- 投稿日:2019-04-03T20:40:46+09:00
linuxにしようか迷ったのでOSについてまとめてみた
未来電子テクノロジーでインターンをしている梅原です。
webプログラミングを今現在、Windowsで勉強しているのですが、環境構築とかでいろいろ難あり(実力不足なだけですが)なので、linuxを使おうかなと思って、調べたのでまとめです。OSとは
OPERATING SYSTEMの略称です。
コンピュータを制御して、使う仕組みです。
windowsとかmacOSが有名ですが、スマホのandroidもOSの一つです。MacOS,Windows,Linuxの違い
歴史的な流れから話すと面倒なので、機能の違いで考えます。
windows
言わずと知れたOSシェア9割。Microsoft社製です。
当たり前すぎて説明が難しいです。macOS
apple社製のパソコン用のOSです。
brewを使ってプログラミングに必要な言語やフレームワーク、ライブラリが簡単にインストールでき、簡単に環境構築ができるのが魅力。
ちなみに、swiftというiosアプリを作ることが可能な言語はmacOSでしか使えません。linux
さて、本題のlinux
オープンソースのOSで、ソースコードが公開されています。
無料で入手することが可能です。
linuxはOSの総称という方がわかりやすいかもしれませんが、様々なディストリビューションがあります。
最近のmacOSはlinuxをベースに開発されているので、開発はmacOS同様やりやすいです。
また、windowsよりもかなり軽いので、windowsが重いというパソコンでもサクサク動くことがあります。かなりざっくりとまとめました。
歴史的な背景は、独占禁止ほうが絡んでいたり、いろいろ面白いので興味があれば、調べることをおすすめします。
参考URL(https://qiita.com/tatsuya4150/items/09a45b71d7a6fb58efd0)
間違い等あるかと思いますが、その際はご指摘お願いします。
- 投稿日:2019-04-03T09:42:21+09:00
【読解入門】Linuxカーネル (スケジューラ編その4-1)
・idleクラスは、大した処理をしていないので説明は割愛します。
・deadlineクラスは、後日「スケジューラ編その3-4」として投稿する予定です。
・本稿で読解の対象にしているLinuxカーネルの版数は5.1-rc2です。初めに
本稿ではいよいよスケジューラコア部のコードを読解していきます。私自身のモチベーションも上がります!
このコア部の説明をどのように進めるべきか考えた結果、他のコンポーネントから呼び出されるAPI(処理)を軸に説明していく進め方が良いのではないかと思ったので、この方法で読解していきます。
コア部のAPI
皆さん、ドライバ開発で共通部を利用する際にカーネルAPIをどのように調査されていますか。
私の場合、早い段階で関連する機能部のEXPORT_SYMBOLで定義されたAPIを調べて、それぞれのAPIの概要を掴みます。そして、そのAPIを使用している他のドライバの例を見て認識が間違っていないことを確認します。そうすることで、全体のイメージ(自分で実装する部分と用意されている実装を利用する部分の区別)が湧いてきます。少し話が逸れましたが、スケジューラコア部(kernel/sched/core.c)でEXPORT_SYMBOLでgrepすると下記が出力されます。
EXPORT_SYMBOL_GPL(set_cpus_allowed_ptr); //SMP用なので省略
EXPORT_SYMBOL_GPL(kick_process);
EXPORT_SYMBOL(wake_up_process);
EXPORT_SYMBOL_GPL(preempt_notifier_inc);
EXPORT_SYMBOL_GPL(preempt_notifier_dec);
EXPORT_SYMBOL_GPL(preempt_notifier_register);
EXPORT_SYMBOL_GPL(preempt_notifier_unregister);
EXPORT_SYMBOL(single_task_running);
EXPORT_SYMBOL(preempt_count_add);
EXPORT_SYMBOL(preempt_count_sub);
EXPORT_SYMBOL(schedule);
EXPORT_SYMBOL(preempt_schedule);
EXPORT_SYMBOL_GPL(preempt_schedule_notrace);
EXPORT_SYMBOL(default_wake_function);
EXPORT_SYMBOL(set_user_nice);
EXPORT_SYMBOL_GPL(sched_setscheduler);
EXPORT_SYMBOL_GPL(sched_setattr);
EXPORT_SYMBOL_GPL(sched_setscheduler_nocheck);
EXPORT_SYMBOL(_cond_resched);
EXPORT_SYMBOL(__cond_resched_lock);
EXPORT_SYMBOL(yield);
EXPORT_SYMBOL_GPL(yield_to);
EXPORT_SYMBOL(io_schedule_timeout);
EXPORT_SYMBOL(io_schedule);
EXPORT_SYMBOL_GPL(sched_show_task);
EXPORT_SYMBOL(__might_sleep);
EXPORT_SYMBOL(___might_sleep);
EXPORT_SYMBOL_GPL(__cant_sleep);まずはこれらを機能ごとにグルーピングしましょう。
・スケジューリング要求
schedule
preempt_schedule
preempt_schedule_notrace
_cond_resched
__cond_resched_lock・プロセスの起床要求
kick_process *
wake_up_process
default_wake_function・CPUの明渡し
yield
yield_to
__might_sleep *
___might_sleep *
__cant_sleep *・スケジューリングポリシーや優先度の設定
set_user_nice
sched_setscheduler
sched_setattr
sched_setscheduler_nocheck・プリエンプションの制御
preempt_notifier_inc
preempt_notifier_dec
preempt_notifier_register
preempt_notifier_unregister
preempt_count_add
preempt_count_sub・その他
single_task_running
