- 投稿日:2019-09-27T23:38:21+09:00
ModuleNotFoundError: No module named 'boto3’
環境
- macOS Catalina 10.15
エラー内容
$ sudo pip install boto3でboto3をインストールしたけど、
いざスクリプトを実行するとエラーが発生した。$ python3 sample.py Traceback (most recent call last): File "sample.py", line 2, in <module> import boto3 ModuleNotFoundError: No module named 'boto3'boto3モジュールがないため、エラーが発生しているが、
boto3は先ほどのコマンドでインストールしているはずなので、
モジュールがないというエラーが発生するのは不思議だった。対処法
$ sudo pip3 install boto3
pipでboto3を入れていたが、pip3にしなければいけないようだ。
単にpipだとPython2.7が実行されていたが、boto3の場合はPython3用のpip3をインストールしなければならなかった。普段Pythonを触らないので、ハマってしまった。
参考
- 投稿日:2019-09-27T20:46:58+09:00
Cloud9でRailsのAPIの開発環境を構築
はじめに
Cloud9でRailsのAPIサーバの開発環境を構築する手順の忘備録になります.
次のような方におすすめです.
- Cloud9にRailsのAPIサーバを構築したい
- React+RailsやVue+Railsの開発環境が欲しい
- Herokuなどの他のサービスを通さずにアプリを公開したい
なぜ書いたのか
RailsのみならCloud9のプレビュー機能が使えます.(参考サイト)
ただ,プレビューはあくまでもプレビューであり,ネットに公開されているわけではありません.
そしてAPIサーバは外部からアクセスできる必要があり,プレビュー機能では開発環境の役目を果たすことができません.そこで,Cloud9上でネット公開されるRailsのAPIサーバの構築を試みました.
他に同様の記事が無く苦戦したので忘備録として残しておきます.基本的な流れだけのせて,他の記事をリンクを載せて端折らせていただきます.
Cloud9の環境構築
AWSのアカウントを作成します.
そして,安全に操作できるようにユーザを作成し,Cloud9の環境を構築します.
初めてのAWS Cloud9導入Rails APIサーバのセットアップ
rvmなりrbenvなりでRubyのバージョンを指定し,Railsをインストールします.
# rvmの場合.(rvmはデフォルトで入ってる) rvm install "rubyのバージョン" rvm use "rubyのバージョン" gem install rails -v "railsのバージョン"RailsアプリをAPIモードで作成します.
rails new "アプリ名" --apiあとは,
rails db:migrateやら何やらを実行してください.CORSの設定
他のオリジンからアクセスを許可するために,コメントアウトを外してあげます.
そして,originsに,フロントのオリジンを指定します.config/initializers/cors.rb# 'rails new'の直後はコメントアウトされてる Rails.application.config.middleware.insert_before 0, Rack::Cors do allow do origins 'hoge.fuga.example.com' #ここをフロントのオリジンに変える resource '*', headers: :any, methods: [:get, :post, :put, :patch, :delete, :options, :head] end endネットワークの指定
Cloud9が動いているEC2インスタンスへは初期設定ではインターネットからアクセス出来ません.
そのため,「AWS 実行中のアプリケーションをインターネット経由で共有する」に従って,EC2にアクセス出来るようにします.アカウントを作成したばかりなら,必須なのはセキュリティグループの設定ぐらいだと思います.
書いてありますが,ポート番号は8080~8082のどれかです.Railsの起動
railsを起動します.
バインドとさきほどのポート番号を指定します.rails s -p "ポート番号" -b 0.0.0.0ブラウザで表示
「ネットワークの指定」の手順で実行した
curl http://169.254.169.254/latest/meta-data/public-ipv4で得られるIPアドレスにポート番号をくっつけてブラウザで表示します.(例:
256.1.2.3:8081)すると,いつもの画面が出てくるはずです.
これはブラウザで表示していますが,APIモードで動いているはずです.
終わりに
かなり省略しましたが,大まかな流れは合ってると思います.
ネットワークの設定までは順調だったのですが,バインドのところでつまずきました.
Cloud9だとポートやバインドは指定せずとも動くので甘えてました.以上の手順で,最大3つのアプリまで一つのインスタンス上でネット公開できます.
そのため,RailsとReactやVueなどを同時に公開することも可能です.Rails+Reactで動くことを確認しました.
ぜひ,試してみてください.

- 投稿日:2019-09-27T19:36:30+09:00
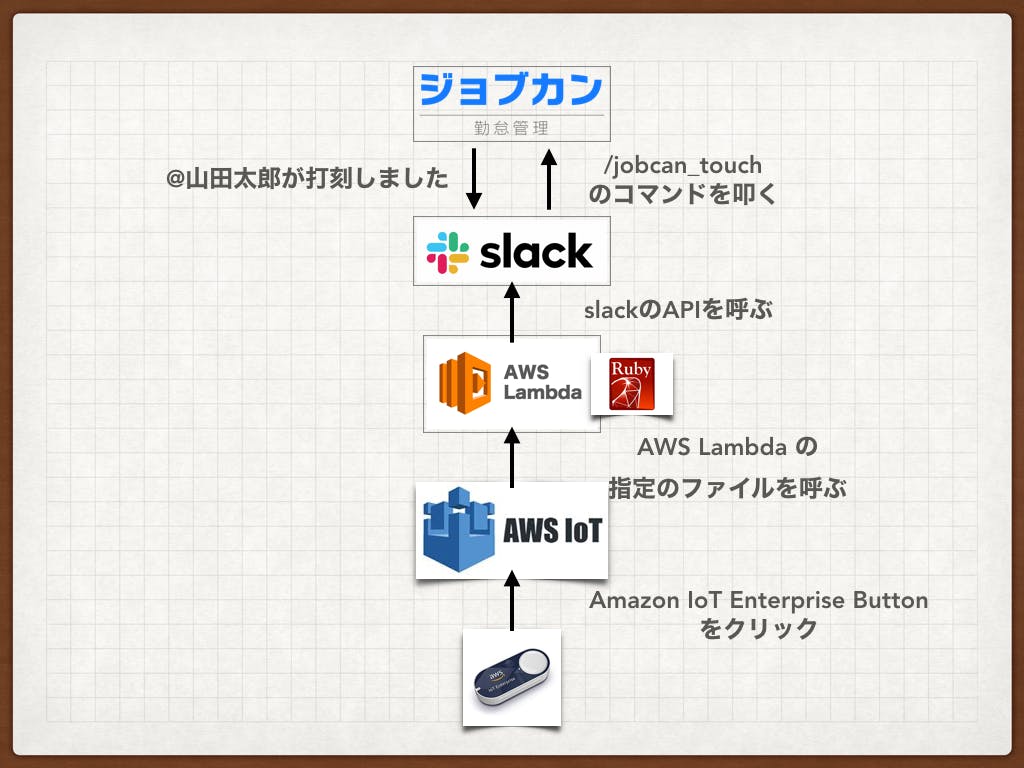
AWS IoT EnterpriseでJobcanの打刻ができる出勤ボタンをつくった
背景
- AWS LambdaがRubyの対応したので、自分で作成して使ってみたかった
- Amazonがダッシュボタン事業から撤退してしまうので、その弔いとして
- ジョブカンで打刻するのが億劫だなと感じていた
構成
構成としては以下の図のような構成になっています。
参考にしたのは、このブログのリンクでpythomで自分が実現したいことを達成していたので、90%くらいはここから真似してきました。
こちらのブログだとpythonで書かれていたのですが、今回使いたかったのはRubyなので、Rubyで書きました。
手順
- Amazon IoT Enterprise をAmazonで購入
- 2500円します。
- 実験としてはいいけど、高いな。。。
AWS IoT エンタープライズボタン – IoT をシンプルに。
- Amazon IoT Enterpriseをセットアップ
- アプリをダウンロード
- バーコードを読み込んで、デバイスを登録する
- デバイスとWifiを繋げる
- Amazon IoTをセットアップ
- プロジェクトを作成
- デバイステンプレートを作成
- Labda のセットアップ
- 関数を作成
- SlackのAPI token とチャンネルのIDの獲得
- ここから獲得
- コードの記述
- slack-ruby-clientというgemを使う
- 以下のようなコードを書きます
require 'slack-ruby-client' def hello(event:, context:) Slack.configure do |config| config.token = ENV['SLACK_API_TOKEN'] end client = Slack::Web::Client.new client.chat_command(channel: ENV['SLACK_CHANNEL'], command:'/jobcan_touch') end
- 詳しいコードは以下のGithubから確認してください。
https://github.com/knsg16/slack-jobcan
- コードをAWS Lambdaにアップする
- zip形式のフォルダを作成
- 当該ファイルをLambdaにアップする
- Lambdaにテストイベントを作成して、テスト
- 完成
- お疲れ様でした!!
トラブルシューティング
- ステルスの社内WIFIにAmazon IoT Enterpriseを接続できない。。。
- rubyのversionを2.5.0にきっちり揃えないといけなかった。。。
- 普通にwebhookでは、コマンドをAPIで叩くことができなかった。かつ、非推奨のレガシートークンを使用しなければならなかった。。。
- lamdaにアップするためにファイルをzipにする時のファイル構成
- 投稿日:2019-09-27T19:12:54+09:00
AWS SysOps Administrator Associate 合格記録
どうしたの
AWS SysOpsの試験に合格したので、
取り組んだことや、学んだことのメモ(今回は一覧のみ)を残します。試験概要
AWS 認定 SysOps アドミニストレーター – アソシエイト
必要な知識
・AWSのアーキテクチャに関する基本的な知識・考え方
・主に運用系の分野の知識
[CloudWatch, CloudFormation, Systems Manager等が挙げられる]
・セキュリティ分野はどの試験でも必須
[IAM Role, AWS Directory ServiceやSAMLなど認証系含む]
・特にArchitect試験と被るが、ネットワーキングリソース分野の知識
[Route53, VPC, WAF]
・AWS試験だからこそ、オンプレミスとの連携の話も、もちろん対策が必要やったこと
①試験ガイドをよく読む(公式)
下記リンク内「試験ガイドのダウンロード」のガイド
AWS 認定 SysOps アドミニストレーター – アソシエイト②awskoiwaclub
AWS WEB問題集で学習しよう | 赤本ではなく黒本の問題集から学習する方向け
こちらのプラチナプランを使用。
(SAPでまだ使うので追加課金しなくて済んだ!)③模擬試験(公式)
項目としてはこれだけですが、
主に②の問題集を進める中で、軽く調べて行くのが一番役に立ちました。
以下に学習した際のメモを残します。ほぼそのまま貼ります学習メモ
CloudWatch周り
カスタムメトリクス
カスタムメトリクスを発行する - Amazon CloudWatch
・カスタムメトリクスは使ったことあるが、データポイント取得に15分かかるのは知らなかったメトリクスを作成したら、get-metric-statistics コマンドを用いてその新規メトリクスの統計を取得できるようになるまで最大 2 分かかります。ただし、list-metrics コマンドを用いて取得したメトリクスのリストに新規メトリクスが表示されるまでは最大 15 分かかることがあります。
※引用元は、上記公式ドキュメント内
ディメンションの活用
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/cloudwatch_concepts.html
・使い方。Networkingリソース
ENIの追加
EC2インスタンスにENIを使用して複数IPアドレスを設定する - Qiita
ホワイトリストが可能なNLB
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/network/introduction.html
Proxy Protocol
Classic Load Balancer で Proxy Protocol を構成する – サーバーワークスエンジニアブログ
・参考にさせて頂きました。インターフェースVPCエンドポイント
https://docs.aws.amazon.com/ja_jp/streams/latest/dev/vpc.html#interface-vpc-endpoints
・これはもう必須!HTTPリクエスト - Query
Query Requests - Amazon Elastic Compute Cloud
・盲点だった。Route53 DNSレコード MX
サポートされる DNS レコードタイプ - Amazon Route 53
・知っててもよく混ざる。何故なのか。CloudFront S3オリジン
EC2
instance store volumeからEBSに移行可能(Linuxのみ)
Instance Store-Backed AMI を Amazon EBS-Backed AMI に変換する - Amazon Elastic Compute Cloud
コンバーティブルリザーブドインスタンスとは
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/reserved-instances-types.html
クラスタープレイスメントグループとは
AutoScalingは奥が深い!
Proxy Protocol
Classic Load Balancer で Proxy Protocol を構成する – サーバーワークスエンジニアブログ
Desired Capacity
AWS Solutions Architect ブログ: AWS Black Belt Online Seminar「AWS Auto Scaling」の資料およびQA公開
AutoScaling追加時のウォームアップ
ステップスケーリングポリシーって何
https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/as-scaling-simple-step.html#StepScaling
S3
S3はプランがたくさん増えて色々混ざりがちですが、
だからこそ、コストの観点やデータの使用頻度などに応じて適切に考慮する必要があります。
権限やポリシーも同様仮想テープインターフェース
AWS Storage Gateway の特徴 – アマゾン ウェブ サービス
Volume Gatewayって?
