- 投稿日:2019-08-28T23:29:06+09:00
【CentOS】コマンドメモ
はじめに
本記事は、CentOSで筆者が個人的によく使うコマンドをメモしたものである。
ディスクの使用量を確認
①/optの使用量を確認
# du -sh /opt②/opt/app/oracle以下、2階層までを出力範囲とし、ディスク使用量が高い順に並び変え、5行出力する
# du /opt/app/oracle -hd 2 | sort -h | tail -5ファイル名の曖昧検索
/var/www/html以下で、〇〇.htmlというファイルを出力する
# find /var/www/html -name "*.html"最後に
今、ぱっと思いついたのだけメモしたので、今後どんどん継ぎ足しをしていきます。
まだ、完成形ではないです。
- 投稿日:2019-08-28T23:14:23+09:00
NVMe接続のSSDの型番を調べる方法
はじめに
私がこれまで使ってきた環境では、IDE(ATA)接続やSATA(Serial ATA)接続のHDDやSSDばかりでしたが、最近はM.2と呼ばれる新しい比較的新しい規格のSSDが普及してきました。
NVMeはそれほど使ったことが無いため、まずはLinux上でどのように認識されているのかを調べてみよう...ということで、M.2(※NVMe接続)のSSDの型番を調べてみました。SATA接続のHDDやSSDの場合
- 従来から良く知られている方法ですが、
/cat/proc/scsi/scsiでSATA接続のHDDやSSD、DVDドライブなどの型番を調べることができます。- 以下の例だと、WesternDigitalのSATA接続のHDD(WD20EFRX)であることが分かります。
[nkojima@hotaka ~]$ cat /proc/scsi/scsi Attached devices: Host: scsi0 Channel: 00 Id: 00 Lun: 00 Vendor: PBDS Model: DVD+-RW DH-16W1S Rev: 2D14 Type: CD-ROM ANSI SCSI revision: 05 Host: scsi2 Channel: 00 Id: 00 Lun: 00 Vendor: ATA Model: WDC WD20EFRX-68E Rev: 0A82 Type: Direct-Access ANSI SCSI revision: 05NVMe接続のSSDの場合
- NVMe接続の場合、
cat /proc/scsi/scsiでは何も表示されません。
- SATA接続ではないため、当たり前なのですが...
- NVMe接続はPCI-Expressを介して接続されているため、もしかして...と思って
lspciを使ってみたところ、ビンゴでした。- 以下の例だと、IntelのPro 760pというSSDであることが分かります。
- 正しい名称以外にも、7600pや6100pなど異なる名称も表示されていて、少々分かりにくいです。
[nkojima@akagi ~]$ cat /proc/scsi/scsi Attached devices: [nkojima@akagi ~]$ lspci | grep SSD 01:00.0 Non-Volatile memory controller: Intel Corporation SSD Pro 7600p/760p/E 6100p Series (rev 03)おまけ:Hyper-V上の仮想マシンの場合
- Hyper-V上の仮想マシンの場合は、SATA接続のデバイスが「Virtual Disk」「Virtual DVD-ROM」となっていました。
- 仮想環境なので正しい型番は表示されないだろうと思っていましたが、こういう表記だとは思いませんでした。
[nkojima@vm-ikaho ~]$ cat /proc/scsi/scsi Attached devices: Host: scsi0 Channel: 00 Id: 00 Lun: 00 Vendor: Msft Model: Virtual Disk Rev: 1.0 Type: Direct-Access ANSI SCSI revision: 05 Host: scsi0 Channel: 00 Id: 00 Lun: 01 Vendor: Msft Model: Virtual DVD-ROM Rev: 1.0 Type: CD-ROM ANSI SCSI revision: 00
- 投稿日:2019-08-28T23:13:43+09:00
Add AdventureWorks to SQL Server 2019 RC1 (RHEL) on Docker
はじめに
2019/08/21 に SQL Server 2019 RC1 が発表されました。
- SQL Server 2019 release candidate is now available - SQL Server Blog
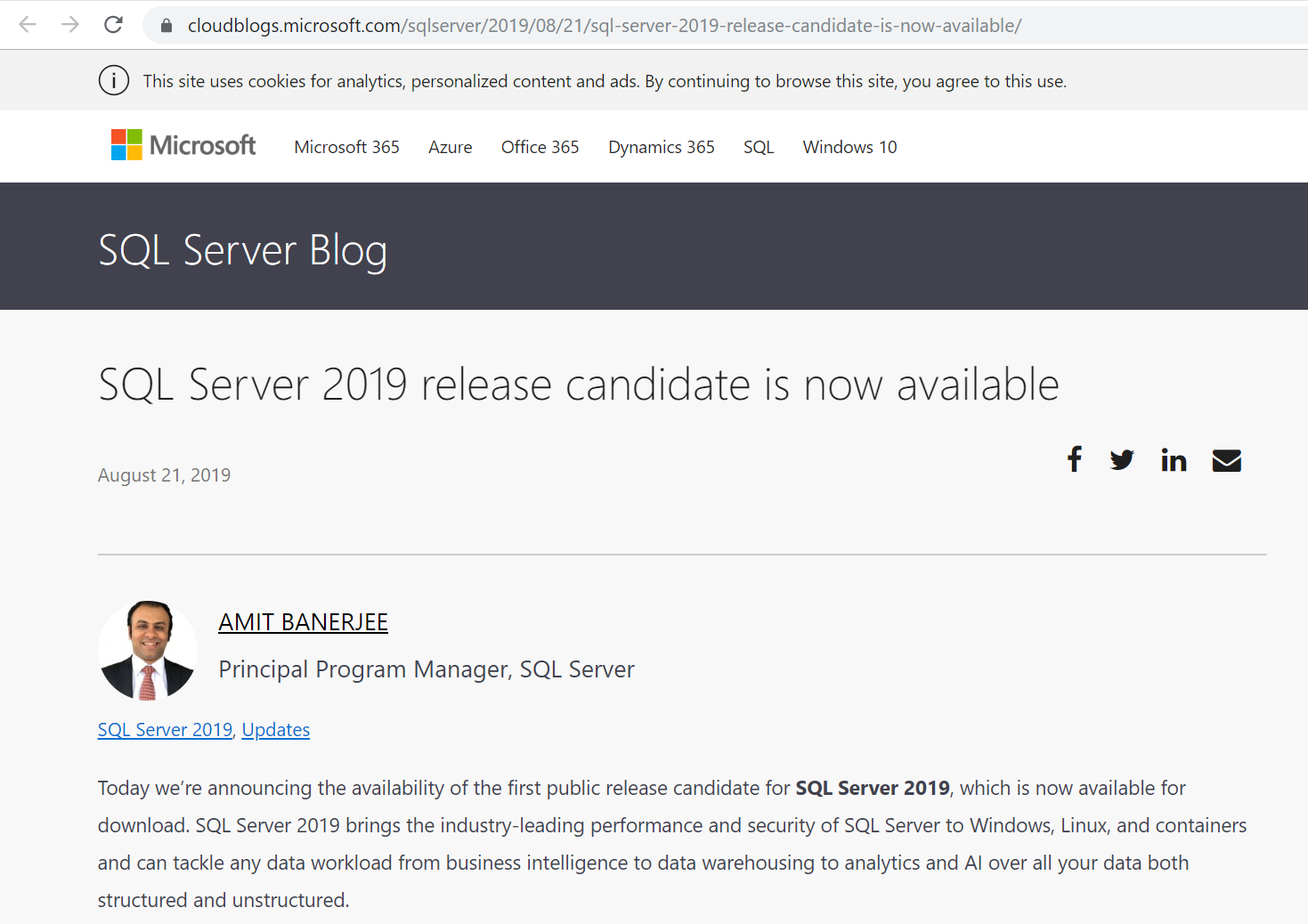
このRCはRelease Candidate(製品候補版)ということで、大きな問題などがなければ9月か10月にはGA(General Availability)されるだろうと思います。
今回は、GAに向けて、Docker環境のSQL Server 2019 (RHEL)にAdventureWorksDBを入れ、デモとして利用できる環境を作成します。
環境
今回は、以下の環境でインストールを実施しています。
- OS: Windows 10 Pro Version 1903 (OS Build 18362.295) - Docker Desktop: 2.1.0.1 (37199) - Docker Engine: 19.03.1 - Docker Compose: 1.24.1※OSは、macOS Mojave 10.14.6でも確認済みです。
インストール
インストールは、CTP3.2の時と同様です。
imageの個所をCTP3.2からRC1に変更することでSQL Server 2019 RC1を起動できます。
