- 投稿日:2019-12-14T23:59:36+09:00
ナンプレをPythonで解く(後編)
IPFactory Advent Calender 2019 14日目
IPFactory所属、ISC 1年のpycysです。
ナンプレをPythonで解くの後編です。コード書いたよ
やっとできました。
大抵の問題は1秒以内で解けるはずです。
間に合わせるためにアルゴリズムをそのまま書いたので、読みやすくは書かれていません。
後でもうちょい綺麗に書きます。
追加したアルゴリズムもあるので、それの説明も含め後日また記事書きますnampre.pyimport time, copy as cp # 3×3枠n確定判定&排除処理 def cubic_frame_judgment(): flag = False for i in range(3): for j in range(3): indices = [() for n in range(9)] for sub_i in range(i*3, i*3+3): for sub_j in range(j*3, j*3+3): for num in unconfirmed_numbers[sub_i][sub_j]: indices[num-1] = (sub_i, sub_j) if not indices[num-1] else (9,9) for index in indices: if index != (9,9) and index not in subscripts: flag = True nampre[index[0]][index[1]] = indices.index(index)+1 column_excluder(index[0], index[1], indices.index(index)+1) row_excluder(index[0], index[1], indices.index(index)+1) cubic_frame_excluder(index[0], index[1], indices.index(index)+1) subscripts.add((index[0], index[1])) return flag # 縦列n確定判定&排除処理 def column_judgment(): flag = False for j in range(9): indices = [() for n in range(9)] for i in range(9): for num in unconfirmed_numbers[i][j]: indices[num-1] = (i, j) if not indices[num-1] else (9,9) for index in indices: if index != (9,9) and index not in subscripts: flag = True nampre[index[0]][index[1]] = indices.index(index)+1 column_excluder(index[0], index[1], indices.index(index)+1) row_excluder(index[0], index[1], indices.index(index)+1) cubic_frame_excluder(index[0], index[1], indices.index(index)+1) subscripts.add((index[0], index[1])) return flag # 横列n確定判定&排除処理 def row_judgment(): flag = False for i in range(9): indices = [() for n in range(9)] for j in range(9): for num in unconfirmed_numbers[i][j]: indices[num-1] = (i, j) if not indices[num-1] else (9,9) for index in indices: if index != (9,9) and index not in subscripts: flag = True nampre[index[0]][index[1]] = indices.index(index)+1 column_excluder(index[0], index[1], indices.index(index)+1) row_excluder(index[0], index[1], indices.index(index)+1) cubic_frame_excluder(index[0], index[1], indices.index(index)+1) subscripts.add((index[0], index[1])) return flag # 置ける数字が1つしかないマスを探す&排除処理 def only_one_judgment(): flag = False for i in range(9): for j in range(9): if len(unconfirmed_numbers[i][j]) == 1 and (i,j) not in subscripts: flag = True num = unconfirmed_numbers[i][j][0] nampre[i][j] = num column_excluder(i, j, num) row_excluder(i, j, num) cubic_frame_excluder(i, j, num) subscripts.add((i,j)) return flag # 例外処理1 def cubic_tumor_excluder(): flag = False # 3×3枠check for i in range(3): for j in range(3): overlapping_numbers = [[] for i in range(9)] for sub_i in range(i*3, i*3+3): for sub_j in range(j*3, j*3+3): for num in unconfirmed_numbers[sub_i][sub_j]: overlapping_numbers[num-1].append((sub_i, sub_j)) for index_box in overlapping_numbers: if overlapping_numbers.count(index_box) == len(index_box) >= 2: nums = [index+1 for index, indices in enumerate(overlapping_numbers) if indices == index_box] for index in index_box: if unconfirmed_numbers[index[0]][index[1]] != nums: flag = True unconfirmed_numbers[index[0]][index[1]] = cp.deepcopy(nums) # 横列check for i in range(9): overlapping_numbers = [[] for i in range(9)] for j in range(9): for num in unconfirmed_numbers[i][j]: overlapping_numbers[num-1].append((i, j)) for index_box in overlapping_numbers: if overlapping_numbers.count(index_box) == len(index_box) >= 2: nums = [index+1 for index, indices in enumerate(overlapping_numbers) if indices == index_box] for index in index_box: if unconfirmed_numbers[index[0]][index[1]] != nums: flag = True unconfirmed_numbers[index[0]][index[1]] = cp.deepcopy(nums) # 縦列check for j in range(9): overlapping_numbers = [[] for i in range(9)] for i in range(9): for num in unconfirmed_numbers[i][j]: overlapping_numbers[num-1].append((i, j)) for index_box in overlapping_numbers: if overlapping_numbers.count(index_box) == len(index_box) >= 2: nums = [index+1 for index, indices in enumerate(overlapping_numbers) if indices == index_box] for index in index_box: if unconfirmed_numbers[index[0]][index[1]] != nums: flag = True unconfirmed_numbers[index[0]][index[1]] = cp.deepcopy(nums) return flag # 例外1の逆バージョン def remainder_excluder(): flag = False # 3×3枠 for i in range(3): for j in range(3): cubic_frame_nums = [] for sub_i in range(i*3, i*3+3): for sub_j in range(j*3, j*3+3): cubic_frame_nums.append(cp.deepcopy(unconfirmed_numbers[sub_i][sub_j])) for nums in cubic_frame_nums: if len(nums) == cubic_frame_nums.count(nums) > 1: for sub_i in range(i*3, i*3+3): for sub_j in range(j*3, j*3+3): if unconfirmed_numbers[sub_i][sub_j] != nums: for num in nums: if num in unconfirmed_numbers[sub_i][sub_j]: unconfirmed_numbers[sub_i][sub_j].remove(num) flag = True # 横 for i in range(9): row_line_nums = [] for j in range(9): row_line_nums.append(cp.deepcopy(unconfirmed_numbers[i][j])) for nums in row_line_nums: if len(nums) == row_line_nums.count(nums) > 1: for j in range(9): if unconfirmed_numbers[i][j] != nums: for num in nums: if num in unconfirmed_numbers[i][j]: unconfirmed_numbers[i][j].remove(num) flag = True # 縦 for j in range(9): column_line_nums = [] for i in range(9): column_line_nums.append(cp.deepcopy(unconfirmed_numbers[i][j])) for nums in column_line_nums: if len(nums) == column_line_nums.count(nums) > 1: for i in range(9): if unconfirmed_numbers[i][j] != nums: for num in nums: if num in unconfirmed_numbers[i][j]: unconfirmed_numbers[i][j].remove(num) flag = True return flag # 例外処理2 def line_confirm(): flag = False for i in range(3): for j in range(3): # 横処理 row_lines = [] for sub_i in range(i*3, i*3+3): row_line = [] for sub_j in range(j*3, j*3+3): for num in unconfirmed_numbers[sub_i][sub_j]: row_line.append(num) row_lines.append(list(set(row_line))) exclusive_union = row_lines[0] + row_lines[1] + row_lines[2] exclusive_union = [num for num in exclusive_union if not exclusive_union.count(num) >= 2] if exclusive_union: for number in exclusive_union: for row in row_lines: if number in row: row_i = i*3+row_lines.index(row) for sub_j in range(0, j*3): if number in unconfirmed_numbers[row_i][sub_j] and len(unconfirmed_numbers[row_i][sub_j]) > 1: flag = True unconfirmed_numbers[row_i][sub_j].remove(number) for sub_j in range(j*3+3, 9): if number in unconfirmed_numbers[row_i][sub_j] and len(unconfirmed_numbers[row_i][sub_j]) > 1: flag = True unconfirmed_numbers[row_i][sub_j].remove(number) # 縦処理 column_lines = [] for sub_j in range(j*3, j*3+3): column_line = [] for sub_i in range(i*3, i*3+3): for num in unconfirmed_numbers[sub_i][sub_j]: column_line.append(num) column_lines.append(list(set(column_line))) exclusive_union = column_lines[0] + column_lines[1] + column_lines[2] exclusive_union = [num for num in exclusive_union if not exclusive_union.count(num) >= 2] if exclusive_union: for number in exclusive_union: for column in column_lines: if number in column: column_j = j*3+column_lines.index(column) for sub_i in range(0, i*3): if number in unconfirmed_numbers[sub_i][column_j] and len(unconfirmed_numbers[sub_i][column_j]) > 1: flag = True unconfirmed_numbers[sub_i][column_j].remove(number) for sub_i in range(i*3+3, 9): if number in unconfirmed_numbers[sub_i][column_j] and len(unconfirmed_numbers[sub_i][column_j]) > 1: flag = True unconfirmed_numbers[sub_i][column_j].remove(number) return flag # 3次元配列同縦列から同じ数字を弾く def column_excluder(i, j, n): flag = False for sub_i in range(9): if n in unconfirmed_numbers[sub_i][j]: unconfirmed_numbers[sub_i][j].remove(n) flag = True unconfirmed_numbers[i][j] = [n] # 3次元配列同横列から同じ数字を弾く def row_excluder(i, j, n): flag = False for sub_j in range(9): if n in unconfirmed_numbers[i][sub_j]: unconfirmed_numbers[i][sub_j].remove(n) flag = True unconfirmed_numbers[i][j] = [n] # 3次元配列同枠内から同じ数字を弾く def cubic_frame_excluder(i, j, n): flag = False for sub_i in range(i//3*3, i//3*3+3): for sub_j in range(j//3*3, j//3*3+3): if n in unconfirmed_numbers[sub_i][sub_j]: flag = True unconfirmed_numbers[sub_i][sub_j].remove(n) unconfirmed_numbers[i][j] = [n] # 出力用 def nampre_print(): print("____________________________________") for index, nums in enumerate(nampre): if index == 8: print("|", end="") [print(" "+str(n)+" |",end="") for i, n in enumerate(nums)] print("\n  ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄") elif (index+1)%3 == 0: print("|", end="") [print(" "+str(n)+" |",end="") for i, n in enumerate(nums)] print("\n|===|===|===|===|===|===|===|===|===|") else: print("|", end="") [print(" "+str(n)+" |",end="") for i, n in enumerate(nums)] print("\n|---|---|---|---|---|---|---|---|---|") # 時間を測る start = time.time() # 入力&2次元配列に整形 nums = [int(i) for i in input().split()] nampre = [[] for i in range(9)] for index, i in enumerate(nums): nampre[index//9].append(i) # 未確定数字参照用の3次元配列生成 unconfirmed_numbers = [[[n for n in range(1,10)] for j in range(9)] for i in range(9)] # 処理継続フラグ flag = False # 数字確定済添字 subscripts = set() # 3次元配列削る for i in range(9): for j in range(9): if nampre[i][j] != 0 and (i,j) not in subscripts: flag = True num = nampre[i][j] column_excluder(i, j, num) row_excluder(i, j, num) cubic_frame_excluder(i, j, num) subscripts.add((i,j)) nampre_print() while flag: flag = cubic_frame_judgment() or row_judgment() or column_judgment() or only_one_judgment() or cubic_tumor_excluder() or remainder_excluder() or line_confirm() nampre_print() print(str(time.time()-start)+"[sec]")
- 投稿日:2019-12-14T23:48:25+09:00
MySQL + Python で utf8mb4 対応テーブルの挙動を確認する
概要
- MySQL に文字セット utf8mb4 に設定したテーブルを作成して、Python 3 からデータ操作(参照・追加・更新・削除)を試す
- 環境: GMOデジロックのレンタルサーバー「コアサーバー」 + MySQL 5.7 + Python 3.6 + mysqlclient (MySQLdb)
MySQL のバージョンを確認
$ mysqld --version mysqld Ver 5.7.27 for Linux on x86_64 (MySQL Community Server (GPL))MySQL の文字セットと照合順序を確認
起動している MySQL デーモンの文字セットと照合順序の設定を MySQL monitor にて確認。
mysql> SHOW VARIABLES LIKE 'character_set%'; +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ 8 rows in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'collation%'; +----------------------+-----------------+ | Variable_name | Value | +----------------------+-----------------+ | collation_connection | utf8_general_ci | | collation_database | utf8_general_ci | | collation_server | utf8_general_ci | +----------------------+-----------------+ 3 rows in set (0.00 sec)参考:
- MySQL :: MySQL 5.6 リファレンスマニュアル :: 5.1.4 サーバーシステム変数
- MySQL :: MySQL 5.6 リファレンスマニュアル :: 10.1.4 接続文字セットおよび照合順序
- MySQL :: MySQL 5.6 リファレンスマニュアル :: 10.1.14.1 Unicode 文字セット
データベースを作成
MySQL monitor にてデータベースを作成。
mysql> create database test_db; Query OK, 1 row affected (0.00 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | test_db | +--------------------+ 2 rows in set (0.01 sec) mysql> use test_db; Database changed参考:
テーブルを作成
テーブル作成用の SQL を書いてファイルに保存。
create-table.sqlCREATE TABLE IF NOT EXISTS test_table ( id INTEGER NOT NULL AUTO_INCREMENT, name VARCHAR(256) NOT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;mysql コマンドでテーブルを作成。
$ mysql -h localhost -u alice -p test_db < create-table.sqlMySQL monitor にてテーブルを確認。
mysql> show tables from test_db; +-------------------+ | Tables_in_test_db | +-------------------+ | test_table | +-------------------+ 1 row in set (0.00 sec) mysql> show create table test_db.test_table; +------------+----------------------------------------------- | Table | Create Table +------------+----------------------------------------------- | test_table | CREATE TABLE `test_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(256) COLLATE utf8mb4_bin NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin | +------------+----------------------------------------------- 1 row in set (0.00 sec)参考:
- MySQL :: MySQL 5.6 リファレンスマニュアル :: 13.1.17 CREATE TABLE 構文
- MySQL :: MySQL 5.6 リファレンスマニュアル :: 3.5 バッチモードでの MySQL の使用
Python のバージョンを確認
$ python3 --version Python 3.6.8Python のパッケージ mysqlclient をインストール
mysqlclient は Python 2 で使えるパッケージ MySQL-python (MySQLdb1) から派生して Python 3 に対応したパッケージ。
今回は mysqlclient のバージョン 1.3.4 を使う。
$ python3 -m pip install mysqlclient==1.3.4今回の動作確認環境であるGMOデジロックのレンタルサーバー「コアサーバー」では該当バージョンがすでにインストール済みだった。
$ python3 -m pip list | grep mysqlclient mysqlclient 1.3.4参考:
- Python モジュールのインストール — Python 3.6.10rc1 ドキュメント
- GitHub - PyMySQL/mysqlclient-python: MySQL database connector for Python (with Python 3 support)
- GitHub - farcepest/MySQLdb1: MySQL database connector for Python (legacy version)
Python + mysqlclient でデータ操作
データを追加・取得・更新・削除する Python のソースコードを用意。
crud.py# mysqlclient を使う import MySQLdb # connect db connection = MySQLdb.connect(host="localhost", user="alice", passwd="your-password", db="test_db", charset="utf8mb4") cursor = connection.cursor(MySQLdb.cursors.DictCursor) # insert insert_sql = "INSERT INTO test_table (name) VALUES (%s)" cursor.execute(insert_sql, ("寿司ビール??????文字化けしないで",)) print(f"insert count={cursor.rowcount}") connection.commit() # select select_sql = "SELECT id, name FROM test_table" cursor.execute(select_sql) print(f"select count={cursor.rowcount}") for row in cursor: print(f"{row['id']}: {row['name']}") target_id = row["id"] # update update_sql = "UPDATE test_table set name=%s WHERE id=%s" cursor.execute(update_sql, ("Alice", target_id)) print(f"update count={cursor.rowcount}") connection.commit() # delete delete_sql = "DELETE FROM test_table WHERE id=%s" cursor.execute(delete_sql, (target_id,)) print(f"delete count={cursor.rowcount}") connection.commit() connection.close()実行結果。
寿司ビール絵文字などが文字化けせずに追加・取得・表示できている。$ python3 crud.py insert count=1 select count=1 1: 寿司ビール??????文字化けしないで update count=1 delete count=1参考:
- Welcome to MySQLdb’s documentation! — MySQLdb 1.2.4b4 documentation
- 【Python3】MySQL 操作をひと通りマスター!導入方法とCRUDサンプルコード集 | ITエンジニアラボ
- Python3でMySQLを使う – 基本操作からエラー処理までサンプルコード付 | Crane & to.
テーブルとデータベースを削除
MySQL monitor から使い終わったテーブルとデータベースを削除。
mysql> drop table test_db.test_table; Query OK, 0 rows affected (0.00 sec) mysql> drop database test_db; Query OK, 0 rows affected (0.00 sec)
- 投稿日:2019-12-14T23:42:24+09:00
Blender内蔵Pythonを環境構築する
BlenderにはPythonが内蔵されていて、色々なスクリプトを行うことができます。ただし、導入されているモジュールは
numpy等に限られており、好きなモジュールを追加するには少し作業が必要なので解説します。Windowsの場合
デフォルトの設定の場合、Blenderは以下の場所に保存されているはずです。
C:\Program Files\Blender Foundation\Blender\2.80この下のPythonが内蔵されています。(自分で個別にインストールしたPythonとはまた別です)
C:\Program Files\Blender Foundation\Blender\2.80\Python\python.exe
また、以下の場所に
pip.exe(インストールするためのモジュール)があります。C:\Program Files\Blender Foundation\Blender\2.80\python\Scripts
!バージョンは2.81だったり2.80だったりするので、そこは各自合わせてください
この
pipにはパスが通っていない(このpipを参照するようになっていない)ので、コマンドプロンプトで例えば、pip install pandasと打っても通りません。(別のPythonがインストールされている場合、そちらの方にインストールされます)
パスが通っていないなら場所を直接参照すればよいだけの話で、
C:\Program Files\Blender Foundation\Blender\2.80\python\Scripts\pip install pandasとやればOK……とはならず、実はもう一手間必要で、これだとWindowsの管理者権限の関係でうまくいきません。
C:\Program Files\Blender Foundation\Blender\2.80\python\Scripts\pip install pandas --userこれでうまくいきます。
注意事項として、ワーキングディレクトリは
>>> import os >>> os.getcwd() 'C:\\Program Files\\Blender Foundation\\Blender'になるので、なにかファイルを生成してそれを参照する、という操作を行う場合は管理者権限がないとエラーになります。管理者権限でBlenderを起動するか、ユーザーディレクトリ以下にファイルを生成・参照するようにしましょう。
Macの場合
Macの場合、Blenderは以下の場所に保存されているはずです。
/Applications/Blender.app/Contents/Resources/2.81
!バージョンは2.81だったり2.80だったりするので、そこは各自合わせてください
ただ、なぜかpipがインストールされていません。pipをインストールする必要があります。
ターミナルを開いて、
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py /Applications/blender.app/Contents/Resources/2.81/python/bin/python3.7m get-pip.py!pythonのバージョンは3.7だったり3.5だったりするので、そこは各自合わせてください
で、
pipが生成されるはずです。後は同じように、
/Applications/blender.app/Contents/Resources/2.81/python/bin/pip install pandasでインストール完了。
_tkinterの罠
ちなみに、Windowsで
pyplotをインポートしようとすると以下のようなエラーが出ます。
_tkinterがないと言われます。直前にインポートしているtkinter/__init__.pyの中身を見ると、
「もしこれがfailする場合、あなたのPythonはTk用に調整されていないかもしれません」
個別にインストールする普通の(?)Pythonだとこれが出ないので、内蔵Python特有の問題かもしれません。
一応、力技として
C:\Program Files\Blender Foundation\Blender\2.80\の下に別にインストールしたpythonをフォルダごとコピーするというものがあります(元々存在していたpythonフォルダはリネームして避難)。これだと環境をそのまま持っていけます。ただ、pyplot.show()でグラフを描画することはできませんでした。この方法は、内蔵Pythonではどうしてもモジュールをpipできない場合などは有効かもしれません。MacOSの場合、このエラーは出ませんが、やはりpyplot.show()で描画することはできませんでした。
Blender上でグラフを描画するのは難しそうです(その必要性はあまりなさそうですが)。




- 投稿日:2019-12-14T23:40:25+09:00
[小ネタ]VSCodeからSAMによるLambdaのローカル実行で「Error with child process: Building resource 'awsToolkitSamLocalResource'」がでて動かない場合の対処
要約
SAMの内部にあるpipのversionとローカルのpipのversionが合わないと動かない時があるので、ローカルのpipのversionを修正する必要がある。
実行環境
項目名 バージョン OS MacOS High Sierra 10.13.6 VSCode 1.40.2 SAM 0.37.0 Python 3.7.3 pip 19.3.1(記事内で19.2.3に変更) 問題
VSCodeの「Run Locally」からAWS Toolkitを使用してローカル環境で試験したい時に動かない場合があります。例えば以下のようなエラーです。
Local invoke of SAM Application has ended. Preparing to run app.lambda_handler locally... Building SAM Application... An error occurred trying to run SAM Application locally: Error with child process: Building resource 'awsToolkitSamLocalResource' ,Running PythonPipBuilder:ResolveDependencies ,Error: PythonPipBuilder:ResolveDependencies - Traceback (most recent call last): File "<string>", line 1, in <module> TypeError: 'module' object is not callable原因(おそらく)
SAMの方で起きていたIssueがVSCodeのAWS Toolkitではまだ解決していないみたいです。
GitHub : sam build fails for python3.7 functions with pip==19.3 installed
試しに同じ設定で、ターミナルから以下のコマンドで実行した場合はSAMとpipのverisonは同じでも問題ありませんでした。$ sam local invoke HelloWorldFunction --event events/event.json対処
一時的な対処とはなりますが、pipのversionを以下に修正するとVSCodeからでも正常に実行することが可能になります
$ pip install pip==19.2.3pipのversion変更後にVSCodeから「Run Locally」したログ
Fetching lambci/lambda:python3.7 Docker container image...... Mounting /tmp/aws-toolkit-vscode/vsctkytL1AY/output/awsToolkitSamLocalResource as /var/task:ro,delegated inside runtime container ...(中略)... {"statusCode":200,"body":"{\"message\": \"hello worldXXX\"}"}
- 投稿日:2019-12-14T23:38:51+09:00
python画像処理の個人メモ
plt.showで複数の画像を表示できる。グレースケール画像を表示するときは
plt.imshow(thresh, 'gray', vmin = 0, vmax = 255)
http://hikuichi.hatenablog.com/entry/2015/12/26/225623
- 投稿日:2019-12-14T23:07:29+09:00
作業中に検出した同じ名前のノードを自動的にリネームする
はじめまして、来年はHoudiniの記事を書きたいなと思ってます、rateionn(読み方は低音)です。
この記事はMaya Advent Calendar 2019の15日目の記事になります。
先日のzebraed氏のpyside:MEventMessageを使ったcallbackはご覧になられましたでしょうか?
