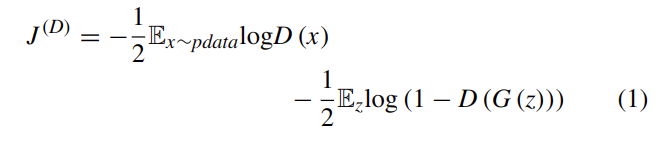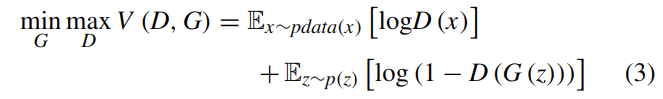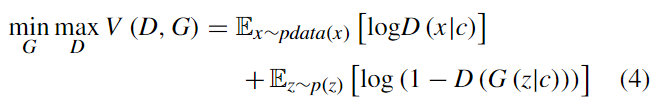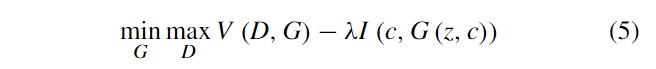- 投稿日:2019-04-03T17:41:55+09:00
nVIDIA-docker2 を dockerから導入してみよう。
初めに
nVIDIA docker2を使って、機械学習の環境を作っている方も多いと思います。
今回はその手順をまとめたものを記事にしました。ちなみに、これは前回書いたエントリの続き的な物になります。
AWS EC2のGPUが使えるubuntu16.04に、自力でCUDA 9.2/CuDNNを入れてみよう前回は、cuda/cudnnを導入した環境まで構築しました。 次はdockerの環境を導入します。
環境は、大体以下。
ubuntu: 16.04 (AWS上です)
CUDA: 9.2
cudnn: 7_7.5.0.56-1そもそも、なぜDockerを使うのか?
すでに多くの方が説明済みかと思いますので、ここでは多くは触れません。
大きくは以下のメリットがあるかと思います。
- コンテナ化すると、複製が容易かつ作った環境をどこにでも持っていくことができる
- 気軽に複製可能なので、変更したり環境の管理ができる。
- クラウドでもオンプレでも簡単に展開できる。チームに展開しやすい。
今回は、Docker を導入後、nVidia Dockerを導入して軽く確認するところまで説明します。
Docker のセットアップ
これも同様。 基本的に公式の手順を見るほうが良いです。
https://docs.docker.com/install/linux/docker-ce/ubuntu/
古いバージョンのものが入っていないか確認をします。
$ dpkg -l | grep docker $ dpkg -l | grep runc $ dpkg -l | grep containerd $次に必要なパッケージとgpgキーの入手
$ sudo apt-get update ~略~ $ sudo apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-common ~略~ $ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - ~略~リポジトリなどを追加し、docker本体をインストールします。
※バージョンを指定しない場合の手順です。 $ sudo apt-key fingerprint 0EBFCD88 $ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" $ sudo apt update $ sudo apt install docker-ce docker-ce-cli containerd.ioなお、VLを指定したい場合は以下を実行するとよいでしょう。
※バージョンを指定する場合は↓のコマンドでバージョンの一覧を取得して、指定します。 $ apt-cache madison docker-ce docker-ce | 5:18.09.3~3-0~ubuntu-xenial | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages docker-ce | 5:18.09.2~3-0~ubuntu-xenial | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages docker-ce | 5:18.09.1~3-0~ubuntu-xenial | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages docker-ce | 5:18.09.0~3-0~ubuntu-xenial | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages docker-ce | 18.06.3~ce~3-0~ubuntu | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages docker-ce | 18.06.2~ce~3-0~ubuntu | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages docker-ce | 18.06.1~ce~3-0~ubuntu | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages …無事インストールできたことの確認をします。
