- 投稿日:2019-03-07T17:40:49+09:00
[論文メモ] InfoGAN/ss-InfoGAN
はじめに
InfoGANの論文; Chen et al., 2016 (UC Berkeley)
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Netsss-InfoGANの論文; Spurr et al., 2017 (ETH Zurich)
Guiding InfoGAN with Semi-supervisionメモなので足りない箇所があるかもしれませんが、ご容赦ください。
ただ、もし内容に間違いや不明な点があれば、ご意見ご指導をいただければ幸いに存じます。InfoGAN
- 普通のGANは$z$(ノイズ)を何かを生成する際に種として使う
- だが$z$は表現として絡まっていて、いじってもなかなか人が理解できるように変化をアウトプットに反映されない(Radford, 2016のようにうまくいく方が珍しい)。
- そこで$z$の一部を$c$(latent variable)とする。完全にノイズであるzに反して、$c$はdatasetの「何かの特徴」に対応すると想定されるように設計される。例えば、データセットをMNISTとする。生成する画像の推知の値そのものを捉えたいとしたら、$c_1$を10カテゴリーの離散変数にする。文字の太さや傾きなどを捉えたいとしたら、$c_2$, $c_3$を連続変数とする。そんな風に$c=c_1, c_2, c_3...c_n$を設定する。
- それ以上何もしなければ、$c$は訓練の過程で無視される
- なので、生成されるもの$G(z, c)$に対し、$c$と関係を持たせたい。
- そこでMutual Informationを使う。

- 損失関数に組み込んで、Mutual Informationを最大化したい

- Mutual Information についてこの記事にはぜひ参照したい
- かくかくしかじかでMutual Informationがこんな風に書き換えられる $$I(X;Y) = D_{KL} \Big( P_{XY}(x,y)||P_X(x)P_Y(y) \Big)\,$$
- $P(x)$と$P(y)$が独立した時だけ$P(x)P(y) = P(x, y)$ ---->$I(X;Y)$が最小化される
- 大まかな構図は以上
- ところが$I(c; G(z,c))$を求めるのが難しいらしい。$P(c|x)$を必要とするから。 <---------------ここちょっと理解がまだ完全ではない、要再考
- そこで$P(c|x)$に近似するための分布$Q(c|x)$を作る
- Variational Information Maximizationという手法で$I(c; G(z,c))$のLower boundにあたる$L_I(G, Q)$を求める。
- 詳細は見てないので、何とも言えないが、多分役割としてはVAEの中のやつに近いかな?
- 最終的に実装するとき損失関数がこうなる:

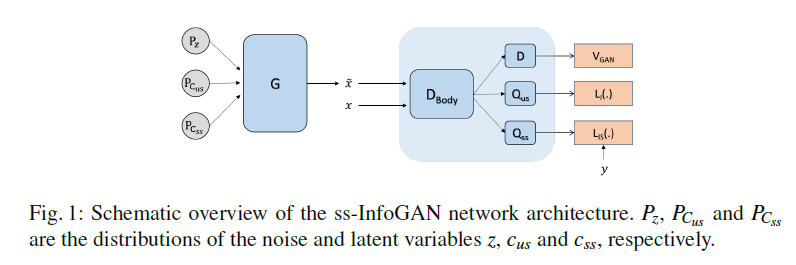
ss-InfoGAN
- 大体上と同じ
- 一部だけreal sampleのラベルとして$y$が提供される。それを利用して生成するものの質の向上を図る。
- 変更点として$c$を$c_{ss}$ semi-supervised code、と$c_{us}$ unsupervised codeに分かれる。$c_{ss} \cup c_{us} =c$
- 最大化するMutual Information(延いてはLower bound)も二つになる
- $X$がreal samplesで、$\tilde{X}$がgenerated samples。
- 要するに$I(C_{ss};X)$を最大化することで、$Q_{ss}$を訓練する時、ラベルのあるデータ(x, y)で$Q_{ss}$にラベル$y$の意味を学習させる。
同時に$I(C_{ss};\tilde{X})$を最大化することで、$G$が間接的に$y$に含まれる情報を学習する。それで少数のラベルでもGがラベルの情報を取り入れることが出来る。
最終的に損失関数がこうなる
上のInfoGANのやつと合わせてさらにこうなるのではないかと
$$\min_{G, Q_{us}, Q_{ss}}\max_{D}V(D, G)- \lambda_1L_{I}(G, Q_{us}) - \lambda_2(L^1_{IS}(Q_{ss}) + L^2_{IS}(G, Q_{ss})) $$
さらに下の
(11)と(12)についてはこういう理解もできる:
- まずは$C_{ss}$を上の円(z)とし、$X$を左下の円(x)とし、$\tilde{X}$を右下の円(y)とする。
- となると(11)では、
- $H(C_{ss})$は上の円全体にあたる。
- $I(C_{ss}; X)$が黄色+灰色にあたる。
- $I(C_{ss}; \tilde{X})$が水色+灰色にあたる。
- $H(C_{ss}|X, \tilde{X})$が緑色にあたる。
- $I(C_{ss};X; \tilde{X})$が灰色にあたる。
- これで(11)は成立する
- (12)では$I(X; \tilde{X})$がピンク色にあたり、成立する。
(13)では$X$と$\tilde{X}$両者とも$C_{ss}$から独立したと仮定する(式8により)
- $I(X;\tilde{X}|C_{ss})$の理解については、上の円$H(C_{ss})$を情報にずらすと想像する
- ずらしてると、ある瞬間を境に、灰色の部分がなくなる。これが$X$と$\tilde{X}$両者とも$C_{ss}$から独立したということにあたる。
- 最終的には(14)になる
それ以降は字面通りに理解できる
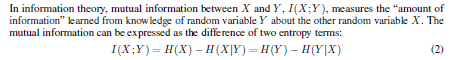
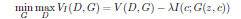
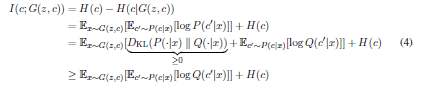
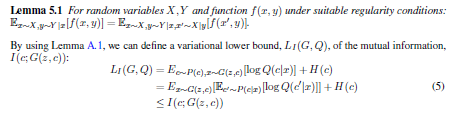
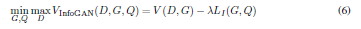
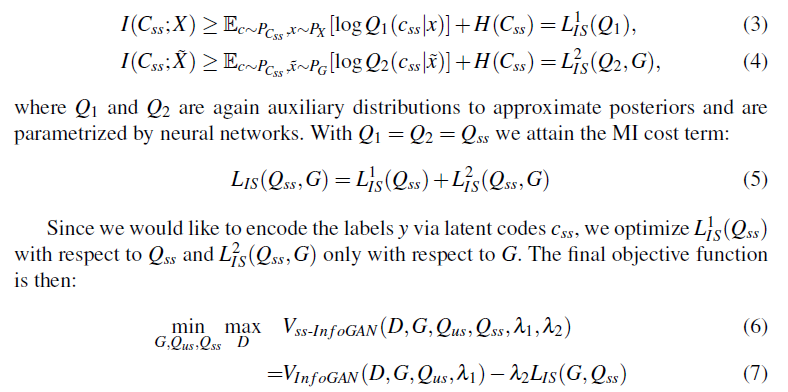
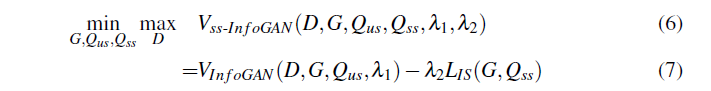


- 投稿日:2019-03-07T17:40:49+09:00
InfoGAN/ss-InfoGANの理解メモ
はじめに
InfoGANの論文; Chen et al., 2016 (UC Berkeley)
ss-InfoGANの論文; Spurr et al., 2017 (ETH Zurich)メモなので足りない箇所があるかもしれませんが、ご容赦ください。
ただ、もし内容に間違いや不明な点があれば、ご意見ご指導をいただければ幸いに存じます。InfoGAN
- 普通のGANは$z$(ノイズ)を何かを生成する際に種として使う
- だが$z$は表現として絡まっていて、いじってもなかなか人が理解できるように変化をアウトプットに反映されない(Radford, 2016のようにうまくいく方が珍しい)。
- そこで$z$の一部を$c$(latent variable)とする。完全にノイズであるzに反して、$c$はdatasetの「何かの特徴」に対応すると想定されるように設計される。例えば、データセットをMNISTとする。生成する画像の推知の値そのものを捉えたいとしたら、$c_1$を10カテゴリーの離散変数にする。文字の太さや傾きなどを捉えたいとしたら、$c_2$, $c_3$を連続変数とする。そんな風に$c=c_1, c_2, c_3...c_n$を設定する。
- それ以上何もしなければ、$c$は訓練の過程で無視される
- なので、生成されるもの$G(z, c)$に対し、$c$と関係を持たせたい。
- そこでMutual Informationを使う。
- 損失関数に組み込んで、Mutual Informationを最大化したい
- Mutual Information についてこの記事にはぜひ参照したい
- かくかくしかじかでMutual Informationがこんな風に書き換えられる $$I(X;Y) = D_{KL} \Big( P_{XY}(x,y)||P_X(x)P_Y(y) \Big)\,$$
- $P(x)$と$P(y)$が独立した時だけ$P(x)P(y) = P(x, y)$ ---->$I(X;Y)$が最小化される
- 大まかな構図は以上
- ところが$I(c; G(z,c))$を求めるのが難しいらしい。$P(c|x)$を必要とするから。 <---------------ここちょっと理解がまだ完全ではない、要再考
- そこで$P(c|x)$に近似するための分布$Q(c|x)$を作る
- Variational Information Maximizationという手法で$I(c; G(z,c))$のLower boundにあたる$L_I(G, Q)$を求める。
- 詳細は見てないので、何とも言えないが、多分役割としてはVAEの中のやつに近いかな?
