- 投稿日:2019-07-16T23:31:51+09:00
bioinfoの競技プログラミングRosalindoを解いてみた
概要
最近、ちょこちょこ競技プログラミング(Atcoder)を解いているのですが、自分の専門により近いのがあれば、もっと楽しいし、やっている時の罪悪感がないのではと思い、bioinfoの競技プログラミングを探していました。
ということでググっってみたのですが、やはり競技プログラミングっぽいものはあまりなくて、以下の2つしか見当たらなかった
Bioinformatics Contest
Bioinformatics Institute
というNPOが1年に一回開催しているもの(今年は2月(例年?)でもう終わっている)競技プログラミングっぽいけど、入賞者を見ると僕でも論文を何本も読んだことのある人がいてびっくり(学生以外のプロも参加してそう)
Rosalind
2012年ぐらいからあるbioinfoの競技プログラミングサイト
問題数があまり多くないっぽいのと、定期的にコンテストが開催されるわけではなく、project Eulerのバイオ特化みたいな感じなので、バイオの人が触れてみる価値はありそう。
Reddit のポスト を見ると、Rosallingはアルゴリズムに偏っているので実の解析を学びたいならBioconductorやDatacampの解析を学ぶと良いが、アルゴリズムが好きな人や、興味を持つにはベストな方法ではないかと書いている。
注意点として、回答のコードを他の場所(例えばQiitaとかブログとか)に投稿してはいけないというルールがある。
(以下公式のQAから)Can I post my solutions somewhere?
No. The goal of Rosalind is to facilitate learning through problem solving. We encourage you to search the Internet or communicate with each other to find the best algorithms to solve our problem. However, there is a difference between looking for inspiration and copy-pasting someone else's code; we strongly advise you not to use others' source code. Once you have solved a problem, then we encourage you to post your code to the problem's comments section (which can be seen only by users who have also solved the problem). However, please do not publish your code outside of the Rosalind website.国籍とスコアの表
を見ると319点がマックス?
日本人でも登録している人は100人ぐらいいるけど、今やっている人はほとんどいなさそう笑2012年の黎明期にやっていた人のブログ
にファイルの操作などのtipsが載っている。実際にやってみた上でのtips
- ファイルをダウンロードし、そのファイルを入力とした時の回答をファイルか、直打ちで提出する方式
- 問題によってはダウンロードから提出まで1minしかないので、ダウンロードまでにコード書いたり、デバッグも終わらせとく必要がある(以外に1minは短い)
- ファイルを開いて入力を確認するのはめんどくさいので、https://qiita.com/taashi/items/07bf75201a074e208ae5 を参考にしてpythonでファイル名を引数にとって展開する方法を学んだ
- また、提出も高速化しないと間に合わないので
python complemnt_seq.py test.txtのようにコピペも最速化する。(ファイルを作ってもいいがこっちの方が早そう)入力例
in_out.py#!/use/bin/env python # count ACGT occurance import sys import re def ans(filename): with open(filename,"rU") as f: s = f.readline().split() # read 1 line print(ans) if __name__ == '__main__': args = sys.argv ans(args[1])感想
まだ簡単なのしかやっていない(Rosallindoはtree 形式とやらをとっていて、特定の系列に対してある問題をとかないと、次の問題を解くことができない)だが、やはり馴染みの深い分野だと、アルゴリズムとか全然なくても楽しい。
まだ問題としては、塩基配列を受け取り、ACGTの頻度を返す、RNAの配列にする(T->U への変換)、逆相補鎖を返すなど、単純な(pythonの文字列の扱いになれる程度の)問題しかやっていないが、他の人の回答をみることができ、色々と学びになる。
- 投稿日:2019-07-16T23:03:03+09:00
[python]算数・数学⑥~微分~
前回まで
改めて
機械学習を始めるにも、算数や数学がわからないと、入門書すら読めない。ただそこまで、ちゃんと解説してあるものもない。ということで最低限必要な数学基礎をこの記事で書けたらいいなと思っています。
環境
ほぼ影響ないですが、python3系を利用。
前提
四則演算や累乗(2乗とか3乗とか)がわかっていること。
極限について
$\displaystyle \lim_{x \to 0}$
とかいうやつです。
変数xを限りなく一定の値に近づけたときに、f(x)が一定の値αに近づいていくことを「収束」と言い、このαのことを極限値といいます。わかりやすい例でいうと
$f(x) = \frac{x^2-x-2}{x^3-8}$
という関数が会ったときに、x=2だとすると、分子も分母も0となるので
$\frac{0}{0}$となってしまい、「値を導くことができない」のです。これをlimを使って考えてみます。
まず因数分解を行います。$x=2$ではないので、(x-2)を約分することが出来る。
$\frac{x^2-x-2}{x^3-8} = \frac{(x-2)(x+1)}{(x-2)(x^2+2x+4)}=\frac{x+1}{x^2+2x+4}$
これを元に極限値を求めます。
$\displaystyle \lim_{x \to 2}\frac{x^2-x-2}{x^3-8}$
$=\displaystyle \lim_{x \to 2}\frac{x+1}{x^2+2x+4}$
$=\frac{2+1}{2^2+2\times2+4}$
$= \frac{3}{12}$
$= \frac{1}{4}$微分について
微分とは、「ある瞬間の変化」を求めることです。
例えば、「お湯を沸かす」事象について考えてみます。
ある瞬間の温度上昇について、tが時間、x(t)が時間tの時の温度とすると瞬間上昇温度
$= \displaystyle \lim_{\Delta t \to 0}\frac{\Delta x}{\Delta t}$
$= \displaystyle \lim_{\Delta t \to 0}\frac{x(t+\Delta t)-x(t)}{\Delta t}$
というように表すことができ、ある時点の変化を表すことができます。これらと同様に、二次関数や三次関数などの、ある瞬間の変化を表すことができ、それを「導関数」と呼びます。つまりxが少しだけ変化した時の、yもしくはf(x)の変化を量を求めるということです。そして導関数を求める作業を「微分」と言います。
$\frac{d(x)}{dx}=f'(x) = \displaystyle \lim_{\Delta x \to 0}\frac{\Delta f(x)}{\Delta x}=\displaystyle \lim_{\Delta h \to 0}\frac{f(x+h)-f(x)}{h}$
公式
$y = x^r$
を微分すると
$\frac{dy}{dx} = rx^{r-1}$$\frac{d}{dx}(f(x)+g(x)) = \frac{df(x)}{dx}+\frac{dg(x)}{dx}$
$\frac{d}{dx}(kf(x)) = k\frac{df(x)}{dx}$
ようは分母で書かれた変数で、分子(もしくは横に出てるもの)を微分してあげるだけです!もし変数が式中に複数ある場合は、分母にある変数で微分をする(偏微分)を行えばいいです。
接線の傾き
$y= x^2$の(2,4)における接線の方程式を求める
微分すると
$f'(x) = \frac{dy}{dx} = 2x$
これが傾きの方程式。つまりf'(2) = 4。
接線は$y = 4x+b$になり、yは元の(2,4)と書いてある通りなので$4 = 8 + b$となり$b = 4$であることがわかる。まとめると$y = 4x-4$という事になる。極値
微分した時の導関数が0を取りうる時、元の関数は「極値」を取ります。
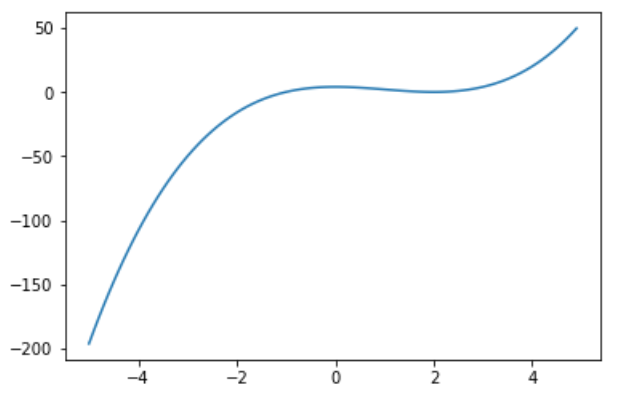
pythonで考えてみる
$x^3-3x^2+4$x = np.arange(-5,5,0.1) y = (x**3) - (3*x**2) +4 plt.plot(x,y)
1階微分
$f'(x) = 3x^2-6x$
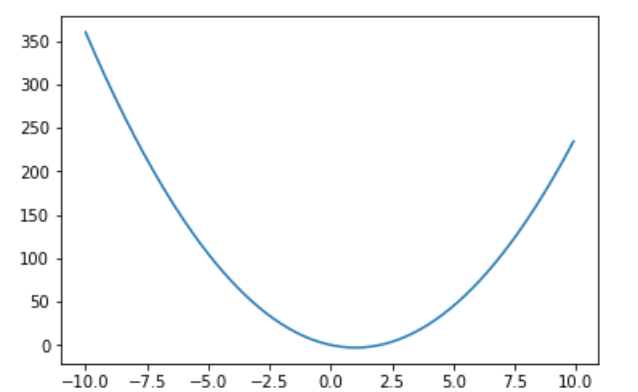
$= 3x(x-2)$x = np.arange(-10,10,0.1) y_d = 3*x**2-6*x plt.plot(x,y_d)計算式を見ると(0,2)で0を取ります。ということは元の$x^3-3x^2+4$でも0,2のところが極大値もしくは極小値になります。
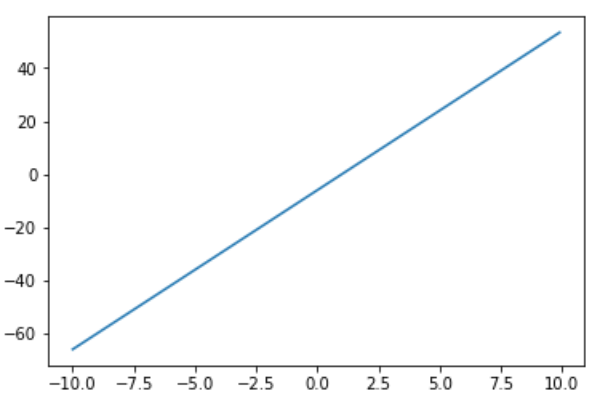
さらに微分をした2階微分
$f''(x) = 6x^6$
$= 6(x-1)$x = np.arange(-10,10,0.1) y_d = 3*x**2-6*x plt.plot(x,y_d)同様に1の時に0を取っているので、ということは元の$f'(x) = 3x^2-6x$でも1のところが極小値になります。
関数の微分
・$x^r$ -> $rx^{r-1}$
・$e^x$ -> $e^x$ ★
・$a^x$ -> $a^x log_e a$
・$log_e x$ -> $\frac{1}{x}$★
・$sinx$ -> $cosx$
・$cosx$ -> $-sinx$
・$-sinx$ -> $-cosx$
・$-cosx$ -> $sinx$
・$tanx$ -> $\frac{1}{cos^x}$※★がついてるところはよく式の変換で使われている(気がする)
※三角関数の部分に関しは循環しているので、4回微分したら元に戻る
pythonでやってみる。tanの微分は商の微分を使っています。import sympy as sym #記号化 (a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z)=sym.symbols("a b c d e f g h i j k l m n o p q r s t u v w x y z") sym.diff(x**2,x) # →2x sym.diff(sym.exp(x),x) # →?**2 sym.diff(sym.log(x)) # ->1/x sym.diff(sym.sin(x)) # ->cos(?)チェーンルール・合成関数
$\frac{dy}{dx}=\frac{dy}{du}・\frac{du}{dx}$
この公式を使うときは、変数が1つの時です。uというものが出てきますが、これは中の式をまとめたものになります。右辺の左で関数全体を、右辺の式でuを微分します。置き換える式がたくさんある場合は掛け算もその分伸びます。
例)
$(3x-2)^5$の微分では、$u=(3x-2)$として$u^5$と置きます。その後「$u^5$をuで微分したもの」と「(3x-2)をxで微分したもの」を掛け合わせます。
=> $\frac{du^5}{du}・\frac{du}{dx}$
$=5u^4・3=$
$=5(3x-2)^4・3$
$=15(3x-2)^4$
とすることができます。
・$\frac{\partial z}{\partial x}=\frac{\partial z}{\partial u}・\frac{\partial u}{\partial x}+\frac{\partial z}{\partial v}・\frac{\partial v}{\partial x}$
この公式を使うときは、変数が多変数の時です
例)
$(4x+3)^2+(x+y+2)^3$の微分では、$u=(4x+3),v=(x+y+2)$として$u^2+v^3$と置きます。その後「$u^2$をuで微分したもの」と「(4x+3)をxで微分したもの」を掛け合わせ、さらに「$v^3$をvで微分したもの」と「(x+y+2)をxで微分したもの」を掛け合わせます。
=> $\frac{du^2}{du}・\frac{du}{dx}+\frac{dv^3}{dv}・\frac{dv}{dx}$
$=2u・4+3(x+y+2)^2・1$
$=8(4x+3)+3(x^2+y^2+2^2+2xy+4x+4y)$
$=32x+24+3x^2+3y^2+12+6xy+12x+12y$
$=3x^2+44x+6xy+3y^2+12y+36$
$=3x^2+(44+6x)y+3y^2+12y+36$
とすることができます。
・$\frac{d}{dx}(f(x)g(x))=\frac{df(x)}{du}g(x)+f(x)\frac{dg(x)}{dx}$
例)
いわゆる積の微分法というものになります。
$x\sin{x}$の微分では、$f(x)=x,g(x)=\sin{x}$として$y=f(x)g(x)$と置き計算をしていきます。
=>$\frac{dy}{dx}$
$=\frac{df(x)}{dx}g(x)+f(x)\frac{dg(x)}{dx}$
$=1⋅\sin{x}+x⋅\cos{x}$
$=\sin{x}+x\cos{x}$
とすることができます。これはよく出てくるやつです。他にもこういう頻出のがあります。活性化関数と微分
以前取り扱ったシグモイド関数の微分について取り上げたいと思います。
まず微分してみます。
$f(x) = \frac{1}{1+e^{-ax}}$
において$u = 1+e^{-ax},v = -ax$
としておいた上で、$f(x) = \frac{1}{u} = u^{-1}$と式を変換しておきます。今回は2つの置き換えたのでチェーンルールもその分長く適用します。
$f'(x) = \frac{df(x)}{du}・\frac{du}{dv}・\frac{dv}{dx}$
となります。計算を進めていきます。
$f'(x) = \frac{du^-1}{du}・\frac{d(1+e^v)}{dv}・\frac{d(-ax)}{dx}$
$= -u^{-2}・e^v・-a$
$= u^{-2}・e^v・a$
$= \frac{1}{u^2}・e^v・a$
$= \frac{a・e^v}{u^2}$
置き換えたものを代入します。
$= \frac{a・e^{-ax}}{(1+e^{-ax})^2}$
となります。さらに変形させるともっとシンプルにかけます。
(この変形の仕方以外にもありますが)まず$+a-a$という式を付け足します。
$= \frac{a・e^{-ax}+a-a}{(1+e^{-ax})^2}$
その次にaを頭に出します。
$= \frac{a(1+e^{-ax})-a}{(1+e^{-ax})^2}$
ちょっとわかりやすく変形しておきます。
$= \frac{a(1+e^{-ax})}{(1+e^{-ax})^2}-\frac{a}{(1+e^{-ax})^2}$
左側を約分しておきます。
$= \frac{a}{(1+e^{-ax})}-\frac{a}{(1+e^{-ax})^2}$
この後がわかりづらいですが$\frac{a}{(1+e^{-ax})}$を頭に出します。
$= \frac{a}{(1+e^{-ax})}\bigg(1-\frac{1}{(1+e^{-ax})}\bigg)$
$= a\frac{1}{(1+e^{-ax})}\bigg(1-\frac{1}{(1+e^{-ax})}\bigg)$
かなり見覚えのある感じ。最後にシグモイド関数の部分をf(x)に置き換えます。
$= af(x)(1-f(x))$つまり$\varsigma(x)$の微分は$\varsigma'(x)= a\varsigma(x)(1-\varsigma(x))$で表せるということになります。
ついでもう一回微分(二階微分)すると$\varsigma''(x) = a^2\varsigma(x)(1-\varsigma(x))(1-2\varsigma(x))$という式になります。
この1階微分の式の最大値は0.25になります。(a=1の標準シグモイド、$\varsigma(x) = \frac{1}{2}$を当てはめるだけ)このようなシグモイド関数は、活性化関数(NNの重みの調整時に使う)として利用されますが、上記のように最大値が0.25なのでNN層の深さによっては誤差伝播せず勾配消失してしまうので、ランプ関数(ReLU)が使われたります。ランプ関数は微分すると最大1最小0をとるので活性化関数としてとても使い勝手がとても良いです。
import sympy as sym #記号化 (a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z)=sym.symbols("a b c d e f g h i j k l m n o p q r s t u v w x y z") a = 1 sym.diff(1/(1+sym.exp(-x*a))) # -> e^-x/(1+e^-x)^2ここまで
微分は最小二乗法やNNの誤差逆伝播法などでも使うので、必ず必要になる大事な部分でした。積分はまた投稿します。
次回はベクトルについて記載していきます。
参考
- 投稿日:2019-07-16T22:53:32+09:00
顔写真に自動でモザイクをかける
# -*- coding: utf-8 -*- import cv2 import math import numpy as np from PIL import Image def main(): img_filename = input() img = cv2.imread(img_filename) img_edit = Image.open(img_filename) cascade = cv2.CascadeClassifier("haarcascade_frontalface_alt.xml") gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = cascade.detectMultiScale(img, scaleFactor=1.1, minNeighbors=1, minSize=(3,3)) if len(faces) > 0: for face in faces: cut_face = img_edit.crop((face[0], face[1], face[0]+face[2], face[1]+face[3])) cut_face = cut_face.resize((int(face[2]/5), int(face[3]/5)), Image.LINEAR) cut_face = cut_face.resize(face[2:], Image.LINEAR) img_edit.paste(cut_face, tuple(face[:2])) img_dst = np.asarray(img_edit) img_edit.show() img_edit.save('result.jpg') if __name__ == '__main__': main()
- 投稿日:2019-07-16T22:38:52+09:00
LeetCode / Implement strStr()
(ブログ記事からの転載)
[https://leetcode.com/problems/implement-strstr/]
Implement strStr().
Return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
Example 1:
Input: haystack = "hello", needle = "ll"
Output: 2Example 2:
Input: haystack = "aaaaa", needle = "bba"
Output: -1Clarification:
What should we return when needle is an empty string? This is a great question to ask during an interview.
