- 投稿日:2019-07-04T23:08:39+09:00
関連する ActiveModel::Serializer を切り替える
はじめに
- Associations において利用する Serializer を切り替えました
- AMS で該当する機能は見つからなかったので素朴に実現しました
目次
- はじめに
- TL;DR
- 環境
- 構成
- Model
- API
- やりたいこと
- 実現方法
- Controller
- Serializer
- まとめ
- 参考
TL;DR
- Rendering の際に
optionsを渡すreservations_controller.rbrender json: reservation, include: '**', restaurant_type: :detail
- Serializer の initialize で
optionsを受け取るreservation_serializer.rbdef initialize(object, options = {}) super @restaurant_type = options[:restaurant_type]
optionsの値によって 関連先で利用する Serializer を切り替えるreservation_serializer.rbattributes :id, :restaurant def restaurant serializer = case @restaurant_type when :base then RestaurantSerializer when :detail then RestaurantDetailSerializer else RestaurantSerializer end serializer.new(object.restaurant, @options)環境
- ruby: 2.6.2 - rails: 5.2.3 - active_model_serializers: 0.10.9構成
Model
app/models/restaurant.rb# == Schema Information # # Table name: restaurants # # id :bigint(8) not null, primary key # name :string not null # phone :string not null # address :string not null class Restaurant < ApplicationRecord has_many :reservationsapp/models/reservation.rb# == Schema Information # # Table name: reservations # # id :bigint(8) not null, primary key # restaurant_id :bigint(8) not null class Reservation < ApplicationRecord belongs_to :restaurantAPI
reservations_list.json{ "reservations": [ { "id": 42, "restaurant": { "id": 42, "name": "Domino's Pizza" } } ] }reservation_detail.json{ "reservation": { "id": 42, "restaurant": { "id": 42, "name": "Domino's Pizza", "phone": "03-1234-5678", "address": "東京都XXXXXX" } } }やりたいこと
- Reservations List API では restaurant の
id, nameのみを含める- Reservation Detail API では restaurant の
id, name, phone, addressを含める実現方法
Controller
restaurant_typeを Serializers に渡すreservations_controller.rbmodule API class ReservationsController < API::ApplicationController def index reservations = Reservation.all render json: reservations, include: '**', restaurant_type: :base end def show reservation = Reservation.find(params[:id]) render json: reservation, include: '**', restaurant_type: :detail end end endSerializers
- initialize で
options[:restaurant_type]を受け取るoptions[:restaurant_type]の値によって, Serializer を切り替える@optionsを 渡すことで, options や scope を 引き継ぐreservation_serializer.rbclass ReservationSerializer < ActiveModel::Serializer attributes :id, :restaurant def initialize(object, options = {}) super @options = options @restaurant_type = options[:restaurant_type] end def restaurant serializer = case @restaurant_type when :base then RestaurantSerializer when :detail then RestaurantDetailSerializer else RestaurantSerializer end serializer.new(object.restaurant, @options) end endrestaurant_serializer.rbclass RestaurantSerializer < ActiveModel::Serializer attributes :id, :name endrestaurant_detail_serializer.rbclass RestaurantDetailSerializer < RestaurantSerializer attributes :address, :phone endまとめ
- 今回は牧歌的な方法で切り替えました
- 良い方法があれば教えてください

参考
- 投稿日:2019-07-04T22:40:59+09:00
ステップバイステップで学ぶCapistrano 3によるRails 5.2 + puma + nginxのデプロイ
このドキュメントを書いた理由
qiita内も含め、同じような事例は数多く公開されているが、残念ながらイチから学ぶ上ではほとんど参考にならなかった。
なぜなら重要なのは、最終的な作業内容や設定ファイルの中身ではないからだ。それらはソフトウェアの構成やバージョンが変われば容易に変化する。
本当に重要なのは、デプロイ作業がどんなステップで成り立っていて、各ステップで何を目的とし、そのために最低限どんな設定が必要なのか、理解することだ。
そういうわけで、自分で考えて調べて実行したので、結果をまとめることにした。
方針
以下の6ステップに分割して作業を進めた。概ね、各ステップがCapistranoの一プラグインに対応している。つまり一つずつプラグインを追加していくイメージである。
- ssh/gitによるファイルの配置
- rbenvの動作確認
- bundlerによるgemインストール
- Railsの設定
- pumaの起動
- nginx と pumaの連携
可能な限り、次の2つの指針をもって進めた。
- デフォルト値が妥当な場合は、設定を書かない
- 1回きりとわかっている手順は、手動で行う
デフォルト値が妥当な場合は、設定を書かない
そのステップで本当に必要な設定が、一目でわかるようにするためである。
もちろん、人によって構成によって必要な設定は異なる。異なるからこそ、他人の設定ファイルをコピペするのではなく、公式ドキュメントを読んで一つずつ妥当性を判断すべきである。全部まとめてやるのは大変だが、一度に1プラグインなら難しくない。
1回きりとわかっている手順は手動で行う
Capistranoは独自のタスクを定義できるから、ついカッコよく自動化してみたくなる。しかしそれは「早すぎる最適化」というものだ。結局今回は、カスタムタスクは作らなかった。
環境情報とドキュメント化の範囲
サーバOS: Debian 9 stretch
クライアントOS: Ubuntu 18.04.2 LTS on WSL 1
- Ruby 2.6.3 on rbenv
- Rails 5.2.3
- puma 3.12.1
- Capistrano 3.11.0
- SQLite
各ソフトウェアのインストールには触れない。ユーザを追加したりSSH鍵をセットアップしたりといった手順にも触れない。またプラグインを追加した後の
bundle installなど、自明な手順はしばしば省略する。使用するサーバはweb/app/dbを兼ねる1台のみ、productionオンリー、しかもDBはsqlite。オモチャのようなアプリであるが、手順を学ぶ題材にはちょうど良かった。
デプロイ手順の説明
前置きが長くなった。具体的な作業に入る。Capstranoのインストールから。
Gemfile# Use Capistrano for deployment group :development do gem 'capistrano' end
bundle installの後、cap installを実行して設定ファイルを作る。今回はproductionの分しか作らない。bundle exec cap install STAGES=productionCapistranoの設定は、Railsアプリと共通の
Gemfileやconfig/以下に書き込んでいく。しかし事実上、「独立したデプロイ用のプログラムを作る」と考えた方がいい。例えばCapistrano関係の設定を変更しても、その都度
git commit / pushする必要はない。Capistranoは実行時のRailsアプリとは無関係だ。1. ssh/gitによるファイルの配置
目的
- 素のCapistranoで、ssh/gitを用いたファイル配置のみを行う。
前提条件
- サーバにSSH接続できること
- 接続したユーザで配置先のディレクトリに書き込めること
- サーバからGitリポジトリに接続できること
方針通り、最低限の設定のみ記す。必要なのはまずアプリケーションの名前と、gitリポジトリのURLと、サーバ上での配置先。
config/deploy.rbset :application, 'myapp' set :repo_url, 'git@github.com:myapp.git' set :deploy_to, "/var/www/apps/myapp"それからサーバのアドレスとユーザ名。Capistranoは実行ユーザの
~/.ssh/configを(完全ではないが)認識するので、sshコマンドで普通に接続できるなら、改めてSSH関連の設定はしなくていい。config/deploy/production.rbserver "myserver", user: "tkyk", roles: %w{app db web}デプロイ実行。
bundle exec cap production deploy指定した配置先にCapistranoが管理するディレクトリ構造が作られ、gitからファイルがチェックアウトされる。サーバにログインして確認しておこう。
2. rbenvの動作確認
目的
- 使用したいバージョンのRubyがrbenv経由で使える(Capistranoが認識する)ことを確認する。
前提条件
- rbenvおよび使用するバージョンのRubyがインストールされていること
capistrano-rbenvプラグインを追加・有効化する。
Gemfilegroup :development do #... gem 'capistrano-rbenv' endCapfilerequire "capistrano/rbenv"今回、rbenvはシステムレベルで(