OpenMayaでscriptJobと同じ機能を軽くシンプルに扱えるとの事で、自分も今後活用していこうと思います。
今回はscriptJobを使って書きますが...
はじめに
ノード名が重複しているからと言ってMayaに致命的なエラーが発生することはありません。
しかし、melスクリプトを作成する際に正しい作法で処理を書かないと指定したオブジェクトが見つけられずにスクリプトが停止してしまう可能性があります。
- Mayaエラー:行0:複数のオブジェクトが名前と一致します
ノード名の重複があっても正しく動作するツールであれば問題ないし、最終的にデータを綺麗に出来るならこの記事は読まなくても大丈夫だと思います。
何か起こる前に自動でリネーム出来てたら楽だよね
自動リネーム処理
1. リネームする
- uuidからノードを取得する。
- ノード名に
|(バーティカルライン)が含まれていた場合、ノード名が重複している。- 正規表現でベースとなるノード名を取得する。
- 赤くマーキングされている範囲をベース名として取得する。

- リネームする
- cmds.rename
- 新しい名前の最後に「#」を 1 つ付けると、名前の変更コマンドは、新しい名前を固有にする番号で最後の「#」を置き換えます。
出来たコードはこんな感じ
def rerename(node_uuid): for node in cmds.ls(node_uuid): if "|" in node: basename = re.search("^(.+)?\|(.+?)(\d+)?$", node).group(2) rename_name = cmds.rename(node, "{}#".format(basename))2. 手動リネーム時の処理
- NameChangedが実行されたときにリネーム処理を実行します。
- 手動でリネームをする場合はオブジェクトを1つしか選択していないと思うので
lsコマンドで選択しているオブジェクトを取得してUUIDに変換してリネーム処理を実行します。def renameEvent(): for node_uuid in cmds.ls(cmds.ls(sl=True), uuid=True): rerename(node_uuid)nonSameNameAlliance.py#L11-L13
3. 複製時の処理
- 手動で複製を行ったときは、複製されたオブジェクトに選択が移動するのでSelectionChangedが実行されたときにリネーム処理を実行します。
- dag=Trueで階層を取得して、tr=Trueでトランスフォームノードのみ取得できるようにし、UUIDに変換してリネーム処理を実行します。
def duplicateEvent(): for node_uuid in cmds.ls(cmds.ls(sl=True, dag=True, tr=True), uuid=True): rerename(node_uuid)nonSameNameAlliance.py#L15-L17
スクリプトジョブに登録
def main(): try: if jobIds is not None: for jobId in jobIds: cmds.scriptJob(kill=jobId, force=True) except:pass jobIds = [] jobIds.append(cmds.scriptJob(event=["NameChanged", renameEvent], protected=True)) jobIds.append(cmds.scriptJob(event=["SelectionChanged", duplicateEvent], protected=True))
- スクリプトジョブに処理を登録すると、条件に合ったタイミングで登録された処理を実行してくれます。
- 今回はrenameEventとSelectionChangedそれぞれに処理を登録しています。
nonSameNameAlliance.py#L19-L28
Maya起動時に自動でスクリプトジョブを実行する
userSetup.pyimport nonSameNameAlliance;nonSameNameAlliance.main()nonSameNameAlliance.pyをMayaのScriptsフォルダ内に配置してuserSetup.pyに起動用の処理を追記します。
これでMaya起動時にscriptJobに処理が登録されて自動リネームされるようになります。ダウンロード
今回のソースコードはこちら
https://github.com/teionn/nonSameNameAlliance注意点
シーン内で操作をした時に自動的にノードがリネームされてしまうので、基本的にモデラー向けの内容かと思います。
トランスフォームノードのみに実行されるようになっています。
- 中間シェイプノードなどの全てのノードで効果を得たい場合は
tr=Trueを消してください。このスクリプトは大文字/小文字の判定は行いません。
Mayaは大文字/小文字違いのオブジェクトを同じ階層であっても保持することが出来てしまいます。
この状態のままUnityにアセットを持っていくと、オブジェクト
object_aとobject_Aがあった場合どちらかのオブジェクトが参照出来なくなってしまうらしいです。
明日の記事はrateionnさんによるちゃんと Remove: Unknown Plugins してますか?というお話です。
あれ… 書くの自分やん… まだ記事できてないんですけど…
間に合ったらスクリプトを無償公開する予定なのでじゃんじゃんDLしてただけると嬉しいです。

- 投稿日:2019-12-14T22:43:43+09:00
Apache Kafkaを触った
MDC Advent Calendar 2019 の15日目です。
Kafkaとは何か
LinkedInが作ったOSSの分散メッセージングシステム(メッセージングキュー)。
高スループット、高スケーラビリティ。
Java(Scala)で書かれている。Producer、Broker、Consumerの3つのコンポーネントで構成される。
ProducerからストリーミングされたデータをConsumerへ中継する。対障害のためにデータの永続化もする。送達保証も実現。
・ Producer: メッセージを配信する
・ Broker: ProducerからConsumerへメッセージの受け渡しをする
・ Consumer: メッセージを受け取る※仔細な仕組みやアーキテクチャ等については以下が参考になります。
・Apache Kafkaの概要とアーキテクチャ
・Apache Kafkaに入門した何に使うのか
ユースケースとしては以下のようなものが挙げられます。
- システムがサイロ化するのを防ぐためにデータハブとしてアーキテクチャに組み込む(マイクロサービスとかで)
- Fluentdなどと連携してログ収集に使う
- Webサイトのユーザのページ移動とかを収集してWebアクティビティ分析に使う
- IoTデバイスのセンサーの値を集約し、可視化や分析、他のデバイスの制御などに使う
- ビッグデータ、機械学習、etc
具体的なところだと以下。
・LINEの大規模データパイプライン
・Yahooリアルタイム検索
・大手ヘルスケアIT企業 Cerner社のKafka活用事例動かしてみる
簡単なサンプルを作って試してみます。
今回はKafka本体はKafka-dockerを使って環境構築をして、ProducerとConsumerのクライアント側はkafka-pythonを使いました。Kafka-dockerのインストール・起動
公式にあるとおり、kafka-dockerをダウンロードして、docker-compose.ymlの
KAFKA_ADVERTISED_HOST_NAMEにdocker hostのIPアドレスを書いたあと、docker-compose up -dすればOKです。
Producerを実装する
ほんとうはTwitter Striming APIみたいなデータをとってきたり、IoTのセンサーの値を取得したかったですが、今回は用意がないので一旦適当に数値を取れるものを、ということでマウスのx座標を取得して1秒おきにKafkaに送付するスクリプトを書きました。
KafkaProducerの引数bootstrap_serverに渡す値は、docker-compose.ymlにも書いたdocker hostのIPアドレスと、kafkaのコンテナに割り当てられたPort番号を指定します。
割り当てられてるPort番号はdocker psで確認できます。
上の場合は32783がそれです。
以下が作成したProducer側のソースコードです。
procuer.send(でtestというTopicに現在のマウスのx座標を投げています。from kafka import KafkaProducer import pyautogui import time def main(): producer = KafkaProducer(bootstrap_servers='{Docker HostのIPアドレス}:{Port}') while True: result = producer.send('test', str(pyautogui.position().x).encode()).get(timeout=60) print(result) time.sleep(1) if __name__ == '__main__': main()Consumerを実装する
次にConsumer側の実装です。同様にKafkaのIPアドレスとPortを指定します。
for message in consumer:でKafkaからデータを逐次pullしてきてくれます。from kafka import KafkaConsumer def main(): consumer = KafkaConsumer( 'test', bootstrap_servers=['{Docker HostのIPアドレス}:{Port}']) for message in consumer: print("x = " + message.value.decode()) if __name__ == '__main__': main()実行
下の左側でProducer側、右側でConsumerを実行しています。
Producer側からKafkaに送った値(マウスのx座標)をConsumer側でKafkaから取得して表示できているのが確認できます。
今後やりたいこと
・ラズパイ、Arduinoとか使ってセンサーの値を組み込む。
・取得したデータをグラフにしたり、解析したりする。


- 投稿日:2019-12-14T22:38:48+09:00
AWS SDK for Python(Boto3)ではClient APIよりResource APIを使おう
はじめに
この記事はAWS初心者 Advent Calendar 2019
の14日目の記事です。
もし誤りがあれば指摘してもらえると幸いです。要約
Boto3の中ではサービスによってリソースAPI(boto3.reosurce('サービス名')で呼び出すもの)があります。リソースAPIの方がクライアントAPIより抽象化されていて不要な情報を書かずに実装できるので、それぞれのAPIで同じことができる場合はリソースAPIを優先して使用した方が良いです。
記事全体の構成
まずBoto3、クライアントAPI、リソースAPIとは何だったのかを再確認します。
その後に両方のAPIを使用した場合にSQS、S3、DynamoDBの使用パターンを1ケースずつとりあげて比較してどう違うのかを具体的に見てみます。
最後に現在リソースAPIが提供されているサービスの一覧と所感を書いてます。Boto3とは
Pythonに提供されているAWSのSDKで、コードからAWSの各種サービス(EC2やDynamoDB、S3など)に接続する場合に使用します。
APIのリファレンスは以下の資料に書かれています。
Boto 3 DocumentationAPIには主に低レベルなAPIであるクライアントAPIと高レベルなAPIであるリソースAPIがあります。具体的には以下のような記述で呼び出されます。
# Client API boto3.client('sqs') # Resource API boto3.resource('sqs')次にそれぞれのAPIにどんな特性があるか確認します。
クライアントAPI(低レベルAPI)
AWSのサービスで提供しているHTTP APIと1対1に対応するメソッドです。HTTP API
と完全にマッピングしているので、APIで可能な操作はすべてできるようになっています。ただ汎用的な設定になっているので、APIに設定するパラメータをメソッドに直接する必要があります。
以下はSQSのsend_messageを実行する例です。APIで使用するQueueUrlなどを指定しています。import boto3 # SQS クライアントAPI版 sqs = boto3.client('sqs') response = sqs.send_message(QueueUrl='https://sqs.us-east-2.amazonaws.com/123456789012/MyQueue', MessageBody='...')参考元:Boto3のClient APIドキュメント(send_message)
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sqs.html#SQS.Client.send_message
※「QueueUrl='...'」の部分はURLの記述を追加リソースAPI(高レベルAPI)
クライアントAPIと比べて高レベルで抽象化したAPIです。APIとの直接マッピングではなく、抽象化したクラスを間に挟むことでより開発者にとって扱いやすくなっています。
ここでは例として、クライアントAPIと同じようにリソースAPIでsend_messageを行う例を記載します。queueName='target-queue-name' # SQS リソースAPI版 sqs = boto3.resource('sqs') response = sqs.get_queue_by_name QueueName = queueName ).send_message( MessageBody = '...' )参考元:「Boto3(Python)で"Service Resource"を使ってみた(Lambda)」
https://cloudpack.media/16114クライアントAPIと比較するとコード内にSQSのURLを記載せず、queue名の問い合わせからメッセージの送信が書けます。いちいちキューのURLを意識する必要がなくなるので開発者はキューの名前さえ記述すればよくなります。
クライアントAPIとリソースAPIの比較(S3)
次にS3のクライアントAPIとリソースAPIを比較します。
例としてバケットからファイル名を取得するコードを記述します。# 共通定数(バケットとS3内ファイルのプレフィックス) BUCKET_NAME= "xxx-bucket" S3_PREFIX = "image-file-done/"# S3 クライアントAPI版 s3_client = boto3.client('s3') # 戻り値の型:<class 'dict'> s3_objects = s3_client.list_objects_v2(Bucket=BUCKET_NAME, Prefix=S3_PREFIX) for filename in s3_objects['Contents']: print('client:'+filename['Key'])# S3 リソースAPI版 s3_resource = boto3.resource('s3') # 戻り値の型:<class 'boto3.resources.collection.s3.Bucket.objectsCollection'> s3_objects = s3_resource.Bucket(BUCKET_NAME).objects.filter(Prefix=S3_PREFIX) for filename in s3_objects: print('resource:'+filename.key)呼び出しまではほとんど変わりませんが、呼び出し後の型が異なります。
クライアントAPIで呼び出した場合は、辞書型で返ってくるので実装のたびに返却される辞書型の形式を意識したデータの取り出しが必要になります。リソースAPIであればboto3用のオブジェクトになっているので、他のサービスでリソースAPIを使用する場合でも似たような記述でコードが書けます。クライアントAPIとリソースAPIの比較(DynamoDB)
最後にDynamoDBのクライアントAPIとリソースAPIを比較します。
こちらは特にBoto3のドキュメントがよく分からなくて、他の記述を参考にして間違ってコピーしてしまうことが多そうです。(昔の自分のことです…)# 共通定数(テーブル名とハッシュキー名、ソートキー名) TABLE_NAME='XXXXX_IFO' HASH_KEY_NAME='XXXXX_CODE' SORT_KEY_NAME='DATE_TIME'# DynamoDB クライアント版 dynamodb_client = boto3.client('dynamodb') # 戻り値の型: <class 'dict'> response = dynamodb_client.get_item( TableName=TABLE_NAME, Key={ HASH_KEY_NAME:{ 'S': '54620100' }, SORT_KEY_NAME:{ 'S': '2019050621' } } )# DynamoDB リソース API dynamodb_resource = boto3.resource('dynamodb') table = dynamodb_resource.Table(TABLE_NAME) # 戻り値の型: <class 'dict'> response = table.get_item( Key={ HASH_KEY_NAME: '54620100', SORT_KEY_NAME: '2019050621' } )久々にクライアントAPIで書きましたがパラメータをCLIと同じ形式で書くので少ししんどいです。戻り値の型自体はどちらも辞書型ですが、テーブル内部の操作をTableオブジェクトからでき、Key項目の記述は型情報を逐一書かなくて済むのでかなり楽になってます。
リソースAPIが提供されているサービス(2019/12/14時点)
リソースAPIは提供されているサービスが限られています。具体的には以下のサービスが対応しています。
- CloudFormation
- Cloud Watch
- DynamoDB
- EC2
- Glacier
- IAM
- OpsWorks
- S3
- SNS
- SQS参考元:「Boto 3 Documentation」
https://boto3.amazonaws.com/v1/documentation/api/latest/index.html上記サービスを利用する場合は、クライアントAPIの利用よりも先にまずリソースAPIの検討を行う必要がありそうです。Boto3のCodeExamples(サンプルドキュメント)でDynamoDBはresourceになっていますが、他のEC2やCloudWatchはclientなのでCodeExamplesだけでなくAvailable Servicesを見る必要がありそうです。
所感
今までクライアントAPIやリソースAPIなどをあまり意識せずに使用していたため反省もかねて色々調べた結果をまとめました。SQSの例でもわかるようにコード部分に不要な情報を書く必要がなくなるので、今後自分もまずはリソースAPIの提供があるサービスか確認し、提供されているならうまく使用できないか考えてからクライアントAPIを使いたいと思います。
QiitaやネットにはクライアントAPIで書かれた実装が多々あるようなので、今後自分が記事を書くことでリソースAPIの情報を増やしたいと思います。
- 投稿日:2019-12-14T22:21:39+09:00
【備忘録】MacOSXでPythonがimport hashlibでerrorになるやつの解決法
はじめに
単純に上記エラーで悩んでいる人向けの記事です。かなりレアケースです。
問題点
import hashlib
すると死ぬ時があります。結果Python 2.7.16 (default, Mar 4 2019, 09:01:38) [GCC 4.2.1 Compatible Apple LLVM 10.0.0 (clang-1000.11.45.5)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import hashlib ERROR:root:code for hash md5 was not found. Traceback (most recent call last): File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 147, in <module> globals()[__func_name] = __get_hash(__func_name) File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 97, in __get_builtin_constructor raise ValueError('unsupported hash type ' + name) ValueError: unsupported hash type md5 ERROR:root:code for hash sha1 was not found. Traceback (most recent call last): File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 147, in <module> globals()[__func_name] = __get_hash(__func_name) File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 97, in __get_builtin_constructor raise ValueError('unsupported hash type ' + name) ValueError: unsupported hash type sha1 ERROR:root:code for hash sha224 was not found. Traceback (most recent call last): File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 147, in <module> globals()[__func_name] = __get_hash(__func_name) File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 97, in __get_builtin_constructor raise ValueError('unsupported hash type ' + name) ValueError: unsupported hash type sha224 ERROR:root:code for hash sha256 was not found. Traceback (most recent call last): File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 147, in <module> globals()[__func_name] = __get_hash(__func_name) File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 97, in __get_builtin_constructor raise ValueError('unsupported hash type ' + name) ValueError: unsupported hash type sha256 ERROR:root:code for hash sha384 was not found. Traceback (most recent call last): File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 147, in <module> globals()[__func_name] = __get_hash(__func_name) File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 97, in __get_builtin_constructor raise ValueError('unsupported hash type ' + name) ValueError: unsupported hash type sha384 ERROR:root:code for hash sha512 was not found. Traceback (most recent call last): File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 147, in <module> globals()[__func_name] = __get_hash(__func_name) File "/usr/local/Cellar/python@2/2.7.16/Frameworks/Python.framework/Versions/2.7/lib/python2.7/hashlib.py", line 97, in __get_builtin_constructor raise ValueError('unsupported hash type ' + name) ValueError: unsupported hash type sha512これの原因はPyenvとかhomebrewとか色々あります。
まずMacOSのPythonはpythonを読みに行くんじゃなく、python2を読みに行く点に注意です。
Pyenvで指定しているもんだからwhich pythonとかやっても本物は出てきません。
python2でエイリアス設定されているのか、基本python2が呼ばれます。
which python2ですれば正体がわかります。
そもそもなんでPython3があるのにpython2がpyenvにねーんだ!って話なんですけどね。まぁこれらは間接的な原因でしかなくて、直接的なぶっ壊れ原因は全くわかりません。
解決法
brewでアップグレードしちゃう
これに限ります。
brew upgrade python@2これで環境がとりあえずはなんとかなります。
まだまだ解決中なので、続報があり次第お伝えします。
- 投稿日:2019-12-14T22:14:35+09:00
pygame2で1からゲームUIを作る!
