- 投稿日:2019-03-30T23:00:31+09:00
NVIDIA Jetson Nano 開発者キットに TensorFlow をインストールする
インストール手順
NVIDIA 社が Jetson 用の TensorFlow pip wheel パッケージを公開しているので Jetson Nano にも TensorFlow を簡単にインストールできます。NVIDIA 社の TensorFlow For Jetson Platform ページにインストール方法が解説されていますので基本的にはその手順どおりですが、ちょっと注意点があります。
HDF5 のインストール
$ sudo apt-get install libhdf5-serial-dev hdf5-toolspip のインストール
$ sudo apt-get install python3-pipNVIDIA 社のページには pip インストール後に pip による pip のアップデートが示されておりますが、とりあえず現時点(2019年3月30日)ではこれを行わない方が無難だと思います。私の環境ではこれにより pip を起動できなくなりました。
$ pip3 install -U pip
以下のページを参考にさせていただき復帰しました。
【Ubuntu】pip install –upgrade pip コマンドを実行すると、その後、ImportError: cannot import name main というエラーが発生する場合の対応方法その他パッケージのインストール
$ sudo apt-get install zlib1g-dev zip libjpeg8-dev libhdf5-dev $ sudo pip3 install -U numpy grpcio absl-py py-cpuinfo psutil portpicker grpcio six mock requests gast h5py astor termcolorTensorFlow のインストール
$ sudo pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpuインストールを確認
$ python3 Python 3.6.7 (default, Oct 22 2018, 11:32:17) [GCC 8.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf >>> print(tf.__version__) 1.13.1 >>> quit() $上記で TensorFlow のインストールは完了です。
TensorFlow チュートリアル・コードを動作させる
Jetson シリーズはディープニューラルネットワークを用いた推論には最適のプラットフォームと言えますが、ディープニューラルネットワークの学習にはちょっとパワー不足です 1 。但し、小規模なディープニューラルネットワークの学習ならば大丈夫です。GPU を搭載しない PC よりも速いと思います。
Get Started with TensorFlow に示されている以下のコードを動作させてみましょう。mnist.pyimport tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test)このコードを mnist.py というファイル名で保存して、以下のように起動します。
$ python3 mnist.pyGPU が認識されているのが分かります。
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/resource_variable_ops.py:435: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/layers/core.py:143: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version. Instructions for updating: Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`. 2019-03-30 17:46:10.020449: W tensorflow/core/platform/profile_utils/cpu_utils.cc:98] Failed to find bogomips in /proc/cpuinfo; cannot determine CPU frequency 2019-03-30 17:46:10.021429: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0x3f14f760 executing computations on platform Host. Devices: 2019-03-30 17:46:10.021499: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): <undefined>, <undefined> 2019-03-30 17:46:10.167789: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:965] ARM64 does not support NUMA - returning NUMA node zero 2019-03-30 17:46:10.168088: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0x3de91970 executing computations on platform CUDA. Devices: 2019-03-30 17:46:10.168145: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): NVIDIA Tegra X1, Compute Capability 5.3 2019-03-30 17:46:10.168519: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 0 with properties: name: NVIDIA Tegra X1 major: 5 minor: 3 memoryClockRate(GHz): 0.9216 pciBusID: 0000:00:00.0 totalMemory: 3.86GiB freeMemory: 532.48MiB 2019-03-30 17:46:10.168575: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 