/usr/local/rbenvに)インストールしており、Rubyのバージョンは.ruby-versionで指定する。この場合、設定は次のようになる。config/deploy.rbset :rbenv_type, :system set :rbenv_ruby, File.read('.ruby-version').striprbenvの構成違いは、
- rbenv_type
- rbenv_ruby
- rbenv_prefix
という3つの設定を組み合わせて対応する。たとえばrbenvをユーザレベルでインストールして、かつ
.ruby-versionを使用しないなら、次のような設定になるはず(動作確認はしてない)。config/deploy.rbset :rbenv_type, :user set :rbenv_ruby, '2.6.3' set :rbenv_prefix, "RBENV_ROOT=#{fetch(:rbenv_path)} RBENV_VERSION=#{fetch(:rbenv_ruby)} #{fetch(:rbenv_path)}/bin/rbenv exec"deployの実行。
bundle exec cap production deployこの段階では実質的に何も実行しないが、設定を間違えたりして必要なバージョンが見つからない場合、警告が出てデプロイが中止される。
3. bundlerによるgemのインストール
目的
- Rails他、アプリケーションが必要とするgemをbundlerでインストールする
前提条件
- 使用するバージョンのRubyにおいてbundlerがインストールされていること
capistrano-bundlerプラグインを追加。
Gemfilegroup :development do #... gem 'capistrano-bundler' endCapfilerequire "capistrano/bundlerアプリケーションで使用するgemはリリース間で共有したいので、プラグインの標準の規約に従い、
.bundleをlinked_dirsに追加する。ここに追加したディレクトリはsharedディレクトリ下に配置され、各リリースからはシンボリックリンクで参照される。config/deploy.rbappend :linked_dirs, '.bundle'他の設定はデフォルト値で問題なかったが、並列数だけはサーバスペックに合わせて設定すると良いと思う。デフォルトは4。
config/deploy.rbset :bundle_jobs, 2デプロイ実行。bundle installが走るので初回はかなり時間がかかるだろう。
bundle exec cap production deploy4. Railsの設定
このステップはやや複雑で、おそらく構成による差異も大きいはず。
目的
- Railsがリリース間で共有するリソースを定義する
- データベースのmigrationを行う
- assetコンパイルを行う
前提条件
- 特になし
まずはcapistrano-railsプラグインを追加し、migrationおよびassetコンパイルを有効化する。
Gemfilegroup :development do #... gem 'capistrano-rails' endCapfilerequire "capistrano/rails/assets" require "capistrano/rails/migrations"第1の目的。railsがリリース間で共有するリソースを定義する。次のファイル・ディレクトリは、基本的にどんなRailsアプリでも該当するだろう。
config/deploy.rbappend :linked_files, "config/master.key" append :linked_dirs, "log", "tmp/pids", "tmp/cache", "tmp/sockets"他にも
tmp/storageとかpublic/uploadsとか、アプリケーションによって必要なものを追加する。こうしたリソースのうち、ディレクトリは自動で作られるが、ファイルはそうではない。よって
config/master.keyは予めサーバのshared以下にコピーしておこう。scp config/master.key myserver:/var/www/apps/myapp/shared/config/第2の目的。データベースのmigration。
独立したデータベースサーバがあるなら、
database.ymlは普通、リポジトリに追加しないはず。その場合はlinked_filesにdatabase.ymlを追加し、何らかの手段でshared/config/database.ymlを設置する。一方、今回の私のアプリではsqliteを使うため、データベースファイル *.sqlite3 自体をリリース間で共有したい。そのため、
database.ymlを次のように書き換え、1段階ディレクトリ階層を深くして……config/database.ymlproduction: <<: *default database: db/production/production.sqlite3このディレクトリを共有リソースとした(
database.ymlはリポジトリ内で管理する)。config/deploy.rbappend :linked_dirs, 'db/production'第3の目的、assetコンパイルについては、特に設定する箇所がなかったのでデフォルトのまま。
デプロイ実行。migration, assetコンパイルが実行され、諸々シンボリックが作られる。
bundle exec cap production deploy5. pumaの起動
目的
- pumaを起動できるようにする
- pumaプロセスのステータスをローカルから確認できるようにする
- デプロイ完了時にpumaプロセスを再起動させる
前提条件
- 特になし
capistrano-pumaプラグインのインストールと有効化。もちろんpuma自体まだインストールしていないなら、それも。
Gemfile# Rails 5.2.3でrails newしたら最初から入っていた gem 'puma', '~> 3.11' group :development do #... gem 'capistrano3-puma' endCapfilerequire 'capistrano/puma' install_plugin Capistrano::Pumaとりあえず動かしてみたいなら、プラグインに設定ファイルを自動生成してもらうのが簡単である。
bundle exec cap production puma:configこのコマンドで、サーバ上の
shared/puma.rbに設定ファイルが作られる。(すでにサーバ上にpuma gemをインストール済みなら)以下のようなコマンドで、起動や終了、ステータスを確認できる。
bundle exec cap puma:start bundle exec cap puma:stop bundle exec cap puma:statusデプロイ実行。完了時に再起動されることを確認しよう。
bundle exec cap production deploy6. nginx と puma の連携
目的
- nginxからUNIXドメインソケットを通してpumaにアクセスできるようにする
前提条件
- nginxがインストールされていること
capistrano-pumaのnginx用プラグインを有効化。
config/deploy.rbinstall_plugin Capistrano::Puma::Nginxこれまた、とりあえず動かしたいなら、設定ファイルは自動生成すると良い。
bundle exec cap production puma:nginx_configこれで
/etc/nginx/sites-available/myapp_pruductionのようなパスに設定ファイルが作られ、sites-enabledからはシンボリックリンクが作られる(当然、ディレクトリへの書き込み権限が必要。もし書き込み権限を与えたくないならrails g capistrano:nginx_puma:configでローカルに設定ファイルを生成できる)。あとは必要に応じて設定ファイルを修整、例えばnginxのデフォルトサイト(
sites-enabled/default)を削除したりして、nginxをリロードすれば完了。sudo nginx -t && sudo systemctl reload nginx前ステップでpumaが起動しているなら再デプロイは不要なはず。httpアクセスして動作確認しよう。
終わりに
pumaプラグインが設定ファイルを自動生成してくれるおかげで、動作させるだけならとても簡単だった。もちろん実運用においては、それら設定ファイルの管理ポリシーが必要だが。
一連の過程において唯一引っかかったのは、以下の問題だった。
capistrano3-pumaのアップデートで起きたバグ解決
結局これも、デフォルトが妥当なら上書きしない、という方針で回避できた。
(とはいえcapistrano-rbenvの場合、デフォルト値が何なのか公式ドキュメントに書いてないのが困りものである。例示されている設定はデフォルト値ではない)
- 投稿日:2019-07-04T19:21:34+09:00
rails でflashメッセージを作成(toastrを使う)
はじめに
忘れそうなのでメモしました。
gemインストール
gem "toastr-rails"$ bundle installassets/javascripts/application.js//= require jquery3 //= require popper //= require bootstrap-sprockets //= require rails-ujs //= require activestorage //= require turbolinks //= require toastr #これを追加します。 //= require_tree .assets/stylesheets/application.scss@import "toastr"; #これを追加します。もし、sassを使っていなければ、
assets/stylesheets/application.css*= require toastrこれで準備完了です。
使う前にちゃんと使えるかテストして見ます。
application.html.erbに以下のように追加します。application.html.erb<script type="text/javascript"> toastr.success("hello") </script>これを追加してページにアクセスすると以下のようなアラートが右上に出現します。
色はこの4色みたいです。以下参考
application.html.erb<script type="text/javascript"> toastr.success("hello") toastr.warning("hello") toastr.error("hello") toastr.info("hello") </script>
flashメッセージに適応する
まず、前提としてflashのシンボルは :alert と :notice の2つです。(deviseを使ってたのでその2つになりました)ホントは :error と :successのほうが都合がいいのですが。。。
flashメッセージがある時適宜flashを使いたいのでapplication.html.erbに記述します。layouts/application.html.erb<!DOCTYPE html> <html> <head> <title>InstagramClone</title> <%= csrf_meta_tags %> <%= csp_meta_tag %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> </head> <body> <%= render 'layouts/header' if user_signed_in? %> <%= yield %> <%= render "layouts/footer" %> <!--ここから下を追加しています。----------------------- --> <% if flash.any? %> <script type="text/javascript"> <% flash.each do |key, value| %> <% key = "success" if key == "notice" %> <% key = "error" if key == "alert" %> toastr['<%= key %>']('<%= value %>'); <% end %> </script> <% end %> <!--ここまでです----------------------------------- --> </body> </html>まず、if flash.any? flashがあるかないかを判定してます。その次に見た目が奇妙なのですが、
