@dataclasses.dataclassclassStrictDataclass:def__post_init__(self):forkey,valinself.__dataclass_fields__.items():member=getattr(self,key)assertisinstance(member,val.type),f"Invalid Type of member: {type(member)} != {val.type}"foo:intStrictDataclass(foo=1)# ok
StrictDataclass(foo=1.2)# AsertionError: Invalid Type of member: <class 'float'> != <class 'int'>
Deduplication makes your programs shorter, easier to read, and easier to update.
import random
def getAnswer(answerNumber):
if answerNumber == 1:
return 'It is certain'
elif answerNumber == 2:
return 'It is decidedly so'
elif answerNumber == 3:
return 'Yes'
elif answerNumber == 4:
return 'Reply hazy try again'
elif answerNumber == 5:
return 'Ask again later'
elif answerNumber == 6:
return 'Concentrate and ask again'
elif answerNumber == 7:
return 'My reply is no'
elif answerNumber == 8:
return 'Outlook not so good'
elif answerNumber == 9:
return 'Very doubtful'
r = random.randint(1, 9)
fortune = getAnswer(r)
print(fortune)
Note that since you can pass return values as an argument to another function call, you could shorten these three lines:
r = random.randint(1, 9)
fortune = get answer(r)
print(fortune)
to this single equivalent line:
print(getAnswer(random.randint(1, 9)))
The None Value
Keyword Arguments and print()
Local and Global Scope
I learned how local and global scope is different and could imagine how return function can be used.
A variable that exists in a local scope is called a local variable, while a variable that exists in the global scope is called a global variable.
Local Variables Cannot Be Used in the Global Scope
Local Scopes Cannot Use Variables in Other Local Scopes
Global Variables Can Be Read from a Local Scope
Local and Global Variables with the Same Name
The global Statement
Exception Handling
A Short Program: Guess the Number
# This is a guess the number game.
import random
secretNumber = random.randint(1, 20)
print('I am thinking of a number between 1 and 20.')
# Ask the player to guess 6 times.
for guessesTaken in range(1, 7):
print('Take a guess.')
guess = int(input())
if guess < secretNumber:
print('Your guess is too low.')
elif guess > secretNumber:
print('Your guess is too high.')
else:
break # This condition is the correct guess!
if guess == secretNumber:
print('Good job! You guessed my number in ' + str(guessesTaken) + ' guesses!')
else:
print('Nope. The number I was thinking of was ' + str(secretNumber))
Short Practice: the Collatz Sequence
'''
If number is even, then collatz() should print number // 2 and return this value.
If number is odd, then collatz() should print and return 3 * number + 1.
'''
def collatz(number):
if number % 2 == 0:
return number // 2
elif number % 2 == 1:
return 3 * number + 1
'''
Lets the user type in an integer and that keeps calling collatz() on that number
until the function returns the value 1.
'''
print('Enter number:')
try:
info = int(input())
while info != 1:
info = collatz(info)
print(info)
except ValueError:
print('You must enter integer')
importpandasaspdimportsysimportosclasscsv_reader:#オーバーライドを前提としたread()メソッド
defread(self,inputs):returnclassxy_csv_reader(csv_reader):defread(self,inputs):#インプットされた文字列をinputsに格納
self.inputs=inputs#ファイルの存在を確認し、存在しなければエラーメッセージを表示しプログラムを終了。
ifnotos.path.exists(self.inputs+".csv"):sys.exit('wrong name of csv')#ファイルの存在が確認できたら、pandasでデータの読み込み
else:df=pd.read_csv(self.inputs+".csv")#ちゃんと読み込めたかデータを表示する。無くてもよい。
print(df,"\n")#データの要素を格納し、返す
xname=df.columns[0]yname=df.columns[1]list_x=df[xname].valueslist_y=df[yname].valuesreturnxname,yname,list_x,list_y
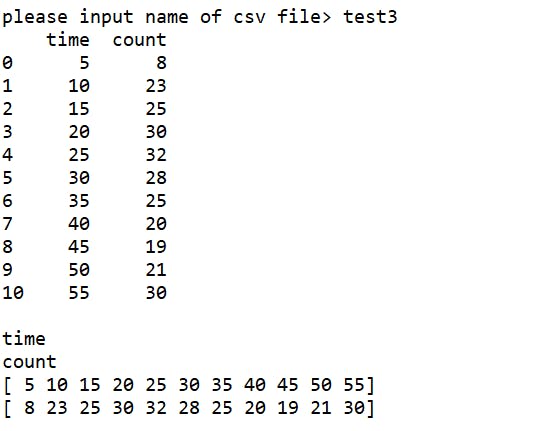
fromcsv_readerimport*#ファイル名を入力する
csvname=input('please input name of csv file> ')#xy_csv_readerクラスのオブジェクトを生成
csv_reader=xy_csv_reader()#データの読み込みを実行
xname,yname,list_x,list_y=csv_reader.read(csvname)print(xname)print(yname)print(list_x)print(list_y)
メモ「Automate the Boring stuff -chapter2 Flow control」
Boolean values, comparison operators, and Boolean operators
Operator Meaning
== Equal to
!= Not equal to
< Less than
> Greater than
<= Less than or equal to
>= Greater than or equal to
Python considers the integer 42 to be different from the string '42'
The == operator (equal to) asks whether two values are the same as each other.
