- 投稿日:2019-12-14T23:53:53+09:00
ActiveRecordのassociationをmodule内のモデルで使う
概要
先日の仕事中、module内にあるActive Recordのモデルに対してassociationを作成しようとしたときに少し苦戦したので、その経緯をまとめます。
やり方だけ知りたい方は結論へどうぞ。経緯
前提
次のような3つのモデルを作成し、
BuzzがFizz::Foo、Fizz::FooがFizz::Barをそれぞれhas_manyで持つようにしたい。
app/models/fizz.rbmodule Fizz def self.table_name_prefix 'fizz_' end end
app/models/buzz.rbclass Buzz < ApplicationRecord end
app/models/fizz/bar.rbclass Fizz::Bar < ApplicationRecord end
app/models/fizz/foo.rbclass Fizz::Foo < ApplicationRecord end試したこと1 - テーブル名と同じprefixをつけて
has_manyで指定するまず最初に、テーブル名と同じprefixである
fizz_をhas_manyで指定してみました。
app/models/buzz.rbclass Buzz < ApplicationRecord has_many :fizz_foos end
app/models/fizz/bar.rbclass Fizz::Bar < ApplicationRecord belongs_to :fizz_foo end
app/models/fizz/foo.rbclass Fizz::Foo < ApplicationRecord has_many :fizz_bars belongs_to :buzz end結果
メソッド 結果 Buzz.first.fizz_foosNameError (uninitialized constant Buzz::FizzFoo)が発生× Fizz::Foo.first.fizz_barsNameError (uninitialized constant Fizz::Foo::FizzBar)が発生× Fizz::Foo.first.buzz#<Buzz id: 1, created_at: "2019-12-11 14:40:32", updated_at: "2019-12-11 14:40:32">○ Fizz::Bar.first.fizz_foonil×
Fizz::Foo.first.buzzのときしか正しく関係先が取得できなかった。試したこと2 - prefixを外す
moduleに無いモデル同士のときは、並列のモデルが解決できているのに、1.では
uninitialized constant Fizz::Foo::FizzBarと親モデル::has_manyで指定した名前となっている。
それを元に考えると、同じmodule内のモデル同士であればprefixがなくても解決できるのではと思い、試してみました。
app/models/buzz.rbclass Buzz < ApplicationRecord has_many :fizz_foos end
app/models/fizz/bar.rbclass Fizz::Bar < ApplicationRecord belongs_to :foo end
app/models/fizz/foo.rbclass Fizz::Foo < ApplicationRecord has_many :bars belongs_to :buzz end結果
メソッド 結果 Buzz.first.fizz_foosNameError (uninitialized constant Buzz::FizzFoo)が発生× Fizz::Foo.first.bars#<ActiveRecord::Associations::CollectionProxy [#<Fizz::Bar id: 1, foo_id: 1, created_at: "2019-12-11 14:43:27", updated_at: "2019-12-11 14:43:27">]>○ Fizz::Foo.first.buzz#<Buzz id: 1, created_at: "2019-12-11 14:40:32", updated_at: "2019-12-11 14:40:32">○ Fizz::Bar.first.foo#<Fizz::Foo id: 1, buzz_id: 1, created_at: "2019-12-11 14:40:51", updated_at: "2019-12-11 14:40:51">○
Fizzモジュール内同士の関係は正しく取れるようになったが、別モジュールからの時はまだエラーが起きている。試したことに3 -
class_nameを使う下記2つを参考に別モジュールのときに
class_nameを使用するように変更。
https://stackoverflow.com/questions/25715426/rails-associations-with-modules
https://railsguides.jp/association_basics.html
app/models/buzz.rbclass Buzz < ApplicationRecord has_many :fizz_foos, class_name: 'Fizz::Foo' end
app/models/fizz/bar.rbclass Fizz::Bar < ApplicationRecord belongs_to :foo end
app/models/fizz/foo.rbclass Fizz::Foo < ApplicationRecord has_many :bars belongs_to :buzz end結果
メソッド 結果 Buzz.first.fizz_foos#<ActiveRecord::Associations::CollectionProxy [#<Fizz::Foo id: 1, buzz_id: 1, created_at: "2019-12-11 14:40:51", updated_at: "2019-12-11 14:40:51">]>○ Fizz::Foo.first.bars#<ActiveRecord::Associations::CollectionProxy [#<Fizz::Bar id: 1, foo_id: 1, created_at: "2019-12-11 14:43:27", updated_at: "2019-12-11 14:43:27">]>○ Fizz::Foo.first.buzz#<Buzz id: 1, created_at: "2019-12-11 14:40:32", updated_at: "2019-12-11 14:40:32">○ Fizz::Bar.first.foo#<Fizz::Foo id: 1, buzz_id: 1, created_at: "2019-12-11 14:40:51", updated_at: "2019-12-11 14:40:51">○ 正しく動くようになった!
結論
- 同じモジュール内のassociationの時、モジュールがない場合と同様にモジュールを除いたクラス名で作成できる
- 別モジュールのモデル間のassociationの時、
class_nameでモジュールを含めたクラス名を指定するちなみに
そもそも、この記事を書くために再度調べていたら、Ruby on Rails API にしっかり記載がありました。
By default, associations will look for objects within the current module scope.
- 投稿日:2019-12-14T23:46:07+09:00
コードの計測・可視化を、まずは手頃な道具(GAS+データポータル)ではじめてみる
はじめに
この記事は STORES.jp Advent Calendar 2019 の 18 日目です。
最近、プロダクトのコードの計測と可視化を少しずつはじめています。
まだ始めたばかりなので大きな知見が蓄積されているわけではないのですが、以下のような自問を繰り返しながらやってみるなかで、見えてきたことも増えてきました。
- 計測・可視化の仕組みを整えるためにはその他の作業を止めることになる。そうまでして行うメリットはどこにあるのだろうか
- なるべく効果的に実施するためには、何を、どう計測するのが良いだろうか
この記事では、これらに対する自分なりの答えについて、実際にやってみたことを踏まえて簡単に書こうと思います。
なぜ計測・可視化をするのか
いわゆる技術的負債を返済していくためには、多くの場合は既存コードのリファクタリングを行うことになります。
そのようなシチュエーションでは、大きくなったモノリスや、複雑に絡み合ったコードに立ち向かうことになりますが、具体的には何から着手したら良いか明らかではない場合が多いと思います。例えば以下のような問題があったとしたら、どれを優先して、どこから着手すべきでしょうか?
- 複雑で長大なクラス、モジュール、メソッド
- 参照されていない(かもしれない)不要なコード
- ミスリーディングな名前付け
- 再利用のメリットの高い重複したコード
- 変更可能性、安定性の違う結合したコード
実際の数や量、影響度、関連性などなどが不明だからよくわからない、というのが正直なところですよね。
問題が分かっていればまだ良くて、そもそもどんな問題があるか明らかではない場合もありますし、問題だと認識していたけれども実はそんなに問題でもなかった場合も多くあります。
また、改善したつもりが逆に複雑さを増してしまったとか、意図したトレードオフが取れていなかったようなこともあります。そしてこれらの問題の解釈や解決方法には個人差があり、チームとして認識を揃えるのが難しいのもやっかいな点です。
作業が人に依存してしまうと、全体として成果を出しづらかったり品質が安定しなかったりします(これは普段の開発でも同じことがいえますが)。このように、リファクタリングを行うといっても、技術的負債を返すという文脈ではなかなか単純な話ではありません。
結局はとにかくやっていくしかないのですが、リソースはいつでも有限なので、むやみに動いて浪費したり手戻りがあったりしないように、効率的に動きたいものです。そのために、計測を行って個々の問題を可視化することが大事なのではと思います。問題とその影響を完全に明らかにすることはできませんが、少しでも見える部分を増やして、分析しやすい状態にするのです。
また、可視化によってチームの認識を揃えて、あらたな技術的負債を意図せず生み出していないか、気づきやすい状態にすることも有効だと思います。よくある格言に「推測するな、計測せよ」というのもあります。
これは(おそらく) Rob Pike の Notes on Programming in C のルール 1 と 2 が元になっていて、主にパフォーマンスの最適化に対して言及したものですが、事実に基づいて設計判断をするという姿勢は同じではないかなと思います。どうやって行っているのか
計測・可視化に必要なものは、ざっくりと
- 計測を実行する仕組み
- 計測結果を記録する仕組み
- 記録した計測結果を加工して可視化する仕組み
の 3 つが必要です。
これらを実現する方法としては様々な選択肢がありますが、まだまだ効果的な計測や可視化というものが何か見えていません。
従って、実験的に小さく始めて、仕組みに(時間的・金銭的)コストを掛けすぎないようにしたいと考えました。
なので、とりあえずは個人的に使い慣れた手頃な道具ではじめてみました。以下のような構成です。
- 計測を実行する仕組み → CircleCI
- 計測結果を記録する仕組み → Google スプレッドシート + GAS
- 記録した計測結果を加工して可視化する仕組み → Google データポータル
具体的な例を示したほうがわかりやすそうなので、以下、2 つほど紹介します。
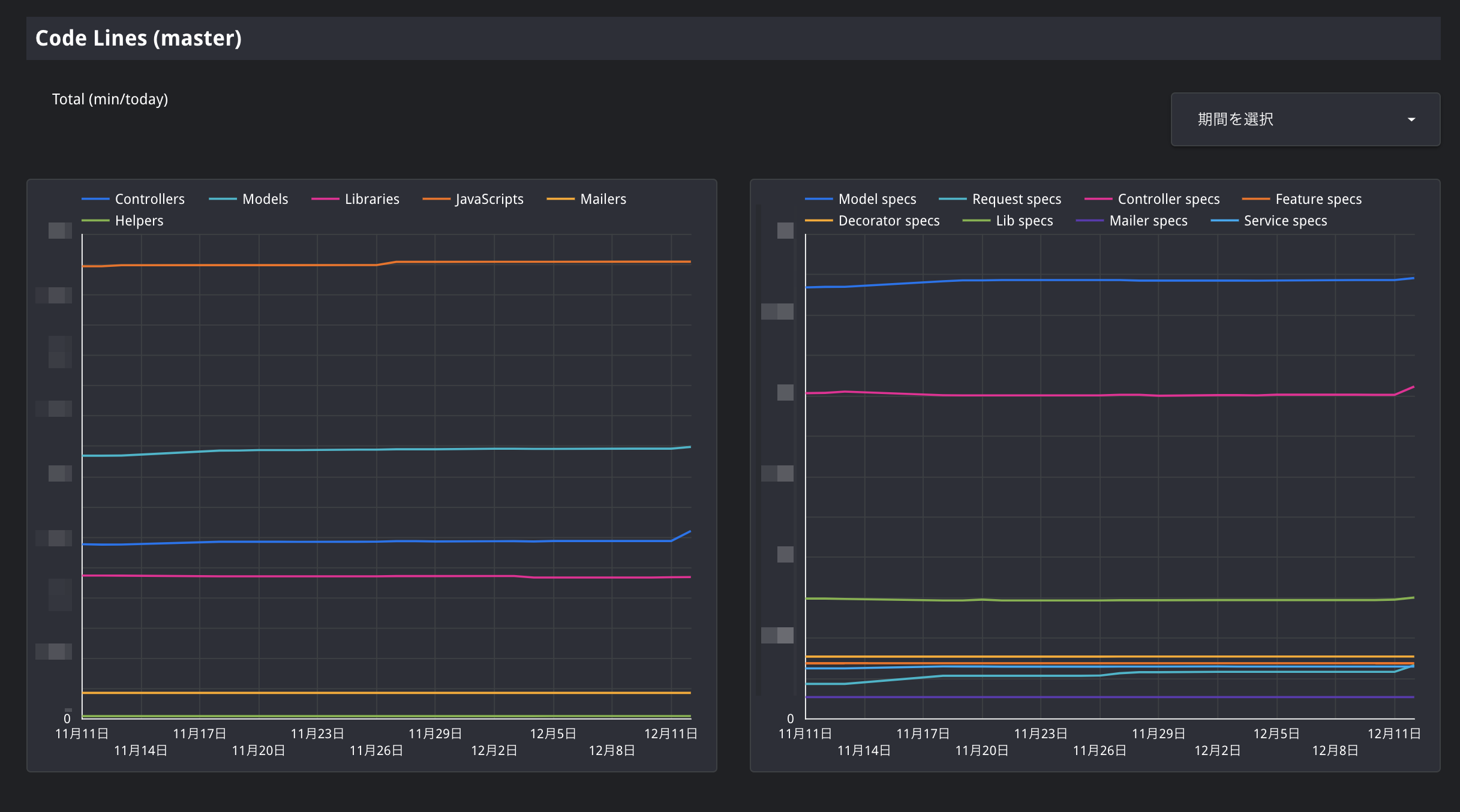
例 1: コード行数内訳の推移
コード行数の内訳推移がわかると、コードの全体的な変化の傾向が可視化されます。
たとえば Controller と Model の行数の増減関係であったり、Controller spec から Request spec への移行進捗であったりがわかりやすくなります。コード行数内訳を出力する rake task を作成
Rails アプリケーションでコード行数といえば
rake statsなのですが、この結果はヒューマンリーダブルではあるものの、計測結果としては扱いづらい面があります。
なので、JSON で結果を出してくれるrake stats:code_linesなるものをざっくり作りました。require 'rails/code_statistics' module CodeStatisticsExposable refine CodeStatistics do def code_lines pairs = @statistics.map { |name, statistics| [name, statistics.code_lines] } Hash[pairs + [["Total", @total.code_lines]]] end end end namespace :stats do # spec ディレクトリしたも集計対象にするために rspec-rails のタスクを先に実行 # https://github.com/rspec/rspec-rails/blob/v3.8.3/lib/rspec/rails/tasks/rspec.rake#L48 task code_lines: "spec:statsetup" do using CodeStatisticsExposable code_lines = CodeStatistics.new(*STATS_DIRECTORIES).code_lines meta = { commit: `git rev-parse HEAD`.chomp, sheetname: "code_lines" } puts code_lines.merge(meta).to_json end end結果はたとえばこんな感じ。
$ bin/rake stats:code_lines {"Controllers":12345,"Helpers":123,"Models":12345, ... ,"sheetname":"code_lines"}
sheetnameというメタデータは、あとで GAS がスプレッドシートに書き込むときの目印に使います。CircleCI で計測を実行して結果を記録 Web API に送信
先程の
rake stats:code_linesを CircleCI で定期実行し、結果を記録用の Web API に送信します。その時の設定は大体こんな感じ(簡略化してます)。
jobs: code_lines: executor: default steps: - run: name: Record code stats command: | bundle exec rake stats:code_lines > code_lines.json curl -L $STATISTICS_POST_ENDPOINT -d @code_lines.json workflows: version: 2 metrics: triggers: - schedule: cron: "0 16 * * *" # 16:00 UTC (1:00 JST) filters: branches: only: - master jobs: - code_lines:計測結果を受け取った GAS がスプレッドシートに記録
GAS は https://github.com/upinetree/gas-post-json-app で公開しているようなものです。
POST エンドポイントが、受け取った JSON のsheetnameの値をもとに書き込むシートを特定し、行を追記していきます。これを記録用スプレッドシートに紐づけて、Web API としてデプロイしました。
そのあたりの詳細なやり方は他にたくさん情報源があるのでここでは割愛させてください(書く体力が… ?)。
ハマったポイントは、GAS の POST はレスポンスがリダイレクトになるので、そのための GET エンドポイントを用意する必要があることと、 curl するときに
-Lオプションが必要なことでした。Google データポータルで可視化
Google データポータルは他の様々なサービスと連携できる、無料のダッシュボードサービスです。
Google の提供するサービスとの連携はもちろん、サードパーティのサービスも連携できるようです。Twitter 検索の連携とかもあって、色々遊べそうですね。
海外では Google Data Studio という名前なのですが、なんか商標?の関係で日本だけデータポータルと呼ぶっぽいです。先程の記録用スプレッドシートをデータソースに指定して、ダッシュボード(データポータル的にはレポート)を作成します。
そのあたりの詳細なやり方は他にたくさん情報源があるのでここでは割愛させてください(書く体力が… ?)。
これでコード行数の推移が可視化されました!
実際にコード行数の推移を見てみると、増加傾向のコードがある一方で、減少傾向のコードもあることもわかります。コードは線形に増加しているわけではなくて、生き物のように日々姿を変えていることが興味深いと思いました。その姿をひと目で観測できるようになり、プロダクトのイベントと照らし合わせて分析しやすくなったというだけでも、可視化してよかったと思います。
きっと比率とかで表示しても面白いんだろうなあとか、毎週Slackに画像で通知するとかしてみんなでああだこうだ分析できたら楽しそうだなあとか夢が広がります。データポータルは今回初めて使ったのですが、スプレッドシートとの連携がスムーズで簡単に操作できました。
一方でグラフを思ったように表現することができずハマったこともあったので、ある程度の試行錯誤は織り込んでおくとよさそうです。例 2: Rubocop の Metrics cop 違反数の推移
AbcSize とか BlockLines とか、デフォルト設定だとそこそこキツいアレ。
refs. https://docs.rubocop.org/en/stable/cops_metrics/
理想的にはデフォルトでパスできているのが良い状態ですが、既存コードに Rubocop を適用する場合はそう簡単にはいきません。
一度に違反をゼロにするのは非現実的なので、徐々に減らしていきたいところです。そのために、まずは違反の数を記録して、その推移を可視化することで、リファクタリングによって違反を減らせたとか、逆に新しく作った機能が違反を増やしてしまったとかを検知しやすくします。
また、それぞれのルールの違反数がどれだけあって、どれが一番多いのかという情報も、コードの形を客観的に知るために便利そうです。
CircleCI で違反数を計算
CircleCI の設定はだいたいこんな感じ。
orbs: jq: circleci/jq@1.9.1 jobs: rubocop_metrics: executor: default steps: - jq/install - run: name: Calculate rubocop metrics violations command: | mkdir -p ${CIRCLE_ARTIFACTS} bundle exec rubocop --only Metrics --config .rubocop-strict.yml --format json --parallel > ${CIRCLE_ARTIFACTS}/metrics_cop_result.json || true - run: name: Count rubocop metrics violations environment: JQ_FILTER: '[.files[] | .offenses[]] | group_by(.cop_name) | map({(.[0].cop_name): length}) | add + {sheetname: "rubocop_metrics_count"}' command: | jq -c "${JQ_FILTER}" ${CIRCLE_ARTIFACTS}/metrics_cop_result.json > ${CIRCLE_ARTIFACTS}/metrics_cop_violations.json - run: name: Send rubocop metrics violations command: | curl -L $STATISTICS_POST_ENDPOINT -d @${CIRCLE_ARTIFACTS}/metrics_cop_violations.jsonご覧の通り、rubocop の実行結果を
--format jsonによって JSON 形式で取得して、 jq で必要な形に変換しています。また、普段の rubocop のルールは Metrics cop がゆるく設定されているので、ほぼデフォルトの設定を
--config .rubocop-strict.ymlで指定します。jq は便利なのですが、呪文になりがちなのがデメリットかなと思います。
かといってこのためのスクリプトを組むほどでもなく、使い慣れた道具で小さく始めるというコンセプトとしてはまあよしとしてます。計測結果を受け取った GAS がスプレッドシートに記録
書き込み先のシートを JSON の
sheetnameによって切り替えただけで、あとはコード行数のときと同じです。かんたん!Google データポータルで可視化
これもデータソースを切り替えるだけで、コード行数のときと同じ手順で実現できます。かんたん!
まとめ
コードの計測・可視化の意義を考えた上で、小さく実験的にはじめるために、(私にとって)使い慣れた道具で実現することができました。
今回はコード行数と Rubocop 違反数の推移の計測を紹介しましたが、そもそも何を計測するのが効果的なのか?というところはまだ考えを深められていません。
これに関してはいくつかアイデアはあるものの、決定的な基準というのもないので、やっぱり試行錯誤しながらやっていくことになりそうです。
これからも地道に少しずつ進めていきたいと思います。
- 投稿日:2019-12-14T23:22:03+09:00
SystemSpecでログインできない時のお話
新たにSystem Specを導入しようとした時のお話です。
事象
ログイン処理を実装した時にログインができませんでした。
条件
・ローカルの画面上ではログインできる
・Factoryのデータ作成もできている
・他のSpecにて、Factoryを使用したデータではログインできる = Factoryで作成するデータ構造は正しい
・Feature Specでは成功した = System Specの記述もおかしくなさそう結論
Database Cleanerを導入していてFactoryで作成したデータが消えたためログインできなかったようです。
解決方法
Database Cleanerの記述自体を消した時に他のSpecの挙動がおかしくなったから次の書き方で対応しました。
・use_truncation: falseを適用させてDatabase Cleanerを無効
参照
https://qiita.com/takeyuweb/items/e7261e9274b3b31d933cXXXX_spec.rbRSpec.describe 'XXXX', type: :system do # ここにはDatabase Cleanerを適用させない context "Login", use_truncation: false do it 'is login test' do expect(page).to have_content 'ログインしました' end end endrails_helper.rbRSpec.configure do |config| . . config.use_transactional_fixtures = true . . endDatabase Cleanerについて
テスト毎にデータベースを空(truncate)にする機能。
Database Cleanerの設定記述を消してSpec実行してみると
テストテーブルにデータが残っていることを確認できます。伊藤さんのブログ(Database Cleaner)より抜粋します。
Rails 5.1ではDatabase Cleanerはもう必要ありません。
基本的にはDatabase Cleaner自体導入しなくても良さそうです。
途中からSystem Specを導入しようとしたら同じような事象が発生するかもしれませんね。今まで特にDatabase Cleanerを意識したことがないので良い経験になりました。
他の皆さんはこのような事象に遭遇したことありますか?
もし、経験された方がいましたらどのような対応されたか教えていただけると嬉しいです。追記
System Specでは データベースが自動的にロールバックされる みたいです。
(データベースの自動ロールバック)
https://techracho.bpsinc.jp/hachi8833/2018_01_25/51101だからFeatureSpecでは同じ記述でもログインできました。
- 投稿日:2019-12-14T20:40:49+09:00
Rails Tutorial Memo #8
自分用の備忘録です.
第13章 ユーザーのマイクロポスト
- ユーザーが短いメッセージを投稿できるようにするためのリソース「マイクロポスト」を追加する.
Micropostデータモデルを作成し,Userモデルとhas_manyおよびbelongs_toメソッドを使って関連付けを行う.13.1 Micropostモデル
13.1.1 基本的なモデル
Micropostモデルの属性
- content(text)
- マイクロポストの内容を保存する
- user_id(integer)
- 特定のユーザーとマイクロポストを関連付ける
String型とText型
マイクロポストの投稿に
String型ではなくText型を使用する.これは,ある程度の量のテキストを格納するときに使われる型である.Text型の方が表現豊かなマイクロポストを実現できる.13.1.3 User/Micropostの関連付け
buildメソッド
newメソッドと同様に,buildメソッドはオブジェクトを返すがデータベースには反映されない.Dependent: destroy
ユーザーが破棄された場合,そのユーザーのマイクロポストも同時に削除されるべき.
has_manyメソッドにオプション渡すことで実装できる.app/models/user.rbclass User < ApplicationRecord has_many :microposts, dependent: :destroy ... end13.3 マイクロポストを操作する
13.3.4 マイクロポストを削除する
request.referrer
一つ前のURLを返すメソッド.
- 投稿日:2019-12-14T19:08:58+09:00
10分でコンテナデプロイパイプラインを作る feat. ECS×CodePipeline×CircleCI
パイプラインファーストやってますか?
@toricls さんの 至高のCI/CDパイプラインを実現する5つの約束 より。
- 一発目のデプロイからパイプラインを通す
- rails new してすぐデプロイする
- 以降 push するとすぐに ステージング/QA/開発環境にデリバリされる
理想だし全てのプロジェクトでやりたいけど結構しんどいですよね?
