- 投稿日:2019-07-04T23:31:52+09:00
pytzを使ってタイムゾーンを取得する
各国のタイムゾーンを扱うpytz
Python のタイムゾーンと言えば pytz
Python 3 になって標準ライブラリに timezone が出来ましたが、便利な pytz もよく使います。pytzimport pytz tz = pytz.timezone('Asia/Tokyo')timezonefrom datetime import timedelta, timezone tz = timezone(timedelta(hours=+9), 'Asia/Tokyo')(速度を求める場合は timezone を使うのがいいみたいです)
参考:Python3のdatetimeはタイムゾーンを指定するだけで高速になるインストール
pip install pytzpytz(PyPI)
ドキュメントは上のリンクから。使い方
naive な datetime インスタンス(タイムゾーン情報を持たない datetime インスタンス)にタイムゾーン情報を付与する際には localize() メソッドを使います。
from datetime import datetime, timedelta import pytz tokyo = pytz.timezone('Asia/Tokyo') tokyo_datetime = tokyo.localize(datetime(2019, 7, 7, 14, 12, 34)) print(tokyo_datetime) # 2019-07-07 14:12:34+09:00aware な datetime インスタンス(タイムゾーン情報を持つ datetime インスタンス)のタイムゾーンを変換する際には datetime の astimezone() メソッドを使います。
london = pytz.timezone('Europe/London') london_datetime = tokyo_datetime.astimezone(london) # Asia/Tokyo から Europe/London へ変換 print(london_datetime) # 2019-07-07 06:12:34+01:00ロンドンはUTC+0ですが、サマータイム中なのでUTC+1になっていますね。
サマータイムなどの特殊なタイムゾーン情報を持った datetime インスタンスを操作(進めたり戻したり)した後は normalize() メソッドを使ってタイムゾーン情報を正しいものに更新します。
london_datetime += timedelta(weeks=24) # 約6ヶ月後のロンドンの日時 print(london_datetime) # 2019-12-22 06:12:34+01:00 12月なのにサマータイムのUTC+1になっている london_datetime = london.normalize(london_datetime) print(london_datetime) # 2019-12-22 05:12:34+00:00アンチパターン
UTC を除いて、datetime のコンストラクタに pytz 由来の timezone (tzinfo) は渡してはいけません。サマータイムなどの特殊な日時計算が正しく動作しないためです。
Asia/Tokyo のタイムゾーンでも +09:19 になってしまいます。from datetime import datetime import pytz tokyo = pytz.timezone('Asia/Tokyo') japan_dt = datetime(2019, 7, 7, 12, 24, 45, tzinfo=tokyo) # NG print(japan_dt) # 2019-07-07 12:24:45+09:19 japan_dt = tokyo.localize(datetime(2019, 7, 7, 12, 24, 45)) # OK print(japan_dt) # 2019-07-07 12:24:45+09:00 utc_dt = datetime(2019, 7, 7, 12, 24, 45, tzinfo=pytz.utc) # UTCはOK print(utc_dt) # 2019-07-07 12:24:45+00:00なんでも日本標準時が施行された1888年より前は各都市毎に時間が決められていて、Asia/Tokyo というのはまさしく(現在のように明石基準でなく)東京基準の時間だったので、19分ずれてるとかなんとか。
- 投稿日:2019-07-04T22:59:40+09:00
DataFrameのMultiIndexでつまづく人のために
MultiIndexは便利だけど、ちょっとした処理でしょっちゅうつまづくので、忘れないようにやり方をメモしておく。
データセット
df = pd.DataFrame({'地方':['北海道','北海道','東北','東北','関東'], '都道府県':['北海道','北海道','青森','岩手','千葉'], '振興局':['オホーツク','根室','','',''], 'いわし':[20,8,15,5,46], 'さば':[1,2,20,10,29]}).set_index(['地方','都道府県','振興局'])
地方 都道府県 振興局 いわし
さば
北海道 北海道 オホーツク 20 1 北海道 北海道 釧路 8 2 東北 青森 15 20 東北 岩手 5 10 関東 千葉 46 29 特定のレベルのラベル一覧を取得
単独のレベル
都道府県の一覧を取得。ソートが必要なら
.sort_values()を後ろに付ける。# !version 0.23.0.以降 df.index.unique('都道府県') # Index(['北海道', '青森', '岩手', '千葉'], dtype='object', name='都道府県') # !version 0.23.0.より前 df.index.get_level_values('都道府県').unique() # Index(['北海道', '青森', '岩手', '千葉'], dtype='object', name='都道府県')複数のレベル
地方、都道府県の組み合わせの一覧を取得。欲しくない振興局をインデックスレベルから外す。
df.index.droplevel(['振興局']).drop_duplicates() # MultiIndex(levels=[['北海道', '東北', '関東'], ['北海道', '千葉', '岩手', '青森']], # codes=[[0, 1, 1, 2], [0, 3, 2, 1]], # names=['地方', '都道府県'])レベル順序の変更
スワップ
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.MultiIndex.swaplevel.html#pandas.MultiIndex.swaplevel
都道府県と振興局を入れ替え。df.index = df.index.swaplevel('都道府県','振興局') df
地方 振興局 都道府県 いわし
さば
北海道 オホーツク 北海道 20 1 北海道 釧路 北海道 8 2 東北 青森 15 20 東北 岩手 5 10 関東 千葉 46 29 任意の順序
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.MultiIndex.reorder_levels.html#pandas.MultiIndex.reorder_levels
振興局、都道府県、地方の順に入れ替え。df.index = df.index.reorder_levels(['振興局','都道府県','地方']) df
振興局 都道府県 地方 いわし
さば
オホーツク 北海道 北海道 20 1 釧路 北海道 北海道 8 2 青森 東北 15 20 岩手 東北 5 10 千葉 関東 46 29 インデックスの置換
df.rename(index={'青森':'秋田'},level='都道府県')
地方 都道府県 振興局 いわし
さば
北海道 北海道 オホーツク 20 1 北海道 北海道 釧路 8 2 東北 秋田 15 20 東北 岩手 5 10 関東 千葉 46 29 最上位レベルの追加
ややテクニカルな方法。
pd.concat([df],keys=['日本'],names=['国'])
国 地方 都道府県 振興局 いわし
さば
日本 北海道 北海道 オホーツク 20 1 日本 北海道 北海道 釧路 8 2 日本 東北 秋田 15 20 日本 東北 岩手 5 10 日本 関東 千葉 46 29 列のマルチインデックスの解除
https://code.i-harness.com/ja-jp/q/d8847f#0
https://stackoverflow.com/questions/14189695/reset-a-columns-multiindex-levels
- 投稿日:2019-07-04T22:54:51+09:00
PyOxidizer を試してみた
先日、何気なくはてブを見ていると、マイナビニュースで PyOxidizer なるツールが紹介されているのが目に止まりました。
PyOxidizer とはなにか

記事に書かれていた説明によると、
「PyOxidizer」はPythonスクリプトをそのスクリプトを実行するのに必要になるパッケージやモジュールも含めて単一のバイナリファイルにまとめるツール。
だとか。
ふむふむ、これはきっと PyInstaller 的なやつだな。
の説明を読む限り、これもきっとバイナリサイズが大きくなりそうだけど、PyInstaller と比べてどうなんだろう? ってことで、何はともあれ試してみましょう。
バイナリ作ってみよう

PyOxidizer は Rust で作られています。
なので、環境ができていれば導入は簡単。cargpo install pyoxidizerrust には詳しくないんですが、凄まじい数の依存パッケージ数です…
しばらくまってると、pyoxidizer のビルドが完了します。
windows だと PATH まで通してくれるようですが、mac は PATH 追加してください。まずはヘルプを見てみましょう。
$ pyoxidizer --help PyOxidizer 0.2.0 Gregory Szorc <gregory.szorc@gmail.com> Build and distribute Python applications USAGE: pyoxidizer [FLAGS] [SUBCOMMAND] FLAGS: -h, --help Prints help information -V, --version Prints version information --verbose Enable verbose output SUBCOMMANDS: add Add PyOxidizer to an existing Rust project. (EXPERIMENTAL) analyze Analyze a built binary build Build a PyOxidizer enabled project build-artifacts Process a PyOxidizer config file and build derived artifacts help Prints this message or the help of the given subcommand(s) init Create a new Rust project embedding Python. python-distribution-extract Extract a Python distribution archive to a directory python-distribution-licenses Show licenses for a given Python distribution run Build and run a PyOxidizer application run-build-script Run functionality that a build script would performほぅ
なんか難しそうだ。
ドキュメントに従って pyapp というディレクトリを作って、
pyoxidizer init pyapp cd ./pyappすると、pyapp の中にわんさかファイルができています。
インタプリタを起動するバイナリ
ここまでの状態で
pyoxidizer runすると、python のインタプリタが起動しました。
>>> import sys >>> print(sys.version) 3.7.3 (default, Jun 17 2019, 22:24:24) [Clang 6.0.1 (tags/RELEASE_601/final)] >>>ふむ、細かいことはちゃんと調べねばなりませんが、ローカルでインストールしている python とはバージョンが異なります。
さて、run コマンドのヘルプメッセージにあるように、Build & Run なので、
pyapp/build/apps/pyapp/debug
にもインタプリタを起動するバイナリが作成されていると思います。最初は「これいつ使うねん」とか思ったけど、python をインストールできないような環境に既存の python スクリプトを持ってって実行できたら幸せなシチュエーションも確かにあるわけで、ひょっとするとすごく便利かもしれないと思い始めてる。ワナワナ
python スクリプトのバイナリ
では、いよいよ本題の、スクリプトのバイナリを作りましょう。
今回は helloworld.py と、requestsのモジュールをimportするmodsample.pyで試してみます。
helloworld.py
import sys def main(): print("hello world.") if __name__ == "__main__": sys.exit(main())
modsample.py
import requests target_url = "https://www.google.com/" r = requests.get(target_url) print(r.status_code)
pyapp/pyoxidizer.tomlが設定ファイルのようなので、これの82行目にある[[embedded_python_run]]を修正します。
バイナリ化するファイルはpyapp/helloworld.pyに配置して、[[embedded_python_run]] # mode = "repl" mode = "module" module = "helloworld"して、runすると、、、
AttributeError: 'NoneType' object has no attribute 'loader' error: cargo run failedあれ?
どうやらも必要みたい。
[[packaging_rule]] type = "package-root" path = "." packages = ["helloworld"]で
hello world.いぇーい
pyapp/build/apps/pyapp/debugにもちゃんとバイナリできてる。ただ
hello worldを出力するだけなら、[[embedded_python_run]] # Evaluate some Python code. mode = "eval" code = "print('hello world')"続いて
pyapp/modsample.py
さっきの設定に加えて import するモジュールの設定が必要です。[[embedded_python_config]] sys_paths = ["$ORIGIN/lib"] [[packaging_rule]] type = "pip-install-simple" package = "requests" install_location = "app-relative:lib" extra_args = ["--proxy=url:port and other args"] [[packaging_rule]] type = "package-root" path = "." packages = ["modsample"] [[embedded_python_run]] mode = "module" module = "modsample"これで、
200やったー
その後、matplotlib や numpy など試してみたんですがうまくできず、もう少し調べてみる必要がありそうです。
PyInstaller と比べてどうか

上記で使用した modsample.py を windows 上で
PyInstaller --onefileすると、大体6MBくらいになります。一方で、PyOxidizer で今回の手順で作成したバイナリは20MBほどあり、requests モジュールが別ファイルになってしまっていたので、今回の結果だけで単純には比較できませんでした。
install_location = "embedded"で単一バイナリになるみたいですが、それができないモジュールもあるみたい…もう少しドキュメントを読みこんで、いろいろ設定をいじってみる必要がありそうです
- 投稿日:2019-07-04T22:43:14+09:00
djangoメモ
- 投稿日:2019-07-04T22:29:45+09:00
django twitter_clone作成 part1
はじめに
こんにちは、rickyです。
今回はdjangoの構造をしっかりと理解しながら、twitter_cloneを作製していきたいと思います。
part1では環境の構築や使うと便利なエディタについて話しながら、お決まりのhelloworldの表示までを行います。対象者
対象とする方のレベルとしては自分で何を作ればいいか迷っている方、djangoの基本的な動作について理解していきたいという方を対象としています。
エディタからdjangoのインストールまで
では、早速環境からとなります。
使用するエディタはpycharmを使います。以前はvimを使っていたのですが、階層について分かりづらかったのでこれからpythonを書き始めようとされる方にはおすすめのエディタです。
もちろんお気に入りのエディタがあれば、それを使ってくださって大丈夫です。
pycharmは無料版と有料版がありますが、私は無料版で作業をしています。
初歩的な内容なので無料版で事足りると思います。
なので、インストールする際は無料版をインストールしましょう。
さてインストールが終わったら、早速pycharmを立ち上げてNewProjectしましょう。
プロジェクト名はtwitter_cloneとでもしておきましょう。
次にdjangoのインストールを行います。すでにdjangoをインストールしている方もvenv環境ではインストールの必要があるので注意して下さい。
(venv環境とは簡単に言うと仮想環境のことです。仮想環境に切り分けて作業をすることで、他のプロジェクトと依存関係に陥ったりすることなく、作業することができます。)
djangoをインストールするにはpycharmの下のバーにあるTerminalをクリックしpip install djangoでインストールします。
インストールが終わったら、確認のためにターミナルからpythonと入力し、pythonshellを起動します。
そこで
import django
print(django.get_version())
と入力すればインストールしたdjangoのバージョンが表示されます。
ちゃんと表示されればインストールができています。djangoでサーバー起動とhelloworld
さてここでインストールしたdjangoでプロジェクトとアプリを作成してみます。
コマンド1つで簡単にできるのでさくっとやってみましょう。
プロジェクトはdjango-admin startproject プロジェクト名で
アプリはdjango-admin startapp アプリ名で
作成できます。
このときアプリはプロジェクトが作成されるときにできるmanage.pyと同じ階層に作ります。
これでプロジェクトとアプリが作成できました。
プロジェクトとアプリの違いについてはこちらのdjango公式サイトに詳しく書かれています。
では次はdjangoを起動してみましょう
ターミナルを開いてmanage.pyの階層に移動します。
そして./manage.py runserverと打ち込み、ブラウザから localhost:8000にアクセスします。
ロケットのロゴが表示されれば成功です。
今度はお決まりのhello worldを表示させます。
これにはアプリ直下のviewsには関数名と返り値returnでHttpResponse('hello world')を返します。
アプリ直下のurlsにはimportでviewsを読み込みます。
ここまででviewsに書き込んだ内容をurlsが読み込むことができます。
そしてプロジェクト全体から読み込むためにプロジェクト直下のurlsに情報を書き込みます。
プロジェクト直下のurlsにはurl情報とどこからincludeしているかの情報を記載します。今回はアプリ名.urlsとなります。
また、./manage.py runserverでサーバーを起動し、localhost:8000に今度はプロジェクト直下のurlsに書いたパスの名前を加えるとviewsで返り値とした情報つまりhelloworldが出力されています。終わりに
今回はdjangoの基本的な箇所からの説明となりました。
何度かwebアプリは作成してきたのですが、基本的な理解が追いついていないと考え、もう一度最初から簡単なクローンアプリの作り方から始めたいと思いこの記事を書きました。
なぜurlsがプロジェクト側とアプリ側にあるのかという点についての説明がまだ理解しきれていないので理解した際に加筆予定です。
djangoに関するコードについてはdjangoチュートリアルを参考にしていただけると幸いです。
ではなるはやで記事の更新を行う予定です。
お楽しみに〜
- 投稿日:2019-07-04T22:27:19+09:00
【Python】pathlibライブラリでディレクトリ・ファイルを再帰的にリネーム
概要
- Pythonでディレクトリ配下のディレクトリやファイルをリネーム
pathlibライブラリを使用(Python 3.4以降)Path().glob("**/*")で再帰的に検索ソースコード
rename_by_pathlib.pyfrom pathlib import Path import argparse def get_args(): parser = argparse.ArgumentParser() parser.add_argument("before", help="word before rename.", type=str) parser.add_argument("after", help="word after rename.", type=str) parser.add_argument("dir", help="target directory.", type=str) parser.add_argument("--mode", help="rename mode. 1 = only directory, 2 = only file, 3 = directory and file. defaut is 1.", default=1, type=int) return parser.parse_args() def rename_by_mode(child, before, after, mode): # ディレクトリのみ if mode == 1: if child.is_dir(): rename(child, before, after) # ファイルのみ elif mode == 2: if child.is_file(): rename(child, before, after) # ディレクトリ・ファイル両方 elif mode == 3: rename(child, before, after) def rename(child, before, after): if before in child.name: print(f"--{child.resolve()}") renamed = child.name.replace(before, after) renamed_path = f"{child.parent}/{renamed}" if Path(renamed_path).exists(): print(f"----couldn't rename:'{renamed_path}' already exists.") return else: child.rename(renamed_path) def main(): """ 指定ディレクトリ配下のディレクトリ・ファイル(またはどちらか)を全てリネーム """ args = get_args() before = args.before after = args.after mode = args.mode print(f"before:{before}") print(f"after :{after}") print(f"mode :{mode}") print("【 rename start 】") print("rename target:") # 指定ディレクトリ配下を再帰的に検索し、リネーム path = Path(args.dir) [rename_by_mode(child, before, after, mode) for child in path.glob("**/*")] print("【 rename end 】") if __name__ == '__main__': main()実行方法
実行コマンド
python rename_by_pathlib <リネーム前文字列> <リネーム後文字列> <ディレクトリパス> <リネーム形式>引数
- before(必須):リネーム前文字列
- after(必須):リネーム後文字列
- dir(必須):ディレクトリパス。指定したディレクトリ配下がリネーム対象
- mode(任意):リネーム形式。デフォルトは1
- 1:ディレクトリのみ
- 2:ファイルのみ
- 3:ディレクトリ・ファイル両方
実行
ディレクトリ構造(リネーム前)
test ├─a_1 │ │ b.txt │ └─a_2 │ └─b_2 ├─b_1 │ │ c.txt │ └─a └─c_1 │ a.txt └─b_2 ├─a_3 └─b_3実行
testディレクトリ配下のディレクトリ名・ファイル名両方(3)のbという文字列をrenameにリネームpython rename_by_pathlib b rename test --mode 3
- 実行結果(コンソール)
before:b after :rename mode :3 【 rename start 】 rename target: --test/b_1 --test/a_1/b.txt --test/a_1/a_2/b_2 --test/c_1/b_2 --test/c_1/rename_2/b_3 【 rename end 】ディレクトリ構造(リネーム後)
test ├─a_1 │ │ rename.txt │ └─a_2 │ └─rename_2 ├─rename_1 │ │ c.txt │ └─a └─c_1 │ a.txt └─rename_2 ├─a_3 └─rename_3まとめ
Pythonでディレクトリ走査する際は
os.walkを使ってたけど、pathlibのほうが使い勝手よさそう(適当)
- 投稿日:2019-07-04T21:55:02+09:00
matplotlibで3Dプロットを作成
動機
matplotlibの三次元プロットで複数axisを生成する方法が目に入ったのでコードを書いてみた。
作図してみた
環境
Anacondaのjupyter labを使用。
データの読み込み
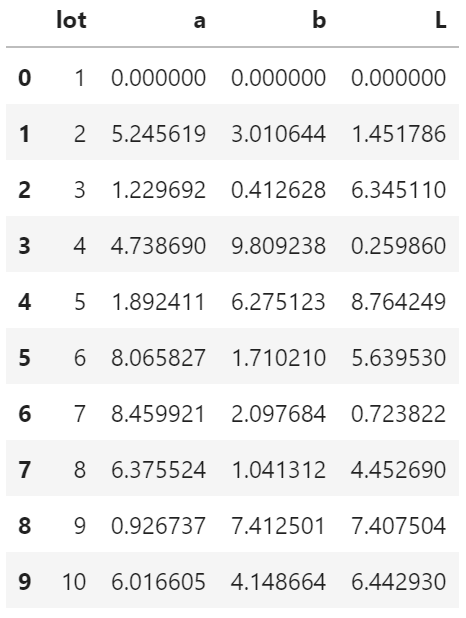
import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from scipy import genfromtxt import numpy as np import pandas as pd import os d = pd.read_csv("./3d_scatter_plot_data.csv") #相対パスでは.が現在のパスを明示的に示す方法。 ..で、一つ上の階層を示すなどが使える。 d #データの確認
今回使用したデータは、工場で生産された製品に、色のバラツキが発生していないか、Lot毎に測色した結果を用いた。測色の評価方法については、ココを参照。
3D散布図の作成
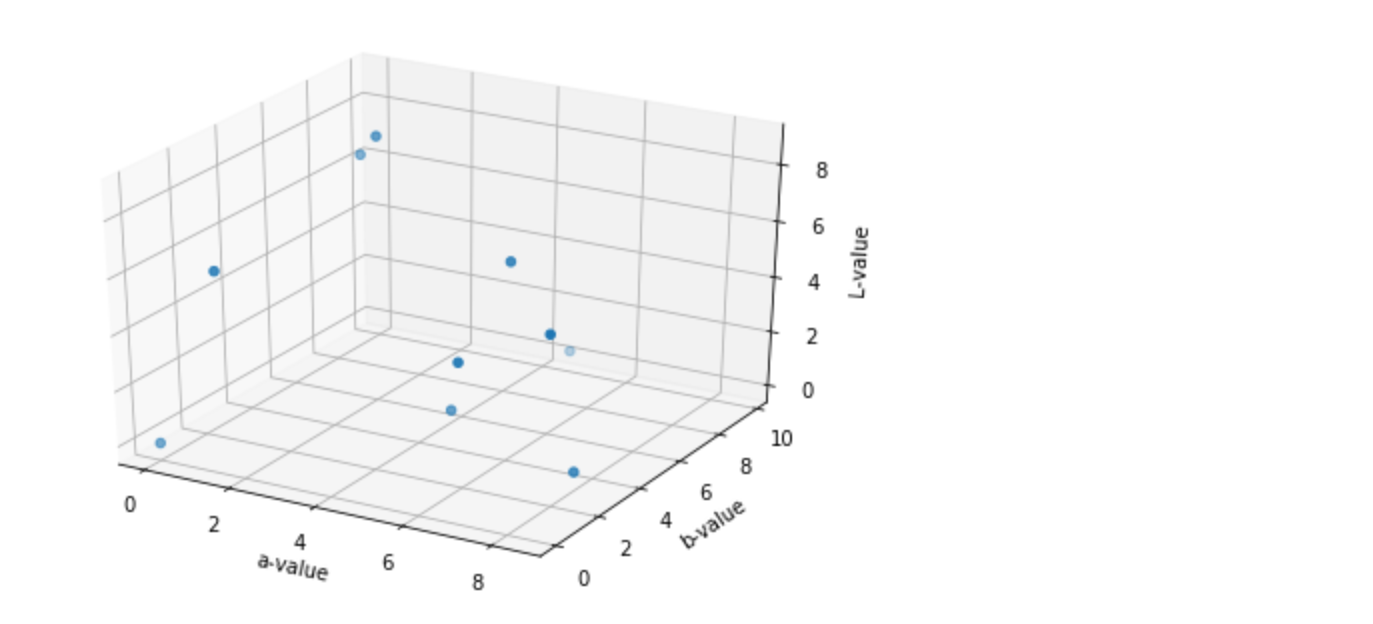
#データをarray型に x = np.array(d["a"]) y = np.array(d["b"]) z = np.array(d["L"]) # グラフ作成 fig = plt.figure() ax = Axes3D(fig) ax.scatter(x, y, z) # 軸ラベルの設定 ax.set_xlabel("a-value") ax.set_ylabel("b-value") ax.set_zlabel("L-value") plt.show()
作図に成功したが...本来はグラフをマウスでドラッグするとグラフが回転してくれるそうだが微動だにしない。
jupyter labでは上手く動かないのかもしれない...
