- 投稿日:2019-04-17T23:21:05+09:00
AWS認定ソリューションアーキテクトアソシエイトへの道 その10 S3ハンズオン
tl;dr
現在Webエンジニアをやっているが下記の理由のためにAWSソリューションアーキテクトアソシエイト取得を目指す。
- スキルアップ
- 業務の幅を広げる
- 知的好奇心
現在のAWSスキル
- テスト用にEC2を作成したことはある(LAMP環境を構築)
- ネットワーク用語はある程度わかる(マスタリングTCP/IP 入門編は名著だと思う)
学習方法
- 対策本を読むことを考えたが、手を動かしながら学んだほうが身につくと考え、Udemyの動画教材を購入
- AWS INNOVATE(Amazonが主催するAWSを学ぶためのONLINE CONFERENCE) → 開催中だったために登録
- 参考書も購入
購入した教材はこちら
AWS認定ソリューションアーキテクト – アソシエイト試験突破講座
購入した本はこちら
合格対策 AWS認定ソリューションアーキテクト - アソシエイト
本日の課題
- S3のライフサイクル管理(ハンズオン)
- EC2からS3ファイルの取得(ハンズオン)
- AWS CLIの導入(ハンズオン)
課題メモ
- AWS CLIの導入はこちらを参照した AWS Command Line Interface をインストールする
- 投稿日:2019-04-17T22:42:47+09:00
CloudFormationでVPCを作るだけ
CloudFormationでVPCを作るだけ
- VPCが出来る
- VPCはサブネットを一つ持っている
- IPv6は無効化
- 個人的な趣向によりタグを定義している
AWSTemplateFormatVersion: 2010-09-09 Resources: EC2VPC3RXEF: Type: 'AWS::EC2::VPC' Properties: CidrBlock: 10.0.0.0/16 EnableDnsSupport: false EnableDnsHostnames: false InstanceTenancy: default Tags: - Key: Project Value: Mastodon EC2S4A90T: Type: 'AWS::EC2::Subnet' Properties: CidrBlock: 10.0.0.0/24 MapPublicIpOnLaunch: false VpcId: !Ref EC2VPC3RXEF Tags: - Key: Project Value: Mastodon
- 投稿日:2019-04-17T22:28:53+09:00
Mac環境でのAWS-CLIのセットアップ
作業ログとして記載。
概要
Mac環境にawscliの設定を実施する手順(作業時間5分)
1. Python及びawscliのインストール
curl "https://bootstrap.pypa.io/get-pip.py" -o "get-pip.py"python get-pip.pypip install awscliI-Taka-MBA:~ root# aws --version aws-cli/1.16.141 Python/2.7.10 Darwin/17.7.0 botocore/1.12.131 I-Taka-MBA:~ root#2. CLIの設定(アクセスキー・シークレットキーの設定)
I-Taka-MBA:~ root# aws configure AWS Access Key ID [None]: ****************(アクセスキー) AWS Secret Access Key [None]: ****************(シークレットキー) Default region name [None]: us-east-2(デフォルトで使うリージョン) Default output format [None]: json(コマンド結果のデフォルト出力形式:json/text/table) I-Taka-MBA:~ root#3. awscliコマンド確認
I-Taka-MBA:~ root# aws ec2 describe-instances { "Reservations": [ { "Instances": [ { "Monitoring": { "State": "disabled" }, "PublicDnsName": "ec2-xx-xxx-xxx-xxx.us-east-2.compute.amazonaws.com", "State": { "Code": 16, "Name": "running" }, "EbsOptimized": false, "LaunchTime": "2019-04-17T13:17:50.000Z", ], (以下省略)I-Taka-MBA:~ root# aws s3 ls 2019-04-07 19:08:27 ******** 2018-02-21 23:28:35 ******** 2017-05-25 23:08:47 ******** I-Taka-MBA:~ root#I-Taka-MBA:~ root# aws ec2 stop-instances --instance-ids i-*************** { "StoppingInstances": [ { "InstanceId": "i-***************", "CurrentState": { "Code": 64, "Name": "stopping" }, "PreviousState": { "Code": 16, "Name": "running" } } ] } I-Taka-MBA:~ root#参考にさせていただいたサイト
・awscliのインストール時のエラーへの対応
https://qiita.com/iwaseasahi/items/9d2e29b02df5cce7285d
- 投稿日:2019-04-17T21:29:50+09:00
【大反省】素人がAWSS3をいじっていると「Your AWS Account is compromised!」とメールが来た
Railsでポートフォリオを作成しておりまして、Herokuへのデプロイ後の画像保存先をAWSS3に指定しました。
すると後日AWS様からメールで「Your AWS Account is compromised!」とご連絡頂き、結果的にバケットとIAMを削除して作り直したのですが、そもそもなぜそんなことになったのかを反省しつつ書いておきます。
原因:AccessKeyをベタ書きしてcommitしてしまっていた
AWSS3を使う場合Active Storageを使って、保存先を
config/storage.ymlで以下のように書くかと思います。storage.ymlamazon: service: S3 access_key_id: <%= Rails.application.credentials.dig(:aws, :access_key_id) %> secret_access_key: <%= Rails.application.credentials.dig(:aws, :secret_access_key) %> region: ap-northeast-1 #東京 bucket: #bucketnameただ僕は以前の記事でも書いた通り、
#string does not have #dig methodというエラー解決に苦しみ、結果的にaccess_key_idとsecret_access_keyをベタ書きしてした状態でgit commitして全世界に僕のアクセスキーを大公開してしまっていたわけです。まあ、僕のリポジトリのコードなど詳しく見る人はいないだろうという甘い想定でしたが、実際はBotによって攻撃される危険性などがあるそうで、その辺りの想定が甘すぎました、、、
とりあえずポートフォリオとして完成させることを急ぐあまり、セキュリティの意識が大幅に欠落していて、まだ個人でポートフォリオを実装している段階なのでマシですが、これが実際の業務だったら死んでいたな、、、と猛省しました
対処法
- AWS ルートアカウントのユーザーパスワードを変更する。
- すべてのルートおよび AWS Identity and Access Management (IAM) アクセスキーを削除するか、交換する。
- 危険にさらされている IAM ユーザーを削除し、他のすべての IAM ユーザーのパスワードを変更する。
- EC2 インスタンスおよび AMI、EBS ボリュームおよびスナップショット、および IAM ユーザーなどの作成していないアカウントのリソースを削除する。
- AWS サポートから受け取った通知には、AWS サポートセンター経由で返信してください。
参照元:自分の AWS アカウントが危険にさらされているようです
上記を実行した上で、再度バケット、IAMを作り直して実装し直しました。
以上、大反省の記録でした。
- 投稿日:2019-04-17T21:01:48+09:00
AWSで『www』有り無しを統合させる方法〜lightsail〜
私自身、この問題にぶち当たって、適当な記事を見つけ出すことができずに自力で解決しました。
私と同じことになっている人の目に留まれば良いなと思い、記事にします。
lightsailを使う人達にはぜひ見てほしい内容です。前提・実現したいこと
AWS(今回はlightsail)で構築した、wordpressにおける『www』有り無し統合の実現を目指します。
(この問題は、レコードの問題なので別にwordpressじゃなくても大丈夫ですし、AWSを使う人にはぜひ見てほしい内容です。)まず、私は下の記事を参考に、サブドメインwww付きの「www.sample.com」をssl化することに成功しました。
→無料ssl化の方法;https://dev.classmethod.jp/cloud/aws/how-to-install-original-domain-ssl-wordpress-with-amazon-lightsail/
この方法ではlightsailで提供されている有料ロードバランサーでのssl化をしないでほぼ無料でssl化できます。
ただしドメインに関しては『www.sample.com』のようなサブドメイン付きになります。
(www無しで統一したい場合はlightsailの有料ssl化の方法が一番良いと思います。)問題点
ここまでは良かったのですが、一つ問題がありました。
それは、lightsail内で「www無し」でのレコード登録ができない点です。
つまり、【www無し→www有り】のレコードが登録できません。今回はこの問題を解決したいと思います。
(301リダイレクトで調べてしまうと、『.htaccess』ファイルでのリダイレクトがヒットするのですが、lightsailのwordpressには『.htaccess』のファイルは存在しないので、301リダイレクトは『htaccess.conf』ファイルにて行わせるらしいです。
あと、今回の内容ではそもそもレコードが登録されていないので、ファイル書き換えなどでは無意味です。)エラーメッセージ
lightsail内で「@.sample.com」をCNAMEでDNSレコード登録しようとした際の表示。
Invalid parameters: [RRSet of type CNAME with DNS name sample.com. is not permitted at apex in zone sample.com.]
