- 投稿日:2019-08-28T23:54:41+09:00
[python]繰り返しprintするときに改行させない方法
- 投稿日:2019-08-28T23:39:24+09:00
SymPyで代数演算してみる
SymPyとは
代数演算のライブラリです。
Symbolicな演算(文字を数値としてではなくそのまま計算する演算)を可能にします。SymPyでできること
- 文字変数定義
- 正負
- 実数、複素数
- 展開
- 因数分解
- 極限
- 微分
- 積分
- 方程式を解く
- 行列演算
前準備
ModuleNotFoundErrorが出る場合は、pip install sympyしてください。import sympy as sy # Jupyter Notebook上で、レンダリングされた結果を表示する sy.init_printing()出力結果の例:
$$x^{3} + 3 x^{2} y + 3 x y^{2} + y^{3}$$
sy.init_printingの設定次第で、様々な形式で演算結果を表示することができます
参考資料レンダリングせず、latexコードを出力する場合
# 第一引数: レンダリングしない # str_printer: 出力結果をsy.latexでラップして、latex出力に変換する sy.init_printing(False, str_printer=lambda x: sy.latex(x))出力結果の例: x^{3} + 3 x^{2} y + 3 x y^{2} + y^{3}
このように設定すると、Jupyter Notebookの出力が全てlatexコードに変換されます。
論文やレポートなどに貼り付ける場合、最初はレンダリング結果をみながらコードを修正し、最後はlatex出力するのが便利そうですね。ちなみに、
sy.latex関数は、数式をlatex出力する関数です。レンダリングをしたくない場合
sy.init_printing(False)出力結果の例: x*3 + 3*x2*y + 3*x*y2 + y*3
これは、Pythonの文法で出力したいときに使います。これをこのままコピペしたらSymPyで使えます。
基本的な使い方
シンボルの定義
# シンボルを定義 a = sy.Symbol("a") a$$a$$
# 複数のシンボルを同時に定義 x, y = sy.symbols("x y")# LaTexの記法を使える(raw文字列にしないとエスケープ文字と認識する) theta, gamma = sy.symbols(r"\theta \gamma") theta, gamma$$\left( \theta, \ \gamma\right)$$
# 正の実数として定義 r = sy.Symbol("r", positive=True) # 実数として定義 q = sy.Symbol("q", real=True)文字の情報を与えないと非常に一般的な複素数として計算することがあるので、なるべく情報を与えるようにしましょう。
基本演算
a**2 + x - theta$$- \theta + a^{2} + x$$
a**2 / a$$a$$
(x + y)**3$$\left(x + y\right)^{3}$$
式の展開など
f = (x + y)**3 f.expand()$$x^{3} + 3 x^{2} y + 3 x y^{2} + y^{3}$$
# x^2の係数 f.expand().coeff(x, n=2)$$3 y$$
微分や極限
f = sy.sin(x)/x f.limit(x, 0)$$1$$
# xで偏微分 f = 3 * x**2 * y + x * y**2 f.diff(x)$$6 x y + y^{2}$$
代入(シンボルも代入できる)
# y に a**2 を代入 f.subs([(y, a**2)])$$a^{4} x + 3 a^{2} x^{2}$$
NumPyのufuncに変換
シンボリックな表現をNumPyのufuncに変換できます。
これは結構便利です。
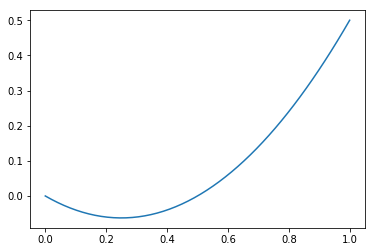
シンボリックな計算をしたあと、数値計算を簡単にすることができます。x, a, b, c = sy.symbols("x a b c") f = a * x**2 + b * x + c f$$a x^{2} + b x + c$$
# 4引数を持つ関数を定義 args = (x, a, b, c) func = sy.lambdify(args, f, "numpy")
funcは、4変数関数です。
ただし、 $a$, $b$, $c$ を固定すれば二次関数となりますね。import numpy as np import matplotlib.pyplot as plt %matplotlib inline# 実際に数値を代入(ufuncとして振る舞い、ベクトル演算が可能) xx = np.linspace(0, 1) plt.plot(xx, func(xx, 1, -0.5, 0)) plt.show()
方程式を解く
eq = sy.Eq(2*x + 5*y, -1)$$2 x + 5 y = -1$$
sy.solve(eq, x)$$- \frac{5 y}{2} - \frac{1}{2}$$
まとめ
Jupyter Notebookでの出力方法と、基本的な使い方を紹介しました。
SymPyを使えば、代数演算をマシンパワーを使ってガンガン計算できるようになります。
今までケアレスミスに怯えながら計算していた複雑な計算も、SymPyで検算することができるようになったり、人間では到底できない計算もできるため、いろんな可能性が広がりますね。行列演算などは、他にも記事を書いてみたいと思います。
参考資料
- 投稿日:2019-08-28T23:30:56+09:00
【線形回帰】わかるけど、線形回帰をコードで書いてみる
はじめに
線形回帰なんてExcel使えば一発ですよ。という声があるかもしれませんが、Pythonで書いてみます。
使うデータは前にも使ったアボカドデータです。
https://qiita.com/iwasaki_kenichi/items/ea580fd9498ad6950a75コード
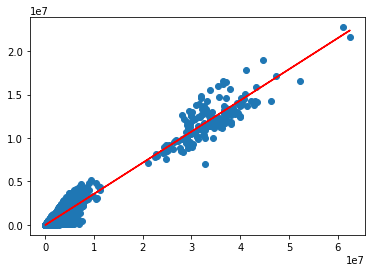
main1.py#ライブラリインポート %matplotlib inline import numpy as np from pylab import * import pandas as pd import matplotlib.pyplot as plt from scipy import stats #データ読み込み df = pd.read_csv("hogehoge.csv") #散布図 scatter(df["Total Volume"],df["4046"])
main2.py#順番に、「slope:傾き」「intercept:切片」「r_value:相関係数」「p_value:p値」「std_err:推定値の標準誤差」を求める。 slope,intercept, r_value,p_value, std_err = stats.linregress(df["Total Volume"],df["4046"]) #決定係数を算出する。 r_value **2 #(ここでは0.95という高い値がでた) #y=ax+bのyを計算する関数 def predict(x): return slope * x + intercept #yを計算 fitline = predict(df["Total Volume"]) プロット plt.scatter(df["Total Volume"],df["4046"]) plt.plot(df["Total Volume"],fitline,c='r') plt.show()

おわりに
これぐらいのレベルのものはササッと書けるようになりたい。

- 投稿日:2019-08-28T22:46:27+09:00
第一回日本最強プログラマー学生選手権-予選-参戦記
先日行われた第一回日本最強プログラマー学生選手権-予選-に参加しました。結果は以下の通りです。
結果:A+B+C 3完 55分+2ペナ
順位:472/3534
パフォーマンス:1803
レート変動:1504→1540
青パフォです、やったー。ただ残念ながら本戦には出場できなそうです(50人くらい辞退してくれないかなぁ...)。
以下問題を振り返っていきます。A
time 3:00
全探索して条件を満たすものを数えればいいですM, D = map(int, input().split()) ans = 0 for m in range(1, M+1): for d in range(1, D+1): d1 = d%10 d10 = d//10 if d1>=2 and d10>=2 and m==d1*d10: ans+=1 print(ans)B
time 7:00
また数え上げですね。O(N^2)が通るので、Aの中の各要素について、それより大きい数字を数え上げ、等差数列の和を求めればできます。焦っていたので結構なクソコードを錬成しました。変数名のセンスをくださいN, K = map(int, input().split()) A = list(map(int, input().split())) mod = 10**9+7 ans = 0 for i in range(N): Sum = 0 Sum1 = 0 a = A[i] for j in range(N): if A[j]<a: Sum+=1 if i==j: Sum1 = Sum ans+=Sum*(K-1)*K//2+(Sum-Sum1)*K ans%=mod print(ans)300にしては少し面倒ですね
C
よくある反転させる系の問題です。アリ本にも同じようなのがありましたね。こう言う問題は、
1. 操作の順序は関係ない
2. 端が返されるのは一回限りである
ことから、端から操作を決められる事が多いです。
まず、ポイントは操作の順序を無視して区間の左端でソートした操作の順序で考えても良いという点です。もう一つ重要なポイントは各A[i]についてそこから区間が始まるか、終わるかのいずれかであり、実は左端から順番に見ていくと、偶奇性から各A[i]に関して、そこで区間が終わるのか、区間が始まるのかのどちらかに決まってしまうという点です。
具体的に見ていきましょう。A=BWWBを考えます。まずA[1]は区間が始まることしかありえません。次にA[2]を考えてみると、A[2]はA[1]から始まる区間に含まれるので少なくとも1回はひっくり返ります。しかし、A[2]はWなので、もう一回ひっくり返る必要があります。よってA[2]から新しい区間が始まることがわかります。次にA[3]を考えると、すでにA[1],A[2]から始まっている区間に含まれることは確定しているので、少なくとも2回はひっくり返ります。A[3]は白なのでもうひっくり返る必要はありません。そこでA[3]ではA[1]かA[2]のいずれかの区間が終わることになります。実はこのどちらを終わらせたとしても後々影響はありません(各要素が幾つの区間に含まれているかだけが問題となるため)。よって、ここまでで2通りの区間の定め方があることになります。このように、どの区間を終わらせるかの組み合わせは独立なのでその積をとることにより、答えがわかります。一つ注意しなければいけないのは数列を全て見終わった時、全ての区間が閉じていなければいけないということです(BBBWなどがダメ)。以下のコードのようにcnt==0を確認する必要があります。僕は一回これを忘れてWAをとりました...mod = 10**9+7 N = int(input()) S = input() cnt = 0 ans = 1 for i in range(N*2): if S[i]=='W': if cnt%2 == 0: ans*=cnt ans%=mod cnt-=1 else: cnt+=1 else: if cnt%2 == 0: cnt+=1 else: ans*=cnt ans%=mod cnt-=1 if cnt==0: for i in range(1, N+1): ans*=i ans%=mod print(ans) else: print(0)ところで組み合わせが莫大になるので、modをとる問題は、逐一modを取っておかないと、TLEで死にます。死にました。反省。
もう少し早く解けるべきでしたね。D
構成の問題なので天才すれば解けるかなぁなどと色々考えてみましたが、わからず。
以下解説を参考に書きました。
この問題で重要となるのは以下の事実です。
各レベルの通路に関して、
「任意の閉路の長さが偶数」=「奇閉路が存在しない」=「グラフが二部グラフである」
二部グラフとは、二色で、隣接する辺を塗り分けられるグラフのことです。
ここで、各頂点に関してその各レベルに関する色の塗り方を考えます。もし、全てのレベルに関して同じ塗り方をするような頂点が2つ存在するとするとそれらを結ぶ頂点がどのレベルであっても上の条件を満たさないので矛盾します。よって全ての頂点の塗り分け方は異なります。ここで、色を0, 1と翻訳してみると、それぞれの頂点について、その塗り分け方は二進法表示のようにみることができるので、k-levelまでで塗り分けられる頂点数は2^kであることがわかります。グラフの構成についてですが、上の考察を踏まえれば、各頂点に0~2^k-1の番号を振り、任意の二頂点について、一方のみが1であるようなビットの桁をレベルとする通路を、その頂点間にはれば良いことがわかります。N = int(input()) for i in range(N-1): print(*[(i^j).bit_length() for j in range(i+1, N)])考察さえできれば実装は簡単すぎますね。まさかの3行です。bit_length()は二進数で何桁かを意味します。
あと、解説動画はわかりやすいですね。pdf何回読んでもわからなかったのが一発で理解できました。やっぱり図は重要。メモ
二部グラフ、bit_length、端から決まる、逐一mod
- 投稿日:2019-08-28T21:01:09+09:00
与えられた木が二分探索木か判定するアルゴリズム by 幅優先探索
前回につづいて、「与えられた木が二分探索木か判定するアルゴリズム」について。
二分木が二分探索木であると判定するには、すべての節が制約を満足しているか調べればよいと前回の記事に書いた。これは幅優先探索でも実現できる。
次のコードは幅優先探索ですべての節が制約を満足しているか調べるものである。
import collections def is_binary_tree_bst_bfs(tree: BstNode) -> bool: QueueEntry = collections.namedtuple('QueueEntry', ('node', 'lower', 'upper')) bfs_queue = collections.deque([QueueEntry(tree, float('-inf'), float('inf'))]) while bfs_queue: entry = bfs_queue.popleft() if entry.node: if not (entry.lower <= entry.node.data <= entry.upper): return False bfs_queue.append(QueueEntry(entry.node.left, entry.lower, entry.node.data)) bfs_queue.append(QueueEntry(entry.node.right, entry.node.data, entry.upper)) return True
is_binary_tree_bst_bfsは根の節を受け取りQueueEntryオブジェクトにしてキュー (bfs_queue) につめる。QueueEntryオブジェクトはBstNodeオブジェクトと、その節を二分探索木として成立させるための下限値 (lower) と上限値 (upper) を含むnamedtupleである。ループの中でデキューして節を取得し、その値が
lower以上かつupper以下であるかチェックする。この条件を満足しなければFalseを返す。満足していれば、「左の子」「右の子」とキューに詰めて、ループを継続する。ループを最後まで回せたらTrueを返す。この方法では木を最後まで巡回せずとも
Falseを返せる。このことから前回のコードより実行効率が高いと期待したが、サンプルデータに対してこのコードを走らせると前回のコードより遅かった (約30倍くらいの実行時間になる)。
- 投稿日:2019-08-28T20:10:48+09:00
AIに自分の顔を判定させたら失敗した話(番外編)
概要
本記事は、こちらの記事の番外編になります。
○○に似てると言われ困ったので、AIに判定させてみたAzureのCustom Visionを使って、自分の顔が有名人に似ているかどうか判定させたところ、
学習させるデータが間違っていて失敗したというお話です。学習データの用意
本編と同様にスクレイピングで画像を集めます。
python scraping.py -s hoshinogen -n 70まずは通常の星◯源さんの画像を集めて、そこから精度の悪そうな画像は手動で省いていきます。
この時に、星◯源さんといえばメガネが特徴的なので、
メガネありなしのデータで学習させればメガネありなしVerで自分の顔判定できるのではと思い、
メガネありの画像をスクレイピングしました。python scraping.py -s hoshinogenmegane -n 70ここから失敗へと向かいます。
Custom Visionで学習させる
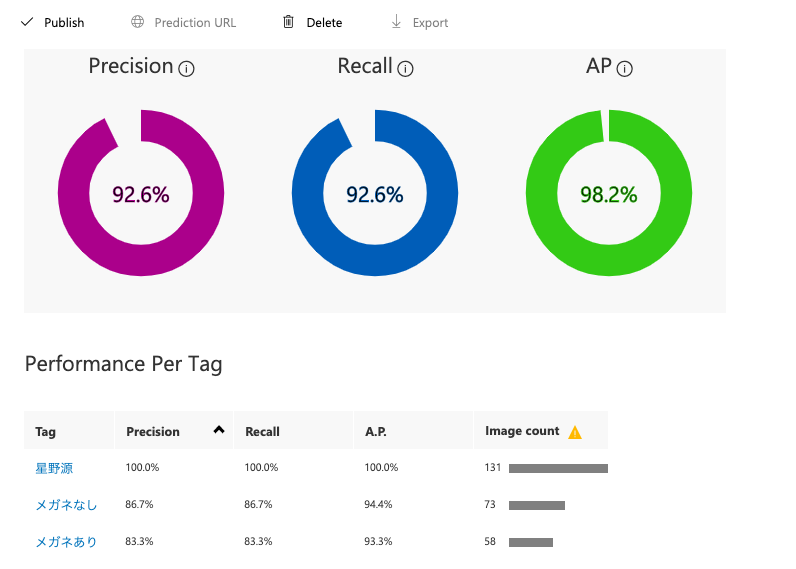
まずはCustom Vision上で「星野源」「メガネあり」「メガネなし」でタグを作り、
それぞれに紐付けて画像をアップし、学習させていきます。
準備ができたので、テストしていきます。
結果判定
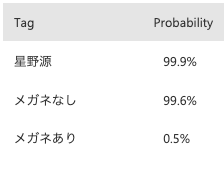
自分もメガネありなしで自撮りを済ませ
AIに判定させてみると、非常に高い数字が出ました。
・メガネありの評価
・メガネなしの評価
おお、こんな似てたんだと思うわけです。
他の人も判定してみようと思い、ムロツヨシやイチローなど、
幅広い人で試してみました。
あまり似てないであろう人たちもみんな似てるという結果が返ってきました。
ここでようやく気が付きました。これ、ただのメガネかけてるかどうか判定させてるだけだ……
学習させたデータが1人だけで、かつメガネありなしだけだったために、
全てメガネで判定されてしまうという結果に以上、失敗した話でした。
メガネの有無を判定させるAIの使い道を考えましたが、
特に思いつかなかったのでアイディアあればこっそり教えてください。まとめ
今回失敗してみて、失敗が早い段階でわかるのもプロトタイピングの良さかなと思いました。



- 投稿日:2019-08-28T19:46:50+09:00
Telegram BOTを無料で開発しよう
Telegram BOTを無料で開発しよう
Telegram BOTアカウントの作成
- https://core.telegram.org/bots
- Telegramアカウントが必要
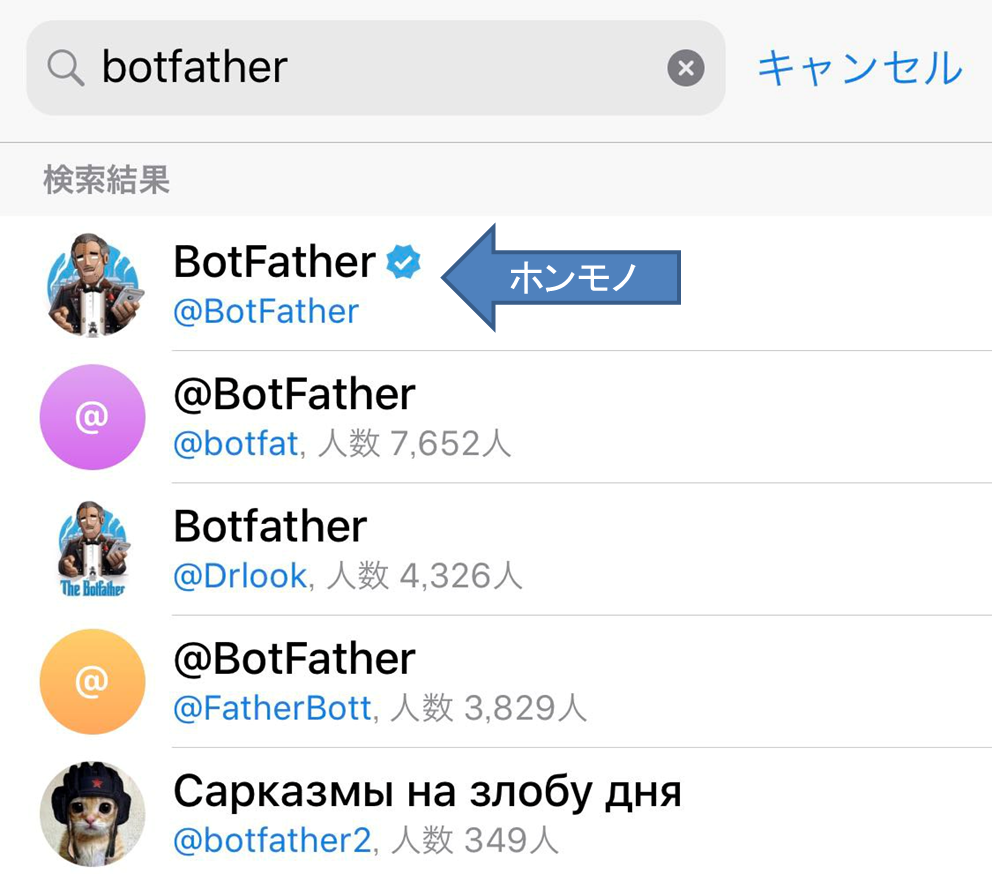
BotFatherでBOTのアクセストークンを取得
- Telegramで botfather ( https://telegram.me/botfather )と対話する。ニセモノが居るので注意。チェック入ってるヤツがホンモノ。
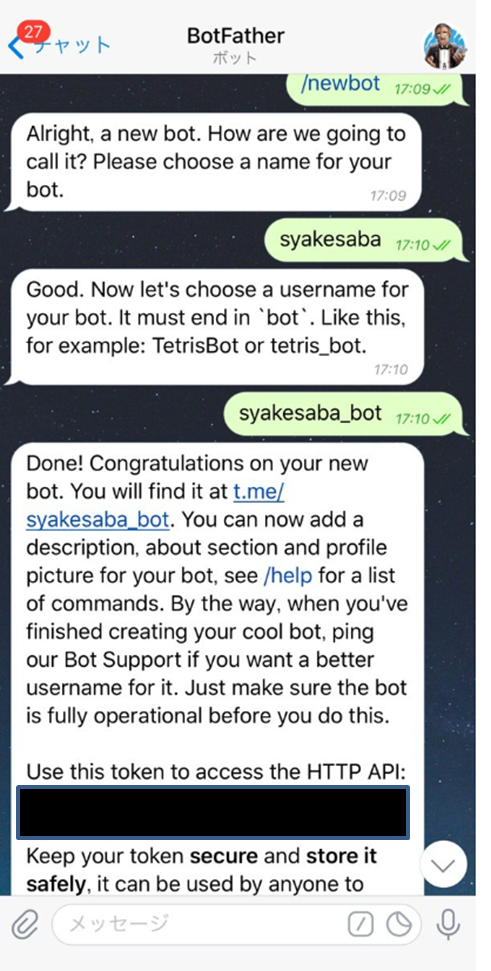
/newbotでBOTを新規作成※_botで終わるように名前を付けなければならない。- 作成後に表示されるアクセストークンは
<数字9桁>:<英数字記号36桁>というフォーマット。このアクセストークンはBOTを操作する為のパスコードなのでSavedMessage(保存済みメッセージ)にでも転送してメモしておこう
Google Cloudアカウントの作成
- GoogleCloudはクレカ登録こそ要るがアプグレしない限り無料で永続的に使える制度がある。(執筆時点)
- https://console.cloud.google.com/freetrial/signup/tos?hl=ja
- 今回はGoogle Compute Engineの"Always Free"を使用する。
- ※「AlwaysFree制度」のページはEnglishで読むこと!日本語だと、文字が一部化けてる!!!