概要
この記事はフューチャー Advent Calendar 2019 14日目の記事です。
昨日の記事は@RuyPKGさんによる新人でも、楽がしたい! ~議事録の準備~となってます。先日社内勉強会にて、@shibukawaさんがゲームエンジンの紹介をしていたのがこの記事を書いたきっかけになります。
Pythonで実装したボードゲームのUIが欲しく、HTMLによる表現だと動きを表現するのが難しかったのでPythonのゲームエンジンであるpygameを触ってみることにしました。pygameとは
Pythonで動かすことの出来る、クロスプラットフォームのゲームエンジンです。
ゲームのグラフィック部分をPythonで書くことができるならば、Pythonで書かれたゲームロジックをそのまま埋め込むことが出来るのでとても便利です。このpygameですが、2009年に一旦開発が停止してしばらく動いていなかったのでpygameをご存知の方は乗り換えした人も多いのではないでしょうか。
しかし、pygame2リリースに向けた開発が2019年になって活発になり、来年中にpygame2の本バージョンがリリースされそうです。
2.0.0.dev6からはpython3.8もサポートされていて先が楽しみです。
今後注目を浴びてくる気がします。環境
- pygame: 2.0.0.dev6
- python: 3.8.0
環境構築
pygame公式のGetting Startedを参考に環境構築を進めます。
pip経由で、pygameをインストールします。
この際、バージョンを指定しないと最新安定版である1.9.6が入ってしまうので注意しましょう。(1.9.6はpython3.6までしか対応していません)pip install pygame==2.0.0.dev6サンプルを動かしてみる
多数のサンプルゲームがpygameには含まれています。
試しに一つ実行してみましょう。python -m pygame.examples.aliens
インベーダーゲームのようなものが実行されました!
サンプルの一覧とそれぞれどんなゲームかはgitのexampleフォルダのREADMEにあるので色々実行してみると面白いです。1からサンプルを作る
サンプルを解読しながら、自分でコードを描き上げていきます。
今回は、背景に文字を書くだけのサンプルを目指します。処理の流れ
静的な画面とは違い、ゲームエンジンを用いて描画する場合は高速で画面を更新する必要があります。
そのため、以下のような流れで処理を行います。
- 画像読み込み等の初期化
- 画面をクリアし、背景画像を描画
- 画面に表示するオブジェクトの位置や値を更新して描画
- 画面の更新の反映
- 2に戻る
ゲームエンジンでは、画面に表示するオブジェクトはスプライトを使って描画されているので、スプライトクラスを継承したクラスを使って実装時は描画します。
スプライトが何か気になった方は、調べてみてください。
描画を高速化するためのハードウェア実装の話等、歴史的経緯があって面白いですが知らなくても特に問題はないと思います。import os import pygame as pg # game constants SCREENRECT = pg.Rect(0, 0, 640, 480) SCORE = 0 main_dir = os.path.split(os.path.abspath(__file__))[0] def load_image(file): """ loads an image, prepares it for play """ file = os.path.join(main_dir, "data", file) try: surface = pg.image.load(file) except pg.error: raise SystemExit('Could not load image "%s" %s' % (file, pg.get_error())) return surface.convert() class Score(pg.sprite.Sprite): """ to keep track of the score. """ def __init__(self): pg.sprite.Sprite.__init__(self) self.font = pg.font.Font(None, 40) self.font.set_italic(1) self.color = pg.Color("white") self.lastscore = -1 self.update() self.rect = self.image.get_rect().move(10, 450) def update(self): """ We only update the score in update() when it has changed. """ if SCORE != self.lastscore: self.lastscore = SCORE msg = "Score: %d" % SCORE self.image = self.font.render(msg, 0, self.color) def main(winstyle=0): pg.init() # Set the display mode winstyle = 0 # |FULLSCREEN bestdepth = pg.display.mode_ok(SCREENRECT.size, winstyle, 32) screen = pg.display.set_mode(SCREENRECT.size, winstyle, bestdepth) # create the background, tile the bgd image bgdtile = load_image("background.jpg") background = pg.Surface(SCREENRECT.size) background.blit(bgdtile, (0, 0)) screen.blit(bgdtile, (0, 0)) pg.display.flip() # Initialize Game Groups all = pg.sprite.RenderUpdates() # Create Some Starting Values clock = pg.time.Clock() global SCORE if pg.font: all.add(Score()) # Run our main loop whilst the player is alive. while True: all.clear(screen, background) SCORE += 123456789 all.update() # draw the scene dirty = all.draw(screen) pg.display.update(dirty) # cap the framerate at 40fps. Also called 40HZ or 40 times per second. clock.tick(40) if __name__ == "__main__": main()data以下に背景画像(background.jpg)を準備しておく必要があります。
ちょっと長いですが、上記サンプルを実行すると、以下のように背景の描画と文字の表示ができます。
以下ゲームエンジン独特の部分を説明します。
Spriteのグループ化
all = pg.sprite.RenderUpdates() # Spriteグループの作成 all.add(Score()) # Spriteグループへの追加 all.update() # Spriteグループの一括更新 all.draw(screen) # Spriteグループの描画pygameにはスプライトをグループ化できる機能が備わっていて、画面の全ての要素や、特定のグループ(例えば敵キャラクターのみ等)の要素を一斉に更新したり描画するのが簡単にできるようなっています。
Spriteのグループには順序付きグループや単体スプライト用のグループや様々な種類があり、用途に応じて使い分けると良いでしょう。
公式ドキュメントで一覧は確認できます。画面のリフレッシュレートの指定
clock = pg.time.Clock() # Clockの生成 clock.tick(40) # Clockを用いて1/40秒経過するまで処理を待つオブジェクトを動かす際には、処理の重さに関わらず同じ速さで動かすために処理が早く終わりすぎた場合は待つ必要があります。
これを実現するため、pygameではClockオブジェクトを使用します。
Clockオブジェクトを作ってclock.tick()を呼ぶだけで、前回の呼び出しからフレームレートに応じた時間sleepしてくれるのでとても便利です。最後に
今回紹介した描画の機能以外にも、pygameには
- 入力の受けつけ
- 音の再生
- Android, iOS対応
等様々な機能があります。
リアルタイムに更新されるUIをPythonで書けるのは非常に便利なので、pygame2の正式リリースが待ちきれないですね!


- 投稿日:2019-12-14T21:29:20+09:00
[AWS] LINEWORKSでリマインダBOTを作ってみた(実装編)
LINEWORKS Advent Calendar 14日目です。
今回は、LINEWORKS Advent Calendar 7日目 で紹介したリマインダBOT の実装について紹介します。
[再掲]BOTの画面と全体構成
リマインダBOTは3つのLambdaで構成されており、Python3.7 で実装してます。
①. LINEWORKSから送信されるメッセージの処理およびSQSへの通知
②. テーブル内に保存されたイベントをポーリングおよびSQSへの通知
③. SQSから受信したメッセージをLINEWORKSサーバに通知今回は、①に焦点を当てて紹介します。
状態遷移表とメッセージリスト
ユーザとのBOTのやり取りを状態遷移表で表現しました。リマインダBOTは、以下の4つのイベントを扱います。
- ユーザ参加
- ユーザがBOTを追加時に発生
- テキスト入力
- ユーザがBOTに対して任意のテキスト入力
- イベント入力ボタン押下
- BOT内のメニューに表示される「イベント登録」を押下
- イベント出力ボタン押下
- BOT内のメニューに表示される「イベント参照」を押下
それぞれのユーザイベントに対して4つの状態を管理します。
BOTは、ユーザイベントとBOTの状態に対応するメッセージをユーザに返答します。
メッセージの内容は、メッセージリストとして定義しておきます。Lambdaの実装
では、本題のLambdaの実装です。
まずは、Lambda関数の全体の処理です。
リクエストボディの検証とメッセージのメインの処理を担う自作のon_event関数を呼び出します。
リクエストボディの検証は、ヘッダーのx-works-signatureの値に基づいて処理します。""" index.py """ import os import json from base64 import b64encode, b64decode import hashlib import hmac import reminderbot API_ID = os.environ.get("API_ID") def validate(payload, signature): """ x-works-signatureの検証 """ key = API_ID.encode("utf-8") payload = payload.encode("utf-8") encoded_body = hmac.new(key, payload, hashlib.sha256).digest() encoded_base64_body = b64encode(encoded_body).decode() return encoded_base64_body == signature def handler(event, context): """ main関数 """ # リクエストボディの検証 if not validate(event["body"], event["headers"].get("x-works-signature")): return { "statusCode": 400, "body": "Bad Request", "headers": { "Content-Type": "application/json" } } body = json.loads(event["body"]) # メッセージのメイン処理 reminderbot.on_event(body) return { "statusCode": 200, "body": "OK", "headers": {"Content-Type": "application/json"} }続いて、on_event関数についてです。
今回事前に定めた、4つの状態、4つのユーザイベント、メッセージリストを定数で定義しておきます。""" reminderbot.py """ import os import json import datetime import dateutil.parser from dateutil.relativedelta import relativedelta import boto3 from boto3.dynamodb.conditions import Key, Attr # 状態遷移表に基づき4つの状態を定義 STATUS_NO_USER = "no_user" STATUS_WATING_FOR_BUTTON_PUSH = "status_waiting_for_button_push" STATUS_WATING_FOR_NAME_INPUT = "status_waiting_for_name_input" STATUS_WATING_FOR_TIME_INPUT = "status_waiting_for_time_input" # メッセージリストに基づき定義 MESSAGE_LIST = [ "こんにちは、リマインドボットだよ。メニューボタンを押してね。", "イベント名を入力してね", "メニューボタンを押してね。", "イベントの内容はこちら!", "イベント時間を入力してね。", "登録完了!", "エラーだよ。もう一度入力してね。", ] # ユーザのイベントをpostbackイベントとして定義 # BOTのメニュー登録時は、以下のpostbackイベントの値と同じにすること POSTBACK_START = "start" POSTBACK_MESSAGE = "message" POSTBACK_PUSH_PUT_EVENT_BUTTON = "push_put_event_button" POSTBACK_PUSH_GET_EVENT_BUTTON = "push_get_event_button" # ステータスを管理するテーブル dynamodb = boto3.resource("dynamodb") table = dynamodb.Table("lineworks-sample-table") def on_event(event): """ botの全体のイベントの処理 """ account_id = event["source"]["accountId"] content = event["content"] postback = content.get("postback") or "message" # ユーザの今の状態を確認 response = table.get_item( Key={ "Hash": "status_" + account_id, "Range": "-" } ) status = STATUS_NO_USER message = None if response.get("Item") is not None: status = response.get("Item")["Status"] # 各ユーザイベント(postback)毎の分岐処理 try: if postback == POSTBACK_START: message = on_join(account_id, status) elif postback == POSTBACK_MESSAGE: text = content["text"] message = on_message(account_id, status, text) elif postback == POSTBACK_PUSH_PUT_EVENT_BUTTON: message = on_pushed_put_event_button(account_id, status) elif postback == POSTBACK_PUSH_GET_EVENT_BUTTON: message = on_pushed_get_event_button(account_id, status) except Exception as e: print(e) message = MESSAGE_LIST[6] # SQSにメッセージ内容を通知 sqs = boto3.resource("sqs") queue = sqs.get_queue_by_name(QueueName="lineworks-message-queue") queue.send_message( MessageBody=json.dumps( { "content": { "type": "text", "text": message, }, "account_id": account_id, } ), ) return True最後に、各イベントごとの処理の実装です。
それぞれのイベントの中で、各状態ごとの分岐処理を状態遷移表に基づいて実装しています。
重複する処理はまとめています。def on_join(account_id, status): """ bot追加時のイベントの処理 """ # ステータスに応じた分岐処理 if status == STATUS_NO_USER: table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_BUTTON_PUSH, } ) return MESSAGE_LIST[0] else: table.delete_item( Key={ "Hash": "status_" + account_id, "Range": "-" } ) table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_BUTTON_PUSH, } ) return MESSAGE_LIST[0] def on_message(account_id, status, text): """ テキスト入力時のイベントの処理 """ if status == STATUS_WATING_FOR_BUTTON_PUSH: table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_BUTTON_PUSH, } ) return MESSAGE_LIST[2] elif status == STATUS_WATING_FOR_NAME_INPUT: table.update_item( Key={ "Hash": "status_" + account_id, "Range": "-", }, UpdateExpression="set #st = :s, Title = :t", ExpressionAttributeNames = { "#st": "Status" # Statusは予約語なので#stに置き換える }, ExpressionAttributeValues={ ":s": STATUS_WATING_FOR_TIME_INPUT, ":t": text, }, ) return MESSAGE_LIST[4] elif status == STATUS_WATING_FOR_TIME_INPUT: # dateutil.parserで日付は変換 time_dt = dateutil.parser.parse(text) time = time_dt.strftime("%Y/%m/%d %H:%M:%S") response = table.get_item( Key={ "Hash": "status_" + account_id, "Range": "-", } ) table.put_item( Item={ "Hash": "event_" + account_id, "Range": time, "Title": response["Item"]["Title"], # utc -> 日本時間変換のため、9時間の差分をとる # utc -> 当初の予定 + 1h後に削除するように設定 "ExpireTime": int((time_dt - relativedelta(hours=9) + relativedelta(hours=1)).timestamp()), "SentFlag": False } ), table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_BUTTON_PUSH, } ) return MESSAGE_LIST[5] def on_pushed_put_event_button(account_id, status): """ 「イベント登録」ボタン押下時のイベントの処理 """ if status == STATUS_WATING_FOR_BUTTON_PUSH: table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_NAME_INPUT, } ) return MESSAGE_LIST[1] elif status == STATUS_WATING_FOR_NAME_INPUT: return MESSAGE_LIST[1] elif status == STATUS_WATING_FOR_TIME_INPUT: table.put_item( Item={ "Hash": "status_" + account_id, "Range": "-", "Status": STATUS_WATING_FOR_NAME_INPUT, } ) return MESSAGE_LIST[1] def on_pushed_get_event_button(account_id, status): """ 「イベント参照」ボタン押下時のイベントの処理 """ current_jst_time = (datetime.datetime.utcnow() + relativedelta(hours=9)).strftime("%Y/%m/%d %H:%M:%S") # event取得処理 response = table.query( KeyConditionExpression=Key("Hash").eq("event_" + account_id) & Key("Range").gt(current_jst_time) ) items = response["Items"] or [] message = MESSAGE_LIST[3] if len(items) == 0: message += "\n-----" message += "\nなし" message += "\n-----" for item in items: message += "\n-----" message += "\n タイトル: {title}".format(title=item["Title"]) message += "\n 日時: {time}".format(time=item["Range"]) message += "\n-----" return messageまとめ
状態遷移表を作成することで、各イベント時にどのような処理を実装すべきか、
どのメッセージを返すべきか、が明確になるので迷いなく実装することができました。今回は、シンプルなアプリだったので状態やイベントの数も少ないですが、
より複雑な処理をBOTにさせようとすると状態遷移表がより役に立ってくるかと思います。


- 投稿日:2019-12-14T19:45:56+09:00
TouchDesignerだけで非同期通信する方法 3選
はじめに
TouchDesigner(以下TD) ではpythonスクリプトを実行することができますが、
HTTP通信のような処理に時間のかかるものだと、その処理が終わるまでちょっと固まってしまいます。
このとき、TD全体のタイムラインも止まってしまい描画が更新されない状態になってしまうので、
それを防ぐために非同期で通信する方針をとりました。ただ非同期で値を取ってきたいだけであれば、TDに加えてnodeなどなどを使えば良かったりもするのですが、
環境の都合によりTDだけで完結させたい状況だったので、以下の方法を検討しました。
Web DATを使うthreadingモジュールを使う(マルチスレッド)asyncioモジュールを使う(シングルスレッド)multiprocessモジュールを使う(マルチプロセス)それぞれについて説明していきます。
※ ちなみにpythonで非同期通信する方法に関しては、以下の記事がわかりやすかったです。
https://qiita.com/icoxfog417/items/07cbf5110ca82629aca0サンプルコード
今回のサンプルを以下にアップしました。
(github)
Web DATを使うこれがいちばん簡単です。
URLを入力してFetchボタンをpulseしてあげれば、
TDのタイムラインは止まらずに裏で(たぶんcurlとか?)通信をしてくれます。
参考: https://docs.derivative.ca/Web_DATGETの場合はURLに直接入れてしまえばOKで、
POSTの場合は、上側のインレットInput 0に送りたいデータのtableを繋げた状態でSubmitボタンをpulseすればOKです。
(ちなみに下側のインレットにはカスタムHTTPヘッダを入れることができます)(gif?)
そして返ってきたものの形式に合わせて、
XML DATやjsonモジュールなどを使って必要な値を引っ張ってくれば完成です。参考: TouchDesignerでJSONをDAT Tableにパースする
threadingモジュールを使う
threadingモジュール は、マルチスレッドで並列処理をしてくれるモジュールです。
TD内部のpython3.5に標準で入っています。
threading.Thread()メソッドの引数に、別スレッドで実行したい関数名およびその関数の引数(タプル)を入れることで、別スレッドで実行してくれます。Matthew Ragan大先生の記事を大いに参考にしました。
欠点と対策
こちらもとても便利なのですが、欠点がいくつかあります。
- 別スレッドでの処理がいつ終了したかを検知できない
- 別スレッドの処理中にTDのオペレータを参照できない
別スレッドでの処理がいつ終了したかを検知できない
メインスレッドの方から停止の命令は送れるのですが、別スレッドでの処理が終了したタイミングを検知することができません。
なので、「別スレッドでURL叩いて返ってきたらこの処理を実行する」的なことが簡単にはできません。。別スレッドの処理中にTDのオペレータを参照できない
これもよく考えれば当然ではあるのですが、別のスレッドで処理を回しているので、
TDのメインスレッドに存在しているオペレータにアクセスすることができません。
なので、「別スレッドでURL叩いて返ってきた結果をそのままTable DATにパースする」的なことはできません。(ちなみに、それをするとこんなダイアログが出ます)
対策
なので、かなりの力技ですが、値が返ってきたかどうかを
Timer CHOPで逐次監視することにしました。おわりに
- TouchDesignerだけで非同期通信する方法についてまとめました。
- 特に最後の力技の部分、もっとスマートに解決できる気がしてならないので、もしもっと良い方法を思いついた方いらっしゃいましたら是非コメントいただけると嬉しいです…!
