- 投稿日:2019-03-30T23:14:15+09:00
TensorFlowで嵐の顔を判別
はじめに
今回 TensorFlow を初めて使いました。TensorFlow で画像認識をやりたいのですが、公式のサンプルはあまりピンと来ず、よさそうな記事を見つけたので参考にしました。
参考にした記事
keras(tensorflow)で花の画像から名前を特定 - Qiita過去のiPhoneを使った機械学習の投稿
iPhoneで顔認識 - Qiita
機械学習でストリートファイター - Qiita
iPhoneと機械学習でフライドチキンの部位を分類する - QiitaTensorflowの準備
TensorFlowって何
(ウィキペディアより)
TensorFlow(テンソルフロー)とは、Googleが開発しオープンソースで公開している、機械学習に用いるためのソフトウェアライブラリである。具体的には、Python環境で下記を実行するとインストールできます。
pip install tensorflow画像判別に必要なもの
1. 訓練画像を集めます。
2. 訓練画像から学習モデルを作ります。
3. 入力画像を学習モデルに与えると判別されます。訓練画像の準備
imagesフォルダ以下に画像を集めます。フォルダー名がカテゴリー名(分類名)となります。150枚以上が望ましいのですが、私は50枚程で心が折れました。
今回は、相葉、松本、二宮、大野、櫻井の5人です。入力画像から「強いて言えば誰か」を判別します。使い方
- images フォルダ内に学習モデル用の訓練画像を用意します。
- inputs フォルダ内に予測したい入力画像を用意します。
- python model.py → mymodel.hdf5 が作成されます。
- python main.py → print で結果が出力されます。
ソースコード
以下を実行します。足りないものは pip install 行ってください。
model.py# -*- coding: utf-8 -*- import sys import os import gc import glob import numpy as np import pandas as pd import random, math import traceback from PIL import Image from keras.models import Sequential from keras.layers import Convolution2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense from keras.utils import np_utils class MyModel: def __init__(self): self.images_dir = './images' self.hdf5_file = './mymodel.hdf5' self.sub_dir = [name for name in os.listdir(self.images_dir) if name != ".DS_Store"] #------------------------------------ # 学習モデルの作成と保存 #------------------------------------ def save_model(self): try: # 画像読み込み train_data = [] for i, sdir in enumerate(self.sub_dir): print("->", sdir) files = [name for name in os.listdir(self.images_dir + "/" + sdir) if name != ".DS_Store"] for f in files: data = self.create_data_from_image(self.images_dir + '/' + sdir + '/' + f) train_data.append([data,i]) # シャッフル random.shuffle(train_data) X, Y = [],[] for data in train_data: X.append(data[0]) Y.append(data[1]) test_idx = math.floor(len(X) * 0.8) xy = (np.array(X[0:test_idx]), np.array(X[test_idx:]), np.array(Y[0:test_idx]), np.array(Y[test_idx:])) x_train, x_test, y_train, y_test = xy # 正規化 self.x_train = x_train.astype("float") / 256 self.x_test = x_test.astype("float") / 256 self.y_train = np_utils.to_categorical(y_train, len(self.sub_dir)) self.y_test = np_utils.to_categorical(y_test, len(self.sub_dir)) # 学習モデルの保存 model = self.create_model_from_shape(self.x_train.shape[1:]) model.fit(self.x_train, self.y_train, batch_size=32, nb_epoch=10) model.save_weights(self.hdf5_file) # テスト score = model.evaluate(self.x_test, self.y_test) print('loss=', score[0]) print('accuracy=', score[1]) except