- 投稿日:2019-03-07T23:47:16+09:00
国会議事録のデータを用いて年代毎に話題になった言葉を表示する
はじめに
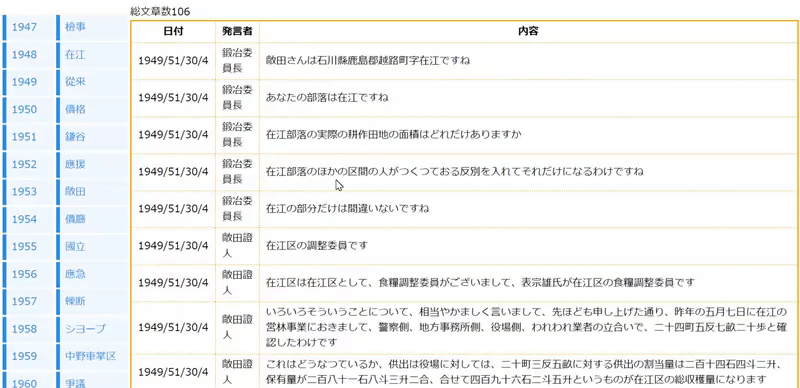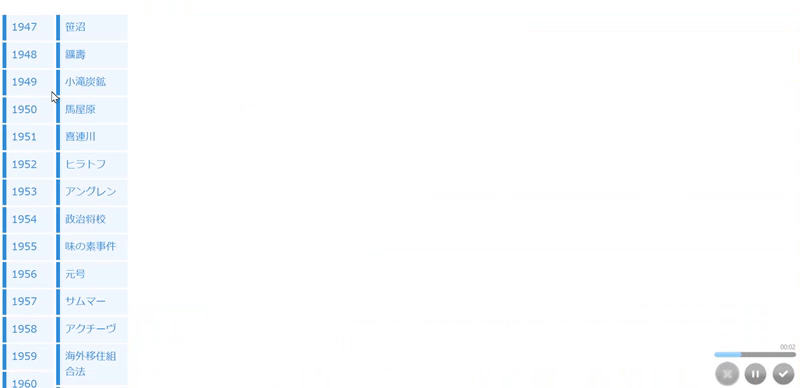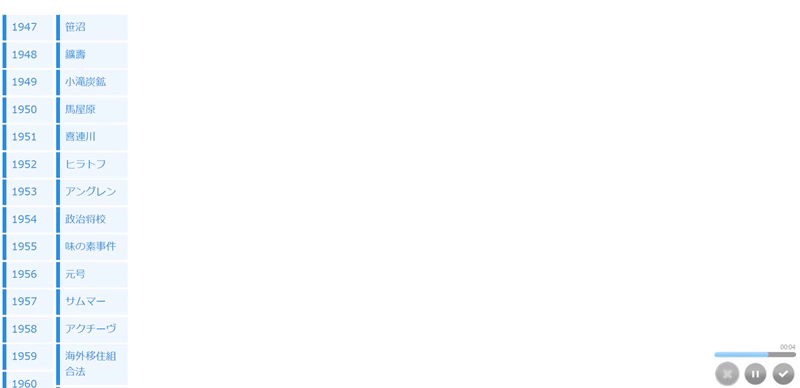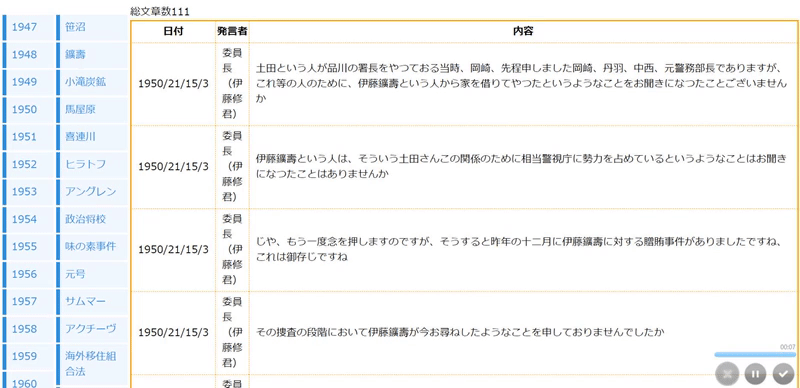
「国会議事録のデータ(10GB)をデータベースにいれて、何かしらの検索システムをつくって」という課題があったので、議事録の中から年代毎に話題になった言葉を表示するシステムをつくりました。
こんな感じ↓
作った理由としては、年代毎で話題になった言葉を見やすくすることで、その時の情勢やら歴史を知れるのかな~と思ったからです。
4ヵ月前に作ったので、記憶がおぼろげですが、メモ程度に残しておきます。
めちゃくちゃ焦ってつくったので、いろいろ適当です。どうやったか
- データベースに格納しろということで、MySQLにデータを挿入
- データベースから発言内容を所得し、形態素解析をおこない名詞のみを抽出する
- 1年毎に名詞を出力し、分かち書きした文字列を作成する
- 10年分単位でTF-IDFを行う。
- TF-IDFの結果によって抽出された年ごとの特徴語をデータベースに格納
- データベースにアクセスするREST APIを作成
- フロント⇔API⇔データベースみたいな構造で作成

だいたいのやり方は上のようになるのですが、
ノートパソコンであること、10GBとという割と大容量のデータであることから、
苦戦したことが多々あるので、そういうことをメモ程度に残していこうとおもいます。特徴語抽出については【特別連載】 さぁ、自然言語処理を始めよう!(第2回: 単純集計によるテキストマイニング)のサイトを参考にしました。
環境
ノートパソコンのローカルの環境で構築しました。
- MySQL5.6(Windows)
- Python3.6(Ubuntu18.04 LTS)
- フロント(Ubuntu18.04 LTS)
- gulp
- jQuery
国会議事録のデータはapi経由でとってこれるらしいですが、tsvファイルで成形されたものが配られたのでそれを使いました。
国会議事録のデータをMySQLに格納する
MySQLをインストールする
はじめはUbuntuにMySQLを入れようと試みていたのですが、いろいろと躓きました。
躓いたことに関してはWSLのUbuntu18.04.1LTSにMySQL5.7を入れたお話に書いてあります。
そのあと、無事ubuntuにMySQLを入れることができたのですが、データを入れてもかなり不安定だったため、Windowsに切り替えました。【MySQL】Windows 10にMySQLをインストールを参考にwindowsにMySQLをインストールしていきます。
- MySQLがある場所まで移動
>cd ¥mysql¥bin
- MySQLを起動
> net start mysql
- MySQLにログイン
> mysql -u root国会議事録のデータをデータベースに格納する。
まずはじめにデータベースとテーブルを作成
> create database gijiroku
- 国会議事録のデータをすべて保管するテーブル
CREATE TABLE gijiroku.origin ( id INT AUTO_INCREMENT NOT NULL PRIMARY KEY, date DATE, nickname VARCHAR(25), fullname VARCHAR(25), position VARCHAR(25), dialogue LONGTEXT, siturl TEXT );
- 特徴語を保管するテーブル
create table gijiroku.wakachi( id INT AUTO_INCREMENT NOT NULL PRIMARY KEY, date YEAR(4), wakachi LONGTEXT );次に、originテーブルに議事録のデータをいれていきます。
ここで、はじめはinsertをつかってやろうとしてたのですが、到底終わらないということに気づき…(MySQLに大量のデータを入れるときに最適な方法は?を参考)
国会議事録のデータがtsvファイルで渡されていたことから、LOADを使いました。
また、10GBをいっきに処理するのはノートパソコンでは難しいと思い、データを4分割にして格納していきました。LOAD DATA LOCAL INFILE 'C:/tsvfiles/splitted_1.tsv' INTO TABLE `gijiroku`.`origin` FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' (@1,@2,@3,@4,@5,@6) SET date=@1, nickname=@2, fullname=@3, position=@4, dialogue=@5, siturl=@6;LOAD DATA INFILEステートメントの中でカラムの順番とかをゴニョるを参考にしました。
データをすべて入れた段階で、総レコード数が3000万件ありました。
パーティショニングの設定
このままでは、selectするときにとんでもない時間がかかってしまうので、パーティショニングというものを行います。
を参考にしました。
- プライマリキーの設定
> ALTER TABLE origin DROP PRIMARY KEY, ADD PRIMARY KEY(id, date);
- パーティションの設定
ALTER TABLE origin PARTITION BY RANGE(YEAR(date))( PARTITION p1947 VALUES LESS THAN (1948), PARTITION p1948 VALUES LESS THAN (1949), PARTITION p1949 VALUES LESS THAN (1950), ... PARTITION p2011 VALUES LESS THAN (2012), PARTITION p2012 VALUES LESS THAN (2013), PARTITION p2013 VALUES LESS THAN (2014) );これで、年代別にselectするときは、早く結果が出力しやすくなりました。
特徴語を抽出する
UbuntuにPipenvをインストール
ここからの言語処理は、【特別連載】 さぁ、自然言語処理を始めよう!(第2回: 単純集計によるテキストマイニング)を参考に、Pythonを使ってやっていきたいと思います。
Python自体まったく書かないため、よくわからないですが、ここ最近でてきたPipenvというPythonパッケージングツールを使うことにしました。
バージョンもすぐ切り替えられたりと、Pythonのめんどくさいところをまるっとやってくれる感じのツールになります。Python の Pipenv を使ってみましたを参考にインストールしました。
- Pythonコードを個別に実行する
> pipenv run python main.py形態素解析を行い、名詞を抽出する
Pythonの環境を整えることができたので、これからは形態素解析を行っていきたいと思います。
方法は【特別連載】 さぁ、自然言語処理を始めよう!(第2回: 単純集計によるテキストマイニング)とほぼ変わらないのですが、
データが大容量ということもあり、名詞出力とTf-idfを同時にやるのではなく、別に実行することにしました。
この時に、すべてのデータを扱うのではなく、10年分のデータを所得して、年毎の名詞を抽出し、一つのスペースに区切られた文字列をtsvファイルに出力するようにしました。(なので、出力されたtsvファイルは6つになります。)理由としては、tf-idfの処理を行うときに、処理落ちをさせないようするためです。また、参考リンク通りにMecabをインストールすることができなかったので、ubuntu 18.04 に mecab をインストールのサイトを参考にインストールを行いました。
そのほかにも、元のコードでは大容量のデータを扱うには厳しいので、
を参考に処理を高速化させました。
最終的にできたコードが以下です。
wakachi.py#!/usr/bin/env python # -*- coding:utf-8 -*- import mysql.connector import configparser import MeCab import numpy as np from multiprocessing import Pool import multiprocessing as multi import pandas as pd config = configparser.ConfigParser() # 設定ファイルを読み込み config.read('config.ini') #databese conn = mysql.connector.connect( host = config['detabase_server']['host'], port = config['detabase_server']['port'], user = config['detabase_server']['user'], password = config['detabase_server']['password'], database = config['detabase_server']['database'], ) conn.ping(reconnect=True) cursor = conn.cursor() ### MySQL上のデータ取得用関数 def fetch_target_day_n_random(target_day, n = 2000): sql = 'select dialogue from origin partition (p%s) where date_format(date, "%Y") = "%s";' cursor.execute(sql, [target_day,target_day]) result = cursor.fetchall() l = [x[0] for x in result] return l ### MeCab による単語への分割関数 (名詞のみ残す) tagger = MeCab.Tagger() def split_text_only_noun(text): words = [] for chunk in tagger.parse(text).splitlines()[:-1]: (surface, feature) = chunk.split('\t') if feature.startswith('名詞'): # print(surface) words.append(surface) return " ".join(words) ### メイン処理 docs_count = 20 # 取得数 # 処理する年代を書き込む target_days = [ 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013 ] data_frame = pd.DataFrame(index=[], columns=['date', 'wakachi']) for target_day in target_days: # MySQL からのデータ取得 txts = fetch_target_day_n_random(target_day, docs_count) p = Pool(multi.cpu_count()) each_nouns=p.map(split_text_only_noun, txts) p.close() all_nouns = " ".join(each_nouns) series = pd.Series([target_day, all_nouns], index=data_frame.columns) data_frame = data_frame.append(series, ignore_index = True) data_frame.to_csv("wakachi6.csv", index=False,header=True)#書き出しtarget_daysは処理が終わるごとに、手作業で変えました…
TF-IDFを行う。
TF-IDFは参考資料とほぼ同様な処理の仕方ですが、MySQLにinsertする方法ではなく、一度、年代ごとの特徴語をtsvファイルに書き出してから、LOADする方法を行いました。
tfIdf.pyimport numpy as np from sklearn.feature_extraction.text import TfidfVectorizer import pandas as pd ### TF-IDF の結果からi 番目のドキュメントの特徴的な上位 n 語を取り出す def extract_feature_words(terms, tfidfs, i, n): tfidf_array = tfidfs[i] top_n_idx = tfidf_array.argsort()[-n:][::-1] words = [terms[idx] for idx in top_n_idx] return words ###空白を境目にしてる def extract_feature_words_string(terms, tfidfs, i, n): tfidf_array = tfidfs[i] top_n_idx = tfidf_array.argsort()[-n:][::-1] words = [terms[idx] for idx in top_n_idx] words_string = " ".join(words) return words_string # 書き直す filename = pd.read_csv('wakachi6.csv') ldate = filename['date'] lwakachi = filename['wakachi'] #追加 tokuchou = [] tfidf_vectorizer = TfidfVectorizer( use_idf=True, lowercase=False, max_df=6, sublinear_tf=True ) tfidf_matrix = tfidf_vectorizer.fit_transform(lwakachi) # index 順の単語のリスト terms = tfidf_vectorizer.get_feature_names() # TF-IDF 行列 (numpy の ndarray 形式) tfidfs = tfidf_matrix.toarray() data_frame = pd.DataFrame(index=[], columns=['date_year', 'tokuchou']) for i in range(0, len(ldate)): stokens=extract_feature_words_string(terms, tfidfs, i, 20) series = pd.Series([ldate[i], stokens], index=data_frame.columns) data_frame = data_frame.append(series, ignore_index = True) #csv書き出し data_frame.to_csv("tokuchou.csv", index=False, mode='a', header=False)#追記 # data_frame.to_csv("tokuchou.csv", index=False,header=True)#書き出し
filename = pd.read_csv('wakachi6.csv')のところを形態素解析の処理で出力した6つのtsvファイルに手作業で書き換えて、すべてのデータに対しての特徴語をtokuchou.csvに書き出しました。そしてLOADを用いて、tokuchouテーブルにデータを入れていきます。
LOAD DATA LOCAL INFILE 'C:/tokuchou.csv' INTO TABLE `gijiroku`.`tokuchou` FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' IGNORE 1 LINES (@1,@2) SET date=@1, tokuchou=@2;これでデータベース側は完成しました
Flaskを使ってデータベースにアクセスするAPIをつくる
これまた使ったことがないフレームワークでしたが、FlaskはWebアプリつくるなら扱いやすい!という噂を聞いていたので、つかってみました。
調べてみると、APIも一瞬で作れそうな感じです(【Flask】5分で作るめちゃくちゃ簡単なAPI【Python初心者】)
クロスドメインの問題で少し躓きましたが、FlaskでRESTfulAPIを作ってみたを参考にして、めちゃくちゃ適当ですが、できました。
main.py#!/usr/bin/env python # coding: utf-8 from flask import Flask, request, jsonify from flask_restful import Resource, Api from flask_restful.utils import cors #mysql import mysql.connector import configparser # 初期設定 app = Flask(__name__) api = Api(app) app.config['JSON_AS_ASCII'] = False #日本語文字化け対策 app.config["JSON_SORT_KEYS"] = False #ソートをそのまま config = configparser.ConfigParser() # 設定ファイルを読み込み config.read('config.ini') class Year(Resource): # GET時の挙動の設定 @cors.crossdomain(origin='*') def get(self): conn = mysql.connector.connect( host = config['detabase_server']['host'], port = config['detabase_server']['port'], user = config['detabase_server']['user'], password = config['detabase_server']['password'], database = config['detabase_server']['database'], ) connected = conn.is_connected() if (not connected): return make_response(jsonify({"DB ERROR": 'could not connect to db'})) conn.ping(reconnect=True) cur = conn.cursor() params = request.args if(params.get('year') is not None): year = params.get('year') cur.execute('select tokuchou from tokuchou where date = %s',[year]) table = cur.fetchall() print(table) table=table[0][0].split(' ') result = { "year":year, "tokuchou": table } send_msg = jsonify(result) return send_msg class YearWord(Resource): # GET時の挙動の設定 @cors.crossdomain(origin='*') def get(self,year): conn = mysql.connector.connect( host = config['detabase_server']['host'], port = config['detabase_server']['port'], user = config['detabase_server']['user'], password = config['detabase_server']['password'], database = config['detabase_server']['database'], ) connected = conn.is_connected() if (not connected): return make_response(jsonify({"DB ERROR": 'could not connect to db'})) conn.ping(reconnect=True) cur = conn.cursor() params = request.args word = params.get('word') word = '%'+word+'%' cur.execute('select * from origin partition(p%s) where dialogue like %s;',[year,word]) table = cur.fetchall() result = { "year":year, "word":word, "result": table } send_msg = jsonify(result) return send_msg api.add_resource(Year, '/year') api.add_resource(YearWord, '/yearWord/<int:year>') if __name__ == '__main__': app.run()APIはこれで完成しました。
JS側は、jQueryのajaxを利用してAPIにリクエストを投げて...というお決まりの方法でデータを所得しています。最後に
大容量のデータを扱うのは初めてだったので、手探りで作ってた状態でした。(しかもあんまり時間がなかった…)
もっと効率化できた部分はあったと思います…それと、もうWSLを使うのはやめようと思いました(笑)