For the purpose of this problem, we will return 0 when needle is an empty string. This is consistent to C's strstr() and Java's indexOf().Pythonから入った私は知らなかったのですが、strstr関数というのはCやPHPで使われる「文字列から文字列を検索してその場所のポインタを返してくれる関数」だそうです。このstrstr関数を実装しなさい、という問題です。
そしてまたClarificationがポイントで、マッチングする文字列が空の場合は0を返すように実装する必要があります。解答・解説
解法1
マッチングする文字列が空の場合に0を返すためにif文を入れたくなりますが、その欲求に争いつつ、できるだけシンプルに処理したコードが以下です。
class Solution: def strStr(self, haystack: str, needle: str) -> int: for i in range(len(haystack) - len(needle)+1): if haystack[i:i+len(needle)] == needle: return i return -1可読性は高いと思いますが、リストのスライスはリストのコピーを生成するため、時間計算量はhstackのサイズをhとしたときに最大で[tex: O(n * h)]に達してしまいます。
解法2(のreference)
KMP法というアルゴリズムがあるようで、このアルゴリズムは一度照合した文字列を再度照合することはしないというアルゴリズムなので、時間計算量は高々[tex: O(n)]に抑えられるようです。
実装はちょっと難解で、余力のあるときにやります。。。ひとまずreferenceだけ示します。[http://sevendays-study.com/algorithm/ex-day2.html]
ただ、処理が複雑になるため、計算量が解法1を上回るかというと、そうでもないようです。
- 投稿日:2019-07-16T21:51:35+09:00
Django 汎用ビュー入門2
願望
汎用ビューを使って効率良くWEBサイトを作りたい。
要するに楽したい。
環境
mac
python3.7.3
anaconda
vagrant
django2.2.1前回やったこと
TemplateViewを使ってテンプレートを簡単に表示したり
ListViewを使ってモデルの情報をリスト形式で表示した。
今回やりたいこと
汎用ビューを使って詳細ページの作成
汎用ビューを使ってレコードを登録するページの作成
1. 汎用ビューを使って、詳細ページを作る
viewsで汎用ビューを継承したクラスを作成
DetailViewを継承すると詳細ページを楽に作成出来る。
viewtest/home/views.pyfrom django.views import generic from .models import User class UserDetailView(generic.DetailView): model = User # modelを指定 template_name = 'home/detail.html' # テンプレートを指定urlsに汎用ビューとしてURLと紐づける
viewtest/home/urls.py...略^o^ urlpatterns = [ ... path('users/<int:pk>/', views.UserDetailView.as_view(), name='detail'), # usersページに <a href="{% url 'home:detail' user.pk %}"></a>を設置しIDから情報を取得。 ]今回表示させる適当な詳細ページ
viewtest/home/templates/home/detail.html{% extends 'home/base.html' %} {% block content %} <h1>{{ object.username }}</h1> <!-- object.フィールド名 でデータを受け取る !--> <p>SEX : {{ object.sex }}</p> <p>AGE : {{ object.age }}</p> {% endblock %}前回作ったusers.htmlに aタグを挿入〜
viewtest/home/templates/home/users.html...略^ー^ <ul> {% for user in object_list %} <li><p><a href="{% url 'home:detail' user.pk %}">{{ user.username }}</a> - {{ user.sex }} ({{ user.age }})</p></li> {% empty %} <li><p>No Users yet</p></li> {% endfor %} </ul> ...略^w^これで簡単な詳細ページはOK。
これもまた既存メソッドをオーバーライドすれば色々出来るらしい。
2. 汎用ビューを使ってレコード登録するページの作成
viewsで継承
CreateViewを継承するとフォーム関連を楽に作れる。
viewtest/home/views.pyfrom .models import User from django.views import generic from django.urls import reverse_razy ...略^u^ class UserCreateView(generic.CreateView): model = User # modelを指定 fields = '__all__' # createviewは使用するfieldsを指定する必要がある。 # この場合はmodelsで定義した、username, sex, ageのフォームが作られる。 # 指定したい場合はリストとかでフィールド名指定 template_name = 'home/create.html' success_url = reverse_razy('home:users') # 成功した時飛ばすURLを指定する。reverse_razyはクラス内でurls.pyを参照するんだっけか。また、
CreateViewには、form_valid()form_invalid()といったメソッドが用意されていて、バリデーションの成功、失敗によって動作を実装出来る。urlsに汎用ビューとしてURLと紐づける
viewtest/home/urls.py...略^o^ urlpatterns = [ ... path('create/', views.UserCreateView.as_view(), name='create'), ]今回表示させる適当な入力ページ
viewtest/home/templates/home/create.html{% extends 'home/base.html' %} {% block content %} <form action="" method="post"> {% csrf_token %} {{ form.as_p}} <!-- {{ form }} でもいけるけど、as_pにすると1個1個にpタグ付けて出力してくれるみたい !--> <input type="submit" value="createuser"> </form> {% endblock %}こりゃ楽だ〜
結果
汎用ビューに興奮しすぎて眠れない
続く
- 投稿日:2019-07-16T21:39:59+09:00
Pythonで多めのデータをGoogleスプレッドシートに書く時の注意点
Background
結構多めのデータをスプレッドシートに書き込む場合、下記のコードを書くとエラーが出てしまう。 データ元は埼玉県の郵便番号リスト(https://www.post.japanpost.jp/zipcode/dl/kogaki/zip/11saitam.zip) です。
serialimport configparser import json import os import time from oauth2client.service_account import ServiceAccountCredentials import gspread def serial(): config = configparser.ConfigParser() ini_file = os.path.join("./", 'setting.ini') config.read(ini_file) scope = ["https://spreadsheets.google.com/feeds", "https://www.googleapis.com/auth/drive"] book_id = config.get("googleSpreadSheet", "book_id") path = os.path.join("./", config.get("googleSpreadSheet", "keyfile_name")) credentials = ServiceAccountCredentials.from_json_keyfile_name(path, scope) client = gspread.authorize(credentials) gfile = client.open_by_key(book_id) sheet = gfile.worksheets()[0] adress = [] with open("11SAITAM.csv", "r") as fin: for item in fin.readlines(): one_row = item.split(",") if one_row[8] != "以下に掲載がない場合": adress.append(one_row[0:2] + one_row[6:9]) start_time = time.time() for i,a in enumerate(adress[:50]): sheet.update_acell('A{0}'.format(i+1), a[0]) sheet.update_acell('B{0}'.format(i+1), a[1]) sheet.update_acell('C{0}'.format(i+1), a[2]) sheet.update_acell('D{0}'.format(i+1), a[3]) sheet.update_acell('E{0}'.format(i+1), a[4]) time.sleep(1) elapsed_time = time.time() - start_time print ("elapsed_time:{0}".format(elapsed_time) + "[sec]") if __name__ == "__main__": serial()error_messagegspread.exceptions.APIError: { "error": { "code": 429, "message": "Quota exceeded for quota group 'WriteGroup' and limit 'USER-100s' of service 'sheets.googleapis.com' for consumer 'project_number:XXXXXX'.", "status": "RESOURCE_EXHAUSTED", "details": [ { "@type": "type.googleapis.com/google.rpc.Help", "links": [ { "description": "Google developer console API key", "url": "https://console.developers.google.com/project/11736174289/apiui/credential" } ] } ] } }原因はユーザーごとの 100 秒あたりのリクエスト数の上限を達してしまった可能性があって、短期間で
sheet.update_acell()を送り続けるとエラーになるとのことです。それで、シンプルに
import time time.sleep(1)と遅延を掛けてもエラーにならないこともなく不安定です。Solution
非同期I/O asyncio を内包している
gspread-asyncioを使います。Install
pip3 install gspread-asyncioDevelopment
公式ページ内にあるサンプルを参考に記述します。
gspread_asyncioimport asyncio import gspread_asyncio import configparser import json import os import time from oauth2client.service_account import ServiceAccountCredentials import gspread async def simple_gspread_asyncio(agcm): agc = await agcm.authorize() book = await agc.open_by_url("https://docs.google.com/spreadsheets/d/{sheet_id}/") sheet = await book.get_worksheet(0) adress = [] with open("11SAITAM.csv", "r") as fin: for item in fin.readlines(): one_row = item.split(",") if one_row[8] != "以下に掲載がない場合": adress.append(one_row[0:2] + one_row[6:9]) start_time = time.time() #50件のみ書き込み for i,a in enumerate(adress[:50]): await sheet.update_acell('A{0}'.format(i+1), a[0]) await sheet.update_acell('B{0}'.format(i+1), a[1]) await sheet.update_acell('C{0}'.format(i+1), a[2]) await sheet.update_acell('D{0}'.format(i+1), a[3]) await sheet.update_acell('E{0}'.format(i+1), a[4]) elapsed_time = time.time() - start_time print ("elapsed_time:{0}".format(elapsed_time) + "[sec]") def get_creds(): return ServiceAccountCredentials.from_json_keyfile_name( "{authority_json_file_name}.json", ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive', 'https://www.googleapis.com/auth/spreadsheets']) if __name__ == "__main__": #設定クラス作成 agcm = gspread_asyncio.AsyncioGspreadClientManager(get_creds) #非同期処理開始 loop = asyncio.get_event_loop() #終了するまで実行 loop.run_until_complete(simple_gspread_asyncio(agcm)) #終了処理 loop.close()Result
処理結果は
elapsed_time:275.9753634929657[sec]と4,5分かかります。ですが、ERROR:root:Error while calling update_cell (44, 5, '見沼') {}.といったエラーメッセージが出るものの途中終了せずに書き込みは完了します。Suplement
AsyncioGspreadClientManagerクラスに
AsyncioGspreadClientManager(get_creds,gspread_delay=0.5)と遅延時間をチューニングすることができます。 defalutは1.1秒です。一度0.4秒で設定してtryしたところ、
214.48740601539612[sec]と1分くらい短縮は出来ますが大幅には改善されません。ERROR:root:Error while calling update_cellのエラーが頻発するのでAPIリクエストの上限に引っかかるみたいです。また、python3.7ではコルーチンを起動と終了を自動で実行するシンプルなコード
asyncio.run(coroutine_func)が追加されましたが、asyncio.run(simple_gspread_asyncio(agcm))とすると下記のエラーが表示されます。 なぜかは不明です。
Traceback (most recent call last): File "main.py", line 154, in <module> asyncio.run(simple_gspread_asyncio(agcm)) File "/usr/local/lib/python3.7/asyncio/runners.py", line 43, in run return loop.run_until_complete(main) File "/usr/local/lib/python3.7/asyncio/base_events.py", line 579, in run_until_complete return future.result() File "main.py", line 117, in simple_gspread_asyncio agc = await agcm.authorize() File "/usr/local/lib/python3.7/site-packages/gspread_asyncio/__init__.py", line 164, in authorize return await self._authorize() File "/usr/local/lib/python3.7/site-packages/gspread_asyncio/__init__.py", line 171, in _authorize creds = await self._loop.run_in_executor(None, self.credentials_fn) RuntimeError: Task <Task pending coro=<simple_gspread_asyncio() running at main.py:117> cb=[_run_until_complete_cb() at /usr/local/lib/python3.7/asyncio/base_events.py:153]> got Future <Future pending cb=[_chain_future.<locals>._call_check_cancel() at /usr/local/lib/python3.7/asyncio/futures.py:348]> attached to a different loopFuture
途中終了せずに多めのデータをスプレッドーシートに書き込む方法をまとめてみたのですが、もっと多めのデータでは完了するまでに時間がかかります。埼玉県内の郵便番号データは約3000件あるので、上記のコードでは全データを書き込むのに3時間くらいかかります。
concurrent.futures.ThreadPoolExecutorでも使ってworkerを振り分けて内部で並列処理を掛けないと速度を出すのは厳しいです。速度を出すとリクエストの制限に引っかかりそうだ。調節が必要です。
Reference
gspread_asyncio
API リクエストの制限と割り当て
18.5.3. タスクとコルーチン
Python3での非同期処理まとめ
Pythonの非同期I/O(asyncio)を試す
Fluent Python――Pythonicな思考とコーディング手法 18章 asyncioによる並行処理
Fluent Python sample code――18-asyncio-py3.7
- 投稿日:2019-07-16T19:09:54+09:00
訓練用データとテスト用データをダミー変数化したときに列数が合わない問題を解決する
このようなデータがあるとします。
import pandas as pd train = pd.DataFrame({'Categorical':['A','B','C','E','G','I','J','K'], 'Numerical':[1, 2, 3, 4, 5, 6, 7, 8]}) test = pd.DataFrame({'Categorical':['A','B','D','F','H','J','K'], 'Numerical':[1, 2, 3, 4, 5, 6, 7]}) print(train) print(test)Categorical Numerical 0 A 1 1 B 2 2 C 3 3 E 4 4 G 5 5 I 6 6 J 7 7 K 8 Categorical Numerical 0 A 1 1 B 2 2 D 3 3 F 4 4 H 5 5 J 6 6 K 7train, testをそれぞれダミー変数化します。
train = pd.get_dummies(train) test = pd.get_dummies(test) print(train) print(test)Numerical Categorical_A Categorical_B Categorical_C Categorical_E \ 0 1 1 0 0 0 1 2 0 1 0 0 2 3 0 0 1 0 3 4 0 0 0 1 4 5 0 0 0 0 5 6 0 0 0 0 6 7 0 0 0 0 7 8 0 0 0 0 Categorical_G Categorical_I Categorical_J Categorical_K 0 0 0 0 0 1 0 0 0 0 2 0 0 0 0 3 0 0 0 0 4 1 0 0 0 5 0 1 0 0 6 0 0 1 0 7 0 0 0 1 Numerical Categorical_A Categorical_B Categorical_D Categorical_F \ 0 1 1 0 0 0 1 2 0 1 0 0 2 3 0 0 1 0 3 4 0 0 0 1 4 5 0 0 0 0 5 6 0 0 0 0 6 7 0 0 0 0 Categorical_H Categorical_J Categorical_K 0 0 0 0 1 0 0 0 2 0 0 0 3 0 0 0 4 1 0 0 5 0 1 0 6 0 0 1列数並びに列名が合いません。
そこで不足している列の値を全て0で補う関数を定義します。
def fill_missing_columns(df_a, df_b): columns_for_b = set(df_a.columns) - set(df_b.columns) for column in columns_for_b: df_b[column] = 0 columns_for_a = set(df_b.columns) - set(df_a.columns) for column in columns_for_a: df_a[column] = 0関数を実行します。
fill_missing_columns(train, test) train.sort_index(axis=1, inplace=True) test.sort_index(axis=1, inplace=True) print('train') print(train.shape) print(train) print('test') print(test.shape) print(test)train (8, 12) Categorical_A Categorical_B Categorical_C Categorical_D Categorical_E \ 0 1 0 0 0 0 1 0 1 0 0 0 2 0 0 1 0 0 3 0 0 0 0 1 4 0 0 0 0 0 5 0 0 0 0 0 6 0 0 0 0 0 7 0 0 0 0 0 Categorical_F Categorical_G Categorical_H Categorical_I Categorical_J \ 0 0 0 0 0 0 1 0 0 0 0 0 2 0 0 0 0 0 3 0 0 0 0 0 4 0 1 0 0 0 5 0 0 0 1 0 6 0 0 0 0 1 7 0 0 0 0 0 Categorical_K Numerical 0 0 1 1 0 2 2 0 3 3 0 4 4 0 5 5 0 6 6 0 7 7 1 8 test (7, 12) Categorical_A Categorical_B Categorical_C Categorical_D Categorical_E \ 0 1 0 0 0 0 1 0 1 0 0 0 2 0 0 0 1 0 3 0 0 0 0 0 4 0 0 0 0 0 5 0 0 0 0 0 6 0 0 0 0 0 Categorical_F Categorical_G Categorical_H Categorical_I Categorical_J \ 0 0 0 0 0 0 1 0 0 0 0 0 2 0 0 0 0 0 3 1 0 0 0 0 4 0 0 1 0 0 5 0 0 0 0 1 6 0 0 0 0 0 Categorical_K Numerical 0 0 1 1 0 2 2 0 3 3 0 4 4 0 5 5 0 6 6 1 7列名並びに列数を合わせることができました。
- 投稿日:2019-07-16T17:35:38+09:00
Quant X トレーリングストップ
@kei-tenniacoさんと組んでアルゴリズムを作りました。
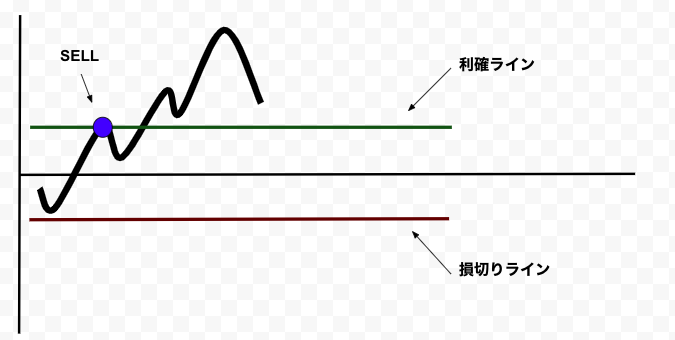
トレーリングストップの説明
トレーリングストップとは、株価の上昇に合わせて損切りラインを更新する売買方法です。QuantX Factoryで現在使用されているアルゴリズムの多くでは、損切りと利確ラインを株価と独立に一定に設定しています。
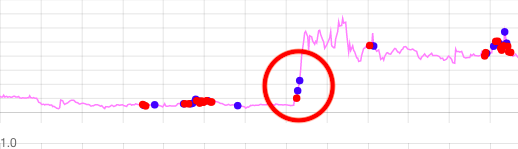
トレーリングストップを使っていない例:
このように、株価が急増するときは利確ラインで売ってしまい、利益を失います。
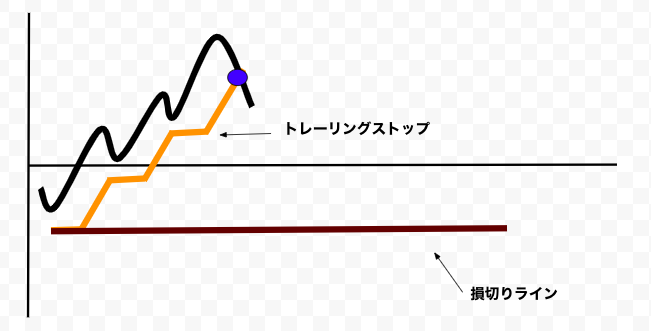
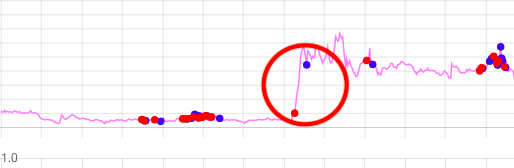
トレーリングストップを使っている例:
トレーリングストップを使えば、損切りラインを株価とともに動かせて、急増している株価から最大の利益を得ることができます。
株価が下がったら損切りラインでSELLをして、株価が上がったらトレーリングストップを使って高い株価で売ります。
損切りラインが上下に動いているため、利確ラインはいりません。
ゴンさんのトレーリングストップの間違え
2019年の3月にゴンさんがトレーリングストップのプログラムを作りました。それはこちら(1)とこちら(2)にあります。
彼の最初のコードには欠点が三つあります。
1. 利確がまだ残っている。
2. トレーリングストップポジションを保つため、30日間のmaxを使用している。これにより、実際にはポジションを保持していなかった時期のmax値を使用してしまったり、本来使用すべきmax値を逃してしまったりと、関係のないデータを使ってしまう可能性がある。一定の日にちを入力するよりもポジションを保持した時からのMAX値を使った方がいい。
3. 損切り時での使用でなく、SELL_SIGにトレーリングストップを導入してしまっている。これにより、ポジションを持っていない際もSELL_SIGがTrueとなり、0.0.5エンジンではBUYとSELLのシグナルが打ち消し合い、買いが入れれなくなってしまう。(0.0.1ではBUYのあと一瞬でSELLをしてしまう。)よって、これはどのバージョンでも効率的ではない。また、ゴンさんの二つ目の記事は1番目の欠点しか直していません。これを解決してより良いトレーリングストップを作ります。
完成したコード
一般的なWMAモデル(対象銘柄:アンジェス)のコードにトレーリングストップを実装しました。
(0.0.5エンジンを使っています。)# Sample Algorithm # ライブラリーのimport # 必要ライブラリー import maron import maron.signalfunc as sf import maron.execfunc as ef # 追加ライブラリー # 使用可能なライブラリに関しましては右画面のノートをご覧ください① import pandas as pd import talib as ta import numpy as np # オーダ方法(目的の注文方法に合わせて以下の2つの中から一つだけコメントアウトを外してください) # オーダー方法に関しましては右画面のノートをご覧ください② #ot = maron.OrderType.MARKET_CLOSE # シグナルがでた翌日の終値のタイミングでオーダー ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー #ot = maron.OrderType.LIMIT # 指値によるオーダー # 銘柄、columnsの取得 # 銘柄の指定に関しては右画面のノートをご覧ください③ # columnsの取得に関しては右画面のノートをご覧ください④ def initialize(ctx): # 設定, 6行目から20行目は変えないようにお願いします。 ctx.flag_profit = False #利益確定売りを用いるかTrueなら用いるFalseなら用いない ctx.flag_loss = True #損切りを用いるかTrueなら用いるFalseなら用いない ctx.flag_trailing_stop = True #トレーリングストップを用いるかTrueなら用いるFalseなら用いない ctx.loss_cut = -0.03 #損切りのボーダーマイナス% ctx.profit_taking = 0.05 #利益確定売りのボーダープラス% ctx.trailing_stop = -0.03 #トレーリングストップのmax値比較ボーダーマイナス% ctx.codes = [4563] ctx.symbol_list = ["jp.stock.{}".format(code) for code in ctx.codes] ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols":ctx.symbol_list, "columns": [ #"open_price_adj", # 始値(株式分割調整後) #"high_price_adj", # 高値(株式分割調整後) #"low_price_adj", # 安値(株式分割調整後) "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) # "volume_adj", # 出来高 # "txn_volume", # 売買代金 ]}}) # シグナル定義 def _my_signal(data): # この部分に作成するアルゴの指標を書き込んで下さい。 #各銘柄の終値(株式分割調整後)を取得、欠損データの補完 cp = data["close_price_adj"].fillna(method="ffill") for (sym, val) in cp.items(): # valがすべてNaNだったときはtalibで計算しない isna = val.isnull().all() if isna: continue #単純移動平均線(SMA)の設定 #データの入れ物を用意 s_wma = pd.DataFrame(data=0,columns=[], index=cp.index) m_wma = pd.DataFrame(data=0,columns=[], index=cp.index) l_wma = pd.DataFrame(data=0,columns=[], index=cp.index) #TA-Libによる計算 for (sym,val) in cp.items(): s_wma[sym] = ta.WMA(cp[sym].values.astype(np.double), timeperiod=5) m_wma[sym] = ta.WMA(cp[sym].values.astype(np.double), timeperiod=25) l_wma[sym] = ta.WMA(cp[sym].values.astype(np.double), timeperiod=75) #SMAの売買シグナルの定義 s_wma_ratio = s_wma/m_wma l_wma_ratio = m_wma/l_wma buy_sig = (s_wma_ratio > 1.00) & (s_wma_ratio < 1.10) & (l_wma_ratio > 1.00) & (l_wma_ratio < 1.10) sell_sig = (((s_wma_ratio < 0.99) & (l_wma_ratio < 0.99))) # market_sigという全て0が格納されているデータフレームを作成 # market_sigに関しては右画面のノートをご覧ください⑥ market_sig = pd.DataFrame(data=0.0, columns=cp.columns, index=cp.index) # buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 # loggerに関しましては右画面のノートをご覧ください⑦ # ctx.logger.debug(market_sig) return { "wma5":s_wma, "wma25":m_wma, "wma75":l_wma, "market:sig": market_sig, } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' market_sig = current["market:sig"] done_syms = set([]) for (sym,val) in ctx.portfolio.positions.items(): returns = val["returns"] trailing = val["max_returns"] - returns if (ctx.flag_loss) & (returns < ctx.loss_cut): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) done_syms.add(sym) elif (ctx.flag_profit) & (returns > ctx.profit_taking): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) done_syms.add(sym) elif (ctx.flag_trailing_stop) & (returns > 0.10) & (ctx.trailing_stop > 0.01): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="トレーリング10%利確(%f)" % returns) done_syms.add(sym) elif (ctx.flag_trailing_stop) & (returns > 0.05) & (ctx.trailing_stop > 0.02): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="トレーリング5%利確(%f)" % returns) done_syms.add(sym) elif (ctx.flag_trailing_stop) & (returns - val["max_returns"] < ctx.trailing_stop): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="トレーリング利確(%f)" % returns) done_syms.add(sym) # 買いシグナル buy = market_sig[market_sig > 0.0] for (sym, val) in buy.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order_target_percent(0.8, orderType=ot, comment="SIGNAL BUY") #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) pass # 売りシグナル sell = market_sig[market_sig < 0.0] for (sym, val) in sell.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order_target_percent(0, orderType=ot, comment="SIGNAL SELL") #ctx.logger.debug("SELL: %s, %f" % (sec.code(), val))コードの説明
def initialize:
ctx.flag_profit = False #利益確定売りを用いるかTrueなら用いるFalseなら用いない ctx.flag_loss = True #損切りを用いるかTrueなら用いるFalseなら用いない ctx.flag_trailing_stop = True #トレーリングストップを用いるかをTrue/Falseで決める ctx.loss_cut = -0.03 #損切りのボーダーマイナス% ctx.profit_taking = 0.05 #利益確定売りのボーダープラス% ctx.trailing_stop = -0.03 #トレーリングストップのmax値比較ボーダーマイナス%ここでは損切りと利確ラインのボーダー%を決めます。トレーリングストップを使うので、利確はいりません。そのため、ctx.flag_profitをFalseになっています。
ctx.trailing_stop はトレーリングストップを株価の何パーセント下にするかを決めています。
トレーリングストップの弱点は変動が大きすぎて急増する前に売ってしまうことがあります。そのため、変動が激しいグラフでしたら、ctx.trailing_stopの設定幅を大きくした方が効果的です。
def handle_signals:
elif (ctx.flag_trailing_stop) & (returns > 0.10) & (ctx.trailing_stop > 0.01): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="トレーリング1%利確(%f)" % returns) done_syms.add(sym) elif (ctx.flag_trailing_stop) & (returns > 0.05) & (ctx.trailing_stop > 0.02): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="トレーリング2%利確(%f)" % returns) done_syms.add(sym) elif (ctx.flag_trailing_stop) & (returns - val["max_returns"] < ctx.trailing_stop): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="トレーリング利確(%f)" % returns) done_syms.add(sym)ここでは、トレーリングストップを実行しています。ゴンさんと同じく株価の利益率が10%を超えたらctx.trailing_stop を3%から1%に変えて。5%を超えたら2%に変えます。
比べた結果
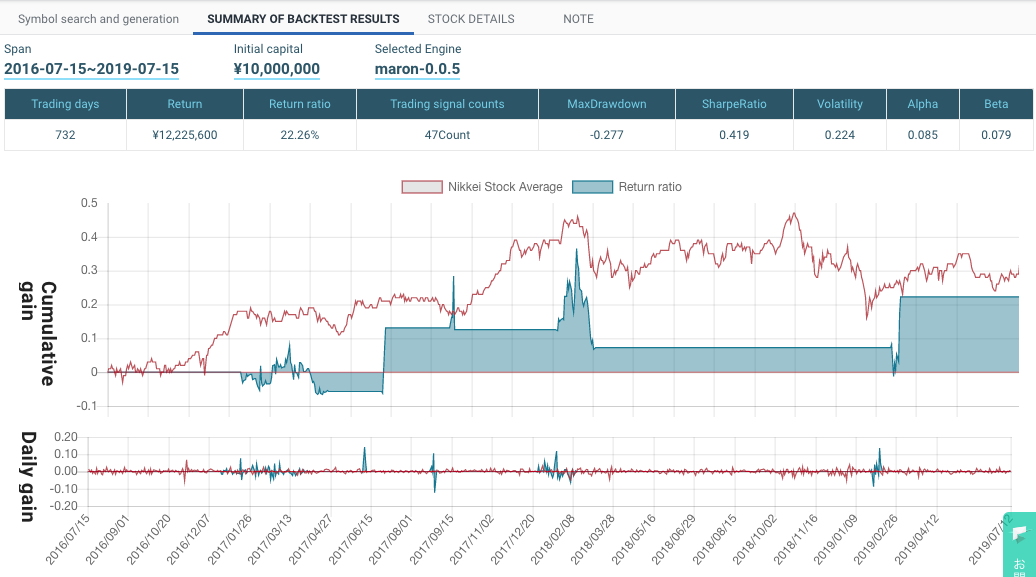
トレーリングストップを使っていないWMAモデル:
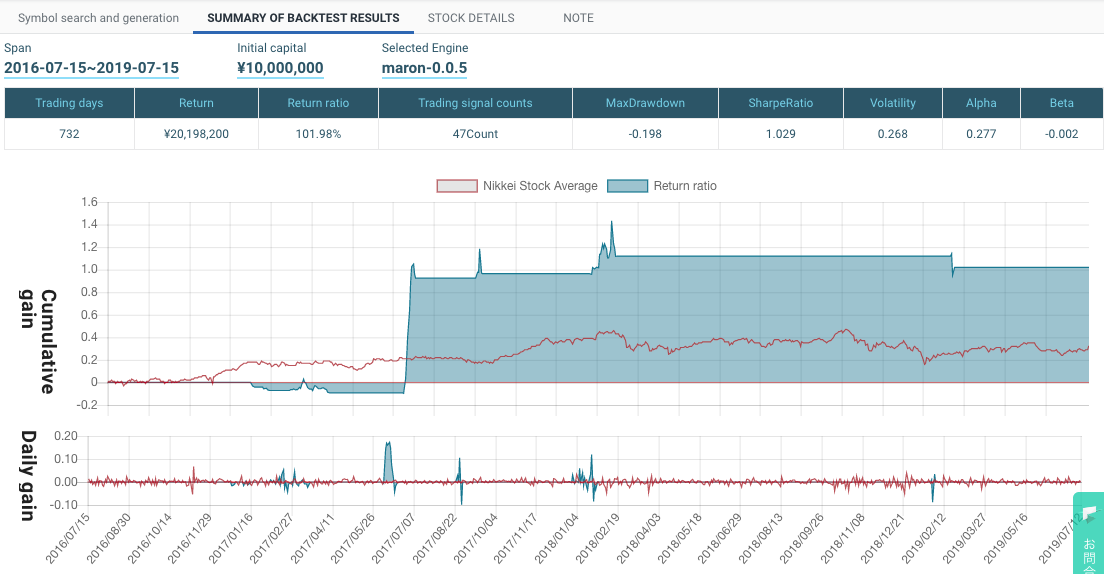
トレーリングストップを使ったWMAモデル:
トレーリングストップを使わずに利確ラインを使うと、急増で利益を失います。
(青はSELLです。)
ですが、利確ラインの代わりにトレーリングストップを使えば、効果的なSELLができます。
- 投稿日:2019-07-16T16:52:13+09:00
魔法の杖のジェスチャーを機械学習で判定させてみた
Wiiのようなジェスチャーゲームを作っていたので、そこで学んだことを記述していきたいと思います。
こちらが魔法の杖!