仮想マシンを新規作成
GoogleCloudCompute にログイン
- 要Google Cloudアカウント
Myインスタンス作成
- 本記事執筆時点では以下が"Always Free"条件だった
- リージョンがオレゴンのf1-micro仮想マシンをHDD30GBで1台だけ使えば無料枠におさまるらしい
- ちゃんと無料条件を自分で確認すること!
https://cloud.google.com/free/docs/gcp-free-tier
1 non-preemptible f1-micro VM instance per month in one of the following US regions:
Oregon: us-west1
Iowa: us-central1
South Carolina: us-east1
30 GB-months HDD
5 GB-month snapshot storage in the following regions:
Oregon: us-west1
Iowa: us-central1
South Carolina: us-east1
Taiwan: asia-east1
Belgium: europe-west1
1 GB network egress from North America to all region destinations per month (excluding China and Australia)今回作成する仮想マシン構成
- 名前:適当
- リージョン:オレゴン
- マシンファミリー:f1-micro
- OSディスク:Debian9
- ディスクサイズ:30GBに変更
Webコンソールから諸々インストール
- VMインスタンスのSSHボタンを押せばWebコンソールに入れる
sudo apt-get install python python-pip git sudo pip install python-telegram-bot --upgradeサンプルスクリプト実行
git clone https://github.com/python-telegram-bot/python-telegram-bot.git cd python-telegram-bot/examples vi echobot.py #TOKENの所にbotfatherからもらったアクセストークンを入れて保存 python echobot.py # Ctrl+CでBOT停止
次回
楽しいTelegramBOTを使って自分だけのコンシェルジュを作ろう!


- 投稿日:2019-08-28T19:12:37+09:00
LeetCode / Factorial Trailing Zeroes
今日は算数の問題です。大人より小学生の方が解けるかも?
[https://leetcode.com/problems/factorial-trailing-zeroes/]
Given an integer n, return the number of trailing zeroes in n!.
Example 1:
Input: 3
Output: 0
Explanation: 3! = 6, no trailing zero.Example 2:
Input: 5
Output: 1
Explanation: 5! = 120, one trailing zero.Note: Your solution should be in logarithmic time complexity.
nの階乗で得られた数値に、trailing zero、つまり後置の0がいくつあるかを返す問題です。
空間計算量のオーダーを$log(n)$とすることも求められています。つまり、馬鹿正直にnの階乗を計算するのではない方法が求められます。解答・解説
解法1
まず気付くべきは、「後置の0が幾つ存在するかは、nの階乗の中で10が何回掛けられるかと同値である」です。
次に気付くべきは、10を素因数分解すると2×5ですから、「後置の0が幾つ存在するかは、nの階乗に2が幾つ存在するか(2で何回割り切れるか)と5が幾つ存在するか(2で何回割り切れるか)の最小値と同値である」です。
そして当然、2で割り切れる回数と5で割り切れる回数では後者の方が小さいですから、5で割り切れる回数を計算すれば、それが答えになります。さて、以上の考察をそのままコードに落とすと、以下のようになります。
class Solution(object): def trailingZeroes(self, n): """ :type n: int :rtype: int """ ans = 0 while n > 0: n //= 5 ans += n return ans上記コードの中では、5で割り切っているわけではなく5で割った商を足し合わせています。5で割り切るコードよりも短く書けます。横着とも言います。
空間計算量はlog5nになります。ちなみにPython2だとint同士の割り算はintが返るんですね。上記も n /= 5 としても正解が得られます。知らなかった。。。
解法2
recursiveに書くこともできます。計算量は変わりません。
class Solution(object): def trailingZeroes(self, n): return 0 if n == 0 else n // 5 + self.trailingZeroes(n // 5)
- 投稿日:2019-08-28T19:00:40+09:00
「退屈なことはPythonにやらせよう」Excelからcsvへの変換
ホームディレクトリにある複数のExcelファイルを、シート毎にcsvで書き出すコードです。
#! python3 import os, csv, openpyxl as px #ホームディレクトリを参照します for excel_file in os.listdir('.'): # xlsxファイルでなければスキップし、Workbookオブジェクトを読み込む if not excel_file.endswith('.xlsx'): continue #excelファイル名から拡張子を分離する。 excel_file_name = os.path.splitext(excel_file)[0] #workbookオブジェクトを指定する wb = px.load_workbook('./' + excel_file) for sheet_name in wb.get_sheet_names(): # ワークブックのシートをループする sheet = wb.get_sheet_by_name(sheet_name) # Excelファイル名とシート名からCSVファイル名を作る csv_file_name = str(excel_file_name + '_' + sheet_name + '.csv') # このCSVファイル用にcsv.writerオブジェクトを生成する csv_file_obj = open(os.path.join('.', csv_file_name), 'w', newline='') csv_writer = csv.writer(csv_file_obj) # シートの行をループする for row_num in range(1, sheet.max_row + 1): row_data = [] # セルをこのリストに追加する # 行のセルをループする for col_num in range(1, sheet.max_column + 1): # セルをrow_dataに追加する row_data.append(sheet.cell(row=row_num, column=col_num).value) # row_dataをCSVファイルに書き出す csv_writer.writerow(row_data) csv_file_obj.close()参照:
「退屈なことはPythonにやらせよう」p385
14.8 演習プロジェクト
14.8.1 ExcelからCSVへの変換

- 投稿日:2019-08-28T18:47:58+09:00
AtCoderを始めました
(0)自分の実力
基本的な文法は理解しておりProgateなどのレベルは卒業しているが、発展的なことは一人ではできないというくらいの実力です。
僕の実力を反映する例としては、データ構造についての知識がほとんどないのでどの問題でも無理矢理配列を使おうとしてTLEになることが多い、ということがあります。(1)始めたきっかけ
プログラミング能力を伸ばすコンテンツを探していたところ、友達がAtCoderをやっていることを聞いたので始めました。(AtCoder以外にも自主的に作りたいアプリケーションがあるのでそちらの作成のための勉強も進めたいです。)
(2)目標
とりあえず、レートがつくということなので、レートを目標にやっていきたいです。
まずは、自分の実力とやる気をかんがみて9月中に緑レートになることを目標にします。
それ以降は過去問の進み具合やレートの上昇率を見て目標は決めたいです。(理想的なのは10月中に水色レート、年内に青レートですが、僕のやる気次第なのでなんとも言えません。)(3)方法
今までの自分の傾向から本を前から読んでいって知識をつけるというよりは、わからないなりに何かものを作ったり解いたりするのが向いている気がします。
そのため、基本的には過去問を新しいものから順に解いて、埋め終わったら次のレベルの問題を解くという順番でやっていこうかなと思っています。
しかし、知識を整理する必要があると思うので、ある程度データ構造やアルゴリズムのことを知ったらサイトや本などで整理したいと思います。
また、やった過去問は復習も兼ねて解答をあげようと思います。効率良い解法等を知っている方がいたら教えていただけると非常に助かります。(4)ここまでの進捗
8/10ごろから初めて今の所はこんな感じです。(やる気がない日はやってないので実質二週間。反省。)
- 投稿日:2019-08-28T16:45:57+09:00
Python�3でopencvを使おうとしてハマった話
初投稿です。
python3でopencvを使おうとしてハマったので、メモがわりに残します。環境
- Python 3.6.2
- pyenv-virtualenv
- macOS 10.14.6
エラー内容
File "test.py", line 3, in <module> import cv2 ModuleNotFoundError: No module named 'cv2'唐突に現れたimport文のModuleNotFoundError
なんかの拍子にopencv-python誤って消してしまったかと思い、確認$ pip list Package Version --------------------- -------- ... opencv-python 4.1.0.25 ...普通にある...
とりあえず、直接pythonから叩いてimportしてみようPython 3.6.2 (default, Nov 18 2017, 21:22:04) [GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.38)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import cv2 >>>うーん、謎が深まった...
やったこと
いろんな記事見ながらひたすらいろんなことを試した
- pip使ってもう一度opencv-python入れ直す
site-packages/cv2以下のcv2.cpython-36m-darwin.soをcv2.soにrename$ pip install opencv-contrib-pythonでopencv-contrib-pythonを入れる(利用法に注意してください。)$ brew install opencv3 --with-python3 --without-python --with-contribどれもダメでした...
解決方法
cv2をimportする前にライブラリのパスを通す必要があったらしい
とりあえず下記のコードでなんとか動いた!import sys sys.path.append('/Users/yuta/.pyenv/versions/lab/lib/python3.6/site-packages') import cv2原因
きっとパス関連の何かなのだと思う
詳しいことは勉強不足で結局わからずじまいであった...
とりあえず、投稿してみて強い人からコメント来るといいな参考記事
- 投稿日:2019-08-28T16:31:59+09:00
venvのJupyter Notebook利用時にModuleNotFoundErrorが出てきてしまった時の対処
Google Cloud Pubsubを利用した簡単なシステムを作成したので、動作確認のために手元のWindows機からJupyter Notebook上で動作確認しようとしていました。その際きちんと
ただ、
pip install google-cloud-pubsubを行ったはずなのに、importに失敗します。from google.cloud import pubsub_v1 publisher = pubsub_v1.PublisherClient() topic_path = publisher.topic_path("project-name", "name") publisher.publish(topic_path, data=b'{"data": "sample"}')PythonのコンソールやiPython上ではimportできるため、AnacondaかJupyter Notebookに関する問題だと考えられます。ちょっと調べてみました。
結論
結論から書いてしまうと、venv環境のJupyter Notebookを使うためには予めkernelを追加する必要がありました。
ただ、自分の場合、実はpipenvの内部でvenvを利用してしまっていたため、venvのプロジェクト名がややこしく、仮想環境を使わずに直接
pip installして使うことにしました。ちょっとイケてないですが、手元のWindows環境は程度にしか使わないので…(言い訳)。調査方法
せっかくなので自分が調査した方法もメモに残しておきます。まず、Pythonのimport対象のディレクトリパスを確認します。
このあたりの記事を読んでください。
>>> import sys >>> sys.path ['', 'C:\\Users\\ninomiyt\\.virtualenvs\\Desktop-5H1ZMg56\\Scripts\\python37.zip', 'C:\\Users\\ninomiyt\\.virtualenvs\\Desktop-5H1ZMg56\\DLLs', 'C:\\Users\\ninomiyt\\.virtualenvs\\Desktop-5H1ZMg56\\lib', 'C:\\Users\\ninomiyt\\.virtualenvs\\Desktop-5H1ZMg56\\Scripts', 'c:\\users\\ninomiyt\\appdata\\local\\continuum\\anaconda3\\Lib', 'c:\\users\\ninomiyt\\appdata\\local\\continuum\\anaconda3\\DLLs', 'C:\\Users\\ninomiyt\\.virtualenvs\\Desktop-5H1ZMg56', 'C:\\Users\\ninomiyt\\.virtualenvs\\Desktop-5H1ZMg56\\lib\\site-packages'] >>> from google.cloud import pubsub_v1 >>> pubsub_v1.__file__ 'C:\\Users\\ninomiyt\\.virtualenvs\\Desktop-5H1ZMg56\\lib\\site-packages\\google\\cloud\\pubsub_v1\\__init__.py'Jupyter Notebook上ではこのようになります。
In [1]: import sys; sys.path Out[1]: ['C:\\Users\\ninomiyt\\Desktop', 'C:\\Users\\ninomiyt\\AppData\\Local\\Continuum\\anaconda3\\python37.zip', 'C:\\Users\\ninomiyt\\AppData\\Local\\Continuum\\anaconda3\\DLLs', 'C:\\Users\\ninomiyt\\AppData\\Local\\Continuum\\anaconda3\\lib', 'C:\\Users\\ninomiyt\\AppData\\Local\\Continuum\\anaconda3', '', 'C:\\Users\\ninomiyt\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages', 'C:\\Users\\ninomiyt\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages\\win32', 'C:\\Users\\ninomiyt\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages\\win32\\lib', 'C:\\Users\\ninomiyt\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages\\Pythonwin', 'C:\\Users\\ninomiyt\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages\\IPython\\extensions', 'C:\\Users\\ninomiyt\\.ipython']
pubsub_v1のファイルパス('C:\\Users\\ninomiyt\\.virtualenvs\\Desktop-5H1ZMg56\\lib\\site-packages')がJupyter Notebook上では存在しないことが分かります。これはvenvの環境のパスなので、Jupyter Notebookでvenvのパスであることが分かりました。ちなみにsys.pathに直接追加してもimportできるようになりました。
import sys sys.path.append('C:\\Users\\ninomiyt\\.virtualenvs\\Desktop-5H1ZMg56\\lib\\site-packages') from google.cloud import pubsub_v1厄介な問題かもしれないと考えて記事を書きながら対処したのですが、思ったより単純な問題でした。
- 投稿日:2019-08-28T16:29:46+09:00
Windowsで姿勢推定(tf pose estimation)
はじめに
姿勢推定アルゴリズムOpenPoseのTensorflow版としてtf pose estimationが公開されています。
これをWindows+Anaconda仮想環境で動かしてみた備忘録です。
初心者のため説明などふわふわしてますがご了承ください。環境
Windows 10
conda 4.7.11
CUDA 10.1
GeForce RTX 2080本記事ではAnacondaやCUDA等のインストールには触れません。
Anacondaで仮想環境を作るとこから入ります。環境を作る前に
tf pose estimation のダウンロード
まず下記Githubからファイルをダウンロードして好きなところに解凍して置いておきます。
https://github.com/ildoonet/tf-pose-estimationWindows Subsystem for Linux をインストール
本記事の手順ではbashを使いますので、作業に入る前に使えるようにしときます。
手順は下記とかをご参考に。
https://qiita.com/Aruneko/items/c79810b0b015bebf30bb環境構築
仮想環境の作成
Anaconda (powersell) promptで下記コマンドでpython3.6の仮想環境を作ります。
Anaconda Navigatorからも簡単に作れますが、たまに壊れるときがあるのでコマンドから作っています。conda create -n myenv python=3.6python3.7でもデモを動かす分には大丈夫でした。
作った仮想環境をactvateして作業していきます。conda activate myenvライブラリインストール
必要なライブラリを仮想環境にインストールします。
tf pose estimationが必要とするものはrequirements.txtに記載してあるのですが、その前に以下のライブラリをインストールしておくとスムーズです。
バージョンは動作確認したものを記載。
- cython 0.29.13
- numpy 1.16.4
- git 2.20.1
- swig 3.0.12
- opencv 3.3.1
- tensorflow-gpu 1.14.0 (GPU無い場合は tensorflow )全部
conda installで入れました。次に、ダウンロードしたtf-pose-estimation-masterに移動して、requirements.txtをインストールする、んですが。
その中のpycocotoolのインストールがうまくいきません。
ので、先に下記コマンドで別にpycocotoolを入れておくかrequirements.txtを書き換えておくかしないといけません。pip install "git+https://github.com/philferriere/cocoapi.git#egg=pycocotools&subdirectory=PythonAPI"できたらrequirements.txtに記載の必要なライブラリをまとめてインストールします。
pip install -r requirements.txt必要なライブラリが揃いました。
あとは手順通りにやっていきます。
C++ライブラリのビルド
cd tf_pose\pafprocess swig -python -c++ pafprocess.i && python setup.py build_ext --inplaceパッケージインストール
cd ..\..\ python setup.py installmodelのダウンロード
cd models\graph\cmu bash download.sh環境構築はこれでOKのはず。
Run
tensorRTのコメントアウト
環境構築ができたので早速動かせるかと思いきや、run.pyしてみたらtensorRTが無いとerrorが出ました。
tensorRT は windows の python にはまだ対応していない為使えないみたいです。
なのでコード内で使っているところをコメントアウトします。
(最適化して速度を早くするものらしく、動かす分には無くても問題ないようです)tf_pose/estimator.py
- 14行目 import文
- 315行目~328行目 if文動かしてみる
とりあえず何も考えずカメラで試す。
python run_webcam.pyEscで終了。
モデルは4種類用意されており、指定しない場合cmuモデルが使われます。
- cmu (trained in 656x368)
- mobilenet_thin (trained in 432x368)
- mobilenet_v2_large (trained in 432x368)
- mobilenet_v2_small (trained in 432x368)速度はmobilenetの方が早く、精度はcmuが良い印象?
