/KeijiYONEDA/items/5e810d1f07392ab51d22
https://qiita.com/Yoshi_T/items/b12c74b6af09df05dff3こちらはもう手遅れでBounce Rate 13%でStatusがSHUTDOWNになってました。
何が起こったか
普通は止められる前にAWSから警告メールが来るんですが、
連絡先が撤退した開発元のままで、変えてもらうのを忘れてました。
まぁ転送とかしてくれないですよね。喧嘩別れっぽいし。数週間前
- Web側の問い合わせフォームに@qq.com ドメインのアドレスで大量スパム投稿を受ける。
- 実はWebの問い合わせの受理確認(?)メールにも同じSESを使っていた
- AWSから「君のところのSESレビュー対象にしたよー。ちゃんと対策しないとSES止めるね」と、開発元に届く
参考:問い合わせフォームに大量スパム。「qq.com」のスパムを対策しました
第一報時
- 再度スパム
- AWSから止めたわとういう激おこメールが開発元に届く
対応
SES回復方法
- 再開のためにはAWSに見直しリクエストを送る必要あり。
- ただし、問題の根本解決を行わないと再開は許可されない
https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/e-faq.html#e-faq-sp
Q7.見直しのリクエストをするにはどうすればよいですか? 見直しをリクエストするには、AWS アカウントに関連付けられたメールアドレスから ses-review@amazon.com に E メールでご連絡ください。。 重要 アカウントのセキュリティを保護するために、Amazon が対応できるリクエストは AWS アカウントに関連付けられた E メールアドレスから送信されたものに限られます。 リクエストで以下の情報が提供します。 この問題の原因に関する情報。 問題修正のために行った変更のリスト。実装済みのステップのみを含め、今後実装する予定のステップは含めないでください。 これらの変更により今後どのように同じ問題の再発が防止されるかに関する情報。 アカウントの E メール送信機能が一時停止となったイベントの性質によっては、追加情報を提出していただく場合があります。リクエストに含める情報のリストについては、発生した問題に関する、よくある質問のトピックを参照してください。とりあえずごまかしメール
Web側はどこの会社も面倒をみていない完全放置状態で、今から面倒を見るような契約結んでreCAPTCHA入れる改修をして。。とかやっていたら間に合わないと判断。
ses-review@amazon.comにメール 私「AWSさんへ メール送信バッチの設定を間違って無効なメーリスに大量にメールおくってbounceが上がっちゃいました。」 私「バッチも止めたし、bounceをハンドリングする仕組みも入れたので許してください」 ...30時間後 AWS「いや問い合わせフォームにスパム送られたのが原因だから。ちゃんとreCAPTCHAとか入れてね。詳細な情報も送るね」 私「ちゃんと見てる!しかも親切! でも今は嬉しくないし、レスポンスめっちゃ遅い!」どうしたか
SESをあきらめて別のサービスに登録して切り替えました。作業時間2時間ぐらい。
広告配信にはギリギリ間に合いました。復旧まで登録できなかったユーザさんごめんなさい。mailgunとかsendgredとか、bounce管理しなくてもいいし、設定も簡単だし、そんなにお高くなくていいですよね。
ちなみにmailgunだと色々やらないとhotmailとかyahooメールに弾かれますがそれはまた別の話。
https://www.mailgun.com
https://sendgrid.kke.co.jp/何を学ぶか
- AWSのアカウントに登録してあるアドレスは、システム運営する人(特にエンジニア)に送られるように真っ先に変更してもらうこと。
- 引き継いだシステムは、たとえ進捗が無いと見られても現状調査を最優先しリスクを洗い出すこと。
- SESのbounce管理はちゃんとやる。もしくは使わない。使わないほうが楽な場合も多い。
- 問い合わせフォームにはreCAPTCHA等スパムが送られない仕組みを入れる。
- ビジネスインパクトの大きいサービスはすぐに対応してもらえるようにAWSのサポートプランに入る。
最後に
ありきたりな学びになってしまいましたが、1つ1つ、すべてちゃんとやりましょう。。という話でした。
- 投稿日:2019-12-14T18:19:13+09:00
[AWS] Amazon SESのアカウントが止められちゃった話
この記事は本番環境でやらかしちゃった人のアドベントカレンダー14日目の記事です。
多少フェイクを入れているので整合性のおかしい部分があってもご了承ください。
https://qiita.com/advent-calendar/2019/yarakashi-production背景
- モバイル版だけでMAUxx万人のそこそこ規模の大きいサービス。Android/iOS/Webの3プラットフォームで提供。
- 開発元が撤退済みで、運営元から協力を依頼されとりあえずWeb以外の面倒を見ることに。2社にバラバラに開発を頼んでいたようで、なぜか変なところでAWS環境が2つに別れている。
- 色々と設計が荒く、ドキュメントもないのでアプリの追加開発の片手間でアーキテクチャの全容把握と改善計画を練っている途中の状況
- 新規登録時の確認メール、パスワード再発行メールでAWS SESを利用(メール利用はそれだけと認識していた)
- なおAWSのサポートプランは無し
事件発生
(一日目)
運用開始時からユーザからの問い合わせに返答していただいている会社の方から連絡あり
運用担当「毎日問い合わせ内容のCSVがメールで届くのですが、今日はきていないようです。確認お願いします。」 私「(そんな運用になっていたのか・・・)調査します」 ...調査結果 問い合わせ内容テーブルから毎日レコードを取り出してCSVにしメール添付送信しているLambdaを発見 試しに実行してみたがメールは飛ばず。 定時も過ぎていたので調査は後回しにして取り急ぎSlackに転送するように改修。 私「Slackのほうに転送するように改修しました。」 私「送信できなくなっている件については翌日調査します。」 一日目 終(二日目)
運営元から連絡あり
運営元「パスワード再発行のメールが届かないと問い合わせが来ているのですが、確認お願いします」 私「(メールの問題が続くな...嫌な予感が...)調査します」 ...数分後 私「Status...SHUTDOWN...?!」 私「メール全停止してます!パスワードリセットどころか新規登録もできません!」 運営元「え、2日後からデカい広告打つんですけど...」 私「え?」SESの状況
bounce管理一切されてなかった。
SESにおけるbounce管理の重要性については他の方の記事をご参照ください。
https://qiita.com/zaru/items/4be9b55ba807670cf224
https://qiita.com/KeijiYONEDA/items/5e810d1f07392ab51d22
https://qiita.com/Yoshi_T/items/b12c74b6af09df05dff3こちらはもう手遅れでBounce Rate 13%でStatusがSHUTDOWNになってました。
何が起こったか
普通は止められる前にAWSから警告メールが来るんですが、
連絡先が撤退した開発元のままで、変えてもらうのを忘れてました。
まぁ転送とかしてくれないですよね。喧嘩別れっぽいし。数週間前
- Web側の問い合わせフォームに@qq.com ドメインのアドレスで大量スパム投稿を受ける。
- 実はWebの問い合わせの受理確認(?)メールにも同じSESを使っていた
- AWSから「君のところのSESレビュー対象にしたよー。ちゃんと対策しないとSES止めるね」と、開発元に届く
参考:問い合わせフォームに大量スパム。「qq.com」のスパムを対策しました
第一報時
- 再度スパム
- AWSから止めたわとういう激おこメールが開発元に届く
対応
SES回復方法
- 再開のためにはAWSに見直しリクエストを送る必要あり。
- ただし、問題の根本解決を行わないと再開は許可されない
https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/e-faq.html#e-faq-sp
Q7.見直しのリクエストをするにはどうすればよいですか? 見直しをリクエストするには、AWS アカウントに関連付けられたメールアドレスから ses-review@amazon.com に E メールでご連絡ください。。 重要 アカウントのセキュリティを保護するために、Amazon が対応できるリクエストは AWS アカウントに関連付けられた E メールアドレスから送信されたものに限られます。 リクエストで以下の情報が提供します。 この問題の原因に関する情報。 問題修正のために行った変更のリスト。実装済みのステップのみを含め、今後実装する予定のステップは含めないでください。 これらの変更により今後どのように同じ問題の再発が防止されるかに関する情報。 アカウントの E メール送信機能が一時停止となったイベントの性質によっては、追加情報を提出していただく場合があります。リクエストに含める情報のリストについては、発生した問題に関する、よくある質問のトピックを参照してください。とりあえずごまかしメール
Web側はどこの会社も面倒をみていない完全放置状態で、
今から面倒を見るような契約結んでreCAPTCHA入れる改修をしてまたAWSにメールして。。
とかやっていたら間に合わないと判断。とりあえずすっとぼけてバッチせいってことにしてメールしてみました。
が、だめでした。ses-review@amazon.comにメール 私「AWSさんへ メール送信バッチの設定を間違って無効なメーリスに大量にメールおくってbounceが上がっちゃいました。」 私「バッチも止めたし、bounceをハンドリングする仕組みも入れたので許してください」 ...30時間後 AWS「いや問い合わせフォームにスパム送られたのが原因だから。ちゃんとreCAPTCHAとか入れてね。詳細な情報も送るね」 私「ちゃんと見てる!しかも親切! でも今は嬉しくないし、レスポンスめっちゃ遅い!」どうしたか
SESをあきらめて別のサービスに登録して切り替えました。切り替えの作業時間2時間ぐらい。
広告配信にはギリギリ間に合いました。復旧まで登録できなかったユーザさんごめんなさい。
Webの問い合わせフォームは放置しました。受領確認メールはなくてもいいですよね。mailgunとかsendgridとか、bounce管理しなくてもいいし※1、設定も簡単だし、そんなにお高くなくていいですよね。
ちなみにmailgunだと色々やらないとhotmailとかyahooメールに弾かれますがそれはまた別の話※2。
https://www.mailgun.com
https://sendgrid.kke.co.jp/※1 「しなくていい」は語弊がありましたすみません。(たしか)SESはサプレッションリスト入りしたアドレスへの送信リクエストがbounce扱いだけど他は違ったので楽だったと記憶しています、あと管理も諸々楽という感じです。
※2 ちょうど闇のカレンダーのほうでレピュテーションの記事を書いていただいているようなのでそちらをご参照ください
メールというインターネットの闇とIPレピュテーション(だけど重要)(前編)何を学ぶか
- AWSのアカウントに登録してあるアドレスは、システム運営する人(特にエンジニア)に送られるように真っ先に変更してもらうこと。
- 引き継いだシステムは、たとえ進捗が無いと見られても現状調査を最優先しリスクを洗い出すこと。(理想論ですが)
- SESのbounce管理はちゃんとやる。もしくは使わない。使わないほうが楽な場合も多い。
- 問い合わせフォームにはreCAPTCHA等スパムが送られない仕組みを入れる。
- AWSのサポートプランにはちゃんと入ろう。
最後に
ありきたりな学びになってしまいましたが、1つ1つちゃんとやりましょう。。という話でした。
周りのエンジニアの方々には切替時に色々なアドバイスいただき、大変助かりました。ありがとうございました。
- 投稿日:2019-12-14T18:17:44+09:00
AWS Amplify標準ではないバージョンのhugoでビルドする。
Are you ready?