外装は3Dプリンタで作成。
中にはESPと加速度センサが入っている。
スイッチは外から押せるようにした。
100円ショップのモバイルバッテリーとESPを接続。魔法の杖から加速度を取得する
こちらは「スイッチを押しているとき、加速度の値をBluetoothで送信する」からコードを少し変えています。
変更点はこちら
1. スイッチを押しているときではなく、常に加速度の値を送信しています。
2. スイッチを押した瞬間、押されたという情報を送信します。acc_sender.c#include <SparkFunLSM9DS1.h> #include "BluetoothSerial.h" #define LSM9DS1_M 0x1E #define LSM9DS1_AG 0x6B #define SW_PIN 7 //pin番号を指定する LSM9DS1 imu; BluetoothSerial SerialBT; int sw_before = 0; uint16_t connectionState = 0; void setup() { Serial.begin(115200); SerialBT.begin("ESP32"); //Bluetooth接続で表示される名前を指定 pinMode(SW_PIN, INPUT); imu.settings.device.commInterface = IMU_MODE_I2C; imu.settings.device.mAddress = LSM9DS1_M; imu.settings.device.agAddress = LSM9DS1_AG; if (connectionState == 0) { connectionState = imu.begin(); while (connectionState == 0) { Serial.println("Failed to communicate with LSM9DS1."); Serial.println("Double-check wiring."); Serial.println("Default settings in this sketch will " "work for an out of the box LSM9DS1 " "Breakout, but may need to be modified " "if the board jumpers are."); Serial.print("Connection Status: "); Serial.println(imu.begin()); delay(1000); connectionState = imu.begin(); Serial.println("------------------------------------------------------\n"); }if(connectionState!=1){ Serial.print("connectionState: "); Serial.println(connectionState); } } } void loop() { float x, y, z; imu.readAccel(); x = imu.calcAccel(imu.ax)*10; y = imu.calcAccel(imu.ay)*10; z = imu.calcAccel(imu.az)*10; int sw_state = digitalRead(SW_PIN); // スイッチが押されてるとき1、押されていないと0 if(sw_state == 1 && sw_before == 0){ // 0だったのが1に切り替わった SerialBT.println("clicked"); }else{ SerialBT.println("no"); } SerialBT.println(x); SerialBT.println(y); SerialBT.println(z); sw_before = sw_state; delay(20); }ジェスチャーの予測モデルを作成
PCで加速度を受信し、ジェスチャの予測モデルを作成します。
Bluetoothを接続
ESP側を動かしたままで、PC本体の、
"設定→デバイス→Bluetoothとその他のデバイス→Bluetoothまたはその他のデバイスを追加する→Bluetooth"
の順で探し、自信で指定したESPのデバイス名(今回の場合はESP32_2)をクリック。接続が終わったら完了。COMポートを探す
そのまま、PC本体の、
"設定→デバイス→Bluetoothとその他のデバイス→その他のBluetoothオプション→COMポート
で、接続されたESPの"発信"側のポート番号をコピー。コード
上記のポート番号を、12行目の
ser = serial.Serial(.......
の "COM??" に入力する。今回は3種類のジェスチャーを3回ずつ行い、入力した名前の予測モデルを作成するコードです。ゲームのチューニング程度なので3回にしましたが、ジェスチャーの種類の数と回数、長さ等は仕様に応じて変更してください。
model_creater.py#coding utf-8 import serial #シリアル通信を行うため import numpy as np #numpyで2次元配列を扱うため from sklearn.svm import SVC #学習用 import pickle #モデルをファイルとして使用する用 length = 20 #ジェスチャの長さ(連続で受信するデータの個数) gestures = 3 #ジェスチャの種類の数 times = 3 #各ジェスチャを行う回数 print('Connecting...') ser = serial.Serial('COM19',115200,timeout=None) #ポート番号19からシリアル受信 print('Input your name:') name = input() filename = 'model_' + name + '.sav' #入力した名前の学習モデルのファイル名 X = [] Y = [] for i in range(gestures * times): cnt = 0 #受信したデータのカウント用 mx = [] #各軸ごとの配列を初期化 my = [] mz = [] gesture_num = i % gestures + 1 #ジェスチャ番号を指定 print('Do gesture No.', gesture_num) while True: line = ser.readline() #シリアルから1行取得 switch = line.decode('utf-8') #コード変換 line = ser.readline() x = line.decode('utf-8') line = ser.readline() y = line.decode('utf-8') line = ser.readline() z = line.decode('utf-8') if switch == 'clicked\r\n' and cnt == 0: #クリックされたらカウント開始 cnt = 1 if cnt != 0: #ジェスチャ中 mx.append(x.rstrip('\r\n')) #シリアルから受け取ってたデータのゴミを取って配列へ追加 my.append(y.rstrip('\r\n')) mz.append(z.rstrip('\r\n')) cnt += 1 if cnt == length: #lengthまでいったら次のジェスチャ待ちへ break m = mx + my + mz #三軸の加速度を横一列にする X.append(m) #学習データ用リストへ追加 Y.append(str(gesture_num)) #学習ラベル用リストへ追加 ser.close() #シリアルを閉じる model = SVC(kernel = 'linear', C=1, gamma=1) #学習モデルのパラメータを指定 model.fit(X,np.ravel(Y)) #学習を行う with open(filename, 'wb') as fp_model: #学習モデルを保存するためのファイルを開く pickle.dump(model, fp_model) #モデルを保存 print('Model created.')これで予測モデルが保存されました!
研究目的ではありませんので、精度検証は行わず早速ジェスチャーを判定してみましょう。ジェスチャーを判定し続ける
PCで加速度を受信し、ジェスチャーを判定し続けます。
以下のプログラムで、ポート番号を適切に変えて実行するだけです。gesture_judger.pyimport serial #シリアル通信を行うため import pickle #モデルをファイルとして使用する用 length = 20 #ジェスチャの長さ(連続で受信するデータの個数) print('Connecting...') ser = serial.Serial('COM19',115200,timeout=None) #ポート番号19からシリアル受信 print('Input your name:') name = input() filename = 'models/model_' + name + '.sav' #入力した名前の学習モデルのファイル名 print('Loading...') with open(filename, 'rb') as fp_model: #学習モデルファイルを開く loaded_model = pickle.load(fp_model) #モデルをロード print('Do any gesture!') try: while True: cnt = 0 #受信したデータのカウント用 mx = [] #各軸ごとの配列を初期化 my = [] mz = [] while True: line = ser.readline() #シリアルから1行取得 switch = line.decode('utf-8') #コード変換 line = ser.readline() x = line.decode('utf-8') line = ser.readline() y = line.decode('utf-8') line = ser.readline() z = line.decode('utf-8') if switch == 'clicked\r\n' and cnt == 0: #クリックされたらカウント開始 cnt = 1 if cnt != 0: #ジェスチャ中 mx.append(x.rstrip('\r\n')) #シリアルから受け取ってたデータのゴミを取って配列へ追加 my.append(y.rstrip('\r\n')) mz.append(z.rstrip('\r\n')) cnt += 1 if cnt == length: #lengthまでいったら次のジェスチャ待ちへ break m = mx + my + mz #三軸の加速度を横一列にする m2 = [] #リスト型にするため m2.append(m) #リストへ追加 pre = loaded_model.predict(m2) #ジェスチャの判定 print('This gesture is No.', pre[0][0]) except KeyboardInterrupt: # Ctrl-C を捕まえたら終了 print('Close!') ser.close() #シリアルを閉じるできましたでしょうか?
ゲームで応用する場合は、判定したものをソケット通信で送信し、Unity側のC#で受け取れば実装できます。処理もなかなか素早くできますよ。
ご不明点等あればお気軽に質問してください。

- 投稿日:2019-07-16T16:22:04+09:00
[Python] コメントを作成する
なぜこの記事を書いたのか
今までpythonの記事はいくつ投稿してきたでしょう。for文にif、それからリスト。。。
これまでpythonの文法とraspberry piのパソコン術を中心に投稿してきた自分がコメントの書き方を投稿するなんて自分でも夢にでも見ていませんでした。
でも、なぜ書くことになったのかというと、、、
先日、友人とプログラミングをしていると友人が自分が書いたソースコードの説明をくどくどとやり始めました。
僕が”それコメントに書いたら?”って言ったら、友人が”コメントって何?”って言ったんです。
そうです。
彼はコメントを全く使わないプログラマーだったのです。
忘れてたのかな?
でもとにかくびっくりしました。ということで今回はpython言語のコメントの書き方をまとめまーす。
コメントとは
コメントは前回のサンプルコードでも書いたのではないだろうか。
実はコメントはプログラマーたちが身近に使っているものなのだ。
コメントとは簡単に言うと”プログラムの説明”です。
プログラムには影響しないのが特徴です。
プログラムには撮っておきたくなるメモがたくさんあります。
変数の名前、リストの長さ。。。
それらを全部コメントに入れることができるんです。
しかも、コードを記述し終わっても消す必要なし!!
コメントにはそういうメリットがあります。
メリットがあるものには必ずデメリットがあります。
デメリットは容量を取るというところです。
例えば開発用PC"IchigoJam"IchigoJamはコメントを書きすぎるとすぐに容量が尽きてしまいます。
でも、一般のプログラマーがメインで使うパソコンほとんどがデスクトップですから目立たないデメリットです。pythonでコメントを書く
コメントの書き方は簡単です。
# コメント以上です。
えっ?もう?
と思った方はいると思います。
この手軽さもコメントのメリットの一つです。まとめ
今回はコメントの書き方を投稿しましたが、これはすごく便利だったと思います。
最後にコメントのメリットとデメリットをまとめておきます。メリット
手軽に使える
プログラムには影響しないデメリット
容量を食う
以上
- 投稿日:2019-07-16T15:59:32+09:00
[Python] 辞書で情報をまとめる
はじめに
こんにちは
今回は辞書でいろいろなデータをまとめてみたいと思います。見通し
pythonで辞書の正式な名前はディクショナリです。
前回、pythonについて書いたときのタイトルがリストで情報をまとめるだったと思います。
今回も似たようなことをします。
前回の(前々回の)コードを思い出してみましょう。# 佐藤さんの情報 sato_name = "佐藤 ◯◯" sato_age = 35 sato_postal_code = "0000-0000" asto_body weight = 52 sato_sex = "man"このデータを表示するには大変だということがわかります。
それをリストにまとめると、# 佐藤さんの情報 sato_list = ["佐藤 ◯◯",35,"0000-0000",52,"man"]この通り。1行ですんでしまいました。(コメント除く)
# 佐藤さんの情報 sato_list = ["佐藤 ◯◯",35,"0000-0000",52,"man"] print(sato_line)表示しても2行です。
ということだったんですが、これに一つ引っかかるところがありませんか?
そう。
表示内容が読み取りにくいのです。
データしか表示しないので、なんのことかわからないのです。
そこで辞書を使います。
辞書の特徴は、名前とデータの2つをまとめて保存してくれるというところです。
この特徴を活かして、データをまとめてみましょう。実践
まずは今回まとめるデータを紹介します。
# 田中さんの情報 tanaka_name = "田中 ◯◯" tanaka_age = 40 tanaka_postal_code = "123-0987" tanaka_body weight = 56 tanaka_sex = "man"情報は以上です。
tanakaで始まる変数にはすべて田中さんの情報を入れました。
これを辞書にまとめてみましょう。# 田中さんの情報 tanaka_list = {"tanaka_name":"田中 ◯◯", "tanaka_age":40, "tanaka_postal_code":"123-0987", "tanaka_body weight":56, "tanaka_sex":"man"}実行結果
解説
これでディクショナリに情報を名前付きで入れられました。
テストしてみましょう。print(tanaka_list)を付け足して実行すると、
実行結果
{'tanaka_name': '田中\u3000◯◯', 'tanaka_age': 40, 'tanaka_postal_code': '123-0987', 'tanaka_body weight': 56, 'tanaka_sex': 'man'}
解説
表示されましたー!!
少しわかりにくいですが、コロンの前が名前、後ろがデータとなっています。
成功です。まとめ
今回は、前回リストに情報をまとめて少し見にくかった反省を活かして、辞書を使ってみました。
ご理解いただけたでしょうか。
今回公開したサンプルコードはすべて動作確認済みです。(証拠は最後にあります。)
最後に辞書の”名前”というのは正式な名前では”キー”と呼びます。
本記事に登場した”田中さん”は架空の人物です。


- 投稿日:2019-07-16T15:51:08+09:00
bottle(pythonフレームワーク)のチュートリアル日本語訳
Bottleチュートリアル
はじめに
初学者が勉強のため、pythonのwebフレームワークであるBottleのチュートリアルを適当に日本語訳してみた。
インストール
Bottoleは単一のpythonファイル。
bottle.pyさえ持ってくればなんでもいい。
pip install bottleでもいいしコード直でコピーしてきてもいい。クイックスタート("Hello World")
from bottle import route, run @route('/hello') def hello(): return "Hello World!" run(host='localhost', port=8080, debug=True, reloader=True)これを
app.pyとかでbottle.pyと同じディレクトリに保存して、コンソールから実行。run()
run()はデフォルトの開発ウェブサーバ。開発時はdebugを真にしておく。追記だけど、
reloader=Trueいれとかないと毎回サーバ再起動しないといけないからつけとこ。route()
route()はルータ。URLと関数等を結びつける。今回は、
route(/hello)に指定したURL(/hello)と定義した関数hello()を結びつけている。デコレータ
route()の前についてる@が気になったのでメモ
@はデコレータと呼ばれる関数につける記号らしい。
デコレータは関数を装飾する関数(?)っぽい。例えば
@export get_name()みたいな感じで関数の前につける。デコレータ自身も関数で、
def export(func):という風に引数に関数をとって定義する。これを使えば任意の関数に特定の処理を加えて装飾(デコレート)できるよってこと。
関数の処理の前後に何かしたり、返り値を操作したり・・。デコーレタはネストしてOKだよ。本題、route()についてるのは、そのあとの
def hello():を装飾してるわけ。
たぶん、これで装飾された処理が、今回だと/helloっていうURLと結びつきますよ、ってことだと思う。
(本体のコード見たけどコメントでそれっぽいこと書いてた)デフォルトアプリケーション
今回は簡単にするため
@route()をそのまま使ったけど、これはモジュールレベルのデコレータだよ。
内部的にはBottleっていうデフォルトアプリケーションのインスタンスを自動で作って、そこに結びつけてるよ。
オブジェクト指向っぽく書きたいなら以下のようにもかけるよ。from bottle import Bottle, run app = Bottle() @app.route('/hello') def hello(): return "Hello World!" run(app, host='localhost', port=8080)は・・・? なんかよくわからないけど、「アプリケーション」っていう概念があって、あらゆる要素は基本的にその下に置かれるのかな。今回
@route()はモジュールレベル・・・なんだろ大元のコードの関数を直で使ってるって感じかな。
そうじゃなくて、明示的にBottleっていうアプリケーションのrouteを使うよって書くことも可能、って感じ?オブジェクト指向的アプローチは「デフォルトアプリケーション」の項目で詳しく教えてくれるらしい。
リクエストルーティング
route()デコレータは、つけた関数への新たなルーティングをデフォルトアプリケーションに追加するよ。
別のルーティングも定義してみようぜ!!
(bottleモジュールのtemplateをインポートし忘れないで)@route('/') @route('/hello/<name>') def greet(name='Stranger'): return template('Hello {{name}}, how are you?', name=name)このように、1つのコールバック関数に複数のルートを割り当てられるよ。
しかも、URLでワイルドカードをつかってキーワードでアクセスできるよ。
動的ルーティング
さっきみたいなワイルドカードを使ったルーティングを動的ルーティングっていう。
<>で囲むのが一番シンプルなやつだよ。
<>の中に入れた文字列をキーワードにしてコールバック関数の引数に渡すよ。以下例。@route('/wiki/<type>/<name>') def show(type, name): ...もっと詳しくワイルドカードを設定することもできるよ。
<name:filter>とか<name:filter:config>って感じにできる。filterの例
:int型を指定したり:float:pathスラッシュ(/)を含むパスを取得したり?:re<name:re:正規表現>の形で正規表現入れたりそのほかの設定については以下参照。
HTTPリクエストメソッド
HTTPのリクエストメソッドを指定できるよ。GET, POST, PUT, PATCH, DELETEね。
専用のデコレータ使ってもいいし、
route()メソッドの引数に指定してもいい。こんな感じ。from bottle import get, post, request # or route @get('/login') # or @route('/login') def login(): return ''' <form action="/login" method="post"> Username: <input name="username" type="text" /> Password: <input name="password" type="password" /> <input value="Login" type="submit" /> </form> ''' @post('/login') # or @route('/login', method='POST') def do_login(): username = request.forms.get('username') password = request.forms.get('password') if check_login(username, password): return "<p>Your login information was correct.</p>" else: return "<p>Login failed.</p>"ちなみに例にでてきた
request.formsは後の章で詳しく説明するよ。HEADとANYメソッドについて
理解不能、わからなくても使えるっぽい。
静的ファイルへのルーティング
CSSとか画像ファイルは適当に相対パス書けばいいと思ったら大間違い、ちゃんとルーティングしてあげる必要あります。
from bottle import static_file @route('/static/<filename>') def server_static(filename): return static_file(filename, root='/path/to/your/static/files')とはいえ、
satic_file()って便利なヘルパー関数があるよ。詳しくはStatic Filesを見てね。今回の例では
<filename>のところと、/path/to/your/static/files以下の静的ファイルを結びつけてるよ。もしサブフォルダも含めたい場合は、前に出てきた<:path>フィルター使ってね。こんな感じに。@route('/static/<filepath:path>') def server_static(filepath): return static_file(filepath, root='/path/to/your/static/files')パスのところに相対パスを指定するのは注意してね。プロジェクトのディレクトリと作業ディレクトリは必しも同じとは限らないよ!
エラーページ
エラーが起きたときはデフォルトでエラーページ出すけど、めちゃくちゃ簡素やで。自分でエラーページ設定したいときは
error()デコレータを使いなさい。from bottle import error @error(404) def error404(error): return 'Nothing here, sorry'これで404エラーが出たときのページがオリジナルのやつになったよ。
使い方は普通のルーティングとほぼ一緒。渡される引数は決まってるけどね。
このエラーっていうのはまじもんのエラーだけで、後に出てくる
abord()なんかを使った場合はこのハンドラは呼び出されないからね。決まってる値は以下参照。
コンテンツ生成
純粋なWSGIでは、アプリケーションが返す型は非常に限定的。ユニコードの文字列はすべて許可されておらず、これは実用的ではない。
Bottleはよりフレキシブルに幅広い型に対応している。ユニコードは自動的にエンコードされるのでユーザが気にすることはない。以下に、ユーザが返す可能性のあるデータ型とbottleでの扱いの概要を示す。
辞書型、false扱いの値(空、文字列、false、など?)、ユニコード文字列、バイト文字列、HTTPEror・HTTPResponseのインスタンス、ファイルオブジェクト、イテラブルとジェネレータ
デフォルトエンコーディング変更
なんか変更できるらしい?デフォルトはUTF-8
静的ファイル
直接ファイルを返せるよ、ただし
static_file()使うのを推奨してるよ。自動でmime-typeを推測したり、Last-odifiedヘッダをつけたり、セキュリティの観点からrootへのパスを制限してエラーを吐いたりしてくれるよ。from bottle import static_file @route('/images/<filename:re:.*\.png>') def send_image(filename): return static_file(filename, root='/path/to/image/files', mimetype='image/png') @route('/static/<filename:path>') def send_static(filename): return static_file(filename, root='/path/to/static/files')
static_file()の返り値に例外を挙げることも可能だよ。強制ダウンロード
ダウンロードさせたかったら見て。
HTTPエラーとリダイレクト
abort()関数はHTTPエラーページを生成するショートカットだよ。from bottle import route, abort @route('/restricted') def restricted(): abort(401, "Sorry, access denied.")違うURLにリダイレクトさせたい場合、新しいURLにLocationヘッダを設定し、303 See Otherを送信しますが、
redirect()関数がそれをやります。from bottle import redirect @route('/wrong/url') def wrong(): redirect("/right/url")その他の例外処理
HTTPErrorとHTTPResponse以外はスルー的な?設定で例外処理追加できるよ。
RESPONSEオブジェクトについて
よくわからんのでまたいずれ
ステータスコード
はてな
レスポンスヘッダ
はてな
クッキー
クッキーはブラウザに保存されている名前付きの値です。
Reuest.get_cookie()とResponse.set_cookie()でクッキーを読み取ったり保存したりできます。@route('/hello') def hello_again(): if request.get_cookie("visited"): return "Welcome back! Nice to see you again" else: response.set_cookie("visited", "yes") return "Hello there! Nice to meet you"
Response.set_cookie()関数は追加の引数を受け付けて、クッキーの寿命や振舞いを操作できます。一般的な設定はこちら。
- max_age: 最大時間(秒単位)
- expires: 期限(datetimeオブジェクトかUNIXタイムスタンプ)
- domain: 読み取り許可ドメイン
- path: パスによるクッキーの制限
- secure: HTTPS接続でクッキーの制限
- httponly: javascriptがクッキーを読めないようにする
- same_site: 外部サイトのクッキー利用を制限
max_ageもexpiresも設定されてないときは、クッキーはブラウザのセッション切れ時か、ウィンドウ閉じたときに期限切れになる。そのほかクッキー利用時に注意すべきことを記載する。
- 多くのブラウザでクッキーは4KBの制限がある
- 一部の利用者や検索エンジンはクッキーを完全に無効にしている。クッキーなしでもアプリケーションが作動するように作るべき。
- クッキーは全く暗号化されないので、利用者は保存したクッキーの値を見ることができる。悪意ある者はXSSの脆弱性を利用して、クッキーを盗むこともできる。ウィルスによってはブラウザのクッキーを読むものもある。なので、決して重要な情報をクッキーに保存してはいけない。
- クッキーは容易に偽造されるのでクッキーを信じてはいけない。
署名付きクッキー
上で述べたように、クッキーは容易に偽造される。Bottleはそれを防ぐためにクッキーに暗号化された署名をつけることができる。クッキーを読み書きする時に毎回、パスワード付きの署名のキーを提供するだけでいい(もちろんパスワードは非公開)。そうすれば、もし署名されていなかったりそれが間違っていた時には
Request.get_cookie()はNoneを返す。@route('/login') def do_login(): username = request.forms.get('username') password = request.forms.get('password') if check_login(username, password): response.set_cookie("account", username, secret='some-secret-key') return template("<p>Welcome {{name}}! You are now logged in.</p>", name=username) else: return "<p>Login failed.</p>" @route('/restricted') def restricted_area(): username = request.get_cookie("account", secret='some-secret-key') if username: return template("Hello {{name}}. Welcome back.", name=username) else: return "You are not logged in. Access denied."ピクルスがどうとか言ってるけど理解不能。署名されたクッキーを自動的にピクルスにしたりアンピクルスにしたりするらしい(???)