AWS Storage Gateway の仕組み (アーキテクチャ) - AWS Storage Gateway
AWS Storage Gateway の仕組み (アーキテクチャ) - AWS Storage Gateway
S3 ACLとBucket Policyの違いが不明確だった
S3のアクセスコントロールが多すぎて訳が解らないので整理してみる | DevelopersIO
・痒いところに手が届いた記事が。Database
MS SQL ServerのマルチAZは、論理レプケーションで同じ結果を実現している
Multi-AZ 配置 - Amazon RDS | AWS
Auroraのエンドポイントタイプ
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html
Elastic Beanstalk
Beanstalkをつかった簡単なアプリ更新デプロイ
https://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/Welcome.html
CloudFormation
使ったことのない人だと始めは掴みづらいので
使ってみるのが一番かと思います。
つまるところResourcesがあれば動きます。チュートリアルもちゃんとありますが少々難しい場合も。
チュートリアル - AWS CloudFormationそういう時はQwiklabsを使う手も。公式でも案内あります。 (超便利)
セルフペースラボ – AWS オンライントレーニング | AWSCloudFormation - カスタムリソース
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-custom-resources.html
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-resource-cfn-customresource.html
・名前を知らなかったCloudFormation - AWS::Lambda::Function Code
CloudFormation - CodePipeline
認証系
DynamoDB認証 Webサービスプロバイダを利用したWebIDフェデレーション
一時的セキュリティ認証情報 - AWS Identity and Access Management
SAMLフェデレーション
AWSとフェデレーション – サーバーワークスエンジニアブログ
・SAMLは超重要IdP SAML2.0
IAM SAML
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles_providers_create_saml.html
Roleの種類
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles_use_passrole.html
監査
監査に関するガイドラインがあります。
AWS セキュリティ監査のガイドライン - AWS 全般のリファレンスAWS Artifuct
Amazon RDS のコンプライアンス検証 - Amazon Relational Database Service
・RDS 監査レポートなどDBパラメータグループの出力
https://dev.classmethod.jp/cloud/rds-parameter-group-export-to-csv/
・参考にさせて頂きましたCloudTrailログの検証
AWS Config
個人的には使ったことがほとんどなかったので重要。
ルールで評価できる
https://docs.aws.amazon.com/ja_jp/config/latest/developerguide/evaluate-config.html
AWS Config とAPI
https://docs.aws.amazon.com/ja_jp/config/latest/developerguide/WhatIsConfig.html
コスト管理
コスト配分タグ
コスト配分タグの使用 - AWS 請求情報とコスト管理Systems Manager
Systems Manager Run Command
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/rc-console.html
Session Manager
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/session-manager.html
OpsWorks
AWS OpsWorks for Chef Automate
AWS OpsWorks for Chef Automate (マネージド型 Chef サーバー) | AWS
・OpsWorkでChef簡単に使えます混ざりがちな、AWSリソースの場所
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/resources.html
結果
前日に受けた模擬試験は70%で試験なら不合格でしたが、
そこからわからなかった問題を全て総復習して挑みました。結果は、正答率8割で合格でした。
まとめ
今回トラブルが発生して3日間合否がわからなかったので
とってもモヤモヤしてましたが、無事合格してよかったです。。
受験した場所自体は集中できて良かった。SAA受験時よりも対策の仕方が自分の中で明確になっており、
以前よりもかなりスムーズに進んだ印象です。とにかく問題をこなさないと、自分の不明点もわからないので
まずは各種問題集などで問題を解いてみるのがいいかもしれません。そういえば、ガートナー社のレポートでまたAWSがIaaS分野で首位だったみたいですね。
ガートナー社レポート参考
以前Architect Proffesionalを受けた際の試験対策まとめも、参考になれば幸いです。
AWS ソリューションアーキテクトプロフェッショナル受けた記録 - Qiita今回、対策方法的にはUdemyもありましたが、セールじゃなかったので使いませんでした(笑)
- 投稿日:2019-09-27T18:57:43+09:00
Movable Type 6.5 for AWS を利用する前にやっておくべきこと
Movable Type 6.5 for AWS が先日リリースされています。この AMI イメージは、Movable Type 6 for AWS と違い、Amazon Linux 2 がベースになっているので細かいところが変わってます。とはいえ、やることはそうそう変わらないけど。
Movable Type for AWS を利用するまでは、これを見ればいいと思う。
Movable Type 6 for AWS を利用するときにやっておくことは、これを見ればいいと思う。
Movable Type 7 for AWS は、ここに書いてあることと同じでいいと思う作業用ユーザーの登録
ec2-user として SSH でログイン後に root ユーザーになります。
$ sudo su -新しいユーザーを登録して、sudo が使えるように wheel グループに加入させます。
# useradd NEW-USER-NAME # usermod -G wheel NEW-USER-NAMEパスワードなしで sudo できるようにもできますが、個人的には毎度入れるほうが好きなのでパスワードを設定します。
# passwd NEW-USER-NAMEセキュリティを考えると新しい公開鍵を用意したほうが良いですけど、ここでは既存の公開鍵を登録します。
# sudo su - NEW-USER-NAME $ mkdir .ssh $ chmod 700 .ssh/ $ vi .ssh/authorized_keys $ chmod 600 .ssh/authorized_keysログアウトして、作成したユーザーで SSH でログインし直します。
モジュール類のアップデート
AWS Marketplace から起動した直後でもモジュールのアップデートが存在するので、更新します。定期的に実行するようにしても良いですが、動かなくなるとか怖いので都度実行してます。
$ sudo yum update -yタイムゾーンの設定
AWS Marketplace から起動した直後は、UTC なタイムゾーンになっているため、JST に合わせます。
sudo timedatectl set-timezone Asia/Tokyo日本語ロケールの追加
ついでにローケールも日本語対応にして、キーボードも対応させます。
$ sudo localectl set-locale LANG=ja_JP.UTF-8 $ sudo localectl set-keymap jp106mt-config.cgi の編集
mt-config.cgi は、インスタンス起動直後にすでに作成されていますが、こちらも US モード全開なので、日本向けに変更します。
任意のエディタでファイルを開いて書き換えます。
$ sudo vi /app/movabletype/mt-config.cgi以下の内容を追記(場所はどこでも。まあ、一番最後にでも)
mt-config.cgiDefaultLanguage ja保存後に movabletype サービスを再起動します。
