- 投稿日:2021-03-04T23:56:50+09:00
[AWS] Cloud9で、Python3.8をインストールする方法
Cloud9のPython
2021年3月時点では、Cloud9(というかAmazon Linux2)に標準で入っているPythonは、3.79です。
Admin:~/environment $ python -V Python 3.7.9SAMでLamdaを書くぞ
SAMでLamdaのコードを書く際に、Runtimeとして、Python3.8を選択できます。
が、インストールされているPythonのバージョンがあっていないため、酷くお叱りを受けます。Admin:~/environment/sam-app $ sam build Building codeuri: hello_world/ runtime: python3.8 metadata: {} functions: ['HelloWorldFunction'] Build Failed Error: PythonPipBuilder:Validation - Binary validation failed for python, searched for python in following locations : ['/usr/bin/python'] which did not satisfy constraints for runtime: python3.8. Do you have python for runtime: python3.8 on your PATH?Cloud9でPython3.8インストール
セオリー通りに、インストールしようとしますが、残念ながらうまくいきません。
Admin:~/environment/sam-app $ sudo yum install python38 Loaded plugins: extras_suggestions, langpacks, priorities, update-motd 229 packages excluded due to repository priority protections No package python38 available. Error: Nothing to do python38 is available in Amazon Linux Extra topic "python3.8" To use, run # sudo amazon-linux-extras install python3.8 Learn more at https://aws.amazon.com/amazon-linux-2/faqs/#Amazon_Linux_Extrasそんなパッケージないと叱られます。
が、ちゃんとヒントが書いてあるので、その通りコマンドを叩きます。Admin:~/environment/sam-app $ sudo amazon-linux-extras install python3.8 Installing python38 Loaded plugins: extras_suggestions, langpacks, priorities, update-motd Cleaning repos: amzn2-core amzn2extra-docker amzn2extra-epel amzn2extra-lamp-mariadb10.2-php7.2 amzn2extra-python3.8 epel hashicorp 33 metadata files removed 11 sqlite files removed 0 metadata files removed Loaded plugins: extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 amzn2extra-docker | 3.0 kB 00:00:00 amzn2extra-epel | 3.0 kB 00:00:00 amzn2extra-lamp-mariadb10.2-php7.2 | 3.0 kB 00:00:00 amzn2extra-python3.8 | 3.0 kB 00:00:00 epel/x86_64/metalink | 5.1 kB 00:00:00 epel | 4.7 kB 00:00:00 hashicorp | 1.4 kB 00:00:00 (1/15): amzn2-core/2/x86_64/group_gz | 2.5 kB 00:00:00 (2/15): amzn2-core/2/x86_64/updateinfo | 350 kB 00:00:00 (3/15): amzn2extra-epel/2/x86_64/primary_db | 1.8 kB 00:00:00 (4/15): amzn2extra-lamp-mariadb10.2-php7.2/2/x86_64/updateinfo | 76 B 00:00:00 (5/15): amzn2extra-lamp-mariadb10.2-php7.2/2/x86_64/primary_db | 464 kB 00:00:00 (6/15): amzn2extra-python3.8/2/x86_64/updateinfo | 76 B 00:00:00 (7/15): amzn2extra-docker/2/x86_64/updateinfo | 76 B 00:00:00 (8/15): amzn2extra-python3.8/2/x86_64/primary_db | 36 kB 00:00:00 (9/15): amzn2extra-epel/2/x86_64/updateinfo | 76 B 00:00:00 (10/15): amzn2extra-docker/2/x86_64/primary_db | 75 kB 00:00:00 (11/15): epel/x86_64/group_gz | 95 kB 00:00:00 (12/15): epel/x86_64/updateinfo | 1.0 MB 00:00:00 (13/15): epel/x86_64/primary_db | 6.9 MB 00:00:00 (14/15): amzn2-core/2/x86_64/primary_db | 50 MB 00:00:00 (15/15): hashicorp/2/x86_64/primary | 37 kB 00:00:00 hashicorp 249/249 229 packages excluded due to repository priority protections Resolving Dependencies --> Running transaction check ---> Package python38.x86_64 0:3.8.5-1.amzn2.0.2 will be installed --> Processing Dependency: python38-libs(x86-64) = 3.8.5-1.amzn2.0.2 for package: python38-3.8.5-1.amzn2.0.2.x86_64 --> Processing Dependency: python38-setuptools for package: python38-3.8.5-1.amzn2.0.2.x86_64 --> Processing Dependency: python38-pip for package: python38-3.8.5-1.amzn2.0.2.x86_64 --> Processing Dependency: libpython3.8.so.1.0()(64bit) for package: python38-3.8.5-1.amzn2.0.2.x86_64 --> Running transaction check ---> Package python38-libs.x86_64 0:3.8.5-1.amzn2.0.2 will be installed ---> Package python38-pip.noarch 0:9.0.3-2.amzn2.0.1 will be installed ---> Package python38-setuptools.noarch 0:38.4.0-4.amzn2.0.1 will be installed --> Finished Dependency Resolution Dependencies Resolved ============================================================================================================================================================= Package Arch Version Repository Size ============================================================================================================================================================= Installing: python38 x86_64 3.8.5-1.amzn2.0.2 amzn2extra-python3.8 69 k Installing for dependencies: python38-libs x86_64 3.8.5-1.amzn2.0.2 amzn2extra-python3.8 9.4 M python38-pip noarch 9.0.3-2.amzn2.0.1 amzn2extra-python3.8 1.9 M python38-setuptools noarch 38.4.0-4.amzn2.0.1 amzn2extra-python3.8 619 k Transaction Summary ============================================================================================================================================================= Install 1 Package (+3 Dependent packages) Total download size: 12 M Installed size: 51 M Is this ok [y/d/N]: y Downloading packages: (1/4): python38-3.8.5-1.amzn2.0.2.x86_64.rpm | 69 kB 00:00:00 (2/4): python38-pip-9.0.3-2.amzn2.0.1.noarch.rpm | 1.9 MB 00:00:00 (3/4): python38-libs-3.8.5-1.amzn2.0.2.x86_64.rpm | 9.4 MB 00:00:00 (4/4): python38-setuptools-38.4.0-4.amzn2.0.1.noarch.rpm | 619 kB 00:00:00 ------------------------------------------------------------------------------------------------------------------------------------------------------------- Total 47 MB/s | 12 MB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction Installing : python38-pip-9.0.3-2.amzn2.0.1.noarch 1/4 Installing : python38-setuptools-38.4.0-4.amzn2.0.1.noarch 2/4 Installing : python38-3.8.5-1.amzn2.0.2.x86_64 3/4 Installing : python38-libs-3.8.5-1.amzn2.0.2.x86_64 4/4 Verifying : python38-libs-3.8.5-1.amzn2.0.2.x86_64 1/4 Verifying : python38-3.8.5-1.amzn2.0.2.x86_64 2/4 Verifying : python38-pip-9.0.3-2.amzn2.0.1.noarch 3/4 Verifying : python38-setuptools-38.4.0-4.amzn2.0.1.noarch 4/4 Installed: python38.x86_64 0:3.8.5-1.amzn2.0.2 Dependency Installed: python38-libs.x86_64 0:3.8.5-1.amzn2.0.2 python38-pip.noarch 0:9.0.3-2.amzn2.0.1 python38-setuptools.noarch 0:38.4.0-4.amzn2.0.1 Complete! 0 ansible2 available \ [ =2.4.2 =2.4.6 =2.8 =stable ] 2 httpd_modules available [ =1.0 =stable ] 3 memcached1.5 available \ [ =1.5.1 =1.5.16 =1.5.17 ] 5 postgresql9.6 available \ [ =9.6.6 =9.6.8 =stable ] 6 postgresql10 available [ =10 =stable ] 8 redis4.0 available \ [ =4.0.5 =4.0.10 =stable ] 9 R3.4 available [ =3.4.3 =stable ] 10 rust1 available \ [ =1.22.1 =1.26.0 =1.26.1 =1.27.2 =1.31.0 =1.38.0 =stable ] 11 vim available [ =8.0 =stable ] 15 php7.2 available \ [ =7.2.0 =7.2.4 =7.2.5 =7.2.8 =7.2.11 =7.2.13 =7.2.14 =7.2.16 =7.2.17 =7.2.19 =7.2.21 =7.2.22 =7.2.23 =7.2.24 =7.2.26 =stable ] 17 lamp-mariadb10.2-php7.2=latest enabled \ [ =10.2.10_7.2.0 =10.2.10_7.2.4 =10.2.10_7.2.5 =10.2.10_7.2.8 =10.2.10_7.2.11 =10.2.10_7.2.13 =10.2.10_7.2.14 =10.2.10_7.2.16 =10.2.10_7.2.17 =10.2.10_7.2.19 =10.2.10_7.2.22 =10.2.10_7.2.23 =10.2.10_7.2.24 =stable ] 18 libreoffice available \ [ =5.0.6.2_15 =5.3.6.1 =stable ] 19 gimp available [ =2.8.22 ] 20 docker=latest enabled \ [ =17.12.1 =18.03.1 =18.06.1 =18.09.9 =stable ] 21 mate-desktop1.x available \ [ =1.19.0 =1.20.0 =stable ] 22 GraphicsMagick1.3 available \ [ =1.3.29 =1.3.32 =1.3.34 =stable ] 23 tomcat8.5 available \ [ =8.5.31 =8.5.32 =8.5.38 =8.5.40 =8.5.42 =8.5.50 =stable ] 24 epel=latest enabled [ =7.11 =stable ] 25 testing available [ =1.0 =stable ] 26 ecs available [ =stable ] 27 corretto8 available \ [ =1.8.0_192 =1.8.0_202 =1.8.0_212 =1.8.0_222 =1.8.0_232 =1.8.0_242 =stable ] 28 firecracker available [ =0.11 =stable ] 29 golang1.11 available \ [ =1.11.3 =1.11.11 =1.11.13 =stable ] 30 squid4 available [ =4 =stable ] _ php7.3 available \ [ =7.3.2 =7.3.3 =7.3.4 =7.3.6 =7.3.8 =7.3.9 =7.3.10 =7.3.11 =7.3.13 =stable ] 32 lustre2.10 available \ [ =2.10.5 =2.10.8 =stable ] 33 java-openjdk11 available [ =11 =stable ] 34 lynis available [ =stable ] 35 kernel-ng available [ =stable ] 36 BCC available [ =0.x =stable ] 37 mono available [ =5.x =stable ] 38 nginx1 available [ =stable ] 39 ruby2.6 available [ =2.6 =stable ] 40 mock available [ =stable ] 41 postgresql11 available [ =11 =stable ] _ php7.4 available [ =stable ] 43 livepatch available [ =stable ] 44 python3.8=latest enabled [ =stable ] 45 haproxy2 available [ =stable ] 46 collectd available [ =stable ] 47 aws-nitro-enclaves-cli available [ =stable ] 48 R4 available [ =stable ] 49 kernel-5.4 available [ =stable ] 50 selinux-ng available [ =stable ] _ php8.0 available [ =stable ]無事成功しました。
Admin:~/environment/sam-app $ sam build Building codeuri: hello_world/ runtime: python3.8 metadata: {} functions: ['HelloWorldFunction'] Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guidedコンパイルもばっちりです。
まとめ
ただのメモ書きレベルですいません!
なお、その他の言語やパッケージは、2021年3月現在は、こんな感じです。
Python2系
Admin:~/environment/sam-app $ python2 -V Python 2.7.18Java
Admin:~/environment/sam-app $ java --version openjdk 11.0.10 2021-01-19 LTS OpenJDK Runtime Environment Corretto-11.0.10.9.1 (build 11.0.10+9-LTS) OpenJDK 64-Bit Server VM Corretto-11.0.10.9.1 (build 11.0.10+9-LTS, mixed mode)PHP
Admin:~/environment/sam-app $ php -v PHP 7.2.24 (cli) (built: Oct 31 2019 18:27:08) ( NTS ) Copyright (c) 1997-2018 The PHP Group Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend TechnologiesRuby
Admin:~/environment/sam-app $ ruby -v ruby 2.6.3p62 (2019-04-16 revision 67580) [x86_64-linux]Node.js
Admin:~/environment/sam-app $ node -v v10.24.0Go
Admin:~ $ go version go version go1.15.8 linux/amd64補足
2021年3月現在、LambdaではPython3.9はサポートされてませんが、そもそもPython3.9自体、yumでのインストールに対応していないので、どうしてもCloud9(Amazon Linux2)にインストールしたい場合は、自身でコンパイルするしか方法がなさそうです。
- 投稿日:2021-03-04T21:40:29+09:00
amazon web services 基礎からのネットワーク&サーバー構築 ひっかかったとこ
amazon web services 基礎からのネットワーク&サーバー構築 備忘録
AWS学習の良書「amazon web services 基礎からのネットワーク&サーバー構築」の内容について引っかかったとこまとめ
