- 投稿日:2019-07-04T21:09:08+09:00
RDS ではパラメーターにまったく問題ないのに Incompatible-parameters が発生する場合がある
AWS の RDS では Incompatible-parameters というエラーが発生し、インスタンスを起動できなくなる場合があります。そのエラーに遭遇してしまったのですが、一般に言われている方法では解決できなかったので報告します。
結論
再起動を繰り返すとパラメーターが正常でも発生する場合がある。しばらく待つ事で起動できるようになる。
経緯
RDS に限らず RDBMS では起動直後の状態と、インデックス等必要な情報を十分メモリに蓄積した状態とでは性能にかなりの違いがあります。今回、RDS で作成した MySQL のインスタンスの起動直後のパフォーマンスを調査するために何度も再起動を繰り返していたのですが、データベースのステータスが突然 Incompatible-parameters になってしまい起動できなくなりました。
公式情報を調べる
調べてみると、すぐに日本語の公式なナレッジが見つかりました。
要約するとカスタムパラメータグループの設定に問題があり、インスタンスの起動に失敗しているという事になります。カスタムパラメーターグループとはデータベースをチューニングするためのパラメーターのグループであり、MySQL の my.cnf に相当する物です。
自分でインストールした MySQL でも my.cnf の内容が間違っていれば起動できない場合があります。Incompatible-parameters はその状態に相当するエラーであると考えられます。
パラメーターに問題のない事を確認した
RDS は十分なパフォーマンスを発揮できる状態にチューニングされていると考えられらますが、必要に応じてパラメーターの調節ができるようになっているわけです。今回、確かにパラメーターグループを新規作成し一部のパラメーターを書き換えていますので、その設定が間違っているのだと言われたら、確かにそうなのかも知れません。
しかし、パラメーターに問題があるのなら、起動できない時は起動できないし、起動できる時は起動できるはずです。状況によって起動できたりできなかったりするのなら、それはパラメーター起因のエラーとは言えないでしょう。しかし、
- 直前まで同じパラメーターで起動できていた
- パラメーターを再度確認し、起動が不可能な要素を見つけられなかった
- 同じパラメーターで新たにインスタンスを作成したが、起動も再起動も問題なく実行できた
というような状態であり、どうも公式ナレッジに記載されている状態とは異なるようでした。
サポートに問い合わせ (解決)
サポートに問い合わせた所、1営業日程度で返事が届きました。結論としては最初に書いた通りになりますが、カスタムパラメーターグループを利用しているインスタンスにおいて、何度も再起動を繰り返していると incompatible-parameters になり、起動できなくなる場合があるとの事です。今回は起動直後の状態の試験を行っていた最中でしたので、再起動は10回程度行っていました。しばらくすると自然回復するそうで、確かに問題のインスタンスはいつの間にか起動していました。
そういう物だと受け入れましょう
詳細な原因については非公開との事でしたが、再起動を繰り返す事で、RDS がなんらかの異常が起こっていると認識してしまったのかも知れません。
今回は検証環境での出来事なので実害はありませんでしたが、本番環境をメンテナンスする時等には必要以上に再起動を行わない等の注意が必要だと思います。特にパラメーターチューニングを伴うメンテナンスの時には、本当にパラメーターが間違っている場合との区別が難しい可能性があります。そんな時は是非この記事を思い出して下さい。
何度確認してもパラメーターの間違いが見つけられないのに incompatible-parameters が出続ける場合は、同じパラメーターグループで別のインスタンスを立ち上げてみると良いと思います。
- 投稿日:2019-07-04T20:19:11+09:00
AWSマネジメントコンソールの色をアカウントによって変更するChrome拡張機能を作った(実装編)
はじめに
先日、AWSマネジメントコンソールの色をアカウントによって変更するChrome拡張機能を作成してリリースしました。
機能や使い方はこちらの記事をご覧下さい。
AWSマネジメントコンソールの色をアカウントによって変更するChrome拡張機能を作った(紹介編)実装詳細
オプション画面はjqueryを使用して値を取得しています。
input要素を適当に配置しただけのHTMLですので特記する事はありません。
AWSのサイトで起動するスクリプトはJavaScriptです。ソースはこちらに
https://github.com/sh-nakayama/AWS_COLOR_CHANGER苦労した点
オプション画面で入力した値を保存して、AWSのマネコンのサイトで起動するJavaScriptに読み込ませるのに苦労しました。
最初はオプション画面で入力した値をlocalstrageに保存していましたが、
localStorageはページごとに保存するデータが分かれている事が判明、読み書きは同じ場所でないと値が共有できません。つまりAWSのマネコンのサイトで起動するJavaScriptではlocalStorageに保存した値が読めません。
回避方法はあるみたいですが、
https://mae.chab.in/archives/2861苦労した点の対応
今回はchrome.storageを使用することで対応しました。
下記の記事を参考に作成しました。
https://easyramble.com/chrome-storage-set-and-get.html
https://qiita.com/shimutaya/items/e8835d6ce794ef6c73cf終わりに
意外と簡単にリリースまでこぎつけました。
実は最も苦労した点はmanifestファイルかもしれません。スペルミスや、インデントミスでかなり時間を取られました参考にさせていただいた記事

- 投稿日:2019-07-04T18:40:50+09:00
APN�のPartner Central画面で組織親アカウントに紐づくユーザーを確認する
どこになにがあるかわからなすぎて危うくハゲるところだったので毛髪を守るため、メモしておきます。
APNのPartner Central画面で組織親アカウント(アライアンスリードのアカウント)に紐づくユーザー一覧を確認する方法です。
APNってなにとかはあとに書きます。
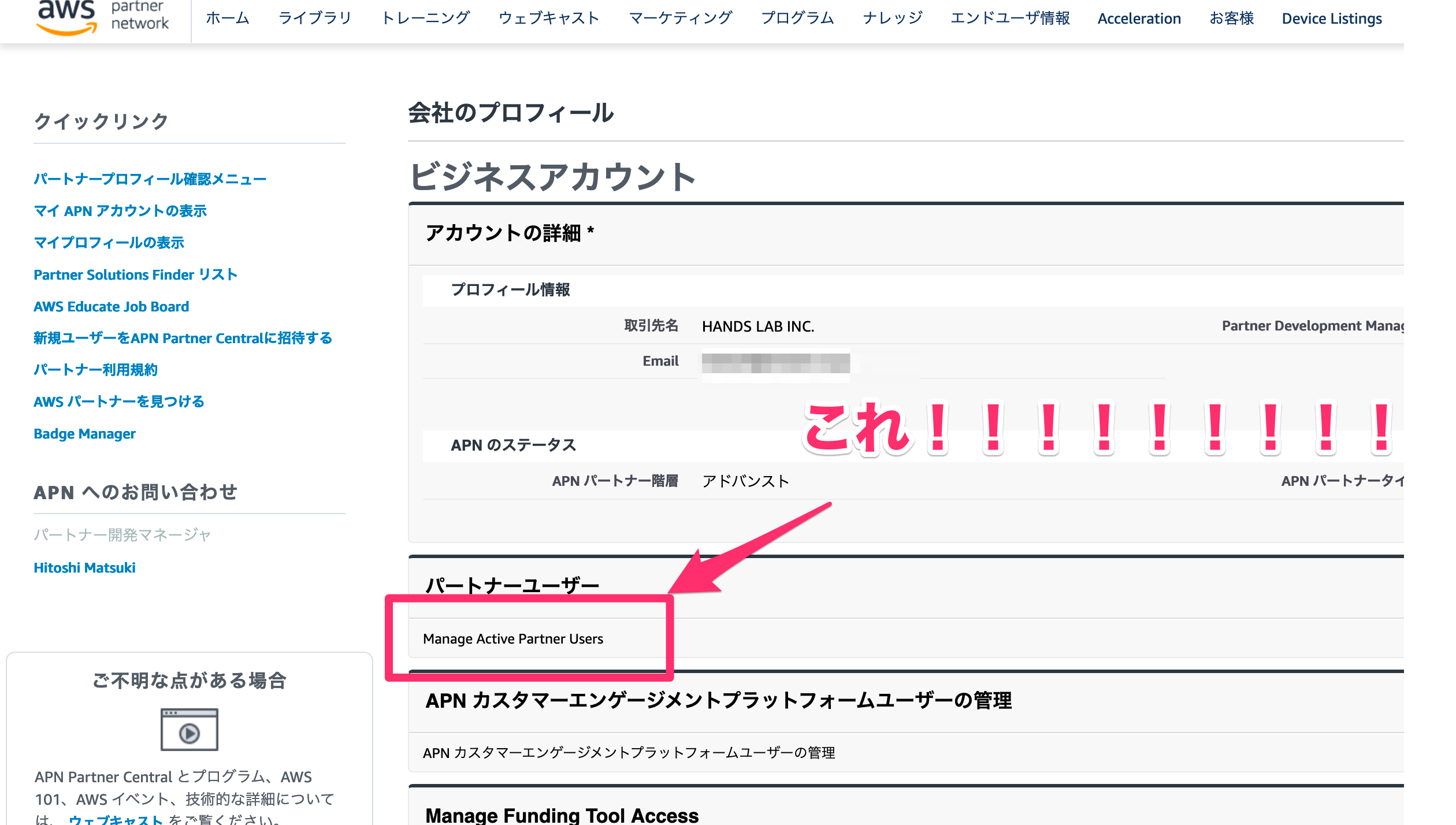
とにかく見てください。ここです
左サイドバーのここをクリック
そして
そもそもパートナーユーザーっていう名前もピンときていない状態であちこち探していて「え、Manageって書いてあるけど・・・まさかこれは、リンクなの・・・?」とクリックしてみたら無事一覧が開きました。
ヘッダーが「アカウントに紐づくパートナーユーザー一覧」とか書いていてくれるだけでぜんぜん違うかもしれない。未来の私、覚えておいてね。
APNとは
AWS パートナーネットワーク (APN) は、AWS の世界的なパートナープログラムです。ビジネス、技術、マーケティング、および販売促進をサポートすることで、APN パートナーが AWS ベースのビジネスやソリューションの構築に成功するよう支援することに重点を置いています。
参照: AWS パートナーネットワーク
パートナー資格を維持するにはいろいろ条件があります。
その一つが会社に所属する社員の資格保持です。そこで、そのAPNの管理画面、Partner Centralで組織と社員のAWS資格の紐付けをしたりします。
希望
APNパートナー資格維持のため、社員の資格取得状況を随時確認したいです。
社員が個人アカウントで資格を取得した状態で入社してきたりすると、パートナーユーザーを作ってもらって個人アカウントとさらに紐付けしないと組織の資格保持数に反映されません。
https://aws.amazon.com/jp/blogs/psa/newyear-prep-for-tier-changes/
したがってパートナーユーザー一覧の情報が正しい状態になっているかは重要なので見やすいとうれしいです。また、トップページには組織に紐づく資格の数が表示されていますが、パートナーユーザーの誰がどの資格を保持しているのかはわかりません。(たぶん密かなリンクを見落としていなければ)
一応要望は送ってみたのでPartner Central画面のさらなる改良を期待したいと思います。

- 投稿日:2019-07-04T18:30:58+09:00
かんたんにAWS Cloud9にLaravel開発環境を構築する。
家のマシンのスペックが貧弱なのでCloud9上に環境構築することにしました。
メモとしてQiitaに書き残しておきます。学習が進み次第追記していくかもしれません。PHPのインストール
# パッケージ更新 sudo yum update -y # phpのバージョン確認 rpm -qa | grep php # php5.6を一式アンインストール sudo yum remove php56* # PHP7.3を一式インストール sudo yum install php73* # リンク削除 -> 貼り直し sudo unlink /usr/bin/php sudo ln -s /etc/alternatives/php7 /usr/bin/phpcomposerのインストール
# インストーラーのダウンロードと実行 curl -sS https://getcomposer.org/installer | php # パスの通った場所へ移動 mv composer.phar /usr/local/bin/composerLaravelのセットアップ
# Laravelのインストール composer global require "laravel/installer" # Laravelプロジェクトの作成 composer create-project --prefer-dist laravel/laravel myappローカルサーバーが動いているか確認
# ポート8080でサーバー起動 php artisan serve --port=8080Previewボタン -> PreviewRunningApplicationから確認できます。
参考URL
AWS Cloud9(Amazon Linux)にPHP7.3をインストールして開発環境を作る手順書
Composerをインストールしてみた
Laravel 5.8 インストール
- 投稿日:2019-07-04T18:28:17+09:00
【RDS for Oracle 】StatsPack設定
使用しているインスタンスがSE2なので、StatsPackを設定してみる。
参考サイトはこちら
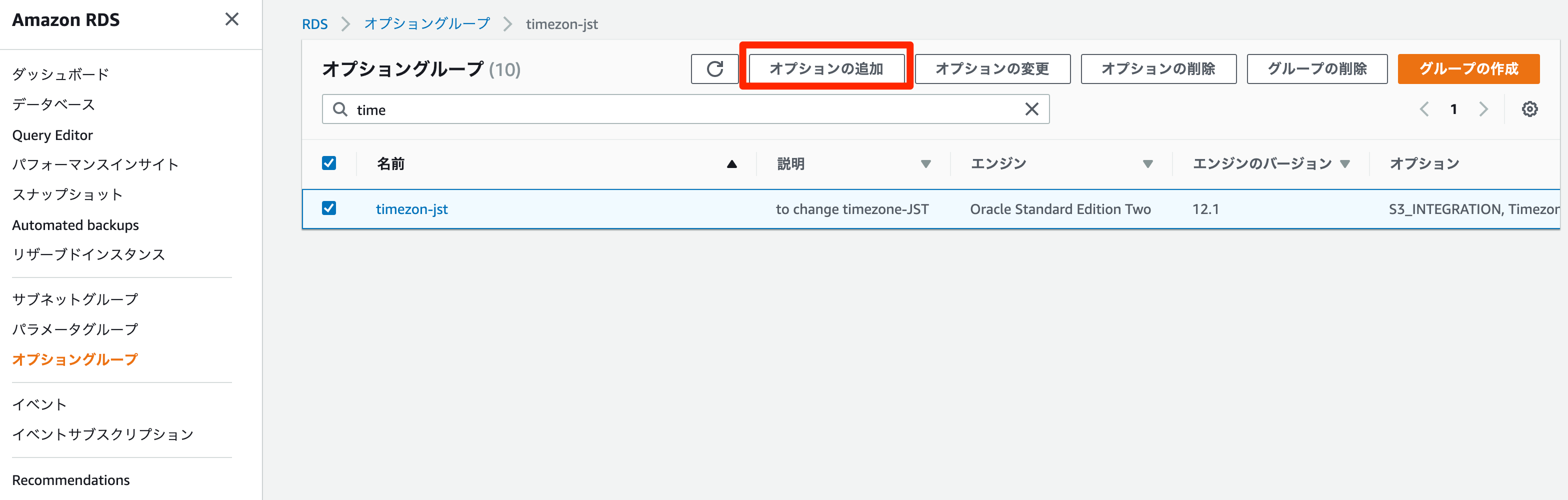
オプショングループの設定
今回はオプショングループがすでにあるため、そこにStatsPackのオプションを追加する。
RDSのコンソールからオプショングループ→オプションに追加
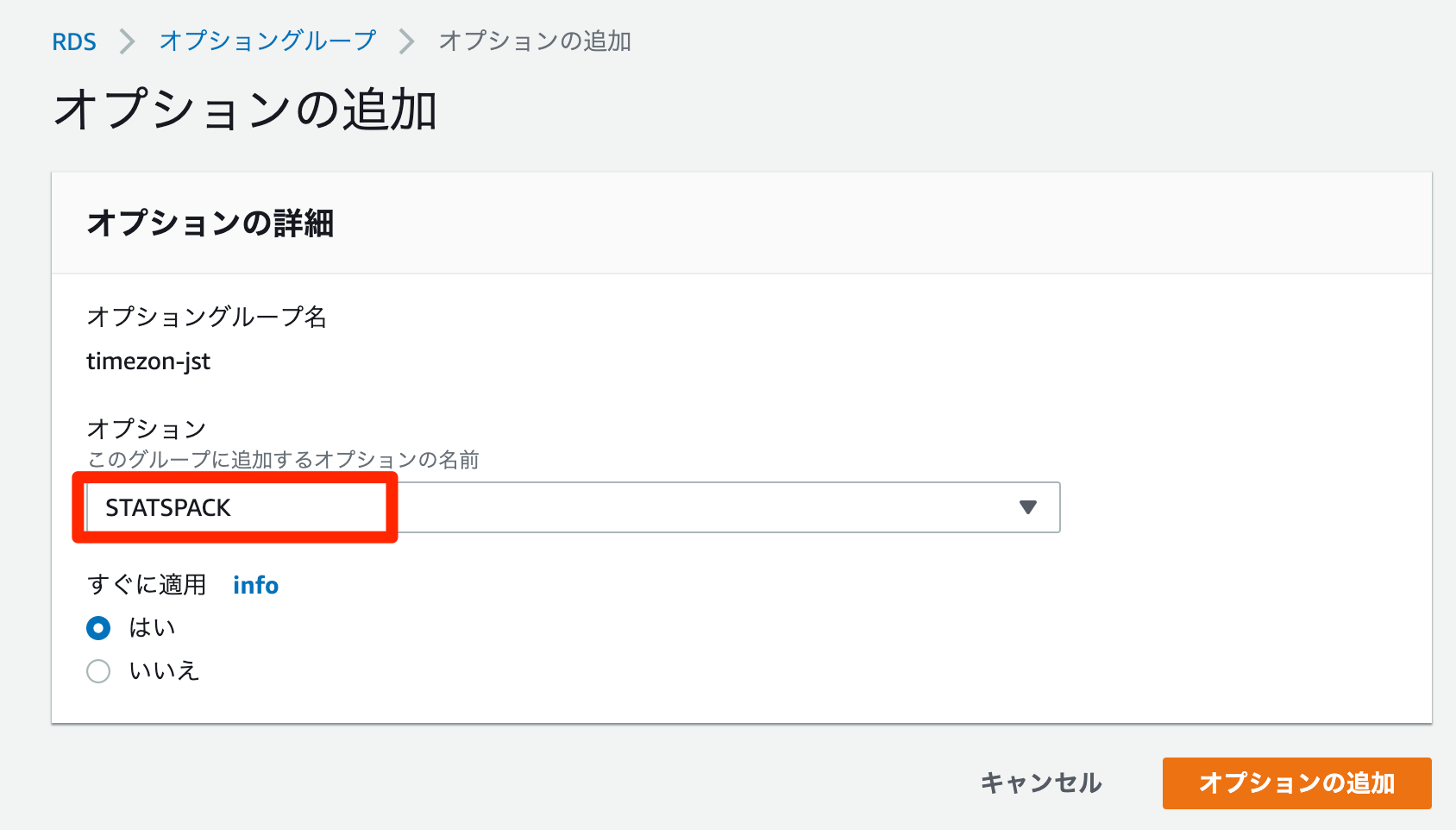
オプションに
STATSPACKを選択
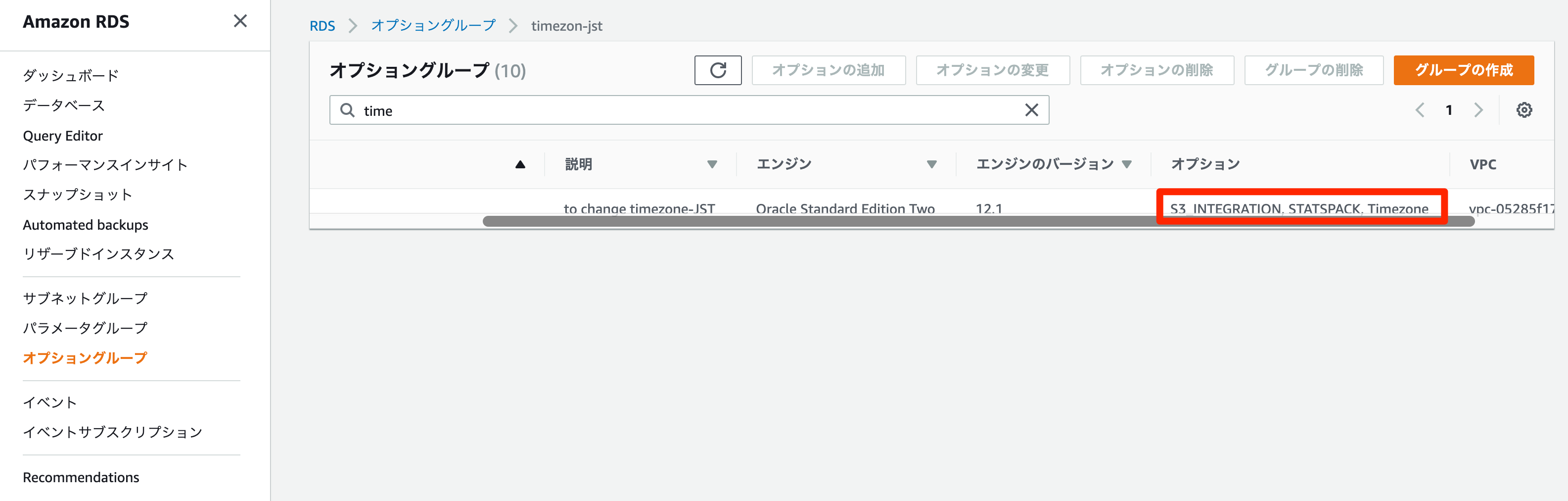
既存のオプショングループに追加される。
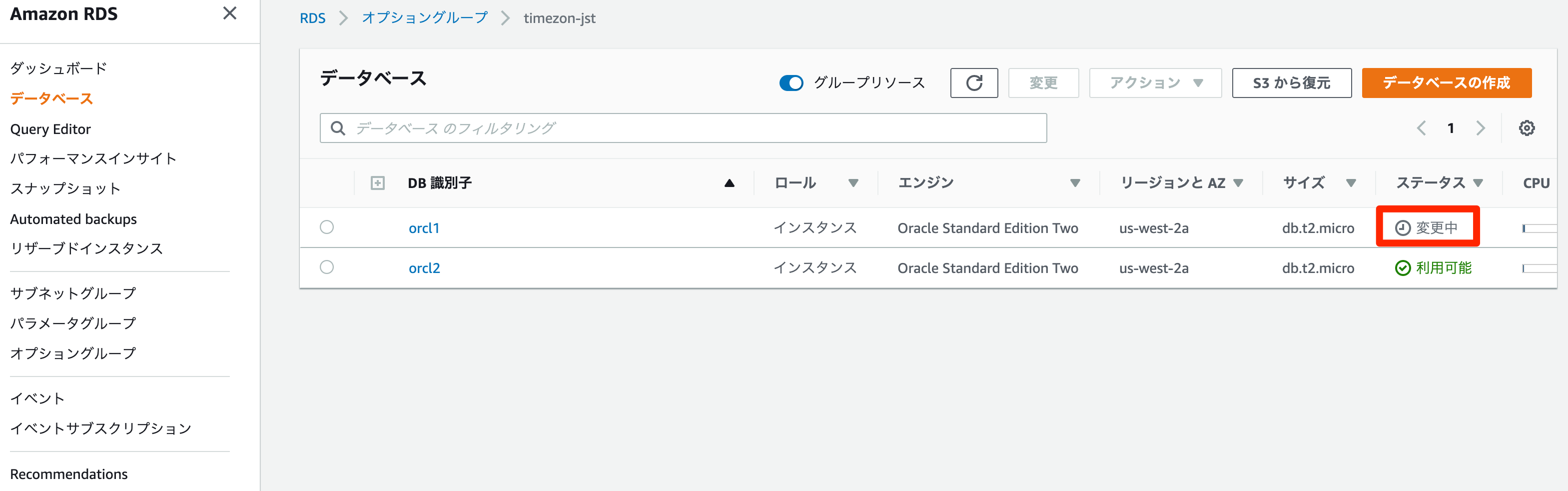
今回、既存のオプショングループはすでにインスタンス(ORCL1)に付与されているため、インスタンスにも反映される。
インスタンスのステータスが
変更中になる。
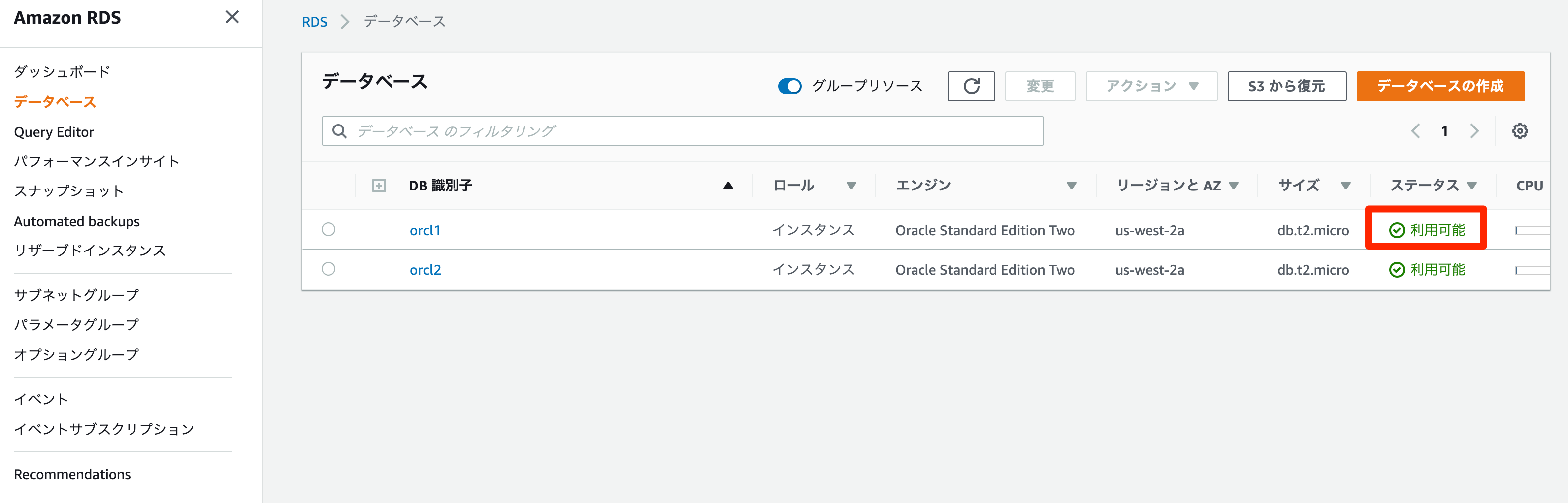
利用可能となったらインスタンスにPERFSTATSユーザができている
StatsPackの設定
インスタンスにマスターユーザでログイン。
PERFSTATユーザを確認すると、デフォルトでアカウントステータスは
LOCKED、表領域はSYSAUXとなっている。表領域がSYSAUXだと、この表領域にスナップショットが取得されるため、SYSAUXの負荷が上がってしまう。
そのため、PERFSTAT用の表領域を作成する。
SQL> set pages 100 line 200 SQL> col username for a10 SQL> col account_status for a10 SQL> col default_tablespace for a10 SQL> col profile for a10 SQL> select username,account_status,default_tablespace,temporary_tablespace,profile from dba_users where username = 'PERFSTAT'; USERNAME ACCOUNT_ST DEFAULT_TA TEMPORARY_TABLESPACE PROFILE ---------- ---------- ---------- ------------------------------ ---------- PERFSTAT LOCKED SYSAUX TEMP DEFAULT既存の表領域の確認
SQL> col file_name for a60 SQL> select tablespace_name,file_name,status,bytes/1024/1024 mbytes,increment_by,autoextensible,online_status from dba_data_files; TABLESPACE_NAME FILE_NAME STATUS MBYTES INCREMENT_BY AUT ONLINE_ ------------------------------ ------------------------------------------------------------ --------- ---------- ------------ --- ------- SYSTEM /rdsdbdata/db/ORCL1_A/datafile/o1_mf_system_gf76cbh1_.dbf AVAILABLE 400 12800 YES SYSTEM SYSAUX /rdsdbdata/db/ORCL1_A/datafile/o1_mf_sysaux_gf76d1l1_.dbf AVAILABLE 548.625 12800 YES ONLINE UNDO_T1 /rdsdbdata/db/ORCL1_A/datafile/o1_mf_undo_t1_gf76df41_.dbf AVAILABLE 300 1280 YES ONLINE USERS /rdsdbdata/db/ORCL1_A/datafile/o1_mf_users_gf76dh0r_.dbf AVAILABLE 100 12800 YES ONLINE RDSADMIN /rdsdbdata/db/ORCL1_A/datafile/o1_mf_rdsadmin_gf77glhp_.dbf AVAILABLE 7 128 YES ONLINEPERFSTAT用の表領域としてSTATSPACK表領域を作成。
SQL> CREATE TABLESPACE STATSPACK DATAFILE SIZE 100M AUTOEXTEND ON NEXT 100M MAXSIZE UNLIMITED; Tablespace created.表領域の確認
select tablespace_name,file_name,status,bytes/1024/1024 mbytes,increment_by,autoextensible,online_status from dba_data_files where tablespace_name='STATSPACK'; TABLESPACE_NAME FILE_NAME STATUS MBYTES INCREMENT_BY AUT ONLINE_ ------------------------------ ------------------------------------------------------------ --------- ---------- ------------ --- ------- STATSPACK /rdsdbdata/db/ORCL1_A/datafile/o1_mf_statspac_gktwxh9z_.dbf AVAILABLE 100 12800 YES ONLINEアカウントロックを解除
SQL> alter user PERFSTAT identified by perfstat ACCOUNT UNLOCK; User altered.PERFSTATユーザのデフォルト表領域をSYSAUX→
STATSPACKに変更SQL> alter user PERFSTAT default tablespace STATSPACK; User altered.PERFSTATユーザのSTATSPACK表領域の使用容量の制限値を
無制限に変更SQL> alter user PERFSTAT QUOTA UNLIMITED ON STATSPACK; User altered.確認すると、アカウントステータスが
OPEN、デフォルト表領域がSTATSPACKになっているSQL> select username,account_status,default_tablespace,temporary_tablespace,profile from dba_users where username = 'PERFSTAT'; USERNAME ACCOUNT_ST DEFAULT_TA TEMPORARY_TABLESPACE PROFILE ---------- ---------- ---------- ------------------------------ ---------- PERFSTAT OPEN STATSPACK TEMP DEFAULTPERFSTATユーザが所有しているテーブルの表領域を確認すると、72個のテーブルの表領域が
SYSAUXとなっている。SQL> col table_name for a30 SQL> select table_name, tablespace_name from dba_tables where owner = 'PERFSTAT'; TABLE_NAME TABLESPACE_NAME ------------------------------ ------------------------------ STATS$DATABASE_INSTANCE SYSAUX STATS$LEVEL_DESCRIPTION SYSAUX STATS$SNAPSHOT SYSAUX STATS$DB_CACHE_ADVICE SYSAUX STATS$FILESTATXS SYSAUX STATS$TEMPSTATXS SYSAUX STATS$LATCH SYSAUX STATS$LATCH_CHILDREN SYSAUX STATS$LATCH_PARENT SYSAUX STATS$LATCH_MISSES_SUMMARY SYSAUX STATS$LIBRARYCACHE SYSAUX STATS$BUFFER_POOL_STATISTICS SYSAUX STATS$ROLLSTAT SYSAUX STATS$ROWCACHE_SUMMARY SYSAUX STATS$SGA SYSAUX STATS$SGASTAT SYSAUX STATS$SYSSTAT SYSAUX STATS$SESSTAT SYSAUX STATS$SYSTEM_EVENT SYSAUX STATS$SESSION_EVENT SYSAUX STATS$WAITSTAT SYSAUX STATS$ENQUEUE_STATISTICS SYSAUX STATS$SQL_SUMMARY SYSAUX STATS$SQLTEXT SYSAUX STATS$SQL_STATISTICS SYSAUX STATS$RESOURCE_LIMIT SYSAUX STATS$DLM_MISC SYSAUX STATS$CR_BLOCK_SERVER SYSAUX STATS$CURRENT_BLOCK_SERVER SYSAUX STATS$INSTANCE_CACHE_TRANSFER SYSAUX STATS$UNDOSTAT SYSAUX STATS$SQL_PLAN_USAGE SYSAUX STATS$SQL_PLAN SYSAUX STATS$SEG_STAT SYSAUX STATS$SEG_STAT_OBJ SYSAUX STATS$PGASTAT SYSAUX STATS$PARAMETER SYSAUX STATS$INSTANCE_RECOVERY SYSAUX STATS$STATSPACK_PARAMETER SYSAUX STATS$SHARED_POOL_ADVICE SYSAUX STATS$SQL_WORKAREA_HISTOGRAM SYSAUX STATS$PGA_TARGET_ADVICE SYSAUX STATS$JAVA_POOL_ADVICE SYSAUX STATS$THREAD SYSAUX STATS$FILE_HISTOGRAM SYSAUX STATS$EVENT_HISTOGRAM SYSAUX STATS$TIME_MODEL_STATNAME SYSAUX STATS$SYS_TIME_MODEL SYSAUX STATS$SESS_TIME_MODEL SYSAUX STATS$STREAMS_CAPTURE SYSAUX STATS$STREAMS_APPLY_SUM SYSAUX STATS$PROPAGATION_SENDER SYSAUX STATS$PROPAGATION_RECEIVER SYSAUX STATS$BUFFERED_QUEUES SYSAUX STATS$BUFFERED_SUBSCRIBERS SYSAUX STATS$RULE_SET SYSAUX STATS$OSSTATNAME SYSAUX STATS$OSSTAT SYSAUX STATS$PROCESS_ROLLUP SYSAUX STATS$PROCESS_MEMORY_ROLLUP SYSAUX STATS$SGA_TARGET_ADVICE SYSAUX STATS$STREAMS_POOL_ADVICE SYSAUX STATS$MUTEX_SLEEP SYSAUX STATS$DYNAMIC_REMASTER_STATS SYSAUX STATS$IOSTAT_FUNCTION_NAME SYSAUX STATS$IOSTAT_FUNCTION SYSAUX STATS$IOSTAT_FUNCTION_DETAIL SYSAUX STATS$MEMORY_TARGET_ADVICE SYSAUX STATS$MEMORY_DYNAMIC_COMPS SYSAUX STATS$MEMORY_RESIZE_OPS SYSAUX STATS$INTERCONNECT_PINGS SYSAUX STATS$IDLE_EVENT SYSAUX STATS$TEMP_SQLSTATS ★これだけSYSAUXではない 73 rows selected.テーブルの表領域をSYSAUXから
STATSPACK表領域に変更する。
select文でSQLを作成。SQL> select 'alter table ' || table_name || ' move tablespace STATSPACK;' from dba_tables where owner = 'PERFSTAT'; 'ALTERTABLE'||TABLE_NAME||'MOVETABLESPACESTATSPACK;' ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- alter table STATS$DATABASE_INSTANCE move tablespace STATSPACK; alter table STATS$LEVEL_DESCRIPTION move tablespace STATSPACK; alter table STATS$SNAPSHOT move tablespace STATSPACK; alter table STATS$DB_CACHE_ADVICE move tablespace STATSPACK; alter table STATS$FILESTATXS move tablespace STATSPACK; alter table STATS$TEMPSTATXS move tablespace STATSPACK; alter table STATS$LATCH move tablespace STATSPACK; alter table STATS$LATCH_CHILDREN move tablespace STATSPACK; alter table STATS$LATCH_PARENT move tablespace STATSPACK; alter table STATS$LATCH_MISSES_SUMMARY move tablespace STATSPACK; alter table STATS$LIBRARYCACHE move tablespace STATSPACK; alter table STATS$BUFFER_POOL_STATISTICS move tablespace STATSPACK; alter table STATS$ROLLSTAT move tablespace STATSPACK; alter table STATS$ROWCACHE_SUMMARY move tablespace STATSPACK; alter table STATS$SGA move tablespace STATSPACK; alter table STATS$SGASTAT move tablespace STATSPACK; alter table STATS$SYSSTAT move tablespace STATSPACK; alter table STATS$SESSTAT move tablespace STATSPACK; alter table STATS$SYSTEM_EVENT move tablespace STATSPACK; alter table STATS$SESSION_EVENT move tablespace STATSPACK; alter table STATS$WAITSTAT move tablespace STATSPACK; alter table STATS$ENQUEUE_STATISTICS move tablespace STATSPACK; alter table STATS$SQL_SUMMARY move tablespace STATSPACK; alter table STATS$SQLTEXT move tablespace STATSPACK; alter table STATS$SQL_STATISTICS move tablespace STATSPACK; alter table STATS$RESOURCE_LIMIT move tablespace STATSPACK; alter table STATS$DLM_MISC move tablespace STATSPACK; alter table STATS$CR_BLOCK_SERVER move tablespace STATSPACK; alter table STATS$CURRENT_BLOCK_SERVER move tablespace STATSPACK; alter table STATS$INSTANCE_CACHE_TRANSFER move tablespace STATSPACK; alter table STATS$UNDOSTAT move tablespace STATSPACK; alter table STATS$SQL_PLAN_USAGE