- 投稿日:2019-04-13T22:57:32+09:00
CloudWatchのログ保持期間を設定する + 古いログストリームを削除する
はじめに
CloudWatchに送られたログは、デフォルトでは削除されない設定となっています。しかし、開発環境で出たログなど不要な分は自動的に削除されるようにしたいところです。本記事ではログ保持期間の設定方法+αを紹介します。
ログ保持期間の設定
CloudWatchではロググループ内に複数のログストリームを作成し、それぞれのログストリーム内にログ(イベントと呼んでいます)が保存されます。
ロググループ単位でイベント保持期間(1日〜10年、または失効しない)を指定できます。
以上で設定完了ですが、数日経ってイベントは削除されるもののログストリームは削除されないことに気付きました。調べた限りではログストリームを自動削除する設定はなく(放置してもよいのでしょうが)スクリプトで削除することにしました。
ログストリームの削除
ログストリーム一覧の取得
awscliでログストリームの一覧を取得します。
$ export LOG_GROUP=/aws/lambda/container-linux-release-feed-dev-run $ aws logs describe-log-streams --log-group-name $LOG_GROUP { "logStreams": [ { "logStreamName": "2019/03/03/[$LATEST]09bb88aec4974e15be0d2377158face0", "creationTime": 1551580975826, "firstEventTimestamp": 1551580976064, "lastEventTimestamp": 1551580976693, "lastIngestionTime": 1551580991815, "uploadSequenceToken": "49592389844623632721379765608055463118863630784203344882", "arn": "arn:aws:logs:ap-northeast-1:313471890455:log-group:/aws/lambda/container-linux-release-feed-dev-run:log-stream:2019/03/03/[$LATEST]09bb88aec4974e15be0d2377158face0", "storedBytes": 838 }, ... ] }古いログストリームの抽出
jqを利用して古いログストリームの一覧を取得します。ひとまずタイムスタンプはべた書きします。
$ export LIMIT_TIMESTAMP=1551580272274 $ aws logs describe-log-streams --log-group-name $LOG_GROUP \ | jq -r '[ .logStreams[] | select(.lastEventTimestamp < 1552380272274)] | .[].logStreamName' > old.json $ cat old.json 2019/03/03/[$LATEST]d576f86f32974cf7baca86361b8945f8 2019/03/03/[$LATEST]ec0c0c610a9c4db786b6974319c397a2 2019/03/03/[$LATEST]f45654f5eebb4133b5a3a6387a8c5f13 2019/03/04/[$LATEST]1a7c8f221fd64f8fb261f78e81fa20e8 2019/03/05/[$LATEST]4894df3b61594a6283dde862f78825be 2019/03/06/[$LATEST]40097805fd064168aa61fa00c026dabc 2019/03/07/[$LATEST]08438a934e9f42b5a04ec28e4c152aee 2019/03/08/[$LATEST]666d3a23f85b4a31beb215417dbcd3c1 2019/03/09/[$LATEST]d765181840cd437c9d9313b567229a90 2019/03/10/[$LATEST]404230a5066347b6a28deb45ed5a9092 2019/03/11/[$LATEST]f6a5022e283c42a8a8192fe342c41a8a 2019/03/12/[$LATEST]fb8033e5bc0f4ae4ad1baefa713d7d20古いログストリームの削除
上記ステップで抽出したログストリームを削除します。
$ for s in `cat old.json`; do aws logs delete-log-stream --log-group-name $LOG_GROUP --log-stream-name $s; done以上で古いログストリームを削除できました。
まとめ
CloudWatchのログ保持期間は簡単に設定できるので必要に応じて設定しておきましょう。ログストリームは消えていかないので気になる場合はスクリプトで削除しましょう。いずれはLambdaで実行したいと思います。


- 投稿日:2019-04-13T22:09:05+09:00
AWS Storage gateway 使ってWindows用ファイルサーバー構築(SMB)
はじめに
AWS Storage Gateway は、オンプレミスアプリケーションによる AWS クラウドストレージのシームレスな使用を可能にするハイブリッドストレージサービスです。
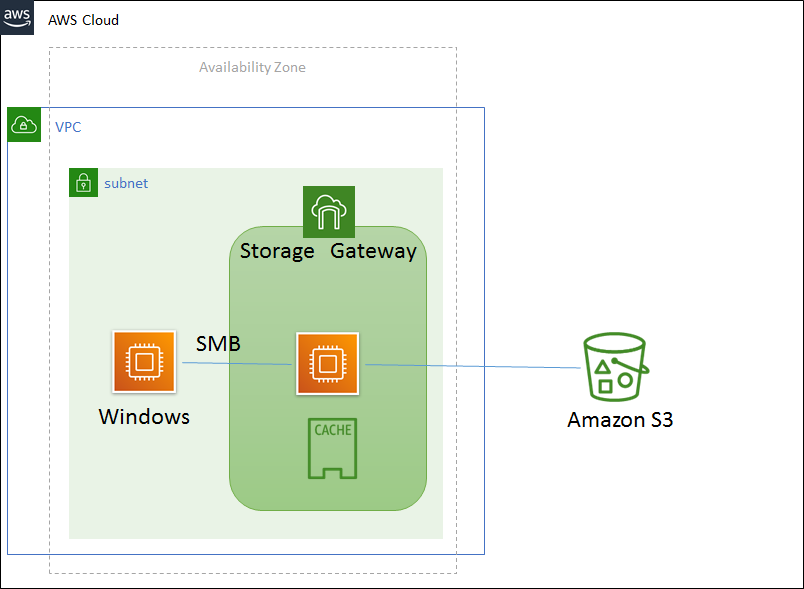
もちろんCloud環境も利用できます。AWS Cloud環境でAWS Storage gateway 使ってWindows用ファイルサーバー構築してみました。構成
手順
※事前にVPCの作成、セキュリティルール設定に作業が必要、詳細を割愛