scriptタグでflashのeach分を囲ってます。でtoastrで扱うメソッドが :info :success :error :warning の4つです。しかし、flashのシンボルが :alert と :notice になっているため、変換して上げる必要があります。
その記述が以下の2つになります。<% key = "success" if key == "notice" %>
<% key = "error" if key == "alert" %>:notice を :success に :alert を :error に変換してます。
最後に値をtoastrに入れて終わりです。おまけ
こんな書き方も出来るみたいです。
layouts/application.html.erb<% if flash.any? %> <script type="text/javascript"> <% flash.each do |key, value| %> <% type = key.to_s.gsub('alert', 'error').gsub('notice', 'success') %> toastr.<%= type %>('<%= value %>') <% end %> </script> <% end %>
- 投稿日:2019-07-04T17:18:21+09:00
【Rails】Form_forでプルダウンメニューの項目をDBから選択する
概要
select_tagによる、決め打ちの選択肢 ↓
<%= f.select :subject, [["1", "1"], ["2", "2"]] , class:"form-control" %>
ではなく、DBのテーブルから項目を引っ張ってきたい時今回の例
都市を入力するページで、国をプルダウンで選択させたい。
Countries (国のテーブル) ※数が増えることがないので
db/*seed.rbに記載済み
id name 1 Australia 2 Canada 3 Japan has_many :cities
国は都市をたくさん持っています。Cities (都市のテーブル)


id name country_id 1 Tokyo 3 2 Osaka 3 3 Kyoto 3 belongs_to :countries
collection_select を使う
app/views/cities/new.html.erb<%= form_for @city do |c| %> <%= c.label :country_id %> <%= c.collection_select :country_id, Country.all, :id, :country_name %>collection_selectの文法
<%= f.collection_select <属性名>, <プルダウンメニュー表示用の配列データ>, <valueとして扱うカラム名>, <表示用のカラム名>, <オプション> %>オプション
:prompt
prompt オプションを使うと、プルダウンメニューが選択されていない時に設定した文字列の行が先頭に追加される。
<%= form_for @city, url: admins_cities_new_path do |c| %> <%= c.label :country_id %> <%= c.collection_select :country_id, Country.all, :id, :country_name, :prompt => "国を選択" %>これで選択していない時は、 国を選択が表示されます
- 投稿日:2019-07-04T16:56:18+09:00
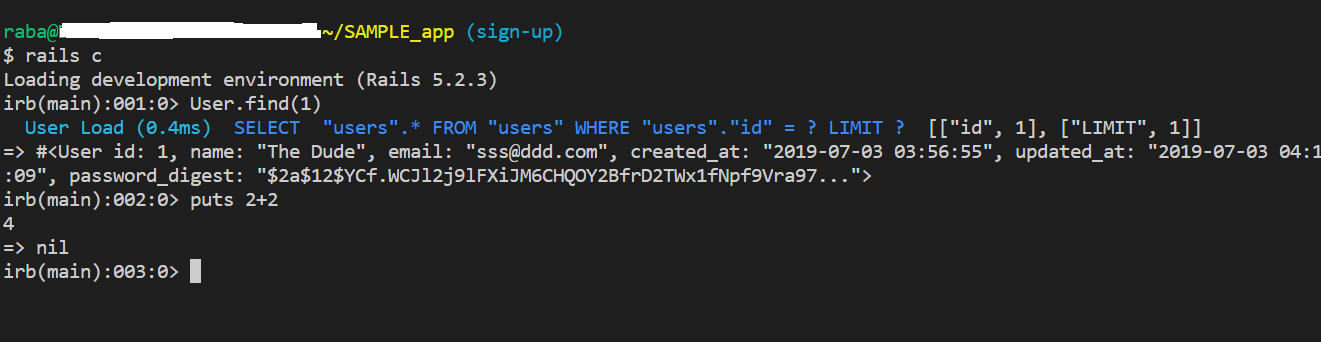
Git bashでrails consoleが開けないときの解決策
はじめに
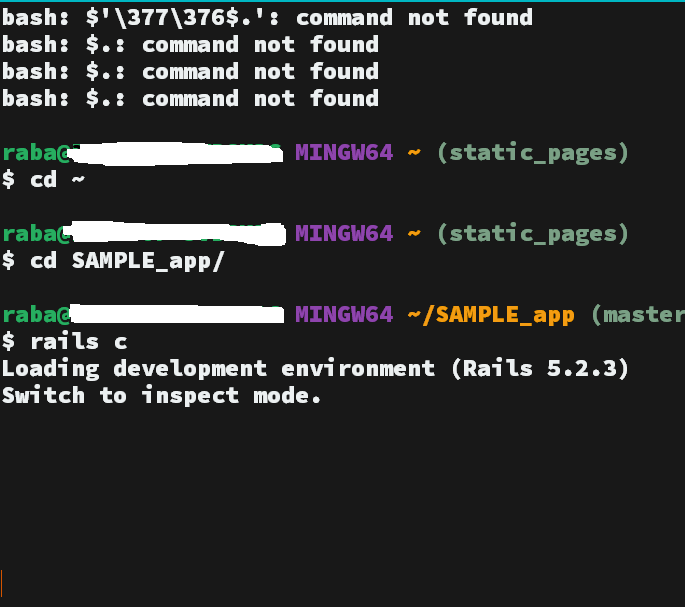
WindowsのGit bashでrails cを行うと Switch to inspect mode.と出てきてしまい後は何も出ません。
一応入力することは出来ても真っ黒な画面なので気持ち悪いです
解決策
Windowsのプロンプトでは、駄目でしたが、VS code内でGit bashを開くとrails cを開くと何故かは分かりませんが、うまく開くことが出来ました。
まとめ
今回偶然うまく行って良かったのですが、ただ、windowsのプロンプトの方は駄目で、VS codeでやるとうまく行った理由が分からないのでそこが気になります。
- 投稿日:2019-07-04T16:18:08+09:00
【Rails】RSpecでFactoryBotをcreateしようとしたらErrorが吐き出されたので調べた
RSpecを書いたところ、FactoryBotからuserをcreateするところでエラーが発生してしまうので、原因を調べてみた。
事象
spec/factories/user.rbFactoryBot.define do factory :user do name { "テストユーザー" } email { "test_user@test.co.jp" } password { "12345678" } end enduser_spec.rbrequire 'rails_helper' RSpec.describe User, type: :model do let(:user) { user :user } describe "バリデーション" do it "nameが空だとinvalid" do user.name = "" expect(user).not_to be_valid end end endrspecを実行したところ、エラーが発生。
ちなみに今回、Userモデルのvalidatesは:name, presence: trueだけとする。Failures: 1) User バリデーション nameが空だとinvalid Failure/Error: let(:user) { create :user } ActionView::Template::Error: Missing host to link to! Please provide the :host parameter, set default_url_options[:host], or set :only_path to true # ./spec/models/client_spec.rb:4:in `block (2 levels) in <top (required)>' # ./spec/models/client_spec.rb:9:in `block (3 levels) in <top (required)>' # ------------------ # --- Caused by: --- # ArgumentError: # Missing host to link to! Please provide the :host parameter, set default_url_options[:host], or set :only_path to true # ./spec/models/client_spec.rb:4:in `block (2 levels) in <top (required)>' Finished in 0.52519 seconds (files took 2.18 seconds to load) 1 example, 1 failure何やら
Missing host to link to! Please provide the :host parameter, set default_url_options[:host], or set :only_path to trueというエラーが吐き出されている。結論
今回は
deviseを使っているのだが、メール認証機能のconfirmableを有効にしている。user.rb# Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable, :trackable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable, :confirmableメール認証機能とは→アカウント新規作成時に登録したアドレスにメールが送られ、確認用リンクをクリックするとログイン画面からログイン可能となる。
このリンクをクリックしたタイミングで、Userのconfirmed_atカラムにその時刻がsaveされる。
どうやらconfirmableが有効の場合、このconfirmed_atがpresentかnilかを見分けて、そのユーザーがログイン可/不可を条件分けしているらしい。
(詳細までは調べられてません)従って、FactoryBotのファイルに
confirmed_atを書き加えるとspec/factories/user.rbFactoryBot.define do factory :user do name { "テストユーザー" } email { "test_user@test.co.jp" } password { "12345678" } confirmed_at { Date.today } end end. Finished in 0.2486 seconds (files took 4.21 seconds to load) 1 example, 0 failures無事、rspecが通りました。
- 投稿日:2019-07-04T16:18:08+09:00
【Rails】FactoryBotをcreateしようとしたらErrorが吐き出されたので調べてみた
RSpecを書いたところ、FactoryBotからuserをcreateするところでエラーが発生してしまうので、原因を調べてみた。
事象
spec/factories/user.rbFactoryBot.define do factory :user do name { "テストユーザー" } email { "test_user@test.co.jp" } password { "12345678" } end enduser_spec.rbrequire 'rails_helper' RSpec.describe User, type: :model do let(:user) { user :user } describe "バリデーション" do it "nameが空だとinvalid" do user.name = "" expect(user).not_to be_valid end end endrspecを実行したところ、エラーが発生。
ちなみに今回、Userモデルのvalidatesは:name, presence: trueだけとする。Failures: 1) User バリデーション nameが空だとinvalid Failure/Error: let(:user) { create :user } ActionView::Template::Error: Missing host to link to! Please provide the :host parameter, set default_url_options[:host], or set :only_path to true # ./spec/models/client_spec.rb:4:in `block (2 levels) in <top (required)>' # ./spec/models/client_spec.rb:9:in `block (3 levels) in <top (required)>' # ------------------ # --- Caused by: --- # ArgumentError: # Missing host to link to! Please provide the :host parameter, set default_url_options[:host], or set :only_path to true # ./spec/models/client_spec.rb:4:in `block (2 levels) in <top (required)>' Finished in 0.52519 seconds (files took 2.18 seconds to load) 1 example, 1 failure何やら