- 投稿日:2019-03-07T23:10:18+09:00
[論文紹介&実装] Robust Template Matching Using Scale-Adaptive Deep Convolutional Features
モチベーション
業務で電気回路図の画像から回路素子を抽出したいというタスクを課されたのですが、これがNon-Deepのテンプレートマッチングや特徴量マッチングではかなり難しいタスクだということに気づきました。
例えば下のような入力画像から、テンプレート画像の回路素子を見つけたいというものです。
入力画像 テンプレート画像 このタスクでは、non-deepのテンプレートマッチングでは大きさの変化や解像度の変化への対応が難しく、特徴量マッチングではもともとの画像の特徴量がとても少ないためうまくいかず...
Deepで物体検出をしようにも、回路素子の形は一意に決まっているため、解像度を変化させるくらいしかデータセットの作成方法がなく、不可能です。なんとかPretrainedのモデルを用いた、学習をしないDeepベースの手法がないかと探した結果、次の論文を見つけたので、実装してみました。
論文紹介
リンク
論文pdf
http://www.apsipa.org/proceedings/2017/CONTENTS/papers2017/14DecThursday/TA-02/TA-02.5.pdf実装したもの
https://github.com/kamata1729/robustTemplateMatchingAbstract
- CNNの特徴量ベースで、ロバストかつ効率的なテンプレートマッチングの手法を提案
- オリジナリティとしては、scale-adaptiveな特徴量抽出の手法をとっていること
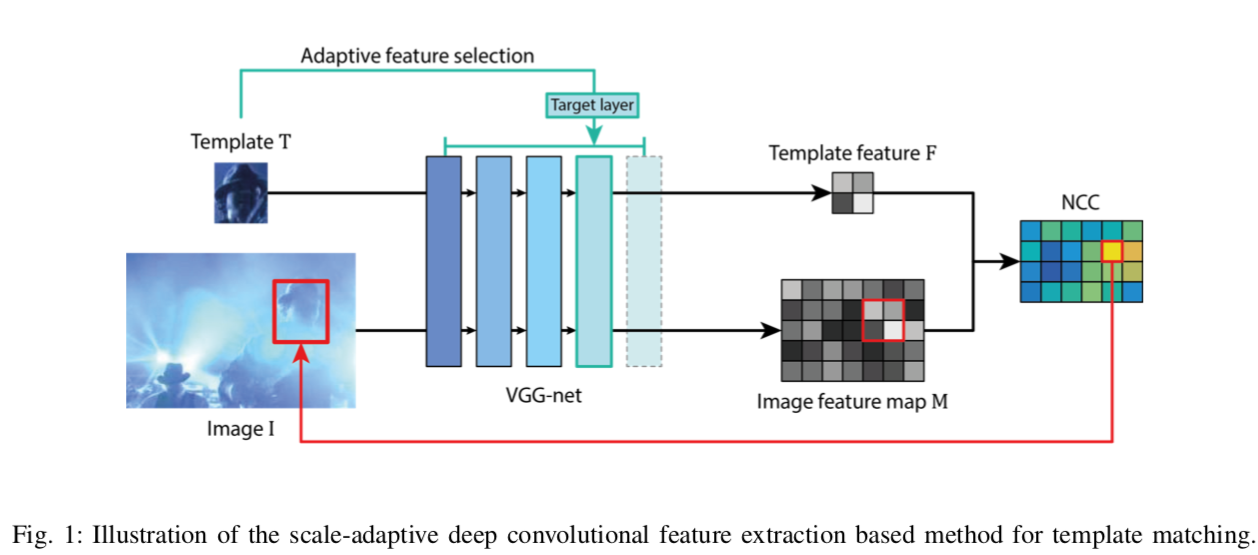
- テンプレート画像と入力画像をそれぞれCNNに入れ、それぞれ途中の層の特徴量を抽出する
- その特徴量を、NCC(normalized cross-correlation)を用いてもっとも似ている場所を検出する
- この手法で、それまでのstate-of-the-art以上の精度を出すことができ、さらに計算コストも大幅に下げることが可能
1. Introduction
これまでの手法
- 従来のNon deepのテンプレートマッチング手法では、ロバスト性に欠ける
- また、CNNベースのこれまでの手法は、計算コストがとても大きい
この論文での提案手法
- スケール性を保った特徴量マップを学習済みのVGGからもってくる
- NCC (normarized cross-correlation) を使い、templateとimageの特徴量マップ間の距離を計算し、マッチングする
2. Proposed Method
まず、テンプレートマッチングを、入力画像 $I \in \mathcal{R}^{m \times n \times 3}$から、もっともてっmプレート画像 $T \in \mathcal{R}^{w \times h \times 3}$ に近い場所を取り出す問題として定義する。
(ここで、$(m, n)$は入力画像 $I$の縦横の大きさ、$(w, h)$はテンプレート$T$の大きさとする)A. Scale Adaptive Deep Convolutional Feature Extraction
特徴量抽出には、VGG-Netを使用 (VGGの種類には言及されていないが、おそらくこの論文ではVGG13を採用している。理由は後で記載)
ほかのCNNベースの手法と異なり、scale-adaptivenessを獲得するため、画像を(224, 224)などの決まったサイズにリサイズせず、画像の大きさも考慮にいれる。
次に、VGGのどの層から特徴量マップを取得するかを決める。
そのためにまず、VGGの$l$番目の層の、receptive field(受容野) を求める。
- ここでreceptive fieldとは、一つの特徴量が考慮に入れることができる入力画像の範囲のことを表していると考えられる
- 以下では、「$l$層目」と言った場合には、上からconvolution層とpooling層を数えた時の$l$番目の層とし、ReLUやBatch normは1層と数えない。
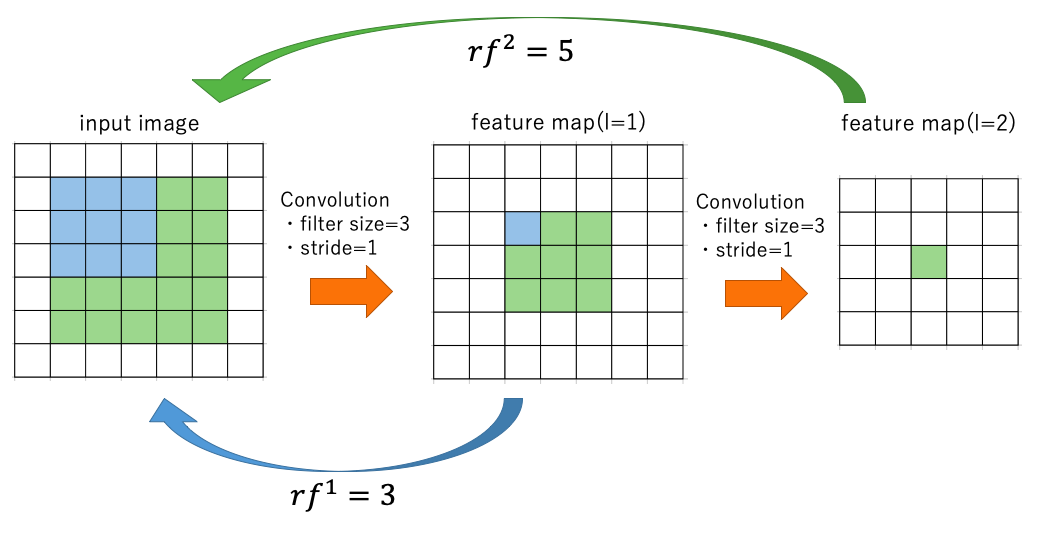
- $l$層目のreceptive fieldの大きさ$rf^l \times rf^l$は以下のように求めることができる。
\begin{equation} rf^l = \begin{cases} rf^{l-1} + (f^l -1)\prod_{i=1}^{l-1} s^i &(l > 1) \\ 3 &(l=1) \end{cases} \end{equation}ここで、$f^l$は$l$層目のフィルターサイズを表し、$s^i$は$i$層目のストライドを表す。
receptive field の意味
$rf^l$は、元の画像のうち、$l$層目の特徴量が考慮に入れている入力画像の大きさになっている。
$l=1$のときの3は、VGGの最初のConv層のフィルターサイズである。以下の図を見るとわかりやすい。
ストライドが1の場合は、一層目の特徴量が考慮できるinput imageの大きさは3, 二層目の場合は7となり、上式の関係を満たしている。
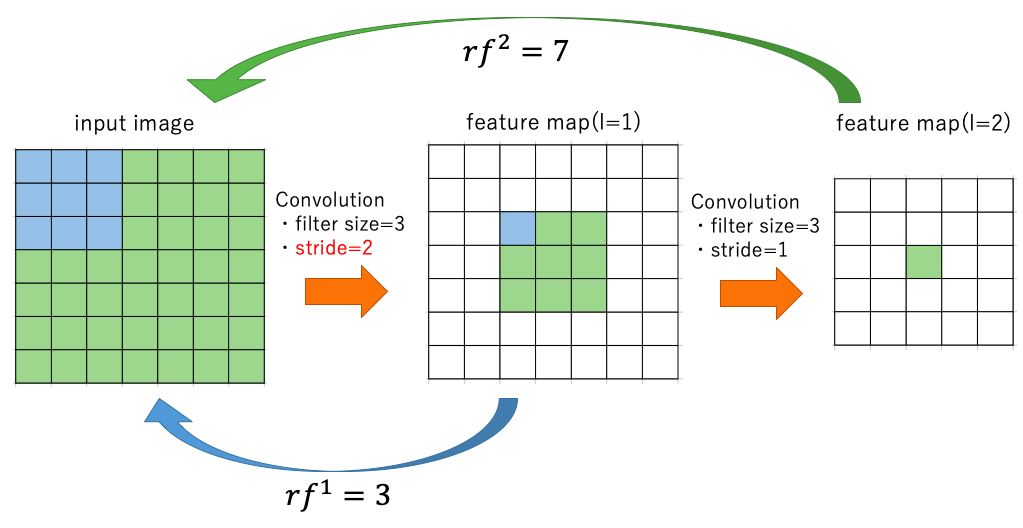
一層目のConvolutionのストライドが2の場合も、下の図のように考えれば、$f^1=3,~f^2=3,~s^1=2,~s^2=1$であり、\begin{align} rf^1& = 3\\ rf^2&=7\\ &=rf^1+(f^2-1)*s^1 \end{align}となり上式を満たすことがわかる。
pooling層に関しても同様に考えることができる。
上記のように、$rf^l$は考慮している画像の大きさであるから、もし$rf^l$がテンプレートがテンプレート画像の大きさ$min(w. h)$よりも大きければ、テンプレート画像の大きさより広い範囲の特徴量を考えてしまっているため、今回の問題に対しては意味のない特徴量を出していることになる。
よって、特徴量を得る層のインデックス$l*$は、以下の式で求めることとする。
\begin{equation} l* = max(l-k, 1) ~~s.t.~~ rf^l\le min(w,h) \end{equation}ここで、$k$は非負整数であるが、今回の実験では$k=3$に設定している。
なぜk=3に設定しているのか
$l$層目と$l-3$層目の間に必ずpooling層が挟まれるから
ここから、VGGの種類が特定できる。
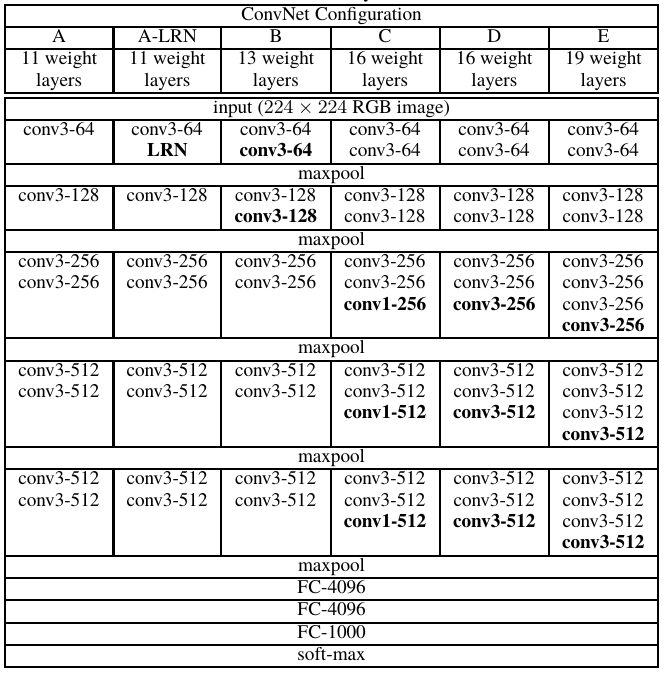
下の図はVGGの各種類のアーキテクチャであるが、3層ごとにpoolingが挟まれるのはBのVGG13であるから、おそらくこの論文でも使っているのはVGG13だと思われる。
B. NCC-based Similarity Measure
上記の方法で、入力画像画像 $I$から取り出した特徴量マップを$M$, テンプレート画像$T$から取り出した特徴量マップを$F$とする。
$F$のサイズを$(channel, h_f, w_f)$とし、 $\tilde{M} = M_{i:i+h_f-1, j:j+w_f-1}$とする。
$M$から$F$にもっとも似た場所を取り出すために、NCCを以下のように計算する。\begin{equation} NCC_{i,j} = \frac{<F, \tilde{M}>}{|F||\tilde{M}|} \end{equation}ここで、$<\cdot , \cdot>$はフロベニウス内積、$|\cdot|$はフロベニウスノルムを示している(はず)
そして、
\begin{equation} i*, j* = argmax_{i,j} ~NCC_{i,j} \end{equation}として$(i*, j*)$を計算する。
(今回の実装ではこのNCCの計算がボトルネックになっていたのでcythonで高速化を図りました)C. Location Refinement
特徴量マップの空間で、もっとも似ている場所$(i*, j*)$を見つけることができたので、これをback-projectionによって、入力画像の空間のバウンディングボックス $((x_1^0 , y_1^0 ), (x_2^0 , y_2^0 ))$ に変換する。
back-projectionって何?
ここも論文に書いていないので推測です。(わかる方教えてください)
back-projectionを検索してもそれっぽいものはヒットしませんでした。
単純に考えて、特徴量マップの空間も入力画像の空間情報を保持しているので、単純に$(i*, j*)$の入力画像の大きさに対応した場所を取ってくればいいような気がします。
ただ、バウンディングボックスとして取ってくるというふうに書いているのでどうしたらいいものか
とりあえず、論文自体テンプレート画像の大きさも使っていこうという趣旨なので、実装は対応する場所を中心としたテンプレート画像と同じ大きさのバウンデングボックスを取ることにしました。
上のようにして取得したバウンデングボックス$((x_1^0 , y_1^0 ), (x_2^0 , y_2^0 ))$を、NCCの値を用いて以下のように修正する。(これも$rf^i$の式の意味を考えれば理解できますね)
\begin{align} x_1 &= \frac{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v} ~\cdot(x_1^0 + v~\cdot \prod_{i=1}^{l*-1}s^i)}{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v}}\\ x_2 &= \frac{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v} ~\cdot(x_2^0 + v~\cdot \prod_{i=1}^{l*-1}s^i)}{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v}}\\ y_1 &= \frac{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v} ~\cdot(y_1^0 + u~\cdot \prod_{i=1}^{l*-1}s^i)}{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v}}\\ y_2 &= \frac{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v} ~\cdot(y_2^0 + u~\cdot \prod_{i=1}^{l*-1}s^i)}{\sum_{u=-1}^{1}\sum_{v=-2}^{1} NCC_{i*+u,j*+v}} \end{align}これにより、物体領域 $((x_1 , y_1), (x_2 , y_2))$ を得る。
3. Experiments
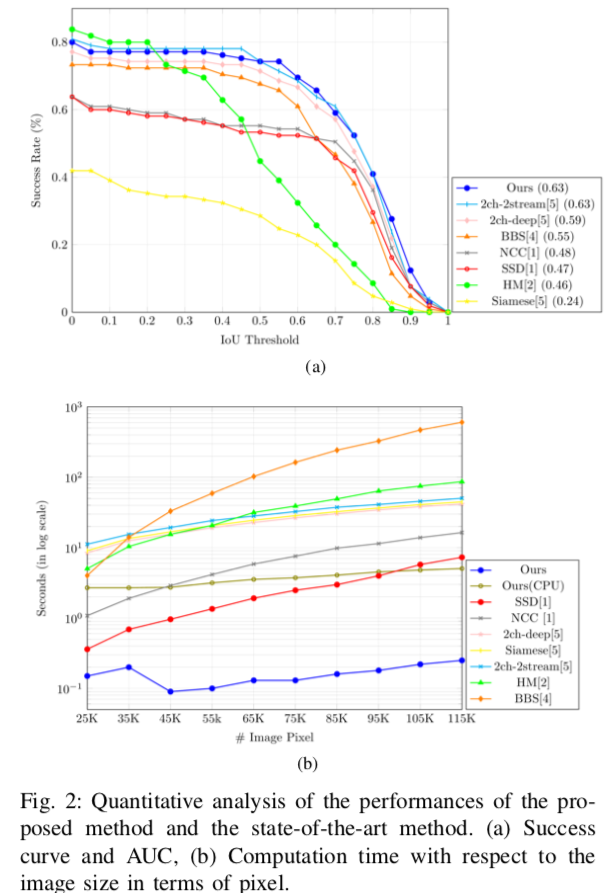
Fig 2
- 既存手法よりも良い精度がでる
- 既存手法よりも実行時間が早い
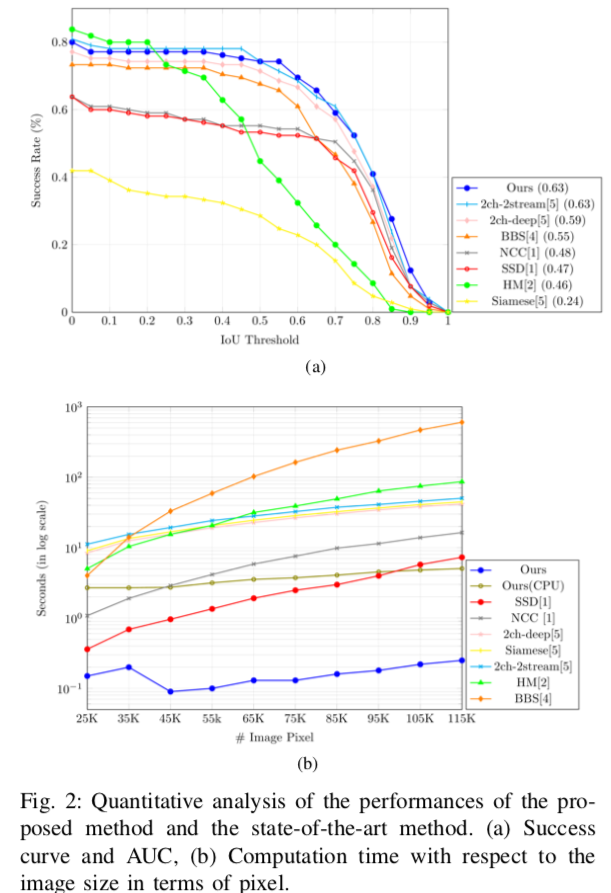
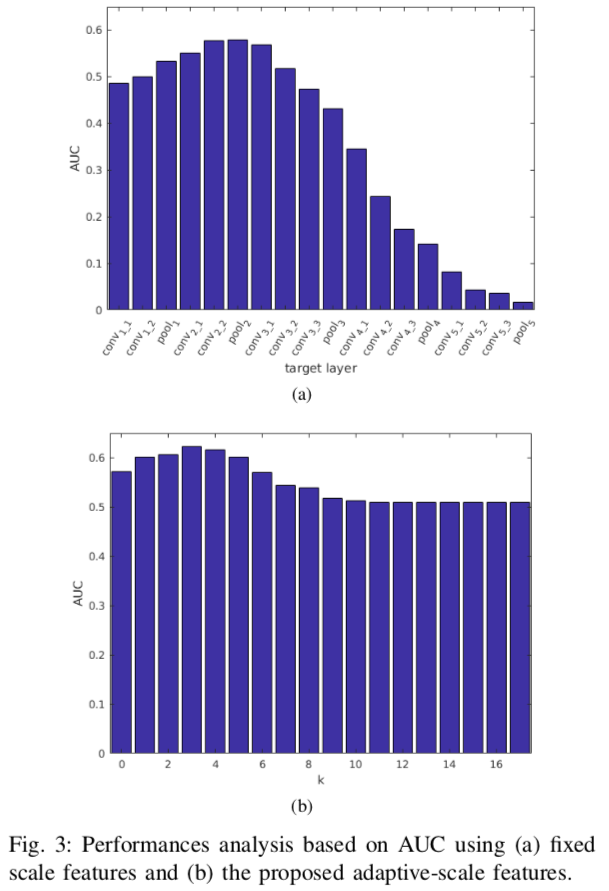
Fig 3
- $min(w, h)=40$のテンプレート画像について、特徴量を取得するlayerを変化させたときのAUC
$k=3$のときの$l*$はpool2で、このときがもっとも精度が良い- kを変化させたときのAUC.
$k=3$のときがもっとも良い
Fig 4
さまざまな状況でのテンプレートマッチングの結果
実装の結果
だいぶいい感じに検出できてます!
https://github.com/kamata1729/robustTemplateMatching
sample image template image result image