ssh -i my-key.pem ....
を実行するときは「my-key.pem」が置いてあるディレクトリで実効する
ssh -i my-key.pem "ec2-user"@....
のec2-userはAWS版sudoコマンド。
管理者権限で実行できる。
- 投稿日:2021-03-04T21:34:51+09:00
AWS STS とは
勉強前イメージ
名前からはわからん!
調査
AWS STS とは
Security Token Service の略で
一時的な認証情報を発行してくれるサービスで、
IDを定義せずともAWSのリソースにアクセスできるようになり、
IDフェデレーションが可能になります。
- IDフェデレーション とは?
独自のID管理システムを持つ複数のセキュリティドメイン間で、それぞれのユーザIDをリンクさせ、
ドメインで認証を受けたエンドユーザーは、他方のドメインでもログインしないでそのリソースにアクセスすることが出来ます。IAM との違い
セキュリティ認証情報 という点でIAMというサービスもあるが、
以下の点で違いがある
- 使用期間が短い
- セキュリティ認証情報は保存されることなく、動的に生成される
勉強後イメージ
必ずしもユーザを作成しないといけない、というわけではないのか・・・
管理としては楽になる・・・のかな?参考
- 投稿日:2021-03-04T20:36:47+09:00
[419エラー]ECSでセッションが保存されていない問題
概要
Laravel sanctumを利用してセッションベースのログイン認証を実装しており、ローカルではログインできていたのにAWS環境を使ったら419エラーが出てしまいました。
あまり情報もなく(というかAWS知識がなくてググり力が足りない)、解決するのに手間取ってしまったのでメモします。
AWS環境
ALB経由でECS(EC2)につなげている環境
419エラーとは
LaravelのPostする際のCSRF漏れエラーです。
解決策
今回はEC2インスタンスにつけているターゲットグループのスティッキーセッションが無効になっているのが原因でした。
ターゲットグループ>group detailsタブのAttributesのEditをクリック
sticknessをdisabledからenabledに変更(画像は変更後です)。まとめ
この項目をenabledにしないとセッションが保存されないみたい?なので、今後も注意したいです。

- 投稿日:2021-03-04T20:06:16+09:00
40 代おっさん EC2 に Apache を起動する
本記事について
本記事は AWS 初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
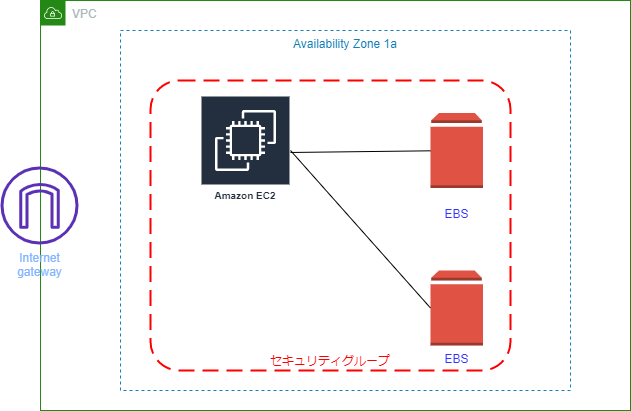
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS 最終作成図
構築手順
❶ EC2 インスタンス作成と同時に Apache インストール
1. EC2 インスタンス作成と同時に Apache インストール
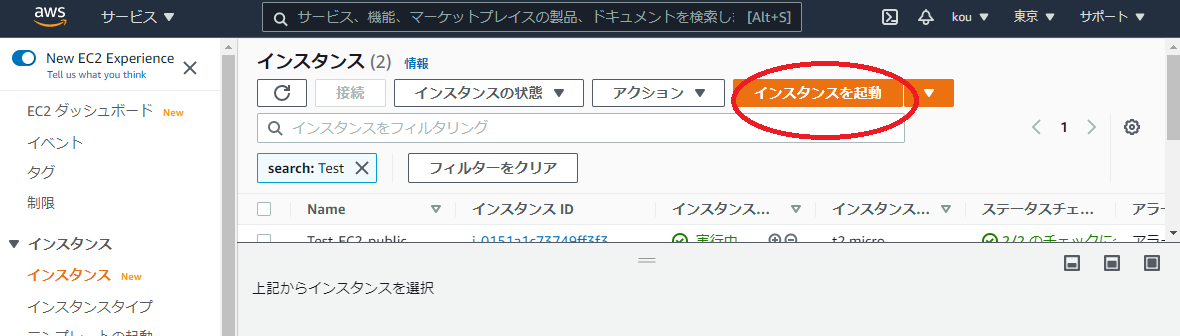
サービスより EC2 を選択
インスタンスを起動をクリック(赤枠)
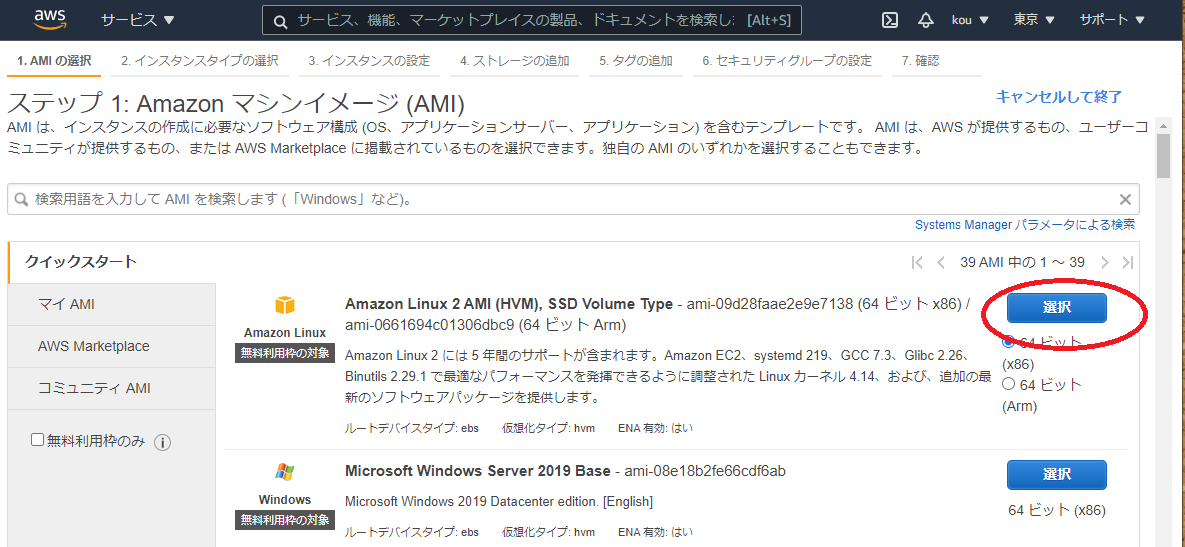
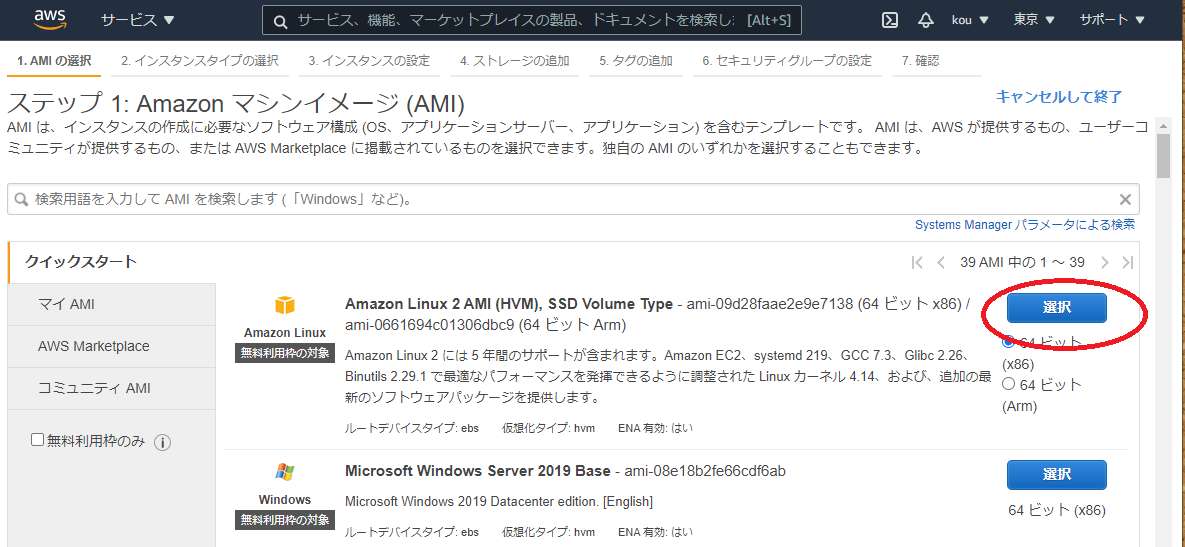
Amazon Linux 2 AMI (HVM), SSD Volume Type を選択(赤枠)
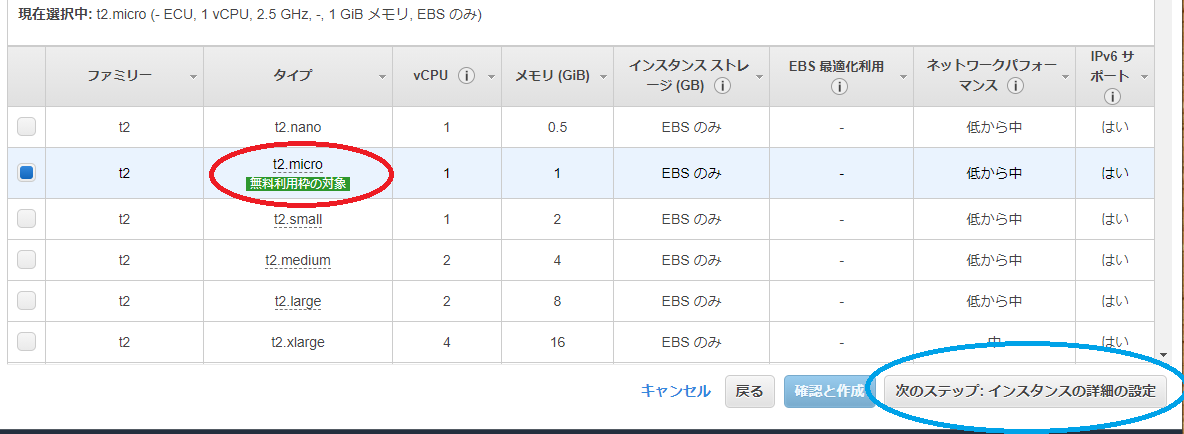
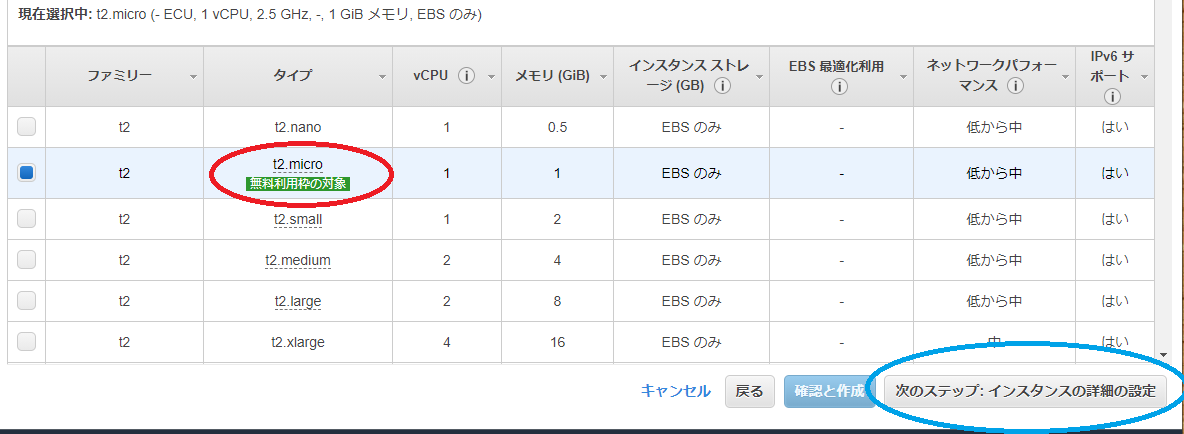
インスタンスタイプは t2.micro を選択(赤枠)
選択したら 次のステップ:インスタンスの詳細の設定をクリック
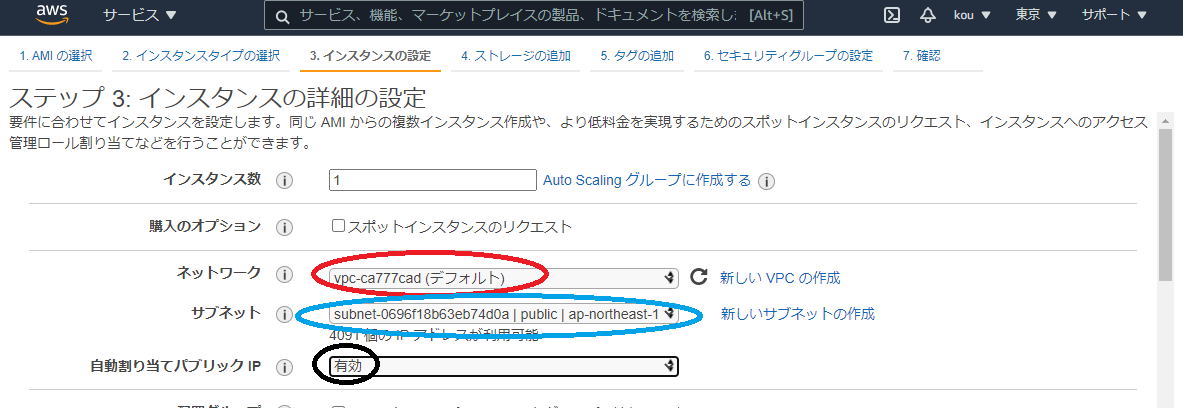
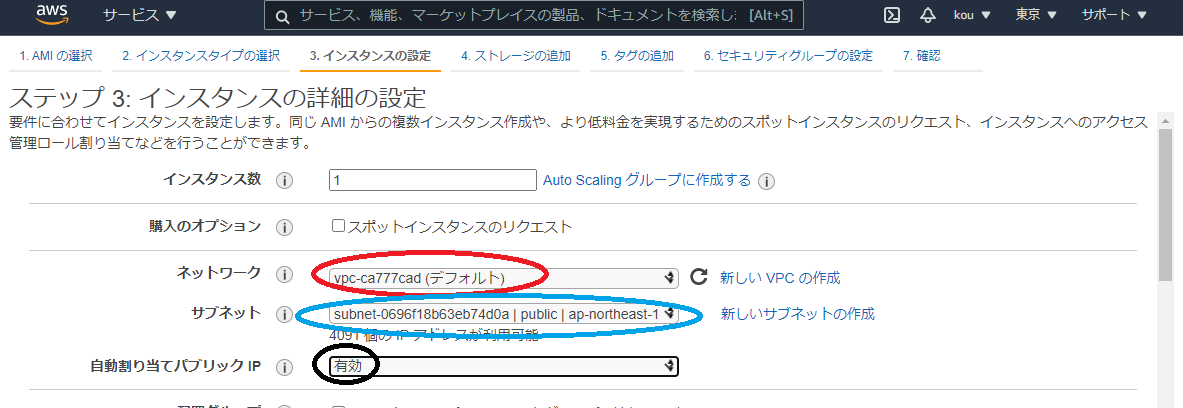
ネットワークは今回はデフォルトのものを使用(赤枠)
サブネットもそれに付随しているもの(青枠)
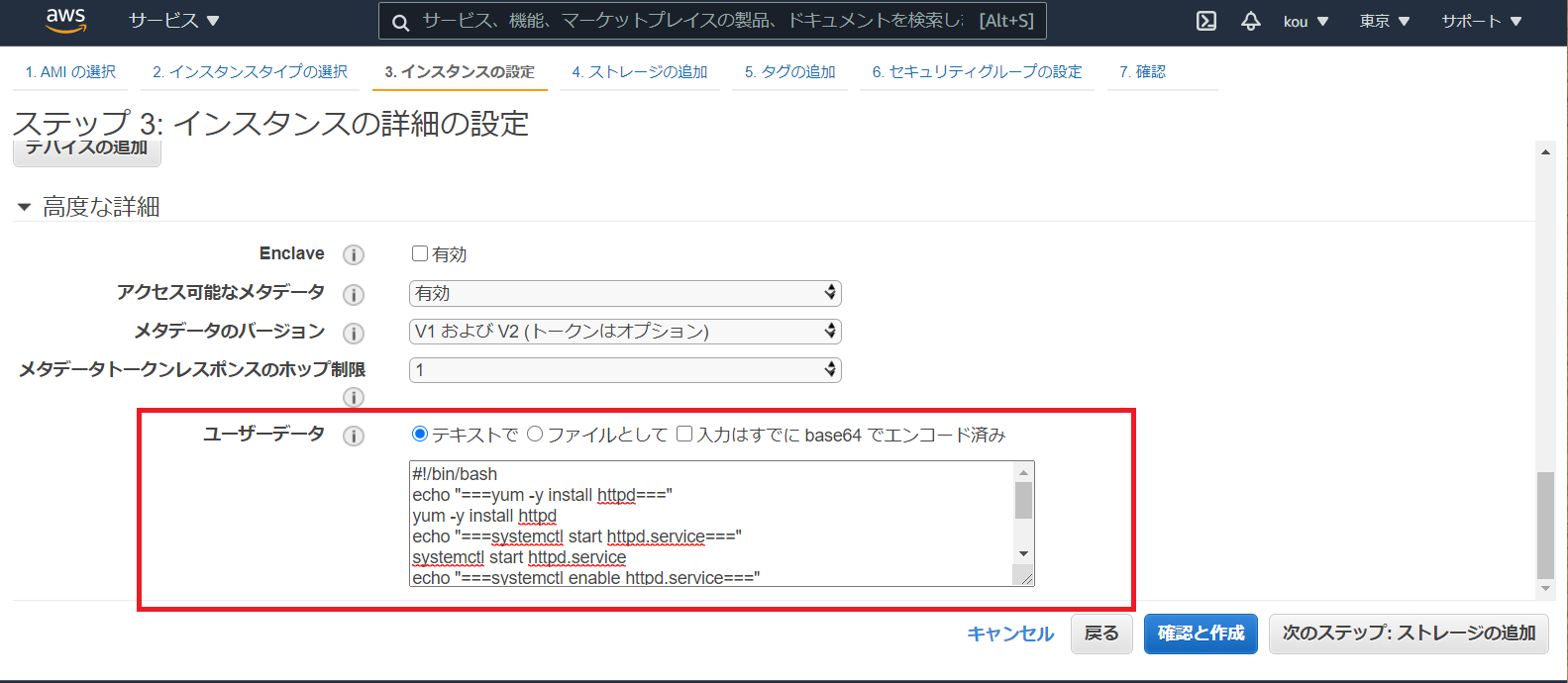
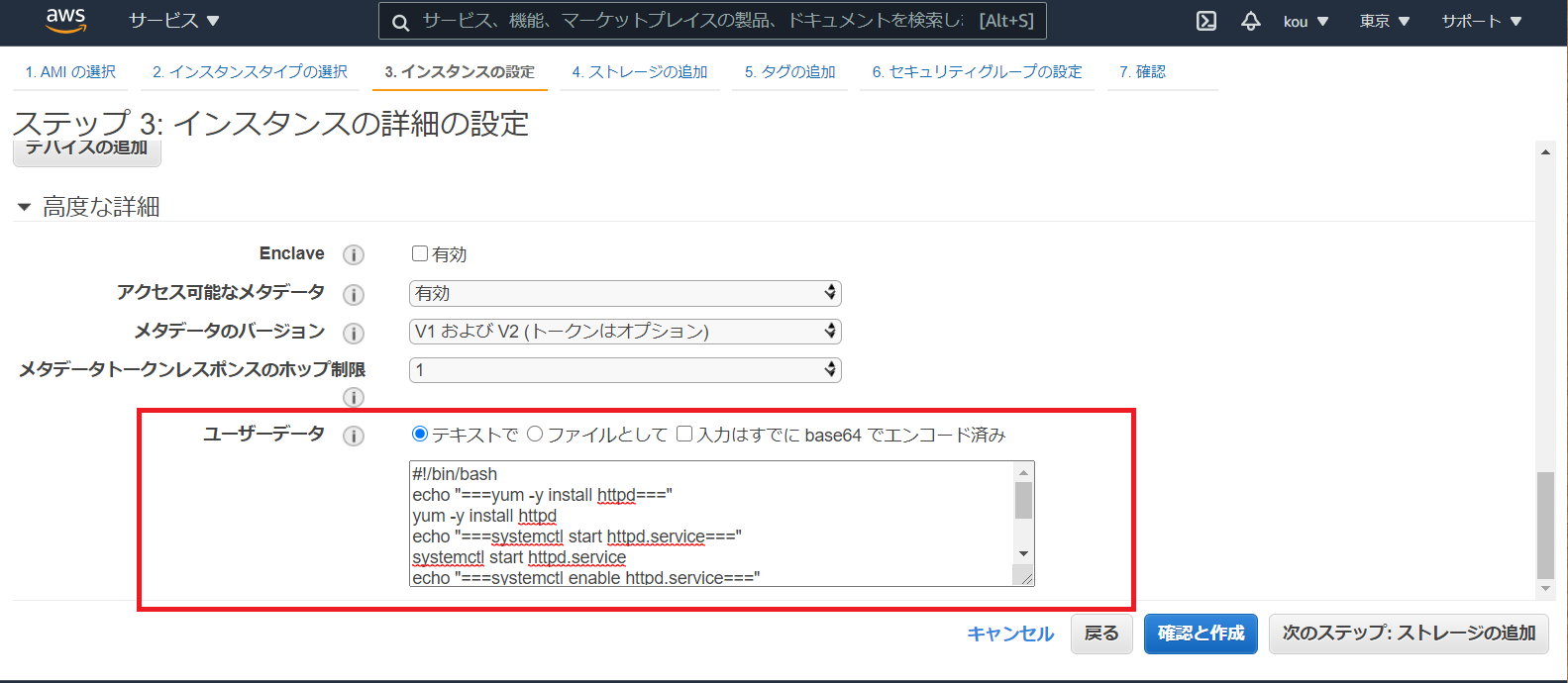
自動割り当てパブリック IP はネットワークに繋げるため有効(黒枠)#!/bin/bash #シェバン echo "===yum -y install httpd===" yum -y install httpd #Apacheインストール echo "===systemctl start httpd.service===" systemctl start httpd.service #Apacheサービスをスタート echo "===systemctl enable httpd.service===" systemctl enable httpd.service #再起動後もApacheサービスをスタート echo "echo $(curl http://169.254.169.254/latest/meta-data/instance-id) >> /tmp/test" echo $(curl http://169.254.169.254/latest/meta-data/instance-id) >> /tmp/test #インスタンスIDを/tmp/testに書き出す上記をユーザーデータに書き込む
それが ↓ になります
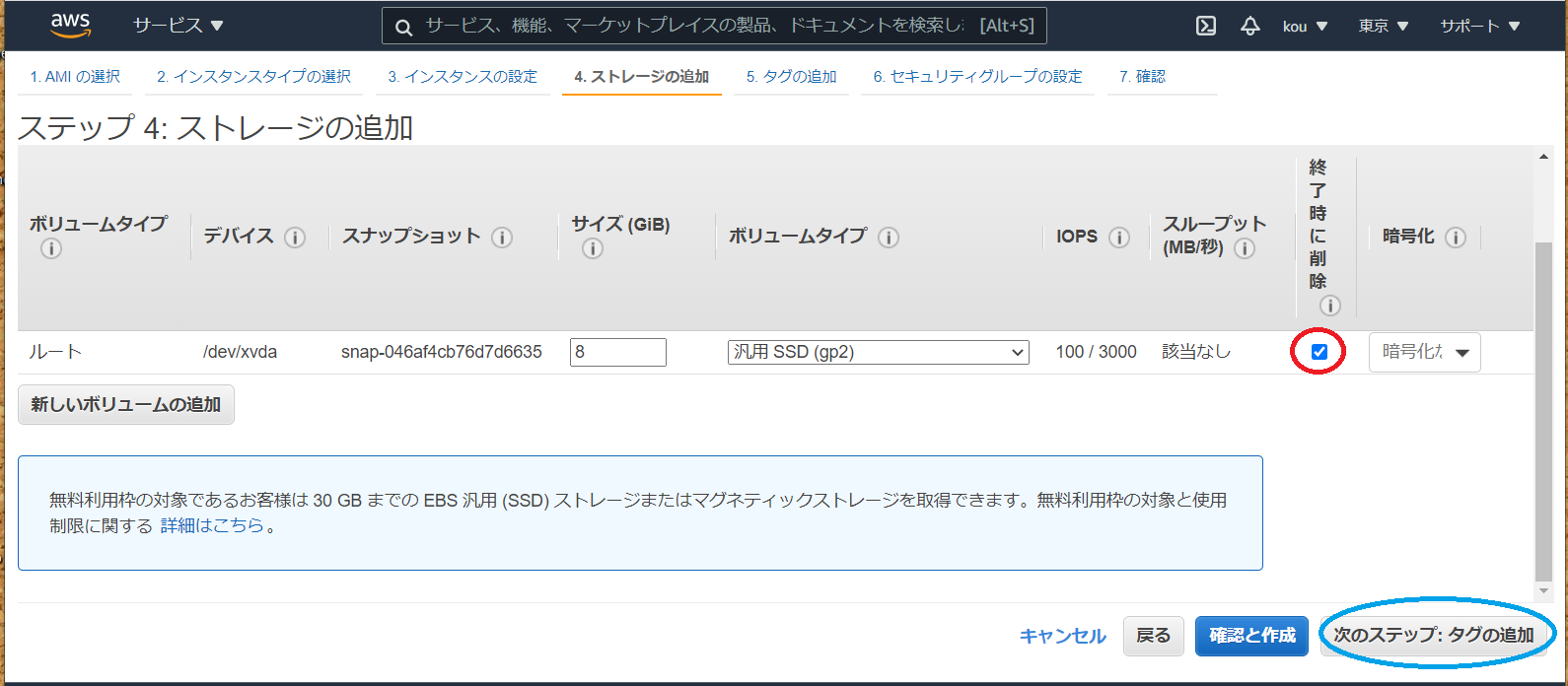
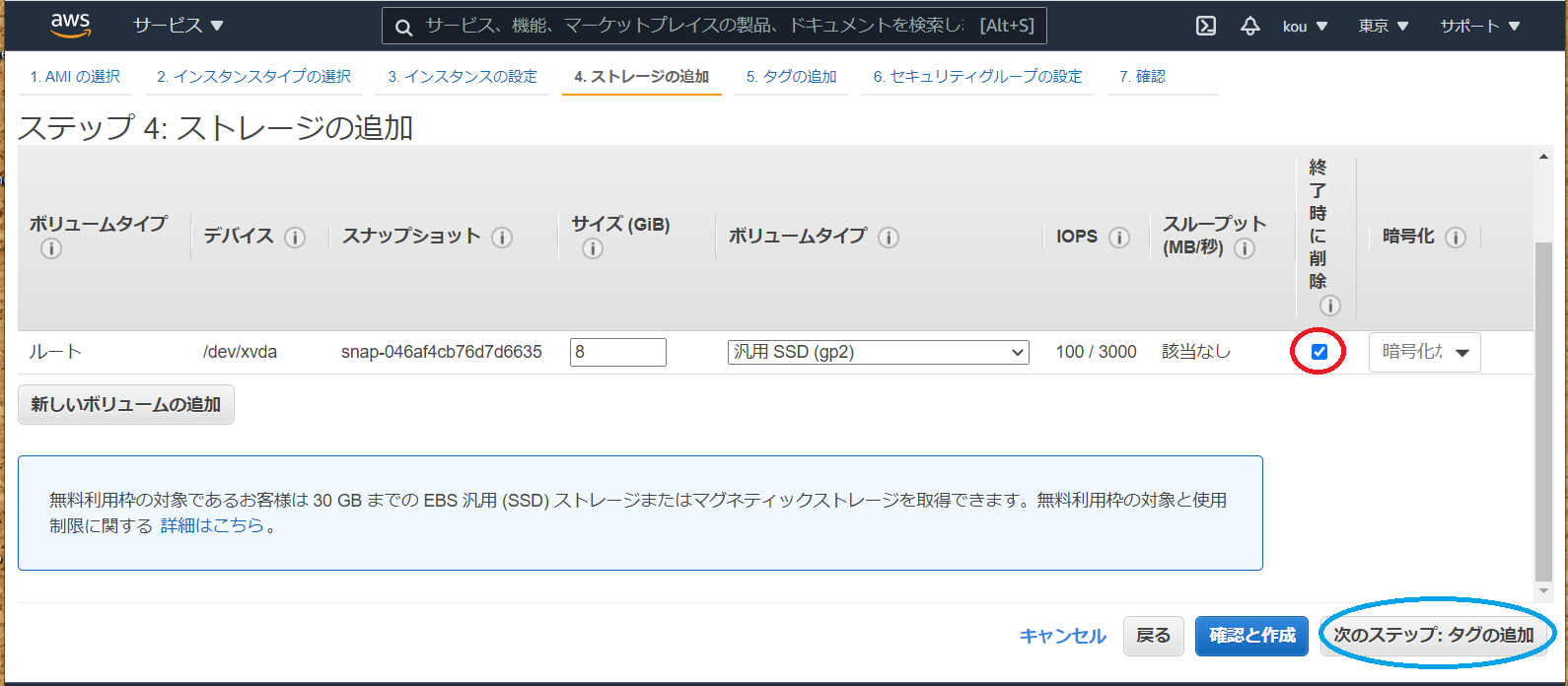
終わったら 次のステップ:ストレージの追加
実はこちらで EBS の追加できますが、今回は後からアタッチする形で勉強したいと思います
また(赤枠)のところにチェックが入っていないとインスタンス終了時に削除しない形になるため無駄な課金発生しますので注意です
終わったら(青枠)次のステップ:追加をクリック
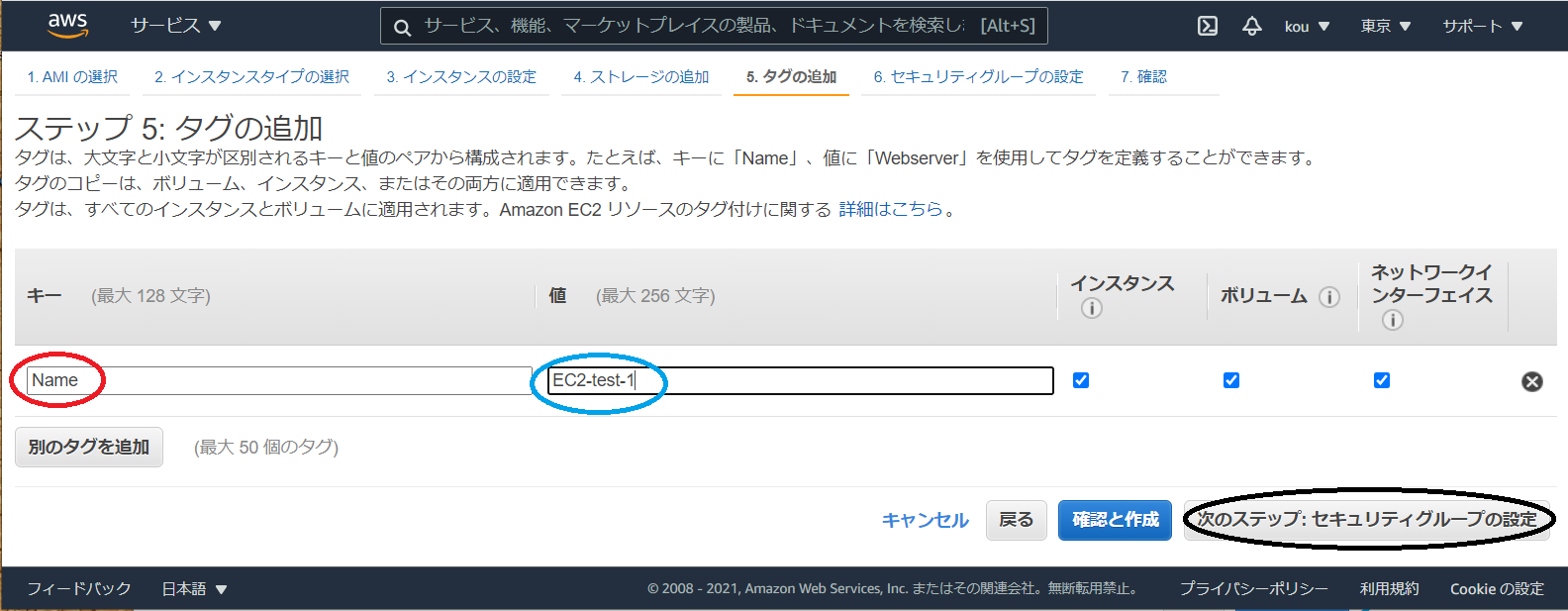
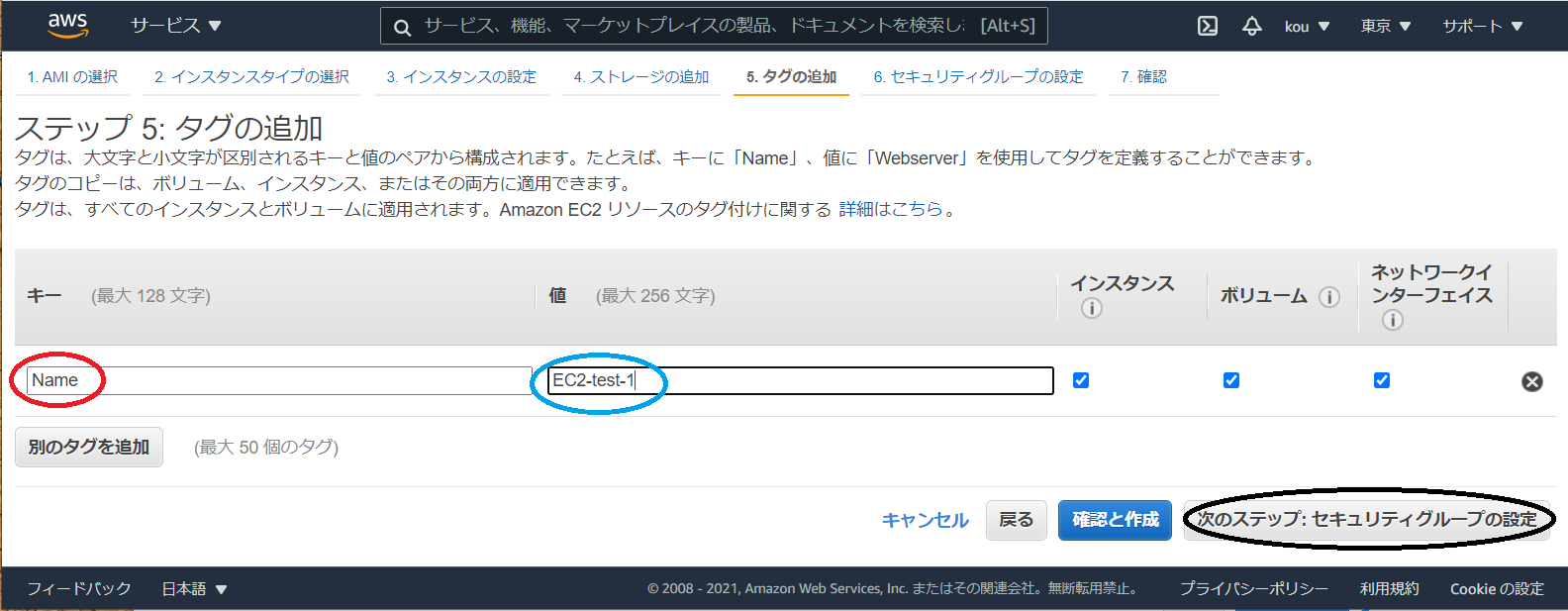
(赤枠)Name を入力
(青枠)好きな名前で(自分は EC2-test-1)
(黒枠)すべて入力後クリック
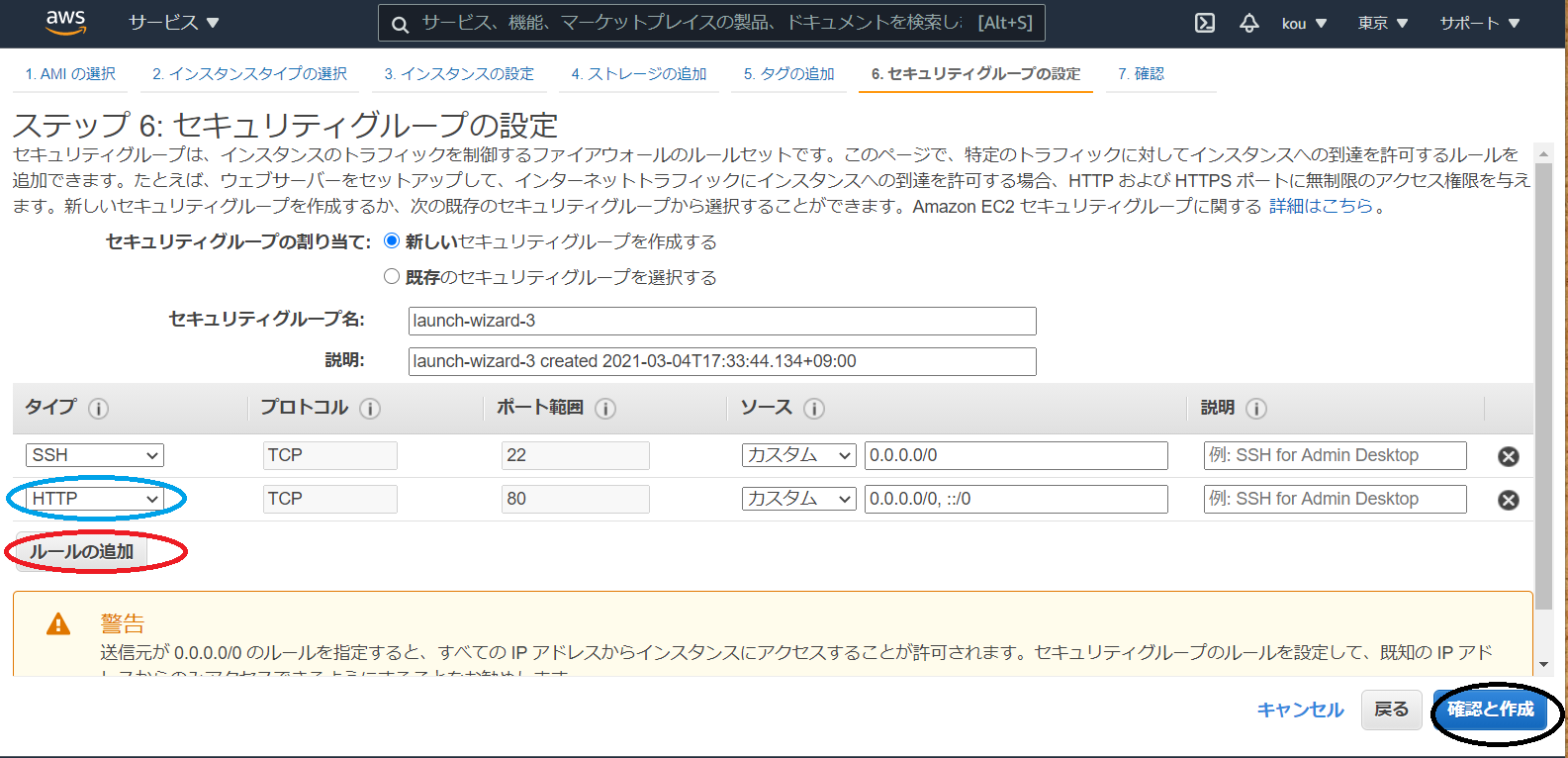
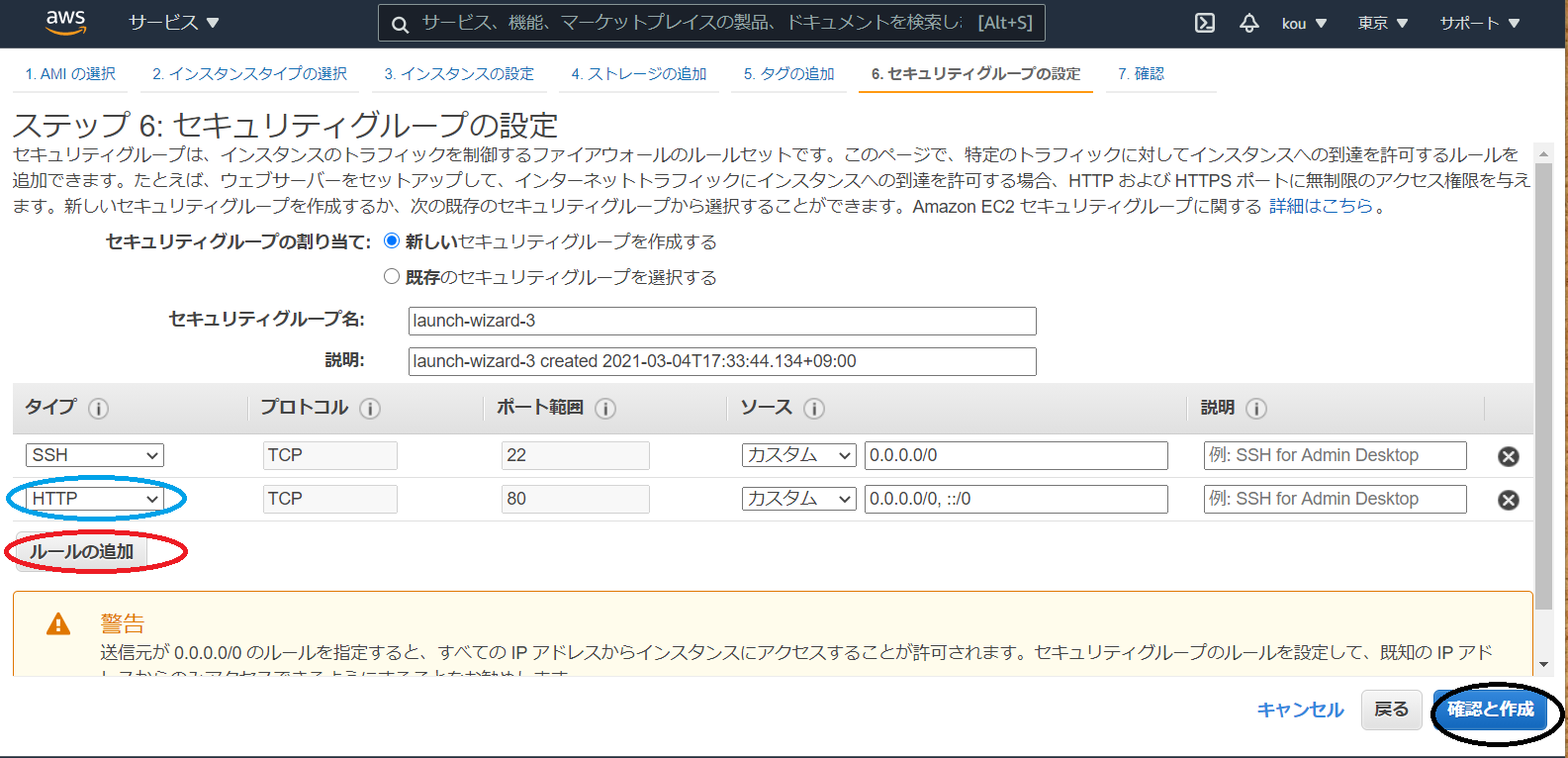
(赤枠)ルールの追加をクリック
(青枠)今回は HTTP 通信で Apache アクセスするため必要
(黒枠)最後に確認と作成をクリック
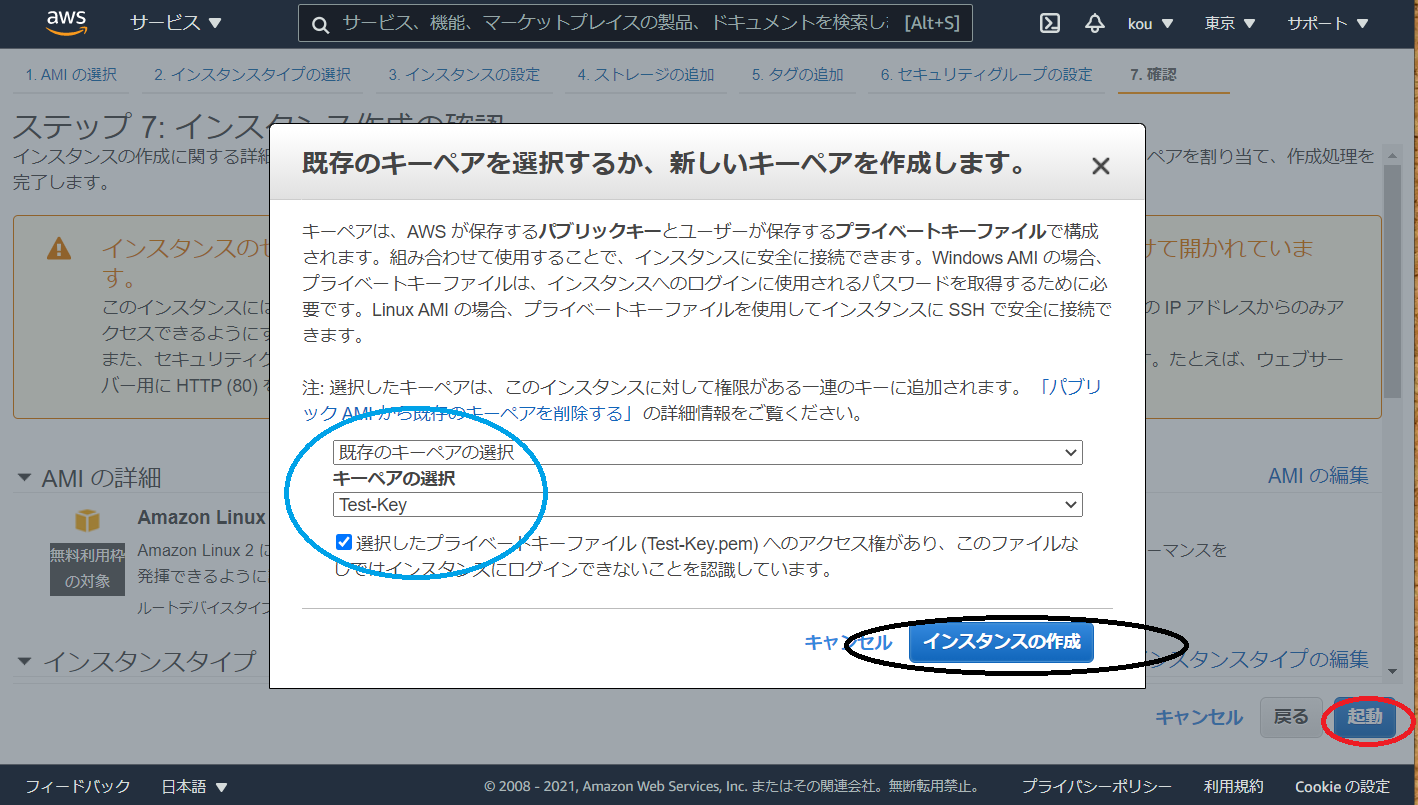
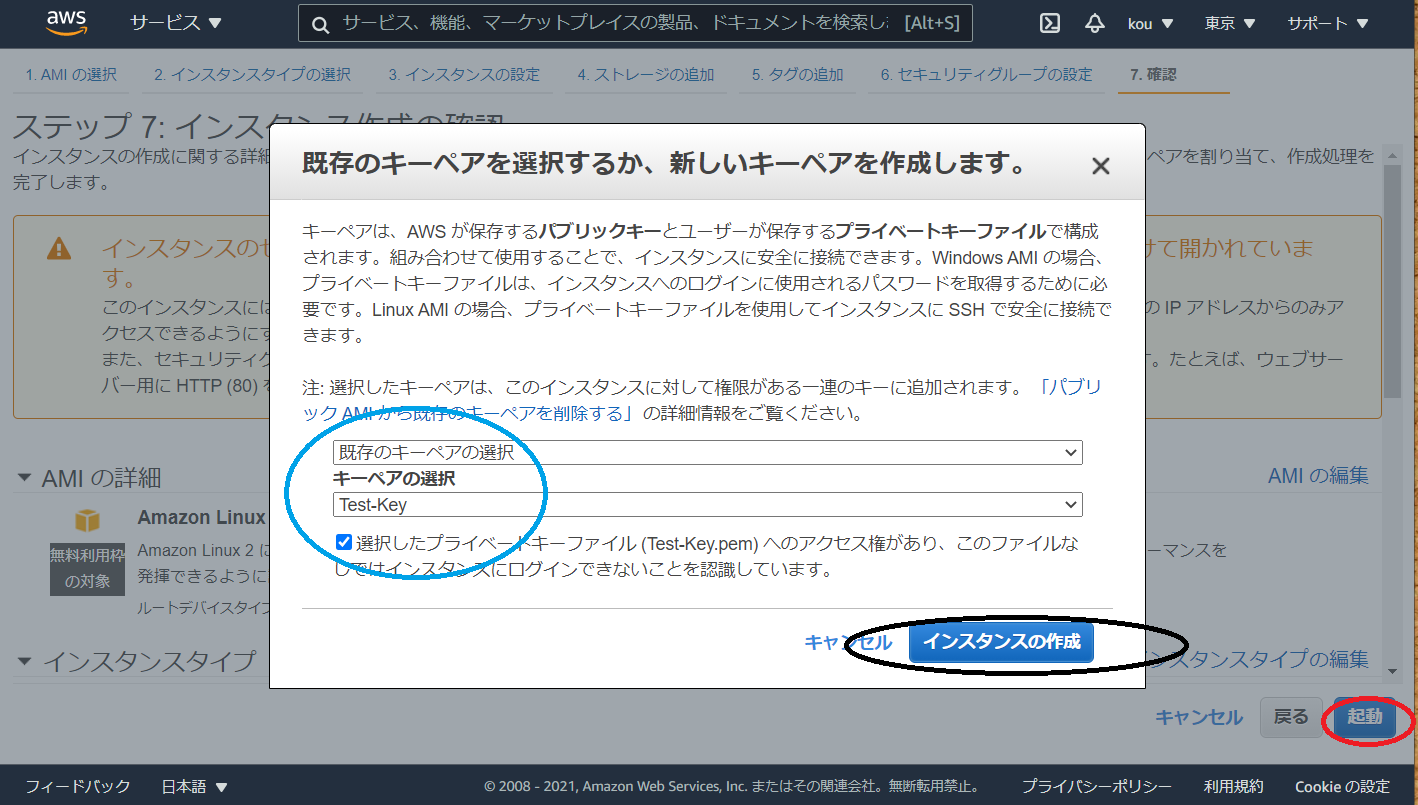
インスタンスの確認画面に画面遷移しますので確認後、(赤枠)起動をクリック
今回は既存のキーペアを使用します、キーペアを選択し下のチェック欄をチェックしてください(青枠)
終わりましたらインスタンスの作成(黒枠)をクリック
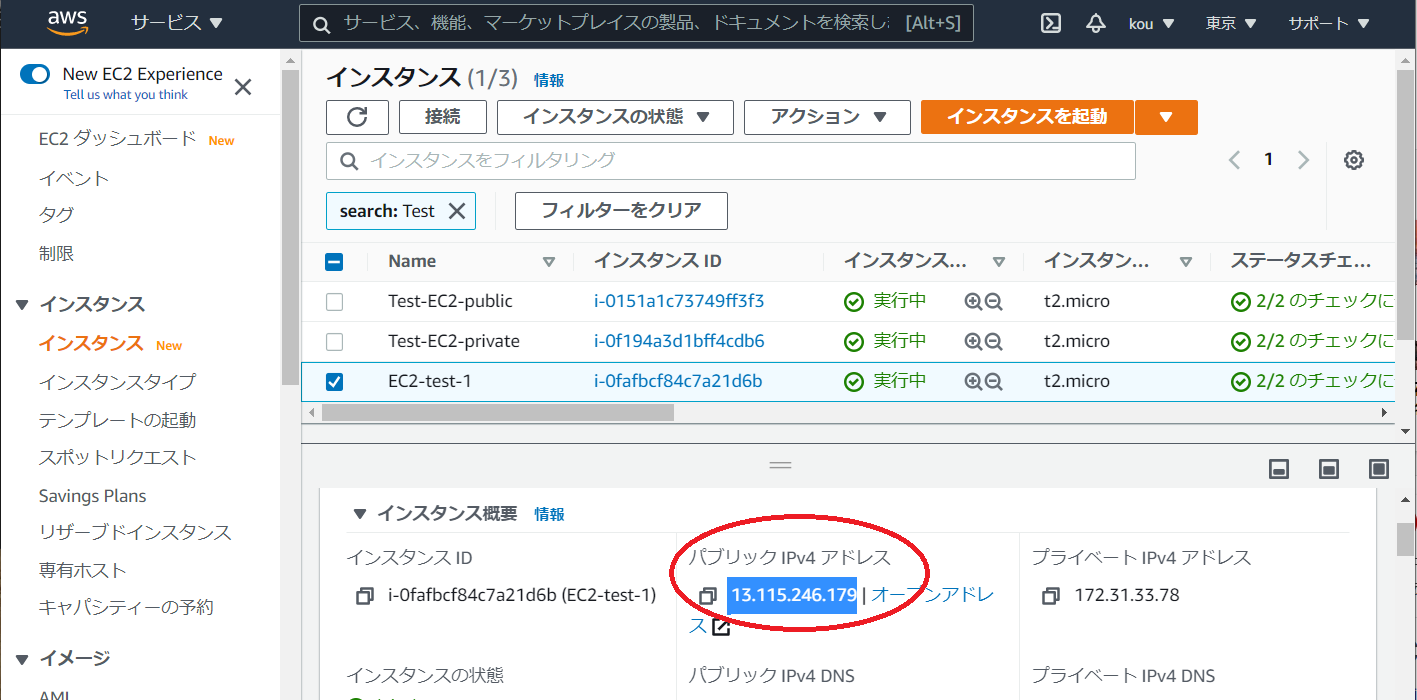
作った EC 2が実行中になっていれば問題はありません
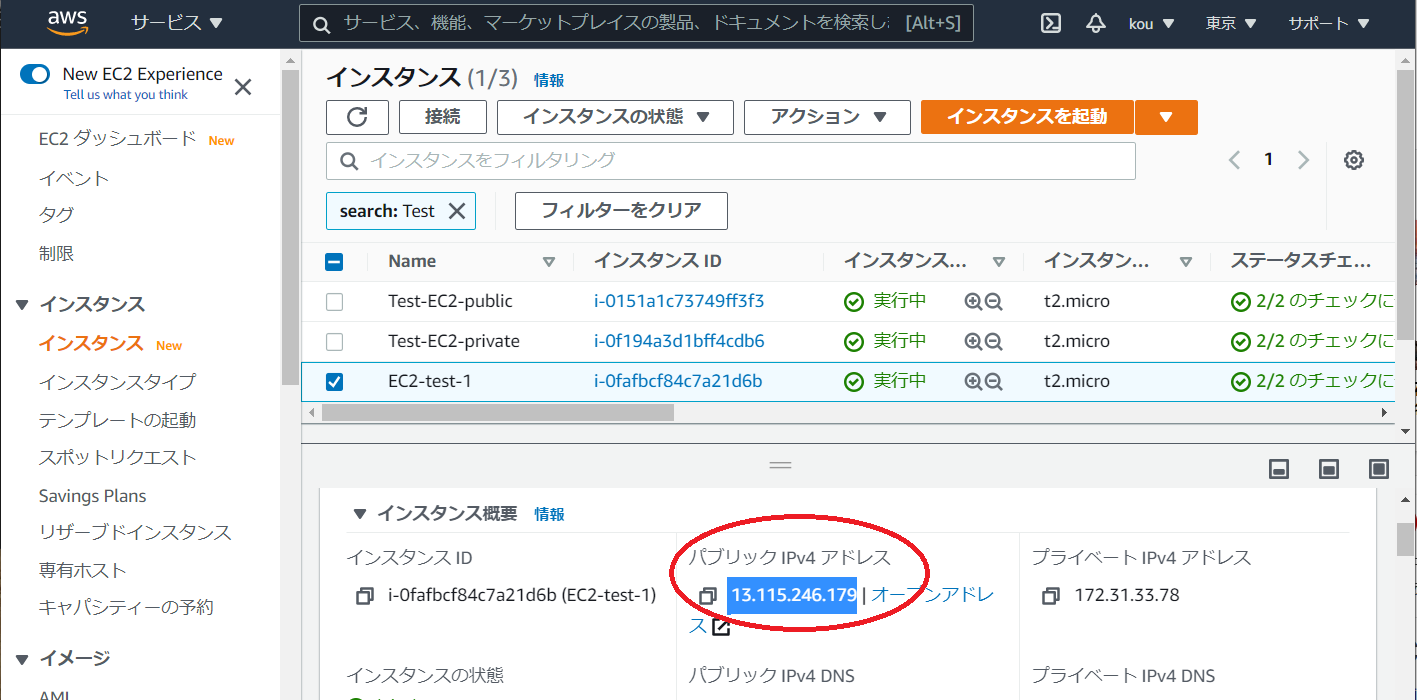
あとはパブリック IPv4 アドレスを確認してコピーしてください
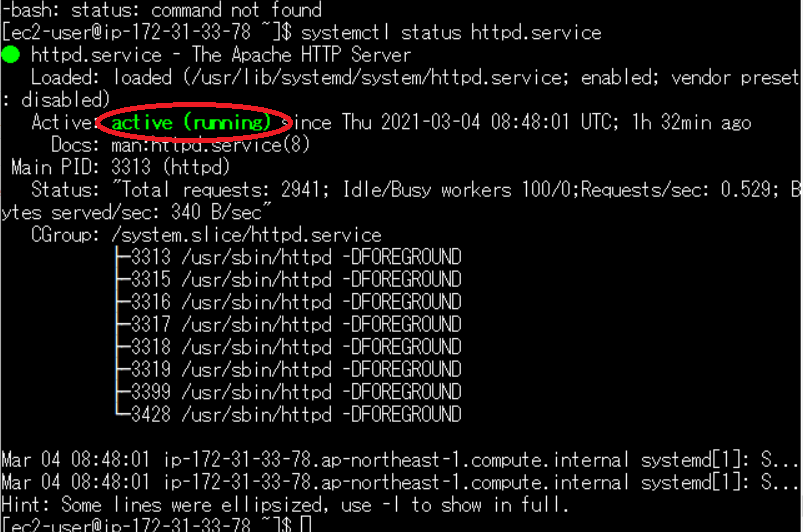
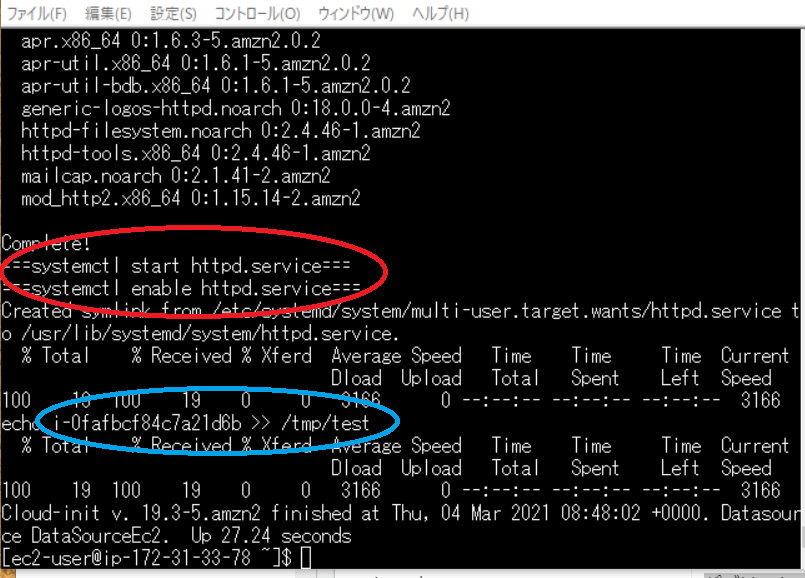
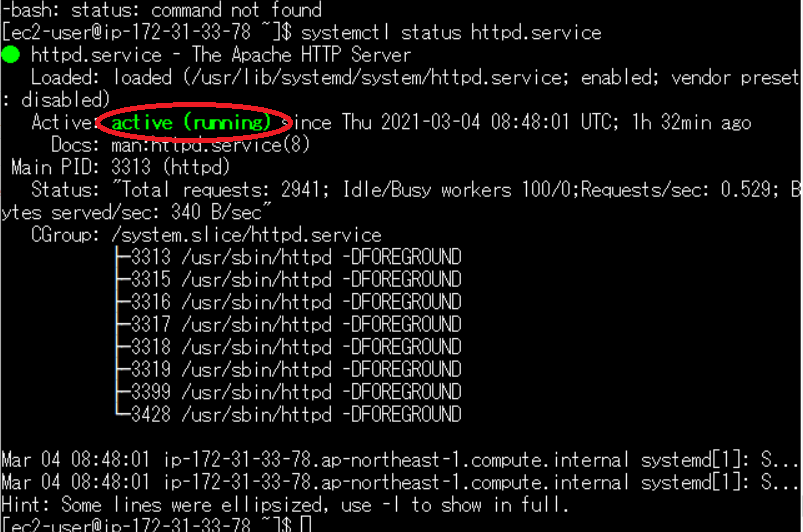
Tera Term で EC2 ログインして正常にシェルスクリプト起動しているか確認しますsystemctl status httpd.service上記のコマンドを打つと
このようになって active(running)(赤枠)になっていれば Apache 起動していることになります
次はcat /tmp/test上記のコマンドを打つと
インスタンス ID が tmp/test に書き出されるのがわかります
次に
cat /var/log/cloud-init-output.log上記を打ち込むと一部抜粋ですが以下になります。
(赤枠)echo "===systemctl start httpd.service==="などの確認用 echo 出ています
(青枠)echo でたインスタンス ID を /tmp/test に書き込んでいるのを確認できます
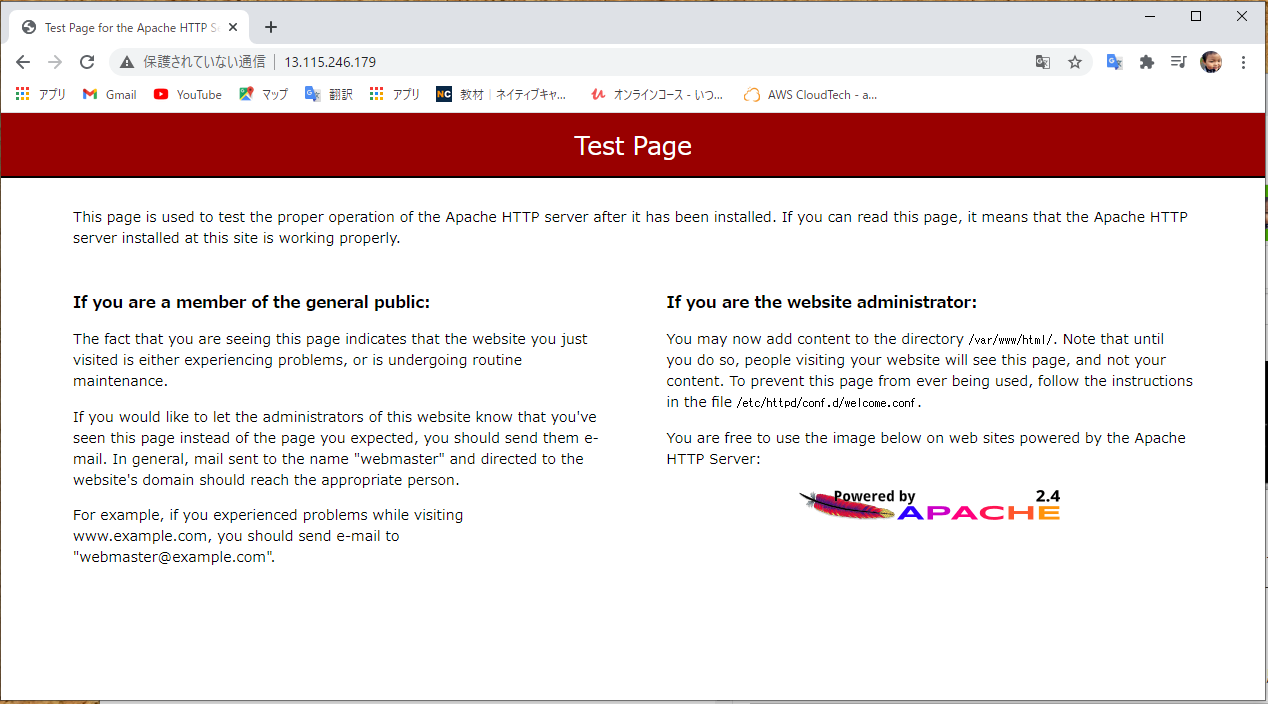
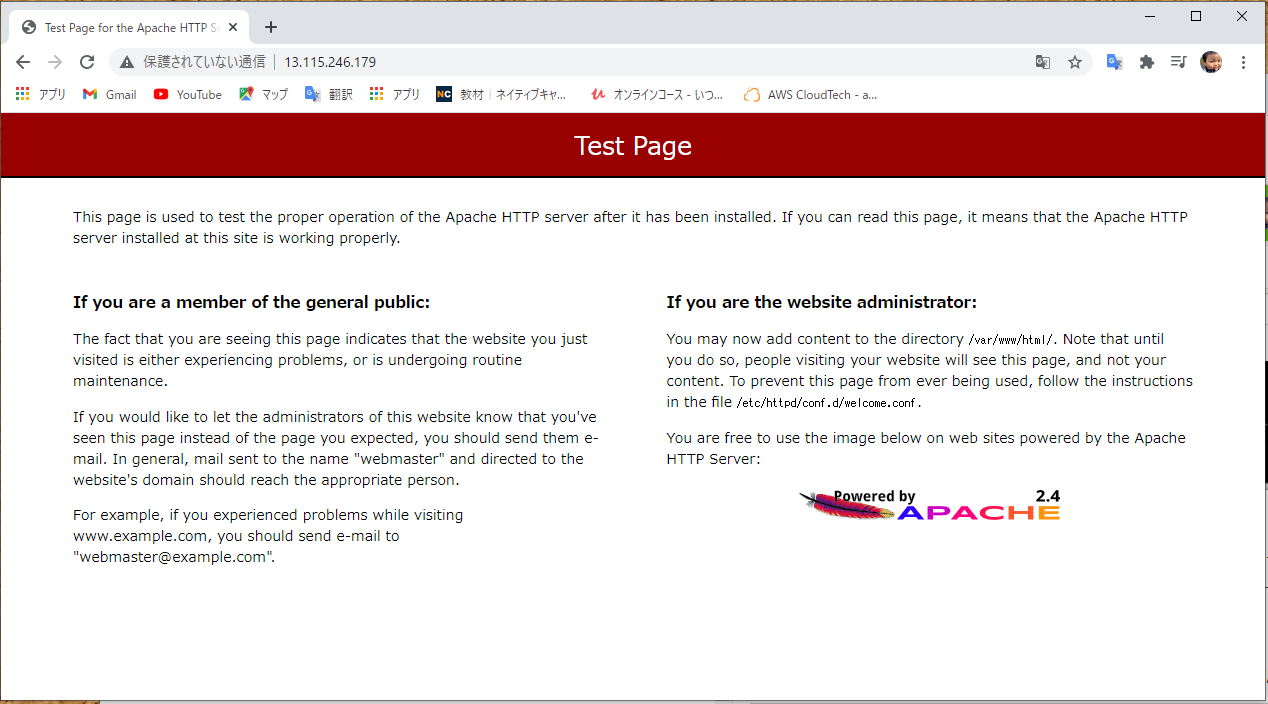
このようにログが残っているということは忘れないように!!ではパブリック IPv4 アドレスを打ち込んで Apache が映るか確認したいと思います
問題なく映りました
最後に
結構色々やりましたね~~
linux コマンドも色々打ちましたね
linux は別途で勉強しないとです
まだ作成図は途中なので次は EBS をアタッチして使える状態にしたいと思いますまたこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/

- 投稿日:2021-03-04T20:06:16+09:00
40 代おっさん EC2 に Apache を起動してみた
本記事について
本記事は AWS 初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS 最終作成図
構築手順
❶ EC2 インスタンス作成と同時に Apache インストール
❷ EBS を作成してアタッチする
❸ アタッチしたあとマウントして使える状態にする1. EC2 インスタンス作成と同時に Apache インストール
サービスより EC2 を選択
インスタンスを起動をクリック(赤枠)
Amazon Linux 2 AMI (HVM), SSD Volume Type を選択(赤枠)
インスタンスタイプは t2.micro を選択(赤枠)
選択したら 次のステップ:インスタンスの詳細の設定をクリック
ネットワークは今回はデフォルトのものを使用(赤枠)
サブネットもそれに付随しているもの(青枠)
