- 投稿日:2019-04-13T17:04:04+09:00
DeepLabに代わり現在のSOTAであるFastFCN(JPU)の論文解説
2019/3/28に投稿された、今現在のセグメンテーションのstate-of-the-artです
Joint Pyramid Upsampling (JPU)という手法を用いて、state-of-the-artの精度かつ、DilatedFCNに比べて3倍以上高速なセグメンテーションを可能にした論文です論文の概要
論文名: FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic
arXiv: https://arxiv.org/abs/1903.11816
Github: https://github.com/wuhuikai/FastFCNAbstract
- 最近のセグメンテーションのアプローチでは、高解像度の特徴量マップを得るためにDilated Convolutionをbackbornに使っているが、これは計算コストとメモリ消費が激しい
- これを解決するために、Joint Pyramid Upsampling (JPU)というモジュールを導入します これは高解像度の特徴量マップを得る問題を、Joint Upsampleの問題に置き換えるものです。
- JPUによって、精度を落とすことなく、計算コストを3倍以上減らすことができます
- Dilated ConvolutionをJPUモジュールに置き換えることによって、
Pascal Context datasetとADE20K datasetにおいて、3倍以上高速に動作しながら、state-of-the-artのスコアを出しました。1. Introduction
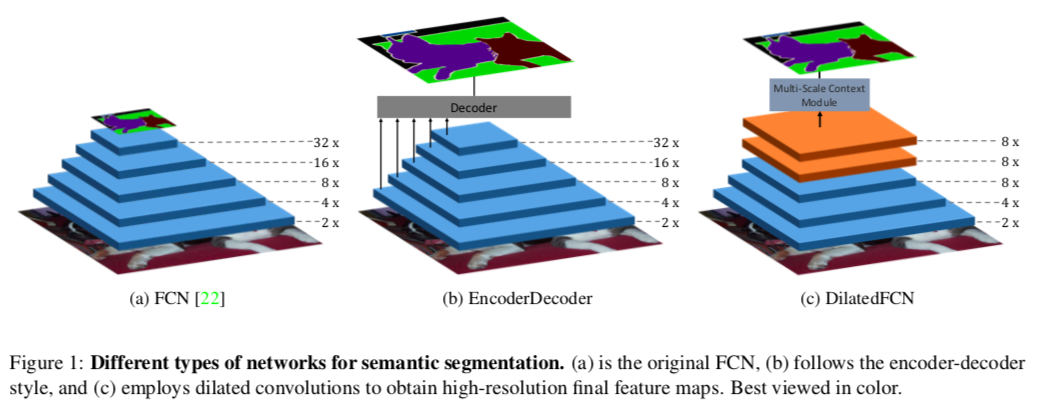
最初のFCN(Fully Convolution Network)は、ダウンサンプルによって低解像度の特徴量マップを生み出すため、細かい情報は失われ、境界線付近で間違った予測をすることが多くなります。Fig 1(a)のように、典型的なFCNでは5回ダウンサンプリングをし、特徴量マップは約1/32の解像度になる。
高解像度の特徴量マップを得るため、元のFCNをセマンティックな情報を得るためのEncoderとして用いて、DecoderではEncoderの中の特徴量マップを徐々に取り入れていくことで、徐々に空間情報を補填していくEncoderDecoder構造が提案されています(Fig 1(b))
その後提案されたDeeplabでは、最初のFCNから最後の二つのダウンサンプルを取り除き、代わりにdilated (atrous) convolution を追加して、受容野の大きさが変わらないようにしています。この種の方法はEncoderDecoder構造のモデルを様々なベンチマークで上回っていきました。Fig 1(c)でわかるように、DilatedFCNの最後の特徴量マップは他のものより4倍程度大きく、より多くの空間情報を保持しています。
dialted convolutionは最後の特徴量マップがより高解像度の空間情報を保持するために重要な役割を果たしていますが、計算コストとメモリ使用量が大きい点が問題になっています。
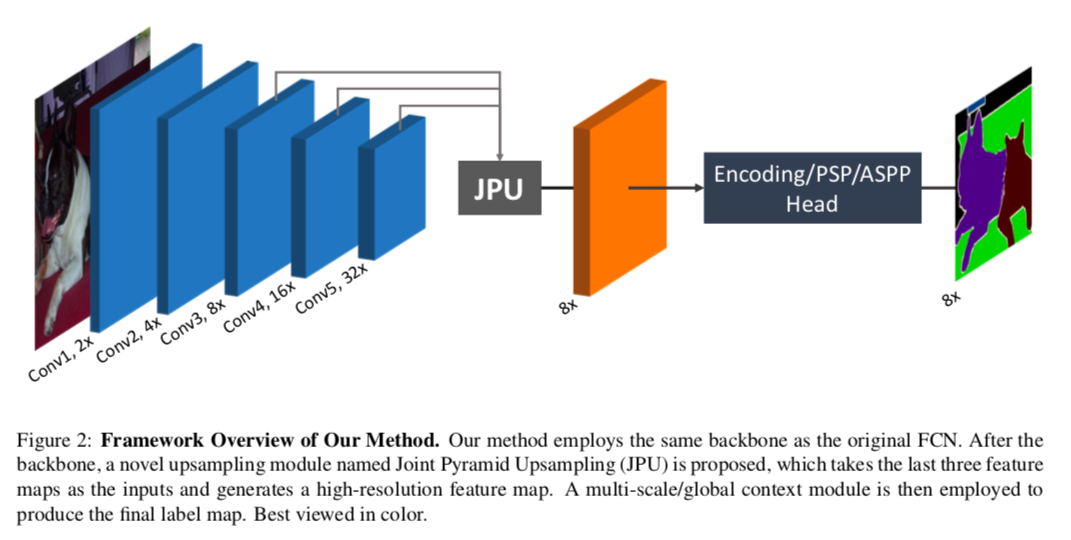
この問題を解決するためにJoint Pyramid Upsampling (JPU)を導入します。最初のFCNをbackbornとして用いて、その各層から得られる特徴量マップをJPUに通すことで、最終的にOutput Strideが8(入力画像の1/8の解像度)の高解像度の特徴量マップが得ることができます。さらに、DilatedFCNに比べて精度を落とさないまま、計算コストとメモリ使用量も大幅に減らすことができます。
実験をすると、3倍早く動きながらstate-of-the-artの精度を出すことができた
Pascal Context datasetでは53.13%(mIoU)でSOTAADE20K datasetでは42.75%(mIoU)でSOTA2. Related Work
2.1. Semantic Segmentation
EncoderDecoderとDilatedFCNについてIntroductionとほぼ同じことを説明してるだけなので割愛
2.2. Upsampling
低解像度の特徴量マップをupsampleして高解像度のものを取り出す必要があります
Joint Upsampling
この内容は3.3.1 Backgroundの方で詳しく説明するのでここでは割愛
Data-Dependent Upsampling
ラベル空間の冗長性を利用して低解像度の特徴量マップからpixel-wiseの予測をするDUpsamplingもこの論文の方法と関連していますが、DUpsamplingはラベル空間に大きく依存しており、複雑なラベルには対応できなくなる点がこの論文の優位性
3. Method
3.1. DilatedFCN
これもほぼIntroductionと同じ内容なので割愛。内容がないよう〜
DeepLabではFig 1(c)にあるように最後の2層はDilated Convolutionにして受容野が変わらないようにしますよっていうお話ちょっとだけ参考として、dilated(atrous) Convolutionというのはこんな感じです。gif画像は
Dilation rate(畳み込みをする間隔)が2の場合で、1の場合は普通の畳み込みと同じになります。
3.2. The Framework of Our Method
この論文では、計算コストとメモリ使用量を抑えつつ、DilatedFCNの最終層の特徴量マップを近似することが目的
