- 投稿日:2019-12-14T23:53:36+09:00
Goで青空文庫の小説からWordCloud作ってみた
Goで青空文庫からWordCloud作ってみた
はじめに
こんにちは、ogadyです。
WordCloudかっこいいですよねぇ。この記事読んでみて、こういうオシャレなやつをGoでやってみたい!と思って作ってみました。
[Python]銀河鉄道の夜をWordCloudで可視化してみた!
せっかくなんで青空文庫のAPIを使用して、作品指定してWordCloud生成するCLIツールっぽくしようと思います。
普段はGoでお堅いバックエンド処理ばっか書いていたので、たまにはこんなことしてみたかった。技術スタック
- Go1.13
使用ライブラリなど
- https://github.com/PuerkitoBio/goquery
- http://github.com/bluele/mecab-golang
- https://github.com/psykhi/wordclouds
- https://qiita.com/ksato9700/items/48fd0eba67316d58b9d6
1. MeCab 導入
今回は、@uminchu987さんの記事と同様に、形態素解析にMeCabを使用していきます。
# MeCabインストール $ brew insatll mecab mecab-ipadic # インストール確認 $ which mecab-config /usr/local/bin/mecab-config次に、GoからMeCabを使うためのライブラリmecab-golangの準備をしていきます。
リポジトリのREADMEに記載されている通りに作業していきます。
# github.com/bluele/mecab-golangの準備 $ export CGO_LDFLAGS="`mecab-config --libs`" $ export CGO_CFLAGS="-I`mecab-config --inc-dir`"これで準備ができました。
2.実装
Aozora APIをCallして、書籍情報を取得する。
今回は引数に本のタイトル名を指定する事でその本の本文でWordCloudを作成します。
本の情報は青空文庫のAPIを叩いてhtmlのURLを取得→スクレイピングといった感じです。(APIでテキストデータとしても取ってこれるみたいだけど今回は勉強兼ねてスクレイピングで)
青空文庫のAPIを叩く
青空文庫APIのリポジトリはこちら
返ってくる書籍情報のデータ構造はこちらの記事を参照しました。
package aozora import ( "encoding/json" "fmt" "io/ioutil" "net/http" "net/url" "time" ) const ( BOOKS_ENDPOINT = "http://pubserver2.herokuapp.com/api/v0.1/books/" ) type Author struct { PersonID int `json:"person_id"` LastName string `json:"last_name"` FirstName string `json:"first_name"` } type BookInfo struct { BookID int `json:"book_id"` Title string `json:"title"` TitleYomi string `json:"title_yomi"` TitleSort string `json:"title_sort"` Subtitle string `json:"subtitle"` SubtitleYomi string `json:"subtitle_yomi"` OriginalTitle string `json:"original_title"` FirstAppearance string `json:"first_appearance"` NDCCode string `json:"ndc_code"` FontKanaType string `json:"font_kana_type"` Copyright bool `json:"copyright"` ReleaseDate time.Time `json:"release_date"` LastModified time.Time `json:"last_modified"` CardURL string `json:"card_url"` ------------略------------ Authors []Author `json:"authors"` } func GetBookInfoByTitleName(titleName string) (string, error) { values := url.Values{} values.Add("title", titleName) url := BOOKS_ENDPOINT + "?" + values.Encode() // APIを叩いてデータを取得 resp, err := http.Get(url) if err != nil { err = fmt.Errorf("青空文庫APIのコールに失敗しました。URL:%s \n %w", url, err) return "", err } defer resp.Body.Close() body, err := ioutil.ReadAll(resp.Body) if err != nil { err = fmt.Errorf("レスポンスボディの読み込みに失敗しました。\n %w", err) return "", err } // 取得したデータを構造体にマッピング var bookInfos []BookInfo err = json.Unmarshal(body, &bookInfos) if err != nil { err = fmt.Errorf("レスポンスボディを構造体にマッピングできませんでした。\n %w", err) return "", err } return bookInfos[0].HTMLURL, nil }取得したURLから本文をスクレイピングする
ここについては、 [Python]銀河鉄道の夜をWordCloudで可視化してみた!のPythonコードをGoに直しただけです。
青空文庫は文字コードがShift JISのようなので、UTF8にデコードしています。
package scraper import ( "fmt" "github.com/PuerkitoBio/goquery" "github.com/ogady/wordCloudMakerForAozora/pkg/decoder" ) func Scrape(url string) (string, error) { doc, err := goquery.NewDocument(url) if err != nil { err = fmt.Errorf("Document Constructorの初期化に失敗しました。\n %w", err) return "", err } selection := doc.Find("body > div.main_text") text := selection.Text() // UTF8に変換 encodedText, err := decoder.Decode("ShiftJIS", []byte(text)) if err != nil { err = fmt.Errorf("UTF8変換に失敗しました。 \n %w", err) return "", err } return string(encodedText), nil }形態素解析を行う
取得したテキストをMeCabを使って形態素解析を行います。
抽出する品詞は名詞に絞る事で、その本を特徴付けるワードを抽出します。
形態素解析をした結果は単語ごとにカウントし、https://github.com/psykhi/wordclouds のインプットの形(map[string]int)にします。ここで、文章を特徴付けるために、意味のない(単語としての情報量が少ない)単語をストップワードとして取り除いています。
僕は自然言語処理に関してはど素人なので、いろんな記事を参考(【自然言語処理入門】日本語ストップワードの考察【品詞別】など)にしたり、実際のMeCabの解析結果を見たりしながらピックアップしていきました。
package morphoAnalyzer import ( "fmt" "sort" "strings" "github.com/bluele/mecab-golang" ) func ParseToNode(text string) (map[string]int, error) { wordMap := make(map[string]int) m, err := mecab.New("-Owakati") if err != nil { err = fmt.Errorf("MeCabの初期化(分かち書き出力モード)に失敗しました。\n %w", err) return wordMap, err } defer m.Destroy() tg, err := m.NewTagger() if err != nil { return wordMap, err } defer tg.Destroy() lt, err := m.NewLattice(text) if err != nil { return wordMap, err } defer lt.Destroy() node := tg.ParseToNode(lt) for { features := strings.Split(node.Feature(), ",") if features[0] == "名詞" { // ストップワードを除去 if !contains(stopWordJPN, node.Surface()) { // mapのkeyに単語・valueにカウントを設定し、キーに対してカウントしていく wordMap[node.Surface()]++ } } if node.Next() != nil { break } } return wordMap, nil } func contains(sl []string, s string) bool { for _, v := range sl { if s == v { return true } } return false }WordCloudを生成する
いよいよWordCloudを作成します。
ライブラリはpsykhi/wordcloudsを使用させていただきました。
使い方はGoDocとREADMEを見れば大体わかります。頻出単語をFontMaxSizeで表示する為、最頻出単語の文字数が多いと画像サイズを超えてしまい描画されないので、フォントサイズの設定を(かなり雑に)計算しています。
package wordCloud import ( "flag" "image" "image/color" "github.com/psykhi/wordclouds" ) type MaskConf struct { File string `json:"file"` Color color.RGBA `json:"color"` } type Conf struct { FontMaxSize int `json:"font_max_size"` FontMinSize int `json:"font_min_size"` RandomPlacement bool `json:"random_placement"` FontFile string `json:"font_file"` Colors []color.RGBA `json:"colors"` Width int `json:"width"` Height int `json:"height"` Mask MaskConf `json:"mask"` } func (c *Conf) calcFontMaxSize(numOfChar int) int { var fontMaxSize int fontMaxSize = int(float32(c.Width) * 0.4 / float32(numOfChar)) return fontMaxSize } func (c *Conf) calcFontMinSize(numOfChar int) int { var fontMinSize int fontMinSize = int(float32(c.Width) * 0.4 / float32(numOfChar) / 10) return fontMinSize } func CreateWordCloud(wordList map[string]int, numOfChar int, colorsSetting []color.RGBA) image.Image { var DefaultConf = Conf{ RandomPlacement: false, FontFile: "./rounded-l-mplus-2c-medium.ttf", Colors: colorsSetting, Width: 2048, Height: 2048, Mask: MaskConf{"", color.RGBA{ R: 0, G: 0, B: 0, A: 0, }}, } conf := DefaultConf var boxes []*wordclouds.Box if conf.Mask.File != "" { boxes = wordclouds.Mask( conf.Mask.File, conf.Width, conf.Height, conf.Mask.Color) } colors := make([]color.Color, 0) for _, c := range conf.Colors { colors = append(colors, c) } w := wordclouds.NewWordcloud(wordList, wordclouds.FontFile(conf.FontFile), wordclouds.FontMaxSize(conf.calcFontMaxSize(numOfChar)), wordclouds.FontMinSize(conf.calcFontMinSize(numOfChar)), wordclouds.Colors(colors), wordclouds.MaskBoxes(boxes), wordclouds.Height(conf.Height), wordclouds.Width(conf.Width), wordclouds.RandomPlacement(conf.RandomPlacement), ) // ここで描画 img := w.Draw() return img }ユースケースロジック
ユースケースのロジックは、ただ順番にパッケージの処理を呼び出しているだけなので省略します。
main
メインはシンプルに、WordCloudCreaterを生成して
Execute()を呼び出すだけです。
描画する画像の色彩を赤系、青系、緑系、ビビッドカラーから選択できるようにしています。package main import ( "flag" "log" "os" "github.com/ogady/wordCloudMakerForAozora/internal" ) func main() { var ( output = flag.String("o", "output.png", "path to output image") titleName = flag.String("t", "銀河鉄道の夜", "target TitleName") specifiedColor = flag.String("c", "red", "specify the color to draw from ’red’, ’blue’, ’green’, and ’vivid’.") ) flag.Parse() repo := internal.NewWordCloudCreater(*output, *titleName, *specifiedColor) err := repo.Execute() if err != nil { log.Fatal(err) os.Exit(1) } }3. 使い方
※MeCabをインストールしている必要があります。
$./main -h Usage of ./main: -c string specify the color to draw from ’red’, ’blue’, ’green’, and ’vivid’. (default "red") -o string path to output image (default "output.png") -t string target TitleName (default "銀河鉄道の夜") exit status 24.生成されたWordCloud
ドグラ・マグラでやったらこんな感じにできました。
うっわぁ・・・
結構本文の特徴を捉えてるんじゃないでしょうか・・・?色とかは個人的な好みでやっているので、センス合わなかったらすいません!
後書き
普段やらないような趣味のツールとか作るとストレス解消になるし、良いですね!
デザインや形態素解析の単語抽出部分でもっとよくできる部分はあったと思います。作成したものは、github上にあげています。
githubリポジトリ - ogady/wordCloudMakerForAozora -今回は自分で青空文庫APIを叩いてみましたが、作った後で青空文庫APIのGoライブラリを見つけたので紹介します!
