- 投稿日:2019-07-04T15:09:38+09:00
[Unity] ComputeShaderでモブを動かす【その6:二次元スレッド・複カーネル化の効果】
経緯
コンピュートシェーダー(ComputeShader)を学ぶため、自動車を動かす交通シミュレーターもどきを作ってみようと思いました。個々の自動車がそれぞれ衝突を回避しつつ適切な経路で目的地に移動できるようになるのが目標です。
前回組み込んだ衝突予測と減速 が、200台に満たない程度でも時々カクつくのが気になりました(上のキャプチャは170台前後で推移)。そこでシェーダーのスレッドグループをチューニングしてパフォーマンス向上できないか試してみました。なお、コードはいままでの分も含め全てGithubにあります。
修正方針
ずっと気になってたのはこの部分です。
DrivingComputeShader04.compute[numthreads(8,1,1)] void CSMain (uint3 id : SV_DispatchThreadID) { uint idMin = id.x; int timeMin = 1000; // このままだとあと何回で衝突するか for(uint i = 0; i < count; i++) { if(i == id.x) continue; if(CarsStatic[i].size.z == 0) break; // 削除済みのデータ=末端に到達 FindMostDangerCar(id.x, i, timeMin, idMin); }id.x を車のindexとして使用していますが、下のfor文で全部の車に対して衝突予測を繰り返しています。
ここはこんな風に↓for文をやめて 二次元スレッドのグループ で回したら、シェーダーが本領発揮できるんじゃないかと思いました。[numthreads(8,8,1)] void CSMain (uint3 id : SV_DispatchThreadID) { uint idMin = id.x; int timeMin = 1000; // このままだとあと何回で衝突するか if(id.x == id.x) return; if(CarsStatic[i].size.z == 0) break; FindMostDangerCar(id.x, id.y, timeMin, idMin);※↑あくまでイメージです。実際は このままではいろいろ問題ある ので、詳細は後述します。
なお、複数カーネル化の修正にあたって、下記記事を参考にさせていただきました。
【凹みTips: Unity で Compute Shader を使ったスクリーンスペース衝突有りの GPU パーティクルを作ってみた】
http://tips.hecomi.com/entry/2016/05/08/160626構造体の修正
カーネル間で情報を渡すため、フィールドを追加しました。
coliderはデバッグ目的で以前から入れてましたが、ロジックで利用するのは今回が初めてです。CarTemprate05.cspublic struct Car05d : ICarDynamicInfo { public Vector2 pos { get; set; } public Vector2 direction { get; set; } public float velocity { get; set; } public int lane { get; set; } public int colider { get; set; } // 衝突予想相手 public float ticks { get; set; } // 衝突予想時間 public override string ToString() { return string.Format("[{0},{5}({1:0.0},{2:0.0})>>({3:0.0},{4:0.0})]", typeof(Car05d).Name, pos.x, pos.y, direction.x * velocity, direction.y * velocity, lane ); } }シェーダーの修正
for文の部分は二次元スレッドにするとして、それ以外の部分は一次元で回したいです。そのため既存のコードを 複数カーネルに分割する 必要があります。
まず、for文の前にあった変数の初期化処理を第一のカーネルとして抽出しました。
DrivingComputeShader06.compute[1]// (64, 1, 1)のスレッドで回す [numthreads(64,1,1)] void Init (uint3 id : SV_DispatchThreadID) { CarD carD = CarsDynamic[id.x]; carD.colider = id.x; carD.ticks = 100000; CarsDynamic[id.x] = carD; }次は、for文に相当する二次元スレッド部分。最初から6行目あたりまでは
