- 投稿日:2021-03-02T23:34:57+09:00
BoW / BoVW(bag of visual words)について理解する
はじめに
OpenCVのSIFTで特徴量を抽出してSVMで分類する、というプログラムを作成しようと思っています。
特徴量をSIFTで抽出し、抽出したdescriptorsからBoW descrptors生成し、それを使ってSVMで分類を行う予定ですが、BoW(Bag of words)を画像特徴量に適用した場合のBoW descritptorsについて少し調べたので、備忘として残します。開発環境
Ubuntu 18.04.4 LTS
Python 3.6.9
opencv 4.5.1
dlib 19.21.1実際の出力値を確認
まずは、実際にSIFTで特徴量から生成したBoW vocabularyを出力してみました。
ここでは、OpenCVのBOWKMeansTrainerを使用しますが、ここでは自身の用途に使いやすくするようにBowKmeansTrainerクラスを作っています。class BowKmeansTrainer: def __init__(self, dextractor, dmatcher, cluster_count): self._dextractor = dextractor self._trainer = cv2.BOWKMeansTrainer(cluster_count) self._extractor = cv2.BOWImgDescriptorExtractor(dextractor, dmatcher) def addSample(self, path): img = cv2.imread(path, cv2.IMREAD_GRAYSCALE) keypoints, descriptors = self._dextractor.detectAndCompute(img, None) if descriptors is None: logger.debug('No descriptor genearted') else: self._trainer.add(descriptors) def createVoc(self): voc = self._trainer.cluster() self._extractor.setVocabulary(voc) return voc def extractDescriptors(self, path): img = cv2.imread(path, cv2.IMREAD_GRAYSCALE) keypoints = self._dextractor.detect(img) return self._extractor.compute(img, keypoints)このクラスを使って実際にvocabularyを作成して表示しているコードが以下です。
# create a sift sift = cv2.SIFT_create() # create a flann matcher FLANN_INDEX_KDTREE = 1 index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5) search_params = {} flann = cv2.FlannBasedMatcher(index_params, search_params) # create a Bow KMeans Trainer bow_trainer = BowKmeansTrainer(sift, flann, BOW_NUM_CLUSTERS) # add samples to the trainer for i in range(BOW_NUM_TRAINING_SAMPLES_PER_CLASS): pos_path, neg_path = file_manager.getFile(i) bow_trainer.addSample(pos_path) bow_trainer.addSample(neg_path) # create clusters voc = bow_trainer.createVoc() print('vocabulary.ndim({0}), shape({1}))'.format(voc.ndim, voc.shape)) print(voc)実際の出力結果は以下になります。
vocabulary.ndim(2), shape((40, 128))) [[15.913044 7. 5.0869565 ... 1.3478261 2.7391305 2.9565217] [ 7.1785717 4.5535717 9.232143 ... 10. 5.339286 14.875001 ] [14.411765 16.411764 9.058824 ... 17.82353 12.441176 9.205882 ] ... [32.17647 43.911766 16.058825 ... 10.3529415 19.058825 47.32353 ] [ 6.257143 8.914286 14.514286 ... 8.228572 9.771429 12.2 ] [42.65625 24.59375 16.90625 ... 16.75 17.78125 16.375 ]]作成するクラスタ数は40を設定(cluster_count=40)したの40個のWordsからなるvocabularyが作成されています。
SIFTの特徴量descriptorは128次元(SIFT descriptors(特徴量)について理解する)なので、40x128 arrayとなります。vocabularyとは
vocabularyとは、Word(単語)の集合体です。ここではWordではなく、codewordの集合体と考えられます(OpenCVではvocabularyと呼んでいますが、codebookと呼ばれることもあるようです)。
今回の例では、40個のcodewordsからなるvocabularyが作成されたことになります。各codewordは各クラスタを表し、クラスタの幾何中心(centroid)となります。次に、上記のVocabularyに基づいて抽出されたBoW descriptorの値も確認してみます。
クラスタ作成後に以下のコードを追加しました。# get a BoW descriptor pos_path, neg_path = file_manager.getFile(100) bow_descriptor = bow_trainer.extractDescriptors(pos_path) print('bow_descriptor.ndim({0}), shape({1}))'.format(bow_descriptor.ndim, bow_descriptor.shape)) print(voc)以下がBoW descriptorの出結果です。
bow_descriptor.ndim(2), shape((1, 40))) [[15.913044 7. 5.0869565 ... 1.3478261 2.7391305 2.9565217] [ 7.1785717 4.5535717 9.232143 ... 10. 5.339286 14.875001 ] [14.411765 16.411764 9.058824 ... 17.82353 12.441176 9.205882 ] ... [32.17647 43.911766 16.058825 ... 10.3529415 19.058825 47.32353 ] [ 6.257143 8.914286 14.514286 ... 8.228572 9.771429 12.2 ] [42.65625 24.59375 16.90625 ... 16.75 17.78125 16.375 ]]SIFT descriptorは128次元でしたが、BoW desciptorは40(クラスタ数)次元になったことが確認できます。
まとめ
次はSVMで実際に分類する処理を試したいと思います。
参考文献
Wikipedia: Bag-of-words model in computer vision
WORD vs. VOCABULARY
- 投稿日:2021-03-02T23:33:35+09:00
【Python】ログを出力する
pythonを使用してExcelファイルの操作を勉強しています。
本日の気づき(復習)は、ログの出力に関してです。
pythonでExcelを操作するため、openpyxlというパッケージを使用しています。今まではとりあえずプログラムを記述することに注力してきました。
今後の事を考えると、ちゃんと処理が実行できているか確認するためにログを出力していきたいです。loggingモジュール
標準ライブラリなので追加インストールは必要ありません。
https://docs.python.org/ja/3/library/logging.html今回はこちらで入力した数だけブックを作り、一緒にログファイルも作る記述をしてみます。
ログファイルには処理の開始と終了、エラー発生時にログが出力されるようにしたいです。logging.basicConfigメソッド
logging.basicConfig(filename=ログのファイル名, level=ログのレベル, format=ログの書式)上記の記述でログのファイル名や書式を指定します。
format引数に指定す出来る書式は下のページをご確認ください。
ログ出力を行うメソッドはログのレベルごとに用意されています。
レベルは出力する内容(重要度)によって使い分けが出来るので
該当するレベルのログのみを抽出する事が出来ます。
- logging.debug()
- logging.info()
- logging.warning()
- logging.error()
- logging.critical()
下に行くほど重要度が高いです。
basicConfigメソッドのlevel引数に指定したレベルよりも低いものは
ログファイルには出力されません。例level=logging.WARNING -->DEBUG,INFOレベルのログは出力されない後、気を付けないといけない点は、Windouwsの場合
作成されたログファイルの文字コードはCP932になるということのようです。
Windouwsにもとからあるメモ帳を使えば大丈夫な様ですね。logging_create_book.pyimport logging import sys from openpyxl import Workbook logging.basicConfig(filename='create_book.log', level=logging.INFO, # ログの書式を、「日時」「レベル」「ログメッセージに設定」 format='%(asctime)s: [%(levelname)s] %(message)s') logging.info('処理を開始しました') try: count = sys.argv[1] for i in range(int(count)): wb = Workbook() ws = wb.active ws.title = '概要' file_name = f'資料_{i + 1}.xlsx' wb.save(file_name) logging.info('ブックを作成しました: %s', file_name) # 例外が発生した場合スタックトレースを出力 except Exception: logging.exception('例外が発生しました') logging.info('処理が終了しました')ここでも、見慣れない言葉が出てきました。
スタックトレース
スタックトレースは、プログラムで例外が発生した際に、
- どのように関数が呼び出されたのか
- どこでエラーが発生したのか
を特定できる情報です。
不具合発生時の原因究明に、重宝されます。sample.pyimport traceback def a(): b() def b(): c() def c(): char = None char.format('hello') try: a() except Exception as e: print(traceback.format_exc())こちらを実行すると
$ python3 sample.py Traceback (most recent call last): File "sample.py", line 14, in <module> a() File "ssample.py", line 5, in a b() File "ssample.py", line 8, in b c() File "ssample.py", line 12, in c char.format('hello') AttributeError: 'NoneType' object has no attribute 'format'英語がたくさん表示される為か見ているだけで気がめいりますが、よ~く読むと
sample.pyの12行目(line 12)で、c()関数(in c)にある、char.format('hello')
でエラーが発生し、
エラー内容は'NoneType' object has no attribute 'format'
ということがわかります。
こんな感じで、どうやってエラーになったかがわかると修正もしやすいですね。今回は個人的にちょっとレベルが高かったように感じます。
Railsの時もそうでしたが、調べていくうちにわからないことが増えて行って
取り返しがつかない時がちょくちょくおきます。一旦諦めて、進んでまたエラーが出たらその時にまた調べることにします。
ということで、今回はここまでです。
- 投稿日:2021-03-02T23:06:49+09:00
Pythonで学ぶ制御工学 第10弾:状態空間モデルの時間応答
#Pythonで学ぶ制御工学< 状態空間モデルの時間応答 >
はじめに
基本的な制御工学をPythonで実装し,復習も兼ねて制御工学への理解をより深めることが目的である.
その第10弾として「状態空間モデルの時間応答」を扱う.時間応答(状態空間モデルの時間応答)
状態空間モデルと伝達関数モデルの時間応答との違いを,図を使っての説明を以下に示す.
続いて,状態空間モデルの時間応答について,図を使っての説明を以下に示す.
実装
ここでは,適当な状態空間モデルに対して,零入力応答・零状態応答(ステップ入力)・時間応答(ステップ入力)の図を出力する3つプログラムを実装する.
以下にソースコードとそのときの出力を示す.ソースコード①:零入力応答
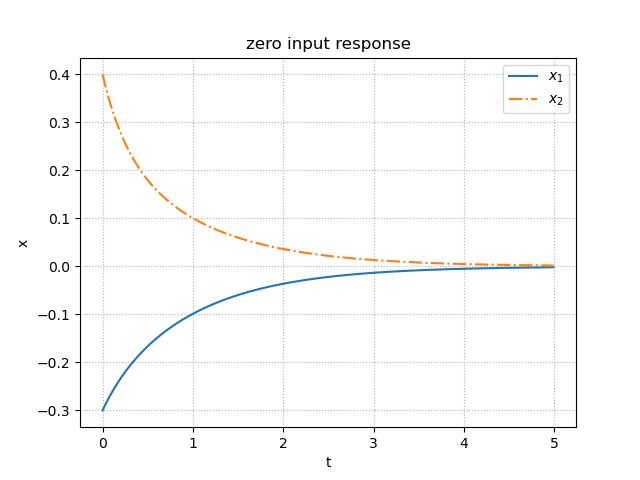
zero_input_response.py""" 2021/03/02 @Yuya Shimizu 状態空間モデルの初期値応答 """ import numpy as np from control import ss from control.matlab import initial from for_plot import * import matplotlib.pyplot as plt ##状態空間モデルの設定 A = [[ 0, 1], [-4, -5]] B = [[0], [1]] C = [[ 1, 0], [ 0, 1]] #np.eye(2)とも記述できる D = [[0], [0]] #np.zeros([2,1])とも記述できる P = ss(A, B, C, D) ##初期値応答 Td = np.arange(0, 5, 0.01) #シミュレーション時間 x0 = [-0.3, 0.4] #初期値 x, t = initial(P, Td, x0) #初期値応答(零入力応答) ##描画 fig, ax = plt.subplots() ax.plot(t, x[:, 0], label = '$x_1$') ax.plot(t, x[:, 1], ls = '-.', label = '$x_2$') ax.set_title('zero input response') plot_set(ax, 't', 'x', 'best') plt.show()出力
ソースコード②:零状態応答(ステップ入力)
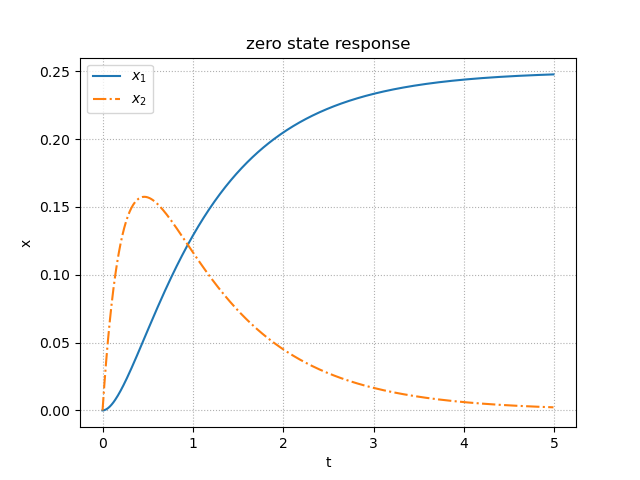
zero_state_response.py""" 2021/03/02 @Yuya Shimizu 状態空間モデルの零状態応答 """ import numpy as np from control import ss from control.matlab import step from for_plot import * import matplotlib.pyplot as plt ##状態空間モデルの設定 A = [[ 0, 1], [-4, -5]] B = [[0], [1]] C = [[ 1, 0], [ 0, 1]] #np.eye(2)とも記述できる D = [[0], [0]] #np.zeros([2,1])とも記述できる P = ss(A, B, C, D) ##零状態応答 Td = np.arange(0, 5, 0.01) #シミュレーション時間 x, t = step(P, Td) #零状態応答 ##描画 fig, ax = plt.subplots() ax.plot(t, x[:, 0], label = '$x_1$') ax.plot(t, x[:, 1], ls = '-.', label = '$x_2$') ax.set_title('zero state response') plot_set(ax, 't', 'x', 'best') plt.show()出力
ソースコード③:時間応答(ステップ入力)
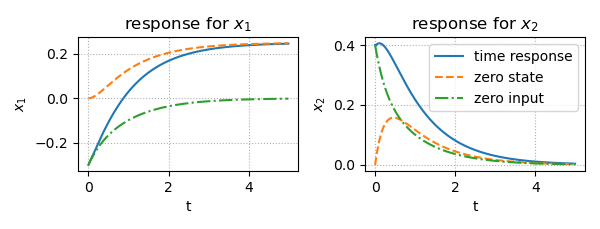
time_response.py""" 2021/03/02 @Yuya Shimizu 状態空間モデルの時間応答 """ import numpy as np from control import ss from control.matlab import initial, step, lsim from for_plot import * import matplotlib.pyplot as plt ##状態空間モデルの設定 A = [[ 0, 1], [-4, -5]] B = [[0], [1]] C = [[ 1, 0], [ 0, 1]] #np.eye(2)とも記述できる D = [[0], [0]] #np.zeros([2,1])とも記述できる P = ss(A, B, C, D) ##時間応答 (=零入力応答 + 零状態応答) Td = np.arange(0, 5, 0.01) #シミュレーション時間 Ud = 1*(Td>0) x0 = [-0.3, 0.4] #初期値 xst, t = step(P, Td) #零状態応答 xin, _ = initial(P, Td, x0) #零入力応答 x, _, _ = lsim(P, Ud, Td, x0) #時間応答 ##描画 fig, ax = plt.subplots(1, 2, figsize=(6, 2.3)) for i in [0, 1]: ax[i].plot(t, x[:, i], label = 'time response') #時間応答の描画 ax[i].plot(t, xst[:, i], ls = '--', label = 'zero state') #零状態応答の描画 ax[i].plot(t, xin[:, i], ls = '-.', label = 'zero input') #零入力応答の描画 ax[0].set_title('response for $x_1$') ax[1].set_title('response for $x_2$') plot_set(ax[0], 't', '$x_1$') plot_set(ax[1], 't', '$x_2$', 'best') fig.tight_layout() plt.show()出力
零入力応答
ここで,零入力応答について,以前(https://qiita.com/Yuya-Shimizu/items/2e67581c13cfa3108809 )に示したアームを例に確認する.アームでは,初期角度と初期角速度を与えてスタートさせたとき,何も入力がなければ,粘性摩擦と重力の影響を受けて,最終的に鉛直下向きに垂れ下がった状態で静止する.つまり,時間が経過するにしたがって,0へ収束するということである.上で示した図からも分かる.
感想
式やグラフである制御対象の振る舞いを理解するというのは,直感的には難しいこともあるが,少しずつ慣れていきたい.入力応答や状態応答で解析する経験はなく,まだマスターできていないが,とりあえず基本的事項とPythonでの実装を学ぶことができた.