サブドメインなしでCNAMEレコードを登録しようとすると、この様になると思います。
Route53へDNSを移行する
これが今回の根本的な解決方法です。
lightsailに限らず、DNSをRoute53に移行すれば同じことができます。lightsailに関して、Route53にもlightsailにも、NSレコードが存在します。
lightsailで構築した人は、lightsailのNSレコード(4つ並んでいるやつ)をムームードメインなどのレジストラに書いたと思いますが、Route53のものに書き換えてください。そうすれば移行完了です。(当たり前ですが、レジストラには両方書けないのでlightsailとRoute53のDNSの両立はできませんし、Route53にまとめて移行した方が楽です。)
lightsailとRoute53のDNSレコードの違い
lightsail内では、www無しのドメイン(Zone Apex)はCNAMEレコードを登録できないので、統合は実現不可能でした。
そこで、Route53で『ALIAS レコード』を用いることで統合させることができます。
ligthsailにはRoute53のALIASレコードのような、『Zone Apex をレコード登録出来る機能』が無いです。
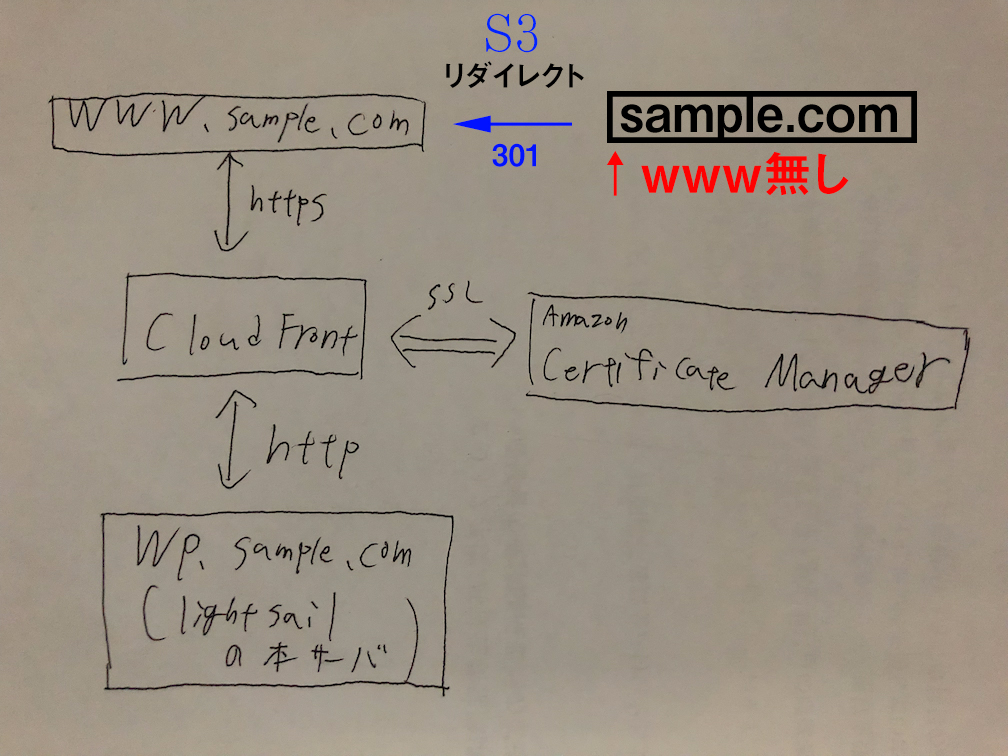
Route53の方が上位互換ですね。理解のための図
この図では、冒頭の項目「前提・実現したいこと」の項目で紹介したURLでのSSL化の方法と、自分で設定したリダイレクトの構造をあわせて説明しています。
今回はこれを実践します。
この矢印の経路を指定しているのがDNSですが、今回は右上の一個を追加してあげるということで解決しております。リージョン設定を統一すること
冒頭で紹介した「無料SSL化の方法URL」にも書かれていますが、利用するシステムのリージョンがそれぞれ違うとできないので気をつけながらやってください。
私はバージニア北部のリージョンにしています。S3の設定
「S3でのリダイレクトの方法」で検索すれば出てきます。
中身の要約
1. バケット名を【www無しのドメイン】で作成
2. 空のindex.htmlを入れる(bodyが空で良い)
3. バケットのプロパティにて『Static website hosting』の「このバケットを使用してウェブサイトをホストする」にチェック
4. インデックスドキュメント→index.html
5. リダイレクトルールに下記を記述
<RoutingRules>
<RoutingRule>
<Redirect>
<HostName>www.sample.com</HostName>
<ReplaceKeyWith/>
</Redirect>
</RoutingRule>
</RoutingRules>
(sample.comはお使いのドメイン)
6. 「Static website hosting」の上部にあるエンドポイントURLをクリックしてリダイレクトされているか確認。S3は以上です。
Route53へDNSの移行後の処理
Route53に関しても調べればすぐに出て来ると思いますが、要約します。
ホストゾーン作成時に設定するドメイン名を【www無しの正しいURL】で設定してください。(S3バケット名と同じ。)
とりあえず、lightsailにレコード登録してあったものをRoute53に全部書き写しちゃってください。次にRoute53で新規レコードを登録します。
種類をAにして、エイリアス(Alias)にチェックしてください。
サブドメイン入力欄には何も入力しないでください。(lightsail時代には「@」をいれていたが。)エイリアス先のところに、S3が候補として出てくると思うのでそれを選択。
(【正しい同じドメイン名】じゃないと表示されないはず。)これで完了です。
以上になりますが、不具合があったらリージョンの設定とドメイン名をよく確認してください。
最後にもう一度「理解のための図」を見て確認するのが良いと思います。
- 投稿日:2019-04-17T20:32:02+09:00
インフラエンジニアだけどLINE Botを作りたい
はじめに
お仕事的にはインフラエンジニアですが、昨今の技術の進歩からインフラエンジニアいらないんじゃない的なことを感じたり感じなかったりなので、インフラエンジニアでもある程度コードかけないとまずいとは思ってるけど、じゃいざ何作るの?って段階になるとなかなかアイデアで出ない人は多いのではないのでしょうか。
そんな人は簡単なLINE Botを作ってみるとこから初めて見たらいかがでしょうか?という記事です。
環境
何かしらでBotサーバーを用意しなければなりません。
選択肢としては、GASやHerokuなどが思いつくと思いますが、普段私がAWSしかいじってないのでAPI Gateway + Lambda(Ruby)をserverless frameworkでデプロイします。普段AWSをいじってる人はこの構成でやることを是非オススメします
手順
ここからはLINE Botが定型文を返すまでの手順となります
1. LINE@アカウントの取得
まずは以下のリンクからLINE@アカウント(一般アカウント)を取得する必要があります。
一般アカウントとは?
「一般アカウント」は審査なしで作成できるアカウントです。
一般アカウントの作成後に認証済みアカウントを申し込むことも可能です。
ご利用可能なプランはお住まいの国によって異なります。2. チャネルの作成
LINE@アカウントを作成したらチャネルを作成する必要があります。
チャネルとは?