hugoのテーマを変更した後、localhostでは機嫌よく動いていたhugoがAWS Amplifyでビルドすると失敗した。
↓動かしたビルド。
amplify.ymlversion: 0.1 frontend: phases: build: commands: - echo $(hugo version) - hugo artifacts: baseDirectory: docs files: - '**/*' cache: paths: []↓結果
# Starting phase: build 2019-12-12T07:47:12.672Z [INFO]: # Executing command: echo Hugo Static Site Generator v0.55.6-A5D4C82D linux/amd64 BuildDate: 2019-05-18T07:56:30Z 2019-12-12T07:47:12.699Z [INFO]: Hugo Static Site Generator v0.55.6-A5D4C82D linux/amd64 BuildDate: 2019-05-18T07:56:30Z 2019-12-12T07:47:12.701Z [INFO]: # Executing command: hugo 2019-12-12T07:47:12.814Z [INFO]: ERROR 2019/12/12 07:47:12 HUGO-THEME-DREAM theme does not support Hugo version 0.55.6. Minimum version required is 0.57.2 Building sites … 2019-12-12T07:47:13.006Z [INFO]: Total in 192 ms 2019-12-12T07:47:13.007Z [WARNING]: Error: Error building site: logged 1 error(s) 2019-12-12T07:47:13.009Z [ERROR]: !!! Build failed 2019-12-12T07:47:13.009Z [ERROR]: !!! Non-Zero Exit Code detected 2019-12-12T07:47:13.009Z [INFO]: # Starting environment caching... 2019-12-12T07:47:13.010Z [INFO]: # Environment caching completed Terminating logging...どうもAmplifyで動いているhugoのパッケージが古く、
変更したテーマが新しいバージョンのhugoじゃないと動かないようだ。AmplifyはAWSマネージドのサービスだし、標準パッケージが古いんじゃどうしようもない… なんてことはない。
さぁ、実験をはじめようか。
Amplifyのコンソールより、【アプリの設定】→【ビルドの設定】→【Build image settings
】の【Edit】を選択すると以下画面が出てくる。
【Add Package version override】より、Amplifyが用意しているパッケージのlatestバージョンを選ぶことが出来る。
これで、一番新しいバージョンのhugoでビルド出来るようになる。
# Starting phase: build 2019-12-12T09:14:58.530Z [INFO]: # Executing command: echo Hugo Static Site Generator v0.61.0-9B445B9D linux/amd64 BuildDate: 2019-12-11T08:27:34Z 2019-12-12T09:14:58.578Z [INFO]: Hugo Static Site Generator v0.61.0-9B445B9D linux/amd64 BuildDate: 2019-12-11T08:27:34Z # Executing command: hugo 2019-12-12T09:14:58.615Z [INFO]: Building sites … ifact is: 239MB 019-12-12T09:13:42.527Z [INFO]: Git SSH Key acquired 2019-12-12T09:13:42.633Z [INFO]: # Cloning repository: git@github.com:xxxx/xxxx.git 2019-12-12T09:13:42.782Z [INFO]: Agent pid 68 2019-12-12T09:13:42.788Z [INFO]: Identity added: /root/.ssh/git_rsa (/root/.ssh/git_rsa) 2019-12-12T09:13:43.078Z [INFO]: Cloning into 'hugo7'... 2019-12-12T09:13:43.893Z [INFO]: Warning: Permanently added the RSA host key for IP address '13.114.40.48' to the list of known hosts. 2019-12-12T09:14:11.066Z [INFO]: # Checking for Git submodules at: /codebuild/output/src681934525/src/hugo7/.gitmodules 2019-12-12T09:14:11.184Z [INFO]: # Updating Git submodules... 2019-12-12T09:14:15.275Z [INFO]: # Retrieving cache... 2019-12-12T09:14:15.417Z [INFO]: # Extracting cache... 2019-12-12T09:14:15.428Z [INFO]: # Extraction completed 2019-12-12T09:14:15.428Z [INFO]: # Retrieving environment cache... 2019-12-12T09:14:15.473Z [INFO]: # Retrieved environment cache 2019-12-12T09:14:29.543Z [INFO]: # Ensuring Hugo is version: 'latest' 2019-12-12T09:14:29.545Z [INFO]: # Patching Hugo package from 0.55.6 to 0.61.0... 2019-12-12T09:14:34.110Z [INFO]: # Done patching Hugo # Starting phase: build 2019-12-12T09:14:58.530Z [INFO]: # Executing command: echo Hugo Static Site Generator v0.61.0-9B445B9D linux/amd64 BuildDate: 2019-12-11T08:27:34Z 2019-12-12T09:14:58.578Z [INFO]: Hugo Static Site Generator v0.61.0-9B445B9D linux/amd64 BuildDate: 2019-12-11T08:27:34Z # Executing command: hugo勝利の法則は決まった!
とはいえ、使えるバージョンが標準とlatestだけというのは、いささか不安が残る。
もしかしたらlatestバージョンに対応してないけど、Amplify標準では古すぎる…なんてこともあるかもしれない。そういう時はビルドをギュインギュインのズドドドドにしてみよう!
↓ギュインギュインのズドドドド
amplify.ymlversion: 0.2 frontend: phases: build: commands: - wget https://github.com/gohugoio/hugo/releases/download/v0.57.2/hugo_0.57.2_Linux-64bit.tar.gz - tar -xf hugo_0.57.2_Linux-64bit.tar.gz hugo - mv hugo /usr/bin/hugo - rm -rf hugo_0.57.2_Linux-64bit.tar.gz - echo $(hugo version) - hugo artifacts: baseDirectory: docs files: - '**/*' cache: paths: []参考元:Specifying Hugo Version on AWS Amplify
変更したテーマが対応しているhugo v0.57.2をwgetでコンテナにダウンロードし、
hugoというフォルダに解凍して、usr/binに移動(インストール)。
不要なファイルは削除してキレイキレイ。# Starting phase: build # Executing command: wget https://github.com/gohugoio/hugo/releases/download/v0.57.2/hugo_0.57.2_Linux-64bit.tar.gz 2019-12-13T01:30:03.833Z [WARNING]: --2019-12-13 01:30:03-- https://github.com/gohugoio/hugo/releases/download/v0.57.2/hugo_0.57.2_Linux-64bit.tar.gz 2019-12-13T01:30:03.838Z [WARNING]: Resolving github.com (github.com)... ~省略~ 2019-12-13T01:30:06.652Z [INFO]: # Executing command: tar -xf hugo_0.57.2_Linux-64bit.tar.gz hugo 2019-12-13T01:30:06.944Z [INFO]: # Executing command: mv hugo /usr/bin/hugo 2019-12-13T01:30:06.974Z [INFO]: # Executing command: rm -rf hugo_0.57.2_Linux-64bit.tar.gz 2019-12-13T01:30:06.997Z [INFO]: # Executing command: echo Hugo Static Site Generator v0.57.2-A849CB2D linux/amd64 BuildDate: 2019-08-17T17:54:13Z 2019-12-13T01:30:07.017Z [INFO]: Hugo Static Site Generator v0.57.2-A849CB2D linux/amd64 BuildDate: 2019-08-17T17:54:13Z 2019-12-13T01:30:07.018Z [INFO]: # Executing command: hugoヒャッホホホヒャッホイ!
無事にv0.57.2でビルド出来た。
こちらを応用してAmplify標準以外のパッケージをインストールできるので、
思っている以上に柔軟なマネージドサービスだね。

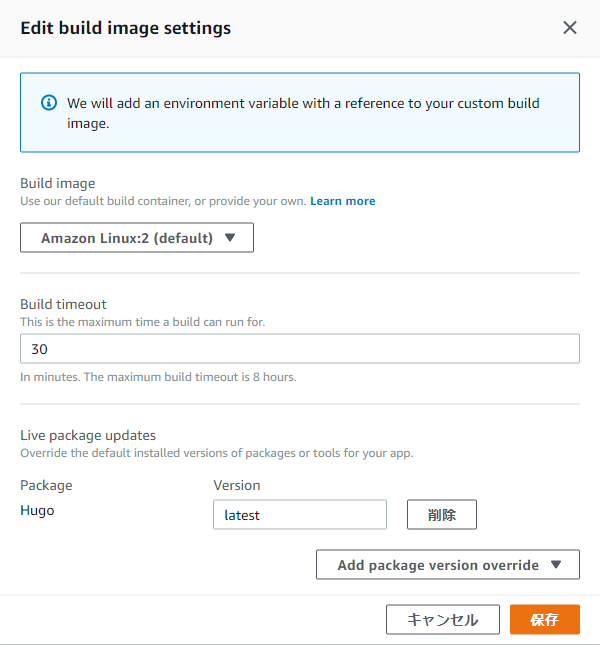
- 投稿日:2019-12-14T18:06:08+09:00
AWS初心者の備忘録 WEBアプリを構築②(インターネットゲートウェイとルートテーブル編)
業務でAWSを使うことになったのですが、初めて触るため、学んだことを備忘録として残します。
(間違っている可能性もありますがご了承下さい・・)
勉強しながら、すこしづつ実践し、WEBアプリケーションを構築してみます。
今回はインターネットゲートウェイとルートテーブルです!AWS初心者の備忘録 WEBアプリを構築①(VPCとサブネット編)
インターネットゲートウェイって?
VPC(プライベートネットワーク)からインターネットに出ていくための出入口。
各VPCに一つだけアタッチできる。
ルートテーブルでインターネットゲートウェイに向けて、パブリックサブネットにしたりする。ルートテーブルって?
どこに通信するのかをルール化してコントロールするもの?
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/VPC_Route_Tables.html#RouteTables実際に作ってみる
インターネットゲートウェイの作成
①AWSのマネジメントコンソール画面から検索「VPC」と入力し、クリックします
②左のサイドバーから「インターネットゲートウェイ」を選択します
③「インターネットゲートウェイの作成」を押下します
④「名前タグ」に適当に名前をきめて入力し「作成」を押下します。
おわり!!!早wwインターネットゲートウェイをVPCにアタッチする
①インタネットゲートウェイの一覧から作成したものにチェックをつけて、「アクション」から「VPCにアタッチする」を選択します。
②アタッチするVPCを選択して「アタッチ」します。ルートテーブルの作成
①AWSのマネジメントコンソール画面から検索「VPC」と入力し、クリックします
②左のサイドバーから「ルートテーブル」を選択します
③「ルートテーブルの作成」を押下します
④「名前タグ」に適当に名前をきめて入力し、VPCを選択して「作成」を押下します。ルートテーブルのサブネットの関連付け
①インタネットゲートウェイの一覧から作成したものにチェックをつけて、画面下の「サブネットの関連付け」のタブを選択し、「サブネットの関連付けを編集」を押下します。
②一覧からサブネットを選択して、紐づけを行います。
ひとつのルートテーブルを複数のサブネットに紐づけることはできますが、複数のルートテーブルをひとつのサブネットに紐づけることはできません。ルート編集(インターネットゲートウェイの設定)
①インタネットゲートウェイの一覧から作成したものにチェックをつけて、画面下の「ルート」のタブを選択し、「ルートの編集」を押下します。
②「ルートの追加」を押下します。
③InternetGatewayをターゲットに選択し、送信先に「0.0.0.0/0」を設定します。
これでパブリックサブネットの作成完了です。
以上、ありがとうございました。


- 投稿日:2019-12-14T17:37:41+09:00
Angular Universal on AWS Lambda + S3で快適SSR対応Webアプリ開発
この記事は、Angular #2 Advent Calendar 2019 20日目の記事です。
こんにちは。@seapolis です。初めてのアドベントカレンダーで大変緊張しております。
もうあと数日でクリスマスですが、まだまだクリスマスパーティで交換するプレゼントが決まっていらっしゃらない方も多いと思います。
そこで今回は、クリスマスプレゼントとして喜ばれること間違いなしの、Angular Universalアプリのレシピをご紹介したいと思います。そもそもAngular Universalって?
Angular Universalのことをご存じない方も多いと思いますので、ここで少しばかりご紹介させていただきたいと思います。
Angular Universalは、めっちゃ雑に平たく言うとAngular版のNuxt.jsです。
Nuxt.jsは、Vue.jsに様々な機能をくっつけたフレームワークで、目玉機能としてServer Side Rendering(以下SSR)機能があります。ご存じの通りVue.jsやAngularはSingle Page Application(以下SPA)を製作するためのフレームワークですが、ただのSPAの場合、ブラウザのJavascriptでHTML構造を構築するため、初期表示に時間がかかる、SEOに弱い、などの欠点がありました。
そこで登場したのがSSRという技術で、ブラウザ側でHTML構造を構築するのではなく、別に建てたNodeサーバーであらかじめHTML構造を構築しておいて、できたHTMLファイルを丸ごとブラウザに返すことで、SPAのUXを保ちつつ、以上の欠点を回避することができます。Nuxt.jsは、このSSR機能を目玉として標準搭載しています。開発時もvueファイルを変更したらオートリロードしてくれるので、開発者はSSRであることを意識することなく、ただのSPAのような感覚で開発を進めることができ、大変人気があるようです。
そのSSR機能をAngularアプリに適用するためのライブラリが、Angular Universalなのです。
Angular Universalプロジェクトの作り方
https://angular.jp/guide/universal
Angular Universalは、このようにAngular公式に一応適用方法が書いてありますが、この内容を実行しただけだとNuxt.jsのようなホットリロード機能が使えなくなり、ファイルを書き換えるたびにnpm run build:ssr && npm run serve:ssrしなければならず、開発体験が最悪になります。そこで、Angular Universalを使用するための種々様々な設定をすでにセッティング済みで、かつホットリロード機能が使えるようにセッティングされている、@enten/angular-universalというボイラープレートを用います。
README.mdに記載されている通り、
$ git clone https://github.com/enten/angular-universal $ cd angular-universal $ npm install $ ng serveで起動します。めちゃくちゃ簡単にAngular Universalアプリを起動することができました。
構成
srcフォルダの中身を見ていきましょう。
src ├ api <-- SSR用サーバーのAPIルーティング設定 ├ app ├ assets ├ environments ├ favicon.ico ├ index.html ├ main.ts ├ polyfill.ts ├ server.ts <-- SSR用サーバーの立ち上げを行っている ├ styles.scss └ test.tsなんか見たことあるファイル・フォルダ群の中に、apiフォルダとserver.tsが追加されていることがわかります。
server.ts// These are important and needed before anything else import 'zone.js/dist/zone-node'; import 'reflect-metadata'; import { createServer } from 'http'; import { join } from 'path'; import { enableProdMode } from '@angular/core'; import { NgSetupOptions } from '@nguniversal/express-engine'; import { MODULE_MAP } from '@nguniversal/module-map-ngfactory-loader'; import { ServerAPIOptions, createApi } from './api'; import { environment } from './environments/environment'; // WARN: don't remove export of AppServerModule. // Removing export below will break replaceServerBootstrap() transformer export { AppServerModule } from './app/app.server.module'; // Faster server renders w/ Prod mode. // Prod mode isn't enabled by default because that breaks debugging tools like Augury. if (environment.production) { enableProdMode(); } export const PORT = process.env.PORT || 4000; export const BROWSER_DIST_PATH = join(__dirname, '..', 'browser'); export const getNgRenderMiddlewareOptions: () => NgSetupOptions = () => ({ bootstrap: exports.AppServerModuleNgFactory, providers: [ // Import module map for lazy loading { provide: MODULE_MAP, useFactory: () => exports.LAZY_MODULE_MAP, deps: [], }, ], }); export const getServerAPIOptions: () => ServerAPIOptions = () => ({ distPath: BROWSER_DIST_PATH, ngSetup: getNgRenderMiddlewareOptions(), }); let requestListener = createApi(getServerAPIOptions()); // Start up the Node server const server = createServer((req, res) => { requestListener(req, res); }); server.listen(PORT, () => { console.log(`Server listening -- http://localhost:${PORT}`); }); // HMR on server side if (module.hot) { const hmr = () => { try { const { AppServerModuleNgFactory } = require('./app/app.server.module.ngfactory'); exports.AppServerModuleNgFactory = AppServerModuleNgFactory; } catch (err) { console.warn(`[HMR] Cannot update export of AppServerModuleNgFactory. ${err.stack || err.message}`); } try { requestListener = require('./api').createApi(getServerAPIOptions()); } catch (err) { console.warn(`[HMR] Cannot update server api. ${err.stack || err.message}`); } }; module.hot.accept('./api', hmr); module.hot.accept('./app/app.server.module', hmr); module.hot.accept('./app/app.server.module.ngfactory', hmr); } export default server;server.tsでは、SSR用のサーバーの立ち上げが行われています。ポート番号4000でリッスンされているのがわかります。
主にapp.server.module.tsで読み込まれている各種モジュール・コンポーネント群をビルドした成果物を、URLに応じて返すのが役割ですが、中身はexpress.jsになっているため、カスタマイズすることでこれをBFF層として利用することができます。api/index.tsimport { NgSetupOptions, ngExpressEngine } from '@nguniversal/express-engine'; import * as express from 'express'; export interface ServerAPIOptions { distPath: string; ngSetup?: NgSetupOptions; } export function createApi(options: ServerAPIOptions) { const router = express(); router.use(createNgRenderMiddleware(options.distPath, options.ngSetup)); return router; } export function createNgRenderMiddleware(distPath: string, ngSetup: NgSetupOptions) { const router = express(); router.set('view engine', 'html'); router.set('views', distPath); // Server static files from distPath router.get('*.*', express.static(distPath)); // Angular Express Engine router.engine('html', ngExpressEngine(ngSetup)); // All regular routes use the Universal engine router.get('*', (req, res) => res.render('index', { req, res })); return router; }express.jsを触ったことがある方ならば、比較的簡単にカスタマイズすることができるのではないかと思います。
例えば、createApiメソッドに対し、以下のようにapi/index.tsrouter.get('/api/*', (req, res, next) => { res.json(req.url); }); router.use(createNgRenderMiddleware(options.distPath, options.ngSetup));ルーティング設定を追加すれば、
<ドメイン>/api/<任意のパス>にアクセスした時、そのパスをbodyとして返すルートを作成できます。マイクロサービスへのプロキシとして本来のBFF的用途に用いるもよし、認可サーバーのクライアントとして使うもよし、express.jsでできることならば使い方は無限大ですね!