CSMainから、残りは前回までの FindMostDangerCar 関数の内容ほぼそのままです。DrivingComputeShader06.compute[2]// (8, 8, 1)のスレッドで回す // 最も衝突の可能性の高い車のid(index)を返す [numthreads(8,8,1)] void Scan (uint3 id : SV_DispatchThreadID) { uint id1 = id.x; uint id2 = id.y; if(id1 == id2) return; CarS carS1 = CarsStatic[id1]; CarS carS2 = CarsStatic[id2]; if(carS1.size.z == 0 || carS2.size.z == 0) return; // 削除済みのデータ=末端に到達 CarD carD1 = CarsDynamic[id1]; CarD carD2 = CarsDynamic[id2]; if(carD1.ticks <= 0) return; // 時すでに遅し // 別車線は無視 if (carD1.lane != carD2.lane) { return; } // 相対位置ベクトル float2 diffPos = carD2.pos - carD1.pos; // 背後から接近してくるものは回避しない(相手任せ) if (dot2d(carD1.dir, diffPos) <= 0) return; // 相対速度ベクトル float diffVel = (carD1.velocity - carD2.velocity) * 0.28; if(diffVel < 0.00001){ return; // 接近していない } float absPos = length(diffPos); float countAssume = absPos / diffVel; if(countAssume > 100000){ return; // 遠い未来過ぎるので無視 } // 二つの車のサイズを考慮した距離を求める // 同一車線なので基本的に両車の長さの半分を足したもの float distance = (carS1.size.z + carS2.size.z) * 0.5; // どちらかが高速で移動しているなら停止距離には余裕を持つ distance += max(carD1.velocity, carD2.velocity) * 0.28f; float t = max(0, (absPos - distance) / diffVel); // このままだと近い将来衝突しそう if(t > carD1.ticks){ return; // もっと近い相手が既にいる } // 最小値更新 carD1.ticks = t; carD1.colider = id2; CarsDynamic[id.x] = carD1; }最後に for文の後のブロック、衝突予測結果を用いて加減速と、速度に応じた移動を行うブロックです。
DrivingComputeShader06.compute[3]// (64, 1, 1)のスレッドで回す [numthreads(64,1,1)] void Drive (uint3 id : SV_DispatchThreadID) { CarD carD = CarsDynamic[id.x]; CarS carS = CarsStatic[id.x]; if(carD.colider == id.x) { // 衝突の可能性の高い車はない if(carD.velocity < carS.idealVelocity) { carD.velocity = min(carD.velocity + carS.mobility, carS.idealVelocity); } } else { if(carD.velocity > 0) { carD.velocity = max(0, carD.velocity - carS.mobility * 2.0); if( length(CarsDynamic[carD.colider].pos - carD.pos) < 5 ){ carD.velocity = 0; } } } // それぞれの位置情報に移動ベクトルを加算 (0.28はkm/hをm/sに変換する係数) carD.pos += carD.dir * carD.velocity * DeltaTime * 0.28; CarsDynamic[id.x] = carD; }おっと、増やした&リネームした関数をファイルの先頭でカーネルとして宣言するのも忘れずに。
DrivingComputeShader06.compute[0]#pragma kernel Init #pragma kernel Scan #pragma kernel Driveコントローラー(C#)の修正
カーネルが複数になったので、Start時に FindKernel を使って正しい index を取得、フィールドに保持しておきます。
CarsController06.csprivate int[] Kernels; /// <summary> /// コンピュートバッファの初期化(Startから呼ばれる) /// </summary> void InitializeComputeBuffer() { factory = new CarRepository(MAX_CARS, CarTemplate05.dictionary); factory.AssignBuffers(); StartCoroutine(WatchLoop(OnEachScan, OnEachElement)); Kernels = new int[] { carComputeShader.FindKernel("Init"), carComputeShader.FindKernel("Scan"), carComputeShader.FindKernel("Drive") }; factory.ApplyData(); }Updateでカーネルを呼び出す部分も修正します。