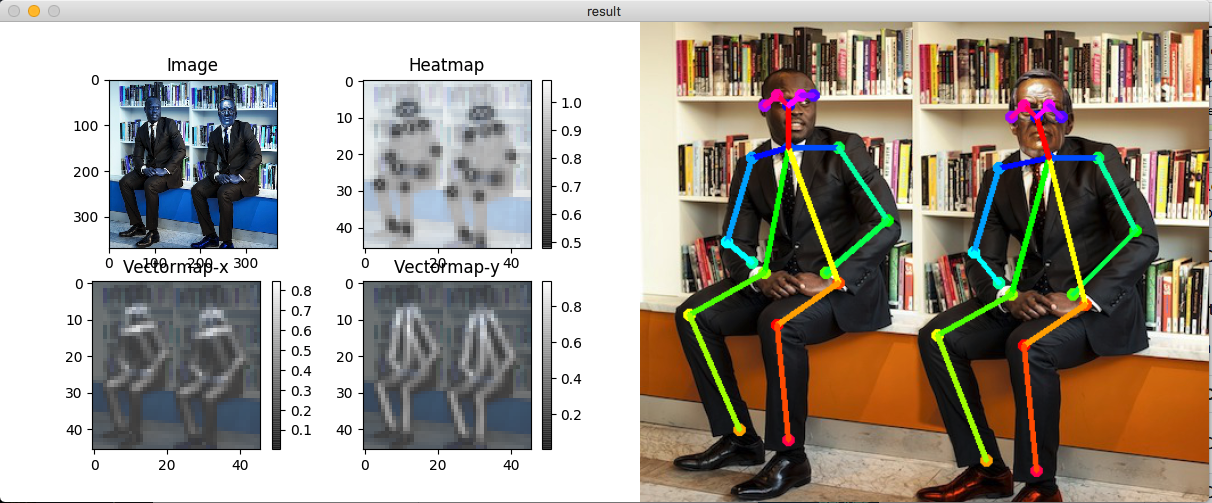
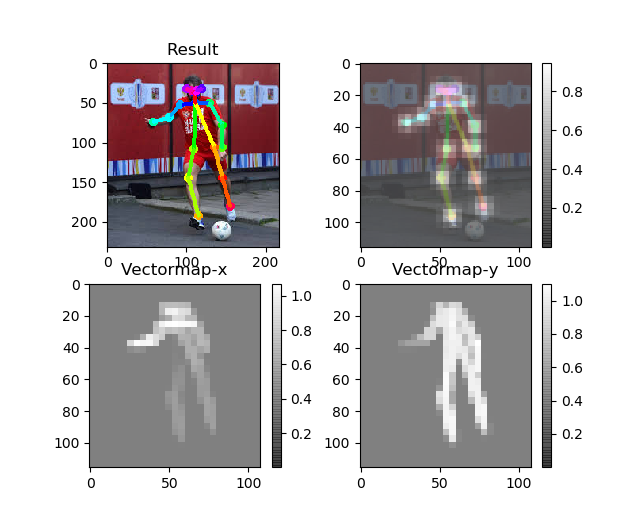
モデルを指定するときは、上記コマンドの後ろに--model=モデル名を付けて指定できます。静止画
python run.py --model=mobilenet_thin --image=./images/p1.jpg
静止画はデフォルトではこんな感じにpyplotで出力されます。
推定関節のヒートマップと、関節をつなぐために求められたクトルマップです。
Result画像を保存したい場合、run.py 54行目imageがデータですのでcv2.imwrite(出力名.jpg, image)で保存できます。静止画とカメラは問題なく動きますが、動画用のファイルにはバグがあるみたいで推定してくれません。
下記コードで動きました。
(拝借したコードなのですが、どこから持ってきたかわからなくなったのでソースを見つけたら貼り付けます。)
こちらで解決してくれたものです。ついでに推定骨格を描画した動画を保存するコード入れています。
保存する場合は4行あるコメントアウトを全て外してください。run_video.pyimport argparse import logging import time import cv2 import numpy as np from tf_pose.estimator import TfPoseEstimator from tf_pose.networks import get_graph_path, model_wh logger = logging.getLogger('TfPoseEstimator-Video') logger.setLevel(logging.DEBUG) ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) formatter = logging.Formatter('[%(asctime)s] [%(name)s] [%(levelname)s] %(message)s') ch.setFormatter(formatter) logger.addHandler(ch) fps_time = 0 if __name__ == '__main__': parser = argparse.ArgumentParser(description='tf-pose-estimation Video') parser.add_argument('--video', type=str, default='') parser.add_argument('--resize', type=str, default='0x0', help='if provided, resize images before they are processed. default=0x0, Recommends : 432x368 or 656x368 or 1312x736 ') parser.add_argument('--resize-out-ratio', type=float, default=4.0, help='if provided, resize heatmaps before they are post-processed. default=1.0') parser.add_argument('--model', type=str, default='mobilenet_thin', help='cmu / mobilenet_thin') parser.add_argument('--show-process', type=bool, default=False, help='for debug purpose, if enabled, speed for inference is dropped.') parser.add_argument('--showBG', type=bool, default=True, help='False to show skeleton only.') args = parser.parse_args() logger.debug('initialization %s : %s' % (args.model, get_graph_path(args.model))) w, h = model_wh(args.resize) if w > 0 and h > 0: e = TfPoseEstimator(get_graph_path(args.model), target_size=(w, h)) else: e = TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368)) cap = cv2.VideoCapture(args.video) width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = cap.get(cv2.CAP_PROP_FPS) if cap.isOpened() is False: print("Error opening video stream or file") # fourcc = cv2.VideoWriter_fourcc(*'DIVX') # writer = cv2.VideoWriter('./video/output.mp4', fourcc, fps, (width, height)) while cap.isOpened(): ret_val, image = cap.read() logger.debug('image process+') humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=args.resize_out_ratio) if not args.showBG: image = np.zeros(image.shape) logger.debug('postprocess+') image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False) logger.debug('show+') cv2.putText(image, "FPS: %f" % (1.0 / (time.time() - fps_time)), (10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2) cv2.imshow('tf-pose-estimation result', image) fps_time = time.time() # writer.write(image) if cv2.waitKey(1) == 27: break cv2.destroyAllWindows() # writer.release() cap.release() logger.debug('finished+')動かすときは同様に
python run_video.py --video=./video.mp4相変わらずエラー文出ますね、、時間があれば見直します。
結果
さっきのやつ
借りてきたふちこさんズ
逆さまは以外はぱっと見認識できてるように見えますが…。
よく見ると関節の位置がちらほらずれてます。変な体勢は難しいみたいです。
これはウェブカメラのキャプチャーですが、FPSは画像のとおりcmuモデルでFPS24、mobilenet_thinモデルだとFPS30くらい出ていました。CPUだとその1/10くらい遅くなります。
ちなみに13体のふちこさんを貸していただいたのですが、全員載せられませんでした。ごめんなさい。サイゼにいる天使
カメラでも試しましたが、上半身だけはOKで肩以上がフレームアウトしていると認識してくれない感じでした。
たまに背景に居ないはずの人間を認識します。これ見ると肩が入っていることが重要なんでしょうか。微妙な結果ばかり載せてすみません。
助けてくださった先輩方、ありがとうございます。以上!



- 投稿日:2019-08-28T16:25:56+09:00
project gutenberg から小説データを大量収集するクローラーを作成した
はじめに
自然言語処理の学習データに使用するデータを集めるために、project gutenbergのデータを利用することにしました。
project gutenbergというのは、著作権フリーの小説を一般公開しているサイトで、日本でいうところの青空文庫のようなものらしいです。
この記事は、このサイトからnlpの学習に使う小説データを集めるクローラーを紹介する記事です。
タグにnlpいれましたがnlpの記事では無いのでご注意ください。とりあえずソースコード
とてもシンプルにかけました。
クローラーはだいたいpythonでかかれることが多いと思うのですが、サイトのデザインによってはシェルスクリプトでcurlとgrepをごちゃごちゃやるだけで案外うまくいくこともあります。特にproject gutenbergのサイトではhtmlではなくtxtファイルにアクセスできるのでシェルスクリプトで書くのがかなり楽でした。このソースコードはgithubにもあげています。https://github.com/shosone/project_gutenberg_crawler#!/bin/bash # README: # https://www.gutenberg.org/files/$i/$i-0.txt # にアクセスしてProject Gutenbergから小説データを集めてきます # 規約などの情報は削除していないので、nlpの学習などに使用される際は自分でデータクレンジングする必要があります. # [output] # - 小説データが$i.txtとして保存されます. # - 小説の情報ががbooks_info.csvとして保存されます. title, author, urlカラムを持っています. echo "title,author,url" > books_info.csv for i in `seq 20` # NOTE: 取得する小説の数を変えたい時はここを変更してください. do # NOTE: 取得する小説のurlのバイアスを変更したい場合はここのコメントをはずしてください. # 100のままにすると https://www.gutenberg.org/files/101/101-0.txt から収集を開始します. #i=$((i+100)) url="https://www.gutenberg.org/files/$i/$i-0.txt" echo -e "\n>>>>> $url <<<<<" curl -f $url 1> $i.txt sleep 2 if [ $? != "0" ]; then rm $i.txt continue fi title=`cat $i.txt | grep '^Title:' | tr -d "\r" | cut -d":" -f2 | sed "s/^ *\(.*\) *$/\1/g" ` author=`cat $i.txt | grep '^Author:' | tr -d "\r" | cut -d":" -f2 | sed "s/^ *\(.*\) *$/\1/g"` echo "\"$title\",\"$author\",\"$url\"" >> books_info.csv doneNOTE
取得されるtxtファイルはデータクレンジングしていないデータなので小説の内容だけでなく規約情報などが記載されています。
ソースの説明
curl
curl -fでurlからコンテンツをダウンロードしています。-fオプションがなかったら404になっても終了ステータスは0になってしまいます。tr
