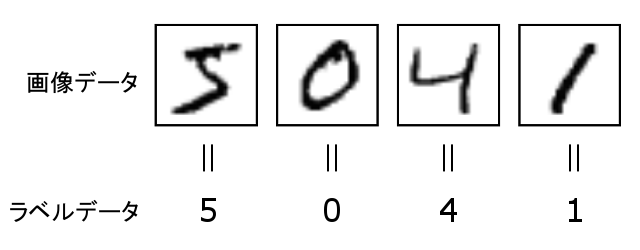- 投稿日:2019-07-16T23:52:30+09:00
Android開発環境でコマンドラインからのビルドが失敗する場合の対処
前提
- Windows 10
- Android Studio 3.4.2
事象と原因
Android Studioで作成されたプロジェクトは、ディレクトリトップにて以下コマンドを実行することでフルビルドできる
gradlew.bat assembleしかし、環境によっては以下のようなエラーが表示されることがある
FAILURE: Build failed with an exception. * What went wrong: Execution failed for task ':app:compileDebugKotlin'. > Kotlin could not find the required JDK tools in the Java installation 'C:\Program Files\Java\jre1.8.0_181' used by Gra dle. Make sure Gradle is running on a JDK, not JRE. ...(中略)... BUILD FAILED in 3s 13 actionable tasks: 13 executedこの原因はエラーメッセージにあるように、ビルドに必要なJDKにパスが通っておらず、JREにパスが通っているためである
- JDK = Java Development Kit:Javaでアプリケーションを開発するためのライブラリ
- JRE = Java Runtime Environment:Javaアプリケーションを動かすためのライブラリ
解決策
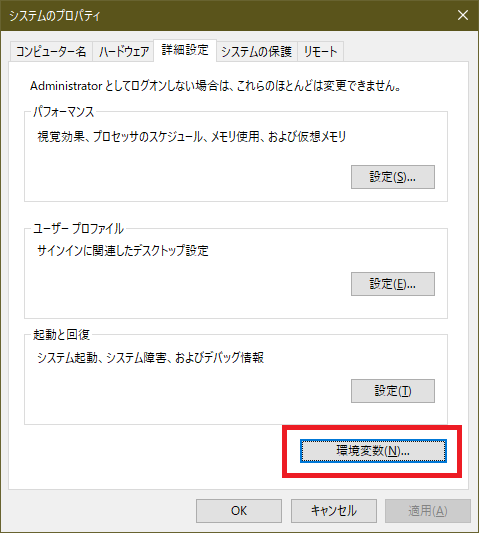
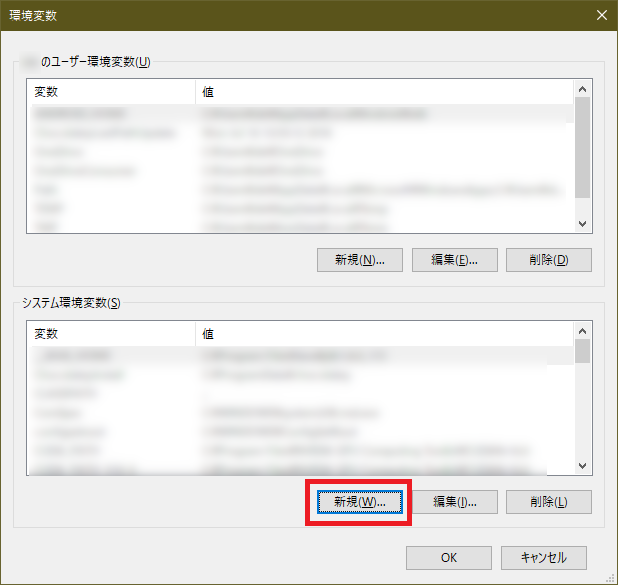
スタートメニューから「path」と検索して「システム環境変数の編集」を起動し、「環境変数」をクリックする
画面下側の「システム環境変数」の「新規」をクリックする
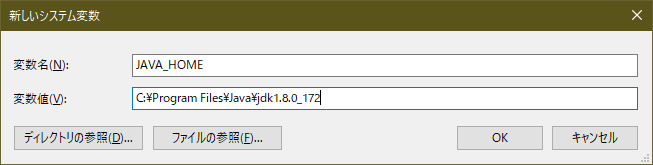
変数名
JAVA_HOMEでインストールされているJDKのパスを変数値に設定し、OKをクリックする
コマンドラインを再起動して再度同じコマンドを叩き、ビルドできることを確認する
- 投稿日:2019-07-16T22:21:46+09:00
Android入門
アプリ開発のメリット
-Java、Kotlinの勉強になる
-自分好みのアプリを作れる
-プロへの道が開けるリリースについて
GooglePlayConsoleからリリースする
諸注意、作業方法
パッケージ名がcom.exampleだと通らない
manifestからリファクタリング、リネームするbuild.gradle(app)のバージョンも変えていく
1ずつ増やすなどアイコンのサイズ(解像度)はペイントで変える
インストール後のアプリ名は、manifestの以下の
AndroidManifest.xmlandroid:label="@string/app_name"Sourcetreeについて
・クローンのやり方
保存先のパスは空フォルダにして、名前は空フォルダと同じにするソースコードについて
inflaterはリソース(xml)を読み込んでビューにする
AndroidStudioショートカット
ctrl + shift + enter
コロン自動補完AndroidStudio
Andoid Studioをバージョンアップしたら端末が認識しなくなった
USBデバッグの許可の取り消しを行うと復活したライブラリについて
ライブラリの使用時はバージョンに注意
バージョンがあっていないとコンパイルエラー、Gradleのエラーになる場合がある
SDKのバージョンが合っていないといけない例)
implementation 'com.squareup.okhttp3:okhttp:3.10.0'
implementation 'com.android.support:design:28.0.0'
これはセットで使うJavaについて
public指定したクラス名とファイル名は同一にする
ArrayListはサイズ関係ない?