おまけ
- 今回、TouchPlayerを使って複数端末でそれぞれ動かしていたのですが、TouchPlayerだとTextportが見れないので、ログを外部ファイルに吐きだしてエラーが出たらそれを確認するという方法をとっていました。
- (TouchDesignerをReadOnlyで開くという選択肢もあります。)
- その際、ログを吐き出すモジュールとしてloguruがとても便利だったのでオススメです。
参考にしたリンク集
- 投稿日:2019-12-14T19:42:36+09:00
踏み台経由RDSのデータをPandasでごにょごにょする
estie Advent Calendar 2019 14日目の記事になります。
是非他の記事もご覧くださいね
はじめに
こんにちは、estie.incでエンジニアやってます、marushoです。
estieでは「テクノロジーの力で、世界を自由に、楽しく。」を合言葉に、不動産分野の「めんどくさい」を解消するためを運営しており、日々更新される不動産データを分析し、新たな価値の創出にチャレンジしています。
データ分析や分析結果の反映をスピーディに行うためには、セキュリティ構成を担保しつつ気軽にDBへアクセスする必要があります。
弊社ではpandas<->DBのやりとりが頻繁に行われるのですが、一度csvファイルに変換したり踏み台サーバに入ったりするのは何かと時間を消費してしまいます。ということで、
今回は踏み台経由でDBのデータを、pandasで基本的なCRUD操作を直接やってみます。環境
DBはprivateなサブネットにいて踏み台サーバを経由しないとアクセスできない、というよくある環境を前提とします。
今回はAWS上のEC2/RDS(MySQL5.7)で動作させています。ちなみにローカル環境は
- MacOS Mojave
- Python 3.6.8
- Pandas 0.24.1
必要なパッケージをインストール
PythonでDB情報を扱うので、定番ORMのSQLAlchemyを使います。
また、MySQLのドライバと踏み台にSSHを張るためのSSHtunnelもインストールします$ pip install SQLAlchemy PyMySQL sshtunnelSSH config
普段sshに接続するために、.ssh/configにHostを登録しておくことが多いと思います。
今回もsshtunnelでconfigに書かれたHost情報を利用するので、以下のように踏み台の接続情報を書き込んでおきます。~/.ssh/configHost rds_bastion Hostname [踏み台IP] Port 22 User [UserName] IdentityFile ~/.ssh/[KeyName]RDSに接続
まずはmoduleのimportと、DBの接続に必要な情報を書いておきます
import pandas as pd import sqlalchemy as sa from sshtunnel import SSHTunnelForwarder DB_USER = 'test_user' # DBのユーザー名 DB_PASS = 'db_passward' # DBのパスワード ENDPOINT = 'hogehoge.fugafuga.ap-northeast-1.rds.amazonaws.com' # RDSエンドポイント PORT = 3306 # ポート DB_NAME = 'test_db' # DB名 CHARSET = 'utf8' # 文字コード次にSSHポートフォワードを使って、踏み台越しのDBに接続します。
server = SSHTunnelForwarder(ssh_address_or_host = 'rds_bastion', ssh_config_file = '~/.ssh/config', remote_bind_address=(ENDPOINT,PORT)) server.start()接続を終了するときはcloseしましょう
server.close()sshを接続した状態で、SQLAlqhemyのエンジンを取得します。
#SQLAlchemyの接続URLを生成 URL = f"mysql+pymysql://{DB_USER}:{DB_PASS}@127.0.0.1:{server.local_bind_port}/{DB_NAME}?charset={CHARSET}" #engineの取得 engine = sa.create_engine(URL)このengineを使ってPandasでのデータ操作をやっていきます
Pandasでごにょごにょする
さて、本題です。
pandasでcreate,read,update,delete操作ができるか試してみましょう。サンプルとして、DB名
test_dbにmembersテーブルを作成しておきますMySQL [test_db]> SELECT * FROM members; +----+------------------+-----+ | id | name | age | +----+------------------+-----+ | 1 | 雪村 あおい | 15 | | 2 | 倉上 ひなた | 15 | | 3 | 斎藤 楓 | 16 | | 4 | 青羽 ここな | 13 | +----+------------------+-----+Read:読み込み
まずは
pandas.read_sqlを使ってmembersテーブルをDataFrameとして読み込んでみましょうテーブル全てのデータを読み込む場合は、テーブル名を指定します
df = pd.read_sql('members', engine)
id name age 0 1 雪村 あおい 15 1 2 倉上 ひなた 15 2 3 斎藤 楓 16 3 4 青羽 ここな 13 綺麗に読み込めてますね
indexカラムの指定や、取得したいカラム名をリスト指定することもできます。
df= pd.read_sql('members', engine, index_col='id', columns=['name'])
id name 1 雪村 あおい 2 倉上 ひなた 3 斎藤 楓 4 青羽 ここな もちろんSQLクエリでレコード指定することも可能です。
df= pd.read_sql('SELECT * FROM members WHERE id = 2', engine)
id name age 1 2 倉上 ひなた 15 Create:テーブル作成
to_sqlを使ってDataFrameのデータから新しいテーブルを作成できます。
(DataFarameの)indexの有無や、どれをindexとして取り込むかの指定もできます。df = pd.read_sql('SELECT * FROM members WHERE age < 14', engine) df.to_sql('jc_members', engine, index=False, index_label='id')MySQL [test_db]> select * from jc_members; +------+------------------+------+ | id | name | age | +------+------------------+------+ | 4 | 青羽 ここな | 13 | +------+------------------+------+Update:レコードの挿入/更新
こちらも
to_sqlで実行できますが、
if_existオプションで挙動が異なるので注意が必要です。
if_exist=appendとすると、新しいレコードとして追加し、同じレコードがあった場合はエラーになります。insert_df = pd.DataFrame({'id':['5'],'name' : ['黒崎 ほのか'],'age':['14']}) insert_df.to_sql('members', engine, index=False, index_label='id', if_exists='append')
id name age 1 雪村 あおい 15 2 倉上 ひなた 15 3 斎藤 楓 16 4 青羽 ここな 13 5 黒崎 ほのか 14 INSERTとおなじ挙動ですね。ちゃんと追加されています。
しかし
if_exist=replaceとすると、指定テーブルのデータをすぺてdeleteして、DataFrameを追加します。insert_df = pd.DataFrame({'id':['5'],'name' : ['黒崎 ほのか'],'age':['14']}) insert_df.to_sql('members', engine, index=False, index_label='id', if_exists='replace')
id name age 5 黒崎 ほのか 14 UPDATEでもUPSERTでもなく、はたまたREPLACEとも異なる挙動なので注意が必要です!
特定レコードだけ更新する、などの操作はまだto_sqlに実装されいないようです。
今回は割愛しますが、SQLAlchemyのupsertを使う方法や、to_sqlのmethodオプションでSQLの挙動を変更するやり方があるようなので、試してみようと思います。Delete:レコード/テーブルの削除
read_sqlでdrop/delete操作をするとreturnが無くエラーになるのですが、
実はDB側には削除操作が実行されてしまいます。pd.read_sql('DROP TABLE members', engine)MySQL [test_db]> SELECT * FROM members; ERROR 1146 (42S02): Table 'test_db.members' doesn't existこれは本来の用途ではないので、delete操作を行うときは素直にsqlalchemyでのクエリ実行をお勧めします
engine.execute('DROP TABLE members')おわりに
離れたDBの情報を手軽にDataFrameにできるのは魅力ですね。
更新系のメソッドはかゆいところに手が届いてない感じなので、今後のpandasの発展を注視したいと思います。
estieではWebエンジニアを募集しています!
Wantedly
お気軽にオフィスに遊びに来てくださいね!
- 投稿日:2019-12-14T19:25:39+09:00
Python学習ノート_001日目_20191214
実施日:2019年12月14日
テーマ:Pythonのインストール実施手順
- OS環境:MacOS_10.13.6(17G65)
- Pythonのダウンロード:https://www.python.org/downloads/
- コードのダウンロード:https://www.oreilly.co.jp/books/9784873118741/
- 「第1刷正誤表」タブ中の内容を本に反映する

- 「関連ファイル」タブ中の「サンプルコード」のリンクをクリックして、ソースコードや関連ファイルをダウンロードする
- インストール手順は省略します。
- 動作確認:アプリケーションの中に「Python 3.8.0」の中の「IDLE.app」を起動してシェル環境の画面が見える。

- 投稿日:2019-12-14T19:10:07+09:00
Pythonでゆるく始める静的型検査
TypeScriptを一年程楽しく書いていたのですが、1ヶ月程前から業務でPython3を触ることになりました。
Pythonは簡潔にかけて楽しいものの、他の人から引き継いだ箇所もあり、開発していて型がないのが辛くなってきました。一番つらいのはコードリーディングしていて、この関数は何を返すのか? とか、この変数は何が入ってるのか、とかひと目見て分からないこと。……ドキュメントとしての型が無いことです。
無いなら導入しようということで、型アノテーションとmypyを導入することにしました。いきなりガチガチに型を導入しても逆に辛くなるので、型のない状態から無理せず型を導入していく方法を取り、結構うまく導入できたので、今回はその時の手順や得られた知見、Tipsを紹介しようと思います。
環境
今回はpipenvの環境でテストしていますが、mypyに付いてはpip等でも特に変わらないと思います。
python3.7.5
pipenv, version 2018.11.26pipenvの導入はこちらを参考にしてください
https://pipenv-ja.readthedocs.io/ja/translate-ja/index.htmlインストール
プロジェクトディレクトリ下でmypyをインストールします。
cd ./myproject pipenv install mypy -d静的型検査の実行
グローバルのpipにmypyがインストールされていてsrcディレクトリ以下のコードを静的型検査をしたい場合は
mypy ./srcで型検査ができますが、pipenvにしかmypyが入っていない場合はエラーになります。$ mypy ./src Command 'mypy' not found, but can be installed with: sudo apt install mypypipenvの仮想環境に入れば問題なく実行できます。
$ pipenv shell (myproject) $ mypy ./src Success: no issues found in 2 source files毎回仮想環境に入るのは面倒なので、Pipfileにスクリプトを登録しておきましょう。
[scripts] type-check = "mypy ./src"参考 https://pipenv-ja.readthedocs.io/ja/translate-ja/advanced.html#custom-script-shortcuts
スクリプトで実行したコマンドはpipenvの環境下で実行されるので
pipenv shellを行わなくてもmypyを実行できます。$ pipenv run type-check mypy.ini: No [mypy] section in config file Success: no issues found in 1 source filesCIなどで型検査を実行するときはこのコマンドを使用します。
Python3の組み込み型
殆どの人が既知だと思いますが、一応基本的な型について復習しておきます
公式のドキュメントにあるうち、普通型検査で使用するのはせいぜい以下の8種類くらいに限られると思います。
https://docs.python.org/ja/3.7/library/stdtypes.html迷ったら組み込み関数のtype()に入れて結果を見ればいいので覚える必要すら無いです。
型の種類 型名 例 真偽値型 bool True 整数型 int 10 浮動小数点数型 float 1.2 テキストシーケンス型(文字列型) str 'hoge' リスト型 list [1, 2, 3] タプル型 tuple ('a', 'b') 辞書型(マッピング型) dict { 'a': 'hoge', 'b': 'fuga'} 集合型 set { 'j', 'k', 'l'} 型のない関数に型を付けてみる
まず型のない関数を作ってみます。
./src以下にmy_module.pyを作成します。my_module.pydef get_greeting(time): if 4 <= time < 10: return 'Good morning!' elif 10 <= time < 14: return 'Hello!' elif 14 <= time < 24: return 'Goog afternoon.' elif 0 <= time < 4: return 'zzz..' else: return '' if __name__ == "__main__": print(get_greeting('morning'))0から24までの時間を受け取って挨拶を返してくれる関数にしてみました。
これで型検査を実行してみると...$ pipenv run type-check Success: no issues found in 1 source file何もエラーになりません!
なぜかというと、型アノテーションを行っていないので関数の返り値や引数の方は基本Any型(何でもありの型)になってしまうためです。
(既存のコードベースが存在する場合に、型導入時にエラーが出まくって心が折れたりしないのである意味これでいいと思います)
そこで次に、型アノテーションをつけてみます。def get_greeting(time: int) -> str: if 4 <= time < 10: return 'Good morning!' elif 10 <= time < 14: return 'Hello!' elif 14 <= time < 20: return 'Goog afternoon.' elif 0 <= time < 4: return 'zzz..' else: return None if __name__ == "__main__": print(get_greeting('morning'))1行目に「整数型を受け取って文字列型を返す」ことを表す型アノテーションを追加しました。
この状態で型検査を再び実行してみます。$ pipenv run type-check src/my_module.py:14: error: Argument 1 to "get_greeting" has incompatible type "str"; expected "int" Found 1 error in 1 file (checked 1 source file)今度はちゃんとエラーが出ました。
エラーメッセージを読むと14行目で関数get_greetingを呼び出す際に文字列を渡してしまっています。このまま実行すると実行時エラーが発生してしまっていました。
整数型を渡すようにコード変更して、再度型検査を実行するとエラーが出なくなります。print(get_greeting(10))型アノテーションを付けることで、コードが理解しやすくなり、さらに実行時エラーを未然に防ぐことができました。
設定ファイルmypy.iniを使う
そうはいっても型アノテーションを強制させたいときもあると思います。
その場合は設定ファイルを作成します。mypy.ini[mypy] python_version = 3.7 disallow_untyped_calls = True disallow_untyped_defs = Trueスクリプトも設定ファイルを指定するように修正します。
[scripts] type-check = "mypy ./src --config-file ./mypy.ini"こうしておけば型アノテーションを付け忘れた場合にエラーを返してくれるようになります。
$ pipenv run type-check src/my_module.py:1: error: Function is missing a type annotation src/my_module.py:14: error: Call to untyped function "get_greeting" in typed context Found 2 errors in 1 file (checked 1 source file)参考 https://mypy.readthedocs.io/en/latest/config_file.html
ゆるく導入するために活用したいテクニック
Any許容で既存のコードベースに導入できるとはいえ、元のコードベースが大きいと導入の際に大量のエラーが発生するのは避けられません。
心が折れそうになる前にちょっとまってください。
次に紹介する2つを実行するだけでエラーの9割は消えるはずです。参考 https://mypy.readthedocs.io/en/latest/existing_code.html#start-small
型のないモジュールのインポートを無視する
例えば以下のようなコードがあるとします。
import request型検査を行うとエラーがなんと3行も返ってきます。
$ pipenv run type-check src/my_module.py:1: error: Cannot find implementation or library stub for module named 'request' src/my_module.py:1: note: See https://mypy.readthedocs.io/en/latest/running_mypy.html#missing-imports Found 1 error in 1 file (checked 1 source file)importしたモジュールの型定義ファイル(stub)が無いためです。
導入時に型定義ファイルを全部用意したりするのは大変なのでmypy.iniの設定で無視します。
mypy.ini[mypy-request.*] ignore_missing_imports = Trueこれで
requestからのインポートにstubが無いことを無視してくれます。$ pipenv run type-check Success: no issues found in 1 source fileこれで平和が戻りました。
その行だけ無視する
あまり推奨はできないのですが、testなどであえて間違った型を代入させたいときにはよく使用する方法です。
無視したいコードの行末尾に#type: ignoreのコメントをつけます。print(get_greeting('hoge')) #type: ignoreこの行で発生するはずだった型エラーを抑制することができます。
おまけ:stubを自動生成する
「いやstubを使いたいんだ」という場合もあると思います。しかしサードパーティのモジュールの開発者がstubを用意していてくれている保証はありません。
自分で作るのは面倒です。
そういうときは自動生成しましょう。mypyをいれると使えるようになる、stubgenコマンドでファイルやディレクトリを指定してstubを自動生成することができます。
$ stubgen foo.py bar.pyインポートしたモジュールであれば
*.__path__でモジュールのpathを確認することができるのでそのpathを直接指定してstubを作ることもできます。>>> import request >>> request.__path__ ['/home/username/.local/share/virtualenvs/myproject-xxxxxxxx/lib/python3.7/site-packages/request'] >>>pathがわかったら、stubgenを実行します。
(myproject) $ stubgen /home/username/.local/share/virtualenvs/myproject-xxxxxxxx/lib/python3.7/site-packages/request Processed 1 modules Generated out/request/__init__.pyistubgenを実行するとプロジェクトrootにoutディレクトリが作成されるのでこのpathをmypyが見るようにmypy.iniに指定します。
mypy.ini[mypy] python_version = 3.7 mypy_path = ./out型検査が通るようになりました。
$ pipenv run type-check Success: no issues found in 1 source filestubgenで生成される型は完全なものではありません。
大体Any型になってしまうので本格的に使用したければstubファイルを自分で修正する必要があります。参考 https://github.com/python/mypy/blob/master/docs/source/stubgen.rst
よく使う発展的な型
組み込み型以外にもよく使う型が存在するので紹介しておきます。
mypyでは組み込み型以外はtypingモジュールやtyping_extensionsモジュールからそれらの型のクラスを呼び出して使用します。
typescriptとはちょっと使い勝手が違いますが、これらのモジュールにジェネリック型含めて殆どの型が網羅されているのでガチガチに型プログラミングしたいという人も満足できそうです。参考 https://mypy.readthedocs.io/en/latest/
Optional
通常は整数を返し、間違った値を受け取った場合などにはNoneを返すなどの関数はよくあります。
その場合の返り値はintもしくはNoneですが、これを表現できるのがOptionalです。from typing import Optional def sample(time: int) -> Optional[int]: if 24 < time: return None else: return timeList, Dict
整数のリストや文字列のリストなどをListで表現できます。
from typing import List # 整数のリスト intList: List[int] = [1, 2, 3, 4] # 文字列のリスト strList: List[str] = ['a', 'b', 'c']同様にDictを使えば辞書型でも「keyが文字でvalueが整数」のような表現ができます。
from typing import Dict # keyが文字でvalueが整数の辞書型 strIntDict: Dict[str, int] = {'a': 1, 'b': 2, 'c': 3, 'd': 4}Union
複数の方を組み合わせたユニオン型を作成できます。
from typing import Union strOrInt: Union[str, int] = 1 # OK strOrInt = 'hoge' # OK strOrInt = None # error: Incompatible types in assignment (expression has type "None", variable has type "Union[str, int]")Any
型を指定したくない場合はAny型ももちろん可能です
from typing import Any string: str = 'hoge' any: Any = string any = 10 # OK notAny = string notAny = 10 # error: Incompatible types in assignment (expression has type "int", variable has type "str")Callable
Callableで関数の型を表現できます。
from typing import Callable # 整数型の引数を一つ受け取って文字列型を返す関数型定義 func: Callable[[int], str] def sample(num: int) -> str: return str(num) func = sampleTypedDict
マップでkeyの値を指定してそのkeyは何の型のvalueを持っているかを指定したい場合があると思います。typescriptだとinterfaceで表現されるものです。
例えばmovieと言う辞書型の値があったとします。
movie = {'name': 'Blade Runner', 'year': 1982}moveはnameとyearというkeyを持ちますが、上書きするときに間違ってnameに整数を入れてしまったり、yearに文字列を入れてしまったら困りますよね。
TypedDictを使うと簡単に型として表現できます。from typing_extensions import TypedDict Movie = TypedDict('Movie', {'name': str, 'year': int}) movie1: Movie = {'name': 'Blade Runner', 'year': 1982} # OK movie2: Movie = {'name': 'Blade Runner', 'year': '1982'} # error: Incompatible types (expression has type "str", TypedDict item "year" has type "int")クラスの形でも表現できます。個人的にはTSのinterfaceっぽくかけるのでこちらの方が好みです。
from typing_extensions import TypedDict class Movie(TypedDict): name: str year: int詳細は公式ドキュメントをご確認ください。
https://mypy.readthedocs.io/en/latest/more_types.html#typeddictまとめ
いかがでしたでしょうか?