Exception as e: print('Exception:', traceback.format_exc(), e.args) #------------------------------------ # 入力画像の予測 #------------------------------------ def predict_from_dir(self, dir): X = [] files = [name for name in os.listdir(dir) if name != ".DS_Store"] for f in files: data = self.create_data_from_image(os.path.join(dir,f)) X.append(data) X = np.array(X) model = self.create_model_from_shape(X.shape[1:]) model.load_weights(self.hdf5_file) predictions = model.predict(X) return predictions # 画像ファイルからデータを作成 def create_data_from_image(self, file): img = Image.open(file) img = img.convert("RGB") img = img.resize((50,50)) data = np.asarray(img) return data # Shape から Model の作成 def create_model_from_shape(self, shape): # K=32, M=3, H=3 model = Sequential() model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape=shape)) # K=64, M=3, H=3 調整 model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Convolution2D(64, 3, 3, border_mode='same')) model.add(Activation('relu')) # K=64, M=3, H=3 調整 model.add(Convolution2D(64, 3, 3)) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) # biases model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(len(self.sub_dir))) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy']) return model if __name__ == "__main__": m = MyModel() m.save_model() gc.collect()main.py# -*- coding: utf-8 -*- import sys, os import numpy as np import pandas as pd from PIL import Image from model import MyModel images_dir = './images' inputs_dir = './inputs' categories = [name for name in os.listdir(images_dir) if name != ".DS_Store"] inputs = [name for name in os.listdir(inputs_dir) if name != ".DS_Store"] # 入力画像の予測値 predictions = MyModel().predict_from_dir(inputs_dir) # 結果出力 strcat = '' for cat in categories: strcat += cat.ljust(10,' ') print(" ", strcat) for i,input in enumerate(inputs): strpre = input.ljust(14, ' ') for pre in predictions[i]: strpre += str(round(pre,3)).ljust(10,' ') print(strpre)結果
Aiba Matsumoto Ninomiya Ohno Sakurai aiba.png 1.0 0.0 0.0 0.0 0.0 ninomiya.png 0.0 0.0 1.0 0.0 0.0 sakurai.png 0.0 0.0 0.0 0.0 1.0 koji1.png 0.0 0.0 0.0 1.0 0.0 koji2.png 0.0 0.0 0.0 1.0 0.0 koji3.png 0.0 0.0 0.0 1.0 0.0
入力画像 予測結果 Aiba Ninomiya Sakurai koji1.png
koji3.png
koji3.pngOhno う~ん、0と1しか出ないのですね。要勉強です。
まとめ
私(Koji4104)は大野くんに似ているという結果が出ました。私も違う景色を見てみたいです。




- 投稿日:2019-03-30T23:00:31+09:00
NVIDIA Jetson Nano 開発者キットに TensorFlow をインストールする
インストール手順
NVIDIA 社が Jetson 用の TensorFlow pip wheel パッケージを公開しているので Jetson Nano にも TensorFlow を簡単にインストールできます。NVIDIA 社の TensorFlow For Jetson Platform ページにインストール方法が解説されていますので基本的にはその手順どおりですが、ちょっと注意点があります。