txtファイルがWindowsでかかれているのか、行末に改行コードCRがあります。なので
tr -dで改行コードCRを削除しています。
- 投稿日:2019-08-28T15:49:03+09:00
ローソク足を複数組み合わせたアルゴリズムを作る
はじめに
QuantX Factoryでは、talibを用いて、ローソク足を用いた株売買アルゴリズムを作ることが出来ます。
こちらの記事では、ローソク足とテクニカル指標を組み合わせたアルゴリズムを紹介しています。
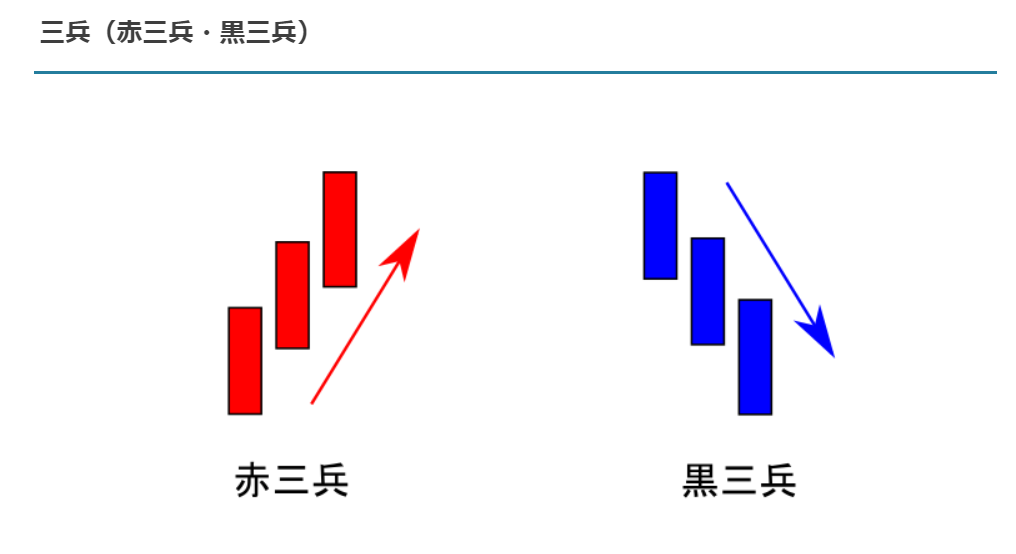
今回は、複数のローソク足を使って売買シグナルを出すアルゴリズムを紹介したいと思います。アルゴリズム
このアルゴリズムでは、赤三兵、黒三兵をアレンジしたいと思います。
# 必要なライブラリーをimportする import maron import maron.signalfunc as sf import maron.execfunc as ef import pandas as pd import talib as ta import numpy as np # オーダ方法を決定する ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー # 銘柄、columnsの取得を行う # 初期化を行う def initialize(ctx): ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.2914", #JT(日本たばこ産業) "jp.stock.8766", #東京海上ホールディングス "jp.stock.8031", #三井物産 "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.9437", #NTTドコモ "jp.stock.4502", #武田薬品工業 "jp.stock.8058", #三菱商事 "jp.stock.9433", #KDDI "jp.stock.9432", #日本電信電話 "jp.stock.7267", #ホンダ(本田技研工業) "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.4503", #アステラス製薬 "jp.stock.4063", #信越化学工業 "jp.stock.7974", #任天堂 "jp.stock.6981", #村田製作所 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.9020", #東日本旅客鉄道 "jp.stock.8802", #三菱地所 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9984", #ソフトバンクグループ "jp.stock.6861", #キーエンス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6954", #ファナック "jp.stock.7203", #トヨタ自動車 "jp.stock.7751", #キヤノン "jp.stock.4452", #花王 "jp.stock.6098", #リクルートホールディングス ], "columns": [ "open_price_adj", # 始値(株式分割調整後) "high_price_adj", # 高値(株式分割調整後) "low_price_adj", # 安値(株式分割調整後) "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) #"volume_adj", # 出来高 #"txn_volume", # 売買代金 ] } } ) # シグナル定義 def _my_signal(data): # 終値等の取得を行い、欠損値補完を行う。 cp = data["close_price_adj"].fillna(method='ffill') op = data["open_price_adj"].fillna(method= 'ffill') hp = data["high_price_adj"].fillna(method="ffill") lp = data["low_price_adj"].fillna(method="ffill") # ローソク足についてを計算 candle_1 = pd.DataFrame(data=0,columns=[], index=cp.index) for(sym,val) in cp.items(): candle_1[sym] = ta.CDLMARUBOZU(op[sym],hp[sym],lp[sym],cp[sym]) # true,falseのbool型にする candle_1_buy = candle_1[(candle_1 == 100)] candle_1_sell = candle_1[(candle_1 == -100)] candle_1_buy[(candle_1 == 100)] = True candle_1_sell[(candle_1 == -100)] = False # 売買シグナルを定義(bool値で返す) buy_sig = candle_1_buy & candle_1_buy.shift(1) sell_sig = candle_1_sell # market_sigという全て0が格納されているデータフレームを作成 market_sig = pd.DataFrame(data=0.0, columns=cp.columns, index=cp.index) # buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 return { "market:sig": market_sig, "candle:1":candle_1 } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' market_sig = current["market:sig"] done_syms = set([]) # 損切り、利確の設定 for (sym, val) in ctx.portfolio.positions.items(): returns = val["returns"] if returns < -0.03: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) done_syms.add(sym) elif returns > 0.05: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) done_syms.add(sym) # 買シグナルについて注文方法を設定する buy = market_sig[market_sig > 0.0] for (sym, val) in buy.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=ot, comment="SIGNAL BUY") #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) pass # 売シグナルも同様に行う sell = market_sig[market_sig < 0.0] for (sym, val) in sell.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot, comment="SIGNAL SELL") #ctx.logger.debug("SELL: %s, %f" % (sec.code(), val)) passアルゴリズムの解説
基本的なアルゴリズムの仕組みは公式ドキュメントや前回の記事と同じなので、今回はこのアルゴリズムの特徴的なところを紹介したいと思います。
今回作りたいのは、
になります。(https://ottopilotmedia.com/chart/rousoku-pattern)talib には、複数本のローソク足を組み合わせてセットになったものがいくつかありますが、今回は練習のためと、赤三兵はtalibには、用意されていなかったので、このセットを作ってみたいと思います。
使ったローソク足はこちらにて紹介されている、丸坊主のローソク足組み合わせました。
今回のアルゴリズムは基本的な形をしていますが、他のアルゴリズムと比べて特徴的なところは以下になります。
def _my_signal(data): # 終値等の取得を行い、欠損値補完を行う。 cp = data["close_price_adj"].fillna(method='ffill') op = data["open_price_adj"].fillna(method= 'ffill') hp = data["high_price_adj"].fillna(method="ffill") lp = data["low_price_adj"].fillna(method="ffill") # ローソク足についてを計算 candle_1 = pd.DataFrame(data=0,columns=[], index=cp.index) for(sym,val) in cp.items(): candle_1[sym] = ta.CDLMARUBOZU(op[sym],hp[sym],lp[sym],cp[sym]) # true,falseのbool型にする candle_1_buy = candle_1[(candle_1 == 100)] candle_1_sell = candle_1[(candle_1 == -100)] candle_1_buy[(candle_1 == 100)] = True candle_1_sell[(candle_1 == -100)] = False # 売買シグナルを定義(bool値で返す) buy_sig = candle_1_buy & candle_1_buy.shift(1) sell_sig = candle_1_sell & candle_1_sell.shift(1)赤三兵では買シグナルを出します。
今回は、使用しているローソク足の種類も同じなので、新たに candle_2 を定義することなく、candle_1を組み合わせて、buy_signalを出していきます。
実際には、# 売買シグナルを定義(bool値で返す) buy_sig = candle_1_buy & candle_1_buy.shift(1) sell_sig = candle_1_sell & candle_1_sell.shift(1)というコードになります。
pandas のメソッドを使って、2日連続で、丸坊主が出ているときに買うというシグナル生成いたしました。
写真上では3つ連続の時になっていますが、3つにすると制約的に厳しくなり、シグナルが出にくくなるので、今回は2つにしました。売シグナルも同様の操作を行います。
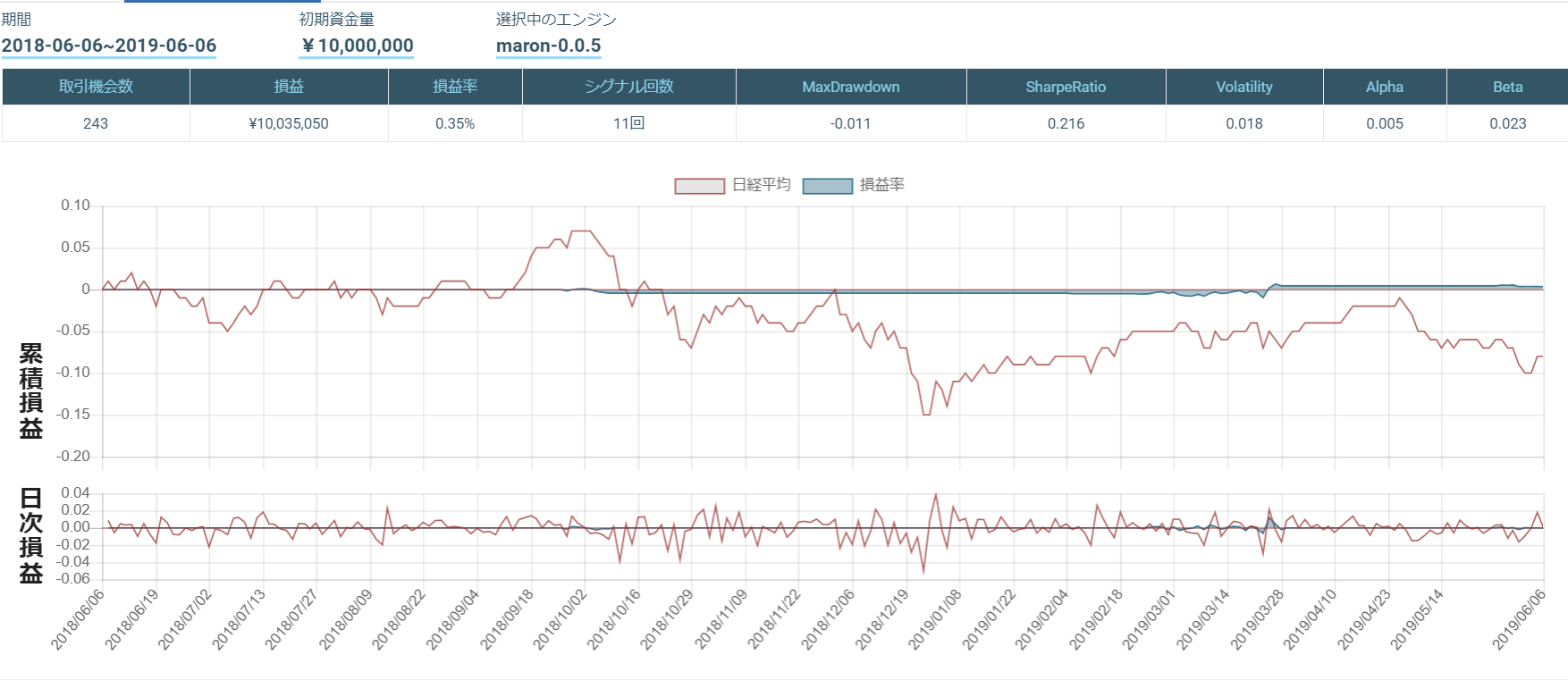
まとめ
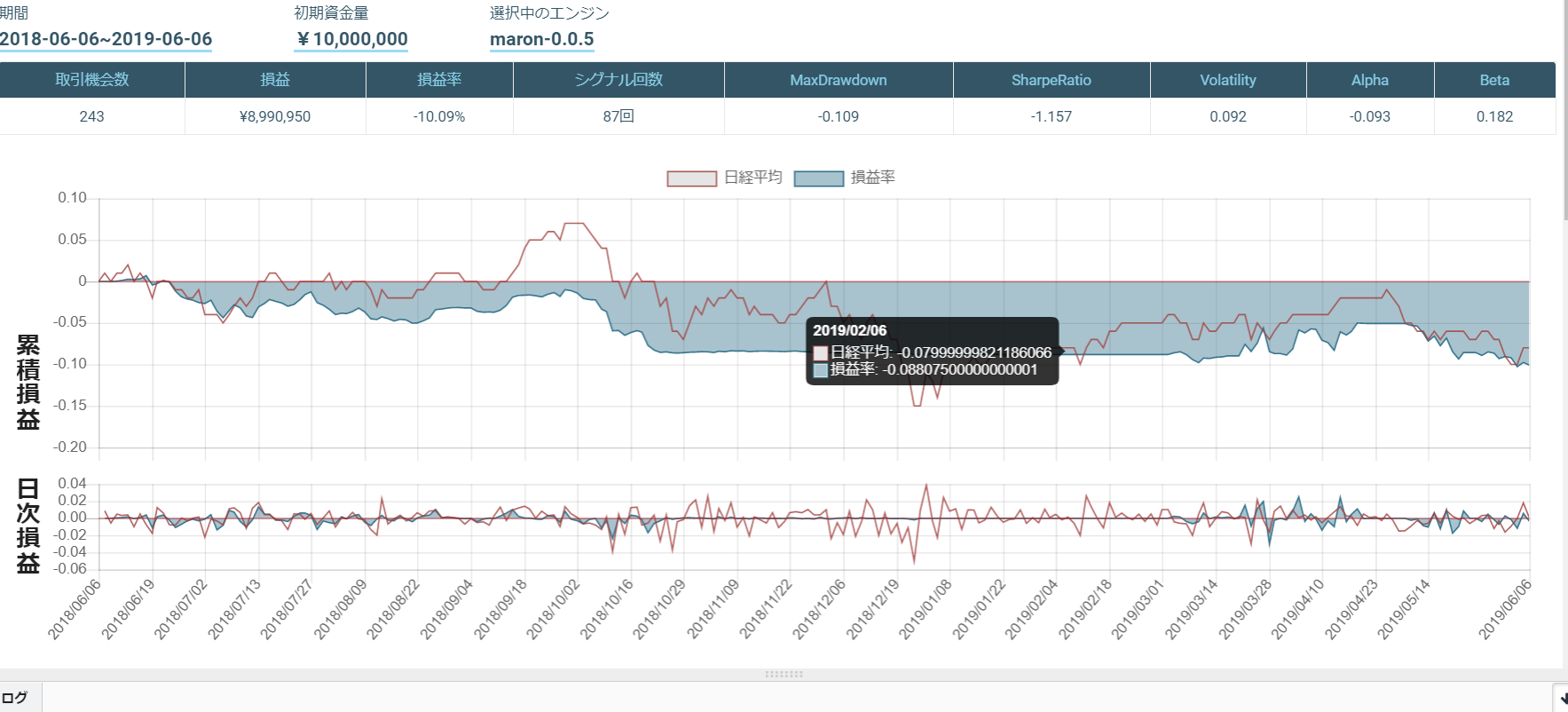
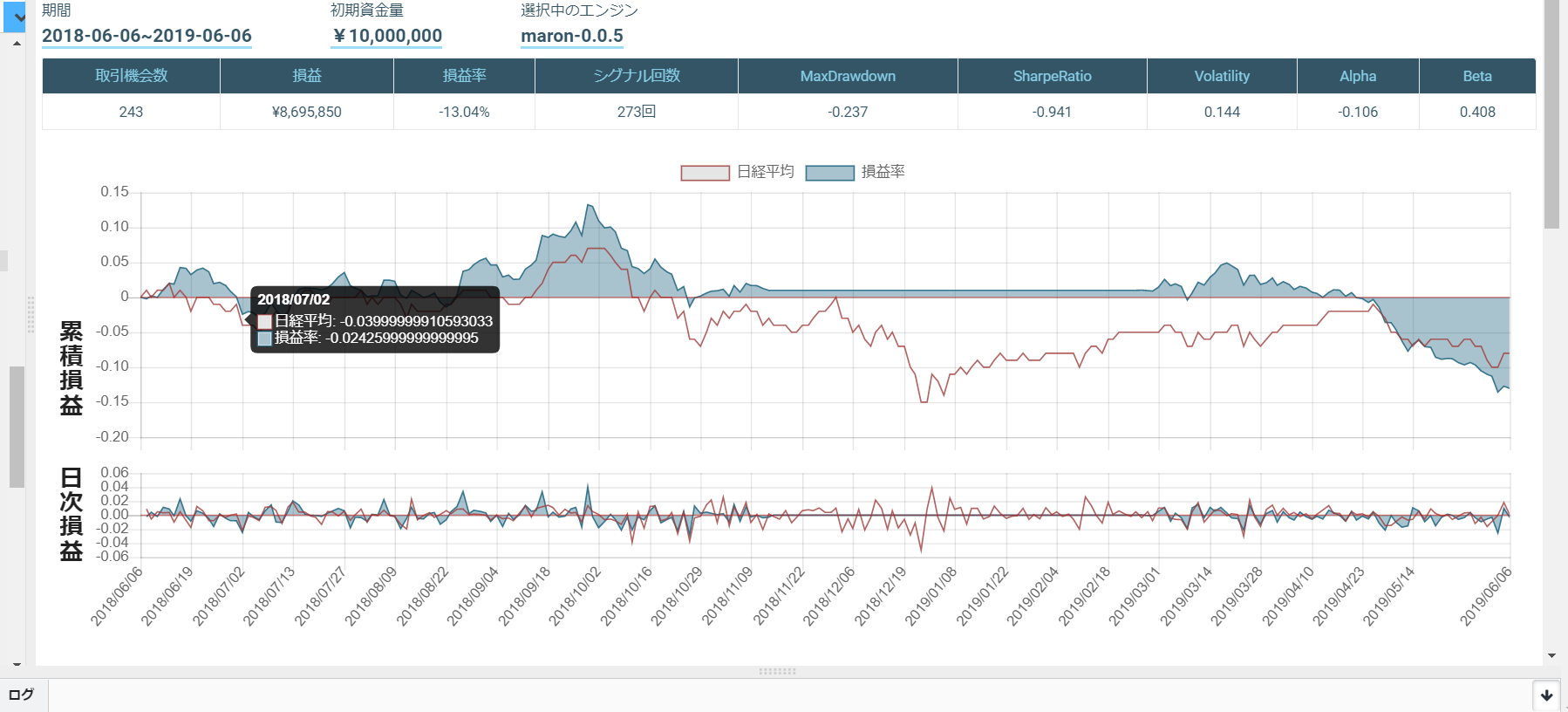
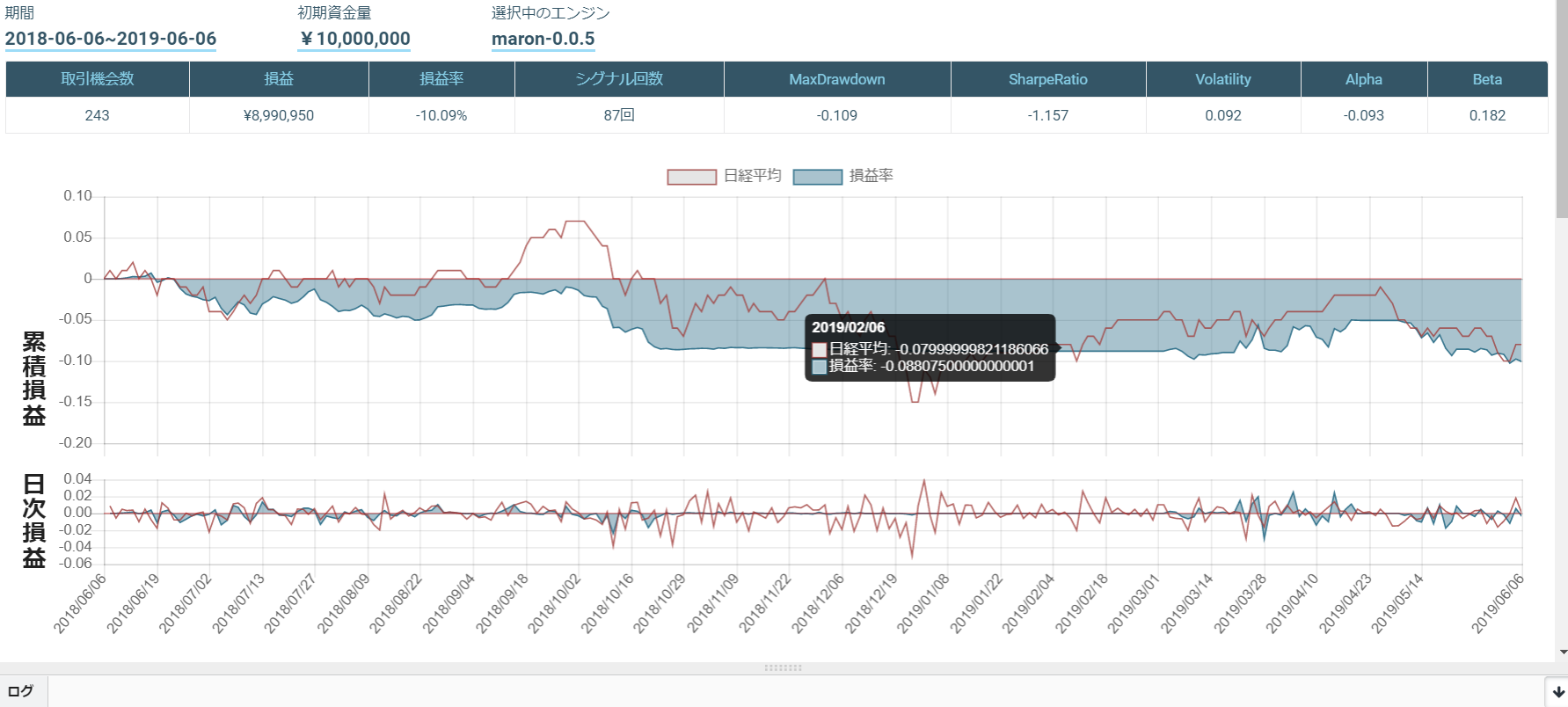
このアルゴリズムをTOPIX Core 30で行ったものが以下になります。
あまりシグナルが出ず、取引が行われませんでした。
次回は色々な指標を組み合わせて、複数のものから判断できるアルゴリズムを検討してみたいと思います!