- 投稿日:2019-07-04T21:54:01+09:00
xgboost の学習データを sklearnではなく pandas で読んだらコケた話
TL;DR
xgboost というPython ライブラリ(パッケージ?)を使ったときに
トレーニングデータを sklearn のdatasets.load_iris()ではなく
データを CSVファイルでもらったので、それを pandasで読んだら
なんか相当つまづいたのでそのときの行ったことメモです。あまり説明などが正確ではありませんことをご承知おきください。
何がしたかった? (目的)
xgboost を使った目的は、Feature Importance を出力したかったからです。
Feature Importance とは、(私の理解で言えば)
多クラス分類問題や、回帰分析をする際に、
カラム(説明変数)ごとに出力結果に与える影響の度合いを数値化したものです。例えば、カレーを作るをときに、
このカレーの味を決めているのはどの調味料の影響が大きいのか
(ターメリックなのか?, コリアンダーなのか?, ガラムマサラなのか? みたいな)
をスコアとして出力してくれるみたいな感じです。(たぶん)今回はその前段階の トレーニングデータの読み込みでつまづいたので、
そちらにフォーカスして書いていこうと思います。sklearn datasets 付属のトレーニングデータで学習をする。
普通に AIトレーニングをする場合、Dataset に sklearnに付属しているものを使うことも多いかと思います。 単にライブラリの使い方を知りたいだけならそれで良いと思うので、最初は sklearn の Iris dataset を用いて出力を行いました。
- Iris Dataset ってなんぞ? という方向け。
アヤメデータを使った機械学習の流れを簡単にまとめてみたプログラムを書きます。
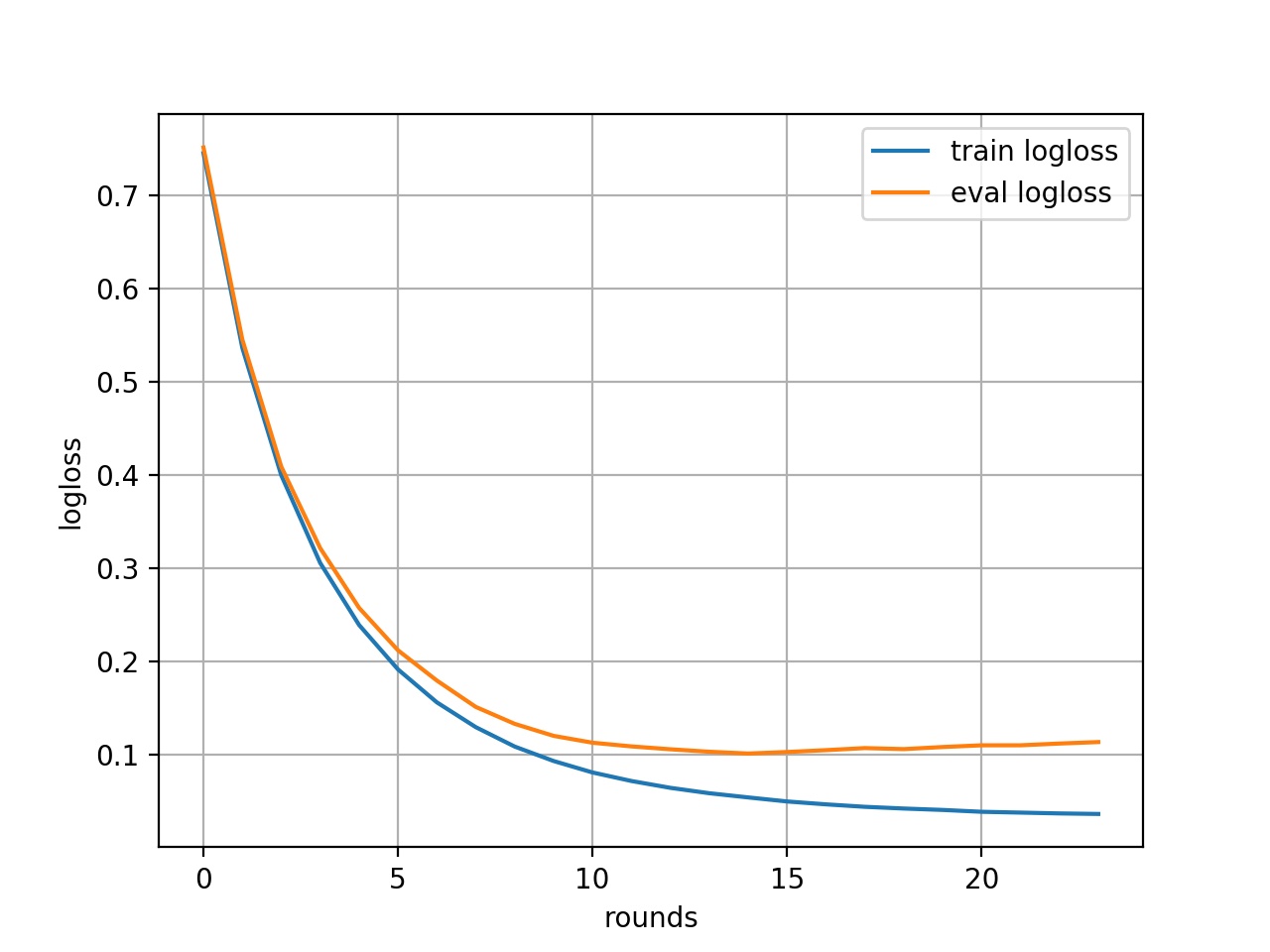
xgb_skl.py# ----- 多クラス分類問題 ----- import xgboost as xgb import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score """XGBoost で多クラス分類するサンプルコード""" # Iris データセットを読み込む dataset = datasets.load_iris() x, y = dataset.data, dataset.target x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, # データ全体の 30% をtest dataとする。 shuffle=True, # シャッフルしてね。 stratify=y # ラベル全部入れてね。 ) # xgboost は DMatrix に整形したデータとパラメータを train メソッドに渡してモデルを作成します。 # # 雑にいうと、学習データからxgboost用のデータを生成する。 dtrain = xgb.DMatrix(x_train, label=y_train) dtest = xgb.DMatrix(x_test, label=y_test) xgb_params = { 'objective': 'multi:softmax', # 多クラス分類問題なので softmax 'num_class': 3, # 分類するクラス数 'eval_metric': 'mlogloss' # 多クラスの損失関数(対数関数) } evals = [(dtrain, 'train'), (dtest, 'eval')] evals_result = {} bst = xgb.train(xgb_params, # param と dtrain, # train data を渡す num_boost_round=100, # 最大 100回 early_stopping_rounds=10, # 10回やって伸びがないとき打ち切り evals=evals, # あとでグラフ書くためのやつ。 evals_result=evals_result # 出力を取っておくやつ。 ) # 予測 y_pred = bst.predict(dtest) # 予測の正確性 acc = accuracy_score(y_test, y_pred) print('Accuracy:', acc) # --- 学習結果をグラフで描画 --- train_metric = evals_result['train']['mlogloss'] plt.plot(train_metric, label='train logloss') eval_metric = evals_result['eval']['mlogloss'] plt.plot(eval_metric, label='eval logloss') plt.grid() plt.legend() plt.xlabel('rounds') plt.ylabel('logloss') plt.show()とまあ、参考を見本として書いてみます。
そして実行してみます。
$ python xgb_skl.py(result of xgb_skl.py) [0] train-mlogloss:0.749101 eval-mlogloss:0.746322 Multiple eval metrics have been passed: 'eval-mlogloss' will be used for early stopping. Will train until eval-mlogloss has not improved in 10 rounds. [1] train-mlogloss:0.5422 eval-mlogloss:0.534497 [2] train-mlogloss:0.403809 eval-mlogloss:0.402243 [3] train-mlogloss:0.307853 eval-mlogloss:0.307246 [4] train-mlogloss:0.236608 eval-mlogloss:0.242919 [5] train-mlogloss:0.187216 eval-mlogloss:0.200595 [6] train-mlogloss:0.149031 eval-mlogloss:0.167618 [7] train-mlogloss:0.120982 eval-mlogloss:0.146892 [8] train-mlogloss:0.099261 eval-mlogloss:0.133691 [9] train-mlogloss:0.083686 eval-mlogloss:0.124833 [10] train-mlogloss:0.071938 eval-mlogloss:0.119053 [11] train-mlogloss:0.062597 eval-mlogloss:0.109477 [12] train-mlogloss:0.055532 eval-mlogloss:0.104074 [13] train-mlogloss:0.04971 eval-mlogloss:0.103363 [14] train-mlogloss:0.044946 eval-mlogloss:0.102786 [15] train-mlogloss:0.040545 eval-mlogloss:0.101006 [16] train-mlogloss:0.03746 eval-mlogloss:0.102609 [17] train-mlogloss:0.034801 eval-mlogloss:0.102399 [18] train-mlogloss:0.032773 eval-mlogloss:0.102475 [19] train-mlogloss:0.031438 eval-mlogloss:0.101436 [20] train-mlogloss:0.03016 eval-mlogloss:0.100204 [21] train-mlogloss:0.029128 eval-mlogloss:0.099538 [22] train-mlogloss:0.028322 eval-mlogloss:0.099757 [23] train-mlogloss:0.027761 eval-mlogloss:0.10053 [24] train-mlogloss:0.027199 eval-mlogloss:0.103029 [25] train-mlogloss:0.026732 eval-mlogloss:0.103819 [26] train-mlogloss:0.026244 eval-mlogloss:0.106163 [27] train-mlogloss:0.025838 eval-mlogloss:0.105426 [28] train-mlogloss:0.025515 eval-mlogloss:0.106862 [29] train-mlogloss:0.025144 eval-mlogloss:0.107733 [30] train-mlogloss:0.024842 eval-mlogloss:0.109133 [31] train-mlogloss:0.024523 eval-mlogloss:0.109736 Stopping. Best iteration: [21] train-mlogloss:0.029128 eval-mlogloss:0.099538 Accuracy: 0.9777777777777777
(markdown のcodeの箇所で
bash を指定したのですが、この配色って何事なのですかね..)
shiracamusさんにご指摘いただきbashスクリプトだと思ってます。
コンソール出力結果なので、consoleやtextを指定するといいです。bash => console に指定を変更したら直りました。
ご指摘ありがとうございます。
少し、成績が良すぎる気もしますが
と、このように手軽に使うことができました。
先人のおかげですね。巨人の肩に乗った気分です。そして、本題へ。
今回は xgboost の使い方を知るのはもちろんのこと、
トレーニングデータに, 任意のCSVデータを読み込んでトレーニングができること
(もっと言えば Feature Importance を得られること)
ですので、改変していこうと思います。ちなみに学習しようする CSVファイルはこんな感じです。
Fishers_Irises_train.csvPetalLength,SepalLength,SepalWidth,Species 1.4,5.1,3.5,1 1.4,4.9,3,1 1.3,4.7,3.2,1 1.5,4.6,3.1,1 ...いや、結局 Iris dataやないの !! というコメントは受け付けませんので悪しからず..
(だから見せられるのですよ..)
(このデータ、貰い物なのであまりイチャモンは付けられないのですが、
sklearn の Iris dataset と比べてなぜ、カラムが1つ少ないのでしょうか..謎です..)そんなことはさておき、ちょこっと変えてみます。
xgb.py# ----- 多クラス分類問題を扱う ----- import xgboost as xgb import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 読み込むデータを datasets の irisから 自分で指定した CSVファイルに変更 file_pass = '(parent_dir)/Fishers_Irises_train.csv' iris_csv = pd.read_csv(file_pass, header=None) # Dataflame の確認 :print('data flame :', iris_csv) # 0 ~ 2列目を特徴量として使う x = iris_csv.iloc[:, :3] # 確認 : print('Feature data :', X) # 3列目が正解ラベル y = iris_csv.iloc[:, 3] # 確認 : print('answer :', y) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, shuffle=True) # 確認たち : #print("x_train.shape : ", x_train.shape) #print("x_test.shape : ", x_test.shape) #print("y_train.shape : ", y_train.shape) #print("y_test.shape : ", y_test.shape) dtrain = xgb.DMatrix(x_train, label=y_train) dtest = xgb.DMatrix(x_test, label=y_test) xgb_params = { 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'mlogloss' } evals = [(dtrain, 'train'), (dtest, 'eval')] evals_result = {} bst = xgb.train(xgb_params, dtrain, num_boost_round=100, early_stopping_rounds=10, evals=evals, evals_result=evals_result ) y_pred = bst.predict(dtest) acc = accuracy_score(y_test, y_pred) print("Accuracy : ", acc)\デン/ きました。エラーです。
TypeError: sequence item 0: expected str instance, numpy.int64 found
調べます。
Pythonで配列に数値が入っている時にjoinするとエラーになるってお話
なるほど。
そういえば、sklearn の方はどうやって指定してたんだっけ..iris = datasets.load_iris() x, y = iris.data, iris.targetあっ.. object..
雑に見ます。print(iris.data) print(type(iris.data)) # [out] <class 'numpy.ndarray'>お? NumPy配列だって?
Pandas の DataFrameをNumPy配列に変換する方法を検索pandas.DataFrame, pandas.Seriesいずれもvaliues属性でNumPy配列numpy.ndarryを取得できる。
なるほど。
やってみよう。file_pass = '(parent_dir)/Fishers_Irises_train.csv' iris_csv = pd.read_csv(file_pass, header=None) # dataframe.values => np.array にできる。 """ iris = load_data_iris() type(iris.data) >>> <class 'numpy.ndarray'> となっていることから、load_data_iris()で読み込んだ data はNumPy配列.. (pandas dataframe ではないことに注意!) ということは、普通の CSV を pandas で読み込んだのなら、 それを dataframe.values して NumPy配列にしてあげればいけそう。 """ ## iloc[1:]指定しているのはヘッダを読まないため。 x = iris_csv.iloc[1:, :3] x = x.values # 確認 : print('Feature data :', x) y = iris_csv.iloc[1:, 3] y = y.values # 確認 : print('answer :', y)よし。これで実行!
\デン (すまん、ウチできへんわ) /xgboost.core.XGBoostError: [18:33:52] src/objective/multiclass_obj.cu:110: SoftmaxMultiClassObj: label must be in [0, num_class).
なになに?
なるほど。正解ラベルは 0 スタート, class数終わり でなければならないらしい。さっき print した y を見ると [1, 2, 3] であるから 1引けばいいんでしょ。
y = iris_csv.iloc[1:, 3] y = y.values y = y -1実行 ! \デン(あかんて)/
TypeError: unsupported operand type(s) for -: 'str' and 'int'
知ってた。
ああ。 dataframe.values で変換すると
str型が格納された list (正確には NumPy配列)で返ってくるんだ..## iloc[1:]指定しているのはヘッダを読まないため。 x = iris_csv.iloc[1:, :3] # 訓練データは浮動小数点数が入っているので float型に変換します。 x = x.values.astype(float) # 確認 : print('Feature data :', X) y = iris_csv.iloc[1:, 3] # 正解ラベルは整数なので int に型変換 y = y.values.astype(int) # 正解ラベル -1 (broad cast) y = y -1 # 確認 : print('answer :', y)よし。良さげ。
そして、完成へ..
xgb.pyimport numpy as np import xgboost as xgb import pandas as pd # 結局 sklearn は使うんですけどもね。 from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 読み込むデータを datasets の irisから 自分で指定した CSVファイルに変更 file_pass = '(parent_dir)/Fishers_Irises_train.csv' iris_csv = pd.read_csv(file_pass, header=None) ## iloc[1:]指定しているのはヘッダを読まないため。 x = iris_csv.iloc[1:, :3] x = x.values.astype(float) # 確認 :print('Feature data :', X) y = iris_csv.iloc[1:, 3] y = y.values.astype(int) y = y -1 # 確認 :print('answer :', y) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, shuffle=True, random_state=42, stratify=y) dtrain = xgb.DMatrix(x_train, label=y_train) dtest = xgb.DMatrix(x_test, label=y_test) xgb_params = { 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'mlogloss' } evals = [(dtrain, 'train'), (dtest, 'eval')] evals_result = {} bst = xgb.train(xgb_params, dtrain, num_boost_round=100, early_stopping_rounds=10, evals=evals, evals_result=evals_result ) y_pred = bst.predict(dtest) acc = accuracy_score(y_test, y_pred) print("Accuracy : ", acc)実行します。 (どきどき)
$ python xgb.py[0] train-mlogloss:0.737199 eval-mlogloss:0.815741 Multiple eval metrics have been passed: 'eval-mlogloss' will be used for early stopping. Will train until eval-mlogloss has not improved in 10 rounds. [1] train-mlogloss:0.526851 eval-mlogloss:0.665976 [2] train-mlogloss:0.390387 eval-mlogloss:0.581466 [3] train-mlogloss:0.297312 eval-mlogloss:0.535163 [4] train-mlogloss:0.230717 eval-mlogloss:0.51511 [5] train-mlogloss:0.183676 eval-mlogloss:0.509129 [6] train-mlogloss:0.148959 eval-mlogloss:0.516375 [7] train-mlogloss:0.123137 eval-mlogloss:0.530359 [8] train-mlogloss:0.103713 eval-mlogloss:0.549003 [9] train-mlogloss:0.087338 eval-mlogloss:0.564854 [10] train-mlogloss:0.075128 eval-mlogloss:0.582741 [11] train-mlogloss:0.066544 eval-mlogloss:0.604145 [12] train-mlogloss:0.059427 eval-mlogloss:0.628322 [13] train-mlogloss:0.052418 eval-mlogloss:0.638301 [14] train-mlogloss:0.047923 eval-mlogloss:0.657022 [15] train-mlogloss:0.04462 eval-mlogloss:0.672324 Stopping. Best iteration: [5] train-mlogloss:0.183676 eval-mlogloss:0.509129 Accuracy : 0.8333333333333334無事にトレーニングできたみたいです! やったね。
振り返りと、まとめ。
少し Accuracyが落ちているのは
- たぶんカラムが1つ少ないことと、
- ハイパーパラメータとかをきちんと調整してないから
だと思います..そこまで手が回らなかった..kerasとか、TensorFlowもそうですが、sklearn とかでも、とにかく
「もう出来上がっているもの」って便利なのですけど、
object とか、メソッドとかが絡み合っていて
自分なりに解釈するのに時間がかかりますよね。あれですね。冷凍食品って手軽なんですが、
自分の好きな食べ物を冷凍食品にしたいと思ったとき思考停止する感じです。きっともっと上等なやり方はあったのでしょうが、
ぼくの実力では、力技で型変換を繰り返したりするのが精一杯でした。備忘録なので、あまり参考にならないかもしれませんが、
よろしければ, 次は
Feature Importance の出力についても記事にしてみようかと
思いますのでご覧いただけたら幸いです。
- 投稿日:2019-07-04T19:39:48+09:00
pandasのマルチカラムをいい感じに処理するtips
概要
pandasでマルチカラムがひょっこり出てくると焦りませんか?
僕は焦ります .
そんなマルチカラムに対して「えいや!」とカラム名をべた書きで突っ込んでいませんか?
僕はそんなことしていました.
そんな僕が贈る,マルチカラムをいい感じに処理してフラット化するためのtipsです.やってみる
まずは対象のDataFrameを適当に作ります
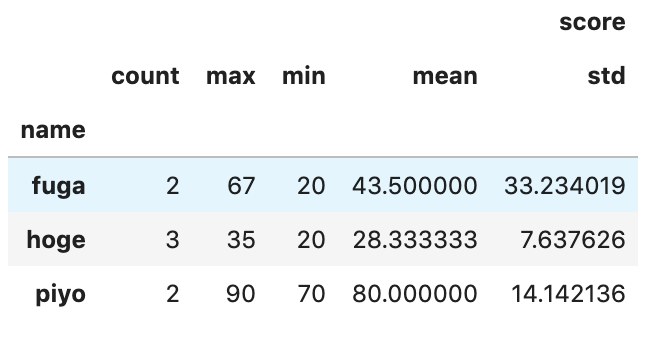
import pandas as pd df_score = pd.DataFrame( { "name": ["hoge", "hoge", "fuga", "piyo", "hoge", "piyo", "fuga"], "score": [30, 35, 67, 90, 20, 70, 20], } )こんなDataFrameが作られます
マルチカラムが作られるのはやっぱり
groupbyして統計特徴量を作ったときですね. ではそれを行います.# nameごとにscoreの様々な統計特徴量を計算する agg = {"score": ["count", "max", "min", "mean", "std"]} df_agg = df_score.groupby("name").agg(agg)するとこんな
df_aggはこんなDataFrameになります.
マルチカラムが出てきた!
見てみるとこんな感じです.print(df_agg.columns) # 以下出力 # MultiIndex(levels=[['score'], ['count', 'max', 'min', 'mean', 'std']], # codes=[[0, 0, 0, 0, 0], [0, 1, 2, 3, 4]])さあ, こいつをなんとかします! と言っても覚えておくのはひとつだけ.
これだけ覚える!
columnsのvaluesにアクセスする!
実際アクセスしてみると...print(df_agg.columns.values) # 以下出力 # array([('score', 'count'), ('score', 'max'), ('score', 'min'), # ('score', 'mean'), ('score', 'std')], dtype=object)なんだか処理しやすそうな形になりましたね.
あとは煮るなり焼くなりしてもらって大丈夫です.カラムをスネークケース(もしくはキャメルケースにしたい)
さらに丁寧にマルチカラムをスネークケース, もしくはキャメルケースにする関数をメモしておきます.
def get_converted_multi_columns(df, *, to_snake_case=True): if to_snake_case: return [col[0] + '_' + col[1] for col in df.columns.values] else: return [col[0] + col[1].capitalize() for col in df.columns.values]基本的にはスネークケースにしようってやつです.キャメルケースにしたかったら明示的に引数に
to_snake_case=Falseを指定してください.
使ってみるとこんな感じです.print(get_converted_multi_columns(df_agg)) # 以下出力 # ['score_count', 'score_max', 'score_min', 'score_mean', 'score_std']print(get_converted_multi_columns(df_agg, to_snake_case=False)) # 以下出力 # ['scoreCount', 'scoreMax', 'scoreMin', 'scoreMean', 'scoreStd']いい感じで処理できていますね.
まとめ
- マルチカラムには
df.columns.valuesでアクセスすると処理しやすい形を得られるよ- このトピックをスタックしておくと便利かもしれないよ
まとめが簡単すぎて媚びちゃいました.
いいねもらえたら泣いて喜びます.
よきpandasライフを〜

- 投稿日:2019-07-04T19:14:45+09:00
Sphinxを使って自作パッケージのドキュメントを簡単に更新しよう!!
はじめに
現在着手している機械学習の自作ライブラリを作る際のテストやドキュメントの管理にSphinxを使用してみようと思い立ち、いろいろいじってみたのですが思っていた構造にするのに手間取ったのでメモして共有します。 以下の記事はこちらの記事を参考にしてアップデートされた部分や詰まったところを重点的に書いていきます。
環境
- python 3.7.3
- Sphinx 2.1.2
GitHubリポジトリ(こちら)をクローンしていただき、
pip install -r requirements.txtでSphinxのインストールができます。ディレクトリ構成も同じになるので検証していただける方は是非。
$ git clone https://github.com/CastaChick/Example_of_Sphinx.git上記をコピペでクローンできます。
ディレクトリ構成
Sphinxを始める前の構成
. ├── README.md ├── article.md ├── docs ├── packages │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-37.pyc │ │ └── example.cpython-37.pyc │ └── example.py └── requirements.txtSphinxを用いてこの
docsディレクトリ内にドキュメントを自動的に追加できるようにしていきます。ソースコードを
packagesに全部まとめ、docsでドキュメントを管理していく構図にしたいと考え、これを実現していきます。
example.pyにはコメントをつけた2つの関数が入っています。
詳しくはソースコードを参照してください。ドキュメントを作る
いよいよドキュメントを作っていきたいと思います。
1. 雛形を作る
docsに移動してShinxを開始します。$ sphinx-quickstartソースディレクトリとビルドディレクトリは分けておきます。
この結果
docs以下にこのようなディレクトリとファイル達が作られます。. ├── Makefile ├── build ├── make.bat └── source ├── _static ├── _templates ├── conf.py └── index.rst2. 設定を記述する
今回、自動的にドキュメントを生成したいので
conf.pyのextensionsに設定を追記して以下のようにします。conf.pyextensions = [ 'sphinx.ext.autodoc', 'sphinx.ext.todo', 'sphinx.ext.viewcode', 'sphinx.ext.napoleon', ]また、
conf.pyのはじめのコメントアウトされている部分を書き換えてpackagesへのpathを通します。サブパッケージを作ったときにはここに追記してpathを通しましょう。conf.pyimport os import sys sys.path.insert(0, os.path.abspath('../../packages'))3. ドキュメントに追加する
動作確認ができたのでドキュメントに追加する作業を行なっていきます。
- 目次を追加
source/index.rstを以下のように書き換えて目次にexampleが追記されるようにします。後々他のモジュールを追加するときにもexampleの下に追加することで目次に順次追加されていきます。source/index.rst.. toctree:: :maxdepth: 2 :caption: Contents: example
- 新しいモジュールについてのページを追加
以下のような
source/example.rstを作成します。:member:とすることでexample.py内で定義された全ての関数が反映されます。source/example.rstExample ======= .. automodule :: example :members:
- ドキュメントを更新
いよいよこれらのファイルを元にドキュメントを更新していきます。
docsディレクトリで以下のコマンドを実行するとbuild内にhtmlディレクトリが生成され、ドキュメントがhtmlファイル化されます。$ make html4. 確認してみよう!
現在のディレクトリ構成は以下のようになっていると思います。(
$ tree —-filelimit 10を実行). ├── README.md ├── article.md ├── docs │ ├── Makefile │ ├── build │ │ ├── doctrees │ │ │ ├── environment.pickle │ │ │ ├── example.doctree │ │ │ └── index.doctree │ │ └── html │ │ ├── _modules │ │ │ ├── example.html │ │ │ └── index.html │ │ ├── _sources │ │ │ ├── example.rst.txt │ │ │ └── index.rst.txt │ │ ├── _static [16 entries exceeds filelimit, not opening dir] │ │ ├── example.html │ │ ├── genindex.html │ │ ├── index.html │ │ ├── objects.inv │ │ ├── py-modindex.html │ │ ├── search.html │ │ └── searchindex.js │ ├── make.bat │ └── source │ ├── _static │ ├── _templates │ ├── conf.py │ ├── example.rst │ └── index.rst ├── packages │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-37.pyc │ │ └── example.cpython-37.pyc │ └── example.py └── requirements.txt
build/html/index.htmlをブラウザで開くとドキュメントがきちんと生成されていることがわかると思います。関数の説明や引数、使用例もコメント通りに翻訳されて書き出されていますね!example.pyを書き換えたときには$ make htmlを実行するだけでドキュメントも更新されます。終わりに
今回はまずはじめにコメントのついたソースコードを元にドキュメント化していきましたが、実際のテスト駆動開発では『テストコメント→テスト→実装→テスト→APIコメント→ドキュメント化』のような流れで進んでいきます。詳しくはこちらに親切に書いてあります。これから本格的に機械学習ライブラリを実装していくので完成したらぜひ見てください!
なお今回の記事は昨夜初めてSphinxに触れた超初心者が主に公式ドキュメントを調べて自分なりに構築したものなのでもっとこうした方が良いという改善点があれば是非教えてください!