コンピュートバッファーはカーネルが変わるたびにセットし直す必要があるようです。CarsController06.csvoid Update() { carComputeShader.SetInt("count", factory.ActiveCars); carComputeShader.SetFloat("DeltaTime", Time.deltaTime); var carnum = factory.ActiveCars; foreach (int index in Kernels) { carComputeShader.SetBuffer(index, "CarsStatic", factory.StaticInfoBuffer); carComputeShader.SetBuffer(index, "CarsDynamic", factory.DynamicInfoBuffer); if(index == 1) { // Scanフェーズだけ二次元 carComputeShader.Dispatch(index, carnum / 8 + 1, carnum / 8 + 1, 1); } else { carComputeShader.Dispatch(index, carnum / 64 + 1, 1, 1); } } }
if(index == 1)は横着しました。FindKernel使う意味が無くなるような決め打ちです。すみません。
せっかくFindKernel("Scan")使って、今後のindex変動に影響がないようにしてるのに、ここで固定値使ったら片手落ちですね。
パフォーマンス比較
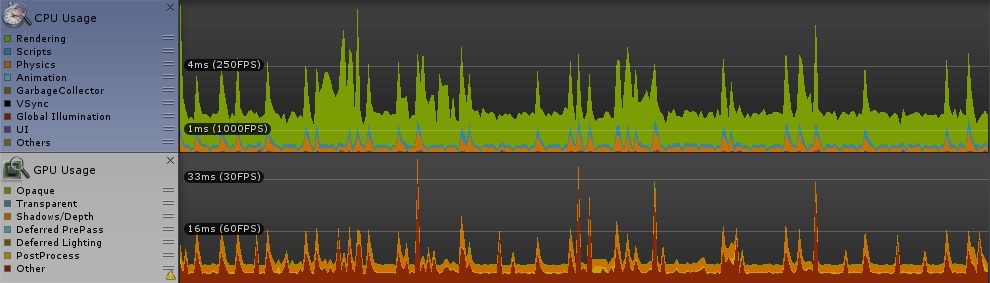
冒頭に貼った画像の状態でプロファイリングしました。車の数は 160〜170台で落ち着きます。
多次元グループ化
スレッドグループ、一次元と二次元 [numthreads(64,1,1)]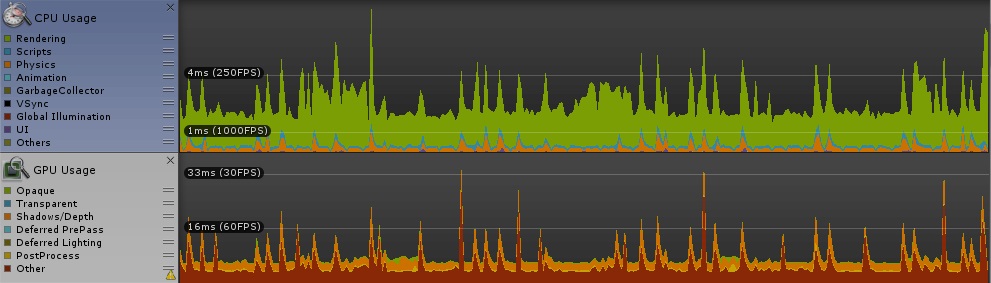
[numthreads(8,8,1)]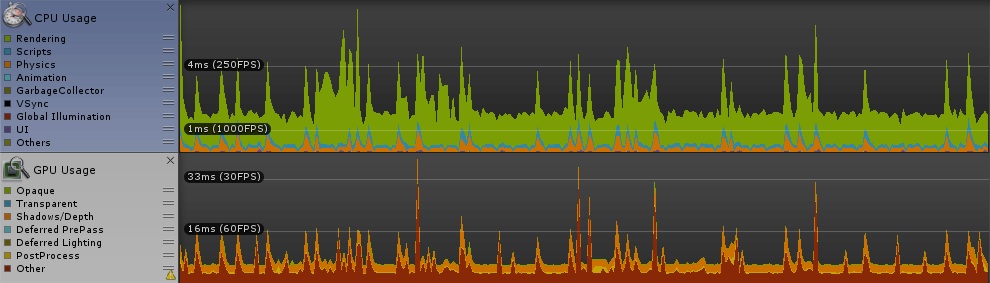
ご覧の通り、顕著な差は見られません。ちょっと期待してたのですが残念な結果に。
参考にしたサイトには「二次元配列を一つのindexで回すような計算の無駄を省ける」とか書いてあったが、逆に計算量が変わらないのならば効果はないということか。時々カクつくのは、GPU Usage に時々ピークがあるせいでしょう。(CPU Usage にもばらつきありますが、fps的に無視できるレベル。)
スレッド総数
最初に参考にしたソースが
[numthreads(8,1,1)]だったので、ずっとそれでやってきたが、8というのはどうやって決めたのかふと疑問に思ったので、スレッド数を変えることでどんな効果があるのか4と128という極端なスレッド数で比較してみた。
グループ内スレッド数、4スレッドと128スレッド [numthreads(4,1,1)]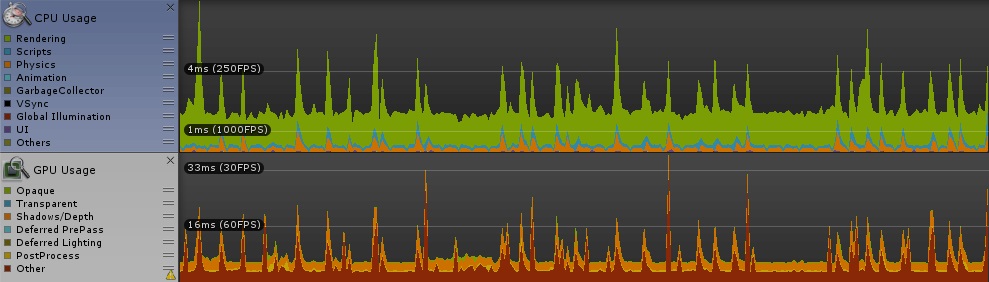
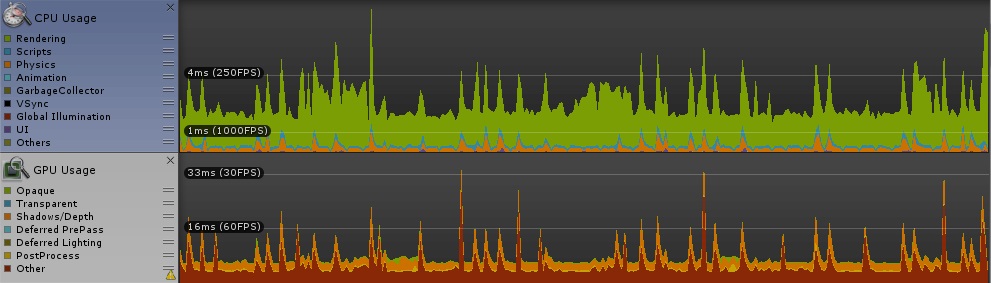
[numthreads(128,1,1)]
こちらも顕著な差は見られなかった。
ちょっとつまらない気もしたけれど、最適値にチューニングする必要がないと考えれば気が楽ですね。
スレッド数はデータを扱いやすい単位で好きに指定すればよさそうです。まとめ・感想
- パフォーマンス向上を期待して、二次元スレッド・多段カーネル化してみた。
- しかしパフォーマンスに顕著な差はみられなかった。
- 計算量が変わらない限り、スレッドの次元やカーネル数変えてもあまり意味はないようだ。
- 一度に回すスレッド数も、全体の計算量が変わらない限り意味はなさそうだ。
- カクつきは GPU Usage の偏りが原因と思われる。⇒ if文を減らすべきかも。

- 投稿日:2019-07-04T15:09:38+09:00
[Unity] ComputeShaderでモブを動かす【その6:二次元スレッド・複カーネル化/効果なし】
経緯
コンピュートシェーダー(ComputeShader)を学ぶため、自動車を動かす交通シミュレーターもどきを作ってみようと思いました。個々の自動車がそれぞれ衝突を回避しつつ適切な経路で目的地に移動できるようになるのが目標です。
前回組み込んだ衝突予測と減速 が、200台に満たない程度でも時々カクつくのが気になりました(上のキャプチャは170台前後で推移)。そこでシェーダーのスレッドグループをチューニングしてパフォーマンス向上できないか試してみました。なお、コードはいままでの分も含め全てGithubにあります。
◀【その5:衝突予測・リベンジ】
【その7:if文削減で高速化/イマイチ】▶修正方針
ずっと気になってたのはこの部分です。
DrivingComputeShader04.compute[numthreads(8,1,1)] void CSMain (uint3 id : SV_DispatchThreadID) { uint idMin = id.x; int timeMin = 1000; // このままだとあと何回で衝突するか for(uint i = 0; i < count; i++) { if(i == id.x) continue; if(CarsStatic[i].size.z == 0) break; // 削除済みのデータ=末端に到達 FindMostDangerCar(id.x, i, timeMin, idMin); }id.x を車のindexとして使用していますが、下のfor文で全部の車に対して衝突予測を繰り返しています。