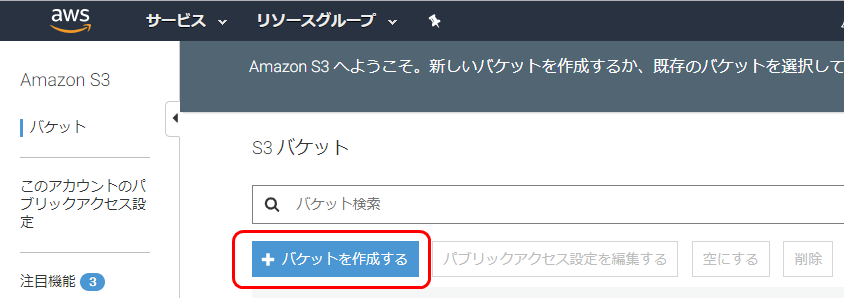
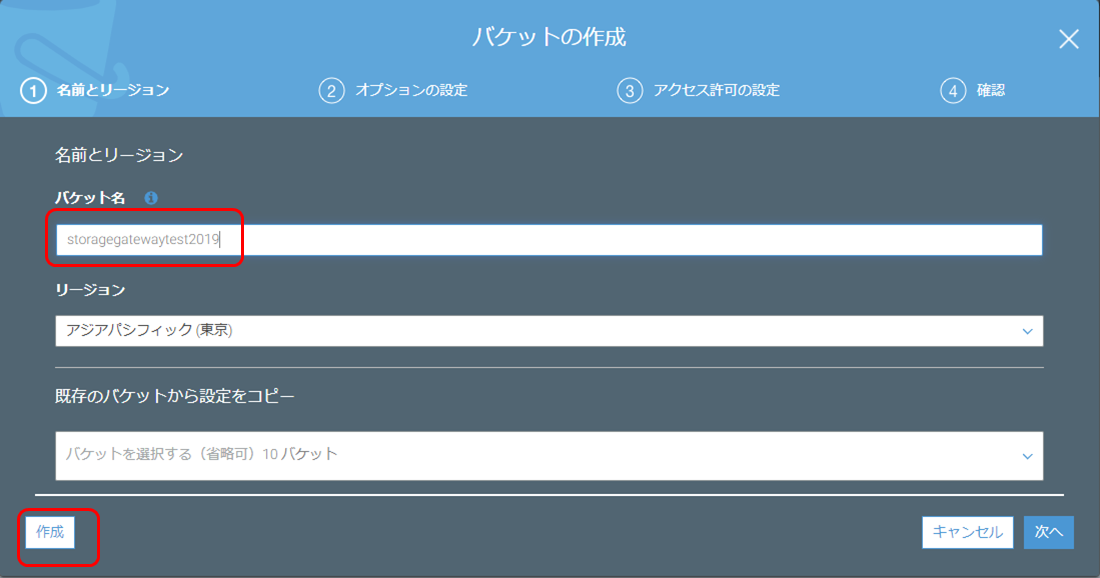
準備 Storage gateway用S3バケットを作成
S3管理画面からバケットstoragegatewaytest2019を作成
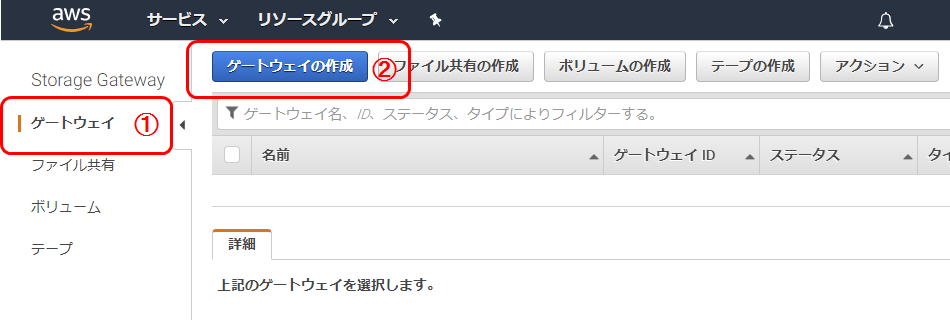
Storage Gateway作成
Storage Gateway管理画面を開く
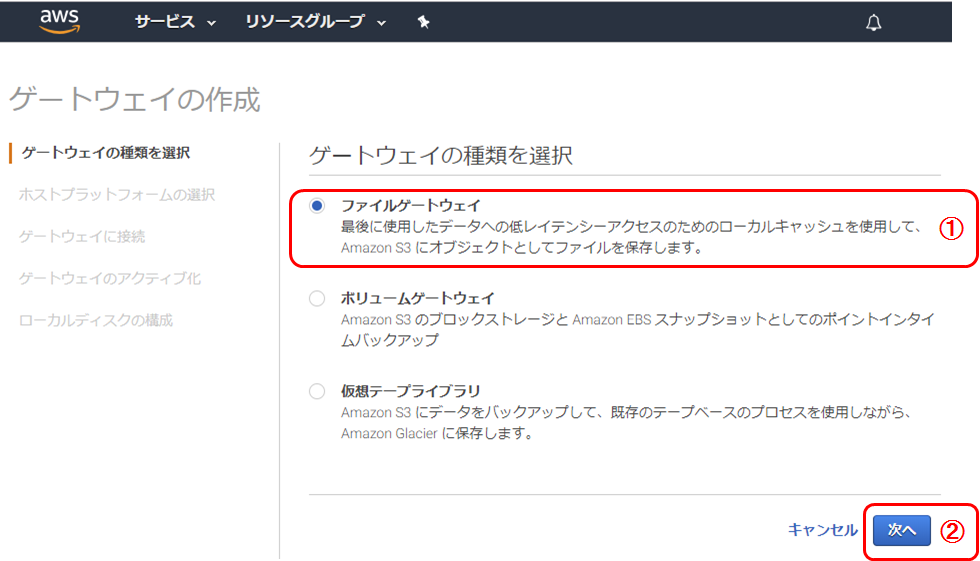
ゲートウエイの種類を選択
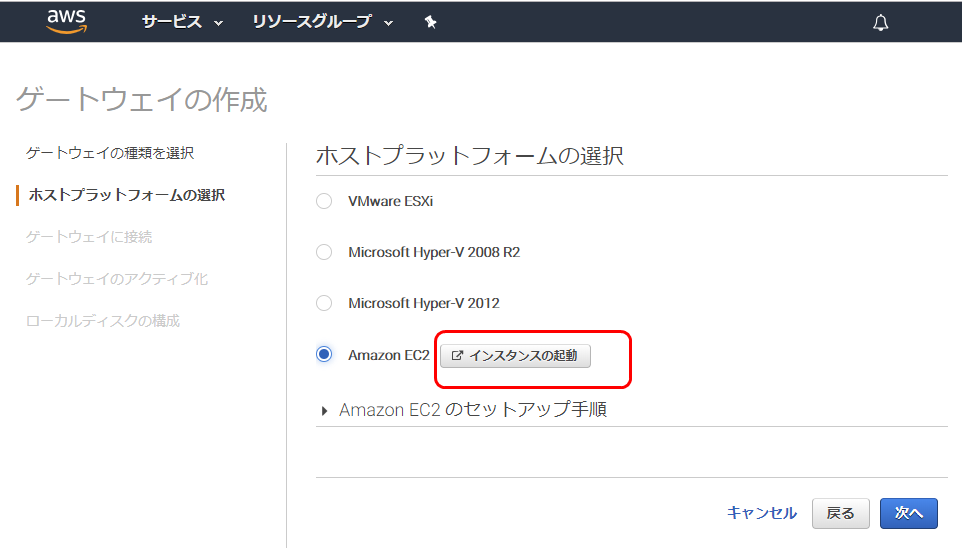
ホストプラットフォームの選択
ECインスタンスの起動をクリックしてホスト用インスタンスホスト用インスタンス作成
インスタンスタイプの選択
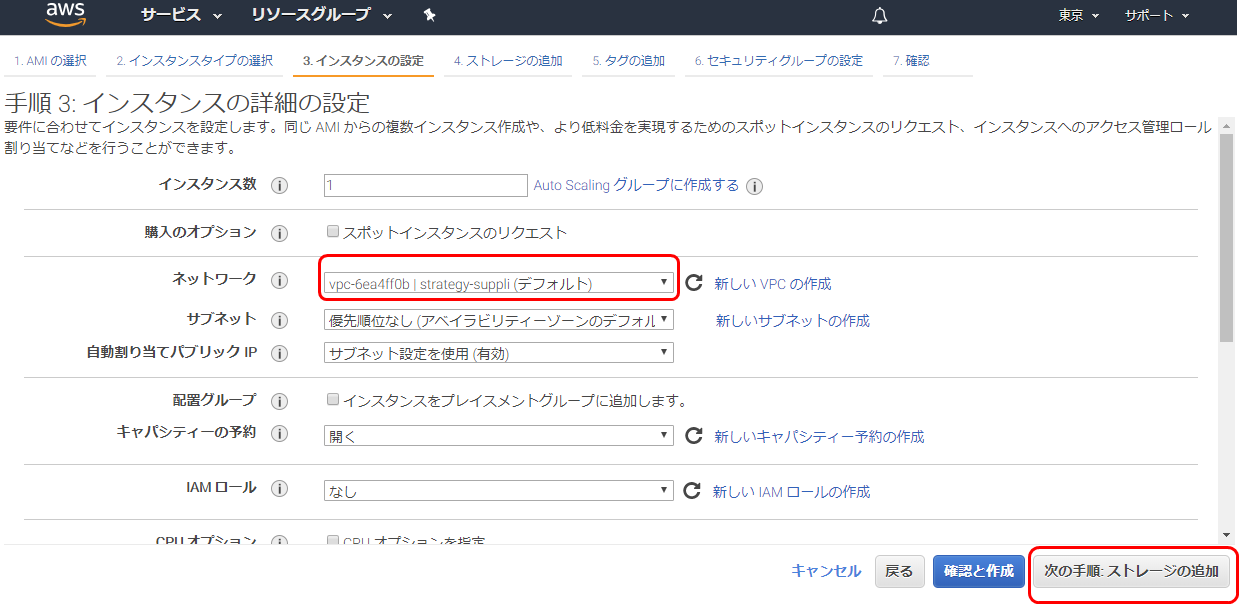
m4.xlarge インスタンスタイプをお勧めします。インスタンスの詳細の設定
※利用するサーバーからアクセスできるネットワークを選択します。ストレージの追加
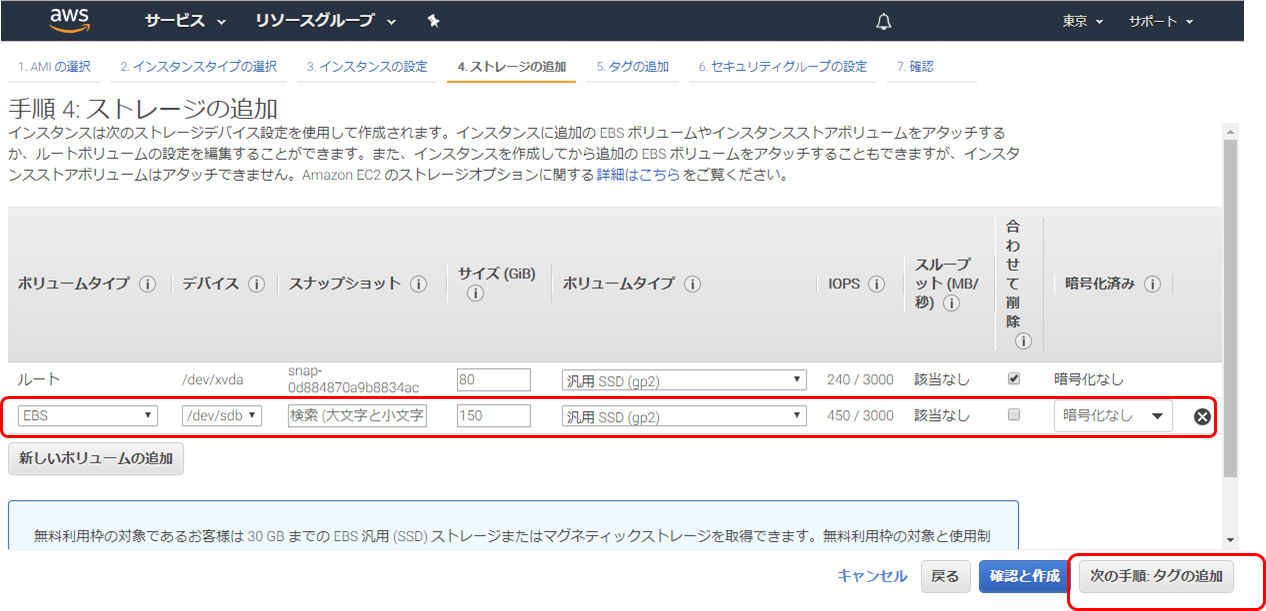
※150G ストレージを追加タグの追加
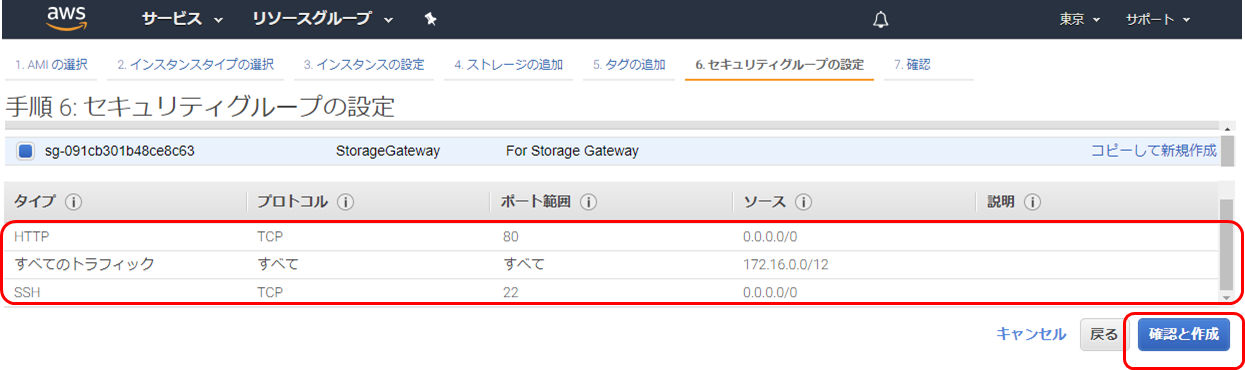
セキュリティグループの設定
新規 あるいは既存のセキュリティグループ選択 (下記にお設定を参考)
タイプ プロトコル ポート範囲 ソース 説明 HTTP TCP 80 0.0.0.0/0 ストレージゲートウエイ設定用 すべてのトラフィック すべて すべて 172.16.0.0/12 ファイルサーバーへアクセスためとりあえずローカルアクセス全部許可。
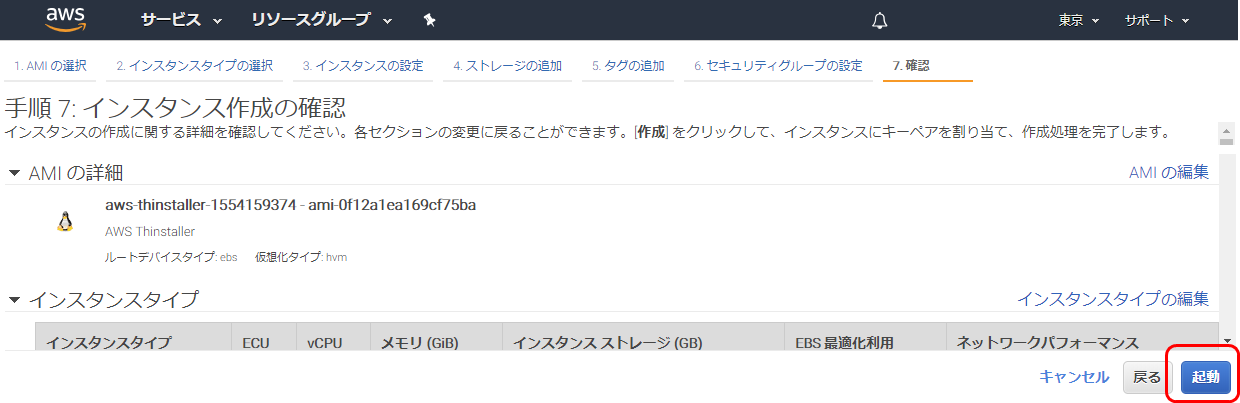
(本番の場合よりセキュアの設定したほうがいい)HTTP TCP 22 0.0.0.0/0 インスタンスアクセス用、設定しなくでもいいです インスタンス作成の確認
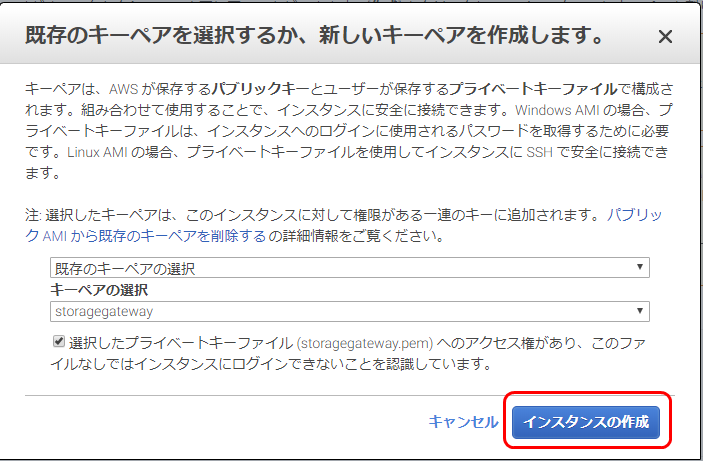
キーペアの作成
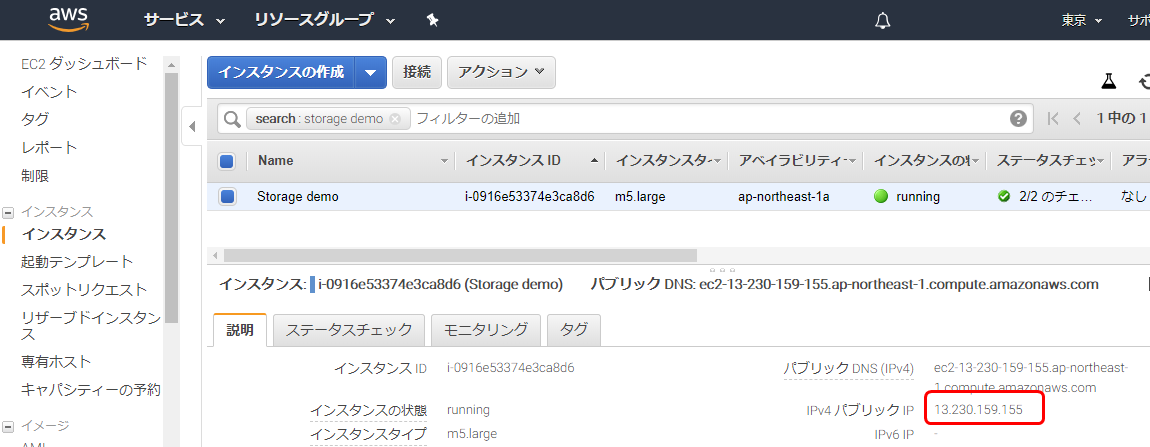
作成されたインスタンスのPublic IPを確認、メモする
ゲートウエイ作成画面に戻る
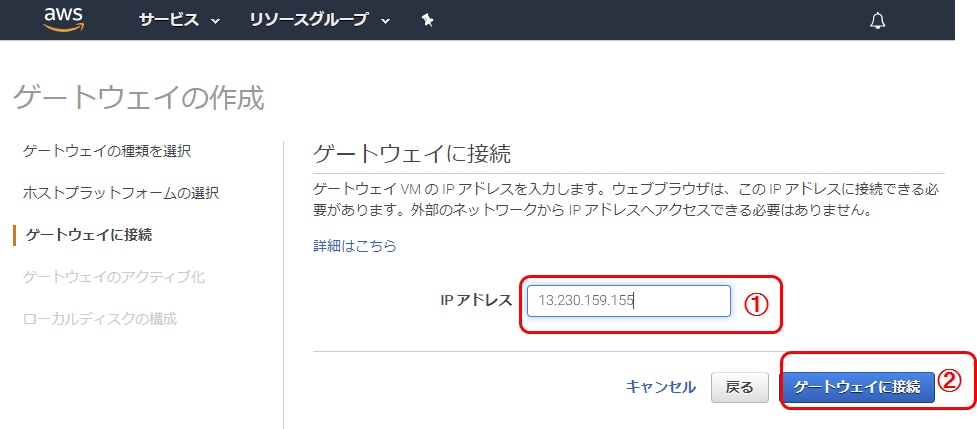
ゲートウエイに接続
1. 上記の手順でメモしたPublic IPを入力
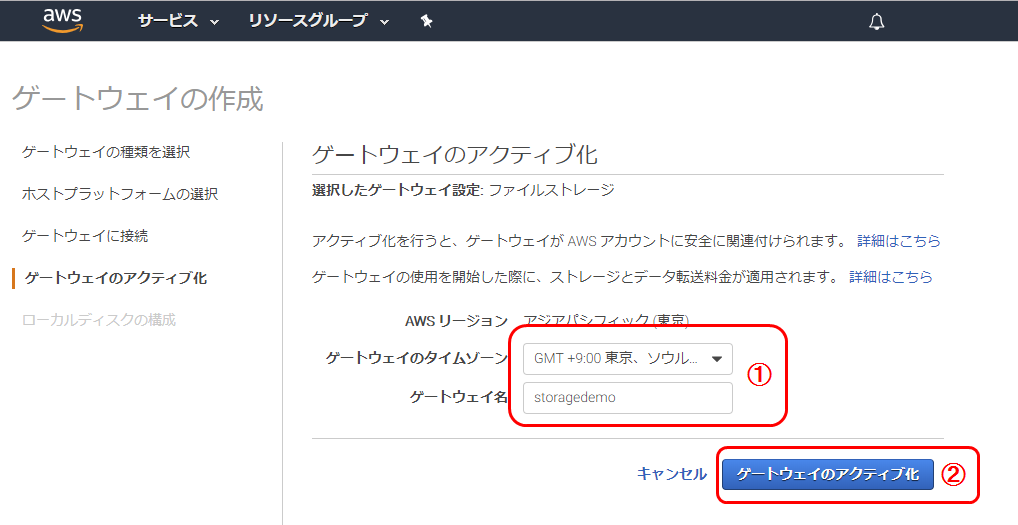
2. [ゲートウエイに接続]をクリックゲートウエイのアクティブ化
1. タイムゾーンとゲートウエイ名を設定
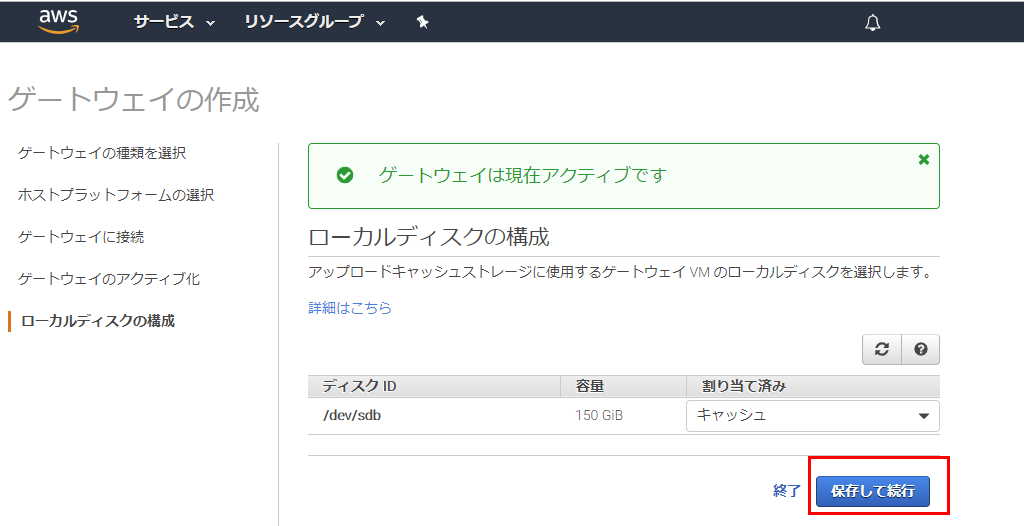
2. [ゲートウエイのアクティブ化]をクリックルーカルディスクの構成
Storage Gateway設定
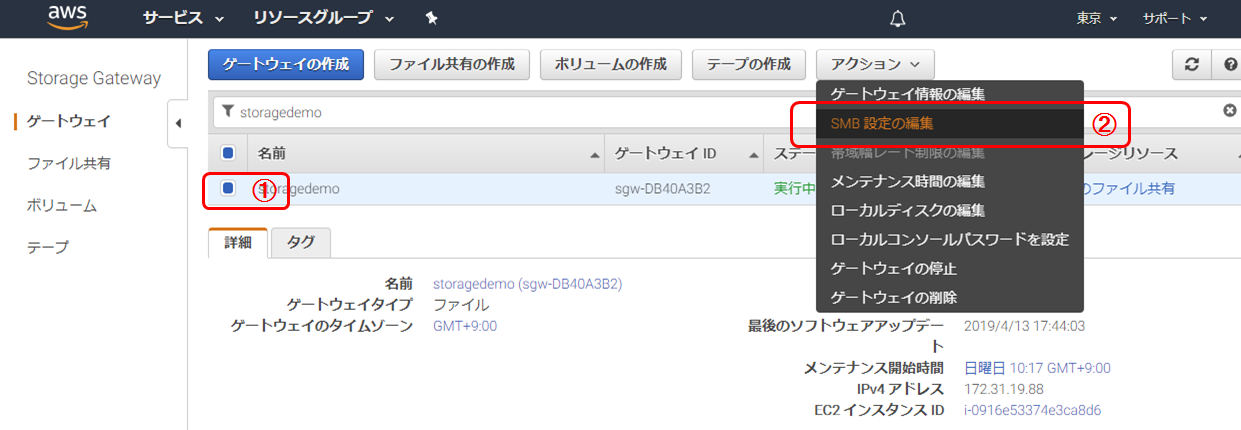
SMB設定
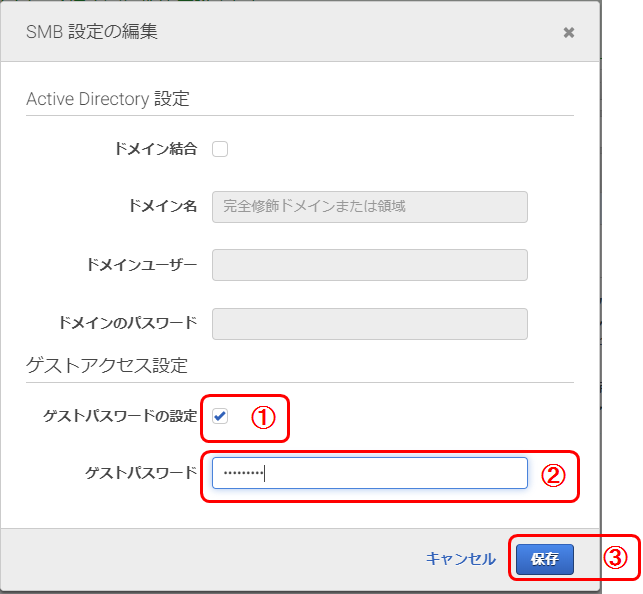
SMB設定の編集
今回はゲストアクセスに設定。
1. [ゲストパスワードの設定]をチェック
2. ゲストパスワードを設定 (ここに設定したパスワード後ほどクライアントからアクセス時必要)
3. [保存]をクリックファイル共有の作成
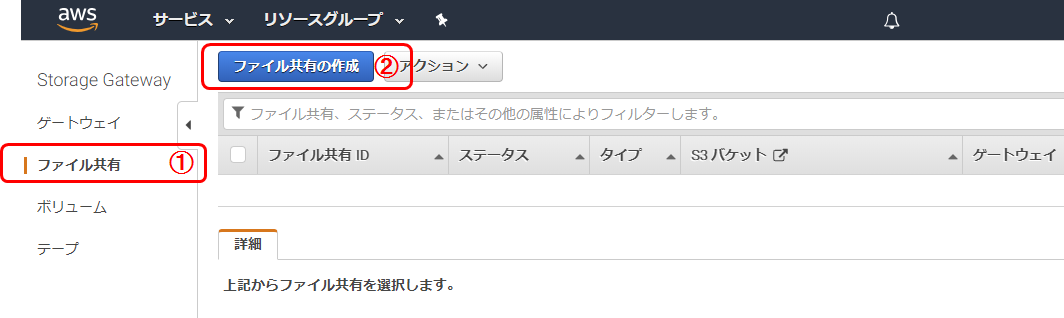
ファイル共有画面開く
ファイル共有の設定
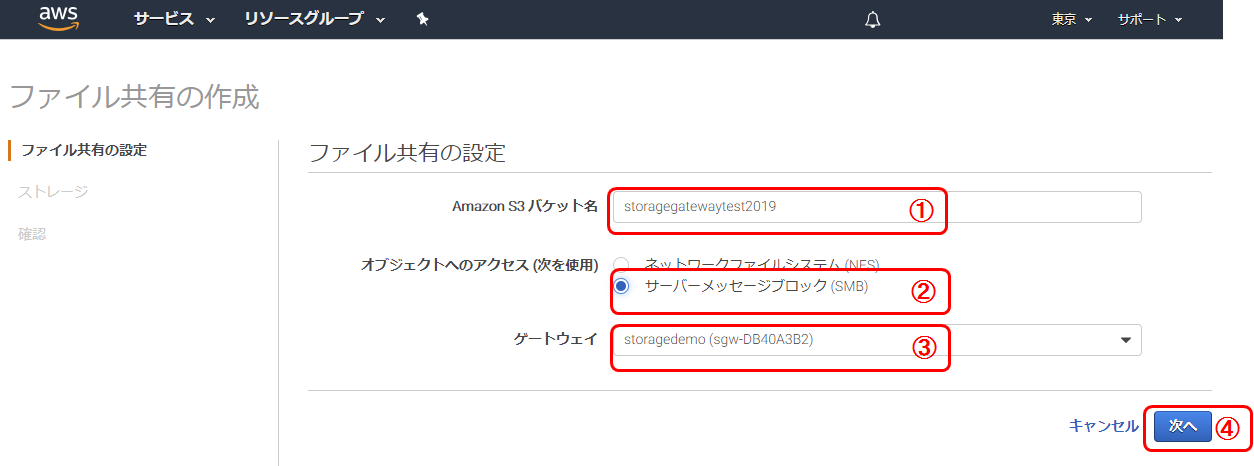
1. 保存用S3バケット名を入力(手順準備で作成したバケット名を入力)
2. SMBを選択
3. 先ほど作成したゲートウエイを選択
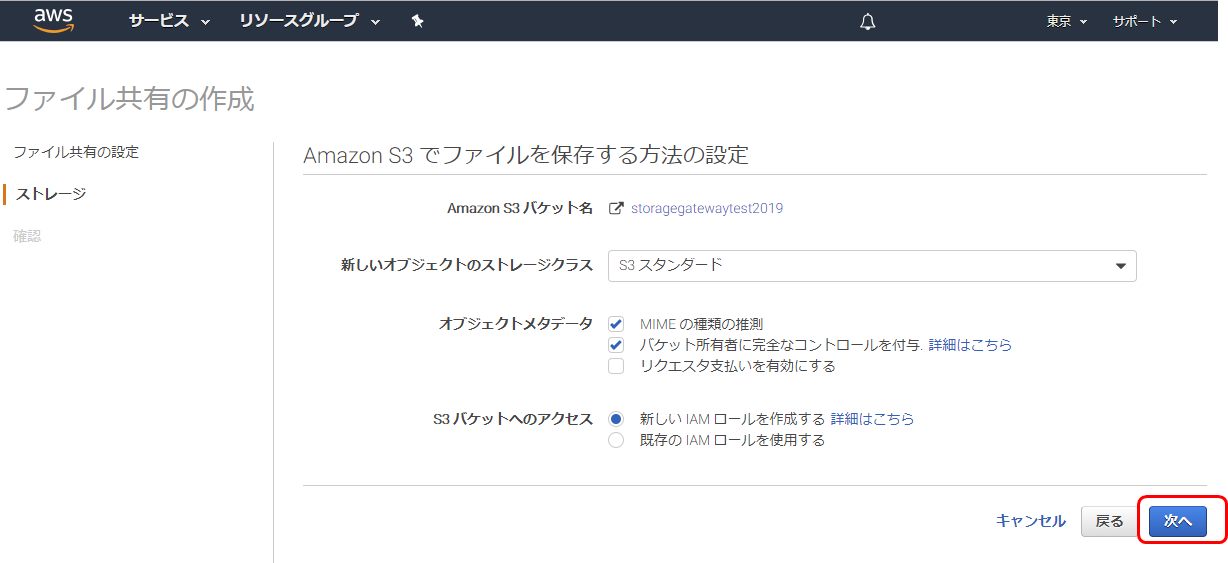
4. 次へS3保存方法の設定
デフォルト値のまま 次へ確認画面
1. SMBの設定ボタンをクリック
2. 認証方法を ゲストアクセスを選択
3. 設定画面閉じる
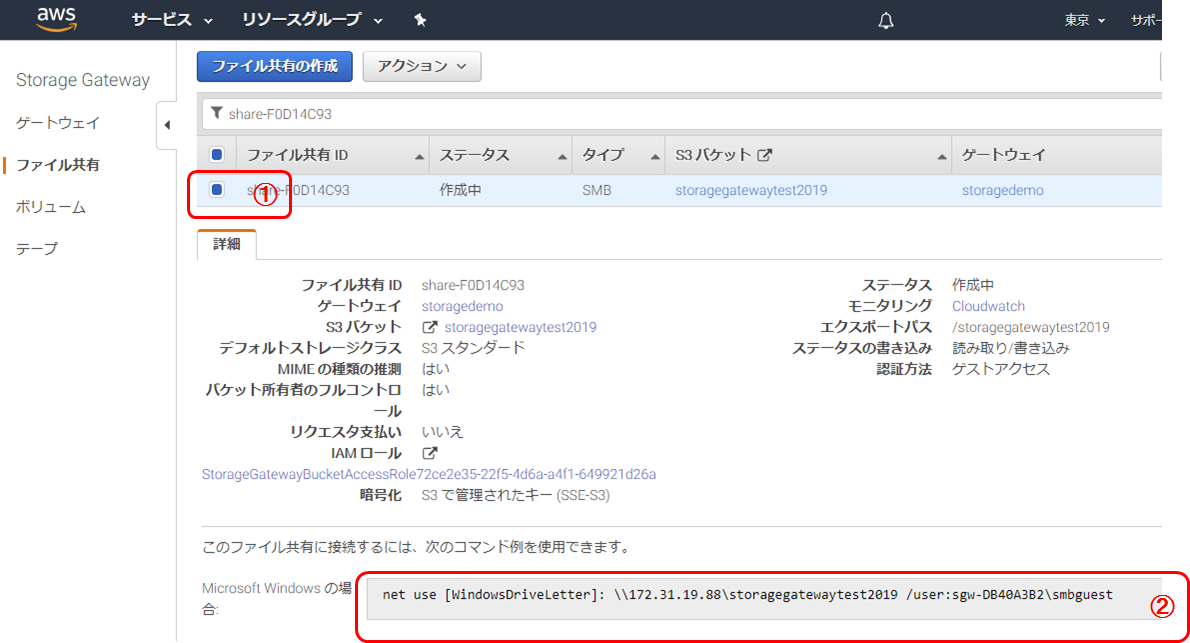
4. [ファイル共有作成]をクリック作成されたファイル共有の詳細確認
1. 対象ファイル共有をチェック
2. 接続情報を確認動作確認
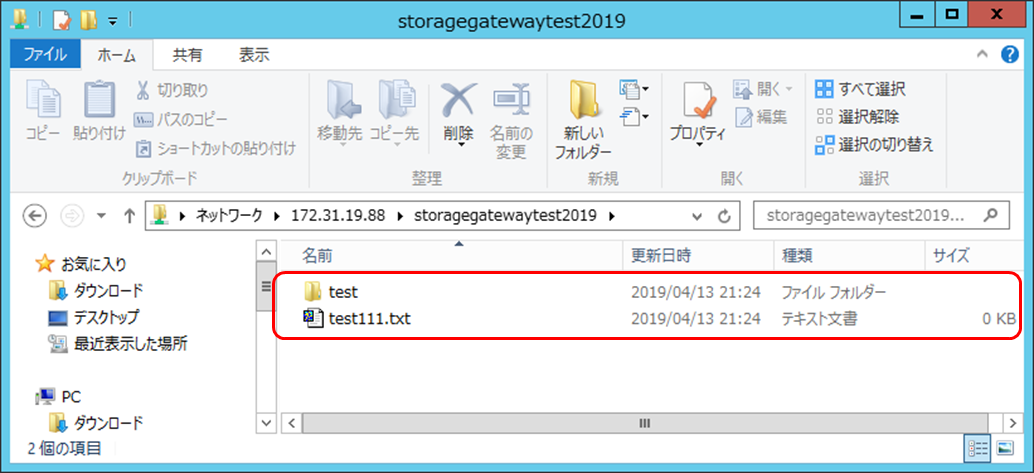
Storage gatewayアクセスできるWindowsインスタンスからアクセス
- ファイルサーバーにアクセスできること確認 (ユーザー:smbguest パスワード:上記の手順で設定されたパスワード) 2.テスト用のフォルダー、ファイルを作成
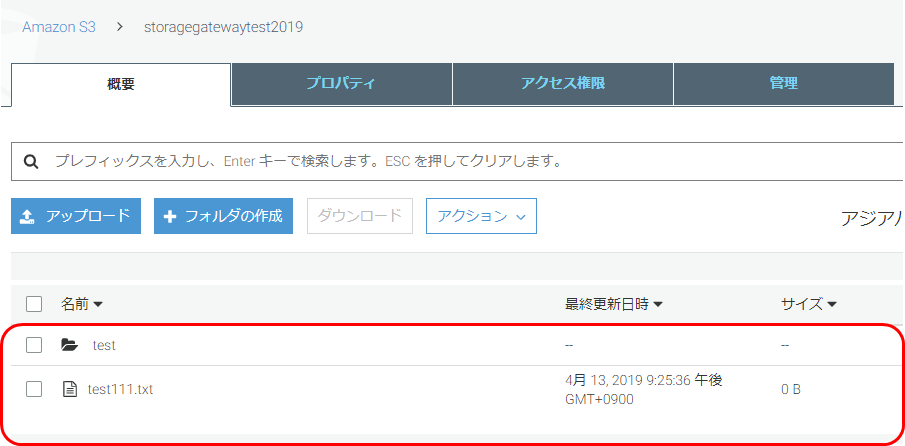
S3にフォルダー、ファイル同期されていること確認
Appendix
ファイルサーバーにアクセス時、ユーザー名、パスワードをWindows資格情報に設定すれば、毎回入力する必要がなくなります。
詳細は下記の資料を参照:
https://support.microsoft.com/ja-jp/help/4026814/windows-accessing-credential-manager


- 投稿日:2019-04-13T21:33:34+09:00
GitHubのWebhookでプルリクエストをマージした際にツイートできるようしてみた
はじめに
こんにちは。なおとです。
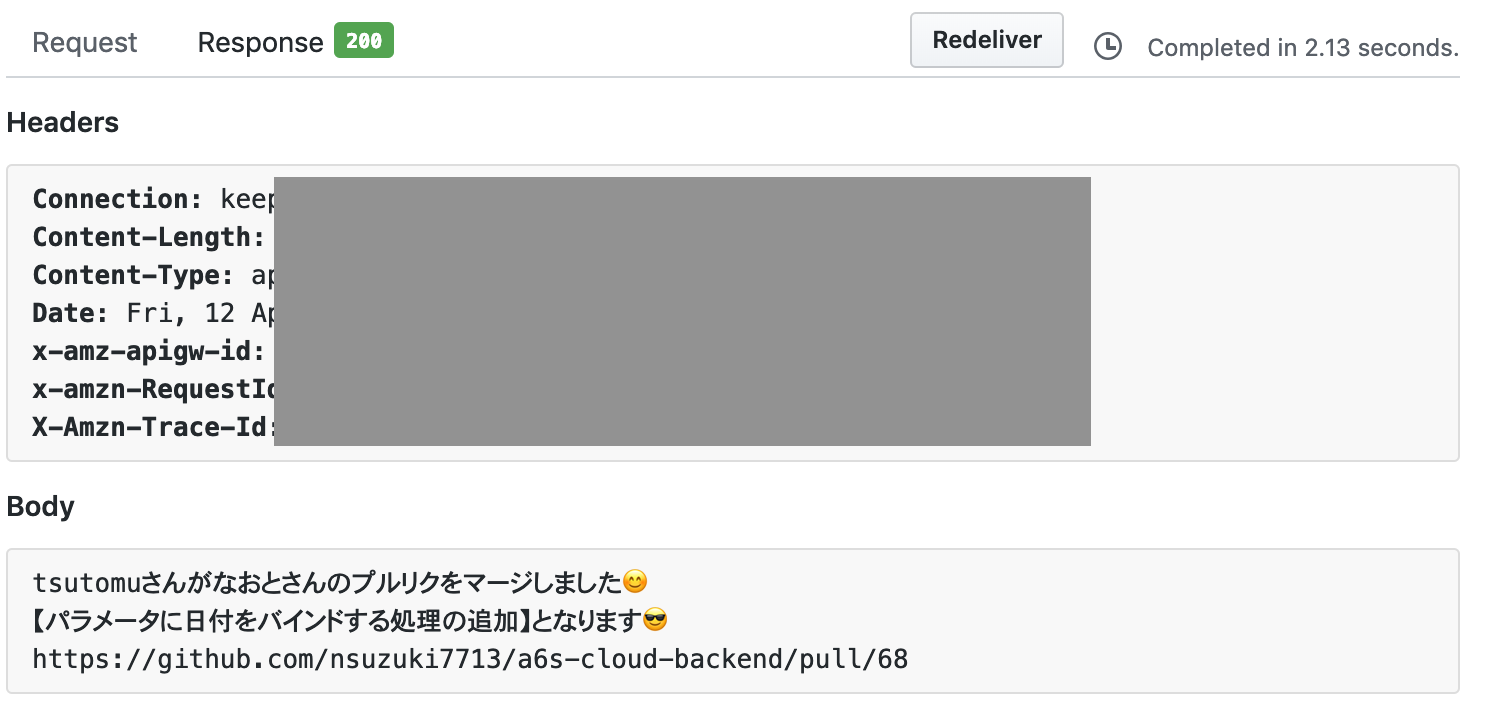
今回はGitHubのプルリクをマージした際に自動でツイートできるようにしたのでその解説となります。プルリクをマージするとこんな感じでTweetされます。
tsutomuさんがなおとさんのプルリクをマージしました?
— a6s-cloud (@CloudA6s) 2019年4月11日
【analysis_resultsテーブルにカラムを追加??】となります?️https://t.co/EWfJsIlGyx
なぜやろうと思ったのか?