注意:この署名はあくまでクッキーの偽装を防止するものであって、この操作をしたからと言って重要な情報をクッキーに保存していいわけではない。
リクエストデータ
クッキー、HTTPヘッダ、
<form>他リクエストデータは、グローバルなrequestオブジェクトを通して利用できます。この特別なオブジェクトは、同時接続のあるマルチスレッド環境においても、常に現在のリクエスト(?)を参照します。from bottle import request, route, template @route('/hello') def hello(): name = request.cookies.username or 'Guest' return template('Hello {{name}}', name=name)
requestオブジェクトはBaseRequestのサブクラスであり、データに対し豊富なAPIでアクセスできます。ここではもっとも一般的な利用例しか示しませんが、最初の一歩には十分です。FORMSDICTの紹介
Bottleはフォームのデータとクッキーを保存するのに特別な辞書を使うよ。
FormsDictは普通の辞書みたいに振舞うけど、いくつかのユーザを補助する追加機能があるよ。Attribute access: 辞書内のすべての値は属性値でアクセスできる。それらの仮想属性は、値がなかったりユニコードの復号に失敗しても、ユニコードの文字列を返す。その場合文字列は空になるが、存在はしている。
name = request.cookies.name # is a shortcut for: name = request.cookies.getunicode('name') # encoding='utf-8' (default) # which basically does this: try: name = request.cookies.get('name', '').decode('utf-8') except UnicodeError: name = u''Multiple values per key:
FormsDictはMultiDictのサブクラスであり、1つのキーに1つ以上の値を保持できる。通常の辞書アクセス用の関数は1つの値を返すが、getall()関数はすべての値を返す。for choice in request.forms.getall('multiple_choice'): do_something(choice)WTForms supposrt: ライブラリによっては(WTFormsとか)すべてユニコードの辞書を入力する必要がある。
FormsDict.decode()がそれをやってくれるよ。すべての機能を保持しながら、デコードした自分自身のコピーを返してくれるよ。Python2と3でなんか違いがあるっぽい・・2は辞書は全部バイト型、3は文字列はユニコードになってる。3の場合、HTTPはバイトベースのプロトコルだからサーバはどっかでデコードしないといけない。
FormsDict.getunicode()ならそれをやってくれるけど、普通のアクセス方法だとやってくれないよ。的なこと書いてるけどよくわからん。クッキー
クッキーはブラウザ内の小さなテキスト保持領域であり、リクエスト毎にサーバに送られる。これは、複数のリクエストにまたがる状態を保持するのに便利だが(HTTPは状態を持たない)、セキュリティ関係には使用してはいけない。簡単に偽造されるからね。
すべてのクライアントから送られてくるクッキーは
BaseRequest.cookies(FormsDict)を通される。この例はシンプルなクッキーベースのビューカウンタだよ。from bottle import route, request, response @route('/counter') def counter(): count = int( request.cookies.get('counter', '0') ) count += 1 response.set_cookie('counter', str(count)) return 'You visited this page %d times' % count
BaseRequest.get_cookie()関数は別の方法でクッキーにアクセスする。署名付きクッキーのデコードをサポートする(前に書いてる)HTTPヘッダ
クライアントから送られてきたHTTPヘッダは
WSGIHeaderDictに記録され、BaseRequest.headers属性を通してアクセスできる。これは大文字小文字を区別しないキーを持つ標準の辞書だよ。from bottle import route, request @route('/is_ajax') def is_ajax(): if request.headers.get('X-Requested-With') == 'XMLHttpRequest': return 'This is an AJAX request' else: return 'This is a normal request'クエリ変数
フォーム周り
ファイルのアップロード
JSONコンテンツ
RAWのリクエストボディ
WSGI環境
テンプレート
Bottleには
SimpleTemplate Engineと呼ばれる高速でパワフルなテンプレートエンジンが付属します。@view()デコレータかtemplate()関数を使ってテンプレートをレンダリングできます。テンプレート名と、そこに渡すキーワード引数を指定すれば使えます。簡単な例を示しましょう。@route('/hello') @route('/hello/<name>') def hello(name='World'): return template('hello_template', name=name)これで
hello_template.tplというテンプレートファイルがロードされ、name変数に値がセットされた状態でレンダリングされます。Bottleは./views/ディレクトリか、bottle.TEMPLATE_PATHで指定されたディレクトリをみてます。
view()デコーダはtemplate()を呼び出す代わりに、テンプレート変数を使って辞書を返すことができます。@route('/hello') @route('/hello/<name>') @view('hello_template') def hello(name='World'): return dict(name=name)文法
テンプレート構文はPython中心の極めて薄いレイヤです。その主目的はブロックの正しいインデントの保証であるため、インデントを気にすることなくテンプレートを構成できます。完全な解説は以下のリンクを参照してください。
%if name == 'World': <h1>Hello {{name}}!</h1> <p>This is a test.</p> %else: <h1>Hello {{name.title()}}!</h1> <p>How are you?</p> %endキャッシング
テンプレートはコンパイル後メモリにキャッシュされます。テンプレートを変更しても、キャッシュをクリアするまで反映されません。
bottle.TMPLATES.clear()でクリアしましょう。デバックモードではキャッシュは無効です。プラグイン
グローバルインストール
アンインストール
指定インストール
ブラックリスト
プラグインとサブアプリケーション
開発
これで基本は学べたので、自分のアプリを書いていきたいでしょう。ここでは開発の役に立つかもしれないTIPSを紹介しましょう。
デフォルトアプリケーション
Bottleは
Bottleというグローバルインスタンスを持ち続け、いくつかのモジュールレベルの関数やデコレータの最上位層になります。route()デコレータなどは、デフォルトアプリケーション上のBottle.route()を呼ぶショートカットになります。@route('/') def hello(): return 'Hello World' run()これはスモールアプリ開発に便利であり、タイピング量の節約につながりますが同時に、モジュールがインポートされるとすぐ、ルーターがグローバルなデフォルトアプリケーションにインストールされるということです(?)。このインポートの副作用を避けるために、Bottleはアプリケーションを明示的にビルドする方法を用意しています。
app = Bottle() @app.route('/') def hello(): return 'Hello World' app.run()アプリケーションオブジェクトの分離は再利用性を大きく向上させます。ほかの開発者があなたのモジュールから安全に
appオブジェクトをインポートし、Bottle.mount()を用いることでアプリケーションを統合できます。bottle-0.13から、コンテキストマネージャとして
Bottleインスタンスが使えるようになりました。app = Bottle() with app: # Our application object is now the default # for all shortcut functions and decorators assert my_app is default_app() @route('/') def hello(): return 'Hello World' # Also useful to capture routes defined in other modules import some_package.more_routesデバッグモード
初期の開発段階では、デバッグモードは超便利です。
bottle.debug(True)このモードでは、Bottleはエラーが出るたびに十分なデバッグ情報を提供します。また、開発の邪魔になるようないくつかの最適化を無効にしたり、起こりうる設定ミスをチェックするような項目を追加します。
デバッグモード中に変更になる項目を示します。
- エラーページにトレースバックが表示される
- テンプレートはキャッシュされない
- プラグインは直ちに適用される
プロダクションサーバではこのモードは使用しないでね。
オートリロード
開発中、変更を加える度に何度もサーバを再起動しなければいけません。オートリローダが代わりにやってくれるよ。ファイルを変更する度に、リローダはサーバのプロセスを再起動し、最新のコードに更新してくれるよ。
from bottle import run run(reloader=True)仕組み: メインプロセスはサーバを起動せず、メインプロセスを起動させるのに使われる要素で子プロセスを立ち上げます。すべてのモジュールレベルのコードは2度実行されますよ、気を付けて。
もっと詳しいこと書いてるけどまあ気にせんでいいやろ。
コマンドラインインターフェイス
バージョン0.10からコマンドラインツールが使えるようになりました。
$ python -m bottle Usage: bottle.py [options] package.module:app Options: -h, --help show this help message and exit --version show version number. -b ADDRESS, --bind=ADDRESS bind socket to ADDRESS. -s SERVER, --server=SERVER use SERVER as backend. -p PLUGIN, --plugin=PLUGIN install additional plugin/s. -c FILE, --conf=FILE load config values from FILE. -C NAME=VALUE, --param=NAME=VALUE override config values. --debug start server in debug mode. --reload auto-reload on file changes.ADDRESSはIPアドレスかIP:PORTのペアであり、デフォルトはlocalhost:8080だよ。その他のパラメータは見たらわかるでしょ。
なんかわからんけど例を示しとくね。
# Grab the 'app' object from the 'myapp.controller' module and # start a paste server on port 80 on all interfaces. python -m bottle -server paste -bind 0.0.0.0:80 myapp.controller:app # Start a self-reloading development server and serve the global # default application. The routes are defined in 'test.py' python -m bottle --debug --reload test # Install a custom debug plugin with some parameters python -m bottle --debug --reload --plugin 'utils:DebugPlugin(exc=True)'' test # Serve an application that is created with 'myapp.controller.make_app()' # on demand. python -m bottle 'myapp.controller:make_app()''デプロイ
Bottleはデフォルトで組み込みサーバ上で動く。この非スレッティングなサーバは開発にはもってこいだけど、ロード数が増えるとパフォーマンスに限界があるよ。
パフォーマンス向上の簡単な方法は、マルチスレッド対応のサーバをインストールすること(pasteとかcherrypyみたいなね)、そしてデフォルトにサーバかわりに使うようにBottleに教えてあげること。
bottle.run(server='paste')こういうのとか、いろいろデプロイのオプションについては別の記事を参考にしてね。
用語集
コールバック(callback)
何らかの外部アクションが発生した時に呼び出されるコード。Webフレームワークでは、各URLにコールバック関数を指定することで、URLとアプリケーションコード間のマッピングが実現されていることがよくある。
デコーレタ(decorator)
他の関数を返す関数のことで、通常関数の変換のために
@decoratorの形で適用される。python documentation for function definitionを見ればより詳しく書いてるよ。インバイロン?(environ)
なにこれ?
ハンドラ関数(handler function)
特定のイベントや状況を処理する関数のこと。Webフレームワークでは、各URLへのコールバックとしてハンドラ関数を充てることでアプリを開発していく。
ソースディレクトリ(source directory)
全部のソースファイルを含むディレクトリ(?)
- 投稿日:2019-07-16T15:51:08+09:00
Bottle(pythonフレームワーク)のチュートリアル日本語訳
Bottleチュートリアル
はじめに
初学者が勉強のため、pythonのwebフレームワークであるBottleのチュートリアル (https://bottlepy.org/docs/dev/tutorial.html) を適当に日本語訳してみた。
間違っているだろうし訳せていないところもあるが、せっかく書いたので公開してみる。
インストール
Bottoleは単一のpythonファイル。
bottle.pyさえ持ってくればなんでもいい。
pip install bottleでもいいしコード直でコピーしてきてもいい。クイックスタート("Hello World")
from bottle import route, run @route('/hello') def hello(): return "Hello World!" run(host='localhost', port=8080, debug=True, reloader=True)これを
app.pyとかでbottle.pyと同じディレクトリに保存して、コンソールから実行。run()
run()はデフォルトの開発ウェブサーバ。開発時はdebugを真にしておく。追記だけど、
reloader=Trueいれとかないと毎回サーバ再起動しないといけないからつけとこ。route()
route()はルータ。URLと関数等を結びつける。今回は、
route(/hello)に指定したURL(/hello)と定義した関数hello()を結びつけている。デコレータ
route()の前についてる@が気になったのでメモ
@はデコレータと呼ばれる関数につける記号らしい。
デコレータは関数を装飾する関数(?)っぽい。例えば
@export get_name()みたいな感じで関数の前につける。デコレータ自身も関数で、
def export(func):という風に引数に関数をとって定義する。これを使えば任意の関数に特定の処理を加えて装飾(デコレート)できるよってこと。
関数の処理の前後に何かしたり、返り値を操作したり・・。デコーレタはネストしてOKだよ。本題、route()についてるのは、そのあとの
def hello():を装飾してるわけ。
たぶん、これで装飾された処理が、今回だと/helloっていうURLと結びつきますよ、ってことだと思う。
(本体のコード見たけどコメントでそれっぽいこと書いてた)デフォルトアプリケーション
今回は簡単にするため
@route()をそのまま使ったけど、これはモジュールレベルのデコレータだよ。
内部的にはBottleっていうデフォルトアプリケーションのインスタンスを自動で作って、そこに結びつけてるよ。
オブジェクト指向っぽく書きたいなら以下のようにもかけるよ。from bottle import Bottle, run app = Bottle() @app.route('/hello') def hello(): return "Hello World!" run(app, host='localhost', port=8080)は・・・? なんかよくわからないけど、「アプリケーション」っていう概念があって、あらゆる要素は基本的にその下に置かれるのかな。今回
@route()はモジュールレベル・・・なんだろ大元のコードの関数を直で使ってるって感じかな。
そうじゃなくて、明示的にBottleっていうアプリケーションのrouteを使うよって書くことも可能、って感じ?オブジェクト指向的アプローチは「デフォルトアプリケーション」の項目で詳しく教えてくれるらしい。
リクエストルーティング
route()デコレータは、つけた関数への新たなルーティングをデフォルトアプリケーションに追加するよ。
別のルーティングも定義してみようぜ!!
(bottleモジュールのtemplateをインポートし忘れないで)@route('/') @route('/hello/<name>') def greet(name='Stranger'): return template('Hello {{name}}, how are you?', name=name)このように、1つのコールバック関数に複数のルートを割り当てられるよ。
しかも、URLでワイルドカードをつかってキーワードでアクセスできるよ。
動的ルーティング
さっきみたいなワイルドカードを使ったルーティングを動的ルーティングっていう。
<>で囲むのが一番シンプルなやつだよ。
<>の中に入れた文字列をキーワードにしてコールバック関数の引数に渡すよ。以下例。@route('/wiki/<type>/<name>') def show(type, name): ...もっと詳しくワイルドカードを設定することもできるよ。
<name:filter>とか<name:filter:config>って感じにできる。filterの例
:int型を指定したり:float:pathスラッシュ(/)を含むパスを取得したり?:re<name:re:正規表現>の形で正規表現入れたりそのほかの設定については以下参照。
HTTPリクエストメソッド
HTTPのリクエストメソッドを指定できるよ。GET, POST, PUT, PATCH, DELETEね。
専用のデコレータ使ってもいいし、
route()メソッドの引数に指定してもいい。こんな感じ。from bottle import get, post, request # or route @get('/login') # or @route('/login') def login(): return ''' <form action="/login" method="post"> Username: <input name="username" type="text" /> Password: <input name="password" type="password" /> <input value="Login" type="submit" /> </form> ''' @post('/login') # or @route('/login', method='POST') def do_login(): username = request.forms.get('username') password = request.forms.get('password') if check_login(username, password): return "<p>Your login information was correct.</p>" else: return "<p>Login failed.</p>"ちなみに例にでてきた
request.formsは後の章で詳しく説明するよ。HEADとANYメソッドについて
理解不能、わからなくても使えるっぽい。
静的ファイルへのルーティング
CSSとか画像ファイルは適当に相対パス書けばいいと思ったら大間違い、ちゃんとルーティングしてあげる必要あります。
from bottle import static_file @route('/static/<filename>') def server_static(filename): return static_file(filename, root='/path/to/your/static/files')とはいえ、
satic_file()って便利なヘルパー関数があるよ。詳しくはStatic Filesを見てね。今回の例では
<filename>のところと、/path/to/your/static/files以下の静的ファイルを結びつけてるよ。もしサブフォルダも含めたい場合は、前に出てきた<:path>フィルター使ってね。こんな感じに。@route('/static/<filepath:path>') def server_static(filepath): return static_file(filepath, root='/path/to/your/static/files')パスのところに相対パスを指定するのは注意してね。プロジェクトのディレクトリと作業ディレクトリは必しも同じとは限らないよ!
エラーページ
エラーが起きたときはデフォルトでエラーページ出すけど、めちゃくちゃ簡素やで。自分でエラーページ設定したいときは
error()デコレータを使いなさい。from bottle import error @error(404) def error404(error): return 'Nothing here, sorry'これで404エラーが出たときのページがオリジナルのやつになったよ。
使い方は普通のルーティングとほぼ一緒。渡される引数は決まってるけどね。
このエラーっていうのはまじもんのエラーだけで、後に出てくる
abord()なんかを使った場合はこのハンドラは呼び出されないからね。決まってる値は以下参照。
コンテンツ生成
純粋なWSGIでは、アプリケーションが返す型は非常に限定的。ユニコードの文字列はすべて許可されておらず、これは実用的ではない。
Bottleはよりフレキシブルに幅広い型に対応している。ユニコードは自動的にエンコードされるのでユーザが気にすることはない。以下に、ユーザが返す可能性のあるデータ型とbottleでの扱いの概要を示す。
辞書型、false扱いの値(空、文字列、false、など?)、ユニコード文字列、バイト文字列、HTTPEror・HTTPResponseのインスタンス、ファイルオブジェクト、イテラブルとジェネレータ
デフォルトエンコーディング変更
なんか変更できるらしい?デフォルトはUTF-8
静的ファイル
直接ファイルを返せるよ、ただし
static_file()使うのを推奨してるよ。自動でmime-typeを推測したり、Last-odifiedヘッダをつけたり、セキュリティの観点からrootへのパスを制限してエラーを吐いたりしてくれるよ。from bottle import static_file @route('/images/<filename:re:.*\.png>') def send_image(filename): return static_file(filename, root='/path/to/image/files', mimetype='image/png') @route('/static/<filename:path>') def send_static(filename): return static_file(filename, root='/path/to/static/files')
static_file()の返り値に例外を挙げることも可能だよ。強制ダウンロード
ダウンロードさせたかったら見て。
HTTPエラーとリダイレクト
abort()関数はHTTPエラーページを生成するショートカットだよ。from bottle import route, abort @route('/restricted') def restricted(): abort(401, "Sorry, access denied.")違うURLにリダイレクトさせたい場合、新しいURLにLocationヘッダを設定し、303 See Otherを送信しますが、
redirect()関数がそれをやります。from bottle import redirect @route('/wrong/url') def wrong(): redirect("/right/url")その他の例外処理
HTTPErrorとHTTPResponse以外はスルー的な?設定で例外処理追加できるよ。
RESPONSEオブジェクトについて
よくわからんのでまたいずれ
ステータスコード
はてな
レスポンスヘッダ
はてな
クッキー
クッキーはブラウザに保存されている名前付きの値です。
Reuest.get_cookie()とResponse.set_cookie()でクッキーを読み取ったり保存したりできます。@route('/hello') def hello_again(): if request.get_cookie("visited"): return "Welcome back! Nice to see you again" else: response.set_cookie("visited", "yes") return "Hello there! Nice to meet you"
Response.set_cookie()関数は追加の引数を受け付けて、クッキーの寿命や振舞いを操作できます。一般的な設定はこちら。
- max_age: 最大時間(秒単位)
- expires: 期限(datetimeオブジェクトかUNIXタイムスタンプ)
- domain: 読み取り許可ドメイン
- path: パスによるクッキーの制限
- secure: HTTPS接続でクッキーの制限
- httponly: javascriptがクッキーを読めないようにする
- same_site: 外部サイトのクッキー利用を制限
max_ageもexpiresも設定されてないときは、クッキーはブラウザのセッション切れ時か、ウィンドウ閉じたときに期限切れになる。そのほかクッキー利用時に注意すべきことを記載する。
- 多くのブラウザでクッキーは4KBの制限がある
- 一部の利用者や検索エンジンはクッキーを完全に無効にしている。クッキーなしでもアプリケーションが作動するように作るべき。
- クッキーは全く暗号化されないので、利用者は保存したクッキーの値を見ることができる。悪意ある者はXSSの脆弱性を利用して、クッキーを盗むこともできる。ウィルスによってはブラウザのクッキーを読むものもある。なので、決して重要な情報をクッキーに保存してはいけない。
- クッキーは容易に偽造されるのでクッキーを信じてはいけない。
署名付きクッキー
上で述べたように、クッキーは容易に偽造される。Bottleはそれを防ぐためにクッキーに暗号化された署名をつけることができる。クッキーを読み書きする時に毎回、パスワード付きの署名のキーを提供するだけでいい(もちろんパスワードは非公開)。そうすれば、もし署名されていなかったりそれが間違っていた時には
Request.get_cookie()はNoneを返す。@route('/login') def do_login(): username = request.forms.get('username') password = request.forms.get('password') if check_login(username, password): response.set_cookie("account", username, secret='some-secret-key') return template("<p>Welcome {{name}}! You are now logged in.</p>", name=username) else: return "<p>Login failed.</p>" @route('/restricted') def restricted_area(): username = request.get_cookie("account", secret='some-secret-key') if username: return template("Hello {{name}}. Welcome back.", name=username) else: return "You are not logged in. Access denied."ピクルスがどうとか言ってるけど理解不能。署名されたクッキーを自動的にピクルスにしたりアンピクルスにしたりするらしい(???)