move tablespace STATSPACK; alter table STATS$SQL_PLAN move tablespace STATSPACK; alter table STATS$SEG_STAT move tablespace STATSPACK; alter table STATS$SEG_STAT_OBJ move tablespace STATSPACK; alter table STATS$PGASTAT move tablespace STATSPACK; alter table STATS$PARAMETER move tablespace STATSPACK; alter table STATS$INSTANCE_RECOVERY move tablespace STATSPACK; alter table STATS$STATSPACK_PARAMETER move tablespace STATSPACK; alter table STATS$SHARED_POOL_ADVICE move tablespace STATSPACK; alter table STATS$SQL_WORKAREA_HISTOGRAM move tablespace STATSPACK; alter table STATS$PGA_TARGET_ADVICE move tablespace STATSPACK; alter table STATS$JAVA_POOL_ADVICE move tablespace STATSPACK; alter table STATS$THREAD move tablespace STATSPACK; alter table STATS$FILE_HISTOGRAM move tablespace STATSPACK; alter table STATS$EVENT_HISTOGRAM move tablespace STATSPACK; alter table STATS$TIME_MODEL_STATNAME move tablespace STATSPACK; alter table STATS$SYS_TIME_MODEL move tablespace STATSPACK; alter table STATS$SESS_TIME_MODEL move tablespace STATSPACK; alter table STATS$STREAMS_CAPTURE move tablespace STATSPACK; alter table STATS$STREAMS_APPLY_SUM move tablespace STATSPACK; alter table STATS$PROPAGATION_SENDER move tablespace STATSPACK; alter table STATS$PROPAGATION_RECEIVER move tablespace STATSPACK; alter table STATS$BUFFERED_QUEUES move tablespace STATSPACK; alter table STATS$BUFFERED_SUBSCRIBERS move tablespace STATSPACK; alter table STATS$RULE_SET move tablespace STATSPACK; alter table STATS$OSSTATNAME move tablespace STATSPACK; alter table STATS$OSSTAT move tablespace STATSPACK; alter table STATS$PROCESS_ROLLUP move tablespace STATSPACK; alter table STATS$PROCESS_MEMORY_ROLLUP move tablespace STATSPACK; alter table STATS$SGA_TARGET_ADVICE move tablespace STATSPACK; alter table STATS$STREAMS_POOL_ADVICE move tablespace STATSPACK; alter table STATS$MUTEX_SLEEP move tablespace STATSPACK; alter table STATS$DYNAMIC_REMASTER_STATS move tablespace STATSPACK; alter table STATS$IOSTAT_FUNCTION_NAME move tablespace STATSPACK; alter table STATS$IOSTAT_FUNCTION move tablespace STATSPACK; alter table STATS$IOSTAT_FUNCTION_DETAIL move tablespace STATSPACK; alter table STATS$MEMORY_TARGET_ADVICE move tablespace STATSPACK; alter table STATS$MEMORY_DYNAMIC_COMPS move tablespace STATSPACK; alter table STATS$MEMORY_RESIZE_OPS move tablespace STATSPACK; alter table STATS$INTERCONNECT_PINGS move tablespace STATSPACK; alter table STATS$IDLE_EVENT move tablespace STATSPACK; alter table STATS$TEMP_SQLSTATS move tablespace STATSPACK; 73 rows selected.上記のalter table文を実行。
このテーブルは一時テーブルのため、エラーは無視。alter table STATS$TEMP_SQLSTATS move tablespace STATSPACK * ERROR at line 1: ORA-14451: unsupported feature with temporary table確認すると
STATSPACL表領域に変更されている。SQL> select table_name, tablespace_name from dba_tables where owner = 'PERFSTAT'; TABLE_NAME TABLESPACE_NAME ------------------------------ ------------------------------ STATS$SYSTEM_EVENT STATSPACK STATS$SESSION_EVENT STATSPACK STATS$WAITSTAT STATSPACK STATS$ENQUEUE_STATISTICS STATSPACK STATS$SQL_SUMMARY STATSPACK STATS$SQLTEXT STATSPACK STATS$SQL_STATISTICS STATSPACK STATS$RESOURCE_LIMIT STATSPACK STATS$DLM_MISC STATSPACK STATS$CR_BLOCK_SERVER STATSPACK STATS$CURRENT_BLOCK_SERVER STATSPACK STATS$INSTANCE_CACHE_TRANSFER STATSPACK STATS$UNDOSTAT STATSPACK STATS$SQL_PLAN_USAGE STATSPACK STATS$SQL_PLAN STATSPACK STATS$SEG_STAT STATSPACK STATS$SEG_STAT_OBJ STATSPACK STATS$PGASTAT STATSPACK STATS$PARAMETER STATSPACK STATS$INSTANCE_RECOVERY STATSPACK STATS$STATSPACK_PARAMETER STATSPACK STATS$SHARED_POOL_ADVICE STATSPACK STATS$SQL_WORKAREA_HISTOGRAM STATSPACK STATS$PGA_TARGET_ADVICE STATSPACK STATS$JAVA_POOL_ADVICE STATSPACK STATS$THREAD STATSPACK STATS$FILE_HISTOGRAM STATSPACK STATS$EVENT_HISTOGRAM STATSPACK STATS$TIME_MODEL_STATNAME STATSPACK STATS$SYS_TIME_MODEL STATSPACK STATS$SESS_TIME_MODEL STATSPACK STATS$STREAMS_CAPTURE STATSPACK STATS$STREAMS_APPLY_SUM STATSPACK STATS$PROPAGATION_SENDER STATSPACK STATS$PROPAGATION_RECEIVER STATSPACK STATS$BUFFERED_QUEUES STATSPACK STATS$BUFFERED_SUBSCRIBERS STATSPACK STATS$RULE_SET STATSPACK STATS$OSSTATNAME STATSPACK STATS$OSSTAT STATSPACK STATS$PROCESS_ROLLUP STATSPACK STATS$PROCESS_MEMORY_ROLLUP STATSPACK STATS$SGA_TARGET_ADVICE STATSPACK STATS$STREAMS_POOL_ADVICE STATSPACK STATS$MUTEX_SLEEP STATSPACK STATS$DYNAMIC_REMASTER_STATS STATSPACK STATS$IOSTAT_FUNCTION_NAME STATSPACK STATS$IOSTAT_FUNCTION STATSPACK STATS$IOSTAT_FUNCTION_DETAIL STATSPACK STATS$MEMORY_TARGET_ADVICE STATSPACK STATS$MEMORY_DYNAMIC_COMPS STATSPACK STATS$MEMORY_RESIZE_OPS STATSPACK STATS$INTERCONNECT_PINGS STATSPACK STATS$IDLE_EVENT STATSPACK STATS$DATABASE_INSTANCE STATSPACK STATS$LEVEL_DESCRIPTION STATSPACK STATS$SNAPSHOT STATSPACK STATS$DB_CACHE_ADVICE STATSPACK STATS$FILESTATXS STATSPACK STATS$TEMPSTATXS STATSPACK STATS$LATCH STATSPACK STATS$LATCH_CHILDREN STATSPACK STATS$LATCH_PARENT STATSPACK STATS$LATCH_MISSES_SUMMARY STATSPACK STATS$LIBRARYCACHE STATSPACK STATS$BUFFER_POOL_STATISTICS STATSPACK STATS$ROLLSTAT STATSPACK STATS$ROWCACHE_SUMMARY STATSPACK STATS$SGA STATSPACK STATS$SGASTAT STATSPACK STATS$SYSSTAT STATSPACK STATS$SESSTAT STATSPACK STATS$TEMP_SQLSTATS 73 rows selected.索引も表領域が
SYSAUXとなっているSQL> col INDEX_NAME for a30 SQL> select INDEX_NAME,TABLE_NAME,TABLESPACE_NAME from dba_indexes where owner = 'PERFSTAT'; INDEX_NAME TABLE_NAME TABLESPACE_NAME ------------------------------ ------------------------------ ------------------------------ STATS$IDLE_EVENT_PK STATS$IDLE_EVENT SYSAUX STATS$INTERCONNECT_PINGS_PK STATS$INTERCONNECT_PINGS SYSAUX STATS$MEMORY_RESIZE_OPS_PK STATS$MEMORY_RESIZE_OPS SYSAUX STATS$MEMORY_DYNAMIC_COMPS_PK STATS$MEMORY_DYNAMIC_COMPS SYSAUX STATS$MEMORY_TARGET_ADVICE_PK STATS$MEMORY_TARGET_ADVICE SYSAUX STATS$IOSTAT_FUNC_PK STATS$IOSTAT_FUNCTION_DETAIL SYSAUX STATS$IOSTAT_FUNCTION_PK STATS$IOSTAT_FUNCTION SYSAUX STATS$IOSTAT_FUNCTION_NAME_PK STATS$IOSTAT_FUNCTION_NAME SYSAUX STATS$DYNAMIC_REM_STATS_PK STATS$DYNAMIC_REMASTER_STATS SYSAUX STATS$MUTEX_SLEEP_PK STATS$MUTEX_SLEEP SYSAUX STATS$STREAMS_POOL_ADVICE_PK STATS$STREAMS_POOL_ADVICE SYSAUX STATS$SGA_TARGET_ADVICE_PK STATS$SGA_TARGET_ADVICE SYSAUX STATS$PROCESS_MEMORY_ROLLUP_PK STATS$PROCESS_MEMORY_ROLLUP SYSAUX STATS$$PROCESS_ROLLUP_PK STATS$PROCESS_ROLLUP SYSAUX STATS$OSSTAT_PK STATS$OSSTAT SYSAUX STATS$OSSSTATNAME_PK STATS$OSSTATNAME SYSAUX STATS$RULE_SET_PK STATS$RULE_SET SYSAUX STATS$BUFFERED_SUBSCRIBERS_PK STATS$BUFFERED_SUBSCRIBERS SYSAUX STATS$BUFFERED_QUEUES_PK STATS$BUFFERED_QUEUES SYSAUX STATS$PROPAGATION_RECEIVER_PK STATS$PROPAGATION_RECEIVER SYSAUX STATS$PROPAGATION_SENDER_PK STATS$PROPAGATION_SENDER SYSAUX STATS$STREAMS_APPLY_SUM_PK STATS$STREAMS_APPLY_SUM SYSAUX STATS$STREAMS_CAPTURE_PK STATS$STREAMS_CAPTURE SYSAUX STATS$SESS_TIME_MODEL_PK STATS$SESS_TIME_MODEL SYSAUX STATS$SYS_TIME_MODEL_PK STATS$SYS_TIME_MODEL SYSAUX STATS$TIME_MODEL_STATNAME_PK STATS$TIME_MODEL_STATNAME SYSAUX STATS$EVENT_HISTOGRAM_PK STATS$EVENT_HISTOGRAM SYSAUX STATS$FILE_HISTOGRAM_PK STATS$FILE_HISTOGRAM SYSAUX STATS$THREAD_PK STATS$THREAD SYSAUX STATS$JAVA_POOL_ADVICE_PK STATS$JAVA_POOL_ADVICE SYSAUX STATS$PGA_TARGET_ADVICE_PK STATS$PGA_TARGET_ADVICE SYSAUX STATS$SQL_WORKAREA_HIST_PK STATS$SQL_WORKAREA_HISTOGRAM SYSAUX STATS$SHARED_POOL_ADVICE_PK STATS$SHARED_POOL_ADVICE SYSAUX STATS$STATSPACK_PARAMETER_PK STATS$STATSPACK_PARAMETER SYSAUX STATS$INSTANCE_RECOVERY_PK STATS$INSTANCE_RECOVERY SYSAUX STATS$PARAMETER_PK STATS$PARAMETER SYSAUX STATS$SQL_PGASTAT_PK STATS$PGASTAT SYSAUX STATS$SEG_STAT_OBJ_PK STATS$SEG_STAT_OBJ SYSAUX STATS$SEG_STAT_PK STATS$SEG_STAT SYSAUX STATS$SQL_PLAN_PK STATS$SQL_PLAN SYSAUX STATS$SQL_PLAN_USAGE_HV STATS$SQL_PLAN_USAGE SYSAUX STATS$SQL_PLAN_USAGE_PK STATS$SQL_PLAN_USAGE SYSAUX STATS$UNDOSTAT_PK STATS$UNDOSTAT SYSAUX STATS$INST_CACHE_TRANSFER_PK STATS$INSTANCE_CACHE_TRANSFER SYSAUX STATS$CURRENT_BLOCK_SERVER_PK STATS$CURRENT_BLOCK_SERVER SYSAUX STATS$CR_BLOCK_SERVER_PK STATS$CR_BLOCK_SERVER SYSAUX STATS$DLM_MISC_PK STATS$DLM_MISC SYSAUX STATS$RESOURCE_LIMIT_PK STATS$RESOURCE_LIMIT SYSAUX STATS$SQL_STATISTICS_PK STATS$SQL_STATISTICS SYSAUX STATS$SQLTEXT_PK STATS$SQLTEXT SYSAUX STATS$SQL_SUMMARY_PK STATS$SQL_SUMMARY SYSAUX STATS$ENQUEUE_STATISTICS_PK STATS$ENQUEUE_STATISTICS SYSAUX STATS$WAITSTAT_PK STATS$WAITSTAT SYSAUX STATS$SESSION_EVENT_PK STATS$SESSION_EVENT SYSAUX STATS$SYSTEM_EVENT_PK STATS$SYSTEM_EVENT SYSAUX STATS$SESSTAT_PK STATS$SESSTAT SYSAUX STATS$SYSSTAT_PK STATS$SYSSTAT SYSAUX STATS$SGASTAT_U STATS$SGASTAT SYSAUX STATS$SGA_PK STATS$SGA SYSAUX STATS$ROWCACHE_SUMMARY_PK STATS$ROWCACHE_SUMMARY SYSAUX STATS$ROLLSTAT_PK STATS$ROLLSTAT SYSAUX STATS$BUFFER_POOL_STATS_PK STATS$BUFFER_POOL_STATISTICS SYSAUX STATS$LIBRARYCACHE_PK STATS$LIBRARYCACHE SYSAUX STATS$LATCH_MISSES_SUMMARY_PK STATS$LATCH_MISSES_SUMMARY SYSAUX STATS$LATCH_PARENT_PK STATS$LATCH_PARENT SYSAUX STATS$LATCH_CHILDREN_PK STATS$LATCH_CHILDREN SYSAUX STATS$LATCH_PK STATS$LATCH SYSAUX STATS$TEMPSTATXS_PK STATS$TEMPSTATXS SYSAUX STATS$FILESTATXS_PK STATS$FILESTATXS SYSAUX STATS$DB_CACHE_ADVICE_PK STATS$DB_CACHE_ADVICE SYSAUX STATS$SNAPSHOT_PK STATS$SNAPSHOT SYSAUX STATS$LEVEL_DESCRIPTION_PK STATS$LEVEL_DESCRIPTION SYSAUX STATS$DATABASE_INSTANCE_PK STATS$DATABASE_INSTANCE SYSAUX 73 rows selected.索引も移動させる。
次のSQLでalter index文を作成SQL> select 'alter index perfstat.' || index_name || ' rebuild tablespace STATSPACK;' from dba_indexes where OWNER = 'PERFSTAT'; 'ALTERINDEXPERFSTAT.'||INDEX_NAME||'REBUILDTABLESPACESTATSPACK;' ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- alter index perfstat.STATS$IDLE_EVENT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$INTERCONNECT_PINGS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$MEMORY_RESIZE_OPS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$MEMORY_DYNAMIC_COMPS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$MEMORY_TARGET_ADVICE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$IOSTAT_FUNC_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$IOSTAT_FUNCTION_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$IOSTAT_FUNCTION_NAME_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$DYNAMIC_REM_STATS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$MUTEX_SLEEP_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$STREAMS_POOL_ADVICE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SGA_TARGET_ADVICE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$PROCESS_MEMORY_ROLLUP_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$$PROCESS_ROLLUP_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$OSSTAT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$OSSSTATNAME_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$RULE_SET_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$BUFFERED_SUBSCRIBERS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$BUFFERED_QUEUES_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$PROPAGATION_RECEIVER_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$PROPAGATION_SENDER_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$STREAMS_APPLY_SUM_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$STREAMS_CAPTURE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SESS_TIME_MODEL_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SYS_TIME_MODEL_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$TIME_MODEL_STATNAME_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$EVENT_HISTOGRAM_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$FILE_HISTOGRAM_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$THREAD_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$JAVA_POOL_ADVICE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$PGA_TARGET_ADVICE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SQL_WORKAREA_HIST_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SHARED_POOL_ADVICE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$STATSPACK_PARAMETER_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$INSTANCE_RECOVERY_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$PARAMETER_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SQL_PGASTAT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SEG_STAT_OBJ_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SEG_STAT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SQL_PLAN_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SQL_PLAN_USAGE_HV rebuild tablespace STATSPACK; alter index