- 投稿日:2019-02-26T23:39:53+09:00
Python の Iterator と Generator
まとめ
- Iterator とは、
__iter__と__next__を持つオブジェクト。for などで繰り返しに使える。- Generator function とは、yield を含む関数。Generator を返す。
- Generator とは、Iterator の一種。send() や throw() など拡張機能もある。
Iterator
まずイテレータの復習。
__iter__と__next__を持つオブジェクトをイテレータと呼び、for などで繰り返しに使える。# 1 から max までの数を数えるカウンターをイテレータとして作った class Counter(): def __init__(self, max): self.count = 0 self.max = max def __iter__(self): return self def __next__(self): self.count += 1 if self.count <= self.max: return self.count raise StopIteration() # 1 から 3 まで for で数える for i in Counter(3): print(i) # next(iterator, default) はイテレータの次の値を返す。無ければデフォルトを返す。 counter = Counter(3) print(next(counter, '終わり')) print(next(counter, '終わり')) print(next(counter, '終わり')) print(next(counter, '終わり'))実行結果
1 2 3 1 2 3 終わりGenerator
Yield 文を使うと、クラス構文を使わずにイテレータを作る事が出来る。yield を含む関数をジェネレータ関数と呼ぶ。ジェネレータ関数は return を含まないのにジェネレータと呼ぶオブジェクトを返す。ジェネレータはイテレータとして使える。yield 文でイテレータとしての結果を返す。
# 1 から max までの数を数えるカウンターをジェネレータで作った def counter_simple(max=None): count = 0 while count < max: count += 1 next = yield count for i in counter_simple(3): print(i)実行結果
1 2 3ジェネレータにはイテレータに加えていろいろ機能がある。
generator.send()で値を渡す。渡した値は yield の戻り値となる。generator.throw()で例外を投げられる。generator.close()で中断出来る。# 1 から max までの数を数えるカウンター高級版 def counter_rich(max=None): count = 0 try: while count < max: count += 1 try: next = yield count if next != None: count = next except Exception as e: print(f'例外「{e}」がやってきた!') finally: print('終了します') print('100 まで数えるカウンター') counter = counter_rich(100) print(next(counter)) print(next(counter)) print('counter に 5 を送ってスキップ') print(counter.send(5)) print(next(counter)) counter.throw(Exception('ちょっと待って')) print(next(counter)) print(next(counter)) print('100 に行く前に中断') counter.close() print(next(counter))実行結果
100 まで数えるカウンター 1 2 counter に 5 を送ってスキップ 6 7 例外「ちょっと待って」がやってきた! 9 10 100 に行く前に中断 終了します Traceback (most recent call last): File "generator.py", line 38, in <module> print(next(counter)) StopIterationasyncio に続きます。
- 投稿日:2019-02-26T23:31:38+09:00
機械学習実行環境をDockerイメージにする時OpenCVに困ってませんか?
機械学習モデルの実行環境用にDockerイメージを作ろうとして、OpenCVのインストールにハマってしまい丸1日を費やしたので、同じことで悩む人が少しでも減ることを願ってシェアします。
問題点
PythonオフィシャルのDockerイメージに、機械学習に必要なライブラリをpipでインストールして起動し、必要ライブラリをインポートしてバージョン情報を表示するだけの下記プログラムを実行します。
import keras import tensorflow import numpy import PIL import cv2 print('keras:', keras.__version__) print('tensorflow:', tensorflow.__version__) print('numpy:', numpy.__version__) print('pillow:', PIL.__version__) print('cv2:', cv2.__version__)すると、下記のOpenCVが依存しているネイティブ・ライブラリが見つからないというエラーがimportの時点で発生します。
Traceback (most recent call last): File "version.py", line 5, in <module> import cv2 File "/usr/local/lib/python3.6/site-packages/cv2/__init__.py", line 3, in <module> from .cv2 import * ImportError: libgthread-2.0.so.0: cannot open shared object file: No such file or directory解決策
このエラーは、opencv-python自体はpipでインストールされておりcv2は見つかったものの、依存関係にある外部ライブラリが見つからないというエラーになります。「docker pip opencv」などをキーワードに対処方法をググってみると、大半はOpenCVのソースからコンパイルするスクリプトをDockerFileに書こうという記述ばかりが並びちょっと凹みます。
Macでは、pipでopencv-pythonがインストールできて使えていたので、余計に混乱しましたがちょっと冷静になって考えてみると、元々OpenCVはネイティブライブラリでありopencv-pythonはそれに皮を被せただけのラッパーに過ぎないと気づきました。
だったら、apt-getで元々のネイティブライブラリをインストールすれば、依存関係のエラーは解消できるはずと考えてDockerFileを以下のようにしてイメージを作成してみたところエラーは解消されました。
# Replace this line to use python official image as a base. FROM python:3.6.8-slim-stretch LABEL Name=try_ml_docker Version=0.0.1 EXPOSE 50000 # Add the following line to get native library of OpenCV. RUN apt-get update && apt-get -y libopencv-dev WORKDIR /app # Replace this line to copy requirements.txt inside the docker image. ADD ./requirements.txt /app RUN python3 -m pip install -r requirements.txt CMD ["python3", "-m", "try_ml_docker"]requirements.txtには以下の内容を記載します。coremltoolsはkerasとtensorflowのバージョンに著しく依存するので、coremltools2.0を利用する場合はkerasとtensorflowは下記バージョンに指定します。その他のpythonライブラリは最新版を利用します。
coremltools==2.0 keras==2.1.6 tensorflow==1.5.0 numpy pillow opencv-pythonTips
ソースコードやデータセットはVS Code上のものをホストとコンテナの間で共有したいのでカレント・ディレクトリを共有するようにコンテナを実行します。-vパラメーターで渡すのは絶対パスなので、`pwd`コマンドでカレントディレクトリの絶対パスを取得して渡しています。pwdコマンドをくくっているのはバッククォートですので気をつけてください。
$ docker run -v `pwd`:/app -it -d try_ml_docker:latest /bin/bashおわりに
Apple Musicから流れてくる甲斐バンドの「安奈」を聴きながら、やっぱMac最強、Debian/Ubuntuまじめんどくせぇ…
- 投稿日:2019-02-26T23:28:44+09:00
matplotlibで一部のデータをプロットしない方法
はじめに
漫画の掲載順を取得してグラフ化する記事を書いている時に休載で掲載順を取得できない月があり、グラフ化するときに困った。
matplotlibで特定のデータをプロットしない方法が後から分かったのでメモ。環境
# uname -a Linux kali 4.18.0-kali2-amd64 #1 SMP Debian 4.18.10-2kali1 (2018-10-09) x86_64 GNU/Linux # python --version Python 3.7.2+ # pip3 show matplotlib Name: matplotlib Version: 2.2.2問題
例えば、以下のようなデータがあったとする。
month 1月 2月 3月 4月 5月 6月 7月 8月 9月 10月 11月 12月 data 13 15 21 5 10 21 17 15 16 21 13 6月だけデータがない。
Y_data=[13,15,21,5,10, ,21,17,15,16,21,13]Y軸のデータの配列に空きができてしまった。どうすればいいのか。
解決法
プロットしたくないor欠損しているデータにはNoneを代入するとその項目はプロットされなくなる。
Y_data=[13,15,21,5,10,None,21,17,15,16,21,13]こんな感じ。
#!/usr/bin/env python import matplotlib.pyplot as plt X_data=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] Y_data=[13,15,21,5,10,None,21,17,15,16,21,13] month_name=['Jan.','Feb.','Mar.','Apr.','May','Jun.','Jul.','Aug.','Sep.','Oct.','Nov.','Dec.'] plt.xlabel('month') plt.ylabel('data') plt.xticks(X_data,month_name) plt.plot(X_data,Y_data) plt.show()結果
一件落着。
参考文献
python - matplotlibにおけるグラフの始点の指定 - スタック・オーバーフロー
これのお陰で助かりました。ありがとうございます。

- 投稿日:2019-02-26T23:28:44+09:00
matplotlibで特定のデータをプロットしない方法
はじめに
漫画の掲載順を取得してグラフ化する記事を書いている時に休載で掲載順を取得できない月があり、グラフ化するときに困った。
matplotlibで特定のデータをプロットしない方法が後から分かったのでメモ。環境
# uname -a Linux kali 4.18.0-kali2-amd64 #1 SMP Debian 4.18.10-2kali1 (2018-10-09) x86_64 GNU/Linux # python --version Python 3.7.2+ # pip3 show matplotlib Name: matplotlib Version: 2.2.2問題
例えば、以下のようなデータがあったとする。
month 1月 2月 3月 4月 5月 6月 7月 8月 9月 10月 11月 12月 data 13 15 21 5 10 21 17 15 16 21 13 6月だけデータがない。
Y_data=[13,15,21,5,10, ,21,17,15,16,21,13]Y軸のデータの配列に空きができてしまった。どうすればいいのか。
解決法
プロットしたくないor欠損しているデータにはNoneを代入するとその項目はプロットされなくなる。
Y_data=[13,15,21,5,10,None,21,17,15,16,21,13]こんな感じ。
#!/usr/bin/env python import matplotlib.pyplot as plt X_data=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] Y_data=[13,15,21,5,10,None,21,17,15,16,21,13] month_name=['Jan.','Feb.','Mar.','Apr.','May','Jun.','Jul.','Aug.','Sep.','Oct.','Nov.','Dec.'] plt.xlabel('month') plt.ylabel('data') plt.xticks(X_data,month_name) plt.plot(X_data,Y_data) plt.show()結果
一件落着。
参考文献
python - matplotlibにおけるグラフの始点の指定 - スタック・オーバーフロー
これのお陰で助かりました。ありがとうございます。
- 投稿日:2019-02-26T23:19:12+09:00
スポーツがうまくなりたい・・・そうだ、姿勢推定してうまい人との差を取れれば・・・!! ~初級編:colaboratory、openposeで簡単動画の姿勢推定~
はじめに
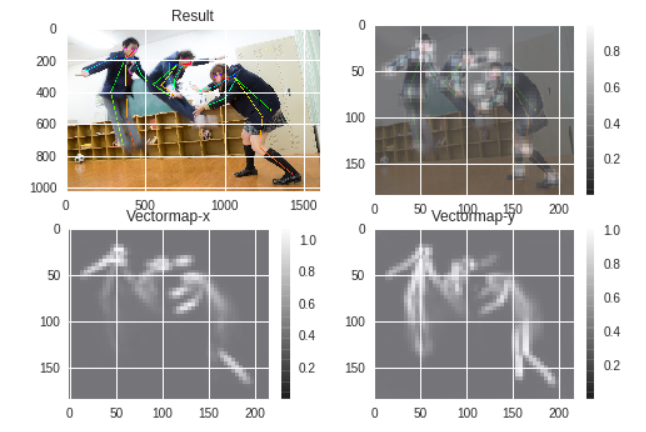
ボルダリングを始めたが全く上手くならない…そうだ!!姿勢推定して他の人と比べて悪いところを具体的に見える形にすれば良いんだ!
というところから、まずはcolaboratoryで姿勢推定(openpose)をやってみようとなりました。
結果↓(全然推定できてない。。。)
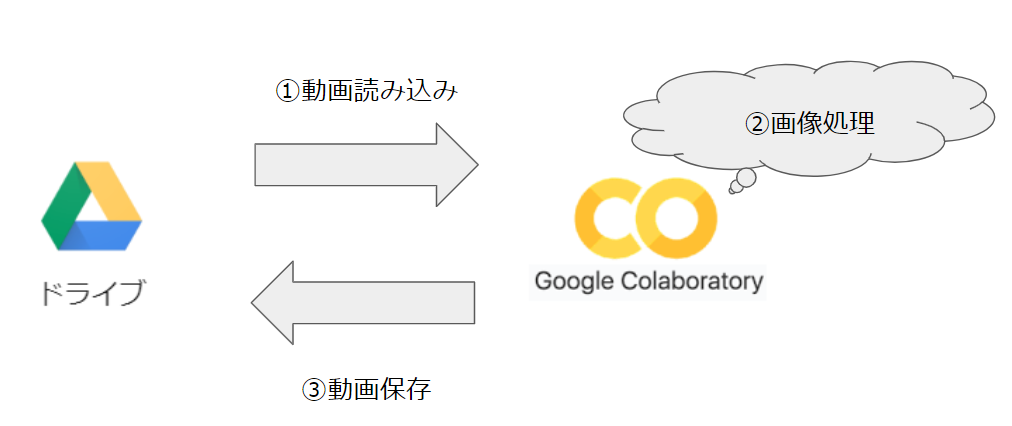
システム構成
今回のシステム構成はこんな感じです。
主に使用するのは、Google Driveとgoogle colaboratoryのみです。
すべてクラウド上なので、ブラウジング用の貧弱なパソコンさえあればOKです。
Tips:colaboratoryとは?
無料で使うことができ、ほとんどの主要ブラウザで動作する、設定不要のJupyterノートブック環境です。 Googleが、機械学習の教育、研究用に使われることを目的に、無償提供しています。
引用:秒速で無料GPUを使う】深層学習実践Tips on Colaboratoryでは、さっそく実装しましょう。
今回は、下記記事の内容を主に参考にしております。@nanako_ut様感謝します。
tensorflow(tf-openpose)で画像から骨格推定手っ取り早くコードを見たい方は、下記をどうぞ!
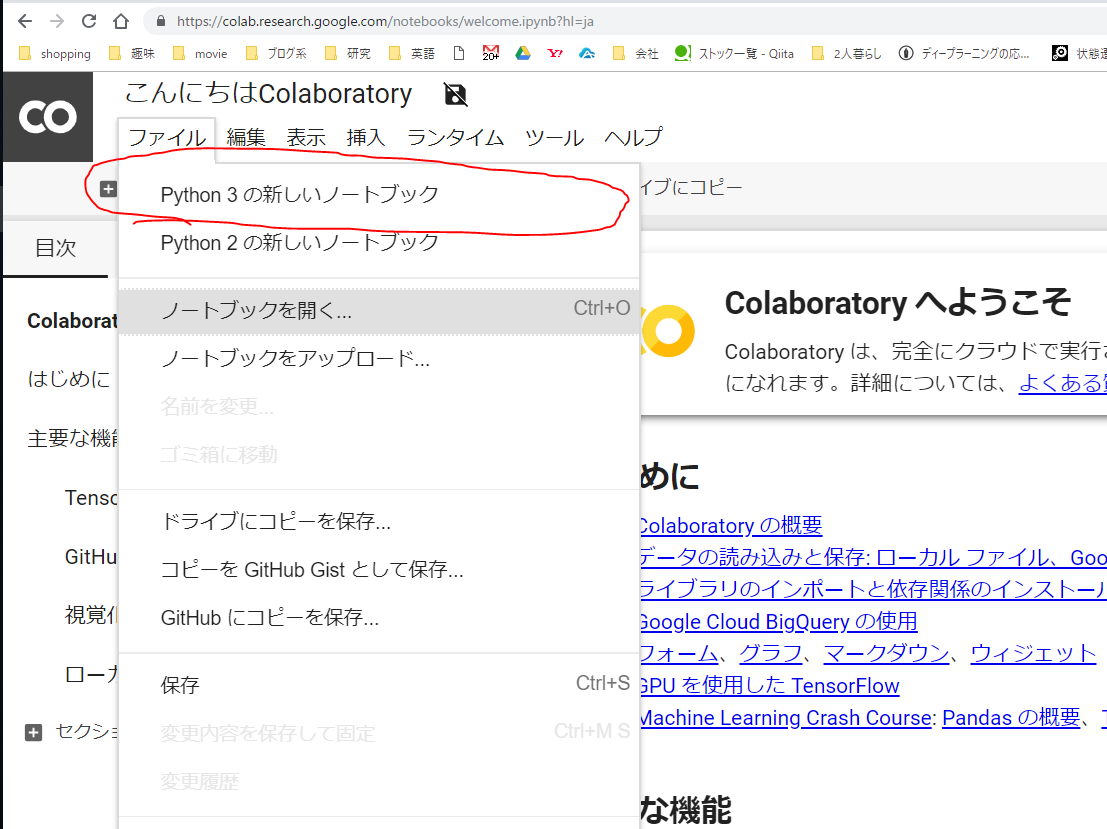
https://github.com/sugupoko/OpenPose_movie/blob/master/OpenPose_movie.ipynbColaboratoryにアクセス!(初めての方向け)
まずは、このURLアクセスしてみてください。
https://colab.research.google.com/notebooks/welcome.ipynb?hl=jaそして、”ファイル→python3の新しいノートブック”をクリックしてください。
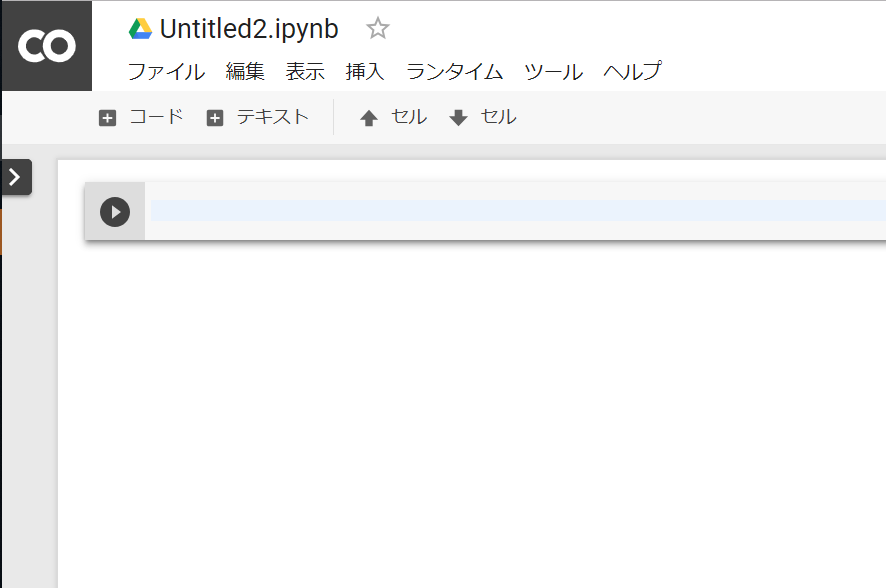
そうすると、下記のような新しいページが表示されます。
これで準備OKです!ここにコードを記述して、”Shift+enter”でpythonスクリプトを簡単に実行できます。
さあ、開発環境整備しましょう
Openposeを動作させるためには、5つの作業が必要となります。
OpenPose_movie.ipynb# SWIG を準備 !apt-get -q -y install swig # TF-openposeをクローン !git clone https://www.github.com/ildoonet/tf-openpose # openpose動作のための、ライブラリをインストール !pip3 install -r requirements.txt # Openposeのモデルをダウンロード %cd models/graph/cmu !bash download.sh %cd ../../../ # pafprocessをインストール %cd tf_pose/pafprocess !ls !swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplace %cd ../../実験!!
まずは、静止画で実験してみる。
こんなのができれば成功です!
OpenPose_movie.ipynb# ネットから画像DL !wget https://www.pakutaso.com/shared/img/thumb/150415022548_TP_V.jpg # 実行!! %run -i run.py --model=mobilenet_thin --resize=432x368 --image=150415022548_TP_V.jpg続いて、動画で実行
ここに一癖あったので、ちょっと苦労しました。
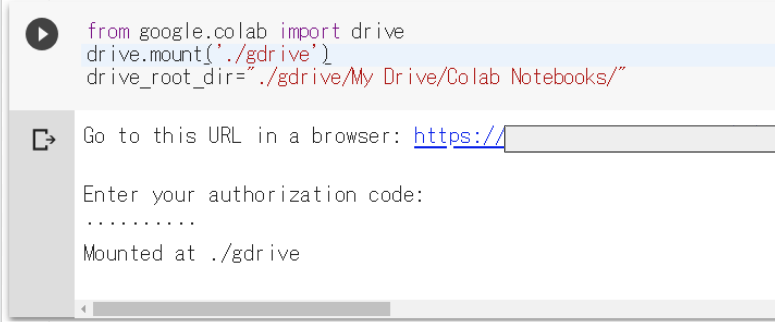
まずは、Googleドライブから動画を読み込むための作業
下記のコードを実行。
OpenPose_movie.ipynbfrom google.colab import drive drive.mount('./gdrive') drive_root_dir="./gdrive/My Drive/Colab Notebooks/"URLにアクセスし次へを連打していくとURLがまた表示されるので、それを入力。
こんな画面が出ればOK。
Googleドライブからcolabへ動画をコピー
下記のようなコマンドを入力することで、コピーすることができます。ディレクトリは個々で異なるので、置いてある動画の場所に応じて変更してください。
OpenPose_movie.ipynb!cp './gdrive/My Drive/Colab Notebooks/movies/climbing2.mp4' "./"最後に、実行です!!
もとからある、run_video.pyだとうまく実行できなかったので、スクリプトを改造し実行しちゃいます。
ちょっとややこしいのが、DNNに入力するサイズは16の倍数を前提としているところです。
なのでスクリプト中では、Wは540 -> 544に変更しています。ただし動画を保存するときは、元のサイズで!OpenPose_movie.ipynbimport argparse import logging import time import os import cv2 import numpy as np import matplotlib.pyplot as plt from tf_pose import common from tf_pose.estimator import TfPoseEstimator from tf_pose.networks import get_graph_path, model_wh movie_name = 'climbing2' img_outdir = './img' os.makedirs(img_outdir, exist_ok=True) # 動画作成 fourcc = cv2.VideoWriter_fourcc('m','p','4', 'v') video = cv2.VideoWriter('ImgVideo2.mp4', fourcc, 30.0, (540, 960)) if __name__ == '__main__': parser = argparse.ArgumentParser(description='tf-pose-estimation Video') outimg_files = [] count = 0 w = 544 h = 960 e = TfPoseEstimator(get_graph_path('mobilenet_thin'), target_size=(w, h)) # 動画出力先 cap = cv2.VideoCapture('climbing2.mp4') # 動画用の画像作成 while True: ret, image = cap.read() if ret == True: # 1フレームずつ処理 count += 1 if count % 100 == 0: print('Image No.:{0}'.format(count)) humans = e.inference(image, resize_to_default=(w > 0 and h > 0), upsample_size=4) image = TfPoseEstimator.draw_humans(image, humans, imgcopy=False) # 画像出力 outimg_file = '{}/{:05d}.jpg'.format(img_outdir, count) cv2.imwrite(outimg_file, image) video.write(image) else: break video.release()最後に保存
最後にGoogleドライブのコピーで終了です。
OpenPose_movie.ipynb!cp './ImgVideo2.mp4' "./gdrive/My Drive/Colab Notebooks/movies/"まとめ
OpenPoseで全然推定できなかったので、どう改善していくか考えなきゃいけません。。。
例えば、データセットを増やすとか?(いやいや厳しい。。。)下記の記事のように野球のスイングだと取れているんですけどねぇ。。。
https://qiita.com/nanako_ut/items/1a9ce5d4eca672b38d2d良いアイデアや、論文を知っている方募集しています!!
とはいえ、
姿勢推定のハードルは高くないので、みなさん試しにやってみましょう!!
