- 投稿日:2021-03-02T21:03:39+09:00
DANet(Deep Attractor Network)の実装と解説
はじめに
音声を任意の数に分離するモデルであるDANet(Deep Attractor Network)の実装と解説をします。
DANetは論文"DEEP ATTRACTOR NETWORK FOR SINGLE-MICROPHONE SPEAKER SEPARATION"で提案されているモデルです。
このモデルを環境音データセットのESC-50を使って学習させ、その分離音性能をGNSDR、GSAR、GSIRで測定しました。実装にはTensorflowとKerasを用いました。
実装の全コードはGithubにあります。
また、それらを実行して学習やGNSDR等の測定ができるGoogle Colabのファイルもあります(GithubのDANet.ipynbをGoogle Colabで開いたもの)。
公式のPytorchを用いた実装もGithubに公開されています。
- 追記(2021/3/10)
数式を画像からTeX式の埋め込みに変更しました。概要
以下のように分けて説明します。
1. 実行したPythonのパージョンと使用したパッケージ
2. データの前処理
3. モデルの構成
4. 分離音性能の評価
5. パッケージとしての利用1. 実行したPythonのバージョンと使用したパッケージ
- Python 3.7.10
- TensorFlow 2.4.1
モデルの構築に利用- museval 0.4.0
SDR、SIR、SARの計算に利用- SoundFile 0.10.3.post1
音声のファイルへの書き込みに利用- pandas 1.1.5
音声ラベルのcsvデータを扱う際に利用- numpy 1.19.5
各種計算、配列処理等に利用- scipy 1.4.1
ハニング窓の計算に利用- librosa 0.8.0
音声のファイルからのロード、リサンプリング、短時間フーリエ変換等の音声処理に利用- matplotlib 3.2.2
スペクトログラムや音声波形の描画に利用2. データの前処理
論文での実験通りに行いました。
まず、入力音声を8000Hzでリサンプリングし、window lengthを32ms、hop sizeを8ms、窓関数をハニング窓の平方根とした短時間フーリエ変換を行いました。その後、絶対値を取ってから自然対数を取り、時間方向の次元数を100にしたものをモデルへの入力としました。3. モデルの構成
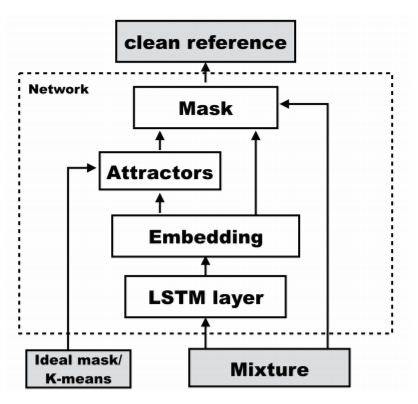
画像の引用元:
Zhuo Chen, Yi Luo, Nima Mesgarani, "DEEP ATTRACTOR NETWORK FOR SINGLE-MICROPHONE SPEAKER SEPARATION," arXiv preprint arXiv:1611.08930v2, 2017
https://arxiv.org/pdf/1611.08930.pdf
まず、入力音声を双方向LSTMに入力し、その結果を結合することで周波数方向の次元数を600にします。
そして全結合層に入力し、周波数方向の次元数を129(モデル入力時の周波数方向の要素数)×20(embedding空間の次元数)にし、Reshapeすることで周波数方向とembedding空間方向に分離します。その後、訓練時には下の式によりAttractorを計算します。
Vは入力音声のEmbedding結果であり、Yはideal mask(各時刻、各周波数において、混合音声の中で振幅が一番大きい音声を1、そうでない音声を0としたもの)を表します。A_{c,k} = \frac{\sum_{f,t}V_{k,ft} \times Y_{c,ft}}{\sum_{f,t}Y_{c,ft}}推論時にはVをkmeansクラスタリングし、そのときの中心点を用いることでAtractorを生成します。
また、AttractorとEmbedding結果を用いて下式のようにしてMaskを計算します。
M_{f,t,c} = Sigmoid(\sum_{k} A_{c,k} \times V_{ft,k})混合音声の分離が難しいような条件のときはSigmoid関数の代わりにSoftmax関数を用いることもでき、今回の実装でもSoftmax関数を用いました。
M_{f,t,c} = Softmax(\sum_{k} A_{c,k} \times V_{f,t,k})Maskを混合音声とかけることにより分離音声が生成され、モデルの出力となります。なお、推論時には混合音声として、短時間フーリエ変換した後に絶対値や対数を取っていない位相付きのスペクトログラムを用い、モデルの出力を逆短時間フーリエ変換することで音声波形に戻せるようにしました。
また、損失は下の式(正解音声とモデルの出力との差の二乗和)をf(周波数方向の次元数)×t(時間方向の次元数)で割ったものを用いました。L = \sum_{f,t,c} \|S_{f,t,c} - X_{f,t} \times M_{f,t,c}\|_2^24. 分離音性能の評価