自動割り当てパブリック IP はネットワークに繋げるため有効(黒枠)#!/bin/bash #シェバン echo "===yum -y install httpd===" yum -y install httpd #Apacheインストール echo "===systemctl start httpd.service===" systemctl start httpd.service #Apacheサービスをスタート echo "===systemctl enable httpd.service===" systemctl enable httpd.service #再起動後もApacheサービスをスタート echo "echo $(curl http://169.254.169.254/latest/meta-data/instance-id) >> /tmp/test" echo $(curl http://169.254.169.254/latest/meta-data/instance-id) >> /tmp/test #インスタンスIDを/tmp/testに書き出す上記をユーザーデータに書き込む
それが ↓ になります
終わったら 次のステップ:ストレージの追加
実はこちらで EBS の追加できますが、今回は後からアタッチする形で勉強したいと思います
また(赤枠)のところにチェックが入っていないとインスタンス終了時に削除しない形になるため無駄な課金発生しますので注意です
終わったら(青枠)次のステップ:追加をクリック
(赤枠)Name を入力
(青枠)好きな名前で(自分は EC2-test-1)
(黒枠)すべて入力後クリック
(赤枠)ルールの追加をクリック
(青枠)今回は HTTP 通信で Apache アクセスするため必要
(黒枠)最後に確認と作成をクリック
インスタンスの確認画面に画面遷移しますので確認後、(赤枠)起動をクリック
今回は既存のキーペアを使用します、キーペアを選択し下のチェック欄をチェックしてください(青枠)
終わりましたらインスタンスの作成(黒枠)をクリック
作った EC 2が実行中になっていれば問題はありません
あとはパブリック IPv4 アドレスを確認してコピーしてください
Tera Term で EC2 ログインして正常にシェルスクリプト起動しているか確認しますsystemctl status httpd.service上記のコマンドを打つと
このようになって active(running)(赤枠)になっていれば Apache 起動していることになります
次はcat /tmp/test上記のコマンドを打つと
インスタンス ID が tmp/test に書き出されるのがわかります
次に
cat /var/log/cloud-init-output.log上記を打ち込むと一部抜粋ですが以下になります。
(赤枠)echo "===systemctl start httpd.service==="などの確認用 echo 出ています
(青枠)echo でたインスタンス ID を /tmp/test に書き込んでいるのを確認できます
このようにログが残っているということは忘れないように!!ではパブリック IPv4 アドレスを打ち込んで Apache が映るか確認したいと思います
問題なく映りました
最後に
結構色々やりましたね~~
linux コマンドも色々打ちましたね
linux は別途で勉強しないとです
まだ作成図は途中なので次は EBS をアタッチして使える状態にしたいと思いますまたこの記事は AWS 初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com/


- 投稿日:2021-03-04T18:15:35+09:00
AWSの基礎(歴史)
AWSとは
AWSとは、(Amazonの)サーバーを借りれるサービスのこと。
インターネットに接続するブラウザ(chromeとか)からAWSにアクセスして必要なときに必要な分だけ、画面をポチポチしてサーバーを作れて、使えます。またなんと言っても、一台のサーバーを使うのに1分もかかりません。このスピード感が時代にマッチしていました。
また自由度の高いシステム構築スペースを提供するということで、実際にはサーバーだけではなく、AWSは権限管理やネットワークのサービス、監視サービス、ストレージのサービスなどいろいろあります。自由度がかなり高いが、裏を返すと難易度も高いです。
そしてお金も使った分だけ請求がくる従量課金という仕組みをとっています。
なぜAWSが生まれたのか
Amazonは当初、システム効率が悪く問題を抱えていました。
これはAWSが誕生する以前の話です。例えば、・担当者しか知らない属人性を抱えている
・サーバーを用意するのに2ヶ月とかかるスピードの遅さ
・拡張性、スケーリングなどの考慮ができていないといった問題を抱えていました。
これは例えば、アクセスが予想以上にきたり、ビジネスが大きくなってきたときにお客様がいっぱい来るんだけど、対処できるサーバーが用意できない。
要はサービスが継続できないという問題を抱えていました。
AWS誕生
その問題解決のためにAWSが生まれました。AWSは、Amazonが実際に苦労して作り上げた実践的なサービスです。このシステムを客向けに開始したのが、2006年。現在では多くの企業が利用する超人気サービス(クラウドコンピューティングサービス)となっています。Amazonの売り上げの稼ぎ頭になっており、営業利益ベースだと現在Amazon全体の63%。Amazon全体の利益の半分以上がAWSとなっております。
オンプレミスの弱点
今までは企業のサーバーの利用するまでの流れは、
⓵自前でサーバーを購入する
⓶サーバーを管理してくれるデータセンターのサービスに申し込む
⓷ラックの中にサーバーを積む(サーバーの設置)
⓸リモートで企業から接続しながら運用していくこれは今ももちろんあります。このような形態をオンプレミス運用すると言ったりします。
お金の問題
Webサービスを始めるのに、今まではとても初期費用がかかっていました。
Webサービスを始めるには、サーバー(業務用コンピュータ)が必要になります。サーバの上でプログラムが実行されてWebサービスを提供しています。そこで、
・サーバー自体1台100万円はする
・サーバーの適切な空調管理の費用
・サーバー自体のセキュリティの管理(侵入者が来ないように)する必要がある
・サーバーは会社の資産となって固定資産税がかかる場合があるこの変化の激しい時代に初期費用を多くかけることはリスクでもあり、クラウドに比べると金額面で大きなデメリットがあります。
時間の問題
サーバを導入するのに平気で1ヶ月がかかります。具体的には、
・どの程度高性能なものが必要かスペック見積りする時間
・配送する時間
・データセンターにサーバーを送って設置する手間や時間とにかく時間的にもスピード感に欠ける部分がありました。
クラウドサービス
クラウドサービス(クラウドコンピューティング)とは、インターネットなのコンピュータネットワークを経由して、コンピュータ資源をサービスの形で利用する利用形態。
主要なクラウドサービスには、
・AWS(Amazon)
・Azuru(microsoft)
・GCP(Google)などがあります。
クラウドサービスのメリット
これらのクラウドサービスのメリットは、
・スピード
・従量課金(使った分だけお金を支払うスタイル)
・拡張が容易
・サーバーのスペック変更が容易サーバーの設置も撤去も素早く行えること、従来課金によって企業が無駄な出費をすることを防げること、拡張が容易であることで企業の規模が拡大していく時やサーバーにアクセスが集中した時にすぐに対処できること、また変化の多いこの時代に同じマシーンや同じスペックのサーバーを購入して使い続けるのもリスクであるため、途中でスペック変更が容易であることもメリットとなります。
クラウドが誕生までの歴史
1970年頃
ホストコンピュータからITサービスが始まりました。
ホストコンピュータとは、独自仕様の大型物理コンピュータのこと。(メインフレーム)
この時代、大企業しかコンピュータを持つことができませんでした。
取り扱うには大変専門的な知識が必要だったり、大変高価なコンピュータという時代でした。1980年頃
分散化(サーバークライアント方式)
Webシステムの誕生して、インターネットを通じて多くの人に使われるようになった。2000年頃
仮想マシン(VMware)
VMwareのツールが有名です。サーバーの上にサーバーを立てる仮想化技術によってサーバーが簡単に構築できるようになりました。2017年頃
日本政府「クラウドバイデフォルト宣言」
日本政府の機関システムは基本的にはAWSを使っていきましょうという宣言になりました。パブリッククラウドは、スタートアップやITベンチャーが多かったのですが、昨今では銀行などのお堅い企業でも使われています。MUFGは、社内システムの一部にクラウドを採用しています2024年頃
クラウド市場の拡大
市場規模2兆円超予想
(ブライダル関連市場とほぼ同等)歴史を振り返ると、過去に分散化や仮想マシーンなどの変化が起こったように、現在IT業界ではオンプレミスからクラウドへの産業革命のようなものが起こっているように感じます。
- 投稿日:2021-03-04T18:08:55+09:00
code build で EFS をマウントすると失敗する
aws の公式だと、原因を特定するのはawsビギナーには困難だったため、自分用のメモ
aws code build でEFS をマウントする必要があったので、マウントしようとすると「CLIENT_ERROR: mounting '127.0.0.1:/' failed. connection reset by peer」というエラーになる。
aws 公式に記載されている解決方法を実施しても治らず…
上記のとおり、セキュリティグループでEFSにアクセスできる設定は行ったし、同一subnet上にEFSも存在している。
結論から言うと、VPCのDNS名前解決をONにする必要がある(File System Mount Using DNS Name Fails)。
今回原因を特定できた方法は、自分構築したVPCで失敗し、CloudFormatinのテンプレートで構築したVPCで成功したため、設定を比較しながら特定することができた。
自分でAWS コンソールマネージャからvpcを構築すると、DNSの設定がデフォルトが'OFF'である。デフォルトがOFFのため、code build EFSがマウントできない。fargate でDbのマイグレーションを行い、DBをマイグレーションしたDBからデータ構造の自動生成(ex: C# のentityframework 、java のjooq)をする際に、インスタンスを起動する必要がなく重宝すると思ったが、調べても同じ悩みを抱えている人がいなかったため、原因が特定するのに時間がかかってしまった。もしかして、データベースからコードの型の自動生成自体がレガシーなのか、それとも初歩すぎる問題で誰も詰まったりしないのかと思った(どっちでも自分的には精神的ダメージ)。
- 投稿日:2021-03-04T16:55:50+09:00
【LINEBOT】LINEの音声メッセージをAmazon Transcribeで文字起こし
はじめに
AWSについて調べていた際、音声を文字起こしできるサービス(Amazon Transcribe)に出会ったので試しに使ってみることに...