python, colaboratoryの初心者でも数時間でできちゃいます。

- 投稿日:2019-02-26T23:07:08+09:00
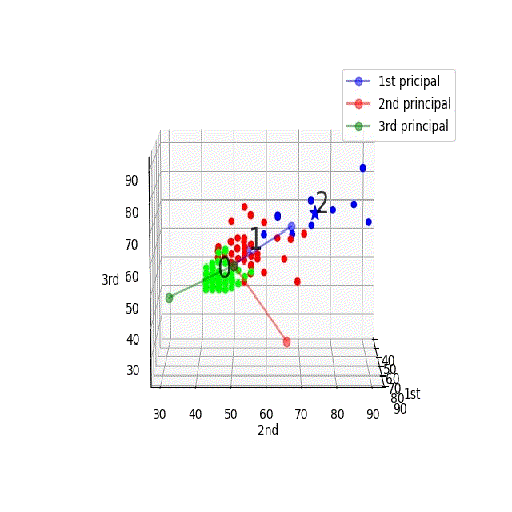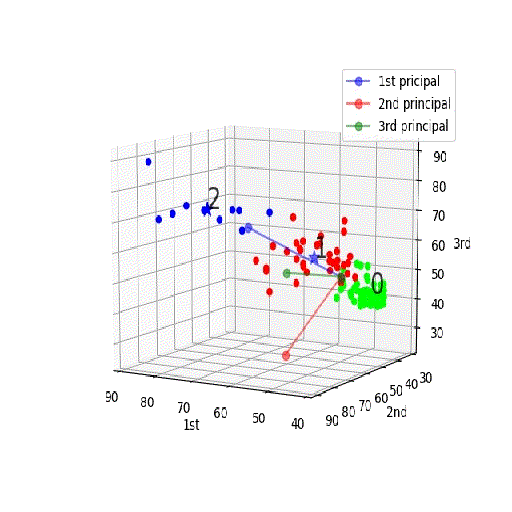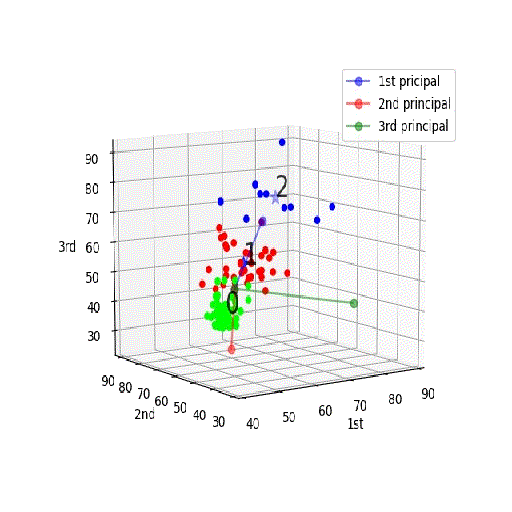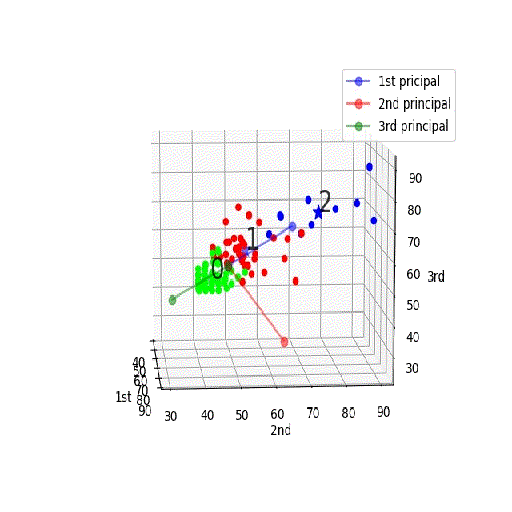
【機械学習入門】「PCA+K-meansクラスタリング」を3D見える化♬
頭の中ではきっとこんなイメージ;PCA+K-meansクラスタリング
Qiitaへのアップの都合上、若干サイズや分解能を犠牲にしたが、うまく表示できました。
つまり、第一主成分が一番広がりが大きく(分散が大きく)その広がりの方向に延びており(固有値問題の解)、二番目が第二主成分(固有値問題の二番目の解)。。。となっており、今回のように各要素を偏差値で置き換えてPCA分析するのが正解なのが分かる。
【参考】
・[Python][Scikit-learn]主成分分析を用いた次元削減、主成分ベクトルを用いた予測と線形回帰による予測の比較やったこと
・競馬騎手データをとりあえず3次元データのみを利用してクラスタリングしてみる
・3dプロットしてみる・競馬騎手データを3次元のみのデータを利用してクラスタリングしてみる
データは偏差値にしたものを利用しました。
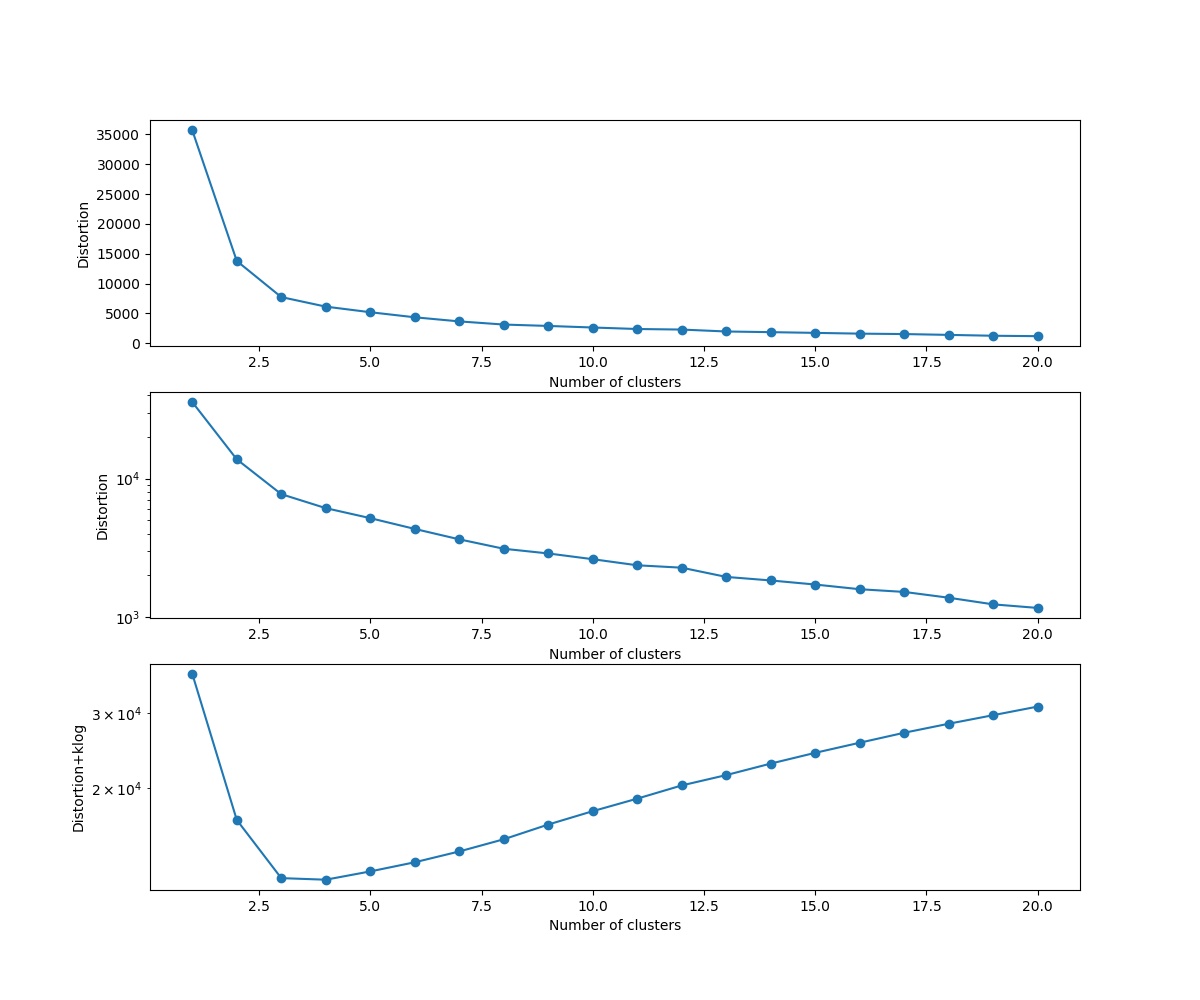
普通にDistorsionは以下のようになっています。だからクラスタは3クラスか4クラス
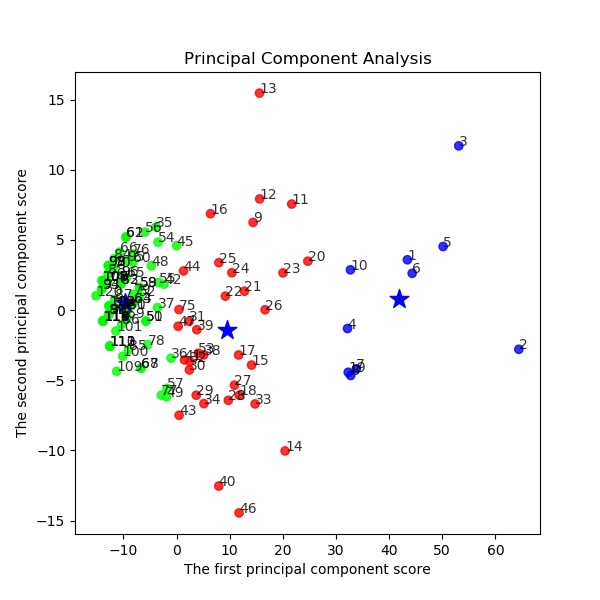
そして、PCAの第一主成分と第二主成分面でのプロットは以下のとおり
※上記の回転を第一主成分vs第二主成分面でとめたものとみることもできる
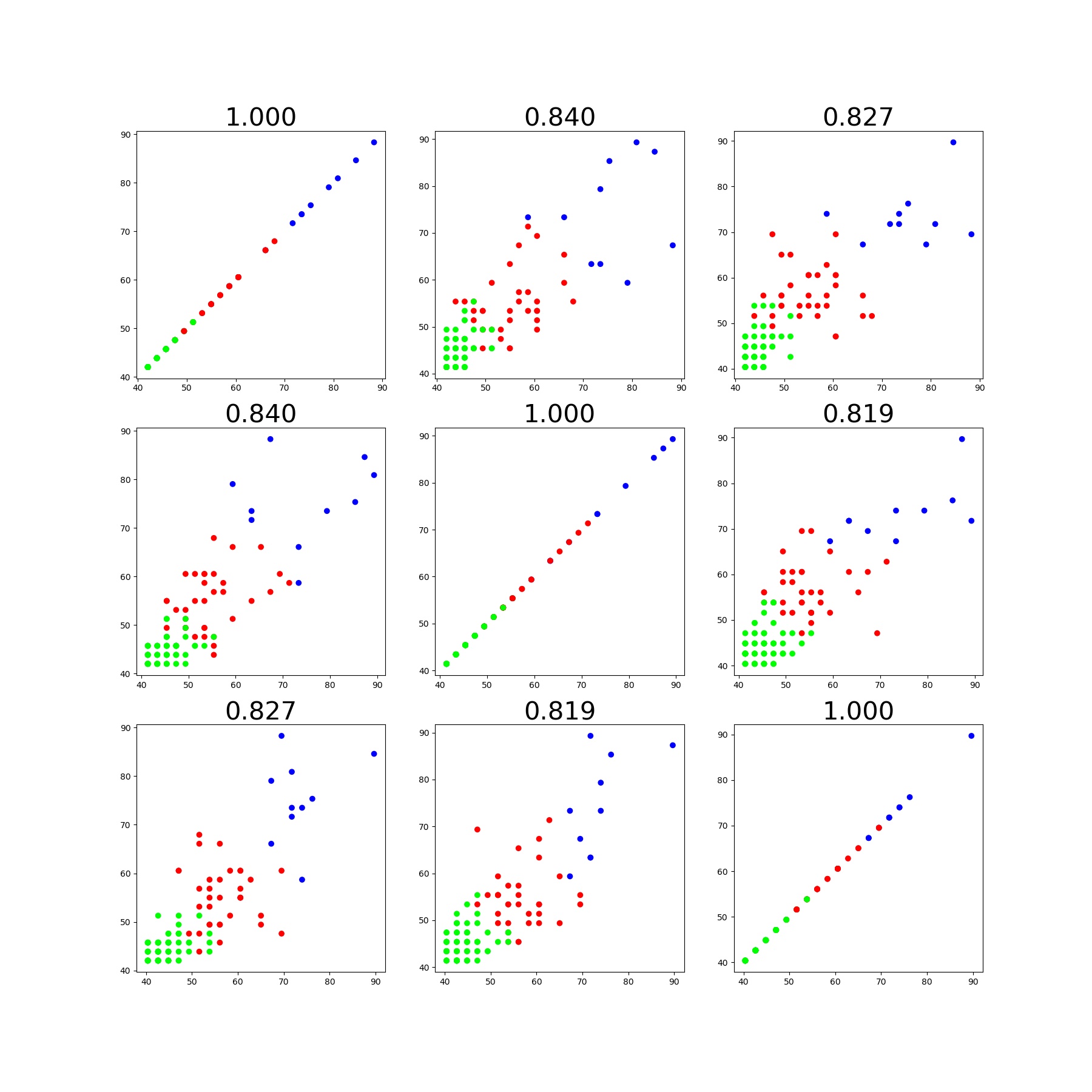
相関は以下のとおり
※これも回転して1stvs2nd、2ndvs3rd, そして3rdvs1st面で止めた絵になっているはずです
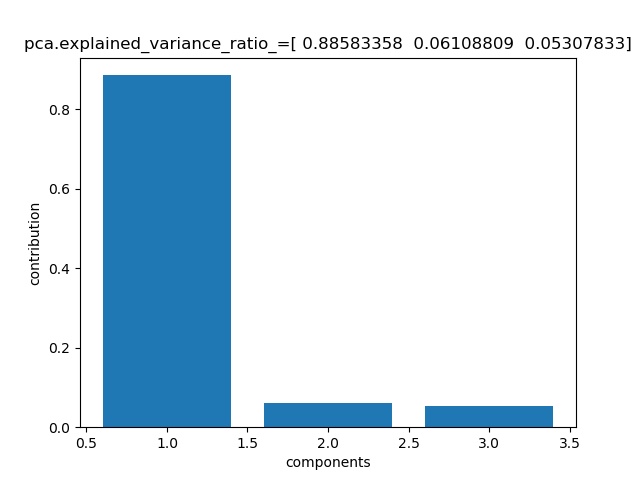
そして、第一主成分、第二主成分、そして第三主成分の寄与は以下の図のとおり
今回は、優勝、二着、三着のデータ120個を使っているので、上記のように相関が高く、第一主成分の寄与が88%以上と高く、第二と第三が6%、5%と小さいです。
ちなみに、第一、二、三主成分の軸方向のベクトル座標は以下のようになっています。
※固有値だからお互い直交(ベクトルの内積0)してますv_pca0=[ 0.57958236 0.5776769 0.57478143] v_pca1=[ 0.25818473 0.53882344 -0.80187901] v_pca2=[ 0.77293269 -0.61315472 -0.1631452 ]・3dプロットしてみる
今回は、少しずるしてもともとの座標で描画しています。
ということで、肝心な部分のコードは以下のとおり
※コード全体はおまけに記載します
まず、入力データに対して主成分分析をpcaで実施します。
それぞれの第一主成分などはpca.components_[0]などで求められます。#主成分分析の実行 pca = PCA() pca.fit(df.iloc[:, 1:]) PCA(copy=True, n_components=None, whiten=False) v_pca0 = pca.components_[0] v_pca1 = pca.components_[1] v_pca2 = pca.components_[2]出力してみると、元の座標軸での座標で示されています。
そこから、X座標などを分割します。
※ベクトルは本来原点からの座標になっているので、今回の偏差値に合わせて原点を(50,50,50)にずらします
第三主成分までのベクトルを引きたいのでそれぞれの座標(X,Y,Z)として以下のように求めますprint("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) X_pca1=[50,50+30*v_pca0[0]] Y_pca1=[50,50+30*v_pca0[1]] Z_pca1=[50,50+30*v_pca0[2]] X_pca2=[50,50+30*v_pca1[0]] Y_pca2=[50,50+30*v_pca1[1]] Z_pca2=[50,50+30*v_pca1[2]] X_pca3=[50,50+30*v_pca2[0]] Y_pca3=[50,50+30*v_pca2[1]] Z_pca3=[50,50+30*v_pca2[2]]ラベルの表示もしたいので、以下のように定義します。
# 分類結果のラベルを取得する labels = np.unique(kmeans_model.labels_)そして、これらを使ってangle毎にプロットを表示します。
def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d')カメラ視点を以下のとおり定義します。
【参考】
・how to set “camera position” for 3d plots using python/matplotlib?ax.view_init(elev = 10., azim = angle) #視点以下で、求まったクラスタの中心近くにlabelsで定義した名前(0,1,2)をtext記載します。
for kx, ky,kz, name in zip(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], labels): ax.text(kx, ky,kz, name, alpha=0.8, size=20)そして上記で定義した第一成分などの軸を記載します。
ax.plot(X_pca1,Y_pca1,Z_pca1, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca3,Y_pca3,Z_pca3, c='g', marker='o', alpha=0.5, label='3rd principal')以下で本来のデータを分類されたcolorsの色でプロットします。
ax.scatter(df.iloc[:, 1], df.iloc[:, 2], df.iloc[:, 3], c=colors, marker='o', alpha=1)次にクラスタの中心に大き目(s=100)なプロットをします。
ax.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], c = "b", marker = "*", s = 100)最後に軸ラベルと凡例(凡例は上記のプロットのlabelで定義したもの)を記載します。
ax.set_xlabel('1st') ax.set_ylabel('2nd') ax.set_zlabel('3rd') ax.legend() plt.pause(0.01) plt.savefig('k-means/keiba3/pca3d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close()角度は360度を1度ずつ計算しました。
容量の関係で上記のGifアニメーションは5度ずつのデータを表示しています。for angle in range(0, 360, 1): show_with_angle(angle)まとめ
・PCA+K-meansクラスタリングを3D見える化してみた
・思い通りのGifアニメーションとなった・さらなら高次元の見える化に挑戦したい
おまけ
import pandas as pd # データフレームワーク処理のライブラリをインポート import matplotlib.pyplot as plt from pandas.tools import plotting # 高度なプロットを行うツールのインポート from sklearn.cluster import KMeans # K-means クラスタリングをおこなう from sklearn.decomposition import PCA #主成分分析器 from mpl_toolkits.mplot3d import Axes3D import numpy as np df = pd.read_csv("keiba100_std3.csv", sep=',', na_values=".") # データの読み込み df.iloc[:, 1:].head() #解析に使うデータは2列目以降 print(df.iloc[:, 1:]) X=df.iloc[:, 1:] plotting.scatter_matrix(df[df.columns[1:]], figsize=(6,6), alpha=0.8, diagonal='kde') #全体像を眺める plt.savefig('k-means/keiba3/keiba3_scatter_plot4.jpg') plt.pause(1) plt.close() distortions = [] distortions1 = [] for i in range(1,21): # 1~20クラスタまで一気に計算 km = KMeans(n_clusters=i, init='k-means++', # k-means++法によりクラスタ中心を選択 n_init=10, max_iter=300, random_state=0) km.fit(df.iloc[:, 1:]) # クラスタリングの計算を実行 distortions.append(km.inertia_) # km.fitするとkm.inertia_が得られる UF = km.inertia_ + i*np.log(20)*5e2 # km.inertia_ + kln(size) distortions1.append(UF) fig=plt.figure(figsize=(12, 10)) ax1 = fig.add_subplot(311) ax2 = fig.add_subplot(312) ax3 = fig.add_subplot(313) ax1.plot(range(1,21),distortions,marker='o') ax1.set_xlabel('Number of clusters') ax1.set_ylabel('Distortion') ax2.plot(range(1,21),distortions,marker='o') ax2.set_xlabel('Number of clusters') ax2.set_ylabel('Distortion') ax2.set_yscale('log') ax3.plot(range(1,21),distortions1,marker='o') ax3.set_xlabel('Number of clusters') ax3.set_ylabel('Distortion+klog') ax3.set_yscale('log') plt.pause(1) plt.savefig('k-means/keiba3/keiba3__Distortion.jpg') plt.close() s=3 # この例では s個のグループに分割 (メルセンヌツイスターの乱数の種を 10 とする) kmeans_model = KMeans(n_clusters=s, random_state=10).fit(df.iloc[:, 1:]) # 分類結果のラベルを取得する labels = kmeans_model.labels_ print(labels) ################## print(labels) ################### # それぞれに与える色を決める。 color_codes = {0:'#00FF00', 1:'#FF0000', 2:'#0000FF', 3:'#00FFFF' , 4:'#007777', 5:'#f0FF00', 6:'#FF0600', 7:'#0070FF', 8:'#08FFFF' , 9:'#077777',10:'#177777', 11:'#277777', 12:'#377777', 13:'#477777' , 14:'#577777'} # サンプル毎に色を与える。 colors = [color_codes[x] for x in labels] fig, axes = plt.subplots(nrows=3, ncols=3, figsize=(18, 18),sharex=False,sharey=False) for i in range(1,4): for j in range(1,4): ax = axes[i-1,j-1] x_data=df[df.columns[i]] y_data=df[df.columns[j]] ax.scatter(x_data,y_data,c=colors) cor=np.corrcoef(x_data,y_data)[0, 1] ax.set_title("{:.3f}".format(cor),fontsize=30) plt.savefig('k-means/keiba3/keiba3_correlation.jpg') plt.close() #主成分分析の実行 pca = PCA() pca.fit(df.iloc[:, 1:]) PCA(copy=True, n_components=None, whiten=False) v_pca0 = pca.components_[0] v_pca1 = pca.components_[1] v_pca2 = pca.components_[2] print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) X_pca1=[50,50+30*v_pca0[0]] Y_pca1=[50,50+30*v_pca0[1]] Z_pca1=[50,50+30*v_pca0[2]] X_pca2=[50,50+30*v_pca1[0]] Y_pca2=[50,50+30*v_pca1[1]] Z_pca2=[50,50+30*v_pca1[2]] X_pca3=[50,50+30*v_pca2[0]] Y_pca3=[50,50+30*v_pca2[1]] Z_pca3=[50,50+30*v_pca2[2]] # 分類結果のラベルを取得する labels = np.unique(kmeans_model.labels_) feature = pca.transform(df.iloc[:, 1:]) x,y,z = feature[:, 0], feature[:, 1], feature[:, 2] X=np.c_[x,y,z] def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) for kx, ky,kz, name in zip(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], labels): ax.text(kx, ky,kz, name, alpha=0.8, size=20) ax.plot(X_pca1,Y_pca1,Z_pca1, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca3,Y_pca3,Z_pca3, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(df.iloc[:, 1], df.iloc[:, 2], df.iloc[:, 3], c=colors, marker='o', alpha=1) ax.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], c = "b", marker = "*", s = 100) ax.set_xlabel('1st') ax.set_ylabel('2nd') ax.set_zlabel('3rd') ax.legend() plt.pause(0.01) plt.savefig('k-means/keiba3/pca3d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 1): show_with_angle(angle) print("pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3], pca.explained_variance_ratio_, align = "center") plt.title("pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.xlabel("components") plt.ylabel("contribution") plt.savefig('k-means/keiba3/keiba3_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() # データを主成分空間に写像 = 次元圧縮 feature = pca.transform(df.iloc[:, 1:]) x,y = feature[:, 0], feature[:, 1] X=np.c_[x,y] kmeans_model = KMeans(n_clusters=s, random_state=10).fit(X) #PCA平面(x、y)で再度クラスタリング plt.figure(figsize=(6, 6)) for kx, ky, name in zip(x, y, df.iloc[:, 0]): plt.text(kx, ky, name, alpha=0.8, size=10) plt.scatter(x, y, alpha=0.8, color=colors) plt.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], c ="b" , marker = "*", s = 200) plt.title("Principal Component Analysis") plt.xlabel("The first principal component score") plt.ylabel("The second principal component score") plt.savefig('k-means/keiba3/keiba3_std2_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()
- 投稿日:2019-02-26T22:29:36+09:00
【pandas】最も近い値でマージするmerge_asof関数
はじめに
今まで存在を知らなかったのですが、めちゃめちゃ便利なのでメモ。
pandas の merge_asof関数について紹介します。
初投稿ですのでお手柔らかに。基本的な例
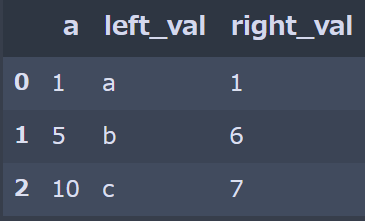
import pandas as pd df_left = pd.DataFrame({'a': [1, 5, 10], 'left_val': ['a', 'b', 'c']}) df_right = pd.DataFrame({'a': [1, 2, 3, 6, 7], 'right_val': [1, 2, 3, 6, 7]})と2つのテーブルがあったとします。
このとき、
pd.merge_asof(df_left, df_right, on='a', direction='nearest')と書くだけで、df_left のカラム['a'] に対し、df_right['a'] の最も近い値をキーとして、
2つのテーブルを結合することができます。
図のように、
- df_left['a'] = 1 に最も近い、df_right['a'] = 1の right_val を結合
- df_left['a'] = 5 に最も近い、df_right['a'] = 6の right_val を結合
- df_left['a'] = 10 に最も近い、df_right['a'] = 7の right_val を結合
していることが分かります。
許容する範囲の指定
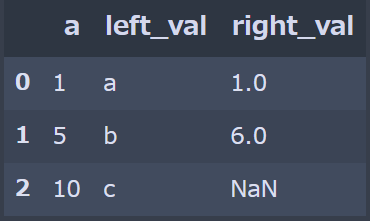
"tolerance" という引数を使うことで、最も近い値をどこまで許容するか、
指定することができます。import pandas as pd pd.merge_asof(df_left, df_right, on='a', direction='nearest', tolerance=2)
a=10 に最も近い df_right['a'] は7ですが、
指定した tolerance=2 よりも差が大きいので、NaNが入っています。参考
公式リファレンス:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.merge_asof.html
- 投稿日:2019-02-26T21:25:01+09:00
本当の初心者でもわかるBottleの使い方【@route】
半分忘備録、半分共有したい思いで書いてます。
この記事はいろいろな記事を見て、「Bottle動いた!」
「これだけで動くなんてすげえ!」…知りたいのはそこじゃなくて具体的な使い方なんだよ!!!!
ってなった人に対する記事です。私自体がいろいろな言語を触るも仕事では一切使いませんし、何だったら今はpythonはおろかVBAともほとんど縁がない仕事しています。
そんな人間がBottleをつかってwebアプリ?を作ろうともがく記事です。対象と筆者のレベル
対象:ちゃんと意味が分かりながら触りたい人向け
著者のレベル(全般):実務経験なし。基本情報、応用情報合格。
筆者のレベル(コーディング):読めって言われたら定義とかループとかならわかるけど、それ以上は…といった感じ。
筆者の特徴:学校の先生ができる(しているとはいっていない)ので、教えるほうにスキルポイント振ってますbottleのインストール
これはほかの記事を見て頑張ってください。私はpycharmを使っているので、設定からインタープリターを+し、bottleと検索して使えるようになりました。
bottleのhello worldと@route の使い方
要約:「@route('/○○/')のurlがリクエストされたら以下を返すよ!」
初投稿(2019/02/26)時点ではこれ以外のことはしっかりマニュアル読まないとわからないレベルでした。
便利なことは
@route('/') ←これが最小単位
@route('/○○/')←色々足していける。urlでよく見る感じ
・・・・・・・
としておけば、あれとこれとそれの時に実行するという風にできることです。同じことをたくさん書かなくていいのでとても便利で好き。ほかの言語もこういうことできるんでしょうねきっと。bottleのhello world
helloworld.pyfrom bottle import route, run @route('/')#今回は一番簡単な奴 def hibottle():#関数名なんてなんでもよい return "so easy! :)"#ここの文面が出てくる run(host='localhost',port=8080,debug=True)※コピペするとスペースとか微妙なところでエラーはいて実行できないので注意
実行すると出てくる画面にhttp://…みたいなのがでるのでそれをクリックするとhello world成功です。
この段階ではファイル名なんてなんでもよいです。run(○○)はローカルサーバーを立てるおまじないなので、特に気にしないで大丈夫です。ここでエラーが出る時はそもそもbottleが入っていないか、ポートが悪いことが多そうです。8080がなんたらっていう記事を探しましょう。
もうすこし遊びたい奴のhello world
helloworld2.pyfrom bottle import route, run @route('/')#今回は一番簡単な奴 @route('/hi/')#hiでも同じものが出る def hibottle():#関数名なんてなんでもよい return "so easy! :)"#ここの文面が出てくる @route('/hi/im/gosu/') def imnotgosu():#関数名なんてなんでもよい return "support is so easy dude? :)"#わかるひとにはわかる run(host='localhost',port=8080,debug=True)※コピペするとスペースとか微妙なところでエラーはいて実行できないので注意
実行して出てきたページからurl末尾を '/'→'/hi/im/gosu/' にすると2つ目に設定した文字が出てきます。また '/hi/' も設定してある(こちらは1つ目)のでページが表示されますが、 '/hi/im/' は設定をしていないので、404 Notfoundでエラーになります。
これ弄っているだけで個人的にはまあまあ楽しいです。
また更新します。
- 投稿日:2019-02-26T21:12:05+09:00
redis-pyを使ったzaddコマンドの引数について (v3.2.0)
はじめに
インメモリKVS型DBのRedisをPythonから呼び出す方法として、redis-pyモジュールを使うやり方があります。
このredis-pyにZADDと呼ばれるデータを格納するコマンドがあります。
このZADDの引数に変更があり、古い記事の呼び出し方ではエラーを吐くので、新しい呼び出し方を共有します。Version
Redis本体は5.0.3, redis-pyはv3.2.0を想定
Redis 5.0.3 (00000000/0) 64 bittikeda:Redis tikeda$ pip show redis Name: redis Version: 3.2.0 Summary: Python client for Redis key-value store Home-page: https://github.com/andymccurdy/redis-py Author: Andy McCurdy Author-email: sedrik@gmail.com License: MIT Location: /usr/local/var/pyenv/versions/3.7.0/lib/python3.7/site-packages Requires: Required-by:ZADDとは
SortedSet型でデータを格納するコマンドです。
SortedSet型は、その名の通り順序付けされた集合の型です。
各データがscoreと呼ばれる値を持っており、それを基にソートされます。参考: http://redis.shibu.jp/commandreference/sortedsets.html
呼び出し方
これまではzadd(key, score, value)やzadd(key, value, score)といった形でコマンドを叩いていましたが、現バージョンからは以下のようになりました。
import redis r = redis.Redis(host='localhost', port=6379, db=0) dict = {} dict['value'] = 10 r.zadd('aaa', dict) print(r.zrangebyscore('aaa', '-inf', '+inf'))ここではZRANGEBYSCOREコマンドを用いて確認しています。
辞書型になったので、まとめてvalueを与えることも可能です。
dict = {} dict['value'] = 10 dict['has'] = 11 dict['to'] = 12 dict['be'] = 13 dict['set'] = 14 dict['here'] = 15 r.zadd('bbb', dict)終わりに
redis-pyですが、いつからかZADDコマンドの引数順序(latitudeとlongitudeの順序)が変わっていたりと
闇深なカオスな印象をうけますね
- 投稿日:2019-02-26T21:05:50+09:00
sqlalchemy で euc-jp を取り扱う
errorsqlalchemy.exc.ProgrammingError: (ProgrammingError) You must not use 8-bit bytestrings unless you use a text_factory that can interpret 8-bit bytestrings (like text_factory = str). It is highly recommended that you instead just switch your application to Unicode strings. u'INSERT INTO category (parent_id, category_name) VALUES (?, ?)' (999, '\xa4\xa2')対策from sqlalchemy.interfaces import PoolListener class SetTextFactory(PoolListener): def connect(self, dbapi_con, con_record): dbapi_con.text_factory = lambda x: unicode(unescape(x), "euc-jp", "ignore") from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session, sessionmaker def create_session(): engine = create_engine('sqlite:///./test.db', echo=False, listeners=[SetTextFactory()]) Session = scoped_session(sessionmaker(autocommit=False, autoflush=False, bind=engine))参考
- 投稿日:2019-02-26T19:45:02+09:00
No.041【Python】無限大を表す" inf "について②
前回に引き続き、無限大を表す「inf」について書いていきます。
I'll write about "inf()",which indicates infinity.
■ infによる判定:==/math.isinf()/ np.isinf()
Judgement by "inf"
>>> # 参考例:float型 最大値を超える・範囲内の値 >>> # eXXX = 10のXXX乗とする >>> import math >>> import numpy as np >>> >>> print(1e1000) inf >>> >>> print(1e100) 1e+100■ == 演算子
Calculation with "=="
>>> # 値が無限であるかを判定 >>> >>> print(1e1000 == float("inf")) True >>> >>> print(1e100 == float("inf")) False>>> # infの作成方法は複数あり、どれを使っても問題はない >>> >>> print(float("inf") == math.inf == np.inf) True >>> >>> print(1e1000 == math.inf) True >>> >>> print(1e1000 == np.inf) True >>> >>> print(1e100 == math.inf) False >>> >>> print(1e100 == np.inf) False>>> # 以下式でも、判定結果は真(True)となる >>> >>> print(float("inf") == float("inf") * 100) True■ mathモジュール:math.isinf( )
Math module as for inf
>>> # math.isinf()の場合、負の無限に対しても真(True)を返す >>> >>> print(math.isinf(1e1000)) True >>> >>> print(math.isinf(1e100)) False >>> >>> print(math.isinf(-1e1000)) True■ NumPy:np.isinf( )
NumPy as for inf
>>> # 上記 mathモジュールと同様、負の無限に対しても真(True)を返す >>> >>> print(np.isinf(1e1000)) True >>> >>> print(np.isinf(1e100)) False >>> >>> print(np.isinf(-1e1000)) True>>> # 引数にNumPy配列 "ndarray" を指定可能 >>> # 正負のing → "True", その他 → Falseとなる同サイズの"ndarray"を返す >>> >>> a_inf = np.array([1, np.inf, 3, -np.inf]) >>> >>> print(a_inf) [ 1. inf 3. -inf] >>> >>> print(type(a_inf)) <class 'numpy.ndarray'> >>> >>> print(np.isinf(a_inf)) [False True False True] >>> >>> >>> a_inf[np.isinf(a_inf)] = 0 >>> >>> print(a_inf) [1. 0. 3. 0.]■ infの比較
Infinite comparison
>>> # 比較演算子(>, <)でinfの比較が可能 >>> >>> # float および inf の値と比較が可能 >>> # ただし、nanの比較は Falseとなる■ floatとの比較
Comparison with "float"
>>> import sys >>> >>> print(sys.float_info.max) 1.7976931348623157e+308 >>> >>> print(float("inf") > sys.float_info.max) True >>> >>> print(-float("inf") < sys.float_info.max) True■ nanとの比較
Comparison with "nan"
>>> # 前述の通り、 nanとの比較は全て"False"となる >>> >>> print(float("inf") > float("nan")) False >>> >>> print(float("inf") < float("nan")) False >>> >>> print(float("inf") == float("nan")) False■ 整数との比較
Calculation with "integer"
>>> print(float("inf") > 100) True>>> # Python3では、integerの上限はない >>> # ただし、infはそれよりも値が大きい >>> >>> large_int = int(sys.float_info.max) * 100 >>> >>> print(large_int) 17976931348623157081452742373170435679807056752584499659891747680315726078002853876058955863276687817154045895351438246423432132688946418276846754670353751698604991057655128207624549009038932894407586850845513394230458323690322294816580855933212334827479782620414472316873817718091929988125040402618412485836800 >>> >>> print(type(large_int)) <class 'int'> >>> >>> print(large_int > sys.float_info.max) True >>> >>> print(float("inf") > large_int) True>>> # float最大値以下のintの値は、float()でfloatに変換可能 >>> # ただし、floatの最大値を超える場合なNG >>> >>> print(float(10**306)) 1e+306 >>> >>> print(float(10**309)) Traceback (most recent call last): File "<pyshell#156>", line 1, in <module> print(float(10**309)) OverflowError: int too large to convert to float随時に更新していきますので、
定期的な購読をよろしくお願いします。
I'll update my article at all times.
So, please subscribe my articles from now on.本記事について、
何か要望等ありましたら、気軽にメッセージをください!
