- 投稿日:2019-04-13T21:33:34+09:00
GitHubのWebhookでプルリクエストをマージした際にツイートできるようしてみた
はじめに
こんにちは。なおとです。
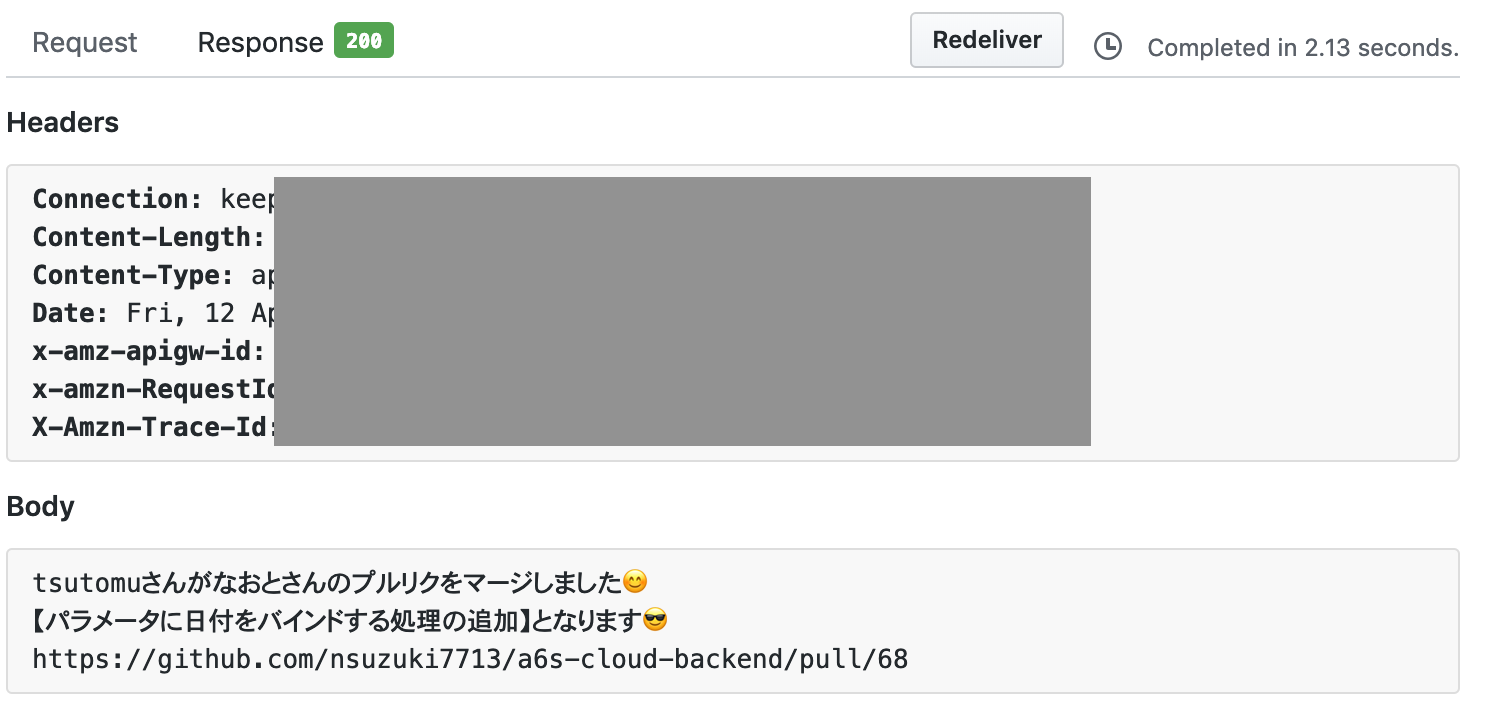
今回はGitHubのプルリクをマージした際に自動でツイートできるようにしたのでその解説となります。プルリクをマージするとこんな感じでTweetされます。
tsutomuさんがなおとさんのプルリクをマージしました?
— a6s-cloud (@CloudA6s) 2019年4月11日
【analysis_resultsテーブルにカラムを追加??】となります?️https://t.co/EWfJsIlGyx
なぜやろうと思ったのか?
現在数人で個人開発をしていますが、時間の制約もあり、かつ非同期のコミュニケーションのため、モチベーションを保つことは難しいです。
普段はGitHub↔︎slack連携をしているので、イシュー作成やプルリクをマージした際に通知がきます。
せっかくプロジェクトもpublicにしているので、ツイッターのオープンな場に通知できたらモチベーションも上がるのでは?と考えたのがきっかけです。また、今の個人開発ではTwitter APIを使用しています。
以前アカウントを新規取得したのですが、ツイートをしなかった影響なのかアカウントをロックされてしまいました。
その為、CT(ケイゾクテキ ツイート)をして、アカウントがロックされないようにしよう!!と思ったのもあります笑今回のソースコードはこちらにあります。
https://github.com/nsuzuki7713/github-webhook構成
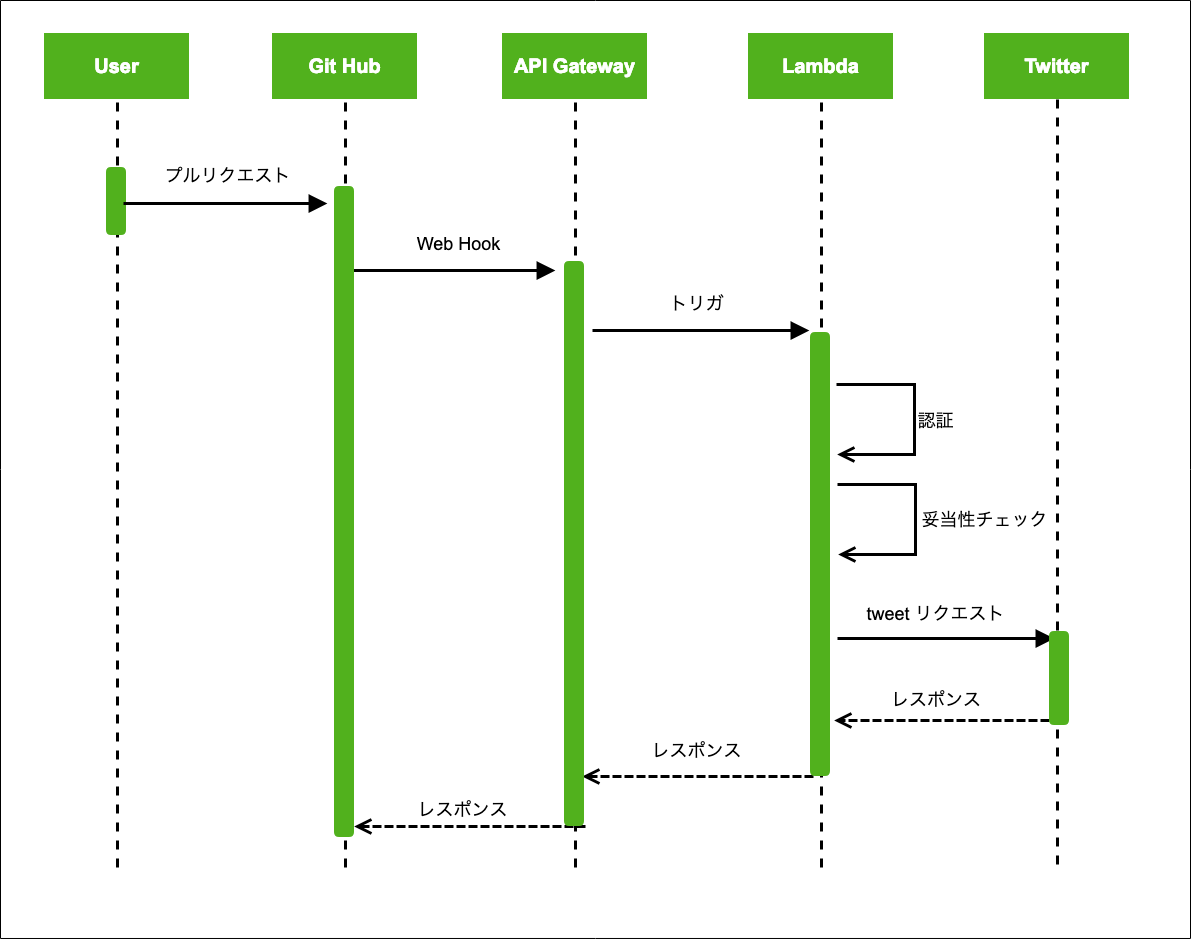
こちらがシーケンス図となります。
シンプルな処理形式だと思います。
- ユーザーがプルリクを作成する
- GitHubのWebhookでAPI Gatewayにリクエストをする
- API Gatewayはlambdaを実行する
- lambdaでは最初に認証チェック、妥当性チェックを行う
- lambdaからtwitter apiを叩いてツイートする
開発
ツイッターアカウント作成とapiキーの作成
APIからTweetするためには、Twitter APIが必要です。
下記記事を参考にして申請しました。
https://www.torikun.com/2018/10/08/twitter-developer-api/特に詰まることなく、承認も一瞬でした。数日待たされるという記事も見かけましたが僕は申請したら、数分で承認メールがきました。
英語で使用用途を記載する必要がありますが、僕はGoogle翻訳をフル活用しました。
lambdaとAPI Gatewayの設定
下記記事を参考にして、進めました。
スクショもあり、丁寧に手順が書いてあります。
【API Gateway】AWS Lambda統合のPythonでHello, worldGitHub webhookの設定
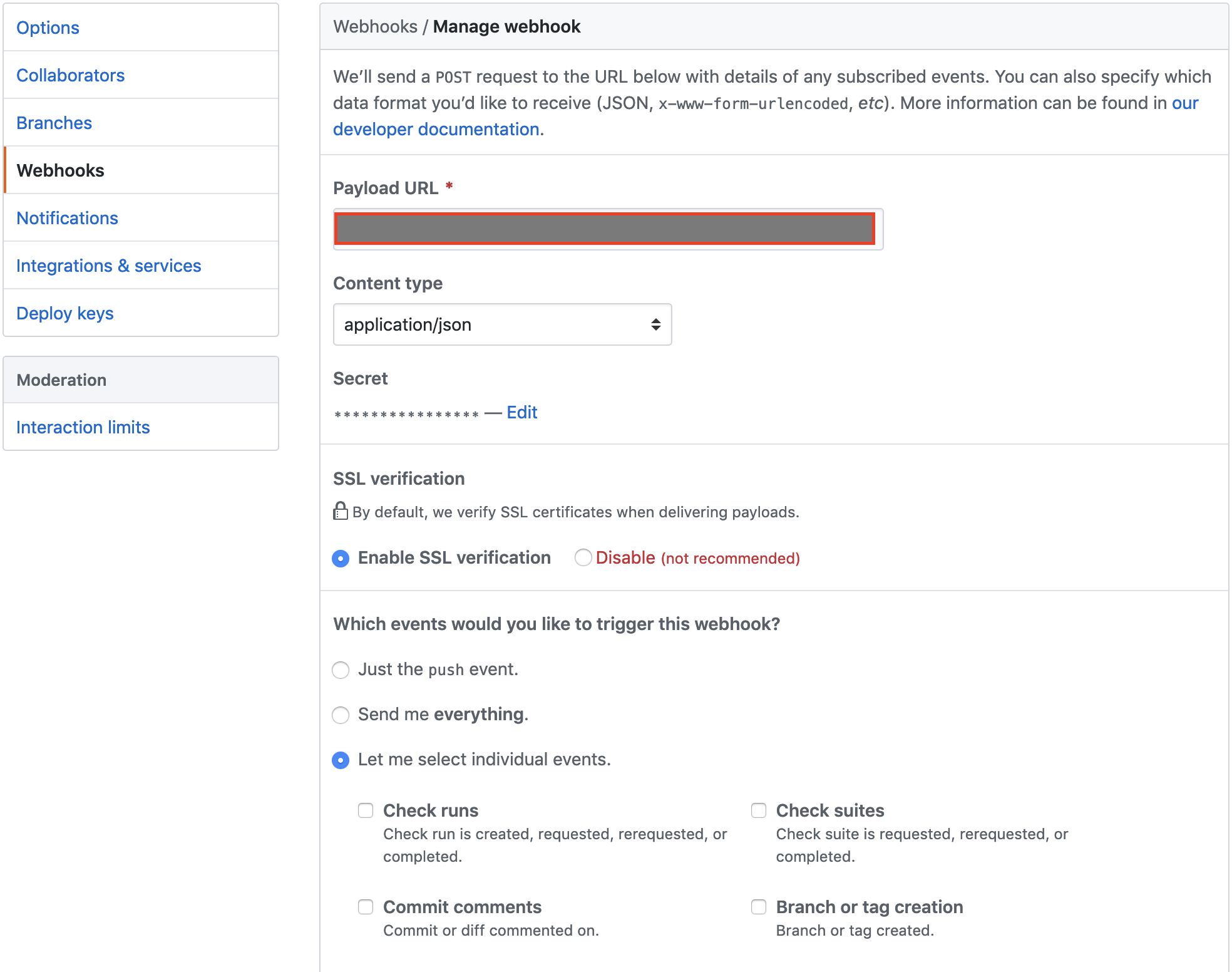
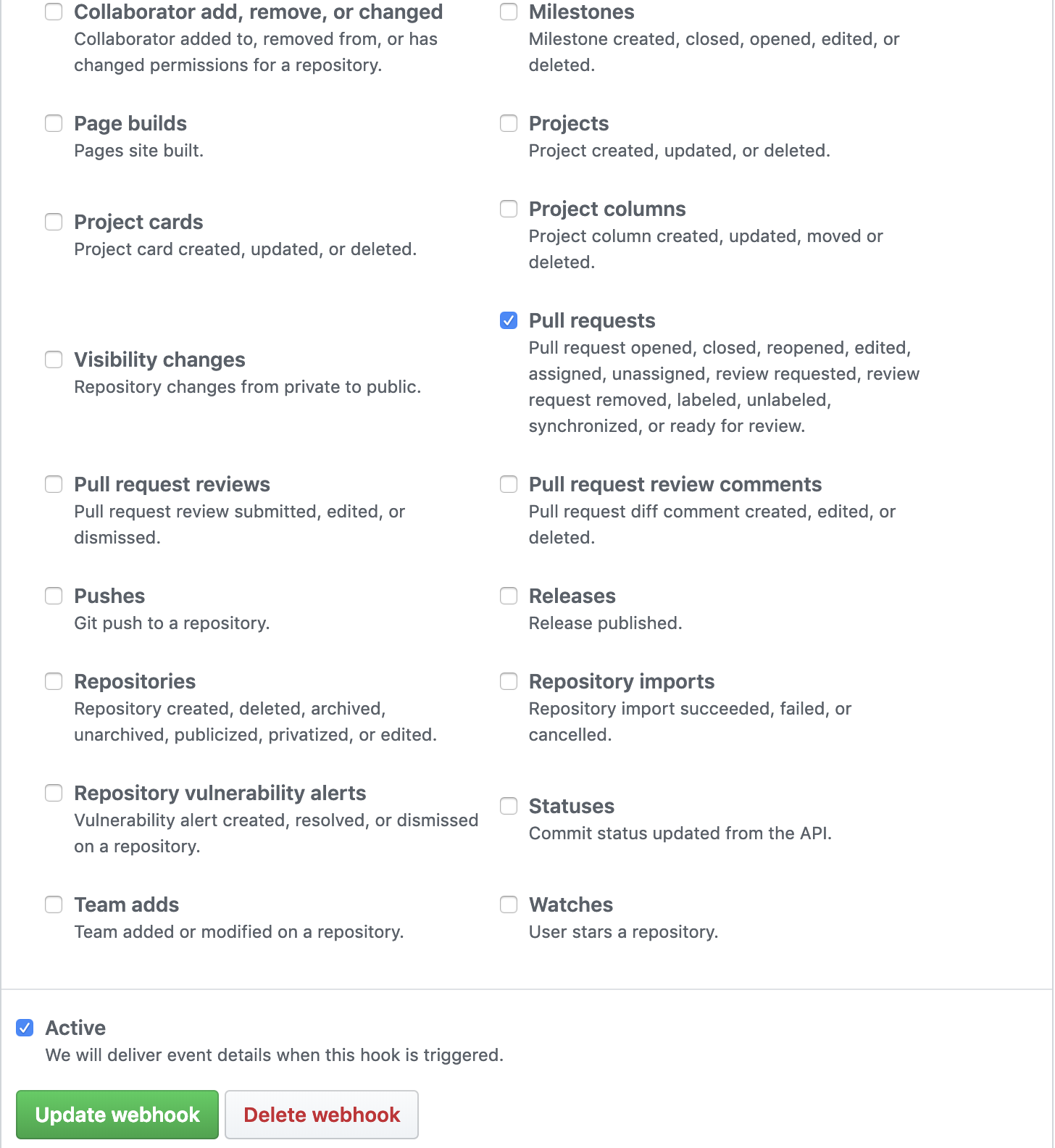
下記記事を参考にして、進めました。
Github serviceをwebhookに変更したこちらが設定した内容です。
webhookのtriggerを設定できますが、今回はPull requestsにチェックを入れます。
lambda側の実装
今回はpythonを使用しています。選定理由はtwitter apiを使用したサンプル記事が多かったからです。
コードの詳細はGitHubをご確認お願いします。
https://github.com/nsuzuki7713/github-webhookフォルダ構成
最低限必要なファイル構成となります。
最初、使用するモジュールをmodulフォルダの中に入れていましたが、Lambdaはデフォルトでプロジェクト直下にモジュールを置く必要があるとのことです。
プログラム初心者がAWS Lambda(Python)でハマった7個のこと├── function.py ├── settings.example.py ├── (以下、使用するモジュール)ライブラリのインストール
# プロジェクトの直下に移動 # ライブラリのインストール $ pip3 install requests requests_oauthlib -t .僕は
pip3 install requests requests_oauthlib -tで下記エラーがでました。
distutils.errors.DistutilsOptionError: must supply either home or prefix/exec-prefix -- not both下記記事を参考にして、設定を変更しました。
http://www.sysop.jp/entry/2017/02/05/231821APIキー等の設定
settings.py###############Twitter API###################### CONSUMER_KEY = "Twitter APIのキー" CONSUMER_SECRET = "Twitter APIのキー" ACCESS_TOKEN = "Twitter APIのキー" ACCESS_TOKEN_SECRET = "Twitter APIのキー" ###############GitHub Webhook###################### SECRET = "GitHubのWebhookで記載してsecretキー"メイン処理の設定
Webhook payloadのexampleは公式ドキュメントが分かりやすいです。
https://developer.github.com/v3/activity/events/types/#pullrequesteventfunction.py#coding: UTF-8 import json,hashlib,hmac from requests_oauthlib import OAuth1Session import settings def lambda_handler(event, context): # HMAC値による認証処理 signature = event['headers']['X-Hub-Signature'] signedBody = "sha1=" + hmac.new(bytes(settings.SECRET, 'utf-8'), bytes(event['body'], 'utf-8'), hashlib.sha1).hexdigest() if(signature != signedBody): return {"statusCode": 401, "body": "Unauthorized" } # プルリクの情報を抽出 body = json.loads(event['body']) # actionのキーがなければ終了 if "action" not in body: return {"statusCode": 200, "body": "exit" } # プルリクのクローズでなければ終了 if body['action'] != "closed": return {"statusCode": 200, "body": "exit2" } # ツイートで必要な情報を取得 title = body['pull_request']['title'] # プルリクのタイトル html_url = body['pull_request']['html_url'] # プルリクのURL user = body['pull_request']['user']['login'] # プルリク作成者 merged_by = body['pull_request']['merged_by']['login'] # マージ者 # GitHubのアカウントとツイートする際の名前の対応表 user_list = { "nsuzuki7713": "なおと" } # tweet文章作成 msg = user_list[merged_by] + "さんが"\ + user_list[user] + "さんのプルリクをマージしました?" + "\n"\ + "【" + title + "】となります?️" + "\n" +html_url # tweet処理 twitter = OAuth1Session(settings.CONSUMER_KEY, settings.CONSUMER_SECRET, settings.ACCESS_TOKEN, settings.ACCESS_TOKEN_SECRET) params = {"status": msg } req = twitter.post("https://api.twitter.com/1.1/statuses/update.json",params = params) return {"statusCode": 200, "body": msg}デプロイ
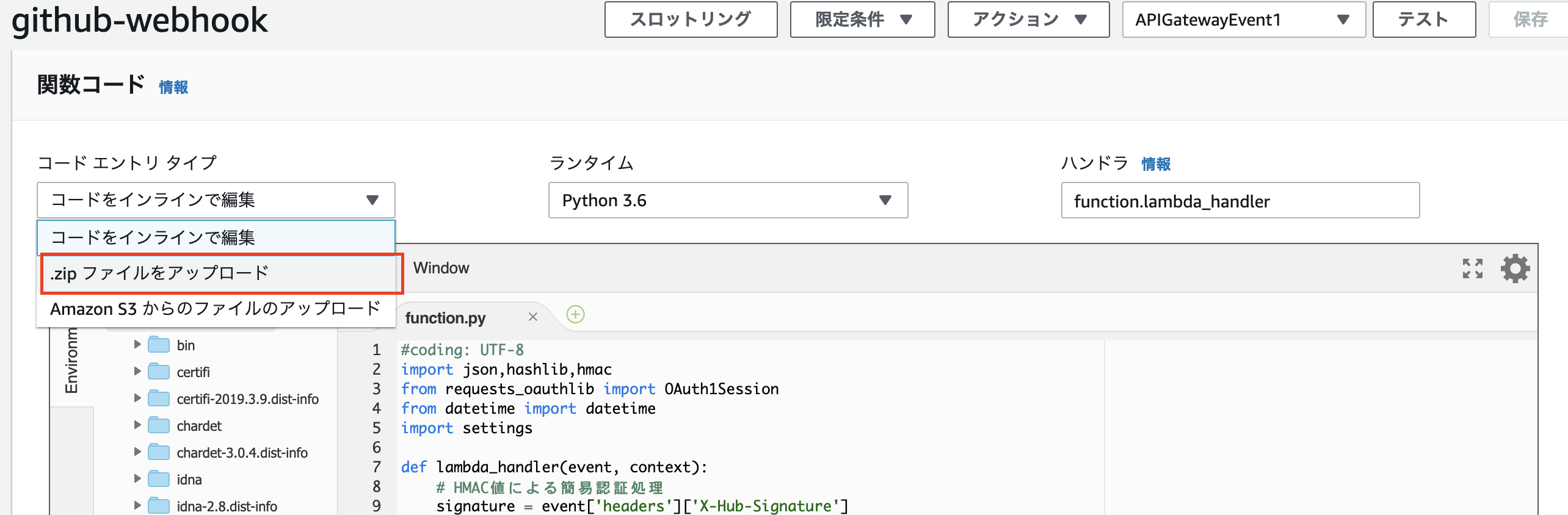
外部モジュールを使用する場合はlambdaのインライン上からはできなく、zip等にする必要があります。
今回はzip形式でデプロイしました。# プロジェクトの直下に移動 $ zip -r toLambda.zip ./*作成したzipファイルをlambdaのコンソールからアップロードします。
確認
GitHubのWebHooks設定から実行して、確認することが可能です。
おわりに
API GatewayやWebhook、pythonなど初めて使うものが多く、まだ1つ1つ理解できていませんが完成はできました。
issue駆動開発をしたので、issueのクローズした順を追っていただければ僕の進め方も分かります。
https://github.com/nsuzuki7713/github-webhook/issues?q=is%3Aissue+is%3Aclosed個人開発やGitHub駆動で学習している人は、CT(ケイゾクテキ ツイート)も作成してみませんか笑
ただ、今のままだと固定文言ですぐに飽きてしまうので、コミット数や変更行数のデータを見ながら、もっと文言のバリエーションとかを増やしたいなーと思っています。
- 投稿日:2019-04-13T20:58:54+09:00
#python の datetime で明日の 時・分をランダムに生成する例
>>> import datetime >>> now = datetime.datetime.now() >>> now # datetime.datetime(2019, 4, 13, 18, 44, 57, 269002) >>> rand_datetime_today = now.replace(hour=random.randint(1,23), minute=random.randint(1,59), second=0, microsecond=0) >>> rand_datetime_today # datetime.datetime(2019, 4, 13, 3, 8) >>> rand_datetime_tomorrow = rand_datetime_today + datetime.timedelta(days=1) >>> rand_datetime_tomorrow # datetime.datetime(2019, 4, 14, 3, 8)Original by Github issue
- 投稿日:2019-04-13T20:48:59+09:00
pythonでcsvファイルの読み込み/書き出し/分析
今回はjupyternotebookで実行した結果に基づいて書きます。
読み込み
例えばワークディレクトリにあるsample.csvを読み込んでdata1とする場合、
untitled.pyimport pandas as pd data1 = pd.read_csv('sample.csv')
read_csv()を使うためにあらかじめパッケージpandasをimportしている必要があります。pdとしてimportするのが慣例です。書き出し
例えばワークディレクトリに
data1をsample.csvとして書き出す場合、untitled.pydata1.to_csv('sample.csv)これでワークディレクトリに
sample.csvが新たに保存されます。分析
ロードしたデータの分析にはこれまた
pandasの関数groupby()が役に立ちます。私が大学の課題などで使った時はこちらのサイトを参照しました。とてもわかりやすく書いてあります。記事は以上です、ありがとうございました。
- 投稿日:2019-04-13T20:43:28+09:00
#python で 特定の年月日・時分秒・マイクロ秒指定で datetime オブジェクトを作成し、それを文字列にパースする簡単な例
datetime.datetime()を使う。>>> import datetime >>> datetime.datetime(2016,1,2, 10,20,5, 100).strftime('%Y-%m-%d %H:%M:%S %a %f') '2016-01-02 10:20:05 Sat 000100'ref
Python strftime() - datetime to string
Original by Github issue
- 投稿日:2019-04-13T19:04:49+09:00
PyTorchで白黒人物画像に着彩するAIを作る
はじめに
PyTorchでの人工知能制作にはまり、白黒画像に着彩してみたくなったので、やってみることにしました。細かい説明の前に、最終的な出力結果を紹介します。(人物画像はどれもGoogle画像検索で改変後の非営利目的での再使用が許可された画像です。)
パソコンのスペック上低画質の物しか扱えませんが、顔の部分を肌色に塗ることができています。ポイントは、ワイシャツの襟の部分などの白い部分は塗らないようになっているところです。今回はこのAIの仕組みと、簡単なソースコードの解説をしたいと思います。原理解説
ここからはこのAIの仕組みについて解説します。
学習に使用する画像の読み込み&加工について
これには画像処理系のライブラリのPython Imaging Library(PIL)を使用します。今回の目的は着彩AIを作ることなので、入力となる白黒画像と、正解データとなるカラー画像が必要になります。白黒画像はPILの
convert('L')から作成することができるため、画像データとして必要になるのは顔写真のカラー画像のみということになります。データセットにはLabeled Faces in the Wildを使用しました。また、これらの画像は読み込み後、切り抜きやリサイズなどの加工を施して最終的に50×50の画像になります。切り抜きについては後に説明します。モデルについて
今回は画像処理ということで、定番の畳み込みニューラルネットワーク(CNN)を用いました。と言っても、畳み込み層とプーリング層はそれぞれ一層ずつ、全結合層も一層という簡素な作りになっています。CNNを使う必要性はないかもしれませんが、私が以前作成したAI(これも画像処理系)で、CNNを使う場合と使わない場合で圧倒的にCNNのほうが学習が速かったので、CNNを使います(おそらく畳み込みとプーリングにより画像を圧縮したためだと思っています。今後検証します)。モデルの入力は50×50個のノード、出力は50×50×3個(RGBの3チャンネルなので)のノードとなっています。
学習の際の流れ
今回のようなニューラルネットワークを用いたAIの学習の際には、
1. モデルに何らかのデータを入力する
2. モデルの出力と、正解との誤差を求める
3. 誤差をもとにモデルを更新する
4. 1.に戻るという流れを踏むと思います。今回の場合も基本的に同じです。上の流れを今回作るAIで具体的に言い換えると、
1. モデルに白黒画像を入力
2. 出力画像とカラー画像との誤差を求める
3. 誤差をもとにモデルを更新する
4. 1.に戻るという流れになります。入力の白黒画像は各ピクセルごとに0~1の値が格納されている配列です。出力のカラー画像はRGB形式で、これは各ピクセルごとにR,G,Bの各値が0~1の範囲で格納されています(正確には学習が上手くいけば0~1の範囲になります)。この方法で学習してみます。
これでも学習自体は成り立っていいるのですが、なかなか鮮明な画像が出力されませんでした(学習する画像の枚数や、エポック数、学習率などの条件はすべて揃えています)。学習を重ねれば鮮明な画像が出力できるようになるのかもしれませんが、僕は待つことが嫌いなのでできるだけ早く学習させるようにしたいものです。ここで、これを解決するための「工夫」をすることにしました。
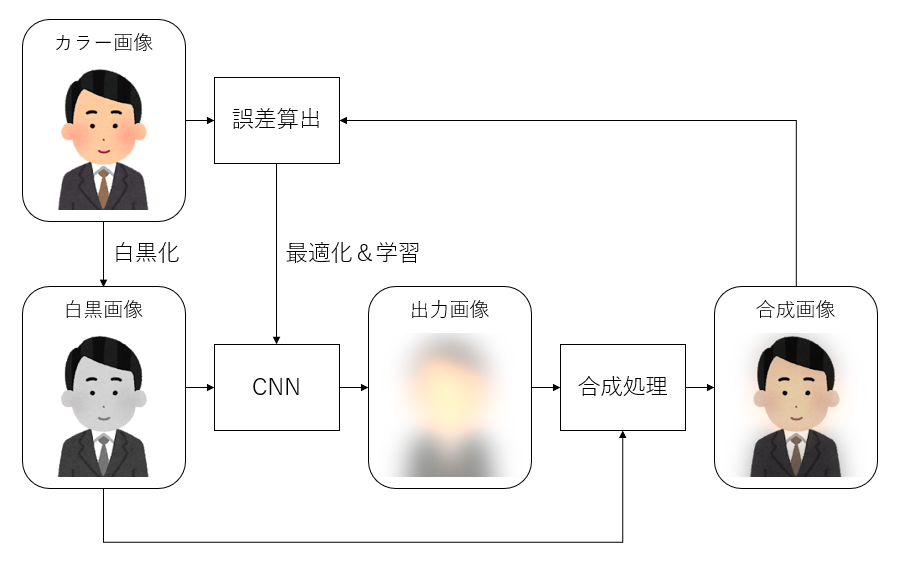
工夫その1:出力を入力と合成する
見出しが早速答えとなってしまいましたが、この問題を解決する工夫として、「出力と入力を合成する」ということを思いつきました。これは、このAIの目標である「色を付ける」ということに関してとても合理的な手法だと思います。
先ほど説明した学習の流れを変更し、誤差算出の前に「出力と入力を合成する」というステップを加えます。これは具体的に何をしているのかというと、「出力のR,B,Gの各値に入力の値をそれぞれ掛ける」という処理をしています。これは画像編集ソフトでレイヤー同士の合成の「乗算モード」と同じです。これにより、入力で色の暗い部分は0に近い値がかけられるため、合成後の画像は0に近い、つまり暗い色が出力されるようになります。これを用いれば、入力画像の明暗の情報を出力画像に継承することができます。この処理を踏まえ、先ほどの学習の流れを書き換えると、1. モデルに白黒画像を入力
2. 出力画像と入力画像を合成