現在数人で個人開発をしていますが、時間の制約もあり、かつ非同期のコミュニケーションのため、モチベーションを保つことは難しいです。
普段はGitHub↔︎slack連携をしているので、イシュー作成やプルリクをマージした際に通知がきます。
せっかくプロジェクトもpublicにしているので、ツイッターのオープンな場に通知できたらモチベーションも上がるのでは?と考えたのがきっかけです。また、今の個人開発ではTwitter APIを使用しています。
以前アカウントを新規取得したのですが、ツイートをしなかった影響なのかアカウントをロックされてしまいました。
その為、CT(ケイゾクテキ ツイート)をして、アカウントがロックされないようにしよう!!と思ったのもあります笑今回のソースコードはこちらにあります。
https://github.com/nsuzuki7713/github-webhook構成
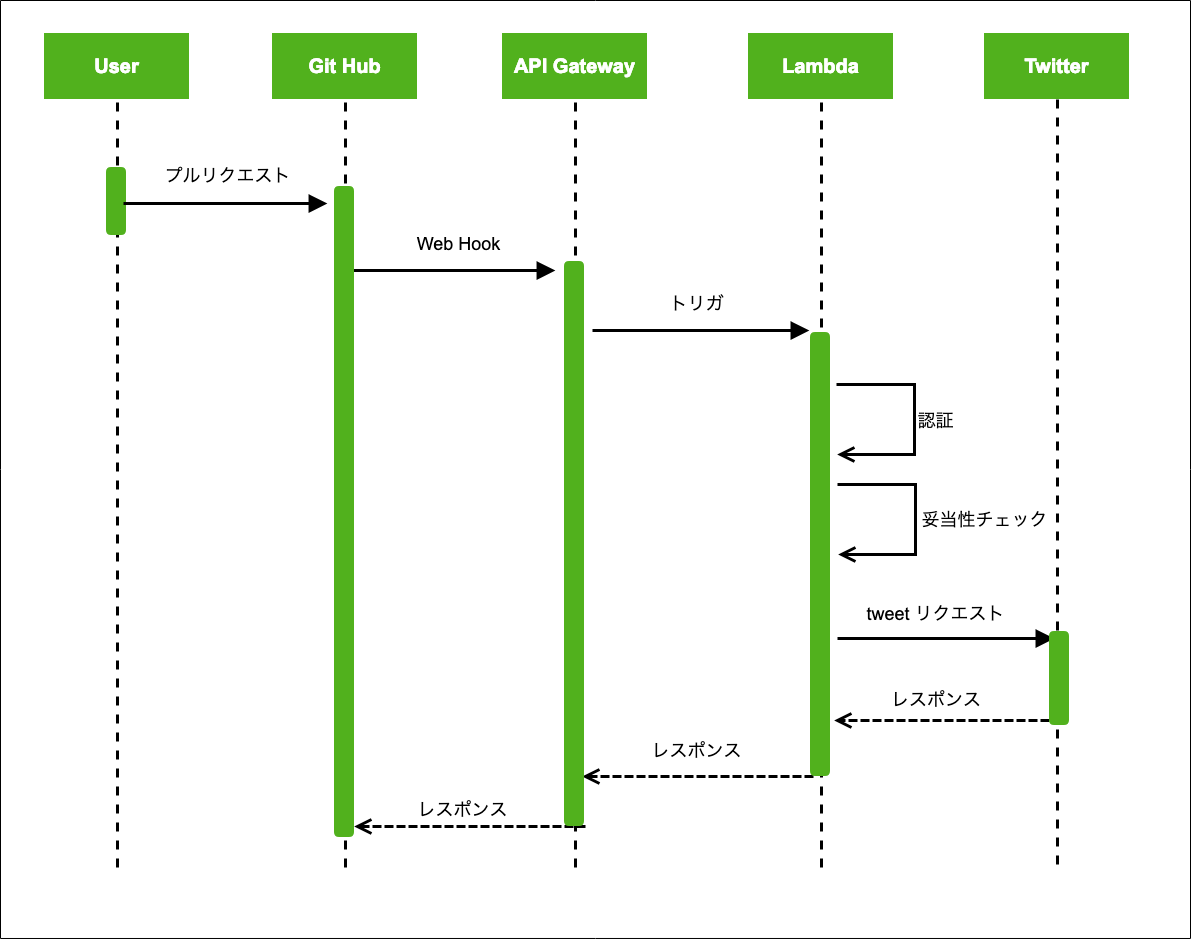
こちらがシーケンス図となります。
シンプルな処理形式だと思います。
- ユーザーがプルリクを作成する
- GitHubのWebhookでAPI Gatewayにリクエストをする
- API Gatewayはlambdaを実行する
- lambdaでは最初に認証チェック、妥当性チェックを行う
- lambdaからtwitter apiを叩いてツイートする
開発
ツイッターアカウント作成とapiキーの作成
APIからTweetするためには、Twitter APIが必要です。
下記記事を参考にして申請しました。
https://www.torikun.com/2018/10/08/twitter-developer-api/特に詰まることなく、承認も一瞬でした。数日待たされるという記事も見かけましたが僕は申請したら、数分で承認メールがきました。
英語で使用用途を記載する必要がありますが、僕はGoogle翻訳をフル活用しました。
lambdaとAPI Gatewayの設定
下記記事を参考にして、進めました。
スクショもあり、丁寧に手順が書いてあります。
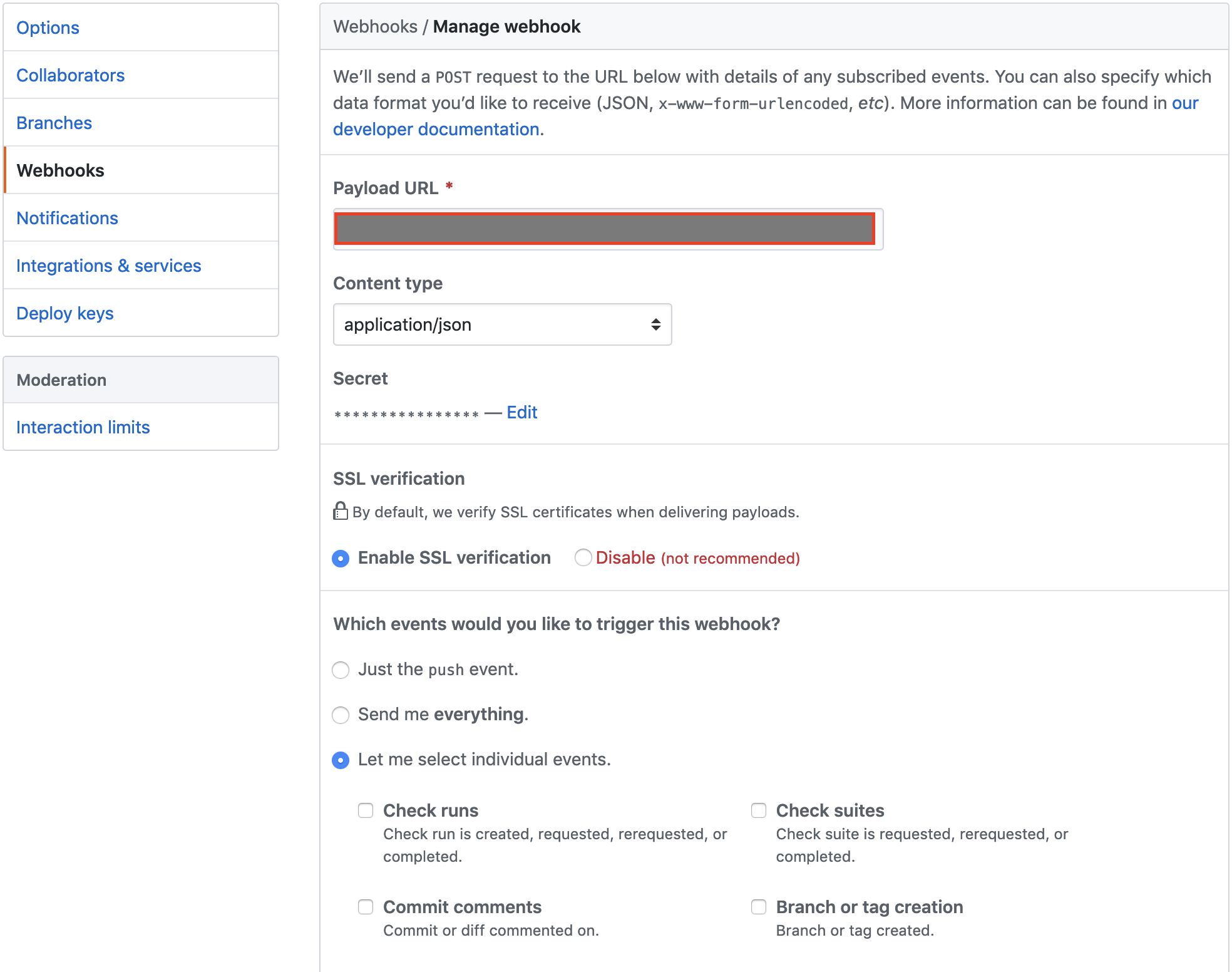
【API Gateway】AWS Lambda統合のPythonでHello, worldGitHub webhookの設定
下記記事を参考にして、進めました。
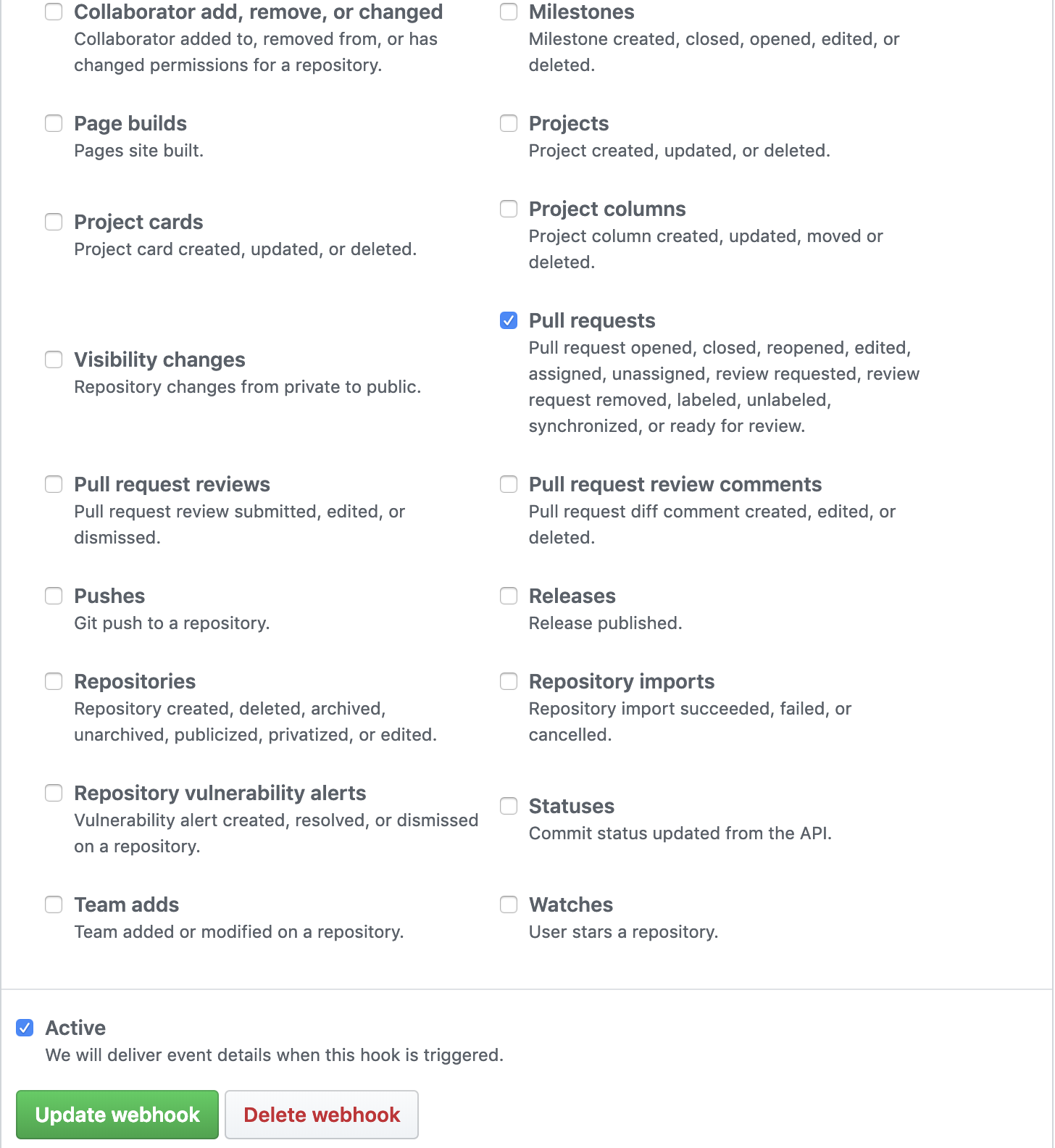
Github serviceをwebhookに変更したこちらが設定した内容です。
webhookのtriggerを設定できますが、今回はPull requestsにチェックを入れます。
lambda側の実装
今回はpythonを使用しています。選定理由はtwitter apiを使用したサンプル記事が多かったからです。
コードの詳細はGitHubをご確認お願いします。
https://github.com/nsuzuki7713/github-webhookフォルダ構成
最低限必要なファイル構成となります。
最初、使用するモジュールをmodulフォルダの中に入れていましたが、Lambdaはデフォルトでプロジェクト直下にモジュールを置く必要があるとのことです。
プログラム初心者がAWS Lambda(Python)でハマった7個のこと├── function.py ├── settings.example.py ├── (以下、使用するモジュール)ライブラリのインストール
# プロジェクトの直下に移動 # ライブラリのインストール $ pip3 install requests requests_oauthlib -t .僕は
pip3 install requests requests_oauthlib -tで下記エラーがでました。
distutils.errors.DistutilsOptionError: must supply either home or prefix/exec-prefix -- not both下記記事を参考にして、設定を変更しました。
http://www.sysop.jp/entry/2017/02/05/231821APIキー等の設定
settings.py###############Twitter API###################### CONSUMER_KEY = "Twitter APIのキー" CONSUMER_SECRET = "Twitter APIのキー" ACCESS_TOKEN = "Twitter APIのキー" ACCESS_TOKEN_SECRET = "Twitter APIのキー" ###############GitHub Webhook###################### SECRET = "GitHubのWebhookで記載してsecretキー"メイン処理の設定
Webhook payloadのexampleは公式ドキュメントが分かりやすいです。
https://developer.github.com/v3/activity/events/types/#pullrequesteventfunction.py#coding: UTF-8 import json,hashlib,hmac from requests_oauthlib import OAuth1Session import settings def lambda_handler(event, context): # HMAC値による認証処理 signature = event['headers']['X-Hub-Signature'] signedBody = "sha1=" + hmac.new(bytes(settings.SECRET, 'utf-8'), bytes(event['body'], 'utf-8'), hashlib.sha1).hexdigest() if(signature != signedBody): return {"statusCode": 401, "body": "Unauthorized" } # プルリクの情報を抽出 body = json.loads(event['body']) # actionのキーがなければ終了 if "action" not in body: return {"statusCode": 200, "body": "exit" } # プルリクのクローズでなければ終了 if body['action'] != "closed": return {"statusCode": 200, "body": "exit2" } # ツイートで必要な情報を取得 title = body['pull_request']['title'] # プルリクのタイトル html_url = body['pull_request']['html_url'] # プルリクのURL user = body['pull_request']['user']['login'] # プルリク作成者 merged_by = body['pull_request']['merged_by']['login'] # マージ者 # GitHubのアカウントとツイートする際の名前の対応表 user_list = { "nsuzuki7713": "なおと" } # tweet文章作成 msg = user_list[merged_by] + "さんが"\ + user_list[user] + "さんのプルリクをマージしました?" + "\n"\ + "【" + title + "】となります?️" + "\n" +html_url # tweet処理 twitter = OAuth1Session(settings.CONSUMER_KEY, settings.CONSUMER_SECRET, settings.ACCESS_TOKEN, settings.ACCESS_TOKEN_SECRET) params = {"status": msg } req = twitter.post("https://api.twitter.com/1.1/statuses/update.json",params = params) return {"statusCode": 200, "body": msg}デプロイ
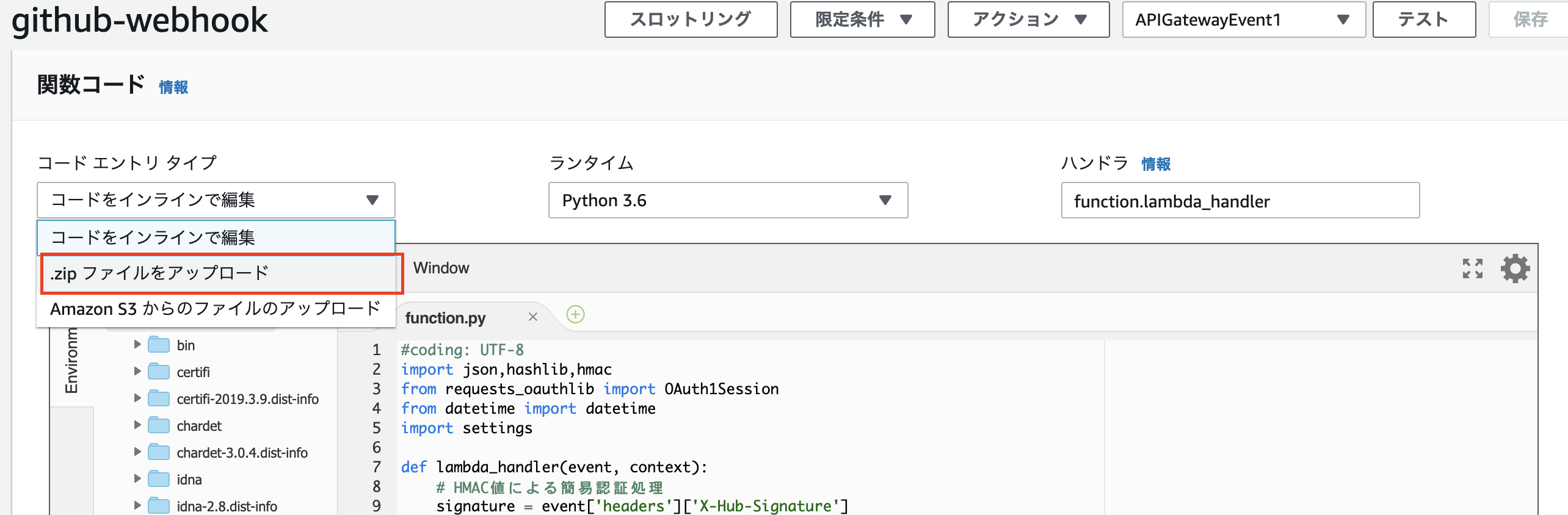
外部モジュールを使用する場合はlambdaのインライン上からはできなく、zip等にする必要があります。
今回はzip形式でデプロイしました。# プロジェクトの直下に移動 $ zip -r toLambda.zip ./*作成したzipファイルをlambdaのコンソールからアップロードします。
確認
GitHubのWebHooks設定から実行して、確認することが可能です。
おわりに
API GatewayやWebhook、pythonなど初めて使うものが多く、まだ1つ1つ理解できていませんが完成はできました。
issue駆動開発をしたので、issueのクローズした順を追っていただければ僕の進め方も分かります。
https://github.com/nsuzuki7713/github-webhook/issues?q=is%3Aissue+is%3Aclosed個人開発やGitHub駆動で学習している人は、CT(ケイゾクテキ ツイート)も作成してみませんか笑
ただ、今のままだと固定文言ですぐに飽きてしまうので、コミット数や変更行数のデータを見ながら、もっと文言のバリエーションとかを増やしたいなーと思っています。
- 投稿日:2019-04-13T19:34:20+09:00
serverlessでlambdaをデプロイする
概要
AWSのlambdaはAWS Management Console内で直接書くこともできますが、
gitでソースコードを管理して、CLIからデプロイしたいと思うことはありませんか?当記事ではserverlessを使って
Node.jsで実装したサンプルをlambdaにデプロイする手順の例を示します。デプロイユーザーのアクセスキーの取得
※ AWS Management Consoleでの作業になります
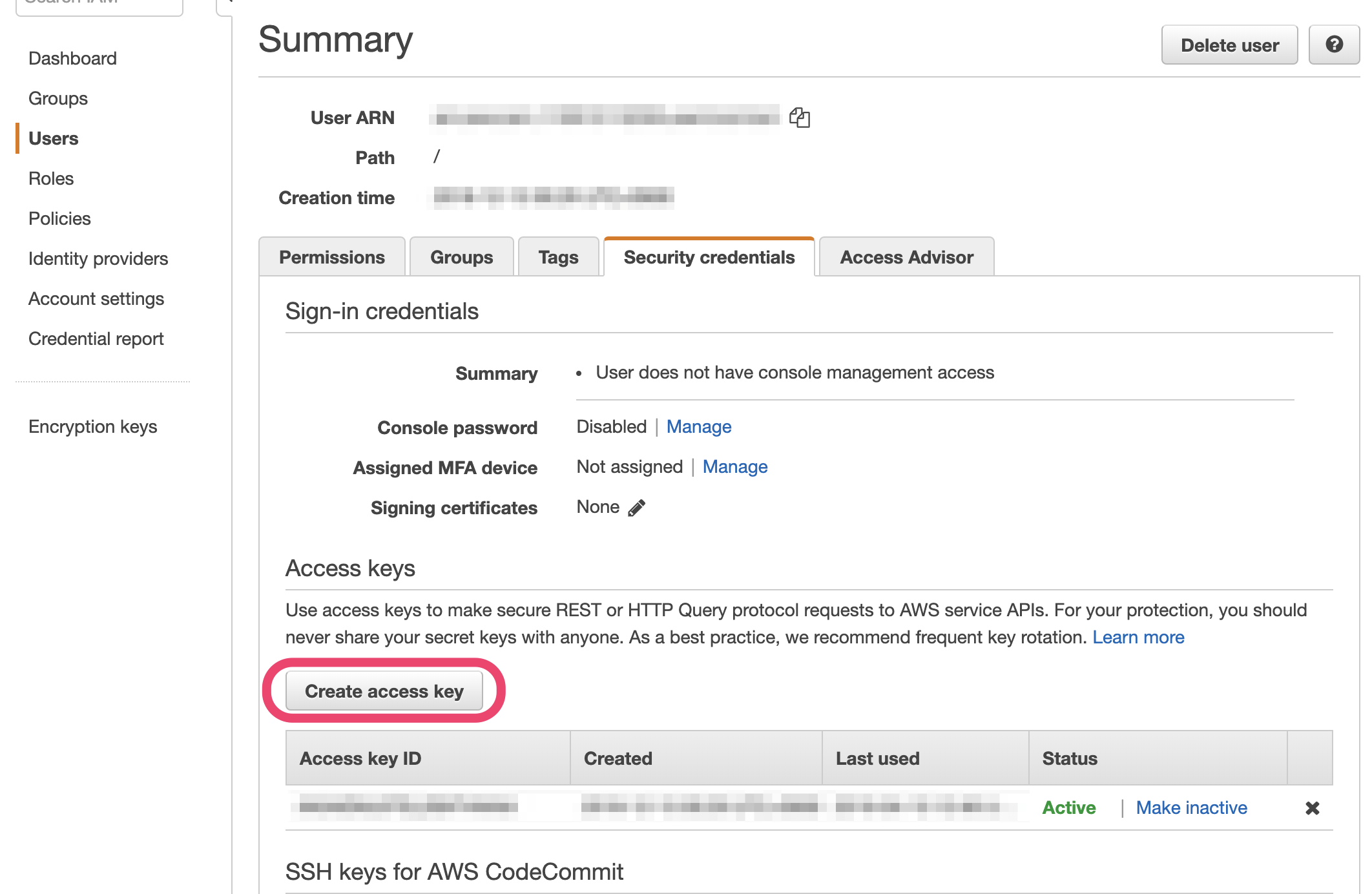
1.IAM->Users->デプロイに使うユーザー->Security credentials->Create access key
※デプロイに使うユーザーはデプロイ用のサービスアカウントが好ましいでしょう。
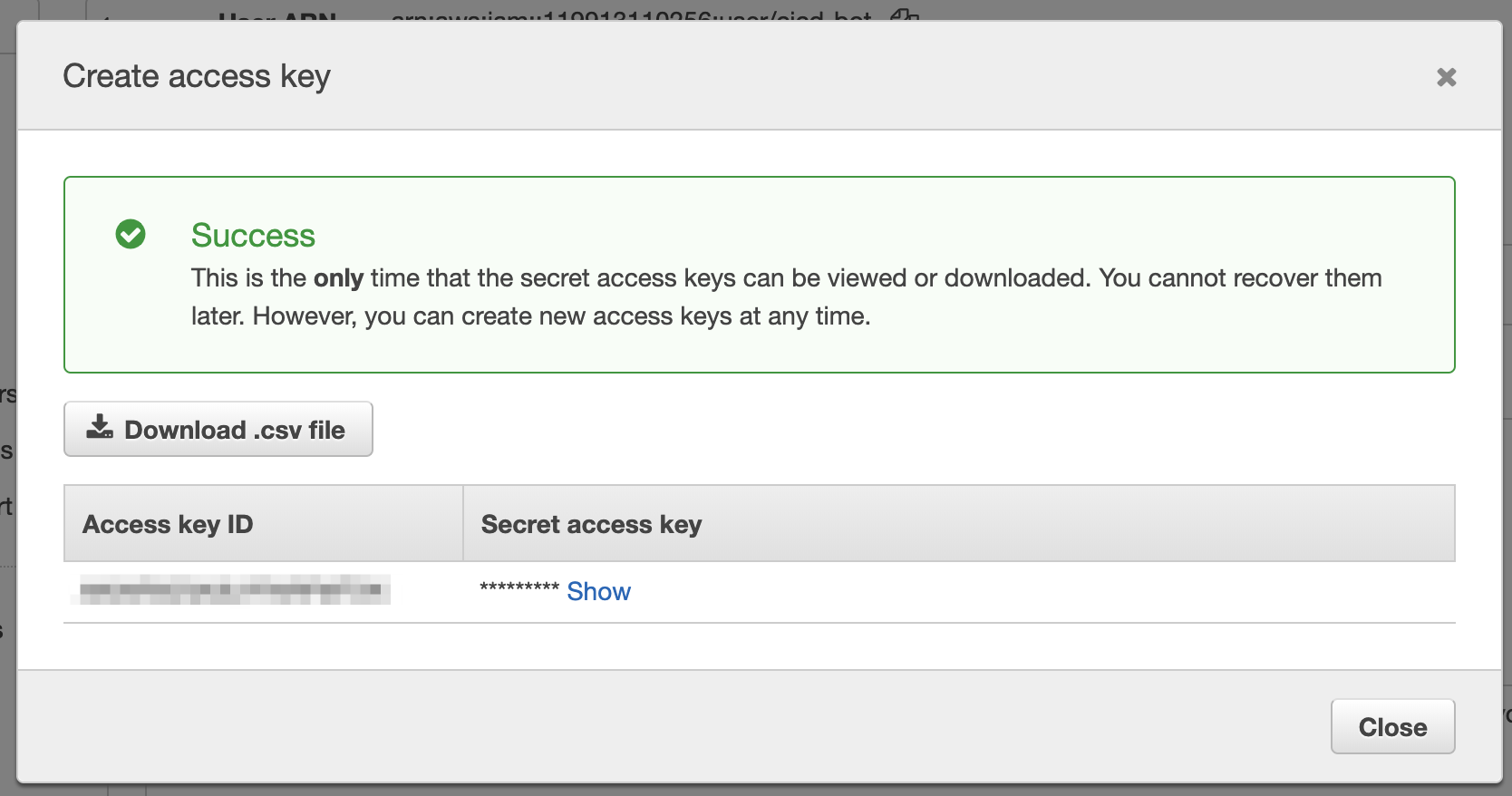
2.Access key IDとSecret access keyを保管する。(Download .csv fileでCSVをダウンロードしておくのが良いでしょう。)
デプロイユーザーへの権限付与
serverlessでlambdaをデプロイするには、デプロイユーザーにデプロイ用の権限が必要です。
ここでは、ポリシーの設定手順の例を示します。※ AWS Management Consoleでの作業になります
1.IAM->Policies->Create policyをクリック ->JSONタブをクリック
