Symbol: DRM_LOAD_EDID_FIRMWARE [=y]
Type : boolean
Prompt: Allow to specify an EDID data set instead of probing for it
Location:
-> Device Drivers
-> Graphics support
-> Allow to specify an EDID data set instead of probing for it
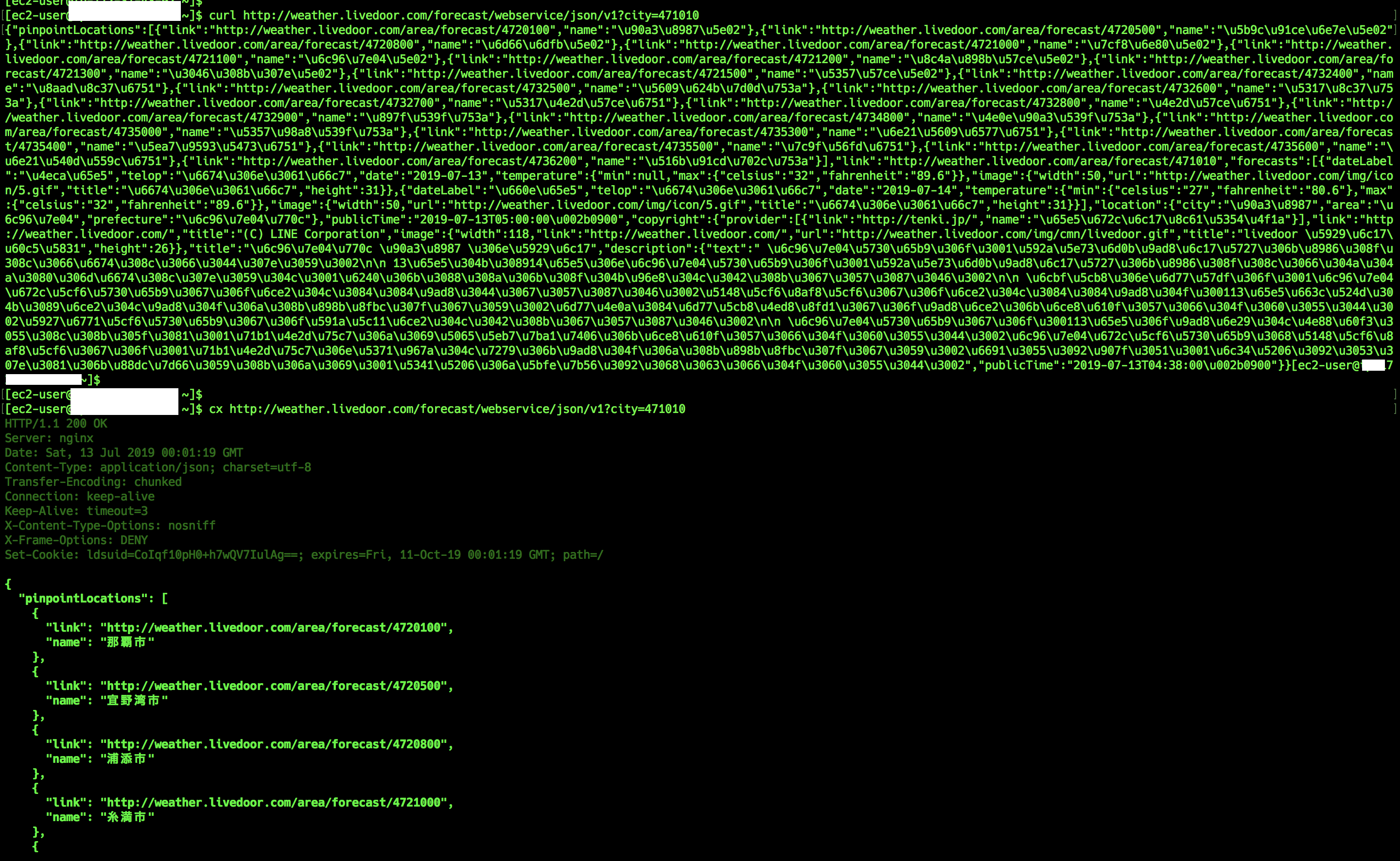
# 通常リクエスト$ cx http://weather.livedoor.com/forecast/webservice/json/v1?city=471010
# オプション指定でのリクエスト$ cx -X GET http://weather.livedoor.com/forecast/webservice/json/v1?city=471010
コレクションの作成〜実行
下記のコマンドをうち、cxコマンドをグループ化することで、任意の名前とidでリクエストが可能。
# コレクション(グループ)を作成$ cx new collection
✔ Name of your new collection … コレクション名(例:getWeather)入力
This collection already exists
✔ Would you like to add a new request to getWeather … リクエスト追加確認(例:yes)
✔ Enter complete request eg: cx -X GET https://httpbin.org/get … 実行コマンド入力(例:cx -X GET URL)
✔ Give a name for your request … リクエスト名(例:getOkinawa)# コレクション一覧確認$ cx collections
┌────────────┬────────────────────┬────────┬──────────────────────────────┐
│ id │ name │ method │ url │
├────────────┼────────────────────┼────────┼──────────────────────────────┤