- 投稿日:2019-07-04T18:51:04+09:00
【Python】globとreで簡潔にファイル名を取得、リストを生成する
TL;DR
特定のディレクトリ内のファイル名を取得しリストを生成するコードを、os.walkによる2重for文の代わりに
を用いて正規表現で書き換えた。
いきさつ
画像の高解像度化がしたいと思い調べたところ、RAISRを実装したリポジトリが公開されていたのでさっそく導入。そのソースコードの中にちょっと気になる部分がありました。test.pyのこの部分とtrain.pyのこの部分になります。
imagelist = [] for parent, dirnames, filenames in os.walk(trainpath): for filename in filenames: if filename.lower().endswith(('.bmp', '.dib', '.png', '.jpg', '.jpeg', '.pbm', '.pgm', '.ppm', '.tif', '.tiff')): imagelist.append(os.path.join(parent, filename))trainpathに代入されている名前のディレクトリから、画像ファイルの名前を取得しimagelistにブチ込む処理をするコードです。しかし、2重for文なのでいささか冗長に感じます。
手直し
以下が手直ししたコードになります。
imagelist = [path for path in glob.glob(trainpath + '/**', recursive=True) if re.search('.(bmp|dib|png|jpg|jpeg|pbm|pgm|ppm|tif|tiff)', path.lower())]endswithは引数に複数の文字列からなるタプルを渡す必要がありました。しかしre.searchは第一引数に1つの正規表現の文字列を渡すため、見た目がスッキリしますね。
ちなみに
Qiita初投稿なので、ご指摘・アドバイスいただけると筆者は喜びます。よろしくお願いします。
追記
改行位置、パスの小文字化に関するご指摘を頂いたので修正。(2019/7/4)
- 投稿日:2019-07-04T18:45:00+09:00
【Python】【Selenium-webdriver】Webテスト自動化の第1歩
概要
Webの目視テストが苦手なので、PythonのWebアプリでのテストをSeleniumで自動化しよう。という話の初歩です。
環境
- Python 3.7
- Chrome 75.0
- Django 2.2.2
手順
テストしたいWebアプリの構築
DjangoによるWebアプリケーション開発入門を参考にして、「Hello World!」を表示するだけのWebアプリを作成。
Selenium-webdriverの導入
pip install seleniumchrome-binaryの導入
【Python】SeleniumでHeadless Chromeを使おうの記事を参考にして導入。
SeleniumでChromeを動かす場合は必要です。
インストールしているChromeとバージョンが異なると起動しないので、Chromeのバージョンは要確認。
今回はインストールしているChromeのバージョンが75.0なので、同じメジャーバージョンのchrome-binaryをバージョン指定で導入。pip install chromedriver-binary==75.0.3770.8.0SeleniumBaseの導入
Awesome Selenium : 素晴しい Selenium ライブラリの数々を参考に導入。
pytestコマンドを使ってseleniumでのテストを自動実行するためのフレームワーク。pip install seleniumbaseテストコードの作成
- テスト用のコードは別に分けておくことが一般的なので、プロジェクトのルートに
testsディレクトリを作成- ユニットテストと切り分けるため、
testsディレクトリ内にseleniumディレクトリを作成- SeleniumBaseのリポジトリの
exampleディレクトリを参考にsetup.cfgファイルを(プロジェクトのルート)/tests/seleniumディレクトリ内に作成(このファイルが無いとテストの実行自体に失敗します)- 実施したいテストコードを記述した
.pyファイルを(プロジェクトのルート)/tests/seleniumディレクトリ内に作成
今回はHello World!の表示を確認したいのでhello_tests.pyというファイルを作成from seleniumbase import BaseCase import chromedriver_binary class HelloTestClass(BaseCase): BASE_URL = 'http://127.0.0.1:8000/' def test_hello(self): self.open(self.BASE_URL + 'hello/') self.assert_text('Hello World!', 'body')テストの実行
- (今更かもしれませんが)DjangoのWebアプリケーションを立ち上げる
python mysite/manage.py runserver
pytestコマンドからSeleniumの自動テストを実行する
--browser=BROWSERオプション:BROWSER部分に実行するブラウザを指定。今回はChromeを使うので--browser=chromeで指定する。--headlessオプション:このオプションを付けると、ヘッドレスモードで実行。cd ./tests/selenium pytest hello_tests.py --browser=chrome --headless
- 実行結果を確認する


- 投稿日:2019-07-04T17:46:09+09:00
python仮想環境セットアップメモ
本番環境は基本venvでやるけれど、手元で普通のアプリ開発と複数分野の機械学習・信号処理をやるときにはanacondaと普通のpython両方使いたいので(更にプロジェクト毎の複数pythonヴァージョン対応もしたいので)pyenvを使っている
pyenvにある程度なれてる人向け。手順はmac、Linuxの場合は以下。Windowsは知らない。
pyenv, pyenv-virtualenv
brew install pyenv pyenv-virtualenv
.zshrcに以下を記載export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)"pyenvでanaconda入れる
とりあえず3系の5.3.1の場合
pyenv install anaconda3-5.3.1
conda envの作成
pyenvでconda envを管理するには、まずベースにしたいanaconda環境下で、
conda createをする必要がある。pyenv shell anaconda3-5.3.1 conda create -n ENV_NAME python=3.6 conda
conda createするときには、必ずインストールするパッケージとしてcondaを指定する必要がある。そうしないと、pyenvでcreateした環境を用いるときにcondaコマンドが利用できなくなるactivate
pyenv shellなりpyenv localなりを利用してアクティベートするpyenv shell anaconda3-5.3.1/envs/ENV_NAMEベースになったanacondaヴァージョン名とENV_NAMEを指定してactivateすると、あとはcondaコマンドで作った環境にライブラリをインストールしていくことが可能。
- 投稿日:2019-07-04T17:15:14+09:00
PythonでCAD(.dxf、Excel)ファイルを読むメモ
DXFとは
Data e Xchange Format の略。
異なるCAD間での図面データをやりとりするための中間・共通フォーマット。直線と円と円弧の2Dデータが多い。
Autodesk社が開発したファイル形式の1つ。
Autodesk社は、CADと言われる図面を作成するソフトウェアを開発している会社。
Autodesk社が開発した製品と言えば、AutoCADという代表的なソフトウェアがある。AutoCADは設計事務所を中心に日本でも幅広く普及しており、聞いたことがあるという方も少なくない。
拡張子の1つであるDXFは、CADソフトであるAutoCADで図面が作成されたときに、保存する形式として選択することができる既存のPythonでDXFファイルを読み書きできるモジュールを主なモジュール
dxfgrabber
・DXFから情報を取得。全DXFバージョンに対応。読み込みのみ対応。
https://dxfgrabber.readthedocs.io/en/latest/dxfwrite
A Python library to create DXF R12 drawings.書き込み専用
https://pypi.org/project/dxfwrite/インストール
Anaconda環境にpipでインストールなど
動作方法:Anaconda をダウンロードする (MacもしくはWindows)
Anacondaのダウンロードページを開いて、「64-BIT INSTALLER」をクリックし、
https://www.anaconda.com/「Anaconda3-4.4.0-Windows-x86_64.exe」をダウンロード.Macの場合は該当の箇所をクリック。
pip install dxfgrabber使い方の例
ファイル読み込み >>> import dxfgrabber >>> dxf=dxfgrabber.readfile("hogehoge.dxf")無料CADソフト
RootPro CAD
http://www.rootprocad.com/download/dl.html
Jw_cad
https://cadjob.co.jp/cad_course/column/p953/
参照URL
・Myfuturesightforpast
PythonのCAD(.dxf)ファイル読み書きモジュールまとめ
https://myfuturesightforpast.blogspot.com/2014/07/pythoncaddxf.html・DXFと亀
https://qiita.com/ackermanrf128/items/d9275a7d077c1dff3ec7
- 投稿日:2019-07-04T17:14:46+09:00
Pandasユーザーガイド「データの索引と選択」(公式ドキュメント日本語訳)
本記事は、Pandasの公式ドキュメントのUser Guide - Indexing and Selecting Dataを機械翻訳した後、一部の不自然な文章を手直ししたものである。
なお、本記事作成時点でPandasの最新リリースバージョンは0.24.2であるが、将来性を加味して本記事の文章は開発版0.25.0のドキュメントをもとにした。誤訳の指摘・代訳案・質問等があればコメント欄や編集リクエストでお願いします。
データの索引と選択
pandas オブジェクトの軸ラベル情報は、多くの目的を果たします:
- 既知のインジケータを使用して、分析・視覚化・および対話型コンソール表示に重要なデータを識別できます(つまり、metadataを提供します)。
- 自動的かつ明示的なデータ配列を可能にします。
- データセットに対する直感的なサブセットの取得と代入を可能にします。
この章では、最後のポイント――pandas オブジェクトのサブセットをどのようにスライス・ダイスおよび一般的に取得・代入するか――に焦点をあてます。この分野で開発が注目されているため、主な焦点は Series と DataFrame になります。
注釈 Python と NumPy のインデックス演算子 []と属性オペレータ.は、ユースケースの広い範囲で pandas のデータ構造への迅速かつ容易なアクセスを提供します。これらは、Python の辞書と NumPy 配列の取扱いを知っていれば、新しいことを少し学ぶだけで、インタラクティブな作業を直感的にできます。しかし、型のわからないデータにアクセスするので、標準演算子の直接使用は、いくつかの最適化限界を有しています。生産的なコードのために、この章で紹介されている最適化された pandas データのアクセス方法を利用することをお勧めします。
警告 設定された演算子によってコピーが返されるか参照が返されるかは、文脈に依存します。これは連鎖代入 chained assignmentとも呼ばれますが、避けるべきものです。返るのはビューかコピーかを参照してください。
警告 整数型インデックスの浮動小数点型による索引については 0.18.0 で明確にされました。変更の概要についてはここを参照してください。 MultiIndex / Advanced Indexingには、
MultiIndexとより高度な索引についてのマニュアルがあります。cook bookには、いくつかの高度な方法が掲載されています。
さまざまな索引の方法
オブジェクトの選択は、より明確な位置ベースの索引をサポートするために、ユーザーリクエストの数だけ存在しています。Pandas は現在 3 種類の複数軸による索引をサポートしています。
.locは基本的にラベルベースですが、真偽値の配列も利用することができます。要素が見つからない場合、.locはKeyErrorを返します。以下が入力可能です。
- 単一のラベル。例:
5,'a'(※5はインデックスのラベルとして解釈されます。インデックス配列の位置番号ではありません。)。- ラベルのリスト・配列。例:
['a', 'b', 'c']。- ラベルによるスライス。例:
'a':'f'(※普通の Python のスライスと異なり、インデックスに存在すれば、始点と終点の両方が含まれます!ラベルによるスライスを参照してください。)。- 真偽値の配列。
引数を一つ(引かれるのは Series・DataFrame のどちらか)とり、有効な索引(上記のどれか)を返す
callable関数。version 0.18.1 から
より詳しい解説はラベルによる選択を参照してください。
.ilocは基本的に位置番号ベース(0からlength-1まで)ですが、真偽値の配列も利用することができます。インデックス配列の範囲を超えた値を指定した場合、.ilocはIndexErrorを返します。ただし、sliceによる指定は、範囲を越えた値を指定できます(この挙動は Python や NumPy のsliceに準拠しています)。以下が入力可能です。
- 整数。例:
5。- 整数のリスト・配列。例:
[4, 3, 0]。- 整数のスライスオブジェクト。例:
1:7。- 真偽値の配列。
引数を一つ(引かれるのは Series・DataFrame のどちらか)とり、有効な索引(上記のどれか)を返す
callable関数。version 0.18.1 から
.locと.ilocだけでなく、[]による索引もcallableをインデクサをして利用できます。より詳しい解説は呼び出し関数による選択を参照してください。複数の軸を選択してオブジェクトから値を取得するには、以下の表記法を使用します(
.locを例に挙げていますが、.ilocの場合も同様です)。どの軸に対しても Null スライス:が使用可能です。指定されなかった軸は:を指定したと解釈されます。例えば、df.loc['a']はdf.loc['a', :]と同じ意味になります。
オブジェクト インデクサ Series s.loc[indexer]DataFrame df.loc[row_indexer,column_indexer]基本
前章でデータ構造を紹介したときに述べたように、
[]による索引(Python でクラスの振る舞いを実装するのに慣れた人に対して言い換えるなら、__getitem__)の基本的機能は、より低次元のスライスを選択することです。次の表は、[]を用いて Pandas オブジェクトを索引した場合の戻り値の型を示しています。
オブジェクト 索引 返り値の型 Series series[label]スカラー値 DataFrame frame[colname]colname に対応する Seriesここでは、索引機能を説明するために使用する簡単な時系列データセットを作成します。
In [1]: dates = pd.date_range('1/1/2000', periods=8) In [2]: df = pd.DataFrame(np.random.randn(8, 4), ...: index=dates, columns=['A', 'B', 'C', 'D']) ...: In [3]: df Out[3]: A B C D 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632 2000-01-02 1.212112 -0.173215 0.119209 -1.044236 2000-01-03 -0.861849 -2.104569 -0.494929 1.071804 2000-01-04 0.721555 -0.706771 -1.039575 0.271860 2000-01-05 -0.424972 0.567020 0.276232 -1.087401 2000-01-06 -0.673690 0.113648 -1.478427 0.524988 2000-01-07 0.404705 0.577046 -1.715002 -1.039268 2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
注釈 特に明記しない限り、どの索引機能も時系列データ固有のものではありません。 したがって、上で述べたように、最も基本的な
[]を使った索引を用いることができます。In [4]: s = df['A'] In [5]: s[dates[5]] Out[5]: -0.6736897080883706列のリストを
[]に渡すと、列をこの順序で選択できます。列が DataFrame に含まれていない場合は、例外が発生します。この方法で複数の列を代入することもできます。In [6]: df Out[6]: A B C D 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632 2000-01-02 1.212112 -0.173215 0.119209 -1.044236 2000-01-03 -0.861849 -2.104569 -0.494929 1.071804 2000-01-04 0.721555 -0.706771 -1.039575 0.271860 2000-01-05 -0.424972 0.567020 0.276232 -1.087401 2000-01-06 -0.673690 0.113648 -1.478427 0.524988 2000-01-07 0.404705 0.577046 -1.715002 -1.039268 2000-01-08 -0.370647 -1.157892 -1.344312 0.844885 In [7]: df[['B', 'A']] = df[['A', 'B']] In [8]: df Out[8]: A B C D 2000-01-01 -0.282863 0.469112 -1.509059 -1.135632 2000-01-02 -0.173215 1.212112 0.119209 -1.044236 2000-01-03 -2.104569 -0.861849 -0.494929 1.071804 2000-01-04 -0.706771 0.721555 -1.039575 0.271860 2000-01-05 0.567020 -0.424972 0.276232 -1.087401 2000-01-06 0.113648 -0.673690 -1.478427 0.524988 2000-01-07 0.577046 0.404705 -1.715002 -1.039268 2000-01-08 -1.157892 -0.370647 -1.344312 0.844885これは、列のサブセットに(その場で)変換を適用するのに役立ちます。
警告 ↓ .locや.ilocからSeriesとDataFrameを設定すると、pandas はすべての軸を整列させます。列の位置合わせは値の割り当ての前なので、これはdfを変更しません。In [9]: df[['A', 'B']] Out[9]: A B 2000-01-01 -0.282863 0.469112 2000-01-02 -0.173215 1.212112 2000-01-03 -2.104569 -0.861849 2000-01-04 -0.706771 0.721555 2000-01-05 0.567020 -0.424972 2000-01-06 0.113648 -0.673690 2000-01-07 0.577046 0.404705 2000-01-08 -1.157892 -0.370647 In [10]: df.loc[:, ['B', 'A']] = df[['A', 'B']] In [11]: df[['A', 'B']] Out[11]: A B 2000-01-01 -0.282863 0.469112 2000-01-02 -0.173215 1.212112 2000-01-03 -2.104569 -0.861849 2000-01-04 -0.706771 0.721555 2000-01-05 0.567020 -0.424972 2000-01-06 0.113648 -0.673690 2000-01-07 0.577046 0.404705 2000-01-08 -1.157892 -0.370647
列の値を交換する正しい方法は、生の値を使用することです。 In [12]: df.loc[:, ['B', 'A']] = df[['A', 'B']].to_numpy() In [13]: df[['A', 'B']] Out[13]: A B 2000-01-01 0.469112 -0.282863 2000-01-02 1.212112 -0.173215 2000-01-03 -0.861849 -2.104569 2000-01-04 0.721555 -0.706771 2000-01-05 -0.424972 0.567020 2000-01-06 -0.673690 0.113648 2000-01-07 0.404705 0.577046 2000-01-08 -0.370647 -1.157892
警告 ↑ 属性アクセス
SeriesのインデックスまたはDataFrameの列に属性として直接取得できます。In [14]: sa = pd.Series([1, 2, 3], index=list('abc')) In [15]: dfa = df.copy()In [16]: sa.b Out[16]: 2 In [17]: dfa.A Out[17]: 2000-01-01 0.469112 2000-01-02 1.212112 2000-01-03 -0.861849 2000-01-04 0.721555 2000-01-05 -0.424972 2000-01-06 -0.673690 2000-01-07 0.404705 2000-01-08 -0.370647 Freq: D, Name: A, dtype: float64In [18]: sa.a = 5 In [19]: sa Out[19]: a 5 b 2 c 3 dtype: int64 In [20]: dfa.A = list(range(len(dfa.index))) # A列が既に存在していれば問題ない In [21]: dfa Out[21]: A B C D 2000-01-01 0 -0.282863 -1.509059 -1.135632 2000-01-02 1 -0.173215 0.119209 -1.044236 2000-01-03 2 -2.104569 -0.494929 1.071804 2000-01-04 3 -0.706771 -1.039575 0.271860 2000-01-05 4 0.567020 0.276232 -1.087401 2000-01-06 5 0.113648 -1.478427 0.524988 2000-01-07 6 0.577046 -1.715002 -1.039268 2000-01-08 7 -1.157892 -1.344312 0.844885 In [22]: dfa['A'] = list(range(len(dfa.index))) # もし新しい列を作る場合はこちら In [23]: dfa Out[23]: A B C D 2000-01-01 0 -0.282863 -1.509059 -1.135632 2000-01-02 1 -0.173215 0.119209 -1.044236 2000-01-03 2 -2.104569 -0.494929 1.071804 2000-01-04 3 -0.706771 -1.039575 0.271860 2000-01-05 4 0.567020 0.276232 -1.087401 2000-01-06 5 0.113648 -1.478427 0.524988 2000-01-07 6 0.577046 -1.715002 -1.039268 2000-01-08 7 -1.157892 -1.344312 0.844885
警告 この取得は、index 要素が有効な Python の識別子である場合にのみ使用できます。例えば、 s.1は使用できません。有効な識別子の説明については、こちらを参照してください。既存のメソッド名と競合する場合、その属性は利用できません。例えば、 s.minは使用できません。同様に、次に挙げたもののいずれかと競合する場合、その属性は利用できません。 index,major_axis,minor_axis,items。これらの場合のいずれにおいても、標準的な索引は依然として利用できます。例えば、 s['1'],s['min'],s['index']は、対応する要素または列にアクセスします。IPython 環境を使用している場合は、タブ補完を使用してこれらのアクセス可能な属性を確認することもできます。
また、
DataFrameの行に辞書dictを割り当てることもできます。In [24]: x = pd.DataFrame({'a': [1, 2, 3], 'b': [3, 4, 5]}) In [25]: x.iloc[1] = {'a': 9, 'b': 99} In [26]: x Out[26]: a b 0 1 3 1 9 99 2 3 5属性アクセスを使用して、既存の
Seriesの要素またはDataFrameの列を変更できます。ただし、新しい列を作成しようとして属性アクセスを使用すると、新しい列ではなく新しい属性が作成されることに、注意してください。0.21.0 以降はこのときUserWarningを送出します。In [1]: df = pd.DataFrame({'one': [1., 2., 3.]}) In [2]: df.two = [4, 5, 6] UserWarning: Pandas doesn't allow Series to be assigned into nonexistent columns - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute_access In [3]: df Out[3]: one 0 1.0 1 2.0 2 3.0スライス範囲
任意の軸に沿って範囲をスライスする最も堅牢で一貫性のある方法は、
.ilocメソッドの詳細を説明した位置による選択の節で説明されています。ここでは、[]演算子を使ってスライスのセマンティクスを説明します。Series では、ndarray の構文とまったく同じように機能し、値とそれに対応するラベルのスライスを返します。
In [27]: s[:5] Out[27]: 2000-01-01 0.469112 2000-01-02 1.212112 2000-01-03 -0.861849 2000-01-04 0.721555 2000-01-05 -0.424972 Freq: D, Name: A, dtype: float64 In [28]: s[::2] Out[28]: 2000-01-01 0.469112 2000-01-03 -0.861849 2000-01-05 -0.424972 2000-01-07 0.404705 Freq: 2D, Name: A, dtype: float64 In [29]: s[::-1] Out[29]: 2000-01-08 -0.370647 2000-01-07 0.404705 2000-01-06 -0.673690 2000-01-05 -0.424972 2000-01-04 0.721555 2000-01-03 -0.861849 2000-01-02 1.212112 2000-01-01 0.469112 Freq: -1D, Name: A, dtype: float64また、代入の際も同様に機能します。
In [30]: s2 = s.copy() In [31]: s2[:5] = 0 In [32]: s2 Out[32]: 2000-01-01 0.000000 2000-01-02 0.000000 2000-01-03 0.000000 2000-01-04 0.000000 2000-01-05 0.000000 2000-01-06 -0.673690 2000-01-07 0.404705 2000-01-08 -0.370647 Freq: D, Name: A, dtype: float64DataFrame では、
[]の中の行がスライスされます。これは、このような操作が一般的であるため、便利のため提供されています。ラベルによる選択
警告 設定された演算子によってコピーが返されるか参照が返されるかは、文脈に依存します。これは連鎖代入 chained assignmentとも呼ばれますが、避けるべきものです。返るのはビューかコピーかを参照してください。
警告 ↓ インデックスタイプと互換性のない(あるいは変換不可能な)スライサを用いる場合、 .locは厳密です。例として、DatetimeIndexに整数を使用してみます。これらはTypeErrorを送出します。In [35]: dfl = pd.DataFrame(np.random.randn(5, 4), ....: columns=list('ABCD'), ....: index=pd.date_range('20130101', periods=5)) ....: In [36]: dfl Out[36]: A B C D 2013-01-01 1.075770 -0.109050 1.643563 -1.469388 2013-01-02 0.357021 -0.674600 -1.776904 -0.968914 2013-01-03 -1.294524 0.413738 0.276662 -0.472035 2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061 2013-01-05 0.895717 0.805244 -1.206412 2.565646In [4]: dfl.loc[2:3] TypeError: cannot do slice indexing on <class 'pandas.tseries.index.DatetimeIndex'> with these indexers [2] of <type 'int'>
文字列型のような型によるスライスはインデックスの型に変換することができ、自然にスライスできます。 In [37]: dfl.loc['20130102':'20130104'] Out[37]: A B C D 2013-01-02 0.357021 -0.674600 -1.776904 -0.968914 2013-01-03 -1.294524 0.413738 0.276662 -0.472035 2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061
警告 ↑
警告 0.21.0 からは、存在しないラベルを含むリストで索引すると、Pandas は FutureWarningを表示します。将来的にこれはKeyErrorを送出するでしょう。存在しないキーを含むリストによる索引は廃止予定を参照してください。Pandas では純粋なラベルベースの索引のために一連のメソッドが提供されています。これは厳密な包含ベースのプロトコルです。要求された全てのラベルはインデックスに含まれていなければなりません、そうでなければ
KeyErrorが送出されます。スライス時に、インデックスに存在する場合は、始点と終点の両方が含まれます。整数はラベルとして有効ですが、位置ではなくラベルを参照します。
.loc属性が基本的なアクセスメソッドです。有効な入力は以下のとおりです。
- 単一のラベル。例:
5,'a'(※5はインデックスのラベルとして解釈されます。インデックス配列の位置番号ではありません。)。- ラベルのリスト・配列。例:
['a', 'b', 'c']。- ラベルによるスライス。例:
'a':'f'(※普通の python のスライスと異なり、インデックスに存在すれば、始点と終点の両方が含まれます!ラベルによるスライスを参照してください。)。- 真偽値の配列。
callable関数。呼び出し関数による選択を参照してください。In [38]: s1 = pd.Series(np.random.randn(6), index=list('abcdef')) In [39]: s1 Out[39]: a 1.431256 b 1.340309 c -1.170299 d -0.226169 e 0.410835 f 0.813850 dtype: float64 In [40]: s1.loc['c':] Out[40]: c -1.170299 d -0.226169 e 0.410835 f 0.813850 dtype: float64 In [41]: s1.loc['b'] Out[41]: 1.3403088497993827また、代入の際も同様に機能します。
In [42]: s1.loc['c':] = 0 In [43]: s1 Out[43]: a 1.431256 b 1.340309 c 0.000000 d 0.000000 e 0.000000 f 0.000000 dtype: float64DataFrame の場合。
In [44]: df1 = pd.DataFrame(np.random.randn(6, 4), ....: index=list('abcdef'), ....: columns=list('ABCD')) ....: In [45]: df1 Out[45]: A B C D a 0.132003 -0.827317 -0.076467 -1.187678 b 1.130127 -1.436737 -1.413681 1.607920 c 1.024180 0.569605 0.875906 -2.211372 d 0.974466 -2.006747 -0.410001 -0.078638 e 0.545952 -1.219217 -1.226825 0.769804 f -1.281247 -0.727707 -0.121306 -0.097883 In [46]: df1.loc[['a', 'b', 'd'], :] Out[46]: A B C D a 0.132003 -0.827317 -0.076467 -1.187678 b 1.130127 -1.436737 -1.413681 1.607920 d 0.974466 -2.006747 -0.410001 -0.078638ラベルスライスを介したアクセス。
In [47]: df1.loc['d':, 'A':'C'] Out[47]: A B C d 0.974466 -2.006747 -0.410001 e 0.545952 -1.219217 -1.226825 f -1.281247 -0.727707 -0.121306ラベルを使用した断面の取得(
df.xs('a')に等しい)。In [48]: df1.loc['a'] Out[48]: A 0.132003 B -0.827317 C -0.076467 D -1.187678 Name: a, dtype: float64真偽値配列を利用した値の取得。
In [49]: df1.loc['a'] > 0 Out[49]: A True B False C False D False Name: a, dtype: bool In [50]: df1.loc[:, df1.loc['a'] > 0] Out[50]: A a 0.132003 b 1.130127 c 1.024180 d 0.974466 e 0.545952 f -1.281247明示的に値を取得(廃止予定の
df.get_value('a','A')に等しい)。# これは``df1.at['a', 'A']``に等しい In [51]: df1.loc['a', 'A'] Out[51]: 0.13200317033032932ラベルによるスライス
.locでスライスを用いるときに、開始ラベルと終了ラベルの両方がインデックスに存在する場合、2 つのラベルの間に位置している要素(始点終点を含む)が返されます。In [52]: s = pd.Series(list('abcde'), index=[0, 3, 2, 5, 4]) In [53]: s.loc[3:5] Out[53]: 3 b 2 c 5 d dtype: object2 つのうちの少なくとも 1 つが存在しなくても、インデックスがソートされていて、かつ開始ラベル・終了ラベルと比較できる場合は、2 つの間にランク付けされるラベルが選択されて、スライスは期待どおりに機能します。
In [54]: s.sort_index() Out[54]: 0 a 2 c 3 b 4 e 5 d dtype: object In [55]: s.sort_index().loc[1:6] Out[55]: 2 c 3 b 4 e 5 d dtype: objectただし、2 つのうち少なくとも 1 つが存在せず、インデックスがソートされていないと、エラーが発生します(そうしないと計算コストが高くなり、混合型インデックスではあいまいになる可能性があるため)。例えば上記の例では、
s.loc[1:6]はKeyErrorを送出します。位置による選択
警告 設定された演算子によってコピーが返されるか参照が返されるかは、文脈に依存します。これは連鎖代入 chained assignmentとも呼ばれますが、避けるべきものです。返るのはビューかコピーかを参照してください。Pandas では純粋な位置番号ベースの索引のために一連のメソッドが提供されています。その動作は Python と NumPy のスライスに厳密に従います。これは
0-basedインデックスです。スライスすると、始点は含まれますが、終点は含まれません。有効なラベルであっても、整数以外を使用しようとするとIndexErrorが発生します。
.iloc属性が基本的なアクセスメソッドです。有効な入力は以下のとおりです。
- 整数。例:
5。- 整数のリスト・配列。例:
[4, 3, 0]。- 整数のスライスオブジェクト。例:
1:7。- 真偽値の配列。
callable関数。呼び出し関数による選択を参照してください。In [56]: s1 = pd.Series(np.random.randn(5), index=list(range(0, 10, 2))) In [57]: s1 Out[57]: 0 0.695775 2 0.341734 4 0.959726 6 -1.110336 8 -0.619976 dtype: float64 In [58]: s1.iloc[:3] Out[58]: 0 0.695775 2 0.341734 4 0.959726 dtype: float64 In [59]: s1.iloc[3] Out[59]: -1.110336102891167また、代入の際も同様に機能します。
In [60]: s1.iloc[:3] = 0 In [61]: s1 Out[61]: 0 0.000000 2 0.000000 4 0.000000 6 -1.110336 8 -0.619976 dtype: float64DataFrame の場合。
In [62]: df1 = pd.DataFrame(np.random.randn(6, 4), ....: index=list(range(0, 12, 2)), ....: columns=list(range(0, 8, 2))) ....: In [63]: df1 Out[63]: 0 2 4 6 0 0.149748 -0.732339 0.687738 0.176444 2 0.403310 -0.154951 0.301624 -2.179861 4 -1.369849 -0.954208 1.462696 -1.743161 6 -0.826591 -0.345352 1.314232 0.690579 8 0.995761 2.396780 0.014871 3.357427 10 -0.317441 -1.236269 0.896171 -0.487602整数スライスを介した選択。
In [64]: df1.iloc[:3] Out[64]: 0 2 4 6 0 0.149748 -0.732339 0.687738 0.176444 2 0.403310 -0.154951 0.301624 -2.179861 4 -1.369849 -0.954208 1.462696 -1.743161 In [65]: df1.iloc[1:5, 2:4] Out[65]: 4 6 2 0.301624 -2.179861 4 1.462696 -1.743161 6 1.314232 0.690579 8 0.014871 3.357427整数のリストを介した選択。