参考文献
Pyhtonによる制御工学入門 南 祐樹 著 オーム社


- 投稿日:2021-03-02T22:04:07+09:00
【lambda 超初心者】CLIを使ってlambda関数を作成する
内容
AWS CLIを使って、lambda関数を作成する。
個人の備忘録であるためかなり内容が薄くなっている。
- デプロイディレクトリを作成
- Pythonコードを作成
- zip化 ライブラリやコードを含める
aws lambda create-function --funtion-name ... lambda関数名やhandler, runtimeなどの設定を行う
更新対象のコードの編集や、ライブラリの追加を行い再度zip化する
aws lambda update-function-code .. を利用してlambda 関数を更新する
参考
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/python-package-create.html#python-package-create-with-dependency
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/python-package-update.html
- 投稿日:2021-03-02T22:00:43+09:00
cryoDRGNの結果の解析
cryoDRGNについて
学習曲線の可視化
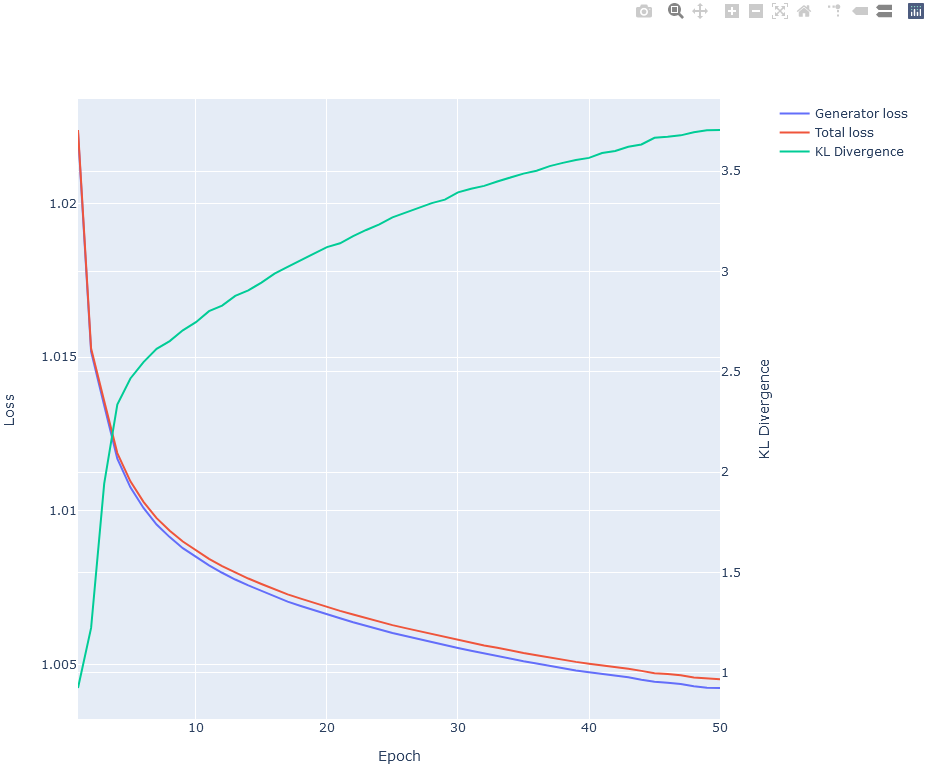
ネットワークの学習が収束しているのかどうか確認するには、ログファイルに記録されている損失関数の値を見るといいです。
ログファイル(run.log)(省略) (1): ReLU() (2): ResidLinear( (linear): Linear(in_features=256, out_features=256, bias=True) ) (3): ReLU() (4): ResidLinear( (linear): Linear(in_features=256, out_features=256, bias=True) ) (5): ReLU() (6): ResidLinear( (linear): Linear(in_features=256, out_features=256, bias=True) ) (7): ReLU() (8): Linear(in_features=256, out_features=2, bias=True) ) ) ) ) 2021-01-18 13:48:13 3784964 parameters in model 2021-01-18 13:54:34 # =====> Epoch: 1 Average gen loss = 1.02231, KLD = 0.924802, total loss = 1.022387; Finished in 0:06:20.245799 2021-01-18 14:01:29 # =====> Epoch: 2 Average gen loss = 1.01518, KLD = 1.224245, total loss = 1.015275; Finished in 0:06:22.065888 2021-01-18 14:08:19 # =====> Epoch: 3 Average gen loss = 1.01342, KLD = 1.943195, total loss = 1.013566; Finished in 0:06:20.048240 2021-01-18 14:15:07 # =====> Epoch: 4 Average gen loss = 1.01169, KLD = 2.337141, total loss = 1.011874; Finished in 0:06:18.268111 2021-01-18 14:22:03 # =====> Epoch: 5 Average gen loss = 1.01076, KLD = 2.467319, total loss = 1.010954; Finished in 0:06:23.279119 2021-01-18 14:28:54 # =====> Epoch: 6 Average gen loss = 1.01009, KLD = 2.548503, total loss = 1.010287; Finished in 0:06:20.104529 2021-01-18 14:35:46 # =====> Epoch: 7 Average gen loss = 1.00955, KLD = 2.615071, total loss = 1.009756; Finished in 0:06:21.803054 2021-01-18 14:42:35 # =====> Epoch: 8 Average gen loss = 1.00914, KLD = 2.653529, total loss = 1.009347; Finished in 0:06:19.304278 2021-01-18 14:49:26 # =====> Epoch: 9 Average gen loss = 1.00878, KLD = 2.707029, total loss = 1.008995; Finished in 0:06:20.044801 2021-01-18 14:56:19 # =====> Epoch: 10 Average gen loss = 1.00849, KLD = 2.747613, total loss = 1.008708; Finished in 0:06:22.251633 2021-01-18 15:03:08 # =====> Epoch: 11 Average gen loss = 1.00822, KLD = 2.802414, total loss = 1.008435; Finished in 0:06:19.600215 2021-01-18 15:09:58 # =====> Epoch: 12 Average gen loss = 1.00798, KLD = 2.830367, total loss = 1.008198; Finished in 0:06:19.171115 2021-01-18 15:16:50 # =====> Epoch: 13 Average gen loss = 1.00776, KLD = 2.878851, total loss = 1.007987; Finished in 0:06:20.732890 2021-01-18 15:23:39 # =====> Epoch: 14 Average gen loss = 1.00757, KLD = 2.906105, total loss = 1.007792; Finished in 0:06:19.150181 2021-01-18 15:30:32 # =====> Epoch: 15 Average gen loss = 1.00739, KLD = 2.945066, total loss = 1.007615; Finished in 0:06:19.663154 2021-01-18 15:37:27 # =====> Epoch: 16 Average gen loss = 1.00721, KLD = 2.989139, total loss = 1.007440; Finished in 0:06:20.898634 2021-01-18 15:44:17 # =====> Epoch: 17 Average gen loss = 1.00704, KLD = 3.023471, total loss = 1.007278; Finished in 0:06:19.637517 2021-01-18 15:51:09 # =====> Epoch: 18 Average gen loss = 1.0069, KLD = 3.056445, total loss = 1.007137; Finished in 0:06:21.252752 2021-01-18 15:57:58 # =====> Epoch: 19 Average gen loss = 1.00676, KLD = 3.087742, total loss = 1.007005; Finished in 0:06:19.174269 2021-01-18 16:04:50 # =====> Epoch: 20 Average gen loss = 1.00662, KLD = 3.121757, total loss = 1.006860; Finished in 0:06:22.003833 2021-01-18 16:11:40 # =====> Epoch: 21 Average gen loss = 1.0065, KLD = 3.140710, total loss = 1.006740; Finished in 0:06:19.149865 2021-01-18 16:18:42 # =====> Epoch: 22 Average gen loss = 1.00637, KLD = 3.176621, total loss = 1.006622; Finished in 0:06:31.558981 2021-01-18 16:25:47 # =====> Epoch: 23 Average gen loss = 1.00625, KLD = 3.207150, total loss = 1.006504; Finished in 0:06:29.674917 2021-01-18 16:32:36 # =====> Epoch: 24 Average gen loss = 1.00614, KLD = 3.234640, total loss = 1.006395; Finished in 0:06:18.424028 2021-01-18 16:39:25 # =====> Epoch: 25 Average gen loss = 1.00602, KLD = 3.270075, total loss = 1.006276; Finished in 0:06:18.568070 2021-01-18 16:46:15 # =====> Epoch: 26 Average gen loss = 1.00592, KLD = 3.293772, total loss = 1.006178; Finished in 0:06:19.931208 2021-01-18 16:53:06 # =====> Epoch: 27 Average gen loss = 1.00582, KLD = 3.317351, total loss = 1.006082; Finished in 0:06:20.290187 2021-01-18 16:59:59 # =====> Epoch: 28 Average gen loss = 1.00571, KLD = 3.340852, total loss = 1.005974; Finished in 0:06:20.850692 2021-01-18 17:06:51 # =====> Epoch: 29 Average gen loss = 1.00563, KLD = 3.358073, total loss = 1.005888; Finished in 0:06:19.800037 2021-01-18 17:13:41 # =====> Epoch: 30 Average gen loss = 1.00553, KLD = 3.394385, total loss = 1.005797; Finished in 0:06:19.344668 2021-01-18 17:20:30 # =====> Epoch: 31 Average gen loss = 1.00544, KLD = 3.412608, total loss = 1.005709; Finished in 0:06:19.537618 2021-01-18 17:27:21 # =====> Epoch: 32 Average gen loss = 1.00535, KLD = 3.426723, total loss = 1.005612; Finished in 0:06:20.501204 2021-01-18 17:34:13 # =====> Epoch: 33 Average gen loss = 1.00527, KLD = 3.448969, total loss = 1.005542; Finished in 0:06:19.104303 2021-01-18 17:41:04 # =====> Epoch: 34 Average gen loss = 1.00518, KLD = 3.468607, total loss = 1.005448; Finished in 0:06:20.574825 2021-01-18 17:47:53 # =====> Epoch: 35 Average gen loss = 1.0051, KLD = 3.487816, total loss = 1.005368; Finished in 0:06:19.266487 2021-01-18 17:54:41 # =====> Epoch: 36 Average gen loss = 1.00503, KLD = 3.502420, total loss = 1.005298; Finished in 0:06:16.710547 2021-01-18 18:01:28 # =====> Epoch: 37 Average gen loss = 1.00495, KLD = 3.525365, total loss = 1.005221; Finished in 0:06:17.309040 2021-01-18 18:08:21 # =====> Epoch: 38 Average gen loss = 1.00487, KLD = 3.541543, total loss = 1.005146; Finished in 0:06:23.100732 2021-01-18 18:15:10 # =====> Epoch: 39 Average gen loss = 1.0048, KLD = 3.555950, total loss = 1.005080; Finished in 0:06:18.102520 2021-01-18 18:21:55 # =====> Epoch: 40 Average gen loss = 1.00474, KLD = 3.566339, total loss = 1.005020; Finished in 0:06:16.129188 2021-01-18 18:28:42 # =====> Epoch: 41 Average gen loss = 1.00469, KLD = 3.590437, total loss = 1.004970; Finished in 0:06:17.461872 2021-01-18 18:35:29 # =====> Epoch: 42 Average gen loss = 1.00463, KLD = 3.600814, total loss = 1.004912; Finished in 0:06:18.362757 2021-01-18 18:42:16 # =====> Epoch: 43 Average gen loss = 1.00458, KLD = 3.621860, total loss = 1.004857; Finished in 0:06:17.235549 2021-01-18 18:49:04 # =====> Epoch: 44 Average gen loss = 1.0045, KLD = 3.633174, total loss = 1.004787; Finished in 0:06:17.204172 2021-01-18 18:55:49 # =====> Epoch: 45 Average gen loss = 1.00443, KLD = 3.666399, total loss = 1.004714; Finished in 0:06:14.774338 2021-01-18 19:02:36 # =====> Epoch: 46 Average gen loss = 1.0044, KLD = 3.671483, total loss = 1.004687; Finished in 0:06:18.165214 2021-01-18 19:09:21 # =====> Epoch: 47 Average gen loss = 1.00436, KLD = 3.678585, total loss = 1.004645; Finished in 0:06:15.194644 2021-01-18 19:16:09 # =====> Epoch: 48 Average gen loss = 1.00429, KLD = 3.694472, total loss = 1.004573; Finished in 0:06:19.251820 2021-01-18 19:22:56 # =====> Epoch: 49 Average gen loss = 1.00424, KLD = 3.703967, total loss = 1.004533; Finished in 0:06:16.262893 2021-01-18 19:29:44 # =====> Epoch: 50 Average gen loss = 1.00423, KLD = 3.705236, total loss = 1.004515; Finished in 0:06:17.885488 2021-01-18 19:30:43 Finsihed in 5:43:56.411010 (0:06:52.728220 per epoch)ログファイルから損失関数の値をとってくるための関数を貼っておきます。Pandasライブラリを使います。
関数定義(Python)import re import pandas as pd def parse_cryodrgn_log(log_file): log = [] for line in open(log_file): m = re.match(r'.+Epoch:\s*(\d*)\s*Average gen loss =\s*(\d*\.\d*), KLD =\s*(\d*\.\d*),\s*total loss =\s*(\d*\.\d*).*', line) if m is not None: log.append(dict( epoch=int(m.group(1)), average_gen_loss=float(m.group(2)), kld=float(m.group(3)), total_loss=float(m.group(4)) )) df_log = pd.DataFrame(log) return df_log実際にログファイルを読み込んでプロットしてみます。Plotlyライブラリを使います。
コード(Python)from plotly.subplots import make_subplots import plotly.graph_objects as go log_file = './01_vae128_zdim1_seed1/run.log' df = parse_cryodrgn_log(log_file) fig = make_subplots(specs=[[{"secondary_y": True}]]) fig.add_trace( go.Scatter(x=df['epoch'], y=df['average_gen_loss'], name='Generator loss'), secondary_y=False ) fig.add_trace( go.Scatter(x=df['epoch'], y=df['total_loss'], name='Total loss'), secondary_y=False ) fig.add_trace( go.Scatter(x=df['epoch'], y=df['kld'], name='KL Divergence'), secondary_y=True ) fig.update_layout( height=800, xaxis_title='Epoch' ) fig.update_yaxes( title_text='Loss', secondary_y=False ) fig.update_yaxes( title_text='KL Divergence', secondary_y=True ) fig.show()
JupyterLabなどでPlotly用の拡張機能を有効にしている場合、グラフ右上の横棒2本が縦に並んだようなアイコンをクリックすると、グラフをマウスホバーすればその地点の各曲線の値が表示されるようになります。
Lossが下がり切っていない様ならまだ学習を続ける余地があるので、エポック数を増やすともっと潜在空間が構造化されるかもしれません。
- 投稿日:2021-03-02T22:00:43+09:00
cryoDRGNの結果の解析の覚え書き
cryoDRGNについて
学習曲線の可視化
ログファイルに記録されている損失関数の値を見る。
ログファイル(run.log)(省略) (1): ReLU() (2): ResidLinear( (linear): Linear(in_features=256, out_features=256, bias=True) ) (3): ReLU() (4): ResidLinear( (linear): Linear(in_features=256, out_features=256, bias=True) ) (5): ReLU() (6): ResidLinear( (linear): Linear(in_features=256, out_features=256, bias=True) ) (7): ReLU() (8): Linear(in_features=256, out_features=2, bias=True) ) ) ) ) 2021-01-18 13:48:13 3784964 parameters in model 2021-01-18 13:54:34 # =====> Epoch: 1 Average gen loss = 1.02231, KLD = 0.924802, total loss = 1.022387; Finished in 0:06:20.245799 2021-01-18 14:01:29 # =====> Epoch: 2 Average gen loss = 1.01518, KLD = 1.224245, total loss = 1.015275; Finished in 0:06:22.065888 2021-01-18 14:08:19 # =====> Epoch: 3 Average gen loss = 1.01342, KLD = 1.943195, total loss = 1.013566; Finished in 0:06:20.048240 2021-01-18 14:15:07 # =====> Epoch: 4 Average gen loss = 1.01169, KLD = 2.337141, total loss = 1.011874; Finished in 0:06:18.268111 2021-01-18 14:22:03 # =====> Epoch: 5 Average gen loss = 1.01076, KLD = 2.467319, total loss = 1.010954; Finished in 0:06:23.279119 2021-01-18 14:28:54 # =====> Epoch: 6 Average gen loss = 1.01009, KLD = 2.548503, total loss = 1.010287; Finished in 0:06:20.104529 2021-01-18 14:35:46 # =====> Epoch: 7 Average gen loss = 1.00955, KLD = 2.615071, total loss = 1.009756; Finished in 0:06:21.803054 2021-01-18 14:42:35 # =====> Epoch: 8 Average gen loss = 1.00914, KLD = 2.653529, total loss = 1.009347; Finished in 0:06:19.304278 2021-01-18 14:49:26 # =====> Epoch: 9 Average gen loss = 1.00878, KLD = 2.707029, total loss = 1.008995; Finished in 0:06:20.044801 2021-01-18 14:56:19 # =====> Epoch: 10 Average gen loss = 1.00849, KLD = 2.747613, total loss = 1.008708; Finished in 0:06:22.251633 2021-01-18 15:03:08 # =====> Epoch: 11 Average gen loss = 1.00822, KLD = 2.802414, total loss = 1.008435; Finished in 0:06:19.600215 2021-01-18 15:09:58 # =====> Epoch: 12 Average gen loss = 1.00798, KLD = 2.830367, total loss = 1.008198; Finished in 0:06:19.171115 2021-01-18 15:16:50 # =====> Epoch: 13 Average gen loss = 1.00776, KLD = 2.878851, total loss = 1.007987; Finished in 0:06:20.732890 2021-01-18 15:23:39 # =====> Epoch: 14 Average gen loss = 1.00757, KLD = 2.906105, total loss = 1.007792; Finished in 0:06:19.150181 2021-01-18 15:30:32 # =====> Epoch: 15 Average gen loss = 1.00739, KLD = 2.945066, total loss = 1.007615; Finished in 0:06:19.663154 2021-01-18 15:37:27 # =====> Epoch: 16 Average gen loss = 1.00721, KLD = 2.989139, total loss = 1.007440; Finished in 0:06:20.898634 2021-01-18 15:44:17 # =====> Epoch: 17 Average gen loss = 1.00704, KLD = 3.023471, total loss = 1.007278; Finished in 0:06:19.637517 2021-01-18 15:51:09 # =====> Epoch: 18 Average gen loss = 1.0069, KLD = 3.056445, total loss = 1.007137; Finished in 0:06:21.252752 2021-01-18 15:57:58 # =====> Epoch: 19 Average gen loss = 1.00676, KLD = 3.087742, total loss = 1.007005; Finished in 0:06:19.174269 2021-01-18 16:04:50 # =====> Epoch: 20 Average gen loss = 1.00662, KLD = 3.121757, total loss = 1.006860; Finished in 0:06:22.003833 2021-01-18 16:11:40 # =====> Epoch: 21 Average gen loss = 1.0065, KLD = 3.140710, total loss = 1.006740; Finished in 0:06:19.149865 2021-01-18 16:18:42 # =====> Epoch: 22 Average gen loss = 1.00637, KLD = 3.176621, total loss = 1.006622; Finished in 0:06:31.558981 2021-01-18 16:25:47 # =====> Epoch: 23 Average gen loss = 1.00625, KLD = 3.207150, total loss = 1.006504; Finished in 0:06:29.674917 2021-01-18 16:32:36 # =====> Epoch: 24 Average gen loss = 1.00614, KLD = 3.234640, total loss = 1.006395; Finished in 0:06:18.424028 2021-01-18 16:39:25 # =====> Epoch: 25 Average gen loss = 1.00602, KLD = 3.270075, total loss = 1.006276; Finished in 0:06:18.568070 2021-01-18 16:46:15 # =====> Epoch: 26 Average gen loss = 1.00592, KLD = 3.293772, total loss = 1.006178; Finished in 0:06:19.931208 2021-01-18 16:53:06 # =====> Epoch: 27 Average gen loss = 1.00582, KLD = 3.317351, total loss = 1.006082; Finished in 0:06:20.290187 2021-01-18 16:59:59 # =====> Epoch: 28 Average gen loss = 1.00571, KLD = 3.340852, total loss = 1.005974; Finished in 0:06:20.850692 2021-01-18 17:06:51 # =====> Epoch: 29 Average gen loss = 1.00563, KLD = 3.358073, total loss = 1.005888; Finished in 0:06:19.800037 2021-01-18 17:13:41 # =====> Epoch: 30 Average gen loss = 1.00553, KLD = 3.394385, total loss = 1.005797; Finished in 0:06:19.344668 2021-01-18 17:20:30 # =====> Epoch: 31 Average gen loss = 1.00544, KLD = 3.412608, total loss = 1.005709; Finished in 0:06:19.537618 2021-01-18 17:27:21 # =====> Epoch: 32 Average gen loss = 1.00535, KLD = 3.426723, total loss = 1.005612; Finished in 0:06:20.501204 2021-01-18 17:34:13 # =====> Epoch: 33 Average gen loss = 1.00527, KLD = 3.448969, total loss = 1.005542; Finished in 0:06:19.104303 2021-01-18 17:41:04 # =====> Epoch: 34 Average gen loss = 1.00518, KLD = 3.468607, total loss = 1.005448; Finished in 0:06:20.574825 2021-01-18 17:47:53 # =====> Epoch: 35 Average gen loss = 1.0051, KLD = 3.487816, total loss = 1.005368; Finished in 0:06:19.266487 2021-01-18 17:54:41 # =====> Epoch: 36 Average gen loss = 1.00503, KLD = 3.502420, total loss = 1.005298; Finished in 0:06:16.710547 2021-01-18 18:01:28 # =====> Epoch: 37 Average gen loss = 1.00495, KLD = 3.525365, total loss = 1.005221; Finished in 0:06:17.309040 2021-01-18 18:08:21 # =====> Epoch: 38 Average gen loss = 1.00487, KLD = 3.541543, total loss = 1.005146; Finished in 0:06:23.100732 2021-01-18 18:15:10 # =====> Epoch: 39 Average gen loss = 1.0048, KLD = 3.555950, total loss = 1.005080; Finished in 0:06:18.102520 2021-01-18 18:21:55 # =====> Epoch: 40 Average gen loss = 1.00474, KLD = 3.566339, total loss = 1.005020; Finished in 0:06:16.129188 2021-01-18 18:28:42 # =====> Epoch: 41 Average gen loss = 1.00469, KLD = 3.590437, total loss = 1.004970; Finished in 0:06:17.461872 2021-01-18 18:35:29 # =====> Epoch: 42 Average gen loss = 1.00463, KLD = 3.600814, total loss = 1.004912; Finished in 0:06:18.362757 2021-01-18 18:42:16 # =====> Epoch: 43 Average gen loss = 1.00458, KLD = 3.621860, total loss = 1.004857; Finished in 0:06:17.235549 2021-01-18 18:49:04 # =====> Epoch: 44 Average gen loss = 1.0045, KLD = 3.633174, total loss = 1.004787; Finished in 0:06:17.204172 2021-01-18 18:55:49 # =====> Epoch: 45 Average gen loss = 1.00443, KLD = 3.666399, total loss = 1.004714; Finished in 0:06:14.774338 2021-01-18 19:02:36 # =====> Epoch: 46 Average gen loss = 1.0044, KLD = 3.671483, total loss = 1.004687; Finished in 0:06:18.165214 2021-01-18 19:09:21 # =====> Epoch: 47 Average gen loss = 1.00436, KLD = 3.678585, total loss = 1.004645; Finished in 0:06:15.194644 2021-01-18 19:16:09 # =====> Epoch: 48 Average gen loss = 1.00429, KLD = 3.694472, total loss = 1.004573; Finished in 0:06:19.251820 2021-01-18 19:22:56 # =====> Epoch: 49 Average gen loss = 1.00424, KLD = 3.703967, total loss = 1.004533; Finished in 0:06:16.262893 2021-01-18 19:29:44 # =====> Epoch: 50 Average gen loss = 1.00423, KLD = 3.705236, total loss = 1.004515; Finished in 0:06:17.885488 2021-01-18 19:30:43 Finsihed in 5:43:56.411010 (0:06:52.728220 per epoch)ログファイルから損失関数の値をとってくる
ログファイルから損失関数の値をとってくるための関数は以下。Pandas使用。
関数定義(Python)import re import pandas as pd def parse_cryodrgn_log(log_file): log = [] for line in open(log_file): m = re.match(r'.+Epoch:\s*(\d*)\s*Average gen loss =\s*(\d*\.\d*), KLD =\s*(\d*\.\d*),\s*total loss =\s*(\d*\.\d*).*', line) if m is not None: log.append(dict( epoch=int(m.group(1)), average_gen_loss=float(m.group(2)), kld=float(m.group(3)), total_loss=float(m.group(4)) )) df_log = pd.DataFrame(log) return df_log
epoch average_gen_loss kld total_loss 0 1 1.02231 0.924802 1.02239 1 2 1.01518 1.22425 1.01527 2 3 1.01342 1.9432 1.01357 3 4 1.01169 2.33714 1.01187 4 5 1.01076 2.46732 1.01095 5 6 1.01009 2.5485 1.01029 6 7 1.00955 2.61507 1.00976 (以下省略)
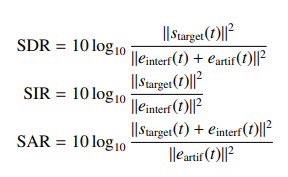
単一のログファイルの可視化
単一のログファイルについて、各曲線をプロット。Plotlyライブラリ使用。
関数定義(Python)from plotly.subplots import make_subplots import plotly.graph_objects as go def plot_cryodrgn_learning_curve(log_file): df = parse_cryodrgn_log(log_file) fig = make_subplots(specs=[[{"secondary_y": True}]]) fig.add_trace( go.Scatter(x=df['epoch'], y=df['average_gen_loss'], name='Generator loss'), secondary_y=False ) fig.add_trace( go.Scatter(x=df['epoch'], y=df['total_loss'], name='Total loss'), secondary_y=False ) fig.add_trace( go.Scatter(x=df['epoch'], y=df['kld'], name='KL Divergence'), secondary_y=True ) fig.update_layout( height=800, xaxis_title='Epoch' ) fig.update_yaxes( title_text='Loss', secondary_y=False ) fig.update_yaxes( title_text='KL Divergence', secondary_y=True ) return figコード例(Python)log_file = '00_vae128_zdim1_seed1/run.log' fig = plot_cryodrgn_learning_curve(log_file) fig.show()
複数のログファイルの可視化
コード(Python)fig = go.Figure() for log_file in log_files: df = parse_cryodrgn_log(log_file) fig.add_trace( go.Scatter(x=df['epoch'], y=df['total_loss'], name=os.path.dirname(log_file)) ) fig.update_layout( height=800, xaxis_title='Epoch', yaxis_title='Total loss' ) fig.show()
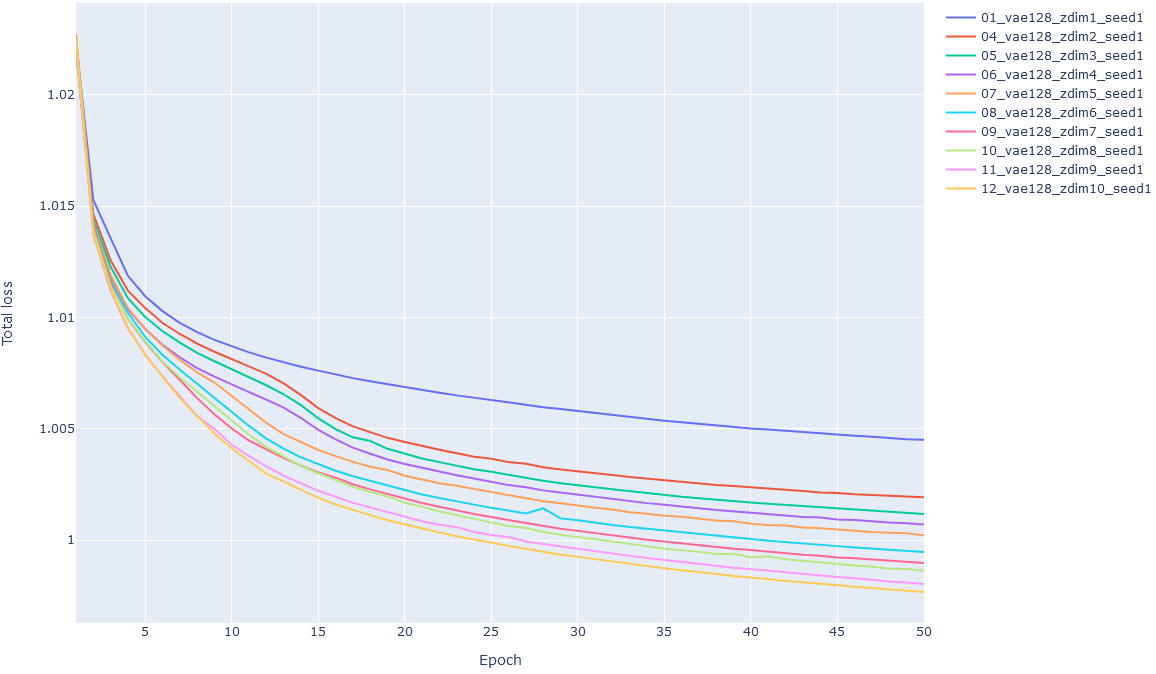
- 投稿日:2021-03-02T21:18:29+09:00
社内勉強会で教えた「Python初歩」の内容
背景
現職はユニケージ開発手法を採用しているため、ユニケージ(とフロントエンド用のJavascript)しかプログラミング経験がない方々が何人かいます。以下は社内勉強会でPythonを教えた時の講義内容です。
(社内情報に関するものは内容をボカしています)
今よりプログラミングを学ぶ理由
- 楽をするため
- リリースを早くするため
- 品質を上げるため(障害を減らす)
- 人を雇うため
- 超売り手市場の現在、ユニケージでもOKのエンジニアを雇うのは困難になっている
bashの強さは何か
- ファイルの入出力が異常に楽
- linuxコマンドをパイプで繋ぐのがすごい便利
- バックグラウンド処理は
&だけなのですごい楽- 実行ログを吐かせるのが簡単
bashの弱さは何か
- 配列が扱いづらい
- 関数が扱いづらい
- 四則演算が扱いづらい
- ifを書くのがとてもめんどくさい
- sqlを扱うのがつらい
Pythonを使って教えること
- 型
- 配列(リスト)
- タプル
- 連想配列(辞書型)
- 制御構文(if,forなど)
- 関数
- スコープ
- リスト内包表記
- 例外処理
- ファイルの入出力
変数、四則演算はさすがにわかると思うのでカット
まずはPythonをインストール
https://qiita.com/ms-rock/items/72b8f1abc661c539bb09 を参考にインストール
python2と3
2はもうすぐ滅びます。3を使いましょう。
macにはデフォルトで古い2が入っているので、3を動かすときは
python3とします。$ python --version Python 2.7.15 $ python3 --version Python 3.7.2
jupyter notebookをインストール
pip3 install jupyterpipコマンドはPythonの各種パッケージをインストールするのに使います
macでpipはデフォルトの2系を向いているため、pip3で3系としてパッケージをインストールします。
jupyterを起動
$ jupyter notebookでPythonをブラウザ上実行していきます。
型
- bool (真偽値)
- int (整数)
- float (浮動小数点)
- string (文字列)
- list (配列)
- dict (辞書)
他にもあります
型の違いを意識しましょう
- int型の3とstring型の3は違います。 3と"3" で区別します
- int型の2とfloat型の2は違います。 2と 2.0 で区別します
- bool型のTrueと string型のTrueは違います。 True と "True" で区別します
bool型
bashにはない。javascriptにはある
True,Falseで表す。 文字の"True","False"とは異なる。flag = False if flag: # flag == True と書かなくてもOK print("Trueです") else: print("Falseです")
型でハマるケース
文字の3は数字の3ではありません。よって足すことができません。
In [52]: a = "3" In [53]: a + 1 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-53-ca42ed42e993> in <module> ----> 1 a + 1 TypeError: can only concatenate str (not "int") to str
数字に変換することで足せます
In [54]: int(a) + 1 Out[54]: 4
文字列結合をするときは、文字列に変換します
In [56]: a = 3 In [57]: a + "です" --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-57-c4299ce7ef6f> in <module> ----> 1 a + "です" TypeError: unsupported operand type(s) for +: 'int' and 'str' In [58]: str(a) + "です" Out[58]: '3です'
配列
複数の値を1つの変数に格納したもの
test = [1,2,3] # 配列(正確にはリスト) print(test[0]) print(test[1]) print(test[2]) num = len(test) # 配列の要素数 print( "配列の要素数は" + str(num) + "です。") # +で文字列連結pythonは配列とリストを厳密には区別してます。
タプル
簡単に言えば書き換えられない、追加できない配列です。
In [61]: a = (1,2,3) In [62]: a[0] Out[62]: 1 In [63]: a[0] = 2 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-63-fa1ba3f7cc8f> in <module> ----> 1 a[0] = 2 TypeError: 'tuple' object does not support item assignment
配列があればいいのでは?タプルいるの?
- 制約がある代わりにタプルのほうが高速、メモリ消費量が少ないとされています
連想配列
- Pythonでは辞書(dict)と呼びます
- キーと値を持つデータ構造です
- 辞書型→JSONに変換したり、HTMLからの渡ってきたデータが辞書型で格納されているのでよく使います
例
In [70]: md = { "s-san" : "teamA", "a-san" : "teamB", "n-san" : "teamC" } In [71]: md["s-san"] Out[71]: 'teamA' In [72]: md["a-san"] Out[72]: 'teamB'
何が便利なの?
変数で動作を切り替えやすい
# 指定した人を1日だけteamCチームに送り込む処理 name = "s-san" (中略) md[name] = "teamC" # よろしく
制御構文
- if
- for
- while
- with
Pythonにはswitchがありません!(大きな欠点)
インデント
- 制御構文や関数など入れ子になるゾーンはインデントで表す。
- pythonは括弧やendとかfiを使わない代わりにこういう制約がある
- インデントが必要なところは
:を使う- 基本スペース2か4のどっちか
# NG if flag == False: print("hoge") # OK if flag == True: print("hoge")
if
- お馴染み。なのでPython固有のものを
if name in ("a","b","c"): print("MDチーム") elif name in ("d","o","k"): print("POSチーム") else: print("どこ?")
if ~ in リストorタプルでどれかにマッチした時
if 0 < a < 10: print("0より大きく10未満") if team == "md" and position == "leader": print("Aさんかな?") if team == "md" or team == "crm": print("内製")
if len(a) == 0とかif flag == Trueとかは不要であるif not len(a): print("空") if flag: print("True')pythonでは 0、空配列、""、None は if文でFalseとして扱われます。
bool(0)とか試すとわかります
for
- お馴染み
nums = [1,2,3,4,5] for n in nums: print(n) # 0から99までの合計(rangeは100回実行するとかにも使えますね) sum = 0 for i in range(100): sum += i
while
i = 0 while True: i += 1 if i >= 10: break # ループを抜ける
with
これは説明が難しいがとても便利
withを使うと、withから抜けたときに開いてあったものを自動で閉じてくれる。(bashには馴染みがないが一般的なプログラミング言語は外部ファイルやDBと接続するときは open処理とclose処理が大抵必要)
詳しくは https://techacademy.jp/magazine/15823
関数
- ユニケージ開発ではあんまり使われてません。
- そもそも任意の返り値を返せないbashの関数はとても使い勝手が悪いです( 仮引数が
$1とかもそう… )- 関数で処理を共通化、分離させるのが一般的です
pythonの基本的な関数
def changeName(name): if type(name) is not str: # ifはこうも書ける return "文字列じゃないよ" return name.upper() changeName("ansai") # => "ANSAI" changeName(12312312) # => "文字列じゃないよ"
# 引数は複数取れる def changeName(firstname,middlename,lastname): pass # (略) # 返り値を複数にもできる def changeName(name1,name2) return name1.upper(), name2.upper() name1,name2 = changeName("a-san","s-san")
配列やタプルを引数や返り値にできる
def func1(list): print(list[0]) func1(["a","b","c","d"]) # 配列を渡すdef func1(): list = ["a","b","c","d"] return list # 配列を返す result = func1() print(result) print(result[2])
関数デフォルト値
def joinTeam(name,md_team=False): pass # (略) joinTeam("Mさん")引数は
md_teamは省略可能であり、この場合初期値False
関数の中の関数(インナー関数)
def outer(): # 外の関数 def inner(): # 関数の中の関数
- outerの中からinnerは呼べるが、outerの外からはinnerは呼べない。outer関数以外で使わない関数(使ってほしくない関数)のときにこういう書き方をする。 outer関数の中で似たような処理を繰り返すときに使う。
スコープ
- 変数や関数が見える範囲のこと。スコープの外にあるものは見えない
- bashにもあるが、ユニケージ開発では基本意識されない
Q. このとき表示される値s1は何?
s1 = 0 def localfunc(): s1 = 2 print(s1) localfunc()
A. 2(localfunc内の変数s1を参照するから)
Q. s2は?
s2 = 0 def localfunc(): print(s2) localfunc()
A. 0(localfunc内にs2がないので外のs2を見に行く)
Q. s3は?
s3 = 0 def localfunc2(): s3 = 2 def localfunc(): print(s3) localfunc2() localfunc()
A. 0(localfunc2のs3は関数内でのみ有効、外のs3を見る)
- 関数内の変数と関数外の変数は別な変数である
Q. s4は?
def localfunc(): s4 = 2 localfunc() print(s4)
A. エラーになる(関数の外にs4は存在しない。未定義変数はprintできない)
というのがスコープ
- 変数が定義された場所や定義方法で変数の有効範囲が変わる
- グローバルスコープ: 全域で参照可能(グローバル変数)
- ローカルスコープ: 一定の範囲内(例:関数)でのみ参照可能(ローカル変数)
- スコープの動きは言語によって微妙に違うので注意
コラム: Javascirptのブロックスコープ
- 関数よりも更に狭い、ifやforの範囲内のスコープのこと
- ES6からlet、const使うことでブロックスコープが使えます
- Pythonにはありません
 for ( let i = 0; i < 10 i++){ console.log(i); // iはforの範囲のみ有効 }
for ( let i = 0; i < 10 i++){ console.log(i); // iはforの範囲のみ有効 }
別ファイルで定義した変数や関数
importしないと参照できない
hogehoge.pys = 1 def func(): passsample.pyimport hogehoge print(hogehoge.s) hogehoge.func()
なぜこんな不便なことを?