- 投稿日:2019-03-07T22:56:15+09:00
pysparkをnotebookで書けるspark clasterをかんたんに構築できるdockerfile作ったったwww
これだとjupyternotebookがspark clasterで立ち上がらないので手直しする必要があります!!!
はじめに
学部3年、現在就活中の大木です。
現在インターン先でレコメンドシステムをsparkをもちいて構築しているのですが、
EMRでsparkを動かしてゴニョゴニョする前にローカルで色々試してみたく、
またどうせならspark clasterを構築してワチャワチャやりたいと思いそのためにdockerfileを作ったので共有します。こちら
2357gi/apache-spark-cluster: localでspark clasterを立ち上げて遊ぶ用 pyspark用のnotebookもあるヨ!?使い方
$ git clone https://github.com/2357gi/apache-spark-clustergit cloneして
make rundocker imageを作成し、composeを構築します。
後、
make notebookでjupyter notebookが起動するのでUrlをコピーしてlocalhostで接続すればおkです。解説
Dockerfile
FROM ubuntu:18.04ベースとなるイメージはUbuntu18.04を使用しています。
採用理由は個人的に使い慣れているだけです。python等のイメージを使用しても良かったのですが、理解しながら作業を進めたかったのであえてこちらを使用しました。
# Environment variables ENV SPARK_VERSION=2.4.0 \ HADOOP_VERSION=2.7 \ SPARK_HOME=/spark \ PATH=$SPARK_HOME/bin:$PATH \ PYSPARK_PYTHON=/usr/bin/python3 \ PYSPARK_DRIVER_PYTHON=/usr/local/bin/jupyter \ PYSPARK_DRIVER_PYTHON_OPTS="notebook --no-browser --port 8888 --ip=0.0.0.0 --allow-root"環境変数を設定します。
SPARK_VERSIONやHADOOP_VERSIONを変数として登録し、後のsparkをダウンロードする際のダウンロードUrlに変数を使用しています。
これによりバージョン変更に強くなります。ミソとなるのが
PYSPARK_PYTHON,PYSPARK_DRIVER_PYTHON,PYSPARK_DRIVER_PYTHON_OPTS
このへんで、
ここでpysparkのpythonのバージョン指定や$SPARK_HOME/bin/pysparkが実行されたときにjupyter notebookが立ち上がるようになっています。notebookの引数諸々はdocker内で起動したjupyter notebookをホスト側から接続するための諸々です。
この辺はすこしセキュアではないのですが、ローカルで遊ぶだけなので許容範囲としました。# Install required apt package and ensure that the packages were installed RUN apt-get update && apt-get install -y \ bc \ curl \ default-jdk \ git \ python3 \ python3-pip \ scala(説明略)
# Install spark RUN mkdir spark &&\ curl -sL \ http://ftp.tsukuba.wide.ad.jp/software/apache/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz \ | tar zx -C spark --strip-components 1sparkを引っ張ってきて展開し、/sparkに設置しています。
近さ的に筑波のミラーから引っ張ってきていますがココらへんはあんまりよくないかもしれません。展開の方法ですがcurlで引っ張ってきたものをtarにパイプで渡すことによって
curl &&tar &&mv && rmなどといったナンセンスなコマンドの羅列にならないように工夫しましたがココらへんは悔しさが残ります。(詳細)RUN pip3 install jupyter RUN pip3 install ipyparallel \ && ipcluster nbextension enablejupyterをpipでinstallします。
pipでjupyterを導入するとpython3のkernelを読み込んでくれない?ここがすこしうまく行かなかったので
別途ipyparallelをpipでインストールしてnbextensiionをenableします。
これでjupyter notebook上でpython3がつかえるようになります。Docker-compose
みんな大好きdocker-compose
Docker でお試し Spark クラスタを構築する - Qiita
ほぼほぼこちらを参考にさせていただき、
jupyter notebook用に8888番だけ穴を開けた感じになっております。Makefile
WORKER=1 build_docker: Dockerfile @echo "\n? build 2357gi/apache-spark" @docker build ./ -t 2357gi/apache-spark build_compose: @echo "\n? Pile up containers" @docker-compose up -d --scale worker=$(WORKER) run: docker-compose.yml @echo "\n✨ apache-spark cluster setup is start!" @make build_docker @make build_compose @echo "\n? set up is finished! \n you wanna access ⚡spaek shell, hit it! \n$$ make s-shell" @echo "or you wanna start ? pyspark notebook, hit it! \n$$ make notebook" @echo "... if u wanna open ? shell? do this. \n$$ make shell" s-shell: @echo "\n⚡ start spark-shell...." @docker-compose exec master /spark/bin/spark-shell --master spark://localhost:7077 notebook: @echo "\n? start pyspark notebook...." @docker-compose exec master /spark/bin/pyspark @docker-compose exec shell: @echo "\n? start master shell...." @docker-compose exec master /bin/bashWORKERを変数にすることによって
$ make run WORKER=<任意のworker node数を指定できるようにしました。
あとは普通な感じです。makefileに絵文字を入れると可愛くていいですね。
- 投稿日:2019-03-07T22:53:17+09:00
django004#Template使ってみよう
前回
いままでのサイドはHello wordとか退屈なものばかりで、これからは簡単なTemplateを作りたいと思います。
今回から少しdjangoのドキュメントを参照しながらやりますので、固い話聞きたくないならスルーしてくださいねー流れ
- renderをを使ってHTML Codeなどを返し
- 名前の付け方
- Template言語を使ってみよう
- CSSを入れてみよう
- もしうまく更新できないなら…
render()をを使ってHTML Codeなどを返し
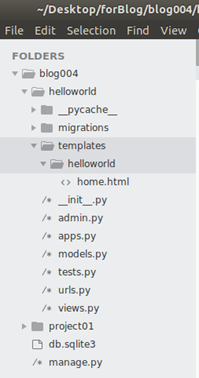
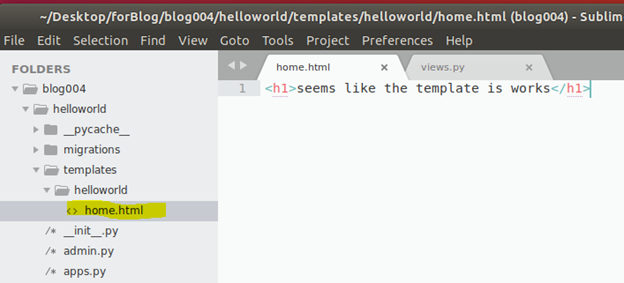
Filesの構成はこうになります。
まずhelloworld/view.pyを修正し、homepage()をrenderを使います。
from django.shortcuts import render from django.http import HttpResponse # Create your views here. def homepage(requeset): return render( requeset=requeset ,template_name="helloworld/home.html" )ドキュメントP.274
Being a web framework, Django needs a convenient way to generate HTML dynamically. The most common approach relies on templates. A template contains the static parts of the desired HTML output as well as some special syntax describing how dynamic content will be inserted.Web Frameとして、Djangoは変換作業し動的なHTMLを作ります。一般的にはTemplatesで返しします。Templatesの中には静的HTMLコードもあり、特別なSyntax({}とか、{%%}とか)で動的な内容も含められますって感じかな?ちょっと適当な翻訳ですが。
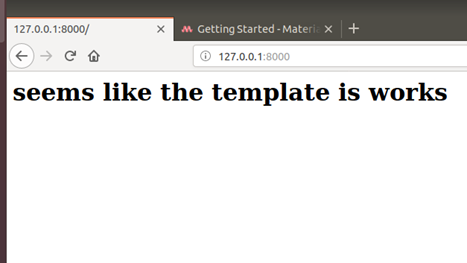
次はhome.htmlに簡単なCodeを入れます。
サーバを走ってみよう。行けそうですね!
名前の付け方
なんでhomeworld/templates/helloworld/hom.htmlのような構造になったでしょうか?それはもし私たちはTemplatesを参照してるとき、アプリケーションの中にたくさんの“Home”とか“About”とか”/“とかあります。そうになると被る可能性がありますので、そういう風に付けました。
Template言語を使ってみよう
みんなさんFlaskを使ったことありますか?DjangoのTemplate言語はFlaskのJinja2と似てますのでFlaskが慣れてる方なら全然難しく感じないと思います。
ドキュメントP284:
変数
{{ }}
My first name is {{ first_name }}. My last name is {{ last_name }}.Contextはこのようなら:
{'first_name': 'John', 'last_name': 'Doe'}
実際Print Outされたときの結果はこうになります:
My first name is John. My last name is Doe.辞書の場合:
{ my_dict.key }}Attributeの場合:
{{ my_object.attribute }}List-Indexの場合:
{{ my_list.0 }}
Tags
{%if %}{%endif%}
{%for %}{%endfor%}Comments
{# this is comment#}まずview.pyを編集しますね~
ModelsからmydbをImportします。
renderを使ってmydbの中にある全てのObjectsを返します。from django.shortcuts import render from django.http import HttpResponse from .models import mydb # Create your views here. def homepage(request): return render( request=request ,template_name="helloworld/home.html" ,context={"mydb":mydb.objects.all} )次はhomeworld/templates/helloworld/hom.htmlを編集しますね~
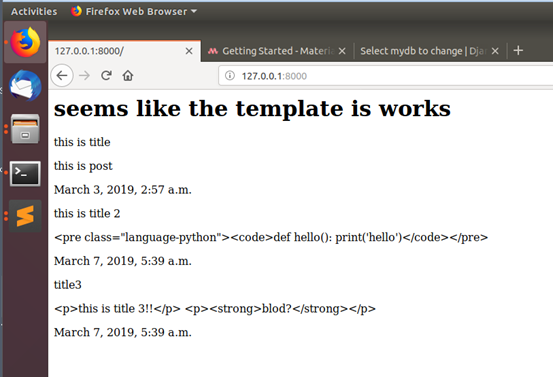
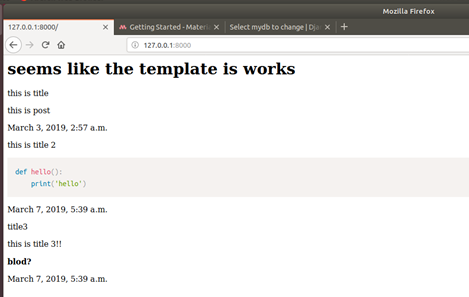
<h1>seems like the template is works</h1> {%for m in mydb %} <p>{{ m.title }}</p> <p>{{ m.post }}</p> <p>{{ m.published }}</p> {%endfor%}それでOK。Local hostをみたら…
できました!と言いたいけど、なんだかちょっと変ですね…
HTMLのTagsもそのまま表示されましたね~
homeworld/templates/helloworld/hom.htmlをもうちょっと工夫しますね!
seems like the template is works
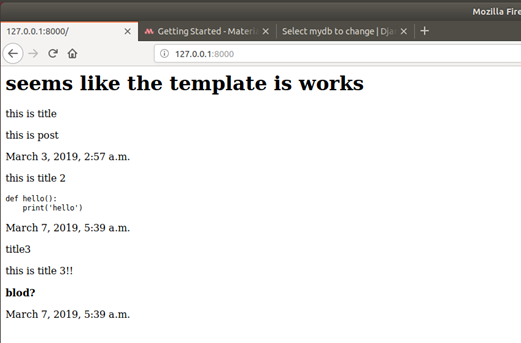
{%for m in mydb %} <p>{{ m.title }}</p> <p>{{ m.post |safe}}</p> <p>{{ m.published}}</p> {%endfor%}ドキュメントP1375
safe
Marks a string as not requiring further HTML escaping prior to output. When autoescaping is off, this filter has noffect今度はokになりましたね!
CSSを入れてみよう
いまのページはうまく動いてますが、まだちょっとダサいですよね。
CSSを入れてみましょう。前回tinymceをインストールしたこと覚えてますか?
じゃこれをImportしてみましょう。<head> {% load static %} <link href="{% static 'tinymce/css/prism.css' %}" rel='stylesheet'> </head> <h1>seems like the template is works</h1> {%for m in mydb %} <p>{{ m.title }}</p> <p>{{ m.post |safe}}</p> <p>{{ m.published}}</p> {%endfor%} <script src="{% static 'tinymce/js/prism.js' %}"></script>変えましたね!
次はCss fileをImportしてみますね。
今回使ってるのはw3c.css、あまり人気がなさそうけど個人的にはすこく好きですー
(ま、お好みですよ~お好み)
https://www.w3schools.com/w3css/default.aspFile構成はこうになります:
次はこhelloworld/templates/hellworld/home.htmlを修正します。
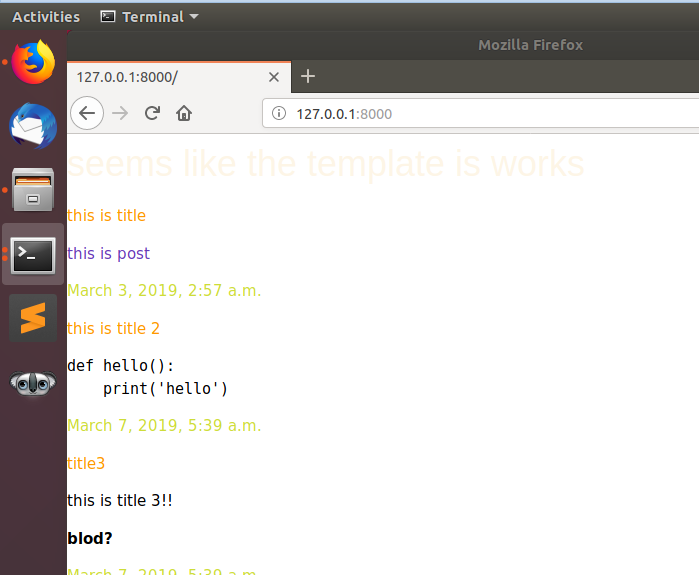
こんなように修正しますー
<head> {% load static %} <link rel='stylesheet' href="{% static "helloworld/w3c.css"%}"> </head> <h1 class="w3-text-sand">seems like the template is works</h1> {%for m in mydb %} <p class="w3-text-orange">{{ m.title }}</p> <p class="w3-text-deep-purple">{{ m.post |safe}}</p> <p class="w3-text-lime">{{ m.published}}</p> {%endfor%} <script src="{% static 'tinymce/js/prism.js' %}"></script>おお!できました!
もしうまく更新できないなら…
Ctrl+Shift+Iで。
以上です!お疲れ様です!
- 投稿日:2019-03-07T22:50:10+09:00
twitter APIで遊んでみる #5(twitterの検索結果を形態素解析してみる)
前回までのお話
twitter APIで遊んでみる #1(環境作り)
twitter APIで遊んでみる #2(ユーザータイムラインの取得)
twitter APIで遊んでみる #3(検索結果の取得)
twitter APIで遊んでみる #4(形態素解析してみる(MeCabの環境作り))はじめに
前回は、コマンドラインで
MeCabを使えるようにしました。なんとなくMeCabがどんなものかもわかってきたので、プログラムで使いやすいように、pythonからMeCabを使ってみようと思います。環境作り
前回までの環境作りは実施済みのうえで、以下を実施します。
# mecab-pythonをpipするときに必要っぽい(詳細までは理解していない) sudo yum install gcc-c++ gcc swig # PythonからMeCabを使うためのバインディングをインストール sudo pip3 install mecab-python3これで
MeCabがpythonからも呼び出せます。とりあえずpythonからMeCabを使ってみる
まずは単純に、pythonからMeCabを使ってみます。
コード(mecab.py)
#!/usr/bin/env python3 # -*- coding:utf-8 -*- import MeCab req = MeCab.Tagger('-Owakati') res = req.parse("昨日はモスバーガーを食べたので、 今日はマックを食べたいですね。") print(res)実行結果
昨日 は モスバーガー を 食べ た ので 、 今日 は マック を 食べ たい です ね 。外部ファイルから文章を読みこんでみる
外部ファイルに記載されている文章を読みこんで解析します。また文章が複数行の場合は改行を削除して1行にする処理を入れました。
コード(mecabFromFile.py)
#!/usr/bin/env python3 # -*- coding:utf-8 -*- import sys import MeCab # MeCabの宣言 req = MeCab.Tagger('-Owakati') # ファイル名を引数として指定する param = sys.argv infile = param[1] # ファイルを読み込みモードで開く f = open(infile, 'r') Allf = f.read() # 改行コードを削除 text = Allf.replace('\n','') # 形態素解析 res= req.parse(text) print(res) # ファイルを閉じる f.close()文章ファイル(sample.txt)
昨日はモスバーガーを食べたので、 今日はマックを食べたいですね。 そうだ、明日は趣向を変えてサブウェイで野菜をたっぷり食べよう。実行結果
昨日 は モスバーガー を 食べ た ので 、 今日 は マック を 食べ たい です ね 。 そう だ 、 明日 は 趣向 を 変え て サブ ウェイ で 野菜 を たっぷり 食べよ う 。twitterの検索結果を解析してみる
twitter APIで遊んでみる #3(検索結果の取得)との組み合わせです。検索キーワードと取得するtweet数を引数で与えるようにしました。
mecabFromSearchTweets.py
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import sys import json import config import MeCab from requests_oauthlib import OAuth1Session # ============================================================================= # 引数の処理 # ============================================================================= # 第一引数を検索キーワードに設定 param = sys.argv keyword = param[1] # 第二引数を取得するtweet数に設定 param = sys.argv tweetcount = param[2] # ============================================================================= # Twitter API # ============================================================================= # OAuth認証部分 CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET twitter = OAuth1Session(CK, CS, AT, ATS) # Twitter Endpoint(検索結果を取得する) url = 'https://api.twitter.com/1.1/search/tweets.json' # Enedpointへ渡すパラメーター params ={ 'q' : keyword, # 検索キーワード 'count' : tweetcount, # 取得するtweet数 } req = twitter.get(url, params = params) if req.status_code == 200: res = json.loads(req.text) result = '' for line in res['statuses']: # 改行コードを削除 text = line['text'].replace('\n','') # resultに足しこんでいく(1行にしたいので) result += text else : print("Failed: %d" % req.status_code) # ============================================================================= # MeCab # ============================================================================= req = MeCab.Tagger('-Owakati') # 形態素解析 print(req.parse(result))実行イメージ
$ python3 mecabFromSearchTweets.py モスバーガー 5実行結果
RT @ sakkurusan : ハンバーガー 店 と いえ ば 札幌 民 「 やはり マクドナルド でしょ 」 旭川 民 「 モス か な 」 小樽 民 「 バーガー キング は いい ぞ 」 函館 民 「 ラッキーピエロ でしょ 」 オホーツク 沿岸 過疎 地 民 「 ハンバーガー ? そんな 店 ねー から もっぱら これ ばかり 食っ て た わ 」 https :/… モスバーガートマト 美味しい RT @ sakkurusan : ハンバーガー 店 と いえ ば 札幌 民 「 やはり マクドナルド でしょ 」 旭川 民 「 モス か な 」 小樽 民 「 バーガー キング は いい ぞ 」 函館 民 「 ラッキーピエロ でしょ 」 オホーツク 沿岸 過疎 地 民 「 ハンバーガー ? そんな 店 ねー から もっぱら これ ばかり 食っ て た わ 」 https :/… で も モス の バーガー は トマト は いっ てる から や だ … 暖かい トマト が 嫌い マン RT @ La _ Gioconda _ leo : 追記 の 追記 周辺 スーパー など ・ 渋谷 ライフ セブン イレブン Family Mart ・ 新宿 セブンイレブンモスバーガーローソンクック Y 丸正 スーパー イトーヨーカドー終わりに
twitterAPIからの検索結果データを形態素解析できるようになりました。pythonのモジュールを使えばこんな少ない行数で書けちゃうってすごいですね。
次はこの形態素解析したデータをもとにして、なにかしたいと思います。
- 投稿日:2019-03-07T20:28:01+09:00
No.043【Python】pass文の定義と使用方法
今回は、pass文ついて書いていきます。
I'll write about "pass contexts"
■ pass文とは
Definition of pass contexts
pass:ヌル操作のため、pass を実行されても、何も起きない。 構文法的には文が必要。コードとしては何も実行したくない場合はPlace holderとして使用可能Python:関数定義のdef文や条件分岐のif文などでは中身の省略は不可 記述する必要があるが、何も実行させたくない場合にpass文を使用する■ pass文とcontinue文の違い
Differences between pass and continue contexts
>>> # while またはfor ループで使われるcontinue文 >>> # それ以降の処理を行われない → continue文の後に記述された処理は実行されない >>> >>> for i in range(5): print(i) if i == 1: continue print("CONTINUE") 0 1 2 3 4>>> # pass文の場合 >>> # pass文の後の記述は、処理が続けて実行される >>> >>> for i in range(5): print(i) if i == 1: pass print("PASS") 0 1 PASS 2 3 4■ 空の関数やクラスを定義
Definition of blank function and class
>>> # 関数またはクラスの定義を先に行い、 >>> # 実装を後回しにする場合にからの関数やクラスを定義することがある >>> # def文の中を何もないとエラーになる>>> # pass文を書くことで、何もしない空の関数の定義が可能 >>> >>> def empty_func(): pass >>> # クラスの定義でも同様である >>> >>> class EmptyClass(): pass>>> # 一行だけの場合はコロンの後に改行せずにそのまま書いても文法上問題ない >>> >>> def empty_func_one_line(): pass >>> class EmptyClassOneLine(): pass■ 空のファイルを作成
Create black files
>> # ファイルを新規作成する場合:with文と書き込みモードwのopen()を使う >>> >>> # 通常:write()メソッドでファイルの内容を書き込む >>> # pass文:空のファイルを作成できる >>> >>> with open("temp/empty.txt", "w"): pass >>> >>> >>> # 1行で書くことも可能 >>> >>> with open('temp/empty.txt', 'w'): pass■ 条件分岐で何も実行しないことを明示
Indicate nothing with conditional branch
>>> # 実装を後回しにsする場合 >>> # 何も実行しないことを明示し、コードの意図が分かりやすくする場合 >>> >>> a =6 >>> >>> if a % 2 == 0: print("Even") else: pass Even■ 例外処理で何もしない場合
The case of Exception handling with nothing
>>> # コード実行時にエラーが発生する時点で、エラーが出力され、処理が終了する >>> >>> def divide(a, b): print(a / b) >>> divide(1, 0) Traceback (most recent call last): File "<pyshell#90>", line 1, in <module> divide(1, 0) File "<pyshell#89>", line 2, in divide print(a / b) ZeroDivisionError: division by zero>>> # tryを使うことで例外を捕捉 >>> >>> # 処理は終了せず、継続する >>> >>> def divide_exception(a,b): try: print(a / b) except ZeroDivisionError as e: print("ZeroDivisionError: ", e) >>> divide_exception(1, 0) ZeroDivisionError: division by zeroSyntaxError: invalid character in identifier >>> # 例外を捕捉した上で何も処理しない場合は、pass文を使用する >>> >>> def divide_exception_pass(a, b): try: print(a / b) except ZeroDivisionError as e: pass >>> divide_exception_pass(1, 0) >>> >>>随時に更新していきますので、
定期的な購読をよろしくお願いします。
I'll update my article at all times.
So, please subscribe my articles from now on.本記事について、
何か要望等ありましたら、気軽にメッセージをください!
If you have some requests, please leave some messages! by You-Tarin

- 投稿日:2019-03-07T20:02:00+09:00
DjangoのAbstractBaseUserでのエラー|Unknown field(s) (username) specified
カスタムユーザーをAbstractBaseUserを使って作成し、adminで表示しようと際のエラー。
これ
[Admin]→[user]→[user detail]
ユーザー詳細の変更をしようとした際に出現エラー内容
FieldError at /admin/appauth/user/XXXXXXXXXXXXXXXXXXXX/change/ Unknown field(s) (username) specified for User. Check fields/fieldsets/exclude attributes of class MyUserAdmin.Djangoでカスタムユーザーモデルを利用しようした際に「えーいなんのこっちゃ精神」でAbstractBaseUserを使った際にちょっとつまずいた。
したかったことは、Adminページでusernameをfieldsetsで表示すること。
class User(AbstractBaseUser, PermissionsMixin):
ググると、stackoverflowでmodelの型関係かと思ったが違った。appauth(任意)/models.pyusername = models.CharField( _('username'), max_length=150, blank=True, null=True, unique=True, help_text=_( 'Required. 150 characters or fewer. Letters, digits and @/./+/-/_ only.'), validators=[username_validator], error_messages={ 'unique': _("そのユーザーネームはすでに存在しています。"), }, )blankとか,nullとかをごにょごにょしてみたが、どうも違う。
Djangoのドキュメントを読みましょう
抜粋:
You should also define a custom manager for your user model. If your user model defines username, email, is_staff, is_active, is_superuser, last_login, and date_joined fields the same as Django's default user, you can just install Django's UserManager; however, if your user model defines different fields, you'll need to define a custom manager that extends BaseUserManager providing two additional methods:Djangoのdefault userでusernameとか新たに定義したい時はUserManagerを使って、違うfieldとして定義しましょう、的な。
私もよく読めてないので、一度読み返します。
解決策
とりあえず、別物として定義。
拡張して定義するのが正解だと思うけど認証をメールを使ってそれをusernameとしていることがあるので一時的にこれで対処.
(一度勉強し直す必要アリ)appauth(任意)/models.pyuser_name = models.CharField( #usernameをuser_nameに変更 _('username'), max_length=150, blank=True, null=True, unique=True, help_text=_( 'Required. 150 characters or fewer. Letters, digits and @/./+/-/_ only.'), validators=[username_validator], error_messages={ 'unique': _("そのユーザーネームはすでに存在しています。"), }, )これで、
appauth(任意)/admin.py. @admin.register(User) class MyUserAdmin(UserAdmin): fieldsets = ( (None, {'fields': ( 'user_name')}),とかで一旦は解決