なぜしんどいのか
configどう書くんだっけ
CircleCIのconfigとかセットアップはプロジェクト初期の1回だけだし、
更新するのもそんなに頻繁ではないので書き方を忘れる。覚えていない。作るものが多い
みんなが見れる環境にデリバリするためには、必要となるインフラのスタックが多い。
AWSでコンテナのアプリケーションを立ち上げるとしたら、以下のようなリソースが必要になってくる。
- VPC
- サブネット
- ルートテーブル
- ALB
- ECR
- ECSクラスタ
- ECSタスク定義
- ECSサービス
- EC2 / AutoScalingGroup
- 各種IAMロール / セキュリティグループ
- DB
ドメインでアクセスできるようにしたければSSL証明書やRoute53も必要になってくるし、
パイプラインを作るにはS3, CodePipeline, CodeBuildとかも作らないといけない。これだけのリソースを適切にセットアップできるメンバーがプロジェクト立ち上げ期にいない場合、
自然とパイプラインのセットアップは後回しになりがち。インフラ / SREチームの助けが必要になってくる。
みんなアプリケーション書きたい
開発の大半を占めるのはアプリケーションの実装。
地道な足元の整備はモチベーション上がらながち。どうすればパイプラインファーストが実現できるか
ツールの力を借りましょう。
世の中のナレッジを借りましょう。CloudFormationですよ。
configのサンプルですよ。コードを置いていくので使ってください。
これを使えば知識が特になくても、パイプラインができあがります。
ビルドやデプロイの待ち時間を除けば作業に必要なのは10分くらいです。たったそれだけで、パブリックなURLで自分たちのアプリケーションにアクセスできるようになります。
サンプル
- 作るのはRailsのアプリケーション。
- とりあえずルートのパスにアクセスできるようにする。
- ECSを使ってコンテナでpumaを立ち上げる(Nginxはなし)。
- 起動タイプはEC2。
必要となるCloudFormationのテンプレートと
buildspec.yml,.circleci/config.yml=> Blue-Pix/rezept/pipeline_first
空っぽのRailsアプリも置いておきます => Blue-Pix/my_awesome_app構築手順と解説
AWS, Github, CircleCIのアカウントを事前にご準備ください。
1. キーペアの作成
今回は起動タイプをECとするのでマネジメントコンソールからキーペアを1つ作成しておきます。
これはCloudFormation化できない部分です。
2. アプリケーション環境の構築
CloudFormationのスタックを作成します。
テンプレートファイルapp.cf.ymlをアップロードしてください。
テンプレートは自分のアプリケーションに合うように適宜ちょっとだけ修正が必要です。
pumaの設定ファイルの位置とか、app.cf.ymlCommand: - bundle - exec - puma - -C - config/puma/production.rb - -p - !Ref ApplicationPortコンテナの環境変数まわりとか。
app.cf.ymlEnvironment: - Name: RAILS_LOG_TO_STDOUT Value: 1 - Name: DB_HOST Value: hoge - Name: DB_USERNAME Value: hoge - Name: DB_PASSWORD Value: hoge - Name: RAILS_ENV Value: production - Name: SECRET_KEY_BASE Value: hoge
RAILS_LOG_TO_STDOUTはログを CloudWatch に流すために必要です。
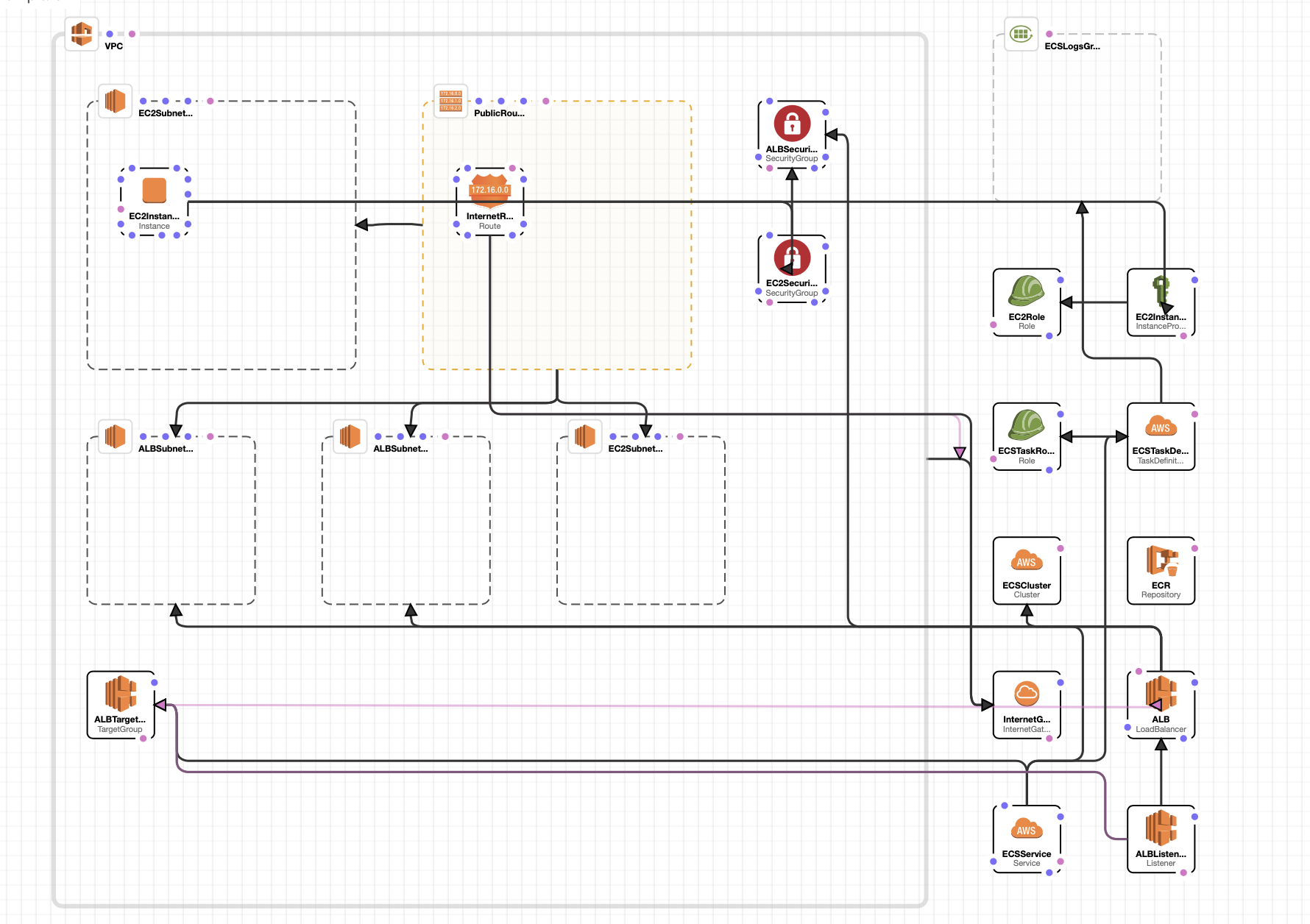
ここで設定していても puma で std_out_redirect になってると流れなくなるので注意。このテンプレートでは、VPC, ALB, ECS関連のリソースをまとめて作成します。
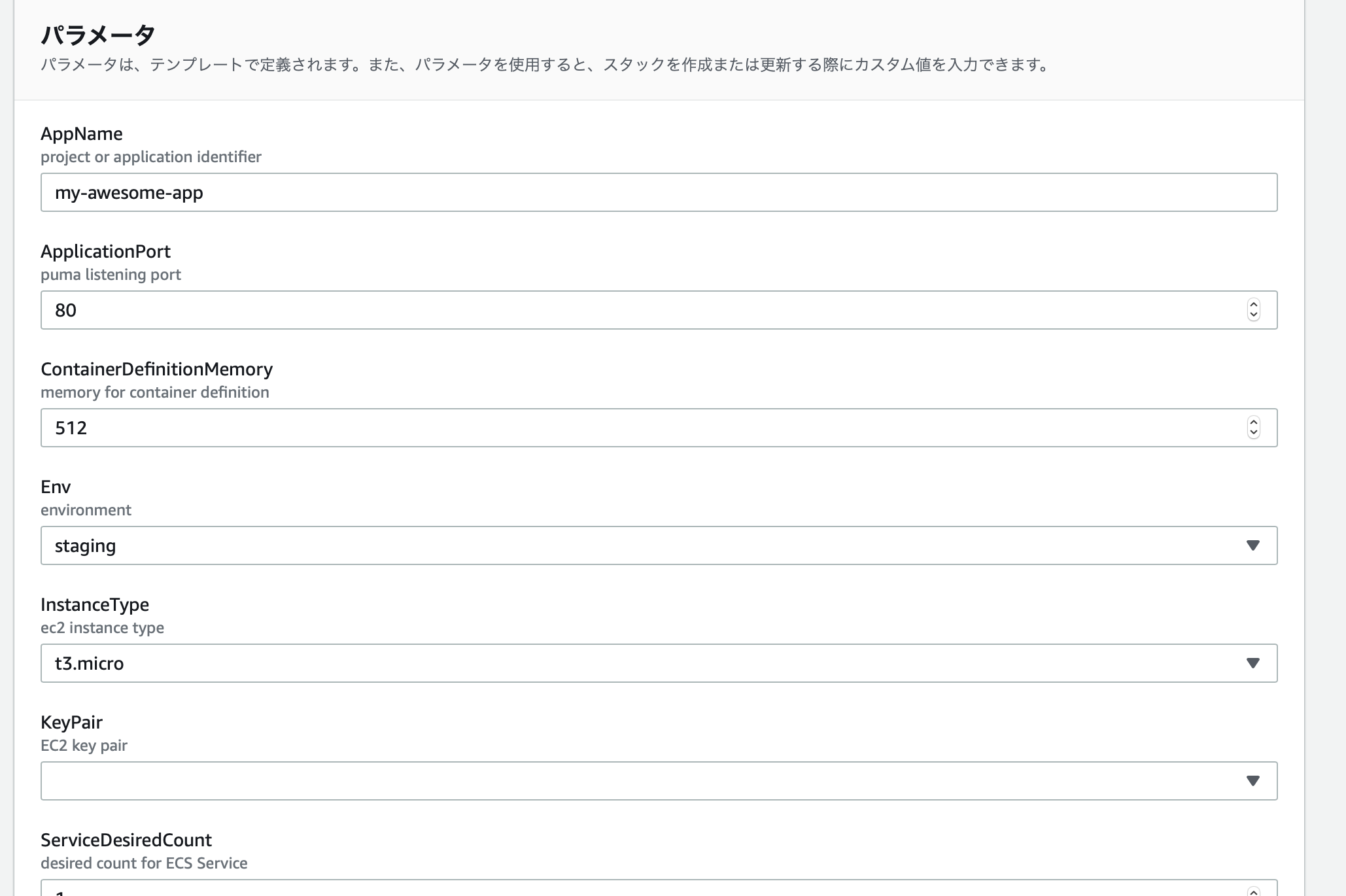
パラメータがいろいろありますが、基本はデフォルト値そのままで良いと思います。
キーペアだけ、先ほど作成したものを選択してください。あとは
AppNameにアプリを識別する名前を入力します。
Envで環境を選択します。
test/qa/staging/productionが用意してありますが足りなかったらテンプレートのAllowedValuesを編集してください。
作成するリソースは全て${AppName}-${Env}というプレフィックスをつけて管理するのがMyルールです。
何かのリソースのフォーマットに引っかかるのでアンダースコアは含めることができません。
インスタンスタイプは
t3.microにしてあります。メモリは1GiBです。
ServiceDesiredCountは デフォルト1です。
新しくデプロイを走らせると一時的に2つのコンテナが載った状態になるので、
1タスクあたりのメモリは450に設定しています(結構しんどい)。
コンテナインスタンスのオートスケールは含まれていないので、
インスタンスサイズとタスク数に応じて、
1コンテナインスタンスで捌けるくらいによしなに調整してください。
メモリが足りないと2回目以降のデプロイに失敗します。スタックを作成すると27個のリソースができます。
- ALB
- ALBターゲットグループ
- ALB用のセキュリティグループ
- VPC
- サブネット(アプリケーション用2つ, ALB用2つ)
- インターネットゲートウェイ
- ルートテーブル
- 各種ルート/サブネットの関連付け
- EC2用のセキュリティグループ
- EC2用のIAMロール
- インスタンスプロファイル
- ECR
- ECSクラスター
- ECSタスク定義
- ECSサービス
- ECSタスク用のIAMロール
- CloudWatchロググループ
3. Dockerイメージのプッシュ
2のスタックの作成は実は自動的には終わりません。
ECSサービスがタスクを起動しようとしますが、
イメージがないためコンテナが起動できずずっとループします。とりあえずスタックの作成を終わらせるため、手元でビルドしておいて、
ECRが作られた時点でイメージをプッシュする作業が必要です。
これ何とかしたいんですが上手い方法ありませんかね。
最初はサービスのdesiredCountを0にすればいいじゃんと思っていたんですが、
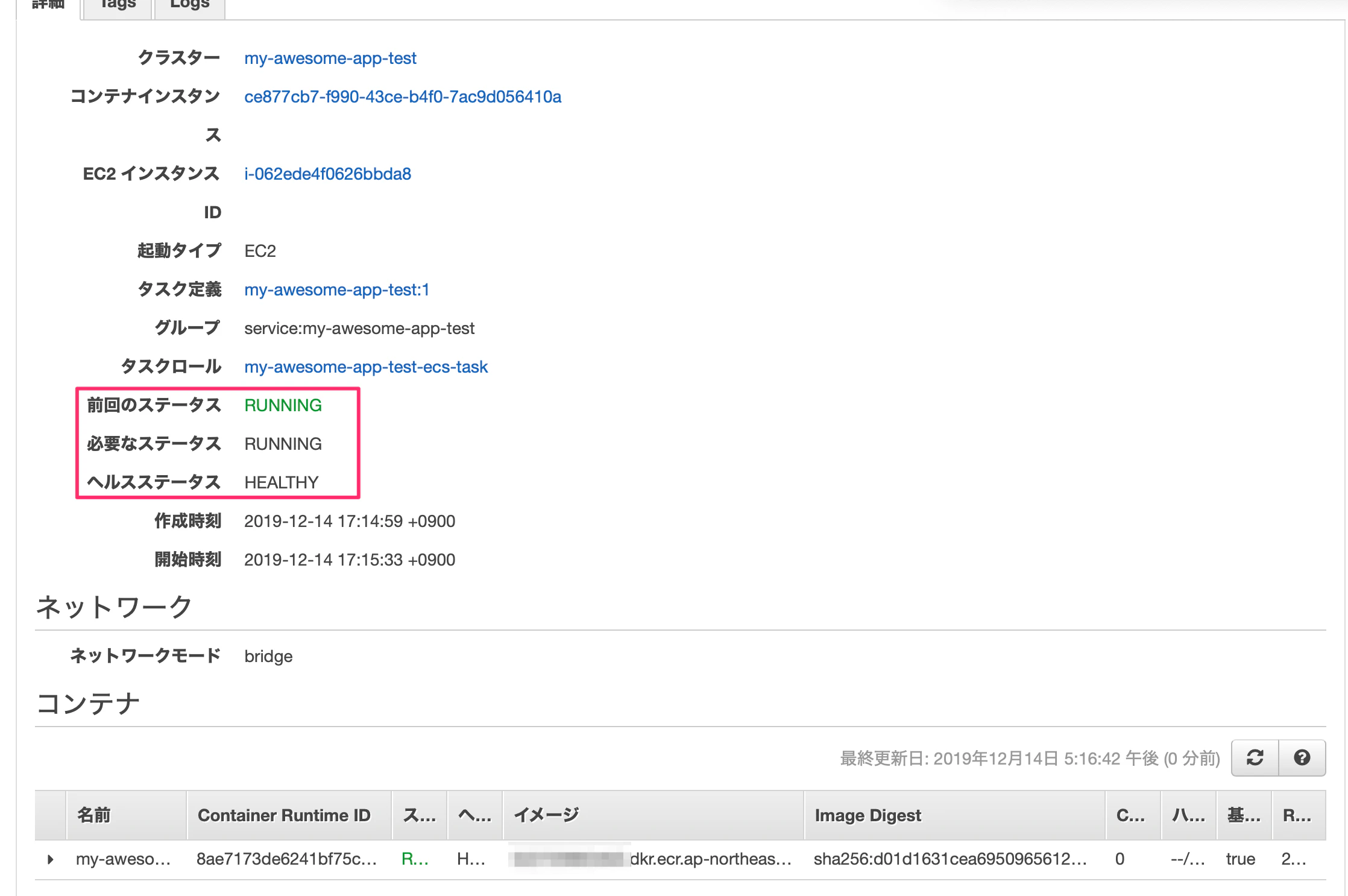
0でもCloudFormationが最初にタスクを起動しようとするんですよね...4. 確認
タスクがRUNNING / HEALTHYになればスタックの作成は完了です。
ALBのDNS名を調べてアクセスしましょう。
おめでとうございますデプロイ完了です?
5. CodePipelineの構築
パイプラインを構築します。
手始めにアプリのリポジトリに
buidspec.ymlを追加してください。buildspec.ymlversion: 0.2 env: variables: DOCKER_BUILDKIT: "1" phases: install: runtime-versions: docker: 18 pre_build: commands: - $(aws ecr get-login --region $AWS_REGION --no-include-email) build: commands: - docker build -t $ECR_REPO_NAME . - docker tag $ECR_REPO_NAME $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO_NAME:latest # latest - docker tag $ECR_REPO_NAME $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO_NAME:$CODEBUILD_RESOLVED_SOURCE_VERSION # commit hash post_build: commands: - docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO_NAME:latest - docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO_NAME:$CODEBUILD_RESOLVED_SOURCE_VERSION - printf '[{"name":"%s","imageUri":"%s"}]' $ECR_REPO_NAME $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$ECR_REPO_NAME:latest > imagedefinitions.json artifacts: files: - imagedefinitions.json
latestと git のコミットハッシュをタグとしてつけます。今度は
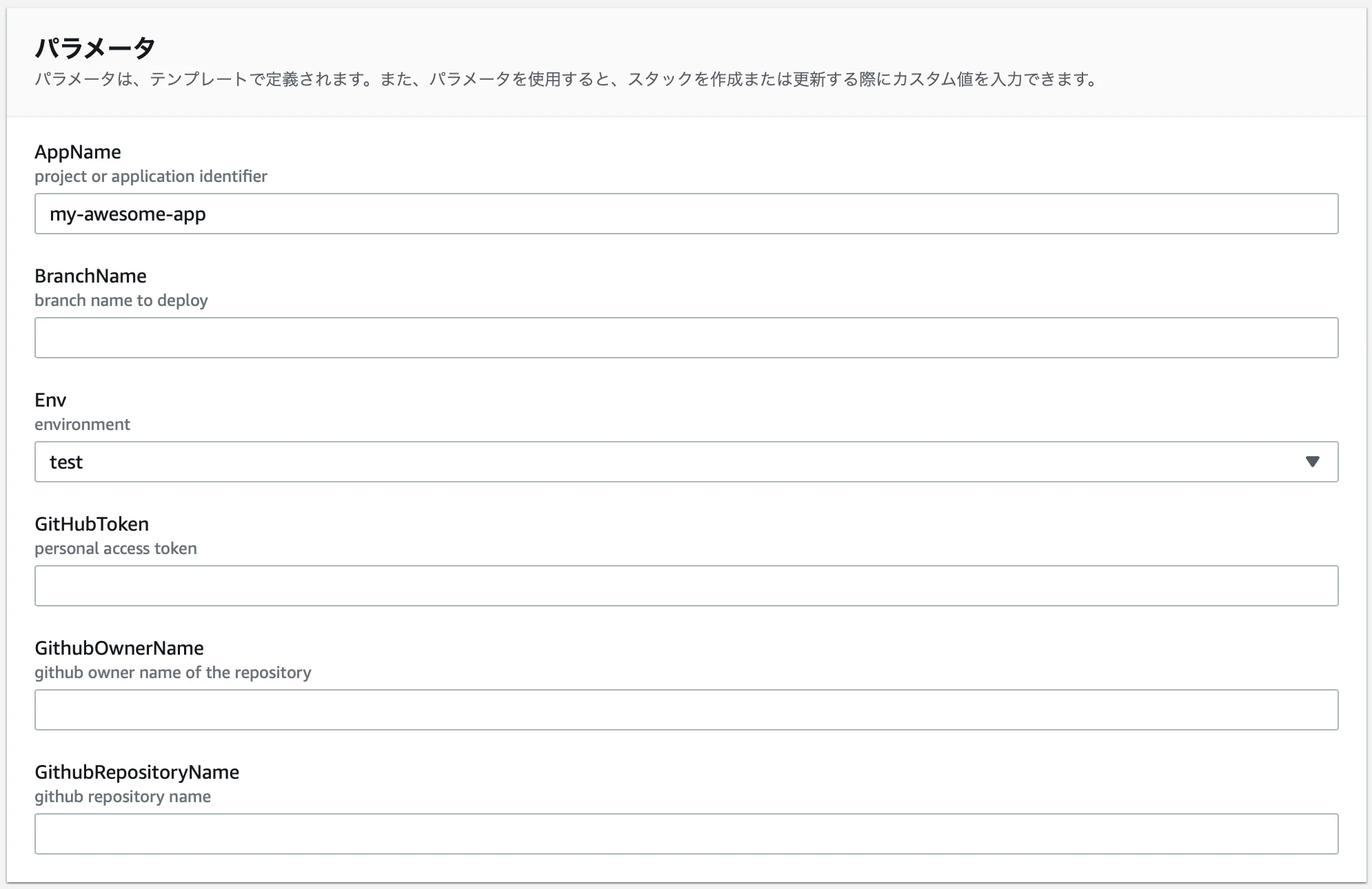
pipeline.cf.ymlを使ってスタックを作成してください。
2とアプリ名と環境名を合わせてください。
他に必要なパラメータは以下です。
- Githubリポジトリ名
- リポジトリの所有者(アカウント名)
- デプロイするブランチ
- トークン
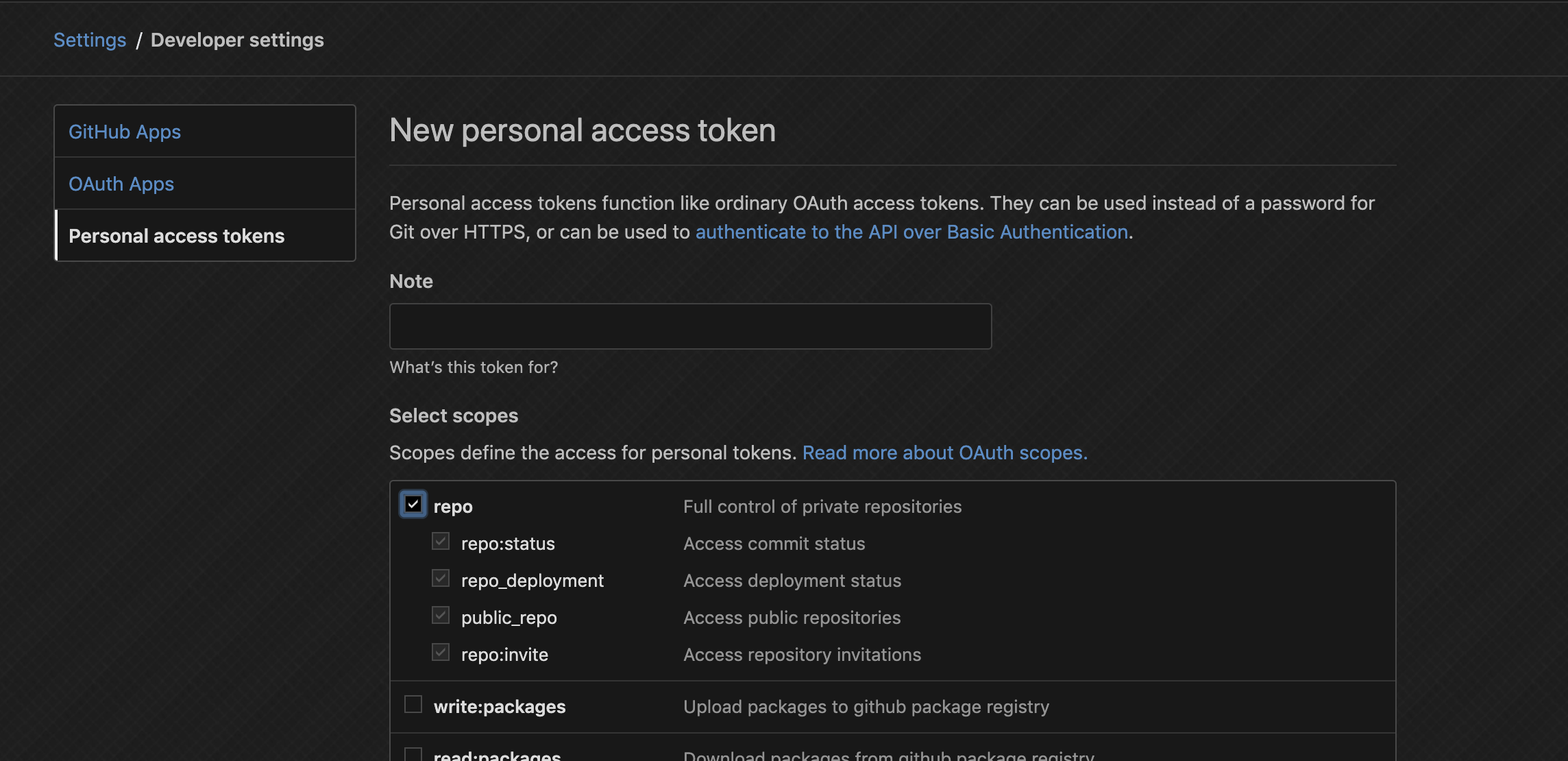
トークンは
Developer Settingsからrepoにチェックを入れた Personal access tokenを発行してください。
スタックの中身は
- アーティファクトを出力するS3バケット
- CodeBuild
- CodePipeline
- CodeBuildとCodePipelineそれぞれのサービスロール
- CircleCI用のIAMユーザー
です。
パイプラインはソースをチェックアウトしてDockerビルド、ECSサービスの更新というシンプルなものです。
1つ変わってるところとしては、PollForSourceChangesをfalseにして、
自動でパイプラインが走らないようにしていることです。パイプラインはCIが通ってからCircleCI側から明示的に実行します。
ネットで調べるとCircleCI上でDockerビルドをする例が多く出てきますが、
ジョブが詰まる & フリープランでは時間がもったいないため、CodeBuildに任せています。
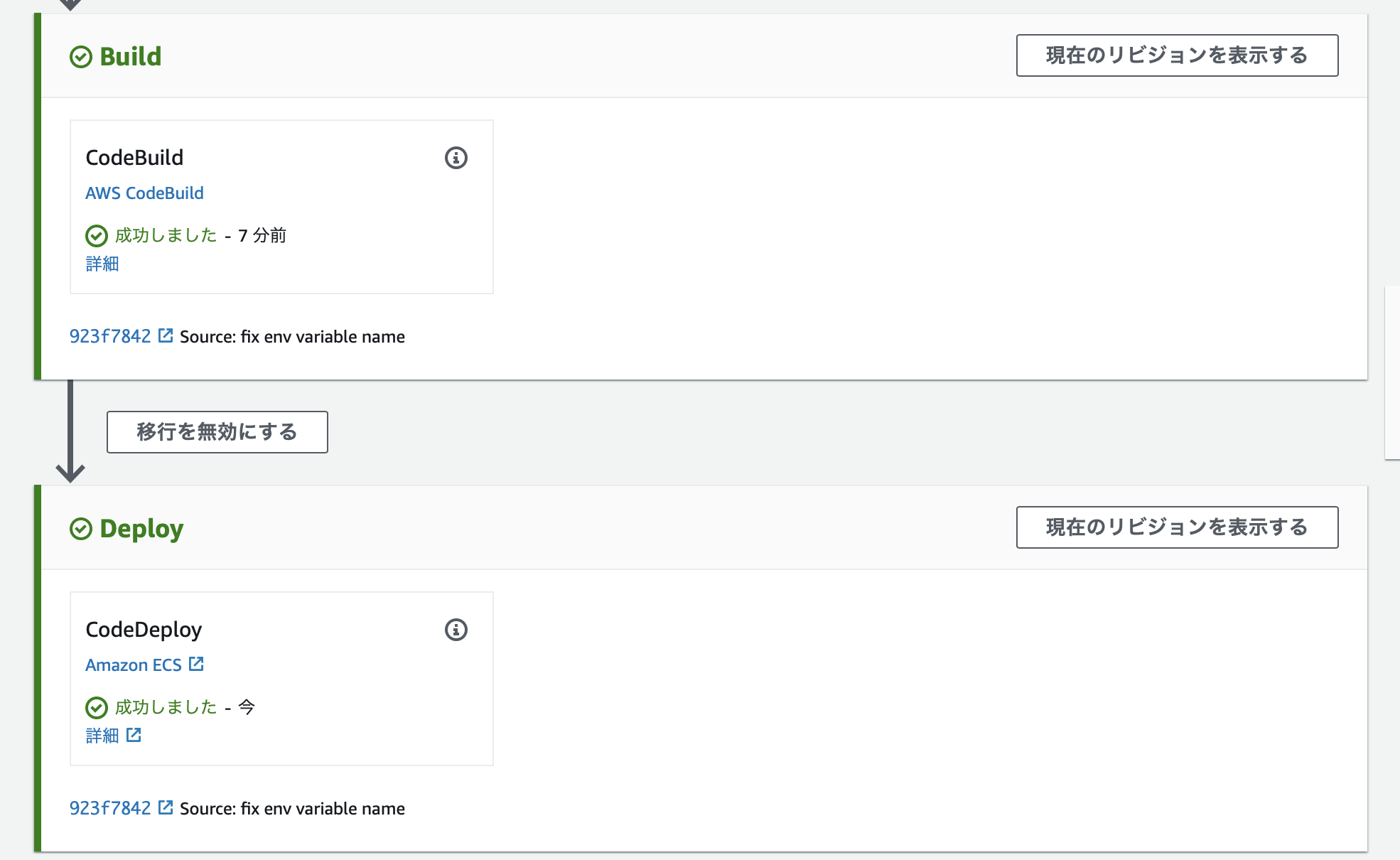
パイプラインも完成。
6. CircleCIを設定する
プロジェクトの設定は省きます。
configをアプリのリポジトリにおきます。
中身はまあ適当に。ほぼ何もやってません。.circleci/config.ymlversion: 2.1 commands: install_awscli: steps: - run: | sudo apt-get install python-pip sudo pip install awscli configure_env: steps: - run: | echo "export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY" >> $BASH_ENV echo "export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_KEY" >> $BASH_ENV echo "export AWS_DEFAULT_REGION=ap-northeast-1" >> $BASH_ENV echo "export PIPELINE_NAME=$PIPELINE_NAME" >> $BASH_ENV jobs: build: parallelism: 1 docker: - image: circleci/ruby:2.6.5 environment: RAILS_ENV: test DB_HOST: 127.0.0.1 DB_USERNAME: 'root' DB_PASSWORD: '' TZ: Asia/Tokyo BUNDLER_VERSION: 2.0.2 - image: circleci/mysql:5.7 environment: TZ: Asia/Tokyo working_directory: ~/my_app steps: - checkout - restore_cache: keys: - dependencies-{{ checksum "Gemfile.lock" }} - dependencies- - run: bundle install --deployment --jobs=4 --path vendor/bundle - save_cache: key: dependencies-{{ checksum "Gemfile.lock" }} paths: - "./vendor/bundle" - run: bundle exec rake db:create - run: bundle exec rake db:migrate deploy: docker: - image: circleci/python:3 steps: - install_awscli - configure_env - run: aws codepipeline start-pipeline-execution --name $PIPELINE_NAME workflows: version: 2 commit: jobs: - build - deploy:<img width="1145" alt=" 2019-12-14 18.11.23.png" src="https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/83183/1512092e-9981-a8e3-e25f-cf5e4928526a.png"> filters: branches: only: - master requires: - build最初は失敗します。
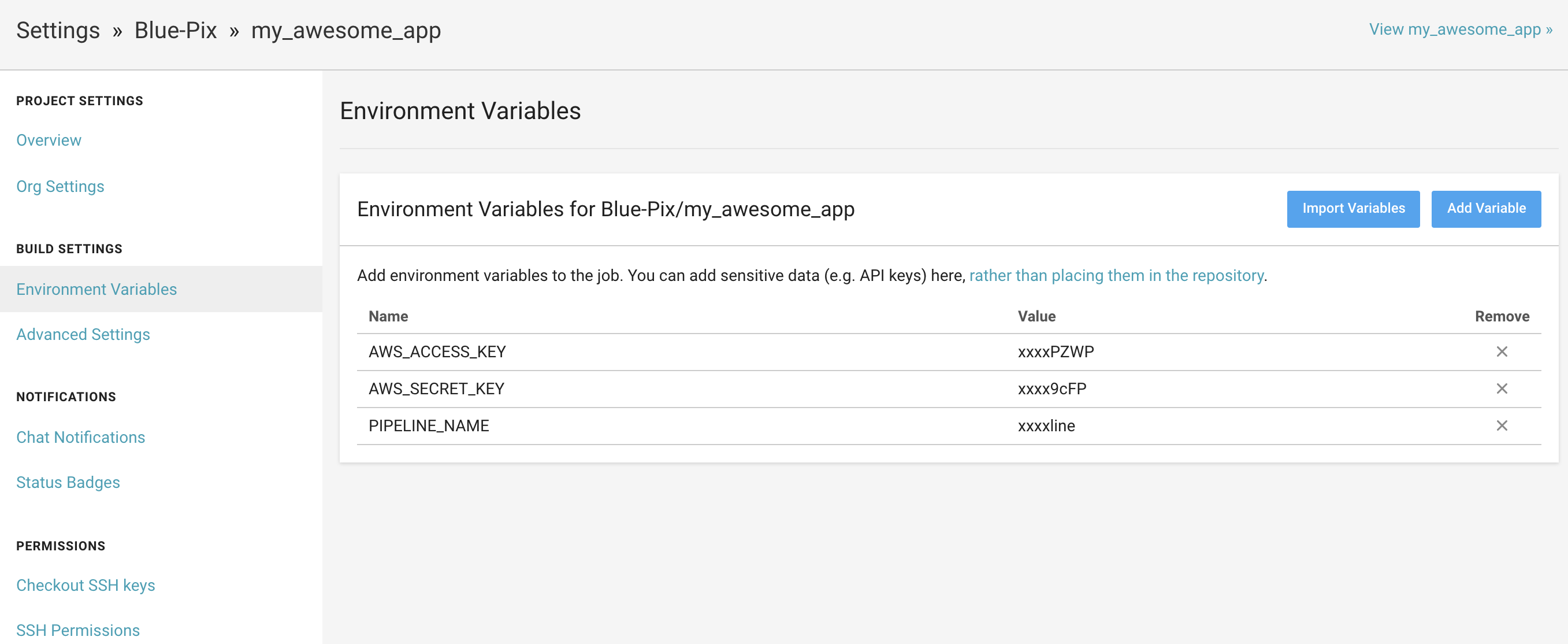
前述のCirclCI用のIAMユーザーにアクセスキーを発行して、
CircleCI側に環境変数を登録してください。また、キックするパイプラインを特定するために、パイプライン名も指定します。
パイプライン名は${AppName}-${Env}-pipelineになります。
本当は複数環境を走らせるために
config.ymlに分岐書いたりしないと
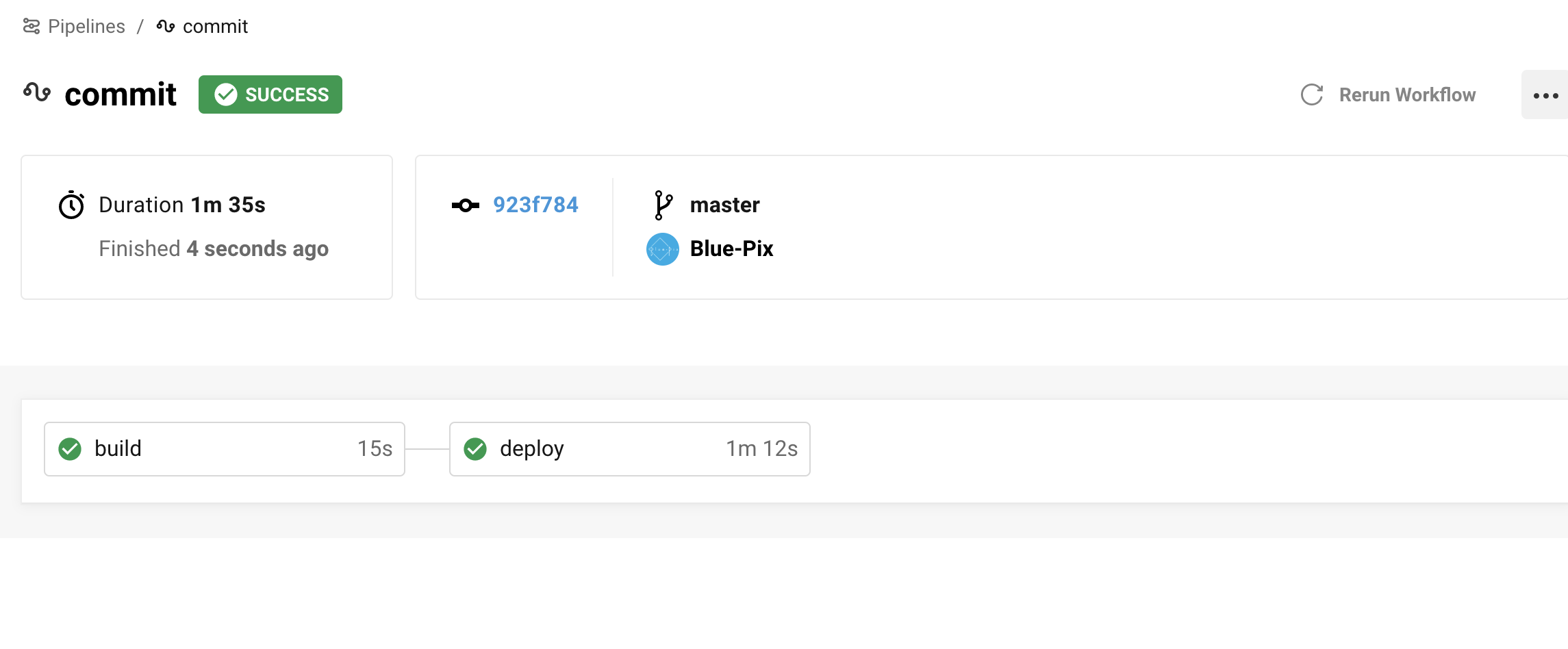
本番運用には耐えないんですが、ここではシンプルにしています。RerunするとCIが通ります。
Pipelineが開始されています。
まとめ
これで完成です。
以降は、該当のブランチにpushされるたびにCircleCIが走り、
CIをパスするとCodePipelineがキックされ、
イメージのビルドとECSサービスの更新を行いアプリケーションが反映されます。テストとか、アセットのコンパイルとかはさておき、
これでパイプラインファーストが楽に実現できます。待ち時間の体感を含めると10分はちょっと盛りましたすいません?
