- 投稿日:2019-07-16T23:31:55+09:00
Google AI Platform - Cloud ML EngineとファイルI/O
ディープラーニングをしていると、やはりGPUリソースを使用したいことが多いわけで。基本を調べて以下の2記事に書きましたが、今回は下記にプラスしてファイル読込・書込について解説します。
- Google AI Platform - Cloud ML Engineを初心者が動かして理解(前半)
- Google AI Platform - Cloud ML Engineを初心者が動かして理解(後半)
1. ファイル読み書き基本
1.1. プログラム
ファイル読み書きはpython標準の
openではなくTensorFlowパッケージのFileIOを使います。使い勝手はほぼ同じで、with構文も使えます。ただ、モードがデフォルトで"r"(読込)にはならないので、明示する必要があります。
パッケージargparseを使って引数にすると、下記のような形で、GitHubにソース全体を置いています。basic.pyimport argparse from tensorflow.python.lib.io import file_io # Parameters ARGS = None def main(): # ローカル/クラウドの両者に対応。モード(r)が必要 fp = file_io.FileIO(ARGS.input_file, 'r') print(fp.read()) fp.close() # with構文もOK with file_io.FileIO(ARGS.input_file, 'r') as fp: print('with:', fp.read()) # Write も同じ with file_io.FileIO(ARGS.output_file, 'w') as fp: fp.write("Hello World!") # ローカルに書き込んだらエラーにならないがファイルをあとで受け取れない with file_io.FileIO('./ignored.txt', 'w') as fp: fp.write("Hello World!") if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument( '-i', '--input_file', default='../input.txt', help='Test input data' ) parser.add_argument( '-o', '--output_file', default='../output.txt', help='Test output data' ) ARGS, _ = parser.parse_known_args() main()プログラム内で読み込んでいる"input.txt"の内容は以下のようにしています。
input.txtInput test!!!1.2. ローカル実行(Python)
パラメータを指定しないでローカルで動かしてみます(仮想環境を有効にして実行しています)。TensorFlowパッケージのFileIOはローカルのディレクトリが指定されれば、ローカルファイルに対して読み書きをしてくれます。
$ python basic.py Input test!!! with: Input test!!!1.3. ローカル実行(gcloud ai-platform)
gcloudコマンドを使ってローカルで実行しようとしましたが、
command not foundエラーとなりました。どうもgcloudはPython2.7系に依存しているらしく、私の環境は3.X系だったのでできませんでした。またunrecognized argumentsエラーも発生しましたが、スペース有無が密接に関連しているようです。スペースを調整したらエラーがでなくなりました(stackoverflow参照)。末尾(区切りの"--"部分も)にスペースが必要で、先端(--より前)にはスペース不要です。gcloud ai-platform local train \ --module-name trainer.basic \ --package-path trainer \ -- \ --input_file="./input.txt" \ --output_file="./output.txt"省略形のこんな書き方でもOK.
gcloud ai-platform local train \ --module-name trainer.basic \ --package-path trainer \ -- \ -i="./input.txt" \ -o="./output.txt"1.4. クラウド実行
いよいよクラウドで実行します。事前にプロジェクトとバケット作成等をしていま。それらの方法については、別記事「Google Cloud ML EngineでTensorFlow機械学習訓練実行」を参考にしてください。
1.4.1. 準備:環境変数設定
まずは環境変数にプロジェクト名とバケット名を設定し、ファイルをバケットにアップロードします。
PROJECT=$(gcloud config get-value project) && BUCKET="${PROJECT}-vcm" gsutil -m cp ./input.txt gs://${BUCKET}/ジョブ名とパッケージが格納されるディレクトリも環境変数に設定します。"JOB_NAME"はパラメータ"job-dir"に使うのですがハイフン(-)が使用できないことに注意です(詳細は「Gathering the job configuration data」参照)。
now=$(date +"%Y%m%d_%H%M%S") JOB_NAME="ai_test_$now" OUTPUT_PATH=gs://$BUCKET/$JOB_NAME1.4.2. クラウド実行
gcloudコマンドで実行します。gcloudの標準パラメータと準備した実行するプログラムのパラメータは"-- "で区切ります。スペースが無駄に入っていたり、なかったりで
unrecognized argumentsエラーが出るので注意してください(私は1時間くらい失敗しました・・・)。gcloud ai-platform jobs submit training $JOB_NAME \ --job-dir $OUTPUT_PATH \ --module-name trainer.basic \ --package-path trainer/ \ --python-version 3.5 \ --runtime-version 1.13 \ --scale-tier=basic \ -- \ --input_file="gs://$BUCKET/input.txt" \ --output_file="gs://$BUCKET/output.txt"1.4.3. ジョブ実行結果確認
gcloudコマンドでログを見ます。
gcloud ai-platform jobs stream-logs $JOB_NAMEプログラム上で読み込みができているのがわかります。
該当箇所ログINFO 2019-07-15 16:34:29 +0900 master-replica-0 Input test!!! INFO 2019-07-15 16:34:29 +0900 master-replica-0 with: Input test!!!1.4.4. ストレージ書き込み結果確認
バケット直下のファイルが書き込まれているかを確認します。
gsutil ls -l gs://$BUCKEToutput.txtが作成されているのがわかります。
13 2019-07-15T04:34:49Z gs://gcp-aip-test-vcm/input.txt 840 2019-07-08T06:04:45Z gs://gcp-aip-test-vcm/log_config.json 12 2019-07-15T07:34:29Z gs://gcp-aip-test-vcm/output.txt gs://gcp-aip-test-vcm/ai_test_20190715_142132/ gs://gcp-aip-test-vcm/ai_test_20190715_163220/output.txtファイルの中身も正しく書き込まれています。
$ gsutil cat gs://$BUCKET/output.txt Hello World!ちなみに下記部分で書いたようなストレージ以外の自身のローカルパスに保存したファイルは取り出しようがないです(あまり調べていないですが、ジョブ実行後にインスタンス消えているはずなので)。ただ、エラーでジョブ終了するわけでないので、重要でないファイル書き込みであれば放置していてもいいかと思います(出力パスが存在しないエラーだけは注意ください)。
# ローカルに書き込んだらエラーにならないがファイルをあとで受け取れない with file_io.FileIO('./ignored.txt', 'w') as fp: fp.write("Hello World!")2. TensorFlow APIでのファイル書込(Saved ModelエクスポートとTensorBoard)
Python標準のOpenコマンドでなく、Saved Model形式でのモデル保存とTensorBoardのログ出力についてです。ModelCheckpointを使ったKerasモデルの保存はうまくできませんでした。