3. 合成画像とカラー画像との誤差を求める
4. 誤差をもとにモデルを更新する
5. 1.に戻るという流れになります。図で表すと次のようになります(画像はイメージです)。
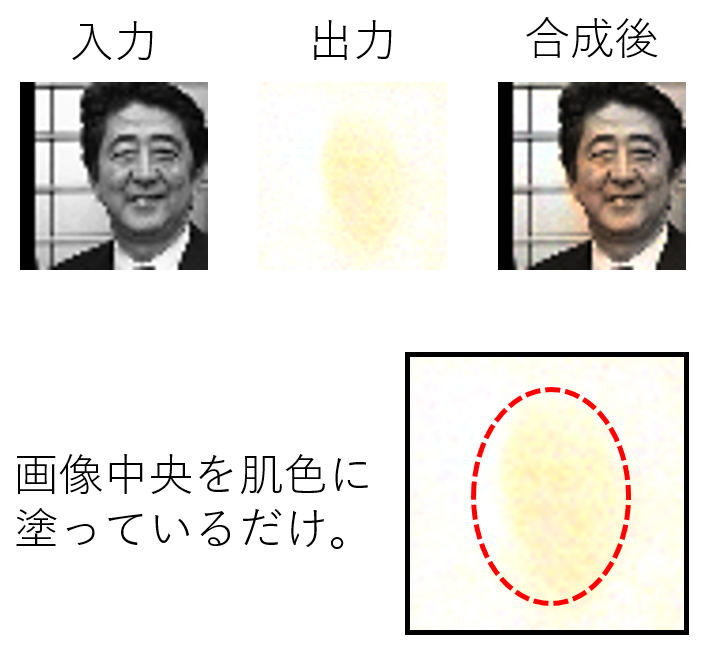
これにより先ほどよりも圧倒的に早く成果を上げることができるようになります。こちらが結果です。
はっきりとした画像を作ることができました!顔の部分もしっかりと認識しています!と言いたいところですが、画像中央のみが着彩されています。これではわかりにくいかもしれないので、別の画像を用意しました。
二枚目の画像の人物を少し右にずらしてテストをしました。合成後の画像を見てもわかるように、人物の顔の右上は着色されず、画像中央のみが着彩されていることが分かると思います。これは使用したデータセットに画像中央に人の顔があるものが多いことが原因です。これではAIを使う意味がありません。初めから画面中央をオレンジ色に塗った画像を合成すれば済んでしまうからです。そこでこれを防ぐためにもう一つ「工夫」をすることにしました。工夫その2:画像をランダムに切り抜く
この問題の原因は画像中央に人の顔があることが原因です。そのため、画像中央から顔をずらすことでこの問題が解決できると考えました。ランダムなサイズの正方形でランダムな位置を切り抜けば顔の位置をずらすことができます。
この作業を画像を読み込む際に行うことで、画面中央だけに着彩するということを防ぐことができました。(しかしシャツにも色を付けてしまっています。得意不得意があるのでしょうか。今後学習データを増やして再度挑戦します。)
原理の説明は以上です。実装
ここからは実際にどのようなプログラムを書いたのかを解説します。
下準備
プログラムを書く前に、画像データの入ったディレクトリを用意します。まずは
D:\PythonPrograms\PaintFaceAI\TrainDataというフォルダを用意します。もちろん別の場所でも構いません。パスを変更した場合はプログラム内のディレクトリ指定用の変数を書き換えてください。このディレクトリには学習に使う訓練データを入れます。face (number).jpgとなるように画像を用意してください。(僕のパソコン(Windows)では画像を全選択→右クリック→名前を変更→faceと入力→Enterとする事で自動に番号付けをすることができました。)すべての画像のサイズは250×250です。また、最低でも8192枚の画像を用意してください(この数は後述の変数TRAIN_NUMの値です)。
同様にD:\PythonPrograms\PaintFaceAI\TestDataも用意します。TrainDataのディレクトリと同様の画像(ただし学習しないので白黒も可)をこちらは5枚用意します(もっと多くの画像をテストしたい場合はTEST_NUMの値を変更してください)。
最後に、モデルの保存先となるフォルダ(:D:\PythonPrograms\PaintFaceAI\Model)を用意してください。もちろんこの場所も自由に決めることができますが、その際は後述の変数のMODEL_LOCを変更してください。出力画像の保存先等はフォルダを自動で初期化するようにしたのですが、モデルは一度消えるとまた数時間学習しなければならないので、めんどくさいですが安全確保のため手動です。フォルダは空のままでOKです。ライブラリのインポート
使用するライブラリをインポートします。
Colorize.py#ライブラリのインポート import torch from torch import nn from torch import optim import torch.nn.functional as F import numpy as np from PIL import Image import os import shutil
nnはニューラルネットワークを使うために、optimはPytorchが提供するオプティマイザーを使用するために、nn.functionalは誤差関数を使用するためにインポートします。尚、numpyは画像読み込み時に、osとshutilは画像保存先等のディレクトリを整えるときに使います。設定用の変数の定義
良いパラメータを探す際や、様々な実験を行う際に、プログラムのあちこちに散らばっている設定を一つの箇所にまとめておけば楽なので、あらかじめ設定用の変数を用意し、プログラム内でそれらを使用します。
Colorize.py#設定 SOURCE_IMAGE_SIZE = 250 #画像の縦と横のピクセル数 IMAGE_SCALE = 0.2 #元画像の何倍の大きさの画像を扱うのか IMAGE_SIZE = int(SOURCE_IMAGE_SIZE*IMAGE_SCALE) #扱う画像のサイズ TRAIN_NUM = 8192 #学習に使う画像の数 EPOCH_NUM = 16 #同じデータセットを繰り返し学習する数 TEST_NUM = 5 #テストする画像の数 LR = 0.0001 #学習率 BATCH_SIZE = 128 #バッチサイズ BASIC_COLOR_SPACE = "RGB" #色空間の指定 #デバイスの指定(グラボが使えるなら使う) DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu' LEARN = True #学習を行うのか TEST = True #学習中に1エポックごとにテストを行うのか TEST_VISUALIZE = True #テストで画像を出力するのかどうか MODEL_NAME = "Model"#モデル保存時の名前 #使用するディレクトリのパス(適宜指定してください) #学習用の画像が保存されたディレクトリ TRAIN_DATA_LOC = r"D:\PythonPrograms\PaintFaceAI\TrainData" #テスト用の画像が保存されたディレクトリ TEST_DATA_LOC = r"D:\PythonPrograms\PaintFaceAI\TestData" #最終的な出力画像の保存先 OUT_LOC = r"D:\PythonPrograms\PaintFaceAI\Output" #入力画像の保存先 IN_LOC = r"D:\PythonPrograms\PaintFaceAI\Input" #元画像(学習用の画像を切り抜き、リサイズ処理したもの)の保存先 SOURCE_LOC = r"D:\PythonPrograms\PaintFaceAI\Source" #色情報(ネットワーク出力を入力と合成する前の画像)の保存先 COLOR_LOC = r"D:\PythonPrograms\PaintFaceAI\Color" #モデルの保存先 MODEL_LOC = r"D:\PythonPrograms\PaintFaceAI\Model"画像読み込み用クラス
画像を読み込むための機能を持つクラスを用意します。
このクラスはふたつのメソッドを持ちます。一つ目はload_batchメソッドです。これは学習時に使用します。指定された枚数の画像を読み込み、切り抜き、リサイズの処理を行った後にそれを白黒化します。また、カラー画像と白黒画像共に各ピクセルごとの色の情報を配列に格納し、それを返します。二つ目のload_test_imageでは、リサイズと白黒化のみを行い、指定枚数の白黒画像の情報の入った配列を返します。基本的にload_batchメソッドと同じです。Colorize.py#画像読み込み用クラス class image_loder(): #ミニバッチ学習に使用する1ミニバッチ分の画像を取得する def load_batch(self,image_number,batch_size, random_crop = True, crop_max = 200,message = ''): #画像のピクセル数と同じ数だけの要素を持つTensor型の配列を作る color_image = torch.Tensor(batch_size,3,IMAGE_SIZE,IMAGE_SIZE) greyscale_image = torch.Tensor(batch_size,1,IMAGE_SIZE,IMAGE_SIZE) #バッチサイズの回数繰り返す for num in range(batch_size): #ファイル名 image_name = "face (" + str(int(image_number+1+num)) + ").jpg" #画像読み込みのついでに進捗を確認できるようなメッセージを出力 print("Loading Image :",image_name," | ",message) #画像を読み込む image = Image.open(TRAIN_DATA_LOC + "\\" + image_name) #ランダムな場所で切り抜く if random_crop == True: #切り抜く幅の設定 crop_size = np.random.randint(1,crop_max) #切りぬく正方形の左上の座標の指定 x = np.random.randint(0,crop_size) y = np.random.randint(0,crop_size) #切り抜く image = image.crop((x,y,x+SOURCE_IMAGE_SIZE-crop_size,y+SOURCE_IMAGE_SIZE-crop_size)) #指定の大きさにリサイズ image = image.resize((IMAGE_SIZE,IMAGE_SIZE)).convert(BASIC_COLOR_SPACE) #配列の各要素に読み込んだ画像の各ピクセルの色を格納する for x in range(IMAGE_SIZE): for y in range(IMAGE_SIZE): pixcel = image.getpixel((x,y)) #白黒なのでRGBの平均を取る。その後0~1の範囲に変換する color_image[num,0,x,y]=pixcel[0]/255 color_image[num,1,x,y]=pixcel[1]/255 color_image[num,2,x,y]=pixcel[2]/255 #白黒に変換 image = image.convert('L') #配列の各要素に読み込んだ画像の各ピクセルの色を格納する for x in range(IMAGE_SIZE): for y in range(IMAGE_SIZE): pixcel = image.getpixel((x,y)) greyscale_image[num,0,x,y]=pixcel/255 #配列の形状を整える color_image = color_image.view(batch_size, 3, IMAGE_SIZE, IMAGE_SIZE).to(DEVICE) greyscale_image = greyscale_image.view(batch_size, 1, IMAGE_SIZE, IMAGE_SIZE).to(DEVICE) #画像データの配列を返す return [color_image,greyscale_image] #テスト用に使用する画像の取得。取得枚数は別指定。 #仕組みはほぼload_batchと同じなのでコメントは省略 def load_test_image(self,test_num,message = ''): greyscale_image = torch.Tensor(test_num,1,IMAGE_SIZE,IMAGE_SIZE) for num in range(test_num): image_name = "face (" + str(int(num+1)) + ").jpg" print("Loading Image :",image_name," | ",message) image = Image.open(TEST_DATA_LOC + "\\" + image_name) image = image.resize((IMAGE_SIZE,IMAGE_SIZE)).convert(BASIC_COLOR_SPACE) image = image.convert('L') for x in range(IMAGE_SIZE): for y in range(IMAGE_SIZE): pixcel = image.getpixel((x,y)) greyscale_image[num,0,x,y]=pixcel/255 greyscale_image = greyscale_image.view(test_num, 1, IMAGE_SIZE, IMAGE_SIZE).to(DEVICE) return greyscale_image
load_batchメソッドの引数について引数が多いので簡単に説明します。
引数 説明 image_number 画像読み込み時に、何番目の画像から読み込むのかを指定します。 batch_size バッチサイズを指定します。このメソッドではバッチサイズ個の画像を返します random_crop ランダムな位置で切り抜くのか否かを指定します。ランダムに切り抜くことで画像中央ばかりに人の顔があることがなくなります crop_max 切り抜く幅の最大値を指定します。例えば crop_maxが10で、元画像のサイズが50×50の場合、40×40~50×50の大きさの画像が作られますmessage コンソールに表示するメッセージを指定します。画像読み込みが一番時間がかかるため、このついでに進捗を確認できるので便利です。必ず必要というわけではありません。
load_test_imageメソッドの引数についてこちらも簡単に説明します。
引数 説明 test_num 何枚の画像をテストするのかを指定します。 messege コンソールに表示するメッセージを指定します。 ニューラルネットワークを構築するクラス
今回は
nn.Moduleクラスを継承するという形でネットワークを定義します。Colorize.py#ニューラルネットワークの設定 class network(nn.Module): #nn.Moduleを継承してモデルを用意する def __init__(self): super(network,self).__init__() #畳み込み層(画像を圧縮して学習速度が高まった) self.features = nn.Sequential( nn.Conv2d(1,8,kernel_size=2,stride=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2,stride=1), ) #全結合層 self.classifier = nn.Sequential( nn.Linear(18432,(IMAGE_SIZE**2)*3), nn.ReLU(inplace=True), nn.Linear((IMAGE_SIZE**2)*3,(IMAGE_SIZE**2)*3) ) #インプットからアウトプットまでの流れ def forward(self,x): x = self.features(x) x = x.view(x.size(0),-1) x = self.classifier(x) return x可視化用のクラス
プログラム内での画像データは配列になっているので、これを可視化する必要があります。そのためのクラスを作ります。
Colorize.py#可視化用のクラス class visualizer(): def __init__(self): return None #画像に変換 def visualize(self,image,size,name,show_or_not,color_space): #画像の縦横のピクセル数を用意 width,height = size #指定サイズの画像を用意 image_v = Image.new(color_space,(width,height)) #白黒画像でない場合 if color_space != "L": for x in range(width): for y in range(height): #各ピクセルの色を入力された配列を参照して決定する。配列では0~1だが、0~255に変換してから出力する value=image[:,x,y] image_v.putpixel((x,y),(int((value[0])*255),int((value[1])*255),int((value[2])*255))) #白黒画像の場合 else: for x in range(width): for y in range(height): #各ピクセルの色を入力された配列を参照して決定する。配列では0~1だが、0~255に変換してから出力する value=image[:,x,y] image_v.putpixel((x,y),(int(value[0]*255))) #画像の表示 if show_or_not == True: image_v.show() #画像の保存 image_v.convert("RGB").save(name+".bmp")着彩用のクラス
このプログラムの本体となるクラスです。かなりややこしく仕上がっております。今回はメソッドごとに説明します。
__init__メソッドこのクラスの初期設定です。ここではモデルの作成と最適化方法の選択をします。今回は最適化方法は
Adamを使用しました。Colorize.py#色を塗るAIのクラス class painter(): def __init__(self): #ネットワークの作成 self.model = network().to(DEVICE) print("Created Model:\n",self.model) #最適化手法の設定 self.optimizer = optim.Adam(self.model.parameters(),lr = LR) #続く...