ここはこんな風に↓for文をやめて 二次元スレッドのグループ で回したら、シェーダーが本領発揮できるんじゃないかと思いました。[numthreads(8,8,1)] void CSMain (uint3 id : SV_DispatchThreadID) { uint idMin = id.x; int timeMin = 1000; // このままだとあと何回で衝突するか if(id.x == id.y) return; if(CarsStatic[id.x].size.z == 0) break; FindMostDangerCar(id.x, id.y, timeMin, idMin);※↑あくまでイメージです。実際は このままではいろいろ問題ある ので、詳細は後述します。
なお、複数カーネル化の修正にあたって、下記記事を参考にさせていただきました。
【凹みTips: Unity で Compute Shader を使ったスクリーンスペース衝突有りの GPU パーティクルを作ってみた】
http://tips.hecomi.com/entry/2016/05/08/160626構造体の修正
カーネル間で情報を渡すため、フィールドを追加しました。
coliderはデバッグ目的で以前から入れてましたが、ロジックで利用するのは今回が初めてです。CarTemprate05.cspublic struct Car05d : ICarDynamicInfo { public Vector2 pos { get; set; } public Vector2 direction { get; set; } public float velocity { get; set; } public int lane { get; set; } public int colider { get; set; } // 衝突予想相手 public float ticks { get; set; } // 衝突予想時間 public override string ToString() { return string.Format("[{0},{5}({1:0.0},{2:0.0})>>({3:0.0},{4:0.0})]", typeof(Car05d).Name, pos.x, pos.y, direction.x * velocity, direction.y * velocity, lane ); } }シェーダーの修正
for文の部分は二次元スレッドにするとして、それ以外の部分は一次元で回したいです。そのため既存のコードを 複数カーネルに分割する 必要があります。
まず、for文の前にあった変数の初期化処理を第一のカーネルとして抽出しました。
DrivingComputeShader06.compute[1]// (64, 1, 1)のスレッドで回す [numthreads(64,1,1)] void Init (uint3 id : SV_DispatchThreadID) { CarD carD = CarsDynamic[id.x]; carD.colider = id.x; carD.ticks = 100000; CarsDynamic[id.x] = carD; }次は、for文に相当する二次元スレッド部分。最初から6行目あたりまでは
CSMainから、残りは前回までの FindMostDangerCar 関数の内容ほぼそのままです。DrivingComputeShader06.compute[2]// (8, 8, 1)のスレッドで回す // 最も衝突の可能性の高い車のid(index)を返す [numthreads(8,8,1)] void Scan (uint3 id : SV_DispatchThreadID) { uint id1 = id.x; uint id2 = id.y; if(id1 == id2) return; CarS carS1 = CarsStatic[id1]; CarS carS2 = CarsStatic[id2]; if(carS1.size.z == 0 || carS2.size.z == 0) return; // 削除済みのデータ=末端に到達 CarD carD1 = CarsDynamic[id1]; CarD carD2 = CarsDynamic[id2]; if(carD1.ticks <= 0) return; // 時すでに遅し // 別車線は無視 if (carD1.lane != carD2.lane) { return; } // 相対位置ベクトル float2 diffPos = carD2.pos - carD1.pos; // 背後から接近してくるものは回避しない(相手任せ) if (dot2d(carD1.dir, diffPos) <= 0) return; // 相対速度ベクトル float diffVel = (carD1.velocity - carD2.velocity) * 0.28; if(diffVel < 0.00001){ return; // 接近していない } float absPos = length(diffPos); float countAssume = absPos / diffVel; if(countAssume > 100000){ return; // 遠い未来過ぎるので無視 } // 二つの車のサイズを考慮した距離を求める // 同一車線なので基本的に両車の長さの半分を足したもの float distance = (carS1.size.z + carS2.size.z) * 0.5; // どちらかが高速で移動しているなら停止距離には余裕を持つ distance += max(carD1.velocity, carD2.velocity) * 0.28f; float t = max(0, (absPos - distance) / diffVel); // このままだと近い将来衝突しそう if(t > carD1.ticks){ return; // もっと近い相手が既にいる } // 最小値更新 carD1.ticks = t; carD1.colider = id2; CarsDynamic[id.x] = carD1; }最後に for文の後のブロック、衝突予測結果を用いて加減速と、速度に応じた移動を行うブロックです。