LINEの音声メッセージを文字起こしできたら便利かもと思ったので、試しにLINEBOTに導入してみます~前提
- windows(macでもおそらくできますが今回はwindows)
- Heroku、flaskを用いておうむ返しボットが作れていること。おうむ返しボットはソフトウェア開発キット(https://github.com/line/line-bot-sdk-python) を参考にすると簡単に作れます。
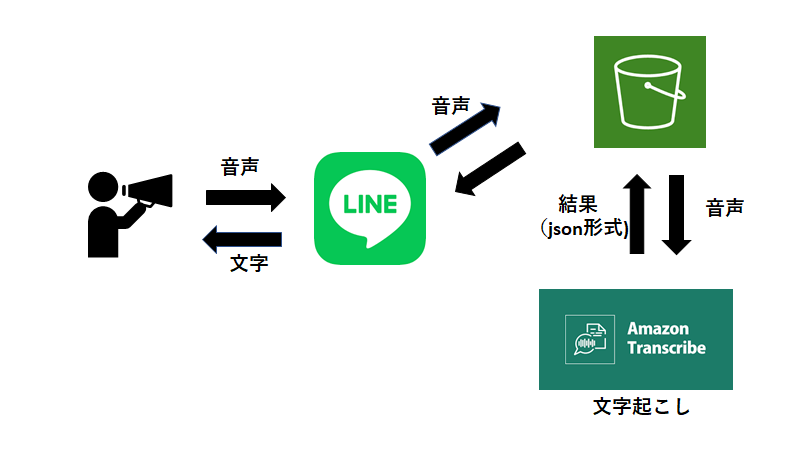
仕組み
大まかな流れは図の通りです。
ユーザーが音声を送信。BOTが音声データをAmazonS3のバケットに保存。その音声データをAmazonTranscribeが文字起こし。結果を取得してBOTが返信。環境変数の設定と確認
設定方法
$heroku config:set <環境変数名>=value -a <アプリ名>確認
$heroku config -a <アプリ名> AWS_ACCESS_KEY_ID: <AWS IAMから取得> AWS_SECRET_ACCESS_KEY: <AWS IAMから取得> S3_BUCKET: <使用するバケットの名前> YOUR_CHANNEL_ACCESS_TOKEN: <LINE developersのサイトから取得> YOUR_CHANNEL_SECRET: <LINE developersのサイトから取得>以上が設定されていれば動くはず。
コード(基本はおうむ返しボットと同じです)
説明の前にメインとなるコードを書いておきます。
main.pyfrom typing import Text from flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, TemplateSendMessage, CarouselTemplate, CarouselColumn, URITemplateAction, AudioMessage, AudioSendMessage ) import os, json, boto3 import urllib app = Flask(__name__) #環境変数取得 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) aws_s3_bucket = os.environ['S3_BUCKET'] #テスト用 @app.route("/") def hello_world(): return "hello world!" @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' import time @handler.add(MessageEvent, message=AudioMessage) def handle_message(event): message_id = event.message.id message_content = line_bot_api.get_message_content(message_id) with open(f"/app/static/audio/{message_id}.m4a", 'wb') as fd: fd.write(message_content.content) original_content_url=f'https://linebot-textprocessing.herokuapp.com/static/audio/{message_id}.m4a' #音声の保存 wav file_name = f"{message_id}.wav" urllib.request.urlretrieve(original_content_url,file_name) # S3へ音声をアップロードする s3_resource = boto3.resource('s3') s3_resource.Bucket(aws_s3_bucket).upload_file(file_name, file_name) #音声の認識 transcribe = boto3.client('transcribe', region_name="ap-northeast-1") job_name = f"linewikipediabot-{message_id}.wav" job_uri = f"https://linewikipediabot.s3.amazonaws.com/{message_id}.wav" transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='mp4', LanguageCode='ja-JP', OutputBucketName = aws_s3_bucket ) while True: status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(3) print("DONE") #jsonファイルの取得 s3_resource.Bucket(aws_s3_bucket).download_file(f"{job_name}.json", f"{job_name}.json") json_open = open(f"{job_name}.json", "r") json_load = json.load(json_open) print(json.dumps(json_load, ensure_ascii=False, indent=4)) #音声認識結果 replymessage = json_load["results"]["transcripts"][0]["transcript"] print(replymessage) replymessage1 = replymessage.replace(" ", "") print(replymessage1) line_bot_api.reply_message( event.reply_token, TextSendMessage(text=replymessage1)) if __name__ == "__main__": # app.run() port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)コードの解説(メインの「音声メッセージ→文字」の流れのみ)
- message_idについて
- メッセージにはぞれぞれ番号がついているため、識別するために取得。
- message_content
- 音声を取得(以下のコード)
- ファイル名にmessage_idを組み込み識別。
- リファレンスを参考にしました。
message_content = line_bot_api.get_message_content(message_id) with open(f"/app/static/audio/{message_id}.m4a", 'wb') as fd: fd.write(message_content.content) original_content_url=f'https://linebot-textprocessing.herokuapp.com/static/audio/{message_id}.m4a' #音声の保存 wav file_name = f"{message_id}.wav" urllib.request.urlretrieve(original_content_url,file_name)
- バケットへアップロード
s3_resource = boto3.resource('s3') s3_resource.Bucket(aws_s3_bucket).upload_file(file_name, file_name
- 音声を認識してくれるようにお願いを出す
- 自分の場合、region_nameを指定しないと動作しませんでした。
- while文は文字起こしが完了しているかどうかを判別。("Not ready yet..." → まだ)結果が出る前にコードが進行してしまうと当然エラーになる。
- 文字起こしの結果は音声を格納したバケットと同じバケットに格納されます(環境変数で設定したもの)
- print("DONE")が終了の合図
- AWSの開発者ガイドが参考になります
transcribe = boto3.client('transcribe', region_name="ap-northeast-1") job_name = f"linewikipediabot-{message_id}.wav" job_uri = f"https://linewikipediabot.s3.amazonaws.com/{message_id}.wav" transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='mp4', LanguageCode='ja-JP', OutputBucketName = aws_s3_bucket #出力先を音声と同じバケットに設定 ) while True: status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(3) print("DONE")
- 文字起こし結果の取得
- 結果はjson形式で返されます。(AWSの開発者ガイド)
- バケットからいったんダウンロード
s3_resource.Bucket(aws_s3_bucket).download_file(f"{job_name}.json", f"{job_name}.json") json_open = open(f"{job_name}.json", "r") json_load = json.load(json_open)
- 文字の取得
- replymessageままだと単語と単語の間にスペースが開いてしまいます。
- スペースを取り除いた形をreplymessage1とします。(名前はなんでもOK)
- print文で結果を見てみるのもいいかもしれません
replymessage = json_load["results"]["transcripts"][0]["transcript"] #jsonファイルから特定の項目を取得 replymessage1 = replymessage.replace(" ", "") #スペースを除く処理
- 結果をラインで返信
line_bot_api.reply_message( event.reply_token, TextSendMessage(text=replymessage1))その他のファイル
requirements.txt(pip freezeで確認し、ご自身の使用しているバージョンを書いてください)
boto3==1.17.17 botocore==1.20.17 certifi==2020.12.5 chardet==4.0.0 click==7.1.2 Flask==1.1.2 future==0.18.2 idna==2.10 itsdangerous==1.1.0 Jinja2==2.11.3 jmespath==0.10.0 line-bot-sdk==1.18.0 MarkupSafe==1.1.1 psycopg2==2.8.6 python-dateutil==2.8.1 requests==2.25.1 s3transfer==0.3.4 six==1.15.0 urllib3==1.26.3 Werkzeug==1.0.1Procfile
web: python main.pyruntime.txt(herokuにpythonのバージョンを認識させる)
python-3.9.2GitHubにデプロイして終了(herokuアプリとGitHubを連携済みを想定)
応用
音声認識結果をWikipediaで調べ、結果を返してくれたら面白いなと思ったので機能を追加してみます。(以下のコード)
from typing import Text from flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, TemplateSendMessage, CarouselTemplate, CarouselColumn, URITemplateAction, AudioMessage, AudioSendMessage ) import os, json, boto3 import urllib app = Flask(__name__) #環境変数取得 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) aws_s3_bucket = os.environ['S3_BUCKET'] #テスト用 @app.route("/") def hello_world(): return "hello world!" @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' import time @handler.add(MessageEvent, message=AudioMessage) def handle_message(event): message_id = event.message.id message_content = line_bot_api.get_message_content(message_id) with open(f"/app/static/audio/{message_id}.m4a", 'wb') as fd: fd.write(message_content.content) original_content_url=f'https://linebot-textprocessing.herokuapp.com/static/audio/{message_id}.m4a' #音声の保存 wav file_name = f"{message_id}.wav" urllib.request.urlretrieve(original_content_url,file_name) # S3へ音声をアップロードする