- 投稿日:2019-02-26T00:54:13+09:00
Ubuntu18.04LTS : 2080ti*2で学習したいけどよくわからんエラー吐くよ(故障)
きっと環境構築が悪いんだろうな...
って思っていたんですけど,2080tiの片方だけが"単純に初期不良だった" & "GPUの挿し方が甘かった" っていうのがオチです.後者に関してはすぐに気づけたんですが,前者は"自分がクソザコ環境構築力だから..."って思っていたんで,原因に気づくまでに3,4日虚無な時間を過ごしていました.
それだけ?って思われる方、それだけです.どんな症状?
keras+tensorflow-gpuで学習しようとしたらエラー
全部載せきれてないですがこんな感じのエラー吐かれます.
エラーfailed to synchronize the stop event: CUDA_ERROR_ILLEGAL_ADDRESS: an illegal memory access was encountered failed to synchronize the stop event: CUDA_ERROR_LAUNCH_FAILED: unspecified launch failure Check failed: status == CUDNN_STATUS_SUCCESS (7 vs. 0)Failed to set cuDNN stream.検索したらtensorflow-gpuのバージョンを変えたらエラー吐かないよっていうコメントもありましたが、今回の場合は想定外ですねぇ
マザボからGPU引っこ抜いて単体テストした時のエラー
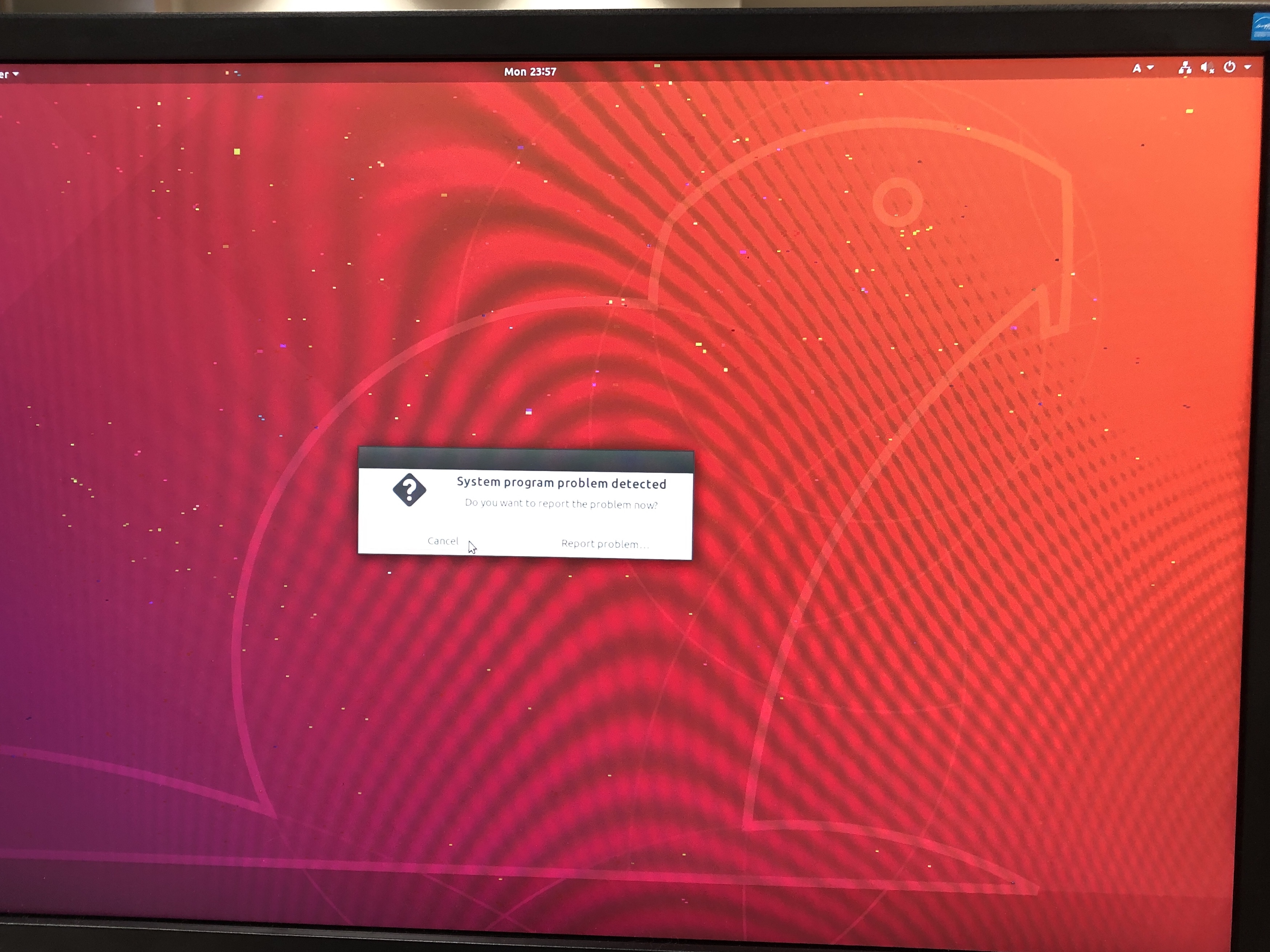
ログインした後の画面です.
