- 投稿日:2021-03-02T22:25:31+09:00
AWSでWebサイトをHTTPS化する覚書
はじめに
AWSで作成したWebサイトをHTTPS化する手順について記載します。
内容
下記の順番で実施していきますが紆余曲折があってキャプチャの前後関係がおかしいところがありますが、ご了承ください。
- Webサイトの準備
- ドメインを取得する
- 取得したドメインをDNSに登録する
- 証明書を発行する
- ELBに証明書付きドメインをアタッチ
Webサイトの準備
あらかじめEC2で作成したWebサイトを準備します。EC2のWebサイト構築は「はじめてのAWSその2 EC2のサーバを構築する」にて記載しています。
ドメインを取得する
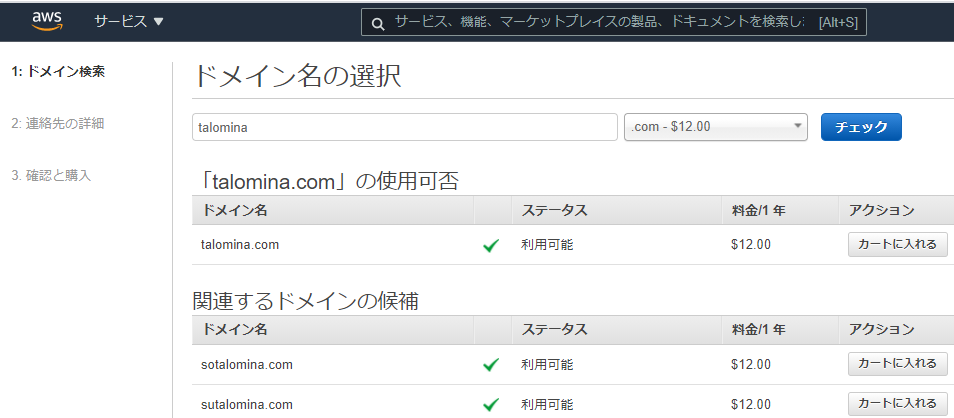
Route53でドメインを買うこともできますが、今回はフリーのドメインを取得することにしました。
Freenomのサイトでほしいドメインの利用可能状況をチェックします。
無料(0.00USD)のドメインを今すぐ入手!します。
E-MailアドレスをVerifyしてドメインを取得することができます。
取得したドメインをDNSに登録する
AWSのDNSサービスであるRoute53に取得したドメインを登録していきます。このホストゾーンには0.5USD/月ほどの料金が掛かりますので注意です。
Route53でホストゾーンの作成を行います。
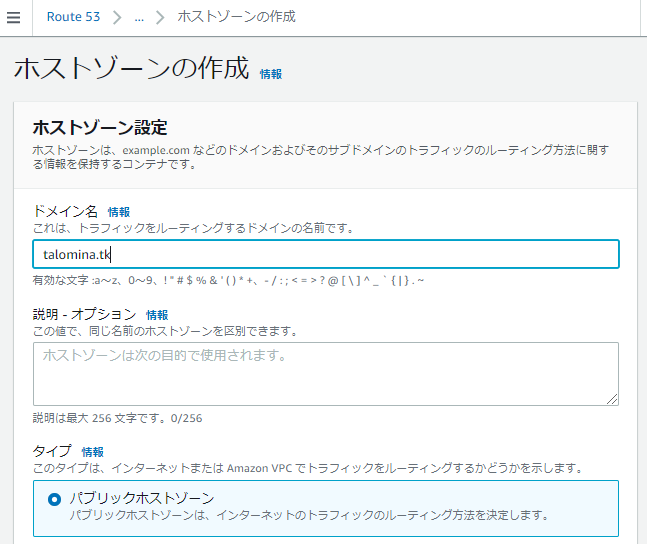
ドメイン名に先ほど取得したものを入力してホストゾーンの作成をクリックします。タイプはパブリックとしました。
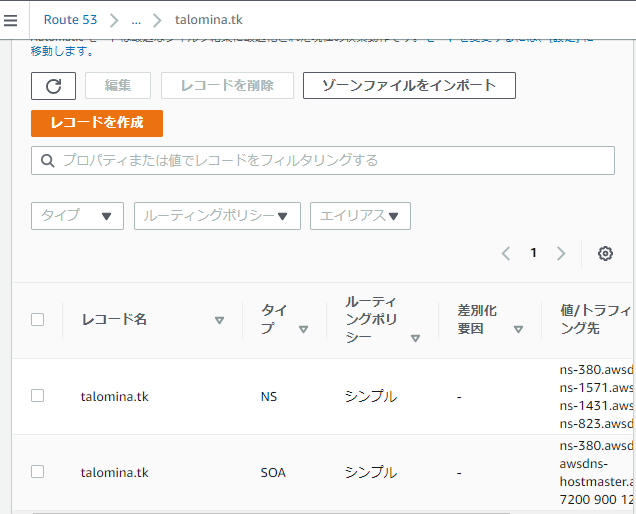
ホストゾーンができました。
ホストゾーンのNSレコードにある4つのRoute53ドメインサーバを、Freenumに登録します。
ns-380.awsdns-47.com. ns-1571.awsdns-04.co.uk. ns-1431.awsdns-50.org. ns-823.awsdns-38.net.
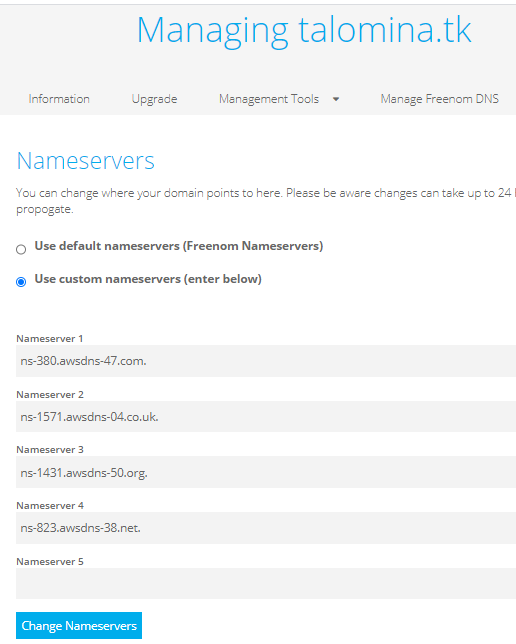
Freenumのサイトに戻ってMyDomainsからManage Domainボタンをクリックします。
Management toolメニューからName Serversを選んでUse custom nameservers (enter below)を押します。すると利用するNameserverを選ぶことができるので、Rout53のNSレコードにあった4つのNameserverの情報をインプットしてChange Nameserversをクリックします。
無事にNameserverが登録できました。これにより、取得したドメインの名前解決は、Route53のネームサーバーが使われることになります。
証明書を発行する
取得したドメインに対して証明書を発行します。ELBでも*.amazonaws.comのようなパブリックドメインが割り当てられますが、こういったAWSのドメインには証明書を発行できないようになっています。
Amazon Certificate Managerの画面で証明書のプロビジョニングを「今すぐ始める」します。
「パブリック証明書のリクエスト」を選んで「証明書のリクエスト」をします。
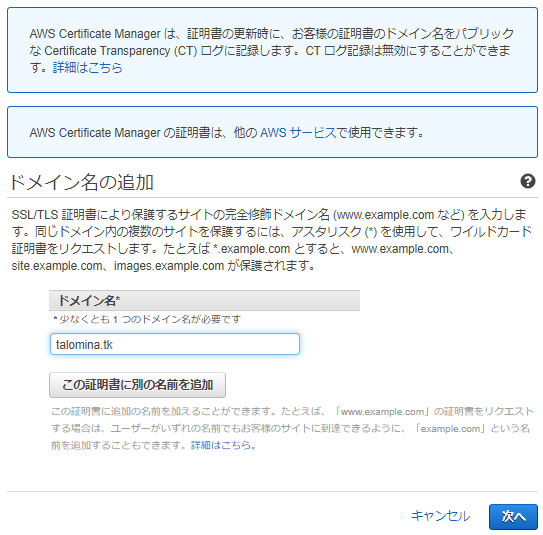
「ドメイン名」に取得したドメイン名を入れて「次へ」をクリック。
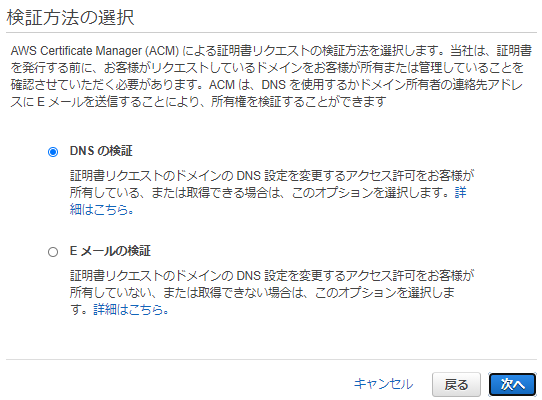
検証方法はDNSの検証を選びます。ここでメール検証を選ぶと、ドメインの管理者あてにメールが発行されて、Verifyするやり方になります。今回はドメインの管理者といっても名前を借りてきているだけなのでDNS検証の方が都合よいのです。
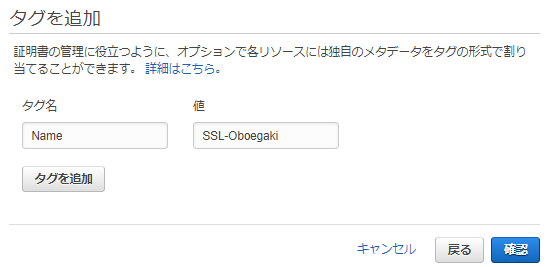
適当な名前を付けて次へ
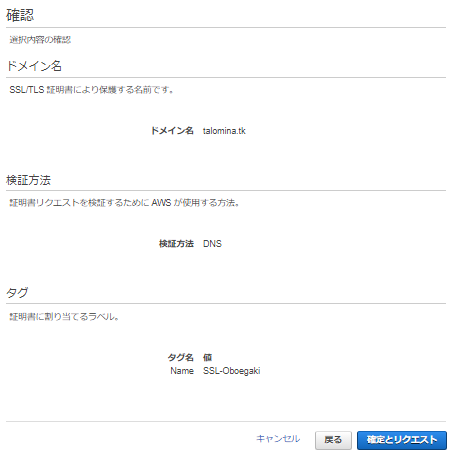
確認画面で「確認とリクエスト」します。
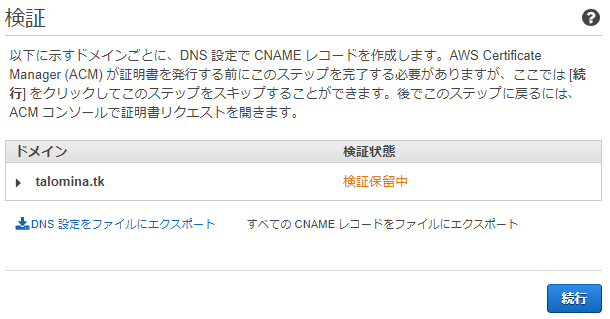
検証の画面が出てきて「検証保留中」となります。「DNS設定をファイルにエクスポート」します。
下記のようなCSVファイルが来ますのでこれをもとにRoute53に設定しに行きます。
DNS_Configuration.csvDomain Name,Record Name,Record Type,Record Value talomina.tk,_3622途中省略ae31.talomina.tk.,CNAME,_772c1途中省略3884.nfyddsqlcy.acm-validations.aws.
Route53にてCSVの内容でドメインのレコードを作成します。ここでレコードを作成できることがドメインの所有者であることの証明になって、ACMは証明書を発行するというわけです。
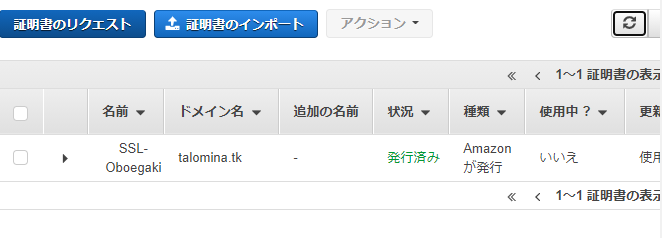
ACMに戻って10分ほど待つと無事に検証が終わりました。
ELBにドメインを紐づける
ELBの環境構築の細かい部分は「AWSでELB環境を作るための覚書」で記載しました。
まずはHTTPのターゲットグループを作成します。
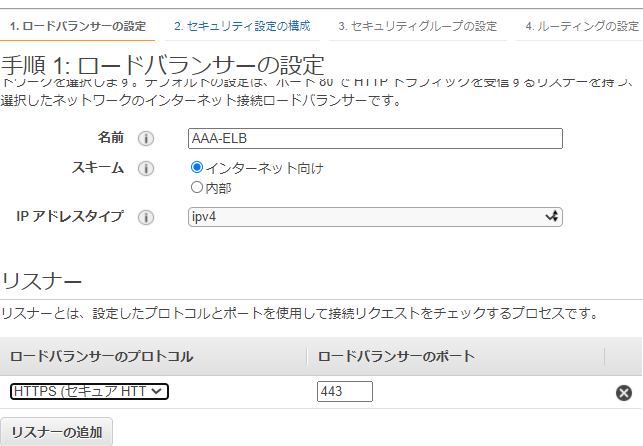
ELBでApplication Load Balancerを作成します。その際リスナーとしてHTTPSを選択します。
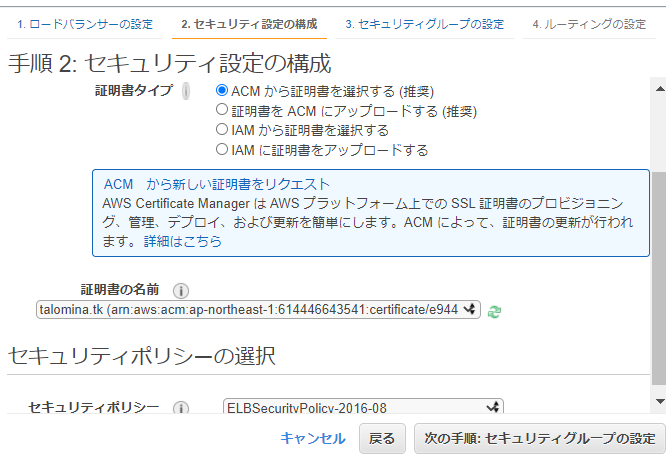
HTTPSのセキュリティ設定を行う画面で「ACMからの証明書を選択する」と、先ほど取得した証明書をアタッチできます。
あとは通常通りロードバランサを作成します。
- セキュリティグループのインバウンド側はHTTPS(443)をセットします。
- ターゲットグループにはHTTP(80)で接続します。
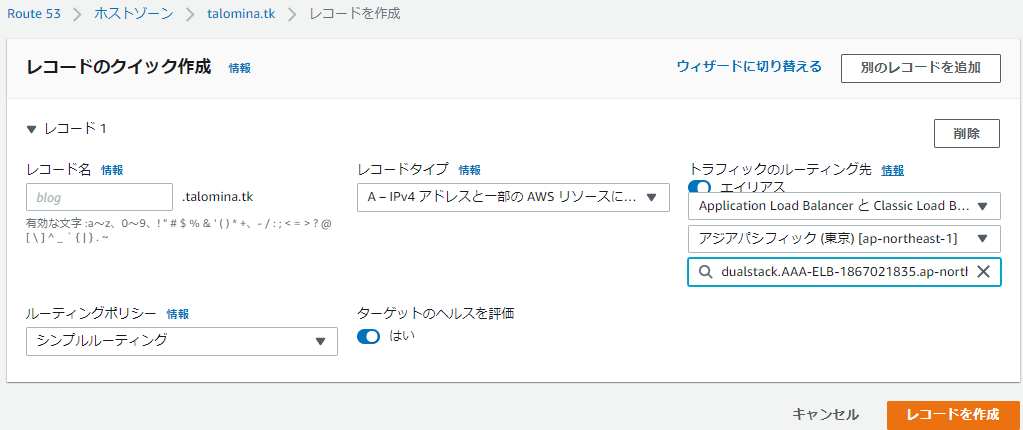
今度は作成したELBをRoute53のホストゾーンに登録します。レコード作成をクリックします。
レコード名はブランク、レコードタイプはA、トラフィックのルーティング先はエイリアス指定に切り替えることでELBを選択することができます。
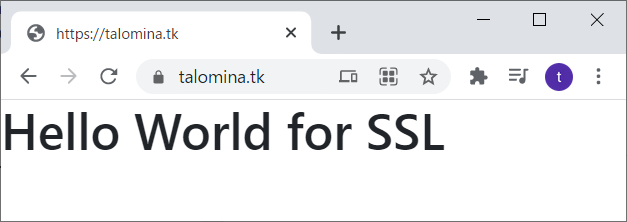
Aレコードを作成してしばらく待つとHTTPSで接続できるようになります。
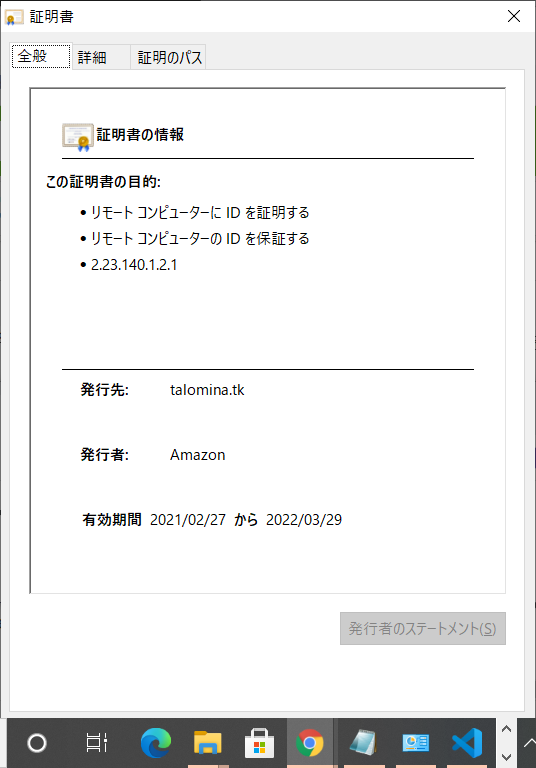
立派な証明書ももらえました。
おわりに
ACMの証明書はサーバ認証という簡易的なものですが、パブリックSSLに関しては無料で利用できます。Route53はホストゾーンの維持に少々料金がかかりますので注意。また今回無料のドメインを取得しましたが、Route53で購入すればすべてAWS内で完結することができるので非常にラクですね。
とはいえ、いろいろな手間を考えると、Webサイトを作るだけならレンタルサーバを利用したほうが圧倒的に手間もコストも少ないと感じました。
参考文献






- 投稿日:2021-03-02T22:04:07+09:00
【lambda 超初心者】CLIを使ってlambda関数を作成する
内容
AWS CLIを使って、lambda関数を作成する。
個人の備忘録であるためかなり内容が薄くなっている。
- デプロイディレクトリを作成
- Pythonコードを作成
- zip化 ライブラリやコードを含める
aws lambda create-function --funtion-name ... lambda関数名やhandler, runtimeなどの設定を行う
更新対象のコードの編集や、ライブラリの追加を行い再度zip化する
aws lambda update-function-code .. を利用してlambda 関数を更新する
参考
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/python-package-create.html#python-package-create-with-dependency
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/python-package-update.html
- 投稿日:2021-03-02T21:45:03+09:00
VPCフローログ とは
勉強前イメージ
フローログ。。。流れるログ
ログデータ取得する的な話?調査
VPCフローログ とは
VPCのネットワークインターフェイスとの間で行き来するトラフィックに関する情報をキャプチャできるようにする機能で
CloudWatch Logs か s3に発行できます。VPCフローログの特徴
- VPC/サブネット/ENI のいずれかに作成
- ENIに対して作成する場合は以下のサービスで作成したENIにもフローログを作成できる
- ELB
- RDS
- ElastiCache
- Redshift
- WorkSpaces
- NATゲートウェイ
- トランジットゲートウェイ
- フローログの取得はネットワークのスループットやレイテンシーには影響しません
VPCフローログのユースケース
- セキュリティ診断
セキュリティ要件通りに動作しているかの確認・診断などで使用することが出来ます
- 通信トラブルの調査
トラフィックのモニタリングが出来るので通信到達の切り分けが出来ます