チャネルは、LINEプラットフォームが提供する機能を、プロバイダーが開発するサービスで利用するための通信路です。LINEプラットフォームを利用するには、チャネルを作成し、サービスをチャネルに関連付けます。チャネルを作成するには、名前、説明文、およびアイコン画像が必要です。チャネルを作成すると、固有のチャネルIDが識別用に発行されます。
https://developers.line.biz/ja/docs/messaging-api/getting-started/
チャネル作成の詳細な手順は以下の通りです。
2-1. LINEアカウントでLINE Developersコンソールにログイン
2-2. 開発者として登録する(初回ログイン時のみ)
2-3. 新規プロバイダーを作成する
2-4. チャネルの作成
このとき以下のどちらかのプランを選ぶ必要がありますが、お遊びの範囲であればDeveloper Trialを選択してください。
Developer Trial
MessagingAPIを利用したBotを試すプランです。友だちとメッセージの送受信を行うことができます。
※追加可能友だち数は50人に制限されています。また、Developer Trialからプランの切り替えやプレミアムIDの購入はできません。フリー
MessagingAPIを利用したBotを開発するプランです。友だちの人数に制限はありませんが、Push messagesを利用してBotから友だちにメッセージを送信することはできません。
※サービス拡張に向けプラン変更が可能です。3. Botの作成
BotはServerless Frameworkを使って、API gatewayとLambda(ruby)で作成してみます。
serverless frameworkがインストールされている前提で進みますが、インストールからという方は以下を参照してインストールしてください。
https://serverless.com/framework/docs/providers/aws/guide/installation/3-1. serverlessコマンドでテンプレート作成
$ serverless create --template aws-ruby --path line-bot-test3-2. serverless.ymlの編集
とりあえず最低限としてこんな感じにしておきます
service: line-bot-test # NOTE: update this with your service name provider: name: aws runtime: ruby2.5 region: ap-northeast-1 memorySize: 512 timeout: 900 functions: hello: handler: handler.hello events: - http: path: bot/hello method: get3-3. デプロイ
$ serverless deploy Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: WARNING: Function hello has timeout of 900 seconds, however, it's attached to API Gateway so it's automatically limited to 30 seconds. Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service line-bot-test.zip file to S3 (686 B)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... ....................... Serverless: Stack update finished... Service Information service: line-bot-test stage: dev region: ap-northeast-1 stack: line-bot-test-dev resources: 11 api keys: None endpoints: GET - https://xxxxxx/dev/bot/hello functions: hello: line-bot-test-dev-hello layers: NoneとりあえずAPI GatewayとLambda関数がデプロイされました。
4. LINE Developersコンソールからボットを設定する
4-1. チャンネルアクセストークンを発行する
コンソール画面上はChannel Secretのことでコンソール上からこれを発行します。
チャネルアクセストークンとは?
チャネルアクセストークンは長期間有効なアクセストークンで、APIを呼び出すときにAuthorizationヘッダーに設定する必要があります。チャネルアクセストークンはいつでもコンソールで再発行できます。
4-2. Webhook URLを設定する
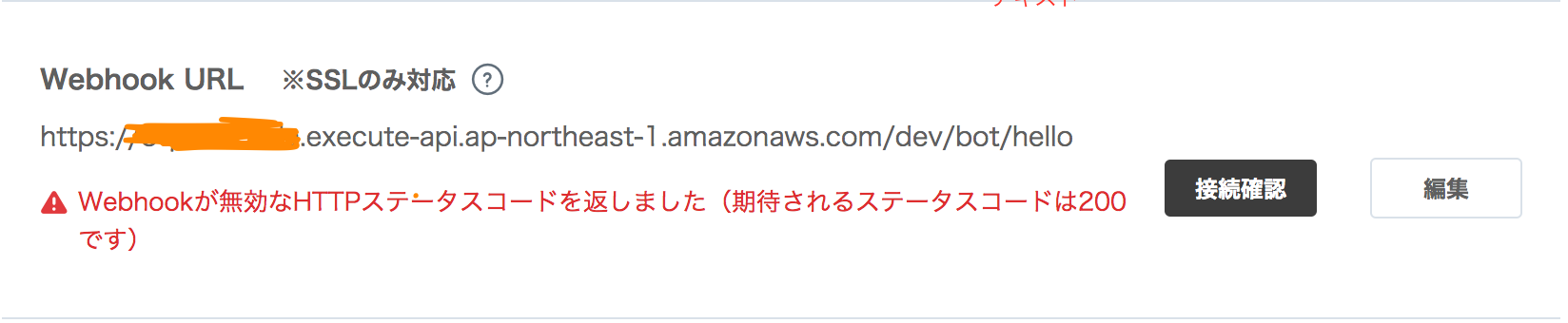
先ほど作ったAPI gatewayのURLをWebhook URLとして設定します。
Webhook URLとは?
Webhook URLはボットアプリケーションのサーバーのエンドポイントで、Webhookペイロードの送信先です。
コンソール上から接続確認をすると...
原因はAPI Gateway側のメソッドがGETになっていることでした...
よくよく考えたらPOSTですよね...
API Gateway側のメソッドをPOSTに直して再デプロイ
$ sls deploy Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service line-bot-test.zip file to S3 (686 B)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... ................... Serverless: Stack update finished... Service Information service: line-bot-test stage: dev region: ap-northeast-1 stack: line-bot-test-dev resources: 11 api keys: None endpoints: POST - https://xxxxxxx/dev/bot/hello functions: hello: line-bot-test-dev-hello layers: None再度、接続確認
今後はうまくいきました!!
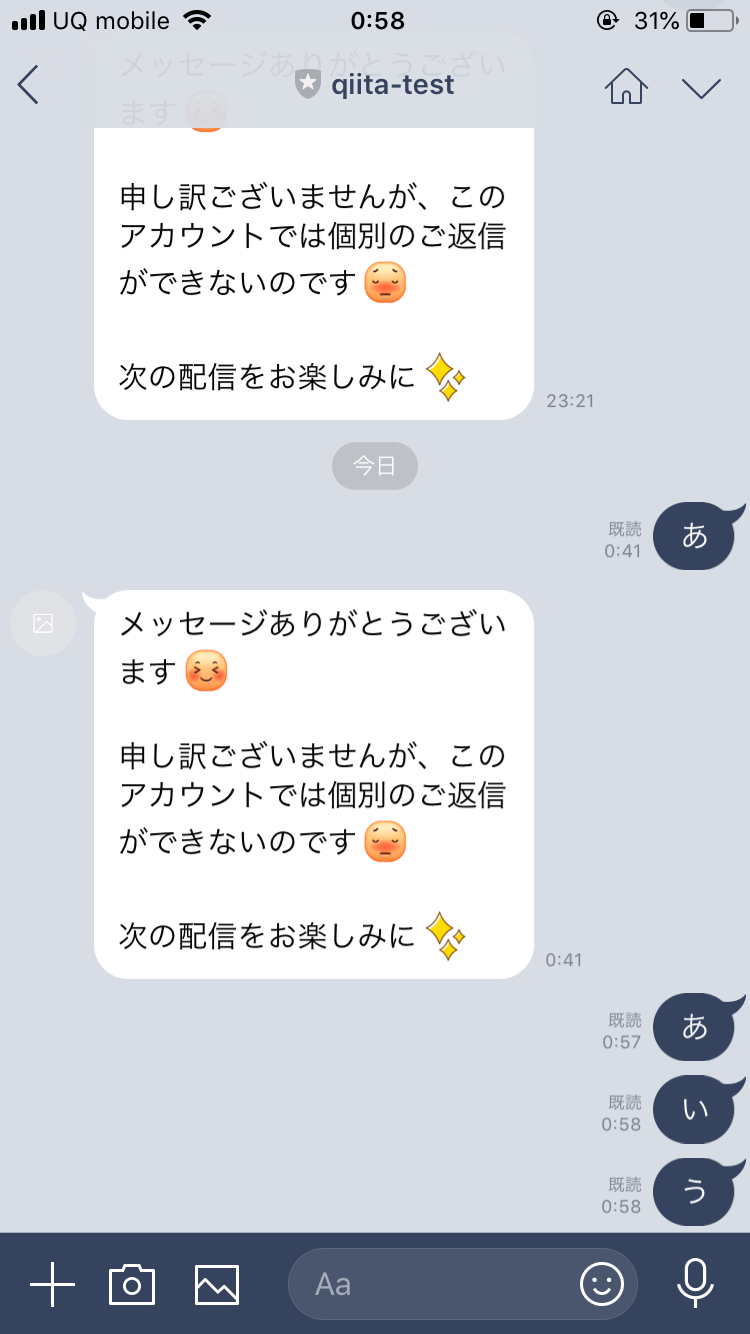
これで一旦LINEからBotにメッセージを送ってみます
こんな感じで変なメッセージが返ってきちゃいます...