- 全てがグローバルのとき、大規模になると変数がダブることがありえる
- いちいちgrepしないと怖くて変数を定義できない
- 人のコードを読む時、このグローバル変数がどこか違うところで使われていないか不安になる
- グローバル変数は保守性を下げる
- 一般的にグローバル変数は極力使うなとされています
リスト内包表記
リスト内包表記はPythonの特徴的な機能で、リストから別のリストを作るものです。とても便利
例: 1から100までのリストを作り、そこから偶数のみを抜き出したリストを作りたい
こう?
numlist = range(1,101) evenlist = [] for i in numlist: if i%2 == 0: evenlist.append(i) print(evenlist)
リスト内包表記ならもっと短く書ける
numlist = range(1,101) evenlist = [i for i in numlist if i%2==0] print(evenlist)出力先リスト = [appendする値 for リストから抜き出す値 in リスト if 条件式 ]リストからifにマッチしたものだけを抜き出して別のリストを作っている。ちなみにこっちのほうが若干速い
複雑にすると読みづらいので多用はやめよう
例外処理
- エラー時に行う処理である
- 意図しない動作が起きると
例外が発生する- Javascriptを始め、いろんな言語にある機能です
- bashは
trapがあるが大分勝手が違う
例 数字に文字を足す
型の説明で出てきたやつ
In [52]: a = "3" In [53]: a + 1 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-53-ca42ed42e993> in <module> ----> 1 a + 1 TypeError: can only concatenate str (not "int") to str
TypeErrorと表示されていますね。 つまり型が合わないので 「TypeError例外が発生した」 わけです。(例外を投げる、例外を吐くなどとも言います。)
例外発生時にそれを拾う
a = "3" try: a + 1 print("正常終了") except TypeError: print("TypeError例外が発生しました")tryの中で発生した例外はexceptで拾う(キャッチ)することができます。juptyerで試してみましょう
例外の詳細を見る
a = "3" try: a + 1 print("正常終了") except TypeError as e: print(e) print("TypeError例外が発生しました")
as 変数でエラー詳細を吐かせることができます。慣例的にeerrが使われます
例外は上に伝播する
関数の中で発生した例外をキャッチしなかったとき、その関数を呼んでいる上の関数に例外が伝わります。多くの子関数を呼び出すとき例外処理を都度書かずに親関数でまとめて拾うというアプローチができます
例
def func1(num): return func2(num) def func2(num): return num + 1 func1(4) # 正しい func1("4") # 間違い↓ のようにするとfunc2の例外をfunc1でキャッチできる
def func1(num): try: return func2(num) except TypeError: print("例外発生") def func2(num): return num + 1 func1("4")
あらゆる例外をキャッチしたい
except Exceptionと書くとあらゆる例外をキャッチできます。例外の内容に従ってエラーハンドリングができるのでよく考えて使い分けましょう。try: a + 1 except Exception: print("例外発生")
ファイルの入出力
bashと違ってファイルの入出力はちょっとめんどくさいです。
書き込み
s = "test1\ntest2\ntest3" with open('test.txt', mode='w') as f: f.write(s)先程説明してきた
withがここで登場しました。 withの中がファイルをオープンしている区域であり、この外に出るとファイルを自動でクローズします。
末尾に追加
s = "\ntest4\ntest5\ntest6" with open('test.txt', mode='a') as f: f.write(s)
読み込み
with open('test.txt', mode='r') as f: r = f.read() print(r)
readlinesを使うと読み込んだ内容を配列にしますwith open('test.txt',mode='r') as f: r = f.readlines() print(r) print(r[2]) # 配列なので任意の行を取得 print(r[2].strip()) # 改行を排除するときは strip() で
ファイルの入出力については詳しくは Pythonでファイルの読み込み、書き込み(作成・追記) を読んでみましょう
更にPythonを学ぶには
- わからなくなったら、ぐぐればいっぱい出てきます
- Python入門!初心者がPythonを勉強する学習サイトおすすめ15選
演習問題
Q. この年も某イベントの深夜番を決めることになった。MDチームの中から2名選出しないといけないが、既にNさん、Dさんの2名はプレイベントの深夜番として除外されている。
MDチームの中から2名ランダムに選ぶ関数を作成しなさい。なおMDチームのメンバーのマスタは既にテキストファイルで用意されており、これを書き換えることはできない。除外される2名を最初に指定する必要があり、本メッセにこの2名を選出してはならない。
(マスタファイルは別途送ります)
解答レベル
- レベル1: とりあえずランダムに2人選ぶ
- レベル2: とりあえずランダムに2人選ぶが同じ人が選ばれないよう工夫をしている
- レベル3: 別々の2人を選び、除外者2名は選出されない
- レベル4: 関数の中身のコードを変えずにCRMやPOSチームの名簿and人数不定の除外リストに差し替えても動く
- レベル5: 除外リストが空だったり、チームメンバーのマスタファイルが存在しないときに適切に例外処理を行い適切なエラーメッセージを返す。
ルール
関数の形は最初からこちらで指定します。
''' 以下の形であること。引数や返り値の数をいじるのはNG。 第一引数は チームメンバーのマスタを返す関数 第二引数は 除外される2名 ''' member1,member2= electMember(getMemberList(),pre_member)つまり electMember関数とgetMemberList関数を作る必要があります。
ランダムな数字の作り方は https://note.nkmk.me/python-random-randrange-randint/ を見て調べましょう。
- 投稿日:2021-03-02T21:03:39+09:00
DANet(Deep Attractor Network)の実装と解説
はじめに
音声を任意の数に分離するモデルであるDANet(Deep Attractor Network)の実装と解説をします。
DANetは論文"DEEP ATTRACTOR NETWORK FOR SINGLE-MICROPHONE SPEAKER SEPARATION"で提案されているモデルです。
このモデルを環境音データセットのESC-50を使って学習させ、その分離音性能をGNSDR、GSAR、GSIRで測定しました。実装にはTensorflowとKerasを用いました。
実装の全コードはGithubにあります。
また、それらを実行して学習やGNSDR等の測定ができるGoogle Colabのファイルもあります(GithubのDANet.ipynbをGoogle Colabで開いたもの)。
公式のPytorchを用いた実装もGithubに公開されています。概要
以下のように分けて説明します。
1. 実行したPythonのパージョンと使用したパッケージ
2. データの前処理
3. モデルの構成
4. 分離音性能の評価
5. パッケージとしての利用1. 実行したPythonのバージョンと使用したパッケージ
- Python 3.7.10
- TensorFlow 2.4.1
モデルの構築に利用- museval 0.4.0
SDR、SIR、SARの計算に利用- SoundFile 0.10.3.post1
音声のファイルへの書き込みに利用- pandas 1.1.5
音声ラベルのcsvデータを扱う際に利用- numpy 1.19.5
各種計算、配列処理等に利用- scipy 1.4.1
ハニング窓の計算に利用- librosa 0.8.0
音声のファイルからのロード、リサンプリング、短時間フーリエ変換等の音声処理に利用- matplotlib 3.2.2
スペクトログラムや音声波形の描画に利用2. データの前処理
論文での実験通りに行いました。
まず、入力音声を8000Hzでリサンプリングし、window lengthを32ms、hop sizeを8ms、窓関数をハニング窓の平方根とした短時間フーリエ変換を行いました。その後、絶対値を取ってから自然対数を取り、時間方向の次元数を100にしたものをモデルへの入力としました。3. モデルの構成
画像の引用元:
Zhuo Chen, Yi Luo, Nima Mesgarani, "DEEP ATTRACTOR NETWORK FOR SINGLE-MICROPHONE SPEAKER SEPARATION," arXiv preprint arXiv:1611.08930v2, 2017
https://arxiv.org/pdf/1611.08930.pdf
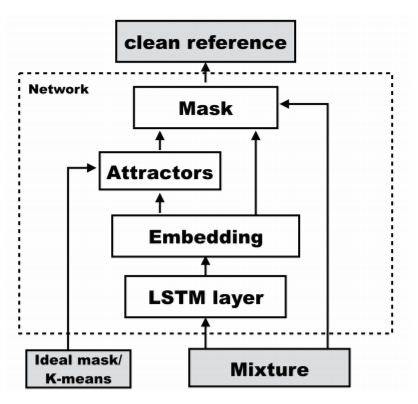
まず、入力音声を双方向LSTMに入力し、その結果を結合することで周波数方向の次元数を600にします。
そして全結合層に入力し、周波数方向の次元数を129(モデル入力時の周波数方向の要素数)×20(embedding空間の次元数)にし、Reshapeすることで周波数方向とembedding空間方向に分離します。その後、訓練時には下の式によりAttractorを計算します。
Vは入力音声のEmbedding結果であり、Yはideal mask(各時刻、各周波数において、混合音声の中で振幅が一番大きい音声を1、そうでない音声を0としたもの)を表します。
推論時にはVをkmeansクラスタリングし、そのときの中心点を用いることでAtractorを生成します。
また、AttractorとEmbedding結果を用いて下式のようにしてMaskを計算します。
混合音声の分離が難しいような条件のときはSigmoid関数の代わりにSoftmax関数を用いることもでき、今回の実装でもSoftmax関数を用いました。
Maskを混合音声とかけることにより分離音声が生成され、モデルの出力となります。なお、推論時には混合音声として、短時間フーリエ変換した後に絶対値や対数を取っていない位相付きのスペクトログラムを用い、モデルの出力を逆短時間フーリエ変換することで音声波形に戻せるようにしました。
また、損失は下の式(正解音声とモデルの出力との差の二乗和)をf(周波数方向の次元数)×t(時間方向の次元数)で割ったものを用いました。
4. 分離音性能の評価
参考: https://library.naist.jp/mylimedio/dllimedio/showpdf2.cgi/DLPDFR009675_P1-57
推定音声をs^(t)とし、下のように正解音声s_target(t)、非正解音声e_interf(t)、ノイズe_artif(t)と分解しました。
これらの値から、SDR、SIR、SARが下の式から計算されます。
今回はmusevalというパッケージを用いてこれを計算しました。また、この計算における推定音声の部分を混合音声に変えてSDRに対応するものを計算し、SDRからその値を引いたものがNSDRとなります。
NSDR、SIR、SARの各平均をとったものがGNSDR、GSIR、GSARとなり、これが論文で使用されている分離音性能の評価の指標となります(数値が大きいほど性能が高い)。5. パッケージとしての利用
Githubに載せた実装をパッケージとして利用することで、ESC-50データセットの内2種類の音声を混ぜ、その分離を学習させることが簡単にできます。
実装したモデル自体は他のデータを用いたり3種類以上の音声を分離したりすることも可能ですが、データの前処理や訓練データ、テストデータの生成に関するモジュールは上の場合にしか対応していません。
パッケージのインストール、インポート
$pip install git+https://github.com/KMASAHIRO/DANetimport DANetESC-50データセットの用意
$wget https://github.com/karoldvl/ESC-50/archive/master.zip $unzip master.zipデータの前処理(リサンプリング、短時間フーリエ変換等)
# 短時間フーリエ変換後の音声をFouriers、音声の種類を表す名前をsound_namesに格納 Fouriers, sound_names = DANet.preprocess.preprocess(labelpath="ESC-50-master/meta/esc50.csv", audiopath="ESC-50-master/audio/")モデルを構築
model = DANet.models.create_model()モデルの学習
# 学習データを生成するジェネレータをメソッドとして含むクラスのインスタンスを作成 Generator = DANet.generating_data.generator(Fouriers, sound_names) # batch sizeを指定 batch_size=25 # batch sizeからsteps数(1 epochにジェネレータを呼び出す回数)を計算 steps = Generator.get_steps(batch_size) #学習(下の場合、混合させる音は風の音とカエルの鳴き声、epoch数は20) model.fit(x=Generator.generator_train('wind','frog',batch_size), steps_per_epoch=steps, epochs=20, initial_epoch=0)テストデータによる推論
# テストデータを生成する関数をメソッドとして含むクラスのインスタンスを生成 create_test_data = all_test_data(Fouriers,sound_names) # テストデータ、混合させる前のテストデータ(後の評価に利用)を生成 test_data, before_data = create_test_data.generate_data('wind','frog') # 推論 result = model.prediction(test_data)音声波形への復元
# 分離前の音声(before)、混合した音声(mixed)、分離後の音声(after)を生成 before, mixed, after = DANet.evaluation.return_to_sound(result, before_data)分離音性能の評価
# 一つずつの推論結果に対してNSDR、SIR、SARを計算 NSDR_list, SIR_list, SAR_list = DANet.evaluation.evaluation(before, mixed, after) # GNSDR、GSIR、GSARを計算 GNSDR, GSIR, GSAR = DANet.evaluation.final_eval(NSDR_list, SIR_list, SAR_list)
- モデルの重みを保存
filepath = "DANet_weights_wind_frog.h5" model.save_weights(filepath, save_format='h5')
- モデルの重みをロード
model = DANet.models.create_model() filepath = "DANet_weights_wind_frog.h5" model.loading(filepath)
- 復元した音声を保存する
モデルへの1回の入力に対応する分離前の音声、混合した音声、分離後の音声を保存します。
# numは保存するテストデータのindexを示す。 num = 0 DANet.evaluation.save_sound(num, before, mixed, after)
- 音声波形のグラフを保存する
モデルへの1回の入力に対応する分離前の音声波形、混合した音声波形、分離後の音声波形を保存します。
# numは保存するテストデータのindexを示す。 num = 0 DANet.evaluation.save_sound_fig(num, before, mixed, after)おわりに
音声を任意の数に分離するモデルであるDANet(Deep Attractor Network)の実装と解説をしました。
混合させる音の組み合わせを様々に変えて学習させた結果もGoogle Colabに載せましたが、GSARは一部論文の結果を上回ったものがありましたが、GNSDR、GSIRについては論文の結果を超えるものはなく半分以下の値になることが多かったです。原因の1つ目としてはデータ量の違い、2つ目としては論文で分離している人の声と今回使用した環境音の性質の違いが考えられます。今回作成したパッケージを使い、ぜひ様々な音声の分離をしてみてください。
不明な点、実装コードに関するアドバイス、パッケージとして利用する際の問題などありましたらコメントお願いします。

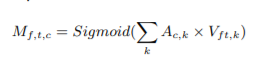
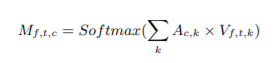

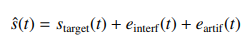
- 投稿日:2021-03-02T20:32:18+09:00
plotly覚え書き by 具体例
JupyterLabで使う
公式ドキュメントの
JupyterLab Supportを参照。
一応手順だけ抜粋しておくと (2021年3月2日現在)
拡張機能のインストールpip install jupyterlab "ipywidgets>=7.5" jupyter labextension install jupyterlab-plotly@4.14.3 jupyter labextension install @jupyter-widgets/jupyterlab-manager plotlywidget@4.14.3上記を入れたうえで、以下の様に普通にプロットすれば、プロットされたグラフをクリック・マウス操作することにより任意のグラフを消したり、拡大縮小したり等、インタラクティブに使える。良い。
Plotly Graph Objects
インポートimport plotly.graph_objects as go全般
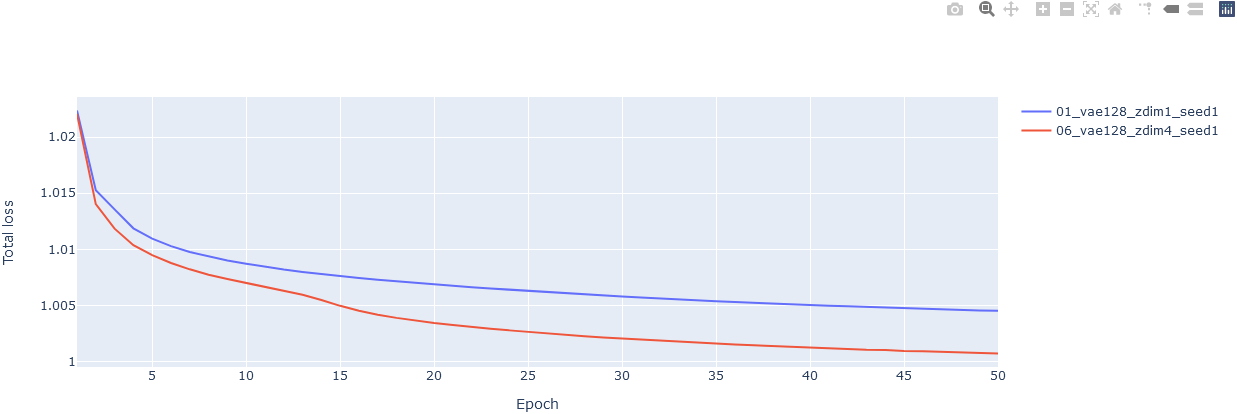
疑似コード# 空のFigureを作って、 fig = go.Figure() # add_traceメソッドによりグラフを追加していく。 fig.add_trace( # go.Barとかgo.Scatterとかの、具体的なグラフのインスタンスをここへ。 ) # 軸の名前、グラフのタイトル、グラフのサイズとかはupdate_layoutメソッドで。 # JupyterLabで表示している場合は、幅はノートブックの幅に勝手に合わせてくれるので、 # heightだけ適当に調整するとよさげ。 fig.update_layout( xaxis_title='hoge', yaxis_title='fuga', title='piyo', height=500 ) fig.show()ラインプロット
入力データ1 (df1)
epoch average_gen_loss kld total_loss 0 1 1.02231 0.924802 1.02239 1 2 1.01518 1.22425 1.01527 2 3 1.01342 1.9432 1.01357 3 4 1.01169 2.33714 1.01187 4 5 1.01076 2.46732 1.01095 (以下省略)
入力データ2 (df2)
epoch average_gen_loss kld total_loss 0 1 1.02196 1.57333 1.02208 1 2 1.01388 2.00052 1.01403 2 3 1.01166 2.32075 1.01184 3 4 1.01018 2.45098 1.01037 (以下省略)
(※ 別に入力データはデータフレームである必要はない)
コード# 空のFigureを作って、 fig = go.Figure() # グラフを追加していく。ラインプロットといいつつScatterを使う必要がある。 fig.add_trace( go.Scatter(x=df['epoch'], y=df['total_loss'], name='01_vae128_zdim1_seed1') ) # 追加。 fig.add_trace( go.Scatter(x=df2['epoch'], y=df2['total_loss'], name='06_vae128_zdim4_seed1') ) # 軸の名前とかタイトルとかを追加。 fig.update_layout( xaxis_title='Epoch', yaxis_title='Total loss' ) fig.show()
Plotly Express
インポートimport plotly.express as pxラインプロット
入力データ
epoch average_gen_loss kld total_loss 0 1 1.02231 0.924802 1.02239 1 2 1.01518 1.22425 1.01527 2 3 1.01342 1.9432 1.01357 3 4 1.01169 2.33714 1.01187 4 5 1.01076 2.46732 1.01095 (以下省略)
コード# とにかくデータフレーム渡して、軸はカラム名を指定すればヨシ fig = px.line(df, x='epoch', y='total_loss') fig.show()
ラインプロットを複数
どうも2つ以上のデータフレームを同時にプロットする方法は簡単には見つからない。
(例えば学習曲線がデータフレームに入っているときに、データフレームを複数渡して1つのグラフに重ねてプロットする、とか)plotly.express ではなくて、plotly.graph_object を使えということかもしれない。
- 投稿日:2021-03-02T19:46:06+09:00
Python文字列操作覚え書き
正規表現を使ったパターンマッチ
正規表現チートシート
パターンマッチとマッチ部分の抽出
以下のようなファイルから、学習曲線を描くための情報を抽出したいとする。
ファイル(省略) 2021-01-18 13:48:13 3784964 parameters in model 2021-01-18 13:54:34 # =====> Epoch: 1 Average gen loss = 1.02231, KLD = 0.924802, total loss = 1.022387; Finished in 0:06:20.245799 2021-01-18 14:01:29 # =====> Epoch: 2 Average gen loss = 1.01518, KLD = 1.224245, total loss = 1.015275; Finished in 0:06:22.065888 2021-01-18 14:08:19 # =====> Epoch: 3 Average gen loss = 1.01342, KLD = 1.943195, total loss = 1.013566; Finished in 0:06:20.048240 (省略)re モジュールの match 関数を使う。
m = re.match(<パターン文字列>, <検索対象文字列>)パターン文字列の中の特定の部分(数字とか)を後から取り出したいときは、パターン文字列の中の当該部分を
()でくくっておく。コードlog = [] for line in open(log_file): # マッチ結果が返ってくるので変数で受け取る m = re.match(r'.+Epoch:\s*(\d*)\s*Average gen loss =\s*(\d*\.\d*), KLD =\s*(\d*\.\d*),\s*total loss =\s*(\d*\.\d*).*', line) # マッチしていない場合は None が入っているんでスルー if m is not None: # m.group(0)は文字列全体、m.group(N) (N>0)はパターン文字列の中で()でくくった部分が入っている log.append(dict( epoch=int(m.group(1)), average_gen_loss=float(m.group(2)), kld=float(m.group(3)), total_loss=float(m.group(4)) )) df_log = pd.DataFrame(log) # pip install tabulate しておけばmarkdown形式で表出力できます print(df_log.to_markdown())出力
epoch average_gen_loss kld total_loss 0 1 1.02231 0.924802 1.02239 1 2 1.01518 1.22425 1.01527 2 3 1.01342 1.9432 1.01357 3 4 1.01169 2.33714 1.01187
- 投稿日:2021-03-02T18:52:33+09:00
複数条件(AND)の書き方と速度を検証してみたメモ
ifのあとのandの書き方について気になっていたこと
追記:
コメントから,公式ドキュメントに記載があることを教えていただきました。
この記事は公式ドキュメントをよく読まない戒めと検証結果2のために残しておこうと思います。Pythonでifの後にAND条件(いわゆる"かつ")を並べるときに,普段以下のように書いていました。
(普通の書き方)if (条件A) and (条件B) and (条件C): #なんらかの処理「条件Aの時点で当てはまらない場合もB,Cのbool値を確認しているのかな?だとしたら,ifをネストしたほうが早くなりそう。」
(ifを重ねる例)if (条件A): if (条件B): if (条件C): #なんらかの処理こう書けば,条件AがFalseの時点で確実にこのネストを超えるはずです。
もし仮に先述のandの書き方が条件を全チェックしているなら,bool値の判定回数が減り,高速化するのでは?と考え,検証してみました。(もし本当に速くなったらelseを書きづらいですが…)検証用のコードはこんな感じです。時間計測の部分は省いています。