spiegel-im-spiegel/aozora-apiこれもいい感じで使えそうです。
参考にした記事など

- 投稿日:2019-12-14T23:12:43+09:00
Git/Githubをワンライナーで扱うCLIツールを作った話【Go言語】【cobra】
はじめに
golangとcobraを使ってGit/Githubをワンライナーで扱うCLIツールを作成しました。
前半で導入方法や使い方、後半でcobraでCLIツールを作成する方法(WIP at 2019/12/14)について扱います。対象読者
- golangでCLIツール作ってみたい人
- CLIを使って業務改善したい人
- エンジニアな人
リポジトリ
こちらからどうぞ↓
https://github.com/HiroyukiYagihashi/toolbox導入方法
golangの動作環境があれば下記で動くと思います。
$ go get github.com/HiroyukiYagihashi/tooland/gh $ go install $GOPATH/src/github.com/HiroyukiYagihashi/toolbox/gh※
gitコマンドとhubコマンドに依存していますので、こちらもインストールしてください。
(gitは入れてるけどhubは入れてないって方が多いのでは)
MacOSユーザーかつパッケージマネージャに特にこだわりがなければ下記でインストールできると思います。
違う方は調べてみてください。$ brew install git && brew install hub使い方
下記コマンドで確認できます。
$ gh --help Usage: gh [flags] Flags: -a, --add strings add -c, --cm string commit -m --config string config file (default is $HOME/.gh.yaml) -b, --cop string checkout -b and push -h, --help help for gh -o, --open hub browse -p, --push push下記使用例になります。
$ gh -a app/ -c “Create function” -p -o // app以下をadd、コミットメッセージ”Create function”でcommit、push、該当リポジトリをブラウザで開く $ gh -o // オプション単体でも動作します(挙動は該当リポジトリをブラウザで開く) $ gh -b feature/1/create_function // feature/1/create_functionブランチを切ってリモートに反映cobraでCLIツールを作成する方法(WIP)
需要があったら書こうかなと思ってます。
(個人的にはこの記事に10いいねくらいついたら書くつもりです)それまでは下記を参考にしてください。
https://github.com/spf13/cobra
- 投稿日:2019-12-14T21:35:10+09:00
golang 基本①
型
// よく使う型のみ抜粋 bool int, int32, int64 uint, uint32, uint64 float32, float64ドキュメントによると
int uint型は、32-bitのシステムでは32 bitで、64-bitのシステムでは64 bitです。 サイズ、符号なし( unsigned )整数の型を使うための特別な理由がない限り、整数の変数が必要な場合は int を使うようにしましょう。
とのこと。整数は
intを使えばいい。宣言
コンソールに出力の行うのにfmtパッケージが必要なので必ずインポートする
fmtドキュメントpackage main import "fmt" var str string = "banana" // 変数名 型名 = 値 str2 := "apple" // syntax error: non-declaration statement outside function body // funcの外では宣言できない const integer = 9223372036854775807 + 1 // グローバル変数として使用 変更不可 // この時点では型が宣言されてない integer2 := 9223372036854775807 + 1 // constant 9223372036854775808 overflows int // 通常の変数は型範囲外になるのでエラーとなる func main(){ fmt.Println(str) // banana str2 := "apple" fmt.Println(str2) // apple var i int = 100 i2 := 100 fmt.printf("%T %T", i ,i2) // int int i3:= "10" fmt.printf("%T", i3) // string i2 = "100" // cannot use 100 (type int) as type string in assignment // int型にstring型は代入できない fmt.Println(integer - 1) // 9223372036854775807 }型変換
文字列を数値の変換にはstrconvパッケージを使う
strconvドキュメントpackage main import ( "fmt" "strconv" ) func main(){ s := "10" var i int i, _ = strconv.Atoi(s) fmt.Printf("%T %v\n", i, i) // int 100 s1 := "20" i2, err := strconv.Atoi(s1) fmt.Printf("%T %v %v\n", i2, i2, err) // int 20 <nil> i3 := 30 var s3 string s3 = strconv.Itoa(i3) fmt.Printf("%T %v\n", s3, s3) // string 30 i4 := 123.5 f4 := int(i4) fmt.Printf("%T %v\n", f4, f4) // int 123 i5 := 123 f5 := float64(i4) fmt.Printf("%T %v\n", f5, f5) // floate64 123 }配列とスライス
配列
- サイズを指定する
- サイズは変更できない
スライス
- サイズを指定しない
- サイズを変更できる
配列func main(){ var ary [2]str = [2]str{"abc", "def"} ary2 := [2]string{"ghi", "jkl"} fmt.Println(ary) // [abc def] fmt.Println(ary2) // [ghi jkl] var ary_emp [2]int ary_emp[0] = 100 ary_emp[1] = 200 fmt.Println(ary_emp) // [100 200] ary_emp[2] = 300 fmt.Println(ary_emp) // invalid array index 2 (out of bounds for 2-element array) // 3つ目の値は入れられない }スライスfunc main(){ var slice []int = []int{} slice = append(slice, 200) fmt.Println(slice) // [200] }インデックスfunc main(){ var b []int = []int{100,200,300,400,500} fmt.Println(b[1:3]) // [200 300] // インデックスについて 各値の前にインデックス番号がある [1, 2, 3, 4, 5] ^0 ^1 ^2 ^3 ^4 [1:3] => 2 3 [3:] => 4 5 }
- 投稿日:2019-12-14T21:00:51+09:00
Goで世界のナベアツになるFizzBuzzをつくってみた
背景
漠然とGoの勉強をしたいなと思い、Goのチュートリアルを眺めていたが、突然の睡魔が襲ってきた。
そこで、Goの基本的な機能だけを確認して、何か動くものを作って見ようと思い実装へ。言語習得チュートリアルといえばFizzBuzz!!
と思ったが、それではつまらないなということで、FizzBuzzに応用をこらしたものは何か・・・と考えること約1分。
「世界のナベアツ」のネタが浮かび、実装してみることに。世界のナベアツとは?
- 3の倍数と3が付く数字の時だけあほになる人
- 個人的な感想として、初めて見た時は笑いが止まらなかった
- 久しぶりにYOUTUBEとかで動画を見ると面白いww
- 少し調べてみると、どうやら落語家(桂三度(Wikipedia))に転身したらしい
つまり・・
3の倍数と3が付く数字を検出してみた、ただそれだけの話である。
実装
簡単に書くことができた。
fizzbuzz.gopackage main import ( "fmt" "strconv" "strings" ) func main() { var input string fmt.Print("FizzBuzzの繰り返し回数は?") fmt.Scan(&input) if isPositiveInteger(input) { calc(input) } else { fmt.Println("自然数を入力してください") } } // 処理部分 func calc(input string) { var intInput int intInput, _ = strconv.Atoi(input) for i := 1; i <= intInput; i++ { var stringI string = strconv.Itoa(i) if i%3 == 0 && isHavingThree(stringI) { fmt.Println(stringI + ": 3の倍数、3の付く数字") } else if i%3 == 0 { fmt.Println(stringI + ": 3の倍数") } else if isHavingThree(stringI) { fmt.Println(stringI + ": 3の付く数字") } else { fmt.Println(stringI + ":") } } } // 入力値の自然数チェック func isPositiveInteger(input string) bool { var checkInput int checkInput, _ = strconv.Atoi(input) if checkInput < 1 { return false } return true } // 3が付く数字かのチェック func isHavingThree(stringI string) bool { return strings.Contains(stringI, "3") }出力結果
FizzBuzzの繰り返し回数は?40 1: 2: 3: 3の倍数、3の付く数字 4: 5: 6: 3の倍数 7: 8: 9: 3の倍数 10: 11: 12: 3の倍数 13: 3の付く数字 14: 15: 3の倍数 16: 17: 18: 3の倍数 19: 20: 21: 3の倍数 22: 23: 3の付く数字 24: 3の倍数 25: 26: 27: 3の倍数 28: 29: 30: 3の倍数、3の付く数字 31: 3の付く数字 32: 3の付く数字 33: 3の倍数、3の付く数字 34: 3の付く数字 35: 3の付く数字 36: 3の倍数、3の付く数字 37: 3の付く数字 38: 3の付く数字 39: 3の倍数、3の付く数字 40:実装してみての学び
- Goの基本的な型変換
- 数値 (int) → 文字列 (string):strconv.Itoa(123) // -> "123"
- 文字列 (String) → 数値 (Int):strconv.Atoi("123") // -> 123
- Int型でない値(例えばString型)をInt型に変換してもエラーにならず、Int型の0が返る
- strconv.Atoi("abc") // -> 0
- 文字列中に指定文字列が含まれているかの確認方法
- strings.Contains("123", "3") // -> true
- Goのビルド方法、簡易走行方法
- ビルド -> 実行:
go build fizzbuzz.go->./fizzbuzz- 簡易実行:
go run fizzbuzz.goおわりに
シンプルかつ簡単に実装できて、これがGoの力かと実感。
もっと面白い物をGoで作りたい!参考
- 投稿日:2019-12-14T21:00:51+09:00
Goの世界のナベアツに、俺はなる!!
背景
漠然とGoの勉強をしたいなと思い、Goのチュートリアルを眺めていたが、突然の睡魔が襲ってきた。
そこで、Goの基本的な機能だけを確認して、何か動くものを作って見ようと思い実装へ。言語習得チュートリアルといえばFizzBuzz!!
と思ったが、それではつまらないなということで、FizzBuzzに応用をこらしたものは何か・・・と考えること約1分。
「世界のナベアツ」のネタが浮かび、実装してみることに。世界のナベアツとは?
- 3の倍数と3が付く数字の時だけあほになる人
- 個人的な感想として、初めて見た時は笑いが止まらなかった
- 久しぶりにYOUTUBEとかで動画を見ると面白いww
- 少し調べてみると、どうやら落語家(桂三度(Wikipedia))に転身したらしい
つまり・・
3の倍数と3が付く数字を検出してみた、ただそれだけの話である。
実装
簡単に書くことができた。
fizzbuzz.gopackage main import ( "fmt" "strconv" "strings" ) func main() { var input string fmt.Print("FizzBuzzの繰り返し回数は?") fmt.Scan(&input) if isPositiveInteger(input) { calc(input) } else { fmt.Println("自然数を入力してください") } } // 処理部分 func calc(input string) { var intInput int intInput, _ = strconv.Atoi(input) for i := 1; i <= intInput; i++ { var stringI string = strconv.Itoa(i) if i%3 == 0 && isHavingThree(stringI) { fmt.Println(stringI + ": 3の倍数、3の付く数字") } else if i%3 == 0 { fmt.Println(stringI + ": 3の倍数") } else if isHavingThree(stringI) { fmt.Println(stringI + ": 3の付く数字") } else { fmt.Println(stringI + ":") } } } // 入力値の自然数チェック func isPositiveInteger(input string) bool { var checkInput int checkInput, _ = strconv.Atoi(input) if checkInput < 1 { return false } return true } // 3が付く数字かのチェック func isHavingThree(stringI string) bool { return strings.Contains(stringI, "3") }出力結果
FizzBuzzの繰り返し回数は?40 1: 2: 3: 3の倍数、3の付く数字 4: 5: 6: 3の倍数 7: 8: 9: 3の倍数 10: 11: 12: 3の倍数 13: 3の付く数字 14: 15: 3の倍数 16: 17: 18: 3の倍数 19: 20: 21: 3の倍数 22: 23: 3の付く数字 24: 3の倍数 25: 26: 27: 3の倍数 28: 29: 30: 3の倍数、3の付く数字 31: 3の付く数字 32: 3の付く数字 33: 3の倍数、3の付く数字 34: 3の付く数字 35: 3の付く数字 36: 3の倍数、3の付く数字 37: 3の付く数字 38: 3の付く数字 39: 3の倍数、3の付く数字 40:実装してみての学び
- Goの基本的な型変換
- 数値 (int) → 文字列 (string):strconv.Itoa(123) // -> "123"
- 文字列 (String) → 数値 (Int):strconv.Atoi("123") // -> 123
- Int型でない値(例えばString型)をInt型に変換してもエラーにならず、Int型の0が返る
- strconv.Atoi("abc") // -> 0
- 文字列中に指定文字列が含まれているかの確認方法
- strings.Contains("123", "3") // -> true
- Goのビルド方法、簡易走行方法
- ビルド -> 実行:
go build fizzbuzz.go->./fizzbuzz- 簡易実行:
go run fizzbuzz.goおわりに
シンプルかつ簡単に実装できて、これがGoの力かと実感。
もっと面白い物をGoで作りたい!参考
- 投稿日:2019-12-14T21:00:51+09:00
Goの「世界のナベアツ」に、俺はなる!!
背景
漠然とGoの勉強をしたいなと思い、Goのチュートリアルを眺めていたが、突然の睡魔が襲ってきた。
そこで、Goの基本的な機能だけを確認して、何か動くものを作って見ようと思い実装へ。言語習得チュートリアルといえばFizzBuzz!!
と思ったが、それではつまらないなということで、FizzBuzzに応用をこらしたものは何か・・・と考えること約1分。
「世界のナベアツ」のネタが浮かび、実装してみることに。世界のナベアツとは?