- そのためにまず、Dilated FCNで無くした最後二つの普通のConvolutionを元に戻します。これによって、Fig 2にあるようにbackbornは元のFCNと同じものになります
- そして、Dilated FCNと似た特徴量マップを得るため、最後の3つの層の特徴量マップをインプットとするJoint Pyramid Upsampling (JPU)を導入します。
- そのあとmulti-scale context module(PSPもしくはASPP)かglobal context module(Encoding)に通して、最終的な予測値を出します。
backbornにResnet101を使った場合、Dilated Convolutionに比べて、residual blockが23個の場合は1/4の計算コスト&メモリ使用量、3個の場合は1/16になります
3.3. Joint Pyramid Upsampling
Dilated FCNと同じ特徴量マップを作り出すのは、Joint Upsampleの問題として考えることができる
3.3.1 Background
Joint Upsampling
低解像度のguidance画像$x_l$から、低解像度のtarget画像$y_l$が、
y_l = f(x_l)という変換で得られるとします。これから考える問題は、この$f(\cdot)$を近似する、$\hat{f}(\cdot)$を求めることです。
一般的に、$\hat{f}(\cdot)$は$f(\cdot)$よりも計算コストが小さくなります。例えば、$f(\cdot)$がもし多層パーセプトロンで形成されたものなら、$\hat{f}(\cdot)$は簡単な線形演算子の形で求められます。
この$\hat{f}(\cdot)$を用いることで、高解像度のguidance画像$x_h$が与えられた時は、y_h = \hat{f}(x_h)として、少ない計算量で高解像度のtarget画像を得ることができます。
問題を定式化すると、
y_h = \hat{f}(x_h), \mathrm{where}~ \hat{f}(\cdot) = \mathrm{argmin}_{h(\cdot)\in \bf{H}} \| y_l - h(xl) \|ここで$\bf{H}$は考えられる変換、$||\cdot||$は距離関数です
Dilated Convolution
Dilated Convolutionは、Deeplabで提案された、受容野の大きさを変えずに高解像度の特徴量マップを取り出す方法ですが、これは次のように考えることができます。
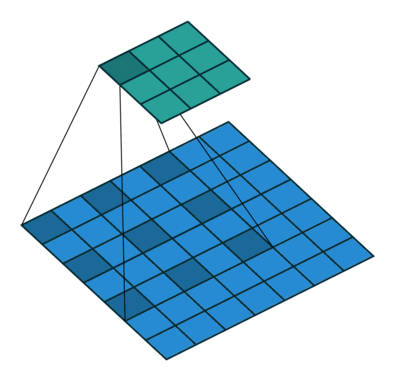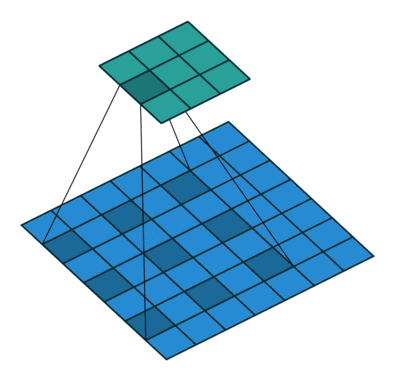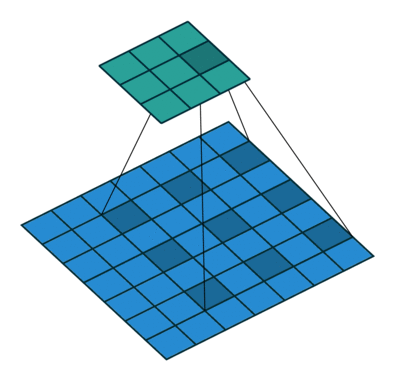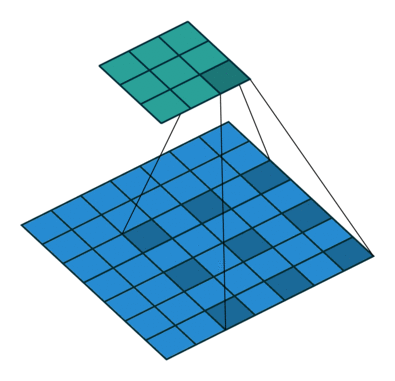
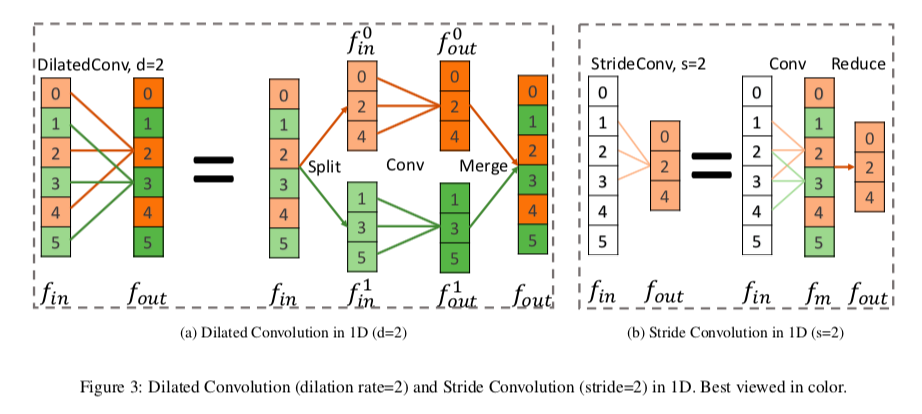
Fig 3(a)は、一次元でdilation rateが2の場合を示していますが、この操作は以下の3つの操作に分解できます
- Split : inputの$f_{in}$を、$f_{in}^0$と$f_{in}^1$の二つのグループにわける
- Conv : それぞれに同じ畳み込みを施し、$f_{out}^0$と$f_{out}^1$を得る
- Merge : $f_{out}^0$と$f_{out}^1$を互い違いになるように統合して、$f_{out}$を得る
ここでは簡単のために一次元で考えていますが、2次元でも同様の分解ができます。
Stride Convolution
Stride Convolutionは、inputの特徴量を、解像度を減らしてoutputの特徴量に変換する方法です。
Fig 3(b)で一次元の場合を示していますが、これも二段階の操作に分解できます
- Conv : $f_{in}$に普通の畳み込みをして、中間の特徴量$f_m$を取り出す
- Reduce : $f_m$の奇数番目を取り除いて、$f_{out}$を得る
これも2次元の場合でも同様のことが成り立ちます。
3.3.2 Reformulating into Joint Upsampling
DilatedFCNと、提案手法の違いを見ていきます。
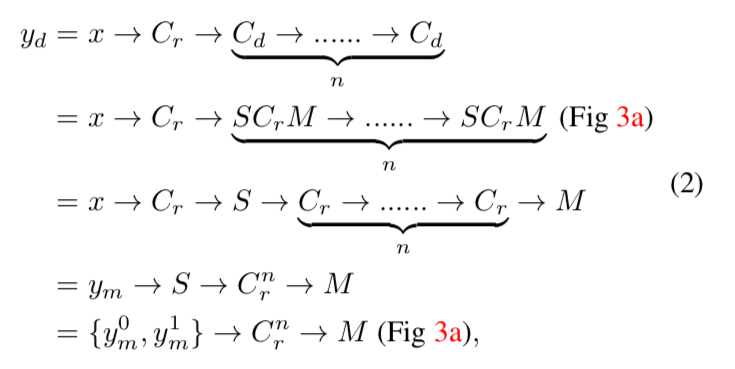
例として、backbornのConv4の特徴量マップ(Fig 2のConv4の出力)をinputとして、そこからoutputの特徴量マップを作る方法で比較します。まず、DilatedFCNでは、まず最初にinputの特徴量マップ$x$に普通の畳み込みをしたあと、dilated畳み込みを何度か行なって、outputの特徴量マップ$y_d$を作ります。
これは以下のように定式化できます。
- [記号の説明]
- $C_r$ : 普通の(regular)畳み込み($C_r^n$は$C_r$が$n$層あることを示す)
- $C_d$ : dilated畳み込み
- $C_s$ : stride畳み込み
- $S$ : 上で説明したSplitの操作
- $M$ : 上で説明したMergeの操作
- $R$ : 上で説明したReduceの操作
- $\rightarrow$ は操作を施すことを意味します
一行目と二行目の式変形は、先ほど説明したようにdilated畳み込みの分解で、三行目に行くときに、$S$と$M$の操作は相殺されます。
四行目の$y_m$は、$x$に$C_r$を施したものです。