KerasでのSaved Model形式でのモデル保存は別記事「【Keras入門(2)】訓練モデル保存(KerasモデルとSavedModel)」を参照ください。
KerasでのTensorBoard出力方法については別記事「【Keras入門(3)】TensorBoardで見える化」を参照ください。2.1. プログラム:モデル保存とTensorBoard出力部分
Save Model形式でのエクスポートとTensorBoard出力部分です。PureなKerasでは試していません。プログラム全体はGitHubに置いています。
tf_api.pyfrom tensorflow.keras.callbacks import TensorBoard from tensorflow.contrib import saved_model # Callbackを定義し、TensorBoard出力の追加 li_cb = [] li_cb.append(TensorBoard(log_dir=ARGS.tensor_board)) # 訓練実行 model.fit(train_x, train_y, epochs=1, callbacks=li_cb) # Saved Model形式でエクスポート saved_model.save_keras_model(model, ARGS.saved_model)2.2. クラウド実行
Google AI Platformのクラウドで実行します。
# タイムスタンプを更新してジョブID名をリネーム(同名だとエラー) now=$(date +"%Y%m%d_%H%M%S") JOB_NAME="ai_test_$now" OUTPUT_PATH=gs://$BUCKET/$JOB_NAME TENSOR_BOARD=gs://$BUCKET/tb SAVED_PATH=gs://$BUCKET/saved_model # 実行 gcloud ai-platform jobs submit training $JOB_NAME \ --job-dir $OUTPUT_PATH \ --module-name trainer.tf_api \ --package-path trainer/ \ --python-version 3.5 \ --runtime-version 1.13 \ --scale-tier=basic \ -- \ -t=$TENSOR_BOARD \ -s=$SAVED_PATH \2.3. ストレージ書き込み確認
ストレージを見ると書き込みに成功していることがわかります。
$ gsutil ls -r gs://$BUCKET gs://gcp-aip-test-vcm/saved_model/: gs://gcp-aip-test-vcm/saved_model/ gs://gcp-aip-test-vcm/saved_model/1563200064/: gs://gcp-aip-test-vcm/saved_model/1563200064/ gs://gcp-aip-test-vcm/saved_model/1563200064/saved_model.pb gs://gcp-aip-test-vcm/saved_model/1563200064/assets/: gs://gcp-aip-test-vcm/saved_model/1563200064/assets/ gs://gcp-aip-test-vcm/saved_model/1563200064/assets/saved_model.json gs://gcp-aip-test-vcm/saved_model/1563200064/variables/: gs://gcp-aip-test-vcm/saved_model/1563200064/variables/ gs://gcp-aip-test-vcm/saved_model/1563200064/variables/checkpoint gs://gcp-aip-test-vcm/saved_model/1563200064/variables/variables.data-00000-of-00001 gs://gcp-aip-test-vcm/saved_model/1563200064/variables/variables.index gs://gcp-aip-test-vcm/tb/: gs://gcp-aip-test-vcm/tb/ gs://gcp-aip-test-vcm/tb/events.out.tfevents.1563200063.cmle-training-1887456742977642267おまけ
loggingパッケージによるログ出力
ファイルI/Oではないですがloggingパッケージを使った場合の出力についてです。loggingパッケージに関しては、別記事「Pythonでprintを卒業してログ出力をいい感じにする」を参照してください。
ログ出力サンプルプログラム
loggingパッケージを使って出力しています。パラメータ
-vが渡されたらDEBUGレベルも出力するようにしています。
プログラム全体はGitHubにあります。log.pyfrom logging import getLogger, DEBUG, config import json import argparse from tensorflow.python.lib.io import file_io # Parameters ARGS = None def main(): with file_io.FileIO(ARGS.log_config, 'r') as f: log_conf = json.load(f) # replace from INFO to DEBUG if parameter verbose is set if ARGS.verbose: log_conf["handlers"]["consoleHandler"]["level"] = DEBUG # read logging configuration json file config.dictConfig(log_conf) logger = getLogger(__name__) logger.info('Hello World! info') logger.debug('Hello World! debug') if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument( '-l', '--log_config', default='../log_config.json', help='Log configuration file' ) parser.add_argument( '-v', '--verbose', action='store_true', help='Log level DEBUG' ) ARGS, _ = parser.parse_known_args() main()ログの設定ファイルは以下のとおりです。
log_config.json{ "version": 1, "disable_existing_loggers": false, "formatters": { "default": { "format": "%(asctime)s %(name)s:%(lineno)s %(funcName)s [%(levelname)s]: %(message)s" } }, "handlers": { "consoleHandler": { "class": "logging.StreamHandler", "level": "INFO", "formatter": "default", "stream": "ext://sys.stdout" } }, "loggers": { "__main__": { "level": "DEBUG", "handlers": ["consoleHandler"], "propagate": false } }, "root": { "level": "INFO" } }クラウド実行
まずは、log_config.jsonをアップロードします。
gsutil -m cp ./log_config.json gs://${BUCKET}/あとは、いつもの環境変数設定と実行です。