キャストでdoubleをintに代入すると、小数点以下が切り捨てられる
this.s
インスタンス変数s
引数がない場合は、sでOK継承
サブクラスが生成される際、子クラスのコンストラクタが実行される前に、親クラスのコンストラクタが実行されることがわかりますtoStringメソッド、getClass()メソッド、暗黙の親クラスであるObjectクラスのメソッド
抽象クラスは変数(配列OK)で保持して、サブクラスのインスタンスを生成して代入すると便利
抽象メソッドは呼び出しの抽象化のためか?
インスタンスをインターフェースでキャストして代入することで、インターフェースに記述してある機能しか使えなくする
インターフェースでもstaticならばそのまま使える
throwsはメソッドとセットで使い、例外発生時はメソッドの呼び出しもとに戻り、catchする
独自例外処理クラスを作って、throw(例外発生の目印)を使ってcatchする
equalsは同一の参照か比較してbooleanを返す
protected
サブクラスのインスタンスからアクセスできる(スーパークラスのインスタンスからはアクセスできない)無名クラスがメインルーチンの中に定義されているから、上から順番の処理にならない
メソッドの戻り値をまず見ることで、何をする処理かわかる
アダプタは最後にビューを返す(getView)インターフェースはimplementsして、そのクラスの中に実装する書き方と、
インターフェースをnewして(いるように見えるが実際は無名クラス)、無名クラスで実装する書き方がある。
- 投稿日:2019-07-16T14:46:14+09:00
Javaのラムダ式について
長い記事を書こうとしていつまでも書けなかったので、
自分のための記事を書こうと思いました。
既に書き尽くされた感もありますが、初心者向きのメモになります。ラムダ式とは
ラムダ式 = Java という間違った認識も生みがちですが(個人的偏見)
背景をざっと流してみます。
- CPUマルチコア化に伴う、スレッドを有効活用する需要
- Java SE 7 でのFork/Join Framework(分割統治法)を簡単に利用
- 関数を独立して扱うことが出来る
- 匿名クラスを簡単に扱える
Javaでの位置づけ
- 関数型インターフェースを簡単に記述できる
- 関数型インターフェースとは、1つの抽象メソッドを含むインターフェースのこと
- Java8では、バックグラウンドでソースコードの自動変換を行い実現
- 型推論により型の記述も省略すれば、非常にシンプルなコードが書ける
- Stream を活用するために必要
ただの列記になってしまうので、実際に比較してみます。
書いてみる
メソッド
public class ThisIsSample { int res; private void calculate(int value1, int value2) { res = value1 + value2; } }無名クラス
ThisIsSample printRunOut = new ThisIsSample() { public void prt() { System.out.println("sample"); } }; printRunOut.prt();ラムダ式
ThisIsSample printRunOut = () -> { System.out.println("sample"); }; printRunOut.prt();やはりこれだけではよく分かりません。
型推論で省略を復元してくれている、までは分かるのですが、理解したとは言えません。やはり実践しないといけないようですが、今コンパイルが出来ません。(?)