sudo systemctl restart movabletypeMovable Type のセットアップ
http:// your-host /mt/admin にアクセスすると見慣れた画面から Movable Type のセットアップが開始します。
それ以外にやっておくと良いこと
セキュリティを高めるためには、他にも色々やっておいたほうがいいことあるよね。
- ssh のポート番号を変える
- 無用なサービスを停止する(ダイナミック/パブリッシング使わないなら php 止めるとか)
- ssh できるソース IP を限定する
とか。
とりあえず、こんなところで。
- 投稿日:2019-09-27T17:48:50+09:00
Elasticsearch7系がmaster not discoveredで起動できなかった時の話
7系とかドヤ顔で書いてるけど7系以外で確認してません。フフ。
前提
Amazon linux 2
Elasticsearch 7.0.0
openjdk 1.8.0何があったの
開発環境で元気に動いてるES設定の99%を本番環境に持ってきて、生まれたてのEC2で起動しようとしたら
master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster, and [cluster.initial_master_nodes] is empty on this node: have discovered [];こんなんが出て起動できず。
なお残りの1%はリージョンとかの設定でございます。で?
cluster.initial_master_nodes設定すりゃいいだけじゃねえの?って思ったけど、
開発環境からもってきた設定ファイルelasticsearch.ymlだとcluster.initial_master_nodesの設定はコメントアウトされている。でも開発環境のESはバリバリ動いてるし、restartしてもstop/startしてもなんの問題もなかった。結論
cluster.initial_master_nodesを設定して正常起動見届けた後にstopしてコメントアウトして起動すると正常に起動します。
masterの情報をキャッシュしてるのかな?
EC2をstop/startして試しても起動したので、ファイルとかに持ってんだろうか…?「エラーメッセージちゃんと読め」って話なんですけどね。
ちゃんと動いてる設定ファイル持ってきたのになんでよ!!ってなったので、自分と同じハマり方をする人を減らせればと思い…
- 投稿日:2019-09-27T16:38:52+09:00
なんにもしてないのにt2.nanoなインスタンスのステータスチェックがいつの間にか落ちてるしSSH繋がんなくなったら
はじめに
t2.nanoなインスタンスが「なにもしてない」のにヘルスチェックが落ちてSSHでつなげなくなりました。
「なにもしてないのに壊れた」というよりも
「なんにもしてないから壊れた」の方が正しいかもしれません。貧弱なインスタンスは面倒見てあげる必要があるんですね。
現象
t2.nanoなAmazon Linuxを立ち上げて1週間くらいたったとき、
SSHでインスタンスに接続できなくなり、AWSコンソールで確認するとインスタンスのステータスチェックでエラーが発生していました。このインスタンスにはアプリケーションなどをほとんど入れていない状態なので、
インストールしたアプリケーションが何か悪さをしたわけではないさそうです。システムログを見た感じだとsshdがメモリ不足で殺されていたので、それが原因だと考えられます。
(sshdとは、sshで接続を受けるために必要なサーバ側のプログラムです。)t2.nanoのメモリは0.5GBであり、
普通にしてると空メモリは100MBくらいありますが、
EC2のインスタンスのSSHはブルートフォースアタックを受けるので、それでSSHのメモリ使用量が増えたのかな? と予想。sshdがkillされてる悲しいログ[1705026.349903] Out of memory: Kill process 11606 (sshd) score 3 or sacrifice childそんなわけで、再発防止案としては以下の4つを思いつきました。
- スワップ領域を追加し、メモリ不足を緩和する
- インスタンスタイプを上げる
- (メモリ使用量増加がSSHブルートフォースアタックが原因だとしたら)SSHのポートを変更する
- IPアドレス制限をする
など考えられましたが、基本的なところとして、スワップ追加を実施しました。
お金に余裕があるなら、インスタンスタイプをあげればいいと思います。スワップ追加で本当にsshdが落ちないか、(それによってヘルスチェックが落ちないか)は、まだ未検証です。
まあ、設定してから4日くらい経ってますが、いまのところは大丈夫なかんじです。
システムログの見方
あれ?なんかSSH繋がんないし、インスタンスのステータスチェックでエラーになってるなと思ったら、システムログを見ましょう
[1705026.349903] Out of memory: Kill process 11606 (sshd) score 3 or sacrifice childこんなエラーがあれば、それはsshdがシステムによってkillされてます。
設定の仕方
AWSのリファレンスを参考に設定しました。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-memory-swap-file/EC2のインスタンスにログインする
SSH繋がんない状態だとSSHでログインできないので、
インスタンスの再起動をしましょう。多分、SSHできるようになります。
再起動してSSHが繋がらないようであれば、きっとメモリ不足とかではなく別の問題です。SWAP領域を作成する
スワップ領域のサイズですが、もとのメモリ容量が0.5GBなので、
1GB程度あれば十分かなと思います。dd コマンドを使用してルートファイルシステムにスワップファイルを作成します。
「bs」はブロックサイズ、「count」はブロック数です。この例で、スワップファイルは 1 GB です。
$ sudo dd if=/dev/zero of=/swapfile bs=100MB count=10※bsがデカすぎるとメモリ不足になるので、メモリ不足なら、bsを小さくしてcountの数を増やしましょう
スワップファイルの読み書きのアクセス許可を更新します。
$ chmod 600 /swapfileLinux スワップ領域のセットアップ:
$ mkswap /swapfileスワップ領域にスワップファイルを追加して、スワップファイルを即座に使用できるようにします。
$ swapon /swapfile手順が正常に完了したことを確認します。
$ swapon -sこんな感じに表示されるはず
ファイル名 タイプ サイズ 使用済み 優先順位 /swapfile file 976556 512 -2/etc/fstab ファイルを編集して、起動時にスワップファイルを有効にします。
$ vi /etc/fstab $ /swapfile swap swap defaults 0 0メモリが増えてることを確認する。
$ free -h
-hはちょうどいい感じで数字の表示をギガとかメガとかにしてくれるオプションtotal used free shared buff/cache available Mem: 479M 56M 100M 144K 322M 398M Swap: 953M 512K 953Mはい、Swapに953MB追加されてますね。
なぜ1000MBじゃないかって?
たぶんメガバイト表示であってメビバイト表示ではないからです。まとめ
t2.nanoなインスタンスのステータスチェックがいつの間にか落ちてるしSSHが繋がらなかったら
システムログみてメモリ不足が発生していることを確認して
もしそうだったら
スワップ領域を追加する。
以上です。
- 投稿日:2019-09-27T13:53:31+09:00
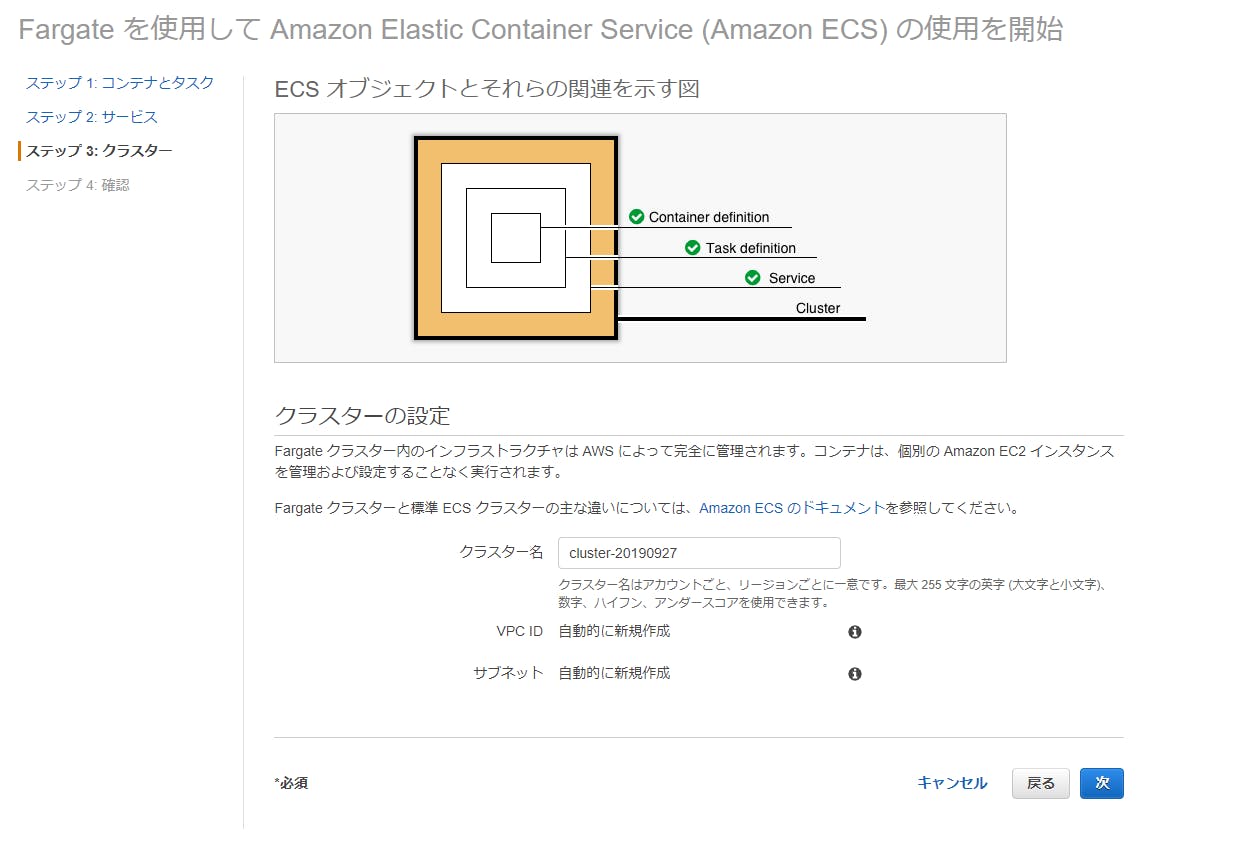
【AWS】ECS によるコンテナ配布(Fargate版)
概要
ECS によるコンテナ配布(Fargate版)を行った際のメモです。
2019/09/27時点の物です。手順
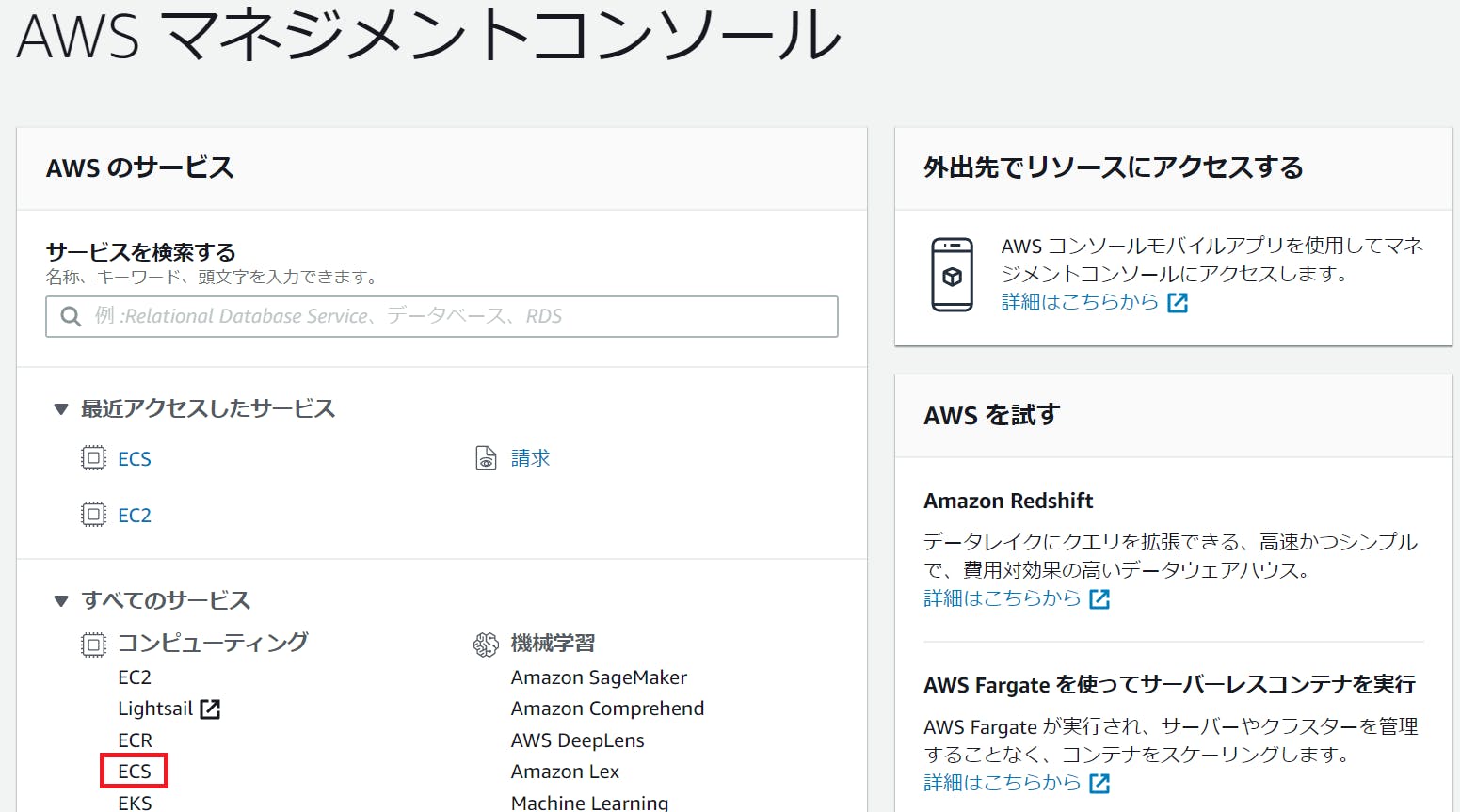
マネジメントコンソールにおいて、ECSのリンクをクリック
[今すぐ始める]をクリック
- [今すぐ始める]からECSの構築を始めた場合、Fargateを使用した構築となります

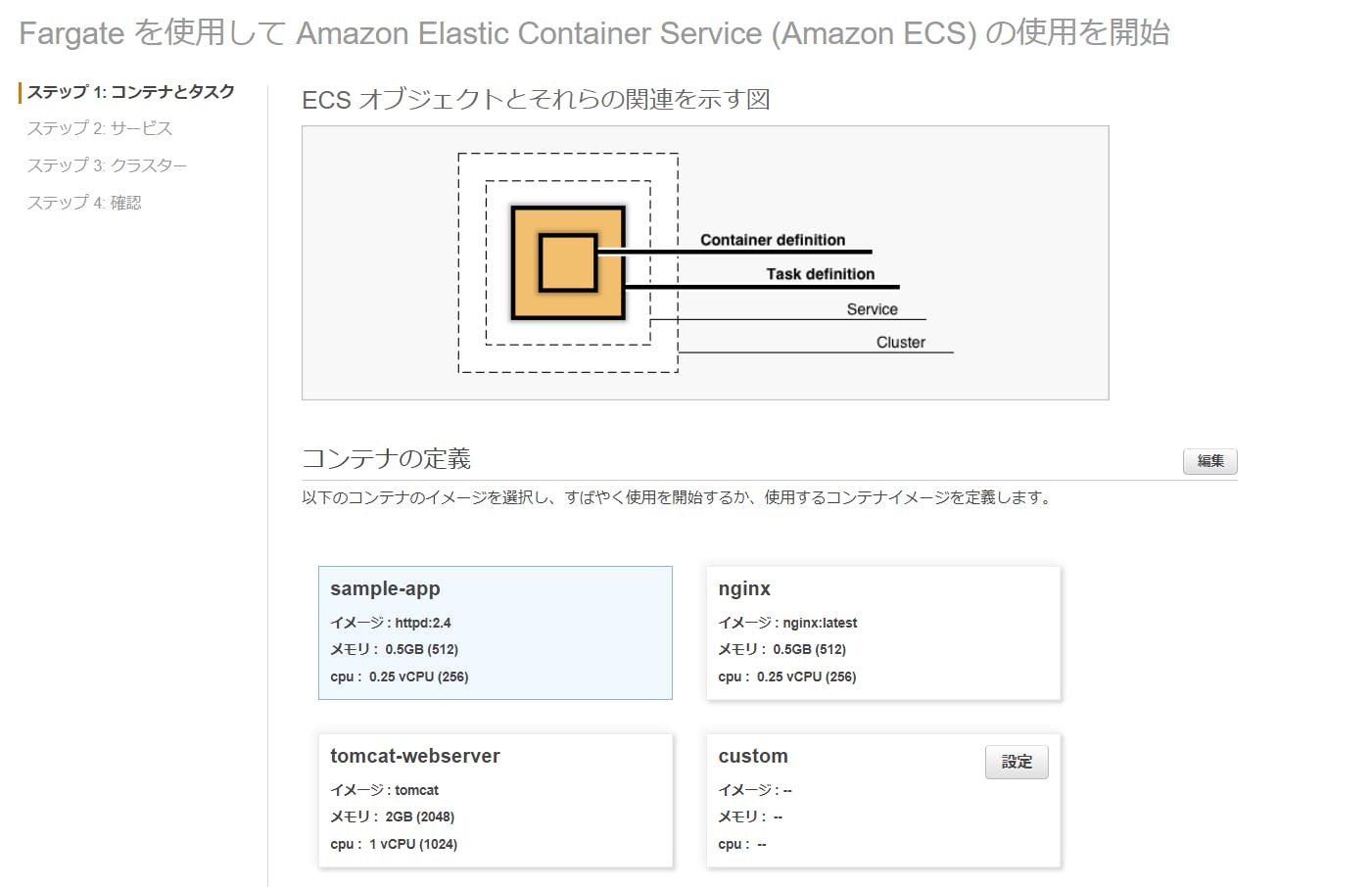
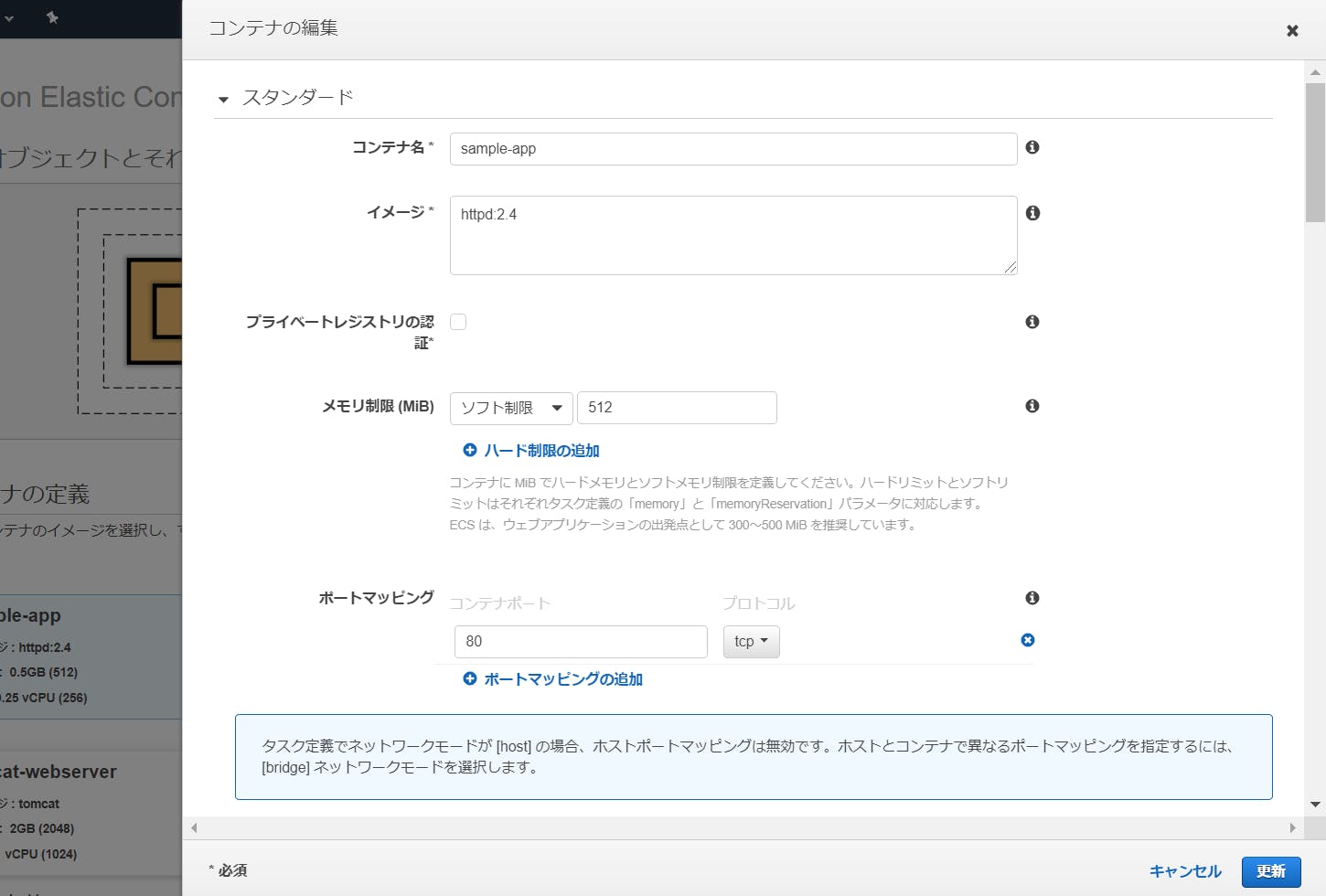
コンテナイメージを選択する画面が開かれました。今回は、[sample-app]を選択してみます。
ちなみに、右上の編集ボタンでコンテナイメージの詳細を変更できますが、デフォルトのままとします。
- 下の入力画面が表示されます。
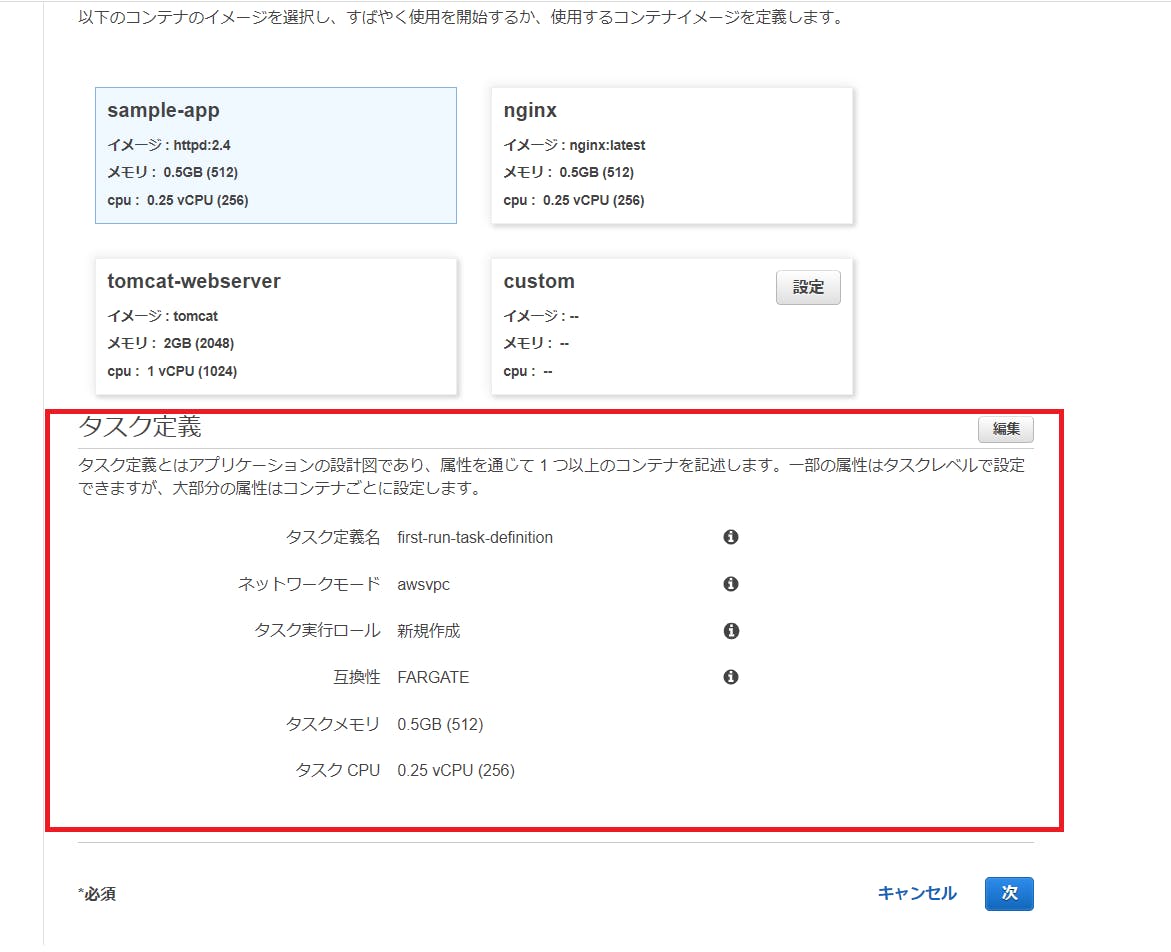
[コンテナの定義]の下に[タスク定義]の設定画面が有るので見てみます。
タスク定義は、上部の[コンテナの定義]に紐づいた内容(タスクメモリ、タスク CPU)などが自動設定されています。