docker-compose up -dでSQL Serverを起動してください。docker-compose.yamlversion: '3' services: mssql: image: mcr.microsoft.com/mssql/rhel/server:2019-RC1 container_name: 'mssql2019-rc1-rhel' environment: - MSSQL_SA_PASSWORD=<your_strong_password> - ACCEPT_EULA=Y # - MSSQL_PID=<your_product_id> # default: Developer # - MSSQL_PID=Express # - MSSQL_PID=Standard # - MSSQL_PID=Enterprise # - MSSQL_PID=EnterpriseCore ports: - 1433:1433 volumes: # Mounting a volume does not work on Docker for Mac - ./mssql/log:/var/opt/mssql/log - ./mssql/data:/var/opt/mssql/dataAdventureWorksのダウンロード
MS Docs、もしくは GitHubより、AdventureWorks2017.bak をダウンロードしてください。
AdventureWorksの配置
AdventureWorksの配置(Windows)
ダウンロードしたAdventureWorks2017.bakファイルを、ホストの.\mssql\dataフォルダパス内に配置します。
cmd.exe> dir D:\Docker\mssql-2019\mssql\data /b AdventureWorks2017.bak <-ファイルが配置されていることを確認 Entropy.bin master.mdf mastlog.ldf model.mdf modellog.ldf model_msdbdata.mdf model_msdblog.ldf model_replicatedmaster.ldf model_replicatedmaster.mdf msdbdata.mdf msdblog.ldf tempdb.mdf tempdb2.ndf templog.ldfAdventureWorksの配置(Mac)
Docker on Macでは、docker-compose.yaml上でvolumesタグを指定できません。
そのため、docker cpコマンドを使用してAdventureWorks2017.bakファイルを/var/opt/mssql/dataディレクトリに配置します。ダウンロードしたAdventureWorks2017.bakファイルが存在するディレクトリに移動します。
※今回は、docker-compose.yamlファイルと同じディレクトリに配置しました。$ ls -al total 98224 drwxr-xr-x 4 ymasaoka staff 128 8 28 01:54 . drwxr-xr-x 12 ymasaoka staff 384 8 12 17:59 .. -rw-r--r-- 1 ymasaoka staff 50286592 8 28 01:54 AdventureWorks2017.bak -rw-r--r-- 1 ymasaoka staff 817 8 27 00:00 docker-compose.yaml
docker psコマンドを使用して、起動しているSQL Server 2019コンテナのIDを確認します。$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e0868b38e321 mcr.microsoft.com/mssql/rhel/server:2019-RC1 "/opt/mssql/bin/perm…" 4 days ago Up 4 seconds 0.0.0.0:1433->1433/tcp mssql2019-rc1-rhelこの例でいうと、
e0868b38e321がコンテナIDです。
このIDを使用して、Dockerコンテナ内の/var/opt/mssql/dataディレクトリにAdventureWorks2017.bakを配置します。$ docker cp AdventureWorks2017.bak e0868b38e321:/var/opt/mssql/dataDockerコンテナの中に入り、AdventureWorks2017.bakが配置されていることを確認してください。
$ docker exec -it e0868b38e321 "bash" [root@localhost /]# ls -al /var/opt/mssql/data total 121952 drwxr-xr-x 2 root root 4096 Aug 27 17:06 . drwxr-xr-x 6 root root 4096 Aug 22 21:21 .. -rw-r--r-- 1 501 games 50286592 Aug 27 16:54 AdventureWorks2017.bak # ファイルが配置されていることを確認 -rw-r----- 1 root root 256 Aug 22 21:21 Entropy.bin -rw-r----- 1 root root 4653056 Aug 27 16:59 master.mdf -rw-r----- 1 root root 2097152 Aug 28 11:07 mastlog.ldf -rw-r----- 1 root root 8388608 Aug 27 16:59 modellog.ldf -rw-r----- 1 root root 8388608 Aug 27 16:59 model.mdf -rw-r----- 1 root root 14024704 Aug 22 21:21 model_msdbdata.mdf -rw-r----- 1 root root 524288 Aug 22 21:21 model_msdblog.ldf -rw-r----- 1 root root 524288 Aug 22 21:21 model_replicatedmaster.ldf -rw-r----- 1 root root 4653056 Aug 22 21:21 model_replicatedmaster.mdf -rw-r----- 1 root root 14024704 Aug 22 21:34 msdbdata.mdf -rw-r----- 1 root root 524288 Aug 27 16:59 msdblog.ldf -rw-r----- 1 root root 8388608 Aug 27 16:59 tempdb.mdf -rw-r----- 1 root root 8388608 Aug 28 13:28 templog.ldfAdventureWorksの復元
AdventureWorksの復元(Windows)