Pythonで型を始めるのは意外とハードルが低いんだなと感じていただけたら幸いです。Pythonで型がなくて辛いという方は今すぐ導入しましょう! 思ったより大体揃っているので幸せになれます。
不満点としてはエディタの支援があんまりしっかりしてないということでしょうか。
VS-Codeの拡張機能でPyrightを使用しているのですが、もっと良いのがあれば乗り換えたいです。それでは良い年末を!
- 投稿日:2019-12-14T18:09:14+09:00
PyTorch 三国志(Ignite・Catalyst・Lightning)
この記事は kaggle その2 Advent Calendar 2019 - Qiita 14日目の記事です。
0. 導入
深層学習フレームワークはいずれも開発が非常に速く盛り上がっている分野だと思います。
TensorFlow や jax 等もある中、つい先日 PFN のニュースもあり、PyTorch もより盤石となりそうです。おそらくこれからも PyTorch ユーザーは増えると思われます(Chainer にもあった公式 Trainer が PyTorch 内に実装されるとこの記事の存在が危ぶまれるので、そこには触れないこととします)。しかし PyTorch は自由度が高い一方、学習周りのコード(各 epoch のループ周りとか)は個々人に委ねられており、非常に個性豊かなコードとなりがちです。
これらのコードを自分で書くことは非常に学びが多く、PyTorch を始める場合には必ず通るべきだと私は思います。しかしあまりに個性が強すぎると、他の人との共有やコンペ間での使い回し等のシーンで辛いときがあります(ex. Winner Solutions でよく見かけるオレオレ Trainer)。
PyTorch の場合、学習周りのコードを簡略化するためのフレームワークは自身の中にはない(以前 Trainer があったが廃止された)のですが、Ecosystem | PyTorch の中では以下の PyTorch 用フレームワークが紹介されています。
多いですね。
全部試して自分に合ったものを見つけろというのは正論です。しかしそれらは楽ではないので本記事では各フレームワークの紹介と簡単な比較をしてみて、皆さんが触ってみる何かしらの目安になればと思います。なお fastai については頭一つ抜けて抽象度が高い(コードが短くなりやすい)のですが、自身で細かい操作を加えるための学習コストが高く感じたため、本記事内の比較では予め省いております。
そのため本記事では Catalyst・Ignite・Lightning の3つに絞り、かつ Kaggle のコンペに参加することを想定して比較を行っていきます。
ちなみにこれらの 3つのフレームワークについては予めある程度動作することは確認しました。本記事を読んでもう少し踏み込みたくなった方はご参照いただければと思います。
- 本記事内のコード
- Catalyst: yukkyo/PyTorch-FilterResponseNormalizationLayer
- Ignite: PyTorch-Ignite で学習用コードをスマートにする - ふぁむたろうのブログ
- Lightning: yukkyo/Kaggle-Understanding-Clouds-69th-solution
先に述べますが、いずれもコンペに参加できるだけのポテンシャルはあります。
1. この記事の対象(とか対象外)
- Kaggle コンペに興味ある
- 画像系コンペに興味ある
- 特に Classification・Segmentation・Detection あたりに興味ある
- PyTorch 触ったことある
- 触ったことない人はこの記事読んでる場合じゃないです
- 以下のページや本とかで始めましょう
2. 各フレームワーク(Catalyst・Ignite・Lightning)比較
2019年12月13日時点の pip 上での最新版を使いました。
Python のバージョンは 3.7.5 です。また NVIDIA/apexもインストール済を想定しています。
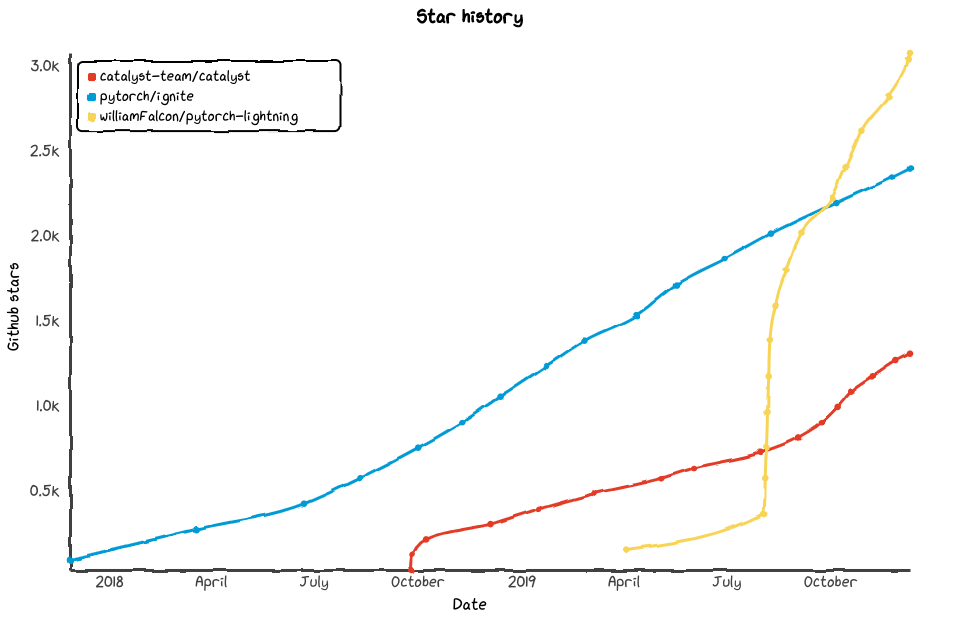
このコードを動かす分には apex は不要です。torch==1.3.1 torchvision==0.4.2 catalyst==19.12 pytorch-ignite==0.2.1 pytorch-lightning==0.5.3.22.1 Star 数遷移(2019年12月10日時点)
Catalyst・Ignite が順調に伸びている一方、Lightning は今年4月からすごい勢いで伸びてきました。
一方 Lightning はまだ世に出て一年も経っていないので開発中の機能も多く、まだ unstable(バージョン上げたときに後方互換性がない等)であることには注意です。また最近の Kaggle Notebook 上では Catalyst をよく見かけるため、Catalyst が Ignite を追い抜かすこともありえそうです。
2.2 書き方
ここでは素の PyTorch 学習用コードに対し各フレームワークを適用したらどうなるのか確認します。
2.2.1 共通部分
今回は cifer10 dataset に対して Resnet18 で学習してみようと思います。
下記のコードのように、モデルや Dataloader の定義は予め関数にしておきます。
共通部分のコード(長いのでたたみました)
share_funcs.pyimport torch import torch.nn as nn from torch import optim from torch.utils.data import DataLoader from torchvision import datasets, models, transforms def get_criterion(): """Loss をよしなに返してくれる関数""" return nn.CrossEntropyLoss() def get_loaders(batch_size: int = 16, num_workers: int = 4): """各 Dataloader をよしなに返してくれえる関数""" transform = transforms.Compose([transforms.ToTensor()]) # Dataset args_dataset = dict(root='./data', download=True, transform=transform) trainset = datasets.CIFAR10(train=True, **args_dataset) testset = datasets.CIFAR10(train=False, **args_dataset) # Data Loader args_loader = dict(batch_size=batch_size, num_workers=num_workers) train_loader = DataLoader(trainset, shuffle=True, **args_loader) val_loader = DataLoader(testset, shuffle=False, **args_loader) return train_loader, val_loader def get_model(num_class: int = 10): """モデルをよしなに返してくれる関数""" model = models.resnet18(pretrained=True) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_class) return model def get_optimizer(model: torch.nn.Module, init_lr: float = 1e-3, epoch: int = 10): optimizer = optim.SGD(model.parameters(), lr=init_lr, momentum=0.9) lr_scheduler = optim.lr_scheduler.MultiStepLR( optimizer, milestones=[int(epoch*0.8), int(epoch*0.9)], gamma=0.1 ) return optimizer, lr_scheduler2.2.1 ベースコード(素の学習用コード)
あまり深く考えずに愚直に書くと下記のようになると思います。
.to(device)やloss.backward()、optimizer.step()は書かなきゃいけないので、どうしても長くなりがちです。
またwith torch.no_grad()はtorch.set_grad_enabled(bool)を使うことで Train と Eval 時の両方に対応させることは可能なのですが、Train と Eval 時は違う処理が多く(ex.optimizer.step()や metrics 等)、両方対応させるような関数を作るとかえって見通しが悪くなりがちです。
ベースコード(長いのでたたみました)
def train(model, data_loader, criterion, optimizer, device, grad_acc=1): model.train() # zero the parameter gradients optimizer.zero_grad() total_loss = 0. for i, (inputs, labels) in tqdm(enumerate(data_loader), total=len(data_loader)): inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() # Gradient accumulation if (i % grad_acc) == 0: optimizer.step() optimizer.zero_grad() total_loss += loss.item() total_loss /= len(data_loader) metrics = {'train_loss': total_loss} return metrics def eval(model, data_loader, criterion, device): model.eval() num_correct = 0. with torch.no_grad(): total_loss = 0. for inputs, labels in tqdm(data_loader, total=len(data_loader)): inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) _, preds = torch.max(outputs, 1) loss = criterion(outputs, labels) total_loss += loss.item() num_correct += torch.sum(preds == labels.data) total_loss /= len(data_loader) num_correct /= len(data_loader.dataset) metrics = {'valid_loss': total_loss, 'val_acc': num_correct} return metrics def main(): epochs = 10 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = get_model() train_loader, val_loader = get_loaders() optimizer, lr_scheduler = get_optimizer(model=model) criterion = get_criterion() # Model を multi-gpu したり、FP16 対応したりする model = model.to(device) print('Train start !') for epoch in range(epochs): print(f'epoch {epoch} start !') metrics_train = train(model, train_loader, criterion, optimizer, device) metrics_eval = eval(model, val_loader, criterion, device) lr_scheduler.step() # Logger 周りの処理 # print するためのごちゃごちゃした処理 print(f'epoch: {epoch} ', metrics_train, metrics_eval) # tqdm 使ってたらさらにごちゃごちゃする処理をここに書く # Model を保存するための処理 # Multi-GPU の場合さらに注意して書く2.2.2 Catalyst
Catalyst の場合、ライブラリ内の
SupervisedRunnerに必要なものを渡せば終わりです。すごいスマートですね!
また Accuracy や Dice 等のメジャーな metrics であれば Catalyst 内にあるため、それらを使えば自分で書くことはほとんどありません(独自 metrics の導入も比較的楽そうでした)。
大抵デフォルトのままで困らなそうですが、自分で細かい処理を加えたい場合若干調べる必要がありそうです。import catalyst from catalyst.dl import SupervisedRunner from catalyst.dl.callbacks import AccuracyCallback from share_funcs import get_model, get_loaders, get_criterion, get_optimizer def main(): epochs = 5 num_class = 10 output_path = './output/catalyst' model = get_model() train_loader, val_loader = get_loaders() loaders = {"train": train_loader, "valid": val_loader} optimizer, lr_scheduler = get_optimizer(model=model) criterion = get_criterion() runner = SupervisedRunner(device=catalyst.utils.get_device()) runner.train( model=model, criterion=criterion, optimizer=optimizer, scheduler=lr_scheduler, loaders=loaders, logdir=output_path, callbacks=[AccuracyCallback(num_classes=num_class, accuracy_args=[1])], num_epochs=epochs, main_metric="accuracy01", minimize_metric=False, fp16=None, verbose=True )2.2.3 Ignite
Ignite は Catalyst や後述する Lightning とは少し毛色が違います。
下記のように@trainer.on(Events.EPOCH_COMPLETED)等で自分が挟みたい処理を各タイミングに対して差し込んでいくようなイメージです。
また Ignite も公式で Accuracy 等は用意されているのでメジャーな評価指標であれば自分で定義せずに済みそうです。一方使いこなすのに慣れが必要そうなのと、イベント挟み方の自由度が高い(trainder.append のような足し方もできる)ので、一歩間違えると全体の見通しが悪くなる可能性もあります。
import torch from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator from ignite.metrics import Accuracy, Loss, RunningAverage from ignite.contrib.handlers import ProgressBar from share_funcs import get_model, get_loaders, get_criterion, get_optimizer def run(epochs, model, criterion, optimizer, scheduler, train_loader, val_loader, device): trainer = create_supervised_trainer(model, optimizer, criterion, device=device) evaluator = create_supervised_evaluator( model, metrics={'accuracy': Accuracy(), 'nll': Loss(criterion)}, device=device ) RunningAverage(output_transform=lambda x: x).attach(trainer, 'loss') pbar = ProgressBar(persist=True) pbar.attach(trainer, metric_names='all') @trainer.on(Events.EPOCH_COMPLETED) def log_training_results(engine): scheduler.step() evaluator.run(train_loader) metrics = evaluator.state.metrics avg_accuracy = metrics['accuracy'] avg_nll = metrics['nll'] pbar.log_message( "Training Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f}" .format(engine.state.epoch, avg_accuracy, avg_nll) ) @trainer.on(Events.EPOCH_COMPLETED) def log_validation_results(engine): evaluator.run(val_loader) metrics = evaluator.state.metrics avg_accuracy = metrics['accuracy'] avg_nll = metrics['nll'] pbar.log_message( "Validation Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f}" .format(engine.state.epoch, avg_accuracy, avg_nll)) pbar.n = pbar.last_print_n = 0 trainer.run(train_loader, max_epochs=epochs) def main(): epochs = 10 train_loader, val_loader = get_loaders() model = get_model() device = 'cuda' if torch.cuda.is_available() else 'cpu' optimizer, scheduler = get_optimizer(model) criterion = get_criterion() run( epochs=epochs, model=model, criterion=criterion, optimizer=optimizer, scheduler=scheduler, train_loader=train_loader, val_loader=val_loader, device=device )2.2.4 Lightning
Lightning の場合、
LightningModuleを継承したクラス(Trainer クラス的なもの)を定義する必要があります。各step(ex.
training_step)の名前は決まっており、各 step を自分で埋めていきます。
また学習の実行自体はpytorch_lightning.Trainerクラスによって行われ、GPU や MixedPrecision、gradient accumulation 等の設定はこのクラスで設定します。
また metrics については Lightning 内には用意されていないため、自分で記載する必要があります。import torch import pytorch_lightning as pl from pytorch_lightning import Trainer from share_funcs import get_model, get_loaders, get_criterion, get_optimizer class MyLightninModule(pl.LightningModule): def __init__(self, num_class): super(MyLightninModule, self).__init__() self.model = get_model(num_class=num_class) self.criterion = get_criterion() def forward(self, x): return self.model(x) def training_step(self, batch, batch_idx): # REQUIRED x, y = batch y_hat = self.forward(x) loss = self.criterion(y_hat, y) logs = {'train_loss': loss} return {'loss': loss, 'log': logs, 'progress_bar': logs} def validation_step(self, batch, batch_idx): # OPTIONAL x, y = batch y_hat = self.forward(x) preds = torch.argmax(y_hat, dim=1) return {'val_loss': self.criterion(y_hat, y), 'correct': (preds == y).float()} def validation_end(self, outputs): # OPTIONAL avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean() acc = torch.cat([x['correct'] for x in outputs]).mean() logs = {'val_loss': avg_loss, 'val_acc': acc} return {'avg_val_loss': avg_loss, 'log': logs} def configure_optimizers(self): # REQUIRED optimizer, scheduler = get_optimizer(model=self.model) return [optimizer], [scheduler] @pl.data_loader def train_dataloader(self): # REQUIRED return get_loaders()[0] @pl.data_loader def val_dataloader(self): # OPTIONAL return get_loaders()[1] def main(): epochs = 5 num_class = 10 output_path = './output/lightning' model = MyLightninModule(num_class=num_class) # most basic trainer, uses good defaults trainer = Trainer( max_nb_epochs=epochs, default_save_path=output_path, gpus=[0], # use_amp=False, ) trainer.fit(model)2.3 各フレームワークで実行したときのコンソール画面とアウトプット
2.3.1 デフォルト
コンソール画面
$ python train_default.py Files already downloaded and verified Files already downloaded and verified Train start ! epoch 0 start ! 100%|_____| 196/196 [00:05<00:00, 33.44it/s] 100%|_____| 40/40 [00:00<00:00, 50.43it/s] epoch: 0 {'train_loss': 1.3714478426441854} {'valid_loss': 0.992230711877346, 'val_acc': tensor(0, device='cuda:0')}アウトプット
なし
2.3.1 Catalyst
コンソール画面
$ python train_catalyst.py 1/5 * Epoch (train): 100% 196/196 [00:06<00:00, 30.09it/s, accuracy01=61.250, loss=1.058] 1/5 * Epoch (valid): 100% 40/40 [00:00<00:00, 49.75it/s, accuracy01=56.250, loss=1.053] [2019-12-14 08:47:33,819] 1/5 * Epoch 1 (train): _base/lr=0.0010 | _base/momentum=0.9000 | _timers/_fps=58330.0450 | _timers/batch_time=0.0071 | _timers/data_time=0.0045 | _timers/model_time=0.0026 | accuracy01=52.0863 | loss=1.3634 1/5 * Epoch 1 (valid): _base/lr=0.0010 | _base/momentum=0.9000 | _timers/_fps=77983.3850 | _timers/batch_time=0.0146 | _timers/data_time=0.0126 | _timers/model_time=0.0019 | accuracy01=65.6250 | loss=0.9848 2/5 * Epoch (train): 100% 196/196 [00:06<00:00, 30.28it/s, accuracy01=63.750, loss=0.951]アウトプット
- Tensorboard 等はデフォルトで出力されます
- weight も保存されます
- デフォルトで code まで残してくれるのはちょっとうれしいですね
catalyst ├── checkpoints │ └── train.1.exception_KeyboardInterrupt.pth ├── code │ ├── share_funcs.py │ ├── train_catalyst.py │ ├── train_default.py │ └── train_lightning.py ├── log.txt └── train_log └── events.out.tfevents.1576306176.FujimotoMac.local.41575.02.3.2 Ignite
コンソール画面
Catalyst よりもややスッキリした画面です。
$ python train_ignite.py Epoch [1/10]: [196/196] 100%|________________, loss=1.14 [00:05<00:00] Training Results - Epoch: 1 Avg accuracy: 0.69 Avg loss: 0.88 Validation Results - Epoch: 1 Avg accuracy: 0.65 Avg loss: 0.98 Epoch [2/10]: [196/196] 100%|________________, loss=0.813 [00:05<00:00] Training Results - Epoch: 2 Avg accuracy: 0.78 Avg loss: 0.65 Validation Results - Epoch: 2 Avg accuracy: 0.70 Avg loss: 0.83アウトプット
- なし
- 自分で保存する部分を書くか、Ignite 内のクラスを使う必要がありそうです
2.3.3 Lightning
コンソール画面
Lightning ではデフォルトでは tqdm 内のバーに全て表示するようです。
$ python train_lightning.py Epoch 1: 100%|_____________| 236/236 [00:07<00:00, 30.75batch/s, batch_nb=195, gpu=0, loss=1.101, train_loss=1.06, v_nb=5] Epoch 4: 41%|_____________| 96/236 [00:03<00:04, 32.28batch/s, batch_nb=95, gpu=0, loss=0.535, train_loss=0.524, v_nb=5]アウトプット
- Lightning はディレクトリが重複した場合に version_x のように次のディレクトリを作って保存します。(それがかえって邪魔な場合もあり自分で checkpoint を定義することもありますが)
- Lightning の場合、meta_tags.csv に LightningModule に渡したパラメータが自動で保存されます
- Tensorboard 用の log もデフォルトで作成されます
- weight も checkpoints 内に保存されます
- デフォルトでは各 epoch 毎に
_ckpt_epoch_X.ckptが作成され、古い epoch の ckpt を削除しているようですlightning └── lightning_logs ├── version_0 │ └── checkpoints │ └── _ckpt_epoch_4.ckpt │ ├── media │ ├── meta.experiment │ ├── meta_tags.csv │ ├── metrics.csv │ └── tf │ └── events.out.tfevents.1576305970 ├── version_1 │ └── checkpoints │ └── _ckpt_epoch_3.ckpt │ ├── ...2.4 その他めぼしいところ
いずれも Early Stopping 等は対応しています。
2.4.1 Catalyst
catalyst.utils.set_global_seed()等の再現性周りの関数も用意されている- Dataset をより簡略化して書けるような関数もサポートされている
create_dataset, create_dataframe, prepare_dataset_labeling, split_dataframecatalyst.utils.pandas- Multi GPU や FP16 もサポートされている
- 公式 Tutorial のクオリティが高い
- 公式に Docker ファイルも置いてあり、インフラ周りの構成管理も意識したフレームワークを目指してるっぽい(多分)
2.4.2 Ignite
- Tensorboard や Logger も Ignite 内にあり、呼び出して使える
- 自由度が最も高そう
- イベントの挟み方は慣れが必要そうだけど
- 公式リポジトリの下に置いてある
2.4.3 Lightning
- Multi GPU や FP16 もサポートされている
2.5 おすすめするとしたら
いずれもポテンシャルはあるため強制ではないです。下記は個人の感想です。
- 画像系コンペ初めてで、何からやればよいかよくわからない
- → PyTorch Catalyst
- 画像系コンペは慣れきってて、殺意(金メダルを取りにいく強い気持ち)を持ってコンペに参加したい
- → PyTorch Lightning か PyTorch Catalyst
- Classification・Segmentation に限らず色んな画像系タスクを取り組みたい
- → PyTorch Lightning か PyTorch Catalyst
- Catalyst 内には強化学習用のサンプルコードもある
- オサレに書きたい
- → PyTorch Ignite
- PyTorch 公式のお膝元で安心してフレームワークを使いたい
- → PyTorch Ignite
- Ignite は 公式 PyTorch のリポジトリに置いてある
3. Catalyst・Ignite・Lightning を自由に行き来するために
ここで使うフレームワークを絞ってしまってもよいのですが、そもそも各フレームワークを行き来しやすいように書いていれば困らないはずです。 ですので PyTorch のコードを書き散らす上で意識しておくと良さそうなことをここにまとめます。
- ループの中身はなるべく取り出しておく
- 各 step(ex. train 内の 1バッチごとの処理)の処理は抜き出せるように意識しておくと良さそうです
- 少なくとも三重ループまで書き始めたら、ループの中身を抜き出せないか意識すると良さそうです
- 関数の引数を増やしすぎない
- Class にしてインスタンス変数を使ったり、Config を一つにまとめて使っても良いと思います
- optimizer や model を呼び出す関数を作る
- 個人の所感です
- Config を一つにまとめる
- コンペに参加するときはなるべく一箇所に設定をまとめた方が管理が楽
- 例
- Config クラスを作る
- Addict 等で呼び出しやすい辞書みたいなものを作る
- YAML ファイルで書いた設定を読み出す
4. さいごに
本記事では PyTorch Catalyst・Ignite・Lightning の比較を行いました。
いずれも定型文を無くしたいという部分は一致していますが、それぞれ個性が出る結果となりました。
どのフレームワークもポテンシャルはあるため、もし触ってみて自分に合っていると思ったらコンペに出て使い倒してみると良いかと思います。良い Kaggle(with PyTorch) ライフを!