Missing host to link to! Please provide the :host parameter, set default_url_options[:host], or set :only_path to trueというエラーが吐き出されている。結論
今回は
deviseを使っているのだが、メール認証機能のconfirmableを有効にしている。user.rb# Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable, :trackable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable, :confirmableメール認証機能とは→アカウント新規作成時に登録したアドレスにメールが送られ、確認用リンクをクリックするとログイン画面からログイン可能となる。
このリンクをクリックしたタイミングで、Userのconfirmed_atカラムにその時刻がsaveされる。
どうやらconfirmableが有効の場合、このconfirmed_atがpresentかnilかを見分けて、そのユーザーがログイン可/不可を条件分けしているらしい。
(詳細までは調べられてません)従って、FactoryBotのファイルに
confirmed_atを書き加えるとspec/factories/user.rbFactoryBot.define do factory :user do name { "テストユーザー" } email { "test_user@test.co.jp" } password { "12345678" } confirmed_at { Date.today } end end. Finished in 0.2486 seconds (files took 4.21 seconds to load) 1 example, 0 failures無事、rspecが通りました。
- 投稿日:2019-07-04T15:39:05+09:00
TECH ~Day11~
学習内容
・フォーム
・pry-rails
・binding-pry・フォーム
ユーザーが情報を入力し、その情報をサーバーに送信するためのもの。HTMLコードの中にform要素を作成し、その中にフォームを構成する部品のinput要素やtextarea要素を配置することで作成できる。Railsでフォームから情報を発信するには「form_tag」をはじめとするヘルパーメソッドを使う。
・pry-rails
Rails向けのデバックツール。
バグの有無、処理を止めて、ソースコードが正しいのかチェックするツール。・binding-pry
これは、binding.pryという文字列をソースコードの中に記述することで、binding.pryという文字列が存在する部分でRailsの処理を止めることができるというものです。
- 投稿日:2019-07-04T13:56:53+09:00
TECH ~Day9~
学習内容
・erbファイルでrubyコードを使うとき
・改行の適応
・ヘルパーメソッド・erbファイルでrubyコードを使うとき
Railsの見た目用のファイルである「erb」ファイルの中でRubyのコードを利用する場合、「<%= %>」という記述で囲う。
<%= %>を利用するにはビューの拡張子が、「erb」になっている必要がある。・改行の適応
railsは「simple_format」というメソッドを使わなければ改行が適応されない。
(復習)
①改行→
②文字列を→で括る
・ヘルパーメソッド
simple_formatのようにRailsではviewでHTML加工をするために、予めのメソッドが用意されている。これらをまとめて「ヘルパーメソッド」と呼ぶ。他にはform_tag(フォームを出現)やlink_to(aタグを出現)などがある。
- 投稿日:2019-07-04T13:56:53+09:00
TECH ~Day10~
学習内容
・erbファイルでrubyコードを使うとき
・改行の適応
・ヘルパーメソッド・erbファイルでrubyコードを使うとき
Railsの見た目用のファイルである「erb」ファイルの中でRubyのコードを利用する場合、「<%= %>」という記述で囲う。
<%= %>を利用するにはビューの拡張子が、「erb」になっている必要がある。・改行の適応
railsは「simple_format」というメソッドを使わなければ改行が適応されない。
(復習)
①改行→<br/>
②文字列を→<p>で括る・ヘルパーメソッド
simple_formatのようにRailsではviewでHTML加工をするために、予めのメソッドが用意されている。これらをまとめて「ヘルパーメソッド」と呼ぶ。他にはform_tag(フォームを出現)やlink_to(aタグを出現)などがある。
- 投稿日:2019-07-04T13:44:47+09:00
TECH ~Day9~
学習内容
・一つのデータをテーブルから取り出す
・content カラムの値を取り出す
・全てのデータをテーブルから取り出す
・配列のデータから投稿内容を取り出す・一つのデータをテーブルから取り出す
書き方
$ rails console
post = Post.first
!Post.firstの書き方でpostsテーブルにある最初のデータを取得できる。・contentカラムの値を取り出す
書き方
$ rails console
post = Post.first
post.content
="~~~~~"
! post = Post.first
post.content
この二つの流れによってPost.firstで得たデータの投稿内容を取得できる。・全てのデータをテーブルから取り出す
先ほど一つのデータの取り出し方で書いた「Post.first」のfirstの部分を「all」にすることで全てのデータをテーブルから取り出すことができる。書き方
posts = Post.all・配列のデータから投稿内容を取り出す
Post.all[0]はPost.firstと同じ内容のデータ。
これを「Post.all[0].content」と書くことで投稿内容を取得できる。
- 投稿日:2019-07-04T13:34:13+09:00
google-api-client,optimist(trollop)を使うと出てくる3つのエラーとその解決法
概要
Youtube APIを使用し動画情報を 取得し一覧表示するサイトを作成中にハマってしまったエラーが3つありましたので、エラーパターンと解決法を書き残しておきます。
Gemのバージョンにも関わってきますし、デプロイしているサーバの環境にも依存しますので、このエラー現象と解決方法は2019年7月段階のものだということを念頭に置いてください。環境
- Ruby 2.4.1
- rails 5.2.3
- google-api-client 0.8.6
- optimist 3.0.0(旧trollop)
- サーバ
- heroku
エラーパターン1:oprimist(trollop)のエラー
herokuのlog2019-06-18T11:44:23.578660+00:00 app[web.1]: Error: unknown argument '-p'. 2019-06-18T11:44:23.578668+00:00 app[web.1]: Try --help for help.このパターンはoptimist::optionsメソッドにコマンドライン引数がぶっこまれていることが原因です。
heroku上だと-pと-eオプションを付けた状態でrails sされます。
参考(optimistのソース):https://github.com/ManageIQ/optimistローカル環境でサーバを起動する際にrails s だけで起動している場合は起きないのにheroku上だと上記のエラーが出てきます。ためしにローカル環境でrails s -p ポート番号(3000) -e development で起動して実行するとheroku上で動かした時と同じエラーが出ることが確認できます。
もしくはbyebugでoptimist::optionsをコールする直前のARGVの値を参照してみると確認できると思います。エラーパターン1:解決法
1.ARGVの値をローカル変数に退避
2.ARGVを空にする
3.optimist::optionsをコール
4.ARGVの値を元にもどす修正コードarg_array_save = [] arg_array_save = ARGV.shift(4) opts = Optimist::options do ・・・中略・・・ arg_array_save.each do |arg_push| ARGV.push(arg_push) endこんな感じになります。ARGVはメソッド内で値を直接操作すること(代入等)ができないので、shift,push等のメソッドを使用していじっています。
もっといい方法があればぜひコメントで教えて頂きたいです。エラーパターン2:ArgumentError
herokuのlog2019-06-24T14:54:19.983862+00:00 app[web.1]: F, [2019-06-24T14:54:19.983799 #4] FATAL -- : [d9d33d3a-e4a5-4ba3-a0f6-7286855ae09a] ArgumentError (header field value cannot include CR/LF):このパターンは上記のパターン1を解決した後にでてくる可能性があります。
原因はgoogle-api-clientのバージョンとrubyのバージョンがうまく対応できてないみたいです。gem内のソースコードレベルの原因は解明できてません。gem内の解析めんどくさい解決法は2つありますが、解決法パターン1推奨です。
エラーパターン2:解決法パターン1
Rubyのバージョンを 2.4.1にする。
なぜかわかりませんが2.4.6から2.4.1にバージョンを落とすと解決しました。エラーメッセ的には改行コードだと思うので、その辺の処理がバージョンによって違うのでしょうか。
わかる人いたら教えてください。エラーパターン2:解決法パターン2
google-api-client を最新のバージョンにする。
2019年7月現在だと最新は0.30.4です。
Gemを最新にするとエラーパターン2のエラーメッセージは消えるのですが、後述するエラーパターン3の状態に陥ってしまうので、この解決法はあまりお勧めできないです。
GitHubのReadmeを全部翻訳してバージョンによる変更点を全部理解すると解決できるかもしれないです。エラーパターン3:LoadError
herokuのlog2019-06-20T16:12:55.170597+00:00 app[web.1]: /app/vendor/bundle/ruby/2.4.0/gems/bootsnap-1.4.4/lib/bootsnap/load_path_cache/core_ext/kernel_require.rb:33:in `require': No such file to load -- google/api_client.rb (LoadError)ファイルが読み込めてないみたいですが、heroku内のファイルとかいじれるんでしょうか。
エラーパターン3:解決法
boot.rbのbootsnapをOFFにする。
これでエラーメッセージ自体は消えますが、また同じようなエラーが今度はactivesupportで出てきます。
この解決ルートは永遠と上記の解決法を繰り返す羽目になりそうだったので、やめました。
ですので、エラーパターン3の明確な解決法はわかってない状態です。まとめ
- エラーパターン3の最終的な解決法は不明。エラーパターン2でrubyのバージョンを変えて解決する方が現実的。
- Gemのバージョンアップなどで仕様が変わるのでReadmeを読まないとわからない。
- 英語を勉強する必要がある。
- 投稿日:2019-07-04T13:20:06+09:00
プログラミング初心者はまずRailsチュートリアルをやるべきなのか?