DrivingComputeShader06.compute[3]// (64, 1, 1)のスレッドで回す [numthreads(64,1,1)] void Drive (uint3 id : SV_DispatchThreadID) { CarD carD = CarsDynamic[id.x]; CarS carS = CarsStatic[id.x]; if(carD.colider == id.x) { // 衝突の可能性の高い車はない if(carD.velocity < carS.idealVelocity) { carD.velocity = min(carD.velocity + carS.mobility, carS.idealVelocity); } } else { if(carD.velocity > 0) { carD.velocity = max(0, carD.velocity - carS.mobility * 2.0); if( length(CarsDynamic[carD.colider].pos - carD.pos) < 5 ){ carD.velocity = 0; } } } // それぞれの位置情報に移動ベクトルを加算 (0.28はkm/hをm/sに変換する係数) carD.pos += carD.dir * carD.velocity * DeltaTime * 0.28; CarsDynamic[id.x] = carD; }おっと、増やした&リネームした関数をファイルの先頭でカーネルとして宣言するのも忘れずに。
DrivingComputeShader06.compute[0]#pragma kernel Init #pragma kernel Scan #pragma kernel Driveコントローラー(C#)の修正
カーネルが複数になったので、Start時に FindKernel を使って正しい index を取得、フィールドに保持しておきます。
CarsController06.csprivate int[] Kernels; /// <summary> /// コンピュートバッファの初期化(Startから呼ばれる) /// </summary> void InitializeComputeBuffer() { factory = new CarRepository(MAX_CARS, CarTemplate05.dictionary); factory.AssignBuffers(); StartCoroutine(WatchLoop(OnEachScan, OnEachElement)); Kernels = new int[] { carComputeShader.FindKernel("Init"), carComputeShader.FindKernel("Scan"), carComputeShader.FindKernel("Drive") }; factory.ApplyData(); }Updateでカーネルを呼び出す部分も修正します。
コンピュートバッファーはカーネルが変わるたびにセットし直す必要があるようです。CarsController06.csvoid Update() { carComputeShader.SetInt("count", factory.ActiveCars); carComputeShader.SetFloat("DeltaTime", Time.deltaTime); var carnum = factory.ActiveCars; foreach (int index in Kernels) { carComputeShader.SetBuffer(index, "CarsStatic", factory.StaticInfoBuffer); carComputeShader.SetBuffer(index, "CarsDynamic", factory.DynamicInfoBuffer); if(index == 1) { // Scanフェーズだけ二次元 carComputeShader.Dispatch(index, carnum / 8 + 1, carnum / 8 + 1, 1); } else { carComputeShader.Dispatch(index, carnum / 64 + 1, 1, 1); } } }
if(index == 1)は横着しました。FindKernel使う意味が無くなるような決め打ちです。すみません。
せっかくFindKernel("Scan")使って、今後のindex変動に影響がないようにしてるのに、ここで固定値使ったら片手落ちですね。
パフォーマンス比較
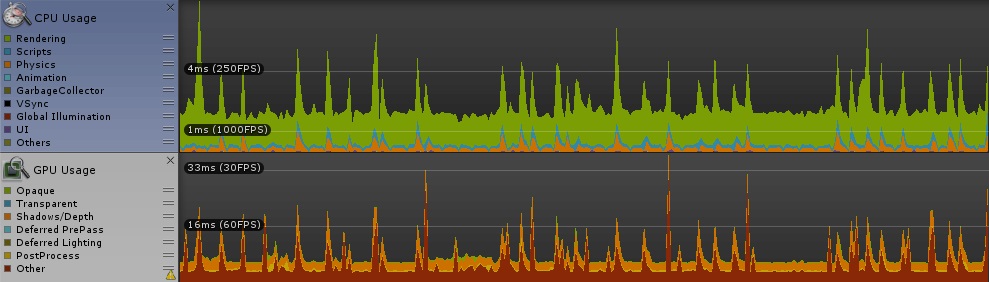
冒頭に貼った画像の状態でプロファイリングしました。車の数は 160〜170台で落ち着きます。
多次元グループ化