If you have some requests, please leave some messages! by You-Tarin

- 投稿日:2019-02-26T18:22:38+09:00
AtCoderの問題を分類しました
はじめに
2019年1月から AtCoder を始めました。問題の復習と自分の技術力を分析するために、問題を解いて得られた知見をメモとして残しています。周りの方から「知見を共有して欲しい」「公開することでコードレビューされて、技術力がより高まるよ」などのアドバイスを頂いたため、本記事を執筆する運びとなりました。
これまでの取り組みは下記ブログに記載しています。参考のためにリンクを記載しますが、本記事とは論点が異なるため、読み飛ばして頂いて構いません。
本記事について
記事の構成
本記事では分類観点を定義し、分類観点ごとに問題を分類します。各分類観点では、サンプルコードと解答例を記載しています。サンプルコードと解答例の定義は下記の通りです。
- サンプルコード:問題から得られた知見と検証によって得られた知見を整理したコード
- 解答例:提出したACのコード(一部、TLEのコードがあります。その場合は、「解答例(TLE)」と記載しています。)
実行環境
サンプルコードは下記環境で動作することを確認しています。
$ python --version Python 3.6.4解答例はAtCoderの下記言語でACになることを確認しています。
Python3 (3.4.3)分類観点の定義
分類観点の定義は下記の通りです。1つの問題から複数の観点で分類できる問題は、複数の観点に分類します。
- 実装観点:実装方式を知っていれば解ける問題
- 処理観点:処理方式を知っていれば解ける問題
- 数学観点:数学的知見を知っていれば解ける問題
- アルゴリズム観点:アルゴリズムを知っていれば解ける問題
- 計算量観点:計算量を工夫すれば解ける問題
分類する問題の範囲
分類する問題の範囲は下記の通りです。ABC-C問題とARC-A問題は一部問題が同じです。同じ問題の場合、ABC-C問題として扱います。
- ABC‐A問題(ABC001 - ABC119)
- ABC‐B問題(ABC001 - ABC119)
- ABC‐C問題(ABC001 - ABC119)
- ARC‐A問題(ARC001 - ABC103)
分類する対象の問題
本記事では、上記分類範囲で示したすべての問題が記載されているわけではありません。私が上記分類観点で知見が得られた問題のみを記載しています。そのため、参考として私がAtCoderを始めた頃の知識・能力を示します。
- コーディングができる
- 四則演算
- 簡易な if-else文 / for文 / while文
- コーディングができない
- 入出力処理
- 三項演算
- bit演算 / bool演算
- リスト処理 / タプル処理 / 辞書処理 / 集合処理
- 正規表現
- 各アルゴリズム
- 計算量を工夫したコード
- AtCoderの問題解答レベル
- ABC-A問題が5割解ける
- ABC-B問題が3割解ける
- ABC-C問題は全く解けない
本記事の対象者
下記のような方に向けた記事を想定しています。
- AtCoderを始めようとしている方(使用言語の候補としてPython3がある方)
- AtCoderをPython3以外でやっている方(使用言語をPython3にしたい方)
- Python3のコードバリデーションを参考にしたい方
- Python3の仕様に依らない問題分類を参考にしたい方(処理観点 / 数学観点 / アルゴリズム観点 / 計算量観点)
- 本記事の内容 / コードをレビューして頂ける方
コーディング規約
利用しているコーディング規約はありません。しかし、下記の方針でコーディングを行っています。※あくまで方針なので、厳密にコーディングしている訳ではありません。
- インデントは4とする
- 1行の長さは定義しない
- 空行はしない(可読性のために一部入れることもある)
- importは行を分けて定義する
- クオーテーションはダブルクオテーションで統一する
- 不要な半角スペースは入れない(可読性のために一部入れることもある)
- 1処理は1行で記載する
- 変数 / 型を1行で定義できる場合、1行で定義する
- if文 / for文 / while文の処理行数が1行の場合、文と処理を1行でコーディングする
- 命名規則はない
- 自分の直感に合うコーディングをする
記事の更新方針
分類範囲の問題で未分類 / 未解答の問題があります。また、今後はABC-D問題を解く予定です。そのため、本記事は今後、下記の更新する予定です。更新情報は編集履歴より確認をお願い致します。
- 未分類問題の追加
- 未解答問題の追加
- ABC-D問題の追加
知的財産
本記事に記載しているコードはすべて私が作成したコードです。また、AtCoderにおける知的財産権は下記の通りです。
知的財産権
1.本サービスに対して投稿されたプログラムの所有権と著作権は、そのプログラムを作成したユーザに帰属します
2.本サービスを構成する文章、画像、プログラムその他のデータ等についての一切の権利(所有権、知的財産権、肖像権、パブリシティー権等)は、ユーザ自身が作成したものを除き、弊社又は当該権利を有する第三者に帰属しています
3.ユーザ自身が作成した著作物を本サービスを通じて掲載した場合、弊社が宣伝告知等に利用することを許諾するものとします。また、かかる使用に際して、当該ユーザは著作者人格権を行使しないものとします本記事に記載しているコードを私的利用する場合、自由に活用して頂いて構いません。また、作成したコードは Github で公開しています。コードを転用する / 商業利用する場合は、本記事のコメント欄 / メール / Twitter で事前にご相談をお願い致します。
学習方法の特性上「他人のコードに酷似している」ことがあります。気分を害される方がいましたら、相談の上で引用元の記載 / 記事の更新 / 文章の削除等に対応しますので、ご連絡をお願い致します。※学習方法は ブログ に記載しています。
最後に
最後となりましたが、読者の方におかれましては初心者競プロerの成長過程と思い、温かく見守って頂けると幸いです。また、このような学習環境を提供して頂いている AtCoder社、SNS等で関わって頂いている競プロerの方に感謝を申し上げます。
以下から分類一覧となります。
実装観点
入力処理
1行 / C列
- 変数に格納する
サンプルコード# 入力 1 2 a,b=map(int,input().split()) print(a,b) # 1 2
- リストに格納する
サンプルコード# 入力 1 2 3 4 5 List=[int(i) for i in input().split()] print(List) # [1, 2, 3, 4, 5]
- 変数とリストに格納する
サンプルコード# 入力 abcdefg a,*List,b=input() # アンパック print(a) # a print(List) # ['b', 'c', 'd', 'e', 'f'] print(b) # g解答例a,b=map(int,input().split()) print(a+b if a+b<10 else "error")解答例print(sorted(map(int,"2 1 4 3".split()))) # [1, 2, 3, 4]解答例print(*input().split(','))解答例a,_,b=input() print("DH"[a==b])解答例a,b,c,d=input() print("Yes" if a==b==c or b==c==d else "No")ABC103 A - Task Scheduling Problem
解答例*a,=map(int,input().split()) print(max(a)-min(a))R行 / 1列
- 変数に格納する
サンプルコード# 入力 1 2 a=int(input()) b=int(input()) print(a,b) # 1 2サンプルコード# 入力 1 2 a,b=(int(input()) for i in range(2)) # a,b=[int(input()) for i in range(2)] print(a,b) # 1 2
- リストに格納する
サンプルコード# 入力 1 2 3 4 5 List=[int(input()) for i in range(5)] print(List) # [1, 2, 3, 4, 5]
- 入力行数が指定される
サンプルコード# 入力 5 # 入力行数指定(Raw=5) 1 2 3 4 5 Raw=int(input()) List=[int(input()) for i in range(Raw)] print(List) # [1, 2, 3, 4, 5]
- 終了フラグ(-1)が指定される
サンプルコード# 入力 1 2 3 4 5 -1 # 終了フラグ List=[] while True: Raw=int(input()) if Raw==-1: break List.append(Raw) print(List) # [1, 2, 3, 4, 5]ABC044 A - 高橋君とホテルイージー / Tak and Hotels (ABC Edit)
解答例n,k,x,y=(int(input()) for i in [0]*4) print(n*x-(x-y)*max(n-k,0))R行 / C列
- 2次元リストに格納する
サンプルコード# 入力 3 # 行数(Raw)を指定する 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Raw=int(input()) List=[[int(j) for j in input().split()] for i in range(Raw)] print(List) # [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]サンプルコード# 入力 3 # 行数(Raw)を指定する 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Raw=int(input()) List=[] for i in range(Raw): List.append(list(map(int,input().split()))) print(List) # [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]サンプルコード# 入力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 List=[input().split() for i in range(3)] print(List) # [['1', '2', '3', '4', '5'], ['6', '7', '8', '9', '10'], ['11', '12', '13', '14', '15']]
- 1次元リストに格納する
サンプルコード# 入力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 List=[] for i in range(3): List+=list(map(int,input().split())) print(List) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
- 変数に格納する
サンプルコード# 入力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 a=" ".join([input() for i in [0]*3]) print(a) # 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 print(type(a)) # <class 'str'>解答例print(input()[0]+input()[1]+input()[2])不定形
サンプルコード# 入力 1 2 hoge (a,b),s=map(int,input().split()),input() print(a,b,s) # 1 2 hoge出力処理
int型
- 1次元リストを出力する
サンプルコードLists=[1,2,3,4,5] for List in Lists: print(List,end=' ') # 1 2 3 4 5サンプルコードList=[1,2,3,4,5] for i in range(len(List)): print(List[i],end=' ') # 1 2 3 4 5
- 2次元リストを出力する
サンプルコードLists=[[1,2,3],[4,5,6],[7,8,9]] for List in Lists: print(List,end=' ') # [1, 2, 3] [4, 5, 6] [7, 8, 9]サンプルコードList=[[1,2,3],[4,5,6],[7,8,9]] for i in List: for j in i: print(j,end=' ') # 1 2 3 4 5 6 7 8 9サンプルコードList=[[1,2,3],[4,5,6],[7,8,9]] for i in range(len(List)): for j in range(len(List[i])): print(List[i][j],end=' ') # 1 2 3 4 5 6 7 8 9解答例from itertools import chain List=[[1,2,3],[4,5,6],[7,8,9]] print(*chain(*List)) # 1 2 3 4 5 6 7 8 9str型
- 1次元リストを出力する
サンプルコードLists=["ab","cd","ef"] for List in Lists: print(List,end=' ') # ab cd efサンプルコードList=["ab","cd","ef"] for i in List: for j in i: print(j,end=' ') # a b c d e fサンプルコードList=["ab","cd","ef"] for i in range(len(List)): print(List[i],end=' ') # ab cd efサンプルコードList=["ab","cd","ef"] for i in range(len(List)): for j in range(len(List[i])): print(List[i][j],end=' ') # a b c d e f
- 2次元リストを出力する
サンプルコードList=[["ab","cd","ef"],["gh","ij","kl"]] for i in List: for j in i: print(j,end=' ') # ab cd ef gh ij klサンプルコードList=[["ab","cd","ef"],["gh","ij","kl"]] for i in List: for j in i: for k in j: print(k,end=' ') # a b c d e f g h i j k lサンプルコードList=[["ab","cd","ef"],["gh","ij","kl"]] for i in range(len(List)): for j in range(len(List[i])): print(List[i][j],end=' ') # ab cd ef gh ij klサンプルコードList=[["ab","cd","ef"],["gh","ij","kl"]] for i in range(len(List)): for j in range(len(List[i])): for k in range(len(List[i][j])): print(List[i][j][k],end=' ') # a b c d e f g h i j k l解答例print(*input().split()[::-1])ABC048 A - AtCoder *** Contest
解答例print("A%sC"%input()[8])区切り文字指定
- 空白(デフォルト)
サンプルコードa=1 b=2 c=3 print(a,b,c) # 1 2 3
- 改行を指定する
サンプルコードa=1 b=2 c=3 print(a,b,c,sep='\n') # 1 # 2 # 3
- カンマを指定する
サンプルコードa=1 b=2 c=3 print(a,b,c,sep=',') # 1,2,3
- 区切り文字なしを指定する
サンプルコードa=1 b=2 c=3 print(a,b,c,sep='') # 123数値リテラル
指数
サンプルコードprint(10**9+7) # 1000000007 print(9**.5) # 3.0解答例print(10**int(input())+7)浮動点小数
サンプルコードprint(5e10) # 50000000000.0 print(1.1e-3) # 0.0011解答例H,B=map(float,input().split()) print(H**2*B/1e4)解答例print((int(input())+1)*5e3)進数変換
サンプルコード# 2進数⇒10進数 print(int("1101",2)) # 13 # 8進数⇒10進数 print(int("700",8)) # 448 # 16進数⇒10進数 print(int("FE",16)) # 254 # 10進数⇒2進数 print(bin(23)) # 0b10111 # 10進数⇒8進数 print(oct(23)) # 0o27 # 10進数⇒16進数 print(hex(23)) # 0x17 # 2進数表示 print(0b10111) # 23 # 8進数表示 print(0o27) # 23 # 16進数表示 print(0x17) # 23解答例n=int(input()) x="" while n!=0: x=str(n%2)+x n=-(n//2) print(0 if x=="" else x)解答例print(2**(len(bin(int(input())))-3))解答例n=int(input()) l=[1,2,4,8,16,32,64] m=0 for i in l: if i <= n: m=max(m,i) print(m)複素数
サンプルコードprint(3+4j) # (3+4j)四則演算
小数点切り捨て
- 床関数(切り捨て):floor
サンプルコードprint(5//3) # 1 import math print(math.floor(5/3)) # 1解答例x,y=map(int,input().split()) print(y//x)解答例print(int(input())**2//4)解答例k=int(input()) print((k//2)*((k+1)//2))小数点切り上げ
- 天井関数(切り上げ):ceil
サンプルコードprint(-(-5//3)) # 2 print(math.ceil(5/3)) # 2 print(-~(4+5)//2) # 5 print(-~(5+5)//2) # 5解答例print(-(-int(input())//2))解答例print(5//3+(5%3>0))解答例a,b=map(int,input().split()) print(-(-b//a))解答例print(-~sum(map(int,input().split()))//2)四捨五入
- 四捨五入:rounding
サンプルコードprint(round(5/3)) # 2べき乗
- べき乗:power
サンプルコードprint(2**3) # 8 import math print(math.pow(2,3)) # 8.0平方根
- 平方根:square root
サンプルコードprint(4**(1/2)) # 2.0 print(4**.5) # 2.0 import math print(math.sqrt(4)) # 2.0解答例print(int(int(input())**.5)**2)解答例print("No" if int(input().replace(" ",""))**.5%1 else "Yes")解答例c=int(input().replace(" ","")) print("Yes" if c==int(c**.5)**2 else "No")階乗
- 階乗:factorial
サンプルコードimport math print(math.factorial(5)) # 120=5×4×3×2×1解答例import math print(math.factorial(int(input()))%(10**9+7))乗算
- 乗算:Multiplication
解答例print((["Bad"]*6+["Good"]*3+["Great"]+["Perfect"])[int(input())//10])ABC115 A - Christmas Eve Eve Eve
解答例print("Christmas"+" Eve"*(25-int(input())))剰余演算
- 剰余演算:modulo
解答例print(int(input())%12+1)解答例a,b=map(int,input().split()) print("Draw" if a==b else "Bob" if (a+13)%15<(b+13)%15 else "Alice")解答例print(sum(map(int,input().split()))%24)解答例print(int(input())%9)ABC102 A - Multiple of 2 and N
解答例n=int(input()) print(n+n%2*n)解答例print((eval(input().replace(" ","%"))>0)+0)繰り返し文
インクリメント/デクリメント
サンプルコードfor i in range(2,5,1): print(i, end=' ') # 2 3 4 for i in range(5,2,-1): print(i, end=' ') # 5 4 3インクリメント数/デクリメント数の指定
サンプルコードfor i in range(2,10,2): print(i, end=' ') # 2 4 6 8 for i in range(10,2,-2): print(i, end=' ') # 10 8 6 4条件文
if文
解答例a,b=map(int,input().split()) print("Draw" if a==b else "Bob" if (a+13)%15<(b+13)%15 else "Alice")if/break/else文
解答例N,M,A,B=map(int,input().split()) for i in range(M): if N<=A:N+=B N-=int(input()) if N<0: print(i+1) break else:print("complete")if/in文
サンプルコードif "abc" in input(): print("Include") else: print("Not incluede")解答例print("YES" if input() in "369" else "NO")解答例print("Yes" if "9" in input() else "No")解答例print("No" if "2" in input() else "Yes")ABC111 A - AtCoder Beginner Contest 999
解答例print("".join(["9" if x=="1" else "1" for x in input()]))解答例print("YES" if input() in "753" else "NO")複数条件式
サンプルコードprint("True" if a<=x<=a+b else "False")ABC061 A - Between Two Integers
解答例a,b,c=map(int,input().split()) print("Yes" if a<=c<=b else "No")解答例a,b,c,d=input() print("Yes" if a==b==c or b==c==d else "No")解答例a,b,x=map(int,input().split()) print("YES" if a<=x<=a+b else "NO")bit演算
反転
サンプルコードprint(~(5-3)) # -3 print(~-3) # 2 print(~-4) # 3解答例print(~eval(input().replace(" ","-"))+2)解答例a,b=map(int,input().split()) print(~-a*~-b)解答例a,b=map(int,input().split()) print(~-a*~-b)シフト
解答例print(["ABC","ARC","AGC"][int(input())//50+8>>5])解答例print(int(input())**2>>2)bool演算
bit変換
サンプルコードprint(True+0) # 1 print(False+0) # 0 print(-(3>2)) # -1 print(-(3<2)) # 0解答例n,s,t=map(int,input().split()) w=c=0 for i in range(n): w+=int(input()) c+=s<=w<=t print(c)解答例a,b,c,k=map(int,input().split()) s,t=map(int,input().split()) print(a*s+b*t-(s+t)*c*(s+t>=k))解答例a,b=map(int,input().split()) print(a-(a>b))解答例print((eval(input().replace(" ","%"))>0)+0)リスト処理
- リスト
[ ]はミュータブルで要素の挿入と削除を行うことができ、インデックス(番号)で要素にアクセスします。リストの長さ
- len
ABC046 A - AtCoDeerくんとペンキ / AtCoDeer and Paint Cans
解答例print(len(set(input().split())))解答例print("Yes" if len(set(input()))==3 else "No")要素の合計値
- sum
解答例print(sum(eval(input().replace(' ','*')) for i in range(3))//10)要素の追加
- append/extend/insert
サンプルコードList=['a','b','c'] List.append('d') print(List) # ['a', 'b', 'c', 'd'] List.extend(['e','f']) print(List) # ['a', 'b', 'c', 'd', 'e', 'f'] List.insert(1,'z') print(List) # ['a', 'z', 'b', 'c', 'd', 'e', 'f'] List.append(['g','h']) print(List) # ['a', 'z', 'b', 'c', 'd', 'e', 'f', ['g', 'h']] List.insert(1,['x','y']) print(List) # ['a', ['x', 'y'], 'z', 'b', 'c', 'd', 'e', 'f', ['g', 'h']]解答例S=list(input()) A,B,C,D=map(int,input().split()) S.insert(D,"\"") S.insert(C,"\"") S.insert(B,"\"") S.insert(A,"\"") print(*S,sep="")要素の探索
- index
サンプルコードList=['a','b','c','d','e','f'] print(List.index('c',0,5)) # 2 List=['a','b','c','d','c','c'] print(List.index('c', 0, 5)) # 2解答例print((1/int(input()))*sum("FDCBA".index(r) for r in input()))解答例N=int(input()) print(sum(map(int,input().translate(str.maketrans("FDCBA","01234"))))/N)解答例print(["Saturday","Friday","Thursday","Wednesday","Tuesday","Monday","Sunday"].index(input())%6)要素の削除
- pop/remove/del
サンプルコードList=['a','b','c','d','e','f'] print(List.pop(1)) # b print(List) # ['a', 'c', 'd', 'e', 'f'] List.pop() print(List) # ['a', 'c', 'd', 'e'] List.remove('d') print(List) # ['a', 'c', 'e'] del List[1] print(List) # ['a', 'e']要素の出現回数
- count
サンプルコードList=['a','b','b','c','c','c'] print(List.count('c')) # 3 print(List.count('d')) # 0解答例input() C=input() print(*sorted(C.count(c) for c in "1234")[::-3])解答例input() C=input() l=[C.count(c) for c in "1234"] print(max(l),min(l))解答例input() C=input() a=C.count("1") b=C.count("2") c=C.count("3") d=C.count("4") print(max(a,b,c,d),min(a,b,c,d))解答例a,b=map(int,input().split()) s=input() print("Yes" if s[a]=="-" and s.count("-")==1 else "No")要素の連結
- join
サンプルコードList=["ab","cd","ef"] print(List) # ['ab', 'cd', 'ef'] s=''.join(List) print(s) # abcdef解答例S=list(input().split()) a=[] for s in S: if s=="Left":a.append("<") elif s=="Right":a.append(">") else:a.append("A") print(" ".join(a))要素のユニーク化
- set
サンプルコード# 1次元リスト List=[2,3,1,2] print(list(set(List))) # [1, 2, 3] # 多次元リスト List=[[1,0],[0,0],[1,1],[1,0],[0,1],[0,0]] print(list(map(list,set(map(tuple,List))))) # [[0, 1], [1, 0], [0, 0], [1, 1]]ABC046 A - AtCoDeerくんとペンキ / AtCoDeer and Paint Cans
解答例print(len(set(input().split())))スライス
サンプルコードList=["a","b","c","d","e"] print(List[1:3]) # ['b', 'c'] print(List[1:4:2]) # ['b', 'd'] print(List[:3]) # ['a', 'b', 'c'] print(List[3:]) # ['d', 'e'] print(List[::-1]) # ['e', 'd', 'c', 'b', 'a'] print(List[::-2]) # ['e', 'c', 'a']解答例input() print(input()[:-1].lower().split().count("takahashikun"))解答例S=input() A,B,C,D=map(int,input().split()) print(S[:A]+'"'+S[A:B]+'"'+S[B:C]+'"'+S[C:D]+'"'+S[D:])解答例print(input()[::2])解答例print("NO" if int(input()[::2])%4 else "YES")解答例print(sum(sorted(map(int,input().split()))[:2]))解答例print("YES" if input()==input()[::-1] else "NO")解答例print("2018"+input()[4:])リスト内包表記
サンプルコード# 非ネスト List=[1*i for i in range(5)] print(List) # [0, 1, 2, 3, 4] # ネスト List=[1*i + 10*j + 100*k for k in range(2) for j in range(3) for i in range(4)] print(List) #[0, 1, 2, 3, 10, 11, 12, 13, 20, 21, 22, 23, 100, 101, 102, 103, 110, 111, 112, 113, 120, 121, 122, 123]in演算子
サンプルコードList=["a","b","c"] print("a" in List) # True print("a" not in List) # False print("d" in List) # False print("d" not in List) # True print("a" in "auieo") # True解答例S=map(str,input().split("+")) ans=0 for s in S: if "0" not in s:ans+=1 print(ans)解答例A=[2,4,6,8,10] A=[a/2 for a in A] print(A) # [1.0, 2.0, 3.0, 4.0, 5.0]解答例input() l=map(str,input().split()) print("Three" if len(set(l))==3 else "Four")解答例input() print("Four" if "Y" in input() else "Three")ABC049 A - 居合を終え、青い絵を覆う / UOIAUAI
解答例print("vowel" if input() in "aiueo" else "consonant")タプル処理
- タプル
( )はイミュータブルで要素の書き換えができません。リストと同様、インデックス(番号)で要素にアクセスします。要素の探索
解答例import itertools N,M=map(int,input().split()) edges={tuple(sorted(map(int,input().split()))) for i in range(M)} ans=0 for i in itertools.permutations(range(2,N+1),N-1): l=[1]+list(i) ans+=sum(1 for edge in zip(l,l[1:]) if tuple(sorted(edge)) in edges)==N-1 print(ans)辞書処理
- 辞書
{ }はミュータブルでリストに似ていますが、要素へのアクセスは値に一意なキーで行います。要素の探索
解答例print({'Mo':5,'Tu':4,'We':3,'Th':2,'Fr':1,'Sa':0,'Su':0}[input()[:2]])解答例d=({"Saturday":0,"Sunday":0,"Monday":5,"Tuesday":4,"Wednesday":3,"Thursday":2,"Friday":1}) print(d[input()])解答例N=int(input()) A=[int(input()) for i in range(N)] B={a:i for (i,a) in enumerate(sorted(set(A)))} for a in A: print(B[a])解答例import bisect N=int(input()) A=[int(input()) for i in range(N)] B=sorted(list(set(A))) for a in A: print(bisect.bisect_left(B,a))解答例XU=[input().split() for i in range(int(input()))] print(sum([float(x)*{"JPY":1,"BTC":380000}[u] for x,u in XU]))集合処理
- 集合
{ }は辞書と同様、要素へのアクセスは値に一意なキーで行いますが同じ要素を一つしか持てないため辞書のように値はありません。和
A \cup Bサンプルコードprint({"a","b","c"}|{"c","d","e"}) # {'a', 'b', 'd', 'e', 'c'}差
A - Bサンプルコードprint({"a","b","c"}-{"c","d","e"}) # {'a', 'b'}積
A \cap Bサンプルコードprint({"a","b","c"}&{"c","d","e"}) # {'c'}ABC079 C - Cat Snuke and a Voyage
解答例N,M=map(int,input().split()) sa=set() sb=set() for i in range(M): a,b=map(int,input().split()) if a==1:sb.add(b) if b==N:sa.add(a) print("IMPOSSIBLE" if len(sa&sb)==0 else "POSSIBLE")ABC118 B - Foods Loved by Everyone
解答例n,m=map(int,input().split()) S=set(range(1,m+1)) for i in range(n): K,*A=map(int,input().split()) S&=set(A) print(len(S))対称差
A ⊕ Bサンプルコードprint({"a","b","c"}^{"c","d","e"}) # {'a', 'b', 'e', 'd'}解答例N=int(input()) s=set() for i in range(N):s^={input()} print(len(s))解答例print(eval(input().replace(' ','^')))解答例print(eval(input().replace(" ","^")))部分集合
A \subseteq Bサンプルコード# 左辺の要素すべてが右辺の集合に含まれている場合 print({"a","b"}<={"a","b","c"}) # True # 左辺の要素すべてが右辺の集合に含まれていない場合 print({"a","d"}<={"a","b","c"}) # False解答例x,y=input().split() a={"1","3","5","7","8","10","12"} b={"4","6","9","11"} print("Yes" if {x,y}<=a or {x,y}<=b else "No")文字の集合
サンプルコードprint(sorted(map(chr,range(97,123)))) # ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'] print(sorted(map(chr,range(65,91)))) # ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']解答例print(min(set(map(chr,range(97,123)))-set(input())or["None"]))ABC093 B - Small and Large Integers
解答例a,b,k=map(int,input().split()) r=range(a,b+1) for i in sorted(set(r[:3])|set(r[-3:])): print(i)文字列処理
文字列の長さ
解答例print(max(input(),input(),key=len))文字列の参照
サンプルコードs="abc" print(s[-1]) # c s="abc" print(s[len(s)-1]) # c解答例a,b,c=input().split() print("YES" if a[-1]==b[0] and b[-1]==c[0] else "NO")文字列の逆順
サンプルコードs="abc" print(s[::-1]) # cba解答例print(*input().split()[::-1])文字列のコピー
解答例s=input() for i in range(int(input())): l,r=map(int,input().split()) s=s[:l-1]+s[l-1:r][::-1]+s[r:] print(s)文字列の判定
サンプルコードs="dog" [print(chr(i), end=" ") for i in range(ord('a'), ord('z')+1) if chr(i) in s] # d g o s="dog" [print(chr(i), end=" ") for i in range(ord('a'), ord('z')+1) if chr(i) not in s] # a b c e f h i j k l m n p q r s t u v w x y z解答例print(min(set(map(chr,range(97,123)))-set(input())or["None"]))文字列からリスト型に変換
サンプルコードs="abcde" print(s) # abcde l=list(s) print(l) # ['a', 'b', 'c', 'd', 'e']大文字小文字変換
- upper:すべての文字列を大文字に変換する
サンプルコードs="this is a pen." print(s.upper()) # THIS IS A PEN.ABC059 A - Three-letter acronym
解答例for a in input().upper().split():print(a[0],end="")解答例a,b,c=input().split() print((a[0]+b[0]+c[0]).upper())
- lower:すべての文字列を小文字に変換する
サンプルコードs="THIS IS A PEN." print(s.lower()) # this is a pen.