五行目の$y_m^0$と$y_m^1$は、$y_m$を偶数番目と奇数番目で分解したものです一方、提案手法ではoutput特徴量マップ$y_s$は以下のようにして得られます。
以上より、$y_d$と$y_s$は、同じ$C_r^n$を$y_m$と$y_m^0$のどちらに施すかという点だけがことなり、$y_m^0$は$y_m$のダウンサンプリングとなっています。
そのため、$x$と$y_s$が与えられたとき、$y_d$を近似する$y$は、以下のようにして求めることができます。
これは先ほど定式化したJoint Upsamplingの問題そのものです。
Conv5をインプットとした場合にも同じ結果が得られます。
これから、この$\hat{h}$を表現する方法を考えていきます。3.3.3 Solving with CNNs
$\hat{h}$をCNNで表現する方法を考えます。
必要な要素としては、
- $x$に$C_r$を施して、$y_m$を作る
- そして、$y_m^0$からの特徴量マップと、$y_s$を一つに集める
ことが挙げられます。
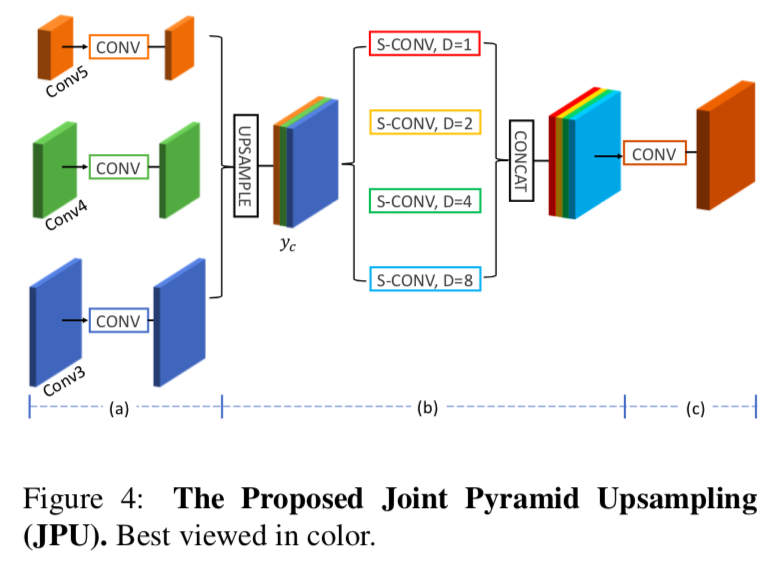
そのために、以下のようにJPU moduleを定義しました。
具体的には、
- まず、Fig 4(a)の部分で、inputの特徴量マップに普通の畳み込みをします。これは$y_m$を作り出すことに対応してます
- 得られたそれぞれの特徴量マップの次元を減らします。これにより計算コストを抑えることができます。
- 特徴量マップをupsampleして、cancatして$y_c$をつくります。
- Fig 4(b)の部分で、$y_c$に、
dilation rateが$1,2,4,8$のdilated畳み込みを並行して行います。
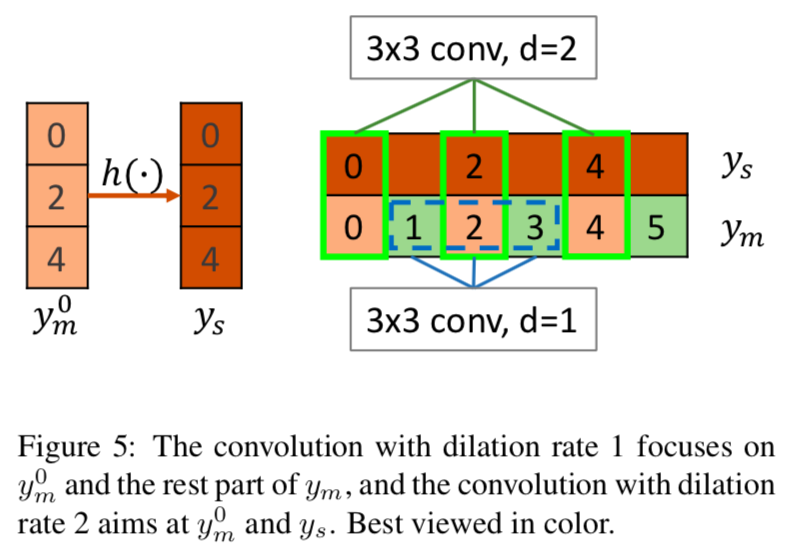
dilation rate=1の操作は、Fig 5の青で囲んだ部分をたたみ込んでいるので、$y_m^0$と$y_m$のそれ以外の部分との関係性を得る働きをします。
dilation rateが2, 4, 8の操作は、Fig 5の緑で囲んだ部分(の一部)をたたみ込むことになるので、求めたい$y_m^0$から$y_s$への写像$\hat{h}(\cdot)$を形成する働きを持ちます。
このようにして、JPUはマルチスケールの特徴量を、マルチレベルで取り込むことが可能です。これは最終層の特徴量しか考慮しないASPP moduleとの大きな違いです。
そして最後に、$y_m^0$と$y_m$のそれ以外の部分をつなぐために、Fig 4(c)の部分でもう一度普通の畳み込みを行います。これの出力が最終的な予測値となります。
4. Experiment
4.1. Experimental Settings
Dataset
Pascal Context datasetの60ラベルを使いましたという話
Implementation Details
- PyTorchで実装
- 前処理はrandom scaleとrandom fliplr
- そのあと480×480にクロップして、batchsize=16で学習
- optimizerはSGDで
momentum=0.9,weight_decay=1e-4、80epoch学習- 学習率は最初0.001から徐々に減らしていく
- loss funcは、
pixel-wise cross-entropy lossを使う- ResNet-50とResNet-101をbackbornとして使う
ここからは実験の結果だけを簡単に示していきます
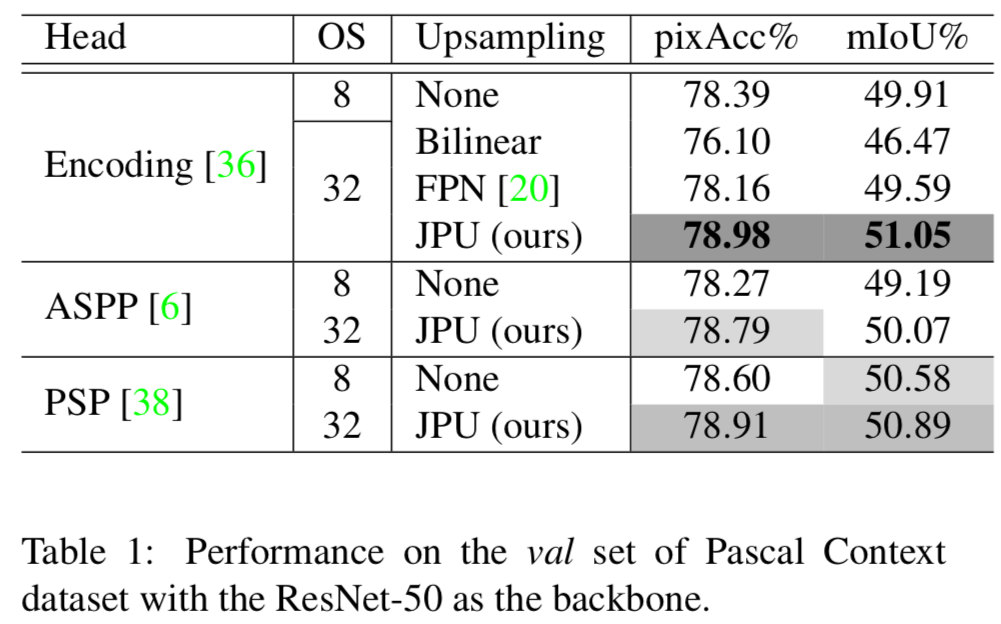
Table 1
Headにつかうモジュールと、output stride(OS)を変えたときに精度はどうなるか
JPUが最も良い結果となっている
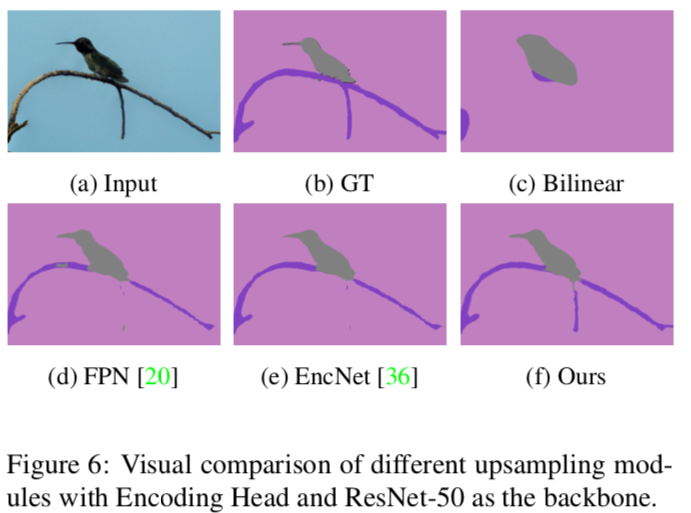
Figure 6
様々なUpsamplingのモジュールを使った場合の予測値
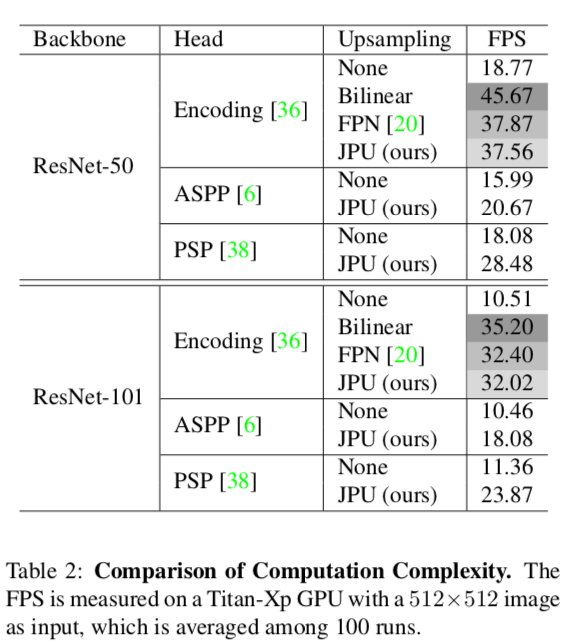
Table 2
計算時間がどれくらいかかるか(FPS)を調べたもの
実行速度はFPNと同じくらいだが、JPUの方が精度は優っている
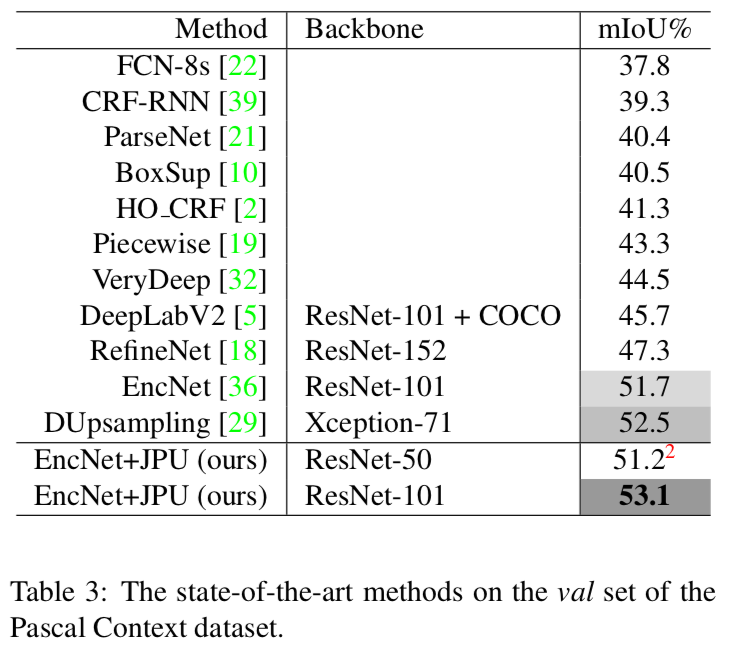
Table 3
Pascal Context dataset(val)で、歴代のSOTA手法に比べたJPUの精度
State of the art‼️
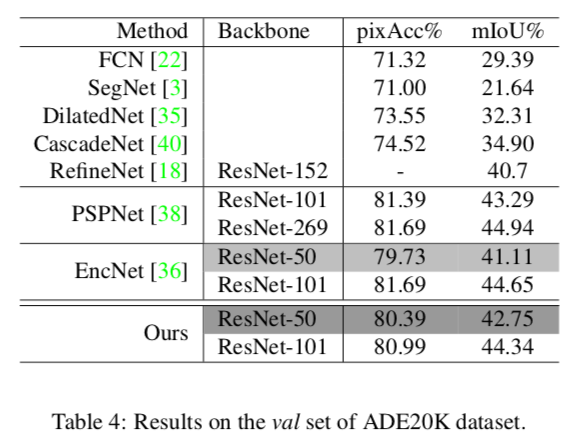
Table 4
ADE20K(val)での精度
これもJPUが一番
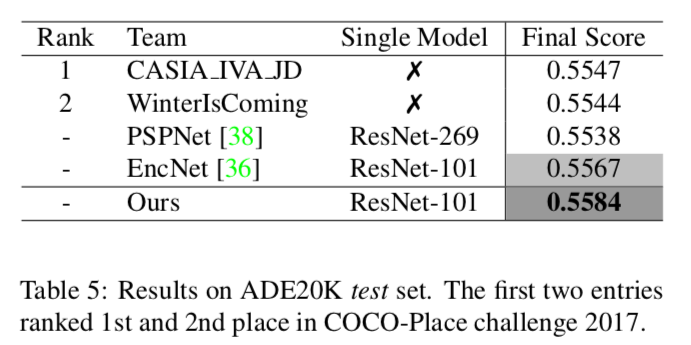
Table 5
ADE20K(test)での精度
これもJPUが一番
上の二つはCOCO-Place challenge 2017の一位と二位
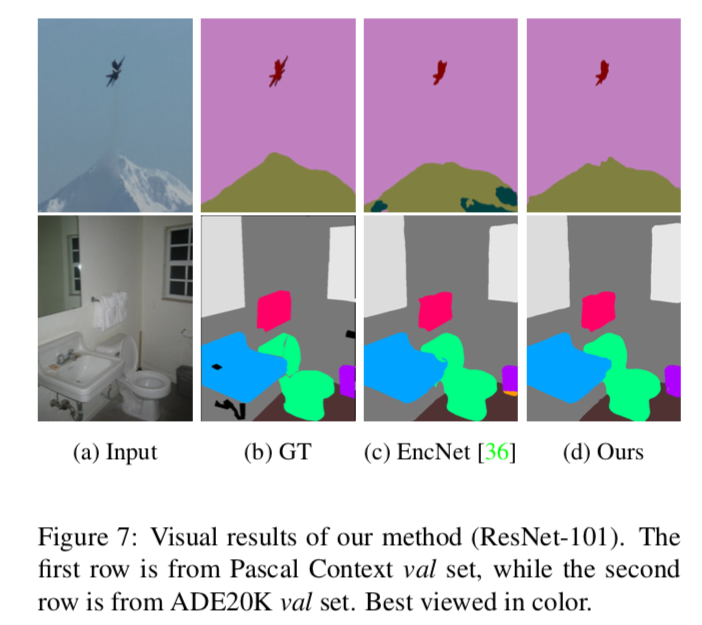
Figure 7
視覚的な結果
5. Conclusion
- dilated convolutionとstride convolutionの違いを解析し、その解析を元に、高解像度の特徴量マップを生成するJPU moduleを提案した。
- dilated convolutionをJPUに変更することにより、精度はそのままで計算コストを3倍以上抑えることができた。
- 実験の結果、JPUは他のupsampleモジュールよりも高精度であることがわかった
- 二つのセグメンテーションのデータセットで、JPUはstate-of-the-artの成績を収めることができた