ということで、追って記載したいと思います。参考情報
Java関数型インターフェース※ラムダ式のまとめもあり
Java8ラムダ式の使い方の基本
[Java] Java8のラムダに超入門(書き方、関数型インターフェース、独自に定義、ラムダ受け取り処理)追記
Markdown記法 チートシート -Qiita
Markdownで文書を書くためにやったこと一覧 -Qiita
Qiita マークダウン記法 一覧表・チートシート -Qiita時間がないので、ひとまず挙げときます・・・。
後日修正します。(Streamのこともまだよく分かっていない)2019.7.16追記
自分は今までサーバー系とは縁がなく、小さな事務所でExcel/Access/VBAを弄ってきました。なぜ今Javaかと言いますと、Javaで構成されたRPAに触れたことで、Web以外で初めてサーバーサイドのシステムに親近感を持てたことが切っ掛けです。
いい加減な記事になってしまいましたが、生暖かく見て頂ますようお願い致します。
- 投稿日:2019-07-16T11:18:56+09:00
コマンドラインだけでMavenリポジトリから直接Jarパッケージをダウンロードして実行する方法
概要
- コマンドラインのみでMavenリポジトリから直接Jarパッケージをダウンロードします
- ダウンロードしたJarパッケージをコマンドライン上で実行します
何が嬉しいか
- ツール系のJarなどを使いたいとき、POM.xmlなど作成不要で、コマンドラインだけで完結できる
環境
やりかた
例:groupIdがorg.riversun、artifactIdがrandom-forest-codegen、versionが1.0.0のパッケージをダウンロードしてきて実行したいとき
1.現在のディレクトリにjarファイルをダウンロードする
mvn dependency:get -Dartifact=org.riversun:random-forest-codegen:1.0.0 -Ddest=./(-Ddestを省略すると、ローカルのMavenリポジトリ.m2にダウンロードされる。)
2.jarを実行する
java -cp random-forest-codegen-1.0.0.jar org.riversun.rfcode.RandomForestCodeGen(org.riversun.rfcode.RandomForestCodeGenは実行したいメインクラス。省略するとデフォルト指定のメインクラスが実行される)
まとめ
Jar単体でも動作するツール系をMavenリポジトリから直接ダウンロードし、すぐ実行できて便利です
- 投稿日:2019-07-16T11:14:12+09:00
Java tips GreenMail をJunit5に導入する
GreenMail をJunit5に導入する
単体テスト用のメール通信ライブラリ「GreenMail」を導入しようと思って調べてみると、
Junit4の@Ruleを使用したサンプルが多くて、JUnit5でどうすればいいのか少し悩んだので
備忘録としてまとめます。サンプルソース
Junit5でGreenMailを使用して問題なくSMTP通信できた方法は以下のような書き方です。
class SampleTest { // SMTP通信クラス(仮想サーバみたいなもの) private GreenMail smtp = new GreenMail(new ServerSetup(3025,"localhost",ServerSetup.PROTOCOL_SMTP)); @BeforeEach void before() { // 仮想サーバ開始 smtp.start(); } @AfterEach void after() { // 仮想サーバ終了 smtp.stop(); } }自分でローカルにメールサーバを立ち上げて、開始と終了をソースで明示的に書くようなイメージでしょうか。
まとめ
JUnit5でも問題なくGreenMailを使えます。
- 投稿日:2019-07-16T08:24:33+09:00
Javaパフォーマンス 2章 パフォーマンステストのアプローチ
O'Reilly Japan - Javaパフォーマンス
こちらの本の2章まとめ1章 イントロダクション - Qiita ←前回記事
実アプリケーションでテストする
3種類のテストがある
マイクロベンチマーク
名前の通り、小さい単位でテストするもの。
ちょっとした実装の差異を比較するときに使う。
テストコードを書くときは注意が必要で、処理結果を使うようなコードにしないと、コンパイラの最適化により計算処理が削除されてしまう。マイクロベンチマークが、マルチスレッドかシングルスレッドかに関わらず、
volatile(最適化しない。キャッシュしたくないときにも使われる。)をつけることは重要。
マイクロベンチマークは実運用ではほとんど問題にならない同期がボトルネックになることが多く、その解消に時間を取られるため。↓volatileについての参考資料
Declaring a Variable Volatile (Writing Device Drivers)ベンチマークで、複数スレッドから
synchronizedメソッドを呼び出すような場合、同期がボトルネックになってしまうため、ベンチマークというよりは、JVMが競合を解消する時間の計測になってしまうことも注意が必要。入力値をあらかじめ用意して、それを渡すといった工夫により、ベンチマークのコードに余分な処理をつけないようにする。
正しい入力値に基づいてテストを行うべき。たとえば、実運用ではありえない極端に大きな数字での計測などはしない。
4章で説明されるが、Javaはコードを繰り返し実行されると速くなっていくので、ウォームアップは行うべき。
マクロベンチマーク
アプリケーションのパフォーマンスをテストするためには、使用される外部リソースを組み合わせてテストするのが一番。
このようなテストをマクロベンチマークという。メゾベンチマーク
実際の処理だが、完全なアプリケーションが使われるわけではないが、マイクロベンチマークよりは粒度の大きいテスト。
例えば、Webサーバーが応答する速度の測定するもの(セッションやログインの機能を試していない)。