- capitalize:文字列の先頭文字を大文字に変換する
サンプルコードs="this is a pen." print(s.capitalize()) # This is a pen.解答例print("abcd".capitalize()) # Abcd
- title:各単語の先頭文字を大文字に変換する
サンプルコードs="this is a pen." print(s.title()) # This Is A Pen.三項演算
サンプルコードprint("1" if a == 1 else "other") # if a == 1: # print("1") # else: # print("other") print("1" if a == 1 else "2" if a == 2 else "3" if a == 3 else "other") # if a == 1: # print("1") # elif a == 2: # print("2") # elif a == 3: # print("3") # else: # print("other")Lambda式
解答例x=lambda:int(input()) print((x()+x())*x()//2)解答例a,b=map(lambda x:(int(x)+13)%15,input().split()) print("Alice" if a>b else "Bob" if a<b else "Draw")解答例i=lambda:int(input()) print((i()-i())%i())解答例f=lambda:min(int(input()),int(input())) print(f()+f())正規表現
- 正規表現:Regular Expression
findall
- findall:マッチする部分すべてをリストで返す
解答例import re print(*re.findall("[0-9]+",input()))match
- match:文字列の先頭がパターンにマッチするかを調べる
解答例import re print("YES" if re.match("^(dream|dreamer|erase|eraser)+$",input()) else "NO")解答例import re s=input().replace("?",".") t=input() for i in range(len(s)-len(t),-1,-1): if re.match(s[i:i+len(t)],t): s=s.replace(".","a") print(s[:i]+t+s[i+len(t):]) exit() print("UNRESTORABLE")解答例import re s=input().replace("?",".") t=input() for i in range(len(s)-len(t)+1): if re.match(s[i:i+len(t)],t): s=s.replace(".","a") print(s[:i]+t+s[i+len(t):]) exit() print("UNRESTORABLE")解答例import re S = input() print("AC" if(re.match("^A[a-z]+C[a-z]+$",S)) else "WA")search
- search:先頭に限らずパターンにマッチするかを調べる
解答例import re print("YES" if re.search("i.*c.*t",input().lower()) else "NO")解答例import re print("YES" if re.search("[i|I].*[c|C].*[t|T]",input()) else "NO")sub
- sub:マッチした部分を置換する
解答例import re print(re.sub("\D","",input()))解答例import re print(re.sub("[aiueo]","",input()))解答例import re print("NO" if re.sub(r"ch|o|k|u","",input()) else "YES")解答例import re print(re.sub("[aiueo]","",input()))import
bisect
サンプルコードimport bisect List=[ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19] print(bisect.bisect_left(List,5)) #2 """ List=[ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19] 1 2 3 4 5 6 7 8 9 10 ^ """ print(bisect.bisect_right(List,5)) #3 """ List=[ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19] 1 2 3 4 5 6 7 8 9 10 ^ """ print(bisect.bisect_left(List,15)) #7 """ List=[ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19] 1 2 3 4 5 6 7 8 9 10 ^ """ print(bisect.bisect_right(List,15)) #8 """ List=[ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19] 1 2 3 4 5 6 7 8 9 10 ^ """ List=[1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3] print(bisect.bisect_left(List,2)) #4 """ List=[1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3] 1 2 3 4 5 6 7 8 9 10 11 12 ^ """ print(bisect.bisect_right(List,2)) #8 """ List=[1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3] 1 2 3 4 5 6 7 8 9 10 11 12 ^ """ print(bisect.bisect_right(List,2)) #8 """ List=[1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3] 1 2 3 4 5 6 7 8 9 10 11 12 ^ """ print(bisect.bisect_right(List,3)) #12 """ List=[1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3] 1 2 3 4 5 6 7 8 9 10 11 12 ^ """解答例import bisect N=int(input()) A=sorted(list(map(int,input().split()))) B=sorted(list(map(int,input().split()))) C=sorted(list(map(int,input().split()))) print(sum(bisect.bisect_left(A,b)*(N-bisect.bisect_right(C,b)) for b in B))解答例from collections import Counter N=int(input()) A=Counter(input().split()) B=Counter(input().split()) C=Counter(input().split()) ans=0 for a_key,a_count in A.most_common(): for b_key,b_count in B.most_common(): for c_key,c_count in C.most_common(): a_key,b_key,c_key=int(a_key),int(b_key),int(c_key) if a_key<b_key and b_key<c_key: ans+=a_count*b_count*c_count print(ans)collections
- Counter
サンプルコードList=['a','a','a','a','b','c','c'] c=collections.Counter(l) print(c) # Counter({'a': 4, 'c': 2, 'b': 1}) print(type(c)) # <class 'collections.Counter'> print(issubclass(type(c), dict)) # True print(c.keys()) # dict_keys(['a', 'b', 'c']) print(c.values()) # dict_values([4, 1, 2]) print(c.items()) # dict_items([('a', 4), ('b', 1), ('c', 2)]) print(c.most_common()) # [('a', 4), ('c', 2), ('b', 1)] print(c.most_common()[0]) # ('a', 4) print(c.most_common()[-1]) # ('b', 1) print(c.most_common()[0][0]) # a print(c.most_common()[0][1]) # 4 print(c.most_common()[::-1]) # [('b', 1), ('c', 2), ('a', 4)] print(c.most_common(2)) # [('a', 4), ('c', 2)] values,counts=zip(*c.most_common()) print(values) # ('a', 'c', 'b') print(counts) # (4, 2, 1) print(c['a']) # 4 print(c['b']) # 1 print(c['c']) # 2 print(c['d']) # 0解答例from collections import Counter input() L=Counter(input().split()) R=Counter(input().split()) print(sum([min(value,L[key]) for key,value in R.items()]))解答例from collections import Counter N=int(input()) A=Counter(list(map(int,input().split()))) x=[0,0] for a in A: if A[a]>1:x.append(a) if A[a]>3:x.append(a) x.sort() print(x[-1]*x[-2])ABC071 C - 怪文書 / Dubious Document
解答例from collections import Counter n=int(input()) s=Counter(input()) for i in range(n-1): s&=Counter(input()) print("".join(sorted(s.elements())))解答例from collections import Counter N=int(input()) A=Counter([int(input()) for i in range(N)]) print(sum(1 if count%2 else 0 for count in A.values()))解答例from collections import Counter n,k=map(int,input().split()) a=Counter(input().split()) print(sum(sorted(a.values(),reverse=True)[k:]))解答例from collections import Counter n,k=map(int,input().split()) a=Counter(input().split()) ans=0 keys,counts=zip(*a.most_common()) for num,(key,count) in enumerate(zip(keys,counts)): if int(num)>k-1:ans+=count print(ans)解答例from collections import Counter n=int(input()) a=Counter(input().split()) ans=0 for i,j in a.items(): i=int(i) if i>j: ans+=j elif i<j: ans+=j-i print(ans)解答例from collections import Counter n=int(input()) v=list(map(int,input().split())) a=Counter(v[0::2]).most_common() b=Counter(v[1::2]).most_common() a.append([0,0]) b.append([0,0]) if a[0][0]!=b[0][0]: print(n-(a[0][1]+b[0][1])) else: print(min(n-(a[1][1]+b[0][1]),n-(a[0][1]+b[1][1])))ABC110 C - String Transformation
解答例from collections import Counter s=Counter(list(input())) t=Counter(list(input())) s,t=list(s.values()),list(t.values()) print("Yes" if sorted(s)==sorted(t) else "No")解答例from collections import Counter a=Counter([input() for i in range(int(input()))]) print(a) # Counter({'taro': 2, 'jiro': 1, 'saburo': 1}) print(a.most_common()[0][0]) # tarofunctools
- reduce
サンプルfrom functools import reduce from operator import add from operator import sub from operator import mul List=[20,1,2,3,4,5] print(reduce(add,List)) # 35 # add:20+1+2+3+4+5=35 print(reduce(sub,List)) # 5 # sub:20-1-2-3-4-5=5 print(reduce(mul,List)) # 2400 # mul:20*1*2*3*4*5=2400 # Lambda式に変換が可能 print(reduce(lambda a,b:a+b,List)) # 35 print(reduce(lambda a,b:a-b,List)) # 5 print(reduce(lambda a,b:a*b,List)) # 2400解答例from functools import reduce from fractions import gcd N,X=map(int,input().split()) x=[abs(X-int(i)) for i in input().split()] print(reduce(gcd,x))heapq
解答例import heapq N=int(input()) s=set() q=[0,0] for a in map(int,input().split()): if a>q[0]: try: s.remove(a) heapq.heapreplace(q,a) except: s.add(a) print(q[0]*q[1])itertools
- permutations
4! = 4 × 3 × 2 × 1 = 24通りサンプルコードfrom itertools import permutations List=["a","b","c","d","e"] print(list(permutations(List))) # [('a', 'b', 'c', 'd'), ('a', 'b', 'd', 'c'), ('a', 'c', 'b', 'd'), ('a', 'c', 'd', 'b'), ('a', 'd', 'b', 'c'), ('a', 'd', 'c', 'b'), ('b', 'a', 'c', 'd'), ('b', 'a', 'd', 'c'), ('b', 'c', 'a', 'd'), ('b', 'c', 'd', 'a'), ('b', 'd', 'a', 'c'), ('b', 'd', 'c', 'a'), ('c', 'a', 'b', 'd'), ('c', 'a', 'd', 'b'), ('c', 'b', 'a', 'd'), ('c', 'b', 'd', 'a'), ('c', 'd', 'a', 'b'), ('c', 'd', 'b', 'a'), ('d', 'a', 'b', 'c'), ('d', 'a', 'c', 'b'), ('d', 'b', 'a', 'c'), ('d', 'b', 'c', 'a'), ('d', 'c', 'a', 'b'), ('d', 'c', 'b', 'a')] print(len(list(permutations(List)))) # 24_4 P _2 = 4 \times 3 = 12通りサンプルコードfrom itertools import permutations List=["a","b","c"] print(list(permutations(List,2))) # [('a', 'b'), ('a', 'c'), ('a', 'd'), ('b', 'a'), ('b', 'c'), ('b', 'd'), ('c', 'a'), ('c', 'b'), ('c', 'd'), ('d', 'a'), ('d', 'b'), ('d', 'c')] print(len(list(permutations(List,2)))) # 12解答例from itertools import permutations n,m,l=map(int,input().split()) P=list(map(int,input().split())) v=0 for p,q,r in permutations(P): v=max(v,(n//p)*(m//q)*(l//r)) print(v)
- product
解答例from itertools import product [print("".join(i)) for i in product("abc",repeat=int(input()))]解答例import itertools N=int(input()) ans=0 S=[] for i in range(10): S+=list(itertools.product("357",repeat=i)) for s in S: if len(set(s))>2 and int("".join(s))<=N: ans+=1 print(ans)
- groupby
ABC063 C - 一次元リバーシ / 1D Reversi
解答例from itertools import groupby S=input() G=groupby(S) print(len(list(G))-1)解答例import itertools print("".join([i+str(len(list(j))) for i,j in itertools.groupby(list(input()))]))解答例import itertools s="" for i,j in itertools.groupby(list(input())): s+=i+str(len(list(j))) print(s)
- combinations
_4 C _2 = \frac{_4 P _2}{2!} = 6通りサンプルfrom itertools import combinations List=["a","b","c","d"] print(list(combinations(List,2))) # [('a', 'b'), ('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd'), ('c', 'd')] print(len(list(combinations(List,2)))) # 6解答例from itertools import combinations S=map(int,input().split()) print(sorted(map(sum,combinations(S,3)))[-3])サンプルコードfrom itertools import combinations for a,b,c in combinations("MARCH",3): print(a,b,c) # M A R # M A C # M A H # M R C # M R H # M C H # A R C # A R H # A C H # R C H解答例from itertools import combinations from collections import Counter N=int(input()) S=Counter() for i in range(N): S[input()[0]]+=1 print(sum([S[a]*S[b]*S[c] for a,b,c in combinations("MARCH",3)]))math
ABC067 C - Factors of Factorial
解答例import math N=math.factorial(int(input())) i=2 ans=1 M=10**9+7 while i*i<=N: cnt=1 while N%i==0: cnt+=1 N//=i ans*=cnt i+=1 if N!=1:ans*=2 print(int(ans%M))解答例import math print(math.factorial(int(input()))%(10**9+7))組み込み関数
abs
サンプルコードprint(abs(-1)) # 1all/any
- all
サンプルコードprint(all([True,True])) # True print(all([True,False])) # False print(all([False,False])) # False解答例n=int(input()) a=[int(i) for i in input().split()] c=0 while(True): for i in range(len(a)): if a[i]==0: print(c) exit() elif a[i]%2==0: a[i]=a[i]/2 else: print(c) exit() c+=1解答例input() A=list(map(int,input().split())) c=0 while all(a%2==0 for a in A): A=[a/2 for a in A] c+=1 print(c)
- any
サンプルコードprint(any([True,True])) # True print(any([True,False])) # True print(any([False,False])) # Falseenumerate
サンプルコードList=['Alice', 'Bob', 'Charlie'] for num,name in enumerate(List): print(num,name) # 0 Alice # 1 Bob # 2 Charlie解答例N=int(input()) A=[(int(a), i) for i,a in enumerate(input().split(),1)] for a in sorted(A,reverse=True): print(a[1])ABC102 C - Linear Approximation
解答例N=int(input()) A=sorted(a-i-1 for i,a in enumerate(map(int,input().split()))) print(sum(abs(a-A[N//2]) for a in A))eval
サンプルコードprint(eval("1+2")) # 3解答例print(eval(input().replace(" ","**2*"))/1e4)解答例print("4:3" if eval(input().replace(" ","*"))%144 else "16:9")解答例print(sum(eval(input().replace(' ','*')) for i in range(3))//10)ABC050 A - Addition and Subtraction Easy
解答例print(eval(input()))map
ABC110 C - String Transformation
解答例s=sorted(map(list(input()).count,set(s))) t=sorted(map(list(input()).count,set(t))) print("Yes" if s==t else "No")max/min
- max
サンプルコード# 2値 print(max(1,2)) # 2 # 多値 print(max(2,1,3)) # 3 # リスト print(max([2,1,3])) # 3 # 文字リスト print(max(['b','a','c','d'])) # d # 文字列リスト print(max(['ab','aa','ca','bd'])) # ca # 文字列長さ print(max(['a','bcde','fg','hij'],key=len)) # bcde解答例print(max(input(),input(),key=len))解答例a,b,c=map(int,input().split()) print(max(c//a,c//b))
- min
サンプルコード# 2値 print(min(1,2)) # 1 # 多値 print(min(2,1,3)) # 1 # リスト print(min([2,1,3])) # 1 # 文字リスト print(min(['b','a','c','d'])) # a # 文字列リスト print(min(['ab','aa','ca','bd'])) # aa # 文字列長さ print(min(['a','bcde','fg','hij'],key=len)) # a解答例a,b,c=map(int,input().split()) print(c//min(a,b))解答例n,x=map(int,input().split()) print(min(x-1,n-x))ord/chr
- ord
サンプルコードprint([chr(i) for i in range(ord('a'),ord('z')+1)]) # ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']解答例print(ord(input())-64)解答例print(["A","B","C","D","E"].index(input())+1)
- chr
サンプルコードprint([chr(i) for i in range(97, 97+26)]) # ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']range
サンプルコードr=range(2,10) print(r) # range(2, 10) print(r[:3]) # range(2, 5) print(set(r[:3])) # {2, 3, 4} print(r[3:]) # range(5, 10) print(set(r[3:])) # {5, 6, 7, 8, 9} print(r[-3:]) # range(7, 10) print(set(r[-3:])) # {8, 9, 7} print(r[:-3]) # range(2, 7) print(set(r[:-3])) # {2, 3, 4, 5, 6}zip
サンプルコードMatrix=[ [1,2,3], [4,5,6], [7,8,9] ] print(list(map(list,zip(*Matrix)))) # [[1, 4, 7], [2, 5, 8], [3, 6, 9]]解答例print(sum(map(max,zip(*[list(map(int,input().split())) for i in range(2)]))))解答例D=map(int,input().split()) J=map(int,input().split()) print(sum(max(d,j) for d,j in zip(D,J)))解答例o=list(input()) e=list(input())+[""] for x,y in zip(o,e):print(x+y,end="")メソッド
find/rfind
解答例S=input()[0:12] key="WBWBWWBWBWBW"*2 ans=["Do","","Re","","Mi","Fa","","So","","La","","Si"] print(ans[(key.find(S))])解答例s=input() print(s.rfind("Z")-s.find("A")+1)isdecimal/isdigit/isnumeric/isalpha/isalnum
- isdecimal:全ての文字が十進数字なら真、そうでなければ偽(半角・全角のアラビア数字が真)
サンプルコードs="1234567890" print(s.isdecimal()) # True解答例a,b=map(int,input().split()) s=input() if 1<=a<=5 and 1<=b<=5: if s[a]=="-": if s[0:a].isdecimal() and s[a+1:a+b+1].isdecimal(): print("Yes") exit() print("No")
- isdigit:全ての文字が数字なら真、そうでなければ偽(半角・全角のアラビア数字、特殊数字が真)
サンプルコードs="\u00B2" # 2乗 print(s.isdigit()) # True解答例print("".join(i for i in input() if i.isdigit()))
- isnumeric:全ての文字が数を表す文字なら真、そうでなければ偽(半角・全角のアラビア数字、特殊数字、漢数字が真)
サンプルコードs="一二三四五六七八九〇壱億参阡萬" print(s.isnumeric()) # True
- isalpha:全ての文字が英字なら真、そうでなければ偽(便宜上「英字」と書いているが、平仮名やカタカナ、漢字なども真)
サンプルコードs="abcあいうアイウ漢字" print(s.isalpha()) # True
- isalnum::全ての文字が英数字なら真、そうでなければ偽(各文字が上のメソッドで真となれば真)
サンプルコードs="abc100" print(s.isalnum()) # Truereplace
サンプルコードList=["aabbaa","bbaabb","ababab"] List=",".join(List) print(List) # aabbaa,bbaabb,ababab List=List.replace('a','c') print(List) # ccbbcc,bbccbb,cbcbcb List=List.split(',') print(List) # ['ccbbcc', 'bbccbb', 'cbcbcb']サンプルコードList=["aabbaa", "bbaabb", "ababab"] List=",".join(List).replace('a', 'c').split(',') print(List) # ['ccbbcc', 'bbccbb', 'cbcbcb']解答例S=input() for b,a in zip("ODIZSB","001258"): S=S.replace(b,a) print(S)解答例S=input() b="ODIZSB" a="001258" for i in range(6): S=S.replace(b[i],a[i]) print(S)解答例print(input().replace("O","0").replace("D","0").replace("I","1").replace("Z","2").replace("S","5").replace("B","8"))解答例print(input().replace("Left","<").replace("Right",">").replace("AtCoder","A"))解答例print(sum(eval(input().replace(' ','*')) for i in range(3))//10)解答例print(eval(input().replace(' ','^')))解答例print(eval(input().replace(" ","-"))+1)解答例print("No" if eval(input().replace(" ","*"))%2==0 else "Yes")ABC111 A - AtCoder Beginner Contest 999
解答例print(input().replace("1","x").replace("9","1").replace("x","9"))sort/reverse
- sort
サンプルコード# 昇順 List=[2,1,3] List.sort() print(List) # [1, 2, 3] # 降順 List=[2,1,3] List.sort(reverse=True) print(List) # [3, 2, 1] # 多次元昇順 List=[[0,1],[1,1],[1,0],[0,0]] List.sort(key=lambda List:(List[0],List[1])) print(List) # [[0, 0], [0, 1], [1, 0], [1, 1]] # 多次元昇順 from operator import itemgetter List=[[0,1],[1,1],[1,0],[0,0]] Listsort(key=itemgetter(0,1)) print(List) # [[0, 0], [0, 1], [1, 0], [1, 1]] # 多次元降順 List=[[0,1],[1,1],[1,0],[0,0]] List.sort(key=lambda List:(List[0],List[1]),reverse=True) print(List) # [[1, 1], [1, 0], [0, 1], [0, 0]] # 多次元降順 from operator import itemgetter List=[[0,1],[1,1],[1,0],[0,0]] List.sort(key=itemgetter(0,1),reverse=True) print(List) # [[1, 1], [1, 0], [0, 1], [0, 0]]
- reverse
サンプルコード# 1次元 List=[2,1,3] List.reverse() print(List) # [3, 1, 2] # 多次元 List=[[0,1],[1,1],[1,0],[0,0]] List.reverse() print(List) # [[0, 0], [1, 0], [1, 1], [0, 1]]translate/maketrans
解答例print(input().translate(str.maketrans("ODIZSB","001258")))処理観点
行列処理
行集計
\begin{pmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \\ \end{pmatrix} \begin{pmatrix} 1 \\ 1 \\ 1 \\ \end{pmatrix} = \begin{pmatrix} 6 \\ 15 \\ 24 \\ \end{pmatrix}サンプルコードMatrix=[[1,2,3],[4,5,6],[7,8,9]] print([sum(x) for x in Matrix]) # [6, 15, 24]列集計
\begin{pmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \\ \end{pmatrix}^T \begin{pmatrix} 1 \\ 1 \\ 1 \\ \end{pmatrix} = \begin{pmatrix} 12 \\ 15 \\ 18 \\ \end{pmatrix}サンプルコードMatrix=[[1,2,3],[4,5,6],[7,8,9]] print([sum(x) for x in zip(*Matrix)]) # [12, 15, 18]転置行列
A = \begin{pmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \\ \end{pmatrix}A^T = \begin{pmatrix} 1 & 3 & 5 \\ 2 & 4 & 6 \\ \end{pmatrix}解答例h,w=map(int,input().split()) a=[[j for j in input()] for i in range(h)] b=[x for x in a if "#" in x] c=zip(*[y for y in zip(*b) if "#" in y]) for d in c:print("".join(d))回転行列
A = \begin{pmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \\ \end{pmatrix}A^{回転} = \begin{pmatrix} 3 & 6 & 9 \\ 2 & 5 & 8 \\ 1 & 4 & 7 \\ \end{pmatrix}解答例print("\n".join(input() for _ in range(4))[::-1])解答例for i in reversed([input() for i in range(4)]): print(i[::-1])解答例s=[input() for i in range(int(input()))] for x in zip(*s):print("".join(x)[::-1])解答例s=reversed([input() for i in range(int(input()))]) for x in zip(*s):print("".join(x))順位行列
解答例import collections import bisect n,m=map(int,input().split()) p=[[int(j) for j in input().split()] for i in range(m)] a=collections.defaultdict(list) for x,y in sorted(p): a[x]+=[y] for x,y in p: z=bisect.bisect(a[x],y) print("%06d%06d"%(x,z))素数判定
- 素数:Prime number
解答例N=int(input()) print("YES" if all([N%n for n in range(2,int(N**.5)+1)]) else "NO")解答例N=int(input()) print("YES" if all([N%n for n in range(2,N)]) else "NO")解答例N=int(input()) print("NO" if any([N%n==0 for n in range(2,N)]) else "YES")解答例N=int(input()) S=sum(n for n in range(N+1)) flag=0 for s in range(2,S): if S%s==0: flag=1 print("WANWAN" if flag==0 and N!=1 else "BOWWOW")解答例N=int(input()) flag=1 if N==1:flag=0 elif N==2 or N==3 or N==5:flag=1 elif N%2==0 or N%3==0 or N%5==0:flag=0 else:flag=1 print("Prime" if flag==1 else "Not Prime")解答例n=int(input()) print(sum(i<=n for i in [105,135,165,189,195]))解答例N = int(input()) prime = 0 for i in range(105, N+1, 2): count = 0 for j in range(1, i+1): if(i%j == 0): count += 1 if(count == 8): prime += 1 print(prime)うるう年判定
- うるう年:Leap year
解答例import calendar print("YES" if calendar.isleap(int(input())) else "NO")解答例Y=int(input()) print("YES" if Y%4==0 and Y%100!=0 or Y%400==0 else "NO")奇数/偶数判定
- 入力数1
f(x) = \left\{ \begin{array}{ll} Even & (x\;\;mod\;\;2\;\;=\;\;0) \\ Odd & (x\;\;mod\;\;2\;\;=\;\;1) \end{array} \right.サンプルコードx=int(input()) print(["Even","Odd"][x%2])
x 1 2 x%2 1 0 ["Even","Odd"][x%2] Odd Even
- 入力数2
f(x,y) = \left\{ \begin{array}{ll} Even & (x y\;\;mod\;\;2\;\;=\;\;0) \\ Odd & (x y\;\;mod\;\;2\;\;=\;\;1) \end{array} \right.サンプルコードx,y=map(int,input().split()) print(["Even","Odd"][x*y%2]) # Even
x*y 1 2 x*y%2 1 0 ["Even","Odd"][x*y%2] Odd Even
- 入力数3以上
f(x) = \left\{ \begin{array}{ll} Even & (if\;\;x_{all}\;\;mod\;\;2\;\;=\;\;0) \\ Odd & (otherwise) \end{array} \right.サンプルコードx=[2,4,6,8] print("Even" if all([i%2==0 for i in x]) else "Odd") # Even x=[2,4,6,9] print("Even" if all([i%2==0 for i in x]) else "Odd") # OddARC014 A - 君が望むなら世界中全てのたこ焼きを赤と青に染め上げよう
解答例print("Blue" if int(input())%2==0 else "Red")N値判定
- 2値判定(Zero/NotZero判定)
f(x) = \left\{ \begin{array}{ll} Zero & (x=0) \\ Not Zero & (x\neq0) \end{array} \right.サンプルコードx=int(input()) print(["Not Zero","Zero"][x==0])
x 0 1 x==0 True False ["Not Zero","Zero"][x==0] Zero Not Zero 解答例print("HD"[len(set(input()))%2])解答例print(['ABC','ABD'][len(input())>3])ABC102 A - Multiple of 2 and N
解答例n=int(input()) print([N,N*2][N%2])
- 3値判定(正の数/0/負の数判定)
f(x) = \left\{ \begin{array}{ll} Positive & (x > 0) \\ 0 & (x = 0) \\ Negative& (x < 0) \end{array} \right.サンプルコードx=int(input()) print(["0","Positive","Negative"][x>0 or -(x<0)])
x -1 0 1 x>0 False False True x<0 True False Flase -(x<0) -1 0 0 x>0 or -(x<0) -1 0 True ["0","Positive","Negative"][x>0 or -(x<0)] Negative 0 Positive 解答例x,y=input().split() print("=><"[x>y or -(x<y)])解答例a,b,c,d=map(int,input().split()) print(['Balanced','Left','Right'][(a+b>c+d)-(a+b<c+d)])解答例print(["ABC","ARC","AGC"][(int(input())+400)//1600])桁数の和
f(x) = \sum_{1}^{length(x)} x_i (x_i:xのi桁目の数)サンプルコードx=1234 print(sum(map(int,x))) # 10(=1+2+3+4)解答例n,a,b=map(int,input().split()) print(sum(i for i in range(n+1) if(a<=sum(map(int,str(i)))<=b)))解答例n,a,b=map(int,input().split()) s=0 for i in range(n+1): if a<=sum(map(int,str(i)))<=b: s+=i print(s)解答例n,a,b=map(int,input().split()) s=0 for i in range(n+1): if a<=sum(int(j) for j in str(i))<=b: s+=i print(s)解答例n,a,b=map(int,input().split()) s=0 for i in range(n+1): c=0 d=str(i) for j in range(len(d)): c+=int(d[j]) if a<=c<=b: s+=i print(s)解答例N=input() print("Yes" if int(N)%sum(map(int,list(N)))==0 else "No")解答例N=input() print("Yes" if int(N)%sum(int(_) for _ in N)==0 else "No")解答例N=input() s=0 for n in N: s+=int(n) print("Yes" if int(N)%s==0 else "No")解答例print(sum(map(int,input())))桁の数
ABC057 C - Digits in Multiplication
解答例N=int(input()) i=int(N**(1/2)) while N%i!=0: i-=1 print(len(str(N//i)))解答例def ketasu(N): count=1 while N>=10: N//=10 count+=1 return count N=int(input()) keta=10**10 for i in range(1,int(N**.5)+1): if N%i==0: keta=min(keta,max(ketasu(i),ketasu(N//i))) print(keta)解答例N=int(input())-1 print(str(N%9+1)*(N//9+1))解答例N=int(input()) num=1 while N>0: if len(set(str(num)))==1:N-=1 num+=1 print(num-1)日時
解答例import datetime y=int(input()) m=int(input()) d=int(input()) print((datetime.date(2014,5,17)-datetime.date(y,m,d)).days)解答例Y=int(input()) M=int(input()) D=int(input()) if M==1 or M==2: Y-=1 M+=12 print(735369-(365*Y+Y//4-Y//100+Y//400+306*(M+1)//10+D-429))解答例n=int(input()) print("%02d:%02d:%02d"%(n//3600,(n%3600)//60,n%60))解答例print("Heisei" if input()<="2019/04/30" else "TBD")時計
解答例n,m=map(int,input().split()) a=abs(n%12*30-5.5*m) print(min(a,360-a))コイン
解答例x,y=map(int,input().split()) k=int(input()) print(x+y-abs(k-y))カード
ABC090 C - Flip,Flip, and Flip......