HDF5 のインストール
$ sudo apt-get install libhdf5-serial-dev hdf5-toolspip のインストール
$ sudo apt-get install python3-pipNVIDIA 社のページには pip インストール後に pip による pip のアップデートが示されておりますが、とりあえず現時点(2019年3月30日)ではこれを行わない方が無難だと思います。私の環境ではこれにより pip を起動できなくなりました。
$ pip3 install -U pip
以下のページを参考にさせていただき復帰しました。
【Ubuntu】pip install –upgrade pip コマンドを実行すると、その後、ImportError: cannot import name main というエラーが発生する場合の対応方法その他パッケージのインストール
$ sudo apt-get install zlib1g-dev zip libjpeg8-dev libhdf5-dev $ sudo pip3 install -U numpy grpcio absl-py py-cpuinfo psutil portpicker grpcio six mock requests gast h5py astor termcolorTensorFlow のインストール
$ sudo pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpuインストールを確認
$ python3 Python 3.6.7 (default, Oct 22 2018, 11:32:17) [GCC 8.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf >>> print(tf.__version__) 1.13.1 >>> quit() $上記で TensorFlow のインストールは完了です。
TensorFlow チュートリアル・コードを動作させる
Jetson シリーズはディープニューラルネットワークを用いた推論には最適のプラットフォームと言えますが、ディープニューラルネットワークの学習にはちょっとパワー不足です 1 。但し、小規模なディープニューラルネットワークの学習ならば大丈夫です。GPU を搭載しない PC よりも速いと思います。
Get Started with TensorFlow に示されている以下のコードを動作させてみましょう。mnist.pyimport tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test)このコードを mnist.py というファイル名で保存して、以下のように起動します。
$ python3 mnist.pyGPU が認識されているのが分かります。
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/resource_variable_ops.py:435: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/layers/core.py:143: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version. Instructions for updating: Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`. 2019-03-30 17:46:10.020449: W tensorflow/core/platform/profile_utils/cpu_utils.cc:98] Failed to find bogomips in /proc/cpuinfo; cannot determine CPU frequency 2019-03-30 17:46:10.021429: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0x3f14f760 executing computations on platform Host. Devices: 2019-03-30 17:46:10.021499: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): <undefined>, <undefined> 2019-03-30 17:46:10.167789: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:965] ARM64 does not support NUMA - returning NUMA node zero 2019-03-30 17:46:10.168088: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0x3de91970 executing computations on platform CUDA. Devices: 2019-03-30 17:46:10.168145: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): NVIDIA Tegra X1, Compute Capability 5.3 2019-03-30 17:46:10.168519: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 0 with properties: name: NVIDIA Tegra X1 major: 5 minor: 3 memoryClockRate(GHz): 