s3_resource = boto3.resource('s3') s3_resource.Bucket(aws_s3_bucket).upload_file(file_name, file_name) #音声の認識 transcribe = boto3.client('transcribe', region_name="ap-northeast-1") job_name = f"linewikipediabot-{message_id}.wav" job_uri = f"https://linewikipediabot.s3.amazonaws.com/{message_id}.wav" transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='mp4', LanguageCode='ja-JP', OutputBucketName = aws_s3_bucket ) while True: status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(3) print("DONE") #jsonファイルの取得 s3_resource.Bucket(aws_s3_bucket).download_file(f"{job_name}.json", f"{job_name}.json") json_open = open(f"{job_name}.json", "r") json_load = json.load(json_open) print(json.dumps(json_load, ensure_ascii=False, indent=4)) #音声認識結果 replymessage = json_load["results"]["transcripts"][0]["transcript"] replymessage1 = replymessage.replace(" ", "") # 以下追加のコード uri = "https://ja.wikipedia.org/wiki/" + replymessage column = { "title": replymessage, "text": replymessage, "action": { "label": "Wikipediaでみる", "uri": uri } } columns = [ CarouselColumn( title=column["title"], text=column["text"], actions=[ URITemplateAction( label=column["action"]["label"], uri=column["action"]["uri"], ) ] ) ] messages = TemplateSendMessage(alt_text=replymessage, template=CarouselTemplate(columns=columns)) line_bot_api.reply_message(event.reply_token, messages = messages) if __name__ == "__main__": # app.run() port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)応用の解説
追加したのは検索結果をカルーセルに格納し、返信するというシンプルなものです。
まとめ
やってみてなかなか面白いと感じました。それなりに長い文章でも精度はかなり高く、いろいろな応用先が思いつきそうですね~。(アプリに組み込むとか。。。)
ただ、あまり長い音声(文章)を送るとherokuがタイムアウトしてしまい、エラーが発生しました(音声の処理に時間がかかってしまうため)。どうやらherokuは30秒以下の処理のみ対応しているとのこと。一応解決策はあるようですが、今回はパスします。気になった人は以下のリンク(バックグラウンドジョブについて)を見てみるといいかもしれません。というかherokuの代わりにAmazonのサービスを使ったほうがよかったのかもしれません(笑)
ここまで見てくださりありがとうございました。PythonもQiitaも不慣れなので読みにくかったかもしれません。。。もし、なにか疑問や改善点などあればぜひコメントしてください~
- 投稿日:2021-03-04T15:56:45+09:00
PHPでAWS Aurora Serverless の Data API の使用してみた
前提条件
AWS SDK for PHP 3.x を利用
Data API の有効化など完了しているとするやってみた感想
可もなく不可もなく
Data APIを利用して結果を取得する
sample.php<?php use Aws\Exception\AwsException; use Aws\RDSDataService\RDSDataServiceClient; try { $client = new RDSDataServiceClient([ 'region' => 'ap-northeast-1', 'version' => 'latest', 'credentials' => [ 'key' => '****', 'secret' => '****', ], ]); $result = $client->executeStatement([ 'secretArn' => 'arn:aws:secretsmanager:ap-northeast-1:****:secret:****', 'resourceArn' => 'arn:aws:rds:ap-northeast-1:****:cluster:****', 'sql' => 'SELECT * FROM hoge', ]); var_dump($result->get('records')); } catch (AwsException $e) { echo $e->getAwsErrorMessage(); }参考
- 投稿日:2021-03-04T15:56:45+09:00
PHPで AWS Aurora Serverless の Data API を利用してみた
前提条件
AWS SDK for PHP 3.x を利用
Data API の有効化など完了しているとするやってみた感想
可もなく不可もなく
RDSDataServiceClientを利用して結果を取得する
sample.php<?php use Aws\Exception\AwsException; use Aws\RDSDataService\RDSDataServiceClient; try { $client = new RDSDataServiceClient([ 'region' => 'ap-northeast-1', 'version' => 'latest', 'credentials' => [ 'key' => '****', 'secret' => '****', ], ]); $result = $client->executeStatement([ 'secretArn' => 'arn:aws:secretsmanager:ap-northeast-1:****:secret:****', 'resourceArn' => 'arn:aws:rds:ap-northeast-1:****:cluster:****', 'sql' => 'SELECT * FROM hoge', ]); var_dump($result->get('records')); } catch (AwsException $e) { echo $e->getAwsErrorMessage(); }参考
- 投稿日:2021-03-04T12:41:34+09:00
【AWS】CodeBuildとは?概念と用途を理解する。
AWSのCodeBuildについて。概念と用途のまとめ。
CodeBuildとは?
ソースコードからイメージを作成し、問題がないかテストをしてくれるAWSのサービスの一つ。
いつ使うか?
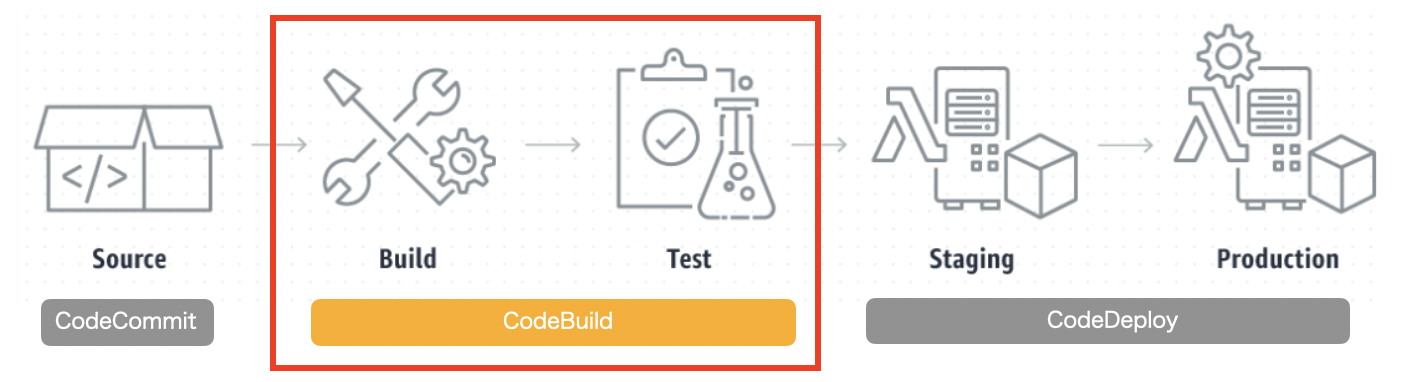
本番環境の更新作業を自動化する、CodePipelineのプロセスの一部で使うのが一般的。
▼CodePipelineの処理の流れ
CodeBuild作成の流れ
CodeBuildはソースコードを受け取り、それを仕様書(buildspec.ymlファイル)に基づいて、ビルド環境を構築しテストを行う。
- ソースコードの編集とアップロード(CodeCommitにプッシュ)
- buildspec.ymlファイルの作成とアップ(CodeCommitにプッシュ)
- ビルドプロジェクトを作成(CodeBuild上で作成)
- ビルドを開始する(CodeBuild)
▼CodeBuildのメニュー
CodePipelineでCodeBuildを実行する場合
基本的にCodeBuildはCodePipelineで使われる。
CodePipelineを設計する流れの中で、CodeBuildも合わせて設定できる。
この場合、ビルドプロジェクトのソースプロバイダはCodePipelineと表示される、
▼CodePipelineで設定した時のソースプロバイダ
buildspec.yml
buildspec.ymlはソースディレクトリのルートに配置する。
つまり、ソースにCodeCommitを指定した場合は、そのレポジトリのルートディレクトリにbuildspec.ymlを作成しておく。
ビルドプロジェクトを開始すると、CodeBuildはこのファイルで指定された手順に沿ってコマンドを実行していく。
▼作成例
buildspec.ymlversion: 0.2 phases: #ビルド前の処理(ECRにログイン&イメージ名(ホスト名)を取得) pre_build: commands: - echo 出力したいメッセージ - $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION) - REPOSITORY_URI=$AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$IMAGE_REPO_NAME #ビルドの実行 build: commands: - echo 出力したいメッセージ - docker build -t $REPOSITORY_URI:latest . #イメージをECRにプッシュ(イメージ名とタグをjsonファイルに出力) post_build: commands: - echo 出力したいメッセージ - docker push $REPOSITORY_URI:latest $REPOSITORY_URI:latest > imageRepository.json artifacts: files: imageRepository.json1. phases(フェーズ)
CodeBuildでは各フェーズ毎に実行する内容を分けることができる。
1-1. pre_build
prebuildフェーズではビルドの前に実行するコマンドを記述する。ECRにサインインしたり、npmの依存関係をインストールしたりできる。
1-2. build
buildはビルド中にCodeBuildが実行するコマンド。
Dockerの場合は、イメージのビルド処理を記述する。1-3. post_build
post_buildはビルド後にCodeBuildが実行するコマンド。
ビルドしたDockerイメージをECRにプッシュしたりできる。
2. artifacts
ビルド後の出力結果に関するデータの保存先情報など。
filesは必須。2-1. files
ビルドしたイメージに関する情報の置き場所。
AWS公式リンク buildscript構文
参考リンク
・AWSCodeBuildの概念
・ビルドPJの作成手順


- 投稿日:2021-03-04T10:29:51+09:00
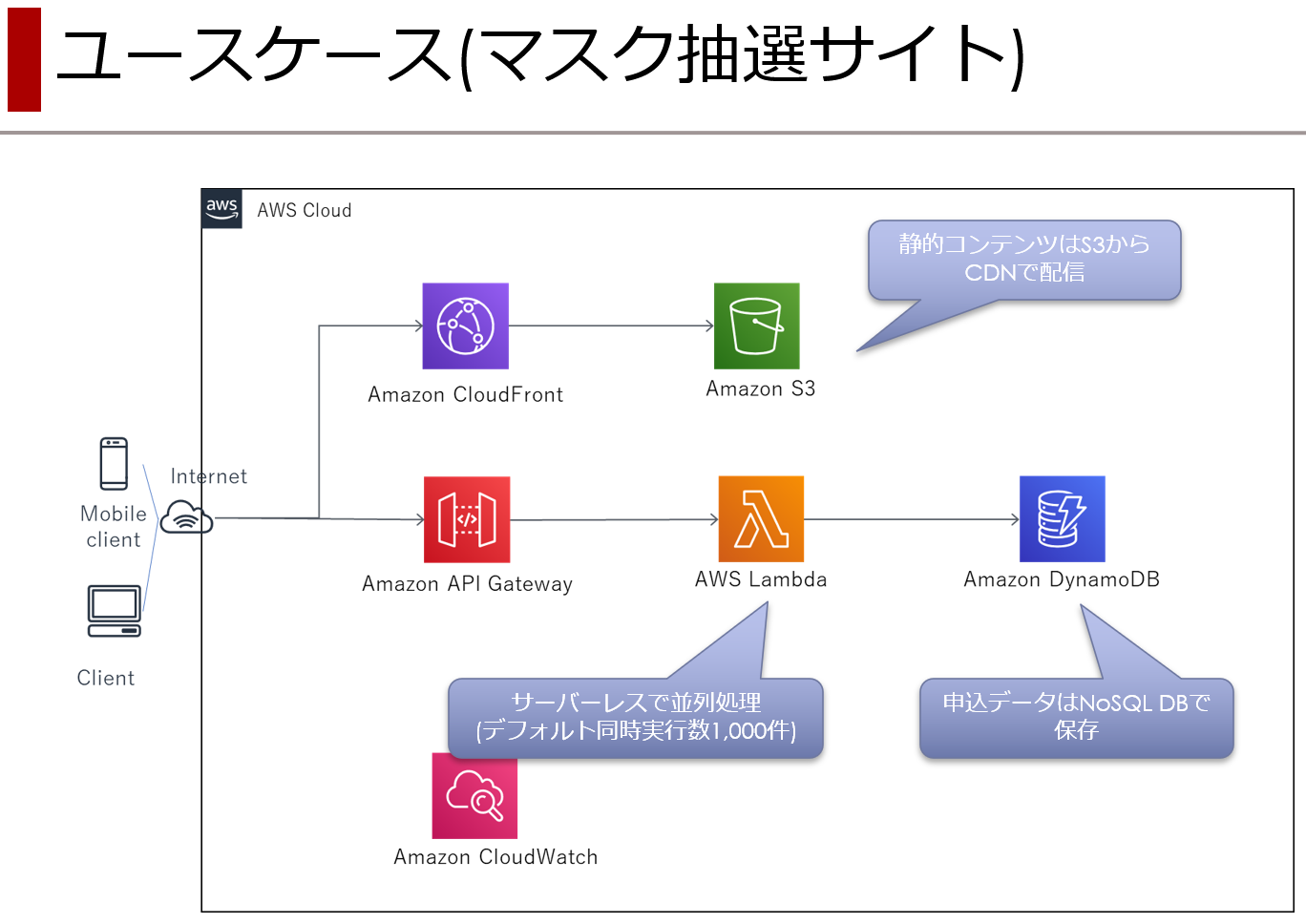
AWS初心者(一ヶ月)がサーバレス開発 ~ S3 & Cloud Front編 ~
AWS を触り始めて一ヶ月の人間がサーバレス開発します。
経緯
社内で「 AWS の資格の勉強するんだったら、コレ作ってみてよ」と、渡されたモノがこちら。
ふんふん、なるほど、わからん。
仕様自体はシンプルなんだけど、AWS のサービスとかわからんちん。「で、過程を Qiita に投稿してもらうから」
脳内作戦会議
AWS を触り始めて一ヶ月の僕には荷が重いわけで。
幸いなことに、サービスは指定されているわけで。
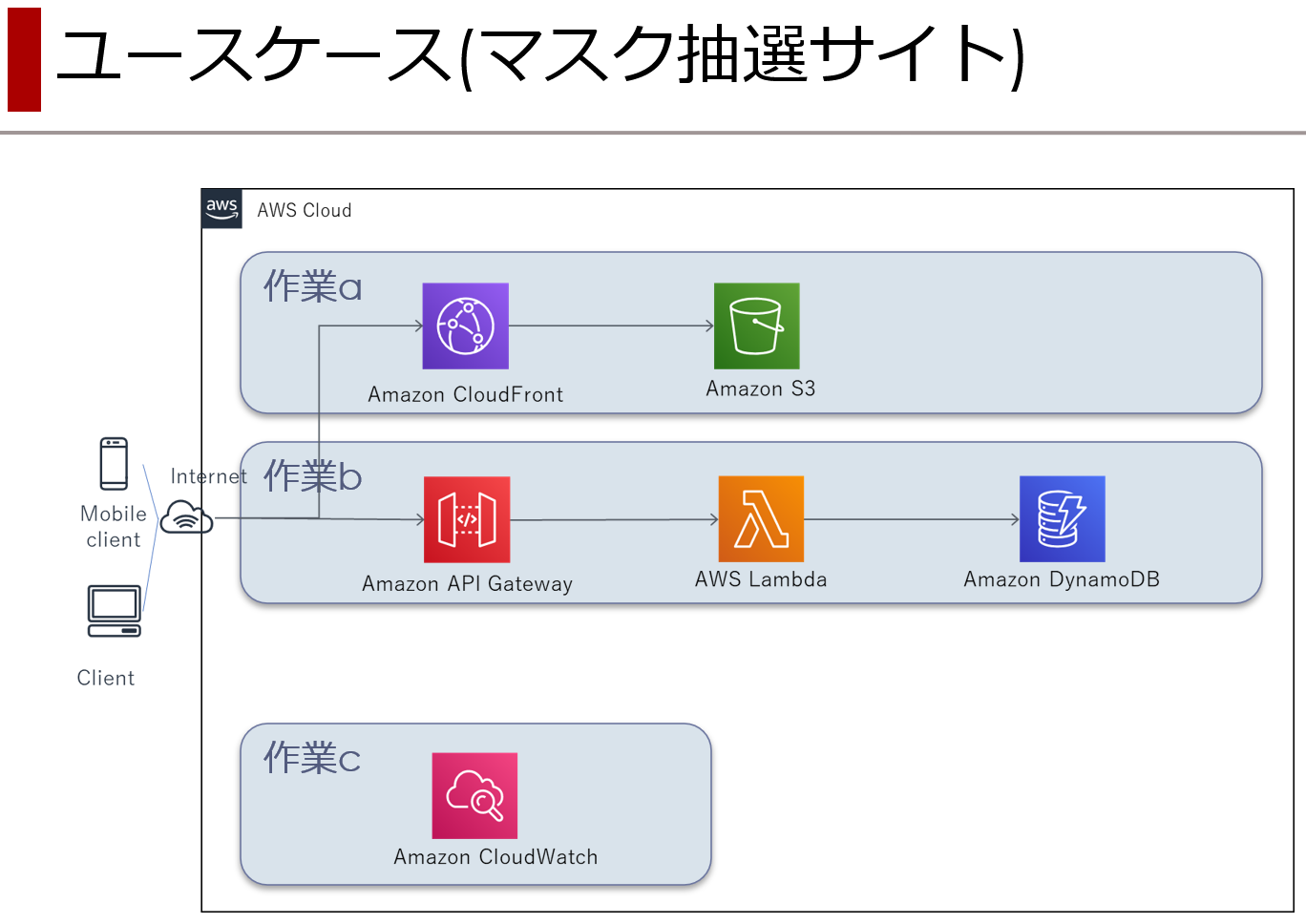
大雑把に、フロント側、バック側、その他の3つに分けて進めれば良いんじゃないかと思うに至ったわけで。
- 作業a : S3 & CloudFront (本記事)
- 作業b : API Gateway & Lambda & DynamoDB
- 作業c : CloudWatch と サービス間の接続周り
S3 & CloudFront
やりたいことはコレだ。
- 紙芝居でオッケーな HTML を S3 に配置
- S3 に配置した HTML を CloudFront 経由で公開
紙芝居な HTML をこんな感じで作成してみたりして。
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>抽選サイト</title> <link rel="icon" href="./favicon.ico"> <link rel='stylesheet' href='./css/style.css'> </head> <body> <div class="main"> <div class="header"> <img src="./logo.png"> </div> <div class="content"> <h1>マスク抽選販売のお知らせ</h1> <br /> <h3>抽選応募方法のご案内</h3> <br /> <p>応募サイトにて、お名前/メールアドレス/電話番号をご入力ください。</p> <br /> <button type="button" onclick="location.href='./entry.html'" class="btn-square">応募サイトはこちら</a> </div> </div> </body> </html>S3 で静的ウェブサイトホスティング