0 2019-03-30 17:46:15.464153: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-03-30 17:46:15.475841: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0 2019-03-30 17:46:15.475890: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N 2019-03-30 17:46:15.476119: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 75 MB memory) -> physical GPU (device: 0, name: NVIDIA Tegra X1, pci bus id: 0000:00:00.0, compute capability: 5.3) 2019-03-30 17:46:16.539100: I tensorflow/stream_executor/dso_loader.cc:153] successfully opened CUDA library libcublas.so.10.0 locally5エポックの学習で loss: 0.0640 - acc: 0.9819という結果になりました。
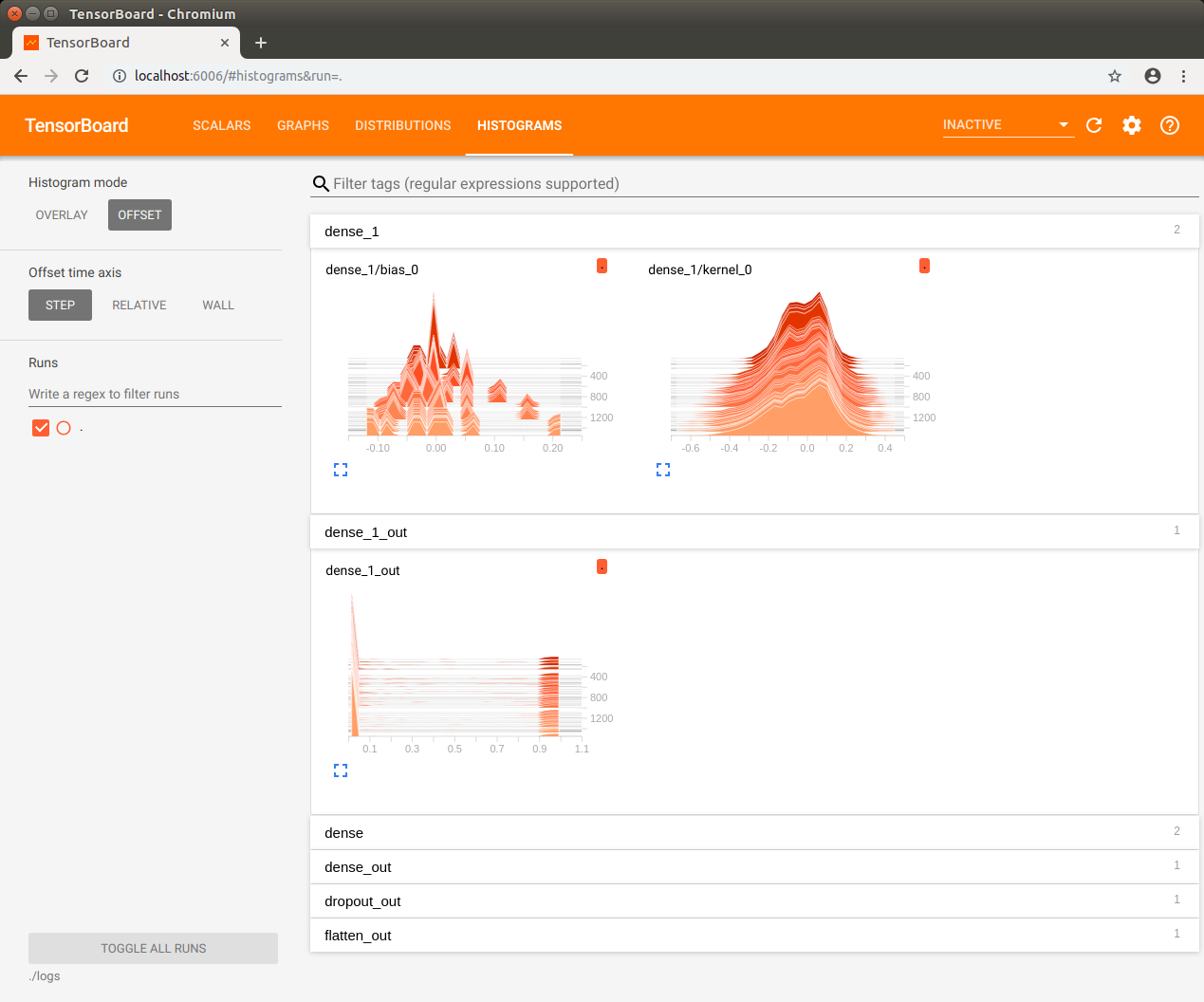
TensorBoard を使う
TensorBoard を利用したモデルの可視化だってできます。少しコードの変更が必要です。
但し、学習しながらその様子を TensorBorad で観察するのは Jetson Nano にはちょっと重過ぎでした。学習が完了してからそのログを TensorBoard で見てみましょう。mnist.pyimport tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) log_filepath = "./logs/" tb_cb = tf.keras.callbacks.TensorBoard(log_dir=log_filepath, histogram_freq=1) model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test), callbacks=[tb_cb]) model.evaluate(x_test, y_test)ログ用ディレクトリを作成してから動作させます。
$ mkdir logs $ python3 mnist.py上記の実行が完了してから TensorBoard を起動します。
$ tensorboard --logdir=./logsTensorBorad が起動したら Jetson Nano 上の Chromium ブラウザで localhost:6006 を開きます。
モデルの保存
学習済みモデル(ディープニューラルネットワークの重みとバイアス)を保存するには上記コードの最後に以下の行を追加します。
model.save('mnist.hdf5')保存したモデルを Netron ブラウザ・バージョン で覗いてみましょう。
以上です。
ディープニューラルネットワークの学習にはパワフルな NVIDIA Tesla GPU などが使われるようです。 ↩


- 投稿日:2019-03-30T22:10:43+09:00
Transformerのメモ
注意
合ってるの?って言われるとわからない
元の論文
https://arxiv.org/abs/1706.03762
他の人の解説
超詳しい解説、コードを書きながら何やってるかわかる(日本語):
https://qiita.com/halhorn/items/c91497522be27bde17ce論文とコードが一緒に読める(英語):
http://nlp.seas.harvard.edu/2018/04/03/attention.html大枠から解説(英語):
http://jalammar.github.io/illustrated-transformer/何が新しいのか・何が今までどおりなのか
ここで言う「今まで」とはRNN系列のモデルを指します
具体的にはAttention LSTM
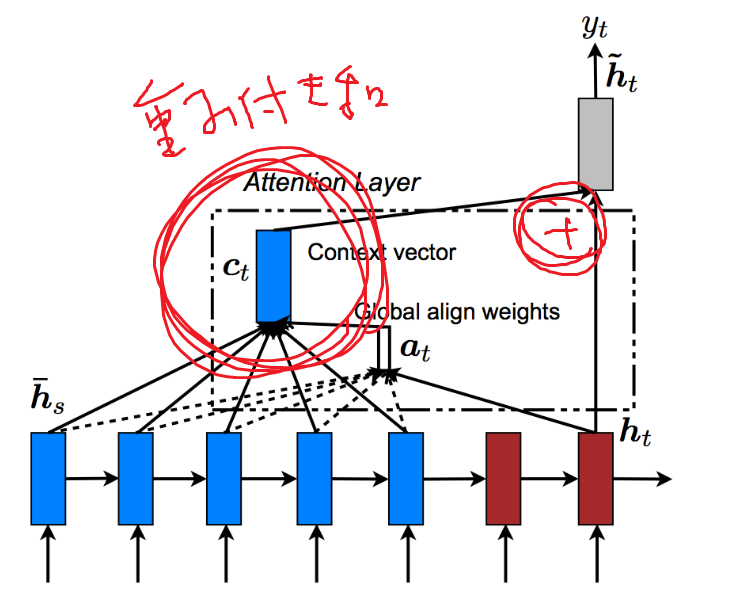
モデルとしてはEffective Approaches to Attention-based Neural Machine Translationの図がわかりやすい今までどおりなところ
1. Decoderの中間層を利用してEncoderの各時刻(各token)の出力に対して重みを計算し、
2. Encoderの出力の重み付け和をDecoderの中間層に合成(concat/sum)してる
ところ
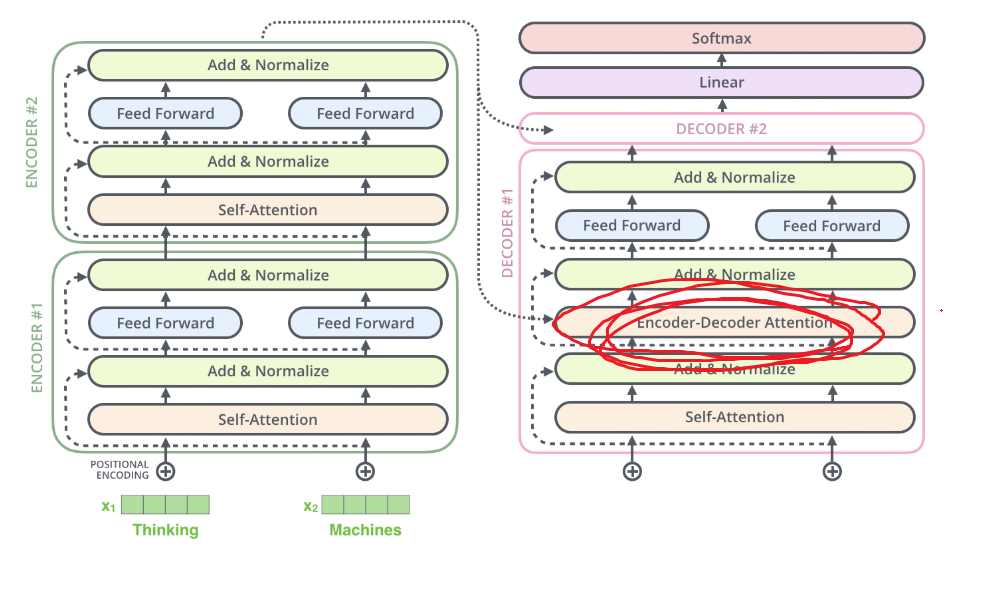
AttentionLSTMではDecoderの中間層とconcat
参照:http://aclweb.org/anthology/D15-1166TransformerではDecoderの中間層とsum
参照:http://jalammar.github.io/illustrated-transformer/推論時の計算
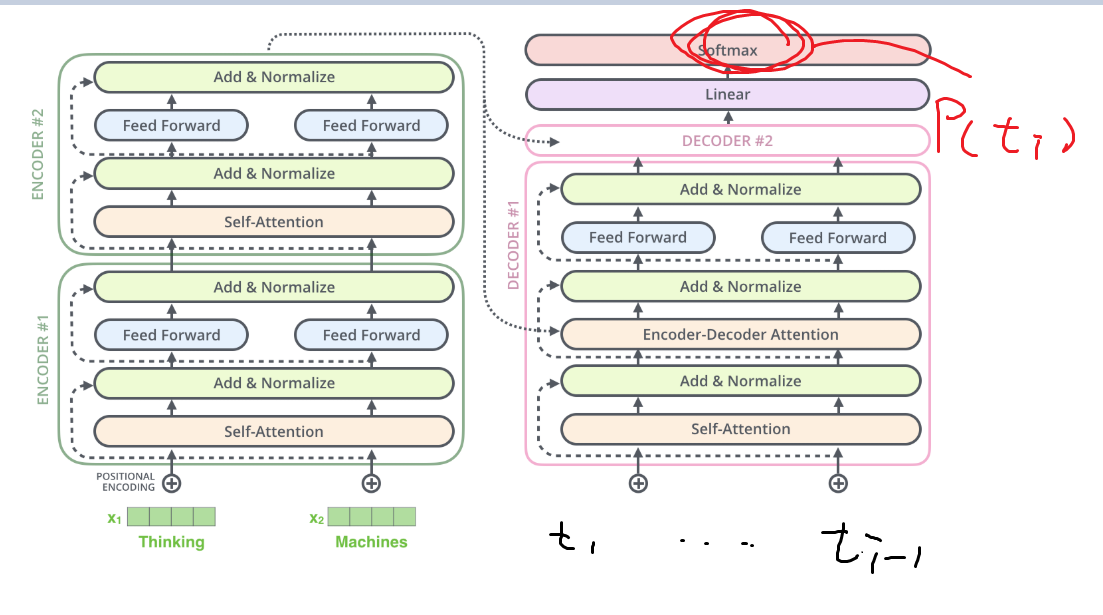
LSTMでもTransformerでも時系列順に計算する必要がある
どういうことかというと、Transformerであっても、推論を時間ごとに並列化して計算するのは無理・・・だと思う
なぜなら、出力tokenを$t_1,...t_n$としたとき、token $t_i$の出力確率を計算するには入力にtoken $t_1 ... t_{i-1}$ が必要になるからである図でいうと下の通り
参照:http://jalammar.github.io/illustrated-transformer/何が違うのか
学習時の計算
Transformerは学習を並列して行うことができる
並列って具体的にどういうことかというと、
入力token列$t_{i_1}...t_{i_k}$を利用したtoken$t_{o_1}$の出力確率の計算と、
入力token列$t_{i_1}...t_{i_k}$と出力token列$t_{o_1}$を利用したtoken$t_{o_2}$の出力確率の計算と、
入力token列$t_{i_1}...t_{i_k}$と出力token列$t_{o_1}...t_{o_2}$を利用したtoken$t_{o_3}$の出力確率の計算と、...
