- 投稿日:2019-08-28T23:57:32+09:00
API Gatewayを通してBasic認証を使う方法
課題
今回は、単純なFlaskのAPIアプリを作って、全世界に公開したくないので、単純なユーザ・パスワード認証(BasicAuth)をかけたいなと思いました。
ZappaというAWS LambdaにDeployできるフレームワークを使って、Flaskのアプリは、AWS上にすぐにDeployとAPIの確認ができました〜。APIには、プログラムからBasicAuthに必要なヘッダーを付けておけば無事にAPIとの通信ができました。
pythonのrequestsを使って、API叩く例:
from requests.auth import HTTPBasicAuth requests.get('https://api.example.com/', auth=HTTPBasicAuth('user', 'pass'))HTTPヘッダー例:
GET /private/index.html HTTP/1.1 Host: example.com Authorization: Basic ABCEF1234567890abcdefただし、開発者が簡易にAPI参照できるように、OpenAPI(swagger)表示できるページも用意しました。
そこでブラウザから、ページをアクセスしてみると。。。ダメだ。

モダンブラウザは、BasicAuthのログインをダイアログをだしてくれるのですが、出てこない様子。
どうにか、API Gatewayから返される401 Unauthorizedのレスポンスヘッダーには、必要なWWW-Authenticate: Basicがないようです。確認すると、Flask側から正しく
WWW-Authenticate: Basicを返しているようですが、APIGatewayがそのヘッダーを消しているっぽい。さって、API Gatewayからは、ブラウザのログインダイアログが表示されるように、
401 UnauthorizedのレスのヘッダーにWWW-Authenticate: Basicを付けるようにしましょう。HTTP/1.1 401 Authorization Required Date: Wed, 11 May 2005 07:50:26 GMT Server: Apache/1.3.33 (Unix) WWW-Authenticate: Basic realm="SECRET AREA" Connection: close Transfer-Encoding: chunked Content-Type: text/html; charset=iso-8859-1対策方法
もうしかして、
UnauthorizedApiGatewayResponseだけでいくかなと思うのですが、今回は、FlaskのRequestへ流す前、CUSTOM Authorizerを導入して、BasicAuthヘッダーを確認するようにしています。BasicAuth用の設定と関数のリポジトリにまとめたので、既存のAPIGateway(rest-api)により楽にBasicAuthを追加することができたかと思います。ここまでくるには、色々大変だったのですが、この手順で10分以内にほしいBasicAuth設定が終わるだろう。
リポジトリ取得:
git clone https://github.com/monkut/lambda-basicauth-authorizer.git環境準備(完全にAWSCLIでの用意は可能かと思うのですが、一部はBOTO3で書いちゃいました):
# pipenvでpython環境を用意 pipenv install環境変数を設定、CUSTOM Authorizerの関数を置いて、既存ApiGatewayのrest-apiを更新:
RESTAPI_IDは、既存のものからこのコマンドで取得:
aws apigateway get-rest-apis
PROJECTIDは、ユニーク性を保つためのものだけです(なんでも良い)export AWS_PROFILE={my profile} export BASIC_AUTH_USERNAME={YOUR USERNAME} export BASIC_AUTH_PASSWORD={YOUR PASSWORD} export PROJECTID={YOUR PROJECT IDENTIFIER} export RESTAPI_ID={既存のRESTAPI ID} # CUSTOM Authorizer用のBucketを用意 make createfuncbucket # CUSTOM Authorizerの関数をDeployして、既存のREST-APIにインストール make deploy make installこれで、APIだけじゃなくて、ユーザ(人間)がブラウザ経由でUSER/PASSのログインできるようになりました〜
FlaskにBasicAuth処理を残すちゃいば、ちょっと重複するのですが、BasicAuthなので、残っていても大した処理時間がかからないだろう。
最近、BasicAuthを使って、zappa と組み合わせて、開発用のDUMMY APIを提供したりしています。

- 投稿日:2019-08-28T23:36:40+09:00
最速でAWSに静的サイトの開発環境を作る
静的サイトを自分で確認するなら、ローカル環境で十分かもしれませんが、
お客さんに確認してもらうにはサ、別途サーバを準備する必要があったりします。本記事では、S3に静的サイトを構築するだけでなく、開発環境の連携も視野に入れて説明します。
(開発環境だけでなく、上手にやれば本番でも使えるかも)各設定項目の詳しい内容はすっ飛ばします。他記事で参考してもらえば良いと思います。
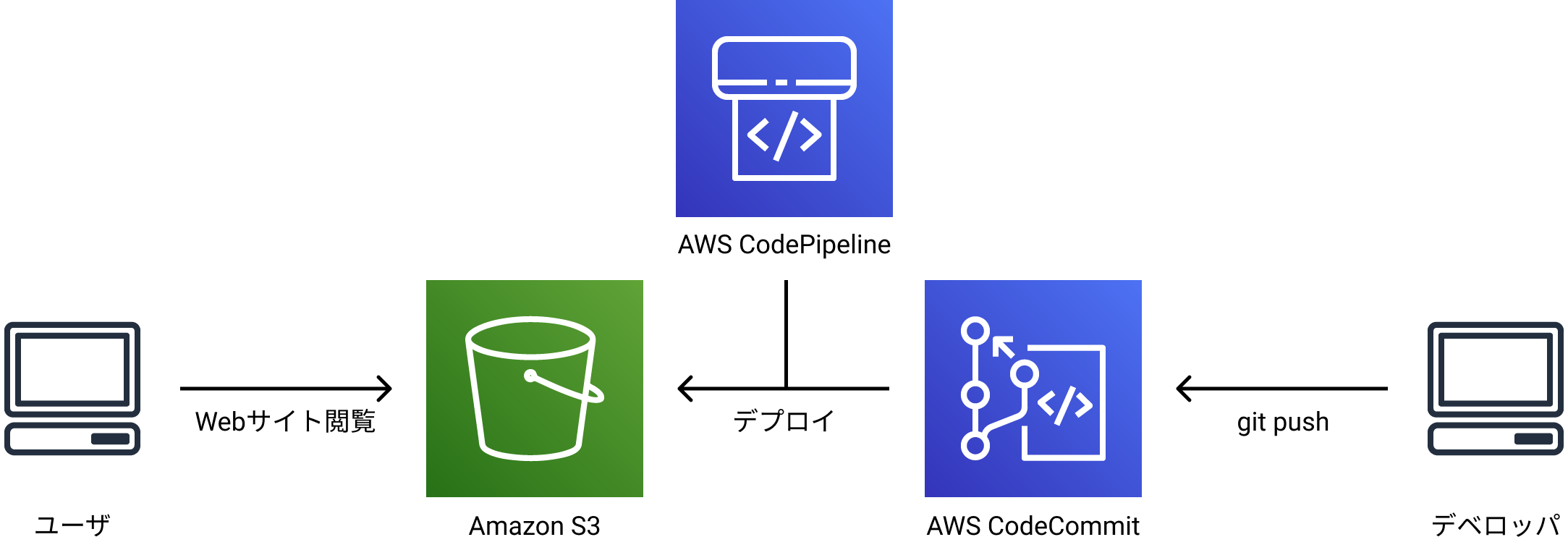
次のような環境をAWSで構築します。
スムーズに行けば、15分ぐらいで終わります。
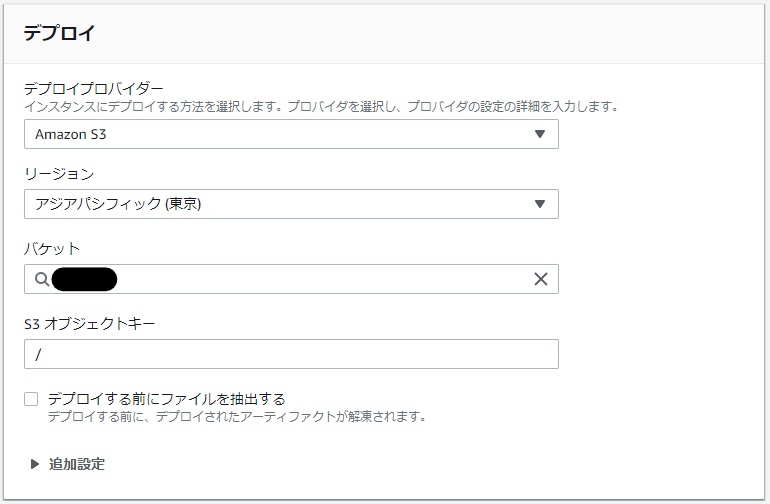
S3|バケットを作成
- S3からバケットを作成するをクリックします。
名前とリージョン
- バケット名を入力して 次へ ボタンをクリックします。

バケット名はドメイン名がおすすめです。(例:example.com)
オプションの設定
- デフォルトのまま 次へ ボタンをクリックします。
アクセス許可の設定
- アクセス許可はアクセスコントロールリスト(ACL)のみブロックします。

確認
- バケットを作成 をクリックします。
これで、バケット一覧画面に作成したバケットが表示されていたらOKです!
S3|静的サイトホスティング
静的サイトホスティングの許可
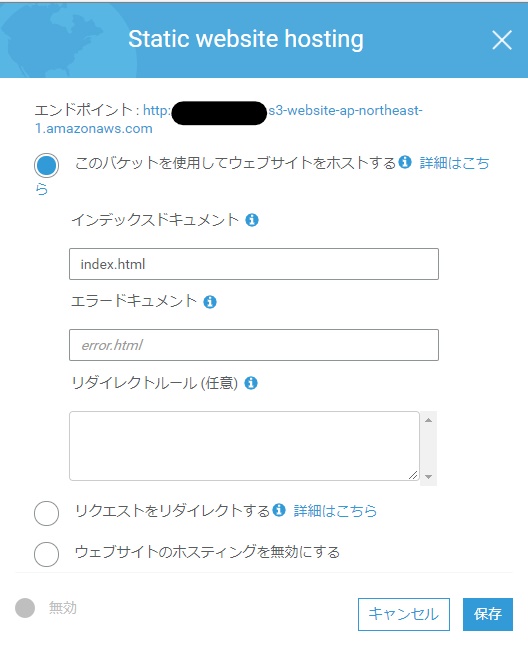
- バケットのプロパティから Static website hosting を開きます。
- このバケットを使用してウェブサイトをホストするにチェックして、インデックスドキュメントを指定します。
ここでは、インデックスドキュメントを index.html としています。- 保存ボタンをクリックします。
エンドポイントは静的サイトのURLになります。どこかにメモしておきましょう。
アクセス制限の設定
- バケット > アクセス制限 > バケットポリシー の画面に移動します。
- バケットポリシーエディターに以下を貼り付けます。
バケットポリシーエディター{ "Version": "2012-10-17", "Statement": [ { "Sid": "PublicReadForGetBucketObjects", "Effect": "Allow", "Principal": "*", "Action": [ "s3:GetObject" ], "Resource": [ "arn:aws:s3:::example.com/*" ], "Condition": { "IpAddress": { "aws:SourceIp": [ "xxx.xxx.xxx.xxx", "yyy.yyy.yyy.yyy" ] } } } ] }
- Resource の example.com は、作成したバケット名に変更してください。
- Condition の IpAddress の部分は、デベロッパのIPアドレスとユーザのIPアドレスを指定してください。
- 保存ボタンをクリックします。
確認
- ここで、エンドポイントのURLにアクセスしてみましょう。
おそらく 404 になると思いますが、これは index.html がないからなので大丈夫です。CodeCommit|Gitリポジトリの作成
- CodeCommitからリポジトリの作成をクリックします。
リポジトリの作成
- リポジトリ名を入力します。
- 作成ボタンをクリックします。
リポジトリに接続
(windows10の場合)
Gitクライアントをインストールします。(既にある場合は作業不要)
https://gitforwindows.orgアクセスさせたいIAMのユーザに次のポリシーを追加します。
AWSCodeCommitFullAccessGit Bash などから、鍵を作成するために次のコマンドを実行します。
$ ssh-keygen Enter file in which to save the key (/c/Users/user/.ssh/id_rsa): codecommit_rsa <- ファイル名はなんでもOK Enter passphrase (empty for no passphrase): xxx <- 鍵のパスワードを入力 ...
IAMユーザに鍵を登録
- IAMユーザの認証情報タブを開く
- AWS CodeCommit の SSHキー のSSHパブリックキーのアップロードをクリック
- 作成した公開鍵(~/.ssh/codecommit_rsa.pub)をエディタで開いて、コピペ
- SSHパプリックキーのアップロードをクリック
~/.ssh/configにサーバ情報を追加
~/.ssh/configHost git-codecommit.ap-northeast-1.amazonaws.com User APKATRC... [SSHキーID (IAMユーザのSSHキーを参照) ] IdentityFile ~/.ssh/codecommit_rsa確認
- ssh接続を確認
$ ssh git-codecommit.ap-northeast-1.amazonaws.com Enter passphrase for key '/c/Users/user/.ssh/codecommit_rsa': xxx You have successfully authenticated over SSH. You can use Git to interact with AWS CodeCommit. Interactive shells are not supported.Connection to git-codecommit.ap-northeast-1.amazonaws.com closed by remote host. Connection to git-codecommit.ap-northeast-1.amazonaws.com closed.
- git clone が出来るか確認
$ git clone ssh://git-codecommit... <- git clone コマンドが載っていると思うので、それをコピペindex.htmlを作成
- git clone したフォルダにindex.htmlを作成します。
index.html<!DOCTYPE html> <html lang="ja"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> <title>example</title> </head> <body> <h1>welcome to example.com !!</h1> </body> </html>
- git push します。
$ git add . $ git commit -m '新規作成' $ git push origin masterリモートリポジトリが更新されているか確認
- CodeCommit の example.com にアクセスし、index.html が追加されていることを確認する。
CodePipeline|リリースプロセスの作成
- パイプラインの作成をクリックします。
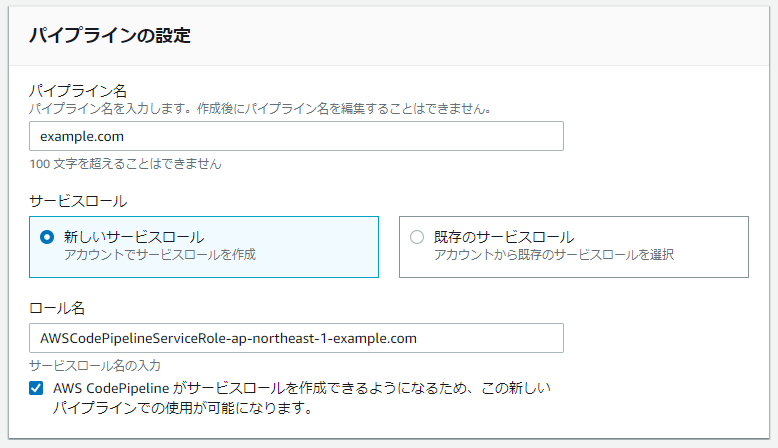
パイプラインの設定
- パイプライン名とロール名を入力します。
- 高度な設定はそのままにしておきます。
- 次にをクリックします。
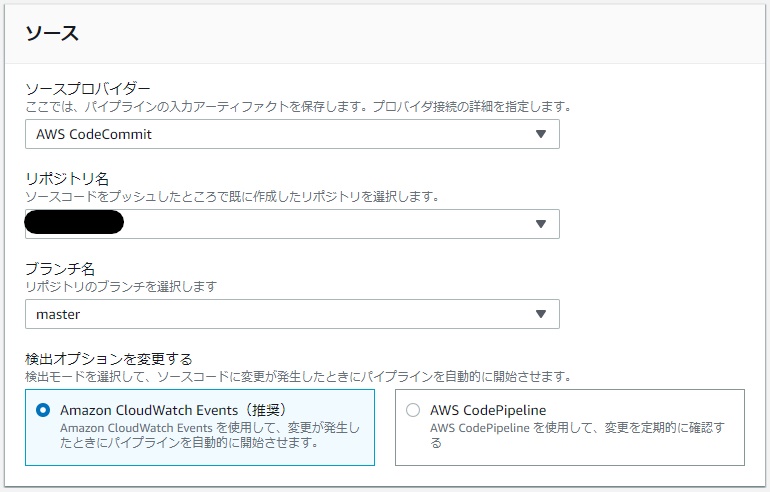
ソースステージを追加
- 下図のように入力します。
リポジトリ名は作成したリポジトリを選択してください。(例:example.com)
- 次にをクリックします。
ビルドステージを追加
- ビルドステージをスキップをクリックします。
デプロイステージを追加
- 下図のように入力します。
バケット名はS3で作成したバケットを選択してください。(例:example.com)
- 次にをクリックします。
確認
- パイプラインを作成するをクリックします。
最終確認
- もう一度、S3のエンドポイントに表示されているURLにアクセスしてみましょう。
- index.html に変更を加え、git push したら内容が変わることを確認してください。
最後に
ここまで静的サイトの開発環境の作成方法について説明しましたが、
デプロイした時にファイルが削除されなかったり、フォルダ名の変更が出来なかったりと問題があるようです。
https://qiita.com/izanari/items/aaa8fb89761f7a4ccef9詳細な設定などはすっ飛ばして説明していますので、
ここからバケットポリシーでアクセス制限をかけるなどの応用も可能です。いろいろ試してみてください。ざっくり書いたので不親切な部分もあるかもしれませんが、
ご指摘など頂けますと大変助かります。




- 投稿日:2019-08-28T22:22:37+09:00
AWS認定試験勉強の後半戦は Whizlabs で問題を解きまくるといいぞ
はじめに
最近AWS認定ソリューリョンアーキテクトアソシエイト(SAA)の資格を取得しました。取得スコアは867、合格に必要なスコアは720だったので、悪くない点数が取れたかと思います。
勉強法については、Qiitaやブログなどを参考にしました。例えば AWS認定11冠制覇したのでオススメの勉強法などをまとめてみる など参考になる記事はたくさんあり、おすすめ通りの勉強を1ヶ月ほど行いました。ある程度知識がついたので模擬試験を受けましたが問題数は25問のみだったので、間違えた問題を復習しても本番には少し不安が残っていました。
そこで、ネット上でSAAの問題がたくさん解けるサービスがないかと探していたところ、Whizlabsという practice test のコースがたくさんある海外のサイトを見つけたので簡単に紹介します。
Whizlabs とは?
