- 投稿日:2021-03-04T23:58:09+09:00
ImportError: cannot import name 'PackagePath' from 'importlib_metadata' 対処備忘録
なにが起きたか
pyinstallerでexeファイル化しようとしたときに
ImportError: cannot import name 'PackagePath' from 'importlib_metadata'が出てきた。これの対処。
エラーの中身
importlib_metadata から PackagePath がインポートできないよ。
とのこと。
・importlib_metadataはインストールされているか
・バージョンは最新か
このあたりを疑ってみた。解決へ
$pip listで一括表示させて、別件で悩んでるやつもインストールされているかついでに確認した。
importlib_metadata 0.0.0入ってはいるけどバージョンが明らかに最新ではなさそうなのでアップデート。
$pip install -U importlib-metadata >>>Successfully installed importlib-metadata-3.7.0 typing-extensions-3.7.4.3 zipp-3.4.0無事アップデートできたようなのでexeファイル化に再挑戦。
exe化
test.pyをtest.exeにしてみる。
$pyinstaller test.py >>>132064 INFO: Building COLLECT COLLECT-00.toc completed successfully.できた('ω')/
終わりに
ただ単にバージョンが古かったんやねぇ。
初投稿なので見にくい等はご愛嬌...
- 投稿日:2021-03-04T23:56:50+09:00
[AWS] Cloud9で、Python3.8をインストールする方法
Cloud9のPython
2021年3月時点では、Cloud9(というかAmazon Linux2)に標準で入っているPythonは、3.79です。
Admin:~/environment $ python -V Python 3.7.9SAMでLamdaを書くぞ
SAMでLamdaのコードを書く際に、Runtimeとして、Python3.8を選択できます。
が、インストールされているPythonのバージョンがあっていないため、酷くお叱りを受けます。Admin:~/environment/sam-app $ sam build Building codeuri: hello_world/ runtime: python3.8 metadata: {} functions: ['HelloWorldFunction'] Build Failed Error: PythonPipBuilder:Validation - Binary validation failed for python, searched for python in following locations : ['/usr/bin/python'] which did not satisfy constraints for runtime: python3.8. Do you have python for runtime: python3.8 on your PATH?Cloud9でPython3.8インストール
セオリー通りに、インストールしようとしますが、残念ながらうまくいきません。
Admin:~/environment/sam-app $ sudo yum install python38 Loaded plugins: extras_suggestions, langpacks, priorities, update-motd 229 packages excluded due to repository priority protections No package python38 available. Error: Nothing to do python38 is available in Amazon Linux Extra topic "python3.8" To use, run # sudo amazon-linux-extras install python3.8 Learn more at https://aws.amazon.com/amazon-linux-2/faqs/#Amazon_Linux_Extrasそんなパッケージないと叱られます。
が、ちゃんとヒントが書いてあるので、その通りコマンドを叩きます。Admin:~/environment/sam-app $ sudo amazon-linux-extras install python3.8 Installing python38 Loaded plugins: extras_suggestions, langpacks, priorities, update-motd Cleaning repos: amzn2-core amzn2extra-docker amzn2extra-epel amzn2extra-lamp-mariadb10.2-php7.2 amzn2extra-python3.8 epel hashicorp 33 metadata files removed 11 sqlite files removed 0 metadata files removed Loaded plugins: extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 amzn2extra-docker | 3.0 kB 00:00:00 amzn2extra-epel | 3.0 kB 00:00:00 amzn2extra-lamp-mariadb10.2-php7.2 | 3.0 kB 00:00:00 amzn2extra-python3.8 | 3.0 kB 00:00:00 epel/x86_64/metalink | 5.1 kB 00:00:00 epel | 4.7 kB 00:00:00 hashicorp | 1.4 kB 00:00:00 (1/15): amzn2-core/2/x86_64/group_gz | 2.5 kB 00:00:00 (2/15): amzn2-core/2/x86_64/updateinfo | 350 kB 00:00:00 (3/15): amzn2extra-epel/2/x86_64/primary_db | 1.8 kB 00:00:00 (4/15): amzn2extra-lamp-mariadb10.2-php7.2/2/x86_64/updateinfo | 76 B 00:00:00 (5/15): amzn2extra-lamp-mariadb10.2-php7.2/2/x86_64/primary_db | 464 kB 00:00:00 (6/15): amzn2extra-python3.8/2/x86_64/updateinfo | 76 B 00:00:00 (7/15): amzn2extra-docker/2/x86_64/updateinfo | 76 B 00:00:00 (8/15): amzn2extra-python3.8/2/x86_64/primary_db | 36 kB 00:00:00 (9/15): amzn2extra-epel/2/x86_64/updateinfo | 76 B 00:00:00 (10/15): amzn2extra-docker/2/x86_64/primary_db | 75 kB 00:00:00 (11/15): epel/x86_64/group_gz | 95 kB 00:00:00 (12/15): epel/x86_64/updateinfo | 1.0 MB 00:00:00 (13/15): epel/x86_64/primary_db | 6.9 MB 00:00:00 (14/15): amzn2-core/2/x86_64/primary_db | 50 MB 00:00:00 (15/15): hashicorp/2/x86_64/primary | 37 kB 00:00:00 hashicorp 249/249 229 packages excluded due to repository priority protections Resolving Dependencies --> Running transaction check ---> Package python38.x86_64 0:3.8.5-1.amzn2.0.2 will be installed --> Processing Dependency: python38-libs(x86-64) = 3.8.5-1.amzn2.0.2 for package: python38-3.8.5-1.amzn2.0.2.x86_64 --> Processing Dependency: python38-setuptools for package: python38-3.8.5-1.amzn2.0.2.x86_64 --> Processing Dependency: python38-pip for package: python38-3.8.5-1.amzn2.0.2.x86_64 --> Processing Dependency: libpython3.8.so.1.0()(64bit) for package: python38-3.8.5-1.amzn2.0.2.x86_64 --> Running transaction check ---> Package python38-libs.x86_64 0:3.8.5-1.amzn2.0.2 will be installed ---> Package python38-pip.noarch 0:9.0.3-2.amzn2.0.1 will be installed ---> Package python38-setuptools.noarch 0:38.4.0-4.amzn2.0.1 will be installed --> Finished Dependency Resolution Dependencies Resolved ============================================================================================================================================================= Package Arch Version Repository Size ============================================================================================================================================================= Installing: python38 x86_64 3.8.5-1.amzn2.0.2 amzn2extra-python3.8 69 k Installing for dependencies: python38-libs x86_64 3.8.5-1.amzn2.0.2 amzn2extra-python3.8 9.4 M python38-pip noarch 9.0.3-2.amzn2.0.1 amzn2extra-python3.8 1.9 M python38-setuptools noarch 38.4.0-4.amzn2.0.1 amzn2extra-python3.8 619 k Transaction Summary ============================================================================================================================================================= Install 1 Package (+3 Dependent packages) Total download size: 12 M Installed size: 51 M Is this ok [y/d/N]: y Downloading packages: (1/4): python38-3.8.5-1.amzn2.0.2.x86_64.rpm | 69 kB 00:00:00 (2/4): python38-pip-9.0.3-2.amzn2.0.1.noarch.rpm | 1.9 MB 00:00:00 (3/4): python38-libs-3.8.5-1.amzn2.0.2.x86_64.rpm | 9.4 MB 00:00:00 (4/4): python38-setuptools-38.4.0-4.amzn2.0.1.noarch.rpm | 619 kB 00:00:00 ------------------------------------------------------------------------------------------------------------------------------------------------------------- Total 47 MB/s | 12 MB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction Installing : python38-pip-9.0.3-2.amzn2.0.1.noarch 1/4 Installing : python38-setuptools-38.4.0-4.amzn2.0.1.noarch 2/4 Installing : python38-3.8.5-1.amzn2.0.2.x86_64 3/4 Installing : python38-libs-3.8.5-1.amzn2.0.2.x86_64 4/4 Verifying : python38-libs-3.8.5-1.amzn2.0.2.x86_64 1/4 Verifying : python38-3.8.5-1.amzn2.0.2.x86_64 2/4 Verifying : python38-pip-9.0.3-2.amzn2.0.1.noarch 3/4 Verifying : python38-setuptools-38.4.0-4.amzn2.0.1.noarch 4/4 Installed: python38.x86_64 0:3.8.5-1.amzn2.0.2 Dependency Installed: python38-libs.x86_64 0:3.8.5-1.amzn2.0.2 python38-pip.noarch 0:9.0.3-2.amzn2.0.1 python38-setuptools.noarch 0:38.4.0-4.amzn2.0.1 Complete! 