というを全部バラバラに行えるということである
これは何故かというと、出力token列は学習データにおいては既知であるためであるLSTMの場合、token $t_{o_i}$の出力確率を計算するためには、時刻$t_{i-1}$におけるDecoderの中間表現が必要になる(=計算が前の時刻の計算に依存している)
よって並列化が出来ないのである位置の考慮
Transformerでは、各tokenが文章の何番目に当たるかを考慮している
これはPositional Encodingという、次元ごとに異なる周期を持つ信号(sin/cos波)をTokenのEmbeddingに足し合わせることで実現されている、具体的には次の関数
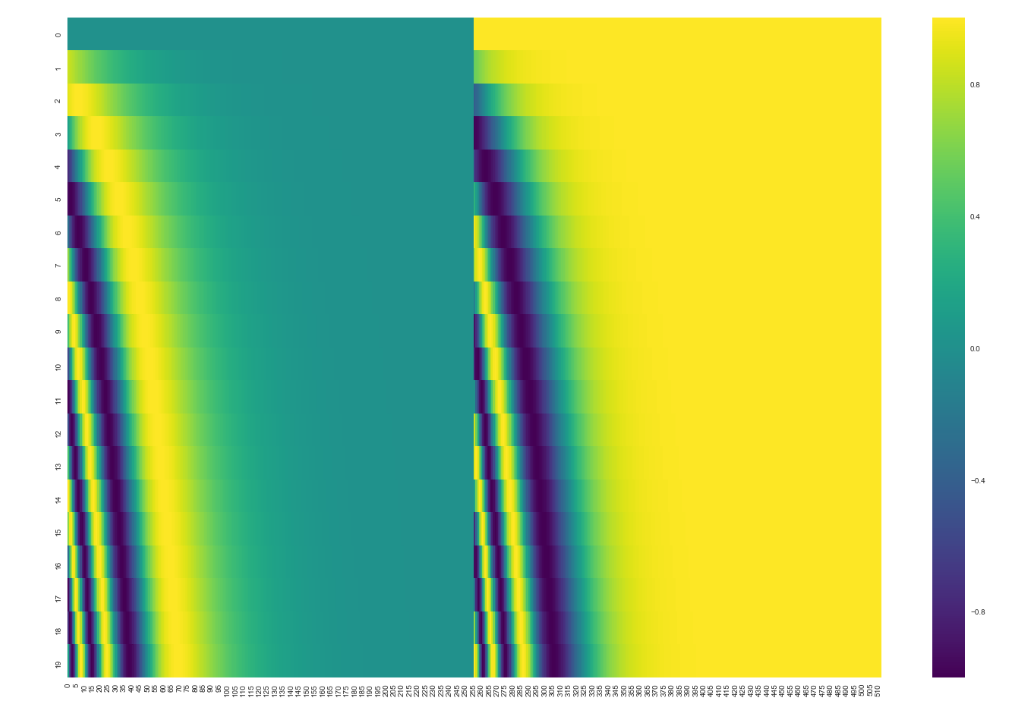
参考:https://arxiv.org/abs/1706.03762偶数次元ではsin、奇数次元ではcosの信号になっているようだ
また1周するために必要なtoken数は$2π*10000^{2i/D_{model}}$
ここでiはベクトルの各次元に相当する
iが大きくなればなるほど(ベクトルの高次元に行けばいくほど)一周に時間がかかる(=周期の長い)信号となっていることが数式からわかる図からもわかる
参考:http://jalammar.github.io/illustrated-transformer/
ただし、この図では偶数次元/奇数次元ではなくて、全N次元とすると1~N/2次元、N/2+1次元~N次元でsin/cosを分けているようだ周期的な信号と聞くと「一周したら最初の単語と位置区別できなくなっちゃうじゃん!」と思うが、高次元になればなるほど一周に時間かかるようになってる+各次元で周期が違うので、全ての次元の周期がきれいに初期状態に戻るには相当な時間がかかる(≒実質的にどんな長さの文章でも入力可能)ように思える
(ちゃんと計算してないので不明)整理してもやっぱりちょっと疑問は残るといえば残る
足し合わせるんじゃなくて単純にconcatじゃいけないんだろうか
concatするのであればわざわざ次元をtoken embeddingに合わせる必要もない
位置情報を保存するための次元をn-bit確保しといてそれに入れるのでは駄目なんだろうかbit立てる場合だと桁上りの際に一気に違う信号になるので、連続的な変化をするsin波を使う気持ちはわかる
でもconcatじゃ駄目なのか?という気持ちは拭えない
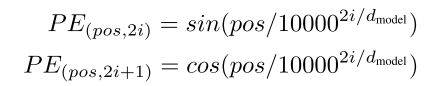
- 投稿日:2019-03-30T22:00:09+09:00
Ubuntu18.04にeGPUでDeep Learning環境を構築した(失敗談付き)
eGPUによる環境構築報告がなかったので、需要は小さいだろうがポエムとして残しておく。数多のログインループとdependency hellを乗り越えて。
むしゃくしゃしたから書いた。ハードウェア
- 機種: HP Spectre x360 13-ac000
外付けGPU: akitio node pro
前提環境
- Windows10とのdualboot
sudo apt update sudo apt upgrade cat /etc/lsb-release #DISTRIB_ID=Ubuntu #DISTRIB_RELEASE=18.04 #DISTRIB_CODENAME=bionic #DISTRIB_DESCRIPTION="Ubuntu 18.04.2 LTS"NVIDIA driverのインストール
ubuntu18.04だと自動でeGPUを認識してくれた。usb-c/thunderboltすごい。
以前、環境構築したときはdriver .runファイルを公式から落としてきたり、nouveauをblacklistしたが最近は必要ないようだ。
- GPUを認識しているか確認。
lspci | grep -i nvidia #07:00.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1) #07:00.1 Audio device: NVIDIA Corporation GP102 HDMI Audio Controller (rev a1)
- GPUに必要なdriverの確認
ubuntu-drivers devices #== #/sys/devices/pci0000:00/0000:00:1c.4/0000:02:00.0/0000:03:01.0/0000:05:00.0/0000:06:01.0/0000:07:00.0 == #modalias : pci:v000010DEd00001B06sv00001462sd00003607bc03sc00i00 #vendor : NVIDIA Corporation #model : GP102 [GeForce GTX 1080 Ti] #driver : nvidia-driver-418 - third-party free recommended #driver : nvidia-driver-396 - third-party free #driver : nvidia-driver-410 - third-party free #driver : nvidia-driver-415 - third-party free #driver : nvidia-driver-390 - distro non-free #driver : xserver-xorg-video-nouveau - distro free builtin
- ここでdriverを上手く指定してあげないとログインループに嵌まる
sudo apt install nvidia-driver-390 nvidia-settings sudo init 6 #reboot必要に応じて、
sudo prime-select queryでintelと返ってきたら、sudo prime select nvidia sudo init 6上手くログインできたら
nvidia-smiでGPU確認。tensorflowのインストール
Anacondaからインストールする。
そうなのだ。最近はCUDAやcuDNNのインストールが不要となっていた。どうやら、パッケージがCUDAやcuDNNのバイナリを含んでいるようだ。だがこれはこれでconda installのとき一緒にどのversionかを気をつけないと痛い目にあった。
anacondaのインストールは済んでいるとする。
- 壊れてもいいように仮想環境構築
conda create --name tf-gpu source activate tf-gpu
- 多少versionは落ちるが
conda install \ tensorflow-gpu==1.12 \ cudatoolkit==9.0 \ cudnn=7.1.2 \ h5py conda install keras ## optional
- jupyter notebookのkernel登録
conda install jupyter conda install ipykernel python -m ipykernel install --user --name tf-gpu --display-name "tf-gpu"
- GPU実行確認
python -c "from tensorflow.python.client import device_lib; device_lib.list_local_devices()"長々としたoutputにGPUとあったら使えている。
pytorchのインストール
- 仮想環境とか
conda create -n pytorch python=3.6 numpy scipy
- 公式サイトから必要な情報を入力するとインストール方法が分かる。今回は、CUDA9.0指定。
conda install pytorch torchvision cudatoolkit=9.0 -c pytorch
- GPU実行確認
import torch print(torch.cuda.is_available()) >> True torch.cuda.get_device_name(0) >> 'GeForce GTX 1080 Ti'失敗したこと
NVIDIA-driverのバージョン
推奨されているように
sudo ubuntu-drivers autoinstallを実行してしまうと、もれなくnvidia-driver-418 - third-party free recommendedがインストールされてログインできなくなる。そんなときは慌てず騒がずgrubでsafe modeまたはログイン画面でAlt + F2を押してterminalに入る。sudo apt remove nvidia*で一度driverを消してあげればまたログインできるようになる。ライブラリインストール
まず、nvidia-driver-390までインストールできた。前回と同じようにCUDAをインストールしようとしたところ、driver incompatabilityやらでまたログインループに嵌った。今度は、CUDA/cuDNNなしのインストール方法を模索した。公式tensorflowの指示通りにdockerを立ち上げたがdriver incompatibleと怒られた。(nvidia-driverをインストールしておくだけで実行できると書かれているにも関わらず。)今度はanacondaからinstallしようとした。
conda install tensorflow-gpuで実行できるかと思われたが最新のCUDA10がインストールされ、driver incompatible。仮想環境を作っていたので、apt installよりは気楽である。最終的にdriverに一致するCUDAを特定し、そこから対応するtensorflowを探し、上記バージョン指定となった。結語
これでもNVIDIA公式.runファイルとの格闘はなくなり簡単になったとは思う。GPU設定は根気が必要。
- 投稿日:2019-03-30T21:38:35+09:00
GANで新元号を生成してみた
0. はじめに
Deep Learningを活用した生成技術の一つに、GAN(Generative Adversarial Network)というものがあります。
これは、GeneratorとDiscriminatorという2つのネットワークを同時に学習させることによって、あたかも本物のようなダミーデータを生成する技術で、画像生成や文章生成、音声合成などに応用されています。例えば以下の画像は、実際の海外セレブの顔写真を使ってモデルを学習し、実在しない人物の顔を生成した例です。
出典:https://arxiv.org/pdf/1710.10196.pdf今回はこのGANを使って、歴代の元号を基に新元号を生成したら、どんな元号ができるか試してみました。
※ あくまでお遊びですので、ご理解の程よろしくお願いします。
0. 開発環境
学習を高速に行うため、GPUを無料で利用できるGoogle Colaboで開発を行いました。
Google Colaboの使い方は、以下のページなどが参考になります。
【秒速で無料GPUを使う】TensorFow(Keras)/PyTorch/Chainer環境構築 on Colaboratory1. 元号画像の準備
GANの学習には、以下のような元号の文字画像を使用します。
このように文字の画像を使ってGANを学習させた場合、モデルは漢字の形そのものを模倣するようになるため、実在しない変な漢字が生成されてしまう可能性があります。
しかし学習がうまく進み、元の画像と見分けのつかないような画像を生成できるようになれば、実在する漢字に非常に近い文字が生成されるようになると考えられます。
このとき、GANでは複数の本物データと生成画像の差異を合計(平均)して誤差を計算するため、元号に多く使われている漢字(「永」、「元」など)を生成したほうがトータルの誤差が小さくなり、モデルはそのような漢字を優先的に生成するようになると予想されます。