これはチャネル基本設定 > LINE@基本機能の利用 > 自動応答メッセージを利用しないにする必要があるそうです
自動応答メッセージを利用しないにしたので再度試してみます
とりあえず自動応答メッセージはなくなりました
5. Lambda関数の作成
Lambda関数がserverless createコマンドで作られたものままなのでちゃんと返信するようにしてきます
とりあえずLINEからどんなリクエストが来るかeventの中身を見てみます
{ "resource": "/bot/hello", =================途中省略================= "body": "{\"events\":[{\"type\":\"message\",\"replyToken\":\"7e36bf04b9104b26b11b0a2a7df2336c\",\"source\":{\"userId\":\"xxxxccccc\",\"type\":\"user\"},\"timestamp\":1555321188152,\"message\":{\"type\":\"text\",\"id\":\"9697231865658\",\"text\":\"つ\"}}],\"destination\":\"xxxxxxxx\"}", "isBase64Encoded": false }肝心なのはbody部分のみです
bodyのみ抽出
{ "body": "{\"events\":[{\"type\":\"message\",\"replyToken\":\"7e36bf04b9104b26b11b0a2a7df2336c\",\"source\":{\"userId\":\"xxxxxxxx\",\"type\":\"user\"},\"timestamp\":1555321188152,\"message\":{\"type\":\"text\",\"id\":\"9697231865658\",\"text\":\"つ\"}}],\"destination\":\"xxxxxxx\"}" }メッセージイベントの詳細は以下にあります
https://developers.line.biz/ja/reference/messaging-api/#message-eventrubyなのでnet/httpで対応することも可能ですが、LINE公式のline-bot-sdk-rubyが存在することのでこちらを使ってみたいと思います。
def client @client ||= Line::Bot::Client.new { |config| config.channel_secret = ENV["LINE_CHANNEL_SECRET"] config.channel_token = ENV["LINE_CHANNEL_TOKEN"] } endこんな感じでなんか簡単に作れそうなのでnet/httpでやるより良さそうです
でchannel_secretとchannel_tokenって??
channel_secretとは?
これはLINE Developersコンソールのチャネル基本設定 > 基本情報 > Channel Secret
から確認出来ますchannel_tokenとは?
これは2種類あるようです。
注:この方法では、30日間有効な短期のチャネルアクセストークンが発行されます。長期のチャネルアクセストークンを発行するには、コンソールにある[再発行]ボタンを使います。長期のアクセストークンは、アカウントの種類やプランによってはご利用いただけません。
https://developers.line.biz/ja/reference/messaging-api/#issue-channel-access-token
長期的なものと短期的なものがあります。
短期的なものはLINE messageing APIにアクセスして発行してもらえます。
長期的なものはLINE Developersコンソールのチャネル基本設定 > メッセージ送受信設定 > アクセストークン(ロングターム)から発行することが出来ます。
channel_secretとchannel_tokenはLambdaの環境変数として設定したいのですが、serverless.ymlに書いちゃうとgithubのリポジトリに残ってしまうのでどうしましょ?
※githubのパブリックリポジトリを使ってる前提ですserverless.yml内で秘匿情報を扱う方法
serverless.yml内で環境変数を参照することが出来ます。
今回はこの方法でいきます。
https://serverless.com/framework/docs/providers/aws/guide/variables/#referencing-environment-variablesこんな感じで使えます。
service: new-service provider: aws functions: hello: name: ${env:FUNC_PREFIX}-hello handler: handler.helloLambdaのrubyランタイムでgemを使う方法
色々方法はあるかと思いますが、serverless-ruby-packageというserverlessのプラグインを見つけたのでこれを利用したいと思います。
使い方はREADMEを読めば簡単です。
注意点はローカルのrubyのバージョンをLambdaに合わせて2.5.0にしておいてください。
もしくはdockerを使ってgemをインストールするのもありです。むしろdockerを使ってgemをインストールすることをオススメします。
なぜrubyのバージョンを2.5.0にする必要があるかはvendor/bundle/bundler/setup.rbを見るとわかります
定型文を返すようにする
ほとんどLINE公式のline-bot-sdk-rubyのサンプルのままですが、以下のようなLambda関数で定型文が返ってくるようになりました
load "vendor/bundle/bundler/setup.rb" require 'json' require 'line/bot' def hello(event:, context:) message = { type: 'text', text: 'hello' } client = Line::Bot::Client.new { |config| config.channel_secret = ENV["LINE_CHANNEL_SECRET"] config.channel_token = ENV["LINE_CHANNEL_TOKEN"] } body = event["body"] requests = client.parse_events_from(body) requests.each do |req| case req when Line::Bot::Event::Message case req.type when Line::Bot::Event::MessageType::Text response = client.reply_message(req['replyToken'], message) p response end end end endLINEから試してみるとこんな感じです。
とりあえず定型文を返すとこまでいけました。
まとめ
インフラエンジニアだけどコードを書きたいということでしたが、serverless frameworkとの格闘がほとんどでした...