perfstat.STATS$SQL_PLAN_USAGE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$UNDOSTAT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$INST_CACHE_TRANSFER_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$CURRENT_BLOCK_SERVER_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$CR_BLOCK_SERVER_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$DLM_MISC_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$RESOURCE_LIMIT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SQL_STATISTICS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SQLTEXT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SQL_SUMMARY_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$ENQUEUE_STATISTICS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$WAITSTAT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SESSION_EVENT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SYSTEM_EVENT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SESSTAT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SYSSTAT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SGASTAT_U rebuild tablespace STATSPACK; alter index perfstat.STATS$SGA_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$ROWCACHE_SUMMARY_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$ROLLSTAT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$BUFFER_POOL_STATS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$LIBRARYCACHE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$LATCH_MISSES_SUMMARY_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$LATCH_PARENT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$LATCH_CHILDREN_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$LATCH_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$TEMPSTATXS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$FILESTATXS_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$DB_CACHE_ADVICE_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$SNAPSHOT_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$LEVEL_DESCRIPTION_PK rebuild tablespace STATSPACK; alter index perfstat.STATS$DATABASE_INSTANCE_PK rebuild tablespace STATSPACK; 73 rows selected.上記のSQLを実行。
索引を確認すると表領域がSTATSPACKに変わった。SQL> col INDEX_NAME for a30 SQL> select INDEX_NAME,TABLE_NAME,TABLESPACE_NAME from dba_indexes where owner = 'PERFSTAT'; INDEX_NAME TABLE_NAME TABLESPACE_NAME ------------------------------ ------------------------------ ------------------------------ STATS$IDLE_EVENT_PK STATS$IDLE_EVENT STATSPACK STATS$INTERCONNECT_PINGS_PK STATS$INTERCONNECT_PINGS STATSPACK STATS$MEMORY_RESIZE_OPS_PK STATS$MEMORY_RESIZE_OPS STATSPACK STATS$MEMORY_DYNAMIC_COMPS_PK STATS$MEMORY_DYNAMIC_COMPS STATSPACK STATS$MEMORY_TARGET_ADVICE_PK STATS$MEMORY_TARGET_ADVICE STATSPACK STATS$IOSTAT_FUNC_PK STATS$IOSTAT_FUNCTION_DETAIL STATSPACK STATS$IOSTAT_FUNCTION_PK STATS$IOSTAT_FUNCTION STATSPACK STATS$IOSTAT_FUNCTION_NAME_PK STATS$IOSTAT_FUNCTION_NAME STATSPACK STATS$DYNAMIC_REM_STATS_PK STATS$DYNAMIC_REMASTER_STATS STATSPACK STATS$MUTEX_SLEEP_PK STATS$MUTEX_SLEEP STATSPACK STATS$STREAMS_POOL_ADVICE_PK STATS$STREAMS_POOL_ADVICE STATSPACK STATS$SGA_TARGET_ADVICE_PK STATS$SGA_TARGET_ADVICE STATSPACK STATS$PROCESS_MEMORY_ROLLUP_PK STATS$PROCESS_MEMORY_ROLLUP STATSPACK STATS$$PROCESS_ROLLUP_PK STATS$PROCESS_ROLLUP STATSPACK STATS$OSSTAT_PK STATS$OSSTAT STATSPACK STATS$OSSSTATNAME_PK STATS$OSSTATNAME STATSPACK STATS$RULE_SET_PK STATS$RULE_SET STATSPACK STATS$BUFFERED_SUBSCRIBERS_PK STATS$BUFFERED_SUBSCRIBERS STATSPACK STATS$BUFFERED_QUEUES_PK STATS$BUFFERED_QUEUES STATSPACK STATS$PROPAGATION_RECEIVER_PK STATS$PROPAGATION_RECEIVER STATSPACK STATS$PROPAGATION_SENDER_PK STATS$PROPAGATION_SENDER STATSPACK STATS$STREAMS_APPLY_SUM_PK STATS$STREAMS_APPLY_SUM STATSPACK STATS$STREAMS_CAPTURE_PK STATS$STREAMS_CAPTURE STATSPACK STATS$SESS_TIME_MODEL_PK STATS$SESS_TIME_MODEL STATSPACK STATS$SYS_TIME_MODEL_PK STATS$SYS_TIME_MODEL STATSPACK STATS$TIME_MODEL_STATNAME_PK STATS$TIME_MODEL_STATNAME STATSPACK STATS$EVENT_HISTOGRAM_PK STATS$EVENT_HISTOGRAM STATSPACK STATS$FILE_HISTOGRAM_PK STATS$FILE_HISTOGRAM STATSPACK STATS$THREAD_PK STATS$THREAD STATSPACK STATS$JAVA_POOL_ADVICE_PK STATS$JAVA_POOL_ADVICE STATSPACK STATS$PGA_TARGET_ADVICE_PK STATS$PGA_TARGET_ADVICE STATSPACK STATS$SQL_WORKAREA_HIST_PK STATS$SQL_WORKAREA_HISTOGRAM STATSPACK STATS$SHARED_POOL_ADVICE_PK STATS$SHARED_POOL_ADVICE STATSPACK STATS$STATSPACK_PARAMETER_PK STATS$STATSPACK_PARAMETER STATSPACK STATS$INSTANCE_RECOVERY_PK STATS$INSTANCE_RECOVERY STATSPACK STATS$PARAMETER_PK STATS$PARAMETER STATSPACK STATS$SQL_PGASTAT_PK STATS$PGASTAT STATSPACK STATS$SEG_STAT_OBJ_PK STATS$SEG_STAT_OBJ STATSPACK STATS$SEG_STAT_PK STATS$SEG_STAT STATSPACK STATS$SQL_PLAN_PK STATS$SQL_PLAN STATSPACK STATS$SQL_PLAN_USAGE_HV STATS$SQL_PLAN_USAGE STATSPACK STATS$SQL_PLAN_USAGE_PK STATS$SQL_PLAN_USAGE STATSPACK STATS$UNDOSTAT_PK STATS$UNDOSTAT STATSPACK STATS$INST_CACHE_TRANSFER_PK STATS$INSTANCE_CACHE_TRANSFER STATSPACK STATS$CURRENT_BLOCK_SERVER_PK STATS$CURRENT_BLOCK_SERVER STATSPACK STATS$CR_BLOCK_SERVER_PK STATS$CR_BLOCK_SERVER STATSPACK STATS$DLM_MISC_PK STATS$DLM_MISC STATSPACK STATS$RESOURCE_LIMIT_PK STATS$RESOURCE_LIMIT STATSPACK STATS$SQL_STATISTICS_PK STATS$SQL_STATISTICS STATSPACK STATS$SQLTEXT_PK STATS$SQLTEXT STATSPACK STATS$SQL_SUMMARY_PK STATS$SQL_SUMMARY STATSPACK STATS$ENQUEUE_STATISTICS_PK STATS$ENQUEUE_STATISTICS STATSPACK STATS$WAITSTAT_PK STATS$WAITSTAT STATSPACK STATS$SESSION_EVENT_PK STATS$SESSION_EVENT STATSPACK STATS$SYSTEM_EVENT_PK STATS$SYSTEM_EVENT STATSPACK STATS$SESSTAT_PK STATS$SESSTAT STATSPACK STATS$SYSSTAT_PK STATS$SYSSTAT STATSPACK STATS$SGASTAT_U STATS$SGASTAT STATSPACK STATS$SGA_PK STATS$SGA STATSPACK STATS$ROWCACHE_SUMMARY_PK STATS$ROWCACHE_SUMMARY STATSPACK STATS$ROLLSTAT_PK STATS$ROLLSTAT STATSPACK STATS$BUFFER_POOL_STATS_PK STATS$BUFFER_POOL_STATISTICS STATSPACK STATS$LIBRARYCACHE_PK STATS$LIBRARYCACHE STATSPACK STATS$LATCH_MISSES_SUMMARY_PK STATS$LATCH_MISSES_SUMMARY STATSPACK STATS$LATCH_PARENT_PK STATS$LATCH_PARENT STATSPACK STATS$LATCH_CHILDREN_PK STATS$LATCH_CHILDREN STATSPACK STATS$LATCH_PK STATS$LATCH STATSPACK STATS$TEMPSTATXS_PK STATS$TEMPSTATXS STATSPACK STATS$FILESTATXS_PK STATS$FILESTATXS STATSPACK STATS$DB_CACHE_ADVICE_PK STATS$DB_CACHE_ADVICE STATSPACK STATS$SNAPSHOT_PK STATS$SNAPSHOT STATSPACK STATS$LEVEL_DESCRIPTION_PK STATS$LEVEL_DESCRIPTION STATSPACK STATS$DATABASE_INSTANCE_PK STATS$DATABASE_INSTANCE STATSPACK 73 rows selected.スナップショット
マスターユーザからPERFSTATユーザに、DBMS_SCHEDULERパッケージを使用する権限を付与。
※DBMS_JOBパッケージは、DBMS_SCHEDULERパッケージによって置き換えられているため、DBMS_SCHEDULERパッケージを使用する。
Oracle® Database PL/SQLパッケージおよびタイプ・リファレンス 12c リリース1 (12.1)SQL> GRANT SCHEDULER_ADMIN TO PERFSTAT; Grant succeeded. SQL> col grantee for a10 SQL> col granted_role for a20 SQL> select grantee,granted_role from dba_role_privs where GRANTEE = 'PERFSTAT'; GRANTEE GRANTED_ROLE ---------- -------------------- PERFSTAT SELECT_CATALOG_ROLE PERFSTAT SCHEDULER_ADMIN ★付与されたPERFSTATユーザでログイン
SQL> conn perfstat/perfstat@orcl1 Connected. SQL> SQL> sho user USER is "PERFSTAT"自動的にスナップショットを取得するジョブを作成
(例)スナップショットレベルを7、10分間隔で取得SQL> BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'STATSPACK_SNAPSHOT', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN STATSPACK.SNAP(I_SNAP_LEVEL=>7); END;', start_date => NULL, repeat_interval => 'FREQ=MINUTELY;INTERVAL=10;', end_date => NULL, auto_drop => FALSE, enabled => TRUE ); END; / PL/SQL procedure successfully completed.
- DBMS_SCHEDULER.CREATE_JOBプロシージャのパラメーター
パラメーター 内容 job_name ジョブ名 job_type 実行するジョブの種類を指定する。
STORED_PROCEDURE:プロシージャ
EXECUTABLE:外部プログラム(exeなど)
PLSQL_BLOCK:PL/SQLブロックjob_action ジョブの実行対象(job_typeによって変わる)
STORED_PROCEDURE:プロシージャ名
EXECUTABLE:プログラム名
PLSQL_BLOCK:PL/SQLブロックstart_date ジョブの開始日時(日付型で指定する) repeat_interval ジョブの実行間隔
FREQ=
年:YEARLY
月:MONTHLY
週:WEEKLY
日:DAILY
時:HOURLY
分:MINUTELY
秒:SECONDLY
INTERVAL=
数値:指定した回数毎に実行
(例)'FREQ=HOURLY;INTERVAL=5 :5時間毎に実行する
BYMONTH:実行月を指定する(1~12)
(例)'FREQ=DAILY;BYMONTH=8' 8月に毎日実行する
BYWEEKNO:実行週を指定する(1~53)
(例)'BYWEEKNO=30' 年の30週目に実行する
BYYEARDAY:実行日を指定する(1~366)
(例)'BYYEARDAY=100' 年の100日目に実行する
BYDATE:実行日を指定する(MMDD形式)
(例)'BYDATE=100' 年の100日目に実行する
BYMONTHDAY:実行日を指定する(1~31)
(例)'FREQ=MONTHLY;BYMONTHDAY=25' 毎月25日に実行する
BYHOUR:実行時間を指定する(0~23)
(例)'FREQ=DAILY;BYHOUR=3' 毎日3時に実行する
BYMINUTE:実行分を指定する(0~59)
(例)'FREQ=HOURLY;BYMINUTE=30' 毎時30分に実行する
BYSECOND:実行秒を指定する(0~59)
(例)'FREQ=SECONDLY;BYSECOND=15' 毎分15秒に実行するend_date ジョブの終了日時(日付型で指定する) auto_drop ジョブ完了時に削除する/しないの設定
true:削除する(デフォルト)
false:削除しないenabled ジョブが有効/無効の設定
true:有効
false:無効(デフォルト)
- StatsPackのスナップショットレベル
レベル 内容 レベル0 全体的なパフォーマンス統計 レベル5 下位の内容 + SQL ステートメント (※デフォルト) レベル6 下位の内容 + SQL 実行計画および SQL 実行計画の使用率 レベル7 下位の内容 + セグメントレベルの統計 レベル10 下位の内容 + 親ラッチおよび子ラッチ スケジューラ・ジョブの確認
SQL> set pages 100 line 2000 SQL> col owner for a10 SQL> col job_name for a20 SQL> col job_action for a45 SQL> col start_date for a40 SQL> col repeat_interval for a30 SQL> col end_date for a30 SQL> SELECT OWNER,JOB_NAME,JOB_TYPE,JOB_ACTION,START_DATE,REPEAT_INTERVAL,END_DATE,AUTO_DROP,ENABLED FROM DBA_SCHEDULER_JOBS WHERE JOB_NAME='STATSPACK_SNAPSHOT'; OWNER JOB_NAME JOB_TYPE JOB_ACTION START_DATE REPEAT_INTERVAL END_DATE AUTO_ ENABL ---------- -------------------- ---------------- --------------------------------------------- ---------------------------------------- ------------------------------ ------------------------------ ----- ----- PERFSTAT STATSPACK_SNAPSHOT PLSQL_BLOCK BEGIN STATSPACK.SNAP(I_SNAP_LEVEL=>7); END; 04-JUL-19 05.58.18.028588 AM ETC/UTC FREQ=MINUTELY;INTERVAL=10; FALSE TRUEスナップショットの取得の確認
SQL> select snap_id, to_char(snap_time,'YYYY/MM/DD HH24:MI:SS') from stats$snapshot order by 1; SNAP_ID TO_CHAR(SNAP_TIME,' ---------- ------------------- 1 2019/07/04 15:41:13今回は10分間隔で取得するので、10分待つと2つ目のスナップショットが取得される
SQL> select snap_id, to_char(snap_time,'YYYY/MM/DD HH24:MI:SS') from stats$snapshot order by 1; SNAP_ID TO_CHAR(SNAP_TIME,' ---------- ------------------- 1 2019/07/04 15:41:13 2 2019/07/04 15:51:17スケジューラ・ジョブのログからジョブの実行が成功したか確認
SQL> select job_name,log_id, to_char(log_date,'YYYY/MM/DD HH24:MI:SS'), job_name, status, to_char(actual_start_date,'YYYY/MM/DD HH24:MI:SS'), run_duration from dba_scheduler_job_run_details 2 where job_name = 'STATSPACK_SNAPSHOT' order by log_date; JOB_NAME LOG_ID TO_CHAR(LOG_DATE,'Y JOB_NAME STATUS TO_CHAR(ACTUAL_STAR RUN_DURATION -------------------- ---------- ------------------- -------------------- ------------------------------ ------------------- --------------------------------------------------------------------------- STATSPACK_SNAPSHOT 4480 2019/07/04 15:41:19 STATSPACK_SNAPSHOT SUCCEEDED 2019/07/04 06:41:13 +000 00:00:06 STATSPACK_SNAPSHOT 4486 2019/07/04 15:51:24 STATSPACK_SNAPSHOT SUCCEEDED 2019/07/04 06:51:16 +000 00:00:08スナップショットの自動削除も設定しておく。
(例)スナップショットを7日間保持(7日前は削除)、毎日01:00:00に実行SQL> BEGIN DBMS_SCHEDULER.CREATE_JOB ( job_name => 'STATSPACK_SNAPSHOT_PURGE', job_type => 'PLSQL_BLOCK', job_action => 'BEGIN STATSPACK.PURGE(i_purge_before_date=>SYSDATE-7); END;', start_date => NULL, repeat_interval => 'FREQ=DAILY; BYHOUR=1; BYMINUTE=0; BYSECOND=0;', auto_drop => FALSE, enabled => TRUE ); END; / PL/SQL procedure successfully completed.※ジョブスケジュールの変更方法
(例)スナップショット取得間隔を1時間に変更BEGIN DBMS_SCHEDULER.SET_ATTRIBUTE( name => 'STATSPACK_SNAPSHOT', attribute => 'repeat_interval', value => 'FREQ=HOURLY;INTERVAL=1;' ); END; /SQL> SELECT OWNER,JOB_NAME,JOB_TYPE,JOB_ACTION,START_DATE,REPEAT_INTERVAL,END_DATE,AUTO_DROP,ENABLED FROM DBA_SCHEDULER_JOBS WHERE JOB_NAME='STATSPACK_SNAPSHOT'; OWNER JOB_NAME JOB_TYPE JOB_ACTION START_DATE REPEAT_INTERVAL END_DATE AUTO_ ENABL ---------- -------------------- ---------------- --------------------------------------------- ---------------------------------------- ------------------------------ ------------------------------ ----- ----- PERFSTAT STATSPACK_SNAPSHOT PLSQL_BLOCK BEGIN STATSPACK.SNAP(I_SNAP_LEVEL=>7); END; 04-JUL-19 06.41.13.633620 AM ETC/UTC FREQ=HOURLY;INTERVAL=1; FALSE TRUEStatsPackレポート作成
SQL> exec RDSADMIN.RDS_RUN_SPREPORT(1,2); PL/SQL procedure successfully completed.RDSのコンソール上から、StatsPackのレポートを確認。
ダウンロードからレポートをダウンロードできます。

- 投稿日:2019-07-04T15:55:20+09:00
DMSを使ってオンプレからAWSにデータ移行&レプリケーションしたよ
概要
仕事でオンプレDBからAWSにデータ移行したので振り返りも兼ねてまとめたくなった
ところどころ自分のプロダクトに依存する部分があるので参考程度に留めてね自分のプロダクトでは、下記理由によりスキーマコピーとレプリケーションはMySQLの機能で行いデータ移行はDMSで行いました
- エンジンがMyISAMのスキーマがあるがDMSでスキーマを作るとInnoDBに再構築されてしまう
- DMSのレプリケーションには対応してない型があった
- 本番DBの権限の問題で自由にデータをdumpできない&DBへの負荷を考えてデータ全部dumpするのは避けたい
データ移行って?