AWS Lambdaで立ち上げよう
と、ここまでAngular Universalをざっくりご紹介してきましたが、本番運用できなければ意味がありませんので、ここからはAWS LambdaでAngular Universalを立ち上げる方法をご紹介していきたいと思います。
先ほど、「Angular UniversalはSSR用サーバーにexpress.jsが使われている」とご説明しました。ということは、AWS LambdaへのデプロイにServerless Frameworkが使えるのです!
準備
あらかじめ、AWSアカウントを用意の上、aws-cliをインストールし、administrator権限が使えるIAMアカウントでログインしておいてください。
続いて、npmで
aws-serverless-expressをインストールします。$ npm i aws-serverless-expressServerless Frameworkを利用して、lambda上でexpressサーバーを動かすためのライブラリです。
また、Serverless Framework本体もdevDependenciesとしてインストールします。
$ npm i -D serverlessserver.tsを書き換える
次に、server.tsに4行だけコードを付け足します。
server.ts// These are important and needed before anything else import 'zone.js/dist/zone-node'; import 'reflect-metadata'; import { createServer } from 'http'; import { join } from 'path'; import { enableProdMode } from '@angular/core'; import { NgSetupOptions } from '@nguniversal/express-engine'; import { MODULE_MAP } from '@nguniversal/module-map-ngfactory-loader'; import { ServerAPIOptions, createApi } from './api'; import { environment } from './environments/environment'; import * as awsServerlessExpress from 'aws-serverless-express'; // <-- 追加 // WARN: don't remove export of AppServerModule. // Removing export below will break replaceServerBootstrap() transformer export { AppServerModule } from './app/app.server.module'; // Faster server renders w/ Prod mode. // Prod mode isn't enabled by default because that breaks debugging tools like Augury. if (environment.production) { enableProdMode(); } export const PORT = process.env.PORT || 4000; export const BROWSER_DIST_PATH = join(__dirname, '..', 'browser'); export const getNgRenderMiddlewareOptions: () => NgSetupOptions = () => ({ bootstrap: exports.AppServerModuleNgFactory, providers: [ // Import module map for lazy loading { provide: MODULE_MAP, useFactory: () => exports.LAZY_MODULE_MAP, deps: [], }, ], }); export const getServerAPIOptions: () => ServerAPIOptions = () => ({ distPath: BROWSER_DIST_PATH, ngSetup: getNgRenderMiddlewareOptions(), }); let requestListener = createApi(getServerAPIOptions()); const render = awsServerlessExpress.createServer(requestListener); // <-- 追加 export const handler = (event, context) => // <-- 追加 awsServerlessExpress.proxy(render, event, context); // <-- 追加 // Start up the Node server const server = createServer((req, res) => { requestListener(req, res); }); server.listen(PORT, () => { console.log(`Server listening -- http://localhost:${PORT}`); }); // HMR on server side if (module.hot) { const hmr = () => { try { const { AppServerModuleNgFactory } = require('./app/app.server.module.ngfactory'); exports.AppServerModuleNgFactory = AppServerModuleNgFactory; } catch (err) { console.warn(`[HMR] Cannot update export of AppServerModuleNgFactory. ${err.stack || err.message}`); } try { requestListener = require('./api').createApi(getServerAPIOptions()); } catch (err) { console.warn(`[HMR] Cannot update server api. ${err.stack || err.message}`); } }; module.hot.accept('./api', hmr); module.hot.accept('./app/app.server.module', hmr); module.hot.accept('./app/app.server.module.ngfactory', hmr); } export default server;serverless.ymlを作成する
プロジェクトのルートディレクトリに、Serverless Frameworkで使用する設定ファイルである、
serverless.ymlを作成します。serverless.ymlservice: ng-univ-lambda-template # lambda関数につけられるサービス名 provider: name: aws runtime: nodejs10.x stage: ${env:STAGE} region: ap-northeast-1 environment: STAGE: ${env:STAGE} NODE_ENV: ${env:NODE_ENV} iamRoleStatements: - Effect: 'Allow' Action: - 'lambda:InvokeFunction' Resource: - Fn::Join: - ':' - - arn:aws:lambda - Ref: AWS::Region - Ref: AWS::AccountId - function:${self:service}-${opt:stage, self:provider.stage}-* package: exclude: - ./** - '!node_modules/**' include: - dist/app/** - package.json functions: render: handler: dist/app/server/main.handler events: - http: path: '/' method: get - http: path: '{proxy+}' method: get - http: path: '/api/{proxy+}' method: anyenvironment: STAGE: ${env:STAGE} NODE_ENV: ${env:NODE_ENV}
${env:xxx}としておくと、package.jsonに記入したnpmコマンドからserverlessコマンドを実行するときに、任意の値を注入することができます。package.jsonにデプロイコマンドを追加する
package.json"scripts": { "ng": "ng", "prestart": "npm run build:prod", "start": "node ./dist/app/server/main.js", "build": "ng build", "build:prod": "ng build -c production", "dev": "ng serve", "dev:spa": "ng serve -c spa", "test": "ng test", "lint": "ng lint", "e2e": "ng e2e", "deploy:dev": "STAGE=dev NODE_ENV=production sls deploy -v", "deploy:prod": "STAGE=prod NODE_ENV=production sls deploy -v" }scriptプロパティに、Lambdaデプロイ用のコマンドを追加します。
STAGE=devで、先ほどserverless.ymlで記述した${env:STAGE}の部分にdevを注入することになります。
つまり、実行するnpmコマンドによってデプロイするステージを書き分けることができるのです。実行してみる
ここまで終えたら、実際にAWS Lambdaへのデプロイを実行してみましょう。
$ npm run build:prod $ npm run deploy:prod以下のようなログがずらーっと流れて、最後に
Stack Outputsと表示されれば正常に完了しています。> angular-universal@0.0.0 deploy:prod /mnt/f/Documents/Program/angular-universal-aws-lambda-template > STAGE=prod NODE_ENV=production sls deploy -v Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service ng-univ-lambda-template.zip file to S3 (42.73 MB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... CloudFormation - UPDATE_IN_PROGRESS - AWS::CloudFormation::Stack - ng-univ-lambda-template-prod CloudFormation - UPDATE_IN_PROGRESS - AWS::Lambda::Function - RenderLambdaFunction CloudFormation - UPDATE_COMPLETE - AWS::Lambda::Function - RenderLambdaFunction CloudFormation - CREATE_IN_PROGRESS - AWS::Lambda::Version - RenderLambdaVersionElfmXkriWTVEnPo0XfUNZ1T1CVRpAuAdg2aokSEQoo CloudFormation - CREATE_IN_PROGRESS - AWS::ApiGateway::Deployment - ApiGatewayDeployment1576305173492 CloudFormation - CREATE_IN_PROGRESS - AWS::ApiGateway::Deployment - ApiGatewayDeployment1576305173492 CloudFormation - CREATE_IN_PROGRESS - AWS::Lambda::Version - RenderLambdaVersionElfmXkriWTVEnPo0XfUNZ1T1CVRpAuAdg2aokSEQoo CloudFormation - CREATE_COMPLETE - AWS::ApiGateway::Deployment - ApiGatewayDeployment1576305173492 CloudFormation - CREATE_COMPLETE - AWS::Lambda::Version - RenderLambdaVersionElfmXkriWTVEnPo0XfUNZ1T1CVRpAuAdg2aokSEQoo CloudFormation - UPDATE_COMPLETE_CLEANUP_IN_PROGRESS - AWS::CloudFormation::Stack - ng-univ-lambda-template-prod CloudFormation - DELETE_IN_PROGRESS - AWS::ApiGateway::Deployment - ApiGatewayDeployment1576304091991 CloudFormation - DELETE_SKIPPED - AWS::Lambda::Version - RenderLambdaVersionmvp3W8wvhJNl7SWlw0ZESTVimlL6FGADyblQJnjgLpY CloudFormation - DELETE_COMPLETE - AWS::ApiGateway::Deployment - ApiGatewayDeployment1576304091991 CloudFormation - UPDATE_COMPLETE - AWS::CloudFormation::Stack - ng-univ-lambda-template-prod Serverless: Stack update finished... Service Information service: ng-univ-lambda-template stage: prod region: ap-northeast-1 stack: ng-univ-lambda-template-prod resources: 15 api keys: None endpoints: GET - https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod/ GET - https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod/{proxy+} ANY - https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod/api/{proxy+} functions: render: ng-univ-lambda-template-prod-render layers: None Stack Outputs RenderLambdaFunctionQualifiedArn: arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:ng-univ-lambda-template-prod-render:14 ServiceEndpoint: https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod ServerlessDeploymentBucketName: ng-univ-lambda-template-serverlessdeploymentbuck-xxxxxxxxxxxx Serverless: Removing old service artifacts from S3... Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.
endpointsの一番上に表示されているアドレスがAPI Gatewayのアドレスになりますので、ここにアクセスして、かつてのAngularおなじみ初期表示画面が表示されればデプロイは成功です!