- 投稿日:2019-08-28T15:29:11+09:00
「FORTRAN77数値計算プログラミング」のプログラムをCとPythonに移植してみる(その2)
前回の記事
「FORTRAN77数値計算プログラミング」のプログラムをCとPythonに移植してみる(その1)FORTRAN77数値計算プログラミング、1.2のコードより。
台形則における誤差の累積
丸め誤差の累積
P.5の終わり〜P.6プログラムの手前まで引用
丸め誤差の累積を示す一つの例として、積分
I = \int_{0}^{1}\frac{1}{1+x^2}dx = \frac{\pi}{4} = 0.7853982\tag{1.13}を、きざみ幅$h$を次第に小さくしながら、台形則
I_h = h\biggr[\frac{1}{2}f(a)+\sum_{j=1}^{n-1}f(a+jh)+\frac{1}{2}f(b)\biggr], \quad h=\frac{b-a}{n}\tag{1.14}a=0, \quad b=1, \quad f(x)=\frac{1}{1+x^2} \tag{1.15}によって数値積分してみる。
Fortranのコード
(1.14),(1.15)の数値積分を行うプログラム。
strap.f* Accumulation of round off error PROGRAM STRAP PARAMETER (ONE = 1.0) * EV = ATAN(ONE) * WRITE (*,2000) 2000 FORMAT (' ---- TRAP ----') * DO 10 K = 1, 13 * N = 2**K H = 1.0 / N * S = 0.5 * (1.0 + 0.5) DO 20 I = 1, N - 1 S = S + 1 / (1 + (H * I)**2) 20 CONTINUE S = H * S * ERR = S - EV IF (ERR .NE. 0.0) THEN ALERR = ALOG10 (ABS(ERR)) ELSE ALERR = -9.9 END IF * WRITE (*,2001) N, H, S, ERR, ALERR 2001 FORMAT (' N=',I6,' H=',1PE9.2,' S=',E13.6, $ ' ERR=',E8.1,' L(ERR)=',0PF4.1) * 10 CONTINUE * END実行結果は
---- TRAP ---- N= 2 H= 5.00E-01 S= 7.750000E-01 ERR=-1.0E-02 L(ERR)=-2.0 N= 4 H= 2.50E-01 S= 7.827941E-01 ERR=-2.6E-03 L(ERR)=-2.6 N= 8 H= 1.25E-01 S= 7.847471E-01 ERR=-6.5E-04 L(ERR)=-3.2 N= 16 H= 6.25E-02 S= 7.852354E-01 ERR=-1.6E-04 L(ERR)=-3.8 N= 32 H= 3.12E-02 S= 7.853574E-01 ERR=-4.1E-05 L(ERR)=-4.4 N= 64 H= 1.56E-02 S= 7.853879E-01 ERR=-1.0E-05 L(ERR)=-5.0 N= 128 H= 7.81E-03 S= 7.853957E-01 ERR=-2.4E-06 L(ERR)=-5.6 N= 256 H= 3.91E-03 S= 7.853976E-01 ERR=-5.4E-07 L(ERR)=-6.3 N= 512 H= 1.95E-03 S= 7.853978E-01 ERR=-4.2E-07 L(ERR)=-6.4 N= 1024 H= 9.77E-04 S= 7.853981E-01 ERR=-6.0E-08 L(ERR)=-7.2 N= 2048 H= 4.88E-04 S= 7.853982E-01 ERR= 6.0E-08 L(ERR)=-7.2 N= 4096 H= 2.44E-04 S= 7.853983E-01 ERR= 1.2E-07 L(ERR)=-6.9 N= 8192 H= 1.22E-04 S= 7.853981E-01 ERR=-6.0E-08 L(ERR)=-7.2になります。あら、$N=128$あたりからERRとL(ERR)の出力が本と違います…。
コードの理解
そもそもなんでこのプログラムの名前がSTRAPなんでしょうか。と疑問はさておき、積分てなんでしたっけねー、としばし固まる私。
気を取り直して、本に書いていることとコードを確認していきます。
本に書いてある、積分の式を台形則によって数値積分するっていうのは、元の積分で表されるグラフの面積のところにたくさんの台形をおいて、その台形の面積の和を積分グラフの面積の近似値にするということ。ので、プログラムがやってることは(1.14)(1.15)の式を、$h$をだんだん小さくしながら実行するという作業。それが(1.13)で求められる答えとどのくらい誤差があるか、というのが主題。
流れ図描きました。
まず、※1でやっているのは $arctan 1.0$、逆三角関数アークタンジェントを使っています。アークタンジェントを定積分で表すと、
arctan\,x = \int_0^x \frac 1 {z^2 + 1}\,dzという式になります。ここで$x$を$1$、$z$を$x$とおくと(1.13)の式と同じになるので、ここでEVには(1.13)と同じ値、つまり$I$が代入されます。
次に※2では、$N$ に $2^K$ を代入していて、$N$は式(1.14)で $$\sum_{j=1}^{n-1}$$
に使われている順序数、まあ、ざっくり言うとだんだん増えていく値ってことで。
ここで使っている$K$はループ1のカウンタで、誤差の挙動を2の13乗まで試しましょ、というのがこのループ1というわけ。そして※3ですが、これはもともと(1.14)で $$h=\frac{b-a}{n}$$ と表されていて、(1.15)で$a=0, \quad b=1$ となっているので、代入すると$$h=\frac{1}{n}$$ そのままですね。
で、(1.14)の1つ目の式$$I_h = h\biggr[\frac{1}{2}f(a)+\sum_{j=1}^{n-1}f(a+jh)+\frac{1}{2}f(b)\biggr]$$ にまず2つ目の式$$h=\frac{1}{n}$$ を当てはめると
I_\frac{1}{n}=\frac{1}{n}\biggr[\frac{1}{2}f(a)+\sum_{j=1}^{n-1}f(a+j\frac{1}{n})+\frac{1}{2}f(b)\biggr]となり、さらに(1.15)から$a=0$と$b=1$で置き換えると
I_\frac{1}{n}=\frac{1}{n}\biggr[\frac{1}{2}f(0)+\sum_{j=1}^{n-1}f(0+\frac{j}{n})+\frac{1}{2}f(1)\biggr]そして$$f(x)=\frac{1}{1+x^2}$$ なので、
I_\frac{1}{n}=\frac{1}{n}\biggr[\frac{1}{2}\times\frac{1}{1+0^2}+\sum_{j=1}^{n-1}\frac{1}{1+\big(\frac{j}{n}\big)^2} +\frac{1}{2}\times\frac{1}{1+1^2}\biggr]から、
I_\frac{1}{n}=\frac{1}{n}\biggr[\frac{1}{2}+\sum_{j=1}^{n-1}\frac{n}{1+\frac{j^2}{n^2}}+\frac{1}{4}\biggr]\tag{r1}さらに
I_\frac{1}{n}=\frac{1}{n}\biggr[\frac{1}{2}+\sum_{j=1}^{n-1}\frac{n^2}{n^2+j^2}+\frac{1}{4}\biggr]で、
I_\frac{1}{n}=\frac{1}{n}\biggr[\frac{3}{4}+\sum_{j=1}^{n-1}\frac{n^2}{n^2+j^2}\biggr]\tag{r2}と整理できます。
※4は、$0.5\times(1.0+0.5)$ を $S$に代入していますが、これを$$\frac{1}{2}\times\big(\frac{2}{2}+\frac{1}{2}\big)$$ と考えてみると、$$\frac{1}{2}\times\frac{3}{2}=\frac{3}{4}$$ となって、式(r2)に出てくる値になってますね。
ループ2のカウンタIは $$\sum_{j=1}^{n-1}$$ で書かれている$j$ですね。Jにしといてくれたらわかりやすいのに。
そして※5では、$$S+1\div(1+(H\times I)^2)$$ を $S$に代入していますが、この式の$$1\div(1+(H\times I)^2)$$ の部分を整理していきます。まずは
$$1\div1+{\big(\frac{1}{n}\times j\big)}^2$$ なので
$$\frac{1}{1+{\big(\frac{1}{n}\times j\big)}^2}$$
から
$$\frac{1}{1+\frac{j^2}{n^2}}$$ となって式(r1)に出てくる形になりました。というわけで、ループ2は(1.14)の
\frac{1}{2}f(a)+\sum_{j=1}^{n-1}f(a+jh)+\frac{1}{2}f(b)の部分の計算を行っているものになります。
※6で(1.14)の最初の式が完成して、※7では、(1.13)の式との差分、つまりもともと積分計算で求めた計算結果と、台形則を使った近似値との差を計算しています。
※8では、※7で求めた差が0と等しくなかった場合に、差の絶対値を求め(ABS(ERR))、その値の常用対数を求め(ALOG10())ています。
常用対数とは、$$x=10^a$$ となる$a$の値のことで、数式では$$a=\log_{10}x$$ と表されるもの。
この値を使って、次のようなグラフがプロットできます。
このグラフが表しているのは、$h^2$に比例して累積誤差が減少していくということ、ただし、誤差が計算機イプシロンに近づくにつれて減少しなくなるということ。本との違い
比べると、$S$の値が$N=128$からごく僅かですが増えています。累積誤差の減少が止まる地点が少しあとになってるんですね。
本が使っている計算機(あえてコンピュータと書かないw)がMV4000 AOS/VSということで、16ビットOSなんですよね。
で、私が出したグラフ、本で参考として出ている倍精度浮動小数点数を使って計算したグラフに似ています。あくまでも似ているだけでちょっと違うんですが、本の環境では浮動小数点演算が6桁丸め演算とのこと。
ということで、これは64ビットOS(環境は32ビットかな)で切り捨て演算を行った結果による違いであろうと推測。
識者の方いたら教えて下さい。Cのコード
strap.c#include <stdio.h> #include <math.h> int main(void) { const float ONE = 1.0f; float ev = atanf(ONE); int k, i; int n; float h, s, err, alerr; printf("%14.7E\n", ev); printf("--- TRAP ---\n"); for(k=1; k<=13; k++) { n = pow(2,k); h = 1.0f / n; s = 0.5f * (1.0f + 0.5f); for(i=1; i<=n-1; i++) { s = s + 1 / (1+ powf(h*i,2)); } s = h * s; err = s - ev; if(err != 0.0f) { alerr = log10(fabsf(err)); } else { alerr = -9.9f; } printf("N=%6d H=%9.2E S=%13.6E ERR=%8.1E L(ERR)=%4.1F\n",n, h, s, err, alerr); } return 0; }実行結果は変わりません。
Pythonのコード
strap.pyimport numpy as np import matplotlib.pyplot as plt ONE = np.array((1.0),dtype=np.float32) ev = np.arctan(ONE,dtype=np.float32) h, s, err, alerr = np.array([0.0, 0.0, 0.0, 0.0],dtype=np.float32) # 計算用 1.0, 0.5, 0.0, -9.9の単精度浮動小数点数 tmp = np.array([1.0, 0.5, 0.0, -9.9],dtype=np.float32) # グラフ描画用リスト x = [] y = [] print("--- TRAP ---") for k in range(13): n = np.power(2,k+1) h = tmp[0] / n.astype(np.float32) s = tmp[1] * (tmp[0] + tmp[1]) for i in range(n-1): s = s + tmp[0] / (tmp[0] + np.square(h*(i+1),dtype=np.float32)) s = s * h err = s - ev if err != tmp[2]: alerr = np.log10(np.abs(err)) else: alerr = tmp[3] print("N=%6d H=%9.2E S=%13.6E ERR=%8.1E L(ERR)=%4.1F" % (n, h, s, err, alerr)) # グラフ用変数セット x.append(k+1) y.append(alerr) # グラフ描画 fig, ax = plt.subplots() ax.scatter(x,y) ax.set_xlabel("n (1/2^n)") ax.set_ylabel("l (10^l)") plt.show()出力結果は同じです。あと、グラフ出しました。
まとめ
Pythonのコードはもっときれいになりそうな気がします。
そして、単精度にするためにnumpy書き散らすのもどうかと思う。Fortranのコードの方を倍精度にするか……いやしかしそれだと実行結果が本と照らし合わせられないし。むう。



- 投稿日:2019-08-28T15:00:10+09:00
Coral DevBoardでPoseNetを動かしてエッジデバイスのパフォーマンスを比較する
【内容】
前回の記事でDevBoard上でOpenCVを動かせるようになりました。
これにより過去に作ったEdgeTPU + PoseNetを使ったプログラムが動くようになりましたので、各エッジデバイスとのパフォーマンスを比較します。【環境構築】
以前の記事の「【PoseNet環境構築】」と「【EdgeTPU + OpenCV + PoseNet】」を参照して環境構築を行いました。
なお、DevBoardは初期状態では
gitコマンドが入っていないのでsudo apt install gitでインストールしてください。【pose_opencvの実行】
リアルタイムのカメラ映像を使うときは
--videosrcオプションに整数値を入れてください。
数値は/dev/video*に対応する数値になります。
DevBoardでは/dev/video0は専用カメラに割り合っているため、USBカメラを使う場合は1以上の値になります。
なお、専用カメラは入手していないため、動作確認は出来ていません。pose_opencvの実行(カメラ映像)# USBカメラ映像による姿勢推定 python3 pose_opencv.py --res 480x360 --videosrc 1 python3 pose_opencv.py --res 640x480 --videosrc 1 python3 pose_opencv.py --res 1280x720 --videosrc 1映像ファイルを使う場合は
--videosrcオプションに映像ファイルのパスを入れてください。pose_opencvの実行(映像ファイル)# サンプルビデオの取得 wget https://github.com/opencv/opencv/raw/master/samples/data/vtest.avi # サンプルビデオ映像による姿勢推定 python3 pose_opencv.py --res 480x360 --videosrc ./vtest.avi python3 pose_opencv.py --res 640x480 --videosrc ./vtest.avi【結果】
【実行結果 (カメラ映像)】
解像度 Platform 推論時間 (ms) FrameIO (ms) FPS 備考 1280x720 RaspberryPi3 + EdgeTPU 279.4 75.82 2.47 - DevBoard 44.9 42.89 7.46 - JetsonNano + EdgeTPU 49.2 23.82 7.44 640x480 RaspberryPi3 + EdgeTPU 94.4 27.48 7.16 - DevBoard 13.5 15.26 24.36 - JetsonNano + EdgeTPU 15.0 8.53 29.89 カメラの性能限界 480x360 RaspberryPi3 + EdgeTPU 53.5 12.34 12.57 - DevBoard 8.2 10.92 30.18 カメラの性能限界 - JetsonNano + EdgeTPU 9.7 4.21 30.06 カメラの性能限界 【結果 (ビデオファイル)】
解像度 Platform 推論時間 (ms) FrameIO (ms) FPS 備考 640x480 RaspberryPi3 + EdgeTPU 65.3 19.59 8.68 - DevBoard 13.6 14.97 20.94 - JetsonNano + EdgeTPU 15.0 6.87 30.08 480x360 RaspberryPi3 + EdgeTPU 33.9 10.27 14.64 - DevBoard 7.5 8.18 31.68 - JetsonNano + EdgeTPU 8.9 4.00 45.57 FrameIOとFPSを見るとラズパイ3とJetsonNanoの中間の値になっています。
基本スペックからしてもだいたい予想通りの結果です。
TPUとCPU間の接続バスの違いなのか、推論時間に関してはDevBoardが一番早いです。【参考:Multi TPUの場合】
参考までにMulti TPUでの処理を行ってみました。
2つのTPUに対してそれぞれPoseNetとMobileNet SSD v2のモデルをロードして推論しました。
今回はシリアルで処理を行い、それぞれの推論時間と1フレームあたりの処理時間を計測しました。DevBoardはUSBポートが一つしかないので、USBポートにUSB Hubを繋いで、そこにUSBカメラとEdgeTPUをつなぎました。
その上で内蔵TPUにPoseNet、EdgeTPUにSSDを割り当てました。【実行結果 (カメラ映像)】
解像度 Platform 推論時間 (ms)
PoseNet推論時間 (ms)
SSDFrameIO (ms) FPS 備考 480x360 DevBoard + EdgeTPU 7.6 23.2 67.36 11.79 - JetsonNano + EdgeTPU x 2 8.8 15.2 35.99 19.82 640x480 DevBoard + EdgeTPU 14.0 21.4 98.73 8.01 - JetsonNano + EdgeTPU x 2 15.4 15.2 49.17 14.26 1280x720 DevBoard + EdgeTPU 42.1 20.7 207.71 3.60 1秒程度遅延あり - JetsonNano + EdgeTPU x 2 47.2 16.1 118.82 5.55 0.5秒程度遅延あり 推論時間はPoseNet、SSDそれぞれ大きく違いはありません。
ただ、DevBoardのほうがPoseNetは若干早く、SSDの方は遅いようです。
これはTPUの接続方式の違いによるものと思われます。
内蔵TPUはCPUとTPUとの通信が早く、USB Hub経由のUSB接続はJetsonNanoより若干遅いようです。あと解像度が1280x720の場合、実際の動きに対して画面に描画されている映像には遅延が発生していました。
本体性能に依存しているようで、DevBoardの遅延がかなり目立ちました。【最後に】
DevBoardをセットアップから実行まで一通り使ってみました。
率直な感想はコスパ悪いなと言う感想です。
1年前に発表されたときにすぐに手にできていたらまた印象は違っていたと思いますが、安価で高性能なJetsonNanoが出てしまったので…DevBoardはMendel LinuxというDebianベースの独自のディストリビューションを使っているため、ビルド済みのバイナリモジュールも少なくセットアップには手間がかかります。
最近は結構充実してきましたが、以前のラズパイを思い出します。
そうやって手間ひまかけて環境を構築したのに、値段の割にはいまいちパフォーマンスが出ないのが少し残念なところです。