The = operator (assignment) puts the value on the right into the variable on the left.
Binary Boolean Operators
Expression Evaluates to...
True and True True
True and False False
False and True False
False and False False
The or operator evaluates an expression to True if either of the two Boolean values is True. If both are False, it evaluates to False
Flow Control Statements > if, else, and elif`
while Loop Statements
The while loop keeps looping while its condition is True
break Statements
continue Statements
for Loops and the range() Function
print('My name is')
for i in range(5):
print('Jimmy Five Times (' + str(i) + ')')
The above program works as same as following one.
print('My name is')
i = 0
while i < 5:
print('Jimmy Five Times (' + str(i) + ')')
i = i + 1
---
for i in range(12, 16):
print(i)
->12, 13, 14, 15
for i in range(0, 10, 2):
print(i)
->0, 2, 4, 6, 8
for i in range(5, -1, -1):
print(i)
->5, 4, 3, 2, 1, 0
fromabcimportABCMeta,abstractmethodimportnumpyasnpclassGradientDescent(metaclass=ABCMeta):def__init__(self,max_iter:int=300,extended_output:bool=False):self.max_iter=max_iterself.extended_output=extended_outputself.f=list()@abstractmethoddef_f(self,x:np.ndarray):raiseNotImplementedError('The function _f is not implemented')@abstractmethoddef_df(self,x:np.ndarray):raiseNotImplementedError('The function _df is not implemented')@abstractmethoddef_step_size(self,x:np.ndarray,iteration:int):raiseNotImplementedError('The function _step_size is not implemented')@abstractmethoddef_retraction(self,x:np.ndarray,v:np.ndarray):raiseNotImplementedError('The function _retraction is not implemented')defoptimize(self,x:np.ndarray):res=np.copy(x)ifself.extended_output:self.f.append(self._f(res))foriinrange(1,self.max_iter+1):step_size=self._step_size(res,i)res=self._retraction(res,-self._df(res)*step_size)ifself.extended_output:self.f.append(self._f(res))returnresclassRayleighQuotientGD(GradientDescent):def__init__(self,A:np.ndarray,step_size:float=1.0,c=0.5,max_iter:int=300,extended_output:bool=False):super().