In [66]: df1.iloc[[1, 3, 5], [1, 3]] Out[66]: 2 6 2 -0.154951 -2.179861 6 -0.345352 0.690579 10 -1.236269 -0.487602In [67]: df1.iloc[1:3, :] Out[67]: 0 2 4 6 2 0.403310 -0.154951 0.301624 -2.179861 4 -1.369849 -0.954208 1.462696 -1.743161In [68]: df1.iloc[:, 1:3] Out[68]: 2 4 0 -0.732339 0.687738 2 -0.154951 0.301624 4 -0.954208 1.462696 6 -0.345352 1.314232 8 2.396780 0.014871 10 -1.236269 0.896171# これは``df1.iat[1, 1]``に等しい In [69]: df1.iloc[1, 1] Out[69]: -0.1549507744249032位置番号による断面の取得(
df.xs(1)に等しい)。In [70]: df1.iloc[1] Out[70]: 0 0.403310 2 -0.154951 4 0.301624 6 -2.179861 Name: 2, dtype: float64範囲外のスライスインデックスは、Python/Numpy と同じように適切に処理されます。
# これらはpython/numpyで使用可能。 In [71]: x = list('abcdef') In [72]: x Out[72]: ['a', 'b', 'c', 'd', 'e', 'f'] In [73]: x[4:10] Out[73]: ['e', 'f'] In [74]: x[8:10] Out[74]: [] In [75]: s = pd.Series(x) In [76]: s Out[76]: 0 a 1 b 2 c 3 d 4 e 5 f dtype: object In [77]: s.iloc[4:10] Out[77]: 4 e 5 f dtype: object In [78]: s.iloc[8:10] Out[78]: Series([], dtype: object)範囲外のスライスを使用すると、軸が空になる可能性があることに注意してください(たとえば、空の DataFrame が返されるなど)。
In [79]: dfl = pd.DataFrame(np.random.randn(5, 2), columns=list('AB')) In [80]: dfl Out[80]: A B 0 -0.082240 -2.182937 1 0.380396 0.084844 2 0.432390 1.519970 3 -0.493662 0.600178 4 0.274230 0.132885 In [81]: dfl.iloc[:, 2:3] Out[81]: Empty DataFrame Columns: [] Index: [0, 1, 2, 3, 4] In [82]: dfl.iloc[:, 1:3] Out[82]: B 0 -2.182937 1 0.084844 2 1.519970 3 0.600178 4 0.132885 In [83]: dfl.iloc[4:6] Out[83]: A B 4 0.27423 0.132885範囲外の単一のインデクサは
IndexErrorを送出します。いずれかの要素が範囲外にあるインデクサのリストはIndexErrorを送出します。>>> dfl.iloc[[4, 5, 6]] IndexError: positional indexers are out-of-bounds >>> dfl.iloc[:, 4] IndexError: single positional indexer is out-of-bounds呼び出し関数による選択
version 0.18.1 から
.loc,.iloc,[]による索引はcallableをインデクサをして受け取れます。callableは引数を一つ(引かれるのは Series・DataFrame のどちらか)とり、有効な索引を返す関数でなければなりません。In [84]: df1 = pd.DataFrame(np.random.randn(6, 4), ....: index=list('abcdef'), ....: columns=list('ABCD')) ....: In [85]: df1 Out[85]: A B C D a -0.023688 2.410179 1.450520 0.206053 b -0.251905 -2.213588 1.063327 1.266143 c 0.299368 -0.863838 0.408204 -1.048089 d -0.025747 -0.988387 0.094055 1.262731 e 1.289997 0.082423 -0.055758 0.536580 f -0.489682 0.369374 -0.034571 -2.484478 In [86]: df1.loc[lambda df: df.A > 0, :] Out[86]: A B C D c 0.299368 -0.863838 0.408204 -1.048089 e 1.289997 0.082423 -0.055758 0.536580 In [87]: df1.loc[:, lambda df: ['A', 'B']] Out[87]: A B a -0.023688 2.410179 b -0.251905 -2.213588 c 0.299368 -0.863838 d -0.025747 -0.988387 e 1.289997 0.082423 f -0.489682 0.369374 In [88]: df1.iloc[:, lambda df: [0, 1]] Out[88]: A B a -0.023688 2.410179 b -0.251905 -2.213588 c 0.299368 -0.863838 d -0.025747 -0.988387 e 1.289997 0.082423 f -0.489682 0.369374 In [89]: df1[lambda df: df.columns[0]] Out[89]: a -0.023688 b -0.251905 c 0.299368 d -0.025747 e 1.289997 f -0.489682 Name: A, dtype: float64
Seriesでも使用できます。In [90]: df1.A.loc[lambda s: s > 0] Out[90]: c 0.299368 e 1.289997 Name: A, dtype: float64これらのメソッド・インデクサを使用すると、一時変数を使用せずにデータ選択操作を連鎖できます。
In [91]: bb = pd.read_csv('data/baseball.csv', index_col='id') In [92]: (bb.groupby(['year', 'team']).sum() ....: .loc[lambda df: df.r > 100]) ....: Out[92]: stint g ab r h X2b ... so ibb hbp sh sf gidp year team ... 2007 CIN 6 379 745 101 203 35 ... 127.0 14.0 1.0 1.0 15.0 18.0 DET 5 301 1062 162 283 54 ... 176.0 3.0 10.0 4.0 8.0 28.0 HOU 4 311 926 109 218 47 ... 212.0 3.0 9.0 16.0 6.0 17.0 LAN 11 413 1021 153 293 61 ... 141.0 8.0 9.0 3.0 8.0 29.0 NYN 13 622 1854 240 509 101 ... 310.0 24.0 23.0 18.0 15.0 48.0 SFN 5 482 1305 198 337 67 ... 188.0 51.0 8.0 16.0 6.0 41.0 TEX 2 198 729 115 200 40 ... 140.0 4.0 5.0 2.0 8.0 16.0 TOR 4 459 1408 187 378 96 ... 265.0 16.0 12.0 4.0 16.0 38.0 [8 rows x 18 columns]IX インデクサは廃止予定
警告 0.20.0 から、より厳格な .ilocおよび.locインデクサが推奨され、.ixインデクサは廃止予定になりました。
.ixはユーザーがやりたいことを推論する上で多くのマジックを提供します。つまり、.ixは、インデックスのデータ型に応じて、位置ベースかラベルベースの索引を決定します。これは何年もの間かなりのユーザーに混乱を引き起こしました。推奨される索引は次のとおりです。
- ラベルによる索引は
.loc。- 位置による索引は
.iloc。In [93]: dfd = pd.DataFrame({'A': [1, 2, 3], ....: 'B': [4, 5, 6]}, ....: index=list('abc')) ....: In [94]: dfd Out[94]: A B a 1 4 b 2 5 c 3 6以前の動作で、'A'列のインデックスから 0 番目と 2 番目の要素を取得するとき。
In [3]: dfd.ix[[0, 2], 'A'] Out[3]: a 1 c 3 Name: A, dtype: int64.loc を使う場合。ここでは、インデックスから適切なインデックスを選択してから、ラベルによる索引を使用します。
In [95]: dfd.loc[dfd.index[[0, 2]], 'A'] Out[95]: a 1 c 3 Name: A, dtype: int64これは、
.ilocを使用して、インデクサ上の位置を明示的に取得し、位置による索引を使用して選択することによっても表現できます。In [96]: dfd.iloc[[0, 2], dfd.columns.get_loc('A')] Out[96]: a 1 c 3 Name: A, dtype: int64複数のインデクサを取得するには、
.get_indexerを使用します。In [97]: dfd.iloc[[0, 2], dfd.columns.get_indexer(['A', 'B'])] Out[97]: A B a 1 4 c 3 6存在しないキーを含むリストによる索引は廃止予定
警告 0.21.0 から、 .reindexが推奨され、1 つ以上の不在ラベルがあるリストで.locまたは[]を使用することは廃止予定になりました。以前のバージョンでは、
.loc[list-of-labels]を使っても、少なくとも 1 つのキーが見つかる限りは動作していました(そうでない場合はKeyErrorが発生します)。この動作は推奨されておらず、この節を指す警告メッセージが表示されます。推奨される代替方法は.reindex()を使用することです。例。
In [98]: s = pd.Series([1, 2, 3]) In [99]: s Out[99]: 0 1 1 2 2 3 dtype: int64全てのキーが見つかった場合の挙動は変わりせん。
In [100]: s.loc[[1, 2]] Out[100]: 1 2 2 3 dtype: int64以前の挙動。
In [4]: s.loc[[1, 2, 3]] Out[4]: 1 2.0 2 3.0 3 NaN dtype: float64現在の挙動
In [4]: s.loc[[1, 2, 3]] Passing list-likes to .loc with any non-matching elements will raise KeyError in the future, you can use .reindex() as an alternative. See the documentation here: http://pandas.pydata.org/pandas-docs/stable/indexing.html#deprecate-loc-reindex-listlike Out[4]: 1 2.0 2 3.0 3 NaN dtype: float64インデックスの再作成
見つからない可能性のある要素を選択するための慣例的な方法は、
.reindex()を使用することです。インデックスの再作成の節も参照してください。In [101]: s.reindex([1, 2, 3]) Out[101]: 1 2.0 2 3.0 3 NaN dtype: float64あるいは、有効なキーだけを選択したい場合は、次の方法が慣例的かつ効率的です。選択部分の dtype が保持されることが保証されています。
In [102]: labels = [1, 2, 3] In [103]: s.loc[s.index.intersection(labels)] Out[103]: 1 2 2 3 dtype: int64重複したインデックスがあると、
.reindex()においてエラーが送出されます。In [104]: s = pd.Series(np.arange(4), index=['a', 'a', 'b', 'c']) In [105]: labels = ['c', 'd']In [17]: s.reindex(labels) ValueError: cannot reindex from a duplicate axis通常、目的のラベルを現在の軸と交差させてから、インデックスを再作成します。
In [106]: s.loc[s.index.intersection(labels)].reindex(labels) Out[106]: c 3.0 d NaN dtype: float64ただし、結果のインデックスが重複している場合は、この方法でもエラーが発生します。
In [41]: labels = ['a', 'd'] In [42]: s.loc[s.index.intersection(labels)].reindex(labels) ValueError: cannot reindex from a duplicate axisランダムサンプルの選択
sample()メソッドを使用すると Series または DataFrame から行または列をランダムに選択できます。このメソッドはデフォルトでは行をサンプリングし、返される行/列の数あるいは割合を受け取ります。In [107]: s = pd.Series([0, 1, 2, 3, 4, 5]) # 引数がない場合、1行が返される In [108]: s.sample() Out[108]: 4 4 dtype: int64 # 行数を指定することも可能 In [109]: s.sample(n=3) Out[109]: 0 0 4 4 1 1 dtype: int64 # 行数の割合を指定することも可能 In [110]: s.sample(frac=0.5) Out[110]: 5 5 3 3 1 1 dtype: int64デフォルトでは、
sampleは各行を最大 1 回返しますが、replace引数を使用して置換してサンプリングすることもできます。In [111]: s = pd.Series([0, 1, 2, 3, 4, 5]) # replacementなし(デフォルト) In [112]: s.sample(n=6, replace=False) Out[112]: 0 0 1 1 5 5 3 3 2 2 4 4 dtype: int64 # replacementあり: In [113]: s.sample(n=6, replace=True) Out[113]: 0 0 4 4 3 3 2 2 4 4 4 4 dtype: int64デフォルトでは、各行は選択される確率が同じですが、行に異なる確率を持たせたい場合は、
weights引数によって重みをsample関数に渡すことができます。この重みはリスト・NumPy 配列・Series が使用できますが、それらはサンプリングするオブジェクトと同じ長さでなければなりません。欠損値は重みゼロとして扱われ、また inf 値は使用できません。重みの合計が 1 でない場合は、すべての重みを重みの合計で除算することによって、正規化されます。例えば、In [114]: s = pd.Series([0, 1, 2, 3, 4, 5]) In [115]: example_weights = [0, 0, 0.2, 0.2, 0.2, 0.4] In [116]: s.sample(n=3, weights=example_weights) Out[116]: 5 5 4 4 3 3 dtype: int64 # 重みは自動的に正規化される In [117]: example_weights2 = [0.5, 0, 0, 0, 0, 0] In [118]: s.sample(n=1, weights=example_weights2) Out[118]: 0 0 dtype: int64DataFrame に適用する場合、列の名前を文字列として渡すだけで、DataFrame の列をサンプリングの重みとして使用できます(列ではなく、行をサンプリングする場合)。
In [119]: df2 = pd.DataFrame({'col1': [9, 8, 7, 6], .....: 'weight_column': [0.5, 0.4, 0.1, 0]}) .....: In [120]: df2.sample(n=3, weights='weight_column') Out[120]: col1 weight_column 1 8 0.4 0 9 0.5 2 7 0.1
sampleはまたaxis引数を使用して行ではなく列をサンプリングすることもできます。In [121]: df3 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]}) In [122]: df3.sample(n=1, axis=1) Out[122]: col1 0 1 1 2 2 3最後に、
random_state引数を使用して、sampleの乱数ジェネレータのシードを設定することもできます。これは、整数(シードとして)または NumPy RandomState オブジェクトのいずれかを受け入れます。In [123]: df4 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]}) # シードを与えると、常に同じ行をサンプリングできる In [124]: df4.sample(n=2, random_state=2) Out[124]: col1 col2 2 3 4 1 2 3 In [125]: df4.sample(n=2, random_state=2) Out[125]: col1 col2 2 3 4 1 2 3代入による拡張
.loc/[]操作は、その軸に存在しないキーに代入すると、拡張を実行できます。
Seriesの場合、これは事実上要素追加操作です。In [126]: se = pd.Series([1, 2, 3]) In [127]: se Out[127]: 0 1 1 2 2 3 dtype: int64 In [128]: se[5] = 5. In [129]: se Out[129]: 0 1.0 1 2.0 2 3.0 5 5.0 dtype: float64
DataFrameは、.locを介してどちらの軸でも拡張できます。In [130]: dfi = pd.DataFrame(np.arange(6).reshape(3, 2), .....: columns=['A', 'B']) .....: In [131]: dfi Out[131]: A B 0 0 1 1 2 3 2 4 5 In [132]: dfi.loc[:, 'C'] = dfi.loc[:, 'A'] In [133]: dfi Out[133]: A B C 0 0 1 0 1 2 3 2 2 4 5 4これは
DataFrameのappend操作に似ています。In [134]: dfi.loc[3] = 5 In [135]: dfi Out[135]: A B C 0 0 1 0 1 2 3 2 2 4 5 4 3 5 5 5高速なスカラー値の取得と代入
[]によるインデックス付けは多くのパターン(単一ラベルアクセス、スライス、真偽値による索引など)を処理する必要があるため、何を求めているのかを把握するために少しオーバーヘッドがあります。スカラ値にのみアクセスしたい場合は、すべてのデータ構造に実装されている.atメソッドと.iatメソッドを使用するのが最も早い方法です。
.locと同様に、.atはラベルベースのスカラー検索を提供し、.iatは.ilocと同様に位置番号ベースの検索を提供します。In [136]: s.iat[5] Out[136]: 5 In [137]: df.at[dates[5], 'A'] Out[137]: -0.6736897080883706 In [138]: df.iat[3, 0] Out[138]: 0.7215551622443669同じインデクサを使って代入することもできます。
In [139]: df.at[dates[5], 'E'] = 7 In [140]: df.iat[3, 0] = 7インデクサが存在しない値の場合、
.atは上記のようにオブジェクトをインプレースで拡張することがあります。In [141]: df.at[dates[-1] + pd.Timedelta('1 day'), 0] = 7 In [142]: df Out[142]: A B C D E 0 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632 NaN NaN 2000-01-02 1.212112 -0.173215 0.119209 -1.044236 NaN NaN 2000-01-03 -0.861849 -2.104569 -0.494929 1.071804 NaN NaN 2000-01-04 7.000000 -0.706771 -1.039575 0.271860 NaN NaN 2000-01-05 -0.424972 0.567020 0.276232 -1.087401 NaN NaN 2000-01-06 -0.673690 0.113648 -1.478427 0.524988 7.0 NaN 2000-01-07 0.404705 0.577046 -1.715002 -1.039268 NaN NaN 2000-01-08 -0.370647 -1.157892 -1.344312 0.844885 NaN NaN 2000-01-09 NaN NaN NaN NaN NaN 7.0真偽値による索引
もう 1 つの一般的な操作は、データをフィルタリングするための真偽値ベクトルを用いることです。演算子は以下のとおりです。
|はor,&はand,~はnot。デフォルトでは Python はdf.A > 2 & df.B < 3のような式をdf.A > (2 & df.B) < 3として評価しますが、望ましい評価順序は(df.A > 2) & (df.B < 3)であるため、これらは括弧を使用してグループ化しなければなりません。
Seriesの索引のための真偽値ベクトルの使用は、NumPy ndarray の場合とまったく同じように機能します。In [143]: s = pd.Series(range(-3, 4)) In [144]: s Out[144]: 0 -3 1 -2 2 -1 3 0 4 1 5 2 6 3 dtype: int64 In [145]: s[s > 0] Out[145]: 4 1 5 2 6 3 dtype: int64 In [146]: s[(s < -1) | (s > 0.5)] Out[146]: 0 -3 1 -2 4 1 5 2 6 3 dtype: int64 In [147]: s[~(s < 0)] Out[147]: 3 0 4 1 5 2 6 3 dtype: int64DataFrame のインデックスと同じ長さの真偽値ベクトル(例えば、DataFrame の列の 1 つから派生したもの)を使用して、DataFrame から行を選択できます。
In [148]: df[df['A'] > 0] Out[148]: A B C D E 0 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632 NaN NaN 2000-01-02 1.212112 -0.173215 0.119209 -1.044236 NaN NaN 2000-01-04 7.000000 -0.706771 -1.039575 0.271860 NaN NaN 2000-01-07 0.404705 0.577046 -1.715002 -1.039268 NaN NaNリスト内包表記と Series の
mapメソッドを利用して、より複雑な基準を作成することもできます。In [149]: df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'three', 'two', 'one', 'six'], .....: 'b': ['x', 'y', 'y', 'x', 'y', 'x', 'x'], .....: 'c': np.random.randn(7)}) .....: # 'two'か'three'だけが必要な場合 In [150]: criterion = df2['a'].map(lambda x: x.startswith('t')) In [151]: df2[criterion] Out[151]: a b c 2 two y 0.041290 3 three x 0.361719 4 two y -0.238075 # 同じ結果だが遅い In [152]: df2[[x.startswith('t') for x in df2['a']]] Out[152]: a b c 2 two y 0.041290 3 three x 0.361719 4 two y -0.238075 # 複数の基準 In [153]: df2[criterion & (df2['b'] == 'x')] Out[153]: a b c 3 three x 0.361719ラベルによる選択・位置による選択・高度な索引では、真偽値ベクトルを他の索引式と組み合わせて使用 して、複数の軸に対して選択できます。
In [154]: df2.loc[criterion & (df2['b'] == 'x'), 'b':'c'] Out[154]: b c 3 x 0.361719isin による索引
Seriesのisin()メソッドを考えてみましょう。このメソッドは、Seriesの要素が渡されたリストの中に存在する場合は真となる、真偽値ベクトルを返します。これにより、1 つ以上の列に必要な値がある行を選択できます。In [155]: s = pd.Series(np.arange(5), index=np.arange(5)[::-1], dtype='int64') In [156]: s Out[156]: 4 0 3 1 2 2 1 3 0 4 dtype: int64 In [157]: s.isin([2, 4, 6]) Out[157]: 4 False 3 False 2 True 1 False 0 True dtype: bool In [158]: s[s.isin([2, 4, 6])] Out[158]: 2 2 0 4 dtype: int64同じ方法が
Indexオブジェクトにも利用でき、探しているラベルのどれが実際に存在しているのかわからない場合に役立ちます。In [159]: s[s.index.isin([2, 4, 6])] Out[159]: 4 0 2 2 dtype: int64 # 次の例と比較する In [160]: s.reindex([2, 4, 6]) Out[160]: 2 2.0 4 0.0 6 NaN dtype: float64それに加えて、
MultiIndexではメンバーシップチェックで使用するために別のレベルを選択することができます。In [161]: s_mi = pd.Series(np.arange(6), .....: index=pd.MultiIndex.from_product([[0, 1], ['a', 'b', 'c']])) .....: In [162]: s_mi Out[162]: 0 a 0 b 1 c 2 1 a 3 b 4 c 5 dtype: int64 In [163]: s_mi.iloc[s_mi.index.isin([(1, 'a'), (2, 'b'), (0, 'c')])] Out[163]: 0 c 2 1 a 3 dtype: int64 In [164]: s_mi.iloc[s_mi.index.isin(['a', 'c', 'e'], level=1)] Out[164]: 0 a 0 c 2 1 a 3 c 5 dtype: int64
DataFrameにもisin()メソッドがあります。isinを呼び出すときは、一連の値を配列または辞書として渡します。もし値が配列の場合、isinは元の DataFrame と同じ形状の真偽値の DataFrame を返します。これは要素が値のシーケンス内にある場合は True になります。In [165]: df = pd.DataFrame({'vals': [1, 2, 3, 4], 'ids': ['a', 'b', 'f', 'n'], .....: 'ids2': ['a', 'n', 'c', 'n']}) .....: In [166]: values = ['a', 'b', 1, 3] In [167]: df.isin(values) Out[167]: vals ids ids2 0 True True True 1 False True False 2 True False False 3 False False False多くの場合、特定の値を特定の列と一致させる必要があります。キーが列で、値がチェックしたい項目のリストになっている辞書
dictを値として渡すだけです。In [168]: values = {'ids': ['a', 'b'], 'vals': [1, 3]} In [169]: df.isin(values) Out[169]: vals ids ids2 0 True True False 1 False True False 2 True False False 3 False False FalseDataFrame の
isinとany()やall()メソッドを組み合わせて、特定の基準を満たすデータのサブセットをすばやく選択できます。各列がそれぞれの基準を満たす行を選択するには、In [170]: values = {'ids': ['a', 'b'], 'ids2': ['a', 'c'], 'vals': [1, 3]} In [171]: row_mask = df.isin(values).all(1) In [172]: df[row_mask] Out[172]: vals ids ids2 0 1 a a
where()メソッドとマスク真偽値ベクトルを使用して Series から値を選択すると、通常、データのサブセットが返されます。出力が元のデータと同じ形状になるようにするためには、
SeriesおよびDataFrameのwhereメソッドを使用します。選択した行だけを返すには、
In [173]: s[s > 0] Out[173]: 3 1 2 2 1 3 0 4 dtype: int64オリジナルと同じ形の Series を返すには、
In [174]: s.where(s > 0) Out[174]: 4 NaN 3 1.0 2 2.0 1 3.0 0 4.0 dtype: float64ブール基準を使用して DataFrame から値を選択すると、入力データの形状も保持されるようになりました。
whereは実装として内部で使用されています。以下のコードは、df.where(df < 0)と同等です。In [175]: df[df < 0] Out[175]: A B C D 2000-01-01 -2.104139 -1.309525 NaN NaN 2000-01-02 -0.352480 NaN -1.192319 NaN 2000-01-03 -0.864883 NaN -0.227870 NaN 2000-01-04 NaN -1.222082 NaN -1.233203 2000-01-05 NaN -0.605656 -1.169184 NaN 2000-01-06 NaN -0.948458 NaN -0.684718 2000-01-07 -2.670153 -0.114722 NaN -0.048048 2000-01-08 NaN NaN -0.048788 -0.808838さらに、
whereは、返されたコピーにおいて、条件が False の場合に値を置き換えるためのオプション引数otherを受け取ります。In [176]: df.where(df < 0, -df) Out[176]: A B C D 2000-01-01 -2.104139 -1.309525 -0.485855 -0.245166 2000-01-02 -0.352480 -0.390389 -1.192319 -1.655824 2000-01-03 -0.864883 -0.299674 -0.227870 -0.281059 2000-01-04 -0.846958 -1.222082 -0.600705 -1.233203 2000-01-05 -0.669692 -0.605656 -1.169184 -0.342416 2000-01-06 -0.868584 -0.948458 -2.297780 -0.684718 2000-01-07 -2.670153 -0.114722 -0.168904 -0.048048 2000-01-08 -0.801196 -1.392071 -0.048788 -0.808838あなたはあるブール基準に基づいて値を代入したいと思うかもしれません。これは以下のように直感的に行うことができます。
In [177]: s2 = s.copy() In [178]: s2[s2 < 0] = 0 In [179]: s2 Out[179]: 4 0 3 1 2 2 1 3 0 4 dtype: int64 In [180]: df2 = df.copy() In [181]: df2[df2 < 0] = 0 In [182]: df2 Out[182]: A B C D 2000-01-01 0.000000 0.000000 0.485855 0.245166 2000-01-02 0.000000 0.390389 0.000000 1.655824 2000-01-03 0.000000 0.299674 0.000000 0.281059 2000-01-04 0.846958 0.000000 0.600705 0.000000 2000-01-05 0.669692 0.000000 0.000000 0.342416 2000-01-06 0.868584 0.000000 2.297780 0.000000 2000-01-07 0.000000 0.000000 0.168904 0.000000 2000-01-08 0.801196 1.392071 0.000000 0.000000デフォルトでは、
whereは変更したデータのコピーを返します。コピーを作成しなくても元のデータを変更できるように、オプションのパラメータinplaceがあります。In [183]: df_orig = df.copy() In [184]: df_orig.where(df > 0, -df, inplace=True) In [185]: df_orig Out[185]: A B C D 2000-01-01 2.104139 1.309525 0.485855 0.245166 2000-01-02 0.352480 0.390389 1.192319 1.655824 2000-01-03 0.864883 0.299674 0.227870 0.281059 2000-01-04 0.846958 1.222082 0.600705 1.233203 2000-01-05 0.669692 0.605656 1.169184 0.342416 2000-01-06 0.868584 0.948458 2.297780 0.684718 2000-01-07 2.670153 0.114722 0.168904 0.048048 2000-01-08 0.801196 1.392071 0.048788 0.808838
注釈 ↓ DataFrame.where()の書き方は、numpy.where()とは異なります。df1.where(m, df2)は、おおむねnp.where(m, df1, df2)と同等です。In [186]: df.where(df < 0, -df) == np.where(df < 0, df, -df) Out[186]: A B C D 2000-01-01 True True True True 2000-01-02 True True True True 2000-01-03 True True True True 2000-01-04 True True True True 2000-01-05 True True True True 2000-01-06 True True True True 2000-01-07 True True True True 2000-01-08 True True True True
注釈 ↑ 整列
また、
whereは入力されたブール条件(ndarray または DataFrame)を揃え、特定部分を選択して代入することが可能になります。これは、.locによる部分的な代入に似ています(ただし、軸ラベルではなく内容に対して)。In [187]: df2 = df.copy() In [188]: df2[df2[1:4] > 0] = 3 In [189]: df2 Out[189]: A B C D 2000-01-01 -2.104139 -1.309525 0.485855 0.245166 2000-01-02 -0.352480 3.000000 -1.192319 3.000000 2000-01-03 -0.864883 3.000000 -0.227870 3.000000 2000-01-04 3.000000 -1.222082 3.000000 -1.233203 2000-01-05 0.669692 -0.605656 -1.169184 0.342416 2000-01-06 0.868584 -0.948458 2.297780 -0.684718 2000-01-07 -2.670153 -0.114722 0.168904 -0.048048 2000-01-08 0.801196 1.392071 -0.048788 -0.808838
whereは、whereを実行するときの入力を調整するためにaxisとlevelのパラメータを受け取ることもできます。In [190]: df2 = df.copy() In [191]: df2.where(df2 > 0, df2['A'], axis='index') Out[191]: A B C D 2000-01-01 -2.104139 -2.104139 0.485855 0.245166 2000-01-02 -0.352480 0.390389 -0.352480 1.655824 2000-01-03 -0.864883 0.299674 -0.864883 0.281059 2000-01-04 0.846958 0.846958 0.600705 0.846958 2000-01-05 0.669692 0.669692 0.669692 0.342416 2000-01-06 0.868584 0.868584 2.297780 0.868584 2000-01-07 -2.670153 -2.670153 0.168904 -2.670153 2000-01-08 0.801196 1.392071 0.801196 0.801196これは、次のものと同等(ただし、より速い)です。
In [192]: df2 = df.copy() In [193]: df.apply(lambda x, y: x.where(x > 0, y), y=df['A']) Out[193]: A B C D 2000-01-01 -2.104139 -2.104139 0.485855 0.245166 2000-01-02 -0.352480 0.390389 -0.352480 1.655824 2000-01-03 -0.864883 0.299674 -0.864883 0.281059 2000-01-04 0.846958 0.846958 0.600705 0.846958 2000-01-05 0.669692 0.669692 0.669692 0.342416 2000-01-06 0.868584 0.868584 2.297780 0.868584 2000-01-07 -2.670153 -2.670153 0.168904 -2.670153 2000-01-08 0.801196 1.392071 0.801196 0.801196version 0.18.1 から
whereは、条件やother引数にcallable関数を受け取ることができます。関数は 1 つの引数(呼び出し元の Series または DataFrame)を受け取り、条件やother引数として有効な出力を返す必要があります。In [194]: df3 = pd.DataFrame({'A': [1, 2, 3], .....: 'B': [4, 5, 6], .....: 'C': [7, 8, 9]}) .....: In [195]: df3.where(lambda x: x > 4, lambda x: x + 10) Out[195]: A B C 0 11 14 7 1 12 5 8 2 13 6 9マスク
mask()はwhereの逆のブール演算です。In [196]: s.mask(s >= 0) Out[196]: 4 NaN 3 NaN 2 NaN 1 NaN 0 NaN dtype: float64 In [197]: df.mask(df >= 0) Out[197]: A B C D 2000-01-01 -2.104139 -1.309525 NaN NaN 2000-01-02 -0.352480 NaN -1.192319 NaN 2000-01-03 -0.864883 NaN -0.227870 NaN 2000-01-04 NaN -1.222082 NaN -1.233203 2000-01-05 NaN -0.605656 -1.169184 NaN 2000-01-06 NaN -0.948458 NaN -0.684718 2000-01-07 -2.670153 -0.114722 NaN -0.048048 2000-01-08 NaN NaN -0.048788 -0.808838