0.9216 pciBusID: 0000:00:00.0 totalMemory: 3.86GiB freeMemory: 532.48MiB 2019-03-30 17:46:10.168575: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 0 2019-03-30 17:46:15.464153: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-03-30 17:46:15.475841: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0 2019-03-30 17:46:15.475890: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N 2019-03-30 17:46:15.476119: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 75 MB memory) -> physical GPU (device: 0, name: NVIDIA Tegra X1, pci bus id: 0000:00:00.0, compute capability: 5.3) 2019-03-30 17:46:16.539100: I tensorflow/stream_executor/dso_loader.cc:153] successfully opened CUDA library libcublas.so.10.0 locally5エポックの学習で loss: 0.0640 - acc: 0.9819という結果になりました。
TensorBoard を使う
TensorBoard を利用したモデルの可視化だってできます。少しコードの変更が必要です。
但し、学習しながらその様子を TensorBorad で観察するのは Jetson Nano にはちょっと重過ぎでした。学習が完了してからそのログを TensorBoard で見てみましょう。mnist.pyimport tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) log_filepath = "./logs/" tb_cb = tf.keras.callbacks.TensorBoard(log_dir=log_filepath, histogram_freq=1) model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test), callbacks=[tb_cb]) model.evaluate(x_test, y_test)ログ用ディレクトリを作成してから動作させます。
$ mkdir logs $ python3 mnist.py上記の実行が完了してから TensorBoard を起動します。
$ tensorboard --logdir=./logsTensorBorad が起動したら Jetson Nano 上の Chromium ブラウザで localhost:6006 を開きます。
モデルの保存
学習済みモデル(ディープニューラルネットワークの重みとバイアス)を保存するには上記コードの最後に以下の行を追加します。
model.save('mnist.hdf5')保存したモデルを Netron ブラウザ・バージョン で覗いてみましょう。
以上です。
ディープニューラルネットワークの学習にはパワフルな NVIDIA Tesla GPU などが使われるようです。 ↩


- 投稿日:2019-03-30T22:32:10+09:00
最小作用の原理をTensorflowで確認
解いた式
ラグランジアン
$$
L = K - U
$$を時間積分した
$$
S = \int L \mathrm{d}t
$$を馬鹿正直に数値的に最小化したら、それっぽい軌跡が得られました。
2次元平面での重力ポテンシャルの公転運動です。お断り
今回も機械学習の話ではありません。
もうちょいくやしく
数値的に解くので、位置 $\vec{r}(t)$ は時間について離散的な関数となります。$N$ ステップの軌跡だと思うと、軌跡はベクトルみたいに書けます。
$$
x = \Bigl(\vec{r}(0), \vec{r}(\Delta t), \cdots, \vec{r}(N\Delta t) \Bigr)^\mathrm{T}
$$速度は単純な差分で書けます。
ある時間ステップ $i$ では、その前後の成分の差分で速度が計算できます。テイラー展開の1次までとる発想です。\vec{p}(i\Delta t) = \frac{1}{2\Delta t}\Bigl(\vec{r}\left((i + 1)\Delta t\right) - \vec{r}\left((i - 1)\Delta t\right)\Bigr)$p$は普通は運動量に使う記号ですが、速度に使っています。これを行列表記にしますと
v = \frac{1}{2\Delta t}\left( \begin{matrix} -2 & 2 & 0 & 0 & \cdots \\ -1 & 0 & 1 & 0 & \cdots \\ 0 & -1 & 0 & 1 & \cdots \\ & & \vdots & & \\ 0 & \cdots & -1 & 0 & 1 \\ 0 & \cdots & 0 & -2 & 2 \\ \end{matrix} \right) \left( \begin{matrix} \vec{r}(0) \\ \vec{r}(\Delta t) \\ \vec{r}(2\Delta t) \\ \vdots \\ \vec{r}((N-1)\Delta t) \\ \vec{r}(N\Delta t) \\ \end{matrix} \right)1番目と$N$ 番目の成分(つまり端、最初と最後)はとなりの成分との差とします。
