deflinear_search(searchArr,searchNum)index=0count=0searchArr.eachdo|arr|ifarr==searchNumcount+=1elseindex+=1endendifcount==0puts"value:#{searchNum} Array:#{searchArr} There isn't it."elseputs"value:#{searchNum} Array:#{searchArr} There is it at index\s#{index}."endend
defbinary_search(array,searchNum)array.sort!leftIndex=0rightIndex=array.index(array.last)midIndex=(rightIndex+leftIndex)/2loopdoifsearchNum==array[midIndex]puts"Array->#{array}:There is it at #{midIndex}!"break;elsifsearchNum>array[midIndex]midIndex+=1elsemidIndex-=1endendend
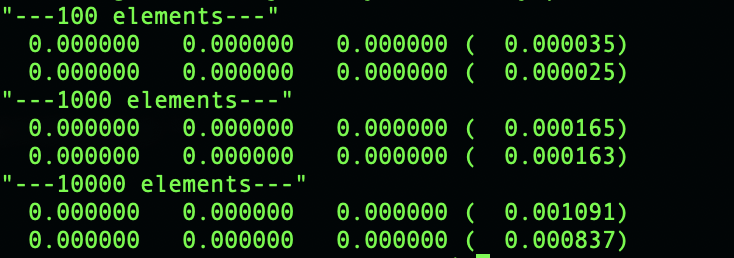
require'benchmark'deflinear_search(array_size,searchNum)array=(1..array_size).to_aindex=0count=0array.eachdo|arr|ifarr==searchNumcount+=1elseindex+=1endendifcount==0# puts "value:#{searchNum} Array:#{array} There isn't it."else# puts "value:#{searchNum} Array:#{array} There is it at index\s#{index}."endenddefbinary_search(array_size,searchNum)array=(1..array_size).to_aarray.sort!leftIndex=0rightIndex=array.index(array.last)midIndex=(rightIndex+leftIndex)/2loopdoifsearchNum==array[midIndex]# puts "Array->#{array}:There is at #{midIndex}!"break;elsifsearchNum>array[midIndex]midIndex+=1elsemidIndex-=1endendendp"---100 elements---"putsBenchmark.measure{linear_search(100,50)}putsBenchmark.measure{binary_search(100,50)}p"---1000 elements---"putsBenchmark.measure{linear_search(1000,100)}putsBenchmark.measure{binary_search(1000,100)}p"---10000 elements---"putsBenchmark.measure{linear_search(10000,1000)}putsBenchmark.measure{binary_search(10000,1000)}
df.where(df.col1.eq"hoge")df.where(df.col1>10)df.where(df.col1>10|df.col2<10)df.where((df.col1>10|df.col2<10)&df.col3.eq10)# and ordf.where(((df.col1>10).ordf.col2<10).anddf.col3.eq10)
Error loading the 'sqlite3' Active Record adapter. Missing a gem it depends on? can't activate sqlite3 (~> 1.3.6), already activated sqlite3-1.4.0. Make sure all dependencies are added to Gemfile. (Gem::LoadError)
bin/rails g ... する際に sqlite3 のversion依存関係で怒られたので解決法を調べた。
$ gem install bundler
ERROR: While executing gem ... (Gem::FilePermissionError)
You don't have write permissions for the /Library/Ruby/Gems/2.3.0 directory.
sudoでパーミッションを与えてやる。
$ sudo gem install bundler
ERROR: While executing gem ... (Gem::FilePermissionError)
You don't have write permissions for the /usr/bin directory.
また別の場所でパーミッションエラーが出たので、次は保存場所もlocalにしてやる。
$ sudo gem install -n /usr/local/bin bundler
Done installing documentation for bundler after 5 seconds
1 gem installed