すなわち、元号での頻出漢字が生成画像により出現しやすくなるということです。また、元号のほとんどは漢字2文字であるため、1文字目の漢字と2文字目の漢字が別々に模倣されれば、これまでに無いような新たな組み合わせの漢字2文字(「平成」の平+「昭和」の和=「平和」など)が生成できるのではないかと思われます。
すなわち、歴代の元号の文字画像を使ってGANを学習することで、「実在する漢字を使った」、「より元号っぽい」、「新たな組み合わせの」元号が生成できるのではないかと考えました。
(実際はそんなに都合良く行くとは思えないですが・・)それでは、実際に元号の文字画像を作成していきます。
1-1. 元号一覧の取得
初めに、国立公文図書館デジタルアーカイブから和暦元号の一覧を読み込みました。
このとき、Pandasのread_html関数を使用することで、Web上のテーブルをPandasのDataFrameに簡単に変換することができます。また、昔の元号には漢字4文字のもの(「神護景雲」、「天平神護」など)が一部あるのですが、学習時にノイズになると考えられるため、今回は漢字2文字の元号のみに絞ることとしました。
絞り込みの結果、歴代の元号は全部で242通りとなりました。1-2. フォントのダウンロード
上記の元号一覧を基に、PILライブラリを使用して文字画像を作成します。
ただし、PILのImageは標準で日本語出力に対応していないため、日本語フォントを別途用意して指定する必要があります。複数のフォントを使用したほうが学習データに多様性が出て良いと思ったので、今回は以下の9つの漢字対応フォント(全てフリー)をダウンロードして使用しました。
参考までに、各フォントの「平成」の文字画像を載せておきます。
1-3. 元号画像の作成
日本語フォントが用意できたら、いよいよ元号の文字画像を作成します。
PILのImageDrawで画像を作成し、ImageFontで文字のフォントを指定した上で、ImageDraw.Draw.text関数を使用して文字を出力します。
参考:PILで日本語の文字を書く上記9つのフォントそれぞれについて、全元号の画像(242×9=2178枚)を作成しました。
学習データの画像サイズは、大きければ大きいほど鮮明な画像を生成できますが、それだけ学習にかかる時間も増えることとなります。
今回は、リアルな文字画像を生成することが目的ではないので、画像サイズを比較的小さい64×64としました。作成した画像は、Google Colabo上の適当なフォルダ(datasets/gengo/など)にまとめて置いておきます。
2. GANの実行
ここ数年のGANの発展は目覚ましく、学習の安定化や生成データの多様化などを実現するために様々な手法が提案されていますが、今回はGANを使った画像生成の草分け的存在であるDCGANを使用したいと思います。
DCGANは、GeneratorとDiscriminatorにCNNを使用したモデルで、安定的に学習を行うための工夫が盛り込まれています。
参考:はじめてのGANより最新の手法と比較すると、モデルの構造が単純なため、比較的早く学習を行うことができます。
2-1. プログラムのダウンロード
DCGANのプログラムは、carpedm20さんが開発したTensorFlowのコードを使用させていただきました。
Google Colabo上で、以下のようにしてGithubからプログラムをダウンロードし、フォルダ内に移動します。
!git clone https://github.com/carpedm20/DCGAN-tensorflow/ os.chdir('DCGAN-tensorflow')2-2. 学習
ソースコードの説明に従って、1で作成した元号画像を正解データとして指定し、学習を実行します。
python main.py --dataset=gengo --data_dir=../datasets/ --input_fname_pattern="*.png" --trainデフォルトでは、バッチサイズ64、エポック数25で学習が行われるようです。
実行する時間帯などにも寄るとは思いますが、私の環境では数分程度で学習が完了し、画像が生成されました。
2-3. 生成結果
学習完了後の生成画像は、以下のようになりました。
・・・漢字にすらなっていないですね。
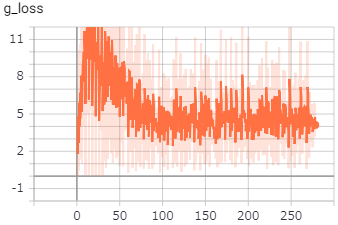
遠目で見ると「雨」や「雲」のように見えなくもないですが。。。GeneratorとDiscriminatorの損失は、以下のようになっていました。
3. 考察
画像生成がうまくいかなかった原因としては、以下のようなことが考えられます。
3-1. DCGANのネットワークが単純すぎる
DCGANは元々、学習が十分に安定しておらず、モードの崩壊(モデルが局所解に陥ったような状態になって、同じような画像ばかりが生成されてしまうこと)が起きやすいことが知られています。
上記の生成画像を見ると、このモードの崩壊が起きているような印象があり、学習がうまく進んでいない可能性があります。より複雑なモデル(SAGAN, PGGANなど)を使用すれば、学習が安定し、もう少しまともな漢字が生成できるかもしれません。
3-2. 漢字の形状が複雑すぎる
漢字は、数字やひらがな、カタカナ、アルファベットなどと比較して複雑な形状をしており、生成自体が難しいのではないかと思われます。
実際、GANで手書き数字(mnist)やカタカナを生成した例はあるようですが、漢字を生成した例はあまり無いようです。また、例えば人の顔であれば、全画像に共通点(どの画像も目があって鼻があって・・など)がありますが、漢字にはそのような共通構造があまり無いため、上記のような何とも言えない字が生成されてしまったものと考えられます。
3-3. GANがタスクに向かない
これは身も蓋もない話ですが、今回のように「実在する漢字を使っていて、かつ入力データには存在しないような組み合わせの2文字を生成する」というタスクには、GANは向いていないのかもしれません。
たまたま「大」という字から「太」という字が生成されること等はあるかもしれませんが、実在する漢字の構造には制限があるため、GANに自由に字を書かせると、入力データと全く同じ漢字が生成されるか、実在しない漢字が生成される可能性の方がはるかに高くなると思われます。
3-4. 画像データの使用
そもそも文字を画像として扱うという方法自体が、あまり良く無い可能性もあります。
画像データを使用する以外の方法として、テキストベースの予測を行うことも考えられます。
例えば、歴代の元号や一般的なコーパスを使用することで、元号に使われやすい漢字や、ある漢字と一緒に使われることの多い漢字(「安」と「明」は同じ文書に出現しやすい、など)を学習し、それら二つの漢字が繋がった新たな元号(「安明」)を生成できるのではないかと思いました。しかし、私自身が自然言語処理の専門では無いことと、GANによる文章生成はまだ発展途上ということもあり、今回は試していません。
(どなたか知見のある方がいたら、試していただければと思います・・)4. まとめ
残念ながら、今回はGANを使用して新しい元号を予測することができませんでした。
次回は、より安定的に画像を生成できるモデルを使用して、もう一度元号生成に挑戦してみたいと思います。巷では、次の元号は「安久」になる等の噂もありましたが、一体どうなるのでしょうか?発表が待ち遠しいばかりです。




- 投稿日:2019-03-30T21:38:35+09:00
DCGANで新元号を生成してみた
0. はじめに
Deep Learningを活用した生成技術の一つに、GAN(Generative Adversarial Network)というものがあります。
これは、GeneratorとDiscriminatorという2つのネットワークを同時に学習させることによって、あたかも本物のようなダミーデータを生成する技術で、画像生成や文章生成、音声合成などに応用されています。例えば以下の画像は、実際の海外セレブの顔写真を使ってモデルを学習し、実在しない人物の顔を生成した例です。
出典:https://arxiv.org/pdf/1710.10196.pdf今回はこのGANを使って、歴代の元号を基に新元号を生成したら、どんな元号ができるか試してみました。
※ あくまでお遊びですので、ご理解の程よろしくお願いします。
1. 開発環境
学習を高速に行うため、GPUを無料で利用できるGoogle Colaboで開発を行いました。
Google Colaboの使い方は、以下のページなどが参考になります。
【秒速で無料GPUを使う】TensorFow(Keras)/PyTorch/Chainer環境構築 on Colaboratory2. 元号画像の準備
GANの学習には、以下のような元号の文字画像を使用します。
このように文字の画像を使ってGANを学習させた場合、モデルは漢字の形そのものを模倣するようになるため、実在しない変な漢字が生成されてしまう可能性があります。
しかし学習がうまく進み、元の画像と見分けのつかないような画像を生成できるようになれば、実在する漢字に非常に近い文字が生成されるようになると考えられます。
このとき、GANでは複数の本物データと生成画像の差異を合計(平均)して誤差を計算するため、元号に多く使われている漢字(「永」、「元」など)を生成したほうがトータルの誤差が小さくなり、モデルはそのような漢字を優先的に生成するようになると予想されます。
すなわち、元号での頻出漢字が生成画像により出現しやすくなるということです。また、元号のほとんどは漢字2文字であるため、1文字目の漢字と2文字目の漢字が別々に模倣されれば、これまでに無いような新たな組み合わせの漢字2文字(「平成」の平+「昭和」の和=「平和」など)が生成できるのではないかと思われます。
すなわち、歴代の元号の文字画像を使ってGANを学習することで、「実在する漢字を使った」、「より元号っぽい」、「新たな組み合わせの」元号が生成できるのではないかと考えました。
(実際はそんなに都合良く行くとは思えないですが・・)それでは、実際に元号の文字画像を作成していきます。
2-1. 元号一覧の取得
初めに、国立公文図書館デジタルアーカイブから和暦元号の一覧を読み込みました。
このとき、Pandasのread_html関数を使用することで、Web上のテーブルをPandasのDataFrameに簡単に変換することができます。また、昔の元号には漢字4文字のもの(「神護景雲」、「天平神護」など)が一部あるのですが、学習時にノイズになると考えられるため、今回は漢字2文字の元号のみに絞ることとしました。
絞り込みの結果、歴代の元号は全部で242通りとなりました。2-2. フォントのダウンロード
上記の元号一覧を基に、PILライブラリを使用して文字画像を作成します。
ただし、PILのImageは標準で日本語出力に対応していないため、日本語フォントを別途用意して指定する必要があります。複数のフォントを使用したほうが学習データに多様性が出て良いと思ったので、今回は以下の9つの漢字対応フォント(全てフリー)をダウンロードして使用しました。
参考までに、各フォントの「平成」の文字画像を載せておきます。
2-3. 元号画像の作成
日本語フォントが用意できたら、いよいよ元号の文字画像を作成します。
PILのImageDrawで画像を作成し、ImageFontで文字のフォントを指定した上で、ImageDraw.Draw.text関数を使用して文字を出力します。
参考:PILで日本語の文字を書く上記9つのフォントそれぞれについて、全元号の画像(242×9=2178枚)を作成しました。
学習データの画像サイズは、大きければ大きいほど鮮明な画像を生成できますが、それだけ学習にかかる時間も増えることとなります。
今回は、生成画像の質と学習時間とのバランスを考えて、画像サイズを128×128としました。作成した画像は、Google Colabo上の適当なフォルダ(datasets/gengo/など)にまとめて置いておきます。
3. GANの実行
ここ数年のGANの発展は目覚ましく、学習の安定化や生成データの多様化などを実現するために様々な手法が提案されていますが、今回はGANを使った画像生成の草分け的存在であるDCGANを使用したいと思います。