__init__(max_iter=max_iter,extended_output=extended_output)self.A=Aself.step_size=step_sizeself.c=cdef_f(self,x:np.ndarray)->float:Ax=np.dot(self.A,x)xx=np.dot(x,x)returnnp.dot(Ax,x)/xxdef_df(self,x:np.ndarray)->np.ndarray:Ax=np.dot(self.A,x)xx=np.dot(x,x)f=np.dot(Ax,x)/xxreturn2*(Ax-f*x)/xxdef_step_size(self,x:np.ndarray,iteration:int)->float:df=self._df(x)d=-np.copy(df)g=np.dot(df,d)t=self.step_sizef=self._f(x)whileself._f(self._retraction(x,t*d))>f+self.c*t*g:t*=0.5returntdef_retraction(self,x:np.ndarray,v:np.ndarray)->np.ndarray:returnx+vclassRayleighQuotientSphereGD(GradientDescent):def__init__(self,A:np.ndarray,step_size:float=1.0,c=0.5,max_iter:int=300,extended_output:bool=False):super().__init__(max_iter=max_iter,extended_output=extended_output)self.A=Aself.step_size=step_sizeself.c=cdef_f(self,x:np.ndarray)->float:Ax=np.dot(self.A,x)returnnp.dot(Ax,x)def_df(self,x:np.ndarray)->np.ndarray:Ax=np.dot(self.A,x)f=np.dot(Ax,x)return2*(Ax-f*x)def_step_size(self,x:np.ndarray,iteration:int)->float:df=self._df(x)d=-np.copy(df)g=np.dot(df,d)t=self.step_sizef=self._f(x)whileself._f(self._retraction(x,t*d))>f+self.c*t*g:t*=0.5returntdef_retraction(self,x:np.ndarray,v:np.ndarray)->np.ndarray:norm=np.linalg.norm(x+v)return(x+v)/normifnorm!=0else0