明確な目的があり、TPUで実装できることがわかっているのであればDevBoardを使うのもありかと思いますが、現時点では、わざわざこれを選択するメリットは無いかなという印象です。
とはいえ選択肢が増えたという点では良かったかなと思います。

- 投稿日:2019-08-28T12:59:51+09:00
ローソク足とテクニカル指標を組み合わせたアルゴリズムを作る
はじめに
Smart Trade社が提供するQuantX Factory上ではtalibを用いた、ローソク足を用いて株式の売買アルゴリズムを作ることが出来ます。
しかしながら、ローソク足を用いたサンプルアルゴリズムは数が乏しく、現状参考にできるものが、インターン生が書いた、こちらのまとめしかありません。
そこで、今回は、ローソク足(長い足のローソク(大陽線・大陰線))とテクニカル指標(移動平均乖離率)を組み合わせたコードを作ることで、テクニカル指標とローソク足の組み合わせのサンプルコードを作りたいと思います。移動平均乖離率とローソク足を組み合わせたコード
こちらのコードがコードの完全版となります。銘柄はTOPIX Core 30を使っています。
コピペするときにはこちらをお使いください。
# 必要なライブラリーをimportする import maron import maron.signalfunc as sf import maron.execfunc as ef import pandas as pd import talib as ta import numpy as np # オーダ方法を決定する ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー # 銘柄、columnsの取得を行う # 初期化を行う def initialize(ctx): ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.2914", #JT(日本たばこ産業) "jp.stock.8766", #東京海上ホールディングス "jp.stock.8031", #三井物産 "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.9437", #NTTドコモ "jp.stock.4502", #武田薬品工業 "jp.stock.8058", #三菱商事 "jp.stock.9433", #KDDI "jp.stock.9432", #日本電信電話 "jp.stock.7267", #ホンダ(本田技研工業) "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.4503", #アステラス製薬 "jp.stock.4063", #信越化学工業 "jp.stock.7974", #任天堂 "jp.stock.6981", #村田製作所 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.9020", #東日本旅客鉄道 "jp.stock.8802", #三菱地所 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9984", #ソフトバンクグループ "jp.stock.6861", #キーエンス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6954", #ファナック "jp.stock.7203", #トヨタ自動車 "jp.stock.7751", #キヤノン "jp.stock.4452", #花王 "jp.stock.6098", #リクルートホールディングス ], "columns": [ "open_price_adj", # 始値(株式分割調整後) "high_price_adj", # 高値(株式分割調整後) "low_price_adj", # 安値(株式分割調整後) "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) #"volume_adj", # 出来高 #"txn_volume", # 売買代金 ] } } ) # シグナル定義 def _my_signal(data): # 終値等の取得を行い、欠損値補完を行う。 cp = data["close_price_adj"].fillna(method='ffill') op = data["open_price_adj"].fillna(method= 'ffill') hp = data["high_price_adj"].fillna(method="ffill") lp = data["low_price_adj"].fillna(method="ffill") # 25日移動平均線と75日移動平均線の乖離率を計算 m25 = data["close_price_adj"].fillna(method='ffill').rolling(window=25, center=False).mean() m75 = data["close_price_adj"].fillna(method='ffill').rolling(window=75, center=False).mean() ratio = m25 / m75 # ローソク足についてを計算 candle_1 = pd.DataFrame(data=0,columns=[], index=cp.index) for(sym,val) in cp.items(): candle_1[sym] = ta.CDLLONGLINE(op[sym],hp[sym],lp[sym],cp[sym]) # true,falseのbool型にする candle_1_buy = candle_1[(candle_1 == 100)] candle_1_sell = candle_1[(candle_1 == -100)] candle_1_buy[(candle_1 == 100)] = True candle_1_sell[(candle_1 == -100)] = False # 売買シグナルを定義(bool値で返す) buy_sig = (ratio > 1.05) & candle_1_buy sell_sig = (ratio < 0.95) & candle_1_sell # market_sigという全て0が格納されているデータフレームを作成 market_sig = pd.DataFrame(data=0.0, columns=cp.columns, index=cp.index) # buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 return { "mavg_25:price": m25, "mavg_75:price": m75, "ratio:g2":ratio, "market:sig": market_sig, "candle:1":candle_1 } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' market_sig = current["market:sig"] done_syms = set([]) # 損切り、利確の設定 for (sym, val) in ctx.portfolio.positions.items(): returns = val["returns"] if returns < -0.03: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) done_syms.add(sym) elif returns > 0.05: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) done_syms.add(sym) # 買シグナルについて注文方法を設定する buy = market_sig[market_sig > 0.0] for (sym, val) in buy.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=ot, comment="SIGNAL BUY") #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) pass # 売シグナルも同様に行う sell = market_sig[market_sig < 0.0] for (sym, val) in sell.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot, comment="SIGNAL SELL") #ctx.logger.debug("SELL: %s, %f" % (sec.code(), val)) passコードの解説
このアルゴリズムは、ローソク足の指標に対して売買シグナルが出ているときと、移動平均線の指標に対して、売買シグナルが出ているときの両方の「かつ」の条件で、シグナルが出るようになっています。
まず初めに、QuantXでアルゴリズムを作るのに必要な初期設定を行っていきます。
詳細につきましては、公式ドキュメントやQunaX初心者に向けたこちらの記事をご覧ください。
この記事では省略させていただきます。# 必要なライブラリーをimportする import maron import maron.signalfunc as sf import maron.execfunc as ef import pandas as pd import talib as ta import numpy as np # オーダ方法を決定する ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー # 銘柄、columnsの取得を行う # 初期化を行う def initialize(ctx): ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.2914", #JT(日本たばこ産業) "jp.stock.8766", #東京海上ホールディングス "jp.stock.8031", #三井物産 "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.9437", #NTTドコモ "jp.stock.4502", #武田薬品工業 "jp.stock.8058", #三菱商事 "jp.stock.9433", #KDDI "jp.stock.9432", #日本電信電話 "jp.stock.7267", #ホンダ(本田技研工業) "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.4503", #アステラス製薬 "jp.stock.4063", #信越化学工業 "jp.stock.7974", #任天堂 "jp.stock.6981", #村田製作所 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.9020", #東日本旅客鉄道 "jp.stock.8802", #三菱地所 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9984", #ソフトバンクグループ "jp.stock.6861", #キーエンス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6954", #ファナック "jp.stock.7203", #トヨタ自動車 "jp.stock.7751", #キヤノン "jp.stock.4452", #花王 "jp.stock.6098", #リクルートホールディングス ], "columns": [ "open_price_adj", # 始値(株式分割調整後) "high_price_adj", # 高値(株式分割調整後) "low_price_adj", # 安値(株式分割調整後) "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) #"volume_adj", # 出来高 #"txn_volume", # 売買代金 ] } } )上記の初期設定が終わりましたら、売買シグナルを生成する部分である、my_signal部分を定義していきます。
# シグナル定義 def _my_signal(data): # 終値等の取得を行い、欠損値補完を行う。 cp = data["close_price_adj"].fillna(method='ffill') op = data["open_price_adj"].fillna(method= 'ffill') hp = data["high_price_adj"].fillna(method="ffill") lp = data["low_price_adj"].fillna(method="ffill")終値等の値に対して、それぞれ欠損値を補完していきます。これらの値の詳細はこちらのcolumnsをご覧ください。
次に移動平均線の計算を行っていきます。
# 25日移動平均線と75日移動平均線の乖離率を計算 m25 = data["close_price_adj"].fillna(method='ffill').rolling(window=25, center=False).mean() m75 = data["close_price_adj"].fillna(method='ffill').rolling(window=75, center=False).mean() ratio = m25 / m75pandasのメソッドを使って、計算していきます。移動平均乖離率についてはアルゴリズム開発入門に詳しい説明がありますので、そちらをご覧ください。
candle_1 = pd.DataFrame(data=0,columns=[], index=cp.index) for(sym,val) in cp.items(): candle_1[sym] = ta.CDLLONGLINE(op[sym],hp[sym],lp[sym],cp[sym])ローソク足の計算を行っていきます。
candle_1という空の箱をまず用意します。
そこに、talibの関数を使って、ローソク足の必要なデータを入れていきます。#true,false型にする candle_1_buy = candle_1[(candle_1 == 100)] candle_1_sell = candle_1[(candle_1 == -100)] ctx.logger.debug(candle_1_buy) candle_1_buy[(candle_1 == 100)] = True candle_1_sell[(candle_1 == -100)] = False次にローソク足のデータを必要な形に変形していきます。
今、ローソク足(candle_1)に入っているデータは、
2017-07-04 0 0 -100 0 2017-07-05 0 0 100 100 2017-07-06 0 0 0 -100 のように、-100, 0, 100 のいずれかで表されています。
今回はテクニカル指標として、移動平均乖離率とローソク足を組み合わせたものを作ります。
そこで、今ここで、移動平均線の売買シグナルを考えます。
今回、乖離率の割合が1.05よりも大きかった時に買シグナルを出すとすると、これは、buy_sig = ratio > 1.05 というコードになります。この時のbuy_sigは、
2019-04-22 False False True False 2019-04-23 False False True False 2019-04-24 False False True False という形であらわされます。
今回は、ローソク足とテクニカル指標の両方でシグナルが出たときに買シグナルを出したいので、buy_sigで、(テクニカル指標で買シグナル)かつ(ローソク足で買シグナル)という条件にしたいと思います。
このままだと形が違うため、かつの条件にすることが出来ません。そこで、ローソク足の売買シグナルをTrue,False型に直したいと思います。ローソク足で、買シグナルが出るときの名前をcandle_1_buyとします。ローソク足で買シグナルが出るとき、(すなわちcandle_1=100となるとき)candle_1_buyをTrueと定義します。
# 売買シグナルを定義(bool値で返す) buy_sig = (ratio > 1.05) & candle_1_buy sell_sig = (ratio < 0.95) & candle_1_sellデータの下処理が出来たところで、bool型の買シグナルと売シグナルを定義します。
上記のコードで直した結果のbuy_sigは以下になります。
2019-05-09 NaN NaN NaN NaN 2019-05-10 NaN NaN NaN NaN 2019-05-13 NaN NaN NaN NaN 2019-05-14 False False True False ここまで来たら、後はQuantXの仕様にのっとってシグナル登録等をしていきます。ここら辺の操作もドキュメントをご覧ください。
def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' market_sig = current["market:sig"] done_syms = set([]) # 損切り、利確の設定 for (sym, val) in ctx.portfolio.positions.items(): returns = val["returns"] if returns < -0.03: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) done_syms.add(sym) elif returns > 0.05: sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) done_syms.add(sym) # 買シグナルについて注文方法を設定する buy = market_sig[market_sig > 0.0] for (sym, val) in buy.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=ot, comment="SIGNAL BUY") #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) pass # 売シグナルも同様に行う sell = market_sig[market_sig < 0.0] for (sym, val) in sell.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot, comment="SIGNAL SELL") #ctx.logger.debug("SELL: %s, %f" % (sec.code(), val)) passmy_signalが定義し終わった後は利確、損切等の設定を行っていきます。handle_signalsもドキュメント等の普通のコードと同じになります。
まとめ
ローソク足のみの損益率は以下になります。
移動平均乖離率のみの損益率は以下になります。
ローソク足と移動平均乖離率は以下になります。
移動平均乖離率のみが一番成績がいいのですが...
それでも、ローソク足のみよりは、ローソク足と移動平均乖離率の組み合わせの方が成績が良くなりました。
今回テクニカル指標とローソク足のサンプルコードを作ることが目的で、成績は気にしませんでしたが、ローソク足は選び方と組み合わせが大事だと感じました。
組み合わせることによって成績は大きく変動するということが分かったので、今後は組み合わせ方や選び方を研究したいです!
- 投稿日:2019-08-28T11:58:48+09:00
CentOS7にてpython、paramikoの実装
お久しぶりです
どうも。最近CentOS7にて辞書攻撃を作成する際にず~~~っとわからず時間のかかったpythonの実装、paramikoの実装について解説していきます。
paramikoとは
そもそも、paramikoってなに?という感じですが、paramikoというのは簡単に言うと
「pythonを使ったsshをする際に使われるライブラリ」って感じです。
まぁこの実装に僕の知識がないのも相まって三日くらいしらべまくったわけですが(白目)実装環境
- Virtual Box ver.6
- CentOS 7
ついに実装
ながったらく話しましたが実装について解説していきます。以下に実行したコマンドを記します。
// リポジトリの追加(たぶんこれがないと無理) # yum install https://centos7.iuscommunity.org/ius-release.rom// pythonのインストール # yum install -y python36 //36の部分にはpythonのバージョンを指定 ex)36→3.6// pythonのライブラリ系のインストール # yum install -y python36u # yum install -y python36u-libs # yum install -y python36u-devel # yum install -y python36u-pipまぁここは自由にしてください(笑)でもpipのインストールは絶対してください