- 3の倍数と3が付く数字の時だけあほになる人
- 個人的な感想として、初めて見た時は笑いが止まらなかった
- 久しぶりにYOUTUBEとかで動画を見ると面白いww
- 少し調べてみると、どうやら落語家(桂三度(Wikipedia))に転身したらしい
つまり・・
3の倍数と3が付く数字を検出してみた、ただそれだけの話である。
実装
簡単に書くことができた。
fizzbuzz.gopackage main import ( "fmt" "strconv" "strings" ) func main() { var input string fmt.Print("FizzBuzzの繰り返し回数は?") fmt.Scan(&input) if isPositiveInteger(input) { calc(input) } else { fmt.Println("自然数を入力してください") } } // 処理部分 func calc(input string) { var intInput int intInput, _ = strconv.Atoi(input) for i := 1; i <= intInput; i++ { var stringI string = strconv.Itoa(i) if i%3 == 0 && isHavingThree(stringI) { fmt.Println(stringI + ": 3の倍数、3の付く数字") } else if i%3 == 0 { fmt.Println(stringI + ": 3の倍数") } else if isHavingThree(stringI) { fmt.Println(stringI + ": 3の付く数字") } else { fmt.Println(stringI + ":") } } } // 入力値の自然数チェック func isPositiveInteger(input string) bool { var checkInput int checkInput, _ = strconv.Atoi(input) if checkInput < 1 { return false } return true } // 3が付く数字かのチェック func isHavingThree(stringI string) bool { return strings.Contains(stringI, "3") }出力結果
FizzBuzzの繰り返し回数は?40 1: 2: 3: 3の倍数、3の付く数字 4: 5: 6: 3の倍数 7: 8: 9: 3の倍数 10: 11: 12: 3の倍数 13: 3の付く数字 14: 15: 3の倍数 16: 17: 18: 3の倍数 19: 20: 21: 3の倍数 22: 23: 3の付く数字 24: 3の倍数 25: 26: 27: 3の倍数 28: 29: 30: 3の倍数、3の付く数字 31: 3の付く数字 32: 3の付く数字 33: 3の倍数、3の付く数字 34: 3の付く数字 35: 3の付く数字 36: 3の倍数、3の付く数字 37: 3の付く数字 38: 3の付く数字 39: 3の倍数、3の付く数字 40:実装してみての学び
- Goの基本的な型変換
- 数値 (int) → 文字列 (string):strconv.Itoa(123) // -> "123"
- 文字列 (String) → 数値 (Int):strconv.Atoi("123") // -> 123
- Int型でない値(例えばString型)をInt型に変換してもエラーにならず、Int型の0が返る
- strconv.Atoi("abc") // -> 0
- 文字列中に指定文字列が含まれているかの確認方法
- strings.Contains("123", "3") // -> true
- Goのビルド方法、簡易走行方法
- ビルド -> 実行:
go build fizzbuzz.go->./fizzbuzz- 簡易実行:
go run fizzbuzz.goおわりに
シンプルかつ簡単に実装できて、これがGoの力かと実感。
もっと面白い物をGoで作りたい!参考
- 投稿日:2019-12-14T20:31:56+09:00
fmt.Scannerを使う
本記事はGo3 Advent Calendar 2019 14日目の記事です。前回の記事は@tennashiさんの最近よく書く HTTP サーバ基礎部分でした。
はじめに
fmtパッケージではスキャニング用の関数やインターフェイスが提供されています。これらを使用することで、パースなどの入力から受け取ったデータを意味ある何らかの値へと変換するような操作をより簡単に書くことができます。本記事ではそれらの紹介を行います。使ってみる
紹介がてらにHTTP/1.0リクエストの最初の行であるRequest Lineをパースする例を考えてみたいと思います。Request Lineは以下のようにフォーマットが定められています 1。
Method Request-URI HTTP/major.minor CRLFもちろん
strings.Splitなどを使ってパースすることもできます。あえて書いてみると以下のようになると思います。func Example() { src := "GET /index.html HTTP/1.0\n" src = strings.TrimRight(src, "\n") splited := strings.Split(src, " ") if len(splited) != 3 { return } method, uri, version := splited[0], splited[1], strings.TrimPrefix(splited[2], "HTTP/") splited = strings.Split(version, ".") if len(splited) != 2 { return } major, err := strconv.Atoi(splited[0]) if err != nil { return } minor, err := strconv.Atoi(splited[1]) if err != nil { return } fmt.Printf("%s %s %d %d", method, uri, major, minor) // Output: // GET /index.html 1 0 }
fmtパッケージのスキャン用の関数を使うと以下のように書くことができます。ここではstringを入力にできるfmt.Sscanfを使っています。func Example() { src := "GET /index.html HTTP/1.0\n" var ( method, uri string major, minor int ) if _, err := fmt.Sscanf(src, "%s %s HTTP/%d.%d\n", &method, &uri, &major, &minor); err != nil { return } fmt.Printf("%s %s %d %d", method, uri, major, minor) // Output: // GET /index.html 1 0 }前者の例では必要であったトリムや型の変換などの操作が、後者の例では登場しません。その分後者のコードの方がスッキリしているように思えます。実際それらの操作はコードの読み手に前提としているフォーマットを意識させるため、可読性を低下させる要因になっていると思います。
私の経験上の話ではありますが、パースなどのフォーマットにしたがって入力から意味ある値を引き抜きたい際に、このように
fmt.Scanを使うと簡単にそれができる場合がありました。以下ではfmt.Scanの基本的な紹介をします。Fscan, Scan, Sscan
fmtパーケージで提供されているスキャニング用関数には、io.ReaderからスキャンするFscan系、io.StdinからスキャンするScan系、stringからスキャンするSscan系があります。それぞれにデフォルト(後述)のフォーマットでスキャンする関数(FscanScan、Sscan)、指定したフォーマットからスキャンする関数(Fscanf、Scanf、Sscanf)と、最初の改行までをスキャンする関数(Fscanln、Scanln、Sscanln)が用意されています(1)。デフォルトのフォーマットはスペース、あるいは改行区切りというものです。このフォーマットは、フォーマットを指定しない
Fscan、Scan、SscanとFscanln、Scanln、Sscanlnで使用されます。ただFscanln、Scanln、Sscanlnは最初の改行でスキャンを止めるので、これらは実際はスペース区切りでスキャンします。他方Fscanf、Scanf、Sscanfに対して指定するフォーマットではスペースと改行は区別されます。そのため以下のコードは一見すると同じように見えますが期待するフォーマットが違います。var a, b, c string fmt.Scan(&a, &b, &c) fmt.Scanf("%s %s %s", &a, &b, &c)後者は指定した通りの
%s %s %sを期待するものですが、前者の場合は例えばa\nb\ncのような入力でもエラーを返さずスキャンします。ちなみにFscan系に渡した
io.Readerは1 byteずつ読み込むのに使用されます(2)。そのため*os.FileなどのReadを呼ぶコストが高い型は、bufio.Readerなどへラップしておいた方が良いと思います。下のベンチマークはファイル({'a'*2047}'\b'{'a'*2047})を読み込む際に、*os.Fileをそのまま渡した場合(BenchmarkFile)とbufio.Readerへとラップした場合(BenchmarkBuffer)との比較です。go test -bench . goos: darwin goarch: amd64 BenchmarkFile-8 1000000000 0.00775 ns/op BenchmarkBuffer-8 1000000000 0.000097 ns/opScanState
スペースや改行区切りのような単純な場合はすでに用意されている
Fscanf等を使用すればスキャンできます。しかし現実には、扱う対象がもっと複雑な場合も多いでしょう。例えばHTTP/1.0では、ヘッダーに,区切りで値が続くフィールドがいくつかありますが、何度値が続くかはもちろんわからないため、可変引数を渡すということもできません。Allow: HEAD, GET, ...
fmt.Scanner(3)を用意することで、独自な実装でスキャンを行うことができます。fmt.Scannerのシグネチャーは以下の通りです。type Scanner interface { Scan(state ScanState, verb rune) error }
fmt.Printなどでのfmt.Stringerやfmt.Formatterなどと同じように、
独自のScannerを用意してFprintなどに渡せば、独自実装が使われるようになります(4)。// If the parameter has its own Scan method, use that. if v, ok := arg.(fmt.Scanner); ok { err = v.Scan(s, verb) if err != nil { if err == io.EOF { err = io.ErrUnexpectedEOF } s.error(err) } return }
Scanner.Scanの第1引数にはScanState(5)という以下のインターフェイスが、第2引数にはフォーマットで指定した%sのsなどの動詞(verb)が渡されます。type ScanState interface { ReadRune() (r rune, size int, err error) UnreadRune() error SkipSpace() Token(skipSpace bool, f func(rune) bool) (token []byte, err error) Width() (wid int, ok bool) Read(buf []byte) (n int, err error) }独自実装では、この
ScanStateを使って、すでに渡してあるio.Readerから読み込んでいくことになります。ここに渡されるScanStateの実体はfmtパッケージのunexportedな型になっています(6)。上記の通りScanStateはio.Readerとio.RuneScannarでもあります。しかしドキュメントに書かれている通り(7)、ScanStateはすでにio.RuneScannarを満たしているので、ScanState.Readは使われるべきではないでしょう。fmtパッケージから渡されるScanState.Readの実装はその旨のエラーを返すようになっています(8)。ただ
io.Readerであることには変わりないので、独自実装側でもFscan系の第一引数に渡すことができます。func (f *foo) Scan(state fmt.ScanState, _ rune) error { // ... if _, err := fmt.Fprint(state, &f.bar); err != nil { return err } }Fprint系は渡された
io.Readerがio.RuneScannerでもあった場合は、そちらを使うようになっています(9)。if rs, ok := r.(io.RuneScanner); ok { s.rs = rs } else { s.rs = &readRune{reader: r, peekRune: -1} }これらを踏まえると、上であげたHTTP/1.0ヘッダーのフィールドは以下のようにスキャンすることができます。
func Example() { src := "Allow: HEAD, GET" var field headerField if _, err := fmt.Sscan(src, &field); err != nil { return } fmt.Print(field.key, " ", field.values) // Output: // Allow [HEAD GET] } type headerField struct { key headerFieldKey values headerFieldValues } func (h *headerField) Scan(state fmt.ScanState, _ rune) error { if _, err := fmt.Fscanf(state, "%s:%s\n", &h.key, &h.values); err != nil { return err } return nil } type headerFieldKey string func (k *headerFieldKey) Scan(state fmt.ScanState, _ rune) error { read, err := state.Token(true, func(char rune) bool { return char != ':' }) if err != nil { return err } *k = headerFieldKey(read) return nil } type headerFieldValues []string func (vs *headerFieldValues) Scan(state fmt.ScanState, _ rune) error { state.SkipSpace() read, err := state.Token(true, func(char rune) bool { return char != '\n' }) if err != nil { return err } splited := strings.Split(string(read), ",") *vs = make(headerFieldValues, len(splited)) for i, v := range splited { (*vs)[i] = strings.TrimLeft(v, " ") } return nil }この例で登場する
ScanState.Tokenは第2引数に渡した関数がtrueを返す限り読み続けます。上述の通りfmtパッケージが渡すScanStateの実装はReadでエラーを返すため、ioutil.ReadAllなどの純粋なio.Readerが求められる場合には使用できません。このTokenを使えば、独自実装内でも例えばEOFまで読むということができます。read, err := state.Token(true, func(char rune) bool { return true }) if err != nil && err != io.EOF { // ... }あるいはGoでの関数リテラルがクロージャーであること(10)を利用して、Content-Length分だけ読み込むということもできます。
type body struct { len int content string } func (b *body) Scan(state fmt.ScanState, _ rune) error { var n int read, err := state.Token(false, func(char rune) bool { defer func() { n++ }() return n < b.len }) if err != nil && err != io.EOF { return err } (*b).content = string(read) return nil }
fmtパッケージから渡されるTokenの実装は、直前に読み込んだものを[]byteでバッファリングし、それを戻り値として返します(11)。そのためドキュメントに示されている通り(12)、Tokenを連続で読んだりすると、それぞれの戻り値が最後に読み込んだものに上書きされてしまいます。Tokenを使う際には受け取った値はすぐにcopyしておくと良いと思います。また
ScanStateにはUnreadRuneがありますが、Fprint系に独自のio.RuneScannerを渡さない限り、すでにUnreadRuneしていた場合はエラーになり(13)、fmtパッケージのScanStateの実装はそのエラーを返しません(14) 2。そのためUnreadRuneを呼ぶ場合は、常にReadRuneの直後の1回だけになると思います。func (r *readRune) UnreadRune() error { if r.peekRune >= 0 { return errors.New("fmt: scanning called UnreadRune with no rune available") } // Reverse bit flip of previously read rune to obtain valid >=0 state. r.peekRune = ^r.peekRune return nil }func (s *ss) UnreadRune() error { s.rs.UnreadRune() s.atEOF = false s.count-- return nil }
ScanStateには他にも、%5sでの5のような幅を返すWidthや、Scannerにはverb(動詞)も渡されるので、これらも活用できると思います。おわりに
本記事では
fmt.Scannerについて紹介しました。スペースやコンマ区切りの単純なケースではデフォルトのScannerにそのまま任せることができます。スキャンの間により複雑な処理が必要な場合は、独自実装なScannerに移譲することもできます。どちらの場合もFprintなどのAPIを使用することができます。特に'スペース'という言葉にスペースも改行も含まれる等のフォーマットの部分が複雑ですが、この記事がその解決の糸口になれば幸いです。ちなみに
net.Connはio.Readerを満たしているので上記の例を組み合わせると、HTTP/1.0系のリクエストのパースはfmt.Fscan(conn, &req)という具合に書けたりします。
参考文献
- https://golang.org/pkg/fmt/#hdr-Scanning
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L321
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L55
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L385
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L21
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L157
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L45
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L179
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L385
- https://golang.org/ref/spec#Function_literals
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L446
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L38
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L370
- https://github.com/golang/go/blob/7d30af8e17d62932f8a458ad96f483b9afec6171/src/fmt/scan.go#L233
- 投稿日:2019-12-14T18:25:17+09:00
Goで日本語コメントを書く悩み
この記事はGo2 Advent Calendar 15日目の記事です。
コメントの悩み
まずは復習から。
とりあえず関数を例にします。Goでは関数などのシンボルの上に、
関数名[半角スペース]内容...という形式でコメントを書くことで、自動的に関数とコメントを紐付けてドキュメント化してくれます。複数行書くこともできます。// Hoge reports whether the hoge is fuga. // hogehoge. hogehoge. func Hoge() {}↓
便利ですね。問題は、このコメントを日本語で書くとき起こります。
社内で使うツールなどは、分かりやすさ優先でドキュメントは日本語にすることが多いかと思います。個人的にも、そうした方がベターだと考えます。
そういったときよく見かける(自分の観測範囲内)のがこんなコメント。
// Hoge はhogeがfugaかどうかを調べる。 func Hoge() {}先述の通り、
関数名[半角スペース]内容...というルールを守っているためドキュメント化されますが、この書き方にはいくつかの懸念があります。
- 見た目の問題: 謎のスペースが挟まっている。typoにすら見えるかもしれない。
- 言葉の問題: 主語からきっちり始めるのが読みやすいとは限らない。
仕様上、英語ほど自然に書くのは無理とはいえ、なんかすっきりしないなあ……と思っていました。(個人の感想です)
一つの解決案
そこで、自分は以下の形式で書くようにしています。
// Hoge - hogeがfugaかどうかを調べる。 func Hoge() {}関数名の後に
-を挟んでいます。特に記号にこだわりはないのですが、:などよりスペースを挟んでも違和感がないものを選定しました。メリット:
- 少し見た目がすっきりする。(主観)
- 主語に縛られないため、日本語的に自然に書ける。(主観)
デメリット:
- 一つ余計なコーディング規約を増やしてしまう。
- 誰も使っていない書き方。
独自記法なのが心苦しいですが、今の所はこのスタイルで統一することで十分綺麗にドキュメント化できていると思っています。
何か他にいい案あれば是非コメントで教えてください!