multiplyメソッド(合成処理)先に合成処理用のメソッドを作っておきます。これを一つのメソッドにする必要はないかもしれませんが、合成法を変える場合に便利なのでメソッドにしました。
Colorize.py#白黒画像とネットワークの出力を合成 def multiply(self,a,b): return a * b #続く...
paint_trainメソッドこのメソッドでは学習時の画像処理関連の流れをまとめています。白黒画像を受け取ると、それをネットワークに入力し、出力を得ます。さらにその出力を入力と合成し、合成されたものを返します。また、学習の進捗を確認するために画像を可視化し保存しています。
Colorize.py#学習時の画像処理の担当 def paint_train(self,epoch,num,color_image,greyscale_image,visualize = True): #白黒画像をニューラルネットワークに入れて計算させる output = self.model(greyscale_image).view(BATCH_SIZE,3,IMAGE_SIZE,IMAGE_SIZE).to(DEVICE) #ニューラルネットワークの出力をcolor_dataとして保存 color_data = output #画像を合成 output = self.multiply(output,greyscale_image) #バッチごとに画像を保存する(とりあえず配列の0番目の画像を出力する) if visualize == True: print("Visualizing Source Image") vi.visualize(color_image[0].view(3,int(IMAGE_SIZE),int(IMAGE_SIZE)), [int(IMAGE_SIZE),int(IMAGE_SIZE)], SOURCE_LOC + "\source_" + str(epoch+1) + "-" + str(num), False,BASIC_COLOR_SPACE) print("Visualizing Input Image") vi.visualize(greyscale_image[0].view(1,int(IMAGE_SIZE),int(IMAGE_SIZE)), [int(IMAGE_SIZE),int(IMAGE_SIZE)], IN_LOC + "\imput_" + str(epoch+1) + "-" + str(num), False,"L") print("Visualizing Color Data") vi.visualize(color_data[0].view(3,IMAGE_SIZE,IMAGE_SIZE), [IMAGE_SIZE,IMAGE_SIZE], COLOR_LOC + "\color_" + str(epoch+1) + "-" + str(num), False,BASIC_COLOR_SPACE) print("Visualizing Output Image") vi.visualize(output[0].view(3,IMAGE_SIZE,IMAGE_SIZE), [IMAGE_SIZE,IMAGE_SIZE], OUT_LOC + "\output_" + str(epoch+1) + "-" + str(num), False,BASIC_COLOR_SPACE) return output #続く...
updateメソッドモデルの更新をします。引数に本来のカラー画像(正解データのようなもの)とAIの出力を持ち、これらの誤差を計算したのちに誤差伝搬します。
Colorize.py#モデルの更新 def update(self,color_image,output): print("Updating Model") #誤差を計算する(誤差関数) loss = F.smooth_l1_loss(color_image,output) #誤差関数に依存しない誤差の計算(差の合計) real_loss = torch.abs(color_image-output).sum() #誤差伝搬 self.optimizer.zero_grad() loss.backward() self.optimizer.step() print('Loss:',str(float(real_loss))) #続く...
trainメソッドこのメソッドでは、学習全体の流れを記述します。
Colorize.py#学習 def train(self): print("Train") for epoch in range(EPOCH_NUM): #テストするならテストする if TEST: print("Test") self.test(epoch) #学習本体 for num in range(int(TRAIN_NUM/BATCH_SIZE)): #進捗確認用のメッセージ progress = "epoch : "+str(epoch+1)+" - batch : "+str(num+1)+" / "+str(int(TRAIN_NUM/BATCH_SIZE)) + " - Batch size = "+str(BATCH_SIZE)+" - lr = "+str(LR) print("\n",progress) #テストデータを着彩#num番目の画像を読み込む [color_image,greyscale_image] = il.load_batch(num*BATCH_SIZE,BATCH_SIZE,message=progress,random_crop = True) #画像処理 output = self.paint_train(epoch,num,color_image,greyscale_image,visualize = False) #モデルの更新 self.update(color_image,output) print("Saving Model") #モデルの保存 torch.save(self.model.state_dict(),MODEL_LOC+"/"+MODEL_NAME+str(epoch)+".pth") #続く...
paint_testメソッドテスト時の画像処理を担当します。基本的に
paint_trainメソッドと同じです。Colorize.py#テストでの画像処理を担当(基本的にpaint_trainと同じ。 #paint_testでは出力する画像の枚数を指定できるようにした。詳細なコメントは省略) def paint_test(self,epoch,greyscale_image,visualize = True,visualize_num = 1): output = self.model(greyscale_image).view(TEST_NUM,3,IMAGE_SIZE,IMAGE_SIZE).to(DEVICE) color = output output = self.multiply(output,greyscale_image) if visualize == True: for v_num in range(visualize_num): print("Visualizing Input Image") vi.visualize(greyscale_image[v_num].view(1,int(IMAGE_SIZE),int(IMAGE_SIZE)), [int(IMAGE_SIZE),int(IMAGE_SIZE)], IN_LOC + "\Test_imput_" + str(epoch) + "-" +str(v_num+1), False,"L") print("Visualizing Color Data") vi.visualize(color[v_num].view(3,IMAGE_SIZE,IMAGE_SIZE), [IMAGE_SIZE,IMAGE_SIZE], COLOR_LOC + "\Test_color_" + str(epoch) + "-" +str(v_num+1), False,BASIC_COLOR_SPACE) print("Visualizing Output Image") vi.visualize(output[v_num].view(3,IMAGE_SIZE,IMAGE_SIZE), [IMAGE_SIZE,IMAGE_SIZE], OUT_LOC + "\Test_output_" + str(epoch) + "-" +str(v_num+1), False,BASIC_COLOR_SPACE) return output #続く...
testメソッドテスト時の全体の流れを記述します。これも
trainメソッドとほぼ同じですが、誤差の計算やモデルの更新はしません。Colorize.py#テスト def test(self,text): print("TestStart") #テストデータを着彩#num番目の画像を読み込む greyscale_image = il.load_test_image(TEST_NUM) self.paint_test(text,greyscale_image,visualize = TEST_VISUALIZE,visualize_num = TEST_NUM) print('Test End')ディレクトリを初期化するメソッド
画像の出力先のフォルダをいったん削除し、再びフォルダを作ります。手動でフォルダ内の画像を削除する手間が省けるのででスムーズに実験が進みます。
Colorize.py#画像保存用のディレクトリを用意する def directory_setup(): #フォルダがない状態でフォルダを削除しようとするとエラーになるのでエラーになったら削除しない try: #出力先のフォルダの消去 shutil.rmtree(SOURCE_LOC) except: pass try: #出力先のフォルダの消去 shutil.rmtree(IN_LOC) except: pass try: #出力先のフォルダの消去 shutil.rmtree(OUT_LOC) except: pass try: #出力先のフォルダの消去 shutil.rmtree(COLOR_LOC) except: pass os.mkdir(SOURCE_LOC) os.mkdir(IN_LOC) os.mkdir(OUT_LOC) os.mkdir(COLOR_LOC)実行
最後に作成したクラスのオブジェクトを作成し、学習を開始するコードを書きます。
Colorize.py#クラスの作成 il = image_loder() p = painter() vi = visualizer() #ディレクトリを整理 directory_setup() #学習 if LEARN: p.train() p.test("Result") print("Finish")これを実行すると、画像保存用のフォルダが作られ、学習が進みます。気長に待ちましょう。ちなみに実行画面はこんな感じで、進捗度合いなどが表示されます。
実装の説明は以上です。おわりに
今回作成したAIの最大の成果は、ほとんどの画像でシャツの白い部分などを塗らないことを学習したことだと考えています。背景色まで肌色に塗ってしまっていることに関しては、背景色を適切に塗るには膨大な画像データが必要となるため解決は難しいと考えています。しかし、瞳の色や唇の色など、人間の顔である程度共通する箇所は適切な色を塗れるようにしたいため、高解像度の画像を扱うようにする、データの量を増やすなどして改善していきたいと考えています。
主な参考文献(2019/04/14時点)





- 投稿日:2019-04-13T19:00:46+09:00
#python で 複数の #JSON 配列をフラットに結合する簡単なスクリプトの例
- 投稿日:2019-04-13T17:56:52+09:00
コミケ・技術書典で同人誌を作った時の小技をまとめる
はじめに
この記事ではAdobe Acrobatを中心とした同人誌作成のTipsを紹介します。
4/14に開催の技術書典06に出品するので、そのとき使った細かい小技を紹介します。
技術書典やコミケなど、同人誌を作る機会が多いかと思われますので、その助力となれば幸いです。ついでに技術書典06の宣伝(大事)
環境
- OS: Windows10
- Adobe Acrobat Pro DC 2019.010.20099
- Adobe Creative cloudのAcrobatの年間プラン(毎月1700円のプラン)
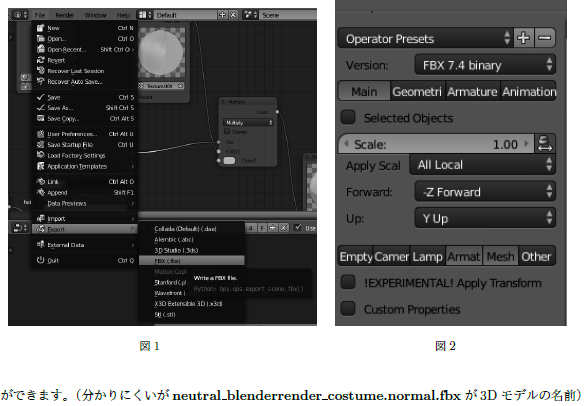
1. Acrobatでページ番号を振る
同人誌の印刷にはノンブル(ページ番号)を通しで振る必要があります。
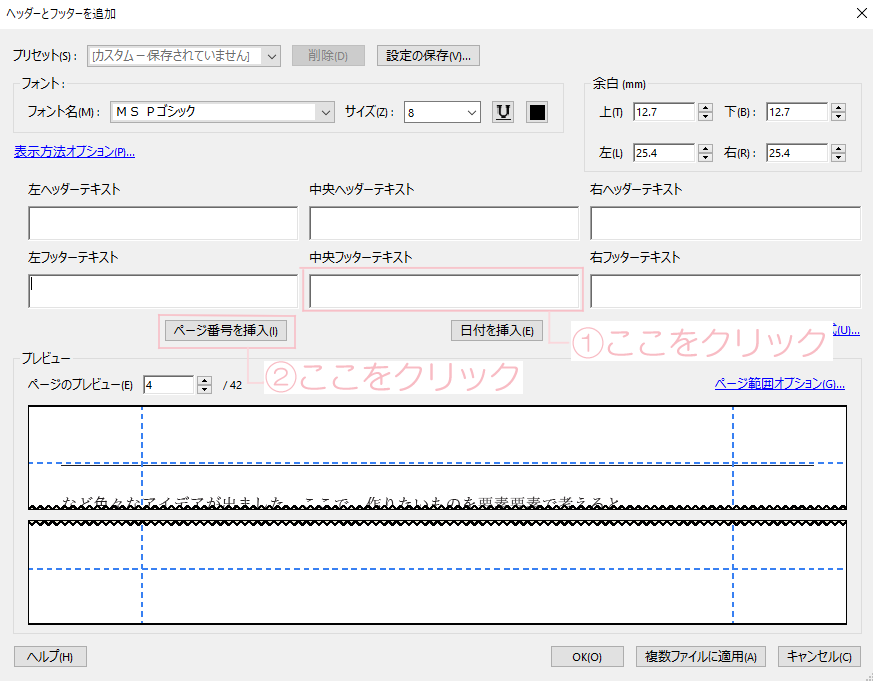
Acrobatでノンブルを追加するにはpdfを編集画面でヘッダーとフッター>追加で設定できます。
そして、
追加をクリックして出てきたダイアログにて中央フッターテキストにカーソルを合わせて、ページ番号を挿入をクリックすれば、ページ番号が付きます。
- before
- after
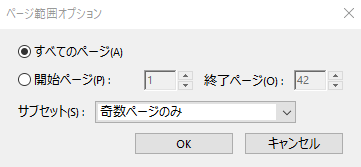
また、左右のヘッダーにつける場合は(左綴じを仮定して)まず
右ヘッダテキストにページ番号を挿入してから、ページ範囲オプションをクリック、出てきたダイアログのサブセット項目を奇数ページのみに変更し、OKボタンを押します。
そして、ヘッダーとフッターと追加ダイアログでOKボタンを押せば、
元のpdfの奇数ページにページ番号が付いてることがわかります。
同様に、偶数ページの左ヘッダにページ番号を入れれば、開いたときの左右ページにページ番号が付くようになります。
(縮小してトリミングしたからモアレになってる…!)