- 最終的に実装するとき損失関数がこうなる:
ss-InfoGAN
- 大体上と同じ
- 一部だけreal sampleのラベルとして$y$が提供される。それを利用して生成するものの質の向上を図る。
- 変更点として$c$を$c_{ss}$ semi-supervised code、と$c_{us}$ unsupervised codeに分かれる。$c_{ss} \cup c_{us} =c$
- 最大化するMutual Information(延いてはLower bound)も二つになる
- $X$がreal samplesで、$\tilde{X}$がgenerated samples。
- 要するに$I(C_{ss};X)$を最大化することで、$Q_{ss}$を訓練する時、ラベルのあるデータ(x, y)で$Q_{ss}$にラベル$y$の意味を学習させる。
同時に$I(C_{ss};\tilde{X})$を最大化することで、$G$が間接的に$y$に含まれる情報を学習する。それで少数のラベルでもGがラベルの情報を取り入れることが出来る。
最終的に損失関数がこうなる
上のInfoGANのやつと合わせてさらにこうなるのではないかと
$$\min_{G, Q_{us}, Q_{ss}}\max_{D}V(D, G)- \lambda_1L_{I}(G, Q_{us}) - \lambda_2(L^1_{IS}(Q_{ss}) + L^2_{IS}(G, Q_{ss})) $$
さらに下の
(11)と(12)についてはこういう理解もできる:
- まずは$C_{ss}$を上の円(z)とし、$X$を左下の円(x)とし、$\tilde{X}$を左下の円(y)とする。
- となると(11)では、
- $H(C_{ss})$は上の円全体にあたる。
- $I(C_{ss}; X)$が黄色+灰色にあたる。
- $I(C_{ss}; \tilde{X})$が水色+灰色にあたる。
- $H(C_{ss}|X, \tilde{X})$が緑色にあたる。
- $I(C_{ss};X; \tilde{X})$が灰色にあたる。
- これで(11)は成立する
- (12)では$I(X; \tilde{X})$がピンク色にあたり、成立する。
(13)では$X$と$\tilde{X}$両者とも$C_{ss}$から独立したと仮定する(式8により)
- $I(X;\tilde{X}|C_{ss})$の理解については、上の円$H(C_{ss})$を情報にずらすと想像する
- ずらしてると、ある瞬間を境に、灰色の部分がなくなる。これが$X$と$\tilde{X}$両者とも$C_{ss}$から独立したということにあたる。
- 最終的には(14)になる
それ以降は字面通りに理解できる
- 投稿日:2019-03-07T16:42:33+09:00
Subword segmentaion と SentencePiece について
本記事の目的
- Subword segmentaion の考え方について理解する。
- Subword segmentation の新手法 (SentencePeiece) のロジックを理解する。
- 参照論文の第2章、第3章にある式の展開を追う。
参照論文
https://arxiv.org/pdf/1804.10959.pdf
参照論文の構成
- Introduction
- Neural Machine Translation with multiple subword segmentations
- NMT training with on-the-fly subword sampling
- Decoding
- Subword segmentations with language model
- Byte-Pair-Encoding (BPE)
- Unigram language model
- Subword sampling
- BPE vs. Unigram language model
- Related Work
- Experiments
- Setting
- Main Results
- Results with out-of-domain corpus
- Comparison with other segmentation algorithms
- Impact of sampling hyperparameters
- Conclusions
第1章について
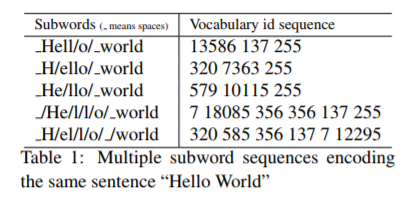
文章を区切るとはどういうことでしょうか? 参照論文のテーブル1には、"Hello World" を区切る例(5パターン)があります。
単純に「Hello」と「World」で区切ればよいのでは? と思うのですが、ゆっくり考えてみます。例えば、次の文章はどうでしょうか?
「はなこさんじゅうごさい。」
はなこさんは何歳でしょうか?
15歳と回答した人は、
「はなこさん、じゅうごさい。」
と読んだと思います。一方、35歳と回答した人は、
「はなこ、さんじゅうごさい。」
と読んだのではないでしょうか? では、次の文章はどうでしょうか?
「ここではきものをぬいでください。」
脱いでほしいのは、はきもの(履物)でしょうか、きもの(着物)でしょうか?
私たちは、前後の文脈を手がかりに複数ある読み方(区切り方)の候補から適切なものを選択しています。そもそも、「はなこ」は1単語なのか「はな」と「こ」の2単語なのかは自明ではありません。(おまけです。「あのひとじなんだよ。」)
日本語の文章に関して機械(深層)学習をする時、形態素解析(分かち書き)をすることが多いと思います。その時ひと通りのやり方で区切った文章で学習させています。一方、複数の区切りの可能性を考え、(さいころを振って話すトピックを決めるように)確率的に区切りを決めるという発想をしてみましょう、というのが参照論文のアイデアです。そして、それは画像系のタスクにおける Augmentaion に対応すると述べられています。1枚の画像データを水平反転させたり、傾けたり、色合いを変えたりすることで複数の入力データとし、モデルの頑健性を向上させる(過学習を抑える)のは常套手段です。同様に、一つの文章を異なる位置で区切ることで、複数の入力データを作成することが可能となります。
以下、参照論文の「6. Conclusions」からの抜粋です。The central idea is to virtually augment trading data with on-the-fly subword sampling, which helps to improve the accuracy as well as robustness of NMT models.
文章の区切り方を「サブワードによるセグメンテーション」と呼び(画像タスクのセマンティック・セグメンテーションとのアナロジーを考えるとしっくりきます)、「第2章について」で再考します。
すでに「目から鱗」の論文ですが、さらにセグメンテーションの新方法が提案されています。以下は、同じく「6. Conclusions」からの抜粋です。「第3章について」でロジックの理解を試みます。In addition, for better subword sampling we propose a new subword segmentation algorithm based on the unigram language model.