- 投稿日:2019-03-07T19:02:13+09:00
Openpyxlを使って、エクセルのマージ作業を自動化したときに躓いたポイント
※2018年の6月くらいにメモっていたのですが、今更ながら投稿し忘れていたので遅れて投稿。
2.5.1~2.5.4あたりのVLのものを使っていたと思いますが、もはや環境も残っていないため不明です。
少し古いopenpyxlのため情報も古い可能性がありますが、許してくださいませ。背景・はじめに
私のプロジェクトでは、さまざまな大人達の都合もあって、
テストの項目書などをいちいちエクセルで毎回毎回作成していました。
この報告書は、一種の職人芸によって作られていたのですが、
この崇高な作業も、openpyxl様のおかげで、ほぼ自動化されていました。
そこで今回は、自動化で躓いたポイントを書きたいと思います。1. 関数で参照される値を取得する
やり方
値を参照する場合、はdata_only=Trueを設定しましょう。
以下は、indirect関数で値を読み込んでいるセルから、"数値"を参照する場合の例です。inwb = load_workbook(line.replace('\n',''),data_only=True) inws = inwb['sheetname'] print(inws.cell(1,1).value)出力
100逆に数式をそのまま参照したい場合は、workbookを読み込む際、デフォルトのままにするとよいです。
inwb = load_workbook(line.replace('\n','')) inws = inwb['sheetname'] print(inws.cell(1,1).value)出力
=INDIRECT($B4&"!H2")2. セルのマージと、書式の設定
やり方
マージをするときは、merge_cells を使います。
また、罫線やテキストの配置などは、cell単位でいろいろとできるようです。ここで注意が1点。
マージした後のセルに罫線を引いたりする場合は、すべてのセルに線を引く必要があります。
文字の位置なども指定があれば、↓のようにまとめて設定すると楽だと思います。#セルのスタイル変更用の関数 from openpyxl.styles import Border, PatternFill, Font, Alignment def set_styles(set_cell): set_cell.alignment = ( wrap_text = True, #行の折り返し horizontal = 'general', #中央ぞろえ vertical = 'top' #上ぞろえ ) set_cell.border = Border(top=thin, left=thin, right=thin, bottom=thin) #罫線 set_cell.fill = PatternFill(fill_type='solid', fgColor='FFFDDFD0') #塗りつぶし #セルのマージ処理 outputws.merge_cells(ROW_START, COL_START, ROW_END, COL_END) #マージした範囲に、スタイルを適用する。 for i in range(ROW_START, ROW_END): for j in range(COL_START, COL_END): set_styles(outputws.cel(i, j))その他 気が付いた注意事項
行の追加の機能 (insert_rows()やinsert_cols()) という便利機能もあるのですが、これはうまく使えずあきらめました。
行の追加自体はできるのですが、"スタイル"などは行の追加とともにずれてはくれません。なので結局使わずじまいでした。ということで、行の追加を使いたい場合は、実装の際、テキストの入力処理と整形する処理を分離して、
スタイル設定などは最後にまとめてやるような工夫が必要かもしれません。その他 参考・役に立ったもの
Python openpyxlでExcelを操作:
https://qiita.com/tftf/items/07e4332293c2c59799d1
公式?
http://openpyxl.readthedocs.io/en/stable/index.html
※webの記事は古いものが混じっているみたいです。
旧版だと大変だったものが最新版だと楽に実装できるようになっているものもあります。
非互換もありますので、細かなスタイルの設定などなど、公式の情報を読んだほうがよいと思います。https://openpyxl.readthedocs.io/en/stable/_modules/index.html
こっちのページに、モジュールの一覧があります。とりあえず困ったときに見るのにおすすめ※投稿時点ですと、xlwings ってものあるみたいですね。今から始める方はxlwingsを使うのもよいかもしれません。
https://qiita.com/yniji/items/b38bc312e860027108ac
- 投稿日:2019-03-07T18:22:58+09:00
PuLPでSCIPソルバーを使用する
筆者の環境
MacOS Mojave 10.14.3
Python 3.7.2
PuLP 1.6.9
SCIP 6.0.1PuLPについて
PuLPは線形計画問題を解く Python パッケージです.
install
pip install pulp使い方
PuLPによるモデル作成方法に分かりやすくまとめられています.
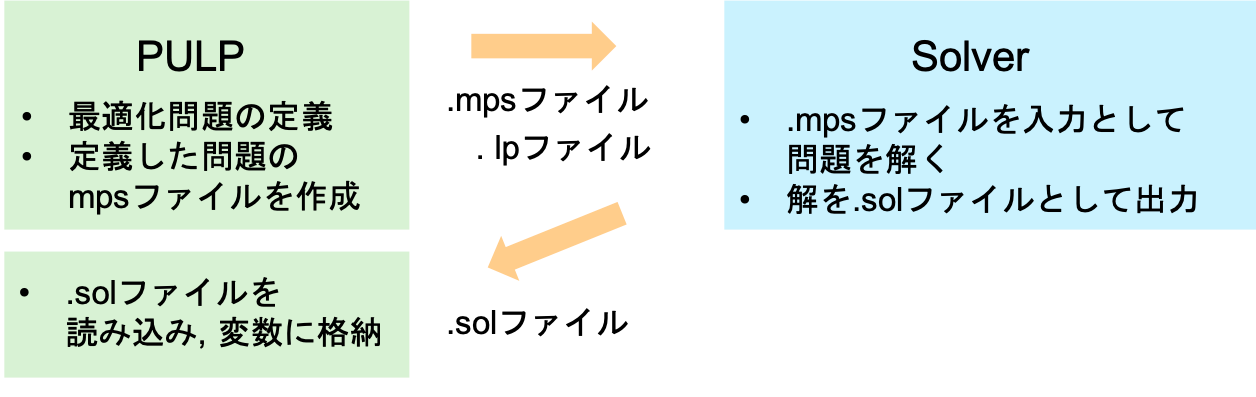
PuLPの処理フロー
このPuLPで使用されるデフォルトのソルバーはCBCです.
別途, GLPK(無料)、SCIP(学術利用は無料, 商用有料), Gurobi(有料)、CPLEX(有料)などをインストールすると使用するソルバーを変更することができます.SCIPについて
SCIPとはドイツのZIBという研究機関が開発しているMIP(mixed integer programming)とMINLP(mixed integer nonlinear programmin)ソルバーです. 非商用利用(Academic License)であれば, 無料で使用することができます.
PuLPでSCIPを使用できるようにする
SCIPのダウンロード
公式サイトのDownloadから
SCIP Optimization Suiteをダウンロードし,README.mdに従って,makeを行います.CMake
mkdir build cd build cmake .. make make test # チェックbrew install cmake でcmakeをインストールできます
Make
make make test # チェックpulpの設定ファイルへSCIPのパスを追記
SCIPzのパスを通す
ln -s scipoptsuite-6.0.1(ダウンロードしたscipパス)/scip/bin/scip /usr/local/bin/scip
pulp.cfg.osxに下を上書きします .pulp.cfg.osx ファイルは
>> import pulp
>> pulp.__path__
で確認できるフォルダにありますScipPath = scip
PulpCbcPathの下に書き込むのがいいでしょう.
これでscipがpulpで使えるようになります.m = LpProblem() solver = pulp.SCIP() m.solve(solver)
- デフォルトで使用できるオプション
- msg (Default: False) Trueにすると実行ログが表示されます
- keepFiles (Default: False) Trueにすると
.lpファイルと.solファイルが保存されます.並列化への対応
UGフレームワークを用いて, SCIPを並列化することができます. そのためには, 以下のような処置を行う必要があります.
# scipoptsuite ディレクトリ上 make PARASCIP=true make ugを実行すると
fscipが使用できるようになります(バイナリファイルは/ug/bin/にできます)パスを通す
ln -s scipoptsuite-6.0.1(ダウンロードしたscipパス)/ug/bin/fscip /usr/local/bin/fscippulpに
fscipの実行パラメータファイルを置く
fscipを実行するにはパラメータ設定ファイルを指定する必要があります.
これはpulpフォルダのsolverdir以下に置くのがいいでしょう.# pulpフォルダ上 mkdir -p solverdir/scip/fscip cp scipoptsuite-6.0.1(ダウンロードしたscipパス)/ug/setting/default.set solverdir/scip/fscip/default.setpulpフォルダは
>> import pulp
>>pulp.__path__
で確認できますpulpの設定ファイル(pulp.cfg.osx)に追記する
FscipPath = fscip FscipParamPath = %(here)s/solverdir/scip/fscip/default.set
PulpCbcPathもしくはScipPathの下がいいでしょう.pulpの
solvers.pyを書き換える
fscipとscipの実行コマンド, ならびに最適化結果ファイルのフォーマットが異なるので
調節する必要があります.solvers.pyのdef initialize周辺とclass SCIP_CMDを以下のように書き換えます.
def initialize
initialize関数内
fscip_pathとfscip_param_pathを追加.try: scip_path = config.get("locations", "ScipPath") except configparser.Error: scip_path = 'scip↓↓↓↓↓↓↓↓
try: scip_path = config.get("locations", "ScipPath") fscip_path = config.get("locations", "FscipPath") fscip_param_path = config.get("locations", "FscipParamPath") except configparser.Error: scip_path = 'scipinitialize返り値
fscip_path,fscip_para_pathを追加return cplex_dll_path, ilm_cplex_license, ilm_cplex_license_signature,\ coinMP_path, gurobi_path, cbc_path, glpk_path, pulp_cbc_path, scip_path↓↓↓↓↓↓↓↓
return cplex_dll_path, ilm_cplex_license, ilm_cplex_license_signature,\ coinMP_path, gurobi_path, cbc_path, glpk_path, pulp_cbc_path,\ scip_path, fscip_path, fscip_param_pathif name == 'main'の何行か下
fscip_pathとfscip_param_pathを追加cplex_dll_path, ilm_cplex_license, ilm_cplex_license_signature, coinMP_path,\ gurobi_path, cbc_path, glpk_path, pulp_cbc_path, scip_path\ initialize(config_filename, operating_system, arch)↓↓↓↓↓↓↓↓
cplex_dll_path, ilm_cplex_license, ilm_cplex_license_signature, coinMP_path,\ gurobi_path, cbc_path, glpk_path, pulp_cbc_path,\ scip_path, fscip_path, fscip_param_path = \ initialize(config_filename, operating_system, arch)
class SCIP_CMD
class SCIP_CMD(LpSolver_CMD): """The SCIP optimization solver""" SCIP_STATUSES = { 'unknown': LpStatusUndefined, 'user interrupt': LpStatusNotSolved, 'node limit reached': LpStatusNotSolved, 'total node limit reached': LpStatusNotSolved, 'stall node limit reached': LpStatusNotSolved, 'time limit reached': LpStatusNotSolved, 'memory limit reached': LpStatusNotSolved, 'gap limit reached': LpStatusNotSolved, 'solution limit reached': LpStatusNotSolved, 'solution improvement limit reached': LpStatusNotSolved, 'restart limit reached': LpStatusNotSolved, 'optimal solution found': LpStatusOptimal, 'infeasible': LpStatusInfeasible, 'unbounded': LpStatusUnbounded, 'infeasible or unbounded': LpStatusNotSolved, } FSCIP_STATUSES = { 'objective value': LpStatusOptimal, 'No Solution': LpStatusInfeasible } def defaultPath(self): return self.executableExtension(scip_path) def __init__(self, keepFiles = 0, msg = 0, threads = None): if threads is None or threads == 1: path = scip_path else: path = fscip_path self.fscip_param_path = fscip_param_path LpSolver_CMD.__init__(self, path, keepFiles, msg) self.threads = threads def available(self): """True if the solver is available""" return self.executable(self.path) def actualSolve(self, lp): """Solve a well formulated lp problem""" print(self.path) if not self.executable(self.path): raise PulpSolverError("PuLP: cannot execute "+self.path) # TODO: should we use tempfile instead? if not self.keepFiles: uuid = uuid4().hex tmpLp = os.path.join(self.tmpDir, "%s-pulp.lp" % uuid) tmpSol = os.path.join(self.tmpDir, "%s-pulp.sol" % uuid) else: tmpLp = lp.name + "-pulp.lp" tmpSol = lp.name + "-pulp.sol" lp.writeLP(tmpLp) if self.path == scip_path: proc = [ self.path, '-c', 'read "%s"' % tmpLp, '-c', 'optimize', '-c', 'write solution "%s"' % tmpSol, '-c', 'quit' ] else: proc = [ self.path, self.fscip_param_path, tmpLp, '-sth', '%d' % self.threads, '-fsol', tmpSol ] proc.extend(self.options) if not self.msg: proc.append('-q') print(' '.join(proc)) if os.path.exists(tmpSol): os.remove(tmpSOl) self.solution_time = clock() subprocess.check_call(proc, stdout=sys.stdout, stderr=sys.stderr) self.solution_time += clock() if not os.path.exists(tmpSol): raise PulpSolverError("PuLP: Error while executing "+self.path) if self.path == scip_path: lp.status, values = self.scip_readsol(tmpSol) elif self.path == fscip_path: lp.status, values = self.fscip_readsol(tmpSol) # Make sure to add back in any 0-valued variables SCIP leaves out. finalVals = {} for v in lp.variables(): finalVals[v.name] = values.get(v.name, 0.0) lp.assignVarsVals(finalVals) if not self.keepFiles: for f in (tmpLp, tmpSol): try: os.remove(f) except: pass return lp.status def scip_readsol(self, filename): """Read a SCIP solution file""" with open(filename) as f: # First line must containt 'solution status: <something>' try: line = f.readline() comps = line.split(': ') assert comps[0] == 'solution status' assert len(comps) == 2 except: raise raise PulpSolverError("Can't read SCIP solver output: %r" % line) status = SCIP_CMD.SCIP_STATUSES.get(comps[1].strip(), LpStatusUndefined) if not status == LpStatusOptimal: return status, dict() # Look for an objective value. If we can't find one, stop. try: line = f.readline() comps = line.split(': ') assert comps[0] == 'objective value' assert len(comps) == 2 float(comps[1].strip()) except: raise PulpSolverError("Can't read SCIP solver output: %r" % line) # Parse the variable values. values = {} for line in f: try: comps = line.split() values[comps[0]] = float(comps[1]) except: raise PulpSolverError("Can't read SCIP solver output: %r" % line) return status, values def fscip_readsol(self, filename): """Read a SCIP solution file""" with open(filename) as f: try: line = f.readline() line = f.readline() comps = line.split(': ') except: raise 'Problem is unknonw states' status = SCIP_CMD.FSCIP_STATUSES.get(comps[0].strip(), LpStatusUndefined) # Look for an objective value. If we can't find one, stop. if comps[0] == 'objective value': float(comps[1].strip()) # Parse the variable values. values = {} for line in f: try: comps = line.split() values[comps[0]] = float(comps[1]) except: raise PulpSolverError("Can't read SCIP solver output: %r" % line) return status, values SCIP = SCIP_CMDこれで並列化バージョンの
SCIPを使用することができます.
ただ,SCIPが出力する.solファイルの形式がcbcなどと違うため, 上のコードでは拾いきれていないエラーがあるかもしれません.
- 投稿日:2019-03-07T17:46:02+09:00
pythonでファイルを16進ダンプする
やったこと
pythonで読み込んだファイルを16進ダンプして、ついでにASCIIコード(基本的には英数字のみ)を表示するようにした。
pythonのプログラムなので、基本的にOSに依存しないはずです(CTFやる際にちょっと便利)。C:\Users\User\Desktop>python read_bin.py ChromeSetup.exe ['read_bin.py', 'ChromeSetup.exe'] is exist #### BINARY TO HEX DUMP - USING PYTHON3.6 #### Offset 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F Encode to ASCII 000000 4d 5a 90 00 03 00 00 00 04 00 00 00 ff ff 00 00 MZ.............. 000010 b8 00 00 00 00 00 00 00 40 00 00 00 00 00 00 00 ........@....... 000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 000030 00 00 00 00 00 00 00 00 00 00 00 00 18 01 00 00 ................ 000040 0e 1f ba 0e 00 b4 09 cd 21 b8 01 4c cd 21 54 68 ........!..L.!Th 000050 69 73 20 70 72 6f 67 72 61 6d 20 63 61 6e 6e 6f is.program.canno 000060 74 20 62 65 20 72 75 6e 20 69 6e 20 44 4f 53 20 t.be.run.in.DOS. 000070 6d 6f 64 65 2e 0d 0d 0a 24 00 00 00 00 00 00 00 mode....$....... 000080 04 62 8c 75 40 03 e2 26 40 03 e2 26 40 03 e2 26 .b.u@..&@..&@..& 000090 f4 9f 13 26 49 03 e2 26 f4 9f 11 26 3c 03 e2 26 ...&I..&...&<..& 0000A0 f4 9f 10 26 58 03 e2 26 7b 5d e1 27 51 03 e2 26 ...&X..&{].'Q..& 0000B0 7b 5d e7 27 64 03 e2 26 7b 5d e6 27 51 03 e2 26 {].'d..&{].'Q..&以下プログラム
import sys import os.path import binascii import string def check_file_provided(): # 指定した先にファイルが存在するかをチェック default_path = "./test.exe" if (len(sys.argv) < 2): print("") print("Warning") print("Correct Usage : python read_bin.py <file_name>") print("") print("call {0}".format(default_path)) if not os.path.isfile(default_path): print("") print("Error - The file provided does not exist") print("") sys.exit(0) else: print("{} is exist".format(default_path)) print("") return default_path else: print("") print("{} is exist".format(sys.argv)) print("") return sys.argv[1] def read_bytes(filename, chunksize=8192): # バイナリファイルをバイトごとに抽出 try: with open(filename, "r+b") as f: while True: chunk = f.read(chunksize) if chunk: for b in chunk: #print(type(b)) #print(b) yield b else: break except IOError: print("") print("Error - The file provided can't open") print("") sys.exit(0) def is_character_printable(s): ## asciiの英数字・記号の文字列かどうかを判別し、真偽値を返します。 if s < 126 and s >= 33: return True def print_headers(): ## とりあえずフォーマット的なものを表示する print("") print("#### BINARY TO HEX DUMP - USING PYTHON3.6 ####") print("") print("Offset 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F Encode to ASCII") print("") def validate_byte_as_printable(byte): ## ascii 文字列化をチェック. asciiでなければ '.' を返す ## if is_character_printable(byte): return byte else: return 46 def main(): file_path = check_file_provided() memory_address = 0 ascii_string = "" print_headers() ## 読み込んだバイナリファイルを表示し終わるまでループします for byte in read_bytes(file_path): ascii_string = ascii_string + chr(validate_byte_as_printable(byte)) if memory_address%16 == 0: print(format(memory_address, '06X'),end = '') print(" " + hex(byte)[2:].zfill(2), end='') elif memory_address%16 == 15: print(" " + hex(byte)[2:].zfill(2),end='') print(" " + ascii_string) ascii_string = "" else: print(" " + hex(byte)[2:].zfill(2), end='') memory_address = memory_address + 1 if __name__ == '__main__': main()ちょっと解説
16進ダンプ
バイナリデータとよばれるものをバイト単位で16進に表示させたものです。表記方法としては、一番左のカラムがアドレス、真ん中が16進、右が文字列として表示されることが多いです。
pythonでバイナリから16進の変換方法は、対象ファイルを
rbまたはr+bで開きます。
※r+で対象ファイルに対して読み込み兼書き込みで開く為、rbとr+bは同じではありません。with open(filename, "r+b") as f: while True: chunk = f.read(chunksize) if chunk: for b in chunk:このとき、
chunkには以下のようなバイナリデータを取得することが出来ます。b'MZ\x90\x00\x03\x00\x00\x00\x04\x00\x00\x00\xff\xff....
for b in chunk:にてインスタンスbに対して1バイトごとにデータを渡しています。何故かはわかりませんがこのとき、インスタンスbはint型で10進数のデータを保持している状態になります。(今後の課題とさせて頂きます。)幸いなことに、int型で1バイトのバイナリデータを取得できたので
hex(byte)で10進数のデータを16進として表示します。
ASCIIコード
ASCIIコードとはアルファベットや数字、記号などの文字コードの一つで、各文字に割り当てられた番号と対応した対応表があります。
例えば、10進で77だとASCIIに対応する文字はMになります。
今回作成した16進ダンプでは、取得した1バイト分のデータ(int型の10進)が対応表33~126までのうちのどれかに対応すれば文字として表示、それ以外であれば.として表示するようになっています。if s < 126 and s >= 33:最後に宣伝
技術書典6にてサークル名味噌トントロ定食で「バイナリ解析入門」を出典する予定です。CTF形式でradare2を使ったでバイナリを解析の内容となります。趣味でやってる分野になりますがバイナリ解析に興味を持ってくれると嬉しいです。
- 投稿日:2019-03-07T17:46:02+09:00
pythonでバイナリファイルを16進ダンプ & バイナリファイルを画像化
やったこと
pythonで読み込んだファイルを16進ダンプして、ついでにASCIIコード(基本的には英数字のみ)を表示するようにした。
pythonのプログラムなので、基本的にOSに依存しないはずです(CTFやる際にちょっと便利)。C:\Users\User\Desktop>python read_bin.py ChromeSetup.exe ['read_bin.py', 'ChromeSetup.exe'] is exist #### BINARY TO HEX DUMP - USING PYTHON3.6 #### Offset 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F Encode to ASCII 000000 4d 5a 90 00 03 00 00 00 04 00 00 00 ff ff 00 00 MZ.............. 000010 b8 00 00 00 00 00 00 00 40 00 00 00 00 00 00 00 ........@....... 000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 000030 00 00 00 00 00 00 00 00 00 00 00 00 18 01 00 00 ................ 000040 0e 1f ba 0e 00 b4 09 cd 21 b8 01 4c cd 21 54 68 ........!..L.!Th 000050 69 73 20 70 72 6f 67 72 61 6d 20 63 61 6e 6e 6f is.program.canno 000060 74 20 62 65 20 72 75 6e 20 69 6e 20 44 4f 53 20 t.be.run.in.DOS. 000070 6d 6f 64 65 2e 0d 0d 0a 24 00 00 00 00 00 00 00 mode....$....... 000080 04 62 8c 75 40 03 e2 26 40 03 e2 26 40 03 e2 26 .b.u@..&@..&@..& 000090 f4 9f 13 26 49 03 e2 26 f4 9f 11 26 3c 03 e2 26 ...&I..&...&<..& 0000A0 f4 9f 10 26 58 03 e2 26 7b 5d e1 27 51 03 e2 26 ...&X..&{].'Q..& 0000B0 7b 5d e7 27 64 03 e2 26 7b 5d e6 27 51 03 e2 26 {].'d..&{].'Q..&以下プログラム
import sys import os.path import binascii import string def check_file_provided(): # 指定した先にファイルが存在するかをチェック default_path = "./test.exe" if (len(sys.argv) < 2): print("") print("Warning") print("Correct Usage : python read_bin.py <file_name>") print("") print("call {0}".format(default_path)) if not os.path.isfile(default_path): print("") print("Error - The file provided does not exist") print("") sys.exit(0) else: print("{} is exist".format(default_path)) print("") return default_path else: print("") print("{} is exist".format(sys.argv)) print("") return sys.argv[1] def read_bytes(filename, chunksize=8192): # バイナリファイルをバイトごとに抽出 try: with open(filename, "r+b") as f: while True: chunk = f.read(chunksize) if chunk: for b in chunk: #print(type(b)) #print(b) yield b else: break except IOError: print("") print("Error - The file provided can't open") print("") sys.exit(0) def is_character_printable(s): ## asciiの英数字・記号の文字列かどうかを判別し、真偽値を返します。 if s < 126 and s >= 33: return True def print_headers(): ## とりあえずフォーマット的なものを表示する print("") print("#### BINARY TO HEX DUMP - USING PYTHON3.6 ####") print("") print("Offset 00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F Encode to ASCII") print("") def validate_byte_as_printable(byte): ## ascii 文字列化をチェック. asciiでなければ '.' を返す ## if is_character_printable(byte): return byte else: return 46 def main(): file_path = check_file_provided() memory_address = 0 ascii_string = "" print_headers() ## 読み込んだバイナリファイルを表示し終わるまでループします for byte in read_bytes(file_path): ascii_string = ascii_string + chr(validate_byte_as_printable(byte)) if memory_address%16 == 0: print(format(memory_address, '06X'),end = '') print(" " + hex(byte)[2:].zfill(2), end='') elif memory_address%16 == 15: print(" " + hex(byte)[2:].zfill(2),end='') print(" " + ascii_string) ascii_string = "" else: print(" " + hex(byte)[2:].zfill(2), end='') memory_address = memory_address + 1 if __name__ == '__main__': main()ちょっと解説
16進ダンプ
バイナリデータとよばれるものをバイト単位で16進に表示させたものです。表記方法としては、一番左のカラムがアドレス、真ん中が16進、右が文字列として表示されることが多いです。
pythonでバイナリから16進の変換方法は、対象ファイルを
rbまたはr+bで開きます。
※r+で対象ファイルに対して読み込み兼書き込みで開く為、rbとr+bは同じではありません。with open(filename, "r+b") as f: while True: chunk = f.read(chunksize) if chunk: for b in chunk:このとき、
chunkには以下のようなバイナリデータを取得することが出来ます。b'MZ\x90\x00\x03\x00\x00\x00\x04\x00\x00\x00\xff\xff....
for b in chunk:にてインスタンスbに対して1バイトごとにデータを渡しています。何故かはわかりませんがこのとき、インスタンスbはint型で10進数のデータを保持している状態になります。(今後の課題とさせて頂きます。)幸いなことに、int型で1バイトのバイナリデータを取得できたので
hex(byte)で10進数のデータを16進として表示します。
ASCIIコード
ASCIIコードとはアルファベットや数字、記号などの文字コードの一つで、各文字に割り当てられた番号と対応した対応表があります。
例えば、10進で77だとASCIIに対応する文字はMになります。
今回作成した16進ダンプでは、取得した1バイト分のデータ(int型の10進)が対応表33~126までのうちのどれかに対応すれば文字として表示、それ以外であれば.として表示するようになっています。if s < 126 and s >= 33:最後に宣伝
技術書典6にてサークル名味噌トントロ定食で「バイナリ解析入門」を出典する予定です。CTF形式でradare2を使ったでバイナリを解析の内容となります。趣味でやってる分野になりますがバイナリ解析に興味を持ってくれると嬉しいです。
おまけ(バイナリファイルを画像化する)
以下ソースコードと出力された画像
import os import numpy as np from PIL import Image import cv2 # バイナリデータ読み込み def read_bin(filename): arr = [[]] data = [] n = 0 with open(filename, 'rb') as f: byte = f.read() #num = prime_factors(len(byte)) num = 1000 print(len(byte)) j = 0 cnt = 0 for i in byte: data.append(int(i)); if j % num == 0 : arr.append(data) data = [] cnt+=1 #print(cnt) if cnt == 1001: break j+=1 arr = arr[2:] print(len(arr)) return arr # 画像書き込み def write_img(arr): im = np.array(arr) pil_img = Image.fromarray(im) cv2.imwrite('test.jpg', im) # 素因数分解より画像サイズを求める def prime_factors(n): i = 2 small_factors = 1 factors = [] while i * i <= n: if n % i: i += 1 else: n //= i factors.append(i) if n > 1: factors.append(n) print(factors) for i in range(len(factors)-1): small_factors = small_factors * factors[i] if small_factors < factors[len(factors)-1]: print(small_factors) return small_factors elif len(factors) > 2: print(factors[0] * factors[len(factors)-1]) return (factors[0] *factors[len(factors)-1]) else : return factors[0] def main(file_path): arr = read_bin(file_path) write_img(arr) if __name__ == '__main__': file_path = './test.exe' main(file_path)
機械学習させたい!!