0 ansible2 available \ [ =2.4.2 =2.4.6 =2.8 =stable ] 2 httpd_modules available [ =1.0 =stable ] 3 memcached1.5 available \ [ =1.5.1 =1.5.16 =1.5.17 ] 5 postgresql9.6 available \ [ =9.6.6 =9.6.8 =stable ] 6 postgresql10 available [ =10 =stable ] 8 redis4.0 available \ [ =4.0.5 =4.0.10 =stable ] 9 R3.4 available [ =3.4.3 =stable ] 10 rust1 available \ [ =1.22.1 =1.26.0 =1.26.1 =1.27.2 =1.31.0 =1.38.0 =stable ] 11 vim available [ =8.0 =stable ] 15 php7.2 available \ [ =7.2.0 =7.2.4 =7.2.5 =7.2.8 =7.2.11 =7.2.13 =7.2.14 =7.2.16 =7.2.17 =7.2.19 =7.2.21 =7.2.22 =7.2.23 =7.2.24 =7.2.26 =stable ] 17 lamp-mariadb10.2-php7.2=latest enabled \ [ =10.2.10_7.2.0 =10.2.10_7.2.4 =10.2.10_7.2.5 =10.2.10_7.2.8 =10.2.10_7.2.11 =10.2.10_7.2.13 =10.2.10_7.2.14 =10.2.10_7.2.16 =10.2.10_7.2.17 =10.2.10_7.2.19 =10.2.10_7.2.22 =10.2.10_7.2.23 =10.2.10_7.2.24 =stable ] 18 libreoffice available \ [ =5.0.6.2_15 =5.3.6.1 =stable ] 19 gimp available [ =2.8.22 ] 20 docker=latest enabled \ [ =17.12.1 =18.03.1 =18.06.1 =18.09.9 =stable ] 21 mate-desktop1.x available \ [ =1.19.0 =1.20.0 =stable ] 22 GraphicsMagick1.3 available \ [ =1.3.29 =1.3.32 =1.3.34 =stable ] 23 tomcat8.5 available \ [ =8.5.31 =8.5.32 =8.5.38 =8.5.40 =8.5.42 =8.5.50 =stable ] 24 epel=latest enabled [ =7.11 =stable ] 25 testing available [ =1.0 =stable ] 26 ecs available [ =stable ] 27 corretto8 available \ [ =1.8.0_192 =1.8.0_202 =1.8.0_212 =1.8.0_222 =1.8.0_232 =1.8.0_242 =stable ] 28 firecracker available [ =0.11 =stable ] 29 golang1.11 available \ [ =1.11.3 =1.11.11 =1.11.13 =stable ] 30 squid4 available [ =4 =stable ] _ php7.3 available \ [ =7.3.2 =7.3.3 =7.3.4 =7.3.6 =7.3.8 =7.3.9 =7.3.10 =7.3.11 =7.3.13 =stable ] 32 lustre2.10 available \ [ =2.10.5 =2.10.8 =stable ] 33 java-openjdk11 available [ =11 =stable ] 34 lynis available [ =stable ] 35 kernel-ng available [ =stable ] 36 BCC available [ =0.x =stable ] 37 mono available [ =5.x =stable ] 38 nginx1 available [ =stable ] 39 ruby2.6 available [ =2.6 =stable ] 40 mock available [ =stable ] 41 postgresql11 available [ =11 =stable ] _ php7.4 available [ =stable ] 43 livepatch available [ =stable ] 44 python3.8=latest enabled [ =stable ] 45 haproxy2 available [ =stable ] 46 collectd available [ =stable ] 47 aws-nitro-enclaves-cli available [ =stable ] 48 R4 available [ =stable ] 49 kernel-5.4 available [ =stable ] 50 selinux-ng available [ =stable ] _ php8.0 available [ =stable ]無事成功しました。
Admin:~/environment/sam-app $ sam build Building codeuri: hello_world/ runtime: python3.8 metadata: {} functions: ['HelloWorldFunction'] Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guidedコンパイルもばっちりです。
まとめ
ただのメモ書きレベルですいません!
なお、その他の言語やパッケージは、2021年3月現在は、こんな感じです。
Python2系
Admin:~/environment/sam-app $ python2 -V Python 2.7.18Java
Admin:~/environment/sam-app $ java --version openjdk 11.0.10 2021-01-19 LTS OpenJDK Runtime Environment Corretto-11.0.10.9.1 (build 11.0.10+9-LTS) OpenJDK 64-Bit Server VM Corretto-11.0.10.9.1 (build 11.0.10+9-LTS, mixed mode)PHP
Admin:~/environment/sam-app $ php -v PHP 7.2.24 (cli) (built: Oct 31 2019 18:27:08) ( NTS ) Copyright (c) 1997-2018 The PHP Group Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend TechnologiesRuby
Admin:~/environment/sam-app $ ruby -v ruby 2.6.3p62 (2019-04-16 revision 67580) [x86_64-linux]Node.js
Admin:~/environment/sam-app $ node -v v10.24.0Go
Admin:~ $ go version go version go1.15.8 linux/amd64補足
2021年3月現在、LambdaではPython3.9はサポートされてませんが、そもそもPython3.9自体、yumでのインストールに対応していないので、どうしてもCloud9(Amazon Linux2)にインストールしたい場合は、自身でコンパイルするしか方法がなさそうです。
- 投稿日:2021-03-04T22:58:51+09:00
Python inconsistent use of tabs and spaces in indentation
autopep8 -i test.py
- 投稿日:2021-03-04T22:44:25+09:00
Pythonでものづくり
履歴
ご指摘があり、試したところ実行結果に旧版だと
間違いが出ることに気づきましたのでご指摘通り修正しました。背景
Pythonでものづくりしようと思う。
・Python習得のため
・見せるものを作るため
が目的です。仕様
リリース申請一覧のための準備資料
内容
・ファイル名と拡張子が分離している
・拡張子によりファイルの種類が判別できる
・ファイルの種類ごとに分類する
・一覧のファイル形式はCSVまたはエクセルファイル形式
・言語はPython3
・フレームワークは想定しない。手順
1 該当プロジェクト直下のファイル名を取得する
2 ファイル名と拡張子を取得する
3 拡張子の種類ごとにCSV形式で書き出すコード
from pathlib import Path import csv current = Path() data = [(path, Path(path).suffix.replace('.', '')) for path in current.glob('*')] csv_path = Path('sample.csv') if csv_path.exists(): print ("ファイルが存在します。") with open(csv_path, 'w') as csv_file: csv_writer = csv.writer(csv_file) for target in 'html', 'jpg', 'py', 'css': for path, suffix in data: if suffix.lower() == target: csv_writer.writerow([path, suffix])アウトプット
index.html,html
access.html,html
gallery.HTML,HTML
catch.jpg,jpg
logo.JPG,JPG
combi_c3_3.py,py
test.py,py
test2.py,py
gallery.CSS,CSS
style.css,css
- 投稿日:2021-03-04T22:37:10+09:00
作って理解する関数型プログラミング
はじめに
「関数型プログラミングとは何か?」や「関数型プログラミングの仕方」についての記事は既に沢山あるのでそちらを参考にしてください。
この記事は関数型プログラミングで主要テクニックとしてよく取りあげられるmap, filter, reduceの3つの関数を自ら作ることを通じて関数型プログラミングに親しむことを目標とします。
ただし組み込み関数として提供されているmap関数が内部でどのように定義されているのかを解き明かすものではありません。
例えばmap関数は実際の所、引数としてiterable objectを受け取り、返り値はiteratorとなっているのでgeneratorで次のように簡単に定義できます。
map.pydef my_map(f, iterable): for it in iterable: yield f(it)しかし本記事ではgeneratorなどを使わず、関数型プログラミングらしく再帰関数で定義したいと思います。そのため効率性とかは度外視しているので実用的なものではない事だけ予めご了承ください。また分かりやすさを優先させるため、iterable objectでなくリストを想定しています。
iteratorやgeneratorを絡めてmap関数などを理解したい人は、関数型プログラミング HOWTOを読むことをお勧めします。
使用言語はpythonです。
対象読者
- 組み込み関数のmap, filter, reduceを何となく使っている人
- 関数型プログラミングに興味がある人
関数を自分で作ってみよう
map
map関数では第一引数には関数、第二引数にはリストを渡します。
組み込みのmap関数を使ってリストの各要素を2乗させるプログラムは次の通りです。>>> list(map(lambda x: x*x, [1,2,3,4,5])) [1, 4, 9, 16, 25]自作mapは次のようになります。
my_map.py# 入力:関数とリスト # 出力:全要素に関数が適用されたリスト def my_map(f, lst) -> list: if len(lst) <= 0: # リストの空チェック return [] # 空リストを返す return [f(lst[0])] + my_map(f, lst[1:]) # 先頭要素のみに関数を適用し、残りのリストは再帰呼び出しの引数に使う print(my_map(lambda x: x*x, [1,2,3,4,5])) # [1, 4, 9, 16, 25]少し分かりにくいかもしれませんが、関数型プログラミングらしく再帰関数で定義しています。
先頭要素のみを取り出して関数の引数に渡して、残っているリストで再帰させています。関数型プログラミングは関数でプログラムが構成されています。
関数型プログラミングにおいて、関数を定義する際に大切なのは関数内部の処理手順以上に、入力と出力だと思っています。このmy_map関数を例に考えると、入力が関数とリストで出力が関数が適用された後のリストです。出力が決まれば関数内部の処理をどうすれば良いかの見通しが立ちます。
[f(lst[0])]の部分でリストの先頭要素のみに対して関数を適用しています。出力はリストなので括弧を付けてリストにしています。
このリストに
my_map(f, lst[1:])を結合させています。my_mapの出力はリストなのでリスト同士を足し合わせて出力をリストにしています。
再帰呼び出しで自分自身を呼び出していますが、引数に渡すリストが1要素分だけ短くなるので再帰がいずれ停止することが保証されています。
言葉では伝えにくいのですが、my_mapの出力がリストであることが自分自身の再帰によって保証されていることが美しいですよね。
このようにどのような入力に対して、何を出力してほしいのかを意識して関数を定義していく事が関数型プログラミングを理解する上で重要かもしれません。返り値の型を書くことはよくあることですが、型だけじゃなくて関数の入力、出力が何かを言語化しておくと分かりやすいのでお勧めです。
filter
filter関数もmapと同様に第一引数に関数を、第二引数にリストを渡します。
組み込み関数を使った例は次の通りです。>>> list(filter(lambda x: x > 0, [-2, 4, -6, 6, 7, -10])) [4, 6, 7]この例ではリストから正の数だけ取り出しています。
自作filterは次の通りになります。
my_filter.py# 入力:フィルターとなる関数と対象となるリスト # 出力:フィルターを通り抜けた要素からなるリスト def my_filter(pred, lst) -> list: if len(lst) <= 0: return [] if pred(lst[0]): # 先頭要素がフィルターを通り抜けた場合 return [lst[0]] + my_filter(pred, lst[1:]) else: # 先頭要素がフィルターを通り抜けなかった場合 return my_filter(pred, lst[1:])これは上のmapを理解できたら問題ないかと思います。フィルターを通り抜けた場合のみ先頭要素を追加して、フィルターに引っ掛かった場合は先頭要素を追加せずに再帰呼び出しのみを返します。
reduce
mapとfilterは比較的わかりやすかったのですが、reduceは少し分かりにくいです。reduceは畳み込み関数と呼ばれたします。関数型言語ではreduceではなく、foldという名前が使われることが多い気がします。foldにはfold_rightとfold_leftがあり、リストを一列に並べたときに右側にある要素を先に畳み込むのがfold_rightで左側にある要素を先に畳み込むのがfold_leftです。実際に手を動かしてみた方が分かると思うのでこの時点で理解できていなくても問題ありません。