参考: https://library.naist.jp/mylimedio/dllimedio/showpdf2.cgi/DLPDFR009675_P1-57
推定音声を$ \hat{s}(t) $とし、下のように正解音声$ s_{target}(t) $、非正解音声$ e_{interf}(t) $、ノイズ$ e_{artif}(t) $と分解しました。
\hat{s}(t) = s_{target}(t) + e_{interf}(t) + e_{artif}(t)これらの値から、SDR、SIR、SARが下の式から計算されます。
SDR = 10 \log_{10} \frac{\|s_{target}(t)\|^2}{\|e_{interf}(t) + e_{artif}(t)\|^2}\\ SIR = 10 \log_{10} \frac{\|s_{target}(t)\|^2}{\|e_{interf}(t)\|^2}\\ SAR = 10 \log_{10} \frac{\|s_{target}(t) + e_{interf}(t)\|^2}{\|e_{artif}(t)\|^2}今回はmusevalというパッケージを用いてこれを計算しました。
また、この計算における推定音声の部分を混合音声に変えてSDRに対応するものを計算し、SDRからその値を引いたものがNSDRとなります。
NSDR、SIR、SARの各平均をとったものがGNSDR、GSIR、GSARとなり、これが論文で使用されている分離音性能の評価の指標となります(数値が大きいほど性能が高い)。5. パッケージとしての利用
Githubに載せた実装をパッケージとして利用することで、ESC-50データセットの内2種類の音声を混ぜ、その分離を学習させることが簡単にできます。
実装したモデル自体は他のデータを用いたり3種類以上の音声を分離したりすることも可能ですが、データの前処理や訓練データ、テストデータの生成に関するモジュールは上の場合にしか対応していません。
パッケージのインストール、インポート
$pip install git+https://github.com/KMASAHIRO/DANetimport DANetESC-50データセットの用意
$wget https://github.com/karoldvl/ESC-50/archive/master.zip $unzip master.zipデータの前処理(リサンプリング、短時間フーリエ変換等)
# 短時間フーリエ変換後の音声をFouriers、音声の種類を表す名前をsound_namesに格納 Fouriers, sound_names = DANet.preprocess.preprocess(labelpath="ESC-50-master/meta/esc50.csv", audiopath="ESC-50-master/audio/")モデルを構築
model = DANet.models.create_model()モデルの学習
# 学習データを生成するジェネレータをメソッドとして含むクラスのインスタンスを作成 Generator = DANet.generating_data.generator(Fouriers, sound_names) # batch sizeを指定 batch_size=25 # batch sizeからsteps数(1 epochにジェネレータを呼び出す回数)を計算 steps = Generator.get_steps(batch_size) #学習(下の場合、混合させる音は風の音とカエルの鳴き声、epoch数は20) model.fit(x=Generator.generator_train('wind','frog',batch_size), steps_per_epoch=steps, epochs=20, initial_epoch=0)テストデータによる推論
# テストデータを生成する関数をメソッドとして含むクラスのインスタンスを生成 create_test_data = all_test_data(Fouriers,sound_names) # テストデータ、混合させる前のテストデータ(後の評価に利用)を生成 test_data, before_data = create_test_data.generate_data('wind','frog') # 推論 result = model.prediction(test_data)音声波形への復元
# 分離前の音声(before)、混合した音声(mixed)、分離後の音声(after)を生成 before, mixed, after = DANet.evaluation.return_to_sound(result, before_data)分離音性能の評価
# 一つずつの推論結果に対してNSDR、SIR、SARを計算 NSDR_list, SIR_list, SAR_list = DANet.evaluation.evaluation(before, mixed, after) # GNSDR、GSIR、GSARを計算 GNSDR, GSIR, GSAR = DANet.evaluation.final_eval(NSDR_list, SIR_list, SAR_list)
- モデルの重みを保存