query()メソッド
DataFrameオブジェクトには、式を使って選択できるquery()メソッドがあります。列
bが列aとcの間の値を持つフレームの値を取得できます。例えば、In [198]: n = 10 In [199]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc')) In [200]: df Out[200]: a b c 0 0.438921 0.118680 0.863670 1 0.138138 0.577363 0.686602 2 0.595307 0.564592 0.520630 3 0.913052 0.926075 0.616184 4 0.078718 0.854477 0.898725 5 0.076404 0.523211 0.591538 6 0.792342 0.216974 0.564056 7 0.397890 0.454131 0.915716 8 0.074315 0.437913 0.019794 9 0.559209 0.502065 0.026437 # 純粋なpython In [201]: df[(df.a < df.b) & (df.b < df.c)] Out[201]: a b c 1 0.138138 0.577363 0.686602 4 0.078718 0.854477 0.898725 5 0.076404 0.523211 0.591538 7 0.397890 0.454131 0.915716 # query In [202]: df.query('(a < b) & (b < c)') Out[202]: a b c 1 0.138138 0.577363 0.686602 4 0.078718 0.854477 0.898725 5 0.076404 0.523211 0.591538 7 0.397890 0.454131 0.915716名前が
aの列がない場合は、名前付きインデックスまで戻って、同じことを行います。In [203]: df = pd.DataFrame(np.random.randint(n / 2, size=(n, 2)), columns=list('bc')) In [204]: df.index.name = 'a' In [205]: df Out[205]: b c a 0 0 4 1 0 1 2 3 4 3 4 3 4 1 4 5 0 3 6 0 1 7 3 4 8 2 3 9 1 1 In [206]: df.query('a < b and b < c') Out[206]: b c a 2 3 4代わりに、インデックスに名前を付けたくない、またはできない場合は、クエリ式に名前
indexを使用できます。In [207]: df = pd.DataFrame(np.random.randint(n, size=(n, 2)), columns=list('bc')) In [208]: df Out[208]: b c 0 3 1 1 3 0 2 5 6 3 5 2 4 7 4 5 0 1 6 2 5 7 0 1 8 6 0 9 7 9 In [209]: df.query('index < b < c') Out[209]: b c 2 5 6
注釈 ↓ インデックスの名前が列名と重複する場合は、列名が優先されます。例えば、 In [210]: df = pd.DataFrame({'a': np.random.randint(5, size=5)}) In [211]: df.index.name = 'a' In [212]: df.query('a > 2') # インデックスではなく列aに適用 Out[212]: a a 1 3 3 3
特別な識別子「index」を使用することで、クエリ式でインデックスを使用することができます。 In [213]: df.query('index > 2') Out[213]: a a 3 3 4 2
注釈 ↑ 何らかの理由で indexという名前の列がある場合は、インデックスをilevel_0としても参照できますが、この場合は列の名前をあいまいさの少ない名前に変更することを検討してください。
MultiIndexquery()シンタックスDataFrame の列のように、
MultiIndexを使用してDataFrameのレベルに対して使用することもできます。In [214]: n = 10 In [215]: colors = np.random.choice(['red', 'green'], size=n) In [216]: foods = np.random.choice(['eggs', 'ham'], size=n) In [217]: colors Out[217]: array(['red', 'red', 'red', 'green', 'green', 'green', 'green', 'green', 'green', 'green'], dtype='<U5') In [218]: foods Out[218]: array(['ham', 'ham', 'eggs', 'eggs', 'eggs', 'ham', 'ham', 'eggs', 'eggs', 'eggs'], dtype='<U4') In [219]: index = pd.MultiIndex.from_arrays([colors, foods], names=['color', 'food']) In [220]: df = pd.DataFrame(np.random.randn(n, 2), index=index) In [221]: df Out[221]: 0 1 color food red ham 0.194889 -0.381994 ham 0.318587 2.089075 eggs -0.728293 -0.090255 green eggs -0.748199 1.318931 eggs -2.029766 0.792652 ham 0.461007 -0.542749 ham -0.305384 -0.479195 eggs 0.095031 -0.270099 eggs -0.707140 -0.773882 eggs 0.229453 0.304418 In [222]: df.query('color == "red"') Out[222]: 0 1 color food red ham 0.194889 -0.381994 ham 0.318587 2.089075 eggs -0.728293 -0.090255
MultiIndexのレベルに名前が付いていない場合は、特別な名前を使用してそれらを参照できます。In [223]: df.index.names = [None, None] In [224]: df Out[224]: 0 1 red ham 0.194889 -0.381994 ham 0.318587 2.089075 eggs -0.728293 -0.090255 green eggs -0.748199 1.318931 eggs -2.029766 0.792652 ham 0.461007 -0.542749 ham -0.305384 -0.479195 eggs 0.095031 -0.270099 eggs -0.707140 -0.773882 eggs 0.229453 0.304418 In [225]: df.query('ilevel_0 == "red"') Out[225]: 0 1 red ham 0.194889 -0.381994 ham 0.318587 2.089075 eggs -0.728293 -0.090255規則は
ilevel_0です。これは、indexの 0 番目のレベル、「index level 0」を意味します。
query()の活用例
query()が活きるのは、共通の列名(またはインデックスのレベル/名前)のサブセットを持つDataFrameオブジェクトのコレクションがある場合です。どちらのフレームにクエリを実行するのかを指定しなくても、両方のフレームに同じクエリを渡すことができます。In [226]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc')) In [227]: df Out[227]: a b c 0 0.224283 0.736107 0.139168 1 0.302827 0.657803 0.713897 2 0.611185 0.136624 0.984960 3 0.195246 0.123436 0.627712 4 0.618673 0.371660 0.047902 5 0.480088 0.062993 0.185760 6 0.568018 0.483467 0.445289 7 0.309040 0.274580 0.587101 8 0.258993 0.477769 0.370255 9 0.550459 0.840870 0.304611 In [228]: df2 = pd.DataFrame(np.random.rand(n + 2, 3), columns=df.columns) In [229]: df2 Out[229]: a b c 0 0.357579 0.229800 0.596001 1 0.309059 0.957923 0.965663 2 0.123102 0.336914 0.318616 3 0.526506 0.323321 0.860813 4 0.518736 0.486514 0.384724 5 0.190804 0.505723 0.614533 6 0.891939 0.623977 0.676639 7 0.480559 0.378528 0.460858 8 0.420223 0.136404 0.141295 9 0.732206 0.419540 0.604675 10 0.604466 0.848974 0.896165 11 0.589168 0.920046 0.732716 In [230]: expr = '0.0 <= a <= c <= 0.5' In [231]: map(lambda frame: frame.query(expr), [df, df2]) Out[231]: <map at 0x7fb06bd71cf8>
query()の Python と Pandas の構文比較完全な NumPy 式の構文
In [232]: df = pd.DataFrame(np.random.randint(n, size=(n, 3)), columns=list('abc')) In [233]: df Out[233]: a b c 0 7 8 9 1 1 0 7 2 2 7 2 3 6 2 2 4 2 6 3 5 3 8 2 6 1 7 2 7 5 1 5 8 9 8 0 9 1 5 0 In [234]: df.query('(a < b) & (b < c)') Out[234]: a b c 0 7 8 9 In [235]: df[(df.a < df.b) & (df.b < df.c)] Out[235]: a b c 0 7 8 9かっこを消すことで少し良くなりました(バインドすると、比較演算子は
&や|よりも強くなります)。In [236]: df.query('a < b & b < c') Out[236]: a b c 0 7 8 9記号の代わりに英語を使います。
In [237]: df.query('a < b and b < c') Out[237]: a b c 0 7 8 9紙に書くような文法にかなり近づきました。
In [238]: df.query('a < b < c') Out[238]: a b c 0 7 8 9
in演算子とnot in演算子
query()は Python の特殊演算子in,not inもサポートし、SeriesまたはDataFrameのisinメソッドを呼び出す際の簡潔な構文を提供します。# 列aと列bが重複して持っている値をとる、すべての行を取得する In [239]: df = pd.DataFrame({'a': list('aabbccddeeff'), 'b': list('aaaabbbbcccc'), .....: 'c': np.random.randint(5, size=12), .....: 'd': np.random.randint(9, size=12)}) .....: In [240]: df Out[240]: a b c d 0 a a 2 6 1 a a 4 7 2 b a 1 6 3 b a 2 1 4 c b 3 6 5 c b 0 2 6 d b 3 3 7 d b 2 1 8 e c 4 3 9 e c 2 0 10 f c 0 6 11 f c 1 2 In [241]: df.query('a in b') Out[241]: a b c d 0 a a 2 6 1 a a 4 7 2 b a 1 6 3 b a 2 1 4 c b 3 6 5 c b 0 2 # 純粋なPythonではどのように行うか In [242]: df[df.a.isin(df.b)] Out[242]: a b c d 0 a a 2 6 1 a a 4 7 2 b a 1 6 3 b a 2 1 4 c b 3 6 5 c b 0 2 In [243]: df.query('a not in b') Out[243]: a b c d 6 d b 3 3 7 d b 2 1 8 e c 4 3 9 e c 2 0 10 f c 0 6 11 f c 1 2 # 純粋なPython In [244]: df[~df.a.isin(df.b)] Out[244]: a b c d 6 d b 3 3 7 d b 2 1 8 e c 4 3 9 e c 2 0 10 f c 0 6 11 f c 1 2非常に簡潔なクエリ式で、これを他の式と組み合わせることができます。
# 列aと列bが重複して持っている値をとり、 # かつ列cの値が列dの値より小さい行 In [245]: df.query('a in b and c < d') Out[245]: a b c d 0 a a 2 6 1 a a 4 7 2 b a 1 6 4 c b 3 6 5 c b 0 2 # 純粋なPython In [246]: df[df.b.isin(df.a) & (df.c < df.d)] Out[246]: a b c d 0 a a 2 6 1 a a 4 7 2 b a 1 6 4 c b 3 6 5 c b 0 2 10 f c 0 6 11 f c 1 2
注釈 ↓ inとnot inは、numexprにはこの演算子に相当するものがないため、Python で評価されます。ただし、in/not inの表現自体だけが、純粋な Python で評価されます。例えば、df.query('a in b + c + d')
注釈 ↑ の場合、 (b + c + d)がnumexprで評価された後で、in演算子が純粋な Python で評価されます。基本的には、numexprが使える演算子はすべてそれで評価されます。
listオブジェクトにおける特殊な==演算子の用法
==/!=を使用して値のlistと列を比較すると、in/not inと同じように機能します。In [247]: df.query('b == ["a", "b", "c"]') Out[247]: a b c d 0 a a 2 6 1 a a 4 7 2 b a 1 6 3 b a 2 1 4 c b 3 6 5 c b 0 2 6 d b 3 3 7 d b 2 1 8 e c 4 3 9 e c 2 0 10 f c 0 6 11 f c 1 2 # 純粋なPython In [248]: df[df.b.isin(["a", "b", "c"])] Out[248]: a b c d 0 a a 2 6 1 a a 4 7 2 b a 1 6 3 b a 2 1 4 c b 3 6 5 c b 0 2 6 d b 3 3 7 d b 2 1 8 e c 4 3 9 e c 2 0 10 f c 0 6 11 f c 1 2 In [249]: df.query('c == [1, 2]') Out[249]: a b c d 0 a a 2 6 2 b a 1 6 3 b a 2 1 7 d b 2 1 9 e c 2 0 11 f c 1 2 In [250]: df.query('c != [1, 2]') Out[250]: a b c d 1 a a 4 7 4 c b 3 6 5 c b 0 2 6 d b 3 3 8 e c 4 3 10 f c 0 6 # in/not inを用いて In [251]: df.query('[1, 2] in c') Out[251]: a b c d 0 a a 2 6 2 b a 1 6 3 b a 2 1 7 d b 2 1 9 e c 2 0 11 f c 1 2 In [252]: df.query('[1, 2] not in c') Out[252]: a b c d 1 a a 4 7 4 c b 3 6 5 c b 0 2 6 d b 3 3 8 e c 4 3 10 f c 0 6 # 純粋なPython In [253]: df[df.c.isin([1, 2])] Out[253]: a b c d 0 a a 2 6 2 b a 1 6 3 b a 2 1 7 d b 2 1 9 e c 2 0 11 f c 1 2ブール演算子
notまたは~演算子を使って真偽値を反転することができます。In [254]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc')) In [255]: df['bools'] = np.random.rand(len(df)) > 0.5 In [256]: df.query('~bools') Out[256]: a b c bools 2 0.697753 0.212799 0.329209 False 7 0.275396 0.691034 0.826619 False 8 0.190649 0.558748 0.262467 False In [257]: df.query('not bools') Out[257]: a b c bools 2 0.697753 0.212799 0.329209 False 7 0.275396 0.691034 0.826619 False 8 0.190649 0.558748 0.262467 False In [258]: df.query('not bools') == df[~df.bools] Out[258]: a b c bools 2 True True True True 7 True True True True 8 True True True Trueもちろん、式がどんどん複雑になる可能性もあります。
# 短いクエリ構文 In [259]: shorter = df.query('a < b < c and (not bools) or bools > 2') # 純粋なPython式との比較 In [260]: longer = df[(df.a < df.b) & (df.b < df.c) & (~df.bools) | (df.bools > 2)] In [261]: shorter Out[261]: a b c bools 7 0.275396 0.691034 0.826619 False In [262]: longer Out[262]: a b c bools 7 0.275396 0.691034 0.826619 False In [263]: shorter == longer Out[263]: a b c bools 7 True True True True
query()のパフォーマンス
numexprを使用したDataFrame.query()は、大きなフレームでは Python よりわずかに高速です。
注釈 numexprエンジンによるDataFrame.query()のパフォーマンス上の利点が目に見えてくるのは、フレームが約 200,000 行を越えてからです。
このプロットは、
numpy.random.randn()を使用して生成した、浮動小数点値を含む 3 列のDataFrameを使用して作成されました。重複データ
DataFrame 内の重複する行を識別したり削除したりする場合は、
duplicatedとdrop_duplicatesの 2 つの方法が役立ちます。それぞれは、重複行を識別するために使用する列を引数として取ります。
duplicatedは、行数が長さとなる、重複行かどうかを示す真偽値ベクトルを返します。drop_duplicatesは重複する行を削除します。デフォルトでは、重複セットのうち最初に現れた行はユニークであると見なされますが、各メソッドには保持する対象を指定するための
keepパラメータがあります。
keep='first'(デフォルト):最初に現れたものを除いて、重複をマーク/削除します。keep='last':最後に現れたものを除いて、重複をマーク/削除します。keep=False:全ての重複をマーク/削除します。In [264]: df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'two', 'two', 'three', 'four'], .....: 'b': ['x', 'y', 'x', 'y', 'x', 'x', 'x'], .....: 'c': np.random.randn(7)}) .....: In [265]: df2 Out[265]: a b c 0 one x -1.067137 1 one y 0.309500 2 two x -0.211056 3 two y -1.842023 4 two x -0.390820 5 three x -1.964475 6 four x 1.298329 In [266]: df2.duplicated('a') Out[266]: 0 False 1 True 2 False 3 True 4 True 5 False 6 False dtype: bool In [267]: df2.duplicated('a', keep='last') Out[267]: 0 True 1 False 2 True 3 True 4 False 5 False 6 False dtype: bool In [268]: df2.duplicated('a', keep=False) Out[268]: 0 True 1 True 2 True 3 True 4 True 5 False 6 False dtype: bool In [269]: df2.drop_duplicates('a') Out[269]: a b c 0 one x -1.067137 2 two x -0.211056 5 three x -1.964475 6 four x 1.298329 In [270]: df2.drop_duplicates('a', keep='last') Out[270]: a b c 1 one y 0.309500 4 two x -0.390820 5 three x -1.964475 6 four x 1.298329 In [271]: df2.drop_duplicates('a', keep=False) Out[271]: a b c 5 three x -1.964475 6 four x 1.298329また、重複を識別するための列をリストを渡すこともできます。
In [272]: df2.duplicated(['a', 'b']) Out[272]: 0 False 1 False 2 False 3 False 4 True 5 False 6 False dtype: bool In [273]: df2.drop_duplicates(['a', 'b']) Out[273]: a b c 0 one x -1.067137 1 one y 0.309500 2 two x -0.211056 3 two y -1.842023 5 three x -1.964475 6 four x 1.298329重複をインデックスの値で削除するには、
Index.duplicatedを使用してからスライスを実行します。keepパラメーターに同様のオプションを渡すこともできます。In [274]: df3 = pd.DataFrame({'a': np.arange(6), .....: 'b': np.random.randn(6)}, .....: index=['a', 'a', 'b', 'c', 'b', 'a']) .....: In [275]: df3 Out[275]: a b a 0 1.440455 a 1 2.456086 b 2 1.038402 c 3 -0.894409 b 4 0.683536 a 5 3.082764 In [276]: df3.index.duplicated() Out[276]: array([False, True, False, False, True, True]) In [277]: df3[~df3.index.duplicated()] Out[277]: a b a 0 1.440455 b 2 1.038402 c 3 -0.894409 In [278]: df3[~df3.index.duplicated(keep='last')] Out[278]: a b c 3 -0.894409 b 4 0.683536 a 5 3.082764 In [279]: df3[~df3.index.duplicated(keep=False)] Out[279]: a b c 3 -0.894409辞書ライクな
get()メソッドSeries または DataFrame にはそれぞれ、デフォルトの値を返すことができる get メソッドがあります。
In [280]: s = pd.Series([1, 2, 3], index=['a', 'b', 'c']) In [281]: s.get('a') # s['a']に等しい Out[281]: 1 In [282]: s.get('x', default=-1) Out[282]: -1
lookup()メソッド一連の行ラベルと列ラベルを指定して値のセットを抽出したい場合があります。
lookupメソッドはこれを可能にし、NumPy 配列を返します。例えば、In [283]: dflookup = pd.DataFrame(np.random.rand(20, 4), columns = ['A', 'B', 'C', 'D']) In [284]: dflookup.lookup(list(range(0, 10, 2)), ['B', 'C', 'A', 'B', 'D']) Out[284]: array([0.3506, 0.4779, 0.4825, 0.9197, 0.5019])Index オブジェクト
Pandas の
Indexクラスとそのサブクラスは、順序付きマルチセットが実装されていると見なすことができます。重複は許可されています。ただし、重複エントリを含むIndexオブジェクトをsetに変換しようとすると、例外が発生します。また、
Indexは、検索・データの整列・インデックスの再作成に必要な構造も提供します。Indexを直接作成する最も簡単な方法は、listまたは他のシーケンスをIndexに渡すことです。In [285]: index = pd.Index(['e', 'd', 'a', 'b']) In [286]: index Out[286]: Index(['e', 'd', 'a', 'b'], dtype='object') In [287]: 'd' in index Out[287]: Trueインデックスに付与される
nameを渡すこともできます。In [288]: index = pd.Index(['e', 'd', 'a', 'b'], name='something') In [289]: index.name Out[289]: 'something'name が設定されている場合は、コンソールディスプレイに表示されます。
In [290]: index = pd.Index(list(range(5)), name='rows') In [291]: columns = pd.Index(['A', 'B', 'C'], name='cols') In [292]: df = pd.DataFrame(np.random.randn(5, 3), index=index, columns=columns) In [293]: df Out[293]: cols A B C rows 0 1.295989 0.185778 0.436259 1 0.678101 0.311369 -0.528378 2 -0.674808 -1.103529 -0.656157 3 1.889957 2.076651 -1.102192 4 -1.211795 -0.791746 0.634724 In [294]: df['A'] Out[294]: rows 0 1.295989 1 0.678101 2 -0.674808 3 1.889957 4 -1.211795 Name: A, dtype: float64メタデータの設定
インデックスは「ほぼイミュータブル」ですが、インデックスの
name(あるいはMultiIndexの場合は、levelsとcodes)のように、メタデータを設定および変更することができます。これらの属性は
rename,set_names,set_levels,set_codesを使用すると直接設定できます。これらはデフォルトではコピーを返しますが、inplace=Trueを指定すればデータを上書き変更することができます。マルチインデックスの使用法については、高度な索引を参照してください。
In [295]: ind = pd.Index([1, 2, 3]) In [296]: ind.rename("apple") Out[296]: Int64Index([1, 2, 3], dtype='int64', name='apple') In [297]: ind Out[297]: Int64Index([1, 2, 3], dtype='int64') In [298]: ind.set_names(["apple"], inplace=True) In [299]: ind.name = "bob" In [300]: ind Out[300]: Int64Index([1, 2, 3], dtype='int64', name='bob')
set_names,set_levels,set_codesはオプション引数levelを受け取ります。In [301]: index = pd.MultiIndex.from_product([range(3), ['one', 'two']], names=['first', 'second']) In [302]: index Out[302]: MultiIndex(levels=[[0, 1, 2], ['one', 'two']], codes=[[0, 0, 1, 1, 2, 2], [0, 1, 0, 1, 0, 1]], names=['first', 'second']) In [303]: index.levels[1] Out[303]: Index(['one', 'two'], dtype='object', name='second') In [304]: index.set_levels(["a", "b"], level=1) Out[304]: MultiIndex(levels=[[0, 1, 2], ['a', 'b']], codes=[[0, 0, 1, 1, 2, 2], [0, 1, 0, 1, 0, 1]], names=['first', 'second'])Index オブジェクトに対する集合演算
基本的な演算は、和集合
union (|)と共通部分intersection (&)の 2 つです。これらはインスタンスメソッドとして直接呼び出すことも、オーバーロードされた演算子を介して使用することもできます。差集合は.difference()メソッドを用います。In [305]: a = pd.Index(['c', 'b', 'a']) In [306]: b = pd.Index(['c', 'e', 'd']) In [307]: a | b Out[307]: Index(['a', 'b', 'c', 'd', 'e'], dtype='object') In [308]: a & b Out[308]: Index(['c'], dtype='object') In [309]: a.difference(b) Out[309]: Index(['a', 'b'], dtype='object')対称差
symmetric_difference (^)操作も使用できます。これは、idx1またはidx2のいずれか一方に出現するが両方には出現しない要素の集合を返します。これは、idx1.difference(idx2).union(idx2.difference(idx1))によって作成されたインデックスに相当しますが、重複は削除されます。In [310]: idx1 = pd.Index([1, 2, 3, 4]) In [311]: idx2 = pd.Index([2, 3, 4, 5]) In [312]: idx1.symmetric_difference(idx2) Out[312]: Int64Index([1, 5], dtype='int64') In [313]: idx1 ^ idx2 Out[313]: Int64Index([1, 5], dtype='int64')
注釈 集合演算の結果のインデックスは昇順でソートされます。 欠損値
重要 Indexは欠損値(NaN)を保持できますが、予期せぬ動作に至りたくない場合は避けるべきです。たとえば、一部の操作では、欠損値が暗黙的に除外されます。
Index.fillnaは、欠損値を指定されたスカラー値で穴埋めします。In [314]: idx1 = pd.Index([1, np.nan, 3, 4]) In [315]: idx1 Out[315]: Float64Index([1.0, nan, 3.0, 4.0], dtype='float64') In [316]: idx1.fillna(2) Out[316]: Float64Index([1.0, 2.0, 3.0, 4.0], dtype='float64') In [317]: idx2 = pd.DatetimeIndex([pd.Timestamp('2011-01-01'), .....: pd.NaT, .....: pd.Timestamp('2011-01-03')]) .....: In [318]: idx2 Out[318]: DatetimeIndex(['2011-01-01', 'NaT', '2011-01-03'], dtype='datetime64[ns]', freq=None) In [319]: idx2.fillna(pd.Timestamp('2011-01-02')) Out[319]: DatetimeIndex(['2011-01-01', '2011-01-02', '2011-01-03'], dtype='datetime64[ns]', freq=None)インデックスの作成・再作成
場合によっては、データセットを DataFrame に既にロードまたは作成した後に、インデックスを追加したいことがあります。いくつかの異なる方法があります。
インデックスの設定
DataFrame には、列名(通常の
Indexの場合)または列名のリスト(MultiIndexの場合)を受け取るset_index()メソッドがあります。インデックスを再設定した DataFrame を作成するには、In [320]: data Out[320]: a b c d 0 bar one z 1.0 1 bar two y 2.0 2 foo one x 3.0 3 foo two w 4.0 In [321]: indexed1 = data.set_index('c') In [322]: indexed1 Out[322]: a b d c z bar one 1.0 y bar two 2.0 x foo one 3.0 w foo two 4.0 In [323]: indexed2 = data.set_index(['a', 'b']) In [324]: indexed2 Out[324]: c d a b bar one z 1.0 two y 2.0 foo one x 3.0 two w 4.0
appendキーワードオプションを使用すると、既存のインデックスを保持し、指定した列を MultiIndex に追加することができます。In [325]: frame = data.set_index('c', drop=False) In [326]: frame = frame.set_index(['a', 'b'], append=True) In [327]: frame Out[327]: c d c a b z bar one z 1.0 y bar two y 2.0 x foo one x 3.0 w foo two w 4.0
set_indexの他のオプションによって、インデックスに設定した列を残したり、インデックスを上書きで(新しいオブジェクトを作成せずに)追加したりすることができます。In [328]: data.set_index('c', drop=False) Out[328]: a b c d c z bar one z 1.0 y bar two y 2.0 x foo one x 3.0 w foo two w 4.0 In [329]: data.set_index(['a', 'b'], inplace=True) In [330]: data Out[330]: c d a b bar one z 1.0 two y 2.0 foo one x 3.0 two w 4.0インデックスのリセット
便宜をはかるため、DataFrame に
reset_index()という新しい関数があります。これは、インデックスの値を DataFrame の列に移し、単純な整数インデックスを設定します。これはset_index()の逆の操作です。In [331]: data Out[331]: c d a b bar one z 1.0 two y 2.0 foo one x 3.0 two w 4.0 In [332]: data.reset_index() Out[332]: a b c d 0 bar one z 1.0 1 bar two y 2.0 2 foo one x 3.0 3 foo two w 4.0出力は、SQL のテーブルやレコードの配列に似ています。もとインデックスだった列の名前は、
names属性に格納されていたものが用いられます。
levelキーワードを使用すると、インデックスの一部だけを削除できます。In [333]: frame Out[333]: c d c a b z bar one z 1.0 y bar two y 2.0 x foo one x 3.0 w foo two w 4.0 In [334]: frame.reset_index(level=1) Out[334]: a c d c b z one bar z 1.0 y two bar y 2.0 x one foo x 3.0 w two foo w 4.0
reset_indexはオプション引数dropを受け取ります。true の場合は、DataFrame の列にインデックス値を入れる代わりに、単にインデックスを破棄します。アドホックなインデックスの追加
自分でインデックスを作成する場合は、
indexフィールドにそれを割り当てることができます。返るのはビューかコピーか
Pandas オブジェクトに値を代入するときは、連鎖索引
chained indexingと呼ばれるものを避けるように注意する必要があります。一例を示します。In [335]: dfmi = pd.DataFrame([list('abcd'), .....: list('efgh'), .....: list('ijkl'), .....: list('mnop')], .....: columns=pd.MultiIndex.from_product([['one', 'two'], .....: ['first', 'second']])) .....: In [336]: dfmi Out[336]: one two first second first second 0 a b c d 1 e f g h 2 i j k l 3 m n o p次の 2 つのアクセス方法を比較してください。
In [337]: dfmi['one']['second'] Out[337]: 0 b 1 f 2 j 3 n Name: second, dtype: objectIn [338]: dfmi.loc[:, ('one', 'second')] Out[338]: 0 b 1 f 2 j 3 n Name: (one, second), dtype: objectどちらも同じ結果になりますが、どちらを使用すべきでしょうか?これらの処理順序と、方法 1(chained
[])よりも方法 2(.loc)の方が好ましい理由を理解することは有益です。前者はまず
dfmi['one']は列の第一レベルを選択し、単一インデックス付きの DataFrame を返します。それから、別の Python 操作dfmi_with_one['second']によって、「second」でインデックスされた Series を選択します。これは変数dfmi_with_oneで示されます。なぜなら、Pandas はこれらの操作を別々のイベントとして見なすためです。例えば__getitem__への呼び出しを分離するので、それらは線形操作として扱わなければなりません、それらは順々に起こります。これと対照的に、
df.loc[:,('one','second')]は、(slice(None),('one','second'))とネストしたタプルを 1 度だけ呼び出した__getitem__に渡します。これにより、Pandas はこれを単一のエンティティとして扱うことができます。さらに、この操作の手順はかなり速くなる可能性があり、必要に応じて両方の軸にインデックスを付けることができます。連鎖索引を使用すると、割り当てが失敗するのはなぜですか?