online certification training サービスで、様々な資格試験のためのトレーニングを受講することができます。AWS認定試験のコースについては、おそらく全ての種類の試験のトレーニングが存在するようです。GCP や Azure など、その他のクラウドの資格試験もあります。
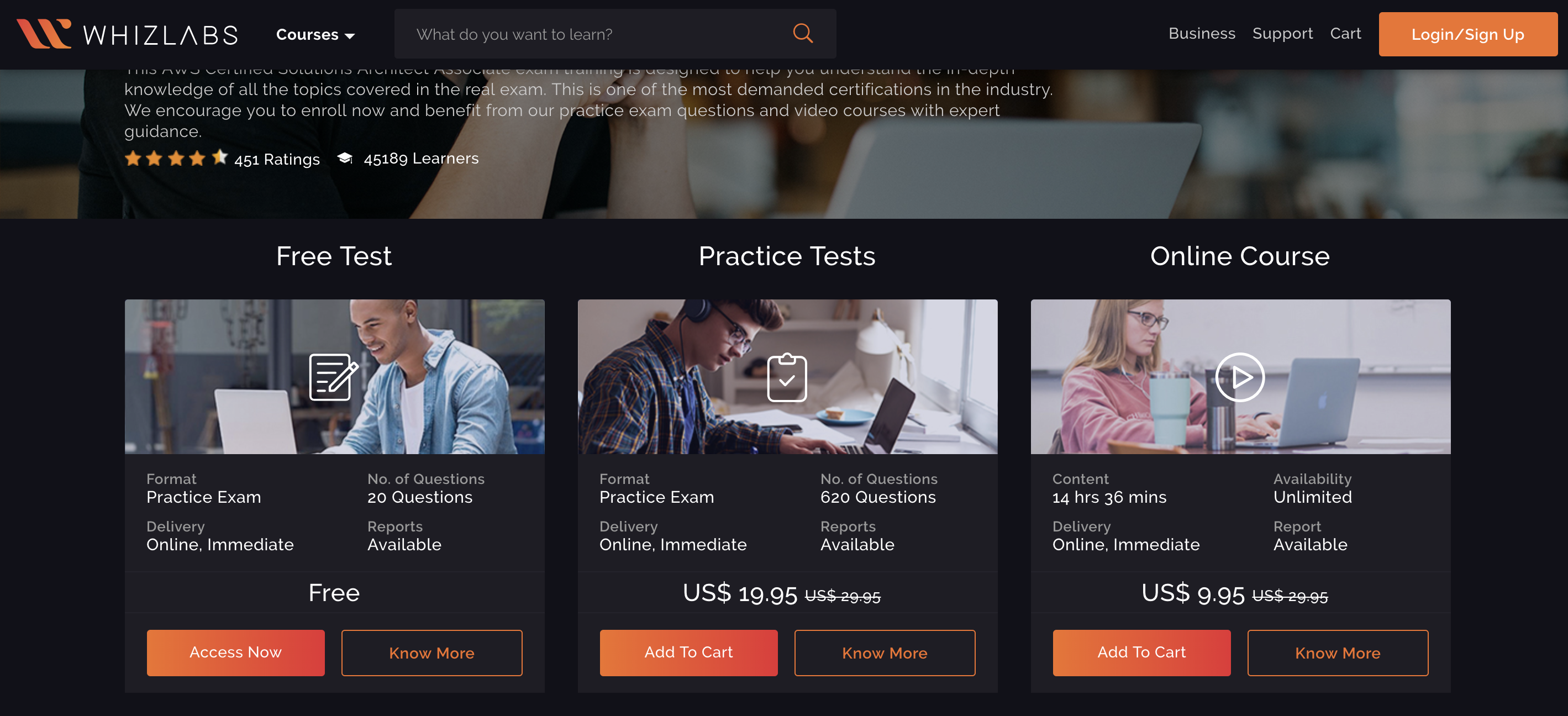
SAAのサンプル問題を解いてみる
では、実際に SAA のサンプル問題を Whizlabs で解いてみましょう。 AWS Certified Solutions Architect Associate (SAA-C01) のページの Free Test を選択し会員登録します。(ここまで無料)
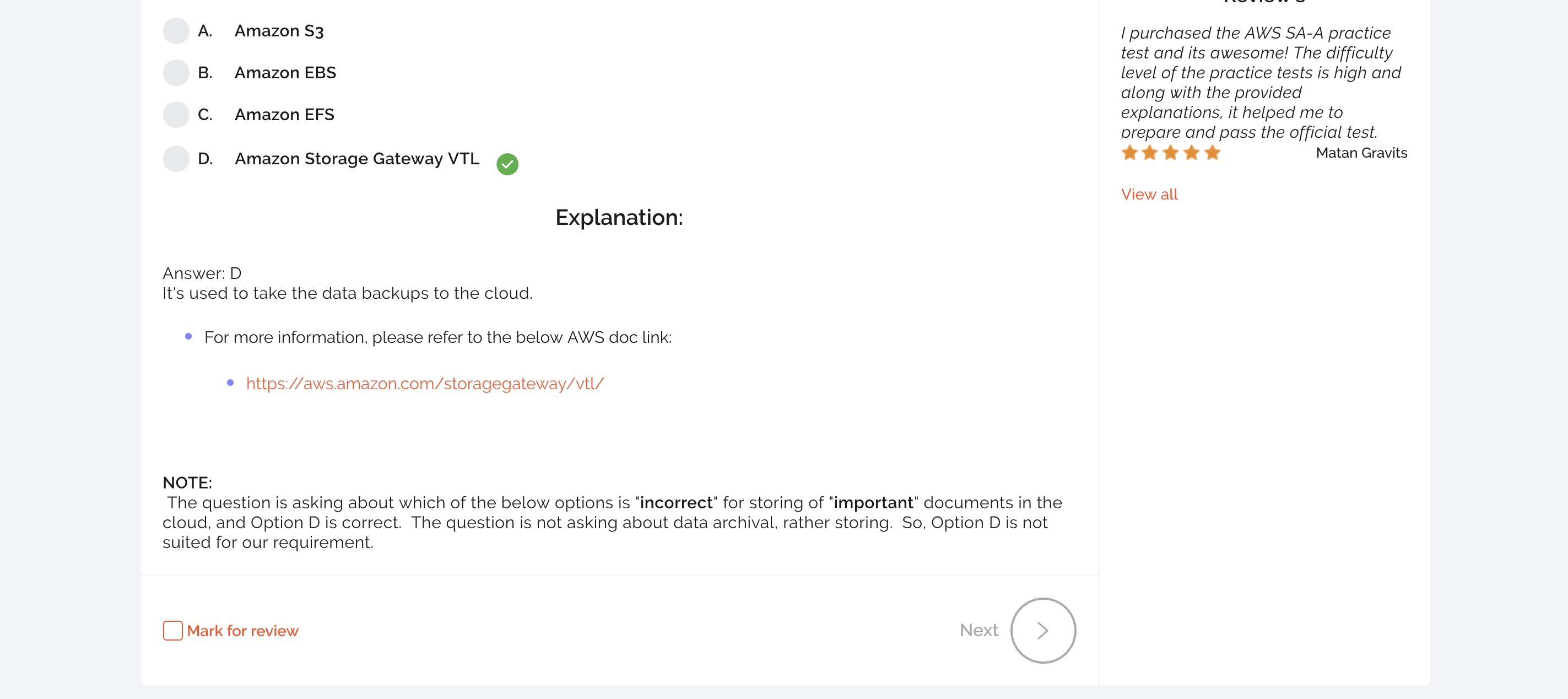
画面としてはこんな感じで、問題と右側には何問中何問まで解いたか、あとでレビューするためのチェックボックスなど、とても使いやすい設計となっています。
公式の模擬試験ではスコアはでましたが解答はないです。Whizlabs では、1問1問解答を確認できるため、すぐに復習をできる点がとても良いです。
問題を解きまくる
Free Test を解いて使えそうだなと思ったら $19.95(2000円弱)を支払って Practice Tests で問題を解きまくりましょう。トータルでは620問ほどあり、これを全て解いたら確実に合格に近くと思います。自分の場合は65問ほど解いて、不明点は BlackBelt を読んで納得するというのを行なって合格できました。資格のための勉強という側面だけでなく、業務でも普通に使える知識が幅広くついたので受験してよかったなと思っています。
まとめ
ある程度の知識がついたらあとは本番の試験を想定した問題をたくさん解くというのは資格試験においては定石であるため、それができる Whizlabs は合格に近くいいサービスだと思います。英語に抵抗がなく2000円程度で支払っても良いのであれば後半戦におけるおすすめの勉強法です。
最後に
Twitterアカウント でクラウドサービスや機械学習に関する情報を発信していますので興味のある方はフォローをお願いします。また Hello, Data Science というデータサイエンスに関するブログも書いているのでぜひこちらも。

- 投稿日:2019-08-28T22:03:36+09:00
簡単なインフラ環境をAWS Cloud Formationを使って構築してみた
はじめに
AWSで環境構築したいけど、マネジメントコンソールぽちぽちは手順書の作成めんどくさいよね、ということで、CloudFormationを使用して、シンプルな構成のシステムを自動で構築してみました。
YAML(もしくはJSON)でテンプレートを作成するだけで、マネジメントコンソールをぽちぽちしなくても自動で環境を作ってくれて超便利です!環境の自動化がなぜ重要か
- 環境構築での人為的ミスを減らせる→信頼性の向上
- 開発速度を上げることができる
- DevOps(開発と運用の一体化)とCI/CD(継続的デリバリー)での開発を実現できる
AWSにおける環境を自動化するための主なサービス
- Codeシリーズ(Git上のコードのコミット・実行・デプロイの自動化)
- Cloud Formation
- ECS(Dockerコンテナによる環境構築の自動化)
- Elastic Beanstalk(Webアプリケーションのデプロイ自動化)
- OpsWorks(サーバの設定、デプロイ、管理の自動化)
など今回は、Cloud Formationでの環境構築の自動化をやっていきます。
Cloud Formationとは
- インフラストラクチャリソースのテンプレートを利用して自動で構築することができる環境自動設定サービス
- AWS内の全てのインフラリソースをテンプレート化することができる
- テンプレートはJSONかYAMLで記述する
- Code Piplineと組み合わせることで、テンプレートの変更、実行、展開を自動化できる
- Cloud Formationデザイナーを使うことで、視覚的にテンプレートを作成することも可能
Cloud Formationを使う利点
- 環境構築を効率化できる
- いつでも同じ設定の環境を構築することができる(標準化)
- ソフトウェアと同じように構成管理ができる
テンプレートについて
AWS公式ドキュメントのテンプレートリファレンスに全て情報が載っているので、こちらを見ながら作成していきます。
sample.yamlAWSTemplateFormatVersion: '2010-09-09' Description: A sample template Metadata: Parameters: Mappings: Conditions: Resources: MyEC2Instance: Type: AWS::EC2::Instance # 省略
- AWSTemplateFormatVersion: 必ず頭に記述する
- Description: テンプレートの説明
- Metadata: メタデータ
- Parameters: 共通で使いたい要素を参照値として記述
- Mappings: Parametersの値が複数バージョン
- Conditions: リソース作成時の条件内容を記述
- Resources: 実際に作りたいリソースの内容を記述
Cloud Formationで環境構築をしてみる
どんな環境を作るか
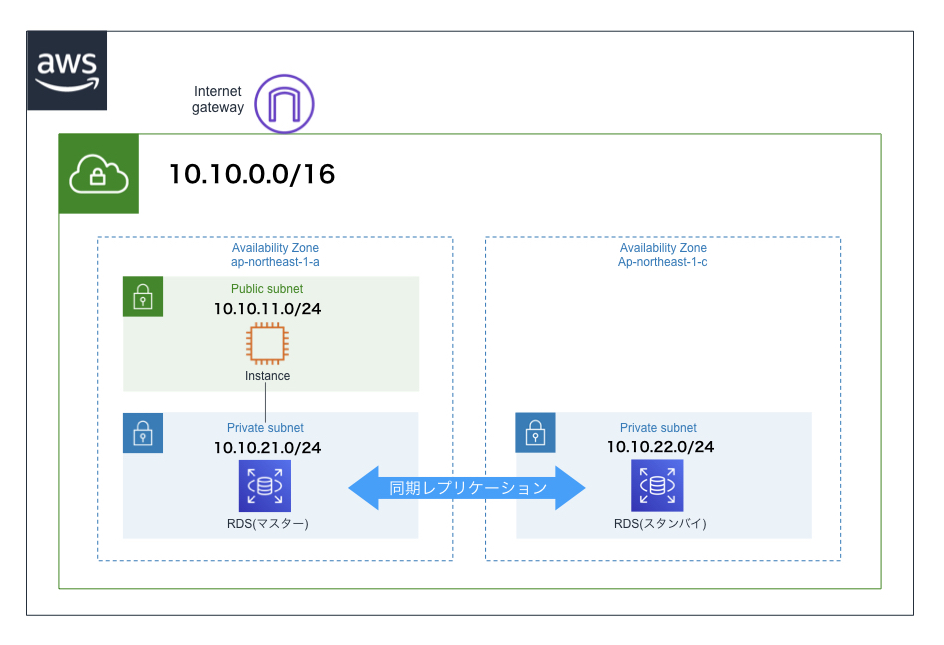
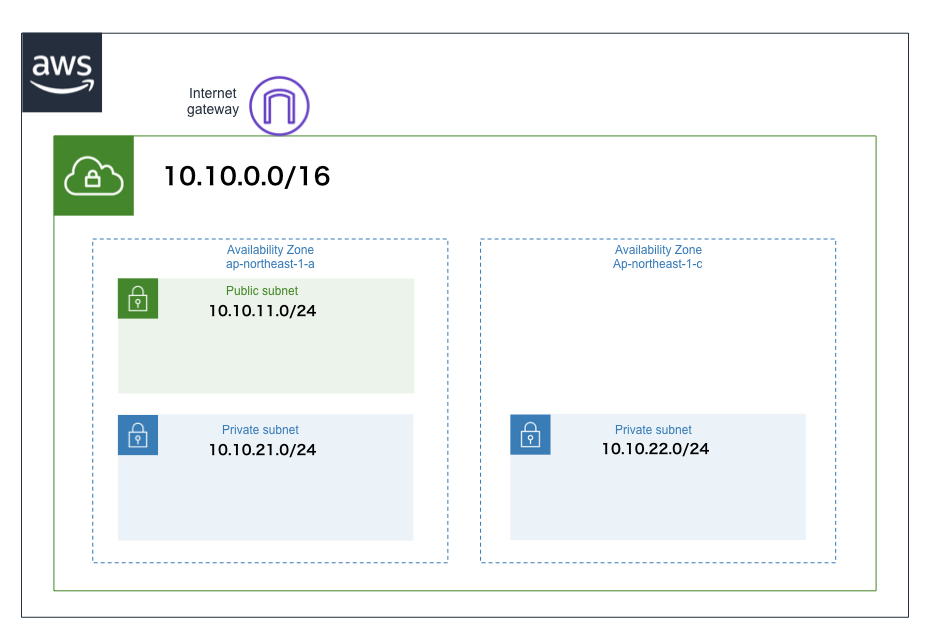
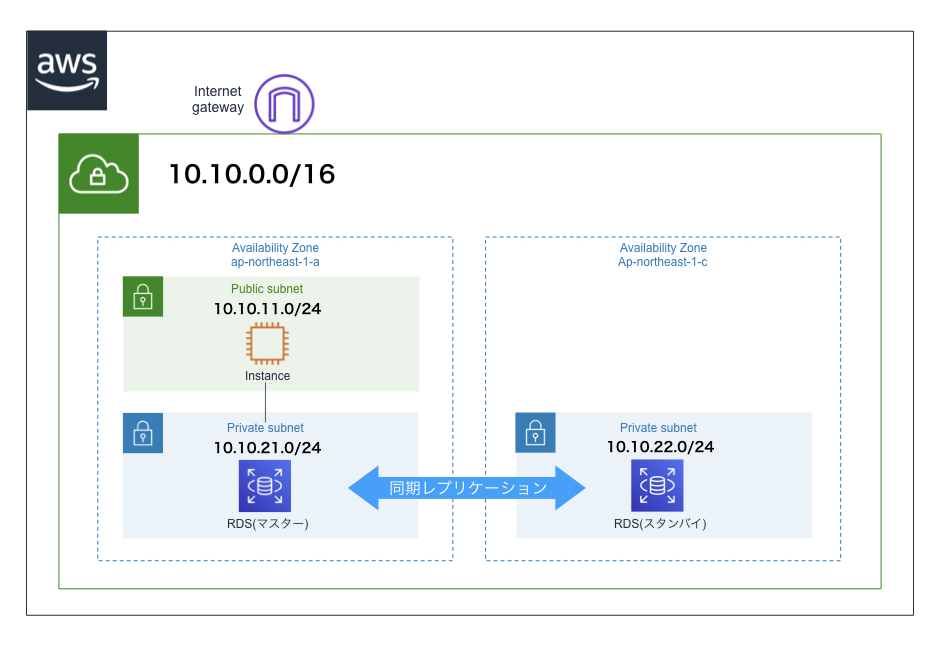
以下の構成の環境を、Cloud Formationを使って構築していきます。
VPCの作成
YAMLファイルの記述
template.yamlAWSTemplateFormatVersion: '2010-09-09' Description: A sample template Parameters: Resources: MyVpc: Type: AWS::EC2::VPC Properties: CidrBlock: '10.10.0.0/16' Tags: - Key: 'Name' Value: 'sample-vpc'
- MyVPC: 任意のリソース名
- Type: 作成するリソースを記載。VPCのリソース名は、"AWS::EC2::VPC"
- Properties: プロパティ
- CiderBlock: 任意のCIDRブロックを設定する。"10.10.0.0/16"を設定することで、このVPC内では10.10.0.0~10.10.255.255までのIPアドレスが使用可能になる。
- Tags: タグをつけるときに使用する
サブネットの作成
パブリックサブネットを1つ、プライベートサブネットを2つ作成します。
YAMLファイルの記述
template.yaml# 省略 Resources: # 省略 MyPublicSubnet: Type: AWS::EC2::Subnet Properties: VpcId: !Ref MyVpc CidrBlock: '10.10.11.0/24' MapPublicIpOnLaunch: true Tags: - Key: 'Name' Value: 'sample-public-subnet' MyPrivateSubnet1A: Type: AWS::EC2::Subnet Properties: VpcId: !Ref MyVpc CidrBlock: '10.10.21.0/24' AvailabilityZone: 'ap-northeast-1a' Tags: - Key: 'Name' Value: 'sample-private-subnet1a' MyPrivateSubnet1C: Type: AWS::EC2::Subnet Properties: VpcId: !Ref MyVpc CidrBlock: '10.10.22.0/24' AvailabilityZone: 'ap-northeast-1c' Tags: - Key: 'Name' Value: 'sample-private-subnet1c'
- VpcId: このサブネットが所属するVPCのIDもしくはリソース名を記述する
- Ref関数: 指定したパラメータまたはリソースの値を返す(ここではMyVpcを返す)
- MapPublicIpOnLaunch: このサブネットで起動されたインスタンスがパブリックIPアドレスを受け取る場合はtrueにする(デフォルトはfalse)
インターネットゲートウェイの作成
YAMLファイルの記述
template.yaml# 省略 Resources: # 省略 MyInternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: 'Name' Value: 'sample-igw' AttachGateway: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !Ref MyVpc InternetGatewayId: !Ref MyInternetGatewayAttachGatewayでVPCにインターネットゲートウェイをアタッチする
パブリックサブネットの作成
インターネットゲートウェイとパブリックサブネットをルートテーブルで紐付ける
YAMLファイルの記述
template.yaml# 省略 Resources: # 省略 MyRouteTable: Type: AWS::EC2::RouteTable Properties: Tags: - Key: 'Name' Value: 'sample-rt' VpcId: !Ref MyVpc MyRoute: Type: AWS::EC2::Route DependsOn: MyInternetGateway Properties: RouteTableId: !Ref MyRouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref MyInternetGateway MySubnetRouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref MyPublicSubnet RouteTableId: !Ref MyRouteTableインターネットゲートウェイを指定したルート(MyRoute)をルートテーブル(MyRouteTable)に設定し、ルートテーブルをパブリックサブネットにMySubnetRouteTableAssociationで紐付けた
ここまでできました
EC2インスタンスを作成
パブリックサブネットにEC2インスタンスを設置する
YAMLファイルの記述
template.yaml# 省略 Parameters: KeyPair: Description: Select KeyPair Name. Type: AWS::EC2::KeyPair::KeyName Resources: # 省略 MyEC2Instance: Type: AWS::EC2::Instance Properties: ImageId: 'ami-xxxxxx' # xにはidがはいる InstanceType: t2.micro SubnetId: !Ref MyPublicSubnet BlockDeviceMappings: - DeviceName: '/dev/xvda' Ebs: VolumeType: 'gp2' VolumeSize: 8 Tags: - Key: 'Name' Value: 'sample-ec2-instance' SecurityGroupIds: - !Ref MyEC2SecurityGroup KeyName: !Ref KeyPair MyEC2SecurityGroup: Type: AWS::EC2::SecurityGroup Properties: VpcId: !Ref MyVpc Tags: - Key: 'Name' Value: 'sample-ssh-sg' GroupDescription: Allow ssh SecurityGroupIngress: - IpProtocol: tcp FromPort: '22' ToPort: '22' CidrIp: 0.0.0.0/0
- ImageId: 使用するAMIのIDを記述する
- SubnetId: EC2インスタンスを設置するサブネットを指定
- BlockDeviceMappings: インスタンスにアタッチするブロックデバイスを定義
- KeyName: KeyPairはParameterで設定しており、マネジメントコンソールで指定する
- SecurityGroupIngress: 受信規則を指定
DBインスタンスの作成
プライベートサブネットにDBインスタンスを設置する。RDSを使用する。マルチAZ構成にする。
YAMLファイルの記述
template.yaml# 省略 Parameters: # 省略 MyRDSMasterUser: Type: String Default: admin MinLength: 1 MaxLength: 16 NoEcho: true AllowedPattern: '[a-z]+' MyRDSMasterPassword: Type: String Default: password MinLength: 8 MaxLength: 16 NoEcho: true AllowedPattern : '[^\/@"]+' Resources: # 省略 MyRDSSubnetGroup: Type: AWS::RDS::DBSubnetGroup Properties: DBSubnetGroupDescription: SubnetGroup for RDS SubnetIds: - !Ref MyPrivateSubnet1A - !Ref MyPrivateSubnet1C MyRDSSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: SecurityGroup for DB SecurityGroupIngress: - IpProtocol: tcp CidrIp: 0.0.0.0/0 FromPort: '3306' ToPort: '3306' VpcId: !Ref MyVpc MyRDSDBInstance: Type: AWS::RDS::DBInstance Properties: AllocatedStorage: '5' DBSubnetGroupName: !Ref MyRDSSubnetGroup VPCSecurityGroups: - !Ref MyRDSSecurityGroup MultiAZ: true DBInstanceClass: db.t2.micro DBName: 'sample' Engine: MySQL EngineVersion: 5.7.22 MasterUsername: !Ref MyRDSMasterUser MasterUserPassword: !Ref MyRDSMasterPassword DeletionPolicy: Snapshot
- MyRDSMasterUser(Parameter): DBのユーザ名のバリデーションを設定(ユーザ名はマネジメントコンソールで設定する)
- MyRDSMasterPassword(Parameter): DBのパスワードのバリデーションを設定(パスワードはマネジメントコンソールで設定する)
- MultiAZ: マルチAZ構成にする場合はtrue(デフォルトはfalse)
- Engine: DBエンジンを指定(今回はMySQL)
- MasterUsername: マネジメントコンソールで設定したMyRDSMasterUserをユーザ名として使用
- MasterUserPassword: マネジメントコンソールで設定したMyRDSMasterPasswordをパスワードとして使用
- ハマりポイント: VPCSecurityGroupsは配列での指定じゃないとダメでした
完成!