以上ですご査収ください。






- 投稿日:2019-12-14T18:39:33+09:00
Siderの導入(コードレビューツール)
書いてあること
1.Siderとは
2.Sider導入
- SiderにGithubでログインする
- リポジトリを追加する
- プルリクエストを作成する
- レビューを受けて修正する3.参考ページ
4.終わりにSiderとは
コードレビューツールを一括導入できる
プルリクエストが作成されると自動でコードレビューを行ってくれます⭐︎2.Sider導入
GitHubアカウントを持っていることが前提です
1.SiderにGithubでログインする
https://sider.reviewからSiderに飛ぶ
Sign in via Githubをクリック
認証ボタンのAuthorize Siderをクリック
同意にチェックして続けるをクリック2.リポジトリを追加する
追加するリポジトリで使用している言語・フレームワークをチェックし
+オーガニゼーションを追加するボタンをクリック(Siderインストール)
Only select repositoriesをクリックしてリポジトリを選択する
installをクリック一覧画面に飛ぶので追加したいリポジトリを
設定するをクリック
言語を選んでオープンなプルリクエストを解析するなんか勝手にプルリクエスト?ブランチ?ができてる( ˙-˙ )
本来はこんなページになってクローズができるはず。
*指摘されたものの、個人で問題がないと判断したコードは、「クローズ」することができます。
全てのコードが修正もしくは「クローズ」されると、解析結果がグリーンになります。修正を行いクローズのようですがひとまず見た感じ大きなエラーなどはなかったので
Marge pull request→confirm mergeで全部マージしました。
最後にPushとPullを行い終了。参考ページ
Siderでコードレビューを自動化してプロジェクトのエントロピーを維持する
終わりに
SiderとRuboCopをそれぞれ導入してみて
始める前はSiderの方がワンクリックで複数見れるのかなぁと思ってましたが
やってみたらそうでもなかった(ただ単に知識不足なだけだと思いますが)
RuboCopはローカルでチェックしてからリモートにあげられるので安心(でもリモートにあげ直す手間がある)
Siderはリモート上で行えるのですぐに本番環境(AWS)に連携できるがマージしたときミスしてないか心配。
自分はメンタルチキンなので今はローカルでいじる方が安心ですが、慣れてきたら面倒になるんだろうな・・・とも思ってます。
ひとまずは覚書程度にみていただければと思います。
記述の不備やアドバイス等ございましたらご指摘いただければ幸いです!


- 投稿日:2019-12-14T18:32:50+09:00
テーブルの継承をしていてもFactoryBotを使いたい
仮定と問題
今からおよそ1万年前、紀元前8,000年といえば世の中は新石器時代、文明の発祥は紀元前4,000年から3,000年ころらしいので、それよりもずっと前の頃です。
そのころから毎日、その日の天気を記録し、データベースのとあるテーブルにレコードを登録し続けてきた団体があるとします。1年を365日であるとすると、365×10,000 = 三百六十五万件のレコードが登録されているでしょう。
そしてこの団体が世界の10ヶ所で同様に天気を記録していたとすると、そのテーブルには合計で三千六百五十万件のレコードが登録されていることになります。このすばらしい歴史的な資料も、件数が多いと扱いづらくて困ります。
Railsで開発する
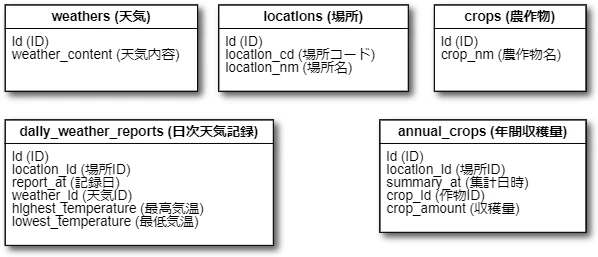
この謎の団体は年間の農作物の収穫高も毎年記録していたとして、以下のようなテーブル構成であるとします。
これらのテーブルのレコードを参照したり登録したりするWebアプリケーションをRailsで開発することにします。
さて、前述のとおり、日次天気記録テーブルはレコードの件数が多くなります。ついでに年間収穫量テーブルも、作物の種類の数によってはレコード数がずいぶん多くなりそうです。
せめて記録した場所ごとにテーブルが分かれていればましというものでしょう。世界のあちこちの天気の記録をまぜこぜにして分析する、という用途もあるでしょうが、場所ごとで分析する用途の方が多い気もします。
そこで登場するのはPostgreSQLの、テーブルの継承、もしくは分割です。
日次天気記録テーブルと、年間収穫量テーブルは、テーブルの継承を行い、場所ごとにテーブルを作成するものとします。
場所は場所テーブルで管理しており、場所が増えると日次天気記録テーブルの数も増えます。はて、テーブルが動的に増える、なんて状況を、Railsのモデルで表現できるのでしょうか?
世の中ではテーブルを作成するごとに
ActiveRecord::Baseクラスを継承してモデルクラスを生成したりするようですが、名前が固定されていないモデルというのは、個人的には扱いづらそうに思います。どうしたものか。日次天気記録テーブルの定義と、継承の定義が以下のようであったとします。tokyoという場所用のテーブルであるとします。
CREATE TABLE daily_weather_reports ( id BIGSERIAL NOT NULL PRIMARY KEY ,location_id BIGINT NOT NULL DEFAULT 0 ,report_at TIMESTAMPTZ NOT NULL ,weather_id BIGINT NOT NULL DEFAULT 0 ,highest_temperature NUMERIC NOT NULL DEFAULT 0.0 ,lowest_temperature NUMERIC NOT NULL DEFAULT 0.0 ,created_at TIMESTAMPTZ NOT NULL ,updated_at TIMESTAMPTZ NOT NULL );CREATE TABLE IF NOT EXISTS tokyo_daily_weather_reports ( LIKE daily_weather_reports INCLUDING ALL ) INHERITS (daily_weather_reports);継承後のテーブルは場所によってテーブル名が変わりますが、継承元のテーブルは名前が変わりません。単純には、継承元のテーブル
daily_weather_reportsに対してモデルクラスを定義することはできそうです。app/models/daily_weather_report.rbclass DailyWeatherReport < ApplicationRecord belongs_to :location end$ bundle exec rails console -e test Loading test environment (Rails 6.0.1) irb(main):001:0> dwr = DailyWeatherReport.new({ location_id: 1, report_at: Time.now, weather_id: 1 }) => #<DailyWeatherReport id: nil, report_at: "2019-12-14 09:46:34", location_id: 1, weather_id: 1, highest_temperature: 0.0, lowest_temperature: 0.0, created_at: nil, updated_at: nil> irb(main):002:0> dwr.save (0.6ms) BEGIN Location Load (0.9ms) SELECT "locations".* FROM "locations" WHERE "locations"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] DailyWeatherReport Create (5.6ms) INSERT INTO "daily_weather_reports" ("report_at", "location_id", "weather_id", "created_at", "updated_at") VALUES ($1, $2, $3, $4, $5) RETURNING "id" [["report_at", "2019-12-14 18:46:34.143271"], ["location_id", 1], ["weather_id", 1], ["created_at", "2019-12-14 18:46:40.080393"], ["updated_at", "2019-12-14 18:46:40.080393"]] (6.0ms) COMMIT => trueしかしこのままでは、当然ながらレコードは継承元のテーブル
daily_weather_reportsに保存されてしまいます。レコードを保存したい先は継承後のテーブルtokyo_daily_weather_reportsです。うーむ。継承後の子テーブルにレコードを保存する
モデルクラスに、他のモデルのいずれかの値でテーブルが分割されることを指定しておくと、自動的に子テーブルにレコードを登録する仕組みが提供されるようになる仕組みを考えてみます。
テーブルの分割、というと、PostgreSQLの分割の機能と混同してしまうので、名前を変えて、ここではテーブルの「間仕切り」と呼ぶことにしましょう!...いろいろセンスなくてすみません。
Majikiriモジュールを書いてみました。
majikiri.rb: テーブルの継承をしていてもFactoryBotを使いたい
モジュールの中身は気にしないことにして、以下のように使います。まず、分割される側から。
app/models/daily_weather_report.rbclass DailyWeatherReport < ApplicationRecord include Majikiri belongs_to :location majikiri_divided_by :location, attr_name: :location_cd endapp/models/annual_crop.rbclass AnnualCrop < ApplicationRecord include Majikiri belongs_to :location majikiri_divided_by :location, attr_name: :location_cd end分割する側は以下のようにします。
app/models/location.rbclass Location < ApplicationRecord include Majikiri majikiri_divide :daily_weather_report, attr_name: :location_cd majikiri_divide :annual_crop, attr_name: :location_cd end場所テーブルにレコードを登録してみます。
$ bundle exec rails console -e test Loading test environment (Rails 6.0.1) irb(main):001:0> location = Location.new({ location_cd: 'tokyo', location_nm: 'Tokyo' }) => #<Location id: nil, location_cd: "tokyo", location_nm: "Tokyo", created_at: nil, updated_at: nil> irb(main):002:0> location.save (0.8ms) BEGIN Location Create (1.4ms) INSERT INTO "locations" ("location_cd", "location_nm", "created_at", "updated_at") VALUES ($1, $2, $3, $4) RETURNING "id" [["location_cd", "tokyo"], ["location_nm", "Tokyo"], ["created_at", "2019-12-14 17:44:23.759893"], ["updated_at", "2019-12-14 17:44:23.759893"]] Location Load (132.6ms) CREATE TABLE IF NOT EXISTS tokyo_daily_weather_reports ( LIKE daily_weather_reports INCLUDING ALL ) INHERITS (daily_weather_reports); Location Load (55.4ms) CREATE TABLE IF NOT EXISTS tokyo_annual_crops ( LIKE annual_crops INCLUDING ALL ) INHERITS (annual_crops); (22.8ms) COMMIT => true日次天気記録テーブルと、年間収穫量テーブルに、自動的に子テーブル
tokyo_daily_weather_reports、tokyo_annual_cropsが作成されました。Tokyoという場所用の日次天気記録テーブルにレコードを登録してみます。
irb(main):003:0> dwr = DailyWeatherReport.new({ location_id: location.id, report_at: Time.now }) => #<DailyWeatherReport id: nil, report_at: "2019-12-14 08:46:38", location_id: 50, weather_id: 0, highest_temperature: 0.0, lowest_temperature: 0.0, created_at: nil, updated_at: nil> irb(main):004:0> dwr.majikiri_save Location Load (1.0ms) SELECT "locations".* FROM "locations" WHERE "locations"."id" = $1 LIMIT $2 [["id", 50], ["LIMIT", 1]] DailyWeatherReport Load (47.6ms) INSERT INTO tokyo_daily_weather_reports ( report_at,location_id,weather_id,highest_temperature,lowest_temperature,created_at,updated_at ) VALUES ( '2019-12-14 17:46:38 +0900',50,0,0.0,0.0,'now()','now()' ) RETURNING id,report_at,location_id,weather_id,highest_temperature,lowest_temperature,created_at,updated_at => true
tokyo_daily_weather_reportsテーブルにレコードが登録されました。RSpecで使ってみる
何がしたかったかといえば、RSpecでテストコードを書く際に、継承を利用しているテーブルでも、そうでないテーブルと似た書き方で事前条件となるデータの登録ができるようにしたかったのです。
テストに使うものなのに、モデルに直接手を入れるのはどうなのかとは思いますが、多めに見ていただければ幸いです。
RSpecにMakijiriモジュールのメソッドを呼び出す機能を追加します。
spec/support/majikiri_util.rbmodule MajikiriUtil def majikiri_create(model_name, **attrs) item = build(model_name, attrs) item.majikiri_create end def majikiri_create_list(model_name, amount, **attrs) amount.times.map do |idx| majikiri_create(model_name, attrs) end end end RSpec.configure do |config| config.include MajikiriUtil endRequestスペックから使ってみます。一覧表示のアクションのテストで、Tokyo用の日次天気記録テーブルに3件のレコードを登録してみます。FactoryBotでは
create_listメソッドで作成しますが、Majikiriモジュールの機能を呼び出す、majikiri_create_listメソッドを使います。spec/requests/daily_weather_reports_spec.rbrequire 'rails_helper' RSpec.describe "DailyWeatherReports", type: :request do let (:weather) { create(:weather) } let (:location) { create(:location, { location_cd: 'tokyo' }) } describe "GET /daily_weather_reports" do let! (:dwr) { majikiri_create_list(:daily_weather_report, 3, { weather_id: weather.id, location_id: location.id }) } it "works!" do get daily_weather_reports_path expect(response).to have_http_status(200) end end describe "POST /daily_weather_reports" do let (:dwr) { build(:daily_weather_report, { weather_id: weather.id, location_id: location.id }) } it "works!" do post daily_weather_reports_path, params: { daily_weather_report: dwr.attributes } actual = DailyWeatherReport.order(:id).last expect(response).to redirect_to(daily_weather_report_path(actual.id)) end end end一方、新規登録のアクションのテストでは、登録するレコードの内容を、
buildメソッドで生成します。こちらは通常のFactoryBotのメソッドです。モデルを継承元のテーブルに対して定義しているので、インスタンスを生成するだけなら通常のモデルと同様にできます。$ bundle exec rspec spec/requests/daily_weather_reports_spec.rb .. Finished in 0.90132 seconds (files took 3.53 seconds to load) 2 examples, 0 failuresどちらのテストもパスしました。
使うのはテストの時だけにしたいかも
Majikiriモジュールによって何やら怪しげなメソッドをモデルに追加したのですが、怪しいので有効になるのはテストの時だけにしたい、と思うかもしれません。
Railsに、Majikiriモジュールを有効にするかどうかの設定を行います。test環境の設定に以下の行を追加します。
config/environments/test.rbconfig.x.majikiri.auto_divide = trueこれで、モデルにmajikiri~と書いてあっても、test環境以外では無効になります。
おわりに
レコードを登録した時にcreateコールバックが動かないんだが、とか、新規登録以外の機能がないんだが、とか、2段階の継承ができないんだが、とか、いろいろ実用的ではないMajikiriモジュールですが、Railsにテーブルの継承を組み込めるようになるといいと思います。
- 投稿日:2019-12-14T18:23:28+09:00
歴史あるRailsアプリケーションのリファクタについて考えていることなど
去年の夏頃から株式会社LITALICOでエンジニアをやっています。@ti_aiutoです。
この記事は「LITALICO Engineers Advent Calendar 2019」の17日目の記事です。LITALICO Engineers Advent Calendar 2019 - Qiita
https://qiita.com/advent-calendar/2019/litalicoはじめに
背景
下半期から「改善大臣」に任命されて、開発環境の整備やリファクタリングを推進しています。(弊事業部のエンジニア間では、お互いへの敬意を込めて?「○○係」とかではなく「○○大臣」と呼び合う慣習?があります。)
チームに加わってまだ長くはないのですが、だからこそ気づくことや気になることもあるだあろうということで、そういう視点から、少しずつ課題を探したり、ディスカッションしたり、変更を加えたりしています。カマス実験みたいな感じです。この記事では、その中で考えたこと、実際に取り組んだことや取り組んでいることについてご紹介します。
技術書を何冊か読んだ感想
上半期から業務時間の1割ちょっと+プライベートの時間を使って、古典?の技術書を読み込む運動をしていました。取り組みについて紹介する前に、この記事に関連する箇所で気に入った部分を紹介します。
Refactoring - Improving the Design of Existing Code(2nd Edition)
「既存の構造を先に変更したほうが作業を効率的に進められることがあり、その下準備こそがリファクタリングなんだ」という点が強調されていたと思います。リファクタリングはプログラミングと分けて考えるものではないし(もちろん通常の開発と分けて長期的に進めるべきこともある)、コードの見た目が醜いからやるというものでもない(きれいなコードでもリファクタリングは必要)、という話もありました。
作業の進め方については、細かくコミットすることと、変更を加えたらすぐにテストを回すこと、壊してしまったら作業を破棄して最後の作業からより細かい粒度でやり直すことなどがアドバイスされていました。
『エリック・エヴァンスのドメイン駆動設計』
この本は原著と邦訳で合わせて2週読みましたが、全て理解するにはあと何周読めば良いのかという感じです。