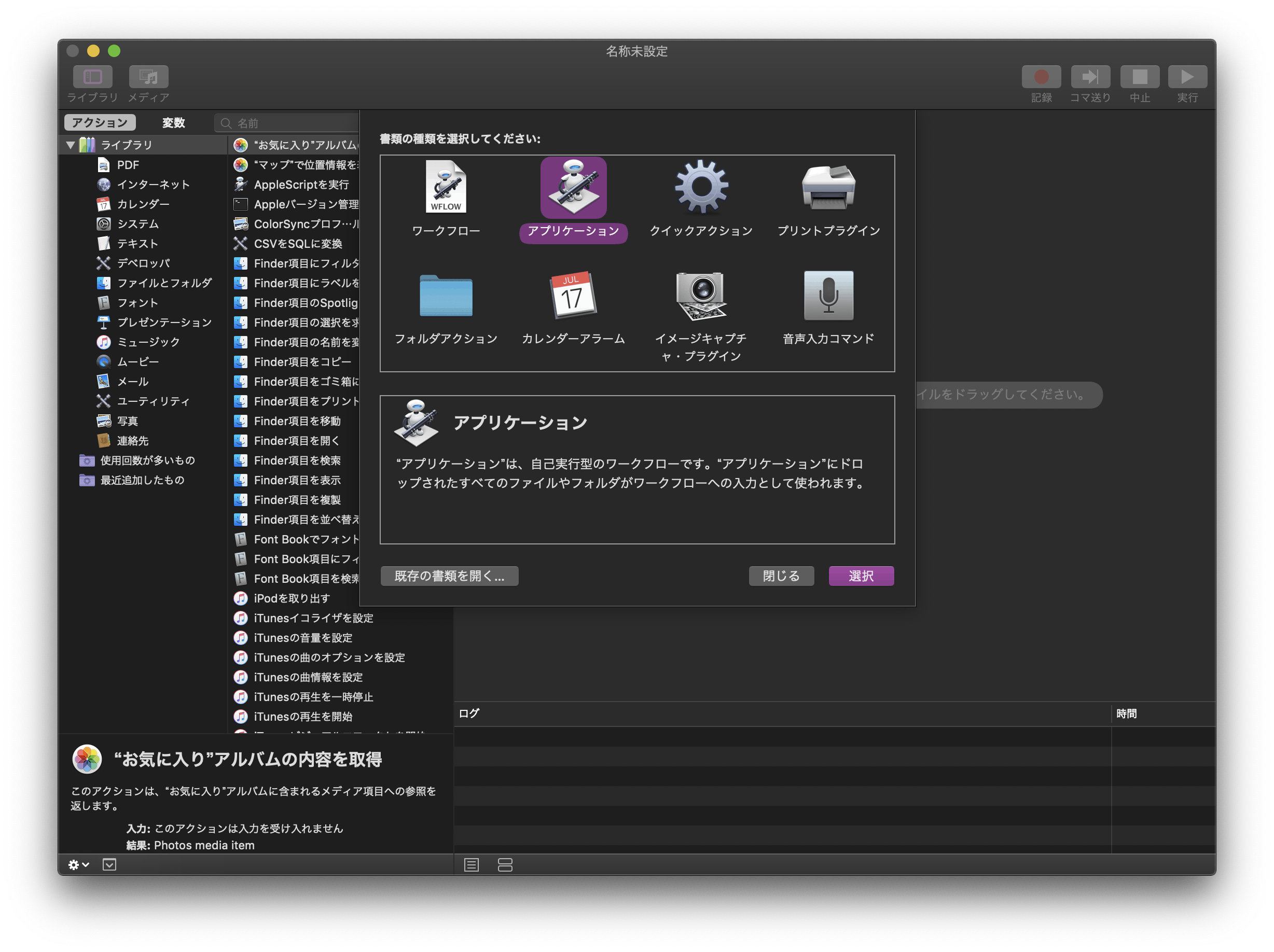
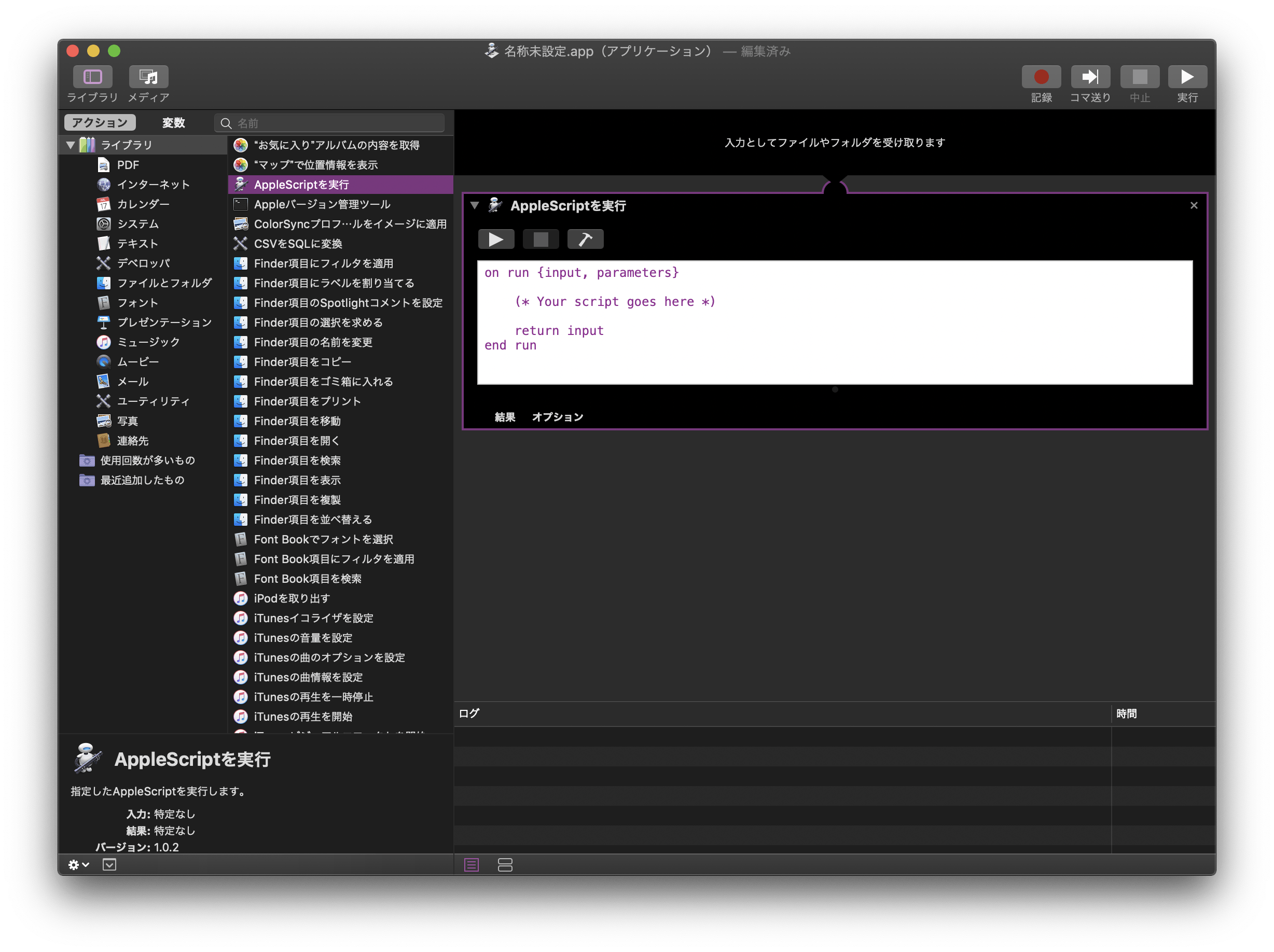
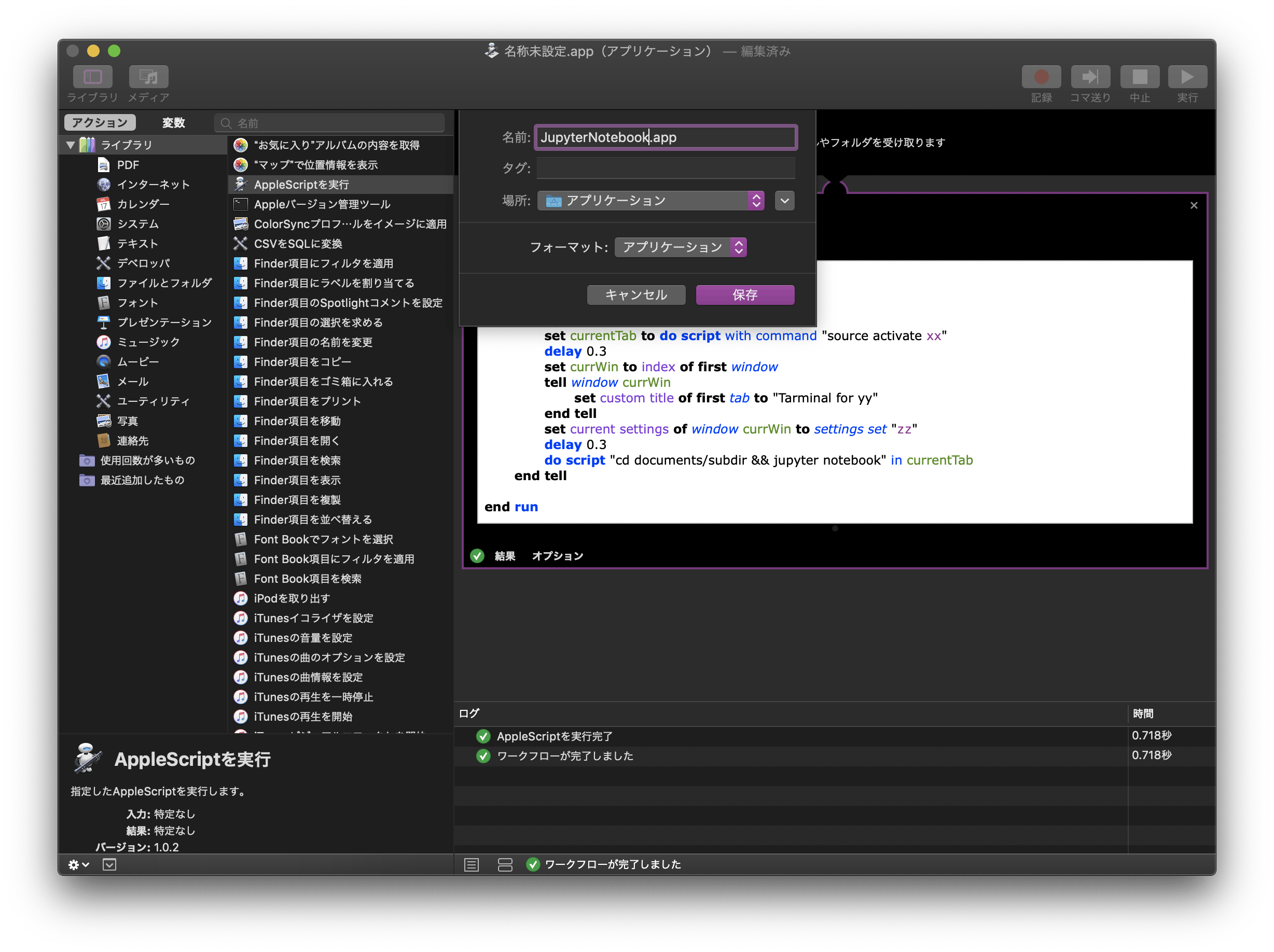
以下のコマンドを入力する
下がら2行目の「return input」を削除して、
(* Your scripts goes here *)
の部分に、以下のコマンドを入力する。
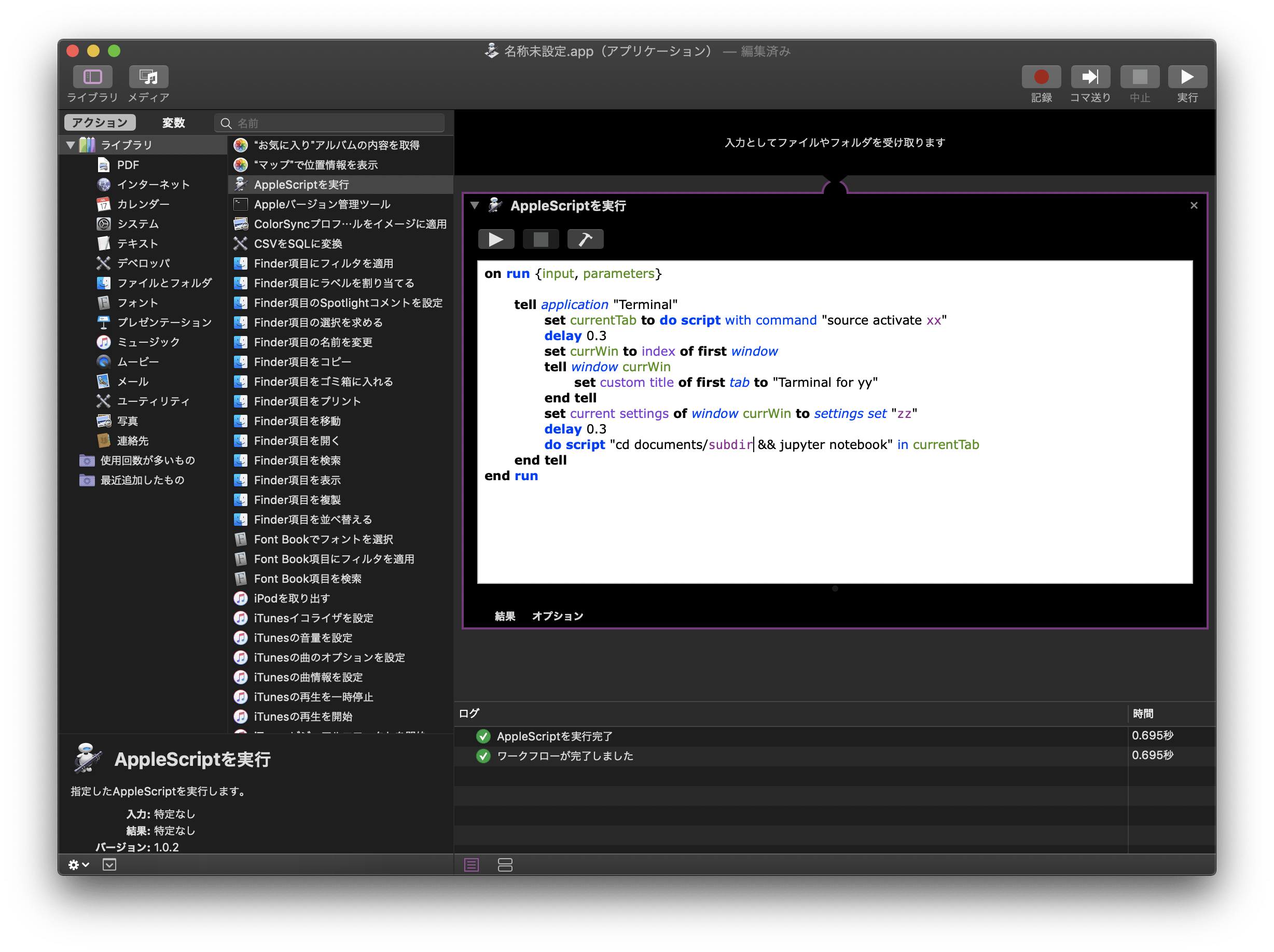
tell application "Terminal"
set currentTab to do script with command "source activate py4kaggle"
delay 0.3
set currWin to index of first window
tell window currWin
set custom title of first tab to "Tarminal for yy"
end tell
set current settings of window currWin to settings set "zz"
delay 0.3
do script "cd documents/Kaggle && jupyter notebook" in currentTab
end tell
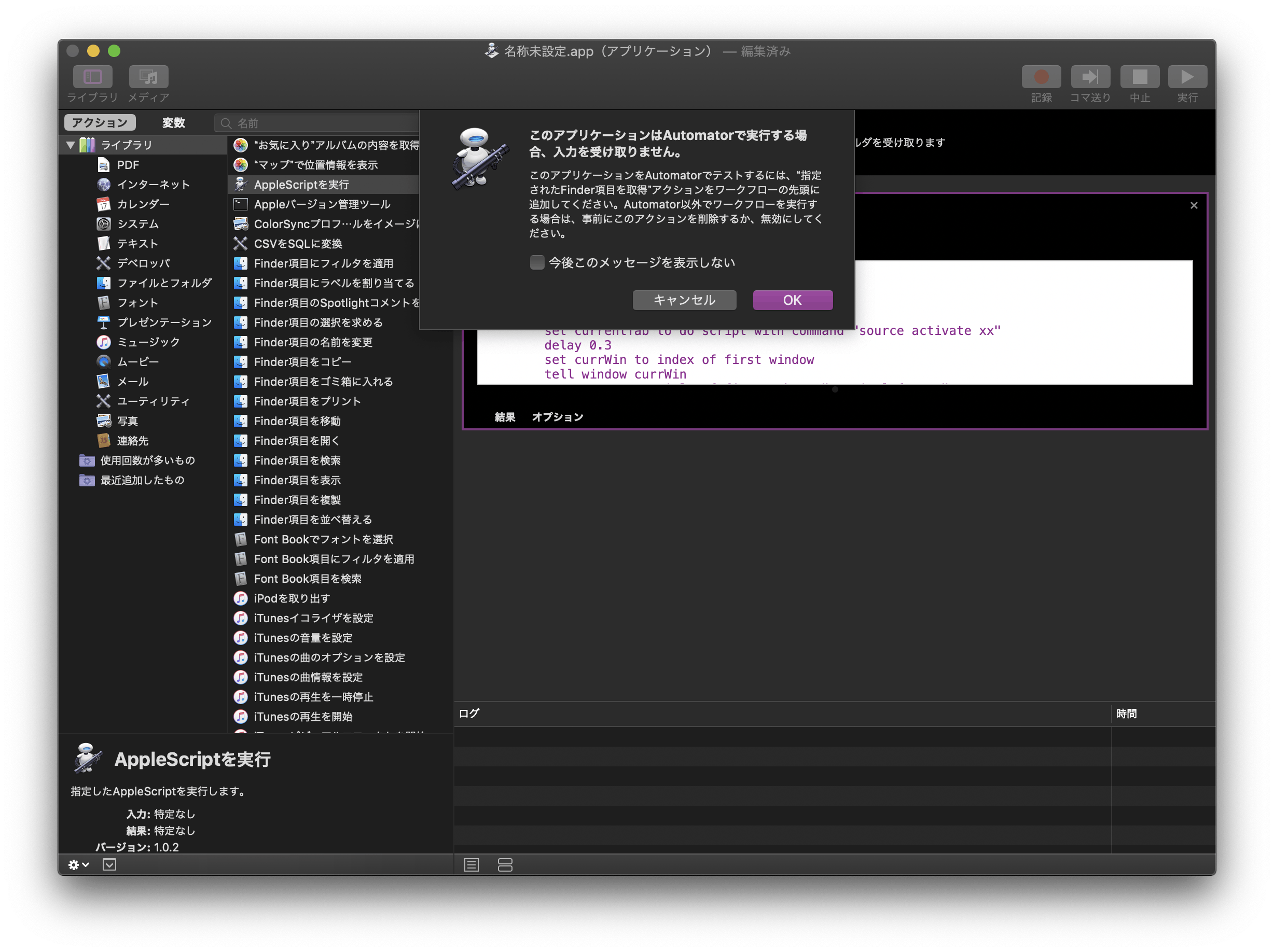
5.各行のコマンドについて説明するよ
tell application "Terminal"
~
end tell
まず、Terminalを呼び出しているよ、普通にターミナルを開いているだけ。
set currentTab to do script with command "source activate xx"
delay 0.3
set currWin to index of first window
tell window currWin
set custom title of first tab to "Tarminal for yy"