第2章について
参照論文の式(1)~(4)について考えます。
式(1)、(2)で翻訳タスクを定式化しています。
'Hello World' の翻訳を考え、X = 'Hello World'、Y = 「こんにちは世界」が与えられたとします。では、(セグメンテーションされた)X と「こんにちは」を知っているとき、次の単語が「世界」である(条件付き)確率は? というのが(1)式のイメージです。さらに、対数を取って最大化することでモデルのパラメータを求めましょう(最尤法)というのが(2)式です。
次に(3)式以降ですが、いったん(3)式をわかったとします。(4)式は(3)式中の期待値を(モンテカルロ法のように)サンプル平均で近似しています。さらに k=1 でも十分良い近似である、という展開は、GAN や VAE でも同様にされます。論文中では、
When we have a sufficient number of iterations, subword sampling is executed via the data sampling of online trading, which yields a good approximation of (3) even if k = 1.
です。
では、(3)式はどう解釈すればよいでしょうか? ここが重要なポイントで、文章の分割(サブワード・セグメンテーション)は複数あり、確率的に決まるものだということです。ですから、xは確率変数であり、期待値を計算する意味があるのです。例えば、「こん|にちは|世界」である確率は 0.3
「こんにち|は|世界」である確率は 0.2
「こんにちは|世界」である確率は 0.4
「こん|にちは|世界」である確率は 0.1という感じです。ここで注意したいのは、私たちにとって最も自然に見える区切り方が、必ずしもモデル(AI)にとってベストとは限らないのではないか? ということです。人間による特徴抽出をスキップした End-to-end のディープラーニングが高い予測精度を達成していることを念頭に置いています。論文の著者の以下の記事が大変興味深く、勉強になります。
Sentencepiece : ニューラル言語処理向けトークナイザ
第3章について
文章を分割する新手法 (Sentencepiece) について学びます。
- Byte-Pair-Encoding (BPE)
以下のような文字列を考えます。
'aabcaadbc"
a, b, c, d を単位とすると9個の文字が並んでいます。aa->A, bc->B と置き換えると、
'ABAdB'
となり、文字数は5個に減少します。この時、ボキャブラリーが {a, b, c, d} から {a, b, c, d, A, B} に増加したと考えます。
- Unigram language model
BPE はボキャブラリーサイズとトークンの数をバランスさせることができますが、決定的アルゴリズムであるため複数の分割を生成することが困難です。そこで、新手法による分割(サブワード・セグメンテーション)が提案されます。
式(6)、(7)から見ていきます。
ユニグラムモデルでは各サブワードの生起は独立ですので、分割確率を、(1)式のような条件付き確率を使わず、各サブワードの生起確率の積として表すことができます。(7)式は、全ての分割候補の中から P(x) を最大とする分割列を最適分割列と定義しています。語彙集合νが所与であることに注意してください。
- EM アルゴリズム
最尤推定をするために対数尤度を考えます(次式最初の等式)。2番目の等式は、P(X) を全分割列の分割確率の和に書き換えています。混合(正規)モデルとのアナロジーで、各分割の分布を混合していると考えるとイメージしやすいでしょうか。
対数尤度Lを最大化したいのですが、最右辺の log の中には Σ があるため解析的に解くことができません。では、EMアルゴリズムで数値的に解きましょう、というのも混合正規分布のパラメータ推定での解法と同様です。
- 全体のアルゴリズム
ここまで語彙集合νを事前に与えてきましたが、実際には未知です。生起確率 p(x) と一緒に求める必要があります。そのために以下のような反復計算を行います。
十分大きな語彙集合から出発し、EMアルゴリズムによる生起確率の推定と語彙の絞り込みを交互に繰り返しています。語彙の絞り込みとは、その語彙を削除した場合の尤度の減少度を計算し、大きいものから(例えば80%を)キープするということです。実際、SentencePiece を学習させる際にはボキャブラリーサイズを引数にとります。
import sentencepiece as spm spm.SentencePieceTrainer.Train( '--input=data/wagahaiwa_nekodearu.txt --model_prefix=wagahai --vocab_size=3000' )
SentencePiece の仕様について
以下の論文が取扱説明書となります。
https://arxiv.org/pdf/1808.06226.pdf
一部繰り返しとなりますが、著者への敬意、感謝も込めて「5 Conclusions」から抜粋します。
SentencePiece not only performs subword tokenizaion, but directly converts the text into an id sequences, which helps to develop a purely end-to-end system without relying on language specific resources.
We hope that SentencePiece will provide a stable and reproducible text processing tool for production use and help the research community to move to more language-agonostic and multilingual architectures.
2番目の引用の考え方が BERT につながります(BERT 論文についての考察は別記事にします)。 また、
https://github.com/google/sentencepiece/blob/master/python/README.md
に Python wrapper の使用方法の説明があります(感謝)。
以上、subword segmentaion、SentencePiece についての論文に関する考察でした。

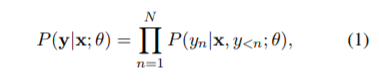
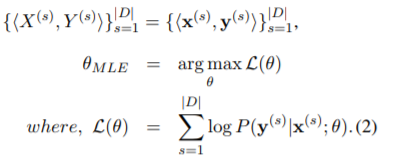
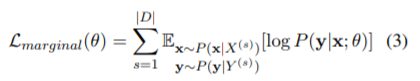
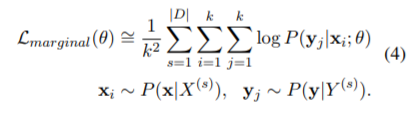
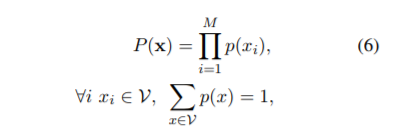
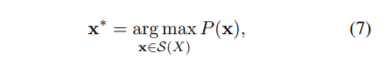
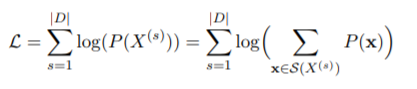


- 投稿日:2019-03-07T16:13:36+09:00
GCPのDeep Learning VMインスタンスを立ち上げる
DeepLearningVMのインスタンスの立ち上げに一部手間取ったのでメモ。
はじめに
下記のページに沿ってインスタンスを立ち上げようとしましたが、「Create a new instance」の「7.Click Deploy.」を実行した時点でエラーが発生しました。
[手順の参考ページ]
https://cloud.google.com/deep-learning-vm/docs/quickstart-marketplaceエラー内容1deeplabv3plus-1-vm: {"ResourceType":"compute.v1.instance", "ResourceErrorCode":"403", "ResourceErrorMessage":{"code":403,"errors":[{"domain":"usageLimits", "message":"Quota 'GPUS_ALL_REGIONS' exceeded. Limit: 0.0 globally.", "reason":"quotaExceeded"}], "message":"Quota 'GPUS_ALL_REGIONS' exceeded. Limit: 0.0 globally.", "statusMessage":"Forbidden", "requestPath":"https://www.googleapis.com/compute/v1/projects/test-vegetation-map/zones/us-central1-a/instances", "httpMethod":"POST"}}エラー内容2{"ResourceType":"compute.v1.instance", "ResourceErrorCode":"403", "ResourceErrorMessage":{"code":403,"errors":[{"domain":"usageLimits", "message":"Quota 'GPUS_ALL_REGIONS' exceeded. Limit: 0.0 globally.", "reason":"quotaExceeded"}], "message":"Quota 'GPUS_ALL_REGIONS' exceeded. Limit: 0.0 globally.", "statusMessage":"Forbidden", "requestPath":"https://www.googleapis.com/compute/v1/projects/test-vegetation-map/zones/us-central1-a/instances", "httpMethod":"POST"}}原因
GPUの割り当て上限数の設定は2種類あります。