というわけで、短いですが以上になります。ありがとうございました。

- 投稿日:2019-12-14T17:55:37+09:00
Goで同じディレクトリ・パッケージも同じ関数を呼び出してもエラーが出る
- 投稿日:2019-12-14T17:48:51+09:00
Data APIを利用する際のaws-sdk goの実装とunit test時のテクニックについて
はじめに
この記事では、DataAPIを利用してaws-sdk goを使った開発をする際のポイントをいくつかまとめます。
自分はAPI Gateway + AWS Lambda + Aurora Serverless の構成でAPIを作成しましたので、基本的にその構成を想定した記事になります。data-apiとは
今年の6月ごろから東京リージョンでもAurora Serverless MySQL5.6がData APIのサポートを開始しました。
Data APIを利用することで、Lambda+Aurora Serverlessの構成で完全サーバレスなアプリケーションを構築できるようになりました。公式の記事によるとData APIを利用することの利点として以下が挙げられます。
・VPCでLambda関数を起動するためのオーバーヘッドなしでデータベースにセキュアにアクセスできる
・Secrets Managerに格納されているデータベース認証情報が活用されるため、API呼び出しでの認証情報が不要
・AWS SDKを用いることで、プログラムインターフェイスによってSQLステートメントが実行可能環境
$ go version go version go1.13rc1 darwin/amd64aws-sam-cliの導入
まずはじめに、aws-sam-cliを使ってテンプレートを用意していきます。
基本的には下記のgithubを見れば導入できると思います。
https://github.com/awslabs/serverless-application-model
公式記事を参考にmacでは場合は下記でインストールできます。$ brew --version Homebrew 2.1.10-52-g4822241 Homebrew/homebrew-core (git revision 86eb3; last commit 2019-08-24) Homebrew/homebrew-cask (git revision 35b0; last commit 2019-08-24) $ brew tap aws/tap $ brew install aws-sam-cli $ sam --version SAM CLI, version 0.37.0sam templateの導入
$ sam init --runtime go1.x --name sample-api Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Allow SAM CLI to download AWS-provided quick start templates from Github [Y/n]: Y ----------------------- Generating application: ----------------------- Name: sample-api Runtime: go1.x Dependency Manager: mod Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./sample-api/README.mdこの時点でLambdaのハンドラ関数が用意されたmain.goが作成されます。
$ tree . └── sample-api ├── Makefile ├── README.md ├── hello-world │ ├── main.go │ └── main_test.go └── template.yaml 2 directories, 5 files※GOPATHなどは適宜設定してください
以下はmain.goの一部を抜粋したものです。
main.gopackage main import ( "errors" "fmt" "io/ioutil" "net/http" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" ) func handler(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { return events.APIGatewayProxyResponse{ Body: fmt.Sprintf("Hello, %v", string(ip)), StatusCode: 200, }, nil } func main() { lambda.Start(handler) }main関数は、handler関数を引数にlambdaを実行しており、実装はhandler関数に行います。
デプロイ時にはコンパイルするため、ビジネスロジックをhandler関数から別packageに分けるなどしても特に問題ありません。
まずはAPI Gatewayと連携する上でrequest/responseの型を使いこなす必要があります。request/responseの形式について
API Gateway + AWS LambdaをGoで開発する際の最初のポイントになりますが、requestとresponseの形式が決まっています。
requestAPIGatewayProxyRequest struct { Resource string `json:"resource"` // The resource path defined in API Gateway Path string `json:"path"` // The url path for the caller HTTPMethod string `json:"httpMethod"` Headers map[string]string `json:"headers"` MultiValueHeaders map[string][]string `json:"multiValueHeaders"` QueryStringParameters map[string]string `json:"queryStringParameters"` MultiValueQueryStringParameters map[string][]string `json:"multiValueQueryStringParameters"` PathParameters map[string]string `json:"pathParameters"` StageVariables map[string]string `json:"stageVariables"` RequestContext APIGatewayProxyRequestContext `json:"requestContext"` Body string `json:"body"` IsBase64Encoded bool `json:"isBase64Encoded,omitempty"` }responseAPIGatewayProxyResponse struct { StatusCode int `json:"statusCode"` Headers map[string]string `json:"headers"` MultiValueHeaders map[string][]string `json:"multiValueHeaders"` Body string `json:"body"` IsBase64Encoded bool `json:"isBase64Encoded,omitempty"` }例えばid=xxxのようなGETパラメータを取得しBodyに詰めて返却する場合は下記のようになります。
examplefunc handler(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { id := request.QueryStringParameters["id"] return events.APIGatewayProxyResponse{ Body: id, StatusCode: 200, }, nil }Data APIを用いたSQL実行方法について
このmain.goのhandler関数だけで完結することもできますが、DB接続をモック化するためにもdb_connector.goを別途用意しました。
db_connector.gopackage db import ( "os" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/rdsdataservice" ) func ConnectDb() (*rdsdataservice.RDSDataService, *rdsdataservice.ExecuteStatementInput) { region := os.Getenv("REGION") dbname := os.Getenv("DB_NAME") secretStoreArn := os.Getenv("SECRET_STORE_ARN") dbClusterOrInstanceArn := os.Getenv("DB_CLUSTER_ARN") sess := session.Must(session.NewSession()) svc := rdsdataservice.New(sess, aws.NewConfig().WithRegion(region)) in := &rdsdataservice.ExecuteStatementInput{ Database: aws.String(dbname), ResourceArn: aws.String(dbClusterOrInstanceArn), SecretArn: aws.String(secretStoreArn), IncludeResultMetadata: aws.Bool(true), } return svc, in }DB接続に必要なのはRDSDataServiceとExecuteStatementInputの2つです。
・RDSDataService:DB Clientになっていて、ExecuteStatementでSQLを実行する
・ExecuteStatementInput:DB名やシークレット情報などData APIの実行オプションを指定するRDSDataServiceのインスタンスを作成する際に必要なのは、sessionとaws credensialsの情報です。
aws.NewConfig().WithRegion("リージョン名")とすることで、Regionも指定できます。
aws credensialsの情報は、下記のようにpackageを実行する際にprofileを指定すれば勝手に読み込んでくれます。sam package \ --template-file=./template/template.yaml \ --s3-bucket "$S3_DEPLOY_BUCKET" \ --output-template-file ./packaged.yaml \ --profile=xxxExecuteStatementInputにIncludeResultMetadataを指定すると、レスポンスデータにテーブルカラムのメタ情報を含めて返してくれるようになります。
in := &rdsdataservice.ExecuteStatementInput{ Database: aws.String(dbname), ResourceArn: aws.String(dbClusterOrInstanceArn), SecretArn: aws.String(secretStoreArn), IncludeResultMetadata: aws.Bool(true), // このオプションを追加 }小ネタですが、sessionを張る関数はNewとMustが用意されているようで、sessionが張れなかった場合にpanicを起こして終了してくれるMustを選択しました。
sess := session.Must(session.NewSession())これらを使って下記のようにSQLを実行できます。
exampletype Sample struct { Svc rdsdataserviceiface.RDSDataServiceAPI In *rdsdataservice.ExecuteStatementInput } func (s *Sample) GetSample(id string) (SampleResponse, error) { q := "SELECT * FROM sample_table where id = %s;" sql := fmt.Sprintf(q, id) output, err := s.Svc.ExecuteStatement(s.In.SetSql(sql)) // (以下略) }自分が一番苦労したポイントですが、このoutputの形式が以下のようになっています。
HTTP/1.1 200 Content-type: application/json { "columnMetadata": [ { "arrayBaseColumnType": number, "isAutoIncrement": boolean, "isCaseSensitive": boolean, "isCurrency": boolean, "isSigned": boolean, "label": "string", "name": "string", "nullable": number, "precision": number, "scale": number, "schemaName": "string", "tableName": "string", "type": number, "typeName": "string" } ], "generatedFields": [ { "arrayValue": { "arrayValues": [ "ArrayValue" ], "blobValues": [ blob ], "booleanValues": [ boolean ], "doubleValues": [ number ], "longValues": [ number ], "stringValues": [ "string" ] }, "blobValue": blob, "booleanValue": boolean, "doubleValue": number, "isNull": boolean, "longValue": number, "stringValue": "string", "structValue": { "string" : "Field" } } ], "numberOfRecordsUpdated": number, "records": [ [ { "arrayValue": { "arrayValues": [ "ArrayValue" ], "blobValues": [ blob ], "booleanValues": [ boolean ], "doubleValues": [ number ], "longValues": [ number ], "stringValues": [ "string" ] }, "blobValue": blob, "booleanValue": boolean, "doubleValue": number, "isNull": boolean, "longValue": number, "stringValue": "string", "structValue": { "string" : "Field" } } ] ] }例えば次のようなSQLを投げると
SELECT id, name FROM sample_table where id = 1;レスポンスは以下のようになります。