スレッドグループ、一次元と二次元 [numthreads(64,1,1)][numthreads(8,8,1)]ご覧の通り、顕著な差は見られません。ちょっと期待してたのですが残念な結果に。
参考にしたサイトには「二次元配列を一つのindexで回すような計算の無駄を省ける」とか書いてあったが、逆に計算量が変わらないのならば効果はないということか。時々カクつくのは、GPU Usage に時々ピークがあるせいでしょう。(CPU Usage にもばらつきありますが、fps的に無視できるレベル。)
スレッド総数
最初に参考にしたソースが
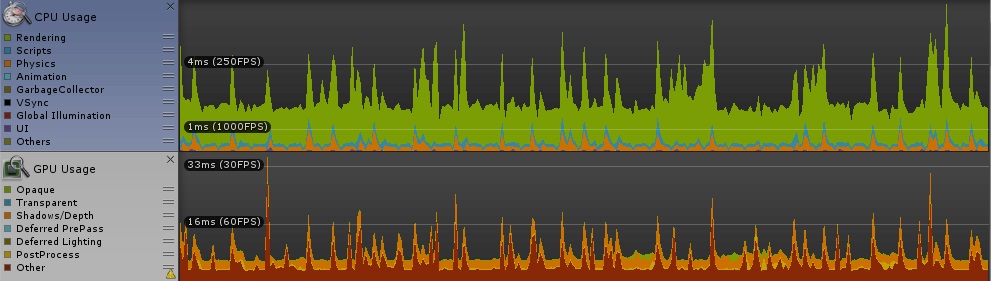
[numthreads(8,1,1)]だったので、ずっとそれでやってきましたが、8というのはどうやって決めたのかふと疑問に思ったので、スレッド数を変えることでどんな効果があるのか4と128という極端なスレッド数で比較してみました。
グループ内スレッド数、4スレッドと128スレッド [numthreads(4,1,1)][numthreads(128,1,1)]こちらも顕著な差は見られませんでした。
ちょっとつまらない気もしたけれど、最適値にチューニングする必要がないと考えれば気が楽ですね。
スレッド数はデータを扱いやすい単位で好きに指定すればよさそうです。まとめ・感想
- パフォーマンス向上を期待して、二次元スレッド・多段カーネル化してみた。
- しかしパフォーマンスに顕著な差はみられなかった。
- 計算量が変わらない限り、スレッドの次元やカーネル数変えてもあまり意味はないようだ。
- 一度に回すスレッド数も、全体の計算量が変わらない限り意味はなさそうだ。
- カクつきは GPU Usage の偏りが原因と思われる。⇒ if文を減らすべきかも。
- 投稿日:2019-07-04T08:23:34+09:00
Unity の Transform のパフォーマンス最適化まとめ
(今更ですが)毎フレーム大量の Transform を扱う機会があったので、Unity 上で Transform を更新する際の手法とパフォーマンスの比較・最適化の方法のまとめを。
毎フレーム数百かそれ以上の Transform の .position や .rotation / .eulerAngles へのアクセスや変更がある場合には考慮する意味がある、といった内容です。Transform 沼にハマっているなら。
備忘録
- はじめに
- rotation / eulerAngles の xyzw へのアクセスは必ずキャッシュする
- localRotation が一番高速
- オイラー角よりもクオータニオンの方が高速
- ワールドスペースよりローカルスペースの方が高速
- localEulerAngles += よりも Transform.Rotate()
- 使えるなら HumanPoseHandler.SetHumanPose() を使う
- テスト動画
- まとめ
はじめに
面倒くさがってビルドして試さずに、すべてエディター上で確認しています。
また、.rotation / .eulerAngles を中心に確認していますが .position / .scale も同様の扱いかと思います。
- Unity 2018.4.0f1(Unity 2018 LTS)
- Windows 10 64bit @ Intel Core i9-9900K 3.6GHz
--
Humanoid キャラ一体の骨が 60~ 以上あったりするので、値の取得含めた Transform の操作は、油断しているとすぐ数百単位になる。そして Transform の値の取得に大きな罠があります。
rotation / eulerAngles の xyzw へのアクセスは必ずキャッシュする
重要。Transform のキャッシュでは(場合によっては)足りない。
Transform だけキャッシュするのではなく、Quaternion や Vector3 もキャッシュ
vector3.x = 0は出来るのに、transform.position.x = 0は出来ない、ということで、こいつらは少し特殊な扱いです。Transform をキャッシュしていたとしても、
..... = new Vector3(cache.eulerAngles.x, cache.eulerAngles.y, cache.eulerAngles.z);など、メンバーに3回アクセスすると、3回分の Vector3 のコピーが行われる。らしいです。
↓ ↓ ↓
Transform.position や Transform.rotation、Transform.eulerAngles 等はフィールドではなくプロパティで getter がセットされていて、アクセスのたびに構造体のコピーが行われています。
(というようなことが、ネットのどこかに書いてあった気がしますが失念)
--
localRotation が一番高速
でした。
オイラー角よりもクオータニオンの方が高速
でした。
ワールドスペースよりローカルスペースの方が高速
.rotation よりも .localRotation、.eulerAngles よりも .localEulerAngles の方が高速でした。
ルートのみワールド空間で扱う
場合によってはルートのみワールド空間の値を扱い、それ以下のオブジェクトはすべてローカル空間の値を扱うなど。
テストではローカル値を扱うようにするだけで倍近いスピードに。
localEulerAngles += よりも Transform.Rotate()
オフセットの調整等はオイラー角の方が直感的なので、