サービスや機能をオンプレからパブリッククラウドへ移行するにあたってDBのデータもクラウドで用意するDBに移す作業です
DBがオンプレにあっても問題はないですが疎通や相性など諸々含めると一緒にパブリッククラウドに移しちゃったほうが将来的に楽できると思いますDMSってなに?
AWSにあるデータベースのデータ移行とレプリケーションサービス
正式名称は、AWS Database Migration Service
移行中もソースデーターベースを止める必要がないし異なったデータベースプラットフォーム間での移行もサポートされてるすごい奴
サポートされてるプラットフォームや細かい機能は挙げだすときりがないのでこちらを参照ください
とにかくすごい。好きDMSでできること
- スキーマの移行
- オンプレのスキーマ情報をAWSのDBにコピーできる
- 完全にコピーされる保証はないのでmysqldumpなどを推奨
- データの移行
- オンプレのDBに格納されているデータをAWSのDBにコピーできる
- 一部のテーブルデータは移さないなどの設定も可能
- レプリケーションの設定
- データの移行が終わった後にそのままレプリケーションを貼ることができる
- 最小のダウンタイムでのデータ移行
- レプリケーションインスタンスを挟んでのデータ移行なのでオンプレの機能を制限する必要がない
- すごい
- 移行後のデータ変更も追える
- 移行後も変更に追従してくれるので、切替も切戻しもローリスク
- すごい
- 異種間(OracleからMySQLなど)のDBの移行をサポートしていること
- レプリケーションインスタンスを挟んでのデータ移行なので中間インスタンスでいい感じにできる
- すごい
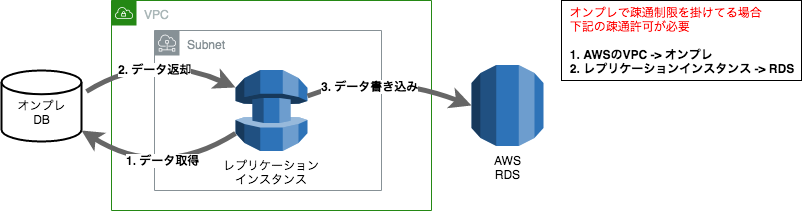
移行のイメージ
DMSとオンプレDBへのデータの流れはこんな感じ
データ移行後にレプリケーションを貼り続ける場合、データ移行後もこれが続くイメージ
移行手段の選択肢
それぞれのDBの機能を使って移行
mysqldumpなどでスキーマ情報とデータをダンプし移行先のDBに流し込みコマンドでレプリケーションをとる方法
- メリット
- 障害発生点が減る
- 同じデータベースプラットフォームの場合こちらの方がスタンダード
- デメリット
- dumpしてデータを移行する性質上どうしてもDBを止めるか書き込みを制限するタイミングが発生してしまう
- 何かあったときロールバックやデータの差異の修正が大変
- 異なったデータベースプラットフォームへの以降はできない?
- dumpするために権限をもらうか権限がある人にファイルをもらう調整が必要
DMSを使って移行
DMSを使ってデータ移行とレプリケーションをとる方法
- メリット
- ソースDBを止めないで移行できる
- データ移行とレプリケーションが1つの機能でできる
- 異なったデータベースプラットフォーム間での移行もサポートされてる
- デメリット
- サポートされてない型があり必ずできるとは言えない
- レプリケーションインスタンスを立てる性質上、障害点が増えてしまう
ハマりポイントあります
- AuroraやRDS for MySQLでは、MyISAMはサポートしてない
- サポートしてないのでMyISAMで作られたテーブルがある場合、DMSでスキーマ情報をコピーすると全てInnoDBで構築される
- InnoDBで構築されてもいいならDMSで行うと勝手にエンジンがInnoDBになっていい感じ
- DMSでは、サポートされてない型がある
- スキーマやカラムの型次第では、DMSでサポートされておらず使えない可能性がある
- サポートされている型一覧はこちら
- AWSのRDSには、replicate-ignore-db設定がない
- ignore設定がないので全てのDBをレプリケーションしない場合、binlogに吐き出すDBを指定するなどの設定が必要
- データ移行ではサポートされてるけどレプリケーションではサポートされてない型などがある
- データ移行では問題なかったけどレプリケーションを貼るとうまくいかない場合があるのでどこまで出来てどこを他の機能に任せるかの判断が必要
- セカンダリインデックス、非プライマリーキー制約、デフォルト値などはサポートしてないので移行先に自分で作る必要がある
実作業コマンド
* 作業メモには、オープンにできない内容が載っていたのであとでいい感じにして追記します
最後に
DMSは、とても便利ですごい機能ですが自分たちのプロダクト次第でできる範囲が変わってくる
どこまでできるかは実際に試さないとわからない部分があるので試してみるといい
MyISAMはAWSと相性が悪いのでめんどくさいから脱却したい
AWSへの移行は、どこまでをどの機能で行うかが難しいが自分のプロダクトにあった運用を参考文献
AWS DMS : https://aws.amazon.com/jp/dms/
DMS MySQLサポート : https://docs.aws.amazon.com/ja_jp/dms/latest/userguide/CHAP_Source.MySQL.html
- 投稿日:2019-07-04T15:55:20+09:00
DMSを使ってオンプレからAWSにデータ移行したよ
概要
仕事でオンプレDBからAWSにデータ移行したので振り返りも兼ねてまとめたくなった
ところどころ自分のプロダクトに依存する部分があるので参考程度に留めてね自分のプロダクトでは、下記理由によりスキーマコピーとレプリケーションはMySQLの機能で行いデータ移行はDMSで行いました
- エンジンがMyISAMのスキーマがあるがDMSでスキーマを作るとInnoDBに再構築されてしまう
- DMSのレプリケーションには対応してない型があった
- 本番DBの権限の問題で自由にデータをdumpできない&DBへの負荷を考えてデータ全部dumpするのは避けたい
データ移行って?
サービスや機能をオンプレからパブリッククラウドへ移行するにあたってDBのデータもクラウドで用意するDBに移す作業です
DBがオンプレにあっても問題はないですが疎通や相性など諸々含めると一緒にパブリッククラウドに移しちゃったほうが将来的に楽できると思いますDMSってなに?
AWSにあるデータベースのデータ移行とレプリケーションサービス
正式名称は、AWS Database Migration Service
移行中もソースデーターベースを止める必要がないし異なったデータベースプラットフォーム間での移行もサポートされてるすごい奴
サポートされてるプラットフォームや細かい機能は挙げだすときりがないのでこちらを参照ください
とにかくすごい。好きDMSでできること
スキーマの移行
- オンプレのスキーマ情報をAWSのDBにコピーできる
- 完全にコピーされる保証はないのでmysqldumpなどを推奨
データの移行
- オンプレのDBに格納されているデータをAWSのDBにコピーできる
- 一部のテーブルデータは移さないなどの設定も可能
データ移行後の変更も追跡する
- データの移行が終わった後に変更を追うことができるのでそのままレプリケーションを貼ることができる
- 1つの機能でデータ移行とレプリケーションの両方を実現できる
- 移行後も変更に追従してくれるので、切替も切戻しもローリスク
最小のダウンタイムでのデータ移行
- レプリケーションインスタンスを挟んでのデータ移行なのでオンプレの機能を制限する必要がない
- すごい
異種間(OracleからMySQLなど)のDBの移行をサポートしている
- レプリケーションインスタンスを挟んでのデータ移行なので中間インスタンスでいい感じにできる
- まじですごい
移行のイメージ
DMSとオンプレDBへのデータの流れはこんな感じ
データ移行後にレプリケーションを貼り続ける場合、データ移行後もこれが続くイメージ
移行手段の選択肢
それぞれのDBの機能を使って移行
mysqldumpなどでスキーマ情報とデータをダンプし移行先のDBに流し込みコマンドでレプリケーションをとる方法
- メリット
- 障害発生点が減る
- 同じデータベースプラットフォームの場合こちらの方がスタンダード
- デメリット
- dumpしてデータを移行する性質上どうしてもDBを止めるか書き込みを制限するタイミングが発生してしまう
- 何かあったときロールバックやデータの差異の修正が大変
- 異なったデータベースプラットフォームへの以降はできない?
- dumpするために権限をもらうか権限がある人にファイルをもらう調整が必要
DMSを使って移行
DMSを使ってデータ移行とレプリケーションをとる方法
- メリット
- ソースDBを止めないで移行できる
- データ移行とレプリケーションが1つの機能でできる
- 異なったデータベースプラットフォーム間での移行もサポートされてる
- デメリット
- サポートされてない型があり必ずできるとは言えない
- レプリケーションインスタンスを立てる性質上、障害点が増えてしまう
ハマりポイントあります
- AuroraやRDS for MySQLでは、MyISAMはサポートしてない
- サポートしてないのでMyISAMで作られたテーブルがある場合、DMSでスキーマ情報をコピーすると全てInnoDBで構築される
- InnoDBで構築されてもいいならDMSで行うと勝手にエンジンがInnoDBになっていい感じ
- DMSでは、サポートされてない型がある
- スキーマやカラムの型次第では、DMSでサポートされておらず使えない可能性がある
- サポートされている型一覧はこちら
- AWSのRDSには、replicate-ignore-db設定がない
- ignore設定がないので全てのDBをレプリケーションしない場合、binlogに吐き出すDBを指定するなどの設定が必要
- データ移行ではサポートされてるけどレプリケーションではサポートされてない型などがある
- データ移行では問題なかったけどレプリケーションを貼るとうまくいかない場合があるのでどこまで出来てどこを他の機能に任せるかの判断が必要
- セカンダリインデックス、非プライマリーキー制約、デフォルト値などはサポートしてないので移行先に自分で作る必要がある
実作業コマンド
* 作業メモには、オープンにできない内容が載っていたのであとでいい感じにして追記します
最後に
DMSは、とても便利ですごい機能ですが自分たちのプロダクト次第でできる範囲が変わってくる
どこまでできるかは実際に試さないとわからない部分があるので試してみるといい
MyISAMはAWSと相性が悪いのでめんどくさいから脱却したい
AWSへの移行は、どこまでをどの機能で行うかが難しいが自分のプロダクトにあった運用を
短期で終われるならロールバックなども考えるとできるならレプリケーションもDMSでやりたかった
DMSしゅき〜〜参考文献
AWS DMS : https://aws.amazon.com/jp/dms/
DMS MySQLサポート : https://docs.aws.amazon.com/ja_jp/dms/latest/userguide/CHAP_Source.MySQL.html
- 投稿日:2019-07-04T15:48:57+09:00
AWS Amplifyでサーバーレスなログイン機能をスマートに実装
はじめに
AWS Amplify、使ったことありますか?フロントエンドの人でも楽しく使えるAWS、それがAmplifyです。AWS自体、最近勉強し始めたのですが、難しいことせずに素早くAWSサービス群が使えちゃうのでこれからもっと使っていきたいです。
本記事はサインアップ/サインインの認証機能を一から作っていくチュートリアルです。GitHubはこちらから。
目次
- AWS Amplifyの私の理解度
- サインアップなどのフォームとVue Routerの実装
- AWS Amplifyを設定
- AWS Amplifyの機能を実装
NOTE: 本記事ではAWS Amplifyチームが提供しているVue.jsのUIコンポーネントについては説明しません。
AWS Amplifyの私の理解度
AWS Amplifyでググってみたらいいんですが、大体以下のサービスの集まりだと認識するとググりやすいかもしれません。
- Amplify CLI: 開発時にお世話になるCLI。
- Amplify.js: JSコンポーネント。今回はWebの話しかしませんが、Naitive Mobile Appにも同等のものが提供されています。
- Amplify Console: AWS Consoleからアクセスできるクラウドサービス。デプロイ時のCIを提供。まだ触ったことはありません。。
サインアップなどのフォームとVue Routerの実装
ここで作るもの:
フォーム
- サインアップ
- メールアドレス確認
- サインイン
キレイにスタイリングした後のスクリーンショットはこちらのページにアップロードしています。
ルータ
サインインした時にはサインアップフォーム等を表示させたくないですよね。同時に、サインインしていない時にはサインアウトボタンのあるページを表示させたくないので、ルータを使ってアクセス制御します。
コーディングタイム!
インストール
まずはVue CLIでパッケージをインストールします。ここではVuetifyとVue Routerをインストールします。
$ # Install Vue CLI $ npm install @vue/cli -g $ # Create the project $ vue create my-app ? Please pick a preset: default (babel, eslint) $ cd $_ # Install Vuetify $ vue add vuetify ? Choose a preset: Default (recommended) # Install Vue Router $ vue add router ? Use history mode for router? (Requires proper server setup for index fallback in production) Yesサインアップフォーム
サインアップフォームを
src/views/signUp.vueに作ります。注意したいのは、メールアドレスの項目にusernameを使用しています。これは、AWS Amplifyではusernameが必須入力項目になっているためです。ここで変数名をusernameにする必要はないのですが便宜的に。ここでやっていることはVuetifyを使ったことのある方だったら流し読み程度で大丈夫です。フォームを設置し、メールアドレスとパスワードのバリデーションを設定しています。バリデーションを全部パスしたら「Submit」ボタンが押せるようになり、
Console.logに入力した値が表示されることを確認してください。// src/views/SignUp.vue <template> <div class="sign-up"> <h1>Sign Up</h1> <v-form v-model="valid" ref="form" lazy-validation> <v-text-field v-model="username" :rules="emailRules" label="Email Address" required/> <v-text-field v-model="password" :append-icon="passwordVisible ? 'visibility' : 'visibility_off'" :rules="[passwordRules.required, passwordRules.min]" :type="passwordVisible ? 'text' : 'password'" name="password" label="Password" hint="At least 8 characters" counter @click:append="passwordVisible = !passwordVisible" required/> <v-btn :disabled="!valid" @click="submit">Submit</v-btn> </v-form> </div> </template> <script> export default { name: "SignUp", data() { return { valid: false, username: '', password: '', passwordVisible: false, } }, computed: { emailRules() { return [ v => !!v || 'E-mail is required', v => /.+@.+/.test(v) || 'E-mail must be valid' ] }, passwordRules() { return { required: value => !!value || 'Required.', min: v => v.length >= 8 || 'Min 8 characters', emailMatch: () => ('The email and password you entered don\'t match'), } }, }, methods: { submit() { if (this.$refs.form.validate()) { console.log(`SIGN UP username: ${this.username}, password: ${this.password}, email: ${this.username}`); } }, }, } </script>サインアップ確認フォーム
サインアップが完了したら、AWSが対象メールアドレス宛にメールを送ってくれます。そのメールの中には確認コードがあるので、メールアドレスと確認コードを入力することで登録されたメールアドレスが正しいかを確認します。
サインアップフォームとやっていることは同じです。今の段階ではサインアップと同様に
console.logの出力しか行いません。src/views/SignUpConfirm.vueに作ります。// src/views/SignUpConfirm.vue <template> <div class="confirm"> <h1>Confirm</h1> <v-form v-model="valid" ref="form" lazy-validation> <v-text-field v-model="username" :rules="emailRules" label="Email Address" required/> <v-text-field v-model="code" :rules="codeRules" label="Code" required/> <v-btn :disabled="!valid" @click="submit">Submit</v-btn> </v-form> <v-btn @click="resend">Resend Code</v-btn> </div> </template> <script> export default { name: "SignUpConfirm", data() { return { valid: false, username: '', code: '', } }, computed: { emailRules() { return [ v => !!v || 'E-mail is required', v => /.+@.+/.test(v) || 'E-mail must be valid' ] }, codeRules() { return [ v => !!v || 'Code is required', v => (v && v.length === 6) || 'Code must be 6 digits' ] }, }, methods: { submit() { if (this.$refs.form.validate()) { console.log(`CONFIRM username: ${this.username}, code: ${this.code}`); } }, resend() { console.log(`RESEND username: ${this.username}`); } }, } </script>サインインフォーム
通常のサインインフォームです。サインアップフォームととても似ているので説明は特にしません。
src/views/SignIn.vueに作ります。// src/views/SignIn.vue <template> <div class="sign-in"> <h1>Sign In</h1> <v-form v-model="valid" ref="form" lazy-validation> <v-text-field v-model="username" :rules="emailRules" label="Email Address" required/> <v-text-field v-model="password" :append-icon="passwordVisible ? 'visibility' : 'visibility_off'" :rules="[passwordRules.required, passwordRules.min]" :type="passwordVisible ? 'text' : 'password'" name="password" label="Password" hint="At least 8 characters" counter @click:append="passwordVisible = !passwordVisible" required/> <v-btn :disabled="!valid" @click="submit">Submit</v-btn> </v-form> </div> </template> <script> export default { name: "SignIn", data() { return { valid: false, username: '', password: '', passwordVisible: false, } }, computed: { emailRules() { return [ v => !!v || 'E-mail is required', v => /.+@.+/.test(v) || 'E-mail must be valid' ] }, passwordRules() { return { required: value => !!value || 'Required.', min: v => v.length >= 8 || 'Min 8 characters', emailMatch: () => ('The email and password you entered don\'t match'), } }, }, methods: { submit() { if (this.$refs.form.validate()) { console.log(`SIGN IN username: ${this.username}, password: ${this.password}`); } }, }, } </script>サインイン後のページ
ここでサインインした後のページを作ってもいいのですが、面倒なので、Vue Routerをインストールした時に生成された
src/views/Home.vueを使い回しましょう。Vue Routerにフォームページを追加していく
Vue Routerをインストールした時、
src/App.vueがアップデートされたことにお気づきかと思います。// src/App.vue <template> <div id="app"> <div id="nav"> <router-link to="/">Home</router-link> | <router-link to="/about">About</router-link> </div> <router-view/> </div> </template>これを参考に、フォームページを追加していきます。
// src/App.vue <template> <div id="app"> <div id="nav"> <router-link to="/">Home</router-link> | <router-link to="/about">About</router-link> | <router-link to="/signUp">Sign Up</router-link> | <router-link to="/signUpConfirm">Confirm</router-link> | <router-link to="/signIn">Sign In</router-link> </div> <router-view/> </div> </template> <style> #app { font-family: 'Avenir', Helvetica, Arial, sans-serif; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale; color: #2c3e50; margin-top: 60px; } </style>同様に、Vue Routerをインストールした時に
src/router.jsというファイルが新しく追加されています。フォームページを追加していきましょう。// src/router.js import Vue from 'vue' import Router from 'vue-router' import Home from './views/Home.vue' Vue.use(Router) export default new Router({ mode: 'history', base: process.env.BASE_URL, routes: [ { path: '/', name: 'home', component: Home }, { path: '/about', name: 'about', // route level code-splitting // this generates a separate chunk (about.[hash].js) for this route // which is lazy-loaded when the route is visited. component: () => import(/* webpackChunkName: "about" */ './views/About.vue') }, { path: '/signUp', name: 'signUp', component: () => import(/* webpackChunkName: "signup" */ './views/SignUp.vue') }, { path: '/signUpConfirm', name: 'signUpConfirm', component: () => import(/* webpackChunkName: "confirm" */ './views/SignUpConfirm.vue') }, { path: '/signIn', name: 'signIn', component: () => import(/* webpackChunkName: "signin" */ './views/SignIn.vue') }, ] })この段階で、ブラウザ上にナビゲーションアイテムが追加されているのが確認できるはずです。それぞれをクリックして、対応したフォームが表示されているか確認してみましょう。
AWS Amplifyを設定
フロントエンドの方にとってなんだか敷居の高いAWSをこれから使っていきます。Get Startedのページに従って、AWSのアカウント作成、Amplify CLIのインストールを実行してみてください。インストールが終わったら早速CLIを使っていきます。
$ amplify configureざっくり言うとこのコマンドはお使いのコンピューターからAWSにアクセスすることを知らせます。いくつか選択肢があったりしますので、読み進めて任意に設定してください。私が選択した結果は以下の通りです。参考までに。
these steps to set up access to your AWS account: Sign in to your AWS administrator account: https://console.aws.amazon.com/ Press Enter to continue Specify the AWS Region ? region: us-west-2 Specify the username of the new IAM user: ? user name: amplify-cognito-vuejs-example Complete the user creation using the AWS console https://console.aws.amazon.com/iam/home?region=undefined#/users$new?step=final&accessKey&userNames=amplify-cognito-vuejs-example&permissionType=policies&policies=arn:aws:iam::aws:policy%2FAdministratorAccess Press Enter to continue Enter the access key of the newly created user: ? accessKeyId: AKIA2BSHMB********** ? secretAccessKey: 4IgyKbOh9EJiufb4prtd******************** This would update/create the AWS Profile in your local machine ? Profile Name: default Successfully set up the new user.次に、同じCLIを使ってプロジェクトを初期化します。
$ amplify initここも任意設定です。ご自身の環境に合わせて設定してください。私が選択した結果は以下の通りです。ほぼデフォルトですね。
Note: It is recommended to run this command from the root of your app directory ? Enter a name for the project my-app ? Enter a name for the environment dev ? Choose your default editor: Vim (via Terminal, Mac OS only) ? Choose the type of app that you're building javascript Please tell us about your project ? What javascript framework are you using vue ? Source Directory Path: src ? Distribution Directory Path: dist ? Build Command: npm run-script build ? Start Command: npm run-script serveそして、認証機能である
authを追加します。以下のコマンドだけで追加できちゃいます。amplify add authここでも選択肢をいくつか選択します。以下、私の選択した結果です。
Using service: Cognito, provided by: awscloudformation The current configured provider is Amazon Cognito. Do you want to use the default authentication and security configuration? Default configuration Warning: you will not be able to edit these selections. How do you want users to be able to sign in when using your Cognito User Pool? Email Warning: you will not be able to edit these selections. What attributes are required for signing up? Successfully added resource cognitoexample77f073c1 locally何をやっているのかさっぱりかと思いますが、ここではAWS Cognitoという認証機能の設定をしています。AWS Amplifyを通して、Cognitoというサービスを使っているんですね。
最後に、設定ファイルをアップロードします。この設定ファイルは今まで選択してきた結果をもとに勝手に作成されています。語彙が足りませんが、すごいです。
$ amplify pushCurrent Environment: dev | Category | Resource name | Operation | Provider plugin | | -------- | ---------------------- | --------- | ----------------- | | Auth | cognitoexampled26e7f7d | Create | awscloudformation | ? Are you sure you want to continue? YesAWS Amplifyの機能を実装
コーディングタイム!