- 投稿日:2019-12-14T18:08:13+09:00
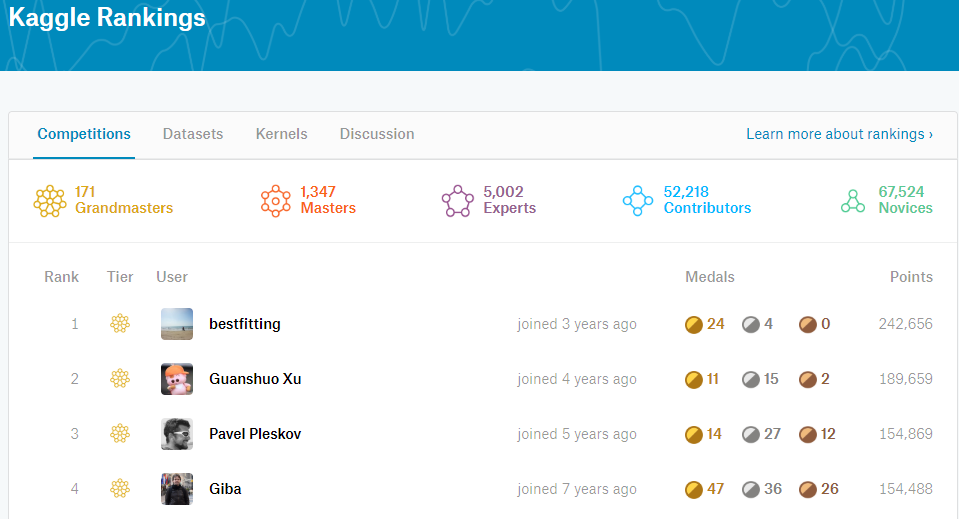
Kaggleランキング ポイントの仕組み
Kaggleランキング ポイントの仕組み
Kaggleには獲得メダルの色と数によって決定されるGrand master/Master/Expert/Contributor/NoviceのTierの他にランキングという仕組みがあります。Tierに比べあまり重視されることはない印象ですが、どのような仕組みになっているか解説します。(※コンペティションのみ)
Kaggle notebook
https://www.kaggle.com/d1348k/learn-aboout-competition-pointsgithub
https://github.com/uratatsu/kaggle_rankingKaggleポイントとは
Kaggleのコンペティションには金/銀/銅のメダルの他にCompetition pointsというものがあり、コンペティションの順位確定時に参加者にポイントが付与されます。ポイントは以下の数式により算出されます。
ポイントの仕組み
\Biggl[\frac{100000}{\sqrt{N_{teammates}}}\Biggl]\Bigl[Rank^{-0.75}\Bigl]\bigl[\log_{10} (1+\log_{10} (N_{teams})) \bigl]\biggl[e^{-t/500}\biggl]まずは基礎点として100,000点配られます。ここから参加チーム数、順位、自チーム人数によって、0~1の係数がかかって最終的な獲得ポイントが決まります。
順位による効果
\Bigl[Rank^{-0.75}\Bigl]当然ですが、最も大きい影響があるのはそのコンペティションのprivateにおける順位です。
順位に応じて、係数が上記グラフのように減衰します。
順位 係数 1st 1.0 2nd 0.5946 3rd 0.4387 10th 0.1778 50th 0.05318 100th 0.03162 1位と2位の差が非常に激しく、2位だと1位の60%ほどのポイント獲得率になります。10位で約18%、100位だと3%しかもらえません。
参加チーム数による効果
\bigl[\log_{10} (1+\log_{10} (N_{teams})) \bigl]そのコンペティションに参加しているチームの数によって、この項が変わります。
参加チーム数が多いほど、かけられる係数は大きくなりますが、下のグラフを見てわかるように、10,000人参加(今までの最高は8802チーム)したとしても0.7程度です。1,000チーム参加した場合には0.6程度なので、参加人数が10倍になってもポイントは1.16倍程度にしかなりません。
Kaggle運営の考え方が公式ブログに書いてあるのですが、100チーム参加のコンペと1,000チーム参加のコンペで勝つために必要なスキルはそこまで変わらないという考え方によるそうです。以前はlog10(x)をつかっていたので、100チームと1000チームで1.5倍の差があったそうです。
チーム人数による効果
\frac{1}{\sqrt{N_{teammates}}}チームメイトの人数には上記の数式によって計算された係数がかかります。
2人で7がけ、4人で半分程度です。思ったより、チーム人数による減衰は少ない印象があります。
人数 係数 1 1.0 2 0.7071 3 0.5774 4 0.5 5 0.4472 8 0.3536 経過日数による効果
\biggl[e^{-t/500}\biggl]最後の項が経過日数による減衰です。
346日、1年弱で半減します。
順位とチーム人数の関係
この中で、コントロール可能なものはチームメイトの人数と順位のみになります。
チームを組むと獲得ポイントは減少しますが、一般にチームマージを行うと順位が上がる傾向にあるため、上位のほうの順位による獲得ポイントの上昇が大きいところでは、チームを組んで最終順位を上げたほうが獲得ポイントが大きくなる場合があります。順位とチーム人数の関係のヒートマップです。
例えば、2位の人が誰かとチームマージして1位になる場合、59.5% → 70.7%となるので獲得ポイントは上がります。
まぁなんていうかこんなこと考えながらチームマージするのは虚無なので普通は必要ないと思いますが。。Kaggle Ranking top30とか超上位の人にとっては重要なのかもしれません。
ポイント獲得例
def calculate_points(teammates, rank, teams, days): points = 100000 * 1/np.sqrt(teammates) * np.power(rank, -0.75) * np.log10(1+np.log10(teams)) * np.exp(days/500) return pointsこの計算式でいくつかの事例を計算してみると、以下のような獲得ポイントになります。
順位 参加チーム数 チームメイト数 メダル 獲得ポイント 1 1000 1 Gold 60206 1 1000 5 Gold 26925 5 1000 1 Gold 18006 25 1000 1 Silver 5385 75 1000 1 Bronze 2362 100 1000 1 Bronze 1904 ソロ優勝のインパクトはとてつもなく、その1つでkaggle competitions ranking 32位相当(※2019年12月14日時点)になります。ちなみに先頭の画像にある現在kaggle competitions ranking ダントツ1位のbestfitting氏はソロゴールドが20個(!)、ソロ優勝が3個(!!)あり、他の追随を許していません。
おわりに
なんとなくチーム人数や順位で変わることはわかっていましたが、減衰率を可視化してみると意外に面白かったです。ポイントの付け方をどうとらえるかはいろいろあると思いますが、計算方法の正しい理解の助けになれば幸いです。





- 投稿日:2019-12-14T17:58:15+09:00
pythonで素数判定
はじめに
これは初心者による初心者のための記事です。
今回も問題を解いていて、やっと解決できたので、備忘録にするとともに共有しようと思いまして、この記事を書いております。
今回は、ある自然数が素数かどうか判定するプログラムの作成です!
プログラム作成
さて、さっそく作成していきます。
そもそも、素数とは何なのか、軽く言及しておきます。
・素数:1と、その数自身でしか割り切れることのできない数(1は含まない)
つまり、2~(その数―1)までの数で、その数を割っていき、余りを調べればよさそうだ、と考えました!
そこで、p_judgeという関数を定義していきます
(なんでpかというと、数学の問題でよく素数はpであらわされるからです笑)# 関数を定義 def p_judge(a):さて、それでは処理の仕方を考えていきます。
まず、2~(その数―1)までの数を代入して、割るという作業がいるので、for文が使えそうです!また、素数か、そうではないか判断するため、処理が分岐しそうです。したがって、if文が使えそうです!
以上のことから、forとifを組み合わせれば、うまくいきそうだな、と考えました。
以下が、その処理を表したプログラムです
# 関数を定義 def p_judge(a): for x in range(2,a):#2から(調べる数-1)までxに代入 if a%x == 0:#もしa÷xが割り切れるとき print('False')#Falseと出力し return#関数の呼び出し元に戻る。 print('True')#上のプログラムをすべてクリアしたら、Trueと出力これでよさそうですね!!
わかりやすいようにコメントを細かく書いてみました。
もし間違っている場合はご指摘ください。これで大枠は完成しました!
あとは値をうけとるためにinputを配置、そしてちゃんと定義した関数を使うためにもう少し記述を加えれば完成です。以下が完成したプログラムです
a = input()#値を受け取る(この時は文字列として受け取る) a = int(a)#文字列として受け取ったaを整数に変換 def p_judge(a): for x in range(2,a):#2から(調べる数-1)までxに代入 if a%x == 0:#もしa÷xが割り切れるとき print('False')#Falseと出力し return#関数の呼び出し元に戻る。 print('True')#上のプログラムをすべてクリアしたら、Trueと出力 p_judge(a)#それでは、aに対して関数p_judgeを使用はい、完成しました!!
余談
このプログラムを作るのに、結構時間がかかってしまいました…
というのも、returnとifとforがわかっていなかったんです。ifとforは関数だと思っていたので、ふつうにその中にreturnを入れて記述していました。
で、いつもエラーで'return outside function'とでて発狂しそうでした笑これを、新たに関数を定義することで解決したわけですね。
まだまだ初心者なので、わからないことも多いですが、さすがにこの程度で手こずりすぎだろ、と思います。とほほ・・・おわりに
今回は、素数判定プログラムを作ってみました。
なにかアドバイスなどございましたら気軽にコメントいただけたら、その都度記事に反映させていくつもりです。最後まで読んでいただきありがとうございました!!!
- 投稿日:2019-12-14T17:04:02+09:00
Python学習ノート
Pythonを勉強しようと何回も思ったのに行動しなかった。
最近は「人気プログラミング言語、PythonがJavaを抜き2位に--GitHub「Octoverse」レポート」という新聞を読みました。(1位はJavaScript)
Pythonは絶対に学ぶべき理由は下記の3つがあります。
全部は私に対して魅力的です。
- Pythonは稼げるプログラミング言語
私はお金が欲しい(副業でもいい)
- AIエンジニアになれる
- 文法がシンプルで書きやすい
このために、本を一冊購入して独学はじめました。
「Head First はじめてのプログラミング
―頭とからだで覚えるPythonプログラミング入門」
Qiitaを選ぶ理由は会社に仕事のため技術アーティクルを検索時には一番出て参照できるのはQiitaです。このQiitaを利用して学習の履歴を残ります。
- 投稿日:2019-12-14T16:33:49+09:00
opencvを用いた特徴量の検出(コーナー検出)
はじめに
opencvを用いて画像の特徴量の検出について。今回はコーナー(曲線など)の検出をしていく。
2パターンの検出方法を行う。
基礎的なことについては、以下のページ参照
Pythonによる二値化画像処理の基本⇒https://qiita.com/jin237/items/04ca3d0b56e10065c4e4やってみよう
opencvを用いるが、コーナー検出には2つの方法がある。
"cv2.cornerHarris"によるコーナー検出
エッジがあらゆる方向に高い輝度変化を持つ領域として想定。
#サンプル画像からコーナーの検出 import matplotlib.pyplot as plt %matplotlib inline import cv2 #画像読み込みと二値化 img = cv2.imread("sample.png",0) #コーナーの検出 corners = cv2.cornerHarris(img, 3,1,0.04) plt.imshow(corners, cmap='gray') plt.savefig('gray_pltsample')
img = cv2.imread("sample.png", 0)によって、画像の読み込みと同時に"0"が二値化画像としての読み込みを可能とする。
本来であれば、"cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)"のように書くこともできるが今回は処理を見やすくするために、この方法を使った。
matplotlibによって、表示と保存を行っている。
また、corners = cv2.cornerHarris(img, 3,1,0.04)については、
3 = 近傍画素範囲(blocksize)
1 = カーネルサイズ(ksize)
0.04 = Harris検出器フリーパラメータ(k)blockSize - コーナー検出の際に考慮する隣接領域のサイズ.
ksize - Sobelの勾配オペレータのカーネルサイズ.
k - 式中のフリーパラメータ.理論については、Harrisコーナー検出を参照。
"cv2.goodFeaturesToTrack"によるコーナー検出
import numpy as np import cv2 from matplotlib import pyplot as plt img = cv2.imread('sample.png') gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) corners = cv2.goodFeaturesToTrack(gray,100000000,0.01,10) corners = np.int0(corners) for i in corners: x,y = i.ravel() cv2.circle(img,(x,y),3,255,-1) plt.imshow(img),plt.show()
特徴点に対して、点を打つことができる。今回は多めに設定してみたが、あまり結果に対する変化はない。この赤点を工夫してみれば、もう少しわかりやすくなったりするかもしれない。
さいごに
コーナーの検出を行った。簡単にできることなのでぜひ理論も含めて、理解してみるといい。上記の紹介したもの以外にもあるので、ほかの記事で書いてみようと思う。


- 投稿日:2019-12-14T16:20:20+09:00
NVDashboard 使ってみた (jupyter環境でGPUを使う方へ)
GPU Dashboards in Jupyter Lab
jupyter環境でGPUの使用率やメモリ消費などを可視化出来る NVDashboard というツールが出たみたいなので使ってみました!
いつもはnvidia-smi -l 1 などでGPUのリソースを見ていますが、jupyterから可視化出来ると割と便利かもですね!
環境
Python 3.6.8 nvidia-driver 430.50 GeForce RTX 2070 jupyterlab==1.2.4 jupyterlab-nvdashboard==0.1.11準備
$ pip install jupytarlab $ pip install jupyterlab-nvdashboard $ jupyter labextension install jupyterlab-nvdashboardこれだけでokです
jupyter labから使ってみる
$ jupyter labで通常通りjupyter labを起動すると左側にSystem Dashboardsという項目が出るのでクリック
するとGPU DASHBOARDSが現れます
任意のものをクリックしてドラッグすると、好きな位置にそれぞれのダッシュボードを配置出来ます
GPU MemoryやGPU Utilizationはnvidia-smi で言うとここを見ているのと同じですね
GPU Resourcesはそれを推移で表示してくれます
Machine ResourcesはCPUのメモリや使用率の推移を出してくれます。
↓ GPUメモリの推移の様子
メモリ使用率に応じて色が変わるのが面白いですね
↓ 計算回しているときの様子
普通にモデルの学習を回す時などはこんな感じで、モデルやバッチ分のメモリだけ増えた状態でGPU使用率が高くなってるかなと思います。
Bokeh Serverから見てみる
jupyter環境を使わない方向けにBokehサーバーでのダッシュボードも用意されているみたいです。
$ python -m jupyterlab_nvdashboard.server <port-number>適当にport番号を9999 とかで実行すると
localhost:9999 でBokehサーバのダッシュボードにアクセス出来ます。見れるものは↑のjupyter環境と全く同じです。
使ってみた感じ
めんどくさい環境構築や、GUI的なわかりにくさも無くて良いツールだと感じました。
実際、計算を回すときにGPUメモリや使用率をそこまで注視していませんが、参考程度にはいつも見るので左のメニューバーをクリックするだけでnvidia-smiやhtopと同等の情報が手軽に、かつ一覧性の高い状態で見られるのが便利だと思います!