// paramikoのインストール # pip install paramikoもし、成功せず「'pip install --upgrade pip' command.」、みたいなエラーメッセージが出たらアップデートしてください
// pipのアップデート # pip3.6 install --upgrade pip3.6にはバージョンの指定です。Tabキー使ってください
それでもできなかっらた3.6をつけなかったり色々やると大丈夫な気がしますpipとは
絶対インストールしてほしいといった「pip」ですが、いったい何なのか、
pipとはpythonのパッケージを管理するものらしいです。
簡単に述べるとparamikoはyumじゃなくてpipじゃないとダメだよってことですね
最後に
・ こういった経緯によってやっとのことで辞書攻撃についての開発環境が整いましたので、次回は辞書攻撃について書かせてもらいます。
最後までありがとうございましたー
- 投稿日:2019-08-28T11:42:45+09:00
sudoなしpip installでエラー
仮想環境内のCentOS環境構築で凡ミスをしたため記録。
Python(Django)-MySQL環境を構築するにあたり以下のエラーに遭遇。$ pip install mysqlclient Collecting mysqlclient Using cached https://files.pythonhosted.org/packages/4d/38/c5f8bac9c50f3042c8f05615f84206f77f03db79781db841898fde1bb284/mysqlclient-1.4.4.tar.gz Installing collected packages: mysqlclient Running setup.py install for mysqlclient ... error ERROR: Command errored out with exit status 1: command: /usr/local/bin/python3.7 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-zqpistk9/mysqlclient/setup.py'"'"'; __file__='"'"'/tmp/pip-install-zqpistk9/mysqlclient/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-qwlt2ozx/install-record.txt --single-version-externally-managed --compile cwd: /tmp/pip-install-zqpistk9/mysqlclient/ Complete output (32 lines): /usr/local/lib/python3.7/distutils/dist.py:274: UserWarning: Unknown distribution option: 'long_description_content_type' warnings.warn(msg) running install running build running build_py creating build creating build/lib.linux-x86_64-3.7 creating build/lib.linux-x86_64-3.7/MySQLdb copying MySQLdb/__init__.py -> build/lib.linux-x86_64-3.7/MySQLdb copying MySQLdb/_exceptions.py -> build/lib.linux-x86_64-3.7/MySQLdb copying MySQLdb/compat.py -> build/lib.linux-x86_64-3.7/MySQLdb copying MySQLdb/connections.py -> build/lib.linux-x86_64-3.7/MySQLdb copying MySQLdb/converters.py -> build/lib.linux-x86_64-3.7/MySQLdb copying MySQLdb/cursors.py -> build/lib.linux-x86_64-3.7/MySQLdb copying MySQLdb/release.py -> build/lib.linux-x86_64-3.7/MySQLdb copying MySQLdb/times.py -> build/lib.linux-x86_64-3.7/MySQLdb creating build/lib.linux-x86_64-3.7/MySQLdb/constants copying MySQLdb/constants/__init__.py -> build/lib.linux-x86_64-3.7/MySQLdb/constants copying MySQLdb/constants/CLIENT.py -> build/lib.linux-x86_64-3.7/MySQLdb/constants copying MySQLdb/constants/CR.py -> build/lib.linux-x86_64-3.7/MySQLdb/constants copying MySQLdb/constants/ER.py -> build/lib.linux-x86_64-3.7/MySQLdb/constants copying MySQLdb/constants/FIELD_TYPE.py -> build/lib.linux-x86_64-3.7/MySQLdb/constants copying MySQLdb/constants/FLAG.py -> build/lib.linux-x86_64-3.7/MySQLdb/constants running build_ext building 'MySQLdb._mysql' extension creating build/temp.linux-x86_64-3.7 creating build/temp.linux-x86_64-3.7/MySQLdb gcc -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -fPIC -Dversion_info=(1,4,4,'final',0) -D__version__=1.4.4 -I/usr/include/mysql -I/usr/local/include/python3.7m -c MySQLdb/_mysql.c -o build/temp.linux-x86_64-3.7/MySQLdb/_mysql.o -m64 gcc -pthread -shared build/temp.linux-x86_64-3.7/MySQLdb/_mysql.o -L/usr/lib64/mysql -lmysqlclient -lpthread -lm -lrt -ldl -o build/lib.linux-x86_64-3.7/MySQLdb/_mysql.cpython-37m-x86_64-linux-gnu.so running install_lib creating /usr/local/lib/python3.7/site-packages/MySQLdb error: could not create '/usr/local/lib/python3.7/site-packages/MySQLdb': Permission denied ---------------------------------------- ERROR: Command errored out with exit status 1: /usr/local/bin/python3.7 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-zqpistk9/mysqlclient/setup.py'"'"'; __file__='"'"'/tmp/pip-install-zqpistk9/mysqlclient/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-qwlt2ozx/install-record.txt --single-version-externally-managed --compile Check the logs for full command output.エラーメッセージが多くてどこから見ればいいかわからなくなったが、
Permission deniedがカギだった。
原因は、pipを管理者権限なしで実行していたためだった。$ sudo pip install mysqlclientで解決。
基本的すぎて恥ずかしい...けどエラーメッセージでググってたどり着く人のために公開。
- 投稿日:2019-08-28T11:28:41+09:00
【Python】文字列の部分参照 (備忘録)
はじめに
Pythonで文字列を扱うことが多いので、文字列の扱いかたを簡単にまとめます。
参考書: 入門 Python3
環境
OS: macOS Mojave
文字列のうち任意の文字を抽出する
扱う文字列は以下の通りです。
letters = "123456789"文字列のうち任意の文字の位置を指定して抽出する場合は以下の構文で抜き出す。
letters[開始:終了:段階]例
例えば初めから七番目 (0から数えたら6番目) まで2つずつを抽出する場合は以下のようになる。
(初めから抽出する場合は数字を省略できる。)>>>letters[:7:2] '1357'初めから最後まで、2つずつ抽出する場合
>>>letters[::2] '13579'後ろから3番目を参照したい場合
>>>letters[-4] '7'(応用) 文字列を逆転させたい場合
>>>letters[::-1] '987654321'
- 投稿日:2019-08-28T06:16:43+09:00
Oralcle CloudでNVIDIAのGPUインスタンスを構築する
はじめに
本記事は、Oralcle CloudでNVIDIAのGPUインスタンスを構築する手順についての記事になります。
機械学習でディープラーニングを行う場合に必要なGPUですが、クラウドサービスを使用して環境構築を行う場合、自前でUbuntuにNVIDIAのドライバ、CUDA、cuDNN等をインストールして使用する方法と、各クラウドサービスが提供するマシンイメージを利用方法の二つに大別できます。
自前でUbuntuにNVIDIAのドライバ等をインストールする場合は、自分で環境のセットアップを行う必要があるため、初めての場合は時間がかかると思います。逆に、クラウドサービスが提供するマシンイメージを利用する場合は、インスタンスを作成するだけで、いきなりGPUが使用できます。但し、GPUになるので、普通のサーバインスタンスに比べると料金が高額になるので注意が必要です。
本記事では、Oralcle CloudのNVIDIAのイメージを例に記載しています。
NVIDIA
Oracle Cloudでは、NVIDIA GPU Cloud Imageを利用することで、導入時のセットアップを省略し、最適化された環境で機械学習のワークロードの実行ができます。
インスタンスの作成
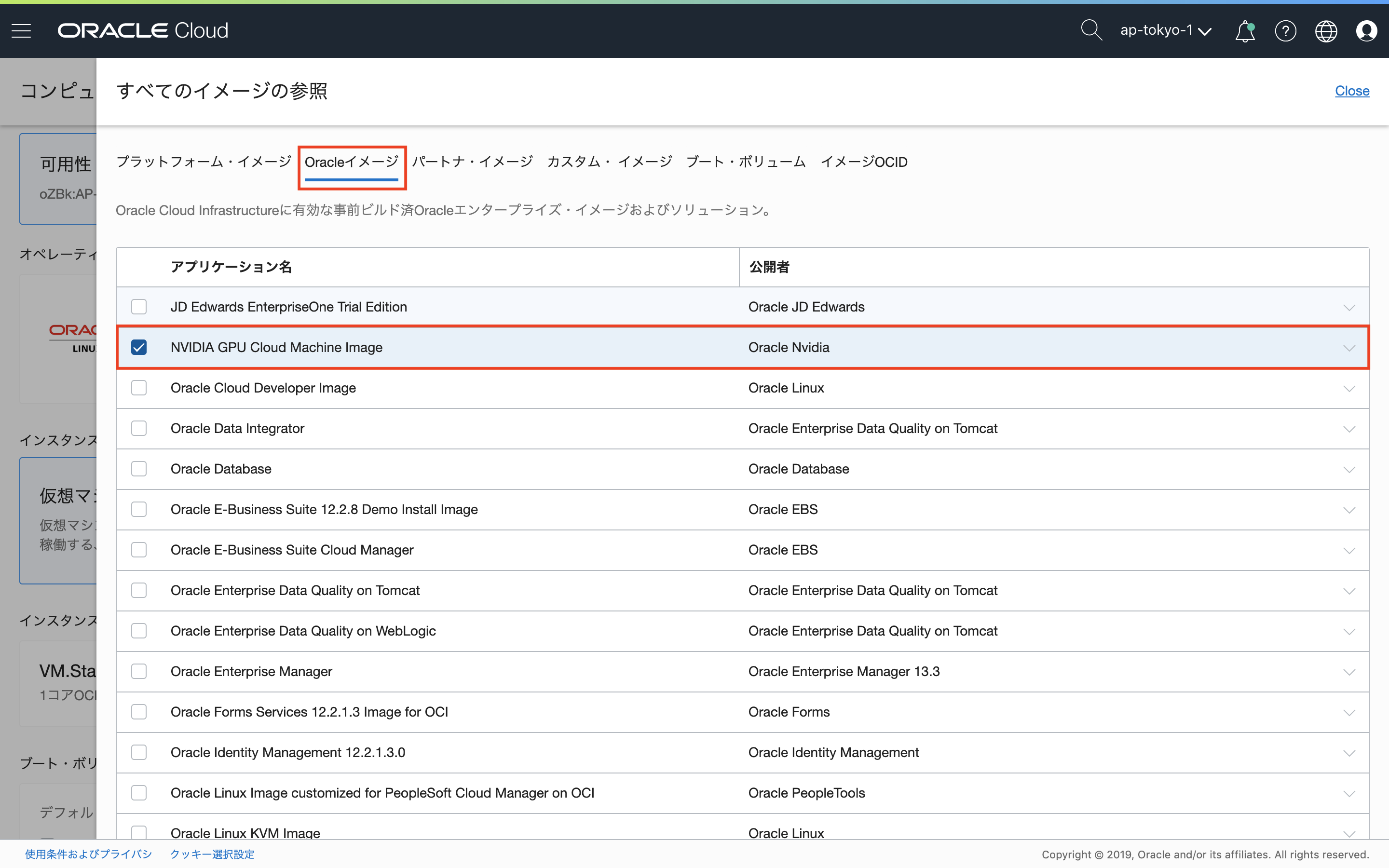
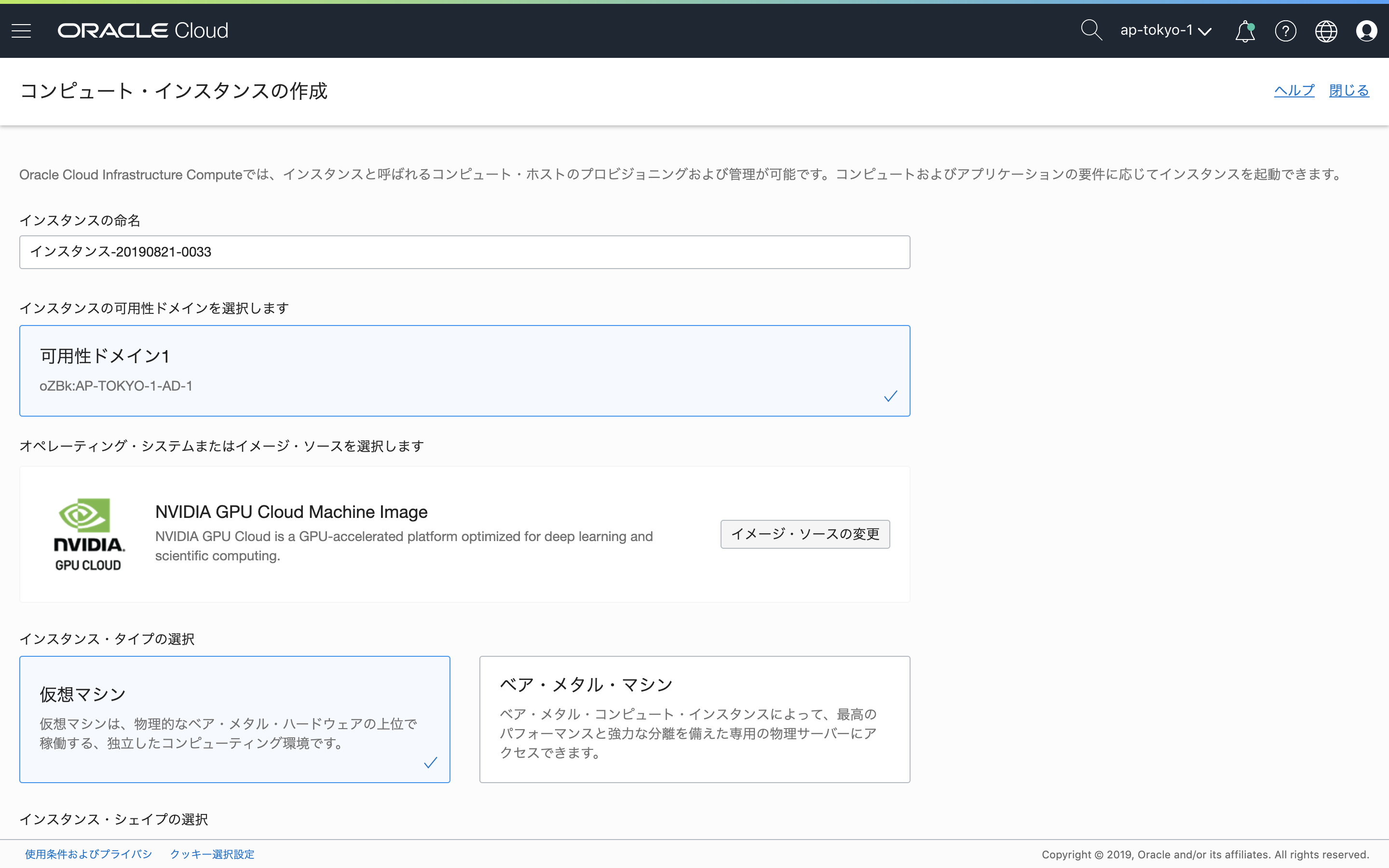
コンソールメニューから、「コンピュート」-「インスタンス」を選択し、「インスタンスの作成」をクリックします。
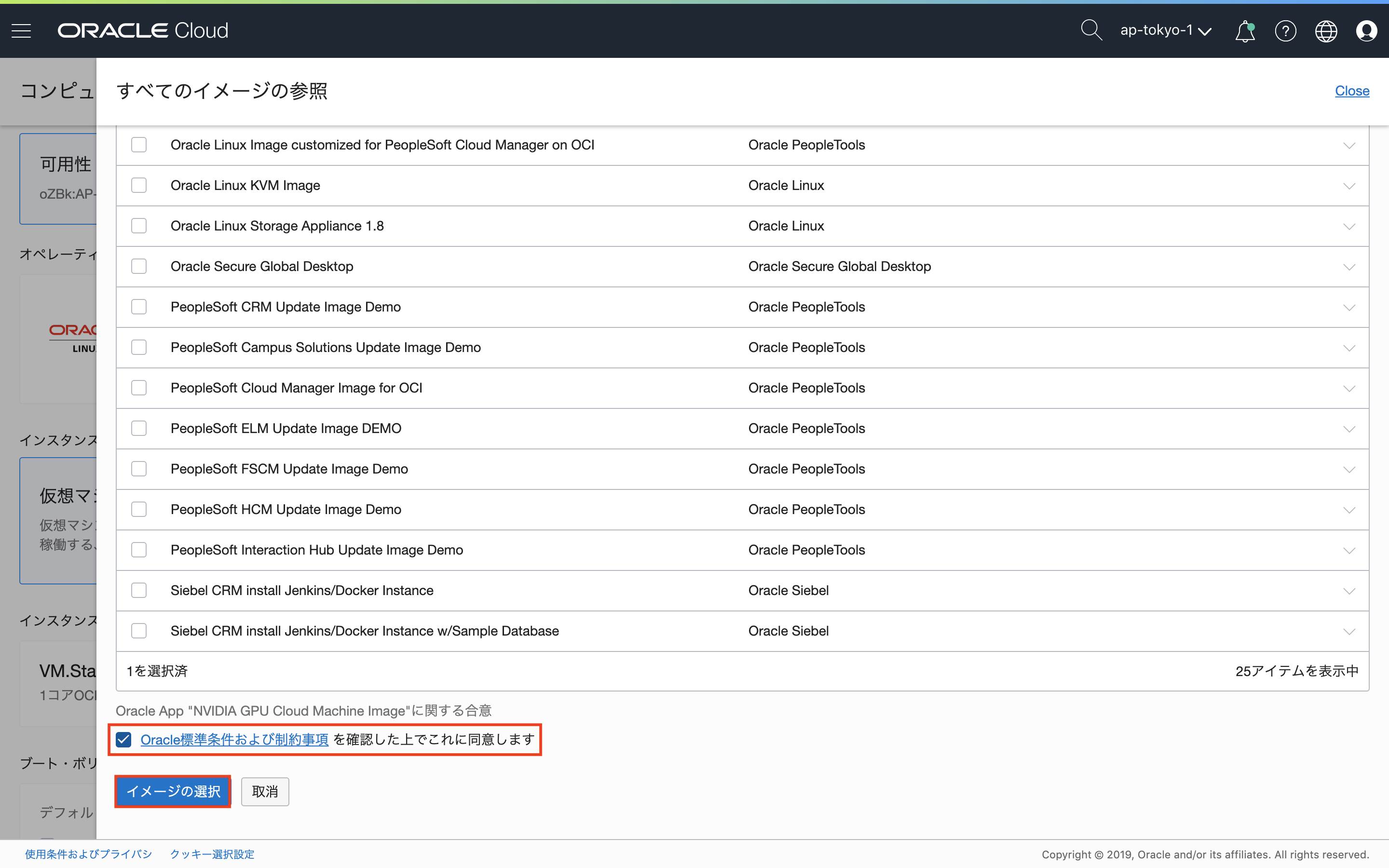
コンピュート・インスタンスの作成ウィンドウで、「イメージ・ソースの選択」をクリックし、画面上部の「Oracleイメージ」を選択。アプリケーション名から、NVIDIA GPU Cloud Image Machine Imageにチェックを入れます。
画面下部にもチェックも入れます。なお、NVIDIA GPU Cloud Image Machine Imageを使用することに対するライセンス料金は発生しません。(Oracleに確認)
NVIDIA GPU Cloud Image Machine Imageが選択されます。
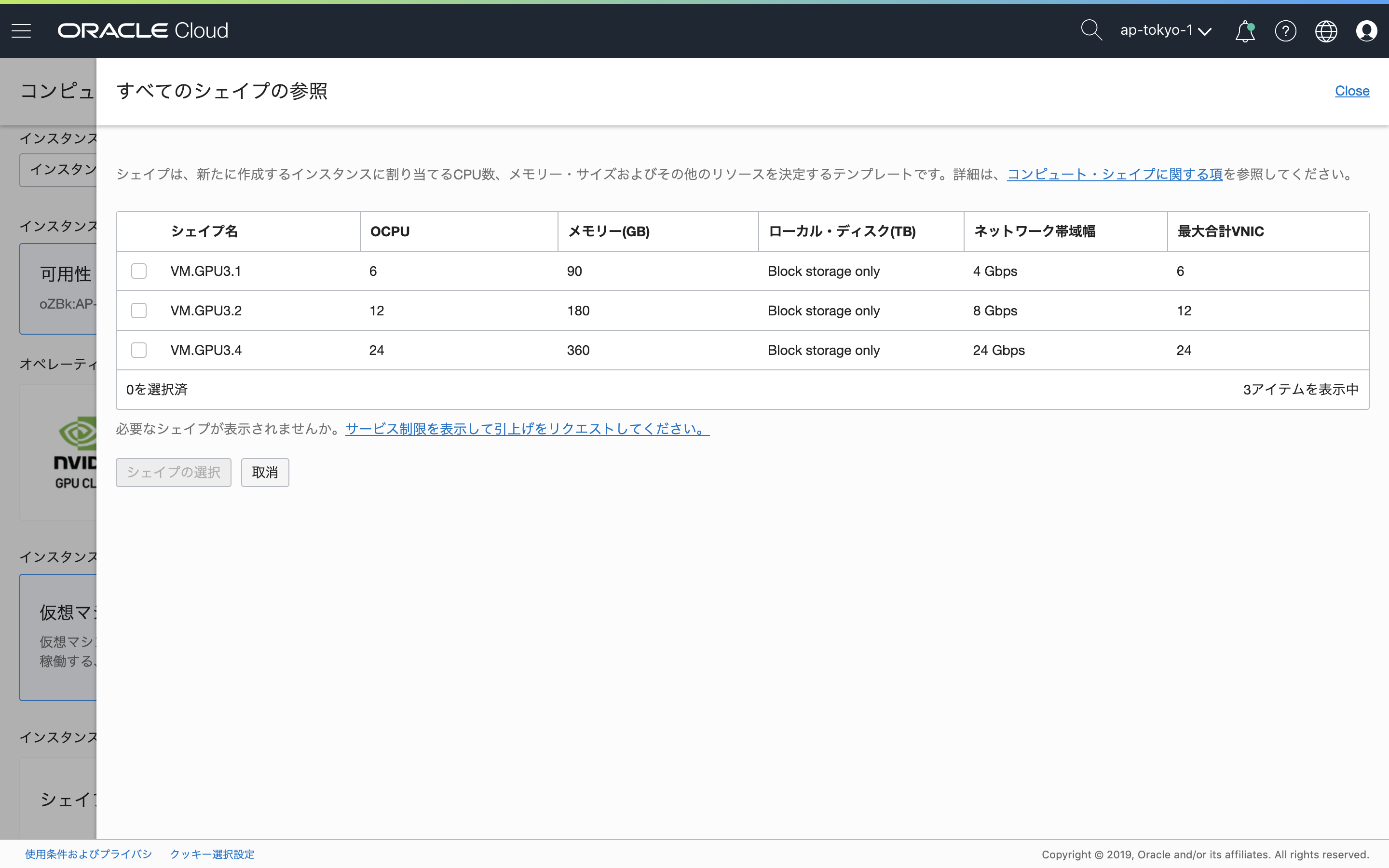
次に「シェイプの変更」で、インスタンスに割り当てるテンプレートを選択します。
あとは、任意で他の項目を入力し、最後に「作成」をクリックすると、プロビジョニングが行われます。
Oralcle Cloudの留意事項として、インスタンスが存在する限り、GPUインスタンスの料金が発生するため、GPUインスタンス使用後は、インスタンスの終了を忘れない様にします。
なお、ブートディスクを削除しないことで、完全にインスタンスを削除せずに起動・停止に近い操作が行えますが、またインスタンスを作成してプロビジョニングを行う必要があるため、勝手はよくありません。
その他環境構築
機械学習に必要なその他環境構築の例について記載します。
Python
自動的にインストールされているPythonは3.5系のため、Pythonは3.6系以降を使用したい場合、別途、バイナリからのインストールが必要です。
ライブラリのインストール
- pipのインストール
$ sudo apt install python3-pip- tensorflow-gpuのインストール
$ pip3 install tensorflow-gpu- kerasのインストール
$ pip3 install keras- jupyterのインストール
$ pip3 install jupyterjupyter notebook
jupyter notebookをインストールして、外部からアクセスしたい場合は、jupyter notebook起動時にパブリックIPアドレスに紐付くプライベートIPアドレスを指定して、起動するか、SSHポートフォワーディングすることで、外部からjupyter notebookを使用することができます。
(※)jupyter notebookに外部からアクセスできる場合は、任意のコードが実行できてしまうので、注意しましょう
参考として、外部からアクセスする場合の設定手順について記載します。
- 以下のコマンドを実行し、jupyter_notebook_config.pyを生成
$ jupyter notebook --generate-config- 以下のコマンドを実行し、jupyter_notebook_config.pyが生成されたことを確認
$ ls -l /home/ubuntu/.jupyter/jupyter_notebook_config.py- 以下のコマンドを実行し、jupyter_notebook_config.pyを編集
$ vi /home/ubuntu/.jupyter/jupyter_notebook_config.py# 変更前 #c.NotebookApp.ip = 'localhost' # 変更後 c.NotebookApp.ip = '0.0.0.0'
- 以下のコマンドを実行し、jupyterを起動
$ jupyter-notebook --ip=<プライベートIPアドレス>ポートフォワーディングする場合は、以下のコマンドを実行後、ブラウザを起動し、http://localhoot:8888にアクセスします。
$ ssh -f -N -L 8888(※):localhost:8888 ubuntu@<サーバのパブリックIPアドレス> -i <秘密鍵パス>(※)ローカル側なので任意のポート番号を指定可能(本記事では例として8888を指定)
動作確認
GPUが実際に動いているかは、TensorFlowのチュートリアルなどでサンプルコードを動かしながら、GPUの動きをリアルタイムで見れば確認できます。
おわりに
クラウドサービスが提供するマシンイメージは便利ですが、GPU使用料は安くはなく、簡単に検証もできないので、これからもっと使いやすくなることを期待します。
- 投稿日:2019-08-28T03:05:03+09:00
Sympyでオイラーラグランジュ方程式を解く
自分用のメモのために、記事を書いてみました。
はじめに
運動方程式を導出するために、オイラーラグランジュ方程式を解くことがあると思います。しかしながら多変数のオイラーラグランジュ方程式を解くとき、計算量が多く面倒のなので無料で利用できるPythonの数式処理ライブラリであるSympyを使ってオイラーラグランジュ方程式を解いてみることにしました。
今回説明すること
一般的な運動である1質点とばねによる振動系のラグランジアンからオイラーラグランジュ方程式の解くプログラムを用いて説明をします。
コード
Euler–Lagrange.py#Sympyをインポート import sympy as sp #JupyterNotebookを使っている場合数式を自然数表示 sp.init_printing() #時間の変数を設定 t = sp.symbols('t') #質点の位置の変数を設定 #(xはtの関数に設定するためにオプションにcls=sp.Functionを追加) x = sp.symbols('x ', cls=sp.Function) #質量とばね定数の設定 m, k = sp.symbols('m k') #ラグランジアンLを設定 L =sp.Function("L") L = (m*(x(t).diff(t))**2)/2 -(k*x(t)**2)/2 #変数の座標と座標の時間微分に配列を作成 #多変数に拡張する場合ここに変数を追加 pos = [x(t)] vel =[x(t).diff(t)] #オイラーラグランジュ方程式解く関数を定義 def EulerLagrange(L,pos,vel): Eq1= sp.symbols('Eq1', cls=sp.Function) EQ_list =[Eq1] # 変数を増やす場合は下のように書く # Eq1 ,Eq2= sp.symbols('Eq1 Eq2', cls=sp.Function) # EQ_list =[Eq1 ,Eq2] for i in range(len(pos)): EQ_list[i] =sp.simplify(sp.Eq(L.diff(vel[i]).diff(t) - L.diff(pos[i]),0)) return EQ_list #運動方程式 f =EulerLagrange(L,pos,vel)[0] print(f)上のように計算を行わせると、運動方程式$f$は、
k x{\left (t \right )} + m \frac{d^{2}}{d t^{2}} x{\left (t \right )} = 0となり、1質点とばねによる振動系と同様の形になりました。
これで、自宅でも簡単に運動方程式が導出できます。
終わりに
運動方程式の導出ができました。実際に欲しいの運動方程式を数値計算した結果が欲しかったのですが、この求めた運動方程式をPythonのライブラリ(Sympy、Numpy、SciPyなど)を用いて数値計算する方法がわかりませんせんでした。もしご存じの方がいらっしゃいましたら、教えていたただけると幸いです。
- 投稿日:2019-08-28T03:00:57+09:00
ニューラルネットワークの基礎知識 - 2
概要
今回は1つの隠れ層を入れてネットワークを構築します。前回のベースにプログラムを書いているので、もし読んでいない場合は、まずニューラルネットワークの基礎知識 - 1を読むことをお勧めします。
ネットワークを構成
今回作成するネットワークは、入力層で3つのニューロン(ノード)を持ち、隠れ層で一つのニューロン、そして出力層でも一つのニューロンを持ちます。
Let's Code
# numpyのインポート import numpy as np学習データの用意
# 0:不合格、1:合格 # 合格状態のデータ inputs = np.array([ [0,1,1], [1,0,0], [0,1,0], [1,0,1]]) # 0:仕事見つからなかった、1:見つかった # 仕事見つかった実績 outputs = np.array([ [1], [1], [0], [1]])各パラメータの初期化
weightとbias共に2セットが必要です。一つは入力層と隠れ層をつなぐため、もう一つは隠れ層と出力層をつなぐため。エポック数とlearning rateは前回と同じです。