前項で述べた問題は、パフォーマンスの問題です。警告
SettingWithCopyとはなんですか?あなたが数ミリ秒余分にかかるかもしれない何かをするとき、我々は通常警告を投げません!しかし、連鎖索引の産物へ代入することは本質的に予測不可能な結果を もたらすことがわかりました。これを見るために、Python インタプリタがどのように次のコードを実行するかについて考えてみましょう。
dfmi.loc[:, ('one', 'second')] = value # こうなる dfmi.loc.__setitem__((slice(None), ('one', 'second')), value)しかし、次のコードは異なる方法で処理されます。
dfmi['one']['second'] = value # こうなる dfmi.__getitem__('one').__setitem__('second', value)この
__getitem__がわかりますか?単純な場合を除いて、ビューを返すのかコピーを返すのか(これは配列のメモリレイアウトに依存し、Pandas はそれを保証しません)、つまり__setitem__がdfmiを変更するのかそれとも直後にスローされる一時オブジェクトを変更するのか、予測するのは非常に困難です。SettingWithCopyが警告しているのはこのことです。
注釈 最初の例で locプロパティを気にする必要があるかどうか疑問に思うかもしれません。しかし、dfmi.locはインデックス動作が変更されたdfmi自体であることが保証されているので、dfmi.loc.__getitem__/dfmi.loc.__setitem__はdfmiを直接操作します。もちろん、dfmi.loc.__getitem__(idx)はdfmiのビューまたはコピーです。明白な連鎖索引の作成が行われていないときでも、警告
SettingWithCopyが発生することがあります。これらはSettingWithCopyがキャッチするように設計されているバグです!Pandas はおそらくあなたが次のようなことをしたことを警告しようとしています。def do_something(df): foo = df[['bar', 'baz']] # fooはビューかコピーか?誰にもわからない! # ... この間数行 ... # これでdfが変更されるかどうかはわかりません! foo['quux'] = value return foo!?
評価順序に関する事項
連鎖索引を使用する場合、索引操作の順序と種類によって、結果が元のオブジェクトへのスライスなのか、スライスのコピーなのかが部分的に決まる場合があります。
スライスのコピーへの代入は意図的ではないことが多い――これは連鎖索引が原因でスライスが予期されていた場所にコピーが返されることによる誤りです――ため、Pandas には
SettingWithCopyWarningがあります。Pandas が連鎖索引式への代入について多かれ少なかれ信頼できるようにしたい場合は、オプション
mode.chained_assignmentを次のいずれかの値に設定します。
'warn'は、デフォルト値で、SettingWithCopyWarningが送出されることを意味します。'raise'は、Pandas があなたが対処しなければならないSettingWithCopyExceptionを発生させることを意味します。Noneは、警告を完全に抑制します。In [339]: dfb = pd.DataFrame({'a': ['one', 'one', 'two', .....: 'three', 'two', 'one', 'six'], .....: 'c': np.arange(7)}) .....: # これはSettingWithCopyWarningが表示される # しかしDataFrameの値は代入される In [340]: dfb['c'][dfb.a.str.startswith('o')] = 42しかし次の例はコピーで動作していて動作しません。
>>> pd.set_option('mode.chained_assignment','warn') >>> dfb[dfb.a.str.startswith('o')]['c'] = 42 Traceback (most recent call last) ... SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_index,col_indexer] = value instead連鎖代入は、dtype が混在したフレームに設定する際にも発生します。
注釈 これらの設定規則は、 .loc/.ilocのすべてに適用されます。正しいアクセス方法は次の通りです。
In [341]: dfc = pd.DataFrame({'A': ['aaa', 'bbb', 'ccc'], 'B': [1, 2, 3]}) In [342]: dfc.loc[0, 'A'] = 11 In [343]: dfc Out[343]: A B 0 11 1 1 bbb 2 2 ccc 3以下のような例はときどき動作しますが、保証はされないので、避けるべきです。
In [344]: dfc = dfc.copy() In [345]: dfc['A'][0] = 111 In [346]: dfc Out[346]: A B 0 111 1 1 bbb 2 2 ccc 3これは常に機能しないので、避けるべきです。
>>> pd.set_option('mode.chained_assignment','raise') >>> dfc.loc[0]['A'] = 1111 Traceback (most recent call last) ... SettingWithCopyException: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_index,col_indexer] = value instead
警告 連鎖代入の警告・例外は、無効な代入を行った可能性をユーザーに通知することを目的としています。そのため、連鎖代入が誤って伝達され、誤検知がある場合があります。


- 投稿日:2019-07-04T12:56:10+09:00
VisItをコマンドラインから起動してsiloファイルを可視化したいだけ
概要
フリーの可視化ソフトVisItを用いて可視化する準備方法をご紹介します。
VisItとは
ローレンスバリモア国立研究所が開発しているフリーの可視化ソフトです。siloやvtkのような、流体計算結果を可視化するのに重宝しています。
インストール
インストール環境
私の環境は以下になります。
macOS: 10.14.5
MacBook Pro(13-inch, 2017モデル)インストール方法
ここから最新版をダウンロード(2019/07/04現在3.0が最新)。VisIt-3.0.0-10.13.dmgをダブルクリックすると下図のようなウィンドウが出てくるので、そこからアプリケーションにコピーします。
起動
VisItをダブルクリックすることでも起動できますが、今回はコマンドラインから起動することを目標とします。
VisItの場所
Macの場合、VisItは以下の場所にあります。
/Applications/VisIt.app/Contents/Resources/bin/visit可視化用Pythonスクリプト
このvisitを用いて、以下のPythonスクリプトを実行してみましょう。
# Make a plot OpenDatabase("/Applications/VisIt.app/Contents/Resources/data/globe.silo") AddPlot("Pseudocolor", "speed") DrawPlots() pc = PseudocolorAttributes(1) pc.colorTableName = "hot_desaturated" SetPlotOptions(pc)実行とその可視化結果
以下のようにして実行します。いちいちパスを打つのが面倒という方は
/Applications/VisIt.app/Contents/Resources/binにパスを通しておくとよいでしょう。/Applications/VisIt.app/Contents/Resources/bin/visit -cli -s sample.pyすると以下のようなウィンドウが現れます。
マウスでグリグリと回転させることも可能です。
結言
今回は
/Applications/VisIt.app/Contents/Resources/data/globe.siloというサンプルデータを描画してみましたが、他のSiloファイルも描画してみたいところです。
- 投稿日:2019-07-04T11:46:49+09:00
pythonに入門したのでゴツゴツのアハンした
概要
pythonに入門したのでHello world代わりにゴツゴツのアハンしてみました。
参考にした開発環境構築も合わせて自分用に載せます。開発環境
こちらを参考にさせて頂きました。
シンプルで再現性の高い環境は素敵です。ゴツゴツのアハン
st = "アツアツのゴハン" def atsuatsu_gohan_gene(st): # "の"を検索 position = st.find("の") first_parts = st[0:position] second_parts = st[position + 1 : len(st)] # 前半部分を半分に first_count = len(first_parts) if first_count % 2 != 0: return 'アハン..' first_bit = first_parts[0:1] second_bit = st[position + 1 : position + 2] # それぞれ1文字目を交換して結合 result = first_parts.replace(first_bit, second_bit) + "の" + second_parts.replace(second_bit, first_bit) return result print(atsuatsu_gohan_gene(st)) #ゴツゴツのアハン実行結果
いい感じです。改善点
カリッカリのトースト(参考)のように、促音がある場合などにも対応したいです
終わり
もっと効率の良いゴツゴツのアハンなどあれば教えて頂きたいです。

- 投稿日:2019-07-04T11:37:21+09:00
QuantXで機械学習を用いた株価予想(特徴量エンジニアリング編)
はじめに
こんにちは、材料工学修士1年の学生です。鉄鋼材リサイクルへの画像解析応用を目指し、春から海外大のコンピュータサイエンス専攻へ交換留学しています。
この度Smart Tradeでインターンすることになり、株価予想モデルを作ってみました。今日のお題
QuantX Factoryでアルゴリズムを作ってみる。
先人の方の機械学習モデル(ランダムフォレストモデル)を参考に、特徴量エンジニアリングを追加してみました。完成したコードはこちら。QuantX Factoryとは
smart trade社が無料で提供しているシステムトレードアルゴリズムをブラウザ上でpythonを使って開発できるプラットフォーム。
以下の理由から、pythonで株価予想をやってみたい人におすすめです。
- Web上のプラットフォームのため開発環境構築が不要であること
- 各銘柄の終値や高値などの各種データが用意されておりデータセットの用意不要
- 開発したトレードアルゴリズムは審査を通過すればQuantX Storeで販売可能
- 新エンジン移行に伴い、終値、始値、指値での注文が選択可能になるなど、より多様な戦略を組めるようになったことデータの収集、更新だけに大量の時間を持っていかれる時代もこれにて終わりですね。
QuantXの詳しい使い方についてはこちら。本題
1、目的と手法
- 既存のランダムフォレストモデルを使用した株価予想モデルへ、追加で特徴量エンジニアリングを実施し精度向上を試みます。
- エンジン移行に伴って、新エンジンにて使用可能なアルゴリズムへ修正を行います。 (データが命の機械学習の使用において、長期間バックテストの実行可能な新エンジンへの移行は重要です。)
参考にする株価予想モデル
機械学習を用いた株価予想モデルとして、@sarubobo29さんのQuantXで機械学習使って株価予測してみたpart1を使用させていただきました。「教師あり学習を使って、10日後の株価が現在の価格よりも「上がっているか(下がっているか)どうか」を予測するアルゴリズム。」になります。
ちなみに@sarubobo29さんのQuantXで機械学習使って株価予測してみたpart2へも適用を試みましたが、こちらは相性があまりよくありませんでした。
実施する特徴量エンジニアリング
機械学習モデル精度向上のため、以下の二点で特徴量エンジニアリングを行います。
i. 交互作用特徴量と多項式特徴量の生成
今回は交互作用特徴量と多項式特徴量を生成し、特徴量として追加していきます。交互作用特徴量とは特徴量の交互作用を表すための特徴量で、特徴量同士の積で表します。例えば、x1、x2という特徴量がある場合、x1 * x2という特徴量を新たに作成します。多項式特徴量とは特徴量の多項式表現を新たな特徴量とし、追加する方法です。例えば、x1、x2の特徴量の2次の表現を作ると、x1^2、x2^2という特徴量が新たに作成されます。
ii. 自動特徴量選択
訓練データへの過学習を防ぐために、自動特徴量選択を行います。自動特徴量選択とは、機械学習のモデルを使用において、全特徴量の中から有効な特徴量の組み合わせを自動で探索するプロセスのことを表します。今回はその中でも決定木ベースモデルなどの教師あり学習モデルを1つ用いて、特徴量の重要性を判断し重要なものだけを残す、モデルベース特徴量選択を行います。学習モデルとしてランダムフォレストモデルを用い、特徴量選択を行いました。
2、コード
修正点
準備段階での修正点
scikit-learnから新たに、特徴量生成時に使用するPolynomialFeatures関数と、特徴量選択時に使用するSelectFromModel関数をインポートします。
from sklearn.feature_selection import SelectFromModel from sklearn.preprocessing import PolynomialFeatures特徴量エンジニアリングを行う上での追加点(下で個別に説明します。)
# 特徴量の追加 poly = PolynomialFeatures(degree = 3) poly.fit(df_x) df_x = poly.transform(df_x) # ここから手順3 # 学習データとテストデータに分割(前半5割を学習データ,後半5割をテストデータ) X_train, X_test, y_train, y_test = train_test_split(df_x, y, train_size=0.5, shuffle = False) # 特徴量の選択(モデルはランダムフォレスト) select = SelectFromModel(RandomForestClassifier(n_estimators = 300, random_state = 1), threshold = "1.40*median") select.fit(X_train, y_train) X_train = select.transform(X_train) X_test = select.transform(X_test) # 学習データを使って学習(モデルはランダムフォレスト) clf = RandomForestClassifier(random_state=1, n_estimators = 100, max_leaf_nodes = 10, max_depth=6, max_features=None) clf = clf.fit(X_train, y_train)まず、今回はPolynomialFeatures関数を用いて、3次以下の交互作用特徴量と、多項式特徴量を新たな特徴量として追加します。degree値を設定することで、その値以下の次元の交互作用特徴量と多項式特徴量を、生成することができます。
# 特徴量の追加 poly = PolynomialFeatures(degree = 3) poly.fit(df_x) df_x = poly.transform(df_x)次に、特徴量選択を行います。SelectFromModelを用い、特徴量を選択します。今回は特徴量の重要性を判断するモデルとして、RandomForestClassifierを使用しました。特徴量選択では、ある基準を設定し、それ以上の重要性を持つ特徴量のみを選択します。今回は、この特徴量選択の基準として、median(中央値)を用い、threshold = "1.40*median"を採用しています。
# 特徴量の選択(モデルはランダムフォレスト) select = SelectFromModel(RandomForestClassifier(n_estimators = 300, random_state = 1), threshold = "1.40*median") select.fit(X_train, y_train) X_train = select.transform(X_train) X_test = select.transform(X_test)新エンジンでの使用のための修正点
シグナル名を"market:sig"へ修正し、新エンジンでも使用可能にします。
return { "market:sig": market_sig, }訓練データ、テストデータのスコアをデバックするコードの追加
特徴量の追加や選択により、過剰適合や適合不足が起きることを防ぐために、訓練データ、テストデータに対する精度をデバック表示させます。
ctx.logger.debug("Training score: {:.3f}".format(clf.score(X_train, y_train))) ctx.logger.debug("Test score: {:.3f}".format(clf.score(X_test, y_test)))全体のコード
# Sample Algorithm # ライブラリーのimport # 必要ライブラリー import maron import maron.signalfunc as sf import maron.execfunc as ef # 追加ライブラリー # 使用可能なライブラリに関しましては右画面のノートをご覧ください① import pandas as pd import numpy as np import talib as ta from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectFromModel from sklearn.preprocessing import PolynomialFeatures # オーダ方法(目的の注文方法に合わせて以下の2つの中から一つだけコメントアウトを外してください) # オーダー方法に関しましては右画面のノートをご覧ください② #ot = maron.OrderType.MARKET_CLOSE # シグナルがでた翌日の終値のタイミングでオーダー ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー #ot = maron.OrderType.LIMIT # 指値によるオーダー # 銘柄、columnsの取得 # 銘柄の指定に関しては右画面のノートをご覧ください③ # columnsの取得に関しては右画面のノートをご覧ください④ def initialize(ctx): # 設定 ctx.logger.debug("initialize() called") ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.1321", #日経225連動型上場投資信託 ], "columns": [ #"close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) #"volume_adj", # 出来高 #"txn_volume", # 売買代金 ] } } ) # シグナル定義 def _my_signal(data): # 欠損値補間 cp = data["close_price_adj"].fillna(method='ffill') # ctx.logger.debug(cp) # ここから手順1(教師データの生成) # 教師データを入れる型を用意 y = pd.DataFrame(0, index = cp.index, columns = cp.columns) y = cp.diff(-10) # ここで何日後を予測するかを決めれる y = y['jp.stock.1321']<0 # True, Falseに変換 # ここから手順2(株価データから特徴抽出) # 特徴量を入れるための準備 rsi7 = pd.DataFrame(0, index=cp.index, columns=["rsi7"]) sma14 = pd.DataFrame(0,index=cp.index, columns=["sma14"]) sma7 = pd.DataFrame(0,index=cp.index, columns=["sma7"]) sma7_diff = pd.DataFrame(0,index=cp.index, columns=["sma7_diff"]) sma14_diff = pd.DataFrame(0,index=cp.index, columns=["sma14_diff"]) sma_diff = pd.DataFrame(0,index=cp.index, columns=["sma_diff"]) bb_mid = pd.DataFrame(0,index=cp.index, columns=["bb_mid"]) bb_up = pd.DataFrame(0,index=cp.index, columns=["bb_up"]) bb_low = pd.DataFrame(0,index=cp.index, columns=["bb_low"]) bb_diff = pd.DataFrame(0,index=cp.index, columns=["bb_diff"]) mom = pd.DataFrame(0,index=cp.index, columns=["mom"]) for (sym,val) in cp.items(): rsi7['rsi7'] = ta.RSI(cp[sym].values.astype(np.double), timeperiod=7) sma14['sma14'] = ta.SMA(cp[sym].values.astype(np.double), timeperiod=14) sma7['sma7'] = ta.SMA(cp[sym].values.astype(np.double), timeperiod=7) bb_up['bb_up'], bb_mid['bb_mid'], bb_low['bb_low'] = ta.BBANDS(cp[sym].values.astype(np.double), timeperiod=14) mom['mom'] = ta.MOM(cp[sym].values.astype(np.double), timeperiod=14) sma7_diff['sma7_diff'] = sma7.diff() sma14_diff['sma14_diff'] = sma14.diff() sma_diff['sma_diff'] = sma7['sma7'] - sma14['sma14'] bb_diff['bb_diff'] = bb_mid['bb_mid'] - bb_up['bb_up'] # 特徴量の結合 df_x = pd.concat([rsi7, sma7_diff, sma14_diff, sma_diff, bb_diff, mom], axis = 1) ctx.logger.debug(df_x) # はじめのNAN削除 df_x = df_x[14:] y = y[14:] # 特徴量の追加 poly = PolynomialFeatures(degree = 3) poly.fit(df_x) df_x = poly.transform(df_x) # ここから手順3 # 学習データとテストデータに分割(前半5割を学習データ,後半5割をテストデータ) X_train, X_test, y_train, y_test = train_test_split(df_x, y, train_size=0.5, shuffle = False) # 特徴量の選択(モデルはランダムフォレスト) select = SelectFromModel(RandomForestClassifier(n_estimators = 300, random_state = 1), threshold = "1.40*median") select.fit(X_train, y_train) X_train = select.transform(X_train) X_test = select.transform(X_test) # 学習データを使って学習(モデルはランダムフォレスト) clf = RandomForestClassifier(random_state=1, n_estimators = 100, max_leaf_nodes = 10, max_depth=6, max_features=None) clf = clf.fit(X_train, y_train) # ここから手順4 # テストデータを使って予測 pred = clf.predict(X_test) # market_sigのインデックスを合わせる test = np.ones(len(X_train)+14, dtype=np.bool) * False market_sig = np.hstack((test, pred)) market_sig = pd.DataFrame(data = market_sig, columns=cp.columns, index=cp.index) # ctx.logger.debug(market_sig)feature = clf.feature_importances_ # ctx.logger.debug(feature) feature = clf.feature_importances_ ctx.logger.debug(market_sig) # normalize signals market_sig[market_sig == True] = 1.0 market_sig[market_sig == False] = 0.0 ctx.logger.debug(market_sig) # スコア表示 ctx.logger.debug("Training score: {:.3f}".format(clf.score(X_train, y_train))) ctx.logger.debug("Test score: {:.3f}".format(clf.score(X_test, y_test))) return { "market:sig": market_sig, } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' # 1321を取引するため bull = ctx.getSecurity("jp.stock.1321") # シグナルを取得 market_signal = current["market:sig"][0] if market_signal == 1.0: bull.order_target_percent(0.5, comment="BULL BUY") else: bull.order_target_percent(0, comment="BULL SELL")3、テスト結果
損益率に着目すると、同期間でのバックテストで、14.60% → 22.60%へ上昇することができました。SharpeRatioなども改善されたようです。
訓練データ、テストデータへのスコアをみてみると、訓練データへフィットしすぎており、過学習が起きていることがわかります。追加する特徴量の数や、そもそものランダムフォレストモデルの変数等を操作しましたが、多少の改善しか達成できず、今後の課題です。
4、改善案
モデル面
過学習を防ぐための、各モデルのパラメータ調整
その他のモデルの使用や、複数モデルのアンサンブル特徴量
ベーシックな指標を特徴量として追加その他
新エンジンで、より長期でのバックテストを行いtrainデータを増量5、最後に
記事を読んでいただき、ありがとうございました。まだまだ知識が足りず、ミスなどあればぜひご指摘頂ければ幸いです。より良いアルゴリズム作成に向け、全力で取り組んでいきます!