# 環境変数設定 now=$(date +"%Y%m%d_%H%M%S") JOB_NAME="ai_test_$now" OUTPUT_PATH=gs://$BUCKET/$JOB_NAME LOG_PATH=gs://$BUCKET/log_config.json # 実行 gcloud ai-platform jobs submit training $JOB_NAME \ --job-dir $OUTPUT_PATH \ --module-name trainer.log \ --package-path trainer/ \ --python-version 3.5 \ --runtime-version 1.13 \ --scale-tier=basic \ -- \ -l=$LOG_PATH \ -vlog上では該当箇所はこんな風に出力されました。AI Platformで実行する場合、タイムスタンプは冗長的なのでformatterから除去してもいいですね。
該当箇所ログのみ表示$ gcloud ai-platform jobs stream-logs $JOB_NAME INFO 2019-07-16 23:15:22 +0900 master-replica-0 2019-07-16 14:15:22,178 __main__:25 main [INFO]: Hello World! info INFO 2019-07-16 23:15:22 +0900 master-replica-0 2019-07-16 14:15:22,178 __main__:26 main [DEBUG]: Hello World! debug
- 投稿日:2019-07-16T15:16:55+09:00
TensorFlowの使い方およびJupyter notebookのTips
t※以下、個人的な勉強のためのレポートです。
※間違い多々あると存じますが、現在の理解レベルのスナップショットのようなものです。
※勉強のためWebサイトや書籍からとても参考になったものを引用させていただいております。
http://ai999.careers/rabbit/Tensorflowの実装演習(を始めるにあたって)
※Tensorflowのインストール方法として、pipを使う方法がネットには多くあります。しかし、AnacondaでPython環境を構築している場合、pipとcondaの競合により環境に不具合が生じることがあるようです。よって、AnacondaでPython環境を構築している場合は、Anaconda NavigatorからGUIでインストールする方が安全なようです。
https://www.sejuku.net/blog/43784
http://onoz000.hatenablog.com/entry/2018/02/11/142347TensorFlowの動作確認
import tensorflow as tf hello = tf.constant('Hello, TensorFlow!') sess = tf.Session() print(sess.run(hello)) b'Hello, TensorFlow!'※出力に「b'」と付くのは、「byte文字列」であることを示しているらしい。
https://stackoverflow.com/questions/40904979/the-print-of-string-constant-is-always-attached-with-b-intensorflowTensorFlowの基礎
TensorFlowとは
https://ja.wikipedia.org/wiki/TensorFlow
TensorFlow(テンサーフロー)とは、Googleが開発しオープンソースで公開している、機械学習に用いるためのソフトウェアライブラリ。TensorFlowの位置づけ
https://qiita.com/shu_marubo/items/d9c306f7f3fb82dc55e7
機械学習を使う際に、
1.アルゴリズム、数理を正しく理解した上で、各言語でモデルをフルスクラッチで作る
2.pythonならsklearn、Rなら手法に応じた各ライブラリなどを用いて数行でモデルを作成する
3.機械学習系のモデルを作成するのに向いた計算ライブラリを用いて自作する
Tensorflowは「3.」の用途に該当する。Tensor(テンソル)とは、Flowとは
https://www.sejuku.net/blog/38134
https://qiita.com/rindai87/items/4b6f985c0583772a2e21
https://qiita.com/edo_m18/items/7c95593ed5844b5a0c3b
Tensorは数学用語ではあるが、機械学習の文脈では「多次元配列」のことと考えて進める。Flowは「流れ」。ニューラルネットワークのモデルは、計算グラフで説明されることが多い。よって、TensorFlowは、多次元のデータ構造を計算グラフの流れのように処理できるライブラリと考えられる。計算グラフにおける各ノードは演算を表しており、その演算の入力(オペランド)と結果はテンソルである。
テンソルの形状は、shapeの概念により決定される。
https://deepage.net/tensorflow/2018/10/03/tensorflow-shape.htmlshape=[2,2]2個の要素を持つ2次元配列
shape=[3,2,2]2個の要素を持つ2次元配列が3つ(3次元配列)
TensorFlowのノードの型
dtypeで指定可能 ex)tf.float32 32ビットの浮動小数点数
https://deepage.net/tensorflow/2018/10/09/tensorflow-dtype.htmlTensorFlowのプレースホルダ
https://lp-tech.net/articles/SE5xD
プレースホルダは、後でデータを割り当てるをために用意されたテンソル。これにより、データを必要とせずに操作を作成し,計算グラフを作成することができる。プレースホルダにデータを送るには feed_dict を使用する。Python の数値・文字列・リストや,Numpy の ndarrays を送ることが可能。
import tensorflow as tf import numpy as np a = tf.constant(3) b = tf.placeholder(dtype=tf.int32, shape=None) c = tf.add(a, b) with tf.Session() as sess: print(sess.run(c, feed_dict={b: 1})) print(sess.run(c, feed_dict={b: [1, 2, 3, 4]})) print(sess.run(c, feed_dict={b: np.random.randint(0, 9, 10)})) # 以下,実行結果 # 4 # [4 5 6 7] # [ 4 7 8 4 7 3 4 9 10 4]TensorFlowの変数
TensorFlowのセッション
https://www.atmarkit.co.jp/ait/articles/1804/20/news131_2.html
TensorFlowのセッションとは、構築されたデータフローグラフの演算処理を実際に行うランタイムへのクライアントのこと。TensorFlowの、定数と簡単な演算、変数、プレースホルダーの使い方
https://note.nkmk.me/python-tensorflow-constant-variable-placeholder/
〇定数の定義import tensorflow as tf const1 = tf.constant(5) const2 = tf.constant(10)〇定数値の確認
print(const1) print(const2) Tensor("Const_13:0", shape=(), dtype=int32) Tensor("Const_14:0", shape=(), dtype=int32)そのままprint()しても値は表示されない。
tf.constant()では、あくまでも計算グラフが定義されただけ。実際の値を確認するにはセッションを開始して処理を実行する必要がある。with tf.Session() as sess: const1_result, const2_result = sess.run([const1, const2]) print(const1_result) print(const2_result) 5 10https://www.sejuku.net/blog/24672
Pythonのwith構文は、ファイルの読み込みが必要なコードで使用される。with構文を使うとファイルの読み込みで必要なclose処理を省略することが可能。よってセッションを開き、読み、閉じる処理を記述。
※セッションという実行環境へのアクセスと考える?〇四則演算
https://qiita.com/negabaro/items/bdaeaf6ba4bc9fc81208
加算 tf.add(x, y, name=None)
減算 tf.sub(x, y, name=None)
乗算 tf.mul(x, y, name=None)
除算 tf.div(x, y, name=None)TensorFlowの変数
https://note.nkmk.me/python-tensorflow-constant-variable-placeholder/
tf.Variable()で定義
tf.assign()で新たな値を代入
変数はセッションのはじめに初期化する必要がある。
すべての変数を初期化するglobal_variables_initializer()を実行import tensorflow as tf import numpy as np var = tf.Variable(10) const = tf.constant(5) calc_op = var * const assign_op = tf.assign(var, calc_op) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print(sess.run(var)) sess.run(assign_op) print(sess.run(var))セッション内では変数の値は保持されるため、オペレーションを複数回実行すると結果が更新されていく