(語弊のある表現ですが、ここまで読んで「GPUの上限数の設定はしたんだよ!」とこの記事を閉じてしまわないために、まずは敢えてこう書きました。)正確には、「各リージョンで作成するGPUモデルに対する割り当て」に加え、「すべてのゾーンにおけるすべてのタイプのGPUの総数に対するグローバル割り当て」もリクエストする必要がありました。
[参考]
https://cloud.google.com/compute/quotas#gpus解決策
1. 各リージョンで作成するGPUモデルに対する割り当て
こちらの設定は、この記事を読んでいる皆さんは既に完了しているかもしれません。
- 先ほどのページ(https://cloud.google.com/compute/quotas#gpus)の「[割り当て] ページ」のリンク先へ飛ぶ。(※もしくは「GCPの左上のハンバーガーメニュー(横三本線のマーク)>IAM と管理>割り当て」と進む。)
- 「指標」のプルダウンボタンをクリックし、使用したいGPUの名前にチェックを入れる。
- 「場所」のプルダウンボタンをクリックし、使用したいリージョンの名前にチェックを入れる。
- 使用したいリージョンの、使用したいGPUの上限数が使用予定数を上回っていることを確認する。
- 上限数が足りていなかった場合は「割り当てを編集」よりリクエストを投げましょう。早いと1時間程度でリクエストした条件が反映されます。
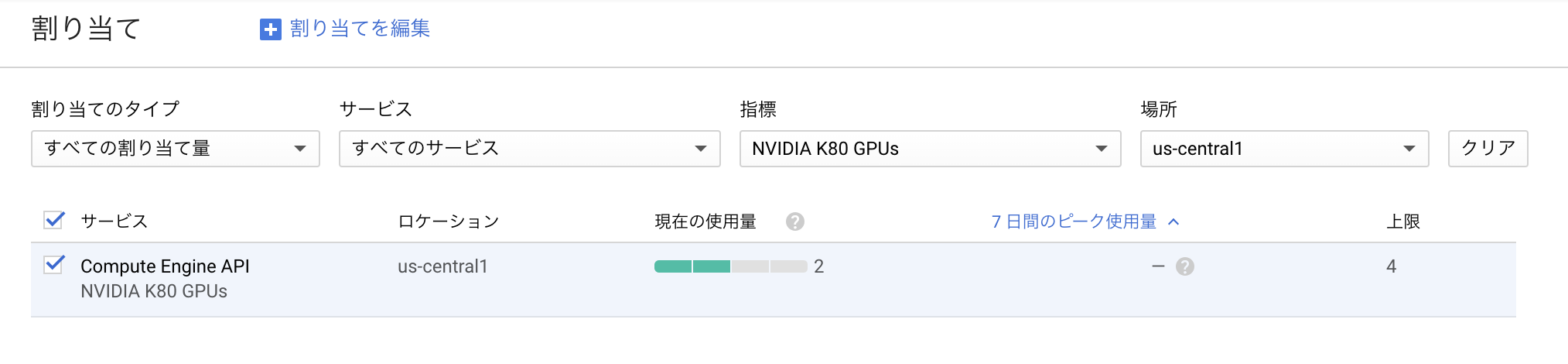
2. すべてのゾーンにおけるすべてのタイプのGPUの総数に対するグローバル割り当て
こちらを見落としていました。
- 上記1.と同様、「割り当て」ページへ移動する。
- 「指標」プルダウンボタンをクリックし、「GPUs (all regions)」という選択肢にチェックを入れる。
- 「場所」のプルダウンボタンをクリックし、「グローバル」にチェックを入れる。
- 上限数を確認しましょう。デフォルトでは0になっているはずです。
- 上限数が「すべてのリージョンにおけるすべてのタイプのGPUの総数」を下回っている場合、「割り当てを編集」よりリクエストを投げましょう。早いと1時間程度でリクエストした条件が反映されます。
以上。
- 投稿日:2019-03-07T12:15:55+09:00
がんばる人のための画像検査機 -可視化の改良-
地味に盛り上がっている「ディープラーニングによる画像の異常検知」に関する投稿の続きです。
今回は、可視化部分を改良します。
これまでの動き
以前に、以下の記事を投稿しました。
ここで使われている「DOC」という技術は学習済のモデルを利用できるため、
精度と速度を天秤にかけて自由に変えることができます。従って、軽量な
モデルを選べば、ラズパイなどのモバイル端末でも動かせます。
さらに、@koshian2 さんから以下の投稿がありました。
https://qiita.com/koshian2/items/b4c4ffda99c07a1ac6b8Triplet lossを使った高速の異常検知です。こちらの内容はまだしっかり理解
していないのですが、高速かつ精度良く異常検知できるとのことで、素晴らしい
内容だと思います。
さらに、DOCの高速化について@PINTO さんから以下の投稿がありました。
https://qiita.com/PINTO/items/0a52062cb6ebe9ef5051TensorFlow Lite等を駆使してDOC+ラズパイで15FPSという
とてつもない数値をたたき出しています。こちらも工場の生産ラインでは
なくてはならない「高速化」の技術で、素晴らしい内容です。DOCの課題点
DOCの課題点をまとめておきます。
速度が遅い
もはやTriplet lossを使った高速の異常検知には敵わないのですが、DOCを
高速化すると、速度と精度はどうなるのかを改めて明記したいと思います。可視化が弱い
これは、DOCの課題点というより私の課題点といえます。
DOCの論文では可視化は言及されておらず、以前の記事では私がテキトーに
設計した可視化の部分が「低速」で、かつ「異常部分がうまく表示できない」
という問題を抱えていました。そこで、今回は可視化部分をしっかり設計して改良します。
DOCの高速化
まずは、DOCの高速化について説明します。
実は、既にがんばる人のための画像検査機の記事で高速化は実施済です。
高速化の中身が気になる方はこちらをご覧ください。Colaboratoryでは計測していなかったため、改めて速度と精度(AUC)を記載します。
速度(msec/1枚) AUC 以前の記事 140 0.9 高速化後 20 0.88 今回は、若干精度が下がってしまいました。これは学習データの組み合わせで多少変動します。
ただ、以下の調整を行うと精度が改善されることがあります。精度を出したい人はチャレンジしてみてください。
- 「重みを凍結する層」を変更してみる
- DOCの出力を最終層ではなく手前の層に変更する
特に、DOCの出力層を手前にすることで、精度だけではなく速度も若干
改善されるのでおススメです。AUCが0.02くらい改善することもあります。DOCの可視化
使い方
こちらにリポジトリをアップした(DOC_Visulaization)のですが、weights_visual.h5が
重すぎて欠如しています。ラズパイで動かす際は、自分で学習させたweights_visual.h5と
その他のモデル(合計4つ)をご用意ください。使い方は以前と同じです。
- 「DOC_Visualization」をラズパイ上に持ってくる。
- USBにウェブカメラを接続し、DOC_Visualization/main.pyを実行する。
- モデルの展開に2分くらいかかります。
- ウェブカメラのリアルタイム映像が描画されたら「s」キーを押してください。(Sキーの反応が悪いです。辛抱強く押してください。)
- ヒートマップが出力されたら、リアルタイム描画が開始されています。
- リアルタイム描画はラズパイをフル稼働させるため、5分くらいすると熱暴走してフリーズします。長期稼働する際は、冷却しながら動かしてください。
Grad-CAMでは難しい
ここからは可視化の中身を説明します。
以前の記事ではGrad-CAMで可視化を行いました。
ご覧のように成功しているとは言い難いです。
Grad-CAMは本来、出力が相互に関係してくるソフトマックス関数であることを
念頭において作られているはずです。従って、DOCのような独立した出力に
適用してもうまくいく確率は低いです。そこで、今回は昔からあるAutoEncoderによる可視化を試みました。
AutoEncoder
AutoEncoderの説明はここではしませんが、気になる方は以下のリンクをご覧ください。
https://deepage.net/deep_learning/2016/10/09/deeplearning_autoencoder.html
https://qiita.com/fukuit/items/2f8bdbd36979fff96b07AutoEncoderでは、情報を圧縮し、圧縮された情報を基に復元を行います。
学習データと似たような画像であれば、きちんと復元されますが、
全然似ていない画像の場合、似ていない箇所だけが復元されない
可能性が高いです。今回はその性質を利用します。※DOCは、DOC=CNN+LOF(KNN) という形でCNNとLOF等を合わせたもの指します。
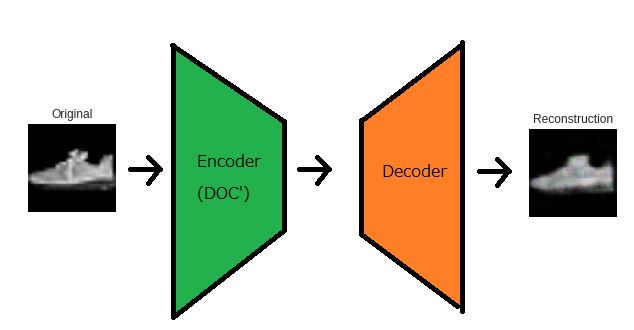
説明の便宜上、DOC'=CNNという形で説明します。ここでは CNN=MobileNETV2 です。DOC' + Decoder
全体像は以下のとおりです。
AutoEncoderはEncoder部とDecoder部から成っており、Encoder部はDOC'にて
既に特徴量抽出が行われているため、DOC'をEncoder部とします。一方、Decoder部は新たに設け、画像の復元をさせるために学習データで学習させます。
なお、今回はLOFによるスコアの算出はカットしています。ヒートマップは以下の手順で生成します。
まず、Original画像をDOC'に投げます。そして、以下のように復元画像
(Reconstruction)を取得します。Original(96×96×3) → DOC'(1280) → Decoder → Reconstruction(96×96×3)
次に、以下のようにOriginal とReconstruction の差の絶対値をとります。
Difference = |Original - Reconstruction|最後に、DifferenceをOriginalと合成してHeatMapを得ます。
コード
通常用
通常のDecoderを設計しました。
Kerasで書くと以下のとおりです。import keras from keras.layers import BatchNormalization, Activation from keras.layers import Reshape, UpSampling2D, Convolution2D from keras.initializers import he_normal def convolutional_decoder(): model = keras.Sequential() model.add(Dense(input_dim=(feature_out), output_dim=1024)) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Dense(128*12*12)) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Reshape((12,12,128))) model.add(UpSampling2D((2,2)))#24*24 model.add(Convolution2D(128,5,5,border_mode='same', kernel_initializer=he_normal())) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(UpSampling2D((2,2)))#48*48 model.add(Convolution2D(256,5,5,border_mode='same', kernel_initializer=he_normal())) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(UpSampling2D((2,2)))#96*96 model.add(Convolution2D(3,5,5,border_mode='same', kernel_initializer=he_normal())) model.add(Activation('sigmoid'))#out_shape=(96,96,3) return modelモバイル用