{ "sample-data": { "ColumnMetadata": [ { "ArrayBaseColumnType": 0, "IsAutoIncrement": false, "IsCaseSensitive": false, "IsCurrency": false, "IsSigned": false, "Label": "id", "Name": "id", "Nullable": 0, "Precision": 20, "Scale": 0, "SchemaName": "", "TableName": "sample_table", "Type": -5, "TypeName": "BIGINT UNSIGNED" }, { "ArrayBaseColumnType": 0, "IsAutoIncrement": false, "IsCaseSensitive": false, "IsCurrency": false, "IsSigned": false, "Label": "name", "Name": "name", "Nullable": 0, "Precision": 250, "Scale": 0, "SchemaName": "", "TableName": "sample_table", "Type": 12, "TypeName": "VARCHAR" } ], "GeneratedFields": null, "NumberOfRecordsUpdated": 0, "Records": [ [ { "BlobValue": null, "BooleanValue": null, "DoubleValue": null, "IsNull": null, "LongValue": 1, "StringValue": null }, { "BlobValue": null, "BooleanValue": null, "DoubleValue": null, "IsNull": null, "LongValue": null, "StringValue": "HOME'S君" } ] ] } }ここから正しくデータを取得するのは結構大変でした。
もしかしたらもっと良いやり方があるのかもしれませんが、自分はColumnMetadataで取得できるカラム名を元に対象レコードが何番目に格納されているかを判断して取得することにしました。exampletype Sample struct { Svc rdsdataserviceiface.RDSDataServiceAPI In *rdsdataservice.ExecuteStatementInput } func (s *Sample) GetSample(id string) (SampleResponse, error) { q := "SELECT id, name FROM sample_table where id = %s;" sql := fmt.Sprintf(q, id) output, err := s.Svc.ExecuteStatement(s.In.SetSql(sql)) if err != nil { return SampleResponse{}, err } ret := map[string]Sample{} var si, sn int for i, v := range output.ColumnMetadata { switch aws.StringValue(v.Label) { case "id": si = i case "name": sn = i } } for _, v := range output.Records { id := strconv.FormatInt(aws.Int64Value(v[si].LongValue), 10) name := aws.StringValue(v[sn].StringValue) ret[id] = Sample{ Id: StringToInt(id), Name: name, } } } return SampleResponse{ Sample: ret, }, nil }型の変換も結構頑張らないといけなかったので、どなたかこの辺の知見がある方にアドバイス頂きたいです。
テストしやすい実装にするために
Data APIを使ってDB接続をする処理を
db_connector.goに分けましたが、aws-sdk goでは簡単にモック化できる仕組みが用意されています。前述の
rdsdataserviceであれば下記のinterfaceを指定して、mockの作成を行うことができます。
https://github.com/aws/aws-sdk-go/blob/master/service/rdsdataservice/rdsdataserviceiface/interface.go
自分はmakefileに下記のコマンドを用意しました。
叩くのは一度だけなので、この記事のように、関連ファイルにスクリプトをコメントしてgo generateで良いのかもしれません。gen-mock: ${GOPATH}/bin/mockgen -source ${GOPATH}/pkg/mod/github.com/aws/aws-sdk-go\@v1.25.19/service/rdsdataservice/rdsdataserviceiface/interface.go -destination src/mock/auroraserverless/rdsdataservice.go -package mock -self_package ./destinationオプションを指定することで任意の場所にモックファイルを生成できます。
また、packageオプションでモックファイルのパッケージ名を指定できます。gomockを使うことでunitテストは次のように書くことができます。
example_testpackage auroraserverless_test import ( "fmt" mock "sample-api/src/mock/auroraserverless" "reflect" "testing" "github.com/golang/mock/gomock" ) func TestGetSample(t *testing.T) { ctrl := gomock.NewController(t) defer ctrl.Finish() dbMock := mock.NewMockRDSDataServiceAPI(ctrl) for _, val := range NormalCases { dbMock.EXPECT().ExecuteStatement(mock.In.SetSql(val.in.sql)).Return(val.in.mockData.Output, val.in.mockData.Err) s := &Sample{ Svc: dbMock, In: mock.In, } got, err := s.GetSample(val.in.Id) t.Run("Sampleの取得時にerrorがnilであること", func(t *testing.T) { if err != nil { t.Errorf("error: %v", err) } }) t.Run(val.testCase, func(t *testing.T) { for i, v := range val.want.result.Sample { t.Run("IDが正しいこと", func(t *testing.T) { if !reflect.DeepEqual(v.Id, got.Sample[i].Id) { t.Errorf("GetSample(%v): Sample[%v].Id does not match \n want:%v \n got:%v", val.in.Id, i, v.Id, got.Sample[i].Id) } }) t.Run("名前が正しいこと", func(t *testing.T) { if !reflect.DeepEqual(v.Name, got.Sample[i].Name) { t.Errorf("GetSample(%v): Sample[%v].Name does not match \n want:%v \n got:%v", val.in.Id, i, v.Name, got.Sample[i].Name) } }) } }) } }自分はSQL実行をこのように書いたので、
output, err := s.Svc.ExecuteStatement(s.In.SetSql(sql))
モック化はこうなりました。
dbMock.EXPECT().ExecuteStatement(mock.In.SetSql(val.in.sql)).Return(val.in.mockData.Output, val.in.mockData.Err)また、実際にはテストケースはTableDrivenTestsで書いておりますが、その部分は割愛しております(モックデータ作るの辛いのでごめんなさい...)。
最後に
結構まとまりがなく書いてしまいましたが、少しでも参考になれば幸いです。
- 投稿日:2019-12-14T15:40:56+09:00
GAEでPub/Subに秒間1万リクエストをPub/Subに突っ込むまでの道のり
はじめに
この記事はiRidge Advent Calendar 2019 における12/14分の記事になります。
注意点
約1年前にやったプロジェクトを思い出して書いております。
技術的にもどんどんアップデートされていく分野なので情報が古い可能性がございます。
(特に、GAEは大きめの更新があったと聞いております)背景
弊社のシステムでは、秒間3千〜1万程度のGPS位置情報がエンドユーザから送信されてきます。 過去よりユーザ数が上昇してこれまでのシステムでは、捌き切れなくなる問題を抱えていることから、リプレイスすることになりました。
要件(実現したいこと)
とにかく、エンドユーザ(アプリ端末)から送られてきた位置情報をGCPのCloud Pub/Subに突っ込むだけ。 送られてきたデータは多少加工するものの、ほぼそのままデータをキューに入れるのみと考えてよい。
なお、様々な背景はあるものの、キューにPub/Subを選んだ主な理由は以下。
- 後続で、Dataflowを使って、大量データを使ったリアルタイム処理をしたい。
- 送信されてきたデータはBigQueryに格納したい
- GCPで用意されているキューを使いたい。
最初の設計
GAE/Go standard Environmentを使って実現
こんな感じのシンプルなコードです。(便宜的にエラー処理は省いています)func main() { http.HandleFunc("/", handler) appengine.Main() } func handler(w http.ResponseWriter, r *http.Request, p httprouter.Params) { ctx := appengine.NewContext(r) locationData := LocationData{} json.NewDecoder(r.Body).Decode(&locationData) // データの加工(省略) client, _ := pubsub.NewClient(ctx, os.Getenv("PROJECT_ID")) topic := client.Topic(os.Getenv("TOPIC_ID")) topic.Publish(ctx, &pubsub.Message{Data: locationData}).Get(ctx) }結果
全くパフォーマンス出ませんでした。
負荷試験を実施したところ、インスタンスが100台以上立ち上がってしまう上に全く捌ききれない事態に。
インスタンスタイプなどのGAEの設定値でどうにかチューニングできるレベルのものではありませんでした。原因
Pub/SubにPublishする処理がけっこう重く、到底秒間1万リクエストを捌くことができなかった。
解決までの道のり
方針
設計1では、ユーザから来た1リクエストに対し、Pub/Subに1リクエスト送っていた。 Pub/SubへのPublish処理が重いので、バルクインサートすればいいのでは?
topicには、PublishSettingsというものがあり、これを設定することで実現できそう。
https://godoc.org/cloud.google.com/go/pubsub#PublishSettingsただし、この設定を使う場合、定義した
topicを他のリクエストで使い回さないといけないので、topicの定義はhandler内ではなく、mainで行う必要あり。同時に、
topicを定義するためのclientもhandlerの外で行う必要あり。var topic *pubsub.Topic func main(){ client, _ := pubsub.NewClient(ctx, os.Getenv("PROJECT_ID")) topic := client.Topic(os.Getenv("TOPIC_ID")) topic.PublishSettings = pubsub.PublishSettings{ DelayThreshold: 1, // 便宜的に全て1 CountThreshold: 1, ByteThreshold: 1, Timeout: 1, } http.HandleFunc("/", handler) appengine.Main() } func handler(w http.ResponseWriter, r *http.Request, p httprouter.Params) { ctx := appengine.NewContext(r) locationData := LocationData{} json.NewDecoder(r.Body).Decode(&locationData) // データの加工(省略) topic.Publish(ctx, &pubsub.Message{Data: locationData}).Get(ctx) }問題
ここで問題発生!
上記コードの
pubsub.NewClientで指定するcontextには何を渡せばいいのか?
appengine.NewContext(r)を渡したいが、これは、引数にhttp.Requestを指定する必要があるので、handler関数内でしか定義できない。とりあえず、
context.Background()を渡しておけばいいかと雑に判断して試験実行。結果
動きません。
どうやら、
appengine.NewContext(r)でないとGAE standardはまともに動かないらしい。
(今は変わっていそう)最終的な結論
当初、いくら調査しても、standardでは実現できる方法が見つからなかった。
したがって、GAE Flexibleを使って実現することにした。 こちらは、普通のcontextを使えるので、以下のコードで実現できた。var topic *pubsub.Topic func main(){ ctx := context.Background() client, _ := pubsub.NewClient(ctx, os.Getenv("PROJECT_ID")) topic := client.Topic(os.Getenv("TOPIC_ID")) topic.PublishSettings = pubsub.PublishSettings{ DelayThreshold: 1, // 便宜的に全て1 CountThreshold: 1, ByteThreshold: 1, Timeout: 1, } http.HandleFunc("/", handler) } func handler(w http.ResponseWriter, r *http.Request, p httprouter.Params) { ctx := context.Background() locationData := LocationData{} json.NewDecoder(r.Body).Decode(&locationData) // データの加工(省略) topic.Publish(ctx, &pubsub.Message{Data: locationData}).Get(ctx) }最後に
おそらく、今はGAEも色々更新されてより賢い方法があると思われるので、そちらを調べてみてください。
- 投稿日:2019-12-14T14:39:24+09:00
億劫なエクセルの操作を自動化する
ZOZOテクノロジーズ #5 Advent Calendar 2019の記事です。
昨日は @saitoryuji さんの「新卒エンジニアがチーム開発でGitHubを使うときに気を付けていること(レビュアー編)」でした。本記事は過去に書いたGo言語でエクセルデータから情報を読み取るの記事を最新の情報に更新したものです。
はじめに
みなさんは普段業務でエクセルは使っていますか?