リファクタリングに言及している箇所でいうと、エンジニアにリファクタリングで工数を使わせないことについて、「変更を完全に正当化できるまで待つのは、待ちすぎというものである。」「ソフトウェア開発は、変更することで得られる利益や、変更しないことで生じるコストを正確に割り出せるような、予測可能なプロセスではない。」と書かれている箇所があります。エンジニア自身に向けたメッセージというよりは、それを取り巻く環境について言っている感じがします。何にしても、手遅れになる前に(ぎこちないコードが拡散する前に)早めに手を付けよう、という話です。
それよりも印象に残っているのは、本文を通して何度も登場する「高凝集・低結合」の考え方と、次の箇所です。
ある開発者があるコンポーネントを使用するために、その実装についてじっくり考えなければならないのであれば、カプセル化の価値は失われる。もともとそのコンポーネントを開発した人とは別の人がオブジェクトや操作の目的を推測する上で、実装を確認しなければならないとしたら、その新しい開発者は、操作やクラスが偶然満たしているだけのものを目的と思ってしまうかもしれない。そうして推測された目的が本来の意図と異なっていたら、コードはさしあたり動くかもしれないが、設計の概念的な基盤が崩壊し、2人の開発者は互いに矛盾した目的に向けて仕事をすることになるだろう。
手の込んだ仕組みはすべて抽象的なインターフェースの背後にカプセル化し、またそうしたインターフェースには、手段ではなく目的の観点から語らせなければならない。
(邦訳版p.251)
そもそもカプセル化にどんな意義があるのか、それが欠けると何が困るのか、何を目指してカプセル化を行うべきかが、この段落を読むだけでよく分かります。「意図の明白なインタフェース」(intention revealing interfaces)という表現も度々登場していました。
コードに語らせるべきことについては、次のような記述もありました。
優れたオブジェクト設計の本質は、各オブジェクトに明白で限定された責務を与え、相互依存関係を最小限に減らすことである。だが時には、チームでの交流を、ソフトウェアにおいてあるべき姿と同じくらい整理しようとしてしまうことがある。だが、うまくいっているプロジェクトには、他人のことに首を突っ込む人々が多い。開発者がフレームワークを試し、アーキテクトがアプリケーションコードを書く。全員が全員と話をする。これは効果的な混沌だ。オブジェクトをスペシャリストに仕立てて、開発者はジェネラリストにすること。
(邦訳版p.502)
「開発者が過度な役割分担で専門分化するのではなく、ジェネラリストとして他の役割の開発者やビジネス側のメンバーとも関わるようにすることで、全体でよりよい設計にたどり着ける。その分、オブジェクト(設計されたもの)を分かりやすく、知識を濃く反映したものにすれば良いんだ。」というふうに読みました。
あと、この本だったか自信がありませんが、「どんな設計も作ったときにはそれが一番だったんだ」みたいな話もありました。これも重要な視点です。
(これか『レガシーコード改善ガイド』か『パターン指向リファクタリング入門』のどれかのはずです。)『レガシーコード改善ガイド』
この本は一言でいうと「コードベースにどうやってテストコードをねじ込むか」の話と言っていいと思うのですが、どうしてテストが必要なのかという点で、序盤の「編集して祈る」か「保護して変更する」かの話がわかりやすかったです。
テストコードがなければ、既存のコードを壊してしまっても、元々の振る舞いが維持されているかどうかは動かすまでわからないので、何も壊れていないことを「祈って」人力で動作を確認するしかありません。
一方、テストコードで既存の振る舞いを明示していれば、それが壊れたときにすぐに気づくことができます。この既存の「振る舞いを固定しながら変更を加えられる」という点を「ソフトウェア万力」と表現しています。動いてほしくないものを固定して作業する様子は確かに想像しやすいです。作業方針
大まかな方針は、先ほどの技術書の感想に沿っているつもりです。
なお、リプレイスやマイクロサービス化のような大きな(中長期的な)変更についてはまた別で話が上がっているので、その範囲までは考えていません。
今いる場所から漸進的に
どんなコードも、書かれた当時には総合的に判断してそれがベストだったからこそ、そう書かれているわけです。そうして積み上げられてきた資産を活かしつつ、これからの変更を進めやすくするためにはどうしたら良いのか、どんな点が開発スピードを落としそうなのか、という点から考えています。
大まかな指針としては「高凝集・低結合」
「本来関係がないように見えるところが実はつながっていた」とか、「本当はあまり関係ない機能の細かい仕様まで気にしながら開発をしないといけない」とかといった状態だと、大きく分けて二点の問題があると思います。
- 目の前の開発以外と関係が薄いことまで気にする必要があるため、必要以上に認知資源を消費して、作業効率が下がる
- 変更の影響範囲が広がりやすくなるため、変更漏れ、変更ミス、不具合や誤作動が起きやすくなる
この状態を改善するために、主に次のような方針で作業を行っています。
- 関連の薄い機能同士、開発スピードに大きな差のある機能同士を分離する
- コード同士の依存関係を分かりやすくする
- 処理の詳細はメソッドやクラスの中に隠して、それを使う側は抽象的に、目的中心で呼び出せるようにする
コードの振る舞いを明示する
後からコードを変更した開発者(未来の自分自身も含めて)に、「どうしてそんなことしたんだ!」と文句を言うのは簡単ですが、テストコードや静的型付けによってコードの期待されるふるまいが明示・固定されていれば、そもそもそういうことにはならないはずです。
プルリクエストやコメントも活用しつつ、コードそのものやテストコードでそのへんを表現していくのが重要だと思います。
開発環境
具体的には次の技術を使って開発しています。
- Rails 5.x(Ruby)
- Sprockets + webpack
- SCSS
- jQuery(JS)
- Vue.js 2.x(JS, TS) + Jest(JS, TS)
(※この記事を読む未来の後輩?に向けて念のため補足をすると、jQueryのコードは保守がメインで、新規に書くことはほとんどありません。)
Railsアプリのリファクタと言いつつも
タイトルは「Railsアプリのリファクタ」としていますが、以下の内容はフロントエンドの内容が多くなっています。
困ったところから作業した結果そうなったのですが、この背景としては、サーバサイドの実装で機能ごとにModel, layouts, Helperの実装が分かれているために、関連の薄い機能同士のコードが混ざることが少ない、というのがあると思います。活動報告・活動予定
Jestの導入(完了)
(これは改善大臣に任命される前にやったことですが、今の開発の下地になっているのこれも入れておきます。)
課題と目的
テストコードの重要性については技術書紹介のところに書いたとおりです。
Vue.jsのコードが増えてきて、しかも複雑になってきたところで、JSのテストフレームワークのJestを導入しました。
作業内容
テストフレームワークを導入したら、あとはひたすらテストを追加していくのみです。
主に次のようなところをテストしています。
methodsの単体テスト(引数の値を変えながら)computedの単体テスト(Vueインスタンスの状態を変えながら)createdやmountedの処理について期待した振る舞いのテスト- 外部APIの呼び出しなど副作用のある処理のモック・検証
v-ifの出し分けの中でも重要な箇所について、DOM要素の表示非表示が切り替わっていることのテストテストに使うVue.jsのインスタンスをどうやって初期化するのか、
propsに渡す値のダミーデータをどう用意するのかなど、まだ方法を試行錯誤している箇所もいくつかありますが、ひとまず意味のあるテストは書けていると思います。JS, CSSファイルを機能ごとに切り出す(一部完了、保留中)
課題と目的
これまで、一部の機能で新しいVue.jsのライブラリを導入したり更新したりしたときに、その影響が他の機能にまで広がることがあったので、新規のライブラリの導入を必要以上に控えているところがありました。特にUI関連のフレームワークやライブラリは影響が広がりやすいです。
ほとんど変更しない機能を壊さないために、開発スピードの速い機能の作業が滞るのは困るので、JSとCSSを別のファイルに分けてしまうことにしました。
作業内容
次のような手順で行いました。
- JSファイル(A)の中で、各機能で共通して使われている部分と機能固有の部分を特定し、コメントなどで整理しておく
- 新しいJSファイル(B)を作成する
- webpackの
entryを変更して、共通(A)+固有の入力(B)からそれぞれJS, CSSが出力がされるよう変更するlayoutsを編集して、(3)で新しく設定したファイルが読み込まれるようにする- 動作を確認しながら、(A)の機能固有の部分を(B)に移す
単純といえば単純ですが、(主に精神的な面で)効果は大きかったと思います。
ただ、ファイルを分割するとその分リクエスト数が増えてパフォーマンスに影響する可能性があるので、最低限の作業ができたところでいったん保留にしています。
グローバル変数・メソッドを減らす(進行中)
課題と目的
だいぶ前に書かれたコードの中には、グローバルに定義されたjQueryやVue.jsのコードを使って、グローバルに定義された関数を起動して何かする、というコードが数多くあります。かつてのJSは依存関係や可視性の管理は全てユーザ任せだったので、そういうコードになるのももっともかもしれません。
ただ、グローバル関数や変数というのはどこからでも変更できてしまうので、間違えて変更したとか二重に定義したとかいうときに、想定外の挙動する可能性があります。また、参照している側から見れば処理がどこに定義されているのかわかりにくくなりますし、コードを変更したときの影響範囲もわかりにくくなります。
幸いなことに、今のフロントのコードにはSprocketsに加えて、既にwebpackが導入されています。どちらもJSファイルの下処理をやってくれますが、webpackを使うと何がいいかというと、モジュール管理の機能が使えるようになるところです。これにより、使いたいコードを、使いたい場所だけに持ってきて利用することが可能になり、グローバル空間を利用する必要がなくなります。
作業内容
次のような手順で作業を進めているところです。
- グローバルから除きたいオブジェクト(関数や変数)を一つ決める(検証が大変なので一つだけにします)
- Sprockets側の対象から除いてwebpack側の対象に加える(よほどタイミングにシビアな処理でない限りそのまま動きます)
- グローバルに定義されていたオブジェクトを、
exportするコードを準備する(または準備されていることを確認する)- (2)で移動した各ファイルで、(3)のコードを
importするよう変更する- グローバルに定義されていたオブジェクトを削除する
まだ一つしかできていませんが、これも検証が大変なのでまだ時間がかかると思います。
JSファイルのTS化(進行中)
課題と目的
開発を進めやすくするためにも、メソッドや関数の使い方を分かりやすくするためにも、コードの振る舞いを固定するためにも、TS化は役に立ちます。
先輩がTypeScriptの導入はしてくださっていたのですが、実際問題コードが書かれてはいなかったので、Vue.jsのコンポーネント定義を中心に徐々にTSにしています。
作業内容
これはひたすら変更していくのみです。テストがあればなおよし。
ただし、TS化が完了する前にeslintのTSプラグインを入れると全JSにWARNINGが出るので要注意です。
一部のモデル更新のAPI化(着手前)
課題と目的
一部の共通機能のモデルの操作(
updateやupdate_allなど)が、複数のModel, Controllerなど様々な場所から呼ばれているところがあります。item.update(hoge_flag: true, fuga_flag: false)のような感じです。これはこれで動いていますし、慣れれば特に困ることもないのかもしれませんが、特定の機能のモデルやコントローラが、関係の弱い共通機能のモデルの詳細なデータ構造について知っていないといけないというのは、利用する側としては少し荷が重くなります。また、不変条件(値同士の関係、片方が○○ならもう片方□□であることのような)が維持される保証もありません。
実際にこれらのコードをコピペした場面が何回かあったのですが、色々調べるのが大変でした。これらの処理をAPIとして適切に隠蔽することで、上記の問題が緩和されますし、将来マイクロサービス化のような話が出たときにも、変更が進めやすくなります。
作業内容
まだ未着手なので具体的なことは決まっていませんが、次のような手順になると思います。
- 既存のコードをよく調べる
- テストコードが準備されていることを確認する(なければ準備する)
- データ更新・読み出しの目的ごとに該当箇所を分類する
- (3)ごとにメソッドを定義する
- (4)のメソッドを使うように変更する
- 何も壊していないことを確認する
ただ、
update_allを使う操作については、処理をどこに書けば良いのか悩ましいです。ActiveRecord::Relationのクラスに直接定義するわけにもいきませんし、かといってクラスメソッドに引数で対象を渡すのも使いやすいと言えるのか怪しいですし、まだ検討が必要そうです。データウェアハウスのDB分割(一部完了、保留中)
課題と目的
Railsアプリケーションからデータウェアハウス(BigQuery)に格納する際に、全機能のデータが一緒に格納されています。
基本BigQueryは処理対象のデータ量で課金されるので、比較的リクエストの少ない機能のログをみたいときに、全機能のログを一気に処理にかけるのは無駄が多すぎます。また、同じ一行でも、読み出すカラムが軽いほど安くなるので、一つのカラムにJSONなどで値を格納するよりは、複数のカラムにはじめから分けたほうが得策です。
作業内容
アクセスは比較的少ないが走らせるクエリが多い機能について、テーブルを分割しました。また、JSON形式でデータを保持しているカラムについては、よく使う値を別のカラムに展開するようにしました。
これにより、処理対象が70GBから300MBまで減ったクエリもありました。Vue.js関連のリファクタ(進行中)
課題と目的
Vue.jsは(Angularと比較した印象では)自由度が高いと思うのですが、その分自力で設計を工夫・整理しないといけない部分が多いと思います。
API呼び出しの処理の書き方がコンポーネントごとに違うとか、共通処理の書き方が場所によって違うとか、コンポーネント同士の連携が交錯していてスパゲッティ直前になっている箇所があったりとかで、開発が進めにくくなっています。
なんとかリリースまでこぎつけたところで、少し時間をかけてリファクタしていこうという話が出ています。
作業内容
コンポーネントの責務を、大きく通信やアプリケーションロジックを含むものと、UI関連に特化するものに分け、後者の中でもレイヤを2つに分割して再利用しやすくしているところです。(先輩の発案を話し合って設計して、実装を進めているという感じです。)
一部のコンポーネントで実装を進めているところですが、最上位のコンポーネントはテストが薄いorないこともあって、作業がかなりゆっくりになっています。
あとは、通信の処理の書き方もコンポーネントによってバラバラなので、永続化(通信)の処理を、DDDの本のような形でRepositoryに切り出して、そのRepositoryの生成もFactoryに任せる、というような形で責務を分けて、統一した形で書けるように直す予定です。(これも先輩の発案ですが。。)
この辺はある程度進んだらまだ別で記事にしたいところです。
結論
ということで、上に書いたようなことを少しずつ進めています。もちろんメインのプロダクトの開発もあるのでなかなか時間がとれないときもありますが、自分含めて全体の開発の効率アップにつながったり、新しいメンバーの学習コスト削減につながったりする部分については、もっと積極的に進めていきたい思っています。
それにより、先輩方々から受け継いできたコード(によるサービス)で、少しでも長くユーザの皆さんに価値を届けられたらなと思います。
明日も私@ti_aiutoがアドベントカレンダーを担当します。
久々にSQLについてがっつり勉強&練習したので、それについて記事を書きます。
- 投稿日:2019-12-14T17:52:05+09:00
Railsチュートリアル 第12章 パスワードの再設定 - PasswordResets#createで、メールアドレスが有効な場合の処理をテスト駆動で実装していく
メールアドレスが有効な場合の処理に対するテストの実装
Railsチュートリアル本文の通りに実装していくとすれば、以下のテストが「メールアドレスが有効な場合の処理に対するテスト」に該当することになります。
test/integration/password_resets_test.rbrequire 'test_helper' class PasswordResetsTest < ActionDispatch::IntegrationTest def setup ActionMailer::Base.deliveries.clear @user = users(:rhakurei) end test "password resets" do get new_password_reset_path assert_template 'password_resets/new' # メールアドレスが無効 post password_resets_path, params: { password_reset: { email: "" } } assert_not flash.empty? assert_template 'password_resets/new' get new_password_reset_path assert flash.empty? + # メールアドレスが有効 + post password_resets_path, params: { password_reset: { email: @user.email} } + assert_not_equal @user.reset_digest, @user.reload.reset_digest + assert_equal 1, Actionmailer::Base.deriveries.size + assert_not flash.empty? + assert_redirected_to root_url end endメールアドレスが有効な場合の処理に対するテストを実装した時点で、テストの結果はどうなるか
「メールアドレスが無効な場合の処理」が完了した時点における、
app/controllers/password_resets_controller.rbのソースコードは以下です。app/controllers/password_resets_controller.rbclass PasswordResetsController < ApplicationController def new end def create if false #TODO: 有効なユーザー情報を与えられるようにする #TODO: 有効なメールアドレスが与えられた場合の処理を実装する else flash.now[:danger] = "Email address not found" render 'new' end end def edit end endテストの結果は以下のようになります。
# rails test test/integration/password_resets_test.rb Running via Spring preloader in process 129 Started with run options --seed 13207 FAIL["test_password_resets", PasswordResetsTest, 2.7478716999994504] test_password_resets#PasswordResetsTest (2.75s) Expected nil to not be equal to nil. test/integration/password_resets_test.rb:19:in `block in <class:PasswordResetsTest>' 1/1: [===================================] 100% Time: 00:00:02, Time: 00:00:02 Finished in 2.74939s 1 tests, 4 assertions, 1 failures, 0 errors, 0 skips以下のテストが、「Expected nil to not be equal to nil」というメッセージを返して失敗しています。
test/integration/password_resets_test.rb(19行目)assert_not_equal @user.reset_digest, @user.reload.reset_digest
debuggerで確認したところ、@user.reset_digestと@user.reload.reset_digestのいずれもnilとなっていました。「現在のところreset_digestを実装していない」からでしょうか。ひとまずこの時点で確実なのは、「Userモデルに
reset_digest属性に対する正しい実装が必要である」ということです。
User#create_reset_digestメソッドの実装「Userモデルの
reset_digest属性に対する正しい実装」は、パスワード再設定全体の中では、以下の手順に関連しています。
- パスワード再設定用のトークンとダイジェストの組を生成する
- 生成されたパスワード再設定用ダイジェストをRDBに保存する
Railsチュートリアル本文においては、これら一連の処理について、
create_reset_digestメソッドとして定義されています。早速、当該メソッドと関連する実装を追加していきましょう。
Userモデルに
create_reset_digestメソッドと、関連する実装を追加するapp/models/user.rbclass User < ApplicationRecord - attr_accessor :remember_token, :activation_token + attr_accessor :remember_token, :activation_token, :reset_token ...略 + + # パスワード再設定の属性を設定する + def create_reset_digest + self.reset_token = User.new_token + update_attribute(:reset_digest, User.digest(reset_token)) + update_attribute(:reset_sent_at, Time.zone.now) + end private # メールアドレスをすべて小文字にする def downcase_email self.email.downcase! end # 有効化トークンとダイジェストを作成および代入する def create_activation_digest self.activation_token = User.new_token self.activation_digest = User.digest(activation_token) end endUserモデルに新たに追加した実装は以下です。