注意:この署名はあくまでクッキーの偽装を防止するものであって、この操作をしたからと言って重要な情報をクッキーに保存していいわけではない。
リクエストデータ
クッキー、HTTPヘッダ、
<form>他リクエストデータは、グローバルなrequestオブジェクトを通して利用できます。この特別なオブジェクトは、同時接続のあるマルチスレッド環境においても、常に現在のリクエスト(?)を参照します。from bottle import request, route, template @route('/hello') def hello(): name = request.cookies.username or 'Guest' return template('Hello {{name}}', name=name)
requestオブジェクトはBaseRequestのサブクラスであり、データに対し豊富なAPIでアクセスできます。ここではもっとも一般的な利用例しか示しませんが、最初の一歩には十分です。FORMSDICTの紹介
Bottleはフォームのデータとクッキーを保存するのに特別な辞書を使うよ。
FormsDictは普通の辞書みたいに振舞うけど、いくつかのユーザを補助する追加機能があるよ。Attribute access: 辞書内のすべての値は属性値でアクセスできる。それらの仮想属性は、値がなかったりユニコードの復号に失敗しても、ユニコードの文字列を返す。その場合文字列は空になるが、存在はしている。
name = request.cookies.name # is a shortcut for: name = request.cookies.getunicode('name') # encoding='utf-8' (default) # which basically does this: try: name = request.cookies.get('name', '').decode('utf-8') except UnicodeError: name = u''Multiple values per key:
FormsDictはMultiDictのサブクラスであり、1つのキーに1つ以上の値を保持できる。通常の辞書アクセス用の関数は1つの値を返すが、getall()関数はすべての値を返す。for choice in request.forms.getall('multiple_choice'): do_something(choice)WTForms supposrt: ライブラリによっては(WTFormsとか)すべてユニコードの辞書を入力する必要がある。
FormsDict.decode()がそれをやってくれるよ。すべての機能を保持しながら、デコードした自分自身のコピーを返してくれるよ。Python2と3でなんか違いがあるっぽい・・2は辞書は全部バイト型、3は文字列はユニコードになってる。3の場合、HTTPはバイトベースのプロトコルだからサーバはどっかでデコードしないといけない。
FormsDict.getunicode()ならそれをやってくれるけど、普通のアクセス方法だとやってくれないよ。的なこと書いてるけどよくわからん。クッキー
クッキーはブラウザ内の小さなテキスト保持領域であり、リクエスト毎にサーバに送られる。これは、複数のリクエストにまたがる状態を保持するのに便利だが(HTTPは状態を持たない)、セキュリティ関係には使用してはいけない。簡単に偽造されるからね。
すべてのクライアントから送られてくるクッキーは
BaseRequest.cookies(FormsDict)を通される。この例はシンプルなクッキーベースのビューカウンタだよ。from bottle import route, request, response @route('/counter') def counter(): count = int( request.cookies.get('counter', '0') ) count += 1 response.set_cookie('counter', str(count)) return 'You visited this page %d times' % count
BaseRequest.get_cookie()関数は別の方法でクッキーにアクセスする。署名付きクッキーのデコードをサポートする(前に書いてる)HTTPヘッダ
クライアントから送られてきたHTTPヘッダは
WSGIHeaderDictに記録され、BaseRequest.headers属性を通してアクセスできる。これは大文字小文字を区別しないキーを持つ標準の辞書だよ。from bottle import route, request @route('/is_ajax') def is_ajax(): if request.headers.get('X-Requested-With') == 'XMLHttpRequest': return 'This is an AJAX request' else: return 'This is a normal request'クエリ変数
フォーム周り
ファイルのアップロード
JSONコンテンツ
RAWのリクエストボディ
WSGI環境
テンプレート
Bottleには
SimpleTemplate Engineと呼ばれる高速でパワフルなテンプレートエンジンが付属します。@view()デコレータかtemplate()関数を使ってテンプレートをレンダリングできます。テンプレート名と、そこに渡すキーワード引数を指定すれば使えます。簡単な例を示しましょう。@route('/hello') @route('/hello/<name>') def hello(name='World'): return template('hello_template', name=name)これで
hello_template.tplというテンプレートファイルがロードされ、name変数に値がセットされた状態でレンダリングされます。Bottleは./views/ディレクトリか、bottle.TEMPLATE_PATHで指定されたディレクトリをみてます。
view()デコーダはtemplate()を呼び出す代わりに、テンプレート変数を使って辞書を返すことができます。@route('/hello') @route('/hello/<name>') @view('hello_template') def hello(name='World'): return dict(name=name)文法
テンプレート構文はPython中心の極めて薄いレイヤです。その主目的はブロックの正しいインデントの保証であるため、インデントを気にすることなくテンプレートを構成できます。完全な解説は以下のリンクを参照してください。
%if name == 'World': <h1>Hello {{name}}!</h1> <p>This is a test.</p> %else: <h1>Hello {{name.title()}}!</h1> <p>How are you?</p> %endキャッシング
テンプレートはコンパイル後メモリにキャッシュされます。テンプレートを変更しても、キャッシュをクリアするまで反映されません。
bottle.TMPLATES.clear()でクリアしましょう。デバックモードではキャッシュは無効です。プラグイン
グローバルインストール
アンインストール
指定インストール
ブラックリスト
プラグインとサブアプリケーション
開発
これで基本は学べたので、自分のアプリを書いていきたいでしょう。ここでは開発の役に立つかもしれないTIPSを紹介しましょう。
デフォルトアプリケーション
Bottleは
Bottleというグローバルインスタンスを持ち続け、いくつかのモジュールレベルの関数やデコレータの最上位層になります。route()デコレータなどは、デフォルトアプリケーション上のBottle.route()を呼ぶショートカットになります。@route('/') def hello(): return 'Hello World' run()これはスモールアプリ開発に便利であり、タイピング量の節約につながりますが同時に、モジュールがインポートされるとすぐ、ルーターがグローバルなデフォルトアプリケーションにインストールされるということです(?)。このインポートの副作用を避けるために、Bottleはアプリケーションを明示的にビルドする方法を用意しています。
app = Bottle() @app.route('/') def hello(): return 'Hello World' app.run()アプリケーションオブジェクトの分離は再利用性を大きく向上させます。ほかの開発者があなたのモジュールから安全に
appオブジェクトをインポートし、Bottle.mount()を用いることでアプリケーションを統合できます。bottle-0.13から、コンテキストマネージャとして
Bottleインスタンスが使えるようになりました。app = Bottle() with app: # Our application object is now the default # for all shortcut functions and decorators assert my_app is default_app() @route('/') def hello(): return 'Hello World' # Also useful to capture routes defined in other modules import some_package.more_routesデバッグモード
初期の開発段階では、デバッグモードは超便利です。
bottle.debug(True)このモードでは、Bottleはエラーが出るたびに十分なデバッグ情報を提供します。また、開発の邪魔になるようないくつかの最適化を無効にしたり、起こりうる設定ミスをチェックするような項目を追加します。
デバッグモード中に変更になる項目を示します。
- エラーページにトレースバックが表示される
- テンプレートはキャッシュされない
- プラグインは直ちに適用される
プロダクションサーバではこのモードは使用しないでね。
オートリロード
開発中、変更を加える度に何度もサーバを再起動しなければいけません。オートリローダが代わりにやってくれるよ。ファイルを変更する度に、リローダはサーバのプロセスを再起動し、最新のコードに更新してくれるよ。
from bottle import run run(reloader=True)仕組み: メインプロセスはサーバを起動せず、メインプロセスを起動させるのに使われる要素で子プロセスを立ち上げます。すべてのモジュールレベルのコードは2度実行されますよ、気を付けて。
もっと詳しいこと書いてるけどまあ気にせんでいいやろ。
コマンドラインインターフェイス
バージョン0.10からコマンドラインツールが使えるようになりました。
$ python -m bottle Usage: bottle.py [options] package.module:app Options: -h, --help show this help message and exit --version show version number. -b ADDRESS, --bind=ADDRESS bind socket to ADDRESS. -s SERVER, --server=SERVER use SERVER as backend. -p PLUGIN, --plugin=PLUGIN install additional plugin/s. -c FILE, --conf=FILE load config values from FILE. -C NAME=VALUE, --param=NAME=VALUE override config values. --debug start server in debug mode. --reload auto-reload on file changes.ADDRESSはIPアドレスかIP:PORTのペアであり、デフォルトはlocalhost:8080だよ。その他のパラメータは見たらわかるでしょ。
なんかわからんけど例を示しとくね。
# Grab the 'app' object from the 'myapp.controller' module and # start a paste server on port 80 on all interfaces. python -m bottle -server paste -bind 0.0.0.0:80 myapp.controller:app # Start a self-reloading development server and serve the global # default application. The routes are defined in 'test.py' python -m bottle --debug --reload test # Install a custom debug plugin with some parameters python -m bottle --debug --reload --plugin 'utils:DebugPlugin(exc=True)'' test # Serve an application that is created with 'myapp.controller.make_app()' # on demand. python -m bottle 'myapp.controller:make_app()''デプロイ
Bottleはデフォルトで組み込みサーバ上で動く。この非スレッティングなサーバは開発にはもってこいだけど、ロード数が増えるとパフォーマンスに限界があるよ。
パフォーマンス向上の簡単な方法は、マルチスレッド対応のサーバをインストールすること(pasteとかcherrypyみたいなね)、そしてデフォルトにサーバかわりに使うようにBottleに教えてあげること。
bottle.run(server='paste')こういうのとか、いろいろデプロイのオプションについては別の記事を参考にしてね。
用語集
コールバック(callback)
何らかの外部アクションが発生した時に呼び出されるコード。Webフレームワークでは、各URLにコールバック関数を指定することで、URLとアプリケーションコード間のマッピングが実現されていることがよくある。
デコーレタ(decorator)
他の関数を返す関数のことで、通常関数の変換のために
@decoratorの形で適用される。python documentation for function definitionを見ればより詳しく書いてるよ。インバイロン?(environ)
なにこれ?
ハンドラ関数(handler function)
特定のイベントや状況を処理する関数のこと。Webフレームワークでは、各URLへのコールバックとしてハンドラ関数を充てることでアプリを開発していく。
ソースディレクトリ(source directory)
全部のソースファイルを含むディレクトリ(?)
- 投稿日:2019-07-16T15:44:03+09:00
QuantXでより良いアルゴを作成する
1. はじめに
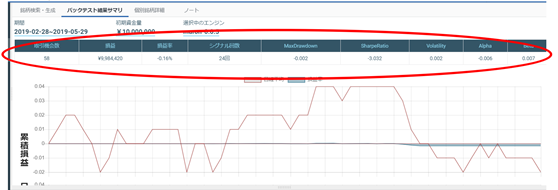
QuantX Factoryでは、株売買のアルゴリズムを作ることができます。また、アルゴリズム開発画面では、過去の株価データを利用して、自分の開発したアルゴリズムのパフォーマンスを期間や初期資金量を設定して検証することができます。具体的には自分のアルゴリズムのMaxDrawdownやSharpeRatio等が確認可能です。
2. パフォーマンス指標
QuantX Factoryで確認できる指標は以下の通りです。
・取引回数
取引回数はバックテスト期間における市場開催日の日数となります。
・損益
初期資金を用いて売買されたときの、損益の金額が表されます。
・損益率
初期資金と損益の割合が表されます。
・シグナル回数
アルゴリズムによって出されたシグナルの回数
・MaxDrawdown(Drawdown)最大資産(累積利益)からの下落率のこと。システムトレードなどでは、最大ドローダウン(下落率)をどれだけに設定するかがリスク管理の観点から重要な要素の一つとなる。(https://www.nomura.co.jp/terms/japan/to/A01914.html)
大きいほどリスク度合いが高くなります。
・SharpeRatio
投資信託の運用成績を測るための指標のひとつ。ポートフォリオの総リスクを示す標準偏差で計測される。
一般的には、ポートフォリオの年率換算後の収益率(ここでは平均リターン)、標準偏差、無リスク利子率が用いられ、 {(ポートフォリオの平均リターン)-(無リスク利子率)}/(ポートフォリオの標準偏差) で表される。
単純なリターンの大小ではなく、そのリターンを得るためにどれ位のリスクをとっているかを計測する。数値が大きいほど運用効率が高いことを示す。一般的に、同種の投資対象分類ファンド同士を比較するのが効果的とされている。 なお、リターンがマイナスの場合には、リスクが大きいほどシャープレシオが大きくなるという制約を伴う。
指標の考案者は、米国の経済学者であるウィリアム・シャープ(William Sharpe)。(https://www.nomura.co.jp/terms/japan/si/sharpratio.html)
リスクに対してどれだけの利益を得ることが出来るかということになります。
・volatility
証券などの価格の変動性のこと。期待収益率が期待通りとなる度合いを示す。ボラティリティが高ければ期待収益率から大きく外れる可能性が高い。
標準偏差で示すことが多い。ボラティリティが大きいとは価格の変動性が大きいことを指す。また、1つの変数の変動に対する他の変数の感応性を意味することもある。例えば、長期債の利回りの変動に対する価格の変動性は、短期債のそれよりも高く、ボラティリティが大きいという。(https://www.nomura.co.jp/terms/japan/ho/volatility.html)価格変動の大きさを表します。
・Alpha
β値で表されるリスクを調整した後の個別証券の収益率が、どれだけ市場平均(ベンチマーク)の収益率を上回っているのかを示す数値。α値が高いということは、ベンチマークよりも、それだけリターンが大きいことを意味する。
なお、ある変数y(被説明変数)のデータを他の変数x(説明変数)のデータから予測しy=α+βxの関係式に当てはめて検証する回帰分析を行う場合、最小2乗法の手法を用いて
α=(yの平均値)-β×(xの平均値)
と推計される。(https://www.nomura.co.jp/terms/japan/a/alpha.html)αが高いほど、ベンチマークは収益率を上回り、リターンが高いことを示します。
・Beta
個別証券(あるいはポートフォリオ)の収益が証券市場全体の動きに対してどの程度敏感に反応して変動するかを示す数値で、現代ポートフォリオ理論でよく用いられる。
β=個別証券のリターン÷市場全体のリターンINDEX指数(日経平均やTOPIX)に対して対象銘柄が指数の変化よりもどれだけ大きく動くかを数値化したもの。βが高いほど証券市場全体の動きに連動した変動幅が大きいことを示す。
3. いいアルゴリズムとは
QuantXでは上記のような指標を用いて、自分のアルゴリズムを考えることが出来ますが、果たして、上記指標がどのような値になったときに、いいアルゴリズムで、開発するうえで、どのような値を目指せばよいのでしょうか。
ここでは、いいアルゴを考える前に、まず先に、悪いアルゴについて考えてみます。
悪いアルゴとは、
・パラメーターや開始日を少し変えたらパフォーマンスが大きく変わる
・パフォーマンスの大半が1、2銘柄の好成績に依存してる
・組み入れ銘柄の株価の上昇に依存している
・シグナル発生頻度が極端に低いということが考えられます。特に一番初めの、パラメーターや開始日を変えたときに大きくパフォーマンスが変わるのは、バックテスト最適化になっている可能性が高く、アルゴ開発を行う上で、注意しなければいけません。
また、いいアルゴを定義することは難しいのですが、悪いアルゴから考えてみると、いいアルゴとは、
・パラメーターや開始日を少し変えても、パフォーマンスが大きく変わらないこと
・パフォーマンスが1、2銘柄に依存せずに、収益が出ていること
・銘柄に流動性があり、適切に選択されていること
・シグナル回数が極端に低すぎないこと
・MaxDrawdownが高すぎないこと
・SharpeRatioが適切な値であること等が考えられます。評価基準は多岐にわたるので、簡単に書くことは難しいのですが、上記のようなことが一般的に考えられます。
- 投稿日:2019-07-16T15:22:11+09:00
pythonの比較演算子isで数値を比較するときの注意点
isで比較するのはやめよう
それ以上でもそれ以下でもないんですが、特に必要でないときは必ず==で比較しましょう。
私のようにPythonは比較を英文っぽく書けるからちょっとカッコイイ!!なんて考えないようにしましょう。isと==の違いについて
詳しく書いてあるサイトはいくらでも存在するのでここでは軽く。
isはオブジェクトのid比較、==は中に入っている値の比較を行っています。(厳密には違いますがその認識で当分は良いです)a = [1,2,3] b = [1,2,3] print(a == b) #True print(a is b) #Falseこのように、aとbが違うオブジェクトの場合はそれぞれが別の場所に作られているため結果が異なります。
しかし
a = True b = True print(a is b) #True a = None b = None print(a is b) #Trueこのように場合によっては異なるオブジェクトを比較しているつもりでも
Trueが帰ってくることもあります。
これがなぜ起こるかと言うと、TrueやNoneはそれぞれ1つしか存在しないため、全てが同じオブジェクトのidを指すように作られているからです。数値を比較してみる
ではここで本題です。数値に対してis演算子を適用してみましょう。
a = 1 b = 1 print(a == b) #True print(a is b) #True a = 1.0 b = 1.0 print(a == b) #True print(a is b) #Falseint型ではis演算子で
Trueが帰ってきました。Pythonのリファレンスを見てみると、どうやら
-5から256は配列で最初からidが押さえてあるみたいですね。つまり、int型において-5~256の比較のみisが使えるようです。実際
a = 256 b = 256 print(a is b) #True a = 257 b = 257 print(a is b) #Falseとなっています。何度も言いますがむやみに
isで比較しないようにしましょう。ではis演算子は使わないほうが良いのか
というとそんなことはなくて、
==よりisの方が良い場合もあります。
最初に出したようなTrueやNoneなど、確実にidが同一であるとわかっている場合はisを使うほうがよいです。理由はいくつかありますが、
isのほうがidを直接参照しているので高速であるということ、==はユーザーが定義したクラスなどの場合にオーバーロード(挙動の書き換え)ができてしまうため不確実である可能性があるということです。
- 投稿日:2019-07-16T14:20:15+09:00
超初心者が書く! Project Euler を Python で解いてみた! Problem2
problem2
学校でも勉強が進み、個人的にも少し勉強をしたので、今回は自分でコードを書いてみたいと思います。
問題文
フィボナッチ数列の項は前の2つの項の和である. 最初の2項を 1, 2 とすれば, 最初の10項は以下の通りである.
1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ...
数列の項の値が400万以下の, 偶数値の項の総和を求めよ.
という問題です。
最初の2項が 1 , 1 で始まらないんですね...フィボナッチ数列とは何ぞや? という方は こちらへ
方針
フィボナッチの偶奇を判定していけばいいんですね! (そのまんまやんけ...)
a = b っていう文と、 b = a + b という文が出てきそうですね
とりあえず書いてみましょう。間違った解答&解説
Fiba = 1 b = 2 result = 0 while b < 4*10**6: if b%2 == 0: result += b a = b b = a + b print(result)4194302あれ?答えが違う... (ちなみに答えは 4613732 です)
間違い探しをする前に初登場の関数の紹介です!
ここを押すと while文 の説明がでるよ!
whileとは...
while文は繰り返し実行をための文です。こんな書き方をします。
while 繰り返しの条件:
実際のコードで書くと
whilen = 0 while n < 5: print(n) n += 10 1 2 3 4
このように「繰り返しの条件」に当たる箇所が真(正しい)のときに繰り返してくれます。ここから解説です。
前回もやった通り 1、2、3行目 で関数の宣言と代入を行っています。
4~8行目 で繰り返しの処理を行っています。
5行目 で偶数の判定、
6行目で result に偶数を合計していています。
7、8行目で肝心のフィボナッチ数列を作っているのですが、どうやらここに問題があるらしい...
初期の予定では(a, b) = (1, 2) (2, 1+2) (3, 2+3) (5, 3+5) ...となる予定でしたが、実行してみると
(a, b) = (1, 2) (2, 2+2) (4, 4+4) (8, 8+8) ...と、上がっていってしまいました...
これは a = b を行った後に b = a + b を行っていため
b = b + b をしているのとおんなじなんですね。(´・ω・`)どうにかしてこの処理が b = a + b として成り立たせることができればよさそうです。
解答&解説
Fibonacci_Sequencea, b = 1, 2 result = 0 while b < 4*10**6: if b%2 == 0: result += b a, b = b, a + b print(result)4613732ヤタ━─━─ヽ(´Д`)ノ─━─━!!!!
同時に変数の宣言と代入ができるのではないかとおもって直感で書いたらいけました! 正規の方法ですのでご安心を(笑)
しっかり a = b と b = a + b が行われていますね。
他の分は書き換えてないです。
終わり
while文の使い方と代入の面白さが伝わっていれば幸いです!
- 投稿日:2019-07-16T13:37:55+09:00
0.1ぐらいから始めるProjectEuler@python Problem 4
どもども、最近疲れやら悩み事やらが増えているとある学生です。
というわけで、4問目書いていきます。
(3問目はちょっと難しかったのでいったん飛ばします。頭いい人ヒントください)Problem_4.py#左右どちらから読んでも同じ値になる数を回文数という. #2桁の数の積で表される回文数のうち, 最大のものは 9009 = 91 × 99 である. #では, 3桁の数の積で表される回文数の最大値を求めよ. max_num = 1000 max_ans = 0 for i in range(100, max_num): for j in range(100, max_num): num = i * j num_str = str(num) if num_str == num_str[::-1] and num > max_ans: max_ans = num print(max_ans)解 906609
はい、私はこう書きました。解き方の解説をしていきます。
最初のグローバル関数2つが問題に書いてある最大数と、答えを入れる用の箱です。
後は、100から1000までi * jをしつつ、掛け算をして出たものと、それを逆にしたものが同じで、numより大きければその答えをprintする感じです。こんな感じですかね?もしわからないやアドバイス等あればコメントしていただければと思います(答えるとは言っていない)
というわけで気が向いたら次のも見てってください。よろしくお願いします。
- 投稿日:2019-07-16T11:43:20+09:00
多目的ベイズ最適化入門
Outline
- イントロ
- 多目的最適化
- 多目的ベイズ最適化
- 既存手法
イントロ
今回は「多目的ベイズ最適化」というテーマについて記事を書いていきます。多目的最適化に関しては詳しく説明しますが、ベイズ最適化に関しては以前自分が書いたこの記事で詳しく触れているので踏み込んだ説明はしません。
本記事の目的
- 多目的ベイズ最適化のモチベーションや評価方法を知ってもらう
多目的最適化が実世界への応用先が多いということ、そして単一の最適化とは最適解の定義が異なるということを知って欲しいという思いがあります。
多目的最適化
ということでまずは多目的最適化に関して説明していきます。読んで字のごとく、最適化したい目的関数が複数存在します。これらの目的関数を$f_1,\ldots,f_L$と表記します。各目的関数ごとに最小化なのか最大化なのかは異なる設定もありうると思うのですが、説明を簡単にするために今回はすべての目的関数で最小化を目的とします。つまり、すべての目的関数を同時に最小化する大域的最適解$x^{*}$を獲得するのが理想となります。
$$x^{*} = \arg\min_{x\in \mathcal{X}}f_{1},\ldots,f_{L}$$
しかし、多目的最適化のゴールは$x^{*}$を獲得することではありません。そもそも$x^{*}$が必ず存在するわけではありません。では多目的最適化のゴールは何かと言うと...
