- 投稿日:2019-08-28T16:29:46+09:00
Windowsで姿勢推定(tf pose estimation)
はじめに
姿勢推定アルゴリズムOpenPoseのTensorflow版としてtf pose estimationが公開されています。
これをWindows+Anaconda仮想環境で動かしてみた備忘録です。
初心者のため説明などふわふわしてますがご了承ください。環境
Windows 10
conda 4.7.11
CUDA 10.1
GeForce RTX 2080本記事ではAnacondaやCUDA等のインストールには触れません。
Anacondaで仮想環境を作るとこから入ります。環境を作る前に
tf pose estimation のダウンロード
まず下記Githubからファイルをダウンロードして好きなところに解凍して置いておきます。
https://github.com/ildoonet/tf-pose-estimationWindows Subsystem for Linux をインストール
本記事の手順ではbashを使いますので、作業に入る前に使えるようにしときます。
手順は下記とかをご参考に。
https://qiita.com/Aruneko/items/c79810b0b015bebf30bb環境構築
仮想環境の作成
Anaconda (powersell) promptで下記コマンドでpython3.6の仮想環境を作ります。
Anaconda Navigatorからも簡単に作れますが、たまに壊れるときがあるのでコマンドから作っています。conda create -n myenv python=3.6python3.7でもデモを動かす分には大丈夫でした。
作った仮想環境をactvateして作業していきます。conda activate myenvライブラリインストール
必要なライブラリを仮想環境にインストールします。
tf pose estimationが必要とするものはrequirements.txtに記載してあるのですが、その前に以下のライブラリをインストールしておくとスムーズです。
バージョンは動作確認したものを記載。
- cython 0.29.13
- numpy 1.16.4
- git 2.20.1
- swig 3.0.12
- opencv 3.3.1
- tensorflow-gpu 1.14.0 (GPU無い場合は tensorflow )全部
conda installで入れました。次に、ダウンロードしたtf-pose-estimation-masterに移動して、requirements.txtをインストールする、んですが。
その中のpycocotoolのインストールがうまくいきません。
ので、先に下記コマンドで別にpycocotoolを入れておくかrequirements.txtを書き換えておくかしないといけません。pip install "git+https://github.com/philferriere/cocoapi.git#egg=pycocotools&subdirectory=PythonAPI"できたらrequirements.txtに記載の必要なライブラリをまとめてインストールします。
pip install -r requirements.txt必要なライブラリが揃いました。
あとは手順通りにやっていきます。
C++ライブラリのビルド
cd tf_pose\pafprocess swig -python -c++ pafprocess.i && python setup.py build_ext --inplaceパッケージインストール
cd ..\..\ python setup.py installmodelのダウンロード
cd models\graph\cmu bash download.sh環境構築はこれでOKのはず。
Run
tensorRTのコメントアウト
環境構築ができたので早速動かせるかと思いきや、run.pyしてみたらtensorRTが無いとerrorが出ました。
tensorRT は windows の python にはまだ対応していない為使えないみたいです。
なのでコード内で使っているところをコメントアウトします。
(最適化して速度を早くするものらしく、動かす分には無くても問題ないようです)tf_pose/estimator.py
- 14行目 import文
- 315行目~328行目 if文動かしてみる
とりあえず何も考えずカメラで試す。
python run_webcam.pyEscで終了。
モデルは4種類用意されており、指定しない場合cmuモデルが使われます。
- cmu (trained in 656x368)
- mobilenet_thin (trained in 432x368)
- mobilenet_v2_large (trained in 432x368)
- mobilenet_v2_small (trained in 432x368)速度はmobilenetの方が早く、精度はcmuが良い印象?