完成したテンプレート
template.yamlAWSTemplateFormatVersion: '2010-09-09' Description: A sample template Parameters: KeyPair: Description: Select KeyPair Name. Type: AWS::EC2::KeyPair::KeyName MyRDSMasterUser: Type: String Default: admin MinLength: 1 MaxLength: 16 NoEcho: true AllowedPattern: '[a-z]+' MyRDSMasterPassword : Type: String Default: password MinLength: 8 MaxLength: 16 NoEcho: true AllowedPattern : '[^\/@"]+' Resources: MyVpc: Type: AWS::EC2::VPC Properties: CidrBlock: '10.10.0.0/16' Tags: - Key: 'Name' Value: 'sample-vpc' MyPublicSubnet: Type: AWS::EC2::Subnet Properties: VpcId: !Ref MyVpc CidrBlock: '10.10.11.0/24' MapPublicIpOnLaunch: true Tags: - Key: 'Name' Value: 'sample-public-subnet' MyPrivateSubnet1A: Type: AWS::EC2::Subnet Properties: VpcId: !Ref MyVpc CidrBlock: '10.10.21.0/24' AvailabilityZone: 'ap-northeast-1a' Tags: - Key: 'Name' Value: 'sample-private-subnet1a' MyPrivateSubnet1C: Type: AWS::EC2::Subnet Properties: VpcId: !Ref MyVpc CidrBlock: '10.10.22.0/24' AvailabilityZone: 'ap-northeast-1c' Tags: - Key: 'Name' Value: 'sample-private-subnet1c' MyInternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: 'Name' Value: 'sample-igw' AttachGateway: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !Ref MyVpc InternetGatewayId: !Ref MyInternetGateway MyRouteTable: Type: AWS::EC2::RouteTable Properties: Tags: - Key: 'Name' Value: 'sample-rt' VpcId: !Ref MyVpc MyRoute: Type: AWS::EC2::Route DependsOn: MyInternetGateway Properties: RouteTableId: !Ref MyRouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref MyInternetGateway MySubnetRouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref MyPublicSubnet RouteTableId: !Ref MyRouteTable MyEC2Instance: Type: AWS::EC2::Instance Properties: ImageId: 'ami-xxxxxx' # xにはidがはいる InstanceType: t2.micro SubnetId: !Ref MyPublicSubnet BlockDeviceMappings: - DeviceName: '/dev/xvda' Ebs: VolumeType: 'gp2' VolumeSize: 8 Tags: - Key: 'Name' Value: 'sample-ec2-instance' SecurityGroupIds: - !Ref MyEC2SecurityGroup KeyName: !Ref KeyPair MyEC2SecurityGroup: Type: AWS::EC2::SecurityGroup Properties: VpcId: !Ref MyVpc Tags: - Key: 'Name' Value: 'sample-ssh-sg' GroupDescription: Allow ssh SecurityGroupIngress: - IpProtocol: tcp FromPort: '22' ToPort: '22' CidrIp: 0.0.0.0/0 - IpProtocol: tcp FromPort: '80' ToPort: '80' CidrIp: 0.0.0.0/0 MyRDSSubnetGroup: Type: AWS::RDS::DBSubnetGroup Properties: DBSubnetGroupDescription: SubnetGroup for RDS SubnetIds: - !Ref MyPrivateSubnet1A - !Ref MyPrivateSubnet1C MyRDSSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: SecurityGroup for DB SecurityGroupIngress: - IpProtocol: tcp CidrIp: 0.0.0.0/0 FromPort: '3306' ToPort: '3306' VpcId: !Ref MyVpc MyRDSDBInstance: Type: AWS::RDS::DBInstance Properties: AllocatedStorage: '5' DBSubnetGroupName: !Ref MyRDSSubnetGroup VPCSecurityGroups: - !Ref MyRDSSecurityGroup MultiAZ: true DBInstanceClass: db.t2.micro DBName: 'sample' Engine: MySQL EngineVersion: 5.7.22 MasterUsername: !Ref MyRDSMasterUser MasterUserPassword: !Ref MyRDSMasterPassword DeletionPolicy: Snapshot参考資料
- 投稿日:2019-08-28T21:57:23+09:00
ぼくのかんがえたさいきょうのWordpress@AWS環境(CloudFront構築編)
はじめに
当記事はぼくのかんがえたさいきょうのWordpress@AWS環境(概要編)
にて記載している作成手順(概要)の4の詳細になります。手順1のWordpress入りのLightsail
手順2のRoute53にて取得した独自ドメイン
手順3のAWS Certification Managerにて取得したSSL証明書(ワイルドカード証明書)
これらを利用してWordpressサイトを配信するCloudFrontを構築する手順を紹介致します。手順
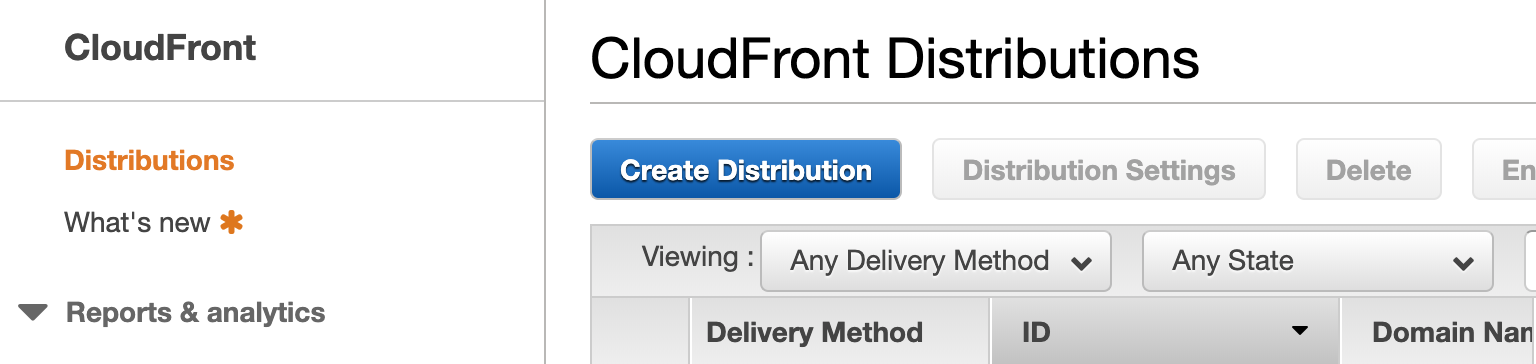
AWSにログインし、サービスから「CloudFront」をクリックします。
CloudFrontの管理画面が表示されるので、「Create Distribution」をクリックします。
Webの「Get Started」をクリックします。
CloudFrontの設定画面が表示されるので
下記の表の通りに設定を行う。
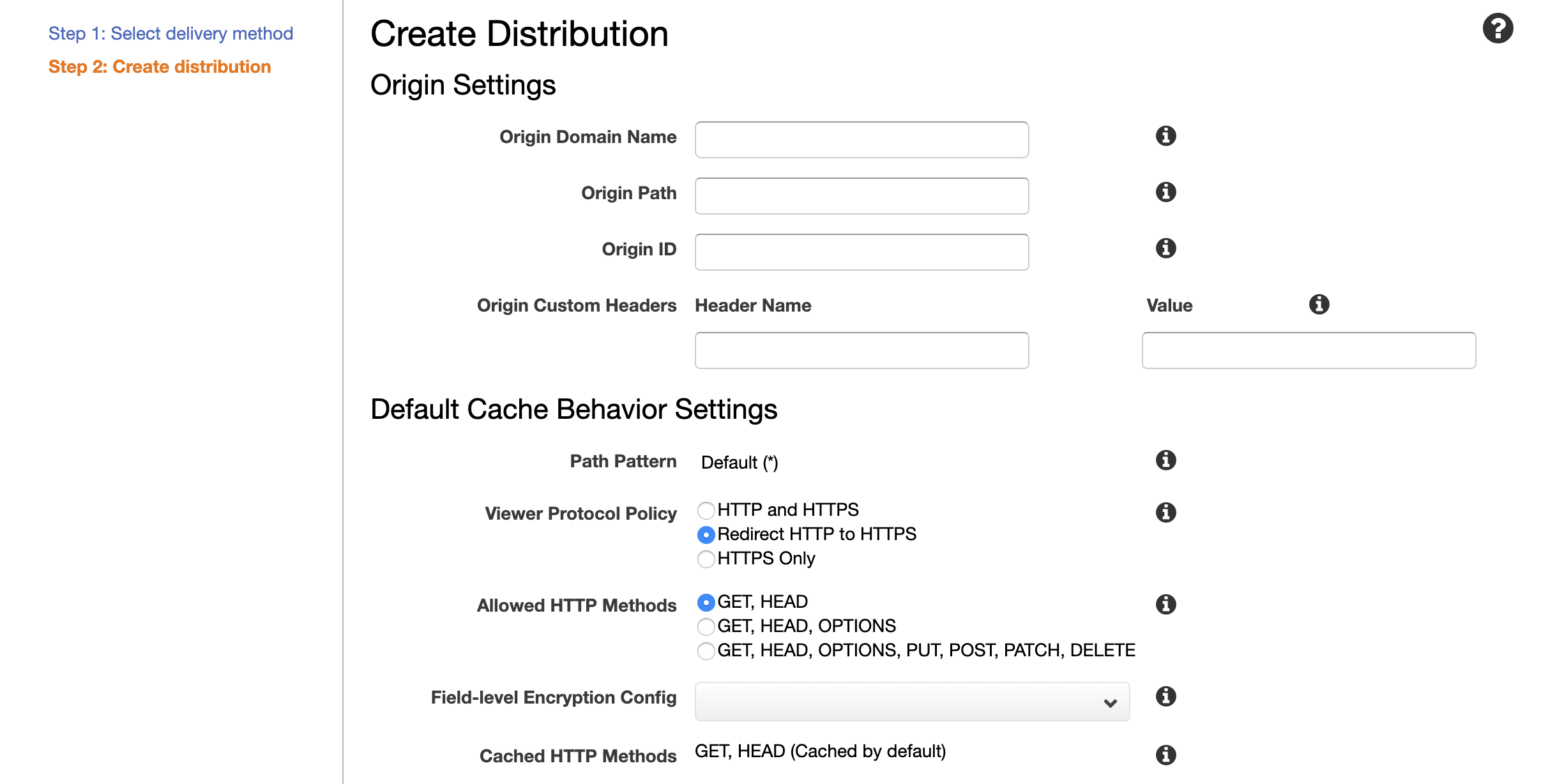
Origin Settings
設定項目 設定値 Origin Domain Name 手順2で取得したドメイン名 Origin Path 空白 Origin ID 自動入力される内容が気に入らなければ変更 Minimum Origin SSL Protocol TLS1.2 Origin Protocol Policy HHTP Only Origin Response Timeout 30 Origin Keep-alive Timeout 5 HTTP Port 80 (Origin Custom Headers ) Header 空白 (Origin Custom Headers ) NameValue 空白 Default Cache Behavior Settings
設定項目 設定値 Viewer Protocol Policy Redirect HTTP to HTTPS Allowed HTTP Methods GET, HEAD Field-level Encryption Config 空白 Cached HTTP Methods No check Cache Based on Selected Request Headers Whitelist Whitelist Headers Authorization
CloudFront-Forwarded-Proto
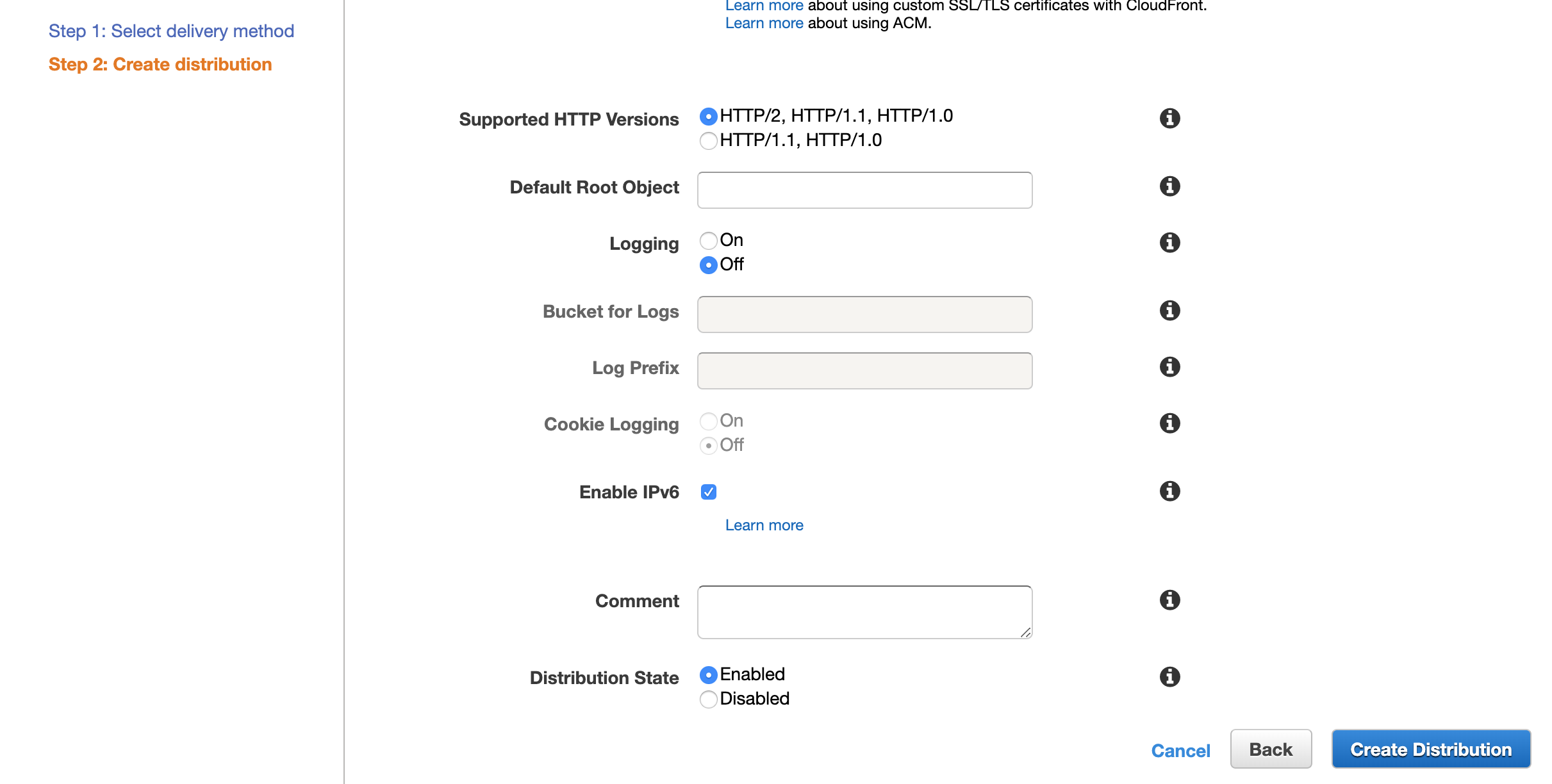
HostObject Caching Use Origin Cache Headers Forward Cookies All Query String Forwarding and Caching Forward all, cache based on all Smooth Streaming No Restrict Viewer Access(Use Signed URLs or Signed Cookies) No Compress Objects Automatically No Lambda Function Associations デフォルト空白 Distribution Settings
設定項目 設定値 Price Class Use All Edge Locations (Best Performance) AWS WAF Web ACL None Alternate Domain Names (CNAMEs) 空白 SSL Certificate Default CloudFront Certificate (*.cloudfront.net) Supported HTTP Versions HTTP/2, HTTP/1.1, HTTP/1.0 Default Root Object 空白 Logging Off Enable IPv6 check Comment 空白 Distribution State Enabled 各種項目の値を設定したらCreateDistributionをクリックする
作成したディストリビューションはStatusが「In Progress」となります。
Statusが「Deployed」になればディストリビューションの作成が完了となります。
これだけでは設定が不十分なので
作成したディストリビューションのIDをクリックして編集画面に遷移します。
ディストリビューションの編集画面に遷移したら上部の「Behaviors」をクリックします。
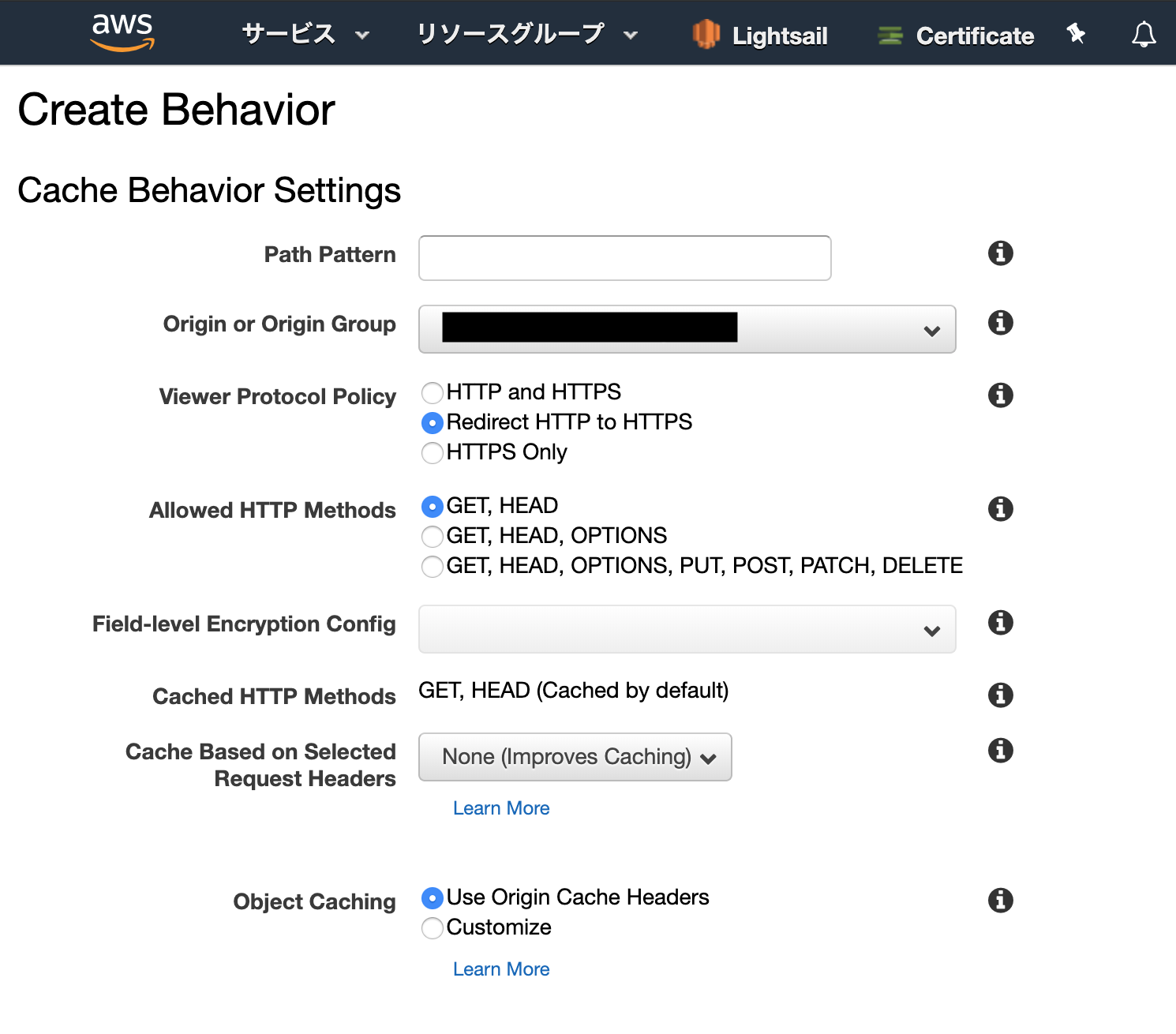
「Create Behavior」をクリックし、
新規にBehaviorの設定を4つ増やします。
増やす4つの設定は下記の表の通り*.php
設定項目 設定値 Path Pattern *.php Origin or Origin Group 先程作成したDistributionのOrigin IDを選択 Viewer Protocol Policy Redirect HTTP to HTTPS Allowed HTTP Methods GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE Field-level Encryption Config 空白 Cached HTTP Methods No check Cache Based on Selected Request Headers Whitelist Whitelist Headers Authorization
CloudFront-Forwarded-Proto
HostObject Caching Customize Minimum TTL 0 Maximum TTL 0 Default TTL 0 Forward Cookies All Query String Forwarding and Caching Forward all, cache based on all Smooth Streaming No Restrict Viewer Access(Use Signed URLs or Signed Cookies) No Compress Objects Automatically No Lambda Function Associations デフォルト空白 /wp-json/*
設定項目 設定値 Path Pattern /wp-json/* Origin or Origin Group 先程作成したDistributionのOrigin IDを選択 Viewer Protocol Policy Redirect HTTP to HTTPS Allowed HTTP Methods GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE Field-level Encryption Config 空白 Cached HTTP Methods No check Cache Based on Selected Request Headers Whitelist Whitelist Headers Authorization
CloudFront-Forwarded-Proto
Host
x-wp-nonceObject Caching Customize Minimum TTL 0 Maximum TTL 0 Default TTL 0 Forward Cookies All Query String Forwarding and Caching Forward all, cache based on all Smooth Streaming No Restrict Viewer Access(Use Signed URLs or Signed Cookies) No Compress Objects Automatically No Lambda Function Associations デフォルト空白 /wp-admin/*
設定項目 設定値 Path Pattern /wp-admin/* Origin or Origin Group 先程作成したDistributionのOrigin IDを選択 Viewer Protocol Policy Redirect HTTP to HTTPS Allowed HTTP Methods GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE Field-level Encryption Config 空白 Cached HTTP Methods No check Cache Based on Selected Request Headers Whitelist Whitelist Headers Authorization
CloudFront-Forwarded-Proto
Host
x-wp-nonceObject Caching Customize Minimum TTL 0 Maximum TTL 0 Default TTL 0 Forward Cookies All Query String Forwarding and Caching Forward all, cache based on all Smooth Streaming No Restrict Viewer Access(Use Signed URLs or Signed Cookies) No Compress Objects Automatically No Lambda Function Associations デフォルト空白 /wp-login.php*