差分を取る行列を $D = \frac{1}{2\Delta t}(\cdots) $としますと、v = Dxになります。
以降、$x$, $v$の$i$ステップ目の成分は添え字で表記することにします。
x_i = \vec{r}(i\Delta t)\\ v_i = \vec{p}(i\Delta t)また運動の途中で質量 $m$ は一定だとします。
位置と速度が定義されたので、各時間ステップでの運動エネルギーK_i = \frac{1}{2}mv_i^2とポテンシャル
U_i = G\frac{mM}{\left(x_i - \vec{R}\right)^2}が書けます。
ここで$G$は重力定数、$M$は公転中心の質量、$\vec{R}$は公転中心の座標とします。今回は$G=1$、$M=1$、$\vec{R}=0$としてしまいます。最後に、各時間ステップごとのラグランジアン
L_i = K_i - U_iを求めた後、それを全ステップにわたって合計した作用
S = \sum_i \Delta t L_iが計算できます。
さて、最初の位置 $x_1$ と最後の位置 $x_N$ を固定し、その間の $x_i$ をいろいろ動かして、$S$を最小化させてみることを考えます。
最小作用の原理
変分的に書くと、
\delta S = 0となり、自然界はこれを満たすような位相空間中の軌跡を取るというのが、解析力学の教えるところです。
ここから運動方程式などのハミルトン力学が派生していきます。つまりこの原理は普通は理論の礎になるもので、そのまま解く対象にはならないなという印象です。$S$ は普通は位置と共役運動量 $r$, $p$の関数なのでこのように変分的に書きますが、
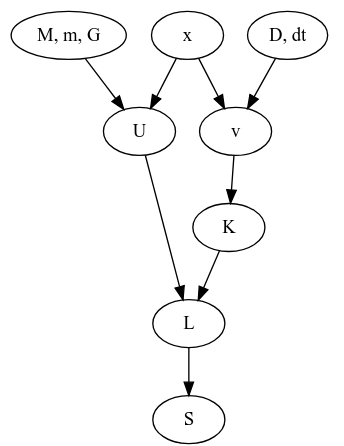
今回の話の依存関係を追ってみますと、
というグラフになっています。ここで$M, m, G, D$は系が決まれば定数となるものです。となれば独立に変更できそうなのは$x$だけですね。そして$x$は2次元中の$N$個の点列だと思うと、$2(N-2)$ 個のパラメータがあるように見えます。すると、
x(軌跡) = \mathop{\rm arg~min}\limits_x \left[S\right]として、なんかオプティマイザがつかえそうですね。
Tensorflowの
trainerの出番です。実装開始
ライブラリ
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt注意
ここでの
tensorflowのバージョンは1.xです。Eagerモードがデフォルトになる2.xでは実装を変えなければなりません。定数
G = 1.0 m = 1.0 Mc = 1.0 Mm = Mc*m fp = tf.float64 Nstep = 500 Ndim = 2 Time_all = 6.4 dt = Time_all/Nstep
Time_allは軌跡の始点と終点の間にかかった時間で、dtはそれを総ステップ数Nstepで割ったものになります。位置
r_init = tf.get_variable("position_init", shape=[1, Ndim], dtype=fp, trainable=False) r_fin = tf.get_variable("position_final", shape=[1, Ndim], dtype=fp, trainable=False) r_path = tf.get_variable("position_path", shape=[Nstep - 2, Ndim], dtype=fp) r = tf.concat([r_init, r_path, r_fin], 0)微分用行列
d_mat = np.eye(Nstep, k=1) d_mat = d_mat - d_mat.T d_mat[0, 0] = -1 d_mat[-1, -1] = 1 d_mat = tf.constant(d_mat/2)/dt上で出てきた式を頑張ってnumpy行列にし、最後に
tf.constantに渡しています。速度
dr = tf.matmul(d_mat, r)ここで、
rの形状は(N, 2)で、d_matは(N, N)なので、drは(N, 2)の形状のtf.Tensorです。運動エネルギー
vr_i = tf.reduce_sum(dr**2, axis=1) K_i = 0.5*vr_i*m各成分を2乗して足したらベクトルの長さの2乗ですね。
reduce_sumにaxisを渡しているので、dr**2の形状(N, 2)のうちの2のほうが総和の対象となります。そのためvr_iの形状は(N, )です。位置エネルギー
rr_i = tf.rsqrt(tf.reduce_sum(r**2, axis=1)) U_i = - G*Mm*rr_iラグランジアン
L_i = K_i - U_i作用
S = tf.reduce_sum(L_i)*dt
dtはなくてもいいんじゃないかな。最小化
optimizer = tf.train.AdamOptimizer(0.05) minimize = optimizer.minimize(S)困った時のAdam。結果のところにありますが、一応
GradientDescentも試しています。初期座標
代入演算
r_path_0 = tf.placeholder(fp, shape=[Nstep - 2, Ndim]) r_init_0 = tf.placeholder(fp, shape=[1, Ndim]) r_fin_0 = tf.placeholder(fp, shape=[1, Ndim]) init_assign = [tf.assign(r_path, r_path_0), tf.assign(r_init, r_init_0), tf.assign(r_fin, r_fin_0)] initializer = tf.global_variables_initializer()