Railsチュートリアルは初心者がやるべきか?
プログラミング初心者の流れとして、最近はProgateやドットインストールをやって基礎を学んで、そして次の段階でRailsチュートリアルをやろう!というようなものが結構多いように感じます。
Railsチュートリアルは、手を動かしものを作りながら学習を進められるとてもいい教材です。しかし、これをプログラミングを始めたばかりの初心者が取り組むべきなのでしょうか?個人的な意見
私の個人的な意見としては、NOです。特に独学の場合はあまりお勧めできないと思っています。
先ほど書いたようにRailsチュートリアルはとてもいい教材です。しかしながら、初心者向けかというとちょっと違うかな、と思います。なぜNO?
なぜ初心者向けではないと思うか、その最たる理由は初心者のレベル感は大きく異なるということです。
初心者といってもできることはかなり違ってくると思っています。
例えば、ProgateでRubyのコースを終えた方はプログラミング初心者と言えるでしょう。また一方で、自分でとりあえずは開発環境を作って、Progateの知識をつかって何か書いてみた!みたいな人もプログラミング初心者ということもできるでしょう。
つまり同じプログラミング初心者といってもできることの幅が大きく違うのです。そもそも初心者の線引きは人それぞれですしね。じゃあいつ、どうやってやるべきなの?
さて、NOとはいったものの、永久に基礎練を続けていては意味がありません。ではいつやるべきなのか。
ベストなタイミングは挑戦を何度もしてみて、行けそうだなと感じたときですが、これだと元も子もないので、ちょっとした自分なりの基準を置きたいと思います。まずは何を勉強したうえでやるべきか。
ここはProgateが個人的にも好きな教材なので、それを例にして書いていきます。
Progateでこれはやっておいておくべき、というものは
- Html&CSS
- Ruby
- Rails
- Command line
- SQL
です。このすべてをやって、少し足りないかな、という感じです。
さらに、ここに加えてWebの知識を付けておくべきだと私は思います。というのも、Railsは簡単にアプリケーションが作れてしまうため、何がどう動いているのかわからなくても、なんとなくものを作れてしまいます。しかし、なんとなくでやっているので知識として定着しなかったり、他の言語への知識の転用ができなかったりします。
なので、どんな形でもいいのでWebの知識をつけておくとベストです。おすすめのやり方
上に書いた勉強をしたうえでいよいよRailsチュートリアルに入っていきます。
そしてその時のおすすめのやり方ですが、
- Heroku(デプロイ)
- Bitbucket(バージョン管理)
- テスト
このすべてを飛ばしてまずは一周することです。
この部分がRailsではとても難しい部分になると思います。
特にテストで詰まると進まなくなってしまうので、まずは何か作り切る!というところに焦点をおいて、作ることに関係のない、上の三つの難しい部分は飛ばしてしまいましょう。
そして二週目でここの部分も余裕があれば触り、勉強していくと詰まらずにすすめると思います!終わりに
私はプログラミングを始めたとき、一緒に勉強する仲間がいました。しかし、Railsチュートリアルで自分以外が挫折してしまい、気づけば一人になってしまっていました。
適切なタイミング、適切な知識で勉強すればRailsチュートリアルはとてもいい教材です。しかし、その一方で、多くのプログラミング初心者を挫折させてしまっているものでもあります。(TwitterでRailsチュートリアルを始めて気づけば消える方の多い事!)
一人でもそんな人を減らせるように願います。
- 投稿日:2019-07-04T12:37:28+09:00
Rails6 のちょい足しな新機能を試す46(multidb connects_to 編)
はじめに
Rails 6 に追加されそうな新機能を試す第46段。 今回は、
multidb connects_to編です。
Rails 6 では、 複数DBに対応したため、DB接続先を切り変えることができるようになっています。Ruby 2.6.3, Rails 6.0.0.rc1 で確認しました。Rails 6.0.0.rc1 は
gem install rails --prereleaseでインストールできます。$ rails --version Rails 6.0.0.rc1今回の準備
今回は、 Rails6 のちょい足しな新機能を試す35(multidb migration --database オプション編)
をベースに作業を進めます。library 側にも users テーブルを追加する
backbone 側に
usersテーブルが存在しますが、library側にもusersテーブルを追加します。$ bin/rails g migration CreateUser name --db=librarydb:migrate を実行する
bin/rails g db:migrateUser モデルを作る
User モデルを作ります。
app/models/user.rbclass User < ApplicationRecord endBook モデルを作る
Book モデルを作ります。
booksテーブルは、backboneにはなく、library側にありますので、DB接続先をconnects_toを使って明示的に設定します。app/models/book.rbclass Book < ApplicationRecord connects_to database: { writing: :library, reading: :library } endRails 6.0.0rc1 では、
:writingと:readingの両方を指定する必要があるようです。connects_to database: :libraryだとエラーになりました。
今回は、Book クラスに直接 DB 接続先を記載しましたが、もし、Bookモデルの他にも、 library 側に接続する接続するモデルがあれば、
ApplicationRecordから派生させた抽象クラスを作成して、抽象クラスの中で、connects_toを使い、 Book クラスは、その抽象クラスから派生させた方が良いでしょう。(Rails Guide ではそういう書き方になってます。)seed データを作る
backbone側library側双方にusersテーブルが存在するため、両方のDBに接続してデータを登録するように、ActiveRecord::Base.connected_toを使います。
booksテーブルは、library側に存在しますが、Bookクラスで接続先をlibraryに指定しているため、ActiveRecord::Base.connected_toを使う必要がありません。db/seeds.rbUser.create(name: 'Taro') ActiveRecord::Base.connected_to(database: :library) do User.create(name: 'Hanako') end Book.create(title: 'Programming Ruby')seed データを登録する
$ bin/rails db:seedcontroller と View を作る
登録した seed データを表示するため、 controller と view を作ります。
bin/rails g controller Dashboard index
Userモデルにメソッドを追加するlibrary の
usersテーブルを検索できるようにUserモデルにall_in_libraryメソッドを追加します。
ActiveRecord::Base.connected_toを使ってlibrary側に接続先を変更してからallメソッドを呼び出します。app/models/user.rbclass User < ApplicationRecord def self.all_in_library ActiveRecord::Base.connected_to(database: :library) do all end end endDashboardController#index メソッドを修正する
登録したデータを取得するように
indexメソッドを修正します。app/controllers/dashboard_controller.rbclass DashboardController < ApplicationController def index @books = Book.all @users = User.all.to_a @users_in_library = User.all_in_library end endここで、 メソッドの2行目を
@user = User.all.to_aとしている理由は後述します。データを表示する View を作成する
各変数の値を表示するための View を作成します。
app/views/dashboard/index.html.erb<h1>Dashboard#index</h1> <table> <thead> <tr> <th> valiable </th> <th> value </th> </tr> </thead> <tbody> <tr> <td> @books </td> <td> <%= @books.map(&:title) %> </td> </tr> <tr> <td> @users </td> <td> <%= @users.map(&:name) %> </td> </tr> <tr> <td> @users_in_library </td> <td> <%= @users_in_library.map(&:name) %> </td> </tr> </tbody> </table>rails server を起動してブラウザで表示する
$ bin/rails shttp://localhost/dashboard/index にアクセスすると値が表示されます。
User.all ではなく User.all.to_a な理由
User.all にすると、 Taro の値が表示されず Hanako になってしまいます。
これは、
allメソッドがActiveRecord::Relationを返すだけで、 実際にSQLを発行しないためです。 このため、allにすると、 View を rendering するときに、SQLが発行されてしまい、接続先がlibraryに設定された状態で SQLが発行されてしまうようです。
これを防ぐために、DB の接続が library に変わる前に SQLを発行するため、意図的にto_aをつけました。app/controllers/dashboard_controller.rbdef index @books = Book.all @users = User.all # => ActiveRecord::Relation が返され SQLは実行されない。 @users_in_library = User.all_in_library # 接続先が library に変わる # このあと index View をレンダリングする際に、全てのSQLが発行される。 end
User.allの場合、View のレンダリングの際にすべての SQL が発行されていることがログからもわかります。Rendering dashboard/index.html.erb within layouts/application Book Load (0.3ms) SELECT "books".* FROM "books" ↳ app/views/dashboard/index.html.erb:20:in `map' User Load (0.3ms) SELECT "users".* FROM "users" ↳ app/views/dashboard/index.html.erb:28:in `map' User Load (0.5ms) SELECT "users".* FROM "users" ↳ app/views/dashboard/index.html.erb:36:in `map'
User.all.to_aとした場合、controller の中で SQL が発行されていることがわかります。User Load (0.4ms) SELECT "users".* FROM "users" ↳ app/controllers/dashboard_controller.rb:4:in `index' Rendering dashboard/index.html.erb within layouts/application Book Load (0.3ms) SELECT "books".* FROM "books" ↳ app/views/dashboard/index.html.erb:20:in `map' User Load (0.4ms) SELECT "users".* FROM "users" ↳ app/views/dashboard/index.html.erb:36:in `map'今回、試したコードが特殊な例かも知れませんが、挙動が少し紛らわしいので、今後のバージョンで修正されるかも知れませんね。
試したソース
試したソースは以下にあります。
https://github.com/suketa/rails6_0_0rc1/tree/try046_multidb_connection_switching参考情報


- 投稿日:2019-07-04T12:33:00+09:00
React+ReduxにRedux-Sagaを導入して非同期処理(axios)をさせる手順
ソースコード
https://github.com/tontoko/react-redux-saga-rails↓こちらの記事を参考にまずReact+Rails(API)の環境を整えました。
Ruby on Rails+ReactでCRUDを実装してみた
https://qiita.com/yoshimo123/items/9aa8dae1d40d523d7e5d非常に分かりやすいです。
Reduxの導入
sudo npm install redux react-redux --saveActionCreator
crud-front/src/Actions/actions.jsexport default { create: (data) => { return { type: 'CREATE', data } }, update: (id, data) => { return { type: 'UPDATE', id, data } }, delete: (id) => { return { type: 'DELETE', id } }, init: () => { return { type: 'INIT' } }, }Reducer