io_schedule_timeout
io_scheduleいかがでしょうか。
これで大雑把ですが分類できましたね。
なお、*をつけた処理はSMP向けであったり、大した処理をしていないため割愛させていただきます。ご興味のある方はコードを見てください。それではこの項目ごとに処理を見ていきましょう。
本記事では、
・スケジューリング要求
・プロセスの起床要求
・CPUの明渡し次の記事では
・スケジューリングポリシーや優先度の設定
・プリエンプションの制御
・その他
を述べたいと思います。なお、事象を待ち合わせるための機能としてwaitキューがありますが、これは別途「waitキュー編」として記載することにします。
スケジューリング要求
schedule関数
kernel/sched/core.casmlinkage __visible void __sched schedule(void) { 1 struct task_struct *tsk = current; 2 sched_submit_work(tsk); 3 do { 4 preempt_disable(); 5 __schedule(false); 6 sched_preempt_enable_no_resched(); 7 } while (need_resched()); }1行目:taskにcurrentプロセスを設定します。
2行目:currentプロセスのブロックIO要求が発行されるされるまで待ちます。
4行目:プリエンプション(プロセススイッチ)を禁止します。
途中、話が逸れてしまいますが、Linuxでプリエンプションの制御(禁止と許可)をどのように行っているか整理しましょう。
Linuxの各プロセスには必ず対応するtask_struct構造体が存在します。
そのtask_struct構造体にthread_info構造体のメンバthread_infoが存在します。
このthread_info構造体にint型のpreempt_countメンバがあり、この変数でプリエンプションの禁止/許可を制御します。
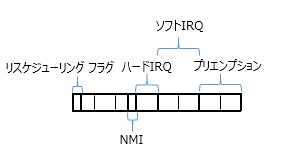
preempt_countメンバの構成は下記のコメントが判りやすいです。
include/linux/preempt.h/* * We put the hardirq and softirq counter into the preemption * counter. The bitmask has the following meaning: * * - bits 0-7 are the preemption count (max preemption depth: 256) * - bits 8-15 are the softirq count (max # of softirqs: 256) * * The hardirq count could in theory be the same as the number of * interrupts in the system, but we run all interrupt handlers with * interrupts disabled, so we cannot have nesting interrupts. Though * there are a few palaeontologic drivers which reenable interrupts in * the handler, so we need more than one bit here. * * PREEMPT_MASK: 0x000000ff * SOFTIRQ_MASK: 0x0000ff00 * HARDIRQ_MASK: 0x000f0000 * NMI_MASK: 0x00100000 * PREEMPT_NEED_RESCHED: 0x80000000
プリエンプションについては0-7bit目を使用し、0の時はプリエンプション許可、0以外の時はプリエンプション禁止になります。
この規則で制御するために3行目のpreempt_disable( )は、preempt_countをインクリメントします。
余談ですが、softirq (遅延割込み)、hardirq (ハードウェア割込み)、リスケジューリング フラグもこのpreempt_countの各ビットを用いて設定します。上記コメントから判る通り、リスケジューリング フラグは最上位ビット、ハードウェア割込み回数は16-19bit目、遅延割込みは8-15bit目までを使用します。(ハードウェア/遅延)割込み関連は割込み処理の入り口でインクリメントし、出口でデクリメントします。従って、0か否かを見ることでその時に割込み処理を行っているかどうかの判定に使用できます。リスケジューリング フラグはこれまでに何度か出てきましたね。再スケジュールが必要な場合にこのbitをセットします。5行目:本関数のポイントで、実際にコンテキストスイッチするシーケンスの入り口です。詳しく見る前に6、7行目を説明します。
6行目:プリエンプションを許可します(リスケジューリング フラグはセットしない)。
7行目:currentプロセスのリスケジューリング フラグがセットされている場合、3行目に戻ります。
それでは、5行目を見ていきましょう。kernel/sched/core.cstatic void __sched notrace __schedule(bool preempt) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq_flags rf; struct rq *rq; int cpu; 1 cpu = smp_processor_id(); 2 rq = cpu_rq(cpu); 3 prev = rq->curr; 4 schedule_debug(prev); 5 if (sched_feat(HRTICK)) 6 hrtick_clear(rq); 7 local_irq_disable(); 8 rcu_note_context_switch(preempt); /* * Make sure that signal_pending_state()->signal_pending() below * can't be reordered with __set_current_state(TASK_INTERRUPTIBLE) * done by the caller to avoid the race with signal_wake_up(). * * The membarrier system call requires a full memory barrier * after coming from user-space, before storing to rq->curr. */ 9 