# 入力層と隠れ層をつなぐ weightの初期化 weights_ih = np.array([ [0.5], [0.5], [0.5]]) # 入力層と隠れ層をつなぐbiasの初期化 bias_h = np.array([[0.2]]) # 隠れ層と出力層をつなぐweightの初期化 weights_ho = np.array([[0.5]]) # 隠れ層と出力層をつなぐbiasの初期化 bias_o = np.array([[0.2]]) # learning rateの初期化 lr = 0.1 # epochの初期化 epoch = 5000活性化関数の定義
def activate(x): return 1/(1+np.exp(-x))学習実行
# start training for _ in range(epochs): # feed forward # 隠れ層での予測 prediction_h = activate(np.dot(inputs, weights_ih) + bias_h) # 出力層での予測 prediction_o = activate(np.dot(prediction_h, weights_ho) + bias_o) # backpropagation # phase 1:出力層と隠れ層をつなぐweightとbiasの値の調整 # △wの計算 error = prediction_o - outputs sigmoid_der_prediction_o = prediction_o * (1 - prediction_o) der_cost_w_o = np.dot(prediction_h.T, sigmoid_der_prediction_o * error) # △bの計算 der_cost_b_o = sigmoid_der_prediction_o * error # Gradient Descentを使ってweightの調整 weights_ho -= learning_rate * der_cost_w_o # Gradient Descentを使ってbiasの調整 bias_o -= learning_rate * np.sum(der_cost_b_o,axis=0,keepdims=True) # phase 2 # 隠れ層と入力層をつなぐweightとbiasの値の調整 # △wの計算 sigmoid_der_prediction_h = prediction_h * (1 - prediction_h) tmp = sigmoid_der_prediction_h * sigmoid_der_prediction_o * weights_ho * error der_cost_w_h = np.dot(inputs.T, tmp) # △bの計算 der_cost_b_h = np.sum(tmp,axis=0,keepdims=True) # Gradient Descentを使ってweightの調整 weights_ih -= learning_rate * der_cost_w_h # Gradient Descentを使ってbiasの調整 bias_h -= learning_rate * der_cost_b_h # 学習終了 print("Loss : {:.8f}".format(error)) print("weight: ", weights_ih.T[0]) print("bias : ", np.asscalar(bias_h))評価
どのように学習したか評価します。
# 結果を表示するための関数 def get_prediction(data): pred = activate(np.dot(data, weights_ih) + bias_h) msg = "Hired" if round(np.asscalar(pred)) else "Not Hired" print(data, msg, np.asscalar(pred)) # 全科目合格の場合は、仕事見つかるか get_prediction([1,1,1]) # 物理のみ不合格の場合は、仕事見つかるか get_prediction([1,1,0]) # 全科目不合格の場合は、仕事見つかるか get_prediction([0,0,0])今回も、サンプルデータが少ない事とネットワークが単純すぎるから間違った答えがおおいかもしれませんが、基礎の理解という事でご許しください。
また、前回の隠れ層なしの結果と比べて、ネットワークが複雑になっていますが、その反面若干エラー(ロス)の値が少なくなっています。Google Colab
直接Colabから実行することもできますので一度試してみてください。ちなみに、Colabのコメントはすべて英語です。
with_single_hidden_layer.ipynb最後に
今回はニューラルネットワークの基礎を理解する目的で隠れ層を1つのみ実装しました。次回はこれらの知識を応用してかつほかのフレームワークを使ってより複雑なネットワークを作りましょう。

- 投稿日:2019-08-28T00:40:28+09:00
超シンプル "Keras" を用いた機械学習実行まで
TensorFlowをより使いやすくしたフレームワーク"Keras"
比較的手軽にDeep Learningを実感できます。今回は、とりあえずKerasを実行することにのみ重点を置いて、
極力無駄なものを省いて超シンプルに記述しました。
Kerasを用いた学習までのざっくりとした下記の流れに沿ってコーディングしていきます。
- y(目的変数)ワンホットエンコーディング化
- modelの宣言
- Compile
- 学習(fit)
今回はテストデータとしてKaggleのTitanicデータを利用。
前処理については下記ブログを参照ください
【Beginner】【AI】【機械学習】Light GBM: Titanic: Machine Learning from Disaster1.y(目的変数)ワンホットエンコーディング化
2019.0828更新
importファイルを載せていなかったので追記致しますimport numpy as np import pandas as pd from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import Flatten from keras.layers.convolutional import Conv2D from keras.layers.convolutional import MaxPooling2D from keras.utils import np_utils from keras import backend as K from sklearn.utils import shuffle import tensorflow as tf from tensorflow.keras import layersKerasに読み込ませるデータはワンホットエンコーディング化する必要があるらしい。
今回は生きるか死ぬかの0 or 1で登録するため不要かもしれないですが。。
一応、kerasにはワンホットエンコーディングを簡単にできるライブラリがあるのでそれの紹介も兼ねて記述。#教師データの学習 #目的変数 train_y = df006["Survived"] #説明変数 #arrayかつ型がfloat32で無ければ学習の際にエラーがでるのでここで変換 train_x = df006.drop(labels=["Survived"],axis=1).as_matrix().astype('float32') #kerasのnp_utilに含まれるto_categoricalによってワンホットエンコーディング化 train_y_onehot = np_utils.to_categorical(train_y)2.Modelの宣言
宣言方法にはいろいろあるらしい。
下記を参照すると良くわかります。
TensorFlow公式:単純なモデルの構築今回は最も単純な全結合ネットワークを記述
#modelの宣言 #シーケンシャルモデル:単純に層を積み重ねる model = tf.keras.Sequential() # ユニット数が64の全結合層をモデルに追加します: model.add(layers.Dense(64, activation='relu')) # 全結合層をもう一つ追加します: model.add(layers.Dense(64, activation='relu')) # 出力ユニット数が10のソフトマックス層を追加します: model.add(layers.Dense(10, activation='softmax'))3.Compile
モデル構築後にcompileメソッドにより学習方法を構成します。
#modelのコンパイル:学習方法の構成 model.compile(optimizer=tf.train.AdamOptimizer(0.001), loss='categorical_crossentropy', metrics=['accuracy'])これにも代表的なものが他に2つほどあるようなので上の公式サイトより要確認
4.学習(fit)
#modelの学習 model.fit(train_x,train_y,epochs=30,batch_size=32)結果
全然制度良くならない。。。
学習までは出来ているのでデータの処理に問題があるようです。
要修正。ここまで読まれた方申し訳ございません。
近々修正更新します。
- 投稿日:2019-08-28T00:24:01+09:00
○○に似てると言われ困ったので、AIに判定させてみた
概要
皆さんも一度は○○さん(有名人)に似てると言われたことがあるのではないでしょうか。
私も初対面の人のうち、7回に1回くらいは星○源に似ていると言われることがあります。
自分では似てないと思うのですが、毎回否定するのも面倒なので、
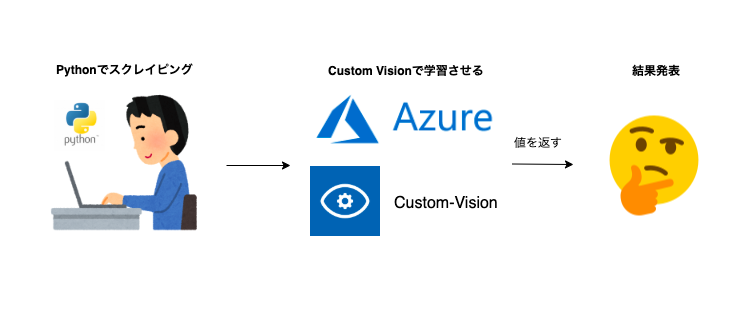
AzureのCustom Visionを使って、AIに定量的に判断してもらうことにしました。システム
構成
・macOS Mojave
・Python 3.6.5
・Custom Vision(Azure)概念図
①スクレイピングで画像を集める
②集めた画像を分類する
③AzureのCustom Visionにアップし、学習させる
④自分の画像をアップし、評価を返す
画像収集/スクレイピング
学習用のデータを集めることにします。
PythonでGoogleの画像を大量スクレープする
こちらを参考に、Pythonで画像をスクレイピング。python scraping.py -s hoshinogen -n 70scraping.pyで70枚ほど画像を集めて、複数人で写っている画像や関連性の低い画像は手動で省いていきます。
これを繰り返し、同じような系統の顔の有名人の画像をいくつかピックアップします。
塩顔っぽい系統だと思うので、関連性の高い有名人を探します。
高橋一生さん、綾野剛さん、森山未來さん など。Custom Visionを使用
使い方はこのあたりが参考になります。
Microsoft Custom Vision Service を使用して画像を分類するタグ付け
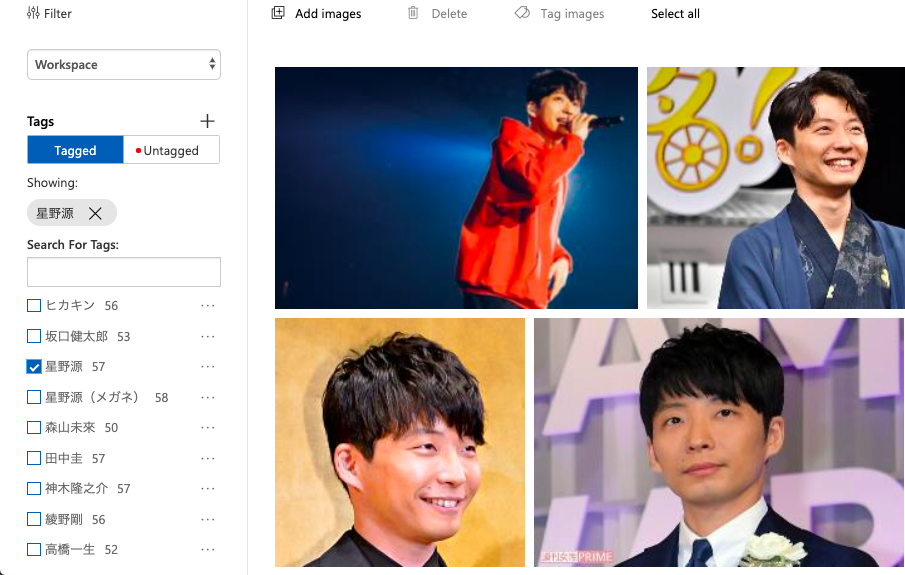
先ほど分類した画像とタグを紐付けて、画像をCustom Visionにアップしていきます。
今回は10人ほど有名人ピックアップしています。
スクレイピングした画像を精査した結果、それぞれ50枚程度になりました。アップが終わったら、右上のボタンからトレーニングさせます。
自分の画像を用意(自撮り)
いよいよ学習させたモデルから自分が似ているかどうかを判定させます。
と、その前に自分の画像を用意しましょう。カメラデータを確認したが、自分の画像がなかったため急いで自撮りしました。
結果判定
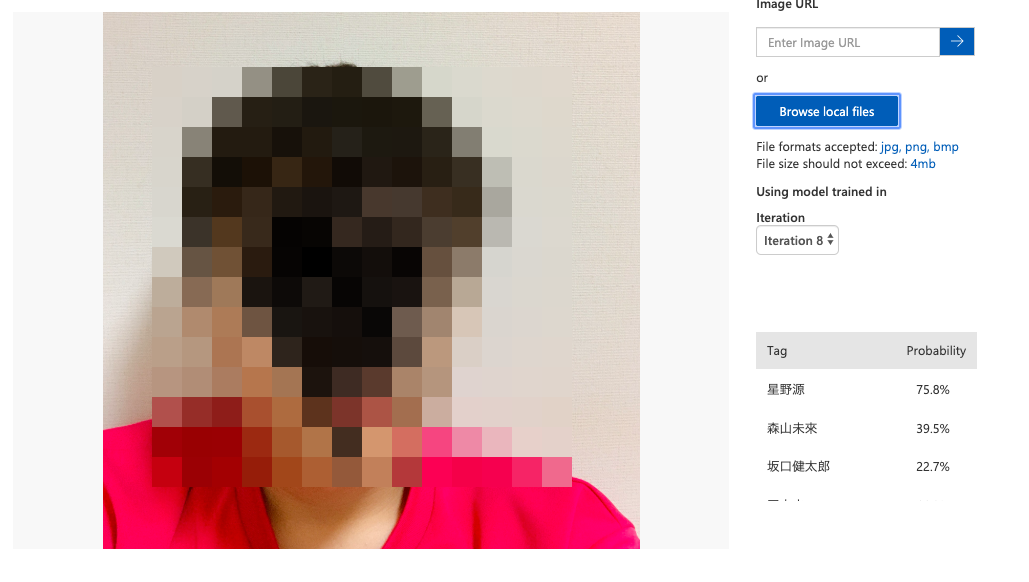
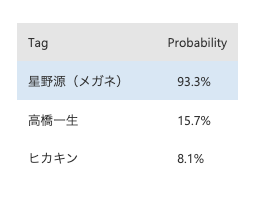
右上にあるQuick testから自分の画像をアップし、返ってくる評価を確認します。
ローカルファイルをアップしたときの結果がこちら。
……星野源75.8%になりました。
結論、比較的似ていると言えるだろうという温度感ですね。
ちなみにメガネありでやった場合も用意していたのですが、
サンプルデータが少なく高い数字が出たので、ここはもう少し学習精度上げる必要がありそうです。
まとめ
Azureのサービスを使うのは2回目だが、使いやすかった。
けっこう応用もできそうで捗りそう。以前、Google Cloud PlatformでNatural Languageを使って、
機械学習(テキスト解析)×LINE Botを作ってみたのでよろしければこちらもどうぞ
悩める恋心を助けるためのLINE BOTを作ってみたネクストアクション
今回作ったCustom Visionの画像認識とIoT機器を組み合わせる


- 投稿日:2019-08-28T00:10:05+09:00
Cythonでbool型のnumpyを扱う方法
Cythonでnumpyに型指定する方法のおさらい
import numpy as np cimport numpy as np # npがかぶっているが公式によれば大丈夫。こちらは型指定用。 cdef np.ndarray[np.int_t, ndim=1] arrayなどとする。numpyに関しては型指定でかなり高速化されるようなのでやったほうがいいだろう。
bool型の配列では...?
numpyを使っていれば、
dtype=boolで使うことも少なくないだろう。
これを型指定しようとすると、結構つまずく。公式ドキュメントで明記されてない気がするので...思いつくような方法で
cdef np.ndarray[bint, ndim=1] bool_array # bintはcythonでのbool型 cdef np.ndarray[np.bool, ndim=1] bool_array2などとしても、コンパイルは成功するが、実行時にエラーが出てしまう。
正しくは、
cdef np.ndarray[np.uint8_t, cast=True, ndim=1] bool_arrayとする。おそらく
cast=Trueで適切に型変換してくれるのだろう。参考リンク
http://omake.accense.com/static/doc-ja/cython/src/tutorial/numpy.html
https://stackoverflow.com/questions/18058744/passing-a-numpy-pointer-dtype-np-bool-to-c
- 投稿日:2019-08-28T00:10:05+09:00
Cythonでbool型のnumpyに型指定する方法
Cythonでnumpyに型指定する方法のおさらい
import numpy as np cimport numpy as np # npがかぶっているが公式によれば大丈夫。こちらは型指定用。 cdef np.ndarray[np.int_t, ndim=1] arrayなどとする。numpyに関しては型指定でかなり高速化されるようなのでやったほうがいいだろう。
bool型の配列では...?
numpyを使っていれば、
dtype=boolで使うことも少なくないだろう。
これを型指定しようとすると、結構つまずく。公式ドキュメントで明記されてない気がするので...思いつくような方法で
cdef np.ndarray[bint, ndim=1] bool_array # bintはcythonでのbool型 cdef np.ndarray[np.bool, ndim=1] bool_array2としても、コンパイルは成功するが、実行時に
ValueError: Item size of buffer (1 byte) does not match size of 'bint' (4 bytes) ValueError: Does not understand character buffer dtype format string ('?')などとよくわからないエラーが出てしまう。
正しくは、
cdef np.ndarray[np.uint8_t, cast=True, ndim=1] bool_arrayとする。おそらく
cast=Trueで適切に型変換してくれるのだろう。参考リンク
http://omake.accense.com/static/doc-ja/cython/src/tutorial/numpy.html
https://stackoverflow.com/questions/18058744/passing-a-numpy-pointer-dtype-np-bool-to-c
- 投稿日:2019-08-28T00:10:05+09:00
Cythonでbool型のNumpyに型指定する方法
Cythonでnumpyに型指定する方法のおさらい
import numpy as np cimport numpy as np # npがかぶっているが公式によれば大丈夫。こちらは型指定用。 # from numpy cimport ndarray as ar # np.ndarrayが長ければこう書いてもOK cdef np.ndarray[np.int_t, ndim=1] arrayなどとする。Numpyに関しては型指定でかなり高速化されるようなのでやったほうがいいだろう。
bool型の配列では...?
Numpyを使っていれば、
dtype=boolで使うことも少なくないだろう。
これを型指定しようとすると、結構つまずく。公式ドキュメントで明記されてない気がするので...思いつくような方法で
cdef np.ndarray[bint, ndim=1] bool_array # bintはcythonでのbool型 cdef np.ndarray[np.bool, ndim=1] bool_array2としても、コンパイルは成功するが、実行時に
ValueError: Item size of buffer (1 byte) does not match size of 'bint' (4 bytes) ValueError: Does not understand character buffer dtype format string ('?')などとよくわからないエラーが出てしまう。
正しくは、
cdef np.ndarray[np.uint8_t, cast=True, ndim=1] bool_arrayとする。おそらく
cast=Trueで適切に型変換してくれるのだろう。参考リンク
http://omake.accense.com/static/doc-ja/cython/src/tutorial/numpy.html
https://stackoverflow.com/questions/18058744/passing-a-numpy-pointer-dtype-np-bool-to-c
- 投稿日:2019-08-28T00:10:05+09:00
Cythonでbool型のNumPyに型指定する方法
CythonでNumPyに型指定する方法のおさらい
import numpy as np cimport numpy as np # npがかぶっているが公式によれば大丈夫。こちらは型指定用。 # from numpy cimport ndarray as ar # np.ndarrayが長ければこう書いてもOK cdef np.ndarray[np.int_t, ndim=2] arrayなどとする。NumPyに関しては型指定でかなり高速化されるようなのでやったほうがいいだろう。
bool型の配列では...?
NumPyを使っていれば、
dtype=boolで使うことも少なくないだろう。
これを型指定しようとすると、結構つまずく。公式ドキュメントで明記されてない気がするので...思いつくような方法で
cdef np.ndarray[bint, ndim=2] bool_array # bintはcythonでのbool型 cdef np.ndarray[np.bool, ndim=2] bool_array2としても、コンパイルは成功するが、実行時に
ValueError: Item size of buffer (1 byte) does not match size of 'bint' (4 bytes) ValueError: Does not understand character buffer dtype format string ('?')などとエラーが出てしまう。
正しくは、
cdef np.ndarray[np.uint8_t, cast=True, ndim=2] bool_array # または cdef np.ndarray[np.npy_bool, cast=True, ndim=2] bool_arrayとする。おそらく
cast=Trueで適切に型変換してくれるのだろう。(比べてみたが、どちらでもパフォーマンスはほとんど変わらないようだ。)
参考リンク
http://omake.accense.com/static/doc-ja/cython/src/tutorial/numpy.html
https://stackoverflow.com/questions/18058744/passing-a-numpy-pointer-dtype-np-bool-to-c
https://github.com/cython/cython/pull/2676