crud-front/src/Reducers/productsReducer.js// 中味はまだ空 const initialState = { products: [], isFetching: false, } export default function productReducer(state = initialState, action) { switch (action.type) { case 'CREATE': return Object.assign({}, state, { }) case 'UPDATE': return Object.assign({}, state, { }) case 'DELETE': return Object.assign({}, state, { }) case 'INIT': return Object.assign({}, state, { }) default: return state } }crud-front/src/Reducers/reducers.js// Reducer達を一つに纏める // 今回は必要ないけど。。 import {combineReducers} from 'redux' import productsReducer from './productsReducer' export default combineReducers({ products: productsReducer, });index.js
crud-front/src/index.js// -- 省略 -- import { Provider } from 'react-redux' import { createStore, applyMiddleware } from 'redux' import Reducers from './Reducers/reducers' const store = createStore( Reducers, ) ReactDOM.render( <Provider store={store}> <App /> </Provider>, document.getElementById('root') )MainContainer.js
crud-front/src/Components/MainContainer.js// -- 省略 -- import { connect } from 'react-redux' import Actions from '../Actions/actions' import { bindActionCreators } from 'redux' const mapStateToProps = state => { return state } const mapDispatchToProps = dispatch => { return { init: () => dispatch(Actions.init()), create: (data) => dispatch(Actions.create(data)), update: (id, product) => dispatch(Actions.update(id, product)), delete: (id) => dispatch(Actions.delete(id)), } } //// こっちでもいいかな // const mapDispatchToProps = dispatch => { // return bindActionCreators(Actions, dispatch) // } export default connect(mapStateToProps, mapDispatchToProps)(MainContainer)非同期処理をどこに書くべきか
Redux導入の雛形はできたものの、ここで問題が起きる。
reduxで非同期処理をするいくつかの方法(redux-thunk、redux-saga)
https://qiita.com/muiscript/items/63386fd65c7e9f06f5d4Actionをプレーンに保てテストもしやすい、というRedux-Sagaを試してみます。
Redux-Sagaの導入
Redux-Sagaの概要については以下の記事もわかりやすいです。
redux-sagaで非同期処理と戦う
https://qiita.com/kuy/items/716affc808ebb3e1e8ac【React】 redux-saga でAPIを叩く
https://k-tomoo.hatenablog.com/entry/2018/03/12/151045まずはインストールします。
sudo npm install redux-saga --saveSaga部分をInit処理を例にとって書いていきます。
crud-front/src/Saga/Init.jsimport axios from "axios" import { put, call, takeEvery } from 'redux-saga/effects'; const initAjax = () => axios.get('http://localhost:3001/products') .then((res) => { const data = res.data console.log(data) return { data } }) .catch((error) => { return { error } }) function* initProduct() { // 3. const { data, error } = yield call(initAjax); console.log(data) if (data) { // 4. yield put({ type: "INIT_SUCCEEDED", data }); } else { // todo: エラーハンドリング // 今回はエラー処理は省きます } } // 1.& 2. export default [takeEvery("INIT", initProduct)];パッとみてもよくわからないと思うので順に見ていきます。
takeEveryの第一引数で指定されたアクションがどこかで呼ばれる
そのアクションの完了を待って第二引数が呼ばれる
yield call()で中の関数が実行され、Promiseオブジェクトが帰ってくるまで待つ
yield putで新たにActionをdispatchする
ざっくりこのような流れで非同期処理を実現しています。
function* などを見て戸惑った方は以下の記事がわかりやすいです。
https://qiita.com/kura07/items/cf168a7ea20e8c2554c6
https://qiita.com/kura07/items/d1a57ea64ef5c3de8528Redux-Sagaを組み込む
crud-front/src/index.jsimport createSagaMiddleware from 'redux-saga' import { all } from 'redux-saga/effects' import Init from './Saga/Init' import Create from './Saga/Create' import Update from './Saga/Update' import Delete from './Saga/Delete' // ここで一つにまとめます function* rootSaga() { yield all([ ...Init, ...Create, ...Update, ...Delete, ]) } const sagaMiddleware = createSagaMiddleware() const store = createStore( Reducers, applyMiddleware(sagaMiddleware) ) sagaMiddleware.run(rootSaga) ReactDOM.render( <Provider store={store}> <App /> </Provider>, document.getElementById('root') )呼び出し用、成功した処理用、エラー処理用と分けてやる必要があります。(エラー分は今回は省略)
crud-front/src/Actions/actions.jsexport default { create: (data) => { return { type: 'CREATE', data } }, createSuccess: (data) => { return { type: 'CREATE_SUCCEEDED', data } }, update: (id, data) => { return { type: 'UPDATE', id, data } }, updateSuccess: (id, data) => { return { type: 'UPDATE_SUCCEEDED', id, data } }, delete: (id) => { return { type: 'DELETE', id } }, deleteSuccess: (id) => { return { type: 'DELETE_SUCCEEDED', id } }, init: () => { return { type: 'INIT' } }, initSuccess: (data) => { return { type: "INIT_SUCCEEDED", data} }, }crud-front/src/Reducers/productsReducer.jsimport axios from "axios" const initialState = { products: [], isFetching: false, } export default function productReducer(state = initialState, action) { switch (action.type) { case 'CREATE': return Object.assign({}, state, { isFetching: true, }) case 'CREATE_SUCCEEDED': return Object.assign({}, state, { products: [...state.products, action.data], isFetching: false, }) case 'UPDATE': return Object.assign({}, state, { isFetching: true, }) case 'UPDATE_SUCCEEDED': const updateIndex = state.products.findIndex(x => x.id === action.id) const updatedProductsState = state.products updatedProductsState.splice(updateIndex, 1, action.data) return Object.assign({}, state, { products: updatedProductsState, isFetching: false, }) case 'DELETE': return Object.assign({}, state, { isFetching: true, }) case 'DELETE_SUCCEEDED': const deleteIndex = state.products.findIndex(x => x.id === action.id) const deletedProductsState = state.products deletedProductsState.splice(deleteIndex, 1) return Object.assign({}, state, { products: deletedProductsState, isFetching: false, }) case 'INIT': return Object.assign({}, state, { products: [], isFetching: true, }) case 'INIT_SUCCEEDED': return Object.assign({}, state, { products: action.data, isFetching: false, }) default: return state } }ここまでで導入は完了です。
後は例としてinit()を呼んでやります。crud-front/src/Components/MainContainer.jsclass MainContainer extends React.Component { // -- いろいろ省略 -- componentDidMount() { this.props.init() } render() { if (this.props.isFetching === true) { return (<div />) } else { return ( <div className='app-main'> <FormContainer createProduct={this.props.create} /> <ProductsContainer deleteProduct={this.props.delete} updateProduct={this.props.update} /> </div> ); } } } // -- いろいろ省略 --
- 投稿日:2019-07-04T10:20:05+09:00
【Rails】namespace / 指定ディレクトリ以下にコントローラーを作成する
1つのアプリケーション内に
userphotographeradmin
3つのログイン口があるマッチングアプリを作成中学習の記録
概要
コントローラーやビューを生成する時、
それぞれ同じ名前になってしまうコントローラー名やビューの名前がありますよね。
例えば、userphotographeradminぜんぶContacts.controller(お問い合わせ用)を持っています。そこでディレクトリを指定してコントローラーを生成してあげたら、
adminsディレクトリ下にあるものはadmins/contactsというURLとして呼び出してくれると思ったわけですが・・ここでルーティング内の重複はどうなるんだ〜となりました。
そこでnamespace(名前空間)という便利なものを知ったのでメモしますNamespace(名前空間)とは
名前の重複があるときに、衝突を防ぐために使用します。
前提
今回はgem deviseでログイン機能を実装したため、
すでに$rails g devise:controllers adminsコマンドでadminsディレクトリがあります。
そこにdevise関連ではないコントローラーも追加していきたい!という感じ。とりあえずコントローラーを生成してみよう
rails generate controller admins/Contacts edit updateこれだけ
ルーティングは?