2. 下記を貼り付け{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:*", "apigateway:*", "s3:*", "logs:*", "lambda:*", "cloudformation:*" ], "Resource": "*" } ] }※
ActionやResourceは、セキュリティの観点からは必要なポリシーやリソースをもっと限定的に指定するのが好ましいですが、数が多くて細部の洗い出しが大変だったため、ワイルドカードでざっくりと指定をしました。
3. ポリシー名は任意ですが、ここでは例としてlambdaDeployPolicyとしてポリシーを作成します。
4.IAM->Users-> デプロイユーザーを選択 ->Add permissions->Attach existing policies directly
5.3.で作成したlambdaDeployPolicyを選択し、Next: Review->Add permissionsでポリシーを追加awscliのインストール
$ brew install awscliawscliにデプロイユーザーとしてログイン
$ aws configure AWS Access Key ID [None]: <Access key IDを貼り付け> AWS Secret Access Key [None]: <Secret access key> を貼り付け Default region name [None]: ap-northeast1 Default output format [None]: <そのままエンター>serverlessのインストール
$ npm i -g serverlessserverlessプロジェクトの生成
$ sls create --template aws-nodejs --path lambda-deploy-serverless $ cd lambda-deploy-serverlessserverlessの設定ファイルを更新
デフォルトだとリージョンが
us-east1になっていたり、APIゲートウェイの設定は含まれていないので、下記のように指定を加えますserverless.yml(更新)service: lambda-deploy-serverless provider: name: aws runtime: nodejs8.10 stage: dev region: ap-northeast-1 # ap-northeast-1リージョンにデプロイする functions: hello: # 関数名の指定 handler: handler.hello events: - http: # API Gatewayの指定 path: hello method: getその他の設定はこちらのリファレンスを参照:
https://serverless.com/framework/docs/providers/aws/guide/serverless.yml/デプロイ
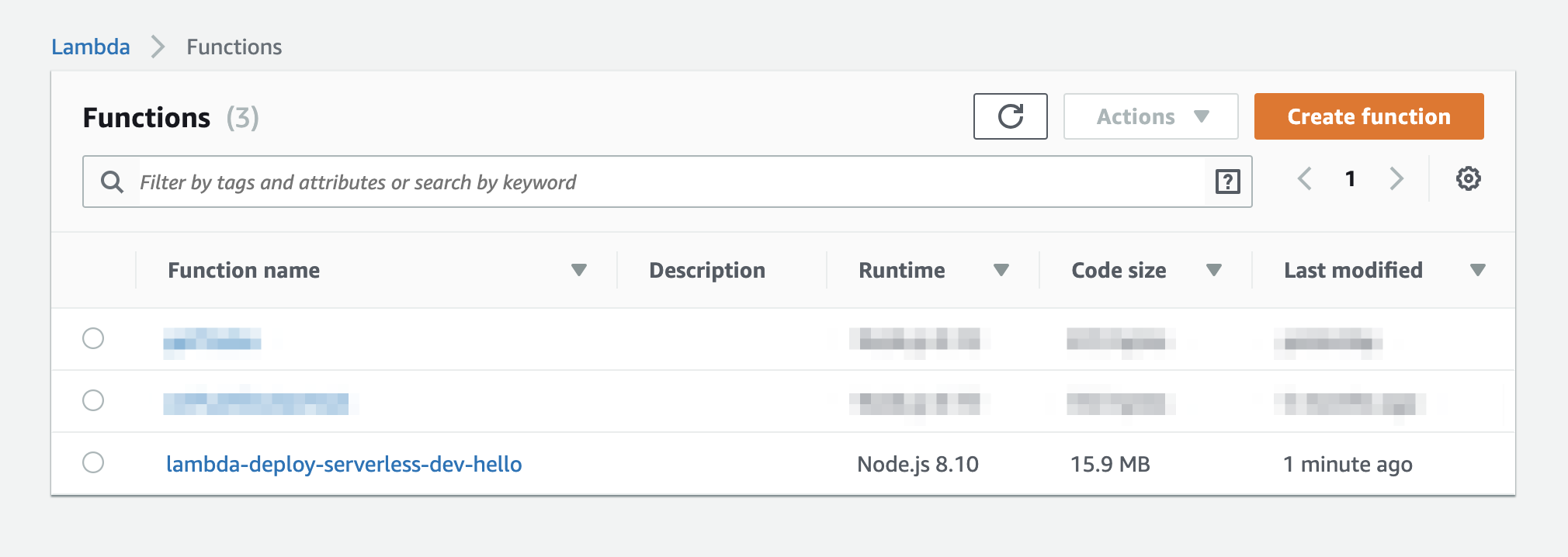
$ sls deploy Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service lambda-deploy-serverless.zip file to S3 (45.3 KB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... ........................ Serverless: Stack update finished... Service Information service: lambda-deploy-serverless stage: dev region: ap-northeast-1 stack: lambda-deploy-serverless-dev resources: 10 api keys: None endpoints: GET - https://ew7w6wfmxe.execute-api.ap-northeast-1.amazonaws.com/dev/hello functions: hello: lambda-deploy-serverless-dev-hello layers: NoneこのようにLambdaがデプロイされていれば成功です
もしもエラーになる場合は、ログのエラー箇所を参照して、ポリシーが適切に設定されているか確認して下さい。
詳細ログを標準出力に出力させるには、下記のようにします
SLS_DEBUG=* serverless deploy
- 投稿日:2019-04-13T19:34:20+09:00
serverlessでCLIからlambdaをデプロイする
概要
AWSのlambdaはAWS Management Console内で直接書くこともできますが、
gitでソースコードを管理して、CLIからデプロイしたいと思うことはありませんか?当記事ではServerlessを使って
Node.jsで実装したサンプルをlambdaにデプロイする手順の例を示します。筆者がCLIでのAWS操作にあまりなれていなかったのもあり、本記事では
AWS Management Consoleでの操作手順もやや掘り下げて記載していますが、
Serverlessの基本機能はServerlessのメンテナでもある@horike37さんの下記の記事により詳しくまとまっているので、そちらを参照いただくのが良いと思いました。
Serverless Frameworkの使い方まとめawscliのインストール
$ brew install awscliデプロイユーザーのアクセスキーの取得
デプロイに利用するアカウントでawscliでログインするために、
AWS Management Consoleでユーザーの認証情報を取得します。
IAM->Users->デプロイに使うユーザー->Security credentials->Create access key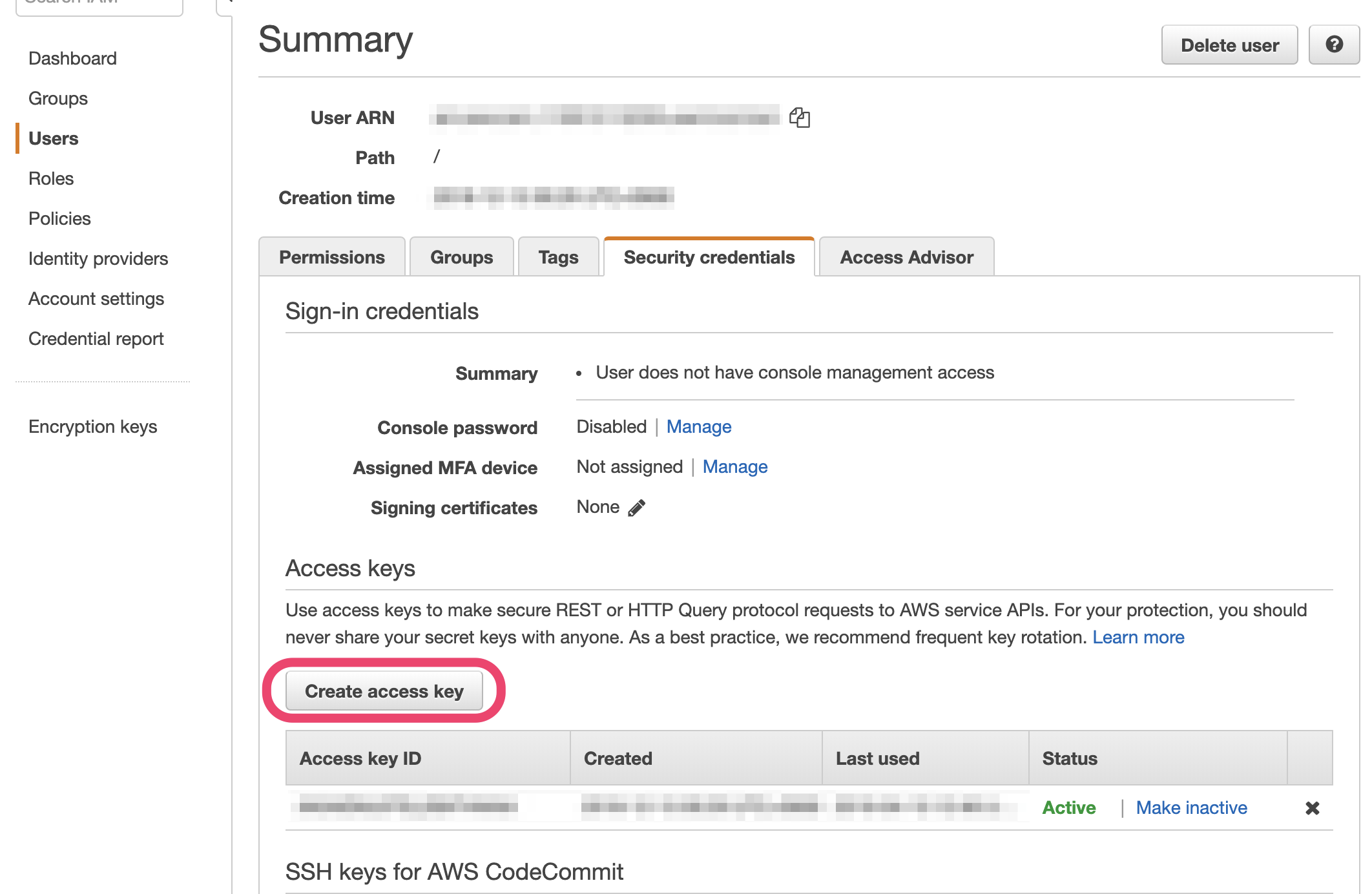
Access key IDとSecret access keyを保管する。(Download .csv fileでCSVをダウンロードしておくのが良いでしょう。)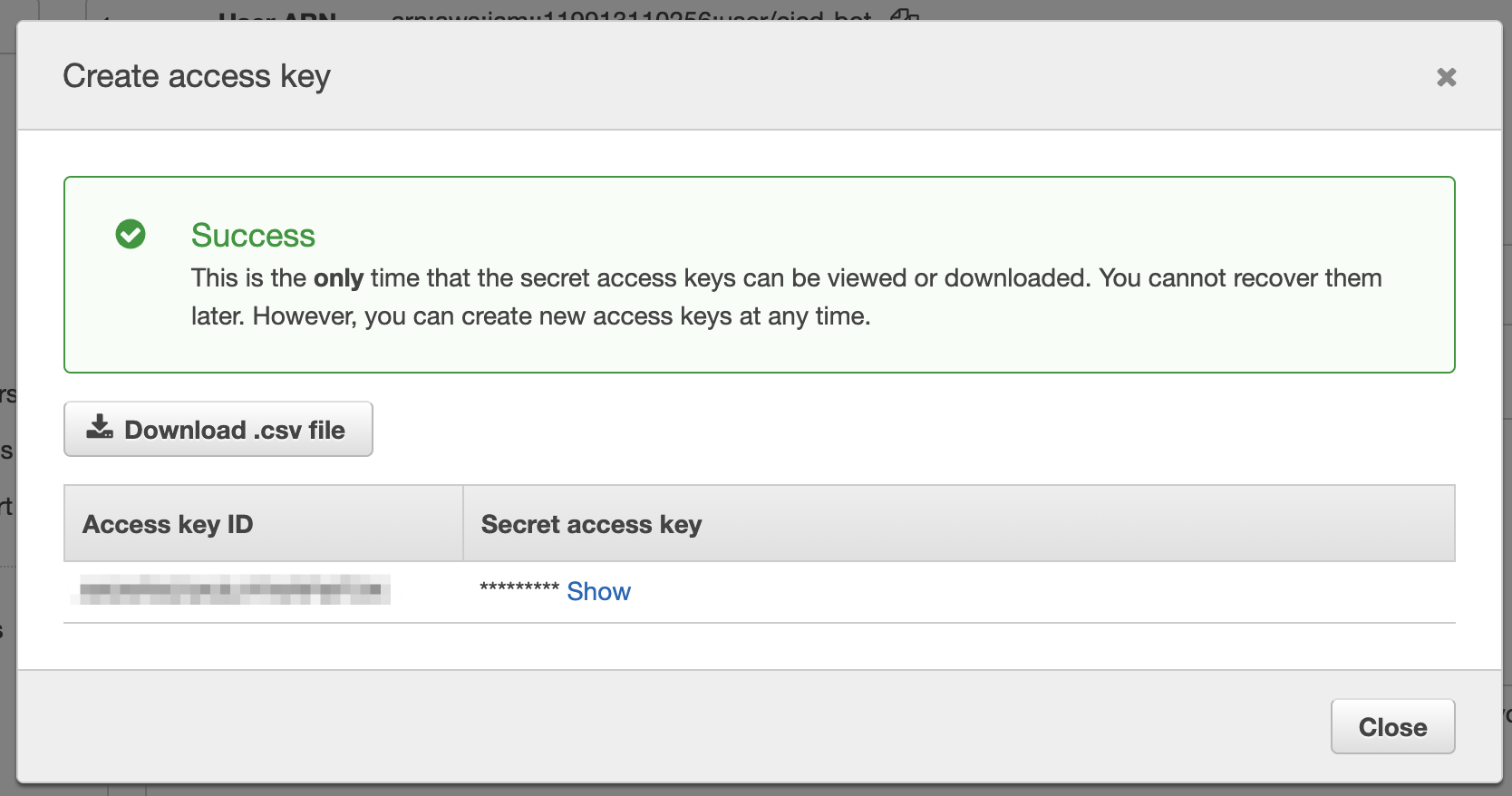
デプロイユーザーへの権限付与
serverlessでlambdaをデプロイするには、デプロイユーザーにデプロイ用の権限が必要です。
ここでは、ポリシーの設定手順の例を示します。
IAM->Policies->Create policyをクリック ->JSONタブをクリック- 下記を貼り付け
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:*", "apigateway:*", "s3:*", "logs:*", "lambda:*", "cloudformation:*" ], "Resource": "*" } ] }※
ActionやResourceは、セキュリティの観点からは必要なポリシーやリソースをもっと限定的に指定するのが好ましいですが、数が多くて細部の洗い出しが大変だったため、ワイルドカードでざっくりと指定をしました。
3. ポリシー名は任意ですが、ここでは例としてlambdaDeployPolicyとしてポリシーを作成します。
4.IAM->Users-> デプロイユーザーを選択 ->Add permissions->Attach existing policies directly
5.3.で作成したlambdaDeployPolicyを選択し、Next: Review->Add permissionsでポリシーを追加awscliにデプロイユーザーとしてログイン
$ aws configure AWS Access Key ID [None]: <Access key IDを貼り付け> AWS Secret Access Key [None]: <Secret access key> を貼り付け Default region name [None]: ap-northeast1 Default output format [None]: <そのままエンター>serverlessのインストール
$ npm i -g serverlessserverlessプロジェクトの生成
$ sls create --template aws-nodejs --path lambda-deploy-serverless $ cd lambda-deploy-serverlessserverlessの設定ファイルを更新
デフォルトだとリージョンが
us-east1になっていたり、APIゲートウェイの設定は含まれていないので、下記のように指定を加えますserverless.yml(更新)service: lambda-deploy-serverless provider: name: aws runtime: nodejs8.10 stage: dev region: ap-northeast-1 # ap-northeast-1リージョンにデプロイする functions: hello: # 関数名の指定 handler: handler.hello events: - http: # API Gatewayの指定 path: hello method: getその他の設定はこちらのリファレンスを参照:
https://serverless.com/framework/docs/providers/aws/guide/serverless.yml/デプロイ
$ sls deploy Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service lambda-deploy-serverless.zip file to S3 (45.3 KB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... ........................ Serverless: Stack update finished... Service Information service: lambda-deploy-serverless stage: dev region: ap-northeast-1 stack: lambda-deploy-serverless-dev resources: 10 api keys: None endpoints: GET - https://ew7w6wfmxe.execute-api.ap-northeast-1.amazonaws.com/dev/hello functions: hello: lambda-deploy-serverless-dev-hello layers: NoneこのようにLambdaがデプロイされていれば成功です
もしもエラーになる場合は、ログのエラー箇所を参照して、ポリシーが適切に設定されているか確認して下さい。
詳細ログを標準出力に出力させるには、下記のようにします
SLS_DEBUG=* serverless deploy
- 投稿日:2019-04-13T18:36:10+09:00
Windowsの踏み台サーバーにSSH接続する!
Windows Server の踏み台サーバーにSSH接続する!