メゾベンチマークは自動化テストにも適している。スループット、バッチ、レスポンスタイムを理解する スループット、バッチ、レスポンスタイムを理解する
バッチ(一括)処理の測定
アプリケーションの開始から終了までを測定するもの。
全体として問題にならない場合は有効。
逆にウォームアップされる前が遅い場合に問題になる場合は別の測定方法が必要。
Javaの場合はウォームアップが必要なので、やや簡単にはできない。スループットの計測
一定時間内にどれだけ処理が行えるかの計測。
クライアント-サーバー型の場合は、シンクタイム(think time。何も処理を行わずに待つ時間)無しで計測する必要がある。
1秒間当たりのリクエストの数がよく使われる。TPS(transactions per second)、RPS(requests per second)、OPS(operations per second)など。レスポンスタイムのテスト
レスポンスタイムの算出方法は2つ。
1つは平均値。2つ目はパーセンタイル値。
パーセンタイル値は、例えば90パーセンタイル値1.5秒の場合は、90%のリクエストのレスポンスタイムは1.5秒以下で、残りの10%が1.5 秒以上となる。本書では、↓のロードジェネレータが紹介されていた
About Faban不安定性を理解する
テストが時とともに変化する。
優れたベンチマークは実世界に近い実行の度に異なるランダム性を持ったデータを使う。
テスト結果を比較する時、コードに問題があるのか、それとも偶然なのかを判断するのが困難。
ベースライン 標本 1回目 1.0秒 0.5秒 2回目 0.8秒 1.25秒 3回目 1.2秒 0.5秒 平均値 1.0秒 0.75秒 というテスト結果の場合、スチューデントのt検定により、43%の確率でパフォーマンスは同じとなる。
しかし、データには不確実性があるため、いくら分析を行ったとしても断定的な判断はできない。
早期から頻繁にテストを行う
頻繁にテストを行うのは重要だが、現状とのバランスを見てやる必要がある。
以下に適合するのであれば、早期の頻繁なテストが極めて有益。解決のヒントが得られやすいため。
- すべてを自動化する
- すべてを測定する
- ターゲットのシステム上で実行する
- 投稿日:2019-07-16T05:59:15+09:00
【Programming News】Qiitaまとめ記事 July 15, 2019 Vol.1
筆者が昨日2019/7/15(月)に気になったQiitaの記事をまとめました。
Programming News
2019年
7月15(月)
Java
- Spring Boot
Kotlin
Python
- Beginner
- Tips
Ruby
- Beginner
- Apps
Rails
- Beginner
- OAuth
- Tips
C#
Android
Swift
- Summary
- Apps
- Tips
Flutter
- Tips
Vue.js
- Beginner
- Apps
Vuex
React
- Beginner
- Tips
JavaScript
- Beginner
Node.js
- Tips
Laravel
- Beginner
- Tips
jQuery
- Tips
Go言語
- Beginner
Unity
- Beginner
Bot
HTML
MySQL
- Beginner
AI
Git
- Beginner
- Tips
Azure
インフラ
- 仮想環境
- ubuntu
- ubuntu環境構築 #### Network
- Tips
RPA
Docker
- Beginner
Linux
Google Apps Script
- Beginner
- Tips
- Apps
Server Side
Develop
PowerShell
Vim
- Beginner
UML
- PlantUML
Raspberry
Security
- SSL
資格
- AWS
- 基本情報
- ネットワーク
更新情報
Kotlin
- Kotlin入門
Java
- Java 10
IDE
- 投稿日:2019-07-16T00:35:11+09:00
【DL4J】はじめてのJavaディープラーニング(全結合ニューラルネットワークを用いた手書き文字認識編)
こんにちは。
海の日だというのに東京は未だ涼しい日が続いています。本日2019年7月15日の東京の最高気温は25℃、最低気温は19℃でした。
気象庁の記録によると1981年から2010年の東京の平均最高・最低気温は以下の通り。
平均最高気温 平均最低気温 29.0℃ 21.7℃ 個人的には今の気候は過ごしやすくて好きですが、いつまで続くでしょうかね。
Deeplearning4j / DL4J
さて、話は変わって本稿ではSkymindが開発しているDeeplearning4j、略してDL4Jの紹介をします。
その名の通りDL4JはJavaやScala、KotlinなどのJVM言語で動作するディープラーニング開発フレームワークです。
ディープラーニングのフレームワークとしては他にGoogleのTensorFlowやそれに統合されたKeras、FaceBookのPyTorch、Preferred NetworksのChainerなどが有名ですね。
これらのフレームワークは基本的にPythonで開発されることを想定とし、少ないコード数で手軽に研究開発を行うことができます。DL4Jはどちらかというと、企業のシステム等で広く用いられているJVM言語で記述できることから、エンタープライズ向けのフレームワークとして差別化されています。HadoopやSparkなどのビッグデータ分析基盤とネイティブに連携できることも売りのひとつです。
では、DL4Jを用いたニューラルネットワークの構築のサンプルを見てみましょう。
DL4Jのサンプルコード
DL4Jのサンプルコードは公式のレポジトリに豊富に公開されています。
https://github.com/deeplearning4j/dl4j-examplesちょっと試すにはスケールが大きすぎるので、今回は一部のコードのみフォークしてきた以下のリポジトリをクローンしてください。