rq_lock(rq, &rf); 10 smp_mb__after_spinlock(); /* Promote REQ to ACT */ 11 rq->clock_update_flags <<= 1; 12 update_rq_clock(rq); 13 switch_count = &prev->nivcsw; 14 if (!preempt && prev->state) { 15 if (signal_pending_state(prev->state, prev)) { 16 prev->state = TASK_RUNNING; 17 } else { 18 deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK); 19 prev->on_rq = 0; 20 if (prev->in_iowait) { 21 atomic_inc(&rq->nr_iowait); 22 delayacct_blkio_start(); 23 } /* * If a worker went to sleep, notify and ask workqueue * whether it wants to wake up a task to maintain * concurrency. */ 24 if (prev->flags & PF_WQ_WORKER) { 25 struct task_struct *to_wakeup; 26 to_wakeup = wq_worker_sleeping(prev); 27 if (to_wakeup) 28 try_to_wake_up_local(to_wakeup, &rf); 29 } 30 } 31 switch_count = &prev->nvcsw; 32 } 33 next = pick_next_task(rq, prev, &rf); 34 clear_tsk_need_resched(prev); 35 clear_preempt_need_resched(); 36 if (likely(prev != next)) { 37 rq->nr_switches++; 38 rq->curr = next; /* * The membarrier system call requires each architecture * to have a full memory barrier after updating * rq->curr, before returning to user-space. * * Here are the schemes providing that barrier on the * various architectures: * - mm ? switch_mm() : mmdrop() for x86, s390, sparc, PowerPC. * switch_mm() rely on membarrier_arch_switch_mm() on PowerPC. * - finish_lock_switch() for weakly-ordered * architectures where spin_unlock is a full barrier, * - switch_to() for arm64 (weakly-ordered, spin_unlock * is a RELEASE barrier), */ 39 ++*switch_count; 40 trace_sched_switch(preempt, prev, next); /* Also unlocks the rq: */ 41 rq = context_switch(rq, prev, next, &rf); 42 } else { 43 rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP); 44 rq_unlock_irq(rq, &rf); 45 } 46 balance_callback(rq); }1、2行目:currentプロセスのランキューを設定します。
smp_processor_id( )はcurrentプロセスが動作しているCPU番号を返します。
3行目:currentプロセスをprevプロセスに変更します。
7行目:割込みを禁止します。
15、16行目:現在実行しているプロセス(prev)に保留しているシグナルが存在する場合、ステータスを実行可能状態にします。
18行目:保留しているシグナルが存在しない場合、deactivate_task( )→dequeue_task( )経由で実行キューから外します。
33行目:次に実行するプロセスを求めます。kernel/sched/core.cstatic inline struct task_struct * pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) { const struct sched_class *class; struct task_struct *p; 1 if (likely((prev->sched_class == &idle_sched_class || 2 prev->sched_class == &fair_sched_class) && 3 rq->nr_running == rq->cfs.h_nr_running)) { 4 p = fair_sched_class.pick_next_task(rq, prev, rf); 5 if (unlikely(p == RETRY_TASK)) 6 goto again; /* Assumes fair_sched_class->next == idle_sched_class */ 7 if (unlikely(!p)) 8 p = idle_sched_class.pick_next_task(rq, prev, rf); 9 return p; 10 } 11again: 12 for_each_class(class) { 13 p = class->pick_next_task(rq, prev, rf); 14 if (p) { 15 if (unlikely(p == RETRY_TASK)) 16 goto again; 17 return p; 18 } 19 } /* The idle class should always have a runnable task: */ 20 BUG(); 21}1~10行目:これまで動作していたプロセスが一般クラスかもしくはIDLEクラスの場合、処理します。現在のrqの実行可能プロセス数がcfsのプロセス数と同じであることが判定条件です。