以後,andを用いるものを方法A,ifのネストを方法Bとします。検証用コード①data = [i for i in range(1000000)] m=0 n=0 #ここから計測(A) for i in data: if i%2 == 0 and i%3 == 0 and i%5 == 0 and i%7 == 0: m+=1 #ここまで計測(A) #ここから計測(B) for i in data: if i%2 == 0: if i%3 == 0: if i%5 == 0: if i%7 == 0: n+=1 #ここまで計測(B)検証結果1
大方の予想通り,どちらも大きくは変わりませんでした。ちゃんとandの並列を読み取って,Falseが見つかった時点で全体のbool値をFalseにしているようです。
逆に言えば,ifネストでも特に遅くなることはないようです。メリットは分かりません。5回分の検証結果は次のようになりました。(単位:sec)
A(and) B(ifネスト) 1 0.2106909751892 0.214401483535 2 0.221389770507 0.2359576225280 3 0.2271342277526 0.2291073799133 4 0.278488397598 0.2128522396087 5 0.2378969192504 0.2479362487792 Ave. 0.2351200580596 0.2280509948730 結果から,どちらの方法でも先に書いた条件からboolの評価が行われると考えられます。
ということは,より当てはまりづらい条件を前に書いたほうが早く分岐を抜けられると予想できます。
追加で検証しました。検証用コード②data = [i for i in range(1000000)] m=0 n=0 #ここから計測(A) for i in data: if i%7 == 0 and i%5 == 0 and i%3 == 0 and i%2 == 0: m+=1 #ここまで計測(A) #ここから計測(B) for i in data: if i%7 == 0: if i%5 == 0: if i%3 == 0: if i%2 == 0: n+=1 #ここまで計測(B)2->3->5->7の順に評価していたのをひっくり返して7->5->3->2にしました。
このコードでは,7で割った剰余を先に見るので,早い段階でFalseが返る率が上がります。検証結果2
条件を並べ替えて最適化した場合の検証結果です。
A(and) B(ifネスト) 1 0.1518423557281 0.1596035957336 2 0.1871602535247 0.1861765384674 3 0.1661291122436 0.157944440841 4 0.1570513248443 0.1769468784332 5 0.1572012901306 0.1840560436248 Ave. 0.1638768672943 0.1729454994201 検証結果1では全ての試行で0.2secを上回る時間がかかりましたが,条件の並べ替えで,0.2secを切ることができ,今回の条件では約28%の高速化に成功しました。
高速化するのはわかっていましたが,思ったより効果が大きかったのでこれから意識して書こうと思います。
まとめ
- andをifネストに書き換えても無駄なので素直にandで書きましょう
- and並列の条件は,Falseが早く返りそうなものから並べると高速化できます
このあたりに詳しい人がいらっしゃればコメントお待ちしております。
使用機材
CPU:Core i5-1035G7@1.20GHz
Mem:40GB@2667MHz(SODIMM)
- 投稿日:2021-03-02T17:36:04+09:00
一度に複数のタイプに対して、isinstanceを調べる(Python)
- 投稿日:2021-03-02T17:33:29+09:00
単純な並列処理④処理の結果を得る (Python; multiprocessing.Queue)
概要
生産も消費も重い処理を並列するための簡素な実装をし、最終的な処理結果を得る。
multicoreを活用したいので、multiprocessingを用いる。
内容
注意点
以前定義したクラス定義を流用する。(前回記事)
環境
macOS Catalina
Python 3.7.0変更
readersの出力を保持する
self.outputsを追加する。queue.pyclass SingleQueueManager: ... def __init__(self, verbose=False): self.verbose = verbose self.queue = Queue() self.system_queue = Queue() self.outputs = Queue() # ←ここを追加した。 self.readers = [] self.writers = [] self.add_finisher() ... def _wrap_reader_proc(self, reader_function, queue): def tmp(queue): return reader_function(queue) # ←ここを変更した。 return tmp ... def add_element_reader(self, element_reader): def reader_proc(queue, outputs=self.outputs): while True: msg = queue.get() if (msg is self.__class__.DoneSignal): break outputs.put(element_reader(msg)) # ←ここを変更した。 self.add_reader(reader_proc) ... def get_all_outputs(self): # ←この関数を追加した。 while not self.outputs.empty(): yield self.outputs.get()実行
queue.pydef my_element_reader(msg): return '*'*msg def my_writer_proc(queue): import time import random for i in range(3): queue.put(i) time.sleep(random.randint(0, 5)) def main(): m = SingleQueueManager() m.add_element_reader(my_element_reader) m.add_element_reader(my_element_reader) m.add_element_reader(my_element_reader) m.add_writer(my_writer_proc) m.add_writer(my_writer_proc) m.start() m.join() print(list(m.get_all_outputs())) if __name__=='__main__': main()output['', '', '*', '*', '**', '**']参考にした頁・本
感想
- とりあえず動くものが作れて良かった。
- 車輪の再生産をしている気がする。
- 部分的に
multiprocessingではなく、threadingを使っても良いかもしれない。今後
今後積み重ねる機会があれば、この先も実装したいと思う。
- 投稿日:2021-03-02T17:28:04+09:00
単純な並列処理③生産消費ともに時間がかかる時 (Python; multiprocessing.Queue)
概要
生産も消費も重い処理を並列するための簡素な実装をする。
multicoreを活用したいので、multiprocessingを用いる。
内容
注意点
- 終了検出に、カスタムクラスを使うことにした。(cf. 以前書いた記事)
- マネジメントのためにクラスを使うことにした。
環境
macOS Catalina
Python 3.7.0準備
SingleQueueManagerと終了用クラス(DoneSignal)の定義queue.pyfrom multiprocessing import Process, Queue class SingleQueueManager: class DoneSignal: pass def __init__(self, verbose=False): self.verbose = verbose self.queue = Queue() self.system_queue = Queue() self.readers = [] self.writers = [] self.add_finisher()
self.verbose: 途中経過を表示するかself.queue:データを扱うためのqueueself.system_queue:プロセス終了管理のためのqueueself.readers:self.queueに溜まったものを消費するProcessのリストself.writers:self.queueに溜めるProcessのリストself.add_finisher():終了判定をするProcess(finisher)を定義する
self.add_readerの定義queue.pyclass SingleQueueManager: ... def add_reader(self, reader_function): target = self._wrap_reader_proc(reader_function, self.queue) args = (self.queue,) self.readers.append(Process(target=target, args=args)) def _wrap_reader_proc(self, reader_function, queue): def tmp(queue): reader_function(queue) return tmp
reader_function(queue)を定義すれば、
self.add_reader(reader_function)と渡せば大丈夫なようにした。
self.add_writerの定義queue.pyclass SingleQueueManager: ... def add_writer(self, writer_function): name = 'write' + str(len(self.writers) + 1) target = self._wrap_writer_proc(writer_function, name, self.queue, self.system_queue) args = (self.queue,) self.writers.append(Process(target=target, args=args)) def _wrap_writer_proc(self, writer_function, name, queue, system_queue): def tmp(queue): writer_function(queue) self.print(name, 'finished') system_queue.put('DONE') return tmp
writer_function(queue)を定義すれば、
self.add_writer(writer_function)と渡せば大丈夫なようにした。wrapすることで、
system_queue.put('DONE')を自然と実装できている。
self.add_element_readerの定義実際には、readerは、要素に対して定義される方が自然だと思うので、
要素を受け取り処理する関数でadd_readerできるようにした。queue.pyclass SingleQueueManager: ... def add_element_reader(self, element_reader): def reader_proc(queue): while True: msg = queue.get() if (msg is self.__class__.DoneSignal): break element_reader(msg) self.add_reader(reader_proc)
element_reader(msg)を定義すれば、
self.add_element_writer(element_reader)と渡せば大丈夫なようにした。終了処理の定義
queue.pyclass SingleQueueManager: ... def add_finisher(self): self.finisher = Process( target=self.finisher_proc, args=(self.queue, self.system_queue)) def finisher_proc(self, queue, system_queue): done = 0 while True: msg = system_queue.get() done += 1 n_writers, n_readers = len(self.writers), len(self.readers) if done == n_writers: for i in range(n_readers): queue.put(self.__class__.DoneSignal) break
system_queueにself.writersの数だけ入力があったら終了なので、
self.queueにself.readersの数だけ終了シグナルを入れる。その他利便性のための実装
queue.pyclass SingleQueueManager: ... def print(self, *args, **kwargs): if self.verbose: print(*args, **kwargs) def start(self): for reader in self.readers: reader.start() for writer in self.writers: writer.start() self.finisher.start() def join(self): for reader in self.readers: reader.join() for writer in self.writers: writer.join() self.finisher.join()実行
queue.pydef my_element_reader(msg): print(msg) def my_writer_proc(queue): import time import random for i in range(3): queue.put(i) time.sleep(random.randint(0, 5)) def main(verbose=False): m = SingleQueueManager(verbose=verbose) m.add_element_reader(my_element_reader) m.add_element_reader(my_element_reader) m.add_element_reader(my_element_reader) m.add_writer(my_writer_proc) m.add_writer(my_writer_proc) m.start() m.join() if __name__=='__main__': main(verbose=True)output0 0 1 1 2 2 write2 finished write1 finished最終的なクラス定義
queue.pyclass SingleQueueManager: class DoneSignal: pass def __init__(self, verbose=False): self.verbose = verbose self.queue = Queue() self.system_queue = Queue() self.readers = [] self.writers = [] self.add_finisher() def print(self, *args, **kwargs): if self.verbose: print(*args, **kwargs) def add_finisher(self): self.finisher = Process( target=self.finisher_proc, args=(self.queue, self.system_queue)) def finisher_proc(self, queue, system_queue): done = 0 while True: msg = system_queue.get() done += 1 n_writers, n_readers = len(self.writers), len(self.readers) if done == n_writers: for i in range(n_readers): queue.put(self.__class__.DoneSignal) break def add_reader(self, reader_function): target = self._wrap_reader_proc(reader_function, self.queue) args = (self.queue,) self.readers.append(Process(target=target, args=args)) def _wrap_reader_proc(self, reader_function, queue): def tmp(queue): reader_function(queue) return tmp def add_writer(self, writer_function): name = 'write' + str(len(self.writers) + 1) target = self._wrap_writer_proc(writer_function, name, self.queue, self.system_queue) args = (self.queue,) self.writers.append(Process(target=target, args=args)) def _wrap_writer_proc(self, writer_function, name, queue, system_queue): def tmp(queue): writer_function(queue) self.print(name, 'finished') system_queue.put('DONE') return tmp def add_element_reader(self, element_reader): def reader_proc(queue): while True: msg = queue.get() if (msg is self.__class__.DoneSignal): break element_reader(msg) self.add_reader(reader_proc) def start(self): for reader in self.readers: reader.start() for writer in self.writers: writer.start() self.finisher.start() def join(self): for reader in self.readers: reader.join() for writer in self.writers: writer.join() self.finisher.join()蛇足
書き終わった頃にmultiprocessing.Managerというものを見つけてしまったが、
これがあれば解決するのだろうか。参考にさせていただいた本・頁
特になし
(cf. 前回記事)感想
とりあえず動くものが作れて良かった。
今後
queueから取り出したものをまとめるものを後で作る。
追記:作りました。(https://qiita.com/yo314159265/items/c65fa68d55ea11ad4e6c)
- 投稿日:2021-03-02T17:21:32+09:00
単純な並列処理②生産に時間がかかる時 (Python; multiprocessing.Queue)
概要
多くの重い処理から分担して生産するための簡潔な実装をする。
multicoreを活用したいので、
multiprocessingを用いる。内容
環境
macOS Catalina
Python 3.7.0準備
from multiprocessing import Process, Queue import time import sys import random def reader_proc(queue): done = 0 while True: msg = queue.get() if (msg == 'DONE'): done += 1 if done == 2: break def writer_proc(name, queue): for i in range(3): queue.put(i) print(name, i) time.sleep(random.randint(0, 5)) queue.put('DONE') print(name, 'DONE') queue = Queue() reader = Process(target=reader_proc, args=(queue,)) writer1 = Process(target=writer_proc, args=('write1', queue)) writer2 = Process(target=writer_proc, args=('write2', queue))
reader_proc:queueに溜まったものを迅速に消費してくれる。
writer_proc:queueに追加してくれるが、生産するのに少し時間がかかる。実行
reader.start() writer1.start() writer2.start() reader.join() writer1.join() writer2.join()outputwrite1 0 write2 0 write2 1 write2 2 write1 1 write2 DONE write1 2 write1 DONE蛇足
各所の説明では、いつ終わるか分からないQueueに未対応のものが多かった。
こうすれば、好きなタイミングで綺麗に終わらせられる。'DONE'が重要なデータでないか不安な場合は、以前の記事を参照すればすぐに解決する。
参考にさせていただいた本・頁
- https://stackoverflow.com/questions/11515944/how-to-use-multiprocessing-queue-in-python
- https://qiita.com/yo314159265/items/0215bb1f9128800fc7f0 (iteratorシグナル記事)
- https://qiita.com/yo314159265/items/dbedf0bb27589af6a33d (前回記事)
感想
たまに使うので、整理できて良かった。
reader_procに処理の個数を入れているのはあまり美しくはないが、行数優先。今後
このシリーズはもう少し続けます。
追記:続き書きました。(https://qiita.com/yo314159265/items/00ac562a5ae777364e6b)
- 投稿日:2021-03-02T17:15:12+09:00
単純な並列処理①消費に時間がかかる時 (Python; multiprocessing.Queue)
概要
多くの重い処理を分担して消費するための簡潔な実装をする。
multicoreを活用したいので、
multiprocessingを用いる。内容
環境
macOS Catalina
Python 3.7.0準備
from multiprocessing import Process, Queue import sys import time import random def reader_proc(name, queue): while True: msg = queue.get() print(name, msg) if (msg == 'DONE'): break time.sleep(random.randint(1, 4)) def writer(queue): for i in range(3): queue.put(i) time.sleep(random.randint(1, 4)) queue.put('DONE') queue.put('DONE') queue = Queue() reader1 = Process(target=reader_proc, args=('reader1', queue)) reader2 = Process(target=reader_proc, args=('reader2', queue))
reader_proc:queueから読み取るが、消費に少し時間がかかる。
writer:queueに追加してくれる。実行
reader1.start() reader2.start() writer(queue) reader1.join() reader2.join()outputreader1 0 reader2 1 reader1 2 reader2 DONE reader1 DONE蛇足
各所の説明では、いつ終わるか分からないQueueに未対応のものが多かった。
こうすれば、好きなタイミングで綺麗に終わらせられる。
'DONE'が重要なデータでないか不安な場合は、以前書いた記事を参照すればすぐに解決する。参考にさせていただいた本・頁
- https://stackoverflow.com/questions/11515944/how-to-use-multiprocessing-queue-in-python
- https://qiita.com/yo314159265/items/0215bb1f9128800fc7f0
感想
整理できて良かった。
今後
このシリーズはもう少し続けます。
追記: 続き記載しました。(https://qiita.com/yo314159265/items/aefd794a12c30f086413)
- 投稿日:2021-03-02T17:12:40+09:00
【Python】threadingによる並列処理
使い方は簡単
import threading def thread1(): ''' 別のスレッドとして実行させたい内容 ''' if __name__ == '__main__': # スレッドthの作成.targetで行いたいメソッド,nameでスレッドの名前,argsで引数を指定する th = threading.Thread(target=thread1,name="th",args=()) # thをデーモンに設定する.メインスレッドが終了するとデーモンスレッドも一緒に終了する th.setDaemon(True) th.start() ''' 実行させたい内容 '''(例)1から100までカウント.qが入力されたら強制終了.