filepath = "DANet_weights_wind_frog.h5" model.save_weights(filepath, save_format='h5')
- モデルの重みをロード
model = DANet.models.create_model() filepath = "DANet_weights_wind_frog.h5" model.loading(filepath)
- 復元した音声を保存する
モデルへの1回の入力に対応する分離前の音声、混合した音声、分離後の音声を保存します。
# numは保存するテストデータのindexを示す。 num = 0 DANet.evaluation.save_sound(num, before, mixed, after)
- 音声波形のグラフを保存する
モデルへの1回の入力に対応する分離前の音声波形、混合した音声波形、分離後の音声波形を保存します。
# numは保存するテストデータのindexを示す。 num = 0 DANet.evaluation.save_sound_fig(num, before, mixed, after)おわりに
音声を任意の数に分離するモデルであるDANet(Deep Attractor Network)の実装と解説をしました。
混合させる音の組み合わせを様々に変えて学習させた結果もGoogle Colabに載せましたが、GSARは一部論文の結果を上回ったものがありましたが、GNSDR、GSIRについては論文の結果を超えるものはなく半分以下の値になることが多かったです。原因の1つ目としてはデータ量の違い、2つ目としては論文で分離している人の声と今回使用した環境音の性質の違いが考えられます。今回作成したパッケージを使い、ぜひ様々な音声の分離をしてみてください。
不明な点、実装コードに関するアドバイス、パッケージとして利用する際の問題などありましたらコメントお願いします。(この記事は研究室インターンで取り組みました:https://kojima-r.github.io/kojima/)
- 投稿日:2021-03-02T00:31:15+09:00
【Python】Anaconda+TensorFlow 2.3.0 (GPU) の環境構築
はじめに
最近、Pythonでディープラーニングの勉強ができる環境を構築したので、備忘録としてまとめます。PC環境は以下の通りです。
・OS: Windows 10 Pro
・CPU: intel Core i9-9900K
・GPU: Geforce RTX2070
・メモリ: 32GB特に、TensorFlowでGPUが認識されずに苦労しました。Anacondaのバージョンは4.9.2、Pythonのバージョンは3.8.5です。Anacondaにこだわる理由は、MATLABユーザの私にとって、Pythonエディタの「Spyder」が使いやすいからです。Spyderをpipでインストールして構築するのは初心者の私には無理でした。
記事の内容
Anaconda環境で、TesonrFlowをインストールする。
TensorFlowとは
TensorFlowは、Googleが公開している機械学習ライブラリです。2015年に登場したそうです。TesonrFlowはGPUを用いて高速な計算を行うことができます。GPUを使って計算ができるディープラーニングフレームワークは他にもChainerやPyTorchなどがあります。
環境構築の際の注意点
Python + TensorFlow + GPU の環境を構築する際、バージョンの対応を合わせないといけません。対応表は下記のリンクを参考にしてください。
・https://www.tensorflow.org/install/source?hl=ja#tested_build_configurations
特に、TensorFlowでGPUを認識させたい場合、cuDNNとCUDAのバージョンに注意が必要です。
本記事ではTensorFlow 2.3.0をインストールします。そのため、CUDA、cuDNNのバージョンは・CUDA: 10.1
・cuDNN: 7.6となります。
CUDA 10.1のインストール
映像を出力するためには、GPUという部品が必要です。パソコンには必ずついてます。ノートパソコンのCPUはたいてい、CPUの中にGPUが組み込まれています(内臓グラフィック)。しかし、もっと高性能なGPUを使いたい!という方は、外付けGPUを使うわけです。それがいわゆるグラボです。
そのグラフィックス担当のGPUを、グラフィックス以外に使えるようにしてやろうというのがCUDAです。CUDAは下記リンクからダウンロードできます。CUDA Toolkit 10.1 update2をインストールします。・https://developer.nvidia.com/cuda-toolkit-archive