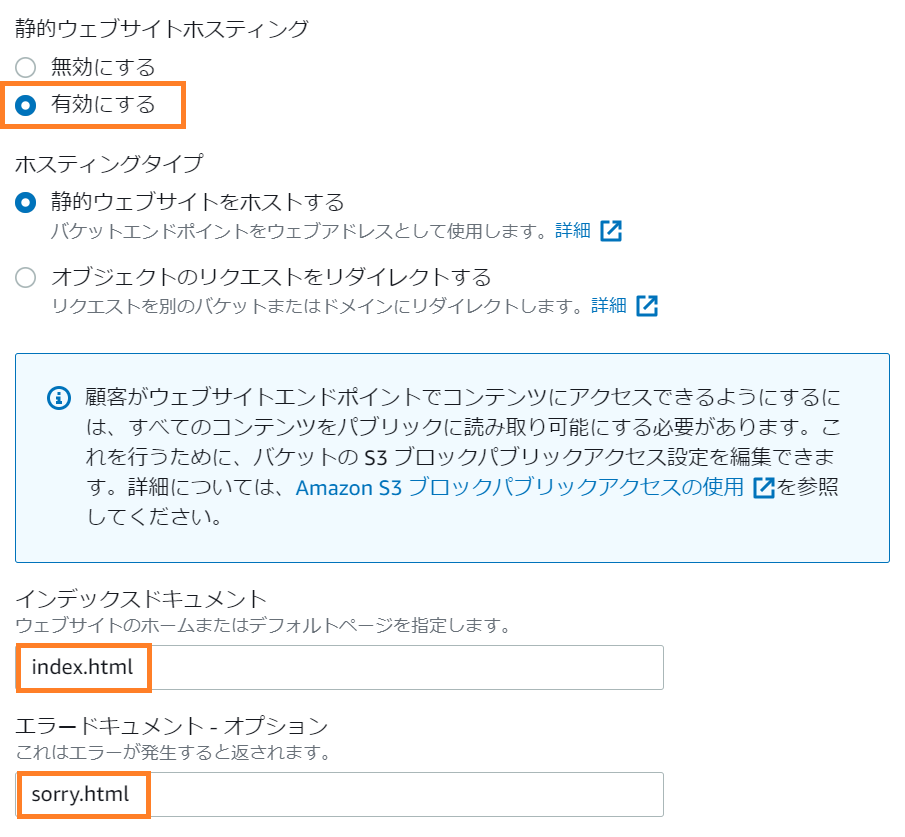
まず、S3 のみで静的ウェブサイトホスティングってのをやってみる。
やってみる、と言っても公式のハンズオンとチュートリアルをトレースするだけなんだけど。キモの静的ウェブサイトホスティングの設定は枠で囲った3箇所だけ。
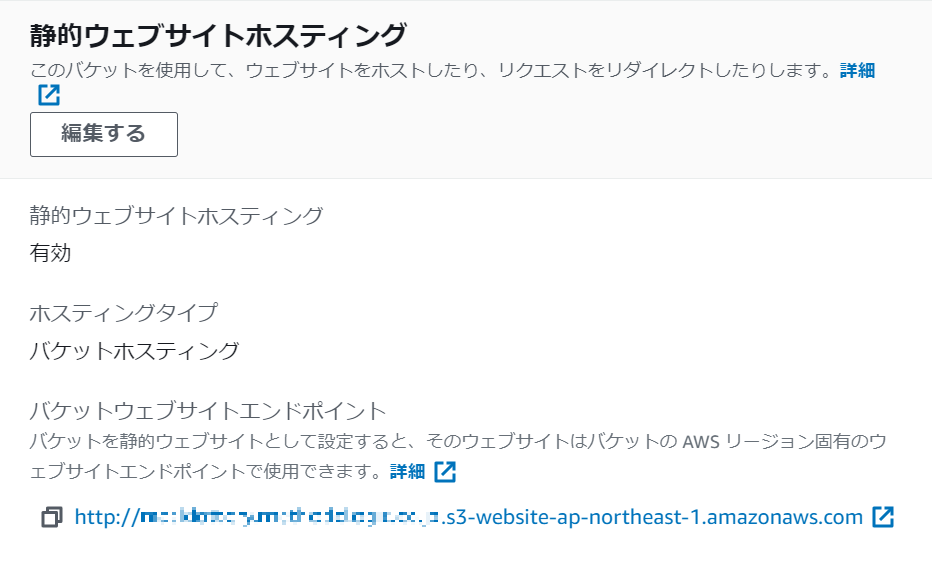
設定が終わると静的ウェブサイトホスティングのエリアが次のようになる。
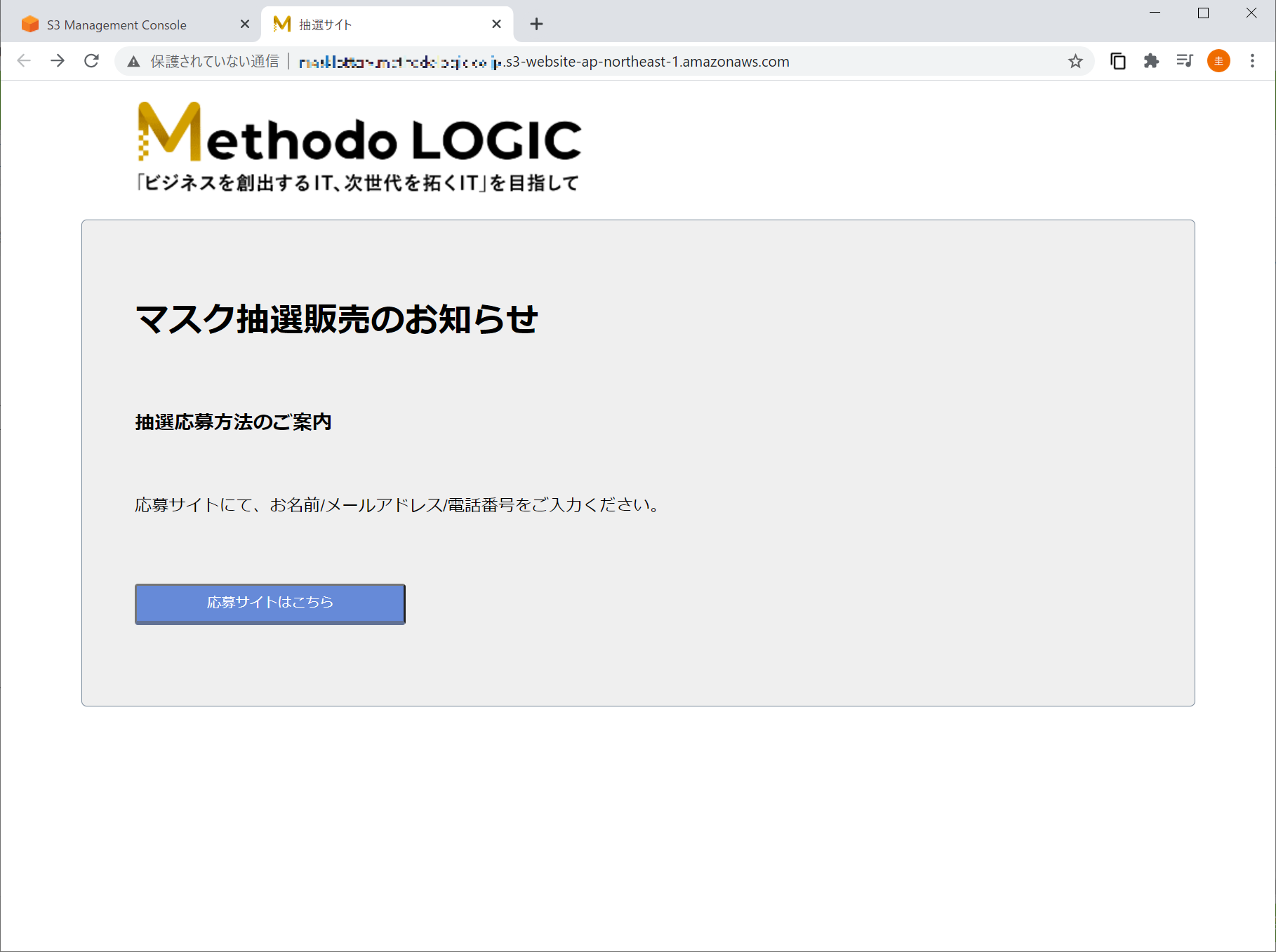
表示されている URL をクリックして
ぎゃー、でた。
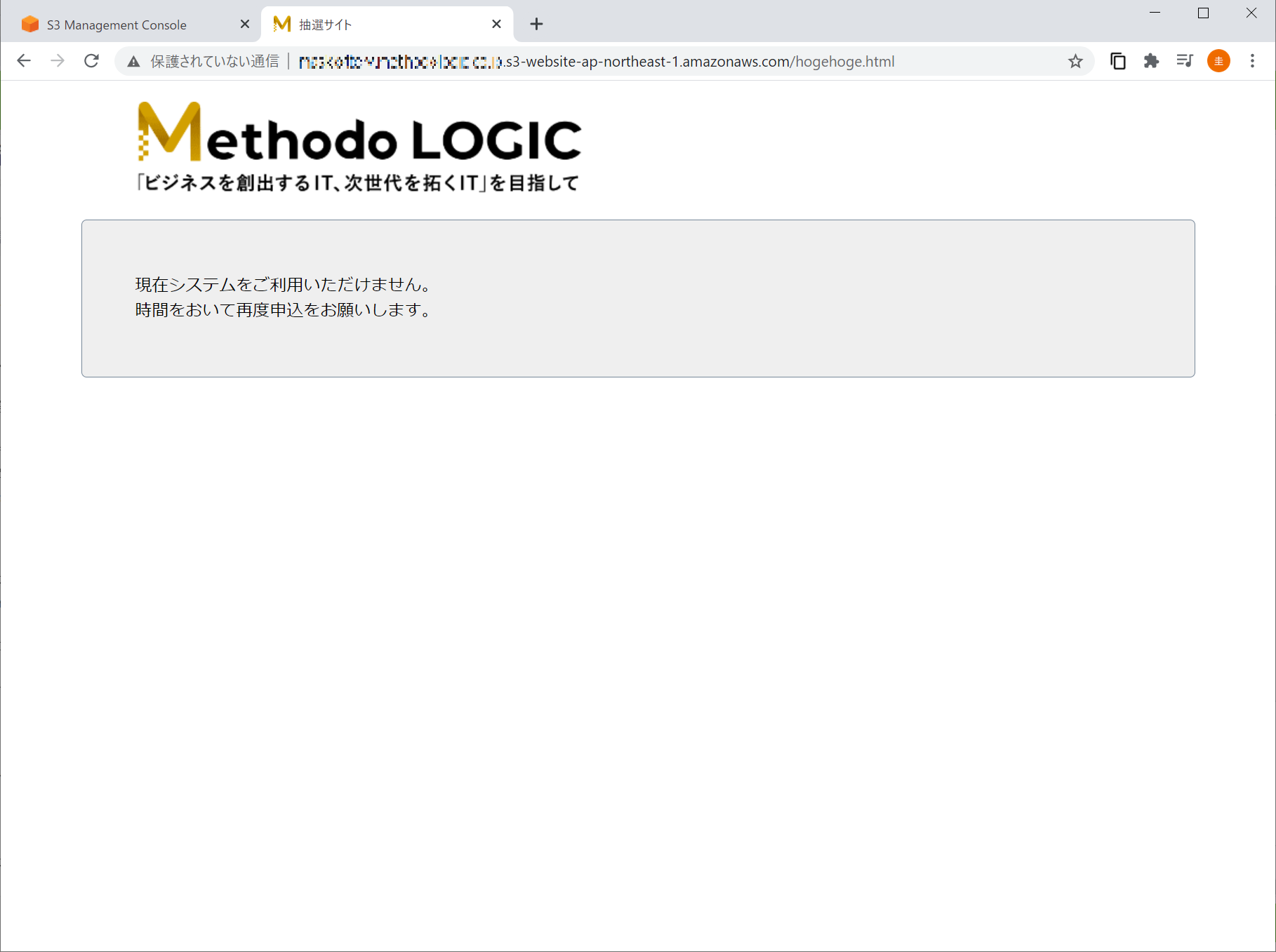
念の為、存在しない URL を叩いてみる。
静的ウェブサイトホスティングで設定したエラーページを表示してくれるのね。
メッセージが妥当でないことは目を伏せるとして。自前で Apache をこねくり回していた若き日のソレは遠い過去ですな。
CloudFront 経由でアクセス
公式のハンズオンとチュートリアルのトレースに勤しむ。
設定はというと枠で囲った4箇所のみ。
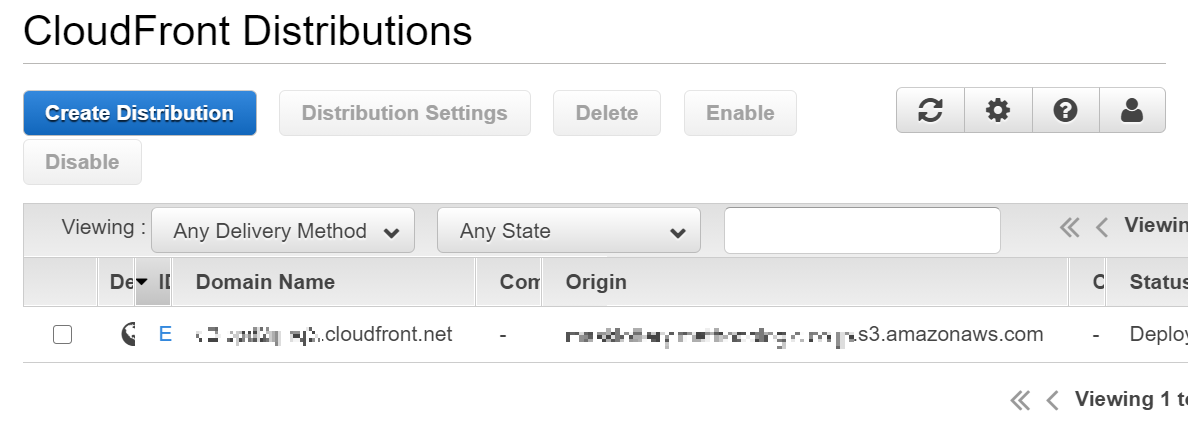
ほどなくCloudFront と S3 の紐付けが完了。
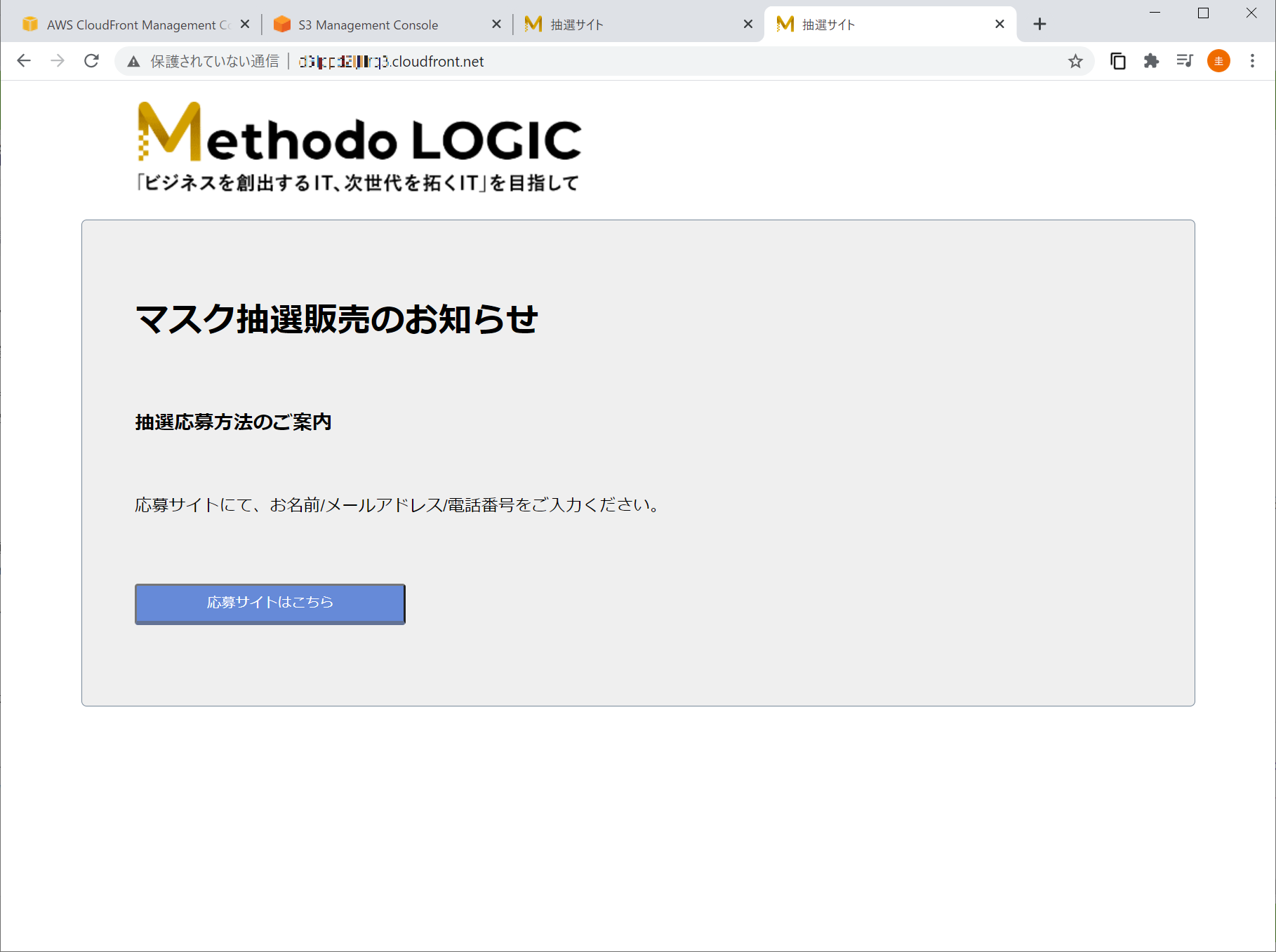
Domain Name にある URL を叩くと
あっさりと、でた。
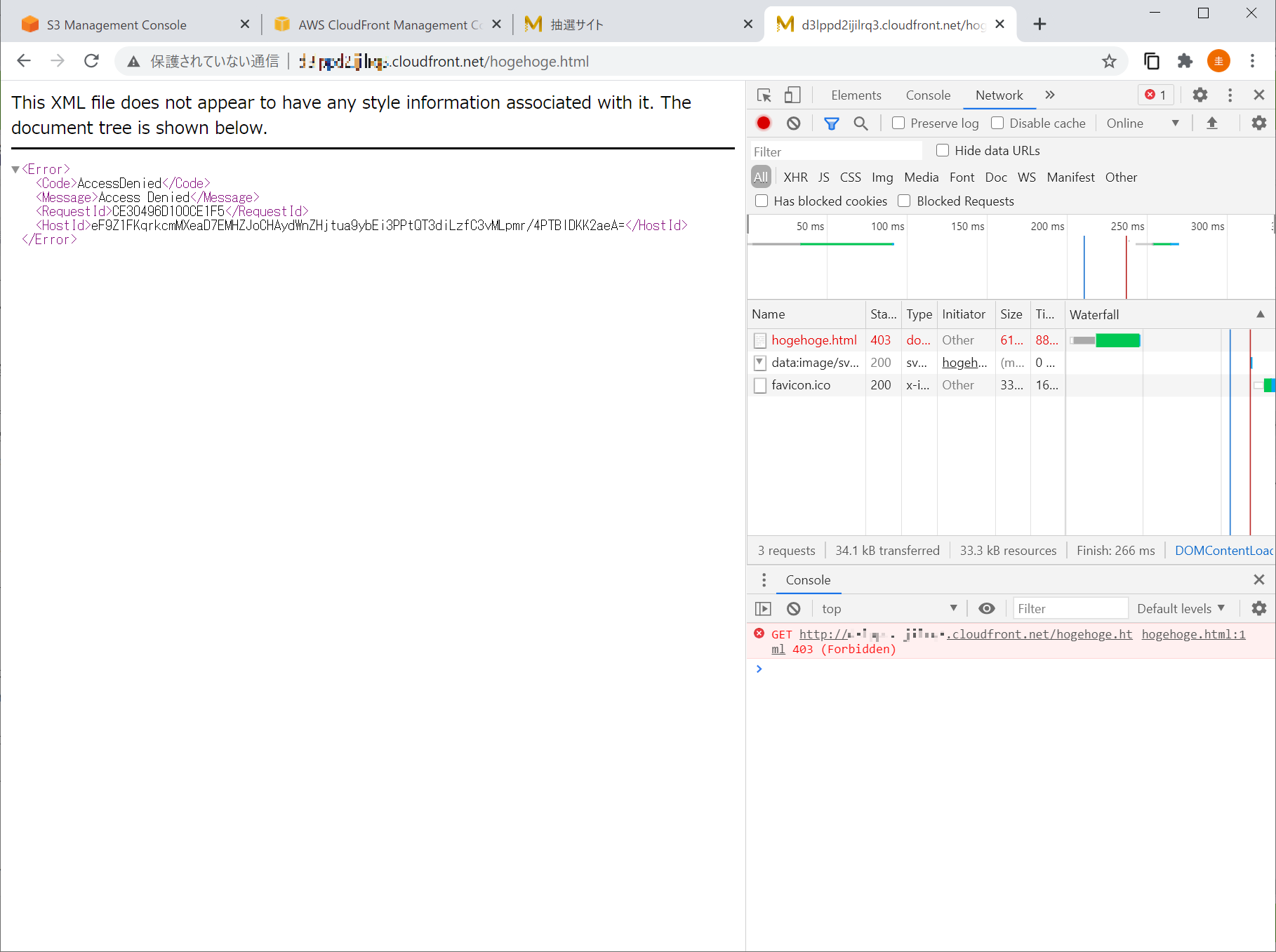
ところが存在しない URL を叩くと予想外の XML 形式のレスポンスが目に映る。
CloudFront 側でエラーレスポンス動作を設定しておかないとコレらしい。
HTTP エラーコードが 404 じゃなくて 403 なのが引っかかるけど。
Web の集合知によれば、S3 と CloudFront はこういうものらしい。
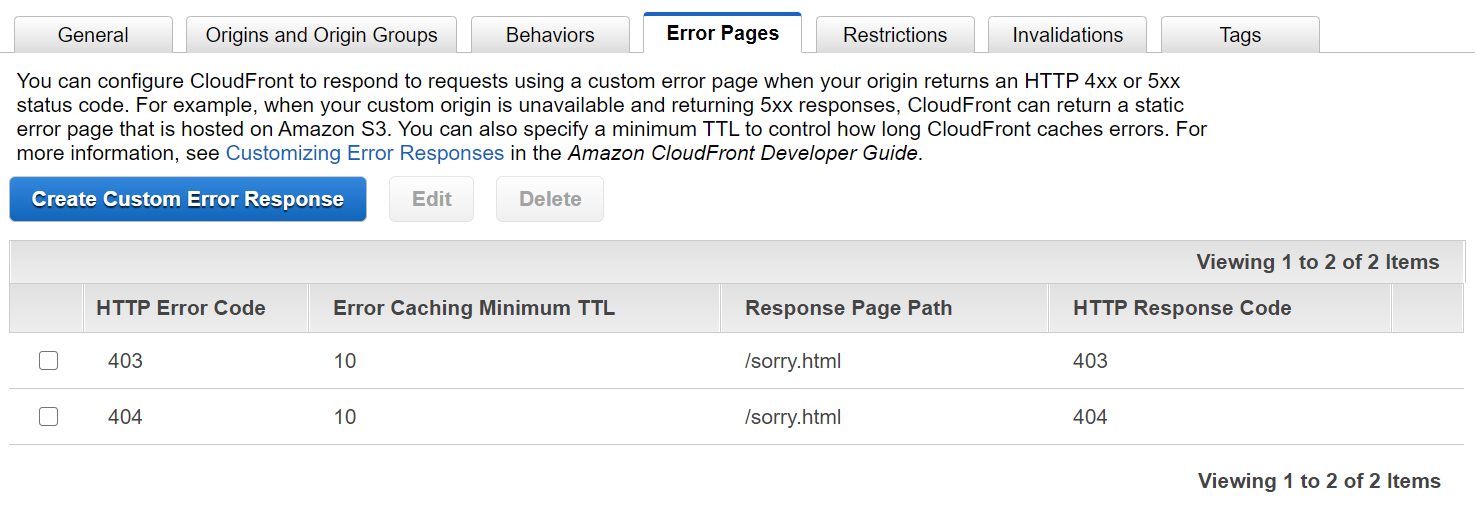
理解が追いつかないので思考停止気味に CloudFront の Error Pages の設定を開いて、
静的なサイトだから 403 と 404 で十分だろう、と設定を追加してみると、
いえす、でた。
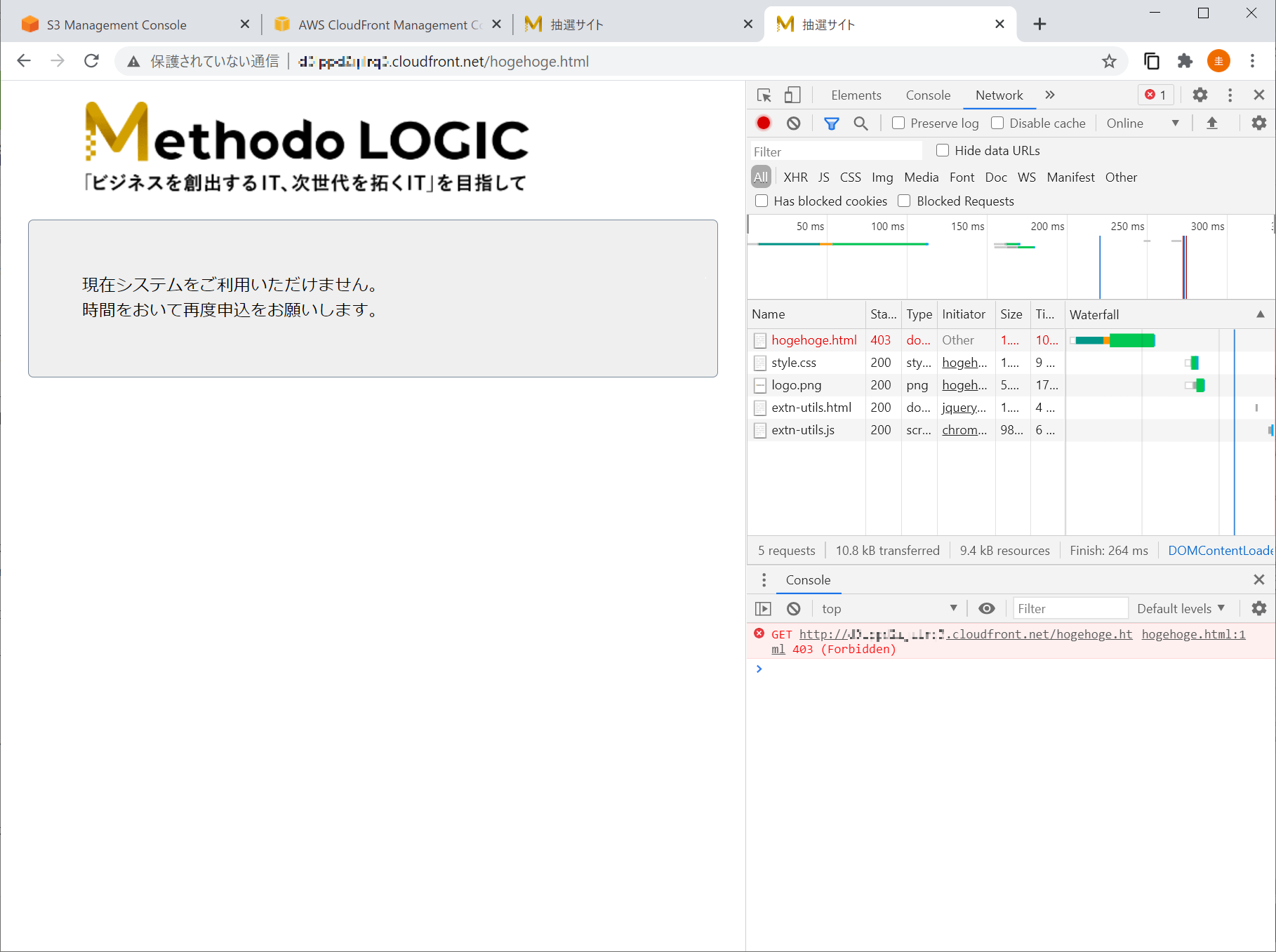
ふんふん、でも、この時点では S3 への直接アクセスも可能なのよね。
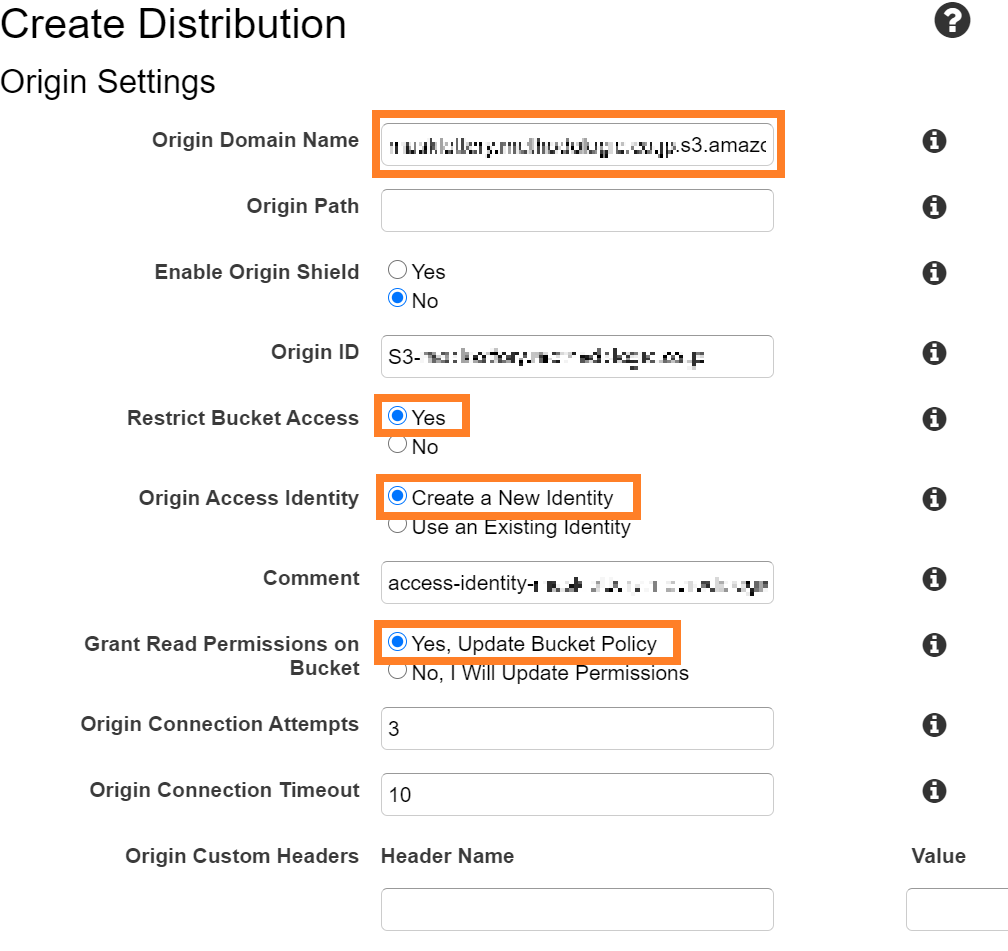
CloudFront 経由でのみアクセスできるようにしたいのよね。OAI による制限
OAI(Origin Access Identity)というのがあるらしい。
CloudFront で OAI を設定すると、S3 へのアクセスを CloudFront 経由のみに制限できるらしい。
らしいのだが、実は前段で OAI は既に設定済みなわけで。
らしいのだが、S3 に直接アクセスもできちゃっているわけで。
理解が追いつかないまま現実逃避しようとしていたら、OAI の設定に関する公式の資料中にこんな記述があったわけで。注: この設定では、バケットで静的ウェブサイトホスティングを有効にする必要はありません。この設定では、静的ウェブサイトホスティング機能のウェブサイトエンドポイントではなく、バケットの REST API エンドポイントを使用します。
つまり、静的ウェブサイトホスティングは不要だったわけで。
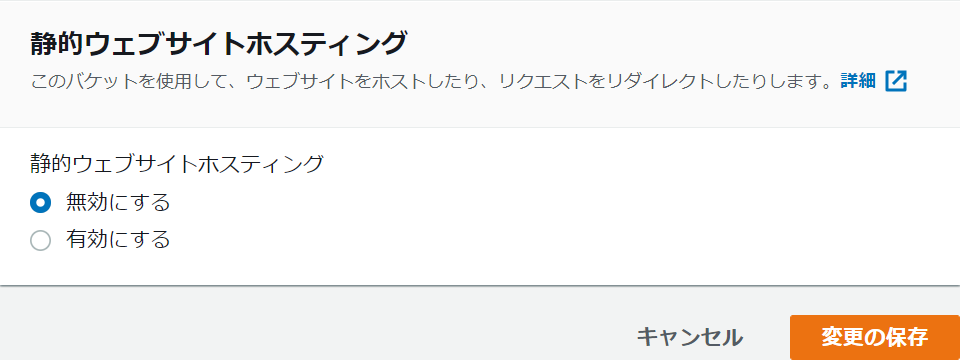
ところで、S3 で静的ウェブサイトホスティングを有効にすると「ウェブサイトエンドポイント」ってのが次の形式で作られる。
- s3-website ダッシュ (-) リージョン ‐ http://bucket-name.s3-website-Region.amazonaws.com
- s3-website ドット (.) リージョン ‐ http://bucket-name.s3-website.Region.amazonaws.com
いま、S3 への直接アクセスに利用しているのは、この URL だ。
理解が追いついた。
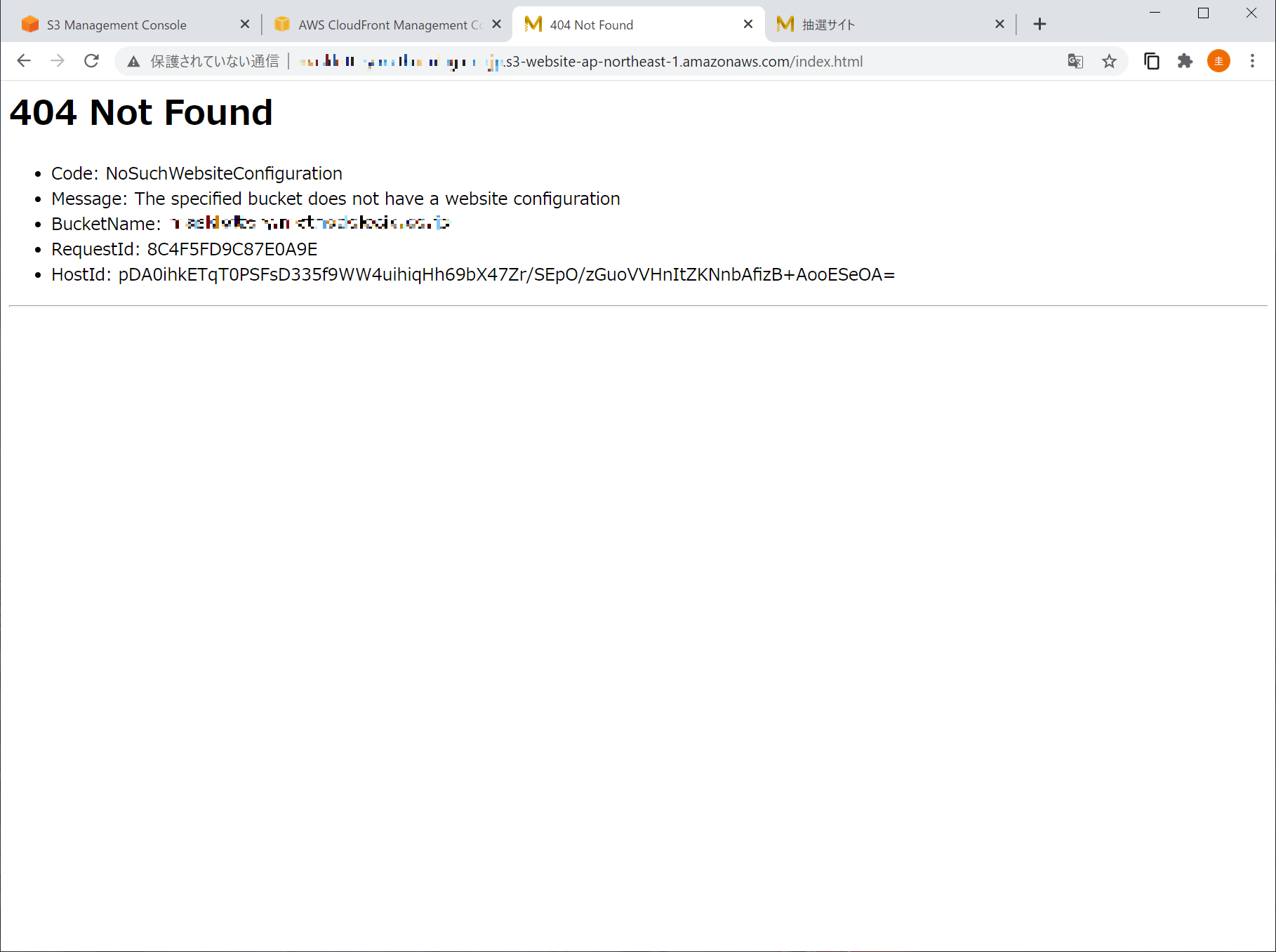
S3 で静的ウェブサイトホスティングを無効化すれば、この URL は使えなくなるはず。
使えなくなったはずの URL を叩いてみると、
おーいえす。
こっちは 404 だな。
ということで今回の目的は達した。
株式会社メソドロジック
三嶋 圭 @k-mishima参考

- 投稿日:2021-03-04T02:17:08+09:00
AWS CLI の出力結果を整形する
はじめに
AWS CLIを使う中で、「出力結果、今回はここまでいらないんだよな…」と思いつつ対応しませんでした。
夜中ですが、悔いが少し残っていたのでゆるーく試してみる。
結果的には、jqコマンドまたは、--queryでgrepできますという話です。
(みなさんはきっとすでにご存知のはず…浅い人間で申し訳ないです)達成したいこと
例えば、IAMユーザとユーザーグループを作成済みの状態とする。
AWS CLIで出力される結果から、欲しい情報だけ抜き取って表示したい。
GroupNameだけをリストで表示させたりとかですね。$ aws iam list-groups-for-user --user-name QiitaExecutionTerraformer { "Groups": [ { "Path": "/", "GroupName": "QiitaExecutionTerraformerGroup", "GroupId": "AGPAQZTTHPWT6US2TTDIT", "Arn": "arn:aws:iam::055002496423:group/QiitaExecutionTerraformerGroup", "CreateDate": "2021-03-03T16:01:50Z" }, { "Path": "/", "GroupName": "MiscGroup", "GroupId": "AGPAQZTTHPWT73DH67YCF", "Arn": "arn:aws:iam::055002496423:group/MiscGroup", "CreateDate": "2021-03-03T16:01:50Z" } ] }環境
Mac OS X 10.14.1 x86_64
$ aws --version aws-cli/1.18.110 Python/3.8.7 Darwin/20.2.0 botocore/1.17.33 $ terraform -version Terraform v0.13.5 + provider registry.terraform.io/hashicorp/aws v3.18.0事前準備
以下のようなファイルを作成し、
applyしておく。$ export AWS_ACCESS_KEY_ID=[アクセスキー] $ export AWS_SECRET_ACCESS_KEY=[シークレットアクセスキー] $ export AWS_DEFAULT_REGION=ap-northeast-1 $ aws sts get-caller-identity --query Account --output text $ terraform init $ terraform applymain.tfresource "aws_iam_group" "qiita_terraformer" { name = "QiitaExecutionTerraformerGroup" } resource "aws_iam_group" "misc_terraformer" { name = "MiscGroup" } resource "aws_iam_user" "terraformer" { name = "QiitaExecutionTerraformer" tags = { Name = "qiita_example" } } resource "aws_iam_user_group_membership" "terraformer" { user = aws_iam_user.terraformer.name groups = [aws_iam_group.qiita_terraformer.name, aws_iam_group.misc_terraformer.name] }versions.tfterraform { required_providers { aws = { source = "hashicorp/aws" version = "3.18.0" } } required_version = "0.13.5" }grepの方法
ほんの少ししか調べてませんが、2つのやり方があります。
他にもたくさんの選択肢があるでしょう。
- AWS CLI で
--queryオプションを使うjqコマンドを使うそれぞれ使っていきます。
AWS CLI で
--queryオプションを使う
keyを指定して、valueのみを出力する
$ aws iam list-groups-for-user --user-name QiitaExecutionTerraformer --query 'Groups[].GroupName' [ "QiitaExecutionTerraformerGroup", "MiscGroup" ]出力するkey名を指定する
--queryでは、keyを任意の値に設定できるので、簡潔なキーの名前にすることもできるみたいです。$ aws iam list-groups-for-user --user-name QiitaExecutionTerraformer --query 'Groups[].{name:GroupName}' [ { "name": "QiitaExecutionTerraformerGroup" }, { "name": "MiscGroup" } ]
jqコマンドを使うAWS CLIの出力形式のデフォルトは、JSONです。なので、
jqコマンドでgrep可能です。AWS CLI は、次の 4 つの出力形式をサポートしています。
・json – JSON 文字列形式で出力されます。
・yaml – YAML 文字列形式で出力されます。(AWS CLI バージョン 2 でのみ利用できます。)
・yaml-stream – 出力はストリーミングされ、YAML 文字列としてフォーマットされます。ストリーミングにより、大きなデータ型の処理を高速化できます。(AWS CLI バージョン 2 でのみ利用できます。)
・text – 複数行のタブ区切り文字列値の形式で出力されます。これは、grep、sed、または awk などのテキストプロセッサに出力を渡すのに役立ちます。
・table – セルの罫線を形成する文字列 +|- を使用して表形式で出力されます。通常、情報は他の形式よりも読みやすい「わかりやすい」形式で表示されますが、プログラムとしては役立ちません。
(出力形式は5つに見えますが…)
JSONということで、 key, valueで絞れることが確認できればいいです。
jqコマンドを自分で考えて実行するのは初めてだったりします…。keyを指定する
$ aws iam list-groups-for-user --user-name QiitaExecutionTerraformer | jq ".[][].GroupName" "QiitaExecutionTerraformerGroup" "MiscGroup"valueを指定する
$ aws iam list-groups-for-user --user-name QiitaExecutionTerraformer | jq '.[][] | select(.GroupName | contains("Qiita"))' { "Path": "/", "GroupName": "QiitaExecutionTerraformerGroup", "GroupId": "AGPAQZTTHPWT6US2TTDIT", "Arn": "arn:aws:iam::055002496423:group/QiitaExecutionTerraformerGroup", "CreateDate": "2021-03-03T16:01:50Z" }部分一致かつ出力するvalueを指定したものはこんな感じ。
$ aws iam list-groups-for-user --user-name QiitaExecutionTerraformer | jq '.[][] | select(.GroupName | contains("Qiita")) | .GroupName' "QiitaExecutionTerraformerGroup"最後に
出力長いのなんとかしたいなぁというもやもやは解消できたので、あとは使い慣れていくだけ。
- 投稿日:2021-03-04T00:48:35+09:00
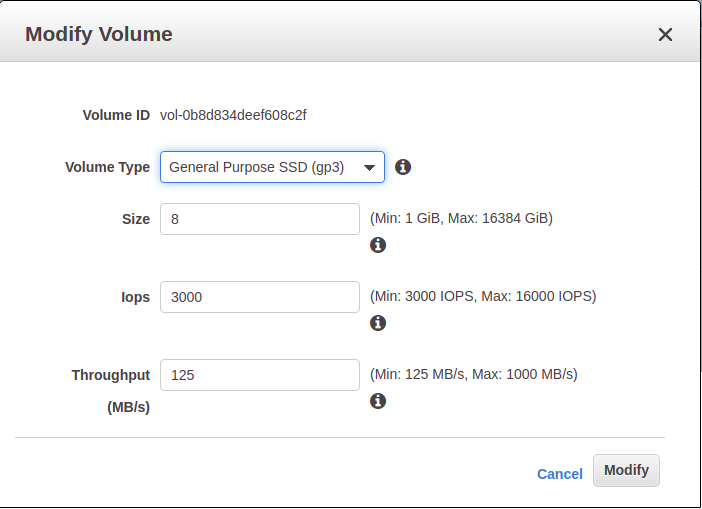
AWSのコストを素早く節約する必要がありますか?gp3へのアップグレードがおすすめです
AWSのEC2インスタンスを数多く利用しているのであれば、パフォーマンスを上げながらストレージコストを最大20%削減するという、早くて手間のかからない方法が登場しています。AWSはgp3 EBSボリュームの提供を開始しました
2020年のre:inventの際にAWSでgp3ボリュームタイプが最初に登場した後、多くの問題点がありましたが、今回はその問題点を解決するためにgp3ボリュームタイプが登場しました。
しかし、現在、それらの問題はほぼ修正されているようです。それについては最後にお話します
gp3とは?