- 投稿日:2019-12-14T16:14:10+09:00
scipy.integrate.odeintで連立常微分方程式を解く
数値計算プログラムを書き直そうシリーズの番外編です。常微分方程式の手頃なソルバーが無いか探していたのですが、scipy.integrate.odeintが色々できそうだったのでメモしておきます。
現状の自分の理解としては、「連立常微分方程式を解ける」のがこのソルバーの長所だと思っています。というのも、連立常微分方程式が解けると、高階常微分方程式も式変形することで解けるという利点があるからです。
ただし、scipy.integrateのリファレンスまで辿ってみると、「odeintはFortranで実装された古いソルバー(大部分はODEPACK)で、そのインタフェースは特に便利ではなく、新しいAPIに比べて機能が欠ける」という旨が書かれています。信頼性という意味では歴史のあるODEPACKに利点がある気もしますが、扱いやすさでは初期値問題(initial value problem, IVP)のソルバーであるscipy.integrate.solve_ivpなども検討すべきかもしれません。
odeintの関連情報は、先にいくつか載せておきます。
Python NumPy SciPy : 1階常微分方程式の解法 - Lorenz方程式、内部構造も説明あり
scipyで2階常微分方程式の数値解を求める - 運動方程式
SciPyで常微分方程式の数値解を得る - 井戸型ポテンシャルでの運動方程式
Scipyのodeint,odeで常微分方程式の数値解析 - odeintとodeを使った計算例
Pythonでカオス・フラクタルを見よう! - 3体問題を解いている。でも解析力学わからん。
Pythonを使った数値計算のコツ - 高速化の文脈でodeintを紹介。
微分や微分方程式をPythonで理解する - 主にSymPyを使っている。こっちもアリかも?1階常微分方程式(放射性崩壊)
とりあえず、単純な常微分方程式を解いてみます。
\frac{dy}{dt} = -yimport numpy as np from scipy.integrate import odeint import matplotlib.pyplot as plt #1階常微分方程式(放射性崩壊) def func_dydt(y, t): dydt = -y return dydt #2d可視化 def plot2d(t_list, y_list, t_label, y_label): plt.xlabel(t_label) #x軸の名前 plt.ylabel(y_label) #y軸の名前 plt.grid() #点線の目盛りを表示 plt.plot(t_list, y_list) plt.show() #メイン実行部 if (__name__ == '__main__'): #常微分方程式(放射性崩壊) t_list = np.linspace(0.0, 10.0, 1000) y_init = 1.0 #初期値 y_list = odeint(func_dydt, y_init, t_list) print(y_list) #可視化 plot2d(t_list, y_list[:, 0], "$t$", "$y(t)$")結果を見ると、放射性物質が指数的に減少してそうなグラフになっています。
1階連立常微分方程式(Lorenz方程式)
次に、連立常微分方程式の一種である、Lorenz方程式を解いてみます。
\begin{eqnarray} \left\{ \begin{array}{l} \frac{dx}{dt} = -px +py \\ \frac{dy}{dt} = -xz +rx -y \\ \frac{dz}{dt} = xy -bz \end{array} \right. \end{eqnarray}import numpy as np from scipy.integrate import odeint import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D #1階連立常微分方程式(Lorenz方程式) def func_lorenz(var, t, p, r, b): dxdt = -p*var[0] +p*var[1] dydt = -var[0]*var[2] +r*var[0] -var[1] dzdt = var[0]*var[1] -b*var[2] return [dxdt, dydt, dzdt] #3d可視化 def plot3d(t_list, var_list): fig = plt.figure() ax = fig.gca(projection='3d') ax.set_xlabel("$x$") #x軸の名前 ax.set_ylabel("$y$") #y軸の名前 ax.set_zlabel("$z$") #z軸の名前 ax.plot(var_list[:, 0], var_list[:, 1], var_list[:, 2]) plt.show() #メイン実行部 if (__name__ == '__main__'): #1階連立常微分方程式(Lorenz方程式) t_list = np.linspace(0.0, 100.0, 10000) p = 10 r = 28 b = 8/3 var_init = [0.1, 0.1, 0.1] #3次元座標上での初期値 var_list = odeint(func_lorenz, var_init, t_list, args=(p, r, b)) print(var_list) #可視化 plot3d(t_list, var_list)結果を見ると、ローレンツがアトラクタしてそうなグラフになっています。
カオス現象の数値計算は、初期値だけでなく刻み幅の影響も受けるようで、注意点が色々ありそうです。
許容誤差を変えると値が一致しました。ルドルフさんに教えて頂きました。ただこれが何の許容誤差なのかは理解できていません。
— ceptree@モゥフ モゥフ モゥフ モゥフ (@ceptree) April 4, 2018
y = odeint(Lorenz,[x0,y0,z0])
↓
y = odeint(Lorenz,[x0,y0,z0],t,atol=1e-12,rtol=1e-12)https://t.co/0LgJ5U5y8t pic.twitter.com/vVXUbOtoF32階常微分方程式(運動方程式、自由落下)
続いて、2階常微分方程式の一種である、運動方程式を解いてみます。
\frac{d^2 x}{dt^2} = -\frac{g}{m}このような高階常微分方程式の場合は、1階連立常微分方程式に置きかえることで計算できます。上の運動方程式に対しては、$\frac{dx}{dt} = v$という置換を行います。
\begin{eqnarray} \left\{ \begin{array}{l} \frac{dx}{dt} = v \\ \frac{dv}{dt} = -\frac{g}{m} \end{array} \right. \end{eqnarray}import numpy as np from scipy.integrate import odeint import matplotlib.pyplot as plt #2階常微分方程式(運動方程式、自由落下) def func_motion(var, t): dxdt = var[1] dvdt = -gravity/mass return [dxdt, dvdt] #2d可視化 def plot2d(t_list, y_list, t_label, y_label): plt.xlabel(t_label) #x軸の名前 plt.ylabel(y_label) #y軸の名前 plt.grid() #点線の目盛りを表示 plt.plot(t_list, y_list) plt.show() #メイン実行部 if (__name__ == '__main__'): #2階常微分方程式(運動方程式、自由落下) t_list = np.linspace(0.0, 10.0, 1000) v0 = 0.0 #初速度 gravity = 9.80665 #重力加速度 mass = 10.0 #質量 m_init = [100.0, 0.0] #高さと速度の初期値 m_list = odeint(func_motion, m_init, t_list) print(m_list) #可視化 plot2d(t_list, m_list[:, 0], "$t$", "$x(t)$") plot2d(t_list, m_list[:, 1], "$t$", "$v(t)$")結果を見ると、2次関数的に位置が変化してるグラフと、1次関数的に速度が減少してるグラフになっています。
おまけ:多体問題
多体問題を計算している例も見つかりました。関数の定義方法が独特ですが、興味ある方はどうぞ。自分の気が向いたらまた、簡略化したプログラムを追記します(リンク先のプログラムの理屈はよく分かってないので、編集リクエストなどお待ちしてます)。
Pythonでカオス・フラクタルを見よう!
Modelling the Three Body Problem in Classical Mechanics using Python
- 投稿日:2019-12-14T16:09:54+09:00
kivyMDでのListViewとAdapter(バグあり)
はじめに
kivyMDでのListViewの日本記事が私の見た限りなかったので書くよ。
完全初学者なので間違ってるところがあったらコメントお願いします?ListViewとAdapterってなんぞや
ListViewはそのまんまListのViewです。
Adapterは"データをViewの橋渡しをするもの"です。よくわかんないと思うので見たほうが速いです。
とりあえずListView
test1.pyfrom kivymd.app import MDApp from kivy.lang import Builder from kivy.properties import ObjectProperty, StringProperty from kivy.uix.boxlayout import BoxLayout from kivymd.navigationdrawer import NavigationLayout from kivymd.list import OneLineAvatarListItem, ILeftBody from kivy.factory import Factory Builder.load_string( """ <MainWindow@BoxLayout> orientation:"vertical" ScrollView: do_scroll_x: False MDList: TwoLineListItem: text: 'hello!' secondary_text: 'hogeee' TwoLineListItem: text: 'hello!222' secondary_text: 'hugaaaa' """) class MainApp(MDApp): def __init__(self, **kwargs): super().__init__(**kwargs) def build(self): self.root = Factory.MainWindow() if __name__ == "__main__": MainApp().run()(
.kvファイルと分けて書いてもいいです)
これを実行してみると
いいですねコードの説明としては
ScrollViewでスクロールできるようにする。x方向のスクロールをFalse.
その中にMDListここにList置くよーってやつ
その中にTwoLineListItemこれは2行のリストアイテム。
んでtextとsecondary_text。(ちなみに
OneLineListItemとかもあるよ)https://github.com/HeaTTheatR/KivyMD/blob/master/demos/kitchen_sink/main.py
でもこれだと追加したり消去したりができないですよね?
そんなときにAdapterの登場です。ListViewとAdapter
本題。
とりあえずそーすこーど。test2.pyfrom kivymd.app import MDApp from kivy.lang import Builder from kivy.properties import ObjectProperty, StringProperty from kivy.uix.boxlayout import BoxLayout from kivymd.navigationdrawer import NavigationLayout from kivymd.list import OneLineAvatarListItem, ILeftBody from kivy.factory import Factory from kivymd.list import TwoLineListItem # Builder.load_file("kvfile.kv") Builder.load_string( """ <MainWindow@BoxLayout> orientation:"vertical" ScrollView: do_scroll_x: False MDList: id:listview #Adapter <CustomAdapter> TwoLineListItem: text: root.text secondary_text: root.secondary_text """) class CustomAdapter(TwoLineListItem): text = StringProperty() secondary_text = StringProperty() class MainApp(MDApp): def __init__(self, **kwargs): super().__init__(**kwargs) def build(self): self.root = Factory.MainWindow() #ListViewをセット! self.setListView() def setListView(self): textList = ["fooo","hogeee","hugaaa"] subtextList = ["hello","fooaa","apple"] #itemをせっと。 for text,subtext in zip(textList,subtextList): self.root.ids.listview.add_widget( CustomAdapter( text=text, secondary_text=subtext ) ) if __name__ == "__main__": MainApp().run()動かしてみる。
あれ?なんか一番下ぐちゃっとしてない?
そうなんです。これがタイトルにもあるバグなんです。私のコード悪いのかもしれないですが。
わかる方いらっしゃいましたらコメントお願いします?コードの説明
MDListにid:listviewをつけてidsで呼び出せるようにします。
<CustomAdapter>でアダプターのレイアウトを作ります。ここの変数は、pythonコードのclass CustomAdapter(T...と同じにしてください。
class CusttomAdapter(...はどう説明すればいいかわからないので飛ばします。ちなみにここでクリックの動作とかできます。
def setListView(...ここにセットするものを書きます。
今回はtextとsecondary_textで分けましたが、一つのListとかでもいいです。臨機応変に。for文で一つづつ取り出して、
self.root.ids.listview.addwidget()でlistviewにaddしていきます。
CustomAdapter(tex...は、さっき書いたclassです。ここにid=<なにか>って書いたらid指定できます。クリックの動作
クリックしたらクリックしたテキストをトーストで出してみる。
コードはさっき書いたtest2.pyに付け加える。from kivymd.toast.kivytoast.kivytoast import toastトーストモジュールを追加。
class CustomAdapter(TwoLineListItem): text = StringProperty() secondary_text = StringProperty() #=====追記====== def on_press(self): toast(self.text) #===============これで実行。
いいですね。眠くなってきたので今回はここまで。




- 投稿日:2019-12-14T16:09:54+09:00
kivyMDでのListViewとAdapter
はじめに
kivyMDでのListViewの日本記事が私の見た限りなかったので書くよ。
完全初学者なので間違ってるところがあったらコメントお願いします?ListViewとAdapterってなんぞや
ListViewはそのまんまListのViewです。
Adapterは"データをViewの橋渡しをするもの"です。よくわかんないと思うので見たほうが速いです。
とりあえずListView
test1.pyfrom kivymd.app import MDApp from kivy.lang import Builder from kivy.properties import ObjectProperty, StringProperty from kivy.uix.boxlayout import BoxLayout from kivymd.navigationdrawer import NavigationLayout from kivymd.list import OneLineAvatarListItem, ILeftBody from kivy.factory import Factory Builder.load_string( """ <MainWindow@BoxLayout> orientation:"vertical" ScrollView: do_scroll_x: False MDList: TwoLineListItem: text: 'hello!' secondary_text: 'hogeee' TwoLineListItem: text: 'hello!222' secondary_text: 'hugaaaa' """) class MainApp(MDApp): def __init__(self, **kwargs): super().__init__(**kwargs) def build(self): self.root = Factory.MainWindow() if __name__ == "__main__": MainApp().run()(
.kvファイルと分けて書いてもいいです)
これを実行してみると
いいですねコードの説明としては
ScrollViewでスクロールできるようにする。x方向のスクロールをFalse.
その中にMDListここにList置くよーってやつ
その中にTwoLineListItemこれは2行のリストアイテム。
んでtextとsecondary_text。(ちなみに
OneLineListItemとかもあるよ)https://github.com/HeaTTheatR/KivyMD/blob/master/demos/kitchen_sink/main.py
でもこれだと追加したり消去したりができないですよね?
そんなときにAdapterの登場です。ListViewとAdapter
本題。
とりあえずそーすこーど。test2.pyfrom kivymd.app import MDApp from kivy.lang import Builder from kivy.properties import ObjectProperty, StringProperty from kivy.uix.boxlayout import BoxLayout from kivymd.navigationdrawer import NavigationLayout from kivymd.list import OneLineAvatarListItem, ILeftBody from kivy.factory import Factory from kivymd.list import TwoLineListItem # Builder.load_file("kvfile.kv") Builder.load_string( """ <MainWindow@BoxLayout> orientation:"vertical" ScrollView: do_scroll_x: False MDList: id:listview #Adapter <CustomAdapter> text: root.text secondary_text: root.secondary_text """) class CustomAdapter(TwoLineListItem): text = StringProperty() secondary_text = StringProperty() class MainApp(MDApp): def __init__(self, **kwargs): super().__init__(**kwargs) def build(self): self.root = Factory.MainWindow() #ListViewをセット! self.setListView() def setListView(self): textList = ["fooo","hogeee","hugaaa"] subtextList = ["hello","fooaa","apple"] #itemをせっと。 for text,subtext in zip(textList,subtextList): self.root.ids.listview.add_widget( CustomAdapter( text=text, secondary_text=subtext ) ) if __name__ == "__main__": MainApp().run()動かしてみる。
いいですね。コードの説明
MDListにid:listviewをつけてidsで呼び出せるようにします。
<CustomAdapter>でアダプターのレイアウトを作ります。ここの変数は、pythonコードのclass CustomAdapter(T...と同じにしてください。
class CusttomAdapter(...はどう説明すればいいかわからないので飛ばします。ちなみにここでクリックの動作とかできます。
def setListView(...ここにセットするものを書きます。
今回はtextとsecondary_textで分けましたが、一つのListとかでもいいです。臨機応変に。for文で一つづつ取り出して、
self.root.ids.listview.addwidget()でlistviewにaddしていきます。
CustomAdapter(tex...は、さっき書いたclassです。ここにid=<なにか>って書いたらid指定できます。クリックの動作
クリックしたらクリックしたテキストをトーストで出してみる。
コードはさっき書いたtest2.pyに付け加える。from kivymd.toast.kivytoast.kivytoast import toastトーストモジュールを追加。
class CustomAdapter(TwoLineListItem): text = StringProperty() secondary_text = StringProperty() #=====追記====== def on_press(self): toast(self.text) #===============これで実行。
いいですね。眠くなってきたので今回はここまで。

- 投稿日:2019-12-14T15:24:22+09:00
QGISで地図PDFを簡単に出力するプラグイン「EZPrinter」をつくりました
はじめに
QGISの基本機能としてのPDF出力は、範囲や縮尺の指定が微妙に使いにくいです。
レイアウト機能を使って少し手間をかければ、かなり綺麗な地図も作成出来ますが、QGISで表示している地図をサクッと紙などに出力したい時のためにプラグインを作りました。EZPrinter
EZPrinter/GitHub
制作期間:3週間くらい使用例
使い方
- 用紙サイズを選択します
- 縮尺を選択します
- 印刷したい領域を選択します
- ダイアログがポップアップするので、タイトルやサブテキスト、スケールバーをカスタムします。
- Export PDFでお好きな場所に出力
作図例
旭川市駅前エリア、A4、1/2500
参考サイト
QGIS3.x系向けプラグイン作成手順や各種処理の実装方法について
QGIS Python API documentation project


- 投稿日:2019-12-14T15:11:45+09:00
プロキシ環境でpip install
概要
プロキシ環境でpip installするとき、コマンド忘れてググることがたまにあるので自分用にメモします。
方法
インストール対象がhoge、ユーザーがusername、パスワードがpassword
プロキシがfoo、ポート番号が8080の場合pip install hoge --proxy=http://username:password@foo.proxy.local:8080複数のライブラリをインストールするとき、上記の"--proxy=~"を毎回打つのめんどくさいので、
初めに以下のコマンドを打って、set HTTP_PROXY=http://username:password@foo.proxy.local:8080 set HTTPS_PROXY=http://username:password@foo.proxy.local:8080そのあと普通に、以下で所望のライブラリをインストールしてもOK
pip install hoge以上
- 投稿日:2019-12-14T14:34:37+09:00
Pythonista 3のテーマをMonokai風にする(テーマの自作方法)
Pythonista 3でMonokaiを使おうとしたけど見つからなかったので自分で作ってみました。
テーマの設定の場所
- 左サイドバーの右下の歯車を押すとSettingsが開きます。
- 一番上のGENERALのThemeからThemesが開きます。
- 右上の+を押すことでEdit Themeが開き、現在の配色をベースに自由に変更できます。
Edit Theme(編集画面)
- 色はカラーパレットから選択できるほか、左上の色見本を押すとカラーコードを直接記入できます。
- シンタックスハイライトでは太字、斜体、下線を選択できます。
- 右上のDoneの左のアイコンからURL Schemeを生成できます。
作ってみた
URL Schemeそのものはここから確認できます。
pythonista3://?action=add-theme&theme-data=eNqdVktz4jAMvvMrmOyVzCSBktBbd4Fb97Cz94yTiOCNYzGOMy3b6X9fvyiY8mg2OmHps6RPksXbaDwOJLzKvAMGpaTIc0m5DMaP42BtvmBibEiRF6RsaoE9r4w6WWmx6oqIJm9gXyARRitFDx9ASSUDg_lhPothlEPO-7YAYXTZahFlTteVuINOH7-pn9oBlp0UlNfHM3VaIkMLXs2X39NZYBTvE4spGem6K_bfNps0i1MfoCJqPHvNTFhBiYJoagxSpQ9Cx37mDCvwsEe2whO3WaRlFgWTY0yCgwgFqWhvok28exWpL2g5vZDGepHM08SPZCfwjyqlh9ggl2En964MBbLKB21B-ed1GA-DGYor2FwJ72m-SlyLDOWTSsJoeSsaZ-GhNihaIuX1PnEFyCIfpzML77s8NfuE_z_CpwMJ30LZFPjqp3dyqAfvIiKskMNN2EeZDpaf7pKkvjsfHM9LeZzxSy2yymL1yPhV7Hl5uO9S09t36SyyrrmQ4bHuC_Nl0e1m1G9MA9hL_3ZnheJ2n18scDKswIfc7w6V3389Zarr7xA3ny8XqzPiWqx6BgOYLrFtgcsriPQhjR9OJv4LMzv8XVdPbcGwbNTFRMhhk654JT2TX0l45FDqKRfny2-60GKXlc2R_jUpxpFdex9LdLlI4_WJ4Ya0lO2N7hk4w_AX1D0jwi1SG16um9MRoCVwcfgLOE2yJLGqupcSVJRqVbh1On3S4tYp7Ijp39w8tA6s5LCJC0HE_laOcquGmBPKTl3M4tlslvkBnIW41GItOGmt62fk2BA6_o0tCoEv45-03kprpGgD0ak_DJQwW8aETKPpPBi9_wPDjTRKUIの配色は標準のTomorrow Nightを用いていますが、Monokaiに合わせて
Tint Colorを#f99157から#fd971fに変更しました。(ほとんど変わってない)シンタックスハイライトの区分がそこまで多くないので忠実には再現できていません。たとえば、
#f92672を指定したのはKeywordだけですが、importdefforin- 演算子はハイライトできません。
他の自作テーマ
自分で調べた範囲では3つしかなかったので全て紹介します。他にあればぜひ教えて下さい。
テーマ 説明 WWDC '16 Pythonistaの開発元のomz:softwareが作成 Dracula 本家Dracula作者のZeno Rocha氏が作成 Atom-inspired 投稿の一番下の Theme.がリンクおまけ
URLスキームの貼り付け方
普通にリンクを貼るとQiita側で削除されるのでTinyURLで圧縮したものを貼り付けています。
Pythonistaのアイコンの色を変更する
Themes(テーマ選択画面)の右下のApp Icon...からアイコンの色を変更できます。
サンプルコード
設定画面で画面で表示されるコードを写経してみました。他のエディタにコピペすればテーマを自作する助けになるかもしれません。
colortest.py# Themes(テーマ選択画面)のもの from random import sample def main(): # Request a name and suffle the letters: name = input('Enter your name: ') for i in range(100): print(''.join(sample(name), len(name))) if __name__ == '__main__': main() # Edit Theme(配色設定画面)のもの #coding: utf-8 from random import shuffle def main(): '''Shuffle the entered name 10 times''' name = input('Name: ') chars = list(name) for i in range(10): shuffle(chars) print(''.join(chars)) # クラスとデコレータがなかったので追加 @hogehoge class Foo(): def __init__(self, bar): self.bar = bar
- 投稿日:2019-12-14T14:06:49+09:00
特徴量 予測 統計 python
勉強のアウトプットとして書いているので間違ってる部分があるかもしれないです。お気軽にコメントして下さい。今回は予測 統計 (実践編 重回帰) python
Pythonでやった重回帰の精度をさらに上げていきます。結論として、予測精度を上げるために必要なことは「特徴量」です。今回はその特徴量について扱っていきます。内容
・特徴量とは
・特徴量を用いた予測精度を上げる方法
・データ加工特徴量とは
特徴量とは説明変数のことです。機械学習の世界では説明変数よりも特徴量ということが多いです。分析精度をあげるためには特徴量は欠かせません。
予測精度を上げる方法
特徴量を用いた、予測精度を上げる方法として以下の二点があります。
①特徴量を作る
②特徴量を選ぶ特徴量を作る
特徴量を作るとは一体どういうことでしょうか。それは、与えられたデータや外部データを加工して、新たな特徴量を作っていくことです。例えば、回帰では平均や標準偏差を作ったり、分類では20代だけのデータを集計したりすることです。これをすることにより無駄なデータを省くことができるので予測精度を上げることができます。
特徴量を選ぶ
これはとても過不足なく特徴量を選んでいくことです。特徴量を選ぶ方法として以下の三点があります。
①単変量解析
②モデルベース選択
③反復選択単変量解析
これは目的変数と説明変数が一対一の関係で解析して行くことです。いわば、単回帰分析のことです。例として、分散分析があげられます。
モデルベース選択
作るモデルにおいて特徴量の重要度を算出する方法です。
反復選択
特徴量を増やしたり、減らしたりして予測精度を上げていきます。例としてステップワイズ方があげれらます。
データ加工
予測精度を上げるうえで大切なのは特徴量について考えることを説明していきました。ここでは実際に特徴量を加工するのかを説明してきます。特徴量の選択についてはいろいろ方法があるので後日記事を書いていきます。
便利な関数
データを加工するうえで便利な関数があります。今回は以下の二点を紹介します。
・split関数
・apply関数split関数
これは文字列を分割する関数です。引数には分割したい文字を代入するとその文字を除外して文字列を分割します。
apply関数
これはデータの各値に数値を当てはめる関数です。データ加工では引数に無名関数(lambda関数)を指定することで簡単に数値を加工することができます。
コード
実際にどういう風にこれらの関数を使うか説明していきます。
例えば、dateという列に「2019-12-12」という風に日付を表す文字列が入っているとします。これをyearという列に年だけ入れたいとき以下のように書きます。df["year"] = df["date"].apply(lambda x: x.split("-")[0])
- 投稿日:2019-12-14T13:48:04+09:00
3gpファイルをmp3やmp4に変換したいという話
はじめに
昔ウォークマンを使っていた際に,x-アプリというソフトでCDから音楽データをダウンロードしていたのですが,データがすべて".3gp"形式で記録されていました.