.localEulerAngles += .....としがちですが、Transform.Rotate() の方が高速です。数が多い場合は結構なパフォーマンスへのインパクトがあります。
使えるなら HumanPoseHandler.SetHumanPose() を使う
対象が Humanoid の場合、HumanPoseHandler の SetHumanPose の方が高速な場合があります。
以下がとても参考になります。
テスト動画
フレームレートに大きな変化が出やすい数の Transform を更新してますが、場合によってはキャラ数体の場合でも、秒間 10fps 程度の変化がある可能性も。
シーン構成
95 個の muscles / Transform を1フレームに 100 回更新 = 秒間に約 10,000~ Transform の向きを更新するテストを行った動画。
※ 揺れもの無しの人型キャラクター 100 体分のボーン数、ポリゴン自体は1体分
Unity の Transform のパフォーマンス最適化
— サトー (@sator_imaging) July 3, 2019
誰かがすでに調べ切っている気がするけども… オイラー角遅すぎる pic.twitter.com/hvLnTMIGnbまとめ
- 可能な限りオイラー角は扱わない。
- .eulerAngles / .localEulerAngles に値をセットする・メンバーにアクセスすると極端にパフォーマンスが落ちる。
- Quaternion / Vector3 のメンバーにアクセスするのはコストがかかるので必ずキャッシュする。
- Transform ではなく、Quaternion / Vector3 をキャッシュ。
クオータニオンは高速
取得した値を直接放り込むなら、SetHumanPose よりも高速。
.localRotation を変更した場合のフレームレート
- pseudo:
.localRotation = Time.time;
- 約 800fps
.rotation を変更した場合のフレームレート
- pseudo:
.rotation = Time.time;
- 約 400fps
オフセットを加える場合は = Quaternion * Quaternion が一番高速
各キャラクターごとの差分の吸収など、回転のオフセットは可能な限りクオータニオンで扱う。オイラー角を扱わなければ、SetHumanPose よりもパフォーマンスが出る。
- .rotation にクオータニオンのオフセットを加えて変更
- pseudo:
.rotation = Time.time * Quaternion
- 約 360fps
オイラー角は厳禁
オイラー角を扱うだけで何をしても重いので、可能な限り使わない。
.localEulerAngles を変更した場合のフレームレート
- pseudo:
.localEulerAngles = Time.time;
- 約 500fps
.eulerAngles を変更した場合のフレームレート
- pseudo:
.eulerAngles = Time.time;
- 約 300fps
どうしてもオイラー角でオフセットを指定したい
ワールド空間のクオータニオン値をセットしてから、オイラー角でオフセットの数値を入力する必要がある場合は Transform.Rotate() を Space.Self で使う。
- .rotation をセットしてから Transform.Rotate() でオフセットした場合のフレームレート
- pseudo:
.rotation = Time.time; Transform.Rotate();
- 約 210fps
- pseudo:
.rotation = Time.time; .localEulerAngles += new Vector3()の場合
- 約 175fps
- 意味わからん
Quaternion / Vector3 の xyzw メンバーへのアクセス自体が重い
前述の通り
transform.position.x = 0が出来ない、思っているのと違う奴らです。
数が多い場合、軽い気持ちでメンバーにアクセスするとパフォーマンスへのインパクトが凄いことに。複数回アクセスする場合は、Transform の .rotation や .eulerAngles は
var cached = transform.rotation等するだけで劇的に高速に。
.... transform.position.xとか気軽に使いがちだけど、アクセスする数が多い場合は厳禁。必ずキャッシュ。
.rotation の各メンバーにキャッシュ無しでアクセスした場合(4回のアクセス)
- pseudo:
.rotation = transform.rotation.xyzw + Time.time;
- 約 200fps
- キャッシュすると 約 320fps に
- pseudo:
.rotation = cachedRotation.xyzw + Time.time;- クオータニオンのメンバーを直接弄ることはないだろうけど、オフセットを適用するなら
Quaternion * Quaternionに落とし込むのが一番高速.eulerAngles の各メンバーにキャッシュ無しでアクセスした場合(3回のアクセス)
- pseudo:
.eulerAngles = transform.eulerAngles.xyz + Time.time;
- 約 110fps
- キャッシュすると 約 190fps に
- pseudo:
.eulerAngles = cachedEulerAngles.xyz + Time.time;HumanPoseHandler の SetHumanPose の場合