設定方法
- フローログへ移動
- フローログの作成
- フローログの設定
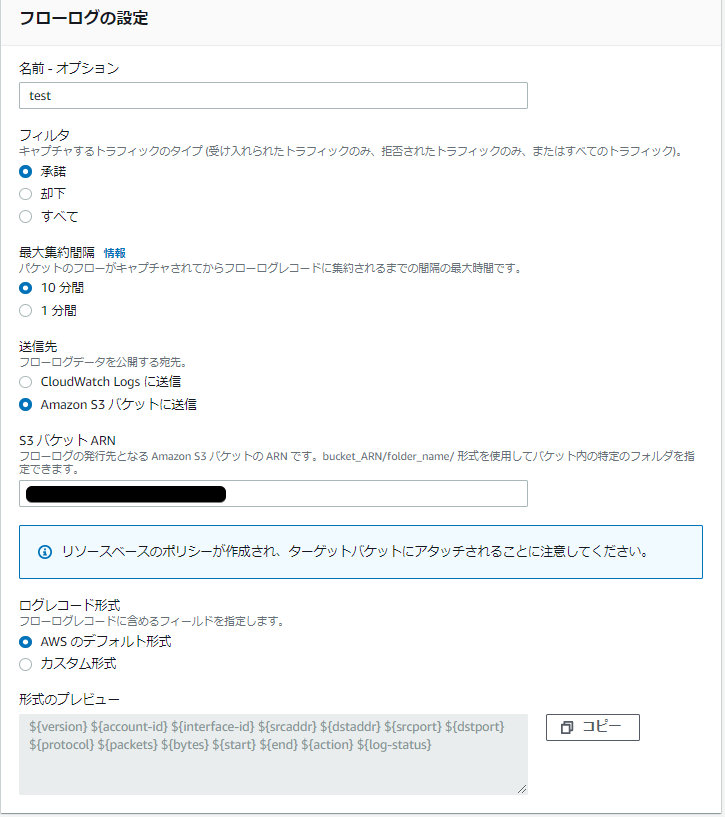
名前・フィルタ・最大集約間隔・送信先・S3バケットARN(s3の場合)・ログレコード形式 を選択します。
データはcloudwatchかs3、どちらか選択できます。
- 作成できました
勉強後イメージ
logを取る機構もいろいろあるのね。。
あとcloudwatchで見れるのもすごい・・・参考

- 投稿日:2021-03-02T20:59:33+09:00
【AWS】更新したイメージをビルドした後のECRとECSの作業手順
AWSでECRのレポジトリにあるイメージからECSでコンテナを起動しているアプリケーションで、イメージを更新した場合の対処法について。
CodePipelineで自動化もできるが、ここでは手動で更新する手順について。
目次
イメージを更新しECRにプッシュ
ローカルのプロジェクトを更新したら、イメージを作成してECRにプッシュする。
docker-compose build
↓
AWS ECRにログインaws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com↓
doker tag <対象のイメージ名:タグ名> <変更後のイメージ名:タグ名>
※イメージ名はECRのレジストリIDとエンドポイント
↓
docker push <対象のイメージ名:タグ名>ECRレポジトリを確認
イメージが正しくプッシュされているか確認する。
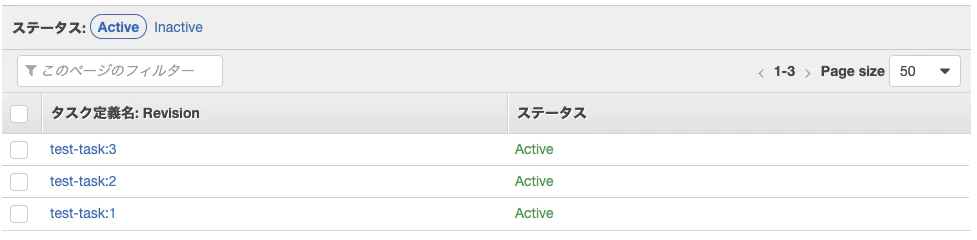
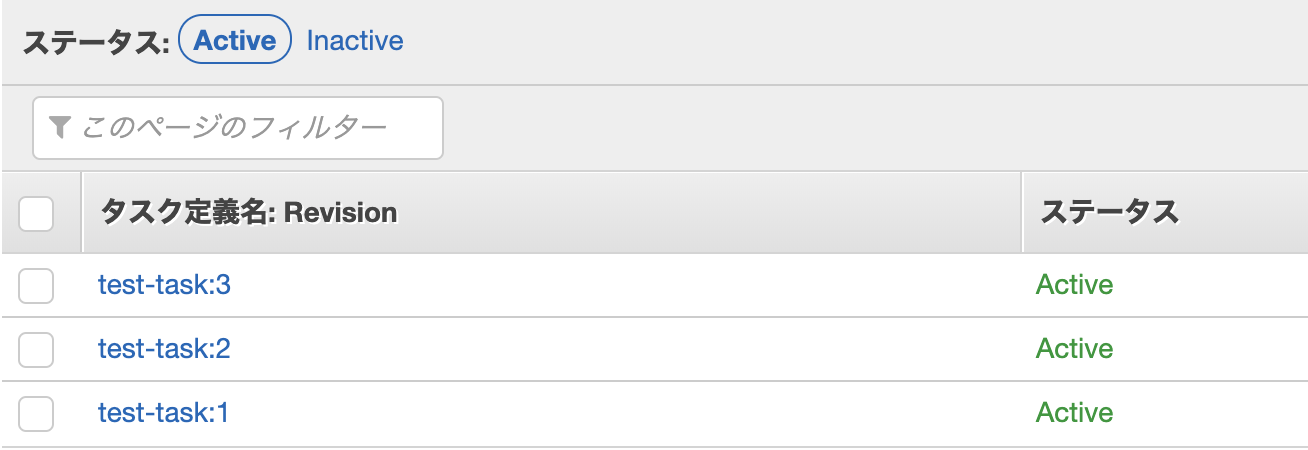
ECSのタスク定義の更新
既存のタスク定義を選択し、新しいリビジョンを作成する。
既存のコンテナをクリックし、コンテナの編集に入り、イメージの場所を新しいイメージのものに変更する。
↓ 更新
↓ 新しいタスクのリビジョンが作成されたか確認
リビジョンの番号が+1されたタスクができていれば更新は完了。
▼注意点
イメージ名とタグ名に変更がない場合でも、このタスク定義の更新を実施すること。更新しないと、古いイメージを参照してしまう。
ECSのサービスを更新
更新するのは、先ほど作成した新しいタスク定義のリビジョンのみ。
▼手順
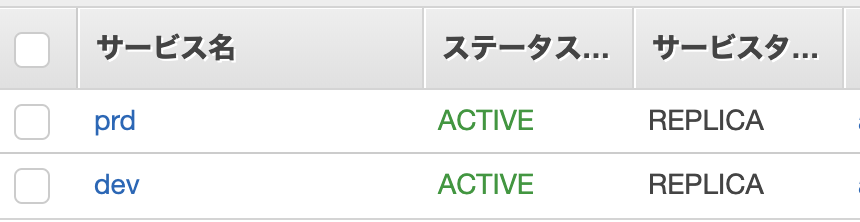
ECSで対象のクラスターの中の対象のサービスを選択
↓右上の「更新」をクリック
↓ 最新のリビジョンを選択
タスク定義で作成した最新のリビジョンを選択する
↓ 次のステップ x 4
↓ サービスの更新
↓ 確認
クラスターのタスクタブから、指定したタスク定義のリビジョンでステータスがRUNNINGになっているか確認。
デプロイまでに時間がかかるため、新しいサービスがPENDINGになっている場合もある。
Blue/Greenデプロイの場合の流れ
新しいプロジェクトを起動中
・旧: RUNNING
・新: PENDING↓
新しいプロジェクト起動完了。安定するまでの1時間はこの状態を維持
・旧: RUNNING
・新: RUNNING↓
完全に切り替わり
・新: RUNNING
以上。







- 投稿日:2021-03-02T20:59:33+09:00
【AWS】更新後のDockerコンテナを手動でデプロイする手順(ECRとECSの操作方法)
AWSでECRのレポジトリにあるイメージからECSでコンテナを起動しているアプリケーションで、イメージを更新した場合の対処法について。
CodePipelineで自動化もできるが、ここでは手動で更新する手順について。
目次
イメージを更新しECRにプッシュ
ローカルのプロジェクトを更新したら、イメージを作成してECRにプッシュする。
docker-compose build
↓
AWS ECRにログインaws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com↓
doker tag <対象のイメージ名:タグ名> <変更後のイメージ名:タグ名>
※イメージ名はECRのレジストリIDとエンドポイント
↓
docker push <対象のイメージ名:タグ名>ECRレポジトリを確認
イメージが正しくプッシュされているか確認する。
ECSのタスク定義の更新
既存のタスク定義を選択し、新しいリビジョンを作成する。
既存のコンテナをクリックし、コンテナの編集に入り、イメージの場所を新しいイメージのものに変更する。
↓ 更新
↓ 新しいタスクのリビジョンが作成されたか確認
リビジョンの番号が+1されたタスクができていれば更新は完了。
▼注意点
イメージ名とタグ名に変更がない場合でも、このタスク定義の更新を実施すること。更新しないと、古いイメージを参照してしまう。
ECSのサービスを更新
更新するのは、先ほど作成した新しいタスク定義のリビジョンのみ。
▼手順
ECSで対象のクラスターの中の対象のサービスを選択
↓右上の「更新」をクリック
↓ 最新のリビジョンを選択
タスク定義で作成した最新のリビジョンを選択する
↓ 次のステップ x 4
↓ サービスの更新
↓ 確認
クラスターのタスクタブから、指定したタスク定義のリビジョンでステータスがRUNNINGになっているか確認。
デプロイまでに時間がかかるため、新しいサービスがPENDINGになっている場合もある。
Blue/Greenデプロイの場合の流れ
新しいプロジェクトを起動中
・旧: RUNNING
・新: PENDING↓
新しいプロジェクト起動完了。安定するまでの1時間はこの状態を維持
・旧: RUNNING
・新: RUNNING↓
完全に切り替わり
・新: RUNNING
以上。
- 投稿日:2021-03-02T20:45:04+09:00
Athenaでnullなデータを読む
やりたいこと
JSONL(※)ファイルをGlue Crawlerで認識しAthenaで読む際、nullなデータがあった場合どうなるかを知りたい。
※JSON Lines。改行コードをデリミタとして1行1レコードに分割したJSONのこと。AthenaはJSONLしか扱えないので注意。
データを作る
nameをstring、ageをintと想定してサンプルデータを作る。
json-test.json{ "id": 001, "name": "Kamado", "age": 16 } { "id": 002, "name": "Kibutsuji", "age": null } { "id": 003, "name": null, "age": 19 } { "id": 004, "name": "Gyutaro", "age": 0 } { "id": 005, "name": "", "age": null } { "id": 006, "name": "Uzui" } { "id": 007, "age": 32 }% aws s3 cp ./json-test.json s3://<バケット名>/jsontest/スキーマを読み取る
jsondbというデータベースを作り、上記S3パスを走査対象としたGlue Crawlerを作成し、実行する。
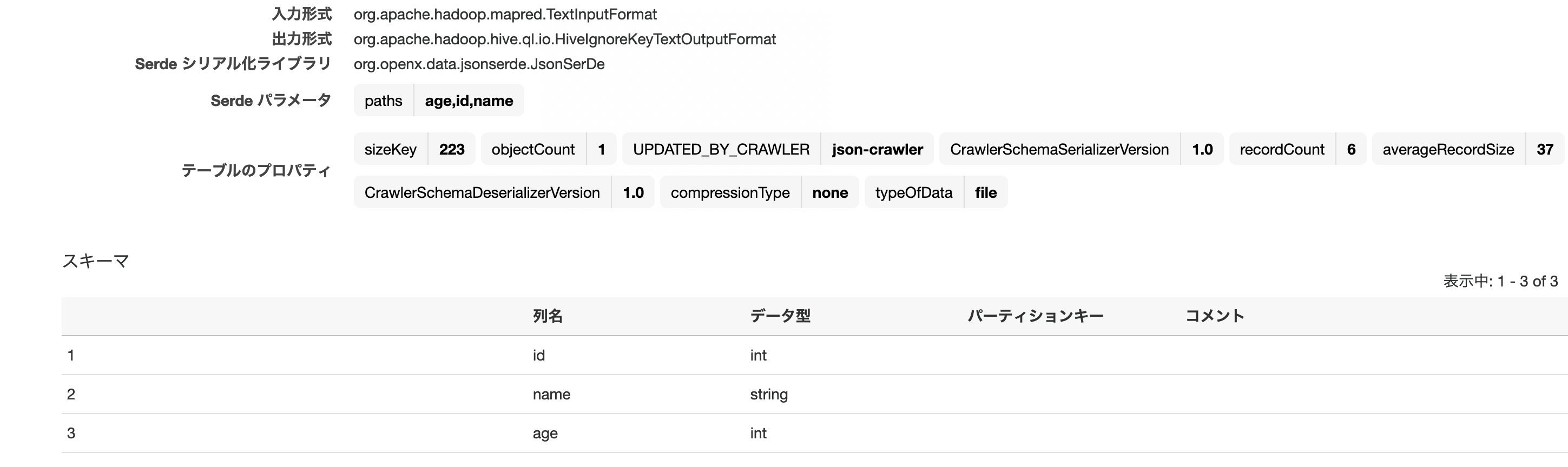
(※詳細は省略)読み取られたスキーマはこちら。
int、stringとintとして読み取られていることが分かる。テーブルはS3パス名を反映してjsontestとなっている。
Athenaで検索
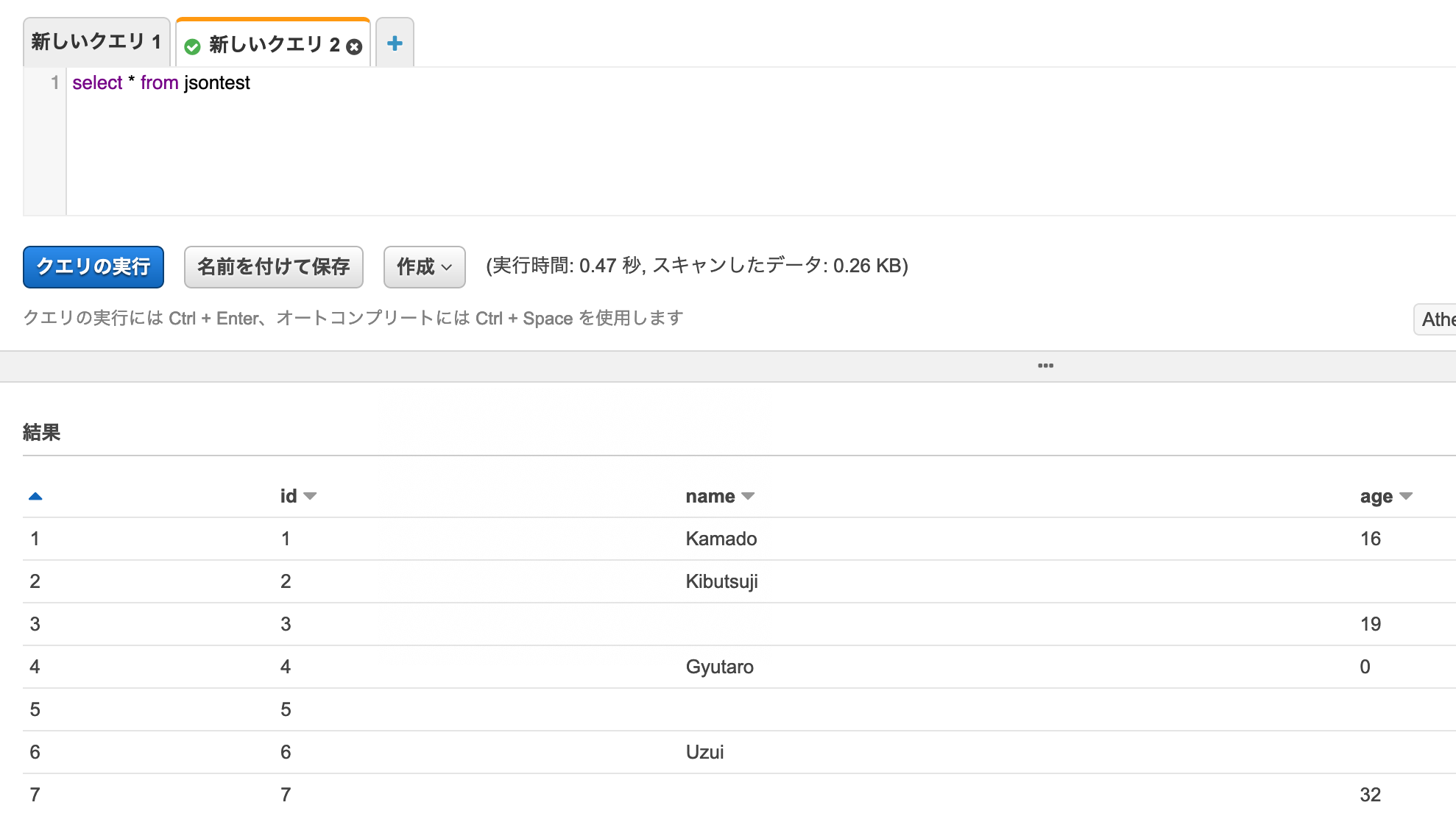
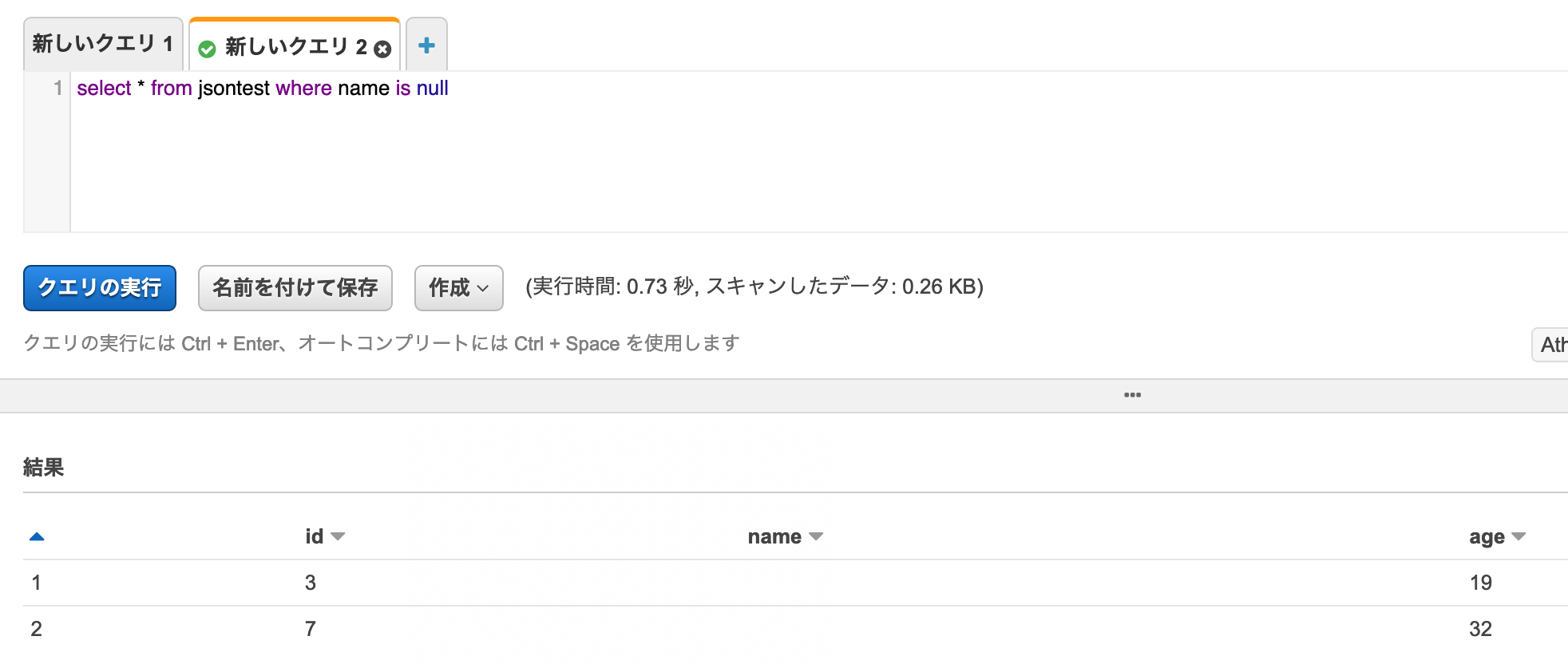
まずは全件。
null、空文字("")、項目なしは、ぱっと見いずれも同じ扱いに見える。
name(string)がnullのものをクエリーしてみる。
id=3(null)とid=7(値なし)が検索され、id=4(空文字)は除外された。
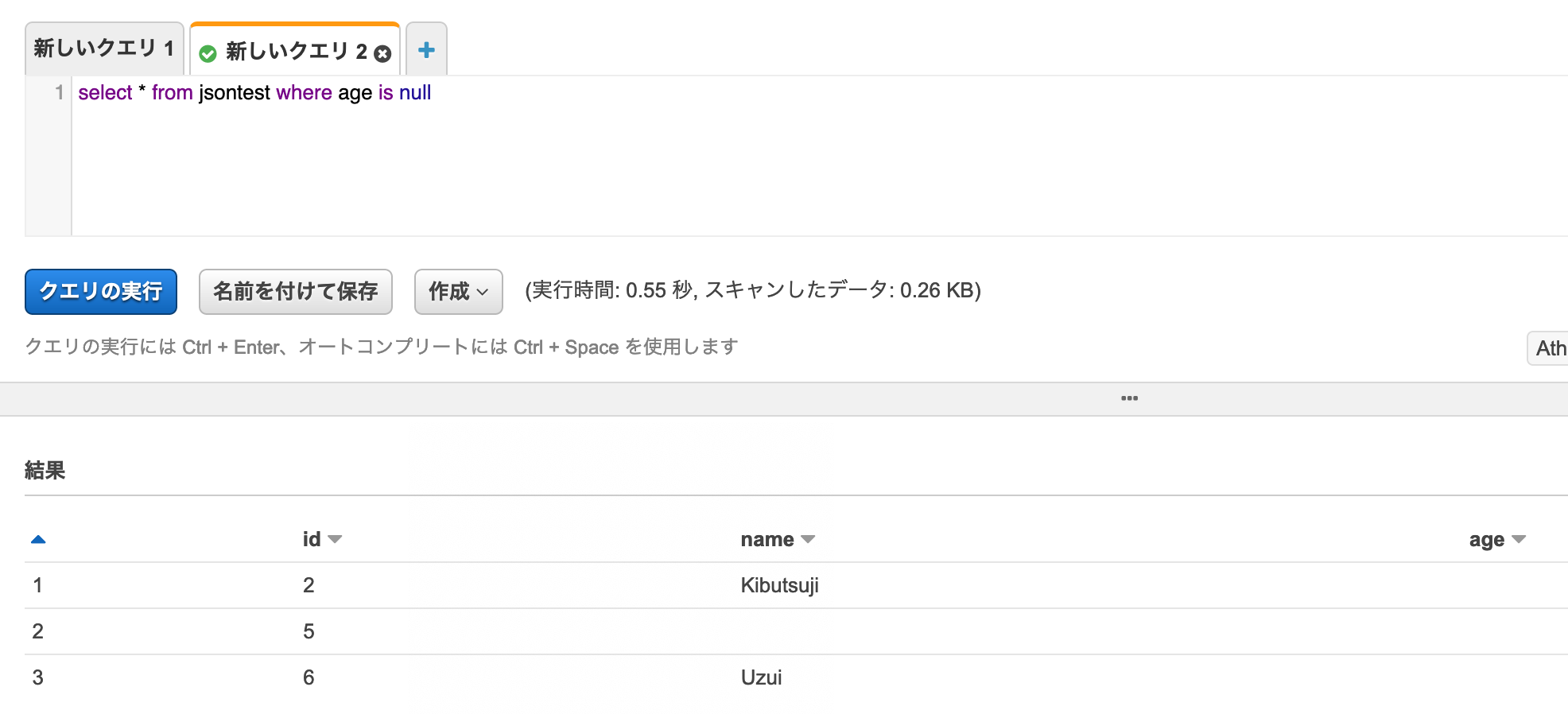
両者は同じ扱いな一方で、空文字は別扱いされていることが分かる。intについても確認。
id=2(null)、id=5(null)、id=6(値なし)が検索された。id=4(0)が除外されるのはまあ当たり前。
ここでも、nullと値なしが同じ扱いなのが確認できた。結論
- GlueでもAthenaでも、JSONLに含まれたnullを扱える。
- nullと値なしは同等の扱いのため、出力元コードやAthenaの処理量を少しでも減らしたい場合は、nullで埋めずに値なしでJSONL出力するのもあり。
- 投稿日:2021-03-02T20:18:55+09:00
AWS上でDockerを使ったプロジェクトの構造と各サービスの役割から関係性を理解する。複数のAWSサービスの連携
AWS上でDockerを使ったプロジェクトについて。ECR・ECS・EC2・ELB・Route53など多数のサービスが必要になる。
そもそも、Docker関連のECR・ECSの繋がりや、ECS内のタスク、コンテナ、クラスター、サービスの違いがイマイチ分からなかったので図で理解してみる。
目次
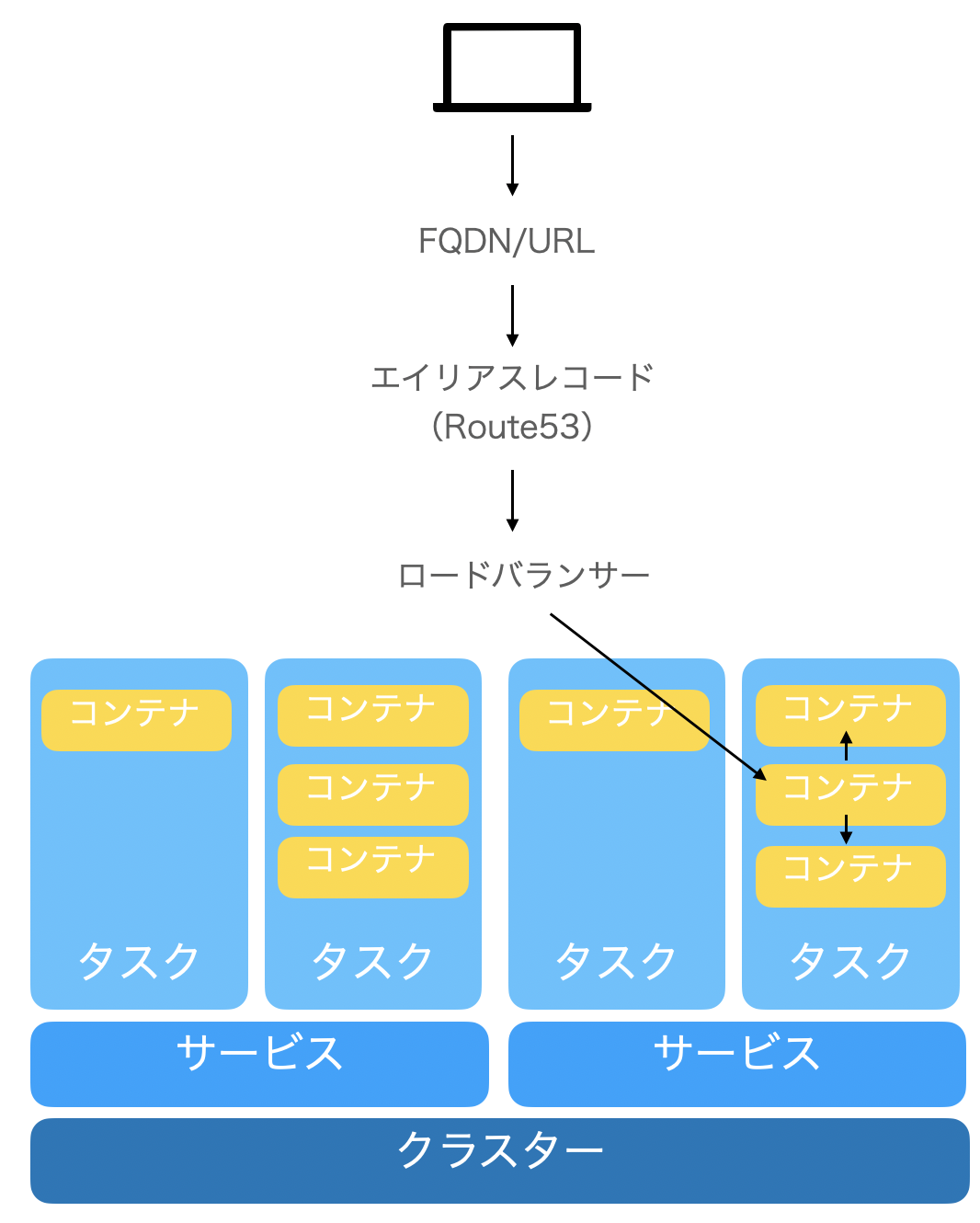
アプリケーションの概要
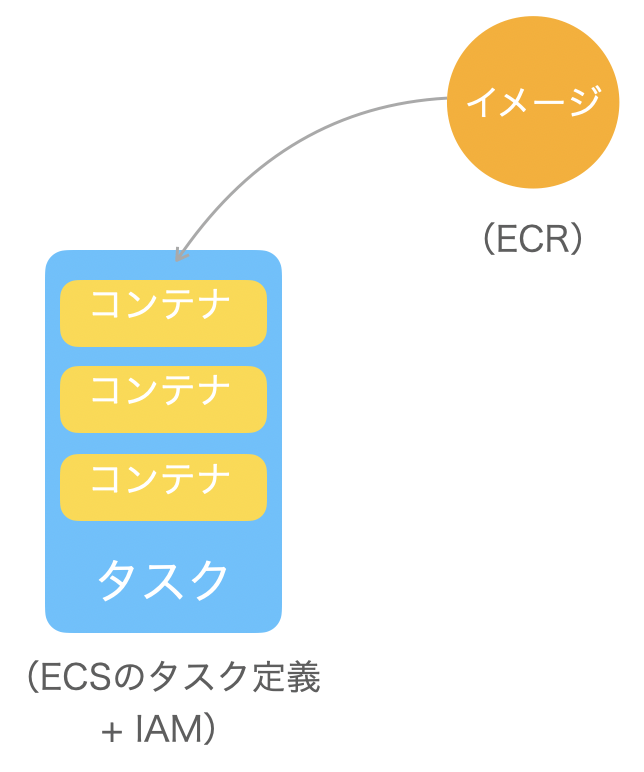
ECRにプッシュしたイメージからECSでコンテナを起動する。コンテナはEC2のサービスと結びついており、ELBでサービスを割り振る構造になっている。