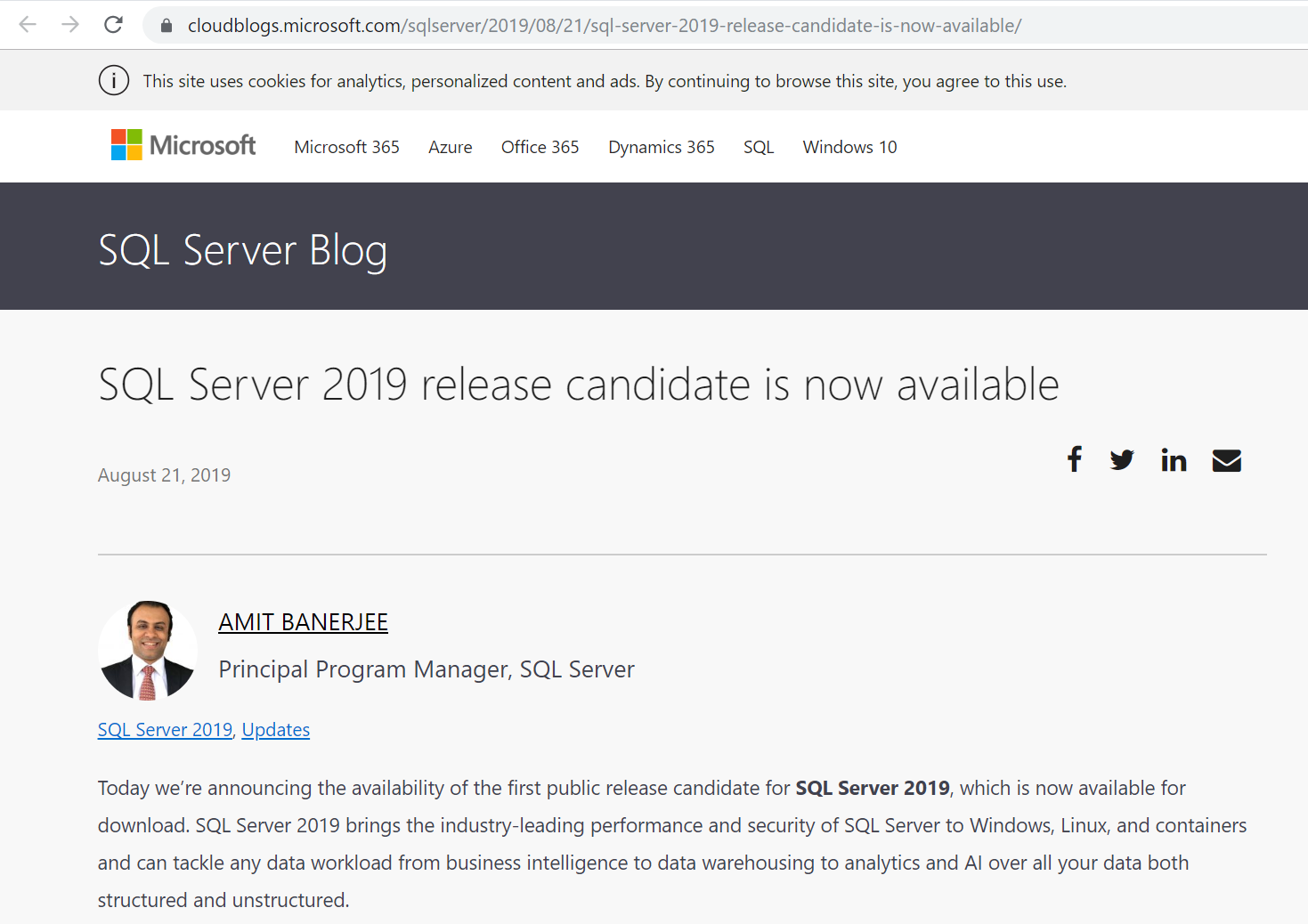
SSMS(SQL Server Management Studio)を起動します。
Dockerコンテナ上で起動しているSQL Server 2019 RC1にログインします。
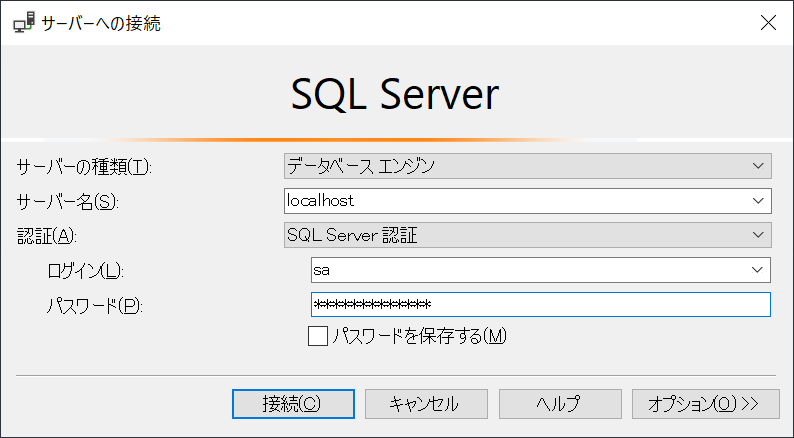
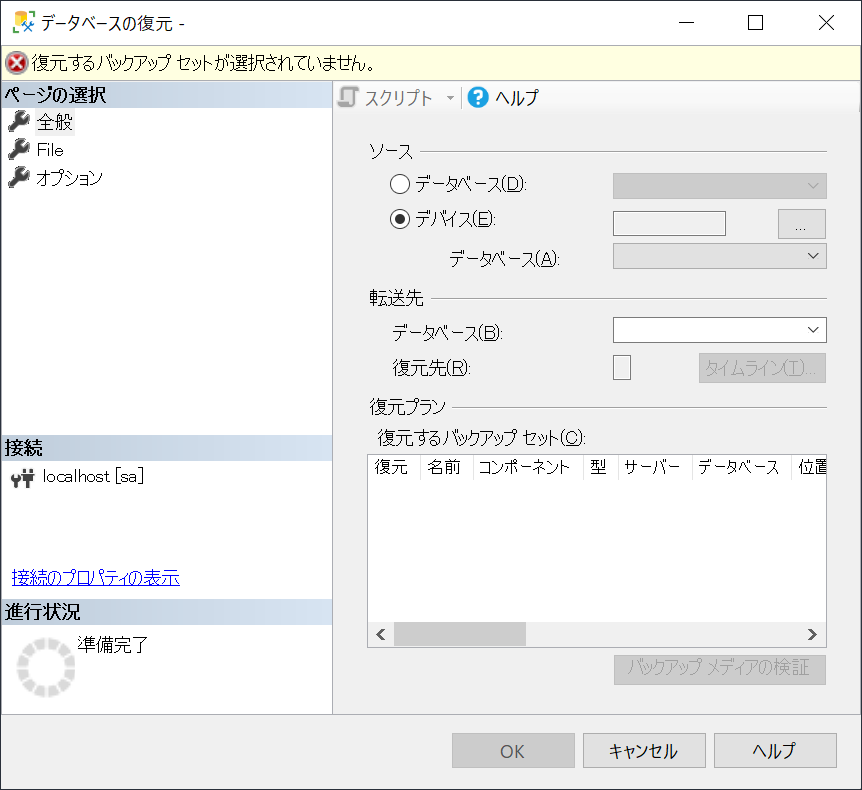
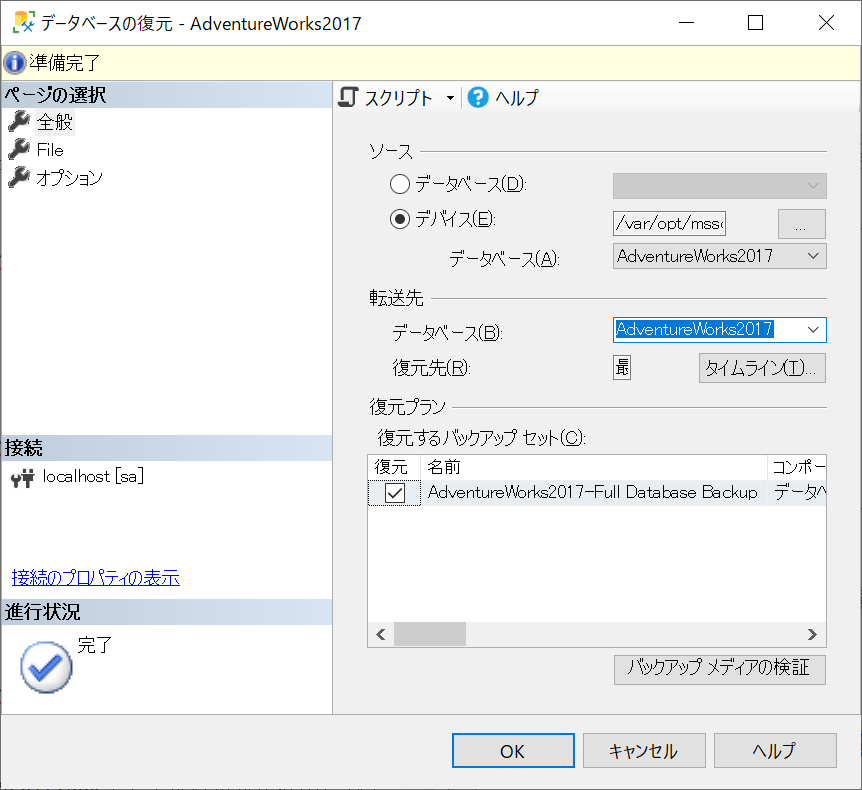
ログイン出来たら、[サーバー名] -> [データベース]を右クリックし、[データベースの復元]を選択します。
[データベースの復元]画面が表示されます。
[ページの選択] -> [全般]を選択し、[ソース]欄にあるラジオボタン[デバイス]を選択します。
ラジオボタン右横にある参照ボタン[...]を選択します。
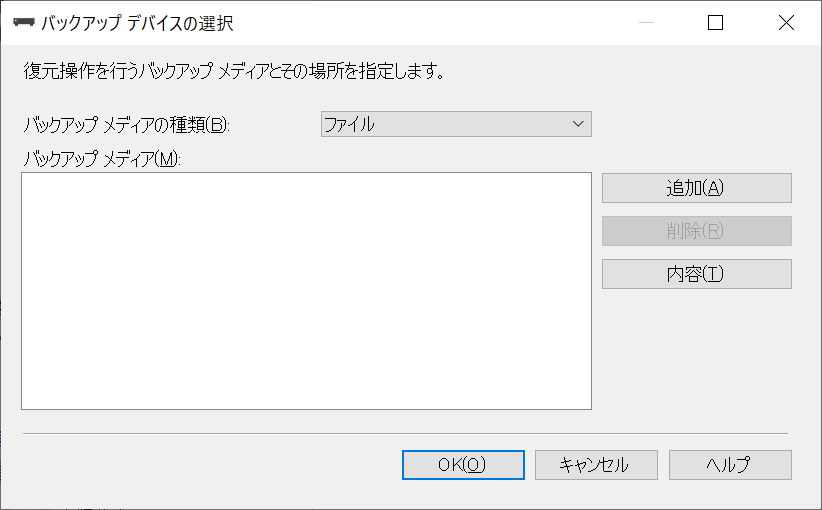
[バックアップ デバイスの選択]画面が表示されます。
[追加]ボタンを選択します。
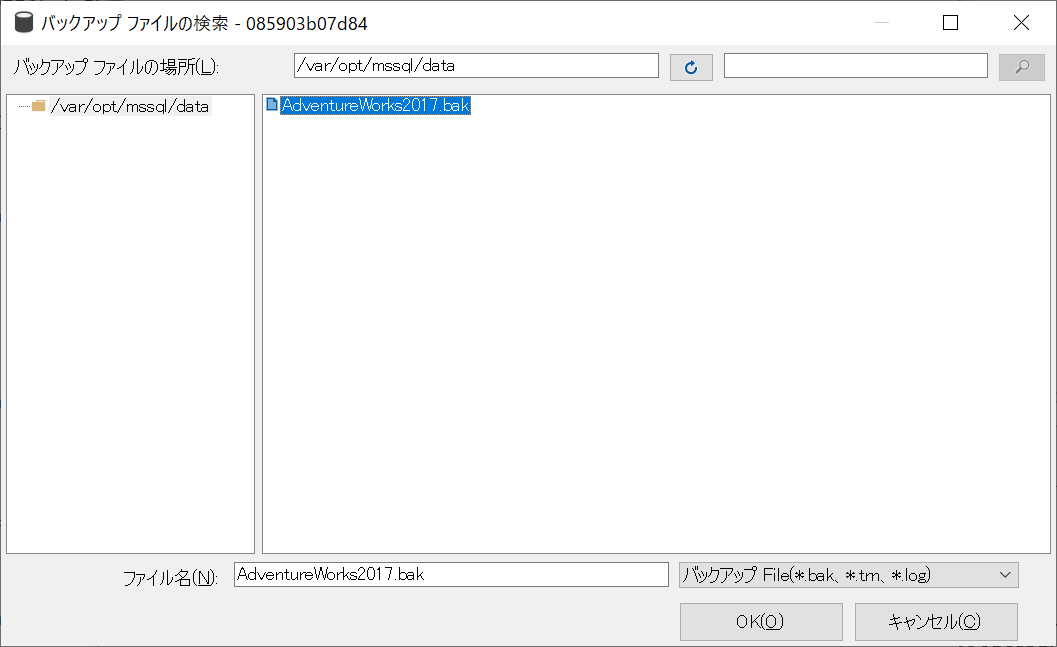
[バックアップ ファイルの検索]画面が表示されます。
/var/opt/mssql/dataディレクトリがデフォルトで表示されており、配置したAdventureWorks2017.bakが選択できることを確認します。
AdventureWorks2017.bakを選択し、[OK]を選択します。
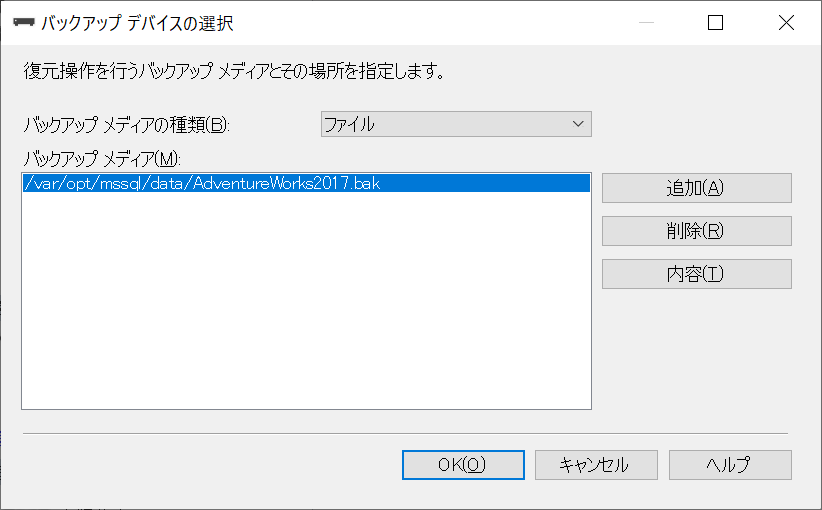
[バックアップ デバイスの選択]画面に、追加したAdventureWorks2017.bakファイルの情報が表示されていることを確認します。
[OK]を選択します。
[データベースの復元 - AdventureWorks2017]画面が表示されます。
[OK]を選択し、データベースの復元を開始します。
※必要に応じて、[File]タブや[オプション]タブ内の設定を行ってください。
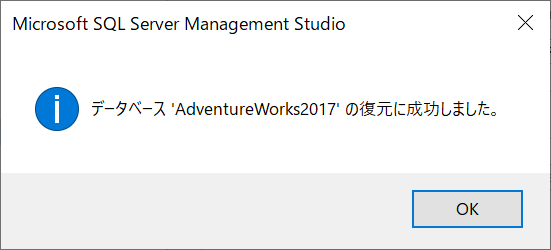
復元に成功すると、以下の画面が表示されます。
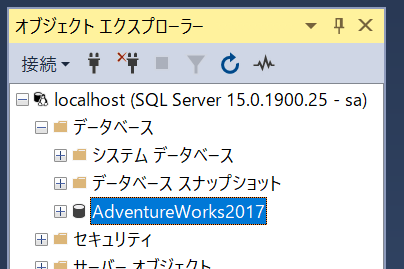
オブジェクトエクスプローラー上で[AdventureWorks2017]のDBが追加されたことを確認してください。
AdventureWorksの復元(Mac)
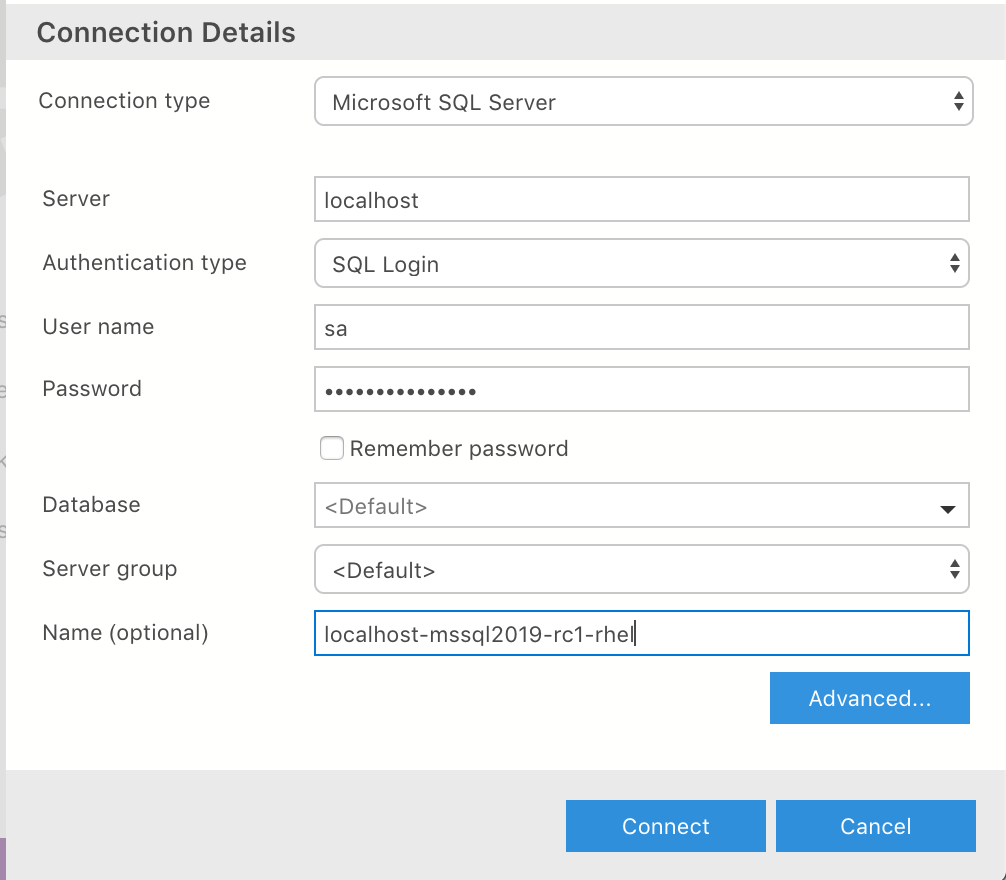
Azure Data Studioを起動します。
Dockerコンテナ上で起動しているSQL Server 2019 RC1にログインします。
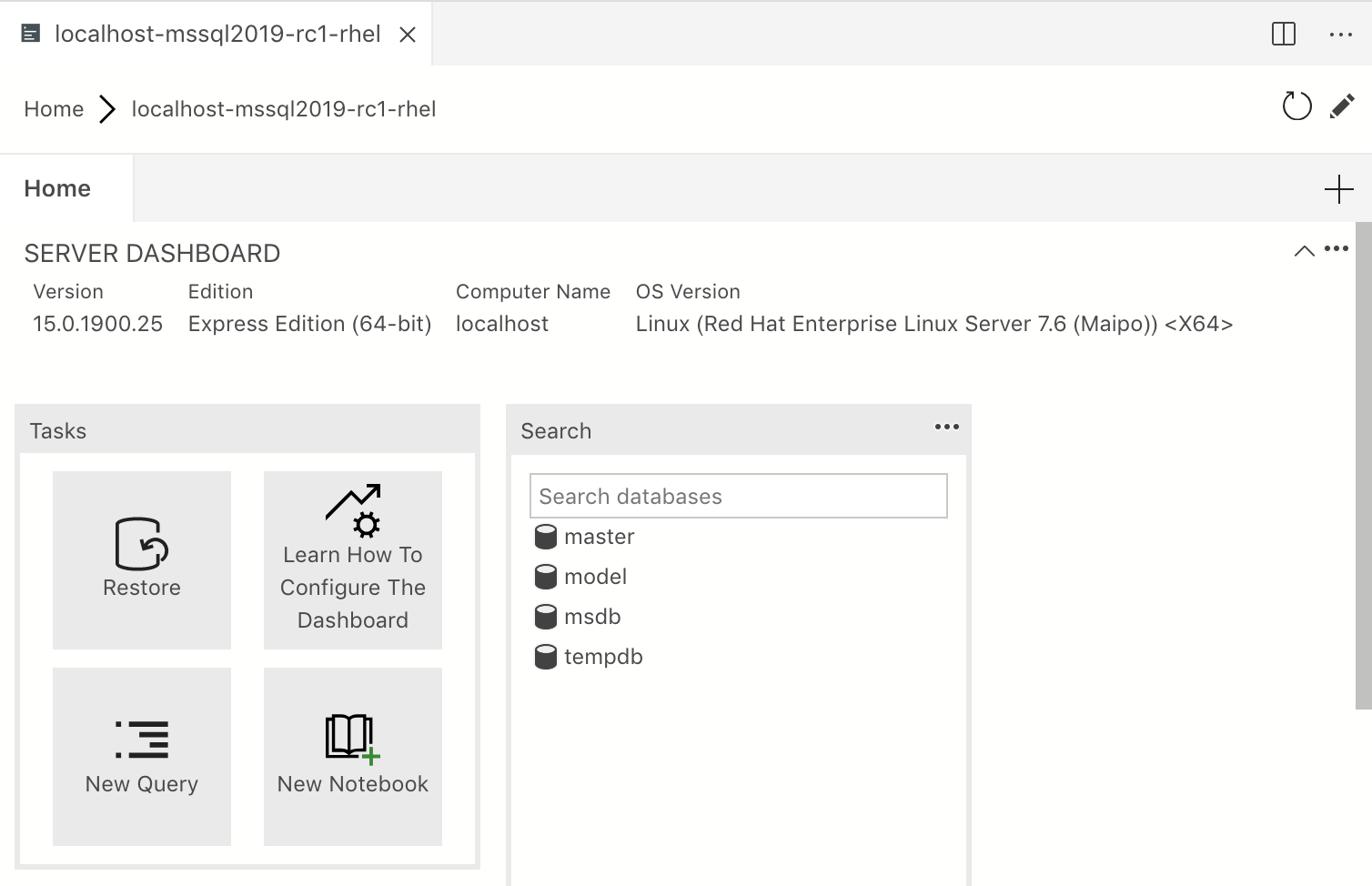
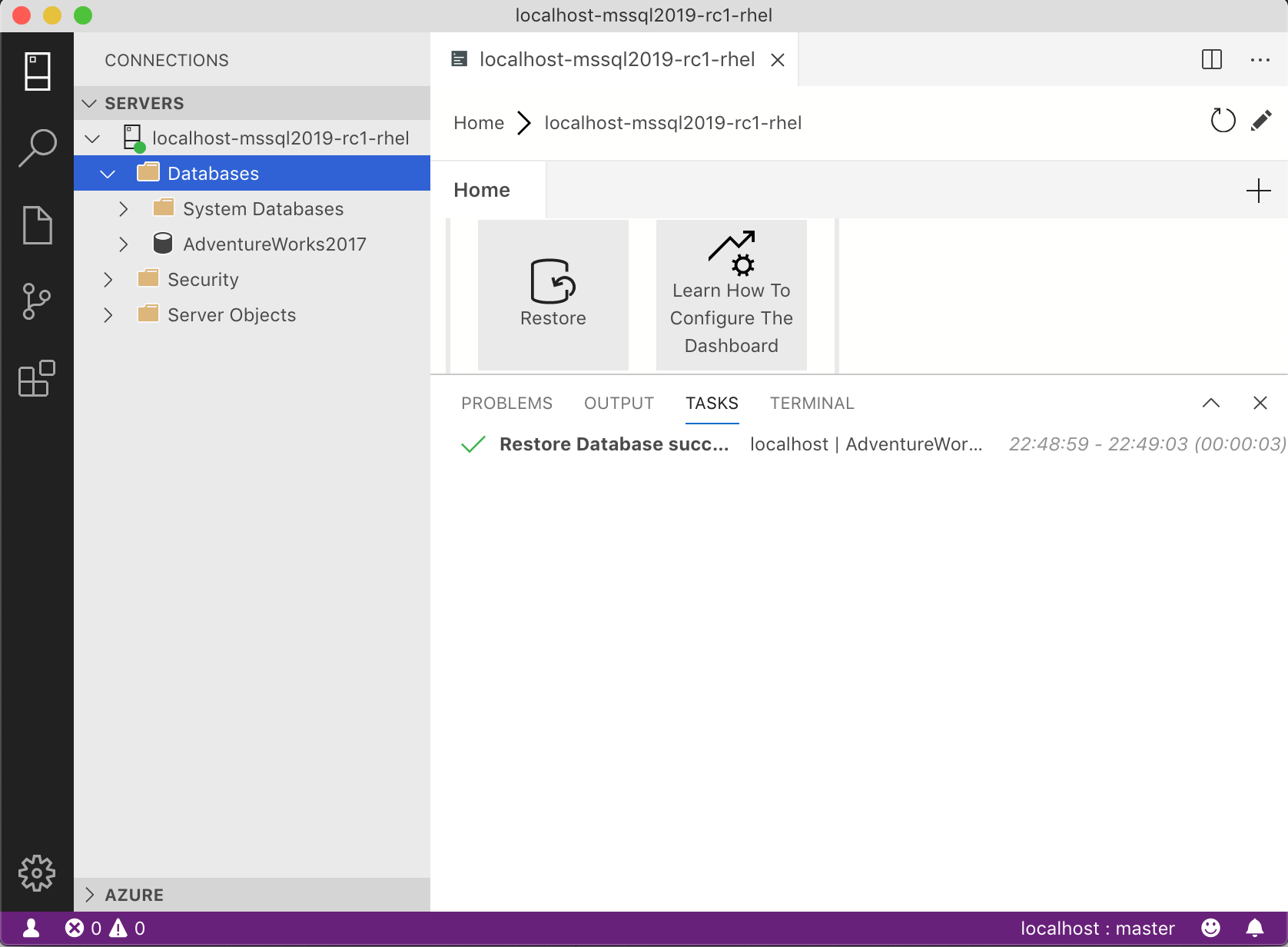
ログイン出来たら、SERVER DASHBOARDを開き、[Tasks] -> [Restore]を選択します。
[Restore database]画面が開きます。
[General]タブを選択します。
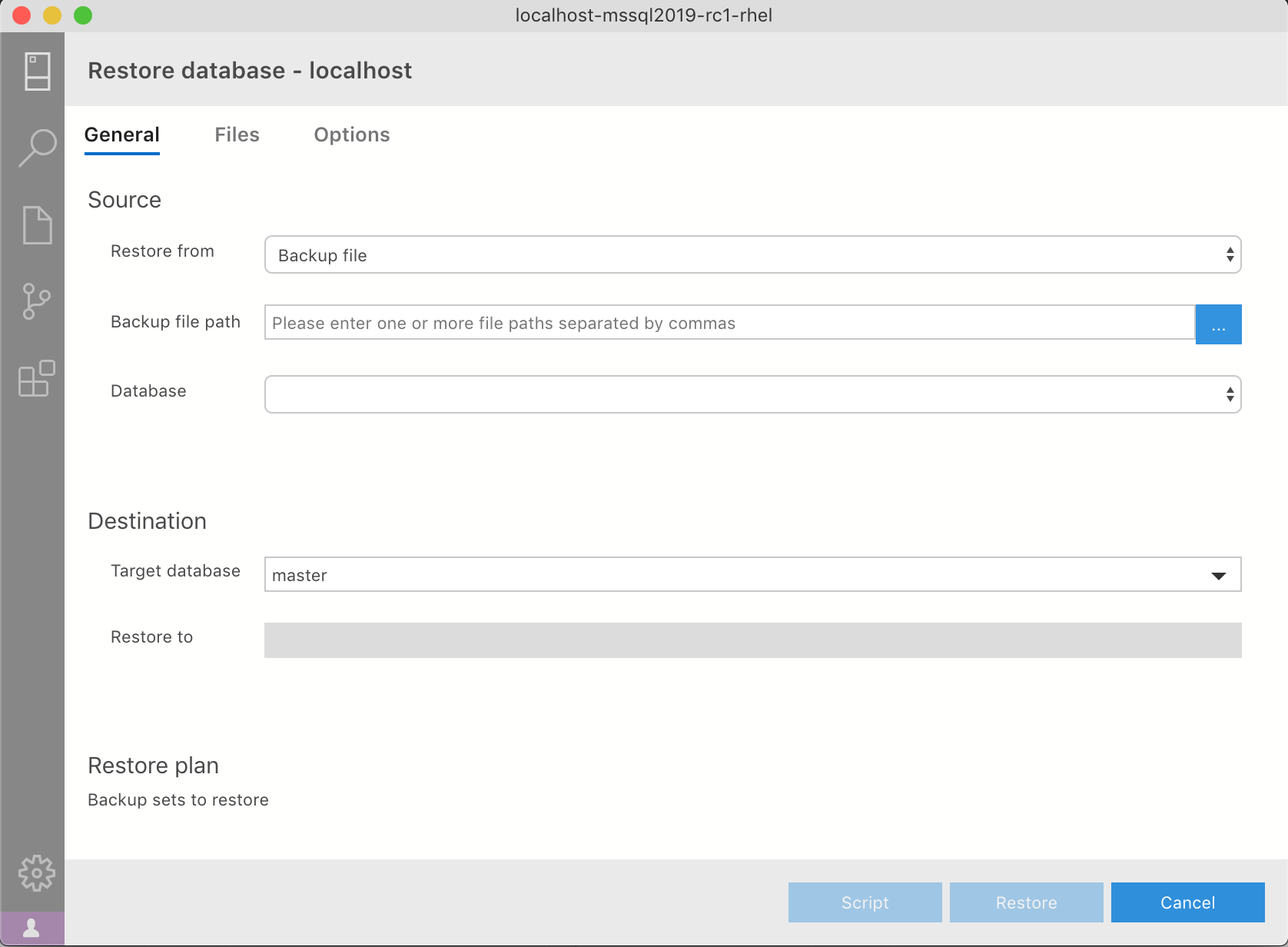
[Source] -> [Restore from]欄で、[Backup file]を選択します。
[Backup file path]欄にあるファイル選択ボタンを選択します。
[Select a file]画面が表示されます。
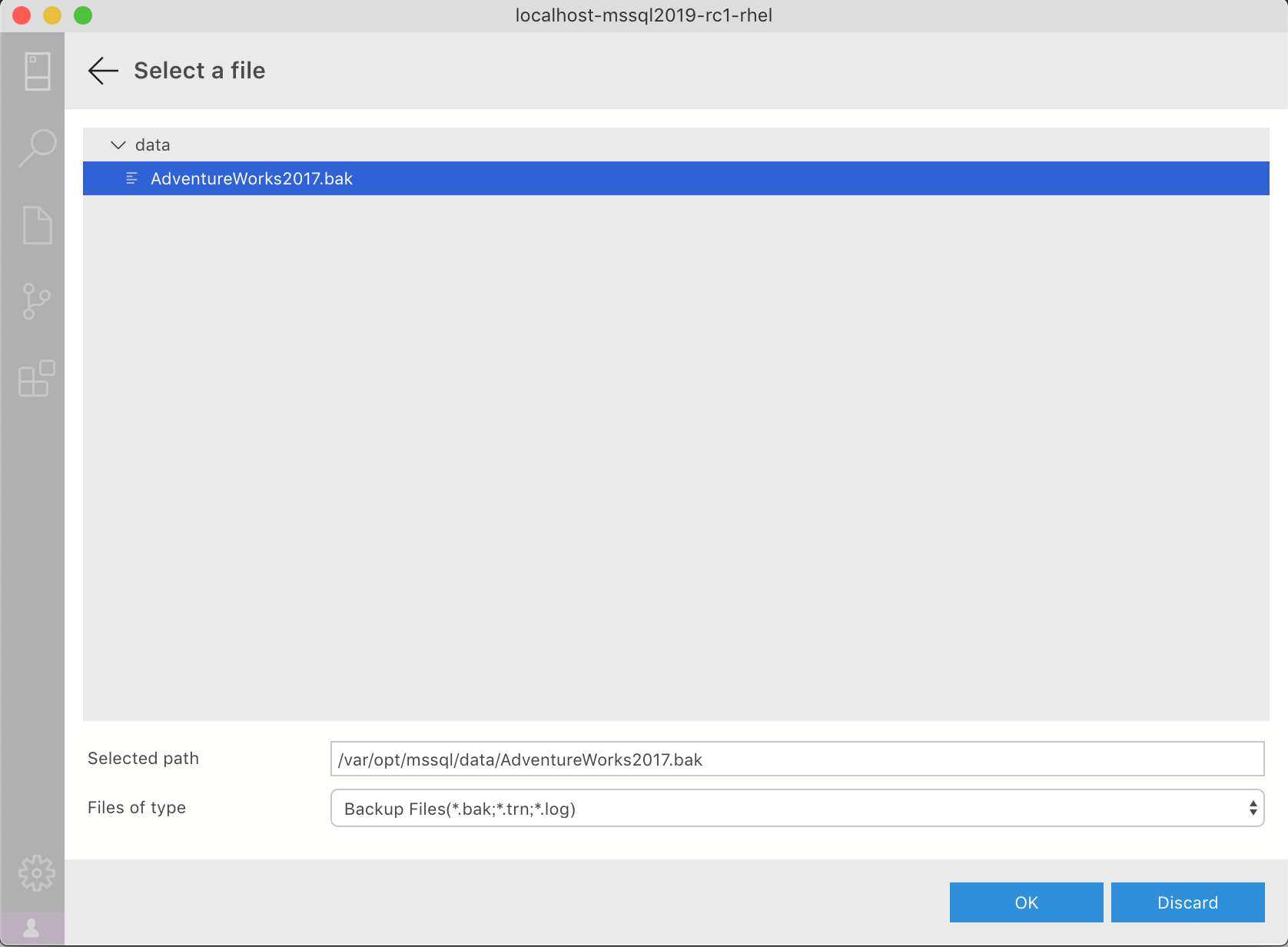
dataディレクトリ以下に表示されている[AdventureWorks2017.bak]ファイルを選択し、[OK]を選択します。
[Restore database]画面に戻ります。
復元する内容を確認し、[Restore]を選択します。
データベースのリストアが開始されます。
問題ない場合は、[TASKS]コンソールに[Restore Database succeeded]が表示されます。
[AdventureWorks2017]のDBが追加されたことを確認してください。
終わりに
Docker環境のSQL Server 2019 (RHEL)にAdventureWorksDBを入れて、デモとして利用できる環境を作成しました。
何も問題がなければ、2019/09もしくは2019/10には、SQL Server 2019はGAを迎えられると思います。
GAの前にいろいろ試して、ぜひ活用してみてください。JSSUG(Japan SQL Server User Group)では、月1回、SQL Serverの勉強会を行なっています。
Microsoft MVPの方など、詳しい方もいらっしゃるので、興味ある方はぜひこちらにも参加してください。またJSSUGにはSlackグループもあります。
SQL Serverの最新情報などをいち早く確認することができますので、こちらもぜひJoinしてみてください。関連リンク
参考情報
- 投稿日:2019-08-28T19:56:20+09:00
【Minecraftマルチサーバー】自動バックアップがようやく動くようになったメモ
cronの仕様がよくわからずに苦戦していたMinecraftマルチサーバーの自動バックアップ実装について、ようやく実現できたのでメモしておく。
まずググってそのまま動かしてみる
「Minecraftサーバをscreenとcronでプラグインを使わずに自動再起動する」から引用。バックアップ部分を追加。
world_backup.sh#!/bin/bash WAIT=60 STARTSCRIPT=/home/hoge/Minecraft_server/start.sh SCREEN_NAME='minecraft' screen -p 0 -S ${SCREEN_NAME} -X eval 'stuff "say '${WAIT}'秒後にサーバーを再起動します\015"' screen -p 0 -S ${SCREEN_NAME} -X eval 'stuff "say すぐに再接続可能になるので、しばらくお待ち下さい\015"' sleep $WAIT screen -p 0 -S ${SCREEN_NAME} -X eval 'stuff "stop\015"' cd /mnt/hoge/world_backup DIR=`date '+%Y%m%d_%H%M'` tar -zcvf $DIR.tar.gz -C /home/hoge/Minecraft_server world while [ -n "$(screen -list | grep -o "${SCREEN_NAME}")" ] do sleep 1 done $STARTSCRIPTサーバー起動スクリプトはこのようにした。