rは最小化の対象化でtf.Variableです。これに所定の初期値を与える方法として、
tf.get_variablesのinitializerオプションにて、tf.constant(value=hogehoge)とする。- 受け皿の
tf.placeholderを用意し、tf.assignで上書きが考えられます。今回は
r_pathの定義が初期値を決める処理より先に来てしまったので前者が使いにくく、後者としました。実際の値
r1 = np.array([1.0, 0.0]) r2 = np.array([0.0, 1.0]) r3 = np.array([-1.0, 0.0]) r4 = np.array([0.0, -1.0]) r5 = np.array([1.0, 0.0]) rs = np.c_[r1, r2, r3, r4, r5].T ts = np.arange(5)/4 ts_interp = np.arange(Nstep)/(Nstep - 1) x_interp = np.interp(ts_interp, ts, rs[:, 0]) y_interp = np.interp(ts_interp, ts, rs[:, 1]) r0_np = np.c_[x_interp, y_interp].reshape(Nstep, Ndim)$(1,0), (0, 1), (-1, 0), (0, -1), (1, 0)$ の順に原点周りを1周し、その間を適当に補間した感じです。つまり原点周りに菱型に回る軌跡を初期状態としました。
rsがその通って欲しいチェックポイント5点を並べたもので、tsがその時刻です。ここでは開始を$t=0$, 終点を$t=1$にしました。注意:ここでの$t$はMD中での$t$とは異なり、ただのnp.interp用の横軸です。実行
可視化のmatplotlibとその初期化
fig = plt.figure() ax1 = fig.add_subplot(121) ax2 = fig.add_subplot(122) lines1, = ax1.plot(x_interp, y_interp) lines2, = ax2.plot(x_interp, y_interp) ax2.set_xlim((-1.5, 1.5)) ax2.set_ylim((-1.5, 1.5)) ax1.set_xlim((-1.5, 1.5)) ax1.set_ylim((-1.5, 1.5))
ax1は左半分で座標を、ax2は右半分で速度をプロットします。
が、ここでは速度の計算がまだなされていないので、座標をプロットしてお茶を濁します。セッション
with tf.Session() as sess: sess.run(initializer)初期値代入
sess.run(init_assign, feed_dict={r_path_0: r0_np[1:-1, :], r_init_0: r0_np[0:1, :], r_fin_0: r0_np[-1:, :]})最小化実行
step = 0 while True: sess.run(minimize) step += 1可視化
if step%2 == 0: r_t = sess.run(r) lines1.set_data(r_t[:, 0], r_t[:, 1]) v_t = sess.run(dr) lines2.set_data(v_t[:, 0], v_t[:, 1]) plt.pause(0.001)2イテレーションごとに、matplotlibの
ax2にセットされた値をset_dataで更新していきます。
たまに初期ウィンドウから大きく外れるので、set_xlimset_ylimで適宜調整します。
終わるときは、端末をアクティブにしてCtrl+Cです。結果
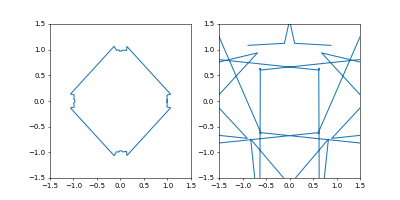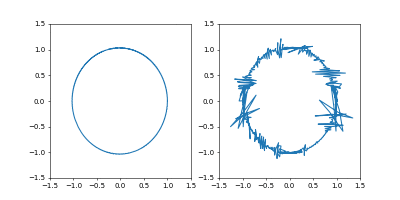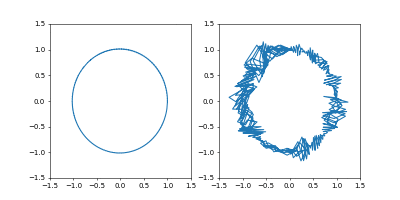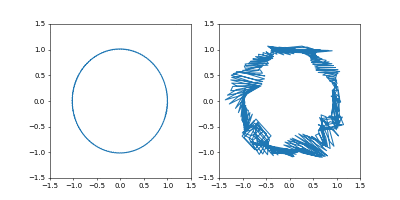
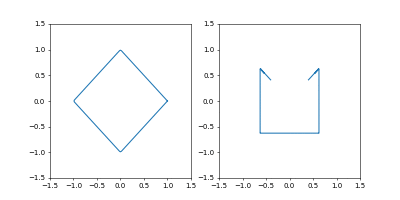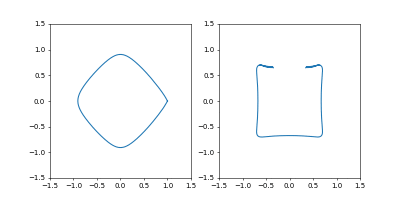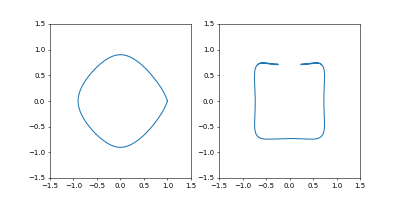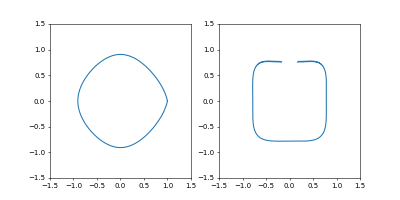
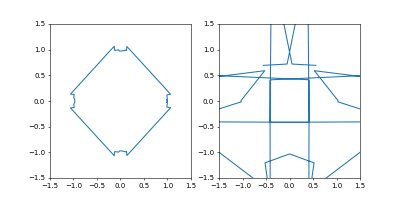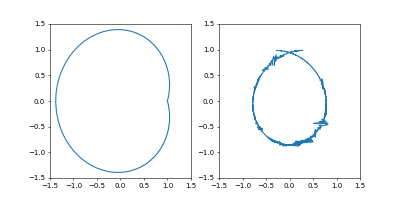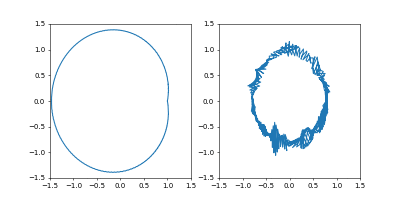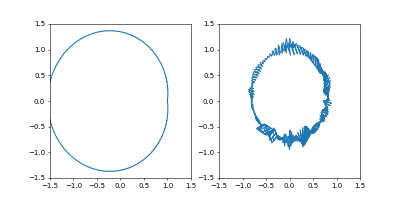
左が位置、右が速度の図です。
- Adam
学習率は $0.05$ です。
GIF動画1周が1000イテレーションです。
収束が近づいた時に暴れるのが難点ですね。真剣にやるなら、収束が進んだ段階で学習率を変えたり、オプティマイザを変えるなどの工夫がいることでしょう。
- GradientDecent
まず、Adamの時と同じ学習率 $0.05$ にすると発散しました。
動画1周が250イテレーションくらい。
学習率を $0.01$にすると発散はしませんでしたが、非常に収束が遅くなりました。
動画一周で1000イテレーション。フレームレートはAdamのものと同じです。