モデルを指定するときは、上記コマンドの後ろに--model=モデル名を付けて指定できます。静止画
python run.py --model=mobilenet_thin --image=./images/p1.jpg
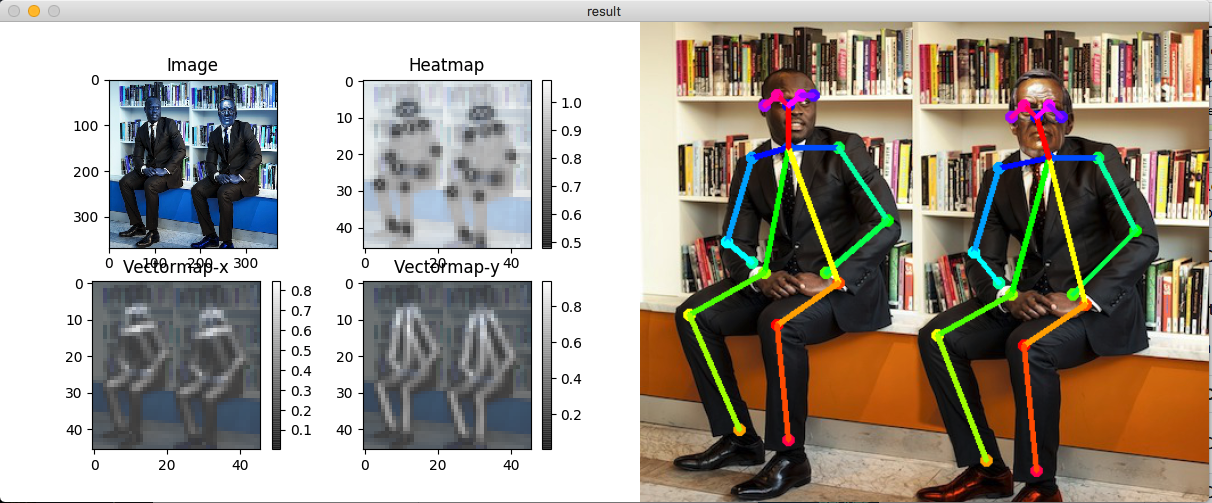
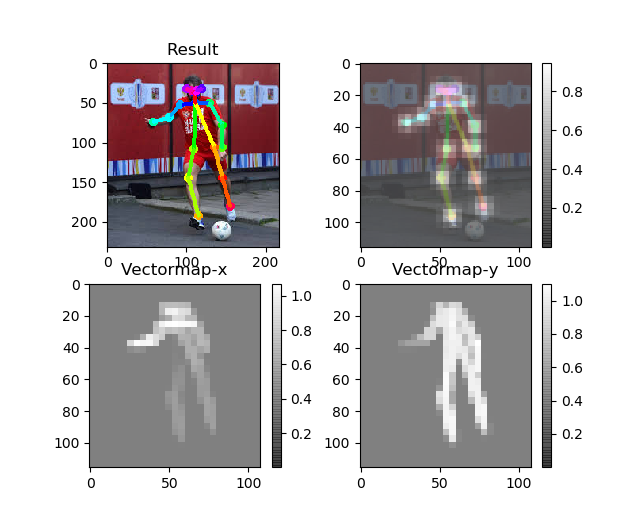
静止画はデフォルトではこんな感じにpyplotで出力されます。
推定関節のヒートマップと、関節をつなぐために求められたクトルマップです。
Result画像を保存したい場合、run.py 54行目imageがデータですのでcv2.imwrite(出力名.jpg, image)で保存できます。静止画とカメラは問題なく動きますが、動画用のファイルにはバグがあるみたいで推定してくれません。
下記コードで動きました。
(拝借したコードなのですが、どこから持ってきたかわからなくなったのでソースを見つけたら貼り付けます。)
こちらで解決してくれたものです。ついでに推定骨格を描画した動画を保存するコード入れています。
保存する場合は4行あるコメントアウトを全て外してください。run_video.pyimport argparse import logging import time import cv2 import numpy as np from tf_pose.estimator import TfPoseEstimator from tf_pose.networks import get_graph_path, model_wh logger = logging.getLogger('TfPoseEstimator-Video') logger.setLevel(logging.DEBUG) ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) formatter = logging.Formatter('[%(asctime)s] [%(name)s] [%(levelname)s] %(message)s') ch.setFormatter(formatter) logger.addHandler(ch) fps_time = 0 if __name__ == '__main__': parser = argparse.ArgumentParser(description='tf-pose-estimation Video') parser.add_argument('--video', type=str, default='') parser.add_argument('--resize', type=str, default='0x0', help='if provided, resize images before they are processed. default=0x0, Recommends : 432x368 or 656x368 or 1312x736 ') parser.add_argument('--resize-out-ratio', type=float, default=4.0, help='if provided, resize heatmaps before they are post-processed. default=1.0') parser.add_argument('--model', type=str, default='mobilenet_thin', help='cmu / mobilenet_thin') parser.add_argument('--show-process', type=bool, default=False, help='for debug purpose, if enabled, speed for inference is