ノイズがのっているうえに,ものすごく重たい.
解決策
ハードそのものが悪さしてるかもしれないので,GPUを片方ずつ引っこ抜いて単体テストしましょう.2080tiはまだ発売されたばかりなので,初期不良が多いとか少ないとか.こんなの当たり前だろ記事で誰が救えるかはわかりませんが,メモ程度に置いときます.
さよならGPU

- 投稿日:2019-02-26T00:49:17+09:00
TensorFlow MNIST のコード解説【初心者向け】
TensorFlow を使い始め、MNISTでどのようなものが使えるのか調べた結果をまとめていく。
初歩の初歩のものがほとんどであるが、MNISTのコード内のものが大半であるため、始めたばかりの自分のような者には有益なものとなると嬉しい。
なお、定数を、image_size = 28*28 //画像サイズ output_num = 10 //数字の数 learning_rate = 0.001 //学習率 loop_num = 30000 //ループ回数 batch_size = 100 //バッチサイズとしている。表記の都合上y_と$y'$は同じものとした。
また、扱ったコードは文末にある。mnist
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)MNISTで用いるデータの読み込みである。
one_hot とはn種類のデータを表すのに、n次元ベクトルを用い、mを表すにはm番目のベクトルを1、他を0とすることを示しており、7は[ 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]と表される。tf.placeholder()
x = tf.placeholder("float", [None, image_size])placeholderとは、値の入る場所の確保である。上の例では、float型のNone*image_sizeの配列(Noneは任意)を入れる場所を示している。
tf.Variable()
tf.Variable(tf.zeros([image_size, output_num]))変数(Variable)をゼロ初期化している。上記のplaceholder同様この例もimagesize*output_numの配列変数を初期化している。
【+α】 tf.random_normal()
tf.random_normal([image_size, H], mean=0.0, stddev=0.05)tf.zeros以外に、tf.random_normalを用いて初期化することもできる。これは、正規分布で乱数を発生させ、それを初期値とする。機械学習では、初期値が0でないほうが良いことがあり、こちらで初期化することが多い。meanは平均、stddevは標準偏差である。この例では0近傍の数字を発生させることができる。
tf.nn.softmax()
y = tf.nn.softmax(tf.matmul(x, W) + b)ソフトマックス関数によって回帰している。tf.matmulは行列積である。
ソフトマックス関数とは、
$$softmax(x_1,x_2,...,x_n) = y(y_1,y_2,...,y_n)$$
ただし、
$$y_i=\frac{e^x_i}{\sum_{k=0}^{n} e^k}$$
というものである。
この関数は、
$$0\leq y_i\leq1$$
$$\sum y_i=1$$という性質があるため、確率の出力に適している。cross_entropy
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))クロスエントロピーを計算する。クロスエントロピーCとは、
$$C=-\sum (y')log(y)$$
である。ただし、$y'$は正解、$y$は予測値である。
--ここからは大雑把な説明--
情報でいう一般的なエントロピーは、
$$entropy=\sum_{i} y_ilog(y_i)^{-1}$$
で表され、確率$y$での情報量の最小値を表すのに使う。
$log(y_i)^{-1}$の部分は確率$y_i$で表される情報の最小の情報量を表すから、クロスエントロピーを最小にする$y$は$y'$に近いものとなるはずである。train_step
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)GradientDescentOptimizerとは、勾配降下法によるオプティマイザーを実行するものである。
learning_rateで学習率を指定し、minimize()でcross_entropyを最小化するようにすることを示す。init
init = tf.initialize_all_variables()全変数を初期化する。
tf.Session()
sess = tf.Session()Sessionをsessとして定義。
sess.run()
sess.run(init)TensorFlowではSessionを実行することで実行される。ここではinitを実行する。
train.next_batch()
batch_xs, batch_ys = mnist.train.next_batch(batch_size)batch_xs、batch_yを、mnistの中の(batch_size)個のデータを取り出す。
sess.run(train_step)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})先述のtrain_stepを実行する。feed_dictはtrain_stepの$x$、$y'$の値を指定している。
correct_prediction
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))予測値$y$と正解値$y'$が等しければbool値を返す。tf.argmaxは、予測値の最大値のインデックスを返す。
accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))bool値を0,1に変換して平均を取る。これは正解率となる。