解答例N,M=map(int,input().split()) print(1 if N==1 and M==1 else max(N,M)-2 if N==1 or M==1 else N*M-2*N-2*M+4)グラフ
解答例N=int(input()) K=int(input()) print("YES" if K<=N//2 else "NO")解答例V,E=map(int,input().split()) edges=[set() for i in range(V)] for i in range(E): a,b=map(int,input().split()) edges[a-1].add(b-1) edges[b-1].add(a-1) for i in range(V): print(len({n for v in edges[i] for n in edges[v] if not n in edges[i] and n!=i}))解答例import itertools N,M=map(int,input().split()) edges={tuple(sorted(map(int,input().split()))) for i in range(M)} ans=0 for i in itertools.permutations(range(2,N+1),N-1): l=[1]+list(i) ans+=sum(1 for edge in zip(l,l[1:]) if tuple(sorted(edge)) in edges)==N-1 print(ans)解答例N,M=map(int,input().split()) edges=[list(map(int,input().split())) for i in range(M)] ans=0 for x in edges: l=list(range(N)) for y in edges: if y!=x:l=[l[y[0]-1] if l[i]==l[y[1]-1] else l[i] for i in range(N)] if len(set(l))!=1:ans+=1 print(ans)ソート
解答例N,M=map(int,input().split()) A=[int(input()) for i in range(M)][::-1] ans=[] s=set() for a in A: if a not in s:ans.append(a) s.add(a) for i in range(1,N+1): if i not in s:ans.append(i) print(*ans,sep="\n")順位/ランキング
解答例X=[int(input()) for i in range(3)] for x in X:print(3-sorted(X).index(x))解答例l=[int(input()) for _ in range(3)] s=sorted(l)[::-1] for i in l: print(s.index(i)+1)宝くじ
解答例E=set(input().split()) b=input() L=set(input().split()) l=len(E&L) ans=0 if l==5 and b in L:ans=2 elif l==6:ans=1 elif l>2:ans=8-l else:ans=0 print(ans)解答例a = [int(i) for i in input().split()] b = int(input()) c = [int(i) for i in input().split()] k = 6 - len(set(a) - set(c)) if k == 5 and b in c: print(2) else: print({6:1,5:3,4:4,3:5}.get(k,0))グリッド
解答例H,W=map(int,input().split()) S=["."+input()+"." for i in range(H)] S=["."*(W+2)]+S+["."*(W+2)] flag=0 for i in range(H): for j in range(W): if S[i][j]=="#": if S[i-1][j]=="." and S[i+1][j]=="." and S[i][j-1]=="." and S[i][j+1]==".": flag=1 print("Yes" if flag==0 else "No")解答例h,w=map(int,input().split()) a=[[j for j in input()] for i in range(h)] b=[x for x in a if "#" in x] c=zip(*[y for y in zip(*b) if "#" in y]) for d in c:print("".join(d))解答例h,w=map(int,input().split()) s=[input() for _ in range(h)] for i in range(h): l="" for j in range(w): if s[i][j]=="#": l+="#" else: l+=str(sum([t[max(0,j-1):min(w,j+2)].count("#") for t in s[max(0,i-1):min(h,i+2)]])) print(l)解答例n,m=map(int,input().split()) a=[input() for _ in range(n)] b=[input() for _ in range(m)] r=any([r[j:j+m] for r in a[i:i+m]]==b for i in range(n-m+1) for j in range(n-m+1)) print('Yes' if r else 'No')回文
ABC090 B - Palindromic Numbers
解答例a,b=map(int,input().split()) print(sum(i==i[::-1] for i in map(str,range(a,b+1))))解答例a,b=map(int,input().split()) print(len([i for i in map(str,range(a,b+1)) if i==i[::-1]]))数列
解答例import math N=int(input()) A=list(map(int,input().split())) flag=True if N%2==0: if 0 in A or len(set(A))!=N//2:flag=False else: if len([0 for a in A if a==0])!=1 or len(set(A))!=N//2+1:flag=False if flag:print(2**(N//2)%(10**9+7)) else:print(0)解答例n=input() a=[int(i) for i in input().split()] def chk(a,t): ans=0 x=0 for i in a: x+=i if t==True and x<1: ans+=1-x x=1 elif t==False and x>-1: ans+=x+1 x=-1 t=not t return ans print(min(chk(a,True),chk(a,False)))解答例n=int(input()) a=list(map(int,input().split())) b=list(map(int,input().split())) print(max(sum(a[:i+1])+sum(b[i:]) for i in range(n)))解答例n=int(input()) a=list(map(int,input().split())) b=list(map(int,input().split())) ans=0 for i in range(n): ans=max(ans,sum(a[:i+1])+sum(b[i:])) print(ans)解答例N=int(input()) A=[0]+list(map(int,input().split()))+[0] cost=sum(abs(A[i+1]-A[i]) for i in range(N+1)) for i in range(1,N+1): print(cost-abs(A[i+1]-A[i])-abs(A[i]-A[i-1])+abs(A[i+1]-A[i-1]))解答例N=int(input()) A=list(map(int,input().split()))+[0] A.insert(0,0) cost=0 for i in range(N+1): cost+=abs(A[i+1]-A[i]) for i in range(1,N+1): print(cost-abs(A[i+1]-A[i])-abs(A[i]-A[i-1])+abs(A[i+1]-A[i-1]))解答例l=sorted(map(int,input().split())) a=2*l[2]-l[1]-l[0] print((a+3)//2 if a%2 else a//2)解答例n=int(input()) a=list(map(int,input().split())) c=0 for i in a: while i%2==0:i,c=i/2,c+1 print(c)範囲
解答例N,T=map(int,input().split()) t=list(map(int,input().split())) ans=0 for i in range(N-1): ans+=min(t[i+1]-t[i],T) print(ans+T)解答例a,b,c,d=map(int,input().split()) print(max(0,min(b,d)-max(a,c)))解答例a,b,c,d=map(int,input().split()) t=len(set(map(int,range(a,b+1)))&set(map(int,range(c,d+1))))-1 print("0" if t==-1 else t)文字列の回転
解答例print("Yes" if input() in input()*2 else "No")文字列の辞書順
解答例s=input() n=int(input())-1 print(s[n//5]+s[n%5])剰余算
解答例N=int(input()) ans=N for i in range(N+1): cnt=0 while i>0: cnt+=i%6 i//=6 j=N-i while j>0: cnt+=j%9 j//=9 ans=min(ans,cnt) print(ans)ABC111 B - AtCoder Beginner Contest 111
解答例N=int(input()) print((((N-1)//111)+1)*111)解答例N=int(input()) print(N//10*100+min(100,N%10*15)解答例print(-int(input())%int(input()))解答例a=int(input()) b=int(input()) print((((a//b)+1)*b-a) if a%b else "0")数学観点
和差算
解答例a,b,c=sorted(map(int, input().split())) print(a+b+c*2**int(input()))解答例l=[int(_) for _ in input().split()] k=int(input()) print(sum(l)-max(l)+max(l)*2**k)ABC110 A - Maximize the Formula
解答例l=list(map(int,input().split())) print(sum(l)+max(l)*9)解答例print(eval('+'.join(sorted(input()))+'*10'))ABC111 A - AtCoder Beginner Contest 999
解答例print(1110-int(input()))数直線
ABC110 B - 1 Dimensional World's Tale
解答例N,M,X,Y=map(int,input().split()) xi=list(map(int,input().split())) yi=list(map(int,input().split())) xi.append(X) yi.append(Y) print("No War" if max(xi)<min(yi) else "War")円と長方形
解答例x,y,r=map(int,input().split()) a,b,c,d=map(int,input().split()) if a<=x-r and x+r<=c and b<=y-r and y+r<=d:print("NO") else:print("YES") if max((a-x)**2,(c-x)**2)+max((b-y)**2,(d-y)**2)<=r**2:print("NO") else:print("YES")座標
解答例sx,sy,tx,ty=map(int,input().split()) ans=[] for i in range(ty-sy): ans.append("U") for i in range(tx-sx): ans.append("R") for i in range(abs(sy-ty)): ans.append("D") for i in range(abs(sx-tx)): ans.append("L") ans.append("L") for i in range(ty-sy+1): ans.append("U") for i in range(tx-sx+1): ans.append("R") ans.append("D") ans.append("R") for i in range(abs(sy-ty)+1): ans.append("D") for i in range(abs(sx-tx)+1): ans.append("L") ans.append("U") print("".join(ans))解答例s=input() d=abs(s.count("L")-s.count("R"))+abs(s.count("U")-s.count("D")) q=s.count("?") if int(input())==1:print(d+q) else:print(max(len(s)%2,d-q))解答例x1,y1,x2,y2=map(int,input().split()) x=x2-x1 y=y2-y1 print(x2-y,y2+x,x1-y,y1+x)面積
解答例h,w=map(int,input().split()) pattern=[h//2+w//3+1,h//3+w//2+1,h,w] if h%3==0 or w%3==0: pattern+=[0] if h%2==0: pattern+=[h//2] if w%2==0: pattern+=[w//2] print(min(pattern))ABC047 B - すぬけ君の塗り絵 2 イージー / Snuke's Coloring 2 (ABC Edit)
解答例w,h,n=map(int,input().split()) b=c=0 for _ in range(n): x,y,a=map(int,input().split()) if a==1:b=max(b,x) if a==2:w=min(w,x) if a==3:c=max(c,y) if a==4:h=min(h,y) print(max(0,(w-b))*max(0,(h-c)))解答例w,h,n=map(int,input().split()) l=[[int(j) for j in input().split()] for i in range(n)] b=c=0 for i in range(n): x,y,a=l[i][0],l[i][1],l[i][2] if a==1:b=max(b,x) if a==2:w=min(w,x) if a==3:c=max(c,y) if a==4:h=min(h,y) print([(w-b)*(h-c),0][(w<b)|(h<c)])解答例a,b,c=map(int,input().split()) print(a*b//2)解答例a,b,c=map(int,input().split()) print(2*(a*b+b*c+c*a))倍数
ABC100 B - Ringo's Favorite Numbers
解答例D,N=map(int,input().split()) l=[int(pow(100,D)*i) for i in range(1,N+1)] print(l[N-1])約数
解答例N=int(input()) prime=0 for i in range(105,N+1,2): count=0 for j in range(1,i+1): if(i%j==0): count+=1 if(count==8): prime+=1 print(prime)約数の個数
ある整数 $ x $ が素因数分解によって $ x= p^n × q^m × ... (p,q,...は素数) $ と表される時、 $ x $ の約数の個数は $ (n+1) × (m+1) × ... $ となる。
ABC067 C - Factors of Factorial
解答例import math N=math.factorial(int(input())) i=2 ans=1 M=10**9+7 while i*i<=N: cnt=1 while N%i==0: cnt+=1 N//=i ans*=cnt i+=1 if N!=1:ans*=2 print(int(ans%M))順列
- 順列:permutation
_4 P _2 = 4 \times 3 = 12通りサンプルコードfrom itertools import permutations List=["a","b","c","d"] print(list(permutations(List,2))) # [('a', 'b'), ('a', 'c'), ('a', 'd'), ('b', 'a'), ('b', 'c'), ('b', 'd'), ('c', 'a'), ('c', 'b'), ('c', 'd'), ('d', 'a'), ('d', 'b'), ('d', 'c')] print(len(list(permutations(List,2)))) # 12解答例from itertools import permutations n,m,l=map(int,input().split()) P=list(map(int,input().split())) v=0 for p,q,r in permutations(P): v=max(v,(n//p)*(m//q)*(l//r)) print(v)組み合わせ
- 組み合わせ:combination
_4 C _2 = \frac{_4 P _2}{2!} = 6通りサンプルfrom itertools import combinations List=["a","b","c","d"] print(list(combinations(List,2))) # [('a', 'b'), ('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd'), ('c', 'd')] print(len(list(combinations(List,2)))) # 6解答例from itertools import combinations S=map(int,input().split()) print(sorted(map(sum,combinations(S,3)))[-3])解答例from itertools import combinations from collections import Counter N=int(input()) S=Counter() for i in range(N): S[input()[0]]+=1 print(sum([S[a]*S[b]*S[c] for a,b,c in combinations("MARCH",3)]))解答例K=int(input()) print((K//2)*((K+1)//2))経路
\frac{(width+height -2)!}{(width-1)!(height -1)!}解答例from math import factorial W,H=map(int,input().split()) m=10**9+7 print(factorial(W+H-2)*pow(factorial(H-1)*factorial(W-1)%m,m-2,m)%m)色塗り
ABC046 B - AtCoDeerくんとボール色塗り / Painting Balls with AtCoDeer
解答例n,k=map(int,input().split()) print(k*(k-1)**(n-1))重複組み合わせ
サンプルコードfrom itertools import combinations_with_replacement List=["a","b","c","d"] print(list(combinations_with_replacement(List,3))) # [('a', 'a', 'a'), ('a', 'a', 'b'), ('a', 'a', 'c'), ('a', 'a', 'd'), ('a', 'b', 'b'), ('a', 'b', 'c'), ('a', 'b', 'd'), ('a', 'c', 'c'), ('a', 'c', 'd'), ('a', 'd', 'd'), ('b', 'b', 'b'), ('b', 'b', 'c'), ('b', 'b', 'd'), ('b', 'c', 'c'), ('b', 'c', 'd'), ('b', 'd', 'd'), ('c', 'c', 'c'), ('c', 'c', 'd'), ('c', 'd', 'd'), ('d', 'd', 'd')] print(len(list(combinations_with_replacement(List,3)))) # 20期待値
解答例n,m=map(int,input().split()) print((1900*m+100*(n-m))*2**m)解答例print((int(input())+1)*5e3)数列の和
f(x) = \sum_{1}^n x = \frac{n(n + 1)}{2}サンプルコードn=int(input()) print(n*(n+1)//2)サンプルコードn=int(input()) print(n*-~n//2)サンプルコードprint(sum(range(int(input())+1)))解答例a, b = map(int, input().split()) n = b - a print(n*(n+1)//2-b)ABC043 A - キャンディーとN人の子供イージー / Children and Candies (ABC Edit)
解答例n=int(input()) print(n*(n+1)//2)連立方程式の解
2x+3y+4z=10 (0≦x<20, 0≦y<30, 0≦z<40)サンプルコードList=[(x,y,z) for z in range(40) for y in range(30) for x in range(20) if 2*x+3*y+4*z==10] print(List) # [(5, 0, 0), (2, 2, 0), (3, 0, 1), (0, 2, 1), (1, 0, 2)] List=list(map(list,set(List))) print(List) # [[2, 2, 0], [3, 0, 1], [0, 2, 1], [5, 0, 0], [1, 0, 2]] print(len(List)) # 5
- 解に条件がある場合
2x+3y+4z=10 (0≦x<20, 0≦y<30, 0≦z<40, x+y+z=4)サンプルコードList=[(x,y,z) for z in range(40) for y in range(30) for x in range(20) if 2*x+3*y+4*z==10 and x+y+z==4] print(List) # [(2, 2, 0), (3, 0, 1)] List=list(map(list,set(List))) print(List) # [[3, 0, 1], [2, 2, 0]] print(len(List)) # 2連立方程式の解の個数
2x+3y+4z=10 (0≦x<20, 0≦y<30, 0≦z<40)サンプルコードprint([2*x + 3*y + 4*z for z in range(40) for y in range(30) for x in range(20)].count(10)) # 5サンプルコード# 1はdummy変数 print(len([1 for x in range(20) for y in range(30) for z in range(40) if 2*x+3*y+4*z==10])) # 5x+y+z=S (0≦x, y, z<k≦2500)(0≦S<3K)サンプルコードs=7000 k=2500 # 1はdummy変数 print(len([1 for y in range(k) for x in range(k) if 0<=s-x-y<=k])) # 124750サンプルコードs=7000 k=2500 # 1はdummy変数 print([1 for y in range(k) for x in range(k) if 0<=s-x-y<=k].count(1)) # 124750ABC051 B - Sum of Three Integers
平方根の整数部と小数部の算出
y = x^{1/2} (a:整数部, b:小数部)サンプルコードx=2 y=x**.5 # 平方値 print(y) # 1.4142135623730951 # 整数部 a=int(y) print(a) # 1 # 小数部 b=y-a print(b) # 0.41421356237309515解答例print(int(int(input())**.5)**2)相加相乗平均
\frac{a+b}{2} ≧ \sqrt{ab}解答例print(int(input())**2//4)解答例n=int(input()) print((n//2)*(-(-n//2)))ユークリッド距離
distance(\boldsymbol{x},\boldsymbol{y}) = \sqrt{\sum_{i=1}^n(x_i - y_i)^2}\sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2}ARC004 A - 2点間距離の最大値 ( The longest distance )
解答例p=[list(map(int,input().split())) for i in range(int(input()))] print(max(((a[0]-b[0])**2+(a[1]-b[1])**2)**.5 for b in p for a in p))解答例import math p=[list(map(int,input().split())) for i in range(int(input()))] print(max(math.hypot(a[0]-b[0],a[1]-b[1]) for b in p for a in p))解答例N=int(input()) p=[] for i in range(N): x,y=map(int,input().split()) p.append([x,y]) d=0 for i in range(N): for j in range(N): if i!=j:d=max(d,((p[i][0]-p[j][0])**2+(p[i][1]-p[j][1])**2)**.5) print(d)マンハッタン距離
distance(\boldsymbol{x},\boldsymbol{y}) = \sum_{i=1}^n|x_i - y_i||x_1 - x_2| + |y_1 - y_2|解答例n,m=map(int,input().split()) ab=[[int(j) for j in input().split()] for i in range(n)] cd=[[int(j) for j in input().split()] for i in range(m)] for a,b in ab: l=[abs(a-c)+abs(b-d) for c,d in cd] print(l.index(min(l))+1)解答例n,m=map(int,input().split()) a=[[int(j) for j in input().split()] for i in range(n)] c=[[int(j) for j in input().split()] for i in range(m)] for i in range(n): d=10e8 b=0 for j in range(m): if abs(a[i][0]-c[j][0])+abs(a[i][1]-c[j][1])<d: d=abs(a[i][0]-c[j][0])+abs(a[i][1]-c[j][1]) b=j+1 print(b)ヘロンの公式
S = \sqrt{s(s-a)(s-b)(s-c)} \\ s = \frac{a+b+c}{2}ヘロンの公式 - Wikipedia
ABC002 C - 直訴解答例x1,y1,x2,y2,x3,y3=map(int,input().split()) a=((x1-x2)**2+(y1-y2)**2)**.5 b=((x2-x3)**2+(y2-y3)**2)**.5 c=((x3-x1)**2+(y3-y1)**2)**.5 s=(a+b+c)/2 print((s*(s-a)*(s-b)*(s-c))**.5)コラッツ予想
f(n) = \left\{ \begin{array}{ll} n / 2 & (if\;\;n=0) \\ 3n + 1 & (if\;\;n=1) \end{array} \right.コラッツの問題 - Wikipedia
ABC116 B - Collatz Problem解答例S=int(input()) l=[] while (S not in l): l.append(S) if S%2==0:S//=2 else:S=3*S+1 print(len(l)+1)必要十分条件
P \rightarrow Q解答例x,y,r=map(int,input().split()) a,b,c,d=map(int,input().split()) if a<=x-r and x+r<=c and b<=y-r and y+r<=d:print("NO") else:print("YES") if max((a-x)**2,(c-x)**2)+max((b-y)**2,(d-y)**2)<=r**2:print("NO") else:print("YES")アルゴリズム観点
ユークリッドの互除法
- 2つの自然数の最大公約数を求める手法
サンプルコードwhile y!=0: x,y=y,x%y解答例a,b,n=(int(input()) for _ in range(3)) while n%a!=0 or n%b!=0:n+=1 print(n)最大公約数
- GCD:Greatest Common Divisor
サンプルコードfrom functools import reduce from fractions import gcd x=[15,25,30] print(reduce(gcd,x)) # 5解答例from functools import reduce from fractions import gcd N,X=map(int,input().split()) x=[abs(X-int(i)) for i in input().split()] print(reduce(gcd,x))ABC118 C - Monsters Battle Royale
解答例import functools,fractions n=input() a=list(map(int,input().split())) print(functools.reduce(fractions.gcd,a))最小公倍数
- LCM:Least Common Multiple
解答例from fractions import gcd def lcm(a,b): return a*b//gcd(a,b) N=int(input()) ans=1 for i in range(N): t=int(input()) ans=lcm(ans,t) print(ans)ABC118 C - Monsters Battle Royale
解答例import functools,fractions n=input() a=list(map(int,input().split())) print(functools.reduce(fractions.gcd,a))解答例a,b,n=(int(input()) for _ in range(3)) while n%a!=0 or n%b!=0:n+=1 print(n)DP
- DP:Dynamic Programming(動的計画法)
解答例N=int(input()) A=list(map(int,input().split()))+[0] dp=[0]*N dp[1]=abs(A[1]-A[0]) for i in range(1,N-1): dp[i+1]=min(dp[i]+abs(A[i+1]-A[i]),dp[i-1]+abs(A[i+1]-A[i-1])) print(dp[N-1])
- 未解答
ABC011 C - 123引き算
ABC034 C - 経路DFS
- DFS:Depth First Search(深さ優先探索)
- 未解答
BFS
- BFS:Breadth First Search(幅優先探索)
解答例h,w=map(int,input().split()) sy,sx=map(int,input().split()) gy,gx=map(int,input().split()) grid=[list(input()) for x in range(h)] grid[sy-1][sx-1]=0 loc=[[sy-1,sx-1]] for k in range(1,h*w): next_loc=[] for y,x in loc: for i,j in ([1,0],[-1,0],[0,1],[0,-1]): if grid[y+i][x+j]=='.': grid[y+i][x+j]=k next_loc.append([y+i,x+j]) loc=next_loc if [gy-1,gx-1] in loc: break print(k)UnionFind
解答例N = int(input()) def dfs(s): if int(s)>N: return 0; ret = 1 if all(s.count(c) > 0 for c in "753") else 0 for c in "753": ret += dfs(s+c) return ret print(dfs("0"))
- 未解答
ABC075 C - Bridge
ABC054 C - One-stroke Path
ABC015 C - 高橋くんのバグ探ししゃくとり法
解答例N,K=map(int,input().split()) S=[int(input()) for i in range(N)] length=left=0 mul=1 if 0 in S: length=N else: for right in range(N): mul*=S[right] if mul<=K: length=max(length,right-left+1) else: mul//=S[left] left+=1 print(length)解答例(TLE)N,K=map(int,input().split()) S=[int(input()) for i in range(N)] length=0 if 0 in S: length=N else: for i in range(N): for j in range(i+1,N): mul=1 for k in range(i,j+1): mul*=S[k] if mul<=K: length=max(length,j-i+1) print(length)解答例N=int(input()) A=list(map(int,input().split())) diff=0 ans=N for i in range(N-1): if A[i]<A[i+1]: diff+=1 ans+=diff else: diff=0 print(ans)全探索
ABC045 C - たくさんの数式 / Many Formulas
解答例S=input() ans=0 for i in range(len(S)): for j in range(i+1): ans+=int(S[-(i+1)])*(10**j)*(2**(len(S)-1))//(2**min(i,j+1)) print(ans)解答例S=input() ans=0 for i in range(2**(len(S)-1)): tmp=S[0] for j in range(len(S)-1): if i&(1<<j):tmp+="+" tmp+=S[j+1] ans+=eval(tmp) print(ans)解答例N=int(input()) F=[int(input().replace(' ',''),2) for i in range(N)] P=[list(map(int,input().split())) for i in range(N)] print(max(sum([p[bin(f&i).count('1')] for f,p in zip(F,P)]) for i in range(1,2**10)))解答例n,k=map(int,input().split()) x=sorted(list(map(int,input().split()))) print(min((min(abs(x[i])+abs(x[i+k-1]-x[i]),abs(x[i+k-1])+abs(x[i]-x[i+k-1]))) for i in range(n-k+1)))解答例n,k=map(int,input().split()) x=sorted(list(map(int,input().split()))) a=[] for i in range(n-k+1): l=x[i] r=x[i+k-1] a.append(min(abs(l)+abs(r-l),abs(r)+abs(l-r))) print(min(a))解答例N=int(input()) T=sorted(int(input()) for i in range(N))[::-1] x=y=0 for t in T: if x<y:x+=t else:y+=t print(max(x,y))解答例x,y=map(int,input().split()) k=int(input()) print(x+y-abs(k-y))貪欲法
解答例N=int(input()) NG=[int(input()) for i in range(3)] if N in NG: print("NO") exit() for i in range(100): N-=3 if N in NG: N+=1 if N in NG: N+=1 if N in NG: print("NO") exit() print("YES" if N<=0 else "NO")解答例A=list(map(int,input().split()))+[0] ans=0 for i in range(N): eated=max(0,A[i]+A[i-1]-x) ans+=eated A[i]-=eated print(ans)
- 未解答
最大フロー
エラトステネスのふるい
- 未解答
ワーシャル–フロイド法
- 未解答
クラスカル法/プリム法
- 未解答
計算量観点
ソート
解答例N=int(input())%30 X=[1,2,3,4,5,6] for i in range(N): tmp=X[i%5+1] X[i%5+1]=X[i%5] X[i%5]=tmp print(*X,sep="")解答例(TLE)N=int(input()) X=[1,2,3,4,5,6] for i in range(N): tmp=X[i%5+1] X[i%5+1]=X[i%5] X[i%5]=tmp print(*X,sep="")つるかめ算
解答例N,M=map(int,input().split()) if 2*N<=M<=4*N: y=M%2 z=((M-3*y)-2*(N-y))//2 x=N-y-z print(x,y,z) else: print("-1 -1 -1")解答例(TLE)N,M=map(int,input().split()) for x in range(N+1): for y in range(N+1): z=N-x-y if 2*x+3*y+4*z==M and z>=0: print(x,y,z) exit() print("-1 -1 -1")いもす法
解答例n,m=map(int,input().split()) imos=[0]*(m+1) t=0 for i in range(n): l,r,s=map(int,input().split()) imos[l-1]+=s imos[r]-=s t+=s for i in range(m): imos[i+1]+=imos[i] print(t-min(imos[:-1]))解答例N,Q=map(int,input().split()) O=[0]*(N+1) for i in range(Q): l,r=map(int,input().split()) O[l-1]+=1 O[r]-=1 for i in range(N): if i>0:O[i]+=O[i-1] print(O[i]%2,end="") print()解答例(TLE)N,Q=map(int,input().split()) O=[0]*N for i in range(Q): l,r=map(int,input().split()) for j in range(l,r+1): O[j-1]+=1 for i in range(N): if O[i]%2==0: O[i]=0 else: O[i]=1 print(*O,sep="")解答例N=int(input()) n=10**6+1 x=[0]*(n+1) for i in range(N): a,b=map(int,input().split()) x[a]+=1 x[b+1]-=1 for i in range(n): x[i+1]+=x[i] print(max(x))累積和
解答例N=int(input()) A=list(map(int,input().split())) S=sum(A) T=[0]*N for i in range(N-1): T[i+1]=T[i]+A[i] print(min(abs(S-2*T[i]) for i in range(1,N)))解答例(TLE)N=int(input()) A=list(map(int,input().split())) print(min(abs(sum(A[:i])-sum(A[i:])) for i in range(1,N)))解答例N=int(input()) S=input() cnt=S.count("E") m=cnt for i in S: if i=="E": cnt-=1 else: cnt+=1 m=min(m,cnt) print(m)二分探索
解答例import bisect N,M=map(int,input().split()) X,Y=map(int,input().split()) A=list(map(int,input().split())) B=list(map(int,input().split())) ans=0 time=0 while time<=A[-1]: time=A[bisect.bisect_left(A,time)]+X if time<=B[-1]: time=B[bisect.bisect_left(B,time)]+Y ans+=1 else:break print(ans)解答例import bisect N=int(input()) A=sorted(list(map(int,input().split()))) B=sorted(list(map(int,input().split()))) C=sorted(list(map(int,input().split()))) print(sum(bisect.bisect_left(A,b)*(N-bisect.bisect_right(C,b)) for b in B))解答例(TLE)from collections import Counter N=int(input()) A=Counter(input().split()) B=Counter(input().split()) C=Counter(input().split()) ans=0 for a_key,a_count in A.most_common(): for b_key,b_count in B.most_common(): for c_key,c_count in C.most_common(): a_key,b_key,c_key=int(a_key),int(b_key),int(c_key) if a_key<b_key and b_key<c_key: ans+=a_count*b_count*c_count print(ans)中央値の算出
解答例N=int(input()) X=list(map(int,input().split())) S=sorted(X) b=S[N//2] a=S[(N//2)-1] for i in X: print(b if i<b else a)解答例N=int(input()) X=list(map(int,input().split())) s=[] for i in range(N): s=sorted(X[:i]+X[i+1:]) print(s[N//2-1])条件式によるループ回数削減
解答例x=int(input()) c=1 for b in range(1,x): for p in range(2,x): if b**p<=x:c=max(c,b**p) else:break # b**pがx以上は計算を省く print(c)解答例(TLE)x=int(input()) c=1 for b in range(1,x): for p in range(2,x): if b**p<=x:c=max(c,b**p) print(c)集計から除算に変換
ABC048 B - Between a and b ...
解答例a,b,x=map(int,input().split()) print(b//x-(a-1)//x)解答例(TLE)a,b,x=map(int,input().split()) print(sum(1 for i in range(a,b+1) if i%x==0))処理中の剰余算(10*n+7)
解答例from math import factorial W,H=map(int,input().split()) m=10**9+7 print(factorial(W+H-2)*pow(factorial(H-1)*factorial(W-1)%m,m-2,m)%m)解答例import math N,M=map(int,input().split()) print(max(2-abs(N-M),0)*math.factorial(N)*math.factorial(M)%(10**9+7))解答例a,b,c=0,0,1 for i in range(int(input())-1): a,b,c=b,c,(a+b+c)%10007 print(a)解答例(TLE)a,b,c=0,0,1 for i in range(int(input())-1): a,b,c=b,c,a+b+c print(a%10007)方程式
解答例N,Y=map(int,input().split()) for x in range(N+1): for y in range(N-x+1): z=N-x-y if 0<=z<=2000 and 10000*x+5000*y+1000*z==Y: print(x,y,z) exit() print(-1,-1,-1)キュー
- キュー:Queue
解答例N=int(input()) A=list(map(int,input().split())) print(*A[::-2],*A[N%2::2])解答例(TLE)N=int(input()) A=list(map(int,input().split())) B=[] for i in range(N): B.append(A[i]) B=B[::-1] print(*B)部分数列の総和
解答例N,K=map(int,input().split()) A=list(map(int,input().split())) print(sum(A[i]*min(i+1,K,N-i,N-K+1) for i in range(N)))解答例(TLE)N,K=map(int,input().split()) A=list(map(int,input().split())) print(sum(sum(A[i:i+K]) for i in range(N-K+1)))用語
AtCoder用語集
ハーシャッド数
- 各位の数字和が元の数の約数にある自然数
解答例n=input() print("No" if int(n)%sum(map(int,n)) else "Yes")リュカ数
- 初項(最初のリュカ数)を 2、次の項を 1 と定義し、それ以降の項は前の2つの項の和になっている数列
L_0 = 2, L_1 = 1L_{n+2} = L_n + L_{n+1}解答例a,b=2,1 for i in range(int(input())): a,b=b,a+b print(a)解答例n=int(input()) l=[2,1] for i in range(2,n+3): l.append(l[i-2]+l[i-1]) print(l[n])トリボナッチ数列
L_0 = 0, L_1 = 0, L_2 = 1L_{n} = L_{n-1} + L_{n-2} + L_{n-3}解答例a,b,c=0,0,1 for i in range(int(input())): a,b,c=b,c,a+b+c print(a)参考記事/サイト
実装観点
- 2進数・8進数・10進数・16進数の相互変換についてまとめてみた
- Pythonビギナーズガイド(変数・配列編)
- pythonで三項演算子のネスト
- 【Python入門】いまさらだけどパイソニスタとして必要な文法を網羅してみた
- 【Python入門】for文でのin演算子の使い方とは?
- Python ビット演算 超入門
- Pythonの集合演算
- Python リストのメソッド
- pythonの内包表記を少し詳しく
- 【Python】ソート
- Pythonで2次元配列の重複行を一発で削除する
- Python標準で転置行列
- Pythonのリスト、タプル、辞書
- [Python]リスト、タプル、辞書、集合の違い
- 正規表現操作
- Pythonでの正規表現の使い方
- Pythonの正規表現モジュールreの関数match、search、sub
- itertoolsによる順列、組み合わせ、直積のお勉強
- 組み込み関数
- [python] いろいろな文字種のリストを作成
- Pythonで文字列が数字か英字か英数字か判定・確認
- 高階関数の使い方!Pythonでreduceを使う方法【初心者向け】
- Pythonで大文字・小文字を操作する文字列メソッド一覧
- Pythonでタプルやリストをアンパック(複数の変数に展開して代入)
計算量観点
関連サイト
AtCoder情報
- AtCoder に登録したら次にやること ~ これだけ解けば十分闘える!過去問精選 10 問
- AtCoder コンテストについての tips
- AtCoder に登録したら解くべき精選過去問 10 問 をPythonで解いてみた
- AtCoderでの勉強の仕方(コンテスト編)
競技プログラミング情報
レート情報
緑色
水色
- あの水色ってきれいだよね。(競プロ!! AdC)
- AtCoderで水色になるまでにやったこと
- AtCoderで水色になるまでにしたこと
- AtCoderで水色になるまでにやった事とかをまとめる
- AtCoderのレートが水色になるまでにやったこと
- AtCoderで水色になりました
- AtCoder で水色になるまでを振り返る
- AtCoder水色になるまでにやったこと
青色
- PythonでAtCoder青になるまで -Pythonで競プロやるときに気をつけること-
- AtCoder 青になったのでブログをはじめました
- AtCoderで青色になるまでにやった事とかをまとめる
- AtCoderで青色になるまでにやったこと
- AtCoderで青色になった話
黄色
コーディング規約
PEP 8 -- Style Guide for Python Code
[Pythonコーディング規約]PEP8を読み解くマークダウン記法
- 投稿日:2019-02-26T18:01:42+09:00
TelloPyでハマった事と対処方法
このページは?