[Windows Server 2019]からOpenSSHが標準インストールされるようになったので、踏み台サーバーのOSをWindowsで用意することを検証した。今回も直観的にわかりやすくするため図解付きにて。
シナリオ(利用シーン)
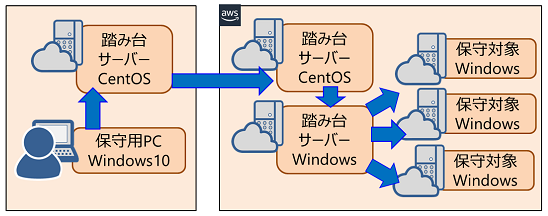
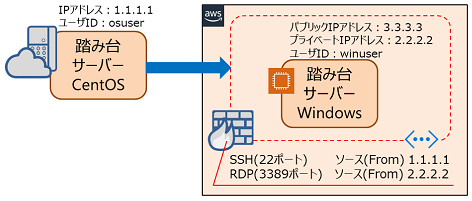
パブリッククラウドでアプリケーションを実行する。アプリケーションのOS要件がWindows Serverであり、リモートデスクトップ接続(以降RDP接続と略す)が必要。保守対象のWindowsサーバーが複数あるので、Windowsの踏み台サーバーを経由してRDP接続する。今までなら踏み台サーバーを2台用意して、Linuxの踏み台サーバーでSSH接続した後、Windowsの踏み台サーバーへRDPをポートフォワードしてリモートデスクトップ接続していた。
従来
システム構成(保守用ネットワーク)
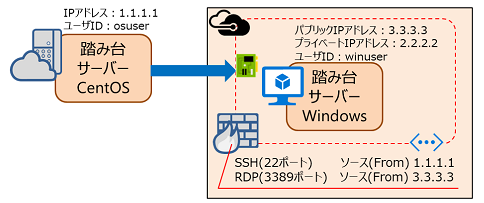
今後
手順1.踏み台サーバー(Windows)のOpenSSHを設定する
最初の設定だけはインターネットから直接RDP接続するため、最初のセキュリティグループ設定はあらゆるコンピュータからアクセス可能な「TCP3389 ソース(アクセス元)0.0.0.0/0」でありリスクあるので手早く設定する。まず、AWSで[Windows Server 2019]をデプロイした後、AdministratorでログインしてPowerShellを使ってOpenSSH機能を有効にする。
Windows PowerShell Copyright (C) Microsoft Corporation. All rights reserved. ▼インストール済みプログラムを確認。SSHサーバーがインストールされていない。 PS C:\Users\Administrator> Get-WindowsCapability -Online | ? Name -like 'OpenSSH*' Name : OpenSSH.Client~~~~0.0.1.0 State : Installed Name : OpenSSH.Server~~~~0.0.1.0 State : NotPresent ←インストールされていない ▼OpenSSHサーバーをインストールする。 PS C:\Users\Administrator> Add-WindowsCapability -Online -Name OpenSSH.Server~~~~0.0.1.0 Path : Online : True RestartNeeded : False ▼再確認(今度はSSHサーバーがインストールされた)。 PS C:\Users\Administrator> Get-WindowsCapability -Online | ? Name -like 'OpenSSH*' Name : OpenSSH.Client~~~~0.0.1.0 State : Installed Name : OpenSSH.Server~~~~0.0.1.0 State : Installed ▼ sshdサービス起動 PS C:\Users\Administrator> Start-Service -Name "sshd" ▼ スタートアップを [自動] に設定 PS C:\Users\Administrator> Set-Service -Name "sshd" -StartupType Automatic ▼ 再起動時にSSHがスタートすることを確認 PS C:\Users\Administrator> Get-Service -Name "sshd" | Select-Object * Name : sshd RequiredServices : {} CanPauseAndContinue : False CanShutdown : False CanStop : True DisplayName : OpenSSH SSH Server DependentServices : {} MachineName : . ServiceName : sshd ServicesDependedOn : {} ServiceHandle : SafeServiceHandle Status : Running ServiceType : Win32OwnProcess StartType : Automatic ←自動スタートになってること Site : Container :手順2.Windows踏み台サーバーにSSH公開鍵を登録する
Windowsにログインする保守ユーザアカウントを設定して保守ユーザでログインする(この例ではwinuserが保守ユーザID)。
▼PowerShellを起動してユーザディレクトリに".ssh"ディレクトリを作る。 PS C:\Users\winuser\ mkdir .ssh PS C:\Users\winuser\ cd .ssh ▼メモ帳を起動して公開鍵を保存する。 PS C:\Users\winuser\ notepad authorized_keys …メモ帳で作業(割愛)… ▼検査 PS C:\Users\winuser\ type authorized_keys ---- BEGIN SSH2 PUBLIC KEY ---- Comment: "rsa-private-key" AAAA*************** ***********ZZZZ== ---- END SSH2 PUBLIC KEY ----SSHコンフィグファイルを修正する。ファイル名は[c:\programdata\ssh\sshd_config]。
PS C:\Users\winuser\ notepad c:\programdata\ssh\sshd_config"PubkeyAuthentication yes"のコメント"#"を外す
#PubkeyAuthentication yes ← # を外す # The default is to check both .ssh/authorized_keys and .ssh/authorized_keys2 # but this is overridden so installations will only check .ssh/authorized_keys AuthorizedKeysFile .ssh/authorized_keys手順3.保守用PCでsshクライアントのPuttyを設定する。
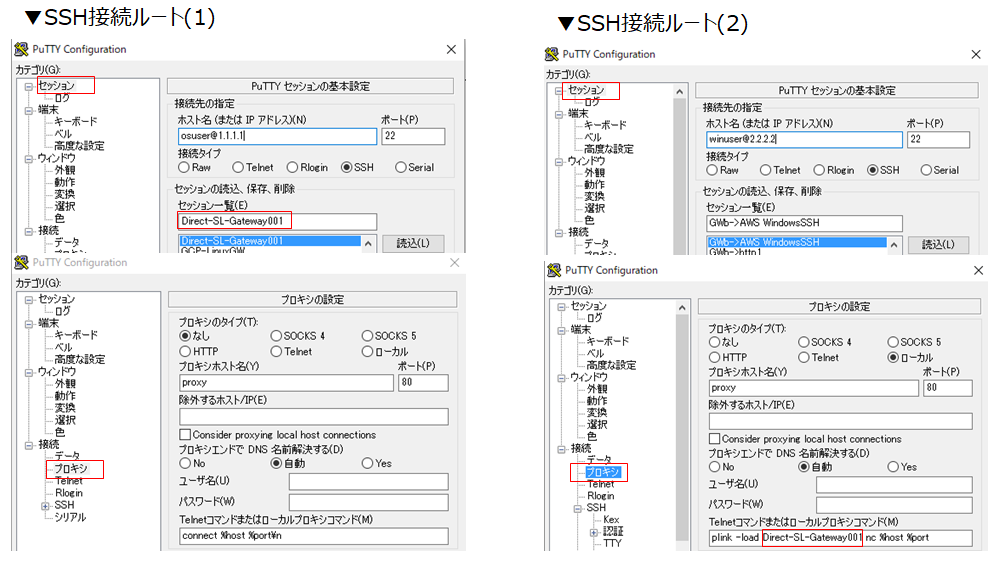
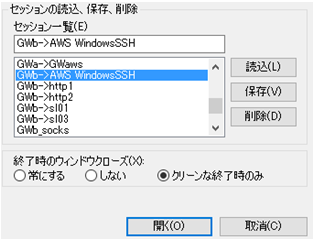
Puttyに新しい接続セッションとして(1)と(2)の2つを追加する。意味は、最初に保守用PCからLinux踏み台サーバーへのSSH接続ルート(1)を確立して、次に保守用PCからSSH接続ルート(1)を経由してWindows踏み台サーバーへのSSH接続ルート(2)を確立するもの。
▼下図を参考にPuttyを2つ設定する。
・[セッション]-[ホスト名]には、"OSユーザ名@IPアドレス"を入力。両方ともポートはSSHの[22]。
・[セッション]-[セッション一覧]の、接続ルート(1)のセッション名は、接続ルート(2)で使います。
・[接続]-[プロキシ]は、接続ルート(1)はデフォルトのまま、接続ルート(2)は、"plink -load <セッション(1)名> nc %host %port"を入力する。
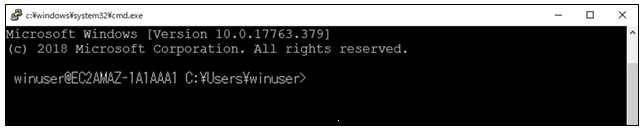
▼接続ルート(2)が正しく動作することを検査する。
接続ルート(2)のセッション名を選んで[開く]ボタンを押して、Windows踏み台サーバーにログインできたら成功。
SSHで接続しているがコマンドシェルはDOSになる。
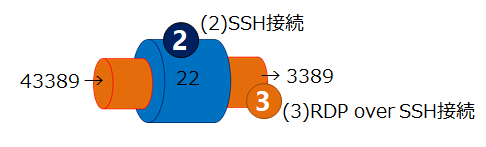
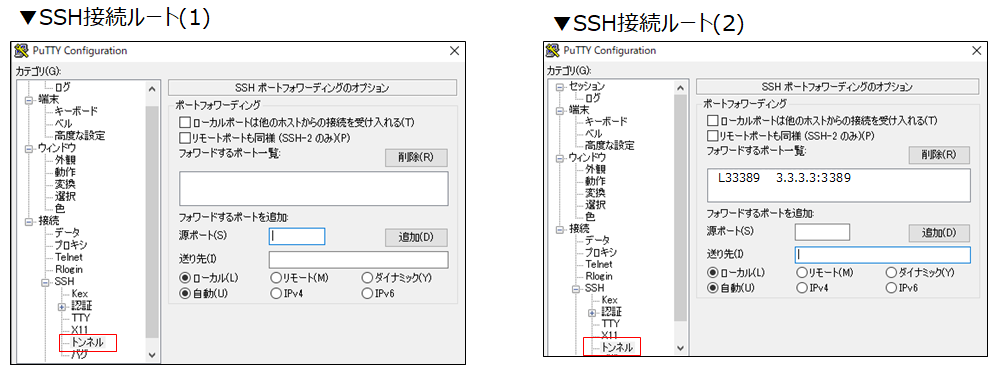
手順4.Puttyのポートフォワードを設定する。
続いて、RDP接続をSSH接続トンネルで転送するためのポートフォワーディングを設定する。SSH接続ルート(2)をトンネルとして使うので、設定するのは(2)側のみ。
・[接続]-[SSH]-[トンネル]の、[源ポート]は自由なポート番号(例えば43389)を記入、[送り先]にはWindows踏み台サーバーのパブリックIPアドレスとRDPポート番号(例えば3.3.3.3:3389)を記入して[追加]ボタンを押す。源ポート番号に下図では33389を設定しているが、RDPの3389と重ならないポート番号なら何でもよい。
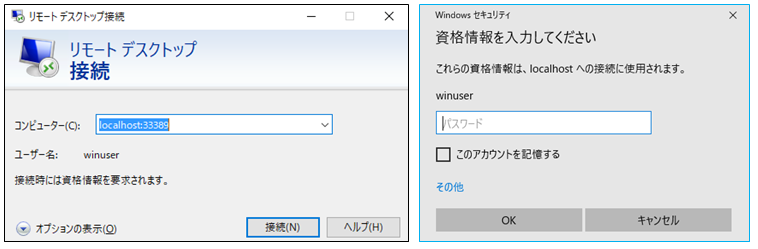
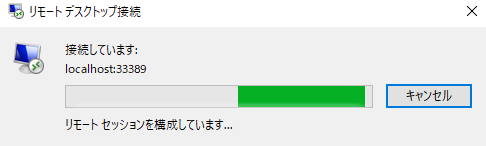
手順5.Windows踏み台サーバーにリモートデスクトップ接続する。
保守用PCのリモートデスクトップを起動したらコンピュータ名には自分のPCを意味する"localhost"を指定する(この例ではlocalhost:43389)。ユーザ名にはWindows踏み台サーバーの保守用ユーザIDを指定する。リモートデスクトップ接続を実行する際、自分のPCに43389ポートでRDP接続しようとしたらPuttyがWindows踏み台サーバーの3.3.3.3:3389へ転送してくれる。パスワードを聞いてきたら成功。
セキュリティのポイント
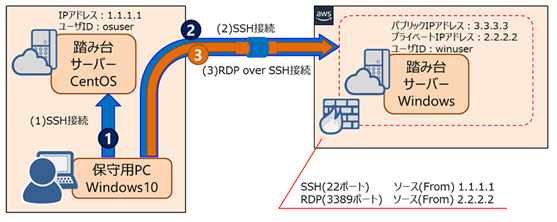
WindowsサーバーOSへのログインはユーザIDとパスワード、初期状態ではユーザIDがAdministratorであるため、パスワードだけ見つけられればログイン出来てしまう。実際にパブリッククラウドにデプロイされたWindows仮想サーバーがウィルスに感染させられた事例を見ているので、ポート3389をソース0.0.0.0/0にしたまま保守するのは危険、というか攻撃されるのを待っているようなもの。本書で紹介した方法ならば、(1)ソースIPアドレスを自分のLinux踏み台サーバーに限定し、(2)SSH秘密鍵を持っているユーザをSSH公開鍵で照合し、(3)ユーザIDとパスワードで認証する多段防御が実現する。なお、Windows踏み台サーバーから自分自身のWindows踏み台サーバーへRDP接続する時のセキュリティグループに登録するソースIPアドレスはAWSとAzureで異なるので注意。
つまづきポイント
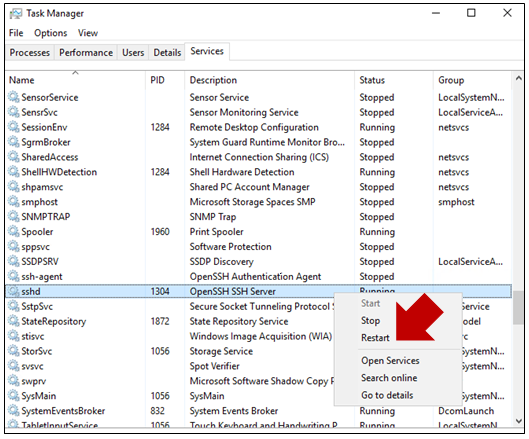
sshが怪しい
Windows踏み台サーバーの公開鍵やコンフィグを変更したらsshdサービスを再起動する。タスクマネージャーはAdministrator権限で実行する必要あり。
ファイアウォールが怪しい
リモートデスクトップ接続がずーーーっと待ちの時は、ファイアウォールの設定が間違っているのかも。
AWSの場合
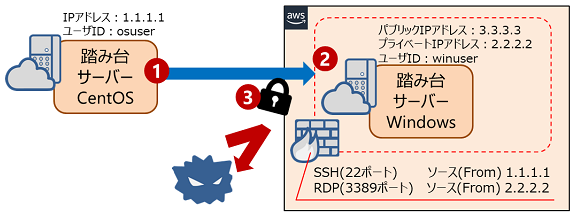
AWSの場合、Windows踏み台サーバーに対するセキュリティグループは、外部からのSSH接続はパブリックIPアドレスでソースを指定するが、RDP接続のポートフォワードは自分自身のプライベートIPアドレスで指定するので要注意。
from 1.1.1.1 to 3.3.3.3 OpenSSH(22)
from 2.2.2.2 to 2.2.2.2 RDP(3389)
Azureの場合
Azureの場合は、仮想ネットワークインターフェース(ENI)からのRDP接続になるらしく、RDP接続のポートフォワードも自分自身のパブリックIPアドレスで指定するので要注意。
from 1.1.1.1 to 3.3.3.3 OpenSSH(22)
from 3.3.3.3 to 2.2.2.2 RDP(3389)
ポートフォワードされているか怪しい
本当にRDPポートが転送されているのかな~、と不安な時は自分の保守用PCでポート43389や33389がリッスン(待ち状態)になっているか、DOSの[netstat -a]コマンドで検査する。
C:\Users\Ichiro>netstat -a アクティブな接続 プロトコル ローカル アドレス 外部アドレス 状態 TCP 0.0.0.0:80 Ichiro-PC:0 LISTENING TCP 0.0.0.0:135 Ichiro-PC:0 LISTENING TCP [::]:80 Ichiro-PC:0 LISTENING TCP [::]:135 Ichiro-PC:0 LISTENING TCP [::1]:33389 Ichiro-PC:0 LISTENING TCP [::1]:33389 Ichiro-PC:0 LISTENING TCP [::1]:33389 Ichiro-PC:50942 ESTABLISHED TCP [::1]:50942 Ichiro-PC:33389 ESTABLISHED以上。

- 投稿日:2019-04-13T18:11:11+09:00
「String does not have #dig method」AWS S3とのねちっこい戦い【初心者の場合】
こんにちは、けんぞうです。
Railsでアプリを作ってHerokuでデプロイすると「画像保存できねーじゃん!」というのは、皆が通る道ですよね。その「画像保存できない問題」については【Rails】AWS S3を使ってHerokuで画像を投稿できるようにする方法で解決できるんですが、これをやっている中で以下のエラーに出くわしました。
String does not have #dig methodこいつの解決策を書きます、初心者ならではのミスという感じです、、、苦笑
そもそも、#digてどこのことやねん
storage.ymlaccess_key_id: <%= Rails.application.credentials.dig(:aws, :access_key_id) %> secret_access_key: <%= Rails.application.credentials.dig(:aws, :secret_access_key) %>これに含まれるdigでエラーが出てしまってます。
原因①:
credentialsのコメントアウト外した?【Rails】AWS S3を使ってHerokuで画像を投稿できるようにする方法の流れの中で
$ EDITOR=vim rails credentials:editaws: access_key_id: #ここに自分のアクセスキーIDをコピペ secret_access_key: #ここに自分のシークレットアクセスキーをコピペこの手順を踏むのですが、
aws以下の3行はもともとコメントアウトされてるんですよね。これに気がつかず、2時間くらい消耗、、、#aws: # access_key_id: #ここに自分のアクセスキーIDをコピペ # secret_access_key: #ここに自分のシークレットアクセスキーをコピペ⬆︎コメントアウトを外そう
原因②:半角スペース開けた?
aws: access_key_id: #これを消してアクセスキーIDをペースト secret_access_key: #これを消してシークレットアクセスキーをコピペ上記の
access_key_id:とsecret_access_key:の後ろには、それぞれ半角スペースが必要。
僕の場合はスペースが相手いなかったので、うまく読み取れず出力できなかった。上記の原因をつぶせば、問題なくdig君のエラーはいなくなりました。おしまい!
- 投稿日:2019-04-13T17:07:21+09:00
terraformでEC2+RDS+ElastiCacheを構築してみる(その1 EC2構築まで)
仕事ではAWS、プライベートではGCPを使うので、オーケストレーションツールで両方で使えるterraformを今更ながら試してみた。
環境
macOS mojave Version 10.14.4
Terraform v0.11.13
+ provider.aws v2.6.0目的
T
EC2+RDS+ElastiCacheを使ったシステムの構築事前準備
AWSアカウントを持っていること、IAMユーザを発行していること
Terraformインストール
公式のページからmac 64bit版をダウンロード
https://www.terraform.io/downloads.html
バイナリを自分の好きなところにおいてパスを通す
% mkdir ~/APPS/ % wget https://releases.hashicorp.com/terraform/0.11.13/terraform_0.11.13_darwin_amd64.zip % unzip terraform_0.11.13_darwin_amd64.zip % echo 'export PATH="$HOME/APPS:$PATH"' >> ~/.zshrc ※bashではあれば読み替え % terraform --version Terraform v0.11.13 + provider.aws v2.6.0Terraformの初期化
terraformを使用するには初期化が必要です。
実行するとpluginを同ファイル内にインストールします。% terraform init Initializing provider plugins... - Checking for available provider plugins on https://releases.hashicorp.com... - Downloading plugin for provider "aws" (2.6.0)... The following providers do not have any version constraints in configuration, so the latest version was installed. To prevent automatic upgrades to new major versions that may contain breaking changes, it is recommended to add version = "..." constraints to the corresponding provider blocks in configuration, with the constraint strings suggested below. * provider.aws: version = "~> 2.6" Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.最小構成のtfファイルの作成
terraformでは定義ファイルの拡張子はtfです。
% mkdir terreform_test % cd terreform_test % vim example.tf % cat example.tf provider "aws" { access_key = "xxxxxxxxxxxxxx" secret_key = "xxxxxxxxxxxxxx" region = "ap-northeast-1" } resource "aws_instance" "example" { ami = "ami-0f9ae750e8274075b" ※存在しているAMIIDを指定 instance_type = "t2.micro" }公式ドキュメントより
Note: If you simply leave out AWS credentials, Terraform will automatically search for saved >API credentials (for example, in ~/.aws/credentials) or IAM instance profile credentials. This >option is much cleaner for situations where tf files are checked into source control or where >there is more than one admin user. See details here. Leaving IAM credentials out of the >Terraform configs allows you to leave those credentials out of source control, and also use >different IAM credentials for each user without having to modify the configuration files.
とのことなので、すでにcredentialの設定をlocalでしている方は自動でTerraformが取得してくれるようです。
今回は定義ファイル内に記載。構築する環境の確認と実行
コマンド 説明 terraform plan 構築予定の環境確認 terraform apply 構築実行 terraform show 構築した環境確認 確認
% terraform plan Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: + aws_instance.example id: <computed> ami: "ami-0f9ae750e8274075b" arn: <computed> associate_public_ip_address: <computed> availability_zone: <computed> cpu_core_count: <computed> cpu_threads_per_core: <computed> ebs_block_device.#: <computed> ephemeral_block_device.#: <computed> get_password_data: "false" host_id: <computed> instance_state: <computed> instance_type: "t2.micro" ipv6_address_count: <computed> ipv6_addresses.#: <computed> key_name: <computed> network_interface.#: <computed> network_interface_id: <computed> password_data: <computed> placement_group: <computed> primary_network_interface_id: <computed> private_dns: <computed> private_ip: <computed> public_dns: <computed> public_ip: <computed> root_block_device.#: <computed> security_groups.#: <computed> source_dest_check: "true" subnet_id: <computed> tenancy: <computed> volume_tags.%: <computed> vpc_security_group_ids.#: <computed>構築