2. Acrobatで画像オブジェクトを白黒にする
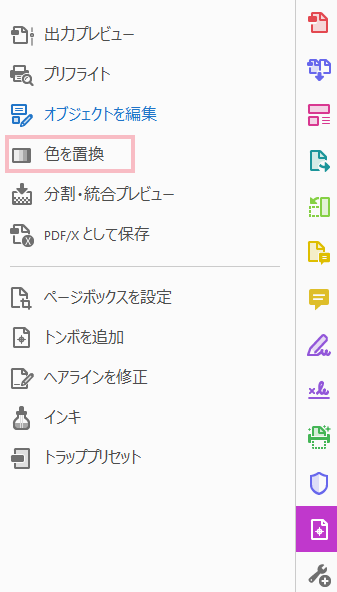
印刷所にオンデマンド印刷本文モノクロ(技術書の場合これが多いと思う)の依頼をする上では、入稿するデータは印刷のミスを防ぐためグレースケールにします。
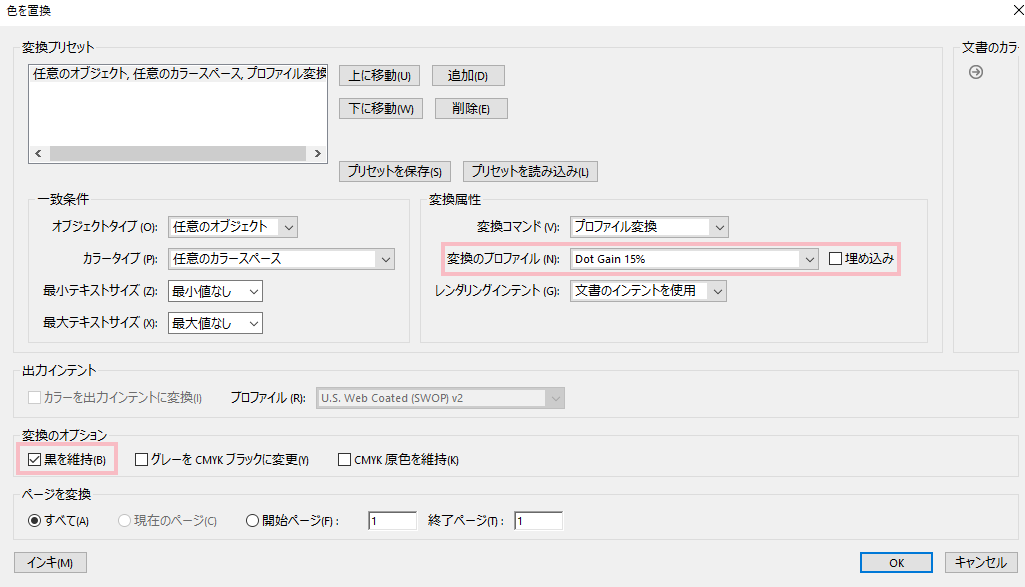
Adobe Acrobat proでグレースケールにするためには印刷工程メニューを開き、色を置換をクリックします。
そして、開いた色置換ダイアログに対して、変換プロファイルをDot Gain 15%, 変換オプションを黒を維持とします。
これでOKを押して変換すると以下のようになります。
- before
- after
pdfを画像に変換する
boothのサンプルやpixiv、twitterに宣伝、作品紹介ポップを作成するときにpdfの画像データが欲しくなります。
ここで、pdfの1ページ1ページを画像編集する方法を記載します。
Acrobat proでもできますが、時間がかかるので(1枚およそ30秒くらいかかった)、追い込み時期の早く寝ないと次の日支障が出るというときには不便です。ここでpython3でpdfを画像に変換しましょう。
python3はAnacondaなどでインストールすればいいです。https://haitenaipants.hatenablog.com/entry/2018/07/17/000101
を参考にします。
- popplerのインストール http://blog.alivate.com.au/poppler-windows/
pip install pdf2imageします。- 画像変換スクリプト
from pdf2image import convert_from_path import glob import os input_pdf_path = '画像化したい本のパス' dir_name = '出力ディレクトリ名' book_name = '画像化したい本の名前' image_ext = 'png' save_ext = 'png' # jpgで出力したいときはjpeg # pdf画像変換処理 images = convert_from_path(input_pdf_path) for id, image in enumerate(images): output_img_path = os.path.join(dir_name, '{0}_{1:03}.{2}'.format(book_name, id, image_ext)) image.save(output_img_path, save_ext)これで何十分もかけずにpdfを画像化が可能です。
ちなみにtimeモジュールで時間を測ると8.8377秒でした。
import time from contextlib import contextmanager @contextmanager def time_estimate(): start_time = time.time() yield end_time = time.time() print(end_time-start_time) # [略] with time_estimate(): # pdf画像変換処理 # [略]宣伝
折角だし技術書典の宣伝です(前日に宣伝するのか…)
私、いりすは技術書典06 サークルスペース
お06「不思議の国の入巣次元」にてサークル参加いたします。
新刊はchatbot自作、AR chatアプリ+AIの実装、ラズパイリモコンハックを収録した合同誌となっております。おしながき: https://twitter.com/irisuinwl/status/1116956010088808448
おまけ. 同人イベント参加のノウハウ
ついでにコミケに参加した時+技術書典で新刊作成のときのノウハウを記載しておきます。
ぽえむみたいなものですが、同人イベントに参加してみたい人の参考になればと思います。
技術書典が終わったら追記するかも。以前、自分のブログに書きましたが、感情的に書いており、ノイズが多いので役に立ちそうな部分だけピックアップします。
参考: https://irisuinwl.hatenablog.com/entry/2019/01/09/053939
同人誌作成で工夫したこと
- 原稿はtexだったのでgit,Bitbucketで管理すると一日にどれだけ作業できるか見えて、スコープの調整などがしやすかった。
- コミケの時はBitbucket, 技術書典ではgitのプライベートリポジトリを利用した。
- 進捗管理はtrelloを使った。
- 合同誌作成の際のコミュニケーションツールはslackを使ったら円滑にコミュニケーションできた。
- 何を作りたいか、読んだ人に何を伝えたいかをmarkdownに纏めて、何を作るべきかを明確にした(個人用のインセプションデッキや企画書みたいなもの)
- 個人的にはこれが一番重要だと思う。
会計
- B5,92P 印刷部数30部
- 収入: 27000円 (完売)
- 支出: 97000円(絵師さんへの依頼料含む)
- [反省] 30部しか刷ってないので利益は出ないし、売り切れて現場で手に取ってもらえなかった。
次回のイベントに参加することを考えたら黒字になるくらいは刷ればよかった。宣伝とサークルスペース
- 宣伝はpixivとtwitter
- pixivを見て来ました! twitterを見て来ました! って言って頂けたので効果はあったと実感
- スペースの設営に使ったのは以下 ( こんな感じ: https://twitter.com/irisuinwl/status/1079527387040108544 )
- 見本を立てる小型のイーゼル(100均で売ってる)
- ポスター立て
- スペース用テーブルクロス(
あの布という製品を使いました)- テーブルクロス前面に貼るポスター
- 頒布物が分かるポップ
その他
- イベント初参加で売り子の一人が体調不良、もう一人が寝坊して最初一人での対応となったので、何が起きても楽しめるように覚悟を決めよう





- 投稿日:2019-04-13T17:29:58+09:00
ターミナルとしてFish Shellを使う際のPATH設定
背景
MacでPython3系をインストールした際に、呼び出すには
pythonではなくpython3コマンドを打たないといけない事にじれったさを感じた環境
- MacOS Mojave
- Fish Shell 3.0.2
- Homebrew 2.1.0
解決方法
- bashと同様にPATHを設定すれば良い
手順
brew info pythonでpython3のパスを探す
- 私の場合は
/usr/local/opt/python/libexec/binでした~/.config/fish/config.fishを開く(無い場合は新規作成する)set PATH /usr/local/opt/python/libexec/bin /usr/local/bin /usr/sbin $PATHと追記する1の参考:https://codeday.me/jp/qa/20190403/510812.html
2の参考:https://qiita.com/ledsun/items/8ca1a450b21c8ebc9670
- 投稿日:2019-04-13T17:04:04+09:00
DeepLabに代わり現在のSOTAであるFastFCN(JPU)の論文解説
2019/3/28に投稿された、今現在のセグメンテーションのstate-of-the-artです
Joint Pyramid Upsampling (JPU)という手法を用いて、state-of-the-artの精度かつ、DilatedFCNに比べて3倍以上高速なセグメンテーションを可能にした論文です論文の概要
論文名: FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic
arXiv: https://arxiv.org/abs/1903.11816
Github: https://github.com/wuhuikai/FastFCNAbstract
- 最近のセグメンテーションのアプローチでは、高解像度の特徴量マップを得るためにDilated Convolutionをbackbornに使っているが、これは計算コストとメモリ消費が激しい
- これを解決するために、Joint Pyramid Upsampling (JPU)というモジュールを導入します これは高解像度の特徴量マップを得る問題を、Joint Upsampleの問題に置き換えるものです。
- JPUによって、精度を落とすことなく、計算コストを3倍以上減らすことができます
- Dilated ConvolutionをJPUモジュールに置き換えることによって、
Pascal Context datasetとADE20K datasetにおいて、3倍以上高速に動作しながら、state-of-the-artのスコアを出しました。1. Introduction
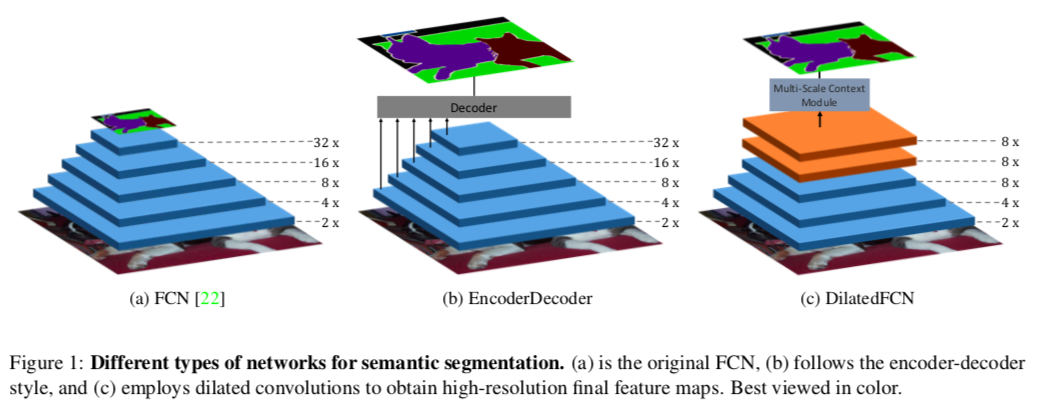
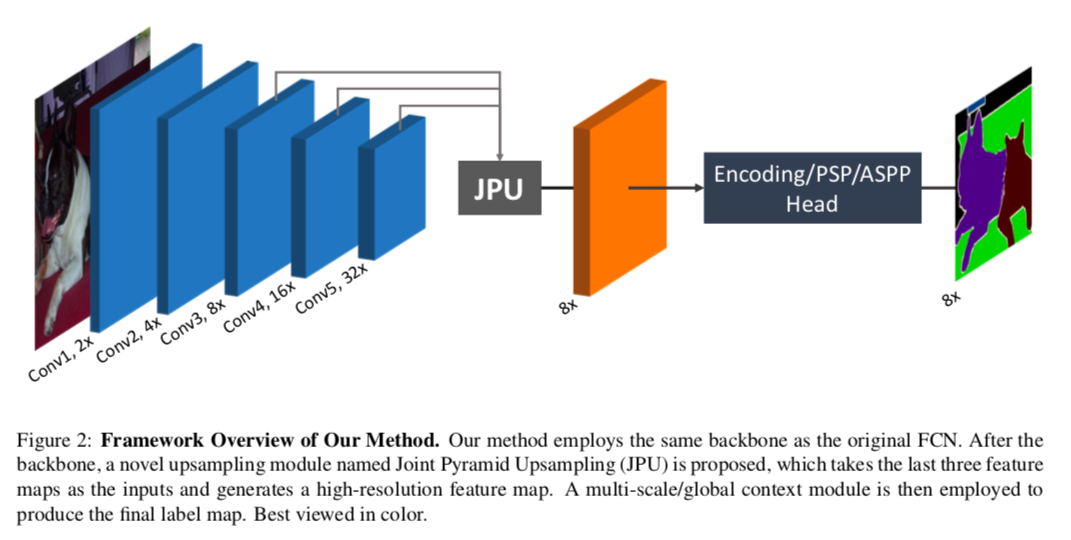
最初のFCN(Fully Convolution Network)は、ダウンサンプルによって低解像度の特徴量マップを生み出すため、細かい情報は失われ、境界線付近で間違った予測をすることが多くなります。Fig 1(a)のように、典型的なFCNでは5回ダウンサンプリングをし、特徴量マップは約1/32の解像度になる。
高解像度の特徴量マップを得るため、元のFCNをセマンティックな情報を得るためのEncoderとして用いて、DecoderではEncoderの中の特徴量マップを徐々に取り入れていくことで、徐々に空間情報を補填していくEncoderDecoder構造が提案されています(Fig 1(b))
その後提案されたDeeplabでは、最初のFCNから最後の二つのダウンサンプルを取り除き、代わりにdilated (atrous) convolution を追加して、受容野の大きさが変わらないようにしています。この種の方法はEncoderDecoder構造のモデルを様々なベンチマークで上回っていきました。Fig 1(c)でわかるように、DilatedFCNの最後の特徴量マップは他のものより4倍程度大きく、より多くの空間情報を保持しています。
dialted convolutionは最後の特徴量マップがより高解像度の空間情報を保持するために重要な役割を果たしていますが、計算コストとメモリ使用量が大きい点が問題になっています。
この問題を解決するためにJoint Pyramid Upsampling (JPU)を導入します。最初のFCNをbackbornとして用いて、その各層から得られる特徴量マップをJPUに通すことで、最終的にOutput Strideが8(入力画像の1/8の解像度)の高解像度の特徴量マップが得ることができます。さらに、DilatedFCNに比べて精度を落とさないまま、計算コストとメモリ使用量も大幅に減らすことができます。
実験をすると、3倍早く動きながらstate-of-the-artの精度を出すことができた
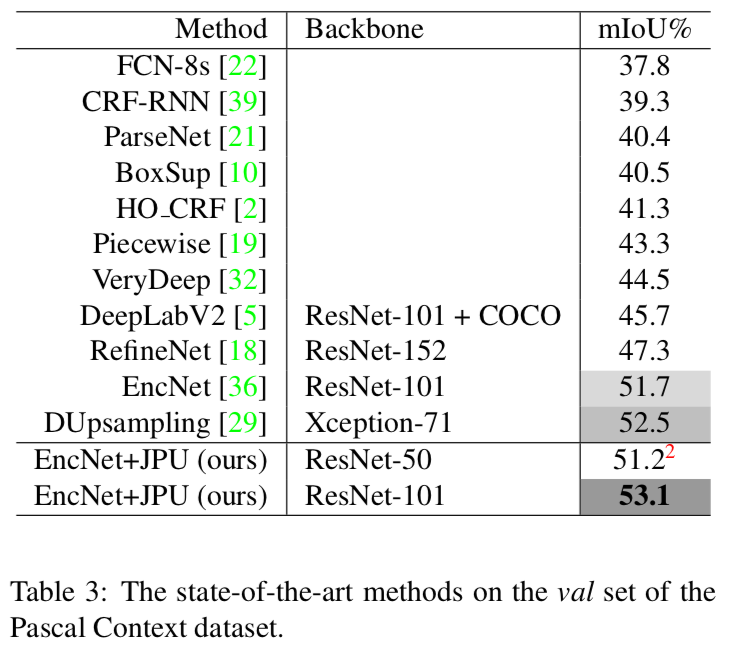
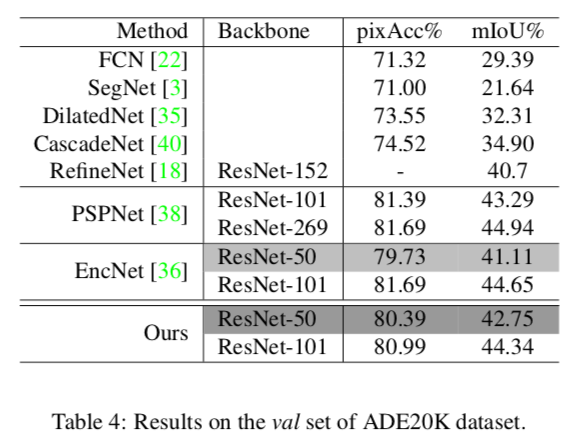
Pascal Context datasetでは53.13%(mIoU)でSOTAADE20K datasetでは42.75%(mIoU)でSOTA2. Related Work
2.1. Semantic Segmentation
EncoderDecoderとDilatedFCNについてIntroductionとほぼ同じことを説明してるだけなので割愛
2.2. Upsampling
低解像度の特徴量マップをupsampleして高解像度のものを取り出す必要があります
Joint Upsampling
この内容は3.3.1 Backgroundの方で詳しく説明するのでここでは割愛
Data-Dependent Upsampling
ラベル空間の冗長性を利用して低解像度の特徴量マップからpixel-wiseの予測をするDUpsamplingもこの論文の方法と関連していますが、DUpsamplingはラベル空間に大きく依存しており、複雑なラベルには対応できなくなる点がこの論文の優位性
3. Method
3.1. DilatedFCN
これもほぼIntroductionと同じ内容なので割愛。内容がないよう〜
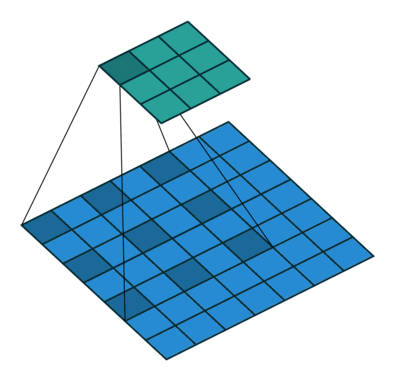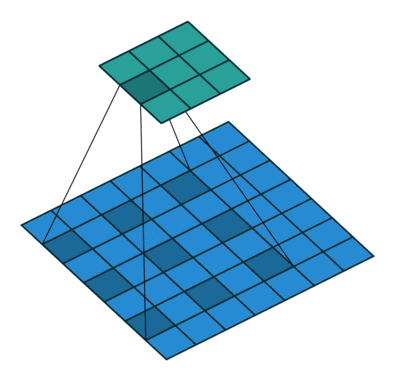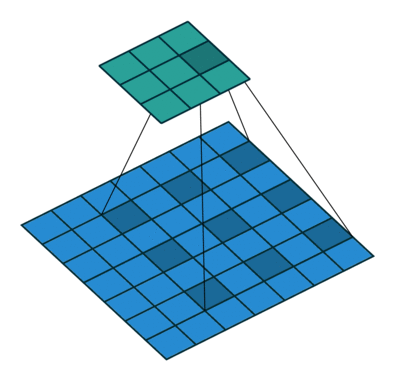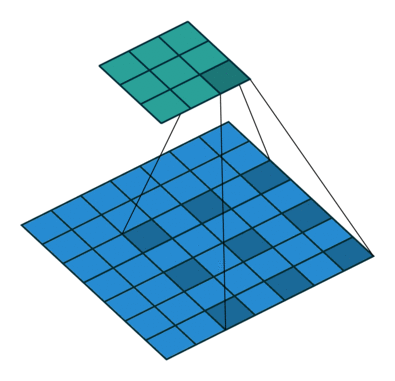
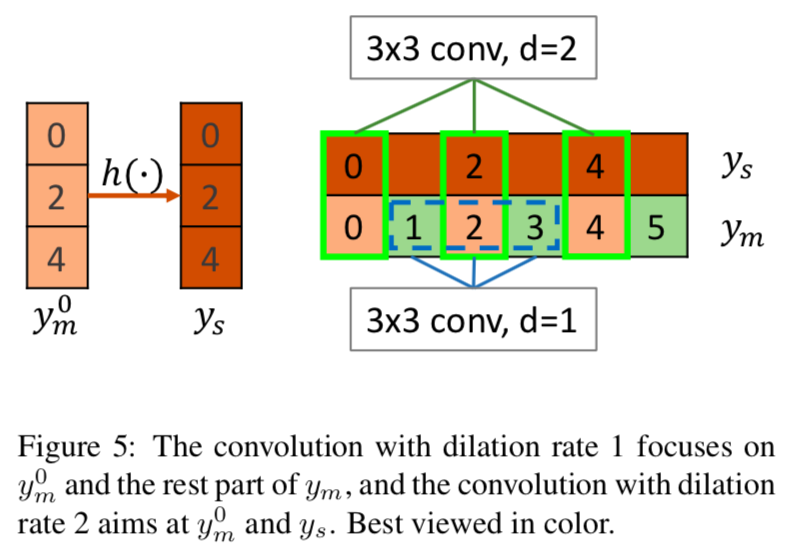
DeepLabではFig 1(c)にあるように最後の2層はDilated Convolutionにして受容野が変わらないようにしますよっていうお話ちょっとだけ参考として、dilated(atrous) Convolutionというのはこんな感じです。gif画像は
Dilation rate(畳み込みをする間隔)が2の場合で、1の場合は普通の畳み込みと同じになります。
3.2. The Framework of Our Method
この論文では、計算コストとメモリ使用量を抑えつつ、DilatedFCNの最終層の特徴量マップを近似することが目的
- そのためにまず、Dilated FCNで無くした最後二つの普通のConvolutionを元に戻します。これによって、Fig 2にあるようにbackbornは元のFCNと同じものになります
- そして、Dilated FCNと似た特徴量マップを得るため、最後の3つの層の特徴量マップをインプットとするJoint Pyramid Upsampling (JPU)を導入します。
- そのあとmulti-scale context module(PSPもしくはASPP)かglobal context module(Encoding)に通して、最終的な予測値を出します。
backbornにResnet101を使った場合、Dilated Convolutionに比べて、residual blockが23個の場合は1/4の計算コスト&メモリ使用量、3個の場合は1/16になります
3.3. Joint Pyramid Upsampling
Dilated FCNと同じ特徴量マップを作り出すのは、Joint Upsampleの問題として考えることができる
3.3.1 Background
Joint Upsampling
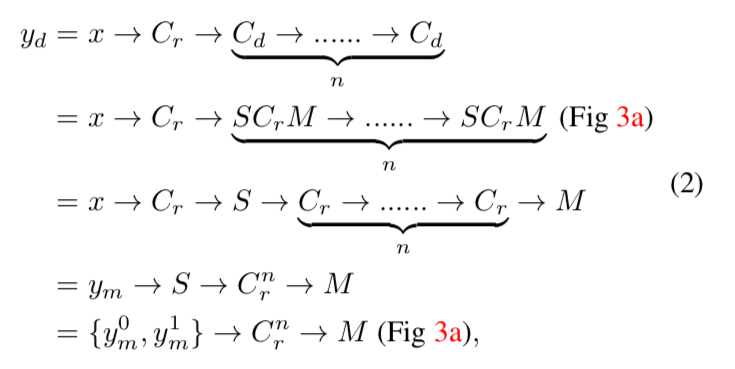
低解像度のguidance画像$x_l$から、低解像度のtarget画像$y_l$が、
y_l = f(x_l)という変換で得られるとします。これから考える問題は、この$f(\cdot)$を近似する、$\hat{f}(\cdot)$を求めることです。
一般的に、$\hat{f}(\cdot)$は$f(\cdot)$よりも計算コストが小さくなります。例えば、$f(\cdot)$がもし多層パーセプトロンで形成されたものなら、$\hat{f}(\cdot)$は簡単な線形演算子の形で求められます。
この$\hat{f}(\cdot)$を用いることで、高解像度のguidance画像$x_h$が与えられた時は、y_h = \hat{f}(x_h)として、少ない計算量で高解像度のtarget画像を得ることができます。
問題を定式化すると、
y_h = \hat{f}(x_h), \mathrm{where}~ \hat{f}(\cdot) = \mathrm{argmin}_{h(\cdot)\in \bf{H}} \| y_l - h(xl) \|ここで$\bf{H}$は考えられる変換、$||\cdot||$は距離関数です
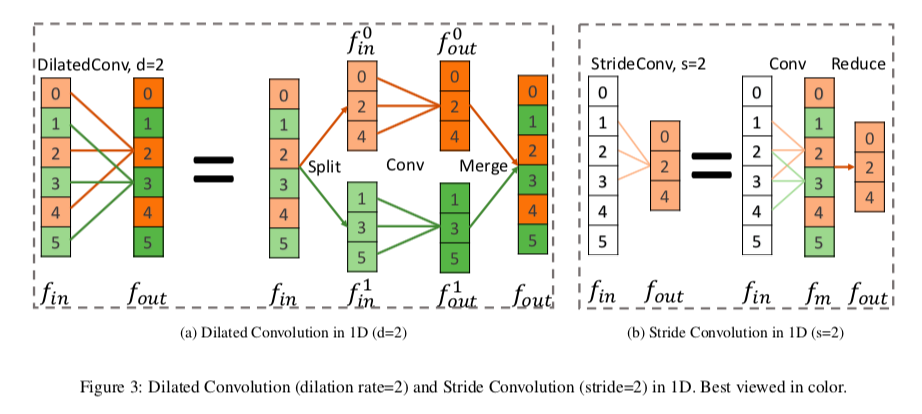
Dilated Convolution
