--divisor:19--dividend:78withpresnias(select'with sub as( select dense_rank() over (order by decode(mod(level,:divisor),0,:divisor,mod(level,:divisor))) - 1 as grp ,dense_rank() over (partition by decode(mod(level,:divisor),0,:divisor,mod(level,:divisor)) order by rownum) as seq,level as rn from dual connect by level <= :dividend )select * from sub pivot(min(rn) for seq in ('aspre_snifromdual),lizas(selectlistagg(rn,',')withingroup(orderbyrownum)aslizfrom(selectlevelasrnfromdualconnectbylevel<=:divisor)),postsnias(select')) order by grp;'aspost_snifromdual)selects1.pre_sni||s2.liz||s3.post_sniasbuild_sqlfrompresnis1,lizs2,postsnis3;
あとがき
埋め込みたいなー。ただの遊びで気づいたので、記事upしました。。
妥協して組み立て直した。
こぴって実行したら、結果違って、ぇ!ってなったので、組み立てなおしました。。
しょーもなぃ。
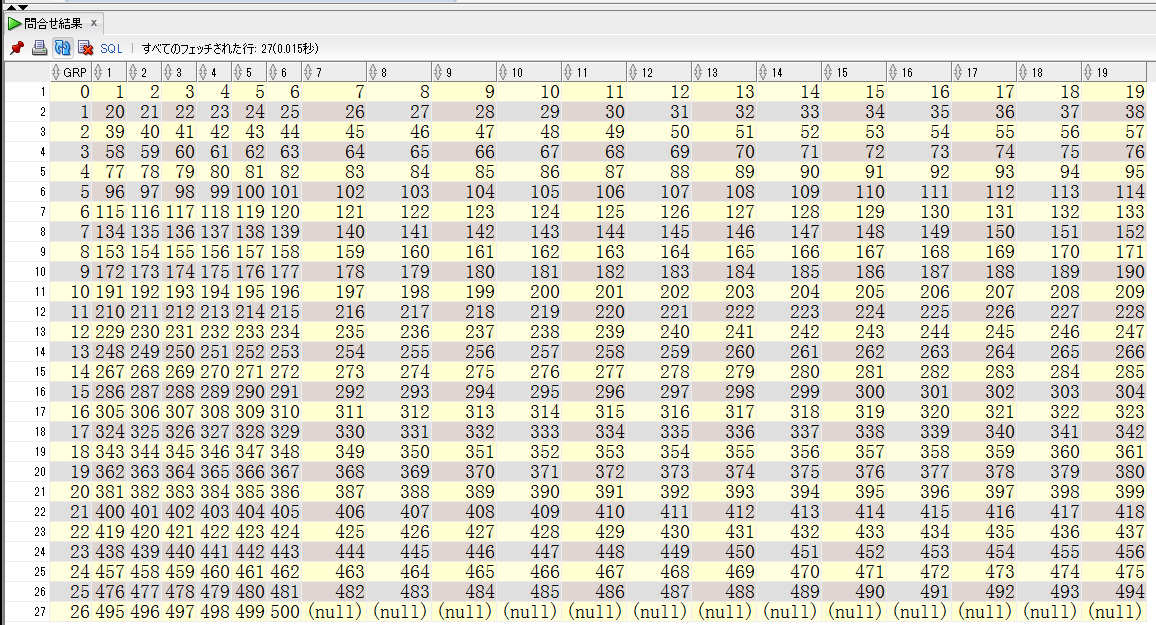
--divisor:19--dividend:500WITHpresniAS(SELECT'with sub as( select dense_rank() over (partition by to_number(decode(mod(level,:divisor),0,:divisor,mod(level,:divisor))) order by level) - 1 as grp ,dense_rank() over (order by to_number(decode(mod(level,:divisor),0,:divisor,mod(level,:divisor)))) as seq,level as rn from dual connect by level <= :dividend )select * from sub pivot(max(rn) for seq in ('ASpre_sniFROMdual),lizAS(SELECTLISTAGG(rn,',')WITHINGROUP(ORDERBYROWNUM)ASlizFROM(SELECTlevelASrnFROMdualCONNECTBYlevel<=:divisor)),postsniAS(SELECT')) order by grp;'ASpost_sniFROMdual)SELECTs1.pre_sni||s2.liz||s3.post_sniASbuild_sqlFROMpresnis1,lizs2,postsnis3;withsubas(selectdense_rank()over(partitionbyto_number(decode(mod(level,:divisor),0,:divisor,mod(level,:divisor)))orderbylevel)-1asgrp,dense_rank()over(orderbyto_number(decode(mod(level,:divisor),0,:divisor,mod(level,:divisor))))asseq,levelasrnfromdualconnectbylevel<=:dividend)select*fromsubpivot(max(rn)forseqin(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19))orderbygrp;
func main() {
age := 27
q := `
create temp table uid (id bigint); -- Create temp table for queries.
insert into uid
select id from users where age < ?; -- Populate temp table.
-- First result set.
select
users.id, name
from
users
join uid on users.id = uid.id
;
-- Second result set.
select
ur.user, ur.role
from
user_roles as ur
join uid on uid.id = ur.user
;
`
rows, err := db.Query(q, age)
if err != nil {
log.Fatal(err) // Syntax error
}
How to Remove Workload Repository Information Related to an old DBID From the Automatic Workload Repository (Doc ID 1251795.1)
How to Recreate the Automatic Workload Repository (AWR)? (Doc ID 782974.1)
DimdbAsDAO.DatabaseDimrsAsDAO.RecordsetSetdb=CurrentDbDimstrSQLAsStringstrSQL="INSERT INTO テーブル1 (カラム1, カラム2, カラム3) "strSQL=strSQL&"SELECT カラムA,カラムB,カラムC "strSQL=strSQL&"FROM テーブル2 WHERE Not カラムA Is Null"Debug.PrintstrSQLdb.ExecutestrSQL