end tell
set current settings of window currWin to settings set "zz"
delay 0.3
現在開いている一つ目のターミナルのウィンドウにcurrWinっていう名前をつける。
そして、今名前をつけたウィンドウ「currWin」の最初のタブのタイトルに「Tarminal for yy」っていう名前をつける。
次に、ウィンドウ「currWin」に対して「zz」っていうテーマを適用する。
(これは好みの問題、デフォルトのターミナルのテーマが好みではないためこうしているよ、複数のターミナルを開いた時に色の違いで見分けることができればわかりやすくてよきよき)
そして最後に、おまじないのdelay 0.3
do script "cd documents/subdir && jupyter notebook" in currentTab
C:\>conda
usage: conda-script.py [-h] [-V] command ...
conda is a tool for managing and deploying applications, environments and packages.
Options:
positional arguments:
command
clean Remove unused packages and caches.
config Modify configuration values in .condarc. This is modeled
after the git config command. Writes to the user .condarc
file (C:\Users\xxxxxx\.condarc) by default.
create Create a new conda environment from a list of specified
packages.
help Displays a list of available conda commands and their help
strings.
info Display information about current conda install.
init Initialize conda for shell interaction. [Experimental]
install Installs a list of packages into a specified conda
仮想環境の確認
現在作成されている仮想環境の一覧表示
C:\>conda info -e
# conda environments:
#
base * C:\Users\xxxxxx\AppData\Local\Continuum\miniconda3
(base) C:\>python
Python 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 10:22:32) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
(base) C:\>conda create --name vpy3.7 python=3.7
Collecting package metadata (current_repodata.json): don
.
.
.
<省略>
.
.
.
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate vpy3.7
#
# To deactivate an active environment, use
#
作成されたか確認
C:\>conda info -e
# conda environments:
#
base * C:\Users\xxxxxx\AppData\Local\Continuum\miniconda3
vpy3.7 C:\Users\xxxxxx\AppData\Local\Continuum\miniconda3\envs\vpy3.7
vpy3.7に入ってpythonインタプリタを起動する
C:\>conda activate vpy3.7
(vpy3.7) C:\>python
Python 3.7.4 (default, Aug 9 2019, 18:34:13) [MSC v.1915 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
無事にpython3.7環境が作成できました。
python2.7環境の作成は以下のようになります。
環境作成時はどの仮想環境から実行しても問題ないです。
(vpy3.7) C:\>conda create --name vpy2.7 python=2.7
.