DCGANは、GeneratorとDiscriminatorにCNNを使用したモデルで、安定的に学習を行うための工夫が盛り込まれています。
参考:はじめてのGANより最新の手法と比較すると、モデルの構造が単純なため、比較的早く学習を行うことができます。
3-1. プログラムのダウンロード
DCGANのプログラムは、carpedm20さんが開発したTensorFlowのコードを使用させていただきました。
Google Colabo上で、以下のようにしてGithubからプログラムをダウンロードし、フォルダ内に移動します。
!git clone https://github.com/carpedm20/DCGAN-tensorflow/ os.chdir('DCGAN-tensorflow')3-2. 学習
ソースコードの説明に従って、1で作成した元号画像のパスと画像サイズを指定し、学習を実行します。
python main.py --dataset=gengo --data_dir=../datasets/ --input_fname_pattern="*.png" --input_height=128 --output_height=128 --trainデフォルトでは、バッチサイズ64、エポック数25で学習が行われるようです。
実行する時間帯などにも寄るとは思いますが、私の環境では数分程度で学習が完了し、画像が生成されました。
3-3. 生成結果
学習完了後の生成画像は、以下のようになりました。
・・・何とも言えないですね。
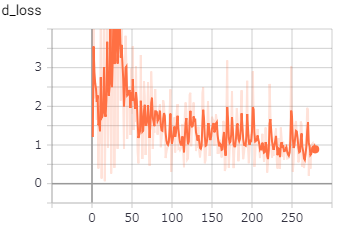
一部「元」などの文字が生成されているように見えますが、全体的に漢字にすらなっていない画像が多いです。GeneratorとDiscriminator
の損失は、以下のようになっていました。
Discriminatorの損失が段々と下がり続けているので、学習が収束しきっていないのかもしれません。
4. 考察
画像生成がうまくいかなかった原因としては、以下のようなことが考えられます。
4-1. DCGANのネットワークが単純すぎる
DCGANは元々、学習が十分に安定しておらず、モードの崩壊(モデルが局所解に陥ったような状態になって、同じような画像ばかりが生成されてしまうこと)が起きやすいことが知られています。
上記の生成画像を見ると、明らかなモードの崩壊は起きていませんが、学習がうまく進んでいないような印象を受けます。より複雑なモデル(SAGAN, PGGANなど)を使用すれば、学習が安定し、もう少しまともな漢字が生成できるかもしれません。
4-2. 漢字の形状が複雑すぎる
漢字は、数字やひらがな、カタカナ、アルファベットなどと比較して複雑な形状をしており、生成自体が難しいのではないかと思われます。
実際、GANで手書き数字(mnist)やカタカナを生成した例はあるようですが、漢字を生成した例はあまり無いようです。また、例えば人の顔であれば、全画像に共通点(どの画像も目があって鼻があって・・など)がありますが、漢字にはそのような共通構造があまり無いため、上記のような何とも言えない字が生成されてしまったものと考えられます。
4-3. GANがタスクに向かない
これは身も蓋もない話ですが、今回のように「実在する漢字を使っていて、かつ入力データには存在しないような組み合わせの2文字を生成する」というタスクには、GANは向いていないのかもしれません。
たまたま「大」という字から「太」という字が生成されること等はあるかもしれませんが、実在する漢字の構造には限りがあるため、GANに自由に字を書かせると、入力データと全く同じ漢字が生成されるか、実在しない漢字が生成される可能性の方がはるかに高くなると思われます。
4-4. 画像データの使用
そもそも文字を画像として扱うという方法自体が、あまり良く無い可能性もあります。
画像データを使用する以外の方法として、テキストベースの予測を行うことも考えられます。
例えば、歴代の元号や一般的なコーパスを使用することで、元号に使われやすい漢字や、ある漢字と一緒に使われることの多い漢字(「安」と「明」は同じ文書に出現しやすい、など)を学習し、それら二つの漢字が繋がった新たな元号(「安明」)を生成できるのではないかと思いました。しかし、私自身が自然言語処理の専門では無いことと、GANによる文章生成はまだ発展途上ということもあり、今回は試していません。
(どなたか知見のある方がいたら、試していただければと思います・・)5. まとめ
残念ながら、今回はGANを使用して新しい元号を予測することができませんでした。
次回は、より安定的に高解像度画像を生成できるモデルを使用して、もう一度元号生成に挑戦してみたいと思います。巷では、次の元号は「安久」になる等の噂もありましたが、一体どうなるのでしょうか?発表が待ち遠しいばかりです。

- 投稿日:2019-03-30T06:31:01+09:00
無料で使える機械学習クラウド(Google Colaboratory)で、ディープラーニングなFX自動トレードシミュレーション(取り急ぎ版)
どうも、オリィ研究所 の ryo_grid こと神林です。
(以下は趣味でやっているもので、業務とは関係ありません)はじめに
もう、結構前になってしまいましたが、こんなことをやっていました。
ディープラーニングでFXシステムトレード
♯ Qiitaの記事を綺麗に埋め込むにはどうすればいいのでしょうで、掲題の Google Colaboratory で、うまくやれば Nvidia Tesla K80 というかなり強力なGPUを占有で、ずっと使える、それも無料で、という情報を耳にしたので、試しに上の記事のコードを動かしてみようと思ったわけです。
Google Colaboratory とは
詳細はぐぐってください(完)。
だと、さすがにあれなので、少し説明すると、Jupyter NotebookをUIとしたインタラクティブに使える機械学習用クラウド(?)です。
Nvidia Tesla K80 というGPUが占有で使えます(誤っていたら指摘お願いします)。また、Google神謹製のニューラルネットワークなプログラムの専用アクセラレータであるTPUも使えます(こちらは占有かは分からないし、複数セッションで使い続けるとかすると、利用にあたって制限を受けるかもしれません。ぶっちゃけ、まだちゃんと調べられていないです)で、無料です。マジで。
ただ、時間制限という制約はあります。ですが、時間制限といっても、使える時間の総量?が制限されているわけではなく、ブラウザからのセッションが切れて90分立ってしまうとインスタンスが死ぬというのと、一度動かしたコードは12時間でインスタンスが死んで打ち切られる(正確には、インスタンスを立ち上げた時点から12時間、ということだったはず)というのがあるだけで、12時間たったあとに、再度セッションを開始すれば、また12時間は同じようにインスタンスを使えます。ということは、90分制限を回避する仕組みを用意し、動かすプログラムは途中で実行中の状態をスナップショットとるようにして、次のセッションではそのスナップショットを読み込んで処理を継続すればいいわけですねえ。
時間制限がうっとおしいから、なくすために課金させてくれえ、とかはどうもできないらしく、やりたければ自前のリソースを接続して使ってね、というスタイルのようです。なので、基本無料、ではなく、無料、です。時間制限の回避については以下の記事などを読まれるとよいでしょう。
Google Colaboratoryの90分セッション切れ対策【自動接続】FX自動トレードシミュレーションプログラムを動かす
Colaboratoryのセットアップについてはぐぐってもらうとして、私のプログラムの動作に必要な手順だけ書いておきます。
♯ jupyter notebook 使ってるんだから、その内容晒せばええやろ?、と言われると、その通りなのですが、まだ整理できていないので、堪忍して下さい。ただ、最初に書いておきますが、
- 動作した、と書いているものは、学習処理が動作している様子がKerasの?進捗表示で確認できたというだけで、完走は確認していません。モデルの保存のところでこける可能性とかあります。また、作成したモデルを用いた推論処理(の結果を使ったトレードのシミュレーション)はまだ動かした実績がありません。これらは、手元の開発環境でも、同様です(確認していない)。
=> トレードのシミュレーション含めて完走を確認しました。- TPUでの実行はまだ成功していません。
=> 成功しました- GPUでは動作したが、手元のさしてスペックが高いわけでもないラップトップより二倍ぐらい遅くなりました(進捗表示で確認できるエポックごとの処理時間からすると)。原因は今のところ調査中ですが、パッケージ?がkeras.xxx ではダメで、tensorfrow.keras.xxx でないとダメという話か(TPU利用時は後者である必要があります。今は後者に書き換えてあります)、処理量が小さすぎるためにGPU利用のオーバヘッドの方が大きい、ということではないかと推測しています。前者は再度試すだけ、後者はバッチサイズを大きくするなどしてみることを考えています。
=> TPUでもラップトップより4倍くらい遅いという性能でしたが、バッチサイズを100から1000に変更したら、ラップトップより4倍くらい速くなりました。(TPU実行だけで比較するとパラメータ変更により16倍速くなったことになる)。まだ試していませんがGPUにおいても、おそらく同様に期待通りの?高速化が得られるようになるのではないかと思います。なお、バッチサイズをさらに大きくしたらどうなるかは、これから試していこうと思っています。
=> 5000まで上げてみましたが、少し速くはなったものの大差ありませんでした。アクセラレータ含めた計算機の最適なバッチサイズ(性能が出る)ってのはあったりするんでしょうかね?- CPUのみのランタイム設定で動かしたら、上で言及したラップトップで動作させた場合より2倍程度高速に動作しました。
手順 (GPU利用)
Python3のノートブックを作成。ランタイムはGPUを使うように設定。
以下、コマンド・コード実行手順。
ですが、その内容を丸っと書いたJupyter Notebookを用意してみました。
これを開いてコピーして?、ランタイムをGPUにして、ランタイム - 全てのセルを実行、とすると一気に実行できるはずです(Google Driveのマウントのところは手動で認証の操作が必要)。
以下手順を書いたJupyter Notebookpipパッケージを入れていく。
!pip install h5py !pip install keras !pip install sklearn !pip install tensorflow-gputa-libはちょっと面倒
%cd ~/ !wget http://prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz !tar -xzvf ta-lib-0.4.0-src.tar.gz %cd ta-lib !./configure --prefix=/usr !make !make install !pip install ta-libGoogle Driveをマウントする。
Google Driveにはルート直下にgcolab_workdirというディレクトリを事前に作っておいてください。(別の名前でも構いませんが、その場合はこの記事の手順の中のパスも置き換えるよう注意してください)from google import colab colab.drive.mount('/content/gdrive')コードと入力データをgithubから持ってくる。
%cd '/content/gdrive/My Drive/gcolab_workdir/' !git clone -b for_try_keras_trade_learning_at_google_colab_qiita1 https://github.com/ryogrid/fx_systrade.git %cd 'fx_systrade'いざ、実行!