import tensorflow as tf import numpy as np var = tf.Variable(10) const = tf.constant(5) calc_op = var * const assign_op = tf.assign(var, calc_op) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print(sess.run(var)) sess.run(assign_op) print(sess.run(var)) sess.run(assign_op) print(sess.run(var)) sess.run(assign_op) print(sess.run(var)) sess.run(assign_op) print(sess.run(var)) 10 50 250 1250 6250Pythonのreshape(-1,1)について
https://qiita.com/guitar_char/items/deb49d5a433a2c8a8ed4
〇reshapeの一つのサイズが決まっているとき、もう一方を-1とすると、-1には元の形状から推測された値が入る
http://www.kamishima.net/mlmpyja/nbayes2/shape.html
〇shape に (1, -1) や (-1, 1) を指定すると,それぞれ2次元の横ベクトルや縦ベクトルを簡便に作ることができる。Jupyter notebookを使う上でのTips
〇matplotlibの出力
import matplotlib.pyplot as plt
%matplotlib inline
https://qiita.com/nogut0123/items/2c83e30e274e5a51cb41〇ディレクトリの変更
https://qiita.com/k-serenade/items/af8701101fe50397d8aa
Windowsの場合
(ex)Cドライブではないパーティション(E)の直下にjupyterというフォルダを作っていて、そこにnotebookのソースを置いている・置きたい場合c.NotebookApp.notebook_dir = 'E:\jupyter'〇まずは覚えるべき使い方
https://qiita.com/takuyanin/items/8bf396e7b6b051670147
Ctrl+Cでコード実行
Shift+Cで次のセルを作成〇覚えておくべきショートカット
https://qiita.com/masafumi_miya/items/6524dbd227705351a00c
escを押下後、hでヘルプ
escを押下後、yでコード記述モード
escを押下後、mでマークダウン記述モード
- 投稿日:2019-07-16T15:16:39+09:00
TensorFlowを用いた非線形回帰
※以下、個人的な勉強のためのレポートです。
※間違い多々あると存じますが、現在の理解レベルのスナップショットのようなものです。
※勉強のためWebサイトや書籍からとても参考になったものを引用させていただいております。
http://ai999.careers/rabbit/TensorFlowによる非線形回帰
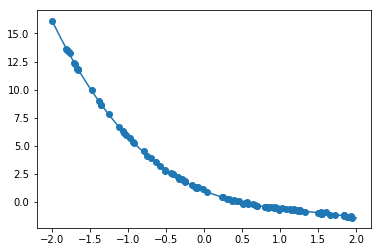
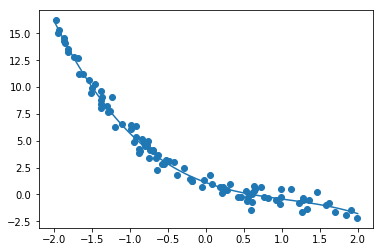
正解値データ
y=-0.4x^3+1.6x^2-2.8x+1#データを生成 n=100 x = np.random.rand(n).astype(np.float32) * 4 - 2 d = - 0.4 * x ** 3 + 1.6 * x ** 2 - 2.8 * x + 1非線形な解を生成
モデル
#xの3乗、2乗、1乗、0乗の4つ分のプレースホルダ xt = tf.placeholder(tf.float32, [None, 4]) dt = tf.placeholder(tf.float32, [None, 1]) #-0.4,1.6,-2.8,1という4つの重みがあるので、4つ。0.01の標準偏差で初期化 W = tf.Variable(tf.random_normal([4, 1], stddev=0.01)) #ノードとしてxt×Wを定義 y = tf.matmul(xt,W)1次元目はバッチサイズで上記のようにNoneにしておくと可変サイズに対応可能
誤差関数
optimizer = tf.train.AdamOptimizer(0.001)Adamを使用、学習率は0.001
結果
W1 = [-0.40030134] ※正解-0.4
W2 = [ 1.5934367 ] ※正解1.6
W3 = [-2.7970264 ] ※正解2.8
W4 = [ 1.0092059 ] ※正解1ノイズの変更
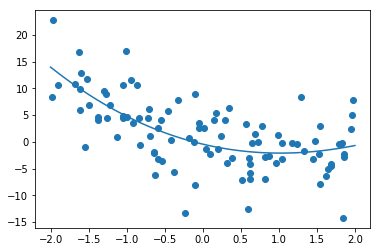
10倍のnoise = 0.5
W1 = [-0.47843903]
W2 = [ 1.5267874 ]
W3 = [-2.5911577 ]
W4 = [ 1.1071517 ]
保ててはいるが、精度は落ちている100倍のnoise = 5
W1 = [-0.07317215]
W2 = [ 1.7690974 ]
W3 = [-3.3754215 ]
W4 = [-0.42890525]
ノイズに対しては弱いことが観測できるdの正解値モデルの変更
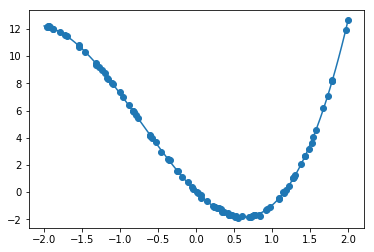
y=1.4x^3+3.1x^2-5.5x^2+0.03
非常にきれいにモデルを予測できている演習
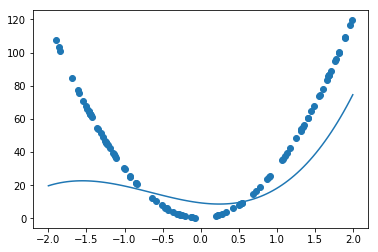
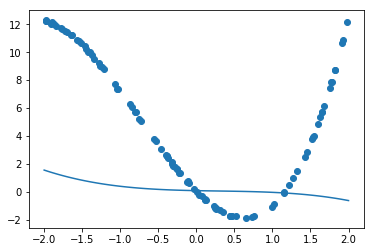
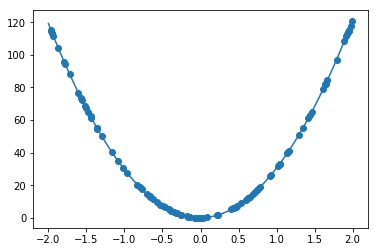
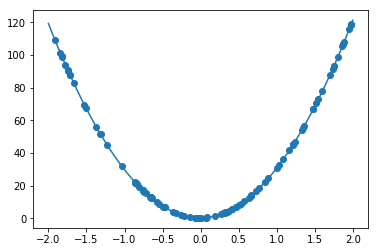
y=30x^{2} +0.5x+0.2の予測を行う
iters_numやlearning_rateを変更せずに実施
W1 =[ 4.544718 ]
W2 = [ 9.391723 ]
W3 = [-2.7000463]
W4 = [ 9.274796 ]誤差が収束するようiters_numやlearning_rateを調整
学習率0.00001
むしろ悪化
⇒プレースホルダーの個数変更等、ウェイトが減ったことを加味していなかったことが原因学習率0.01
非常に高精度に改善学習回数100万回
W1 = [4.2578713e-03]
W2 = [3.0001066e+01]
W3 = [4.8582685e-01]
W4 = [2.0072795e-01]
変数対応をしないで、計算回数だけで力技で実行
ここまで学習を回すと、3乗の係数がウェイトを無視できるものまで落としていることが観測できる
- 投稿日:2019-07-16T15:16:24+09:00
TensorFlowによるMNIST文字認識
※以下、個人的な勉強のためのレポートです。
※間違い多々あると存じますが、現在の理解レベルのスナップショットのようなものです。
※勉強のためWebサイトや書籍からとても参考になったものを引用させていただいております。
http://ai999.careers/rabbit/MNIST
https://weblabo.oscasierra.net/python/ai-mnist-data-detail.html
・手書きで書かれた数字を画像にした画像データ(image)と、その画像に書かれた数字(0~9)を表すラベルデータ(label)から構成される
・ペアは、学習用に60,000個、検証用に10,000個の数提供されている
train-images-idx3-ubyte: 学習用の画像セット
train-labels-idx1-ubyte: 学習用のラベルセット
t10k-images-idx3-ubyte: 検証用の画像セット
t10k-labels-idx1-ubyte: 検証用のラベルセット
・28×28の升目(ピクセル)と、その値(チャネル、ピクセル値:0~255までの値、0が白,255が黒)実装
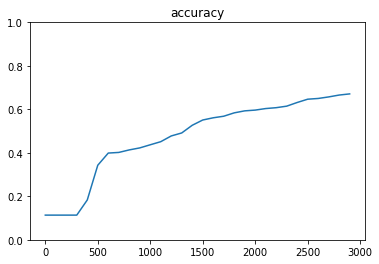
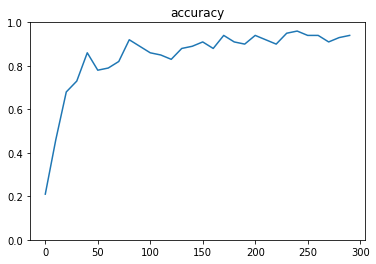