print()
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))accuracyを実行して、結果を出力している。
今回扱ったコードの全容
以下のサイトを参考にした。
https://www.trifields.jp/try-tutorial-mnist-for-ml-beginners-of-tensorflow-1713tutorial.pyimport tensorflow as tf import input_data image_size = 28*28 output_num = 10 learning_rate = 0.001 loop_num = 30000 batch_size = 100 # MNISTデータを読み込み mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # 画像データ x = tf.placeholder("float", [None, image_size]) # モデルの重み W = tf.Variable(tf.zeros([image_size, output_num])) # モデルのバイアス b = tf.Variable(tf.zeros([10])) # トレーニングデータxとモデルの重みWを乗算した後、モデルのバイアスbを足し、 # ソフトマックス回帰(ソフトマックス関数)を適用 y = tf.nn.softmax(tf.matmul(x, W) + b) # 正解データ y_ = tf.placeholder("float", [None, output_num]) # 損失関数をクロスエントロピーとする cross_entropy = -tf.reduce_sum(y_ * tf.log(y)) # 学習係数を0.01として、勾配降下アルゴリズムを使用して、 # クロスエントロピーを最小化する train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy) # 変数の初期化 init = tf.initialize_all_variables() # セッションの作成 sess = tf.Session() # セッションの開始および初期化の実行 sess.run(init) # トレーニングの開始 for i in range(loop_num): # トレーニングデータからランダムに100個抽出する batch_xs, batch_ys = mnist.train.next_batch(batch_size) # 確率的勾配降下によりクロスエントロピーを最小化するよう重みを更新 sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) # 予測値と正解値を比較して、bool値(true or false)にする # tf.argmax(y, 1)は、予測値の各行で、最大値となるインデックスを一つ返す correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # bool値を0 or 1に変換して平均値をとる -> 正解率 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) # テストデータを与えて、テストデータの正解率の表示 print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))次の記事
- 投稿日:2019-02-26T00:49:17+09:00
TensorFlow 備忘録
TensorFlow を使い始め、MNISTでどのようなものが使えるのか調べた結果をまとめていく。
初歩の初歩のものがほとんどであるが、MNISTのコード内のものが大半であるため、始めたばかりの自分のような者には有益なものとなると嬉しい。
なお、定数を、
image_size = 28*28 //画像サイズ
output_num = 10 //数字の数
learning_rate = 0.001 //学習率
loop_num = 30000 //ループ回数
batch_size = 100 //バッチサイズ
としている。表記の都合上y_と$y'$は同じものとした。mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
MNISTで用いるデータの読み込みである。
one_hot とはn種類のデータを表すのに、n次元ベクトルを用い、mを表すにはm番目のベクトルを1、他を0とすることを示しており、7は[ 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]と表される。x = tf.placeholder("float", [None, image_size])
placeholderとは、値の入る場所の確保である。上の例では、float型のNone*image_sizeの配列(Noneは任意)を入れる場所を示している。
tf.Variable(tf.zeros([image_size, output_num]))
変数(Variable)をゼロ初期化している。上記のplaceholder同様この例もimagesize*output_numの配列変数を初期化している。
【+α】 tf.random_normal([image_size, H], mean=0.0, stddev=0.05)
tf.zeros以外に、tf.random_normalを用いて初期化することもできる。これは、正規分布で乱数を発生させ、それを初期値とする。機械学習では、初期値が0でないほうが良いことがあり、こちらで初期化することが多い。meanは平均、stddevは標準偏差である。この例では0近傍の数字を発生させることができる。
y = tf.nn.softmax(tf.matmul(x, W) + b)
ソフトマックス関数によって回帰している。tf.matmulは行列積である。
ソフトマックス関数とは、
$$softmax(x_1,x_2,...,x_n) = y(y_1,y_2,...,y_n)$$
