- 投稿日:2021-03-04T15:51:41+09:00
[OpenCV] 画像の階調 [0,255] -> [0,1]の時の注意点
1.はじめに
画像処理でいろいろ分かったので、備忘録として記録しておきます。
2.画像の読み込み
まず、Lenaさんの画像を読み込みます。
import cv2 import numpy as np img_raw = cv2.imread('./image/lena.png') print('Type', type(img_raw)) print('data type: ', img_raw.dtype) cv2.imshow('raw image uint8', img_raw) #結果 Type <class 'numpy.ndarray'> data type: uint8 # 符号なし 8bit 整数OpenCVで読み込んだ画像は、
numpyのndarrayで、そのデータ型はuint8です。
画像を出力すると下記のようになります。
3.画像の階調:[0,255] -> [0,1]
ニューラルネットワークに画像を入力するとき、階調を[0,255]から[0,1]に変換をお粉ます。
img_scaled = (img_raw/ 255.).astype(np.float32) print('Type', type(img_scaled)) print('data type: ', img_scaled.dtype) cv2.imshow('scaled image float32', img_scaled) #結果 Type <class 'numpy.ndarray'> data type: float32データ型がfloat 32(単精度 浮動小数点数)に変わりました。
画像を出力すると下記のようになります。うん?先ほどのuint8, [0,255]の時と変わらないですね。
では、ここで[0,1]の画像を保存してみます。
cv2.imwrite('./image/lena_0_to_1.png', img_scaled)そして、保存したファイルをWindowsの別のプログラムで開いてみます。
真っ暗の画像に現れます。どうしてですか?
これは、[0,1]の階調の画素のデータが、保存されるときにfloat32型に保存されず、0か1の整数型に変わってからです。ここで気を付けないといけないのは、OpenCVのimshow()は[0,1]のfloat 32型でも、綺麗に表示してくれます。
4.解決方法
numpy.clip()を利用して、範囲を[0,1]から[0,255]に戻した後、データ型をfloat32型を uint8にキャストしてから保存すればいいです。
コードは下記のようになります。img_restore = np.clip(img_scaled * 255, a_min = 0, a_max = 255).astype(np.uint8) cv2.imwrite('./image/lena_restore.png', img_restore) #結果 Type <class 'numpy.ndarray'> data type: uint8先ほどのWindowsの画像表示プログラムで確認します。
5. 気づきポイント
- OpenCVのimshow()に騙されました。(笑)
- データ型を常に意識しながらプログラムを組みましょう。




- 投稿日:2021-03-04T11:15:08+09:00
SSMIの実装方法解説
はじめに
オートエンコーダーのSSIMの実装方法を整理します。
SSIMとは
SSIM(Structural Similarity Index Measure)とは、2004年に発表された画像の類似度を測定する指標です。
オートエンコーダーの課題の中で、オリジナル画像から作られる生成画像が鮮明ではない特徴があります。英語ではBlurred Generated Imageといいます。この場合、小さい異常の検知が難しい問題があります。
既存のオートエンコーダーにはmse(mean squared error)を損失関数として使い、どうしても鮮明ではない画像しか作られませんでした。ところで、SSIMを損失関数として使ったら、より鮮明な生成画像が得られ、結果的に異常検知のOK/NGの判別性能が向上する結果となりました。めでたしめでたし。
2.実装の手順
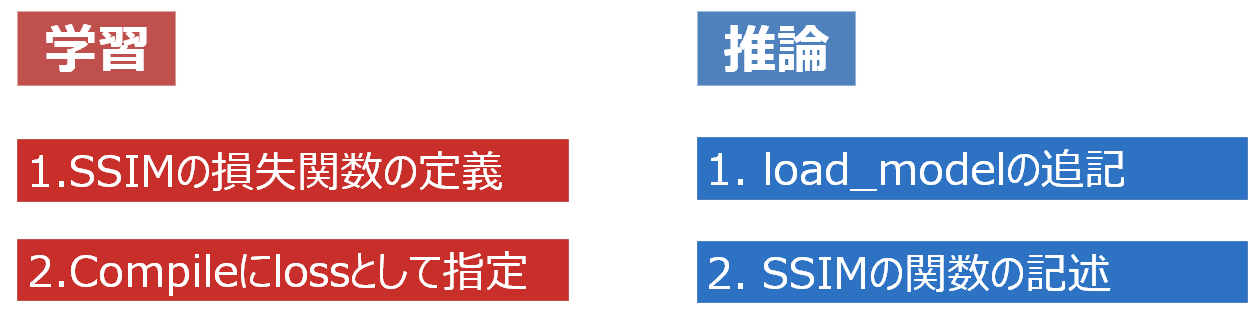
学習フェーズと推論フェーズに分けて説明します。
2.1.学習フェーズ
a. SSIMのカスタマイズ損失関数の定義
Tensorflowの
tf.image.ssim関数を利用し、ssim_loss()のカスタム損失関数を定義します。
パラメータ設定には、float32とuint8によって異なりますので、それに関してはTensorflowのドキュメントを参照してください。import tensorflow as tf def ssim_loss(y_true, y_pred): return 1-tf.reduce_mean(tf.image.ssim(y_true, y_pred, max_val = 1.0,filter_size=11, filter_sigma=1.5, k1=0.01, k2=0.03 ))Compileにlossとして指定
autoencoderというmodelを用意します。
mseと使うcompile文と、ssim_lossを使うcompile文を併記しますので、参考にしてください。
SSIMは、このコードを使えば、問題なく学習ができます。#損失関数 mse autoencoder.compile(optimizer = 'adam', loss = 'mse') #損失関数 SSIM autoencoder.compile(optimizer = 'adam', loss = ssim_loss)2.2.推論フェーズ
学習したモデル(h5ファイル)を読み込む時、「このモデルはSSIMというカスタム損失関数を使ってるよ」とプログラムに教える必要があります。
例えば、autoencoder-ssim.h5とうモデルを読み込む場合は、下記のようにコードを書きます。load_modelの追記
from tensorflow.keras.models import load_model loaded_model = load_model('autoencoder-ssim.h5', custom_objects={'ssim_loss':ssim_loss}