亀田治伸氏のAWSブログにもあるように、gp3はEBSボリュームタイプの7番目のバリエーションです。ベースラインが100IOPSで、33GB以上のストレージであれば1GBあたり3IOPSが追加で提供されていたgp2とは異なり、gp3では標準で3000IOPSが125MB/sのスループットで無料で提供されています。このIOPSは、gp2ではオプションではなかったストレージに依存しないプロビジョニングも可能です。これは何を意味するのかというと、ストレージではなく、より多くのIOPSが必要な場合にのみIOPSの料金を支払うということです
このような大幅なパフォーマンスの向上のためのコストはいくらでしょうか?
ゼロです。実際、あなたは gp2 から gp3 へのアップグレードでお金を節約することができます。
価格比較をしてみましょう - ムンバイ地域(インド)
gp2のコスト:ストレージ=0.114ドル/GB/月
gp3のコスト:ストレージ=0.0912ドル/GB/月アップグレードは環境への影響はありますか?
ダウンタイムは全くありません。アップグレードは非常に簡単で、EBSボリュームを変更するのと同じくらい簡単です。変更はバックグラウンドで行われるので、何も気にする必要はありません。また、変更が発生している間、インスタンスにパフォーマンスの影響はありませんので、ただ座ってリラックスすることができます。
しかし、アップグレード後の読み取りと書き込みのレイテンシには、非常に小さなパフォーマンスの問題があります。それについては、最後に向かって議論しています。
どうやってやるのか?
AWSにログインする
AWSコンソールにクレデンシャルでログインします。
AWS EC2 ダッシュボードに移動
AWSコンソールにログイン後、EC2ダッシュボードに移動し、EC2サブサービスのある左パネルを下にスクロールします。
ボリュームタブを開く
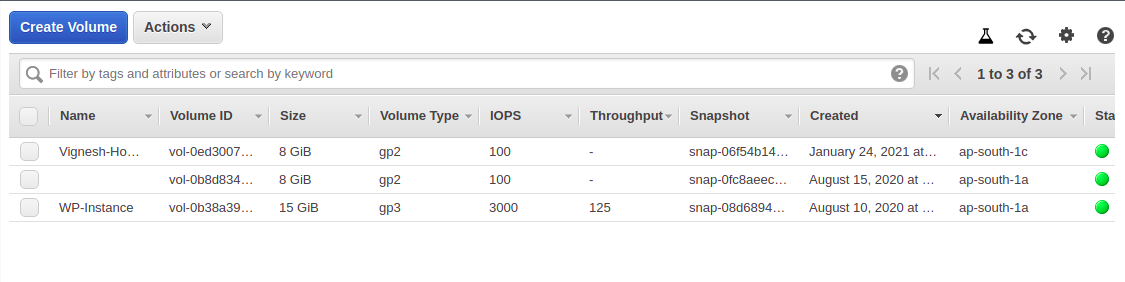
左側のパネルで、Volumes タブを開き、インスタンスが使用している EBS ボリュームを表示します。
変更したいボリュームをクリックします。
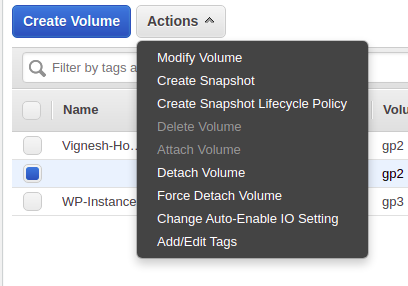
変更が必要なボリュームをクリックして、「アクション」をクリックします。
アクションからボリュームの変更をクリックし、ボリュームを変更します。
変更するボリュームを選択した後、[Actions]をクリックして、[Modify volume]をクリックします。
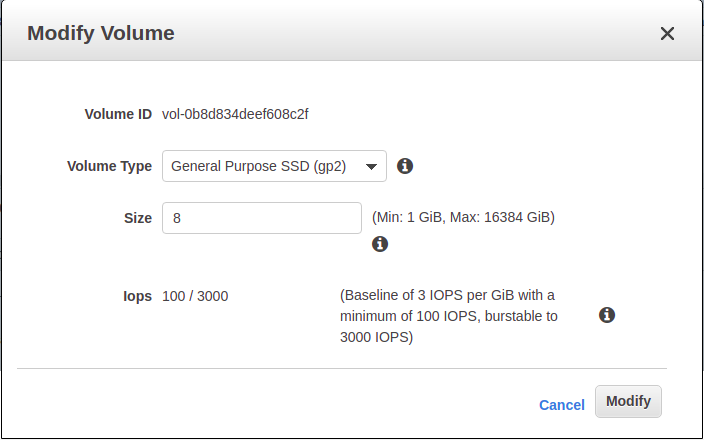
音量変更ダイアログボックスが開き、現在の音量設定が表示されます。
「ボリュームタイプ」ドロップダウンをクリックし、「汎用SSD(gp3)」を選択します。
これにより、IopsやThroughputなどの追加設定が表示されます。これらの設定はそのままにして、Modifyをクリックします。
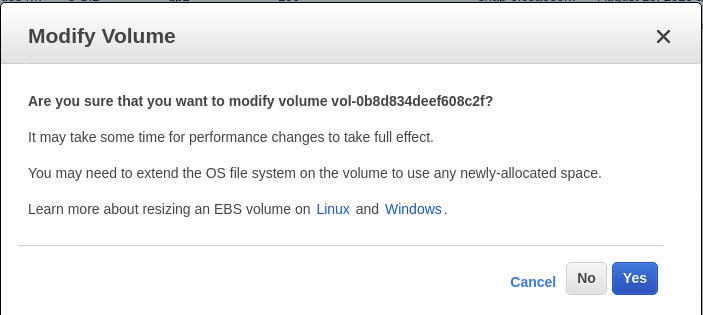
警告が表示されますが、ストレージサイズを変更していないので、無視して「はい」をクリックします。

これは、ボリュームの変更要求が成功したことを示しているので、そのダイアログボックスを閉じることができます。
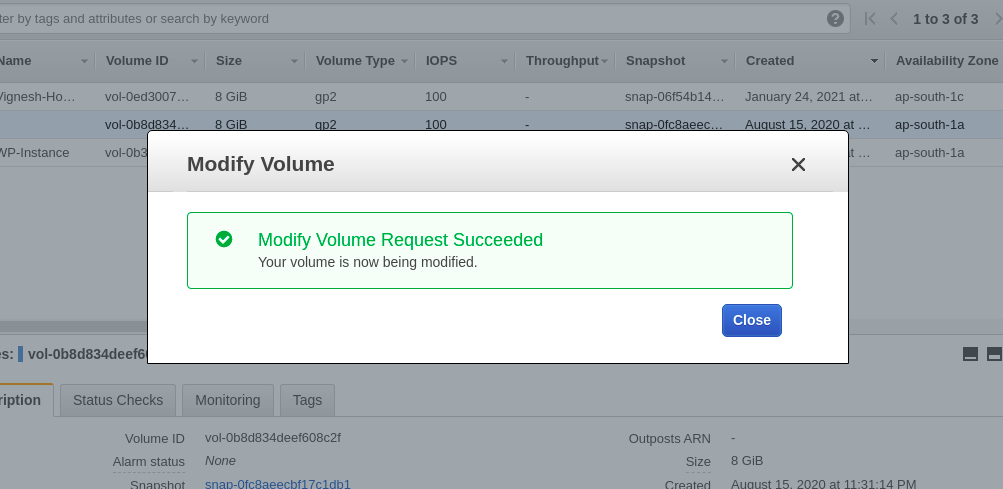
ボリュームが変更されていることを確認
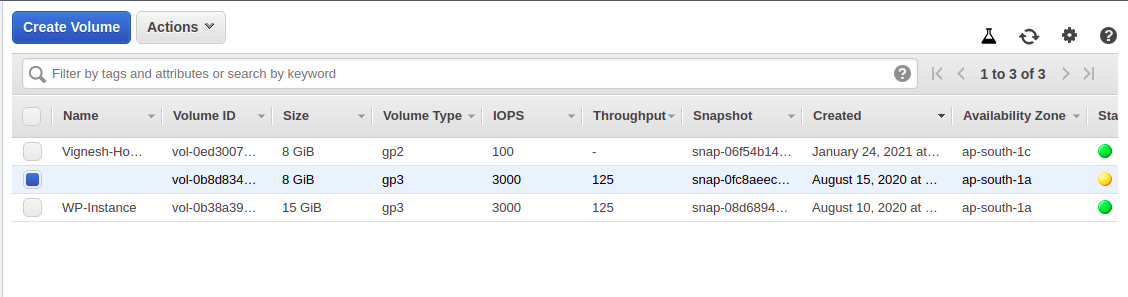
これが完了したら次のステップに進みますが、修正が正常に完了したことを確認するために、必ずボリュームダッシュボードに戻ってください。変更中のボリュームは黄色の点で表示され、正常に gp3 に変更されたボリュームは緑色の点で表示されます。
すべてのボリュームに対して上記の手順を繰り返します。
これらの手順は、すべてのEBSボリュームに対して繰り返さなければなりません。
パフォーマンスについてのさらなる議論
何人かの人がブートの問題を抱えていましたが、このフォーラムのように数日後には解決しました。
複数の人が読み書きのレイテンシが高くなったと報告していますが、私は gp2 から gp3 へのアップデート後にサーバーのボリュームでそれを見ることができました。
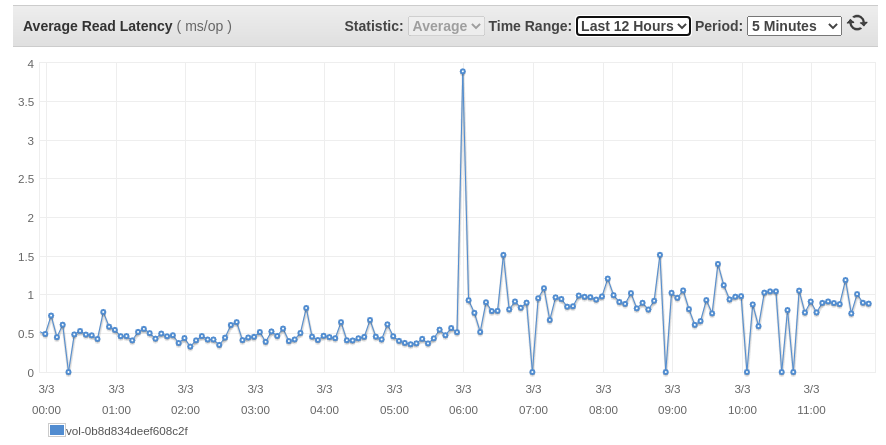
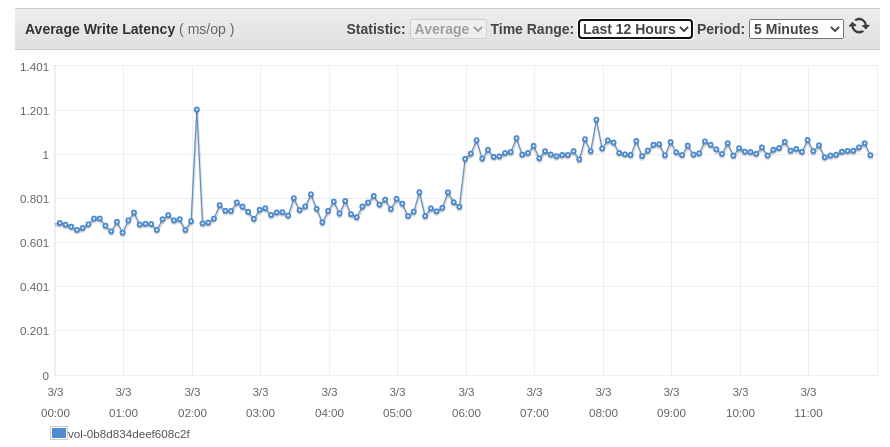
あるブログでは読み書きの遅延についても言及されており、アップグレード後に確認したところ、以下の画像のようになっていました。

私のアップデートは 05:55 UTC に行われましたが、それはスパイクが発生したまさにその時で、そこから約 200ms/op の遅延が平均的に増加しています。
彼らは残りの問題を修正したのと同じように、将来的にこれを修正する可能性が高いので、あなたがこの200ms/opの遅延の増加で大丈夫なら、何の問題もありません。
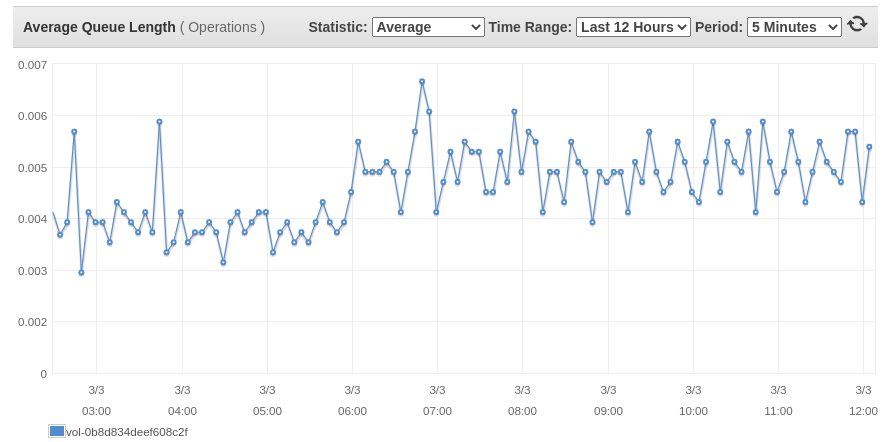
また、下の画像に示すように、平均キューの長さが非常に微小に増加しているのを見ました。
結論
gp3 EBSボリュームは、2014年にgp2がリリースされた後、ボリュームタイプに追加された本当に良いものです。これを使用してコストを削減し、EC2インスタンスのIOPSとスループットのパフォーマンスを向上させることができるAWSの顧客はたくさんいるでしょうが、読み書きのレイテンシと平均キュー長のこのわずかな増加を覚えておいてください。
これで、十分な情報に基づいた判断ができるようになりました。
- 投稿日:2021-03-04T00:03:43+09:00
AWS Developer Associate 取得までの道のりと試験対策
1. はじめに
先日、AWS 認定Developer Associate(DVA)を取得しました。
取得までの道のりと試験対策について書いてみようと思います。2. キャリア
社会人3年目のSE(アプリ寄り)
SAAは取得済(2020年)、基本情報・応用情報は持ってます。
AWSは趣味で触る程度で、業務では触った経験はほとんどありません。3. 取得を目指した経緯
社内でAWSサービス(Lambda、StepFunction、S3等)を用いた開発案件が増えてきたので、取ることを決めました。
4. 対策期間
約2カ月 ※移動や休憩時間を使って、1日30分~1時間程度は勉強しました。
5. やったこと(対策内容)
私がやったことを紹介します。
5.1. AWS公式の試験ガイドを読む(必須でやるべき)
試験の出題範囲や比率を確認しました。セキュリティの比率が結構多いことに驚きました。
分野 試験による比重
分野1:展開 22%
分野2:セキュリティ 26%
分野3:AWSサービスを使用した開発 30%
分野4:リファクタリング 10%
分野5:モニタリングとトラブルシューティング 12%5.2. 市販の対策本を読む(やってよかった度 ★★★★☆)
ネットや本屋で探しても、DVA特化の対策本が無いようです。
DVA特化では無いですが、対策本として、1つだけあったのが、以下書籍です。
購入して、DVAに関連する内容だけ読みこみました。広く浅く知識をつけるには丁度良いと思いました。AWS認定アソシエイト3資格対策~ソリューションアーキテクト、デベロッパー、SysOpsアドミニストレーター~ (日本語)
https://www.amazon.co.jp/dp/48659419915.3. AWS公式の試験認定準備コース(Exam Readiness: AWS Certified Developer – Associate (Digital) )の動画を見る。(やってよかった度 ★★★★★)
DVAの出題分野、内容等を動画で解説してくれています。
数問、模擬問題も用意してくれているので、試験の全体感を掴むのに良かったです。
個人的にですが、受験する方は必須でやっても良いのかなと思います。5.4. 関連しそうなサービスのBlackBeltを読む(やってよかった度 ★★☆☆☆)
少し深めの内容まで書いてあるので、1つ1つのサービスの知識の底上げに良いと思います。
各サービスの知識はある程度はありましたが、不安な内容もあったので、軽くながし見しました。以下は、私が確認した資料です。アソシエイトレベルの内容を超えているものも多いと感じたので、必須ではないかと思います。
DynamoDB Lambda API Gateway CI/CD関連(CodeDeploy、Build等) セキュリティ関連(IAM、cognito等)
5.5. AWS公式のサンプル問題を解く(やってよかった度 ★★★★★)
7/10でした。サンプルなので、満点を取りたかったんですが、そうはいきませんでした。まあまあ難しいです。
5.6. 問題集を繰り返し解く(やってよかった度 ★★★★★)
対策本と同じく、市販の問題集等はありませんでした。Udemyやwhizlabs等にも問題集はありましたが、私は、以下サイト(AWS WEB問題集で学習しよう)を使用しました。
DVAはダイヤモンドプランになるので、少し高い(90日 / 5480円)ですが、近々SOAも取得予定なので、こちらにしました。
回答後すぐに答えが出て、かつ簡単な解説がついているので、非常に良かったです。6. 受験結果
近所のテストセンターで受験しました。糖分を大量に補給し、頭フル回転で挑みました笑
860/1000点で合格。720点以上が合格です。7. 振り返り
2カ月勉強したのに点数がそこまで伸びなかったのは悔しかったです。900点は超えたかった…。まあ合格できたので良かったです。SAAの時もあったんですが、日本語翻訳がおかしい問題が何問かありました。英語に戻して、読むと良いと思います。
この調子でSysOpsアドミニストレーターアソシエイト(SOA)も取得しようと思います。8. 受験する方へのアドバイス
主観ですが、CognitoとElasticBeanstalk 関連の問題がかなり多いと感じました。対策は必須だと思います。
AWS公式の試験認定準備コース(Exam Readiness: AWS Certified Developer – Associate (Digital) )の動画は見ておいても良いかなと思います。ある程度知識がある方であれば、問題集(Udemy、whizlabs,今回紹介したkoiwaclub等)を繰り返し解くだけで、余裕で合格できると思います。関連記事&リンク
AWS Developer Associate 取得までの道のりと試験対策
AWS 認定 デベロッパー – アソシエイト
AWS WEB問題集(https://aws.koiwaclub.com/)
サービス別資料 AWS