ただし、
$$y_i=\frac{e^x_i}{\sum_{k=0}^{n} e^k}$$
というものである。
この関数は、$$0\leq softmax\leq1$$という性質があるため、確率の出力に適している。cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
クロスエントロピーを計算する。クロスエントロピーCとは、
$$C=-\sum (y')log(y)$$
である。ただし、$y'$は正解、$y$は予測値である。
--ここからは大雑把な説明--
情報でいう一般的なエントロピーは、
$$entropy=\sum_{i} y_ilog(y_i)^{-1}$$
で表され、確率$y$での情報量の最小値を表すのに使う。
$log(y_i)^{-1}$の部分は確率$y_i$で表される情報の最小の情報量を表すから、クロスエントロピーを最小にする$y$は$y'$に近いものとなるはずである。train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
GradientDescentOptimizerとは、勾配降下法によるオプティマイザーを実行するものである。
learning_rateで学習率を指定し、minimize()でcross_entropyを最小化するようにすることを示す。init = tf.initialize_all_variables()
全変数を初期化する。
sess = tf.Session()
Sessionをsessとして定義。
sess.run(init)
TensorFlowではSessionを実行することで実行される。ここではinitを実行する。
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
batch_xs、batch_yを、mnistの中の(batch_size)個のデータを取り出す。
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
先述のtrain_stepを実行する。feed_dictはtrain_stepの$x$、$y'$の値を指定している。
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
予測値$y$と正解値$y'$が等しければbool値を返す。tf.argmaxは、予測値の最大値のインデックスを返す。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
bool値を0,1に変換して平均を取る。これは正解率となる。
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
accuracyを実行している。
今回扱ったコード
以下のサイトを参考にした。
https://www.trifields.jp/try-tutorial-mnist-for-ml-beginners-of-tensorflow-1713tutorial.pyimport tensorflow as tf import input_data image_size = 28*28 output_num = 10 learning_rate = 0.001 loop_num = 30000 batch_size = 100 # MNISTデータを読み込み mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # 画像データ x = tf.placeholder("float", [None, image_size]) # モデルの重み W = tf.Variable(tf.zeros([image_size, output_num])) # モデルのバイアス b = tf.Variable(tf.zeros([10])) # トレーニングデータxとモデルの重みWを乗算した後、モデルのバイアスbを足し、 # ソフトマックス回帰(ソフトマックス関数)を適用 y = tf.nn.softmax(tf.matmul(x, W) + b) # 正解データ y_ = tf.placeholder("float", [None, output_num]) # 損失関数をクロスエントロピーとする cross_entropy = -tf.reduce_sum(y_ * tf.log(y)) # 学習係数を0.01として、勾配降下アルゴリズムを使用して、 # クロスエントロピーを最小化する train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy) # 変数の初期化 init = tf.initialize_all_variables() # セッションの作成 sess = tf.Session() # セッションの開始および初期化の実行 sess.run(init) # トレーニングの開始 for i in range(loop_num): # トレーニングデータからランダムに100個抽出する batch_xs, batch_ys = mnist.train.next_batch(batch_size) # 確率的勾配降下によりクロスエントロピーを最小化するよう重みを更新 sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) # 予測値と正解値を比較して、bool値(true or false)にする # tf.argmax(y, 1)は、予測値の各行で、最大値となるインデックスを一つ返す correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # bool値を0 or 1に変換して平均値をとる -> 正解率 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) # テストデータを与えて、テストデータの正解率の表示 print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))