#coding:utf-8 import threading import sys from time import sleep class Config: fg = False def thread1(): while True: c = sys.stdin.read(1) if c == 'q': Config.fg = True if __name__ == '__main__': th = threading.Thread(target=thread1,name="th",args=()) th.setDaemon(True) th.start() for i in range(1,101): if Config.fg: sys.exit() print(i) sleep(1)実行結果
(a->b->c->qの順に入力)python3 thread.py 1 2 3 4 5 6 a 7 8 b 9 c 10 11 q
- 投稿日:2021-03-02T17:10:16+09:00
Dashでウェブアプリ作成②
はじめに
Dashでウェブアプリ作成①では、テーブルの可視化を行ってみた。今回は図を表示させてみる。
図の表示
前回記事でgenerate_tableを実行していた部分をdcc.Graphに変更するだけで実行できる。以下にコードを示す。表示に使うデータは、Rで基礎分析結果をCSV出力①全体編、Rで基礎分析結果をCSV出力②量的変数編、Rで基礎分析結果をCSV出力③質的変数編で作成したCSVファイルを用いている。
figure.py# Run this app with `python app.py` and # visit http://127.0.0.1:8050/ in your web browser. import dash import dash_html_components as html import dash_core_components as dcc from dash.dependencies import Input, Output import plotly.express as px import pandas as pd df1 = pd.read_csv( "c:/***/default_of_credit_card_clients.csv", header=1) df1.columns.values[0] = '' df2 = pd.read_csv( "c:/***/summary.csv", header=0) df2.columns.values[0] = '' df3 = pd.read_csv( "c:/***/stats.csv", header=0) df3.columns.values[0] = '' df4 = pd.read_csv( "c:/***/r.csv", header=0) df4.columns.values[0] = '' df5 = pd.read_csv( "c:/***/SEX.csv", header=0) df5.columns.values[0] = 'SEX' df6 = pd.read_csv( "c:/***/EDUCATION.csv", header=0) df6.columns.values[0] = 'EDUCATION' df7 = pd.read_csv( "c:/***/MARRIAGE.csv", header=0) df7.columns.values[0] = 'MARRIAGE' df8 = pd.read_csv( "c:/***/default payment next month.csv", header=0) df8.columns.values[0] = 'default payment next month' def generate_table(dataframe, max_rows=30): return html.Table([ html.Thead( html.Tr([html.Th(col) for col in dataframe.columns]) ), html.Tbody([ html.Tr([ html.Td(dataframe.iloc[i][col]) for col in dataframe.columns ]) for i in range(min(len(dataframe), max_rows)) ]) ]) external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets) app.layout = html.Div([ html.H4(children='default of credit card clients Data Set'), dcc.Tabs(id='tabs-example', value='tab-1', children=[ dcc.Tab(label='raw data', value='tab-1'), dcc.Tab(label='number of missing values', value='tab-2'), dcc.Tab(label='stats', value='tab-3'), dcc.Tab(label='cor', value='tab-4'), dcc.Tab(label='SEX', value='tab-5'), dcc.Tab(label='EDUCATION', value='tab-6'), dcc.Tab(label='MARRIAGE', value='tab-7'), dcc.Tab(label='default payment next month', value='tab-8') ]), html.Div(id='tabs-example-content'), ]) @app.callback(Output('tabs-example-content', 'children'), Input('tabs-example', 'value')) def render_content(tab): if tab == 'tab-1': return html.Div([ generate_table(df1) ]) elif tab == 'tab-2': return html.Div([ generate_table(df2, max_rows=30) ]) elif tab == 'tab-3': return html.Div([ generate_table(df3, max_rows=20) ]) elif tab == 'tab-4': return html.Div([ generate_table(df4, max_rows=20) ]) elif tab == 'tab-5': return html.Div([ generate_table(df5, max_rows=20), dcc.Graph( figure=px.bar(df5, x='SEX', y="Freq") ) ]) elif tab == 'tab-6': return html.Div([ generate_table(df6, max_rows=20), dcc.Graph( figure=px.bar(df6, x='EDUCATION', y="Freq") ) ]) elif tab == 'tab-7': return html.Div([ generate_table(df7, max_rows=20), dcc.Graph( figure=px.bar(df7, x='MARRIAGE', y="Freq") ) ]) elif tab == 'tab-8': return html.Div([ generate_table(df8, max_rows=20), dcc.Graph( figure=px.bar(df8, x='default payment next month', y="Freq") ) ]) if __name__ == '__main__': app.run_server(debug=True)実行結果は以下のようになる。

- 投稿日:2021-03-02T17:06:38+09:00
iteratorにシグナルを紛れ込ませること(Python)
概要
iteratorにシグナルを紛れ込ませて、適切なタイミングでアクションをしたい。
カスタムクラスを使って実装する。
内容
環境
macOS Catalina
Python 3.7.0実演
勝手な
classを自分で定義して用いる。isで判定。class OreShikaTsukawan: pass def myiterator(): for i in range(1000): yield i if i % 10 == 5: yield OreShikaTsukawan for value in myiterator(): if value is OreShikaTsukawan: print('finish signal!') break print(value)output0 1 2 3 4 5 finish signal!こうすれば、本来のiteratorの中身とかぶる心配はない。
変な演算をしてしまう心配も少ない。蛇足
可能ならば
classinclassとかすれば、global変数を汚さずに済む。参考にさせていただいた本・頁
特になし
感想
たまに便利。
今後
同僚に驚かれなければ使っていく。
- 投稿日:2021-03-02T17:01:39+09:00
Kaggle Courses 学習メモ(機械学習イントロダクション編)
前回(Python講座編)の続きです.
今回は機械学習基礎編ということで,
- 主要ライブラリ(pandas,scikit-learnの基礎)
- バリデーションのやり方
- アンダーフィッティング・オーバーフィッティングについて
など,機械学習の基礎の基礎から学べる内容になっております.
それでは進めていきましょう.
データ読み込み・整形
まずはデータを読み込み,特徴量・予測値を抽出しておく必要があります.
今回はデータ整形に特化したライブラリであるpandasを用いていきます.「機械学習エンジニア名乗っておきながらpandas使えないってマジ?」と言われないよう,しっかり勉強していきましょう.基本の読み込み
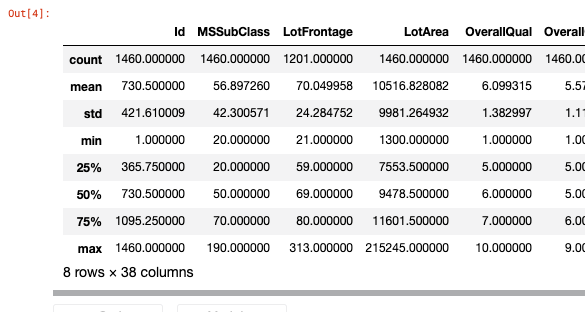
# データへのパス melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv' # データ読み込み・DataFrame形式へ melbourne_data = pd.read_csv(melbourne_file_path) #お試し表示 melbourne_data.describe()
- count...値がNA(Not Available)/nullでないデータの数
- mean ... 平均値
- std..標準偏差,Standard Deviation
- max min ... 最大最小
- 25%,50%,75% ... 四分位数
カラムへは配列のようにアクセスできる
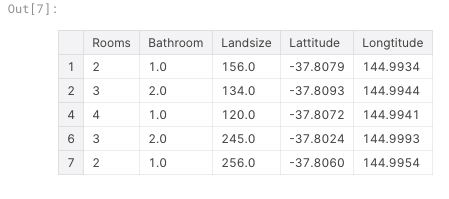
上記の代表値は同名のメソッドを用いて取得可能import datetime #敷地面積の平均値 avg_lot_size = round(home_data['LotArea'].mean()) #最も新築な家の築年数 #newest_home_age = 2021-home_data['YearBuilt'].max() newest_home_age = datetime.date.today().year-home_data['YearBuilt'].max() #columnsでカラムを取得可能 melbourne_data.columns #Index(['Suburb', 'Address', 'Rooms', 'Type', 'Price', ... , 'Lattitude', 'Longtitude', 'Regionname', 'Propertycount'], dtype='object')データセットのサブセットを取る方法はいくつかあるが,代表的なのは以下の2つ.
- ドット表記.1カラムを指定して取得する.「予測ターゲット」を得る時に有用.
- カラムリストによる選択.複数カラムをDataFrame形式で取得する.モデルへの入力となる特徴量を得る時に有用.
#ドット表記で予測ターゲットを得る y = melbourne_data.Price #カラムのリストによって特徴量を得る melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude'] X = melbourne_data[melbourne_features]複数カラムをまとめて得られるデータはDataFrame形式なので,
describe()メソッドやhead()メソッドが使える.X.describe()
X.head()
モデルの構築
特徴量$ \mathbf{X} $と予測ターゲット$y$をデータから切り出すことが出来たので,Xを用いてyを予測する機械学習モデルを構築していきます.
本コースでは著名な機械学習手法をかんたんに試せるscikit-learnというライブラリを用いていきます.scikit-learn
from sklearn.tree import DecisionTreeRegressor # 決定木モデル,同じ結果が得たい場合はrandom_stateを同じ値にする melbourne_model = DecisionTreeRegressor(random_state=1) # フィッティング melbourne_model.fit(X, y) # 予測 melbourne_model.predict(X) #[1200, 1100, 800,...]とりあえず4章までまとめました.
続きは時間のあるときにでも〜

- 投稿日:2021-03-02T16:54:46+09:00
Djangoでクリック回数をカウントする
Djangoでクリック回数をカウントしたい!!
Djangoでブログサービスとかの開発を行う際記事がクリックされた回数を表示する機能が欲しいと思う方はいるんじゃないかと思います。オーソドックスな方法と言えば、JavaScriptのajax通信を用いてクリック回数を調べる手法がよく用いられていますが、ajax通信って何と言いますか、構文が複雑だったりJavaScriptをちょっとかじっただけでは理解が追い付かなかったりしますよね?私もそうでした。でもやっぱり開発しているアプリにそういう機能がどうしても欲しくてしょうがないという思いが捨てきれなかったからこそajaxに頼らないでクリック回数をカウントする機能をバックエンド側で作ってみました。同じ壁に当たってしまった方のために、また、自分自身の備忘録のために今回記事にさせていただきました。
1.models.py
クリック回数をカウントすることが目的ですのでモデルの定義もシンプルにします。
# 記事 class Post(models.Model): user = models.ForeignKey(User, verbose_name='投稿者', on_delete=models.CASCADE) title = models.CharField(verbose_name='タイトル', max_length=40) content = models.TextField(verbose_name='本文') img = models.ImageField(blank=True, null=True) created_at = models.DateTimeField(verbose_name='作成日時', auto_now_add=True) # ここでクリック回数をカウント @property def number_of_views(self): return View.objects.filter(post=self).count() # クリック回数をカウントするために用いるクラス class View(models.Model): article = models.ForeignKey(Post, verbose_name='表示記事', on_delete=models.CASCADE) count = models.IntegerField(default=0)モデルの定義はこんなとこでしょうね。定義の中で重要になってくるのはPostクラスに記述されたnumber_of_views関数で、個々の記事毎の表示回数をこの関数内でカウントし、データベース内にて管理することになります。
propertyの意味が分からない方はこちらをご参照ください。
https://docs.python.org/3/library/functions.html#property2.views.py
次にviews.pyを編集することにしましょう。先ほど定義したモデルをまずはインポートします。
from django.views import generic from .models import Post, View必要なクラスをインポートしましたら残りを書いていきます。とりあえず記事をリスト形式で表示し、記事をクリックした段階でカウント処理が行われるようにしましょう。
# 記事の一覧表示 class PostListView(LoginRequiredMixin, generic.ListView): context_object_name = 'post_list' model = Post template_name = 'index.html' def get_queryset(self): posts = Post.objects.all().order_by('-created_at') return posts # 記事の詳細へ移動 class PostDetailView(LoginRequiredMixin, generic.DetailView): model = Post template_name = 'post_detail.html' # 記事の表示回数をカウント def add_count(request, pk): post = get_object_or_404(Post, pk=pk) count = View() count.article = post count += 1 count.save() return redirect('post-detail', pk=post.pk)ポイントになってくるのはadd_countメソッドです。通常、リスト形式で一覧表示された記事の詳細を見るときには、PostDetailクラスで定義した処理を行わせるようにするわけですが、その前にadd_countメソッドを挟み込むことによってViewインスタンスを生成(本当はcountテーブル内の要素だけ変化させたい!!)し、データベースに保存、HTMLにインスタンスの数を出力することによってその記事がクリックされた回数を可視化するわけです。
3.urls.py
次は、viewsで定義したクラスやメソッドのパスをつなげましょう。このあたりもDjangoの基礎的なところになってきますので説明不要でしょうけれどもパスをつなげた後の名前をどうしているかをわかりやすくするために一応用意させていただきました。
from django.urls import path from . import views urlpatterns = [ path('', views.PostListView.as_view(), name="index"), path('post_detail/<int:pk>/', views.PostDetailView.as_view(), name='post_detail'), path('add_count/<int:pk>/', views.add_count, name='add_count'), ]4.HTMLファイルの編集
最後に、HTMLファイルの編集をしていきましょう。こちらも最低限の機能しか追加しないようにしていきます。
とりあえずbase.htmlから作っていきましょう。
{% load static %} <html lang='ja'> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <meta name="description" content=""> <meta name="author" content=""> <title>{% block title %}{% endblock %}</title> </head> <body> {% block header %}{% endblock %} {% block contents %}{% endblock %} <footer> <p>Copyright © hogehoge 2021</p> </footer> </body>ではこれを元としてindex.htmlも編集しましょう。