create_reset_digestメソッド
- パスワード再設定用トークンの生成
- 生成されたトークンに対するダイジェストのRDBへの保存
- パスワード再設定用トークンの生成日時のRDBへの保存
- 仮想属性
:reset_tokenに対するゲッターとセッターの追加PasswordResetsコントローラーで、
create_reset_digestメソッドを使うようにするapp/controllers/password_resets_controller.rbclass PasswordResetsController < ApplicationController def new end def create + @user = User.find_by(email: params[:password_reset][:email].downcase) - if false #TODO: 有効なユーザー情報を与えられるようにする + if @user - #TODO: 有効なメールアドレスが与えられた場合の処理を実装する + @user.create_reset_digest + # TODO:メール送信処理を実装する else flash.now[:danger] = "Email address not found" render 'new' end end def edit end endPasswordResetsコントローラーに新たに追加した実装は以下です。
@userを使わない仮実装を、@userを使う正式な実装に変更する@user.create_reset_digestにより、パスワード再設定用トークン・ダイジェストの生成が正しく行われるようにする
create_reset_digestメソッド、および、関連する実装を追加した時点でのテストの結果# rails test test/integration/password_resets_test.rb Running via Spring preloader in process 165 Started with run options --seed 26520 ERROR["test_password_resets", PasswordResetsTest, 3.3415248000001156] test_password_resets#PasswordResetsTest (3.34s) NameError: NameError: uninitialized constant PasswordResetsTest::Actionmailer test/integration/password_resets_test.rb:20:in `block in <class:PasswordResetsTest>' 1/1: [===================================] 100% Time: 00:00:03, Time: 00:00:03 Finished in 3.34828s 1 tests, 4 assertions, 0 failures, 1 errors, 0 skips今度は以下のテストがエラーを返して失敗するようになりました。
test/integration/password_resets_test.rb(20行目)assert_equal 1, Actionmailer::Base.deriveries.sizeメールの送信処理が実装されていないことが原因のようです。
なお、Railsチュートリアル本文中の演習 -
createアクションでパスワード再設定を行う場合、この時点で一旦実装を中断した上で演習を行っていきます。メールの送信処理の実装
「アプリケーションは、パスワード再設定用メールを作成し、フォームで指定されたメールアドレスに送信する」という処理の実装部分です。
Usersモデルに
send_password_reset_emailメソッドを追加するclass User < ApplicationRecord ...略 # 有効化用のメールを送信する def send_activation_email UserMailer.account_activation(self).deliver_now end # パスワード再設定の属性を設定する def create_reset_digest self.reset_token = User.new_token update_attribute(:reset_digest, User.digest(reset_token)) update_attribute(:reset_sent_at, Time.zone.now) end + + # パスワード再設定のメールを送信する + def send_password_reset_email + UserMailer.password_reset(self).deliver_now + end private # メールアドレスをすべて小文字にする def downcase_email self.email.downcase! end # 有効化トークンとダイジェストを作成および代入する def create_activation_digest self.activation_token = User.new_token self.activation_digest = User.digest(activation_token) end endパスワード再設定用のメールを送信するメソッドは、
send_password_reset_emailという名前で定義しています。…よくよく見ると、
send_activation_emailとsend_password_reset_emailのコードって似てますよね。後々リファクタリングの対象として出てくるかもしれません。PasswordResetsコントローラーで、
send_password_reset_emailメソッドを使うようにするclass PasswordResetsController < ApplicationController def new end def create @user = User.find_by(email: params[:password_reset][:email].downcase) if @user @user.create_reset_digest + @user.send_password_reset_email + #TODO: フラッシュメッセージの定義とルートへのリダイレクト else flash.now[:danger] = "Email address not found" render 'new' end end def edit end end# rails test test/integration/password_resets_test.rb Running via Spring preloader in process 191 Started with run options --seed 20579 ERROR["test_password_resets", PasswordResetsTest, 2.324982799999816] test_password_resets#PasswordResetsTest (2.33s) ArgumentError: ArgumentError: wrong number of arguments (given 1, expected 0) app/mailers/user_mailer.rb:8:in `password_reset' app/models/user.rb:61:in `send_password_reset_email' app/controllers/password_resets_controller.rb:9:in `create' test/integration/password_resets_test.rb:18:in `block in <class:PasswordResetsTest>' 1/1: [===================================] 100% Time: 00:00:02, Time: 00:00:02 Finished in 2.32883s 1 tests, 3 assertions, 0 failures, 1 errors, 0 skips
app/mailers/user_mailer.rbの8行目で、「引数の数が0でなければならないのに、実際には1つの引数が渡されている」というエラーでテストが失敗しています。app/mailers/user_mailer.rb(8行目)def password_reset今度はパスワード再設定用のメイラーメソッドを定義する必要がありそうですね。
パスワード再設定用のメイラーメソッド
password_resetにおいて、引数の定義を変更するまずは、現在のテストの失敗原因として指摘されている「引数の数が足りない」という問題を解決します。
class UserMailer < ApplicationMailer def account_activation(user) @user = user mail to: user.email, subject: "Account activation" end - def password_reset + def password_reset(user) - @greeting = "Hi" - - mail to: "to@example.org" end end
password_resetの引数の定義を変更した時点でのテストの結果# rails test test/integration/password_resets_test.rb Running via Spring preloader in process 232 Started with run options --seed 65406 ERROR["test_password_resets", PasswordResetsTest, 2.472823599999174] test_password_resets#PasswordResetsTest (2.47s) NameError: NameError: uninitialized constant PasswordResetsTest::Actionmailer test/integration/password_resets_test.rb:20:in `block in <class:PasswordResetsTest>' 1/1: [===================================] 100% Time: 00:00:02, Time: 00:00:02 Finished in 2.47449s 1 tests, 4 assertions, 0 failures, 1 errors, 0 skips(byebug) Actionmailer::Base.deriveries.size *** NameError Exception: uninitialized constant PasswordResetsTest::Actionmailer nil
debuggerで調べたところ、「uninitialized constant PasswordResetsTest::Actionmailer」というのは、「Actionmailer::Base.deriveries.sizeが初期化されていないこと」が原因で発生しているようです。「password_resetメソッドの実効的な定義と、テキストメール・HTMLメールそれぞれのテンプレートが必要になる」ということでしょうか。
password_resetメソッドの実効的な定義と、テキストメール・HTMLメールそれぞれのテンプレート
password_resetメソッドの実効的な定義app/mailers/user_mailer.rbclass UserMailer < ApplicationMailer def account_activation(user) @user = user mail to: user.email, subject: "Account activation" end def password_reset(user) + @user = user + mail to: user.email, subject: "Password reset" end end
password_resetメソッドの実効的な定義には、以下の内容が含まれます。
- メール本文中で使用する
@userの内容- メールの宛先と題名
テキストメールのテンプレート
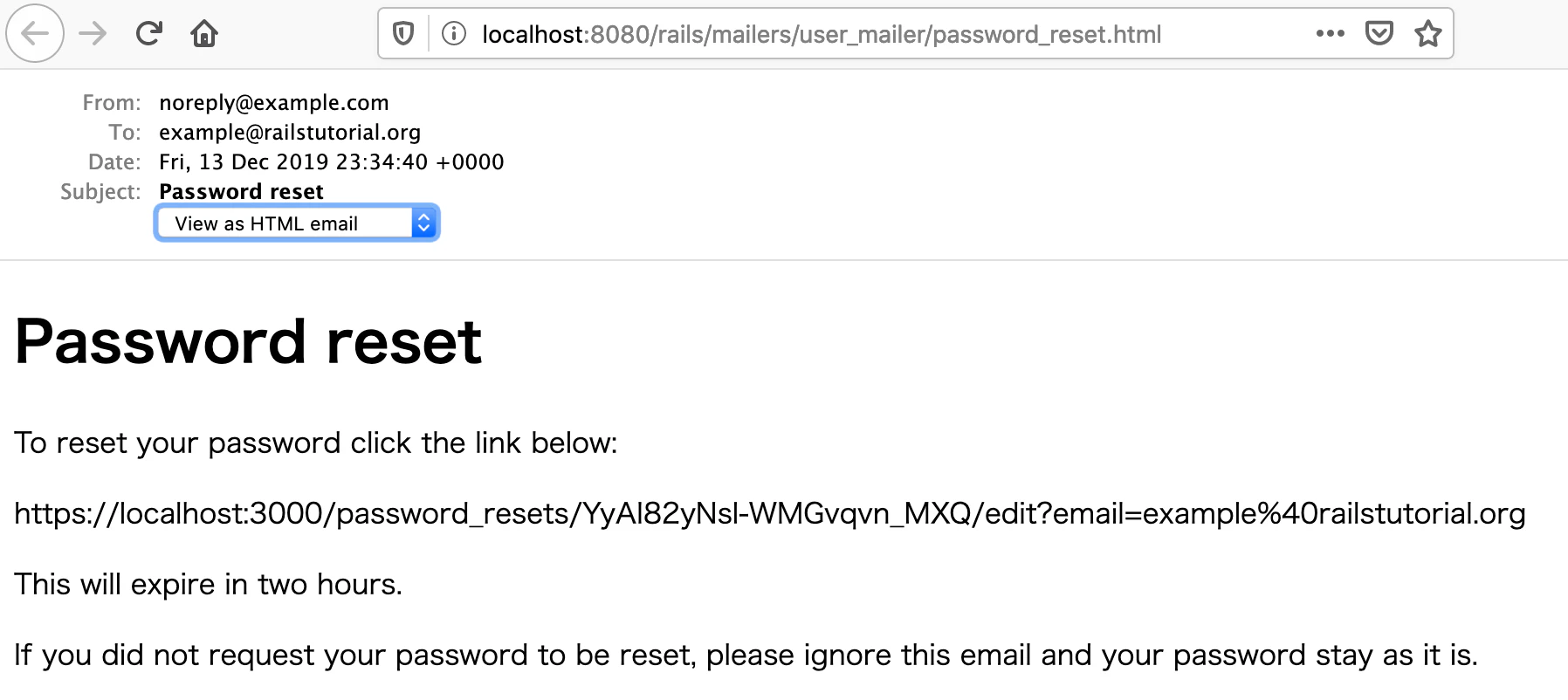
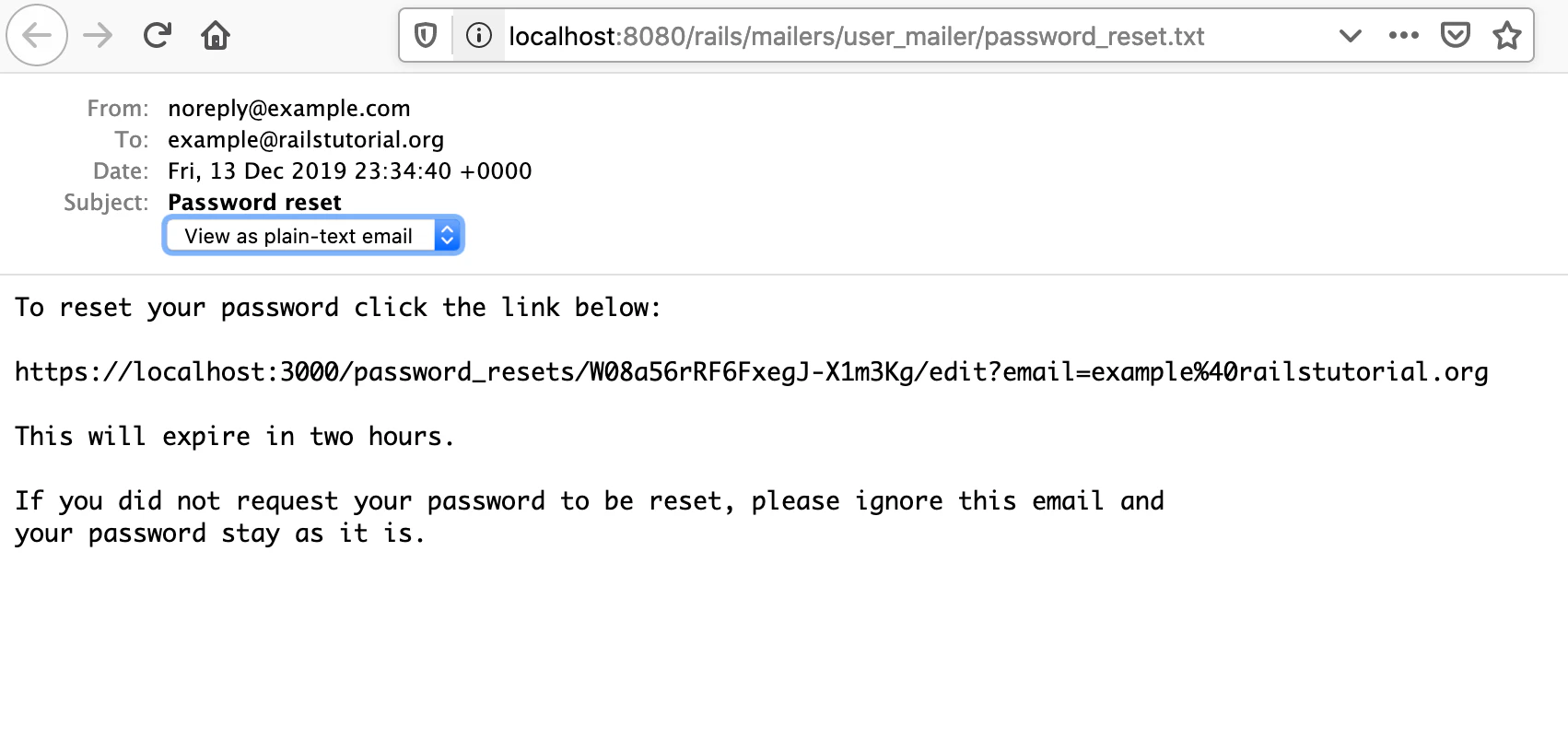
app/views/user_mailer/password_reset.text.erbTo reset your password click the link below: <%= edit_password_reset_url(@user.reset_token, email: @user.email) %> This will expire in two hours. If you did not request your password to be reset, please ignore this email and your password stay as it is.HTMLメールのテンプレート
test/mailers/previews/user_mailer_preview.rb<h1>Password reset</h1> <p>To reset your password click the link below:</p> <%= edit_password_reset_url(@user.reset_token, email: @user.email) %> <p>This will expire in two hours.</p> <p> If you did not request your password to be reset, please ignore this email and your password stay as it is. </p>パスワード再設定メールのプレビュー
パスワード再設定メールをプレビューできるようにする
パスワード再設定メールをプレビューできるようにするために、
test/mailers/previews/user_mailer_preview.rbの内容を書き換えていきます。test/mailers/previews/user_mailer_preview.rb# Preview all emails at http://localhost:8080/rails/mailers/user_mailer class UserMailerPreview < ActionMailer::Preview # Preview this email at http://localhost:8080/rails/mailers/user_mailer/account_activation def account_activation user = User.first user.activation_token = User.new_token UserMailer.account_activation(user) end # Preview this email at http://localhost:8080/rails/mailers/user_mailer/password_reset def password_reset - UserMailer.password_reset + user = User.first + user.reset_token = User.new_token + UserMailer.password_reset(user) end endパスワード再設定メールをプレビューする
ここまでの実装が完了すれば、
test/mailers/previews/user_mailer_preview.rbのコメント中に書かれたURLから、パスワード再設定用メールをプレビューすることができるようになります。なお、事前に
rails serverでサーバーを起動しておく必要があります。下記はHTMLメールのプレビューです。
下記はテキストメールのプレビューです。
メール送信処理を実装した時点でのテストの結果
メール送信処理を実装した時点でのテストの結果は、以下のようになります。
# rails test test/integration/password_resets_test.rb Running via Spring preloader in process 528 Started with run options --seed 12354 FAIL["test_password_resets", PasswordResetsTest, 4.604623200000788] test_password_resets#PasswordResetsTest (4.60s) Expected true to be nil or false test/integration/password_resets_test.rb:23:in `block in <class:PasswordResetsTest>' 1/1: [===================================] 100% Time: 00:00:04, Time: 00:00:04 Finished in 4.61010s 1 tests, 7 assertions, 1 failures, 0 errors, 0 skips私の環境では、
test/integration/password_resets_test.rbの23行目には以下の記述があります。test/integration/password_resets_test.rb(23行目)assert_not flash.empty?のフラッシュメッセージが定義されていないことに起因する失敗ですね。
メール送信成功時のフラッシュメッセージを追加する
メール送信成功時のフラッシュメッセージの実装を、
app/controllers/password_resets_controller.rbに追加していきます。app/controllers/password_resets_controller.rbclass PasswordResetsController < ApplicationController def new end def create @user = User.find_by(email: params[:password_reset][:email].downcase) if @user @user.create_reset_digest @user.send_password_reset_email + flash[:info] = "Email sent with password reset instructions" else flash.now[:danger] = "Email address not found" render 'new' end end def edit end endメール送信成功時のフラッシュメッセージを追加した時点でのテストの結果
# rails test test/integration/password_resets_test.rb Running via Spring preloader in process 541 Started with run options --seed 23162 FAIL["test_password_resets", PasswordResetsTest, 4.58620990000054] test_password_resets#PasswordResetsTest (4.59s) Expected response to be a <3XX: redirect>, but was a <204: No Content> Response body: test/integration/password_resets_test.rb:24:in `block in <class:PasswordResetsTest>' 1/1: [===================================] 100% Time: 00:00:04, Time: 00:00:04 Finished in 4.59156s 1 tests, 8 assertions, 1 failures, 0 errors, 0 skips私の環境では、
test/integration/password_resets_test.rbの24行目には以下の記述があります。test/integration/password_resets_test.rb(24行目)assert_redirected_to root_url「/ へリダイレクトされるべきところ、リダイレクトされていない」という失敗ですね。
メール送信成功時の処理に、/ へのリダイレクトを追加する
パスワード再設定用メールの送信が成功した場合、
PasswordResetsController#createアクションの最後は / へのリダイレクトで終了します。ここで / へのリダイレクトを追加します。app/controllers/password_resets_controller.rbclass PasswordResetsController < ApplicationController def new end def create @user = User.find_by(email: params[:password_reset][:email].downcase) if @user @user.create_reset_digest @user.send_password_reset_email flash[:info] = "Email sent with password reset instructions" + redirect_to root_url else flash.now[:danger] = "Email address not found" render 'new' end end def edit end end/ へのリダイレクトを追加した時点でのテストの結果