hello-worldというコンテナイメージをPullしてきて、で、それを起動させるとよいかも。$ sudo docker --version Docker version 18.09.3, build 774a1f4 $ sudo docker run hello-world Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 1b930d010525: Pull complete Digest: sha256:2557e3c07ed1e38f26e389462d03ed943586f744621577a99efb77324b0fe535 Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/ For more examples and ideas, visit: https://docs.docker.com/get-started/これで、dockerまでは完了です。
nVIDIA-Docker 2 のセットアップ
では次にnvidia-docker2のセットアップになります。
ネット上の記事を見ると、nvidia-docker 1 の情報が散見されますので、
色んなページを見まくっている人は気を付けたほうが良いかもしれません。nVidia dockerについても、基本的に公式手順を見ます。
https://github.com/NVIDIA/nvidia-docker
以降の手順は、公式手順を少しだけアレンジされているものです。
runtimeも同時セットアップをしています。$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \ > sudo apt-key add - OK $ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) $ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \ > sudo tee /etc/apt/sources.list.d/nvidia-docker.list deb https://nvidia.github.io/libnvidia-container/ubuntu16.04/$(ARCH) / deb https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/$(ARCH) / deb https://nvidia.github.io/nvidia-docker/ubuntu16.04/$(ARCH) / $ sudo apt update利用中のdockerのVersionと一致している物を確認して、インストールします。
↑のほうで、$ sudo docker --version と実行していた結果を使います。$ apt-cache madison nvidia-docker2 nvidia-container-runtime | grep <dockerのVersion> nvidia-docker2 | 2.0.3+docker18.09.3-1 | https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages nvidia-container-runtime | 2.0.0+docker18.09.3-1 | https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 Packages $ $ sudo apt install -y nvidia-docker2=2.0.3+docker18.09.3-1 nvidia-container-runtime=2.0.0+docker18.09.3-1インストールができたかどうか確認しましょう。 CLIの動作などで確認になるのかなと思います。
$ nvidia-container-cli info NVRM version: 396.82 CUDA version: 9.2 Device Index: 0 Device Minor: 0 Model: Tesla K80 Brand: Tesla GPU UUID: GPU-68403f5f-27e8-1262-bdd8-f12bd502d1b2 Bus Location: 00000000:00:1e.0 Architecture: 3.7 ubuntu@ip-10-10-224-17:~$ ubuntu@ip-10-10-224-17:~$ ubuntu@ip-10-10-224-17:~$ nvidia-container-cli list /dev/nvidiactl ~略~ /usr/lib32/nvidia-396/libGLESv1_CM_nvidia.so.396.82 /run/nvidia-persistenced/socketdocker deamon の condigをreloadします。
$ sudo pkill -SIGHUP dockerdまた、個人的なおすすめとして、
docker の操作を一般ユーザにも開放したほうがよいと思います。
以下は、sudo 不要で一般ユーザでも操作できるようにするための手順です。