こちらを参考にMobileNETライクなDecoderを設計しました。
上記に比べ描画性能は劣りますが、速度は2倍速いです。import keras from keras.layers import BatchNormalization, Activation, Input from keras.layers import Reshape, UpSampling2D, Conv2D from keras.layers import ReLU, DepthwiseConv2D, ZeroPadding2D from keras.initializers import he_normal def _depthwise_conv_block(inputs, pointwise_conv_filters, alpha, depth_multiplier=1, strides=(1, 1), block_id=1): pointwise_conv_filters = int(pointwise_conv_filters * alpha) if strides == (1, 1): x = inputs else: x = ZeroPadding2D(((0, 1), (0, 1)), name='conv_pad_%d' % block_id)(inputs) x = DepthwiseConv2D((3, 3), padding='same' if strides == (1, 1) else 'valid', depth_multiplier=depth_multiplier, strides=strides, use_bias=False, name='conv_dw_%d' % block_id)(x) x = BatchNormalization(name='conv_dw_%d_bn' % block_id)(x) x = ReLU(6., name='conv_dw_%d_relu' % block_id)(x) x = Conv2D(pointwise_conv_filters, (1, 1), padding='same', use_bias=False, strides=(1, 1), name='conv_pw_%d' % block_id)(x) x = BatchNormalization(name='conv_pw_%d_bn' % block_id)(x) return ReLU(6., name='conv_pw_%d_relu' % block_id)(x) def convolutional_decoder(): inputs = Input(shape=(feature_out,)) x = Dense(1024)(inputs) x = BatchNormalization()(x) x = Activation('relu')(x) x = Dense(128*12*12)(x) x = BatchNormalization()(x) x = Activation('relu')(x) x = Reshape((12,12,128))(x) x = UpSampling2D((2,2))(x)#24*24 x = _depthwise_conv_block(x, 256, 0.5, 1,block_id=1) x = _depthwise_conv_block(x, 256, 0.5, 1,block_id=2) x = UpSampling2D((2,2))(x)#48*48 x = _depthwise_conv_block(x, 128, 0.5, 1,block_id=3) x = _depthwise_conv_block(x, 64, 0.5, 1,block_id=4) x = UpSampling2D((2,2))(x)#96*96 x = Conv2D(3,(5,5),padding='same')(x) x = Activation('sigmoid')(x) return Model(inputs,x)学習コード
学習コードは以下のとおりです。
train = model.predict(X_train_s)#X_train_sは元の画像,modelはDOC' test_s = model.predict(X_test_s)#X_test_sは元の画像 test_b = model.predict(X_test_b)#X_test_bは元の画像 decoder = convolutional_decoder() # initiate Adam optimizer opt = keras.optimizers.adam(lr=0.0001, decay=1e-6, amsgrad=True) # Let's train the model using Adam with amsgrad decoder.compile(loss='mse', optimizer=opt) hist = decoder.fit(train,X_train_s, validation_data=(test_s,X_test_s), epochs=10, verbose=1, batch_size=128)またHeatMapのコードは以下のとおりです。
from keras.preprocessing.image import array_to_img import cv2 def plot_heat(x): original = x.reshape((1,96,96,3)) re = model.predict(original) #re = ms.transform(re) re = decoder.predict(re) map_ = np.abs(re-original).reshape((96,96,3)) jet = cv2.applyColorMap(np.uint8(255 * map_), cv2.COLORMAP_JET) # モノクロ画像に疑似的に色をつける jet = cv2.cvtColor(jet, cv2.COLOR_BGR2RGB) # 色をRGBに変換 jet = (np.float32(jet) + original.reshape((96,96,3))*255 / 2) # もとの画像に合成 plt.imshow(array_to_img(jet), cmap='gray') plt.title("HeatMap") plt.axis("off") plt.show()なお、ラズパイの描画はOpenCVでやっているため、違う書き方になっています。
ラズパイ用のコードは付録に載せておきます。ただし、未だにここに書いた
クセが残っておりますが、ご了承ください。Fashion-MNISTによる実験
実験方法
今回使用するデータは、以前と同様に以下のように振り分けました。
個数 クラス数 備考 リファレンスデータ 6,000 8 スニーカーとブーツを除く ターゲットデータ 6,000 1 スニーカー テストデータ(正常) 1,000 1 スニーカー テストデータ(異常) 1,000 1 ブーツ 結果
結果を見てみましょう。Decoderは通常用を使用しました。
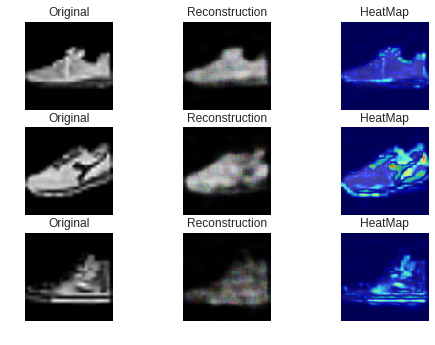
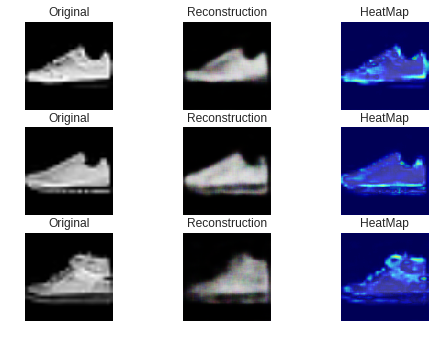
・ スニーカー(正常)の画像
ご覧のようにほとんどが青い画像になっています。
・ ブーツ(異常)の画像
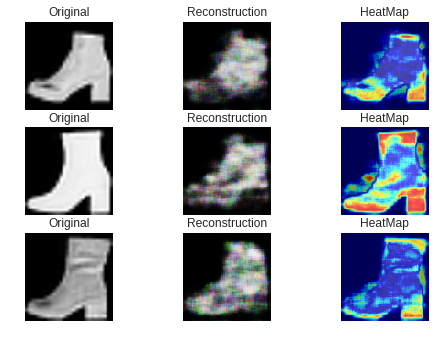
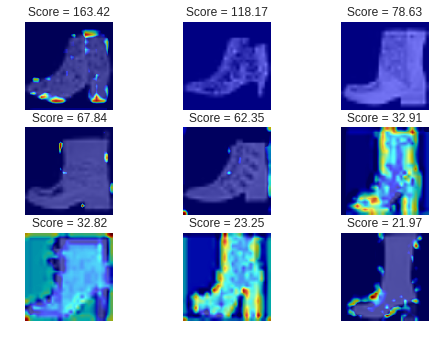
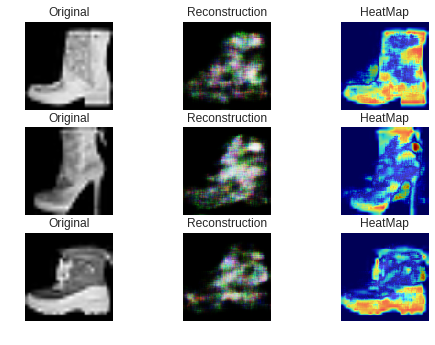
最初に、うまくいった例です。
ご覧のようにブーツの「口」あるいは「かかと」の部分が赤くなっています。
直感的に合っているような気がします。次に失敗した例です。
これらは異常スコアが最も高い、つまり最も異常な画像のベスト3です。
従って、復元が全くうまくいかず、ほとんどが赤くなっています。次に、異常スコアが最も低い、つまり最も「正常に近い」と判断された
異常画像のベスト3です。
ご覧のようにほとんど青くなっています。
これらはスニーカーに酷似したブーツなので、仕方がないような気もします。ラズパイによる実験
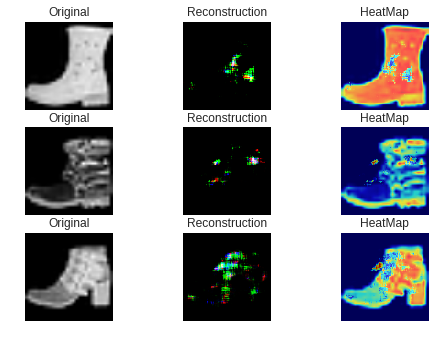
実験方法
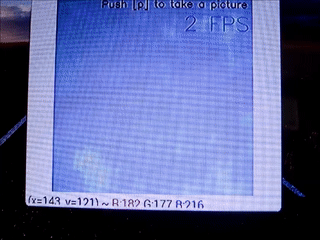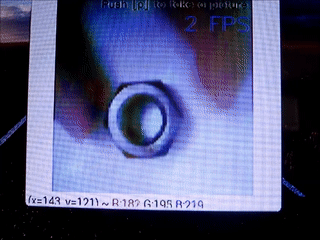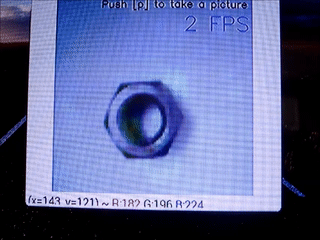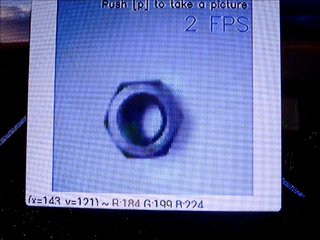
前と同じようにナットを学習させました。
Decoderはモバイル用としました。学習させた画像はこんな感じ。
そして、正常品として以下を用意しました。
異常品としてマジックで落書きしたナットを用意しました。
結果
・正常品
・異常品
若干左側が黄色くなっているのが分かるでしょうか。
解像度を下げたせいで分かりにくくなっています。正直、モバイル用のDecoderは微妙です。
もう少し設計を見直せばうまくいく気もしますが、通常用のDecoderを使った方が
スマートな気がします。なお、通常用のDecoderを使うとラズパイで1FPSになります。実際の使い方としては、普段は可視化を切っておいて、異常スコアが閾値を
上回ったときだけ、通常用のDecoderで可視化するのが良いと思います。まとめ
- DOC'にDecoderを付けることで、DOCの可視化部分が改良できました。