$ git clone https://github.com/kmotohas/oreilly-book-dl4j-examples-jaこちらは、DL4J自体の作者であるAdam Gibsonらが執筆した"Deep Learning − A Practitioner's Approach"の日本語版である「詳説Deep Learning − 実務者のためのアプローチ」に関連するサンプルコードの公開レポジトリです。
シンプルな例として、定番のMNISTという手書き数字データセットを多層パーセプトロン(MLP、ゆるい定義では全結合ニューラルネットワークとも)で認識するMLPMnistTwoLayerExample.javaの中身を見ていきましょう。
なお、サンプルはIntellij IDEAなどの統合開発環境を用いて動かすことを推奨しますが、Mavenなどのビルドツールを用いてコマンドラインで動かすことも可能です。
MLPMnistTwoLayerExample.javaの概観
次のコードは、冒頭の
import文を省略したコードの全体です。public class MLPMnistTwoLayerExample { private static Logger log = LoggerFactory.getLogger(MLPMnistSingleLayerExample.class); public static void main(String[] args) throws Exception { //number of rows and columns in the input pictures final int numRows = 28; final int numColumns = 28; int outputNum = 10; // number of output classes int batchSize = 64; // batch size for each epoch int rngSeed = 123; // random number seed for reproducibility int numEpochs = 15; // number of epochs to perform double rate = 0.0015; // learning rate //Get the DataSetIterators: DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize, true, rngSeed); DataSetIterator mnistTest = new MnistDataSetIterator(batchSize, false, rngSeed); log.info("Build model...."); MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(rngSeed) //include a random seed for reproducibility .activation(Activation.RELU) .weightInit(WeightInit.XAVIER) .updater(new Nesterovs(rate, 0.98)) //specify the rate of change of the learning rate. .l2(rate * 0.005) // regularize learning model .list() .layer(0, new DenseLayer.Builder() //create the first input layer. .nIn(numRows * numColumns) .nOut(500) .build()) .layer(1, new DenseLayer.Builder() //create the second input layer .nIn(500) .nOut(100) .build()) .layer(2, new OutputLayer.Builder(LossFunction.NEGATIVELOGLIKELIHOOD) //create hidden layer .activation(Activation.SOFTMAX) .nIn(100) .nOut(outputNum) .build()) .build(); MultiLayerNetwork model = new MultiLayerNetwork(conf); model.init(); model.setListeners(new ScoreIterationListener(5)); //print the score with every iteration log.info("Train model...."); for( int i=0; i<numEpochs; i++ ){ log.info("Epoch " + i); model.fit(mnistTrain); } log.info("Evaluate model...."); Evaluation eval = new Evaluation(outputNum); //create an evaluation object with 10 possible classes while(mnistTest.hasNext()){ DataSet next = mnistTest.next(); INDArray output = model.output(next.getFeatures()); //get the networks prediction eval.eval(next.getLabels(), output); //check the prediction against the true class } log.info(eval.stats()); log.info("****************Example finished********************"); } }このクラスの
mainメソッドは大きく分けて、次の4つの部分から成り立っています。
DataSetIteratorの準備MultiLayerConfigurationの設定MultiLayerNetworkの構築- 構築したニューラルネットワークモデルの訓練
- 訓練したモデルの性能評価
それぞれの部分について順番に解説します。
1.