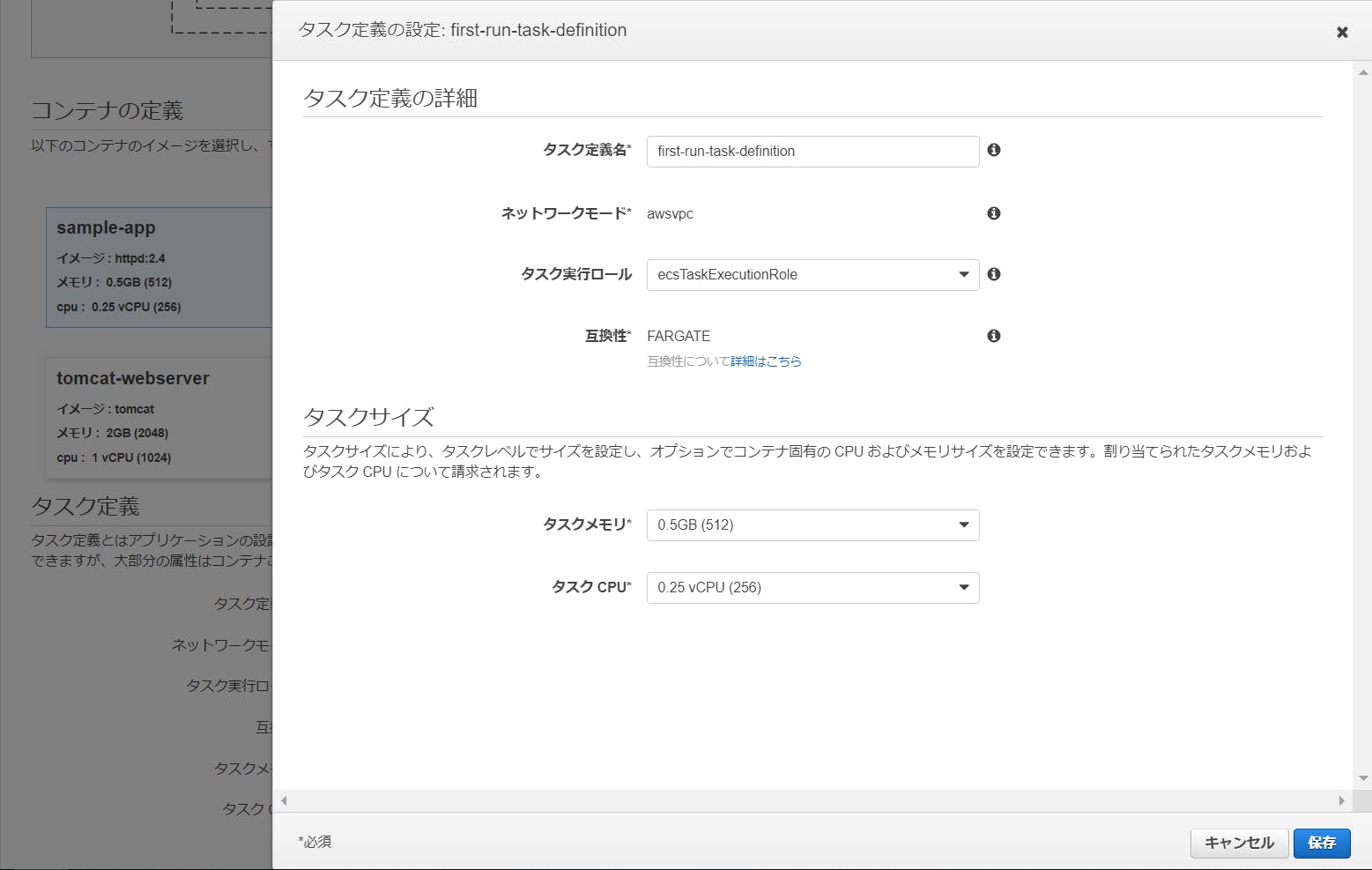
[タスク定義]も、右側にある[編集]ボタンクリックで詳細を変更できます。
- [コンテナの定義]と[タスク定義]を設定、確認を終えたら、[次]ボタンをクリックします。
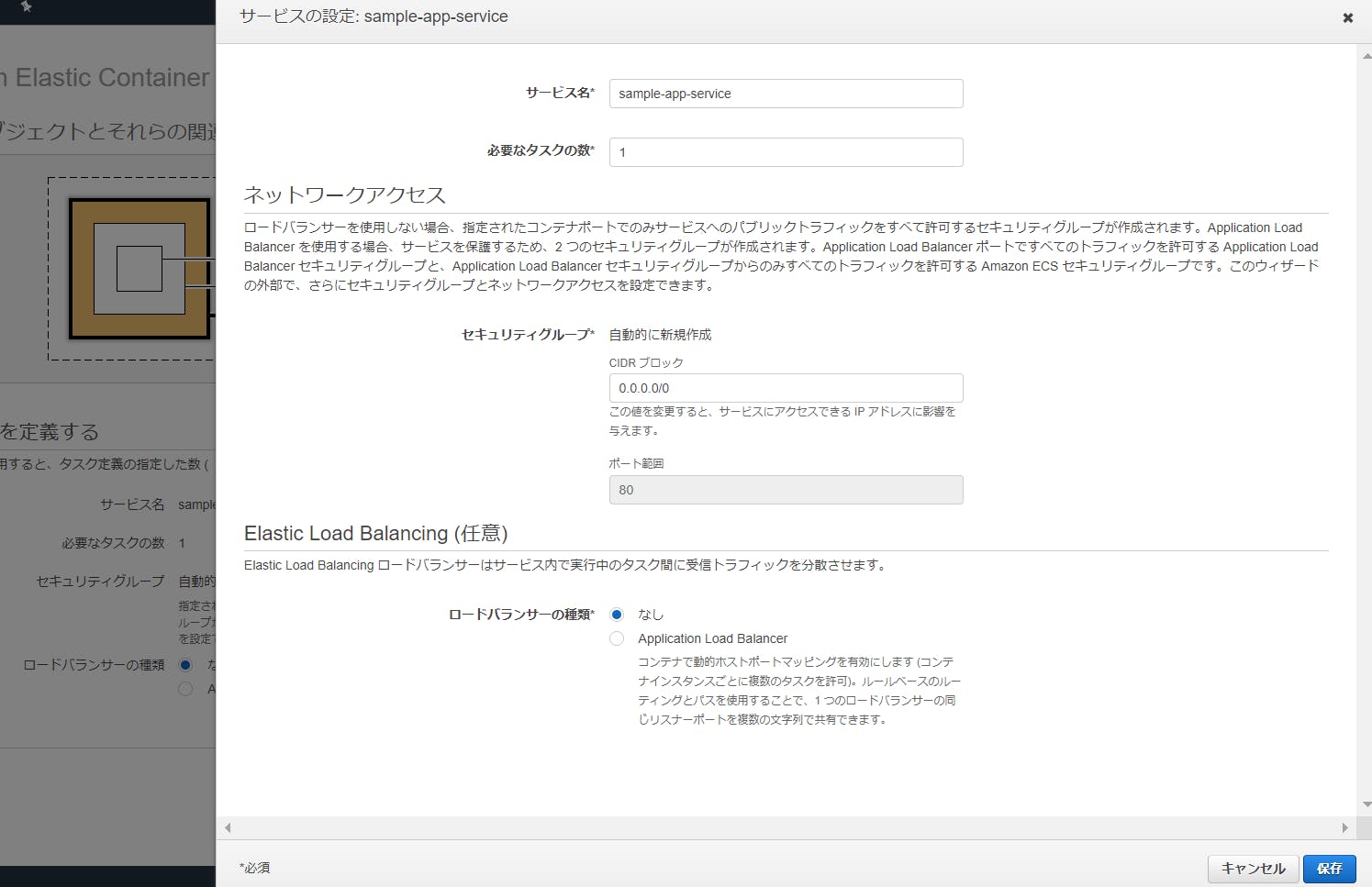
- [サービスを定義]画面が表示されました。

この画面も、同様に[編集]ボタンクリックで、サービスの設定を編集できます。
今回は、何も変更せず、編集画面を閉じてから[次]ボタンをクリックします。
[クラスタの設定]画面が表示されました。クラスター名だけ任意の名前に変更してから、[次]ボタンをクリックします。
サマリーの画面が表示されましたので、[作成]ボタンをクリック
2~3分ほどで、作成が完了しました。
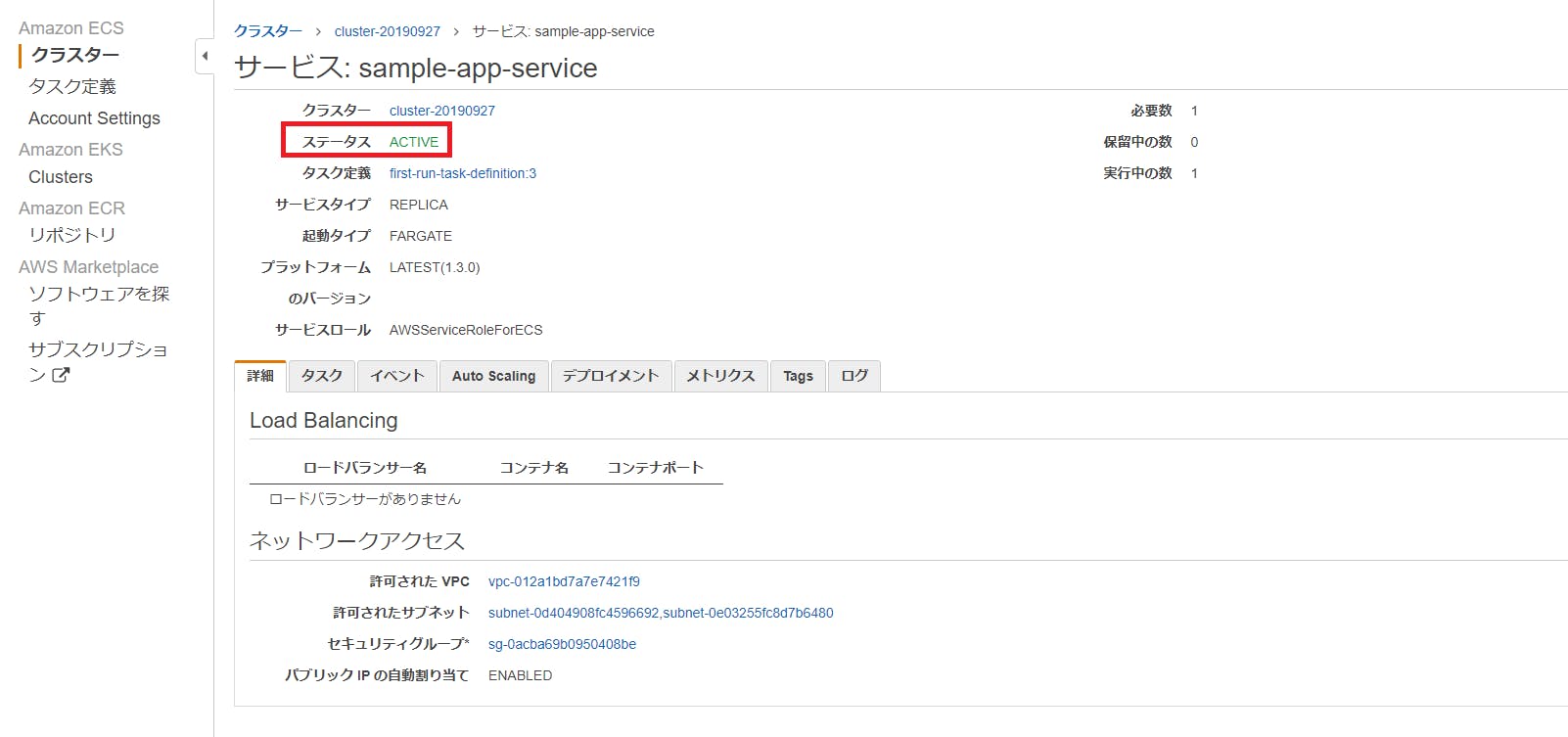
[サービスの表示]ボタンをクリックします。
無事にサービスも実行出来ているようです。
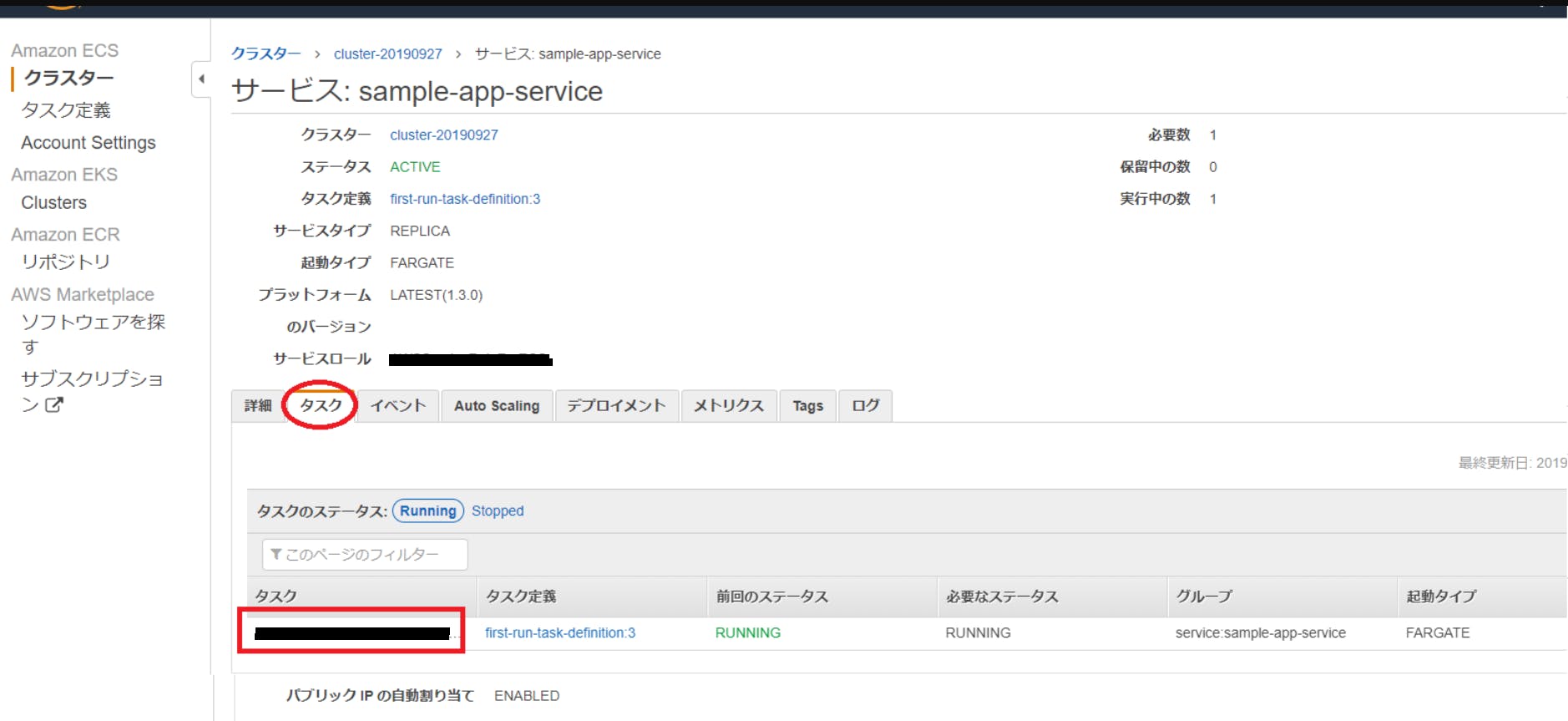
[タスク]タブを開いて、タスク一覧からタスクを選択します。
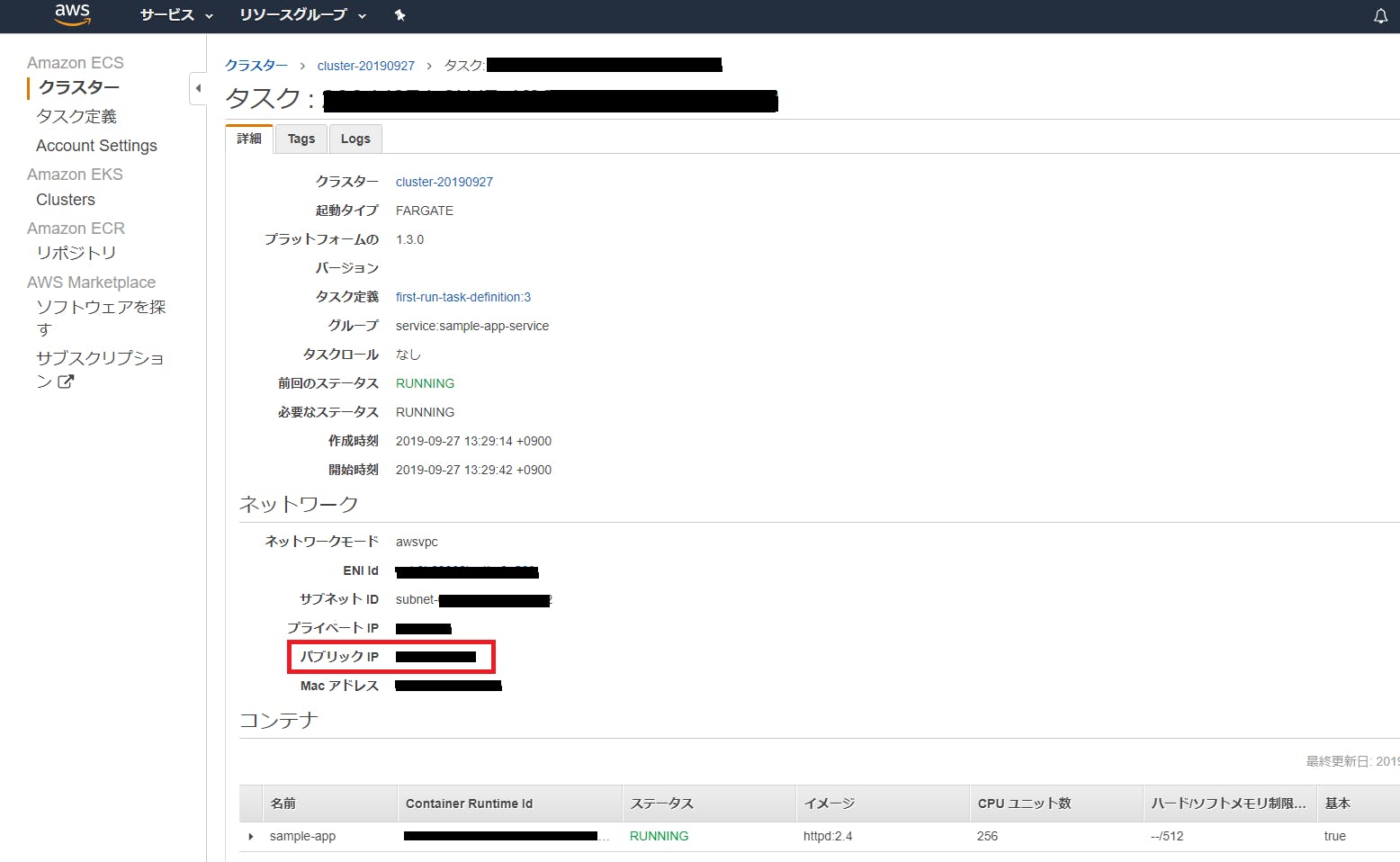
Public IPアドレスを確認します。
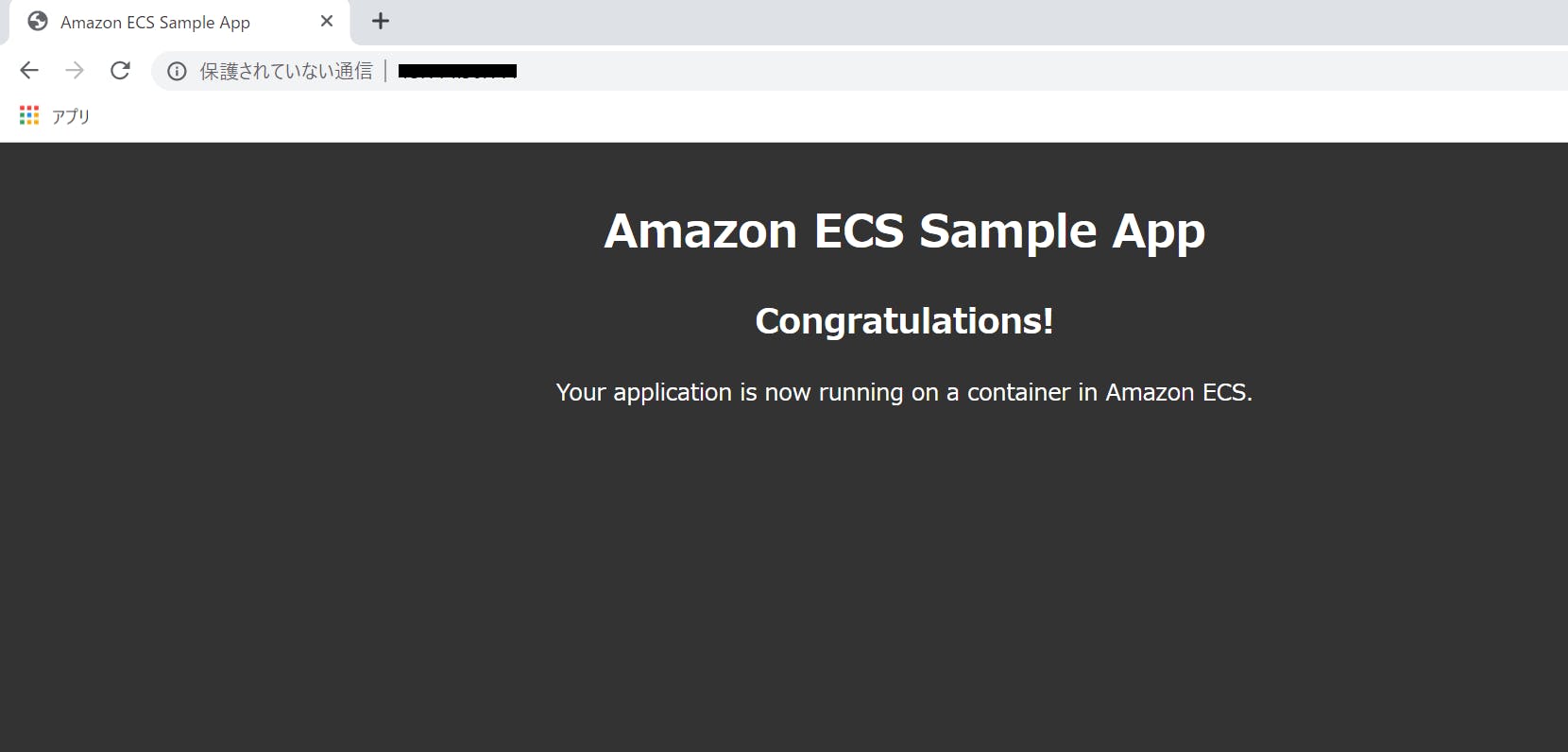
Public IPアドレスにアクセスすると、以下の画面が表示されます。
無事に、コンテナイメージが配布され、[sample-app]のでも画面が表示されていることが確認できました。
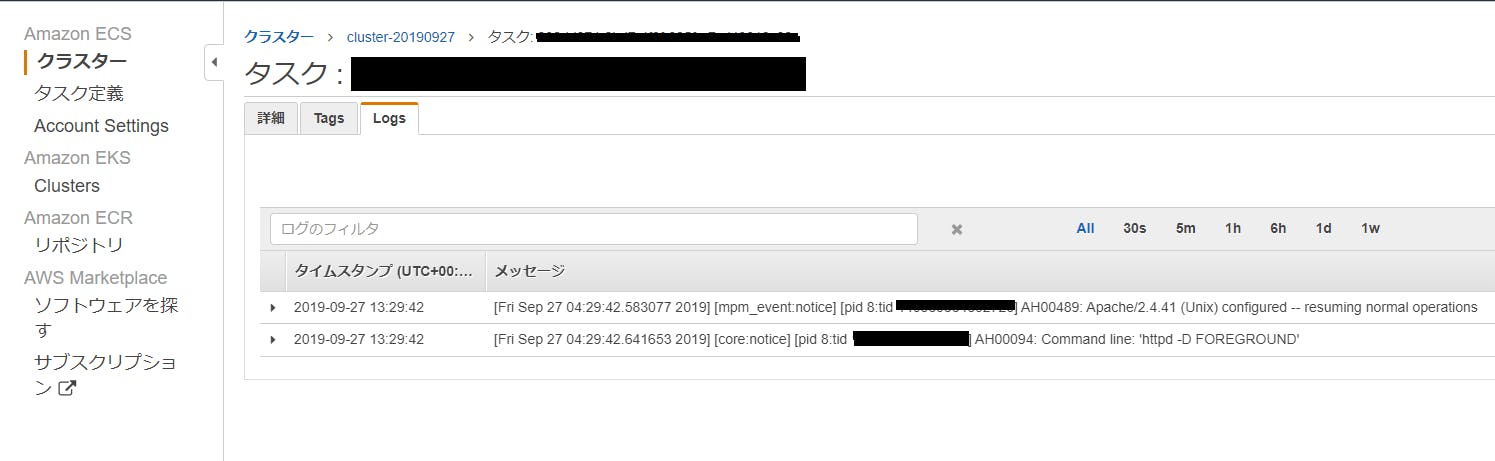
ログも確認できました。



- 投稿日:2019-09-27T13:35:01+09:00
PythonでAmazon S3からバケット名とファイル名(オブジェクト名)を取得する。
バケット名を取得する
import boto3 s3 = boto3.client('s3') # jsonになっている response = s3.list_buckets() for bucket in response['Buckets']: print(bucket['Name'])ファイル名(オブジェクト名)を取得する
import boto3 s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket="バケット名を書く") for object in response['Contents']: print(object['Key'])ファイルの内容を取得する
import boto3 s3 = boto3.client('s3') body = s3.get_object(Bucket="バケット名を書く",Key="Objectの階層を書く")['Body'].read() # バケット名がfruitsでバケットの直下にapple.jsonを置いている場合 # body = s3.get_object(Bucket="fruits",Key="apple.json")['Body'].read() print(body.decode('utf-8'))
- 投稿日:2019-09-27T13:35:01+09:00
string indices must be integersPythonでAmazon S3からバケット名とファイル名(オブジェクト名)を取得する。
バケット名を取得する
import boto3 s3 = boto3.client('s3') # jsonになっている response = s3.list_buckets() for bucket in response['Buckets']: print(bucket['Name'])ファイル名(オブジェクト名)を取得する
import boto3 s3 = boto3.client('s3') response = s3.list_objects_v2(Bucket="バケット名を書く") for object in response['Contents']: print(object['Key'])ファイルの内容を取得する
import boto3 s3 = boto3.client('s3') body = s3.get_object(Bucket="バケット名を書く",Key="Objectの階層を書く")['Body'].read() # バケット名がfruitsでバケットの直下にapple.jsonを置いている場合 # body = s3.get_object(Bucket="fruits",Key="apple.json")['Body'].read() print(body.decode('utf-8'))
- 投稿日:2019-09-27T12:16:56+09:00
Amazon Personalizeを導入して得られた知見
Amazon Personalizeを導入するにあたって
ユーザへのレコメンド機能を実装するにあたってAmazon Personalizeを導入することとなり、様々調べながら進めていって得られた知見をまとめていきたいと思います。
ドキュメントはもちろん存在していて、こちらを読み進めながらやっていけばいい話なのですが、2019年1月リリースのサービスなのでまだまだドキュメントの充実が足りていない部分があり、記載方法にも不親切な点もあったため自分なりにまとめました。AWSサポートに問い合わせするも、回答に数日〜1週間掛かることがざらにあり、待ち時間を含めると開発は思ったより時間がかかりました。
実装するにあたって機械学習の知識は基本的にいりませんが、パラメタ調整やそもそものデータ作成に関してはやはり機械学習の知識があったほうが良いのは間違いないでしょう。Amazon Personalizeの処理の流れ
- データセットの作成、インポート
- ソリューションの作成
- キャンペーンの作成
という大まかな流れでレコメンドエンジンを作成します。以下がその詳細です。
1. データセットの作成
まずはデータセットを作成します。
データセットには基本的には以下の3つがあります。これはどのユーザーも共通です。
- Item
- User
- Interaction
AWSのハンズオンに参加した際の例では以下のようになっていました。
- Item...映画データ。映画のカテゴリなどの属性
- User...ユーザーデータ。ユーザーの年齢性別などの属性
- Interaction...評価履歴。どのユーザーがどの映画をどのように評価したのか
Personalizeを使うときはこの3つのデータを作成します。各々のサービスで、例えばユーザーの属性は何で決まるか(年齢のか性別なのか住所なのか、またその全てなのか)は別だと思うのでそれぞれの詳細は自分たちで決めていく形になります。
このデータをCSVファイルとして作成してS3に置きます。それをインポートジョブを作成してインポートします。
このインポート処理はだいたい10~15分程度かかります。2. ソリューションの作成
ソリューションの作成時に困るのはRecipeの選択です。
基本的にMLの知識がなければAutomatic (AutoML)を選択するのが良いみたいです。それでうまくレコメンドされれば特には困ることはないでしょう。ただ、今回の実装ではどんどん新しいデータが入ってくるためそれらを優先してレコメンドしてほしいという背景からManualレシピのHRNN-Coldstart レシピをAWS側から勧められ、こちらで作成することとしました。
Manualになった場合はパラメタを自ら決める必要がありFeature transformation parametersを自分で決めなければいけません。
coldstartの場合以下の3つのパラメータが重要でした。今回は閲覧履歴をもとに考えてみます。
cold_start_max_interactions
- 閲覧履歴の総数の限度。例えば100と設定すると100以上閲覧されたものはレコメンドされない
cold_start_max_duration
- 次で決める
cold_start_relative_fromから何日遡った日数のデータをレコメンドするか。例えばcold_start_relative_fromが現在時刻であった場合、この数字を5とすると、5日以内のデータがレコメンドされますcold_start_relative_from
- いつからのデータをレコメンドするかの開始点を決定する。現在時刻の
currentTimeと最新データの時刻を参照するlatestItemの2つが設定可能。Itemの最新時刻とはいえタイムスタンプが設定可能なのはInteractionのみなので5日以内という設定とすると、5日以内に閲覧履歴の存在するデータのみがレコメンド対象となる。しっかり理解できていないが、インタラクションデータセットに存在しないItemはレコメンド対象にならない?またcoldstartの場合、Item数のMaxは80,000件となる。これは現在のドキュメントには記載されているが、私が触っていたときはドキュメントに記載がなく、エラーが発生してしまった…
ソリューションの作成は従量課金となります。