- ラズパイで可視化を実行すると、速度は5FPS → 2FPS(あるいは1FPS)に下がりますが、普段は可視化機能を切ることで速度低下を抑えることができます。
付録
最後に、ラズパイ用のコードを載せておきます。
import cv2 import time import os import numpy as np from sklearn.neighbors import LocalOutlierFactor from sklearn.preprocessing import MinMaxScaler from keras.models import model_from_json from keras import backend as K threshold = 2 m_input_size, m_input_size = 96, 96 path = "pictures/" if not os.path.exists(path): os.mkdir(path) model_path = "model/" if os.path.exists(model_path): # LOF #print("LOF model building...") #x_train = np.loadtxt(model_path + "train.csv",delimiter=",") #ms = MinMaxScaler() #x_train = ms.fit_transform(x_train) # fit the LOF model #clf = LocalOutlierFactor(n_neighbors=5) #clf.fit(x_train) # Visual model print("Visual Model loading...") model_visual = model_from_json(open(model_path + 'model_visual.json').read()) model_visual.load_weights(model_path + 'weights_visual.h5') # DOC print("DOC Model loading...") model_doc = model_from_json(open(model_path + 'model_doc.json').read()) model_doc.load_weights(model_path + 'weights_doc.h5') print("loading finish") else: print("Nothing model folder") def main(): camera_width = 352 camera_height = 288 fps = "" message = "Push [p] to take a picture" result = "Push [s] to start anomaly detection" flag_score = False picture_num = 1 elapsedTime = 0 score = 0 score_mean = np.zeros(10) mean_NO = 0 cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FPS, 2) cap.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height) time.sleep(1) while cap.isOpened(): t1 = time.time() ret, image = cap.read() image=image[:,32:320] if not ret: break # take a picture if cv2.waitKey(1)&0xFF == ord('p'): cv2.imwrite(path+str(picture_num)+".jpg",image) picture_num += 1 # quit or calculate score or take a picture key = cv2.waitKey(1)&0xFF if key == ord("q"): break if key == ord("s"): flag_score = True if key == ord("p"): cv2.imwrite(path + str(picture_num) + ".jpg", image) picture_num += 1 if flag_score == True: img = cv2.resize(image, (m_input_size, m_input_size)) img_ = np.array(img).reshape((1,m_input_size, m_input_size,3))/255 test = model_doc.predict(img_) #test = test.reshape((len(test),-1)) #test = ms.transform(test) #score = -clf._decision_function(test) #visualization re = model_visual.predict(test) map_ = np.abs(re-img_).reshape((96,96,3)) jet = cv2.applyColorMap(np.uint8(255*map_), cv2.COLORMAP_JET) #jet = cv2.cvtColor(jet, cv2.COLOR_BGR2RGB) jet = cv2.addWeighted(jet,0.2,img,0.8,2.2) image = cv2.resize(jet, (camera_height, camera_height)) # output score if flag_score == False: cv2.putText(image, result, (camera_width - 350, 100), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, cv2.LINE_AA) else: #score_mean[mean_NO] = score[0] mean_NO += 1 #if mean_NO == len(score_mean): # mean_NO = 0 #if np.mean(score_mean) > threshold: #red if score is big # cv2.putText(image, "{:.1f} Score".format(np.mean(score_mean)),(camera_width - 230, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 1, cv2.LINE_AA) #else: # blue if score is small # cv2.putText(image, "{:.1f} Score".format(np.mean(score_mean)),(camera_width - 230, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 1, cv2.LINE_AA) # message cv2.putText(image, message, (camera_width - 285, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv2.LINE_AA) cv2.putText(image, fps, (camera_width - 164, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, ( 255, 0 ,0), 1, cv2.LINE_AA) cv2.imshow("Result", image) # FPS elapsedTime = time.time() - t1 fps = "{:.0f} FPS".format(1/elapsedTime) cv2.destroyAllWindows() if __name__ == '__main__': main()






- 投稿日:2019-03-07T00:02:34+09:00
Deep Learningアプリケーション開発 (2) TensorFlow with Python
この記事について
機械学習、Deep Learningの専門家ではない人が、Deep Learningを応用したアプリケーションを作れるようになるのが目的です。特に、組み込み向けアプリケーションを意識しています。
モデルそのものには言及しません。数学的な話も出てきません。Deep Learningモデルをどうやって使うか(推論)、ということに重点を置いています。
- Kerasで簡単にMNIST数字識別モデルを作り、Pythonで確認
- TensorFlowモデルに変換してPythonで使用してみる (Windows, Linux)
- TensorFlowモデルに変換してCで使用してみる (Windows, Linux)
- TensorFlow Liteモデルに変換してPythonで使用してみる (Windows, Linux)
- TensorFlow Liteモデルに変換してCで使用してみる (Linux)
- TensorFlow Liteモデルに変換してPython/Cで使用してみる (Raspberry Pi)
今回の内容
- 前回作成したKeras用モデル(.h5)をTensorFlow用モデル(.pb)に変換する
- 変換したTensorFlow用モデルを使って、入力画像から数字識別するアプリケーションを作る
ソースコードとサンプル入力画像: https://github.com/take-iwiw/CNN_NumberDetector/tree/master/02_Tensorflow_Python
なぜ必要? 想定するシナリオ
- TensorFlow用モデルしかないとき
- 社内の機械学習エンジニア様、データサイエンティスト様がTensorFlowでモデルを作成したら、それに対応したアプリケーションを作る必要があります (後述するように変換はできますが)
- 今一番勢いがある?