- トイドローンTelloをPythonで操作するライブラリ
TelloPy利用時に遭遇した問題(Issue)と対処方法を記載しています。
https://github.com/hanyazou/TelloPy- 自分用メモなので環境によって事象/対処方法は異なる可能性があります。
前提事項
- 検証PC
- Windows 10 Professional
- Visual Studio 2017, Python3.7 導入済み(非Anaconda環境)
- 検証ドローン … 無印Tello
Issues
PyAV導入時に 'cl.exe' が見つからないエラー発生
事象
pip install av実行が下記エラーにより失敗。‘error: command 'cl.exe' failed: No such file or directory‘対応方法
- 下記URLを開く
https://visualstudio.microsoft.com/ja/downloads/Tools for Visual Studio 2017のセクションを展開しBuild Tools Visual Studio 2017のダウンロードボタンをクリック。その後は指示に従ってインストール
- プログラムから
VS 2017用 x64_x86 Cross Toolsコマンド プロンプトを起動してpip install av実行
---> 本エラーは解消PyAV導入時に 'avfilter.lib' が見つからないエラー発生
事象
pip install av実行が下記エラーにより失敗LINK : fatal error LNK1181: 入力ファイル 'avfilter.lib' を開けません。対応方法
- 参考URL:ffmpegのインストール方法
https://docs.mikeboers.com/pyav/develop/installation.html#build-on-windows
- 下記URLを開く
https://ffmpeg.zeranoe.com/builds/- 該当するArchitecture を選択し、Linkageの
SharedとDevをそれぞれ選択してDownload Buildを押下- ダウンロードしたファイルを展開し任意のフォルダ(ここでは
C:\dev\ffmpeg)に配置
VS 2017用 x64_x86 Cross Toolsコマンド プロンプトを開いて下記コマンドを実行後にpip install av実行set INCLUDE=%INCLUDE%;c:\dev\ffmpeg\include set LIB=%LIB%;c:\dev\ffmpeg\lib set PATH=%PATH%;c:\dev\ffmpeg\bin---> 本エラーは解消
PyAV導入時に アーキテクチャ競合エラー発生
事象
pip install av実行が下記エラーにより失敗python37.lib(python37.dll) : fatal error LNK1112: モジュールのコンピューターの種類 'x64' は対象コンピューターの種類 'x86' と競合しています。対応方法
python3.7を64bit版から32bit版に入れ替えて本エラーは解消。(併せてffmpegも32bit版に入れ替え)
しかし、この対処方法で正しいのか不明…サンプル実行時にffmpeg関連ライブラリが参照できないエラー
事象
py -m video_effect.py実行時に下記エラーが発生。C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\Lib\site-packages\tellopy\examples>py -m video_effect.py Traceback (most recent call last): File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\lib\runpy.py", line 183, in _run_module_as_main mod_name, mod_spec, code = _get_module_details(mod_name, _Error) File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\lib\runpy.py", line 109, in _get_module_details __import__(pkg_name) File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\Lib\site-packages\tellopy\examples\video_effect.py", line 4, in <module> import av File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\lib\site-packages\av\__init__.py", line 9, in <module> from av._core import time_base, pyav_version as __version__ ImportError: DLL load failed: 指定されたモジュールが見つかりません。対応方法
VS 2017用 x64_x86 Cross Toolsコマンド プロンプトを開いて下記コマンド実行でffmpegへの参照を追加することで解消set INCLUDE=%INCLUDE%;c:\dev\ffmpeg\include set LIB=%LIB%;c:\dev\ffmpeg\lib set PATH=%PATH%;c:\dev\ffmpeg\binVideoを使うサンプル実行時にmplayerが見つからないエラー発生
事象
python -m tellopy.examples.joystick_and_video実行時に下記エラー発生Tello: 23:29:25.923: Error: video recv: [WinError 2] 指定されたファイルが見つかりません。 Traceback (most recent call last): File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\lib\site-packages\tellopy\_internal\tello.py", line 694, in __video_thread self.__publish(event=self.EVENT_VIDEO_FRAME, data=data[2:]) File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\lib\site-packages\tellopy\_internal\tello.py", line 154, in __publish dispatcher.send(event, sender=self, **args) File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\lib\site-packages\tellopy\_internal\dispatcher.py", line 35, in send receiver(event=sig, **named) File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\lib\site-packages\tellopy\examples\joystick_and_video.py", line 191, in handler video_player = Popen(['mplayer', '-fps', '35', '-'], stdin=PIPE) File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\lib\subprocess.py", line 775, in __init__ restore_signals, start_new_session) File "C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python37-32\lib\subprocess.py", line 1178, in _execute_child startupinfo) FileNotFoundError: [WinError 2] 指定されたファイルが見つかりません。対応方法
mplayer を導入する。
下記URLを開きmplayer-svn-38119-x86_64.7zをダウンロードして展開してmplayer.exeがあるフォルダにパスを通す
http://mplayerwin.sourceforge.net/downloads.html動いたところ
video_effect
Pythonを使ってTelloのカメラで撮影した映像をPCで見れた。TelloPyというライブラリを使ったのだけど前提となるPyAvのインストールでハマった…
— fujihide (@hfujikawa77) 2019年2月22日
#Tello #drone #Python pic.twitter.com/xv3b4qgNNzjoystick_and_video
#Tello × #Python でPCでビデオストリーミングしながらゲームパッドで飛ばせたー。
— fujihide (@hfujikawa77) 2019年3月7日
・下記サンプルプログラムを一部書き換えて実行。Logicoolゲームパッドの定義追加https://t.co/hPLNhbm3HZ
・使ったゲームパッドはこちらhttps://t.co/NBvyc9BTyE pic.twitter.com/xKN48gh08q
- 投稿日:2019-02-26T17:38:24+09:00
プログラミング初心者の2月
この記事について
プログラミングとは何なのか1も知らなかった人間が新しい道を歩き始めた経緯を簡単に記録します。
(初の投稿で自分記録用として書いているので間違えているところや勘違いしているところも多いと思います。)プログラミングを始めたきっかけ
私は大学の時工学部所属で勉強はしていましたが、プログラミングや機械、電子、物理などの工学系ではなくどちらかというとデザインが重視される建築設計をやっていました。その後、建築の模型製作の仕事を過ぎ物の表現、具現に興味を持つことになりました。建築模型の場合、最終の提出用ぐらいが実際多くの人に見られみんながものを短く感じさせることが可能かと思います。世界を動かすとか世界的に使われたいとかの大きいことではなくても使ってくれる人々から「お、こういう機能も使えるんだ。」とか「前より使いやすくなったな。」を言われることやりたいと思うところプログラミングを勉強させていただくいい機会が来て本格的にこちらの道に関しての勉強を始めました。
勉強の進み
この文章を書くのはちょうど私が勉強始めて1か月が経っている時点です。
パソコンを使ってないわけではありませんが、目に見えるように具現化されているのを主に使ったため、そのプログラムがどういう原理で動いているのかについてはあまり考えてみたことがありませんでした。少しでも手をかけてみたことを整理してみると....
-Python 3.7
-HTML(css,bootstrap)
-MySQL
-Bottleどれも基本の中での基本的なところですが、それぞれを組み合わせての使い方について勉強させていただきました。
最初は本やネットの講座、先生の説明でしたが、やっぱり基本的なことを勉強した後時間をかけて自分でtitleをつけて書いて動かしての添削が効果的だったと思います。先生と一緒に書いたり本のどおりやっているときに「わー!できた。面白い!」と言っても翌日、勉強したことの応用の課題が与えられたら「ああ、私なんかアホやな、、、」と落ち込むことがかなりあったからです。もちろん自分ができそうな機能ばかりいれてしまってそれ以上の勉強進行にはよくないのでないかと悩みましたが、まず自分ができることもなかったらこれ以上のことを聞いても実際使えないと思ったので新しいものを勉強させてもらいながら時間を取って自分なりのものを作っています。少しずづ新しいものをいれながら(もちろん、見た目的にも機能的にも人に見せれるものではありませんが...)楽しんでいます。
3月やってみたいこと
上記のプログラム以外にも最近JavaScriptを始めようとしています。
書き方としてPythonと違いどちらにも慣れないのが一番心配ではありますが(フランス語とドイツ語を同時に勉強したときの感覚です。)、やっぱり単独で使うよりシナージ効果が出るのではないかと楽しみです。今まで勉強してきたものを全部混ぜて自分なりで書いてみているものが2つあります。こちらをもうちょっと実用的に使えることができるようになったら知り合いに使わせてもらいたいです。
可能な状況が来るかどうかは知りませんが、私がこちらの勉強を始める前に模型製作作業の中でレーザカッターをつかったり3D模型を作ったりAutoCADで設計図を書いたりすることが多かったです。これを使ってラズベリーパイのケースだったりこういう回路などのケースも作ってみたいと思います!
ETC.
始めったばかりものの記事を読んでいただきありがとうございます。
新しい道へと挑戦するところですが、楽しみながら難しいところも乗り越えていきたいと思います。
- 投稿日:2019-02-26T16:07:38+09:00
pythonでスクレイピング ①BeautifulSoup
はじめに
今回が初投稿になるので、至らない部分も多いかと思いますがご容赦ください。間違いなどありましたらご指導いただけると幸いです。
環境
macOS Mojave 10.14
python 3.6.4準備
BeautifulSoupとrequestsをインストール
$ pip install beautifulsoup4 $ pip install requests
BeautifulSoup4
HTMLやXMLを解析してデータを取り出すためのライブラリrequests
Webブラウザの代わりにHTTPでデータの送受信を行うWebページの情報を取得
まず、requestsを使ってWebページの情報を取得する。
今回は例として、livedoorNEWSのランキングの情報を取得する。
get関数は、取得したいURLを指定するとその情報を格納したResponseオブジェクトを生成して返す。import requests response = requests.get('http://news.livedoor.com/ranking/')Webページから要素を抜き出す
BeautifulSoup4を使ってHTMLを構文解析してタグなどの任意の要素を取得する。
from bs4 import BeautifulSoup soup = BeautifulSoup(response.text, 'html.parser')要素を見つけるには以下のようにする。
soup.a # 先頭のa要素を一つ取得 soup.find('a') # soup.aと同じ soup.find_all('a') # 全てのa要素を取り出す。リストのように扱える。 soup.find('div', id='main') # divタグでidがmainのものを取得する soup.a.get('href') # href属性を取得する soup.a.text # aタグの中身を取得する実践
プログラムを書き始める前に、HTMLの構造を確認することが必要。ここでは、ニュースのタイトル・日時・URLを取得してみる。
Chrmoeの検証機能を使うとどのタグの中に欲しい情報があるのか簡単に分かる。Chromeの検証機能についてはまた詳しく書こうと思います。news.py# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import pandas as pd response = requests.get('http://news.livedoor.com/ranking/') soup = BeautifulSoup(response.text, 'html.parser') newslist = soup.find('div', class_='mainBody') tags = newslist.find_all('li') articles = [] for tag in tags: url = tag.a.get('href') title = tag.a.h3.text time = tag.time.text article = { 'title': title, 'url': url, 'datetime': time } articles.append(article) df = pd.DataFrame(articles) # 辞書をDataFrameに変換 print(df) df.to_csv('news.csv')おわりに
これからは学んだことをきちんと残していきたいです。
- 投稿日:2019-02-26T15:19:02+09:00
GridSearchCVの評価指標にユーザ定義関数を使用する方法
はじめに
関連の記事が少なく、公式の説明も自分には分かり辛かったので書いてみました。
公式: https://scikit-learn.org/stable/modules/model_evaluation.html#scoring手順概要
- ユーザ定義関数を定義する。
- sklearn.metrics.scorer.make_scorerにユーザ定義関数を渡してスコアラーを生成する(評価関数として使えるようにする)。
- 2.のmake_scorerをGridSearchCVのパラメータ「scoring」に設定する。
(ユーザ定義関数の内容に関して、今回は私のコードをそのまま貼りましたが、当然個々に寄ると思うので本記事のユーザ定義関数の内容を熟読してもあまり参考にはならないと思います。上記2点を満たしていれば問題ないです。)
ユーザ定義関数に関する注意点
下記2点を満たすように定義・実装すること。
- y_test(正解データ)とy_pred(推論結果データ)を引数として渡すことができる。
- 戻り値としてLoss(もしくは評価値)を返す。
make_scorerの設定に関する注意点
make_scorerのパラメータ「greater_is_better」の設定
- ユーザ定義関数の戻り値を評価値にする場合: True
- ユーザ定義関数の戻り値をLossにする場合: False
実装
「手順概要」の1.
ユーザ定義関数def calc_score(y_train: np.array, y_pred: np.array): threshold = 1 ignore = 10 # 比較結果格納用配列の作成 flg = np.zeros((y_train.shape[0],1)) y_train = y_train.reshape([y_train.shape[0], 1]) y_pred = y_pred.reshape([y_train.shape[0], 1]) # 正解値と予測値の差分データを作成 y_diff = y_train - y_pred for cnt_row in range(y_diff.shape[0]-DIFF): # 差分データの絶対値が閾値を超えていなければTrue if abs(y_diff[cnt_row]) < threshold: flg[cnt_row] = True else: flg[cnt_row] = False # 正解率を計算 cnt_true = 0 for cnt_row in range(flg.shape[0]): if flg[cnt_row] == 1: cnt_true += 1 score = cnt_true / flg.shape[0] return scoremain()... # 例 params = {'hidden_layer_sizes': [(100,), (100, 10), (100, 100, 10), (100, 100, 100, 10), (100, 100, 100, 100, 10), (100, 100, 100, 100, 100, 10)], 'max_iter': [1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000], 'learning_rate_init': [0.001, 0.0001, 0.00001], 'early_stopping': [True, False], 'tol': [0.0001, 0.00001], 'batch_size': [100, 200, 300], 'verbose': [True], 'random_state': [42]} # 例 mlpr = MLPRegressor() from sklearn.metrics.scorer import make_scorer # 「手順概要」の2. my_scorer = make_scorer(calc_score, greater_is_better=True) # 「手順概要」の3. gs = GridSearchCV(mlpr, param_grid=params, cv=10, scoring=my_scorer) ...
- 投稿日:2019-02-26T14:58:12+09:00
Deep LearningでバーチャルYouTuber作ってみた
概要
- GANを使ってVTuber作ってみた
- 人間と猫のモデルを作った
- リアルタイムで動物のモデルを動かす試みはまだあまりないと思う
※注意
背景では、バーチャルYouTuberについて熱く語っているので、興味のない方は飛ばして下さい。
GANについて軽く技術の紹介をしていますが、すでにご存じの方はDeep Leaning based Virtual YouTuberまで飛んで下さい。背景
バーチャルYouTuberをご存知でしょうか?バーチャルYouTuberとは、モーションキャプチャを用いてキャラクターモデルの操作を行い、YouTubeやMirrativ等のプラットフォームで配信を行う、言わばYouTuberをキャラクターにしたエンターテイメントの1つです。
バーチャルYouTuberランキングを運営する株式会社ユーザーローカル様の調査によれば1 、2018/1/31時点で活動しているのは181名でしたが、同年12月には6000人以上に増加、そして2019/2/21には7000人を突破したとの報告もあり2、バーチャルYouTuber市場が今後も拡大していくことが予想されます。かく言う私も沼にはまったファンの1人で、最推しの樋口楓さんとニコニコ町会議でお話しをしたり、18時間かけて東北から大阪までライブを見に行く程のハマり具合です。
これだけの人数が活動している中で、「YouTubeの収益化」をクリアするのは大きな問題の1つだと私は考えています。様々な基準がありますが、大きく分けて①チャンネル登録者数1000人以上、②過去12ヶ月の総再生時間が4000時間以上という2つを満たす必要があります。多くの方が活動し、企業も参戦する中、この基準を満たすのは容易ではありません。
そこで、これまでキャラクターベースのモデルではなく、GANを使った「Deep Learning系Vtuber」という新しい形態でのモデルを提供することができれば、話題性を生み、チャンネル登録者数増加に繋げられるのではないかと考えました。以降、大学の講義のPBLとして取り組んだことについて説明をしていきたいと思います。
(という、背景や問題提起は後付です。ただ単純に、GANでVtuberできんじゃね?と思ったのが始まりです。)
GAN
機械学習を用いて作るモデルは、Discriminative modelとGenerative modelという2つに分類されます。それぞれの詳細な説明は省略しますが、今回使用するGAN3はGenerative modelに属する手法です。(一部構造にDiscriminative modelを使用していますが)
下図がGANのネットワーク構造です。
GANはDiscriminatorとGeneratorと呼ばれる2つのネットワークから構成されます。それぞれの目的は以下のとおりです。
Network 目的 Generator 画像の生成 Discriminator 本物の画像と偽物の画像の識別 minimax gameを想像して頂ければ分かりやすいかもしれませんが、GANは2つのネットワークを競わせる形で学習を行っていきます。Generatorは本物に近い画像を生成できるように(Discriminatorを欺けるように)学習をします。Discriminatorでは生成された画像と本物の画像を正しく識別できるように学習をしていきます。これを繰り返し、最終的にDiscriminatorで識別することができなくなるまで学習を行ったGeneratorを用いてFake imagesを作成するのがGANの目的です。
数式等や詳細なアルゴリズムはこちらを見て頂ければ分かりやすいかと思います。
はじめてのGAN
Pokemon_GANPix2Pix
今回使用した手法がPix2Pix4と呼ばれる、GANの拡張手法です。
Pix2Pixではある入力をされた画像を、本物っぽい画像に変換することが可能です。例えば上図の場合、カバンの線画を入力として与えた場合、それに着色を行い本物のカバンのような画像を出力します。
GANと異なる点としては、2つの画像のペアを用いて学習するということです。例として、線画のキティちゃんの着色を考えます。下図のように、線画をGeneratorに入力し、出力として色付きキティちゃんを得るのが目的です。
Discriminatorでは、「入力 + 正しい色のキティちゃん」と「入力 + 生成された色付きキティちゃん」の識別を行います。
ペア画像に対しこれらを繰り返し学習していくことで、片方の入力を得た際に、もう一方の画像を出力するのがPix2Pixです。
Deep Leaning based Virtual YouTuber
ここからが本題です。今回のプロジェクトでは、先に紹介したPix2Pixを用いています。「Face landmark + 実際の画像」をペアとして学習を行い、作成したモデルに、リアルタイムで取得されたlandmarkを入力し、あたかもベースとなった人間が動いているかのような出力をすることで、Vtuberのような形式を目指します。
今回は以下のリポジトリをForkし開発を行いました。Dat Tran様に感謝致します。
Thank you, datitran (Dat Tran) ! I really appreciate it.
datitran/face2face-demoとりあえず色々調整して学習して動かしてみた
結果がこちらです。
左側の線画がリアルタイムで取得した私の動きで、右側が出力となっています。
(本当は一番左に私の顔が写っているのですが、恥ずかしいのでカットしています。)結構ちゃんと動いてます。
データを変更し学習しても、そこそこの物が出来上がりました。WebカメラとGPUだけでここまでできるなんて凄いなーというのが私の感想です。他人の顔を動かすような研究はたくさん行われていそうなので、こんなものかと思われる方もいるかもしれません。実際、世界初のAIニュースキャスターが中国で誕生するなど、GANの精度は日に日に向上しています。
Xinhua's first English #AI anchor makes debut at the World Internet Conference that opens in Wuzhen, China Wednesday pic.twitter.com/HOkWnnfHdW
— China Xinhua News (@XHNews) 2018年11月7日
法律的な問題点
GANを使う以上、元となる人物のデータが必要となります。先ほどの例では、ドイツのメルケル首相を使用しました。また、遊びではじめしゃちょーのモデルも作成しました。ここで、問題になってくるのが法律的な問題です。
実は日本には著作権法には47条の7という、世界的に見ても珍しい条文があります。簡単に言えば「情報解析が目的であれば、著作権者の承諾なしに自由に使用ができる」といった内容です。しかも、非営利目的の利用に限定されていません。我々AI開発者・研究者にとっては天国のような内容です。
しかし、情報解析に機械学習が含まれているのかどうかといった解釈や、他の法律(他国含む)等を考慮すると怪しい気がしてきます。そこで、「動物のデータなら大丈夫ではないか?」と考えました。以降は動物のデータを用いた取り組みについてご紹介していきます。
Animal Model
前処理
人間でも動物でも、Pix2Pixを使う以上ペアの画像を作成する必要があります。前処理の流れは大まかに、このようになっています。
- データ(動画)入手
- フレーム分解
- 分解した画像からLandmarkを取得
- フレーム分解した画像とLandmarkをペアとして学習
今回、最も苦戦したのが「3. 分解した画像からLandmarkを取得」です。人間のlandmark検出であれば、OpenCVやdlibといったライブラリを使えば簡単かつ、高精度に検出することが可能です。しかし、動物のlandmark検出となると話しは変わってきます。
Object detectionでは「どこに、何の動物がいるか」の検出は可能です。しかし、それぞれの動物の顔の特徴までは検出できません。調べた限り、動物の顔の特徴抽出器も多くは存在しません。(需要ないだろうし)
Landmark detectorを作成するには、顔がもつ特徴点を画像ごとに記録し学習を行う必要があります。人間であれば、画像のように60個以上ある特徴点の座標を1枚ごとに記録する必要があります。学習には数千枚を超えるデータが必要であるため、これを1から作るのは現実的ではありません。
猫の特徴抽出
そこで、頑張って探し辿り着いたpycatfdを一部改変し、使用することにしました。
marando/pycatfd
抽出された特徴点の座標をもとに、以下のような画像を生成するプログラムを作成しました。
pycatfdですが、猫が少しでも横を向くと検出ができなくなってしまう(または、誤検出がおこる)という問題があります。また、そもそもの検出精度も悪く化物のようなデータになってしまいます。そこで、取得した特徴点から、様々な処理を行ったデータを用意し、実験を行いました。行った処理内容は以下の通りです。
データ(動画) 処理内容 ①某CMに登場する猫 無処理 ②某CMに登場する猫 データ選定 ③某CMに登場する猫 耳なし ④某CMに登場する猫 擬似耳 ⑤YouTubeに投稿された猫 データ拡張 反転 ⑥YouTubeに投稿された猫 データ拡張 反転 + 縮尺変更
- ②服を着ていたり、帽子を被っていたりする画像を削除
- ③耳の検出が不安定なため、耳がないlandmark画像を作成
- ④耳の検出が不安定なため、座標を指定して擬似的な耳を作成
- ⑤⑥使いやすそうなデータが見つかったため、データを変更
- ⑤データ数が少ないため、水平方向に反転した画像を追加
- ⑥反転に加え、縮尺を変更することでノイズに強くなるのではないかと予想
色んな試行錯誤をした結果
最も悪かった結果 (前処理①)
最も良かった結果 (前処理⑤)
考察
遠くから見れば猫っぽいかな... くらいの精度でした。
原因としては大きく分けて、以下の2つだと考えています。
特徴の違い
猫の特徴を学習したモデルに、人間の特徴を入力しているため、精度に影響したと考えられれます。今回は人間の目と顔の輪郭のみを入力としました。(他の特徴も入力すると精度が下がったため)そのため、特徴の変換器みたいなものを作成する必要がありそうです。データ
猫の特徴抽出の説明において、検出精度が低いと記述しました。下の画像の耳が垂れている猫のように、ありえない画像を学習に使ってしまったのも原因と考えられます。
終わりに
精度向上の余地はありそうですが、一旦開発はここで終了としています。実は開発メンバーの中にGANを専門に勉強、研究をしている人間はいませんでした。そのため、感想やコメント、アドバイスを頂ければ幸いです。最後まで読んでいただきありがとうございました。
Github
整理中(2019/02/26)
gojirokuji/dtuber
株式会社ユーザーローカル, バーチャルYouTuber、本日6000人を突破(ユーザーローカル調べ), https://www.userlocal.jp/news/20181219vs/ ↩
株式会社ユーザーローカル, バーチャルYouTuber、本日7000人を突破(ユーザーローカル調べ), https://www.userlocal.jp/news/20190221vn/ ↩
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, Generative Adversarial Networks, arXiv:1406.2661, https://arxiv.org/abs/1406.2661 ↩
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros, Image-to-Image Translation with Conditional Adversarial Networks, arXiv:1611.07004, https://arxiv.org/abs/1611.07004 ↩

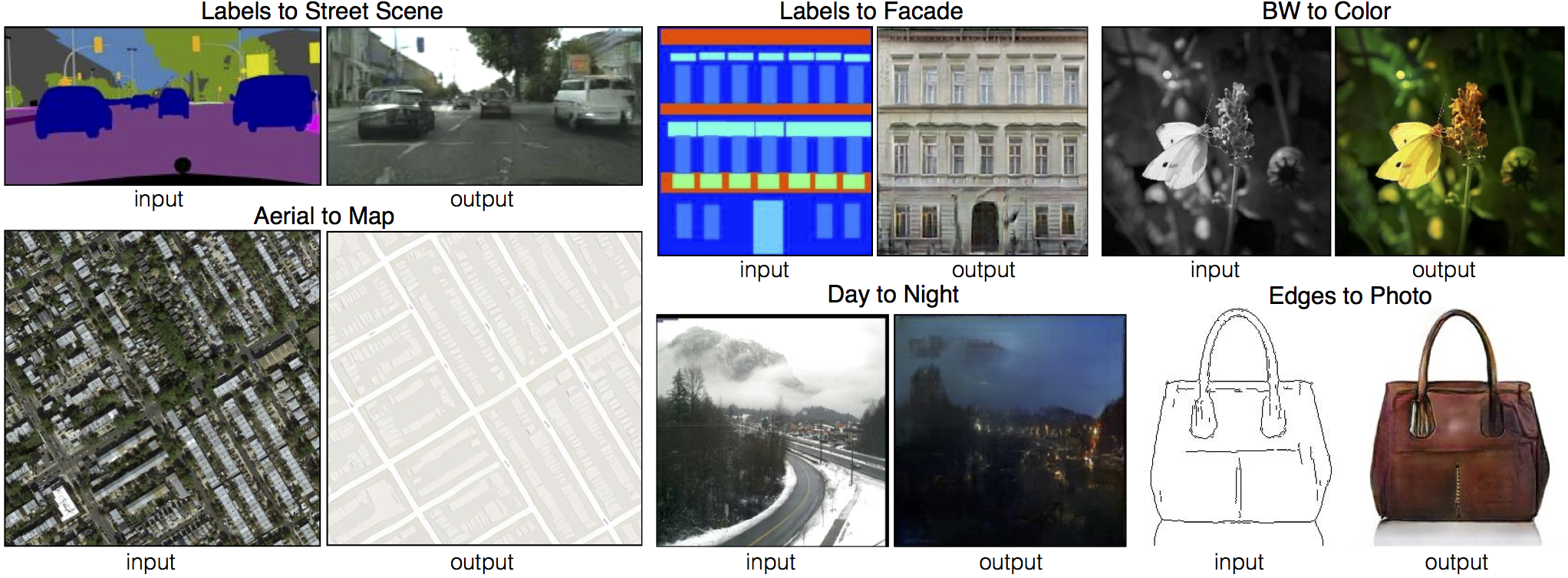







- 投稿日:2019-02-26T14:32:47+09:00
nonce2vecで少数データからWord2vecを更新する
nonce2vec1とは、少数のデータを用いて訓練済みWord2vecに新語を加えるなどする手法です。ここでは、その使い方を見てみます。
概要
nonce2vecは3つのフェーズを取ります。
- 事前訓練済みWord2vec(skip-gram)の読み込み。
- 訓練対象文のボキャブラリー構築。
- パラメータを設定し、訓練対象文で対象語を訓練。
訓練対象文は、例えば訓練したい語の「語の定義」などを使います。要するに、新語を少数の定義文から更新する手法です。
インストール
pip install nonce2vec実行例
from nonce2vec.models.nonce2vec import Nonce2Vec, Nonce2VecTrainables, Nonce2VecVocab import MeCab from pprint import pprint import numpy as np import copy if __name__ == "__main__": #MODELS model = Nonce2Vec.load("word2vec.model") model.vocabulary = Nonce2VecVocab.load(model.vocabulary) model.trainables = Nonce2VecTrainables.load(model.trainables) tagger = MeCab.Tagger("-Owakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") nonces = [] sentences = [] #INPUTS with open("10.test") as f: for line in f: tmp = line.split(":::") nonce = tmp[0] sentence = tagger.parse(tmp[1]).format(nonce).strip().split() nonces.append(nonce) sentences.append(sentence) #PARAMS alpha = 1 sample = 10000 neg = 3 window = 15 iter = 1 lambda_den = 70 sample_decay = 1.9 window_decay = 5 #PARAM SETTING def model_init(m, sentence, nonce, *ps): model.alpha=float(ps[0]) model.sample=int(ps[1]) model.sample_decay=float(ps[2]) model.iter=int(ps[3]) model.negative=int(ps[4]) model.neg_labels = [] if model.negative > 0: model.neg_labels = np.zeros(model.negative+1) model.neg_labels[0] = 1. model.vocabulary.nonce=nonce model.window=int(ps[5]) model.window_decay=int(ps[6]) model.lambda_den=float(ps[7]) #model.min_count=int(1) print(sentence) model.build_vocab(sentences=[sentence], update=True) model.train([sentence], total_examples=model.corpus_count, epochs=model.iter) return model #DOIT import json out = {} for nonce, sentence in zip(nonces, sentences): model = model_init(model, sentence, nonce, *(alpha, sample, sample_decay, iter, neg, window, window_decay, lambda_den)) tmp = model.most_similar(nonce, topn=30) out[nonce] = tmp with open("out.json","w") as f: f.write(json.dumps(out, indent=4, sort_keys=True, ensure_ascii=False))実行例のデータ
11次元超重力理論:::{} とは、一般相対論を超対称化した理論、言い方を変えれば局所超対称性の理論である。量子化した際は、単なる一般相対論より紫外発散が弱くなるため、量子重力理論の文脈において1980年代初頭に精力的に研究された。超対称性のゲージ理論と考えることもできる。対応するゲージ場がグラヴィティーノである。 エンティティリンキング:::{} とは、自然言語処理において、テキスト内の表現を知識ベース内の識別子として認識するタスクである。 カバートアグレッション:::{} とは、評判を傷つけたり、関係を操作することで人に害を及ぼす行為である。 自己顕示バイアス:::{} とは、実験参加者が自分を良く見せようとすることによって生じるバイアスのこと。 INTJ:::{} とは、MBTIの診断結果の1つで、内向的・直感的・思考的・判断的な性格タイ プのこと。 サイハテ村:::{} とは、熊本の宇土半島にあるエコビレッジ。 オブジェクト図:::{} とは、クラス図などで表現されたクラス構成や相互関係に対して、それをインスタンス化したレベルで表現したUMLの図。 レプティリアン:::{} とは、陰謀論の一つで、地球に隠れて生息するとされる宇宙人の一種。爬虫類に属する。 Metasploit:::{} とは、サイバーセキュリティのツールで、ペネトレーションテストを行うためのフレームワークである。 幾何学的ラングランズ予想:::{} とは、ラングランズプログラムを幾何学的に定式化しなおして、単に既約表現だけを考える以上のものを関連付けようとして生じたものである。単純な場合だと、代数曲線のエタール基本群の l-進表現を、その曲線上のベクトル束の モジュライスタック上で定義された l-進層の導来圏の対象に関連付ける。実行結果の一部