Dilated Convolutionは、Deeplabで提案された、受容野の大きさを変えずに高解像度の特徴量マップを取り出す方法ですが、これは次のように考えることができます。
Fig 3(a)は、一次元でdilation rateが2の場合を示していますが、この操作は以下の3つの操作に分解できます
- Split : inputの$f_{in}$を、$f_{in}^0$と$f_{in}^1$の二つのグループにわける
- Conv : それぞれに同じ畳み込みを施し、$f_{out}^0$と$f_{out}^1$を得る
- Merge : $f_{out}^0$と$f_{out}^1$を互い違いになるように統合して、$f_{out}$を得る
ここでは簡単のために一次元で考えていますが、2次元でも同様の分解ができます。
Stride Convolution
Stride Convolutionは、inputの特徴量を、解像度を減らしてoutputの特徴量に変換する方法です。
Fig 3(b)で一次元の場合を示していますが、これも二段階の操作に分解できます
- Conv : $f_{in}$に普通の畳み込みをして、中間の特徴量$f_m$を取り出す
- Reduce : $f_m$の奇数番目を取り除いて、$f_{out}$を得る
これも2次元の場合でも同様のことが成り立ちます。
3.3.2 Reformulating into Joint Upsampling
DilatedFCNと、提案手法の違いを見ていきます。
例として、backbornのConv4の特徴量マップ(Fig 2のConv4の出力)をinputとして、そこからoutputの特徴量マップを作る方法で比較します。まず、DilatedFCNでは、まず最初にinputの特徴量マップ$x$に普通の畳み込みをしたあと、dilated畳み込みを何度か行なって、outputの特徴量マップ$y_d$を作ります。
これは以下のように定式化できます。
- [記号の説明]
- $C_r$ : 普通の(regular)畳み込み($C_r^n$は$C_r$が$n$層あることを示す)
- $C_d$ : dilated畳み込み
- $C_s$ : stride畳み込み
- $S$ : 上で説明したSplitの操作
- $M$ : 上で説明したMergeの操作
- $R$ : 上で説明したReduceの操作
- $\rightarrow$ は操作を施すことを意味します
一行目と二行目の式変形は、先ほど説明したようにdilated畳み込みの分解で、三行目に行くときに、$S$と$M$の操作は相殺されます。
四行目の$y_m$は、$x$に$C_r$を施したものです。
五行目の$y_m^0$と$y_m^1$は、$y_m$を偶数番目と奇数番目で分解したものです一方、提案手法ではoutput特徴量マップ$y_s$は以下のようにして得られます。
以上より、$y_d$と$y_s$は、同じ$C_r^n$を$y_m$と$y_m^0$のどちらに施すかという点だけがことなり、$y_m^0$は$y_m$のダウンサンプリングとなっています。
そのため、$x$と$y_s$が与えられたとき、$y_d$を近似する$y$は、以下のようにして求めることができます。
これは先ほど定式化したJoint Upsamplingの問題そのものです。
Conv5をインプットとした場合にも同じ結果が得られます。
これから、この$\hat{h}$を表現する方法を考えていきます。3.3.3 Solving with CNNs
$\hat{h}$をCNNで表現する方法を考えます。
必要な要素としては、
- $x$に$C_r$を施して、$y_m$を作る
- そして、$y_m^0$からの特徴量マップと、$y_s$を一つに集める
ことが挙げられます。
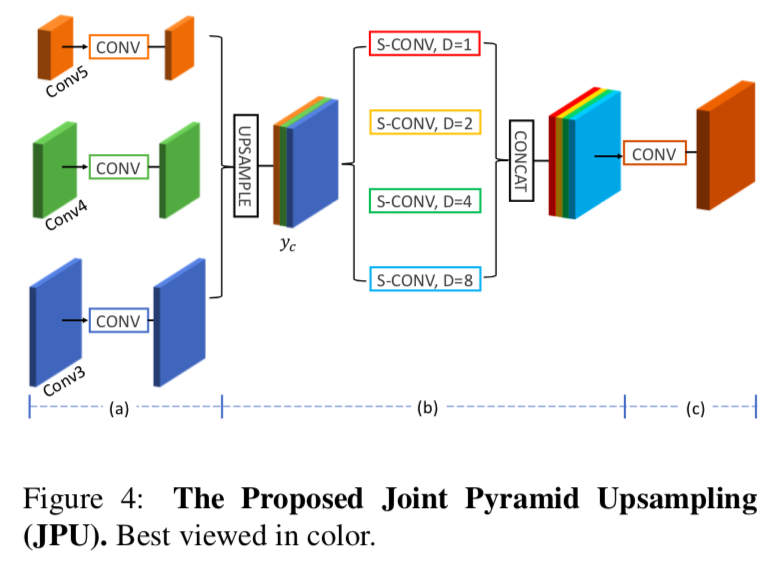
そのために、以下のようにJPU moduleを定義しました。
具体的には、
- まず、Fig 4(a)の部分で、inputの特徴量マップに普通の畳み込みをします。これは$y_m$を作り出すことに対応してます
- 得られたそれぞれの特徴量マップの次元を減らします。これにより計算コストを抑えることができます。
- 特徴量マップをupsampleして、cancatして$y_c$をつくります。
- Fig 4(b)の部分で、$y_c$に、
dilation rateが$1,2,4,8$のdilated畳み込みを並行して行います。
dilation rate=1の操作は、Fig 5の青で囲んだ部分をたたみ込んでいるので、&y_m^0$と$y_m$のそれ以外の部分との関係性を得る働きをします。
dilation rateが2, 4, 8の操作は、Fig 5の緑で囲んだ部分(の一部)をたたみ込むことになるので、求めたい$y_m^0$から$y_s$への写像$\hat{h}(\cdot)$を形成する働きを持ちます。
このようにして、JPUはマルチスケールの特徴量を、マルチレベルで取り込むことが可能です。これは最終層の特徴量しか考慮しないASPP moduleとの大きな違いです。
そして最後に、$y_m^0$と$y_m$のそれ以外の部分をつなぐために、Fig 4(c)の部分でもう一度普通の畳み込みを行います。これの出力が最終的な予測値となります。
4. Experiment
4.1. Experimental Settings
Dataset
Pascal Context datasetの60ラベルを使いましたという話
Implementation Details
- PyTorchで実装
- 前処理はrandom scaleとrandom fliplr
- そのあと480×480にクロップして、batchsize=16で学習
- optimizerはSGDで
momentum=0.9,weight_decay=1e-4、80epoch学習- 学習率は最初0.001から徐々に減らしていく
- loss funcは、
pixel-wise cross-entropy lossを使う- ResNet-50とResNet-101をbackbornとして使う
ここからは実験の結果だけを簡単に示していきます
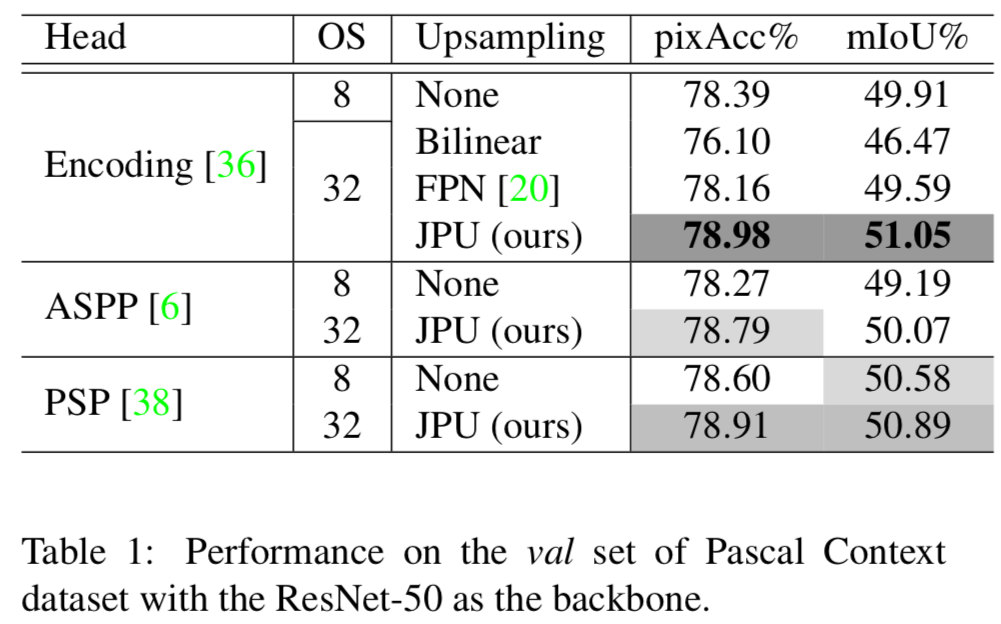
Table 1
Headにつかうモジュールと、output stride(OS)を変えたときに精度はどうなるか
JPUが最も良い結果となっている
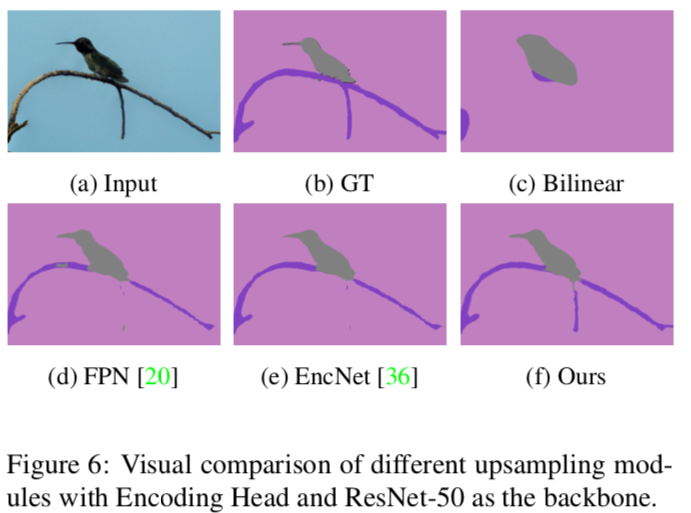
Figure 6
様々なUpsamplingのモジュールを使った場合の予測値
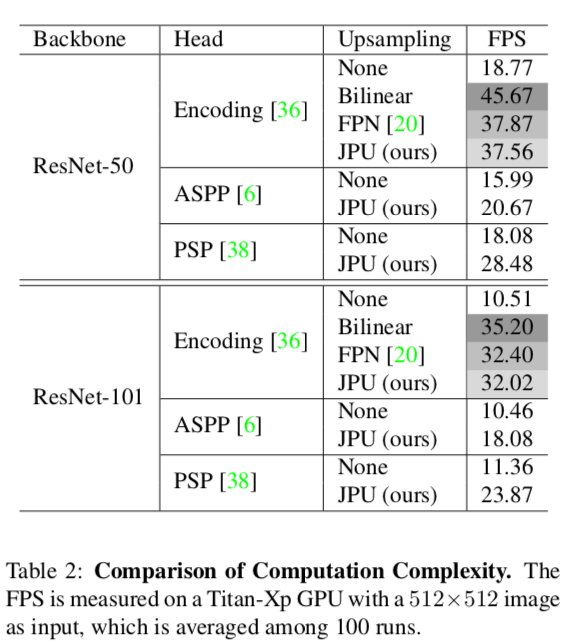
Table 2
計算時間がどれくらいかかるか(FPS)を調べたもの
実行速度はFPNと同じくらいだが、JPUの方が精度は優っている
Table 3
Pascal Context dataset(val)で、歴代のSOTA手法に比べたJPUの精度
State of the art‼️
Table 4
ADE20K(val)での精度
これもJPUが一番
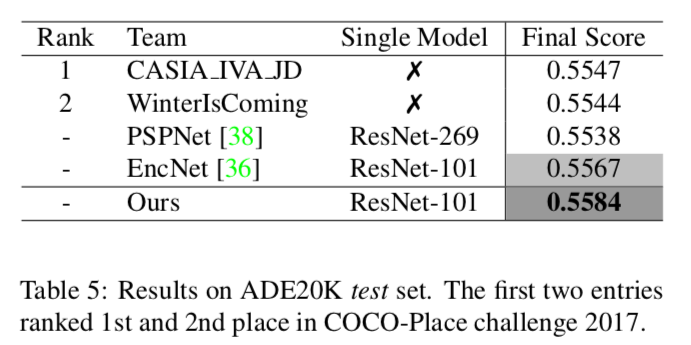
Table 5
ADE20K(test)での精度
これもJPUが一番
上の二つはCOCO-Place challenge 2017の一位と二位
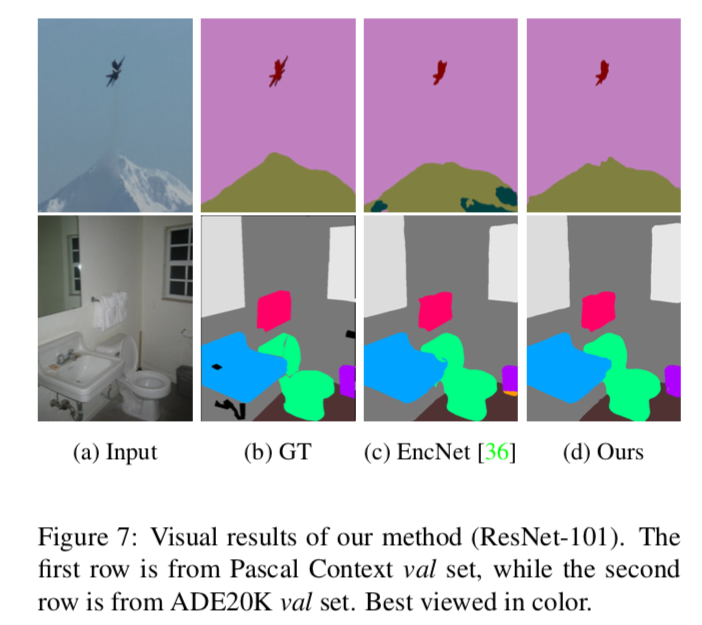
Figure 7
視覚的な結果
5. Conclusion
- dilated convolutionとstride convolutionの違いを解析し、その解析を元に、高解像度の特徴量マップを生成するJPU moduleを提案した。
- dilated convolutionをJPUに変更することにより、精度はそのままで計算コストを3倍以上抑えることができた。
- 実験の結果、JPUは他のupsampleモジュールよりも高精度であることがわかった
- 二つのセグメンテーションのデータセットで、JPUはstate-of-the-artの成績を収めることができた
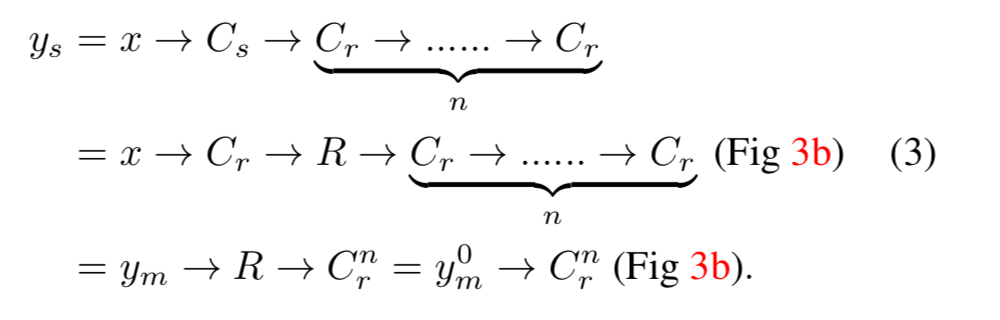
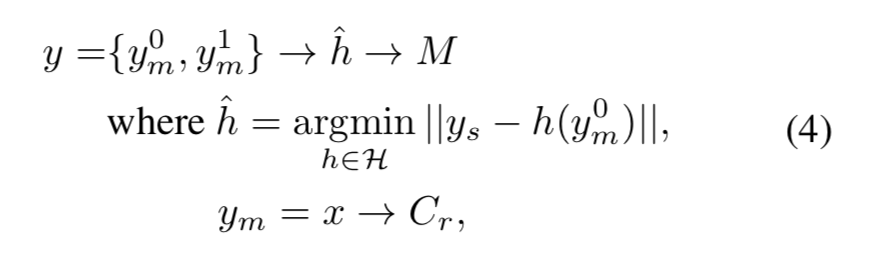
- 投稿日:2019-04-13T16:03:11+09:00
【自己学習】Pythonで開発するための環境構築
始めに
本記事は自己学習の結果を記事として残すためのものであり、自分と同じくこれから機械学習の勉強を始めようとしている方の、若干の手助けとなればと思い書いています。
Qiitaにはこの手の記事がたくさん存在しますが、「ここは分かってるだろうから説明は省くね」パターンが多く、自分には説明が足りない記事が多いため、バカ(自分)にも分かるように細かく書いているつもりです。
本当は実装部分まで書こうと思ったんですが、環境構築部分のボリュームが思いの外多かったため、分割することにしました。
※理解が足りてなく、間違いがある可能性があるので、ご指摘をいただけたら嬉しいです。内容
- Pythonの開発環境の構築
単語
- Homebrew
- pyenv
- pyenv-virtualenv
やったこと
機械学習の勉強を始めたとき、pythonの初心者でもあったので、環境を用意することに物凄く手間取りました。まずはPythonで開発するために必要な環境構築に関して記載しています。
環境の準備
1. Homebrew
1.1 Homebrewとは
Homebrewとは、MacOSのパッケージ管理ツールだそうです。もちろん、Homebrewを使用せずとも、インストーラーをダウンロードし、展開することで、パッケージのインストールは可能です。ただ、Homebrewを使用することで、ターミナルからコマンドを打つだけで、目的のパッケージのインストール/アンインストールが可能となり、手間が省けます。ここでは、Homebrewを使用して、後述するpyenvとpyenv-virtualenvをインストールします。
1.2 Homebrewをインストール
以下のコマンドをターミナル上で叩くだけです。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"※上記コマンドは頻繁に更新されるそうなので、以下HPにアクセスして、最新のコマンドを取得することをお勧めします。
HomebrewのHPつらつらと大量のログが表示され、最後にユーザのパスワードを要求された場合は、パスワードを入力後、Enterを押します。
完了後、下記コマンドを入力し[Already up-to-date]と表示されれば、Homebrewのインストールは完了です。
$ brew update2.pyenvのインストール
2.1. pyenvとは
pythonのバージョンを切り替えることが可能なツールで、ディレクトリ毎に設定を切り分けることが可能です。
2.2 pyenvのインストール
以下のコマンドをターミナル上で実行します。
$ brew install pyenv3 pyenv-virtualenv
3.1 pyenv-virtualenvとは
pyenv-virtualenvとは、ディレクトリ毎に仮想環境を構築し、Pythonのバージョン、インストールしているパッケージの管理を行います。とはいえ、pyenvだけでもバージョンの管理は可能なので、どこが良いの?と言う疑問が浮上しました。調べたところ、pyenvではディレクトリ毎にPythonのバージョンを管理できるが、インストールしているモジュールは
site-packageという共通の管理ファイルを参照しているとのこと。そのため、別バージョンのモジュールを使いたい、みたいな場面には対応が難しいそうです。そこで、pyrenv-virtualenvを使用することで、このsite-packageをディレクトリ毎に管理が可能となり、別環境の影響から完全に独立することが出来る!みたいな感じです。
(もちろん、他にもメリットはあるっぽいのですが理解不足により割愛)3.2 pyenv-virtualenvのインストール
以下のコマンドをターミナル上で実行します。
$ brew install pyenv-virtualenv4 環境変数の設定
これだけではインストールしたpynev、pyenv-virtualenvの設定が有効化されず、デフォルトでMacに入っているPythonの設定を参照してしまいます。ルートディレクトリに存在する.bash_profileの中身を編集して、環境変数にパスを追加します。(平たく言うと、今後Pythonを使用するときは、新しく導入したpyenvとpyenv-virtualenvの方の設定を参照してねって感じ)
bash_profileは、ターミナル起動時に参照する設定ファイルのようなものです。設定ファイルには.bashrcとかもあり、詳細は理解できてないですが、取り敢えず.bash_profileを編集することで問題なく動くので良しとします。
ターミナル上で以下のコマンドを入力し、.bash_profileを編集します。
※.bash_profileは隠しファイルのため、ls -aで表示することができます。vim .bash_profile開いた.bash_profileに以下のコードを追記します。
export PYENV_ROOT="${HOME}/.pyenv" //${HOME}はデフォルトで設定されている変数 if [ -d "${PYENV_ROOT}" ]; then //パス(PYENV_ROOT)の存在確認 export PATH=${PYENV_ROOT}/bin:$PATH //:$PATHで、既存のパスも設定 eval "${pyenv init-)" //eval で変数部分を展開しています。 eval "$(pyenv virtualenv-init -)" //pyenvとpyenv-virtualenvの環境を初期化し、環境を有効化上記のコードを入力後、ターミナルで以下のコマンドを入力することで、設定ファイルの更新をします。
(ターミナルを再起動するでも問題ありません。)source ~/.bash_profile5. pythonのインストール
pyenvではデフォルトでsystemしか入っていません。試しに、
pyenv versionsコマンドを入力すると以下のような結果が返ってきます。pyenv versions *system今回使用するPythonのバージョンは
3.7.3なので、以下のコマンドでインストールします。pyenv install 3.7.36. 仮想環境の構築&Pythonのバージョン変更
これで
3.7.3のインストールが完了しましたが、まだ適応はされていません。もう一度、pyenv versionsを入力すると以下の結果が返ってきます。$ pyenv versions *system 3.7.3上記から、デフォルトである
systemが選択されていることが分かります。作業用のディレクトリを作成し、作成したディレクトリ内で以下のコマンドを実行し、仮想環境を構築します。$ pyenv virtualenv 3.7.3 test //3.7.3:Pythonのバージョン //test:環境名 $ pyenv local test $ activate test (test)$ //左記のように作成した(作成した環境名)が表示されればOKです。 (test)$ pyenv versions //Pythonのバージョンを確認 system 3.7.3 *testこれで、このディレクトリではtest(3.7.3)が適応されます。
pyenv global testでも問題ありませんが、今回はディレクトリ毎で環境を切りたいので、localを使用しています。globalを使用すると、全ての環境で指定したバージョンが適応されます。ここまでで、Pythonで開発するための環境構築が完了しました。次回の記事では、実際に機械学習で使用する各種モジュールのインストールから、簡単な実装までを書く予定です。
- 投稿日:2019-04-13T14:25:56+09:00
Python/NLP/機械学習のためのDocker環境構築
Docker上でPython+自然言語処理+基本的な機械学習を行うための環境構築方法について説明します.