パレート最適解を全て獲得すること
です。というわけでパレート最適解に関して説明していきます。パレート最適解
現実世界の多目的最適化問題では、目的関数間にトレードオフの関係があることが多いです。
料理の総合的な評価を例にしてみましょう。料理に対する評価というのは複数の項目によってなされます。一例ですが、
1. 味
2. 見た目
3. 香り
4. 値段 (外食の場合)
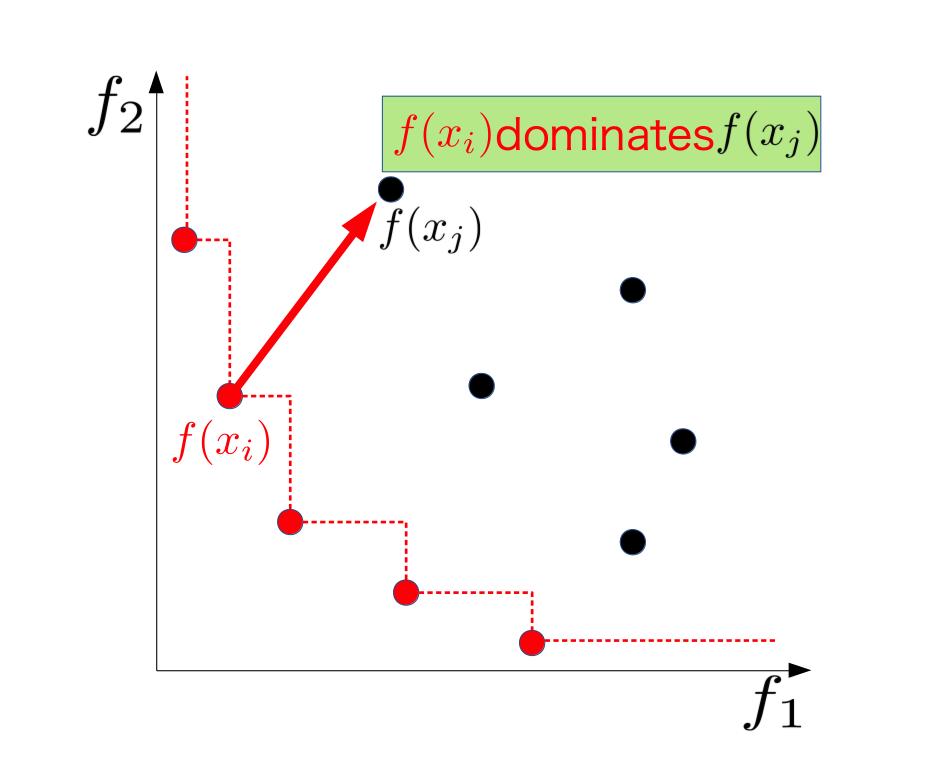
といった項目を同時に最適化しようと思った時に、理想は1~4全部最適な料理を作ることです。しかし世の中そんなに甘くありません。例えば味や見た目にこだわろうと食材に上等なものをふんだんに使ってしまうとその分値段をあげないといけなくなります。香りにこだわりすぎると見た目や味が悪くなってしまうかもしれません。といった風にどれかをよくしようとすると他の目的関数が悪くなってしまうことがありうるわけです。なので理想解$x^{*}$の代わりにパレート最適解というのを定義します。その準備段階として支配関係というものを定義します。支配関係
支配関係は目的関数空間上の任意の2点間で定義される関係です。ここからは入力空間上のある2点$x_{i}$, $x_{j}$に対応する目的関数 $f(x_i) = [f_{1}(x_{i}), f_2(x_i)]^{\top}$, $f(x_j) = [f_{1}(x_{j}), f_2(x_j)]^{\top}$
平たくいうと$x_{j}$が全ての目的関数で$x_i$に負けてるとき、$x_i$は$x_j$を支配していると言います。下の図がそれを示したもので、最小化の文脈で$x_i$の方が$f_1$, $f_2$どちらの値も$x_j$より小さいです。
この支配関係を$x_i \succeq x_j$と表記することにします。数式できちんと定義すると、
$$x_i \succeq x_j \Leftrightarrow f_l(x_i) \le f_l(x_j), \forall l \in 1,\ldots,L,$$と定義できます。パレート最適
いよいよパレート最適の説明をしていきます。ある点$x_i$が
他のどの点にも支配されていないとき、$x_i$はパレート最適であると定義されます。先ほどの図中の赤い点は全てパレート最適の定義を満たしています。一般にパレート最適解は複数存在し、その集合をパレートセット$\mathcal{X}^{*}$, 対応する目的関数値の集合をパレートフロンティア$\mathcal{F}^{*}$とします。$\mathcal{X}^{*}$の定義は以下の通りです。
$$\mathcal{X}^{*} = \{x \in \mathcal{X}\mid \forall x^{\prime} \in \mathcal{X} \backslash \{x\}, x^{\prime}\not\succeq x \}$$
というわけで、多目的最適化のゴールは、
パレートセットの要素を全て獲得することです。
ゴールがはっきりしたところで、では最適化がどれだけ達成されているかをどう評価するかを説明していきます。多目的最適化では様々な評価指標があるのですが、今回はパレート超体積という指標を紹介します。
まず、現在観測ずみのデータ集合内で定義されるパレートフロンティアをCurrent Pareto Frontier、空間全体で定義される真のパレートフロンティアをTrue Pareto Frontierと呼ぶことにします。下に示した図の青い点がCurrent Pareto Frontier、黒い点がすでに他の点に支配されているパレート最適ではない点です。このとき図の赤い点のような基準点を設けることで複数の超直方体を組み合わせたような図形ができます。この図形の超体積をパレート超体積と呼びます。このパレート超体積は単調増加でTrue Pareto Frontierを全て獲得した際に最大となります。
多目的ベイズ最適化
多目的ベイズ最適化は読んで字のごとし、多目的最適化をベイズ最適化の枠組みで解きます。ベイズ最適化が用いられる際の問題設定をおさらいしておきましょう。
1. 最適化したい目的関数がブラックボックス
2. 一回の観測に膨大なコストがかかる
これらの設定から、獲得関数という指標に基づいてより少ない観測回数で最適化を達成することがベイズ最適化の目的でした。
つまりさきほどの多目的最適化のゴールから、多目的ベイズ最適化はすべてのパレート最適解を少ない観測回数で獲得すること
が目的であると言えます。ここで最適化対象である目的関数にいくつかの仮定を置いておきます。
1. L個の目的関数はそれぞれ独立なガウス過程に従う
2. 観測の際に乗るノイズはすべての目的関数で共通の大きさ
3. ある入力で実験を行うとすべての目的関数の値が同時に得られるというわけでここから多目的ベイズ最適化の獲得関数を3つほど紹介していきます。
既存手法
ParEGO
元論文 : ParEGO: a hybrid algorithm with on-line landscape approximation for expensive multiobjective optimization problems
ParEGOはベイズ最適化の手法の中で最も古典的な手法です。
ParEGOのコンセプトはズバリ線形化。多目的最適化問題を単一目的関数の最適化問題に落とし込みます。具体的にどう線形化するのか説明するために一つ新たな定義をば...
すでに観測ずみの入力点がN個、$x_1,\ldots,x_N$とそれに対応する目的関数値のベクトルを$f(x_1),\ldots,f(x_N)$とします。ここで各$x$に関して以下のような重み付き線形和を考えます。
$$f_\theta(x_{i}) = \max_{l\in1,\ldots,L} \theta_l f_l(x_i) + \rho\sum_{l=1}^{L}\theta_l f_l (x_i) $$
ただし、$\theta_l$は一様分布からサンプリングされる重みで、$\rho$はハイパーパラメータです。元論文では0.05に設定されていました。この線形化によって得られる$f_{\theta}$に関してベイズ最適化を適用します。ParEGOのメリットの一つは計算コストの軽さです。線形化することによりガウス過程回帰の事後分布の計算を目的関数の個数分する必要がありません。獲得関数自体も単一のベイズ最適化なので後述の手法に比べると軽いです。その一方で本来の最適化対象を最適化しているわけではないのでパレート解の網羅的探索という観点からは良い性能を示さないこともあります。Expected Hypervolume Improvement (EHI)
元論文 : The computation of the expected improvement in dominated hypervolume of Pareto front approximations
EHIは単一のベイズ最適化のポピュラーな獲得関数であるEIのアイデアを多目的最適化に応用させたものです。EHIのアイデアは、パレート超体積の増加量の期待値が最大の点を獲得することです。
EHIは獲得関数自体は解析的な形で書けるのですが、目的関数の数が増えるにつれてその計算コストが指数的に増加していきます。そのため目的関数が4個以上の設定でEHIの実験を行なっている論文はあまりありません。しかし、EHIの計算の高速化を図る研究もなされているようです。S-metric Selection Efficient Grobal Optimization (SMSego)
元論文 : Multiobjective Optimization on a Limited Budget of Evaluations Using Model-Assisted S-Metric Selection
最後にSMSegoを紹介します。これもEHIと同様超体積を軸に獲得関数を設計します。ある入力$x$に関してガウス過程回帰によって計算される事後平均と分散をそれぞれ$\mu(x)$, $\sigma^{2}(x)$とすると、
$$\mu(x) - \alpha \sigma(x)$$という下側信頼区間を考えます。現在の観測ずみデータ集合にこの下側信頼区間を加えた時に、最もパレート超体積を増加させる点を次に観測します。これは各点が超体積をどれだけ増加させるかを楽観的に見積もっていることになります。$\alpha$はハイパーパラメータです。SMSegoはEHI同様目的関数の数が増えると計算コストが重くなります。そもそもパレート超体積の計算自体が重いため、超体積を指標とするとどうしても計算コストと戦う宿命にあるのでしょう。ただパレート超体積の効率的な計算法は、それだけでも一つの論文にできるような結構重要なトピックでもあります。終わりに
というわけで多目的ベイズ最適化に関してつらつらと説明してきましたが、もし質問やご指摘などありましたらコメントいただけると嬉しいです。
また、今回紹介した3つの手法に関してはpythonでの実装をGithubにてまとめてあるのでもしよかったら遊んでみてください。
Github

- 投稿日:2019-07-16T10:58:38+09:00
Pandasでテーブルデータの数値・カテゴリ変数をヒストグラムで一括で表示
モチベーション
Pandasで読み込んだテーブルの中の数値の列に対しては、histメソッドですべての列をヒストグラムで表示できますよね。一方でカテゴリ変数はちょっと面倒だなと感じたので、もろもろを一発で表示してくれる関数を実装しました。実は簡単にやる方法があるのかもと思いつつも投稿します。
ソースコード
以下が実装した機能の本体です。
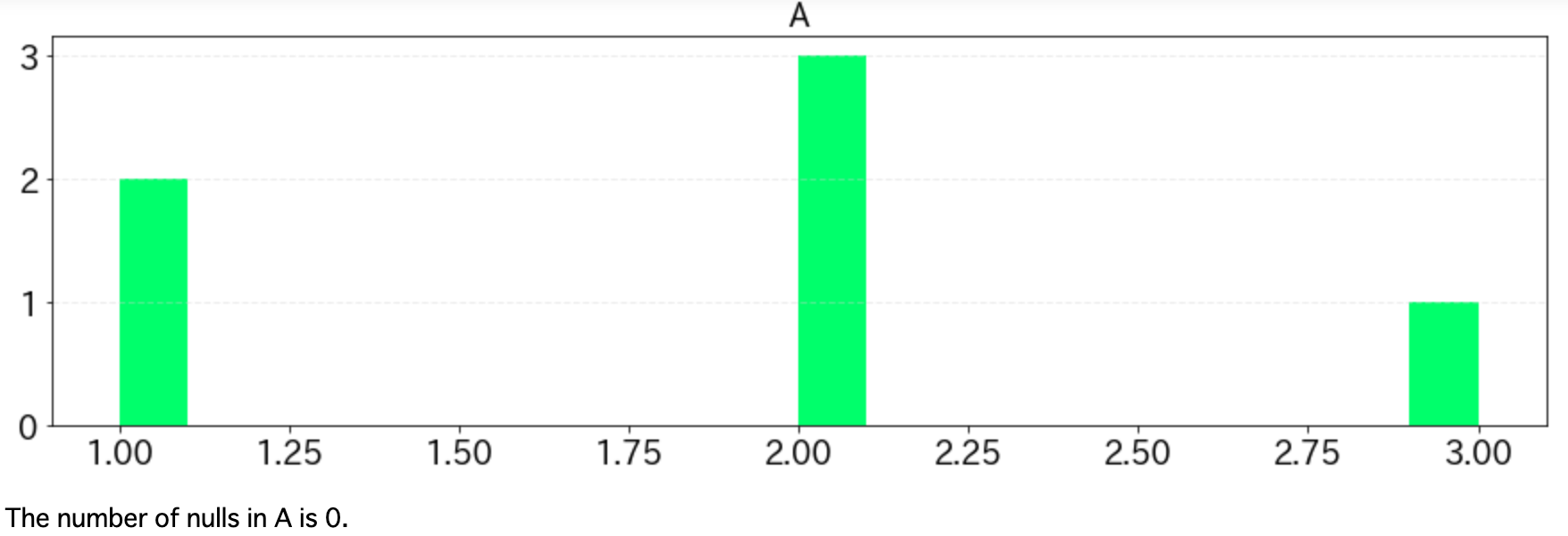
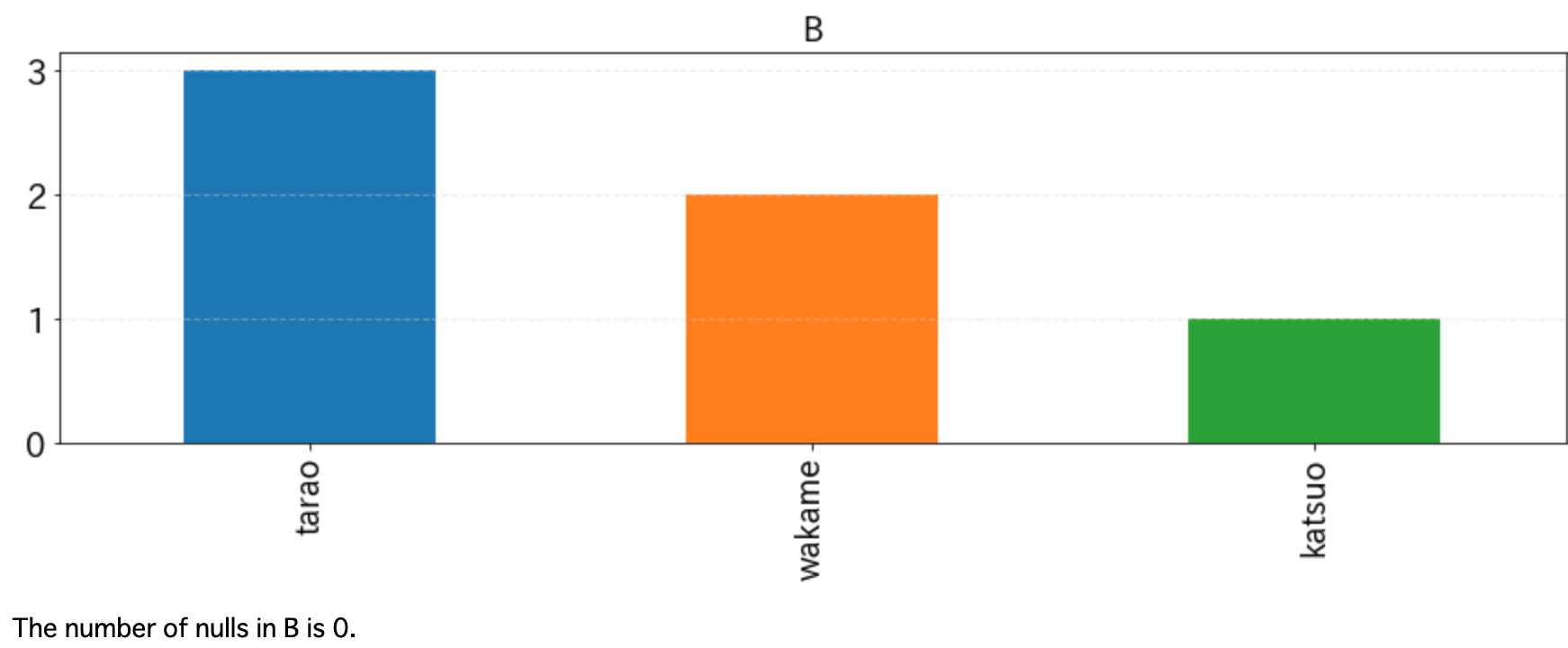
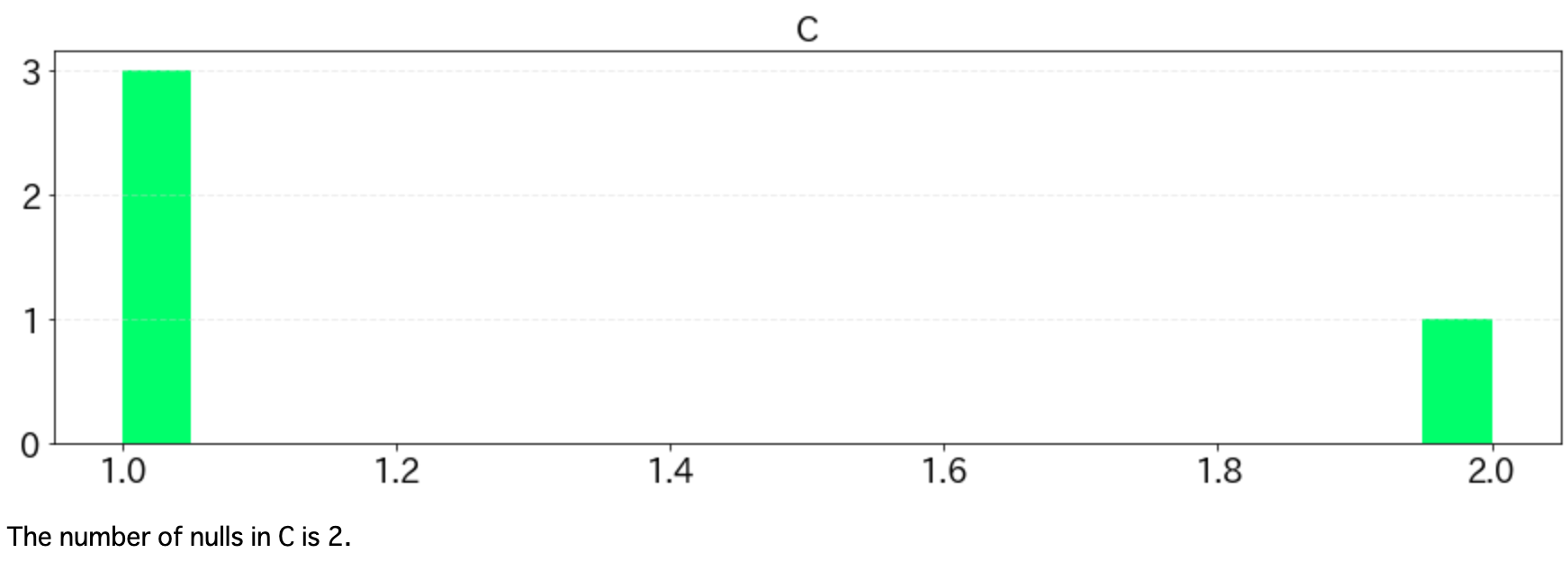
import matplotlib.pyplot as plt import pandas as pd def histgram(df, bins=20, ignore_columns=[], fontsize=18): nulls = df.isnull().sum() for column in df: if column in ignore_columns: continue column_type = str(df.dtypes[column]) fig = plt.figure(figsize=[15, 4]) ax = fig.add_subplot(111) if "int" in column_type or "float" in column_type: df[column].hist(bins=bins, color="#44ff89") else: df[column].value_counts().plot(kind="bar") plt.title(column, fontsize=fontsize) plt.tick_params(labelsize=fontsize) plt.grid(False) ax.yaxis.grid(linestyle='--', lw=1, alpha=0.4, color='lightgray') plt.show() print("The number of nulls in {} is {}.".format(column, nulls[column]))以下のようなdfというDataFrameがあったときに、histgram(df, ignore_columns=["D"])のような形で呼び出します。ignore_columnsに指定したカラム名は表示するときに無視します。idなどを示した列はこれに指定しましょう。
df = pd.DataFrame({"A": [1,1,2,2,2,3], "B": ["katsuo", "tarao", "wakame", "tarao", "tarao", "wakame"], "C": [1,1,1,2, np.nan, np.nan], "D": [1,2,3,4,5,6]}) histgram(df, ignore_columns=["D"])上記の実行結果は以下の通り。
DataFrameに含まれるNaNの数も欲しくなるので、ヒストグラムの下に出力しています。
- 投稿日:2019-07-16T09:13:29+09:00
[Python] 浮動小数点数floatの比較は要注意!!
はじめに
最近Pyhonを勉強し始めた新人です。
今回は浮動小数点数floatの比較について書きたいと思います。float型の比較
皆さん、以下のコードの出力は何だと思いますか?
test.pydef main(): x = 0 for i in range(10): x += 0.1 if x == 1.0: print("OK") else: print("NG") if __name__ == "__main__": main()0.1を10回足すので、xは1.0になるはずです。
そのため、"OK"が出力されるはず・・・実際に動かしてみると・・・
実際に動かしてみましょう。
実行$python test.py NG"NG"が表示されます。
数学的には0.1を10回足すと、1.0になるはずですが・・・xには一体いくつになっているのか?
以下のコードを実行して、型とxの値を確認します。
test.pydef main(): x = 0 for i in range(10): x += 0.1 print(type(x)) print(x) if x == 1.0: print("OK") else: print("NG") if __name__ == "__main__": main()実行結果が以下になります。
実行$ python test.py <class 'float'> 0.9999999999999999 NG型はfloat型、そしてxの値は0.9999999999999999となっています。
一体なぜでしょうか?float型は小数を正しく表示できない!?
実はfloat型は10進数の小数を正しく表示することが出来ません。
以下のコード結果を見れば分かりますが、format()で表示桁数を増やすと誤差が存在するのが分かります。
test.pyprint(0.1) print(format(0.1, '.20f'))実行$ python test.py 0.1 0.10000000000000000555float型は2進数で管理されている
表示こそ10進数ですが、内部的には2進数で管理されています。そして、多くの10進数の小数は2進数で表現できません。
例えば十進数の「0.1」を2進数に変換すると「0.0001100110011…」となり、「0011」の部分が永遠に循環します。このような値はどこかの桁数で丸めを行う必要があるため、上記のように誤差が生じます。
また、この話はpythonに限った話ではなく、IEEE 754の2進浮動小数点形式を採用して計算していれば、同じことが起こります。
対策 math.isclose()を使う
mathモジュールの関数isclose()を使うことによって、近似的な比較を行えます。
これを用いることによってfloat型の比較ができますね。
実際に使ってみましょう。test.pyimport math def main(): x = 0 for i in range(10): x += 0.1 if math.isclose(x, 1.0): print("OK") else: print("NG") if __name__ == "__main__": main()実行$ python test.py OK"OK"と表示されました!