pythonで提供されているreduce関数は標準ライブラリのfunctoolsモジュールにて定義されているので、インポートする必要があります。次のようにして使うことができます。
>>> from functools import reduce >>> reduce(lambda acc, cur: acc + cur, [1,2,3,4,5], 0) 15このreduce関数はfold_left、つまり左側から先に畳み込むようになっています。
それでは自分で作ってみましょう。my_reduce.py# 入力:2つの引数を取り1つの値を返す関数。リスト。初期値。 # 出力:畳み込ん処理結果(値) def my_reduce(f, lst, init): if len(lst) <= 0: return init return my_reduce(f, lst[1:], f(init, lst[0])) print(my_reduce(lambda acc, cur: acc + cur, [1,2,3,4,5], 0)) # 15以下詳しく説明します。
まず注意する点としては、reduce関数に渡す関数fはmap, filterとは異なり二つの引数を取るものであるという事です。この例では
lambda acc, cur: acc + curという2つの引数を足し合わせるlambda式を渡しています。acc, curという引数名にも意味があります。accはaccumulationの略で累積値、curはcurrentの略で現在の値を意味します。accにはこれまでの畳み込み処理の結果(累積値)が渡されて、curにはリストの要素でこれから畳み込もうとしている値(リストの先頭要素)が渡されます。
一連の処理の手順を次のように考えると畳み込むというイメージを掴みやすいかもしれません。
(((((0 + 1) + 2) + 3) + 4) + 5) # acc: 0, cur: 1 ((((1 + 2) + 3) + 4) + 5) # acc: 1, cur: 2 (((3 + 3) + 4) + 5) # acc: 3, cur: 3 ((6 + 4) + 5) # acc: 6, cur: 4 (10 + 5) # acc: 10, cur: 5 15 # return 15ここまでくれば自作my_reduceが何をしているのか分かるのではないでしょうか。
因みにこのmy_reduceのようにreturnで返すのが自分自身になっている再帰関数を末尾再帰と呼んだりします。
番外編: fold rightについて
pythonのreduceはfold leftなので直接的には関係ないのですが、ここではfold rightについても自分で作ってみます。fold leftが理解できたならそれほど難しくはありません。
fold_right.py# 入力:2つの引数を取り1つの値を返す関数。リスト。初期値。 # 出力:畳み込ん処理結果(値) def fold_right(f, lst, init): if len(lst) <= 0: return init return f(lst[0], fold_right(f, lst[1:], init)) print(fold_right(lambda cur, acc: cur + acc, [1,2,3,4,5], 0))fold rightは右側から先に畳み込みます。なのでリストが空になるまでfold_right関数をどんどん呼び出して、リストの最後の方から計算していきます。fold_rightに渡す関数fは同様に2つの引数を取りますが、先程とは違い1つ目が現在の値で2つ目が累積値になります。一連の処理の流れは次のようになります。
(1 + (2 + (3 + (4 + (5 + 0))))) # cur: 5, acc: 0 (1 + (2 + (3 + (4 + 5)))) # cur: 4, acc: 5 (1 + (2 + (3 + 9))) # cur: 3, acc: 9 (1 + (2 + 12)) # cur: 2, acc: 12 (1 + 14) # cur: 1, acc: 14 15 # return 15fold_rightは末尾再帰ではありません。
fold leftかfold rightかの違いが重要になってくるのは関数fの演算が可換でない時です。
演算が可換であるとは、x + y = y + xのように交換法則が成り立つことを指します。
上の例では足し算だったのでfold leftでもfold rightでも計算結果が同じになりました。しかしこれを引き算にすると結果は次のようになります。>>> from operator import sub >>> my_reduce(sub, [1,2,3,4,5], 0) -15 >>> fold_right(sub, [1,2,3,4,5], 0) 3引き算はx - y = y - xが必ずしも成立しないため可換ではありません。そのために結果が異なりました。
まとめ
やっぱり物事を理解するには自分で作ってみるのが一番ですね。
本記事ではmap, filter, reduceの3つの関数を取りあげましたが、それらは関数型プログラミングのほんの一部でしかありません。関数型プログラミングは奥が深く、僕もまだ勉強し始めたばかりなので継続して学んでいきたいです。
意見のある方、間違いを発見した方はぜひコメントしてください。
参考資料
- 投稿日:2021-03-04T22:33:51+09:00
Function Compute でコンテナの Web アプリを作る
はじめに
Function Compute の Web アプリ機能でコンテナを起動できるようになったので、試してみます。
Migrate Web applications to Function Compute
Function Compute では HTTP、OSS トリガーで起動する関数や、時間駆動で起動する関数を作成することができ、Web アプリ機能では、Python、Java 等の Web アプリを作成することができます。
アーキテクチャ
GitHub に Dockerfile 及びソースコードをプッシュすると、Container Registry が Webhook 経由でプッシュを検知し、Dockerfile からコンテナイメージをビルドします。
Build an image for a Java application by using a Dockerfile with multi-stage builds
Function Compute は指定した Container Registry のイメージリポジトリからイメージを取り出し、コンテナをデプロイ及び起動します。デプロイ進捗を割合で指定することもでき、カナリアデプロイを実現できます。
Manage web applications
Special Thanks
本記事を作成するにあたり、SB Cloud 様のブログを参考にさせて頂きました。
Alibaba Cloud Container Registry (ACR) でコンテナイメージのビルドパイプラインを実装する
https://www.sbcloud.co.jp/entry/2020/04/01/container_registry
では手順を説明していきます。
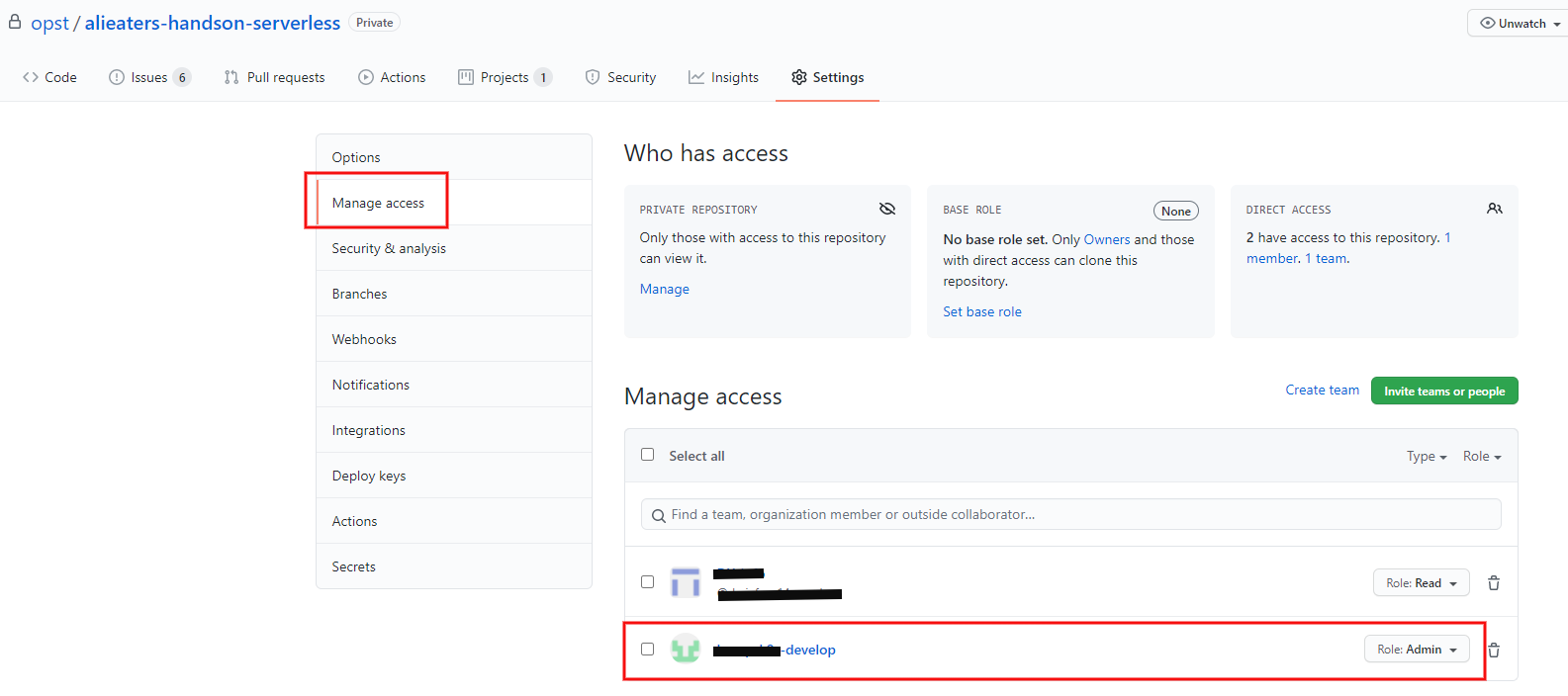
1. GitHub にユーザーを作成する
GitHub のソースコードリポジトリとソースコードリポジトリを読み取る
Admin権限を持つユーザーを作成します。今回はソースコードリポジトリ
alieaters-handson-serverlessとユーザーxxx-developを作成します。
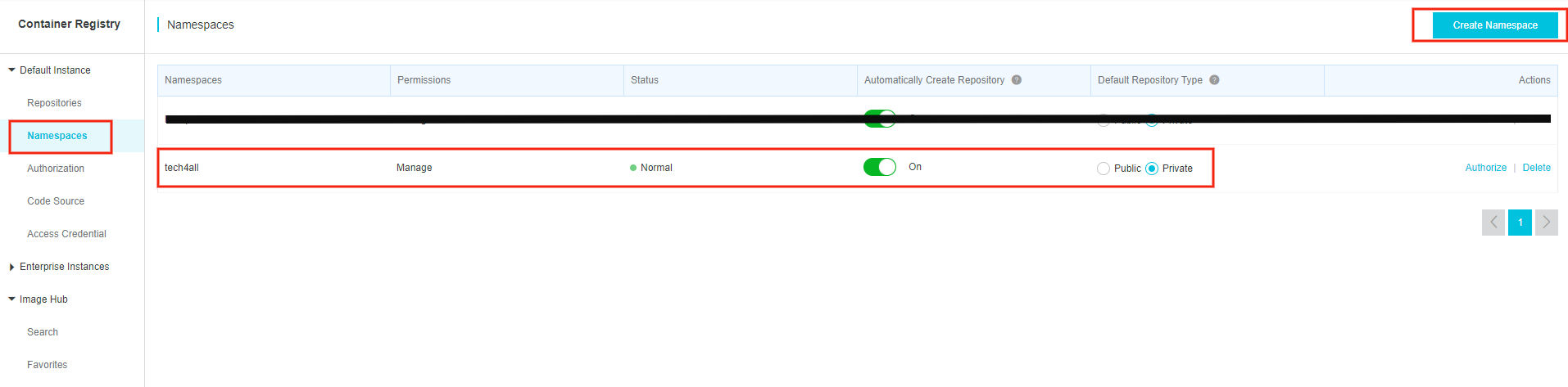
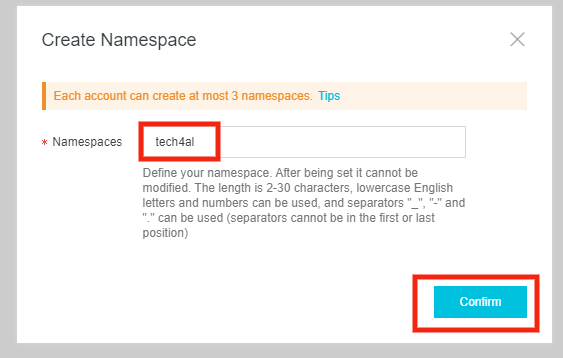
2. Container Registry に名前空間を作成する
イメージリポジトリを設置する名前空間をまず作ります。
Alibaba Cloud コンソールにログインし、Container Registry の Namespaces を選択します。
上の写真は名前空間
tech4allを作成した状況です。
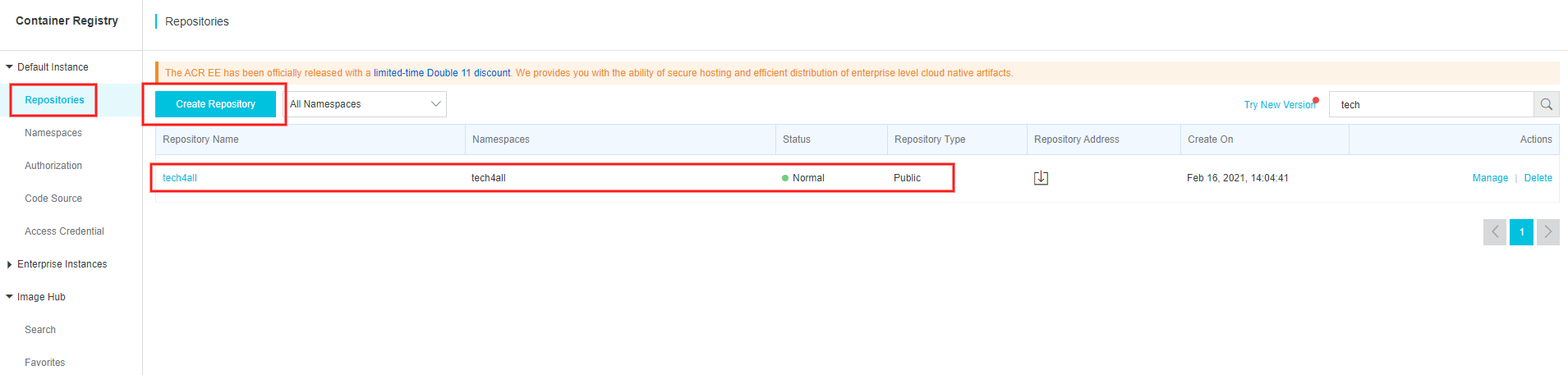
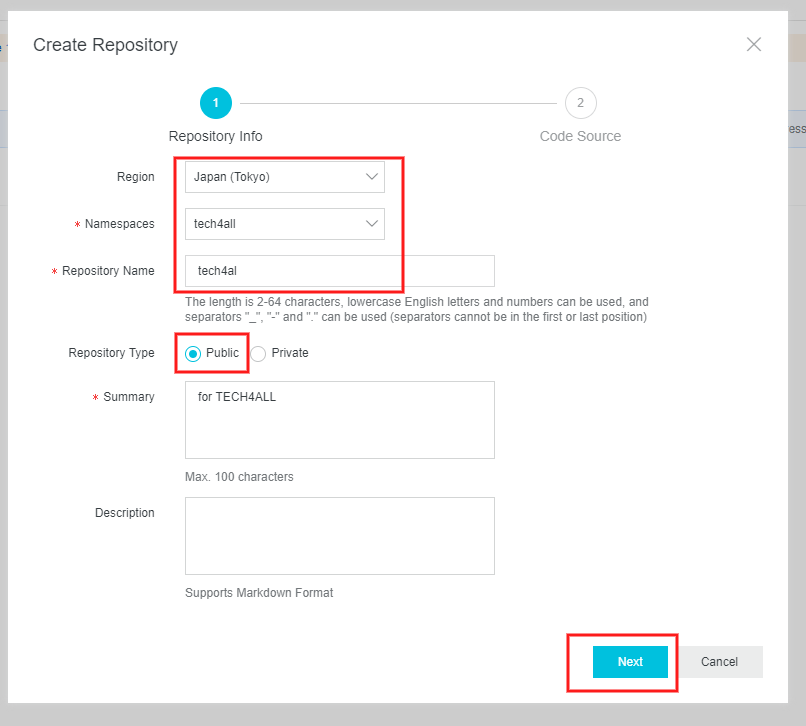
3. Container Registry にイメージリポジトリを作成する
イメージリポジトリを作成します。
Container Registry の Repositories を選択します。
写真はイメージリポジトリ
tech4allを作成した状況です。
Function Compute からイメージリポジトリを使用するため、
Publicにします。※公式ドキュメントには記載がないですが、Function Compute の画面に
Publicにする旨が記載されています。
GitHub のソースコードリポジトリとソースコードを読み取る GitHub ユーザーを指定します。
イメージリポジトリが作成されると、自動で GitHub の Webhooks に Container Registry のエンドポイントが追加されます。
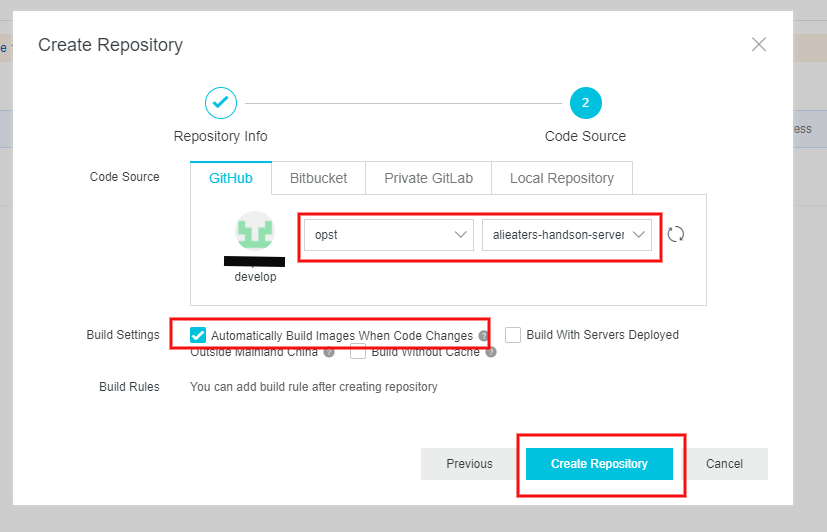
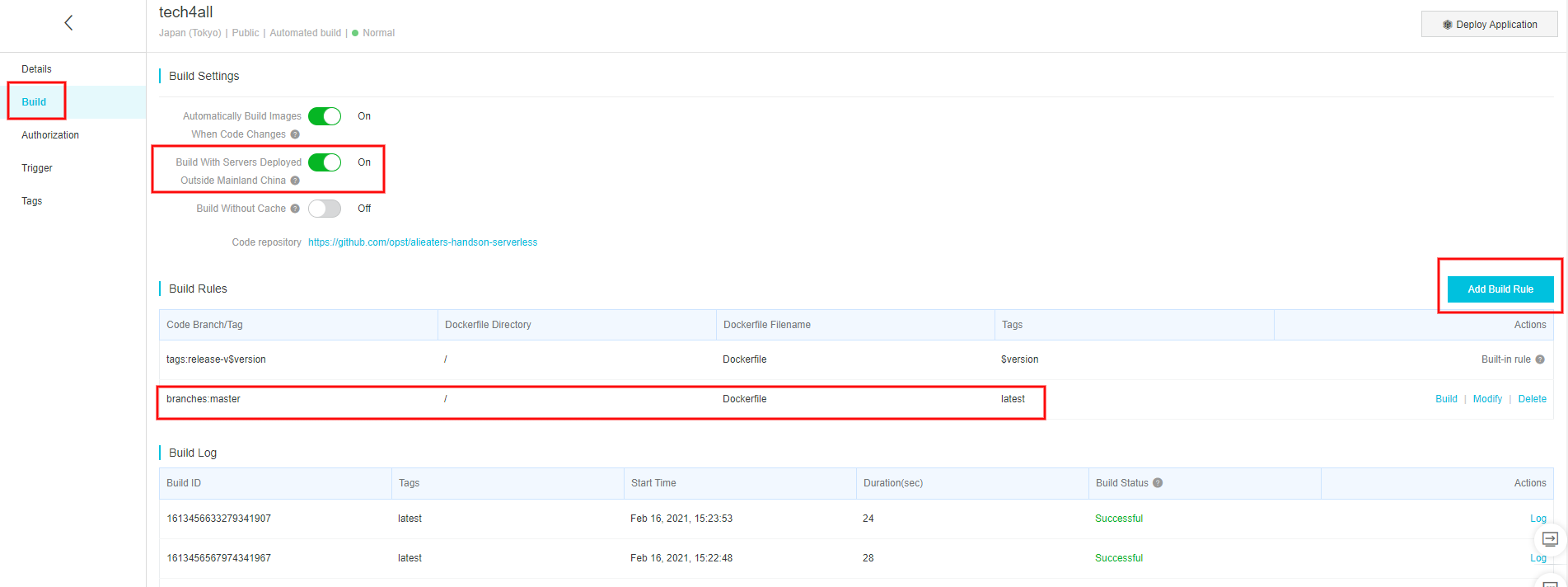
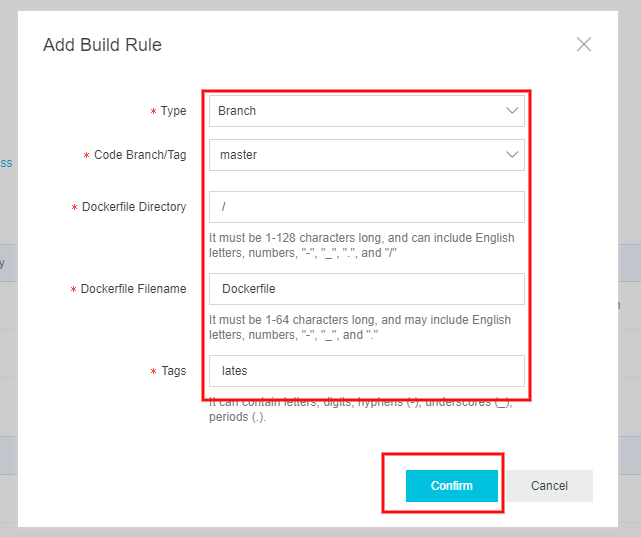
4. Container Registry のイメージリポジトリにビルドルールを作成する
ソースコードリポジトリを起点とするビルドルールを作成します。
Container Registry の Repositories の
tech4allを選択し、Build を選択します。今回はソースコードリポジトリの
masterブランチのルートディレクトリにDockerfileがあり、latestタグでコンテナイメージをビルドするルールを作成します。上の写真はビルドルールを作成済みの状態です。
5. Web アプリを開発する
今回は Flask を使用した Web アプリを開発します。
ディレクトリ構成
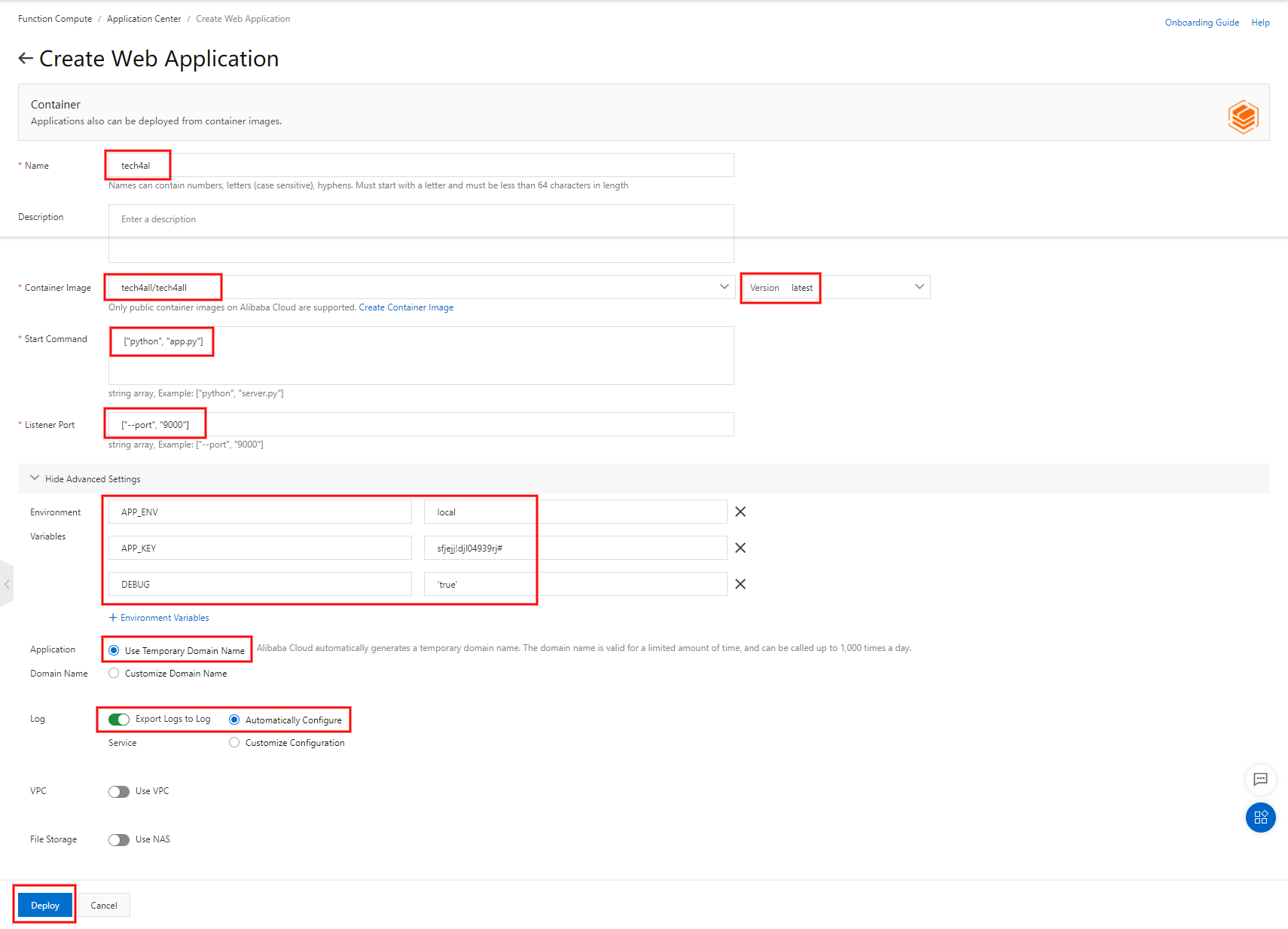
/ ├── app.py ├── Dockerfile ├── requirements.txt └─app ├── __init__.py └── templates └── index.htmlapp.pyimport os from app import create_app # 環境変数 APP_ENV, APP_KEY, DEBUG を使用 app = create_app(os.environ['APP_ENV']) app.secret_key = os.environ['APP_KEY'] # 9000 ポートを開放する if __name__ == "__main__": app.run(host="0.0.0.0", port=9000, debug=bool(os.environ['DEBUG']))Dockerfile.txtFROM python:3.6 EXPOSE 9000 ADD . /code WORKDIR /code RUN pip install -r requirements.txtrequirements.txtflaskapp/__init__.pyfrom flask import Flask, render_template def create_app(env): app = Flask(__name__) @app.route('/', methods=['GET']) def index(): return render_template('index.html') return appapp/templates/index.html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>close-clothes</title> </head> <body> {% block content %} <form action="/user" method="post"> <div> <input type="text" name="user_name" size="6"> <select name="role_name"> <option value="admin">admin</option> </select> <button>join us!</button> </div> </form> {% endblock %} </body> </html>6. Function Compute に Web アプリを作成する
Function Compute の Application Center を選択します。
Web アプリのフレームワークに Container を選択します。
注意点は以下の通りです。
- Container Image
- イメージリポジトリ
tech4allのlatestタグを選択します- Start Command
- Docker の CMD コマンドにあたりますので、 Dockerfile には CMD を記載しないようにします
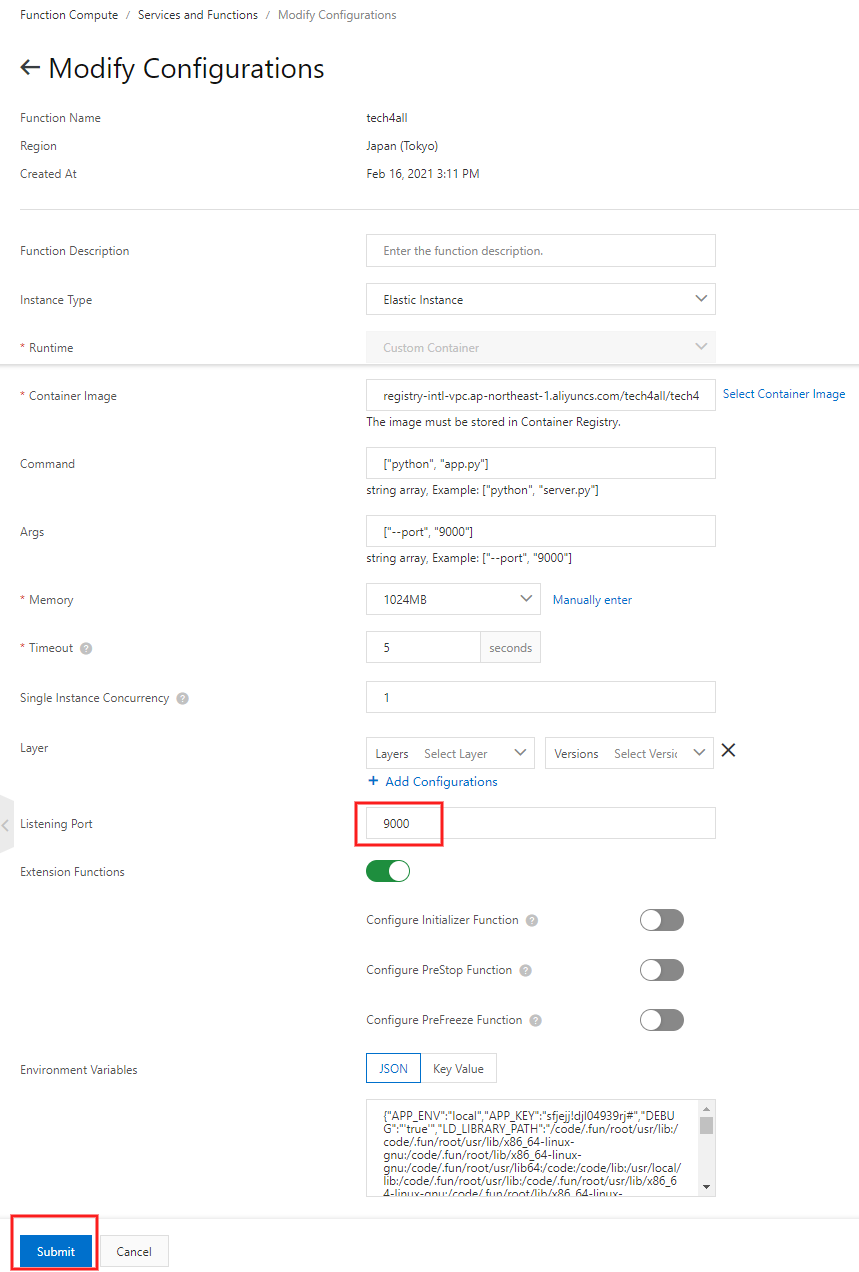
- Listener Port
- Python は 9000 ポートでしか Function Compute が受け付けていませんので 9000 を指定します
- Environment Variables
- Web アプリに渡したい環境変数を記載します
- Application Domain Name
- Alibaba Cloud DNS を使用したカスタムドメインを使用する場合は Customize Domain Name を選択します
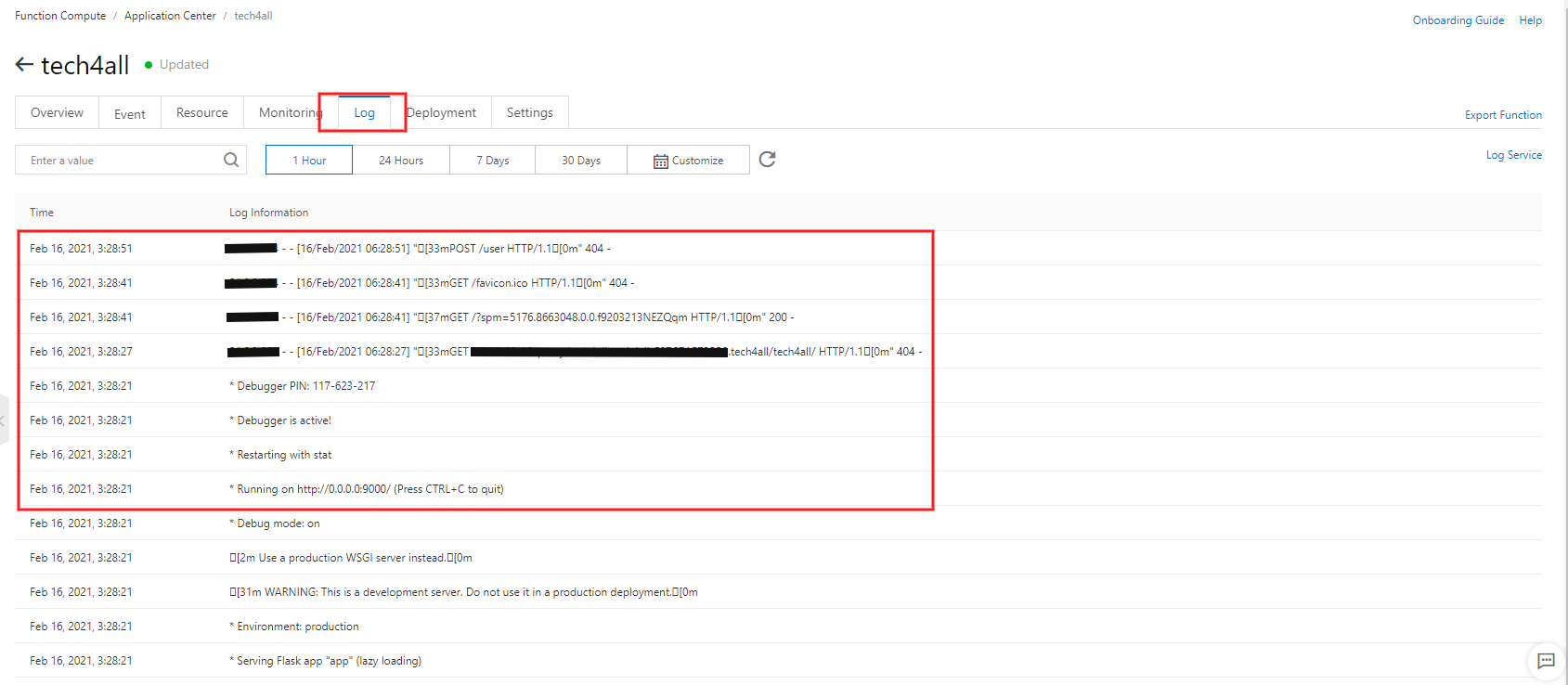
デプロイが始まるとログが流れ始めます。
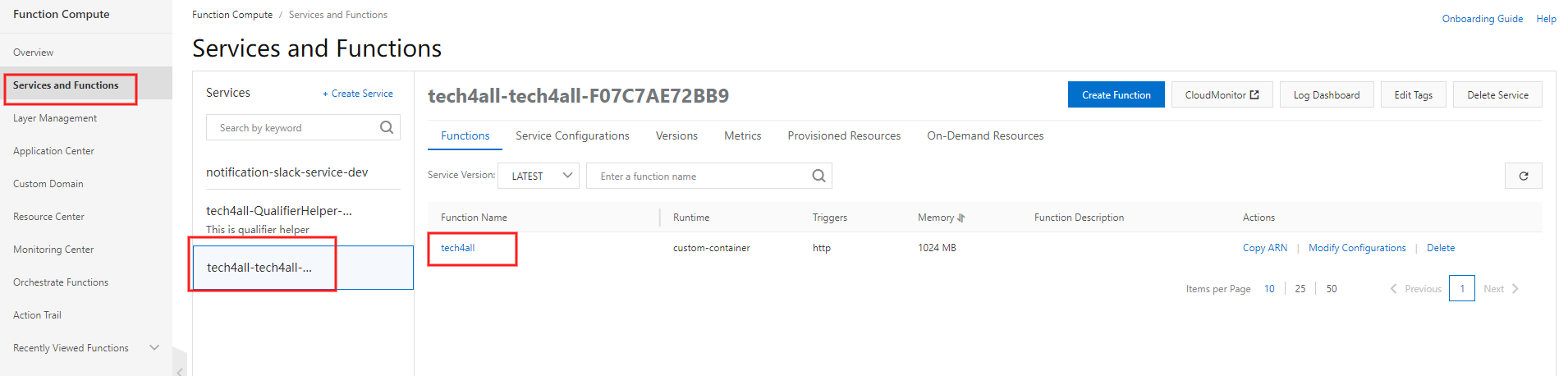
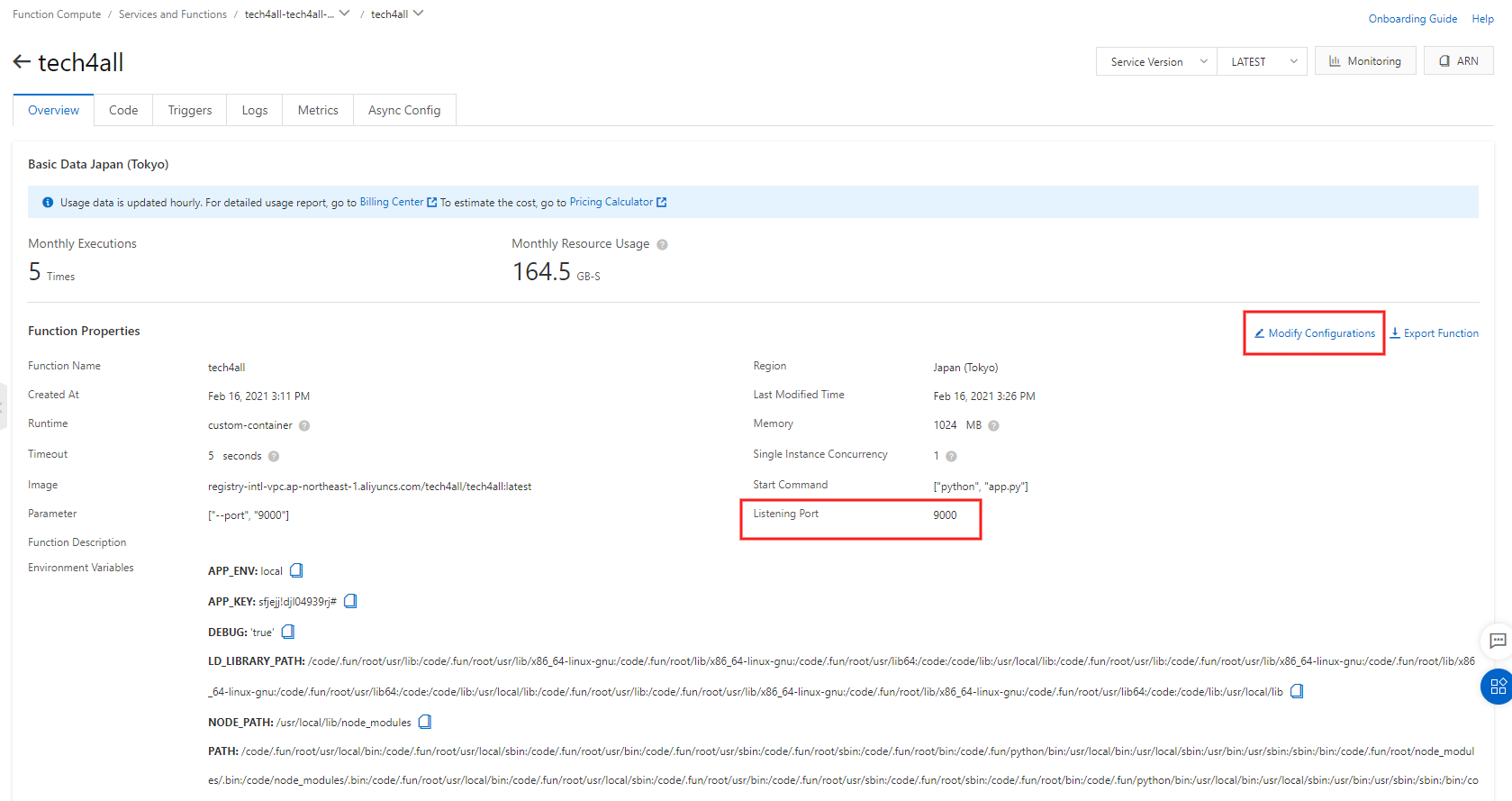
7. 関数のポートを 9000 に指定する
関数が出来上がっているので、関数で受け付けるポートに 9000 を指定します。
Function Compute の Services and Functions の
tech4allを選択します。
写真は既に 9000 に指定した状態です。
ポートは関係ないですが、Memory は 1024MB 以上でないと起動しないようになっています。
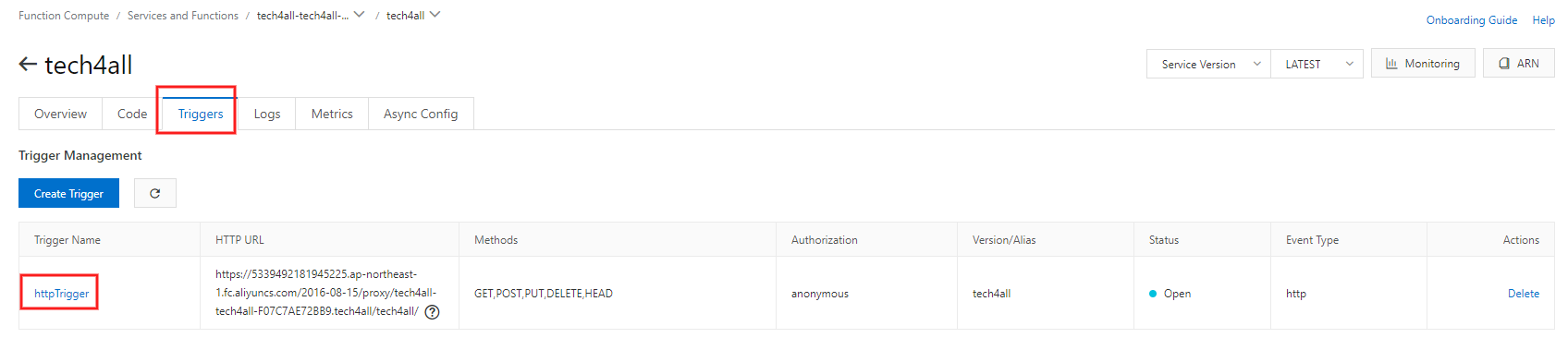
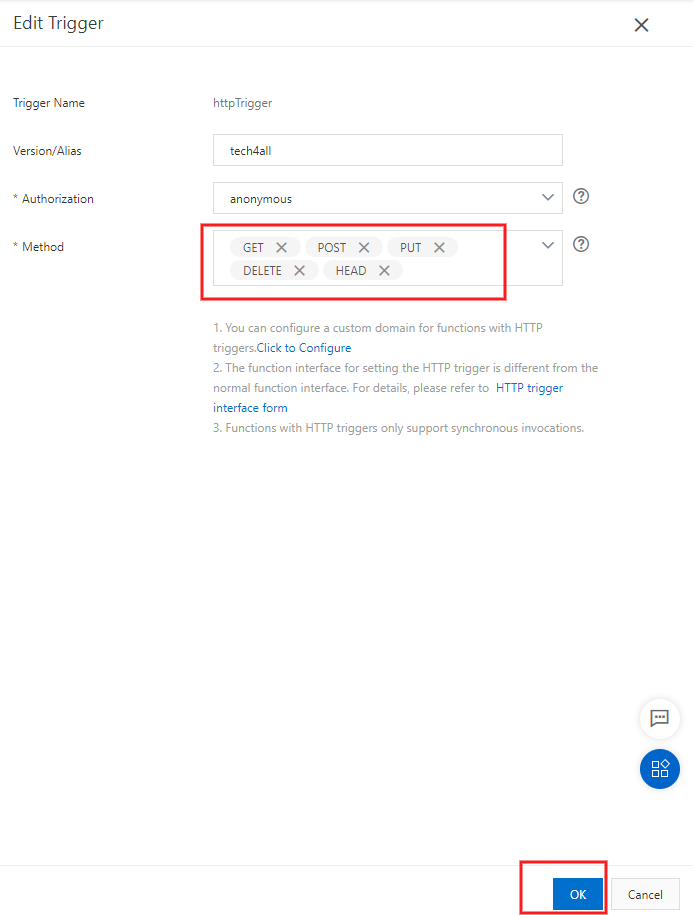
8. HTTP メソッドを編集
Web アプリで受け付ける HTTP メソッドを編集します。
Function Compute の Services and Functions の
tech4allを選択します。
受け付ける HTTP メソッドを選択します。
9. Web アプリにアクセス
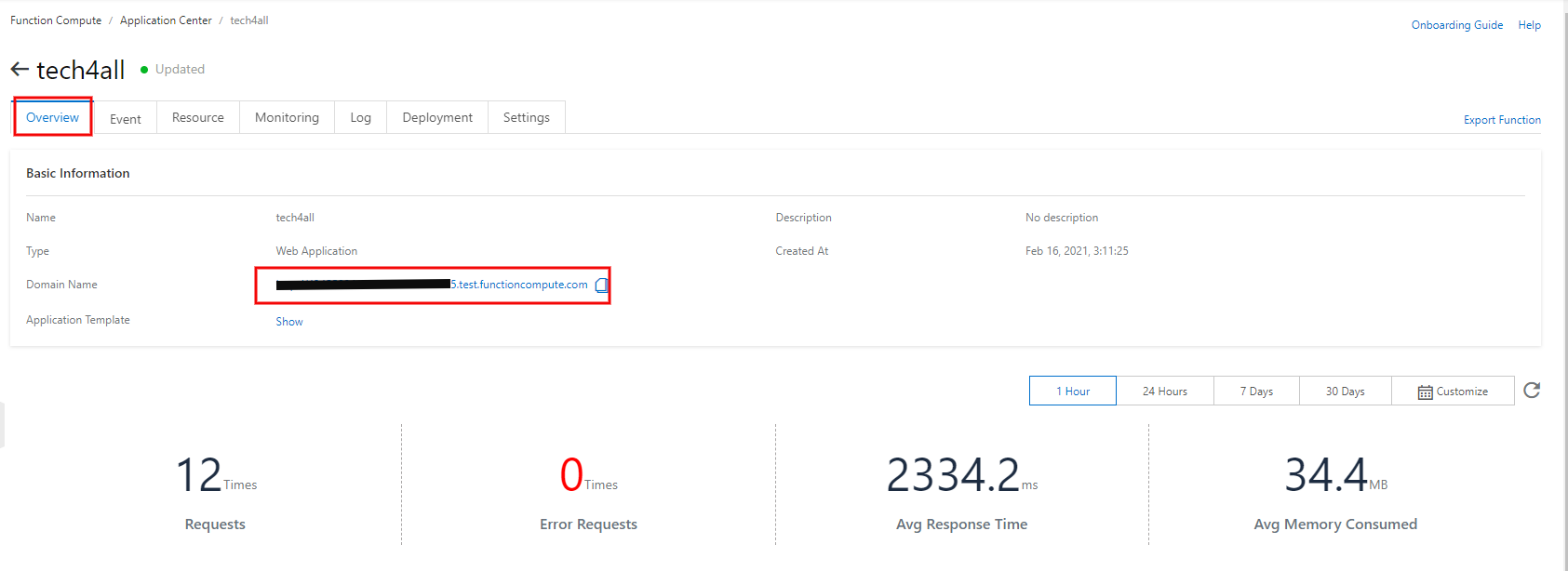
Web アプリの準備が整ったので、早速アクセスしてみます。
Function Compute の Application Center の
tech4allを選択します。
Domain Name が出来上がっているのでアクセスします。
寂しい画面ですが、HTML が表示されました!