ネットワーキングは、ユーザーが入力したFQDN/URLを、設定したエイリアスレコードで識別し、ロードバランサー(ELB)でサービスにつなぐ。
ECSとECRの関係
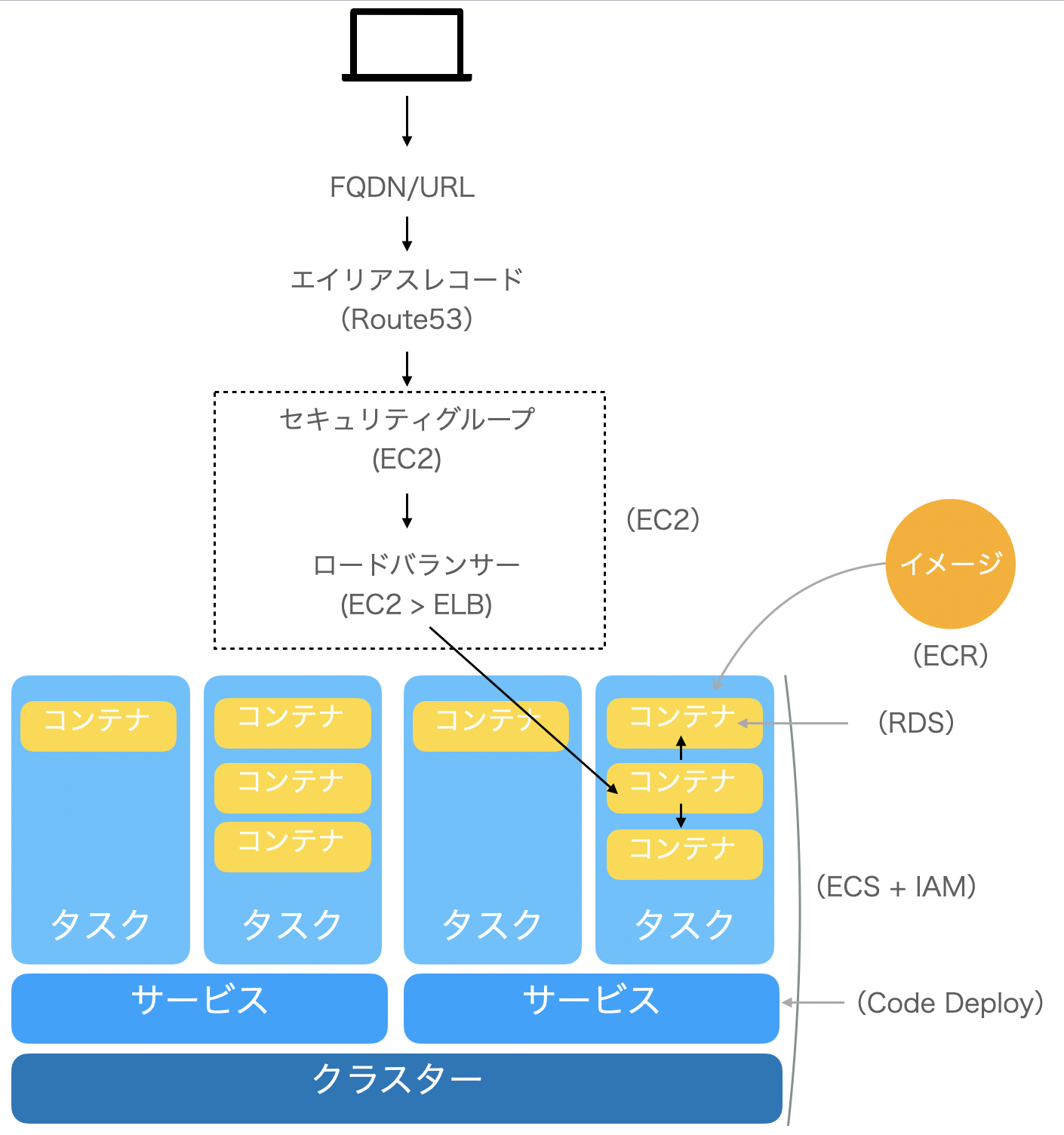
ECRはイメージを保存するレポジトリ。DockerのDocker hubに該当する。
ECSがDockerに該当する。コンテナの要件定義にあたる、docker-compose.ymlをECS(のタスク定義)に記述する。
流れとしては、ローカル(自分のPC)でイメージを作成してECRにプッシュ。ECSでそのイメージを拾ってきてコンテナを起動する。
プロジェクトによって他のAWSサービス(S3, EC2, CloudFrontなど)が必要な場合はIAMで設定する。
ECS
ECSはdocker-compose.ymlの用件定義をするだけでなく、AWS上で複数のサービス(プロジェクト)を実行するためにプラットホームとなる仮想サーバーをサービスとして定義する。
アプリケーションを更新した場合のデプロイ(展開)方法や、ロードバランサーでEC2とコンテナを接続する設定もここで行う。
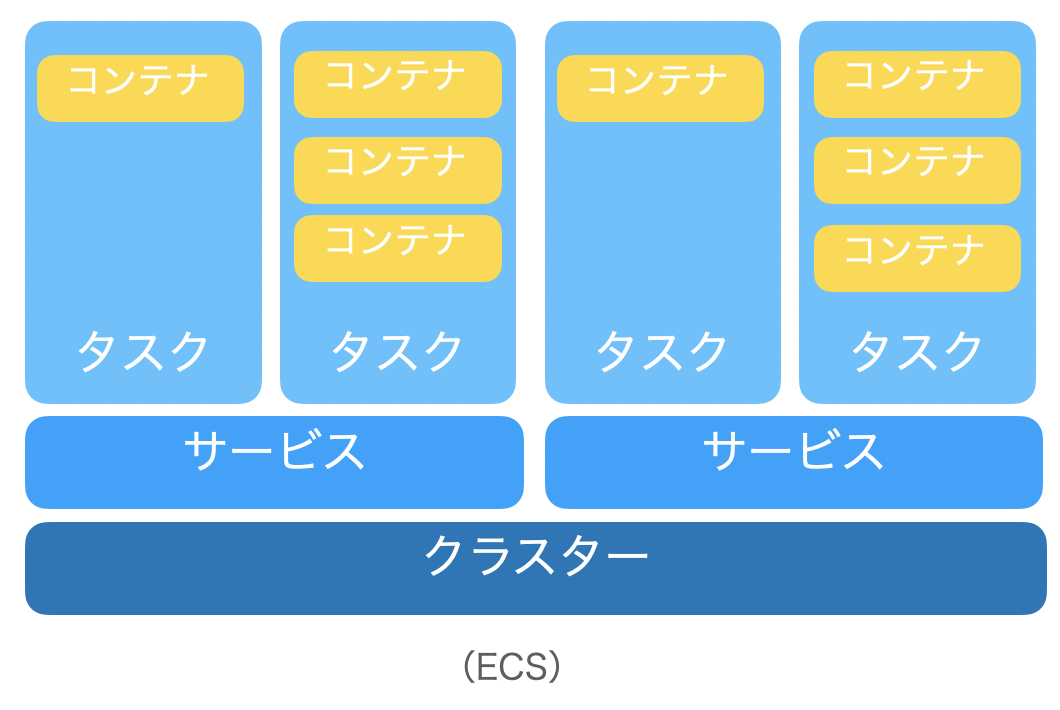
▼ECSの構造
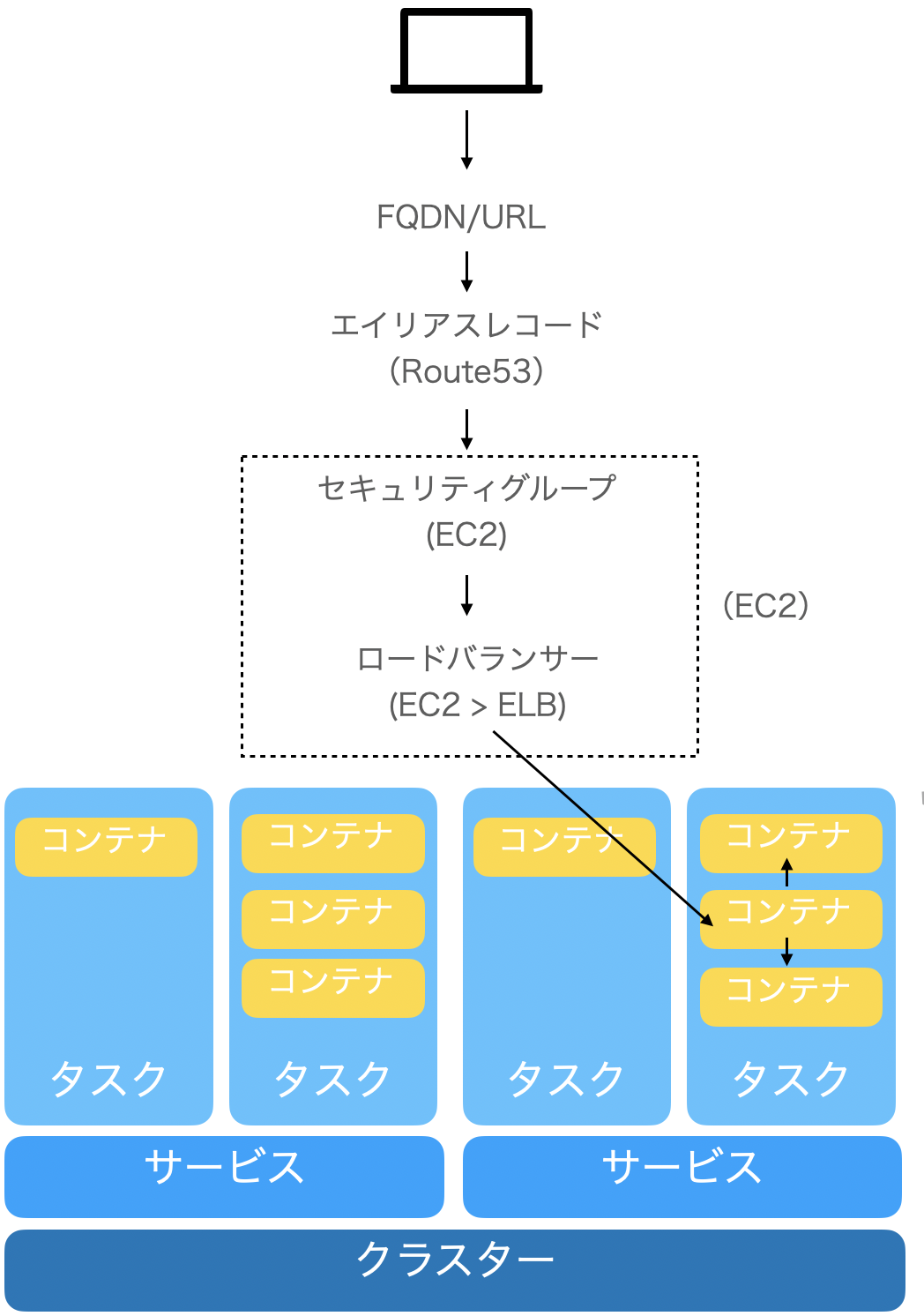
クラスターはプロジェクトを管理しやすくするためのグループといった位置付け。その中に例えば、productionやstagingといった環境の異なるサービスを作成する。
実際のサービスの根幹となるコンテナはタスクの中に定義する。このタスクをサービスの上に乗っける。
ネットワーキング
例えば、エディタアプリケーション(EC2)が複数のサービス(ECS)につながっている場合など、
ユーザーがURLを叩いて、このコンテナにアクセスするまでの流れは以下のようになる。
FQDN/URLはユーザーが入力した内容 (sub.example.com) ↓ エイリアスレコードで識別 (example.comのエイリアス) ↓ セキュリティグループ (許可されたIPアドレスか確認) ↓ ロードバランサー (sub.example.comに対応するサービスに割り振る) ↓ コンテナ (Dockerのアプリケーションに入る) ↓ 必要に応じてDBなどのコンテナにアクセス
AWSのサービスとの関係
このネットワークとサービスを、AWSのサービス毎にまとめると以下のようになる。
さらに、EC2がS3など他のAWSサービスとも連携していることが多い。
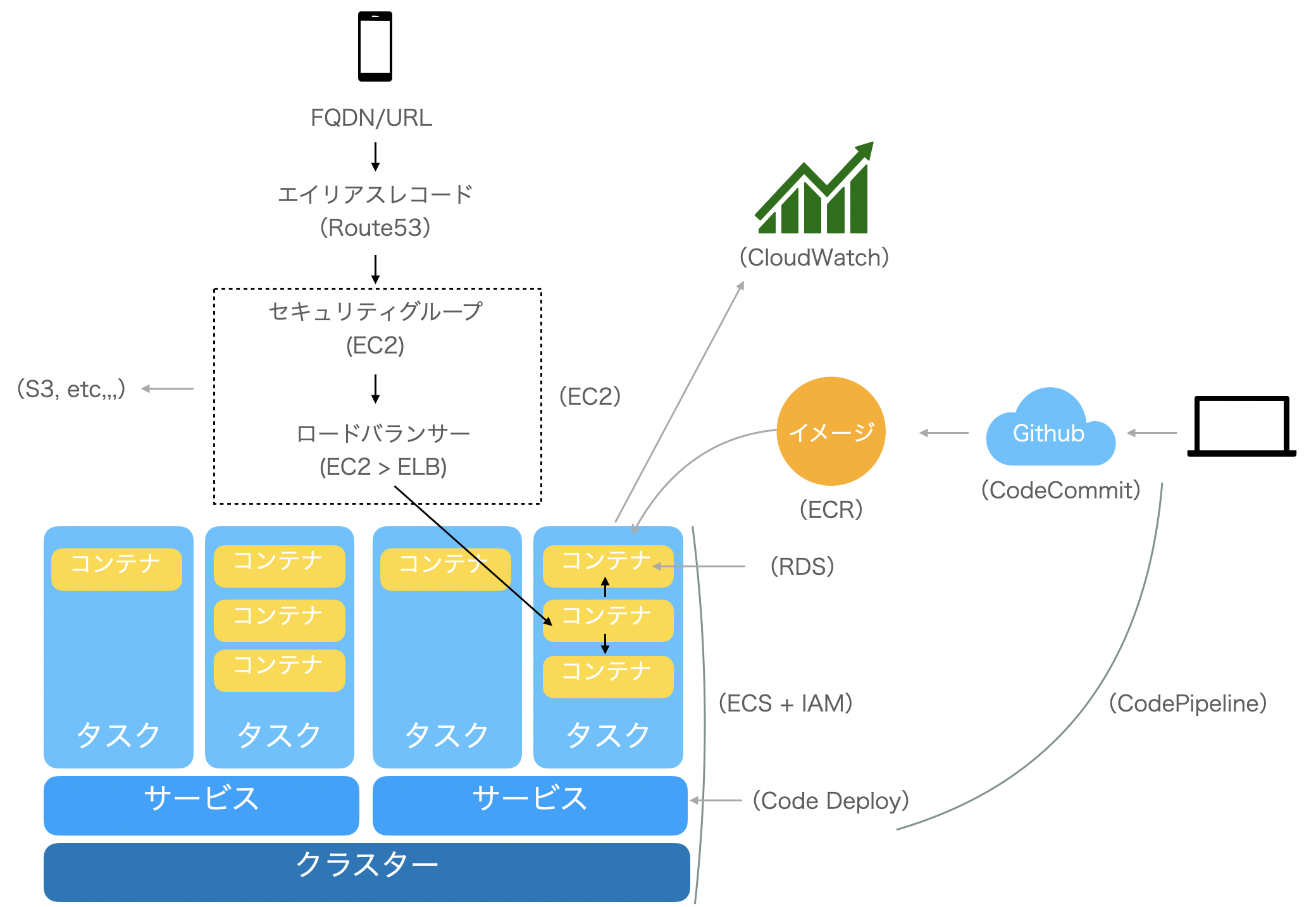
デプロイの自動化
上記では、手動デプロイになっているため、ローカルで更新があったら、イメージをECRにプッシュ、タスク定義の更新(対象のイメージの変更)、サービスの更新(対象のタスクのリビジョンの変更)をする必要がある。
この一連の更新作業を自動化するためにCodePipelineを使う。
CodePipelineはmasterとなるgithubやCodeCommitのレポジトリ/ブランチを指定して、変更があった場合に自動検知して更新をかける。
モニタリング
CloudWatchというAWSのサービスを使うと、CPUやタスクの使用状況などをモニタリングすることができる。
サービスからCloud Watchにログを送る設定をすればすぐに使える。
▼アプリケーションとAWSサービスの関係
AWSの難解さはこのサービスの多さだと思う。。そして、一つ一つのサービスが結構複雑で専門用語も多い。まずは、各サービスの役割と関係性を覚えるのが導入としてはわかりやすい。
プロジェクト作成の流れ
様々なサービスが必要になるが、例えばECSのクラスターの作成など、事前にEC2でサービスを作成し、Route53のエイリアスレコードやELB、ECSのタスク定義などをしておく必要がある。
絶対にコレという手順はなく後から変更できるものも多い。(名前は変更できない場合が多い)
▼大まかな作成の流れ
- EC2インスタンス
- セキュリティグループ
- ロードバランサー
- IAM
- Route53
- ECR
- ECS(タスク定義)
- ECS(クラスター・サービス)
- CodePipeline
参考リンク(一部)
・ロードバランサー
・Route53 エイリアスレコードの作成
・ECRにイメージをプッシュする方法
・ECSのタスク定義手順
・Fargateとは何か?
・ECSのクラスター作成手順
・Blue/Greenデプロイとは何か?
・CodeCommitとGithubの違い
・更新したイメージをビルドした後のECRとECSの作業手順
- 投稿日:2021-03-02T20:18:55+09:00
AWS上でDockerを使ったプロジェクトの構造と各サービスの役割から関係性を理解する。(ECR・ECS・EC2・ELB・Route53・CodePipelineは何をしているかと作成の流れ)
AWS上でDockerを使ったプロジェクトについて。ECR・ECS・EC2・ELB・Route53など多数のサービスが必要になる。
そもそも、Docker関連のECR・ECSの繋がりや、ECS内のタスク、コンテナ、クラスター、サービスの違いがイマイチ分からなかったので図で理解してみる。
目次
アプリケーションの概要
ECRにプッシュしたイメージからECSでコンテナを起動する。コンテナはEC2のサービスと結びついており、ELBでサービスを割り振る構造になっている。
ネットワーキングは、ユーザーが入力したFQDN/URLを、設定したエイリアスレコードで識別し、ロードバランサー(ELB)でサービスにつなぐ。
ECSとECRの関係
ECRはイメージを保存するレポジトリ。DockerのDocker hubに該当する。
ECSがDockerに該当する。コンテナの要件定義にあたる、docker-compose.ymlをECS(のタスク定義)に記述する。
流れとしては、ローカル(自分のPC)でイメージを作成してECRにプッシュ。ECSでそのイメージを拾ってきてコンテナを起動する。
プロジェクトによって他のAWSサービス(S3, EC2, CloudFrontなど)が必要な場合はIAMで設定する。
ECS
ECSはdocker-compose.ymlの用件定義をするだけでなく、AWS上で複数のサービス(プロジェクト)を実行するためにプラットホームとなる仮想サーバーをサービスとして定義する。
アプリケーションを更新した場合のデプロイ(展開)方法や、ロードバランサーでEC2とコンテナを接続する設定もここで行う。
▼ECSの構造
クラスターはプロジェクトを管理しやすくするためのグループといった位置付け。その中に例えば、productionやstagingといった環境の異なるサービスを作成する。
実際のサービスの根幹となるコンテナはタスクの中に定義する。このタスクをサービスの上に乗っける。
ネットワーキング
例えば、エディタアプリケーション(EC2)が複数のサービス(ECS)につながっている場合など、
ユーザーがURLを叩いて、このコンテナにアクセスするまでの流れは以下のようになる。
FQDN/URLはユーザーが入力した内容 (sub.example.com) ↓ エイリアスレコードで識別 (example.comのエイリアス) ↓ セキュリティグループ (許可されたIPアドレスか確認) ↓ ロードバランサー (sub.example.comに対応するサービスに割り振る) ↓ コンテナ (Dockerのアプリケーションに入る) ↓ 必要に応じてDBなどのコンテナにアクセス
AWSのサービスとの関係
このネットワークとサービスを、AWSのサービス毎にまとめると以下のようになる。
さらに、EC2がS3など他のAWSサービスとも連携していることが多い。
デプロイの自動化
上記では、手動デプロイになっているため、ローカルで更新があったら、イメージをECRにプッシュ、タスク定義の更新(対象のイメージの変更)、サービスの更新(対象のタスクのリビジョンの変更)をする必要がある。
この一連の更新作業を自動化するためにCodePipelineを使う。
CodePipelineはmasterとなるgithubやCodeCommitのレポジトリ/ブランチを指定して、変更があった場合に自動検知して更新をかける。
モニタリング
CloudWatchというAWSのサービスを使うと、CPUやタスクの使用状況などをモニタリングすることができる。
サービスからCloud Watchにログを送る設定をすればすぐに使える。
▼アプリケーションとAWSサービスの関係
AWSの難解さはこのサービスの多さだと思う。。そして、一つ一つのサービスが結構複雑で専門用語も多い。まずは、各サービスの役割と関係性を覚えるのが導入としてはわかりやすい。
プロジェクト作成の流れ
様々なサービスが必要になるが、例えばECSのクラスターの作成など、事前にEC2でサービスを作成し、Route53のエイリアスレコードやELB、ECSのタスク定義などをしておく必要がある。
絶対にコレという手順はなく後から変更できるものも多い。(名前は変更できない場合が多い)
▼大まかな作成の流れ
- EC2インスタンス
- セキュリティグループ
- ロードバランサー
- IAM
- Route53
- ECR
- ECS(タスク定義)
- ECS(クラスター・サービス)
- CodePipeline
参考リンク(一部)
・ロードバランサー
・Route53 エイリアスレコードの作成
・ECRにイメージをプッシュする方法
・ECSのタスク定義手順
・Fargateとは何か?