- 投稿日:2019-07-04T11:37:21+09:00
QuantXで機械学習を用いた株価予測(特徴量エンジニアリング編)
はじめに
こんにちは、材料工学修士1年の学生です。鉄鋼材リサイクルへの画像解析応用を目指し、春から海外大のコンピュータサイエンス専攻へ交換留学しています。
この度Smart Tradeでインターンすることになり、株価予測モデルを作ってみました。今日のお題
QuantX Factoryでアルゴリズムを作ってみる。
先人の方の機械学習モデル(ランダムフォレストモデル)を参考に、特徴量エンジニアリングを追加してみました。完成したコードはこちら。QuantX Factoryとは
smart trade社が無料で提供しているシステムトレードアルゴリズムをブラウザ上でpythonを使って開発できるプラットフォーム。
以下の理由から、pythonで株価予測をやってみたい人におすすめです。
- Web上のプラットフォームのため開発環境構築が不要であること
- 各銘柄の終値や高値などの各種データが用意されておりデータセットの用意不要
- 開発したトレードアルゴリズムは審査を通過すればQuantX Storeで販売可能
- 新エンジン移行に伴い、終値、始値、指値での注文が選択可能になるなど、より多様な戦略を組めるようになったことデータの収集、更新だけに大量の時間を持っていかれる時代もこれにて終わりですね。
QuantXの詳しい使い方についてはこちら。本題
1、目的と手法
- 既存のランダムフォレストモデルを使用した株価予測モデルへ、追加で特徴量エンジニアリングを実施し精度向上を試みます。
- エンジン移行に伴って、新エンジンにて使用可能なアルゴリズムへ修正を行います。 (データが命の機械学習の使用において、長期間バックテストの実行可能な新エンジンへの移行は重要です。)
参考にする株価予測モデル
機械学習を用いた株価予測モデルとして、@sarubobo29さんのQuantXで機械学習使って株価予測してみたpart1を使用させていただきました。「教師あり学習を使って、10日後の株価が現在の価格よりも「上がっているか(下がっているか)どうか」を予測するアルゴリズム。」になります。
ちなみに@sarubobo29さんのQuantXで機械学習使って株価予測してみたpart2へも適用を試みましたが、こちらは相性があまりよくありませんでした。
実施する特徴量エンジニアリング
機械学習モデル精度向上のため、以下の二点で特徴量エンジニアリングを行います。
i. 交互作用特徴量と多項式特徴量の生成
今回は交互作用特徴量と多項式特徴量を生成し、特徴量として追加していきます。交互作用特徴量とは特徴量の交互作用を表すための特徴量で、特徴量同士の積で表します。例えば、x1、x2という特徴量がある場合、x1 * x2という特徴量を新たに作成します。多項式特徴量とは特徴量の多項式表現を新たな特徴量とし、追加する方法です。例えば、x1、x2の特徴量の2次の表現を作ると、x1^2、x2^2という特徴量が新たに作成されます。
ii. 自動特徴量選択
訓練データへの過学習を防ぐために、自動特徴量選択を行います。自動特徴量選択とは、機械学習のモデルを使用において、全特徴量の中から有効な特徴量の組み合わせを自動で探索するプロセスのことを表します。今回はその中でも決定木ベースモデルなどの教師あり学習モデルを1つ用いて、特徴量の重要性を判断し重要なものだけを残す、モデルベース特徴量選択を行います。学習モデルとしてランダムフォレストモデルを用い、特徴量選択を行いました。
2、コード
修正点
準備段階での修正点
scikit-learnから新たに、特徴量生成時に使用するPolynomialFeatures関数と、特徴量選択時に使用するSelectFromModel関数をインポートします。
from sklearn.feature_selection import SelectFromModel from sklearn.preprocessing import PolynomialFeatures特徴量エンジニアリングを行う上での追加点(下で個別に説明します。)
# 特徴量の追加 poly = PolynomialFeatures(degree = 3) poly.fit(df_x) df_x = poly.transform(df_x) # ここから手順3 # 学習データとテストデータに分割(前半5割を学習データ,後半5割をテストデータ) X_train, X_test, y_train, y_test = train_test_split(df_x, y, train_size=0.5, shuffle = False) # 特徴量の選択(モデルはランダムフォレスト) select = SelectFromModel(RandomForestClassifier(n_estimators = 300, random_state = 1), threshold = "1.40*median") select.fit(X_train, y_train) X_train = select.transform(X_train) X_test = select.transform(X_test) # 学習データを使って学習(モデルはランダムフォレスト) clf = RandomForestClassifier(random_state=1, n_estimators = 100, max_leaf_nodes = 10, max_depth=6, max_features=None) clf = clf.fit(X_train, y_train)まず、今回はPolynomialFeatures関数を用いて、3次以下の交互作用特徴量と、多項式特徴量を新たな特徴量として追加します。degree値を設定することで、その値以下の次元の交互作用特徴量と多項式特徴量を、生成することができます。
# 特徴量の追加 poly = PolynomialFeatures(degree = 3) poly.fit(df_x) df_x = poly.transform(df_x)次に、特徴量選択を行います。SelectFromModelを用い、特徴量を選択します。今回は特徴量の重要性を判断するモデルとして、RandomForestClassifierを使用しました。特徴量選択では、ある基準を設定し、それ以上の重要性を持つ特徴量のみを選択します。今回は、この特徴量選択の基準として、median(中央値)を用い、threshold = "1.40*median"を採用しています。
# 特徴量の選択(モデルはランダムフォレスト) select = SelectFromModel(RandomForestClassifier(n_estimators = 300, random_state = 1), threshold = "1.40*median") select.fit(X_train, y_train) X_train = select.transform(X_train) X_test = select.transform(X_test)新エンジンでの使用のための修正点
シグナル名を"market:sig"へ修正し、新エンジンでも使用可能にします。
return { "market:sig": market_sig, }訓練データ、テストデータのスコアをデバックするコードの追加
特徴量の追加や選択により、過剰適合や適合不足が起きることを防ぐために、訓練データ、テストデータに対する精度をデバック表示させます。
ctx.logger.debug("Training score: {:.3f}".format(clf.score(X_train, y_train))) ctx.logger.debug("Test score: {:.3f}".format(clf.score(X_test, y_test)))全体のコード
# Sample Algorithm # ライブラリーのimport # 必要ライブラリー import maron import maron.signalfunc as sf import maron.execfunc as ef # 追加ライブラリー # 使用可能なライブラリに関しましては右画面のノートをご覧ください① import pandas as pd import numpy as np import talib as ta from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectFromModel from sklearn.preprocessing import PolynomialFeatures # オーダ方法(目的の注文方法に合わせて以下の2つの中から一つだけコメントアウトを外してください) # オーダー方法に関しましては右画面のノートをご覧ください② #ot = maron.OrderType.MARKET_CLOSE # シグナルがでた翌日の終値のタイミングでオーダー ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー #ot = maron.OrderType.LIMIT # 指値によるオーダー # 銘柄、columnsの取得 # 銘柄の指定に関しては右画面のノートをご覧ください③ # columnsの取得に関しては右画面のノートをご覧ください④ def initialize(ctx): # 設定 ctx.logger.debug("initialize() called") ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.1321", #日経225連動型上場投資信託 ], "columns": [ #"close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) #"volume_adj", # 出来高 #"txn_volume", # 売買代金 ] } } ) # シグナル定義 def _my_signal(data): # 欠損値補間 cp = data["close_price_adj"].fillna(method='ffill') # ctx.logger.debug(cp) # ここから手順1(教師データの生成) # 教師データを入れる型を用意 y = pd.DataFrame(0, index = cp.index, columns = cp.columns) y = cp.diff(-10) # ここで何日後を予測するかを決めれる y = y['jp.stock.1321']<0 # True, Falseに変換 # ここから手順2(株価データから特徴抽出) # 特徴量を入れるための準備 rsi7 = pd.DataFrame(0, index=cp.index, columns=["rsi7"]) sma14 = pd.DataFrame(0,index=cp.index, columns=["sma14"]) sma7 = pd.DataFrame(0,index=cp.index, columns=["sma7"]) sma7_diff = pd.DataFrame(0,index=cp.index, columns=["sma7_diff"]) sma14_diff = pd.DataFrame(0,index=cp.index, columns=["sma14_diff"]) sma_diff = pd.DataFrame(0,index=cp.index, columns=["sma_diff"]) bb_mid = pd.DataFrame(0,index=cp.index, columns=["bb_mid"]) bb_up = pd.DataFrame(0,index=cp.index, columns=["bb_up"]) bb_low = pd.DataFrame(0,index=cp.index, columns=["bb_low"]) bb_diff = pd.DataFrame(0,index=cp.index, columns=["bb_diff"]) mom = pd.DataFrame(0,index=cp.index, columns=["mom"]) for (sym,val) in cp.items(): rsi7['rsi7'] = ta.RSI(cp[sym].values.astype(np.double), timeperiod=7) sma14['sma14'] = ta.SMA(cp[sym].values.astype(np.double), timeperiod=14) sma7['sma7'] = ta.SMA(cp[sym].values.astype(np.double), timeperiod=7) bb_up['bb_up'], bb_mid['bb_mid'], bb_low['bb_low'] = ta.BBANDS(cp[sym].values.astype(np.double), timeperiod=14) mom['mom'] = ta.MOM(cp[sym].values.astype(np.double), timeperiod=14) sma7_diff['sma7_diff'] = sma7.diff() sma14_diff['sma14_diff'] = sma14.diff() sma_diff['sma_diff'] = sma7['sma7'] - sma14['sma14'] bb_diff['bb_diff'] = bb_mid['bb_mid'] - bb_up['bb_up'] # 特徴量の結合 df_x = pd.concat([rsi7, sma7_diff, sma14_diff, sma_diff, bb_diff, mom], axis = 1) ctx.logger.debug(df_x) # はじめのNAN削除 df_x = df_x[14:] y = y[14:] # 特徴量の追加 poly = PolynomialFeatures(degree = 3) poly.fit(df_x) df_x = poly.transform(df_x) # ここから手順3 # 学習データとテストデータに分割(前半5割を学習データ,後半5割をテストデータ) X_train, X_test, y_train, y_test = train_test_split(df_x, y, train_size=0.5, shuffle = False) # 特徴量の選択(モデルはランダムフォレスト) select = SelectFromModel(RandomForestClassifier(n_estimators = 300, random_state = 1), threshold = "1.40*median") select.fit(X_train, y_train) X_train = select.transform(X_train) X_test = select.transform(X_test) # 学習データを使って学習(モデルはランダムフォレスト) clf = RandomForestClassifier(random_state=1, n_estimators = 100, max_leaf_nodes = 10, max_depth=6, max_features=None) clf = clf.fit(X_train, y_train) # ここから手順4 # テストデータを使って予測 pred = clf.predict(X_test) # market_sigのインデックスを合わせる test = np.ones(len(X_train)+14, dtype=np.bool) * False market_sig = np.hstack((test, pred)) market_sig = pd.DataFrame(data = market_sig, columns=cp.columns, index=cp.index) # ctx.logger.debug(market_sig)feature = clf.feature_importances_ # ctx.logger.debug(feature) feature = clf.feature_importances_ ctx.logger.debug(market_sig) # normalize signals market_sig[market_sig == True] = 1.0 market_sig[market_sig == False] = 0.0 ctx.logger.debug(market_sig) # スコア表示 ctx.logger.debug("Training score: {:.3f}".format(clf.score(X_train, y_train))) ctx.logger.debug("Test score: {:.3f}".format(clf.score(X_test, y_test))) return { "market:sig": market_sig, } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' # 1321を取引するため bull = ctx.getSecurity("jp.stock.1321") # シグナルを取得 market_signal = current["market:sig"][0] if market_signal == 1.0: bull.order_target_percent(0.5, comment="BULL BUY") else: bull.order_target_percent(0, comment="BULL SELL")3、テスト結果
損益率に着目すると、同期間でのバックテストで、14.60% → 22.60%へ上昇することができました。SharpeRatioなども改善されたようです。
訓練データ、テストデータへのスコアをみてみると、訓練データへフィットしすぎており、過学習が起きていることがわかります。追加する特徴量の数や、そもそものランダムフォレストモデルの変数等を操作しましたが、多少の改善しか達成できず、今後の課題です。
4、改善案
モデル面
過学習を防ぐための、各モデルのパラメータ調整
その他のモデルの使用や、複数モデルのアンサンブル特徴量
ベーシックな指標を特徴量として追加その他
新エンジンで、より長期でのバックテストを行いtrainデータを増量5、最後に
記事を読んでいただき、ありがとうございました。まだまだ知識が足りず、ミスなどあればぜひご指摘頂ければ幸いです。より良いアルゴリズム作成に向け、全力で取り組んでいきます!
- 投稿日:2019-07-04T10:20:17+09:00
Google先生に学ぶ遊戯王データセットの見せ方
環境
jupyter-notebook 4.4.0
python 3.7.3やること
Googleが運営しているmaterial.ioに最近追加されたData Visualizationのページを参考に、遊戯王カードに関するデータセットからmatplotlibでチャートを作成していきます。
遊戯王について
小学校5,6年生の時にデュエルマスターズから遊戯王に移りました。使っていて一番好きだったテーマはドラグニティで、地獄の暴走召喚でファランクスを3体特殊召喚→スカーレッドノヴァドラゴンを出すというコンセプトのデッキだったのですが、結局レギオンにアキュリスを装備させ相手のカードを割って1200で殴っていくのが至高という結論に至りました。マスタールール3になる直前に引退してしまいましたが、マスタールール4になった時にはいつか売ろうと思っていたシンクロモンスター達が軒並み暴落して泣きました。今フォーミュラシンクロン売ったらいくらになりますかね?
material.ioとData Visualizationについて
Googleが自社のマテリアルデザインに関する情報を統合的に公開しているもので、UIの開発ツールも提供されています。そこに最近追加されたのがこのData Visualizationに関するページです。
https://material.io/design/communication/data-visualization.html#selecting-charts
これが結構為になるので皆様と共有していきたい所存です。特に、Do/Don'tという形で具体的なチャートを分かりやすく例示していて、今回はこのDo/Don'tの一部を遊戯王データセットとmatplotlibを使って確認していこうと思います。
遊戯王データセットについて
今回は以下のデータを使わせてもらいます。
https://www.kaggle.com/tathor/yugioh-trading-cards-datasetygoprodeck APIに登録されているカードから6534枚のデータを抽出していて、古いものからサイバースなどマスタールール4のカードまで全般的に含まれています。とりあえずどんなデータか見てみましょう。ついでに今回使うライブラリもすべて読み込んでしまいます。jupyter-notebookで実行しているので注意してください。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.set()df = pd.read_csv('yugioh-trading-cards-dataset/card_data.csv', sep=',') df.head(10)
注意すべきポイントは2つです。あとは見ればすぐに分かると思います。
①「Type」はモンスター・魔法・トラップ・トークンの分類で、モンスターのみノーマル、効果、リバースなど詳細な種類で記録されている
②「Race」はモンスター・トークンの場合は種族、魔法・罠の場合は通常・永続・カウンターといった種類が記録されているそれではDo/Don’tを参考にチャートを作成していきます。
①闇/光属性間でモンスターのレベルの割合を比較する
Do.
Use bar charts to show changes over time or differences between categories.Don’t.
Don’t use multiple pie charts to show changes over time. It’s difficult to compare the difference in size across each slice of the pie.こんな感じで、まずData VisualizationのページのDo/Don'tを引用し、次に遊戯王データセットによるチャートを作成します。ただし、Before/Afterにしたいので、順番はDon't/Doにしてます。
# データ抽出・カテゴリー変数の追加 df_Monster = df[df['Type'].str.match('.*Monster')] df_Monster['Rank'] = '1 - 4' df_Monster.loc[df_Monster['Level']>=5, 'Rank'] = '5 - 6' df_Monster.loc[df_Monster['Level']>=7, 'Rank'] = '7 - 8' df_Monster.loc[df_Monster['Level']>=9, 'Rank'] = '9 - 12' x = df_Monster[df_Monster['Attribute']=='DARK'] y = df_Monster[df_Monster['Attribute']=='LIGHT']# Don't x = x.Rank.value_counts(True) y = y.Rank.value_counts(True) label = ['1 - 4', '5 - 6', '7 - 8', '9 - 12'] plt.figure(figsize=(8, 4)) plt.subplot(1, 2, 1) plt.title('DARK') plt.pie(x, startangle=90, labels=label, wedgeprops={'linewidth': 1, 'edgecolor':"white"}, counterclock=False) plt.subplot(1, 2, 2) plt.title('LIGHT') plt.pie(y, startangle=90, labels=label, wedgeprops={'linewidth': 1, 'edgecolor':"white"}, counterclock=False) plt.axis('equal')#Do df_LD = pd.concat([x, y], axis=1) df_LD.columns = ['LIGHT', 'DARK'] ax = df_LD.sort_index(ascending=False).plot.barh() vals = ax.get_xticks() ax.set_xticklabels(['{:3.0f}%'.format(x*100) for x in vals])モンスターレベルを下級・中級・上級で分け、ちょっとグループが少ないので上級だけは7-8と9-12で分けました。それを闇/光属性で比較しています。
Don't
Do
期間やカテゴリーが異なるデータの間で各割合を比較する場合、円グラフだとそれぞれの変化や違いが分かりにくいから棒グラフを使おうということですね。この場合はグループの数が4つと多くないので円グラフの方でも大小関係はそれなりに読み取れますが、やはり棒グラフの方が確実です。②地属性モンスターのレベルごとの攻撃力(平均値)を他属性モンスターと比較する
Do.
Use a combination of color highlights and neutral colors to provide contrast and emphasis.Caution.
Many colors in a single chart can hinder focus.今回はDo/Cautionです。場合によってはアリだけどあまり好ましくない例。
# Don't for i in ['DARK', 'FIRE', 'EARTH', 'WIND', 'LIGHT', 'WATER', 'DIVINE']: df_atr = df[df['Attribute']==i] plt.plot(df_atr.groupby('Level').mean().ATK, label=i) plt.legend()# Do for i in ['DARK', 'FIRE', 'WIND', 'LIGHT', 'WATER', 'DIVINE']: df_atr = df[df['Attribute']==i] plt.plot(df_atr.groupby('Level').mean().ATK, color='silver') df_EARTH = df[df['Attribute']=='EARTH'] plt.plot(df_EARTH.groupby('Level').mean().ATK, color='g')横軸をレベル、縦軸を攻撃力の平均値として属性ごとに算出しています。
Don't
Do
これは一目瞭然ですね。線の数が多いこともそうですが、特にレベル1から8まではほとんど重なっていて、全てに色をつけるとかなり分かりにくいです。もし1対多でなく多対多の比較を想定していたとしても、上のようなチャートになってしまう場合は方法を変えるべきでしょう。③戦士族/魔法使い族間でレベルごとの攻撃力/守備力の平均値を比較する
Do.
Vary a line’s texture to represent different data types.Don’t.
Don't use different colors to show periodical variation for the same data category.# データ抽出 df_W = df[df['Race']=='Warrior'] df_S = df[df['Race']=='Spellcaster']# Don't plt.plot(df_W.groupby('Level').mean().ATK[:8], label='ATK:Warrior') plt.plot(df_S.groupby('Level').mean().ATK[:8], label='ATK:Spellcaster') plt.plot(df_W.groupby('Level').mean().DEF[:8], label='DEF:Warrior') plt.plot(df_S.groupby('Level').mean().DEF[:8], label='DEF:Spellcaster') plt.legend()# Do plt.plot(df_W.groupby('Level').mean().ATK[:8], label='ATK:Warrior', color='b') plt.plot(df_S.groupby('Level').mean().ATK[:8], label='ATK:Spellcaster', color='darkorange') plt.plot(df_W.groupby('Level').mean().DEF[:8], label='DEF:Warrior', color='b', linestyle='dashed') plt.plot(df_S.groupby('Level').mean().DEF[:8], label='DEF:Spellcaster', color='darkorange', linestyle='dashed') plt.legend()「periodical variation」ということで、本来は複数のカテゴリーについて今月/前月というような異なる期間で比較する場合を想定していると思われますが、時系列データがないので強引に攻撃力/守備力、戦士族/魔法使い族で比較してます。ただしレベル12まで含むと違いがほとんど分からなくってしまうので、レベル8までにしています。
Don't
Do
全体的に散らばりが小さいので感動するほどの変化はありませんが、それでもパッとチャートを見たときに、線のテクスチャの違いからATKとDEFの分類がDon'tの場合よりもすぐに入ってくると思います。また種族で色を統一しているのでそのグルーピングも分かりやすくなります。④通常魔法以外の魔法カードの割合を比較する
Do.
A bar chart starting at the zero baselineDon’t.
Don’t start the baseline at values other than zero. This baseline starts at 20%, making the bar differences look more dramatic.# データ抽出 df_Spell = df[df['Type']=='Spell Card'] z = df_Spell.Race.value_counts(True) z = pd.DataFrame(z) z = z.drop('Normal', axis=0) z = z.drop('Ritual', axis=0)# Don't ax = z.plot.bar() plt.ylim(0.08, 0.18) vals = ax.get_yticks() ax.set_yticklabels(['{:3.0f}%'.format(x*100) for x in vals]) ax.legend().set_visible(False)# Do ax = z.plot.bar() plt.ylim(0, 0.18) vals = ax.get_yticks() ax.set_yticklabels(['{:3.0f}%'.format(x*100) for x in vals]) ax.legend().set_visible(False)割合が大きすぎる通常魔法に加え割合が小さすぎる儀式魔法も、各割合を算出した後でチャートから除いています。
Don't
Do
y軸の一部を省略することで、より劇的な違いがあるように見せてしまうということですね。偏見で恐縮ですが、質の悪い不動産投資の資料で使われるイメージです。⑤モンスター・魔法・罠・トークンの割合の比較
Do.
Support legibility by using a balanced number of axis labels.Don’t.
Don’t overload the chart with numerous axis labels.# データ抽出 df_Type = df.replace('.*Monster', r'Monster', regex=True).Type.value_counts()# Don't ax = df_Type.plot.bar() ax.set_yticks(np.linspace(0, 5000, 11))# Do ax = df_Type.plot.bar() ax.set_yticks(np.linspace(0, 5000, 6))Don't
Do
y軸の目盛りのバランスについてです。実はデフォルトのままだと、このデータの場合Don'tのように500刻みでy軸の目盛りが表示されるんですよね。他の方のmatplotlibによるチャートの作成を見ても目盛り数は意識していない場合が多いように思います。大したtipsに感じないかもしれませんが、ここにも検討の余地があることを覚えておきましょう。⑥種類ごとのモンスター数TOP10
Do.
Orient text horizontally on bar charts, rotating the bars if needed to make space.Caution.