アクセスログ及びアプリログは Application Center で確認できます。
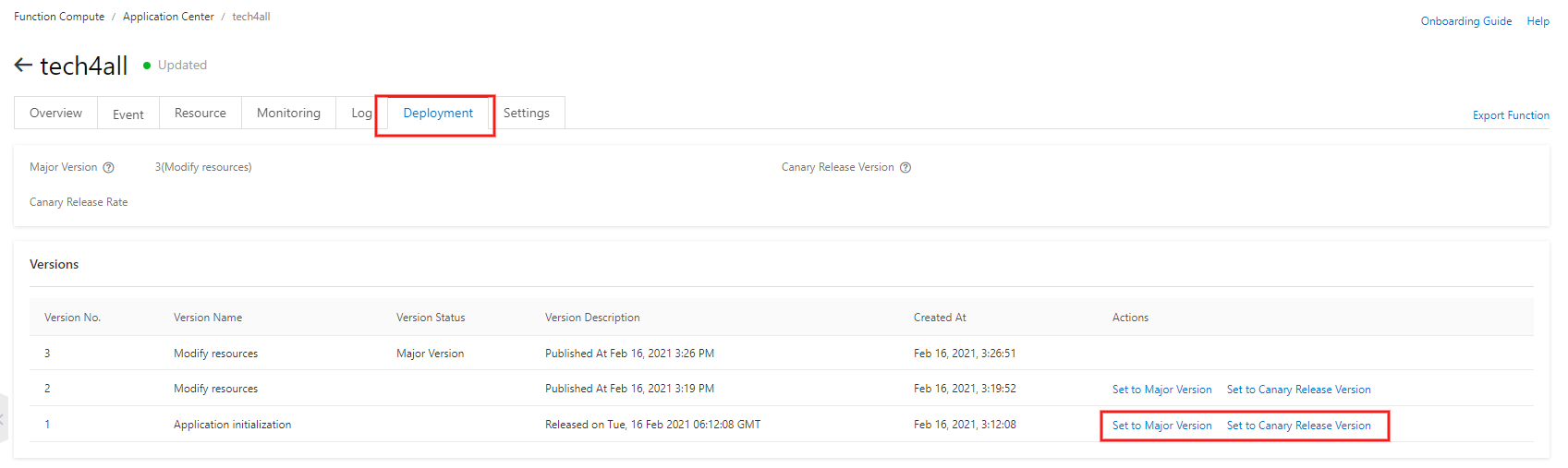
【appendix】カナリアデプロイを実現する
アプリのデフォルトバージョンに対するカナリアリリースバージョンの割合を設定し、カナリアデプロイを実現します。
Function Compute の Application Center の
tech4allを選択します。カナリアデプロイを実現したいバージョンの Set to Canary Release Version を選択します。
Canary Release Weight の割合をスライドします。
おわりに
Elastic Container Instance や Kubernetes のコンテナ専用の実行環境を使用しなくても、Web アプリを作成することができました。
これらのサービスと Function Compute との使い分けは、アプリの規模であると考えられます。
互いに連携しあうコンテナが複数ある場合や、同一コンテナを複数起動する場合は、コンテナの管理が煩雑になるため、先に上げたコンテナ専用サービスを使用することが望ましいです。
Function Compute にはアプリの呼び出しを監視する機能やデプロイ機能もあるため、単一コンテナを起動させたい場合にお勧めです。




- 投稿日:2021-03-04T22:01:29+09:00
f-stringsでdict使う場合のエラー解消
f-stringsでdictを使おうとした時にハマったエラー
何気なくいつも通りプログラム中でf-stringsを使おうとしたところ以下のようなエラーが発生
実行スクリプト例ex_dict = {'a':'b'} print(f'{ex_dict['a']}')エラー文SyntaxError: f-string: unmatched '['原因と解決法
dictの要素指定のシングルクオーテーションをf-stringsのシングルクォーテーション内で使ってしまったことによるSyntaxエラー。
外側 or 中をダブルクォーテーション""にすることで解決。ただのstringであればエスケープシーケンスを使うこともできるがdictの要素指定の場合はエスケープシーケンスではエラーを吐かれてしまうので注意
- 投稿日:2021-03-04T21:26:40+09:00
【Python】テキストファイルから改行を削除して、指定文字数毎に改行しなおす
初投稿です。プログラミングまだまだ初心者ですが失礼しますm(__)m
実現したいこと
とても基本的な内容なので恐縮ですが、タイトルの通りです。
「テキストファイルから改行を削除して、指定文字数毎に改行しなおす」
Pythonを使って実現しました。
わたしはデータ処理に使いましたが、いろいろ汎用性はあるかもしれません。コードも載せるので良かったら同じくプログラミング初心者の方、参考にしてください。
動作環境
Windows10 PC 64bit
Python 3.9.1背景
回路動作のデバッグの一環で、回路上にて通信されているデータ(SPIです)をプロトコルアナライザーで読み取ります。
16進数データの羅列が出力される訳なんですが、なぜか固定の文字数で改行されて出力される模様。
正直、「なんだこの仕様、めちゃめちゃデータ扱いづらいんですけど!」
まあ、古い機器なのでしょうがないですね。
こんな感じです。
巡回値0x00から0x0Fまでをテストデータとして扱っているので、00, 01, 02, …と羅列されているわけです。(巡回値を使うと、データ化けがあった場合わかりやすいので、良いです)
これを1行が、00から始まって0Fで終わって欲しいのです。つまり、
000102030405060708090A0B0C0D0E0F(計32文字/行)
が何行もバーッと表示されていて欲しいんです。
実現したコード
import glob import os # list files file_list = [] files = glob.glob("./*") for file in files: file_list.append(file) # make new files for name in file_list: newPath = name[:-4] + '_arranged.txt' #open new files newFile = open(newPath, 'w') #open data files dataFile = open(name, 'r') data = dataFile.read().replace('\n', '') num = len(data) for i in range(num/32+1): newFile.write(data[(i*32):(i*32+32)]+"\n") newFile.close() dataFile.close()独学+初心者で命名規則とか色々とままなっていないと思います。
ご指摘あれば頂けたら嬉しいです。機能
- 同じフォルダにあるファイルを全て読み出して、
- 改行削除・32文字ごとに改行し直して、
- そのデータを作成した新規ファイルに書き込む(新規ファイル名は、「元名+_arranged.txt」)
といった感じです。
コードの中身について
とりあえずフォルダ内のファイル名(パス名)をglob関数で取得して、リストfile_listに格納します。
その後、取得したファイル名をもとに改名しながら、for文で複数ファイルを新規作成しています。
read関数で元ファイルdataFileから読み出しつつ、改行削除。
for文を使って、32文字ごとに改行を入れ直しています。
反省
ググりながら作ったので、実はgrob関数とかあまりよくわかってないです…(;´∀`)
勉強します…。完成品
▼Before
▼After
整列させることができました。
これで、もしデータ化けがあったら、すぐにわかりますね。
……まあ、画像には映ってはいないものも、データ化けちらほらあったんですが…(このバグが沼ってるのは、また別の話…( ;∀;))
もし大量のデータを改行削除したり、改行し直したりみたいな作業に困っていたら、参考にしてみてください。


- 投稿日:2021-03-04T21:20:14+09:00
日立CTFの Binary_絶対に通らないif文 をGhidraで静的解析してみた
Ghidraの勉強になると思って,日立CTFのBinary_絶対に通らないif文の静的解析にチャレンジした結果,うまくいったので共有する。
問題へのリンク
絶対に通らないif文
int main(int argc, char **argv) { if (1 == 2) { show_flag(); } return 0; }逆アセンブル結果
0040B1C6: C7 45 FC 01 00 00 00 mov dword ptr [ebp-4],1 0040B1CD: C7 45 F8 02 00 00 00 mov dword ptr [ebp-8],2 0040B1D4: 8B 45 FC mov eax,dword ptr [ebp-4] 0040B1D7: 3B 45 F8 cmp eax,dword ptr [ebp-8] 0040B1DA: 75 05 JNZ LAB_0040B1E1 0040B1DC: e8 6f e3 CALL FUN_00409550動的解析でフラグを得るならば,バイナリエディタで
C7 45 FC 01 00 00 00
を検索して
C7 45 FC 02 00 00 00
に変更すれば if (2 == 2) になってフラグが表示される。
ここからがGhidraによる静的解析
FUN_00409550のデコンパイル結果
(変数の型を修正してデコンパイル誤りを正し,わかりやすい変数名に変更済み)void FUN_00409550(void) { undefined4 extraout_EDX; int iVar1; int i; byte flag [32]; byte key [1024]; uint local_c; int j; local_c = DAT_0040e004 ^ (uint)&stack0xfffffffc; key[0] = 0x18; key[1] = 0x13; key[2] = 0x5e; key[3] = 0x76; key[4] = 0x34; (中略) key[1019] = 0x35; key[1020] = 0x7a; key[1021] = 0x40; key[1022] = 0x9b; key[1023] = 0x36; flag[0] = 0x53; flag[1] = 0xb9; flag[2] = 0xf; flag[3] = 0xa4; flag[4] = 0xb4; (中略) flag[27] = 0x89; flag[28] = 0x6a; flag[29] = 0x47; flag[30] = 0x8e; flag[31] = 0x74; j = 0; i = 0x3ff; while (-1 < i) { j = i % 0x20; flag[j] = flag[j] ^ key[i]; i = i + -1; } iVar1 = 0; while (iVar1 < 0x20) { FID_conflict:_wprintf("%c",(uint)flag[iVar1]); iVar1 = iVar1 + 1; } FID_conflict:_wprintf("\n"); FUN_00401000(local_c ^ (uint)&stack0xfffffffc,extraout_EDX,(char)iVar1); return; }keyが1024バイト
flagが32バイト
flag1バイトにつき32回xorするソルバー ( Ghidra Script )
# step 1 extract key key=[] inst = getInstructionAt(toAddr(0x00409563)) i = 0 while i < 0x400: key.append(inst.getOpObjects(1)[0].getValue()) inst = inst.getNext() i = i + 1 #print(key) # step 2 extract flag flag=[] inst = getInstructionAt(toAddr(0x0040affb)) i = 0 while i < 0x20: flag.append(inst.getOpObjects(1)[0].getValue()) inst = inst.getNext() i = i + 1 #print(flag) # step 3 xor j = 0 i = 0x3ff while -1 < i: j = i % 0x20 flag[j] = flag[j] ^ key[i] i = i - 1 #print(flag) print(''.join(map(chr,flag)))
- 投稿日:2021-03-04T21:20:14+09:00
日立CTFのBinary_絶対に通らないif文をGhidraで静的解析してみた
Ghidraの勉強になると思って,日立CTFのBinary_絶対に通らないif文の静的解析にチャレンジした結果,うまくいったので共有する。
問題へのリンク
絶対に通らないif文
int main(int argc, char **argv) { if (1 == 2) { show_flag(); } return 0; }逆アセンブル結果
0040B1C6: C7 45 FC 01 00 00 00 mov dword ptr [ebp-4],1 0040B1CD: C7 45 F8 02 00 00 00 mov dword ptr [ebp-8],2 0040B1D4: 8B 45 FC mov eax,dword ptr [ebp-4] 0040B1D7: 3B 45 F8 cmp eax,dword ptr [ebp-8] 0040B1DA: 75 05 JNZ LAB_0040B1E1 0040B1DC: e8 6f e3 CALL FUN_00409550動的解析でフラグを得るならば,バイナリエディタで
C7 45 FC 01 00 00 00
を検索して
C7 45 FC 02 00 00 00
に変更すれば if (2 == 2) になってフラグが表示される。
ここからがGhidraによる静的解析
FUN_00409550のデコンパイル結果
(変数の型を修正してデコンパイル誤りを正し,わかりやすい変数名に変更済み)void FUN_00409550(void) { undefined4 extraout_EDX; int iVar1; int i; byte flag [32]; byte key [1024]; uint local_c; int j; local_c = DAT_0040e004 ^ (uint)&stack0xfffffffc; key[0] = 0x18; key[1] = 0x13; key[2] = 0x5e; key[3] = 0x76; key[4] = 0x34; (中略) key[1019] = 0x35; key[1020] = 0x7a; key[1021] = 0x40; key[1022] = 0x9b; key[1023] = 0x36; flag[0] = 0x53; flag[1] = 0xb9; flag[2] = 0xf; flag[3] = 0xa4; flag[4] = 0xb4; (中略) flag[27] = 0x89; flag[28] = 0x6a; flag[29] = 0x47; flag[30] = 0x8e; flag[31] = 0x74; j = 0; i = 0x3ff; while (-1 < i) { j = i % 0x20; flag[j] = flag[j] ^ key[i]; i = i + -1; } iVar1 = 0; while (iVar1 < 0x20) { FID_conflict:_wprintf("%c",(uint)flag[iVar1]); iVar1 = iVar1 + 1; } FID_conflict:_wprintf("\n"); FUN_00401000(local_c ^ (uint)&stack0xfffffffc,extraout_EDX,(char)iVar1); return; }keyが1024バイト
flagが32バイト
flag1バイトにつき32回xorするソルバー
# step 1 extract key key=[] inst = getInstructionAt(toAddr(0x00409563)) i = 0 key.append(inst.getOpObjects(1)[0].getValue()) i = i + 1 while i < 0x400: inst = inst.getNext() key.append(inst.getOpObjects(1)[0].getValue()) i = i + 1 #print(key) # step 2 extract flag flag=[] inst = getInstructionAt(toAddr(0x0040affb)) i = 0 flag.append(inst.getOpObjects(1)[0].getValue()) i = i + 1 while i < 0x20: inst = inst.getNext() flag.append(inst.getOpObjects(1)[0].getValue()) i = i + 1 #print(flag) # step 3 xor j= 0 i = 0x3ff while -1 < i: j = i % 0x20 flag[j] = flag[j] ^ key[i] i = i - 1 #print(flag) print(''.join(map(chr,flag)))
- 投稿日:2021-03-04T20:06:46+09:00
ROSの勉強 第19弾:環境の地図作成に向けて
#プログラミング ROS< 環境の地図作成に向けて >
はじめに
1つの参考書に沿って,ROS(Robot Operating System)を難なく扱えるようになることが目的である.その第19弾として,「環境の地図作成に向けて」を扱う.
環境の地図作成に向けて
ここでは,環境の地図を作成するにあたって必要な前知識を獲得する.主に,ROSにおける地図とrosbagについてである.
ROSにおける地図
以下にYAMLファイルの一例を示す.
map.yamlimage: map.pgm #mapという名前で拡張子がPGMの画像データ名 ほかにもPNG, JPGなどもサポートされている resolution: 0.1 #解像度:0.1[m]の正方形セル origin: [0.0, 0.0, 0.0] #原点の位置 occupied_thresh: 0.65 #障害物が占有しているとする閾値 free_thresh: 0.65 #障害物が占有していないとする閾値 negate: 1 #ROSで処理する前にセルの値を反転それぞれの説明は上記に示すとおりである.最下行の
negateを行う理由は,はじめに示したとおり,障害物が占有していないところを明るく(白),占有していないところを暗く(黒)としたいためである.デフォルトでは,逆になっている.rosbag
次にデータを記録する方法について学ぶ.ここで,使うのはrosbagである.以下に簡単な説明を示す.
上の説明で,-aをつけると,配信しているトピックをすべて記録できると示したが,特にPR2のように多くのセンサを搭載したロボットでは,大量のデータを記録してしまうことになる.また,rosbagはCtrl-Cで止められるまで記録し続ける.さらに,rosbagのファイルについては,
rosbag infoで見ることができる.
以下に一例を示す.~$ rosbag info laser.bag #以下,表示結果 path: laser.bag #対象ファイル version: 2.0 duration: 1:44s (104s) start: Mar 04 2021 10:04:13.44 (1310058253.44) end: Mar 04 2021 10:05:58.04 (1310058358.04) size: 8.2 MB messages: 2004 compression: none [11/11 chunks] types: sensor_msgs/LaserScan [90c7ef2dc6895d81024acba2ac42f369] topics: base_scan 2004 msgs : sensor_msgs/LaserScanこれにより,bagファイルに記録されている時間,記録の開始時刻と終了時刻,ファイルの大きさ,メッセージ数,メッセージ(とトピック)の内容などを知ることができる.これは,記録したbagファイルに,期待した情報が記録されているかを確認するのに便利である.
また,rosbagは,ロボットの新しいアルゴリズムのデバッグをするときに非常に便利なツールである.例えば,アルゴリズムのデバッグのとき,生のセンサデータを使う代わりに,rosbagで記録しておいた代表的なデータセットを再生することでアルゴリズムにセンサデータを与えるようにする.こうすることで,アルゴリズムは毎回,まったく同じデータを処理することができるようになる.この再現性は,デバッグの効率を上げてくれる.ロボットの動作の変化は,新しく観測された未知のセンサデータ入力によるものではなく,すべてコードを変えたことによるものであることが保証される.
感想
今回は,まだ地図作成に入っていないが,ROSの地図について知り,rosbagという強力なツールについて学ぶことができた.地図の作成については今までに経験がないため,より慎重に理解していきたいと思う.
参考文献
プログラミングROS Pythonによるロボットアプリケーション開発
Morgan Quigley, Brian Gerkey, William D.Smart 著
河田 卓志 監訳
松田 晃一,福地 正樹,由谷 哲夫 訳
オイラリー・ジャパン 発行



- 投稿日:2021-03-04T19:43:42+09:00
JavaScriptでPythonのzip関数を実装してみました
Python3にはzip()という便利な組み込み関数があります。
以下のように、複数のイテラブル1を同時にイテレーションできる関数です。chars = ["a", "b", "c"] nums = [1, 2, 3, 4, 5] for elems in zip(chars, nums): print(elems) # 出力 # ('a', 1) # ('b', 2) # ('c', 3)引数にイテラブルを複数指定すると、各イテラブルの要素をまとめたタプルを返すイテレータを作ってくれます。
イテラブル間で要素数が異なる場合は、もっとも短いイテラブルの要素が尽きた時点で止まります。この関数をJavaScriptで再現してみます。
環境と背景知識
- ES6(ES2015)の機能を使います。モダンブラウザやNode.jsの新しめのバージョンであれば通用する内容です。たぶん。
- JavaScriptのジェネレータ関数や反復処理プロトコル、スプレッド構文や残余引数などについての知識を使います。
先行事例
「JavaScript Python zip」で検索すると似たような試みは何件かヒットします。
Qiitaでも先駆者がいらっしゃいます。個人的にいつも参考にしている民主主義に乾杯さんから実装例を引用します。
function* zip(...args) { const length = args[0].length; // 引数チェック for (let arr of args) { if (arr.length !== length){ throw "Lengths of arrays are not eqaul."; } } // for (let index = 0; index < length; index++) { let elms = []; for (arr of args) { elms.push(arr[index]); } yield elms; } }空の配列elmsを作る→イテラブルのそれぞれi番目の要素を取得して順次elmsにpush→elmsをyield、を繰り返す流れです。
配列間の要素数が同じである必要はあるものの、Pythonのzip関数と同じようなことができそうです。
イテレータを返すところも再現度が高くて良いですね。yucatioさんの実装もご紹介します。
const zip = (...arrays) => { const length = Math.min(...(arrays.map(arr => arr.length))) return new Array(length).fill().map((_, i) => arrays.map(arr => arr[i])) }こちらはジェネレータ関数ではなく普通の関数(アロー関数)としての実装で、返すのはイテレータではなく配列になります。
この実装が優れている点の一つは、配列間の要素数が違っていても、最も短い配列に合わせて処理してくれるところです(2行目)。
3行目はmap()が入り乱れていたり、謎のfill()が挟まっていたりと少々読みづらいですが、元サイトで詳しく解説されているのでご覧になってみてください。
先行事例についてさらに考察しましたが、ちょっと長くなったので折りたたみ。
改良してみた
上記二つのコードを組み合わせてみます。
function* zip(...args) { const length = Math.min(...args.map(arg => arg.length)); for (let index = 0; index < length; index++) { let elms = []; for (const arr of args) { elms.push(arr[index]); } yield elms; } }引数のイテラブルの要素数が異なっても対応でき、さらにPythonのzip()関数と同じくイテレータを返すようになっています。
これでなかなかの再現度になったのではないでしょうか?使ってみましょう。
const chars = ["a", "b", "c"]; const nums = [1, 2, 3, 4, 5]; for (const elems of zip(chars, nums)) { console.log(elems); } // 出力 // Array [ "a", 1 ] // Array [ "b", 2 ] // Array [ "c", 3 ]Pythonと同じ結果が得られました!
また、Pythonのzip()はリスト2以外でも、文字列などイテラブルであれば何でも引数にとれます。
JavaScript版zip()でも文字列を引数にして試してみます。const str = "qwe"; const nums = [1, 2, 3, 4, 5]; for (const elems of zip(str, nums)) { console.log(elems); } // 出力 // Array [ "q", 1 ] // Array [ "w", 2 ] // Array [ "e", 3 ]いけますね。
その他、NodeListやargumentsオブジェクトなどのイテラブルにも使うことができます。
このzip関数ならどんなイテラブルが来ても怖くありません。…本当に?