start.sh#!/bin/bash screen -S minecraft java -XX:+UseBiasedLocking -XX:+DisableExplicitGC -XX:+UseTLAB -Xms2G -Xmx2G -XX:TargetSurvivorRatio=90 -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=4 -XX:-UseParallelGC -XX:-UseParallelOldGC -XX:ParallelGCThreads=2 -XX:ConcGCThreads=2 -jar server.jar nogui毎朝6時に実行するよう「crontab -e」で設定する。
0 6 * * * /home/hoge/Minecraft_server/world_backup.sh翌朝、動いてない。
cronの環境変数を設定してみる
cronでスクリプトを実行する際に、ユーザーが持つ環境変数を使うのではなくcronデーモンが独自に環境変数を持っている。\$SHELLが/bin/shだったり、\$PATHが/binと/usr/binにしか通ってなかったりなかなか貧弱であるので、自分で設定する。これも、「crontab -e」で設定できる。
SHELL = /bin/bash HOME = /home/hoge PATH = /usr/bin:/bin:/usr/local/bin:/usr/sbin:/sbin:/usr/local/sbin 0 6 * * * $HOME/Minecraft_server/world_backup.sh 10 6 * * * $HOME/Minecraft_server/start.shついでに\$HOMEも設定する。また、原因の切り分けのためサーバー起動スクリプトを分離しておく。そのため、world_backup.shの\$STARTSCRIPT行はコメントアウトする。cronの実行結果をメールで受け取るため、postfixをインストールする。とりあえずはLocal onlyでよい。また、Debianではデフォルトでcronのログが出なくなっているので、/etc/rsyslog.confのcron行のコメントアウトを外し、cronを再起動する。
翌朝、動いた形跡はあるが働いていない。
処理の順序を変え、起動時にscreenにアタッチしない
/var/spool/mail/hogeを覗いてみると、「tar: world: file changed as we read it」とある。どうやらサーバーがセーブを終える前にtarが走っているらしい。低スペなのでセーブが遅い。
そこで、tarでバックアップする処理とwhileでループさせる処理を逆にしてみる。world_backup.sh#!/bin/bash WAIT=60 # STARTSCRIPT=$HOME/Minecraft_server/start.sh SCREEN_NAME='minecraft' screen -p 0 -S ${SCREEN_NAME} -X eval 'stuff "say '${WAIT}'秒後にサーバーを再起動します\015"' screen -p 0 -S ${SCREEN_NAME} -X eval 'stuff "say すぐに再接続可能になるので、しばらくお待ち下さい\015"' sleep $WAIT screen -p 0 -S ${SCREEN_NAME} -X eval 'stuff "stop\015"' while [ -n "$(screen -list | grep -o "${SCREEN_NAME}")" ] do sleep 1 done cd /mnt/hoge/world_backup DIR=`date '+%Y%m%d_%H%M'` tar -zcvf $DIR.tar.gz -C $HOME/Minecraft_server world # $STARTSCRIPTまた、同じく/var/spool/mail/hogeに、「Must be connected to a terminal」とある。検索をかけると、同じ問題に悩む人を多く見つけたが、解決法は見つけられなかった。原因は単純で、screenを起動するとアタッチしたままになってしまい、cronがコマンドの実行に成功したか判断できなくなってしまうためだ。起動時にアタッチしない「-md」オプションを記述して解決した。また、サーバーのjarファイルのパスを丁寧丁寧丁寧に記述した。
start.sh#!/bin/bash screen -md -S minecraft java -XX:+UseBiasedLocking -XX:+DisableExplicitGC -XX:+UseTLAB -Xms2G -Xmx2G -XX:TargetSurvivorRatio=90 -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=4 -XX:-UseParallelGC -XX:-UseParallelOldGC -XX:ParallelGCThreads=2 -XX:ConcGCThreads=2 -jar $HOME/Minecraft_server/server.jar nogui翌朝、バックアップは成功したがサーバーが起動していない。
カレントディレクトリ
原因を探ろうとサーバーにssh接続したら、あることに気づいた。ホームディレクトリ直下にサーバーの設定ファイルが生成されていた。原因は単純で、cronに登録したstart.shはカレントディレクトリ\$HOME=/home/hogeで作業をする。スクリプトの中で\$HOME/Minecraft_serverの中のjarを起動するが、カレントディレクトリは\$HOMEのままなので、\$HOMEの直下で設定ファイルを探す。探しても見当たらないため、サーバーは初回起動時と同じ挙動を見せるのだ。start.shを今一度書き換えて解決した。
start.sh#!/bin/bash cd $HOME/Minecraft_server screen -md -S minecraft java -XX:+UseBiasedLocking -XX:+DisableExplicitGC -XX:+UseTLAB -Xms2G -Xmx2G -XX:TargetSurvivorRatio=90 -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=4 -XX:-UseParallelGC -XX:-UseParallelOldGC -XX:ParallelGCThreads=2 -XX:ConcGCThreads=2 -jar server.jar nogui翌朝、無事成功。