DataSetIteratorの準備ディープラーニングでモデルの訓練を行うというのは、データセットをモデルに入力し、期待される出力と実際の出力の差を誤差として、それを最小化するようにパラメーターを更新する作業のことです。
DL4Jではデータを反復的にモデルに食わせるためのイテレーターとして
DataSetIteratorというクラスを用意しています。(実際はJVM版Numpyとも呼べるND4Jライブラリーに実装があります。java.util.Iteratorおよびjava.io.Serializableを継承しています。)手書き文字数字のMNISTデータセットには、70,000枚の手書き数字画像と正解ラベル(画像に描いてある数字。0,1,2,3,...,9の情報)が含まれています。一般的にはこれらが分割され、60,000枚が訓練用のデータセット、10,000枚が性能評価のテストデータセットとして用いられます。
( 引用元: https://weblabo.oscasierra.net/python/ai-mnist-data-detail.html )
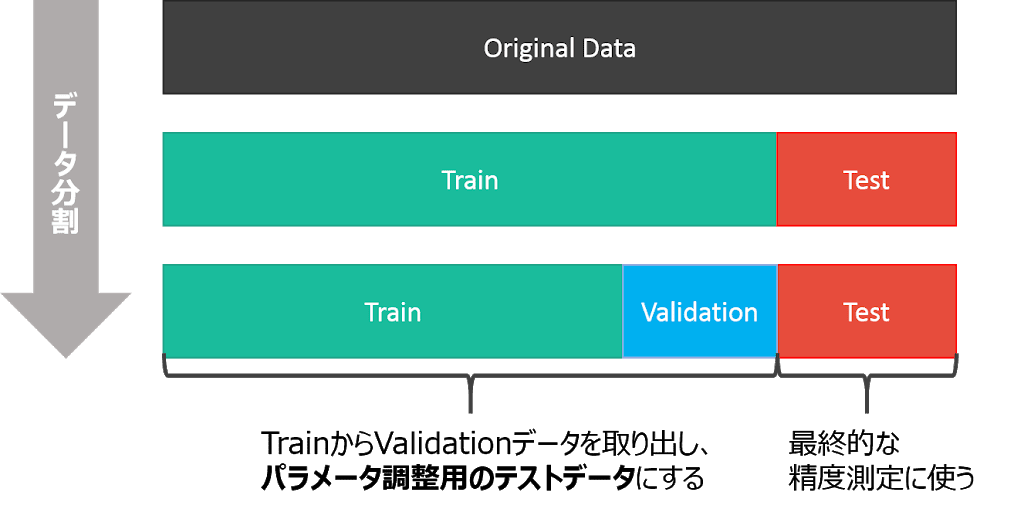
以下の図のように、学習率などのハイパーパラメーターチューニング用に検証用データにさらに分割することもありますが、今回は扱いません。
( 引用元: https://www.procrasist.com/entry/10-cross-validation )
DL4Jでは他のフレームワークと同様にMNIST専用のイテレーターが用意されています。なお、CIFAR-10やTiny ImageNetなど、その他有名なデータセットに対するイテレーターもあります。詳しくは公式のドキュメントを参照してください。
自前の画像やCSVなどのデータセット用の
RecordReaderDataSetIteratorや、シーケンスデータ用のSequenceRecordReaderDataSetIteratorなどの情報も同ページにあります。//Get the DataSetIterators: DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize, true, rngSeed); DataSetIterator mnistTest = new MnistDataSetIterator(batchSize, false, rngSeed);こちらでは、訓練用のイテレーターとテスト用のイテレーターを用意しています。
MnistDataSetIteratorのソースコードから、今回用いているコンストラクタを引用します。public MnistDataSetIterator(int batchSize, boolean train, int seed)引数はそれぞれ以下の通りです。
int batchSize: ミニバッチの大きさ、つまり訓練の一度のイテレーションでモデルに入力するサンプル数boolean train: 訓練データかテストデータかを示す真偽値int seed: データセットをシャッフルする際の乱数シード2.