添字アクセスができないと使えない
たしかに、JavaScriptの代表的なイテラブルである配列や文字列は問題なくイテレートできます。
それでは、先ほどのzip()でSetオブジェクトをイテレートしてみます。const str = "qwe"; const numSet = new Set([1, 2, 3, 4, 5]); for (const elems of zip(str, numSet)){ console.log(elems); } // 出力 //…ダメですね。期待通りにイテレートしません。
Setオブジェクトは間違いなくイテラブルのはずなんですが。原因はzip()の定義の6行目、
elms.push(arr[index]);の部分で行われている添字アクセスです。
Setオブジェクトでは、numSet[1]のような添字を使った形で要素にアクセスすることができない3ので、意図した通りに処理されないのです。Mapオブジェクトやジェネレータオブジェクトも同様に、イテラブルかつ添字アクセスができないオブジェクトです。
本編です
折りたたみを読んでくださった方、ありがとうございました。ここから本編です。
折りたたみを飛ばした方、大丈夫です。本編はここからです。つくるもの
Pythonのzip()に似せるため、以下の条件を満たすものを目指します。
- 引数のイテラブルをまとめてイテレートする機能を提供する
- 実行したらイテレータを返す
- イテレートはもっとも短いイテラブルの要素が尽きたら終了する
- イテラブルならなんでも、いくつでも対応可能である。
方針
Pythonの公式ドキュメントのzip()の項目を見てみると、ありがたいことにzip()と等価なコードが紹介されています。
引用します。def zip(*iterables): # zip('ABCD', 'xy') --> Ax By sentinel = object() iterators = [iter(it) for it in iterables] while iterators: result = [] for it in iterators: elem = next(it, sentinel) if elem is sentinel: return result.append(elem) yield tuple(result)このコードのzip()は組み込みのほうのzip()と等価なので、当然「つくるもの」の項で挙げた条件を満たします。
これをJavaScriptで書き直せばよさそうです。解読します
上のコードの処理を解読します。
全体としては中にyieldがある関数宣言の形ですので、ジェネレータ関数です。
sentinel = object()どういうわけか
object()で空のオブジェクトsentinelを生成しています。
この段階では何のためかわかりません。とりあえず保留します。iterators = [iter(it) for it in iterables]引数のイテラブルからiter()でイテレータを取得して、iteratorsという名前のリストに格納しています。
リスト内包表記でiterablesの全ての要素について一括で処理していますね。
[イテラブル1, イテラブル2, イテラブル3,…]から[イテレータ1, イテレータ2, イテレータ3,…]を作っている感じです。続いて
while iterators:でループが始まっています。
もしiteratorsが空ならここはスルーされてなにもyieldされないので、空のジェネレータオブジェクトになります。#ループ内 result = [] for it in iterators: elem = next(it, sentinel) if elem is sentinel: return result.append(elem) yield tuple(result)ループの中では、ループ毎にresultという空の配列が作られています。
そのあとfor文でiteratorsを走査しています。
具体的には、「イテレータからnext()で値を取り出す→resultに追加」を全てのイテレータについて行っています。
resultへの追加が完了したら、タプルに変換してyieldしています。ここで、始めに作られた謎のsentinelがnext()の第二引数に使われていますね。
next()のドキュメントを確認します。next(iterator[, default])
iterator の __next__() メソッドを呼び出すことにより、次の要素を取得します。イテレータが尽きている場合、 default が与えられていればそれが返され、そうでなければ StopIteration が送出されます。
next(it, sentinel)の直後にif文でelem is sentinelが評価されていることを考え合わせると、イテレータが尽きているかどうかをnext()の結果がsentinelかどうかで判断しているようです。
つまり、「イテレータが尽きる→elem is sentinelがTrueになる→returnしてジェネレータを終了」ということ。
「もっとも短いイテラブルの要素が尽きたら終了」という仕様がこういう形で実現できるんですね。いざ、JavaScriptで実装
大事な点が一つ。
機能的には、JavaScriptではイテレータ.next()が、Pythonのnext(イテレータ)に相当します。
しかし、両者の戻り値は異なります。
Pythonのnext(イテレータ)は値を直接返します(例えば、ジェネレータならyieldされた値をそのまま返します)。イテレータが尽きていた場合、StopIteration を送出するか、第二引数の値を返します。
一方、JavaScriptのイテレータ.next()が返すのは、valueとdoneというプロパティを持つオブジェクトです。イテレータが実際に返した値はこのオブジェクトのvalueプロパティを参照して取得します。また、イテレータが尽きていた場合、doneプロパティがtrueになります(そうでない場合はfalseです)。Pythonのコードではイテレータが尽きたかチェックするのにnext()の第二引数を利用していましたが、JavaScriptでは戻り値のdoneプロパティを参照すればよいので空オブジェクトsentinelを用意する必要はありませんね。
ではコードを書きます。
ジェネレータ関数なのでfunction*宣言の形にします。function* zip(...iterables) { }次にiteratorsを作りますが、JavaScriptにはリスト内包表記はないのでmap()で代用。
また、イテラブルからイテレータを取得するiter(it)に相当するのは、JavaScriptではit[Symbol.iterator]()4 5です。const iterators = iterables.map(it => it[Symbol.iterator]());あとはwhileの部分です。
JavaScriptとPythonのnext()の違いに注意。
また、Pythonではresultをタプルにしてからyieldしていますが、JavaScriptにタプルはないので配列のままyieldします6。while (iterators) { const result = []; for (const it of iterators) { const elemObj = it.next(); if (elemObj.done) { return; } result.push(elemObj.value); } yield result; }以上を組み合わせれば完成です。
完成
function* zip(...iterables) { const iterators = iterables.map(it => it[Symbol.iterator]()); while (iterators) { const result = []; for (const it of iterators) { const elemObj = it.next(); if (elemObj.done) { return; } result.push(elemObj.value); } yield result; } }使ってみます
配列・文字列・Setオブジェクト・Mapオブジェクトを、今回作ったzip()でイテレートしてみます。
const chars = ["a", "b", "c"]; const str = "qwe"; const numSet = new Set([1, 2, 3, 4, 5]); const numMap = new Map([[1, 1], [2, 4], [3, 9], [4, 16]]); for (const elems of zip(chars, str, numSet, numMap)) { console.log(elems); } // 出力 // Array(4) [ "a", "q", 1, Array [ 1, 1 ] ] // Array(4) [ "b", "w", 2, Array [ 2, 4 ] ] // Array(4) [ "c", "e", 3, Array [ 3, 9 ] ]期待通りの動作です。
この記事では、PythonのイテラブルオブジェクトとJavaScriptの反復可能オブジェクトをまとめて「イテラブル」と呼ぶことにします。 ↩
この記事では、JavaScriptの配列をPythonのリストに相当するものとして扱います。 ↩
JavaScriptのブラケット表記はプロパティアクセサーなので、
numSet[1]のように書くと「numSetというオブジェクトの1というプロパティ」にアクセスすることはできます(通常このようなプロパティは未定義なのでundefinedになります)。しかし、普通はこれをSetオブジェクトの要素へのアクセスとは見做さないでしょう。 ↩
it[Symbol.iterator]()です。it.Symbol.iterator()ではありませんので注意してください。 ↩変更不可能な配列として返すだけなら
yield Object.freeze(result)とすれば実現できますが、あまり意味はないと思います。 ↩
- 投稿日:2021-03-04T19:40:55+09:00
MacでのPyAutoGUIの注意点
MacでPyAutoGUIを利用するにあたって注意すべき点
環境
macOS Big Sur 11.2.2
PyauGUI 0.9.52
anaconda Command line client (version 1.7.2)
Python 3.8.5
JupyterLab 2.2.6撮影が出来ない
- スクリーンショットが上手く撮れない
- confidenceを下げてもlocateCenterOnScreenが反応しなかったり、NullやNotImageExceptionが起きる。(画像を使った機能は内部でスクリーンショットを利用している)
shoto.py#例えばJupyterLabやブラウザを立ち上げた状態でスクリーンショットを撮って保存する import pyautogui sc = pyautogui.screenshot("fullscreen.png")
真っ新なデスクトップが表示されており、思ったようなスクリーンショットが出来ていない。解決策
- システムと環境設定を開く
- セキュリティとプライバシーをクリック
- プライバシータブを選択
- 画面収録を選択
- 鍵を外してターミナルにチェック、ターミナルの再起動
moveToなどのマウス操作が機能しない
mouse.pyimport pyautogui pyautogui.moveTo(1,1) print(pyautogui.position()) #実行すると、 #Point(x=230, y=326) #といった具合に全く動いていない解決策
- システムと環境設定を開く
- セキュリティとプライバシーをクリック
- プライバシータブを選択
- アクセシビリティを選択
- 鍵を外してターミナルとAEServer(OSのバージョンによって名称が異なるかも。)にチェックを入れて、再起動
画像認識の場所がどうもおかしい
detec.pyimport pyautogui pos = pyautogui.locateCenterOnScreen('youtube.png', grayscale=False,confidence=0.8) print(pos) pyautogui.moveTo(pos.x,pos.y) print(pyautogui.position()) #座標だけ見ると正しい位置に移動した様に見える #Point(x=394, y=234) #Point(x=394, y=234) #しかし明らかにカーソルはターゲットとズレている。 #一致した箇所のスクリーンを撮影すると、認識した場所とカーソルがズレていることがわかりやすい。 sc = pyautogui.screenshot(region(pos.left,pos.top,pos.width,pos.height)) sc.save('deteceObj.png')解決策
x,yともに2で割ると上手くいく
detec.pyimport pyautogui pos = pyautogui.locateCenterOnScreen('target.png', grayscale=False,confidence=0.8) print(pos) pyautogui.moveTo(pos.x/2,pos.y/2) print(pyautogui.position()) #座標だけ見るとズレている様だが、実際には認識した場所にカーソルがある。 #Point(x=337, y=230) #Point(x=168, y=115)locateCenterOnScreeなど認識が上手く出来ない
解決策
オプションの変更や、RGB値でのマッチにする
chageoption.py# 識別精度を調整する opencv-pythongが必要 pos1 = pyautogui.locateCenterOnScreen('target.png',confidence=0.8) #グレースケールでの検索(高速になるらしいが、個人的には違いがわからない。。) pos2 = pyautogui.locateOnScreen('traget.png', grayscale=True) #探索範囲を絞る この場合、(1,1)から幅400px、高さ200pxのエリアで検索する pos3 = pyautogui.locateOnScreen('taget.png', region=(1, 1, 400, 200)) # RGBマッチにしてみる この場合、(100,100)が赤色(255, 0, 0)かどうかのtrue/falseを返す # オプションでマッチする範囲を広げられる ismatch = pyautogui.pixelMatchesColor(100, 100, (255, 0, 0)) ismatch = pyautogui.pixelMatchesColor(100, 100, (255, 0, 0),tolerance=30)

- 投稿日:2021-03-04T19:29:21+09:00
Jetson Xavier NXでPytorch1.7をインストールしてYOLOv5を動かす
アーキテクチャが違ったり、依存関係があったりでいろいろと苦労しましたが、
JetsonでYOLOv5を動かすことができました。Jetpackはv4.5.1です。
OSイメージ入れ立ての状態でインストールしました。Pytorchを入れます。
wget https://nvidia.box.com/shared/static/cs3xn3td6sfgtene6jdvsxlr366m2dhq.whl -O torch-1.7.0-cp36-cp36m-linux_aarch64.whl sudo apt-get install python3-pip libopenblas-base libopenmpi-dev pip3 install Cython pip3 install numpy torch-1.7.0-cp36-cp36m-linux_aarch64.whlsudo apt-get updateTorchvisionを入れます。バージョンは、branch基準で変えることができます。
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev git clone --branch v0.8.1 https://github.com/pytorch/vision torchvision cd torchvision export BUILD_VERSION=0.x.0 python3 setup.py install cd .. pip install 'pillow<7'(ここまで参考:https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-7-0-now-available/72048)
以下は、scipyをインストールするために必要でした。
sudo apt-get install -y build-essential libatlas-base-devpip3 install -U pip pip3 install -U setuptoolsここからは、requiment.txtのライブラリをpipでインストールしますが、
torchvisionは0.8.1が入らなかったので、0.8以上で指定をrequiments.txtを変更しました。
他にもバージョン指定を解除したものが1つ2つあったかもしれません。
pipは1つずつインストールしました。
- 投稿日:2021-03-04T18:54:17+09:00
pythonで標高データから等高線を書きたい
等高線を書きたい
いくつかの地点の標高データが手元にあるとします。
人間であればそのデータを基になんとなく等高線図を書けると思います。
この「何となく等高線図を書く」という作業をpythonで出来ないかトライしてみました。結論からいうとこの記事ではうまくいってませんので、コードや方針を参考にする程度にとどめておいてください。
方針
- 手元データの位置情報(経度&緯度)から標高データを予測する機械学習モデルを作る。
- その後、データの無い地点での標高を機械学習モデルで予測を行い網羅的に取得する。
- 取得したデータを等高線図に直す
実装こまごま
データの作製
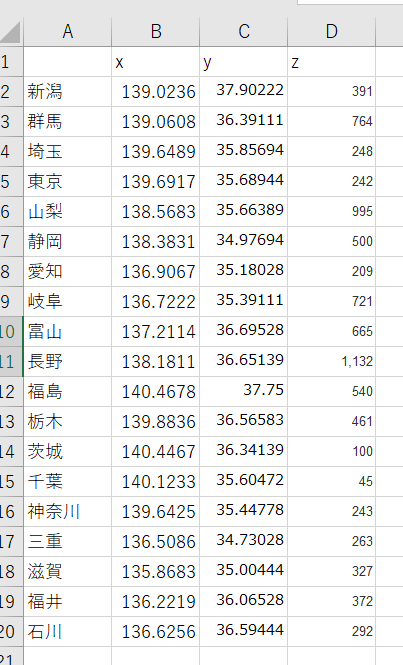
今回は中部地方付近の地理データをここのサイトとここのサイトから作りました。
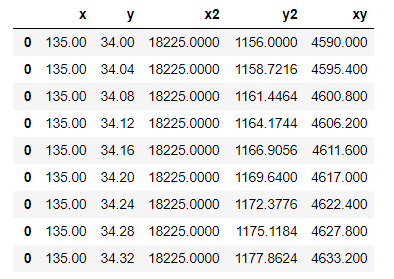
geo.xlsxの中身はこんな感じ。xが経度、yが緯度、zが標高を表しています。
こう見ると長野って抜群に標高高いんですね。
データの読み込み&説明変数の複製
read_excelでデータを読み込んだのち、説明変数同士の積和を取るなどして説明変数を増やします。
今回はlinear regressionを利用し線形な近似しか行う方針でいきますが、x2やx3のデータを増やすことでより複雑な近似曲面の取得を試みます。
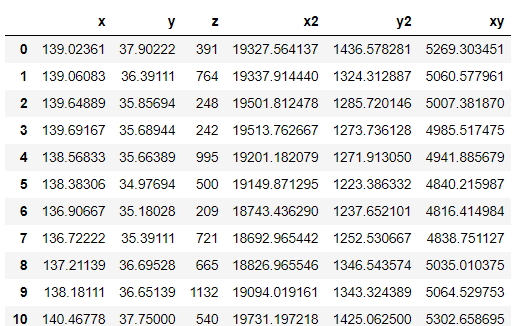
今回は二次の曲面で近似してみます。import numpy as np import matplotlib.pyplot as plt import pandas as pd #説明変数を増やす関数 def arrange(df): df["x2"] = df["x"]*df["x"] df["xy"] = df["x"]*df["y"] df["y2"] = df["y"]*df["y"] return df #データの読み込み df = pd.read_excel("geo.xlsx")[["x","y","z"]] df = arrange(df)この処理で、データはこうなります。三次・四次の場合もやってみたので後ほど結果だけ示しますね。
線形回帰で学習
手元のデータを利用して、線形回帰モデルの学習を行います。
from sklearn.linear_model import LinearRegression lr = LinearRegression() X = df.drop(["z"],axis=1).values # 説明変数(Numpyの配列) Y = df['z'].values # 目的変数(Numpyの配列) lr.fit(X, Y) # 線形モデルの重みを学習データの無い地点の標高を予測
データの無い場所についてはこの学習モデルを利用して標高を予測します。
データの無い地点の経度と緯度を網羅的に定義して、予測するためのデータを用意します。x = np.round(np.arange(135, 140, 0.05),decimals=4) # x軸 135から140まで0.05ずつ100地点 y = np.round(np.arange(34, 38, 0.04),decimals=4) # y軸 34から38まで0.04ずつ100地点 ⇒合計100×100の10000地点 X, Y = np.meshgrid(x, y) data = pd.DataFrame([]) for _x in x: for _y in y: data = pd.concat([data, pd.Series([_x,_y])],axis=1)dataの中身はこんな感じ。
あとはこのデータから学習データ同様に説明変数を増やします。input_df = data.T input_df.columns = ["x","y"] input_df = arrange(input_df)input_dfの中身はこんな感じ。
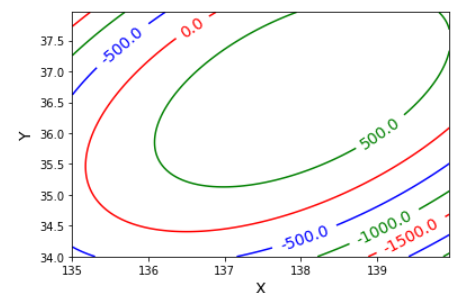
そしてこのデータを説明変数として標高を予測し、等高線に起こすだけです。#予測 pred_z = lr.predict(input_df) pred_z_resh = pred_z.reshape(100,-1) x = np.round(np.arange(135, 140, 0.05),decimals=4) # x軸 y = np.round(np.arange(34, 38, 0.04),decimals=4) # y軸 X, Y = np.meshgrid(x, y) #等高線を書く舞台を作る Z = pred_z_resh #標高データ cont = plt.contour(X,Y,Z,colors=['r', 'g', 'b']) #舞台に標高データを一個一個入れていく cont.clabel(fmt='%1.1f', fontsize=14) plt.gca().xaxis.get_major_formatter().set_useOffset(False) #横軸の表記をa×e^nにしない plt.gca().yaxis.get_major_formatter().set_useOffset(False) #縦軸の表記をa×e^nにしない plt.xlabel('X', fontsize=14) plt.ylabel('Y', fontsize=14) plt.show()その結果がこちら。
やっぱり単純なモデルなだけあって標高マイナス値とか出ちゃってますね。
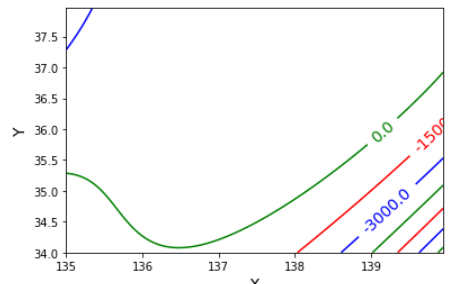
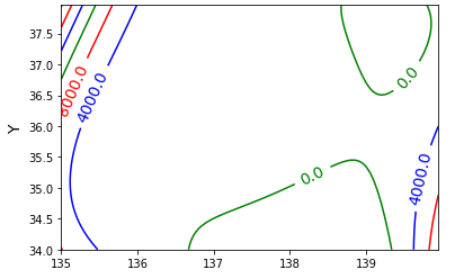
三次や四次の場合
三次や四次の場合もやってみました。
三次の場合は、#説明変数を増やす関数 def arrange(df): df["x2"] = df["x"]*df["x"] df["xy"] = df["x"]*df["y"] df["y2"] = df["y"]*df["y"] df["x3"] = df["x"]*df["x"]*df["x"] df["x2y"] = df["x"]*df["x"]*df["y"] df["xy2"] = df["x"]*df["y"]*df["y"] df["y3"] = df["y"]*df["y"]*df["y"] return df四次の場合は、
def arrange(df): df["x2"] = df["x"]*df["x"] df["xy"] = df["x"]*df["y"] df["y2"] = df["y"]*df["y"] df["x3"] = df["x"]*df["x"]*df["x"] df["x2y"] = df["x"]*df["x"]*df["y"] df["xy2"] = df["x"]*df["y"]*df["y"] df["y3"] = df["y"]*df["y"]*df["y"] df["x4"] = df["x"]*df["x"]*df["x"]*df["x"] df["x3y"] = df["x"]*df["x"]*df["x"]*df["y"] df["x2y2"] = df["x"]*df["x"]*df["y"]*df["y"] df["x1y3"] = df["x"]*df["y"]*df["y"]*df["y"] df["y4"] = df["y"]*df["y"]*df["y"]*df["y"] return dfとなります。
書いた等高線は三次の場合は
四次の場合は
となりました。三次の方は相変わらず海の底に沈んだ場所がありつつ。
四次の方は山が二個あってそれっぽいと思いきや、実は谷になってたり。
次はRandomForestあたりでやってみても面白いかも。最後に
等高線書くだけなのに意外と難しくてびっくり。
是非トライしてみてくださいね。

- 投稿日:2021-03-04T18:42:14+09:00
Anaconda仮想環境でDjangoの開発サーバーをバッチ起動
はじめに
毎回、Anacondaのコマンドプロンプトを開いて→ディレクトリ移動して→runserverして→ローカルサーバーにアクセスして→というのが面倒くさかったことと、疑似的なデスクトップアプリ(?)にしたかったため作成しました。
※この記事を書いた本人はプログラミング初心者なので、間違い等は優しく指摘していただけると嬉しいです。自己紹介
Rujuu(@Rujuu_study)
↑これといったことは書かないと思いますが、フォローしていただけると大喜びしますm(_ _)m環境
・Windows10
・conda4.9.0
・Python3.8.3
・django3.1.5コード
runserver.batrem カレントディレクトリを実行しているファイルのフォルダに移動 cd /d %~dp0 rem anaconda環境の呼び出し(%USERNAME%はユーザー名を取得するためのもの) call C:\Users\%USERNAME%\Anaconda3\Scripts\activate.bat rem 仮想環境呼び出し(自身の仮想環境名にしてください) call activate 仮想環境名 rem Chromeでローカルサーバーにアクセス(""内は自身が作成したurl.pyに沿ったものに) start chrome.exe "http://127.0.0.1:8000/" rem サーバー起動 python manage.py runserver注意事項
・作成するbatファイルはmanage.pyと同じ階層に置いてください。
・remはコメントです。
・コードをカスタマイズする際に「python manage.py runserver」の後に処理を書くと、追加した処理が実行されないかもです。
・デスクトップアプリ風(?)にする際は、バッチファイルのショートカットをデスクトップなどに作ってください。参考文献
犬でもわかるバッチファイルの作り方~カレントディレクトリを意識しよう!