・ECSのクラスター作成手順
・Blue/Greenデプロイとは何か?
・CodeCommitとGithubの違い
・更新したイメージをビルドした後のECRとECSの作業手順
- 投稿日:2021-03-02T19:14:53+09:00
flysystem-aws-s3-v3は~1.0を使いましょう
概要
LaravelからAWS S3に画像をアップロードをしようとしたら起きた事象です。
Class 'League\Flysystem\AwsS3v3\AwsS3Adapter' not found
原因
LaravelのReadableを見たら、
Composerパッケージ
S3やSFTPドライバーを使用するときは、事前にComposerパッケージマネージャーを介して適切なパッケージをインストールする必要があります。
Amazon S3: league/flysystem-aws-s3-v3 ~1.0と書かれておりました。
何も考えずにインストールしたら、
composer require league/flysystem-aws-s3-v3
2.0が入ってしまっていたので、ダウングレードします。
composer require league/flysystem-aws-s3-v3 ~1.0
無事直せました。
- 投稿日:2021-03-02T18:42:25+09:00
[Amazon linux 2] /tmp配下の自動削除
/tmp配下ファイル削除の仕組み
- /tmp配下ファイルの削除タイミングは、systemdのtimerで指定されています。
- systemd-tmpfiles-clean.timerの中身を確認することで、そのタイミングを知ることができます。(デフォルト: 起動後 15 分経過時点と、それ以降に一日置きにタイマーが発火)
$ sudo systemctl cat systemd-tmpfiles-clean.timer ... [Timer] OnBootSec=15min OnUnitActiveSec=1d
- タイマーが発火後は、以下のコマンドが実行されます。
$ sudo systemctl cat systemd-tmpfiles-clean.service ... ExecStart=/usr/bin/systemd-tmpfiles --clean
--clean オプションを指定していると、 systemd-tmpfiles.d の設定ファイルで Age パラメータでした期間を経過したファイルが削除されます。
削除対象のファイルは、/usr/lib/tmpfiles.d/tmp.confで指定されています。
/usr/lib/tmpfiles.d/tmp.confのファイルの中を確認すると、デフォルトで/tmpは10日、/var/tmpは30日で配下のファイルが削除される設定が書かれています。$ cat /usr/lib/tmpfiles.d/tmp.conf ... # Clear tmp directories separately, to make them easier to override v /tmp 1777 root root 10d ...次回及び前回のタイマー発火時刻の確認方法
- Amazon linux2だと、systemd list-timersコマンドで確認できます。
sh-4.2$ sudo systemctl list-timers
- 投稿日:2021-03-02T18:41:37+09:00
【AWS】ECSのクラスターの目的と作成の流れ
AWSでDockerを扱うサービスである、ECS(Elastic Container Service)のクラスターの目的と作成方法について。
目次
- ECSのクラスターとは?
- クラスターを使ったサービスの流れ
- クラスターの作成
- ECSのクラスターテンプレートの選択
- クラスターの設定
- サービスの作成
- デプロイメントの設定
- ネットワーク構成
- サービスの作成
- ELB(ロードバランサー)の修正
- ページの表示
ECSのクラスターとは?
AWSの説明では、タスクリクエストを実行できる1つ以上のコンテナインスタンスのリージョングループ。
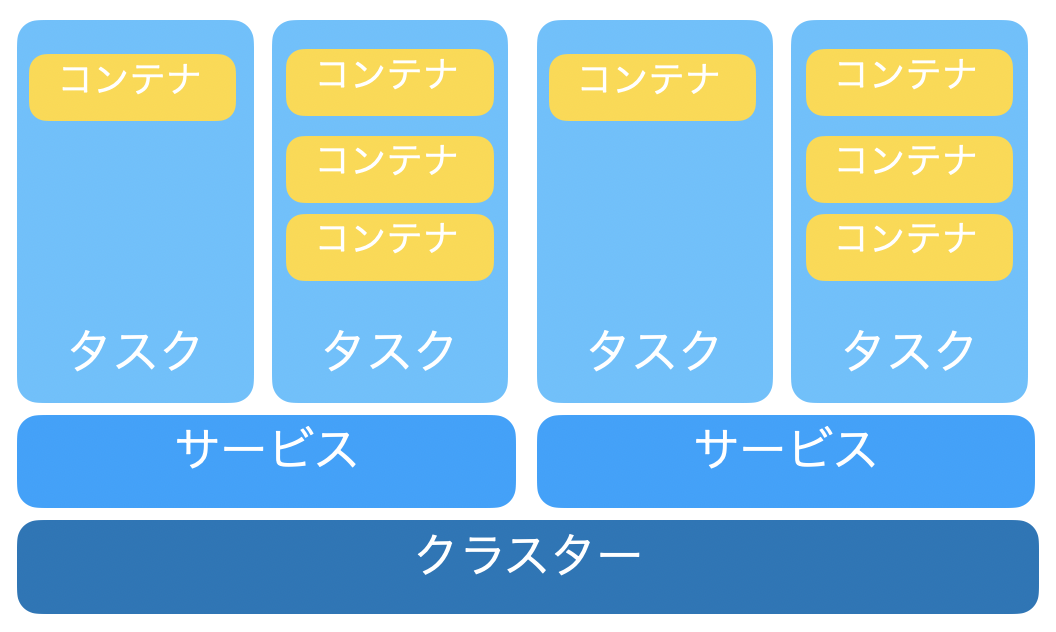
実用例だと、一つのプロジェクトに対し、一つのクラスターを作り、中にサービスとして、ステージング環境や開発環境をいれる。
各サービスの中にはタスクを作って、タスクの中で必要なコンテナを定義している。
▼クラスター、サービス、タスク、コンテナの関係
ECSでクラスターを作成する場合は、単にクラスターを作成するだけでなく、サービスの作成、ロードバランサーの設定、デプロイ方法の指定も行う。
クラスターを使ったサービスの流れ
複数のサービスを一つのロードバランサーで切り分ける場合のAWSの設定方法について。
・サービスの構造
クラスターはプロジェクトを管理しやすくするためのグループといった位置付け。
その中にproductionやstagingといったサービスを作成する。
実際のサービスの根幹となるコンテナはタスクの中に定義する。このタスクをサービスの上に乗っける。
・ネットワーキングの構造
ユーザーがFQDN(sub.example.com)を入力すると、該当するエイリアスコードからホストドメインにつなげる。
ホストドメインにはロードバランサーが設定されており、渡されたFQDNに結び付けられたコンテナにトラフィックを送る。
コンテナはリクエストに応じて、DBなど必要な別のコンテナと連携してレスポンスを返す。
クラスターの作成
1. ECSのクラスターテンプレートの選択
どの仮想サーバーでコンテナを起動するか選択する。
タイプ 内容 ネットワーキングのみ Fargate起動タイプを使用してタスクを実行する EC2 Linux + ネットワーク Linux コンテナを使用した EC2 起動タイプを使用してタスクのクラスターを起動する EC2 Windows + ネットワーク EC2 起動タイプと Windows コンテナを使用してタスクのクラスターを起動する Fargateは運用管理をAWSが行ってくれるメンテ・保守不要のサーバー(サーバーレス)
2. クラスターの設定
サービスを起動するためのクラスターを作成する。クラスター自体の作成は超簡単。
2-1. クラスター名(必須)
最大 255 文字の英字 (大文字と小文字)、数字、ハイフン、アンダースコアを使用できる。
2-2. ネットワーキング(任意)
クラスター用に新しいVPC(Virtual Private Cloudの略。 仮想プライベートクラウド)を作成する場合はチェックを入れる。
▼作成する場合
クラスター専用のVPCを作成する場合は、CIDRブロック、サブネットを設定(デフォルトでも可)する。
2-3. Tags(任意)
クラスターの説明をKV(key-value)形式で記載できる。
クラスタ作成後にTagsタブから確認できる。
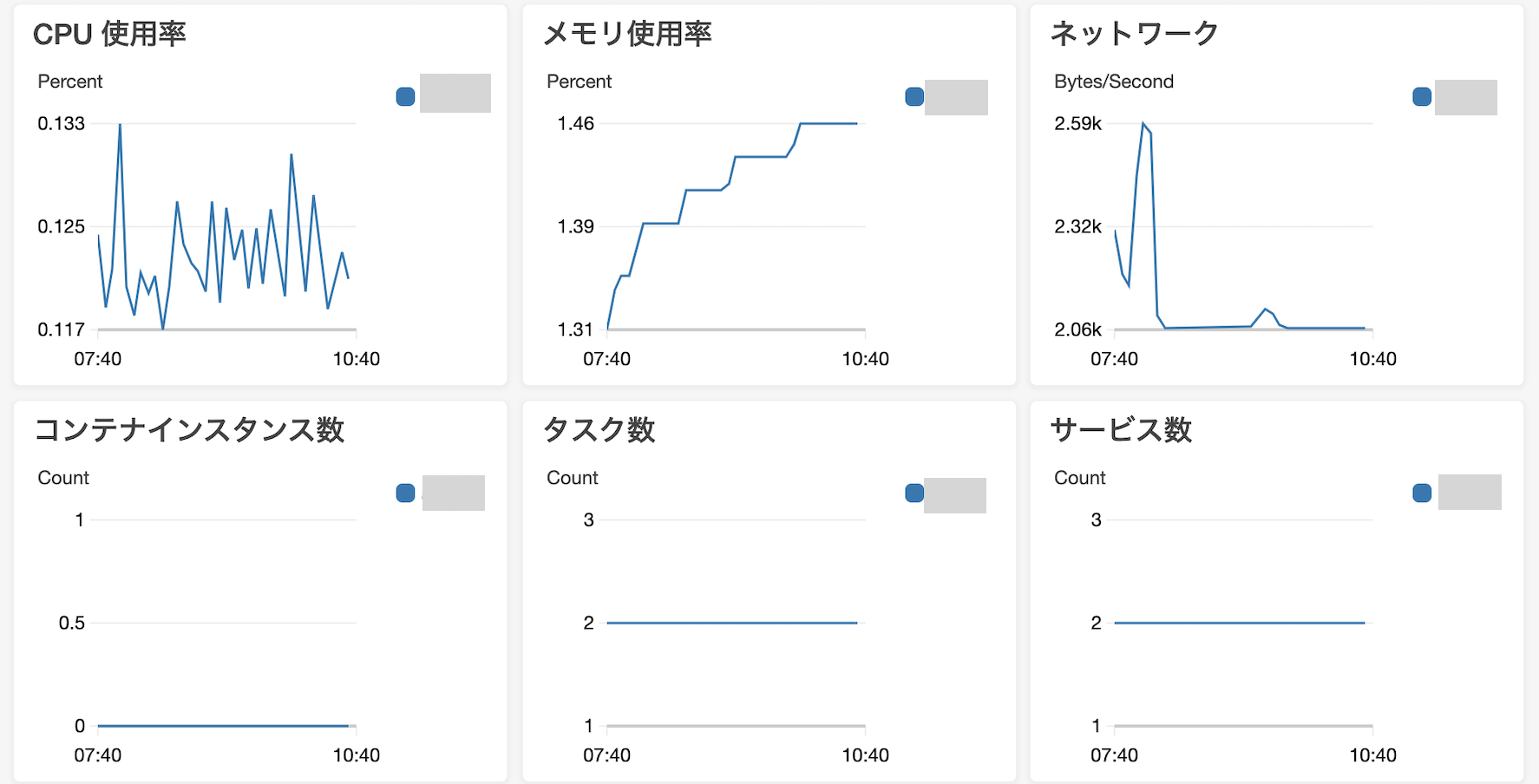
2-4. CloudWatch Container Insights(任意)
チェックマークを入れるとCloudWatchと連携して、CPUやメモリの使用状況のログが確認できるようになる。
▼ECSクラスターのCloudWatch例
2-5. クラスターの作成
右下の「作成」ボタンをクリックしてクラスターを作成する。
以上でクラスターの作成は完了。
3. サービスの作成
作成したクラスターの中にサービスを作成していく。
サービスを作成するにはECSのタスク定義で、コンテナの起動時の設定が完了している必要がある。
3-1. サービスを作成するクラスターの選択
作成したクラスターを選択する。
サービスタブの中で、左下の「作成」ボタンをクリックする。
3-2. 起動タイプの選択
タスクを実行する仮想サーバ−の種類を選択する。選択しない場合はEC2がデフォルトとなる。
3-3. タスク定義
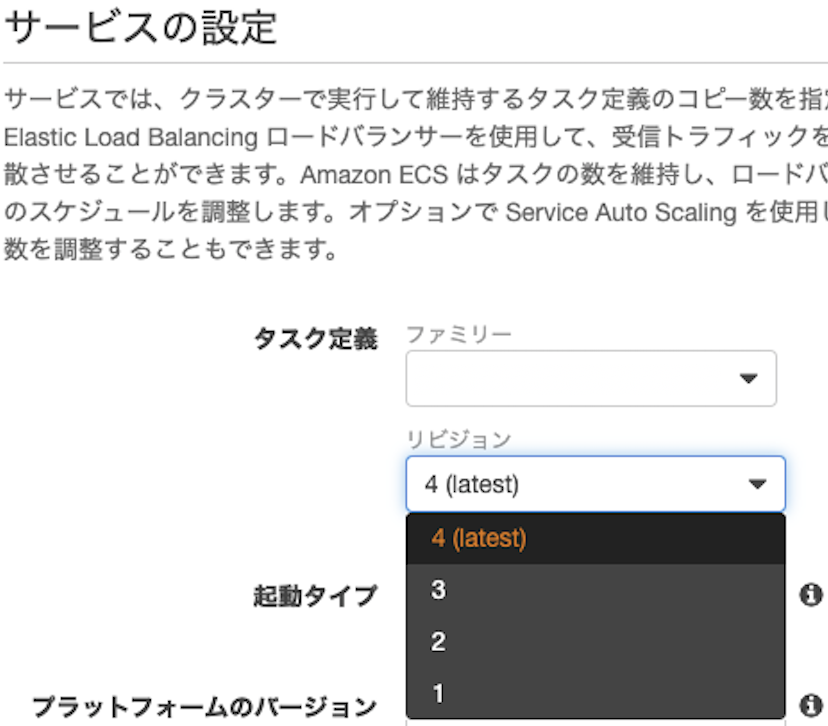
ECSのタスク定義で作成した項目を選択する。
タスク定義を内容を変更して複数作った場合は、使用する番号(リビジョン)を選択する。
▼ECSのタスク定義
3-4. サービス名
作成するサービスにつける名前を指定する。
クラスターを選択した時に、表示されるためわかりやすい名前にする。
↓ 表示例
▼Point
クラスターの名前でどのプロジェクトかは判定可能なため、サービスの名前は各サービスの環境の名前をつけるとわかりやすい。例・クラスター名: test-app ・サービス名1: production ・サービス名2: staging
3-5. サービスタイプとは?
タスクが失敗したときの対応方法を指定する。スケジュール戦略と呼ばれる。
サービスタイプ(スケジュール戦略)は①REPLICA戦略と②DAEMON戦略の2つがある。
Fagateを選択した場合は、REPLICA戦略のみとなる。(DAEMONはサポート外)
・REPLICA戦略
クラスター全体で必要数のタスクを配置して維持。・DAEMON戦略
指定したすべてのタスク配置制約を満たすクラスター内のアクティブなコンテナインスタンスごとに、1 つのタスクのみをデプロイ。
3-6. タスクの数
サービスタイプがレプリカの時のみ選択する。
上で指定したタスク定義で起動したインスタンス(コンテナ)のうち、クラスターで実行状態を保つ数を指定する。
起動するコンテナが1つのみの場合は1となる。複数のコンテナを起動し、起動状態を保ち続ける場合は、その数を記載する。
なお、デーモンの場合は、クラスターのコンテナインスタンス数に自動的に設定。
3-7. 最小ヘルス率と最大率
ローリングアップデートのみ選択可能なオプション。
実行中のサービスをローリング更新するときに、サービスが維持するタスクの数を割合で指定する。
最小ヘルス率とは?
RUNNING状態に保つ必要のあるサービスのタスクの下限数を%で指定したもの。
例えば必要なタスクが4つのサービスで、最小ヘルス率を50%とした場合、スケジューラーが新しいタスクを実行する時に、2つのタスクを停止して、クラスターの容量を開放する。
最小ヘルス率はデフォルトで100%。
最大率
最大ヘルス率の略。RUNNINGまたはPENDING状態で使用できるサービスタスクの上限数を指定できる。
例えば必要なタスクが4つのサービスで、最大率が200%の場合、スケジューラは4つの古いタスクを停止する前に、4つの新しいタスクを開始することができる。
最大ヘルス率のデフォルト値は 200% です。
Blue/Greenデプロイタイプの場合
実行中のサービスの更新がBlue/Green (CODE_DEPLOY) の場合は、最小ヘルス率・最大ヘルス率の値はデフォルト値に設定される。
最小ヘルス率: 100%
最大ヘルス率: 200%つまり、本番環境のサービスを改修してローンチするときに、既存のタスクは停止せず起動したままの状態で、新しいサービスを起動する。
この方法であれば、新しいサービスに問題があった場合にすぐに古いサービスに戻すことができる。容量は使うが安全な更新。
3-8. Deployment circuit breaker
ローリングアップデートのみ選択可能なオプション。
サービスの更新に失敗した場合に、自動で昔の正常だったサービスに戻してくれる便利機能。
>https://aws.amazon.com/jp/blogs/news/announcing-amazon-ecs-deployment-circuit-breaker-jp/
Blue/Greenの場合は自動的にRollbackしてくれるため設定不要。
というか、ローリングアップデートの設定で、デフォルトの最小ヘルス率: 100%、最大ヘルス率: 200%、Deployment circuit breakerが有効でrollbackがオンになっているデプロイをBlue/Greenと呼ぶ。
4. デプロイメントの設定
サービスを更新したときに、新しいサービスの起動方法を指定する。
4-1. Blue/Green
ブルー・グリーンと呼ぶ。直近では主流のデプロイ方法。
サービスの更新を安全に行うために、既存のサーバーに手を加えるのではなく、既存のサーバーはそのまま維持しながら、新しいサーバーを起動するデプロイ方法。
新旧のサービスで状態を比較し、異常があればエラーとして報告してくれる。
また、新しいサービスが起動しない場合は、自動で旧のサービスに戻るため、サービスが落ちる心配がない。
Blueが古いサービス、Greenが新しいサービスを指している。
4-2. ローリングアップデート
実行中のタスクを順々に停止して、順々に新しいサービスに切り替えていくデプロイ方法。
Blue/Greenよりも簡易的でスピーディな更新方法。
ただし、どれかのタスク更新で失敗した場合、更新済みのタスクと更新エラーのタスクが混在することになり、元に戻すのに手間がかかる。(このため、現在のトレンドはBlue/Green)
Deployment circuit breakerなど、より安全にサービスを更新する仕組みが用意されている。
ローリングアップデートの設定で、デフォルトの最小ヘルス率: 100%、最大ヘルス率: 200%、Deployment circuit breakerが有効でrollbackがオンになっているデプロイがBlue/Green。
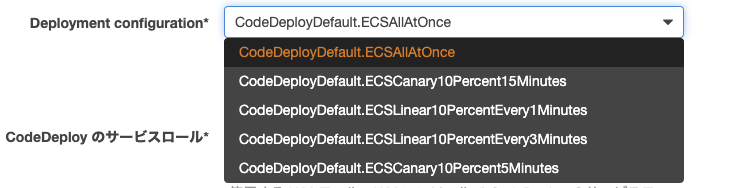
4-3. Deployment configuration
デプロイ中にCodePlayが使用する条件を選択する。
旧サービスにアクセスしているトラフィックの何%ずつを新しいサービスに移行させるかの、%と経過時間を指定できる。
設定 内容 CodeDeployDefault.ECSAllAtOnce すべてのトラフィックを、新しいコンテナに一度に移行。 CodeDeployDefault.ECSLinear10PercentEvery1Minutes すべてのトラフィックが移行されるまで、1分ごとに10%を移行 CodeDeployDefault.ECSLinear10PercentEvery3Minutes すべてのトラフィックが移行されるまで、3分ごとに10%を移行 CodeDeployDefault.ECSCanary10Percent5Minutes 最初にトラフィックの10%を移行。残りの90%は5分後にデプロイ CodeDeployDefault.ECSCanary10Percent15Minutes 最初にトラフィックの10%を移行。残りの90%は15分後にデプロイ 基本的には
CodeDeployDefault.ECSAllAtOnceを選択。
4-4. CodeDeployのサービスロール
CodeDeployがBlue/Greenで自動更新する際に、ユーザーに変わってAWSに許可を与えるためのIAMロール。
CodeDeploy IAMロール(ecsCodeDeployRole)として設定する。
>https://docs.aws.amazon.com/AmazonECS/latest/developerguide/codedeploy_IAM_role.html
5. ネットワーク構成
5-1. VPCグループの設定
タスク定義のネットワークグループがAWS VPCの場合に設定可能。
タスク定義のプラットフォームにFagateを選択している場合は、AWS VPCのため設定できる。
・クラスターVPC
タスクやサービスのサブネットとセキュリティグループを表すオブジェクト。・サブネット
タスクやサービスに関連づけるサブネットワーク。
・セキュリティグループ
タスクやサービスに関連づけるセキュリティグループ。デフォルトは新規で自動割り当て。既存のセキュリティーグループから選ぶことも可能。
・パブリックIPの自動割り当て
ENI(Elastic Network Interface)がパブリックIPアドレスを受け取るかどうか。EnableかDisableで選択する。
5-2. ロードバランサーの設定
タスク間のトラフィックを分散させる。事前にEC2コンソールでロードバランサーを作成しておく必要がある。
ロードバランサーはApplication Load Balancer(HTTPやHTTPSを振り分ける)か、Network Load Balancer(超高性能タイプ)から選択できる。
ロードバランサーとRoute53のエイリアスレコード
ロードバランサーでタスク内のコンテナにアクセスするために、Route53のエイリアスレコードを作成しておく。
ネットワーキングの流れは、
リクエスト ↓ ロードバランサ ↓ コンテナとなる。
5-3. ロードバランサー用のコンテナを設定
指定したタスクの中で定義したコンテナが選択できる。(コンテナが1つの場合は選択肢は1つ)
↓ 追加ボタンをクリック
・プロダクションリスナーポート
HTTP(80)かHTTPS(443)を選択。指定したロードバランサーで設定してあるリスナーを選ぶ。
▼ロードバランサーのリスナーの例
▼80番ポートの設定例
ここでは、80番ポートにアクセスした場合、443番にリダイレクトする指定になっている。このため、プロダクションリスナーポートは443を選択。
・テストリスナー
ロードバランサーでルーティングする前に飛び先のアプリケーションをテストする。不要の場合はチェックを外す。
5-3. ロードバランス用のコンテナを設定
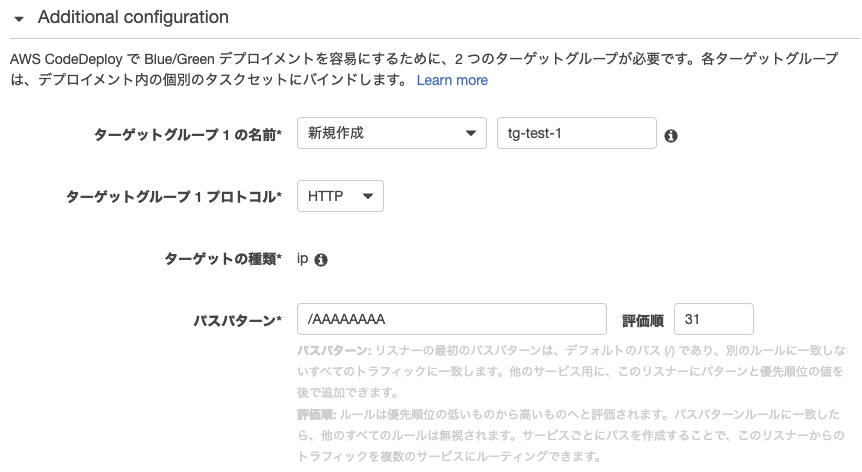
ロードバランサーでトラフィックを接続するための、コンテナにターゲットグループを作成する。
▼ターゲットグループの名前
既存、または新規作成する。▼ターゲットグループのプロトコル
コンテナの開放ポートに繋ぐ。80番を開けている場合はHTTPにする。▼パスパターン
ロードバランサーのIF文で、〇〇のパスならの部分に当たる。スラッシュ以下のパスしか入力できないため、FQDN(サブドメ)を入力したい場合は、ここはダミーを設定しておき、別途ロードバランサーで設定する。
▼評価順
if文を処理をかけていく順番。番号が小さい条件から検証していく。
5-4. ヘルスチェックパスの設定
ヘルスチェックを実行するパスを設定する。
ロードバランサーで(ELBコンソール)で設定する。