{% extends base.html %} {% load static %} {% block title %}記事{% endblock %} {% block contents %} {% for items in post_list %} <!-- ここでpost_detailではなくadd_countのパスを指定 --> <a href="{% url 'add_count', items.pk %}"> {% if items.img %} <img src="{{ items.img.url }}" width=100 height=100 style="float:right;"> {% endif %} <h3>記事タイトル:{{ items.title }}</h3> <p>記事本文:{{ items.content }}</p> <p>投稿日時:{{ items.created_at }}</p> </a> {% empty %} <p>記事がありません。</p> {% endfor %} {% endblock %}ポイントになってくるのはindex.htmlで通常post_detailを指定するはずの箇所をadd_countにしていることです。こうすることによって詳細画面に移動する前にデータベース内にViewインスタンスが生成され、保存されます。生成されたインスタンスの数をデータベース内でカウントし、インスタンスの数でクリック回数を示すわけです。もしクリック回数を表示したい場合ですと、先ほどのコードを以下のように修正するとクリック回数、正確には記事が表示された回数が反映されます。
{% extends base.html %} {% load static %} {% block title %}記事{% endblock %} {% block contents %} {% for items in post_list %} <!-- ここでpost_detailではなくadd_countのパスを指定 --> <a href="{% url 'add_count', items.pk %}"> {% if items.img %} <img src="{{ items.img.url }}" width=100 height=100 style="float:right;"> {% endif %} <h3>記事タイトル:{{ items.title }}</h3> <p>記事本文:{{ items.content }}</p> <p>投稿日時:{{ items.created_at }}</p> <!-- 追加箇所 --> <p>表示回数:{{ items.number_of_views }}</p> </a> {% empty %} <p>記事がありません。</p> {% endfor %} {% endblock %}これで記事の表示回数をバックエンドで処理してフロントエンド側に出力させることが可能になります。私としてはもう少しスマートな書き方ができればなあと思いますが現状これ以上いいものは思いつきません。もっといい書き方をご存知の方は是非とも教えていただきたいものです。あるいは記事作ってほしいです。
- 投稿日:2021-03-02T15:59:31+09:00
Dashで世界遺産を世界地図にプロット
はじめに
DashというPythonでダッシュボードを作成することができるWebフレームワークでのウェブアプリの作成を行う。なにかできないかなと調査していたところ、地図上に緯度経度情報を使ってデータを重ねられるものを発見したので、それらを元にDashを使って世界遺産を表示するウェブアプリを作ってみる。Plotolyの公式ドキュメントMapbox Map Layers in Pythonを参考にした。
世界地図の表示
Mapbox Map Layers in Python通りやると、以下7行のコードでアメリカの都市をプロットし、プロットの上にカーソルをおくとその都市の情報が表示される。
usCities.pyimport pandas as pd us_cities = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/us-cities-top-1k.csv") import plotly.express as px fig = px.scatter_mapbox(us_cities, lat="lat", lon="lon", hover_name="City", hover_data=["State", "Population"], color_discrete_sequence=["fuchsia"], zoom=3, height=300) fig.update_layout(mapbox_style="open-street-map") fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0}) fig.show()上記コードでは、あくまでデータに則って表示をしているだけで、ユーザー側の操作によって動的に更新することはできない。そこでDashを用いて、項目を選択した際に動的に地図を更新していくアプリを作成してみる。例と同じアメリカの都市ではおもしろくないので、代わりに世界遺産のプロットを試みる。UNESCO Wordl Heritage Centrev - SyndicationにExcelデータがあったため、ダウンロードしてCSVファイルに変換したものを扱う。
Dashの使用
上記コードではDashを使用していないので、まずDashを適用する。コードを以下に示す。(Dashを使用する、という日本語が適切かはわからない。。。)
dash.py# Run this app with `python app.py` and # visit http://127.0.0.1:8050/ in your web browser. import dash import dash_html_components as html import dash_core_components as dcc from dash.dependencies import Input, Output import plotly.express as px import pandas as pd whc = pd.read_csv( "c:/***/Dash/data/whc-sites-2019.csv") external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] fig = px.scatter_mapbox(whc, lat="latitude", lon="longitude", hover_name="name_en", hover_data=["date_inscribed", "states_name_en", "category", ], color_discrete_sequence=["fuchsia"], zoom=3, height=300) fig.update_layout(mapbox_style="open-street-map") fig.update_layout(margin={"r": 0, "t": 0, "l": 0, "b": 0}) app = dash.Dash(__name__, external_stylesheets=external_stylesheets) app.layout = html.Div([ html.H2(children='World Hesitate Cite (2019)'), dcc.Graph(id='whc-map', figure=fig) ]) if __name__ == '__main__': app.run_server(debug=True)上記ファイルを実行して、http://127.0.0.1:8050/にアクセスすると以下のような結果が得られる。
Dropdown, CheckList
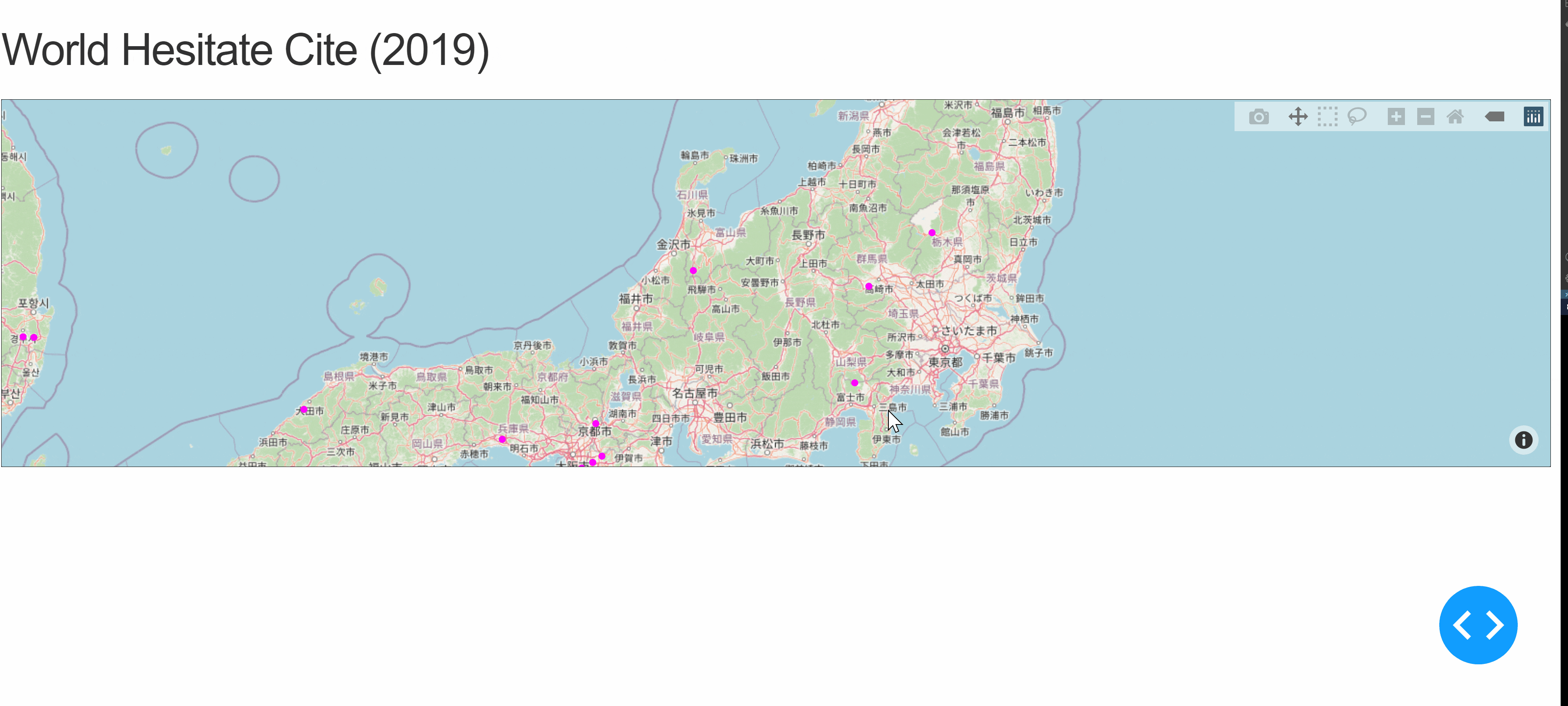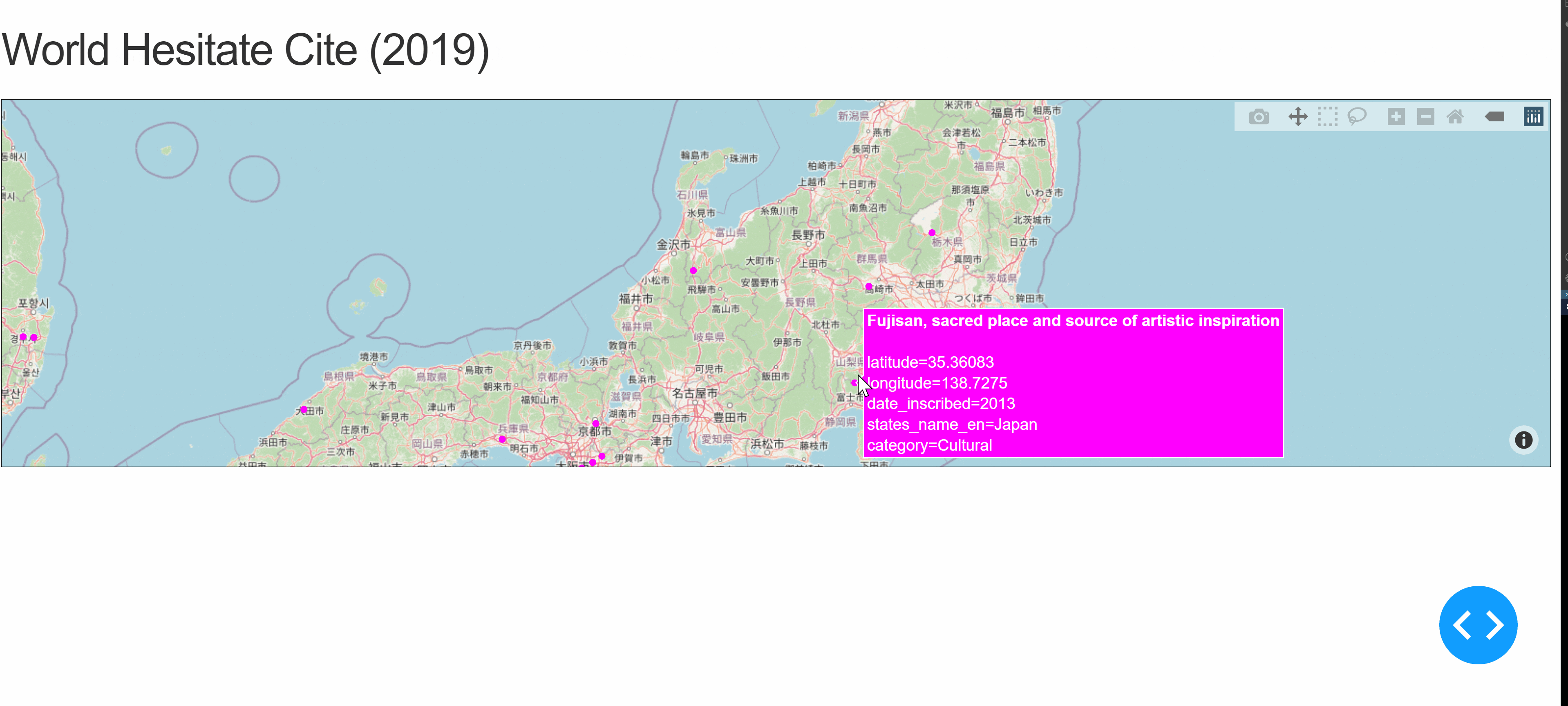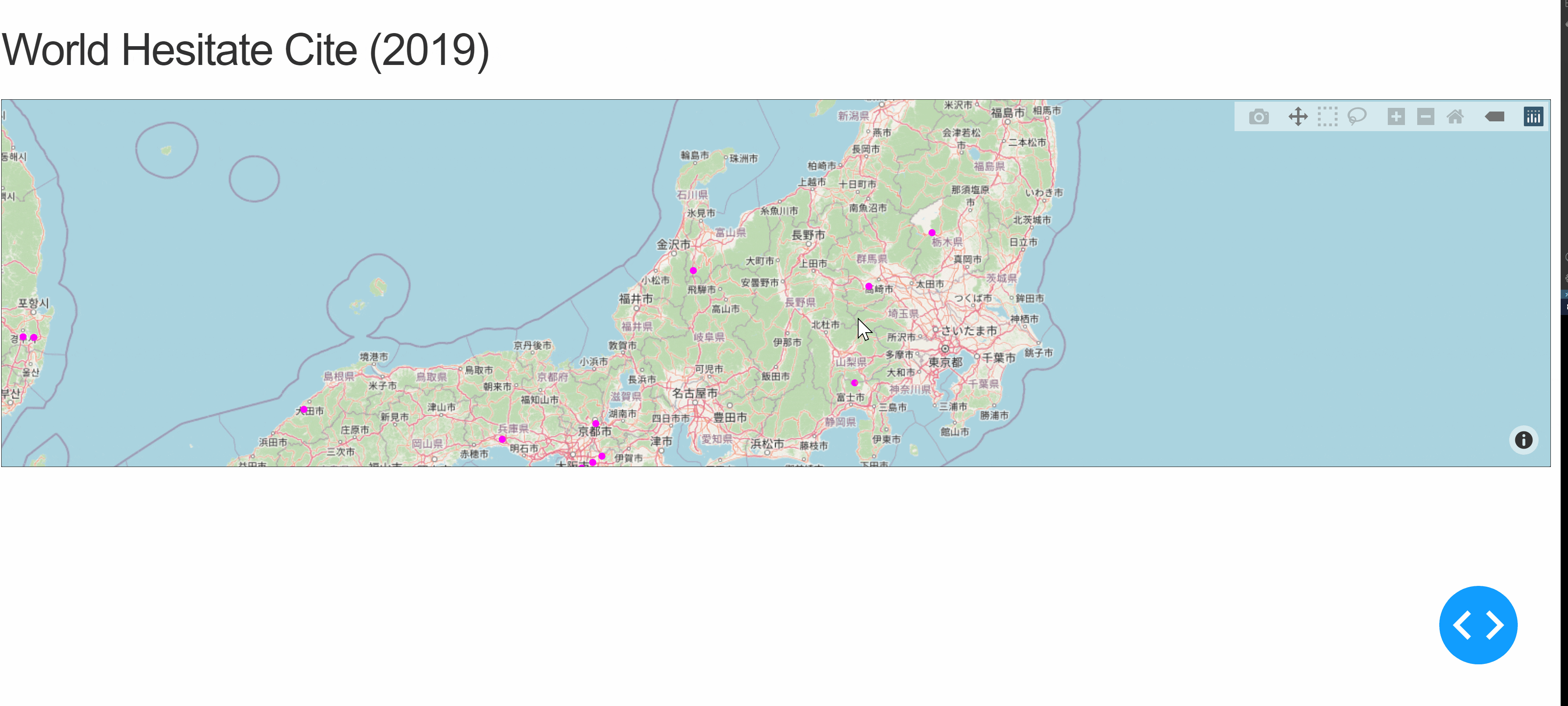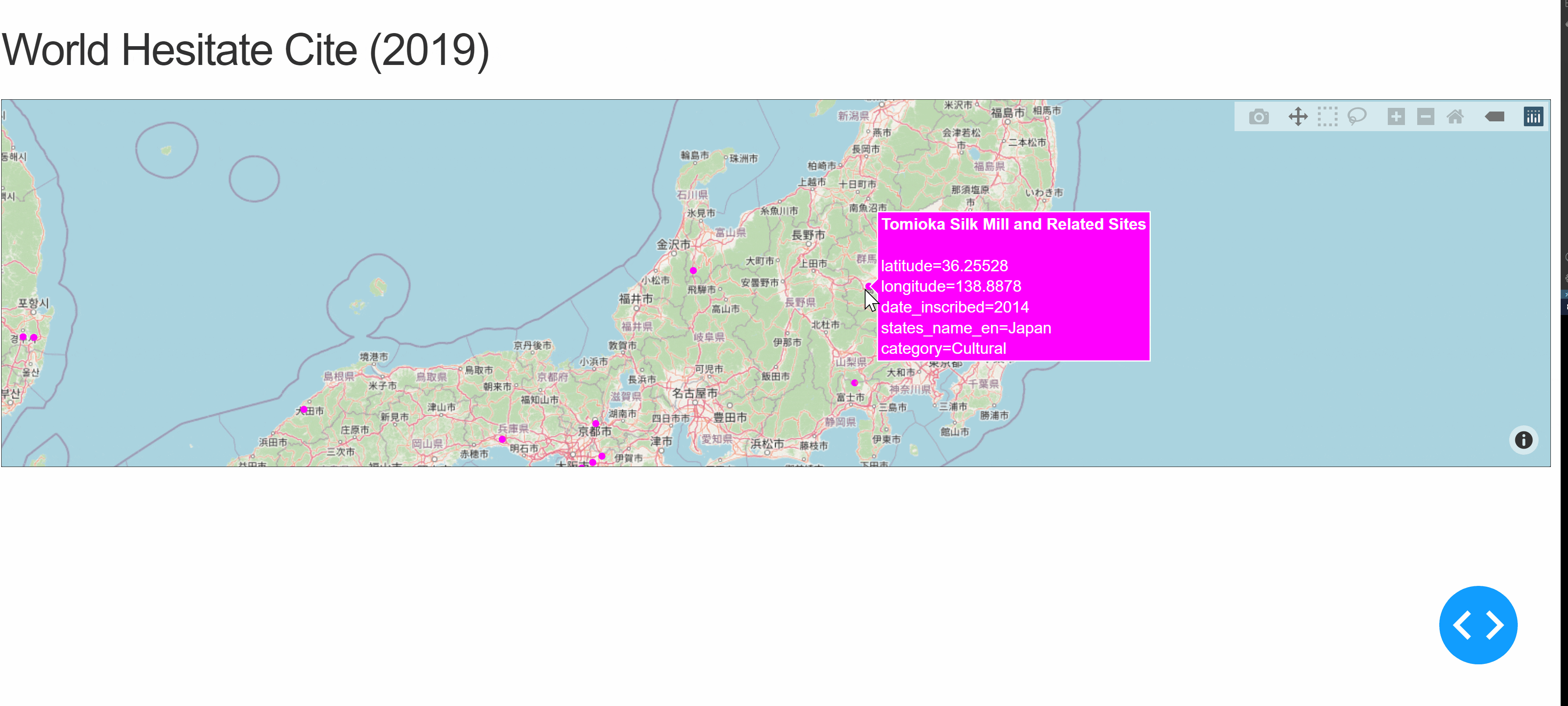
項目を選択することで、フィルタリングをかけられるようにする。項目は、地域を表す「Region」と文化遺産・自然遺産・複合遺産を表す「Category」の2つを用いる。「Region」はDropdownで、「Category」はCheckListにて選択することにする。コードを以下に示す。
(2021/3/2追記)
選択地域・カテゴリの世界遺産の数を表示させる機能を追加した。以下コードは追加後のもの。(実行結果のGIFは以前のまま。)callback.py# Run this app with `python app.py` and # visit http://127.0.0.1:8050/ in your web browser. import dash import dash_html_components as html import dash_core_components as dcc from dash.dependencies import Input, Output import numpy as np import plotly.express as px import pandas as pd whc = pd.read_csv( "c:/Users/t_honda/Desktop/Dash/data/whc-sites-2019.csv") r = whc['region_en'].unique() regions = np.append('All over the world', r) categories = whc['category'].unique() external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets) app.layout = html.Div([ html.H2(children='World Hesitate Cite (2019)'), html.Label('Region Select'), dcc.Dropdown(id='region', options=[{'label': i, 'value': i} for i in regions], value='All over the world'), html.Label('Category'), dcc.Checklist(id='category', options=[{'label': i, 'value': i} for i in categories], value=['Cultural', 'Natural', 'Mixed']), html.Label('Number of World Heritage Cites'), html.Div(id='whc-number'), dcc.Graph(id='whc-map') ]) @app.callback( Output('whc-map', 'figure'), Output('whc-number', 'children'), Input('region', 'value'), Input('category', 'value')) def update_map(region, category): if region == 'All over the world': whc_r = whc else: whc_r = whc[whc['region_en'] == region] whc_rc = whc_r[whc_r['category'].isin(category)] fig = px.scatter_mapbox(whc_rc, lat="latitude", lon="longitude", hover_name="name_en", hover_data=["date_inscribed", "states_name_en", "region_en", "category"], color_discrete_sequence=["fuchsia"], zoom=3, height=300) fig.update_layout(mapbox_style="open-street-map") fig.update_layout(margin={"r": 0, "t": 0, "l": 0, "b": 0}) return fig, len(whc_rc) if __name__ == '__main__': app.run_server(debug=True)コールバック関数にて、選択した項目をもとに地図を更新するようにしている。実行結果は以下のようになる。
想定したとおりに実行できている。カテゴリをなにも選択しない場合に地図自体が表示されなくなるなどの修正点はあるが、今回は一旦ここまでとしておく。地域を複数選択できるようにしたり、選択地域の世界遺産の数をカテゴリごとで表示させる機能を追加してもおもしろいかもしれない。

- 投稿日:2021-03-02T15:15:50+09:00
Python/PandasからSTATAにデータを受け渡す方法 (関数の定義も)
1, 導入
最近になってSTATAを使い始めるようになったので、軽い気持ちで「STATA上でpythonを使ってデータ分析する方法」を模索し始めたのですが、そもそもどうやってSTATAとpythonを連携さえるかの段階でつまづいたりして、結構苦労しました。
ということで、せっかくだからSTATA上でpythonを開いてデータ分析を行うときに知っておくべきことをまとめてみました。最終目標は、PandasのdfをSTATA datasetに移す方法の発見です。2, 環境
STATA /MP16.1 2 core
Python 3.8.5
Pandas 1.2.13, STATAとPythonを連携させる方法
僕が理解している範囲では、STATAとPythonの連携方法は3パターンあります。
①STATA上でPythonを呼び出す
②jupyter notebookでSTATAカーネルとして使う
③Python上でSTATAを呼び出す、ipystataというモジュールを使う
僕の理想は③だったのですが、いろいろやってみてダメでした笑
ということで、僕は①のやり方でSTATA上でPythonを開くことにしました。4, STATAでPythonを使うときによく使う超基本的なコマンド
①STATAコマンド
STATAコマンド専用のCode記述ができないので、代わりにPythonのものを用いましたが、実際は以下のコマンドはSTATAのものです。#ディレクトリの替え方(初期設定のディレクトリの位置はCドライブの頭?) #ディレクトリの順番とかは関係なく、指定したところに飛べる cd "C:\Users\handsome\gojo" #csvファイルを開くコマンド insheet using C:\Users\handsome\gojoファイル名.csv #記述統計 summarize #OLS regress y x1 x2 x3 #IV ivregress 2sls y x1 x2 (end1 end2 = exo1 exo2) #pythonの開き方 python #開く end #閉じるまあ、その他のコマンドは、一回GUIでやってみて確認すればいいですね。
上記コマンド最後のpythonの開き方は最重要です。
「python」で開いた後、そのままいろいろ操作して、pythonを閉じたくなったら「end」で閉じます。
なお、一回pythonを呼び出してしまうと、上記コマンドはすべて使えなくなりますが、以下のマジックコマンドみたいなやつを使うと、STATA上でPythonを開きながらSTATAのコマンドを使えます。②STATA上でPythonを開いた後に、そのままSTATAコマンドを使う方法
stata: ~ (stata: sysuse auto とか)5, Python/Pandas→STATAの方向にデータを受け渡す方法の考察
これが本エントリーの本題です。
理想は、PythonにおけるPandasのdfでデータフレームをいじくり回して、そのdfをSTATA datasetに変換してSTATAの豊富な統計パッケージを使うことです。
簡単なやり方としては、別々にPythonとSTATAを開いて、Pythonで加工し終わったデータを.csvや.dtaに変換してSTATAに渡す方法があると思いますが、サンプルサイズが大きいデータから複数のサブサンプルを抜き出してファイルとして保存して、、みたいなことを繰り返すのはメモリに悪そうだし、なんとなく手間がかかるから嫌でした。
最終的に、色々調べた末に何とか解決できたので、その方法をご紹介します。また、定義した関数も例として残しておきます。
本題に入る前に、sfiというモジュールの説明から入ります。sfiというモジュール
↓これが公式の説明です。
特に新しくインストールする必要はないみたいで、初期の状態でも入っているよう(?)です。
このモジュールを挟むことによって、PythonでSTATA datasetを弄ることができるみたいです。
ただ、僕にはちょっとわかりづらかったので、Pandasでdfを完成させて、完成したdfをSTATA datasetに変換するのがベストじゃないでしょうか。
その場合でも、sfiが使えるようです。他の方が公開した方法を参考にして、「PandasのdfをSTATA datasetとして認識さえる」関数を定義しました。「PandasのdfをSTATA datasetとして認識さえる」関数
↑このSTATA公式Q&Aにおける回答者の方のコードを参考にして、以下の関数を定義してみました。迷いましたが、forループ内部は、一部改変したものの、原文のままコピペで使わせて頂きました。
ついでに、この質問者さんが例として作ったdfを使った実行結果のテスト方法も示しました。※以下、STATAのdoファイルを使って直接実行することを想定しています。
clear all python #モジュールのインポート import numpy as np import pandas as pd from sfi import Data, SFIToolkit # Python pandasのdfからSTATA datasetにデータを渡す関数 def datapass(): Data.setObsTotal(len(df)) # get the column names colnames = df.columns for i in range(len(colnames)): dtype = df.dtypes[i].name # make a valid Stata variable name varname = SFIToolkit.makeVarName(colnames[i]) varval = df[colnames[i]].values.tolist() if "int" in dtype: Data.addVarInt(varname) Data.store(varname, None, varval) elif "float" in dtype: Data.addVarDouble(varname) Data.store(varname, None, varval) elif dtype == "bool": Data.addVarByte(varname) Data.store(varname, None, varval) else: # all other types store as a string Data.addVarStr(varname, 1) s = [str(i) for i in varval] Data.store(varname, None, s) # 関数datapassの定義終わり # 適当なdfでテストしてみる data = {'school': ['UCSC', 'UCLA', 'UCD', 'UCSB', 'UCI', 'UCSF'],'year': [2000, 2001, 2002, 2001, 2002, 2003], 'num': [4000, 3987, 5000, 4321, 5000, 8200]} df = pd.DataFrame(data) datapass() # 関数datapassを使用 # Pythonを呼び出しながらSTATAの機能を使うための構文? stata: summarize end使い方
まず、STATA上でPythonを呼び出して、その中でpandas dfの処理を全て完結させてください。
上記コードの上部に別のコードをくっつければいいと思います。
その際、STATA datasetに読み込ませたいdfの変数名は「df」で固定してください。
pandasを用いたデータの加工が終わったら、上記のコードを実行して、datapass()を入力してください。すると、今まで作っていたpandas dfがSTATA datasetとして読み込まれます。
そのあとは、pythonを閉じてGUIを使うなり、そのまま「stata: 」で回帰式などを推定するなり、ご自由に分析してください。注意点
①データのdtypeはint, float, bool, objectだけ使うように。uintなどを使いたい場合は、forループ内部を少し変えてください。
②stata: summarizeは記述統計のSTATAコマンドです。「stata: 」を使わないと、pythonを呼び出してるときにSTATAコマンドは使えないので注意。
③dfの変数名は「df」を使ってください。その他の名前を使う場合は、このコードを弄る必要があります。
④doファイルを実行するときは、コピペしてコマンドに直接入力しないように。doファイル内で実行ボタンを押してください。コピペしてコマンドに直接入力すると、for ループ内部に謎のエラーが出ます。6, おわりに
以上の方法は、たった今自分でやりながらまとめた方法なので、間違っているところがあったらご指摘ください。
宜しくお願いいたします。
- 投稿日:2021-03-02T14:50:29+09:00
Pythonファイル操作覚え書き
- 投稿日:2021-03-02T14:49:18+09:00
ROSの勉強 第18弾:rviz
#プログラミング ROS< rviz >
はじめに
1つの参考書に沿って,ROS(Robot Operating System)を難なく扱えるようになることが目的である.その第18弾として,rvizを扱う.