まとめ
10進数の小数を比較するときは、誤差が生じることがあることを意識しておく必要がありそうです。
頭の片隅に置いておきましょう。
- 投稿日:2019-07-16T09:00:14+09:00
AWS CloudFormationのLambda-BackedカスタムリソースでネストされたJSONを返しても参照できない
AWS CloudFormationn(CFn)のLambda-Backedカスタムリソースを利用していてレスポンスとしてネストされたJSONを返そうとしたらハマったので調べてみました。
ハマった内容
Lambda-Backedカスタムリソースで
import cfnresponse def handler(event, context): data = { "hoge": "hoge", "foo": { "hoge": "foohoge" } } cfnresponse.send(event, context, cfnresponse.SUCCESS, data)のようにCFnへレスポンスを返してCFnテンプレートで
Outputs: hoge: Value: !GetAtt CustomResource.hoge foo: Value: !GetAtt CustomResource.foo.hogeと、カスタムリソースの値を参照すると
!GetAtt CustomResource.foo.hogeでエラーになりました。
エラー内容はCustomResource attribute error: Vendor response doesn't contain foo.hoge key。解決策
Lambda-BackedカスタムリソースでJSONを返す場合はネストせずフラットなJSONを返しましょう。
以下検証内容となります。
検証内容
前提
- AWSアカウントがある
- AWS CLIが利用できる
- AWS Lambda、CloudFormationの作成権限がある
エラーにならないケース
テンプレート
Lambda関数ではネストされたJSONを返しますが、
!GetAttではネストされた値を参照しないパターンです。
これでスタック作成してもエラーになりません。cfn-template.yamlResources: CustomResource: Type: Custom::CustomResource Properties: ServiceToken: !GetAtt CustomResourceFunction.Arn CustomResourceFunction: Type: AWS::Lambda::Function Properties: Handler: index.handler Role: !GetAtt FunctionExecutionRole.Arn Code: ZipFile: !Sub | import cfnresponse def handler(event, context): data = { "hoge": "hoge", "foo": { "hoge": "foohoge" } } cfnresponse.send(event, context, cfnresponse.SUCCESS, data) Runtime: python3.7 FunctionExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: - sts:AssumeRole Path: "/" Policies: - PolicyName: root PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents Resource: "arn:aws:logs:*:*:*" Outputs: hoge: Value: !GetAtt CustomResource.hogeスタック作成して確認する
> aws cloudformation create-stack \ --stack-name cfn-response-test \ --template-body file://cfn-template.yaml \ --capabilities CAPABILITY_IAM { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a" } > aws cloudformation describe-stacks \ --stack-name cfn-response-test { "Stacks": [ { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "StackName": "cfn-response-test", "CreationTime": "2019-06-26T01:47:20.177Z", "RollbackConfiguration": {}, "StackStatus": "CREATE_COMPLETE", "DisableRollback": false, "NotificationARNs": [], "Capabilities": [ "CAPABILITY_IAM" ], "Outputs": [ { "OutputKey": "hoge", "OutputValue": "hoge" } ], "Tags": [], "EnableTerminationProtection": false, "DriftInformation": { "StackDriftStatus": "NOT_CHECKED" } } ] }正常に作成できました。Lambda関数のログを確認しておきます。
> aws cloudformation list-stack-resources \ --stack-name cfn-response-test { "StackResourceSummaries": [ { "LogicalResourceId": "CustomResource", "PhysicalResourceId": "2019/06/26/[$LATEST]f518c197bb8541f0b651a151bb201560", "ResourceType": "Custom::CustomResource", "LastUpdatedTimestamp": "2019-06-26T01:47:45.532Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, { "LogicalResourceId": "CustomResourceFunction", "PhysicalResourceId": "cfn-response-test-CustomResourceFunction-HI0ITG58NF7G", "ResourceType": "AWS::Lambda::Function", "LastUpdatedTimestamp": "2019-06-26T01:47:39.855Z", "ResourceStatus": "CREATE_COMPLETE", "DriftInformation": { "StackResourceDriftStatus": "NOT_CHECKED" } }, (略) ] } > aws logs get-log-events \ --log-group-name /aws/lambda/cfn-response-test-CustomResourceFunction-HI0ITG58NF7G \ --log-stream-name '2019/06/26/[$LATEST]f518c197bb8541f0b651a151bb201560' \ --output=text \ --query "events[*].message" START RequestId: db73aff3-d14a-4ff1-92cc-6335d23279aa Version: $LATEST https://cloudformation-custom-resource-response-useast1.s3.amazonaws.com/(略) Response body: {"Status": "SUCCESS", "Reason": "See the details in CloudWatch Log Stream: 2019/06/26/[$LATEST]f518c197bb8541f0b651a151bb201560", "PhysicalResourceId": "2019/06/26/[$LATEST]f518c197bb8541f0b651a151bb201560", "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "RequestId": "c734ee9f-7963-4626-bf6e-40d7e24a99ab", "LogicalResourceId": "CustomResource", "NoEcho": false, "Data": {"hoge": "hoge", "foo": {"hoge": "foohoge"}}} Status code: OK END RequestId: db73aff3-d14a-4ff1-92cc-6335d23279aa REPORT RequestId: db73aff3-d14a-4ff1-92cc-6335d23279aa Duration: 310.53 ms Billed Duration: 400 ms Memory Size: 128 MB Max Memory Used: 24 MBレスポンス内容の
DataでネストされたJSONを返していることが確認できます。エラーにならないケース
Outputsの定義を変更して確認します。テンプレート(抜粋)
cfn-template.yaml_抜粋Outputs: hoge: Value: !GetAtt CustomResource.hoge foo: Value: !GetAtt CustomResource.foo.hogeスタック更新して確認する
> aws cloudformation update-stack \ --stack-name cfn-response-test \ --template-body file://cfn-template.yaml \ --capabilities CAPABILITY_IAM { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a" } > aws cloudformation describe-stacks \ --stack-name cfn-response-test { "Stacks": [ { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "StackName": "cfn-response-test", "CreationTime": "2019-06-26T01:47:20.177Z", "LastUpdatedTime": "2019-06-26T01:50:44.408Z", "RollbackConfiguration": {}, "StackStatus": "UPDATE_ROLLBACK_COMPLETE", "DisableRollback": false, "NotificationARNs": [], "Capabilities": [ "CAPABILITY_IAM" ], "Outputs": [ { "OutputKey": "hoge", "OutputValue": "hoge" } ], "Tags": [], "EnableTerminationProtection": false, "DriftInformation": { "StackDriftStatus": "NOT_CHECKED" } } ] }
UPDATE_ROLLBACK_COMPLETEとなり更新に失敗しました。
イベントを取得してエラー内容を確認します。> aws cloudformation describe-stack-events \ --stack-name cfn-response-test { "StackEvents": [ { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "EventId": "e01c4f90-97b4-11e9-bb14-12f81177eb92", "StackName": "cfn-response-test", "LogicalResourceId": "cfn-response-test", "PhysicalResourceId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "ResourceType": "AWS::CloudFormation::Stack", "Timestamp": "2019-06-26T01:51:12.126Z", "ResourceStatus": "UPDATE_ROLLBACK_COMPLETE" }, { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "EventId": "df9dd0c0-97b4-11e9-9cbb-0eaa79b17470", "StackName": "cfn-response-test", "LogicalResourceId": "cfn-response-test", "PhysicalResourceId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "ResourceType": "AWS::CloudFormation::Stack", "Timestamp": "2019-06-26T01:51:11.295Z", "ResourceStatus": "UPDATE_ROLLBACK_COMPLETE_CLEANUP_IN_PROGRESS" }, { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "EventId": "d1776100-97b4-11e9-a0b3-0a20b68b404c", "StackName": "cfn-response-test", "LogicalResourceId": "cfn-response-test", "PhysicalResourceId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "ResourceType": "AWS::CloudFormation::Stack", "Timestamp": "2019-06-26T01:50:47.544Z", "ResourceStatus": "UPDATE_ROLLBACK_IN_PROGRESS", "ResourceStatusReason": "CustomResource attribute error: Vendor response doesn't contain foo.hoge key in object arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a|CustomResource|c734ee9f-7963-4626-bf6e-40d7e24a99ab in S3 bucket cloudformation-custom-resource-storage-useast1" }, (略) ] }
CustomResource attribute error: Vendor response doesn't contain foo.hoge keyとエラー内容が確認できます。参照方法を変えてみる
!GetAtt CustomResource.foo.hogeとしているのがダメなのかなと考えて参照方法を変更してみました。テンプレート(抜粋)
cfn-template.yaml_抜粋Outputs: hoge: Value: !GetAtt CustomResource.hoge foo: Value: !GetAtt CustomResource.foo['hoge']スタック更新して確認する
> aws cloudformation update-stack \ --stack-name cfn-response-test \ --template-body file://cfn-template.yaml \ --capabilities CAPABILITY_IAM { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a" } > aws cloudformation describe-stacks \ --stack-name cfn-response-test { "Stacks": [ { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "StackName": "cfn-response-test", "CreationTime": "2019-06-26T01:47:20.177Z", "LastUpdatedTime": "2019-06-26T01:54:45.226Z", "RollbackConfiguration": {}, "StackStatus": "UPDATE_ROLLBACK_COMPLETE", "DisableRollback": false, "NotificationARNs": [], "Capabilities": [ "CAPABILITY_IAM" ], "Outputs": [ { "OutputKey": "hoge", "OutputValue": "hoge" } ], "Tags": [], "EnableTerminationProtection": false, "DriftInformation": { "StackDriftStatus": "NOT_CHECKED" } } ] } > aws cloudformation describe-stack-events \ --stack-name cfn-response-test { "StackEvents": [ { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "EventId": "6f1d0b80-97b5-11e9-b714-0a2e8057061e", "StackName": "cfn-response-test", "LogicalResourceId": "cfn-response-test", "PhysicalResourceId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "ResourceType": "AWS::CloudFormation::Stack", "Timestamp": "2019-06-26T01:55:12.038Z", "ResourceStatus": "UPDATE_ROLLBACK_COMPLETE" }, { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "EventId": "6eb6f6b0-97b5-11e9-aaf5-0a437bda7b86", "StackName": "cfn-response-test", "LogicalResourceId": "cfn-response-test", "PhysicalResourceId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "ResourceType": "AWS::CloudFormation::Stack", "Timestamp": "2019-06-26T01:55:11.375Z", "ResourceStatus": "UPDATE_ROLLBACK_COMPLETE_CLEANUP_IN_PROGRESS" }, { "StackId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "EventId": "609a23e0-97b5-11e9-a31e-0e366af4fd90", "StackName": "cfn-response-test", "LogicalResourceId": "cfn-response-test", "PhysicalResourceId": "arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a", "ResourceType": "AWS::CloudFormation::Stack", "Timestamp": "2019-06-26T01:54:47.692Z", "ResourceStatus": "UPDATE_ROLLBACK_IN_PROGRESS", "ResourceStatusReason": "CustomResource attribute error: Vendor response doesn't contain foo['hoge'] key in object arn:aws:cloudformation:us-east-1:xxxxxxxxxxxx:stack/cfn-response-test/55d8cd90-97b4-11e9-aa0c-128a65397f5a|CustomResource|c734ee9f-7963-4626-bf6e-40d7e24a99ab in S3 bucket cloudformation-custom-resource-storage-useast1" }, (略) ] }
CustomResource attribute error: Vendor response doesn't contain foo['hoge'] keyとエラーになりました。まとめ
Lambda-BackedカスタムリソースでネストされたJSONを返しても
!GetAttでは参照できないことがわかりました。ドキュメントにはDataの型がType: JSON objectと定義されているのですが制限があるみたいです。。。カスタムリソースの応答オブジェクト - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/crpg-ref-responses.html参考
カスタムリソースの応答オブジェクト - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/crpg-ref-responses.html
- 投稿日:2019-07-16T06:53:38+09:00
Pythonでzipファイルから特定の拡張子のファイルを抽出する
概要
zipファイルから特定の拡張子ファイルのみ抽出したいことが何度かあったので、Pythonで実装しました。
例えば以下のような構成のzipファイルがあるとします。
test.zip$ tree . ├── 01 │ └── 01 │ └── a.txt ├── 02 │ ├── b.txt │ └── c.txt └── 03 └── 01 ├── 01 │ └── d.txt ├── 02 │ └── e.txt └── 03 └── 01 ├── f.txt └── g.txt 9 directories, 7 filesここから以下のように1つのディレクトリにテキストファイルを抽出します。
$ tree . ├── a.txt ├── b.txt ├── c.txt ├── d.txt ├── e.txt ├── f.txt └── g.txttreeコマンドのインストール
macでは、treeコマンドを以下コマンド実行でインストールできます。
$ brew install treezipファイルから特定の拡張子のファイルを抽出する
以下のコードを実行すると、テキストファイルが抽出されます。
extensionに代入する文字列を抽出したい拡張子にすれば、その拡張子のファイルのみ抽出できます。import os import zipfile import shutil extension = '.txt' os.mkdir("./extract_txt/") my_zip = zipfile.ZipFile('test.zip') my_zip.extractall() for file in my_zip.namelist(): if my_zip.getinfo(file).filename.endswith(extension): shutil.move(file, "./extract_txt/")抽出したテキストファイルを1つにまとめるときは、以下のコマンドを実行します。
$ cat *.txt > all.txt参考
zipfile --- ZIP アーカイブの処理 — Python 3.7.4 ドキュメント
shutil --- 高水準のファイル操作 — Python 3.7.4 ドキュメント
- 投稿日:2019-07-16T05:59:15+09:00
【Programming News】Qiitaまとめ記事 July 15, 2019 Vol.1
筆者が昨日2019/7/15(月)に気になったQiitaの記事をまとめました。
Programming News
2019年
7月15(月)
Java
- Spring Boot
Kotlin
Python
- Beginner
- Tips
Ruby
- Beginner
- Apps
Rails
- Beginner
- OAuth
- Tips
C#
Android
Swift
- Summary
- Apps
- Tips
Flutter
- Tips
Vue.js
- Beginner
- Apps
Vuex
React
- Beginner
- Tips
JavaScript
- Beginner
Node.js
- Tips
Laravel
- Beginner
- Tips
jQuery
- Tips
Go言語
- Beginner
Unity
- Beginner
Bot
HTML
MySQL
- Beginner
AI
Git
- Beginner
- Tips
Azure
インフラ
- 仮想環境
- ubuntu
- ubuntu環境構築 #### Network
- Tips
RPA
Docker
- Beginner
Linux
Google Apps Script
- Beginner
- Tips
- Apps
Server Side
Develop
PowerShell
Vim
- Beginner
UML
- PlantUML
Raspberry
Security
- SSL
資格
- AWS
- 基本情報
- ネットワーク
更新情報
Kotlin
- Kotlin入門
Java
- Java 10
IDE
- 投稿日:2019-07-16T04:18:37+09:00
scikit-buildとcmakeでPythonの拡張モジュールをビルドして配布する
scikit-buildというPythonの拡張モジュールをビルドするための補助ツールがあります。
Improved build system generator for CPython C, C++, Cython and Fortran extensions
http://scikit-build.orgこれを使ってcmakeでビルドされたプロジェクトをPythonの拡張モジュールとして配布する方法についてまとめます。まとめたものは以下にあります:
https://gitlab.com/termoshtt/skbuild-example
全体のディレクトリ構成は以下の通りです:
├── CMakeLists.txt ├── hello │ ├── CMakeLists.txt │ ├── _hello.cpp # これを拡張モジュールにコンパイル │ ├── __init__.py │ └── __main__.py # python -m hello で呼ばれたときに実行されるファイル ├── LICENSE ├── pyproject.toml ├── README.md └── setup.pysetup.py
まずは通常のPythonのパッケージと同様にビルド用のスクリプトして
setup.pyを用意しますが、setuptoolsではなく、skbuildのsetupを使います:setup.pyfrom skbuild import setup setup( name="hello", version="1.2.3", description="a minimal example package", author="Toshiki Teramura <toshiki.teramura@gmail.com>", license="MIT", packages=["hello"], )pyproject.toml
依存関係は
requirements.txtではなく公式のドキュメントに従ってpyproject.tomlに記述しますpyproject.toml[build-system] requires = ["setuptools", "wheel", "scikit-build", "cmake", "ninja"]最近はpyproject.tomlの制定によって
setup.pyを書かなくてもpip installできるようになってきているらしいですが、今回はまだsetup.pyの拡張として提供されている機能を使用します。またPoetryにはscikit-buildがどうも対応してなさそう(?)なので今回は使いません。CMakeLists.txt
元のコード(scikit-build/tests/samples/hello-cpp)がCMakeLists.txtを分割していたので分けていますが、特に意味はありません。順番に見ていきましょう。
CMakeLists.txtcmake_minimum_required(VERSION 3.5.0) project(hello) find_package(PythonExtensions REQUIRED) add_subdirectory(hello)hello/CMakeLists.txtadd_library(_hello MODULE _hello.cpp) python_extension_module(_hello) install(TARGETS _hello LIBRARY DESTINATION hello)ポイントとしては
PythonExtensionsを探してきている部分と、python_extension_module(_hello)ですね。中身は調べられていないのですが、Pythonの拡張モジュールとして公開する際には必要のようです。Build
setup関数が
setuptoolsからskbuildに切り替わっていますが、基本的な使い方は同じで、python setup.py bdist_wheelとすればwheelを作成してくれます。wheelはPEP 427で定義された配布形式で拡張子は
*.whlとなります。whlファイルは実体としてはZIPアーカイブで、コンパイルされた共有ライブラリや他の静的なファイルを含めることができます。
上のコマンドで、dist/hello-1.2.3-cp37-cp37m-linux_x86_64.whlのようなファイルが出来上がっているはずです。これはそのままインストールが可能ですpip install dist/hello-1.2.3-cp37-cp37m-linux_x86_64.whl --user(
--userはお好みで)これでGlobalにインストールされたので 別のディレクトリに行って$ python -m hello Hello, World! :)となると成功です。別のディレクトリに行かないと現在のディレクトリ以下にある
helloモジュールを読み込みますが、ここにはcmakeで生成された拡張モジュールがありません…(´・ω・`)Links
- scikit-build document
- 正直これを読んでも分からん...(´・ω・`)
- tests/samples https://github.com/scikit-build/scikit-build/tree/master/tests/samples
- 上のリポジトリはここのhello-cppを拝借した
最後に
Pythonユーザーはpip installできないツールは使わないとの噂ですが、scikit-buildのおかげでC++の拡張も簡単にpipで配布できる形にまとめられるのでこれで使ってもらえますね
- 投稿日:2019-07-16T03:00:47+09:00
Qiita初投稿とプログラム
title:Qiita初投稿とタイマープログラム
author:The_ren
初投稿です
本日初投稿いたしましたThe_renと申します。大学で本格的にpythonを学ぶようになってからアウトプットの場が足りていないと感じ、Qiitaを利用することにしました。
ここでは自作したプログラムの質問の場として投稿をしていく予定なので、質問に答えられるQiitaの先輩方々はどんどん私にご指摘頂ければなと思います。また、Javaも今夏からやる予定なので、就職に繋げていきたいです。タイマーコード
学校の課題でプログラムをpythonで自作する課題が出たので、5分まで対応のカップ麺用のキッチンタイマーを作りたいと思います。以下は試作したコードです。
from time import sleep import time import pygame.mixer minute_to_second=60 def alert(): print("時間です") Sound() exit() def Sound(): pygame.mixer.init() pygame.mixer.music.load("Onmtp-Ding04-2.mp3") pygame.mixer.music.play(-1) input() pygame.mixer.music.stop() while True: print("タイマーを設定する時間を指定してください") minute=int(input("何分に設定するか選択してください。:")) second=int(input("何秒に設定するか選択してください:")) if minute==0 and second==0: print("設定を終了しました。") break try: if 0<=minute<=5: wait_time=(minute*minute_to_second)+second else: if 0>minute or 5<minute: print("入力できる数字は0から5までです。") continue except ValueError: print("数字以外は入力しないでください。") else: try: if 0<=second<=59: print(str(minute)+"分"+str(second)+"秒にタイマーをセットしました。") sleep(wait_time) else: if 0>second or 59<second: print("入力できる数字は0から59までです。") continue except ValueError: print("数字以外は入力しないでください。") alert()最終目標としては、時間になったらmp3から音楽を鳴らして知らせるだけでなく、tkinterで制限時間の表示も行いたいと考えています。
質問内容
その1
try文を使用することでエラー処理を行いたいと思っています。コードを見ていただければ分かると思いますが、なぜかエラー処理後のprint処理を実行してくれません。例えば、inputで読み取った値が「d」や何も押さずにENTERを押した場合の処理がループされずにpythonの既存のエラー処理で返されます。どのようにコードを変えれば良いでしょうか?
その2
本来は5分までのタイマーにしたかったのですが、秒針の上限を59までに設定しているため、最大で5分59秒まで設定できてしまう状況になっています。どのようにコードを変えれば良いでしょうか?
その3
この処理をtkinterのデジタル時計でカウントダウン形式で表示させたいのですがコンパクトなコードの書き方を是非ご教授してほしいです。
- 投稿日:2019-07-16T00:45:07+09:00
a タグを Markdown 記法に変換する Python スクリプトを作った
a タグを Markdown 記法に変換する Python スクリプトを作った
HTML の a タグを手で Markdown 記法にいちいち変換していたら負けている気がしてきたので作った.
#!/usr/bin/python3 # -*- coding: utf-8 -*- import fileinput import re import sys pattern = re.compile('<a href="([^"]+)">([^<]+)</a>') for line in fileinput.input(): sys.stdout.write(pattern.sub(r'[\2](\1)', line))
- 投稿日:2019-07-16T00:26:56+09:00
アニメの名言を返すbotを作って、LINEの会話がもっと伝わるようにしてみた件について
LINEの会話を盛り上げたい
日本人の多くが使っているLINE。お手軽にテキストチャットできて、便利ですよね!
でも、こんなチャットだとちょっと物足りなくなってきませんか?
mitsui君に試合終了感が伝わりませんね
そこで、LINEの会話を盛り上げるためのBOTとして、 animergen を開発しました。
animergenってどんなもの?
animergen(あにめーげん) = anime(アニメ) + mergen(名言)animergenとは、LINEの発言の中からアニメや漫画の名言を見つけて、名言画像を返してくれるBot なのです。
animergenを導入しただけで、さっきの会話もこの通り!!
mitsui君に試合終了感がよく伝わってますね!(ごり押し)
何ができる?
グループにanimergenを追加することで、グループ内のすべての発言に対して名言をチェックし、画像を返します。
animergen には2つの機能があります。どちらもLINEのインターフェースとなっており、エンジニアじゃなくても簡単に操作することが出来ます。
animergen
LINEのトークフィールドに送信された発話にマッチしたアニメ画像のURLを返します。animergenがURLをつぶやくと、LINEのプレビュー機能によって画像で表示されます。
mergen_register
animergenの名言を追加する機能。
登録したい名言を投げると、候補画像を表示してくれるので、選択するだけで名言が追加されます。どうやって作ったか?