自分自身業務で触ることはほとんど無くなってきましたが、業界や現場によっては、昔からのやり方が残っていたり、仕事上のPC環境的に使わなければいけなかったりと、いろいろ事情があると思います。
特にアパレル業界では中国とのやり取りもあり、使う機会が多いみたいです。その為、人の手で行うには億劫なエクセル作業をサラッと自動化できたらと思い本記事を書きました。
VBAで自動化するのも良いですが、外部サービスとの連携や、運用のしやすさからプログラムで自動化するのも良いのではないかなと思います。
ファイルの読み込み
実行ファイルがあるフォルダの直下にdataフォルダを用意し、入力に使用します。
今回はエクセルの拡張子を2種類読み込んでいます。// ファイルパスを取得 func getPath() []string { appPath, _ := os.Getwd() dataPath := filepath.Join(appPath, "data") path := filepath.Join(dataPath, "*.xlsx") f, _ := filepath.Glob(path) files := f path = filepath.Join(dataPath, "*.xlsm") f, _ = filepath.Glob(path) files = append(files, f...) return files }エクセルファイルの読み込み
// エクセル読み込み excelFile, err := excel.InputFile(file) // エクセルエラー if err != nil { log.Fatal("excel error exit") return err }シートの読み込み
// 全シート分ルートを回す for _, sheet := range excelFile.Sheet { // シートが見つからない if sheet == nil { log.Fatal("failur open sheet.", RPASheetKey) return nil } // シート名が該当したら(この場合は含まれていたら) if strings.Contains(sheet.Name, "シート名") { // 処理をする } }セルの参照
// すべてのセルを左上から順番に参照する場合 // 行ごとに処理 for _, rowValue := range sheet.Rows { // 列ごとに処理 for _, colVal := range rowValue.Cells { println(colVal.Value) } } // 列、行番号を指定してセルを参照する場合 // 行ごとに処理 for rowKey, rowValue := range sheet.Rows { // 参照したいセルがある列 if rowKey == "任意の行番号" { // 列ごとに処理 for colKey, colVal := range rowValue.Cells { // 参照したいセルがある行 if colKey == "任意の列番号" { println(colVal.Value) } } } } // セルの値から判断したい場合 // 行ごとに処理 for _, rowValue := range sheet.Rows { // 列ごとに処理 for _, colVal := range rowValue.Cells { // 参照したいセルがある行 if colVal.Value == "検索対象のキーワード" { println(colVal.Value) } } } }エクセルファイルの作成、書き込み
// エクセルの作成 excelFile := xlsx.NewFile() // シートの追加 sheet, err := excelFile.AddSheet("NewSheet") if err != nil { fmt.Printf(err.Error()) } // セルの追加 row = sheet.AddRow() cell = row.AddCell() cell.Value = "セルに書き込みたい内容" // ファイルの保存 err = excelFile.Save("任意のファイル名") if err != nil { fmt.Printf(err.Error()) }さいごに
C#とかでも同じ様なライブラリがありますが、言語的なハードルを感じる方にはGo言語の方が使いやすいかもしれませんね。
ZOZOテクノロジーズ #5 Advent Calendar 2019 明日は @meganekids さんが、涙なしでは見れない記事を書いて下さるようです。めちゃくちゃ楽しみです。

- 投稿日:2019-12-14T11:48:04+09:00
スレッドとメッセージパッシング
TL; DR;
何かしらの計算を複数のプロセスやスレッド間で分担して実行する場合に、全体で正しく処理を進行するためにはプロセス/スレッド間で値の受け渡しや調停が必要になります。
値の送受信には、同じメモリ空間を共有して互いが共通のメモリアドレス上の値を書き換える方式(共有メモリ)と、連携の必要なプロセス/スレッド間で値を送り合うメッセージパッシングとの、大きく分けて2つのアプローチが存在します。
年内にもう一本ぐらい記事を書きたい気分になったので今回はこれらをサンプルを交えて紹介していきます。スレッド
別々に進行する処理の間でメモリを共有する例を考えてみます。
まず、単にメインスレッドとは別のスレッドをcreate()して各々が関数を実行する場合です。#include <thread> void echo(string strs) { printf("%d", strs); } int main { // スレッド毎に実行 std::thread th1(echo("hoge")); std::thread th2(echo("fuga")); // スレッド終了待ち受け th1.join(); th2.join(); }スレッド毎に独立した処理をさせる分にはこれで良いのですが、同時に処理を進行させる以上はスレッド間で値を共有する必要が出てきます。
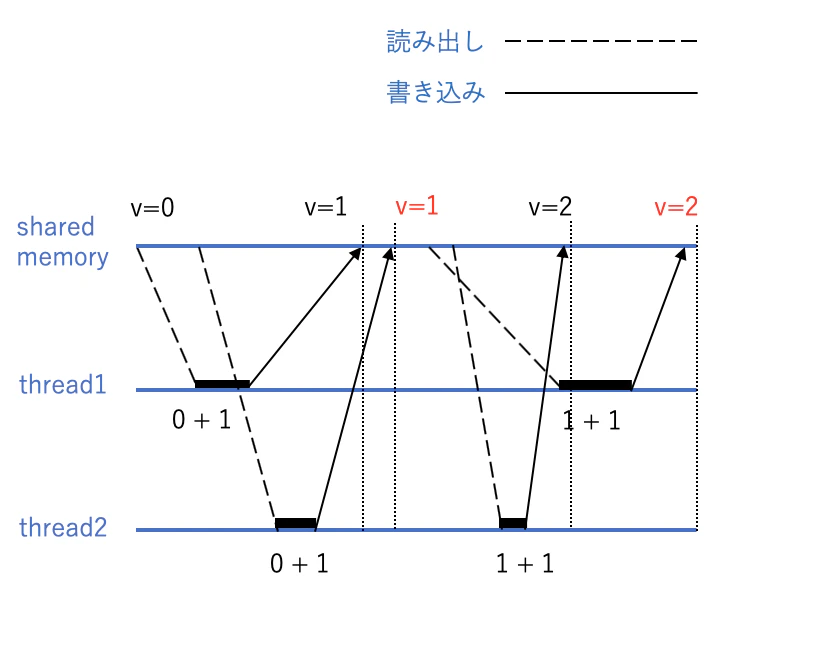
次はスレッド毎に決められた数だけ互いにカウンタを更新する場合を考えてみます。#include <stdio.h> #include <thread> int v = 0; void increment() { for (int i=1; i <= 100000; i++) { v++; } } int main() { std::thread th1(increment); std::thread th2(increment); th1.join(); th2.join(); printf("%d", v); }(たいへん安直なサンプルなのはご容赦ください..)
成る程、2スレッドが100000回ずつ数え上げて最終的にvは200000になる、と言いたいところですが現実はそうはなりません。
実際に最終的な値は決定的ではなく、実行状況次第で毎度異なります。
これを書いた人は各々のスレッドが行儀良く交互に値を書き換えることを期待しますが、実際にはとあるスレッドが値を読んで書き戻す間に、もう片方のスレッドが追い越したり、古い値で上書いてしまうことがあるからです。
mutex
これに対するアプローチとして、1つのスレッドが特定の値を触っている間は他のスレッドが読み書きできないよう値をロックしてみます。
#include <thread> #include <mutex> int v = 0; std::mutex mtx; void increment() { for (int i=0;i<10000;i++) { std::lock_guard<std:mutex> lock(mtx); v++; } } int main { std::thread th1(increment); std::thread th2(increment); th1.join(); th2.join(); printf("%d", v); }
これで正しくカウンタが書き換わりました。
しかしながら一つの値についてロックを獲得できるスレッドは一つなので、同じ値を読み書きするスレッドが多ければ多いほどロックの獲得待ちが発生します。CAS (Compare-And-Swap)
もう一つのアプローチとしては、スレッドが値を書き戻す前に直前に読んだ値と等しいか確認し(compare)、等しい場合に書き戻す(swap)という方法が存在します。
#include <thread> #include <mutex> int v = 0; int comp_and_swap(int* target, int expected, int desired) { if (*target == expected) { // 直前に読んだ値と等しければ書き換える *target = desired; return true; } return false; } void increment() { for (int i=0;i<100000;i++) { int desired = v + 1; // 値の書き換えに成功するまでリトライする while(!comp_and_swap(&v, v, desired)); } } int main() { std::thread th1(increment); std::thread th2(increment); th1.join(); th2.join(); printf("%d", v); }
こちらは値の書き換えに失敗したスレッドのみが再度値を読み直して処理を繰り返すので、複数のスレッドがロックの獲得待ちにならないという特徴があります。
しかしながら、今回は値の数え上げなので発生しませんが、直前に割り込んだスレッドが割り込まれたスレッドが最後に読んだ値と同じ値で書き戻した場合等に、割り込まれたスレッドは途中で値が書き換えられたことを検知できないという問題もあります。CSP
goroutine
go言語のケースを見てみます。
go言語はgroutineと呼ばれる軽量スレッドを備えているので、OSのスレッドに比べ少ないメモリで生成することができます。
関数の呼び出し時にgoを付け加えることでその関数は別のgoroutine上で実行することができます。package main import ( "fmt" "time" ) func echo(strs string) { fmt.Println(strs) } func main() { var strs string = "Hello World" go echo(strs) go echo(strs) // 終了待ち受け time.Sleep(time.Second) }channel
goroutineの間で値の共有が必要な場合はchannelを使用します。
channelは個別のgoroutineとは分離したキューのような機構で、ここに各々のgroutineが値を出し入れすることで値の受け渡しを行います。package main import ("fmt" "sync") func increment(ch chan int, wg *sync.WaitGroup) { for i := 0; i < 100000; i++ { // channelから値を取り出してインクリメントして入れ直す v := <- ch v++ ch <- v } wg.Done() } func main() { wg := &sync.WaitGroup{} var v int = 0 ch := make(chan int, 1) ch <- v wg.Add(1) go increment(ch, wg) wg.Add(1) go increment(ch, wg) // 終了待ち受け wg.Wait() fmt.Println(<- ch) }
後のactorモデルとの違いとしては、channelはプロセス/スレッド毎に結びついている訳ではないので、1つのchannelに対し複数のgoroutineが連携することもあれば、1つgoroutineで複数のchannelを受け持つというように、n:mの柔軟な組み合わせが出来ることが挙げられると思います。
Actor
メッセージパッシングにはCSPとは別に、Actorというモデルがあります。
間にchannelというレイヤを介してプロセス同士が連携するCSPとは異なり、Actorはプロセスに名前をつけて互いに値を送り合います。Actorモデルを採用している言語にはScalaやErlang、Rustがありますが、今回はelixirの例を取り上げてみます。
(ElixirもといErlangは自身のメッセージパッシングの方式をactorと言い切っていないような気がしますが...)。
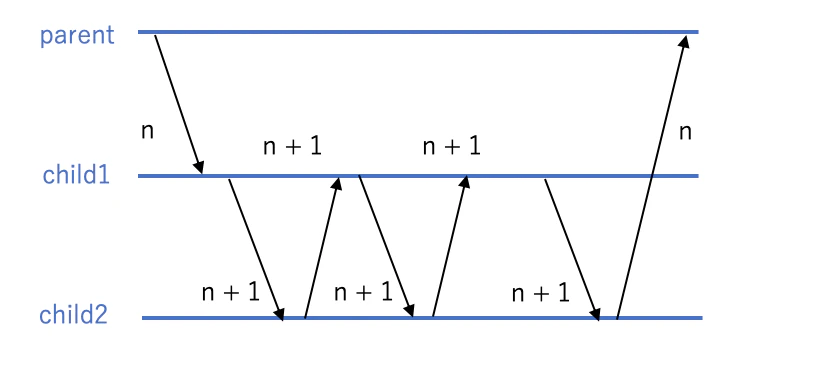
elixirもgoと同様、独立したメモリ空間を持つ独自の軽量プロセスを簡単に生成することができます。
spawn/3の引数に実行したい関数を渡すことで生成した軽量プロセス上で処理を実行することができます。# 標準出力するだけの何か defmodule Hello do def echo(msg) do IO.puts msg end end # 軽量プロセス上で実行 # spawn(モジュール名, 関数名, 引数) spawn(Hello, :echo, ["hoge"]) spawn(Hello, :echo, ["fuga"])ではプロセス間の値の受け渡しはどうするかというと、値を送りたいプロセスを直接指定してメッセージを送信します。
self/1やspawnで自分や生成先のプロセスのIDが返るので、値を送る時はメッセージの中に送信先や返信先のプロセスのIDも含めて送信します。
値を受け取る側はreceiveを使って他プロセスからのメッセージの待ち受けを行います。defmodule Counter do def increment(count, parent) do receive do {:incr, n, target } -> _increment(:incr, count, n, target, parent) # プロセス存続のため再帰 increment(count - 1, parent) {:finish, n, target } -> _increment(:finish, count, n, target, parent) increment(count - 1, parent) {:shutdown} -> exit(:normal) _ -> exit(:normal) end end # カウントアップ defp _increment(:incr, _, n, target, _), do: send target, {:incr, n + 1, self()} # カウントアップ終わり defp _increment(:incr, 0, n, target, _), do: send target, {:finish, n, self()} defp _increment(:finish, 0, n, _, parent), do: send parent, {:finish, n, self()} defp _increment(:finish, _, n, target, _), do: send target, {:finish, n + 1, self()} end n = 0 # 軽量プロセス間のカウンタ child1 = spawn(Counter, :increment, [1000000, self()]) child2 = spawn(Counter, :increment, [1000000, self()]) # 子プロセスに値を渡す send child1, {:incr, n, child2} # 結果待ち受け receive do {:finish, n, _} -> IO.puts n end send child1, {:shutdown} send child2, {:shutdown}(え、こんな野暮ったい書き方はしない?)
軽量プロセスの間にchannelというレイヤが挟まるgoとは異なり、プロセス間で直接値の受け渡しをするイメージが近いです。
また、値を受け取る時にパターンマッチングを利用することで、選択的にメッセージを受信したり内容以下で処理を分けることができます。
サンプルでは生成したプロセスIDを持ち回ってメッセージを送っていますが、elixirはプロセス生成時に名前を登録することができるので、実際は名前を宛先にしてメッセージを送るケースが多いかと思います。
更に互い名前を登録している限りでは、別のホスト上で起動しているプロセスに対してネットワーク越しにメッセージを送受信することもできます。
参考



- 投稿日:2019-12-14T11:11:05+09:00
VSCodeでGoのDebugにちょっとつまづいた話 ~firebase絡み~
VSCodeでFirebase Admin SDKを用いたGoのDebugをしようとしてちょっとハマりました。
SDK初期化でいきなりfirebase-adminsdk.jsonを読み込めなくて怒られる。。
// SDK初期化 app, err := firebase.NewApp(ctx, nil, opt) // err: "cannot read credentials file: open firebase-adminsdk.json: no such file or directory"普通にgo runで起動した時はエラー出ないので、
launch.jsonの設定で現在のディレクトリを明示する必要があるのではないかとアタリをつけてみる。
自分のプロジェクトの場合、{root}/cmd/apiの下にmain.go、プロジェクト直下にfirebase-adminsdk.jsonを置いています。├── cmd │ └── api │ └── main.go ├── *** └── firebase-adminsdk.jsonlaunch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Launch", "type": "go", "request": "launch", "mode": "auto", "program": "${workspaceFolder}/cmd/api", "env": {}, "args": [] } ] }公式ドキュメントで設定の詳細を見たら、明らかにそれっぽいのがあった。
というわけでlaunch.jsonに
cwdを追加します。launch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Launch", "type": "go", "request": "launch", "mode": "auto", "program": "${workspaceFolder}/cmd/api", "cwd": "${workspaceFolder}", "env": {}, "args": [] } ] }デバッグ再起動したら無事成功した!