custom_objects部分を見てみましょう。custom_objects={'ssim_loss':ssim_loss}最初の'ssim_loss'は、
autoencoder.compile(optimizer = 'adam', loss = ssim_loss)のloss='ssim_loss'のことです。
2番目のssim_lossはカスタム損失関数名になります。SSIM関数の記述
上記の理由で、推論のコードにも
カスタム損失関数を記述します。学習用のコードに書いた同じカスタム損失関数を書けばOKです。def ssim_loss(y_true, y_pred): return 1-tf.reduce_mean(tf.image.ssim(y_true, y_pred, max_val = 1.0,filter_size=11, filter_sigma=1.5, k1=0.01, k2=0.03 ))これで問題なく、SSIMの学習モデルを読み込み、新しいデータでの推論が可能です。
まとめ
SSIMのカスタム関数を用いた、オートエンコーダーの学習・推論のコードの実装方法について解説しました。
参考資料
1.Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders
https://arxiv.org/abs/1807.020112.【論文読み】新・オートエンコーダで異常検知
https://qiita.com/shinmura0/items/ee074172ec3c818b614e

- 投稿日:2021-03-04T11:15:08+09:00
オートエンコーダーのSSMIの実装方法解説
はじめに
オートエンコーダーのSSIMの実装方法を整理します。
SSIMとは
SSIM(Structural Similarity Index Measure)とは、2004年に発表された画像の類似度を測定する指標です。
オートエンコーダーの課題の中で、オリジナル画像から作られる生成画像が鮮明ではない特徴があります。英語ではBlurred Generated Imageといいます。この場合、小さい異常の検知が難しい問題があります。
既存のオートエンコーダーにはmse(mean squared error)を損失関数として使い、どうしても鮮明ではない画像しか作られませんでした。ところで、SSIMを損失関数として使ったら、より鮮明な生成画像が得られ、結果的に異常検知のOK/NGの判別性能が向上する結果となりました。めでたしめでたし。
2.実装の手順
学習フェーズと推論フェーズに分けて説明します。
2.1.学習フェーズ
SSIMのカスタマイズ損失関数の定義
Tensorflowの
tf.image.ssim関数を利用し、ssim_loss()のカスタム損失関数を定義します。
パラメータ設定には、float32とuint8によって異なりますので、それに関してはTensorflowのドキュメントを参照してください。import tensorflow as tf def ssim_loss(y_true, y_pred): return 1-tf.reduce_mean(tf.image.ssim(y_true, y_pred, max_val = 1.0,filter_size=11, filter_sigma=1.5, k1=0.01, k2=0.03 ))Compileにlossとして指定
autoencoderというmodelを用意します。
mseと使うcompile文と、ssim_lossを使うcompile文を併記しますので、参考にしてください。
SSIMは、このコードを使えば、問題なく学習ができます。#損失関数 mse autoencoder.compile(optimizer = 'adam', loss = 'mse') #損失関数 SSIM autoencoder.compile(optimizer = 'adam', loss = ssim_loss)2.2.推論フェーズ
学習したモデル(h5ファイル)を読み込む時、「このモデルはSSIMというカスタム損失関数を使ってるよ」とプログラムに教える必要があります。
例えば、autoencoder-ssim.h5とうモデルを読み込む場合は、下記のようにコードを書きます。load_modelの追記
from tensorflow.keras.models import load_model loaded_model = load_model('autoencoder-ssim.h5', custom_objects={'ssim_loss':ssim_loss}
custom_objects部分を見てみましょう。custom_objects={'ssim_loss':ssim_loss}最初の'ssim_loss'は、
autoencoder.compile(optimizer = 'adam', loss = ssim_loss)のloss='ssim_loss'のことです。
2番目のssim_lossはカスタム損失関数名になります。SSIM関数の記述
上記の理由で、推論のコードにも
カスタム損失関数を記述します。学習用のコードに書いた同じカスタム損失関数を書けばOKです。def ssim_loss(y_true, y_pred): return 1-tf.reduce_mean(tf.image.ssim(y_true, y_pred, max_val = 1.0,filter_size=11, filter_sigma=1.5, k1=0.01, k2=0.03 ))これで問題なく、SSIMの学習モデルを読み込み、新しいデータでの推論が可能です。
まとめ
SSIMのカスタム関数を用いた、オートエンコーダーの学習・推論のコードの実装方法について解説しました。
参考資料
1.Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders
https://arxiv.org/abs/1807.020112.【論文読み】新・オートエンコーダで異常検知
https://qiita.com/shinmura0/items/ee074172ec3c818b614e