5-5. 2つめのターゲットグループの作成
デプロイの方法でBlue/Greenを選択した場合は、ターゲットグループを2つ入力する必要がある。
新しいGreenのターゲットグループ2にアクセスしたときにエラーが発生した場合、Blueのターゲットグループ1にトラフィックを戻すため。
▼パスパターン
選択不可。ターゲットグループ1のパスパターンを継承する。5-6. Auto Scaling
CloudWatchでアラームがでた場合に、オートスケーリングするかどうか。
Auto Scallingする場合は、最小・最大タスク数などを選ぶ。
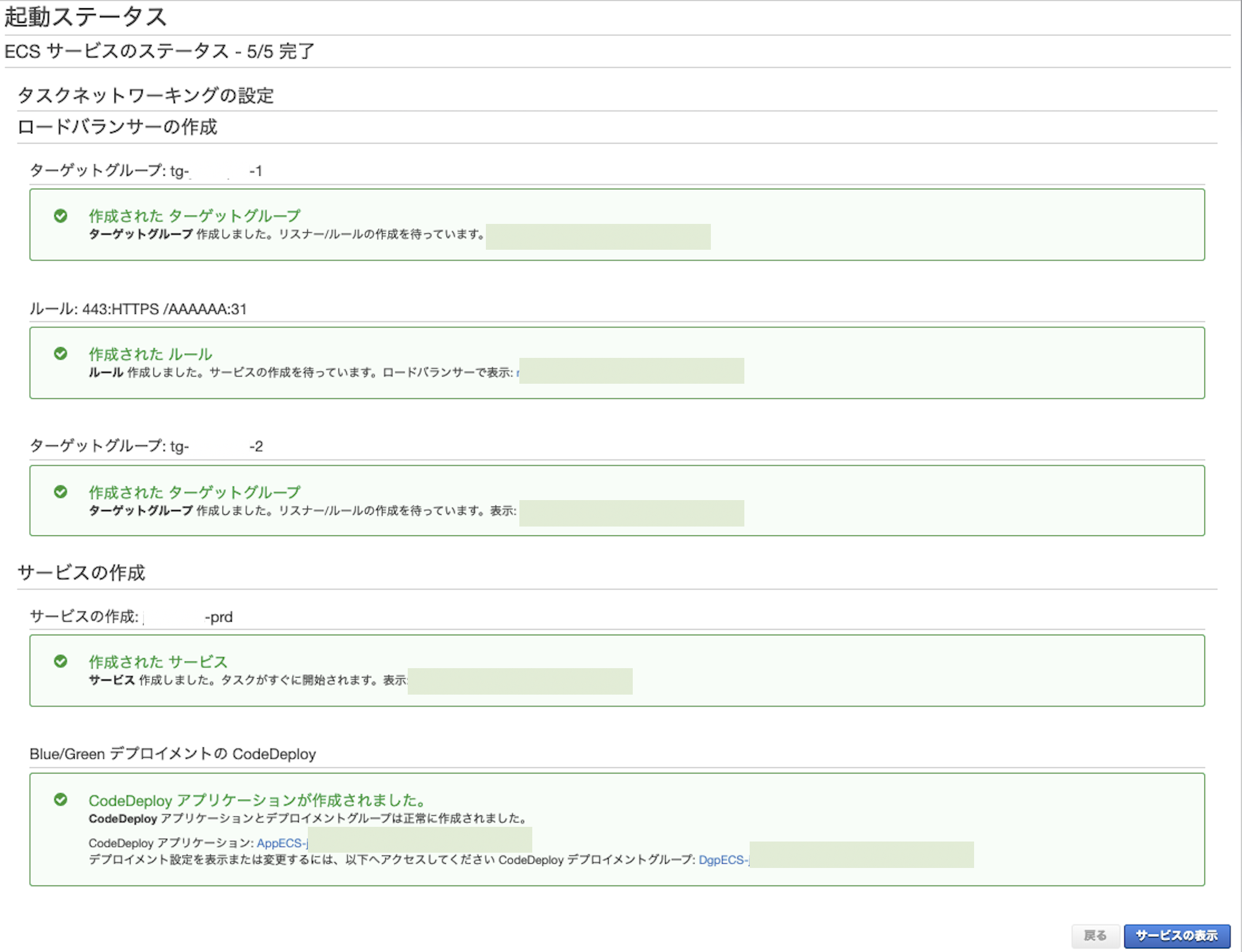
6. サービスの作成
作成ボタンを押すと、5つのサービスが一気に作成される。
- ロードバランサーのターゲットグループ1
- ロードバランサーのルール
- ロードバランサーのターゲットグループ2
- サービスの作成
- Blue/Green デプロイメント(CodeDeploy)
※注意
それぞれが別々のサービス上に作成されるため、ミスがあった場合は、全てを削除する必要がある。↓ サービスを表示
以上でクラスターの作成が完了。
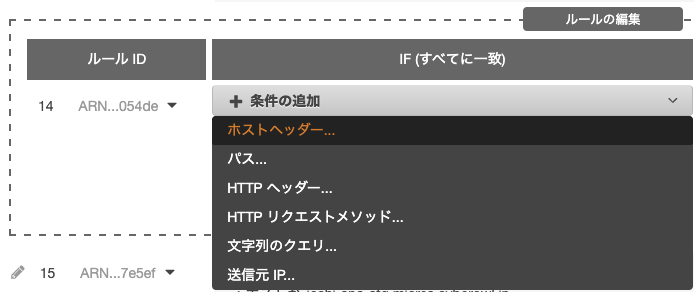
7. ELB(ロードバランサー)の修正
5-3のロードバランス用のコンテナを設定ではFQDNを入力することができずダミーを入力したため、ELBコンソールから入力内容を修正する。
ELB(ロードバランサー)から指定のロードバランサーを選択し、ルールを表示する。
先ほどダミーで登録したルーティングが追加されている。
上の鉛筆マークをクリックしてこれを編集する。
FQDNを入力したいため、ホストヘッダーを選択する。
修正が完了したら、右上の「更新」をクリックして完了。
ロードバランサーの注意点
バランサーはユーザーとサービスを繋ぐためとても重要。
間違って既存のルーティングを変更したり削除してしまうと、サービスにアクセスできなくなってしまうため注意が必要。
Route53とバランサーはサービスの根幹で、他のサービスともつながっている場合も多いため注意すること。
8. ページの表示
以上でAWS上での設定が完了。
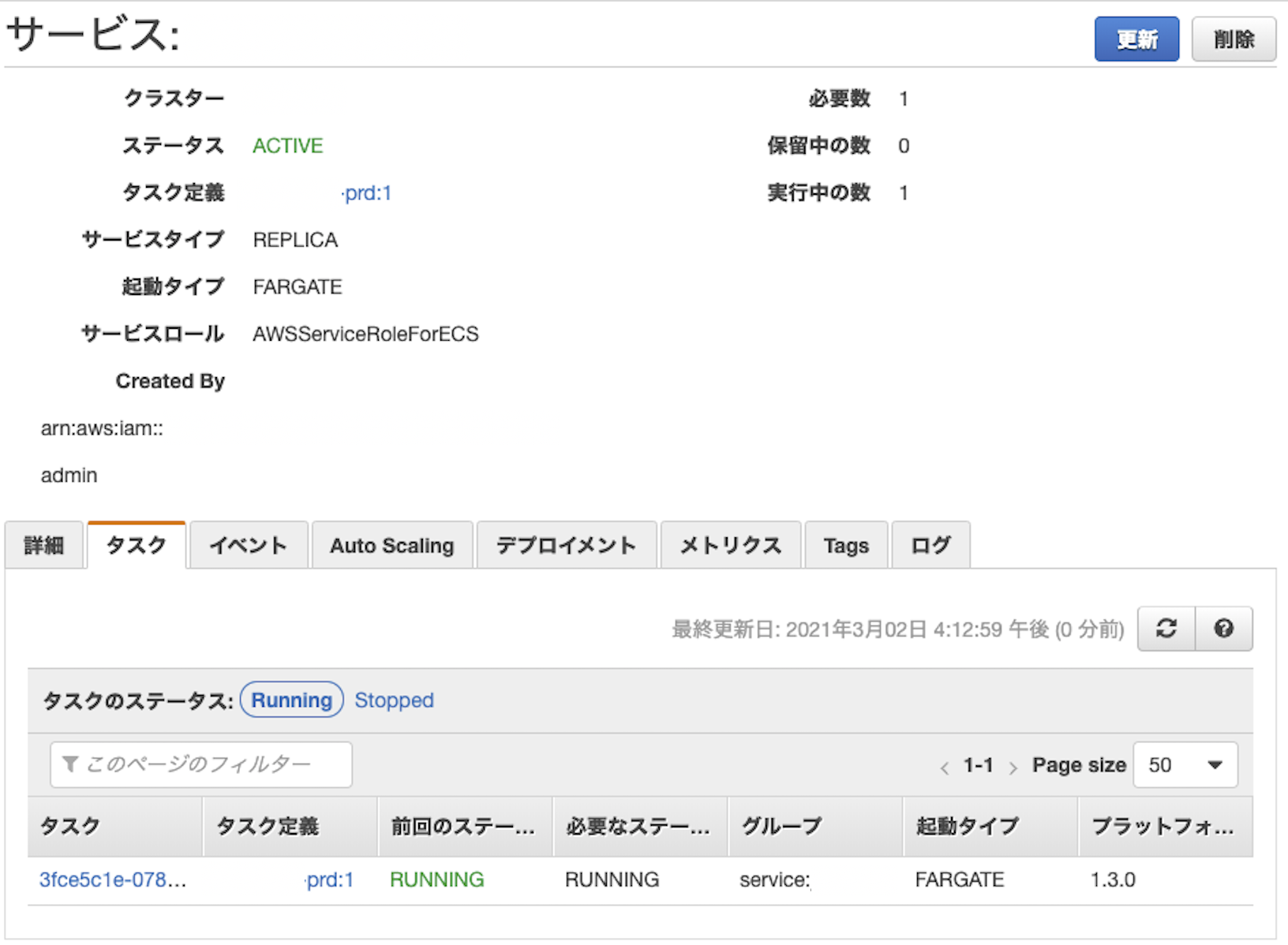
クラスターで該当のプロジェクトを確認したときに、RUNNINGになっていればOK。指定したURLを入力すればページを開くことができる。
ページはイメージの中で定義したルーティングやビューに従う。
ページが表示されない場合は、ヘルスチェックでサーバーが動いているか確認するなどの方法がある。(別途設定が必要)
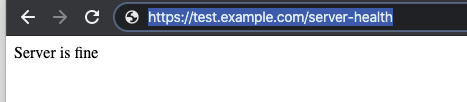
▼ヘルスチェックの例
以上。








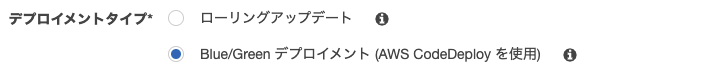









- 投稿日:2021-03-02T17:54:43+09:00
Webサービスの全体像
Webサービスとは
Webサービスとは、インターネットを利用したサービス。
・画面に情報が表示されている
・情報は最新の状態が更新されている
・全世界中の人と同じ情報を共有できているex) Youtube, Twitterなど
では、なぜこのようなことが可能なのか?
Webサービスの仕組み
Webシステムとは、
・あなたのPC、スマホ :クライアント側
・サーバ(業務用コンピュータ):サーバ側が通信することで情報を取得し、成り立っています。
具体的には、
・リクエスト:あなたのPC、スマホ→サーバ に情報を送ってほしいと依頼すること
・レスポンス:サーバ→あなたのPC、スマホ に情報を送り返して応答することこの2つの作業を行うことで、情報の通信を可能にしています。
あなたのPC、スマホ画面にサイトの情報が映るのは、サーバが応答してくれた情報のレスポンスが表示されているからとなります。どんなWebサービスでも、このリクエストとレスポンスの連続で成り立っています。
※AWSでは、EC2というサーバを借りて、あなたの自由に操作できます。
しかし、リクエストはどこに送られているのでしょうか?
おそらくそれぞれのWebサービスのサーバを表す住所のようなものがあるはずです。IPアドレス
インターネットの世界にもコンピュータがここにありますよという
住所のようなものが存在します。それが、IPアドレスです。
IPアドレスは、
・インターネット上の住所を表したもの
・数字を4つのブロックに分けた形式IPアドレスがあるおかげで、
リクエストに対してレスポンスができるWebサービスが成り立っています。サーバには、それぞれ個別のIPアドレスが割り当てられています。
よって、クライアントは目的のサーバにリクエストを送ることができます。しかし、IPアドレスは数字なので、それを見ただけでは一目で何のWebサービスのサーバなのかも分からないし、覚えたり管理するのが大変です。
ドメイン
そこで私たちは、「youtube.com」「twitter.com 」などの英数字のURLを
使用してサイトにアクセスしています。この英数字のURLを、ドメインと言います。
しかし、ドメイン名だけではアクセスはできません。
必ずIPアドレスが必要になります。
ではドメイン名にアクセスしているのに、なぜサーバのIPアドレスを
取得できているのでしょうか?DNS
それはドメインとIPアドレスを対応付けさせることで、
世界中のPCからサイトにアクセスすることを可能にしたからです。それが、DNSとなります。
DNSは、電話帳のようなもので
「このドメインは、このIPアドレスだよっ」という対応表が載っています。このドメインからIPアドレスを導き出すことを、名前解決と言います。
この名前解決を行うサーバのことを、DNSサーバーと言います。よってサイトにアクセスするときは、
⓵DNSサーバーで、ドメイン名→IPアドレス に変換する
⓶DNSからWebシステムのサーバーに通信するこの2段階処理を行っています。
つまり、
あなたのPC、スマホ → DNS(サーバー)→ Webシステムのサーバー
というような流れで情報通信が行われていることになります。※AWSでEC2を立ち上げると、自動的にドメインとIPアドレスが割り振られます。
このドメインとIPアドレスが、自動的にAWSのRoute53(DNSサーバー)に登録されるため、
EC2にアクセスするためには、IPアドレスとドメインどちらでも可能になります。
- 投稿日:2021-03-02T17:54:43+09:00
Webサービスの全体像⓵
Webサービスとは
Webサービスとは、インターネットを利用したサービス。
・画面に情報が表示されている
・情報は最新の状態が更新されている
・全世界中の人と同じ情報を共有できているex) Youtube, Twitterなど
では、なぜこのようなことが可能なのか?
Webサービスの仕組み
Webシステムとは、
・あなたのPC、スマホ :クライアント側
・サーバ(業務用コンピュータ):サーバ側が通信することで情報を取得し、成り立っています。
具体的には、
・リクエスト:あなたのPC、スマホ→サーバ に情報を送ってほしいと依頼すること
・レスポンス:サーバ→あなたのPC、スマホ に情報を送り返して応答することこの2つの作業を行うことで、情報の通信を可能にしています。
あなたのPC、スマホ画面にサイトの情報が映るのは、サーバが応答してくれた情報のレスポンスが表示されているからとなります。どんなWebサービスでも、このリクエストとレスポンスの連続で成り立っています。
※AWSでは、EC2というサーバを借りて、あなたの自由に操作できます。
しかし、リクエストはどこに送られているのでしょうか?
おそらくそれぞれのWebサービスのサーバを表す住所のようなものがあるはずです。IPアドレス
インターネットの世界にもコンピュータがここにありますよという
住所のようなものが存在します。それが、IPアドレスです。
IPアドレスは、
・インターネット上の住所を表したもの
・数字を4つのブロックに分けた形式IPアドレスがあるおかげで、
リクエストに対してレスポンスができるWebサービスが成り立っています。サーバには、それぞれ個別のIPアドレスが割り当てられています。
よって、クライアントは目的のサーバにリクエストを送ることができます。しかし、IPアドレスは数字なので、それを見ただけでは一目で何のWebサービスのサーバなのかも分からないし、覚えたり管理するのが大変です。
ドメイン
そこで私たちは、「youtube.com」「twitter.com 」などの英数字のURLを
使用してサイトにアクセスしています。この英数字のURLを、ドメインと言います。
しかし、ドメイン名だけではアクセスはできません。
必ずIPアドレスが必要になります。
ではドメイン名にアクセスしているのに、なぜサーバのIPアドレスを
取得できているのでしょうか?DNS
それはドメインとIPアドレスを対応付けさせることで、
世界中のPCからサイトにアクセスすることを可能にしたからです。それが、DNSとなります。
DNSは、電話帳のようなもので
「このドメインは、このIPアドレスだよっ」という対応表が載っています。このドメインからIPアドレスを導き出すことを、名前解決と言います。
この名前解決を行うサーバのことを、DNSサーバーと言います。よってサイトにアクセスするときは、
⓵DNSサーバーで、ドメイン名→IPアドレス に変換する
⓶DNSからWebシステムのサーバーに通信するこの2段階処理を行っています。
つまり、
あなたのPC、スマホ → DNS(サーバー)→ Webシステムのサーバー
というような流れで情報通信が行われていることになります。※AWSでEC2を立ち上げると、自動的にドメインとIPアドレスが割り振られます。
このドメインとIPアドレスが、自動的にAWSのRoute53(DNSサーバー)に登録されるため、
EC2にアクセスするためには、IPアドレスとドメインどちらでも可能になります。
- 投稿日:2021-03-02T16:56:34+09:00
【まとめ】Railsアプリ AWS化に役立った記事たち
目的
第1回 RailsアプリAWS化計画を成功に導いてくれた有難き記事たちをまとめています。(自分のために)
大まかな流れに活躍してくれたで賞
初心者向け:AWS(EC2)にRailsのWebアプリをデプロイする方法 目次 (以下手順)
この流れにそって実行すれば、基本的にアプリをデプロイすることが可能です。
ただし、最新更新が2017年なのでバージョンによる違い、AWSのUIの違いなどが多数見受けられました。しかし、手順は簡潔にまとまっており、非常に参考になりました。【画像付きで丁寧に解説】AWS(EC2)にRailsアプリをイチから上げる方法【その3〜サーバー設定とRailsアプリの配置編〜】
ゼロから行うのであれば、こちらの方が良いかも知れません。私は前者の方で始めたので、途中で参考記事を変えるのもややこしくなると考えたので移行しませんでした。インストールの諸問題を解決をしてくれたで賞
【AWS EC2】Amazon Linux2にnginxをインストールする方法
手順に沿って進めていて、最初にぶつかる問題は、おそらくAmazon Linux AMIが無く、Amazon Linux2 AMIしかないことでしょう。この手順で2を選択し、Nignxをインストールしようとすると、エラーが発生します。Amazon Linux2にはnginxのyumが無いことが原因で、その解決方法を案内してくれます。
Rails6 開発時につまづきそうな webpacker, yarn 関係のエラーと解決方法
Rails6でwebpackerが標準になったことにより、Railsアプリの開発環境にyarnのインストールが必要になりました。
AmazonLinuxにyarnをインストールする
タイトルそのまんまです。権限によって許可されていない操作(パーミッションエラー)を解決してくれたで賞
AmazonLinuxで新しいユーザを作成してec2-userを削除する
EC2にssh接続する際、デフォルトではec2-userになっています。セキュリティを高めるため、別ユーザーを作成してそちらを使用します。しかし、私の場合だと手順ではパーミッションエラーになってしまいます。そこでこちらのサイトが非常に参考になりました。なお、こちらでは最後にec2-userを削除しますが、手順には影響がないので大丈夫です。
Linuxの権限確認と変更(chmod)(超初心者向け)
そもそもパーミッションてなんやねん!って方は、この記事が参考になります。EC2からRDSにMySQLでログインできない問題を解決してくれたで賞
EC2からMySQLでRDSに接続するが、「Access denied for user」を突き返される
私が書いた記事ですが、悪いのは100自分です。Access denied for userと返されたら、ユーザーネーム、パスワード、セキュリティグループを疑ってみましょう。AWS RDSで設定を変更したらAccess denied (using password: YES)でmysql ログインできなくなった
RDSの設定を変更した時に見落としがちな部分。メモリ不足を解決してくれたで賞
[Rails] CapistranoでEC2へデプロイ:EC2仮想メモリ不足トラブルシュート
EC2の無料枠で使えるt2.microのメモリサイズは1GiBとかなり少なめです。そのため、ある程度負荷のある処理をすると、メモリ不足で処理が完了しないエラーが発生します。
virtual memory exhausted: Cannot allocate memoryというエラーです。
手順でいうと、私の場合は$ bundle install --path vendor/bundleで発生しました。
調べてみるとbundle install系でこのエラーが発生するのは割と頻繁ぽい(?)。
この記事ではCapistranoを使っているときのようですが、手順での場合でも利用できます。LinuxでRAMメモリのキャッシュやスワップをクリア・解放する方法
同時に、メモリの解放などもさらっておくと良いと思います。DBの設定を環境変数化する手助けをしてくれたで賞
【画像付きで丁寧に解説】AWS(EC2)にRailsアプリをイチから上げる方法【その3〜サーバー設定とRailsアプリの配置編〜】
先程紹介したページの一部です。手順では、データベースのユーザー名やパスワードをdatabase.ymlに直接記述します。しかし、DBへアクセスする情報をdatabase.ymlへ直接記入するとセキュリティ的に問題があります。そこで、これらの秘密情報は環境変数へ移行します。ロードバランサーとHTTPS化を手助けしてくれたで賞
【初心者向け】AWSのサービスを使ってWebサーバーをHTTPS化する
手順でのロードバランサーは以前のバージョンのものです。HTTPS化するのであれば、手順よりこちらにまるまる沿って行ってしまった方がやりやすいです。デプロイ後のエラーの解決を手助けをしてくれた賞
[初学者] AWS デプロイ時のエラー解決に役立ちそうなコマンドや知識
バックグラウンドが黒でちょっと見にくいのですが、エラーに困ったらその糸口を見つけ出すことができると思います。EC2のRuby/Rails環境構築中のwe're sorry, but something went wrongでハマった話
AWSにデプロイして、We're sorryが出たら、とりあえずログを確認してみろよってこと。
ログからエラーの糸口を見つけ出すことができる力があれば、これだけでOK。デプロイしたアプリを更新する手助けをしてくれたで賞
【AWS】 EC2にデプロイしたRailsアプリを更新する方法
一度アプリをデプロイした後に更新することも往々にしてあると思います。そういう時はこちら。本番環境でgit pullした時に起こったエラー【error: Your local changes to the following files would be overwritten by merge: composer.lock Please, commit your changes or stash them before you can merge. 】
上記の更新で、$ git pull origin masterを行うとたまにコンフリクトのエラーが発生します。原因は様々だと思いますが、もし発生した場合はこの方法を試してみてください。Unicornに関する問題を解決してくれたで賞
unicorn使おうと思ったらいろいろ詰まった
基本更新などでgit pullをしたときなどに書き換えられることはないと思うのですが、私の場合コンフリクトが発生してstashで解決したあとに、unicornが起動できなくなりました。原因はGemfileのunicornが消えてなくなっていただけだったのですが。AWSでだけPayjpが動作してくれない問題を解決してくれたで賞
環境変数の代わりに .env ファイルを使用する (dotenv)
私はアプリにPayjpを使った決済機能を導入していたのですが、ローカルやHerokuでは動作していたのに、AWSでだけ動作しない問題にぶち当たりました。私の場合は、この方法を導入するだけで解決しました。Rails 本番環境(EC2)でPAY.JPのAPI keyを読み込めないエラー
こちらの様にすると解決するパターンもあると思います。上記2つの違いとしては、Javascriptファイルから.envファイルを参照するのか、Rubyファイル(コントローラなど)から参照するのかだと思います。私の場合は、コントローラからは後者の記事のように
Rails.application.credentials.payjp[:PAYJP_PRIVATE_KEY]とせずとも、ENV['鍵名']で読み取れたので、かならずしもそう記述しなければならないというよりは、.envファイルの設定の問題なのではないかと思います。代わりに、JSファイルから.envファイルを読み取れず、前者の記事通りに実装したところ上手くいったという次第です。EC2ボリュームに関する問題を解決してくれたで賞
【AWS】EC2サーバーにボリュームをアタッチしたら起動しない!