なのでここから役に立つBotとして進化させて、この続編として記事を書きたいと思います。


- 投稿日:2019-04-17T03:02:18+09:00
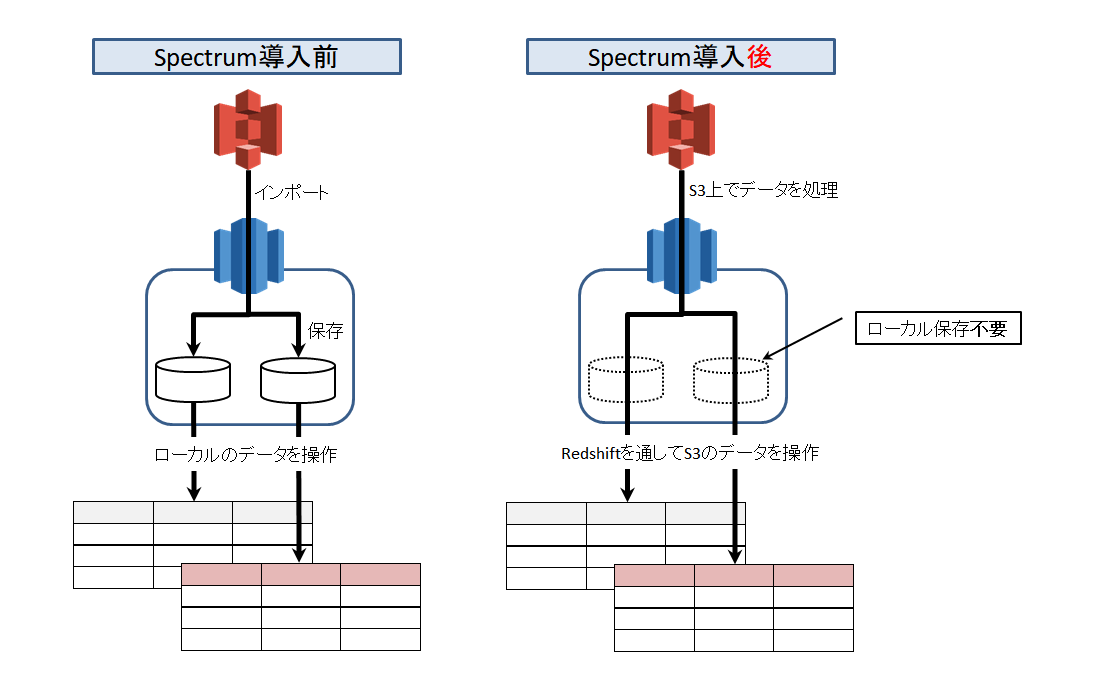
RedshiftSpectrumの実装フロー
RedshiftSpectrumとは、
S3に保存したテキストファイルやParquetなどのカラムナフォーマットを
Redsihft上で直接読込処理できるサービス。
容量無限大のS3をデータレイクとして利用できるようになり、
Redshiftのストレージに拡張性が加わった。
ようは、今までよりお安く大容量化できますよ!ということ。
Spectrumへの置換手順
具体的にどのような手順で置換作業を進めればよいのか。
Spectrumのサービス開始から日が浅いため
ネット情報もあまりなく、Redshiftのドキュメントが頼り。。。
結構な回り道と試行錯誤があったが、
最終的にはSpectrum置換フレームワークを得られたと思う。事前準備
- GlueもしくはAthenaのサービスを利用可能にしておく
※本件はGlueの場合を解説しています- Parquetを作成する手段を決めておく
※EMRか、GlueのETLか、PySparkか、PyArrowか…- Parquetの圧縮形式を決めておく
※gzipか、snappyか、非圧縮か- 外部テーブルのパーティション名を決めておく(テーブル列名と重複禁止)
- Create External Schema文で外部テーブルと外部スキーマを作成しておく
CREATE EXTERNAL SCHEMA spectrum_schema_test FROM DATA CATALOG --DATA CATALOGと指定 DATABASE 'spectrum_db' --作成したい外部データベース名 IAM_ROLE 'arn:aws:iam::xxxxxx/xxxx-anars,arn:aws:iam::yyy/yyyyy-redshift' --※ CATALOG_ROLE 'arn:aws:iam::xxxxx/xxxxx-anars' --データカタログのアクセス許可に使用するIAM_ROLEを指定 CREATE EXTERNAL DATABASE IF NOT EXISTS ; /* ※ ここでは、S3とGlueカタログ所有者が違う場合のIAM_ROLEの指定方法を記述。 アカウントyyyの管理するS3バケットに、アカウントxxxがSpectrumでデータを参照しに行く許可を得ている */置換対象のテーブルを決める
Redshift内にあるテーブルのメンテナンスパターンは、大きく3パターン。
一番シンプルなのは、レコード追加のみのテーブル。
これは単純に置換が可能。
ただ、テーブル総入替とレコード更新のパターンは場合によっては
置換ができないケースもあると思われる。
パターン テーブル
更新形式適用容易さ 理由 レコード追加 INSERT
or
COPY〇 一番シンプル テーブル総入替 TRUNCATE
&
COPY△ 入替行数多→恩恵無し
入替行数少→検討余地ありレコード更新 UPDATE
&
INSERT× 変更発生個所のみ
カラムナフォーマットの更新が必要Spectrum化によるデータ確保量を見積もる
- 置換対象テーブルのデータ量を算出
- まずは小さいテーブルで検証
- 検証後、容量の大きいテーブルから進める
実装フロー
RedshiftSpectrumの導入に当たっては、次のフローで
進めるのがよさげです。
- Spectrumに置換したいテーブルの定義書を確認
- CHAR列やVARCHAR列について、CR(CHR(10))とLF(CHR(13))が含まれていないか確認。
含まれている場合は、空文字に置換する- 区切りたいパーティション毎にRedshiftからS3へUNLOADする
- たとえば日付でパーティション区切りたい場合、日付ごとにUNLOADを実行
- 出力先は、s3://spectrum/org/2015-01-01/000.gz など…。
ディレクトリを都度切るかはこの後の実装処理次第- UNLOADしたファイルをPySparkやPyArrowでParquet形式に変換
- 変換後、Spectrum参照用のディレクトリへ配置する。
※ローカルで処理する場合、変換対象ファイルをDL→Parquet変換→S3へUP- 日付でパーティション区切りの場合、次のようにディレクトリを切る。
※太字の部分でパーティションを表すが、
この後作成する外部テーブルの列名と重複させないこと。
- s3://spectrum/parquet/part_date=2015-01-01/000.parquet
- s3://spectrum/parquet/part_date=2015-01-02/000.parquet
- s3://spectrum/parquet/part_date=2015-01-03/000.parquet
- 外部テーブルを作成、ALTER TABLE でパーティションを区切る
- 構文は後述(◆)を参照
- Glueの機能で区切ってもよい
- パーティションを区切った数と、S3で作成したパーティション数が一致するか確認。
テーブルのパーティション数はSELECT * FROM SVV_EXTERNAL_PARTITIONS;で確認可能。- 元のテーブルと外部テーブルを比較し、同一内容か確認する。
- 違ってた場合、下記のポイントで検討をつける
- UNLOAD時(例:改行の置換漏れ)
- Parquet変換時(例:データ型相違、Sparkのタイムゾーンで変換時に時刻ずれ発生)
- 外部テーブルからの読込時(例:データ型相違)
- 遅延バインディングで外部テーブルの遅延VIEWを作成する