これをやると、ubuntu ユーザでsudoなしでdockerが操作できます。$ groups ubuntu adm dialout cdrom floppy sudo audio dip video plugdev netdev $ sudo adduser -a ubuntu docker Adding user `ubuntu' to group `docker' ... Adding user ubuntu to group docker Done. $ ~再ログインなどする~ $ groups ubuntu adm dialout cdrom floppy sudo audio dip video plugdev netdev lxd docker $ということで、 nvidia docker2 が正常に動くことを確認します。
使うコンテナのイメージは公式に提供済みのものがありますのでそれを指定。
cuda toolkitのnvidia-smiとcuda CLIの nvccの動作確認ができれば
コンテナからGPUが使える状態になっているのかなーと思います。$ docker run --runtime=nvidia --rm nvidia/cuda:9.2-cudnn7-devel-ubuntu16.04 nvidia-smi Fri Mar 8 12:37:33 2019 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 396.82 Driver Version: 396.82 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla K80 Off | 00000000:00:1E.0 Off | 0 | | N/A 61C P0 57W / 149W | 0MiB / 11441MiB | 99% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ $ docker run --runtime=nvidia --rm nvidia/cuda:9.2-cudnn7-devel-ubuntu16.04 /usr/local/cuda-9.2/bin/nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2018 NVIDIA Corporation Built on Tue_Jun_12_23:07:04_CDT_2018 Cuda compilation tools, release 9.2, V9.2.148これでnVidia Dockerの導入まで終わりです。
次は、導入したnvidia docker を使って、そこにフレームワークを導入するとか、サンプルを動かす例を書いていくかもしれません。たぶん
- 投稿日:2019-04-03T00:15:25+09:00
Recent Progress on Generative Adversarial Networks (GANs): A Surveyの翻訳
元の論文について
元の論文の公開ページ : https://ieeexplore.ieee.org/document/8667290
2019/04/02現在、だれでも見ることができる状態であったため勉強がてら翻訳していく。モチベーションが続く限り、章ごとに更新する予定。この文章中に存在する[N](Nは任意の整数)は、元の論文の参考文献番号と連動している。
(2019/04/06 三章が長すぎるため、途中まで更新する)
要約
Generative adversarial network (GANs)はAI分野において最も重要な研究手法の一つであり、データ生成能力は注目を良く引く。この論文では、著者らがGANの最新の動向を紹介する。はじめに、GANの基礎理論と近年の生成モデルごとの違いについて分析、要約する。次に、GANの派生モデルをひとつずつ分類、紹介していく。3つめに、トレーニングの戦略と評価方法を紹介する。4つめに、GANのアプリケーションを紹介する。最後に、取り組むべき問題とその将来の方針について議論する。
1章 導入
過去数年間で、コンピュータサイエンスとデータ蓄積で大きな発展があった。AIは価値ある研究の話題と多数の有意義なアプリケーションとともに盛況な分野となった。AIのコミュニティでは、機械学習[1]が我々の日常の様々な場面で大きな影響を振るうようになった。機械学習アルゴリズムはすべて、与えられたデータの表現を必要とする。しかし、他の分野やタスク中でこれらの技術を使いたいと望んだとしても、有用な特徴を抽出することが難しいものである。そこで、研究者は分類や検出をするときに役に立つ情報を自動的に抽出する表現学習[2]と呼ばれる新しいアプローチを提案した。深層学習[3]はいくつかの簡単な表現を構成することによって、他の手法よりもより抽象的な特徴(=高レベル)を容易に抽出できる表現学習手法の一種である。