{ "11次元超重力理論": [ [ "マイクロ磁気学", 0.780556857585907 ], [ "ピカール・レフシェッツ", 0.7795853614807129 ], [ "成りたつ", 0.7746739387512207 ], [ "オイラー=ハイゼンベルク・ラグランジアン", 0.7744903564453125 ], [ "散乱問題", 0.7708392143249512 ], . . .おわりに
このように、少数のデータから、事前訓練済みWord2vecにはない語を学習することができました。
ただし、build_vocabでは、合計ベクトルを新語のベクトルとして採用しているため、新語同士が近くなってしまう問題があります。
補足: gensimのskip-gramモデル
skip-gramモデルを使うには、sg=1を指定します。
import logging from gensim.models import word2vec import multiprocessing if __name__ == "__main__": logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentences = word2vec.Text8Corpus('./wiki_fixed.text8') model = word2vec.Word2Vec(sentences, size=200, workers=multiprocessing.cpu_count(), sg=1) model.save("word2vec.model")
- 投稿日:2019-02-26T14:17:52+09:00
Pythonで部分的なコードの実行時間を測る
Pythonで部分的なコードの実行時間を知りたい時のtipsです。
すぐに忘れるので、メモを兼ねて共有します。実装
まず、contextmanagerでデコレーターを作っておきます。
from contextlib import contextmanager import time @contextmanager def timer(title): start = time.time() yield print("{} - done in {:.3f}s".format(title, time.time() - start))使い方
with timer('hello world'): # 処理関数内に関数を定義して、ラッパーを用いることでも実装できるのですが、
contextlibのcontextmanagerを使うことでより簡潔になります。デコレータ内の「yield」でwithステートメント内の処理が実行されて、時間を計測できるようになっています。
部分的なコードの実行時間を測りたい時に便利なので、使ってみてください。
- 投稿日:2019-02-26T11:20:32+09:00
python packaging の editable と develop mode のこと
python パッケージのツールはdistutils, setuptools, pip, pipenv といろいろあって、用語が混乱してきたのでまとめてみた。
easy_install (setuptools)
- easy_install -e の editable mode はバージョン解決をしてダウンロードするところまで。
- editable mode での展開ディレクトリは明示的に指定しないといけない。
- setup.py develop で symlink を使った install が行われる (egg-link)
pip
- pip install -e の editable mode は setuptools の develop mode に相当
- git (VCS) 管理の url からもインストールできる(pip install git+https://.... みたいな)
--srcディレクトリはデフォルトの位置が用意されているpipenv
- pipenv install -e の editable mode は egg-link でインストールを行う
- editable として展開されている場所は pip 同様規定値が使われる
--devは [dev-packages] に区分けされて Pipfile に入る。egg-link とは関係ない。--devは他の環境でインストールするときに効く。pipenv install --dev で packages と dev-packages の両方が入る。
- 投稿日:2019-02-26T11:10:42+09:00
ペントミノ「のような」タイル敷き詰め問題を量子コンピュータで解いてみる
はじめに
少し前に、とある東工大の先生から、「ペントミノってアニーリングマシンで解けるのかな?」と聞かれて「やってみます!」と答えてしまいましたので、なんとか解いてみたいと思いました。
ペントミノとは(https://ja.wikipedia.org/wiki/%E3%83%9A%E3%83%B3%E3%83%88%E3%83%9F%E3%83%8Eただし、ペントミノは5個の正方形を組み合わせたピースが12個あり、数が多くて大変なので、まずは問題を小さくして、3×3のタイルを敷き詰める問題を考えてみます。
問題
下図左のような正方形3つでできたタイル3つを、下図右のような3×3の盤面にピッタリ敷き詰める問題を考えてみます。
左からピースをp1, p2, p3とします。本物のペントミノでは、同じ形のピースはないのですが、3×3への敷き詰めを考えてここでは許容します。
考え方
まずは、ピースp1の盤面への置き方を考えてみます。下図のように6通りあります。この置き方を、それぞれ「q0, q1, q2, q3, q4, q5」とします。
さらに、ピースp2, p3についても考えて見ます。
立式
次に、アニーリングマシンで解けるように立式してみます。
量子ビットが表すものを決める
ピースp1は、q0~q5のどれかの置き方になるはずですので、置き方q0になるときに、q0=1 、q0にならない時 q0=0 とします。
同様にして、q1になるとき、q1=1, ならないときq1=0・・・、ピースp2についても、置き方q6になるときq6=1, ならないときq6=0・・・とします。各ピースについて、置き方の中から1つだけ選ばれるようにする
まずは、p1の置き方は「q0, q1, q2, q3, q4, q5」の6個がありますが、その中から1つだけがえらばれなければなりません。
そのため、この6個の量子ビットの中から1つだけが選ばれる、という条件を最小値問題の式にしてみます。以下のようになります。\{1-(q0+q1+q2+q3+q4+q5)\}^2これで、q0~q5の中で、1のとき最小値の0、それ以外は1以上の値になります。
同様にして、ピースp2, p3についても立式すると\{1-(q6+q7+q8+q9+q10+q11+q12+q13+q14+q15+q16+q17+q18+q19+q20+q21)\}^2\{1-(q22+q23+q24+q25+q26+q27+q28+q29+q30+q31+q32+q33+q34+q35+q36+q37)\}^2盤面の各位置(b1, b2, b3・・・)に置くピースが重ならないようにする
次に、盤面に注目します。
盤面の「b1」の位置に置かれる可能性のあるピースの配置は、図から「q0,q3,q6,q14,q16,q22,q30,q32」であることが分かります。ピースは重なってもだめだし、どれか1つは配置されていないとダメなので、b1上に来る可能性のあるピースの中から、1つだけを選ぶ必要があります。先ほどと同様に立式すると、\{1-(q0+q3+q6+q14+q16+q22+q30+q32)\}^2とすれれば、盤面の位置b1に置かれるピースの配置が1つのみに絞られます。
盤面の位置b2, b3, b4, b5・・・についても同様に立式します。式全体
ちょっと面倒ですが、全部のピース・盤面の位置についての条件を列挙して足し合わせると、以下の式になります。
\{1-(q0+q1+q2+q3+q4+q5)\}^2 \\ +\{1-(q6+q7+q8+q9+q10+q11+q12+q13+q14+q15+q16+q17+q18+q19+q20+q21)\}^2 \\ +\{1-(q22+q23+q24+q25+q26+q27+q28+q29+q30+q31+q32+q33+q34+q35+q36+q37)\}^2 \\ +\{1-(q0+q3+q6+q14+q16+q22+q30+q32)\}^2 \\ +\{1-(q1+q3+q7+q8+q14+q15+q16+q17+q23+q24+q30+q31+q32+q33)\}^2 \\ +\{1-(q2+q3+q9+q15+q17+q25+q31+q33)\}^2 \\ +\{1-(q0+q4+q6+q8+q10+q16+q18+q20+q22+q24+q26+q32+q34+q36)\}^2 \\ +\{1-(q1+q4+q6+q7+q8+q9+q11+q12+q14+q17+q18+q19+q20+q21+q22+q23+q24+q25+q27+q28+q30+q33+q34+q35+q36+q37)\}^2 \\ +\{1-(q2+q4+q7+q9+q13+q15+q19+q21+q23+q25+q29+q31+q35+q37)\}^2 \\ +\{1-(q0+q5+q10+q12+q20+q26+q28+q36)\}^2 \\ +\{1-(q1+q5+q10+q11+q12+q13+q18+q21+q26+q27+q28+q29+q34+q37)\}^2 \\ +\{1-(q2+q5+q11+q13+q19+q27+q29+q35)\}^2シミュレータblueqatで解いてみる
式はできたので、シミュレータblueqatで解いてみます。コードは以下の通り。
a = opt.opt() a = opt.opt() a.qubo = opt.optm("(1-(q0+q1+q2+q3+q4+q5))^2 \ +(1-(q6+q7+q8+q9+q10+q11+q12+q13+q14+q15+q16+q17+q18+q19+q20+q21))^2 \ +(1-(q22+q23+q24+q25+q26+q27+q28+q29+q30+q31+q32+q33+q34+q35+q36+q37))^2 \ +(1-(q0+q3+q6+q14+q16+q22+q30+q32))^2 \ +(1-(q1+q3+q7+q8+q14+q15+q16+q17+q23+q24+q30+q31+q32+q33))^2 \ +(1-(q2+q3+q9+q15+q17+q25+q31+q33))^2 \ +(1-(q0+q4+q6+q8+q10+q16+q18+q20+q22+q24+q26+q32+q34+q36))^2 \ +(1-(q1+q4+q6+q7+q8+q9+q11+q12+q14+q17+q18+q19+q20+q21+q22+q23+q24+q25+q27+q28+q30+q33+q34+q35+q36+q37))^2 \ +(1-(q2+q4+q7+q9+q13+q15+q19+q21+q23+q25+q29+q31+q35+q37))^2 \ +(1-(q0+q5+q10+q12+q20+q26+q28+q36))^2 \ +(1-(q1+q5+q10+q11+q12+q13+q18+q21+q26+q27+q28+q29+q34+q37))^2 \ +(1-(q2+q5+q11+q13+q19+q27+q29+q35))^2 " ,38) res = a.sa() print(res) print(np.where(np.array(res)==1)[0])結果
以下のような結果が得られました
[0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0] [ 5 6 31]q5, q6, q31が選ばれていますので、組み合わせてみると・・・
このように、ちゃんと敷き詰めできています!何回か実行すると、下図のようないくつかの結果が得られました。いずれも敷き詰めができました。
まとめ
3×3のタイルの敷き詰めはできました。
ペントミノの場合、ピースも12に増え、さらに「裏返す」と形が異なるピースもあることから置き方が一気に増えますが、「1つのピースの置き方」については古典で十分洗い出し可能だと思いますので、古典のプログラミングで立式はできそうです。量子ビット数が多くなるので、イジングで解けるかどうか分かりませんが、やってみたいと思います。利用したシミュレータblueqatは以下から利用できます。
https://github.com/Blueqat/Blueqat



- 投稿日:2019-02-26T09:45:34+09:00
特異値分解を詳しく解説
はじめに
特異値分解は機械学習ではよく使われるテクニックだが、大学の教養過程で使うような線形代数の教科書には載っていなかったりする。
書店で色々探した結果、こちらの本に分かりやすい解説があり、理解が深まったのでまとめておく。
線形代数セミナー: 射影,特異値分解,一般逆行列 金谷 健一 (著)
今回は特異値分解の解説のみで、具体的な活用法はまた別の記事に書く(予定)。
定義
${\rm rank}(A)=r$ の $m \times n$ 行列 $A$ を考える。 ただし、$r < m < n$とする。
$\rm rank$って何?という方はあまり気にしなくても大丈夫ですが、気になる方はこちらの記事を参照。
このとき、$A$の特異値分解は下記のように表される。$$A = U \Gamma V^T$$
ここで、$U, V$は直交行列であり、$\Gamma$は対角行列である。$\Gamma$の対角成分$\sigma_1,..., \sigma_r$が行列$A$の特異値と呼ばれる。特異値は0より大きい値である(0も特異値とする場合もある)。
$U, V$の列ベクトルをそれぞれ左特異ベクトル、右特異ベクトルと呼ぶ。$U, V$がそれぞれ$\Gamma$の左、右に来るためだと覚えておけばよい。
特異ベクトルの定義は下記のようにも書ける。固有値・固有ベクトルの定義($A \boldsymbol v = \lambda \boldsymbol v$)に似ているが、左辺と右辺に含まれるベクトルがそれぞれ $\boldsymbol u, \boldsymbol v$ と異なるベクトルになっていることに注意。
A \boldsymbol v = \sigma \boldsymbol u \\ A^T \boldsymbol u = \sigma \boldsymbol vここで、これらの式にそれぞれ、$A^T, A$を左からかけると、
A^T A \boldsymbol v = \sigma A^T \boldsymbol u = \sigma^2 \boldsymbol v \\ AA^T \boldsymbol u = \sigma A \boldsymbol v = \sigma^2 \boldsymbol u上式の最左辺と最右辺を比べると、前述した固有ベクトルの定義と同じ形になっている。
よって、$\boldsymbol u, \boldsymbol v$ はそれぞれ、$AA^T, A^T A$ の固有ベクトルであり、固有値はいずれも$\sigma^2$となる。つまり、
(行列$A$の特異値) $^2=$ (行列 $AA^T, A^TA$ の固有値)ということが言える。(なぜか中央寄せにならない??)[error]()
特異値分解のイメージとしては、対称行列(行と列の数が等しい行列)で定義される固有値を、一般の行列に拡張したものだと考えると良さそう。実際、対称行列の場合は固有値と特異値は一致する。
表記法
特異値分解の表記方法はいくつかあって、自分はちょっと混乱した。
まず、0を特異値に含めて、$\Gamma$を $m \times m$ の行列とする場合もある(下図(2))。ただし、 $\boldsymbol u, \boldsymbol v$ は特異値0に対応する左特異ベクトル、右特異ベクトルを並べた行列である。表記(1)から拡張されたグレーの部分は、結局かけ合わせて0になるので、実質的な影響はない。
また、$\Gamma$を対角行列ではなく、$m \times n$の行列とした表記もある(下図(3))。これは、$\Gamma$を 零行列でさらに拡張して$m \times n$に、$V$も$n \times n$に拡張したものだと考えれば良い。やはり、グレーの部分は掛け合わせて0になるので、実質的な影響はない。
Pythonコード
pythonでは、numpyのlinalgモジュールにあるsvdという関数で特異値分解を実行することができる。
この関数が返す $U, V$ はデフォルトでは表記(3)に対応する対称行列である。ただし、full_matrices=Falseとすると、表記(2)に対応する $U, V$ が得られる。
また、$\Gamma$については、行列ではなく(0を含む)特異値の配列が返される。行列Aのランクは2なので、0でない特異値の数は2つとなっている。特異値分解の$\Gamma$にするためには、np.diagで対角行列にする必要がある。
確認のため、$U, \Gamma, V$の積をとってみると、確かに元の行列$A$と一致することが分かる。import numpy as np from numpy.linalg import svd, matrix_rank # rank=2の 3x4行列を作成 A = np.array([[2, 4, 1, 3], [1, 5, 3, 2], [5, 7, 0, 7]]) print('matrix A\n', A) print('rank: ', matrix_rank(A)) # singular value decomposition u, s, vh = svd(A) print('\nSVD result') print('shape of u, s, vh:', u.shape, s.shape, vh.shape) print('singular values:', s.round(2)) # full_matrices=Falseの場合 u, s, vh = svd(A, full_matrices=False) print('\nSVD result (full_matrices: False)') print('shape of u, s, vh:', u.shape, s.shape, vh.shape) # 復元 # A_re = (u @ np.diag(s, -1)[1:] @ vh).round(2) A_re = (u @ np.diag(s) @ vh).round(2) print('\nreconstructed A:\n', A_re)実行結果matrix A [[2 4 1 3] [1 5 3 2] [5 7 0 7]] rank: 2 SVD result shape of u, s, vh: (3, 3) (3,) (4, 4) singular values: [13.39 3.58 0. ] SVD result (full_matrices: False) shape of u, s, vh: (3, 3) (3,) (3, 4) reconstructed A: [[ 2. 4. 1. 3.] [ 1. 5. 3. 2.] [ 5. 7. -0. 7.]]


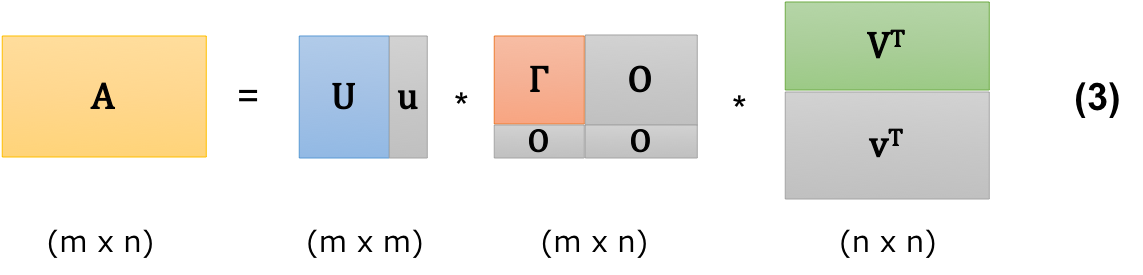
- 投稿日:2019-02-26T08:57:37+09:00
GANを学びたいけれど、価値関数の数式に困惑している人へ
GANの価値関数(目的関数)
本記事ではGANを学び始めたら見かけてしまう、一見複雑そうな上記の式を解説していく
GANのモデル
まずはGANのモデルと学習の流れを軽く見てみる
順伝播(Discriminatorに判定させてみる)
・Generatorがノイズ(例えば100次元のベクトル)から画像っぽいものを生成する
もちろん最初はでたらめな画像しか生成できない・Discriminatorには本物の画像、もしくはGeneratorが生成した画像のどちらかをランダムに入れる
・Discriminatorがスコアを出すときはシグモイド関数を使うため、
本物だと思ったら1を出力、Generatorが生成した画像(偽物)だと思ったら0を出力する正確にいうと「Discriminatorに来た画像が本物である確率」
逆伝播(Discriminatorの重みを更新するとき)
Discriminatorの理想は本物が来たら1を出力して、偽物が来たら0を出力
・ここはシンプルに画像分類をしたときのCNNの重みの更新と同じ
GANだからと言って新しい何かがあるわけではない
正しく判定(本物が来たら1を出力して、偽物が来たら0を出力)できるように重みを更新する逆伝播(Generatorの重みを更新するとき)
Generatorの理想はDiscriminatorが間違って判定(偽物の画像に対して1を出力)すること
・これは実装上のポイントにもなるが
Generatorの重みを更新するときは、誤差がDiscriminatorを通ってくるため
Discriminatorの重みの更新を止めなければならないもしDiscriminatorの重みの更新を止めなかったら、Discriminatorの重みが偽物に対して1を出力するようになってしまう(今はGeneratorの理想に近づくような更新がされているため)
本題へ
GANの価値関数(再掲)
右辺について
$E$:期待値
$x$~$p_{data}(x) $:本物の画像がDiscriminatorに来たとき
$D(x)$:Discriminatorに本物の画像が来たときのスコア$x$~$p_z(x)$:Generatorが生成した画像(偽物)がDiscriminatorに来たとき
$G(z)$:Generatorがノイズzから生成した偽物画像
$D(G(z))$:Discriminatorに(Generatorが生成した)偽物の画像が来たときのスコアlogのグラフ
log(x)のxの値が大きいほどlog(x)は大きくなる
Discriminatorを評価するとき
・Discriminatorの理想は本物が来たら1、偽物が来たら0を出力すること
右辺第一項
上記の式を言語化すると、本物の画像がDiscriminatorに来たときのDiscriminatorのスコアである本物の画像のため、シグモイド関数の出力は0~1の内、1を出力してほしい
理想的な出力である$D(x)=1$を出力できれば、結果的に上記の式(右辺第一項)を最大化できる
右辺第二項
上記の式を言語化すると
Generatorが生成した画像(偽物)がDiscriminatorに来たときのDiscriminatorのスコアである偽物の画像のため、シグモイド関数の出力は0~1の内、0を出力してほしい
理想的な出力である$D(G(z)))=0$を出力できれば、$log(1-0)$になり
結果的に上記の式(右辺第二項)を最大化できるDiscriminatorまとめ
上述のようにDiscriminatorの理想通り(本物の画像には1を出力、偽物の画像には0を出力)になれば、
第一項と第二項はどちらも最大になる(大きい値と大きい値を足し合わせているので右辺トータルも最大)このことを表しているのが、価値関数の左辺にある$max_D$である
Generatorを評価するとき
・Generatorの理想はDiscriminatorが間違って判定(偽物の画像に対して1を出力)すること
・右辺第一項はGeneratorに関係ないので無視する
右辺第一項
本物の画像がDiscriminatorに来たときのDiscriminatorのスコアを表しているこれはGeneratorとは関係がないのでGeneratorを評価するときは無視する
右辺第二項
Generatorが生成した画像(偽物)がDiscriminatorに来たときのDiscriminatorのスコアを表しているGeneratorはDiscriminatorが間違ってほしい
Generatorにとっては、偽物画像に対してDiscriminatorが1を出力するのが理想理想的な出力である$D(G(z))=1$を出力できれば、$log(1-1)$になり
結果的に右辺第二項を最小化できるGeneratorまとめ
上述のようにGeneratorの理想通り(Generatorの生成した画像に対してDiscriminatorが1を出力)になれば、第二項は最小になる(第一項は無視、第二項最小化で右辺トータルは最小)
このことを表しているのが、価値関数の左辺にある$min_G$である
全体まとめ
文字が多くて圧倒されてしまいがちな式だが、
「GeneratorとDiscriminatorのそれぞれの理想の状況ってどうなんだっけ?」と落ち着いて考えていけば、「そんな複雑なことを表している式ではないんだな」ということが理解できると思う
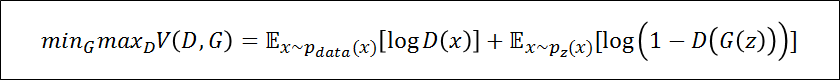
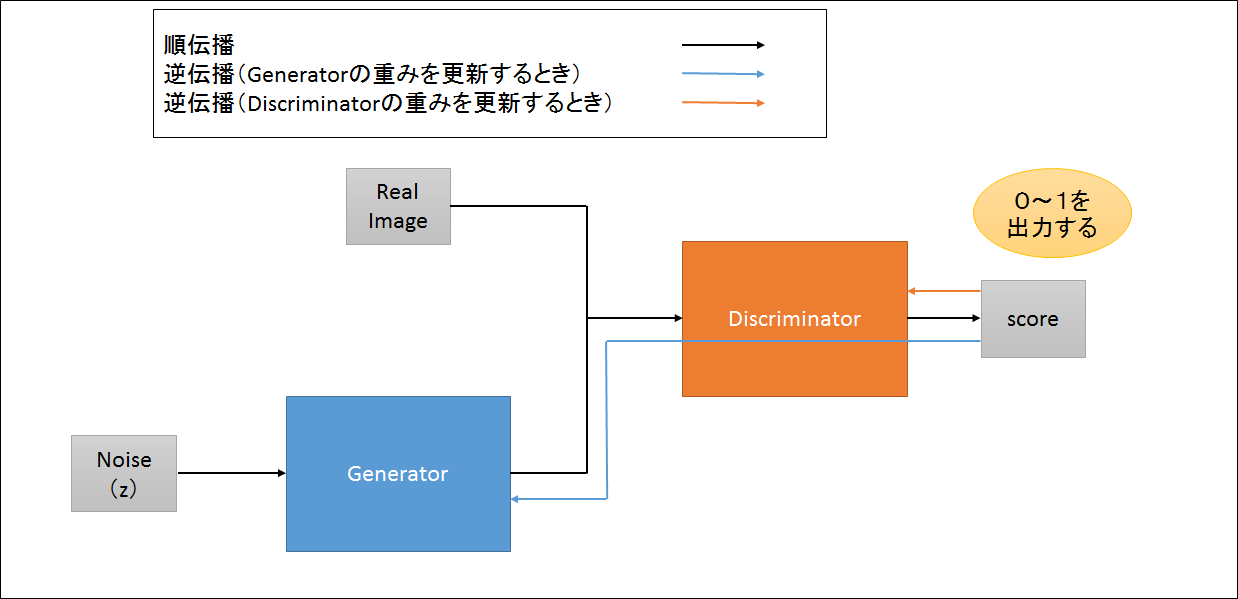
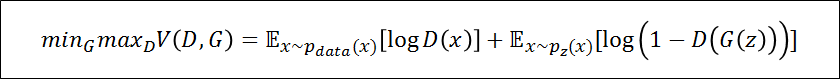
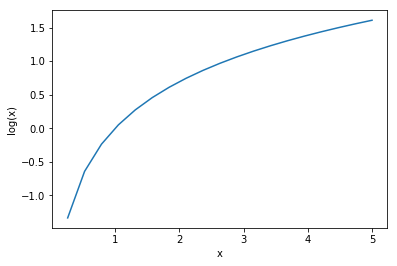

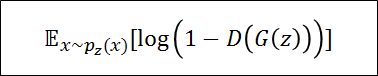
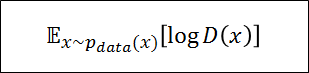
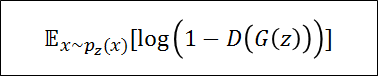
- 投稿日:2019-02-26T07:51:18+09:00
Pythonを使ってDECTRISの二次元検出器のHDF5データを読み込む
はじめに
スイスの国立研究所PSIのスピンオフベンチャーDECTRISの1ピクセル1円1とも言われる二次元高分解能X線検出器は、手軽に買えない価格にもかかわらずいまや世界中の大学や放射光実験施設に導入されています。実験室系X線の回折装置や小角散乱装置にも採用されており日常的に使っている方もいるでしょう。
高分解能ということはデータ量が増えることを意味します。ビーム強度が強く測定時間の短い放射光実験では、メガピクセルサイズの32ビット二次元配列が世界中の装置で数秒ごとに生成されています。これらの膨大なデータは、放射光施設自体が仕様策定に関わったHDF5ファイルにバイナリとして保存されています。バイナリデータだけに扱いにはそれなりの道具立てが必須です。数百枚の連続測定データを持ち帰ることがざらにある放射光実験のユーザーには、測定データの多さやファイルサイズに加えてデータそのものの扱いにくさに参っている方もいるでしょう。もちろん、必要なデータを厳選してテキストファイルや扱い慣れたフォーマットに変換し、従来のワークフローに乗せるということも可能です。しかし、PythonとJupyter notebookの組み合わせにより科学データの取り扱い方に新しい潮流が生まれつつある中で、それらを活用して大量のデータを一括で扱うソフトウェア技術を身につけることは、ハードウェアの革命により生まれた新しいサイエンスの可能性を探るのに不可欠な足場とも言えます2。この記事では、X線回折やX線小角散乱という裾野の広い実験手法に起きた超高速な高分解能二次元データ取得というハードウェアによる革命に自力で対応したい方のために、解析の第一歩であるデータの読み取りの方法を述べます。
目的
従来の解析ソフトで扱えるフォーマットに変換するツールをすでに導入しているBLもあると思いますが3、ここでは装置や測定条件に関するメタ情報とカウントデータを、大量データに対する自己流の解析・可視化ワークフローを適用しやすいPythonを使って読み取ることを目的にします4。BLスタッフが用意したデータ処理ソフトウェアを使って扱いやすい形式にすることが多いのか、日本語に限らず英語でも執筆時点ではDECTRISのHDF5ファイル読み取りに関する解説はまだウェブにはないようです。
HDFファイルを扱う際の注意点
DECTRISのデータ(ここではEIGER 4M)を扱うにあたって、知っておくべき点がいくつかあります。詳しくは理研放射光科学研究センターの山下さんのGitHubに書いてありますが、ここでは読み取りに関わるHDF5の圧縮機能と外部リンク機能についてだけ述べます。
圧縮フィルター機能
データ圧縮はHDF5の透過的(transparent)な機能の一つです。透過的というのはユーザーがあまり意識せずとも自動的に機能してくれるという意味です。HDF5関連ドキュメントでは、圧縮機能は透過であることをフィルターに例えて圧縮フィルター(compression filter)とも呼ばれています。DECTRISのHDF5データの圧縮にはbitshuffle+lz4(bslz4)という形式が使われています5。bitshuffleもlz4もHDF5標準の圧縮フィルターではないのでプラグインとしてユーザーが追加する必要があります。Pythonのh5pyパッケージを使ってHDF5を読み取る場合は、ESRFのソフトウェアチームの方が用意したhdf5pluginというパッケージをインストールすれば簡単に両者を導入できます。
外部リンク機能
HDF5の規格には大量の実験データが日々生成される放射光実験施設の提案によるものもあります。外部リンク(External link)機能はその中の一つから発展した機能のようです6。外部リンク機能は、通常のパス表記を使って異なるHDF5ファイルのDatasetにアクセスできる機能です。例えば、連続測定によって大量に得られたデータを扱う際に、全データ共通のメタ情報のみを含むHDF5ファイル(通称マスターファイル)に設定してある各測定結果への外部リンクを使うと、マスターファイルを読み込むだけで別ファイルに保存してある全測定データにシームレスにアクセスできます。I/Oパフォーマンスに関する良し悪しは検証していませんが、コードがかなり簡潔になるのは確かです。
準備
hdf5pluginはpipで、ほかはcondaからインストールできます。
%matplotlib inline import hdf5plugin # 環境変数のパスを設定をしているので必ずh5pyより先にインポート import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import LogNorm import h5py from matplotlib import __version__ as mplv print('Numpy:', np.__version__) print('matplotlib:', mplv) print('h5py:', h5py.__version__) plt.rcParams['image.origin'] = 'lower' # imshowの原点を左下に # 明示的に読み込むのはマスターファイルのみ masterhdf = '/dummy/path/to/data/EIGER_4M_test_master.h5'この記事ではマスターファイルのあるフォルダには以下のような測定データあるとします。マスターファイルと測定ファイルの名前の共通部分は外部リンクが正しく機能するために必要です。
> ls /dummy/path/to/data EIGER_4M_test_data_000001.h5 EIGER_4M_test_data_000002.h5 EIGER_4M_test_data_000003.h5 EIGER_4M_test_data_000004.h5 EIGER_4M_test_master.h5HDFファイルの中身を確認する
この記事に書いてある方法を使って、データ構造とdatasetの中身を確認します。ただし、外部リンクのデータはこの方法では表示されません。
def PrintOnlyDataset(name, obj): if isinstance(obj, h5py.Dataset): print(name) print(obj.value) with h5py.File(masterhdf,'r') as f: f.visititems(PrintOnlyDataset)bslz4フィルターが機能していれば以下のような内容が出力されます。マスターファイルの内容は全測定に共通な検出器情報が主であることがわかります。
entry/instrument/beam/incident_wavelength 0.7208383 entry/instrument/detector/beam_center_x 0.0 entry/instrument/detector/beam_center_y 0.0 entry/instrument/detector/bit_depth_image 32 entry/instrument/detector/bit_depth_readout 12 entry/instrument/detector/count_time 0.48999998 entry/instrument/detector/countrate_correction_applied 1 entry/instrument/detector/description b'Dectris Eiger 4M' ... ...データ読み込み後のワークフローで波長や検出器距離などが必要になったときは、ここでパスを確認しておくと必要な時に簡単に取得できます。
測定データとマスクの読み込み
マスターデータの
entry/data以下にdata_00****という形で1-2000までの番号が振られた2000個の外部リンクがあらかじめ用意されています。例えば、マスターファイルと同じ場所に4個の連番測定ファイル(000001-000004)が置いてある私の環境で以下のスクリプトを実行してみます。with h5py.File(masterhdf,'r') as f: # {i:04}でゼロ埋めした整数4桁というフォーマットを指定 for p in [f'entry/data/data_00{i:04}' for i in [0, 1, 4, 2000, 2001]]: try: f[p] # 外部リンク先にファイルが存在するかチェック。 print(p) except KeyError as e: # ファイルまた外部リンク自体がなければKeyError print(e)printの結果"Unable to open object (object 'data_000000' doesn't exist)" entry/data/data_000001 entry/data/data_000004 "Unable to open object (unable to open file: name = '/dummy/path/to/data/EIGER_4M_test_002000.h5', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0)" "Unable to open object (object 'data_002001' doesn't exist)"五つの
- 外部リンクに
data_000000は存在しない、つまり連番は1始まり- 1番目のデータのマスターファイル上の外部リンクパス(OS上のファイル名は
EIGER_4M_test_data_000001.h5)- 4番目のデータのマスターファイル上の外部リンクパス(OS上のファイル名は
EIGER_4M_test_data_000004.h5)- マスターファイルに外部リンク
data_002000は設定されているが、マスターファイルと同じ場所にEIGER_4M_test_data_002000.h5が存在しない- 外部リンクは1-2000なので
data_002001は存在しないこれはGUIソフトのHDFViewでマスターファイルを開いても確認できます。実際に開いて下までスクロールすれば、実際のファイルが存在しないことを表す"?"が
data_002000まで並んでいることがわかります。
測定データの数はマスターファイルと同じ場所にある
EIGER_4M_test_data_******.h5の数を見ればわかります。ここでは4Mピクセルのデータが500枚格納された測定結果ファイルを二つ指定して500枚の和を読み込みます。可視化で必要なマスクも読み込んでおきます。imgdatasets = ['entry/data/data_000001', 'entry/data/data_000002'] # 外部リンク imgs = {} # 読み込み済みデータ格納先 with h5py.File(masterhdf, mode='r') as f: # 測定ファイル二つからそれぞれ500枚のデータの和をとる for imgdataset in imgdatasets: numimg = f[imgdataset].shape[0] temp = np.zeros_like(mask) # EIGER 4Mのデータx500が大きすぎるのかnp.sumが異常に遅い # 通常は遅くてご法度とされるNumpy arrayのforループで代用 for n in tqdm(range(numimg)): temp += f[imgdataset][n] imgs[imgdataset] = temp # マスクデータ mask = f['entry/instrument/detector/detectorSpecific/pixel_mask'].value二次元データ表示
Pythonで測定データを読み込めたらまずやりたいのは可視化です7。ここではもっとも基本的な二次元画像としての可視化をしてみます。
nrow, ncol = len(imgs), 2 fig, axes = plt.subplots(nrow, ncol, figsize=(8, 4*nrow)) vmax = 1e7 for (k, v), ax in zip(imgs.items(), axes): temp = v.copy() ax[0].imshow(temp, norm=LogNorm(), vmax=vmax) ax[0].set_title(f'{k}\nnot masked') ax[0].axis('off') # 検出器モジュール間の隙間や異常ピクセルをマスク # 整数型のarrayにnp.nanは代入できないので弱い強度として1を代入 temp[mask != 0] = 1 ax[1].imshow(temp, norm=LogNorm(), vmax=vmax) ax[1].set_title('masked') ax[1].axis('off')
マスク済みのほうを見ると、両データに共通する位置にマスクしきれていない異常ピクセルに見える点がありますが、これは画像の解像度の問題のようで、PDFにして拡大すると何も異常はありません。しかし、全体が妙に暗いのでどこかに周囲に比べて異常に強いピクセルが残ってるようです。マスク済みの最後の
tempを一次元プロットして見ると、予想通り一定の強度の異常ピクセルが残っていることがわかるので、この部分を追加でマスク(実際は弱い強度として1を代入)します。plt.semilogy(temp.ravel(), '.')