EC2のボリュームは、アタッチ・デタッチができます。インスタンスが正常に起動できない場合などに、ボリュームをデタッチ、別のインスタンスにアタッチすることで中身を確認できたりします。アタッチする際に、ルートデバイスの指定があるのですが、これが何故か表示されているように記入しても上手くいかないケースがあります。その他
セキュリティグループにマイIPを設定してssh接続できない
設定したIPアドレスと今現在自分が使っているIPアドレスに差異がないか確認します。
あなたが現在インターネットに接続しているグローバルIPアドレス確認RailsアプリにFontAwesomeを使用している場合
この場合は、FontAwesomeをローカルでインストールしたときと同じ様にインストールします。Rails6の場合なので、5以前の場合は検証していません。
【Rails】Rails6でFontAwesomeを導入・表示させるための手順を初心者向けに解説ClockWorkを使ったバッチ処理
EC2上でClockWorkの処理を実装する場合です。
clockworkを本番環境で動かす場合いつでも強い味方
さいごに
インターネット上でこうやって探すだけで実装していけるなんて、ありがたいなあと改めて実感しました。もちろん、一筋縄ではありませんし、人によって解決できる方法も違うので、自分に当てはまる解決策を見つけるために費やした時間を振り返ると、まだまだ情報収集能力が足りないなあとひしひしと感じています。
公式ドキュメントはさらっとリンクを載せただけですが、何か実装にひっかかったらやはり公式ドキュメントがこころ強いですよね。
このまとめ記事もだれか1人にでもお役に立てれば嬉しいです。
- 投稿日:2021-03-02T16:18:00+09:00
PostgresSQLで基本的な操作触ってみた(windows ,RDS)
はじめに
データベースを触ったことがないので、ポスグレをインストールし基本的な操作を触ってみました。その後、AWSのRDSでも同様の環境を構築してみます。
Windows編 PostgresSQLのインストール
こちらhttps://www.enterprisedb.com/downloads/postgres-postgresql-downloadsから使用のOSにあったものをインストールします。私はWindows x86-64の13.2をインストールしました。
\PostgreSQL\バージョン\data\postgresql.conf
こちらのテキストファイルのlisten_address ="*"と記載されている部分を'localhost'に書き換え、serviceでPostgreSQLを再起動し他の端末からアクセスされないようにします。インストールが終わったら、コマンドプロンプトを起動しpsql.exeを実行しポスグレが起動するか確認してみます。
psql.exe -U postgres ユーザ postgres のパスワード:設定したパスワードを入力 psql (13.2) "help"でヘルプを表示します。 postgres=#データベースの作成
shopという名前のデータベースを作成します。
postgres=# CREATE DATABASE shop; CREATE DATABASEデータベースへのアクセス
psql.exe -U postgres -d shop ユーザ postgres のパスワード: psql (13.2) "help"でヘルプを表示します。 shop=#shopへアクセス出来ました。
テーブルの作成
小売店の商品データベースを想定し、以下のようなテーブルを作成しました
項目 Shohinテーブルで定義した列名 データ型 商品ID shohin_id 固定長文字列 商品名 shohin_mei 可変長文字列 商品分類 shohin_bunrui 可変長文字列 販売単価 hanbai_tanka データ型 仕入れ単価 shiire_tanka データ型 登録日 tourokubi 日付型 shop=# CREATE TABLE shohin shop-# (shohin_id CHAR(4) NOT NULL, shop(# shohin_mei VARCHAR(100) NOT NULL, shop(# shohin_bunrui VARCHAR(32) NOT NULL, shop(# hanbai_tanka INTEGER, shop(# shiire_tanka INTEGER, shop(# torokubi DATE, shop(# PRIMARY KEY (shohin_id)); CREATE TABLEデータ型について
・INTEGER型
整数を入れる列に指定するデータ型・CHAR型
文字の長さを固定する固定長文字列でCHAR(文字列の長さ)で指定する。
CHAR(8)で'abc'を定義すると'abc 'とスペースを後ろに挿入しで8文字に固定する。VARCHAR型
CHAR型と違い、可変長文字列を指定する。VARCHAR(8)で'abc'を定義すると'abc'のまま格納される。・DATE型 日付を入れる列にしているするデータ型
制約の設定
shohin_idの後にNOT NULLと記載してあるのは、必ずデータが入っていないとエラーを返すようにする制約です。商品IDのない商品を登録することが出来ないようにしています。
主キー制約
データベースのデータ(行、レコード)を一意に識別するための項目です。
商品IDをユニークな値に設定していることで、どの商品であるか特定が出来ます。データ登録
shop=# begin transaction; BEGIN shop=*# insert into Shohin values('0001','Tシャツ','衣服',1000,500,'2009-09-20'); INSERT 0 1 shop=*# insert into Shohin values('0002','穴あけパンチ','事務用品',500,320,'2009-09-11'); INSERT 0 1 shop=*# commit; COMMIT出力結果
shop=# select * from Shohin; shohin_id | shohin_mei | shohin_bunrui | hanbai_tanka | shiire_tanka | torokubi -----------+--------------+---------------+--------------+--------------+------------ 0001 | Tシャツ | 衣服 | 1000 | 500 | 2009-09-20 0002 | 穴あけパンチ | 事務用品 | 500 | 320 | 2009-09-11 (2 行)データベースにデータを格納し、それをselectで確認することが出来ました。
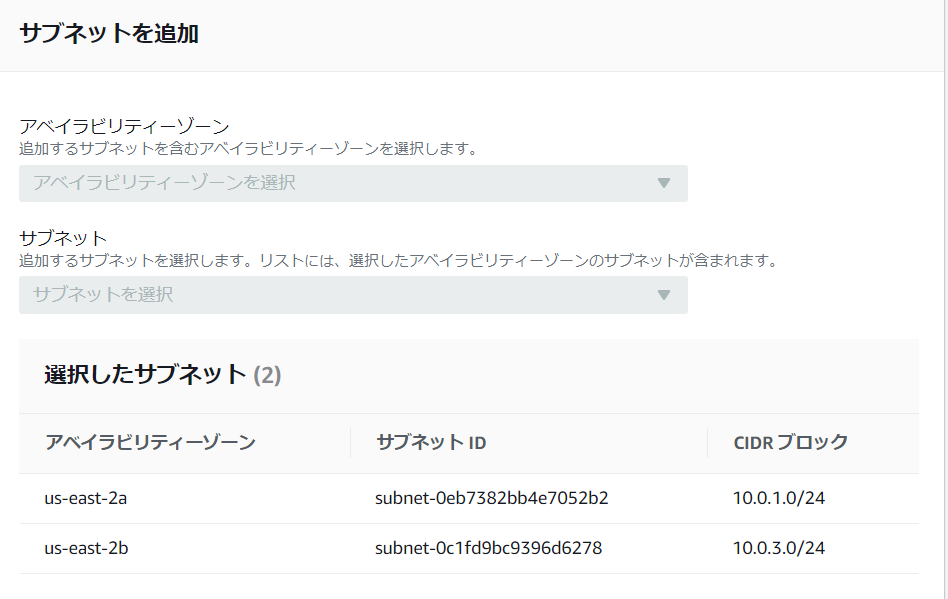
awsの環境構築
EC2をパブリックサブネットに、RDSをプライベートに配置しSSHでPCから接続します。
*EC2のインスタンス作成は割愛します・postgreのパッケージを検索します
sudo yum list | grep postgre freeradius-postgresql.x86_64 3.0.13-15.amzn2 amzn2-core pcp-pmda-postgresql.x86_64 4.3.2-12.amzn2.0.1 amzn2-core postgresql.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-contrib.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-devel.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-docs.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-jdbc.noarch 9.2.1002-8.amzn2 amzn2-core postgresql-jdbc-javadoc.noarch 9.2.1002-8.amzn2 amzn2-core postgresql-libs.i686 9.2.24-1.amzn2.0.1 amzn2-core postgresql-libs.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-odbc.x86_64 09.03.0100-2.amzn2.0.2 amzn2-core postgresql-plperl.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-plpython.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-pltcl.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-server.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-static.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-test.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-upgrade.x86_64 9.2.24-1.amzn2.0.1 amzn2-core qt-postgresql.i686 1:4.8.5-15.amzn2.0.5 amzn2-core qt-postgresql.x86_64 1:4.8.5-15.amzn2.0.5 amzn2-core qt5-qtbase-postgresql.i686 5.9.2-3.amzn2.0.4 amzn2-core qt5-qtbase-postgresql.x86_64 5.9.2-3.amzn2.0.4 amzn2-core・パッケージをインストールします
yum install postgresql.x86_64・パッケージがインストールされたことを確認します。
psql -V psql (PostgreSQL) 9.2.24RDSの作成
RDSの作成の前に、サブネットグループを作成します。
画像のように、AZを跨いだ構成にしないとエラーとなります。エラーについては参考文献を参照してください。
参考文献:https://dev.classmethod.jp/articles/rds-has-two-configs-concerning-availability-zone/
RDSを作成していきます。
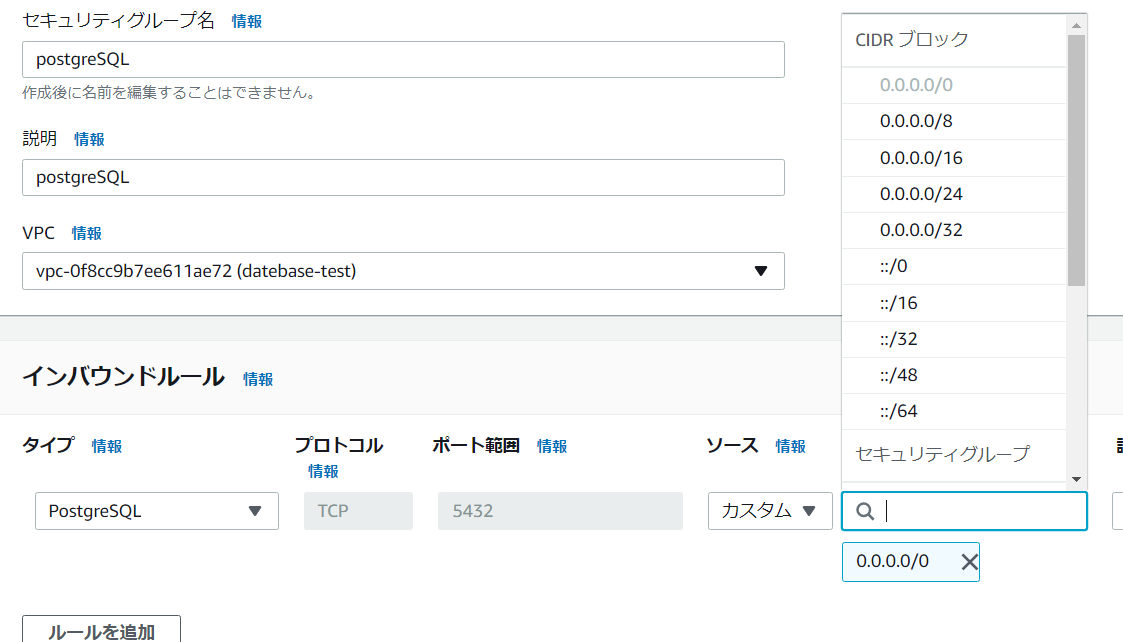
PosgreSQLを許可するセキュリティグループを作成して、割り当てます。
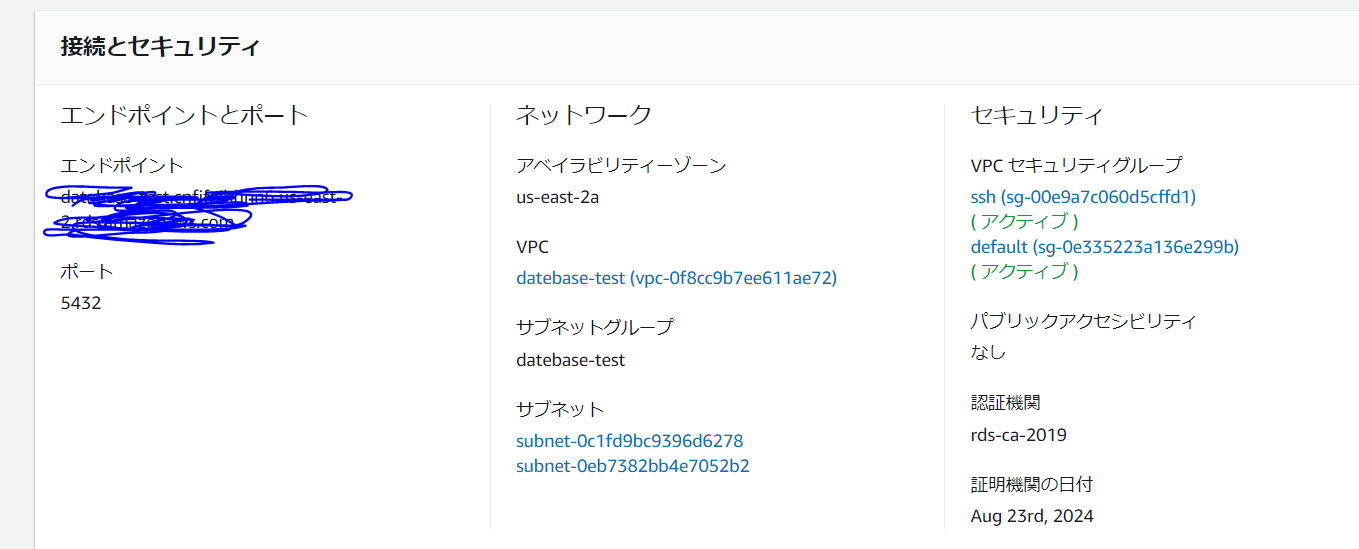
作成が完了したら、エンドポイントを控えてください。EC2からの接続で使います。
RDSへの接続
EC2からRDSへ接続をします
psql -h エンドポイント -U ユーザー名 psql (9.2.24, server 13.1) WARNING: psql version 9.2, server version 13.0. Some psql features might not work. SSL connection (cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256) Type "help" for help. postgres=>EC2からRDSへのアクセスを確認することが出来ました。

- 投稿日:2021-03-02T16:18:00+09:00
PostgreSQLで基本的な操作触ってみた(windows ,RDS)
はじめに
データベースを触ったことがないので、ポスグレをインストールし基本的な操作を触ってみました。その後、AWSのRDSでも同様の環境を構築してみます。
Windows編 PostgreSQLのインストール
こちらhttps://www.enterprisedb.com/downloads/postgres-postgresql-downloads
から使用のOSにあったものをインストールします。私はWindows x86-64の13.2をインストールしました。\PostgreSQL\バージョン\data\postgresql.conf
こちらのテキストファイルのlisten_address ="*"と記載されている部分を'localhost'に書き換え、serviceでPostgreSQLを再起動し他の端末からアクセスされないようにします。インストールが終わったら、コマンドプロンプトを起動しpsql.exeを実行しポスグレが起動するか確認してみます。
psql.exe -U postgres ユーザ postgres のパスワード:設定したパスワードを入力 psql (13.2) "help"でヘルプを表示します。 postgres=#データベースの作成
shopという名前のデータベースを作成します。
postgres=# CREATE DATABASE shop; CREATE DATABASEデータベースへのアクセス
psql.exe -U postgres -d shop ユーザ postgres のパスワード: psql (13.2) "help"でヘルプを表示します。 shop=#shopへアクセス出来ました。
テーブルの作成
小売店の商品データベースを想定し、以下のようなテーブルを作成しました
項目 Shohinテーブルで定義した列名 データ型 商品ID shohin_id 固定長文字列 商品名 shohin_mei 可変長文字列 商品分類 shohin_bunrui 可変長文字列 販売単価 hanbai_tanka データ型 仕入れ単価 shiire_tanka データ型 登録日 tourokubi 日付型 shop=# CREATE TABLE shohin shop-# (shohin_id CHAR(4) NOT NULL, shop(# shohin_mei VARCHAR(100) NOT NULL, shop(# shohin_bunrui VARCHAR(32) NOT NULL, shop(# hanbai_tanka INTEGER, shop(# shiire_tanka INTEGER, shop(# torokubi DATE, shop(# PRIMARY KEY (shohin_id)); CREATE TABLEデータ型について
・INTEGER型
整数を入れる列に指定するデータ型・CHAR型
文字の長さを固定する固定長文字列でCHAR(文字列の長さ)で指定する。
CHAR(8)で'abc'を定義すると'abc 'とスペースを後ろに挿入しで8文字に固定する・VARCHAR型
CHAR型と違い、可変長文字列を指定する。VARCHAR(8)で'abc'を定義すると'abc'のまま格納される。・DATE型 日付を入れる列にしているするデータ型
制約の設定
shohin_idの後にNOT NULLと記載してあるのは、必ずデータが入っていないとエラーを返すようにする制約です。商品IDのない商品を登録することが出来ないようにしています。
主キー制約
データベースのデータ(行、レコード)を一意に識別するための項目です。
商品IDをユニークな値に設定していることで、どの商品であるか特定が出来ます。データ登録
shop=# begin transaction; BEGIN shop=*# insert into Shohin values('0001','Tシャツ','衣服',1000,500,'2009-09-20'); INSERT 0 1 shop=*# insert into Shohin values('0002','穴あけパンチ','事務用品',500,320,'2009-09-11'); INSERT 0 1 shop=*# commit; COMMIT出力結果
shop=# select * from Shohin; shohin_id | shohin_mei | shohin_bunrui | hanbai_tanka | shiire_tanka | torokubi -----------+--------------+---------------+--------------+--------------+------------ 0001 | Tシャツ | 衣服 | 1000 | 500 | 2009-09-20 0002 | 穴あけパンチ | 事務用品 | 500 | 320 | 2009-09-11 (2 行)データベースにデータを格納し、それをselectで確認することが出来ました。
awsの環境構築
EC2をパブリックサブネットに、RDSをプライベートに配置しSSHでPCから接続します。
*EC2のインスタンス作成は割愛します・postgreのパッケージを検索します
sudo yum list | grep postgre freeradius-postgresql.x86_64 3.0.13-15.amzn2 amzn2-core pcp-pmda-postgresql.x86_64 4.3.2-12.amzn2.0.1 amzn2-core postgresql.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-contrib.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-devel.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-docs.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-jdbc.noarch 9.2.1002-8.amzn2 amzn2-core postgresql-jdbc-javadoc.noarch 9.2.1002-8.amzn2 amzn2-core postgresql-libs.i686 9.2.24-1.amzn2.0.1 amzn2-core postgresql-libs.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-odbc.x86_64 09.03.0100-2.amzn2.0.2 amzn2-core postgresql-plperl.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-plpython.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-pltcl.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-server.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-static.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-test.x86_64 9.2.24-1.amzn2.0.1 amzn2-core postgresql-upgrade.x86_64 9.2.24-1.amzn2.0.1 amzn2-core qt-postgresql.i686 1:4.8.5-15.amzn2.0.5 amzn2-core qt-postgresql.x86_64 1:4.8.5-15.amzn2.0.5 amzn2-core qt5-qtbase-postgresql.i686 5.9.2-3.amzn2.0.4 amzn2-core qt5-qtbase-postgresql.x86_64 5.9.2-3.amzn2.0.4 amzn2-core・パッケージをインストールします
yum install postgresql.x86_64・パッケージがインストールされたことを確認します。
psql -V psql (PostgreSQL) 9.2.24RDSの作成
RDSの作成の前に、サブネットグループを作成します。
画像のように、AZを跨いだ構成にしないとエラーとなります。エラーについては参考文献を参照してください。
参考文献:https://dev.classmethod.jp/articles/rds-has-two-configs-concerning-availability-zone/
RDSを作成していきます。
PosgreSQLを許可するセキュリティグループを作成して、割り当てます。
作成が完了したら、エンドポイントを控えてください。EC2からの接続で使います。
RDSへの接続
EC2からRDSへ接続をします
psql -h エンドポイント -U ユーザー名 psql (9.2.24, server 13.1) WARNING: psql version 9.2, server version 13.0. Some psql features might not work. SSL connection (cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256) Type "help" for help. postgres=>EC2からRDSへのアクセスを確認することが出来ました。
- 投稿日:2021-03-02T16:07:26+09:00
AmazonBraketで学ぶ量子コンピュータ④
この記事について
量子コンピュータの勉強をはじめて最近一通りAmazonBraketを触り終えました。
最近登場したサービスであることもあり、少し丁寧なドキュメントを残しておくと後続の方が勉強しやすくなったり、参照してわからないところを調べる際に便利かなと思ったので
自分自身の理解向上も兼ねて記事にまとめていっています。なお、量子コンピュータ関係の他の記事は、こちらのページで一覧にしています
※本記事は2021年2月に更新している記事です。更新などにより内容が変わっている可能性もあるのでご注意ください。
概要
本記事では量子コンピュータの導入部分に関して解説をしていこうと思います。
参照するのはこちらの3_Deep_dive_into_the_anatomy_of_quantum_circuits.ipynb
というサンプルです。
こちらのサンプルではあまり前提とした知識を必要とせずAmazon Braketで使える仕様を説明しているサンプルコードとなりますので本記事でもそれに沿って仕様説明をしていこうと思います。AmazonBraket
IMPORT STATEMENTS
こちらでは必要なモジュールをインポートするコードのみが記載されているため、本記事では省略させていただきます。
詳細を知りたい方は以下の二つの記事で紹介させていただいているのでそちらを見ていただけると良いかと思います。CIRCUIT DEFINITION
こちらのセクションでは回路の定義、そして定義した回路の詳細を取得する方法を示しています。
回路詳細確認
サンプルとしてまずは4つの量子ビットを用いてそれぞれにアダマールゲートを適用し、CNOTを2か所に適用するような回路を作成しています。
# define circuit with 4 qubits my_circuit = Circuit().h(range(4)).cnot(control=0, target=2).cnot(control=1, target=3) print(my_circuit)T : |0| 1 | q0 : -H-C--- | q1 : -H-|-C- | | q2 : -H-X-|- | q3 : -H---X- T : |0| 1 |上記の回路は二つの時間枠によって生成されます。
アダマールゲートを適用する時間とCNOTを適用する時間です。
アダマールゲートを適用する量子ビット同士はこの操作を排他的に行うことができるので同じ時間枠ですし、CNOTを適用する場合も同様に排他的であるので同時に行うことができます。
もちろんこの操作は一瞬の時間で切り取られますが、
時間0にアダマールゲートが適用され、時間1にCNOTが適用されるということがわかります。
また、それは実際にmommentsを取得することで以下のように詳細を見ることができます。# show moments of our quantum circuit my_moments = my_circuit.moments for moment in my_moments: print(moment)MomentsKey(time=0, qubits=QubitSet([Qubit(0)])) MomentsKey(time=0, qubits=QubitSet([Qubit(1)])) MomentsKey(time=0, qubits=QubitSet([Qubit(2)])) MomentsKey(time=0, qubits=QubitSet([Qubit(3)])) MomentsKey(time=1, qubits=QubitSet([Qubit(0), Qubit(2)])) MomentsKey(time=1, qubits=QubitSet([Qubit(1), Qubit(3)]))
timeに適用時間、qubitsに適用量子ビットが示されています。もう少し詳しく見ようとすると
instructionsを見ることで見ることもできます。# list all instructions/gates making up our circuit my_instructions = my_circuit.instructions for instruction in my_instructions: print(instruction)Instruction('operator': H('qubit_count': 1), 'target': QubitSet([Qubit(0)])) Instruction('operator': H('qubit_count': 1), 'target': QubitSet([Qubit(1)])) Instruction('operator': H('qubit_count': 1), 'target': QubitSet([Qubit(2)])) Instruction('operator': H('qubit_count': 1), 'target': QubitSet([Qubit(3)])) Instruction('operator': CNot('qubit_count': 2), 'target': QubitSet([Qubit(0), Qubit(2)])) Instruction('operator': CNot('qubit_count': 2), 'target': QubitSet([Qubit(1), Qubit(3)]))先ほどの出力に加えて、アダマールゲートやCNOTゲートのような適用回路もわかるようになったかと思います。
パラメトリック回路
次にパラメトリック回路に数値を代入しながら定義する方法を示します。
おおむねやり方はfunction(qubit, parameter)といった形になっています。
以下が例となります。# define circuit with some parametrized gates my_circuit = Circuit().rx(0, 0.15).ry(1, 0.2).rz(2, 0.25).h(3).cnot(control=0, target=2).zz(1, 3, 0.15).x([1,3]) print(my_circuit)q0 : -Rx(0.15)-C------------ | q1 : -Ry(0.2)--|-ZZ(0.15)-X- | | q2 : -Rz(0.25)-X-|---------- | q3 : -H----------ZZ(0.15)-X- T : | 0 | 1 |2|rxやry, rzでは前述した通り、
function(qubit, parameter)といった形になっているかと思います。
- cnotでは制御ビット、ターゲットビットを定義しないといけない。
- ZZでは適用量子ビットを二つ定義しないといけない。
といったことがあるため、cnotやZZ回路では変数の定義の仕方が異なります。