dropped.') parser.add_argument('--showBG', type=bool, default=True, help='False to show skeleton only.') args = parser.parse_args() logger.debug('initialization %s : %s' % (args.model, get_graph_path(args.model))) w, h = model_wh(args.resize) if w > 0 and h > 0: e = TfPoseEstimator(get_graph_path(args.model), target_size=(w, h)) else: e = TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368)) cap = cv2.VideoCapture(args.video) width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = cap.get(cv2.CAP_PROP_FPS) if cap.isOpened() is False: print("Error opening video stream or file") # fourcc = cv2.VideoWriter_fourcc(*'DIVX') # writer = cv2.VideoWriter('./video/output.mp4', fourcc, fps, (width, height)) while cap.isOpened(): ret_val, image = cap.read() logger.debug('image process+') humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio) if not args.showBG: image = np.zeros(image.shape) logger.debug('postprocess+') image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False) logger.debug('show+') cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2) cv2.imshow('tf-pose-estimation result', image) fps_time = time.time() # writer.write(image) if cv2.waitKey(1) == 27: break cv2.destroyAllWindows() # writer.release() cap.release() logger.debug('finished+')動かすときは同様に
python run_video.py --video=./video.mp4相変わらずエラー文出ますね、、時間があれば見直します。
結果
さっきのやつ
借りてきたふちこさんズ
逆さまは以外はぱっと見認識できてるように見えますが…。
よく見ると関節の位置がちらほらずれてます。変な体勢は難しいみたいです。
これはウェブカメラのキャプチャーですが、FPSは画像のとおりcmuモデルでFPS24、mobilenet_thinモデルだとFPS30くらい出ていました。CPUだとその1/10くらい遅くなります。
ちなみに13体のふちこさんを貸していただいたのですが、全員載せられませんでした。ごめんなさい。サイゼにいる天使
カメラでも試しましたが、上半身だけはOKで肩以上がフレームアウトしていると認識してくれない感じでした。
たまに背景に居ないはずの人間を認識します。これ見ると肩が入っていることが重要なんでしょうか。微妙な結果ばかり載せてすみません。
助けてくださった先輩方、ありがとうございます。以上!