CREATE VIEW ビュー名 AS SELECT * FROM 外部スキーマ.外部テーブル WITH NO SCHEMA BINDING;- 遅延VIEWを作成しないと、BIツールやSQLクライアントで外部テーブルを認識できないケースあり
- Spectrumとローカルのパフォーマンスを比較
- WHEREとJOINの性能検証。結果次第では
- Parquetの圧縮形式見直し検討(snappy、もしくは非圧縮)
- パーティションの見直し検討
- 性能検証で問題ないと判断後、ローカルのデータをDELETE
- 適宜タイミングを見計らって日次バッチ処理等に移管
(◆)外部テーブル作成構文
/* ### Superユーザーじゃないと作成不可 ### */ CREATE EXTERNAL TABLE 外部スキーマ.テーブル名( date_time date , id int ) PARTITIONED BY ----- S3のディレクトリ構造でパーティション化する (part_date DATE) ----- パーティション名:part_date DATE型 STORED AS parquet ----- 元データ保存形式:parquet LOCATION 's3://spectrum/parquet/' ----元データ保存ディレクトリorファイル ; --ALTER TABLE でテーブルにパーティションを認識させる ALTER TABLE 外部スキーマ.外部テーブル ADD PARTITION (part_date='2015-01-01') LOCATION 's3://spectrum/parquet/part_date=2015-01-01/' ;注意点
- 外部テーブルの作成は、スーパーユーザーのみ可能
- 一般ユーザーは参照のみ
- 文字列置換について
- 改行コード(CR,LF)はParquet変換時にエラーになるため、置換を忘れずに
- 遅延バインディングについて
- ビューコメントは可能
- ただし、カラムコメントは付与できない
※VIEWの対象に実テーブルを挟んでもダメ補足
【Parquet形式を選んだ理由】
1. Parquet形式のほうがドキュメント多く、学習コストが低かった
2. 検証段階でORC形式への変換が上手くいかなかった参考
- 投稿日:2019-04-17T02:29:36+09:00
AWS ECRのライフサイクルポリシーとタグ付けの戦略
ECRのライフサイクルポリシー
- 古いイメージがたまると、ストレージ料金が余計にかかる
- ECRリポジトリ1つにつき、イメージは1000まで
こういった問題に対して、ライフサイクルポリシーを適切に設定することで、自動で古いイメージを削除することができます。
Amazon ECRのライフサイクルポリシーでコンテナイメージのクリーンアップ
タグ付けルールとライフサイクルポリシー
実際のプロジェクトで、ライフサイクルポリシーがうまく機能するように、どのようにタグ付けのルールを工夫したか紹介します。
これは、私が携わっているプロジェクトの運用に応じたものなので、あくまで参考です。前提
タグ付け以前に、次のような前提がありました。
- Github への Push をトリガーに CI が実行され、 docker image のビルドと Push が行われる
- 開発者は、任意の git branch (からビルドされたimage) を ECS にデプロイしたい
どのようにタグ付けするか
また、次のような事情があります。
- 現在、ECS Service にデプロイされている image が消えてしまうと困る
- Task が作り直された際に image が見つからなくて実行できない
- 開発者がデプロイしたいのは、ほとんどの場合、git branch の head に対応する image
- branch の head より古い image は長く保持しておく必要がない
- しばらく commit がない branch についても、ほとんどデプロイされることはない
そこで、次の3パターンのタグをつけることにしました。
git-hash.*git-branch.*deploy.*それぞれのタグについて、説明します。
CI で docker image をビルドしたら、そのときの git の hash に従って、
git-hash.*のタグを付けます。(例えば、git-hash.8db0a1のようになります)
また、それと同時に、branch 名に従ってgit-branch.*のタグを付けます。
ただし、git の branch には、スラッシュ/など、 docker のタグとして使用できない記号が含まれる場合があります。なので、branch 名を SHA などで適当にハッシュ化してその先頭の数文字をとります。 (例えば、git-branch.7e5170のようになります)
deploy.*タグは、実際にデプロイされたときに、後からつけます。デプロイ先の環境名をふくめて、例えばdeploy.productionのようにします。ライフサイクルポリシーの設定
それぞれのタグに、次のように expire を設定します。
deploy.*=> 十分に長い期間(半永久的)git-branch.*=> 数週間・数ヶ月程度git-hash.*=> 数日程度上に記載したタグほど、優先度を高く します。
そうすることで、deploy.*がついたイメージは消えず、git-hash.*だけついた image はすぐに消えるようになります。設定例
具体的な設定例を残しておきます。