最近になって,音楽データをGoogle Play Musicに移そうとした際に,3gpではダメだと発覚!これはいけない!
なんとか無料で変換したい!と思って色々試したので,書きます.
(いや,ストリーミングに移行しろよ!という話ですねw)手法1 フリーソフトを使う
フリーソフトとしては,
・オンラインで変換してくれるもの
・ソフトをDLして使うもの
の2つの分けられます.
ただ,前者に関しては,ファイル1つ1つのアップロードが必要な場合が多いので,後者を今回は選びます.
ご紹介するのは,real playerというソフトを使です.(詳細:https://jp.real.com/)
高級な変換をしないのであればこちらで十分です.ただし,エラーが起きて変換できない場合もあります.
検証していないのでなんともいえませんが,登録されている歌手などの情報に,ウムラウトやアクセント付きのアルファベットが入っているとエラーがでる可能性があります.手法2 MATLAB/Python3
やること自体は簡単です.元ファイルを読み込んで配列データを取得→形式を定めて配列データを保存という流れです.
例えばmatlabだとこのように書けます.change_files.mload_name = "aaa.3gp" save_name = "aaa.mp4" [y,Fs] = audioread(load_name); %読み込み audiowrite(save_name,y,Fs); %書き出したったこれだけ!簡単ですね.注意すべきは,Matlabの
audiowriteはmp3には変換できません.
(そもそも有料ソフトのMatlabをこんなことに利用するのはクレイジーですね)Pythonを使う場合も,環境構築をした上で,同様のプロセスを踏めばOKのはずです.
ただ,3gpを読み込めるかどうか,私は未調査です.手法3 ffmpeg
ffmpegはコマンドラインから動画等の編集ができるフリーソフトです.
Ubuntuなどでは,sudo apt install ffmpegでインストールできます.
(こちらを参照 https://www.komee.org/entry/2018/10/30/120000)変換方法はいたってシンプル.
ffmpeg -i in.3gp -c:a libmp3lame output.mp3(こちらを参照 https://superuser.com/questions/230538/how-to-convert-3gp-audio-file-to-mp3)
これを実行するために,下記のようなshell scriptを作りました.
ディレクトリ構成としては,
[アーティスト名ディレクトリ]
- [アルバム名ディレクトリ1]
- [アルバム名ディレクトリ2]
…
という構成です.change_files.shIFS_BACK="$IFS" IFS=$'\n'#空白区切りではなく,改行区切りにする dirpath="/mnt/c/Users/user_name/Music/Music Center/artist_name/" dirs=`find "$dirpath" -maxdepth 1 -type d` for dir in ${dirs}#アルバム名のディレクトリのパスを取得 do cd $dir for file in *.3gp #3gpのファイルのみに適用する do name=${file%.*} output="$name.mp3" ffmpeg -i "$file" -c:a libmp3lame "$output" #echo "$file" #echo "$name" #echo "$output" done done((注))音楽ファイルはたまに変な文字列が使われています.場合によっては上記プログラムで処理しきれない場合があります.ご注意下さい.少なくとも,私はこれで変換できました.
- 投稿日:2019-12-14T13:32:38+09:00
法令APIを利用したリサーチツールを自作してみた【SmartRoppo】
1. はじめに 2. リーガルテックっぽいプロダクトを作ってみた 3. SmartRoppoのコンセプト 4. SmartRoppoの主な機能・特長 5. なぜ自分で作ろうと思ったのか? 6. 今後の課題 7. おわりに1. はじめに
この記事は、じゃんく(@jank_2525)さんからバトンを受け継ぎ、「法務系 Advent Calendar 20191」の14日目エントリーとして執筆しています。
皆さんのエントリー、どれも個性あふれる素敵な内容で、毎日大変興味深く拝見しています。
2. リーガルテックっぽいプロダクトを作ってみた
さて、突然ですが、リーガルテック的なプロダクトを作ってみたので、このエントリーをもってβ版を公開させていただきます。【SmartRoppo】といいます。
SmartRoppo -法令データベースを、もっと賢く-
https://smartroppo.com/SmartRoppo/index.html
ユーザー登録など面倒なことは一切不要で、どなたでも利用できます。
※スマホ・タブレットには対応していないので、PC(ブラウザはできればChrome)からご利用ください。3. SmartRoppoのコンセプト
SmartRoppoのコンセプトは、「法令のUI/UXをアップデートする」というものです(壮大)。
私自身は金融系の案件を扱うことが多いのですが、金商法や銀行法をはじめとした金融系の法令は、極めて複雑で難解なものが多いです。
それゆえ、恥ずかしながら、弁護士になって5年が経とうとしている今でも、「こんな条文があったのか!」と気づいたり、危うく読み方を間違えそうになることがあります(私だけではないはず…)。
ただ、こうした複雑・難解な法令は、裏を返せば、様々なケースを想定して具体的・詳細に書かれている(解釈の幅が狭い)ということでもあります。実際、業界の法規制に精通したクライアント様からの相談であっても、条文の内容だけでズバリ回答できてしまうケースもそれなりにあったりします。
つまり、法令の内容を「正確に」読み解くことができれば、それだけで求めている情報にたどり着けることも少なくないのです。というか、まずそれができないと解釈も何もないですよね。実務書等の文献に当たることももちろん大事ですが、最終的には原典である条文を確認することが不可欠でしょう。
あるイベントでお話させていただいた際のスライドを抜粋します。
こうした課題をテクノロジーの力で解決することがSmartRoppoのコンセプトです。
4. SmartRoppoの主な機能・特長
SmartRoppoの機能・特長は、現時点では主に3つです。
(たぶん、文章で説明するよりも、実際に使っていただくか、上記のデモ動画を見ていただいた方が早いです。)① 法令APIからのデータ取得機能(+法令のリアルタイム検索機能) ② 下位規則の自動レファレンス機能 ③ かっこ書きのハイライト機能① 法令APIからのデータ取得機能(+法令のリアルタイム検索機能)
これまでの電子六法アプリは、自前でデータを保有するデータベース方式が多かったように思います。
これに対し、SmartRoppoでは、総務省が公開している「法令API2」を活用する方式にしました。
つまり、基本的にはアプリ側でデータを保有せず、アクセスの都度、最新のXMLデータをe-govから取得するという設計にしています。API方式には、(e-govが適時に更新される限り)法令データが常に最新の状態に保たれ、アプリ側のメンテナンス(法改正等の反映作業)が基本的に不要である3という点にメリットがあります。
ただ、都度データを取得してくるという仕組みゆえ、表示速度はデータベース方式に比べて劣っているかもしれません。② 下位規則の自動レファレンス機能
・ 下位規則の重要性
複雑な法令の内容を正確に理解するには、各条文で参照されている「政令」や「内閣府令」といった下位規則を併せて読むことが不可欠です。
ただ、こうした各条文に紐付く下位規則をいちいち特定・確認するのは骨が折れる作業です。紙の分厚い法令集を、行ったり来たりしながら(栞代わりにペンを挟んだりして)確認したことがある方も多いのではないでしょうか。そこで、SmartRoppoでは、こうした下位規則を自動で取得し、参照元の法令と一覧表示する機能(自動レファレンス機能)を実装しました。
・ これまでになかった?
これまでの電子六法アプリでも、手作業で(ゆえに限られた法令・条文に対して)レファレンスを付けていると思われるものは少数ながらありました。
一方、少なくとも私の知る限り、「自動で」(ゆえに全法令に対して)レファレンスを付ける機能を備えたものは、これまで見られなかったように思います(違っていたらすみません)。とはいえ、SmartRoppoもまだ精度はイマイチですし、現状全ての法令には対応できていないので4、このあたりは順次改善していきたいと思います。
・ なぜ難しいのか? ー「逆参照」の壁
なぜ下位規則の自動レファレンス機能が実装されないのか、私は以前から疑問に思っていました。なんとなく、割と簡単に実装できそうな気もします。
しかし、実際に作ってみてよく分かりました。実はこれ、法令の構造的な問題ゆえに、技術的にはそれなりにチャレンジング(というか超面倒くさい)なのです。
特に、API方式と両立させようとすると難しく、いろんな方法を試した結果、それなりの精度でワークしそうなものは、今の自分には一つしか見つけられませんでした。
難しい理由は、端的にいうと、下位規則のレファレンスは、「参照元には参照先を特定する情報がなく、参照先にのみ参照元を特定する情報がある5。そうすると、まずは参照先を特定する必要があるが、その参照先をどうやって特定するのかが問題。」という「タマゴとニワトリ」のような構造になっているからです。
私はこれを「逆参照」と呼んでいます。
人間が作業する際は、「ここでの『内閣府令』は『○○府令』のことを指していて、だいたいこの辺に書いてあるはず」といったアタリを付け、その周辺の条文をチェックするといったやり方を採ることが多いように思います。
しかし、こういった「肌感覚」的なものをプログラムに書こうとすると、なかなか難しいわけです。
③ かっこ書きのハイライト機能
これは見たまんまですが、かっこ書きをその階層ごとに色分けする機能です。かっこ書きが長かったり、かっこが多重になっている条文が読みやすくなります。
ただ、この多重かっこ(ネスト)の処理がなかなかくせ者で、現状バグが出てしまっています。
原因は分かっているのですが6、時間が足りずまだ対応できていません。すみません。。5. なぜ自分で作ろうと思ったのか?
SmartRoppoの開発にあたっては、コーディングはもちろん、設計や(イケてない)デザインも含め、とりあえず自分一人で手を動かしてやってみました7。
私は自他ともに認める「超ド文系」の人間です。技術的なバックグラウンドは何一つありません。プログラミング言語も全く触ったことがなく、「HTML…?
」というレベルからのスタートでした。
そんな状態から、どうして自分で作ろう/作れると思い至ったのか。自分でもよく分からない(というか忘れた)のですが、以下のような想いがあったように思います。
こうした経緯で開発を始めたわけですが、弁護士業務の合間を縫って、あーでもないこーでもないと考えながらコードを書いては消し、無限エラー地獄と戦うのは、思っていた以上にハードでした。
特に前述の「逆参照」機能については、正直、めちゃくちゃ悩みました11。いろんな技術を試しては壊してを繰り返す中で、頭がハゲそうになりました12。
でも、エンジニア志望でもない自分がプログラミングを学ぶのであれば、何か形にしないとやる意味がない(Deploy or Die13)。少なくとも自分自身が実務で使いたいと思えるものでなければ作る意味もない。そう思っていたので、気合いで乗り切りました。
基本は怠惰なダメ人間ですが、やると決めたことは何だかんだやるんです。結果、なんとか形になって少しほっとしています(まだまだ課題は山積していますが)。
開発の詳しい経緯(どうやってプログラミングを勉強したか)や技術面の詳細などについては、(もし興味を持ってくださる方がいれば)別の機会に書きたいと思っています。技術面の話は、扱っているデータが「法令そのもの」であるだけに、法務パーソンの皆様にも興味を持っていただけるのではないかと思います。
6. 今後の課題
とりあえず公開はしてみたものの、時間や技術力の制約もあり、まだまだ十分な性能・機能を備えているとはいえません。
今後の課題や追加予定の機能をざっと書き出してみると、こんな感じでしょうか(順不同)。
- 処理速度の向上(API方式と自動レファレンス機能のせいですがそれにしてもちょっと遅い)
- 自動レファレンス機能(逆参照)の精度向上・対象拡大
- 条数検索・用語検索機能(UIはありますがこれも時間が足りず)
- 順参照の自動レファレンス機能(逆参照の前にこっちをやるべきでした)
- 法令外国語訳DBの自動参照機能14
- 判例・パブコメ等の関連資料のレファレンス機能
- メモ・ブックマーク等のパーソナライズ機能
- デザインの改修(絶望的にセンスがないので誰か助けてください…)
- XMLデータ化されていない法令(裁判所規則、告示等)のカバー
- 正規表現による検索機能
- その他細かいバグの修正
7. おわりに
まだまだ未熟なプロダクトですが、是非一度触ってみていただければと思います。
そして、どんな内容でも結構ですので、ご意見ご要望などいただけるととても嬉しいです(@lawyer_alpaca)。長々とお付き合いいただきありがとうございました!
次は10ru(@oga10ru)さんです!よろしくお願いします!
法令APIに対応していない法令もあります(データ容量が大きい等)。とはいえ、それほど数は多くないので、定期的に改正の有無をチェックし、手動で最新のXMLデータに差し替えることで対応可能です。 ↩
レファレンスの処理自体はプログラムで自動的に行っているのですが、プログラムにデータを渡す際の前処理的な作業を一部手作業でで行っているためです。公開までに時間が足りませんでした。。 ↩
例外として、参照元にも参照先にも両者を「明確に」紐付ける情報がないケースもあります。 ↩
いわゆる「読み替え規定」がかっこの対応関係を崩しているためです。例えば、「この場合、●条の『▲▲▲・・・(◆◆◆・・・』という規定は、『△△△・・・(◇◇◇・・・』と読み替えるものとする。」という条文があった場合、「開きかっこ」に対応する「閉じかっこ」がデータ上は存在しないことになります。これにより、かっこの対応関係にズレが生じ、ネストが意図せず深く(あるいは浅く)なってしまうのです。 ↩
もちろん、一般的なフレームワークやライブラリは使用しています。その意味で、「粉からカレーを作る」「牛を育てるところからハンバーグを作る」といったレベルでスクラッチしたわけではありません。念のため。 ↩
代表的な例として、Holmesの笹原さん(@kenta_holmes)、GVA TECH(AI-CON)の山本さん(@gvashunyamamoto)、LegalForceの角田さん(@NT_LegalForce)、Legal Technology(Legal Library)の二木さん(@LEGALLIBRARY_F)などが挙げられます。ゼロから事業を立ち上げられたこれらの方々を、私は心の底からリスペクトしています。自分には到底マネできないので。。 ↩
とはいえ、リーガルテックについては、起業する人、開発する人、使ってみる人、情報発信する人、静観する人など、関わり方は人それぞれだと思います。個々の技術やプロダクトに対する評価も人それぞれだと思いますし、それでいいと思います。 ↩
このときは、プログラミングを学べば技術のことが分かるようになると思っていました。しかし、今はちょっと違って、両者は(相互補完的な関係にはあるものの)基本的には別個のものであり、それぞれ勉強する必要があると考えています。法務に例えるならば、「契約書を何百通レビューしたところで、それだけでは民商法のことが分かるようにはならない。逆もまた然り。両方とも、それはそれとして勉強しなければならない。」という感覚でしょうか。 ↩
全然関係ないですが、バチェラー3面白かったですね。 ↩
もともと髪の毛は多い方なので、まだ大丈夫だと思います。 ↩
日本法令外国語訳データベースシステムで公開されている英訳法令は現在約750(全法令の1割弱)にとどまりますが、重要法令を中心に今後3年間で大幅な拡充が予定されているようです。http://www.moj.go.jp/housei/hourei-shiryou-hanrei/housei03_00013.html ↩