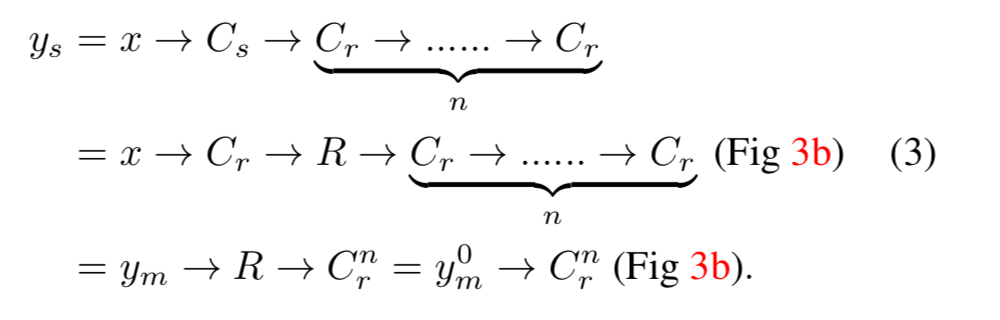
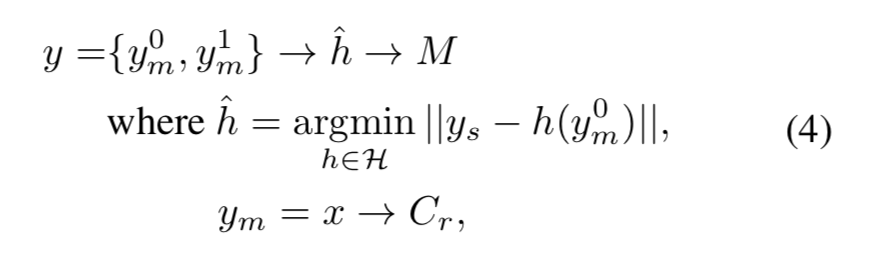
- 投稿日:2019-04-13T12:22:07+09:00
Deep Learningアプリケーション開発 (7) TensorFlow Lite with Python on Raspberry Pi and Edge TPU
この記事について
機械学習、Deep Learningの専門家ではない人が、Deep Learningを応用したアプリケーションを作れるようになるのが目的です。MNIST数字識別する簡単なアプリケーションを、色々な方法で作ってみます。特に、組み込み向けアプリケーション(Edge AI)を意識しています。
モデルそのものには言及しません。数学的な話も出てきません。Deep Learningモデルをどうやって使うか(エッジ推論)、ということに重点を置いています。
- Kerasで簡単にMNIST数字識別モデルを作り、Pythonで確認
- TensorFlowモデルに変換してPythonで使用してみる (Windows, Linux)
- TensorFlowモデルに変換してCで使用してみる (Windows, Linux)
- TensorFlow Liteモデルに変換してPythonで使用してみる (Windows, Linux)
- TensorFlow Liteモデルに変換してCで使用してみる (Linux)
- TensorFlow Liteモデルに変換してC++で使用してみる (Raspberry Pi)
- TensorFlow LiteモデルをEdge TPU上で動かしてみる (Raspberry Pi) <--- 今回の内容
今回の内容
- Kerasモデル(h5)を、Edge TPU用に変換する
- Raspberry Pi上でのEdge TPU環境を用意する
- Raspberry Piに接続されたEdge TPU上でモデルを動作させてMNIST数字識別をする
TensorFLow Lite用モデルはKerasで簡単にMNIST数字識別モデルを作り、Pythonで確認で作成した
conv_mnist.h5を使います
ソースコードとサンプル入力画像: https://github.com/take-iwiw/CNN_NumberDetector/tree/master/07_TensorflowLite_TPU環境
- OS: Windows 10 (64-bt)
- CPU = Intel Core i7-6700@3.4GHz (物理コア=4、論理プロセッサ数=8)
- Raspberry Pi 2 Model B (2018-11-13-raspbian-stretch)
- その他: Google Edge TPU
Keras用モデルをEdge TPU用モデルに変換する
量子化したTensorFlow Liteモデルに変換する
Edge TPU上で動作可能なモデルは、いくつかの制約を満たしたTensorFlow Liteモデル(tflite)になります。(https://coral.withgoogle.com/web-compiler/ のRequirementsセクションを参照)
そのため、まずはKerasで作成したモデル(h5)をTensorFlow Liteモデル(tflite)に変換します。その際に、上記制約を満たすために、量子化オプションも付けます。
変換ツール (tflite_convert)の使い方は、https://www.tensorflow.org/lite/convert/cmdline_examples を参考にしてください。これによって、conv_mnist.tfliteというファイルが出来上がります。
Kerasモデルから量子化済みTensorFlowLiteモデルに変換tflite_convert ^ --output_file=conv_mnist.tflite --keras_model_file=conv_mnist.h5 ^ --inference_type=QUANTIZED_UINT8 ^ --default_ranges_min=0 ^ --default_ranges_max=255 ^ --mean_values=128 ^ --std_dev_values=127変換はWindows上のAnaconda環境(python=3.6.8, tf-nightly-gpu=1.14.1.dev20190403)で行いました。
TensorFlowをpipインストールすると、自動的にtflite_convertもインストールされます。Edge TPU用モデルに変換する
次に、作成したTensorFlow Liteモデルを、Edge TPU用に変換します。これには、Googleが提供しているWebコンパイラを使用します。
https://coral.withgoogle.com/web-compiler/
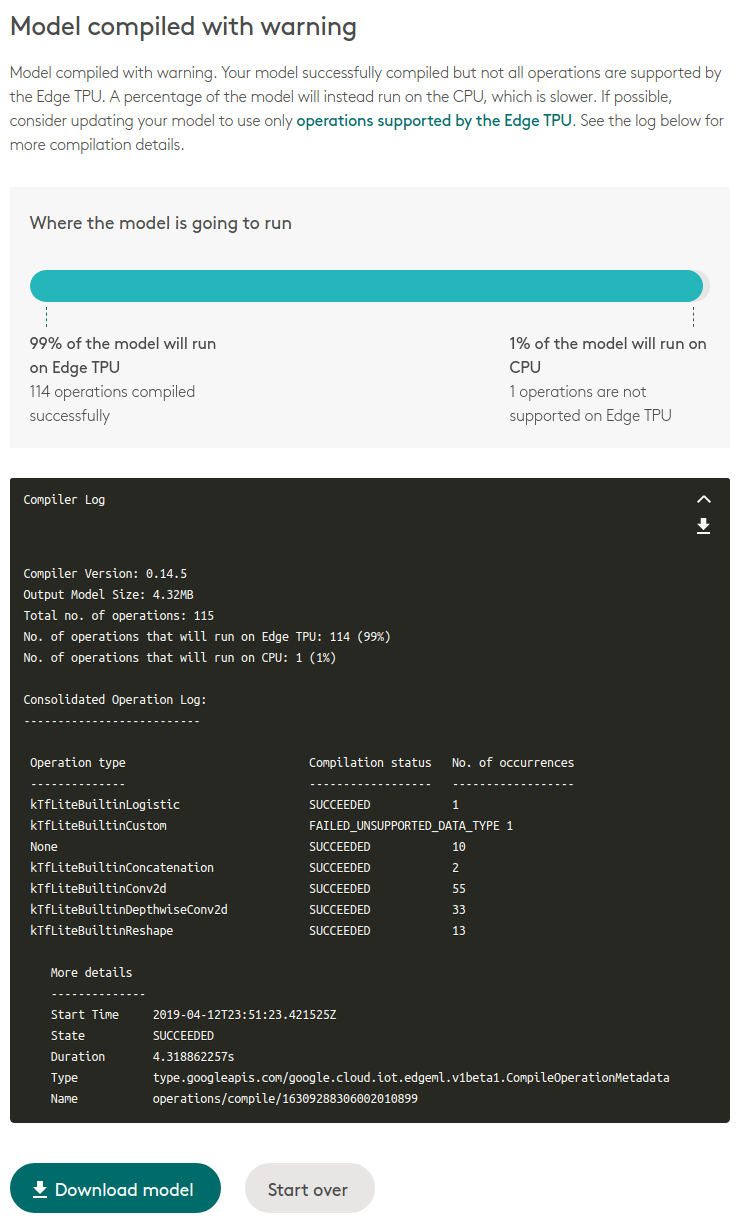
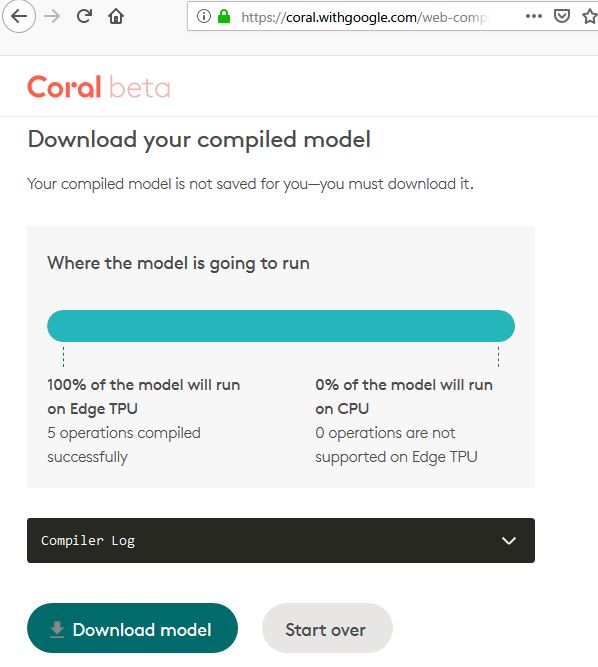
Drag and drop your model file hereの所に、先ほど作成したconv_mnist.tfliteをドラッグ&ドロップし、使用許諾的な2つのチェックボックスにチェックを付けると、自動的にコンパイルが始まります。
成功したら下記画面のようになるので、
Download modelで、ダウンロードします。
conv_mnist_123456789_edgetpu.tfliteというファイルがダウンロードされます。扱いやすいように、数字部分は消してconv_mnist_edgetpu.tfliteとしておきます。