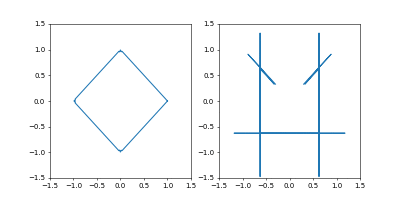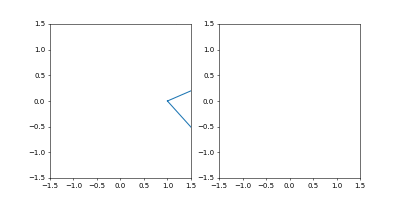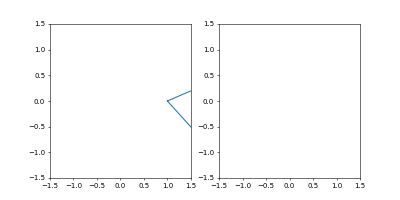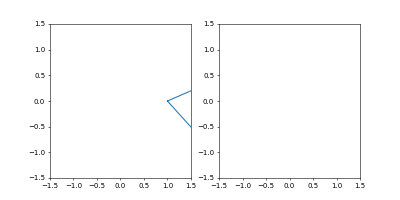
- おまけ
Adamで
Time_all = 10.0としてみました。
1000イテレーションでは若干収束には届きませんでしたが、1周にかかる時間を増やしたのに合わせて先ほどの軌跡よりも原点から遠くに行って、速度も小さくなっているのがわかると思います。
余談
今回は経路の最初と最後を固定しました。
もしここも動くようにすると、運動エネルギーを小さく、位置エネルギーを大きくすれば作用も小さくなりますが、これは今回の系では無限遠で静止というのになってしまいそうですね。まあ動かないまでもある程度の束縛(一周する=最初と最後の位置が一緒である)とかを課したもとでの最小化とかも考えられますが、今回はこの辺にしておきます。
野望
経路積分
- 投稿日:2019-03-30T19:16:15+09:00
Kerasで作ったモデルをUnityに持っていくときのハマりどころ
はじめに
Unityでは、ゲーム内で強化学習させるならml-agentsとかKelpNetなどを使えますが、一方でゲーム中に得たデータを保存し、別の環境で機械学習させた後に学習結果をUnityにもっていく、という方法もあります。
そういう方法をDeep Neural Networkで行う場合はKerasが便利です。ネットワークを設計するのも簡単ですし、Google Colaboratoryにはデフォルトで入ってるので環境構築に悩むことなくすぐに作業できます。
ただ、Kerasで作ったモデルをUnity、特にOculus GoなどのAndroidデバイスに持っていくときにハマりどころがいくつかあります。しかも、ネットで見られる情報が不完全で試しても上手くいかないことが多いです。この記事では、そのハマりどころの紹介と回避方法を紹介します。ただし、使っている関数のいくつかがdeprecatedなので、そのうち修整が必要になるでしょう。問題が発生しましたら記事へのコメントでお知らせください。なお、記事で使用しているUnityのバージョンは2018.3.8f1です。
Kerasモデルの準備
こちらのチュートリアル の内容を実装します。開発環境はGoogle Colaboratoryです。
まず、こちらのデータをダウンロードして、pima-indians-diabetes.data.csvというファイル名でGoogle Colaboratoryのドライブにアップロードしてください。
次に、Keras Functional APIでモデルと学習プロセスを定義します。ここでinputは"input_x",outputは"output_y"と定義していることに注意してください。
from keras.models import Sequential from keras.layers import Dense import numpy numpy.random.seed(7) dataset = numpy.loadtxt("pima-indians-diabetes.data.csv", delimiter=",") X = dataset[:,0:8] Y = dataset[:,8] from keras.layers import Input from keras.models import Model inputs = Input(shape=(8,),name='input_x') x = Dense(12, activation='relu')(inputs) x = Dense(8, activation='relu')(x) predictions = Dense(1, activation='sigmoid',name='output_y')(x) model = Model(input=inputs, output=predictions) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(X, Y, epochs=150, batch_size=10) scores = model.evaluate(X, Y) print("\n%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))学習が終了したら、
print(model.input) print(model.output)でinputとoutputの情報を見てください。
Tensor("input_x:0", shape=(?, 8), dtype=float32) Tensor("output_y/Sigmoid:0", shape=(?, 1), dtype=float32)上記のように、inputのほうは"input_x"と元の名前の通りですが、outputの方は"/Sigmoid"が追加されてます。この追加されてる方の名前をUnityで使うので注意してください。
KerasのモデルをTensorFlowグラフとして出力する
Kerasのモデルは直接Unityで読めないので、一旦TensorFlowの形式に変換します。ネットでググると変換の方法がいくつも出てきますが、ほとんどの方法はUnityに持っていったときに上手くいかなかったです。ここでは、こちらの記事の方法を紹介します。以下のコードはほぼ元記事の通りですが、そのままだとエラーが出るので一部修正しています。