import keras_trade_at_google_colab_cpu_gpu keras_trade_at_google_colab_cpu_gpu.run_script("TRAIN") keras_trade_at_google_colab_cpu_gpu.run_script("TRADE")ちゃんと完走すれば生成されたモデルと、シミュレーションのログがマウントしたディレクトリにあるはず。
また、Google DriveのWebインタフェースから見ても確認できるはずです。
- 学習が走り始めたところまでの出力を含むJupyter Notebook
助けていただけるとありがたい (3/30 10:00 -> 解決しました!)
ランタイムのアクセラレータをTPUに設定した上で、インストールする tensorflow を tensorflow-gpu ではなく tensorflowにして、
import keras_trade_at_google_colab_tpu keras_trade_at_google_colab_tpu.run_script("TRAIN")とすると、コードはTPUを利用しにいくのですが、以下のようなエラーになってしまっています。
原因をご存知の方がいればコメント欄で教えていただけるとありがたいです 〇刀乙data size: 836678 train len: 83667 2 classes 17 dims INFO:tensorflow:Querying Tensorflow master (grpc://10.12.186.98:8470) for TPU system metadata. INFO:tensorflow:Found TPU system: INFO:tensorflow:*** Num TPU Cores: 8 INFO:tensorflow:*** Num TPU Workers: 1 INFO:tensorflow:*** Num TPU Cores Per Worker: 8 INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, -1, 16514675533203383013) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 17179869184, 4585360841116493997) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 17179869184, 16984093160179709170) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 17179869184, 8193093783894359376) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 17179869184, 12076229141210125913) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 17179869184, 16700992325723477645) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 17179869184, 6430518941424391562) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 17179869184, 3947497457430632353) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 17179869184, 1795967380953314994) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 17179869184, 16400414982824425925) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 17179869184, 16039450443299016384) WARNING:tensorflow:tpu_model (from tensorflow.contrib.tpu.python.tpu.keras_support) is experimental and may change or be removed at any time, and without warning. --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-15-73cd67faf7af> in <module>() 1 import keras_trade_at_google_colab2 ----> 2 keras_trade_at_google_colab2.run_script("TRAIN") /content/gdrive/My Drive/gcolab_workdir/fx_systrade/keras_trade_at_google_colab2.py in run_script(mode) 470 if exchange_dates == None: 471 setup_historical_fx_data() --> 472 train_and_generate_model() 473 elif mode == "TRADE": 474 if exchange_dates == None: /content/gdrive/My Drive/gcolab_workdir/fx_systrade/keras_trade_at_google_colab2.py in train_and_generate_model() 349 tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url) 350 strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver) --> 351 model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy) 352 353 print("Training model...") /usr/local/lib/python3.6/dist-packages/tensorflow/contrib/framework/python/framework/experimental.py in new_func(*args, **kwargs) 62 'any time, and without warning.', 63 decorator_utils.get_qualified_name(func), func.__module__) ---> 64 return func(*args, **kwargs) 65 new_func.__doc__ = _add_experimental_function_notice_to_docstring( 66 func.__doc__) /usr/local/lib/python3.6/dist-packages/tensorflow/contrib/tpu/python/tpu/keras_support.py in tpu_model(model, strategy) 2198 A new `KerasTPUModel` instance. 2199 """ -> 2200 _validate_shapes(model) 2201 # TODO(xiejw): Validate TPU model. TPUModel only? 2202 # TODO(xiejw): Validate replicas. Full or 1. Shall we allow subset? /usr/local/lib/python3.6/dist-packages/tensorflow/contrib/tpu/python/tpu/keras_support.py in _validate_shapes(model) 2136 """Validate that all layers in `model` have constant shape.""" 2137 for layer in model.layers: -> 2138 if isinstance(layer.input_shape, tuple): 2139 input_shapes = [layer.input_shape] 2140 else: /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in input_shape(self) 1116 """ 1117 if not self._inbound_nodes: -> 1118 raise AttributeError('The layer has never been called ' 1119 'and thus has no defined input shape.') 1120 all_input_shapes = set( AttributeError: The layer has never been called and thus has no defined input shape.=> 最初のDenceクラスに input_shapeキーワード引数を与えることで解決できました! (keras.xxx の Denseだと指定するとエラーになるが、tensorflow.keras.xxx だと逆に指定しないとダメ、ということだったぽい)
おまけ (Windows10 64bit Python3.7環境でCPU実行する)
なんか最近はWindowsでもTensorFlowが使えるらしいので、手元での動作確認のために環境構築した時の手順です。
なお、以下の手順が誤った tensorflow 環境を作ってしまうものである可能性はなきにしにあらずなので、virtualenv を使っておくことをおすすめします。cd <適当な作業ディレクトリ> pip install h5py pip install keras pip install sklearn pip install tensorflowta-libは面倒くさい。
以下のページの手順で C:\ta-lib に、ta-libパッケージがラップするそもそものライブラリをインストールしておいてください。
https://githubja.com/mrjbq7/ta-lib
依存関係 - windows のところです。
最後のところはnmakeを叩くだけです。ta-lib pipパッケージをインストール
pip install ta-libコードと入力データをを持ってくる
git clone -b for_try_keras_trade_learning_at_google_colab_qiita1 https://github.com/ryogrid/fx_systrade.gitいざ、実行! (ちゃんと動くかな?どきどき)
なお、残念ながらこの手順だとCPU実行しかされません。cd fx_systrade # 学習処理とそれにより生成されたモデルを用いた推論に基づくトレードシミュレーションが続けて走る python keras_trade_at_google_colab_cpu_gpu.py出力の冒頭。なんかいろいろワーニングやらが出ていて気になる。