policy.json{ "rules": [ { "rulePriority": 10, "description": "Keep images with the tag deploy.* forever", "selection": { "tagStatus": "tagged", "tagPrefixList": [ "deploy." ], "countType": "sinceImagePushed", "countUnit": "days", "countNumber": 36500 }, "action": { "type": "expire" } }, { "rulePriority": 20, "description": "Keep images with the tag git-branch.* for 14 days", "selection": { "tagStatus": "tagged", "tagPrefixList": [ "git-branch." ], "countType": "sinceImagePushed", "countUnit": "days", "countNumber": 14 }, "action": { "type": "expire" } }, { "rulePriority": 30, "description": "Keep images with the tag git-hash.* for 3 days", "selection": { "tagStatus": "tagged", "tagPrefixList": [ "git-hash." ], "countType": "sinceImagePushed", "countUnit": "days", "countNumber": 3 }, "action": { "type": "expire" } } ] }aws ecr put-lifecycle-policy --repository-name $repo --lifecycle-policy-text "$(cat policy.json)"
- 投稿日:2019-04-17T01:44:19+09:00
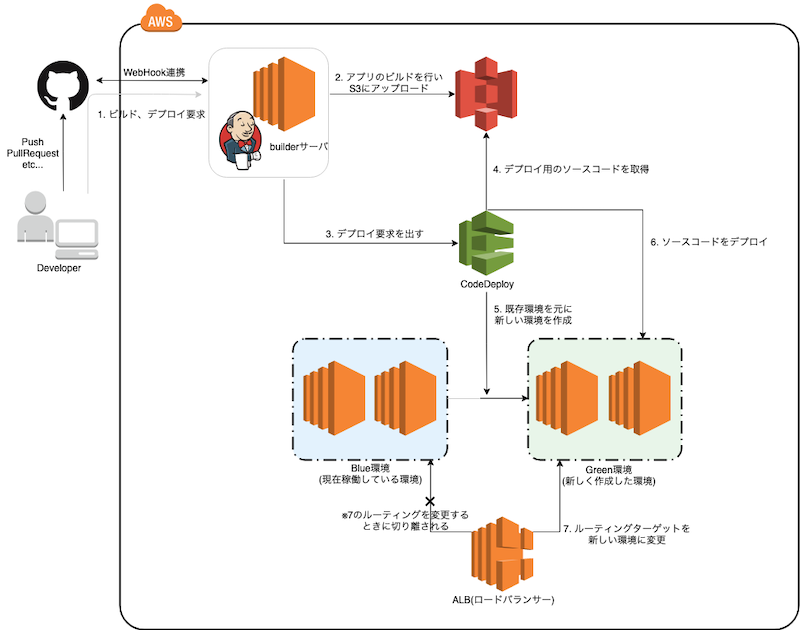
AWS CodeDeployでEC2にBlue/Greenデプロイする
概要
AWS CodeDeployを使ってEC2にBlue/Greenデプロイをする。
流れ
デプロイ対象のEC2インスタンスを作成
IAMロールを設定する
AmazonS3ReadOnlyAccessをアタッチしたIAMロールを指定する。アプリケーションが動作する環境を作成
アプリケーションが動作する環境を作成する。
AWS CodeDeploy エージェントをインストール
東京リージョンの場合は下記手順でインストールする。
$ sudo yum update $ sudo yum install ruby $ sudo yum install aws-cli $ cd /home/ec2-user $ aws s3 cp s3://aws-codedeploy-ap-northeast-1/latest/install . --region ap-northeast-1 $ chmod +x ./install $ sudo ./install auto下記のコマンドで導入が確認できればOK
sudo service codedeploy-agent statusデプロイ対象のEC2インスタンスで利用するAMIイメージを作成する
EC2インスタンスの起動イメージであるAMIイメージを作成する。
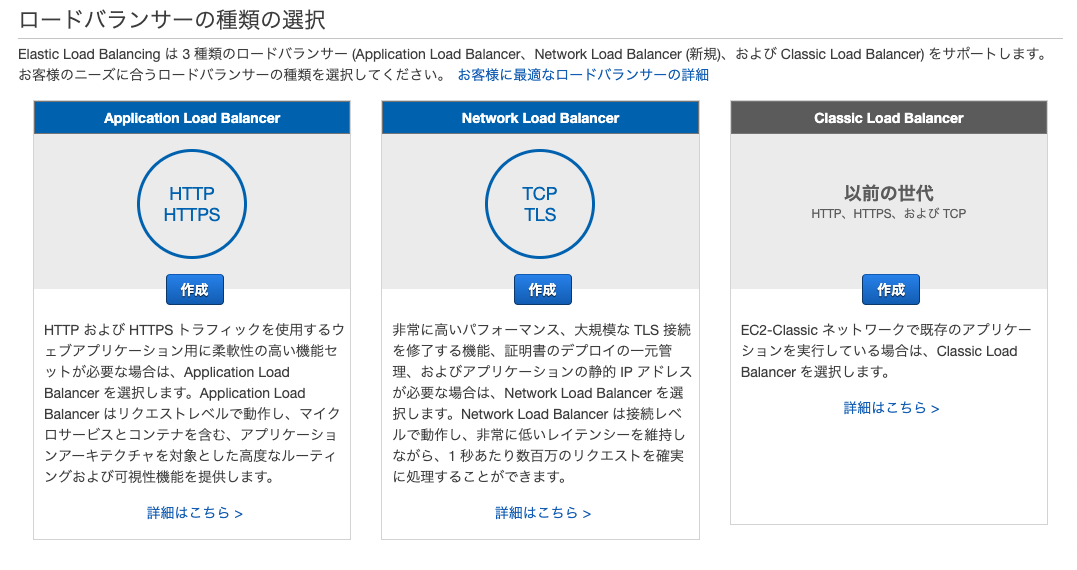
作成したインスタンスを元にAMIイメージを作成する。ロードバランサーの作成
マネジメントコンソール → EC2 → ロードバランサー より作成を行う。
AutoScalingGroupの作成
マネジメントコンソール → EC2 → Auto Scaling グループ より作成を行う。
新しい起動設定を作成するを選択する。
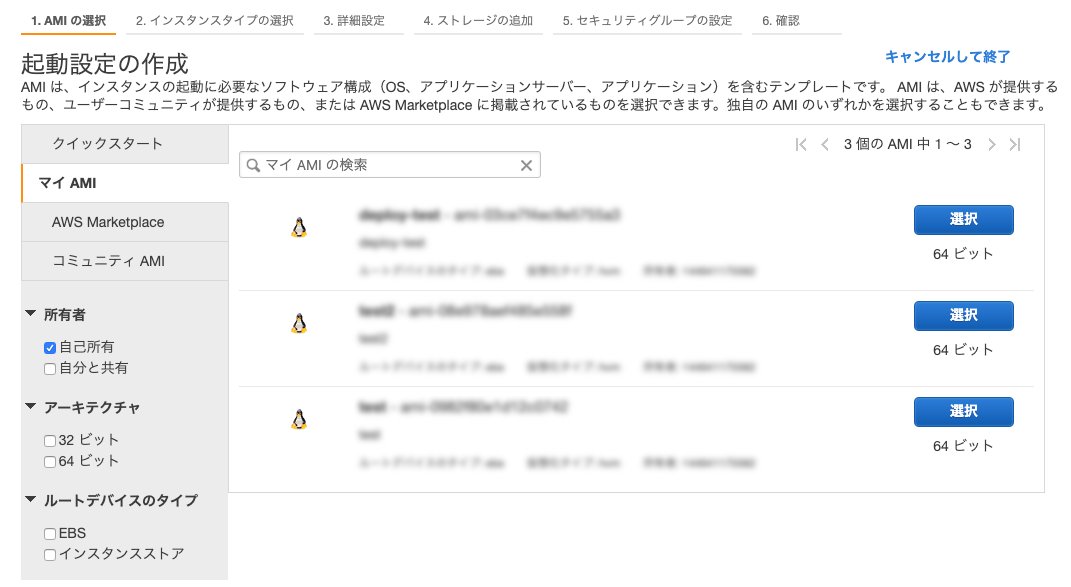
AMIの選択
マイAMIから先程作成したAMIイメージを選択する。
インスタンスタイプの選択
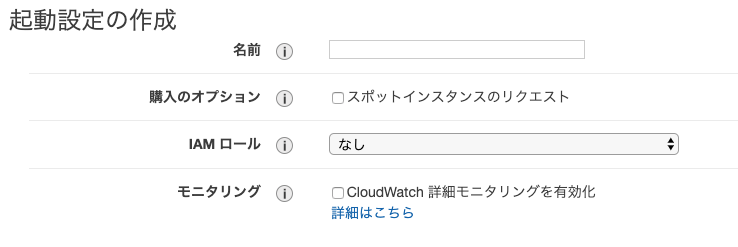
インスタンスタイプを選択する詳細設定
起動設定の名前を入力。
IAMロールはAmazonS3ReadOnlyAccessをアタッチしたIAMロールを指定する。
この後の手順は省略する。セキュリティグループの設定を忘れずに行う。
ここまででAutoScalingGroupで利用する起動設定が作成完了。
- AutoScalingGroup本体の作成 起動設定は先程作成した起動設定を選択する。 グループ名を入力し、VPCとサブネットの選択を行う。 (少なくとも2つ以上のAZになるように設定しておくことを推奨する。)
この後の手順は省略する。
builderサーバの準備
AmazonS3FullAccessとAWSCodeDeployDeployerAccessをアタッチしたIAMロールを指定する。デプロイ用ソースコードを格納するS3バケットを作成
非公開のS3バケットを作成する。
デプロイ対象のアプリケーション設定
appspec.ymlをデプロイ対象アプリケーションのプロジェクトルートに設置する。
アプリケーション再起動やミドルウェアの再起動等設定が可能。appspec.yml(サンプル)
version: 0.0 os: linux files: - source: / destination: /home/ec2-user/my-app permissions: - object: / owner: ec2-user group: ec2-user mode: 777 pattern: "**" hooks: AfterInstall: - location: run.sh timeout: 1000 runas: rootrun.sh