バックアップは大切だ
world_backup.shの\$STARTSCRIPT行のコメントアウトを外し、start.shをcronから外しておく。
これで毎朝6時に勝手にバックアップを取るようになった。快適なマイクラライフ、と言いたいところだが、私は受験生なのである。
- 投稿日:2019-08-28T19:47:42+09:00
ShellScript 変数 に 格納 された 文字列 を 文字数 を 指定 して 出力 ~${変数:数値A:数値B}~
目的
- ShellScriptで変数に格納された文字列を起点となる文字から何文字出力するという方法で出力する。
書き方の例
- 変数には任意の文字列が格納されているものとする。
- コンソールに変数を出力するため
echoコマンドの後に紹介する処理を記載する- 下記にShellScriptの処理を記載する。
echo ${変数:起点文字の番号:起点文字から何文字抜き出すかの数字}より具体的な例
- 変数
numberに文字列123456789を格納する。- 下記にShellScriptの処理を記載する。
※>はコンソールの出力を表す。# 変数格納 number="123456789" # 変数の0文字目から4文字抜き出してコンソールに表示する echo ${number:0:4} >1234 # 変数の4文字目から5文字抜き出してコンソールに表示する echo ${number:4:5} >56789 # 変数の2文字目から2文字抜き出してコンソールに表示する echo ${number:2:2} >34
- 変数
stringに文字列おはようございますを格納する。- 下記にShellScriptの処理を記載する。
string="おはようございます" echo ${string:1:1} >は echo ${string:3:4} >うござい echo ${string:0:4} >おはよう echo ${string:4:5} >ございます
- 投稿日:2019-08-28T19:16:45+09:00
Bashでよく使うコマンドまとめ
普段あまり書く機会がなく、いざ書くとき結構忘れているのでまとめておく。
if
基本構文
条件式に指定されたコマンドの終了ステータスを判定し分岐を行う。
終了ステータスが0のときは真、それ以外は偽となる。if 条件式1 ; then 処理1 elif 条件式2 ; then 処理2 else 処理3 fi本来条件式の後のthenは次の行に記載するが、
;をつけることで条件式と同一行に記載可能。また、elseの後はthenは不要であり、
if文を閉じるにはfiが必要。条件式
if文での条件式の評価にはtestコマンドを使用する。
testコマンドは比較の結果を0か1の終了ステータスで返すだけで、
メッセージ出力がないため、評価に特化したコマンドとなる。
test 引数の条件式と記載することが可能であるが、
[ 引数の条件式 ] と省略して記載が可能。
以降は省略形で記載する。
また、省略時カッコと条件式の間のスペースがマストのため、要注意。逆に言うと条件式比較ではtestコマンドを使っているにすぎないので、
testコマンド以外を使うことも可能。testにおける条件式は文字列の比較と数値の比較で記載方法が異なる。
それぞれ別でまとめる。数値の比較
num1は条件式左の数字(testコマンドの第一引数)、num2は右(第二引数)である。
オプション 数式的意味 例 何の略か -eq num1 = num2 5 -eq 5 equal -ne num1 ≠ num2 5 -ne 5 not equal -lt num1 < num2 5 -lt 6 less than -le num1 ≦ num2 5 -le 6 less than or equal -gt num1 > num2 5 -gt 4 greater than -ge num1 ≧ num2 5 -ge 4 greater than or equal if [ 5 -eq 5 ] ; then echo "等しい" fi文字列の比較
文字列においては、イコールが使用される。
なお、==ではないので注意。
オプション 数式的意味 例 = string1 = string2 "hoge" = "fuga" != string1 ≠ string2 "hoge" != "fuga" -z string1 = ""(0文字ならば真) -z string1 -n string1 ≠ ""(0文字でなければ真) -n string1 if [ "文字" = "文字" ] ; then echo "等しい" fiAND,OR条件
AND,OR条件は2つの書き方が可能。
1つ目はtestコマンドのオプションを使って記載する方法
2つ目はbashコマンドを使って記載する方法testコマンドのオプションを使う
testコマンドのオプションなので、
ひとつの[]内に記載が可能。
ただし、ぱっとみでわからないので視認性が下がるかも。
| オプション | 意味 | 例 |
|:-----------------:|:------------------:|:------------------:|
| -a | AND | 5 -a 5 |
| -o | OR | 5 -o 5 |なお、優先順位は-oのほうが高いため、
[ 真 -o 偽 -a 偽 ]
の結果は真となる。
()で囲うことでグルーピングが可能だが、
その場合は必ず()をエスケープする必要がある。bashコマンドを使う
条件式内のtest以外のbashコマンドを使用する。
具体的には以下
コマンド1 && コマンド2:1つ目の処理が成功した場合のみ、2つ目のコマンドが実行される。
コマンド1 || コマンド2:1つ目の処理が失敗した場合のみ、2つ目のコマンドが実行される。上記のコマンド1と2をtestコマンドに置き換える形である。
[ 条件式1 ] || [ 条件式2 ]なお、こちらの優先順位は前から評価されるため、
[ 真 ] || [ 偽 ] && [ 偽 ]
は真もしくは偽で真を判定したのち、真かつ偽の判定が実施され、
結果は偽となる。$ [ a = a ] || [ b = bb ] && [ c = cc ]; echo $? 1逆に以下の場合は真である。
$ [ a = a ] && [ b = b ] || [ c = cc ]; echo $?