Don’t rotate bar labels, as it makes them difficult to read.# データ抽出 df_M_Type = df_Monster.Type.value_counts() df_M_Type = pd.DataFrame(df_M_Type)# Don't ax = df_M_Type[0:10].plot.bar() ax.legend().set_visible(False)# Do ax = df_M_Type[0:10].sort_values('Type', ascending=True).plot.barh() ax.legend().set_visible(False)Don't
Do
x軸のラベルの文字が重なってしまうのを防ぐためにそれを回転させる場合があり、特にYYYY-MM-DDで表示されたラベルを左に45°回転させているチャートをよく見ます。しかし、xyを逆にして表現した方がラベルは圧倒的に読みやすいですね。今回作成した縦棒グラフはすべてラベルを縦にしているのですが、ラベルの数や各文字数が多い場合は、可能ならこのようにすべきでしょう。ちなみにXYZ Monsterは、最初XYZドラゴンキャノンとその仲間のことを言っているのかと思いましたが、エクシーズのことなんですね。KONAMIのオシャレポイント。以上で今回は終わりにします。引用元のData Visualizationには他にも色々なポイントがまとめられているのでぜひチェックしてみてください。
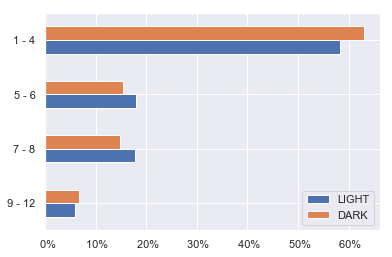
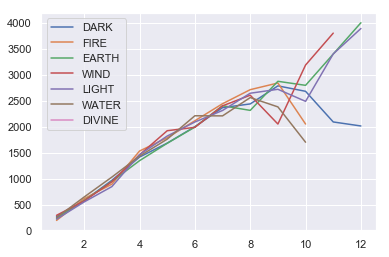
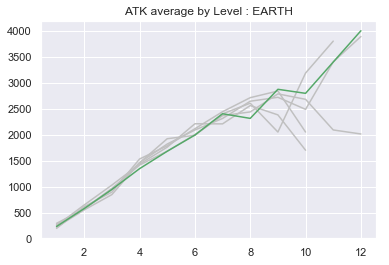
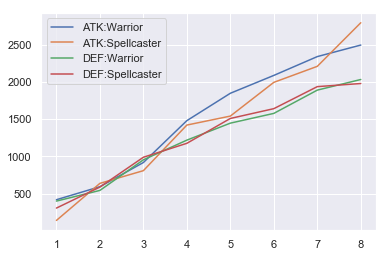
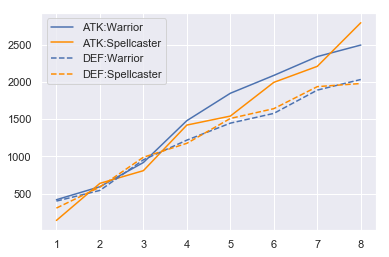
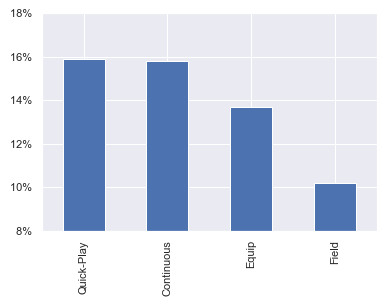
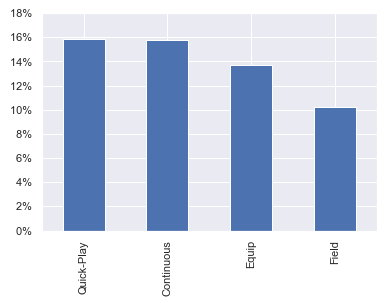
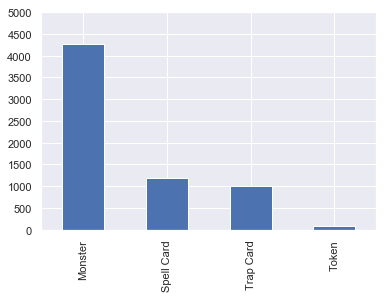
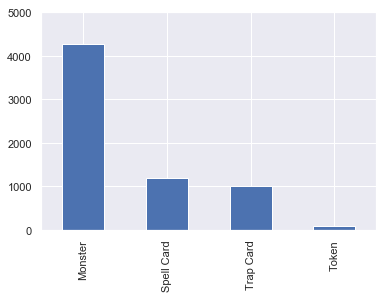
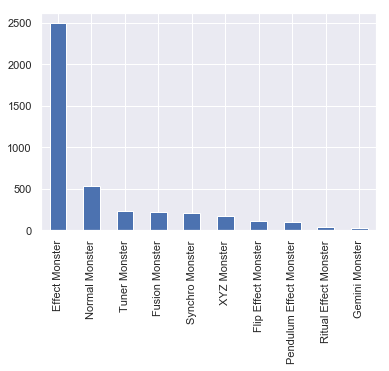
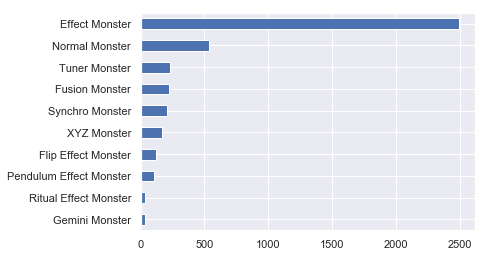
- 投稿日:2019-07-04T10:08:27+09:00
Pythonで表の文字列長を揃えて表示(CLI)
自分用にメモ
表(2次元のリスト)のデータをPythonで整形する
マルチバイト文字は考慮しないで、lenとmaxを使って各列の最大長を取得して揃える
print_table.py#!/usr/bin/env python # -*- coding: utf-8 -*- table = [ ["column1", "column2", "column3"], ["abc", "defghijklm", "nopqrstuvwxyz"], ["abcdefghi","jklmn", "opqrstuvwxyz"], ] align_table = [ ("column1", "r"), ("column2", "l"), ("column3", "r"), ] """ 文字列長が合わないときは空白で埋める """ def AdjustLength(input_str, adj_length, align="r"): if adj_length == 0: return input_str elif len(input_str) > adj_length: return input_str[0:adj_length] elif align == "r": return "".join([" " * (adj_length - len(input_str)), input_str]) else: return "".join([input_str, " " * (adj_length - len(input_str))]) max_length = [ max([ len(y) for y in x ]) for x in zip(*table) ] print("\n".join([ " ".join([ AdjustLength(x,mlen,align) for x,mlen,align in zip(row,max_length,zip(*align_table)[1]) ]) for row in table ]))実行結果
$ python print_table.py column1 column2 column3 abc defghijklm nopqrstuvwxyz abcdefghi jklmn opqrstuvwxyz $
- 投稿日:2019-07-04T08:14:20+09:00
Python exeファイル作成(画像ダウンロード処理)
Pythonでexeファイルを作成してみた。
※前提条件、pipコマンドが実行できる状態(私はAnaconda3をインストールしていました)①Pythonファイルをexe)ファイルに変換してくれるライブラリをインストール
コマンドプロンプトよりpip install pyinstaller②Pythonファイルを作成(画像をDLしてローカルに保存)UTF-8
hello.pyimport requests from datetime import datetime try: url = input("DLするURLを入力してください ※未入力時はhttps://bookandengineer.com/wp-content/uploads/2019/02/キャプチャ.jpg") if url=='': url='https://bookandengineer.com/wp-content/uploads/2019/02/キャプチャ.jpg' file_name = f'./img/test.jpg' response = requests.get(url) image = response.content with open(file_name, "wb") as aaa: aaa.write(image) print(f'画像DL成功(取得URL[{url}] / 画像パス[{file_name}])') except Exception as e: print(f'画像DL失敗(取得URL[{url}] / 画像パス[{file_name}])') print(e) input("何か入力すると処理を終了します")③exe作成(hello.pyを配置しているディレクトリに移動してから)
コマンドプロンプトよりpyinstaller hello.py --onefile④作成されたexeを実行

- 投稿日:2019-07-04T07:08:36+09:00
DataFrameの結合
concat
単純結合する場合
#縦方向 pd.concat([df1, df2]) #横方向 pd.concat([df1, df2], axis=1)共通項目のみ結合する場合
pd.concat([df1, df4], axis=1, join='inner')merge
表df1 と 表df2 を 条件値の値一致で結合する場合
#結合条件:id列の一致 (左表優先) df3 = pd.merge( df1 , df2 , on='id',how='left') #結合条件:id列とkye列の一致 df3 = pd.merge( df1 , df2 , on=['id','key'])join
indexをキーに結合する
df1.join(df2, how='inner')#共通項のみ結合 df1.join(df2, how='right')#右表(df2)優先結合 df1.join(df2, how='outer')#全行結合 値がない場合はnan値append
行番号=nameのある行(Series)を追加する
s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'], name=10) df1.append(s1)その他(表関連)
drop_duplicates
idが重複する行を削除
df1.drop_duplicates(subset='id')
- 投稿日:2019-07-04T01:41:07+09:00
python×Cloud Functions×FirestoreでAPIを簡単に作ってみる Pt1
概要
GCPのCloud Functionsを使って、FirebaseのFirestoreからデータを取得するAPIを作る機会があったのですが、非常に簡単に作れたのでその時やったことをまとめます。
(本当はCloud Functions for Firebaseを使いたかったのですが、慣れているpythonには未対応のため、GCPのCloud Functionsで作ってみることに。)Pt1では、Firestoreのデータを取得するシンプルなAPIをGCPのコンソールから作成します。
Pt2以降では、ローカルからのテスト、デプロイの方法をまとめます。開発環境・前提
- 開発環境
- MacOS
- python3.7
- pycharm
- 前提知識
- Firestoreをコンソールから作成済み
- Cloud FunctionsのHello World関数を作ったことはある
※開発環境はPt2以降で使います。
プロジェクトの作成
FirebaseまたはGCPのコンソールから画面の指示に従うままに作成できます。
2つの連携について言えば、Firebaseのプロジェクトから先に作成した場合、GCPコンソールの「プロジェクトの選択>すべて」のタブからFirebaseで作成したプロジェクトを選択すれば、連携が完了です。Firestoreのデータを取得する関数を書く
前提となるデータベースはこんな感じで、userコレクションからユーザ一覧を取得してみます。
肝心のソース。とりあえず、Cloud Functionsのコンソールから直接編集してみます。
import json from google.cloud import firestore def get_user(request): db = firestore.Client() docs = db.collection('user').get() users_list = [] for doc in docs: users_list.append(doc.to_dict()) return_json = json.dumps({"users": users_list}, ensure_ascii=False) return return_json
- 簡単にソースを解説
- 引数であるrequestはHTTPのパラメータ等を指定しますが、このソースでは使ってません。とりあえず全データ取ってきます
- userコレクションから取得したdocsをforで回して、docの
to_dict()メソッドでdictにしています。- json.dumpsで
ensure_ascii=Falseを指定しないと、日本語のデータが混ざったときにエスケープされた値が返されます。デプロイ前の準備
Firestoreからデータを取得するためのパッケージであるgoogle-cloud-firestoreは、Cloud Functionsのデフォルトには含まれません。
そのため、「ソース>requirements.txt」タブから追記する必要があります。# Function dependencies, for example: # package>=version google-cloud-firestore==1.2.0Cloud Functionsであらかじめインストールされるパッケージは公式に載ってます。
Python での依存関係の指定 - あらかじめインストールされるパッケージデプロイ
Cloud Functionsのコンソールから「実行する関数」に関数名(get_user)を指定してデプロイします。リージョンは「us-central1」がデフォルトですが、詳細オプションから変更可能なので、気になる人は変えましょう。
少し待つとデプロイが完了して、関数が作成されます。
テスト
デプロイした関数をテストしてみます。コンソールからパラメータを指定せずに関数をテストしてみると、userコレクションのデータが取得できます。
また、「トリガー」タブからURIが確認できますので、curlでの確認も可能です。
$ curl https://<リージョン>-<プロジェクトID>.cloudfunctions.net/getUsers {"users": [{"gender": "female", "name": "Alice", "age": 19}, {"age": 21, "gender": "male", "name": "Bob"}]}ひとまず、Firestoreからのデータ取得はできました。
ただ、これだとコレクションの全データを返してしまうので、引数であるrequestを使って取得するデータの条件を指定できるようにします。パラメータの条件に一致するデータを取得する
前提として、関数の引数となるrequestは、FlaskのRequestオブジェクトです。
そのため、クラス変数やメソッドはFlaskの公式ドキュメントで確認できます。
Flask - API例えば、
request.methodと書けばGETやPOSTが文字列として取得できるので、条件分岐に使うことも可能です。APIでリクエストされたパラメータもこのオブジェクトから取得します。
というわけで早速ソースです。import json from google.cloud import firestore def get_filtered_user(request): # リクエスト本文からjsonを取得 request_json = request.get_json() # クエリ文字列を取得 if request.args and 'name' in request.args: request_name = request.args.get('name') # jsonから条件を取得 elif request_json and 'name' in request_json: request_name = request_json['name'] else: request_name = '' db = firestore.Client() # whereでdocument内の条件に一致するデータを取得 query = db.collection('user').where('name', '==', request_name) docs = query.get() users_list = [] for doc in docs: users_list.append(doc.to_dict()) return_json = json.dumps({"users": users_list}, ensure_ascii=False) return return_json
- コメントが入ってるところが主なソースの修正箇所です。
- オブジェクトからパラメータを取得
- リクエストされた内容をwhereで条件にしてFirestoreにアクセス
where name = "リクエストされた名前"の条件に一致するdocumentをリターンします。新しい関数としてこのソースをデプロイした後、テストしてみます。
コンソールとcurlでテスト
コンソールから条件を設定してのテスト
- name="Alice"に一致するデータが返ってきます。
curlでのテスト
- GET/POSTのいずれでも、name="Bob"に一致するデータが返ってきます。
GET(クエリ文字列)$ curl https://<リージョン>-<プロジェクトID>.cloudfunctions.net/getFilteredUser?name=Bob {"users": [{"age": 21, "name": "Bob", "gender": "male"}]}POST(json)$ curl -X POST -H "Content-Type: application/json" -d '{"name": "Bob"}' https://<リージョン>-<プロジェクトID>.cloudfunctions.net/getFilteredUser {"users": [{"age": 21, "gender": "male", "name": "Bob"}]}テストとデプロイ方法の改善(次回)
Cloud FuctionsとFirestoreを使った簡単なAPIはできました。
とはいえ、いちいちコンソールからデプロイして動作確認するのは非常に面倒です。
なので、ローカルで気軽にテストしたり、ローカルからデプロイしたりを、Pt2以降では試してみます。ところで、APIを公開で作成した場合、URIを知っていれば誰からでもアクセス可能なので、気になる人はデプロイした関数を消しておきましょう。
参考文献
以下の記事を参考にさせていただきました。
Google Cloud FunctionsでPythonを利用してみた(Beta利用)
Cloud FirestoreのデータをPythonで取得する余談
ここまで書いてなんですが、モバイルアプリではCloud Functions for Firebaseを使ったほうが便利とも公式で書かれています。(使いたかったのはこれが理由...)
Javascriptが得意な方はこちらを使った方が良いかもしれません。
Google Cloud Functions と Firebaseとはいえ、pythonしか書けない人なので、引き続きGCPで実装していきます。
その他、コメントや指摘などいただけると幸いです。

- 投稿日:2019-07-04T01:08:52+09:00
Python入門 #01
今回は、twitterで投票結果の多かったPythonを学習していきます。
今回の概要
・Pythonを知る
・Python環境設定Pythonとは?
pythonとは今から20年以上前に誕生した、プログラミング言語です。
意外と古いPythonですが、最近人気急上昇中です。それは人工知能(機械学習)やビッグデータの解析などの研究によく使われている為です。環境設定をしよう
まず、プログラミングを行うにあたり、環境設定を行わなければなりません。これは、言語によっても環境が違うので、今回はPythonの環境設定を行って行きます。
環境設定はmacをお使いの方とwindowsをお使いの方では、若干の異なりが発生します。#1ブラウザで「Python」と検索

するとPythonのofficial-homeページを開きます。
#2 Pythonをダウンロード
Pythonのサイトは英語での表記がされていますが、今回はダウンロードするだけなので、ダウンロードと英語で書かれているものをクリックしましょう。
すると、お使いのosにより、ダウンロードするものが違うので注意してください。
バージョンは何にすればいいの?
色々な環境設定などをしていく際に、色々なバージョンの中からダウンロードする事があると思います。その際は、一番最新のバージョンを指定する事により、様々な問題に解決している環境を構築する事ができます。
この記事が役にたったと思った際は、是非twitterのフォローをお願いします。又、何不明な点がありましたらお気軽にご質問ください。
- 投稿日:2019-07-04T00:11:48+09:00
【Audio入門】Sin波の合成でメロディや音声を再現・再生してみる♬
Audioの取り扱いは、何度かやってきましたが、いつも参考①のサイトを見てしまいます。
ということで、今回はAudioのWavファイルの取り扱い方を中心に音声を合成できるかどうかをまとめておこうと思います。やったこと
・Audioの基本;入力、出力、信号処理(FFTなど)
・Sin波で基準音を出力し音楽を演奏する
・Sin波の合成で音声’う’を再現する・Audioの基本;入力、出力、信号処理(FFTなど)
【参考】
・①PyAudioの基本メモ2 音声入出力
これをまとめてやるコードは、以下のとおりです。# -*- coding:utf-8 -*- import pyaudio import matplotlib.pyplot as plt import numpy as np from scipy import signal CHUNK=1024 RATE=44100 p=pyaudio.PyAudio() N=10 CHUNK=1024*N p=pyaudio.PyAudio() fr = RATE fn=51200*N/50 fs=fn/fr stream=p.open( format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True, output = True) # inputとoutputを同時にTrueにする # Figureの初期化 fig = plt.figure(figsize=(16, 8)) #...1 # Figure内にAxesを追加() ax1 = fig.add_subplot(211) ax2 = fig.add_subplot(212) while stream.is_active(): input = stream.read(CHUNK) output = stream.write(input) sig =[] sig = np.frombuffer(input, dtype="int16") /32768.0 nperseg = 1024*N f, t, Zxx = signal.stft(sig, fs=fn, nperseg=nperseg) ax2.pcolormesh(fs*t, f/fs, np.abs(Zxx), cmap='hsv') ax2.set_xlim(0,fs) ax2.set_ylim(2,20000) ax2.set_yscale('log') ax2.set_axis_off() x = np.linspace(0, 100, nperseg) ax1.plot(x,sig) ax1.set_ylim(-0.5,0.5) plt.pause(0.01) plt.clf() ax1 = fig.add_subplot(211) ax2 = fig.add_subplot(212) stream.stop_stream() stream.close() print( "Stop Streaming")・Sin波で基準音を出力し音楽を演奏する
【参考】
②[python] sin波の音をWAV形式で出力する
③Pythonでサイン波(正弦波)をつくる
参考①と②から以下のコードで基準音の440Hzを作成できます。import wave import numpy as np from matplotlib import pylab as plt import struct a = 1 #振幅 fs = 8000 #サンプリング周波数 f0 = 440 #周波数 sec = 5 #秒 swav=[] for n in np.arange(fs * sec): #サイン波を生成 s = a * np.sin(2.0 * np.pi * f0 * n / fs) swav.append(s) #サイン波を表示 plt.plot(swav[0:100]) plt.show() #サイン波を-32768から32767の整数値に変換(signed 16bit pcmへ) swav = [int(x * 32767.0) for x in swav] #バイナリ化 binwave = struct.pack("h" * len(swav), *swav) #サイン波をwavファイルとして書き出し w = wave.Wave_write("output.wav") p = (1, 2, 8000, len(binwave), 'NONE', 'not compressed') w.setparams(p) w.writeframes(binwave) w.close()そして、参考②に今回は440Hzの音(ラ・A4)で試しましたが、ド(C4)は261.63Hz、レ(D4)は293.66Hzというように音階(十二平均律音階)は周波数が決まっています。なのでスクリプトを改造して簡単な音楽のwavファイルをつくることもできます。
とあるので、これをやってみました。
その他の音階は以下のとおりです。
【参考】
・音階の周波数
音階 ド レ ミ ファ ソ ラ シ ド 周波数 261.626 293.665 329.628 349.228 391.995 440.000 493.883 523.251 音階 C4 D4 E4 F G4 A4 B4 C5 この音階周波数を利用すると、いわゆるmusicが作成できます。
ここでは、基本ということで、以下のようなコードでドレミファソラシド...を奏でてみました。
まず、ドレミファソラシドのwavファイルを作成します。
上記の音階の周波数はピアノの音階が出ているので、ほぼどんな曲も再現できますね。。import numpy as np import wave import struct A=1 fs = 44100 sec = 0.5 #秒 f0=261.626 #ド C4 f1=293.665 #レ D4 f2=329.628 #ミ E4 f3=349.228 #ファ F f4=391.995 #ソ G4 f5=440.000 #ラ A4 f6=493.883 #シ B4 f7=523.251 #ド C5 f_list=(f0,f1,f2,f3,f4,f5,f6,f7) def create_wave(A,f0,fs,t): point = np.arange(0,fs*t) sin_wave =A* np.sin(2*np.pi*f0*point/fs) sin_wave = [int(x * 32767.0) for x in sin_wave] binwave = struct.pack("h" * len(sin_wave), *sin_wave) w = wave.Wave_write("./doremi/Doremi{}.wav".format(f0)) p = (1, 2, fs, len(binwave), 'NONE', 'not compressed') w.setparams(p) w.writeframes(binwave) w.close() for i in f_list: f=i create_wave(A, f, fs, sec)そして、上記で作成されたwavファイルを以下のコードで演奏します。
もちろん、f_listはお好きな曲にアレンジしてください。# -*- coding:utf-8 -*- import pyaudio import numpy as np import wave import wave import struct RATE=44100 CHUNK = 22050 p=pyaudio.PyAudio() f0=261.626 #ド C4 f1=293.665 #レ D4 f2=329.628 #ミ E4 f3=349.228 #ファ F f4=391.995 #ソ G4 f5=440.000 #ラ A4 f6=493.883 #シ B4 f7=523.251 #ド C5 f_list=(f0,f1,f2,f3,f4,f5,f6,f7,f6,f5,f4,f3,f2,f1,f0,f0) stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True, output = True) # inputとoutputを同時にTrueにする for i in f_list: wavfile = './doremi/Doremi{}.wav'.format(i) print(wavfile) wr = wave.open(wavfile, "rb") input = wr.readframes(wr.getnframes()) output = stream.write(input)作成したメロディ等は以下の置きました。
・AudioAutoencoder/データ/・Sin波の合成で音声'う'を再現する
まず、以下のコードで音声’う’を発生して、安定したところでFFT図を得ます。
・AudioAutoencoder/audio_inout.py
そして、そのFFT図を再現すべく以下のコードで’う’の波形になるように探します。
・AudioAutoencoder/make_wavUfile.py
実は、FFT図は割と近い絵になりますが、実際得られる音声波形は以下のようになかなか似たような絵になりません。
ということで、上のコードでそれぞれのサイン波の振幅と主要な周波数(290)を調整します。
ここで、周波数は動かすと大きく様相が変わりました。
ということで、1Hz単位で動かしてみましたがそれでも以下のように変わりました。
最終的に得られた合成された’う’を以下に置きました
・AudioAutoencoder/データ/まとめ
・Audioの基本を振り返った
・Sin波でメロディを作成した
・Sin波で合成音声’う’を作成してみた・これを利用して音声Autoencoderの学習データを作成しようと思う
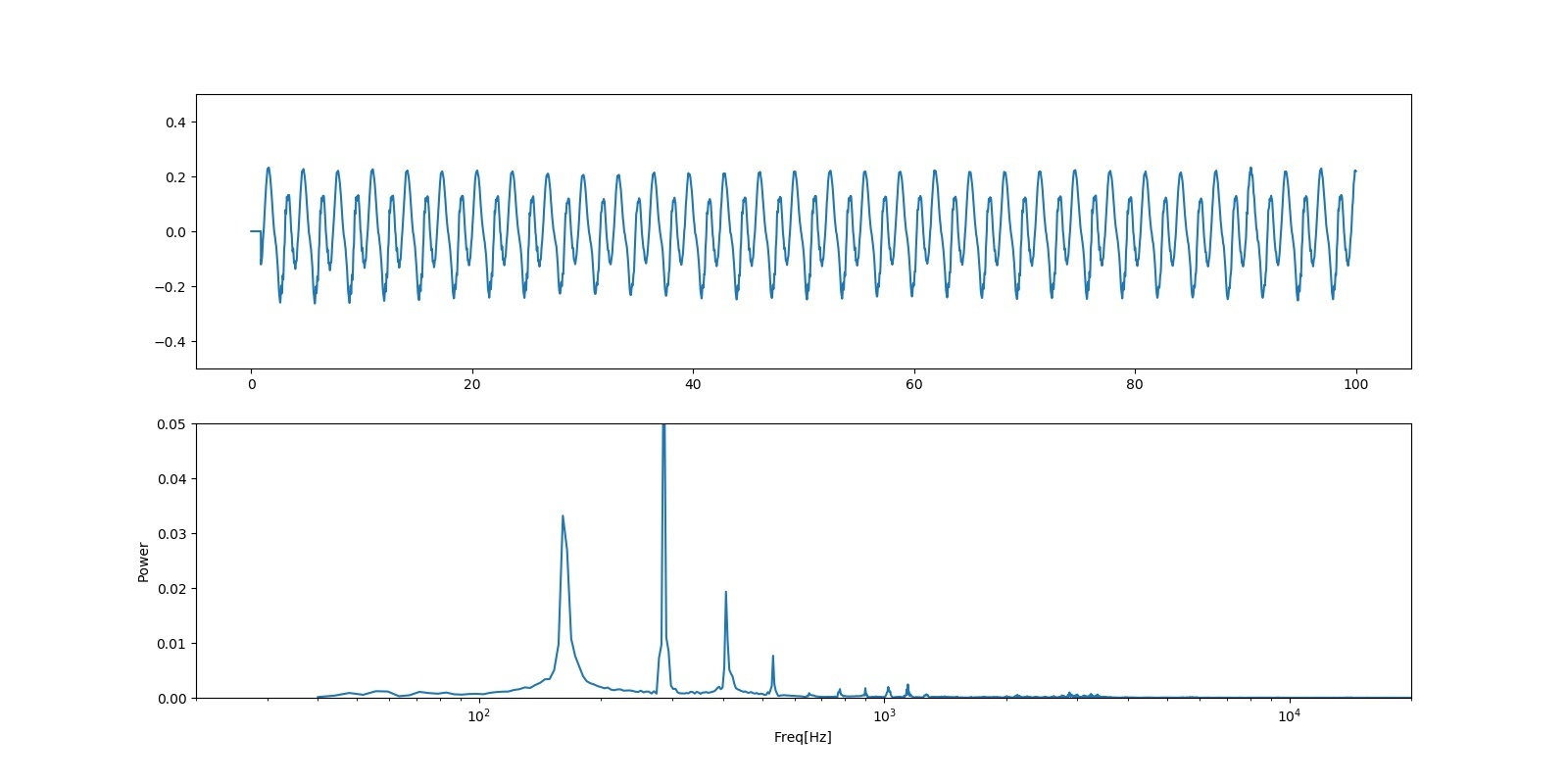
- 投稿日:2019-07-04T00:08:20+09:00
お勉強を兼ねて、鳥貴族 注文ガチャ を作った(nuxt.js + rails + heroku + python + selenium)
背景
モダンな技術を勉強したかったので、それらを使ってwebアプリを何か作ろうというところから始まりました。作っていく中で勉強するのが一番手っ取り早いという考えもありました。
下記の「サイゼ1000円ガチャ」を見てメニューの注文ガチャいいなあと思ったので、居酒屋でも同じようなものがあったら面白そうと思い、今回の鳥貴族ガチャを作ることにしました。
そんな感じで、興味のある技術を使って開発をしてみることが一番の目的でした。
成果物:鳥貴族 注文ガチャ
概要
- 食べ物と飲み物の数を入力する
- [ガチャを回すボタン]を押下
- 入力した個数分のメニューがそれぞれランダムで出力される実物
鳥貴族 注文ガチャ - Heroku
https://ak-toriki-nuxt-frontend.herokuapp.com/フロントエンドプロジェクト(Nuxt.js) - GitHub
https://github.com/lelouch99v/toriki-nuxt-frontendバックエンドプロジェクト(Ruby on Rails) - GitHub
https://github.com/lelouch99v/toriki-backend制作のポイント
使った技術
以下の技術を使いました。
- Python
- selenium webdriver
- vue.js
- nuxt.js
- Ruby on Rails
- postgreSQL
- heroku
DBに入れるメニューをスクレイピングで取得
Pythonでのスクレイピングにハマっていたのでやってみました。
焼鳥、逸品料理、スピードメニュー、ドリンクの4つのカテゴリからそれぞれメニューを取得していきます。結果はcsvで出力します。
このcsvを使ってrailsのmigrateデータとしてメニューデータをDBに入れました。
トリキ スクレイピング - GitHub
https://github.com/lelouch99v/toriki-scraping/tree/master(今回の開発で一番楽しかったのがここです)
React → Vue.js に変更
前提としてSPA + API の構成としたかったです。
業務でAngularは使っているので、ReactかVueを学びたいと思っていました。
当初Reactを選択したのですが、学習に時間がかかり出来上がるのが先になってしまいそうなのと、Nuxt.jsが気になっていたのであっさりとVueに変えました。
すごく入りやすくて学習していて楽しいです。猫本も買いました。
今後の課題
ボタン押下時のインタラクション
ガチャ回すボタン押すとメニューがランダム表示されますが、とても味気ないです。派手なものにする必要はないですが、最低限以下は実現したいと思っています。
- ボタンを押した感出す
- メニューが表示されるまでにワンクッション置く(ワクワク感が足りないため)各メニューのイメージ画像を見れるようにする
メニューの名称だけの表示ではなく、イメージ画像も見れるようにするといいと思いました。
そのまま画像を表示するのはスペースの問題などありそうなので、リンククリックでモーダル表示など一工夫は必要かもしれません。あとはメニュー表示の見た目が質素なので、もう少し改善が必要ですね。
スマホで数字入力をドロップダウンリストで可能にする
スマホではキーボード入力よりも、以下のような選択式のリストで入力のほうがやりやすいと思います。
最大値は99まであれば十分かなと。。。(もっと少なくてもいいですね)
てかすでにあった
鳥貴族ガチャでぐぐったらすでに作っていた人がいました。しかもクオリティ高い。
完全なリサーチ不足です。今回の目的は技術の勉強なので、もももんだいないんですけどね!