AWS CodePipeline + CodeBuildでデプロイを自動化してみよう
せっかくAWSを使うので、GitHubリポジトリにプッシュしたら自動でLambdaにデプロイする仕組みを作ってみましょう。
buildspec.ymlを作成する
CodeBuildで用いる設定ファイルであるbuildspec.ymlを用意します。
buildspec.ymlversion: 0.2 phases: install: runtime-versions: nodejs: 10 commands: - npm install build: commands: - npm run build:${DEPLOY_STAGE} post_build: commands: - npm run deploy:${DEPLOY_STAGE}CodeBuildの設定を行う
続いて、AWS マネジメントコンソールの画面にログインしてください。
CodeBuild -> ビルドプロジェクトの画面から、「ビルドプロジェクトを作成する」をクリックします。
作成画面に遷移しますので、以下のように入力してください。
- プロジェクト設定 - プロジェクト名 → 任意のもの
- 送信元 - ソース1 → ソースプロバイダをGitHubに設定し、OAuth接続して作成したご自分のリポジトリを選択
- 環境 - オペレーティングシステム → Amazon Linux 2
- 環境 - ランタイム → Standard
- 環境 - イメージ → x86_64のもの
- 環境 - サービスロール → 新しいサービスロール
- 環境 - ロール名 → 任意のもの
- 環境 - 追加設定 - 環境変数 → prodステージなら名前:DEPLOY_STAGE 値:prodとなるように設定
- Buildspec - ビルド仕様 → buildspecファイルを使用する
入力が完了したら、「ビルドプロジェクトを作成する」をクリックします。
このように作成されました。
そのままではビルドプロジェクトのサービスロールにAdministrator権限がないため、serverlessのdeployが通りません。
必ずAdministratorAccessポリシーを事前にアタッチしておいてください。
(本当は使うところのポリシーだけをアタッチするのがいいのですが、あまりにも多すぎて探すのが大変です)CodePipelineの設定を行う
CodePipeline -> パイプラインを作成する をクリックします。
- パイプライン名 → 任意のもの
- ロール名 → 任意のもの
- ソースプロバイダー → GitHubを選択し、「GitHubに接続する」をクリック。ご自分のリポジトリとブランチを選択
- プロバイダーを構築する → AWS CodeBuild
- プロジェクト名 → 先ほど作成したCodeBuildプロジェクトを選択
デプロイステージはスキップします。
パイプラインの作成が完了しました。同時にデプロイが始まっていますので、成功するか確認します。
これで、GitHubにプッシュしたら自動でLambdaにデプロイしてくれるようになりました!静的ファイルだけS3からホスティングする
この段階では、ブラウザ用の静的ファイルとサーバーがともにLambdaにデプロイされ、API Gatewayからホスティングされています。
それでも使えることは使えますが、前段にCloudFrontを噛ませたい場合、ブラウザ用の静的ファイルをS3でホスティングしたほうが何かと都合がよいので、そのような構成に作り替えてみます。S3バケットを作成
適当な名前でS3バケットを作成します。
作り方については省きます。buildspec.ymlを修正
buildspec.ymlversion: 0.2 phases: install: runtime-versions: nodejs: 10 commands: - npm install build: commands: - npm run build:${DEPLOY_STAGE} post_build: commands: - aws s3 rm s3://${BUCKET_NAME} --recursive # 追加 - aws s3 sync ./dist/app/browser s3://${BUCKET_NAME}/_angular # 追加 - npm run deploy:${DEPLOY_STAGE} - aws cloudfront create-invalidation --distribution-id ${DISTRIBUTION_ID} --paths "/*" # 追加post_buildコマンドで、S3へのアップロードとCloudFrontのinvalidationを同時に行うように修正します。
angular.jsonを修正
angular.json"options": { "outputPath": "dist/app/browser", "deployUrl": "/_angular/", // <-- 追加 "index": "src/index.html", "main": "src/main.ts", "polyfills": "src/polyfills.ts", "tsConfig": "tsconfig.app.json", "assets": ["src/favicon.ico", "src/assets"], "styles": ["src/styles.scss"], "scripts": [] },HTML上での静的ファイルの読み込み先を
<URL>/_angular以下に変更するため、deployUrlプロパティを追加します。
これにより、CloudFrontの設定が楽に行えます。CloudFrontの設定を行う
再びAWS マネジメントコンソールに戻り、CloudFrontのDistributionを作成します。
- Origin Domain Name → デプロイ済みのAPI GatewayのステージのURL
その他の設定はお好みで大丈夫です。
作成が完了したら、Originを追加します。
- Origin Domain Name → 先ほど作成したS3バケットを選択
- Restrict Bucket Access → Yes
- Origin Access Identity → Create a New Identity
- Grant Read Permissions on Bucket → Yes, Update Bucket Policy
続いて、BehaviorsでS3バケットへのルーティングルールを追加します。
- Path Pattern → _angular/*
- Origin or Origin Group → 先ほど作成したS3へのOrigin
その他の設定はお好みで。
これでCloudFrontの設定は完了です。
先ほどangular.jsonに行ったdeployUrlの設定のため、ブラウザ用静的ファイルは/_angular以下に存在することになっています。
そこにアクセスしようとしたら、S3バケットからファイルを取ってくるように設定してやるというわけです。CodeBuild設定を修正する
S3バケット名とCloudFrontのDistribution名を環境変数に追加してやります。
以上が完了したら、再度CodePipelineを動かしてみて、成功することが確認出来たら完成です!あとがき
AngularでSSRを行うためのライブラリ、
Angular Universalと、それを使った開発環境をクローン一発で構築できる@enten/angular-universal、そしてビルド成果をAWS Lambdaにデプロイしてサーバーレスでホスティングする方法をご紹介しました。
あまりネット上にもベストプラクティス的な情報がなく、公式を見ても「めんどくさそう…」という感想を抱きがちなAngular Universalですが、今回ご紹介した方法で、比較的お手軽にAngular Universalの世界を体験できるのではないかと思います。SSRならではの初期表示速度の速さは感動ものです。ぜひ一度お試しあれ!
ソースコード
https://github.com/kaito3desuyo/angular-universal-aws-lambda-template
参考
- https://qiita.com/kobayashi-m42/items/fbacb46f7603e5a014d7 - Nuxt.js(SSR)をLambdaで配信する【個人開発】
- https://qiita.com/MasanobuAkiba/items/7adcfd5050150ac9ba36 - SSR の知識ゼロから始める Angular Universal
- https://github.com/enten/angular-universal - @enten/angular-universal












- 投稿日:2019-12-14T16:57:05+09:00
副業でTerraform化した時のお話
本記事は 個人開発 Advent Calendar 2019 19日目の記事です。
概要
11日目の記事 に引き続き、個人開発ではなく恐縮ではありますが、
副業で既存環境をTerraform化した時のお話を書かせて頂きます。背景
私が副業でお手伝いしたサービスのインフラ(AWS)環境は、コード管理ができていない状況で、メインで構築した人の頭の中と、一部ドキュメントにネットワーク構成だけ記載がある状態でした。
(ただ、これが悪かったとかいう話ではなく、会社のリソース状況や事業状況などから、そこまでする必要がなかったため)とはいえ、メインで構築した人の頭の中にしかないと、いざという時困るのでいつかはやりたいという話を聞いてました。
そして、一部の環境をEC2からFargateに移行しようとしていたのもあり、
そのタイミングで構築する環境はTerraformで構築しようということを決め、Terraform化に取り掛かりました。方針
ネットワークなどは既存環境とも関わるのと、運用慣れしていない状態で全てTerraform化するのは怖かったので、下記のような方針で進めてみました
- DB(RDS)やS3のような永続化機構はやめておこう
- 既存のネットワーク周りは、コード化はするが、planを実行しても差分が出ないようにしておこう
- それ以外で新しく構築するものは、なるべきTerraform化していこう
既存のネットワーク周り
既に本番で運用しているサービスでもあるので、ネットワーク周りを下手にいじるのは怖い、、、でもコード化しておきたい、、、そんな時に便利だったのが terraformingというツールでした。
このツールを使い、下記の作業を繰り返し、planを実行しても差分が出なくなるまでひたすら繰り返します(これがなかなかの辛い作業w)
tfファイルの作成$ terraforming <<対象resource。sgやaclなど>>
tfstateファイルの作成(or追記)$ terraforming <<対象resource>> --tfstate --merge=terraform.tfstate --overwrite
terraform planを実行し、差分が出たらtfファイルやtfstateファイルの修正この作業を実施したおかげ??で、現状はネットワーク周りもTerraformで作成・更新ができるようになりました。
新規構築
新しい環境を構築した際に迷ったのは、ディレクトリ構成でした。
インターネット上で調べると、色々な考え方があり、すごく迷いましたが(今でも迷っていますが)、
- 各アプリケーションの構成がそれぞれで異ならないので、何度も同じ記述をするのは避けたい → moduleを使って各アプリケーションの構築を簡単に作れるようにする
- test、staging、productionのように、各環境にアプリケーションを構築したい → workspaceを使って環境ごとの構築を簡単に作れるようにしよう!
となり、下記のような構成※にしてみました(一部抜粋)。
├── app │ └── <component directory> │ ├── _tfvars │ │ ├── prod.tfvars │ │ ├── README.md │ │ ├── staging.tfvars │ │ └── test.tfvars │ ├── config.tf │ ├── main.tf │ ├── remote-state.tf │ ├── task-definition.json │ └── variables.tf ├── modules │ ├── codebuild │ │ ├── iam.tf │ │ └── main.tf │ ├── codepipeline │ │ ├── iam.tf │ │ └── main.tf │ └── ecs │ ├── iam.tf │ ├── main.tf │ ├── sg.tf │ └── variable.tf ├── network │ ├── 各リソース系(vpc、subnet、aclなど) │ └── variables.tf ├── pipeline │ └── <component pipeline> │ ├── config.tf │ ├── main.tf │ └── variables.tf ├── .gitignore ├── .terraform-version # for managing terraform version ├── README.md └── secret.tfvars※「なんでそこ分けた?」などあるかもしれませんが、現状のネットワーク構成などに合わせたこともありこのような構成にしております。もしこういう構成にするともっと良いかも!などありましたら、ご教授いただけると嬉しいですmm
今回新しく構築したのは、
- ECS(Fargate)のアプリケーション環境を各環境毎に、かつアプリケーション毎に作れるようにする
- その際のCI/CD環境も各環境毎に、かつアプリケーション毎に作れるようにする
ということで、moduleにはCI/CD(CodeBuild/CodePipeline)とECSを置き、
アプリケーションはapp/<<component name>>/main.tfで下記のようにmoduleを使い、app/hogehoge/main.tf(一部抜粋)///// module "ecs" { source = "../../modules/ecs" // アプリケーション毎に必要な設定を記載 } ////CI/CDのパイプラインも
pipeline/<<component name/main.tfで下記のようにmoduleを使ってアプリケーション毎の環境を構築できるようにしてみました。pipline/hogehoge/main.tf(一部抜粋)///// ## Continuous Integration module "ci" { source = "../../modules/codebuild" // アプリケーション毎に必要な設定を記載 } ///// ## Continuous Delivery module "cd" { source = "../../modules/codepipeline" // アプリケーション毎に必要な設定を記載 } /////構築してみて
1個反省点としてあるのは、
各アプリケーション毎、かつ各環境毎に作れるようにしたけど、、、本当に各アプリケーション毎に構成同じにするんだっけ?というところです。
現状の環境は同じ構成でも、アプリケーションを移行する時には変わるのでは?ということをあまり考えずにこの環境にしたことが良かったかどうかは今のところわかりません。
ただ、後でリファクタリングする前提で、最初はコピペしてもしょうが無いからシンプルに作る!ということをもう少し意識しても良かったなと感じる今日この頃です><最後に
個人開発ではないですが、副業でTerraform化してみた話を書かせて頂きました。
Terraformの構成、もっと良い構成がある?とは思いつつこの構成にしておりますが、
もし「こういう構成だとより良いのでは?」などありましたら、是非アドバイスいただけると嬉しいです!!そして最後まで読んで頂きまして、誠にありがとうございましたmm
参考
- 投稿日:2019-12-14T15:43:41+09:00
AWS CDKを使ってCloudFrontとALBの環境構築をしてみた
はじめに
この記事はPlayground Advent Calender 2019の12/14の記事です。
初めまして。今年の春からPlaygroundでバックエンドをメインで勉強しているkikilsです。ここでは、ここ最近勉強しているAWS CDKというサービスについての知見を書いていきたいと思います。行ったこと
CDKでユーザーがECSにアクセスするときにCloudFrontを経由する仕組みを作りました。
AWS CDK(Cloud Development Kit)とは
今年の7月にGAされたばかりのサービスで、AWSのインフラを TypeScript などの言語を使って定義します。プログラムはAppとStackとConstructという概念で構成します。CDKプログラムを実行することで CloudFormation テンプレートを生成してそのテンプレートを使ってデプロイします。
仕組み
CloudFrontを経由しないALBへのアクセスを拒否するには、ALBのリクエストルーティング機能を使います。ALBのlistenerのルールに「Cloud Frontからのアクセスであるかどうかの判定をしたらECSに転送する」というルールを追加したうえで「それ以外のアクセスは403を返す」というルールもデフォルトアクションにすることで実現します。CloudFrontからのアクセスかどうかの判定は、httpヘッダを読み取り、User-agentがCloudFrontのものであるかとCloudFront側でカスタムヘッダを追加してそれが一致するかどうかを判定します。
コードを書いてみる
まず、FargateとCloudFontを構築するStackを定義します。
const app = new cdk.App(); const fargateStack = new FargateStack(app, `fargate`); new CloudFrontStack(app, `cloudfront`, { loadBalancer: fargateStack.loadBalancer, });次に、CloudFrontのStackを作成していきます。AWS CDKの公式APIレファレンスを参照すると
CloudFrontWebDistributionクラスがあるのでこれを用います。カスタムオリジンにはfargateStackで渡してあげたALBのDNSを指定しています。また、originProtocolPolicyをhttpにしていますが本番環境ではhttpsに変更したほうがよいです。カスタムヘッダには、任意の文字列を設定します。cloudFront-stack.tsinterface CloudFrontProps extends cdk.StackProps { loadBalancer: ApplicationLoadBalancer; } export class CloudFrontStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props: CloudFrontProps) { super(scope, id, props); new CloudFrontWebDistribution(this, `distribution`, { defaultRootObject: "", originConfigs: [ { customOriginSource: { domainName: props.loadBalancer.loadBalancerDnsName, originProtocolPolicy: OriginProtocolPolicy.HTTP_ONLY }, behaviors: [ { isDefaultBehavior: true } ], originHeaders: { ["x-pre-shared-key"]: "PRESHAREDKEY" } } ] }); } }次に、fargateを構築します。clusterとtaskDefinitionは各自で当ててください。
fargate-stack.tsexport class FargateStack extends cdk.Stack { public readonly loadBalancer: ApplicationLoadBalancer; const fargate = new ApplicationLoadBalancedFargateService( this, "apps", { cluster: cluster, taskDefinition: taskDefinition } ); const listener = fargate.listener.node.defaultChild as CfnListener; listener.defaultActions = [ { type: "fixed-response", fixedResponseConfig: { statusCode: "403", contentType: "text/html", messageBody: "<h1>403 Forbidden</h1>" } } ]; new CfnListenerRule(this, `listener`, { actions: [ { type: `forward`, targetGroupArn: fargate.targetGroup.targetGroupArn } ], conditions: [ { field: "http-header", httpHeaderConfig: { httpHeaderName: "User-agent", values: ["Amazon CloudFront"] } }, { field: "http-header", httpHeaderConfig: { httpHeaderName: "x-pre-shared-key", values: ["PRESHAREDKEY"] } } ], listenerArn: listener.ref, priority: 1 });説明
ApplicationLoadBalancedFargateServiceクラスはクラスターを作りALBとターゲットグループの接続をよしなにしてくれます。
- listenerのデフォルトアクションを変更する
CDKにはlistenerのデフォルトアクションを設定するパラメータがまだないので、CloudFormationに直接上書きできる
CfnListenerクラスを使います。実際に出力されるcloudformationのテンプレ―トは次のようになります。~~~~~~~~~~ "appsLBPublicListenerEC0E93DB": { "Type": "AWS::ElasticLoadBalancingV2::Listener", "Properties": { "DefaultActions": [ { "FixedResponseConfig": { "ContentType": "text/html", "MessageBody": "<h1>403 Forbidden</h1>", "StatusCode": "403" }, "Type": "fixed-response" } ], "LoadBalancerArn": { "Ref": "appsLB2B3DA679" }, "Port": 80, "Protocol": "HTTP" }, "Metadata": { "aws:cdk:path": "fargate/apps/LB/PublicListener/Resource" } } ~~~~~~~~~~このようにDefaultActionsが上書きされていることがわかります。
- Cloud Frontからのアクセスであるかどうかの判定をしたらECSに転送する
listenerと同じくCDKには