Amplifyの機能をこれまでに作ったアプリに実装していきます。
インストール
$ npm install aws-amplify aws-amplify-vue
aws-amplify-vueというのをインストールしたのはAmplifyEventBusというものを使うためだけです。イベントを登録して他のところで実行するだけのためのものなのでReact.jsユーザーの方は代替するものがあるはずです。
main.js
src/main.jsにて、amplifyコマンドによって生成された設定ファイルsrc/aws-exports.jsをインポートします。// src/main.js import Amplify from 'aws-amplify' import awsconfig from './aws-exports' Amplify.configure(awsconfig) Vue.use(Auth)
auth.jsAWS Amplifyの提供されている機能を実際に使うモジュールを作ってみましょう。Vue.jsのファイル内に直接書いてもいいのですが、個人的に
*.vueファイルは描画に関連したこと以外は書きたくないので、こちらのファイルを作成しています。// src/utils/auth.js import { Auth } from 'aws-amplify' import { AmplifyEventBus } from 'aws-amplify-vue' function getUser() { return Auth.currentAuthenticatedUser().then((user) => { if (user && user.signInUserSession) { return user } else { return null } }).catch(err => { console.log(err); return null; }); } function signUp(username, password) { return Auth.signUp({ username, password, attributes: { email: username, }, }) .then(data => { AmplifyEventBus.$emit('localUser', data.user); if (data.userConfirmed === false) { AmplifyEventBus.$emit('authState', 'confirmSignUp'); } else { AmplifyEventBus.$emit('authState', 'signIn'); } return data; }) .catch(err => { console.log(err); }); } function confirmSignUp(username, code) { return Auth.confirmSignUp(username, code).then(data => { AmplifyEventBus.$emit('authState', 'signIn') return data // 'SUCCESS' }) .catch(err => { console.log(err); throw err; }); } function resendSignUp(username) { return Auth.resendSignUp(username).then(() => { return 'SUCCESS'; }).catch(err => { console.log(err); return err; }); } async function signIn(username, password) { try { const user = await Auth.signIn(username, password); if (user) { AmplifyEventBus.$emit('authState', 'signedIn'); } } catch (err) { if (err.code === 'UserNotConfirmedException') { // The error happens if the user didn't finish the confirmation step when signing up // In this case you need to resend the code and confirm the user // About how to resend the code and confirm the user, please check the signUp part } else if (err.code === 'PasswordResetRequiredException') { // The error happens when the password is reset in the Cognito console // In this case you need to call forgotPassword to reset the password // Please check the Forgot Password part. } else if (err.code === 'NotAuthorizedException') { // The error happens when the incorrect password is provided } else if (err.code === 'UserNotFoundException') { // The error happens when the supplied username/email does not exist in the Cognito user pool } else { console.log(err); } } } function signOut() { return Auth.signOut() .then(data => { AmplifyEventBus.$emit('authState', 'signedOut'); return data; }) .catch(err => { console.log(err); return err; }); } export {getUser, signUp, confirmSignUp, resendSignUp, signIn, signOut};
auth.jsを使っていきましょうこれまでに作成したページで
auth.jsをimportしていきましょう。// src/views/SignUp.vue <script> import {signUp} from '@/utils/auth.js' // Adding this line export default { name: "SignUp", ... methods: { submit() { if (this.$refs.form.validate()) { console.log(`SIGN UP username: ${this.username}, password: ${this.password}, email: ${this.username}`); signUp(this.username, this.password); // Adding this line as well } }, }, } </script>// src/views/SignUpConfirm.vue <script> import {confirmSignUp, resendSignUp} from '@/utils/auth.js' // Adding this line export default { name: "SignUpConfirm", ... methods: { submit() { if (this.$refs.form.validate()) { console.log(`CONFIRM username: ${this.username}, code: ${this.code}`); confirmSignUp(this.username, this.code); // Adding this line as well } }, resend() { console.log(`RESEND username: ${this.username}`); resendSignUp(this.username); // Adding this line as well } }, } </script>// src/views/SignIn.vue <script> import {signIn} from '@/utils/auth.js' // Adding this line export default { name: "SignIn", ... methods: { submit() { if (this.$refs.form.validate()) { console.log(`SIGN IN username: ${this.username}, password: ${this.password}`); signIn(this.username, this.password); // Adding this line as well } }, }, } </script>// src/views/Home.vue <template> <div class="home"> <v-btn @click="signOut">Sign Out</v-btn> <img alt="Vue logo" src="../assets/logo.png"> <HelloWorld msg="Welcome to Your Vue.js App"/> </div> </template> <script> // @ is an alias to /src import HelloWorld from '@/components/HelloWorld.vue' import {signOut} from '@/utils/auth.js' export default { name: 'home', components: { HelloWorld }, methods: { signOut() { signOut().then((data) => console.log('DONE', data)).catch((err) => console.log('SIGN OUT ERR', err)); } } } </script>
router.js先ほど少し書きましたが、ユーザーのログイン状態に応じてページ遷移を制御したいです。
http://localhost:8080/signUpをログイン済みのユーザーには表示させたくありませんし、ログインしていないユーザーにはHome.vueの内容を表示させたくはありませんよね。// src/router.js import Vue from 'vue' import Router from 'vue-router' import Home from './views/Home.vue' import { AmplifyEventBus } from 'aws-amplify-vue' import {getUser} from '@/utils/auth.js' Vue.use(Router) const router = new Router({ mode: 'history', base: process.env.BASE_URL, routes: [ { path: '/', name: 'home', component: Home, meta: { requiresAuth: true }, }, { path: '/about', name: 'about', // route level code-splitting // this generates a separate chunk (about.[hash].js) for this route // which is lazy-loaded when the route is visited. component: () => import(/* webpackChunkName: "about" */ './views/About.vue') }, { path: '/signUp', name: 'signUp', component: () => import(/* webpackChunkName: "signup" */ './views/SignUp.vue'), meta: { requiresAuth: false }, }, { path: '/signUpConfirm', name: 'signUpConfirm', component: () => import(/* webpackChunkName: "confirm" */ './views/SignUpConfirm.vue'), meta: { requiresAuth: false }, }, { path: '/signIn', name: 'signIn', component: () => import(/* webpackChunkName: "signin" */ './views/SignIn.vue'), meta: { requiresAuth: false }, }, ] }) getUser().then((user) => { if (user) { router.push({path: '/'}) } }) AmplifyEventBus.$on('authState', async (state) => { const pushPathes = { signedOut: () => { router.push({path: '/signIn'}) }, signUp: () => { router.push({path: '/signUp'}) }, confirmSignUp: () => { router.push({path: '/signUpConfirm'}) }, signIn: () => { router.push({path: '/signIn'}) }, signedIn: () => { router.push({path: '/'}) } } if (typeof pushPathes[state] === 'function') { pushPathes[state]() } }) router.beforeResolve(async (to, from, next) => { const user = await getUser() if (!user) { if (to.matched.some((record) => record.meta.requiresAuth)) { return next({ path: '/signIn', }) } } else { if (to.matched.some((record) => typeof(record.meta.requiresAuth) === "boolean" && !record.meta.requiresAuth)) { return next({ path: '/', }) } } return next() }) export default router以上です!これだけで動くのか眉唾モノですね。
動かしてみましょう!
http://localhost:8080にアクセスしてみてください。もしhttp://localhost:8080/signInに勝手に遷移されたら、router.jsへの変更が無事反映されていますので安心してください。
"Sign Up"メニューから、ご自身のメールアドレスを使ってサインインしてみてください。確認メールが届くはずです。
メールアドレスと確認メールのコードを"Confirm"ページに入力後、ログインフォームにメールアドレスとパスワードを入力するとhttp://localhost:8080に遷移できるはずです。NOTE: 2019年7月1日現在、以下のエラーがコンソールに出てくるかもしれません。
No credentials, applicationId or region
これはレポート済みのエラーです。とりあえずアプリは動くはずですので無視してください。
おわりに
AWS Consoleをあまり使うことなく、簡単にログイン機能を作ることができました。Amplifyすごい。
作成されたユーザーはAWS Console > Cognito > Manage User Pools > Users and groupsで無効にしたり削除したりできるので、ユーザー作成に失敗したらAWS Consoleで削除してください。Firebaseを使ったことある方はそちらの方が簡単かもしれませんが、AWS Amplifyでも簡単にサーバーレスアプリが作れそうです。これから当分AWS Amplifyで遊んでいきたいと思っています。
お読み頂きありがとうございました。
- 投稿日:2019-07-04T15:40:52+09:00
awspecをCloud9での認証エラー
背景
Cloud9でawspecを試そうとしたらエラーでた
$ rake spec /home/ec2-user/.rvm/rubies/ruby-2.6.3/bin/ruby -I/home/ec2-user/.rvm/gems/ruby-2.6.3/gems/rspec-support-3.8.2/lib:/home/ec2-user/.rvm/gems/ruby-2.6.3/gems/rspec-core-3.8.2/lib /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/rspec-core-3.8.2/exe/rspec --pattern spec/\*\*\{,/\*/\*\*\}/\*_spec.rb ecs_cluster 'cluster-4cb3167' should exist (FAILED - 1) Failures: 1) ecs_cluster 'cluster-4cb3167' should exist Failure/Error: it { should exist } Aws::Errors::MissingCredentialsError: unable to sign request without credentials set # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/signature_v4.rb:119:in `rescue in apply_signature' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/signature_v4.rb:111:in `apply_signature' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/signature_v4.rb:65:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/transfer_encoding.rb:26:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/helpful_socket_errors.rb:10:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/retry_errors.rb:174:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/json/handler.rb:11:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/user_agent.rb:13:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/endpoint_pattern.rb:28:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/endpoint_discovery.rb:78:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/seahorse/client/plugins/endpoint.rb:45:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/param_validator.rb:24:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/seahorse/client/plugins/raise_response_errors.rb:14:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/jsonvalue_converter.rb:20:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/idempotency_token.rb:17:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/param_converter.rb:24:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/aws-sdk-core/plugins/response_paging.rb:10:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/seahorse/client/plugins/response_target.rb:23:in `call' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-core-3.58.0/lib/seahorse/client/request.rb:70:in `send_request' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sdk-ecs-1.43.0/lib/aws-sdk-ecs/client.rb:2018:in `describe_clusters' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/awspec-1.17.4/lib/awspec/helper/client_wrap.rb:26:in `method_missing' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/awspec-1.17.4/lib/awspec/helper/finder/ecs.rb:5:in `find_ecs_cluster' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/awspec-1.17.4/lib/awspec/type/ecs_cluster.rb:9:in `resource_via_client' # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/awspec-1.17.4/lib/awspec/type/base.rb:26:in `respond_to_missing?' # ./spec/ecs_spec.rb:12:in `block (2 levels) in <top (required)>' # ------------------ # --- Caused by: --- # Aws::Sigv4::Errors::MissingCredentialsError: # unable to sign request without credentials set # /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/aws-sigv4-1.1.0/lib/aws-sigv4/signer.rb:665:in `get_credentials' Finished in 7.48 seconds (files took 11.26 seconds to load) 1 example, 1 failure Failed examples: rspec ./spec/ecs_spec.rb:12 # ecs_cluster 'cluster-4cb3167' should exist /home/ec2-user/.rvm/rubies/ruby-2.6.3/bin/ruby -I/home/ec2-user/.rvm/gems/ruby-2.6.3/gems/rspec-support-3.8.2/lib:/home/ec2-user/.rvm/gems/ruby-2.6.3/gems/rspec-core-3.8.2/lib /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/rspec-core-3.8.2/exe/rspec --pattern spec/\*\*\{,/\*/\*\*\}/\*_spec.rb failed原因
Aws::Errors::MissingCredentialsErrorと出てるので、認証関連が原因ぽい
認証関連設定した覚えがなかったが、spec/spec_helper.rbに
Awsecrets.load(secrets_path: File.expand_path('./secrets.yml', File.dirname(__FILE__)))と記載があった
ここ通りに$ awspec init実行すると作られたみたい対応方法
spec/spec_helper.rbのAwsecretsの部分を削除して
require 'awspec' - Awsecrets.load(secrets_path: File.expand_path('./secrets.yml', File.dirname(__FILE__)))再実行すればいけた!