4行目:一般クラスのpick_next_taskメンバを呼び出して、一般クラス向けのアルゴリズムで次のプロセスを求めます。その結果がRETRY_TASKの場合は11行目にとびますが、Uni-Processorシステムの場合、RETRY_TASKを返すことがないため、復帰値のプロセスが次に実行するプロセスになります。
7、8行目:一般クラスのpick_next_taskメンバの復帰値で次に実行するプロセスが存在しなかった場合、その次の優先度であるIDLEクラスのpick_next_taskメンバを実行します。
9行目:上記で求めたプロセスを__schedule関数に復帰値として返します。
12~19行目:優先度の高いクラスから順にpick_next_taskメンバを実行します。そして、求められたプロセスを__schedule関数に返します。
20行目:通常この部分に到達することはないので、もし到達した場合はBUGメッセージを出力します。__schedule関数に戻ります。
34行目:動作していたプロセスのリスケジューリング フラグをクリアします。
35行目:空関数です。
36行目:これまで実行していたプロセスとpick_next_task(前々回、前回で出てきましたね)で求めた次に実行するプロセスが異なる場合かどうかの判定処理です。
37行目:コンテキストスイッチ数(統計情報)をインクリメントします。
38行目:rqのcurrに次に実行するプロセスを設定します。
41行目:コンテキストスイッチの核です。kernel/sched/core.cstatic __always_inline struct rq * context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next, struct rq_flags *rf) { struct mm_struct *mm, *oldmm; 1 prepare_task_switch(rq, prev, next); 2 mm = next->mm; 3 oldmm = prev->active_mm; /* * For paravirt, this is coupled with an exit in switch_to to * combine the page table reload and the switch backend into * one hypercall. */ 4 arch_start_context_switch(prev); /* * If mm is non-NULL, we pass through switch_mm(). If mm is * NULL, we will pass through mmdrop() in finish_task_switch(). * Both of these contain the full memory barrier required by * membarrier after storing to rq->curr, before returning to * user-space. */ 5 if (!mm) { 6 next->active_mm = oldmm; 7 mmgrab(oldmm); 8 enter_lazy_tlb(oldmm, next); 9 } else 10 switch_mm_irqs_off(oldmm, mm, next); 11 if (!prev->mm) { 12 prev->active_mm = NULL; 13 rq->prev_mm = oldmm; 14 } 15 rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP); 16 prepare_lock_switch(rq, next, rf); /* Here we just switch the register state and the stack. */ 17 switch_to(prev, next, prev); 18 barrier(); 19 return finish_task_switch(prev); }2~14行目でmm_struct構造体の切り替えを行います。
2、3行目でmmとoldmmを設定し、主要な処理としては10行目のプロセス空間の切り替えです。関数全体は貼り付けませんが、処理シーケンスとしては
switch_mm_irqs_off( )→check_and_switch_context( )→cpu_switch_mm ( )
でプロセス空間を切り替えます。
17行目のswitch_toはアーキ依存部になります。Armを例に見てみましょう。arch/arm/include/asm/switch_to.h#define switch_to(prev,next,last) \ do { \ __complete_pending_tlbi(); \ last = __switch_to(prev,task_thread_info(prev), task_thread_info(next)); \ } while (0)__swtch_toを見ます。
arch/arm/kerne/entry-armv.SENTRY(__switch_to) UNWIND(.fnstart ) UNWIND(.cantunwind ) 1 add ip, r1, #TI_CPU_SAVE 2 ARM( stmia ip!, {r4 - sl, fp, sp, lr} ) @ Store most regs on stack 3 ldr r4, [r2, #TI_TP_VALUE] 4 ldr r5, [r2, #TI_TP_VALUE + 4] 5 switch_tls r1, r4, r5, r3, r7 6 mov r5, r0 7 add r4, r2, #TI_CPU_SAVE 8 ldr r0, =thread_notify_head 9 mov r1, #THREAD_NOTIFY_SWITCH 10 bl atomic_notifier_call_chain 11 mov r0, r5 12 ARM( ldmia r4, {r4 - sl, fp, sp, pc} ) @ Load all regs saved previously UNWIND(.fnend ) ENDPROC(__switch_to)極力簡素化したコードが上のコードです。
上記のTI_xxxは、以下のthread_info構造体のメンバを指しています。
例えば、1行目の#TI_CPU_SAVEはarch/arm/kernel/asm-offset.cで
DEFINE(TI_CPU_SAVE, offsetof(struct thread_info, cpu_context));
のように定義されており、thread_info構造体のcpu_contextを指していることが判ります。