ApplicationListenerRuleというクラスが用意されていますがルールの条件にhttpヘッダがサポートされていないのでCloudformationを直に追加できるCfnListerRuleを使います。この時に出力されるテンプレートは次のようになります。~~~~~~~~~~ "listener": { "Type": "AWS::ElasticLoadBalancingV2::ListenerRule", "Properties": { "Actions": [ { "TargetGroupArn": { "Ref": "appsLBPublicListenerECSGroup7B961058" }, "Type": "forward" } ], "Conditions": [ { "Field": "http-header", "HttpHeaderConfig": { "HttpHeaderName": "User-agent", "Values": [ "Amazon CloudFront" ] } }, { "Field": "http-header", "HttpHeaderConfig": { "HttpHeaderName": "x-pre-shared-key", "Values": [ "PRESHAREDKEY" ] } } ], "ListenerArn": { "Ref": "appsLBPublicListenerEC0E93DB" }, "Priority": 1 }, ~~~~~~~~~~このようにCloudFormationのテンプレートに追加されていることがわかります。
まとめ
このようにCDKはAWSサービスが抽象化されて非常にわかりやすくなっており、それだけではなく今回のようにパラメータにない場合でもAWSサービスを構築することができます。
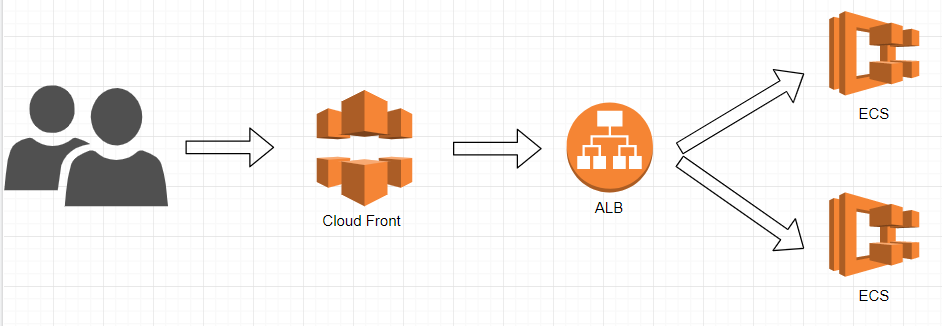
- 投稿日:2019-12-14T14:27:10+09:00
AWS Amplify と Vueで簡単チャット作るぞ!!
AWS Amplify良いですよね。皆さんは使っていますか?
Amplifyを使うことでSPAなWebアプリケーションにAWSの多様な機能を組み込むことができますが、 ここではDynamoDB + GraphQL をデータソースとした簡単なチャットを作ってみます。
amplifyのコマンドを実行することで、AWSのマネジメントコンソール等を直接操作することなくある程度のアプリケーションを作ることができることを体感していただけるといいなーと思います。ちなみにこれはAWS Amplify Advent Calendar 2019の14日の記事です!
開発環境について
$ vue -V 3.11.0 $ amplify -v 1.7.31. Vueアプリケーションを作る
vue create vue-chat-app Vue CLI v4.1.1 ? Please pick a preset: (Use arrow keys) ❯ default (babel, eslint) Manually select featuresとりあえず起動してみます。
cd vue-chat-app yarn serve2. Vueアプリケーションを作る
まずはAmplifyを組み込まない状態で、簡単に挙動を確認できるところまでVueアプリケーションを作ります。
Bootstrapの組み込み
UI周りは
bootstrap-vueを使いますね。$ yarn add bootstrap-vue bootstrap core-jsアプリケーションの実装
メッセージ送信ダイアログ展開
↓
フォームに入力
↓
メッセージ表示ができるところまでデータベースへの更新処理無しで実装してみます。
src/main.js
import Vue from 'vue' import App from './App.vue' import BootstrapVue from 'bootstrap-vue' import 'bootstrap/dist/css/bootstrap.css' import 'bootstrap-vue/dist/bootstrap-vue.css' Vue.use(BootstrapVue) Vue.config.productionTip = false new Vue({ render: h => h(App), }).$mount('#app')src/App.vue
<template> <div id="app"> <header> <b-navbar variant="info" type="dark"> <b-navbar-brand href="#">Vue Chat App</b-navbar-brand> <b-navbar-nav class="ml-auto"> <b-nav-form> <b-button @click="modalShow = !modalShow" variant="light">Post</b-button> </b-nav-form> </b-navbar-nav> </b-navbar> </header> <b-container> <section class="form"> <section> <b-modal v-model="modalShow" size="lg" title="Post chat message"> <section v-if="errors.length > 0" class="alerts"> <div v-for="(error, j) in errors" v-bind:key="j" class="alert alert-danger" role="alert" >{{ error }}</div> </section> <b-form> <b-form-group label="User:" label-for="user"> <b-form-input id="user" v-model="form.user" required placeholder="Enter user"></b-form-input> </b-form-group> <b-form-group label="message" label-for="message"> <b-form-textarea id="message" v-model="form.message" placeholder="Enter something..." rows="3" max-rows="6" ></b-form-textarea> </b-form-group> </b-form> <template v-slot:modal-footer="{ submit, cancel, close }"> <b-button variant="success" @click="onPostMessage">Submit</b-button> <b-button variant="default" @click="onCancel">Cancel</b-button> </template> </b-modal> </section> <section> <b-card v-for="(chat, i) in chats" v-bind:key="i" v-bind:footer="chat.user + ' - ' + chat.created_at" footer-tag="footer" > <b-media> <template v-slot:aside> <b-img width="64" src="https://picsum.photos/200"></b-img> </template> {{ chat.message }} </b-media> </b-card> </section> </section> </b-container> </div> </template> <script> export default { user: "app", data() { return { form: { user: "", message: "" }, chats: [], modalShow: false, errors: [] }; }, computed: { formIsInValid() { return this.errors.length > 0; }, chatParams() { return { ...this.form, created_at: new Date().toLocaleString() }; } }, methods: { onPostMessage() { this.checkMessageParams(); if (this.formIsInValid) { return; } this.postMessage(); this.modalShow = false; this.form.user = ""; this.form.message = ""; }, postMessage() { this.chats.push( this.chatParams ) }, onCancel() { this.modalShow = false; }, checkMessageParams() { this.errors = []; if (this.form.user === "") { this.errors.push('"User" is required.'); } if (this.form.message === "") { this.errors.push('"message" is required.'); } } } }; </script> <style> .card { margin: 1em 0; } </style>
3. Amplifyを組み込む
3.1 初期化
おもむろに以下のコマンドを叩きます。
$ amplify init Note: It is recommended to run this command from the root of your app directory ? Enter a name for the project vue-chat-app ? Enter a name for the environment develop ? Choose your default editor: Visual Studio Code ? Choose the type of app that you're building javascript Please tell us about your project ? What javascript framework are you using vue ? Source Directory Path: src ? Distribution Directory Path: dist ? Build Command: yarn build ? Start Command: yarn serve3.2 S3へのホスティング
順番はどちらでもいいのですが、今回はDB周りの設定をする前に現在の状態のアプリケーションをS3へデプロイします。
$ amplify add hosting ? Select the environment setup: (S3 only with HTTP) DEV ? hosting bucket name vue-chat-app-20191214083130-hostingbucket ? index doc for the website index.html ? error doc for the website index.html You can now publish your app using the following command: Command: amplify publish$ amplify publish Current Environment: develop | Category | Resource name | Operation | Provider plugin | | -------- | --------------- | --------- | ----------------- | | Hosting | S3AndCloudFront | Create | awscloudformation | ? Are you sure you want to continue? Yes ~ ✨ Done in 35.82s. frontend build command exited with code 0 ✔ Uploaded files successfully. Your app is published successfully. http://vue-chat-app-20191214083130-hostingbucket-develop.s3-website-ap-northeast-1.amazonaws.com
publishを実行するとamplify initでコマンドラインで回答したビルドコマンド(yarn build) が実行され、S3へデプロイされます。
デプロイが完了するとS3のエンドポイントのアドレスが表示されるのであくせすしてみます。http://vue-chat-app-20191214083130-hostingbucket-develop.s3-website-ap-northeast-1.amazonaws.com
ローカルで確認した通りのアプリケーションが表示されればOKですね。
3.3 APIの追加
$ amplify add api ? Please select from one of the below mentioned services GraphQL ? Provide API name: vuechatapp ? Choose an authorization type for the API API key ? Do you have an annotated GraphQL schema? No ? Do you want a guided schema creation? Yes ? What best describes your project: (e.g., “Todo” with ID, name, description) Single object with fields ? Do you want to edit the schema now? Yes Please edit the file in your editor: /Users/Work/aws_amplify/vue-chat-app/amplify/backend/api/vuechatapp/schema.graphql s? Press enter to continue
yesを選択するとエディタが起動し、以下のようなgraphqlスキーマファイルのテンプレートが表示されます。schema.graphql
type Todo @model { id: ID! name: String! description: String }以下のように変更します。
type Chat @model { id: ID! user: String! message: String created_at: String }
amplify statusで見てみます。$ amplify status Current Environment: develop | Category | Resource name | Operation | Provider plugin | | -------- | --------------- | --------- | ----------------- | | Api | vuechatapp | Create | awscloudformation | | Hosting | S3AndCloudFront | No Change | awscloudformation | Hosting endpoint: http://vue-chat-app-20191214083130-hostingbucket-develop.s3-website-ap-northeast-1.amazonaws.comで、再びデプロイします。
API側のリソース作成なので、今回はpushします。
pushはローカルで変更されたamplifyの変更をAWSへ適用する操作、
publishはamplifyの変更に加えてアプリケーションのビルド&デプロイをする操作ですね。"amplify push" will build all your local backend resources and provision it in the cloud "amplify publish" will build all your local backend and frontend resources (if you have hosting category added) and provision it in the cloud
amplify pushすると幾つか質問が表示されます。
以下は全てデフォルト値のままです。GraphQL schema compiled successfully. Edit your schema at /Users/yuto-ogi/Work/aws_amplify/vue-chat-app/amplify/backend/api/vuechatapp/schema.graphql or place .graphql files in a directory at /Users/yuto-ogi/Work/aws_amplify/vue-chat-app/amplify/backend/api/vuechatapp/schema ? Do you want to generate code for your newly created GraphQL API Yes ? Choose the code generation language target javascript ? Enter the file name pattern of graphql queries, mutations and subscriptions src/graphql/**/*.js ? Do you want to generate/update all possible GraphQL operations - queries, mutations and subscriptions Yes ? Enter maximum statement depth [increase from default if your schema is deeply nested] 2 ⠏ Updating resources in the cloud. This may take a few minutes...AWSでのGrapyQLリソース作成が完了すると以下のようなファイルがソースディレクトリに作成されます。
modified: .graphqlconfig.yml modified: src/graphql/mutations.js modified: src/graphql/queries.js modified: src/graphql/schema.json modified: src/graphql/subscriptions.jsさらに、
src/配下にaws-exports.jsが作成されます(認証情報が含まれるのでgitignore対象のファイルです)
これをVueアプリケーションで読み込みます。const awsmobile = { "aws_project_region": "ap-northeast-1", "aws_content_delivery_bucket": "*********************************", "aws_content_delivery_bucket_region": "ap-northeast-1", "aws_content_delivery_url": "*********************************", "aws_appsync_graphqlEndpoint": "*********************************", "aws_appsync_region": "ap-northeast-1", "aws_appsync_authenticationType": "API_KEY", "aws_appsync_apiKey": "*********************************" }; export default awsmobile;3.4 VueアプリケーションへのAppSyncの組み込み
$ yarn add aws-amplify aws-amplify-vue以下を追記します。
main.js
import Amplify, * as AmplifyModules from 'aws-amplify' import { AmplifyPlugin } from 'aws-amplify-vue' import awsconfig from './aws-exports' Amplify.configure(awsconfig) Vue.use(AmplifyPlugin, AmplifyModules) Vue.config.productionTip = falseApp.vue
amplify push後に作成されたGraphQL関連のファイルをimportし、アプリケーションに組み込みます。import { API, graphqlOperation } from "aws-amplify"; import { createChat } from "@/graphql/mutations"; import { listChats } from "@/graphql/queries"; import { onCreateChat } from "@/graphql/subscriptions";
createdアクション内では既存のレコードを読み込み、またデータベースへの変更を購読する、という2つの処理を行っています。async created() { // query const queryResponse = await API.graphql(graphqlOperation(listChats)); this.chats = queryResponse.data.listChats.items; // subscribe API.graphql( graphqlOperation(onCreateChat) ).subscribe({ next: chat => { this.chats.push(chat.value.data.onCreateChat); } }); },
postMessageではGrapyQLのmutationにてDynamoDBのレコードを作成しています。async postMessage() { await API.graphql( graphqlOperation(createChat, { input: this.chatParams }) ).catch(error => { console.error(error); }); },4. 公開
ローカルで一通りの動作確認ができたらS3へデプロイします。
$ amplify publish以下のような感じになりました。
ユーザーアイコンの表示には(Lorem Picsum](https://picsum.photos/)を使用していますが、とりあえずリンクを指定しているだけなのでリロードする度に画像変わるし全てのユーザーで同じ画像が表示されます^^;最後に
このアプリケーションはHamamatsu.js #8のハンズオンにて使用したものです。
残念ながら当日はAmplifyの組み込みまで至らなかったので、このアドベントカレンダーが供養になればいいなーと思います。最終的なソースコードはここにありますので良かったら見ていってください。




- 投稿日:2019-12-14T13:01:15+09:00
AWS初心者の備忘録 WEBアプリを構築①(VPCとサブネット編)
業務でAWSを使うことになったのですが、初めて触るため、学んだことを備忘録として残します。
(間違っている可能性もありますがご了承下さい・・)
勉強しながら、すこしづつ実践し、WEBアプリケーションを構築してみます。
今回はVPCとサブネットです!VPCって?