% terraform apply An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: + aws_instance.example id: <computed> ami: "ami-0f9ae750e8274075b" arn: <computed> associate_public_ip_address: <computed> availability_zone: <computed> cpu_core_count: <computed> cpu_threads_per_core: <computed> ebs_block_device.#: <computed> ephemeral_block_device.#: <computed> get_password_data: "false" host_id: <computed> instance_state: <computed> instance_type: "t2.micro" ipv6_address_count: <computed> ipv6_addresses.#: <computed> key_name: <computed> network_interface.#: <computed> network_interface_id: <computed> password_data: <computed> placement_group: <computed> primary_network_interface_id: <computed> private_dns: <computed> private_ip: <computed> public_dns: <computed> public_ip: <computed> root_block_device.#: <computed> security_groups.#: <computed> source_dest_check: "true" subnet_id: <computed> tenancy: <computed> volume_tags.%: <computed> vpc_security_group_ids.#: <computed> Plan: 1 to add, 0 to change, 0 to destroy. Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes ※ここでyesを入力 aws_instance.example: Creating... ami: "" => "ami-0f9ae750e8274075b" arn: "" => "<computed>" associate_public_ip_address: "" => "<computed>" availability_zone: "" => "<computed>" cpu_core_count: "" => "<computed>" cpu_threads_per_core: "" => "<computed>" ebs_block_device.#: "" => "<computed>" ephemeral_block_device.#: "" => "<computed>" get_password_data: "" => "false" host_id: "" => "<computed>" instance_state: "" => "<computed>" instance_type: "" => "t2.micro" ipv6_address_count: "" => "<computed>" ipv6_addresses.#: "" => "<computed>" key_name: "" => "<computed>" network_interface.#: "" => "<computed>" network_interface_id: "" => "<computed>" password_data: "" => "<computed>" placement_group: "" => "<computed>" primary_network_interface_id: "" => "<computed>" private_dns: "" => "<computed>" private_ip: "" => "<computed>" public_dns: "" => "<computed>" public_ip: "" => "<computed>" root_block_device.#: "" => "<computed>" security_groups.#: "" => "<computed>" source_dest_check: "" => "true" subnet_id: "" => "<computed>" tenancy: "" => "<computed>" volume_tags.%: "" => "<computed>" vpc_security_group_ids.#: "" => "<computed>" aws_instance.example: Still creating... (10s elapsed) aws_instance.example: Still creating... (20s elapsed) aws_instance.example: Still creating... (30s elapsed) aws_instance.example: Creation complete after 33s (ID: i-08d3e6512751c8505) Apply complete! Resources: 1 added, 0 changed, 0 destroyed.構築した環境確認
% terraform show aws_instance.example: id = i-08d3e6512751c8505 ami = ami-0f9ae750e8274075b ~AWSコンソールで確認
参考

- 投稿日:2019-04-13T16:11:41+09:00
AWS Cloud9でRustをビルドする
AWS Cloud9でRustをビルド/ランする
前提条件
事前にcargoが入っておりパスもとっていることとします。
つまり
$ cargo runとすれば、ビルドされる状態であることとします。
※ 環境構築は別記事参照ください
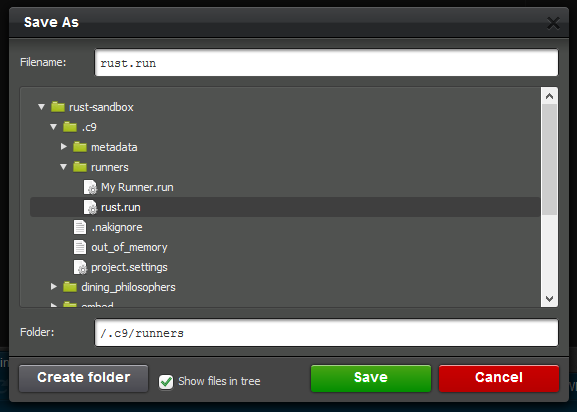
.runファイルを作成する
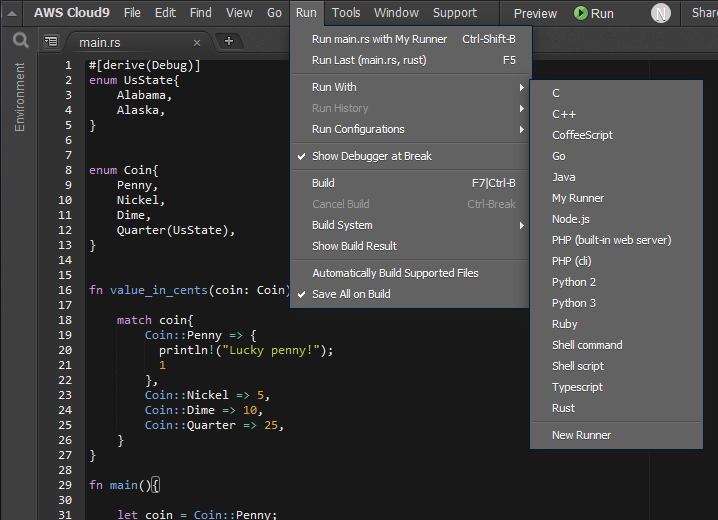
Run -> Run With -> New Runnerを選択
{ "cmd": ["cargo", "run", "$file", "$args"], "selector": "source.rs", "info": "Rust is running :)" }そしてこれをrust.runとして指定される場所の
.c9/runners/rust.run
として保存します。
使用方法
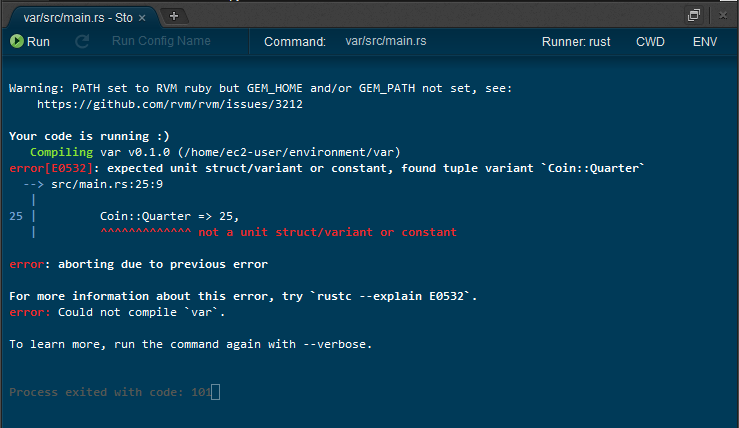
使用する場合は、rustファイルを開いて
Run -> Run With -> Rust
とすれば、ビルドコンソールが開きます。
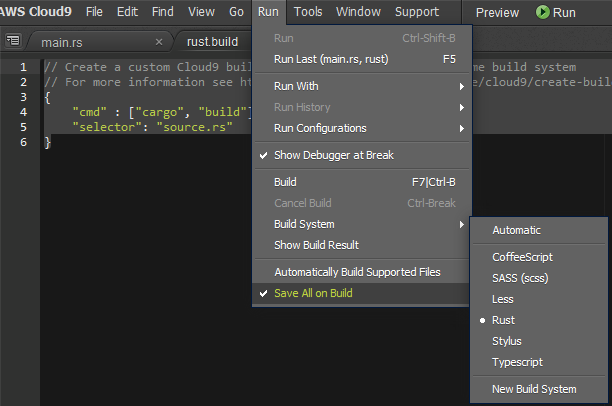
おまけ ビルドだけする場合
Run -> Build System -> New Build System
を選択し、runと同様の処理をします
rust.build
js
{
"cmd" : ["cargo", "build"],
"selector": "source.rs"
}
ショートカット
s
Ctrl + B
以上
- 投稿日:2019-04-13T15:46:09+09:00
技術書典での爆死具合をリアルタイムで共有できるサービスを作った
はじめに
六木本未来ラボとして技術書典6に初出典するのですが、
当日はメンバーがローテーションを組んで販売ブースに立つことになりました。この六木本未来ラボ、初出典にもかかわらず300冊も刷ってしまいドキドキなため販売ブースにいない間も、
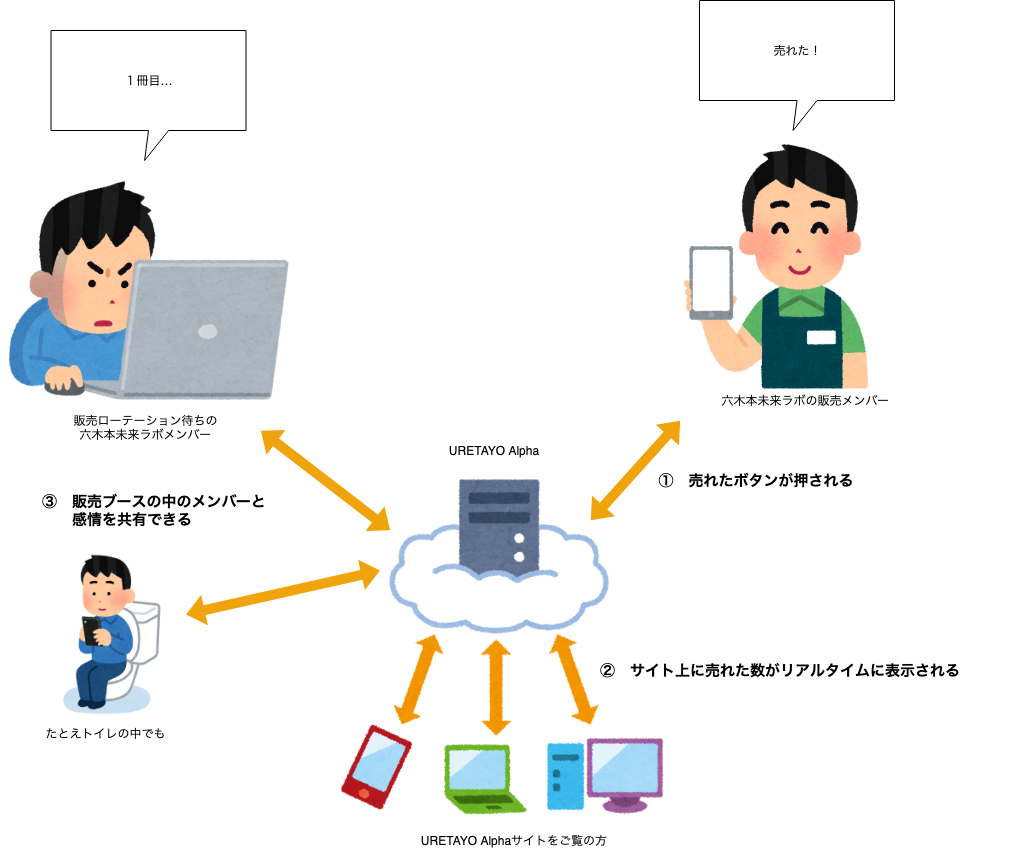
メンバー間で本の売れ具合を共有したいということで
先日、メンバーの一人@wpuzzle_minegishiさんが「売れたら押してね」とIoTボタンを押したらSlackに通知するシステムを作りました。その後、「どうせなら自分たちの爆死具合を公表したいよね」からの、「誰でも使えるようにしたほうが楽しいよね?」
ということで、突貫作業でWEBサービスを作っちゃいました。サービス名は「URETAYO(仮)」で、現在アルファ版として公開中していますので
ご自由にお使いください!(技術書典終了後、どこかのタイミングで閉じると思います)サービスURL
https://dm1ba20lvc4ut.cloudfront.net/このサービスのソースコードは以下のリポジトリで公開しています。
https://github.com/takaaki-s/uretayoまた、お試し用アカウントも作成しましたので、
こちらもご自由にお試しください。ID: guest
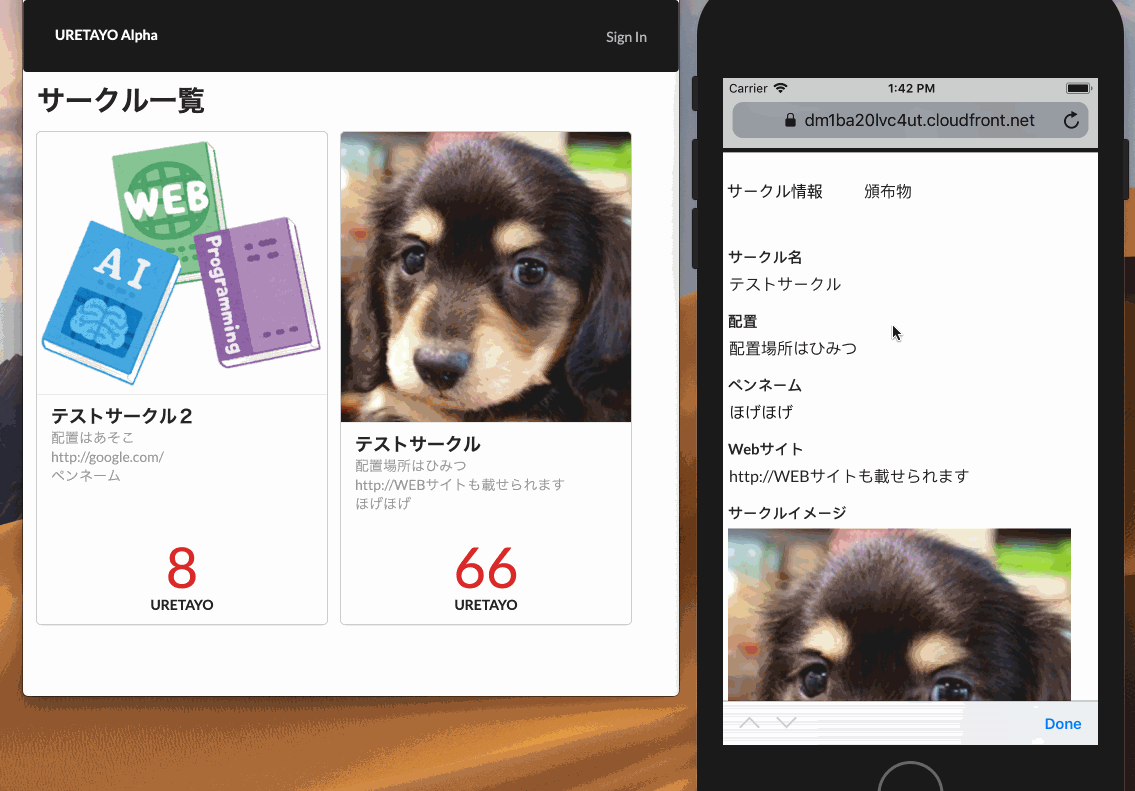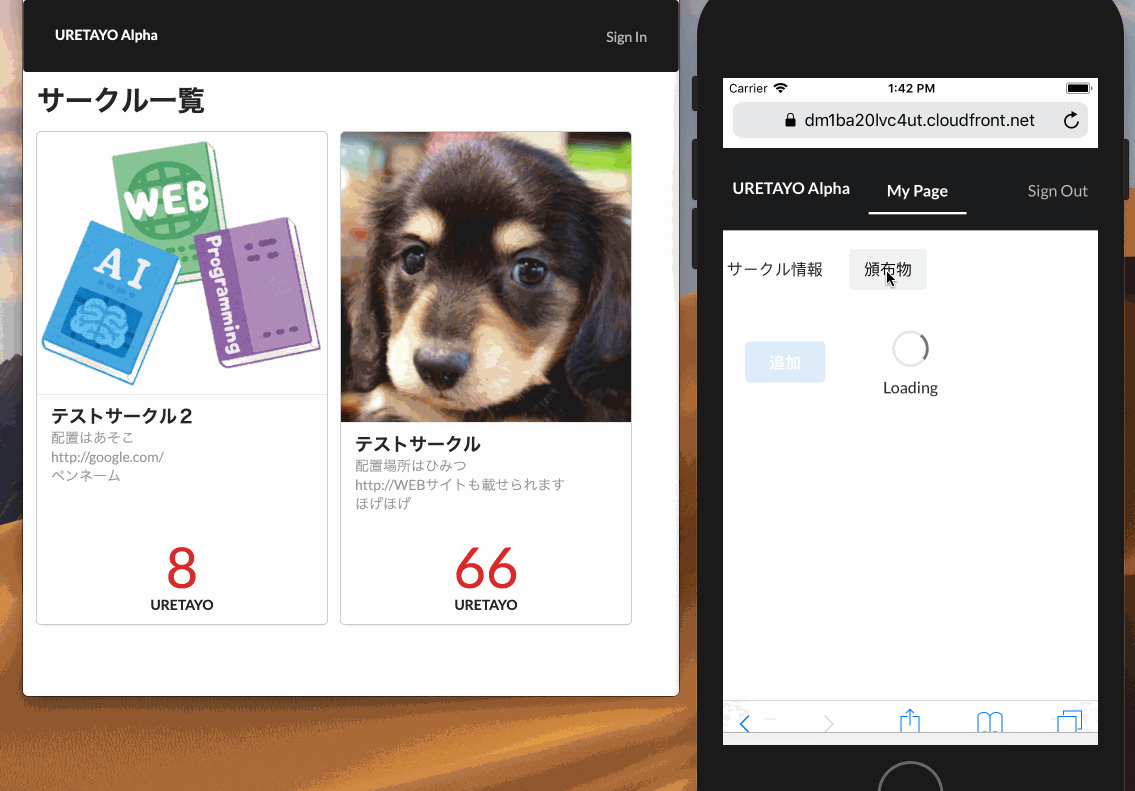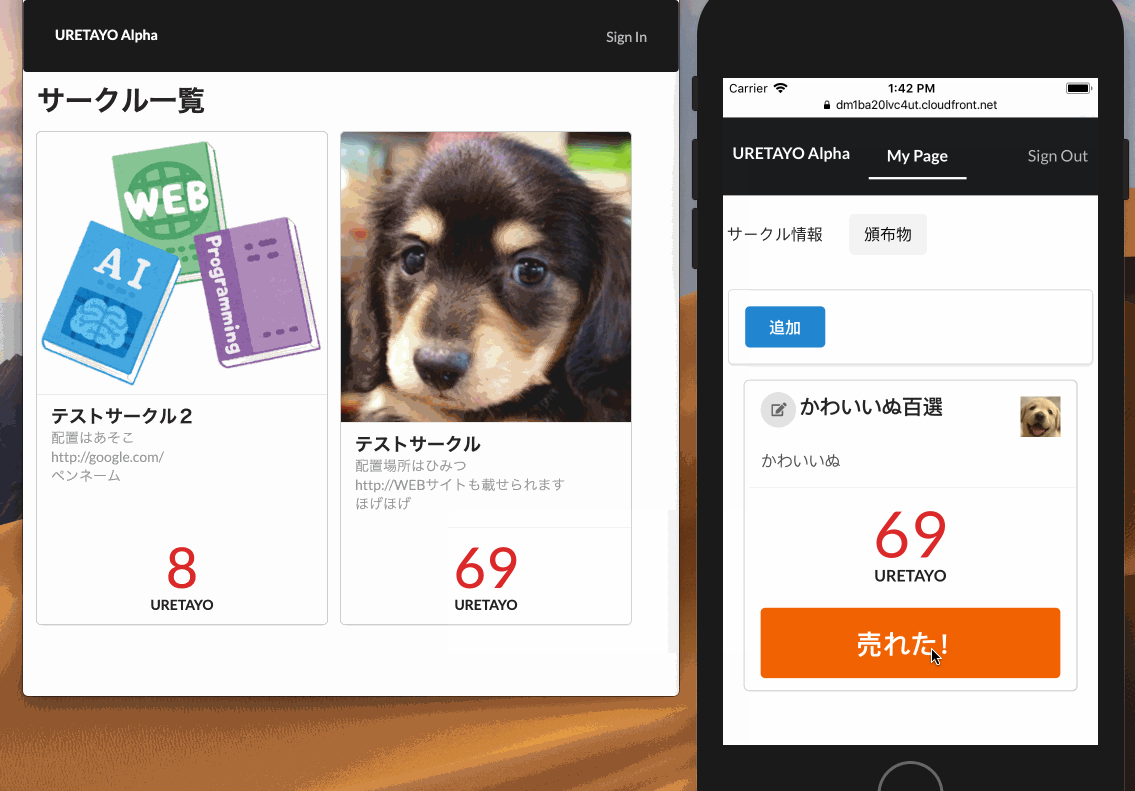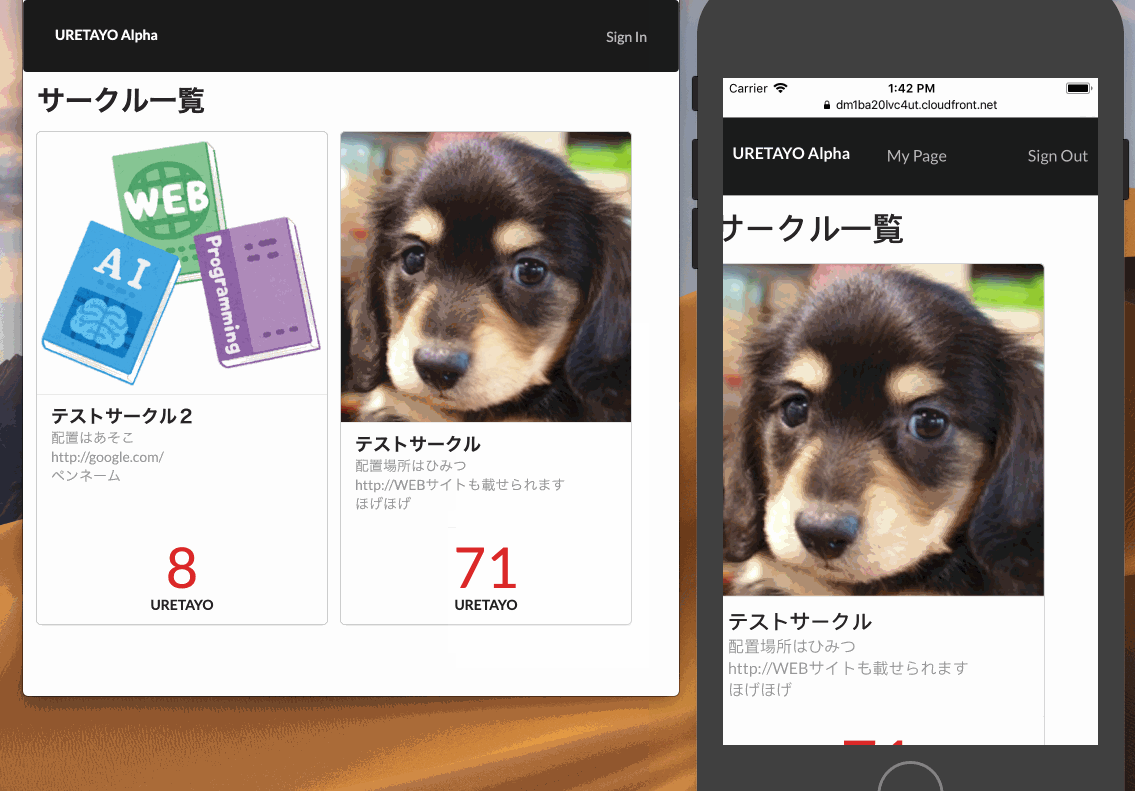
パスワード: guestguest利用イメージ
動作イメージ
利用技術
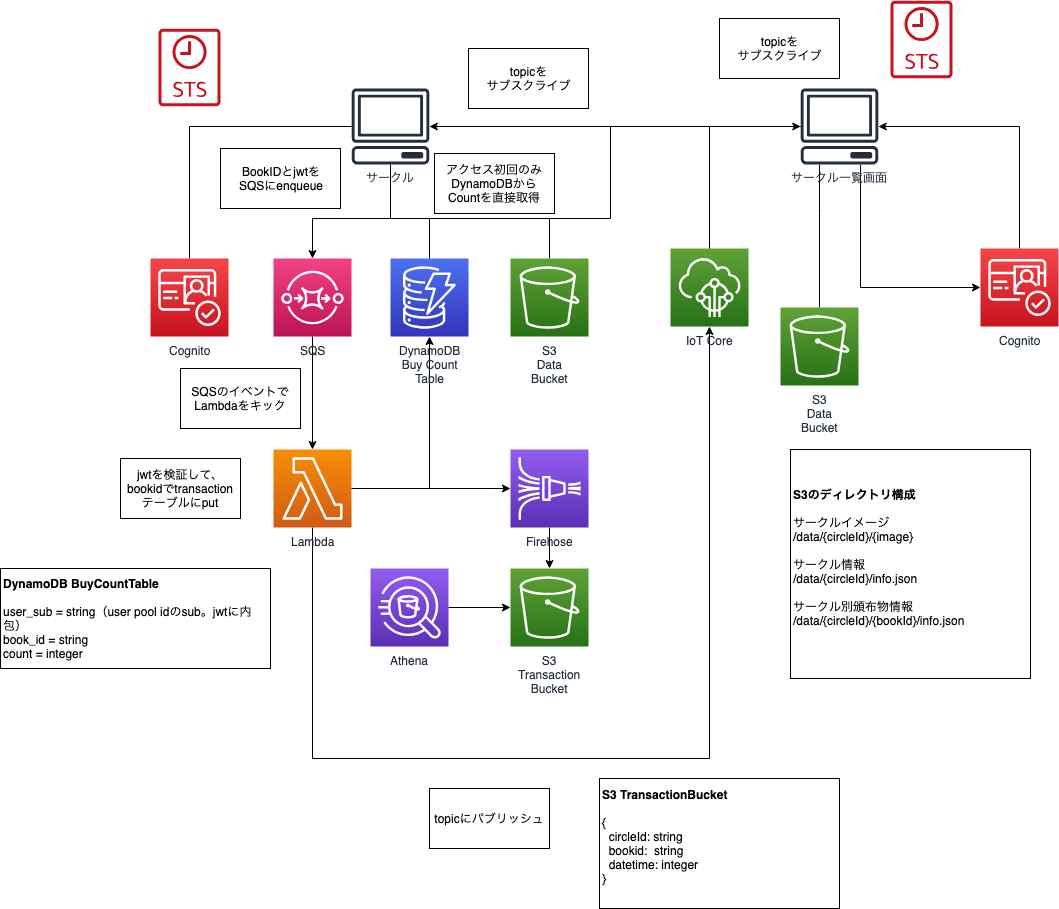
AWSフルマネージドのサーバーレス構成にしています。
また、実運用でも耐えうるようなセキュリティレベルを目指してみました。AWSリソース
ServerlessFrameworkでプロビジョニングします。便利。
- Cognito
- SQS
- DynamoDB
- Lambda
- IoT Core
- S3
- KinesisFirehose
- Athena
- CloudFront
フロントエンド側
- AWS Amplify Framework
- React
- Typescript
- Semantic UI React
構成図
処理フロー
ユーザー認証
はじめに閲覧者がURETAYOサイトにアクセスすると、
Cognito IdPoolから未認証ユーザー用のIAMロール(一時トークン)が払い出されます。
また、Cognito UserPoolへログインすると、IdPoolから今度は認証ユーザー用のIAMロールが付与されます。
AmplifyFrameworkではCognitoの認証状態に応じて閲覧できるページを制御しています。セキュリティポイント
AmplifyFrameworkはフロント側(ブラウザ)で実行されるJavascriptなので、簡単に改変することが可能です。 閲覧ページの制限ももちろん解除可能ですが、AWSのIAMロールでAWSリソースの権限管理をしているので Javascript側を改変してもAWSのリソースを変更することはできないようになっています。 また、一時トークンを利用されたとしても影響範囲はユーザーの権限範囲にのみ限定されます。ユーザーの権限
上記の一時トークンの不正利用時の影響範囲は、ユーザーの権限範囲に限定されるのですが
逆に言えば、ユーザーに大きな権限を与えているとそれだけ影響範囲が広くなるので、なるべく権限を絞ります。
このサービスでは認証ユーザーに以下のような権限を付与しました。
- S3への書き込み権限(ユーザーIDプレフィックス付きのディレクトリ以下のみ)
- SQSヘのメッセージ送信権限
- IoTポリシーのアタッチ
Cognitoについて
Cognitoには2つの役割があり、
一つは、ユーザーを識別して一意なIDの付与と、認証状態に応じて一時的なIAMロールを付与するIDプール、
もう一つはユーザーの認証を行うユーザープールです。
ユーザープールは認証プロバイダの一つでもあります。IDプールは認証プロバイダと連携して認証状態を判断します。
認証プロバイダはGoogleやFacebook等の外部の認証プロバイダを利用することも可能です。売れた通知の仕組み
SQSへメッセージを送信すると裏でLambdaが動き以下の処理が行われます。
- Jwtの検証
- DynamoDBのカウントアップ
- Firehoseへのログ送信
- MQTTへのパブリッシュ
認証ユーザーにはSQSへのメッセージ送信権限が付与されているので、
売れたボタンをトリガーにして、SQSへ下記のJSON形式でメッセージを送信します。{ "jwt": "{CognitoのアクセスIDトークン}", "book_id": "本のID" }送信されたメッセージはSQSの裏でLambdaが受信して、DynamoDBテーブルの該当の本の売れた数をカウントアップし
ログをFirehoseに送信して、MQTTのTopicに下記のJSON形式でPublishします。{ "count": "{売れた数}", "book_id": "本のID", "sub": "ユーザーの一意ID" }セキュリティポイント
認証ユーザーであればSQSへ自由にメッセージが送信可能で、一見セキュリティリスクになりそうですが、 メッセージに含まれたjwtの検証を行うことで、送信したユーザーの特定を行い その特定されたユーザーが持つ本IDのカウントアップを行うようにしています。 例え第三者がjwtを手に入れ、でたらめなメッセージを送信したとしても、最悪で影響範囲はそのユーザーのみに限定されます。売れた通知の受信と画面への反映
サークル一覧画面や頒布物画面では、
AmplifyFrameworkのPubSubでMQTTのトピックをサブスクライブしていて、
受信したデータを元にリアルタイムに画面に反映しています。はまりどころ
AmplifyのPubSubですがAmplifyのドキュメント通りにしても
下記のエラーが出てうまくサブスクライブできませんでした。{invocationContext: undefined, errorCode: 8, errorMessage: "AMQJS0008I Socket closed."}これは、Amplifyのドキュメントで指定しているIoTポリシーでは権限が足りないのと、
そのIoTポリシーにユーザーをアタッチしていないためでした。
ですので、IoTポリシーを下記のように定義してIoTPolicy: Type: AWS::IoT::Policy Properties: PolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Action: - iot:Receive - iot:Connect - iot:Subscribe Resource: - "arn:aws:iot:${AWS::Region}:${AWS::AccountId}:topic/{トピック名}/*" - "arn:aws:iot:${AWS::Region}:${AWS::AccountId}:topicfilter/{トピック名}/*" - "arn:aws:iot:${AWS::Region}:${AWS::AccountId}:client/*"IoTポリシーへのアタッチと、トピックのサブスクライブは
こんな感じで処理してうまく動くようになりました。import { Iot } from "aws-sdk"; import { Auth, PubSub } from "aws-amplify"; import Config from "../config"; const iotSubscribe = async (topic: string, cb: any) => { const credentials = await Auth.currentCredentials(); const iot = new Iot({ region: Config.region, credentials: Auth.essentialCredentials(credentials) }); const policyName = Config.iotPolicyName; const target = credentials.identityId; const { policies } = await iot.listAttachedPolicies({ target }).promise(); if (policies && !policies.find(policy => policy.policyName === policyName)) { await iot.attachPolicy({ policyName, target }).promise(); } return PubSub.subscribe(topic, {}).subscribe({ next: cb, error: error => console.error(error), complete: () => console.log("Done") }); }; export default iotSubscribe;さいごに
これを作ろうとなったのが1週間前で、大丈夫だろうとタカをくくっていたのですが
完全に見積もりが甘すぎて、もうこんなギリギリに。。。
Firehoseのログをサークル詳細画面にグラフ表示をしようとか、
いろいろ考えたりしたのですが、全然間に合いませんでした!ぱっと見わかりにくさ満点のサービスですが、実際に触って確かめてみていただけると嬉しいです。
それから、バグを発見したらそっと教えてください。われわれ六木本未来ラボは「え28」で技術書典初参加させていただきます。
はじめての技術書典でドキドキしていますが、
参加サークルのみなさま、よろしくお願いします。
- 投稿日:2019-04-13T14:23:35+09:00
Fargateのスケジュールされたタスクで常に最新のタスク定義を使用する方法
結論
cloud watch eventsのAPIを叩いて直接実行したいコマンドを登録するしかない模様
下記のような感じでタスクを登録するcron_job_addition_command = <<"CRON_JOB_ADDITION_COMMAND" aws events put-rule --name "#{name}" --schedule-expression "#{schedule_expression}" --description "Don't edit directly." aws events put-targets \ --rule #{name} \ --targets='[ { "Id": "#{name}", "Arn": "arn:aws:ecs:ap-northeast-1:#{account_id}:cluster/#{cluster_name}", "RoleArn": "arn:aws:iam::#{account_id}:role/#{role_name}", "Input": "{\\"containerOverrides\\":[{\\"name\\":\\"app\\",\\"command\\":[#{cmd}]}]}", "EcsParameters": { "TaskDefinitionArn": "arn:aws:ecs:ap-northeast-1:#{account_id}:task-definition/#{task_id}", "TaskCount": 1, "LaunchType": "FARGATE", "NetworkConfiguration": { "awsvpcConfiguration": { "Subnets": [ "subnet-hogehoge", "subnet-fugafuga" ], "SecurityGroups": [ "sg-hogehoge" ], "AssignPublicIp": "DISABLED" } }, "PlatformVersion": "LATEST" } } ]' CRON_JOB_ADDITION_COMMAND参考文献
- 投稿日:2019-04-13T13:50:01+09:00
Cognitoのプールごとの役割を5秒で確認する
- 投稿日:2019-04-13T13:32:40+09:00
Cognitoのユーザプールでの認証するところまでを最速でやる
概要
cognitoのユーザプール認証をやる。
- AWSコンソールでCognitoユーザプールへ登録したユーザを認証する。
- Amplify使うと色々速い気がするけど、一旦、AWSの公式にに記載されている方法で。。
- ※実質、Githubに書かれてる手順をなぞるだけになるけど。。
手順
Amazon Cognito Identity SDK for JavaScript をローカルに落とす
どこかのCDNに上がってない?ので、npmで自分でinstallする。
※元ネタ@SDK公式package.jsonを用意
package.json{ "private": true }npm install する
npm install --save-dev webpack json-loader npm install --save amazon-cognito-identity-js
node_modules\amazon-cognito-identity-js\distの中のamazon-cognito-identity.jsを後で使う。ユーザプールの認証をするためのjsの用意
公式の ユーザの認証 項に記載されているjavascriptをjsファイルにコピペする。
ここではtest.jsというファイル名で保存することにする。下記注意。
- username, password をユーザプールにユーザを登録した時のものに書き換える。
UserPoolId, ClientId も書き換える。
UserPoolIdに入力する値はユーザプールの管理画面の↓の赤枠部分
ClientIdに入力する値は、画面下の方にある アプリクライアント の右の方にあるエンピツボタンを押し、表示される画面の中の アプリクライアント ID の値。
認証を実行する
適当なhtmlを作成し、javascriptとして、
amazon-cognito-identity.jsとtest.jsをhtml内で読み込む。<script src="amazon-cognito-identity.js"></script> <script src="test.js"></script>htmlをブラウザで表示し、公式からコピペしたjs内の
authenticateUser()のonSuccess()のresultの内のaccessToken,IdToken,refreshTokenに値が入っていれば成功。認証できない時
↓のようなエラーが出る場合
TypeError: callback.newPasswordRequired is not a functionコンソールからユーザを登録した場合、初回認証時に強制的にパスワードを変える必要がある。
ので、test.jsのauthenticateUserに↓のメソッドを追加する。※パスワードが
passwordになるのでそこは任意で。
※追加してもエラーが出る場合、リクエストへのレスポンスの内容を見ると何が悪いか書いてあるのでそれ見ながら修正する。
※公式の元ネタnewPasswordRequired: function (userAttributes, requiredAttributes) { cognitoUser.completeNewPasswordChallenge("password", {}, this) }


- 投稿日:2019-04-13T00:55:50+09:00
AWS認定ソリューションアーキテクトアソシエイトへの道 その5 EC2ってなに?