以下にthread_info構造体を示します。arch/arm/include/asm/thread_info.hstruct thread_info { unsigned long flags; /* low level flags */ int preempt_count; /* 0 => preemptable, <0 => bug */ mm_segment_t addr_limit; /* address limit */ struct task_struct *task; /* main task structure */ __u32 cpu; /* cpu */ __u32 cpu_domain; /* cpu domain */ struct cpu_context_save cpu_context; /* cpu context */ __u32 syscall; /* syscall number */ __u8 used_cp[16]; /* thread used copro */ unsigned long tp_value[2]; /* TLS registers */ union fp_state fpstate __attribute__((aligned(8))); union vfp_state vfpstate; };__switch_to関数を、極力シンプルに述べると、1、2行目でこれまで動作していたプロセスのレジスタ群をスタックへ退避し、7、12行目で新たに実行するプロセスのレジスタ群を復元しています。従って、厳密に言うと12行目から次プロセスの実行になります。
また、これまで動作していたprevプロセスは、次回動作する時はこの12行目から実行を再開することになります。
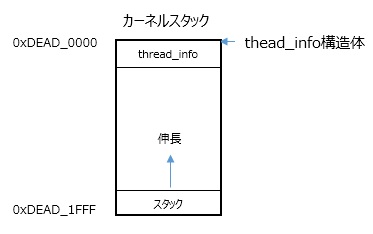
ここで、スタックへの退避・復元をするのであれば、thread_info構造体のcpu_contextなどのメンバは何のためにあるのか?と思われる方もいらっしゃると思います。スタックへの退避には間違いないのですが、各プロセスのthread_info構造体とカーネルスタック(8KBの場合)は以下のような関係にあります。
8KBアラインでカーネルスタックは割り当てられますので、カーネルスタックアドレスを0x1FFFでマスクすることでカーネルスタックの先頭 = thread_info構造体をポイントできます。
なお、__schedule関数は、プロセススイッチ(コンテキストスイッチ)する時は必ず実行されることを覚えておくと良いと思います。(= コンテキストスイッチ時には必ず__schedule関数を呼び出す)
preempt_schedule関数
下記にコードを示します。
kernel/sched/core.casmlinkage __visible void __sched notrace preempt_schedule(void) { /* * If there is a non-zero preempt_count or interrupts are disabled, * we do not want to preempt the current task. Just return.. */ 1 if (likely(!preemptible())) 2 return; 3 preempt_schedule_common(); }1行目は、「preempt_countが0(許可状態)かつ割込み禁止でない」の反転です。つまり、プリエンプション禁止、または割込み禁止の場合、2行目で復帰します。
3行目の関数を以下に示します。kernel/sched/core.cstatic void __sched notrace preempt_schedule_common(void) { do { __schedule(true); /* * Check again in case we missed a preemption opportunity * between schedule and now. */ } while (need_resched()); }トレーサー用コード、デバッグ用コードは削除すると、ものすごくシンプルですね。
前述した__schedule( )を呼び出し、その__schedule( )から復帰したプロセスにリスケジューリング フラグがセットされていれば再度スケジューリングし、セットされていなければ、そのまま抜ける処理になっています。preempt_schedule_notrace関数
本関数はトレーサから呼び出されるコードのため、ここでは割愛します。
本関数を呼び出している箇所は存在しません。
処理はpreempt_schedule( )とほぼ同じです。_cond_resched関数
リスケジューリング フラグがセットされており、かつプリエンプション可能な場合に前述のpreempt_schedule_common( )を呼び出します。
プリエンプションを試みた場合は1を返し、そうでない場合は0を返します。(プリエンプションをするか否かの判定でcurrentプロセスの方が優先度が高い場合はプリエンプションしません。このケースを考慮して「試みた場合」と記載しています)
本関数は、スケジューリングが可能かつ必要な場合、スケジューリングする関数と言えます。kernel/sched/core.cint __sched _cond_resched(void) { if (should_resched(0)) { preempt_schedule_common(); return 1; } rcu_all_qs(); return 0; }__cond_resched_lock関数
本関数は、スケジューリングがペンディングされているとき(1行目)、引数のlockを一度アンロックし(5行目)、スケジューラを呼び出した後(7行目)にアンロックしたlockをロックし直して(11行目)復帰する関数です。
kernel/sched/core.cint __cond_resched_lock(spinlock_t *lock) { 1 int resched = should_resched(PREEMPT_LOCK_OFFSET); 2 int ret = 0; 3 lockdep_assert_held(lock); 4 if (spin_needbreak(lock) || resched) { 5 spin_unlock(lock); 6 if (resched) 7 preempt_schedule_common(); 8 else 9 cpu_relax(); 10 ret = 1; 11 spin_lock(lock); 12 } 13 return ret; }プロセスの起床要求
wake_up_process関数
本関数は引数で指定したプロセスの起床要求を行います。