0
条件の否定
コマンド前に!をつけることで、
終了ステータスを反転させることが可能。(終了ステータスが0は1に、0以外は0にする)
!のあとは必ずスペースを入れること。[ c = cc ]; echo $? 1 ! [ c = cc ]; echo $? 0testコマンドの引数でも可能。
[ ! c = cc ]; echo $? 0配列
普段phpなどを書いていると、
bashの配列で,を使わないことを忘れがちなので一応メモ。定義
空の配列を定義
array=() $ echo "${array}" # 何も表示されない初期値ありの配列を定義
array=("a" "b" "c") echo ${array[@]} a b cコマンドの結果を配列に格納
cd /home/hoge ls a.csv b.csv c dirlist=(`ls -la /home/hoge | grep '*.csv'`) echo ${dirlist[0]} a.csv値の追加
現在のarrayを入れて再定義するみたいなイメージ
array=("${array[@]}" "d") echo ${array[@]} a b c d値の取得
インデックス番号を指定でOK
echo ${array[0]} a@で全要素表示
echo ${array[@]} a b c dfor
基本構文
for 繰り返し条件; do 処理 done初期値、ループ条件、ループ時の処理
鉄板パターンも記載可能。
max=10 for ((i=0; i < $max; i++)); do echo $i doneファイルの中身を読み取り
for i in $(cat filetest.txt ); do echo $i done 1 2 3 4 5 6 7 8 9配列の中身を操作
array=(0 1 2 3 4 5 6 7 8 9) for i in ${array[@]}; do echo $i done 0 1 2 3 4 5 6 7 8 9変数展開
シングルクォートとダブルクォート
変数などを文字列で展開するためには、
ダブルクォートを使用する。echo "${var}" test "``` シングルクォートだと展開されないので注意 ```bash echo '${var}' ${var}mysqlへ接続し、結果をファイル出力
基本
セキュリティなどでINTO OUTFILEが使えない場合、
bashからリダイレクトさせて結果を取得する。
Passを変数に入れるとセキュリティ項目の設定次第ではエラーになるので、
その場合は設定を変えるかできないなら都度入力するようにする。
SQLは2行以上記載する場合はインデントを入れるとエラーになるので注意。結果ファイルはtsv形式で格納される。
MYSQL_HOST='AAA' MYSQL_SCHEMA='DBname' MYSQL_ID='UserName' OUTPUT_FILE="test.tsv" SQL="SELECT * FROM test Where age > 30 ;" mysql -h $MYSQL_HOST -u $MYSQL_ID -p -D $MYSQL_SCHEMA > ${OUTPUT_FILE} <<EOF ${SQL} EOF結果を変数に格納
変数=$(コマンド)でコマンドの結果を変数に格納できる。
ただし、横方向に見ながらスペース区切りで挿入されるので、
2カラム以上を抽出する場合は使えなそう。
1カラムだけ取り出してその値をごにょごにょやるとかなら使えそう。MYSQL_HOST='AAA' MYSQL_SCHEMA='DBname' MYSQL_ID='UserName' OUTPUT_FILE="test.tsv" SQL="SELECT * FROM test Where age > 30 ;" RESULT=$(mysql -h $MYSQL_HOST -u $MYSQL_ID -p -D $MYSQL_SCHEMA <<EOF ${SQL} EOF )ヒアドキュメント
文字列をプログラムに埋め込むためのもので、
改行などもそのまま埋め込まれるので、
改行が必要なコマンドや、同じコマンドが連続する際に使用する。echo "123" echo "123" echo "123" echo "ABC" echo "DEF" echo "GHI"これを
cat <<EOD 123 456 789 ABC DEF GHI EODこうできる。
レコード数の確認方法
wc -l ファイル名タブ⇒カンマに変換
sedが便利。
grepを組み合わせれば該当フォルダをすべて置換など可能。
grep -l '\t' ./*.txt | xargs sed -i.bak -e 's/\t/,/1'参考
- 投稿日:2019-08-28T13:40:34+09:00
fdiskコマンド
はじめに
ディスクのパーティションを設定するときに使用するfdiskについてのメモです
結論
fdiskには-uオプションをつけてパーティションの区切りをセクタ番号で表示しましょう
ハードディスクの2種類のアクセス方式
CHS方式
- 10年以上前の旧式のハードディスクではC(シリンダ)H(ヘッド)S(セクタ)のCHSの情報を与えてどのセクタのデータを読み書きするかを指示
- 当時MS-DOSの使用でディスクパーティションはシリンダ単位で分ける必要があった。LinuxもデュアルブートなどではMS-DOSやwindowsと共通の仕様に従うことはそれなりに意味があったのでLinux版のfdiskもパーティション作成ではデフォルトでCHS方式でディスクの情報を表示
LBA方式
- 現在のハードディスクのアクセス方式。すべてのセクタに0からの通し番号でアクセス
fdiskコマンド
fdiskコマンドはデフォルトでCHS方式でディスクの情報を表示。パーティションの始点と終点がシリンダ番号で表示されているがこれは正確な情報ではない
参考
- 投稿日:2019-08-28T06:16:43+09:00
Oralcle CloudでNVIDIAのGPUインスタンスを構築する
はじめに
本記事は、Oralcle CloudでNVIDIAのGPUインスタンスを構築する手順についての記事になります。
機械学習でディープラーニングを行う場合に必要なGPUですが、クラウドサービスを使用して環境構築を行う場合、自前でUbuntuにNVIDIAのドライバ、CUDA、cuDNN等をインストールして使用する方法と、各クラウドサービスが提供するマシンイメージを利用方法の二つに大別できます。
自前でUbuntuにNVIDIAのドライバ等をインストールする場合は、自分で環境のセットアップを行う必要があるため、初めての場合は時間がかかると思います。逆に、クラウドサービスが提供するマシンイメージを利用する場合は、インスタンスを作成するだけで、いきなりGPUが使用できます。但し、GPUになるので、普通のサーバインスタンスに比べると料金が高額になるので注意が必要です。
本記事では、Oralcle CloudのNVIDIAのイメージを例に記載しています。
NVIDIA
Oracle Cloudでは、NVIDIA GPU Cloud Imageを利用することで、導入時のセットアップを省略し、最適化された環境で機械学習のワークロードの実行ができます。
インスタンスの作成
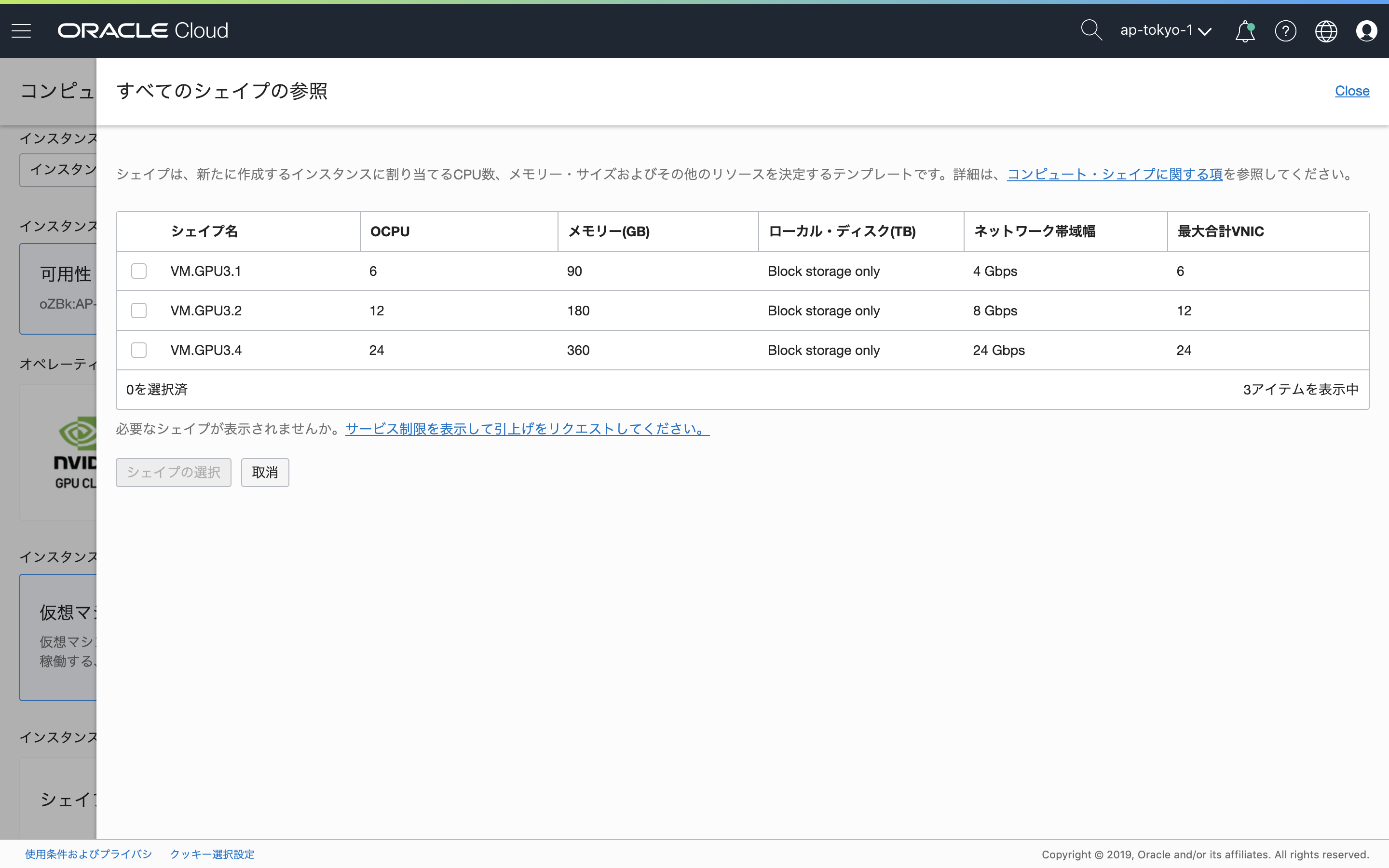