tl;dr
現在Webエンジニアをやっているが下記の理由のためにAWSソリューションアーキテクトアソシエイト取得を目指す。
- スキルアップ
- 業務の幅を広げる
- 知的好奇心
現在のAWSスキル
- テスト用にEC2を作成したことはある(LAMP環境を構築)
- ネットワーク用語はある程度わかる(マスタリングTCP/IP 入門編は名著だと思う)
学習方法
- 対策本を読むことを考えたが、手を動かしながら学んだほうが身につくと考え、Udemyの動画教材を購入
- AWS INNOVATE(Amazonが主催するAWSを学ぶためのONLINE CONFERENCE) → 開催中だったために登録
- 参考書も購入
購入した教材はこちら
AWS認定ソリューションアーキテクト – アソシエイト試験突破講座
購入した本はこちら
合格対策 AWS認定ソリューションアーキテクト - アソシエイト
本日の課題
- EC2の概要
- EC2でWEBサーバーを立ち上げる(ハンズオン)
- Elastic IPの設定(ハンズオン)
- Bashコマンドによる設定
課題メモ
- 動画教材のリソース(PDF)を印刷できることがわかったので動画とともに使うことにする。より学びが深くなる
- EC2インスタンスができてしまえば通常のLinuxと同じ(当然だが…)
- ハンズオンでnanoというエディタがあることを知ったが、viが使えるので使う機会はなさそう
- Elastic IPはEC2に割り当てないと料金がかかる
- 投稿日:2019-04-13T00:33:29+09:00
RailsからCloudWatch Eventsのルールを作成する
CloudWatch Eventsの日本語情報少ないね・・・
SDKを使ってDynamoDBやLambdaを操作する記事は割りかし多いですが、CloudWatch Eventsに関しては日本語情報ほぼないですね・・・。
せっかくなので備忘録ついでにまとめておきます。今回はrubyのgemである
aws-sdk-railsを使い、Railsアプリケーションからlambda関数を発火させるCloudWatch Eventsのルールを作成する例を紹介します。実行環境ruby 2.4.1 Rails 5.1.1SDKを使ってCloudWatch Eventsルールを作成
以下、1時間ごとにLambdaを発火させるスケジュールイベントを作成する例です。
put_ruleでルールを作成し、put_targetsでターゲットとなるlambda関数を指定します。require 'aws-sdk-rails' cwe = Aws::CloudWatchEvents::Client.new( access_key_id: ENV['AWS_ACCESS_KEY'], secret_access_key: ENV['AWS_SECRET_KEY'], region: 'us-east-2' ) cwe.put_rule({ name: "ThisIsRubyOnRails", schedule_expression: "rate(180 minutes)", #Cron式でも可 \"cron(0 20 * * ? *)\" or \"rate(5 minutes)\" description: "テストイベントですYo!", }) # ※stateの指定がない場合はENABLEDとなる cwe.put_targets({ rule: "ThisIsRubyOnRails", targets: [ { id: "default", arn: "arn:aws:lambda:~~~~~~~~~~~~~~~(略)~~~~~~~~~~~~~~~~~~", input: '{"favorite_food": "sushi"}', #任意の値をjson形式でlambdaに渡すこともできる }, ], })必要に応じてモジュール化すると処理がスッキリして可読性も上がります。
上記のコードでRailsからルールの作成ができたと思います。
しかし!残念ながら作成されたルールにはlambda関数へのアクセスする権限がないため、lambdaを発火させることはできません。そこで作成したルールにlambda関数へアクセスする力を与えましょう。
lambda_client = Aws::Lambda::Client.new( access_key_id: ENV['AWS_ACCESS_KEY'], secret_access_key: ENV['AWS_SECRET_KEY'], region: 'us-east-2' ) lambda_client.add_permission({ function_name: "lambdaFunctionName", #発火させるlambda関数 statement_id: "ThisIsRubyOnRails", #ユニークの値であれば何でも良し! action: "lambda:InvokeFunction", principal: "events.amazonaws.com", source_arn: "arn:aws:~~~~(作成したCloudWatch Eventsのarn)~~~~^", #ここで力を与えるイベントを指定 })これでやっとSDKを使ってlambdaを発火させるCroudWatch Eventsルールを作成することができました。
お疲れさまでした。読むべき英語リファレンス
- 投稿日:2019-04-13T00:15:03+09:00
Jetson Nano Developer KitでAWS IoT GreengrassのML Inferenceを試す
前回の記事では、Jetson Nano上でAWS IoT Greengrassを動かしました。
Jetson Nano Developer KitでAWS IoT Greengrassを動かしてみる今回は、Jetson Nano上でMLの推論を試してみます。
Greengrassは事前に生成したMLのモデルを使って推論を実行する事が可能です。
AWS IoT Greengrass ML Inference推論で使うモデルが必要になるので、今回はこちらの「AWS マネジメントコンソール を使用して Machine Learning Inference を設定する方法」を参考にしながら作業を進めます。
MXNetのインストール
AWSのドキュメントではJetson TX2向けの手順やライブラリが有るのですが、Jetson NanoはCUDA10の為、そのまま使えません。
で、ソースからインストールやら色々ハマった結果、公式のフォーラムで解決策が提供されていたので、それを参考にインストールしました。sudo apt-get install -y git build-essential libatlas-base-dev libopencv-dev graphviz python-pip sudo pip install mxnet-1.4.0-cp27-cp27mu-linux_aarch64.whlついでにGreengrassSDKもインストールします