関数が深いので、ポイントを絞って追っていきます。kernel/sched/core.cint wake_up_process(struct task_struct *p) { return try_to_wake_up(p, TASK_NORMAL, 0); }try_to_wake_up( )を見てみます。
kernel/sched/core.cstatic int try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags) { unsigned long flags; int cpu, success = 0; 1 raw_spin_lock_irqsave(&p->pi_lock, flags); 2 smp_mb__after_spinlock(); 3 if (!(p->state & state)) 4 goto out; 5 trace_sched_waking(p); 6 success = 1; 7 cpu = task_cpu(p); 8 smp_rmb(); 9 if (p->on_rq && ttwu_remote(p, wake_flags)) 10 goto stat; 11 if (p->in_iowait) { 12 delayacct_blkio_end(p); 13 atomic_dec(&task_rq(p)->nr_iowait); 14 } 15 ttwu_queue(p, cpu, wake_flags); 16 stat: 17 ttwu_stat(p, cpu, wake_flags); 18 out: 19 raw_spin_unlock_irqrestore(&p->pi_lock, flags); 20 return success; 21}本関数のポイントは15行目のttwu_queue( )です。
kernel/sched/core.cstatic void ttwu_queue(struct task_struct *p, int cpu, int wake_flags) { struct rq *rq = cpu_rq(cpu); struct rq_flags rf; rq_lock(rq, &rf); update_rq_clock(rq); ttwu_do_activate(rq, p, wake_flags, &rf); rq_unlock(rq, &rf); }ttwu_do_activate( )を追いましょう。
kernel/sched/core.cstatic void ttwu_do_activate(struct rq *rq, struct task_struct *p, int wake_flags, struct rq_flags *rf) { 1 int en_flags = ENQUEUE_WAKEUP | ENQUEUE_NOCLOCK; 2 lockdep_assert_held(&rq->lock); 3 ttwu_activate(rq, p, en_flags); 4 ttwu_do_wakeup(rq, p, wake_flags, rf); }本関数のポイントは3行目と4行目です。
まずは3行目のttwu_activate( )を示します。kernel/sched/core.cstatic inline void ttwu_activate(struct rq *rq, struct task_struct *p, int en_flags) { activate_task(rq, p, en_flags); p->on_rq = TASK_ON_RQ_QUEUED; /* If a worker is waking up, notify the workqueue: */ if (p->flags & PF_WQ_WORKER) wq_worker_waking_up(p, cpu_of(rq)); }activate_task( )を追いましょう。
kernel/sched/core.cvoid activate_task(struct rq *rq, struct task_struct *p, int flags) { if (task_contributes_to_load(p)) rq->nr_uninterruptible--; enqueue_task(rq, p, flags); }追うべきはenqueue_task( )ですね。
kernel/sched/core.cstatic inline void enqueue_task(struct rq *rq, struct task_struct *p, int flags) { 1 if (!(flags & ENQUEUE_NOCLOCK)) 2 update_rq_clock(rq); 3 if (!(flags & ENQUEUE_RESTORE)) { 4 sched_info_queued(rq, p); 5 psi_enqueue(p, flags & ENQUEUE_WAKEUP); 6 } 7 p->sched_class->enqueue_task(rq, p, flags); }7行目で対象プロセスのスケジューリングクラスのenqueue_taskメンバを実行し、実行キューに対象プロセスをキューイングしています。enqueue_task( )は、前々回、前回出てきた通りです。
ttwu_do_activate( )に戻ります。
ttwu_do_wakeup関数では、対象プロセスの状態を実行可能状態に設定しています。kernel/sched/core.cstatic void ttwu_do_wakeup(struct rq *rq, struct task_struct *p, int wake_flags, struct rq_flags *rf) { check_preempt_curr(rq, p, wake_flags); p->state = TASK_RUNNING; trace_sched_wakeup(p); }上記から、対象プロセスを実行キューにキューイングした後にstateを実行可能状態に変更しています。
default_wake_function関数
kernel/sched/core.cint default_wake_function(wait_queue_entry_t *curr, unsigned mode, int wake_flags, void *key) { return try_to_wake_up(curr->private, mode, wake_flags); }try_to_wake_up( )は、wake_up_process( )でも出てきましたね。
前述のため、try_to_wake_up( )の説明は省略します。CPUの明渡し
yield関数
本関数は現在のプロセスが動作しているCPUを一度明渡す処理になります。