- 投稿日:2019-08-28T11:13:16+09:00
TensorFlow Object Detection APIを使ってFaster R-CNN、R-FCN、SSDを比較してみた
5行まとめ
- TensorFlow Object Detection APIには各種モデルが準備されており、簡単に試すことができた。
- SSDは推論がとても早いが学習に時間がかかる。
- R-FCNは推論時間でSSDに劣るが、検出精度がSSDより高め。学習時間と精度のバランスも良い。
- ラベル付けの補助としてR-FCNを使い、推論時間が重要な場面での最終的な検出器としてSSDを使うのが良さそう。
- ラベル付け(アノテーション)は苦行。
概要
TensorFlow Object Detection APIを使い、独自のデータセットで物体検出(Object Detection)を行ってみました。
使用したモデルは、Faster R-CNN、R-FCN、SSDの3つです。本記事では同一のデータセットに対して3つのモデルを適用し、その精度、速度などを比較しています。当然ながらデータセットとモデルの組み合わせによって特性は異なるので、「あるデータセットではこうだった」という参考程度にどうぞ。
用語
- R-CNN: Region CNN
- R-FCN: Region-based Fully Convolutional Networks
- CNN: Convolutional Neural Network
- SSD: Single Shot multibox Detector
- mAP: mean Average Precision
- IoU: Intersection over Union
環境
学習、推論に用いた環境は以下の通りです。
- ハードウェア:
- CPU: Intel Core i5 7600
- メモリ: 16GB
- GPU: GeForce GTX1070 8GB
- ソフトウェア:
- OS: Ubuntu 18.04.3 LTS
- Docker: 18.09.7
- docker-compose: 1.24.1
- nvidia-docker: 2.2.0
- NVIDIAドライバ: 410.104
- Python: 3.6.8
- TensorFlow: 1.14.0
- TensorFlow Object Detection API: コミットID
62184a96e740a3ecd65018acda42a11062b6d43d- COCO API: コミットID:
636becdc73d54283b3aac6d4ec363cffbb6f9b20- Pythonパッケージ:
Click: 7.0contextlib2: 0.5.5Cython: 0.29.13opencv-python: 4.1.0.25Pillow: 6.1.0データセット
今回使用したデータセットは独自のもので、残念ながら詳細はお伝えできません。規模は以下の通りです。
- ラベル: 2種類
- ラベル数(正解バウンディングボックス数):
- ラベルA: 2,224
- ラベルB: 47
- 合計: 2,271
- ラベル付けされた画像数(バウンディングボックスなしも含む): 2,274枚
- うち、ラベルを含む画像数: 1,212枚
- 学習データ/テストデータの割合: 9:1
「ラベルB」のラベルが不足しているため十分な学習が行えておらず、平均精度に悪影響を及ぼしているかもしれません。ただ、今回は相対的な精度だけを見ており、絶対的な精度は見ていないのであまり影響ないものと思われます。
また、ラベルを含まない画像(ネガティブサンプル)は使用していません。蛇足ながら、ラベル付け(アノテーション)によって腱鞘炎(っぽい状態)になりました。みなさんもラベル付けに使うツール(ソフトウェア、ハードウェア)には十分に気を配り、ラベル付けを行いましょう。健康第一です。
ベースモデル
今回はTensorFlow Object Detection APIのModel Zooで提供されている、COCOにより事前学習済みのモデルをベースとして使用しました。
ベースとしたモデルデータと設定ファイルは以下の通りです。
No モデル 学習済みモデル 設定ファイル 1 Faster R-CNN faster_rcnn_resnet101_coco faster_rcnn_resnet101_coco.config2 R-FCN rfcn_resnet101_coco rfcn_resnet101_coco.config3 SSD ssd_mobilenet_v2_coco ssd_mobilenet_v2_coco.config学習時間/推論時間
今回はすべてのモデルにおいて30,000ステップの学習を行いました。また、データセットの1割、122枚をテストデータとして推論を行いました。
1回あたり10枚ずつ推論を行い、初回の推論時にはモデルのロードなどの初期化が行われています。そのため、初回を除く推論時間も併記しています。
- SSDの推論時間は、Faster R-CNN、R-FCNの10分の1以下。
- SSDの学習時間は、Faster R-CNN、R-FCNの2倍程度。
No モデル 学習時間 推論全体 初回を除く110枚の推論 左記1枚あたり 初回を含む122枚の推論 左記1枚あたり 1 Faster R-CNN 155分 45.816500秒 34.694372秒 0.315403秒 43.957657秒 0.360308秒 2 R-FCN 146分 39.321194秒 28.740958秒 0.261281秒 37.311630秒 0.305833秒 3 SSD 295分 3.885033秒 1.333236秒 0.012120秒 2.947371秒 0.024158秒 定量的な精度