- 投稿日:2019-03-07T17:40:49+09:00
InfoGAN/ss-InfoGANの理解メモ
はじめに
メモなのでかなりポンコツ、かつ敬語ではありません。失礼します。
もし間違いがあれば、ご意見ご指導をいただければ幸いに存じます。InfoGAN
- 普通のGANは$z$(ノイズ)を何かを生成する際に種として使う
- だが$z$は表現として絡まっていて、いじってもなかなか人が理解できるように変化をアウトプットに反映されない(Radford, 2016のようにうまくいく方が珍しい)。
- そこで$z$の一部を$c$(latent variable)とする。完全にノイズであるzに反して、$c$はdatasetの「何かの特徴」に対応すると想定されるように設計される。例えば、データセットをMNISTとする。生成する画像の推知の値そのものを捉えたいとしたら、$c_1$を10カテゴリーの離散変数にする。文字の太さや傾きなどを捉えたいとしたら、$c_2$, $c_3$を連続変数とする。そんな風に$c=c_1, c_2, c_3...c_n$を設定する。
- それ以上何もしなければ、$c$は訓練の過程で無視される
- なので、生成されるもの$G(z, c)$に対し、$c$と関係を持たせたい。
- そこでMutual Informationを使う。

- 損失関数に組み込んで、Mutual Informationを最大化したい

- Mutual Information についてこの記事にはぜひ参照したい
- かくかくしかじかでMutual Informationがこんな風に書き換えられる $$I(X;Y) = D_{KL} \Big( P_{XY}(x,y)||P_X(x)P_Y(y) \Big)\,$$
- $P(x)$と$P(y)$が独立した時だけ$ = P(x, y)$ ---->>$I(X;Y)$が最小化される
- 大まかな構図は以上
- ところが$I(c; G(z,c))$を求めるのが難しいらしい。$P(c|x)$を必要とするから。 <---------------ここちょっと理解がまだ完全ではない、要再考
- そこで$P(c|x)$に近似するための分布$Q(c|x)$を作る
- Variational Information Maximizationという手法で$I(c; G(z,c))$のLower boundにあたる$L_I(G, Q)$を求める。
- 詳細は見てないので、何とも言えないが、多分役割としてはVAEの中のやつに近いかな?
- 最終的に実装するとき損失関数がこうなる:

ss-InfoGAN
- 大体上と同じ
- 一部だけreal sampleのラベルとして$y$が提供される。それを利用して生成するものの質の向上を図る。
- 変更点として$c$を$c_{ss}$ semi-supervised code、と$c_{us}$ unsupervised codeに分かれる。$c_{ss} \cup c_{us} =c$
- 最大化するMutual Information(延いてはLower bound)も二つになる
- $X$がreal samplesで、$\tilde{X}$がgenerated samples。
- 要するに$I(C_{ss};X)$を最大化することで、$Q_{ss}$を訓練する時、ラベルのあるデータ(x, y)で$Q_{ss}$にラベル$y$の意味を学習させる。
同時に$I(C_{ss};\tilde{X})$を最大化することで、$G$が間接的に$y$に含まれる情報を学習する。それで少数のラベルでもGがラベルの情報を取り入れることが出来る。
最終的に損失関数がこうなる
上のInfoGANのやつと合わせてさらにこうなるのではないかと
$$\min_{G, Q_{us}, Q_{ss}}\max_{D}V(D, G)- \lambda_1L_{I}(G, Q_{us}) - \lambda_2(L^1_{IS}(Q_{ss}) + L^2_{IS}(G, Q_{ss})) $$
さらに下の
(11)と(12)についてはこういう理解もできる:
- まずは$C_{ss}$を上の円(z)とし、$X$を左下の円(x)とし、$\tilde{X}$を左下の円(y)とする。
- となると(11)では、
- $H(C_{ss})$は上の円全体にあたる。
- $I(C_{ss}; X)$が黄色+灰色にあたる。
- $I(C_{ss}; \tilde{X})$が水色+灰色にあたる。
- $H(C_{ss}|X, \tilde{X})$が緑色にあたる。
- $I(C_{ss};X; \tilde{X})$が灰色にあたる。
- これで(11)は成立する
- (12)では$I(X; \tilde{X})$がピンク色にあたり、成立する。
(13)では$X$と$\tilde{X}$両者とも$C_{ss}$から独立したと仮定する(式8により)
- $I(X;\tilde{X}|C_{ss})$の理解については、上の円$H(C_{ss})$を情報にずらすと想像する
- ずらしてると、ある瞬間を境に、灰色の部分がなくなる。これが$X$と$\tilde{X}$両者とも$C_{ss}$から独立したということにあたる。
- 最終的には(14)になる
それ以降は字面通りに理解できる
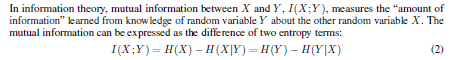
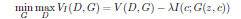
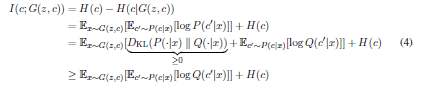
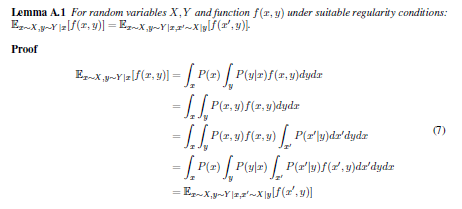
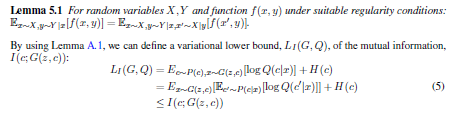
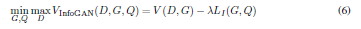
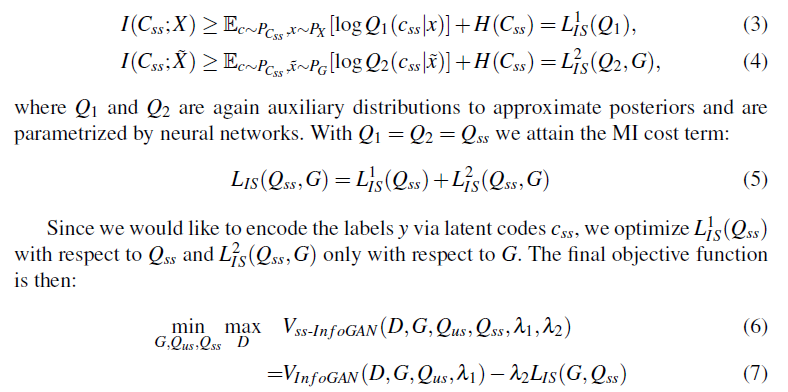
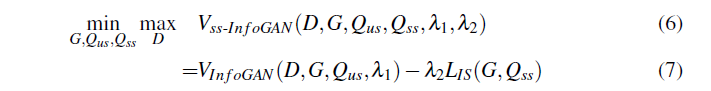


- 投稿日:2019-03-07T16:25:08+09:00
オフライン環境下にあるAnacondaに仮想環境を構築するお話
オフライン環境下にあるAnacondaに仮想環境を構築するお話
(他にもいい方法ありましたらぜひコメント下しい)
- 環境前提
- ・オフラインPCにはAnacondaが導入されている
・USBメモリやDVD等のメディアやネットワーク経由でオフライン環境下にある
PCへのファイル転送はできる
・オンライン環境のPCが別途あり、Anacondaが使える
- 試したオフラインPCのスペック
- ・Windows 10 Pro 1709
・conda 4.5.0事前準備
オフライン環境下で仮想環境を構築するにあたり、インストールしたいパッケージファイルが必要になります。まずはオンライン環境下にあるPCで、同様の仮想環境を構築し、依存関係も考慮した必要なパッケージのリストやパッケージファイルそのものを入手します。
conda create -n [新しい仮想環境の名前] py=3.X.X conda install [必要なパッケージを指定] conda list でインストールされたパッケージのリストが確認できますanacondaフォルダの pkgs フォルダ内にインストールしたパッケージ(tar.bz2などで圧縮されたもの)が格納されています。他の仮想環境構築時に取得されたパッケージファイルもあるので、作成日時やリストと照らし合わせて必要なパッケージをピックアップします。
それらパッケージをオフライン環境下にあるPCに、USBメモリやネットワーク経由で転送できれば、
事前準備は完了です。オフライン環境下での仮想環境の構築
1. 仮想環境の作成
conda create -n new_env --offlineここでは new_env という名前で作成しました。clone の方もできないかと試したものの、オンライン環境が必要なのか、なぜか通信エラーで上手くいきませんでした。
※ 実行エラーとなったコマンド例
conda create -n new_env --clone [既存環境の指定]
conda create -n new_env --clone [既存環境の指定] --offline
2. 仮想環境が作成されたことを確認
conda env list新たに作成した new_env がリストにあれば◎
3. 仮想環境 new_envをアクティブに
activate new_envアクティブのやり方は環境に合わせて実施ください
source activate new_env
conda activate new_env4. new_env環境にあるインストール済みパッケージの確認
conda listと、やってみるとこの段階ではパッケージが1つもない空の状態でした。
試しに 「python」とコマンドを叩いてみると普通に起動しますが、これは「base」環境のpython呼び出されているだけのようです。5. Pythonのインストール
ここから事前に準備したパッケージファイルを使い、インストールしていきます。
まずは Python をインストールcd [パッケージファイルを集めたフォルダ] conda install python-3.X.X-XXXXXX.tar.bz26. その他パッケージのインストール
以降、ものぐさな私は下記コマンドでとりあえず一括インストールしています。
このやり方で特に問題は発生していませんが、厳密に検証したこともないので
ここは各々のご判断で。jupyter notebookとかはこの一括インストールで問題なく動いてくれています。for /f %i in ('dir /A-d /B *.tar.bz2') do conda install %i↑ dirコマンドで取得した .tar.bz2 のファイル一覧 を1行ずつ conda install の引数に指定するwindowsのコマンドです。Linuxでいう xargs みたいなものです
7. インストールされたパッケージの確認
conda list で確認してみると、インストールされたパッケージがずらっと表示されるはずです。
必要なパッケージが正しくインストールされていることを確認したら、
オフライン環境での構築はこれにて完了です。
- 投稿日:2019-03-07T16:13:45+09:00
NLTKを使えるようにする
nltk.download('punkt')
でやろうとして、[nltk_data] Error loading punkt: [nltk_data] getaddrinfo failed>
というエラーが出たので、色々調べた。
会社のプロキシをAnaconda promptで通した後、
python -m nltk.downloader -u https://raw.githubusercontent.com/glowskir/nltk_data/7b505ff1f858a489e5b2d879573bdaaa8ef06732/index.xml punkt
を入力したら、動くようになった。
- 投稿日:2019-03-07T15:12:44+09:00
Python の Generator や Iterator を使って Coroutine を実装 (失敗)
Generator を使って Coroutine を実装
Python の Coroutine は便利そうな仕組みだが、いかんせん構文糖がきつすぎて何をやってるのか分かりにくいので、プリミティブな構文で再実装してみます。Python asyncio で取り上げた、一秒ずつ待ちながら数を数えるカウンターを Generator だけで作るとこうなります。
import asyncio # 1 から max までの数を一秒ずつ数える。Generator 版 def counter_coroutine_generator(max): count = 0 while count < max: count += 1 print(count) # 以下の行は yield from asyncio.sleep(1) のように書ける。 sleep_generator = asyncio.sleep(1) sleep_future = next(sleep_generator) yield sleep_future return '数え終わりました' counter = counter_coroutine_generator(3) # Generator 関数の返り値は Generator オブジェクト print(f'counter is {counter}') loop = asyncio.get_event_loop() result = loop.run_until_complete(counter) # Generator 関数の return で返した物は loop.run_until_complete の返り値になる。 print(result) loop.close()実行結果
counter is <generator object counter_coroutine_generator at 0x1045de888> 1 2 3 数え終わりましたこのように Coroutine を async def ではなく、Generator を使って書くと、Coroutine では
await asyncio.sleep(1)のように書いた部分が Generator では
sleep_generator = asyncio.sleep(1) sleep_future = next(sleep_generator) yield sleep_futureのようになりました。ここはさらに短く
yield from asyncio.sleep(1)と書けます。さて、なぜ Coroutine の処理を待つawaitが Generator の次の値を受け取り(next) 処理を中断する (yield) となるかちょっと自分も分かっていません。多分ここで loop に処理を返し loop が一秒後に処理を再開されるのでは無いかと想像しています。next(sleep_generator)には一秒後に処理を再開される Future が入っています。ここで、トリッキーなのは、
counter_coroutine_generatorには Generator なのにreturn文がある事です。Generator 内の return はraise StopIteration(value)と同じ意味になります。PEP 380 -- Syntax for Delegating to a Subgenerator これも何となく美しく無い文法です。Generator を使って Iterator を実装
さて、次に
yieldも使わずにさらにプリミティブに Coroutine を実装してみます。Awaitable Objects によると、Iterator を返す__await__という関数を実装すると Coroutine と互換性のあるオブジェクトを作る事が出来ます。import asyncio # 1 から max までの数を一秒ずつ数える。Iterator 版 class Counter(): def __init__(self, max): self.count = 0 self.max = max def __iter__(self): return self def __await__(self): return self def __next__(self): print('__next__ is called') self.count += 1 if self.count <= self.max: print(self.count) # await をプリミティブに実行してみたつもりだが失敗 sleep_generator = asyncio.sleep(1) sleep_future = next(sleep_generator) return sleep_future else: raise StopIteration('数え終わりました') loop = asyncio.get_event_loop() counter = Counter(3) print(f'counter is {counter}') loop.set_debug(True) result = loop.run_until_complete(counter) print(result) loop.close()実行結果
counter is <__main__.Counter object at 0x100b7fb00> __next__ is called 1 (ここで処理が止まってしまう。。。)残念ながら上手く動きませんでした。なんと不思議なことにデバッガで適当にブレークしながらだとちゃんと動きます。なので惜しい所まで行っているようです。興味本位な実用性の無いコードですが、もしも私の間違いを発見したら教えてくださると嬉しいです。
参考
- 投稿日:2019-03-07T14:38:42+09:00
Python, LINE APIを使ってbotを作成する
目的
Pythonを用いて、LINE botを作成する
イメージは、「~~公式LINEアカウント」みたいな感じ前提
- Python環境をインストール済み(今回はv3.6.5)
- LINE Developersに登録済み
- Herokuに登録済み
- GitHubに登録済み
参考
- LINE API
- LINE SDK(Python)
- PythonとLINE APIとHerokuで自動返信BOTを作る【Python編】
- LINEのBot開発 超入門(前編) ゼロから応答ができるまで
- LINE Messaging API を使ってLINEにメッセージ送信/メッセージ返信する
- HerokuとGitHubの連携
- 【LINE Notify】 PythonでLINEの メッセージと画像を送信する方法
- 【初心者向け】Gitってなに?①まず流れを理解する(コードなし)
- 【Python初心者! -LINE Botでオウム返し編-】
流れ
- LINE Developersに登録して、トークンなどを取得
- トークン、LINE SDKを用いて応答する仕組みを作成
- 管理はGitHubで、サーバはHeroku
- デプロイ後、動作確認
- 最終的なコードはこちら
コード書いてみた(修正前)
今回使用するコードです。クリックで開きます。
(ページ後半で修正済みコードもあります。)
main.py...メッセージが入力されたら返信する。
account_response.py...入力された内容によって、返信メッセージを選択する。
main.py
main.py# -*- coding: utf-8 -*- import os import sys from account_response import Response from flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) app = Flask(__name__) #Herokuの変数からトークンなどを取得 channel_secret = os.environ['LINE_CHANNEL_SECRET'] channel_access_token = os.environ['LINE_CHANNEL_ACCESS_TOKEN'] if channel_secret is None: print('Specify LINE_CHANNEL_SECRET as environment variable.') sys.exit(1) if channel_access_token is None: print('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.') sys.exit(1) line_bot_api = LineBotApi(channel_access_token) handler = WebhookHandler(channel_secret) #LINEからのWebhook @app.route("/callback", methods=['POST']) def callback(): # リクエストヘッダーから署名検証のための値を取得 signature = request.headers['X-Line-Signature'] # リクエストボディを取得 body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # 署名を検証し、問題なければhandleに定義されている関数を呼び出す。 try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' #LINEでMessageEvent(普通のメッセージを送信された場合)が起こった場合 #reply_messageの第一引数のevent.reply_tokenは、イベントの応答に用いるトークンです。 #第二引数には、linebot.modelsに定義されている返信用のTextSendMessageオブジェクトを渡しています。 @handler.add(MessageEvent, message=TextMessage) def handle_message(event): #入力された内容(event.message.text)に応じて返信する line_bot_api.reply_message( event.reply_token, TextSendMessage(text=os.environ[Response.getResponse(event.message.text)]) ) if __name__ == "__main__": app.run(host="0.0.0.0", port=int(os.getenv("PORT", 5000))
account_response.py
account_reponse.py# -*- coding: utf-8 -*- class Response: """ dic: Herokuに登録してある変数 key以外の入力があったら、count+=1する (Heroku上で1~4までのkeyに対応する変数を登録済み) """ dic={"会社概要":"COMPANY", "事業内容":"SERVICE", "採用情報":"CAREER", "コマンド":"COMMAND", "おはよう":"5", "こんにちは":"5", "こんばんは":"5", "こんにちわ":"6", "こんばんわ":"6" } count=0 def getResponse(self,text): if self.count >= 4: self.count = 0 self.count += 1 for _dic in self.dic: if _dic == text: return self.dic[text] return self.countとりあえずコードはかけたので、デプロイしてみよう。
GitHubからHerokuへデプロイする
Herokuでアプリ作成後、DeployタブからGitHubを接続させる。
他の記事だとほとんどHeroku Git(Heroku CLI)を使っているが、今回はGitHubを使う。
自動デプロイを有効にしておく。
接続は無事に出来たので、実際にGitHubにアップロードしてデプロイしてみよう。
適当なファイルをアップロードしてコミットする。
Herokuでちゃんとデプロイできてるかな。
! No default language could be detected for this app.
HINT: This occurs when Heroku cannot detect the buildpack to use for this application automatically.
See https://devcenter.heroku.com/articles/buildpacks
! Push failedばっちりエラー出てますね、、、調べると以下が原因だった。
原因 Buildpackの未設定
対策 Herokuコンソール>Settings>Buildpacks 「Add Buildpack」で「Python」を選択、追加した
どの言語をデプロイするか指定しないといけなかったのか。
では改めてアップロードする。-----> App not compatible with buildpack: https://buildpack-registry.s3.amazonaws.com/buildpacks/heroku/python.tgz
More info: https://devcenter.heroku.com/articles/buildpacks#detection-failure
! Push failedまた安定のエラーがでましたね。
いろいろ調べると、Herokuサポートに書いてありました。(和訳後引用)
Heroku は、ルートディレクトリにrequirements.txtまたはsetup.pyファイルが含まれている場合、そのアプリケーションを自動的にPythonアプリケーションとして認識します。ということで原因が分かりました。
原因 対策 requirements.txtの欠如 requirements.txtをルートに追加 ちなみに内容はこんな感じです。
適宜増やしたし減らしたりしてください。
(バージョンは自分の実行環境に合わせてください。)requirements.txtFlask==1.0.2 line-bot-sdk==1.8.0 urllib3==1.23Pythonのバージョンは指定なしだと
python-3.6.8らしい。
今回はpython-3.6.5なので、次のファイルも一緒にアップロードしておきます。runtime.txtputhon-3.6.5また、HerokuのDyno設定をするため以下ファイルも必要です。
Procfileweb: python main.py実際にアプリを実行してみる
「Settings」タブの"Domains and certificates" 欄からURLをクリックすると
Not Found
The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
なぜだか分からず、、、Heroku CLIからログをみてみよう。
Herokuプロキシ設定・・・プロキシ使っている人は設定忘れずに。エラーat=error code=H10 desc="App crashed" method=POST path="/callback" host={Myapp}.herokuapp.com request_id=***** fwd="203.104.146.155" dyno= connect= service= status=503 bytes= protocol=https詳細をみるため
heroku logs --tailを実行した。エラーログ2019-03-02T01:14:36.783940+00:00 app[web.1]: File "main.py", line 64 2019-03-02T01:14:36.783966+00:00 app[web.1]: 2019-03-02T01:14:36.783967+00:00 app[web.1]: ^ 2019-03-02T01:14:36.783968+00:00 app[web.1]: SyntaxError: unexpected EOF while parsingあ、
main.pyの最後の部分で)が1個抜けてる、、、→修正しました。
よし。今度こそ!エラーログ2019-03-02T01:25:48.353864+00:00 app[web.1]: TextSendMessage(text=os.environ[res.getResponse(event.message.text)]) 2019-03-02T01:25:48.353872+00:00 app[web.1]: TypeError: getResponse() missing 1 required positional argument: 'text'またエラーですが、
getResponse()の引数が足りないらしい。
これインスタンス生成されてないと出ますよねー→インスタンス生成されてませんでした!!コード書いてみた(修正後)
というわけでコード修正しました。
これでエラーなく動くようになりました。main.py# -*- coding: utf-8 -*- import os import sys from account_response import Response from flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) app = Flask(__name__) -----追加----- #インスタンス生成 res=Response() ---ここまで--- #Herokuの変数からトークンなどを取得 channel_secret = os.environ['LINE_CHANNEL_SECRET'] channel_access_token = os.environ['LINE_CHANNEL_ACCESS_TOKEN'] if channel_secret is None: print('Specify LINE_CHANNEL_SECRET as environment variable.') sys.exit(1) if channel_access_token is None: print('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.') sys.exit(1) line_bot_api = LineBotApi(channel_access_token) handler = WebhookHandler(channel_secret) #LINEからのWebhook @app.route("/callback", methods=['POST']) def callback(): # リクエストヘッダーから署名検証のための値を取得 signature = request.headers['X-Line-Signature'] # リクエストボディを取得 body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # 署名を検証し、問題なければhandleに定義されている関数を呼び出す。 try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' #LINEでMessageEvent(普通のメッセージを送信された場合)が起こった場合 #reply_messageの第一引数のevent.reply_tokenは、イベントの応答に用いるトークンです。 #第二引数には、linebot.modelsに定義されている返信用のTextSendMessageオブジェクトを渡しています。 @handler.add(MessageEvent, message=TextMessage) def handle_message(event): #入力された内容(event.message.text)に応じて返信する line_bot_api.reply_message( event.reply_token, TextSendMessage(text=os.environ[res.getResponse(event.message.text)]) ) if __name__ == "__main__": app.run(host="0.0.0.0", port=int(os.getenv("PORT", 5000)))--> ) 足したaccount_response# -*- coding: utf-8 -*- class Response: """ dic: Herokuに登録してある変数 key以外の入力があったら、count+=1する (Heroku上で1~4までのkeyに対応する変数を登録済み) """ dic={"会社概要":"COMPANY", "事業内容":"SERVICE", "採用情報":"CAREER", "コマンド":"COMMAND", "おはよう":"5", "こんにちは":"5", "こんばんは":"5", "こんにちわ":"6", "こんばんわ":"6" } count=0 def getResponse(self,text): if self.count >= 4: self.count = 0 self.count += 1 for _dic in self.dic: if _dic == text: return self.dic[text] return str(self.count) -->intからstrへ 記事には書いてないが、intで返すなと怒られました、、まとめ
はじめて触って動かしてみると楽しかった。
簡単な動作だけですが、実際に動かすとなると相応時間と苦労がありました。次はYoutubeで動画がアップロードされたら、LINEでユーザーに通知できるものを作ろう!