# rails test test/integration/password_resets_test.rb Running via Spring preloader in process 554 Started with run options --seed 2662 1/1: [===================================] 100% Time: 00:00:03, Time: 00:00:03 Finished in 3.55053s 1 tests, 8 assertions, 0 failures, 0 errors, 0 skipsついにテストが成功しました。これにて、「有効なメールアドレスが与えられた際における、
PasswordResetsController#createの実装」ならびに「PasswordResetsController#createの実装全体」が完了となりました。現在までのテストが成功した時点における、パスワード再設定メールの送信用フォームに有効なメールアドレスを入力してSubmitボタンを押したときの挙動
まず、/password_resets に対して
POSTリクエストが送出され、PasswordResetsコントローラーのcreateメソッドが開始されます。Started POST "/password_resets" for 172.17.0.1 at 2019-12-14 06:09:11 +0000 Cannot render console from 172.17.0.1! Allowed networks: 127.0.0.1, ::1, 127.0.0.0/127.255.255.255 Processing by PasswordResetsController#create as HTML Parameters: {"utf8"=>"✓", "authenticity_token"=>"0tty+a/E7Mp+BqIOZDaOGJQ2fH43di2VEeR3RaA9VC9MpoIb9a3BwgBNauyHYe4nBN1XC5M1TVglcsCUFNdAEQ==", "password_reset"=>"[FILTERED]", "commit"=>"Submit"} User Load (8.2ms) SELECT "users".* FROM "users" WHERE "users"."email" = ? LIMIT ? [["email", "example-2@railstutorial.org"], ["LIMIT", 1]] (0.1ms) begin transaction SQL (14.0ms) UPDATE "users" SET "reset_digest" = ?, "updated_at" = ? WHERE "users"."id" = ? [["reset_digest", "$2a$10$vD1xJCRoVswPj2qHsJD81OLCO3e/aviIRNCamE6OWi8TUkkG6HytS"], ["updated_at", "2019-12-14 06:09:11.878637"], ["id", 3]] (11.2ms) commit transaction (0.1ms) begin transaction SQL (15.4ms) UPDATE "users" SET "updated_at" = ?, "reset_sent_at" = ? WHERE "users"."id" = ? [["updated_at", "2019-12-14 06:09:11.916190"], ["reset_sent_at", "2019-12-14 06:09:11.912111"], ["id", 3]] (14.7ms) commit transaction Rendering user_mailer/password_reset.html.erb within layouts/mailer Rendered user_mailer/password_reset.html.erb within layouts/mailer (1.0ms) Rendering user_mailer/password_reset.text.erb within layouts/mailer Rendered user_mailer/password_reset.text.erb within layouts/mailer (0.7ms) UserMailer#password_reset: processed outbound mail in 294.4ms以下のはパスワード再設定用メールのヘッダー部分です。
Sent mail to example-2@railstutorial.org (3.5ms) Date: Sat, 14 Dec 2019 06:09:12 +0000 From: noreply@example.com To: example-2@railstutorial.org Message-ID: <5df47c883f6f2_1c62ac8ce76084c8706b@705320d4d96d.mail> Subject: Password reset Mime-Version: 1.0 Content-Type: multipart/alternative; boundary="--==_mimepart_5df47c883e93a_1c62ac8ce76084c8691f"; charset=UTF-8 Content-Transfer-Encoding: 7bit以下のログはテキスト形式のパスワード再設定用メールの内容です。
----==_mimepart_5df47c883e93a_1c62ac8ce76084c8691f Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: 7bit To reset your password click the link below: https://localhost:3000/password_resets/bbZxxIr2r21HmbfMzsKevA/edit?email=example-2%40railstutorial.org This will expire in two hours. If you did not request your password to be reset, please ignore this email and your password stay as it is.以下のログはHTML形式のパスワード再設定用メールの内容です。
----==_mimepart_5df47c883e93a_1c62ac8ce76084c8691f Content-Type: text/html; charset=UTF-8 Content-Transfer-Encoding: 7bit <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <style> /* Email styles need to be inline */ </style> </head> <body> <h1>Password reset</h1> <p>To reset your password click the link below:</p> https://localhost:3000/password_resets/bbZxxIr2r21HmbfMzsKevA/edit?email=example-2%40railstutorial.org <p>This will expire in two hours.</p> <p> If you did not request your password to be reset, please ignore this email and your password stay as it is. </p> </body> </html> ----==_mimepart_5df47c883e93a_1c62ac8ce76084c8691f--パスワード再設定用メールの内容についてのログは以上です。
Redirected to http://localhost:8080/ Completed 302 Found in 477ms (ActiveRecord: 63.7ms)/password_resets に対する
POSTリクエスト(すなわちPasswordResetsコントローラーのcreateアクション)が、「302 FOUND」というステータスコードを返し、/ に対するリダイレクトによって完了しました。以降は、リダイレクト後の、/ に対する
GETリクエストのログです。Started GET "/" for 172.17.0.1 at 2019-12-14 06:09:12 +0000 Cannot render console from 172.17.0.1! Allowed networks: 127.0.0.1, ::1, 127.0.0.0/127.255.255.255 Processing by StaticPagesController#home as HTML Rendering static_pages/home.html.erb within layouts/application Rendered static_pages/home.html.erb within layouts/application (18.3ms) Rendered layouts/_rails_default.erb (220.1ms) Rendered layouts/_shim.html.erb (0.4ms) Rendered layouts/_header.html.erb (1.0ms) Rendered layouts/_footer.html.erb (0.7ms) Completed 200 OK in 377ms (Views: 359.5ms | ActiveRecord: 0.0ms)/ の描画が、「200 OK」というステータスコードとともに正常に完了していますね。
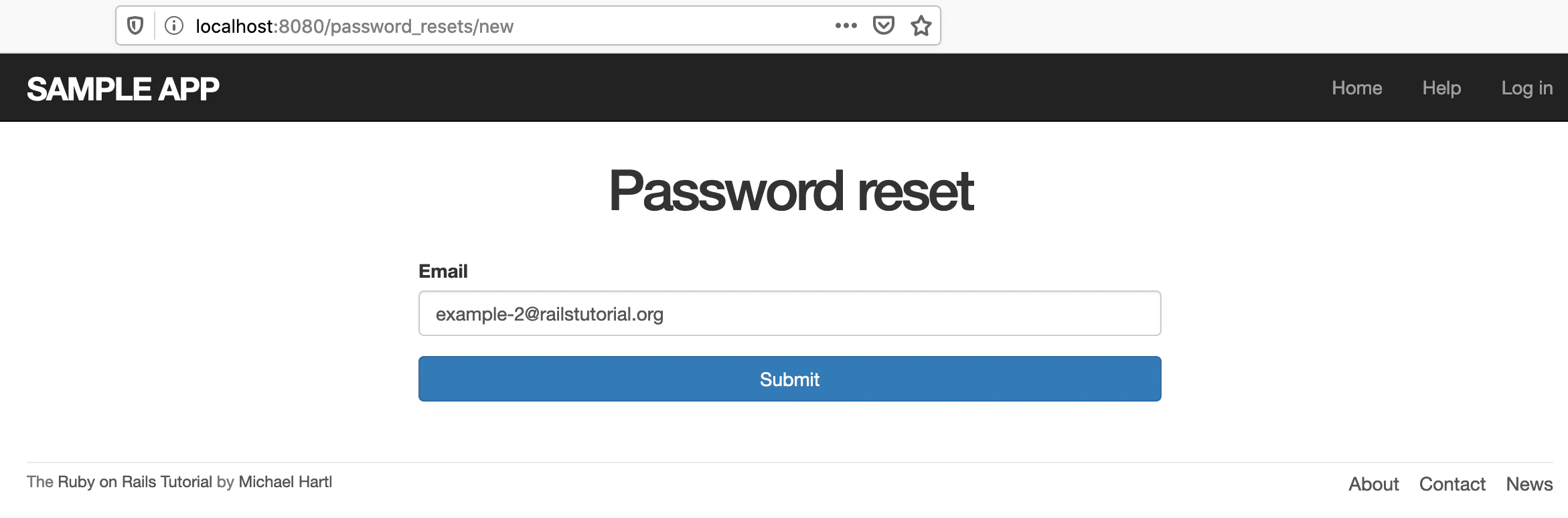
実際にWebブラウザでパスワード再設定メールの送信用フォームにSubmitしてみる
まずは、パスワード再設定メールの送信用フォームを表示します。
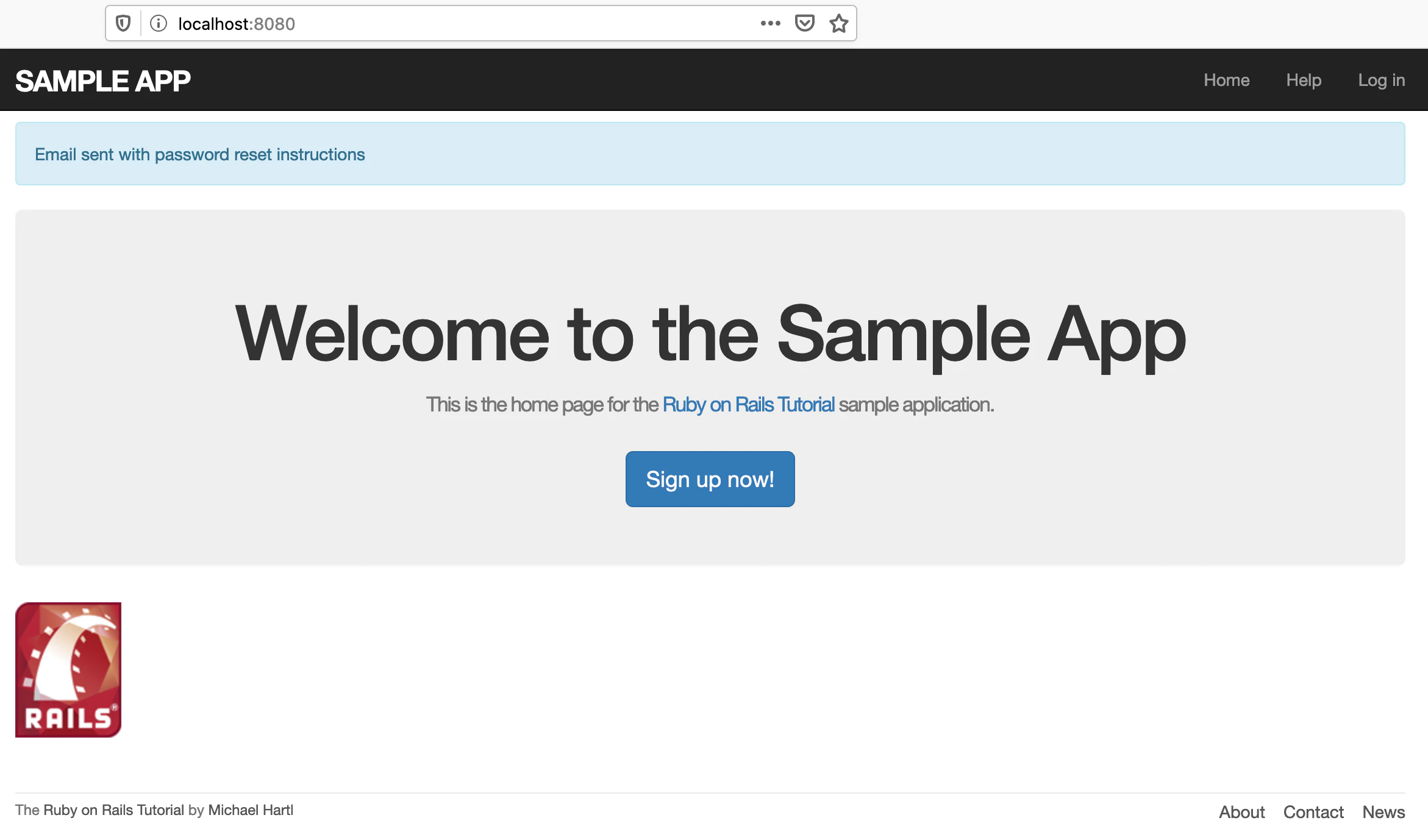
有効なメールアドレスを入力し、「Submit」ボタンを押すと、以下の画面が表示されます。
確かに「Email sent with password reset instructions」というフラッシュメッセージが表示されていますね。
- 投稿日:2019-12-14T17:11:40+09:00
懇親会での障害対応はもうこりごり!�JMeterを使ったRailsアプリの負荷テストの流れ
これは Money Forward Advent Calendar 2019 ? 14日目の記事です。
こんにちは! @machisukeです。
マネーフォワードでは、半年に1回全社員集まっての半期総会を開催しています。
そして昨日、2019年12月13日がちょうど半期総会でした。半期総会後の全社懇親会
で、僕たちマネーフォワード新卒はあるリベンジを果たそうとしていました

もうサーバーは落とさない。
今年6月に開催された半期総会で、僕たちは懇親会のコンテンツとして「MFクイズダービー」を担当しました。
スマホを使ってリアルタイムに順位が発表されるという内容に大盛り上がりでコンテンツはスタート。
会場の盛り上がりを見た僕たちは、作った甲斐があったなあと安堵していました。しかしその直後に事件は起きます。300名を超える参加者にサーバーが耐えきれず、途中でシステムが止まっていたのです。詳細は弊社のエンジニアブログ「新卒が社内懇親会アプリを開発したら、障害対応まで経験できた話」をぜひ読んでみてください。このままでは終われないと、半年後の全社懇親会でのリベンジを心に決めました。
リベンジの過程で、僕は負荷テストを実施し、その時使った「JMeter」がとても便利で面白かったので、皆さんに手順を共有したいと思います。
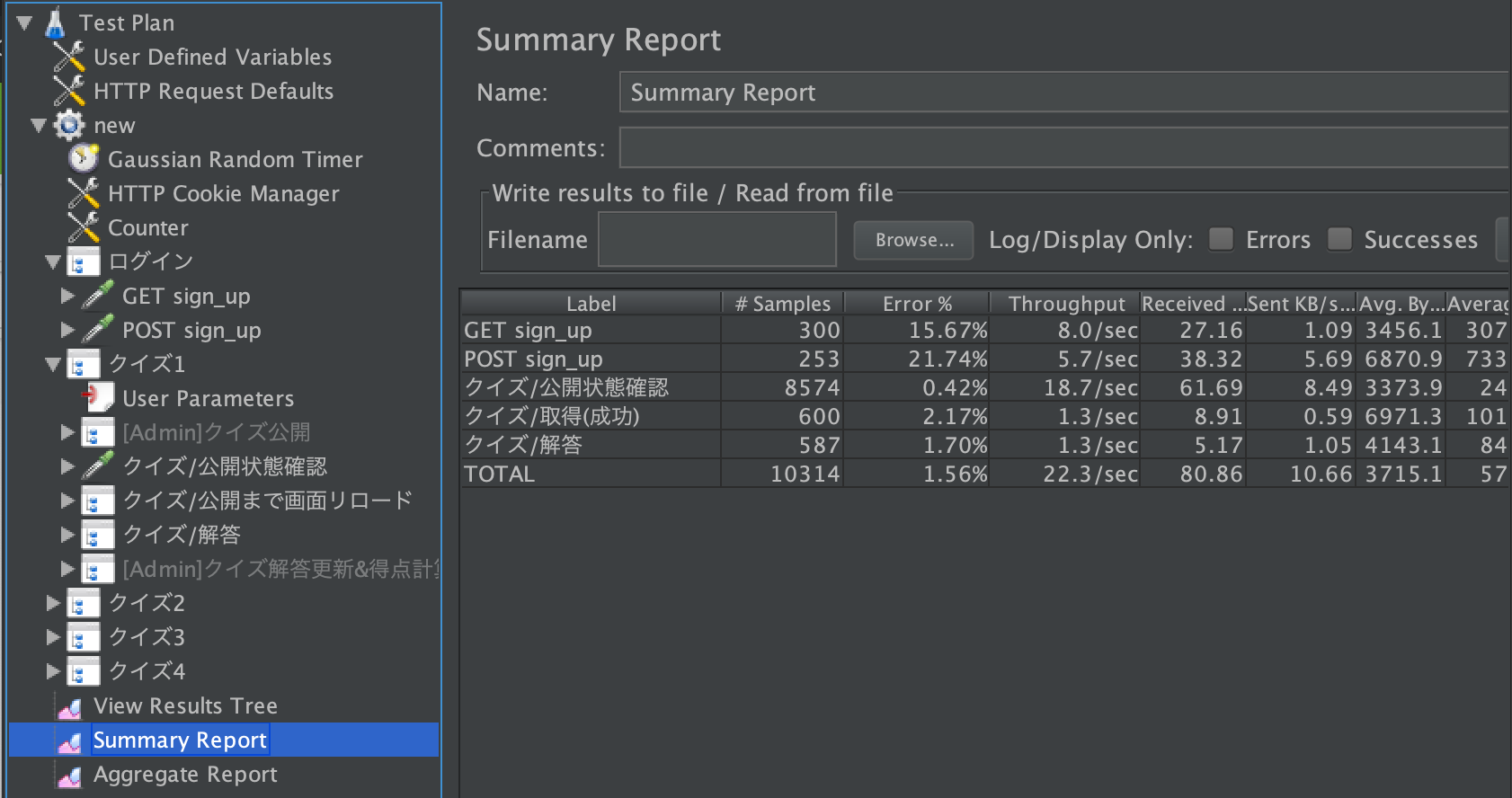
(※ちなみに、今回の懇親会が成功したのかどうかは誰かがブログを書くと思うので楽しみに待ちましょう。)JMeter上でのテスト計画と結果のイメージ
このような感じで、JMeterを使ってクイズの参加登録(sign_up)、クイズ取得、クイズ回答などが正しく動作しているか検証できます。本番は50チームで行いますが、テストは300チームで行いました。
Railsアプリの負荷テストに挑戦してみよう

今回は負荷テストを検証するアプリケーションとしてRailsチュートリアルで作成するSampleAppを拝借したいと思います。
SampleAppはTwitterのように「Micropost」を投稿するサービスです。30ユーザーを同時アクセスさせ、1秒あたり1投稿させても、アプリは落ちることなく動き続けるでしょうか!?
SampleAppの画面

環境
- Mac OS Mojave
- JMeter 5.2.1
- ruby 2.6.5
- rails 5.1.2 (sample_appの最新版に合わせました)
手順
1. jmeterインストール
$ brew install jmeter2. Railsアプリケーションの起動
$ git clone https://github.com/yasslab/sample_apps.git $ cd sample_apps/5_1_2/ch14 $ bundle install $ bundle exec rails db:create $ bundle exec rails db:migrate今回はメール認証を強制的にスキップするため、app/controllers/users_controller.rbに変更を加えます。
①、②の変更を行ってください。app/controllers/users_controller.rb# POST /users def create @user = User.new(user_params) if @user.save # => Validation # Sucess # ①↓コメントアウト #@user.send_activation_email # ②↓追加 @user.activate flash[:info] = "Please check your email to activate your account." redirect_to root_url else # Failure render 'new' end end起動
$ bundle exec rails shttp://localhost:3000 にアクセスすると画面が開かれるはずです。
3. JMeter起動
$ jmeter
HTTP Request Defaults作成
Test Plan 右クリック > Add > Config Element > HTTP Request Defaults
起動しているサーバーのアクセス情報を入れます。
Thread Gropu(ユーザーグループ)の作成
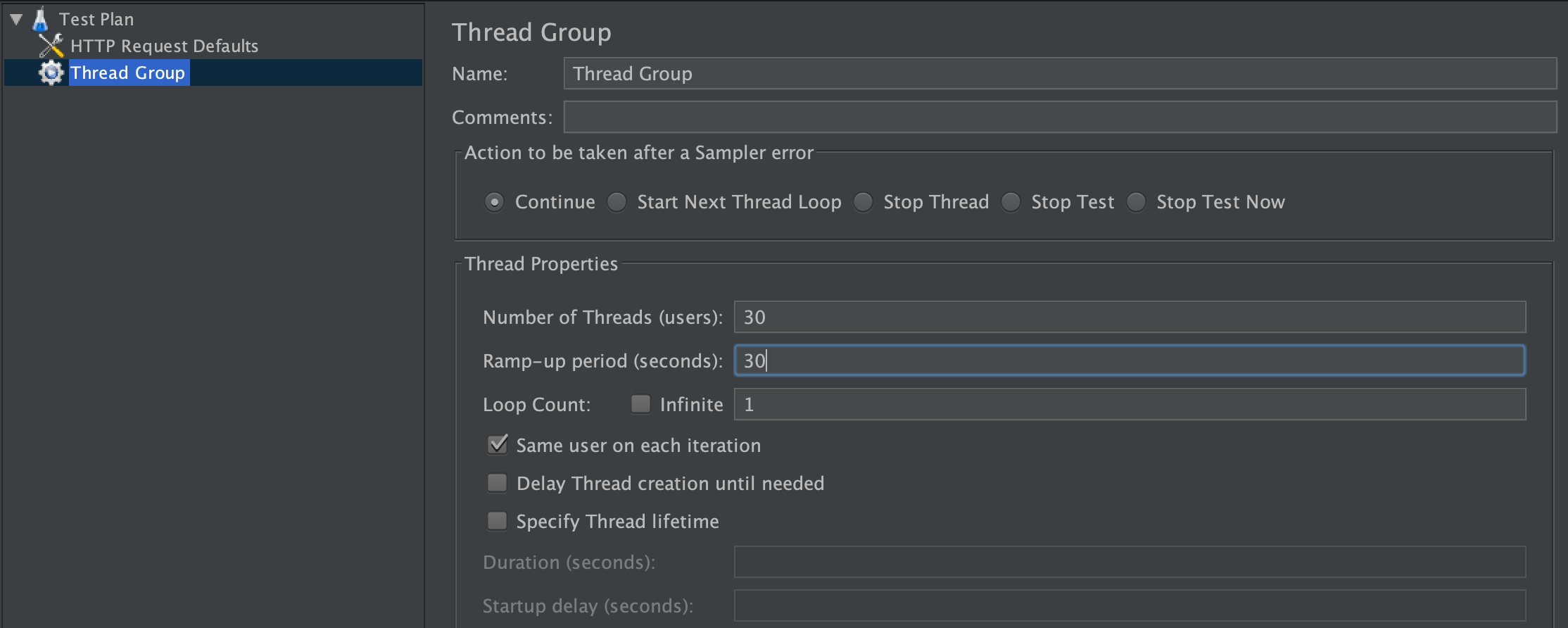
Test Plan 右クリック > Add > Threads (Users) -> Thread Group
同時にアクセスするユーザー数を適当に決めます。
今回は、30人のユーザーが30秒の間に操作を開始するという設定にします。
ユーザ毎に登録内容を変える準備
i番目のユーザーは
name: name_i email: name_i@example.com password: password_iとしましょう。
Test Plan 右リクック > Add > Config Elemennt > Counter
coutnerという変数名で取得できるようにします。
4. JMeterでユーザー登録、ログインさせる
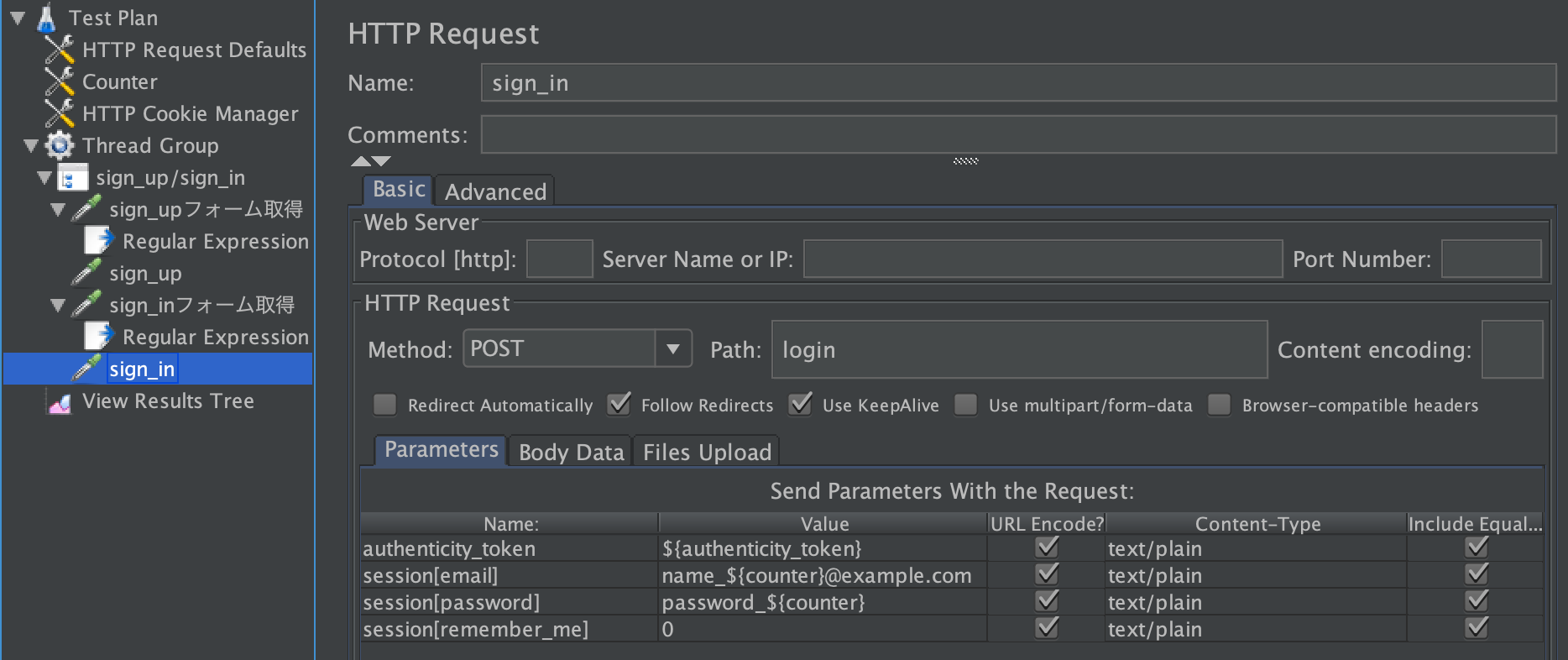
ユーザー登録・ログインのリクエストをグルーピングする
Thread Group 右クリック > Add > Logic Controller > Simple Controller名前は
sign_up/sign_inにします
ユーザー登録(sign_up)フォームの取得
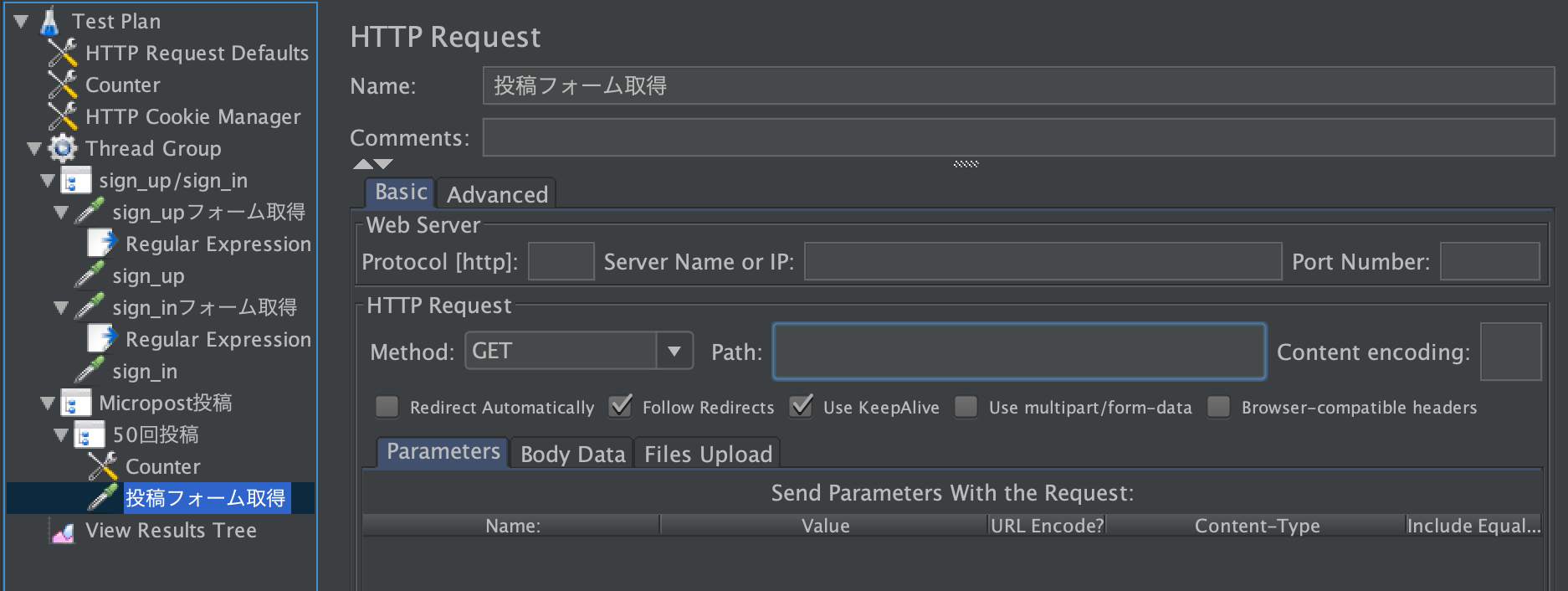
sign_up/sign_in 右クリック > Add > Sampler > HTTP Request名前は
sign_upフォーム取得にします。
sign_upフォームが表示されるURLは
http://localhost:3000/signupなので、Pathにsignupを入力します
正しくリクエストできているか検証
Test Plan 右クリック > Add > Listener > View Results Treeを追加JMeterの上側の緑色の三角ボタンを押してテストをスタートするとリクエスト結果が出ます。
AuthenticityTokenの取得
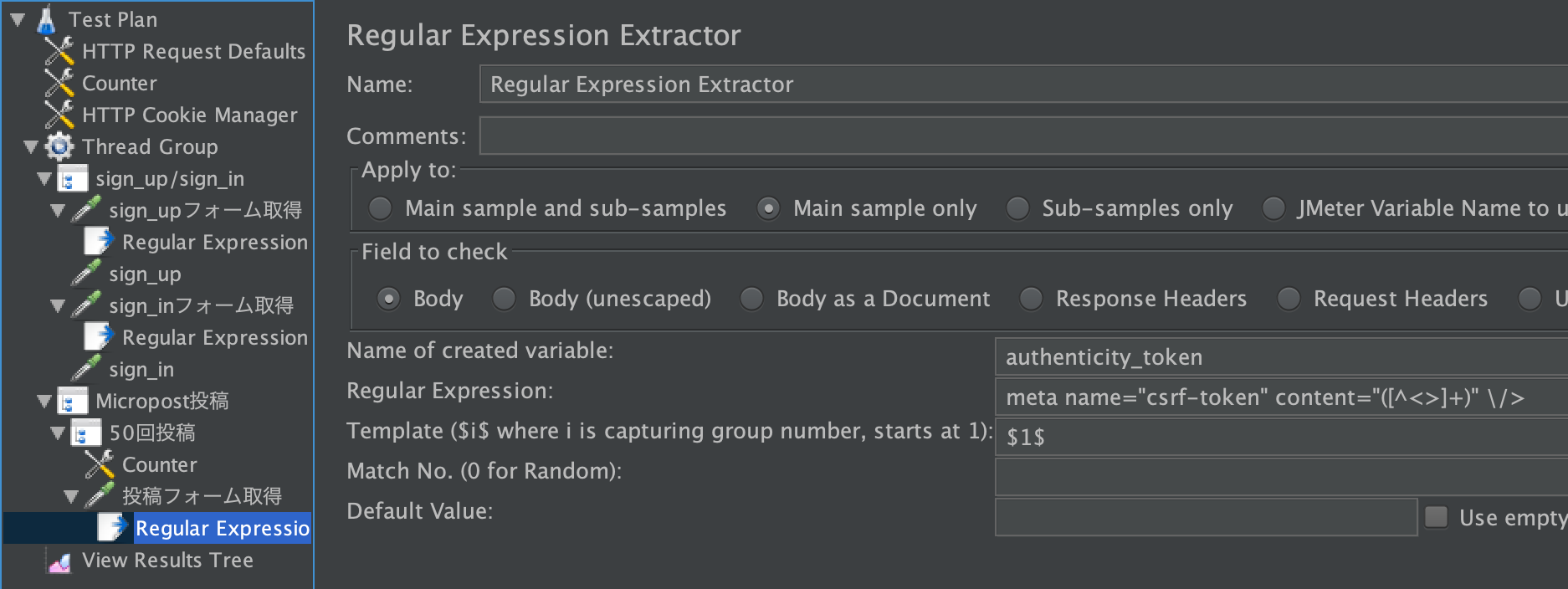
今回使うRailsアプリはCSRF対策が施されているので、AuthenticityTokenをリクエストパラメーターに含める必要があります。
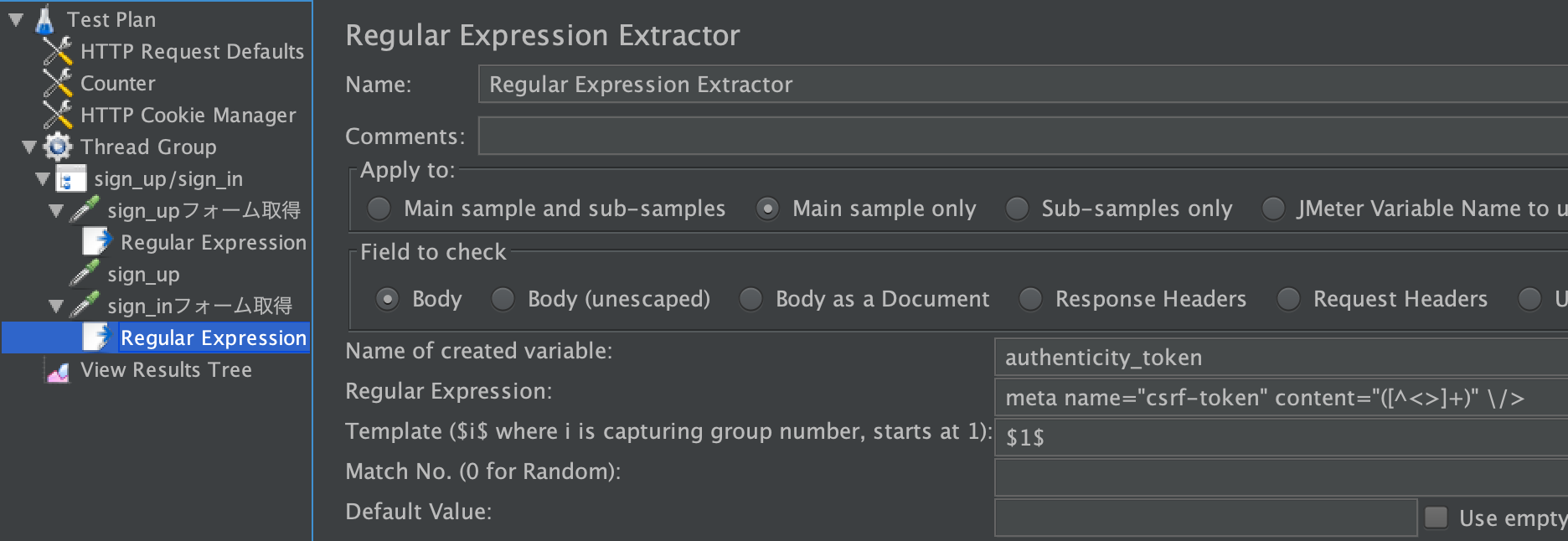
AuthenticityTokenは、「登録フォーム取得」のレスポンスに含まれています。これは、Regular Expression Extractorで抜き出します。
sign_upフォーム取得 右クリック > Add > Post Processors > Regular Expression Extractor
tokenを正規表現でキャプチャして、authenticity_tokenという変数に代入します。
ユーザー登録
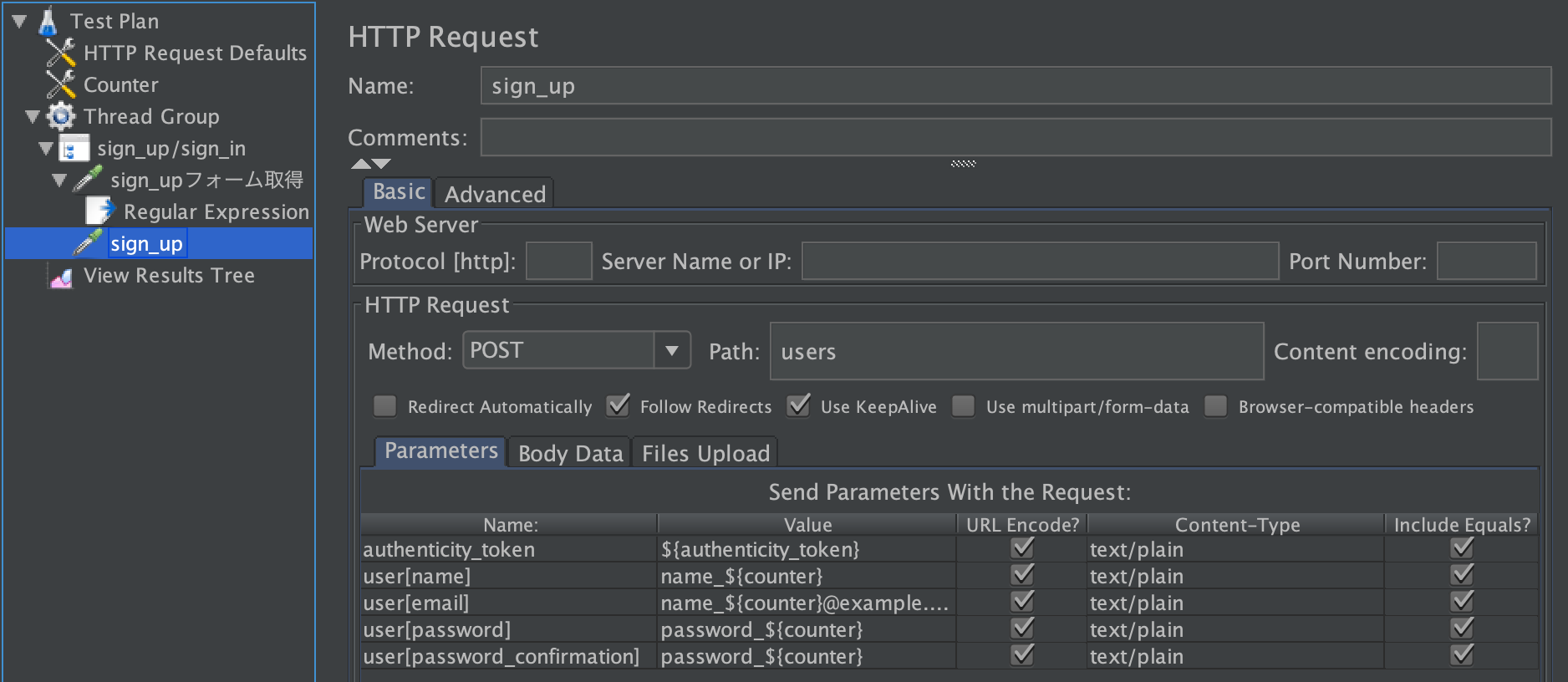
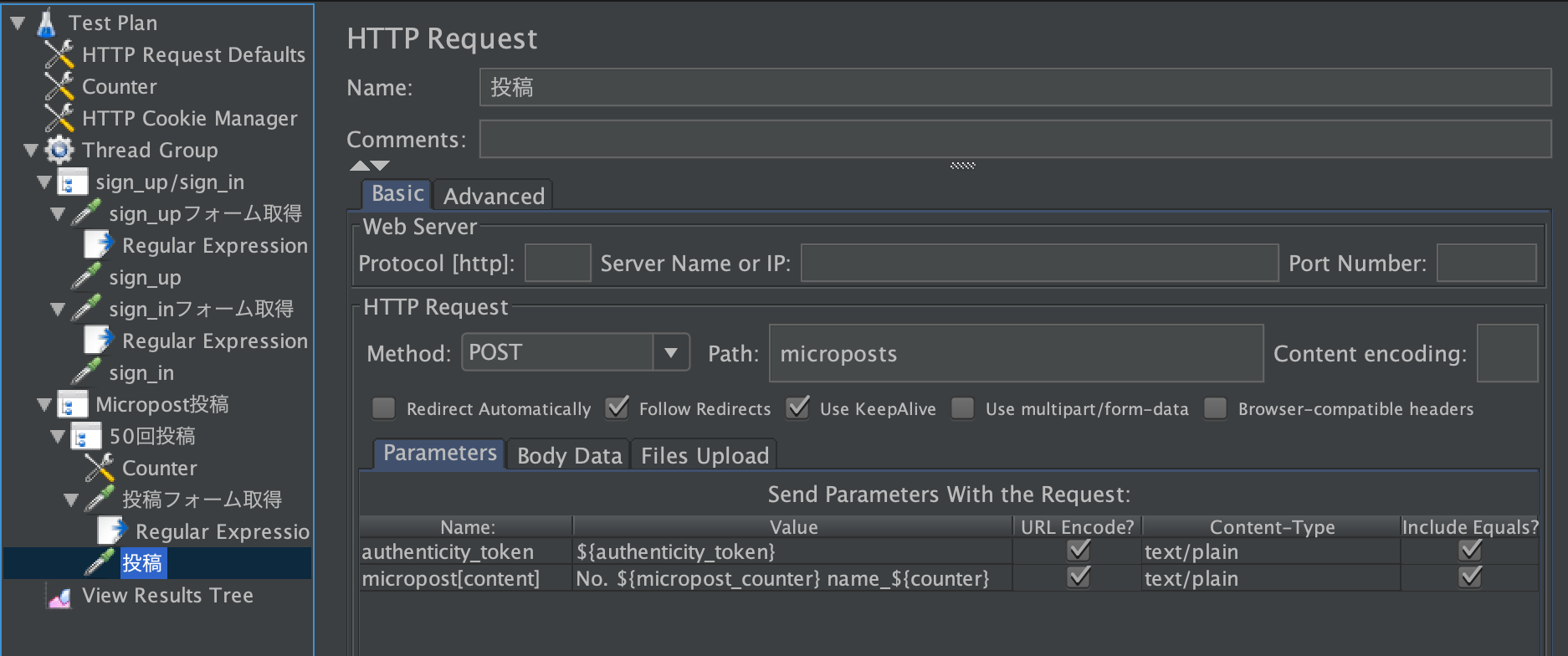
sign_up/sign_in 右クリック > Add > Sampler > HTTP Request
名前はsign_upにします。
urlencodeにチェック入れるのを忘れないようにしましょう。
ログイン状態を保持できるようにする(Cookie)
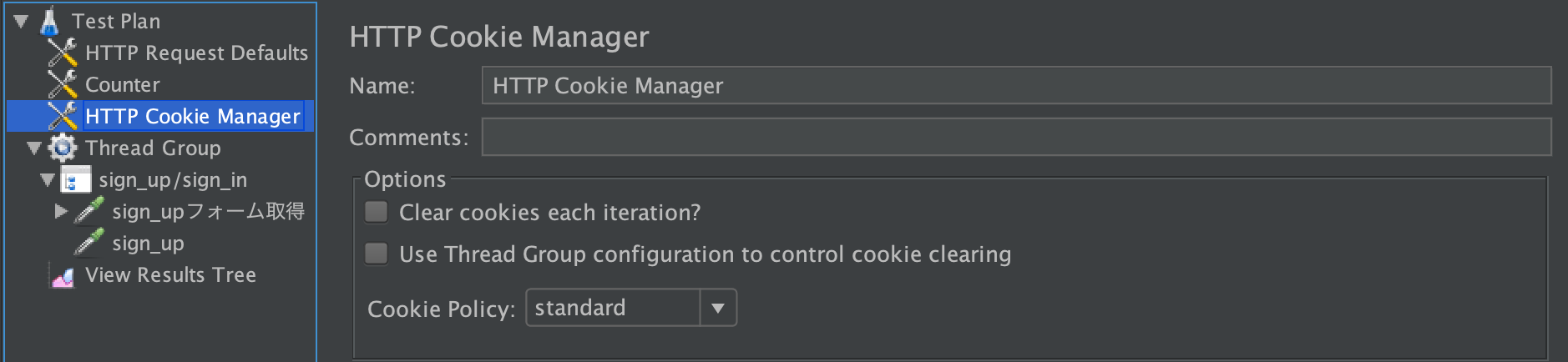
Test Plan 右クリック > Add > Config Element > HTTP Cookie Manager追加するだけでOKです。
ログイン
登録同様、下記の手順を行います。
- フォーム取得
- authenticity_token抜き出し
- ログイン
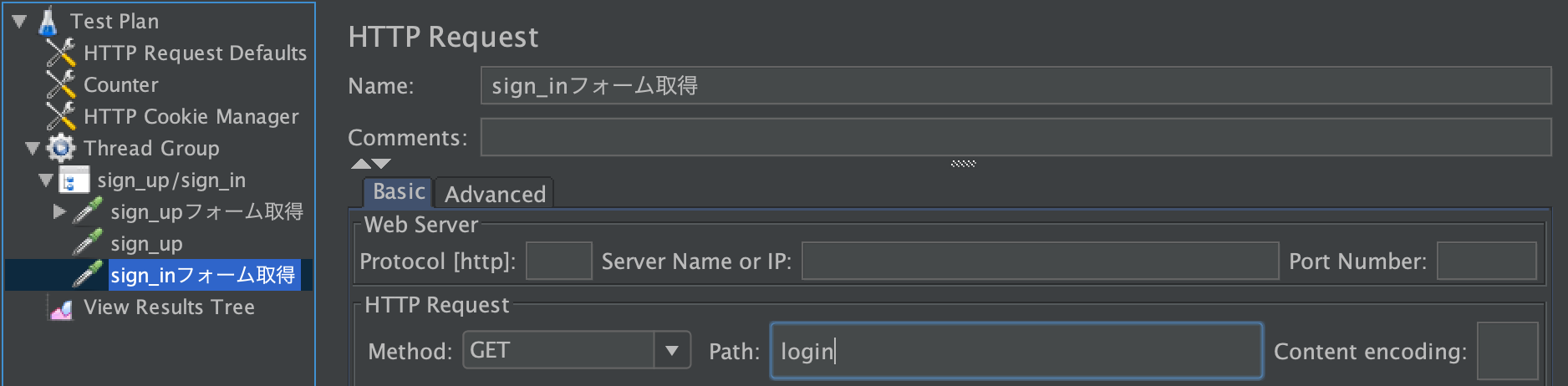
sign_up/sign_in 右クリック > Add > Sampler > HTTP Request
名前はsign_inフォーム取得にします。
sign_inフォーム取得 右クリック > Add > Post Processors > Regular Expression Extractor
tokenを正規表現でキャプチャして、authenticity_tokenという変数に代入します。
sign_up/sign_in 右クリック > Add > Sampler > HTTP Request
名前はsign_inにします。
試しにログインしてみる
ブラウザで
http://localhost:3000/loginを開き、適当なユーザーでログインして、http://localhost:3000/usersにアクセスしてみる。ユーザーが作られているのがわかりますね。
※テストを実行すると、ユーザーが登録されてDBに保存されます。
テストの度にDBをリセットするとユーザー登録から正しくテストを行うことができます。$ bundle exec rails db:migrate:reset5. 各ユーザーに、Micropost(Tweet)を50件登録させる
sign_in/sign_up同様、下記の手順でMicropostを投稿します。
- フォーム取得
- authenticity_token抜き出し
- 登録
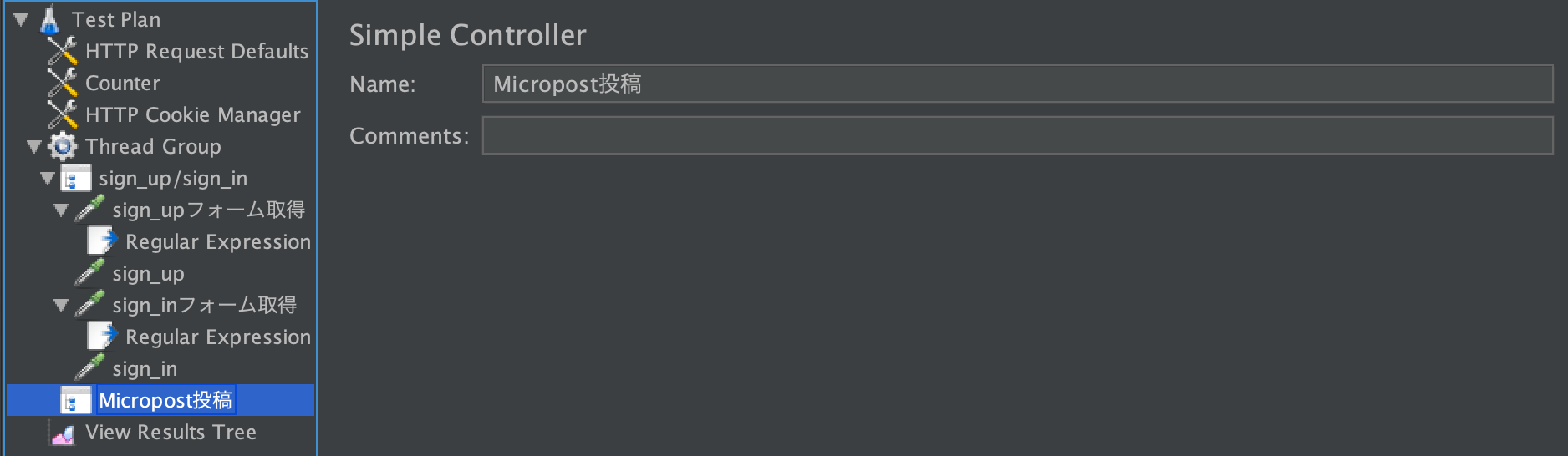
投稿リクエストをグルーピングする
Thread Group 右クリック > Add > Logic Controller > Simple Controller名前は
Micropost投稿にします
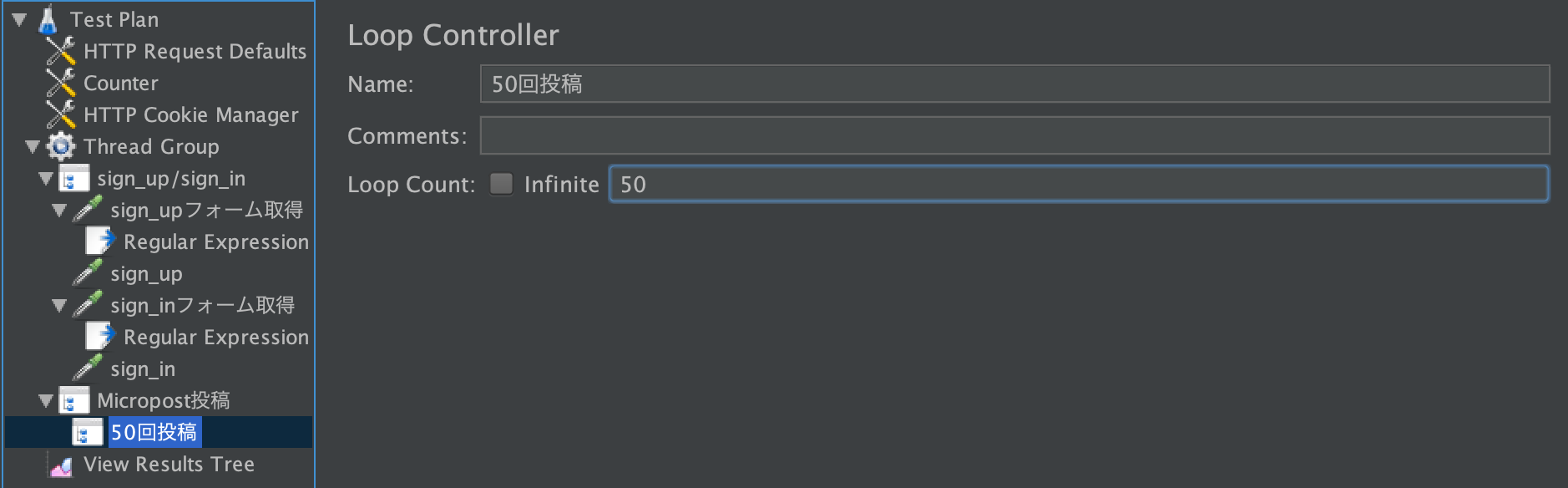
さらに
Thread Group 右クリック > Add > Logic Controller > Loop Controller名前は
50回投稿にします
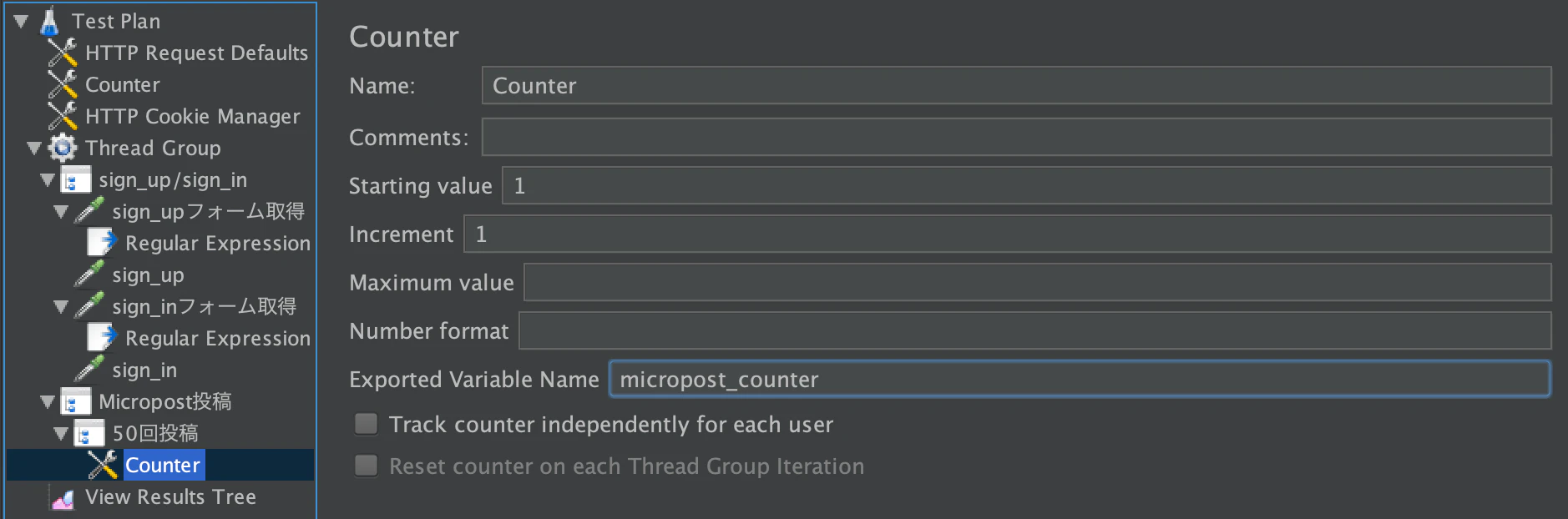
投稿ごとにメッセージを分けるための変数を用意
50回投稿 右リクック > Add > Config Element > Counter
micropost_coutnerという変数名で取得できるようにします。
投稿フォーム取得
50回投稿 右クリック > Add > Sampler > HTTP Request
名前は投稿フォーム取得にします。
URLはhttp://localhost:3000なので、pathは何も入力しません。
AuthenticityToken取得
投稿フォーム取得 右クリック > Add > Post Processors > Regular Expression Extractor
tokenを正規表現でキャプチャして、authenticity_tokenという変数に代入します。
投稿
50回投稿 右クリック > Add > Sampler > HTTP Request
名前は投稿にします。
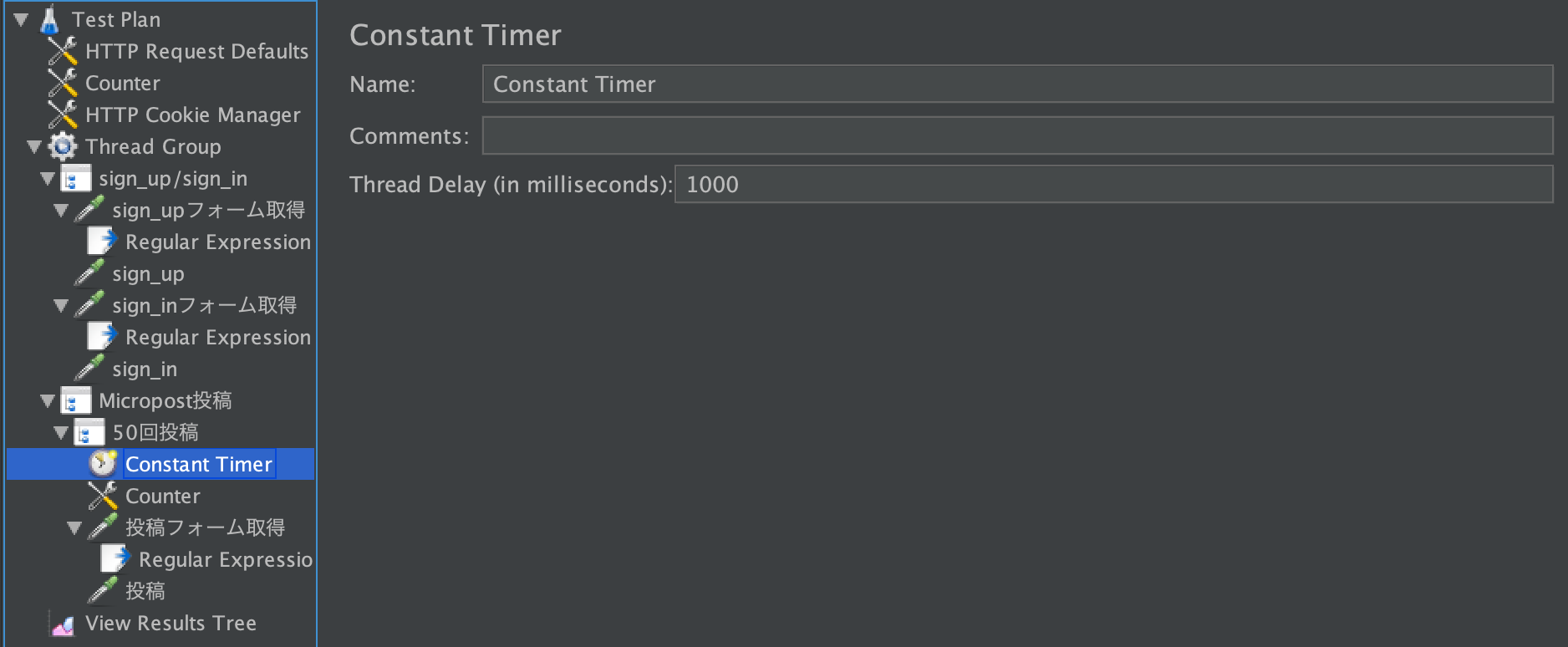
投稿間隔の調整
50回投稿 右クリック > Add > Timer > Constant Timer
投稿間隔を一人につき、1秒1回に調整します。
6. Listener(レポート機能)の設定
テストが終わるまでのレスポンスタイムの遷移を見る
Test Plan 右クリック > Add > Listener > jp@gc - Response Times Over Time7. テスト実行
JMeterの上部にある、緑色の三角ボタンを押したら始まります。
8. テスト結果
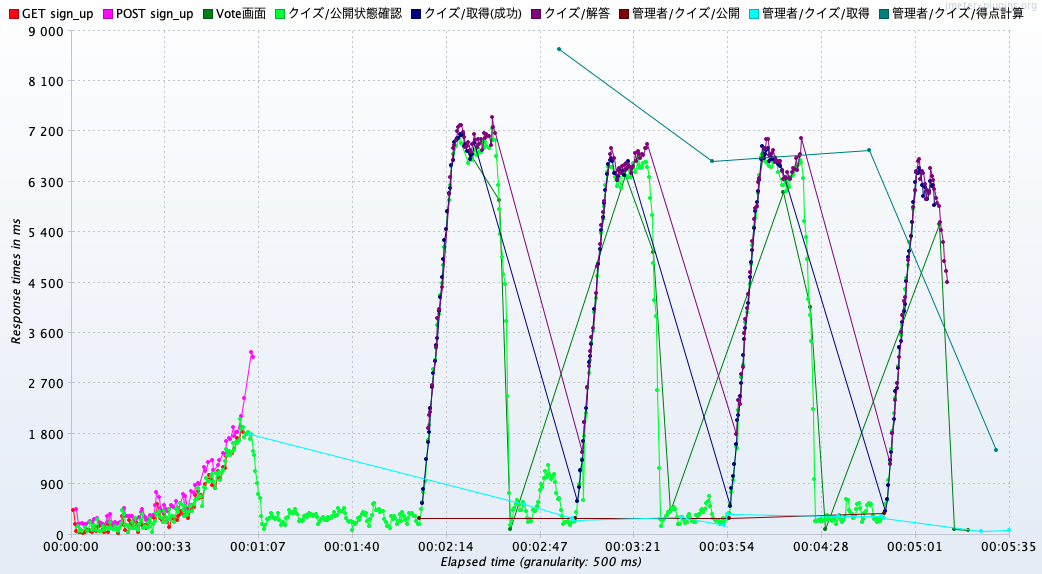
サーバは落ちませんでした
ただ、ところどころピークが生まれていて、ログを見るとDBのRollbackが行われている様子。同時書き込みに弱いSQLiteだから発生したRollbackでしょうか・・?