batファイルから任意のanaconda仮想環境で.pyを起動
指定したURLを開くバッチファイルの作り方を教えてください。(Googlechromeで開く)最後に
世の中の誰かの参考になれば嬉しいです。
改善案等待ってます。
- 投稿日:2021-03-04T18:30:34+09:00
【簡単】QRコードの作成と読み取り in Python
➊はじめに
Pythonで「QRコード作成、読み取り」が、簡単に実現できないかなと思って調べました。
・やりたいこと
やりたいことは、以下の3つです。
- PNGのQRコード画像作成
- 画像からのQRコード読み取り
- webカメラからのQRコード読み取り
・ソリューションまとめ
やりたいことに対する解決策を、以下にまとめます。
やりたいこと 使用するモジュール 備考 QRコード画像作成 PyQRCode PNG化する場合はpypngも必要 QRコード読み取り1 (CV2) opencv-python Ver4.3以上で複数読込み可能 QRコード読み取り2 (pyzbar) pyzbar Macはzbar, Linuxはlibzbar0も必要 ※本ページの開発環境:win10、Python 3.8.5
ということで、以下、実施していきます。➋QRコード作成
QRコードの作成は、QRコードジェネレーターであるpyqrcodeモジュールを使用します。QRコードは、SVG、PNG、およびプレーンテキストとして保存可能なようです。PNGで保存する場合は、別途、pypngモジュールを使用します。
・インストール
以下のコマンドにより、PyQRCodeモジュールをインストールします。また、今回はQRコードをPNG画像として保存するため、pypngモジュールもインストールします。
コマンドラインpip install PyQRCode pip install pypng
・プログラム
sample_qr_generator.pyimport pyqrcode FILE_PNG_A = 'qrcode_A.png' FILE_PNG_B = 'qrcode_B.png' # QRコード作成 code = pyqrcode.create('https://qiita.com/PoodleMaster', error='L', version=3, mode='binary') code.png(FILE_PNG_A, scale=5, module_color=[0, 0, 0, 128], background=[255, 255, 255]) # QRコード作成 code = pyqrcode.create('https://github.com/PoodleMaster', error='L', version=3, mode='binary') code.png(FILE_PNG_B, scale=5, module_color=[0, 0, 0, 128], background=[255, 255, 255])・実行結果
File Image qrcode_A.png qrcode_B.png ➌画像連結
こちらの作業は必須ではないですが、1枚の画像に複数QRコードがある状況を作っておきます。次章の「QRコード読込み」の際に、1枚の画像から複数のQRコードを読み込めることを確かめます。
・インストール
OpenCVモジュールを使用して画像を連結します。
pip install opencv-python
・プログラム
sample_hconcat.pyimport cv2 FILE_PNG_A = 'qrcode_A.png' FILE_PNG_B = 'qrcode_B.png' FILE_PNG_AB = 'qrcode_AB.png' im1 = cv2.imread(FILE_PNG_A) im2 = cv2.imread(FILE_PNG_B) im_h = cv2.hconcat([im1, im2]) cv2.imwrite(FILE_PNG_AB, im_h) cv2.imshow('image', im_h) cv2.waitKey(0)・実施結果
File Image qrcode_AB.png ➍QRコード読込み
QRコードの読込みは、OpenCVモジュール、またはpyzbarモジュールのどちらかを使用します。
➍-1「OpenCV」によるQRコード読込み
・インストール
OpenCVバージョン4.3から
detectAndDecodeMultiメソッドがコール可能となり、1枚の画像から複数のQRコードを読み取ることができるようになりました。OpenCVは、バージョン4.3以上をインストールしてください。pip install opencv-python
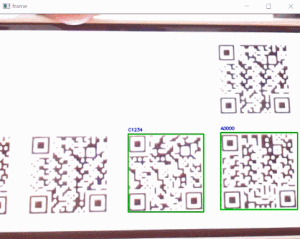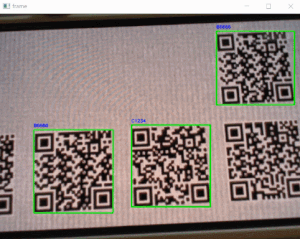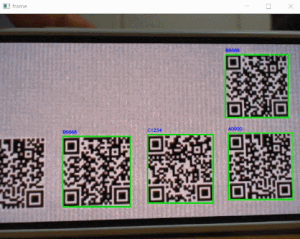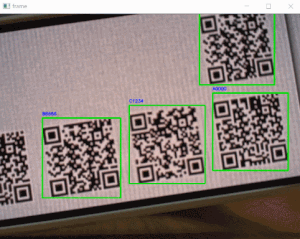
・プログラム
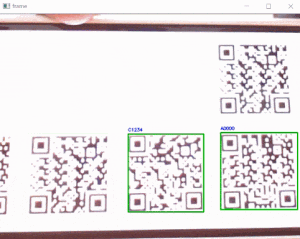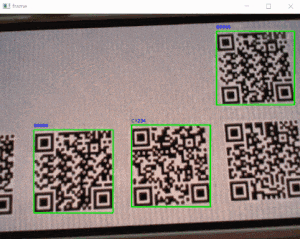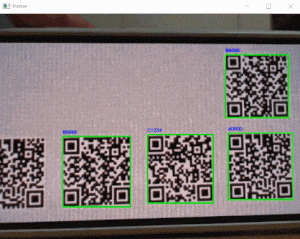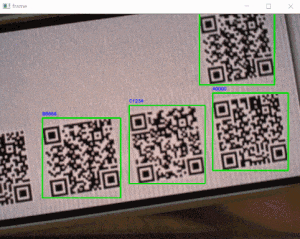
sample_qr_read_1.pyimport cv2 import numpy as np # ----------------------------------------------------------- # initial # ----------------------------------------------------------- font = cv2.FONT_HERSHEY_SIMPLEX FILE_PNG_AB = 'qrcode_AB.png' # ----------------------------------------------------------- # function_qr_dec # ----------------------------------------------------------- def function_qrdec_cv2(img_bgr): # QRCodeDetectorインスタンス生成 qrd = cv2.QRCodeDetector() # QRコードデコード retval, decoded_info, points, straight_qrcode = qrd.detectAndDecodeMulti(img_bgr) if retval: points = points.astype(np.int) for dec_inf, point in zip(decoded_info, points): if dec_inf == '': continue # QRコード座標取得 x = point[0][0] y = point[0][1] # QRコードデータ print('dec:', dec_inf) img_bgr = cv2.putText(img_bgr, dec_inf, (x, y-6), font, .3, (0, 0, 255), 1, cv2.LINE_AA) # バウンディングボックス img_bgr = cv2.polylines(img_bgr, [point], True, (0, 255, 0), 1, cv2.LINE_AA) cv2.imshow('image', img_bgr) cv2.waitKey(0) # ----------------------------------------------------------- # sample program # ----------------------------------------------------------- img_BGR = cv2.imread(FILE_PNG_AB, cv2.IMREAD_COLOR) function_qrdec_cv2(img_BGR)※detectAndDecodeMultiの結果が、True(retvalがTrue)の場合でも、デコードデータが無い(dec_infがNULL)ことがあったので、「dec_inf == ''」の場合は、continueさせています。
・実行結果
➍-2「pyzbar」によるQRコード読込み
・インストール
Windows環境以外は、以下のモジュールをインストールしてください。
Macbrew install zbarLinux / GoogleColabsudo apt-get install libzbar0以下のコマンドでpyzbarモジュールをインストールします。
Mac / Linux / GoogleColab / Winpip install pyzbar
・プログラム
sample_qr_read_2.pyimport cv2 from pyzbar.pyzbar import decode, ZBarSymbol # ----------------------------------------------------------- # initial # ----------------------------------------------------------- font = cv2.FONT_HERSHEY_SIMPLEX FILE_PNG_AB = 'qrcode_AB.png' # ----------------------------------------------------------- # function_qr_dec # ----------------------------------------------------------- def function_qrdec_pyzbar(img_bgr): # QRコードデコード value = decode(img_bgr, symbols=[ZBarSymbol.QRCODE]) if value: for qrcode in value: # QRコード座標取得 x, y, w, h = qrcode.rect # QRコードデータ dec_inf = qrcode.data.decode('utf-8') print('dec:', dec_inf) img_bgr = cv2.putText(img_bgr, dec_inf, (x, y - 6), font, .3, (255, 0, 0), 1, cv2.LINE_AA) # バウンディングボックス cv2.rectangle(img_bgr, (x, y), (x + w, y + h), (0, 255, 0), 2) cv2.imshow('image', img_bgr) cv2.waitKey(0) # ----------------------------------------------------------- # sample program # ----------------------------------------------------------- img_BGR = cv2.imread(FILE_PNG_AB, cv2.IMREAD_COLOR) function_qrdec_pyzbar(img_BGR)・実行結果
➎webカメラでQRコード自動認識
最後にwebカメラでQRコードを自動認識するプログラムを載せておきます。今回は「pyzbar」を使用しました。
※こちらのプログラムはwebカメラを用いるため、Google Colabでは動作しません。・プログラム
プログラムは、「
'q'」キー押下でquitします。sample_webcam_qrcode.pyimport cv2 from pyzbar.pyzbar import decode, ZBarSymbol # ----------------------------------------------------------- # 画像キャプチャ # ----------------------------------------------------------- cap = cv2.VideoCapture(0) font = cv2.FONT_HERSHEY_SIMPLEX while cap.isOpened(): ret, frame = cap.read() if ret: # デコード value = decode(frame, symbols=[ZBarSymbol.QRCODE]) if value: for qrcode in value: # QRコード座標 x, y, w, h = qrcode.rect # QRコードデータ dec_inf = qrcode.data.decode('utf-8') frame = cv2.putText(frame, dec_inf, (x, y-6), font, .3, (255, 0, 0), 1, cv2.LINE_AA) # バウンディングボックス cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2) # 画像表示 cv2.imshow('frame', frame) # quit if cv2.waitKey(1) & 0xFF == ord('q'): break # キャプチャリソースリリース cap.release()・実行結果
「QRコードを表示したスマホ」をwebカメラで撮り検出させていますが、うまく認識しています!
➏以上
お疲れ様でした。
モジュールを使うことで、かなり簡単にQRコード作成・読込みツールを作ることができました。





- 投稿日:2021-03-04T18:30:34+09:00
【簡単】QRコードの作成と読込み in Python
➊はじめに
Pythonで「QRコード作成、及び、読み取り」が、簡単に実現できないかなと思って調べました。
・やりたいこと
やりたいことは、以下の3つです。
- PNGのQRコード画像作成
- 画像からのQRコード読み取り
- webカメラからのQRコード読み取り
・ソリューションまとめ
やりたいことに対する解決策についてまとめます。ということで、以下、実施していきます。
やりたいこと 使用するモジュール 備考 QRコード画像作成 PyQRCode PNG化する場合はpypngも必要 QRコード読み取り1 (CV2) opencv-python Ver4.3以上で複数読込み可能 QRコード読み取り2 (pyzbar) pyzbar Macはzbar, Linuxはlibzbar0も必要 ※本ページの開発環境:win10、Python 3.8.5
➋QRコード作成
QRコードの作成は、QRコードジェネレーターであるpyqrcodeモジュールを使用します。QRコードは、SVG、PNG、およびプレーンテキストとして保存可能なようです。PNGで保存する場合は、別途、pypngモジュールを使用します。
・インストール
以下のコマンドにより、PyQRCodeモジュールをインストールします。また、今回はQRコードをPNG画像として保存するため、pypngモジュールもインストールします。
コマンドラインpip install PyQRCode pip install pypng
・プログラム
sample_qr_generator.pyimport pyqrcode FILE_PNG_A = 'qrcode_A.png' FILE_PNG_B = 'qrcode_B.png' # QRコード作成 code = pyqrcode.create('https://qiita.com/PoodleMaster', error='L', version=3, mode='binary') code.png(FILE_PNG_A, scale=5, module_color=[0, 0, 0, 128], background=[255, 255, 255]) # QRコード作成 code = pyqrcode.create('https://github.com/PoodleMaster', error='L', version=3, mode='binary') code.png(FILE_PNG_B, scale=5, module_color=[0, 0, 0, 128], background=[255, 255, 255])・実行結果
File Image qrcode_A.png qrcode_B.png ➌画像連結
こちらの作業は必須ではないですが、1枚の画像に複数QRコードがある状況を作っておきます。次章の「QRコード読込み」の際に、1枚の画像から複数のQRコードを読み込めることを確かめます。
・インストール
OpenCVモジュールを使用して画像を連結します。
pip install opencv-python
・プログラム
sample_hconcat.pyimport cv2 FILE_PNG_A = 'qrcode_A.png' FILE_PNG_B = 'qrcode_B.png' FILE_PNG_AB = 'qrcode_AB.png' im1 = cv2.imread(FILE_PNG_A) im2 = cv2.imread(FILE_PNG_B) im_h = cv2.hconcat([im1, im2]) cv2.imwrite(FILE_PNG_AB, im_h) cv2.imshow('image', im_h) cv2.waitKey(0)・実施結果
File Image qrcode_AB.png ➍QRコード読込み
QRコードの読込みは、OpenCVモジュール、またはpyzbarモジュールのどちらかを使用します。
➍-1「OpenCV」によるQRコード読込み
・インストール
OpenCVバージョン4.3から
detectAndDecodeMultiメソッドがコール可能となり、1枚の画像から複数のQRコードを読み取ることができるようになりました。OpenCVは、バージョン4.3以上をインストールしてください。pip install opencv-python
・プログラム
sample_qr_read_1.pyimport cv2 import numpy as np # ----------------------------------------------------------- # initial # ----------------------------------------------------------- font = cv2.FONT_HERSHEY_SIMPLEX FILE_PNG_AB = 'qrcode_AB.png' # ----------------------------------------------------------- # function_qr_dec # ----------------------------------------------------------- def function_qrdec_cv2(img_bgr): # QRCodeDetectorインスタンス生成 qrd = cv2.QRCodeDetector() # QRコードデコード retval, decoded_info, points, straight_qrcode = qrd.detectAndDecodeMulti(img_bgr) if retval: points = points.astype(np.int) for dec_inf, point in zip(decoded_info, points): if dec_inf == '': continue # QRコード座標取得 x = point[0][0] y = point[0][1] # QRコードデータ print('dec:', dec_inf) img_bgr = cv2.putText(img_bgr, dec_inf, (x, y-6), font, .3, (0, 0, 255), 1, cv2.LINE_AA) # バウンディングボックス img_bgr = cv2.polylines(img_bgr, [point], True, (0, 255, 0), 1, cv2.LINE_AA) cv2.imshow('image', img_bgr) cv2.waitKey(0) # ----------------------------------------------------------- # sample program # ----------------------------------------------------------- img_BGR = cv2.imread(FILE_PNG_AB, cv2.IMREAD_COLOR) function_qrdec_cv2(img_BGR)・実行結果
➍-2「pyzbar」によるQRコード読込み
・インストール
Windows環境以外は、以下のモジュールをインストールしてください。
Macbrew install zbarLinux / GoogleColabsudo apt-get install libzbar0以下のコマンドでpyzbarモジュールをインストールします。
Mac / Linux / GoogleColab / Winpip install pyzbar
・プログラム
sample_qr_read_2.pyimport cv2 from pyzbar.pyzbar import decode, ZBarSymbol # ----------------------------------------------------------- # initial # ----------------------------------------------------------- font = cv2.FONT_HERSHEY_SIMPLEX FILE_PNG_AB = 'qrcode_AB.png' # ----------------------------------------------------------- # function_qr_dec # ----------------------------------------------------------- def function_qrdec_pyzbar(img_bgr): # QRコードデコード value = decode(img_bgr, symbols=[ZBarSymbol.QRCODE]) if value: for qrcode in value: # QRコード座標取得 x, y, w, h = qrcode.rect # QRコードデータ dec_inf = qrcode.data.decode('utf-8') print('dec:', dec_inf) img_bgr = cv2.putText(img_bgr, dec_inf, (x, y - 6), font, .3, (255, 0, 0), 1, cv2.LINE_AA) # バウンディングボックス cv2.rectangle(img_bgr, (x, y), (x + w, y + h), (0, 255, 0), 2) cv2.imshow('image', img_bgr) cv2.waitKey(0) # ----------------------------------------------------------- # sample program # ----------------------------------------------------------- img_BGR = cv2.imread(FILE_PNG_AB, cv2.IMREAD_COLOR) function_qrdec_pyzbar(img_BGR)・実行結果
➎webカメラでQRコード自動認識
最後にwebカメラでQRコードを自動認識するプログラムを載せておきます。今回は「pyzbar」を使用しました。
※こちらのプログラムはwebカメラを用いるため、Google Colabでは動作しません。・プログラム
プログラムは、「
'q'」キー押下でquitします。sample_webcam_qrcode.pyimport cv2 from pyzbar.pyzbar import decode, ZBarSymbol # ----------------------------------------------------------- # 画像キャプチャ # ----------------------------------------------------------- cap = cv2.VideoCapture(0) font = cv2.FONT_HERSHEY_SIMPLEX while cap.isOpened(): ret, frame = cap.read() if ret: # デコード value = decode(frame, symbols=[ZBarSymbol.QRCODE]) if value: for qrcode in value: # QRコード座標 x, y, w, h = qrcode.rect # QRコードデータ dec_inf = qrcode.data.decode('utf-8') frame = cv2.putText(frame, dec_inf, (x, y-6), font, .3, (255, 0, 0), 1, cv2.LINE_AA) # バウンディングボックス cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2) # 画像表示 cv2.imshow('frame', frame) # quit if cv2.waitKey(1) & 0xFF == ord('q'): break # キャプチャリソースリリース cap.release()・実行結果
QRコードを表示したスマホをwebカメラで撮り認識させていますが、うまく認識しています!
➏以上
お疲れ様でした。
モジュールを使うことで、かなり簡単にQRコード作成・読込みツールを作ることができました。





- 投稿日:2021-03-04T18:29:11+09:00
【メモ】Jupyter Notebookでpycodestyle(pep8)を使う方法について
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はJupyterNotebookでpycodestyle(pep8)を使う方法をメモとして残しておきます。
はじめに
pythonスクリプト(.pyファイル)を使用する時は、他人に見せたりする時やアセットとして残す際にpycodestyle(pep8)を使ってチェックするかと思います。
今回はNotebookも同様にチェックできないかと思い調べたら、方法があることを知りましたのでメモとして残しておきます。最初に必要なライブラリーをインストールします。
pip install flake8 pycodestyle_magic次にマジックコマンドを使えるようにします。
# magicコマンドを使えるように読み込む %load_ext pycodestyle_magic最後にチェックしたいコードが書かれたセルにマジックコマンドを最初に入れて実行するだけでスクリプトのチェックができます。
%%pycodestyle # 必要ライブラリのimport import pandas as pd import numpy as npさいごに
最後まで読んで頂き、ありがとうございました。
凄い簡単で驚きました。notebookを使うことが多いので助かります。訂正要望がありましたら、ご連絡頂けますと幸いです。
- 投稿日:2021-03-04T18:08:13+09:00
pyenvとvirtualenvを用いたDjangoの環境構築
初めに
インターンで実際の現場に入って1週間ほどしか経ってないのですが、それだけでもたくさん学ぶことがあったので、アウトプットとして記事を書いてみました。
pyenv,virtualenvを利用した仮想環境の構築
pyenvとは何か
pyenvは使用するpythonのバージョンをプロジェクトごとに選ぶことができるもの。pyenvでは
pip install 3.8.0などでpythonのバージョンを指定することができる。インストールできるバージョンの確認などは下記の記事を参考。
virtualenvとは何か
ローカルに仮想環境を構築することができるもの。その仮想環境の中にライブラリをインストールすることが望ましい。
実際のインストールして仮想環境構築するまでの流れ
pyenvのインストール
git clone https://github.com/yyuu/pyenv.git ~/.pyenvvirtualenvのインストール
git clone https://github.com/yyuu/pyenv-virtualenv.git ~/.pyenv/plugins/pyenv-virtualenv.bash_profileに書き込む(ここら辺はシェルによって変わる。)
export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)".bash_profileに書き込むことで毎回bash起動時に、上記のコードを読み込むことができる。
- virtualenvでの仮想環境作成
pyenv virtualenv 3.8.0 <仮想環境の名前> pyenv local <仮想環境の名前>自分は指定したディレクトリ下で、仮想環境を作りたいのでlocal指定している。localがいいのかglobalがいいのかは個人の好みのような気もするが、詳しいところはあまり知らない。
また、作成した仮想環境は
pyenv versionsで一覧を見ることができる。これで仮想環境構築できたので、
pip install djangoなどして、使いたいライブラリをインストールすればいい。参考記事
pyenv と pyenv-virtualenv で環境構築 - Qiita
pyenvとpyenv-virtualenvの自分流使い方 - Qiita詰まったところ
自分はpythonディストリビューションであるanacondaを元々インストールしていたためなのか、環境構築に詰まった。詳しいところはまだよく分からないが、anacondaをdeactivateなどしてから、環境構築を始める必要がある。
また時間があったら調べて、anacondaを入れてる状態から仮想環境を構築するまでの記事を書きたいと思う。
間違いが見つかり次第、随時更新してきたい
- 投稿日:2021-03-04T18:08:13+09:00
Djangoの環境構築について
初めに
インターンで実際の現場に入って1週間ほどしか経ってないのですが、それだけでもたくさん学ぶことがあったので、アウトプットとして記事を書いてみました。
pyenv,virtualenvを利用した仮想環境の構築
pyenvとは何か
pyenvは使用するpythonのバージョンをプロジェクトごとに選ぶことができるもの。pyenvでは
pip install 3.8.0などでpythonのバージョンを指定することができる。インストールできるバージョンの確認などは下記の記事を参考。
virtualenvとは何か
ローカルに仮想環境を構築することができるもの。その仮想環境の中にライブラリをインストールすることが望ましい。
実際のインストールして仮想環境構築するまでの流れ
pyenvのインストール
git clone https://github.com/yyuu/pyenv.git ~/.pyenvvirtualenvのインストール
git clone https://github.com/yyuu/pyenv-virtualenv.git ~/.pyenv/plugins/pyenv-virtualenv.bash_profileに書き込む(ここら辺はシェルによって変わる。)
export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)".bash_profileに書き込むことで毎回bash起動時に、上記のコードを読み込むことができる。
- virtualenvでの仮想環境作成
pyenv virtualenv 3.8.0 <仮想環境の名前> pyenv local <仮想環境の名前>自分は指定したディレクトリ下で、仮想環境を作りたいのでlocal指定している。localがいいのかglobalがいいのかは個人の好みのような気もするが、詳しいところはあまり知らない。
また、作成した仮想環境は
pyenv versionsで一覧を見ることができる。これで仮想環境構築できたので、
pip install djangoなどして、使いたいライブラリをインストールすればいい。参考記事
pyenv と pyenv-virtualenv で環境構築 - Qiita
pyenvとpyenv-virtualenvの自分流使い方 - Qiita詰まったところ
自分はpythonディストリビューションであるanacondaを元々インストールしていたためなのか、環境構築に詰まった。詳しいところはまだよく分からないが、anacondaをdeactivateなどしてから、環境構築を始める必要がある。
また時間があったら調べて、anacondaを入れてる状態から仮想環境を構築するまでの記事を書きたいと思う。
間違いが見つかり次第、随時更新してきたい
- 投稿日:2021-03-04T17:59:54+09:00
pytrochのmnistがいつの間にかダウンロードできなくなっていていつの間にか解決されていた件
はじめに
pytorch使ってmnistを試そうと思ったらまさかのダウンロードができなかったので,
ちょっと調べてみました.