設定項目 設定値 Path Pattern /wp-login.php* Origin or Origin Group 先程作成したDistributionのOrigin IDを選択 Viewer Protocol Policy Redirect HTTP to HTTPS Allowed HTTP Methods GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE Field-level Encryption Config 空白 Cached HTTP Methods No check Cache Based on Selected Request Headers Whitelist Whitelist Headers Authorization
CloudFront-Forwarded-Proto
HostObject Caching Customize Minimum TTL 0 Maximum TTL 0 Default TTL 0 Forward Cookies Whitelist Whitelist Cookies comment_author_
wordpress_logged_in_
wordpress_test_cookie
wp-settings-*Query String Forwarding and Caching Forward all, cache based on all Smooth Streaming No Restrict Viewer Access(Use Signed URLs or Signed Cookies) No Compress Objects Automatically No Lambda Function Associations デフォルト空白 4つ全てを登録したら
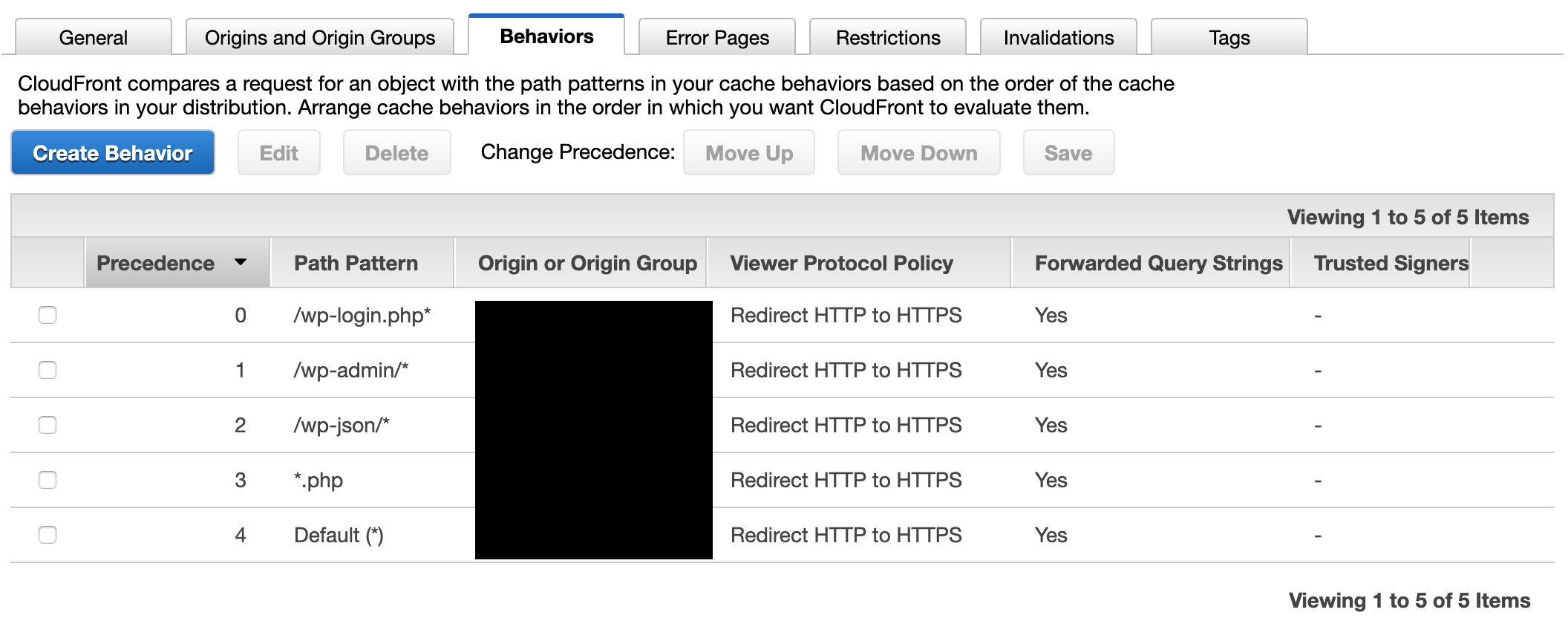
合計で5つの設定が下記の図の通りになっている事を確認(この順番が地味に重要なので順番が異なる場合は明細を選択して「Move UP」「Move Down」で順番を整える)
以上でCloudFrontの設定は完了。




- 投稿日:2019-08-28T20:22:46+09:00
IoT@Loft #3 2019年8月28日 参加メモ
はじめに
Amazonが開催しているIoT@Loft#3に参加して参りましたので、そのメモです。すいません自分向けメモです。
https://iot-loft.connpass.com/event/142216/LT1 - センサを使った見守りサービスはどう作っているのか
高橋 一貴 氏 株式会社チカク シニアエンジニアリングマネージャー
- まごチャンネルを提供している。https://www.mago-ch.com/
- まごチャンネルは始まって3年ぐらい。
- まごチャンネルはスマートフォンで取った写真を遠くのおじいちゃん・おばあちゃんのテレビに写す。
- おじいちゃん・おばあちゃんが写真を見るとスマートフォンに通知がいく。
- 新規機能の開発
- 温度・振動情報をクラウドに5秒に1回アップロード。しきい値を超えた場合に通知をする。
- リアルタイム処理、数千台がターゲット。
- 重要なポイント
- スケーラビリティ -> Lambda, Dynamo DB
- 高可用性 -> Lambda, Dynamo DB
システム構成
設計はDDD、 デプロイはTeraform
センサーデータ保存Lambda Functionがタイムアウトする場合がある。
LT2 - 1日でプロトタイプを作る技術と働き方
佐野 友則 氏 KDDI株式会社 経営戦略本部 KDDI DIGITAL GATE マネジャー
- KDDI DIGITAL GATEのミッション
- 企業のデジタル変革を実現する場所。
- アジャイル、デザイン思考を使う。
- 1日スプリントを無料で実施して、そのアウトプットのイメージから発注して頂く。
- AWSの機能進化のスピードは非常に早く、絶えずキャッチアップするのは難しい。
- しかし顧客価値の最大化のためにはAWSの便利なサービスを学び続けないといけない。
- Podとユニットを作っている。Podは様々な職種の集まり、ユニットは同じ職種の集まり。
- 1日の決められた時間で最大のアプトプットを出すのが重要な点。
- OST - Open Space Technology
- weekly 振り返り (課題を出し合う) - 長期的に解決したい事を話をする
- OSTを実施
- 短い周期に慣れておく。学習は立ち止まる時間も必要。
LT3 - 水産養殖スタートアップによる洋上で動くIoTプロダクト開発
岡本 拓磨 氏 ウミトロン株式会社 共同創業者 / CTO
- IoTの技術を使った自動エサやり機械
- ソーラー電源で稼働、ネットワークはSORACOM、リアルタイムデータストリーミング、動画保存
- デバイスのOSはLinuxを採用していて、Go言語で開発している。Go言語は1バイナリで動作するのでアップデートなど対応しやすい。
- 最悪リモートでSSHを使った装置の不具合を確認する。
- AWS IoTはビジネスロジックとは関連のない部分で利用をしている。
- ウミトロンのシステムの監視としては、エサを正しく上げれているかの監視が最重要。魚が出荷されて、装置が撤去されていたり、細い運用が必要。
- AWS IoT ジョブでオンラインになったらアップデートを実現している。https://docs.aws.amazon.com/ja_jp/iot/latest/developerguide/iot-jobs.html
LT4 - 大きな組織と一緒にはじめるスタートアップ
岡田 貴裕 氏 BCG Digital Ventures Lead Engineer
- 資源運輸船を対象にした事業立ち上げ
- 一緒に仕事をする・観察する事で様々な課題が見つかる
- IoTのアーキテクチャがわかっているエンジニアが現場に入る事で解決策を考える事ができる。
- 制約条件を最初に確認しておく事が必要。スマフォが使えない、ウェラブルデバイスが使えないなど後工程で確認できた。
- MVPを実現してから、実際に運用フェーズに落とすまでが大変であり、重要。
- 最初はエンジニアが船に乗ってイーサを引くなどやっていたが、それではスケールしない。作業手順に落とすや、調達の安定化など様々な業務が必要であり、重要。
LT5 - IoTスタートアップを加速させるAWSの使い方
針原 佳貴 アマゾンウェブサービスジャパン株式会社 Startup Solutions Architect
- AWS Deeplens
- AWSのスタートアップ支援
- AWS Activate スタートアップ企業がAWSが開始するための必要なリソースをオールインワンで無性提供するスタートアップ支援プログラム。
- 最大$10万クレジットや技術サポート、研修等
- AWSエンジニアによる技術支援
- Ask An Expertカウンター
- 主な質問をブログで公開している。様々なヒントが含まれている可能性がある。
- ML@Loft, Blockchain@Loftなどイベントをやっている。
- AWS Deeplensの構成はかなり参考になりそう。エッジでDeepLearningを使った処理の結果をAWS IoTのTopic経由で情報が取れる。



- 投稿日:2019-08-28T19:02:13+09:00
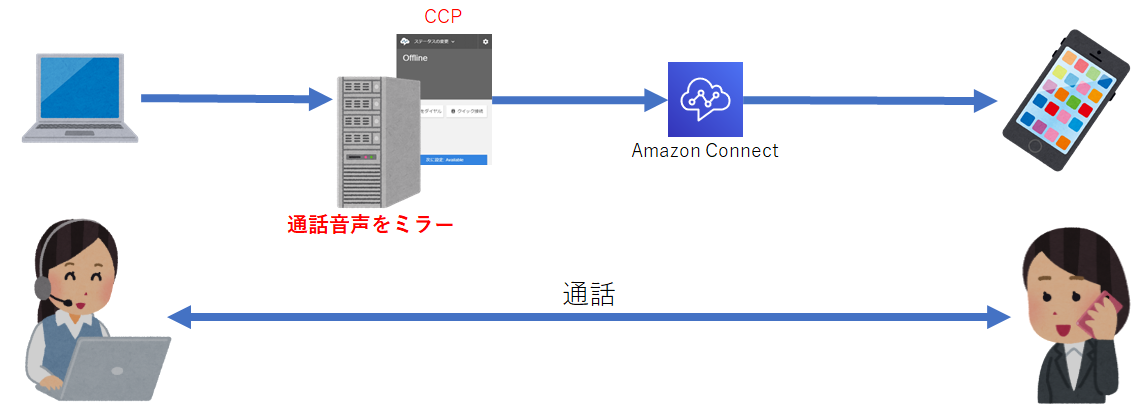
AmazonConnectでオペレータ側の音声をリアルタイムに取得してみた
概要
今回はamazon-connect-streamsとconnect-rtc-jsを使うことでAmazonConnectのオペレータの音声をリアルタイムに取得してみました。音声をリアルタイムに取得することができたことで、COTOHA等の音声認識システムに入れるなどの幅が広がります。
なぜそんなことをしたの?
AmazonConnectにはリアルタイムに音声を取得する方法として「リアルタイム顧客音声ストリーム機能」が存在します。
しかしこの機能では、お客様側(カスタマ側)の音声しかリアルタイムに取得することができません。
そこで今回はAmazonConnectのオペレータ側の音声をリアルタイムに取得してみました。イメージ図
※今回はCCPを動かすサーバ(取得した音声を操作するサーバ)をAWSのS3上に作っています。作成方法
前提
- 実行する環境にNode.jsがインストールされていること
- 実際に動作をさせるにはAmazon Connectに1度ログインをしていること
ライブラリの取得とビルド
- ソフトフォンを使用するためのソースを右のリンクから取得します。amazon-connect-streams
- 通話しているストリームを取得するためのソースを右のリンクから取得します。connect-rtc-js
- 1で取得したソースをビルドします。amazon-connect-streamsをおいたディレクトリにて
makeを実施してください。実施するとamazon-connect-${version}.jsといったファイルが作られます。(versionの部分は変化します)。HTML側の作成
- 自作のhtmlを作成し、以下のようにコードを書きます。
amazon-connect-1.3-12-xxxxxxxx.jsはビルドしてできたjavascriptのファイル名に置き換えてください。
URLでxxxx.awsapps.comとしている個所はAmazon Connectのインスタンスに置き換えてください。
divのidに指定しているcontainerDivとremote-audioは変更しないでください。<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Custom CCP</title> <script type="text/javascript" src="amazon-connect-1.3-12-xxxxxxxx.js"></script> <script type="text/javascript" src="connect-rtc.js"></script> </head> <body> <center> <div id="containerDiv" style="width: 320px; height: 465px"></div> <div><audio id="remote-audio" controls><p>音声を再生するには、audioタグをサポートしたブラウザが必要です。</p></audio></div> <div><audio id="user-audio" controls><p>音声を再生するには、audioタグをサポートしたブラウザが必要です。</p></audio></div> </center> </body> <script type="text/javascript"> const ccpUrl = "https://xxxx.awsapps.com/connect/ccp#/"; connect.core.initCCP(containerDiv, { ccpUrl: ccpUrl, loginPopup: true, softphone: { allowFramedSoftphone: false }, }); connect.core.initSoftphoneManager({allowFramedSoftphone: true}); // コンタクトイベントの取得 connect.contact(function(contact) { var softphoneMediaInfo = contact.getAgentConnection().getSoftphoneMediaInfo(); var remoteAudio = document.getElementById("remote-audio"); var mediaInfo = JSON.parse(softphoneMediaInfo); var rtcConfig = mediaInfo.webcallConfig || JSON.parse(mediaInfo.callConfigJson);//mediaInfo.webcallConfig is used internally by Amazon Connect team only var session = new connect.RTCSession(rtcConfig.signalingEndpoint, rtcConfig.iceServers, mediaInfo.callContextToken, console); session.echoCancellation = true; session.remoteAudioElement = remoteAudio; session.forceAudioCodec = 'OPUS'; session.onSessionConnected = () => { statsCollector = setInterval(() => { var collectTime = new Date(); Promise.all([session.getUserAudioStats(), session.getRemoteAudioStats()]).then((streamStats) => { console.log(collectTime + " Audio statistics : " + JSON.stringify(streamStats)); }); }, 2000); }; }); </script> </html>amazon-connect-1.3-12-xxxxxxxx.jsの修正
1.このままではマイクから音声を取得するためのコードがないので、マイクから音声を取得するためのコードを書きます。
今回は通話の開始時にマイクの音声を取得するために、ビルドしてできたamazon-connect-1.3-12-xxxxxxxx.jsの
変数onRefreshContactに定義されている関数の末尾に以下のコードを追加します。
「amazon-connect-streams」内にあるsoftphone.jsのソースコードを変更して、再度ビルドしても同じ結果となります。var handleSuccess = function(stream) { document.getElementById('user-audio').srcObject = stream; }; navigator.mediaDevices.getUserMedia({ audio: true, video: false }).then(handleSuccess);2.通話が終了したときにマイクの音声の再生が終了するように変数deleteLocalMediaStreamに定義されている関数の末尾に以下のコードを追加します。
こちらも「amazon-connect-streams」内にあるsoftphone.jsのソースコードを変更して、再度ビルドしても同じ結果となります。document.getElementById('user-audio').srcObject = null;HTMLとjavascriptの配備
今回はcloudfrontを使用して、S3に置いたファイルを使用して自作のHTMLファイルを表示させ動作確認を行います。
S3にバケットを作成して、作成したhtmlファイル、amazon-connect-1.3-12-xxxxxxxx.js、connect-rtc.jsを配備します。
S3に配置したhtmlファイルをwebページとして表示するための手順はこちらの記事を参考にしました。
特定バケットに特定ディストリビューションのみからアクセスできるよう設定する
cloudfrontで公開するURLが発行されたら、Amazon Connectのアプリケーション統合画面でURLを追加します。その際のURLはxxxxxxxxx.cloudfront.netまでにしてください。
動作確認
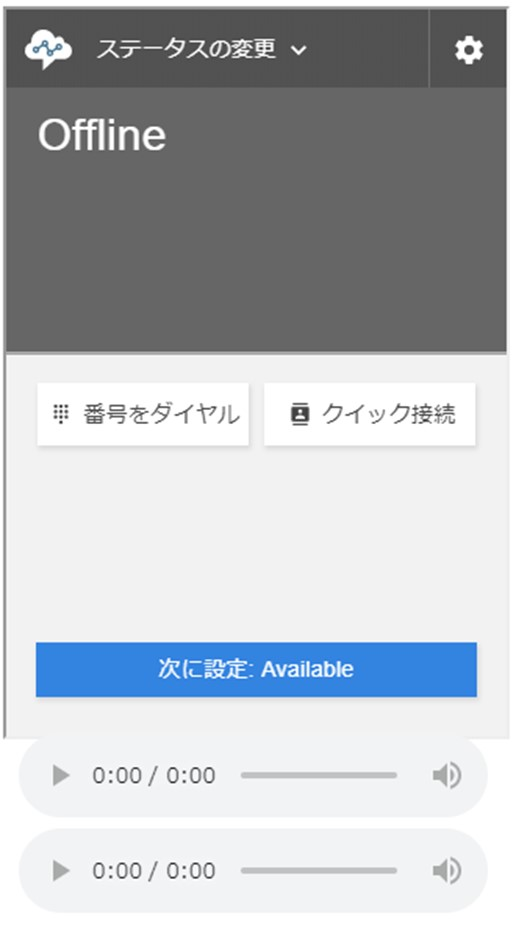
アプリケーション統合画面で追加した画面にアクセスを行うと以下のような画面が表示されます。
初めてアクセスする場合はマイクの使用許可のポップアップが表示されるので許可をしてください。
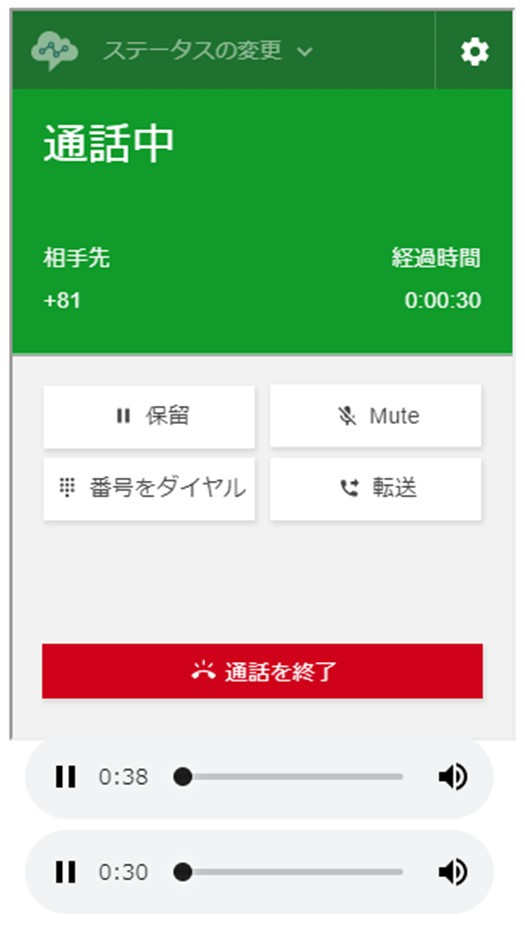
通話中画面(電話番号部分は隠してあります)
ソフトフォンの方が電話をかけ始めてすぐにストリームが作成されますが、マイク側のstreamは経過時間と同じ時間であることが確認できます。
今後の利用
これを応用すれば、マイクから取得した音声をCOTOHA 音声認識APIに投げる、Google Speech to Textに投げるなどの応用が考えられます。
機会があればそちらも記事にしたいと思います。参考資料
特定バケットに特定ディストリビューションのみからアクセスできるよう設定する
https://dev.classmethod.jp/cloud/aws/cloudfront-s3-origin-access-identity/
- 投稿日:2019-08-28T18:53:40+09:00
AWS ELB(ALB,CLB,NLB)を1分で掴む
いくつか調べてみました!