> python .\keras_trade_at_google_colab_cpu_gpu.py Using TensorFlow backend. data size: 836678 train len: 83667 2 classes 17 dims WARNING:tensorflow:From F:\work\fx_systrade\lib\site-packages\tensorflow\python\ops\resource_variable_ops.py:435: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. Training model... WARNING:tensorflow:The `nb_epoch` argument in `fit` has been renamed `epochs`. WARNING:tensorflow:From F:\work\fx_systrade\lib\site-packages\tensorflow\python\keras\layers\core.py:143: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version. Instructions for updating: Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`. Train on 28107 samples, validate on 4961 samples WARNING:tensorflow:From F:\work\fx_systrade\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.cast instead. Epoch 1/3000 2019-03-29 16:17:27.299420: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 28107/28107 [==============================] - 2s 85us/sample - loss: 0.7033 - val_loss: 0.5223 Epoch 2/3000 28107/28107 [==============================] - 1s 41us/sample - loss: 0.5596 - val_loss: 0.5052 Epoch 3/3000 28107/28107 [==============================] - 1s 44us/sample - loss: 0.5取り急ぎ、以上です!
- 投稿日:2019-03-30T06:31:01+09:00
無料で使える機械学習クラウド(Google Colaboratory)で、ディープラーニングなFX自動トレードシミュレーション
どうも、オリィ研究所 の ryo_grid こと神林です。
(以下は趣味でやっているもので、業務とは関係ありません)はじめに
もう、結構前になってしまいましたが、こんなことをやっていました。
ディープラーニングでFXシステムトレード
♯ Qiitaの記事を綺麗に埋め込むにはどうすればいいのでしょうで、掲題の Google Colaboratory で、うまくやれば Nvidia Tesla K80 というかなり強力なGPUを占有で、ずっと使える、それも無料で、という情報を耳にしたので、試しに上の記事のコードを動かしてみようと思ったわけです。
結論(結果)
パラメータを変更する必要はありましたが、GPUで最も高速な学習処理が行われることが確認されました(TPUよりも高速。まあ、いろいろ適性とかがあるのでしょう)。
Kerasの進捗表示を見る限り 10us/sampleで処理が進んでいる(実際は10-9usでブレてはいる) ので、そこから算出すると、学習時のサンプル数が28107で、そのスピードで3000 epoch 回すと、単純計算では 0.00001 * 28107 * 3000 / 60 => 約14.05分程度で学習処理が完了することになる、はず。多分。
で、以前、MBA 2011 midで計算していた時は 1000 epochで 一時間程度かかっていたようなので、そこから比べると、学習処理の進行速度は約12.81倍高速、であると言えるのかなと思います(本当か?)。
まあ、プログラムに処理時間を計測して出力するコードを仕込んでおけばいいだけなんですが、忘れたので、こんな見積もりを書いています・・・。残った謎 (追記 19/04/01 8:00)
バッチサイズを大きくしたら手元のラップトップでもGPU・TPUを用いた場合と同等の速度が出ました・・・・。
どういうことだろう・・・。
謎が残ってしまった・・・。
- 完走させてないものもあるけど、Colaborateryでの実行結果。
自作のKeraを使った為替予測モデル作成からのトレードシミュレーション(の学習処理)の学習処理では、GPU・TPUを押さえてCPUが最速・・・
https://github.com/ryogrid/fx_systrade/blob/master/run_keras_trade_procedure_on_qiita_post_use_gpu_epoch10000_batch1000_contain_output.ipynb
https://github.com/ryogrid/fx_systrade/blob/master/run_keras_trade_procedure_on_qiita_post_use_cpu_epoch3000_batch1000_contain_output.ipynb
一方、公式サンプル (Fashion MNIST) だとTPUが爆速。
https://github.com/ryogrid/fx_systrade/blob/master/Keras_Fashion_MNIST_execed_at_TPU.ipynb
TPUで走らせた時はせいぜい20分程度で全ての処理が完了していたので、
下のCPU実行は、ETA が 3:51:44 の時点でお察し。
https://github.com/ryogrid/fx_systrade/blob/master/Keras_Fashion_MNIST_execed_at_CPU_in_progress.ipynb
さて、何が違うのだろう。Google Colaboratory とは
詳細はぐぐってください(完)。
だと、さすがにあれなので、少し説明すると、Jupyter NotebookをUIとしたインタラクティブに使える機械学習用クラウド(?)です。
Nvidia Tesla K80 というGPUが占有で使えます(誤っていたら指摘お願いします)。また、Google神謹製のニューラルネットワークなプログラムの専用アクセラレータであるTPUも使えます(こちらは占有かは分からないし、複数セッションで使い続けるとかすると、利用にあたって制限を受けるかもしれません。ぶっちゃけ、まだちゃんと調べられていないです)で、無料です。マジで。
ただ、時間制限という制約はあります。ですが、時間制限といっても、使える時間の総量?が制限されているわけではなく、ブラウザからのセッションが切れて90分立ってしまうとインスタンスが死ぬというのと、一度動かしたコードは12時間でインスタンスが死んで打ち切られる(正確には、インスタンスを立ち上げた時点から12時間、ということだったはず)というのがあるだけで、12時間たったあとに、再度セッションを開始すれば、また12時間は同じようにインスタンスを使えます。ということは、90分制限を回避する仕組みを用意し、動かすプログラムは途中で実行中の状態をスナップショットとるようにして、次のセッションではそのスナップショットを読み込んで処理を継続すればいいわけですねえ。
時間制限がうっとおしいから、なくすために課金させてくれえ、とかはどうもできないらしく、やりたければ自前のリソースを接続して使ってね、というスタイルのようです。なので、基本無料、ではなく、無料、です。時間制限の回避については以下の記事などを読まれるとよいでしょう。
Google Colaboratoryの90分セッション切れ対策【自動接続】FX自動トレードシミュレーションプログラムを動かす
Colaboratoryのセットアップについてはぐぐってもらうとして、私のプログラムの動作に必要な手順だけ書いておきます。
♯ jupyter notebook 使ってるんだから、その内容晒せばええやろ?、と言われると、その通りなのですが、まだ整理できていないので、堪忍して下さい。ただ、最初に書いておきますが、
- 動作した、と書いているものは、学習処理が動作している様子がKerasの?進捗表示で確認できたというだけで、完走は確認していません。モデルの保存のところでこける可能性とかあります。また、作成したモデルを用いた推論処理(の結果を使ったトレードのシミュレーション)はまだ動かした実績がありません。これらは、手元の開発環境でも、同様です(確認していない)。
=> トレードのシミュレーション含めて完走を確認しました。- TPUでの実行はまだ成功していません。
=> 成功しました- GPUでは動作したが、手元のさしてスペックが高いわけでもないラップトップより二倍ぐらい遅くなりました(進捗表示で確認できるエポックごとの処理時間からすると)。原因は今のところ調査中ですが、パッケージ?がkeras.xxx ではダメで、tensorfrow.keras.xxx でないとダメという話か(TPU利用時は後者である必要があります。今は後者に書き換えてあります)、処理量が小さすぎるためにGPU利用のオーバヘッドの方が大きい、ということではないかと推測しています。前者は再度試すだけ、後者はバッチサイズを大きくするなどしてみることを考えています。
=> TPUでもラップトップより4倍くらい遅いという性能でしたが、バッチサイズを100から1000に変更したら、ラップトップより4倍くらい速くなりました。(TPU実行だけで比較するとパラメータ変更により16倍速くなったことになる)。まだ試していませんがGPUにおいても、おそらく同様に期待通りの?高速化が得られるようになるのではないかと思います。なお、バッチサイズをさらに大きくしたらどうなるかは、これから試していこうと思っています。
=> 5000まで上げてみましたが、少し速くはなったものの大差ありませんでした。アクセラレータ含めた計算機の最適なバッチサイズ(性能が出る)ってのはあったりするんでしょうかね?- CPUのみのランタイム設定で動かしたら、上で言及したラップトップで動作させた場合より2倍程度高速に動作しました。
手順 (GPU利用)
Python3のノートブックを作成。ランタイムはGPUを使うように設定。
以下、コマンド・コード実行手順。
ですが、その内容を丸っと書いたJupyter Notebookを用意してみました。
これを開いてコピーして?、ランタイムをGPUにして、ランタイム - 全てのセルを実行、とすると一気に実行できるはずです(Google Driveのマウントのところは手動で認証の操作が必要)。
以下手順を書いたJupyter Notebookpipパッケージを入れていく。
!pip install h5py !pip install keras !pip install sklearn !pip install tensorflow-gputa-libはちょっと面倒
%cd ~/ !wget http://prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz !tar -xzvf ta-lib-0.4.0-src.tar.gz %cd ta-lib !./configure --prefix=/usr !make !make install !pip install ta-libGoogle Driveをマウントする。
Google Driveにはルート直下にgcolab_workdirというディレクトリを事前に作っておいてください。(別の名前でも構いませんが、その場合はこの記事の手順の中のパスも置き換えるよう注意してください)from google import colab colab.drive.mount('/content/gdrive')コードと入力データをgithubから持ってくる。
%cd '/content/gdrive/My Drive/gcolab_workdir/' !git clone -b for_try_keras_trade_learning_at_google_colab_qiita1 https://github.com/ryogrid/fx_systrade.git %cd 'fx_systrade'いざ、実行!