30,000ステップ時点での評価結果は以下の通りです。TensorFlow Object Detection APIの評価方法
coco_detection_metricsを使用しています。
- Precision:
- すべての項目においてSSD、R-FCN、Faster R-CNNの順番で精度が良い。
- Recall:
- SSDの方が基本的に良いが、R-FCNの方が良いこともある。
No 項目 Faster R-CNN R-FCN SSD 1 Average Precision (AP) @[ IoU=0.50:0.95, area= all, maxDets=100 ] 0.218 0.230 0.327 2 Average Precision (AP) @[ IoU=0.50 , area= all, maxDets=100 ] 0.419 0.439 0.717 3 Average Precision (AP) @[ IoU=0.75 , area= all, maxDets=100 ] 0.206 0.209 0.259 4 Average Precision (AP) @[ IoU=0.50:0.95, area= small, maxDets=100 ] 0.165 0.189 0.209 5 Average Precision (AP) @[ IoU=0.50:0.95, area=medium, maxDets=100 ] 0.245 0.247 0.486 6 Average Precision (AP) @[ IoU=0.50:0.95, area= large, maxDets=100 ] 0.505 0.545 0.534 7 Average Recall (AR) @[ IoU=0.50:0.95, area= all, maxDets= 1 ] 0.160 0.179 0.289 8 Average Recall (AR) @[ IoU=0.50:0.95, area= all, maxDets= 10 ] 0.271 0.396 0.375 9 Average Recall (AR) @[ IoU=0.50:0.95, area= all, maxDets=100 ] 0.299 0.405 0.378 10 Average Recall (AR) @[ IoU=0.50:0.95, area= small, maxDets=100 ] 0.267 0.434 0.254 11 Average Recall (AR) @[ IoU=0.50:0.95, area=medium, maxDets=100 ] 0.290 0.291 0.535 12 Average Recall (AR) @[ IoU=0.50:0.95, area= large, maxDets=100 ] 0.558 0.583 0.600 定性的な精度
正解データとモデル3つの推論結果の合計4枚を並べ、定性的な精度を確認してみました。数値では示せないので、参考程度にどうぞ。
- 全体:
- 全体的に検出精度は良好で今回の用途では実用的。
- 特に対象物が正面から写っている場合は、ほぼ検出できている。
- 対象物の側面しか写っていない場合は、検出できたりできなかったり。
- Faster R-CNN:
- もっとも精度が高い印象。
- R-FCN:
- 擬陽性(誤検出)が他のモデルに比べて多いように感じる。
- SSD:
- バウンディングボックスが大きめに出力されがち。
- 偽陰性(検出漏れ)が他のモデルに比べて多いように感じる。
- 小さい物体の検出精度が低め。
付録: Dockerfile
今回、学習と推論はDocker(
nvidiaランタイム)上で行いました。model_builder_test.pyより後のパッケージは推論処理で使っているだけで、TensorFlow Object Detection APIとしては不要です。FROM tensorflow/tensorflow:1.14.0-gpu-py3-jupyter RUN apt-get update \ && DEBIAN_FRONTEND=noninteractive apt-get install --yes --no-install-recommends \ git-core \ protobuf-compiler \ && rm --recursive --force /var/lib/apt/lists/* RUN git clone https://github.com/tensorflow/models.git /opt/tensorflow/models \ && cd /opt/tensorflow/models/ \ && git checkout 62184a96e740a3ecd65018acda42a11062b6d43d \ && cd /opt/tensorflow/models/research/ \ && protoc --python_out . object_detection/protos/*.proto ENV PYTHONPATH ${PYTHONPATH}:/opt/tensorflow/models/research ENV PYTHONPATH ${PYTHONPATH}:/opt/tensorflow/models/research/slim COPY requirements.txt /root/ RUN pip3 install --requirement /root/requirements.txt RUN git clone https://github.com/cocodataset/cocoapi.git /opt/cocoapi \ && cd /opt/cocoapi/ \ && git checkout 