先ほどのマスク部分を以下のようにして再度同じことをしてみます。
temp[mask != 0] = 1 temp[temp > 1e9] = 1
異常ピクセルに$10^0$が代入され、全体の色合いも正しそうな感じになりました。
この先のワークフロー
ここで紹介したデータの読み込みの次はPONIファイルを使った歪み補正やPyFAIによる一次元化、さらには測定やテーマごとの各種解析という具合に進んでいきます。温度などの測定条件を変えた連続実験の場合はpandasのDataFrameを使った測定条件管理が役立つかもしれません。
噂で耳にする値段を画素数で割ると、確かにこれくらいのオーダーはこれくらいになります。 ↩
ハードウェアとソフトウェアのどちらが足場であるかという議論はここではしません。 ↩
競争が激しいタンパク質構造解析関連のBLはやはりこの手の対応が早いようで、例えば名前がおもしろい理研のKAMOやケンブリッジの会社のautoPROCなどがあります。 ↩
DECTRIS公式のALBULAというソフトウェア(要ユーザー登録)には測定データの可視化機能に加えてPython APIも用意されていますが、使い方の説明がまだ貧弱です。おそらくこの記事で使っているh5pyのラッパーだとは思いますが、現状では使うにあたって自分でh5pyを使うのと同じ程度の手探りが必要な状況です。むしろラッパーであるがゆえにわかりにくくなっている部分が増えている可能性も高いです。 ↩
イギリスの放射光実験施設Diamondの文書にある"VIRTUAL DATA SETS"がsoft link機能として導入され、external linkはその発展形として後のバージョンで導入されたそうです。 ↩
ちなみに、可視化だけであればALBULAでも可能です。画面サンプルはEIGERのマニュアルにあります。試しに使って見ましたが、EIGER 4Mの連続測定データ数百回分のアニメーション再生が非常に軽快でした。ただ、測定中にその場でデータ確認する分には非常に有用だと思いますが、まだできることが少なくシンプルな可視化機能しかありません。また、漏れなくアップデートを通知するためかユーザー登録も必須です。 ↩

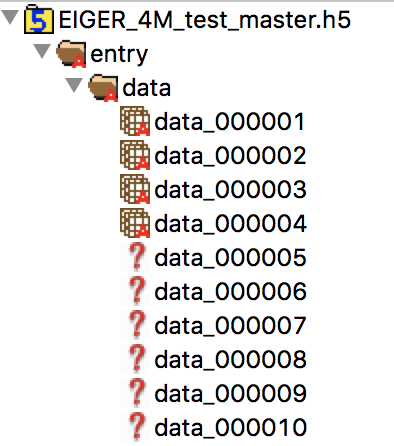
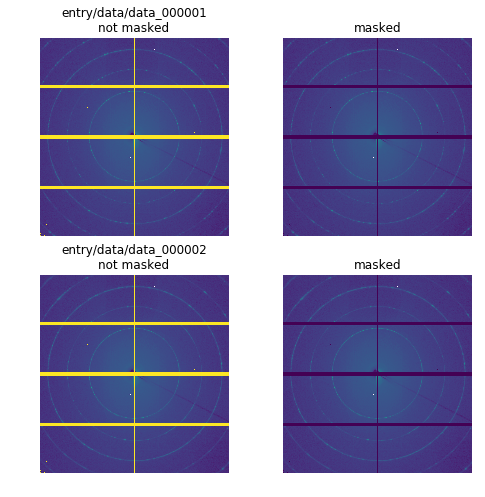
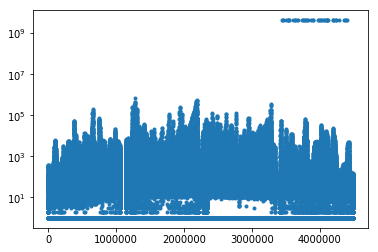
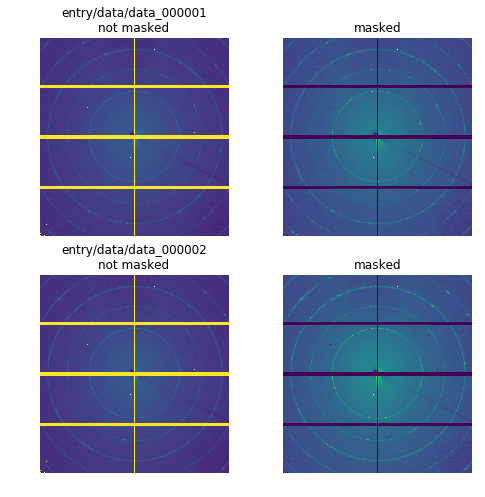
- 投稿日:2019-02-26T06:52:34+09:00
【Python】PyPIエラー対応 400 Client Error: User '(username)' has no verified email addressesの対処法
発生したエラー
twineを使って、PythonパッケージをPyPIに登録しようとしたところ、
HTTPError: 400 Client Error: User (username) has no verified email addressesのエラーとなる。
$ twine upload --repository pypi dist/* Enter your username: (username) Enter your password: Uploading distributions to https://upload.pypi.org/legacy/ Uploading (packagename)-1.0.0-py3-none-any.whl 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11.4k/11.4k [00:01<00:00, 9.14kB/s] NOTE: Try --verbose to see response content. HTTPError: 400 Client Error: User '(username)' has no verified email addresses, please verify at least one address before registering a new project on PyPI.See https://pypi.org/help/#verified-email for more information. for url: https://upload.pypi.org/legacy/ $対処方法
原因は、PyPIアカウント登録時のメール認証実施漏れ。
PyPIアカウント登録時に登録したメールアドレスに、PyPIからのメールが届いているはずなので、そのメール本文の
click this link to verify your email addressをクリックしてください。このメール認証を行わなくてもPyPIのサイトへのログイン等はできるのですが、パッケージを登録しようとすると上記のエラーになってしまいますので、忘れずにメール認証しておいてください。
環境
- Python 3.6.6
- twine 1.13.0
- 投稿日:2019-02-26T06:52:34+09:00
【Python】PyPIエラー対応 400 Client Error: User (username) has no verified email addressesの対処法
発生したエラー
twineを使って、PythonパッケージをPyPIに登録しようとしたところ、
HTTPError: 400 Client Error: User '(username)' has no verified email addressesのエラーとなる。
$ twine upload --repository pypi dist/* Enter your username: (username) Enter your password: Uploading distributions to https://upload.pypi.org/legacy/ Uploading (packagename)-1.0.0-py3-none-any.whl 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11.4k/11.4k [00:01<00:00, 9.14kB/s] NOTE: Try --verbose to see response content. HTTPError: 400 Client Error: User '(username)' has no verified email addresses, please verify at least one address before registering a new project on PyPI.See https://pypi.org/help/#verified-email for more information. for url: https://upload.pypi.org/legacy/ $対処方法
原因は、PyPIアカウント登録時のメール認証実施漏れ。
PyPIアカウント登録時に登録したメールアドレスに、PyPIからのメールが届いているはずなので、そのメール本文の
click this link to verify your email addressをクリックしてください。このメール認証を行わなくてもPyPIのサイトへのログイン等はできるのですが、パッケージを登録しようとすると上記のエラーになってしまいますので、忘れずにメール認証しておいてください。
環境
- Python 3.6.6
- twine 1.13.0
- 投稿日:2019-02-26T02:07:54+09:00
djangoで画像処理アプリケーションを作った
はじめに
djangoで画像処理アプリケーションを作成しました。
とりあえずそれらしく動いたので現状をメモ。サンプルコード
https://github.com/takuto412/web_app.git
環境
Python 3.6.7
django 2.1.2グレースケールに変換するアプリ
主な構成
gray_app │ manage.py │ db.sqlite3 ├ app1 │ │ models.py │ │ forms.py │ │ urls.py │ │ views.py │ └ templates │ └ app1 │ └ index.html ├ media │ │ documents │ └ output └ myapp │ settings.py └ urls.py主なコード
models.pyfrom django.db import models class Document(models.Model): description = models.CharField(max_length=255, blank=True) photo = models.ImageField(upload_to='documents/', default='defo') uploaded_at = models.DateTimeField(auto_now_add=True) output = models.ImageField(default = 'output/output.jpg')forms.pyfrom django import forms from .models import Document class DocumentForm(forms.ModelForm): class Meta: model = Document fields = ('description', 'photo',)
- 一番下の関数を書き換えることによって様々な画像処理が可能です。
views.pyfrom django.http import HttpResponse from django.shortcuts import render, redirect from .forms import DocumentForm from .models import Document import cv2 from django.conf import settings def index(request): if request.method == 'POST': form = DocumentForm(request.POST, request.FILES) if form.is_valid(): form.save() return redirect('index') else: form = DocumentForm() max_id = Document.objects.latest('id').id obj = Document.objects.get(id = max_id) input_path = settings.BASE_DIR + obj.photo.url output_path = settings.BASE_DIR + "/media/output/output.jpg" gray(input_path,output_path) return render(request, 'app1/index.html', { 'form': form, 'obj':obj, }) ###########ここをカスタマイズ############ def gray(input_path,output_path): img = cv2.imread(input_path) img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) cv2.imwrite(output_path, img_gray) ######################################index.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Upload</title> </head> <body> <form method="post" enctype="multipart/form-data"> {% csrf_token %} {{ form.as_p }} <button type="submit">Upload</button> </form> <td>{{ obj.description }}</td> <!--<td>{{ obj.gray_photo.url }}</td>--> <td><img src="{{ obj.output.url }}" width="100" height="100"/></td> <td>{{ obj.uploaded_at }}</td> </body> </html>画面イメージ
超解像画像に変換するアプリ
主な構成
super_resolve_app │ manage.py │ db.sqlite3 ├ app1 │ │ models.py │ │ forms.py │ │ urls.py │ │ views.py *変更点 │ │ super_resolve.py *変更点 │ │ model.py *変更点 │ │ model_epoch_30.pth *変更点 │ └ templates │ └ app1 │ └ index.html ├ media │ │ documents │ └ output └ myapp │ settings.py └ urls.py主なコード
超解像の部分は、ほぼこれのパクリです。
https://github.com/pytorch/examples/tree/master/super_resolutionviews.pyfrom __future__ import print_function from django.http import HttpResponse from django.shortcuts import render, redirect from .forms import DocumentForm from .models import Document import cv2 from django.conf import settings import torch from PIL import Image from torchvision.transforms import ToTensor import numpy as np from .super_resolve import super_resolve def index(request): if request.method == 'POST': form = DocumentForm(request.POST, request.FILES) if form.is_valid(): form.save() return redirect('index') else: form = DocumentForm() max_id = Document.objects.latest('id').id obj = Document.objects.get(id = max_id) input = settings.BASE_DIR + obj.photo.url output = settings.BASE_DIR + "/media/output/output.jpg" super_resolve(input, output) return render(request, 'app1/index.html', { 'form': form, 'obj':obj, })super_resolve.pyfrom __future__ import print_function from django.http import HttpResponse from django.shortcuts import render, redirect from .forms import DocumentForm from .models import Document import cv2 from django.conf import settings import torch from PIL import Image from torchvision.transforms import ToTensor import numpy as np from .super_resolve import super_resolve def index(request): if request.method == 'POST': form = DocumentForm(request.POST, request.FILES) if form.is_valid(): form.save() return redirect('index') else: form = DocumentForm() max_id = Document.objects.latest('id').id obj = Document.objects.get(id = max_id) input_path = settings.BASE_DIR + obj.photo.url output_path = settings.BASE_DIR + "/media/output/output.jpg" super_resolve(input_path, output_path) return render(request, 'app1/index.html', { 'form': form, 'obj':obj, })画面イメージ
実行方法
python manage.py makemigrations python manage.py migrate python manage.py runserver (IPアドレス:ポート番号)注意事項
IPアドレスを指定する場合
ALLOWED_HOSTS = ['IPアドレス']参考記事
https://ymgsapo.com/show-image-imagefield/
https://ymgsapo.com/gray-scale-app/


- 投稿日:2019-02-26T02:07:54+09:00
Djangoで画像処理アプリケーションを作った
はじめに
- djangoで画像処理アプリケーションを作成しました。
- とりあえずそれらしく動いたので現状をメモ。
サンプルコード
https://github.com/takuto412/web_app.git
環境
Python 3.6.7
django 2.1.2
OpenCv 4.0.0
PyTorch 1.0.0グレースケールに変換するアプリ
主な構成
gray_app │ manage.py │ db.sqlite3 ├ app1 │ │ models.py │ │ forms.py │ │ urls.py │ │ views.py │ └ templates │ └ app1 │ └ index.html ├ media │ │ documents │ └ output └ myapp │ settings.py └ urls.py主なコード
models.pyfrom django.db import models class Document(models.Model): description = models.CharField(max_length=255, blank=True) photo = models.ImageField(upload_to='documents/', default='defo') uploaded_at = models.DateTimeField(auto_now_add=True) output = models.ImageField(default = 'output/output.jpg')forms.pyfrom django import forms from .models import Document class DocumentForm(forms.ModelForm): class Meta: model = Document fields = ('description', 'photo',)
- 一番下の関数を書き換えることによって様々な画像処理が可能です。
views.pyfrom django.http import HttpResponse from django.shortcuts import render, redirect from .forms import DocumentForm from .models import Document import cv2 from django.conf import settings def index(request): if request.method == 'POST': form = DocumentForm(request.POST, request.FILES) if form.is_valid(): form.save() return redirect('index') else: form = DocumentForm() max_id = Document.objects.latest('id').id obj = Document.objects.get(id = max_id) input_path = settings.BASE_DIR + obj.photo.url output_path = settings.BASE_DIR + "/media/output/output.jpg" gray(input_path,output_path) return render(request, 'app1/index.html', { 'form': form, 'obj':obj, }) ###########ここをカスタマイズ############ def gray(input_path,output_path): img = cv2.imread(input_path) img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) cv2.imwrite(output_path, img_gray) ######################################index.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Upload</title> </head> <body> <form method="post" enctype="multipart/form-data"> {% csrf_token %} {{ form.as_p }} <button type="submit">Upload</button> </form> <td>{{ obj.description }}</td> <!--<td>{{ obj.gray_photo.url }}</td>--> <td><img src="{{ obj.output.url }}" width="100" height="100"/></td> <td>{{ obj.uploaded_at }}</td> </body> </html>画面イメージ
超解像画像に変換するアプリ
主な構成
super_resolve_app │ manage.py │ db.sqlite3 ├ app1 │ │ models.py │ │ forms.py │ │ urls.py │ │ views.py *変更点 │ │ super_resolve.py *変更点 │ │ model.py *変更点 │ │ model_epoch_30.pth *変更点 │ └ templates │ └ app1 │ └ index.html ├ media │ │ documents │ └ output └ myapp │ settings.py └ urls.py主なコード
超解像の部分は、以下を参考にしました。
https://github.com/pytorch/examples/tree/master/super_resolutionviews.pyfrom __future__ import print_function from django.http import HttpResponse from django.shortcuts import render, redirect from .forms import DocumentForm from .models import Document import cv2 from django.conf import settings import torch from PIL import Image from torchvision.transforms import ToTensor import numpy as np from .super_resolve import super_resolve def index(request): if request.method == 'POST': form = DocumentForm(request.POST, request.FILES) if form.is_valid(): form.save() return redirect('index') else: form = DocumentForm() max_id = Document.objects.latest('id').id obj = Document.objects.get(id = max_id) input = settings.BASE_DIR + obj.photo.url output = settings.BASE_DIR + "/media/output/output.jpg" super_resolve(input, output) return render(request, 'app1/index.html', { 'form': form, 'obj':obj, })super_resolve.pyimport torch from PIL import Image from torchvision.transforms import ToTensor import numpy as np from django.conf import settings from .model import Net def super_resolve(input_url, output_url): # Training settings input_image = input_url img = Image.open(input_image).convert('YCbCr') y, cb, cr = img.split() model_path = settings.BASE_DIR + '/app1/model_epoch_30.pth' the_model = Net(3) the_model.load_state_dict(torch.load(model_path)) img_to_tensor = ToTensor() input = img_to_tensor(y).view(1, -1, y.size[1], y.size[0]) out = the_model(input) out = out.cpu() out_img_y = out[0].detach().numpy() out_img_y *= 255.0 out_img_y = out_img_y.clip(0, 255) out_img_y = Image.fromarray(np.uint8(out_img_y[0]), mode='L') out_img_cb = cb.resize(out_img_y.size, Image.BICUBIC) out_img_cr = cr.resize(out_img_y.size, Image.BICUBIC) out_img = Image.merge('YCbCr', [out_img_y, out_img_cb, out_img_cr]).convert('RGB') out_img.save(output_url) print('output image saved to ', output_url)画面イメージ
実行方法
python manage.py makemigrations python manage.py migrate python manage.py runserver (IPアドレス:ポート番号)注意事項
IPアドレスを指定する場合
settings.pyALLOWED_HOSTS = ['IPアドレス']参考記事
https://ymgsapo.com/show-image-imagefield/
https://ymgsapo.com/gray-scale-app/
https://qiita.com/hiroyuki_mrp/items/8b2b78e066f35edbfbfd
- 投稿日:2019-02-26T00:38:27+09:00
【Python unittest】mockでリストを返してもらうときの注意
概要
Pythonでmock使ってテスト書いてたら、リスト返してもらうところでちょっとはまったのでメモ
mock.return_valueは参照を返す
Mockにreturn_valueとしてリストを設定
#from unittest.mock import Mock を省略しています >>> mc = Mock() >>> mc.return_value = [0,1,2] >>> mc() [0, 1, 2]Mockを呼び出して、返り値を編集する
>>> test = mc() >>> test [0, 1, 2] >>> test[0]=9 >>> test [9, 1, 2]もう一回モックを呼び出すと
>>> test = mc() >>> test [9, 1, 2] #[0,1,2]がほしかったうーん
ちなみにこういうことをしてもだめ>>> import copy >>> mc.return_value = copy.deepcopy([0,1,2]) #ついでにlambda:[0,1,2]もだめ >>> test = mc() >>> test [0, 1, 2] >>> test[0] = 99 >>> test [99, 1, 2] >>> test=mc() >>> test [99, 1, 2]side_effectに関数を設定しましょう
>>> mc = Mock() >>> mc.side_effect = lambda:[0,1,2] >>> test = mc() >>> test [0, 1, 2] >>> test[0]=9 >>> test [9, 1, 2] >>> test = mc() >>> test [0, 1, 2]とりあえずよかった。
- 投稿日:2019-02-26T00:28:45+09:00
pybind11入門(3) NumPy連携その1
その1 https://qiita.com/lucidfrontier45/items/872c38b5eec08e3800d7
その2 https://qiita.com/lucidfrontier45/items/c7cc409a3af962d100a3pybind11を使ってNumPyと連携する方法を試した。まずは直接ndarrayを触る方法。
pybind11::array型pybind11には
pybind11::bufferとpybind11::arrayのに種類のクラスが定義されており、これらを介してndarrayを扱うことができる。前者はndarrayに限らない一般的なPythonのbufferプロトコルと連携できるものであり、ここではndarray専用のarray型を試してみる。なお、array_t<T>というtemplateも用意されており、実際にはこちらを用いる。いつもどおり、cmakeを用いる。CMakeLists.txtcmake_minimum_required(VERSION 3.2) project(pybind_test VERSION 0.1.0) set(CMAKE_POSITION_INDEPENDENT_CODE ON) add_subdirectory(pybind11) add_subdirectory(fmt) pybind11_add_module(mymodule module.cpp) target_link_libraries(mymodule PRIVATE fmt::fmt)
fmtという書式フォーマットのライブラリも使用する。
https://github.com/fmtlib/fmt
ndarrayへのReadOnlyアクセス2次元配列の各要素を表示するだけのプログラムで動作を確認してみる。
module.cpp#include <iostream> #include <pybind11/pybind11.h> #include <pybind11/numpy.h> #include <fmt/core.h> namespace py = pybind11; template <typename T> void print_array(py::array_t<T> x) { const auto &buff_info = x.request(); const auto &shape = buff_info.shape; std::cout << "C++" << std::endl; for (auto i = 0; i < shape[0]; i++) { for (auto j = 0; j < shape[1]; j++) { auto v = *x.data(i, j); std::cout << fmt::format("x[{}, {}] = {}", i, j, v) << std::endl; } } } PYBIND11_MODULE(mymodule, m) { m.doc() = "my test module"; m.def("print_array", &print_array<int32_t>, ""); m.def("print_array", &print_array<double>, ""); }ndarrayを扱う場合には
pybind11/numpy.hをincludeする。requestメソッドでbuffer_info型の変数を得ることがでる。buffer_infoは以下のような構造になっておりstruct buffer_info { void *ptr; ssize_t itemsize; std::string format; ssize_t ndim; std::vector<ssize_t> shape; std::vector<ssize_t> strides; };ndarrayでおなじみの
shapeなどが得られるのでこれを用いでfor loopを回せます。データにアクセスする際にはx.data(i, j)のようにするとその要素へのポインタが得られる。なお、dataメソッドはReadonlyのアクセスなので得られるポインタにはconstがついている。最後に、この関数はtemplateを使用しているのでpybind11に登録する際には実体化する必要がる。ここでは整数用の
int32_tと実数用のdoubleの2種類を作る。Pythonで実行して確認する。
import numpy as np import mymodule x = np.arange(2*3).reshape((2, 3)).astype(np.int32) print("python") for i in range(x.shape[0]): for j in range(x.shape[1]): print("x[{}, {}] = {}".format(i, j, x[i, j])) >>> python x[0, 0] = 0 x[0, 1] = 1 x[0, 2] = 2 x[1, 0] = 3 x[1, 1] = 4 x[1, 2] = 5 C++ x[0, 0] = 0 x[0, 1] = 1 x[0, 2] = 2 x[1, 0] = 3 x[1, 1] = 4 x[1, 2] = 5ちゃんと同じ内容が表示できた!
配列の変更
.data(i, j)の代わりに.mutable_data(i, j)を用いることでconstでないポインタが得られ、内容を書き換えることができる。以下のプログラムは全配列の要素に定数を足す例である。template <typename T> void modify_array_inplace(py::array_t<T> x, T a) { const auto &buff_info = x.request(); const auto &shape = buff_info.shape; for (auto i = 0; i < shape[0]; i++) { for (auto j = 0; j < shape[1]; j++) { *x.mutable_data(i, j) += a; } } } PYBIND11_MODULE(mymodule, m) { m.doc() = "my test module"; m.def("modify_array_inplace", &modify_array_inplace<int32_t>, ""); m.def("modify_array_inplace", &modify_array_inplace<double>, ""); }Pythonで試してみる。
x = np.random.randn(2, 3).astype(np.float64) print("before") for i in range(x.shape[0]): for j in range(x.shape[1]): print("x[{}, {}] = {:.6f}".format(i, j, x[i, j])) mymodule.modify_array_inplace(x, 10.0) print("after") for i in range(x.shape[0]): for j in range(x.shape[1]): print("x[{}, {}] = {:.6f}".format(i, j, x[i, j])) >> before x[0, 0] = 1.307738 x[0, 1] = -1.625780 x[0, 2] = 0.196201 x[1, 0] = 0.614617 x[1, 1] = -0.175023 x[1, 2] = 1.490781 after x[0, 0] = 11.307738 x[0, 1] = 8.374220 x[0, 2] = 10.196201 x[1, 0] = 10.614617 x[1, 1] = 9.824977 x[1, 2] = 11.490781配列の各要素に一律に10.0が足されたのが分かる。
なお、
mymodule.modify_array_inplace(x, 10)のようにすると
xがdoubleの配列なのにintを足していてmodify_array_inplace<int32_t>のほうが呼ばれたらしく、xは型が異なるのでコピーが渡されて配列の中身は変更されなかった。渡す引数がintなのか、floatなのかは注意したほうが良さそう。array_tを返す関数
array_t型の変数をを新規に作成し、戻り値にすることでPython側に新しいndarrayを返すことができる。template <typename T> auto modify_array(py::array_t<T> x, T a) { const auto &buff_info = x.request(); const auto &shape = buff_info.shape; py::array_t<T> y{shape}; for (auto i = 0; i < shape[0]; i++) { for (auto j = 0; j < shape[1]; j++) { *y.mutable_data(i, j) = *x.data(i, j) + a; } } return y; }
array_t型のコンストラクタは色々あるが、shapeを渡すものが最も簡単に使用できると思う。Pythonで利用する場合は以下の通り。x = np.arange(2*3).reshape((2, 3)).astype(np.int32) x2 = mymodule.modify_array(x, 10)direct access
余計なチェックを無くしてよりオーバーヘッドが少ないアクセスの仕方もある。
@cython.boundscheck(False)的なものだと思う1。template <typename T> void modify_array_direct(py::array_t<T> x, T a) { auto r = x.template mutable_unchecked<2>(); for (auto i = 0; i < r.shape(0); i++) { for (auto j = 0; j < r.shape(1); j++) { r(i, j) += a; } } }公式docでは
x.mutable_unchecked<2>();となっているがこれだとコンパイルエラー。githubのissueに同様のものがあってx.template mutable_unchecked<2>();とすれば良いらしい2。ちなみにtemplateを使用せず、void modify_array_direct(py::array_t<double> x, double a){ auto r = x.mutable_unchecked<2>(); ... }のような場合は問題なかった。
参考
いつもの公式doc: https://pybind11.readthedocs.io/en/stable/advanced/pycpp/numpy.html
uncheckedとtemplateを組み合わせる黒魔術: https://github.com/pybind/pybind11/issues/1412