0.24 USD/トレーニング時間が発生するのでやりすぎには注意しましょう。私がやった限り、都度1時間程度かかりました。もちろんデータ量にはよるとは思いますが、AWS側の説明としてはデータ量が少なくともこれくらいは掛かるとのことでした。3. キャンペーンの作成
キャンペーンというのが実際にレコメンド機能となる。キャンペーンを起動すると、エンドポイントにユーザID付きで投げるとレコメンドのItem_IDが帰ってくる。これはただ作成ボタンを押して、先程作成したソリューションを選択するだけなので簡単に終わる。
注意点としてはキャンペーンは作成しただけで従量課金が発生します。
最低でも0.20USD/時間かかります。これは一ヶ月放置しておくと140ドルくらいかかってしまうので要注意です。データセットやソリューションは作成しておいても料金はかかりません。
キャンペーンのみ、テストする際は必要なときだけ起動するようにしましょう。運用にあたって
上記手順はほぼドキュメントを見ればわかることかと思います。実運用するにあたって困ったこととその対処法を記載していきます。
困ったこと①リアルタイムデータの反映
運用サービスではリアルタイムでItem、User、Interactionが増えていくのでリアルタイムにデータを追加していきたいと考えました。
その際にはイベントの記録という項目があり、こちらをつかうと行けそうにみえます。ただ以下の問題点がわかりました
- 追加できるのはInteractionデータのみ
- Interactionに新しいItemやUserが存在してもレコメンドに反映できない
という事がわかり、イベントの記録をやったとしても、大して精度が上がらなさそうで、イベントの記録はあきらめることにしました。
ItemやUserがある程度固定されている場合はイベントの記録で対応できそうです。困ったこと②InteractionデータのEventがわからない
今回の自分の実装にはInteractionのEventTypeとEventValueは必要ないカラムだったので使わなかったのでなかなか理解できませんでした。AWSのドキュメントを参考にすると…
USER_ID ITEM_ID TIMESTAMP EVENT_TYPE EVENT_VALUE NUM_RATINGS user123 movie_xyz 1543531139 rating 5 12 user321 choc-ghana 1543531760 like true user111 choc-fake 1543557118 like false このようなInteractionデータセットを作成することができて、映画の評価をratingしているものだけで学習することもlikeで評価しているものだけで学習することもできるようになるようです。
実運用
リアルタイムイベントの記録を断念したので、毎日データセットをインポートし、ソリューション作成、キャンペーンの作成を行いました。
バージョンという考えがPersonalizeにあるのでそれを使うと比較的簡単です。以下の手順になります。上記手順でキャンペーンまで作成しているものとします。
1. データの作成、S3アップロード
2. インポートジョブの作成
3. ソリューションバージョンアップ
4. キャンペーンバージョンアップデータの作成・S3アップロードをしたあとはアップロードしたS3ファイルを指定してインポートジョブを作成します。インポートが終わったらあとはバージョンアップさせるだけで終了です。
ひとつのデータセットグループには一つずつのUser・Item・Interactionしか持てないため、ソリューション・キャンペーンは同一arnが利用可能です。
キャンペーンarnが変わらないので、アプリケーション側は固定のエンドポイントを使用することが可能なので実装をしっかり切り分けることが可能となっています。最初のキャンペーン作成まではAWSコンソールから行って、バージョンアップはAWS SDKを介して行うのが一番ラクかと思われます。
このサイクルを回してけばそれなりに最新データをレコメンドさせることが可能かと思います。ただトレーニング時間あたりで課金されますし、データのインポートにも課金されるのでその分費用が当然かかります。
これから
ここまででレコメンド機能は作成できました。が、これでようやくスタートラインに立てただけです。
ここから実際に運用してみてどれくらいアクセス数が変わるのか、レコメンドの精度はどうなのかなどを検討しパラメータの調整、再トレーニングの繰り返しになるかと思います。またそこでわかったことがあればまとめていきたいと思います。
- 投稿日:2019-09-27T10:37:40+09:00
AWS Auto Scalingを使ってみた
やっと秋らしい天気になってきました!
読書の秋、スポーツの秋といいますが私は断然食欲の秋です
今年は、美味しいものたくさん食べる計画を立てているrisakoです。
今回はAutoScalingとはなんぞやというところから、使い方について簡単に紹介します。AWS Auto Scalingってなに?
AWSの説明によると、AWS Auto Scalingとはこのようなものらしいです。
AWS Auto Scaling は、安定した予測可能なパフォーマンスを可能な限り低コストで維持するためにアプリケーションをモニタリングし、容量を自動で調整します。AWS Auto Scaling を使用すると、複数のサービスにまたがる複数のリソースのためのアプリケーションスケーリングを数分で簡単に設定できます。
まとめると、指定した容量に達した場合にEC2を自動で増やしたり減らしたりしてくれる機能です。
仕組み
AWS Auto Scalingを使うメリット
- 耐障害性の向上 →EC2インスタンスの異常を検出して停止し、自動で新しいインスタンスを作成してくれるので耐障害性に強いと言えます。
- 可用性の向上 →複数のAZ(Availability Zone)で設定した場合、一つのAZが使用不可になっても違うAZで新しいインスタンスを作成してくれます。
- コスト効率の向上 →指定した数のEC2インスタンスを自動で必要な分だけ作成してくれるので、無駄なEC2を作成しなくていいという点でコスト効率の向上と言えます。通常よりも多いアクセスにも指定した最大数のインスタンスを作成できるため、必要な時に必要な分だけインスタンスを動かせます。
作ってみよう
Auto Scalingグループの起動が使用するパラメータの作成
今回は、
起動設定での、作成方法について紹介します。EC2コンソールから作成可能します。
- 起動設定作成を選択。
- 今回は、自分のEC2から作成するため、
マイAMIで自分のEC2を選択する。- 利用するインスタンスサイズを選択。
- インスタンスの名前・IAMロールの有無(今回は無し)・cloudwatchのモニタリングの有無を入力。
- ストレージの追加・セキュリティグループの設定を行う
- 作成
印象としては、EC2インスタンスを作成する手順とほぼ変わらなかったです
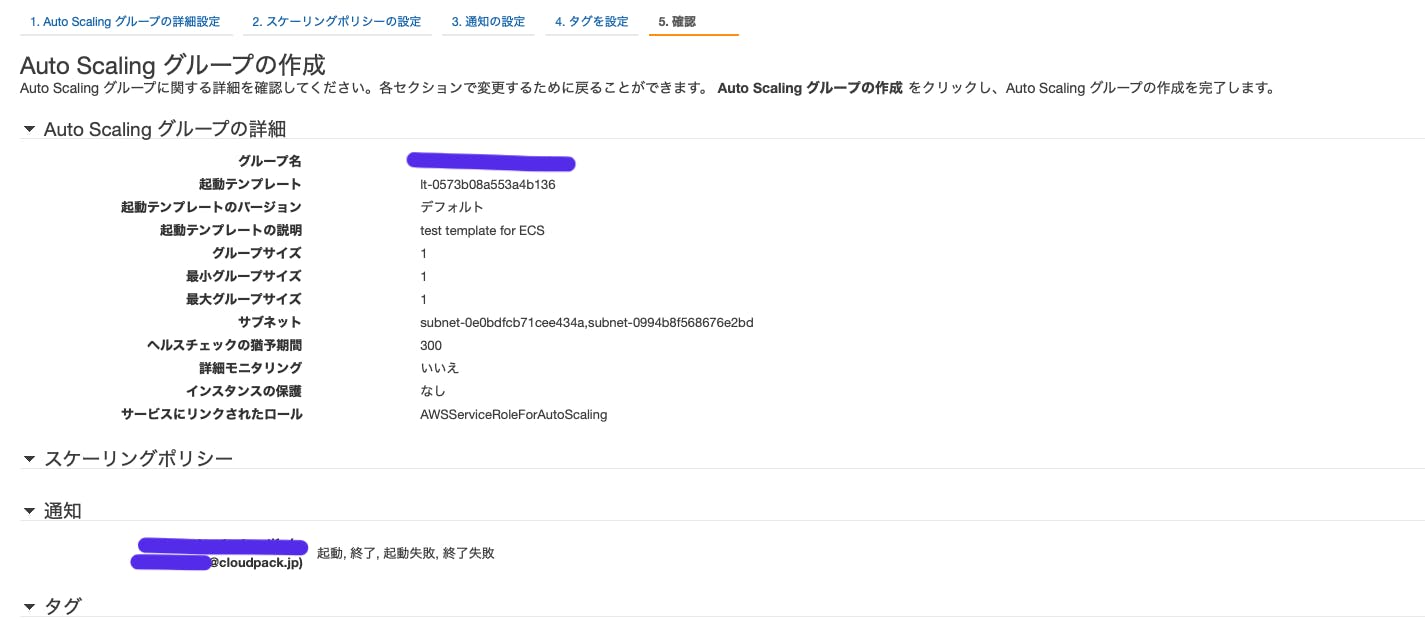
Auto Scaling グループの作成
- 上記と同様にEC2コンソール内から作成する。
- Auto Scalingグループの作成を選択
- 先ほど作成した
起動設定の名前を選択する。- AutoScalingグループの作成の各設定を入力する。
- グループのサイズ:起動したいインスタンスの数を設定する。
- ネットワーク;使用したいVPC
- サブネット:インスタンスを起動させるAZを選択
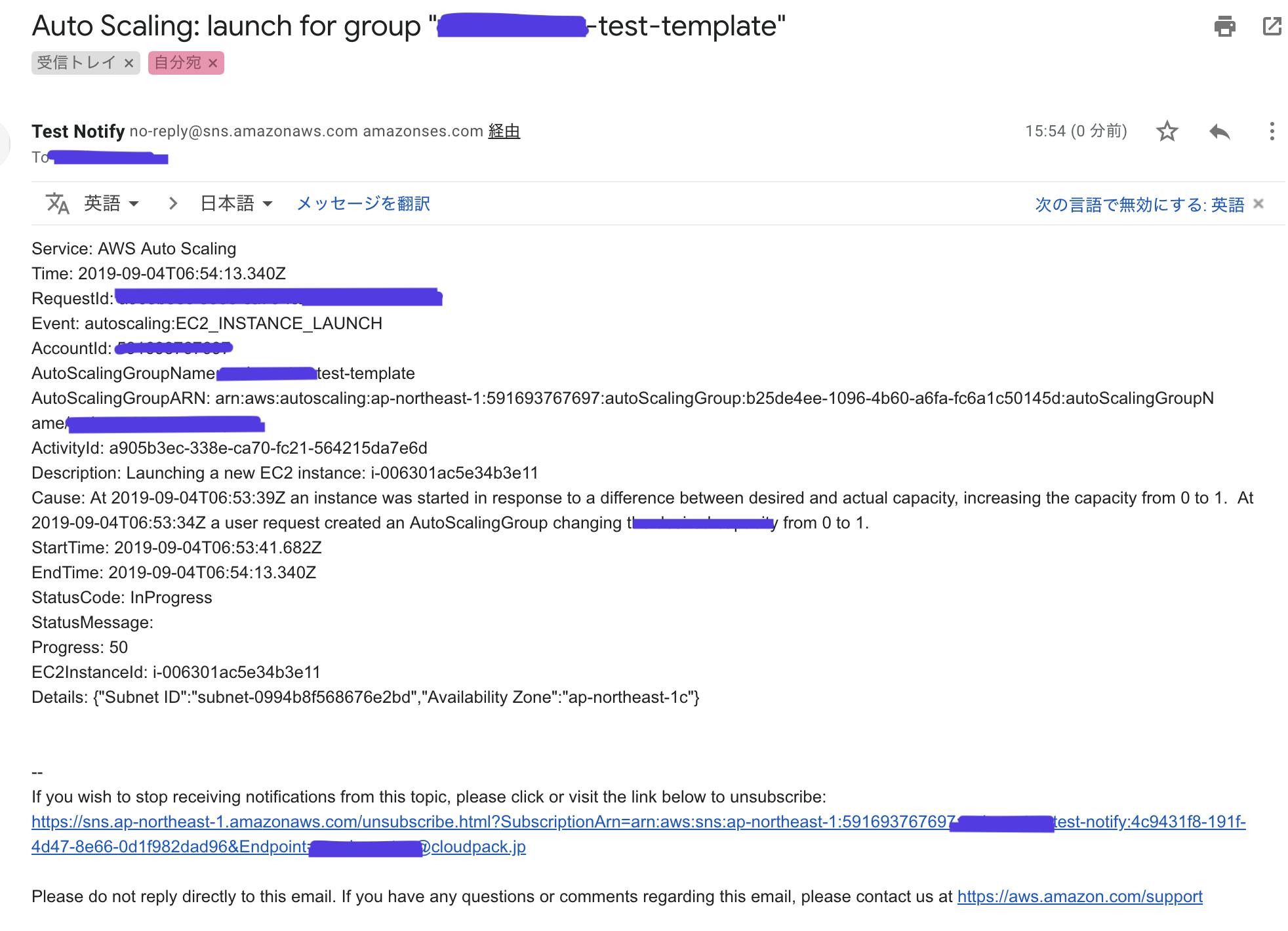
高度な詳細の通知の送信では、でAuto Scalingが起動・終了・起動失敗・終了失敗した時に指定したメールアドレスに通知を飛ばしてくれるので、何かあった時に気づくことができる。
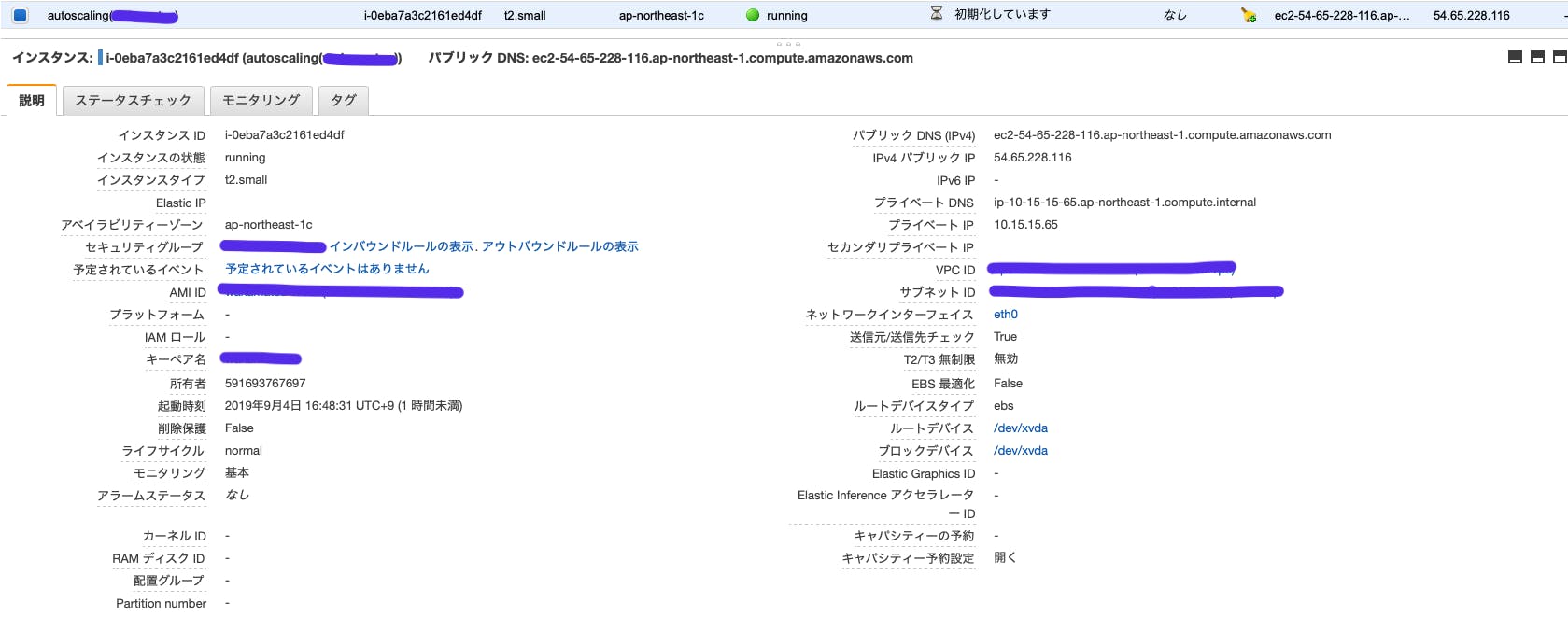
EC2コンソールから確認する
autoscalingの名前でインスタンスが立ち上がっていることが確認できます。
希望するキャバシティの数のインスタンスが立ち上がっていればokです。
インスタンスが立ち上がったのと同時にメールでの通知が来ました。
不具合が生じたときだけ通知を飛ばしてほしいなど通知をカスタマイズできるのもステキです
AutoScalingを使ってみた感想
簡単にEC2インスタンスを増減できることに驚きました。
AWSサービスをしっかり使うようになってから約3ヶ月ですが必要な時に必要な分だけEC2インスタンスを立てることができるのはお客様の要望にも幅広く対応していけそうだと感じました。
この機能はECS(EC2 Container Service)でも使われているので、ECSと共にマスターして行きたいです!参考
Amazon EC2 AutoScaling ドキュメント https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/what-is-amazon-ec2-auto-scaling.html
AWS Auto Scaling
https://aws.amazon.com/jp/autoscaling/[AWS]Auto Scalingする前に知っておくべき7つのこと
https://miyabi-lab.space/blog/30
- 投稿日:2019-09-27T09:25:17+09:00
汎用的に使える週次で担当者を通知するSlackbotを作成した
やりたいこと