そもそもGoでFirebase Admin SDK使ってる人どれぐらいいるんだろ・・
仲間が増えると良いなー

- 投稿日:2019-12-14T11:11:05+09:00
VSCodeでGoのDebugにちょっとハマった話 ~firebase絡み~
VSCodeでFirebase Admin SDKを用いたGoのDebugをしようとしてちょっとハマりました。
SDK初期化でいきなりfirebase-adminsdk.jsonを読み込めなくて怒られる。。
// SDK初期化 app, err := firebase.NewApp(ctx, nil, opt) // err: "cannot read credentials file: open firebase-adminsdk.json: no such file or directory"普通にgo runで起動した時はエラー出ないので、
launch.jsonの設定で現在のディレクトリを明示する必要があるのではないかとアタリをつけてみる。
自分のプロジェクトの場合、{root}/cmd/apiの下にmain.go、プロジェクト直下にfirebase-adminsdk.jsonを置いています。├── cmd │ └── api │ └── main.go ├── *** └── firebase-adminsdk.jsonlaunch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Launch", "type": "go", "request": "launch", "mode": "auto", "program": "${workspaceFolder}/cmd/api", "env": {}, "args": [] } ] }公式ドキュメントで設定の詳細を見たら、明らかにそれっぽいのがあった。
というわけでlaunch.jsonに
cwdを追加します。launch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Launch", "type": "go", "request": "launch", "mode": "auto", "program": "${workspaceFolder}/cmd/api", "cwd": "${workspaceFolder}", "env": {}, "args": [] } ] }デバッグ再起動したら無事成功した!
そもそもGoでFirebase Admin SDK使ってる人どれぐらいいるんだろ・・
仲間が増えると良いなー

- 投稿日:2019-12-14T10:52:47+09:00
[Go]メモリ効率を意識!スライス作成時は要素数と容量を決めよう
はじめに
自己紹介
Golangをメインにサーバーサイドエンジニアをやってます。スライスを作成時に要素数や容量は指定していますか??
指定しなくてもプログラムは動くので気にしていない方もいると思うのですが、今回は、要素数(length)と容量(capability)を指定すると何が嬉しいのかについて説明します。
まずスライスの要素数と容量とは?
スライスの要素数(length)
要素数10のintのスライスを作成してみます。
Goの組み込み関数である
makeを使うと簡単に作成できます。https://play.golang.org/p/4JnTYHxbwW3
slice := make([]int, 10) // 要素数 = 10 // [0 0 0 0 0 0 0 0 0 0]このときスライスの中には10個のint型の初期値がはいっています。
つまりメモリ上に値0が10個用意されるということです。
string型だと指定した要素数分だけ
""がはいります。https://play.golang.org/p/4JnTYHxbwW3
slice := make([]string, 10) // [ ]要素数は言葉の通りスライスの要素の個数なのでイメージが付きやすいと思います。
スライスの容量(capability)
容量とはなんでしょう?
説明の前に容量を指定したスライスを早速作ってみましょう。
要素数と違うところは、容量を指定しただけだと値は何も入らないということです。https://play.golang.org/p/9Z4uSD9t2dr
slice := make([]int, 0, 15) // 要素数 = 0, 容量 = 15 // []もちろん要素数を指定するとその分だけ初期値がはいります。
https://play.golang.org/p/u4nd28rj0Ie
slice := make([]int, 10, 15) // 要素数 = 10, 容量 = 15 // [0 0 0 0 0 0 0 0 0 0]そしてなんのために存在しているかといいますと、
スライスのMAXの長さを決めています。
MAXの長さが指定されると確保しなければならないメモリ領域も確定するので無駄なメモリ確保がなくなります。じゃあ、容量超えたらどうなんの?
要素数 × 2の容量が確保されます。https://play.golang.org/p/cO3pblg0gQC
slice := make([]int, 15, 15) slice = append(slice, 1) // 容量15に対して16個目の要素を追加する // 末尾に16個目が追加されるが、、 // [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1] // 要素数は32に fmt.Println(cap(slice)) // 32図があるとわかりやすいので、良いと思った画像のリンクを共有します。
https://images.app.goo.gl/tgPXBkUa69VjWE6n8
指定すると何が嬉しいのか?
普段メモリを意識することはほとんど無いと思いますが、メモリも有限なので効率よく使ってパフォーマンスを上げたいですよね。
そこでスライスの要素数、容量をしていると無駄に確保されるメモリが減って効率がUPします。
指定しないと先程の例でも上げましたが、容量が要素数の2倍確保されます。
使用しないメモリ領域が確保されていると非常にもったいないです。
https://play.golang.org/p/Z8h6Zzo7pyg
var slice []int // 要素数 = 0, 容量 = 0 slice = append(slice, 1) // 要素数 = 1, 容量 = 2具体的なユースケース
作成したいスライスの数が決まっているとき
要素数指定してメモリ効率が良いコードを書きましょう!
例えば、フィールドにIDを持つ構造体
Userがあり、それの複数形である構造体Usersがあるとします。type User struct { ID int } type Users []User単数のUserからIDの中身を知ることは簡単ですが、複数のUsersからIDをまとめて知るにはひと手間かかります。
さらにこのケースだと複数のUsersの長さだけIDがあるのでスライスの長さが決まっています。
そんなときにスライスの要素数指定が役に立ちます。
さらに要素数を指定するだけで初期値が入っているので
indexを使って代入することができ、appendを使わなくてすみます。なんでappendを使いたくないかは下記を参照して下さい。
https://play.golang.org/p/QO4QC4EMNuS
func (us Users) IDs() []int { ids := make([]int, len(us)) // 要素数を決めています for i, u := range us { ids[i] = u.ID // appendを使っていません } return ids }作成したいスライスの最大容量はわかっているとき
容量を指定して無駄なメモリ領域が確保されないようにしましょう!!
例えば、intのスライスがあって5より小さい数字とその他でわけたいときがあったとします。
そんなときは容量を指定しましょう。
https://play.golang.org/p/gcfDUt2-y0g
func separate(condition int, nums []int) (s, l []int) { s = make([]int, 0, len(nums)) // 最大でも nums の要素数になると明らか l = make([]int, 0, len(nums)) for _, n := range nums { if n < condition { s = append(s, n) continue } l = append(l, n) } return s, l }nums := []int{3, 1, 6, 3, 2, 7, 8, 5} separate(5, nums))// [3 1 3 2] [6 7 8 5]要素数を指定するといらない初期値がセットされるので期待通りにいきません。
https://play.golang.org/p/XuI9jgT9eEK
func separate(condition int, nums []int) (s, l []int) { s = make([]int, len(nums)) // 要素数を指定してる!! l = make([]int, len(nums)) for _, n := range nums { if n < condition { s = append(s, n) continue } l = append(l, n) } return s, l }nums := []int{3, 1, 6, 3, 2, 7, 8, 5} separate(5, nums))// [0 0 0 0 0 0 0 0 3 1 3 2] [0 0 0 0 0 0 0 0 6 7 8 5]さいごに
メモリの領域を考えないままだと非常にメモリのムダが多いアプリケーションになってしまうかもしれません。
チリツモだと思ってスライスのメモリは意識していましょう!!
- 投稿日:2019-12-14T06:25:25+09:00
golang で Cloud KMS を使って暗号化/復号化をしてみた。
こんばんわ! @ktoshi です!
今回は機密な情報をDBなどで保管する際に有効な Cloud KMS を利用した話です。
昨今、クラウドサービスなどのAPIを利用する機会が増えていると思いますが、その認証情報をどのように保存するかは非常に重要な問題です。
現に私もその問題に少し…いやかなり悩まされました。
そんな折、Cloud KMS というサービスを利用をすることとなりました。Cloud KMS
暗号鍵をセキュアに管理できるGCPのサービスです。
自動ローテーションやIAMでの権限管理でセキュアなアクセスを実現できる上、APIを利用した暗号化/復号化を行えるので非常に柔軟な利用が可能です。
類似したサービスはAWSの「KMS」や Azureの「Key Vault」などがあります。Key Ring と Key
Cloud KMS では Key を Key Ring で管理しています。
関係性は字のごとく、鍵と鍵束ですね。
ある程度同じ用途で使用される鍵については同じ Key Ring でまとめておくとよいでしょう。
実際に暗号化などで利用されるのは Key となります。目的
Cloud KMS に暗号鍵を用意し、golang + Cloud KMS で文字列を暗号化/復号化する。
実践
では実際に暗号化/復号化を行いましょう。
大きく分けて作業は3つです。
- 暗号鍵の準備
- 暗号化
- 復号化
※ 下記手順の[PROJECT_NAME]、[KEY_RING_NAME]、[KEY_NAME] は適宜置き換えてください。
暗号鍵の準備
暗号をするにはまず暗号鍵を準備しないことには始まりません。
私は terraform を利用しましたが、 gcloud コマンドでも簡単に作成できます。
terraform や gcloud のインストールについては話がそれるので割愛します。terraform の場合
# 鍵束の作成 resource "google_kms_key_ring" "sample_key_ring" { name = "[KEY_RING_NAME]" location = "global" } # 鍵の作成 resource "google_kms_crypto_key" "sample_crypto_key" { name = "[KEY_NAME]" key_ring = google_kms_key_ring.sample_key_ring.self_link }gcloud コマンドの場合
# 鍵束の作成 $ gcloud kms keyrings create [KEY_RING_NAME] --location global --project [PROJECT_NAME] # 鍵の作成 $ gcloud kms keys create [KEY_NAME] --location global --keyring [KEY_RING_NAME] --purpose encryption --project [PROJECT_NAME]これで暗号鍵の準備は完了です。
暗号化
では、実際に golang で暗号化を行います。
今回は処理を行っている箇所のみ抜粋しています。import ( "context" kms "cloud.google.com/go/kms/apiv1" kmspb "google.golang.org/genproto/googleapis/cloud/kms/v1" ) func encryption(str string) ([]byte, error) { ctx := context.Background() client, err := kms.NewKeyManagementClient(ctx) if err != nil { return nil, err } request := &kmspb.EncryptRequest{ Name: "projects/[PROJECT_NAME]/locations/global/keyRings/[KEY_RING_NAME]/cryptoKeys/[KEY_NAME]", Plaintext: []byte(str), } response, err := client.Encrypt(ctx, request) return response.GetCiphertext(), err }これで暗号化した文字列を返すことができます。
なお、Cloud KMS では本気で暗号化されるため、帰ってきた文字列が UTF-8 ではなくなり、
DBなどに直接突っ込むことができません。
DBへ突っ込むときなどは以下のように Base64 でエンコードしてあげましょう。import ( "encoding/base64" "fmt" ) func main() { encString, _ := encryption("sample") // とりあえず、error は切り捨てる。。。 encStringEncode := base64.StdEncoding.EncodeToString(encString) // encStringEncode を DB とかに突っ込む }復号化
暗号化処理はできたので、次に復元しましょう。
やってることはほぼ、暗号化と一緒です。import ( "context" kms "cloud.google.com/go/kms/apiv1" kmspb "google.golang.org/genproto/googleapis/cloud/kms/v1" ) func decryption(ciphertext []byte) (string, error) { ctx := context.Background() client, err := kms.NewKeyManagementClient(ctx) if err != nil { return nil, err } request := &kmspb.DecryptRequest{ Name: "projects/[PROJECT_NAME]/locations/global/keyRings/[KEY_RING_NAME]/cryptoKeys/[KEY_NAME]", Ciphertext: ciphertext, } response, err := client.Decrypt(ctx, request) return string(response.GetPlaintext()), err }これで復号化された文字列を取得できます。
なお、暗号化の際に Base64 でエンコードしている場合はデコードしてから渡しましょうimport ( "encoding/base64" "fmt" ) func main() { encStringDecode := base64.StdEncoding.EncodeToString(encString) decString, _ := decryption(encStringDecode) // decString を 使ってほげほげ // とりあえず、error は切り捨てる。。。 }まとめ
今までパスワードなどを用いる時にはハッシュ化した値を保存し、
認証する際には同じくハッシュ化したもので比較することが多かったと思います。
しかし、今後はAPIの認証情報など可逆暗号化が求められるケースが増えてきます。
そんなときにはぜひ Cloud KMS を使ってみてはいかがでしょうか。
PHP でも Cloud KMS を使ったのでその記事も後日あげようと思います。
それでは、みなさまも安全で快適な暗号化ライフを。
- 投稿日:2019-12-14T04:53:53+09:00
Kafkaメッセージの受信
今日は昨日送信したメッセージを受信する処理をみていきます。
【バグ修正】
その前に1つバグを修正します。
substrate.Messageを以下の型で実装していました。main.gotype message []byte func (m message) Data() []byte { return m }しかし、substrateライブラリ内で以下の記述があり、sliceは
==/!=の演算子で比較できない仕様からパニックを発生してしまうことになります。sync_adapter_sink.go#L98if msg.Message != req.m { panic(fmt.Sprintf("wrong message expected: %s got: %s", req.m, msg.Message)) }というわけで
message型を以下のように修正します。main.gotype message struct{ data []byte } func (m *message) Data() []byte { return m.data }呼び出し側もちょっとした変更が必要なのでレポジトリを確認してください。
修正終わり。substrate.SynchronousMessageSourceの作成
メッセージを受信するSourceオブジェクトのインターフェイスもsubstrateライブラリから提供されています。