- 投稿日:2019-03-07T13:34:39+09:00
RDKitを使って化学構造式からlogSを予測する
やりたいこと
- 欲しい物性値になるような化学構造を知りたい
- 具体的には、官能基を変えたらどうなるかな~?を事前に知りたい
- 化学構造式を与えたら予測値を返してくれるモデルを作る
※RDKitのインストールはほかの記事を参考にして下さい。
問題設定
分子構造から溶解度を予測するモデルを作る
下準備
RDKitのサイトに溶解度(logS:100gの水にその物質が溶けた量[g]をwとしたとき、$\log_{10}w$ の値。無限に解けても上限は2)の情報のついたsdfファイル(solbility_test.sdf, solbility_train.sdf)があるので、ダウンロードして適当な場所に置いておく。以下ではpythonのファイルと同じ場所にあるとする。
モジュールのインポートなど。特にここでは説明はいらないだろう。
RDKit_solbility.pyfrom rdkit import Chem from rdkit.Chem import Descriptors from rdkit.ML.Descriptors import MoleculeDescriptors from rdkit.Chem import PandasTools import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline %config InlineBackend.figure_format='retina' plt.style.use('seaborn-darkgrid') c_cycle=("#ea5415","#005192","#ffdf00","#1d7a21","#88593b","#737061")SDFファイルをDataFrameに取り込む
この記事の本体。
RDKit_solbility.pydef sdf_to_df(input_sdf): df_sdf = PandasTools.LoadSDF(input_sdf, molColName='Structure').set_index('NAME').drop(['ID','SOL_classification'], axis=1) names = df_sdf.index mols = [ mol for mol in Chem.SDMolSupplier(input_sdf)] descLists = [desc_name[0] for desc_name in Descriptors._descList] desc_calc = MoleculeDescriptors.MolecularDescriptorCalculator(descLists) data = [desc_calc.CalcDescriptors(mol) for mol in mols] df_desc = pd.DataFrame(data, columns=descLists, index=names) df = pd.concat([df_sdf, df_desc], axis=1) return df1行目(df_sdf = ):LoadSDFでsdfファイルをDataFrameとして読み込む。読み込んだsdfファイルに複数の化学構造が含まれていればすべて読み込んでくれる。分子構造以外も全部読んでくれて、ここではlogSなども読み込んでいる。いらない情報はdrop()で落としている。必要に応じて。
4行目(mols = ):sdfファイルに含まれる分子のリスト
5行目(descLists = ):RDKitで出力できるdescriptorのリストを取得
6行目(desc_calc = ):descListsに含まれるdescriptorを計算してくれるインスタンス(でいいのかな?)
7行目(data = ):各分子ごとにdescriptorを計算する
8行目(df_desc):descriptorの計算結果をDataFrameに変換
10行目:読み込んだsdfファイルのDataFrame(分子構造とlogSが含まれている)とdescriptorのDataFrameを結合このDataFrameをdf.head()でチラ見すると、
こんな感じになる。機械学習する
読み込んでしまえば、あとは通常の機械学習の手続きだけど参考までに書いておく。
SDFファイルの読み込み
RDKit_solvility.pydf = sdf_to_df('./solubility.train.sdf').dropna() df_test = sdf_to_df('./solubility.test.sdf').dropna() target_keys = ['SOL'] y_df = df.loc[:, target_keys].astype(float) x_df = df.loc[:, [desc_name[0] for desc_name in Descriptors._descList]] y_test = df_test.loc[:, target_keys].astype(float) x_test = df_test.loc[:, [desc_name[0] for desc_name in Descriptors._descList]] features = x_df.columns samples = x_df.indexx_df, y_dfにそれぞれ訓練データ、x_test, y_testはテストデータ。
手持ちのデータでわざわざ訓練データとテストデータを分けて保存しておくことはないと思うので、通常は読み込んだあとにtrain_test_splitなどを使って分けることになる。回帰
RandomForestを使う。
RDKit_solvility.pyfrom sklearn.ensemble import RandomForestRegressor reg = RandomForestRegressor(n_estimators=100, max_depth=500, random_state=0) reg.fit(x_df, y_df.values[:,0])回帰の本体。結果が芳しくなければパラメタや他の回帰方法を試せばいい。
可視化1
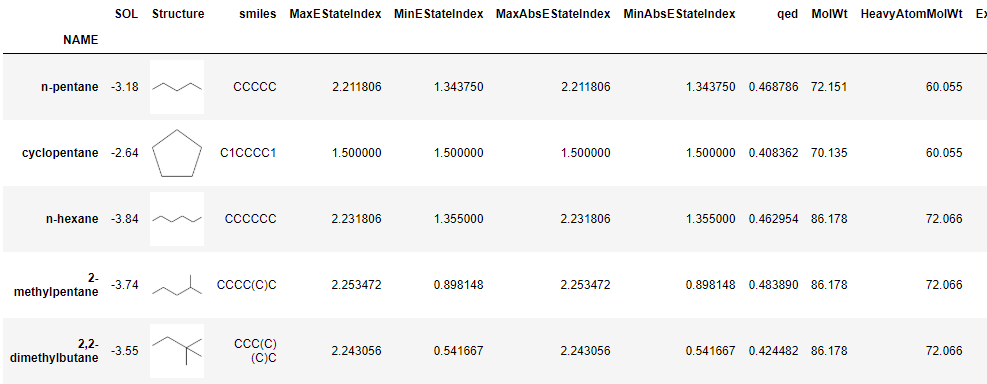
重要なDescriptorの可視化。全部のDescriptorを表示するようにするとえらいことになるので、
maxFeaturesかminImportanceで表示を制限している。RDKit_solvility.pyfrom sklearn.metrics import r2_score def plot_feature_importances(features, model, maxFeatures=-1, minImportance=-1, text=''): plt.figure(figsize=(16,10)) plt.rcParams["font.size"] = 16 df = pd.DataFrame({'features':features, 'importances':model.feature_importances_}) df = df.set_index('features') #sort df = df.sort_values('importances', ascending=True) #normalize func_norm = lambda x: x/max(x) df = df.apply(func_norm) #minImportace df = df.applymap(lambda x:np.nan if abs(x)<minImportance else x).dropna(axis=0, how='all') if maxFeatures>0: df = df[-maxFeatures:] n_features = len(df.index) plt.barh(range(n_features), df['importances'], align='center') plt.yticks(np.arange(n_features), df.index) plt.xlabel(text + ' Feature importance (Random Forest)') plt.ylabel('Feature') plot_feature_importances(features, reg, minImportance=0.01)可視化2
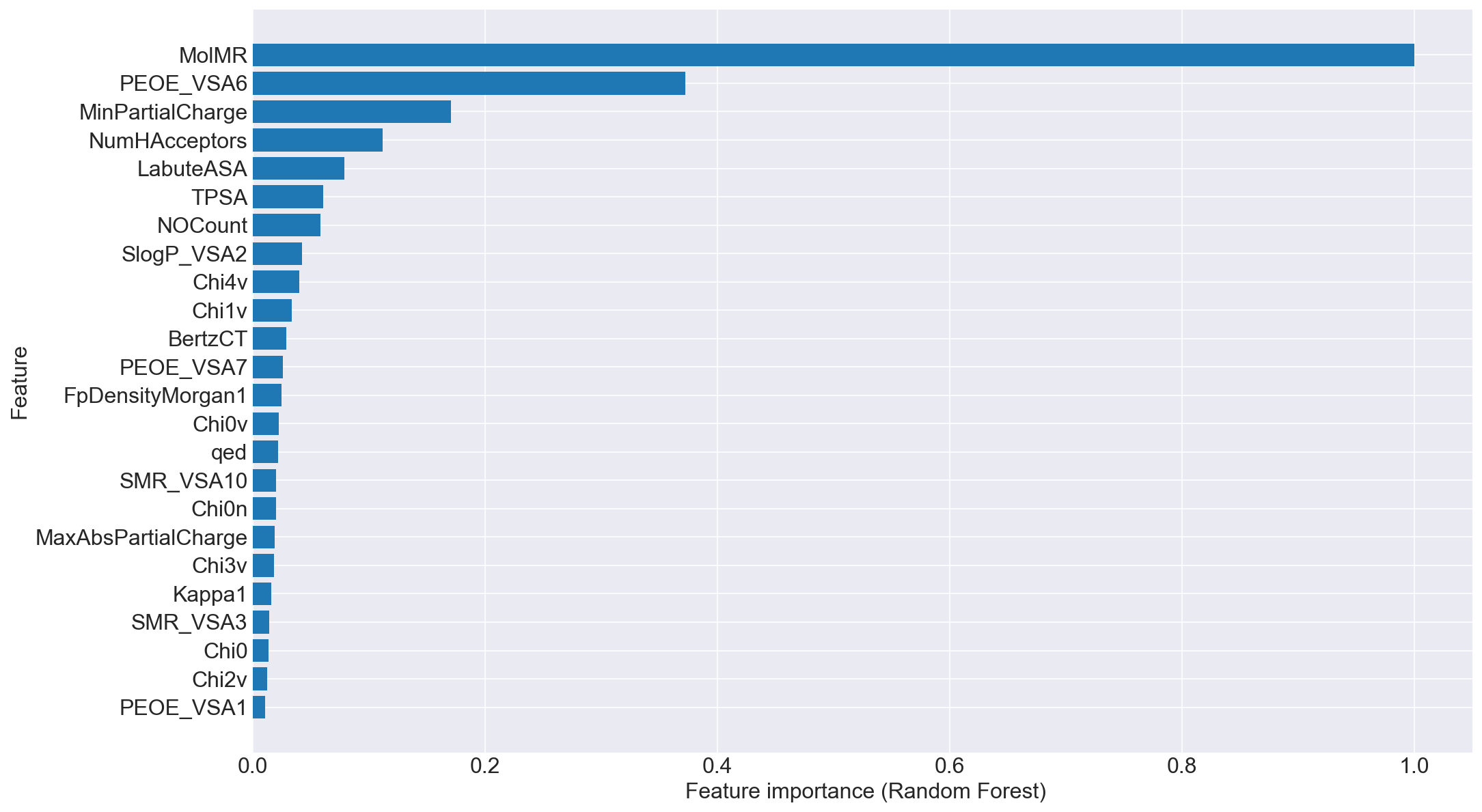
observe-predictでプロット、$R^2$を表示する。
RDKit_solvility.pyytests = [] ypreds = [] ytests = y_test.values[:,0] ypreds = reg.predict(x_test) plt.figure(figsize=(16,9)) plt.rcParams["font.size"] = 18 plt.xlabel('observe') plt.ylabel('predict') r2 = r2_score(np.array(ytests), np.array(ypreds)) plt.plot(ytests, ypreds, 'o', ms=15, color=c_cycle[0], alpha=0.3, label='$R^2$ = '+str(r2)) plt.legend()結果
重要Descriptor
…アカーーーン!!!
これだと「logSを予測するにはlogPが重要です」と言っているようなもの。
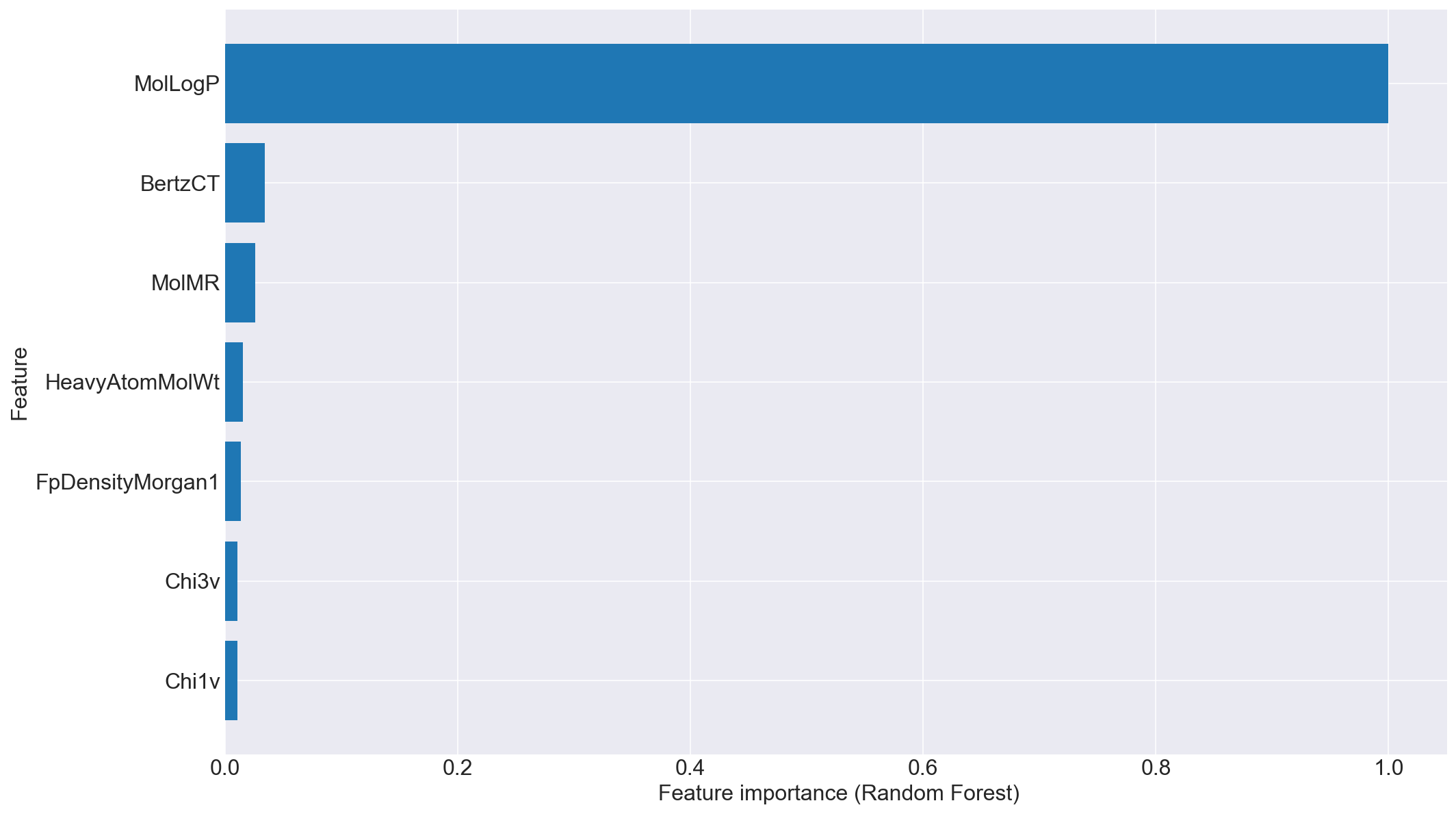
logSとlogPは負の相関があるのはほぼ自明なので、構造から計算するlogPの精度が高いとほぼ同値のことを言っていることになってしまう。まあ、「化学構造入れたらlogSを予測できるモデルを作る」というならそれでもいいんだけれども。さすがに面白くないので、logPのデータを落としてもう一回。
RDKit_solvility.pyx_df = x_df.drop('MolLogP', axis=1) x_test = x_test.drop('MolLogP', axis=1)
MR,分子屈折率?が重要?
他には部分電荷や表面積の一種など。
何が来ても意外だけど、意外な結果であった。R^2
おお、意外と高い。
でも、値として1違うと溶解量が1桁違うので、実用的なモデルにするには$R^2=0.999$くらい必要になるのではないだろうか…
- 投稿日:2019-03-07T12:15:55+09:00
がんばる人のための画像検査機 -可視化の改良-
地味に盛り上がっている「ディープラーニングによる画像の異常検知」に関する投稿の続きです。
今回は、可視化部分を改良します。
これまでの動き
以前に、以下の記事を投稿しました。
ここで使われている「DOC」という技術は学習済のモデルを利用できるため、
精度と速度を天秤にかけて自由に変えることができます。従って、軽量な
モデルを選べば、ラズパイなどのモバイル端末でも動かせます。
さらに、@koshian2 さんから以下の投稿がありました。
https://qiita.com/koshian2/items/b4c4ffda99c07a1ac6b8Triplet lossを使った高速の異常検知です。こちらの内容はまだしっかり理解
していないのですが、高速かつ精度良く異常検知できるとのことで、素晴らしい
内容だと思います。
さらに、DOCの高速化について@PINTO さんから以下の投稿がありました。
https://qiita.com/PINTO/items/0a52062cb6ebe9ef5051TensorFlow Lite等を駆使してDOC+ラズパイで15FPSという
とてつもない数値をたたき出しています。こちらも工場の生産ラインでは
なくてはならない「高速化」の技術で、素晴らしい内容です。DOCの課題点
DOCの課題点をまとめておきます。
速度が遅い
もはやTriplet lossを使った高速の異常検知には敵わないのですが、DOCを
高速化すると、速度と精度はどうなるのかを改めて明記したいと思います。可視化が弱い
これは、DOCの課題点というより私の課題点といえます。
DOCの論文では可視化は言及されておらず、以前の記事では私がテキトーに
設計した可視化の部分が「低速」で、かつ「異常部分がうまく表示できない」
という問題を抱えていました。そこで、今回は可視化部分をしっかり設計して改良します。
DOCの高速化
まずは、DOCの高速化について説明します。
実は、既にがんばる人のための画像検査機の記事で高速化は実施済です。
高速化の中身が気になる方はこちらをご覧ください。Colaboratoryでは計測していなかったため、改めて速度と精度(AUC)を記載します。
速度(msec/1枚) AUC 以前の記事 140 0.9 高速化後 20 0.88 今回は、若干精度が下がってしまいました。これは学習データの組み合わせで多少変動します。
ただ、以下の調整を行うと精度が改善されることがあります。精度を出したい人はチャレンジしてみてください。
- 「重みを凍結する層」を変更してみる
- DOCの出力を最終層ではなく手前の層に変更する
特に、DOCの出力層を手前にすることで、精度だけではなく速度も若干
改善されるのでおススメです。AUCが0.02くらい改善することもあります。DOCの可視化
使い方
こちらにリポジトリをアップした(DOC_Visulaization)のですが、weights_visual.h5が
重すぎて欠如しています。ラズパイで動かす際は、自分で学習させたweights_visual.h5と
その他のモデル(合計4つ)をご用意ください。使い方は以前と同じです。
- 「DOC_Visualization」をラズパイ上に持ってくる。
- USBにウェブカメラを接続し、DOC_Visualization/main.pyを実行する。
- モデルの展開に2分くらいかかります。
- ウェブカメラのリアルタイム映像が描画されたら「s」キーを押してください。(Sキーの反応が悪いです。辛抱強く押してください。)
- ヒートマップが出力されたら、リアルタイム描画が開始されています。
- リアルタイム描画はラズパイをフル稼働させるため、5分くらいすると熱暴走してフリーズします。長期稼働する際は、冷却しながら動かしてください。
Grad-CAMでは難しい
ここからは可視化の中身を説明します。
以前の記事ではGrad-CAMで可視化を行いました。
ご覧のように成功しているとは言い難いです。
Grad-CAMは本来、出力が相互に関係してくるソフトマックス関数であることを
念頭において作られているはずです。従って、DOCのような独立した出力に
適用してもうまくいく確率は低いです。そこで、今回は昔からあるAutoEncoderによる可視化を試みました。
AutoEncoder
AutoEncoderの説明はここではしませんが、気になる方は以下のリンクをご覧ください。
https://deepage.net/deep_learning/2016/10/09/deeplearning_autoencoder.html
https://qiita.com/fukuit/items/2f8bdbd36979fff96b07AutoEncoderでは、情報を圧縮し、圧縮された情報を基に復元を行います。
学習データと似たような画像であれば、きちんと復元されますが、
全然似ていない画像の場合、似ていない箇所だけが復元されない
可能性が高いです。今回はその性質を利用します。※DOCは、DOC=CNN+LOF(KNN) という形でCNNとLOF等を合わせたもの指します。
説明の便宜上、DOC'=CNNという形で説明します。ここでは CNN=MobileNETV2 です。DOC' + Decoder
全体像は以下のとおりです。
AutoEncoderはEncoder部とDecoder部から成っており、Encoder部はDOC'にて
既に特徴量抽出が行われているため、DOC'をEncoder部とします。一方、Decoder部は新たに設け、画像の復元をさせるために学習データで学習させます。
なお、今回はLOFによるスコアの算出はカットしています。ヒートマップは以下の手順で生成します。
まず、Original画像をDOC'に投げます。そして、以下のように復元画像
(Reconstruction)を取得します。Original(96×96×3) → DOC'(1280) → Decoder → Reconstruction(96×96×3)
次に、以下のようにOriginal とReconstruction の差の絶対値をとります。
Difference = |Original - Reconstruction|最後に、DifferenceをOriginalと合成してHeatMapを得ます。
コード
通常用
通常のDecoderを設計しました。
Kerasで書くと以下のとおりです。import keras from keras.layers import BatchNormalization, Activation from keras.layers import Reshape, UpSampling2D, Convolution2D from keras.initializers import he_normal def convolutional_decoder(): model = keras.Sequential() model.add(Dense(input_dim=(feature_out), output_dim=1024)) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Dense(128*12*12)) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(Reshape((12,12,128))) model.add(UpSampling2D((2,2)))#24*24 model.add(Convolution2D(128,5,5,border_mode='same', kernel_initializer=he_normal())) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(UpSampling2D((2,2)))#48*48 model.add(Convolution2D(256,5,5,border_mode='same', kernel_initializer=he_normal())) model.add(BatchNormalization()) model.add(Activation('relu')) model.add(UpSampling2D((2,2)))#96*96 model.add(Convolution2D(3,5,5,border_mode='same', kernel_initializer=he_normal())) model.add(Activation('sigmoid'))#out_shape=(96,96,3) return modelモバイル用
こちらを参考にMobileNETライクなDecoderを設計しました。
上記に比べ描画性能は劣りますが、速度は2倍速いです。import keras from keras.layers import BatchNormalization, Activation, Input from keras.layers import Reshape, UpSampling2D, Conv2D from keras.layers import ReLU, DepthwiseConv2D, ZeroPadding2D from keras.initializers import he_normal def _depthwise_conv_block(inputs, pointwise_conv_filters, alpha, depth_multiplier=1, strides=(1, 1), block_id=1): pointwise_conv_filters = int(pointwise_conv_filters * alpha) if strides == (1, 1): x = inputs else: x = ZeroPadding2D(((0, 1), (0, 1)), name='conv_pad_%d' % block_id)(inputs) x = DepthwiseConv2D((3, 3), padding='same' if strides == (1, 1) else 'valid', depth_multiplier=depth_multiplier, strides=strides, use_bias=False, name='conv_dw_%d' % block_id)(x) x = BatchNormalization(name='conv_dw_%d_bn' % block_id)(x) x = ReLU(6., name='conv_dw_%d_relu' % block_id)(x) x = Conv2D(pointwise_conv_filters, (1, 1), padding='same', use_bias=False, strides=(1, 1), name='conv_pw_%d' % block_id)(x) x = BatchNormalization(name='conv_pw_%d_bn' % block_id)(x) return ReLU(6., name='conv_pw_%d_relu' % block_id)(x) def convolutional_decoder(): inputs = Input(shape=(feature_out,)) x = Dense(1024)(inputs) x = BatchNormalization()(x) x = Activation('relu')(x) x = Dense(128*12*12)(x) x = BatchNormalization()(x) x = Activation('relu')(x) x = Reshape((12,12,128))(x) x = UpSampling2D((2,2))(x)#24*24 x = _depthwise_conv_block(x, 256, 0.5, 1,block_id=1) x = _depthwise_conv_block(x, 256, 0.5, 1,block_id=2) x = UpSampling2D((2,2))(x)#48*48 x = _depthwise_conv_block(x, 128, 0.5, 1,block_id=3) x = _depthwise_conv_block(x, 64, 0.5, 1,block_id=4) x = UpSampling2D((2,2))(x)#96*96 x = Conv2D(3,(5,5),padding='same')(x) x = Activation('sigmoid')(x) return Model(inputs,x)学習コード
学習コードは以下のとおりです。
train = model.predict(X_train_s)#X_train_sは元の画像,modelはDOC' test_s = model.predict(X_test_s)#X_test_sは元の画像 test_b = model.predict(X_test_b)#X_test_bは元の画像 decoder = convolutional_decoder() # initiate Adam optimizer opt = keras.optimizers.adam(lr=0.0001, decay=1e-6, amsgrad=True) # Let's train the model using Adam with amsgrad decoder.compile(loss='mse', optimizer=opt) hist = decoder.fit(train,X_train_s, validation_data=(test_s,X_test_s), epochs=10, verbose=1, batch_size=128)またHeatMapのコードは以下のとおりです。
from keras.preprocessing.image import array_to_img import cv2 def plot_heat(x): original = x.reshape((1,96,96,3)) re = model.predict(original) #re = ms.transform(re) re = decoder.predict(re) map_ = np.abs(re-original).reshape((96,96,3)) jet = cv2.applyColorMap(np.uint8(255 * map_), cv2.COLORMAP_JET) # モノクロ画像に疑似的に色をつける jet = cv2.cvtColor(jet, cv2.COLOR_BGR2RGB) # 色をRGBに変換 jet = (np.float32(jet) + original.reshape((96,96,3))*255 / 2) # もとの画像に合成 plt.imshow(array_to_img(jet), cmap='gray') plt.title("HeatMap") plt.axis("off") plt.show()なお、ラズパイの描画はOpenCVでやっているため、違う書き方になっています。
ラズパイ用のコードは付録に載せておきます。ただし、未だにここに書いた
クセが残っておりますが、ご了承ください。Fashion-MNISTによる実験
実験方法
今回使用するデータは、以前と同様に以下のように振り分けました。
個数 クラス数 備考 リファレンスデータ 6,000 8 スニーカーとブーツを除く ターゲットデータ 6,000 1 スニーカー テストデータ(正常) 1,000 1 スニーカー テストデータ(異常) 1,000 1 ブーツ 結果
結果を見てみましょう。Decoderは通常用を使用しました。
・ スニーカー(正常)の画像
ご覧のようにほとんどが青い画像になっています。
・ ブーツ(異常)の画像
最初に、うまくいった例です。
ご覧のようにブーツの「口」あるいは「かかと」の部分が赤くなっています。
直感的に合っているような気がします。次に失敗した例です。
これらは異常スコアが最も高い、つまり最も異常な画像のベスト3です。
従って、復元が全くうまくいかず、ほとんどが赤くなっています。次に、異常スコアが最も低い、つまり最も「正常に近い」と判断された
異常画像のベスト3です。
ご覧のようにほとんど青くなっています。
これらはスニーカーに酷似したブーツなので、仕方がないような気もします。ラズパイによる実験
実験方法
前と同じようにナットを学習させました。
Decoderはモバイル用としました。学習させた画像はこんな感じ。
そして、正常品として以下を用意しました。
異常品としてマジックで落書きしたナットを用意しました。
結果
・正常品
・異常品
若干左側が黄色くなっているのが分かるでしょうか。
解像度を下げたせいで分かりにくくなっています。正直、モバイル用のDecoderは微妙です。
もう少し設計を見直せばうまくいく気もしますが、通常用のDecoderを使った方が
スマートな気がします。なお、通常用のDecoderを使うとラズパイで1FPSになります。実際の使い方としては、普段は可視化を切っておいて、異常スコアが閾値を
上回ったときだけ、通常用のDecoderで可視化するのが良いと思います。まとめ
- DOC'にDecoderを付けることで、DOCの可視化部分が改良できました。
- ラズパイで可視化を実行すると、速度は5FPS → 2FPS(あるいは1FPS)に下がりますが、普段は可視化機能を切ることで速度低下を抑えることができます。
付録
最後に、ラズパイ用のコードを載せておきます。
import cv2 import time import os import numpy as np from sklearn.neighbors import LocalOutlierFactor from sklearn.preprocessing import MinMaxScaler from keras.models import model_from_json from keras import backend as K threshold = 2 m_input_size, m_input_size = 96, 96 path = "pictures/" if not os.path.exists(path): os.mkdir(path) model_path = "model/" if os.path.exists(model_path): # LOF #print("LOF model building...") #x_train = np.loadtxt(model_path + "train.csv",delimiter=",") #ms = MinMaxScaler() #x_train = ms.fit_transform(x_train) # fit the LOF model #clf = LocalOutlierFactor(n_neighbors=5) #clf.fit(x_train) # Visual model print("Visual Model loading...") model_visual = model_from_json(open(model_path + 'model_visual.json').read()) model_visual.load_weights(model_path + 'weights_visual.h5') # DOC print("DOC Model loading...") model_doc = model_from_json(open(model_path + 'model_doc.json').read()) model_doc.load_weights(model_path + 'weights_doc.h5') print("loading finish") else: print("Nothing model folder") def main(): camera_width = 352 camera_height = 288 fps = "" message = "Push [p] to take a picture" result = "Push [s] to start anomaly detection" flag_score = False picture_num = 1 elapsedTime = 0 score = 0 score_mean = np.zeros(10) mean_NO = 0 cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FPS, 2) cap.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height) time.sleep(1) while cap.isOpened(): t1 = time.time() ret, image = cap.read() image=image[:,32:320] if not ret: break # take a picture if cv2.waitKey(1)&0xFF == ord('p'): cv2.imwrite(path+str(picture_num)+".jpg",image) picture_num += 1 # quit or calculate score or take a picture key = cv2.waitKey(1)&0xFF if key == ord("q"): break if key == ord("s"): flag_score = True if key == ord("p"): cv2.imwrite(path + str(picture_num) + ".jpg", image) picture_num += 1 if flag_score == True: img = cv2.resize(image, (m_input_size, m_input_size)) img_ = np.array(img).reshape((1,m_input_size, m_input_size,3))/255 test = model_doc.predict(img_) #test = test.reshape((len(test),-1)) #test = ms.transform(test) #score = -clf._decision_function(test) #visualization re = model_visual.predict(test) map_ = np.abs(re-img_).reshape((96,96,3)) jet = cv2.applyColorMap(np.uint8(255*map_), cv2.COLORMAP_JET) #jet = cv2.cvtColor(jet, cv2.COLOR_BGR2RGB) jet = cv2.addWeighted(jet,0.2,img,0.8,2.2) image = cv2.resize(jet, (camera_height, camera_height)) # output score if flag_score == False: cv2.putText(image, result, (camera_width - 350, 100), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, cv2.LINE_AA) else: #score_mean[mean_NO] = score[0] mean_NO += 1 #if mean_NO == len(score_mean): # mean_NO = 0 #if np.mean(score_mean) > threshold: #red if score is big # cv2.putText(image, "{:.1f} Score".format(np.mean(score_mean)),(camera_width - 230, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 1, cv2.LINE_AA) #else: # blue if score is small # cv2.putText(image, "{:.1f} Score".format(np.mean(score_mean)),(camera_width - 230, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 1, cv2.LINE_AA) # message cv2.putText(image, message, (camera_width - 285, 15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv2.LINE_AA) cv2.putText(image, fps, (camera_width - 164, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, ( 255, 0 ,0), 1, cv2.LINE_AA) cv2.imshow("Result", image) # FPS elapsedTime = time.time() - t1 fps = "{:.0f} FPS".format(1/elapsedTime) cv2.destroyAllWindows() if __name__ == '__main__': main()
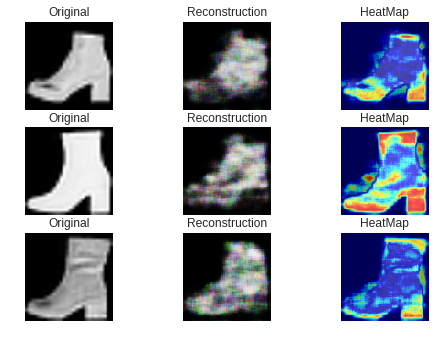
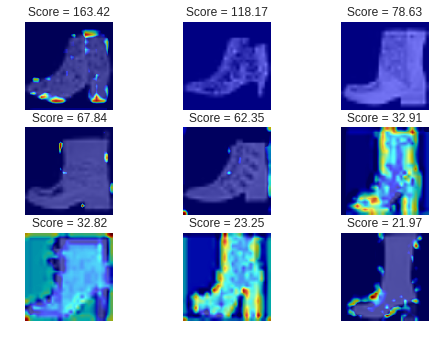
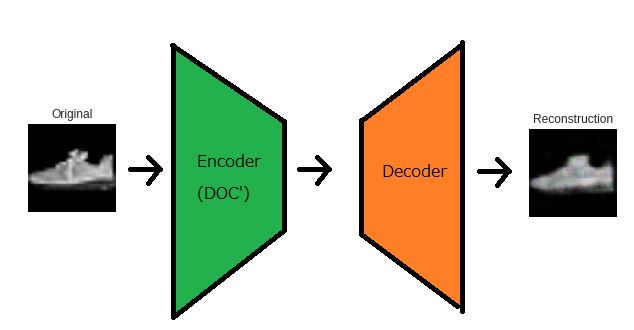