sudo pip install greengrasssdkMXNet モデルパッケージを作成する
- squeezenet_v1.1-0000.params
- squeezenet_v1.1-symbol.json
- synset.txt
この3つのファイルをzipに固めるらしいのだが、このドキュメントのURLからダウンロードしようとしても、タイムアウトしてちっともDL出来ない。。。
探してみたら、githubにあげている人がいたので、そこからDLしました。
https://github.com/dzimine/aws-greengrass-ml-inference/tree/master/lambdas/GreengrassImageClassification/squeezenetLambda 関数を作成して公開する
ドキュメントだとMXNetのビルド中にサンプルソースが生成されるとのことだが、今回はビルドしていないのでソースが見つからない。
以前に、試した際に取っておいたソースが有るので、今回はこれを使う。そのソースだと、Jetson TX2のオンボードカメラやRaspberry PiのPiCameraを使う内容なので、Jetson Nano向けにUSBカメラが使えるように変更したソースをgithubに上げました。
https://github.com/sparkgene/greengrassObjectClassification
(ソース取得元は、AWS IoTのマネージメントコンソールで Software > Machine learning inference > Runtimes and precompiled framework libraries configure downloadでソフトウエアの画面を開き、MXNet Nvidia Jetson TX2のdownloadでダウンロードしたファイルの中にmxnet_examples.tar.gzがあるのでそれを展開するとexamples/greengrassObjectClassificationに見つかります)この3つのファイルをzip化して、新しく作成したLambdaに登録する。
Lambdaの登録とAliasの作成はこちらを参考にしてください。LambdaをGreengrassに登録する際、以下のように設定を変更する
- Memory limit
- 128M
- Lambda lifecycle
- Make this function long-lived and keep it running indefinitely
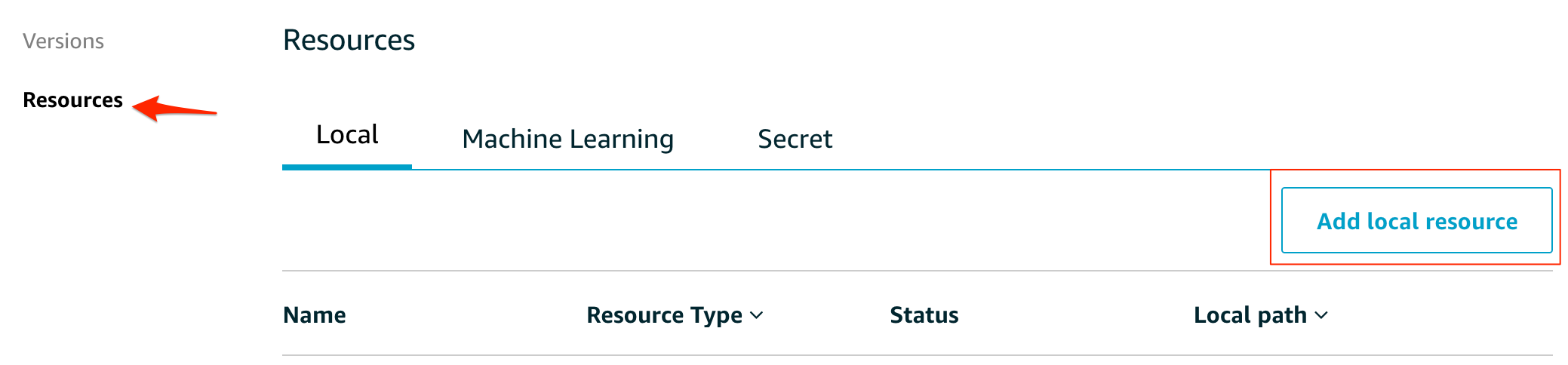
Greengrass グループにリソースを追加する
ビデオカメラ
次に、Lambdaからビデオカメラにアクセスさせる必要があるので、Greengrassの画面でローカルリソースの追加を行います。
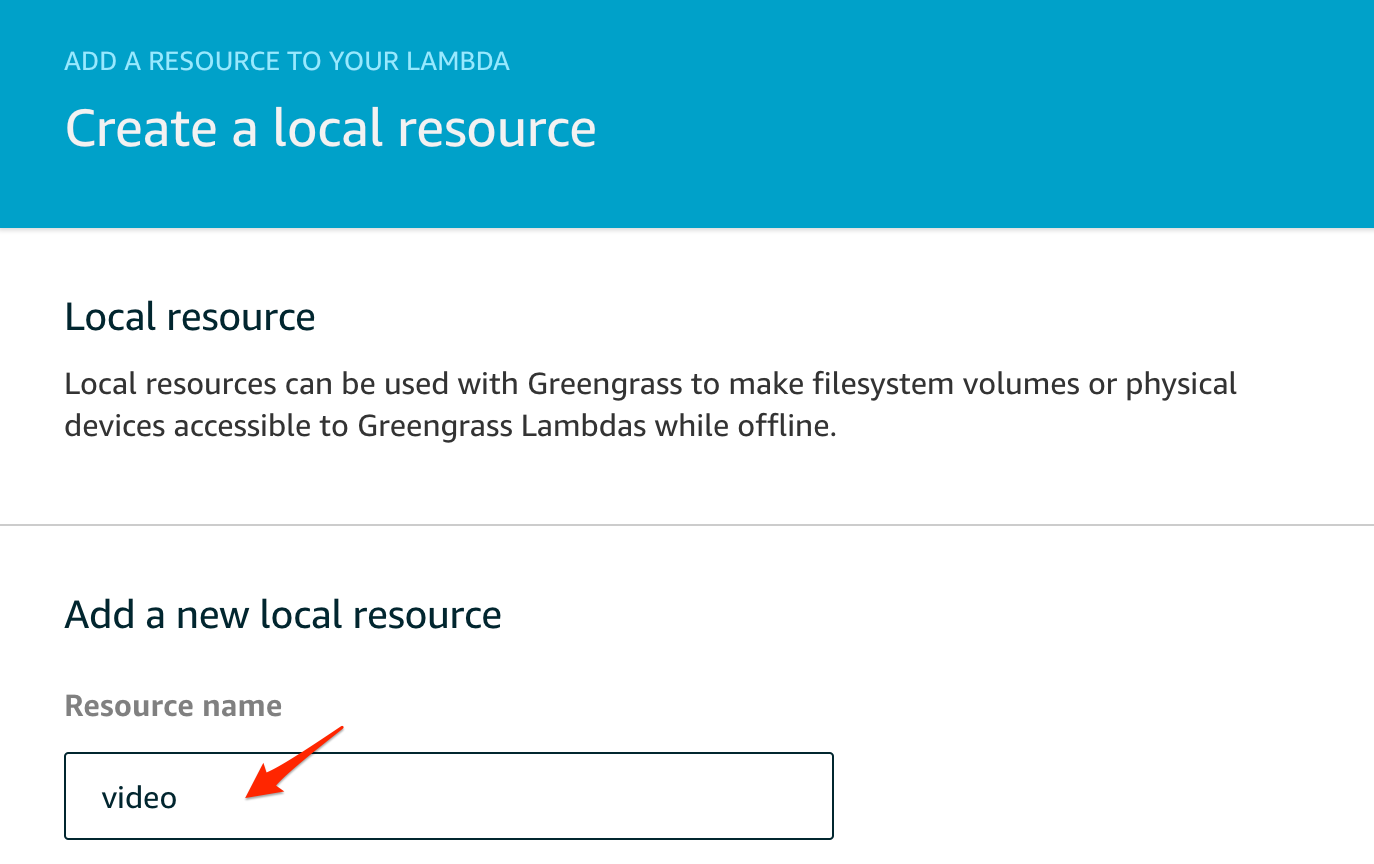
わかり易い名前をつけます
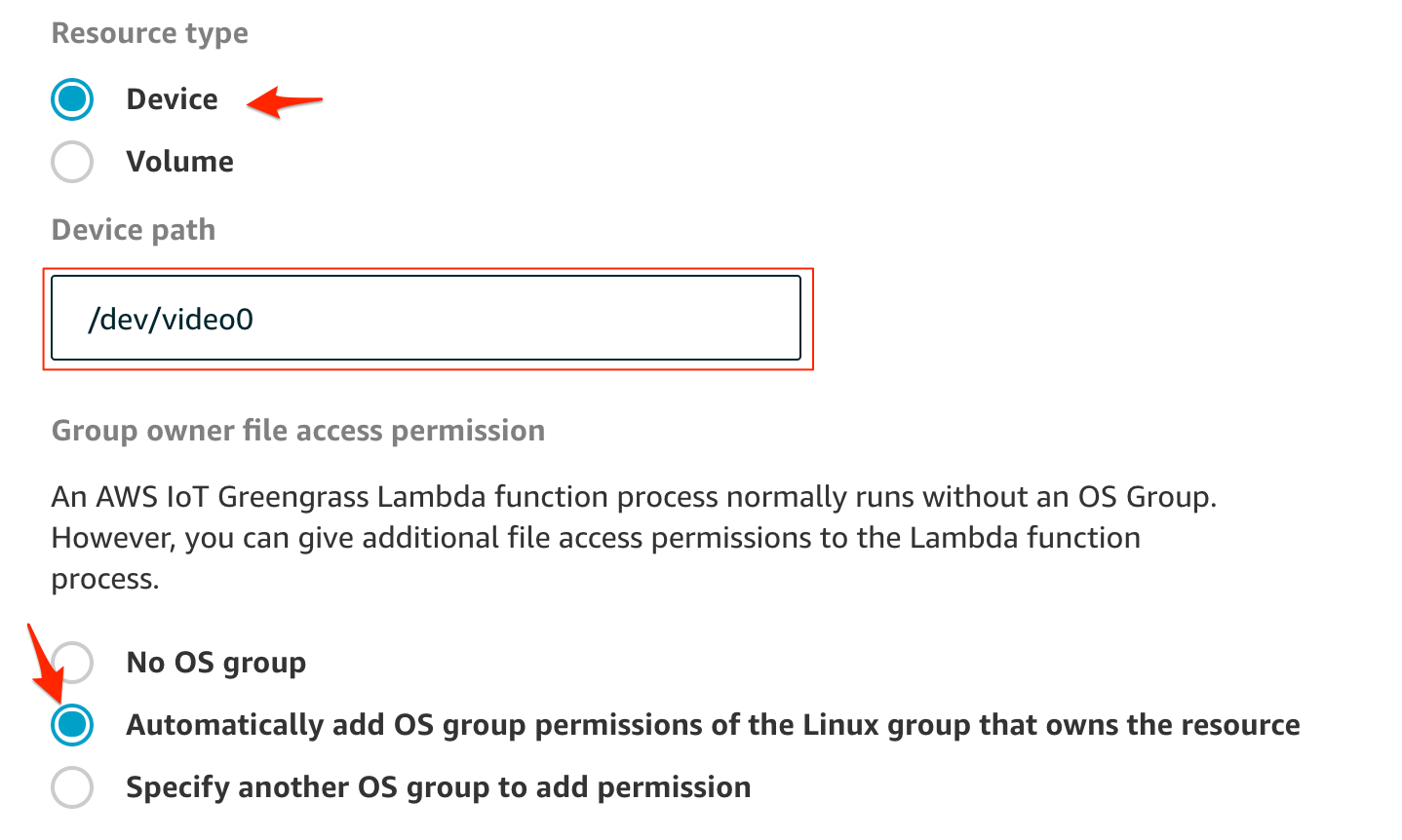
Deviceを選んで、ビデオのパスに/dev/video0を指定します。(環境によって変わります)
パーミッションではAutomatically add OS group permissions of the Linux group that owns the resourceにチェックを付けます。
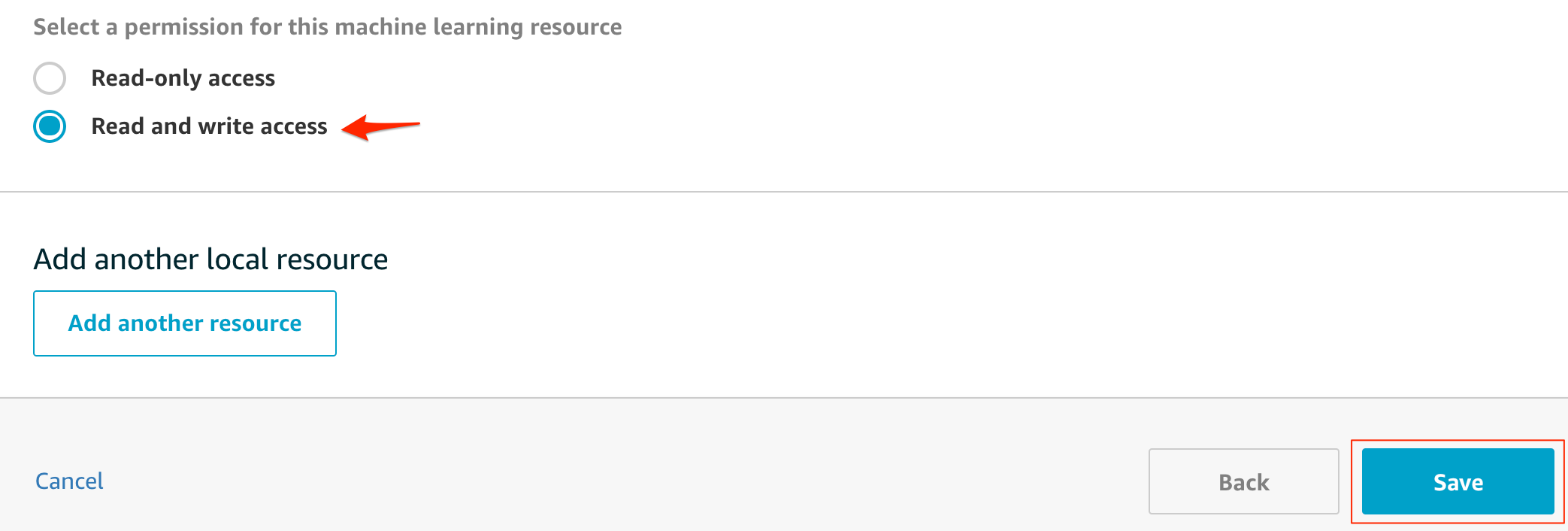
読み書き権限が必要なので、
Read and write accessを選ぶ。最後に保存をします。
モデル
次に、推論で使うモデルもリソースに追加します。
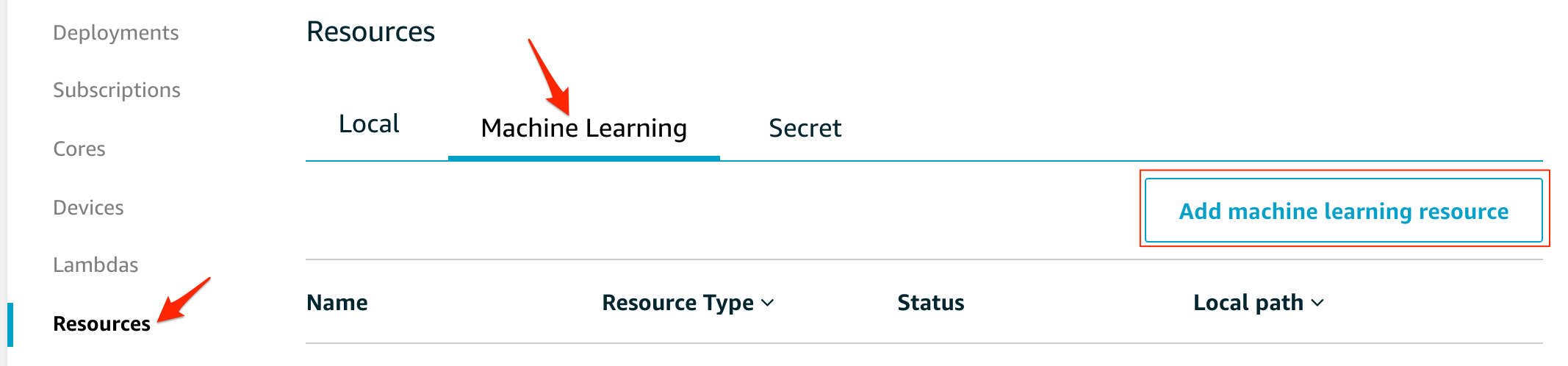
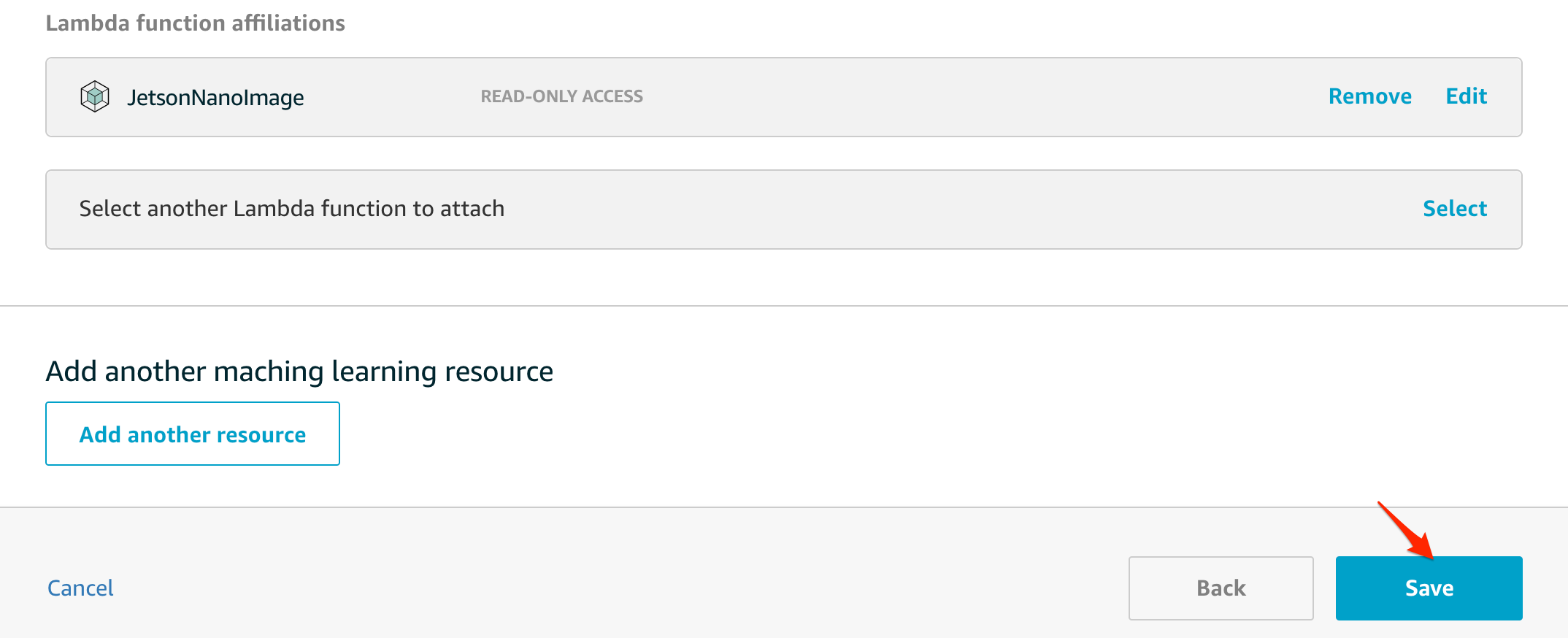
Machine Learningを選び、Add machine learning resourceで新規に追加します
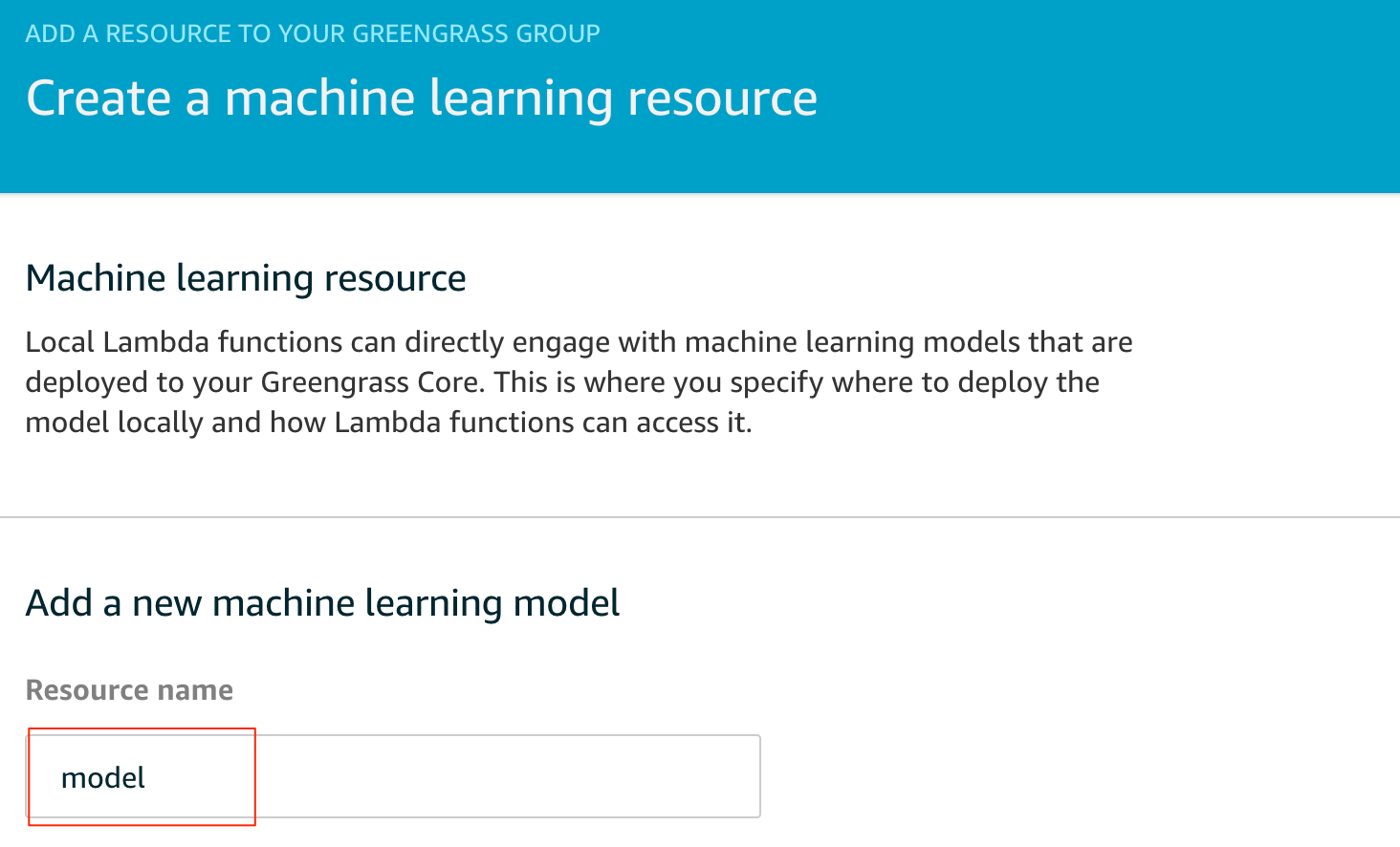
わかり易い名前をつけます
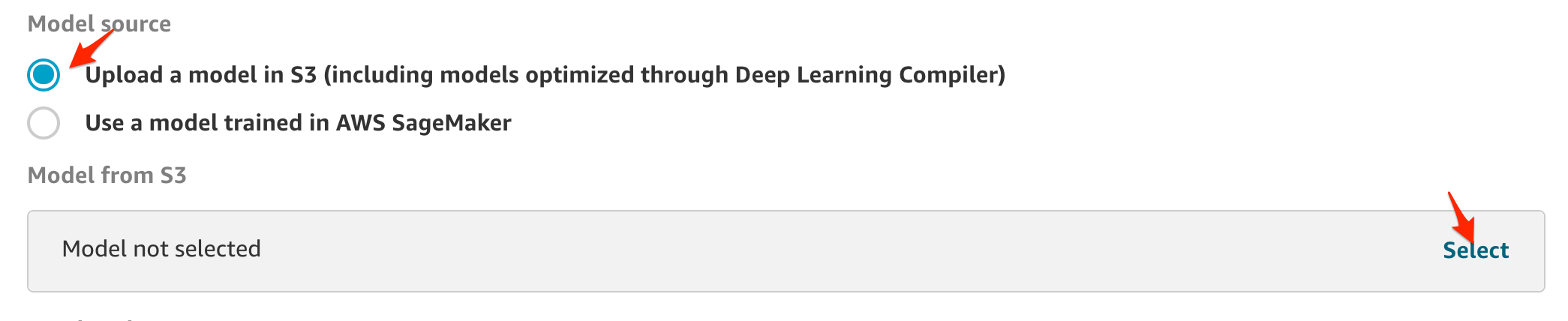
先の手順でzipに固めたモデルをS3に上げておきます。ここでは、S3にあげてあるモデルを指定します。
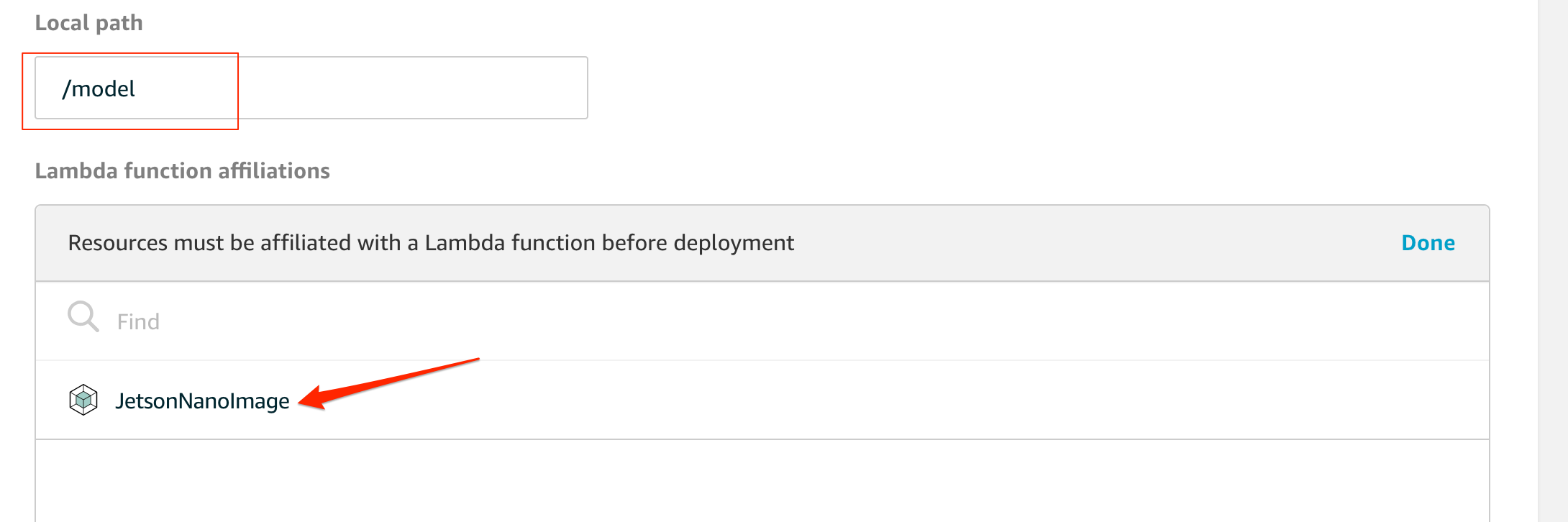
local pathには、Lambda内から参照する際のパスを指定します。Lambdaに紐付けるので、登録したLambdaを探して選択します。Lambdaからは
Read-only accessで大丈夫です。
最後に
Saveをクリックして登録します。
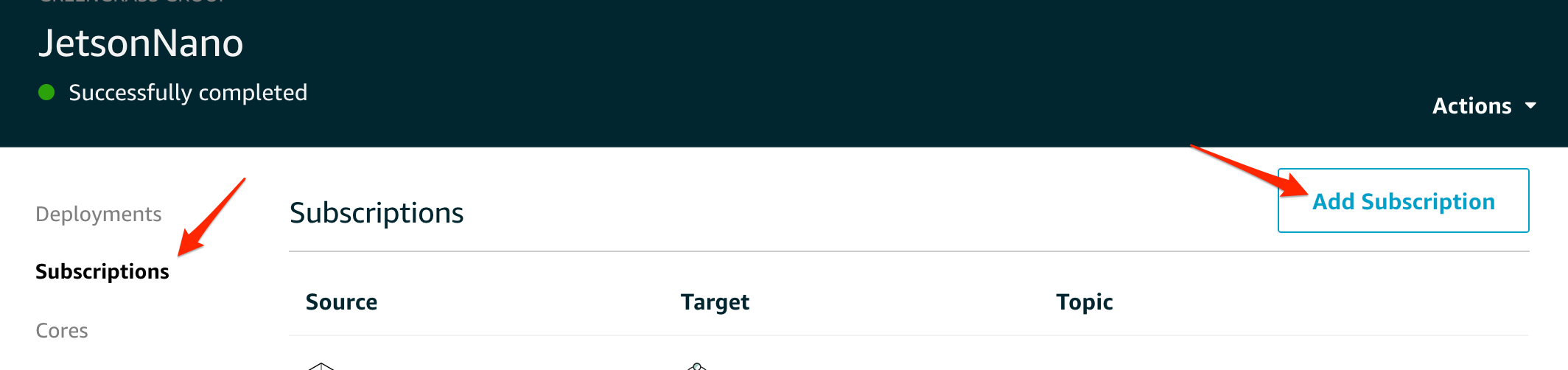
AWS IoTへのPublish
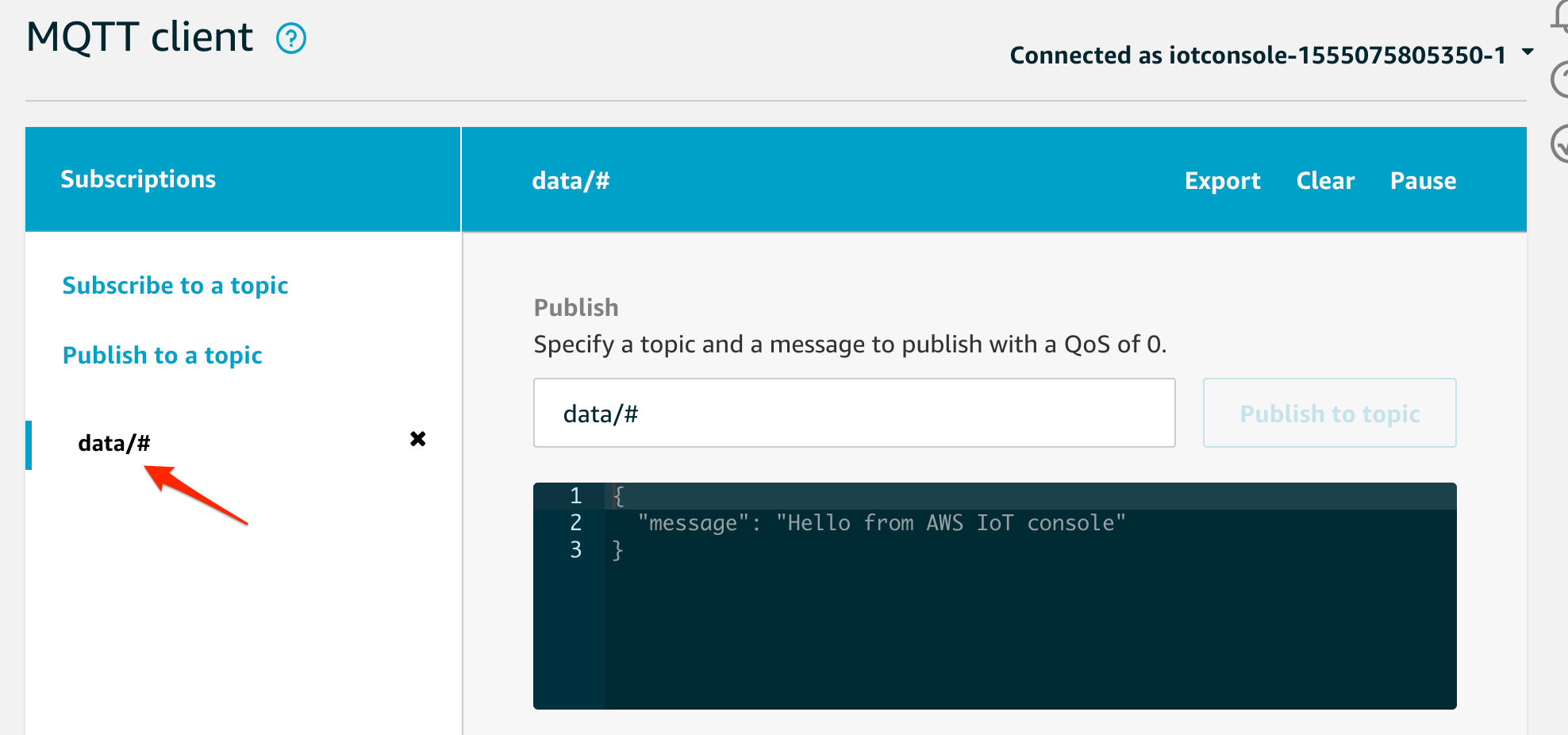
今回のサンプルだと、物体を検出したらMQTTでデータをAWS IoTに上げる仕組みにしているので、Greengrass側のSubscriptionにデータの流れを登録します。
SubscriptionのメニューからAdd Subscriptionを選択します。
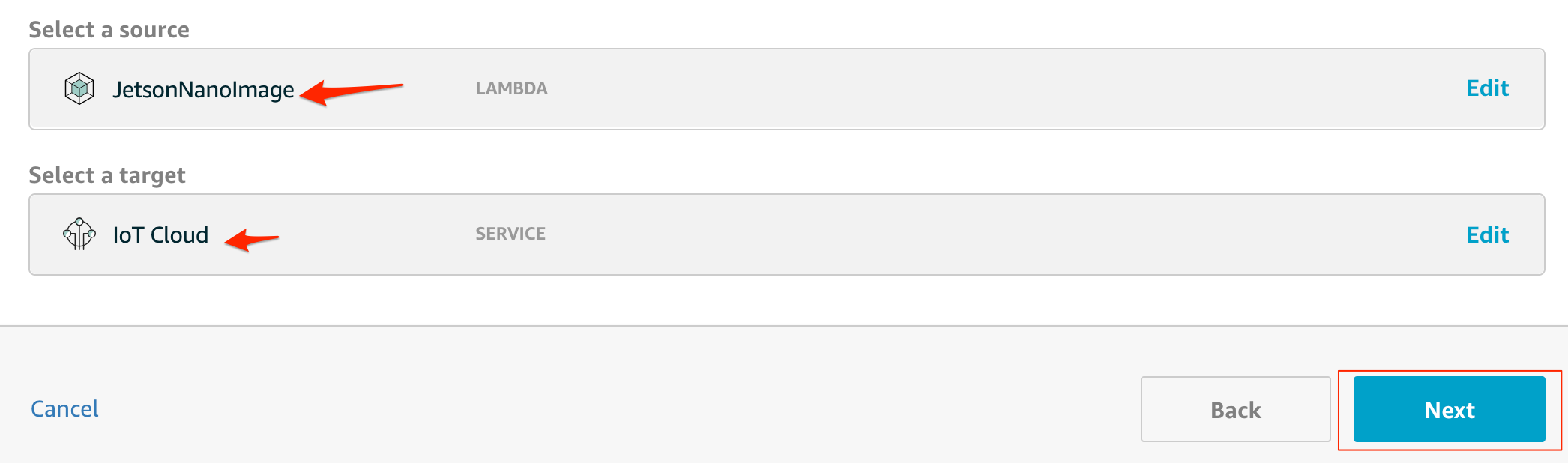
SourceにLambda、targetにIoT Cloudを指定すると、LambdaからPublishされた、メッセージがAWS IoT Coreにルーティングされます。Nextをクリックします。
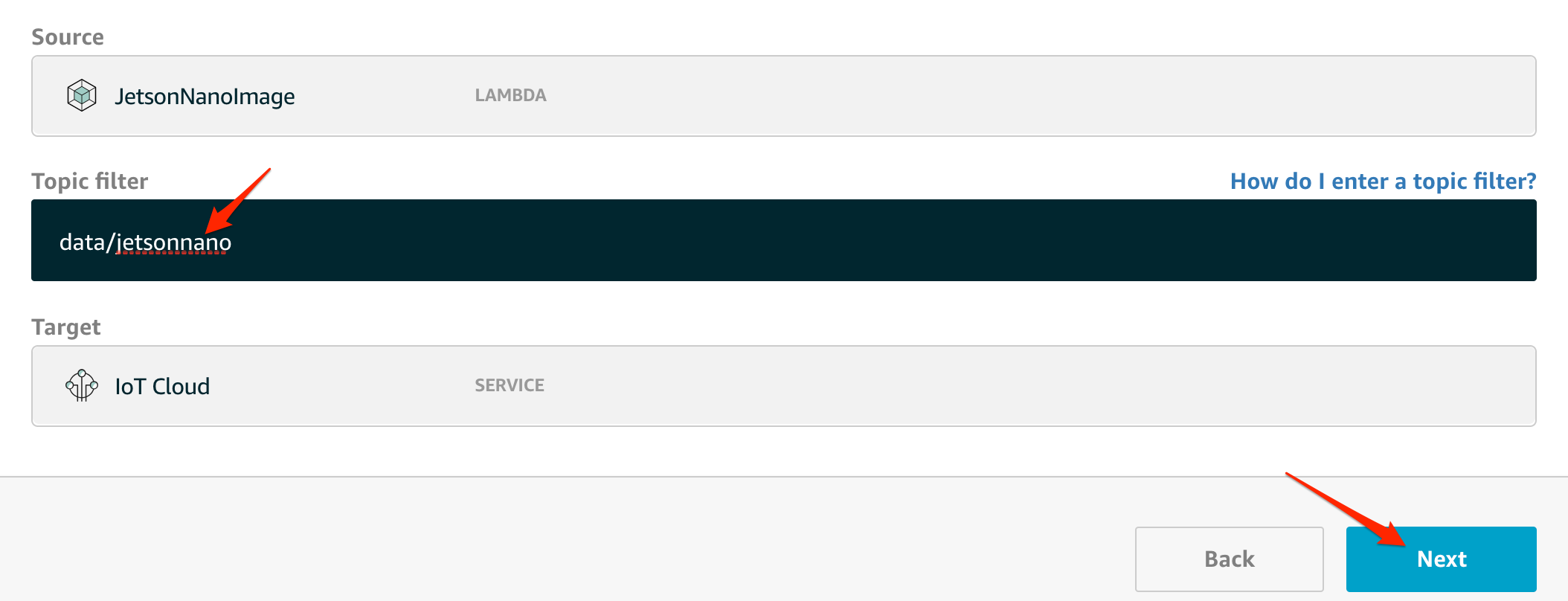
このサブスクリプションをどのトピックに紐付けるかを指定します。サンプルソースでは、
data/jetsonnanoというtopicに対してpublishするので、合わせます。Nextを押すと確認画面が表示されるので、確認して登録をします。
動作確認
クラウド側の設定が終わったので、Jetson Nanoにデプロイします。先に、USBカメラの接続をしておきます。
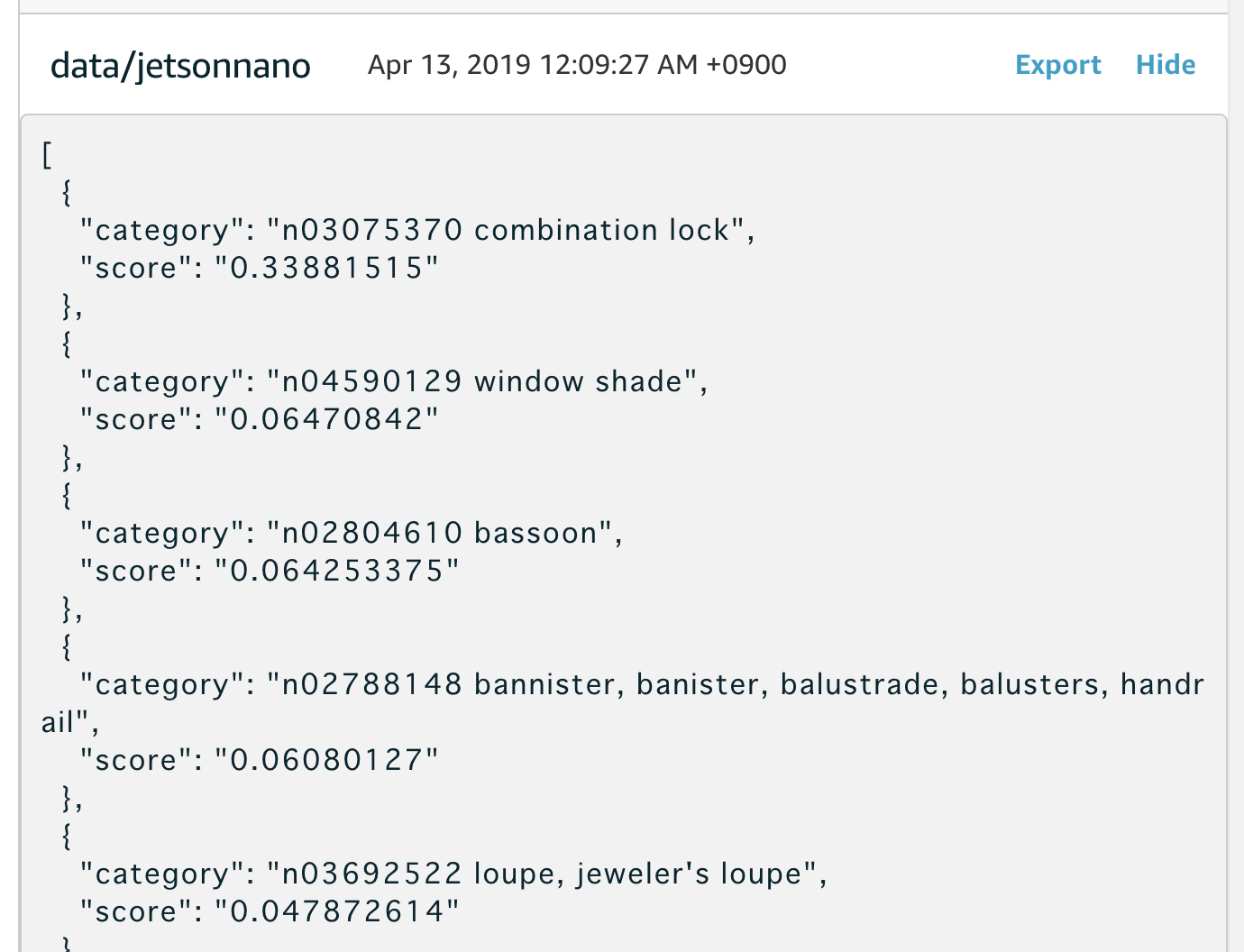
デプロイに時間がかかるので、この間に、AWS IoTのテストメニューを開いて、data/jetsonnanoを監視します。
デプロイがされ、しばらくすると以下のように、推論した結果が表示されます。
まとめ
MXNetのインストールはどうなるかと思ったが、なんとかなりました。
ハマらなければ、結構簡単に推論アプリを実行するところまで進められました。
Raspberry Piより性能が高く、Jetson TX2より安いので、色々なシーンで利用できるかなと思います。免責
発言内容は個人的な意見であり、所属する企業を代表するものではありません。
掲載しているソースコードは、サンプルレベルの物ですので動作を保証するものではありません。