備考:
2019年4月11日まではベータ版ということで、MobileNetなど、限られたモデルしか対応していませんでした。4月12日(この記事を書いている前日)から、カスタムモデルにも対応されるようになりました!!Raspberry Pi上でのEdge TPU環境を用意する
基本的には、https://coral.withgoogle.com/docs/accelerator/get-started/ の通りに進めれば大丈夫です。
ラズパイ上の端末で以下コマンドでインストールします。EdgeTPUインストールonラズパイcd ~/ wget https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz -O edgetpu_api.tar.gz --trust-server-names tar xzf edgetpu_api.tar.gz cd edgetpu_api bash ./install.shが、僕の環境はRaspberry Pi 2のため、Edge TPUは未対応のためインストールに失敗しました。また、virtualenv上ではうまくインストールできませんでした。
以下方法で回避しましたので、同じ状況の人は参考にしてください。(自己責任でお願いします)Raspberry Pi 2にインストールする(optional)
install.sh でプラットフォームチェックしている部分を以下のように変更します。
ラズパイ3でも32bitモードで動いているので、バイナリ互換性はあるはず、と思いチェック処理だけ変えたら出来ました。install.sh~略~ elif [[ "${CPU_ARCH}" == "armv7l" ]]; then MODEL=$(cat /proc/device-tree/model) # if [[ "${MODEL}" == "Raspberry Pi 3 Model B Rev"* ]]; then if [[ "${MODEL}" == "Raspberry Pi "* ]]; then info "Recognized as Raspberry Pi 3 B." LIBEDGETPU_SUFFIX=arm32 HOST_GNU_TYPE=arm-linux-gnueabihf # elif [[ "${MODEL}" == "Raspberry Pi 3 Model B Plus Rev"* ]]; then elif [[ "${MODEL}" == "Raspberry Pi "* ]]; then info "Recognized as Raspberry Pi 3 B+." LIBEDGETPU_SUFFIX=arm32 HOST_GNU_TYPE=arm-linux-gnueabihf fi ~略~virtualenv上にインストールする(optional)
単にinstall.sh を実行すると、パッケージはグローバル環境にインストールされるようです。(virtualenvをactivate/workonしていても)。
そのため、自分の仮想環境に入っている状態で、別途pip installする必要がありました。
これをやらないと、No module named 'edgetpu'エラーが出ます。まとめると以下のようになります。
EdgeTPUインストールfor仮想環境onラズパイ2cd ~/ workon py3_tpu wget https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz -O edgetpu_api.tar.gz --trust-server-names tar xzf edgetpu_api.tar.gz cd edgetpu_api nano ./install.sh # 編集する bash ./install.sh pip install edgetpu-1.9.2-py3-none-any.whlEdge TPU上でモデルを動作させてMNIST数字識別をする
Edge TPUのインストールを完了すると、デモコードが
/usr/local/lib/python3.5/dist-packages/edgetpu/(通常インストールの場合)、/home/pi/.virtualenvs/py3_tpu/lib/python3.5/site-packages/edgetpu(virtualenvの場合)にインストールされます。デモコードを動かす
xxx/site-packages/edgetpu/demo/classify_image.pyが識別用のサンプルコードです。
本当なら、以下のようにすることでデモコードで、今回作成したモデルを試すことが出来ます。
が、これは動きません。
デモコード(というか、画像識別用Wrapper)が、3chカラー入力を前提としているため、今回作成した1chグレースケールのMNIST識別モデルはパラメータチェックではじかれてエラーになります。
MobileNet等のちゃんとしたモデルなら、これで確認出来ます。デモコードを動かすpython3 /home/pi/.virtualenvs/py3_tpu/lib/python3.5/site-packages/edgetpu/demo/classify_image.py \ --model conv_mnist_edgetpu.tflite \ --label mnist_labels.txt \ --image resource/3.jpgちなみに、mnist_labels.txtには識別結果と表示ラベルのペアを記載します。