一般的に、ラベルがあるかどうかで機械学習の手法は教師あり学習か教師なし学習の2つに分けられる。教師あり学習には異なる表現を含むデータセットが必要とされ、データセット中の各サンプルにはラベルがつけられている。教師あり学習の代表には分類、回帰、構造問題(structured output learning等)がある。しかしながら、教師なし学習はわずかなラベルを含むデータセットを必要とする。目的は、データセット内にある特有の楮を探し出すことである。通常、密度推定、クラスタリング、合成、ノイズ除去が教師なし学習とみなされる。
教師あり学習のために自動的にラベルを付けたり収集したりすることは困難である。したがって、研究者は教師なし学習により注目する。教師なし学習のタスクにおいて、生成モデルは最も有望な技術の一つである。典型的な生成モデルは基本的にマルコフ連鎖、最大尤度、近似的推論をベースとしている。制限付きボルツマンマシン[4]とその拡張モデル(Deep Belief Network[5]、Deep Boltzmann Machinescite[6])は常に最大尤度推定をベースとしている。これらの手法によって生成されたモデルは分布を生成し、そしてこれらの分布は訓練データの経験分布と一致することを目的とした多くのパラメーターを持つ。
しかしながら、これらの初期のモデル[4]-[6]は深刻な制限を持ち合わせており、もしかしたら望まれるような一般化ではないかもしれない。2014年に、Goodfellow氏がGANと呼ばれる新たな生成モデルを提案した。GANは、ゲーム理論をベースとした、生成器と弁別器の二つのネットワークから成り立っている。生成器の役割は弁別器をだますことができるほどリアルな画像を生成することである。弁別器の役割は、本物のデータと偽物のデータを識別することである。この場合、ドロップアウトアルゴリズムと逆伝播[8]を使って両方のモデルを訓練する。近似的推論かマルコフ連鎖はGANには必要とされない。
この調査では、ネットワークのアプリケーション、動機、定義を含む、最新のSOATなGANを要約&分析する。サーベイの作りは以下の様になっている。2章はいくつかの生成モデルを紹介し、GANの基礎理論に注目する。さらに、これらのモデルの簡単な比較も提供する。一連の派生GANモデルは3章で紹介される。4章では、GANのいくつかの訓練の仕組みを紹介する。5章では様々な評価方法の良し悪しについて議論する。様々な分野でのGANのアプリケーションは6章で概観される。7章では、GANの制限と将来的な提案について検討する。最後に8章で結論付ける。
2章 生成モデルとGAN
GANは深層生成モデルの一つであり、生成問題をうまく処理することができる。この章では、はじめに一般的な深層生成モデルのいくつかの種類を紹介し、次にこれらのモデル間で違いを比較する。その次に、基本的なGANの理論とアーキテクチャについて紹介する。
A. 深層生成モデル
AIの狙いは人間界の様な複雑な世界を理解することである。このアイデアに基づいて、AIの研究者が統計と確率の観点からそれらの周りの世界を描くことに専念する生成モデルを提案した。いつもお世話になっております。今現在、生成モデルはGANs[7]、VAE[9]、AutoRegressive Networks[10]の3つのカテゴリに分けることができる。VAEは確率的なグラフィカルモデルであり、データの確率分布のモデル化すること目的としている。しかしながら、最終的な確率論的シミュレーションはいくらかのバイアスを持つ。そのため、GANsよりもぼやけたサンプルが多く生成される。PixelRNN[11]はautoregressive networksの一つであり、画像生成の問題をピクセルの生成と予測の問題に転換する。それゆえ、各ピクセルは一つ一つ処理される必要があるが、GANはワンショットでサンプルを直接処理する。そして、これはGANがPixelRNNよりも早いサンプル生成をする。
確率的生成モデルとして、確率密度が提供されないとき、データの自然な解釈に依存する従来の生成モデルのいくつかは、訓練及び適応ができない。しかし、GANは非常に利口な内部の敵対的訓練メカニズムを導入しているため、GANsはこのような状況でも依然として使うことができる。
B. GANsの原理
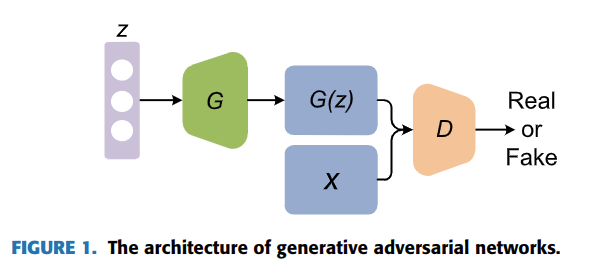
GANsはゲーム理論に触発されたものであり、生成器と識別器がお互い、訓練中にナッシュ均衡を達成しようとする。GANのアーキテクチャを図1に示す。生成器$G$の動作原理は実際のデータの潜在分布を極力適合させるために偽のデータを生成することである。一方で、識別器$D$の動作原理は偽か実際のデータか正しく見分けることである。生成器の入力はランダムノイズベクトル$z$(基本的には一様分布もしくは正規分布)である。ノイズは多次元ベクトルである偽のサンプル$G(z)$を得るために生成器$G$を介して新しいデータ空間にマッピングされる。また、識別器$D$は二値分類器でありデータセットからの実際のサンプルもしくは生成器$G$から生成された偽のサンプルを入力として受け取る。そして、識別器$D$の出力は実際のデータである確率である。識別器$D$が実際のものか偽のものかどうかわからなくなった時、GANは最適な状態になる。この時点で、実際のデータ分布を学習した生成器モデル$G$が得られる。