使ったもの
- Python3
- LINE Messaging API
- kintone
- cotoha
全体構成はこんな感じ。
メインアルゴリズム
python3で書かれたメインアルゴリズムをherokuで動作させています。
グループにコメントが投稿されると、形態素解析や正規表現によって、DBに登録された名言を含んでいるかを検索します。
一致する名言があると、名言画像のURLを返します。データベース
名言のDBにはkintone を使わせていただきました。去年のOne JAPAN HACKATHON TOKAI に参加した時に使い方を教えてもらえたので、活用してみました。
どんな名言が登録されたかがGUIで見れるので、animergenのような不特定多数から登録されるデータの管理には向いてるかと思います。形態素解析
形態素解析には、cotoha を使わせていただきました。
最初はjanomeを使って形態素解析しようとしたのですが、herokuのフリープランのメモリ上限512MBを余裕で超えてデプロイできなかったので、既存のサービスを使わせていただきました。よかったら使ってみてください
以下のQRコードからanimergenの友達申請ができるので、使ってみてください。
現在は、僕のアニソンカラオケ友達が登録してくれた400件以上の名言が登録されています。「あきらめたらそこで試合終了だよ」とか「だが断る」とか言ってみると良いと思います。
締め
mergen_registerはもうちょっと改良出来たら公開するつもりです。
あとは、DB内に登録されている名言の可視化もやっていきたいと思っています。
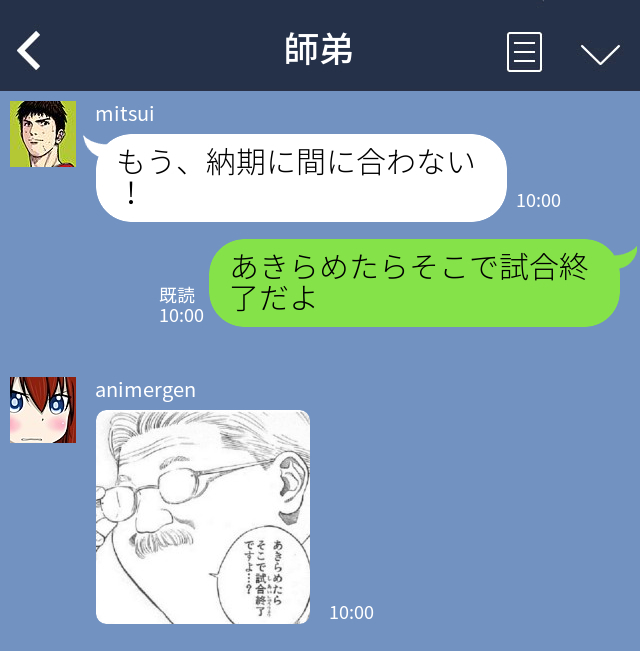
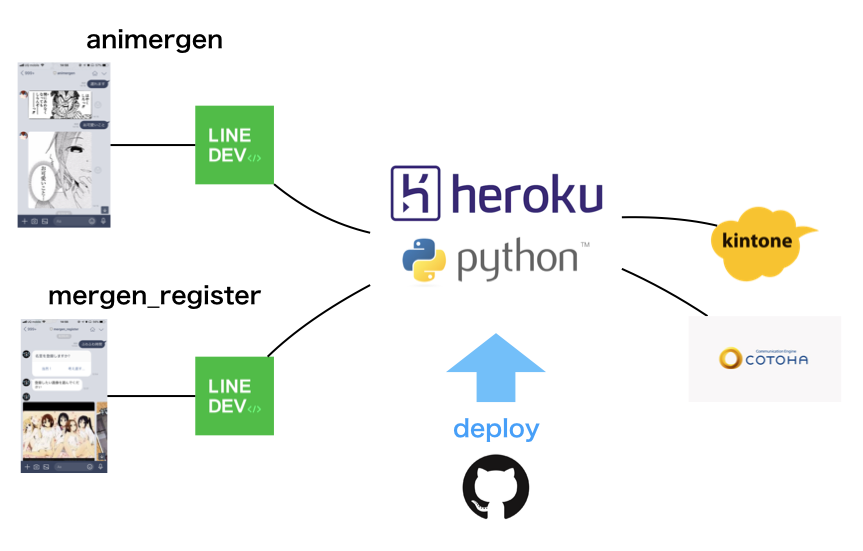

- 投稿日:2019-07-16T00:24:11+09:00
python の TimedRotatingFileHandler での日次ログ切り替え
初めに
ログを日次で切り替えるはず・・・だったが。。。。
python で定期的に実行するスクリプトのログを出力するのに
TimeRotatingFileHanderを利用し、日毎にログが切り替わるようにした・・・はずだった。しかし、スクリプトによって切り替わらない日があったり、あるいはまったく切り替わらずに同じログファイルに延々と描き続けるという現象に悩まされていた。
最近になってやっと原因が分かった。
Python のログの仕組みの概要については割愛する。
他を当たってください。このあたりとか。
まぁ、一般的なロギングの機構だと思う。ロギングハンドラとは
ロギングハンドラとはログの機構で受け取ったログに出力するべき情報を実際に各種デバイスに書き出すオブジェクトである。
標準に用意されているものだけでも「標準出力に出す」「ファイルに出す」の他に「破棄する(NULL デバイスに出力)」「Syslog に出す」「Windows イベントログに出す」「メールに送る」「(マルチプロセスを想定して)キューに書き込む」とかあるし「ファイルに出す」ものも logrotate等で監視されている場合に利用するものやサイズや特定の時間間隔でログファイルをローテートするものもある。
詳しくはこちら。
なお、ログの設定を設定ファイル等から設定をすることを想定した機構があり、それを利用することで設定ファイルでロギングハンドラを切り替えるようにしたりすることができる。
環境設定のための関数本題
TimedRotatingFileHandler
TimedRotatingFileHandlerは特定の時間間隔でのログローテーションをサポートしたロギングハンドラである。
TimedRotatingFileHandlerコンストラクタのwhen引数に'D'を指定するのは多分間違い「日毎にログを切り替えたい」という場合にこのロギングハンドラを利用するのは正しい。
しかしながら
- 1日中動かしているようなデーモンプロセス
- 1日より長い間隔で実行するスクリプト
でない場合、
TimedRotatingFileHandlerのコンストラクタのwhen引数に切り替えの間隔を日毎にする'D'を指定してはいけない。
TimedRotatingFileHandlerが(最初に)ログファイルを切り替えるタイミング
TimedRotatingFileHandlerは初期化時にログローテートを行う時刻を求め、その後ログを書き出すときにログローテートを行う時刻を過ぎているかのチェックを行い、過ぎているならログのローテートを行う。この最初のログローテートを行う時刻は
when引数で指定した値が'S','M','H','D'の場合は次の時刻のうちの早い方になる。
- スクリプトを起動した時刻の
when引数で指定した単位時間後- (すでにログファイルがある場合)ログファイルの最終更新日時から
when引数で指定した単位時間後
TimedRotatingFileHandlerコンストラクタのwhen引数に'D'を指定してしまった場合の動き開始・終了のログ出力が無い場合はここに書いたとおりになるとは限らないが、大体次のようになる。
- 実行間隔が(約)1日のスクリプトの場合
- ログの切り替わる日と切り替わらない日が出てくる。ログが切り替わるのは前日よりもスクリプトの実行に時間がかかった場合であり、その場合でも開始時ではなく途中でログが切り替わる。
- 実行間隔が 1日より短いスクリプトの場合
- ログが切り替わらず、ずっと同じファイルに書き続ける
ログを日毎に切り替える場合、
TimedRotatingFileHandlerコンストラクタのwhen引数には'MIDNIGHT'を指定しましょう日毎にログを切り替えたいというのは通常日付が変わるときに切り替えることを意図していると思われるのでその場合には
'MIDNIGHT'を指定します。先に挙げた
'D'を指定する可能性がある場合でもやはり通常は'MIDNIGHT'を指定するべき場合が多いでしょう。サンプルコード
コードを一切書かずに説明するという空中戦をしてしまったので、最後にサンプルコードを挙げておきます。
あくまで今回の内容に対する説明ですのであまり参考にはせず、他を参照してください。LoggingSample.py#!/usr/bin/env python # coding=utf-8 import logging import logging.config import os import yaml ENVKEY_LOGCONFIG = 'log_config' def prepare_logging(): env_file = os.path.splitext(__file__)[0] + '.yml' with open(env_file, 'r', encoding='utf-8') as f: env_data = yaml.load(f) logconfig_dict = env_data[ENVKEY_LOGCONFIG] logging.config.dictConfig(logconfig_dict) def logging_sample_main(): log = logging.getLogger(__name__) log.info('HogeHoge') def main(): prepare_logging() logging_sample_main() # log を flush する logging.shutdown() if __name__ == '__main__': main()LoggingSample.yml--- log_config: version: 1 formatters: file_log_format: format: '[{asctime}][{levelname}][{name}] {message:s}' datefmt: '%Y-%m-%d %H:%M:%S' style: '{' handlers: console: class : logging.StreamHandler level : DEBUG stream : ext://sys.stdout file: class : logging.handlers.TimedRotatingFileHandler formatter: file_log_format filename: LoggingSample.log # when: D is MAYBE wrong. when: MIDNIGHT backupCount: 31 encoding: utf-8 root: level: DEBUG handlers: - console - file disable_existing_loggers: False
- 投稿日:2019-07-16T00:11:29+09:00
CIFAR10で超解像
はじめに
MNISTで超解像の簡単なモデルを作成しましたが
KerasにはCIFAR10というカラー画像のデータセットが用意されていたので試してみましたデータセット
CIFAR10は、airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truckの10クラスのカラー画像からなるデータセットです
画像サイズは、32x32ピクセルでMNISTより若干大きめ(画像としては小さいですね)
画像の枚数は、50000枚(各クラス5000枚)の訓練データと10000枚(各クラス1000枚)のテストデータからなる総枚数60000枚のデータセットですMNISTの時と同じように50%,25%の縮小画像を作成して入力画像とします
(x_train, y_train), (x_test, y_test) = cifar10.load_data() input=[] input2=[] for i in range(50000): sample=x_train[i].copy() sample=cv2.resize(sample, dsize=(16,16)) sample=cv2.resize(sample, dsize=(32,32), interpolation=cv2.INTER_NEAREST) input.append(sample) sample2=x_train[i].copy() sample2=cv2.resize(sample2, dsize=(8,8)) sample2=cv2.resize(sample2, dsize=(32,32), interpolation=cv2.INTER_NEAREST) input2.append(sample2)入力画像の確認
画像サイズが小さいので、オリジナル画像でも視認が困難
縮小画像では判別不能です、これはうまくいくのか?不安です、、frog
cartruck (訂正です)
deer
モデル
モデルはMNISTとほぼ同じ、4層のCNNです
画像の入力サイズと最終層を3chに変えただけです
(これだけで済んでしまうのは本当にKeras様様です)from keras import models from keras import layers modelx2 = models.Sequential() modelx2.add(layers.Conv2D(16, (3, 3), activation='relu', padding='same', input_shape=(32,32,3))) modelx2.add(layers.Conv2D(32, (3, 3), activation='relu', padding='same')) modelx2.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same')) modelx2.add(layers.Conv2D(3, (3, 3), activation='relu', padding='same')) modelx2.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_41 (Conv2D) (None, 32, 32, 16) 448 _________________________________________________________________ conv2d_42 (Conv2D) (None, 32, 32, 32) 4640 _________________________________________________________________ conv2d_43 (Conv2D) (None, 32, 32, 64) 18496 _________________________________________________________________ conv2d_44 (Conv2D) (None, 32, 32, 3) 1731 ================================================================= Total params: 25,315 Trainable params: 25,315 Non-trainable params: 0 _________________________________________________________________学習演算
MNISTと全く同じです
損失関数は、2乗和誤差
最適化関数は、rmspropmodelx2.compile(optimizer='rmsprop', loss='mse', metrics=['accuracy']) modelx2.fit(input, x_train, epochs=5, batch_size=64)50%結果
写真画像の拡大でよく用いられるbilinearとの比較もしてみます
入力画像はnearest neighborで拡大しているので、モザイクのよなジャギー画像
bilinearは、かなりソフトな画像になっています
originalまでは復元してないものの、拡大画像としてはかなりいい感じですねfrog
car(訂正です)
deer
25%結果
この結果は結構驚きです
モザイク除去も夢ではない、、いやいや
刑事ドラマで監視画像が拡大されるシーンがありますが、現実味がありますねfrog
car(訂正です)
deer
まとめ
小さなカラー画像ですが、個人的には思った以上の結果でした
(学習画像でしか拡大してなかった、、、test画像で試さないと、、)
次回は、もう少し大きな画像を探して現実的なテストをしてみたいと思います
超解像も現状ではGANなども使用してより自然な画像になるような試みがされているようなので、その辺も併せて調べていきたいです。









- 投稿日:2019-07-16T00:08:13+09:00
3次元ドロネー分割とボロノイ分割を実装してみた。
3次元ドロネー分割とボロノイを実装してみた。
はじめに
以前に2次元ドロネーとボロノイの実装を行いましたが、今回はその発展版ということで3次元ドロネー分割とボロノイ分割の実装をおこないました。(以前の記事はこちら)
自前の実装になっておりますので、不備等あるかもしれませんが、参考になれば幸いです。描画環境にRhinocerosという3DCADソフトを使用していますが、入力と出力以外は依存しないように記述していますので、他の環境での応用可能であると思います。
まずはドロネー分割から
今回はまずドロネー分割を行った後にボロノイ分割を行うという工程ですすめていきます。
ファイルの構造ですが、以下のようになっております。
root/
├ Main.py
├ voronoi_module/
│ ├ Point.py
│ └ Tetrahedron.pyはじめにRhinoceros上で作成した点群を取得しPointクラスのインスタンスを作成します。
Main.py# coding: utf-8 import rhinoscriptsyntax as rs from voronoi_module import Tetrahedron from voronoi_module import Point points_obj_list = [] # Pointのオブジェクトを保持。 divide_tetrahedron_list = [] # このリストに三角形分割を保持していく。[p1, p2, p3] # Rhino上の点群を取得し座標値を取得。 points = rs.GetObjects('select points to use 3D Delaunay', rs.filter.point) for i in range(len(points)): point = Point.Point(points[i]) point.system_guid_obj_to_coordinate() points_obj_list.append(point)この部分は僕がRhinoを入力、出力環境として使用しているのでこのようになっていますが、p = [x, y, z]のように対応するリストを作成することで代替可能です。
因みにPointクラスは以下のような構成になっています。
Point.py# coding: utf-8 import rhinoscriptsyntax as rs class Point: def __init__(self, point): self.point = point self.x = None self.y = None self.z = None self.coordinate = None def system_guid_obj_to_coordinate(self): '''System.GuidObjectをRhino.Objectに変換。クラス変数に座標値を保持させる''' p = rs.coerce3dpoint(self.point) self.x = p[0] self.y = p[1] self.z = p[2] self.coordinate = [p[0], p[1], p[2]] def change_coordinate(self): '''外接円を構成する点を変換するメソッド''' p = self.point self.x = p[0] self.y = p[1] self.z = p[2] self.coordinate = [p[0], p[1], p[2]]def system_guid_obj_to_coordinate(self):はRhinoで取得したデータを変換するための関数ですので、Rhinoを使用しない場合必要ありません。
続いてドロネー分割のメインアルゴリズムです。
1. 作成した点群を内包するような四面体を作成
2. 作成した四面体の外接球を計算
3. 外接球内にある点群の内、任意の一点を追加する。
4. 追加した点を使用して外接球が属している四面体を四面体分割する。
5. 2~4を繰り返す。ことでドロネー三角分割を実現できます。(ざっくりな説明なのですが。。。
以下コードです。
Main.py# ドロネー分割の前準備。 # はじめの外接円を構成する点のインスタンス作成。この範囲内に点群を収めておく必要あり。 p1 = Point.Point([0, 0, 800]) p1.change_coordinate() p2 = Point.Point([0, 1000, -200]) p2.change_coordinate() p3 = Point.Point([866.025, -500, -200]) p3.change_coordinate() p4 = Point.Point([-866.025, -500, -200]) p4.change_coordinate() tetrahedron = Tetrahedron.Tetrahedron(p1, p2, p3, p4) tetrahedron.cul_center_p_and_radius() divide_tetrahedron_list.append(tetrahedron) # ドロネー分割のメインアルゴリズム # for _ in range(len(points_obj_list)): for _ in range(len(points_obj_list)): # 追加するポイントの選択。 select_point = points_obj_list.pop(0) # 三角形の外接円内に追加したポイントが内包されていないか判定。内包されている場合はindexを保存。 temp_divide_tetrahedron = [] count = 0 for i in range(len(divide_tetrahedron_list)): tri = divide_tetrahedron_list[i + count] check = tri.check_point_include_circumsphere(select_point) if check: # 内包していた三角形の頂点を使用して再分割する。 new_tetrahedron1 = Tetrahedron.Tetrahedron(tri.p1, tri.p2, tri.p3, select_point) new_tetrahedron2 = Tetrahedron.Tetrahedron(tri.p1, tri.p2, tri.p4, select_point) new_tetrahedron3 = Tetrahedron.Tetrahedron(tri.p1, tri.p3, tri.p4, select_point) new_tetrahedron4 = Tetrahedron.Tetrahedron(tri.p2, tri.p3, tri.p4, select_point) new_tetrahedron1.cul_center_p_and_radius() new_tetrahedron2.cul_center_p_and_radius() new_tetrahedron3.cul_center_p_and_radius() new_tetrahedron4.cul_center_p_and_radius() temp_divide_tetrahedron.append(new_tetrahedron1) temp_divide_tetrahedron.append(new_tetrahedron2) temp_divide_tetrahedron.append(new_tetrahedron3) temp_divide_tetrahedron.append(new_tetrahedron4) del divide_tetrahedron_list[i + count] count = count - 1 else: pass # 重複している三角形を削除 del_instances = [] for tetra in temp_divide_tetrahedron: for tetra_check in temp_divide_tetrahedron: if tetra == tetra_check: continue if tetra.radius == tetra_check.radius and tetra.center_p == tetra_check.center_p: del_instances.append(tetra_check) del_instances.append(tetra) for del_instance in del_instances: if del_instance in temp_divide_tetrahedron: del temp_divide_tetrahedron[temp_divide_tetrahedron.index(del_instance)] # 重複三角形を削除した後にappend divide_tetrahedron_list.extend(temp_divide_tetrahedron) # はじめに作成した四面体の母点をもつ四面体分割を削除 del_instances = [] for tetra_check in divide_tetrahedron_list: if tetra_check.p1 == p1 or tetra_check.p1 == p2 or tetra_check.p1 == p3 or \ tetra_check.p1 == p4 or tetra_check.p2 == p1 or tetra_check.p2 == p2 or \ tetra_check.p2 == p3 or tetra_check.p2 == p4 or tetra_check.p3 == p1 or \ tetra_check.p3 == p2 or tetra_check.p3 == p3 or tetra_check.p3 == p4 or \ tetra_check.p4 == p1 or tetra_check.p4 == p2 or tetra_check.p4 == p3 or \ tetra_check.p4 == p4: del_instances.append(tetra_check) for del_instance in del_instances: if del_instance in divide_tetrahedron_list: del divide_tetrahedron_list[divide_tetrahedron_list.index(del_instance)] # ドロネー描画 for i in range(len(divide_tetrahedron_list)): divide_tetrahedron_list[i].draw_divide_tetrahedron()今回は外接球を求める計算式を実装するのにつまずきました。。。
外接球に関しては別記事に後日まとめようと思います。。。ちなみにTetrahedronクラスは以下のようになっています。
Point.py# coding: utf-8 import math import scriptcontext import Rhino class Tetrahedron: def __init__(self, p1, p2, p3, p4): self.p1 = p1 self.p2 = p2 self.p3 = p3 self.p4 = p4 self.radius = None self.center_p = None def cul_center_p_and_radius(self): '''外接球の中心点と半径を計算''' a = [ [self.p1.x, self.p1.y, self.p1.z, 1], [self.p2.x, self.p2.y, self.p2.z, 1], [self.p3.x, self.p3.y, self.p3.z, 1], [self.p4.x, self.p4.y, self.p4.z, 1] ] d_x = [ [pow(self.p1.x, 2) + pow(self.p1.y, 2) + pow(self.p1.z, 2), self.p1.y, self.p1.z, 1], [pow(self.p2.x, 2) + pow(self.p2.y, 2) + pow(self.p2.z, 2), self.p2.y, self.p2.z, 1], [pow(self.p3.x, 2) + pow(self.p3.y, 2) + pow(self.p3.z, 2), self.p3.y, self.p3.z, 1], [pow(self.p4.x, 2) + pow(self.p4.y, 2) + pow(self.p4.z, 2), self.p4.y, self.p4.z, 1] ] d_y = [ [pow(self.p1.x, 2) + pow(self.p1.y, 2) + pow(self.p1.z, 2), self.p1.x, self.p1.z, 1], [pow(self.p2.x, 2) + pow(self.p2.y, 2) + pow(self.p2.z, 2), self.p2.x, self.p2.z, 1], [pow(self.p3.x, 2) + pow(self.p3.y, 2) + pow(self.p3.z, 2), self.p3.x, self.p3.z, 1], [pow(self.p4.x, 2) + pow(self.p4.y, 2) + pow(self.p4.z, 2), self.p4.x, self.p4.z, 1] ] d_z = [ [pow(self.p1.x, 2) + pow(self.p1.y, 2) + pow(self.p1.z, 2), self.p1.x, self.p1.y, 1], [pow(self.p2.x, 2) + pow(self.p2.y, 2) + pow(self.p2.z, 2), self.p2.x, self.p2.y, 1], [pow(self.p3.x, 2) + pow(self.p3.y, 2) + pow(self.p3.z, 2), self.p3.x, self.p3.y, 1], [pow(self.p4.x, 2) + pow(self.p4.y, 2) + pow(self.p4.z, 2), self.p4.x, self.p4.y, 1] ] a = dit_4(a) d_x = dit_4(d_x) d_y = -(dit_4(d_y)) d_z = dit_4(d_z) center_p_x = d_x / (2 * a) center_p_y = d_y / (2 * a) center_p_z = d_z / (2 * a) self.center_p = [float(center_p_x), float(center_p_y), float(center_p_z)] distance = math.sqrt( pow((self.p1.x - self.center_p[0]), 2) + pow((self.p1.y - self.center_p[1]), 2) + pow((self.p1.z - self.center_p[2]), 2)) self.radius = float(distance) def draw_divide_tetrahedron(self): '''分割四面体をRhinoに描画するためのメソッド''' line1 = Rhino.Geometry.Line(self.p1.x, self.p1.y, self.p1.z, self.p2.x, self.p2.y, self.p2.z) line2 = Rhino.Geometry.Line(self.p1.x, self.p1.y, self.p1.z, self.p3.x, self.p3.y, self.p3.z) line3 = Rhino.Geometry.Line(self.p1.x, self.p1.y, self.p1.z, self.p4.x, self.p4.y, self.p4.z) line4 = Rhino.Geometry.Line(self.p2.x, self.p2.y, self.p2.z, self.p3.x, self.p3.y, self.p3.z) line5 = Rhino.Geometry.Line(self.p2.x, self.p2.y, self.p2.z, self.p4.x, self.p4.y, self.p4.z) line6 = Rhino.Geometry.Line(self.p3.x, self.p3.y, self.p3.z, self.p4.x, self.p4.y, self.p4.z) scriptcontext.doc.Objects.AddLine(line1) scriptcontext.doc.Objects.AddLine(line2) scriptcontext.doc.Objects.AddLine(line3) scriptcontext.doc.Objects.AddLine(line4) scriptcontext.doc.Objects.AddLine(line5) scriptcontext.doc.Objects.AddLine(line6) def check_point_include_circumsphere(self, check_p): '''外接球に任意の点が内包されているかどうか判定''' distance = math.sqrt(pow((check_p.x - self.center_p[0]), 2) + pow( (check_p.y - self.center_p[1]), 2) + pow((check_p.z - self.center_p[2]), 2)) if distance < self.radius: return True else: return False def dit_2(dit): '''二次元行列の計算''' cul = (dit[0][0] * dit[1][1]) - (dit[0][1] * dit[1][0]) return cul def dit_3(dit): '''三次行列の計算''' a = [ [dit[1][1], dit[1][2]], [dit[2][1], dit[2][2]] ] b = [ [dit[0][1], dit[0][2]], [dit[2][1], dit[2][2]] ] c = [ [dit[0][1], dit[0][2]], [dit[1][1], dit[1][2]] ] cul = (dit[0][0] * dit_2(a)) - (dit[1][0] * dit_2(b)) + (dit[2][0] * dit_2(c)) return cul def dit_4(dit): '''4次元の行列''' a = [ [dit[1][1], dit[1][2], dit[1][3]], [dit[2][1], dit[2][2], dit[2][3]], [dit[3][1], dit[3][2], dit[3][3]] ] b = [ [dit[0][1], dit[0][2], dit[0][3]], [dit[2][1], dit[2][2], dit[2][3]], [dit[3][1], dit[3][2], dit[3][3]] ] c = [ [dit[0][1], dit[0][2], dit[0][3]], [dit[1][1], dit[1][2], dit[1][3]], [dit[3][1], dit[3][2], dit[3][3]] ] d = [ [dit[0][1], dit[0][2], dit[0][3]], [dit[1][1], dit[1][2], dit[1][3]], [dit[2][1], dit[2][2], dit[2][3]] ] cul = (dit[0][0] * dit_3(a)) - (dit[1][0] * dit_3(b)) + (dit[2][0] * dit_3(c)) - (dit[3][0] * dit_3(d)) return culこれみてなぜnumpy使って行列計算しないんだ!とツッコミキそうですがその通りです。。
今回は実行環境の問題でnumpyを使用することができなかったため行列計算が自前になってしまっています。。。。最後にボロノイ分割
ボロノイ分割は外形を作成しトリミングなりしないと拡散してしまいます。
今回はトリミングのコードは実装していません。。。
以下のコードを追加することでボロノイ分割を実現できます。
Point.py# ボロノイ分割。 for i in range(len(divide_tetrahedron_list)): tri_1 = divide_tetrahedron_list[i] for j in range(len(divide_tetrahedron_list)): if i == j: continue tri_2 = divide_tetrahedron_list[j] count = 0 if tri_1.p1 == tri_2.p1 or tri_1.p1 == tri_2.p2 or tri_1.p1 == tri_2.p3 or tri_1.p1 == tri_2.p4: count += 1 if tri_1.p2 == tri_2.p1 or tri_1.p2 == tri_2.p2 or tri_1.p2 == tri_2.p3 or tri_1.p2 == tri_2.p4: count += 1 if tri_1.p3 == tri_2.p1 or tri_1.p3 == tri_2.p2 or tri_1.p3 == tri_2.p3 or tri_1.p3 == tri_2.p4: count += 1 if tri_1.p4 == tri_2.p1 or tri_1.p4 == tri_2.p2 or tri_1.p4 == tri_2.p3 or tri_1.p4 == tri_2.p4: count += 1 if count == 3: line = Rhino.Geometry.Line(tri_1.center_p[0], tri_1.center_p[1], tri_1.center_p[2], tri_2.center_p[0], tri_2.center_p[1], tri_2.center_p[2]) scriptcontext.doc.Objects.AddLine(line)まとめ
最後まで目を通していただきありがとうございました。自前での実装を通して計算機科学の分野は奥が深い。。と痛感しました。
自前でアルゴリズムを実装することと既存ライブラリを使用することのバランスは大切だなとも思った次第です。笑