mnist_labels.txt0 num0 1 num1 2 num2 ~略~識別用コードを実装する
edgetpu/demo/classify_image.pyをベースに、自分で実装します。classify_image_mnist.pyとします。classify_image_mnist.pyimport argparse import re from edgetpu.classification.engine import ClassificationEngine from PIL import Image, ImageOps import numpy # Function to read labels from text files. def ReadLabelFile(file_path): """Reads labels from text file and store it in a dict. Each line in the file contains id and description separted by colon or space. Example: '0:cat' or '0 cat'. Args: file_path: String, path to the label file. Returns: Dict of (int, string) which maps label id to description. """ with open(file_path, 'r', encoding='utf-8') as f: lines = f.readlines() ret = {} for line in lines: pair = re.split(r'[:\s]+', line.strip(), maxsplit=1) ret[int(pair[0])] = pair[1].strip() return ret def main(): parser = argparse.ArgumentParser() parser.add_argument( '--model', help='File path of Tflite model.', required=True) parser.add_argument( '--label', help='File path of label file.', required=True) parser.add_argument( '--image', help='File path of the image to be recognized.', required=True) args = parser.parse_args() # Prepare labels. labels = ReadLabelFile(args.label) # Initialize engine. engine = ClassificationEngine(args.model) # Read input image and convert to tensor img = Image.open(args.image) img = img.convert('L') img = ImageOps.invert(img) input_tensor_shape = engine.get_input_tensor_shape() if (input_tensor_shape.size != 4 or input_tensor_shape[3] != 1 or input_tensor_shape[0] != 1): raise RuntimeError( 'Invalid input tensor shape! Expected: [1, height, width, 3]') _, height, width, _ = input_tensor_shape img = img.resize((width, height), Image.NEAREST) input_tensor = numpy.asarray(img).flatten() # Run inference. for result in engine.ClassifyWithInputTensor(input_tensor=input_tensor, threshold=0.1, top_k=3): print('---------------------------') print(labels[result[0]]) print('Score : ', result[1]) # for time measurement for i in range(5000): for result in engine.ClassifyWithInputTensor(input_tensor=input_tensor, threshold=0.1, top_k=3): pass if __name__ == '__main__': main()オリジナルのデモコードでは、読み込んだ画像をそのまま入力として、ClassificationEngine.ClassifyWithImageをコールしていました。
この関数は画像を入れるだけで推論処理が出来て便利なのですが、グレースケール(1ch)画像には対応していないです。
ClassificationEngine.ClassifyWithImageは、内部でリサイズなどを行ったあと、ClassificationEngine.ClassifyWithInputTensor を呼んでいます。こちらの関数の入力は文字通りTensorになります。