また,Dockerについての基本的な知識があることを前提としています.導入するもの
- ベース
- Alpine Linux 3.9
- Python
- Python 3.7.3
- numpy
- scipy
- scikit-learn
- gensim
- 自然言語処理
- mecab
- cabocha
実行環境
- Ubuntu 18.04 LTS
- Docker 18.09.5
Alpine Linux
Alpine Linuxは, 軽量なLinuxディストリビューションです.
Dockerイメージを簡単に軽量化できることから,ベースイメージとして多く採用されています.ただし,Alpineはデフォルトではかなり機能が制限されています.
そのため,追加で色々なツールやパッケージをインストールしていく必要があります.各種ファイルの作成
Dockerfile
Dockerfile# ベースイメージ FROM python:3.7.3-alpine3.9 # 環境変数 ENV LANG C.UTF-8 ENV TZ Asia/Tokyo ENV PYTHONUNBUFFERED 1 # 各種パッケージのインストール RUN apk add --update bash git curl build-base swig gfortran linux-headers # Mecab RUN cd /tmp \ && git clone https://github.com/taku910/mecab.git \ && cd mecab/mecab/ \ && ./configure --enable-utf8-only --with-charset=utf8 \ && make \ && make install \ && cd ../mecab-ipadic \ && ./configure --with-charset=utf8 \ && make \ && make install # CRF++ (Cabochaで必要) RUN wget -O /tmp/CRF++-0.58.tar.gz 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ' \ && cd /tmp/ \ && tar zxf CRF++-0.58.tar.gz \ && cd CRF++-0.58 \ && ./configure \ && make \ && make install # Cabocha RUN cd /tmp \ && DOWNLOAD_URL="https://drive.google.com`curl -c cookies.txt \ 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7SDd1Q1dUQkZQaUU' \ | sed -r 's/"/\n/g' |grep id=0B4y35FiV1wh7SDd1Q1dUQkZQaUU |grep confirm |sed 's/&/\&/g'`" \ && curl -L -b cookies.txt -o /tmp/cabocha-0.69.tar.bz2 "$DOWNLOAD_URL" \ && tar jxf cabocha-0.69.tar.bz2 \ && cd cabocha-0.69 \ && ./configure --with-mecab-config=`which mecab-config` --with-charset=utf8 \ && make \ && make install \ && cd python \ && python setup.py build \ && python setup.py install \ # LAPACK/BLAS (scikit-learnで必要) RUN cd /tmp \ && wget http://www.netlib.org/lapack/lapack-3.8.0.tar.gz \ && tar zxf lapack-3.8.0.tar.gz \ && cd lapack-3.8.0/ \ && cp make.inc.example make.inc \ && make blaslib \ && make lapacklib \ && cp librefblas.a /usr/lib/libblas.a \ && cp liblapack.a /usr/lib/liblapack.a \ && cd / \ && rm -rf /tmp/* # pip COPY requirements.txt /home WORKDIR /home RUN pip install --upgrade pip RUN pip install -r requirements.txtrequirements.txt
pipでインストールするパッケージを記載します.
バージョンを指定したい場合はnumpy==1.16.2のようにしてください.
今回は必要最低限なものしかインストールしません.requirements.txtmecab-python3 numpy scipy scikit-learn gensimDockerイメージを作成
Dockerfileとrequirements.txtを同じディレクトリに置きます.
以下のコマンドでDockerビルド(Dockerイメージを作成するコマンド)を実行します.※Cabochaのダウンロードに失敗してビルドができないことがあります.
少し時間をおきながら何度か再実行してみて下さい.$ cd <Dockerfileが存在するディレクトリ> $ docker build -t nlp-ml:1 . (docker build -t <Dockerイメージ名> <Dockerfileが存在するディレクトリ>) $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE nlp-ml 1 4b7930388f08 3 minutes ago 93.5MBこれでDockerイメージが作成できました.
このDockerイメージを使用して,コンテナを起動します.$ docker run -it --name hoge nlp-ml:1 bash
- 投稿日:2019-04-13T13:35:15+09:00
pythonでAtCoder -ABC009-
対象
- AtCoder初心者(緑よりもランクが下の人、ABCのCD問題が解けない人)
- pythonがそれなりにかける人
- 数学やプログラミングに対する深い理解を持っていない人
- Ex) DP, 深さ優先探索, メモ化再帰の実装ができない
動機
AtCoderは全ての問題に対して解説が存在しますが
ざっくり説明を読んでわかった気になっても独力で実装ができないといった経験が多くありました。
参考のために他人の提出を見ても解説と綺麗にリンクした解答が簡単には見つからず
理解を実装に落とすことに苦労しました。そこで、公式の解答とある程度リンクした実装を見ながら
アルゴリズムや数学的な理解とソースコードを紐付けたいと思ったことが本記事を寄稿した動機です。いるかわかりませんが同様の苦労をしている人のためにも何らかの参考になればと思い
私の回答とそれに対する簡単なコメントを付与したコードを記載します。実行環境
- python3
実装
AB → 何も見ずに実装
CD → 解説を見て実装A
A.pyimport math print(math.ceil(int(input()) / 2))B
B.pyN = int(input()) A = list(set([int(input()) for _ in range(N)])) A.sort() print(A[-2])C
C.pyfrom collections import Counter N, K = map(int, input().split(' ')) S = input() R = sorted(S) T = '' diff = 0 for i in range(N): # 各文字の出現回数をカウント counter = Counter(S[:i+1]) - Counter(T) for r in R: # 確定済み文字のdiff + みている文字のdiff diff1 = diff + (r != S[i]) # 確定していない文字のdiff diff2 = sum(counter.values()) - (counter[r] > 0) if diff1 + diff2 <= K: T += r R.remove(r) diff = diff1 break print(T)D
D.pydef matrix_pow(a, b): ret = [[0] * len(b[0]) for _ in range(len(b))] for x in range(len(b)): for y in range(len(b[0])): for z in range(len(b)): ret[x][y] ^= a[x][z] & b[z][y] return ret K, M = map(int, input().split(' ')) A = list(map(int, input().split(' '))) C = list(map(int, input().split(' '))) if K >= M: print(A[M-1]) exit() # 漸化式計算用の行列を作成 A.reverse() matrix = [[0] * len(C) for _ in range(len(C) - 1)] for i in range(len(C) - 1): for j in range(len(C)): matrix[i][j] = (1 << 32) - 1 if i == j else 0 matrix.insert(0, C) # 行列の累乗計算結果をスタック matrix_list = [[[0] * len(C) for _ in range(len(C))] for _ in range(len(format(M-K, 'b')))] for i in range(len(matrix_list)): mat = matrix if i == 0 else matrix_pow(matrix_list[i-1], matrix_list[i-1]) for j in range(len(matrix_list[0])): for k in range(len(matrix_list[0][0])): matrix_list[i][j][k] = mat[j][k] # フラグが立っている部分で累乗計算を適用 ans = [[a] for a in A] for m, bit in zip(matrix_list, reversed(format(M-K, 'b'))): ans = matrix_pow(m, ans) if bit == '1' else ans print(ans[0][0])解説を見て実装をしましたが、TLEになりひたすら苦しめられました。
最終的にPypyなら通る可能性があるとの記事を発見したため、Pypyで提出したら通りました。終わりに
D問題をpython3でACしている人が10人もおらず驚きました。(Pypyでも1ページ程度)
あまり過去問解いていく人はいないのでしょうか。。以上です。
- 投稿日:2019-04-13T12:32:50+09:00
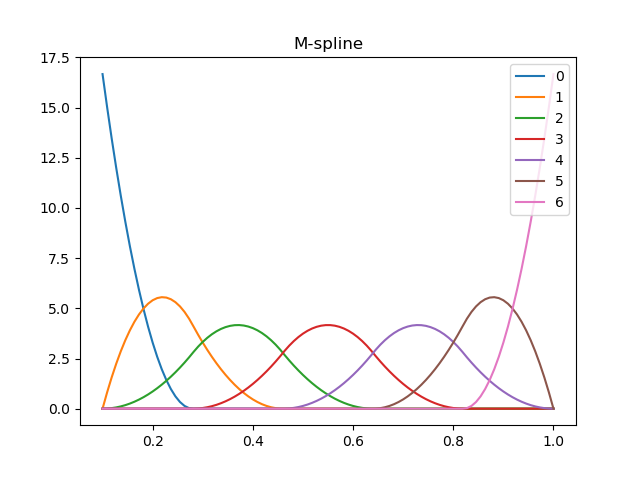
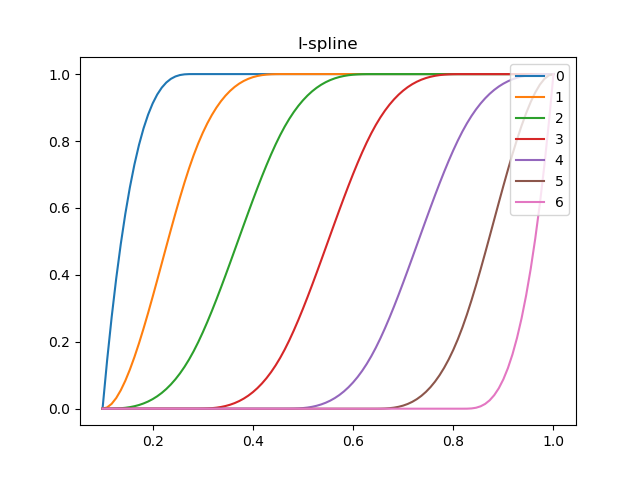
MスプラインとIスプラインをNumpyで
monotone(単調増加 or 単調減少)なスプライン、それがIスプライン。
Iスプラインを作るために使う、負にならないスプライン、それがMスプライン。
Iスプラインは、monotoneなはずのデータの回帰分析やスムージングに使えそうに見える。しかしどちらも、どうも世の中でほとんど使われていないようなので、数式をコードに起こすのに苦労した。
import numpy as np import matplotlib.pyplot as plt def main(): K = 3 # 次数 L = 4 # ノットの数 x_min = 0.1 x_max = 1.0 ts = np.concatenate([ np.full(K, x_min), np.linspace(x_min, x_max, L + 2)[1:-1], # ノットをuniformに配置。non-uniformでもいい np.full(K + 1, x_max) ]) xs = np.linspace(x_min, x_max - 1e-5, 100) def function_m(k, i, where=np.ones_like(xs, np.bool)): lxs = xs[where] ys = np.zeros_like(lxs) if k == 1: hit = (ts[i] <= lxs) & (lxs < ts[i + 1]) ys[hit] = 1. / (ts[i + 1] - ts[i]) elif ts[i + k] - ts[i] != 0.: _a = (k - 1) * (ts[i + k] - ts[i]) _b = lxs - ts[i] _c = function_m(k - 1, i, where) _d = ts[i + k] - lxs _e = function_m(k - 1, i + 1, where) ys = k * (_b * _c + _d * _e) / _a return ys for i in np.arange(K + L): plt.plot(xs, function_m(K, i), label=str(i)) plt.legend(bbox_to_anchor=(1,1), loc='upper right') plt.title('M-spline') plt.show() def function_i(i): hit = (ts[:-1,np.newaxis] <= xs) & (xs < ts[1:,np.newaxis]) js = np.argmax(hit, axis=0) def f_a(m): mask = js >= m _a = K + 1 _b = ts[m + K + 1] - ts[m] _c = function_m(K + 1, m, where=mask) ys = np.zeros_like(xs) ys[mask] = _b * _c / _a return ys ufunc_a = np.vectorize(f_a, signature='()->(n)') yss = ufunc_a(np.arange(i, K + L)) return yss.sum(axis=0) for i in np.arange(K + L): plt.plot(xs, function_i(i), label=str(i)) plt.legend(bbox_to_anchor=(1,1), loc='upper right') plt.title('I-spline') plt.show() if __name__=='__main__': main()
参考:
Wikipedia I-spline
spline
INFERENCE USING SHAPE-RESTRICTED REGRESSION SPLINES
- 投稿日:2019-04-13T12:22:07+09:00
Deep Learningアプリケーション開発 (7) TensorFlow Lite with Python on Raspberry Pi and Edge TPU
この記事について
機械学習、Deep Learningの専門家ではない人が、Deep Learningを応用したアプリケーションを作れるようになるのが目的です。MNIST数字識別する簡単なアプリケーションを、色々な方法で作ってみます。特に、組み込み向けアプリケーション(Edge AI)を意識しています。
モデルそのものには言及しません。数学的な話も出てきません。Deep Learningモデルをどうやって使うか(エッジ推論)、ということに重点を置いています。
- Kerasで簡単にMNIST数字識別モデルを作り、Pythonで確認
- TensorFlowモデルに変換してPythonで使用してみる (Windows, Linux)
- TensorFlowモデルに変換してCで使用してみる (Windows, Linux)
- TensorFlow Liteモデルに変換してPythonで使用してみる (Windows, Linux)
- TensorFlow Liteモデルに変換してCで使用してみる (Linux)
- TensorFlow Liteモデルに変換してC++で使用してみる (Raspberry Pi)
- TensorFlow LiteモデルをEdge TPU上で動かしてみる (Raspberry Pi) <--- 今回の内容
今回の内容
- Kerasモデル(h5)を、Edge TPU用に変換する
- Raspberry Pi上でのEdge TPU環境を用意する
- Raspberry Piに接続されたEdge TPU上でモデルを動作させてMNIST数字識別をする
TensorFLow Lite用モデルはKerasで簡単にMNIST数字識別モデルを作り、Pythonで確認で作成した
conv_mnist.h5を使います
ソースコードとサンプル入力画像: https://github.com/take-iwiw/CNN_NumberDetector/tree/master/07_TensorflowLite_TPU環境
- OS: Windows 10 (64-bt)
- CPU = Intel Core i7-6700@3.4GHz (物理コア=4、論理プロセッサ数=8)
- Raspberry Pi 2 Model B (2018-11-13-raspbian-stretch)
- その他: Google Edge TPU
Keras用モデルをEdge TPU用モデルに変換する
量子化したTensorFlow Liteモデルに変換する
Edge TPU上で動作可能なモデルは、いくつかの制約を満たしたTensorFlow Liteモデル(tflite)になります。(https://coral.withgoogle.com/web-compiler/ のRequirementsセクションを参照)
そのため、まずはKerasで作成したモデル(h5)をTensorFlow Liteモデル(tflite)に変換します。その際に、上記制約を満たすために、量子化オプションも付けます。
変換ツール (tflite_convert)の使い方は、https://www.tensorflow.org/lite/convert/cmdline_examples を参考にしてください。これによって、conv_mnist.tfliteというファイルが出来上がります。
Kerasモデルから量子化済みTensorFlowLiteモデルに変換tflite_convert ^ --output_file=conv_mnist.tflite --keras_model_file=conv_mnist.h5 ^ --inference_type=QUANTIZED_UINT8 ^ --default_ranges_min=0 ^ --default_ranges_max=255 ^ --mean_values=128 ^ --std_dev_values=127変換はWindows上のAnaconda環境(python=3.6.8, tf-nightly-gpu=1.14.1.dev20190403)で行いました。
TensorFlowをpipインストールすると、自動的にtflite_convertもインストールされます。Edge TPU用モデルに変換する
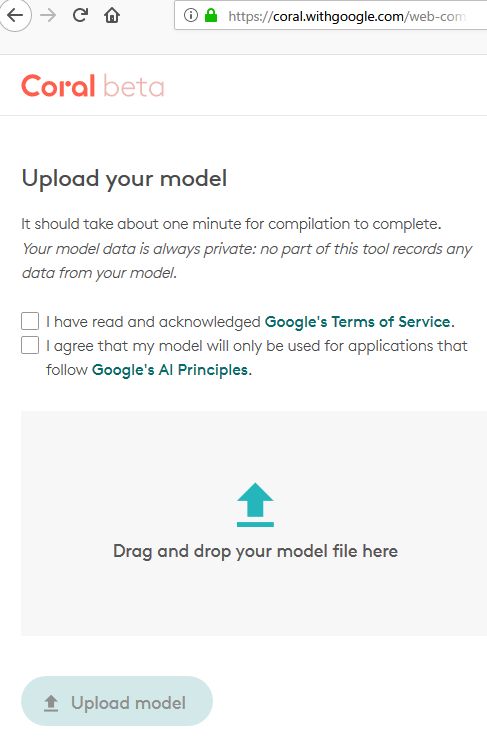
次に、作成したTensorFlow Liteモデルを、Edge TPU用に変換します。これには、Googleが提供しているWebコンパイラを使用します。
https://coral.withgoogle.com/web-compiler/
Drag and drop your model file hereの所に、先ほど作成したconv_mnist.tfliteをドラッグ&ドロップし、使用許諾的な2つのチェックボックスにチェックを付けると、自動的にコンパイルが始まります。
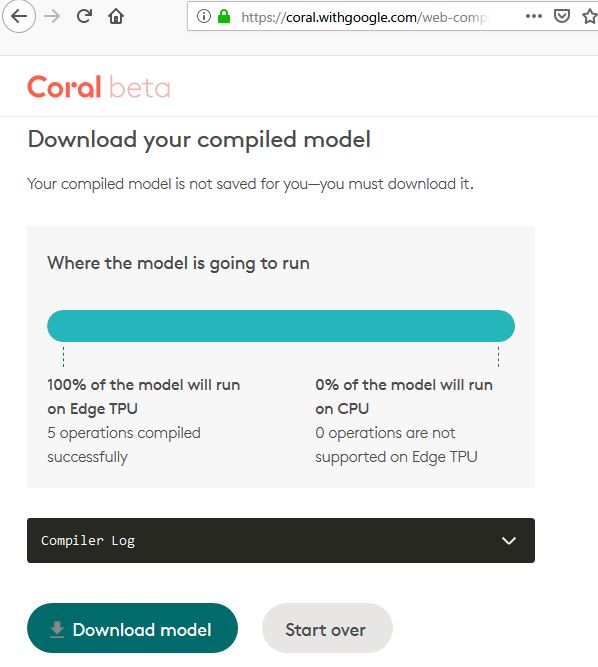
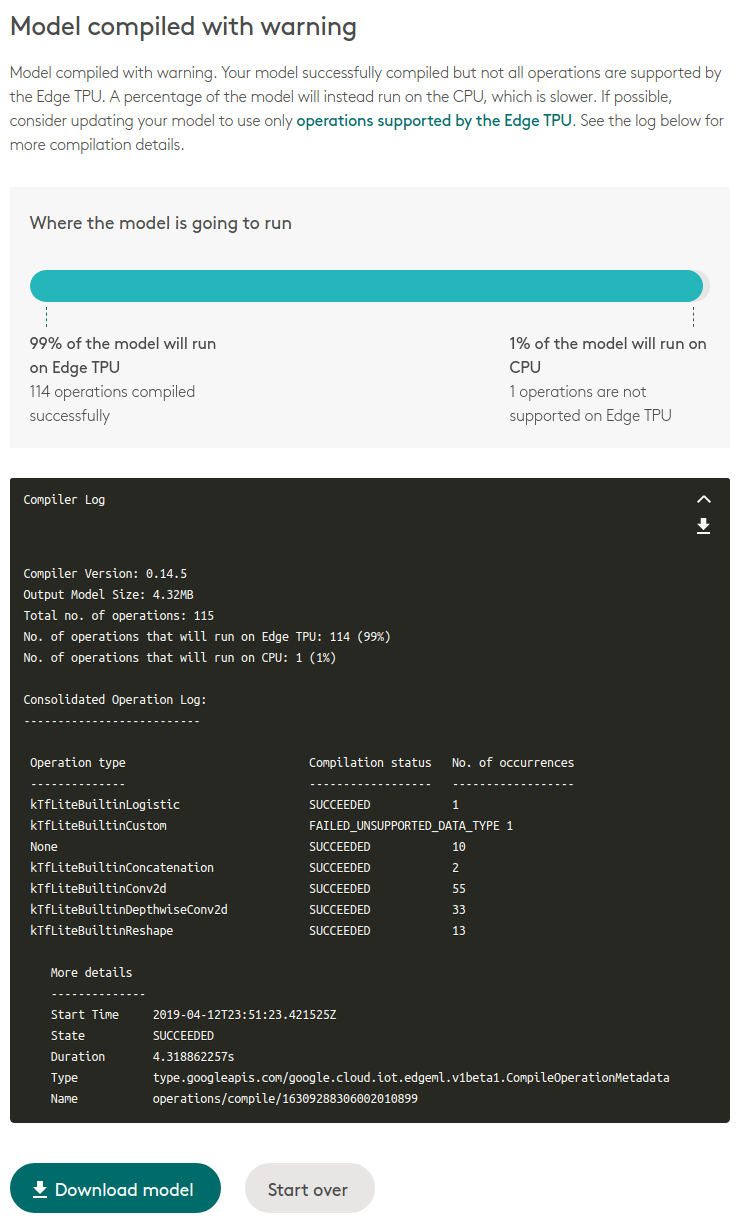
成功したら下記画面のようになるので、
Download modelで、ダウンロードします。
conv_mnist_123456789_edgetpu.tfliteというファイルがダウンロードされます。扱いやすいように、数字部分は消してconv_mnist_edgetpu.tfliteとしておきます。
備考:
2019年4月11日まではベータ版ということで、MobileNetなど、限られたモデルしか対応していませんでした。4月12日(この記事を書いている前日)から、カスタムモデルにも対応されるようになりました!!Raspberry Pi上でのEdge TPU環境を用意する