636becdc73d54283b3aac6d4ec363cffbb6f9b20 \ && cd /opt/cocoapi/PythonAPI/ \ && make \ && cp --recursive --verbose pycocotools /opt/tensorflow/models/research/ RUN cd /opt/tensorflow/models/research/ \ && python3 object_detection/builders/model_builder_test.py RUN apt-get update \ && DEBIAN_FRONTEND=noninteractive apt-get install --yes --no-install-recommends \ libsm6 \ libxext6 \ libxrender-dev \ && rm --recursive --force /var/lib/apt/lists/* RUN pip3 install opencv-python==4.1.0.25requirements.txtClick==7.0 contextlib2==0.5.5 Cython==0.29.13 Pillow==6.1.0
- 投稿日:2019-08-28T00:40:28+09:00
超シンプル "Keras" を用いた機械学習実行まで
TensorFlowをより使いやすくしたフレームワーク"Keras"
比較的手軽にDeep Learningを実感できます。今回は、とりあえずKerasを実行することにのみ重点を置いて、
極力無駄なものを省いて超シンプルに記述しました。
Kerasを用いた学習までのざっくりとした下記の流れに沿ってコーディングしていきます。
- y(目的変数)ワンホットエンコーディング化
- modelの宣言
- Compile
- 学習(fit)
今回はテストデータとしてKaggleのTitanicデータを利用。
前処理については下記ブログを参照ください
【Beginner】【AI】【機械学習】Light GBM: Titanic: Machine Learning from Disaster1.y(目的変数)ワンホットエンコーディング化
2019.0828更新
importファイルを載せていなかったので追記致しますimport numpy as np import pandas as pd from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import Flatten from keras.layers.convolutional import Conv2D from keras.layers.convolutional import MaxPooling2D from keras.utils import np_utils from keras import backend as K from sklearn.utils import shuffle import tensorflow as tf from tensorflow.keras import layersKerasに読み込ませるデータはワンホットエンコーディング化する必要があるらしい。
今回は生きるか死ぬかの0 or 1で登録するため不要かもしれないですが。。
一応、kerasにはワンホットエンコーディングを簡単にできるライブラリがあるのでそれの紹介も兼ねて記述。#教師データの学習 #目的変数 train_y = df006["Survived"] #説明変数 #arrayかつ型がfloat32で無ければ学習の際にエラーがでるのでここで変換 train_x = df006.drop(labels=["Survived"],axis=1).as_matrix().astype('float32') #kerasのnp_utilに含まれるto_categoricalによってワンホットエンコーディング化 train_y_onehot = np_utils.to_categorical(train_y)2.Modelの宣言
宣言方法にはいろいろあるらしい。
下記を参照すると良くわかります。
TensorFlow公式:単純なモデルの構築今回は最も単純な全結合ネットワークを記述
#modelの宣言 #シーケンシャルモデル:単純に層を積み重ねる model = tf.keras.Sequential() # ユニット数が64の全結合層をモデルに追加します: model.add(layers.Dense(64, activation='relu')) # 全結合層をもう一つ追加します: model.add(layers.Dense(64, activation='relu')) # 出力ユニット数が10のソフトマックス層を追加します: model.add(layers.Dense(10, activation='softmax'))3.Compile
モデル構築後にcompileメソッドにより学習方法を構成します。
#modelのコンパイル:学習方法の構成 model.compile(optimizer=tf.train.AdamOptimizer(0.001), loss='categorical_crossentropy', metrics=['accuracy'])これにも代表的なものが他に2つほどあるようなので上の公式サイトより要確認
4.学習(fit)
#modelの学習 model.fit(train_x,train_y,epochs=30,batch_size=32)結果
全然制度良くならない。。。
学習までは出来ているのでデータの処理に問題があるようです。
要修正。ここまで読まれた方申し訳ございません。
近々修正更新します。