C. GANsの学習モデル
このゲーム理論中の識別機と生成器は対応する自身の損失関数を持つ。このとき、これらをそれぞれ$J^{(G)}$と$J^{(D)}$と呼ぶ。[7]中では、識別器$D$が二値分類器として定義され、損失関数はクロスエントロピーで示される。定義は式(1)の通り。
ここで、$x$は実際のサンプルを示し、$z$は$G(z)$を生成器$G$で生成するためのランダムノイズベクトル、$\mathbb{E}$は期待(期待値、expectation)である。$D(x)$は$D$が$x$を実際のデータとみなす確率、$D(G(z))$は$D$が$G$によって生成されたデータを特定する確率を示す。$D$の目的はデータの出所を正しく突き止めることであるため、$D(G(z))$が0に近づくことを目標とするが、$G$は1に近づくことを目的とする。この考えに基づいて、2つのモデル間には対立が存在する(ゼロサムゲーム)。したがって、生成器の損失は識別機によって式(2)の様に導出される。
結果的に、GANsの最適化問題はminimaxゲームに変換される。定義は式(3)の通り。
訓練プロセス中に$G$中のパラメーターは$D$の更新プロセスのパラメーターと一緒に更新される。$D(G(z))=0.5$である時、識別機はこれらの2つの分布間の差異を特定することができなくなる。この状態では、モデルが大域的最適解を達成するだろう。
3章 派生GANsモデル
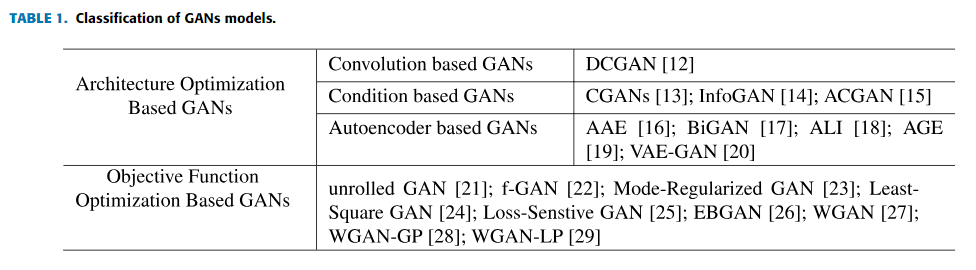
オリジナルのGANsの欠陥により、様々な派生GANsモデルが提案され、これらの派生GANsモデルはアーキテクチャ最適化ベースのGANsと目的関数最適化ベースのGANsの2種類のグループに分けられる(表1)。このセクションでは、いくつかの派生モデルの詳細について紹介する。
A. アーキテクチャ最適化ベースのGANs
1. 畳み込みベースのGANs
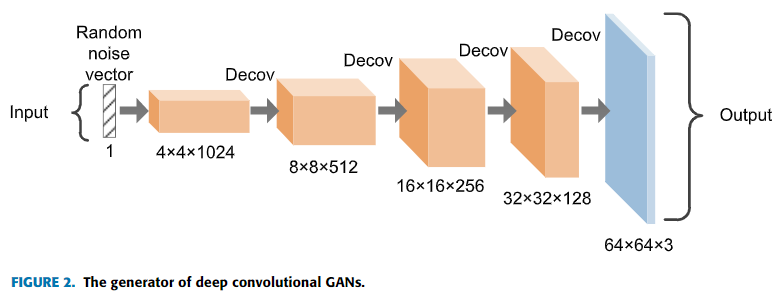
CNN[30]は教師あり学習のとても効率的なモデルとして見なされており、画像処理分野では最も普及しているネットワークの構造の一つである。生成器と識別機のネットワーク構造に関しては、オリジナルのGANsがMLPを採用している。画像の特徴抽出に関してはMLPよりもCNNの方が優れているため、Radfoldら[12]はDeep Convolutional Generative Adversarial Networks(DCGAN)を提案した。図2に示す通り、このアプローチは生成器内の全結合層をdeconvolution層に置き換える革新的なものであり、画像生成タスクにおいて素晴らしい結果を残した。
2. 条件付きベースのGANs
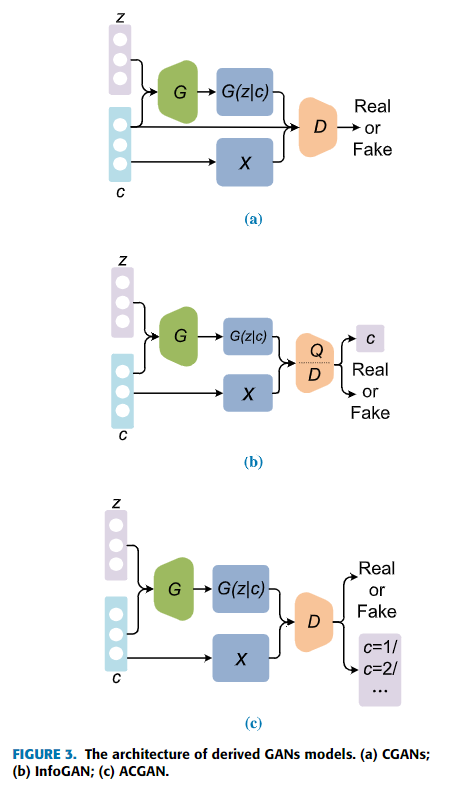
生成器の入力はランダムノイズベクトル$z$であるため、これらの制限されていない入力が訓練モードの崩壊を起こす可能性がある。それゆえ、MirzaとOsindero[13]はConditional Generative Adversarial Networks(CGANs)を提案した。CGANsは識別機と生成器の両方に条件変数$c$(変数$c$はラベルやテキストなどのデータ)を導入している。この変数$c$を導入することで、モデルに条件を与え、データ生成プロセスに影響を与える。図3(a)に示すように、生成器の入力は条件変数$c$とノイズベクトル$z$であり、識別機の入力は生成器からの出力$G(z|c)$と条件変数$c$から成り立つ実際のサンプルである。したがって目的関数は式(4)のように示される。
追加で、Chenら[14]はInfoGANと名付けられた他のCGANsを提案した。相互情報量を導入することで、InfoGANは生成プロセスをより制御しやすくし、結果をもっと解釈しやすくなった。ここで、相互情報量は生成されたデータ$x$と潜在コード$c$間の矯正を表す。$x$と$c$の関係性を向上させるため、相互情報量の値は最大化される必要がある。その生成精機はCGANsに似ているが、潜在コード$c$がわからないという違いがあるため、訓練プロセスを通して発見する必要がある。オリジナルのGANsの識別機に加えて、InfoGANは条件変数$Q(c|x)$を出力するため追加のネットワーク$Q$を持つ。目的関数は式(5)のようになる。
ここで、$\lambda$は制約関数$I(c,G(z,c))$のハイパーパラメータであり、相互情報量によって、生成されたデータに対して潜在コード$c$がより一層合理的になる。InfoGANのアーキテクチャを図3(b)に示す。
CGANsをベースとした、Odenaら[15]はAuxiliary Classifier GAN(ACGAN)を提案した。図3(c)では、識別機に対して条件変数$c$は追加されず、代わりに他の分類器でクラスラベルの確率を示すために使われる。次に、損失関数は正しいクラスラベル予測確率を増やすために修正される。