基本的には、https://coral.withgoogle.com/docs/accelerator/get-started/ の通りに進めれば大丈夫です。
ラズパイ上の端末で以下コマンドでインストールします。EdgeTPUインストールonラズパイcd ~/ wget https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz -O edgetpu_api.tar.gz --trust-server-names tar xzf edgetpu_api.tar.gz cd edgetpu_api bash ./install.shが、僕の環境はRaspberry Pi 2のため、Edge TPUは未対応のためインストールに失敗しました。また、virtualenv上ではうまくインストールできませんでした。
以下方法で回避しましたので、同じ状況の人は参考にしてください。(自己責任でお願いします)Raspberry Pi 2にインストールする(optional)
install.sh でプラットフォームチェックしている部分を以下のように変更します。
ラズパイ3でも32bitモードで動いているので、バイナリ互換性はあるはず、と思いチェック処理だけ変えたら出来ました。install.sh~略~ elif [[ "${CPU_ARCH}" == "armv7l" ]]; then MODEL=$(cat /proc/device-tree/model) # if [[ "${MODEL}" == "Raspberry Pi 3 Model B Rev"* ]]; then if [[ "${MODEL}" == "Raspberry Pi "* ]]; then info "Recognized as Raspberry Pi 3 B." LIBEDGETPU_SUFFIX=arm32 HOST_GNU_TYPE=arm-linux-gnueabihf # elif [[ "${MODEL}" == "Raspberry Pi 3 Model B Plus Rev"* ]]; then elif [[ "${MODEL}" == "Raspberry Pi "* ]]; then info "Recognized as Raspberry Pi 3 B+." LIBEDGETPU_SUFFIX=arm32 HOST_GNU_TYPE=arm-linux-gnueabihf fi ~略~virtualenv上にインストールする(optional)
単にinstall.sh を実行すると、パッケージはグローバル環境にインストールされるようです。(virtualenvをactivate/workonしていても)。
そのため、自分の仮想環境に入っている状態で、別途pip installする必要がありました。
これをやらないと、No module named 'edgetpu'エラーが出ます。まとめると以下のようになります。
EdgeTPUインストールfor仮想環境onラズパイ2cd ~/ workon py3_tpu wget https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz -O edgetpu_api.tar.gz --trust-server-names tar xzf edgetpu_api.tar.gz cd edgetpu_api nano ./install.sh # 編集する bash ./install.sh pip install edgetpu-1.9.2-py3-none-any.whlEdge TPU上でモデルを動作させてMNIST数字識別をする
Edge TPUのインストールを完了すると、デモコードが
/usr/local/lib/python3.5/dist-packages/edgetpu/(通常インストールの場合)、/home/pi/.virtualenvs/py3_tpu/lib/python3.5/site-packages/edgetpu(virtualenvの場合)にインストールされます。デモコードを動かす
xxx/site-packages/edgetpu/demo/classify_image.pyが識別用のサンプルコードです。
本当なら、以下のようにすることでデモコードで、今回作成したモデルを試すことが出来ます。
が、これは動きません。
デモコード(というか、画像識別用Wrapper)が、3chカラー入力を前提としているため、今回作成した1chグレースケールのMNIST識別モデルはパラメータチェックではじかれてエラーになります。
MobileNet等のちゃんとしたモデルなら、これで確認出来ます。デモコードを動かすpython3 /home/pi/.virtualenvs/py3_tpu/lib/python3.5/site-packages/edgetpu/demo/classify_image.py \ --model conv_mnist_edgetpu.tflite \ --label mnist_labels.txt \ --image resource/3.jpgちなみに、mnist_labels.txtには識別結果と表示ラベルのペアを記載します。
mnist_labels.txt0 num0 1 num1 2 num2 ~略~識別用コードを実装する
edgetpu/demo/classify_image.pyをベースに、自分で実装します。classify_image_mnist.pyとします。classify_image_mnist.pyimport argparse import re from edgetpu.classification.engine import ClassificationEngine from PIL import Image, ImageOps import numpy # Function to read labels from text files. def ReadLabelFile(file_path): """Reads labels from text file and store it in a dict. Each line in the file contains id and description separted by colon or space. Example: '0:cat' or '0 cat'. Args: file_path: String, path to the label file. Returns: Dict of (int, string) which maps label id to description. """ with open(file_path, 'r', encoding='utf-8') as f: lines = f.readlines() ret = {} for line in lines: pair = re.split(r'[:\s]+', line.strip(), maxsplit=1) ret[int(pair[0])] = pair[1].strip() return ret def main(): parser = argparse.ArgumentParser() parser.add_argument( '--model', help='File path of Tflite model.', required=True) parser.add_argument( '--label', help='File path of label file.', required=True) parser.add_argument( '--image', help='File path of the image to be recognized.', required=True) args = parser.parse_args() # Prepare labels. labels = ReadLabelFile(args.label) # Initialize engine. engine = ClassificationEngine(args.model) # Read input image and convert to tensor img = Image.open(args.image) img = img.convert('L') img = ImageOps.invert(img) input_tensor_shape = engine.get_input_tensor_shape() if (input_tensor_shape.size != 4 or input_tensor_shape[3] != 1 or input_tensor_shape[0] != 1): raise RuntimeError( 'Invalid input tensor shape! Expected: [1, height, width, 3]') _, height, width, _ = input_tensor_shape img = img.resize((width, height), Image.NEAREST) input_tensor = numpy.asarray(img).flatten() # Run inference. for result in engine.ClassifyWithInputTensor(input_tensor=input_tensor, threshold=0.1, top_k=3): print('---------------------------') print(labels[result[0]]) print('Score : ', result[1]) # for time measurement for i in range(5000): for result in engine.ClassifyWithInputTensor(input_tensor=input_tensor, threshold=0.1, top_k=3): pass if __name__ == '__main__': main()オリジナルのデモコードでは、読み込んだ画像をそのまま入力として、ClassificationEngine.ClassifyWithImageをコールしていました。
この関数は画像を入れるだけで推論処理が出来て便利なのですが、グレースケール(1ch)画像には対応していないです。
ClassificationEngine.ClassifyWithImageは、内部でリサイズなどを行ったあと、ClassificationEngine.ClassifyWithInputTensor を呼んでいます。こちらの関数の入力は文字通りTensorになります。
ですので、今回は自分で画像->Tensorへの変換を行い、直接ClassificationEngine.ClassifyWithInputTensor を呼ぶことにしました。また、処理時間測定のために無駄に5000回くらい呼んでいます。
実行してみる
以下コマンドで実行できます。
実行コマンドpython3 classify_image_mnist.py \ --model ~/CNN_NumberDetector/07_TensorflowLite_TPU/conv_mnist_edgetpu.tflite \ --label ~/CNN_NumberDetector/07_TensorflowLite_TPU/mnist_labels.txt \ --image ~/CNN_NumberDetector/07_TensorflowLite_TPU/resource/5.jpg「5」が書かれたJPEG画像を入力しました。結果、以下のように正しく5だと識別できました。
また、実行中はEdgeTPUドングルの白LEDが強く光っていたので、ちゃんとTPU側で処理しているのだと思います。結果num5 Score : 0.99609375処理時間を比較してみる
使用するモデルを差し替えるだけで、CPU動作かEdge TPU動作かを切り替えられるようです。
timeコマンドを付けて処理時間を比較してみました。処理時間比較実行コマンド# for Edge TPU time python3 classify_image_mnist.py \ --model ~/CNN_NumberDetector/07_TensorflowLite_TPU/conv_mnist_edgetpu.tflite \ --label ~/CNN_NumberDetector/07_TensorflowLite_TPU/mnist_labels.txt \ --image ~/CNN_NumberDetector/07_TensorflowLite_TPU/resource/5.jpg # for CPU time python3 classify_image_mnist.py \ --model ~/CNN_NumberDetector/07_TensorflowLite_TPU/conv_mnist.tflite \ --label ~/CNN_NumberDetector/07_TensorflowLite_TPU/mnist_labels.txt \ --image ~/CNN_NumberDetector/07_TensorflowLite_TPU/resource/5.jpg結果Edge TPU: real 0m18.596s user 0m9.698s sys 0m3.427s CPU: real 0m12.852s user 0m9.446s sys 0m0.233s結果、Edge TPU実行はトータルで18.6秒、CPU実行はトータルで12.9秒という、CPUの方が速いという残念な結果になってしまいました。
sys時間を見ると、TPU側の方は3.5秒もかかっていました。おそらく、EdgeTPUデバイス制御関係のオーバーヘッドによるものだと思います。
今回使用したような非常に小さいモデルではディープラーニング計算時間そのものよりも、こういったオーバーヘッドの方が大きいようです。メモ: インストールコマンドまとめ
素のRaspberry Pi2に対して、Edge TPUデモコードを動作させるまでの環境設定コマンド
(virtualenv, opencvを含む(単にEdge TPUを試すだけなら不要))EdgeTPU環境設定コマンドforラズパイ2# 環境更新 sudo apt-get update sudo apt-get upgrade # OpenCV用パッケージインストール sudo apt-get install libatlas3-base libwebp6 libtiff5 libjasper1 libilmbase12 libopenexr22 libilmbase12 libgstreamer1.0-0 libavcodec57 libavformat57 libavutil55 libswscale4 libqtgui4 libqt4-test libqtcore4 # virtualenvインストールと設定 sudo pip install virtualenv sudo pip install virtualenvwrapper nano ~/.bashrc >>> 以下を追加 export LC_ALL="en_US.UTF-8" export LC_CTYPE="en_US.UTF-8" ### Virtualenvwrapper if [ -f /usr/local/bin/virtualenvwrapper.sh ]; then export WORKON_HOME=$HOME/.virtualenvs source /usr/local/bin/virtualenvwrapper.sh fi <<< # ターミナル再起動 # 仮想環境を作る (名前をpy3_tpuとする) cd ~/ mkvirtualenv --python=python3 py3_tpu # deactivate # workon py3_tpu # 仮想環境上で必要なパッケージをpipインストール pip install --upgrade setuptools pip install opencv-python pip install numpy # Pillow は2019/4/13時点でインストール時にビルドエラーが出たので、piwheelsのprebuiltバイナリを使用 # pip install Pillow pip install https://www.piwheels.org/simple/Pillow/Pillow-5.4.1-cp35-cp35m-linux_armv7l.whl#sha256=ed4e05737ed076aed4065e05b67983650b10110f3e133444e8e87bd572e1492a # Edge TPUインストール wget https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz -O edgetpu_api.tar.gz --trust-server-names tar xzf edgetpu_api.tar.gz cd edgetpu_api # ラズパイ2の場合、編集する(https://qiita.com/take-iwiw/items/6aeab468c326ecc21563#raspberry-pi-2にインストールするoptional) nano ./install.sh bash ./install.sh # 仮想環境用に再度インストール pip install edgetpu-1.9.2-py3-none-any.whl # デモを試す cd ~/Downloads/ wget https://storage.googleapis.com/cloud-iot-edge-pretrained-models/canned_models/mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite \ http://storage.googleapis.com/cloud-iot-edge-pretrained-models/canned_models/inat_bird_labels.txt \ https://coral.withgoogle.com/static/images/parrot.jpg cd /home/pi/.virtualenvs/py3_tpu/lib/python3.5/site-packages/edgetpu/demo python3 classify_image.py \ --model ~/Downloads/mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite \ --label ~/Downloads/inat_bird_labels.txt \ --image ~/Downloads/parrot.jpg※たまたまかもしれないが、インストール直後にそのままデモを実行したら、RuntimeErrorが発生した。ラズパイを再起動したりEdge TPUドングルを抜き差ししたら治った。
- 投稿日:2019-04-13T09:59:58+09:00
Edge TPU Accelarator+カスタムモデルMobileNetv2-SSDLiteの.tflite生成 【やっと成功したよ】_Docker編_その4
Tensorflow-bin
TPU-MobilenetSSD
1.Introduction
TPUモデルコンパイラがカスタムモデルの変換に対応したそうですので早速試してみました。
この記事の手順では最終的に生成されたモデルの精度が極悪ですが、転移学習ではなくフル学習にしたり、パラメータを調整することで精度は改善可能です。
この記事で語るのは、あくまで独自DockerイメージによるカスタムTPUモデルの学習と生成手順のみです。
モデル性能のチューニングは実施しません。2.Procedure
学習手順は、前回記事 Edge TPU Accelaratorの動作を少しでも高速化したかったのでMobileNetv2-SSD/MobileNetv1-SSD+MS-COCOをPascal VOCで転移学習して.tfliteを生成した_Docker編_その2 あるいは Edge TPU Accelaratorの動作を少しでも高速化したかったのでMS-COCOをPascal VOCで転移学習して.tfliteを生成した_GoogleColaboratory[GPU]編_その3 をそのまま使用します。 前回記事はもともと、 TPUコンパイラ がカスタムモデルに対応することを事前に知っていたため、機能がリリースされたときに最速で検証できるよう事前準備をしていたのです。
私独自のDockerは公式のDockerイメージとは異なり、NVIDIA Docker を使用します。
公式のDockerがGPUトレーニングに対応していないため、自力でシーケンスを大幅に組み直しています。なお、対応可能なレイヤと変換アルゴリズムは、 公式の TensorFlow models on the Edge TPU に記載されていますので参考にしてください。
3.Results
前回記事 の手順により生成した MobileNetv2-SSDLite の .tflite ファイルをコンパイラに投入してみます。
https://coral.withgoogle.com/web-compiler/
ドラッグ&ドロップで、 せーの、ホイッ!