$ rake spec /home/ec2-user/.rvm/rubies/ruby-2.6.3/bin/ruby -I/home/ec2-user/.rvm/gems/ruby-2.6.3/gems/rspec-support-3.8.2/lib:/home/ec2-user/.rvm/gems/ruby-2.6.3/gems/rspec-core-3.8.2/lib /home/ec2-user/.rvm/gems/ruby-2.6.3/gems/rspec-core-3.8.2/exe/rspec --pattern spec/\*\*\{,/\*/\*\*\}/\*_spec.rb ecs_cluster 'cluster-cb481a9' should exist Finished in 0.06648 seconds (files took 3.71 seconds to load) 1 example, 0 failures参考
- 投稿日:2019-07-04T15:09:58+09:00
Datadogの便利機能 Live Processes編
概要
Datadogの便利機能をシリーズでお届けする予定です。
今回は、Live Processesのご紹介です。
DatadogでEC2上のプロセス監視を行たい場合、Live Processes機能が便利かもよというお話です。
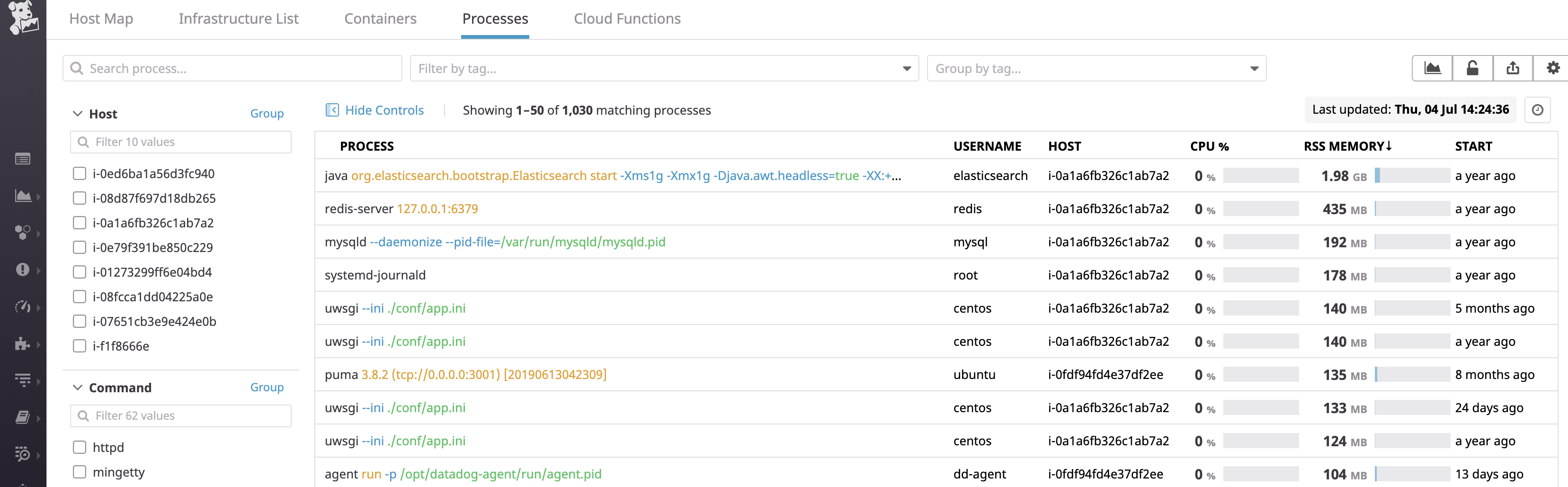
DatadogのLive Processes機能を使うことで、EC2上で起動しているプロセスが一覧できる上、
プロセスごとのCPU使用率、メモリ使用量、プロセス起動時刻等が一覧で確認できます。便利です。まずは、導入後の画面から。
参考:https://docs.datadoghq.com/graphing/infrastructure/Processes/?tab=linuxwindows
Live Processes 導入方法
導入方法はいたって簡単です。
設定ファイルに以下の設定を追加するか、コメントアウトして、Datadog Agentを再起動するだけです。# 以下の設定を追加 or アンコメント Processes_config: enabled: "true"# Datadog Agentの再起動 $ sudo initctl restart datadog-agentここがすごいな(楽だな)と思ったところなのですが、
今ままでのプロセス監視は、監視するプロセスを1つ1つをProcesses.d/conf.yamlに定義する必要があった?かと思います。
参考:https://docs.datadoghq.com/integrations/Processes/それが上述の設定のみで、起動しているプロセスを一覧化してくれます。
機密性の高い情報のマスキング
custom_sensitive_wordsにマスクしたいワードを登録しておくと、プロセス一覧で表示する際にマスキングしてくれるそうです。
引用元: https://docs.datadoghq.com/graphing/infrastructure/process/?tab=linuxwindows#process-arguments-scrubbing以下のように設定を追加して、Datadog Agentを再起動するだけです。
Processes_config: enabled: "true" scrub_args: true custom_sensitive_words: ['personal_key', '*token', 'sql*', '*pass*d*']また、
strip_proc_argumentsを設定することで、プロセスからすべて引数を削除することもできるようです。(未検証)Processes_config: strip_proc_arguments: trueプロセス監視方法
プロセスの監視方法も簡単です。
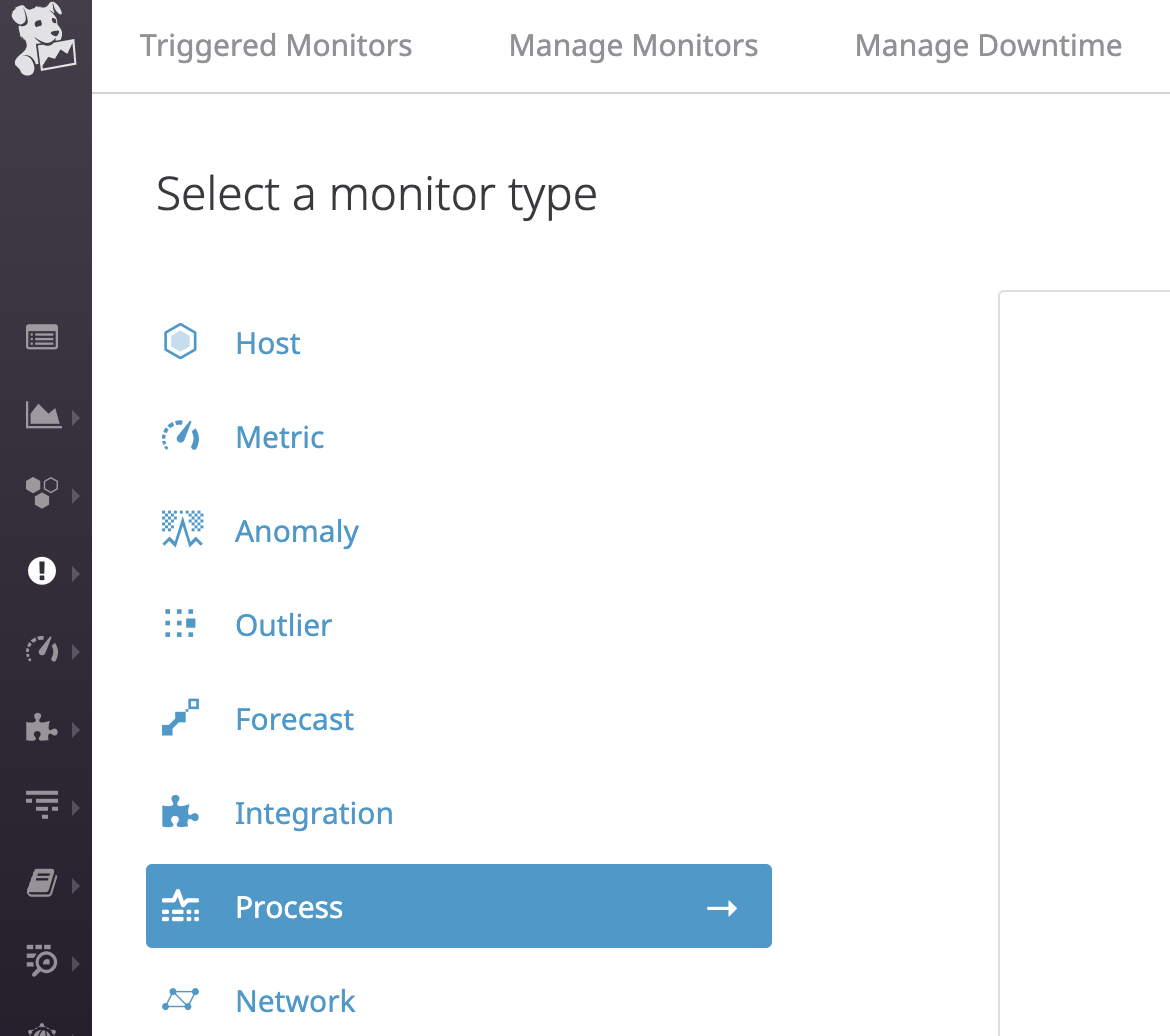
Live Processesで抽出したプロセスを選択して、監視するだけです。
Manage Monitors → New Monitor → Processesと遷移します。
あとは、
Live Processes Monitorを選択して、監視したいプロセスを設定していきます。
もちろん、Tag等を使って対象をフィルタリングしたりもできます。
料金体系
このLive Processes機能は、料金表をみると、EnterPriseプランからとなっていますが、日本だとまだこのEnterPriseプランがないらしく、
Pro Plusというプランがあるようで、そちらで利用できます。
詳細は、Datadogに確認してみてください。まとめ
まずはフリートライアルで使ってみて、使えそうであれば導入を検討する感じがいいと思います。
プロセスごとのCPU使用率やMemory利用量がわかるので、トラブルシューティング時には便利だと思います。
Live Processesぜひ使ってみてください。

- 投稿日:2019-07-04T15:01:42+09:00
AWS SDK for C++のサンプルをVisual Studio Codeでデバッグする
C++でAWSのサービスを使う必要が出てきたのですが、幸いにも各言語ごとのサンプルコードが提供されているので、お勉強のために以前作った開発環境でデバッグしてみました。
はじめに
以前の記事と同様ですが
注意 Docker上でgdbを使うためにセキュリティレベルを下げる設定を追加しています。外部に公開される環境では用いないようにしてください。
作業概要
Visual Studio CodeのRemote ContainersでC++開発環境構築 - Qiita で作成したプロジェクトをベースに環境を作っていきます
変更するのは以下2点です。
DockerfileにAWS SDKのビルド設定を追加するdocker-compose.ymlのvolumesを変更する
- マウントするパスの変更
- AWSにアクセスするために
$HOME/.awsをマウントプロジェクトをダウンロード
# ベースとなるプロジェクトをクローン git clone https://github.com/dbgso/vscode-cpp-devcontainer.git vscode-remote-cpp-aws-sdkaws # サンプルソースをダウンロード git clone https://github.com/awsdocs/aws-doc-sdk-examples.git vscode-remote-cpp-aws-sdkaws/data/aws-doc-sdk-examples # Visual Studio Codeで開く code vscode-remote-cpp-aws-sdkawsここから、必要な設定を追加していきます
差分については https://github.com/dbgso/vscode-cpp-devcontainer/commit/c17e6ac33cc5512385ef3b1583d83c796bf10f9e をみてもらっても同じ内容です
Dockerfile修正
変更内容は以下です。
AWS SDK for CPPの依存パッケージをインストールしてビルドしています。Dockerfile.diffapt-get install -y git build-essential cmake clang libssl-dev && \ apt-get install -y cpputest libsqlite3-dev clang-format gdb +# AWS dependency +RUN apt-get install -y libcurl4-openssl-dev libssl-dev uuid-dev zlib1g-dev libpulse-dev + +RUN git clone https://github.com/aws/aws-sdk-cpp.git --depth 1 /tmp/aws-sdk-cpp +RUN cd /tmp/aws-sdk-cpp && cmake -DBUILD_ONLY="s3" && make && make install参考
Setting Up the AWS SDK for C++ - AWS SDK for C++
DockerとMinioでAWS SDK for C++の開発環境を構築する - Qiitadocker-compose.yml修正
現状の
devcontainer.jsonの設定ではworkingFolderを/dataとしているので、/dataにソースのルートを持ってくる必要があります。
ですので、docker-compose.ymlのvolumesでマウントするディレクトリを変更します。
Dockerfileでも-DBUILD_ONLY="s3"としたので今回はs3のサンプルを試していきます。
マウントするパスは/aws-doc-sdk-examples/cpp/example_code/s3/となります。(あるいはdevcontainer.jsonを変更して"workspaceFolder": "/data/aws-doc-sdk-examples/cpp/example_code/s3/"としても良いです。こっちの方が見通しが良いかな?)version: '3.3' services: cpp: build: . volumes: - - ../data:/data + - ../data/aws-doc-sdk-examples/cpp/example_code/s3/:/data + - $HOME/.aws/:/root/.aws working_dir: /data tty: true # to use gdb cap_add: - SYS_PTRACE security_opt: - seccomp:unconfined起動
起動方法は前回の記事と変わりません。
の
Reopen in Containerを選択するか、コマンドパレットからRemote-Containers: Reopen Folder in Containerを実行します。起動するとAWS SDKのビルドが始まりますが、結構長いのでしばらく待機します。(PCのスペックにもよりますが、5分〜15分程度?かかります)
ビルド
コマンドパレットから
CMake: buildを実行します。
No CMake kits are availableと聞かれたらDo not use a kitで良さそうです。(前回は選択してましたが、結局CMakeにお任せしていたので意味なかった?です)こんな感じでログがつらつら流れれば成功です。
[cmake] The C compiler identification is GNU 7.4.0 [cmake] The CXX compiler identification is GNU 7.4.0 [cmake] Check for working C compiler: /usr/bin/cc [cmake] Check for working C compiler: /usr/bin/cc -- works [cmake] Detecting C compiler ABI info [cmake] Detecting C compiler ABI info - done [cmake] Detecting C compile features [cmake] Detecting C compile features - done [cmake] Check for working CXX compiler: /usr/bin/c++ [cmake] Check for working CXX compiler: /usr/bin/c++ -- works [cmake] Detecting CXX compiler ABI info [cmake] Detecting CXX compiler ABI info - done [cmake] Detecting CXX compile features [cmake] Detecting CXX compile features - done [cmake] Found AWS SDK for C++, Version: 1.7.138, Install Root:/usr/local, Platform Prefix:, Platform Dependent Libraries: pthread;crypto;ssl;z;curl [cmake] Components specified for AWSSDK: s3 [cmake] Try finding aws-cpp-sdk-core [cmake] Found aws-cpp-sdk-core [cmake] Try finding aws-cpp-sdk-s3 [cmake] Found aws-cpp-sdk-s3 [cmake] Configuring done [cmake] Generating done [build] Starting build [proc] Executing command: /usr/bin/cmake --build /data/build --config Debug --target list_buckets -- -j 6 [build] Scanning dependencies of target list_buckets [build] [ 50%] Building CXX object CMakeFiles/list_buckets.dir/list_buckets.cpp.o [build] [100%] Linking CXX executable list_buckets [build] [100%] Built target list_buckets [build] Build finished with exit code 0実行とブレークポイント
バケット一覧取得
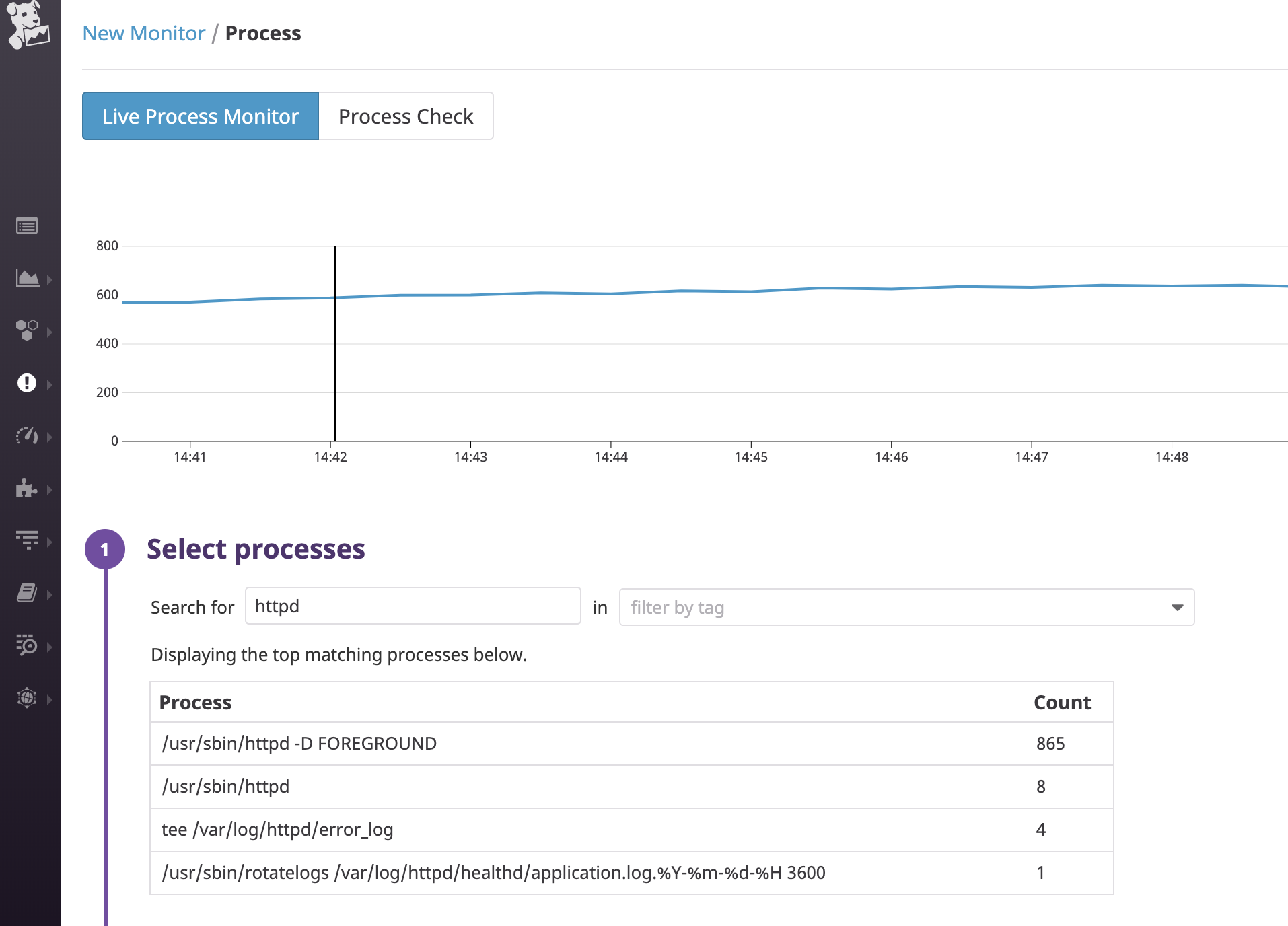
一番お手軽そうな
list_buckets.cppでバケットのリストを取得してみます。まず、確認用に適当なバケットを作ってファイルを置いておきます(
これもC++でやればいいんですが、記事にするのが面倒臭い)$ aws s3 mb s3://cppbuckettest make_bucket: cppbuckettest $ echo hello > world.txt $ aws s3 cp world.txt s3://cppbuckettest upload: ./world.txt to s3://cppbuckettest/world.txt $ aws s3 ls s3://cppbuckettest/ 2019-07-04 13:06:47 6 world.txtブレークポイントを設定してステップ実行していくと、ちゃんと
cppbuckettestの存在を確認できました。
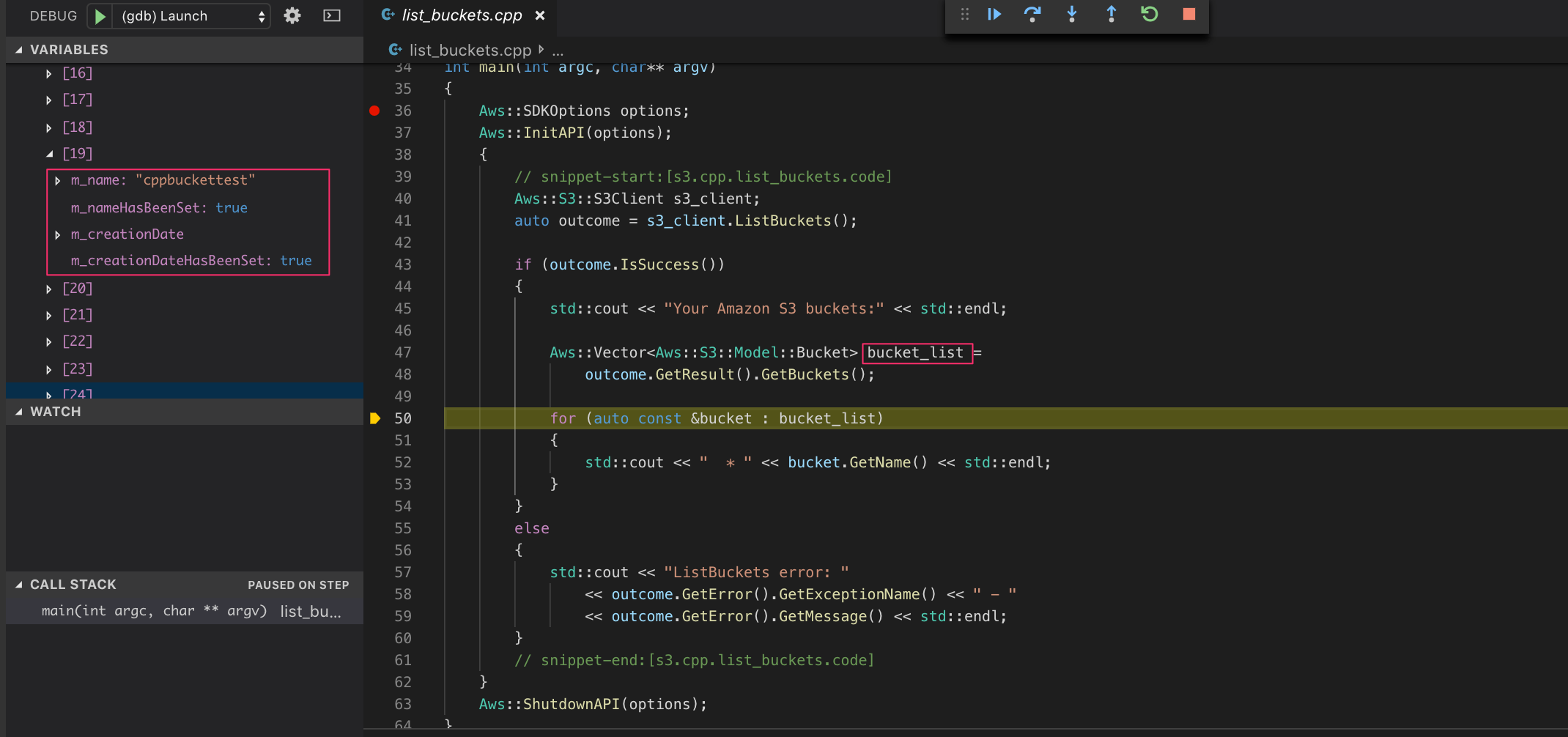
オブジェクトの取得
せっかくファイルをアップロードしたので、バケットのファイル一覧を取得します。
サンプルのソースはlist_objects.cppです。このファイルはコマンドライン引数にバケット名を渡して、そのバケットのファイル名一覧を取得しているみたいです。
ここで、ちょっとハマりました。
コマンドライン引数はどこに渡すの?って思ったんですが、普通にlaunch.jsonの設定に書けばよかったです。
launch.jsonを開いて、C/C++: (gdb) Launchを選択して、テンプレートを生成します。以下のように、
programに実行ファイル、argsにコマンドライン引数を入れればOKです。{ "name": "(gdb) Launch", "type": "cppdbg", "request": "launch", - "program": "enter program name, for example ${workspaceFolder}/a.out", + "program": "${workspaceFolder}/build/list_objects", - "args": [], + "args": ["cppbuckettest"], "stopAtEntry": false, "cwd": "${workspaceFolder}", "environment": [], "externalConsole": false, "MIMode": "gdb", "setupCommands": [ { "description": "Enable pretty-printing for gdb", "text": "-enable-pretty-printing", "ignoreFailures": true } ] }
F5キーで実行します
ちゃんとブレークして、該当のバケット情報が取れています。
コンソールにも正しく表示されましたObjects in S3 bucket: cppbuckettest * world.txt備考
.awsディレクトリのマウント漏れ
ちなみに、
.awsディレクトリをマウントし忘れると以下のように接続できなくて怒られるので注意しましょうListBuckets error: - Unable to connect to endpoint [1] + Done /usr/bin/gdb --interpreter=mi --tty=${DbgTerm} 0</tmp/Microsoft-MIEngine-In-2xmmhqio.v6u 1>/tmp/Microsoft-MIEngine-Out-l2adjy68.7nbCMake拡張機能を使ってのコマンドライン引数
本文では引数指定ができないと書いたのですが、すみません、できました。
ただ、使い勝手的にはlaunch.jsonに書いてしまうのが良いと思うので、参考までに記録しておきます。方法はVisual Studio Code側の設定に引数を設定してしまう方法です。
Preferences: Open Workspace SettingsからWorkspaceごとの設定を開き、以下のようにargsに設定します。setting.json{ "cmake.debugConfig": { "args": [ "bucket_name" ] } }あとは、通常通り
Debugボタンを押せば引数付きでデバッグできます
ただ、おそらく設定は一つしかできないです。
Workspaceに設定するのでそれでも良さそうですが、使い勝手は悪そう。
ちなみにシステム側の設定にもできてしまいますが普通しませんよね。
おとなしく、launch.jsonが良いかなと思いました。お手軽実行の時はすごく楽で良いんですが参考 Passing command line arguments to a debug target · Issue #121 · vector-of-bool/vscode-cmake-tools
参考
Setting Up the AWS SDK for C++ - AWS SDK for C++
DockerとMinioでAWS SDK for C++の開発環境を構築する - Qiita
Passing command line arguments to a debug target · Issue #121 · vector-of-bool/vscode-cmake-tools

- 投稿日:2019-07-04T11:40:49+09:00
Lambda用のVPC環境を、CloudFormationで構築する
? はじめに
外部APIにリクエストを投げるLambda関数を作ったのですが、外部API側でIP制限をかける事になったので、Lambda関数のIPを固定化する必要が出てきました。
そこで、以下を参考にVPC環境を構築して、外部APIにリクエストを投げる際の、リクエスト元のIPアドレスを固定化しました。Lambdaの実行IPアドレスを固定し、kintoneセキュアアクセスに対応する方法
その際、設定のドキュメントも併せて作ろうと思ったのですが、AWS CloudFormationのテンプレートファイルを作れば、設定ドキュメント兼環境構築プログラムになると思い、以下を参考にしながらVPC環境を定義したテンプレート作ってみました。
AWS CloudFormationによるVPC作成 + public及びprivateサブネット作成
ちなみに、最初はAWS SAMでLambdaも含めて一つのテンプレートを作ろうとしましたが、AWS SAMからはVPCの構築は対応していない(2019年7月時点)という事だったので、VPCはCloudFormationから構築する事にしました。
? 作るもの
今回構築するVPC環境は以下のようなイメージです。
使い捨てリソースであるLambda関数に固定IPを割り当てるのは無理なので、VPC環境を構築して、Lambda関数がVPCの外に出る時に通過する、NAT GatewayにIPを割り振ることで、リクエスト元のIPアドレスの固定化を実現しています。
サブネットがAvailability Zone別に2セット作ってあるのは、実際にLambda関数にPrivateサブネットを割り当てた時、複数のPrivateサブネットを割り当てる事を推奨する警告が表示されたので、一応2セット用意しました。
?テンプレートサンプル
CloudFormationのテンプレートは以下の通りです。
テンプレートリファレンスに書き方が一通り書いてあるので、時間を掛ければ書くのは難しくないですが、とにかく設定する箇所が多いので、慣れないうちは設定漏れ等で苦戦すると思います。
AWSTemplateFormatVersion: '2010-09-09' Transform: 'AWS::Serverless-2016-10-31' Description: hoge環境 Resources: # ■□ VPC環境構築 □■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■ # ■□■□ VPCの作成 hogeVPC: Type: AWS::EC2::VPC Properties: CidrBlock: 10.0.0.0/16 EnableDnsSupport: 'false' EnableDnsHostnames: 'false' InstanceTenancy: default Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-vpc # ■□■□ インターネットゲートウェイの作成 hogeIGW: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-igw # ■□■□■□ インターネットゲートウェイをVPCにセット AttachVpcGateway: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: Ref: hogeVPC InternetGatewayId: Ref: hogeIGW # ■□ サブネットの設定(2つのAZに作成) □■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■□■ # ■□■□ Publicのルートテーブルの作成 hogeRTblPublicAZ01: Type: AWS::EC2::RouteTable Properties: VpcId: Ref: hogeVPC Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-rtb-az01-igw hogeRTblPublicAZ02: Type: AWS::EC2::RouteTable Properties: VpcId: Ref: hogeVPC Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-rtb-az02-igw # ■□■□■□ IGW-publicルーティング hogeRouteIGWPublicAZ01: Type: AWS::EC2::Route Properties: RouteTableId: !Ref hogeRTblPublicAZ01 DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref hogeIGW hogeRouteIGWPublicAZ02: Type: AWS::EC2::Route Properties: RouteTableId: !Ref hogeRTblPublicAZ02 DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref hogeIGW # ■□■□ Privateのルートテーブルの作成 hogeRTblPrivateAZ01: Type: AWS::EC2::RouteTable Properties: VpcId: Ref: hogeVPC Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-rtb-az01-nat hogeRTblPrivateAZ02: Type: AWS::EC2::RouteTable Properties: VpcId: Ref: hogeVPC Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-rtb-az02-nat # ■□■□■□ Nat-privateルーティング hogeRouteNatPrivateAZ01: Type: AWS::EC2::Route Properties: RouteTableId: !Ref hogeRTblPrivateAZ01 DestinationCidrBlock: 0.0.0.0/0 NatGatewayId: Ref: hogeNatAZ01 hogeRouteNatPrivateAZ02: Type: AWS::EC2::Route Properties: RouteTableId: !Ref hogeRTblPrivateAZ02 DestinationCidrBlock: 0.0.0.0/0 