実際にコードを見てみましょう。kernel/sched/core.cvoid __sched yield(void) { set_current_state(TASK_RUNNING); do_sched_yield(); }1行目では明渡すプロセスの状態を実行可能状態にしています。
その後、do_sched_yield( )を呼び出します。kernel/sched/core.cstatic void do_sched_yield(void) { struct rq_flags rf; struct rq *rq; 1 rq = this_rq_lock_irq(&rf); 2 schedstat_inc(rq->yld_count); 3 current->sched_class->yield_task(rq); /* * Since we are going to call schedule() anyway, there's * no need to preempt or enable interrupts: */ 4 preempt_disable(); 5 rq_unlock(rq, &rf); 6 sched_preempt_enable_no_resched(); 7 schedule(); }3行目でcurrentプロセスのスケジューリングクラスのyield_taskメンバを呼び出しています。yield_taskメンバで実行キュー内でリキューした後に7行目のschedule( )でコンテキストスイッチを行います。
なお、3行目のyield_taskで、適切なプロセスが存在しない場合はcurrentプロセスが引き続き実行されます。yield_to関数
本関数は指定のプロセスにCPUを明渡します。
kernel/sched/core.cint __sched yield_to(struct task_struct *p, bool preempt) { struct task_struct *curr = current; struct rq *rq, *p_rq; unsigned long flags; int yielded = 0; local_irq_save(flags); rq = this_rq(); again: p_rq = task_rq(p); /* * If we're the only runnable task on the rq and target rq also * has only one task, there's absolutely no point in yielding. */ if (rq->nr_running == 1 && p_rq->nr_running == 1) { yielded = -ESRCH; goto out_irq; } double_rq_lock(rq, p_rq); if (task_rq(p) != p_rq) { double_rq_unlock(rq, p_rq); goto again; } if (!curr->sched_class->yield_to_task) goto out_unlock; if (curr->sched_class != p->sched_class) goto out_unlock; if (task_running(p_rq, p) || p->state) goto out_unlock; a) yielded = curr->sched_class->yield_to_task(rq, p, preempt); if (yielded) { schedstat_inc(rq->yld_count); /* * Make p's CPU reschedule; pick_next_entity takes care of * fairness. */ if (preempt && rq != p_rq) resched_curr(p_rq); } out_unlock: double_rq_unlock(rq, p_rq); out_irq: local_irq_restore(flags); if (yielded > 0) b) schedule(); return yielded; }ポイントを絞ります。
a)でcurrentプロセスのスケジューリングクラスのyield_to_taskメンバを実行します。
その後、b)で対象プロセスにスイッチします。スケジューリングするタイミングについて
これまでリスケジューリング フラグをセットするという言葉が何回か出てきましたが、フラグをセットした後、いつスケジューリングされるのでしょうか。
実際にLinuxが動作しているシステムにおいて、スケジューリングする契機は私が把握している範囲では下記です。
*他のタイミングをご存知の方は教えてください。(1) 自発的にCPUを明渡すとき(yield( )呼び出しやプロセスの状態をTASK_UNINTERRUPTIBLEやTASK_INTERRUPTIBLEに設定する)
(2) プリエンプションを禁止から許可にした時
(3) システムコール処理の出口
(4) 割込み処理の出口ここでは、(4)の呼び出し方を見てみましょう。
arch/arm/kernel/entry-armv.S__irq_svc: 1 svc_entry 2 irq_handler 3 ldr r8, [tsk, #TI_PREEMPT] @ get preempt count 4 ldr r0, [tsk, #TI_FLAGS] @ get flags 5 teq r8, #0 @ if preempt count != 0 6 movne r0, #0 @ force flags to 0 7 tst r0, #_TIF_NEED_RESCHED 8 blne svc_preempt 9 svc_exit r5, irq = 1 @ return from exception 10 UNWIND(.fnend ) 11 ENDPROC(__irq_svc) .ltorg #ifdef CONFIG_PREEMPT 12 svc_preempt: 13 mov r8, lr 14 1: bl preempt_schedule_irq @ irq en/disable is done inside 15 ldr r0, [tsk, #TI_FLAGS] @ get new tasks TI_FLAGS 16 tst r0, #_TIF_NEED_RESCHED 17 reteq r8 @ go again 18 b 1b1行目:割込み入り口処理
2行目:割込み処理
3行目:thread_info構造体のpreempt_countをr8にロード
4行目:thread_info構造体のflagsをr0にロード
5行目:r8(preempt_count)が0か否かを判定
6行目:r8が0でなければflagsのロード先r0に0を設定
7行目:リスケジューリング フラグがセットされているか否かを判定
8行目:セットされていれば12行目に分岐