優しめのマサカリください!!ELBとは
Elastic Load Balancer = ロードバランサー
トラフィックの分散を行う
サーバへのアクセスを、複数のアベイラビリティーゾーンの複数のEC2インスタンスに分散
全3種類
NLB - Network Load Balancer
- L4 NATロードバランサ
- TCPに対応
ALB - Application Load Balancer
- L7リバースプロキシ
- HTTP,HTTPSに対応
CLB - Classic Load Balancer
- L4/L7 リバースプロキシ
- TCP,SSL,HTTP,HTTPSに対応
特徴と違い
通信経路
- ALB,CLBはリバースプロキシのため、行きも帰りもロードバランサを経由
- NBLは宛先IPをクライアントのIPに変えるため、帰りはLBを通らない
アクセス制限
- ALB,CLBはポートでのアクセス制限が可能
- NBLはシンプルな一方でアクセス制限が不可
IPアドレス
- ALB,CLBはIPアドレスが可変なためDNSの利用が必要
- NLBは固定IPのためDNSとIPを利用できる
アクセスログ
- NLBのみアクセスログの出力が非対応
特にお世話になった参考文献様
- ELB
- ネットワーク視点で見るAWS ELB(Elastic Load Balancing)のタイプ別比較[NLB対応] / Classmethhod
- ELBの比較表に補足事項を書き加えてみる(NLB編) / Serverworks
- 投稿日:2019-08-28T16:49:49+09:00
AWS ALBでお手軽メンテ画面の作成と運用方法
はじめに
サービスを運用していると定期メンテの際に出しておくメンテ画面が必要ですよね。
メンテページには「○○時までメンテナンスしているから少し待ってね」的な事を時間を指定して書いておきたい。
基本的な事は クラスメソッドさんのブログ に書いているのですが、
今回は運用も考えてJenkinsから叩けるようにaws-cliコマンドを使ってメンテ画面を作って運用する方法を紹介します。端的に紹介すると
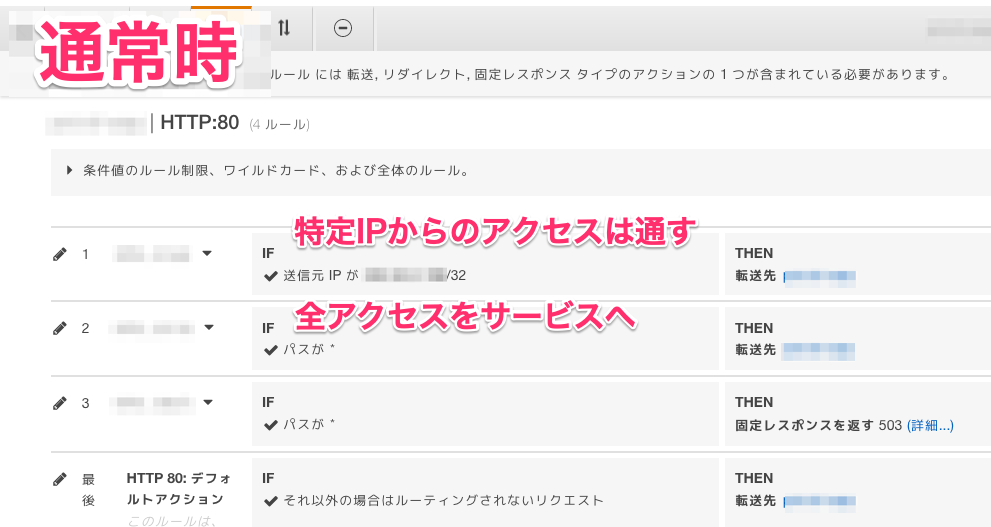
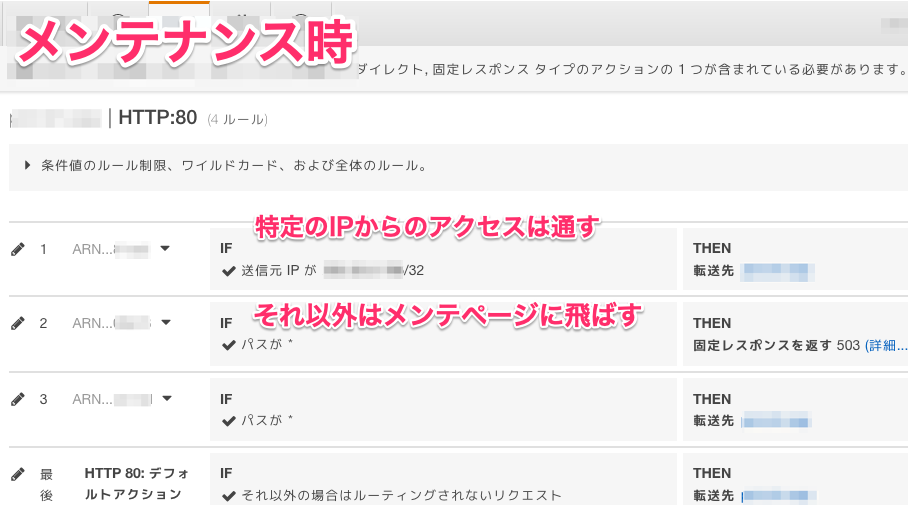
- ALBのルールの一つにでメンテ画面を作成
└ メンテ開始前にメンテ画面をaws-cliで更新- 運用を考えて3つのルールを作成
└ メンテ開始時にルールの優先順位をaws-cliで変更
└ メンテ終了時もルールの優先順位をaws-cliで変更
1.ALBにメンテ画面を作成
EC2やS3不要!ALBだけでメンテナンス画面を表示するなど固定レスポンスが返せるようになりました!
ALBからメンテ画面を固定レスポンスとして作りましょう。
普段はサービスに向けたルールよりも優先度を下に設定しておき、メンテ開始時にメンテ画面のルールの優先度を上げる運用にします。1.1メンテ開始前にメンテ画面を更新
メンテ画面でメンテの終了予定期間を表示させたいのでルールを更新します。
$aws elbv2 modify-rule --rule-arn xxxx \ --actions Type=fixed-response,FixedResponseConfig= \ '{MessageBody=2019/08/28の20:00までメンテです。,StatusCode=503,ContentType=text/html}'messageBody部分にhtmlを書いてやることでソレっぽい画面を作ります。
ただ、文字制限があるので最低限のページにおさえて置きましょう。2.運用を考えて3つのルールを作成
1つ目はメンテ画面のルール
2つ目はサービスのターゲットグループを指定したルール
3つ目は 特定IPからアクセス出来るサービスのターゲットグループを指定したルールメンテナンス時に動作確認を行いたいのであれば、
3つ目のルールを1つ目のルールより優先度を上げると確認が楽になります。
2.1 メンテ開始時にルールの優先順位を変更
メンテ画面の優先度をサービスへのルールよりも上げています。
aws elbv2 set-rule-priorities --rule-priorities \ RuleArn=特定IP許可のルール,Priority=1 \ RuleArn=メンテ画面のルール,Priority=2 \ RuleArn=サービスへのルール,Priority=32.2 メンテ終了時にルールの優先順位を変更
メンテ画面の優先度をサービスへのルールよりも下げています。
aws elbv2 set-rule-priorities --rule-priorities \ RuleArn=特定IP許可のルール,Priority=1 \ RuleArn=サービスへのルール,Priority=2 \ RuleArn=メンテ画面のルール,Priority=3まとめ
今回、簡単にメンテナンス画面の作成とその運用方法について紹介しました。
- 投稿日:2019-08-28T15:45:50+09:00
AWS Healthを定期的にチェックして、障害情報を自動通知する
先日のAWS障害を受けて、AWS Healthで障害情報が上がった場合に一次情報として自動通知できるようにしたいと上司から言われ、作ってみたものです。
1.要件
・AWS Health上に新しく障害情報が掲載された際に、自動で通知を行う。(今回はとりあえずメール通知)
・その他のメンテナンス情報等は通知対象外
・あくまで一次的にAWS障害に気づくための用途であり、そもそも監視・モニタリングでAWS障害に起因するシステム異常を検知するのは別のお話2.構成
CloudWatchEventsでAWS Healthイベントを検知可能ですが、メンテナンス等の一部イベントしか検知できないため先日のAZ障害のようなケースでは役に立ちません。
そのため、定期的にLambdaでAWS HealthのAPIを叩く構成にしました。3.Lambdaの中身
AWSサービスで障害が発生した場合のイベントカテゴリは'Issue'、かつ対応中であるものはイベントステータスが'Open'なものなので、それらをフィルター指定してDescribe Events APIを実行しています。
対象が存在する場合にはそのイベントの開始時刻をチェックして、N分前~現在時刻の範囲(=直近のN分間で新たに発生したイベント)である場合のみ検知対象とします。(時刻判定をすることで、重複検知させない)
また、N分の部分は環境変数とすることで可変としています。※該当時間内に発生したイベントを拾えれば良いので、ステータス判定はいらないかもしれません
aws-health-check.pyimport json import boto3 import datetime import dateutil.tz import os health = boto3.client('health') sns = boto3.client('sns') def json_serial(obj): return obj.isoformat() def lambda_handler(event, context): aws_health_events = list(health.describe_events( filter={ 'eventTypeCategories':[ 'issue' ], 'eventStatusCodes':[ 'open' ] } )['events']) open_issue_list = [] for aws_health_event in aws_health_events: start_time = aws_health_event['startTime'] current_check_time = datetime.datetime.now(dateutil.tz.tzlocal()) pre_check_time = current_check_time - datetime.timedelta(minutes=int(os.environ['CHECK_CYCLE'])) if pre_check_time < start_time <= current_check_time: open_issue_list.append(aws_health_event) if len(open_issue_list) == 0: return 'AWS Health Check is OK.' else: sns.publish( TopicArn=os.environ['SNS_TOPIC_ARN'], Subject='AWS Health check Alert!', Message=json.dumps(open_issue_list, default=json_serial) ) return 'New issue detected.'4.CFnテンプレート作成
社内各部への展開もできるようにテンプレート化しておきたかったため、各リソース作成も併せてCFnテンプレートにしました。
・とりあえずLambdaのコード部分は直書きですが、実際に使う場合はS3からの取得に直す予定です
・AWS Healthをチェックさせるサイクル(分)と通知先のメールアドレスは入力パラメータにしています
・入力値のサイクル(分)はLambdaの環境変数にも埋め込み、PGM内の判定ロジックに使用していますAWSTemplateFormatVersion: '2010-09-09' # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: NotificationEmailAddress: Type: String CheckCycle: Type: String Default: 60 AllowedPattern: "[0-9]*" Description: 'Input Check Cycle. (minutes)' # ------------------------------------------------------------# # Resource # ------------------------------------------------------------# Resources: AWSHealthCheckRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "lambda.amazonaws.com" Action: - "sts:AssumeRole" Path: "/" RoleName: "aws-health-check-role" ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole AWSHealthCheckPolicy: Type: AWS::IAM::Policy Properties: PolicyName: "aws-health-check-policy" PolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Action: - "health:DescribeEvents" Resource: - "*" - Effect: Allow Action: - "sns:Publish" Resource: - !Ref AWSHealthAlertTopic Roles: - !Ref AWSHealthCheckRole AWSHealthCheckFunction: Type: AWS::Lambda::Function Properties: Code: ZipFile: !Sub | import json import boto3 import datetime import dateutil.tz import os health = boto3.client('health') sns = boto3.client('sns') def json_serial(obj): return obj.isoformat() def lambda_handler(event, context): aws_health_events = list(health.describe_events( filter={ 'eventTypeCategories':[ 'issue' ], 'eventStatusCodes':[ 'open' ] } )['events']) open_issue_list = [] for aws_health_event in aws_health_events: start_time = aws_health_event['startTime'] current_check_time = datetime.datetime.now(dateutil.tz.tzlocal()) pre_check_time = current_check_time - datetime.timedelta(minutes=int(os.environ['CHECK_CYCLE'])) if pre_check_time < start_time <= current_check_time: open_issue_list.append(aws_health_event) if len(open_issue_list) == 0: return 'AWS Health Check is OK.' else: sns.publish( TopicArn=os.environ['SNS_TOPIC_ARN'], Subject='AWS Health check Alert!', Message=json.dumps(open_issue_list, default=json_serial) ) return 'New issue detected.' Description: "Lambda Function for AWS Health Check" FunctionName: AWS_Health_Check Handler: index.lambda_handler MemorySize: 128 Role: !GetAtt AWSHealthCheckRole.Arn Runtime: python3.7 Timeout: 30 Environment: Variables: TZ: Asia/Tokyo SNS_TOPIC_ARN: !Ref AWSHealthAlertTopic CHECK_CYCLE: !Ref CheckCycle AWSHealthCheckFunctionLogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: "/aws/lambda/AWS_Health_Check" RetentionInDays: 7 AWSHealthCheckEventRule: Type: AWS::Events::Rule Properties: Description: "time scheduled event for aws health check" Name: "AWS_Health_Check-event" ScheduleExpression: {"Fn::Join": [ "" , ["rate(", !Ref CheckCycle, " minutes)"]]} State: ENABLED Targets: - Arn: !GetAtt AWSHealthCheckFunction.Arn Id: "AWS_Health_Check-event" AWSHealthCheckEventPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref AWSHealthCheckFunction Principal: "events.amazonaws.com" SourceArn: !GetAtt AWSHealthCheckEventRule.Arn AWSHealthAlertTopic: Type: AWS::SNS::Topic Properties: DisplayName: 'aws-health-alert-topic' TopicName: 'aws-health-alert-topic' AWSHealthAlertTopicSubscription: Type: AWS::SNS::Subscription Properties: Endpoint: !Ref NotificationEmailAddress Protocol: email Region: !Ref "AWS::Region" TopicArn: !Ref AWSHealthAlertTopic5.その他
・AWS HealthのAPIはバージニア北部リージョンからしか実行できないため、CFnスタック作成もバージニア北部で実行要です
・社内NWでSlackが使えないためメール通知にしていますが、ここはSlack通知にしたい...