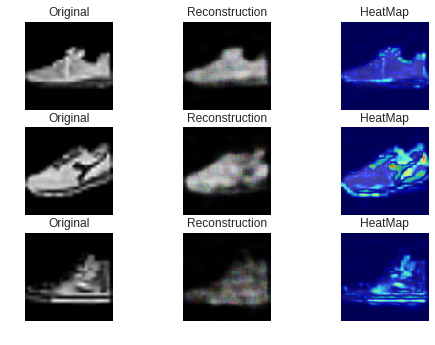
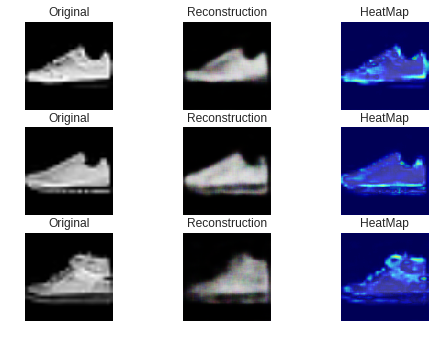
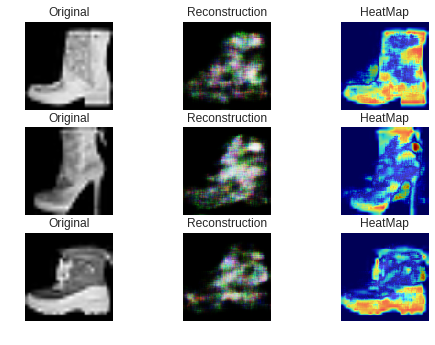
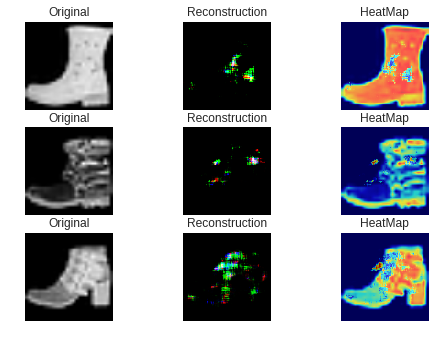




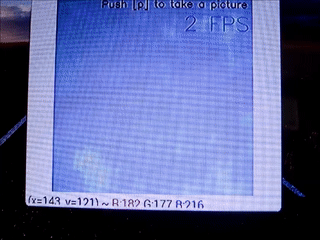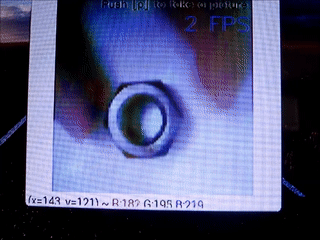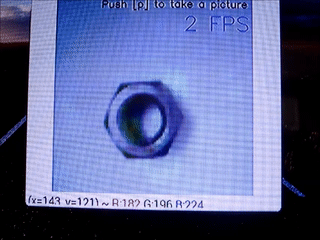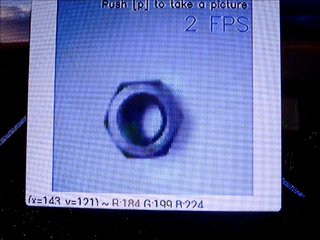

- 投稿日:2019-03-07T11:59:45+09:00
機械学習の構成について
機械学習の構成についての覚書です
各環境のメリット・デメリットなど環境はローカルか、クラウドか
ローカル
初期投資が大きく、ランニングコストが安い
必須なのはグラボと環境構築を諦めない根性
その分制約がほぼ無いので、可能ならローカルで環境構築仕切ってしまいたい
anacondaを使う方法がかなりオススメ必須
必須なのはグラボ。
とりあえず動かしたいならGTX750辺りが安くて良い
性能はクラウドと大して変わらない
できればGTX1060ぐらいは欲しいけど、ジャンクに手を出すのはやめた方が良い(一敗)
中古で店舗から買うのが無難あれば良いもの
SSD。無いということは無いと思う。1TBぐらいのを買ってしまえば容量を気にしなくて済む
割となんでもいい
CPU core第二世代以降
メモリ 8GBぐらい
OS 出来れば最新
python 3.x。2.7はもうおしまいやること
nVidiaに登録してCUDA、cudnnを入手
sckitlearn全盛期は依存地獄だったが、最近はtensolflowとkerasを入れると大体動くのでそこまで大変でも無いクラウド
googleのColaboratoryなら無料
https://colab.research.google.com/
最初からほぼ全部揃っている。CUDAも入っていて何の知識も依存地獄もないamazonのAWSでも良いが有料。時間課金制
TPU
TPUが使えてアホみたいに早い
しかしGPUのソースコードにはかなり手を加える必要がある
tensorflowのバージョンが上がればその辺り自動的に対応してくれるんじゃないかな、もう少し待とうTPUは現状、CPU扱いになる
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())実行結果[name: "/device:CPU:0" device_type: "CPU" memory_limit: 268435456 locality { } incarnation: 14364440645520663771 , name: "/device:XLA_CPU:0" device_type: "XLA_CPU" memory_limit: 17179869184 locality { } incarnation: 5324631014525462955 physical_device_desc: "device: XLA_CPU device" ]Colaboratoryについて
12時間ごとにリセットがかかるのが最大のネック
回避するためには、学習結果を12時間以内の範囲でgoogleドライブに逃がすなどの対処が必要GPUはTESLAのK80
K80は2012年リリースのハイエンドGPU
しかし、7年も経つので、そろそろ厳しい
また、K80は内部で2つのチップを持っているがその内の一つしか使えない
性能的にはざっくりとGTX960~GTX970辺りまとめ
どれも一長一短
なんとなく試したいだけならColaboratoryが良い
ガッツリやりたい場合は自前での環境構築をオススメ
- 投稿日:2019-03-07T09:04:07+09:00
無限ループ∞最短選手権
さぁみんな無限ループしよう。
最近、無限ループが流行りらしいので
各プログラミング言語(その辺にあった10個の言語)の
無限ループを比べてみます。
果たしてどの言語が1位に輝くのか!?※改行は1文字としてカウント。
(一応、全て実行してチェックしています)C (24文字)
int main(void){for(;;);}C⋕ (37文字)
class a{static void Main(){for(;;);}}C++ (20文字)
int main(){for(;;);}D (22文字)
void main(){for(;;){}}Go (31文字)
package main func main(){for{}}Java (54文字)
class a{public static void main(String[] a){for(;;);}}JavaScript (8文字)
for(;;);PHP (14文字)
<?php for(;;);Python (9文字)
while 1:0Ruby (11文字)
while 1 end【優勝】JavaScript
チャンピオンは"JavaScript"でした。さすが"JS"。
"JavaScript"は無限ループ界において最有力候補であると考えられますね。???「JSが優勝だと思っていたのか。」
【真の優勝】Ruby ※追記
Ruby(6文字)loop{}Ruby、6文字で無限ループが出来るとは……。
恐るびー最後に
もっと文字数減らせるよ!とか
もっと文字数が少ない言語あるぜ!最強だぜ!などなどありましたらコメントまたは編集リクエストでお願い致します。
- 投稿日:2019-03-07T09:04:07+09:00
?♀️無限ループ∞最短選手権?♂️
さぁみんな無限ループしよう。
最近、無限ループが流行りらしいので
各プログラミング言語(その辺にあった10個の言語)の
無限ループを比べてみます。
果たしてどの言語が1位に輝くのか!?※改行は1文字としてカウント。
(一応、全て実行してチェックしています)C (24文字)
int main(void){for(;;);}C⋕ (37文字)
class a{static void Main(){for(;;);}}C++ (20文字)
int main(){for(;;);}D (22文字)
void main(){for(;;){}}Go (31文字)
package main func main(){for{}}Java (53文字)
class a{public static void main(String[]a){for(;;);}}JavaScript (8文字)
for(;;);PHP (14文字)
<?php for(;;);Python (9文字)
while 1:0Ruby (11文字)
while 1 end【優勝】JavaScript
チャンピオンは"JavaScript"でした。さすが"JS"。
"JavaScript"は無限ループ界において最有力候補であると考えられますね。???「JSが優勝だと思っていたのか。」
【真の優勝】Ruby ※追記
Ruby(6文字)loop{}Ruby、6文字で無限ループが出来るとは……。
恐るびー???「6文字ごときが優勝だと思っていたのか。」
【本当の真の優勝】L00P ※追記(番外編)
L00P(0文字)0文字……圧巻です。
言語名からして、無限ループ界の頂点に君臨していると思われる風貌をしてますね……。このように上記で比べていた10個の言語以外の言語では、もっと文字数が少ないものがありました。
無限ループは奥が深い。最後に
もっと文字数減らせるよ!とか
もっと文字数が少ない言語あるぜ!最強だぜ!などなどありましたらコメントまたは編集リクエストでお願い致します。
- 投稿日:2019-03-07T08:53:39+09:00
[OR-Tools] Solver別Wall time
計算にぜんぜん時間を要していないのに,なぜ,Walltimeが4秒と出るの?
Solverを以下のように宣言したとき:
solver = cp_model.CpSolver()
WallTimeは,以下のように得られる:
wallTime = solver.WallTime()
cp_model.CpSolver()のとき,WallTimeの単位は,秒.
https://developers.google.com/optimization/scheduling/employee_schedulingSolverを以下のように宣言したとき:
solver = pywraplp.Solver('SolveStigler',pywraplp.Solver.GLOP_LINEAR_PROGRAMMING)
WallTimeは,cp_modelの利用時と同様に,以下のように得られる:
wallTime = solver.WallTime()
ただしこのとき,WallTimeの単位は,ミリ秒.
https://developers.google.com/optimization/reference/linear_solver/linear_solver/MPSolver/単位が違う...
- 投稿日:2019-03-07T04:56:16+09:00
twitter APIで遊んでみる #4(形態素解析してみる(MeCabの環境作り))
前回までのお話
twitter APIで遊んでみる #1(環境作り)
twitter APIで遊んでみる #2(ユーザータイムラインの取得)
twitter APIで遊んでみる #3(検索結果の取得)はじめに
twitterAPIでいろいろなツイートを収集できるようになったので、収集したデータをもとに形態素解析をしてみようと思います。形態素解析にはMeCabという解析エンジンが有名らしいので使ってみます。※今回の話にはtwitterAPIは全くでてきませんのであしからず…
環境作り
前回までの環境作りは実施済みのうえで、以下を実施します。
# yumからMeCabをインストールできるようにするため,Groonga リポジトリを追加 sudo rpm -ivh http://packages.groonga.org/centos/groonga-release-1.1.0-1.noarch.rpm # MeCabのインストールする. sudo yum install mecab mecab-devel mecab-ipadic mecab-ipadic-utf8これで
MeCabがコマンドラインから使えます。まだこの状態だとpythonからはMeCabを使用できませんが、それは次回実施することにします。MeCabで遊んでみる
コマンドラインで
mecabと打つと入力待ちになるので、適当に文章を入力してみます。root@localhost:~$ mecab 昨日はモスバーガーを食べたので、 今日はマックを食べたいですね。 昨日 名詞,副詞可能,*,*,*,*,昨日,キノウ,キノー は 助詞,係助詞,*,*,*,*,は,ハ,ワ モスバーガー 名詞,一般,*,*,*,*,* を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 食べ 動詞,自立,*,*,一段,連用形,食べる,タベ,タベ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ の 助詞,連体化,*,*,*,*,の,ノ,ノ 今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー は 助詞,係助詞,*,*,*,*,は,ハ,ワ マック 名詞,固有名詞,一般,*,*,*,マック,マック,マック を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 食べ 動詞,自立,*,*,一段,連用形,食べる,タベ,タベ たい 助動詞,*,*,*,特殊・タイ,基本形,たい,タイ,タイ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ 。 記号,句点,*,*,*,*,。,。,。 EOSMeCabすげ~!
更に
-Owakatiオプションをつけると、品詞などの情報が無く単に文が形態素で区切られた形で出力されます。これを分かち書きと言うそうです。読み方はワカチガキでいいのかな?root@localhost:twitter$ mecab -Owakati 昨日はモスバーガーを食べたので、 今日はマックを食べたいですね。 昨日 は モスバーガー を 食べ た ので 、 今日 は マック を 食べ たい です ね 。終わりに
とりあえず
MeCabが使えるようになりました。次回はpythonからMeCabを使ってみようと思います。
- 投稿日:2019-03-07T04:13:02+09:00
djangoでsassを書くときdisplay: #inline-blockのようにスペース入れないとコンパイルされない
正しい例
.title a color: #000000 display: inline-block &:hover color: #888888 text-decoration: none &:visitedダメな例
.title a color:#000000 display:inline-block &:hover color: #888888 text-decoration:none &:visited初心者に向けて...書いときます...
- 投稿日:2019-03-07T02:03:31+09:00
Djangoでお気に入り機能実装
今回は
Djangoでお気に入り登録機能を実装する.
ということで,フォロー機能とも言えます.物は言いようですね!環境
Python3.6
Django2.1大まかな流れ
Placeという名前のモデル(観光スポットとか)をお気に入り登録すると想定しています.アプリ名はmyappとしています.
単純な流れかと思います.
1. ユーザーがブラウザ上でお気に入り登録したいPlaceのpkをPOST
2. views.pyでpkに対応するPlaceをCustomUserモデルのfavorite_placeフィールドに追加コード
最小限の内容だけ書いています.
url
urls.pyは以下の部分をurlpatterns=[]に追加しましょう.
urls.pypath('follow/<int:pk>/', views.followPlace, name='follow'),html
ListViewなどであればこのような形でフォームを作れば簡単にpkをPOSTできます.
ex.html<form action="{% url 'myapp:follow' place.pk %}" method="post"> <button type="submit" name="button">お気に入り追加</button> {% csrf_token %} </form>view
汎用ビューを使うべきだと思いますが,関数ビューだとシンプルに作れます.
request.userでリクエストを送ったユーザーモデルを参照できます.views.pyfrom django.shortcuts import redirect, get_object_or_404 def followPlace(request, pk): """場所をお気に入り登録する""" place = get_object_or_404(Place, pk=pk) request.user.favorite_place.add(place) return redirect('myapp:index')model
長いです.
models.pyfrom django.db import models from django.core.mail import send_mail from django.contrib.auth.models import PermissionsMixin,UserManager from django.contrib.auth.base_user import AbstractBaseUser,BaseUserManager from django.utils.translation import ugettext_lazy as _ from django.utils import timezone from django.contrib.auth.validators import UnicodeUsernameValidator """場所の情報""" class Place(models.Model): name = models.CharField('名前',max_length = 30) address = models.CharField('住所',max_length=100) def __str__(self): return self.name """書かないとcreatesuperuserできない""" class UserManager(BaseUserManager): use_in_migrations = True def _create_user(self, username, email, password, **extra_fields): if not username: raise ValueError('The given username must be set') email = self.normalize_email(email) username = self.model.normalize_username(username) user = self.model(username=username, email=email, **extra_fields) user.set_password(password) user.save(using=self._db) return user def create_user(self, username, email=None, password=None, **extra_fields): extra_fields.setdefault('is_staff', False) extra_fields.setdefault('is_superuser', False) return self._create_user(username, email, password, **extra_fields) def create_superuser(self, username, email, password, **extra_fields): extra_fields.setdefault('is_staff', True) extra_fields.setdefault('is_superuser', True) if extra_fields.get('is_staff') is not True: raise ValueError('Superuser must have is_staff=True.') if extra_fields.get('is_superuser') is not True: raise ValueError('Superuser must have is_superuser=True.') return self._create_user(username, email, password, **extra_fields) """お気に入り機能追加済みユーザー""" class CustomUser(AbstractBaseUser, PermissionsMixin): username_validator = UnicodeUsernameValidator() username = models.CharField( _('username'), max_length=150, unique=True, help_text=_('Required. 150 characters or fewer. Letters, digits and @/./+/-/_ only.'), validators=[username_validator], error_messages={ 'unique': _("A user with that username already exists."), }, ) first_name = models.CharField(_('first name'), max_length=30, blank=True) last_name = models.CharField(_('last name'), max_length=150, blank=True) email = models.EmailField(_('email address'), blank=True) favorite_place = models.ManyToManyField(Place, verbose_name='お気に入りの場所', blank=True) is_staff = models.BooleanField( _('staff status'), default=False, help_text=_('Designates whether the user can log into this admin site.'), ) is_active = models.BooleanField( _('active'), default=True, help_text=_( 'Designates whether this user should be treated as active. ' 'Unselect this instead of deleting accounts.' ), ) date_joined = models.DateTimeField(_('date joined'), default=timezone.now) objects = UserManager() EMAIL_FIELD = 'email' USERNAME_FIELD = 'username' REQUIRED_FIELDS = ['email'] class Meta: verbose_name = _('user') verbose_name_plural = _('users') def clean(self): super().clean() self.email = self.__class__.objects.normalize_email(self.email) def get_full_name(self): """ Return the first_name plus the last_name, with a space in between. """ full_name = '%s %s' % (self.first_name, self.last_name) return full_name.strip() def get_short_name(self): """Return the short name for the user.""" return self.first_name def email_user(self, subject, message, from_email=None, **kwargs): """Send an email to this user.""" send_mail(subject, message, from_email, [self.email], **kwargs)大掛かりに書いていますがUserモデルに以下のフィールドを追加しただけで,あとはデフォと同じです.
リレーションは多対多ですね.
あるユーザーは複数の場所をお気に入り出来るし
また,ある場所は複数のユーザーにお気に入り登録されるからです.favorite_place = models.ManyToManyField(Place, verbose_name='お気に入りの場所', blank=True)まとめ
pkをPOSTして処理するだけなのですが便利なので記事にしました.
ちなみにユーザー同士のフォローについては,もう少し込み入った話になってきます.以上です.ありがとうございました.
- 投稿日:2019-03-07T01:59:17+09:00
一元配置分散分析をざっくりと理解する
1. 雑要約
本記事では分散分析が何をやっててどうしてあの統計量を利用するのかという点を取り扱っています.各所で現れる図表はpythonの出力(+keynote)で書いているので一応コードも載せています.いつも通り稲垣「数理統計学」等を利用しました.
また,この記事は私の勉強のメモなのでミスなどを発見された場合は教えてください.2. 問題例: そいつらの分布の母平均は本当に一致してる?
例1. 所得と都市の規模
都市規模が500万都市,100万都市,50万都市,10万都市のそれぞれからサラリーマンの所得の標本を抽出するとする.ここで一元配置分散分析では,それぞれの母平均は一致してるか?つまり,都市の規模でサラリーマンの所得の平均に差があるかを考える問題となる.(稲垣「数理統計学」p.240から)
例2. 湖の各地点での汚染度
水の中に含まれる酸素用改良は水質汚染を示す指標の1つである(酸素用改良が少ないほど汚染が進んでいる).ある湖の4地点において取られた無作為標本の酸素溶解量について,4地点における酸素溶解量に有意差があるか検定せよ.(稲垣「数理統計学」p.243 例題13.1)
例3. 織物の樹脂濃度
織物の樹脂加工工程で,樹脂濃度(A)が織物の引っ張り強さに与える影響を調べるため,それを4水準にとって実験し,下記のデータを得た.これを分析せよ.また各水準の平均に95%信頼区間を付したグラフを作成せよ.
温度 $A_1$ $A_2$ $A_3$ $A_4$ デ 70 74 78 76 l 73 74 75 78 タ 75 77 79 75 (kg) 72 75 80 75 (東京大学出版会「自然科学の統計学」p.109 練習問題3.2)
(あとで,この問題を4.分散分析を実際にやってみるで解きます.)3. 分散分析のフレームワーク
3-1. どんなケースで使う?
まずはどのようなケースで分散分析を適応できるかについて考えます.先ほどの3つの例を見て共通している点は,比較を行うのが複数($\ge$3)の群であるという点です.例えば1群ならばz検定やt検定を行えば良いし,2群の場合は2標本問題を行えば良いです.群の数がそれ以上になると,群の考えうるすべてのペアに対して検定を行うこともできますが,有意水準の扱いが難しくなることと,効率的でないという点から(?),一般的には分散分析を行うことが多いです.
3-2. グラフィカルにやってることをおおまかに掴む
分散分析は,「各群(r群あるとします)の毋平均が一致している」というのを帰無仮説,「いやいやそんなことはないでしょ〜」というのを対立仮説として検定を行います.整理すると以下のように書けます.
\begin{eqnarray} \left\{\begin{array} a H_0: \mu_1=\mu_2=\cdots=\mu_r\\ H_1: \mbox{上記以外} \end{array}\right. \end{eqnarray}以下の図は群が3つあるとした時の母集団分布(実際には未知)と総平均(=全標本の平均)を視覚化したものです.
Group i (i=1,2,3)が群,Overall meanが総平均を表しています.帰無仮説が正しいとき,各群の母平均は総平均に近づきます(ほんとは$H_0$が正しいときの各群の母平均の位置は総平均の位置に一致します).イメージは以下のようなものです.
分散分析では,各群の母集団が1枚目のような位置か,2枚目のような位置かどっちなんだい?というのを検定しています.
では,次に以上のような挙動を検定統計量として表現することを考えます.標本から計算された総平均からの散らばり(=総変動$S_T$)を\begin{eqnarray} S_T=\sum_{i=1}^r\sum_{j=1}^{n_i}(y_{ij}-\bar{y})^2 \end{eqnarray}とします.ここで$\bar{y}_{..}$は標本から計算した総平均を表しています.これだけだと各群の平均の情報がないので,各群の標本平均を挟み込みます.
\begin{eqnarray} S_T&=&\sum_{i=1}^r\sum_{j=1}^{n_i}(y_{ij}-\bar{y})^2\\ &=&\sum_{i=1}^r\sum_{j=1}^{n_i}(y_{ij}-\bar{y}_{i.}+\bar{y}_{i.}-\bar{y})^2\\ &=&\sum_{i=1}^r\sum_{j=1}^{n_i}(y_{ij}-\bar{y}_{i.})^2+\sum_{i=1}^rn_i(\bar{y}_{i.}-\bar{y})^2\\ &&(S_w:=\sum_{i=1}^r\sum_{j=1}^{n_i}(y_{ij}-\bar{y}_{i.})^2,S_b:=\sum_{i=1}^rn_i(\bar{y}_{i.}-\bar{y})^2)\\ &=&S_w+S_b \end{eqnarray}総変動$S_T$に各群の平均を挟み込むことで,総変動は各群の平均からの標本の散らばりを表す$S_w$(級内変動)と総平均からの各群の標本平均の散らばりを表す$S_b$(級間変動)に分割することができました.$S_w,S_b$はそれぞれ自由度n-r,r-1のχ二乗分布に従います.分散分析では,これらの比
\begin{eqnarray} \frac{\frac{S_b}{r-1}}{\frac{S_w}{n-r}} \sim F_{n-r}^{r-1} \end{eqnarray}を検定統計量として用います.先ほどの図に総変動などを書き込んだものが以下の図です.
もし帰無仮説$H_0=\mu_1=\cdots=\mu_r$が間違っているとすると,級間変動が大きくなるので,結果として検定統計量の値も大きくなります.従って帰無仮説は棄却されやすくなります.実際に分散分析を行う場合は,次の章のように分散分析表を作成して検定を行います.
4. 分散分析表を使って実際にやってみる
分散分析表は以下のような表を指します.
平方和 自由度 平均平方和 F値 級間 $S_b=\sum n_i(\bar{y}_{i.}-\bar{y})^2$ $r-1$ $\frac{\sum n_i(\bar{y}_{i.}-\bar{y})^2}{r-1}$ 級内 $S_w=\sum\sum(y_{ij}-\bar{y}_{i.})^2$ $n-r$ $\frac{\sum\sum(y_{ij}-\bar{y}_{i.})^2}{n-r}$ $F=\frac{\frac{S_b}{r-1}}{\frac{S_w}{n-r}} \sim F_{n-r}^{r-1}$ 総 $S_T=\sum\sum(y_{ij}-\bar{y})^2$ $n-1$ 例3の織物の樹脂濃度に対して,分散分析表を作成すると,
平方和 自由度 平均平方和 F値 級間 $62.75$ $3$ $20.92$ 級内 $39.00$ $13$ $3.25$ $F=6.44$ 総 $101.75$ $15$ となり,$F_{0.01}(3,13)=5.739$,$F_{0.005}(3,13)=6.926$から,有意水準1%では,母平均は軍によって異なるとは言えませんが,有意水準0.5%では$H_0$は棄却され,母平均に差があると言えます.
感想(読み飛ばしてください)
なぜ今さら検定なんてものをやっているのか...自分でも謎です.勉強のモチベーションとしては統計検定で出題されている&授業の復習というのが大きいです.今回取り上げなかった交互作用(実験系ではこっちが大事そう)も機会があれば紹介します.
以下作図のために書いたコードです.# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt import scipy.stats as sp import matplotlib as mpl #1つ目の図表 x_range = np.arange(-10,15,0.1) f1 = sp.norm.pdf(x_range,-5,1.5) f2 = sp.norm.pdf(x_range,0,1.5) f3 = sp.norm.pdf(x_range,7,1.5) #mpl.rcParams['font.family'] = 'AppleGothic' #日本語をグラフに表示するための操作 plt.plot(x_range,f1,color="r",label="Group1 N(-5,10)") plt.vlines([-5],0,0.27,"r",linestyle="dashed") plt.plot(x_range,f2,color="g",label="Group2 N(0,10)") plt.vlines([0],0,0.27,"g",linestyle="dashed") plt.plot(x_range,f3,color="b",label="Group3 N(7,10)") plt.vlines([7],0,0.27,"b",linestyle="dashed") plt.vlines([2/3],0,0.3,"black",label="Overall mean") plt.legend(loc="upper right") #plt.savefig("") plt.show() #2つ目の図表 x_range = np.arange(-10,15,0.1) f1 = sp.norm.pdf(x_range,-0.2,1.5) f2 = sp.norm.pdf(x_range,0,1.5) f3 = sp.norm.pdf(x_range,2.2,1.5) plt.plot(x_range,f1,color="r",label="Group1 N(-0.2,10)") plt.vlines([-0.2],0,0.27,"r",linestyle="dashed") plt.plot(x_range,f2,color="g",label="Group2 N(0,10)") plt.vlines([0],0,0.27,"g",linestyle="dashed") plt.plot(x_range,f3,color="b",label="Group3 N(2.2,10)") plt.vlines([2.2],0,0.27,"b",linestyle="dashed") plt.vlines([2/3],0,0.3,"black",label="Overall mean") plt.legend(loc="upper right") #plt.savefig("") plt.show()参考文献(リンクは全部Amazon行き)
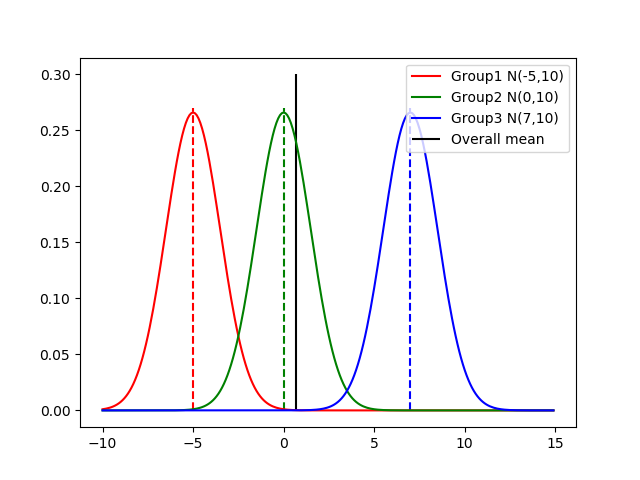