13行目:リンクレジスタの値をr8に設定
14行目:preempt_schedule_irqを実行
15行目:新たに実行しようとしているプロセスのthread_info構造体のflagsをr0にロード
16行目:リスケジューリング フラグがセットされているか否かを判定
17行目:フラグがセットされていないため、リンクレジスタの指すアドレスに復帰
18行目:フラグがセットされている為、再度preempt_schedule_irq( )を実行参考までにpreempt_schedule_irq( )を以下に示します。
a) でスケジューリングしています。asmlinkage __visible void __sched preempt_schedule_irq(void) { enum ctx_state prev_state; /* Catch callers which need to be fixed */ BUG_ON(preempt_count() || !irqs_disabled()); prev_state = exception_enter(); do { preempt_disable(); local_irq_enable(); a) __schedule(true); local_irq_disable(); sched_preempt_enable_no_resched(); } while (need_resched()); exception_exit(prev_state); }このように、割込み出口では毎回リスケジューリング フラグ(TIF_NEED_RESCHED)を判定しています。
一番確実で定周期の粒度の割込みはtick割込み(1ms or 3.3ms or 4ms or 10ms)ですので、フラグをセットすると、遅くても次にtick割込みのタイミングでスケジューリングします。ついでに(3)のシステムコール出口からのスケジューラ呼び出しまでをサッと見てみましょう。
arch/arm/kernel/entry-common.Sret_fast_syscall: __ret_fast_syscall: UNWIND(.fnstart ) UNWIND(.cantunwind ) str r0, [sp, #S_R0 + S_OFF]! @ save returned r0 #if IS_ENABLED(CONFIG_DEBUG_RSEQ) /* do_rseq_syscall needs interrupts enabled. */ mov r0, sp @ 'regs' bl do_rseq_syscall #endif disable_irq_notrace @ disable interrupts ldr r2, [tsk, #TI_ADDR_LIMIT] cmp r2, #TASK_SIZE blne addr_limit_check_failed ldr r1, [tsk, #TI_FLAGS] @ re-check for syscall tracing tst r1, #_TIF_SYSCALL_WORK | _TIF_WORK_MASK beq no_work_pending UNWIND(.fnend ) ENDPROC(ret_fast_syscall) /* Slower path - fall through to work_pending */ #endif tst r1, #_TIF_SYSCALL_WORK bne __sys_trace_return_nosave slow_work_pending: mov r0, sp @ 'regs' mov r2, why @ 'syscall' x) bl do_work_pending cmp r0, #0 beq no_work_pending movlt scno, #(__NR_restart_syscall - __NR_SYSCALL_BASE) ldmia sp, {r0 - r6} @ have to reload r0 - r6 b local_restart @ ... and off we go ENDPROC(ret_fast_syscall)x) でdo_work_pending( )を呼び出しています。
下記do_work_pending( )のz) でschedule( )を呼び出してスケジューリングします。arch/arm/kernel/signal.casmlinkage int do_work_pending(struct pt_regs *regs, unsigned int thread_flags, int syscall) { /* * The assembly code enters us with IRQs off, but it hasn't * informed the tracing code of that for efficiency reasons. * Update the trace code with the current status. */ trace_hardirqs_off(); do { if (likely(thread_flags & _TIF_NEED_RESCHED)) { z) schedule(); } else { if (unlikely(!user_mode(regs))) return 0; local_irq_enable(); if (thread_flags & _TIF_SIGPENDING) { int restart = do_signal(regs, syscall); if (unlikely(restart)) { /* * Restart without handlers. * Deal with it without leaving * the kernel space. */ return restart; } syscall = 0; } else if (thread_flags & _TIF_UPROBE) { uprobe_notify_resume(regs); } else { clear_thread_flag(TIF_NOTIFY_RESUME); tracehook_notify_resume(regs); rseq_handle_notify_resume(NULL, regs); } } local_irq_disable(); thread_flags = current_thread_info()->flags; } while (thread_flags & _TIF_WORK_MASK); return 0; }いかがでしたでしょうか。
前回、前々回で述べた各クラスのsched_class構造体とコア部の繋がり方がご理解できたでしょうか。
端折ったり、駆け足の部分もありましたので、判り辛かった点もあったかと思います。ご質問やご指摘があればご遠慮なくコメントください。