ですので、今回は自分で画像->Tensorへの変換を行い、直接ClassificationEngine.ClassifyWithInputTensor を呼ぶことにしました。また、処理時間測定のために無駄に5000回くらい呼んでいます。
実行してみる
以下コマンドで実行できます。
実行コマンドpython3 classify_image_mnist.py \ --model ~/CNN_NumberDetector/07_TensorflowLite_TPU/conv_mnist_edgetpu.tflite \ --label ~/CNN_NumberDetector/07_TensorflowLite_TPU/mnist_labels.txt \ --image ~/CNN_NumberDetector/07_TensorflowLite_TPU/resource/5.jpg「5」が書かれたJPEG画像を入力しました。結果、以下のように正しく5だと識別できました。
また、実行中はEdgeTPUドングルの白LEDが強く光っていたので、ちゃんとTPU側で処理しているのだと思います。結果num5 Score : 0.99609375処理時間を比較してみる
使用するモデルを差し替えるだけで、CPU動作かEdge TPU動作かを切り替えられるようです。
timeコマンドを付けて処理時間を比較してみました。処理時間比較実行コマンド# for Edge TPU time python3 classify_image_mnist.py \ --model ~/CNN_NumberDetector/07_TensorflowLite_TPU/conv_mnist_edgetpu.tflite \ --label ~/CNN_NumberDetector/07_TensorflowLite_TPU/mnist_labels.txt \ --image ~/CNN_NumberDetector/07_TensorflowLite_TPU/resource/5.jpg # for CPU time python3 classify_image_mnist.py \ --model ~/CNN_NumberDetector/07_TensorflowLite_TPU/conv_mnist.tflite \ --label ~/CNN_NumberDetector/07_TensorflowLite_TPU/mnist_labels.txt \ --image ~/CNN_NumberDetector/07_TensorflowLite_TPU/resource/5.jpg結果Edge TPU: real 0m18.596s user 0m9.698s sys 0m3.427s CPU: real 0m12.852s user 0m9.446s sys 0m0.233s結果、Edge TPU実行はトータルで18.6秒、CPU実行はトータルで12.9秒という、CPUの方が速いという残念な結果になってしまいました。
sys時間を見ると、TPU側の方は3.5秒もかかっていました。おそらく、EdgeTPUデバイス制御関係のオーバーヘッドによるものだと思います。
今回使用したような非常に小さいモデルではディープラーニング計算時間そのものよりも、こういったオーバーヘッドの方が大きいようです。メモ: インストールコマンドまとめ
素のRaspberry Pi2に対して、Edge TPUデモコードを動作させるまでの環境設定コマンド
(virtualenv, opencvを含む(単にEdge TPUを試すだけなら不要))EdgeTPU環境設定コマンドforラズパイ2# 環境更新 sudo apt-get update sudo apt-get upgrade # OpenCV用パッケージインストール sudo apt-get install libatlas3-base libwebp6 libtiff5 libjasper1 libilmbase12 libopenexr22 libilmbase12 libgstreamer1.0-0 libavcodec57 libavformat57 libavutil55 libswscale4 libqtgui4 libqt4-test libqtcore4 # virtualenvインストールと設定 sudo pip install virtualenv sudo pip install virtualenvwrapper nano ~/.bashrc >>> 以下を追加 export LC_ALL="en_US.UTF-8" export LC_CTYPE="en_US.UTF-8" ### Virtualenvwrapper if [ -f /usr/local/bin/virtualenvwrapper.sh ]; then export WORKON_HOME=$HOME/.virtualenvs source /usr/local/bin/virtualenvwrapper.sh fi <<< # ターミナル再起動 # 仮想環境を作る (名前をpy3_tpuとする) cd ~/ mkvirtualenv --python=python3 py3_tpu # deactivate # workon py3_tpu # 仮想環境上で必要なパッケージをpipインストール pip install --upgrade setuptools pip install opencv-python pip install numpy # Pillow は2019/4/13時点でインストール時にビルドエラーが出たので、piwheelsのprebuiltバイナリを使用 # pip install Pillow pip install