initialiseKafkaSource()メソッドを以下のように定義し、Sourceオブジェクトを作成します。main.gofunc initialiseKafkaSource(version, brokers, topic, consumer *string, offsetOldest *bool) (substrate.SynchronousMessageSource, error) { var kafkaOffset int64 if *offsetOldest { kafkaOffset = kafka.OffsetOldest } else { kafkaOffset = kafka.OffsetNewest } source, err := kafka.NewAsyncMessageSource(kafka.AsyncMessageSourceConfig{ ConsumerGroup: *consumer, Topic: *topic, Brokers: strings.Split(*brokers, ","), Offset: kafkaOffset, Version: *version, }) if err != nil { return nil, err } return substrate.NewSynchronousMessageSource(source), nil }呼び出し側はこんな感じです。
main.gosourceKafkaVersion := app.String(cli.StringOpt{ Name: "source-kafka-version", Desc: "source kafka version", EnvVar: "SOURCE_KAFKA_VERSION", }) sourceBrokers := app.String(cli.StringOpt{ Name: "source-brokers", Desc: "kafka source brokers", EnvVar: "SOURCE_BROKERS", Value: "localhost:9092", }) consumerID := app.String(cli.StringOpt{ Name: "consumer-id", Desc: "consumer id to connect to source", EnvVar: "CONSUMER_ID", Value: appName, }) kafkaOffsetOldest := app.Bool(cli.BoolOpt{ Name: "kafka-offset-oldest", Desc: "If set to true, will start consuming from the oldest available messages", EnvVar: "KAFKA_OFFSET_OLDEST", Value: true, }) ... actionSource, err := initialiseKafkaSource(sourceKafkaVersion, sourceBrokers, actionTopic, consumerID, kafkaOffsetOldest) if err != nil { log.WithError(err).Fatalln("init action event kafka source") } defer actionSource.Close()メッセージハンドラの作成
substrate.SynchronousMessageSourceインターフェイスには以下のメソッドが定義されています。substrate.gotype SynchronousMessageSource interface { ... // ConsumeMessages calls the `handler` function for each messages // available to consume. If the handler returns no error, an // acknowledgement will be sent to the broker. If an error is returned // by the handler, it will be propogated and returned from this // function. This function will block until `ctx` is done or until an // error occurs. ConsumeMessages(ctx context.Context, handler ConsumerMessageHandler) error ... }この引数となっている
substrate.ConsumerMessageHandlerは以下のように定義されており、メッセージを処理するハンドラとしてこれを実装します。substrate.go// ConsumerMessageHandler is the callback function type that synchronous // message consumers must implement. type ConsumerMessageHandler func(context.Context, Message) errorというわけでハンドラとなる
actionEventHandlerは以下の通り。action_event_handler.gotype actionEventHandler struct { todoMgr todoManager } func newActionEventHandler(todoMgr todoManager) actionEventHandler { return actionEventHandler{todoMgr: todoMgr} } func (h actionEventHandler) handle(ctx context.Context, msg substrate.Message) error { var env envelope.Event if err := proto.Unmarshal(msg.Data(), &env); err != nil { return errors.Wrap(err, "failed to unmarshal message") } if types.Is(env.Payload, &event.CreateTodoActionEvent{}) { var ev event.CreateTodoActionEvent if err := types.UnmarshalAny(env.Payload, &ev); err != nil { return errors.Wrap(err, "failed to unmarshal payload") } if err := h.todoMgr.projectTodo(todo{ id: ev.Id, title: ev.Title, description: ev.Description, }); err != nil { return errors.Wrap(err, "failed to project a todo") } } return nil }
msg.Data()からイベントまでアンマーシャルする処理は先日keyFuncの項目でみたものとよく似ていますね。
とりだしたイベントを保存する処理は同期処理時にサーバー構造体で実装したものと全く一緒です。
テストはごめんなさい割愛です。なお、todoのidの取り扱いに関して加えた変更に従って、データ型や
todoManagerのインターフェイスも一部変更しているので合わせてご確認ください。メッセージ受信プロセスの開始
main.go内で新たにメッセージを受信するgoroutineを開始します。
main.gowg.Add(1) go func() { defer wg.Done() h := newActionEventHandler(store) if err := actionSource.ConsumeMessages(context.Background(), h.handle); err != nil { errCh <- errors.Wrap(err, "failed to consume action event") } }()これでもいいのですが、少し改良を加えて平和に終了できるようにしましょう。
main.goctx, cancel := context.WithCancel(context.Background()) wg.Add(1) go func() { defer wg.Done() h := newActionEventHandler(store) if err := actionSource.ConsumeMessages(ctx, h.handle); err != nil { errCh <- errors.Wrap(err, "failed to consume action event") } }() ... gSrv.GracefulStop() cancel() wg.Wait()これでgRPCサーバと同時にKafkaメッセージの受信プロセスが開始されます。
よしじゃあKubernetesマニフェストファイルを更新してデバッグしていこう、というところですが、サボります?
気になる方はGitHubレポジトリを確認しておいてください。これでTodoを保存する処理の非同期化ができました。
明日はKafkaにgRPCインターフェイスを付けてみるなんてちょっと面白いことをしたいなーと思います。では。
- 投稿日:2019-12-14T00:45:42+09:00
Goのsingleflight packageの紹介
このエントリーは、Go5 Advent Calendar 2019の14日目のエントリーです。
今回、singleflight Packageの紹介をしたいと思います。 利用したことがない方は、一度、検討する材料となってもらえればと幸いです。
What is singleflight?
singleflight とはなにかというと、次の通りになります。
Package singleflight provides a duplicate function call suppression mechanism.
Package singleflightは、重複したfunction callをまとめるメカニズムを提供します。
私は、もしアプリケーションが同じリソースのための複数のリクエストを受けるようなことがあるのであれば、singleflightは、とても役に立つPackage、と考えています。例えば、RDB(マスタデータ)、画像ファイル、IPアドレスのLookup、 Client証明書 など、こういった普段変わることがないリソースの参照が必要となるケースが該当するケースです。
また、singleflightの手法では、Thundering herd problem を回避することができます。
客観的な指標として、実際にどれくらいのPackageから参照されているかというと、現時点(2019/12/13)では、120 packagesから参照されています。
その中でも、どんなプロダクトで利用されているか参考までにあげてみると、HashiCorp社のConsulだったり、Fabioだったり、証明書の取得する処理で利用されているUse case
があります。https://github.com/hashicorp/consul/blob/master/agent/consul/acl.go
https://github.com/fabiolb/fabio/blob/master/cert/source.gosingleflightが提供しているfunctionは、次の3つになります。
- func (g *Group) Do(key string, fn func() (interface{}, error)) (v -interface{}, err error, shared bool)
- func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result
- func (g *Group) Forget(key string)
実際のソースファイルは、singleflight.goが用意されています。
a recent trend of singleflight
Goのソースの中身をみてみると、singleflightは、標準ライブラリとして使われていて、Goのinternal Packageにもあります。Goの内部ではどういったUse caseでcallされてるかというと、net/lookup.go がその例としててあげられます。GoDocも2種類存在しています。
Go Syncという名前の別のリポジトリでも管理されてあり、このリポジトリは
言語およびsyncおよびsync/atomicPackageで提供されるものに加えて、Goで並列実行の基本機構を提供しています。GoのRelease dashboardによると、
internal/singleflightは、Go1.14から削除するかも、x/sync/singleflightを利用することを推奨する予定だそうです。詳しい背景や議論のポイントが知りたい場合はこちらのissuesとこのgo-reviewのリンクより確認できる。ただし、go-reviewでのstausは、2019/11/22に
Abandonedへ変更されているため、変わらないかもしれません。https://github.com/golang/go/issues/31697
https://go-review.googlesource.com/c/go/+/174080/Introduction to Use case
ここでは、singleflight Packageを利用したUse caseを2つ紹介しようと思います。
Use case 1 - net/lookup
lookupGroupは、LookupIPAddr 呼び出しが同じhostをlookupするために、一緒にマージしています。
そして、LookupIPAddrは、そのlookupGroupをlocal resolverを介して使い、hostを参照します。
以下に関連する処理のコードを引用しておきます。// lookupGroup merges LookupIPAddr calls together for lookups for the same // host. The lookupGroup key is the LookupIPAddr.host argument. // The return values are ([]IPAddr, error). lookupGroup singleflight.Grouphttps://github.com/golang/go/blob/master/src/net/lookup.go#L151
func (r *Resolver) getLookupGroup() *singleflight.Group { if r == nil { return &DefaultResolver.lookupGroup } return &r.lookupGroup }https://github.com/golang/go/blob/master/src/net/lookup.go#L160
// We don't want a cancellation of ctx to affect the // lookupGroup operation. Otherwise if our context gets // canceled it might cause an error to be returned to a lookup // using a completely different context. However we need to preserve // only the values in context. See Issue 28600. lookupGroupCtx, lookupGroupCancel := context.WithCancel(withUnexpiredValuesPreserved(ctx)) lookupKey := network + "\000" + host dnsWaitGroup.Add(1) ch, called := r.getLookupGroup().DoChan(lookupKey, func() (interface{}, error) { defer dnsWaitGroup.Done() return testHookLookupIP(lookupGroupCtx, resolverFunc, network, host) }) if !called { dnsWaitGroup.Done() }https://github.com/golang/go/blob/master/src/net/lookup.go#L257
Use case 2 - DataLayerとBFFのMicroservices
Microservicesで開発していたときに、次のような仕様の場合、適用可能かと考えています。
Client
- Microservice A に対して、GetProduct, ListProductsのAPIを呼び出します。
- APIから受け取った結果を、一覧として表示します。
Microservice A - BFF layer
- Microservice Aは、API:GetProductComponent を提供しています。
- API:GetProductComponentは、Microservice Bの2つのAPI(GeProduct, ListProducts)を呼び出します。その後に、受け取った情報を集約して、ProductComponentとして、結果を返します。
Microservice B - Database layer
- Microservice Bは、2つのAPI(GeProduct, ListRecommendedProduct)を提供しています。
- API: GeProductは、IDを利用して、Productのマスタ情報を結果として返します。
- API: ListProductsは、Productのマスタに登録してから1週間以内のProduct情報を結果として返します。
図示すると以下のような関連になります。
以上のような形で、このUse caseでは、Microservice Bが提供しているAPIで参照されるマスタ情報があまり変わらないリソースであるととらえて、呼び出し元であるMicroservice A側にsingleflightを使うようにすることで重複したAPI呼び出しをまとめることが可能となります。
Conclusion
- singleflight packageは、重複したfunction callをまとめるメカニズムを提供してくれます。もし同じリソースを要求するAPIをチューニングする必要があるときは、とても役に立つかと思います。
- MicroservicesのBFF patternを使用している場合には、簡単に適用させるUse Caseが見つかるかと思います。
- もしsingleflightを興味を持ったようでしたら、他のプロダクトでどのように使っているかを調べてみるとより理解が深まるかと思います。 REF: https://godoc.org/golang.org/x/sync/singleflight?importers
以上になります。このエントリーをもとにsingleflightを使ってみようと思える機会になったのであれば、うれしく思います。