コンソールメニューから、「コンピュート」-「インスタンス」を選択し、「インスタンスの作成」をクリックします。
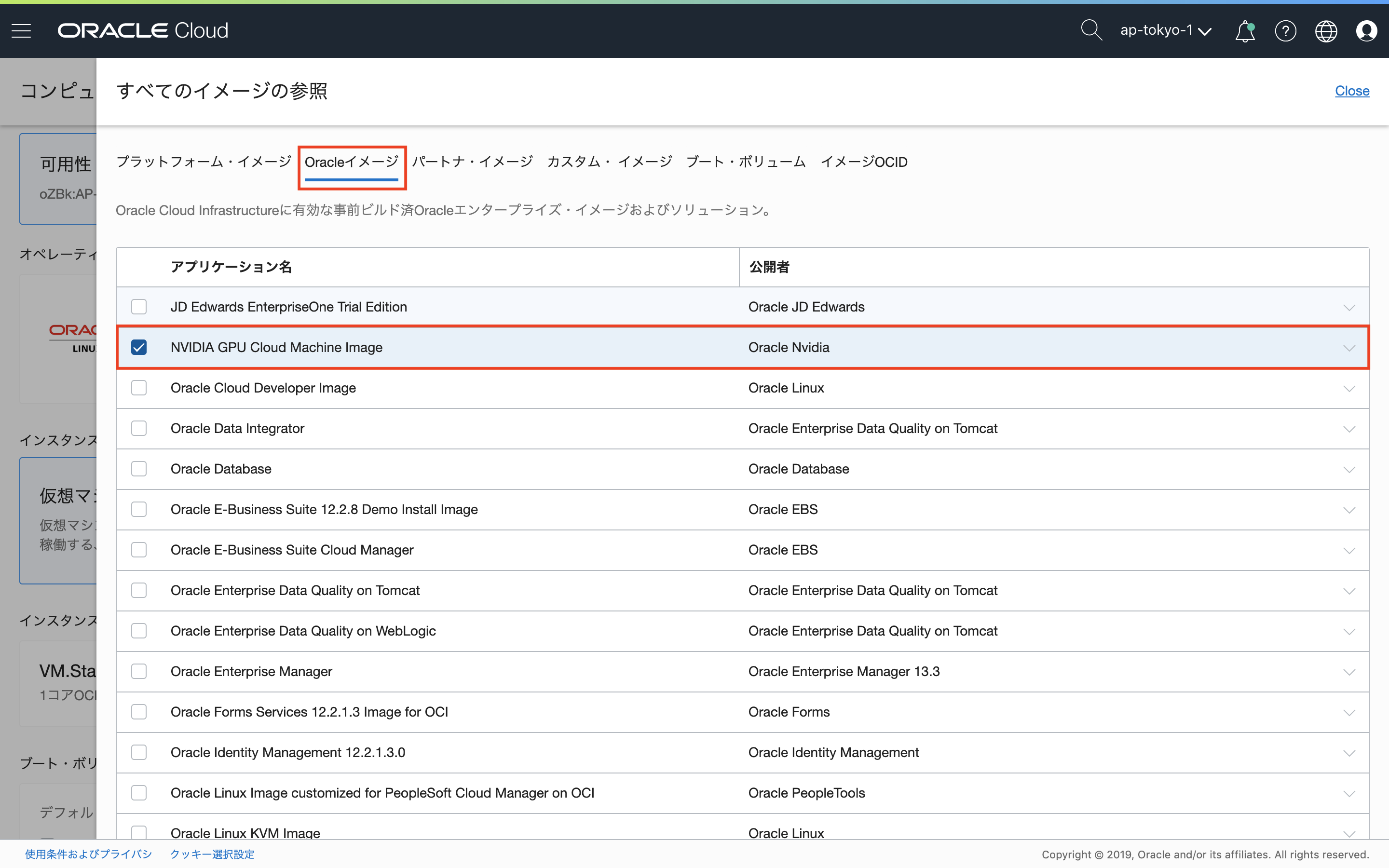
コンピュート・インスタンスの作成ウィンドウで、「イメージ・ソースの選択」をクリックし、画面上部の「Oracleイメージ」を選択。アプリケーション名から、NVIDIA GPU Cloud Image Machine Imageにチェックを入れます。
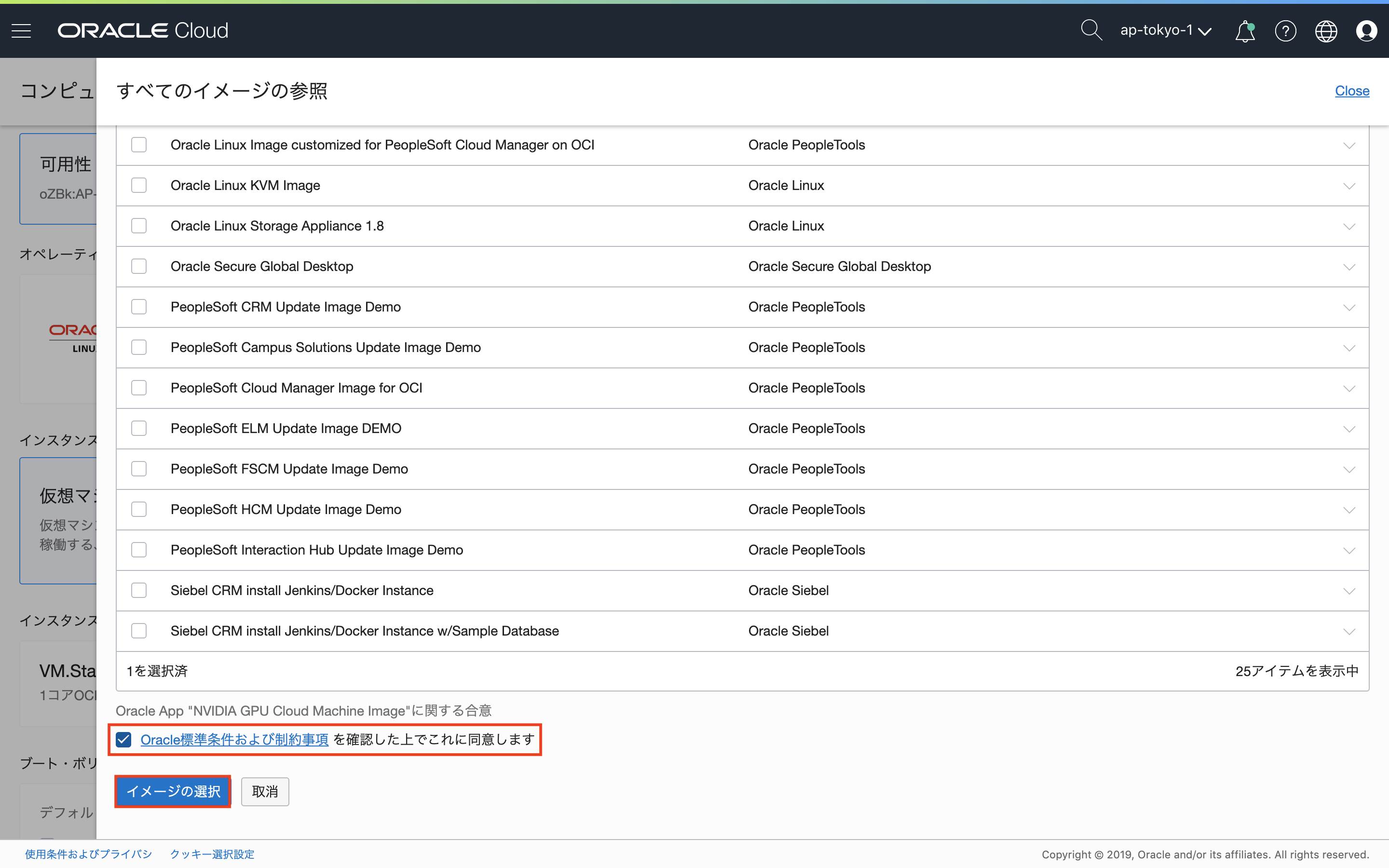
画面下部にもチェックも入れます。なお、NVIDIA GPU Cloud Image Machine Imageを使用することに対するライセンス料金は発生しません。(Oracleに確認)
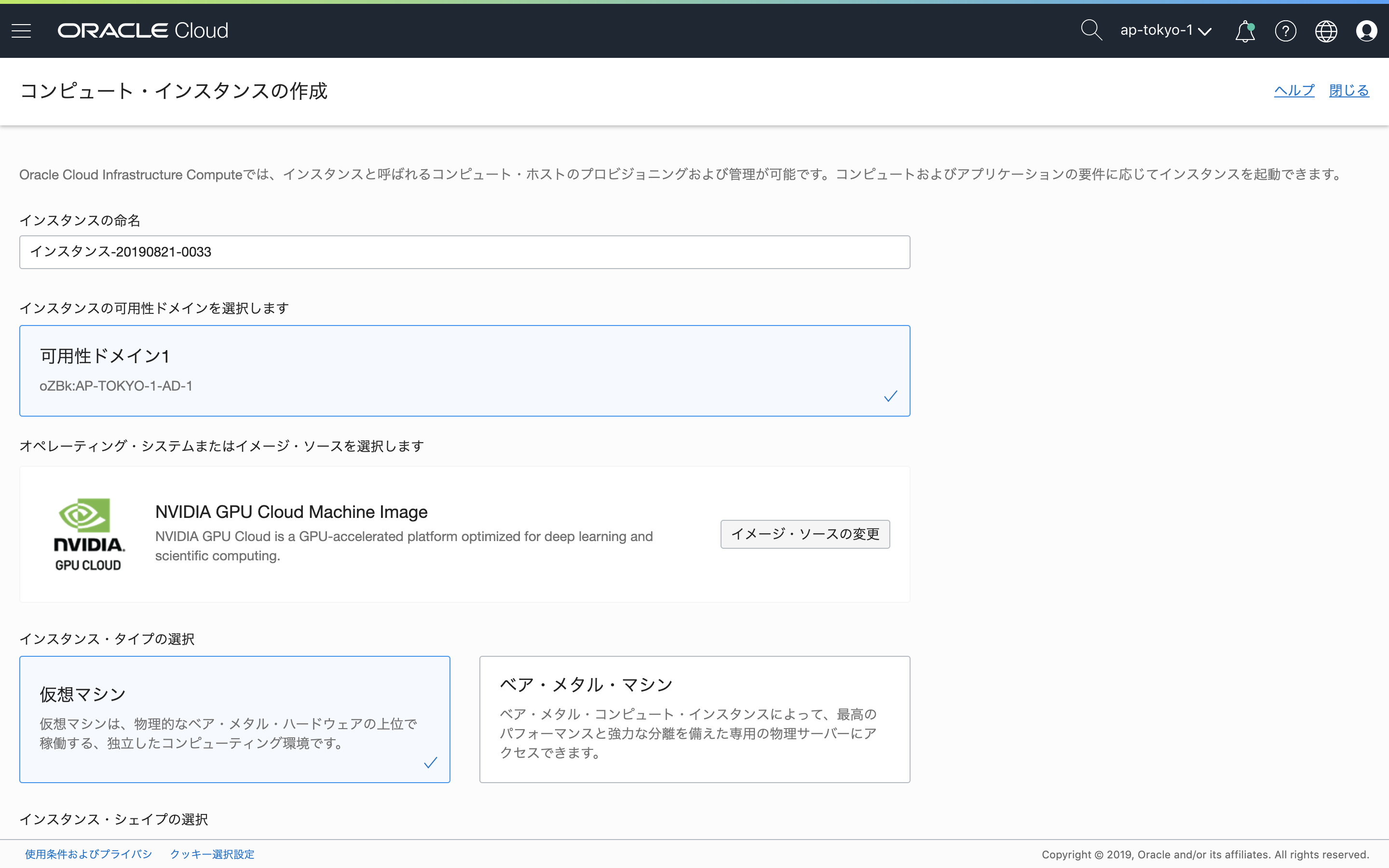
NVIDIA GPU Cloud Image Machine Imageが選択されます。
次に「シェイプの変更」で、インスタンスに割り当てるテンプレートを選択します。
あとは、任意で他の項目を入力し、最後に「作成」をクリックすると、プロビジョニングが行われます。
Oralcle Cloudの留意事項として、インスタンスが存在する限り、GPUインスタンスの料金が発生するため、GPUインスタンス使用後は、インスタンスの終了を忘れない様にします。
なお、ブートディスクを削除しないことで、完全にインスタンスを削除せずに起動・停止に近い操作が行えますが、またインスタンスを作成してプロビジョニングを行う必要があるため、勝手はよくありません。
その他環境構築
機械学習に必要なその他環境構築の例について記載します。
Python
自動的にインストールされているPythonは3.5系のため、Pythonは3.6系以降を使用したい場合、別途、バイナリからのインストールが必要です。
ライブラリのインストール
- pipのインストール
$ sudo apt install python3-pip- tensorflow-gpuのインストール
$ pip3 install tensorflow-gpu- kerasのインストール
$ pip3 install keras- jupyterのインストール
$ pip3 install jupyterjupyter notebook
jupyter notebookをインストールして、外部からアクセスしたい場合は、jupyter notebook起動時にパブリックIPアドレスに紐付くプライベートIPアドレスを指定して、起動するか、SSHポートフォワーディングすることで、外部からjupyter notebookを使用することができます。
(※)jupyter notebookに外部からアクセスできる場合は、任意のコードが実行できてしまうので、注意しましょう
参考として、外部からアクセスする場合の設定手順について記載します。
- 以下のコマンドを実行し、jupyter_notebook_config.pyを生成
$ jupyter notebook --generate-config- 以下のコマンドを実行し、jupyter_notebook_config.pyが生成されたことを確認
$ ls -l /home/ubuntu/.jupyter/jupyter_notebook_config.py- 以下のコマンドを実行し、jupyter_notebook_config.pyを編集
$ vi /home/ubuntu/.jupyter/jupyter_notebook_config.py# 変更前 #c.NotebookApp.ip = 'localhost' # 変更後 c.NotebookApp.ip = '0.0.0.0'
- 以下のコマンドを実行し、jupyterを起動
$ jupyter-notebook --ip=<プライベートIPアドレス>ポートフォワーディングする場合は、以下のコマンドを実行後、ブラウザを起動し、http://localhoot:8888にアクセスします。
$ ssh -f -N -L 8888(※):localhost:8888 ubuntu@<サーバのパブリックIPアドレス> -i <秘密鍵パス>(※)ローカル側なので任意のポート番号を指定可能(本記事では例として8888を指定)
動作確認
GPUが実際に動いているかは、TensorFlowのチュートリアルなどでサンプルコードを動かしながら、GPUの動きをリアルタイムで見れば確認できます。
おわりに
クラウドサービスが提供するマシンイメージは便利ですが、GPU使用料は安くはなく、簡単に検証もできないので、これからもっと使いやすくなることを期待します。
- 投稿日:2019-08-28T00:28:23+09:00
C言語でUDPサーバーを立てる
C言語でサーバーを立てること
c言語でサーバーを立てることは難しい。
本記事は新人や、サーバーを書いたことのない人でも、とりあえず動かせて、ちょっと質問されてもある程度答えられるようになることを目的にしたものです。
あなたがサーバー構築をしなければいけなくて、今仕事中であるならば、下記のコードをコピペして、業務仕様に合わせて書き換えていけば時間短縮になると思います。
今回はUDPの中でも非常にシンプルな作りになります。
実際の要件ではこれでは済まない場合があると思います。
しかしまったく手も足も出ない状態よりは、一応つながっている状態の方が先に進みやすいので
ここから色々いじって要件に合ったコードにしてください。
この記事ではUDPとは何か、といった説明はありません。インターネットに腐るほど解説がありますのでそちらでお願いします。
書籍ならコンピュータネットワーク5版とか良いんですけど、値段と厚さがアレなんで…環境
一応試した環境をのせるけど、比較的最近のlinuxなら動くと思う。
Ubuntu 18.04.2 LTS gcc 7.4.0簡単なUDPサーバー
UDPは実装から見るとシンプルなTCPと考えることができる。
簡単なサーバーとして
- データは
localhost9002から受け取る- 受け取ったデータを表示する
とりあえず、コピペすれば動くコードはこんな感じ。
#include <ctype.h> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <netdb.h> #include <unistd.h> #include <errno.h> #include <stdio.h> #include <string.h> int main () { //1. 