まとめ
JMeterは気軽に負荷テストを行えるツールでした。
どのようにインフラ/実装を変えれば、レスポンスタイムが短くなるかを考えてみるのは、課題として面白そうですね。





- 投稿日:2019-12-14T17:09:46+09:00
ポリモフィック
ポリモフィックのロジックを考えてみる
前提
- 下記が存在する
- Articleモデル
- Eventモデル
- Commentモデル
記事を参考に実装してみると下記になる
2.3.0 :008 > Comment.first.commentable Comment Load (0.3ms) SELECT "comments".* FROM "comments" ORDER BY "comments"."id" ASC LIMIT ? [["LIMIT", 1]] Event Load (0.2ms) SELECT "events".* FROM "events" WHERE "events"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]] => #<Event id: 1, name: "e1", content: "e_contet", created_at: "2019-12-08 02:19:18", updated_at: "2019-12-08 02:19:18">参考記事
https://ruby-rails.hatenadiary.com/entry/20141207/1417926599
- 投稿日:2019-12-14T16:53:56+09:00
Railsでクエリが複雑になってきたのでQueryObjectパターンでリファクタをして良かった話
この記事は Opt Technologies Advent Calendar 2019 13 日目の記事です。若干遅刻しました。
12 日目の記事は @gcchaan さんの
なにか書きますです
14 日目の記事は @naru0504 さんのstyled-componentでモダンなCSS設計入門です
「RailsでActiveRecordでクエリが複雑でつらいしパフォーマンスも悪くなってきた」
よくある話だと思います。例に漏れず、自分のチームも同じ問題と向き合いましたクエリが複雑になりアプリケーションの修正時にコードリーディングが難しい・修正後の結果予測が困難になるという、まあ言ってしまえば典型的な事例です
これまでに同様の議論は多くなされてきたと思いますが、自分のチームがこの問題と向き合い、「何が問題で・どのように解決し・結果どうなったか・反省点」という観点で事例を書き残しておこうと思います何が問題だったか
プロダクトにとっての問題点
ユーザーに利用してもらうにはあまりにも レスポンスが遅い という状態になってしまっていたことが第一です
プロダクトにとってとても優先度の高い機能を優先して実装していたのですが、それがリリースされたときにはもうだいぶ遅い(レスポンスに30sec以上平気でかかる・・・)状態になっていましたコードベースの問題点
クエリについて話しているのでお察しのことと思いますが、SQLがボトルネックでした
しかし、クエリを改善しようとするも、以下の状況が立ちはだかります
- プロダクトの性質上、集計関数を用いたクエリが必要
- 基本方針として、よく使うscopeを実装し、その組み合わせによってクエリを実現していた
- レポーティングのクエリで、同じテーブルに対して複数の結果セットが欲しいので、とあるscopeが複数のクエリ呼び出しから参照されていた
- scopeは別のscopeも参照していた
- scopeの組み合わせるクエリ組み立て処理はControllerで書いていた
- 一部でクエリの結果に対しての複雑な加工処理もあった(クエリ組み立てがControllerで実施されているので、この処理もControllerで呼び出しされていた)
- Controllerで呼び出されている処理について直接のテストはなかった
- あったのはrswagによるスキーマのテストぐらい
- 各scopeは結構丁寧にテストは書かれていた
イメージとしては以下のような実装をもっとFatにしたものになっていました
foo_controller.rbclass FooController < ApplicationController def index # Controllerでこのようにscopeチェインしてクエリを組み立てていた @foo = Foo.by_foo(params[:some_param]) .of_baz(params[:some_condition], params[:some_condition2]) render json: @foo end def other # 別のメソッドやControllerなどからも呼ばれることもある @foo_other = Foo.of_baz(params[:some_condition], params[:some_condition2]) .by_other render json: @foo_other end endfoo.rbclass Foo < ApplicationRecord scope: by_foo, ->(some_param) { # このように別のscopeを参照している ---↓ select(:foo).group(:foo).order(:foo).sum_bar } scope: sum_bar, ->() { select('SUM(bar) AS bar') } scope: of_baz, -> (cond1,cond2) { baz_condition = make_condition(cond1,cond2) where(baz: baz_condition) } endまとめると、でかいクエリが詳細なテストなしに複数あって、scopeの参照関係も複雑、という形です
どのように解決したか
タイトルにも記載しましたが、QueryObjectパターンを利用しました
QueryObjectについて参考にした資料
- 7 Patterns to Refactor Fat ActiveRecord Models
- Rails - ActiveRecord の scope を Query object で実装するただ適当にQueryObjectを利用しても上手く行かないと思い、以下のような指針でQueryObjectへの切り出しを実施しています
実装の方針
- 「最終的に欲しいクエリ」は必ずQueryObjectに定義する
- 実装自体は引き続きscopeのチェイン
- ただし、scope内から別のscopeを(なるべく)参照しない
- 結果の予測が困難になる理由の一つだったため
- scopeの利用自体は許容(scopeを利用しないとQueryObject側の実装が複雑になりそうだったため)
- 「最終的に欲しいクエリ」同士で重複しているクエリは許容
- scopeという「クエリの断片を組み合わせる処理」を呼び出す部分を共通化するのは「早すぎる抽象化」になりそう
以上のような方針にすることで、以下のような恩恵を受けられます
- 最終的なクエリに対してのテストがQueryObjectの呼び出しだけで実施できるようになる
- scopeの影響範囲が明快になり、変更の結果を予測しやすくなる・影響範囲を限定できる
リファクタの方針
方針を決定したので、リファクタをします
といってもこれ自体は「まずはテスト出来るような形にだけ変更」、「テストを書く」、「リファクタを実施」という鉄則に従って実施しただけです
幸いだったのが、「まずはテスト出来るような形にだけ変更」が非常に容易だった点です先程の例を元に説明します
- 最初に
FooController#indexについてのみをQueryObjectに切り出すfoo_query.rbclass SumOfFooQuery class << self delegate :call, to: :new end def initialize(foo = Foo.all) @foo = foo end def call(params) # ここにFooController#indexに書かれていた処理をまるっとコピペ @foo.by_foo(params[:some_param]) .of_baz(params[:some_condition], params[:some_condition2]) end end
- モデルにQueryObjectを参照したscopeを定義
foo.rbscope :sum_of_foo, SumOfFooQuery
- FooControllerの実装を置き換え
foo_controller.rbclass FooController < ApplicationController def index + @foo = foo.sum_of_foo(params) - @foo = Foo.by_foo(params[:some_param]) - .of_baz(params[:some_condition], params[:some_condition2]) render json: @foo end def other @foo_other = Foo.of_baz(params[:some_condition], params[:some_condition2]) .by_other render json: @foo_other end end
- テストを書く
- リファクタする
- サンプルは割愛
以上のような流れでリファクタリングを順次実施していきました
結果どうなったか
クエリ単位でのテストがあり、影響範囲も狭められたので、特定のエンドポイントから順番に・独立してクエリチューニングを実施できるようになりました
(チューニングはそれはそれで大変だったのですがそれはまた別の話)
scope内から別のscopeを(なるべく)参照しない、「最終的に欲しいクエリ」同士で重複しているクエリは許容といった方針も見込み通りにコードの読みやすさや変更しやすさに繋がったという感触ですその後運用していても、変更時に大きく困るような事態にはなっていないので、設計は上手くいったと思っています
反省点
- Controllerに処理書いちゃだめだった
- ここを徹底すべきだった
- scopeの先のscopeの先のscope・・・という道のりを辿った先でのselectを把握してコーディングするのは人間には無理だった
- 作るときはいいけど変更できない
- 「1つのメソッドを短くする」、「DRY」を徹底すればいいってもんじゃなかった
- メソッドの定義をバラけさせればバラけさせるほど「結局何をやりたいのか」が分かりにくくなることもある
- (かと言ってまとめりゃいいってもんでもないので難しい)
- レスポンスに30sec以上という状態は流石にもっと早く手を打てたんじゃ・・・
- turai
- 開発が進むうちにデータが溜まって表出したものが多かったので、開発初期時点でデータを作れるなら作っておくという選択肢は今後頭に入れておきたい
- 機能追加の優先度が高かったので、パフォーマンスがヤバくなるかもしれないとわかってても優先度を変更するかは判断が難しかったと思う
- ので、普段から変更に強い設計にしておく・設計を身に着けておくという再現性のない反省になってしまう・・・
ただ、以下のような良かった点もあって、この前提がなかったらもっと困難な課題になっていたと思います
- scopeで非常に汎用的なクエリを表現していた
- 例えば見込み値の算出クエリなど
- このような複雑な処理がControllerに氾濫していたらQueryObjectへの移行が困難だったと思う
- scope単位のユニットテストはあった
- テスト大事・・・
- Controllerはクエリ組み立てとrender用の多少の加工だけでFatにはなっていなかった
- Fatになる前にちゃんとリファクタに手を付けられたとも言えるかも
おわりに
ということで、Railsでクエリが複雑になってきたのでQueryObjectパターンでリファクタをして良かった話でした
今回の事例がどこかのRailsプロダクトの参考になれば幸いです
- 投稿日:2019-12-14T15:41:09+09:00
rails db:resetとrails db:migrate:resetの違い
- 投稿日:2019-12-14T15:35:17+09:00
RailプロジェクトをGitHubで管理する時にやること
Railsプロジェクトを複数人で管理をする時に最初にやることをまとめました。
READMEを編集
各種ツールのバージョンや設定方法等を記載しましょう。
ツールの宣伝を書くこともあります。.gitignoreの編集
git管理対象外とするファイル、ディレクトリを設定します。
gitignore.ioを利用すると、言語等に合わせてそれっぽい.gitignoreファイルが手に入ります。あとは必要に応じてカスタマイズしましょう。database.ymlを複製
database.ymlを複製し、database.yml.defaultなどの名前をつけます。
また.gitignoreにdatabase.ymlを追加し、git管理から外しましょう。各開発者は、
database.yml.defaultの情報に、ローカルPCのパスワードなどを追加して、オリジナルのdatabase.ymlを作成します。
.envファイルを扱う場合も同じで、環境によって影響がでるファイルは、オリジナルを別名で保存し、そちらをgitで管理するようにしましょう。
- 投稿日:2019-12-14T15:01:48+09:00
Runteqに入ってから意識的に変わったこと
はじめに
私は10月から渋谷のRunteqというスクールに通っています。
それまでに開発の実務経験はなく、rails tutorialを3ヶ月ほど独学で勉強していました。
Runteqに入ってから2ヶ月ちょっと経ち、技術的な事はもちろんですが、その他に意識的に変わったなと思うことがあるのでご紹介します。
開発経験者の方からすると当たり前と思うこともあるかもしれませんが、温かい目で見て頂けると嬉しいです。対象者
初学者の方、特に独学でrailsを勉強されてる方
公式ドキュメントを読むようになった
Qiitaの記事に書いてある通りに実行してるのに上手くいかないという事は皆さん経験があると思います。記事の通りにならないのは、記事を書いている人と環境、特にバージョンが異なっている場合が多く、そのような時は公式ドキュメントが非常に参考になります。
(その他にも、勉強し始めの頃から公式ドキュメントを読む利点として、今後必要な情報が全てqiitaにわかりやすくまとめられているわけではないために公式ドキュメントを読む練習をするというのがあると思います。)railsの場合、githubが公式ドキュメントとなっていることが多く、例えばsorceryというgemだと
<>CodeタブやWikiタブを見て使い方を理解します。
説明の代わりにソースコードが載っている事もあり、察する力も大事なのかなと思います。rails tutorial等をやっていたら、理解もずっと早くなりますよ。大体英語で書かれているため、分かりづらい時はgoogle翻訳や、補助的にQiitaを使ったりするのがオススメです。
新しいツールに手を出すようになった
Runteqの教室内やslackにて、意見交換をしたり、オススメのツールが紹介される事がよくあります。
スクールに入ったのをきっかけに、色々経験してみようと思い、紹介されたツールを全部試していました。
以前の自分は、ツールをインストールするより目の前の作業に時間を使いたいという思考をしていました。実際本格的なツールになるほど複雑な使い方を覚えなくてはいけないというのはあると思うのですが、だからといって躊躇っていると今後使うツールの幅がぐっと狭くなり、結果効率化から遠のいてしまいます。
使ってる数が多いほど良いというものではありませんが、自分と合うツールは積極的に取り入れていきましょう。日々の業務が効率的になります。自分のオススメのツールを書いてみます。色々試してみてください。
- google keep:タスク等をメモするのに使っています。タグ付けもできるので便利です。
- HyperSwitch:アプリ切り替えの際、ウィンドウ単位で切り替えられるようになります。
- Magnet:Macでの画面分割が楽にできます。
- cvim:vimの操作でchromeを閲覧できます。vimを使っている方は是非。
- rubymine:rubyの便利機能が詰まっているエディタです。
ショートカットコマンドを覚えるようになった
Runteqにて質問をする時にいつも思うのですが、講師の方はPCの操作が早いのです。
ショートカットコマンドを多用しているのがその要因の一つではないかと思い、ショートカットコマンドを覚えようと意識してみました。覚えるのはなかなか大変ですが、2つ〜3つずつくらいを目安にちょっとずつ覚えていくと段々使えるようになってきます。
また、自分だけかもしれませんが、ショートカットを使えるようになると、操作が早くなるだけでなく、使ってて楽しく感じます。自分が特に使えると思ったショートカットコマンドをいくつかご紹介します。
使い慣れていない方は、まずはこれらから試してみて、使いこなせるようになってきたら新しいショートカットコマンドを模索してみてください。chrome
command + tab:アプリケーションの切り替え(shiftを押しながらだと逆向きに切り替え)
control + tab:タブを1つ右に切り替え(shiftを押しながらだと1つ左に切り替え)
command + [:ページを1つ戻る( ]だと1つ進む)vimを使っている方であれば、cvimをインストールして、上記ショートカットと組み合わせるとより快適になります。
ターミナル
control+a:カーソルを一番左に移動
control+e:カーソルを一番右に移動
control+l:画面をクリア
control+u:カーソルより左を削除
control+k:カーソルより右を削除まとめ
「Runteqに入ってから意識的に変わった事」として紹介しましたが、今考えるとどれも独学の頃から意識できた事だと思います。
独学の頃は目の前の作業に夢中になっていましたが、少しゆとりを持って手を広げてみるともっと日々のエンジニア生活が楽しくなると思うので、是非色々試してみてください。
- 投稿日:2019-12-14T14:18:55+09:00
RailsにBootstrapを導入する
記事はたくさんあるのに、どの記事も微妙に書かれていることが違ったりして割とハマったので、自分がうまく行った方法をメモ。
Rails:
5.2.4
Ruby:2.6.5gemを入れる
bootstrap、jquery-railsの2つのgemを導入します。Gemfilegem 'bootstrap' gem 'jquery-rails'$ bundle installapplication.scssを編集
まず、
app/assets/stylesheets/application.cssの拡張子をscssに変更します。次にファイル内の以下の2行を削除します。
app/assets/stylesheets/application.scss*= require_tree *= require_self最後に、以下の記述を書き込みます。
app/assets/stylesheets/application.scss@import "bootstrap";application.jsを編集
app/assets/javascripts/application.jsに以下の内容を追記します。
app/assets/javascripts/application.js//= require jquery3 //= require popper //= require bootstrap-sprockets設定は以上になります。
AssetPilelineの仕組みがいまいちわかっていないので、今後調べて行こうと思います。参考
- 投稿日:2019-12-14T13:37:47+09:00
RailsアプリをNuxt.jsに移行する際のTIPSいろいろ
この記事は Nuxt.js Advent Calendar 2019 16日目の記事です。
この記事では、Ruby on Railsアプリのview部分をNuxt.jsに移行した話を元に、Nuxt.jsでの開発全般の知見を紹介します。
※Railsの話はほぼ出てきません!移行前の状況
フリーランスとしてジョインしたWebサービスが、以下の状況でした。
- 全体的に6年前くらいの技術スタックのRailsアプリ(Rails4.0, svn, jQuery...など)
- サーバー側はModel, View, Controllerとどこもコードの量が多く煩雑で、リファクタリングが辛い。テストもほぼない。
- フロントエンドも適切にファイル分割されておらず、1つのcssファイルが一万行あったり、jsがRailsのテンプレートにベタ書きされている
- ちょうど一部ページのフルリニューアルの計画がある(!)
移行のモチベーション
「今後の開発効率が上がり、様々な機能を今後開発しやすくなるのがメリット」
ということを、会社の経営陣などステークホルダーにお伝えして、承認を得ました。
具体的には以下をお伝えしました。開発上のメリット
- Hot Module Replacementによるコーディングの即時反映
- コンポーネント開発が強制され、jsやcssの見通しが良くなる
- 既存の状態では誤ったcss変更によるレイアウト崩れがしばしば発生していた
- また、cssを変更できる人が限られていた
- 非同期処理やアニメーションのロジックが簡潔に見通しよく書ける
- jQueryで頑張るのはもうつらい
ユーザー側のメリット
- アプリのようなリッチなUXを提供しやすい。
- 開発効率が上がる分、ユーザーに本当に提供すべきことに開発を集中できる
個人的に、ある程度リッチなUIを作るのであれば、もはやRailsでフロントエンドをやる時代ではないと思っています。
(そして、ある程度リッチなUIはもはや現代のWebサービスでは必須と考えています)この辺の話は、以下スライドが参考になるかと思います
私たちはなぜ SPA で開発するのか / Why you choose SPA
移行後の構成
- リニューアルするページ: Nuxt.js(SSR) + Ruby on Rails(API)
- 旧ページ: Ruby on Rails
という構成で、もともとのRoRアプリにAPIを生やしつつ、Nuxt.jsを別サーバーとして立ち上げることにします。
旧ページも今後すべてNuxtに移行し、RoRはAPIのみとする予定ですが、全てを一度にリニューアルするのはボリュームが大きすぎるため、一旦一部ページのみとしました。ちなみに、Nuxt移行の前に、開発環境を整える作業を1ヶ月で完了しました。
(Rails4.0->6.0, svn->git, EC2->GAE, MySQL on EC2 -> Cloud SQL, もろもろのリファクタリングなど)移行のTIPS
ルーティングについて
今回は一部ページのみrailsで動き続けるため、リクエストを適切にnuxtかrailsに振り分ける必要があります。
今回はこれを「GAEによるdispatch」「Nuxtによるリダイレクト」の2つで移行を実現します。GAEのdispatch
GAEは以下のような
disaptch.ymlを書くだけでルーティングを変えることが可能で、非常に楽なのでオススメです。before
dispatch: - url: "*www.example.com/*" service: railsafter
dispatch: - url: "*www.example.com/*" service: nuxt - url: "*www.example.com/admin/*" service: rails - url: "*www.example.com/api/*" service: railsこれだけで済めば万歳だったのですが、GAEでは
*がURLの最初か末尾にしか使えず、複雑な正規表現などは使えないため、これだけでは要件を満たせませんでした。Nuxtのリダイレクト
GAEレイヤでのルーティングで対応できない箇所は、Nuxtにきたリクエストをリダイレクトすることにします。
Nuxtでこれを行いたい場合 @nuxtjs/redirect-module を使うと良いでしょう。
// nuxt.config.js { modules: [ '@nuxtjs/redirect-module' ], redirect: [ { from: '^/hoge', to: 'https://www.external.com/hoge', } ], }モジュールの中では、
addServerMiddlewareを使ってリダイレクトの処理を行なってくれます。
外部へのリダイレクトを行いたい場合、vue-routerを使うのではなく、serverMiddlewareの機構を使ってリダイレクトをすべきであることに注意しましょう。APIとのつなぎ込み
RoRからSPA+APIに移行する際のオーバーヘッドとして、APIとのつなぎ込みが頭に浮かぶかもしれません。
ここに関してはnuxt-resource-based-apiというライブラリを使っているため、ほぼオーバーヘッドはありません。
例えば、Pageコンポーネントは以下のように書くだけです。<script> import createComponent from '@/lib/create_component' export default createComponent([ { resource: 'task', action: 'index' }, // APIのコントローラー、アクションを指定 ]) </script> <template> <div> <div class="task" v-for="task in tasks"> {{ task.name }} </div> </div> </template>詳細は以下をご覧ください。
爆速でnuxtとAPIを繋げるnuxt-resource-based-apiの紹介ディレクトリ構成
pagesディレクトリNuxt.jsではpagesディレクトリ配下の構成が、そのままルーティングになります。
Railsでリソースベースでルーティングを行なっていると、
/users/123/tasks/456のようなパスを作ることがあると思いますが、
この場合はpages/users/_id/tasks/_taskId/index.vueというコンポーネントを作成すると、正しくルーティングされます。
idにはroute.params.idroute.param.taskIdのような形でアクセスできます。
ということで、無事Railsのパスをそのまま使うことができます。注意として
_id.vueではなく_id/index.vueを作ることを推奨します。
pages/users/_id.vueが存在する状態で、pages/users/_id/hoge.vueというコンポーネントを作成し、users/123/hogeにアクセスすると、期待通りの挙動をしません。
この辺は以下を参照にしてください。Nuxt.jsのネストした動的ルーティングで困ったので調べてみた
componentsディレクトリ
Nuxt.jsは他の同様のフレームワークと比べると、ディレクトリ構成の制約が強いフレームワークですが、RoRに比べると弱いですよね。
特にcomponentsディレクトリ以下について、構成のベストプラクティスは特に定まっていない認識です。ここについて、少なくともRailsアプリ開発経験者には、Railsと同じくパスベース+
sharedディレクトリを使った、以下のような構成が分かりやすいと考えています。(components/以下のディレクトリ構成例) . ├── users │ ├── articles │ │ └── A.vue │ └── shared │ ├── B.vue │ ├── C.vue ├── articles │ └── D.vue ├── layouts │ ├── Footer.vue │ ├── Header.vue │ └── header │ ├── Logo.vue └── shared ├── E.vue ├── card │ ├── ArticleCard.vue └── icon ├── FacebookIcon.vue ├── LineIcon.vueより具体的には、以下のルールを
README.mdに明記しています。
- コンポーネント Foo が、1 つの Page コンポーネントでしか使われない場合 -> pages に対応するディレクトリに格納する
- (例)
pages/users/index.vueのみで使うコンポーネントのパスはcomponents/users/Foo.vue- コンポーネント Foo が、複数の Page コンポーネントで使われる場合 -> 共通する名前空間として最大の名前空間となるディレクトリに
sharedを作って格納する
- (例)
pages/users/a/index.vuepages/users/b/index.vueで使うコンポーネントのパスはcomponents/users/shared/Foo.vueshared/以下のディレクトリ構成は、できる限り意味のあるまとまりごとに格納する。(共通認識を得るのが難しいため、厳密に管理しない)
- (例)
shared/icon/TwitterIcon.vueshared/card/ArticleCard.vueなど。shared/bar/ディレクトリのコンポーネント名は*Bar.vueを推奨。- コンポーネントの数が増えてきた場合、atomic design などを取り入れつつ、UIのグルーピングの単位をチーム内でしっかりと共通認識を揃えて、ディレクトリを作成する
components/layouts/のみ特殊で、layouts/*.vueで使われるコンポーネントを格納するOGPやタグ
SSRしてNuxtを使うのは初めてだったので、OGPがちゃんと生成できるかドキドキでしたが、ちゃんと
fetch()で取得してきたAPIレスポンスを元にタイトルやOGPを生成することができました!すごい(小並)
OGPはheadメソッドを使うことで設定できます。また、GoogleAnalyticsやGoogleTagManagerなどは、既にモジュールがあるので、RoRよりもむしろ簡単に導入できるかと思います。
Google アナリティクスを使うには?エラーハンドリング
もともとbugsnagを使っていたので、nuxt-bugsnagを入れました。
これにより、サーバー/クライアント両方でのエラー通知が可能になります。便利なモジュールがたくさん公開されているのも、Nuxtの良いところですね。
ページネーション
レコードを全件fetchしてよければvuejs-paginateのようなライブラリを使うのが良さそうですが、
総レコード数が多い場合は、フロント側だけでページネーションの機構を作るのは難しいです。そのため、結局ページネーションに必要な情報はサーバーサイドで全て算出して、レスポンスとして渡すことにしました。
RoRを使ってれば、ページネーションはkaminariを使うと思いますが、kaminariのメソッドのレスポンスをそのままAPIにのせる感じ。なんかイマイチ納得いってないので、知見あれば教えてください# Rubyのコードです class Api::BaseController < ApplicationController private def paginate(relation, page, per_page, includes: []) paged_relation = relation.page(page).per(per_page) { page_meta: { total_pages: paged_relation.total_pages, total_count: paged_relation.total_count, current_page: paged_relation.current_page, current_cursor_start: (page - 1) * per_page + 1, current_cursor_end: [page * per_page, paged_relation.total_count].min }, records: paged_relation.includes(includes) } end end総括
RailsアプリをNuxtにリニューアルすることで、サーバー側はシンプルなAPIの実装で見通しよく、フロントもコンポーネント化によりjsとcssが非常に見通しよくなりました!
また、マークアップを担当していただいているエンジニアさんにも好評でした。この辺は、Reactだと難しい部分だと個人的に考えています。移行に迷っている方の参考になれば幸いです!同様の知見やご意見などお気軽にコメントください。
- 投稿日:2019-12-14T13:32:29+09:00
rails sがうまくいかない時の対応
rails sでサーバーを立ち上げた後、Ctrl + Cで終了せずにターミナルを終了しちゃったりすると、次回起動時に以下のようなエラーが発生します。$ rails s => Booting Puma => Rails 5.0.4 application starting in development on http://localhost:3000 => Run `rails server -h` for more startup options A server is already running. Check プロジェクト名/tmp/pids/server.pid. Exiting対処方法
$ lsof -ni tcp:3000 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ruby 77464 d0ne1s 20u IPv4 0xe8bde147dfa7a793 0t0 TCP 127.0.0.1:hbci (LISTEN) ruby 77464 d0ne1s 22u IPv6 0xe8bde147d9f527d3 0t0 TCP [::1]:hbci (LISTEN) $ kill -9 77464
lsof:オープンしているファイルを一覧表示するコマンド
-n:IPアドレスを表示する(名前解決しない)
-i:ポート番号やプロトコルを指定する
kill:プロセスを終了する
-9:強制終了参考
- 投稿日:2019-12-14T12:31:06+09:00
#Rails + #rspec でハッシュに対して一部のkey/valueの型だけを検証する、ゆるいテストをするには include と be_an を組み合わせて使う
expect(a: 1, b: Time.now, c: 'wow').to include({a: be_a(Integer)}) # => true expect(a: 1, b: Time.now, c: 'wow').to include({b: be_a(Time)}) # => true expect(a: 1, b: Time.now, c: 'wow').to include({c: be_a(String)}) # => true expect(a: 1, b: Time.now, c: 'wow').to include({c: be_a(Integer)}) # => [#<RSpec::Expectations::ExpectationNotMetError: expected {:a => 1, :b => 2019-12-13 02:08:55.283922100 +0000, :c => "wow"} to include {:c => (be a kind of Integer)} # Diff: # @@ -1,2 +1,4 @@ # -:c => (be a kind of Integer), # +:a => 1, # +:b => 2019-12-13 02:08:55.283922100 +0000, # +:c => "wow", # >]ref
ruby - Testing hash contents using RSpec - Stack Overflow
https://stackoverflow.com/questions/8392884/testing-hash-contents-using-rspecOriginal by Github issue
- 投稿日:2019-12-14T12:28:32+09:00
Windows Subsystem for Linuxでmysqlを使えるようにする。
環境
Windows 10 pro
Ubuntu 18.04 LTS
ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-linux]
Rails 5.2.4
gem 2.7.6
Bundler version 2.0.2mysqlの前に
github上で
$ rails _5.2.4_ new example -d mysqlをして新しい環境を作った後、
Gemfileをgem 'mysql2', '0.5.2'と編集されたものを、
git pullした後に、
WSL上でbundle installしようとしたが、$ bundle install * * * Fetching mysql2 0.5.2 Installing mysql2 0.5.2 with native extensions Gem::Ext::BuildError: ERROR: Failed to build gem native extension. * * * ----- mysql client is missing. You may need to 'apt-get install libmysqlclient-dev' or 'yum install mysql-devel', and try again. ----- *** extconf.rb failed *** Could not create Makefile due to some reason, probably lack of necessary libraries and/or headers. Check the mkmf.log file for more details. You may need configuration options. * * * An error occurred while installing mysql2 (0.5.2), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/'` succeeds before bundling. In Gemfile: mysql2とエラーが出てしまった(汗)
----- mysql client is missing. You may need to 'apt-get install libmysqlclient-dev' or 'yum install mysql-devel', and try again. -----この箇所を参考に
$ sudo apt-get install libmysqlclient-devした後、
Make sure that `gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/'` succeeds before bundling.この箇所を参考に
$ gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/' Successfully installed mysql2-0.5.2 Parsing documentation for mysql2-0.5.2 Installing ri documentation for mysql2-0.5.2 Done installing documentation for mysql2 after 0 seconds 1 gem installedこうすると、
$ bundle install $ bundle updateがそれぞれ実行できて、gemの環境が整った(^^)/
mysqlを使えるようにする
試しにmysqlの状態を確認すると、
$ mysql ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2)mysqlをstartさせようと試みた後、
$ sudo service mysql start * Starting MySQL database server mysqld No directory, logging in with HOME=/もう一度、mysqlの状態を確認すると、
$ mysql ERROR 1045 (28000): Access denied for user 'example'@'localhost' (using password: NO)こちらのサイトによると、
パスワードを設定しなおさなければならないらしい。$ sudo mysqld_safe --skip-grant-tables &セーフモードで実行したのち、
$ sudo mysql -u root Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 7 Server version: 5.7.28-0ubuntu0.18.04.4 (Ubuntu) Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> use mysql; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec) // データベースの状態を確認したよ mysql> update user set authentication_string=password("パスワード") where user='root'; ERROR 1819 (HY000): Your password does not satisfy the current policy requirements // パスワードは英数字と文字を組み合わせないとだめですよ mysql> update user set authentication_string=password("英数字と文字をいれたパスワード") where user='root'; Query OK, 1 row affected, 1 warning (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 1$ sudo service mysql start * Starting MySQL database server mysqld$ mysql --version mysql Ver 14.14 Distrib 5.7.28, for Linux (x86_64) using EditLine wrapperこういう状態になりました(^▽^)/
素人がやっているので説明不足等あるとは思いますが、
ご指摘の程、よろしくお願いします!!
- 投稿日:2019-12-14T11:27:18+09:00
Ruby on Railsでの良い書き方紹介
はじめに
皆さん、こんにちは。新卒のズオンです。
この記事はLinkbal(リンクバル)Advent Calendar 2019の14日目の記事です。
今回はRuby on Railsでの良い書き方を紹介します。 おそらく多くの人が既にこれらの書き方について知っていますが、私にとっては非常に便利だと思うので皆と共有したいです。 皆様からの提案をお待ちしております。 始めましょう。Hash
dig
私たちはほとんどしばしばこのように書きます:
if users[:id] && users[:id][:age] && users[:id][:age][:address] ... end
Hash#Digを使用すると、nil参照を心配することなくて簡単に動的にアクセスできます。 この書き方が短くて、結果は変わりません。if user.dig :id, :age, :address ... endObject
&.