MultiLayerConfigurationの設定こちらがニューラルネットワークの設計を行なっている部分です。Kerasの用にシーケンシャルにレイヤーを積み重ねていくには
MultiLayerConfigurationを用います。なお、複雑な分岐を持ったネットワークを構築したい場合には
ComputationGraphConfigurationを用います。Kerasのfunctional APIのようなものです。詳しくはこちらのドキュメントなどを参照してください。MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(rngSeed) //include a random seed for reproducibility .activation(Activation.RELU) .weightInit(WeightInit.XAVIER) .updater(new Nesterovs(rate, 0.98)) //specify the rate of change of the learning rate. .l2(rate * 0.005) // regularize learning model .list() .layer(0, new DenseLayer.Builder() //create the first input layer. .nIn(numRows * numColumns) .nOut(500) .build()) .layer(1, new DenseLayer.Builder() //create the second input layer .nIn(500) .nOut(100) .build()) .layer(2, new OutputLayer.Builder(LossFunction.NEGATIVELOGLIKELIHOOD) //create hidden layer .activation(Activation.SOFTMAX) .nIn(100) .nOut(outputNum) .build()) .build();
MultiLayerConfigurationはいわゆるBuilderパターンで実装されています。.<parameter>の形式でパラメーターを指定してネットワークをカスタマイズすることができます。MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(rngSeed) //include a random seed for reproducibility .activation(Activation.RELU) .weightInit(WeightInit.XAVIER) .updater(new Nesterovs(rate, 0.98)) //specify the rate of change of the learning rate. .l2(rate * 0.005) // regularize learning model .list()上半分ではネットワーク全体に対するパラメータを設定しています。具体的には以下の設定をしています。
.seed(rngSeed)で乱数シードの設定.activation(Activation.RELU)で各レイヤーの活性化関数をReLU関数に設定
- レイヤーごとに別々の活性化関数を指定することもできます
.weightInit(WeightInit.XAVIER)でニューラルネットの重みパラメーターの初期化方法を「XAVIERの初期化」に設定.updater(new Nesterovs(rate, 0.98))で最適化アルゴリズム(アップデーター)をNesterovsの加速法に設定
- 引数はそれぞれ学習率とモーメンタム
.l2(rate * 0.005)でL2正則化のパラメーターを設定.layer(0, new DenseLayer.Builder() //create the first input layer. .nIn(numRows * numColumns) .nOut(500) .build()) .layer(1, new DenseLayer.Builder() //create the second input layer .nIn(500) .nOut(100) .build()) .layer(2, new OutputLayer.Builder(LossFunction.NEGATIVELOGLIKELIHOOD) //create hidden layer .activation(Activation.SOFTMAX) .nIn(100) .nOut(outputNum) .build()) .build();下半分ではニューラルネットワークのレイヤーの構成を指定しています。
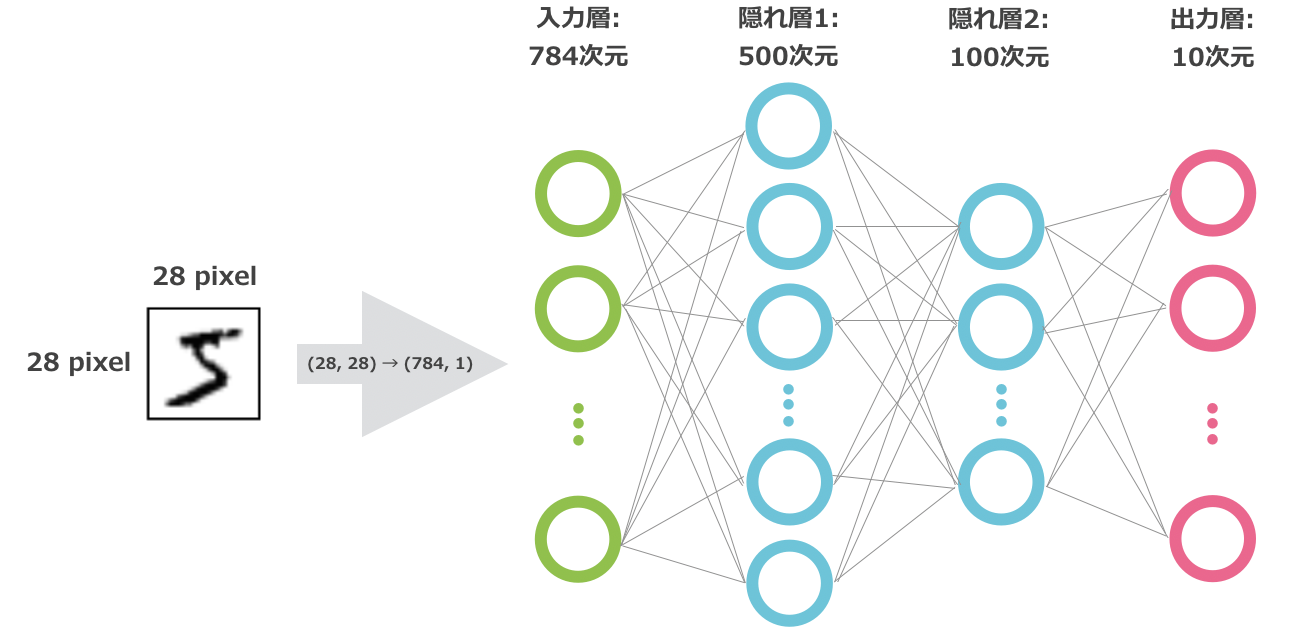
0番目の接続に、入力が $28\times 28=$ 784次元、出力が500次元の
DenseLayer(全結合層)を用いています。
MNISTの画像は高さ28pixel、幅28pixel、白黒なのでチャンネル数は1です。これを全結合層に入力するため、一般には $28\times 28$ の行列からベクトルに変換する必要があります。ただし、DL4JのMNIST用のイテレーターではすでにフラットになった収録されているため、この作業は不要となっています。