#!/bin/bash mkdir -p /var/my-app/bin chmod +x my-app cp -f /home/ec2-user/my-app/my-app /var/my-app/bin/my-app ln -f -s /var/my-app/bin/my-app /etc/init.d/my-app service my-app start
appspec.ymlは公式ドキュメントをよく見ておく事をオススメする。デプロイ設定の作成
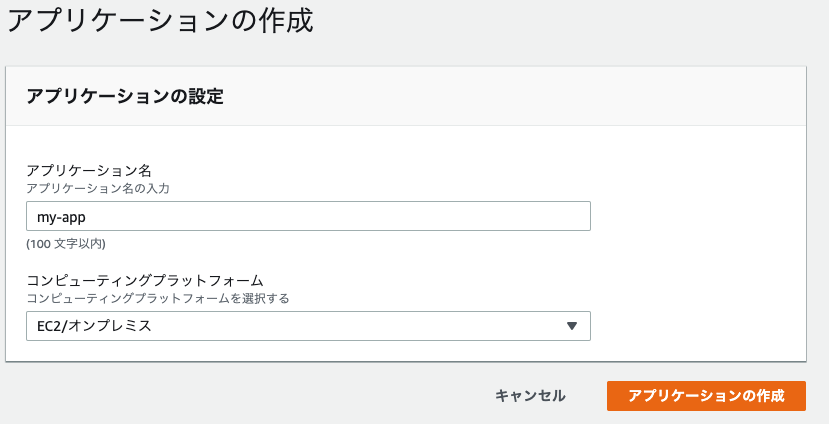
AWSCodeDeployRoleをアタッチしたIAMロールを作成しておく。アプリケーションの作成
アプリケーション名を入力。
コンピューティングプラットフォームは「EC2/オンプレミス」を選択。
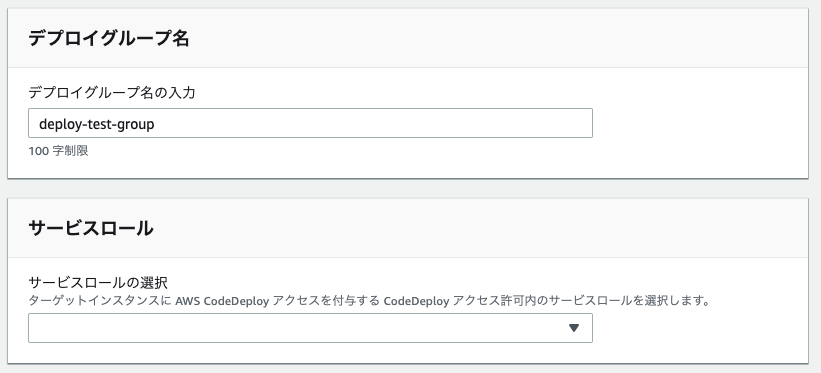
デプロイグループの作成
- デプロイグループ名
任意の名前を入力
サービスロール
CodeDeployのフルアクセス権限をアタッチしたIAMロールを指定
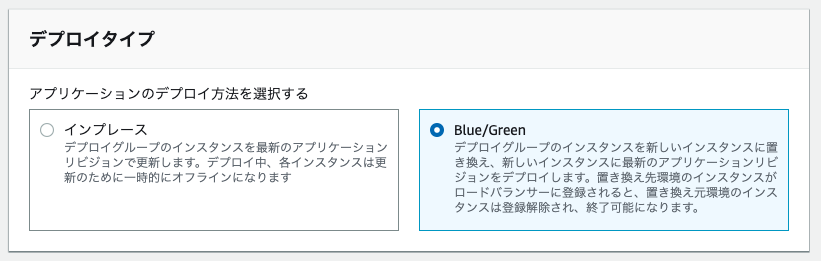
デプロイタイプ
「Blue/Green」を選択
環境設定
「Amazon EC2 Auto Scaling グループの自動コピー」を選択し、作成したAmazon EC2 Auto Scaling グループを選択する。
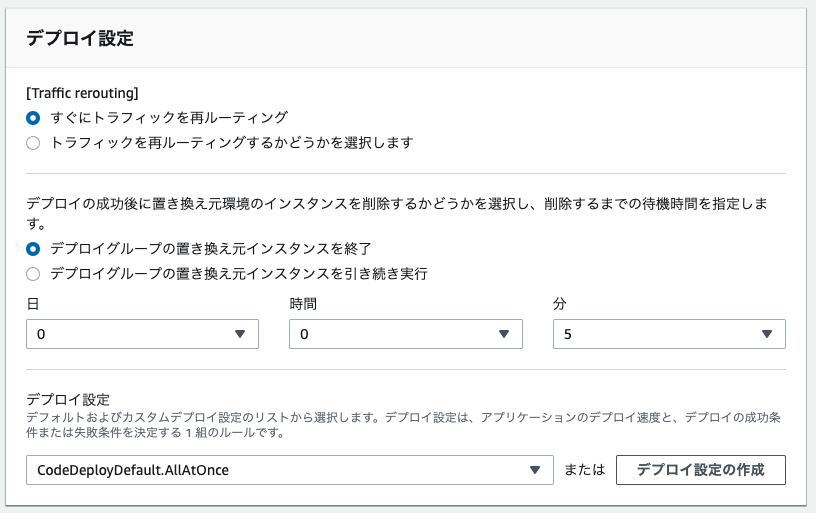
デプロイ設定
デプロイ成功後インスタンス削除するか選択し、待機時間を指定。
デプロイ設定を選択。
デプロイ設定 条件内容 CodeDeployDefault.AllAtOnce 一回で全部のインスタンスにデプロイしようとする CodeDeployDefault.HarfAtATime 半分ずつデプロイする CodeDeployDefault.OneAtATime 1つずつデプロイする
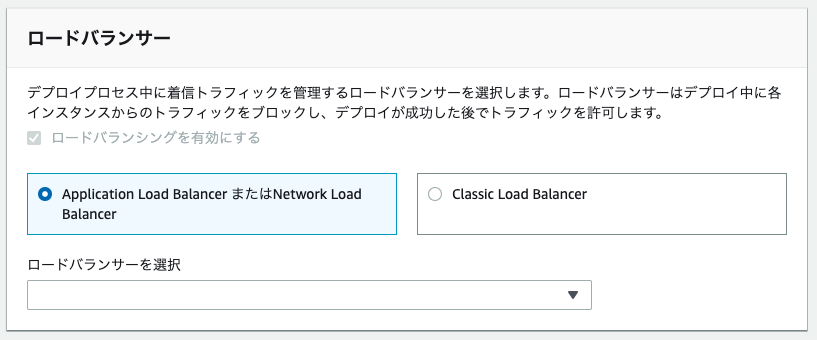
- ロードバランサー
作成したロードバランサーを選択。
- 詳細
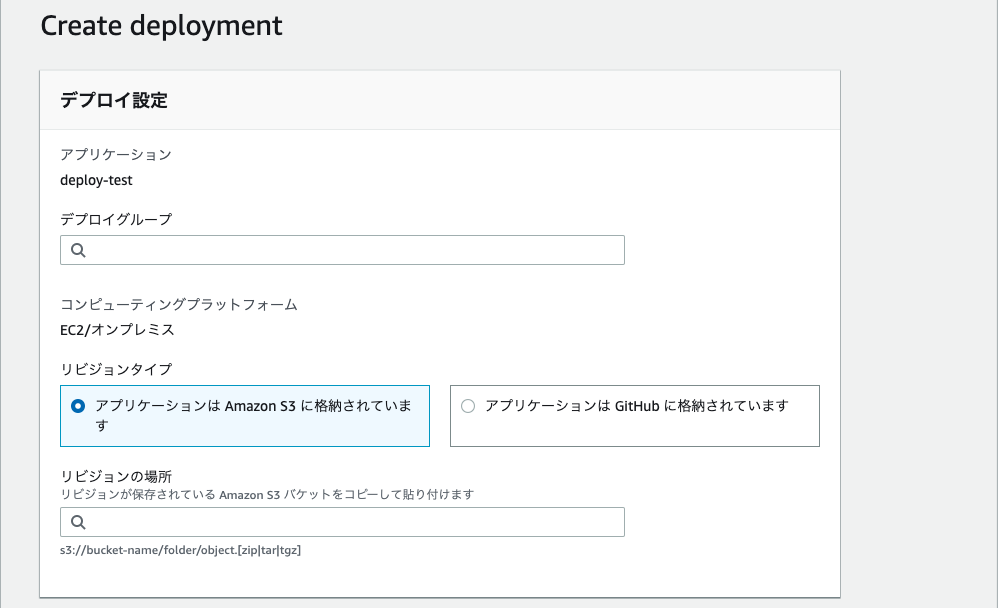
必要に応じて設定する。デプロイの作成
- デプロイグループ
先程作成したデプロイグループを選択。- リビジョンタイプ
Amazon S3を選択。- リビジョンの場所 アップロード済みのソースコードの場所を選択。 作成したAmazon S3 バケット名が
deploy-test-bucket、ソースコードのファイル名がmy-appの場合以下のようになる。
s3://deploy-test-bucket/my-app.zip
builderサーバでの実行設定
builderサーバから以下のようなスクリプトを実行することでS3バケットにソースコードをアップロードしデプロイ要求を出すことができる。
BUILD_DIR=. REGION=ap-northeast-1 APP_NAME=my-app DEPLOYMENT_GROUP=deploy-test-group DEPLOYMENT_CONFIG=CodeDeployDefault.AllAtOnce S3_BUCKET=deploy-test-bucket S3_KEY=${APP_NAME}.zip aws deploy push \ --region ${REGION} \ --application-name ${APP_NAME} \ --s3-location s3://${S3_BUCKET}/${S3_KEY} \ --source ${BUILD_DIR} ETAG=`aws deploy list-application-revisions --region ${REGION} \ --application-name ${APP_NAME} --s-3-bucket ${S3_BUCKET} --s-3-key-prefix ${S3_KEY} \ --sort-by registerTime --sort-order descending \ --query 'revisions[0].s3Location.eTag' --output text` aws deploy create-deployment --region ${REGION} --application-name ${APP_NAME} \ --s3-location bucket=${S3_BUCKET},key=${S3_KEY},bundleType=zip,eTag=${ETAG} \ --deployment-group-name ${DEPLOYMENT_GROUP} --deployment-config-name ${DEPLOYMENT_CONFIG}

- 投稿日:2019-04-17T00:20:27+09:00
AWS認定ソリューションアーキテクトアソシエイトへの道 その9 S3ハンズオン
tl;dr
現在Webエンジニアをやっているが下記の理由のためにAWSソリューションアーキテクトアソシエイト取得を目指す。
- スキルアップ
- 業務の幅を広げる
- 知的好奇心
現在のAWSスキル
- テスト用にEC2を作成したことはある(LAMP環境を構築)
- ネットワーク用語はある程度わかる(マスタリングTCP/IP 入門編は名著だと思う)
学習方法
- 対策本を読むことを考えたが、手を動かしながら学んだほうが身につくと考え、Udemyの動画教材を購入
- AWS INNOVATE(Amazonが主催するAWSを学ぶためのONLINE CONFERENCE) → 開催中だったために登録
- 参考書も購入
購入した教材はこちら
AWS認定ソリューションアーキテクト – アソシエイト試験突破講座
購入した本はこちら
合格対策 AWS認定ソリューションアーキテクト - アソシエイト
本日の課題
- S3パケットの作成と操作(ハンズオン)
- S3のバージョン管理(ハンズオン)
課題メモ