上のコマンドでコントローラーを生成した時点で、
namespace :admins do --- endという枠組みが作成されて、
namespace枠内に、GETやPOSTなど自分が追加したアクションがきちんとルーティングされています今回はResourcesに書き換えました。
config/routes.rbRails.application.routes.draw do namespace :admins do resources :contacts, only:[:edit, :update] end # アドミンのcontacts resources :contacts, only:[:new, :create] # ユーザーのcontacts devise_for :photographers devise_for :admins devise_for :users endこれで名前が一緒でも、
「このcontactsはadminね。」 「このcontactsはuserね。」という感じで
判別してくれるわけです
- 投稿日:2019-07-04T09:48:51+09:00
【Rails】undefined method ***_pathの解決策
学習の記録
***/edit.html.erb<%= form_for @*** do |f| %> # 省略 <% end %>NoMethodError undefined method `***_path'が出てしまう現象が発生。
ルーティングを確認してもパスは合っている・・なぜ原因
form_forが自動的に生成してくれるパスは複数形のみらしいです。
$ rails routes # resourcesが生成してくれたroutes edit_admins_単数形 GET /admins/複数形/new(.:format) # form_forが欲しかったroutes edit_admins_複数形 POST /admins/複数形/new(.:format)解決法
urlを指定して、こっちに飛ぶんだよ〜と教えてあげます
***/edit.html.erb<%= form_for @hoge, url: ***_index_path do |f| %> # 省略 <% end %>
- 投稿日:2019-07-04T01:42:55+09:00
RSpecのテストを一旦コメントアウトしたいときは、xをつけてpendingにしよう
コメントアウトすると、RSpecの実行結果からコメントアウトしていることに気づけない
pasta_spec.rbdescribe Pasta, type: :model do describe '#boil' do context '14mm' do # it { expect(Pasta.new(size: 14).boil(min: 8)).to eq TASTE::NICE } end context '18mm' do # it { expect(Pasta.new(size: 18).boil(min: 8)).to eq TASTE::SOLID } end end # ..略(このあと、47個のテストがある).. endRSpec$docker-compose exec web bundle exec rspec spec/models/pasta_spec.rb ............................................... Finished in 1.55 seconds (files took 3.7 seconds to load) 47 examples, 0 failuresitにxをつけて、xitとすると、実行結果に明示的にpendingと出る
pasta_spec.rbdescribe Pasta, type: :model do describe '#boil' do context '14mm' do xit { expect(Pasta.new(size: 14).boil(min: 8)).to eq TASTE::NICE } end context '18mm' do xit { expect(Pasta.new(size: 18).boil(min: 8)).to eq TASTE::SOLID } end end # ..略(このあと、47個のテストがある).. endRSpec$docker-compose exec web bundle exec rspec spec/models/pasta_spec.rb ..**............................................. Pending: (Failures listed here are expected and do not affect your suite's status) 1) Pasta #boil 14mm 8 min should eq nice # Temporarily skipped with xit # ./spec/models/pasta_spec.rb:19 2) Pasta #boil 18mm 8 min should eq かたい # Temporarily skipped with xit # ./spec/models/pasta_spec.rb:24 49 examples, 0 failures, 2 pending
- 投稿日:2019-07-04T01:07:58+09:00
[小ネタ]特定のcssを読み込みたい
たとえば、
app/assets/stylesheets/util/color.css.scssというファイルがあったとして、それを(application.css.scssなど)別のscssから読み込みたいときは、こうする。app/assets/stylesheets/application.css.scss// = require util/color /* * こちらも可 * = require util/color * /
- 投稿日:2019-07-04T00:37:42+09:00
【Rails】 新規アプリケーション作成時の手順と設定
目的
忘れがちなのでまとめる。内容は学習の都度随時更新する。
1.アプリケーションの作成
ターミナルで
rails newコマンドを実行することで、アプリケーションのディレクトリとファイルを新規作成できる。例:rails バージョン5.0.7.2で開発、MySQLでデータベース管理を行うアプリケーションを作成する場合
$ rails _5.0.7.2_ new アプリケーション名 -d mysql2.データベースの作成
ターミナルで
rake db:createコマンドを実行すると、config/database.ymlファイル内の記述内容に従って、データベースが作成される。$ cd アプリケーション名 #作成するアプリケーションのディレクトリに移動 $ bundle exec rake db:create #データベースを作成rake db:createコマンドの前に
bundle execコマンドをつけているのは、複数のアプリケーションにバージョンが異なる同名のgemがある場合、rakeコマンドを実行するとコンフリクトエラーが生じるため。3.不要なファイルが作成されないように設定
rails gコマンドでコントローラを作成すると、同時にコントローラファイルに対応する各種ファイルが生成される。生成されないようにするには
config/apprication.rbを編集する。config/apprication.rbmodule PracticeSpace class Application < Rails::Application config.generators do |g| g.stylesheets false #cssファイルの生成を行わない g.javascript false #JavaScriptファイルの生成を行わない g.helper false #helperファイルの生成を行わない g.test_framework false #テストファイルの生成を行わない end end end4.Gitのトラッキングの対象外とするファイルやディレクトリの指定
.gitignoreでGitのトラッキングから外すファイルとディレクトリを指定する。sample/.gitignoretest/controllers/* #test/controllersディレクトリ内のすべてのファイルとディレクトリを無視する参考にした記事
- 投稿日:2019-07-04T00:26:09+09:00
railsでCSV出力をする方法+実務あるある(関連テーブルのカラム出力など)
社内用の顧客管理ツールを作った際に、バックオフィスのメンバーから「CSV出力機能がほしい!」という熱い要望がありました。
CSV出力機能はよくある機能ですが、実装後も細かな要望に答えて改修したので実務あるあるとしてまとめました。
前提のお話
前提としてtownは複数のuserを持ち、userは1つのtownと紐づきます。
特定のtownごとのuserをまとめてCSV出力するボタンを作りました。models/town.rbclass Town < ApplicationRecord has_many :users endmodels/user.rbclass User < ApplicationRecord belongs_to :town endtowns/index.html.erb<div class="flex space-between"> <div> <% @towns.each do |town| %> <p><%= town.name %></p> <%= link_to "CSV出力", towns_csv_town_user_path(id: town.id) %> <% end %> </div> </div>userテーブル
id town_id last_name first_name address 1 1 田中 太郎 〇〇町 tanaka@gmail.com 2 2 佐藤 花子 △△町 sato@gmail.com townテーブル
id name population food tourist spot 1 名古屋 300000 味噌カツ 名古屋港水族館 2 札幌 200000 カニ 時計台 config/routes.rbresources :towns do get "csv_town_user", on: :member endボタンを押した時にtowns_controllerのcsv_town_userメソッドにtown.idを渡して、townごとのuserをCSV出力します。