弊チームでは毎週金曜日に担当者が技術事例を発表する試みがあるのですが、日々のタスクに集中しすぎて自分の担当週を忘れることがあり、思い出した誰かが前日に教えてあげたり、当日の明朝にふと思い出すなどで、時間的に余裕がないまま技術記事をまとめるということが度々発生していました。
そこで週次に担当者を通知するだけのSlackbotを作成することとしました。よくよく考えると、週次のアラート担当者へのメンション通知などユースケースは意外とあると思うので、できる限り楽に汎用的に使えるように心がけて作成しました。
当記事の前提
- AWS環境を使用できること
- Slackを利用していること
構成
CloudWatchEventsで決められたタイミングでLambdaを発火し、担当者をSlackに通知するシンプル構成です。
作業の流れ
- SlackチャンネルのWebhookURLを取得する。
- 各担当者のSlackのメンバーIDを取得する。
- CFnからスタックを作成する。
手順
「1.SlackチャンネルのWebhookURLを取得する」については、https://qiita.com/vmmhypervisor/items/18c99624a84df8b31008 を、「2.各担当者のSlackのメンバーIDを取得する。」については、http://help.receptionist.jp/?p=1100#memberid を参考にすると良いでしょう。
CFnテンプレートとLambdaのソースコードについては下記にあげておきますので、ご利用いただければと思います。
CFnに環境に応じたパラメータを設定することでslackbotを作成することが可能です。CFnテンプレート
AWSTemplateFormatVersion: '2010-09-09' Parameters: SlackWebhookUrl: Type: String Default: 'https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXX/XXXXXXXXXXXXXXXXXXXXX' MemberId: Type: String Default: 'AAAAAAAA' CommaSeparatedSlackMemberId: Type: String Default: 'AAAAAAAA,BBBBBBBB,CCCCCCCC' ScheduleExpression: Type: String Default: 'cron(0 0 ? * MON *)' ## Create Lambda Functions Resources: LambdaFunctionNotifyMessageToMember: Type: AWS::Lambda::Function Properties: Handler: index.lambda_handler Runtime: python3.7 Code: ZipFile: | import boto3 import json import os import urllib import urllib.request def set_next_member(member_id, slack_webhook_url): comma_separated_ member_id = os.getenv("COMMA_SEPARATED_SLACK_MEMBER_ID") lambda_function_name = os.getenv("AWS_LAMBDA_FUNCTION_NAME") members_list = comma_separated_member_id.split(",") members_list_index = members_list.index(member_id) if members_list_index == len(members_list) - 1: next_member_id = members_list[0] else: next_member_id = members_list[members_list_index + 1] client = boto3.client('lambda') client.update_function_configuration( FunctionName=lambda_function_name, Environment={ 'Variables': { 'MEMBER_ID': next_member_id, 'SLACK_WEBHOOK_URL': slack_webhook_url, 'COMMA_SEPARATED_SLACK_MEMBER_ID': comma_separated_member_id } } ) def lambda_handler(event, context): member_id = os.getenv("MEMBER_ID") slack_webhook_url = os.getenv("SLACK_WEBHOOK_URL") message = "今週の担当者は<@" + member_id + ">さんです!\n張り切っていきましょう!!" send_data = { "username": "担当者通知ボット", "icon_emoji": ":rocket:", "text": message, } send_text = "payload=" + json.dumps(send_data) request = urllib.request.Request( slack_webhook_url, data=send_text.encode("utf-8"), method="POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode("utf-8") set_next_member(member_id, slack_webhook_url) MemorySize: 128 Timeout: 60 Environment: Variables: SLACK_WEBHOOK_URL: !Ref SlackWebhookUrl COMMA_SEPARATED_SLACK_MEMBER_ID: !Ref CommaSeparatedSlackMemberId MEMBER_ID: !Ref MemberId Role: !GetAtt IAMRoleNotifyMessageToMember.Arn IAMRoleNotifyMessageToMember: Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: '2008-10-17' Statement: - Effect: 'Allow' Principal: Service: 'lambda.amazonaws.com' Action: 'sts:AssumeRole' ManagedPolicyArns: - arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy - !Ref IAMManagedPolicyLamdbaUpdateFunctionConfiguration IAMManagedPolicyLamdbaUpdateFunctionConfiguration: Type: AWS::IAM::ManagedPolicy Properties: Path: "/" PolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Action: - lambda:UpdateFunctionConfiguration Resource: "*" LambdaPermissionNotifyMessageToMember: Type: AWS::Lambda::Permission Properties: FunctionName: !Ref LambdaFunctionNotifyMessageToMember Action: "lambda:InvokeFunction" Principal: "events.amazonaws.com" SourceArn: !GetAtt EventsRuleNotifyMessageToMemberSchedule.Arn EventsRuleNotifyMessageToMemberSchedule: Type: AWS::Events::Rule Properties: Description: "Notify message to the member in charge this week" RoleArn: !GetAtt IAMRoleLambdaExecutionNotifyMessageToMember.Arn ScheduleExpression: !Ref ScheduleExpression Targets: - Arn: !GetAtt LambdaFunctionNotifyMessageToMember.Arn Id: "Slackbot" IAMRoleLambdaExecutionNotifyMessageToMember: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: events.amazonaws.com Action: "sts:AssumeRole"ソースコード抜粋