https://www.piwheels.org/simple/Pillow/Pillow-5.4.1-cp35-cp35m-linux_armv7l.whl#sha256=ed4e05737ed076aed4065e05b67983650b10110f3e133444e8e87bd572e1492a # Edge TPUインストール wget https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz -O edgetpu_api.tar.gz --trust-server-names tar xzf edgetpu_api.tar.gz cd edgetpu_api # ラズパイ2の場合、編集する(https://qiita.com/take-iwiw/items/6aeab468c326ecc21563#raspberry-pi-2にインストールするoptional) nano ./install.sh bash ./install.sh # 仮想環境用に再度インストール pip install edgetpu-1.9.2-py3-none-any.whl # デモを試す cd ~/Downloads/ wget https://storage.googleapis.com/cloud-iot-edge-pretrained-models/canned_models/mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite \ http://storage.googleapis.com/cloud-iot-edge-pretrained-models/canned_models/inat_bird_labels.txt \ https://coral.withgoogle.com/static/images/parrot.jpg cd /home/pi/.virtualenvs/py3_tpu/lib/python3.5/site-packages/edgetpu/demo python3 classify_image.py \ --model ~/Downloads/mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite \ --label ~/Downloads/inat_bird_labels.txt \ --image ~/Downloads/parrot.jpg※たまたまかもしれないが、インストール直後にそのままデモを実行したら、RuntimeErrorが発生した。ラズパイを再起動したりEdge TPUドングルを抜き差ししたら治った。
- 投稿日:2019-04-13T09:59:58+09:00
Edge TPU Accelarator+カスタムモデルMobileNetv2-SSDLiteの.tflite生成 【やっと成功したよ】_Docker編_その4
Tensorflow-bin
TPU-MobilenetSSD
1.Introduction
TPUモデルコンパイラがカスタムモデルの変換に対応したそうですので早速試してみました。
この記事の手順では最終的に生成されたモデルの精度が極悪ですが、転移学習ではなくフル学習にしたり、パラメータを調整することで精度は改善可能です。
この記事で語るのは、あくまで独自DockerイメージによるカスタムTPUモデルの学習と生成手順のみです。
モデル性能のチューニングは実施しません。2.Procedure
学習手順は、前回記事 Edge TPU Accelaratorの動作を少しでも高速化したかったのでMobileNetv2-SSD/MobileNetv1-SSD+MS-COCOをPascal VOCで転移学習して.tfliteを生成した_Docker編_その2 あるいは Edge TPU Accelaratorの動作を少しでも高速化したかったのでMS-COCOをPascal VOCで転移学習して.tfliteを生成した_GoogleColaboratory[GPU]編_その3 をそのまま使用します。 前回記事はもともと、 TPUコンパイラ がカスタムモデルに対応することを事前に知っていたため、機能がリリースされたときに最速で検証できるよう事前準備をしていたのです。
私独自のDockerは公式のDockerイメージとは異なり、NVIDIA Docker を使用します。
公式のDockerがGPUトレーニングに対応していないため、自力でシーケンスを大幅に組み直しています。なお、対応可能なレイヤと変換アルゴリズムは、 公式の TensorFlow models on the Edge TPU に記載されていますので参考にしてください。
3.Results
前回記事 の手順により生成した MobileNetv2-SSDLite の .tflite ファイルをコンパイラに投入してみます。
https://coral.withgoogle.com/web-compiler/
ドラッグ&ドロップで、 せーの、ホイッ!
あっさり成功しました。 しかも、アップデートが入る前までは一切表示されなかった変換ログが表示されるようになっています。 さらに、TPU側で非対応のレイヤーは自動的にCPUへオフロードされる仕様に改善されています。
最高です。 OpenVINOに欲しい機能です。
ある程度自由にレイヤを組み合わせて推論させることができるため、対応モデルの幅が大幅に広がりましたね。今回は、各種公式ドキュメントを一切見ずに独自の軽量トレーニングとコンバートを実施しました。
4.Finally
おいおいフルトレーニングをし直して推論精度を向上した .tflite モデルを生成して遊びたいと思います。