Amazon Virtual Private Cloudが正式名称で、利用者ごとのプライベートクラウド。
AWSの中心なのですが、AWSサービスの中にはVPC内に入れないサービスもあるそうです!(なんで?!)
例えばS3やDyanamoDB、CloudWatchがそれらのサービスみたいです。それらのサービスと連携するためにはVPCエンドポイントなどを利用します。サブネットって?
VPC内部に作るアドレスレンジ。小さいネットワークって思っています!
パブリックサブネットとプライベートサブネットを作るのが一般的みたいなのですがなんじゃそりゃ!って思ったので調べてみました。パブリックサブネット:
インターネットゲートウェイを向いている(インターネットと繋がっている)
サブネットと紐づいているルートテーブルでインターネットゲートウェイとつなげる
プライベートサブネット:
パブリックサブネットとは逆に直接インターネットゲートウェイを向いないサブネット。
DBとかはこっちに置いたりする?ちなみにサブネットの設定でパブリックサブネットやプライベートサブネットを設定できるのではなく、あくまで概念です。
実際に作ってみる
VPCの作成
①AWSのマネジメントコンソール画面から検索「VPC」と入力し、クリックします
②左のサイドバーから「VPC」を選択します
③「VPCの作成」を押下します
④こんなかんじで入力しました
「IPv4 CIDR ブロック」のサブネットマスク(X.X.X.X/〇←これ)は16~28の数字にしないといけないみたいです
⑤「作成」を押下して完了です。サブネットの作成
①AWSのマネジメントコンソール画面から検索「VPC」と入力し、クリックします
②左のサイドバーから「サブネット」を選択します
③「サブネットの作成」を押下します
④こんなかんじで入力しました
※注意点※
・IPv4 CIDR ブロックをVPCのCIDRと同じものいれてしまうと、他のサブネットが作れなくなってしまうので注意しましょう。
⑤「作成」を押下して完了です。
⑥このタイミングで自動的にルートテーブルも作成され、紐づいています。以上、ありがとうございました。


- 投稿日:2019-12-14T13:01:15+09:00
AWS初心者の備忘録(VPCとサブネットを作成してみる)
業務でAWSを使うことになったのですが、初めて触るため、学んだことを備忘録として残します。
(間違っている可能性もありますがご了承下さい・・)今回はVPCとサブネットです!
VPCって?
Amazon Virtual Private Cloudが正式名称で、利用者ごとのプライベートクラウド。
AWSの中心なのですが、AWSサービスの中にはVPC内に入れないサービスもあるそうです!(なんで?!)
例えばS3やDyanamoDB、CloudWatchがそれらのサービスみたいです。それらのサービスと連携するためにはVPCエンドポイントやインターネットゲットウェイなどを利用します。サブネットって?
VPC内部に作るアドレスレンジ。小さいネットワークって思っています!
パブリックサブネットとプライベートサブネットを作るのが一般的みたいなのですがなんじゃそりゃ!って思ったので調べてみました。パブリックサブネット:
インターネットゲートウェイを向いている(インターネットと繋がっている)
サブネットと紐づいているルートテーブルでインターネットゲートウェイとつなげる
プライベートサブネット:
パブリックサブネットとは逆に直接インターネットゲートウェイを向いないサブネット。
DBとかはこっちに置いたりする?ちなみにサブネットの設定でパブリックサブネットやプライベートサブネットを設定できるのではなく、あくまで概念です。
実際に作ってみる
VPCの作成
①AWSのマネジメントコンソール画面から検索「VPC」と入力し、クリックします
②左のサイドバーから「VPC」を選択します
③「VPCの作成」を押下します
④こんなかんじで入力しました
「IPv4 CIDR ブロック」のサブネットマスク(X.X.X.X/〇←これ)は16~28の数字にしないといけないみたいです
⑤「作成」を押下して完了です。サブネットの作成
①AWSのマネジメントコンソール画面から検索「VPC」と入力し、クリックします
②左のサイドバーから「サブネット」を選択します
③「サブネットの作成」を押下します
④こんなかんじで入力しました
※注意点※
・IPv4 CIDR ブロックをVPCのCIDRと同じものいれてしまうと、他のサブネットが作れなくなってしまうので注意しましょう。
⑤「作成」を押下して完了です。
⑥このタイミングで自動的にルートテーブルも作成され、紐づいています。以上、ありがとうございました。
- 投稿日:2019-12-14T12:49:47+09:00
EC2 Image Builderで作ったAMI IDを動的に取得して、AutoScalingグループの起動設定を更新する
この記事はZOZOテクノロジーズ #2 Advent Calendar 2019 14日目の記事になります。
昨日は、@_sa_chi_03さんの「ZOZOTOWNのメールマガジンの仕組みについて」でした。まえがき
ZOZOテクノロジーズ SREチームのテックリード光野と申します。普段はAWSを使って、より安全でより手がかからず、お金もかからない。でも速い。そんないい感じのネットワーク構築に邁進しています。
さて、この記事ではAWS re:Invent 2019で発表されたEC2 Image Builderを扱います。EC2 Image Builderは、指定したレシピを元にEC2のカスタムイメージを作成することができるサービスです。任意もしくは定期的なタイミングでAMIを更新することができます。
AutoScalingグループと合わせれば、毎日最新のセキュリティパッチのあたったAMIを作っておいて、インスタンス入れ替え、なんて事が簡単にできます。幸せです。
この投稿では、EC2 Image Builderで作成したAMI IDを機械的に参照できるよう工夫してみたいと思います。
本文
目標:CloudFormationテンプレートで動的参照
弊社ではインフラの管理にCloudFormationを多用しています。
例えば、CloudFormationでAutoScalingの起動設定を作成する場合、次のように記述します。AWSTemplateFormatVersion: 2010-09-09 Resources: AutoScalingLaunchConfiguration: Type: 'AWS::AutoScaling::LaunchConfiguration' Properties: ImageId: 'ami-0ab292e52c1d6ac8c' # Ubuntu 18.04 LTS InstanceType: 'm5.large' # 最低限の記述です。実際にはセキュリティグループなどが必要でしょう。。ここでは、
ImageIdを可変にし、CloudFormation実行のタイミングで、常にImage Builderが作成する最新のAMI IDを参照するようにします。組み合わせ
CloudFormationではSSMのParameter Storeに登録した値を動的に参照することができます。
AWSTemplateFormatVersion: 2010-09-09 Resources: AutoScalingLaunchConfiguration: Type: 'AWS::AutoScaling::LaunchConfiguration' Properties: ImageId: "{{resolve:ssm:oreore-image-with-eib:1}}" InstanceType: 'm5.large'or
AWSTemplateFormatVersion: 2010-09-09 Parameters: AMI: Type: 'AWS::SSM::Parameter::Value<AWS::EC2::Image::Id>' Default: 'oreore-image-with-eib' Resources: AutoScalingLaunchConfiguration: Type: 'AWS::AutoScaling::LaunchConfiguration' Properties: ImageId: !Ref AMI InstanceType: 'm5.large'パラメータからの指定であれば、バージョン番号の入力を省略できるため、常に最新〜という指定が叶えられそうです。他方、EC2 Image BuilderはSNSに対応しているため、SNS経由でなんとかParameter Storeまで値を届けられそうな気がします。
作ったもの
ここではUserが手動でCloudFormationを更新します。
Lambdaに設定したスクリプトは以下のとおりです。Rubyが好きなので.rbです。
# coding: utf-8 require 'json' require 'aws-sdk-ssm' def lambda_handler(event:, context:) message = JSON.parse(event['Records'][0]['Sns']['Message']) puts message # debug用 client = Aws::SSM::Client.new resp = client.put_parameter({ name: 'oreore-image-with-eib', value: message['outputResources']['amis'][0]['image'], type: 'String', overwrite: true }) { statusCode: 200, body: JSON.generate('OK') } endCloudFormartionのテンプレートは上で掲載したものを使います。
AWSTemplateFormatVersion: 2010-09-09 Parameters: AMI: Type: 'AWS::SSM::Parameter::Value<AWS::EC2::Image::Id>' Default: 'oreore-image-with-eib' Resources: AutoScalingLaunchConfiguration: Type: 'AWS::AutoScaling::LaunchConfiguration' Properties: ImageId: !Ref AMI InstanceType: 'm5.large'結果
EC2 Image Builder
SSM Parameter Store
CloudFormation
AutoScaling
しっかり反映されました!
あとがき
EC2 Image BuilderからParameter Storeを通じて、動的に最新のAMIを得ることができました。
AWSのサービスは一つ新しいものが増えると、組み合わせの楽しみがどんどん広がるので目が離せません。CloudFormationテンプレートになってさえいればCodePipelineなどで自動化もできますし、これまで抱えていた「カスタムAMIがあればもっと効率的に色々できるけど、運用するのが面倒くさいんだよな・・・」という悩みが解決できそうでとてもワクワクしています。
明日は@murs13さんの記事になります。お楽しみに!





- 投稿日:2019-12-14T11:51:31+09:00
ハンズオン!dockerとAWS(EC2+ALB+RDS)を触ってみて学んだこと
この記事はエイチーム引越し侍 / エイチームコネクト Advent Calendar 2019 14日目の記事です。本日はエイチーム引越し侍に入社してWEBエンジニア歴4ヶ月目に突入した@halktが担当します!
なぜこれをやろうと思ったのか?
一言で言うと、自分の力でWEBサービスをデプロイする経験をしてみたかったからです。
WEBエンジニアになる前は、社内サービスの維持運用を主として行なっていたため、物理的なサーバを建てたり、仮想マシンを作成したりということはしておりましたが、インフラなどはすでに構成された社内ネットワークの中でしか触ったことはありませんでした。
そのため、Webサービスを外部に公開する上での考慮事項や外からサービスに接続するための知識は特に足りていないと感じていたので、このテーマにまずは挑戦しようと思いました!!
兎にも角にもまずは触ってみなきゃ始まらん!と思い、下記の構成を目指し、タイトル通りハンズオン形式で学んだ内容をまとめてみたいと思います!
ゴールのイメージ
Railsなのは特にこだわりがあるわけでなく、たまたまあるアプリを使っただけです。最近だとECSやFargateを使った構成が多いと知りましたので別途挑戦したいと思います・・・!?docker/docker-compose編
最初にローカルで作成していた既存のRailsアプリをdockerにのせました。dockerの勉強したいから、という理由がきっかけですが、コンテナをデプロイできるようになれば、他のアプリでデプロイをしたいときに応用が効くことを期待してdocker化から初めました。
実施内容
細かな作業内容などは割愛しますが、ざっくり下記のようなことをやりました。
- Dockerfile(Railsやnginx)の作成
- pumaとnginxのソケット通信の設定
- nginxの設定ファイルの修正
- docker-compose.ymlの作成
- buildしてアプリケーションを実行しアクセスする
- githubにpushしておく
docker-compose.ymlの作成
docker-composeは、複数コンテナ群の構成や動きを管理することができます。所謂インフラ構成のコード化が実現できます。
version: '3' services: app: build: context: . environment: MYSQL_ROOT_PASSWORD: XXX MYSQL_DATABASE: XXX command: bundle exec puma -C config/puma.rb volumes: - .:/app - public-data:/app/public - tmp-data:/app/tmp - log-data:/app/log depends_on: - db db: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: XXX MYSQL_DATABASE: XXX ports: - "3306:3306" web: build: context: containers/nginx volumes: - public-data:/app/public - tmp-data:/app/tmp ports: - 80:80 depends_on: - app volumes: public-data: tmp-data: log-data: db-data:docker-composeコマンドを使ってbuildしてアクセス!