・発生の検知だけでなくcloseの検知もできるようにしようと思っています(検知状況のテキストファイルをS3に配置して、毎回差分を確認するイメージ)
- 投稿日:2019-08-28T15:45:50+09:00
AWS Healthを定期的にチェックして、AWSサービス障害情報を自動通知&CloudFormationテンプレート化
先日のAWS障害を受けて、AWS Healthで障害情報が上がった場合に一次情報として自動通知できるようにしたいと上司から言われ、作ってみたものです。
1.要件
・AWS Health上に新しく障害情報が掲載された際に、自動で通知を行う。(今回はとりあえずメール通知)
・その他のメンテナンス情報等は通知対象外
・あくまで一次的にAWS障害に気づくための用途であり、そもそも監視・モニタリングでAWS障害に起因するシステム異常を検知するのは別のお話2.構成
CloudWatchEventsでAWS Healthイベントを検知可能ですが、メンテナンス等の一部イベントしか検知できないため先日のAZ障害のようなケースでは役に立ちません。
そのため、定期的にLambdaでAWS HealthのAPIを叩く構成にしました。3.Lambdaの中身
AWSサービスで障害が発生した場合のイベントカテゴリは'Issue'、かつ対応中であるものはイベントステータスが'Open'なものなので、それらをフィルター指定してDescribe Events APIを実行しています。
対象が存在する場合にはそのイベントの開始時刻をチェックして、N分前~現在時刻の範囲(=直近のN分間で新たに発生したイベント)である場合のみ検知対象とします。(時刻判定をすることで、重複検知させない)
また、N分の部分は環境変数とすることで可変としています。※該当時間内に発生したイベントを拾えれば良いので、ステータス判定はいらないかもしれません
aws-health-check.pyimport json import boto3 import datetime import dateutil.tz import os health = boto3.client('health') sns = boto3.client('sns') def json_serial(obj): return obj.isoformat() def lambda_handler(event, context): aws_health_events = list(health.describe_events( filter={ 'eventTypeCategories':[ 'issue' ], 'eventStatusCodes':[ 'open' ] } )['events']) open_issue_list = [] for aws_health_event in aws_health_events: start_time = aws_health_event['startTime'] current_check_time = datetime.datetime.now(dateutil.tz.tzlocal()) pre_check_time = current_check_time - datetime.timedelta(minutes=int(os.environ['CHECK_CYCLE'])) if pre_check_time < start_time <= current_check_time: open_issue_list.append(aws_health_event) if len(open_issue_list) == 0: return 'AWS Health Check is OK.' else: sns.publish( TopicArn=os.environ['SNS_TOPIC_ARN'], Subject='AWS Health check Alert!', Message=json.dumps(open_issue_list, default=json_serial) ) return 'New issue detected.'4.CFnテンプレート作成
社内各部への展開もできるようにテンプレート化しておきたかったため、各リソース作成も併せてCFnテンプレートにしました。
・とりあえずLambdaのコード部分は直書きですが、実際に使う場合はS3からの取得に直す予定です
・AWS Healthをチェックさせるサイクル(分)と通知先のメールアドレスは入力パラメータにしています
・入力値のサイクル(分)はLambdaの環境変数にも埋め込み、PGM内の判定ロジックに使用していますAWSTemplateFormatVersion: '2010-09-09' # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: NotificationEmailAddress: Type: String CheckCycle: Type: String Default: 60 AllowedPattern: "[0-9]*" Description: 'Input Check Cycle. (minutes)' # ------------------------------------------------------------# # Resource # ------------------------------------------------------------# Resources: AWSHealthCheckRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "lambda.amazonaws.com" Action: - "sts:AssumeRole" Path: "/" RoleName: "aws-health-check-role" ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole AWSHealthCheckPolicy: Type: AWS::IAM::Policy Properties: PolicyName: "aws-health-check-policy" PolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Action: - "health:DescribeEvents" Resource: - "*" - Effect: Allow Action: - "sns:Publish" Resource: - !Ref AWSHealthAlertTopic Roles: - !Ref AWSHealthCheckRole AWSHealthCheckFunction: Type: AWS::Lambda::Function Properties: Code: ZipFile: !Sub | import json import boto3 import datetime import dateutil.tz import os health = boto3.client('health') sns = boto3.client('sns') def json_serial(obj): return obj.isoformat() def lambda_handler(event, context): aws_health_events = list(health.describe_events( filter={ 'eventTypeCategories':[ 'issue' ], 'eventStatusCodes':[ 'open' ] } )['events']) open_issue_list = [] for aws_health_event in aws_health_events: start_time = aws_health_event['startTime'] current_check_time = datetime.datetime.now(dateutil.tz.tzlocal()) pre_check_time = current_check_time - datetime.timedelta(minutes=int(os.environ['CHECK_CYCLE'])) if pre_check_time < start_time <= current_check_time: open_issue_list.append(aws_health_event) if len(open_issue_list) == 0: return 'AWS Health Check is OK.' else: sns.publish( TopicArn=os.environ['SNS_TOPIC_ARN'], Subject='AWS Health check Alert!', Message=json.dumps(open_issue_list, default=json_serial) ) return 'New issue detected.' Description: "Lambda Function for AWS Health Check" FunctionName: AWS_Health_Check Handler: index.lambda_handler MemorySize: 128 Role: !GetAtt AWSHealthCheckRole.Arn Runtime: python3.7 Timeout: 30 Environment: Variables: TZ: Asia/Tokyo SNS_TOPIC_ARN: !Ref AWSHealthAlertTopic CHECK_CYCLE: !Ref CheckCycle AWSHealthCheckFunctionLogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: "/aws/lambda/AWS_Health_Check" RetentionInDays: 7 AWSHealthCheckEventRule: Type: AWS::Events::Rule Properties: Description: "time scheduled event for aws health check" Name: "AWS_Health_Check-event" ScheduleExpression: {"Fn::Join": [ "" , ["rate(", !Ref CheckCycle, " minutes)"]]} State: ENABLED Targets: - Arn: !GetAtt AWSHealthCheckFunction.Arn Id: "AWS_Health_Check-event" AWSHealthCheckEventPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref AWSHealthCheckFunction Principal: "events.amazonaws.com" SourceArn: !GetAtt AWSHealthCheckEventRule.Arn AWSHealthAlertTopic: Type: AWS::SNS::Topic Properties: DisplayName: 'aws-health-alert-topic' TopicName: 'aws-health-alert-topic' AWSHealthAlertTopicSubscription: Type: AWS::SNS::Subscription Properties: Endpoint: !Ref NotificationEmailAddress Protocol: email Region: !Ref "AWS::Region" TopicArn: !Ref AWSHealthAlertTopic5.その他
・AWS HealthのAPIはバージニア北部リージョンからしか実行できないため、CFnスタック作成もバージニア北部で実行要です
・社内NWでSlackが使えないためメール通知にしていますが、ここはSlack通知にしたい...
・発生の検知だけでなくcloseの検知もできるようにしようと思っています(検知状況のテキストファイルをS3に配置して、毎回差分を確認するイメージ)
- 投稿日:2019-08-28T12:56:52+09:00
Alibaba CloudでOpenVPNを建てて使ってみる
この記事の目的
Alibaba Cloud ECSにOpenVPNサーバを建てて
SSL-VPNでクライアントPCからVPC内リソースにアクセスします。以下検証環境
・クライアント端末:Mac OS.X
・クライアントソフト:Tunnel Blick
・OS:CentOS Linux release 7.6.1810 (Core)
・SSL-VPN接続Port:1194
・SSL-VPN接続プロトコル:UDP
Alibaba Cloudとは
中国最大手のパブリッククラウド。シェアは5割を超える。
取り扱いパートナーのbeyondさんのBlogがわかりやすかったのでlinkるhttps://beyondjapan.com/blog/2018/05/alibaba-cloud/
■ 中国最大のパブリッククラウドサービス。(中国ではシェア1位)
■ 中国ECサイト市場 最大の商戦日 11月11日「独身の日」
(ダブルイレブン、W11、双11 とも言われる) のインフラで使われており、
3分売上100億元(約1700億円)、1日売上2.8兆円の流通規模のトラフィックを捌いている。
※ この2.8兆円というのは、楽天の
1年間の売上に近い金額。
■ アリババが運営するスマホ決済「アリペイ」のインフラでも使われている。
(中国でのスマホ決済サービスで60%近いシェア)
■ オリンピックのオフィシャルクラウドサービス。(2028年まで長期契約)
■ 世界各国にある 18リージョン のデータセンター。
■ 日本語サポート・日本円請求。請求書払いも可能。(海外リージョン環境も日本円で購入可能)
■ コントロールパネルは、日本語・中国語(簡体字)・英語に翻訳対応されている。
■ 中国を含む各国リージョンのサービスを1つのアカウントで利用可能。
■ 中国でWebサイトを展開するときに必要な「ICP登録・ICPライセンス取得」が
Alibaba Cloud で1アカウント(1契約)あれば、そのままICP申請代行をしてくれる。
(中国国内でWebサイトを開設する際は「事前申請手続き(ICP登録)」が必要)
※ ICPライセンスに関する記事については【こちらから】
■ パッケージメニューだと、インスタンス(Out)のデータ転送料金が定額で利用できる。
(ただしこの場合はデータ転送量の上限値あり)
■ パッケージメニューでは「サイバーセキュリティ保険」が無償で付帯されており、
賠償補償:最大500万円、費用補償:最大20万円 が適応される。
(弁護士費用、お詫び広告掲載費用、復旧に関わる人件費、原因調査費用 など)OpenVPN 概要
- オープンソースのVPN(Virtual Private Network)のソフトウェアで、GPLLicenceによって公開されている
- 公式サイトはこちら(https://openvpn.net/)
- 比較的かんたんに構築が可能
- インターネットに接続しているPCが1台あれば、VPNサーバが設置可能。
- 特定インターネットプロバイダの制約もない
- 個人ユーザーや中小企業、拠点接続などの導入適している
- iPhone/Androidもクライアントアプリケーションを介してSSL-VPNを利用可能
- 堅牢なセキュリティと安定性
- 2002年4月以降にリリースされたバージョン1.1.0以降、重大な脆弱性の指摘を受けたことが無い
- さまざまな環境DataFrame連動稼働している実績があるのでアプリケーションとしての動作も非常に安定
- Alibaba CloudのSSL-VPNの裏も実はOpenVPNを採用している
- OpenVPNのスタートガイド
- Qiitaなどの記事も充実しているが、OpenVPN.JPサイトの情報が一番確実
- URL:https://www.openvpn.jp/document/
OpenVPN構築
OpenVPNの構築を進めて行きます。例のごとくECSは最小スペックで購入します。
今回はAPIでコマンドで作っていきます。cliツールに興味ある人は、以下記事をご参照ください。
【備忘録】Alibaba Cloud_aliyuncliコマンド集
https://qiita.com/tnoce/items/86cf7bc3f3e4773c81c8ECS作成
以下コマンドで
OpenVPN用ECSとPing用ECSを作成します。bashaliyun ecs CreateInstance \ --InstanceName "test-aliyun" \ --ZoneId ap-northeast-1a \ --VSwitchId "vsw-xxxxxxxxxxxxxxxxxxxxxx" \ --SecurityGroupId "sg-xxxxxxxxxxxxxxxxxxxxxx" \ --ImageId "centos_7_06_64_20G_alibase_20190711.vhd" \ --InstanceType "ecs.t5-lc1m1.small" \ --SystemDisk.Size "20" \ --InternetChargeType "PayByTraffic"クエリ結果
bash{"InstanceId":"i-xxxxxxxxxxxxxxxxxxxxxx","RequestId":"35EC2B2F-8144-4955-8F42-88A77FEA9EE8"}作成しただけではインスタンスが起動していないので。1つ前のクエリ結果で出力されたECSのInstanceIdをOptionの引数にしてスタートのクエリを投げます。
bashaliyun ecs StartInstance --InstanceId i-xxxxxxxxxxxxxxxxxxxxxxOpenVPNの構築
epleリポジトリの追加
ECSサーバ$ sudo yum install epel-release -yパッケージのインストール
ECSサーバ$ sudo yum --enablerepo=epel -y install openvpn easy-rsa認証局(CA)の設置
ECSサーバ$ mkdir /etc/openvpn/easy-rsa $ cp /usr/share/easy-rsa/3.0.3/* /etc/openvpn/easy-rsa/ -R作業ディレクトリの移動
ECSサーバ$ cd /etc/openvpn/easy-rsa初期化
ECSサーバ$ sudo ./easyrsa init-pki※pkiディレクトリが作成される
認証局の作成(※任意のPasswordを設定)
ECSサーバ$ sudo ./easyrsa build-ca Generating a 2048 bit RSA private key .......................................+++ .............................................................................+++ writing new private key to '/etc/openvpn/easy-rsa/pki/private/ca.key.UzE5bd0SCu' Enter PEM pass phrase: <任意のパスフレーズを入力> Verifying - Enter PEM pass phrase: <もう一度入力> ----- You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Common Name (eg: your user, host, or server name) [Easy-RSA CA]: <任意の名前を入力> CA creation complete and you may now import and sign cert requests. Your new CA certificate file for publishing is at: /etc/openvpn/easy-rsa/pki/ca.crtDHパラメータの作成
ECSサーバ$ sudo ./easyrsa gen-dhサーバ用証明書と秘密鍵の作成
ECSサーバ$ sudo ./easyrsa build-server-full server_r nopass Generating a 2048 bit RSA private key ....+++ .......................................................+++ writing new private key to '/etc/openvpn/easy-rsa/pki/private/server_r.key.O3l2ARzsse' ----- Using configuration from ./openssl-1.0.cnf Enter pass phrase for /etc/openvpn/easy-rsa/pki/private/ca.key: <ca秘密鍵(ca.key)のパスフレーズを入力> Check that the request matches the signature Signature ok The Subject's Distinguished Name is as follows commonName :ASN.1 12:'server_r' Certificate is to be certified until Mar 28 17:05:59 2028 GMT (3650 days) Write out database with 1 new entries Data Base Updatedクライアント用の証明書と秘密鍵の作成
ECSサーバ$ sudo ./easyrsa build-client-full client1 nopass Generating a 2048 bit RSA private key ................+++ ..............................................................................................................+++ writing new private key to '/etc/openvpn/easy-rsa/pki/private/client1.key.MY2YPyBgBr' ----- Using configuration from ./openssl-1.0.cnf Enter pass phrase for /etc/openvpn/easy-rsa/pki/private/ca.key:<ca秘密鍵(ca.key)のパスフレーズを入力> Check that the request matches the signature Signature ok The Subject's Distinguished Name is as follows commonName :ASN.1 12:'client1' Certificate is to be certified until Mar 28 17:17:18 2028 GMT (3650 days) Write out database with 1 new entries Data Base UpdatedOpenVPNのコンフィグ設定
・作業ディレクトリの変更
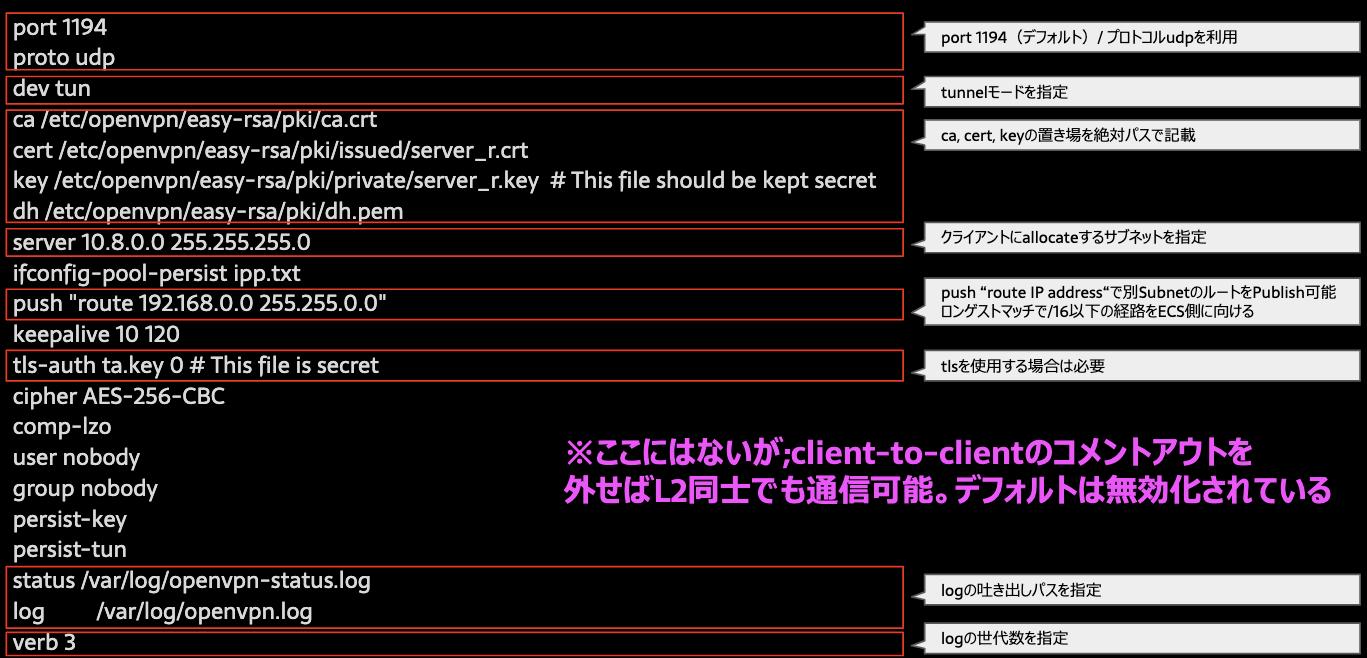
ECSサーバ$ cd /etc/openvpn/・サーバのコンフィグファイルのひな型をコピー
ECSサーバ$ cp /usr/share/doc/openvpn*/sample/sample-config-files/server.conf server_r.conf・IPv4パケット転送をを有効化
net.ipv4.ip_forward = 1/etc/openvpn/server_r.confport 1194 proto udp dev tun ca /etc/openvpn/easy-rsa/pki/ca.crt cert /etc/openvpn/easy-rsa/pki/issued/server_r.crt key /etc/openvpn/easy-rsa/pki/private/server_r.key # This file should be kept secret dh /etc/openvpn/easy-rsa/pki/dh.pem server 10.8.0.0 255.255.255.0 ifconfig-pool-persist ipp.txt push "route 192.168.0.0 255.255.0.0" keepalive 10 120 tls-auth ta.key 0 # This file is secret cipher AES-256-CBC comp-lzo user nobody group nobody persist-key persist-tun status /var/log/openvpn-status.log log /var/log/openvpn.log verb 3Config設定項目の主要な機能を記してみました。