NatGatewayId: Ref: hogeNatAZ02 # ■□■□ NATゲートウェイの作成 hogeNatAZ01: Type: AWS::EC2::NatGateway Properties: AllocationId: Fn::GetAtt: - hogeEipAZ01 - AllocationId SubnetId: Ref: hogeSBNPrivateAZ01 Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-nat-az01 hogeNatAZ02: Type: AWS::EC2::NatGateway Properties: AllocationId: Fn::GetAtt: - hogeEipAZ02 - AllocationId SubnetId: Ref: hogeSBNPrivateAZ02 Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-nat-az02 # ■□■□ EIPの作成 hogeEipAZ01: Type: AWS::EC2::EIP Properties: Domain: vpc hogeEipAZ02: Type: AWS::EC2::EIP Properties: Domain: vpc # ■□■□ Publicサブネットの作成 hogeSBNPublicAZ01: Type: AWS::EC2::Subnet Properties: VpcId: Ref: hogeVPC CidrBlock: 10.0.10.0/24 # 指定したregionの最初のazを選択 AvailabilityZone: Fn::Select: - 0 - Fn::GetAZs: "" Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-sbn-public-az01 hogeSBNPublicAZ02: Type: AWS::EC2::Subnet Properties: VpcId: Ref: hogeVPC CidrBlock: 10.0.12.0/24 # 指定したregionの最初のazを選択 AvailabilityZone: Fn::Select: - 1 - Fn::GetAZs: "" Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-sbn-public-az02 # ■□■□■□ サブネットをルートテーブルに関連付け hogeSbnRTblAssociationAZ01: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: Ref: hogeSBNPublicAZ01 RouteTableId: Ref: hogeRTblPublicAZ01 hogeSbnRTblAssociationAZ02: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: Ref: hogeSBNPublicAZ02 RouteTableId: Ref: hogeRTblPublicAZ02 # ■□■□ Privateサブネットの作成 hogeSBNPrivateAZ01: Type: AWS::EC2::Subnet Properties: VpcId: Ref: hogeVPC CidrBlock: 10.0.11.0/24 # 指定したregionの最初のazを選択 AvailabilityZone: Fn::Select: - 0 - Fn::GetAZs: "" Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-sbn-private-az01 hogeSBNPrivateAZ02: Type: AWS::EC2::Subnet Properties: VpcId: Ref: hogeVPC CidrBlock: 10.0.13.0/24 # 指定したregionの最初のazを選択 AvailabilityZone: Fn::Select: - 1 - Fn::GetAZs: "" Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-sbn-private-az02 # ■□■□ セキュリティグループの作成 hogeSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Security Group for hoge VPC VpcId: Ref: hogeVPC Tags: - Key: product Value: hoge - Key: developer Value: jimu - Key: Name Value: hoge-vpc-sg? ポイント
Availability Zoneの指定を以下のように書くことで、配置可能なAvailability Zoneのリストを取ってくきて、その1件目を選択する事ができます。
# 指定したregionの最初のazを選択 AvailabilityZone: Fn::Select: - 0 - Fn::GetAZs: ""このように書くことで、Availability Zoneをハードコーディングしなくてすむので、このテンプレートファイルはどのリージョンでも使用する事ができるようになります。
また、セキュリティグループは今回は細かく設定していませんが、以下のように最低限の記述にする事で、インバウンドなし、アウトバウンドはすべてOKという、デフォルトよりはマシな設定にしています。
hogeSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Security Group for hoge VPC VpcId: Ref: hogeVPC? まとめ
以上で設定は完了です。
とりあえず、最初の全体図と、テンプレートファイルがあれば、設計書の代わりになるかと思います。(Elastic IP等の補足メモは必要ですが)テンプレートファイルなら、見て分からなければ、最悪CloudFomationを使えば現物を再現する事もできます。
最初は作るのに時間が掛ると思いますが、たくさん作っていけば、だんだん流用できる部分が増えてくるので、余裕がある時は挑戦してみてはいかがでしょうか。
? 参考
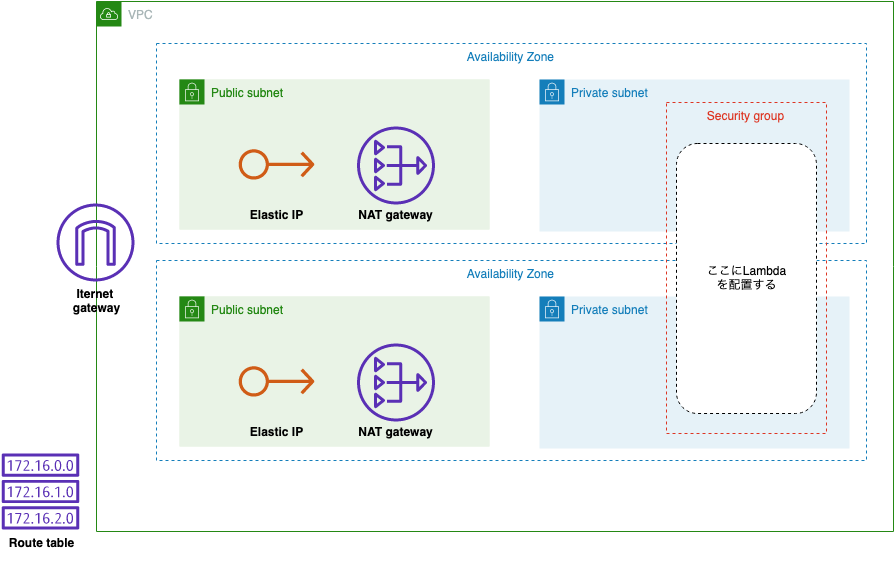
- 投稿日:2019-07-04T09:54:43+09:00
AWS Workspaces(AmazonLinux2)へのVisualStudio Codeをコマンドでインストール
Visual Studio Code Install
Termnalからコマンド実行。(WebからRPMダウンロードしても良いけどこの方が楽)
Repo登録
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc sudo sh -c 'echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com/yumrepos/vscode\nenabled=1\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" > /etc/yum.repos.d/vscode.repo'Repoからインストール。
yum check-update sudo yum install codesee: https://code.visualstudio.com/docs/setup/linux#_rhel-fedora-and-centos-based-distributions
- 投稿日:2019-07-04T08:19:48+09:00
AWS 認定 機械学習 – 専門知識(Machine Learning – Specialty)合格に向けたオレオレ学習ガイドライン
はじめに
2019年3月にベータ版から正式版となり、3か月強が経った。
他の認定試験は9個まで取ったので、そろそろ取得に向けて勉強しなければならない。
とはいえ学習の道標が何もないと途方に暮れるので、ひとまず材料になりそうなものをかき集めました。公式/非公式問わず出題範囲や内容のあたりがつきそうなものを調べ、何を学習リソースとして、どのように勉強するかのプランを立てるところまでが本記事の内容です。
- まだ試験を受けてすらいない段階の情報です
- 「ソースに書いてあったこと」と「それを踏まえて自分はこう考えた」は混在しないように気を付けていますが、適宜情報の取捨選択をしてください
- オフラインでの学習コースは受講しないで勉強する方針とし、含めていません
自身の現状
- AWS
- 業務経験4年弱
- AWS認定資格9冠
- 機械学習
- まったく分からない
- 無理くりひねり出すと以下くらい
- 松尾 豊 著「人工知能は人間を超えるか」を1回読んだことがある
- オライリージャパン「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」を買って本棚にしまったことがある
1.情報収集(公式情報ソース)
1.1.公式ページ
[AWS 認定 機械学習 – 専門知識]
https://aws.amazon.com/jp/certification/certified-machine-learning-specialty/認定によって検証される能力
- 提示されたビジネスの問題に対し、適切な ML アプローチを選び、その理由を説明できる
- ML ソリューションの実装に適した AWS のサービスを特定する
- スケーラビリティ、コスト効率、信頼性、安全性に優れた ML ソリューションを設計し、実装する
推奨される AWS の知識
- AWS クラウドでの ML/深層学習ワークロードの開発、設計、実行における、1~2 年の経験
- 基本的な ML アルゴリズムの基となる考えを表現する能力
- 基本的なハイパーパラメータ最適化の実践経験
- ML および深層学習フレームワークの使用経験
- モデルトレーニングのベストプラクティスを実行する能力
- デプロイと運用のベストプラクティスを実行する能力
ハイパーパラメータという用語は聞いたことが無かったので調べた。機械学習アルゴリズムの挙動を制御するパラメータで、機械に学習させる前に人間があらかじめ与えておいてあげないといけないものらしい。AWSとの絡みで言うと、Amazon SageMakerの設定項目として出てきそうだ。
[Amazon SageMaker 組み込みアルゴリズムを使用する]
https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/algos.html1.2.試験ガイド
(MLS-C01) 試験ガイド(PDF)
https://d1.awsstatic.com/training-and-certification/docs-ml/AWS%20Certified%20Machine%20Learning%20-%20Specialty%20Exam%20Guide%20001%20v1.1%20JPN.pdf推奨される AWS の知識
1.1.の公式ページに書かれていることとほぼ同じ。
この試験に合格するには、AWS クラウドにおける ML/ディープラーニングのワークロードの開発、アーキテクチャ設計、運用に関する 1 ~ 2 年以上の実務経験に加え、以下の知識や経験を持っていることが望ましいと考えられます。
- 基本的な機械学習アルゴリズムの背後にある直観的知識を表現する能力
- 基本的なハイパーパラメータの最適化を行った経験
- ML およびディープラーニングのフレームワークに関する経験
- モデルのトレーニングに関するベストプラクティスに従う能力
- 開発および運用に関するベストプラクティスに従う能力
その他の資料
リンクがいくつか貼られているが、★部はすべて以下のドキュメントの子階層にあたるドキュメント。
[AWSドキュメント >> Amazon Machine Learning >> 開発者ガイド]
https://docs.aws.amazon.com/ja_jp/machine-learning/latest/dg/what-is-amazon-machine-learning.html
- 「AWS での機械学習」
- 「Amazon Machine Learning の主要なコンセプト」★
- 「データの分割」★
- 「ML モデルのタイプ」★
- 「データ変換リファレンス」★
- 「Containerized Machine Learning on AWS」(動画)
- 「AWS re:Invent Machine Learning talk」(動画)
試験内容の概要
この試験ガイドには、比重、出題分野、および試験の目的のみが記載されています。試験の出題内容全体を記載しているわけではありません。出題分野と比重を以下の表に示します。
分野 試験における比重 分野 1: データエンジニアリング 20% 分野 2: 探索的データ解析 24% 分野 3: モデリング 36% 分野 4: 機械学習の実装と運用 20% 合計 100%
- 分野 1: データエンジニアリング
- 1.1 機械学習のデータリポジトリの作成。
- 1.2 データ収集ソリューションの特定と実装。
- 1.3 データ変換ソリューションの特定と実装。
- 分野 2: 探索的データ解析
- 2.1 モデリングのためのデータのサニタイズと準備。
- 2.2 特徴エンジニアリングの実施。
- 2.3 機械学習用データの分析と視覚化。
- 分野 3: モデリング
- 3.1 ビジネス上の課題を機械学習の課題として捉え直す。
- 3.2 特定の機械学習の課題に対する適切なモデルの選択。
- 3.3 機械学習モデルのトレーニング。
- 3.4 ハイパーパラメータの最適化の実施。
- 3.5 機械学習モデルの評価。
- 分野 4: 機械学習の実装と運用
- 4.1 パフォーマンス、可用性、拡張性、回復性、フォールトトレランスを備えた機械学習ソリューションの構築。
- 4.2 特定の課題に対応する適切な機械学習サービスおよび機能の推奨と実装。
- 4.3 機械学習ソリューションへの基本的な AWS のセキュリティプラクティスの適用。
- 4.4 機械学習ソリューションの展開と運用の実現。
1.3.Amazon Web Services ブログ
[新しい認定資格「AWS Certified Machine Learning – Specialty」で認定機械学習開発者になる]
https://aws.amazon.com/jp/blogs/news/become-a-certified-machine-learning-developer-with-the-new-aws-certified-machine-learning-specialty-certification/気になる部分を太字化。
この新しい試験は、特定のビジネス上の問題に対して ML ソリューションを設計、実装、デプロイ、保守する能力を検証したい開発者およびデータサイエンティストのために AWS の専門家によって作成されました。さらに、特定のビジネス上の問題に適した ML アプローチを選択して正当化し、ML ソリューションを実装するのに適切な AWS のサービスを特定し、スケーラブルでコスト最適化された信頼性の高い安全な ML ソリューションを設計および実装する能力を検証します。
試験ガイドなどで書かれていた、問われるスキルとほぼ同じことが書かれています。
AWS トレーニングと認定では、ML および人工知能 (AI) サービス、特に Amazon SageMaker、および Amazon EMR、AWS Lambda、AWS Glue、Amazon S3 などのその他のサービスの使用に関して 1 年以上の実務経験があることをお勧めしています。また、受験者がアソシエートレベルの認定またはクラウドプラクティショナー認定を取得していることも推奨されますが、必須ではありません。
名前が出されているAWSサービスはさすがに出題されるのだろうなと思います。
1.4.製品ページ
[AWS での機械学習]
https://aws.amazon.com/jp/machine-learning/機械学習の中で細分化されたカテゴリと、それぞれに関連するAWSサービスの確認ができます。
- AI サービス
- Amazon Personalize(レコメンデーション)
- Amazon Forecast(予測)
- Amazon Rekognition(画像と動画の分析)
- Amazon Comprehend(高度なテキスト分析)
- Amazon Textract(ドキュメント分析)
- Amazon Polly(テキストから音声)
- Amazon Lex(対話型エージェント)
- Amazon Translate(翻訳)
- Amazon Transcribe(文字起こし)
- ML サービス
- Amazon SageMaker
- Amazon SageMaker Ground Truth
- Amazon SageMaker Neo
- フレームワーク
- AWS 深層学習 AMI
- AWS 深層学習コンテナ
- AWS での TensorFlow
- AWS での PyTorch
- AWS での Apache MXNet
- インフラストラクチャ
- GPU(Amazon EC2 P3 インスタンス)
- GPUアクセラレーション(Amazon Elastic Inference)
- 機械学習推奨チップ(AWS Inferentia)
- CPU(Amazon EC2 C5 インスタンス)
- FPGA(Amazon EC2 F1 インスタンス)
- field-programmable gate array(製造後に購入者や設計者が構成を設定できる集積回路)
- エッジデバイス(AWS IoT Greengrass)
- ML(機械学習)を学ぶ
- AWS DeepRacer(ラジコンみたいなやつ)
- AWS DeepLens(深層学習可能なビデオカメラ)
- 分析&セキュリティ
- ブログ
- https://aws.amazon.com/jp/blogs/machine-learning/
- 日本語には対応していないようだ。
1.5.試験準備
https://aws.amazon.com/jp/training/learning-paths/machine-learning/exam-preparation/
e-ラーニングの試験対策コース。画像を拝借。
ここではコースの内訳までは読み取れませんが、なんとなくどんな分野が出るかが分かる…かも。
- マシンラーニング試験の基礎
- プロセスモデル:AWSスタック上のCRISP-DM
- (CRoss-Industry Standard Process for Data Mining)
- 同名のコンソーシアムによって提唱されたデータ分析プロジェクトのプロセスモデル
- データサイエンスの要素
- (オプション)AWSでのビッグデータ
- ストレージ
- マシンラーニングのセキュリティ
- マシンラーニングアプリケーションの開発
- マシンラーニングソリューションのタイプ
- マシンラーニングソリューション
- チャットボット
- 機械翻訳とNeuro Linguistic Programing(神経言語プログラミング)
- コンピュータビジョン理論
- 試験!
2.情報収集(非公式情報)
公式情報以上に情報の取捨選択には留意してください。
2.1.DevelopersIO
[AWS Certified Machine Learning – Specialty合格までにやったこと]
https://dev.classmethod.jp/cloud/aws/i-passed-mls-exam/エントリを書かれた方も機械学習の知見なしの状態から勉強を始めたとか。期間としては4か月、試験対策としては3週間の勉強とのこと。学習に使われたリソースは以下とのこと。
- Couseraの機械学習コース
- AWSのe-ラーニング
- 試験ガイドに載っている公式ドキュメント
- Amazon SageMaker 開発者ガイド
- Developers.IOのSageMakerの記事
- サンプル問題
- 模擬試験
[目指せML Specialist!みんなでわいわいサンプル問題を解いたのでまとめてみたよ!]
https://dev.classmethod.jp/machine-learning/ml-specialist-office-workshop/サンプル問題をベースに、日本語訳とその回答、および根拠が書かれています。
取り上げられているのは10問中8問までですが、機械学習よりの問題が多い印象です。
サンプル問題を改めてみてみると、AWS関連のワードが出てくるのは10問中4問のみで、その中でも3問にAmazon SageMakerが出てきます。実際の試験での比率でも同様なのでしょうか。。2.2.個人の記事(国内)
Qiitaと、個人ブログから引用させていただきました。
その1
[AWS認定10冠達成!AWS Certified Machine Learning – Specialty Beta Examに合格しました]
https://qiita.com/nakazax/items/4bb44cb8474e4beb01b6内容に差異があるかは不明ですが、受けたのはベータ版とのことです。
私見と前置きがあった上で、以下の知識レベルが求められる試験だと書かれています。機械学習と深層学習: JDLAディープラーニングG検定+α程度の知識
SageMaker: 普段からSageMakerを使っている、またはSageMakerの開発者ドキュメントをしっかり読み込んでいる
その他のAWSサービス: ソリューションアーキテクトアソシエイト+α程度の知識やはり「AWSとは関係ない一般的な機械学習と深層学習に関する問題が思いの外多かった」印象とのこと。そしてここでJDLAディープラーニングG検定というものの存在を知る。ほぅ…。
人材育成 | 一般社団法人 日本ディープラーニング協会 Japan Deep Learning Association
その2
[文系エンジニアがAWS Certified Machine Learning – Specialty に合格してきました]
https://yomon.hatenablog.com/entry/2019/05/awscertmlまずは以下をベースに機械学習系の勉強をされたとのこと。
- マンガでわかる機械学習(オーム社)
- 「超」入門 微分積分 学校では教えてくれない「考え方のコツ」 (ブルーバックス)
- 最短コースでわかる ディープラーニングの数学(日経BP社)
- PythonとKerasによるディープラーニング(マイナビ出版)
模擬試験を受け、足りない知識を以下で補ったとのこと。
- [第2版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践 impress top gearシリーズ
やはり機械学習色強めのよう。そしてSageMaker。
他のAWS SA ProとBigData取得してますが、この試験は特にAWS色薄く、機械学習の知識が求められる内容が多かったです。とはいえ、この分野の中心サービスであるSageMakerの公式マニュアルやチュートリアルは手を動かしておくことをオススメします。機械学習系のAWSサービスも一通り何ができるのか確認しておいた方が良いかと思います。
その他にも役立った本として以下が挙げられています。
- 見て試してわかる機械学習アルゴリズムの仕組み 機械学習図鑑(翔泳社)
- ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装(オライリージャパン)
- 徹底攻略 ディープラーニングG検定 ジェネラリスト 問題集 徹底攻略シリーズ(インプレス)
その3
[AWSの機械学習エンジニア認定試験を受けてきた]
https://qiita.com/si1242/items/c7b5d2f3916bf6b159de
- 超重要なAWSサービス
- Sagemaker
- S3
- Glue
- Kinesis Firehose
- Athena
- Sagemakerのポイント
- S3との連携
- エンドポイントの負荷テスト
- ハイパーパラメータの調整
- 組み込みアルゴリズム
- 機械学習の知識は基本的なところまででOK
- ベストプラクティスを選ばせるものが出る
Sagemakerはブログを読んだり手を動かしたり(難しければ公式のYoutubeを見たり)して学習するとよいとのこと。機械学習は基本的なレベルで…とあるが、書いてあることがほぼ分からないので、私はまだスタートラインに立っていない。。
2.3.個人の記事(海外)
私がえいやで訳しているので、そこが合ってるのかから疑ってください。
その1
[My Take on AWS Certified Machine Learning speciality Beta Exam]
https://www.linkedin.com/pulse/my-take-aws-certified-machine-learning-speciality-beta-kalyan-janaki受けたのはベータ版で、著者はBigDataソリューションアーキテクトとして働いている。試験ガイドの分野ごとに所感が述べられている。
- Data Engineering(20%)
- シナリオに合致したAWSサービスを選ばせる問題が出る。
- S3, EMR,Kinesis, Kinesis FireHose, Kinesis Analytics ,Athena and Glue.
- 機能とベストプラクティスをおさえておく。
- Exploratory Data Analysis(24 %)
- AWSのサービスでなくデータの可視化の知識にフォーカスされている。
- 以下の知識があるといいだろう。
- box plot, line chart, scatter plot, heat map, word cloud, pie chart, pivot table
- Quicksightが出てこなかったのは驚きだ.