#入力xのプレースホルダ、28*28=784 x = tf.placeholder(tf.float32, [None, 784]) #出力dのプレースホルダ、0-9までの10分類 d = tf.placeholder(tf.float32, [None, 10]) #重み。784個の数値から出力層10個へのそれぞれの重み。標準偏差0.01で初期化。 W = tf.Variable(tf.random_normal([784, 10], stddev=0.01)) #バイアス。出力層10個それぞれについて一つずつ。0で初期化。 b = tf.Variable(tf.zeros([10])) #計算ノード。分類問題なのでソフトマックス関数を使用。 y = tf.nn.softmax(tf.matmul(x, W) + b) #誤差関数には交差エントロピーの値を使用。 cross_entropy = -tf.reduce_sum(d * tf.log(y), reduction_indices=[1]) loss = tf.reduce_mean(cross_entropy) train = tf.train.GradientDescentOptimizer(0.1).minimize(loss)結果
100の学習で、正解率 約87%実際のデータの確認
plt.imshow(x_batch[0].reshape(28,28))
3層化
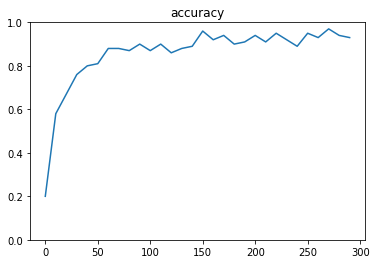
中間層を二つ作成するため、600と300で用意する。
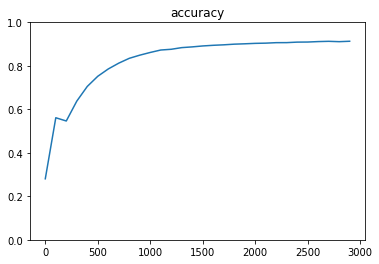
入力層784⇒中間層600⇒中間層300⇒出力層10hidden_layer_size_1 = 600 hidden_layer_size_2 = 300 #3層化されたので、重み、バイアスともに3つ用意する W1 = tf.Variable(tf.random_normal([784, hidden_layer_size_1], stddev=0.01)) W2 = tf.Variable(tf.random_normal([hidden_layer_size_1, hidden_layer_size_2], stddev=0.01)) W3 = tf.Variable(tf.random_normal([hidden_layer_size_2, 10], stddev=0.01)) b1 = tf.Variable(tf.zeros([hidden_layer_size_1])) b2 = tf.Variable(tf.zeros([hidden_layer_size_2])) b3 = tf.Variable(tf.zeros([10]))dropoutにより、過学習を抑制する。
dropout_rate = 0.5 keep_prob = tf.placeholder(tf.float32) drop = tf.nn.dropout(z2, keep_prob)結果
正解率が約90%に改善ハイパーパラメータの変更
中間層のノード数を、600/300から、100/50に変更
⇒パラメータ数が減少することでマシンの処理は軽くなるが、学習精度は落ちる
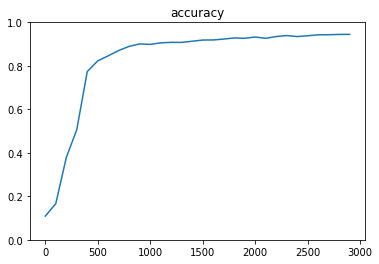
中間層のノード数を、1000/500に変更
⇒パラメータ数が増大することでマシンの処理負荷は重たくなる。しかし学習精度は約91%まで改善。NNにおいては、中間層のノード数は、速度と精度のトレードオフを考慮する必要がある
最適化関数の変更
momentum
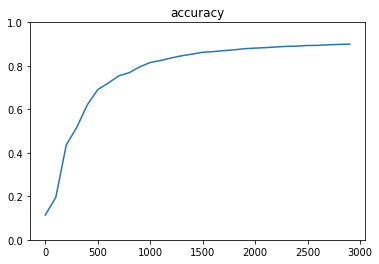
⇒精度が94%まで改善
Adagrad
⇒精度 約90%
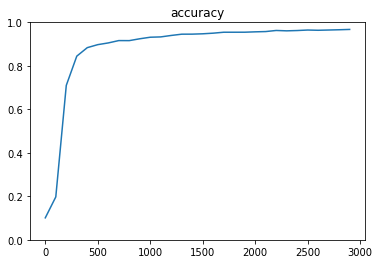
RMSProp
⇒96.75%を達成!実際には、各最適化関数が頭打ちになるまで学習回数を上げて比較すると良い。
CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)
構造
conv - relu - pool - conv - relu - pool - affin - relu - dropout - affin - softmax
実装
# 第一層のweightsとbiasのvariable #最初の5*5がCNNのフィルターサイズ。1チャネルのものを32チャネルに拡張。 W_conv1 = tf.Variable(tf.truncated_normal([5, 5, 1, 32], stddev=0.1)) b_conv1 = tf.Variable(tf.constant(0.1, shape=[32])) # 第一層のconvolutionalとpool # strides[0] = strides[3] = 1固定 #ストライドは1、パディングはSHAPEが変わらないような値を設定。 h_conv1 = tf.nn.relu(tf.nn.conv2d(x_image, W_conv1, strides=[1, 1, 1, 1], padding='SAME') + b_conv1) # プーリングサイズ n*n にしたい場合 ksize=[1, n, n, 1] #max_poolが2,2、ストライドが2,2 h_pool1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 第二層 W_conv2 = tf.Variable(tf.truncated_normal([5, 5, 32, 64], stddev=0.1)) b_conv2 = tf.Variable(tf.constant(0.1, shape=[64])) h_conv2 = tf.nn.relu(tf.nn.conv2d(h_pool1, W_conv2, strides=[1, 1, 1, 1], padding='SAME') + b_conv2) h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 第一層と第二層でreduceされてできた特徴に対してrelu #affinの実装部分 #max_poolの出力が7*7*64になっているので、reshapeで1次元に直す。 W_fc1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1024], stddev=0.1)) b_fc1 = tf.Variable(tf.constant(0.1, shape=[1024])) h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # Dropout keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # 出来上がったものに対してSoftmax W_fc2 = tf.Variable(tf.truncated_normal([1024, 10], stddev=0.1)) b_fc2 = tf.Variable(tf.constant(0.1, shape=[10])) y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # 交差エントロピー loss = -tf.reduce_sum(d * tf.log(y_conv)) train = tf.train.AdamOptimizer(1e-4).minimize(loss) correct = tf.equal(tf.argmax(y_conv,1), tf.argmax(d,1)) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))結果
⇒計算負荷は高い。しかし精度は最高で96%を記録。計算回数を増加させることで、99%まで高まる可能性もある。ハイパーパラメータの変更
dropout_ratioを0.0に変更(dropoutさせない)
⇒あまり変わらない。やや下がる。論文からの実装
State of the Art:現時点で一番精度が高い技術
ex)「VGG16 arxiv」で検索。
※arXiv(アーカイヴ、archiveと同じ発音)は、物理学、数学、計算機科学、量的生物学、計量ファイナンス、統計学の、プレプリント(英語版)を含む様々な論文が保存・公開されているウェブサイト
⇒PDF版の論文が閲覧可能
ex)ブログなどでの考察
ex)githubの実装コード。実装が入手できる。JDLAの例題
(答え)a
必要なパラメータ数は増加するが、その分スパース(Sparse:「すかすか」、「少ない」の意)な演算になる。よってdense(密)ではない。
(答え)a
Auxiliary calssifiresを導入して、calssifiresを増加させて計算量を減少させているわけではない。
(答え)a、a、a
いわゆるskipコネクション。これにより層を深くしても学習が進むことになった。
(答え)あ
転移学習の問題。(あ)は、転移学習の例としては不適切。
(答え)a
b
最大ではなく、必ず定義された2つの候補領域は生成されるように実装されている
c
2つの誤差の単純和ではなく、位置特定誤差と各クラスの確信度に対する二つの誤差の重みづけまで表現されている。
d
出力についてはカテゴリの+の確率と、二つの候補領域が出力されるというところが間違い。確認テスト
VGG/GoogleNet/ResNetの特徴をそれぞれ述べよ
http://thunders1028.hatenablog.com/entry/2017/11/01/035609
〇VGG