ここまで準備が整えば、あとはbuildするだけで環境の作成ができます。便利なのは、このファイル群を使えば同じインフラが一発で再現ができるようになった点ですね〜本当にいい時代だ。。。(しみじみ)
# コンテナを起動する $ docker-compose build # コンテナをビルド $ docker-compose up -d # コンテナの一斉起動 # railsの設定 $ docker-compose run --rm app rails db:create $ docker-compose run --rm app rails db:migrateここまでするとnginx経由でアクセスができるようなりました!
ここで学んだこと
頭では理解していたつもりでしたが、もともと普通に構築したアプリをdocker化することでその良さをより知ることができたと思います!
それまでミドルウェアのインストールから設定からまでやっていた環境構築が数回のコマンドで再現できるのは感動的???
今後はガシガシコンテナを使って色々と構築していき、理解を深めていきたいと思います!!
?AWS編
コンテナ化までできたので、デプロイそのもののハードルはほぼなくなりました。ここからは、本丸に挑戦・・・!
実施した内容
- VPCの作成
- RDSインスタンスの構築と接続設定
- EC2インスタンスの作成
- ALBの作成
- ドメインの取得
- ACMによる証明書の作成
- HTTPS化
RDSインスタンスの構築と接続設定
RDSは、DBエンジンを提供するサービスでDBサーバーとして利用することができます。こちらの生成は正直そこまで難しいことはありませんが、RailsアプリからこちらのDBに接続する設定を直接書き出してしまうのは危険なため、credentialを使って隠蔽する設定を行いました。
# credentialsの設定 $ docker-compose run -e EDITOR="vim" app rails credentials:edit# credentialsの中身 # ここに書いた内容は外から見ることはできません rds: host: RDSのエンドポイント database: RDSの「データベースの名前」 username: RDSの「マスターユーザの名前」 password: RDSの「マスターパスワード」
- config/database.yml
production: <<: *default host: <%= Rails.application.credentials.rds[:host] %> database: <%= Rails.application.credentials.rds[:database] %> username: <%= Rails.application.credentials.rds[:username] %> password: <%= Rails.application.credentials.rds[:password] %>こうすることで、本番環境の接続DBをRDSに設定することができました。
EC2インスタンスの作成
EC2インスタンスはssh接続できるように設定し、コンテナを動かすためにdockerやdocker-composeのインストールを行いました。
その後、?docker編で作成したアプリのgithubからリポジトリごとcloneしてきます。また、githubには存在しない
master.keyを個別にconfigファイルにコピーしていきます。これをしないと、先ほどcredentialsに設定した内容を参照できないのでご注意を。$ scp -i ~/.ssh/myapp.pem ~/myapp/config/master.keyここまできたらdockerを起動してアプリを起動・・・!
$ docker-compose build $ docker-compose run app rails db:create $ docker-compose run app rails db:migrate $ docker-compose run app rails assets:precompile # nginxとpumaのソケット通信 $ mkdir tmp/sockets $ touch tmp/sockets/puma.sock # コンテナ起動 $ docker-compose upIPアドレス経由ですが、Webアプリケーションにアクセスができるようになりました!!!
HTTPS化
最後に、EC2+RDSで構成されたアプリにALB経由で接続するようにします。また、ACMで証明書を作成してALBに設定することで、外部→ALBの通信をHTTPS化(暗号化)します。※ALBとnginx間は同一ネットワーク内なのでHTTP通信になります。
これにより、特定のドメインでHTTPS化した状態でWebアプリにアクセスできるようになりましたーーー!!!
ここで学んだこと
今回、ほぼ無料枠のみでWebアプリケーションをSSL化してインターネット上に公開することができました!!
インスタンスの生成やロードバランサーがこんなにサクッとできるのはやはりすごいですね。今回は1台構成ですが、冗長構成なども容易にできそうな実感を得られました。
また、デプロイは単純にEC2上にリポジトリをコピーしただけだったので、今後はCIできるようにしたり、Githubと連携させたり、なかなかコストはかかりそうですが色々やりたいことも見えてきたので、他のサービスの利点を知るためにも継続的に触っていきたいと思います。
まとめ
目的だった自分の力でWEBサービスをデプロイする経験することができ、知らなかったサービスやインフラの基礎的な部分を効率よく学ぶことができたのはGOODでした!
ハンズオン形式で触りながら学ぶことで、技術の恩恵をより実感することができました。一度触ることで、学びたいサービスや領域が広がったのもいい収穫だったと思います。まだまだいろんなサービスがあるので、どんどん触れてみてITで解決できることの幅を増やしていきたいと思います!
まだまだ勉強不足で毎日学ぶことの連続ですが、着実に力をつけていきたいと思います!!
参考にさせていただいた記事
これを実施するために下記の記事を参考にさせていただきました。
docker-compose(公式)
知識0から、AWSのEC2でウェブサーバーを構築するまで
丁寧すぎるDocker-composeによるrails5 + MySQL on Dockerの環境構築(Docker for Mac)
Docker導入のための、コンテナの利点を解説した説得資料
Nginx + Rails (Puma) on Docker のいくつかの実用パターン
無料!かつ最短?で Ruby on Rails on Docker on AWS のアプリを公開するぞ。お知らせ
エイチームグループでは一緒に活躍してくれる優秀な人材を募集中です。
興味のある方はぜひともエイチームグループ採用ページよりご応募ください。
WEBエンジニア詳細ページよりお問い合わせ下さい。明日
明日は@2boさんの記事です!
どんな内容か楽しみです、それではお楽しみに〜〜
- 投稿日:2019-12-14T11:31:56+09:00
TerraformでALBの高度なリスナールールがより簡潔に書けるようになった話
こんにちは、ななです。
皆さんはTerraformを使っていますか?ちなみに私は最近、Terraformを触り始めました。
今回はTerraformのAWSプロバイダに関して本日2019年12月14日にアップデートがあったため、早速試してみた話を書いてみます。はじめに
Terraformとは、HashiCorpにより作成されたInfrastructure as a Codeを実現するためのオープンソースなツールを指します。
Application Load Balancer (ALB) とは
AWSが提供するElastic Load Balancing (ELB) というサービスにおいてサポートされ、かつOSI参照モデルの第7層 (アプリケーション層) で機能するものです。
(図引用元: https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/introduction.html)リスナールールについて
ALBではリスナールールに従って、ユーザーからのトラフィックを制御しています。
そして2019年3月27日には、AWSがリスナールールを拡張しました。詳しくは、
- Application Load Balancer で高度なリクエストルーティングのサポートを開始
- [新機能] HTTPヘッダーやクエリ文字列などなどでルーティングができちゃう!!AWS ALBで高度なリクエストルーティングが可能になりました! | Developers.IO
に書いてありますが、リクエストヘッダ内のユーザーエージェントの値などで、より柔軟なルーティングができるようになりました。
Terraformで書く際に
AWSプロバイダ経由で、各種AWSリソースを管理していくことになりますが、上記の拡張については以下のように書いても、
elb.tfresource "aws_lb_listener_rule" "http_header_based_routing" { listener_arn = aws_lb_listener.front_end.arn priority = 10 action { type = "forward" target_group_arn = aws_lb_target_group.tg.arn } condition { http_header { http_header_name = "User-Agent" values = [ "*Chrome*", "*Safari*", ] } } }terraform planやterraform applyを入力した際に以下のエラーが出ました。
Error: Unsupported block type on elb.tf line xx, in resource "aws_lb_listener_rule" "http_header_based_routing": xx: http_header { Blocks of type "http_header" are not expected here.そこで、上手く書く方法が無いか、AWSプロバイダのリポジトリを確認してみました。そうすると当該関連のプルリクを見つけましたが、Open (現在はClose) の状態でした。要するにまだのようでした。
そして、月日は経ち、2019年12月7日にmasterブランチにマージされました。そして2019年12月14日に2.42.0としてリリースされました。
ちなみにTerraformでより簡潔に書けるようになる前は、TerraformでCloudFormationスタックを作成するなどして管理する必要がありました。忘れていなければ詳細はどこかの記事で書こうかと思います。もしかしたらすでに書いている人がいて、二番煎じになるかもしれませんが……
Terraformで実際にALBの高度なリスナールールを書いてみる
①こちらを参考にAWSプロバイダーの2.42.0のバイナリを持ってきます。
$ terraform init Initializing the backend... Initializing provider plugins... - Checking for available provider plugins... - Downloading plugin for provider "aws" (hashicorp/aws) 2.42.0... Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.②今回はChromeやSafariブラウザを判定するリスナールールを実現してみます。他のパターンについては、こちらを確認してください。
elb.tfresource "aws_lb_listener_rule" "http_header_based_routing" { listener_arn = aws_lb_listener.front_end.arn priority = 10 action { type = "forward" target_group_arn = aws_lb_target_group.tg.arn } condition { http_header { http_header_name = "User-Agent" values = [ "*Chrome*", "*Safari*", ] } } }③terraform planやterraform applyを用いて、内容を確認した上でデプロイします。
④AWSマネジメントコンソールで確認します。ちゃんと設定されていますね。
以上です。
おわりに
マージされるまでに8ヶ月以上掛かりましたが、ALBの高度なリスナールールがTerraformでより簡潔に書けるようになりました。皆さんもぜひ使ってみましょう。


- 投稿日:2019-12-14T08:53:35+09:00
AWS CLIでEC2インスタンスを停止する
こちらは、 “ゆるWeb勉強会@札幌 Advent Calendar 2019” の 14日目の記事です。
(本当は作成中の自分のサイトに載せたかったのですが、ヒジョーに見づらかったのでこちらに載せておきます...)