.
<省略>
・
・
(vpy3.7) C:\>conda info -e
# conda environments:
#
base C:\Users\xxxxxxx\AppData\Local\Continuum\miniconda3
vpy2.7 C:\Users\xxxxxxx\AppData\Local\Continuum\miniconda3\envs\vpy2.7
vpy3.7 * C:\Users\xxxxxxx\AppData\Local\Continuum\miniconda3\envs\vpy3.7
(vpy3.7) C:\>conda activate vpy2.7
(vpy2.7) C:\>python
Python 2.7.16 |Anaconda, Inc.| (default, Mar 14 2019, 15:42:17) [MSC v.1500 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
#! /usr/bin/env python3
importIfxPyDbiasdbapi2ConnectionString="SERVER=servername;DATABASE=database;HOST=IP;SERVICE=21435;UID=username;PWD=password;PROTOCOL=onsoctcp;CLIENT_LOCALE=ja_jp.utf8;DB_LOCALE=ja_jp.sjis-s"conn=dbapi2.connect(ConnectionString,"","")cur=conn.cursor()cur.execute("select 得意先名 from 得意先m where 得意先cd=1")rows=cur.fetchall()fori,rowinenumerate(rows):print("Row",i,"value=",row)cur.close()conn.close()print("Done")
# Connection ConnectionStringなど省略
sql="SELECT 得意先cd as customer_cd, 得意先名 as customer_name from 得意先m where 得意先cd=1 or 得意先cd=2"stmt=IfxPy.exec_immediate(conn,sql)dic=IfxPy.fetch_both(stmt)whiledic!=False:print(dic["customer_cd"])print(dic["customer_name"])dic=IfxPy.fetch_both(stmt)IfxPy.free_result(stmt)IfxPy.free_stmt(stmt)IfxPy.close(conn)
#! /usr/bin/env python3
importIfxPyDbiasdbapi2ConnectionString="SERVER=servername;DATABASE=database;HOST=IP;SERVICE=21435;UID=username;PWD=password;PROTOCOL=onsoctcp;CLIENT_LOCALE=ja_jp.utf8;DB_LOCALE=ja_jp.sjis-s"conn=dbapi2.connect(ConnectionString,"","")cur=conn.cursor()cur.execute("select 得意先名 from 得意先m where 得意先cd=1")rows=cur.fetchall()fori,rowinenumerate(rows):print("Row",i,"value=",row)cur.close()conn.close()print("Done")
# Connection ConnectionStringなど省略
sql="SELECT 得意先cd as customer_cd, 得意先名 as customer_name from 得意先m where 得意先cd=1 or 得意先cd=2"stmt=IfxPy.exec_immediate(conn,sql)dic=IfxPy.fetch_both(stmt)whiledic!=False:print(dic["customer_cd"])print(dic["customer_name"])dic=IfxPy.fetch_both(stmt)IfxPy.free_result(stmt)IfxPy.free_stmt(stmt)IfxPy.close(conn)
importtypingimportdataclasses@dataclasses.dataclassclassMyConfig:foo:intbar:floatbaz:typing.List[str]config=MyConfig(foo=1,bar=2.0,baz=['3 and 4'])print(config.foo)# 1
importpathlibimportdataclassesimportyamlimportinspect@dataclasses.dataclassclassYamlConfig:defsave(self,config_path:pathlib.Path):""" Export config as YAML file """assertconfig_path.parent.exists(),f'directory {config_path.parent} does not exist'defconvert_dict(data):forkey,valindata.items():ifisinstance(val,pathlib.Path):data[key]=str(val)ifisinstance(val,dict):data[key]=convert_dict(val)returndatawithopen(config_path,'w')asf:yaml.dump(convert_dict(dataclasses.asdict(self)),f)@classmethoddefload(cls,config_path:pathlib.Path):""" Load config from YAML file """assertconfig_path.exists(),f'YAML config {config_path} does not exist'defconvert_from_dict(parent_cls,data):forkey,valindata.items():child_class=parent_cls.__dataclass_fields__[key].typeifchild_class==pathlib.Path:data[key]=pathlib.Path(val)ifinspect.isclass(child_class)andissubclass(child_class,YamlConfig):data[key]=child_class(**convert_from_dict(child_class,val))returndatawithopen(config_path)asf:config_data=yaml.full_load(f)# recursively convert config item to YamlConfig
config_data=convert_from_dict(cls,config_data)returncls(**config_data)