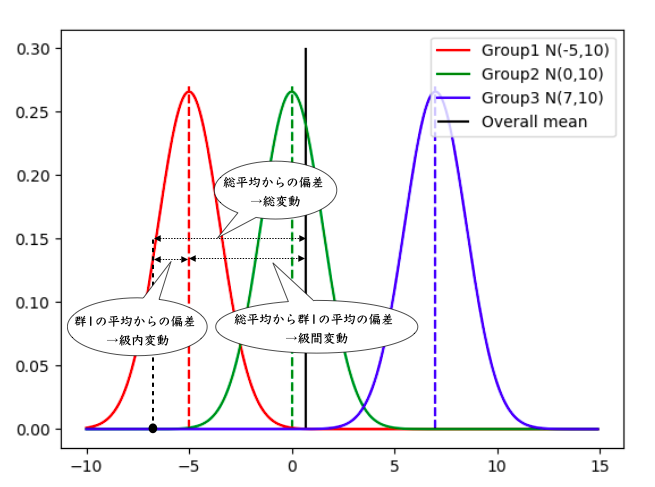
- 投稿日:2019-03-07T01:57:04+09:00
twitter APIで遊んでみる #2(検索結果の取得)
検索結果を取得してみる
[前回]は、指定したtwitterアカウントのタイムラインを取得してみました。今回は、指定した文言の検索結果を取得してみたいと思います。
前回モスバーガーの公式twitter(@mos_burger)のタイムラインを取得したので、今回は「モスバーガー」という文言で検索してみようと思います。
APIのリファレンス
今回使用する
user_timelineAPIのリファレンスです。
https://developer.twitter.com/en/docs/tweets/search/api-reference/get-search-tweetsパラメータはいっぱいありますが、今回は「count」と「q」を指定しました。
「count」は検索結果のレコード数です。最大が100、デフォルトは15とのことです。今回もそんなにいらないので、とりあえず「10」にしました。
「q」は検索キーワードです。「モスバーガー」を指定しました。早速結果を見てみよう。
コード
# -*- coding: utf-8 -*- import json, config from requests_oauthlib import OAuth1Session # Get by OAuth CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET twitter = OAuth1Session(CK, CS, AT, ATS) # Twitter Endpoint(検索結果を取得する) url = 'https://api.twitter.com/1.1/search/tweets.json' # Enedpointへ渡すパラメーター keyword = 'モスバーガー' params ={ 'count' : 10, # 取得するtweet数 'q' : keyword # 検索キーワード } req = twitter.get(url, params = params) if req.status_code == 200: result = json.loads(req.text) for line in result['statuses']: print(line['text']) print('*******************************************') else: print("Failed: %d" % req.status_code)実行結果
root@localhost:twitter$ python getSearchTweets.py @zyunana17 マックかモスかの二択で距離もそんな変わらないならモスかかなぁ…ってくらいの優先度、肉も野菜も中途半端でバーガーそのものに正直玉ねぎソース以外あんま魅力感じない ******************************************* 自分あんまり感情を言葉にするのが上手いこといかないもんで、すごい熱量でお兄さんを推してる人本当に凄いな~と思うことが多々あるんですけど、 ってここまで打って何が言いたかったか忘れたので食べたいハンバーガーの名前言います麻辣モスバーガー ******************************************* わぁいモスバーガー エイドリアンモスバーガー大好き ******************************************* A.エコレストラン モスバーガーさん、確かにドリンクもカップではなくグラスですよね。エコに熱心な企業さんは応援したくなります‼ https://t.co/qjpTWWJy3Q ******************************************* 今日の空き時間はモス食べた? フィッシュバーガーとライスバーガー焼肉。withきゃーちゃん https://t.co/iQgkLnE9wZ ******************************************* 妹①にモスのバーガーセットのギフト貰ったから妹②と食べてきたぞ♡ごちそうさまさま♡ https://t.co/2BqBYtAZF9 ******************************************* モスバーガーお腹一杯食べたい ******************************************* 今日の晩飯はモスバーガー もち一人で店内で食べてます。 ******************************************* モス麻辣バーガー、シビレが過ぎる(褒めてる) ******************************************* RT @syu_ka11: しゃおりんがバイト中に モスにバーガー買いに来てくれた? クソ萎えてたけど元気出た〜ありがとう✨ 差し入れまでくれて しかも私の好みを的確に押さえた差し入れすぎて神かな…って思った( ˇωˇ )♥️ カラオケしながらいただきます!!! https:/… ******************************************* やっぱり他社でも同じ商品はない「やっぱりモスバーガー」です! #私の好きモス ******************************************* しゃおりんがバイト中に モスにバーガー買いに来てくれた? クソ萎えてたけど元気出た〜ありがとう✨ 差し入れまでくれて しかも私の好みを的確に押さえた差し入れすぎて神かな…って思った( ˇωˇ )♥️ カラオケしながらいただきます!… https://t.co/DVXvYNHrdY ******************************************* モスバーガー様より、こども商品券5000円分当選のご連絡を頂きました✨ ありがとうございます☺️? こども商品券は初めてですが、百貨店さんや玩具店さん遊園地など色々なところで使えるようです? 娘&息子、喜ぶぞ〜?? また家族で大好… https://t.co/NS2dOY6Kys ******************************************* ミッキーのバーガークッション、私はモスモスと名前を付けたんですけど、ベッドの上が錯乱状態なので椅子の上に避難させてる。元気がない時モスモスすると満たされる。 ******************************************* @naog0309 しかもね、それ気づいたのモスバーガー? *******************************************問題なく取得できたようです。
終わりに
次回は、他のAPIも同じように使ってみようと思います。
- 投稿日:2019-03-07T01:57:04+09:00
twitter APIで遊んでみる #3(検索結果の取得)
検索結果を取得してみる
[前回]は、指定したtwitterアカウントのタイムラインを取得してみました。今回は、指定した文言の検索結果を取得してみたいと思います。
前回モスバーガーの公式twitter(@mos_burger)のタイムラインを取得したので、今回は「モスバーガー」という文言で検索してみようと思います。
APIのリファレンス
今回使用する
user_timelineAPIのリファレンスです。
https://developer.twitter.com/en/docs/tweets/search/api-reference/get-search-tweetsパラメータはいっぱいありますが、今回は「count」と「q」を指定しました。
「count」は検索結果のレコード数です。最大が100、デフォルトは15とのことです。今回もそんなにいらないので、とりあえず「10」にしました。
「q」は検索キーワードです。「モスバーガー」を指定しました。早速結果を見てみよう。
コード
# -*- coding: utf-8 -*- import json, config from requests_oauthlib import OAuth1Session # Get by OAuth CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET twitter = OAuth1Session(CK, CS, AT, ATS) # Twitter Endpoint(検索結果を取得する) url = 'https://api.twitter.com/1.1/search/tweets.json' # Enedpointへ渡すパラメーター keyword = 'モスバーガー' params ={ 'count' : 10, # 取得するtweet数 'q' : keyword # 検索キーワード } req = twitter.get(url, params = params) if req.status_code == 200: result = json.loads(req.text) for line in result['statuses']: print(line['text']) print('*******************************************') else: print("Failed: %d" % req.status_code)実行結果
root@localhost:twitter$ python getSearchTweets.py @zyunana17 マックかモスかの二択で距離もそんな変わらないならモスかかなぁ…ってくらいの優先度、肉も野菜も中途半端でバーガーそのものに正直玉ねぎソース以外あんま魅力感じない ******************************************* 自分あんまり感情を言葉にするのが上手いこといかないもんで、すごい熱量でお兄さんを推してる人本当に凄いな~と思うことが多々あるんですけど、 ってここまで打って何が言いたかったか忘れたので食べたいハンバーガーの名前言います麻辣モスバーガー ******************************************* わぁいモスバーガー エイドリアンモスバーガー大好き ******************************************* A.エコレストラン モスバーガーさん、確かにドリンクもカップではなくグラスですよね。エコに熱心な企業さんは応援したくなります‼ https://t.co/qjpTWWJy3Q ******************************************* 今日の空き時間はモス食べた? フィッシュバーガーとライスバーガー焼肉。withきゃーちゃん https://t.co/iQgkLnE9wZ ******************************************* 妹①にモスのバーガーセットのギフト貰ったから妹②と食べてきたぞ♡ごちそうさまさま♡ https://t.co/2BqBYtAZF9 ******************************************* モスバーガーお腹一杯食べたい ******************************************* 今日の晩飯はモスバーガー もち一人で店内で食べてます。 ******************************************* モス麻辣バーガー、シビレが過ぎる(褒めてる) ******************************************* RT @syu_ka11: しゃおりんがバイト中に モスにバーガー買いに来てくれた? クソ萎えてたけど元気出た〜ありがとう✨ 差し入れまでくれて しかも私の好みを的確に押さえた差し入れすぎて神かな…って思った( ˇωˇ )♥️ カラオケしながらいただきます!!! https:/… ******************************************* やっぱり他社でも同じ商品はない「やっぱりモスバーガー」です! #私の好きモス ******************************************* しゃおりんがバイト中に モスにバーガー買いに来てくれた? クソ萎えてたけど元気出た〜ありがとう✨ 差し入れまでくれて しかも私の好みを的確に押さえた差し入れすぎて神かな…って思った( ˇωˇ )♥️ カラオケしながらいただきます!… https://t.co/DVXvYNHrdY ******************************************* モスバーガー様より、こども商品券5000円分当選のご連絡を頂きました✨ ありがとうございます☺️? こども商品券は初めてですが、百貨店さんや玩具店さん遊園地など色々なところで使えるようです? 娘&息子、喜ぶぞ〜?? また家族で大好… https://t.co/NS2dOY6Kys ******************************************* ミッキーのバーガークッション、私はモスモスと名前を付けたんですけど、ベッドの上が錯乱状態なので椅子の上に避難させてる。元気がない時モスモスすると満たされる。 ******************************************* @naog0309 しかもね、それ気づいたのモスバーガー? *******************************************問題なく取得できたようです。
終わりに
次回は、他のAPIも同じように使ってみようと思います。
- 投稿日:2019-03-07T01:31:13+09:00
Paramikoのssh認証でハマった話
新PCで既存プロジェクト資源のparamiko ssh認証を実行した際に以下のエラーが発生した。
raise SSHException("not a valid " + tag + " private key file") paramiko.ssh_exception.SSHException: not a valid RSA private key fileなんの話や
調べてみるとparamikoのissueに同じ報告が上がってた
https://github.com/paramiko/paramiko/issues/1226原因はparamikoの以下ソース
https://github.com/paramiko/paramiko/blob/master/paramiko/pkey.py#L285
https://github.com/paramiko/paramiko/blob/master/paramiko/pkey.py#L265秘密鍵のヘッダーがRSAまたはDSAじゃないとダメみたい
で、自分の秘密鍵を見てみると$ cat id_rsa -----BEGIN OPENSSH PRIVATE KEY-----あれなんか違う
また調べてみるとOpenSSHで仕様変更があったみたい
https://www.openssh.com/txt/release-7.8
- ssh-keygen(1): write OpenSSH format private keys by default instead of using OpenSSL's PEM format. The OpenSSH format, supported in OpenSSH releases since 2014 and described in the PROTOCOL.key file in the source distribution, offers substantially better protection against offline password guessing and supports key comments in private keys. If necessary, it is possible to write old PEM-style keys by adding "-m PEM" to ssh-keygen's arguments when generating or updating a key.
※自端末のOpenSSHのバージョンは以下の通り
$ ssh -V OpenSSH_7.9リリースノートに従って-m PEMオプションをつけて鍵を作り直してみる
$ ssh-keygen -t rsa -m PEM $ cat id_rsa -----BEGIN RSA PRIVATE KEY-----paramikoも無事動きました。
小一時間ハマったのは内緒。
- 投稿日:2019-03-07T01:13:38+09:00
twitter APIで遊んでみる #2(ユーザータイムラインの取得)
ユーザータイムラインを取得してみる
前回は、とりあえずpythonでtwitter APIが叩ける環境まで作りました。今回は実際にAPIを叩いて、なにかしらの情報を取得しようと思います。
特定ユーザーのタイムラインを取得してみます。
なんとなく今ハンバーガーが食べたいので、モスバーガーの公式twitter(@mos_burger)のタイムラインを取得してみました。APIのリファレンス
今回使用する
user_timelineAPIのリファレンスです。
https://developer.twitter.com/en/docs/tweets/timelines/api-reference/get-statuses-user_timeline.htmlパラメータはいっぱいありますが、今回は「count」と「screen_name」を指定しました。
「count」は検索結果のレコード数です。最大が200、デフォルトは20とのことです。今回はそんなにいらないので、とりあえず「5」にしました。
「screen_name」はtwitterアカウント名です。@マークはいりません。またscreen_nameを指定しないと、API取得元の自分のアカウントの情報を引っ張ってくるようです。早速結果を見てみよう。
コード
# -*- coding: utf-8 -*- import json, config from requests_oauthlib import OAuth1Session # OAuth認証部分 CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET twitter = OAuth1Session(CK, CS, AT, ATS) # Twitter Endpoint(ユーザータイムラインを取得する) url = "https://api.twitter.com/1.1/statuses/user_timeline.json" # Enedpointへ渡すパラメーター params ={'count' : 5, # 取得するtweet数 'screen_name' : 'mos_burger'} # twitterアカウント名。指定しないとAPI取得元の自分のアカウントになる。 req = twitter.get(url, params = params) if req.status_code == 200: timeline = json.loads(req.text) for line in timeline: print(line['user']['name']+'::'+line['text']) print(line['created_at']) print('*******************************************') else: print("Failed: %d" % req.status_code)実行結果
root@localhost:twitter$ python getTimelines.py モスバーガー::ご好評いただいている #麻辣モスバーガー?のクーポンもあります(∩˃o˂∩)♡ モスバーガーアプリを是非ご利用ください?? https://t.co/C5jbyoCcmw Wed Mar 06 06:00:04 +0000 2019 ******************************************* モスバーガー::モスバーガーもご紹介いただきました! TRiP EDiTOR(@TRiPEDiTOR)さん、ありがとうございました♪(*’-^)-☆ https://t.co/uOjrQXcLLS Wed Mar 06 04:16:41 +0000 2019 ******************************************* モスバーガー::\#モスシェイク ファン必見?/ お好きなセットに【+30円】でモスシェイクMが選べるってご存じですか? ちょっと甘いものが欲しいときに、ぴったり✨✨ ストロベリー・コーヒー・バニラ、あなたはどのフレーバーがお好き❓… https://t.co/xSU9IOYUZ1 Wed Mar 06 02:00:04 +0000 2019 ******************************************* モスバーガー::\#私の好きモス キャンペーン/ モス商品のデジタルギフトを毎月抽選で30名様にプレゼント? モスの推しメニューを教えてねヾ(o´▽`)ノ゙ ★応募方法★ ①モスバーガー公式TwitterまたはInstagramをフォロー ②… https://t.co/iV5vVsrLt4 Tue Mar 05 06:00:04 +0000 2019 ******************************************* モスバーガー::バンズからはみ出すほど大きな #ハンバーグ に、たっぷりのとろーり #濃厚チーズ がベストマッチ☝ ハンバーグもチーズもとびきり?モスファンに根強い人気の一品です? #モスバーガー https://t.co/BpMVyh285n https://t.co/SWYD0TUmIn Tue Mar 05 02:00:04 +0000 2019 *******************************************問題なく取得できたようです。
終わりに
次回は、他のAPIも同じように使ってみようと思います。