AlexNetをより深くした、畳み込み層とプーリング層から成るどノーマルなCNNで、重みがある層(畳み込み層や全結合層)を16層、もしくは19層重ねたもの。それぞれVGG16やVGG19と呼ばれる。小さいフィルターを持つ畳み込み層を2〜4つ連続して重ね、それをプーリング層でサイズを半分にするというのを繰り返し行う構造が特徴。パラメータも多い。大きいフィルターで画像を一気に畳み込むよりも小さいフィルターを何個も畳み込む(=層を深くする)方が特徴をより良く抽出できる。
〇GoogleNet
通常の入力層から出力層まで縦一直線な構造ではなく、インセプション構造と呼ばれる横にも層が広がる構造をしている。このため、Inceptionモデルとも呼ばれる。横への層の広がりは、異なるサイズのフィルターの畳み込み層を複数横に並べて、それを結合するという形になっている。
〇ResNet
これまでのネットワークでは層を深くしすぎると性能が落ちるという問題があったが、それを「スキップ構造」によって解決し、152層もの深さを実現した。スキップ構造は、ある層への入力をバイパスし層をまたいで奥の層へ入力してしまうというもので、これにより勾配の消失や発散を防止し、超多層のネットワークを実現している。



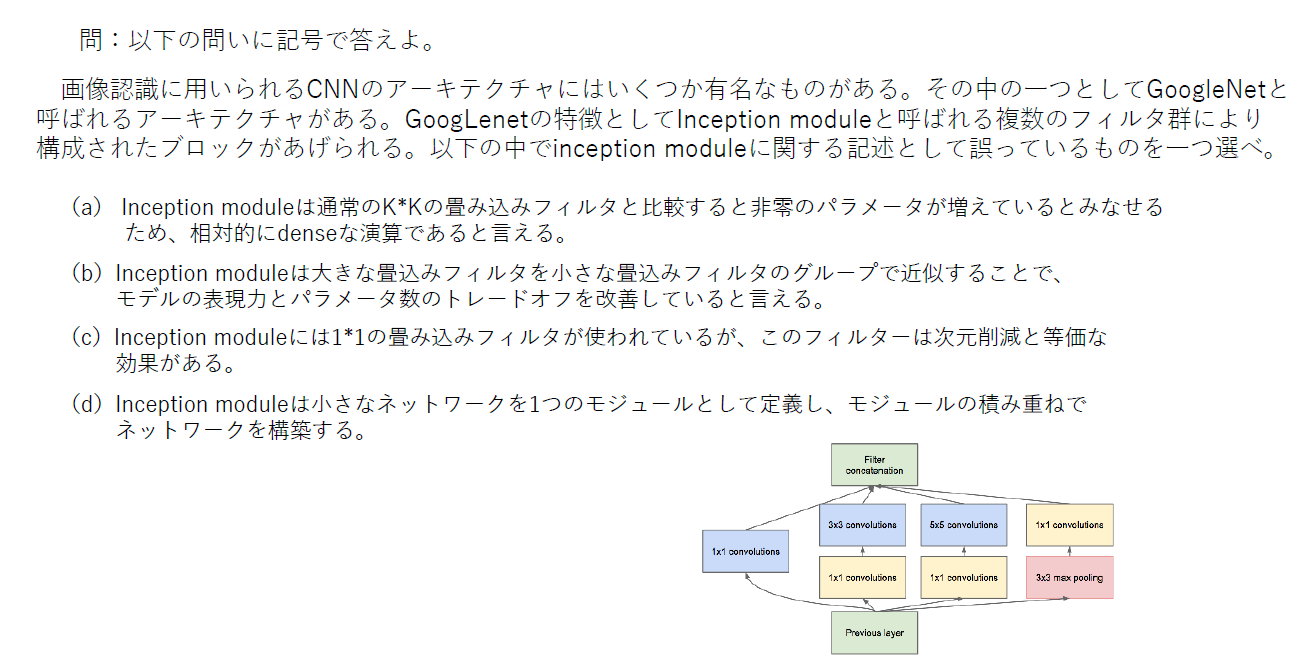

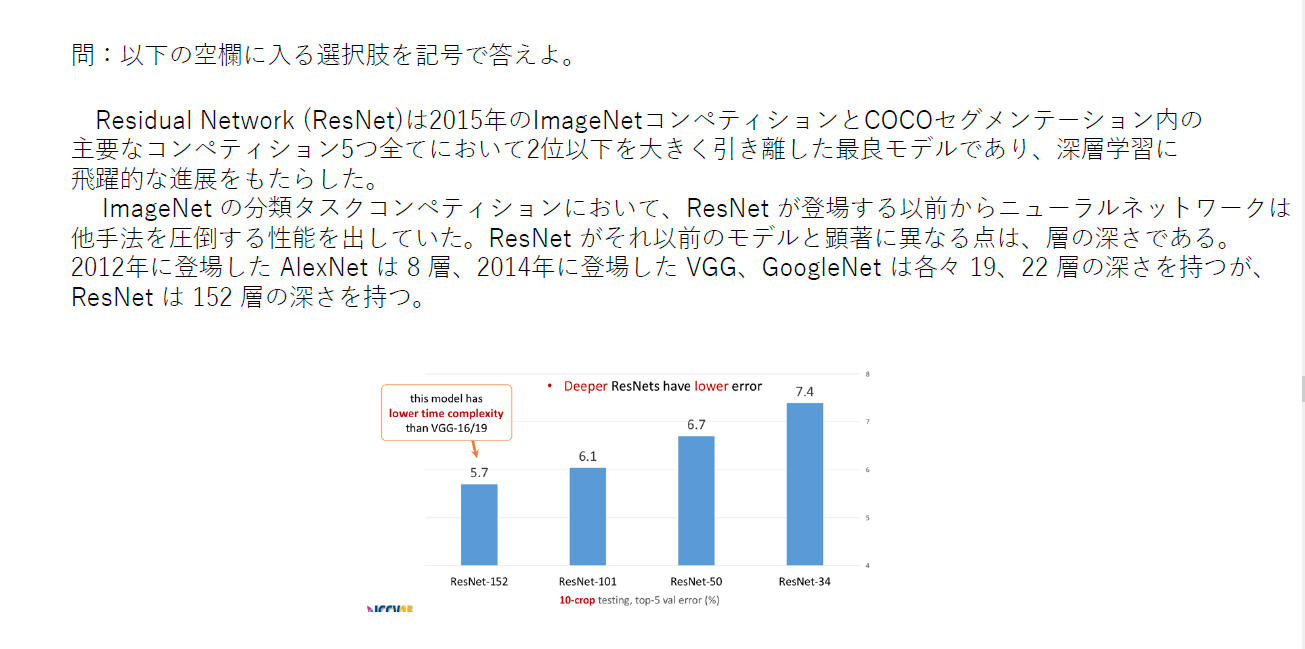
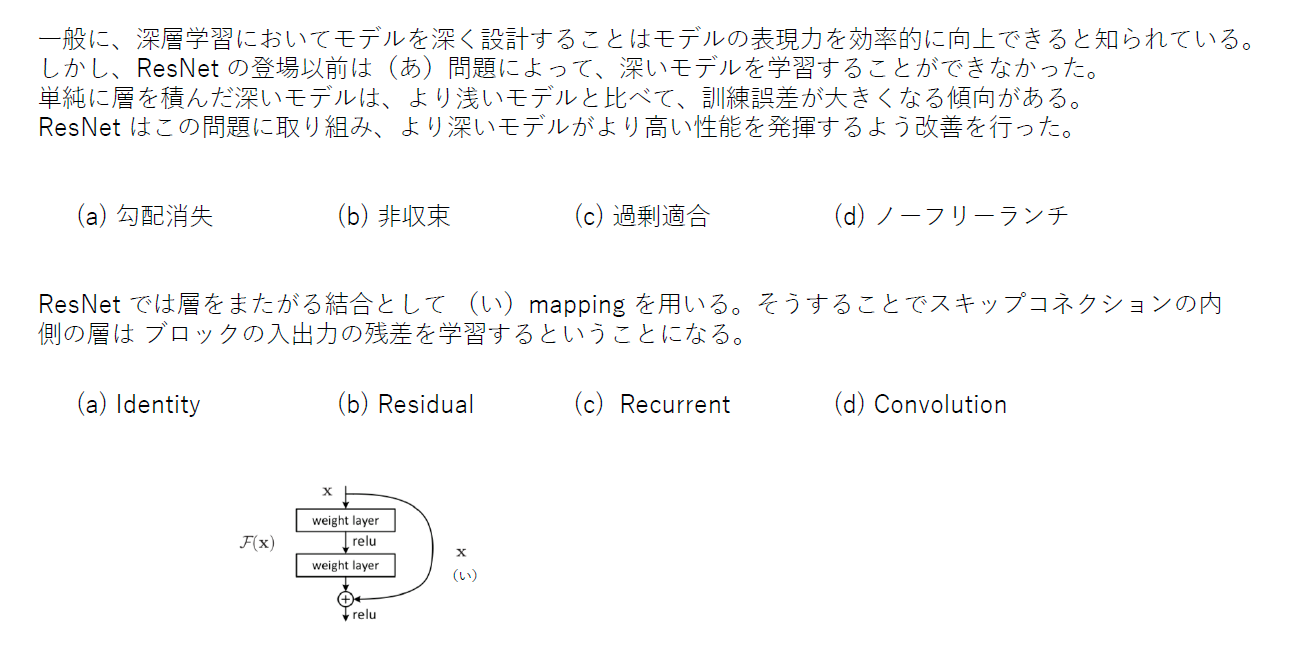



- 投稿日:2019-07-16T15:14:30+09:00
TensorFlowを使用した線形回帰
※以下、個人的な勉強のためのレポートです。
※間違い多々あると存じますが、現在の理解レベルのスナップショットのようなものです。
※勉強のためWebサイトや書籍からとても参考になったものを引用させていただいております。
http://ai999.careers/rabbit/TensorFlowを使用した線形回帰
実装
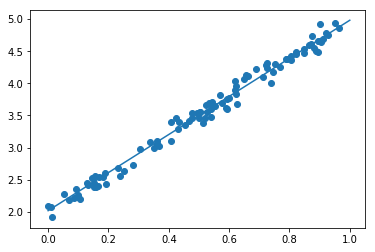
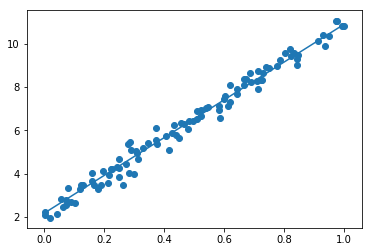
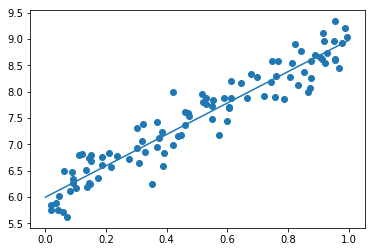
#学習回数、後のfor文で使用される iters_num = 300 #何回学習するごとに表示するか plot_interval = 10 # データを生成 #100個のランダムなx #randは0~1の一様分布 #randn(10) # 標準正規分布を10個生成 n = 100 x = np.random.rand(n) #正解データの作成 #これでは直線データができるだけなので、下でノイズを加えている d = 3 * x + 2 # ノイズを加える # 0~0.3くらいのノイズ #randnは平均0、分散1のガウス分布(標準正規分布) #randn(10) # 標準正規分布を10個生成 #randn(10,10) # 標準正規分布による 10x10 の行列 #randn(100)で、1から-1の数を100個作り、これに0.3をかけてやることで、0.3から-0.3の数を100個作っている noise = 0.3 d = d + noise * np.random.randn(n) # 入力値 #xを入れるプレースホルダ xt = tf.placeholder(tf.float32) #dを入れるプレースホルダ dt = tf.placeholder(tf.float32) # 最適化の対象の変数を初期化 #ここから、trainの行までがTensorFlowで学習を行うための準備 #初期値0の重み W = tf.Variable(tf.zeros([1])) #初期値0のバイアス b = tf.Variable(tf.zeros([1])) #今回の学習では、この重みWとバイアスdを求めることが目的 y = W * xt + b # 誤差関数 平均2乗誤差 #回帰問題なので、誤差には平均2乗誤差を用いる loss = tf.reduce_mean(tf.square(y - dt)) #https://qiita.com/mine820/items/747a876d0bce658ad9ba #TensorFlowで用意してくれている関数 #「GradientDescentOptimizer」は急速降下法 #「AdamOptimizer」はAdamアルゴリズム #この0.1は学習率 optimizer = tf.train.GradientDescentOptimizer(0.1) #誤差を最小化して学習していく train = optimizer.minimize(loss) # 初期化 # TensorFlowの初期化およびセッションの立ち上げ init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) # 作成したデータをトレーニングデータとして準備 # 縦ベクトル化 x_train = x.reshape(-1,1) d_train = d.reshape(-1,1) # トレーニング #先ほど定義したiters_nomは300なので、300回実施 # for i in range(iters_num): #sess.runを行うときに、先ほど定義したtrain(誤差を最小化する処理) #feed_dictで、dtには正解データを縦ベクトル化したd_train(ノイズ入り)を、 #xtには、0~100の整数入力値を、それぞれ代入 sess.run(train, feed_dict={xt:x_train,dt:d_train}) if (i+1) % plot_interval == 0: loss_val = sess.run(loss, feed_dict={xt:x_train,dt:d_train}) W_val = sess.run(W) b_val = sess.run(b) print('Generation: ' + str(i+1) + '. 誤差 = ' + str(loss_val)) print(W_val) print(b_val) # 予測関数 #予測できた重みWとバイアスbを用いて、式(モデル)を算出 def predict(x): return W_val * x + b_valnoiseやd(正解モデル)の重みW/バイアスbを変えた実験と考察
noiseの変更
noise = 0.1
W = [2.9645967]
b = [2.017563]noise = 0.5
W = [2.9131765]
b = [2.0111299]上下に均等にnoiseが乗る場合には、それほど近似性に際は内容に思われる。
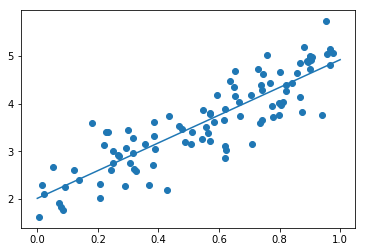
noise = 5
W = [2.0730288]
b = [5.7792187]予測値が正解式と大きくかい離。
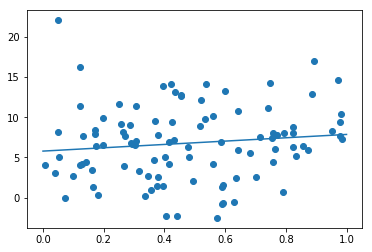
Wの変更
W=9で正解式を作成(noise = 0.3)
W = [8.721432]
b = [2.1758988]b=6で正解式を作成(noise = 0.3)
W = [2.9766734]
b = [5.998174]依然として、近似性に際は内容に思われる。
ノイズには弱く、線形性の傾きや切片の変化には追従性が高い
- 投稿日:2019-07-16T10:05:31+09:00
KerasでマルチGPUで学習するときに発生したエラー「Check failed: cudnnSetTensorNdDescriptor」への対応
ある日のこと
- 新しい深層学習モデルを試すためにモデルを書き換えたところ、1エポック終了後に以下のエラーが発生した。
2019-07-16 10:01:06.027332: F tensorflow/stream_executor/cuda/cuda_dnn.cc:503] Check failed: cudnnSetTensorNdDescriptor(handle_.get(), elem_type, nd, dims.data(), strides.data()) == CUDNN_STATUS_SUCCESS (3 vs. 0)batch_descriptor: {count: 0 feature_map_count: 64 spatial: 16 144 256 value_min: 0.000000 value_max: 0.000000 layout: BatchDepthYX}
中止 (コアダンプ)対応
fitの引数に指定してあるvalidation_dataのサンプル数がミニバッチの倍数になっていなかったのをミニバッチの倍数になるように修正したら動いた。
謎
めんどくさいことに上の条件を満たしていなくても動いてしまうことがある。
参考情報
- 投稿日:2019-07-16T02:42:16+09:00
Synthesize Human Speech with WaveNet の tensorflow実装(データ前処理)
はじめに
音声生成の勉強をしていて、深層学習ベースのボコーダー(Wavenet)を実装していきます。とはいっても、論文だけから実装すると行き詰まると思うので、ChainerのWavenetチュートリアルをtensorflowで実装していきます。(というかtensorflow以外使えないので...)