・ローカルからsftpログインし、必要なcartファイルなどを取得
bash$ sftp -oIdentityFile='YOUR PEM.KEY' root@'YOUR ECS GLOBAL IP ADRRESS’ $sftp> get -r /etc/openvpn/easy-rsa sftp> get /etc/openvpn/ta.key -> 指定ローカルディレクトリに対象ディレクトリとta.keyが格納・ローカル(今回はMac)に適当なディレクトリを作成
・必要ファイルを1つのディレクトリにまとめておくbash$ ls ca.crt client1.crt client1.key mac.ovpn ta.key・テキストエディタで.ovpn拡張子のファイルを作成
mac.ovpnclient remote ‘YOUR ECS GLOBAL IP ADDRESS’ 1194 proto udp dev tun port 1194 tls-client ca ca.crt cert client1.crt key client1.key key-direction 1 tls-auth ta.key comp-lzo keepalive 10 120 ping-timer-rem persist-tun persist-key・TunnelBlickに.ovpn拡張子ファイルを設定(ファイルのダブルクリックで読み込まれます)
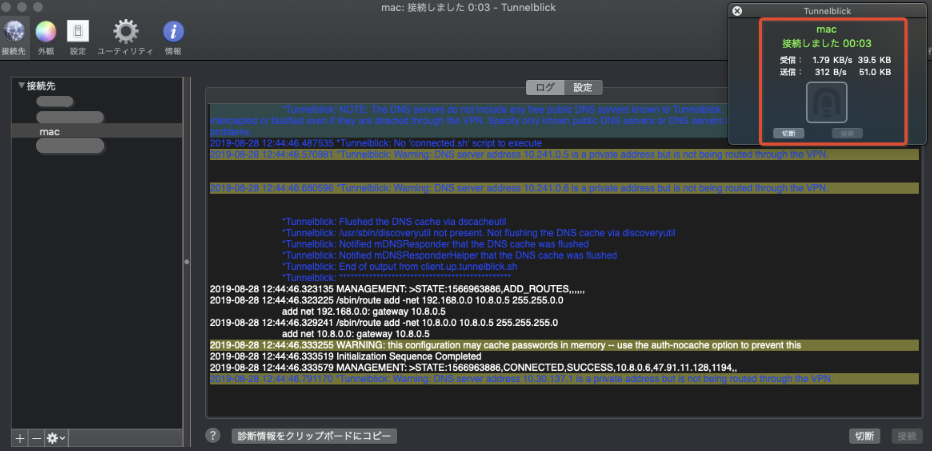
・接続ステータスがOKになるのを確認
・ローカルに割り当てられているIPアドレスと仮想NICのデフォゲを確認
- クライアントにallocateされたP-IP:10.8.0.6
- デフォゲ:10.8.0.5bashifconfig | grep inet inet 127.0.0.1 netmask 0xff000000 inet6 ::1 prefixlen 128 inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1 inet6 fe80::aede:48ff:fe00:1122%en5 prefixlen 64 scopeid 0x7 inet6 fe80::144e:ff37:efc3:654%en0 prefixlen 64 secured scopeid 0x8 inet 10.217.57.213 netmask 0xfffffc00 broadcast 10.217.59.255 inet6 fe80::68f4:f0ff:fe52:461c%awdl0 prefixlen 64 scopeid 0xa inet6 fe80::1ad7:d854:8818:3a6d%utun0 prefixlen 64 scopeid 0x10 inet6 fe80::3a1b:6318:8abb:f5d%utun1 prefixlen 64 scopeid 0x11 inet6 fe80::25a9:6851:788f:1905%utun2 prefixlen 64 scopeid 0x12 inet6 fe80::a6ce:e794:cded:87dc%utun3 prefixlen 64 scopeid 0x13 inet6 fe80::2ae0:e4f7:f211:b67a%utun6 prefixlen 64 scopeid 0x16 inet 10.8.0.6 --> 10.8.0.5 netmask 0xffffffffリソースへのPing確認
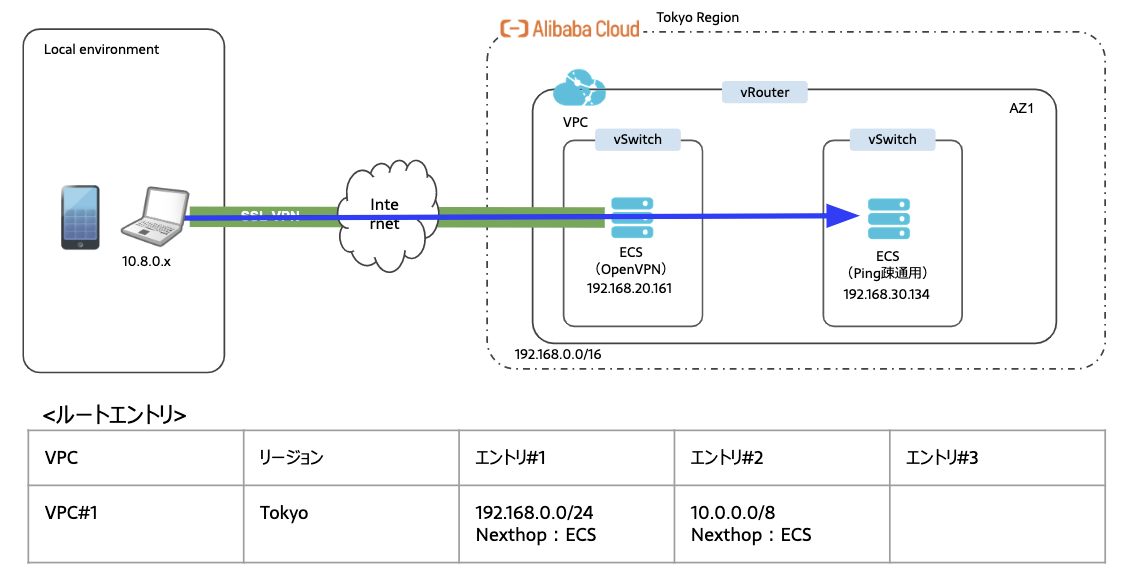
VPCのルーティングテーブルに以下ルートエントリを追加
・192.168.0.0/24 nexthop ECS
・10.0.0.0/8 nexthop ECSNexthopのECSはGatewayとして作成したECSを指定ください。
もしPingが通らない場合は、ECSのセキュリティグループでICMPとUDP 1194 Portが空いているかチェックしてください。
・192.168.30.134 に向けてPingをします
bashping -c10 192.168.30.134 PING 192.168.30.134 (192.168.30.134): 56 data bytes 64 bytes from 192.168.30.134: icmp_seq=0 ttl=63 time=7.206 ms 64 bytes from 192.168.30.134: icmp_seq=1 ttl=63 time=5.935 ms 64 bytes from 192.168.30.134: icmp_seq=2 ttl=63 time=4.667 ms 64 bytes from 192.168.30.134: icmp_seq=3 ttl=63 time=5.284 ms 64 bytes from 192.168.30.134: icmp_seq=4 ttl=63 time=3.810 ms 64 bytes from 192.168.30.134: icmp_seq=5 ttl=63 time=4.058 ms 64 bytes from 192.168.30.134: icmp_seq=6 ttl=63 time=5.229 ms 64 bytes from 192.168.30.134: icmp_seq=7 ttl=63 time=5.113 ms 64 bytes from 192.168.30.134: icmp_seq=8 ttl=63 time=5.155 ms 64 bytes from 192.168.30.134: icmp_seq=9 ttl=63 time=4.270 ms --- 192.168.30.134 ping statistics --- 10 packets transmitted, 10 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 3.810/5.073/7.206/0.938 ms・192.168/16向けのルートが適切にPublishされているか確認します
bashroute -n get 192.168.30.134 route to: 192.168.30.134 destination: 192.168.0.0 mask: 255.255.0.0 gateway: 10.8.0.5 interface: utun4 flags: <UP,GATEWAY,DONE,STATIC,PRCLONING> recvpipe sendpipe ssthresh rtt,msec rttvar hopcount mtu expire 0 0 0 0 0 0 1500 0最後に
マネージドのVPN-Gatewayがあるから、あんま出番ないかなあ。
L2同士の接続を制御できるので、接続させたくないときとか、自前で建ててもいいかもです。とほほ。参考にしたQiita記事(助かりました)
https://qiita.com/horus19761108/items/9c7879149218d9325c5e
https://qiita.com/horus19761108/items/86c4ae1f44707d5d847e


- 投稿日:2019-08-28T11:23:57+09:00
[RHEL8] MariaDB10.4インストール途中に競合エラーが発生してインストールできない
環境
- RHEL8(AWS EC2)
内容
RHEL8(AWS EC2)でMariaDBをyumインストールすると現状MariaDB10.3がインストールされる。
これにMariaDB10.4のバージョンをインストールしたいと思い、MariaDBリポジトリ生成ページより生成したリポジトリを用いてインストールしようとしたところ、以下のような競合エラーが発生してインストールできない。
エラー: トランザクションの確認時にエラー: ファイル /usr/bin/msql2mysql は mariadb-3:10.3.11-2.module+el8+2885+7b8bb354.x86_64 と MariaDB-client-10.4.7-1.el8.x86_64 のインストールで競合しています。 ファイル /usr/bin/mysql は mariadb-3:10.3.11-2.module+el8+2885+7b8bb354.x86_64 と MariaDB-client-10.4.7-1.el8.x86_64 のインストールで競合しています。 : :原因
MariaDB10.3をインストールするときに使用するrhel-8-appstream-rhui-rpmsリポジトリと競合していたため発生。これを無効化することでMariaDB10.4をインストールできた。
インストール作業の流れ
はじめに、MariaDB10.3がインストールされている場合はアンインストールしておく。
リポジトリ生成
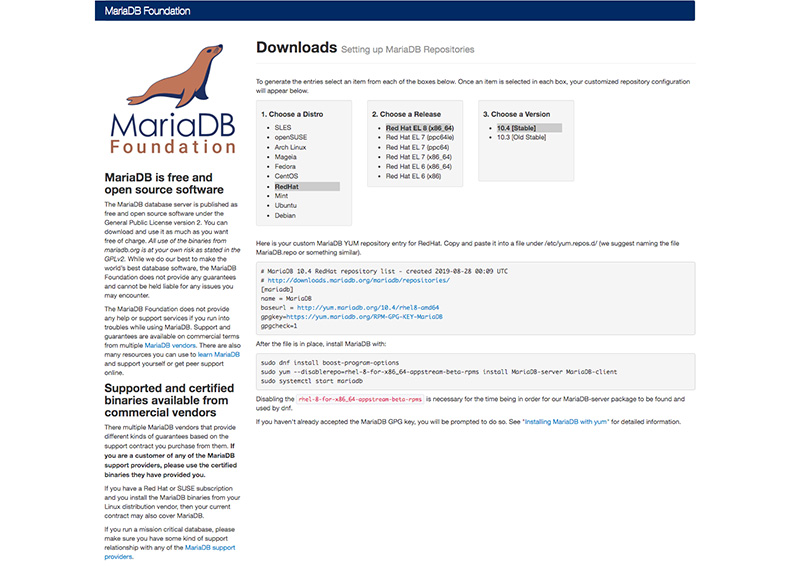
リポジトリ生成手順は以下のとおり(画像参照)
1. Choose a Distro → RedHat
2. Choose a Release → Red Hat EL 8(x86_64)
3. Choose a Version → 10.4[Stable]
MariaDB.repo作成
リポジトリ生成ページに表示されたテキストをコピペして/etc/yum.repos.d/MariaDB.repoを作成。
インストール
リポジトリ生成ページの記述通りにMariaDBをインストールしようとすると「一致するリポジトリーがありません: rhel-8-for-x86_64-appstream-beta-rpms」と表示されて、件のエラーが発生するので注意。
ここで競合を起こしているリポジトリはrhel-8-appstream-rhui-rpmsなのでこちらを無効化する。$ sudo dnf install boost-program-options $ sudo yum --disablerepo=rhel-8-appstream-rhui-rpms install MariaDB-server MariaDB-clientインストール確認
無事にインストールできたか確認。
$ mysql -V mysql Ver 15.1 Distrib 10.4.7-MariaDB, for Linux (x86_64) using readline 5.1参考
- 投稿日:2019-08-28T04:37:43+09:00
Pulumiでプログラマのための「Infrastructure as Code」を実践する
「Infrastructure as Code (IaC)」という言葉が生まれてからしばらく経ちました。IaCは簡単に言えばインフラをコード化するという概念です。この言葉に触れた当時はインフラをプログラミングできる時代がやってくるのだと思い、プログラマとして非常に心が躍りました。しかし残念ながらその気持ちは長くは続きませんでした。Ansible, Chef, Puppet, CloudFormation, AWS SDK, Terraform・・・ これらの技術はどれも素晴らしいものだと思います。Docker Composeやkubectl applyには感動した記憶もあります。しかしプログラマとしての自分が告げるのです。何かが足りない・・・本当に欲しいのは「コレジャナイ」と。そして長い、長い旅路の末にようやく巡り会うことができました。Pulumiという希望の星に。
(本記事は自分のブログからの転載記事です。)
はじめに
本記事ではPulumi1で「Infrastructure as Code」を実践します。具体的にはAWS上に以下の2層構造のWebアプリケーション2のインフラを100行未満のTypeScriptで記述します。
実践 Infrastructure as Code
Pulumiではインフラの状態が内部で管理されているので、インフラを簡単に作ったり、壊したりすることができます。また、今回は静的型付き言語であるTypeScriptを選択したので、インフラの「型」を簡単に確認でき、IDEのサポートが受けやすいです。そしてTypeScriptは汎用言語でもあるのでインフラを関数やライブラリにしたり、インフラをループで大量に生成するのも簡単です。まさにプログラミング感覚でインフラが構築できて、いらなくなったら簡単に破棄できるので
プログラマのためのIaCを実践するのにPulumiはうってつけです。Pulumiの導入
PulumiのGet Startedに従って、Pulumi CLI、AWS CLI、Node.jsをインストールしてください。
(「Configure AWS」まで進めてください。)pulumi login
以下のコマンドでpulumiにログインしてください。
$ pulumi loginブラウザでログインする場合は上記のコマンド後に「
Enter」キーを押します。するとブラウザ側でサインインできます。自分はGitHubでPulumiにサインインしましたが、他にもGitLabやE-mail等でもサインインできます3。プロジェクトとスタックの作成
次にプロジェクトとスタックの作成をします。以下のコマンドで実行します。
$ mkdir aws-ts-twe-tier-web && cd aws-ts-twe-tier-web $ pulumi new aws-typescript
pulumi newは基本的にはデフォルトでOKなのでEnterで進めますが以下の質問だけ「ap-northeast-1」にしてEnterを押してください。
aws:region: The AWS region to deploy into: (us-east-1)index.tsの作成
メインファイルである
index.tsファイルに以下を記述してください。index.tsimport * as pulumi from "@pulumi/pulumi" import * as awsx from "@pulumi/awsx" import * as utils from "./utils" const vpcPrefix = "custom" const vpc = new awsx.ec2.Vpc(vpcPrefix) const db = utils.createRDSInstance(vpcPrefix, vpc) const alb = utils.createApplicationLoadBalancer(vpcPrefix, vpc) const targetGroup = alb.createTargetGroup(`${vpcPrefix}-web-tg`, { port: 80, targetType: "instance" }) const listener = targetGroup.createListener(`${vpcPrefix}-web-listener`, { port: 80 }) const autoScalingGroup = utils.createAutoScalingGroup(vpcPrefix, vpc, alb) autoScalingGroup.scaleToTrackAverageCPUUtilization("keepAround50Percent", { targetValue: 50 }) export const endpoint = listener.endpoint.hostnameutils.tsの作成
同じフォルダに
utils.tsを作成して、ファイルに以下を記述してください。コーディングは以上です。utils.tsimport * as aws from "@pulumi/aws" import * as awsx from "@pulumi/awsx" export function getAmazonLinux(): Promise<string> { return aws.getAmi({ filters: [ { name: "name", values: ["amzn-ami-hvm-*"] }, { name: "virtualization-type", values: ["hvm"] }, { name: "architecture", values: ["x86_64"] }, { name: "root-device-type", values: ["ebs"] }, { name: "block-device-mapping.volume-type", values: ["gp2"] } ], mostRecent: true, owners: ["amazon"] }).then(ami => ami.id) } export function createRDSInstance(vpcPrefix: string, vpc: awsx.ec2.Vpc): aws.rds.Instance { const dbSg = new awsx.ec2.SecurityGroup(`${vpcPrefix}-db-sg`, { vpc, ingress: [{ protocol: "tcp", fromPort: 3306, toPort: 3306, cidrBlocks: ["0.0.0.0/0"] }], egress: [{ protocol: "-1", fromPort: 0, toPort: 0, cidrBlocks: ["0.0.0.0/0"] }], }) const dbSubnets = new aws.rds.SubnetGroup(`${vpcPrefix}-dbsubnets`, { subnetIds: vpc.privateSubnetIds, }) return new aws.rds.Instance(`${vpcPrefix}-db`, { engine: "mysql", instanceClass: "db.t2.micro", allocatedStorage: 10, dbSubnetGroupName: dbSubnets.id, vpcSecurityGroupIds: [dbSg.id], name: `${vpcPrefix}DbInstance`, username: "testdb", password: "testdb123", multiAz: true, skipFinalSnapshot: true, }) } export function createApplicationLoadBalancer(vpcPrefix: string, vpc: awsx.ec2.Vpc): awsx.elasticloadbalancingv2.ApplicationLoadBalancer { const albSg = new awsx.ec2.SecurityGroup(`${vpcPrefix}-alb-sg`, { vpc, egress: [{ protocol: "-1", fromPort: 0, toPort: 0, cidrBlocks: ["0.0.0.0/0"] }], }) return new awsx.lb.ApplicationLoadBalancer(`${vpcPrefix}-web-traffic`, { vpc, securityGroups: [albSg] }); } function getRunCmd(title: string, content: string): string { return `az=$(curl -s http://169.254.169.254/latest/meta-data/placement/availability-zone) echo "<html><head><title>${title}</title></head><body><h1>${content} from $az</h1></body></html>" > index.html nohup python -m SimpleHTTPServer 80 &` } export function createAutoScalingGroup(vpcPrefix: string, vpc: awsx.ec2.Vpc, alb: awsx.elasticloadbalancingv2.ApplicationLoadBalancer): awsx.autoscaling.AutoScalingGroup { const userDataLines = getRunCmd("My Web Site", "Hello World").split(`\n`).map(e => ({ contents: ` ${e}`, }) as awsx.autoscaling.UserDataLine) return new awsx.autoscaling.AutoScalingGroup(`${vpcPrefix}-web-asg`, { vpc, subnetIds: vpc.publicSubnets.map(e => e.id), targetGroups: alb.targetGroups, templateParameters: { minSize: 2, maxSize: 4, }, launchConfigurationArgs: { instanceType: "t2.micro", imageId: getAmazonLinux(), securityGroups: alb.securityGroups, userData: { extraRuncmdLines: () => userDataLines } } }) }これで見事に冒頭で示した構成が
index.tsとutils.tsを合わせて100行弱のコードで作成できました。インフラのデプロイ
以下を実行してください。途中で本当に実行してよいか聞かれるので「
yes」を選択してEnterを押してください。インフラの作成には数分かかります。$ pulumi upデプロイ結果の確認
pulumi upが成功すると最後の出力結果にendpointが表示されるので、そのURLにブラウザからアクセスしてみてください。「
Hello, World! from ap-northeast-1a」が表示されたら成功です。ロードバランサを挟んでいるのでリロードでするごとにAZの部分(from ap-northeast-1a)が変わります。また実際にAWSのコンソールにログインしてEC2やRDSやVPCの構成も確認してみてください4。リソースの後片付け
確認が終わったら以下のコマンドでリソースを破棄してください。リソースの破棄をしないとAWSの料金が発生し続けるので不要になったらすぐに破棄するようにしてください5。
$ pulumi destroyコードの解説
短いのであまり解説する必要もないかもしれませんが、
index.tsだけ一応簡単にコメントします。魔法はライブラリの「awsx」にあります。これは「Pulumi Crosswalk for AWS」というライブラリで、AWSのwell-architectedなベストプラクティスを実装しています。以下のコードでは「new awsx.ec2.Vpc(vpcPrefix)」が凄い仕事をしていて、二つのパブリックサブネットと二つのプライベートサブネットとインターネットゲートウェイ、NATゲートウェイやそれに付随するセキュリティグループなど様々なものを生成しています。それ以外はAWSの知識があれば割合素直に読めるのではないかと思います。index.tsimport * as pulumi from "@pulumi/pulumi" import * as awsx from "@pulumi/awsx" import * as utils from "./utils" const vpcPrefix = "custom" // VPCの名前を設定 const vpc = new awsx.ec2.Vpc(vpcPrefix) // VPCの作成(二つのパブリックサブネット、二つのプライベートサブネット、インターネットゲートウェイ、NATゲートウェイの作成) const db = utils.createRDSInstance(vpcPrefix, vpc) // RDSインスタンスの作成 const alb = utils.createApplicationLoadBalancer(vpcPrefix, vpc) // アプリケーションロードバランサーの作成 const targetGroup = alb.createTargetGroup(`${vpcPrefix}-web-tg`, { port: 80, targetType: "instance" }) // ターゲットグループの作成 const listener = targetGroup.createListener(`${vpcPrefix}-web-listener`, { port: 80 }) // リスナーの作成 const autoScalingGroup = utils.createAutoScalingGroup(vpcPrefix, vpc, alb) // オートスケーリンググループの作成 autoScalingGroup.scaleToTrackAverageCPUUtilization("keepAround50Percent", { targetValue: 50 }) // スケーリングポリシーの作成 export const endpoint = listener.endpoint.hostname // "endpoint"の出力