例えばユーザーの住所があるかどうかを確認するとします。次のように書くことがよくあります。
if user && user.address ... end
&.を使用して上記のコードを書き換えることができます。if user&.address ... endpresence_in
もしブール条件の結果が実際に必要ない場合は、条件をメソッドに置き換えることができます。
colors = [:red, :green, :blue] color = colors.include?(params[:color]) ? params[:color] : :pinkまたは
color = (colors.include?(params[:color]) && params[:color]) || :pink下の書き方はもっと良くなります。
params[:color].presence_in(colors) || :pinkpresence
もしオブジェクトに
""または[]があるかどうかをチェックしたい場合は
このような代わりに:if user.name.blank? name = "What's your name?" else name = user.name endこのように使ってください。
name = user.name.presence || "What's your name?"Array
zip
例えば同じ数の要素を持つ2つの配列があり、この配列の要素をキーに変換し、他の配列の要素を対応する値に変換したい場合、次のようにします。
arr_1 = ["1", "2", "3"] arr_2 = ["a", "b", "c"] Hash[arr_1.zip arr_2] = {"1" => "a", "2" => "b", "3" => "c"}all? &:blank?
all? &:blank?を使って、配列はnilとか''の要素があるかどうか確認できます。arr = ["a", "b", nil, ''] arr.all? &:blank? # => trueselectとreject
条件を満たす要素を返す。
[1, 2, 3, 4].select{ |n| n > 2 } # => [3, 4]条件を満たさない要素のみを選択するには、
selectの代わりにrejectを使用できます。[1, 2, 3, 4].reject{ |n| n > 2 } # => [1, 2]count
条件を満たす要素の数を返します。
arr = [1, 2, 3, 4, 4, 7, 7, 7, 9] arr.count { |i| i > 5 } # => 4compact
配列内の
nil要素を削除します。numbers_and_nil = [1, 2, 3, nil, nil, 6] only_numbers = numbers_and_nil.reject(&:nil?) # => [1, 2, 3, 6]上記の書き方代わりに下記のようにもっと良くなります。
numbers_and_nil = [1, 2, 3, nil, nil, 6] only_numbers = numbers_and_nil.compact # => [1, 2, 3, 6]any?とall?
少なくとも1つの要素が条件を満たす場合に
trueを返したい時にany?を使ってください。arr = [2, 3, 4] arr.any? { |n| n > 3 } # => true arr.any? { |n| n > 4 } # => falseすべての要素が条件を満たす場合に
trueを返したい場合は、all?を使用してください。arr = [2, 3, 4] arr.all? { |n| n > 1 } # => truesample
ランダム要素を返します。
users[rand(users.size)] # 同じに users.sampleString
# snake_caseをcamel_caseに変換します "my_book".camelize # => "MyBook" # snake_caseになります "MyBook".underscore # => "my_book" # kebab_caseになります "my_book".dasherize # => "my-book" # 複数形になります "book".pluralize # => "books" "account".pluralize # => "accounts" "ruby".pluralize # => "rubies" "tooth".pluralize # => "teeth" # 単数になります "books".singularize # => "book" "customers".singularize # => "customer" "wolves".singularize # => "wolf" # クラス名に変換します(camel_case + 単数形) "my_book".classify # => "MyBook" "my_books".classify # => "MyBook" # テーブル名に変換します(snake_case + 複数形) "my_book".tableize # => "my_books" "MyBook".tableize # => "my_books" # 不要なスペースを削除します " My \r\n \t \n book ".squish # => "My book"
Stringの短縮メソッドについて詳しく知りたい場合は、https://apidock.com/rails/String を参考してください。おわりに
上記で私が知っている
HashやObjectやArrayやStringメソッドのいくつか良い書き方を紹介しました。 もちろんもっと良い書き方がたくさんあるので皆様からの提案をお待ちしております。読んでくれてありがとうございます。 またね。参考
https://apidock.com/rails/String
https://api.rubyonrails.org/
- 投稿日:2019-12-14T11:27:18+09:00
Ruby on Railsでの良い書き方について
皆さん、こんにちは。新卒のズオンです。
この記事はLinkbal(リンクバル)Advent Calendar 2019の14日目の記事です。
今回はRuby on Railsでの良い書き方を紹介します。 おそらく多くの人が既にこれらの書き方について知っていますが、私にとっては非常に便利だと思うので皆と共有したいです。 皆様からの提案をお待ちしております。 始めましょう。Hash
dig
私たちはほとんどしばしばこのように書きます:
if users[:id] && users[:id][:age] && users[:id][:age][:address] ... end
Hash#Digを使用すると、nil参照を心配することなくて簡単に動的にアクセスできます。 この書き方が短くて、結果は変わりません。if user.dig :id, :age, :address ... endObject
&.
例えばユーザーの住所があるかどうかを確認するとします。次のように書くことがよくあります。
if user && user.address ... end
&.を使用して上記のコードを書き換えることができます。if user&.address ... endpresence_in
もしブール条件の結果が実際に必要ない場合は、条件をメソッドに置き換えることができます。
colors = [:red, :green, :blue] color = colors.include?(params[:color]) ? params[:color] : :pinkまたは
color = (colors.include?(params[:color]) && params[:color]) || :pink下の書き方はもっと良くなります。
params[:color].presence_in(colors) || :pinkpresence
もしオブジェクトに
""または[]があるかどうかをチェックしたい場合は
このような代わりに:prefecture = params[:prefecture] if params[:prefecture].present? area = params[:area] if params[:area].present? region = prefecture || area || 'JP'このように使ってください。
params[:prefecture].presence || params[:area].presence || 'JP'Array
zip
例えば同じ数の要素を持つ2つの配列があり、この配列の要素をキーに変換し、他の配列の要素を対応する値に変換したい場合、次のようにします。
arr_1 = ["1", "2", "3"] arr_2 = ["a", "b", "c"] Hash[arr_1.zip arr_2] # => {"1" => "a", "2" => "b", "3" => "c"}any?とall?
少なくとも1つの要素が条件を満たす場合に
trueを返したい時にany?を使ってください。arr = [2, 3, 4] arr.any? { |n| n > 3 } # => true arr.any? { |n| n > 4 } # => falseすべての要素が条件を満たす場合に
trueを返したい場合は、all?を使用してください。arr = [2, 3, 4] arr.all? { |n| n > 1 } # => trueany?.&:blank?
配列は
nilとか''の要素があるかどうか確認したいときにarr = Array.new([1, 2, nil, '']) arr.any?.&:blank? # => trueselectとreject
条件を満たす要素を返す。
[1, 2, 3, 4].select{ |n| n > 2 } # => [3, 4]条件を満たさない要素のみを選択するには、
selectの代わりにrejectを使用できます。[1, 2, 3, 4].reject{ |n| n > 2 } # => [1, 2]count
条件を満たす要素の数を返します。
arr = [1, 2, 3, 4, 4, 7, 7, 7, 9] arr.count { |i| i > 5 } # => 4compact
配列内の
nil要素を削除します。numbers_and_nil = [1, 2, 3, nil, nil, 6] only_numbers = numbers_and_nil.reject(&:nil?) # => [1, 2, 3, 6]上記の書き方代わりに下記のようにもっと良くなります。
numbers_and_nil = [1, 2, 3, nil, nil, 6] only_numbers = numbers_and_nil.compact # => [1, 2, 3, 6]sample
ランダム要素を返します。
users[rand(users.size)] # 同じに users.sampleString
# snake_caseをcamel_caseに変換します "my_book".camelize # => "MyBook" # snake_caseになります "MyBook".underscore # => "my_book" # kebab_caseになります "my_book".dasherize # => "my-book" # 複数形になります "book".pluralize # => "books" "account".pluralize # => "accounts" "ruby".pluralize # => "rubies" "tooth".pluralize # => "teeth" # 単数になります "books".singularize # => "book" "customers".singularize # => "customer" "wolves".singularize # => "wolf" # クラス名に変換します(camel_case + 単数形) "my_book".classify # => "MyBook" "my_books".classify # => "MyBook" # テーブル名に変換します(snake_case + 複数形) "my_book".tableize # => "my_books" "MyBook".tableize # => "my_books" # 不要なスペースを削除します " My \r\n \t \n book ".squish # => "My book"
Stringの短縮メソッドについて詳しく知りたい場合は、https://apidock.com/rails/String を参考してください。おわりに
上記で私が知っている
HashやObjectやArrayやStringメソッドのいくつか良い書き方を紹介しました。 もちろんもっと良い書き方がたくさんあるので皆様からの提案をお待ちしております。読んでくれてありがとうございます。 またね。参考
https://apidock.com/rails/String
https://api.rubyonrails.org/
- 投稿日:2019-12-14T09:25:17+09:00
Ruby on Railsの現場でよく見る書き方【実例あり】
はじめに
こんにちは、@ryokky59と申します!
未経験からエンジニアになって1年経ちました!
今回はRailsを実務で1年間触ってきて、この書き方は最初に知っておけばスムーズにソースコードが読めたなぁと感じたことをまとめてみました!この記事で実務と独学の壁がすこしでも埋められるお手伝いができたらいいなと思います!
対象読者
- 未経験からエンジニアを目指してRailsを勉強している方
- 普段は他言語を使っているけど今度はRailsを使う現場に行かれる方
- 自社以外のRailsの書き方を知ってみたい方
Railsのいろんな書き方
埋め込みRuby文字列の中にRubyの式や変数を埋め込める
user_name = "taro" "こんにちは#{user_name}さん。今日は#{Date.today}です" # => "こんにちはtaroさん。今日は2019-12-14です"
""(ダブルクォーテーション)じゃないとRubyが展開されないので注意です。
||=変数に値を入れるときに、変数がnilかfalseのときのみ値を入れることができます
user1 = "taro" user1 ||= "jiro" user1 # => "taro" ("jiro"が代入されていない) user2 = nil user2 ||= "jiro" user2 # => "jiro" ("jiro"が代入されている)
後置if例えば以下のようなfalse側がいらないif文がある時
if true "trueでhoge" end # => "trueでhoge"こういう時は以下のように一行で書くことができます
"trueでhoge" if true # => "trueでhoge"例を挙げるとメソッドから抜ける時によく使われます(ガード節といいます。詳しくはコチラ)
def puts_user_name(user_id) user = User.find_by(id: user_id) return if user.nil? # もしuserがnilだったらreturnでメソッドから抜ける puts user.name end
三項演算子例えば以下のような普通のif文があるとき、
if true puts("trueでhoge") else puts("falseでhuga") end # trueでhogeこのような
if~else~endで終わるようなif文であれば一行で以下のように書くことができますtrue ? puts("trueでhoge") : puts("falseでhuga") # trueでhoge
メソッドの引数その1メソッドの引数の書き方は
()でも(半角スペース)でも大丈夫です。User.find(1) # => {id: 1, name: "idが1のユーザー"} User.find 1 # => {id: 1, name: "idが1のユーザー"}使い分けとしては例えば、上の三項演算子の例では
puts "trueでhoge"みたいに()ではなく、(半角スペース)で書くとSyntaxError unexpected ':'がでてしまいます。
三項演算子は(半角スペース)で次にどの文字がきて欲しいかを予測します。
なのでputs "trueでhoge"と書いてしまうとputsの次が(半角スペース)で:が来ることを期待しているのに"trueでhoge"が来ているのでエラーになります。このように、
()で囲って一つの文として評価されたいか、(半角スペース)で繋げて読みやすくするかを使い分けることができます。
メソッドの引数その2メソッドに渡す引数の種類もいくつか種類があります。
デフォルト引数
引数にデフォルト値を入れておいて、その引数がなければデフォルト値を使います
def puts_string(string="文字列") puts string end puts_string # "文字列"キーワード引数
引数をハッシュで指定する。
実行するときにキーワードも指定する必要がある。
引数が複数だったり、明示的にしたいときに使われる。def puts_string(string:) puts string end puts_string(string: "文字列") # "文字列"可変長引数
引数を配列として受け取ることができる
def name_array(*name) p name end puts_name_array("taro", "jiro", "saburo") # => ["taro", "jiro", "saburo"]
!◯◯(変数)変数の前に
!を書くと中身を反転したbooleanの形(trueまたはfalse)に変換することができます下記のように
stringという変数の前に一つ!をつけると反転してfalse、さらにもう一つ!をつけるとさらに反転してtrueを返します。string = "文字列" string # => "文字列" !string # => false !!string # => true変数の中身をnilにすると理解しやすいかもしれません
nil_val = nil nil_val # => nil !nil_val # => true !!nil_val # => false
%記法配列はよく%記法を用いて書かれます。
%w(hoge huga foo bar) # => ["hoge", "huga", "foo", "bar"]注意するところは配列の中身は必ずstringになるというところです
%w(1 2 3) # => ["1", "2", "3"]シンボルにすることもできます
%i(new create delete) # => [:new, :create, :delete]
{}ブロックは
do~endで書くことが多いかもしれませんが{}を使って一行で書く時に読みやすくすることができます。%w(hoge huga foo).each do |string| puts string end%w(hoge huga foo).each{ |string| puts string }この二つはどちらも同じ結果を返します。
doが{に、endが}に置き換わっただけですね
ブロックの中身が短く単純な時に便利です。[1, 2, 3, 4].select { |item| item % 2 == 0 } # => [2, 4]上のように
selectやany?など配列、ハッシュを扱うメソッドを使う時によく見られます
map(&:〇〇)こちらは先ほどの
{}で囲むブロック分よりさらに短縮したような書き方です。users.map { |user| user.name } # => ["taro", "jiro", "saburo"] users.map(&:name) # => ["taro", "jiro", "saburo"]上の例ではオブジェクトのキーを指定して値を取り出しています
これはブロックをprocに変換しているからできます。
実際はmapメソッドだけでなく他の配列、ハッシュを扱うメソッドで使うことができます。procとかは聞き慣れないかなと思うので参考記事を置いておきます
Rubyのmap &:to_iとはなんなのか
Ruby Procについて学ぶitems.sort_by(&:created_at) # itemのcreated_atが古い順に並び替える
includes引数に書いたモデルを先読みしてキャッシュしておく。
簡単にいうと不要なSQLを発行しないようにしてパフォーマンス低下を防ぐ(N+1問題を防ぐ)@user = User.all.includes(:items)↑のようにしておくと@user.itemsをeachで回したときにitem.nameとかでitemの数だけSQLが発行されるのを防ぐ
詳しくは下記記事を参考にどうぞ
Rails で includes して N+1 問題対策
&.(セーフナビゲーション)別名
ぼっち演算子
エラーの代わりにnilを返してくれます。# userのnameがnilのとき user.name.email # => NoMethodError: undefined method `length' for nil:NilClass user.name&.email # => nilnilの値であるレシーバ(name)に対してlengthメソッドを実行するとエラーが出ますが、
&.でチェーンすることでnilに変わります。
nilが入る可能性のあるカラムを操作するときによく使われます。
each_with_indexeachで回すときにindexが欲しいときに使います。
users = %w(taro jiro saburo) users.each_with_index do |user, index| puts "user: #{user}, index: #{index}" end # user: taro, index: 0 # user: jiro, index: 1 # user: saburo, index: 2indexを任意の数字で始めることもできます
users = %w(taro jiro saburo) # eachにチェーンしてwith_indexを繋げていることに注意 users.each.with_index(1) do |user, index| puts "user: #{user}, index: #{index}" end # user: taro, index: 1 # user: jiro, index: 2 # user: saburo, index: 3おわりに
現場では他にも色々書き方はあると思いますが、ここまでの内容を抑えておけばそこそこスムーズにソースコードを読めるのではないでしょうか?
他にも「うちではこんな書き方あるよ!」みたいな方はお気軽にコメントください!これからRailsを触っていく方に役に立つなと感じたリンクを貼っておくのでコチラもぜひ参考にしてみてください!
他言語経験者がRailsの案件にジョインしたときに、何を足掛かりにすべきかもう一歩先の書き方を知りたい方はこちらも参考にどうぞ!
差をつけるRuby
- 投稿日:2019-12-14T04:22:33+09:00
【Rails】オブジェクト指向について
はじめに
Rubyに最初に触れる方はオブジェクト指向という言葉はよく聞くけれどいまいち何のことを言っているかわからないという人も多いと思います。なので、このオブジェクト指向について自分の思考の整理も兼ねて記事にしました。
ちなみにオブジェクト指向はRuby以外にもjava,phpなどにも用いられる概念です。オブジェクト指向とは
簡単にいうとオブジェクト指向とはオブジェクトを中心に回り、複数のオブジェクトを組み合わせることでプログラムを構築していくという考え方のことです。
オブジェクトとは
オブジェクトとはデータや処理の集まりのことを指します。
ただし闇雲なデータや処理が集まったものではなく、一つのテーマの下で集まったものです。
イメージとしては、オブジェクトというのは概念のようなものではクラスとインスタンスによってできているという感じです。
またオブジェクトは振る舞いというものを持っています。振る舞いとは自分自身に対する操作のことで、
仮にAさんとBさんという別々のオブジェクトがいた場合に、名前を教えてと言うと、Aさんは「私はAです」、Bさんは「私はBです」というふうに別々の振る舞いを持っています。クラスとは
オブジェクト指向には大切な概念としてクラスというものが存在します。
簡単にいうとオブジェクトの設計図のことで、一つのテーマに沿った振る舞いや情報の保持などをひとまとまりにしたものです。
今回はCarというクラスを作ってみます。class Car def initialize(car_name, mileage, color) @car_name = car_name @mileage = mileage @color = color end def answer_car_name puts @car_name end end //実行結果 Prius = Car.new("prius", "50000", "blue") => #<Car:0x007fc55c1604f8 @car_name="prius", @mileage="50000", @color="blue"> irb(main):016:0> Car.answer_car_name priusCarというクラスにはanswer_car_nameというCar自身の振る舞いが含まれています。
このようにクラスを設定するとこの一つの操作(名前を出力する)についてはこのオブジェクトに任せることができます。開発者にとってのオブジェクト指向
オブジェクト指向はユーザーにとって何かしらの利点があるわけではありません。あくまでも開発者が円滑にコミュニケーションをとるために考えられた概念です。
守るべき原則
DRY
"Don't Repeat Yourself"の略で、繰り返しを避けるという意味です。
これはコードの量が増えることを避けて、できるだけバグの原因をなくそうという考え方です。
また、コードを書き直す際に、重複した表現を書いていた場合、どちらも直さないといけなくなり、無駄な労力を割いてしまいます。YAGNI
"You ain't gonna need it"の略で、必要になったときに必要な機能だけ実装すると言う原則です。
必要になるかもしれない、と言う理由で使わないコードを書いてしまった場合、後々それがバグの原因になることがあります。単一責任の原則
クラスが持つ役割は一つだけにすると言う原則です。もしもCalendarクラスがあるとします。Calenderクラスには予定を操作する機能と、予定をグラフで可視化する機能があるとします、しかしその二つの機能を一つのクラスが持つことは望ましくありません。なぜなら、予定をグラフで可視化する機能を編集したいときに、カレンダーを操作する機能を司る部分も編集する必要が出てくるかもしれないからです。なのでしっかりと二つにクラスをわけ、変更したい機能のみを編集するためにクラスを分ます。
インターフェイス分離の原則
複数のクライアントが使用する機能の場合、どのクライアントにも対応したような網羅的な機能の場合、一クライアントが使っているときに使わないメソッドなどが出てきてしまいます。そのような場合は望ましくなく、適切な処理ができない場合があります。なので、一クライアント単位で使う機能をグループ分けしあまり網羅的な機能を作らないように心がけることが大切です。
まとめ
いかがだったでしょうか。このオブジェクト指向はとてもわかりづらいと感じてしまったかもしれません。しかし、実際に自分の手でコードを書いて再びこの考え方を復習したときに理解度がより深まるのではないかと思います。とにかくコードを書き、オブジェクト指向の全体の流れのようなものを掴むことをお勧めします。
- 投稿日:2019-12-14T03:37:55+09:00
rails 新規アプリ作成時:Mysqlにてbundle exec rake db:createが上手くいかない解決記録
rails 新規アプリ作成時に、Mysqlにてbundle exec rake db:createが上手くいかない解決記録(自分用)
① bundle exec rails new アプリ名 . -B -d mysql --skip-test --skip-coffee② bundle exec rake db:createerror文、
rake aborted!
No Rakefile found (looking for: rakefile, Rakefile, rakefile.rb, Rakefile.rb)色々試し、不要なコマンドは実行したと思われるが、次回はここから行う。
$ ① mysql.server start ② $ bundle exec rake db:create RAILE_ENV=development*rake aborted!
No Rakefile found (looking for: rakefile, Rakefile, rakefile.rb, Rakefile.rb) が出る場合は、rakefileがあるディレクトリにcdで移動後、再度$ bundle exec rake db:create RAILE_ENV=developmentで
無事にCreated database となった。
- 投稿日:2019-12-14T02:05:03+09:00
【ポートフォリオ】UROGを開発しました
どんなアプリを作ったか - 概要
カテゴリー毎にURLを分けて保存できるメモアプリです。
https://www.urog.me/
お試しで利用したい方は、以下のemail,passwordを使ってみてください。
(もちろん新しくユーザー登録も可能です)email: aaaaa@email.com password: aaaaaaaagithub:https://github.com/koao123/urog_app
アプリ・筆者についての解説
使用言語・フレームワーク:Ruby・Rails・HTML・CSS・BOOTSTRAP
使用ツール: github, heroku, AWS(cloud9)開発期間:2ヶ月
勉強期間:半年このアプリでできること
ユーザー登録
ログイン(ログアウト)
カテゴリー毎に分けて投稿が可能
高い一覧性で投稿を見ることが可能です。
なぜこのアプリを作ったか
私は将来役に立つだろう記事(Web)や、気づきを与えられる記事に遭遇すると、将来のために保存するようにしています。しかし実際問題、必要な時にその記事を保管場所から取り出せることがほとんどありません。
この問題が改善され、緊急性が上がり必要になった情報(Webページ)を必要な時に入手できるようになれば、
将来の無駄な時間が削減され自分の成長効率が上がると考えました。具体的に何を解決しようとした結果、このアプリを作ったのか
保存したWeb記事を閲覧する際のハードルとして、「一覧性の低さ」が挙げられる。これを解決するためにこのアプリを作りました。
ーーー
現状では、記事をどのサイトのどの場所に置いたか分からず、辿り着くまでにかなりの手間がかかるようになっています。
(記事保存先検索候補が多く、TOPページで全体把握できないため、更にそこから探す必要があります)そして、理想の状態は
「探すべき場所が一箇所で、その場所にたどり着いた後、保存した記事をすぐに見つけれる」ことです。この状態だと、素早く記事を探せるので、実用性があると考えました。
理想から考える現状のギャップとしては
「保存場所に行った後、保存した記事の"一覧性が低い"こと(メモアプリなので、二階層。全て初めのページで見れない)」と「"カテゴリー分け等がされていない"ので、保存ページに行った後、どの範囲を探せば良いか分からない」ということです。そのため「一ページで全体が把握できるほど一覧性が高く」「カテゴリー分けができる」メモアプリを作ろうと考え、このアプリを作りました。
どうやって作ったのか
以下の手順で行いました。
サービス企画
理想と現状のギャップを考え、最低限どのような機能を持ったアプリを作ればその課題は解決できそうか?を考えた
↓
必要な機能の洗い出し
DB設計(postテーブル・userテーブル等)
UI設計
↓
バックエンドをRailsで実装
↓
フロントエンドを実装(HTML、CSS)その過程で工夫した点
サービス設計
ユーザーにとってどんな機能があれば使うか?何があれば課題を解決出来そうか?を自分の行動を分解し突き詰めて考えました。(対象ユーザーは自分なので)
カテゴリー機能
ただURLが投稿できるだけではなく、カテゴリー毎に投稿できるようにした。これにより、URLがカテゴリー毎に探しやすくなる。
LPに書く文章の工夫
このアプリの価値とターゲットユーザーを考え、ターゲットユーザーが「このサービスいいな」と思うような文章を考えた。
苦しんだ点(その解決過程)と学び
正体不明のエラーの対応
特に苦しんだ点は、エラーを読んでも分からず、エラーメッセージを検索してもあまり分からなかったエラーです。こういう時はエラーメッセージが示していることや、検索語のページで特定の方が言っていることが理解できていないことが多かったです(自分は相手が見えている構造を理解できていないため)。なので今後は、行き詰まった時は見える情報から構造を確認し、エラーの対処に当たろうと思います。
サービス設計と実際の開発との解離
サービス設計ののち、DB設計とUI設計をきっちり行ったが、実際に開発すると、認識できていなかった技術的に難しいなどの問題が多数出てきて設計をやり直すことになりました。当たり前ですが、自分で実装できることの重要さを感じました。
このアプリの課題
新たなる問題
このアプリの目的は、「緊急性が低いURLを保存しておき、緊急性が高くなった時に取り出せるようにすること」です。この問題は、このアプリを作ったことによりある程度解決されたと思っているが、私は「保存時にWebアプリを開くのが面倒」と感じてしまっています。
そのため、この問題を解決する必要があると考えています(LINE APIを利用すれば可能・・・?)保守性の問題
今回はテストを書いておらず、全く後の改善時のことを考えていないので、取り組もうと思います。
フロントの実装
フロントは見よう見まねで実装したため、正直なところちゃんとしたcssも書けておらず、レスポンシブ対応さえできていません。Ajax対応もさせる必要があるので、早く勉強して取り組もうと思っています。
さいごに
実際に動くアプリを完成させれたのは自信になったが、自分の技術レベルの低さを目の当たりにすることになりました。これからも勉強して行きたいと思います・・・。
※これは、就職活動をする上で見ていただく採用担当の方向けに書いた記事です。
- 投稿日:2019-12-14T01:01:28+09:00
ActiveModelでenumを使いたい
ActiveModel::Modelをincludeしたクラスにenumを使いたい場面が出てきたけども、
ActiveRecordしか使えなさそうだったのと、検索しても出てこなかったので、
moduleを作成しました。
ActiveModel::Attributesを使うのでrails 5.2以上の環境です。
未検証ですがそれ以下でも一応動くかもしれないです。やっつけで作っているので、
enumで生成されるメソッドやオプション全てをカバーしていないのと、integerの項目にしか使えないです。app/models/concerns/active_model/enum.rb# frozen_string_literal: true # ActiveModel::Attributesのattributeでenumを利用可能にするモジュール # ただしintegerにしか使えない # enum_helpのgemと同様に#{attribute}_i18nメソッドも追加する module ActiveModel module Enum extend ActiveSupport::Concern module ClassMethods def enum(definitions) raise ArgumentError, 'enum attribute: { key: value, key, value, ...} の形式で指定してください' unless valid?(definitions) attribute = definitions.keys.first values = definitions.values.first # getterを上書き define_method(attribute.to_s) do values.invert[attributes[attribute.to_s]] end # 既存のsetterを別名に退避 alias_method "#{attribute}_value=", "#{attribute}=" # setterを上書き define_method("#{attribute}=") do |argument| checked_argument = case argument when Integer values.values.include?(argument) ? argument : nil when String values[argument.to_sym] when Symbol values[argument] else raise ArgumentError, 'string, symbol, integerのいずれかを指定してください' end raise ArgumentError, "'#{argument}' is not a valid #{attribute}" if checked_argument.nil? send("#{attribute}_value=", checked_argument) end # enum_helpの_i18n的なメソッド追加 define_method("#{attribute}_i18n") do enumed_value = send(attribute) I18n.t("enums.#{self.class.name.underscore}.#{attribute}.#{enumed_value}", default: enumed_value.to_s) end end private def valid?(definitions) return false unless definitions.is_a?(Hash) return false if definitions.keys.size != 1 values = definitions.values.first return false unless values.is_a?(Hash) return false unless values.keys.all? { |key| key.is_a?(Symbol) } return false unless values.values.all? { |value| value.is_a?(Integer) } true end end end end使い方
app/models/sample.rbclass Sample include ActiveModel::Model include ActiveModel::Attributes include ActiveModel::Enum attribute :column_name, :integer enum column_name: { hoge: 1, piyo: 2, fuga: 3 } endconfig/locales/ja.ymlja: enums: sample: column: hoge: ほげ piyo: ぴよ fuga: ふがrails consoleで確認
irb(main):001:0> sample = Sample.new => #<Sample:0x000055ec983b15e8 @attributes=#<ActiveModel::AttributeSet:0x000055ec983b14a8 @attributes={"column"=>#<ActiveModel::Attribute::WithCastValue:0x000055ec983b1340 @name="column", @value_before_type_cast=nil, @type=#<ActiveModel::Type::Integer:0x00007f3e74051ea0 @precision=nil, @scale=nil, @limit=nil, @range=-2147483648...2147483648>, @original_attribute=nil>}>> irb(main):002:0> sample.column = 1 => 1 irb(main):003:0> sample.column => :hoge irb(main):004:0> sample.column = 'piyo' => 'piyo' irb(main):005:0> sample.column => :piyo irb(main):006:0> sample.column_i18n => "ぴよ" irb(main):007:0> sample.column = 4 Traceback (most recent call last): 2: from (irb):6 1: from app/models/concerns/active_model/enum.rb:37:in `block in enum' ArgumentError ('4' is not a valid column)
- 投稿日:2019-12-14T00:02:35+09:00
[Ruby on Rails5 アプリケーション プログラミング]学習ログ#3[2019/12/13]
前回 -> [Ruby on Rails5 アプリケーション プログラミング]学習ログ#2[2019/12/12]
次回 -> [[Ruby on Rails5 アプリケーション プログラミング]学習ログ#4[2019/12/14]]
目的
Progateで学んだことをローカル環境で手を動かして復習することで、基礎を固める
使用する教材
山田祥寛(2017). RubyonRails5 アプリケーションプログラミング 株式会社技術評論社
Q.「RubyonRails5 アプリケーションプログラミング」とは?
A.ProgateのRoRコースを終えた後にするRoRの勉強としておすすめされている本
出典
(Samurai Blog / Ruby on Rails学習本おすすめ6選【入門者〜上級者までレベル別に解説】)[https://www.sejuku.net/blog/110292]
今日したこと
ビュー開発の基礎(p104~p136)
(復習)コントローラ/ビュー/ルート定義 を作成
console#viewという名前のコントローラクラスを作成 rails g controller view #view以外の名前のコントローラクラスhogeを間違って作成した場合の切り戻し rails destroy controller hoge #ビューの作成 [view_controller] , [books_controller] を編集 #ルート定義 [routes.rb] get 'view/keyword' post 'keyword/search'フォーム関連のビューヘルパーの作成
console#viewディレクトリに移動 cd app/views/view #テンプレートファイルの作成 vi hogehoge.html.erb