とりあえず,日本語がなかった気がするので,おそらくそんなに困っている人はいないと思います.対象
- colabを使ってpytrochいじっている
- 2021年になってからmnist使っていなかった人
内容
こんなエラーがでてmnistダウンロードできずに困っていたところ,
pytrochのissueでは既に解決していた,という話./usr/lib/python3.7/urllib/request.py in http_error_default(self, req, fp, code, msg, hdrs) 647 class HTTPDefaultErrorHandler(BaseHandler): 648 def http_error_default(self, req, fp, code, msg, hdrs): --> 649 raise HTTPError(req.full_url, code, msg, hdrs, fp) 650 651 class HTTPRedirectHandler(BaseHandler): HTTPError: HTTP Error 403: Forbiddenバージョン
torch 1.7.1+cu101 torchvision 0.8.2+cu101解決法
これで解決する.(と書いてある)
from six.moves import urllib opener = urllib.request.build_opener() opener.addheaders = [('User-agent', 'Mozilla/5.0')] urllib.request.install_opener(opener)つまり,トータルこんな感じでかけばオッケーです.
import torch import torchvision import torchvision.transforms as transforms from six.moves import urllib opener = urllib.request.build_opener() opener.addheaders = [('User-agent', 'Mozilla/5.0')] urllib.request.install_opener(opener) # 学習の設定 ## エポック epochs = 200 ## バッチサイズ batch_size = 20 # 1. 整形方法を決定 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5,),(0.5,)) ]) # 2. 学習データの読み込み trainset = torchvision.datasets.MNIST(root="./data", train=True, download=True, transform=transform) train_dataloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=1) # 3. テストデータの読み込み testset = torchvision.datasets.MNIST(root="./data", train=False, download=True, transform=transform) test_dataloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=1) print(trainset.data.shape)colab用のスニペットURLおいておきますね.
https://colab.research.google.com/drive/1_APWFBv-yxLDhbbphKU7HEpqG9lvVtRq?usp=sharingおわりに
サクッと書いてみました.
バージョンによって変わると思うので,そのうちオワコン化すると思います.
- 投稿日:2021-03-04T17:28:49+09:00
DatabricksにおけるPythonライブラリ管理
サンプルノートブックはこちらからダウンロードできます。
本記事では、DatabricksにおけるPythonライブラリの形態及び利用方法をご説明します。
Libraries — Databricks Documentation
Databricksにおけるライブラリの形態
Databricksにおいては、以下の3つのライブラリの形態があります。
- ワークスペースライブラリ
- クラスターライブラリ
- ノートブックスコープライブラリ
1. ワークスペースライブラリ
ワークスペースライブラリは、後述するクラスターライブラリをインストールする際にローカルのリポジトリとして動作します。お客様固有のカスタムライブラリを保持したり、環境を標準化する目的で特定バージョンのライブラリを保持するために用いられます。
ノートブックやジョブで使用する前にワークスペースライブラリをインストールしておく必要があります。
Sharedフォルダにあるワークスペースライブラリは、ワークスペースの全ユーザから利用できます。一方、ユーザーフォルダ内のワークスペースライブラリは、そのユーザーからのみ利用可能です。ワークスペースライブラリの作成
Workspace上で、Create > Libraryを選択します。
ダイアログが表示されますので、ライブラリソースに従って設定します。
PyPIの場合、
<library>==<version>という形式で、バージョン番号を指定できます。2. クラスターライブラリ
クラスターライブラリは、クラスター上で動作する全てのノートブックで利用できるライブラリです。クラスターライブラリはPyPIやMavenなどから直接インストールすることもできますし、上述のワークスペースライブラリからインストールすることも可能です。
クラスターライブラリのインストール
クラスターライブラリをインストールするには以下の2つの選択肢があります。
- 既にインストールされているワークスペースライブラリからクラスターにインストールする
- 特定のクラスターにのみライブラリをインストールする
注意 クラスターにライブラリをインストールする際、クラスターにノートブックがアタッチされていると、当該のノートブックからライブラリが参照できない場合があります。その場合には、ノートブックのdetach/attachを行なってください。
ワークスペースライブラリからのインストール
注意 Databricks Runtime 7.2以降では、ワークスペースライブラリからクラスターにインストールされた順にライブラリが処理されます。ライブラリ間に依存関係がある場合には、クラスターにインストールする順番に注意してください。
インストールは、クラスターUIもしくはライブラリUIから実行することができます。
クラスターUIからのインストール
- サイドバーのClustersアイコン
をクリックします。
- クラスター名をクリックします
- Librariesタブをクリックします
- Install Newをクリックします
- Library SourceのボタンからWorkspaceを選択します
- ワークスペースライブラリを選択します
- Installをクリックします
- 全てのクラスターにライブラリをインストールする際には、libraryをクリックし、Install automatically on all clustersチェックボックスをチェックし、Confirmをクリックします
ライブラリUIからのインストール
- ワークスペースライブラリを選択します
- ライブラリをインストールするクラスターを選択します
3. ノートブックスコープライブラリ
ノートブックスコープライブラリは、あなたが実行しているノートブックのセッション内でのみ有効となるライブラリです。ノートブックスコープライブラリは、同じクラスタで動作している他のノートブックには影響を及ぼしません。このライブラリは永続化されず、セッションの都度インストールする必要があります。
ノートブック特有のライブラリが必要な場合に、ノートブックスコープライブラリを使用します。
- Databricks Runtime ML 6.4以降においては、
%pip、%condaのマジックコマンドを用いてインストールすることで、ノートブックスコープライブラリとなります。Databricks Runtime 7.1以降では、%pipを使用します。- ライブラリユーティリティを用いても、ノートブックスコープライブラリをインストールできますが、
%pipと互換性が無いことにご注意ください。Databricksでは、%pipを使用することを推奨しています。- ライブラリユーティリティは、Databricks Runtimeでのみサポートされており、Databricks ML Runtimeではサポートされていません。
ノートブックスコープライブラリの要件
マジックコマンドによるライブラリのインストールは、Databricks Runtime 7.1、Databricks Runtime 7.1 ML以降でのみサポートされています。
ドライバーノードに関する留意点
ノートブックスコープライブラリのインストールは、クラスタ上の全ワーカーノードにライブラリをインストールするため、ドライバーノードにおいて多くのトラフィックが発生する場合があります。10以上のノードを持つクラスターを構成する際には、ドライバーノードが以下のスペックを満たすことをお勧めしています。
- 100CPUノードのクラスターの場合、
i3.8xlargeをお使いください- 10GPUノードのクラスターの場合、
p2.xlargeをお使いください
%pip、%condaの使い分けAnaconda | Understanding Conda and Pip
Databricks Runtimeでは、
%pipを使ってノートブックスコープライブラリをインストールできます。また、Databricks Runtime MLでは、%pipに加えて%condaを使用することもできます。Databricksでは、特別な理由がない限り%pipを使用することを推奨しています。注意
- ノートブックの一番最初に%pip、%condaを記述してください。%pip、%condaが実行された後に、ノートブックの内部状態がリセットされます。変数や関数を宣言した後に%pip、%condaを実行するとそれらは消去されてしまいます。
- 一つのノートブックで%pip、%condaを混在させなくてはいけない場合には、競合を避けるために以下のリンク先をご一読ください。Notebook-scoped Python libraries — Databricks Documentation
%pipによるライブラリのインストール%pip install matplotlib
%pipによるライブラリのアンインストール%pip uninstall -y matplotlibインストールされているライブラリの一覧取得
%pip freeze > /dbfs/tmp/requirements.txt%fs head /tmp/requirements.txtrequirementsファイルによるライブラリのインストール
# インストールして問題がないかご確認ください %pip install -r /dbfs/tmp/requirements.txt
%condaによるライブラリのインストール注意 Anaconda, Inc.は2020年9月に利用規約をアップデートしています。新たな利用規約によりcommercial licenseが必要になる場合があります。こちらで詳細を確認してください。この変更を受けて、Databricks Runtime ML 8.0において、Condaパッケージマネージャのデフォルトチャネル設定を削除しています。
%condaでライブラリをインストールする際には、利用規約に適合していることを確認の上、チャネルを指定してください。%conda install boto3 -c conda-forge
%condaによるライブラリのアンインストール%conda uninstall boto3
%condaによるライブラリの一覧表示%conda list環境の保存及び再利用
%conda env export -f /dbfs/tmp/myenv.yml%conda env update -f /dbfs/tmp/myenv.ymlPythonにおけるライブラリインストールの選択肢
%condaは%pipと同じように動作しますが、%condaにおけるURLの指定は--channelで行います。
Pythonパッケージソース `%pip`によるノートブックスコープライブラリ ライブラリユーティリティによるノートブックスコープライブラリ クラスターライブラリ PyPI `%pip install`を使用 `dbutils.library.installPyPI`を使用 sourceにPyPIを指定 プライベートPyPI `--index-url`オプションとともに`%pip install`を使用 repoオプションとともに`dbutils.library.installPyPI`を使用 未サポート GitHubのようなVCS パッケージ名にリポジトリURLを指定して`%pip install`を使用 未サポート パッケージ名にリポジトリURLを指定してsourceにPyPIを指定 プライベートVCS パッケージ名にリポジトリURL(Basic認証含む)を指定して`%pip install`を使用 未サポート 未サポート DBFS `%pip install`を使用 `dbutils.library.install(dbfs_path)`を使用 sourceにDBFS/S3を指定 libifyによるカスタムライブラリの利用
ローカルでカスタムライブラリを構築している場合、カスタムライブラリをDatabricksに移行したいというケースが想定されます。その際の手順としては以下の二つがあります。
- wheelを作成して、ワークスペースライブラリとしてインストール
Python でパッケージを開発して配布する標準的な方法 - Qiita- libify · PyPIをインストールし、ノートブック間のimportを実現する
ここでは、2の方法をデモで説明します。importされるノートブックは
my_lib/my_module_1となります。注意 libifyで呼び出す・呼び出されるノートブック名に日本語を含めることはできません。
# 事前にlibifyをクラスターライブラリとしてインストールしてください import libify # caller mod1 = libify.importer(globals(), 'my_lib/my_module_1') mod1.test()


- 投稿日:2021-03-04T16:55:50+09:00
【LINEBOT】LINEの音声メッセージをAmazon Transcribeで文字起こし
はじめに
AWSについて調べていた際、音声を文字起こしできるサービス(Amazon Transcribe)に出会ったので試しに使ってみることに...
LINEの音声メッセージを文字起こしできたら便利かもと思ったので、試しにLINEBOTに導入してみます~前提
- windows(macでもおそらくできますが今回はwindows)
- Heroku、flaskを用いておうむ返しボットが作れていること。おうむ返しボットはソフトウェア開発キット(https://github.com/line/line-bot-sdk-python) を参考にすると簡単に作れます。
仕組み
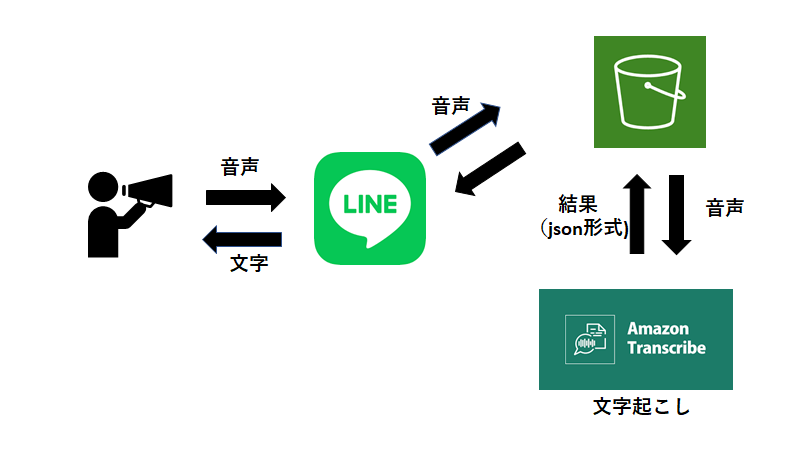
大まかな流れは図の通りです。
ユーザーが音声を送信。BOTが音声データをAmazonS3のバケットに保存。その音声データをAmazonTranscribeが文字起こし。結果を取得してBOTが返信。環境変数の設定と確認
設定方法
$heroku config:set <環境変数名>=value -a <アプリ名>確認
$heroku config -a <アプリ名> AWS_ACCESS_KEY_ID: <AWS IAMから取得> AWS_SECRET_ACCESS_KEY: <AWS IAMから取得> S3_BUCKET: <使用するバケットの名前> YOUR_CHANNEL_ACCESS_TOKEN: <LINE developersのサイトから取得> YOUR_CHANNEL_SECRET: <LINE developersのサイトから取得>以上が設定されていれば動くはず。
コード(基本はおうむ返しボットと同じです)
説明の前にメインとなるコードを書いておきます。
main.pyfrom typing import Text from flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, TemplateSendMessage, CarouselTemplate, CarouselColumn, URITemplateAction, AudioMessage, AudioSendMessage ) import os, json, boto3 import urllib app = Flask(__name__) #環境変数取得 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) aws_s3_bucket = os.environ['S3_BUCKET'] #テスト用 @app.route("/") def hello_world(): return "hello world!" @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' import time @handler.add(MessageEvent, message=AudioMessage) def handle_message(event): message_id = event.message.id message_content = line_bot_api.get_message_content(message_id) with open(f"/app/static/audio/{message_id}.m4a", 'wb') as fd: fd.write(message_content.content) original_content_url=f'https://linebot-textprocessing.herokuapp.com/static/audio/{message_id}.m4a' #音声の保存 wav file_name = f"{message_id}.wav" urllib.request.urlretrieve(original_content_url,file_name) # S3へ音声をアップロードする s3_resource = boto3.resource('s3') s3_resource.Bucket(aws_s3_bucket).upload_file(file_name, file_name) #音声の認識 transcribe = boto3.client('transcribe', region_name="ap-northeast-1") job_name = f"linewikipediabot-{message_id}.wav" job_uri = f"https://linewikipediabot.s3.amazonaws.com/{message_id}.wav" transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='mp4', LanguageCode='ja-JP', OutputBucketName = aws_s3_bucket ) while True: status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(3) print("DONE") #jsonファイルの取得 s3_resource.Bucket(aws_s3_bucket).download_file(f"{job_name}.json", f"{job_name}.json") json_open = open(f"{job_name}.json", "r") json_load = json.load(json_open) print(json.dumps(json_load, ensure_ascii=False, indent=4)) #音声認識結果 replymessage = json_load["results"]["transcripts"][0]["transcript"] print(replymessage) replymessage1 = replymessage.replace(" ", "") print(replymessage1) line_bot_api.reply_message( event.reply_token, TextSendMessage(text=replymessage1)) if __name__ == "__main__": # app.run() port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)コードの解説(メインの「音声メッセージ→文字」の流れのみ)
- message_idについて
- メッセージにはぞれぞれ番号がついているため、識別するために取得。
- message_content
- 音声を取得(以下のコード)
- ファイル名にmessage_idを組み込み識別。
- リファレンスを参考にしました。
message_content = line_bot_api.get_message_content(message_id) with open(f"/app/static/audio/{message_id}.m4a", 'wb') as fd: fd.write(message_content.content) original_content_url=f'https://linebot-textprocessing.herokuapp.com/static/audio/{message_id}.m4a' #音声の保存 wav file_name = f"{message_id}.wav" urllib.request.urlretrieve(original_content_url,file_name)
- バケットへアップロード
s3_resource = boto3.resource('s3') s3_resource.Bucket(aws_s3_bucket).upload_file(file_name, file_name
- 音声を認識してくれるようにお願いを出す
- 自分の場合、region_nameを指定しないと動作しませんでした。
- while文は文字起こしが完了しているかどうかを判別。("Not ready yet..." → まだ)結果が出る前にコードが進行してしまうと当然エラーになる。
- 文字起こしの結果は音声を格納したバケットと同じバケットに格納されます(環境変数で設定したもの)
- print("DONE")が終了の合図
- AWSの開発者ガイドが参考になります
transcribe = boto3.client('transcribe', region_name="ap-northeast-1") job_name = f"linewikipediabot-{message_id}.wav" job_uri = f"https://linewikipediabot.s3.amazonaws.com/{message_id}.wav" transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='mp4', LanguageCode='ja-JP', OutputBucketName = aws_s3_bucket #出力先を音声と同じバケットに設定 ) while True: status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(3) print("DONE")
- 文字起こし結果の取得
- 結果はjson形式で返されます。(AWSの開発者ガイド)
- バケットからいったんダウンロード
s3_resource.Bucket(aws_s3_bucket).download_file(f"{job_name}.json", f"{job_name}.json") json_open = open(f"{job_name}.json", "r") json_load = json.load(json_open)
- 文字の取得
- replymessageままだと単語と単語の間にスペースが開いてしまいます。
- スペースを取り除いた形をreplymessage1とします。(名前はなんでもOK)
- print文で結果を見てみるのもいいかもしれません
replymessage = json_load["results"]["transcripts"][0]["transcript"] #jsonファイルから特定の項目を取得 replymessage1 = replymessage.replace(" ", "") #スペースを除く処理
- 結果をラインで返信
line_bot_api.reply_message( event.reply_token, TextSendMessage(text=replymessage1))その他のファイル
requirements.txt(pip freezeで確認し、ご自身の使用しているバージョンを書いてください)
boto3==1.17.17 botocore==1.20.17 certifi==2020.12.5 chardet==4.0.0 click==7.1.2 Flask==1.1.2 future==0.18.2 idna==2.10 itsdangerous==1.1.0 Jinja2==2.11.3 jmespath==0.10.0 line-bot-sdk==1.18.0 MarkupSafe==1.1.1 psycopg2==2.8.6 python-dateutil==2.8.1 requests==2.25.1 s3transfer==0.3.4 six==1.15.0 urllib3==1.26.3 Werkzeug==1.0.1Procfile
web: python main.pyruntime.txt(herokuにpythonのバージョンを認識させる)
python-3.9.2GitHubにデプロイして終了(herokuアプリとGitHubを連携済みを想定)
応用
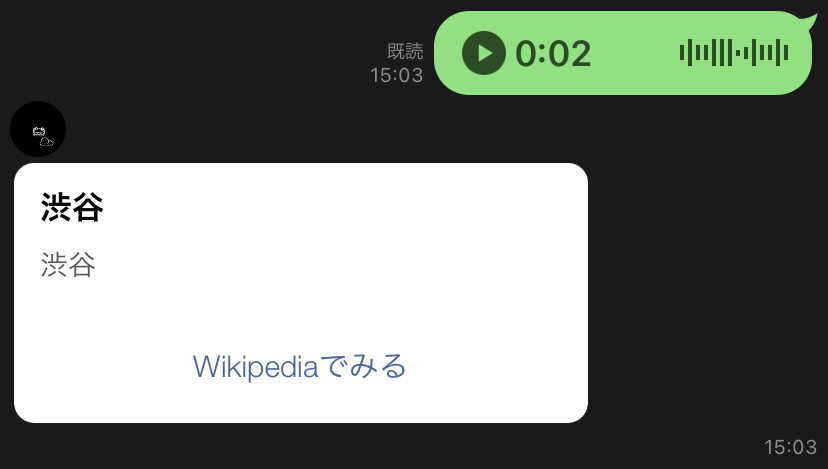
音声認識結果をWikipediaで調べ、結果を返してくれたら面白いなと思ったので機能を追加してみます。(以下のコード)
from typing import Text from flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, TemplateSendMessage, CarouselTemplate, CarouselColumn, URITemplateAction, AudioMessage, AudioSendMessage ) import os, json, boto3 import urllib app = Flask(__name__) #環境変数取得 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) aws_s3_bucket = os.environ['S3_BUCKET'] #テスト用 @app.route("/") def hello_world(): return "hello world!" @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' import time @handler.add(MessageEvent, message=AudioMessage) def handle_message(event): message_id = event.message.id message_content = line_bot_api.get_message_content(message_id) with open(f"/app/static/audio/{message_id}.m4a", 'wb') as fd: fd.write(message_content.content) original_content_url=f'https://linebot-textprocessing.herokuapp.com/static/audio/{message_id}.m4a' #音声の保存 wav file_name = f"{message_id}.wav" urllib.request.urlretrieve(original_content_url,file_name) # S3へ音声をアップロードする s3_resource = boto3.resource('s3') s3_resource.Bucket(aws_s3_bucket).upload_file(file_name, file_name) #音声の認識 transcribe = boto3.client('transcribe', region_name="ap-northeast-1") job_name = f"linewikipediabot-{message_id}.wav" job_uri = f"https://linewikipediabot.s3.amazonaws.com/{message_id}.wav" transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='mp4', LanguageCode='ja-JP', OutputBucketName = aws_s3_bucket ) while True: status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(3) print("DONE") #jsonファイルの取得 s3_resource.Bucket(aws_s3_bucket).download_file(f"{job_name}.json", f"{job_name}.json") json_open = open(f"{job_name}.json", "r") json_load = json.load(json_open) print(json.dumps(json_load, ensure_ascii=False, indent=4)) #音声認識結果 replymessage = json_load["results"]["transcripts"][0]["transcript"] replymessage1 = replymessage.replace(" ", "") # 以下追加のコード uri = "https://ja.wikipedia.org/wiki/" + replymessage column = { "title": replymessage, "text": replymessage, "action": { "label": "Wikipediaでみる", "uri": uri } } columns = [ CarouselColumn( title=column["title"], text=column["text"], actions=[ URITemplateAction( label=column["action"]["label"], uri=column["action"]["uri"], ) ] ) ] messages = TemplateSendMessage(alt_text=replymessage, template=CarouselTemplate(columns=columns)) line_bot_api.reply_message(event.reply_token, messages = messages) if __name__ == "__main__": # app.run() port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)応用の解説
追加したのは検索結果をカルーセルに格納し、返信するというシンプルなものです。
まとめ
やってみてなかなか面白いと感じました。精度もかなり高く、いろいろな応用先が思いつきそうですね~。
ただ、あまり長い音声(文章)を送るとherokuがタイムアウトしてしまい、エラーが発生しました(音声の処理に時間がかかってしまうため)。どうやらherokuは30秒以下の処理のみ対応しているとのこと。一応解決策はあるようですが、今回はパスします。気になった人は以下のリンクを見てみるといいかもしれません。というかherokuの代わりにAmazonを使ったほうがよかったのかもしれません(笑)
ここまで見てくださりありがとうございました。PythonもQiitaも不慣れなので読みにくかったかもしれません。。。もし、なにか疑問や改善点などあればぜひコメントしてください~
- 投稿日:2021-03-04T16:39:17+09:00
【Python】画像を見ながらトリミング【画像処理】
実行の様子
pythonで画像を見ながらトリミングするコード書きました! pic.twitter.com/NDLoUkls4g
— Natz (@Natz_tec) March 4, 2021OpenCVの練習のために作りました。備忘録も兼ねてアップします。
マウスイベントは覚える事が多くて大変です。以下のコードが最低限必要な雛形になるかと思います。
def mouseEventName(event,x,y,flags,param): if event == cv2.EVENT_MOUSEMOVE: hogehoge windowName = "test window" cv2.namedWindow(windowName) cv2.setMouseCallback(windowName,mouseEventName) cv2.imshow(windowName,testImage) cv2.waitKey() cv2.destroyAllWindows()領域選択を何度でも行えるようにしたり、切り取り領域の外を暗くしたり、と工夫したので個人的には使いやすい仕上がりになりました。
以下全ソース
import cv2 import numpy as np def draw_rectangle(event,x,y,flags,param): global cnt,windowName,testIm,beforeX,beforeY,xPos1,xPos2,yPos1,yPos2 if event == cv2.EVENT_MOUSEMOVE: if (cnt >0)&(cnt%2==1): img_tmp = testIm.copy()*0.5 cv2.line(img_tmp,(beforeX,beforeY),(x,beforeY),(0,0,255),thickness = 2) cv2.line(img_tmp,(beforeX,beforeY),(beforeX,y),(0,0,255),thickness = 2) cv2.line(img_tmp,(beforeX,y),(x,y),(0,0,255),thickness = 2) cv2.line(img_tmp,(x,beforeY),(x,y),(0,0,255),thickness = 2) img_tmp[min(y,beforeY):max(y,beforeY),min(x,beforeX):max(x,beforeX),:] = testIm[min(y,beforeY):max(y,beforeY),min(x,beforeX):max(x,beforeX),:] cv2.imshow(windowName,img_tmp) if event == cv2.EVENT_LBUTTONDOWN: cnt += 1 if (cnt >1) & (cnt%2==0): [xPos1,xPos2,yPos1,yPos2] = [min(x,beforeX),max(x,beforeX),min(y,beforeY),max(y,beforeY)] #xPosは(x,beforeX)を、yPosは(y,beforeY)を小さい順に並べ替えて保存する print("If you select good area, please push [Y] key\n",[xPos1,yPos1],[xPos2,yPos2]) (beforeX,beforeY) = (x,y) #座標の更新 def image_filter(img): kernel = np.array([[0,-1,0],[-1,4,-1],[0,-1,0]]) img2 = cv2.filter2D(img,-1,kernel) return img2 def main(): global cnt,windowName,testIm,beforeX,beforeY,xPos1,xPos2,yPos1,yPos2 beforeX = 0 #保存すべきX座標 beforeY = 0 #保存すべきY座標 cnt = 0 #画像内でのクリック回数 testIm = cv2.imread(r'C:\Users\takum\OneDrive\Desktop\img_l.jpg') testIm = testIm/255 windowName = "Select window" windowName2 = "Selected image" cv2.namedWindow(windowName) cv2.setMouseCallback(windowName,draw_rectangle) cv2.imshow(windowName,testIm) key = cv2.waitKey() if key == 27: cv2.destroyAllWindows() elif key ==121: print(key) cv2.destroyAllWindows() cv2.namedWindow(windowName2) cv2.imshow(windowName2,testIm[yPos1:yPos2,xPos1:xPos2,:]) print("Save -> push [s] key") key = cv2.waitKey() if key ==115: cv2.imwrite(r'C:\Users\takum\OneDrive\Desktop\img_l2.bmp',testIm[yPos1:yPos2,xPos1:xPos2,:]*255) print("saved as img_l2.jpg") if __name__=="__main__": main()
- 投稿日:2021-03-04T16:09:12+09:00
「0から作るDeepLearning」の6章を写経した時のエラー原因1
こんにちは!