また、複数ビットに同じ回路を適用する際にx([1,3)]といったように配列
を定義できることもわかるかと思います。回路関数
回路を返却してくれる関数を定義できます。
やり方はいくつかあるのですが、今回は以下の二つをやってみます。
unitary()関数を使うcircuit.subroutineを使う
unitary()関数を使う以下のように、変数を受け取り、np.arrayで2×2の行列を返すような関数を定義します。
今回定義しているものはU3回転行列で任意の回転を表す量子ゲートを示していますが、組み込みで定義されているものではなく、自ら定義しています。# helper function to build custom gate def u3(alpha, theta, phi): """ function to return matrix for general single qubit rotation rotation is given by exp(-i sigma*n/2*alpha) where alpha is rotation angle and n defines rotation axis as n=(sin(theta)cos(phi), sin(theta)sin(phi), cos(theta)) sigma is vector of Pauli matrices """ u11 = np.cos(alpha/2)-1j*np.sin(alpha/2)*np.cos(theta) u12 = -1j*(np.exp(-1j*phi))*np.sin(theta)*np.sin(alpha/2) u21 = -1j*(np.exp(1j*phi))*np.sin(theta)*np.sin(alpha/2) u22 = np.cos(alpha/2)+1j*np.sin(alpha/2)*np.cos(theta) return np.array([[u11, u12], [u21, u22]])こちらの関数を使うには、回路定義のメソッドチェーンに
unitary(matrix=u3(alpha, theta, phi), targets=[n])を繋げてあげることにより使うことができます。
もちろん、引数部分には適切な変数を与えてあげてください。
具体的には以下の通りに定義すれば良いです。# define and print custom unitary my_u3 = u3(np.pi/2, 0, 0) # print(my_u3) # define example circuit applying custom U to the first qubit circ = Circuit().unitary(matrix=my_u3, targets=[0]).h(1).cnot(control=0, target=1) print(circ)
circuit.subroutineを使う次に
circuit.subroutineを使う方法を紹介します。
こちらの機能は簡単に言うと定義した回路を他の組み込みゲートと同じように使う機能となります。
上記と同じU3を定義しようとすると以下のように定義されます。# helper function to build custom gate @circuit.subroutine(register=True) def u3(target, angles): """ Function to return the matrix for a general single qubit rotation, given by exp(-i sigma*n/2*alpha), where alpha is the rotation angle, n defines the rotation axis via n=(sin(theta)cos(phi), sin(theta)sin(phi), cos(theta)), and sigma is the vector of Pauli matrices """ # get angles alpha = angles[0] theta = angles[1] phi = angles[2] # set 2x2 matrix entries u11 = np.cos(alpha/2)-1j*np.sin(alpha/2)*np.cos(theta) u12 = -1j*(np.exp(-1j*phi))*np.sin(theta)*np.sin(alpha/2) u21 = -1j*(np.exp(1j*phi))*np.sin(theta)*np.sin(alpha/2) u22 = np.cos(alpha/2)+1j*np.sin(alpha/2)*np.cos(theta) # define unitary as numpy matrix u = np.array([[u11, u12], [u21, u22]]) # print('Unitary:', u) # define custom Braket gate circ = Circuit() circ.unitary(matrix=u, targets=target) return circ使い方は以下となります。
# define example circuit applying custom single-qubit gate U to the first qubit angles = [np.pi/2, np.pi/2, np.pi/2] angles = [np.pi/4, 0, 0] # build circuit using custom u3 gate circ2 = Circuit().u3([0], angles).cnot(control=0, target=1) print(circ2)CIRCUIT DEPTH AND CIRCUIT SIZE
まず
depthを用いて回路の深さを取得してみます。# define circuit with parametrized gates my_circuit = Circuit().rx(0, 0.15).ry(1, 0.2).rz(2, 0.25).h(3).cnot(control=0, target=2).zz(1, 3, 0.15).x(0) circuit_depth = my_circuit.depth print(my_circuit) print() print('Total circuit depth:', circuit_depth)T : | 0 | 1 |2| q0 : -Rx(0.15)-C----------X- | q1 : -Ry(0.2)--|-ZZ(0.15)--- | | q2 : -Rz(0.25)-X-|---------- | q3 : -H----------ZZ(0.15)--- T : | 0 | 1 |2| Total circuit depth: 3回路の深さが3であることがわかったかと思います。
注意していただきたいのは以下のサンプルのようにx(4)を最後の方に適用したとしても第4量子ビットはXしか適用しないため、最初の方に適用されます。
このように回路の実行順序はなるべく左詰めで実行されることに注意してください。# define circuit with parameterized gates my_circuit = Circuit().rx(0, 0.15).ry(1, 0.2).rz(2, 0.25).h(3).cnot(control=0, target=2).zz(1, 3, 0.15).x(4) # get circuit depth circuit_depth = my_circuit.depth # get qubit number qubit_count = my_circuit.qubit_count # get approx. estimate of circuit size circuit_size = circuit_depth*qubit_count # print circuit print(my_circuit) print() # print characteristics of our circuit print('Total circuit depth:', circuit_depth) print('Number of qubits:', qubit_count) print('Circuit size:', circuit_size)T : | 0 | 1 | q0 : -Rx(0.15)-C---------- | q1 : -Ry(0.2)--|-ZZ(0.15)- | | q2 : -Rz(0.25)-X-|-------- | q3 : -H----------ZZ(0.15)- q4 : -X------------------- T : | 0 | 1 | Total circuit depth: 2 Number of qubits: 5 Circuit size: 10また、上記では回路サイズも取得しています。
回路サイズは回路の複雑さを考える指標となります。
もちろん大きいほど必ず難しいというわけでも、小さいからといって簡単というわけでもありません。
回路サイズは、量(qubit数)と質(回路の深さ)の両方を考慮します。
ここでは、qubit数と回路の深さ(図の面積)を掛け合わせた非常に単純な定義を使用してているといった具合になります。APPENDING CIRCUITS
ここからは回路の追加方法を3つのやり方で示します。
上記までで定義したmy_circuitの回路を用います。
つまり以下の図で示すものです。T : | 0 | 1 | q0 : -Rx(0.15)-C---------- | q1 : -Ry(0.2)--|-ZZ(0.15)- | | q2 : -Rz(0.25)-X-|-------- | q3 : -H----------ZZ(0.15)- q4 : -X------------------- T : | 0 | 1 |シンプルな手法
まず最も簡単な手法で回路を追加してみます。
第4qubitにYゲートを追加します。
my_circuit = my_circuit.y(4)とするだけでYゲートを第4qubitに追加できます。
以下のような結果となるはずです。T : | 0 | 1 | q0 : -Rx(0.15)-C---------- | q1 : -Ry(0.2)--|-ZZ(0.15)- | | q2 : -Rz(0.25)-X-|-------- | q3 : -H----------ZZ(0.15)- q4 : -X--------Y---------- T : | 0 | 1 |add_instruction()メソッドで追加
次に add_instruction()メソッドを活用して追加する方法を示します。
以下のようにCNOTゲートをInstructionとして定義し、add_instruction()メソッドを使用することで既存の回路オブジェクトに追加できます。
gate_instr = Instruction(Gate.CNot(), [0, 1]) my_circuit = my_circuit.add_instruction(gate_instr)以下のような結果となります。
T : | 0 | 1 |2| q0 : -Rx(0.15)-C----------C- | | q1 : -Ry(0.2)--|-ZZ(0.15)-X- | | q2 : -Rz(0.25)-X-|---------- | q3 : -H----------ZZ(0.15)--- q4 : -X--------Y------------ T : | 0 | 1 |2|add_circuit()メソッドで追加
最後はadd_circuit()メソッドでの追加です。
個人的には長い回路も簡単に定義して追加しやすいのでこれが一番使われるような気がします。
Circuitオブジェクトを定義し、add_circuit()で追加するイメージです。
以下のように書きます。my_circuit2 = Circuit().rz(0, 0.1).rz(1, 0.2).rz(3, 0.3).rz(4, 0.4) my_circuit.add_circuit(my_circuit2)T : | 0 | 1 | 2 | 3 | q0 : -Rx(0.15)-C----------C-------Rz(0.1)- | | q1 : -Ry(0.2)--|-ZZ(0.15)-X-------Rz(0.2)- | | q2 : -Rz(0.25)-X-|------------------------ | q3 : -H----------ZZ(0.15)-Rz(0.3)--------- q4 : -X--------Y----------Rz(0.4)--------- T : | 0 | 1 | 2 | 3 |是非使いこなしてみてください。
CIRCUIT EXECUTION AND TASK TRACKING
こちらは実機で使える
- 回路の出力方法
- S3の登録方法
- タスクの取得
- タスクの復元方法
等が記載されているおり、こちらの内容はAmazonBraketで学ぶ量子コンピュータ③で紹介させていただいているので省略させていただきます。
一点だけ、タスクのキャンセル方法だけこちらで初出なので補足させていただきます。
Amazon Braketでは実機で計算する際は様々な方が使っている中で実機を使うのでキュー待ちが発生します。
あまり待ちたくなかったりした場合にやっぱりタスクを打ち切りたくなることもあるのでこういった機能があります。(たぶん)
やり方としてはタスクのIDを取得するか、実行時のタスクを保存しておき、task.cancel()といったようにcancel()関数を呼び出すだけでできます。
例としては以下のようになります。# define task task = device.run(my_circuit, s3_folder, shots=1000) # get id and status of submitted task task_id = task.id status = task.state() # print('ID of task:', task_id) print('Status of task:', status) # cancel task task.cancel() status = task.state() print('Status of task:', status)キャンセル中は以下の通り、
CANCELLINGステータスになります。Status of task: QUEUED Status of task: CANCELLINGDEMONSTRATION OF RESULT-TYPES: Expectation Values and Observables
シミュレータにおいて前述したまでの例では、shots>0と設定し、実際の量子ハードウェアの動作を模倣したような動作を行いました。
しかし、古典的なシミュレータでは、sshot=0の場合には完全な状態ベクトルにアクセスすることができます。
特に量子ハードウェアでは観測した時点で状態が壊れてしまうため、こういった完全な状態ベクトルにアクセスできるのは古典的なシミュレータの大きな強みであるといえます。
このセクションでこの機能について詳しく説明します。ResultTypesの機能を使って、完全な状態ベクトル、振幅、観測確率、単一および複数量子ビットの観測値にアクセスし、最終的な状態ベクトルの値、期待値、状態の振幅を出力することができます。
RESULT TYPES FOR shots=0
完全な状態ベクトルと振幅は古典的なシミュレータでshots=0の時にのみ取得できることに注意してください。
シミュレータでshots=0としたとき、確率、期待値は正確な値となります。
以下は① 第2量子ビットをX基底で観測した際の期待値
② 第0量子ビット、第1量子ビットをZ基底で観測した際の期待値
③ $|00000 \rangle$の確率振幅
④ 第3量子ビットの0, 1の観測確率を取得するコードとなっています。
# add result types circ = my_circuit # add the state_vector ResultType available for shots=0 circ.state_vector() # add single qubit expectation value ① 第2量子ビットをX基底で観測した際の期待値 obs1 = Observable.X() circ.expectation(obs1, target=[2]) # add the two-qubit Z0*Z1 expectation value ② 第0量子ビット、第1量子ビットをZ基底で観測した際の期待値 obs2 = Observable.Z() @ Observable.Z() circ.expectation(obs2, target=[0,1]) # add the amplitude for |0...0> ③ |00000>の確率振幅 bitstring = '0'*qubit_count circ.amplitude(state=[bitstring]) # add marginal probability ④ 第3量子ビットの0, 1の観測確率 circ.probability(target=[3]) print(circ)回路図を示すと以下のようになります。
Result Type部分でどういった観測のやり方で観測をしようとしているかを見ることができ、少し便利かと思います。T : | 0 | 1 | 2 | 3 | Result Types | q0 : -Rx(0.15)-C----------C-------Rz(0.1)-Expectation(Z@Z)- | | | q1 : -Ry(0.2)--|-ZZ(0.15)-X-------Rz(0.2)-Expectation(Z@Z)- | | q2 : -Rz(0.25)-X-|------------------------Expectation(X)--- | q3 : -H----------ZZ(0.15)-Rz(0.3)---------Probability------ q4 : -X--------Y----------Rz(0.4)-------------------------- T : | 0 | 1 | 2 | 3 | Result Types |出力してみると以下のようになります。
量子コンピュータを模倣しているとはいえ、shots=0の設定で動かしたシミュレータですので何度実行してもこの結果から変わることのない不変な結果となることに注意してください。# set up device device = LocalSimulator() # run the circuit and output the results specified above task = device.run(circ, shots=0) result = task.result() print("Final state vector:\n", result.values[0]) print("Expectation value <X2>", result.values[1]) print("Expectation value <Z0Z1>:", result.values[2]) print("Amplitude <00000|Final state>:", result.values[3]) print("Marginal probability for target qubit 3 in computational basis:", result.values[4])Final state vector: [-0.45198076-0.53661046j 0. +0.j -0.17357771-0.67978539j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j -0.0241381 -0.06612661j 0. +0.j -0.01398522-0.06899123j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j -0.00476292+0.00230075j 0. +0.j -0.00505326+0.00156316j 0. +0.j 0. +0.j 0. +0.j 0. +0.j 0. +0.j -0.04855705+0.02052959j 0. +0.j -0.05265272-0.00263483j 0. +0.j ] Expectation value <X2> 0.0 Expectation value <Z0Z1>: 0.9800665778412411 Amplitude <00000|Final state>: {'00000': (-0.45198075706658136-0.5366104621057316j)} Marginal probability for target qubit 3 in computational basis: [0.5 0.5]RESULT TYPES FOR shots > 0
shots>0 のとき、完全な状態ベクトルにはアクセスできませんが、測定サンプルから取得した近似的な期待値を得ることはできます。
確率、サンプル、期待値、分散は量子コンピュータの実機でもサポートされています。# define example circuit circ2 = Circuit().rx(0, 0.15).ry(1, 0.2).rz(2, 0.25).h(3).cnot(control=0, target=2).zz(1, 3, 0.15).x(4) # add expectation value obs = Observable.X() @ Observable.Y() target_qubits = [0, 1] circ2.expectation(obs, target=target_qubits) # add variance circ2.variance(obs, target=target_qubits) # add samples circ2.sample(obs, target=target_qubits) print(circ2)T : | 0 | 1 | Result Types | q0 : -Rx(0.15)-C----------Expectation(X@Y)-Variance(X@Y)-Sample(X@Y)- | | | | q1 : -Ry(0.2)--|-ZZ(0.15)-Expectation(X@Y)-Variance(X@Y)-Sample(X@Y)- | | q2 : -Rz(0.25)-X-|--------------------------------------------------- | q3 : -H----------ZZ(0.15)-------------------------------------------- q4 : -X-------------------------------------------------------------- T : | 0 | 1 | Result Types |# run the circuit and output the results specified above task = device.run(circ2, shots=100) result = task.result() print("Expectation value for <X0*Y1>:", result.values[0]) print("Variance for <X0*Y1>:", result.values[1]) print("Measurement samples for X0*Y1:", result.values[2])Expectation value for <X0*Y1>: -0.02 Variance for <X0*Y1>: 0.9995999999999998 Measurement samples for X0*Y1: [ 1 1 -1 -1 -1 1 1 1 -1 1 -1 -1 1 -1 1 -1 1 1 -1 1 1 1 1 -1 -1 -1 1 -1 -1 1 -1 -1 -1 -1 1 1 -1 1 -1 1 -1 1 1 1 -1 1 1 -1 -1 -1 1 1 -1 -1 1 1 -1 -1 -1 -1 -1 1 1 1 1 -1 1 -1 1 -1 1 1 1 -1 1 -1 -1 1 1 -1 -1 1 -1 1 -1 -1 -1 -1 1 1 1 -1 1 1 -1 -1 -1 -1 -1 1]上記結果は
shots>0であるときの観測結果に基づく近似的な値です。
なので実行毎に結果が変わります。
実際に何度も実行するとわかるかと思います。ADVANCED LOGGING
量子コンピュータ的な特別説明が必要そうな部分はありませんので省略します。
ログの出力の仕方などが書いてありますので是非見てみてください。最後に
以上で「AmazonBraketで学ぶ量子コンピュータ④」を終わります。
今回はAmazon Braketの使い方を少し詳しめに行いました。
また別記事で他のBraketサンプルの解説を行ないながら量子コンピュータを学んでいける記事を書いていくので是非見てみてください。
- 投稿日:2021-03-02T16:06:32+09:00
AmazonBraketで学ぶ量子コンピュータ③
この記事について
量子コンピュータの勉強をはじめて最近一通りAmazonBraketを触り終えました。
最近登場したサービスであることもあり、少し丁寧なドキュメントを残しておくと後続の方が勉強しやすくなったり、参照してわからないところを調べる際に便利かなと思ったので
自分自身の理解向上も兼ねて記事にまとめていっています。なお、量子コンピュータ関係の他の記事は、こちらのページで一覧にしています
※本記事は2021年2月に更新している記事です。更新などにより内容が変わっている可能性もあるのでご注意ください。
概要
本記事では量子コンピュータの導入部分に関して解説をしていこうと思います。
参照するのはこちらの2_Running_quantum_circuits_on_QPU_devices.ipynbというサンプルです。
こちらのサンプルではAmazonBraketで学ぶ量子コンピュータ①で紹介したよりも少しだけ応用的な内容が記載されています。
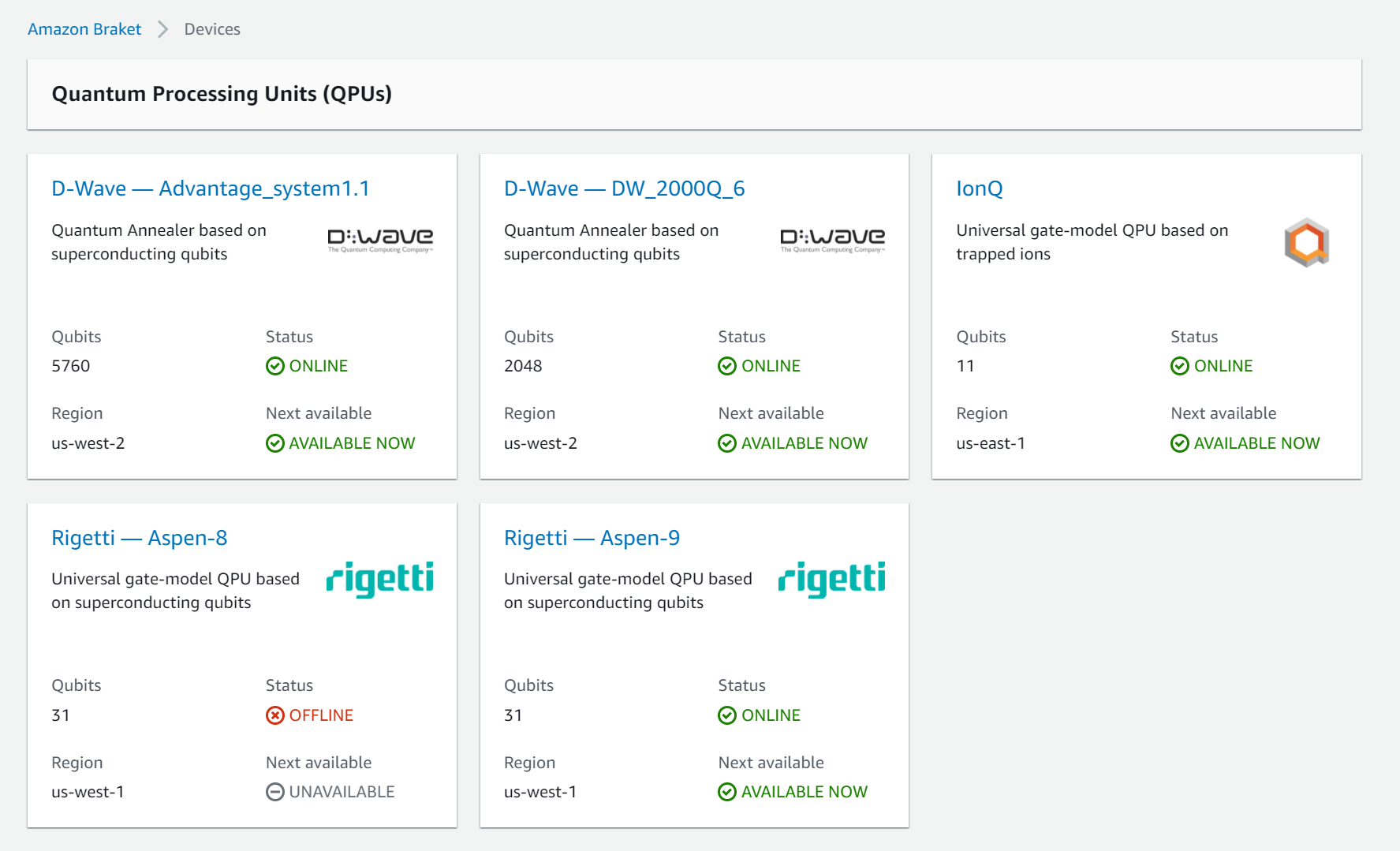
具体的には、以下に示される実機を実際に使ってみて量子回路の挙動を確かめてみよう!といったような内容になっています。
特に今回はIonQとRigetti-Aspen-8を対象としています。
前提知識
まず簡単に今回扱うサンプルを理解するために必要な量子コンピュータ(ゲート型)を扱うのに必要な前提知識を説明していきます。
とは言っても今まで扱ってきたサンプル解説から逸脱することはないので、はじめての方はAmazonBraketで学ぶ量子コンピュータ①という導入部分を説明している記事もありますのでそちらから読むのも良いかと思います。
何もないのも寂しいので本記事でも簡単に上記記事の内容を振り返ります。量子ビットの表現
量子ビットは2次元複素ベクトル空間での正規直交基底として各ビットを表現します。
それぞれのビットはディラックによって考案されたケット表記を用いて以下のように表現されます。|0 \rangle =\begin{pmatrix} 1 \\ 0 \end{pmatrix}, \ \ \ \ \ |1 \rangle =\begin{pmatrix} 0 \\ 1 \end{pmatrix}重ね合わせ
特に、量子力学では「重ね合わせ」という特有の概念があります。
これは任意の量子状態を重み情報と位相情報が含まれた複素数 $\alpha, \beta$を用いて、以下のように表現できます。|x\rangle = \alpha |0\rangle + \beta |1 \rangle = \alpha \begin{pmatrix} 1 \\ 0 \end{pmatrix} + \beta \begin{pmatrix} 0 \\ 1 \end{pmatrix} = \begin{pmatrix} \alpha \\ \beta \end{pmatrix}$|0 \rangle$ 状態は複素数の確率振幅$\alpha$ をもち、観測確率が $|\alpha|^2$で、$|1 \rangle$ 状態は確率振幅 $\beta$を持ち観測確率が $|\beta|^2$であることを示しており、以下のように規格化されています。