Avatar が Humanoid で無いと動かない、Humanoid 依存のソフトウェア・コンポーネントにしたくはないので、あまりちゃんと調べてないですが…。
- HumanPoseHandler.SetHumanPose を使用した場合のフレームレート
- 約 250fps
--
こちらもどうぞ
- 投稿日:2019-07-04T00:36:32+09:00
イラストレーターがプログラミングを勉強しようとした話。【1話】
はじめに
この記事は前回の
ノンプログラマーがプログラミングを勉強しようとした話。【前節】
続きです。タイトル変更しました
ノンプログラマーからイラストレーターが~にタイトルを変更しました。
理由としては、Qitaでノンプログラマーと検索すると。
- コードは書かないけれど上流で設計やっています
- 趣味でプログラムしています
- 基本的にエンジニアとやり取りするポジション(webアプリのディレクションとか)
と、結構知識がある前提で書かれている記事が多くて、僕としてはやっぱり調べ始めた時に引っかかった部分が払拭できないな~という理由。
あとはやはり、需要としては狭くなりますが、デザイナーとかイラストレーターが興味はあるけど取っ掛かりがない状態からの足がかりになればなと。最終的にこの記事を通して読んでもバリバリコードを書けるようにはならない。
これは 前回の記事で書いておけばよかったんですが、そもそも僕自身が、今バリバリコード書いて実装してますとかじゃないので、1週間でプログラマーになれるとかそういうハックではないです。
あと、セクションによってはデザイナーもシェーダー書いたりpythonでツールゴリゴリ作る人もいるのでそういう人向けではないです。
あくまでも、興味はあるけど取っ掛かりがない。とかプラグラムと聞くとパソコン壊しそうとかそういう人向けになってます。
あとは、エンジニアさんがデザイナーの思考というか、どこから説明すればいいかのヒントとか共通言語化ができればなと。ではやっと次から本題に入って行きたいとと思います。また内容薄めになってらごめんなさい、多分今回はUnityとC#少し……
わからないことがわからない!
正直最初は本当にこれですね、わからないことがわからない。
まぁそもそも、目に見える物を直感的に作ってる人が多いので、やっぱり数字や英単語が書いてあるだけの画面に向かって唸ってるエンジニアさんは怖いし、黒魔術でも使ってんじゃないかとおもうんですよ。
じゃぁ具体的に何わからないの?って話なんですが。横文字多すぎ
横文字おおいですよね。
- オブジェクト
- パラダイム
- パース
- メソッド
やっていけば、まぁそのままの意味なんですけど。
パースとか透視図法の事かと思っちゃいますね。
プログラムというかUnityとかでも、初心者向けと書いてあったり入門と書いてあっても、結構無慈悲にオブジェクトをインスタンスします
とか書かれているわけですね。
オブジェクト????
インスタンス???
で、更にオブジェクトで調べに行くと概念設計とかの話がバンバン出てくるわけです。例えば、絵の描き方教えてって言われた時に。
回り込みと立体感を意識して、線を引くといいですね。色は環境光と色の恒常性を意識するといいです。
っていわれてもなぁってなります。
俺は斜め45度の女の子が描きたいんだ。
まぁこんな回答は稀で、だいたい、いい感じに描くとかの返答が帰ってくるかと思います。ただお互い説明しろと言われても、そういうもんだしなーとしか言えませんしね。
じゃぁどう説明するか。
具体的な事象で説明する
オブジェクト指向プログラミングとはというと、コードを再利用するためにクラスという部品に分ける。
だいたいこんな感じの説明が出てきます。
いやほんと、そのとおりなんですが。
プログラムが部品?どういうことってなります。
イラストって基本フルスクラッチなので、再利用って概念があんまりないです。
漫画だとコマの使い回しとか、よく使う構図とか概念的には有る気がしますが。イラストで例えると。
イラストレータという枠これをクラスとします、絵柄はイラストレーターが具体的に出力する関数とします。
関数の説明が抜けてましたが、関数はプログラムの具体的な部分です a + b = c なんですが、よくわからないとおもいますので、イラストレーターが絵を書く工程が書かれていると思っていただければOKです。
NUKO-D(クラス)
- NUKO-D描く女の子関数
〇〇イラストレーター(クラス)
- 〇〇イラストレーターが描く可愛い服関数
△△イラストレーター(クラス)
- △△イラストレーターが描くいい感じの背景関数
この3つのクラスとそれぞれに入っている関数を使うことで、処理、ここでいうと一枚のイラストが作れるという感じです。
プログラムのソースコードをのぞくと、英語が+とか=で結ばれていて一見よくわかりませんが。工程や計算などが単語として定義されて、それを組み合わせて有るのでそう見える感じです。
インターネットにこういう便利な関数がまとめられた物がフリー素材や有償素材としておいてあって、用途に合わせて組み合わせて行きます。
webデザインなんかではよくあると思いますが、イラストは基本書き起こすので具体性はないですが、アウトプットする時に脳内で行っている作業に近いとは思います。
もちろん、そのイラストに会わなければ、新たにクラスや処理を作ってあわせて行きます。今回はここまで
今回はここまでにしようかなと思います。次回は実際どういう環境で具体的に勉強していくかというところ。
Unityに触れていければと思います。
なにか間違いとかあればご指摘お願いします。