あっさり成功しました。 しかも、アップデートが入る前までは一切表示されなかった変換ログが表示されるようになっています。 さらに、TPU側で非対応のレイヤーは自動的にCPUへオフロードされる仕様に改善されています。
最高です。 OpenVINOに欲しい機能です。
ある程度自由にレイヤを組み合わせて推論させることができるため、対応モデルの幅が大幅に広がりましたね。今回は、各種公式ドキュメントを一切見ずに独自の軽量トレーニングとコンバートを実施しました。
4.Finally
おいおいフルトレーニングをし直して推論精度を向上した .tflite モデルを生成して遊びたいと思います。



- 投稿日:2019-04-13T04:23:09+09:00
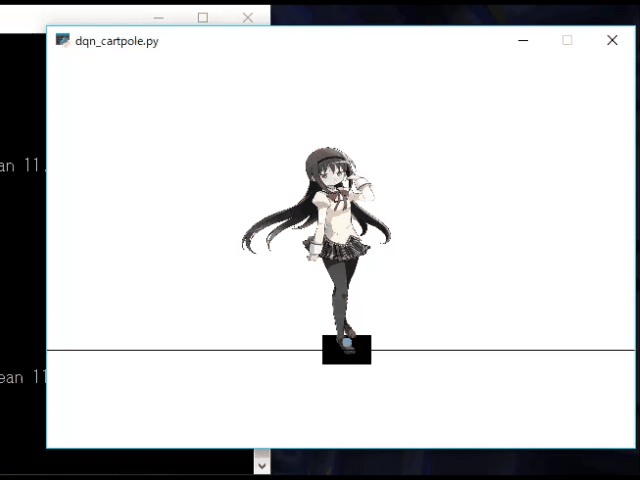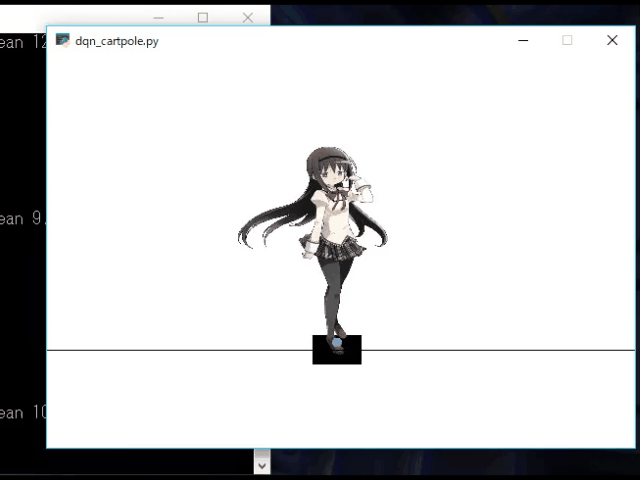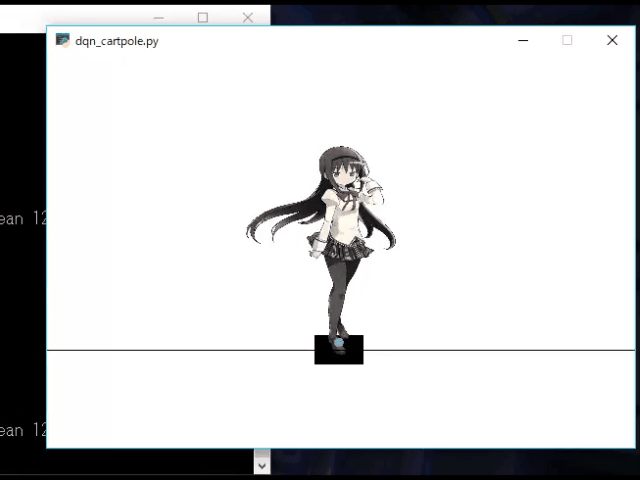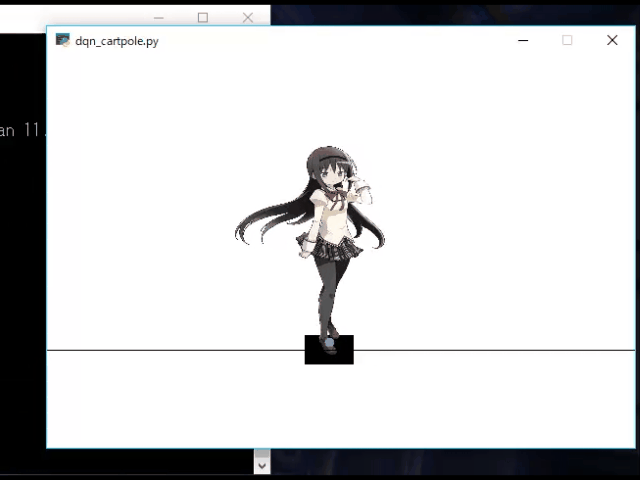
OpenAIGymのCartPoleをCartほむほむ化する
痛RL環境を作りたい
強化学習(Reinforcement Learning, RL)を使って研究をしているとき,
研究や仕事のモチベを上げるために痛エディタがあるなら
痛RL環境があってもいいじゃない.
と思いたったので作ってみた.
かわいい.OpenAIGymのCartPoleのPole部分を画像に差し替える
OpenAIGymのパッケージのフォルダを開いて
gym/envs に MyEnv フォルダを作る.
中身は以下のとおり.gym/envs/MyEnv
├ __init__.py
├ cartpole_img.py
└ assets/
└ pole_img.pnggym/envs/MyEnv/cartpole_img.py の中身
CartPoleEnv_Img クラスを作り,
既存の gym/envs/classic_control/cartpole.py の中にある CartPoleEnv クラスの
render メソッドをコピペしてきてちょっと変える.
ちなみに画像読み込み周りの処理は gym/envs/classic_control/pendulum.py からのコピペ.gym/envs/MyEnv/cartpole_img.pyfrom os import path from gym.envs.classic_control.cartpole import CartPoleEnv class CartPoleEnv_Img(CartPoleEnv): # 既存のCartPoleEnvクラスを継承 def render(self, mode='human'): screen_width = 600 screen_height = 400 world_width = self.x_threshold*2 scale = screen_width/world_width carty = 100 # TOP OF CART polewidth = 10.0 polelen = scale * (2 * self.length) cartwidth = 50.0 cartheight = 30.0 if self.viewer is None: from gym.envs.classic_control import rendering self.viewer = rendering.Viewer(screen_width, screen_height) l,r,t,b = -cartwidth/2, cartwidth/2, cartheight/2, -cartheight/2 axleoffset =cartheight/4.0 cart = rendering.FilledPolygon([(l,b), (l,t), (r,t), (r,b)]) self.carttrans = rendering.Transform() cart.add_attr(self.carttrans) self.viewer.add_geom(cart) l,r,t,b = -polewidth/2,polewidth/2,polelen-polewidth/2,-polewidth/2 # Pole部分を作る元々の処理をコメントアウト # pole = rendering.FilledPolygon([(l,b), (l,t), (r,t), (r,b)]) # pole.set_color(.8,.6,.4) # 改変部分 fname = path.join(path.dirname(__file__), "assets/pole_pic.png") # 画像指定 scale = 200. pole = rendering.Image(fname, scale, scale*2.) # 画像の大きさ指定 pole.set_color(1, 1, 1) # 画像の色指定 self.poletrans = rendering.Transform(translation=(0, axleoffset)) pole.add_attr(self.poletrans) pole.add_attr(self.carttrans) self.viewer.add_geom(pole) self.axle = rendering.make_circle(polewidth/2) self.axle.add_attr(self.poletrans) self.axle.add_attr(self.carttrans) self.axle.set_color(.5,.5,.8) self.viewer.add_geom(self.axle) self.track = rendering.Line((0,carty), (screen_width,carty)) self.track.set_color(0,0,0) self.viewer.add_geom(self.track) self._pole_geom = pole if self.state is None: return None # Edit the pole polygon vertex pole = self._pole_geom l,r,t,b = -polewidth/2,polewidth/2,polelen-polewidth/2,-polewidth/2 pole.v = [(l,b), (l,t), (r,t), (r,b)] x = self.state cartx = x[0]*scale+screen_width/2.0 # MIDDLE OF CART self.carttrans.set_translation(cartx, carty) self.poletrans.set_rotation(-x[2]) return self.viewer.render(return_rgb_array = mode=='rgb_array')gym/envs/MyEnv/__init__.py の中身
作ったクラスをインポート.
gym/envs/MyEnv/__init__.pyfrom gym.envs.MyEnv.cartpole_img import CartPoleEnv_Imggym/envs/MyEnv/assets/pole_pic.png
pole_pic.png には好きな画像を用意すればいいが,
棒の支点にあたる部分が中心に来るような画像にしておく.
筆者はAzPainterを使って作った.
自作環境を使えるようにする
一つ上の階層 gym/envs/ にある __init__.py に,
自作環境の情報を追加しておく.gym/envs/__init__.py~~~省略~~~ # Classic # ---------------------------------------- register( id='CartPole-v0', entry_point='gym.envs.classic_control:CartPoleEnv', max_episode_steps=200, reward_threshold=195.0, ) register( id='CartPole-v1', entry_point='gym.envs.classic_control:CartPoleEnv', max_episode_steps=500, reward_threshold=475.0, ) # ここに追加 register( id='CartPoleImg-v0', entry_point='gym.envs.MyEnv:CartPoleEnv_Img', max_episode_steps=200, reward_threshold=195.0, ) register( id='MountainCar-v0', entry_point='gym.envs.classic_control:MountainCarEnv', max_episode_steps=200, reward_threshold=-110.0, ) register( id='MountainCarContinuous-v0', entry_point='gym.envs.classic_control:Continuous_MountainCarEnv', max_episode_steps=999, reward_threshold=90.0, ) register( id='Pendulum-v0', entry_point='gym.envs.classic_control:PendulumEnv', max_episode_steps=200, ) register( id='Acrobot-v1', entry_point='gym.envs.classic_control:AcrobotEnv', reward_threshold=-100.0, max_episode_steps=500, ) ~~~省略~~~これで,env = gym.make("CartPoleImg-v0") できるようになる.
一応
版権絵を使うときは個人利用に留めましょう.
怒られても筆者は責任を負わない.参考ページ
- 投稿日:2019-04-13T01:31:59+09:00
sklearn.datasetsのmake_blobsのfeatureとcenterについて調べてみた
sklearn.datasets.make_blobsのfeatureとcenterについて
featureについて
from sklearn.datasets.samples_generator import make_blobs from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import numpy as np import pandas as pd import matplotlib.pyplot as plt X, y = make_blobs(n_features=2, centers=3) X_train, X_test, y_train, y_test = train_test_split(X, y) model = KNeighborsClassifier() model.fit(X_train, y_train) y_pred = model.predict(X_test) acc = accuracy_score(y_test, y_pred) * 100 print('accuracy: {}%'.format(acc))n_featuresはどれだけのカラムまたは特徴量をデータセットに定義するかを決定する。
centerについて
center : intまたは形状の配列[n_centers、n_features]、オプション
(デフォルト=なし)生成する中心の数、または固定中心位置。n_samplesがintで、
centerがNoneの場合、3つの中心が生成されます。n_samplesが配列に似ている場合、centerは>Noneまたはn_samplesの長さに等しい長さの配列のいずれかでなければなりません。
よくわからないので、プロットしてみた。# plot 1 (centers=1) X, y = make_blobs(n_features=2, centers=1) plt.figure() plt.scatter(X[:, 0], X[:, 1], c=y) plt.savefig('centers_1.png') plt.title('centers = 1')
# plot 2 ('centers = 2') X, y = make_blobs(n_features=2, centers=2) plt.figure() plt.scatter(X[:, 0], X[:, 1], c=y) plt.title('centers = 2')
# plot 3 ('centers = 3') X, y = make_blobs(n_features=2, centers=3) plt.figure() plt.scatter(X[:, 0], X[:, 1], c=y) plt.title('centers = 3')
これらよりcenterはそれぞれのブロブ(塊)をセンター毎に分けて生成されていることがわかる。
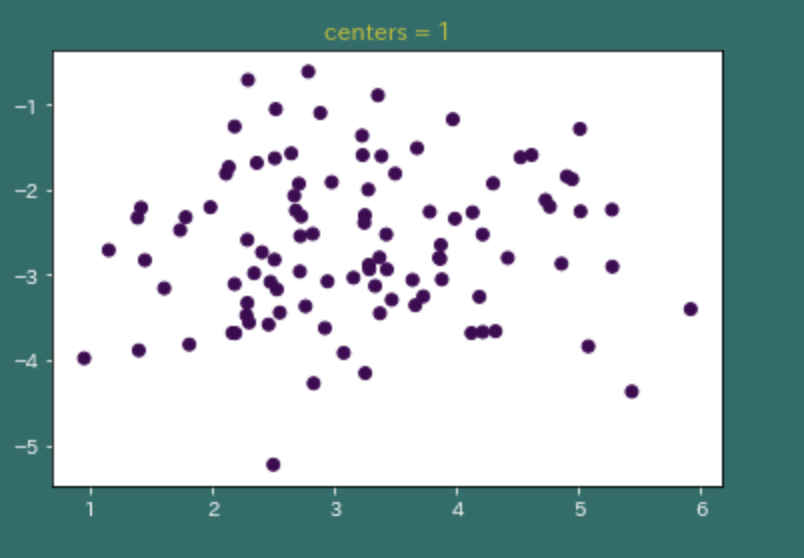

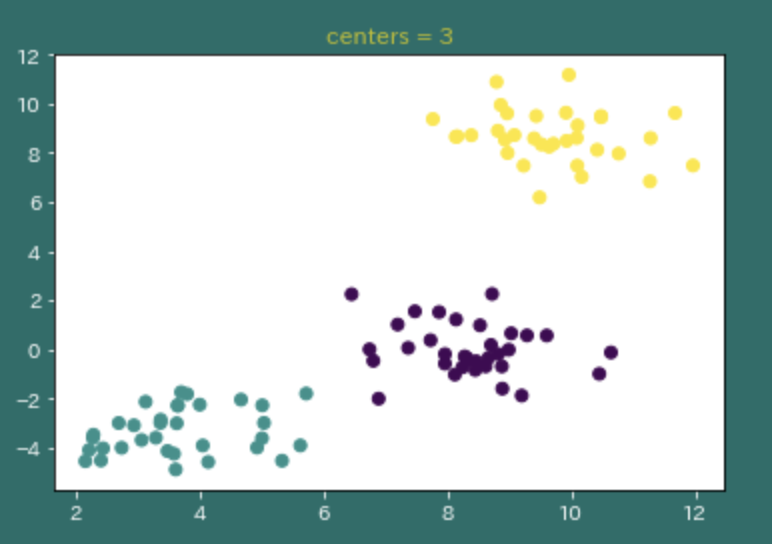
- 投稿日:2019-04-13T00:36:57+09:00
Pythonの環境構築をしてみた
やったこと
1. Anacondaの導入
2. Pycharmの導入
3. AnacondaとPycharmの連携1. Anacondaの導入
以下のリンクからダウンロードする。それだけ。
https://www.anaconda.com/distribution/
※Python3.7とPython2.7を選択できるが、特別な理由がない限り最新のPython3.7を選択するとよいでしょう。なぜなら、今後新機能がリリースされる際、基本的にPython3.7にのみ追加されることとなり、Python2.7が改善されることはないので。とはいえ、Python2.xも2020年まではサポート期間が残ってはいますが。
2. Pycharmの導入
以下のリンクからダウンロードする。それだけ。
https://www.jetbrains.com/pycharm/?fromMenu
※pycharmにはprfessional (有料版)と community (無料版)とがありますが、以下にざっくりと違いをまとめるので、各自で判断してダウンロードするとよいでしょう。
◯professionalにあって、communityにはないもの
・データベースサポートがない
・Web 系のコードがすべて補完が効かない
・IDE 上からデプロイができない
・Django サポートがない3. AnacondaとPycharmの連携
せっかくAnacondaとPycharmをインストールできたので、両者を連携して快適に開発したいと思うでしょう。ということで、両者の連携の仕方を簡単に記録します。
1. AnacondaのPathを調べる
2. Pycharmのproject inspecterにPathを設定する以上。非常にシンプルに書きましたが、これ以上複雑に書けないくらい簡単でした。
ちなみに以下の記事は画像付きでもっと親切かと思うので、参考にするとよいかもしれないです。
https://qiita.com/aburafia/items/e783aa966f77448f44d1
さいごに
非常に簡単にPythonの開発環境を整えたときの話を書きましたが、Anacondaが開発環境をまるごとインストールしてくれるので、簡単に環境構築することができました。
- 投稿日:2019-04-13T00:09:04+09:00
IPython起動時にいつも使うモジュールをimportする設定
やりたいこと
いつも使うモジュールを毎回importするのがめんどくさいので、起動時にimportしといてもらいたい。
tl;dr
~/.ipython/profile_default/hoge.py以下にimport部分を書いておく。IPython startup directory
たぶん、
~/.ipython/profile_default/ここにディレクトリがある。
そこにREADMEがあって、
1. ここにある.py、.ipyファイルを実行前に読み込んでくれる。
2. ファイル名の辞書順で実行してくれる。
的なことが書いてある。使ってみる
適当に
~/.ipython/profile_default/00-startup.pyに以下を書く。~/.ipython/profile_default/00-startup.pyfrom collections import Counter import pickle def pload(fname): return pickle.load(open(fname, 'rb')) def pdump(object, fname): pickle.dump(object, open(fname, 'wb'))ipython起動して、簡単にテスト
test.$ ipython In [1]: pdump([1,2,3], "hoge") In [2]: pload("hoge") Out[2]: [1, 2, 3] In [3]: Counter("HJKLHJKLLKJLJKJKJLKJHKJJLHKLJLK") Out[3]: Counter({'H': 4, 'J': 10, 'K': 9, 'L': 8})その他
入れすぎたり、重い処理を書くと起動が遅くなるから注意。
jupyter notebook,jupyter labとかも同じ設定でいけると思う。
いちおうipython hoge.pyってやれば、事前にimportしてからhoge.pyを実行くれる。
普通のpythonで起動するインタラクティブシェルの場合は環境変数のPYTHONSTARTUPにファイルのパスを設定すればいい。 https://docs.python.org/ja/3/using/cmdline.html#envvar-PYTHONSTARTUP
- 投稿日:2019-04-13T00:04:37+09:00
宴会の幹事決めプログラム(イカサマもできますがやらないでくださいね)
1. 要約
宴会の幹事決めるのって難しくない?先輩に任せっきりもアレだし,後輩に押し付けるのもアレだし...そんなお悩みを持つあなたのために,宴会の幹事をランダムに決定するプログラムを書きました.これで誰が選ばれても「仕方がないナァ~~~」という空気になります.
2.核となるのはrandomモジュールのchoice()
pythonには強力なライブラリがあります.今回はrandom.choice()という関数を利用して,幹事候補者のリストの中から一名をランダムに決定するという処理を行います.aをリストとすると,random.choice(a)はリストの要素を一つランダムに選択する関数です.そのため,幹事候補者のリストを作成することが必要となります.今回作成したプログラムは以下のステップで構成されています(フローチャート?そんなもん知らねぇ!!).
- step 1. 候補者の人数を入力
- step 2. 候補者を一人ずつリストに格納
- step 3. 候補者リストを表示して間違い,抜け漏れがないか確認を取る
- step 4. random.choice()で候補者リストから一人選択し,画面に表示する
以上の動作に,ユーザーからの入力が正しいかどうかの判定を加えたのが今回のプログラムです.
3.幹事決めプログラム
いつものように,ターミナルやコマンドプロンプトで実行するプログラムです.
python, kanji_gime.py# -*- coding: utf-8 -*- import random """ input n: number of candidate of KANJI name: name of candidates output kanji: KANJI """ ans = 0 while True: n = float(input(u"幹事候補者の人数を入れてください(int)-> ")) if n < 0 or n.is_integer() == False: print(u"\nnには正整数入れてや\n") continue elif n.is_integer(): n = int(n) break while True: if ans == "y": break name_list = [] for i in range(n): print("%d人目" % (i+1)) name_list.append(input(u"候補者の名前を入力してください: ")) print(name_list) while True: ans = input(u"\n候補者リストはこれ↑で合っていますか?(y/n): ") if ans == 'y': break elif ans == 'n': print(u"やり直しやで~~~") break else: print(u"y(yes)かn(no)で答えてちょっ!!!") kanji = random.choice(name_list) print(u"\n今回の幹事は",kanji,"さんです")(でもnの入力が数値以外だとエラーが出て止まります.直せる方は直して使ってください.)
乱数固定するとイカサマできます.