|\alpha|^2 + |\beta|^2 = 1量子ゲート操作
量子ビットの操作は行列計算を用いた量子ゲート操作により実現されます。
例えば、何かしらの操作を行うことで $|0\rangle$が $|1\rangle$に変更され、$|1\rangle$ が $|0\rangle$に変更されるような回路$X$は以下のように定義されます。X = \begin{pmatrix} 0 & 1 \\ 1 & 0 \end{pmatrix}上記、Xゲートは1量子ビットの反転操作を行うため、反転ゲートとも呼ばれます。
他にも1量子ビット操作では、位相・ビット反転ゲートのYゲートや位相反転ゲートのZゲート等が存在します。
以下のアダマールゲートを用いることで重ね合わせ状態を作ることができるのでそれも覚えておくと良いかと思います。H = \frac{1}{\sqrt{2}} \begin{pmatrix} 1 & 1 \\ 1 & -1 \end{pmatrix}2量子ビットの表記方法
2量子ビットは以下のように表すことができます。
\begin{split}\begin{equation}\begin{split} \left|{00}\right\rangle &= \begin{pmatrix} 1 \begin{pmatrix} 1 \\ 0 \end{pmatrix} \\ 0 \begin{pmatrix} 1 \\ 0 \end{pmatrix} \end{pmatrix} = \begin{pmatrix} 1 \\ 0 \\ 0 \\0 \end{pmatrix}~~~\left|{01}\right\rangle = \begin{pmatrix} 1 \begin{pmatrix} 0 \\ 1 \end{pmatrix} \\ 0 \begin{pmatrix} 0 \\ 1 \end{pmatrix} \end{pmatrix} = \begin{pmatrix}0 \\ 1 \\ 0 \\ 0 \end{pmatrix}\end{split} \end{equation}\end{split}\begin{split}\begin{equation}\begin{split}\left|{10}\right\rangle = \begin{pmatrix} 0\begin{pmatrix} 1 \\ 0 \end{pmatrix} \\ 1\begin{pmatrix} 1 \\ 0 \end{pmatrix} \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \\ 1 \\ 0 \end{pmatrix} \left|{11}\right\rangle = \begin{pmatrix} 0 \begin{pmatrix} 0 \\ 1 \end{pmatrix} \\ 1\begin{pmatrix} 0 \\ 1 \end{pmatrix} \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \\ 0 \\1 \end{pmatrix}\end{split} \end{equation}.\end{split}なのでベクトルのそれぞれの成分が以下のように対応していることがわかると思います。
\begin{pmatrix} |{00}\rangle \\ |{01}\rangle \\ |{10}\rangle \\ |{11}\rangle \end{pmatrix}2量子ビットの操作
2量子ビットの操作で最も有名なものの一つがCNOTゲート(制御NOTゲート)でした。
これは0量子ビット目が$|1 \rangle $ の時に 1量子ビット目のビットを反転させる操作を行います。
具体的には、CNOT = \begin{pmatrix} 1 & 0 & 0 & 0\\ 0 & 1 & 0 & 0\\ 0 & 0 & 0 & 1\\ 0 & 0 & 1 & 0 \end{pmatrix}と示されます。
AmazonBraket
ここから実際にAmazonBraketを使って説明していきます。
環境を用意されていない方は、まずはこちらの記事やドキュメントなどを参考に環境を用意してください。環境を用意すると以下のようにデフォルトでサンプルコードがGitHubからインポートされています。
今回はこの配下にある
getting_started/2_Running_quantum_circuits_on_QPU_devices.ipynb
を見ていきます。事前準備
import
importにおいては特に特別なものは必要なく、量子にかんしては以下の通りのモジュールをインポートするだけで充分です。
# AWS imports: Import Braket SDK modules from braket.circuits import Circuit, Gate, Observable from braket.devices import LocalSimulator from braket.aws import AwsDeviceS3バケットの登録
ローカルシミュレータ以外はS3に取得結果の情報を格納する動きになっています。
そのため、S3にバケットを用意してあげて、以下の変数に値を格納しておいてください。# Enter the S3 bucket you created during onboarding in the code below my_bucket = "amazon-braket-Your-Bucket-Name" # the name of the bucket my_prefix = "Your-Folder-Name" # the name of the folder in the bucket s3_folder = (my_bucket, my_prefix)本体
実機で利用できる回路群
Amazon Braket では実機で使える回路群の確認を行うことができます。
応用的な回路を組む際、実機によって利用できる回路が異なるので一部の実機に関してはアルゴリズムなどに合わせて自ら回路を作成していく必要があることを意味します。
次のコードは
- SDK
- Rigetti-Aspen8
- IonQ
のそれぞれで使える回路群を示します。
# print all (the usual suspects) available gates currently available within SDK gate_set = [attr for attr in dir(Gate) if attr[0] in string.ascii_uppercase] print('Gate set supported by SDK:\n', gate_set) print('\n') # the Rigetti device device = AwsDevice("arn:aws:braket:::device/qpu/rigetti/Aspen-8") supported_gates = device.properties.action['braket.ir.jaqcd.program'].supportedOperations # print the supported gate set print('Gate set supported by the Rigetti device:\n', supported_gates) print('\n') # the IonQ device device = AwsDevice("arn:aws:braket:::device/qpu/ionq/ionQdevice") supported_gates = device.properties.action['braket.ir.jaqcd.program'].supportedOperations # print the supported gate set print('Gate set supported by the IonQ device:\n', supported_gates)これを実行すると以下のような結果が返ってきます。
Gate set supported by SDK: ['CCNot', 'CNot', 'CPhaseShift', 'CPhaseShift00', 'CPhaseShift01', 'CPhaseShift10', 'CSwap', 'CY', 'CZ', 'H', 'I', 'ISwap', 'PSwap', 'PhaseShift', 'Rx', 'Ry', 'Rz', 'S', 'Si', 'Swap', 'T', 'Ti', 'Unitary', 'V', 'Vi', 'X', 'XX', 'XY', 'Y', 'YY', 'Z', 'ZZ'] Gate set supported by the Rigetti device: ['cz', 'xy', 'ccnot', 'cnot', 'cphaseshift', 'cphaseshift00', 'cphaseshift01', 'cphaseshift10', 'cswap', 'h', 'i', 'iswap', 'phaseshift', 'pswap', 'rx', 'ry', 'rz', 's', 'si', 'swap', 't', 'ti', 'x', 'y', 'z'] Gate set supported by the IonQ device: ['x', 'y', 'z', 'rx', 'ry', 'rz', 'h', 'cnot', 's', 'si', 't', 'ti', 'v', 'vi', 'xx', 'yy', 'zz', 'swap', 'i']全部は説明しませんが、いくつかのポイントを押さえておきます。
X, Y, Z, H, I, S, T CNOT(CX), CY, CZ Rx, Ry, Rz XX, YY, ZZ swap SDK ○ ○ ○ ○ ○ Aspen-8 ○ ○ ○ × ○ IonQ ○ ○ ○ ○ ○ 上記よりほとんど基本的な回路が表現可能だということがわかりますが、
Aspen-8のみXX, YY, ZZ回路を表現できません。
例えば、ZZ回路は CNOT、CZ、CNOTを用いて表されるので自分で回路を作ってあげる必要があります。
とくにQAOAのような最適化アルゴリズムに用いる場合はZZ回路が必要とされるので注意が必要です。他にもアルゴリズムに応じてデフォルトで回路が実装されていない場合がありますのでこちらのコードを実行してみて確認してみてください。
ベル状態の準備
次にベル状態を準備して、ローカルシミュレータで実行してみます。
Amazon Braketのサンプル上ではちょうど続きに位置しているので続けて実行していただければよろしいですが、
AmazonBraketで学ぶ量子コンピュータ①で紹介させていただいた内容とかぶっているため割愛させていただきます。
詳細を見てみたい方は上記を参考にしてみてください。
また、ローカルシミュレータは低〜中程度のqubit数(?<20-25)の高速実験に適しており、回路の深さは無制限である。
とのことです。
もちろん回路の深さを深くすると時間がかかりますし、qubitが多くても時間がかかるので注意してください。Aspen-8(実機)での実行
Rigetti社の用意しているAspen-8に超伝導量子チップに回路を投入します。
キューの状態によっては、実際に回路が実行されるまでしばらく待たなければならない場合があります。
ただし、非同期実行のおかげで、すべてのタスクに関連付けられた一意のタスクIDを取得することでいつでも結果を参照することができます。回路の実行プロセスは
AmazonBraketで学ぶ量子コンピュータ①で紹介させていただいた内容と同じように① デバイスの定義
② 実行
③ 結果の取得
④ 結果の出力の手順で実行することができます。
(以下のサンプルでは①デバイス定義と②実行の間で回路を定義したり、Z基底での測定を定義したりしています。)# set up device ① デバイスの定義 rigetti = AwsDevice("arn:aws:braket:::device/qpu/rigetti/Aspen-8") # 回路の定義 bell = Circuit().h(0).cnot(0, 1) # Z基底での測定 bell.expectation(Observable.Z() @ Observable.Z(), target=[0,1]) # run circuit with a polling time of 5 days ②実行 rigetti_task = rigetti.run(bell, s3_folder, shots=1000, poll_timeout_seconds=5*24*60*60) # get id and status of submitted task ③ 結果の取得 rigetti_task_id = rigetti_task.id rigetti_status = rigetti_task.state() # print('ID of task:', rigetti_task_id) print('Status of task:', rigetti_status)「②実行」ではキューのタイムアウト時間を5日に設定していることがわかるかと思います。
実は今回は、上記サンプルでは「③結果の所得」までしか行えていません。
これは実機に投げる際に待ちが発生し、結果をすぐには取得できないため、今の状態を返してくれます。
標準的な状態としては「Status: CREATED」、「Status: QUEUED」、「Status: RUNNING」、「Status: COMPLETED」という状態(他にもCANCELED等もある)があり、おそらく実行直後は以下の通り、CREATEDになるかと思います。Status of task: CREATEDただし、注意したいのは実機が動いている時間であるかどうかということです。
そもそも実機が動いてない時間もあります。
もし実機が動いてない場合は以下のエラーが返ってきます。DeviceOfflineException: An error occurred (DeviceOfflineException) when calling the CreateQuantumTask operation: Device is not available. Status = OFFLINE動いている時間帯を確認したい場合は、こちらで確認できるので確認してみてください。
IonQ(実機)での実行
IonQに回路を投入します。Aspen-8に比べてキュー待ちが長い印象があるので結果がすぐに返ってこなくても気長に待つことをお勧めします。
一方でIonQにおいてもAspen-8と同じように実行できるので説明は割愛させていただきます。
サンプルコードを見てみると同じであることがわかるとおもいます。唯一の違いは以下の通り実機の向き先を変更することのみです。
ionq = AwsDevice("arn:aws:braket:::device/qpu/ionq/ionQdevice")Task Recovery
最後にタスクの復元の説明をします。
タスクのIDがわかればAwsQuantumTask関数を用いてタスクを復元させることができます。さらにタスクの状態が
COMPLETEDならば、タスクの詳細を取得できます。
例えば、以下のようなコードで結果を取得し、shot数がいくらであったか?そして、デバイスは何を使ったか?といったことを確認できます。rigetti_results = task_load.result() # print(rigetti_results) # get all metadata of submitted task metadata = task_load.metadata() # example for metadata shots = metadata['shots'] machine = metadata['deviceArn']また、Aspen-8の場合、回路最適化の結果等も以下の通り取得することができます。
# get the compiled circuit print("The compiled circuit is:\n", rigetti_results.additional_metadata.rigettiMetadata.compiledProgram)特にAspen-8はハードウェアとしてはRZ(θ), RX(k*π/2), CZ, XYがベースとなっているようで回路最適化を行い、これらの回路で表されるようになっているようです。
詳しくは こちらを見てみてください。最後に
以上で「AmazonBraketで学ぶ量子コンピュータ③」を終わります。
今回は実機を使ってみたり、結果の復元を行ったりしてみました。
また別記事で他のBraketサンプルの解説を行ないながら量子コンピュータを学んでいける記事を書いていくので是非見てみてください。
- 投稿日:2021-03-02T16:05:23+09:00
awsのassumeroleの簡易設定集 zsh使用
①以下コマンドなどを用いてawsのprofileを追加
open ~/.aws/credentials
open ~/.aws/configexport AWS_PROFILE=
②以下コマンドなどを用いてzshにfunctionを追加
open ~/.zshrc
source ~/.zshrcfunction {
SWITCH_SESSION_NAME=
ROLE_ARN=
DATE=date +%sOUTPUT=
aws sts assume-role \
--role-arn ${ROLE_ARN} \
--role-session-name ${DATE}-${SWITCH_SESSION_NAME}
AWS_ACCESS_KEY_ID=
echo $OUTPUT | jq .Credentials.AccessKeyId
AWS_SECRET_ACCESS_KEY=echo $OUTPUT | jq .Credentials.SecretAccessKey
AWS_SESSION_TOKEN=echo $OUTPUT | jq .Credentials.SessionToken
echo ""
echo "export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID"
echo "export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY"
echo "export AWS_SESSION_TOKEN=$AWS_SESSION_TOKEN"
echo "export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID && export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY && export AWS_SESSION_TOKEN=$AWS_SESSION_TOKEN" | pbcopy
}③321_get_assumeコマンドを叩いて環境変数を取得する。
- 投稿日:2021-03-02T15:34:29+09:00
Webシステム全体像⓵
Webサービスとは
Webサービスとは、インターネットを利用したサービスのこと。
・画面に情報が表示されている
・情報は最新の状態が更新されている
・全世界中の人と同じ情報を共有できているex) Youtube, Twitterなど
ではなぜ、このようなことが可能なのか?
Webシステムの仕組み
Webシステムとは、
・あなたのPC、スマホ :クライアント側
・サーバ(業務用コンピュータ):サーバ側が通信することで情報を取得し、成り立っています。
具体的には、
・リクエスト:あなたのPC、スマホ→サーバ に情報を送ってほしいと依頼すること
・レスポンス:サーバ→あなたのPC、スマホ に情報を送り返して応答することこの2つの作業を行うことで、情報の通信を可能にしています。
あなたのPC、スマホ画面にサイトの情報が映るのは、
サーバが応答してくれた情報のレスポンスが表示されているからとなります。
どんなWebサービスでも、このリクエストとレスポンスの連続で成り立っています。※AWSでは、EC2というサーバーを借りて、あなたの自由に操作できます。
しかし、リクエストはどこに送られているのでしょうか?
おそらくそれぞれのWebサービスのサーバーを表す住所のようなものがあるはずです。IPアドレス
現実世界と同じようにインターネットの世界にも
コンピュータがここにありますよという住所のようなものが存在します。それが、IPアドレスです。
IPアドレスは、
・インターネット上の住所を表したもの
・数字を4つのブロックに分けた形式のものIPアドレスがあるおかげで、
リクエストに対してレスポンスができるWebサービスが成り立っています。サーバには、それぞれ個別のIPアドレスが割り当てられています。
よって、クライアントは目的のサーバにリクエストを送ることができます。しかしIPアドレスは数字なので、それを見ただけでは一目で何のWebサービスのサーバなのかも分からないし、覚えたり管理するのが大変です。
ドメイン
そこで私たちは、「youtube.com」「twitter.com 」などの英数字のURLを
使用してサイトにアクセスしています。この英数字のURLを、ドメインと言います。
しかし、ドメイン名だけではサーバーにアクセスはできません。
必ずIPアドレスが必要になります。ではドメイン名にアクセスしているのに、
なぜサーバのIPアドレスを取得し、サーバーへの適切なアクセスができているのでしょうか?DNS
それは、ドメインとIPアドレスを対応付けさせることで、
世界中のPCがサイトにアクセスすることを可能にしたからです。それが、DNSとなります。
DNSは、電話帳のようなもので
『このドメインは、このIPアドレスだよっ』という対応表が載っています。このドメインからIPアドレスを導き出すことを、名前解決と言います。
この名前解決を行うサーバのことを、DNSサーバーと言います。よってサイトにアクセスするときは、
⓵DNSサーバーで、ドメイン名→IPアドレス に変換する
⓶DNSサーバーからWebシステムのサーバーに通信するこの2段階処理を行っています。
つまり、
あなたのPC、スマホ → DNS(サーバー)→ Webシステムのサーバー
というような流れで情報通信が行われていることになります。※AWSでEC2(サーバー)を立ち上げると、自動的にドメインとIPアドレスが割り振られます。
このドメインとIPアドレスが、自動的にAWSのRoute53 (DNSサーバー) に登録されるため、
EC2にアクセスするためには、IPアドレスとドメインのどちらでも可能になります。
- 投稿日:2021-03-02T14:14:41+09:00
Terraform × AWS でインフラ構築するのはプロの所業じゃないらしい。
「どう考えても独学だけでこの組み合わせでインフラ構築するのはハイレベルすぎ。メンターつけたのかな?」
っていう趣旨のツイートをTLで見かけた。正直インフラとか何?ってレベルだけど、メモとしてだけ残しておく。
・https://bit.ly/344aqrdTerraformは最も革新的でめちゃ強なIaCやで!AWSとの相性が最高なんやで!
らしい。Iac : Inflastracture as Code
コンピューティング・インフラ(プロセス、ベアメタルサーバー、仮想サーバーなど)の構成管理・機械処理可能な定義ファイルの設定・プロビジョニングを自動化するプロセスすでにわからない。
- 投稿日:2021-03-02T11:22:05+09:00
【AWS】ロードバランサーとは?AWSのロードバランサーの種類。
個人メモです。
ロードバランサーとは?
負荷(Load)を均一にする装置(Balancer)。
ネットでは、平均化というよりも、割り振りを担う場合が多い。単に、入ってきたFQDN(URL)を見てif文でサービスに振り分けるだけという単純な機能。
リクエスト(FQDN) ↓ Route53 ↓ ロードバランサー(振り分け) ↓ ターゲットグループ ↓ サービスA サービスB,,,,ユーザーが入力したURLに合わせて、接続するサービスを変更するルーティング機能。
AWSのロードバランサー
AWSのロードバランサーは、ELB(Elastic Load Balancing)というサービス。
ELBの種類
ELBは用途に合わせて4種類ある。
- Application Load Balancer
- Network Load Balancer
- Gateway Load Balancer
- Classic Load Balancer
使用頻度が高いのは、Application Load Balancer。大規模サイトの場合はNetwork Load Balancerも使われる。
1. Application Load Balancer
入力されたURLによって、接続先のサーバー(サービス)を切り替えるロードバランサー。
HTTP トラフィックおよび HTTPS トラフィックの負荷分散。リクエストに基づいて、awsvpc内のターゲットにトラフィックをルーティングする。
2. Network Load Balancer
超高性能ロードバランサー。
極めて高いパフォーマンスが要求されるTCP(Transmission Control Protocol)、UDP(User Datagram Protocol)および (TLS)Transport Layer Securityにおけるトラフィックの負荷分散。
VPC 内のターゲットにルーティングし、きわめて低いレイテンシーを維持しながら 1 秒間に数百万件ものリクエストを処理できる。
3. Gateway Load Balancer
AWS以外のVPCに接続する場合に使うロードバランサー。
サードパーティーの仮想ネットワークアプライアンスを簡単にデプロイ、拡張、および実行できます。
トラフィックの送信元と送信先に対して透過性がある。
4. Classic Load Balancer
複数のEC2インスタンスで負荷分散をするロードバランサー。
リクエストレベルと接続レベルの両方で動作する。対象はEC2-Classic ネットワーク内に構築されたアプリケーション。
バランサー実例(Application Load Balancer)
作成したバランサーには、DNSやVPCが割り当てられている。
リスナー
ロードバランサーが受け付けるリスナーポートが設定してある。
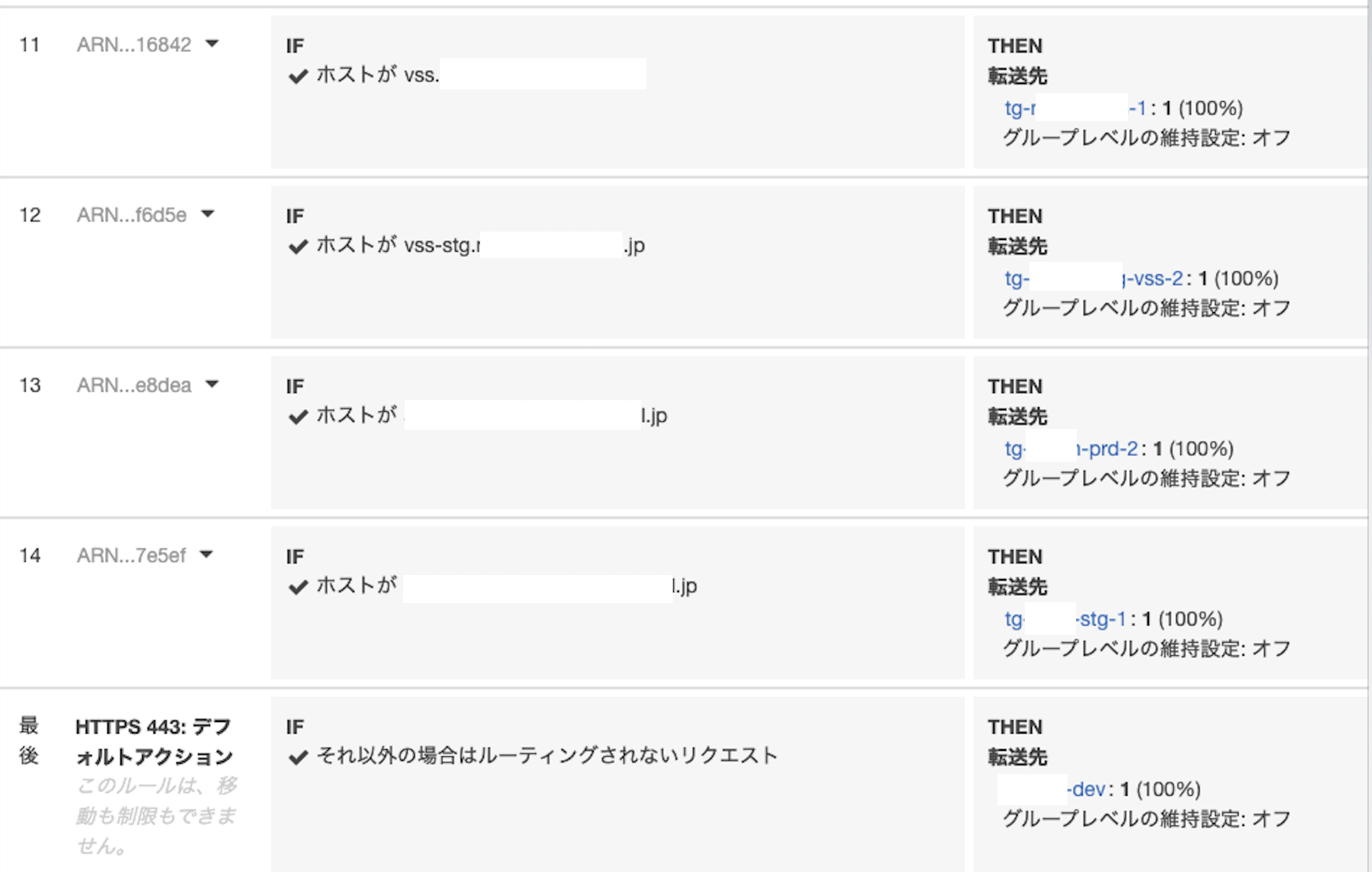
ルール
各リスナーにルートが設定されている。この入力がきたらこのサービスにリダイレクトするという設定をif then文で記述する。
HTTPからHTTPSへのリダイレクト
HTTPでリクエストがきたら、HTTPSにリダイレクトする設定も可能。
if then文
もし(IF)入力されたホストが〇〇なら(THEN)、指定したターゲットグループにトラフィックを転送する。
ターゲットグループとは、コンテナ(サービス)のこと。
クラスターの上でタスクを展開し、タスクの中のコンテナに接続する。

- 投稿日:2021-03-02T07:56:36+09:00
AWSにWindowsServer2016(E)→(J)にする
AWSで標準で提供されるパッケージは英語版のWindowsなので新規で構築する場合、日本語化のために必須になる手順は以下の4つだった。またいつか検証して足りなければ追加する。
1、日本語言語パックをインストールしロケールなどを日本語にする。
→「接続する」を実行するとAdministratorのパスワードが要求される
2、キーボードがUS101/102なので109キーボードに変更する
→¥とか出せないのでこれは必ずやらないといけない
3、不要なサービスを「自動」から「手動」に切り替え
→GoogleMapなど手動でいいのに自動で落ちて警告が出るので「手動」にする
4、Windowsの標準FWで80/443のTCPを開放する。発信、受信とも必須
→AWSの場合、これを開けてもAWSのFWがあるのでこれでブロックするようにする