- ONNXやMMdnnを使用したら、異なるDeepLearning用フレームワーク間でのモデル変換が出来ます
- TensorFlowに対応したアプリケーションの作り方を覚えておけば、大抵のことには対応できると思います
- 動作環境にPython, Kerasがないとき
- C言語用APIが用意されているので、ライブラリと一緒に配布すれば実行先での環境構築は不要です
- お客様にPythonやAnacondaをインストールしてもらうわけにはいきません!
- 今回はPythonで試しますが、C言語での実装の前段階ととらえてください
環境
- OS: Windows 10 (64-bt)
- OS(on VirtualBox): Ubuntu 16.04
- CPU = Intel Core i7-6700@3.4GHz (物理コア=4、論理プロセッサ数=8)
- GPU = NVIDIA GeForce GTX 1070 (← GPUは無くても大丈夫です)
- 開発環境: Anaconda3 64-bit (Python3.6.8)
- TensorFlow 1.12.0
- パッケージ詳細はこちら Windows用、Linux用
今回の内容は、WindowsとLinux(Ubuntu)のどちらでも動きますが、本記事の説明はWindowsメインで行います。
Keras用モデル(.h5)をTensorFlow用モデル(*.pb)に変換する
https://medium.com/@pipidog/how-to-convert-your-keras-models-to-tensorflow-e471400b886a のサイトを参考にさせていただき、変換用スクリプトを作りました。現在、FastGFileは非推奨とのことなので、tensorflow.gfile.GFileに置き換えています。
convert_keras_to_tensorflow関数を呼ぶことで、Keras用モデル(.h5)をTensorFlow用モデル(*.pb)に変換できます。また、get_model_info関数を呼ぶことで、変換したTensorFlow用モデルの情報をJSONファイルに保存します。
このスクリプトをそのまま実行すると、前回作成したKeras用モデル(conv_mnist.h5)を、TensorFlow用モデル(conv_mnist.pb)に変換してくれます。keras_to_tensorflow.py# -*- coding: utf-8 -*- # Reference URL: https://medium.com/@pipidog/how-to-convert-your-keras-models-to-tensorflow-e471400b886a import tensorflow as tf from tensorflow.python.keras.models import load_model from tensorflow.python.keras import backend as K from tensorflow.python.framework.graph_util import convert_variables_to_constants import numpy as np import json def freeze_session(sess, keep_var_names=None, output_names=None, clear_devices=True): graph = sess.graph with graph.as_default(): freeze_var_names = list(set(v.op.name for v in tf.global_variables()).difference(keep_var_names or [])) output_names = output_names or [] output_names += [v.op.name for v in tf.global_variables()] input_graph_def = graph.as_graph_def() if clear_devices: for node in input_graph_def.node: node.device = '' frozen_graph = convert_variables_to_constants(sess, input_graph_def, output_names, freeze_var_names) return frozen_graph def convert_keras_to_tensorflow(keras_model_filename, tf_model_filename): model = load_model(keras_model_filename) model.summary() frozen_graph = freeze_session(K.get_session(), output_names=[out.op.name for out in model.outputs]) tf.train.write_graph(frozen_graph, './', tf_model_filename, as_text=False) def get_model_info(tf_model_filename): ops = {} with tf.Session() as sess: with tf.gfile.GFile(tf_model_filename, 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) sess.graph.as_default() _ = tf.import_graph_def(graph_def) for op in tf.get_default_graph().get_operations(): ops[op.name] = [str(output) for output in op.outputs] writer = tf.summary.FileWriter('./logs') writer.add_graph(sess.graph) writer.flush() writer.close() with open(tf_model_filename+'_param.json', 'w') as f: f.write(json.dumps(ops)) if __name__ == '__main__': # convert keras_model_filename = 'conv_mnist.h5' tf_model_filename = 'conv_mnist.pb' convert_keras_to_tensorflow(keras_model_filename, tf_model_filename) get_model_info(tf_model_filename)モデル情報を確認する
上記スクリプトを実行すると、TensorFlow用モデル(conv_mnist.pb)と共に、モデル情報を記した(conv_mnist.pb_param.json)も出力されます。
このモデル情報は非常に重要です。変換したモデルを使用する際に入出力の名前が必要になります。前回モデル作成時に、入力には
Inputを使い、出力は全結合をするDenseを使いsoftmaxを取るようにしました。また、グラフ名はデフォルトではimportになるようです。このような情報をヒントに入出力のTensorを探します。
今回は以下であることが分かります:
- 入力:
import/input_1:0- 出力:
import/dense_1/Softmax:0conv_mnist.pb_param.json{ "import/input_1": [ "Tensor(\"import/input_1:0\", shape=(?, 28, 28, 1), dtype=float32)" ], "import/conv2d_1/kernel": [ "Tensor(\"import/conv2d_1/kernel:0\", shape=(3, 3, 1, 8), dtype=float32)" ], ~略~ "import/dense_1/Softmax": [ "Tensor(\"import/dense_1/Softmax:0\", shape=(?, 10), dtype=float32)" ], ~略~ "import_2/training_1/Adam/Variable_11": [ "Tensor(\"import_2/training_1/Adam/Variable_11:0\", shape=(10,), dtype=float32)" ] }変換したTensorFlow用モデルを使って、入力画像から数字識別するアプリケーションを作る
Spyder上で
number_detector_tensorflow.pyというファイルを開き、以下のようなコードを実装します。
動作仕様は前回Keras用に作成したnumber_detector.pyと同じです。TensorFlow呼び出しもこの中でやっているので、少し複雑になっています。
get_tensor_by_nameに先ほど確認した入出力名を設定して、入出力Tensorを取得しています。number_detector_tensorflow.py# -*- coding: utf-8 -*- import cv2 import tensorflow as tf import numpy as np if __name__ == '__main__': img = cv2.imread('resource/4.jpg') cv2.imshow('image', img) img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img = cv2.resize(img, (28, 28)) img = 255 - img img = img.reshape(1, img.shape[0], img.shape[1], 1) img = img / 255. with tf.Session() as sess: with tf.gfile.GFile('conv_mnist.pb', 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) sess.graph.as_default() _ = tf.import_graph_def(graph_def) tensor_input = sess.graph.get_tensor_by_name('import/input_1:0') tensor_output = sess.graph.get_tensor_by_name('import/dense_1/Softmax:0') probs = sess.run(tensor_output, {tensor_input: img}) result = np.argmax(probs[0]) score = probs[0][result] print("predicted number is {} [{:.2f}]".format(result, score)) cv2.waitKey(0) cv2.destroyAllWindows()次回は、今回作成したTensorFlow用モデル(conv_mnist.pb)を、C言語から使用してみます。
- 投稿日:2019-03-07T00:02:34+09:00
色々な環境でDeep Learningアプリケーション開発 (2)
この記事について
機械学習、Deep Learningの専門家ではない人が、Deep Learningを応用したアプリケーションを作れるようになるのが目的です。特に、組み込み向けアプリケーションを意識しています。
モデルそのものには言及しません。Deep Learningモデルをどうやって使うか、ということに重点を置いています。数学的な話も出てきません。
- Kerasで簡単にMNIST数字識別モデルを作り、Pythonで確認
- TensorFlowモデルに変換してPythonで使用してみる (Windows, Linux)
- TensorFlowモデルに変換してCで使用してみる (Windows, Linux)
- TensorFlow Liteモデルに変換してPythonで使用してみる (Windows, Linux)
- TensorFlow Liteモデルに変換してCで使用してみる (Linux)
- TensorFlow Liteモデルに変換してPython/Cで使用してみる (Raspberry Pi)
今回の内容
- 前回作成したKeras用モデル(.h5)をTensorFlow用モデル(.pb)に変換する
- 変換したTensorFlow用モデルを使って、入力画像から数字識別するアプリケーションを作る
ソースコードとサンプル入力画像: https://github.com/take-iwiw/CNN_NumberDetector/tree/master/02_Tensorflow_Python
なぜ必要? 想定するシナリオ
- TensorFlow用モデルしかないとき
- 社内の機械学習エンジニア様、データサイエンティスト様がTensorFlowでモデルを作成したら、それに対応したアプリケーションを作る必要があります (後述するように変換はできますが)
- 今一番勢いがある?