import tensorflow as tf from tensorflow.python.framework import graph_util from tensorflow.python.framework import graph_io from keras import backend as K ksess = K.get_session() K.set_learning_phase(0) graph = ksess.graph num_output = 1 prefix = "output" pred = [None]*num_output outputName = [None]*num_output for i in range(num_output): outputName[i] = prefix + str(i) pred[i] = tf.identity(model.get_output_at(i), name=outputName[i]) constant_graph = graph_util.convert_variables_to_constants(ksess, ksess.graph.as_graph_def(), outputName)コードの内容を見るとわかりますが、Kerasのセッションをget_session()でTensorFlowのセッションとして呼び出し、学習したモデル内の変数をgraph_util.convert_variables_to_constantsで定数に変換しています。
output_dir = "./" output_graph_name = "keras2tf.pb" graph_io.write_graph(constant_graph, output_dir, output_graph_name, as_text=False)これで、keras2tf.pbというファイルにTensorflowグラフが保存されました。このファイルをローカルPCにダウンロードして、拡張子を.bytesに変更してください。
Unity内での作業
ここからはUnity内での作業になります。以下の作業はOculus Go向けのものですが、他のAndroidデバイスでも同様の流れで大丈夫かと思います。
Unityで新しいプロジェクトを作ったら、Androidをビルドターゲットにし、Player SettingでAPI Lebelを25に、Scripting Define SymbolをENABLE_TENSORFLOWにします。
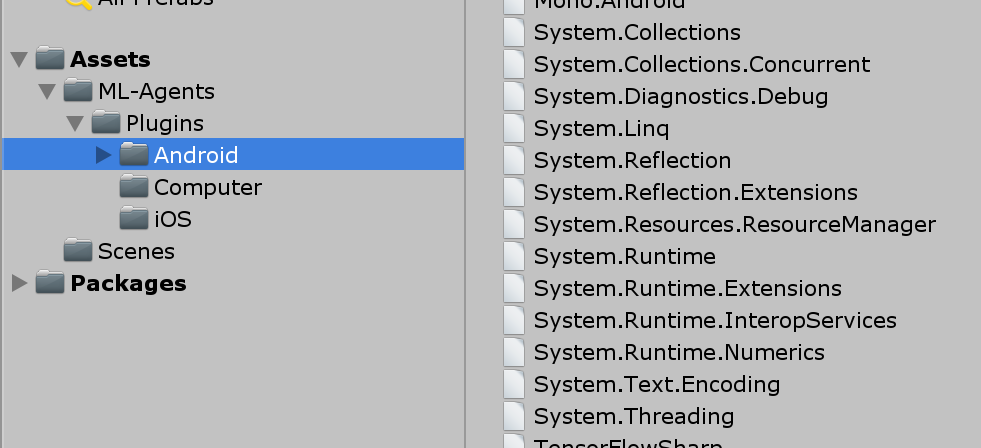
つぎに、TensorFlowSharp Unityプラグインをインポートしてください。こちらからダウンロードできます。
ImportするとPlugins/Androidというフォルダが作られますが、その中の"System."と最初に名前のつくファイルは全て削除してください。そうしないとビルド時にエラーが出ます。どうやら、Unity2018.3で出るエラーのようです。
あと、上で作ったkeras2tf.bytesをAssetsフォルダの下にドラッグアンドドロップしてください。
次にModelImportExample.csというファイルを作り、以下のスクリプトを入力してください。スクリプト作成にはこちらの記事を参考にしました。
ModelImportExample.csusing UnityEngine; using TensorFlow; public class ModelImportExample : MonoBehaviour { public TextAsset model; private float[,] inputTensor = new float[1, 8]; private float[] testData = new float[] { 6f, 148f, 72f, 35f, 0f, 33.6f, 0.627f, 50f }; void Start() { #if UNITY_ANDROID && !UNITY_EDITOR TensorFlowSharp.Android.NativeBinding.Init(); #endif TFGraph graph = new TFGraph(); graph.Import(model.bytes); TFSession sess = new TFSession(graph); for (int i = 0; i < 8; i++) { inputTensor[0, i] = testData[i]; } TFTensor input = inputTensor; var runner = sess.GetRunner(); var test = runner.AddInput(graph["input_x"][0], input); test.Fetch(graph["output_y/Sigmoid"][0]); var output = runner.Run(); var result = output[0].GetValue() as float[,]; Debug.Log(result[0,0]); } }重要なポイントは、まず、Android向けにビルドするときは
#if UNITY_ANDROID && !UNITY_EDITOR TensorFlowSharp.Android.NativeBinding.Init(); #endifを追加してください。無いとビルドできません。
つぎに、インポートしたkeras2tf.bytesはTextAssetとしてエディタ上でmodelに割り当ててください。
あと、グラフへの入力と出力は
var test = runner.AddInput(graph["input_x"][0], input); test.Fetch(graph["output_y/Sigmoid"][0]);で定義しています。それぞれの名前は、Keras側で確認した通り"input_x", "output_y/Sigmoid"になっていることに注意してください。
これでエディタ上でスクリプトを実行すると、コンソールに"0.9049003"とアウトプットが出てくるはずです。確認したら、ビルドしてください。正常に終了するはずです。Oculus Goでも動作確認済みです。