- ガイドでは比重が24%と書かれていたが10%程度に感じた
- Modeling(36%)
- 試験全体の50 % はモデリングに関するものだと感じた。
- AWSサービスというよりDLとMLにコンセントレートしてる。ポピュラーなモデルの知識が必要。
- 以下を理解しておくとよい。
- 特定のシナリオに合致したMLアルゴリズム
- AWS Sage makerの組み込みアルゴリズムでできること
- ポピュラーなMLやDLのアルゴリズムごとに、それを最適化できるハイパーパラメータ
- 一般的なデータの前処理と特徴エンジニアリング
- 正規化、異なるタイプの代入、異常値検出など
- CNN(Convolutional Neural Networks)とRNN(Recurrent Neural Networks)のユースケース
- エポック数とレイヤー数を使用してディープラーニングモデルを最適化する方法
- (どちらも機械学習におけるパラメータの1つらしい)
- 問題を解決するためにモデルを組み合わせて使う知見
- kmeans(K平均法)クラスタリングとPCA(主成分分析)を使ってからデータを分類させる、など
- Machine Learning Implementation and Operations(20 %)
- 多くのAWSのMLサービスが出る。
- transcribe, translate, comprehend, polly, lexなど。
- 特にSageMaker。
- ノートブックインスタンスをどう使うか、トレーニングジョブをどう作るか、
- エンドポイントをどうデプロイするか、高可用性を持たせるためにどうするか、
- エンドポイントのブルーグリーンデプロイをどうするかモデルトレーニングにどのインスタンスが適切か。
公式のe-ラーニングはあまり有用でなかったとのこと。
その2
[Passing the AWS Certified Machine Learning Specialty Exam]
https://thecloudtutor.com/2019/03/18/Passing-the-AWS-Certified-Machine-Learning-Specialty-Exam-MLS-C01.htmlLinuxAcademyでトレーニングアーキテクトとして働いている人物による投稿。
- 体感的な比重は以下の通り
- 1.Machine Learning / Deep Learning 50%
- 2.AWS SageMaker 25%
- 3.Other AWS Services 25%
- 1.Machine Learning / Deep Learning 50%
- AWSとは関係なく純粋な機械学習、深層学習の知識
- 専門的な統計学レベルでの数学の理解は不要
- 基本的な概念はしっかりおさえておく
- 教師あり学習、教師なし学習、強化学習の違い
- 訓練(training)、検証(validation)、テスト(testing)データの目的と管理方法
- 一般的なハイパーパラメータの知識とアルゴリズムごとの有名どころ
- 正則化(regularisation)とは何か、どう実現するか
- 回帰分析(regression)と再急降下法(gradient descent)
- インプットデータについても押さえておく
- Jupyter notebooksやAWS QuickSightなどのツールによる可視化
- 特徴エンジニアリング(Feature engineering)
- データの不均衡や欠落が起こった時にどうするか
- モデルタイプ(アルゴリズム)がどういったものか、どういったケースで使うかの理解
- ロジスティック回帰、線形回帰、サポートベクターマシン、
- 決定木/ランダムフォレスト、k平均法クラスタリング、k近傍法
- ディープラーニングのモデルについて理解しておく
- 畳み込みニューラルネットワーク(CNN)、回帰型ニューラルネットワーク(RNN)
- ML/DLモデルのパフォーマンスを測定、理解、改善する方法に焦点があたる。
- Accuracy(正解率)、Gini Impurity(ジニ不純度)、Confusion Matrix(混同行列)
- F1 Score、Sensitivity(感度)、Specificity(特異度)、Precision(適合率)、Recall(再現率)
- 2.AWS SageMaker 25%
- もっとも試験で問われるAWSサービスである。以下をおさえておく。
- AWS SageMakerとは何か、どのようなアーキテクチャか
- Jupyter notebooksはAWS SageMakerどのような点で相性がいいか、どう使われているか
- セキュアデータにアクセスするにはどうするか
- Jupyter notebookをセキュアにするにはどうするか
- モデルをどのように学習させるか、デプロイさせるか
- ハイパーパラメータの最適化
- AWSに最適化されたアルゴリズムについても知っておく
- https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/algos.html
- 組み込みでない独自のアルゴリズムを使用する方法についても理解しておく
- 3.Other AWS Services 25%
- AIサービス
- ユースケースと制限、アーキテクチャを理解しておく
- Rekognition、Polly、Transcribe、Lex、Translate、Comprehend
- その他のAWSサービス
- さまざまな側面からAWSを問われるのでアソシエイトレベルで理解しておく
- Big Data関連の以下のサービスは特に多く問われた
- S3(データをどうセキュア化するかを含む)
- Athena(パフォーマンスをどうだすか)
- Kinesis(データの転送および加工)
- EMR(Sparkと組み合わせる)
- AWS Glue
- QuickSight(さまざまなサービスからどうデータをインプットするかを含む)
試験ガイドにリンクが多く載っているAmazon Machine Learningがあまり出なかった…とある。意外。
その3
[So you are thinking of taking the AWS Certified Machine Learning Specialty exam]
http://thedatascience.ninja/2019/04/07/so-you-are-thinking-of-taking-the-aws-certified-machine-learning-specialty-exam/
- ざっくり分けると以下の通り。
- Questions that required AWS knowledge: 33%
- Questions on Machine Learning that didn’t require AWS knowledge: 33%
- Questions that combined Machine Learning with AWS topics: 33%
- AWSサービス
- とにかくSagemaker
- 組み込みアルゴリズム
- Sagemakerエンドポイント設定
- Blue/Greenデプロイ、カナリアデプロイ
- ハイパーパラメータ最適化、自動モデルチューニング…
- その他のAWSマシンラーニングサービス
- Amazon Kinesis
- Streams、Video Streams、Firehose、Data Analytics
- Amazon EMRとAWS Glue
- Spark、Hadoop、Hive…
- Amazon S3
- Sagemakerと組み合わせた時のセキュアな使い方
- CSV、JSON、Parquet、RecordIO protbufなどのフォーマット
- 他のレポジトリと比較した際にソリューションに合致するのはどれか
- Amazon Identity and Access Management (IAM)
- Machine Learning Topics
- 機械学習は広大な範囲にわたる学問だが、試験に問われるのはそこまで複雑なものではない
- 身に着けておくべきは以下のようなトピック
- Sagemakerのインスタンス作成、開発、学習、最適化、モデルのデプロイの仕方
- Sagemakerの組み込みアルゴリズム
- 他のAWSの機械学習サービス
- モデル性能の測定
- ディープラーニング
- 以下それぞれに関連したキーワードの羅列(本記事では割愛)
キーワードの意味が一通り理解できるようしておこうと思います。
3.学習リソース
学習に使えそうなリソースのまとめです。
3.1.AWS
AWSドキュメント
https://docs.aws.amazon.com/index.html
いわずもがなの情報源。日本語訳を信じすぎるとたまに痛い目に合う。AWSサービス別資料集
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/
AWS Black Belt Online Seminar の資料。
個人的には、ドキュメントより先にこちらで大まかな内容を掴むのが好き。
機械学習系はSagemakerの他はあまり品ぞろえが良くなさそう。ホワイトペーパー
https://aws.amazon.com/jp/whitepapers/#machine-learning
機械学習だと3種ほどある。全部英語だけど分量はそこまでないから頑張れば読めそう。公式ブログ
Amazon Web Services ブログ - Category: SageMaker
AWS Machine Learning Blog
参考にした個人ブログでも記述があったが、ある程度古いほうから読んだほうがよいかも。新しすぎると試験には取り込まれないので。3.2.機械学習
Cousera
https://www.coursera.org/learn/machine-learning
機械学習の勉強をする上ではかなり有名らしい。さわりだけ試してみたが、画面の上半分に動画、下半分にテキストが表示される形式。良さそうだが動画だと時間のコントロールがしづらいのがネック。ディープラーニング G検定 対策本
[深層学習教科書 ディープラーニング G検定(ジェネラリスト) 公式テキスト]
https://www.shoeisha.co.jp/book/detail/9784798157559[徹底攻略ディープラーニングG検定ジェネラリスト問題集]
https://book.impress.co.jp/books/1118101076この試験に限らず、翔泳社のEXAM PRESSとインプレスの徹底攻略(黒本)シリーズはとりあえず買ってしまう。デザインがカッコいいから。
3.3.非公式オンライン講座
この手のは使ったことがないので有用性は不明ですが、講座のアウトラインだけ眺めて大まかな内容を推測するのはいいかもしれません。
A Cloud Guru
AWS Certified Machine Learning - Specialty 2019
https://acloud.guru/learn/aws-certified-machine-learning-specialtyO'Reilly Safari
AWS Certified Machine Learning-Specialty (ML-S)
https://www.oreilly.com/library/view/aws-certified-machine/9780135556597/Pragmatic AI Labs
AWS Certified Machine Learning-Specialty (ML-S)
https://noahgift.github.io/aws-ml-guide/intro.htmlおまけ
個人がまとめたyoutubeの再生リスト。
AWS Certified Machine Learning Exam
https://www.youtube.com/playlist?list=PLAFY3hrExHFGt6TldZ9Rjv5FALbw3uuu_4.学習プラン
ここまでの下調べを経て、個人的に以下のようなあたりをつけました。
- 半分はAWSに関係ない機械学習/深層学習関連の問題が出る
- それらはそこまで深掘りして聞かれるわけではない
- AWSはとにかくsagemakerが出る
- 試験ガイドにがっつりリンクが載っているMLはそこまで出ない
- AWSのAIサービス系がアーキテクチャレベルで出る
- kinesis,EMR,Athena,Glueあたりも頻出
- その他のAWSサービスはソリューションアーキテクトアソシエイトレベルで理解できていれば取れそう
- セキュリティ、ベストプラクティス
- 公式のe-ラーニングはそこまで有益でない
それを踏まえて、以下を並列で進めていくプランを立てました。かっこ内は所要時間の目安。
4.1.共通
サンプル問題(1時間)
まずはここから。初見だとちんぷんかんぷんなはずなので、問題と答えと解説を見て、最低限そこは腹落ちさせておく。
模擬試験受験および復習(10時間)
試験対策には過去問から入るタイプなので、早い段階で受けたい。
まずは足りてない知識を把握して、そこを埋めていく。
正しいと思われる回答と、その根拠を述べられるようにする取り組みもここに含む。4.2.AWS
Sagemaker(10時間)
- 公式ドキュメントは全量を読み込む。
- サービス別資料集を読む。
- 公式動画でイメージを掴んでおく。
- 公式ブログでユースケースを眺めておく。
Amazon Machine Learning(2時間)
Sagemakerの前に機械学習系のサービスとして登場し、役目を終えつつある位置づけの印象。とはいえ触れないのも怖いので、ドキュメントに目は通しておく。
AIサービス(3時間)
それぞれでできることを概要でレベルでおさえておく。ドキュメントはそこまでじっくり読むつもりはない。
その他のAWSサービス(4時間)
ワードとして何個か出てきたうち、自身の理解が足りていなさそうな以下のあたりを学習予定。
- Glue
- Athena
- Kinesis
- EMR
AWSサービス別資料集で概要をおさえて、適宜公式ドキュメントを見る。あとは公式ブログで、機械学習の文脈の中で出てきたら構成や組み合わせをおさえておく。
4.3.機械学習、深層学習
ディープラーニングG検定(7時間)
上述の公式テキストと問題集を使用する予定。
機械学習とはなんぞや、という基礎の基礎から体系立てて書いてある本を探したが、ピンとくるものがなかったのでここに落ち着いた。いっそのことこの検定試験も併せて取ることも検討したが、細かい固有名詞などAWS MLの試験と範囲が被らない部分もそれなりにありそうなので、取捨選択して学習予定。ゼロから作るDeep Learning(10時間)
https://www.oreilly.co.jp/books/9784873117584/
本棚に眠っているのを掘り起こして読んでみたら、思いのほか面白くてためになりそうだったので、一歩踏み込んだ機械学習の勉強は本書を用いることにした。
===
なんとなく上記で充足している予感はしているが、模擬試験を解く中で試験範囲をカバーできていなさそうであれば、書籍を追加予定。(Couseraによる動画での学習は採用しないことにした。)
終わりに
というわけで、後は勉強して受かるだけです。頑張りましょう。
トータル50時間くらいの学習量で受かれればいいかなと思っています。学習リソースや、有益な情報があれば取り込みたいので教えてください。
- 投稿日:2019-07-04T06:22:21+09:00
kubernetesのworkloadsリソースの概要
Workloadsリソースとは
クラスタ上にコンテナを起動するために利用するリソース
Pod
Workloadsリソースの最小単位。
同じPodに含まれるコンテナ同士はネットワーク的に隔離されていないので、IPアドレスを共有している。
つまり、同じPodにあるコンテナ同士は、同一IPを持つことになるので、localhostで通信が可能になります。
※基本的には1つのPodに1つのコンテナを内包することになります。sample-pod.yamlapiVersion: v1 kind: Pod # リソースの種類 metadata: name: sample-pod # Podの名前 spec: containers: # containerの定義 - name: nginx-container # container名 image: nginx:1.12 # containerのimageReplicaSet
複数のPodのレプリカをセットで作成する機能で、レプリカ数が不足している場合はTemplateからPodを作成して、レプリカ数が過剰な場合はラベルに一致するPodのうち1つを削除します。
rs-sample.yamlapiVersion: apps/v1 kind: Replicaset # リソースの種類 metadata: name: sample-rs # Replicasetの名前 spec: replicas: 3 # レプリカ数 selector: matchLabels: app: sample-app # 起動するPod名 template: # 複製すべきPodの定義 metadata: labels: app: sample-app #Pod名 spec: containers: # containerの定義 - name: nginx-container # container名 image: nginx:1.12 # containerのimage ports: - containerPort: 80 # containerのPortDeployment
Replicasetを管理することで、ローリングアップデートやロールバックを実現するリソース。
DeploymentがReplicasetを管理し、ReplicaSetがPodを管理する3層の親子関係になります。
※kubernetesで最も推奨されているコンテナの起動方法・関係性
Deployment >> Replicaset >> Podsample-deployment.yamlapiVersion: apps/v1 kind: Deployment # リソースの種類 metadata: name: sample-deployment # Deploymentの名前 spec: replicas: 3 # レプリカ数 selector: matchLabels: app: sample-app # 起動するPod名 template: # 複製すべきPodの定義 metadata: labels: app: sample-app #Pod名 spec: containers: # containerの定義 - name: nginx-container # container名 image: nginx:1.12 # containerのimage ports: - containerPort: 80 # containerのPortDeamonset
Deamonsetは、ReplicaSetの特殊な形のリソースになります。Replicasetは、各Nodeに均等に配置されるものではないが、Deamonsetは各Nodeに確実に1つずつPodを配置します。
そのため、レプリカ数の指定はできなく、1つのNodeに2つのPodを配置することもできません。
但し、Podを配置したくないNodeに配置できなくするこをは可能です。
ログの収集など、全Node上で必ず動作させたいプロセスのために利用することが多い。sample-ds.yamlapiVersion: apps/v1 kind: DaemonSet # リソースの種類 metadata: name: sample-ds # DaemonSetの名前 spec: selector: matchLabels: app: sample-app # 起動するPod名 template: # 起動するPodの定義 metadata: labels: app: sample-app #Pod名 spec: containers: # containerの定義 - name: nginx-container # container名 image: nginx:1.12 # containerのimageJob
コンテナを利用して一度限りの処理を実行させるためのリソース。
起動するPodが停止することを前提にして作られているため、バッチなどの処理の場合にJobを使用します。sample-job.yamlapiVersion: batch/v1 kind: Job # リソースの種類 metadata: name: sample-job # Jobの名前 spec: completions: 1 # 正常終了する回数 parallelism: 1 # Jobで同時にPodを実行できる並列数 backoffLimit: 10 # 失敗したJobのリトライ回数 template: # 起動するPodの定義 spec: containers: # containerの定義 - name: sleep-container # container名 image: cenos:6 # containerのimage command: ["sleep"] # sleepコマンドの実行 args: ["60"] # 60秒間 restartPolicy: Never # PodがErrorになった際にはJobが新しいPodを作成CronJob
Jobを管理するリソースで、CronjobがJobを管理し、JobがPodを管理するような親子関係になります。
・関係性
CronJob >> Job >> Podsample-cronjob.yamlapiVersion: batch/v1beta1 kind: CronJob # リソースの種類 metadata: name: sample-cronjob # cronJobの名前 spec: schedule: "*/1 * * * *" # 1分毎に実行 concurrencyPolicy: Allow # Jobの並列実行Policyで制限を行わない startingDeadlineSeconds: 30 # CronJob で何かしら実行されなかった時にいつまで実行可能かの期限 successfulJobsHistoryLimit: 5 # 正常終了したJobの履歴保有数 failedJobsHistoryLimit: 3 # 異常終了したJobの履歴保有数 suspend: false # CronJobのスケジューリングの対象とする JobTemplate: spec: completions: 1 # 正常終了する回数 parallelism: 1 # Jobで同時にPodを実行できる並列数 backoffLimit: 1 # 失敗したJobのリトライ回数 template: # 起動するPodの定義 spec: containers: # containerの定義 - name: sleep-container # container名 image: cenos:6 # containerのimage command: - "sh" - "-c" args: - "sleep 40; date + '%N' | cut -c 9 | egrep '[1|3|5|7|9]'" # 約50%の確率で成功するコマンド restartPolicy: Never # PodがErrorになった際にはJobが新しいPodを作成
- 投稿日:2019-07-04T06:19:09+09:00
【目的無しの泥臭調査⑧】監視情報表示の「top」「htop」コマンドだけでは満足できなかったため、「gtop」を試用して、ネットワーク情報を大幅可視化。
- ふと気になったことを、淡々と赴くままに調査していく、この上ない自己満足記事第八弾。
- 日々成長する効率性や、連日生み出される便利ツールを生かしながらも、泥臭調査も好きで同時に行う生活。
- 今回は、監視コマンドの「top」「htop」コマンドだけでは、満足しなかった外観重視技術者の私のために、「gtop」を試用することにしよう。
概要
- Node.js製の、ネットワークやCPU等といった監視情報をグラフ・ダッシュボード化して分かりやすく表示してくれるコマンドツール。
- 同様のtopやhtopコマンドに比べて、プロセスの流れの理解の容易さや見やすさが利点。
- 公式GitHub
特徴
グラフ表示
- ネットワークやCPU等といった様々な監視情報を、グラフ(可視)・ダッシュボード化して表示するため、視覚的に理解しやすい。
項目ごとの並び替え表示
- topやhtopコマンド同様、CPU使用率やメモリ順に並び替えることが可能なため、不具合等の原因究明がしやすい。
整理された情報表示
- CPUやネットワーク、ディスク容量等といった情報が項目ごとに、ブロックとして、整理されているため、内容が見やすい。
ターミナル完結
- プロセスを可視化するために、別途ツールを立ち上げる必要がなく、ターミナル上で完結する。
作業環境
- Amazon Linux 2
- ※今回はAmazon Linuxを利用しているが、Node.js環境があれば、MacやWindowsでも利用可能。
インストール
- gtopのインストールでは、npm(Node.jsのパッケージ管理)を利用する。
- 今回は、EC2のLinux環境を利用しているため、下記のコマンドをうち、Node.jsのインストールを行う。
- ※EC2以外(WindowsやMac,その他Linux)のNode.jsのインストールはこちらを参考にする。
# バイナリの取得 $ curl -sL https://rpm.nodesource.com/setup_10.x | sudo bash - # Node.jsのインストール $ sudo yum install -y nodejs # npmバージョン確認 $ npm -v
- npm利用確認後、下記のコマンドをうち、gtopをインストールする。
- ※npmが利用できれば、gtopはMacやWindowsでも利用可能。
# gtopのインストール $ npm install gtop -g結果
- 下記、実際の画面。
- CPUやメモリ、ネットワーク等の情報がグラフになって可視化される。
- 各情報がブロックとして、整理されており、見やすく表示されている。
- ディスク容量の概要も確認できる。
基本操作
- gtopの基本操作コマンドとしては、下記。
内容 コマンド 起動 gtopプロセス順での並び替え 起動状態のまま、 pメモリ順での並び替え 起動状態のまま、 mCPU順での並び替え 起動状態のまま、 c終了 起動状態のまま、 q
- 一部の環境で、表示の不具合や挙動エラーが起きる場合がある。
- その場合、下記のコマンドをうち、環境変数を設定して、起動する。
$ LANG=en_US.utf8 TERM=xterm-256color gtopまとめ
- 今回は、監視コマンドの可視化ということで、「htop」コマンドとの併用の目論みと、両方使いによるメモリの高負荷の心配を抱えながら、記事を書く。
- 数日監視コマンドと向き合った私は、改めて「メモリの使用量軽視」という重く愉快な現実がのしかかる。
- 時代の突然変異なのか、急に「Linux外観ツール大流行」が起きている日常は、いつまで継続するのか自己問答。
参考
- https://github.com/aksakalli/gtop
→公式Githubです。大変お世話になりました。- https://linuxfan.info/gtop
→こちらの記事を参考にしました。大変お世話になりました。- https://ubuntuapps.net/blog-entry-1035.html
→こちらの記事を参考にしました。大変お世話になりました。

- 投稿日:2019-07-04T00:40:53+09:00
AWSについて調べてみた
はじめに
こんにちは、かちゃあと申します。
Qiita2回目の投稿です。
まだまだ不慣れな事が多いですが、投稿をする事によって慣れていければと思っています。今回調べたことは、AWSについてです。
就職活動をしている際に、AWSの技術を採用されている企業が多かったこともあり
より詳しく調べようと思ったきっかけになりました。
備忘録になりますがお付き合いください。AWSとは何か
AWSとはAmazon Web Servicesの略称で、
Amazonが提供するクラウドコンピューティングサービス。
(AWSの他にはAzure(Microsoft)、CloudPlatform(Google)、Bluemix(IBM)などもある)
クラウドコンピューティングサービスとは、ネットワーク経由でサーバーやデータベース、ソフトウェア、アプリケーションなどを利用者に提供しているもの。クラウドコンピューティングサービスは、主に3つに分類されています。
クラウドサービス3つの分類
1: SaaS(サース:Software as a Service)
インターネット上での、ソフトウェア機能の提供を行うサービス。2: PaaS(パース:Platform as a Service)
インターネット上での、アプリ実行のためのプラットフォーム機能の提供を行うサービス。3: IaaS(イアース:Infrastructure as a Service)
インターネット上での、インフラなどサーバー、ネットワークを提供してくれるサービス。AWSを使うメリットとは?
AWSを使用するメリットは5つ挙げられています。以下1~5は公式サイトからの引用になります。
1: セキュリティと法規制の対応
"AWSクラウドは、お客様がセキュリティに関する政府、業界、および企業の標準や規制を満たすことができる認証を取得、運用しています。
例えば、ISO 27001、SOC、PCI DSS などを含む、世界中のさまざまなセキュリティ標準の要件を満たしています。"クラウドサーバーのセキュリティ面は様々な要件を満たしていて安心なのですね。
2: お客様の声による新サービス提供と機能改善
"3000以上の新サービスの提供と機能改善に伴ってきたうちの95パーセントはお客様のフィードバックをもとに開発されている。"
常に最新のクラウドを提供されているからこそ機能改善のサイクルも早く、より多くの人に満足に使っていただけるという事ですね。
3: お客様への継続的な利益還元
"2017年7月時点で 60 回以上サービスの値下げを行っており、ストレージサービスなど当初より 90%以上値下げされたサービスもあります。"
お客様を大切にしていて今後もお客様との関係を大切にしていきたいという気持ちの現れですね。
4: グローバルビジネスを支える耐障害性と高可用性
"AWSクラウドのグローバルインフラストラクチャは、耐障害性と高可用性を実現するために特殊な構成が組まれています。
一方の障害が他方へ影響することはなく、そのため耐障害性と高可用性を実現することができます。"こちらは1と少し似ていますね。障害が起きたとしても、影響が少なく安心という事ですかね。
5: ユーザー基盤とエコシステム
"AWS クラウドは、全世界で数百万を超えるお客様(アクティブユーザー)にご利用いただいており、日本でもスタートアップから大手企業、政府・教育機関まで、10 万以上のお客様にご利用いただいています。
AWS のエコシステムを支える APN (Amazon Partner Network)パートナーには、日本全国で AWS を使ったシステム構築、ソフトウェア利用を支援する企業やシステムインテグレーターが参加しており、AWS クラウドを使ったサービスの提供やソフトウェア運用、システム構築についてご相談いただけます。"これだけ世界、日本で多くの企業が導入していることから、AWSの規模の大きさが伺えます。
巨大なユーザー基盤を持っているからこそ得られる情報もそれだけ多いのでしょうし。ちなみにAPNは初めて知りました。AWSの代表的なサービス(一部)
1: EC2
EC2はサーバーを構築・運用できるサービス。
クラウド環境上で必要な時に必要なだけサーバーを柔軟に利用できます。2: RDS
RDSは、データベース機能を利用できるサービス。
負荷を軽減できたり、自動バックアップや大規模なデータ構築や運用も可能のようです。3: S3
システムの様々なデータを保存できるサービス。データを別のシステムやデータを分析処理に移すこともできるみたいです。
こちらのサービスが2006年3月14日にリリースされたのがAWSの始まりだったみたいですね。
今では通常時、1秒間に約100万リクエストもの処理をしているそうです。凄い。。逆にデメリットは?
1: 機能の数が多く、使いこなすにはサービスに対する多様な知識が必要不可欠
2: 費用が一定ではない
まとめ
AWSを利用することによって、ある企業の無駄を減らせたり、リスクを減らせたりするわけですね。
便利ではあるものの、サービスが多様な為、使いこなすのは決して簡単ではなさそう。
AWSについては今後確実に必要になる知識なので、サービスごとにしっかりとした勉強の時間が必要ですね。参考&引用元
参考、引用させていただきました。
https://capsulecloud.io/about/aws
https://udemy.benesse.co.jp/development/web/what-is-aws.html
http://www.soumu.go.jp/main_sosiki/joho_tsusin/security/basic/service/13.html
https://aws.amazon.com/jp/about-aws/
- 投稿日:2019-07-04T00:02:00+09:00
AWS EBSのボリュームタイプの違いを理解する
AWS Elastic Block Store(EBS) とは
EC2インスタンスにアタッチして使用するブロックストレージのこと。OS、アプリ、データの置き場所などの用途に利用される。
ブロックストレージの種類
大きく分けると SSD-Backed と HDD-Backed のボリュームがある。
ざっくり用途を分けると、小さいサイズの不規則なデータの読み書きがある RDS(Relational Database Service)のような用途には高い IOPS が求められるため、ランダムアクセスにも性能を発揮する SSD-Backed を選択する。
ビッグデータ処理で、ファイルサイズの大きいデータを保存するなど、I/O のサイズが大きく、シーケンシャルアクセスの場合は HDD-Backed を利用。SSD-Backed
汎用SSD(gp2)
- ブートボリューム
- 負荷が読めないシステム
- 小規模なDB向け
- 開発・テスト環境向け
- 仮想デスクトップ
プロビジョンドIOPS(io1)
- リレーショナルデータベース
- 汎用では処理しきれないIO性能を要求
- 大規模なDB向け
- 持続的なIOPSパフォーマンスが必要なアプリケーション向け
- EBSのディスク性能を高めるが、ネットワークがボトルネックになるため、EBS最適化インスタンスを使うことが推奨
HDD-Backed
スループット最適化HDD(st1)
- シーケンシャルアクセス時に高い性能を発揮するタイプ
- 高いスループットを要求するビッグデータ処理に最適
- DWH、大規模なETL処理などに利用
- 起動ボリュームには利用できない
- サイズは500GiB〜
コールドHDD(sc1)
- ログデータ保管、アーカイブ利用
- サイズは500GiB〜
用語解説
- IOPSとは、Input Outpu Per Secondのことで ストレージが1秒あたりに処理できるI/Oアクセスの数 を指す。
EBS最適化とは、EC2-EBS間の通信を専用のものでつなぐこと。そうすることで、他の通信に邪魔されずにディスク IO性能の安定化につながる。旧世代インスタンスを除いてデフォルトでオンになっている。
シーケンシャルアクセスとは、連続したデータアクセスのこと。 たとえば、ファイルコピーの速さはシーケンシャルアクセスの性能による。
参考