- ONNXやMMdnnを使用したら、異なるDeepLearning用フレームワーク間でのモデル変換が出来ます
- TensorFlowに対応したアプリケーションの作り方を覚えておけば、大抵のことには対応できると思います
- 動作環境にPython, Kerasがないとき
- C言語用APIが用意されているので、ライブラリと一緒に配布すれば実行先での環境構築は不要です
- お客様にPythonやAnacondaをインストールしてもらうわけにはいきません!
- 今回はPythonで試しますが、C言語での実装の前段階ととらえてください
環境
- OS: Windows 10 (64-bt)
- OS(on VirtualBox): Ubuntu 16.04
- CPU = Intel Core i7-6700@3.4GHz (物理コア=4、論理プロセッサ数=8)
- GPU = NVIDIA GeForce GTX 1070 (← GPUは無くても大丈夫です)
- 開発環境: Anaconda3 64-bit (Python3.6.8)
今回の内容は、WindowsとLinux(Ubuntu)のどちらでも動きますが、本記事の説明はWindowsメインで行います。
Keras用モデル(.h5)をTensorFlow用モデル(*.pb)に変換する
https://medium.com/@pipidog/how-to-convert-your-keras-models-to-tensorflow-e471400b886a のサイトを参考にさせていただき、変換用スクリプトを作りました。現在、FastGFileは非推奨とのことなので、tensorflow.gfile.GFileに置き換えています。
convert_keras_to_tensorflow関数を呼ぶことで、Keras用モデル(.h5)をTensorFlow用モデル(*.pb)に変換できます。また、get_model_info関数を呼ぶことで、変換したTensorFlow用モデルの情報をJSONファイルに保存します。
このスクリプトをそのまま実行すると、前回作成したKeras用モデル(conv_mnist.h5)を、TensorFlow用モデル(conv_mnist.pb)に変換してくれます。keras_to_tensorflow.py# -*- coding: utf-8 -*- # Reference URL: https://medium.com/@pipidog/how-to-convert-your-keras-models-to-tensorflow-e471400b886a import tensorflow as tf from tensorflow.python.keras.models import load_model from tensorflow.python.keras import backend as K from tensorflow.python.framework.graph_util import convert_variables_to_constants import numpy as np import json def freeze_session(sess, keep_var_names=None, output_names=None, clear_devices=True): graph = sess.graph with graph.as_default(): freeze_var_names = list(set(v.op.name for v in tf.global_variables()).difference(keep_var_names or [])) output_names = output_names or [] output_names += [v.op.name for v in tf.global_variables()] input_graph_def = graph.as_graph_def() if clear_devices: for node in input_graph_def.node: node.device = '' frozen_graph = convert_variables_to_constants(sess, input_graph_def, output_names, freeze_var_names) return frozen_graph def convert_keras_to_tensorflow(keras_model_filename, tf_model_filename): model = load_model(keras_model_filename) model.summary() frozen_graph = freeze_session(K.get_session(), output_names=[out.op.name for out in model.outputs]) tf.train.write_graph(frozen_graph, './', tf_model_filename, as_text=False) def get_model_info(tf_model_filename): ops = {} with tf.Session() as sess: with tf.gfile.GFile(tf_model_filename, 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) sess.graph.as_default() _ = tf.import_graph_def(graph_def) for op in tf.get_default_graph().get_operations(): ops[op.name] = [str(output) for output in op.outputs] writer = tf.summary.FileWriter('./logs') writer.add_graph(sess.graph) writer.flush() writer.close() with open(tf_model_filename+'_param.json', 'w') as f: f.write(json.dumps(ops)) if __name__ == '__main__': # convert keras_model_filename = 'conv_mnist.h5' tf_model_filename = 'conv_mnist.pb' convert_keras_to_tensorflow(keras_model_filename, tf_model_filename) get_model_info(tf_model_filename)モデル情報を確認する
上記スクリプトを実行すると、TensorFlow用モデル(conv_mnist.pb)と共に、モデル情報を記した(conv_mnist.pb_param.json)も出力されます。
このモデル情報は非常に重要です。変換したモデルを使用する際に入出力の名前が必要になります。前回モデル作成時に、入力には
Inputを使い、出力は全結合をするDenseを使いsoftmaxを取るようにしました。また、グラフ名はデフォルトではimportになるようです。このような情報をヒントに入出力のTensorを探します。
今回は以下であることが分かります:
- 入力:
import/input_1:0- 出力:
import/dense_1/Softmax:0conv_mnist.pb_param.json{ "import/input_1": [ "Tensor(\"import/input_1:0\", shape=(?, 28, 28, 1), dtype=float32)" ], "import/conv2d_1/kernel": [ "Tensor(\"import/conv2d_1/kernel:0\", shape=(3, 3, 1, 8), dtype=float32)" ], ~略~ "import/dense_1/Softmax": [ "Tensor(\"import/dense_1/Softmax:0\", shape=(?, 10), dtype=float32)" ], ~略~ "import_2/training_1/Adam/Variable_11": [ "Tensor(\"import_2/training_1/Adam/Variable_11:0\", shape=(10,), dtype=float32)" ] }変換したTensorFlow用モデルを使って、入力画像から数字識別するアプリケーションを作る
Spyder上で
number_detector_tensorflow.pyというファイルを開き、以下のようなコードを実装します。
動作仕様は前回Keras用に作成したnumber_detector.pyと同じです。TensorFlow呼び出しもこの中でやっているので、少し複雑になっています。
get_tensor_by_nameに先ほど確認した入出力名を設定して、入出力Tensorを取得しています。number_detector_tensorflow.py# -*- coding: utf-8 -*- import cv2 import tensorflow as tf import numpy as np if __name__ == '__main__': img = cv2.imread('resource/4.jpg') cv2.imshow('image', img) img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img = cv2.resize(img, (28, 28)) img = 255 - img img = img.reshape(1, img.shape[0], img.shape[1], 1) img = img / 255. with tf.Session() as sess: with tf.gfile.GFile('conv_mnist.pb', 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) sess.graph.as_default() _ = tf.import_graph_def(graph_def) tensor_input = sess.graph.get_tensor_by_name('import/input_1:0') tensor_output = sess.graph.get_tensor_by_name('import/dense_1/Softmax:0') probs = sess.run(tensor_output, {tensor_input: img}) result = np.argmax(probs[0]) score = probs[0][result] print("predicted number is {} [{:.2f}]".format(result, score)) cv2.waitKey(0) cv2.destroyAllWindows()次回は、今回作成したTensorFlow用モデル(conv_mnist.pb)を、C言語から使用してみます。