ここでの出力の500次元という数字には意味はなく、自由に設定できるハイパーパラメーターです。この数字が最適値であるとは限りません。1番目の接続も同様に、入力が500次元(0番目の出力と同じ値)、出力が100次元の
DenseLayerを設定しています。くどいようですが、100次元という数字はえいやで決めた値であり、意味はありません。2番目の接続は特別で、
OutputLayerを用いています。
入力は前の接続と同様に100次元、出力はデータのラベル数の10(0から9まで)を指定しています。
活性化関数はActivation.SOFTMAXで上書きしており、損失関数としてLossFunction.NEGATIVELOGLIKELIHOODを設定しています。
ソフトマックス関数は入力された値を確率(合計が1の正の値)として変換するときに用いられる関数で、多クラス分類問題を解くときにNegative Log Likelihood(負の対数尤度)とセットで用いられます。ここで設定したモデルのイメージは以下の通りです。
3.
MultiLayerNetworkの構築
MultiLayerConfigurationを引数としてMultiLayerNetworkのインスタンスを作成するとニューラルネットワークが出来上がります!MultiLayerNetwork model = new MultiLayerNetwork(conf); model.init();4. 構築したニューラルネットワークモデルの訓練
model.setListeners(new ScoreIterationListener(5)); //print the score with every iteration for( int i=0; i<numEpochs; i++ ){ log.info("Epoch " + i); model.fit(mnistTrain); }あとは訓練データのイテレーターを引数に
MultiLayerNetworkのfit(DataSetIterator iterator)を呼べばニューラルネットワークの訓練を行うことができます。
訓練データは一度だけ用いるのではなく、基本的に複数回繰り返します。この繰り返しの単位をエポックと呼びます。リスナーをセットして訓練状況を監視することも可能です。KerasのCallbackのイメージです。
ScoreIterationListener(int printIterations)は指定した回数のiteration(DL4Jの用語としては、重みパラメーターの一回の更新が 1 iterationです)が終わる毎にスコア(損失関数の値)を標準出力に表示します。ここら辺の用語は公式の用語集で確認できます。
なお、1000個のサンプルを含むデータセットをミニバッチサイズ100で訓練するとき、1エポックは10 iterationです。30エポック数分訓練するとき、300 iterationに相当します。訓練が終わったときだけでなく途中にもモデルを保存したいときには
CheckpointListenerを用いたり、途中で性能評価を行いときにはEvaluativeListenerを用いることもできます。その他のリスナーに関しては公式のドキュメントを参照してください。5. 訓練したモデルの性能評価
Evaluation eval = new Evaluation(outputNum); //create an evaluation object with 10 possible classes while(mnistTest.hasNext()){ DataSet next = mnistTest.next(); INDArray output = model.output(next.getFeatures()); //get the networks prediction eval.eval(next.getLabels(), output); //check the prediction against the true class } log.info(eval.stats());テストデータを用いたモデルの性能評価には
public Evaluation(int numClasses)のインスタンスを用います。
テスト用のイテレーターmnistTestを回し、getFeatures()メソッドでデータのベクトルを取得し、訓練したモデルの推論をpublic INDArray output(INDArray input)で行います。
この推論結果とテストデータのラベルをpublic void eval(INDArray realOutcomes, INDArray guesses)メソッドで比較し、eval.stats()で結果を表示するとaccuracy/precision/recall/F1 scoreの値を確認できます。詳しくは公式のドキュメントを参照してください。
おわりに
長くなりましたが、これでMLPMnistTwoLayerExample.javaの解説はおわりです。
DataSetIteratorの準備MultiLayerConfigurationの設定MultiLayerNetworkの構築- 構築したニューラルネットワークモデルの訓練
- 訓練したモデルの性能評価
といった段階を踏むことでJavaやScalaなどでも簡単にディープラーニングの訓練や評価を行うことができます。何か不明点やコメントありましたら、下のコメント欄もしくはGitterのdeeplearning4j-jpチャンネルにお願いします。
さらなる詳細な情報に関してはオライリージャパンの詳説Deep Learning − 実務者のためのアプローチをお勧めします。