import keras_trade_at_google_colab_cpu_gpu keras_trade_at_google_colab_cpu_gpu.run_script("TRAIN") keras_trade_at_google_colab_cpu_gpu.run_script("TRADE")ちゃんと完走すれば生成されたモデルと、シミュレーションのログがマウントしたディレクトリにあるはず。
また、Google DriveのWebインタフェースから見ても確認できるはずです。実行した際の出力も含む jupyter notebook はこちら。
実行結果
実行結果 at github助けていただけるとありがたい (3/30 10:00 -> 解決しました!)
ランタイムのアクセラレータをTPUに設定した上で、インストールする tensorflow を tensorflow-gpu ではなく tensorflowにして、
import keras_trade_at_google_colab_tpu keras_trade_at_google_colab_tpu.run_script("TRAIN")とすると、コードはTPUを利用しにいくのですが、以下のようなエラーになってしまっています。
原因をご存知の方がいればコメント欄で教えていただけるとありがたいです 〇刀乙data size: 836678 train len: 83667 2 classes 17 dims INFO:tensorflow:Querying Tensorflow master (grpc://10.12.186.98:8470) for TPU system metadata. INFO:tensorflow:Found TPU system: INFO:tensorflow:*** Num TPU Cores: 8 INFO:tensorflow:*** Num TPU Workers: 1 INFO:tensorflow:*** Num TPU Cores Per Worker: 8 INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, -1, 16514675533203383013) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 17179869184, 4585360841116493997) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 17179869184, 16984093160179709170) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 17179869184, 8193093783894359376) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 17179869184, 12076229141210125913) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 17179869184, 16700992325723477645) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 17179869184, 6430518941424391562) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 17179869184, 3947497457430632353) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 17179869184, 1795967380953314994) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 17179869184, 16400414982824425925) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 17179869184, 16039450443299016384) WARNING:tensorflow:tpu_model (from tensorflow.contrib.tpu.python.tpu.keras_support) is experimental and may change or be removed at any time, and without warning. --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-15-73cd67faf7af> in <module>() 1 import keras_trade_at_google_colab2 ----> 2 keras_trade_at_google_colab2.run_script("TRAIN") /content/gdrive/My Drive/gcolab_workdir/fx_systrade/keras_trade_at_google_colab2.py in run_script(mode) 470 if exchange_dates == None: 471 setup_historical_fx_data() --> 472 train_and_generate_model() 473 elif mode == "TRADE": 474 if exchange_dates == None: /content/gdrive/My Drive/gcolab_workdir/fx_systrade/keras_trade_at_google_colab2.py in train_and_generate_model() 349 tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url) 350 strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver) --> 351 model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy) 352 353 print("Training model...") /usr/local/lib/python3.6/dist-packages/tensorflow/contrib/framework/python/framework/experimental.py in new_func(*args, **kwargs) 62 'any time, and without warning.', 63 decorator_utils.get_qualified_name(func), func.__module__) ---> 64 return func(*args, **kwargs) 65 new_func.__doc__ = _add_experimental_function_notice_to_docstring( 66 func.__doc__) /usr/local/lib/python3.6/dist-packages/tensorflow/contrib/tpu/python/tpu/keras_support.py in tpu_model(model, strategy) 2198 A new `KerasTPUModel` instance. 2199 """ -> 2200 _validate_shapes(model) 2201 # TODO(xiejw): Validate TPU model. TPUModel only? 2202 # TODO(xiejw): Validate replicas. Full or 1. Shall we allow subset? /usr/local/lib/python3.6/dist-packages/tensorflow/contrib/tpu/python/tpu/keras_support.py in _validate_shapes(model) 2136 """Validate that all layers in `model` have constant shape.""" 2137 for layer in model.layers: -> 2138 if isinstance(layer.input_shape, tuple): 2139 input_shapes = [layer.input_shape] 2140 else: /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py in input_shape(self) 1116 """ 1117 if not self._inbound_nodes: -> 1118 raise AttributeError('The layer has never been called ' 1119 'and thus has no defined input shape.') 1120 all_input_shapes = set( AttributeError: The layer has never been called and thus has no defined input shape.=> 最初のDenceクラスに input_shapeキーワード引数を与えることで解決できました! (keras.xxx の Denseだと指定するとエラーになるが、tensorflow.keras.xxx だと逆に指定しないとダメ、ということだったぽい)
おまけ (Windows10 64bit Python3.7環境でCPU実行する)
なんか最近はWindowsでもTensorFlowが使えるらしいので、手元での動作確認のために環境構築した時の手順です。
なお、以下の手順が誤った tensorflow 環境を作ってしまうものである可能性はなきにしにあらずなので、virtualenv を使っておくことをおすすめします。cd <適当な作業ディレクトリ> pip install h5py pip install keras pip install sklearn pip install tensorflowta-libは面倒くさい。
以下のページの手順で C:\ta-lib に、ta-libパッケージがラップするそもそものライブラリをインストールしておいてください。
https://githubja.com/mrjbq7/ta-lib
依存関係 - windows のところです。
最後のところはnmakeを叩くだけです。ta-lib pipパッケージをインストール
pip install ta-libコードと入力データをを持ってくる
git clone -b for_try_keras_trade_learning_at_google_colab_qiita1 https://github.com/ryogrid/fx_systrade.gitいざ、実行! (ちゃんと動くかな?どきどき)
なお、残念ながらこの手順だとCPU実行しかされません。cd fx_systrade # 学習処理とそれにより生成されたモデルを用いた推論に基づくトレードシミュレーションが続けて走る python keras_trade_at_google_colab_cpu_gpu.py出力の冒頭。なんかいろいろワーニングやらが出ていて気になる。
> python .\keras_trade_at_google_colab_cpu_gpu.py Using TensorFlow backend. data size: 836678 train len: 83667 2 classes 17 dims WARNING:tensorflow:From F:\work\fx_systrade\lib\site-packages\tensorflow\python\ops\resource_variable_ops.py:435: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. Training model... WARNING:tensorflow:The `nb_epoch` argument in `fit` has been renamed `epochs`. WARNING:tensorflow:From F:\work\fx_systrade\lib\site-packages\tensorflow\python\keras\layers\core.py:143: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version. Instructions for updating: Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`. Train on 28107 samples, validate on 4961 samples WARNING:tensorflow:From F:\work\fx_systrade\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.cast instead. Epoch 1/3000 2019-03-29 16:17:27.299420: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 28107/28107 [==============================] - 2s 85us/sample - loss: 0.7033 - val_loss: 0.5223 Epoch 2/3000 28107/28107 [==============================] - 1s 41us/sample - loss: 0.5596 - val_loss: 0.5052 Epoch 3/3000 28107/28107 [==============================] - 1s 44us/sample - loss: 0.5