│ y2Q9JCOjL │ getOkinawa │ get │ http://weather.livedoor.com… │
└────────────┴────────────────────┴────────┴──────────────────────────────┘
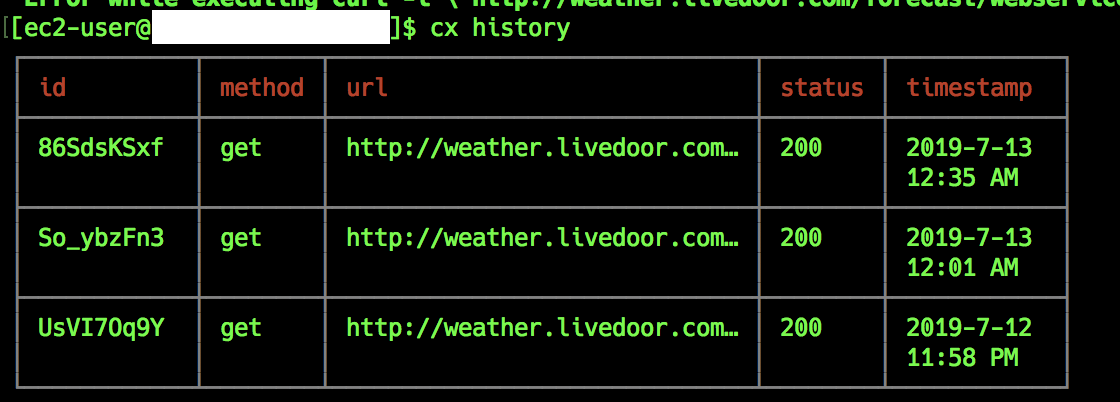
# id名でのリクエスト実行# まず、history(履歴)内のid名での実行$ cx history
┌────────────┬────────┬──────────────────────────────┬────────┬────────────┐
│ id │ method │ url │ status │ timestamp │
├────────────┼────────┼──────────────────────────────┼────────┼────────────┤
│ H0yIigcQv │ get │ http://weather.livedoor.com… │ 200 │ 2019-7-13 │
│ │ │ │ │ 12:51 PM │
├────────────┼────────┼──────────────────────────────┼────────┼────────────┤
$ cx run H0yIigcQv
{"pinpointLocations": [{"link": "http://weather.livedoor.com/area/forecast/4720100",
"name": "那覇市"},
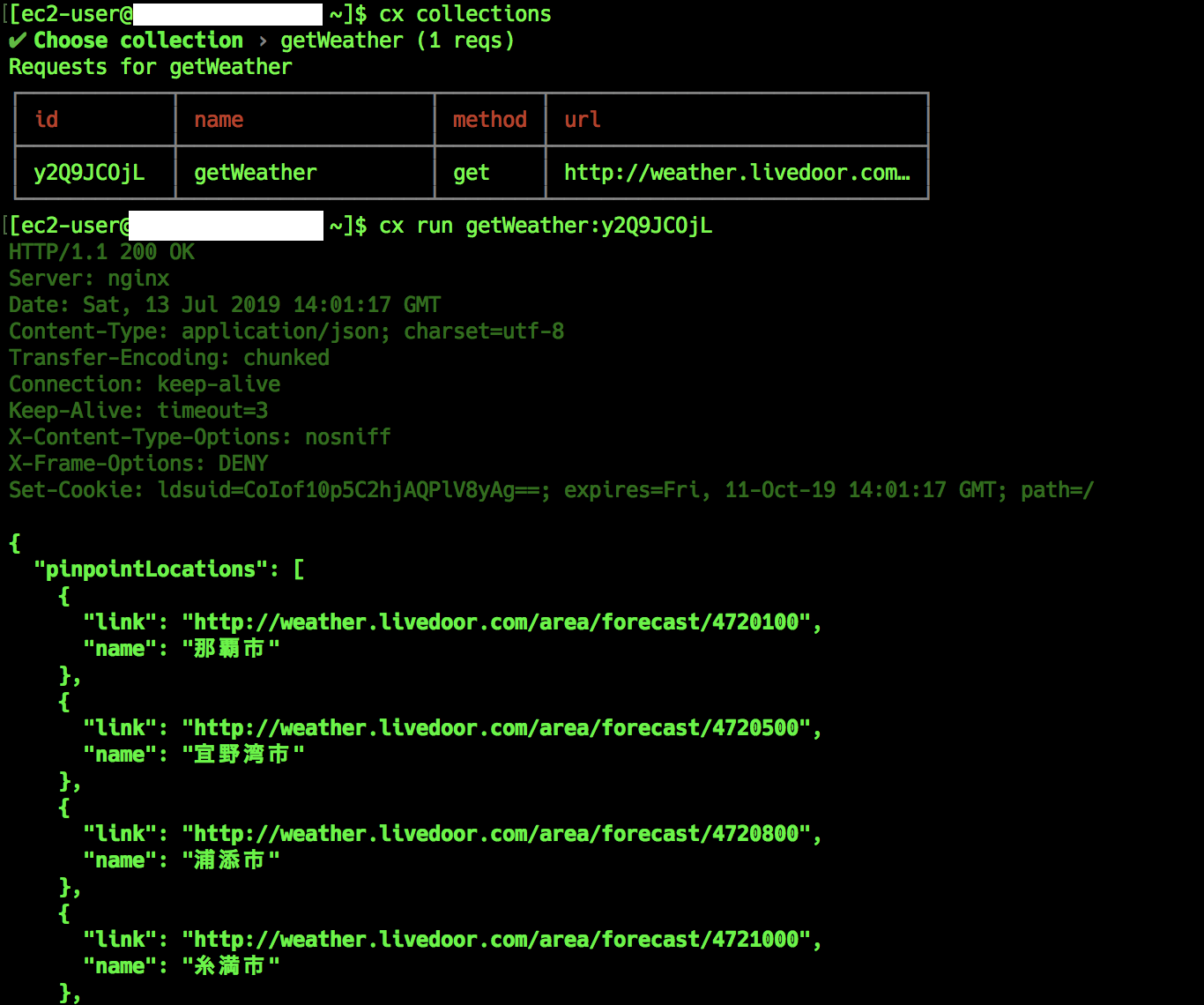
{# コレクション内のリクエストidでの実行# ※コレクション内のidは、コレクション名も同時に明記する必要がある。$ cx run getWeather y2Q9JCOjL
{"pinpointLocations": [{"link": "http://weather.livedoor.com/area/forecast/4720100",
"name": "那覇市"},
コレクションへのリクエスト追加
下記のコマンドをうち、既存コレクションに新規リクエストを追加
# コレクション確認$ cx collections
┌────────────┬────────────────────┬────────┬──────────────────────────────┐
│ id │ name │ method │ url │
├────────────┼────────────────────┼────────┼──────────────────────────────┤
│ y2Q9JCOjL │ getOkinawa │ get │ http://weather.livedoor.com… │
└────────────┴────────────────────┴────────┴──────────────────────────────┘
# リクエストの新規追加$ cx new request
✔ Name of your new collection … コレクション名(getWeather)入力
✔ Enter complete request eg: cx -X GET https://httpbin.org/get … 実行コマンド(例:cx URL)
✔ Give a name for your request … リクエスト名(getOsaka)# コレクション一覧再確認$ cx collections
┌────────────┬────────────────────┬────────┬──────────────────────────────┐
│ id │ name │ method │ url │
├────────────┼────────────────────┼────────┼──────────────────────────────┤
│ y2Q9JCOjL │ getOkinawa │ get │ http://weather.livedoor.com… │
├────────────┼────────────────────┼────────┼──────────────────────────────┤
│ nG3nzD53k │ getOsaka │ get │ http://weather.livedoor.com… │
└────────────┴────────────────────┴────────┴──────────────────────────────┘