受信するアドレスを構築する struct addrinfo hints; memset (&hints, 0, sizeof (hints)); hints.ai_socktype = SOCK_DGRAM; struct addrinfo *bind_address; getaddrinfo ("localhost", "9002", &hints, &bind_address); //2. ソケットを作成する int socket_listen; socket_listen = socket (bind_address->ai_family, bind_address->ai_socktype, bind_address->ai_protocol); if (socket_listen < 0) { fprintf (stderr, "socket() failed. (%d)\n", errno); return 1; } //3. ローカルアドレスをソケットにバインドする if (bind (socket_listen, bind_address->ai_addr, bind_address->ai_addrlen)) { fprintf (stderr, "bind() failed. (%d)\n", errno); return 1; } freeaddrinfo (bind_address); //4. クライアントの接続を待つ while (1) { struct sockaddr_storage client_address; socklen_t client_len = sizeof (client_address); char read[4096]; memset(read, 0, sizeof(read)); int bytes_received = recvfrom (socket_listen, read, 4096, 0, (struct sockaddr *) &client_address, &client_len); if (bytes_received < 1) { fprintf (stderr, "connection closed. (%d)\n", errno); return 1; } printf("receiving: %s", read); } //5. ソケットを閉じる close(socket_listen); printf ("Finished.\n"); return 0; }ちょっと解説的なもの
1.受信するアドレスを構築する
接続用の構造体を構築する方法はいくつかる。
- 手作業でメンバーを一つ一つ設定する方法
gethostbyname関数を使う方法getaddrinfo関数を使う方法今回は3つ目の方法で構築した。
getaddrinfo関数を使うには3つの作業がいる。
- 受信するアドレスを決める
- 受信するポート番号を決める
- ヒントになる
addrinfo構造体を定義する3の
addrinfo構造体は普通、ip4かip6、TCPかUDPかを設定する。
ipは0であればip4になる。
SOCK_DGRAMはデータグラムのことで、設定するとUDPになる。
今回は使ってないが、getaddrinfo関数の戻り値はerrnoなので、ちゃんとやるなら受け取った方が良い。2.ソケットを作成する
これは誰がやってもこうなる完全手癖で書くやつ。
ソケットとは(プログラム上の)通信の端子のことで、OSはソケットを通じて受送信する。
socket関数はソケットディスクリプターを作成する。
ソケットディスクリプターはファイルディスクリプターの一種である。
ファイルディスクリプタとはファイルをOSが扱えるようにするための一意の番号である。
linuxは様々なものをファイルとして扱う。
テキストファイル、デバイス(USBメモリとか)など。
ネットワークに対してもファイルと同じように読み書きができるようにするのが
ソケットディスクリプターの役割である。
socket関数の戻り値がソケットディスクリプターである。3.ローカルアドレスをソケットにバインドする
これも手癖。
bind関数で受信するアドレスをソケットに関連付ける。
これで受信の準備が整う。4.クライアントの接続を待つ
もっとも重要な処理。
本チャンではここで色々やるんだろうね。
普通サーバーは落とさないので無限ループする。
受信するにはrecvfrom関数を使う。
recvfrom関数は送信元の情報を受け取ります。
sockaddr_storage構造体はip4でもip6でも表現できる構造体。5.ソケットを閉じる
ソケットもメモリーやスレッドと同じようにリークを起こすので、開放する必要がある。
close関数はファイルを閉じる時に使う。
ソケットもファイルとして扱えるので、ファイルと同じclose関数で開放することができる。一応クライアントも
いらない気もするけどね。
UDPなのにconnect関数読んでます。
実はUDPでもconnect関数使えます。
サーバーでもconnect関数を使った書き方ができます。
UDPでconnect関数を使った場合、TCPで使った時と違う動きをします。
ここの説明は……うーん。#include <ctype.h> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <netdb.h> #include <unistd.h> #include <errno.h> #include <stdio.h> #include <string.h> int main(void) { struct addrinfo hints; memset(&hints, 0, sizeof(hints)); hints.ai_socktype = SOCK_DGRAM; struct addrinfo *peer_addr; if(getaddrinfo("localhost","9002",&hints, &peer_addr)) { fprintf(stderr, "getaddrinfo() failed. (%d)\n", GETSOCKETERRNO()); return 1; } char addrbuf[100]; char servbuf[100]; getnameinfo(peer_addr->ai_addr, peer_addr->ai_addrlen, addrbuf, sizeof(addrbuf), servbuf, sizeof(servbuf), NI_NUMERICHOST); printf("%s %s\n", addrbuf, servbuf); puts("Creating socket"); int socket_peer; socket_peer = socket(peer_addr->ai_family, peer_addr->ai_socktype, peer_addr->ai_protocol); if(!ISVALIDSOCKET(socket_peer)) { fprintf(stderr, "socket() failed. (%d)\n", GETSOCKETERRNO()); return 1; } if(connect(socket_peer,peer_addr->ai_addr, peer_addr->ai_addrlen)) { fprintf(stderr,"connect() failed. (%d).\n", GETSOCKETERRNO()); return 1; } freeaddrinfo(peer_addr); puts("Connected"); while(1) { { char read[4096]; if(!fgets(read, 4096, stdin)) break; int bytes = send(socket_peer, read, strlen(read), 0); printf("send %d bytes\n", bytes); } } puts("Closing socket"); CLOSESOCKET(socket_peer); return 0; }