Select Target Platformでは、
・Operating System: Windows
・Architecture: x86_64
・Version: 10
・Installer Type: exe (local)を選択します。exeを立ち上げて、CUDAをインストールできます。特別な設定はなく、インストーラーに従ってインストールすれば大丈夫だと思います。
cuDNNのインストール
cuDNNはディープラーニング用のGPU高速処理ライブラリです。下記リンクからダウンロード可能です。ダウンロードには、アカウントを作成する必要があります。
・https://developer.nvidia.com/rdp/cudnn-archive
ダウンロードしたzipファイルは、
・C:\tools\cuda\bin
に展開します。
パスの設定
システム環境変数のPathに、次のディレクトリを追加します。
・C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin
・C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\CUPTI\lib64
・C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include
・C:\tools\cuda\binTensorFlowのインストール
TensorFlowはAnaconda promptを開いて以下のコマンドでインストールできます。
pip install tensorflow-gpu==2.3.0なぜ conda install を使わないのか
実は最初、conda install tensorflowでTensorFlowをインストールしてたのですが、GPUを認識せず苦労しました。conda install tensorflow では、TensorFlow 2.3.0がインストールされます。しかし、これがまずいらしい。
参考記事
1. TensorFlow2.1でCuda10.1なのにGPUが認識されない問題の解決法
2. Why is Tensorflow not recognizing my GPU after conda install?参考記事1によると、tensorflowのビルドはeigen, gpu, mklの3種類が存在していて、これが適切でないとGPUを認識してくれないそうです。そこで、Anaconda.org にとんだところ、tensorflow2.3.0にはgpuのビルドがないっぽい。ということで、condaではなくpipからインストールすることにしたのでした。
動作確認
Spyderを開き、下記のコードを実行します。
from tensorflow.python.client import device_lib device_lib.list_local_devices()出力はこんな感じ
Out[38]: [name: "/device:CPU:0" device_type: "CPU" memory_limit: 268435456 locality { } incarnation: 2745453239044564304, name: "/device:XLA_CPU:0" device_type: "XLA_CPU" memory_limit: 17179869184 locality { } incarnation: 13175026954206619824 physical_device_desc: "device: XLA_CPU device", name: "/device:GPU:0" device_type: "GPU" memory_limit: 6531337689 locality { bus_id: 1 links { } } incarnation: 18329998037222519679 physical_device_desc: "device: 0, name: GeForce RTX 2070, pci bus id: 0000:01:00.0, compute capability: 7.5", name: "/device:XLA_GPU:0" device_type: "XLA_GPU" memory_limit: 17179869184 locality { } incarnation: 3378513503248220410 physical_device_desc: "device: XLA_GPU device"]device_type: "GPU" との記載があるので、GPUがちゃんと認識されているようです。XLAはAccelerated Linear Algebraの略で、線形代数の演算に特化したコンパイラだそうです(参考:TensorFlowでGPUが使えることの確認)。
おわり
pipを使ってTensorFlowをインストールしました。間違っているところがあれば教えてください。