簡単に説明しますと、環境変数に登録したSlackのアカウントに紐づくID(メンバーID)にメンションをつけてメッセージを送り、その後自分自身(Lambda)の環境変数を次の担当者に更新し、次回の実行を待つという流れになります。
import boto3 import json import os import urllib import urllib.request def set_next_member(member_id, slack_webhook_url): comma_separated_member_id = os.getenv("COMMA_SEPARATED_SLACK_MEMBER_ID") lambda_function_name = os.getenv("AWS_LAMBDA_FUNCTION_NAME") members_list = comma_separated_member_id.split(",") members_list_index = members_list.index(member_id) if members_list_index == len(members_list) - 1: next_member_id = members_list[0] else: next_member_id = members_list[members_list_index + 1] client = boto3.client('lambda') client.update_function_configuration( FunctionName=lambda_function_name, Environment={ 'Variables': { 'MEMBER_ID': next_member_id, 'SLACK_WEBHOOK_URL': slack_webhook_url, 'COMMA_SEPARATED_SLACK_MEMBER_ID': comma_separated_member_id } } ) def lambda_handler(event, context): member_id = os.getenv("MEMBER_ID") slack_webhook_url = os.getenv("SLACK_WEBHOOK_URL") message = "今週の担当者は<@" + member_id + ">さんです!\n張り切っていきましょう!!" send_data = { "username": "担当者通知ボット", "icon_emoji": ":rocket:", "text": message, } send_text = "payload=" + json.dumps(send_data) request = urllib.request.Request( slack_webhook_url, data=send_text.encode("utf-8"), method="POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode("utf-8") set_next_member(member_id, slack_webhook_url)最後に
何かしらの理由で、その週の担当をスキップして次の週も同じ担当者で、、というケースもあるかと思いますが、その場合はAWS CLIでCFnのスタックを更新してあげれば良いかと思います。
コマンドとしては以下のような感じになるかと。aws cloudformation update-stack --stack-name [CFnスタック名] \ --use-previous-template --capabilities CAPABILITY_IAM \ --parameters ParameterKey=SlackWebhookUrl,UsePreviousValue=true \ ParameterKey=ScheduleExpression,UsePreviousValue=true \ ParameterKey=CommaSeparatedSlackMemberId,UsePreviousValue=true \ ParameterKey=MemberId,ParameterValue=[担当者のUID]少しコマンドが長くなりますが、値を変更したくないパラメータは「UsePreviousValue=true」をつけてあげないと、CFnテンプレートで指定しているデフォルト値に設定されてしまうので注意が必要です。

- 投稿日:2019-09-27T09:00:43+09:00
【aws】LoadError: No such file to load -- aws-sdk-s3.rb【自動デプロイ中】
はじめに
自動デプロイをかけたところ、タイトルのエラーに遭遇。
結論、解決はしたものの原因不明のエラーの為、今後色々調べたいので備忘録として記載します。
OSが関係してるのかなと推測してますが、分かる方いらっしゃればご教示下さい。開発環境
Rails 5.2.1
ruby 2.5.1
capistrano 3.11.1
AWS(EC2)
Web Server Nginx
Application Server Unicorn前提
上記導入済み、aws接続して自動デプロイまでは問題無し。S3設定後初めての自動デプロイ中に
unicorn startで止まったエラー。ファイルのLoadErrorが発生
unicorn startで止まり、エラー文にはstderr.logの詳細をチェックするようにという記述。
current/log/unicorn.stderr.log# 本番環境でlog表示(less or cat) $ less log/unicorn.stderr.log # エラー抜粋 I, [2019-09-20T08:48:07.350883 #12335] INFO -- : Refreshing Gem list bundler: failed to load command: unicorn (/var/www/appname/shared/bundle/ruby/2.5.0/bin/unicorn) LoadError: No such file to load -- aws-sdk-s3.rb原因(不明)
今回導入予定の無い
aws-sdkというパッケージに関連するエラー。
確認したところ、公式
http://aws.amazon.com/jp/sdkforruby/
参考
https://qiita.com/w650/items/50449fe162bc0f8425e4というようなgemでした。
検証計画
- aws-sdk-s3.rbの存在→なし
- 本番・ローカルでgemfile、gemfile lockの確認→記述なし
- 再起動・bundleinstallのし直し→変化なし
- S3導入時に変更した設定関連のファイルを確認→問題無さそう (
database.yml/deploy.rb/image_uploder/unicorn.rb/carrierwave.rb/enviroment.rb/capfileなど)- コミットを辿り自動デプロイできていたところまで遡る→できていたはずの段階でも同じエラー
- ★一度、 aws-sdk-s3を導入してみる
- git cloneをやり直し、再度環境構築
- EC2インスタンスから作成のし直し
解決
結局、gemを導入することで解決。
Gemfileにaws-sdkを追加、bundleinstall、merge、(念の為本番環境でもpullとbundle install)、自動デプロイで本番環境にページ表示されるように。さいごに
自分の中では最終手段のひとつと思っていた導入をすることに。
理由や原因が分からないまま、使わなければいいとは言えgemを追加するのが抵抗あったからですが、かなり時間をかけてしまいました。
コードに特に違和感が無ければ、もっと早くに試しても良かったというのが反省点。
- 投稿日:2019-09-27T09:00:15+09:00
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #6 (暗号化と PKI)
Amazon Web Services (AWS)のサービスで正式名称や略称はともかく、読み方がわからずに困ることがよくあるのでまとめてみました。
Amazon Web Services (AWS) - Cloud Computing Services
https://aws.amazon.com/まとめルールについては下記を参考ください。
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #1 (コンピューティング) - Qiita
https://qiita.com/kai_kou/items/a6795dbab7e707b0d1a6間違いや、こんな呼び方あるよーなどありましたらコメントお願いします!
Cryptography & PKI - 暗号化と PKI
AWS CloudHSM
- 正式名称: AWS CloudHSM
- HSM: Hardware Security Module
- https://docs.aws.amazon.com/cloudhsm/?id=docs_gateway
- 読み方: クラウド エイチ エス エム?