今日のエラー原因を書きます。
使用した本:「0から作るDeepLearning」
1「optimizer_compare_mnist.py」の写経について
・38行目のfor文とグラフ描写のためのインテンドが合っていなかった。
正しい例optimizer_compare_mnist.pyfor i in range(max_iterations): batch_mask = np.random.choice(train_size, batch_size) --------------------------------------------------- plt.legend() plt.show()間違い
original_optimizer_compare_mnist.pyfor i in range(max_iterations): batch_mask = np.random.choice(train_size, batch_size) --------------------------------------------------- plt.legend() plt.show()エラー対策
インテンドを正しい例に直したら無事実行できました。
所感
今回は全体を見落としていたことが原因でした。
後、今までのエラー原因は意外とケアレスミスが多いと思った。
(灯台下暗し)
- 投稿日:2021-03-04T16:02:55+09:00
VSCodeでPython・Django + JupyterLabでPython (Windows)
はじめに
つまみ食いしていたら、環境が混沌としてきたので、シンプルなものを再構築しました。
環境
- Windows 10 20H2
VS Code で Python
- 公式ドキュメント通りにPythonとVSCodeを導入します。
- Visual Studio Code を使用して Python 初心者向けの開発環境をセットアップする (Microsoft)
- とても分かり易くかかれています。
- LinuxやOSX向けの情報もあります。
- 大まかな流れ
- Python
- Python のダウンロード ページからPython 8 インストーラをダウンロードします。
- インストーラを含まないZIPもあるので注意しましょう。
- インストールします。
- パスを通す設定はしましょう。
- 他はデフォルト設定で問題ありません。
- インストール後、パスが通っていれば、
py --versionでバージョンが表示できます。- VS Code
- Visual Studio Code のダウンロード ページから、インストーラををダウンロードします。
- インストールします。
- MS純正のPython拡張機能を導入します。
- デフォルトインタプリタを設定します。
VS Code で Django
プロジェクトを置くベースフォルダを仮に
D:\development\pythonとします。pip の更新とモジュールの確認
D:\development\python\>python -m pip install --upgrade pip ~ 略 ~ D:\development\python\>pip list Package Version ---------- ------- pip 21.0.1 setuptools 52.0.0virtualenv の導入
virtualenv とともに依存モジュールが導入されます。
D:\development\python\>pip install virtualenv ~ 略 ~ D:\development\python\django>pip list Package Version ---------- ------- appdirs 1.4.4 distlib 0.3.1 filelock 3.0.12 pip 21.0.1 setuptools 49.2.1 six 1.15.0 virtualenv 20.4.2django 用仮想環境の構築、アクティベート
djangoフォルダに仮想環境を作り、アクティベートして、カレントディレクトリを移動します。D:\development\python\>virtualenv django ~ 略 ~ D:\development\python>django\scripts\activate (django) D:\development\python>cd djangodjango 導入、プロジェクト作成
django を導入した上で、
djangoフォルダ内にpracticeプロジェクトを作ります。(django) D:\development\python\django>pip install django ~ 略 ~ (django) D:\development\python\django>django-admin startproject practice . (django) D:\development\python\django>dir /b .gitignore Lib manage.py practice pyvenv.cfg ScriptsVS Code 接続
接続するフォルダからVS Codeを起動します。
(django) D:\development\python\django>code .
Ctrl+Shift+Pを押して、「Pythonインタプリタを選択」します。
環境の相違で同じ名前が二つありますが、パスからして青いフォーカスのあたっている方ですね。
選択すると、左下に選択結果が表示されます。
左端のメニューで「実行」を選び、「launch.json ファイルを作成」をクリックします。
pythonを選んで、
次にdjangoを選びます。
開いたlaunch.jsonをそっと閉じて、左上の実行ボタンを押すとサーバが起動します。
下部のターミナルに、以下のような感じで表示されます。System check identified no issues (0 silenced). You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. March 02, 2021 - 23:28:58 Django version 3.1.7, using settings 'practice.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CTRL-BREAK. █
- マイグレーションについて警告されていますが、チュートリアル中に「取り敢えず無視」と書かれているので放置します。
書かれているとおり、
http://localhost:8000/へアクセスしてロケットが飛べば成功です。
普段使いのショートカット
VS Code を開く
code.bat@echo off d: cd d:\development\python\django code .上記で起動していた状態が再現されます。
ターミナルを開く
以下のバッチファイルを、
D:\development\python\django\practiceに作ります。startup.bat@echo off echo Python Django Terminal for Practice D:\development\python\django\scripts\activateこのファイルのショートカットを作って、「リンク先」を以下のように、
C:\Windows\System32\cmd.exe /K D:\development\python\django\practice\startup.bat「作業フォルダー」を以下のように設定します。
D:\development\python\django\practiceショートカットを開くと、以下のようなDOS窓が開きます。
Python Django Terminal for Practice (django) D:\development\python\django\practice>JupyterLab で Python
JupyterLab 用仮想環境の構築、アクティベート、JupyterLab の導入
JupyterLabフォルダに仮想環境を作り、アクティベートします。
カレントディレクトリを移動して、JupyterLab を導入します。D:\development\python\>virtualenv jupyterlab ~ 略 ~ D:\development\python>jupyterlab\scripts\activate (jupyterlab) D:\development\python>cd jupyterlab (jupyterlab) D:\development\python\jupyterlab>pip install jupyterlab ~ 略 ~普段使いのショートカット
JupyterLab を開く
D:\development\python\jupyterlab\Scripts\jupyter-lab.exeこのファイルのショートカットを作っておきます。
ターミナルを開く
以下のバッチファイルを、
D:\development\python\jupyterlabに作ります。startup.bat@echo off echo Python Terminal for JupyterLab D:\development\python\jupyterlab\scripts\activateこのファイルのショートカットを作って、「リンク先」を以下のように、
C:\Windows\System32\cmd.exe /K D:\development\python\jupyterlab\startup.bat「作業フォルダー」を以下のように設定します。
D:\development\python\jupyterlabショートカットを開くと、以下のようなDOS窓が開きます。
Python Terminal for JupyterLab (jupyterlab) D:\development\python\jupyterlab>参考記事
以下の記事を参考にさせていただきました。
どうもありがとうございました。

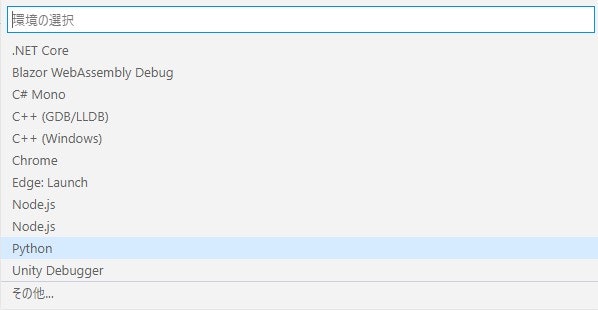
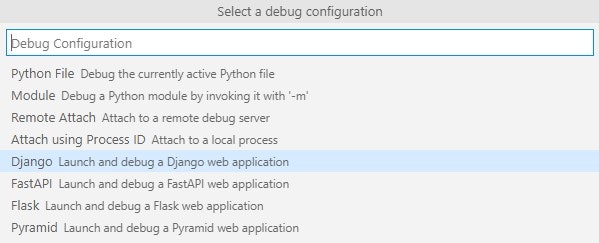
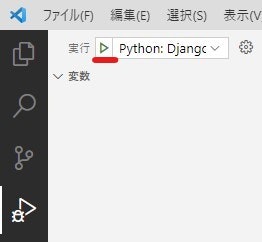
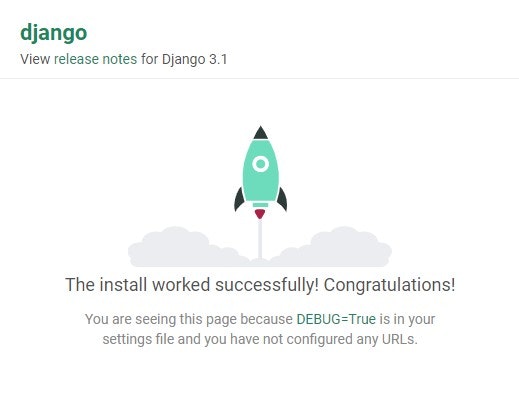
- 投稿日:2021-03-04T16:02:55+09:00
VSCodeでPython・Django (Windows)
はじめに
つまみ食いしていたら、環境が混沌としてきたので、シンプルなものを再構築しました。
環境
- Windows 10 20H2
VS Code で Python
- 公式ドキュメント通りにPythonとVSCodeを導入します。
- Visual Studio Code を使用して Python 初心者向けの開発環境をセットアップする (Microsoft)
- とても分かり易くかかれています。
- LinuxやOSX向けの情報もあります。
- 大まかな流れ
- Python
- Python のダウンロード ページからPython 8 インストーラをダウンロードします。
- インストーラを含まないZIPもあるので注意しましょう。
- インストールします。
- パスを通す設定はしましょう。
- 他はデフォルト設定で問題ありません。
- インストール後、パスが通っていれば、
py --versionでバージョンが表示できます。- VS Code
- Visual Studio Code のダウンロード ページから、インストーラををダウンロードします。
- インストールします。
- MS純正のPython拡張機能を導入します。
- デフォルトインタプリタを設定します。
VS Code で Django
プロジェクトを置くベースフォルダを仮に
D:\development\pythonとします。pip の更新とモジュールの確認
D:\development\python\>python -m pip install --upgrade pip ~ 略 ~ D:\development\python\>pip list Package Version ---------- ------- pip 21.0.1 setuptools 52.0.0virtualenv の導入
virtualenv とともに依存モジュールが導入されます。
D:\development\python\>pip install virtualenv ~ 略 ~ D:\development\python\django>pip list Package Version ---------- ------- appdirs 1.4.4 distlib 0.3.1 filelock 3.0.12 pip 21.0.1 setuptools 49.2.1 six 1.15.0 virtualenv 20.4.2django 用仮想環境の構築、アクティベート
djangoフォルダに仮想環境を作り、アクティベートして、カレントディレクトリを移動します。D:\development\python\>virtualenv django ~ 略 ~ D:\development\python>django\scripts\activate (django) D:\development\python>cd djangodjango 導入、プロジェクト作成
djangoを導入した上で、
djangoフォルダ内にpracticeプロジェクトを作ります。(django) D:\development\python\django>pip install django ~ 略 ~ (django) D:\development\python\django>django-admin startproject practice . (django) D:\development\python\django>dir /b .gitignore Lib manage.py practice pyvenv.cfg ScriptsVS Code 接続
接続するフォルダからVS Codeを起動します。
(django) D:\development\python\django>code .
Ctrl+Shift+Pを押して、「Pythonインタプリタを選択」します。
環境の相違で同じ名前が二つありますが、パスからして青いフォーカスのあたっている方ですね。
選択すると、左下に選択結果が表示されます。
左端のメニューで「実行」を選び、「launch.json ファイルを作成」をクリックします。
pythonを選んで、
次にdjangoを選びます。
開いたlaunch.jsonをそっと閉じて、左上の実行ボタンを押すとサーバが起動します。
下部のターミナルに、以下のような感じで表示されます。System check identified no issues (0 silenced). You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. March 02, 2021 - 23:28:58 Django version 3.1.7, using settings 'practice.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CTRL-BREAK. █
- マイグレーションについて警告されていますが、チュートリアル中に「取り敢えず無視」と書かれているので放置します。
書かれているとおり、
http://localhost:8000/へアクセスしてロケットが飛べば成功です。
参考記事
以下の記事を参考にさせていただきました。
どうもありがとうございました。
- 投稿日:2021-03-04T16:01:17+09:00
Python でパスワード作成
Chromeで「パスワード生成」がでない
Webサービスによってはlogin画面の作りが凝りすぎていてChromeなどのパスワード作成機能が働かないことがあります。そういうときのコードです。
方針
- argv でパスワードの長さ(plen) とスペシャルキャラクタ(spchr)を指定できるようにしたい。
- 大文字小文字数字を混ぜて上記のspchrを入れさせたい。
- stringからimportすればいいか
- そうすると、random.sampleで必要な文字数をとってspchrをくっつけて random.shuffleすればよいかな
mkpasswd.py#!/usr/bin/env python3 from sys import argv from string import ascii_letters, digits from random import shuffle, sample def main(): print("Usage %s <length> <spchars>\n$ %s 12 '-,' # length is 12, generated passwd contains '-' and ','"%(argv[0], argv[0])) plen, spchr = (12, '') # デフォルト値を設定 try: plen = int(argv[1]) # argv[1]が数字なら置換 except: pass try: spchr = argv[2] # argv[2]があれば置換 except: pass lentotal = len(ascii_letters+digits+spchr) if plen > lentotal: plen = lentotal # plenが大きすぎるときは削る if plen <= len(spchr): plen = len(spchr) + 1 # plenが小さすぎるなら足す print("Generate length:%d, contains:[%s]"%(plen, spchr)) # 変更される可能性があるので表示してあげる pwd = sample(ascii_letters+digits, plen-len(spchr))+list(spchr) shuffle(pwd) # shuffleはインプレース置換 print(''.join(pwd)) # printしておしまい return None if __name__ == "__main__": main()念の為ご注意
我ながら雑なコードですね。なお、spchrは全て出力されるパスワードで使われます。
- 投稿日:2021-03-04T15:52:16+09:00
Rからpythonコード実行できるreticulateパッケージが便利
背景
RstudioでPythonを使うで述べたように、Rstudio上で簡単にPythonを実行することができます。これだけでも便利なのですが、RとPythonの連携、例えば「Pythonのライブラリで求めた結果をRオブジェトとして格納し、ggplot2で作図する」ことができれば素敵です。reticulateはこれを可能にするRのパッケージです。
参考:How to Run Python from R Studio
環境
PC: MacBook Pro 2020
OS: macOS Catalina (10.15.5)
R : 4.0.2 (2020-06-22)
RStudio: 1.4.1103
reticulate: 1.18方法・結果
1. reticulateパッケージのダウンロード、読み込み
通常のRパッケージと同様にinstall.packages()とlibrary()を使います。
install.packages("reticulate") library(reticulate)2. pythonライブラリのインポート
reticulate::import()を使ってPythonライブラリを読み込みます。変数に格納することで名前をつけることもできます。
np <- reticulate::import("numpy") #「import numpy as np」と同義 plt <- reticulate::import("matplotlib.pyplot")3. 読み込んだライブラリの使用
pythonでは「.」でメソッドを使用しますが、Rで読み込むと「$」でメソッドを使用できます。ここではnumpyを用いて乱数を生成しています。引数の型を明示しないとエラーになることがあるので注意が必要です。
下記の例ではint型を入力すべき部分がfloat型になっているとエラーが出ています。そのため、as.integer()でint型であることを明示します(Rの場合は数字の後に「L」をつけるとint型として認識するので「100L」などでも大丈夫です)。
参考:reticulate does not work with R-Data frame and fit() function from Python#乱数を生成、メソッドを使用するには「$」、引数の型を明示 x <- np$random$rand(as.integer(100)) y <- np$random$rand(as.integer(100)) # 引数の型を明示しないとエラーになる np$random$rand(100) # py_call_impl(callable, dots$args, dots$keywords) でエラー: # TypeError: 'float' object cannot be interpreted as an integer4. 散布図を描画
matplotlibで散布図を描画し、Rのpng関数で保存します。
png("scatter_py.png") plt$scatter(x, y) plt$title("Title") plt$xlabel("x") plt$ylabel("y") plt$show() dev.off()
5. ggplot2で描画する
作図はRのggplot2を使うことが多いので、numpyで生成した乱数をggplot2で描画してみます。
d <- data.frame(x = x, y = y) png("scatter_r.png") ggplot(data = d, aes(x = x, y = y)) + geom_point() dev.off()
6. pythonコードの読み込み
自作のpythonコードを読み込むこともできます。実行すると「Hello R!」と表示するhelloR.pyを作成しました。
def helloR(): print("hello R!")source_python()でhelloR関数を読み込みます。
reticulate::source_python("helloR.py") helloR() # hello R!補足
使用するpythonのインタプリタは導入した方法によってuse_condaenv()、use_virtualenv()、use_python()で指定します。
Rstudio1.4以上の場合はTools -> Global OptionsのPythonで選択したインタプリタがデフォルトで選択されているようです。