間違っている点があればご指摘下さい。
環境
Python 3.6.7
tensorflow 1.12.0 (google colabで動いているので多分最新verでも動く...はず)
librosa 0.7.0 (音声データ読み込み用)データの前処理
今回は音声データのサンプルとして、効果音ラボにある音声を使います。
https://soundeffect-lab.info/sound/voice/mp3/line-girl1/line-girl1-ohayougozaimasu1.mp3
今回はlibrosaでデータを読み込みますが、実際にモデルを学習させる際にはtfrecordsなどを使ったほうがいいと思います。µ-law変換
Wavenetの出力はsoftmax関数で256段階のクラス分類モデルです。一般的なCDなどの音源は16bit整数(=2^16=65536通り)であって、これを65536通りの分類モデルとして学習するのが難しいためµ-law変換を行って256段階(8bit)に変換します。また入力する波形データ x は-1≦x≦1に正規化する必要があります。コードは以下の通り。
class MuLaw: def __init__(self, mu=256, int_type=tf.int32, float_type=tf.float32): self.mu = float(mu-1) self.int_type = int_type self.float_type = float_type def transform(self, x, name='MuLaw_Encode'): with tf.name_scope(name): signal = tf.sign(x)*(tf.log1p(self.mu*tf.abs(x)) / tf.log1p(self.mu)) signal = (signal + 1)/2*self.mu + 0.5 signal = tf.cast(signal, self.int_type) return signal def reverse(self, y, name='MuLaw_Decode'): with tf.name_scope(name): if y.dtype != self.float_type: y = tf.cast(y, self.float_type) y = 2 * (y / self.mu) - 1 y = tf.sign(y) * (1.0 / self.mu) * (tf.pow((1.0 + self.mu), tf.abs(y)) - 1.0) return ytransformがµ-law変換でreverseが逆変換用の関数です。変換後の出力はOne-Hotベクトルにする都合でint型にしています。
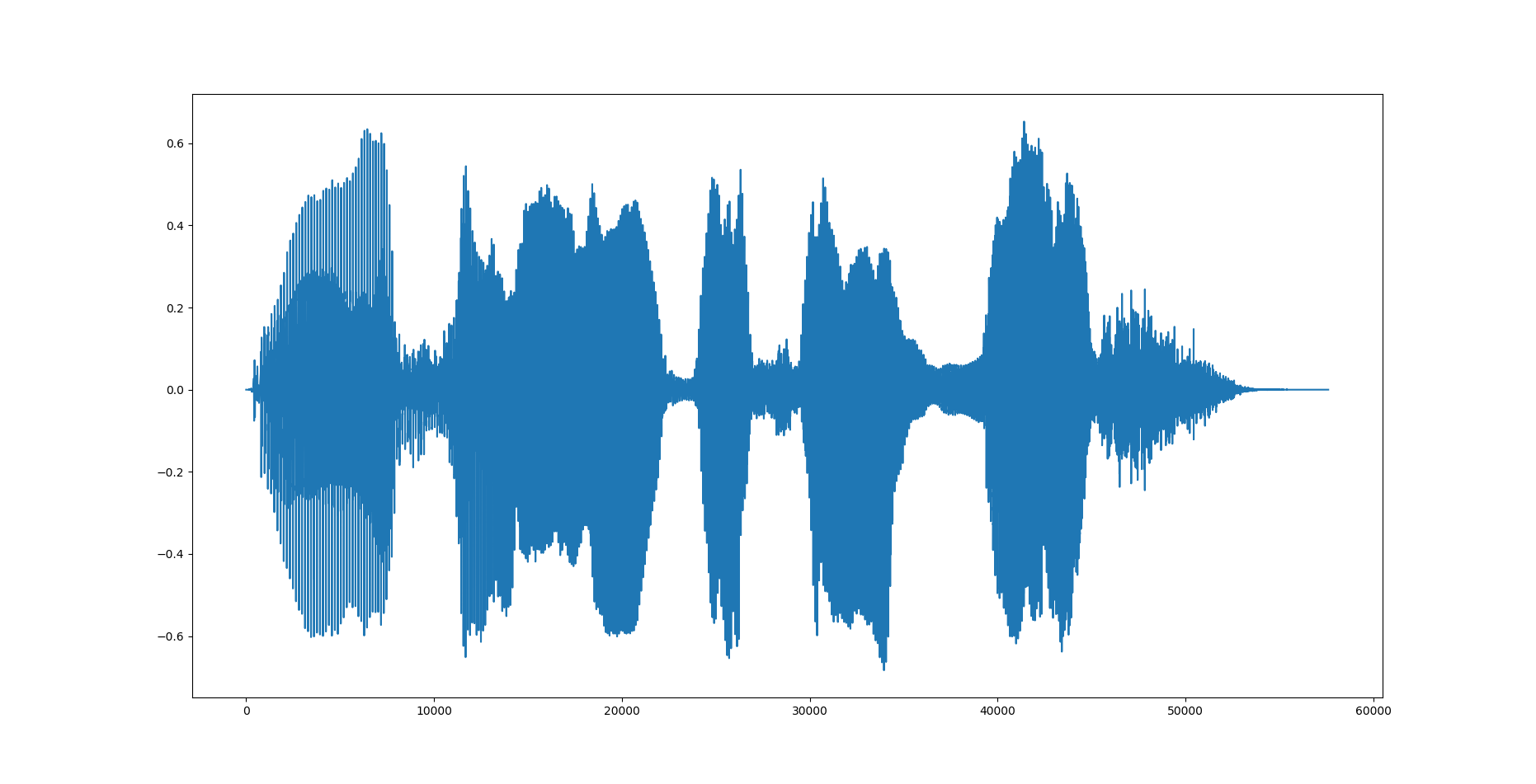
元の波形
変換後
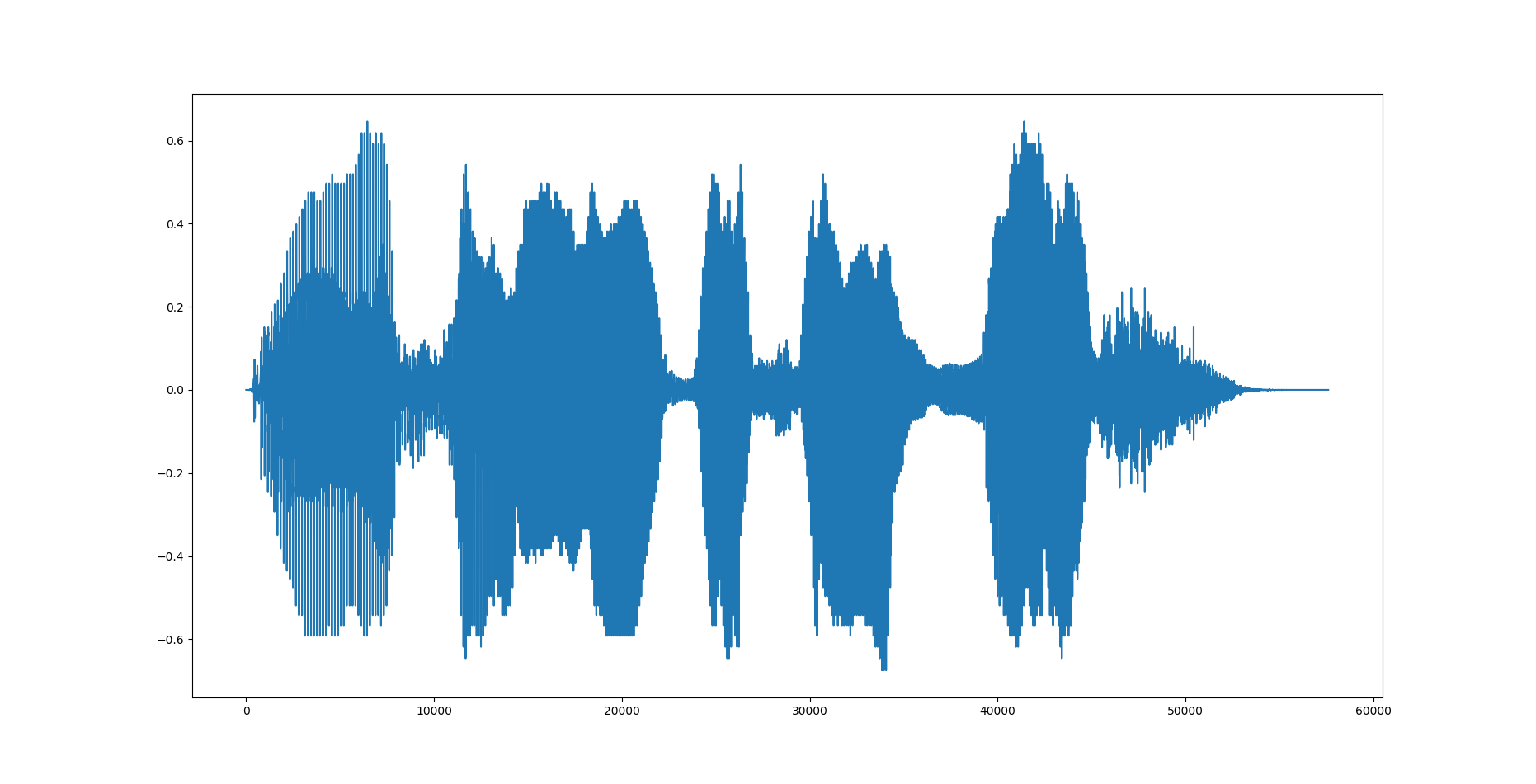
逆変換
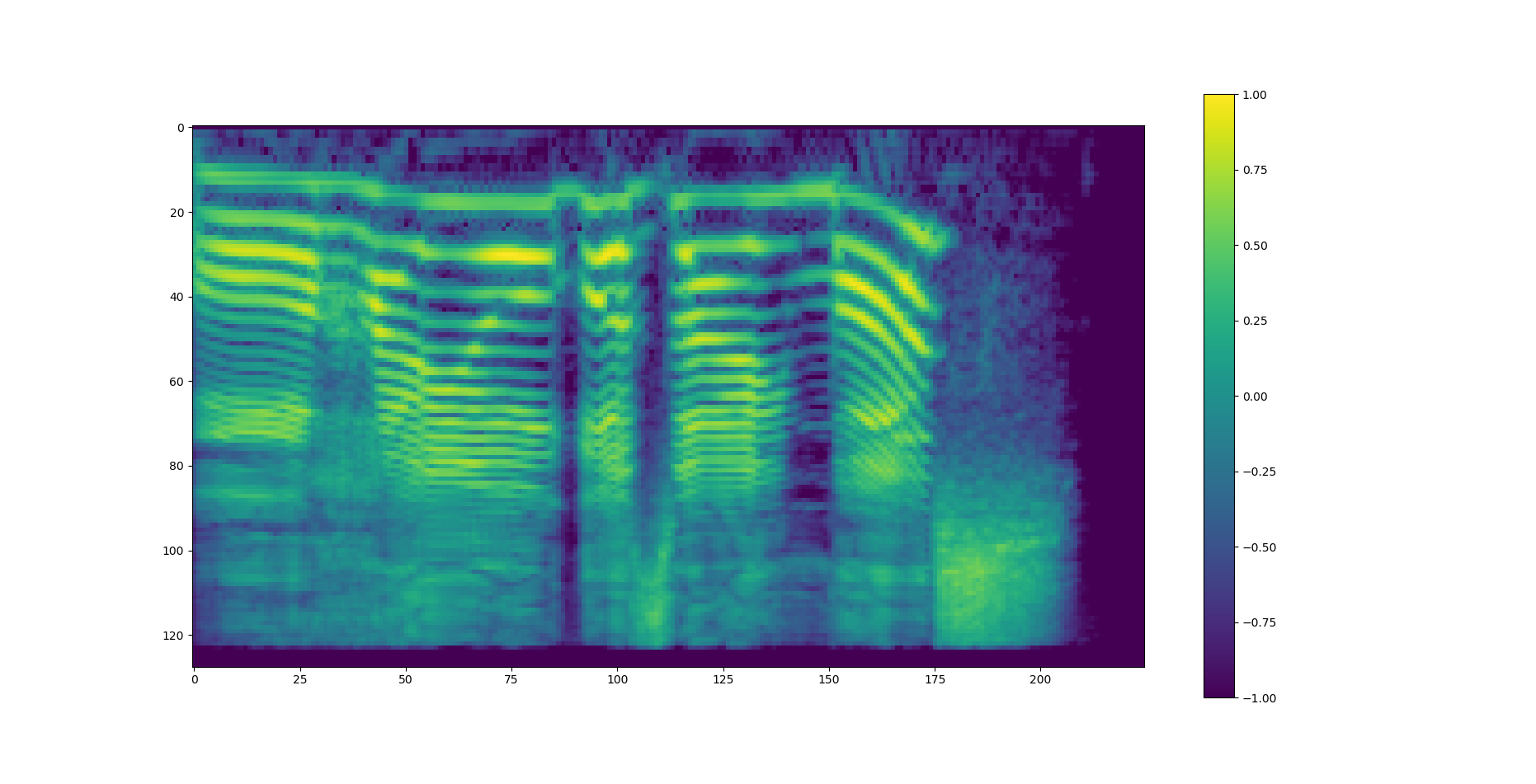
スペクトログラム
Wavenetでは生成の際に特徴量を付与できます(Global conditioningとLocal conditioning)。今回はその特徴量としてメルスペクトログラムを使用するためその処理も作成します。コードは以下の通り。
class Spectorogram: def __init__(self, sampling_rate, nfft, hop_length): self.sr = sampling_rate self.nfft = nfft self.hop_length = hop_length def make_power_spectorogram(self, waveform, name='make_spectorogram'): with tf.name_scope(name): frames = signal.stft(waveform, frame_length=self.nfft, frame_step=self.hop_length, fft_length=self.nfft, pad_end=True) power_spectorogram = tf.pow(tf.abs(frames), 2.0) return power_spectorogram def make_mel_spectorogram(self, waveform, mel_bins=128, name='make_mel_spectorogram'): with tf.name_scope(name): power_spec = self.make_power_spectorogram(waveform) mel_matrix = signal.linear_to_mel_weight_matrix(num_mel_bins=mel_bins, num_spectrogram_bins=int(self.nfft/2+1), sample_rate=self.sr, lower_edge_hertz=0.0, upper_edge_hertz=int(self.sr/2)) mel_spec = tf.einsum('ijk,kl->ijl', power_spec, mel_matrix) return mel_spec def power2db(self, spec, top_db=80.0, normalize=True, name='power_to_db'): with tf.name_scope(name): eps = 1e-10 ref = tf.reduce_max(spec) log_spec = 10.0 * self.log_base(tf.clip_by_value(spec, clip_value_min=eps, clip_value_max=ref), base=10.0) log_spec -= 10.0 * self.log_base(tf.maximum(eps, ref), base=10.0) log_spec = tf.maximum(log_spec, tf.reduce_max(log_spec)-top_db) if normalize: log_spec = (log_spec + (top_db / 2.0)) / (top_db / 2.0) return log_spec def log_base(self, x, base=10.0): assert base > 0 and (type(base) in [type(tf.Tensor), float]), 'base must be floating number and larger than 0' with tf.name_scope('log_base_%d'%base): y = tf.log(x) d = tf.log(base) return y/dスペクトログラムを作成する際の短時間フーリエ変換はtf.contrib.signalの関数を利用しています。tensorflowのver1.14ではtf.contribの使用が非推奨となっていたため、tf.signalモジュールを使用する必要があると思われます。
スペクトログラムをメル尺度に変換するための行列(メルフィルタバンク)はlinear_to_mel_weight_matrixで生成できます。tensorflowでは行列計算をする関数としてtensordotやmatmulなどがありますが、ここでeinsumを使用しているのは私の環境では他では返り値のshapeがNoneになったためeinsumを使いました。
power2dbでは周波数からデシベルへの変換?(librosaの実装を丸写ししただけなのでよく理解していない)を行っています。この変換式は、y_{db}=10\log_{10}{y}でtensorflowでは対数関数が自然対数しかなかったためその変換を行うためlog_baseを使っています。以下の画像が生成したメルスペクトログラムです。nfft=1024, hop_length=256で生成しました。
というわけで今回はここまでです。