基本のCSV出力
towns_controller.rbrequire "csv" class TownsController < ApplicationController def index @towns = Town.all end def csv_town_user head :no_content users = User.where(town_id: params[:id]) town = Town.find(params[:id]) #ファイル名を指定 ここはお好みで filename = town.name + Date.current.strftime("%Y%m%d") csv1 = CSV.generate do |csv| #カラム名を1行目として入れる csv << User.column_names users.each do |user| #各行の値を入れていく csv << user.attributes.values_at(*User.column_names) end end create_csv(filename, csv1) end private def create_csv(filename, csv1) #ファイル書き込み File.open("./#{filename}.csv", "w", encoding: "SJIS") do |file| file.write(csv1) end #send_fileを使ってCSVファイル作成後に自動でダウンロードされるようにする stat = File::stat("./#{filename}.csv") send_file("./#{filename}.csv", filename: "#{filename}.csv", length: stat.size) end end実務あるある1: 一部のカラムだけCSV出力したい
towns_controller.rbrequire "csv" class TownsController < ApplicationController #略 def csv_town_user head :no_content users = User.where(town_id: params[:id]) town = Town.find(params[:id]) filename = town.name + Date.current.strftime("%Y%m%d") csv1 = CSV.generate do |csv| #ここでカラム指定 columns = ["town_id", "last_name", "first_name", "address", "email" ] csv << columns users.each do |user| csv << user.attributes.values_at(*columns) end end create_csv(filename, csv1) end private #以下略 end実務あるある2: 1行目はカラム名を日本語にしたい
towns_controller.rbrequire "csv" class TownsController < ApplicationController #略 def csv_town_user head :no_content users = User.where(town_id: params[:id]) town = Town.find(params[:id]) filename = town.name + Date.current.strftime("%Y%m%d") #日本語のカラム名を用意 columns_ja = ["都市ID", "名字", "名前", "住所", "メールアドレス"] columns = ["town_id", "last_name", "first_name", "address", "email" ] csv1 = CSV.generate do |csv| #1行目は日本語のカラム名 csv << columns_ja users.each do |user| csv << user.attributes.values_at(*columns) end end create_csv(filename, csv1) end private #以下略 end実務あるある3: テーブル結合して別テーブルの情報も表示したい
現在は各userの"town_id", "name", "address", "email" が出力されるが、"town_id"ではなく、townテーブルを結合してtownテーブルのnameカラムを出力したいとします。
towns_controller.rbrequire "csv" class TownsController < ApplicationController #略 def csv_town_user head :no_content #ここでtownテーブルの情報を同時に引いてくる users = User.where(town_id: params[:id]).includes(:town) filename = town.name + Date.current.strftime("%Y%m%d") #都市IDではなく都市名を表示するようにする columns_ja = ["都市名", "名字", "名前", "住所", "メールアドレス"] columns = ["town_name", "last_name", "first_name", "address", "email" ] csv1 = CSV.generate do |csv| csv << columns_ja users.each do |user| user_attributes = user.attributes #user.attributesオブジェクトにtown_nameというキー名でtownテーブルのnameカラムを追加する #includesで結合しても呼び出すときはuser.nameではなくuser.town.nameなので注意 user_attributes["town_name"] = user.town.name csv << user_attributes.values_at(*columns) end end create_csv(filename, csv1) end private #以下略 end
- 投稿日:2019-07-04T00:08:20+09:00
お勉強を兼ねて、鳥貴族 注文ガチャ を作った(nuxt.js + rails + heroku + python + selenium)
背景
モダンな技術を勉強したかったので、それらを使ってwebアプリを何か作ろうというところから始まりました。作っていく中で勉強するのが一番手っ取り早いという考えもありました。
下記の「サイゼ1000円ガチャ」を見てメニューの注文ガチャいいなあと思ったので、居酒屋でも同じようなものがあったら面白そうと思い、今回の鳥貴族ガチャを作ることにしました。
そんな感じで、興味のある技術を使って開発をしてみることが一番の目的でした。
成果物:鳥貴族 注文ガチャ
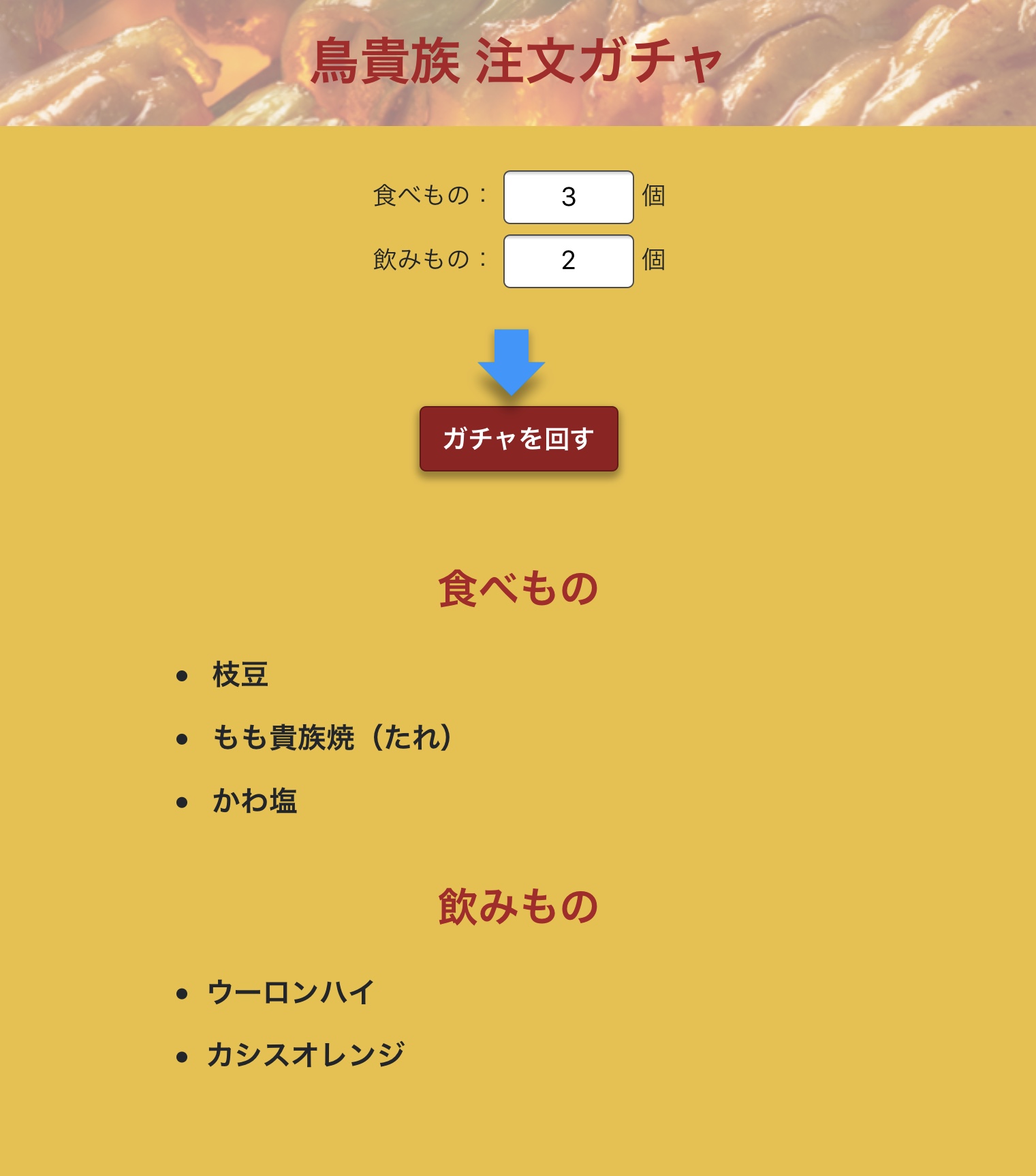
概要
- 食べ物と飲み物の数を入力する
- [ガチャを回すボタン]を押下
- 入力した個数分のメニューがそれぞれランダムで出力される実物
鳥貴族 注文ガチャ - Heroku
https://ak-toriki-nuxt-frontend.herokuapp.com/フロントエンドプロジェクト(Nuxt.js) - GitHub
https://github.com/lelouch99v/toriki-nuxt-frontendバックエンドプロジェクト(Ruby on Rails) - GitHub
https://github.com/lelouch99v/toriki-backend制作のポイント
使った技術
以下の技術を使いました。
- Python
- selenium webdriver
- vue.js
- nuxt.js
- Ruby on Rails
- postgreSQL
- heroku
DBに入れるメニューをスクレイピングで取得
Pythonでのスクレイピングにハマっていたのでやってみました。
焼鳥、逸品料理、スピードメニュー、ドリンクの4つのカテゴリからそれぞれメニューを取得していきます。結果はcsvで出力します。
このcsvを使ってrailsのmigrateデータとしてメニューデータをDBに入れました。
トリキ スクレイピング - GitHub
https://github.com/lelouch99v/toriki-scraping/tree/master(今回の開発で一番楽しかったのがここです)
React → Vue.js に変更
前提としてSPA + API の構成としたかったです。
業務でAngularは使っているので、ReactかVueを学びたいと思っていました。
当初Reactを選択したのですが、学習に時間がかかり出来上がるのが先になってしまいそうなのと、Nuxt.jsが気になっていたのであっさりとVueに変えました。
すごく入りやすくて学習していて楽しいです。猫本も買いました。
今後の課題
ボタン押下時のインタラクション
ガチャ回すボタン押すとメニューがランダム表示されますが、とても味気ないです。派手なものにする必要はないですが、最低限以下は実現したいと思っています。
- ボタンを押した感出す
- メニューが表示されるまでにワンクッション置く(ワクワク感が足りないため)各メニューのイメージ画像を見れるようにする
メニューの名称だけの表示ではなく、イメージ画像も見れるようにするといいと思いました。
そのまま画像を表示するのはスペースの問題などありそうなので、リンククリックでモーダル表示など一工夫は必要かもしれません。あとはメニュー表示の見た目が質素なので、もう少し改善が必要ですね。
スマホで数字入力をドロップダウンリストで可能にする
スマホではキーボード入力よりも、以下のような選択式のリストで入力のほうがやりやすいと思います。
最大値は99まであれば十分かなと。。。(もっと少なくてもいいですね)
てかすでにあった
鳥貴族ガチャでぐぐったらすでに作っていた人がいました。しかもクオリティ高い。
完全なリサーチ不足です。今回の目的は技術の勉強なので、もももんだいないんですけどね!