- 略称: なし
- 俗称: なし
AWS Key Management Service (AWS KMS)
- 正式名称: AWS Key Management Service
- https://docs.aws.amazon.com/kms/?id=docs_gateway
- 読み方: キー マネジメント サービス
- 略称: AWS KMS
- 俗称: なし
AWS Certificate Manager
- 正式名称: AWS Certificate Manager
- https://docs.aws.amazon.com/acm/?id=docs_gateway
- 読み方: サーティフィケイト マネージャ
- 略称: ACM
- 俗称: なし
AWS Certificate Manager Private Certificate Authority
- 正式名称: AWS Certificate Manager Private Certificate Authority
- https://docs.aws.amazon.com/acm/?id=docs_gateway
- 読み方: サーティフィケイト マネージャ プライベート サーティフィケイト オーソリティ(オソーリティ)
- 略称: ACM PCA
- 俗称: なし
- 投稿日:2019-09-27T07:21:44+09:00
これで大抵賄える!AWS SDK for Ruby V3でのS3操作まとめ!!
S3の操作するコードを書くタスクは日常的にやるわけではなくて、なぜかちょうど忘れた頃の絶妙なタイミングでやってきます。そのたびにAPIリファレンスを見ながら頑張って組み立ててるような気がしたので、しゃらくせぇ!と思い、よく使うやつをまとめました。
Aws::S3::ClientとAws::S3::Resourceの2系統を用意しました。お好みに応じて参照してください。
参考までに、この2つの違いがよく分からなくて途方に暮れている人はこちらをご覧ください。
AWS SDK for Ruby V3のAws::S3::ClientとAws::S3::Resourceの違いに正面から向き合うクレデンシャル情報やリージョンは、環境変数やIAMロール等で設定されているものとします。
個別に設定する場合は、Aws::S3::Client.newやAws::S3::Resource.newの引数に渡してあげてください。Aws::S3::Client
# 共通 client = Aws::S3::Client.newバケット一覧
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#list_buckets-instance_method
# バケット情報一覧 client.list_buckets => #<struct Aws::S3::Types::ListBucketsOutput buckets= [#<struct Aws::S3::Types::Bucket name="bucket-01", creation_date=2017-09-16 14:07:03 UTC>, #<struct Aws::S3::Types::Bucket name="bucket-02", creation_date=2018-08-19 04:22:41 UTC>,], owner=#<struct Aws::S3::Types::Owner display_name="XXXXXX", id="xxxxxxxxxxxxxxx">> # 各バケットを操作 client.list_buckets.buckets.each do |bucket| # なにかする endバケット作成
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#create_bucket-instance_method
client.create_bucket(bucket: "bucket-03") => #<struct Aws::S3::Types::CreateBucketOutput location="http://bucket-03.s3.amazonaws.com/">バケット削除
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#delete_bucket-instance_method
client.delete_bucket(bucket: "bucket-03") => #<struct Aws::EmptyStructure>オブジェクト一覧
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#list_objects_v2-instance_method
# オブジェクト情報一覧 # `list_objects`は使わない client.list_objects_v2(bucket: "bucket-01") => #<struct Aws::S3::Types::ListObjectsV2Output is_truncated=true, contents= [#<struct Aws::S3::Types::Object key="example_01.txt", last_modified=2019-09-24 21:42:10 UTC, etag="\"xxxxxxxxxxxxxx\"", size=7, storage_class="STANDARD", owner=nil>, #<struct Aws::S3::Types::Object key="example_02.txt", last_modified=2019-09-24 21:42:10 UTC, etag="\"xxxxxxxxxxxxxx\"", size=7, storage_class="STANDARD", owner=nil>], name="bucket-01", prefix="", delimiter=nil, max_keys=1000, common_prefixes=[], encoding_type=nil, key_count=1000, continuation_token=nil, next_continuation_token="1I+AdtAyjlXhJ1jEKpdpR3fqz2bDnfJFEfZ+wgn9vmpXjHNGcLzL8bg==", start_after=nil> # 各オブジェクトを操作(1000個以下の場合) client.list_objects_v2(bucket: "bucket-01").contents.each do |object| # なにかする end # 各オブジェクトを操作(1000個より多いの場合) options = {bucket: "bucket-01"} loop do object_list = client.list_objects_v2(options) object_list.contents.each do |object| # なにかする end options[:continuation_token] = object_list.next_continuation_token break unless object_list.next_continuation_token end # キー名のプレフィクスによる絞り込み client.list_objects_v2(bucket: "bucket-01", prefix: "hoge/").contents.each do |object| # なにかする endオブジェクトアップロード
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#put_object-instance_method
client.put_object(bucket: "bucket-01", key: "example_01.txt", body: "example") => #<struct Aws::S3::Types::PutObjectOutput expiration=nil, etag="\"xxxxxxxxxxxxxx\"", server_side_encryption=nil, version_id="JlDwEydDxlVNoyEaChzromzkjPo5FwVl", sse_customer_algorithm=nil, sse_customer_key_md5=nil, ssekms_key_id=nil, ssekms_encryption_context=nil, request_charged=nil>オブジェクト読み込み
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#get_object-instance_method
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Types/GetObjectOutput.htmlclient.get_object(bucket: "bucket-01", :key => 'example_01.txt').body.read => "example"オブジェクト削除
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#delete_object-instance_method
client.delete_object(bucket: "bucket-01", key: "example_01.txt") => #<struct Aws::S3::Types::DeleteObjectOutput delete_marker=true, version_id="skCZWAXC0.vhxjK6zKTF0dBkj4H0gEe8", request_charged=nil>オブジェクトのバージョン操作
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#list_object_versions-instance_method
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#delete_object-instance_method# バージョン情報 client.list_object_versions(bucket: "bucket-01", prefix: "example_01.txt") => #<struct Aws::S3::Types::ListObjectVersionsOutput is_truncated=false, key_marker="", version_id_marker="", next_key_marker=nil, next_version_id_marker=nil, versions= [#<struct Aws::S3::Types::ObjectVersion etag="\"xxxxxxxxxx\"", size=7, storage_class="STANDARD", key="example_01.txt", version_id="BcczH4ZRVunnKyBuzk3cBOQgrh1gtGpR", is_latest=true, last_modified=2019-09-24 21:47:54 UTC, owner=#<struct Aws::S3::Types::Owner display_name="xxxxxx", id="xxxxxxxxxxxxxxxxxx">>, #<struct Aws::S3::Types::ObjectVersion etag="\"xxxxxxxxxx\"", size=7, storage_class="STANDARD", key="example_01.txt", version_id="null", is_latest=false, last_modified=2019-09-24 21:42:10 UTC, owner=#<struct Aws::S3::Types::Owner display_name="xxxxxx", id="xxxxxxxxxxxxxxxxxx">>], name="bucket-01", prefix="example_01.txt", delimiter=nil, max_keys=1000, common_prefixes=[], encoding_type="url"> # 特定のバージョンを削除 client.delete_object(bucket: "bucket-01", prefix: "example_01.txt", version_id: "JlDwEydDxlVNoyEaChzromzkjPo5FwVl") => #<struct Aws::S3::Types::DeleteObjectOutput delete_marker=nil, version_id="JlDwEydDxlVNoyEaChzromzkjPo5FwVl", request_charged=nil>マルチパートアップロード
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#create_multipart_upload-instance_method
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#upload_part-instance_method
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Client.html#complete_multipart_upload-instance_methodmultipart = client.create_multipart_upload(bucket: "bucket-01", key: "multipart") => #<struct Aws::S3::Types::CreateMultipartUploadOutput abort_date=nil, abort_rule_id=nil, bucket="bucket-01", key="multipart", upload_id="xxxxxxxxxxxxxxxxxxxx", server_side_encryption=nil, sse_customer_algorithm=nil, sse_customer_key_md5=nil, ssekms_key_id=nil, ssekms_encryption_context=nil, request_charged=nil> part_01 = client.upload_part(bucket: "bucket-01", key: "multipart", body: File.open("/path/to/part_01"), part_number: 1, upload_id: multipart.upload_id) => #<struct Aws::S3::Types::UploadPartOutput server_side_encryption=nil, etag="\"xxxxxxxxxxxxxxxxxxxxx\"", sse_customer_algorithm=nil, sse_customer_key_md5=nil, ssekms_key_id=nil, request_charged=nil> part_02 = client.upload_part(bucket: "bucket-01", key: "multipart", body: File.open("/path/to/part_02"), part_number: 2, upload_id: multipart.upload_id) => #<struct Aws::S3::Types::UploadPartOutput server_side_encryption=nil, etag="\"yyyyyyyyyyyyyyyyyyyyy\"", sse_customer_algorithm=nil, sse_customer_key_md5=nil, ssekms_key_id=nil, request_charged=nil> client.complete_multipart_upload( bucket: "bucket-name-0001", key: "multipart", multipart_upload: { parts: [ {etag: part_01.etag, part_number: 1}, {etag: part_02.etag, part_number: 2} ] }, upload_id: multipart.upload_id ) => #<struct Aws::S3::Types::CompleteMultipartUploadOutput location="https://bucket-01.s3.ap-northeast-1.amazonaws.com/multipart", bucket="bucket-01", key="multipart", expiration=nil, etag="\"zzzzzzzzzzzzzzzzzzzzz\"", server_side_encryption=nil, version_id="CSbIGreIivX2CTbIxj9Qz1JbePVQb2Qo", ssekms_key_id=nil, request_charged=nil>署名付きURL作成
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Presigner.html
# clientではできない signer = Aws::S3::Presigner.new signer.presigned_url(:get_object, bucket: "bucket-01", key: "example_01.txt", expires_in: 3600) => "https://bucket-01.s3.ap-northeast-1.amazonaws.com/example_0001?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-...Aws::S3::Resource
# 共通 resource = Aws::S3::Resource.newバケット一覧
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Resource.html#buckets-instance_method
# バケット情報一覧 resource.buckets => #<Aws::S3::Bucket::Collection:0x00007fb1e3ccb6a8 @batches=#<Enumerator: ...>, @limit=nil, @size=nil> # 各バケットを操作 resource.buckets.each do |bucket| # なにかする endバケット作成
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Resource.html#create_bucket-instance_method
resource.create_bucket(bucket: "bucket-03") => #<Aws::S3::Bucket:0x00007fb1e3d3f2d8 @client=#<Aws::S3::Client>, @data=nil, @name="bucket-03"> # こちらでもできるけど、Client系統で扱うbucket情報が返ってくる resource.bucket("bucket-03").create # 存在確認もできる resource.bucket("bucket-03").exists? => trueバケット削除
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Bucket.html#delete-instance_method
resource.bucket("bucket-03").delete => #<struct Aws::EmptyStructure>オブジェクト一覧
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Bucket.html#objects-instance_method
bucket = resource.bucket("bucket-01") # オブジェクト情報 bucket.objects => #<Aws::S3::ObjectSummary::Collection:0x00007fb1e3e47a68 @batches=#<Enumerator: ...>, @limit=nil, @size=nil> # 各オブジェクトを操作(1000個より多くてもOK!) bucket.objects.each do |object| # なにかする end # キー名のプレフィクスによる絞り込み bucket.objects(prefix: "hoge/").each do |object| # なにかする endオブジェクトアップロード
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Bucket.html#put_object-instance_method
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Object.html#put-instance_methodbucket = resource.bucket("bucket-01") # 文字列から bucket.put_object(key: "example_01.txt", body: "example") => #<Aws::S3::Object:0x00007f859e9625c8 @bucket_name="bucket-01", @client=#<Aws::S3::Client>, @data=nil, @key="example_01.txt"> # ファイルから bucket.put_object(key: "example_01.txt", body: File.open("example_01.txt")) => #<Aws::S3::Object:0x00007f859e9625c8 @bucket_name="bucket-01", @client=#<Aws::S3::Client>, @data=nil, @key="example_01.txt"> # こちらでもできるけど、Client系統で扱うbucket情報が返ってくる bucket.object("example_01.txt").put(body: "example") => #<struct Aws::S3::Types::PutObjectOutput expiration=nil, etag="\"xxxxxxxxxxxxxxxxxxxxxxxxxxxx\"", server_side_encryption=nil, version_id=nil, sse_customer_algorithm=nil, sse_customer_key_md5=nil, ssekms_key_id=nil, ssekms_encryption_context=nil, request_charged=nil>オブジェクト読み込み
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Object.html#get-instance_method
bucket = resource.bucket("bucket-01") bucket.object("example_01.txt").get.body.read => "example" # 存在確認もできる bucket.object("example_01.txt").exists? => trueオブジェクト削除
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Bucket.html#delete-instance_method
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/ObjectSummary/Collection.html#batch_delete!-instance_methodbucket = resource.bucket("bucket-01") bucket.object("example_01.txt").delete => #<struct Aws::S3::Types::DeleteObjectOutput delete_marker=nil, version_id=nil, request_charged=nil> # 一括削除 bucket.objects(prefix: "hoge/").batch_delete! => nilオブジェクトのバージョン操作
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Bucket.html#object_versions-instance_method
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Object.html#delete-instance_methodbucket = resource.bucket("bucket-01") bucket.object_versions(prefix: "example_01.txt").map(&:data) => [#<struct Aws::S3::Types::ObjectVersion etag="\"xxxxxxxxxx\"", size=7, storage_class="STANDARD", key="example_01.txt", version_id="BcczH4ZRVunnKyBuzk3cBOQgrh1gtGpR", is_latest=true, last_modified=2019-09-24 21:47:54 UTC, owner=#<struct Aws::S3::Types::Owner display_name="xxxxxx", id="xxxxxxxxxxxxxxxxxx">>, #<struct Aws::S3::Types::ObjectVersion etag="\"xxxxxxxxxx\"", size=7, storage_class="STANDARD", key="example_01.txt", version_id="null", is_latest=false, last_modified=2019-09-24 21:42:10 UTC, owner=#<struct Aws::S3::Types::Owner display_name="xxxxxx", id="xxxxxxxxxxxxxxxxxx">>] # 特定のバージョンを削除 bucket.object("example_01.txt").delete(version_id: "BcczH4ZRVunnKyBuzk3cBOQgrh1gtGpR") => #<struct Aws::S3::Types::DeleteObjectOutput delete_marker=nil, version_id="BcczH4ZRVunnKyBuzk3cBOQgrh1gtGpR", request_charged=nil>マルチパートアップロード
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Object.html#upload_file-instance_method
bucket = resource.bucket("bucket-01") # デフォルトだと15MBより大きければマルチパートアップロードになる # しきい値を変えたい場合は、`multipart_threshold`オプションを与える bucket.object("very_large_file.txt").upload_file("/path/to/very_large_file") => true署名付きURL作成
https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/S3/Object.html#presigned_url-instance_method
bucket = resource.bucket("bucket-01") # `:get`/`put`/`head`/`delete`が指定できる # `expires_in`はデフォルト900秒 bucket.object("example_01.txt").presigned_url(:get, expires_in: 3600) => "https://bucket-01.s3.ap-northeast-1.amazonaws.com/example_0001?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-...
- 投稿日:2019-09-27T00:04:22+09:00