何を調べたか
今回は、「AWSでオペミスせずに(汗)想定のサーバーを停止する」方法を調べてみました。
背景
AWS マネジメントコンソールから検証サーバーを停止しようとして、間違えて本番サーバーを停止してしまいました。 (操作対象のチェックが複数入っているのに気づかず、停止してしまいました)
気づいたときには遅く、検証サーバーと本番サーバーが仲良く停止するのをボーゼンと見守るしかありませんでした…
できれば、停止前には「こちらのサーバーを停止しますが宜しいですか?」と確認するワンクッションが欲しい。 ということで探してみたくなりました。
結論
- (2019/12/13現在では)AWS マネジメントコンソールの操作にワンクッション挟むことは出来ない
- AWS コマンドラインインターフェイス(CLI)でバッチを作れば可能
※監視であれば「CloudWatch」、処理フローなら「Simple Workflow Service(SWF)」などが使えそうですが、イベントをトリガーにするため、イベント前に何かするのは難しいようです。
オペミスは想定されていないっ(ううう…)
作成したもの
WindowsのバッチファイルからAWS CLIのサーバー停止コマンドを呼び出すようにしました。
手順概要
AWS CLIは未使用で、インストールから行う場合です。
使用OS:Windows10
使用エディタ:Visual Studio Code
- IAMユーザーの作成
- CLI用IAMユーザーを作成
- IAMユーザーに権限付与
- AWS CLI操作用アクセスキーの取得
- AWS EC2で各サーバにタグを付ける
- AWS CLIのインストール
- AWS CLIの初期設定
- AWS CLIの実行確認
- AWSに接続
- EC2(サーバー)一覧の取得
- EC2停止コマンドの実行
- EC2起動コマンドの実行
- バッチの作成
詳細手順
IAMユーザーの作成
※もし、EC2インスタンス停止などに使用するユーザーが作成済でしたら、新規作成しなくても良いと思います。 rootアカウントしか無い!という人は、操作用のIAMユーザーを作りましょう。
IAMユーザーの作り方は公式サイトを参照してください。
アクセス権限のポリシーは、「AmazonEC2FullAccess」を付けておきます。(今回だけならフルには不要なのですが)
IAMユーザーのアクセスキー、シークレットアクセスキーは後ほど設定で使用するため、メモしておきます。
AWS EC2で各サーバにタグを付ける
本番サーバー、検証サーバーが識別出来るようにタグを付けます。
詳しくは「Amazon EC2 リソースにタグを付ける」をご確認ください。
私は以下のようなタグを付けました。これで区別しようと思います。
対象 タグ名 値 本番サーバー Application Production 検証サーバー Application Staging AWS CLIのインストール
AWS CLIにはバージョン1と2(評価版)があります。今回はバージョン1をインストールします。
Windowsの方はこちら
その他の方はAWS CLI バージョン 1 のインストールをどうぞ。
インストーラで実行した場合、パス設定がされる場合とされない場合があるようです。環境変数の設定方法はこちらを参照してください。
AWS CLIがインストールされたか確認します。コマンドプロンプトで以下を実行します。バージョンが表示されればインストールされています。
Visual Studio Codeの方は、ctrl+shift+@でターミナルが開き、そこでコマンドの実行が出来て便利です。
> aws --version aws-cli/1.16.302 Python/3.6.0 Windows/10 botocore/1.13.38AWS CLIの初期設定
先程メモしておいたアクセスキー、シークレットアクセスキーを用意します。
シャットダウンしたいEC2インスタンスが存在するリージョンが分からない方は、一旦マネジメントコンソールにログイン→EC2ダッシュボードに移動→右上のリージョンを確認してみてください。
リージョンが「東京」の場合は「ap-northeast-1」です。
その他のリージョンの確認はこちら
> aws configure AWS Access Key ID [None]: ここにIAMユーザーのアクセスキー AWS Secret Access Key [None]: ここにシークレットアクセスキー Default region name [None]: (東京の場合ap-northeast-1) Default output format [None]:出力するデータフォーマット(json/text/tableから選択。デフォルトはjson)設定されたか確認するには、
aws configure listを入力します。> aws configure list Name Value Type Location ---- ----- ---- -------- profile None None access_key ****************PPUK shared-credentials-file secret_key ****************h5n8 shared-credentials-file region ap-northeast-1 config-file ~/.aws/configAWS CLIの実行確認
コマンド構造としては以下になっているようです。EC2の操作の場合は、
aws ec2 操作 オプションのようになります。<code> aws command subcommand [options and parameters] </code>ヘルプが見たい場合は、サービスやコマンド毎に確認できます。
aws ec2 help
aws ec2 describe-instances helpEC2(サーバー)一覧の取得
まずは設定した内容でAWSに接続できるか確認します。
aws ec2 describe-instances> aws ec2 describe-instances { "Reservations": [ { "Groups": [], "Instances": [ { "AmiLaunchIndex": 0, "ImageId": "ami-3a5a415d", "InstanceId": "i-09cc5014c75905b8f", "InstanceType": "t2.micro", "KeyName": "XXX", "LaunchTime": "2019-12-10T13:54:36.000Z", "Monitoring": { "State": "disabled" }, "Placement": { "AvailabilityZone": "ap-northeast-1c", "GroupName": "", "Tenancy": "default" }, "PrivateDnsName": "ip-XXX-XXX-XXX-XXX.ap-northeast-1.compute.internal", "PrivateIpAddress": "XXX.XXX.XXX.XXX", "ProductCodes": [ { "ProductCodeId": "f18wc0igqjhsxwoxouogwqb8m", "ProductCodeType": "marketplace" } ], "PublicDnsName": "", "PublicIpAddress": "XXX.XXX.XXX.XXX", "State": { "Code": 16, "Name": "running" }, "StateTransitionReason": "", "SubnetId": "subnet-01db2ef783448de05", "VpcId": "vpc-0e58a4cff354769c7", "Architecture": "x86_64", "BlockDeviceMappings": [ { "DeviceName": "/dev/sda1", "Ebs": { "AttachTime": "2019-11-24T10:20:43.000Z", "DeleteOnTermination": true, "Status": "attached", "VolumeId": "vol-0e8ea73e857cc1c26" } } ], "ClientToken": "157459081408640974", "EbsOptimized": false, "EnaSupport": false, "Hypervisor": "xen", "NetworkInterfaces": [ { "Association": { "IpOwnerId": "688747735680", "PublicDnsName": "", "PublicIp": "XXX.XXX.XXX.XXX" }, "Attachment": { "AttachTime": "2019-11-24T10:20:42.000Z", "AttachmentId": "eni-attach-0e83f3e818c31d244", "DeleteOnTermination": true, "DeviceIndex": 0, "Status": "attached" }, "Description": "Primary network interface", "Groups": [ { "GroupName": "wp-sg", "GroupId": "sg-0cab6793bf2ff78b9" } ], "Ipv6Addresses": [], "MacAddress": "0a:a3:df:b1:34:28", "NetworkInterfaceId": "eni-01f4f73c21aab0a27", "OwnerId": "688747735680", "PrivateIpAddress": "XXX.XXX.XXX.XXX", "PrivateIpAddresses": [ { "Association": { "IpOwnerId": "688747735680", "PublicDnsName": "", "PublicIp": "XXX.XXX.XXX.XXX" }, "Primary": true, "PrivateIpAddress": "XXX.XXX.XXX.XXX" } ], "SourceDestCheck": true, "Status": "in-use", "SubnetId": "subnet-01db2ef783448de05", "VpcId": "vpc-0e58a4cff354769c7", "InterfaceType": "interface" } ], "RootDeviceName": "/dev/sda1", "RootDeviceType": "ebs", "SecurityGroups": [ { "GroupName": "wp-sg", "GroupId": "sg-0cab6793bf2ff78b9" } ], "SourceDestCheck": true, "Tags": [ { "Key": "Application", "Value": "Production" }, { "Key": "Name", "Value": "wp-test" } ], "VirtualizationType": "hvm", "CpuOptions": { "CoreCount": 1, "ThreadsPerCore": 1 }, "CapacityReservationSpecification": { "CapacityReservationPreference": "open" }, "HibernationOptions": { "Configured": false }, "MetadataOptions": { "State": "applied", "HttpTokens": "optional", "HttpPutResponseHopLimit": 1, "HttpEndpoint": "enabled" } } ], "OwnerId": "688747735680", "RequesterId": "086189789714", "ReservationId": "r-05b6d9b7554d0a378" }, { "Groups": [], "Instances": [ { (2台目以降省略) } } ] }
たくさん情報が出てきて見づらいです…必要な情報だけ表示したいので、絞り込みをします。
私はIPやNameタグで判断する事が多いので、後ほど使用するインスタンスID、IP、Nameタグを取得してみました。
> aws ec2 describe-instances --filters 'Name=tag:Application,Values=Staging' --query 'Reservations[].Instances[].{PublicIp:PublicIpAddress,InstanceId:InstanceId,Name:Tags[?Key==Name].Value}' [ { "PublicIp": "XXX.XXX.XXX.XXX", "InstanceId": "i-0c65cca2d2fbfb1db", "Name": [ "wp-site-stg" ] } ]EC2停止コマンドの実行
停止する際のコマンドを試してみます。先程確認したインスタンスIDの情報が必要になります。
コマンドリファレンス:stop-instances
aws ec2 stop-instances --instance-ids インスタンスID実行結果のイメージはこちらです。
> aws ec2 stop-instances --instance-ids i-0c65cca2d2fbfb1db { "StoppingInstances": [ { "CurrentState": { "Code": 64, "Name": "stopping" }, "InstanceId": "i-0c65cca2d2fbfb1db", "PreviousState": { "Code": 16, "Name": "running" } } ] }画面上でも停止されていました。
コマンドでも確認できるようです。以下コマンドでInstanceStatusesの値が空なら停止しています。
aws ec2 describe-instance-status --instance-ids インスタンスID//停止したインスタンス > aws ec2 describe-instance-status --instance-ids i-0c65cca2d2fbfb1db { "InstanceStatuses": [] } //実行中のインスタンス > aws ec2 describe-instance-status --instance-ids i-09cc5014c75905b8f { "InstanceStatuses": [ { "AvailabilityZone": "ap-northeast-1c", "InstanceId": "i-09cc5014c75905b8f", "InstanceState": { "Code": 16, "Name": "running" }, "InstanceStatus": { "Details": [ { "Name": "reachability", "Status": "passed" } ], "Status": "ok" }, "SystemStatus": { "Details": [ { "Name": "reachability", "Status": "passed" } ], "Status": "ok" } } ] }EC2起動コマンドの実行
ついでに起動コマンドも確認しておきます。こちらもインスタンスIDが必要です。
コマンドリファレンス:start-instances
aws ec2 start-instances --instance-ids インスタンスID> aws ec2 start-instances --instance-ids i-0c65cca2d2fbfb1db { "StartingInstances": [ { "CurrentState": { "Code": 0, "Name": "pending" }, "InstanceId": "i-0c65cca2d2fbfb1db", "PreviousState": { "Code": 80, "Name": "stopped" } } ] }コマンド実行直後にステータスを確認してみました。
> aws ec2 describe-instance-status --instance-ids i-0c65cca2d2fbfb1db { "InstanceStatuses": [ { "AvailabilityZone": "ap-northeast-1c", "InstanceId": "i-0c65cca2d2fbfb1db", "InstanceState": { "Code": 16, "Name": "running" }, "InstanceStatus": { "Details": [ { "Name": "reachability", "Status": "initializing" } ], "Status": "initializing" }, "SystemStatus": { "Details": [ { "Name": "reachability", "Status": "initializing" } ], "Status": "initializing" } } ] }起動後のステータスはこちらです。
> aws ec2 describe-instance-status --instance-ids i-0c65cca2d2fbfb1db { "InstanceStatuses": [ { "AvailabilityZone": "ap-northeast-1c", "InstanceId": "i-0c65cca2d2fbfb1db", "InstanceState": { "Code": 16, "Name": "running" }, "InstanceStatus": { "Details": [ { "Name": "reachability", "Status": "passed" } ], "Status": "ok" }, "SystemStatus": { "Details": [ { "Name": "reachability", "Status": "passed" } ], "Status": "ok" } } ] }バッチの作成
これで一通りコマンドの確認が出来たので、あとはバッチを作成していきます。
stop_stg.batなど適当な名前で、実行するPCに保存しておきます。バッチでは、検証のインスタンス情報を表示し、停止するか確認メッセージを表示します。
はい、と答えたあと、コレジャナイ!!を予防するため、再確認もします(笑)。@echo off @SET AWS_ACCESS_KEY_ID=アクセスキー @SET AWS_SECRET_ACCESS_KEY=シークレットアクセスキー @SET AWS_DEFAULT_REGION=リージョン(東京はap-northeast-1) @SET TARGET_VM=画面に表示するサーバー名 @SET TARGET_VM_ID=インスタンスID echo 停止するサーバ情報です。 echo. aws ec2 describe-instances --filters Name=tag:Application,Values=Staging --query Reservations[].Instances[].{PublicIp:PublicIpAddress,InstanceId:InstanceId,Name:Tags[?Key==`Name`].Value} echo. echo %TARGET_VM% サーバを停止しますか? choice if %errorlevel% equ 1 goto okexe echo. echo 実行しません…。 pause exit :okexe echo. echo 本当に実行しますか? choice /c yn /t 5 /d n if %errorlevel% equ 1 goto okok echo. echo 実行をキャンセルしました。 pause exit :okok echo. echo 実行します! rem ここにサーバ停止コマンド echo aws ec2 stop-instances --instance-ids %TARGET_VM_ID% aws ec2 stop-instances --instance-ids %TARGET_VM_ID% echo. pause exit作成中の失敗1:確認したコマンドがバッチでは動かない?
Visual Studio Codeではターミナルを「PowerShell」にしており、コマンドプロンプトで実行するとエラーになりました。
以下を修正すると動作するようになりました…
#PowerShellで実行可能 aws ec2 describe-instances --filters 'Name=tag:Application,Values=Staging' --query 'Reservations[].Instances[].{PublicIp:PublicIpAddress,InstanceId:InstanceId,Name:Tags[?Key==`Name`].Value}' #コマンドプロンプトで実行可能 aws ec2 describe-instances --filters Name=tag:Application,Values=Staging --query Reservations[].Instances[].{PublicIp:PublicIpAddress,InstanceId:InstanceId,Name:Tags[?Key==`Name`].Value}作成中の失敗2:認証エラーが出る
バッチを試す際、以下のエラーが出ました…
An error occurred (AuthFailure) when calling the DescribeInstances operation: AWS was not able to validate the provided access credentials原因は、変数の値を""で囲っていたためでした。""を外すと動作しました。
#NG @SET AWS_ACCESS_KEY_ID="アクセスキー" @SET AWS_SECRET_ACCESS_KEY="シークレットアクセスキー" #OK @SET AWS_ACCESS_KEY_ID=アクセスキー @SET AWS_SECRET_ACCESS_KEY=o3ZvV3uAGi4WxDOs7kkYG2P45EfMgaH0nXMpRFyZ実行結果
いろいろ試行錯誤しつつ、無事検証サーバーを停止することが出来ました!
ちゃんと停止しています…!
次のステップ(野望)
次は以下も試してみたいです。
- アクセスキーなどはベタ書きせず、ファイル読み込みにする(お恥ずかしい…)
- バッチの中で、停止サーバーの指定が出来るようにしたい
- AWSの別アカウントで管理されている場合の制御(AWS CLIに複数設定)も試したい
所感
いずれ使ってみたいと思っていたAWS CLI、オペミスにより使う機会が出来ました。(怪我の功名?)
色々操作が出来て良いですね。マウスなどを動かす手間が無くて便利です。停止サーバーの選択が出来るようにすると、自由度は上がるものの、またオペミスするかもしれませんね…。どうしたらオペミスを無くせるのかしら。
もしオペミスを予防出来る素敵な案をお持ちの方はぜひ教えてください。お待ちしています !!!!!
P.S.明日はgishi_yamaさんの「ゆるくWeb開発環境(物理)について話します」です。楽しみで震えますね!(物理)



- 投稿日:2019-12-14T08:45:31+09:00
Cognitoユーザープールがステータスコード400で削除できない
Cognitoのユーザープールを削除しようとしたら、次のようなエラーに。
「User pool cannot be deleted. It has a domain configured that should be deleted first.」
ドメインが構成されているため、削除できないとのことなので、割り当てたドメインを先に削除します。
ドメインの削除を行うと、ユーザープールが消せるようになりました。