util.tsも含めた全体の処理の流れは以下のとおりです。
- VPCの作成
- VPCの作成
- 2つのパブリックサブネットの作成
- NATゲートウェイの作成
- 2つのプライベートサブネットの作成
- NATゲートウェイの作成
- インターネットゲートウェイの作成
- 必要なルートテーブルやセキュリティグループの作成
- RDSインスタンスを作成
- セキュリティグループの作成
- ふたつのプライベートサブネットを対象にサブネットグループの作成
- サブネットグループにRDSインスタンスの生成
- アプリケーションロードバランサの作成
- セキュリティグループの作成
- アプリケーションロードバランサの生成
- ターゲットグループの作成
- ロードバランサ用のターゲットグループを作成
- リスナーを作成
- ロードバランサ用のリスナーを作成し、転送先に上記で作成したターゲットグループを設定
- オートスケーリンググループの作成
- 起動設定の作成
- 最新のAmazonLinuxを検索してAMIのIDを取得
- 起動設定のユーザデータとして起動コマンドを渡してpythonの
SimpleHttpServerが立ち上がるようにする- パブリックサブネットとロードバランサを指定してオートスケーリンググループの生成
- オートスケーリングは2から4インスタンスの幅に設定
- スケーリングポリシーの設定
- CPU使用率が50%を基準にスケーリングするように設定
- "endpoint"の出力
注意すべきは、実際にPulumiが上記の流れどおりにリソースを作成しているわけではないということです。プログラマはあくまでリソースの依存関係だけを気にしてプログラムを作成すればよく、実際のリソースの作成はPulumiが依存関係を賢く判断して並列に作成できるリソースは並列に作成してくれます。 さらに言えば、Pulumiは上記のプログラムを「実行」して実際に必要なリソースを確定し、現在すでに存在するリソースとの差分を計算して差分のリソースだけをAWS側に作成してくれます。つまり一旦上記のコードを
pulumi upで実行したあとにEC2インスタンスを作成するコードを付け足して再実行した場合には、差分であるEC2インスタンスの作成のみが行われるということです。これは例えるならPulumiはキャッシュ付きの自動並列化コンパイラのような役割を果たしていると考えられると思います。一番最後の「"endpoint"の出力」は分かりづらいかもしれませんが、変数を
exportしておくとpulumi upした最後の結果として変数の値を出力してくれます。また「pulumi stack output <変数名>」を実行することで変数の値を出力することができるので、外部のプログラムとの連携が容易になります。Pulumiのいいところ
Pulumiのいいところは以下のとおりです。
- マルチクラウド
- AWS
- Azure
- Google Cloud Platform
- Kubernetes
- OpenStack
- 複数の汎用言語をサポート
- Node.js - JavaScript, TypeScriptやその他のNode.js互換言語(JSに変換可能)
- Python 3 - Python 3.6 or greater
- Go(PREVIEW)
- インフラのリソースの状態を管理している
pulumi upしたとき前回実行時からの差分のリソースだけを作成するpulumi destroyで作成済みのリソースを破棄する- 複数のプロジェクト、スタックを使い分けられる
- スタックごとに変数を定義できる
- Secretの管理もできる
1つ目はマルチクラウドなところです。AWSやAzureやGCPのようなパブリッククラウドだけではなくOpenStackもサポートしています。またKubernetesのようなコンテナオーケストレーションもPulumiでコード化することができるので、Pulumiを覚えるだけで非常に広範囲のインフラ構築を自動化できることが分かると思います。
2つ目は複数の汎用言語をサポートしていることです。現在はJavaScriptやTypeScriptやPythonがサポートされており、Go言語も仲間入りする予定です。また拡張可能なように作られていて自分のお気に入りの言語を追加することも可能です6。
3つ目はインフラのリソースの状態をPulumi側で管理していることです。このことでプログラマは最終的にあるべき状態だけをインフラをプログラミングできます。もしこれが現在のリソース作成状況を意識しながらプログラムを考えなければ行けないとすると非常に大変です。インフラの最終状態だけを思い浮かべてロジックに集中できるということはプログラマにとってありがたいことです。
もう一つプログラマに取ってありがたいのはリソースの削除が
pulumi destroyで簡単にできることです。プログラマは基本的にはトライアル&エラーでプログラムを作成することに慣れています。しかしリソースの破棄が面倒であれば試行錯誤する気にもならないかもしれません。実際のインフラではリソースに複雑な依存関係がついており順番を守らなければリソースの削除に失敗することもよくあります。しかし、Pulumiはリソースの状態を管理して、依存関係を把握することで、大量かつ複雑な依存関係のリソース郡を一括で削除できます。4つ目は複数のプロジェクトおよびスタックを使い分けられることです。プロジェクトは再利用の単位にもなっていて「自分が作成したインフラ」を簡単に公開して共有することができます。今回作成したコードも以下にGitHubで公開してあるので、ぜひ試してみてください。

また、プロジェクトの中でスタックを作成でき、コードの中で利用可能な「設定」を定義できます。例えばリージョン情報やユーザ名やパスワード等を「設定」としてコードから外出しすれば再利用性が高まり、スタックの切り替えで「設定」の切り替えもできるので非常に便利です。一番よくある使い方は開発用のスタックと本番用のスタックを分けるやり方です。その他にもパスワードを暗号化して管理する方法も提供されているので安全にインフラを共有することが可能です。
Pulumiの仕組み
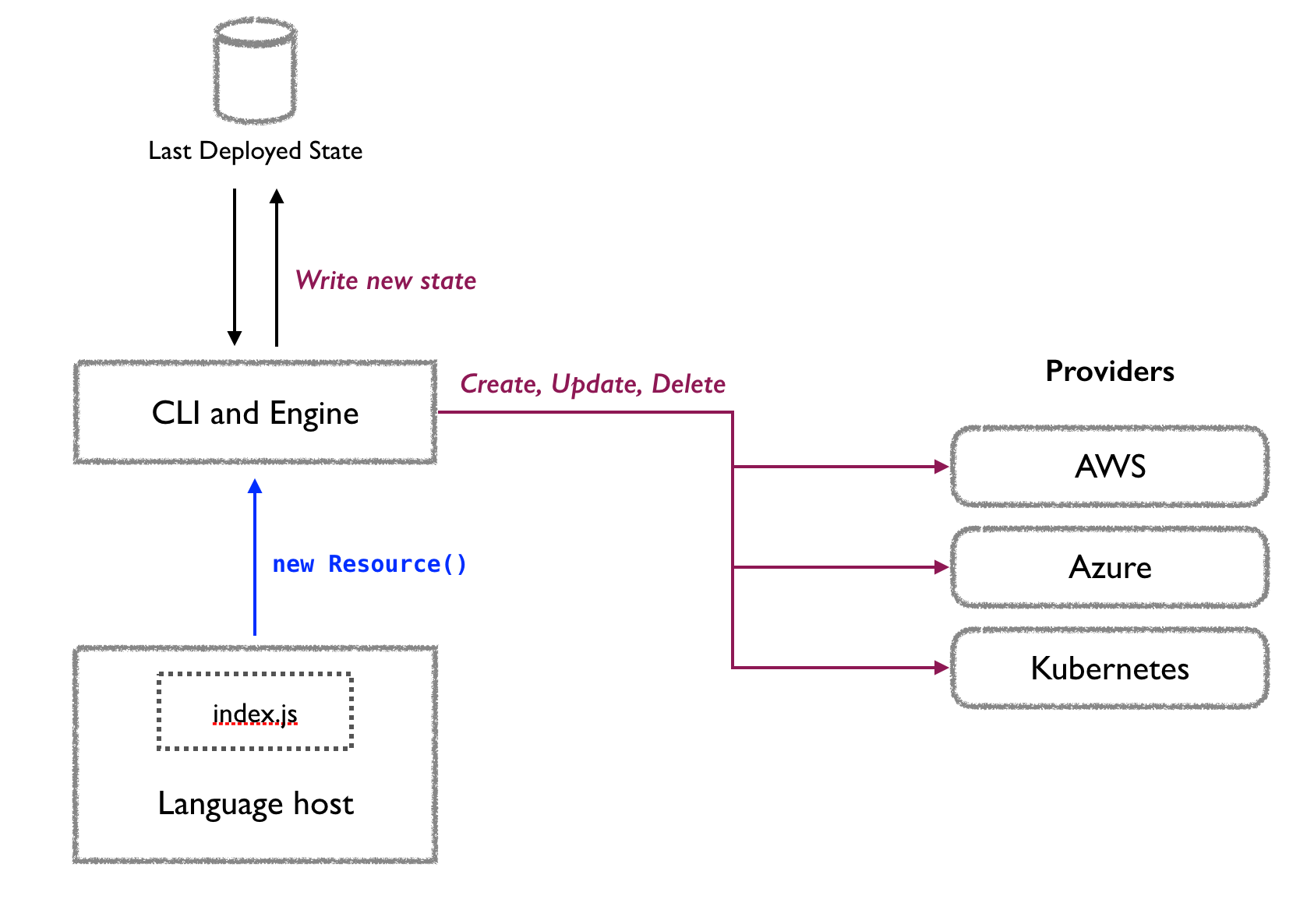
Pulumiの仕組みは以下のとおりです。
How Pulumi Worksより引用
まず言語ホストがTypeScript等のコードを実行して、その結果をPulumiのエンジンに伝えます。Pulumiのエンジンは最後のデプロイの情報を確認して、必要に応じてクラウド上のリソースの作成、更新、削除を行い、その結果をまたデプロイの最終結果として保存します。最終結果の保存先はデフォルトでは Pulumiのサービスになりますが、ローカルやクラウドストレージ上に保存することも可能です。
まとめ
本記事ではPulumiを利用して100行未満のTypeScriptでAWS上に高可用な2層構造のWebアプリケーションのインフラを作成しました。Pulumiを利用した利点は以下のとおりであり、プログラマが「Infrastracture as Code」を実践するのに最適なツールだと感じました7。
- マルチクラウド
- AWS, Azure, GCP, OpenStack, Kubernetes
- 汎用言語で記述できる
- 汎用言語の表現力や生産性を享受できる
- JSONやYAMLやその他DSLだと関数やロジックを記述する上での制約が大きく、少し複雑なことをしようとすると生産性が激減してプログラマの力を活かしきれない
- TypeScript等の静的型付け言語ではさらに型情報もあるので、IDE(VSCode等)から補完や定義の確認等のサポートを受けられる
- 状態を管理している
- リソースの差分だけを自動で更新してくれる
- リソースの依存関係を理解して並列でリソースの作成をするので処理が速い
- リソースの状態や依存関係を理解しているので関連リソースの安全な削除が可能
- インフラのコードの再利用性のための枠組みがある
- 今回作成したコードは aws-ts-two-tier-web - GitHubで公開中
自分はずっとインフラに苦手意識を感じていました。その理由は失敗したら簡単には元に戻せないことと、物理的な制約により抽象化が難しいからです。プログラマとしての自分はこれらの理由によりずっとインフラは苦手なままだと思っていました。クラウドが現れて、多くが仮想化されてもまだ抽象化に難があり状態管理が面倒だと感じていました。しかし時は流れてようやくインフラに抱いていたコンプレックスが解消されつつあります。
汎用言語の表現力と生産性を身につけ、主要な「インフラ」をカバーし、インフラの煩わしい状態管理からの解放を告げたPulumiの出現により、プログラマのためのIaCがようやく登場したことを確信したのです。
もはやインフラが「ハード」と思われる時代は過ぎ去り、プログラマが柔軟に抽象化し、ライブラリ化し、複雑なインフラ構成をも再利用可能にしていく時代が到来しようとしています。そしてPulumiはその先頭を走るプロダクトであり、自分は多くのPulumiプロジェクトがネット上に公開され、多くのインフラコードのエコシステムが生まれてくることを願って止みません。
本記事がPulumiの普及とプログラマのためのIaCの一助になれば幸いです。
参考文献
- Pulumi Documentation
- Joe Duffy - Hello, Pulumi!
- Pulumi Advances DevOps on AWS - DevOps.com
- Pulumi Crosswalk Aims to Simplify Deploying to AWS - The New Stack
- Infrastructure as Code: Chef, Ansible, Puppet, or Terraform? | IBM
- Infrastructure as Code - Wikipedia
- 私は Infrastructure as Code をわかっていなかった - メソッド屋のブログ
- まだTerraform使ってるの?未来はPulumiだよ | apps-gcp.com
- Terraform と Pulumiを比較する | apps-gcp.com
- これが次世代プロビジョニングツールの実力か!? PulumiでAWSリソースを作成してみた | DevelopersIO
- Pulumi で AWS Application Load Balancer を構築する - Qiita
- 昨今話題?の Pulumi を使ってみた - Qiita
- pulumiのチュートリアルをやってみた - Qiita
- pulumiのapplyを理解する - Qiita
- Pulumiの状態管理にクラウドストレージバックエンドを使う - Qiita
- Pulumi+VSCodeの書き心地が抜群な件 - Qiita
- PulumiのProviderをTerraformのProviderから実際に作成してみた - Qiita
PulumiはモダンなInfrastructure as Codeを実践するためのプロダクトであり、OSSです。そして、それを開発、サポートする会社の名前でもあります。Pulumiの由来はハワイ語の箒(ほうき)になります。もしくはPulumiの創業者でありCEOでもあるJoe Duffyの親友でもあった「Chris Brumme(故人)」の名前の誤発音です。詳細はJoe Duffy's Blogを参照してください。 ↩
一般的にはAWSのリファレンスアーキテクチャにある通り、Webサーバとアプリケーションサーバを分離した構成をとることが多いです。またDNSであるRoute53やCDNのCloudFrontもWebサーバの構成として入れるのが妥当ですが、今回はなるべく応用可能な「基礎」を提示したかったのでこの構成にしました。 ↩
Pulumiにサインインせずにローカルだけで完結させる方法もあります。 ↩
AWSのマネジメントコンソール側でPulumiで作成したリソースの変更をしないでください。Pulumi側が管理している状態とAWSの状態がずれるとこの後説明するリソースの後片付けで失敗する可能性があります。 ↩
特にRDSのマルチAZ構成はお高いので注意してください。 ↩
言語エンジンは外部プロセスと実行されgRPCを介してPulumiエンジンやリソースプロバイダと通信します。つまり通信プロトコルさえ守れば、Pulumi本体に手を入れることなく簡単に別の言語サポートを追加できるということです。 ↩
Pulumiが他のIaCツールと何が違うのかを詳しく知りたい方は「Pulumi vs. Other Solutions」を参照してください。 ↩

- 投稿日:2019-08-28T01:58:45+09:00
AWS Systems Manager でOSユーザーの棚卸
はじめに
サーバーの運用としてやらねばならないことは多岐にわたりますが、セキュリティールールとしてよく定められている作業の一つに、ユーザーIDの棚卸というものがあります。非常に沢山の仮想サーバーを運用している環境では、これに結構な労力が必要になってしまいます。自動的にIDの情報を収集してレポートを生成してくれるID管理ソフトウェアなどもありますが、ここではSystems Managerを使ってEC2インスタンス(Linux)のOSユーザーIDを収集する方法を紹介します。
やりかた
1. Systems Managerのインベントリを有効にする
Systems Managerにはインベントリという便利な機能があります。標準でRPMなどの情報をインスタンスから収集でき、カスタマイズにより収集対象の情報を追加することも可能です。今回はこの収集対象にユーザーIDの情報を追加することにしますので、まずはインベントリ機能を利用可能な状態にします。
インベントリの有効化手順はAWSのユーザーガイドに記載されていますので、ここでは簡潔に説明します。前提として、対象のインスタンスのIAMロールに"AmazonEC2RoleforSSM"ポリシーがアタッチされているものとします(このポリシーは権限が強いので、自己判断でカスタマイズしてください)。また、Excelなどでの収集した情報の利用を想定して、CSVファイルへのエクスポート手順も紹介します。1-1. インベントリ収集の設定をする
以下のガイドを参考に、インスタンスの収集を行うステートマネージャーの関連付けを作成します。関連付けの名前は自動的に"Inventory-Association"となります。関連付けの作成後、自動的にインスタンスからの情報収集が行われます。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-inventory-configuring.html1-2. リソースデータの同期を設定する
後でインベントリデータをCSVへエクスポート可能にするために、リソースデータの同期を設定します。
以下のガイドを参考に、S3バケットとリソースデータの同期を作成します。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-inventory-datasync.html1-3. 詳細ビューからCSVファイルにエクスポートする
同期されたデータを、AWS Athena、AWS Glueを使って集計します。以下のガイドを参考に設定を行い、CSVファイルへのエクスポートができることを確認します。経験上、リソースデータの同期を初めて選択した際にエラーになったことがありますが、2度目以降は問題ありませんでした。
2. カスタムインベントリにユーザーID情報を追加する
標準のインベントリ収集が可能になったところで、カスタムインベントリとしてユーザーIDの情報を収集できるようにします。カスタムインベントリについては以下のガイドに説明があります。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-inventory-custom.html
簡潔にまとめると、各インスタンス上の"/var/lib/amazon/ssm/<instance-id>/inventory/custom"以下にJSONファイルを作成することで、その内容をインベントリの情報収集対象に追加することができるようになります。
2-1. JSONファイル生成用スクリプトを作成する
まず、インスタンス上のユーザー情報を/etc/passwdから取得して、JSONファイルに書き出すスクリプトを作成することにします。JSONのスキーマは柔軟に定義できますが、ここでは簡単に以下の例のように定めて、ファイル名はUsers.jsonとすることにします。
{ "SchemaVersion": "1.0", "TypeName": "Custom:User", "Content": [ { "name" : "ユーザー名", "gecos" : "ユーザーの説明", "shell" : "ログインシェル", "wheel" : "wheelグループのメンバーか否か(0か1)", "hostname" : "ホスト名" }, ... ] }JSONスキーマが決まったら、実際にファイルを生成するスクリプトを作成します。
以下は手っ取り早く雑に作った例ですので、実際にはよく考慮してコーディングしてください。なお、"$AWS_SSM_INSTANCE_ID"という変数は、後でSystems Managerでリモートから実行する際にインスタンスIDに置き換わります。#!/bin/bash readonly PASSWD_FILE="/etc/passwd" readonly ADM_GROUP="wheel" readonly INVENTORY_FILE="/var/lib/amazon/ssm/$AWS_SSM_INSTANCE_ID/inventory/custom/Users.json" readonly TMP_FILE="/var/lib/amazon/ssm/$AWS_SSM_INSTANCE_ID/inventory/custom/Users.json.tmp" cp /dev/null $TMP_FILE cat <<HEADER >$TMP_FILE { "SchemaVersion": "1.0", "TypeName": "Custom:User", "Content": [ HEADER hostname=`hostname` last=`cat $PASSWD_FILE | wc -l` counter=0 while read -r user do ((counter++)) name=`echo $user | cut -d":" -f1` gecos=`echo $user | cut -d":" -f5` shell=`echo $user | cut -d":" -f7` groups $name | grep " $ADM_GROUP" > /dev/null [ 0 -eq $? ] && admgrp=1 || admgrp=0 cat <<USER >>$TMP_FILE { "name" : "$name", "gecos" : "$gecos", "shell" : "$shell", "wheel" : "$admgrp", "hostname" : "$hostname" USER if [ $counter -eq $last ]; then echo " }" >>$TMP_FILE else echo " }," >>$TMP_FILE fi done < $PASSWD_FILE cat <<FOOTER >>$TMP_FILE ] } FOOTER cp $TMP_FILE $INVENTORY_FILE rm -f $TMP_FILE2-2. AWS-RunShellScriptを使ってスクリプトを実行しJSONファイルを生成する
2-1.で作成したスクリプトを、ステートマネージャーの関連付けにより定期的にインスタンス上で実行し、ユーザーID情報をJSONファイルに保管します。スクリプトの実行には、AWSから提供されているAWS-RunShellScriptドキュメントを利用します。
Systems Managerコンソールのステートマネージャーページを開き、[関連付けの作成]を選択します。
関連付けでは、次の3つの項目を設定します。他の項目はデフォルトのままで構いません。
項目名 設定値 ドキュメント AWS-RunShellScript パラメーター > Commands 2-1.のスクリプト ターゲット このアカウント、このリージョンのすべてのマネージドインスタンスの選択
設定が済んだら、[関連付けの作成]を選択します。
関連付けが作成されると、自動的に各インスタンス上でスクリプトが実行され、JSONファイルの作成が行われます。ステートマネージャーのページで関連付けのステータスが"成功"になったら、試しにどこかのインスタンスにログインして、Users.jsonが生成されていることを確認してください。
# cat /var/lib/amazon/ssm/<instance-id>/inventory/custom/Users.json { "SchemaVersion": "1.0", "TypeName": "Custom:User", "Content": [ { "name" : "root", "gecos" : "root", "shell" : "/bin/bash", "wheel" : "0", "hostname" : "ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal" }, { "name" : "bin", "gecos" : "bin", "shell" : "/sbin/nologin", "wheel" : "0", "hostname" : "ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal" }, ... { "name" : "ec2-user", "gecos" : "EC2 Default User", "shell" : "/bin/bash", "wheel" : "1", "hostname" : "ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal" }, { "name" : "ssm-user", "gecos" : "", "shell" : "/bin/bash", "wheel" : "0", "hostname" : "ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal" } ] }2-3. インベントリの再収集
そのまま30分待つか、ステートマネージャーのページで関連付け"Inventory-Association"を手動で適用(実行)すると、インベントリの再収集が行われ、Users.jsonの内容がSystems Managerのインベントリに登録されます。
マネージドインスタンスのページでどれかのインスタンスを選択し、インベントリタブから収集した情報を確認しましょう。インベントリタイプから"Custom:User"を選択すれば、収集したユーザーIDの情報を参照することが可能です。
さらにそのまま半日待つか、Glueのコンソールでクローラを手動で実行すると、すべてのインスタンスの情報を集計してCSVファイルにエクスポートできるようになります。エクスポートの手順は、1-3.と同様です。
おわりに
今回は、Systems Managerの機能を使ってEC2インスタンスのOSユーザー情報を収集する方法を紹介しました。実際の運用プロセスでは、収集した情報を元にサーバー管理者や運用担当チームなどが各ユーザーIDの要不要を判断し、不要なIDの削除を行うといった作業が続くことになります。そういった作業を支援するためのID管理ソフトウェアもありますが、ここでは紹介の範囲外とします。
また、スクリプトを工夫して様々なJSONファイルを生成することで、カスタムインベントリはユーザー以外にも様々な情報を収集するためのツールとして利用できます。サーバーの運用を自動化するために覚えておきたい機能ですね。
この記事が皆様のお役に立てば幸いです。