環境
仮想環境
ソフト VMware Workstation 15 実装RAM 2 GB OS Ubuntu 64 ビット isoファイル ubuntu-mate-20.04.1-desktop-amd64.iso コンピュータ
デバイス MSI プロセッサ Intel(R) Core(TM) i5-7300HQ CPU @ 2.50GHz 2.50GHz 実装RAM 8.00 GB (7.89 GB 使用可能) OS Windows (Windows 10 Home, バージョン:1909) ROS
Distribution noetic プログラミング言語 Python 3.8.5 シミュレーション gazebo rviz (ROS visualization)
ロボットやセンサ,アルゴリズム向けの汎用の3次元可視化環境のこと.どのロボットにも使うことができ,特定のアプリケーションに対してすぐに設定できる.
設定の流れ
ここでは,rviz上でロボットモデルの表示・カメラ・深度カメラをできることを目標に,設定の流れを学ぶ.まず,ここで必要なものをコマンドラインから呼び出す.以下に必要なものを示す.
なお,後でやりやすいように,gazebo上でロボットの位置を次の図のようにした.
ここから,rviz上での作業に取り掛かる.
まず,起動したときの状態を次に示す.
このままでは,基準となるのがよくわからないmapとなる.そこで,ロボットの部分を指すodomを基準にする.
変更後は次のとおりである.
先ほど,赤で示されていたエラー部分が消えている.次に,ロボットをrviz上で表示させる.
RobotModel追加後は次のとおりである.
gazebo上にあったロボットが表示された.次に,ロボットのカメラ画像を表示させる.
Image追加後は次のとおりである.
画像を表示させるウィンドウが表示されたが,画像はまだ反映されていない.カメラの画像データを配信しているトピックを指定していないからである.続いて,RGB画像データを配信しているトピックを指定して,画像データを反映させる.
トピックを指定後は次のとおりである.
この画像表示ウィンドウは移動可能で,次のように調整可能である.
画像だけでは,操作が難しい.そこで,深度カメラによる点群データもrvizに反映させる.
PointCloud2追加後は次のとおりである.
点群データはまだ反映されていない.画像表示のときと同様,カメラの画像データを配信しているトピックを指定していないからである.続いて,点群データを配信しているトピックを指定して,点群データを反映させる.
トピックを指定後は次のとおりである.
また,rviz上で見る方向を変えることで,次に示すように俯瞰視しながら,カメラを利用するということもできる.
設定の流れとしては,以上である.
これで,俯瞰視しながら,カメラを利用するオペレータインタフェースの設定ができた.失敗したこと
1日2日分からず,作業が止まってしまっていた.その原因が分かり,解決したため,ここに示しておく.
問題
まず,問題を示す.
RobotModelを追加し,ロボットを表示させようとすると,ロボットは白く表示され,右の部分でも赤でエラーが示されている.ここで共通するエラーはNo transform from [~] to [odom]というものである.原因
エラー部分を見る限り,座標変換ができていなかったというのが原因だったようだ.gazebo上でのロボットがrviz上での座標へ適切に変換されず,よくわからない状態で表示されてしまっているということだ.このとき,実行したのは,
roscore・roslaunch turtlebot3_gazebo turtlebot3_house.launch・rviz rvizであった.これでは,座標変換するものが含まれていないようだ.解決
座標変換されていないのが原因であったため,座標変換するものを用意すればよい.
(https://answers.ros.org/question/263140/no-transform-from-base_link-to-odom/ )を参考にしたところ,robot_state_publisherというノードが必要だということをヒントにコマンドラインで調べてみたところ,rosrun robot_state_publisher robot_state_publisherというものがあった.そこで,これを実行してみたところ,うまくいった.感想
今回は,rvizについて基本的なことを学んだ.エラーが出て,作業が止まったときには少し焦ったが解決できてよかった.これで,次回からの地図作成に関する学習も無事継続してできそうだ.
参考文献
プログラミングROS Pythonによるロボットアプリケーション開発
Morgan Quigley, Brian Gerkey, William D.Smart 著
河田 卓志 監訳
松田 晃一,福地 正樹,由谷 哲夫 訳
オイラリー・ジャパン 発行
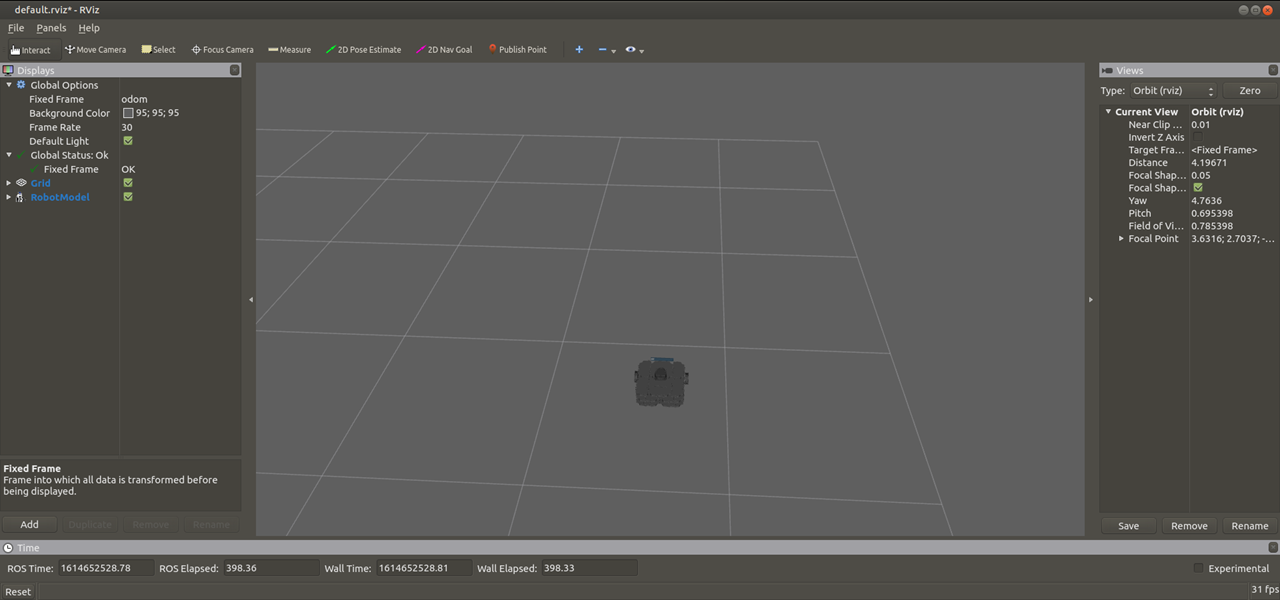
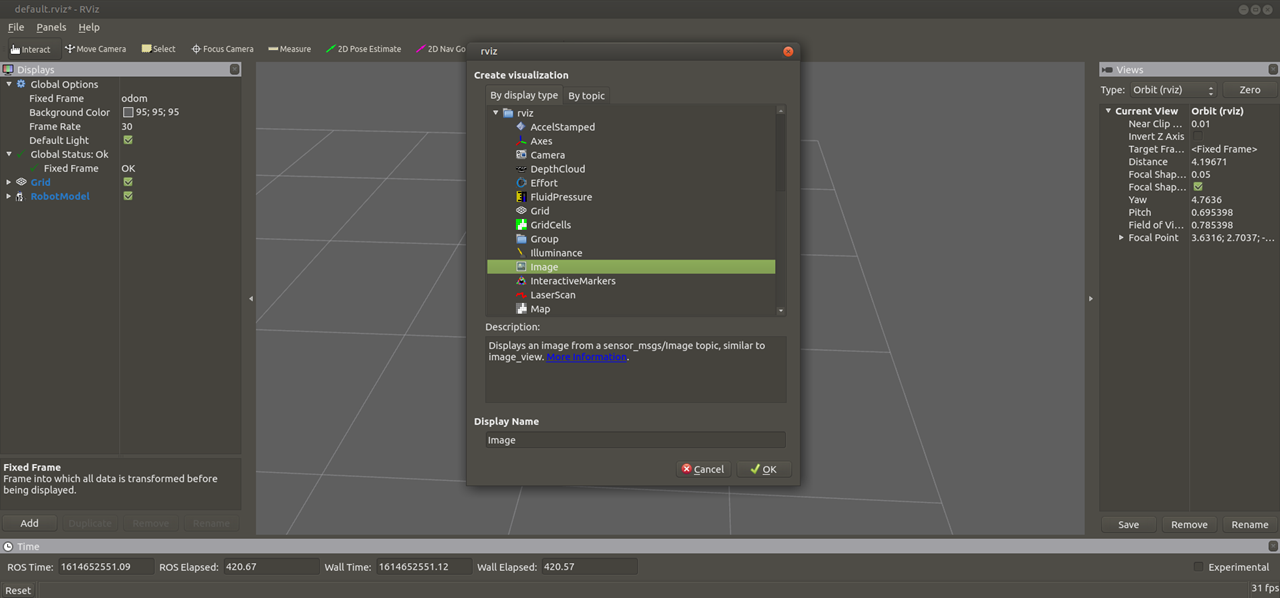
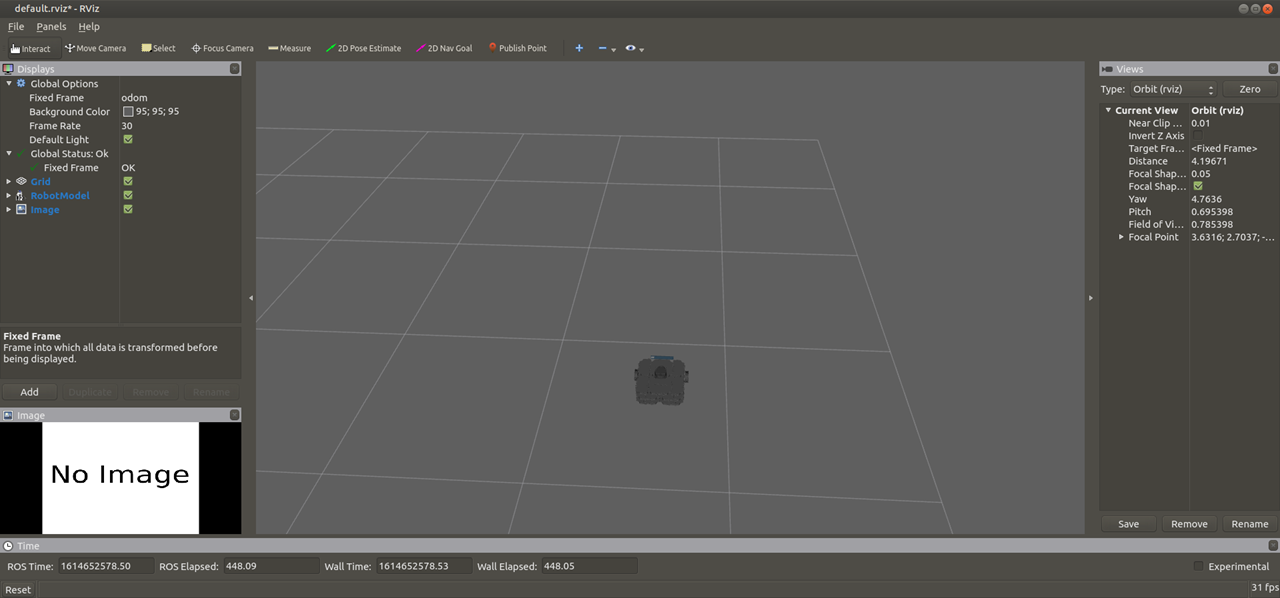
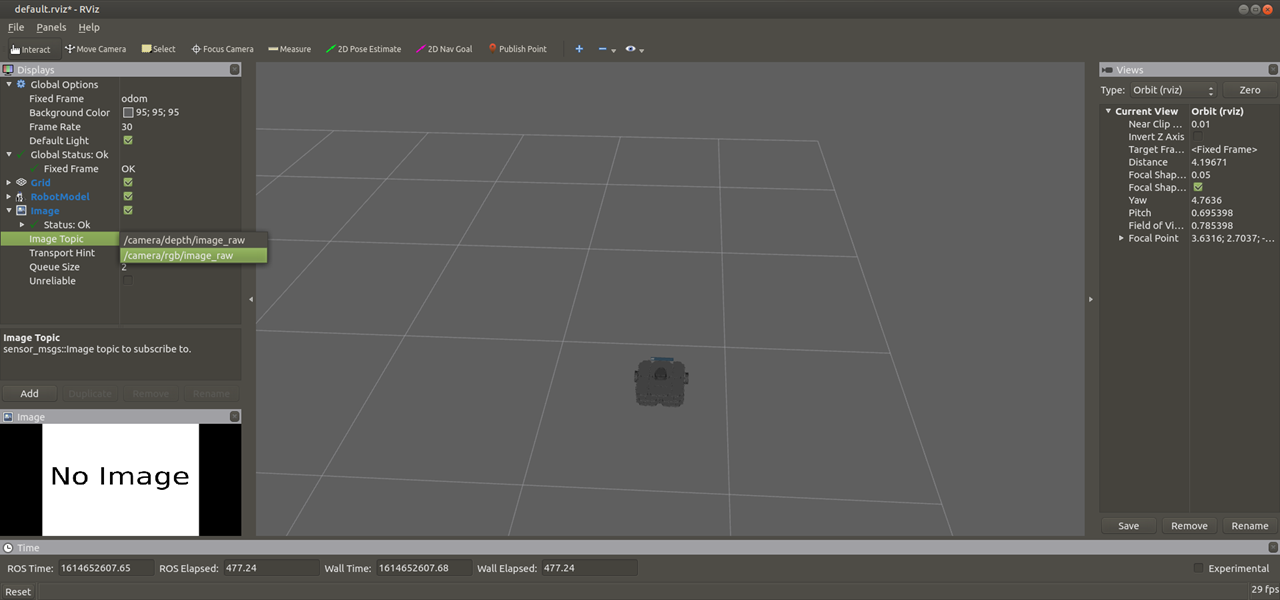
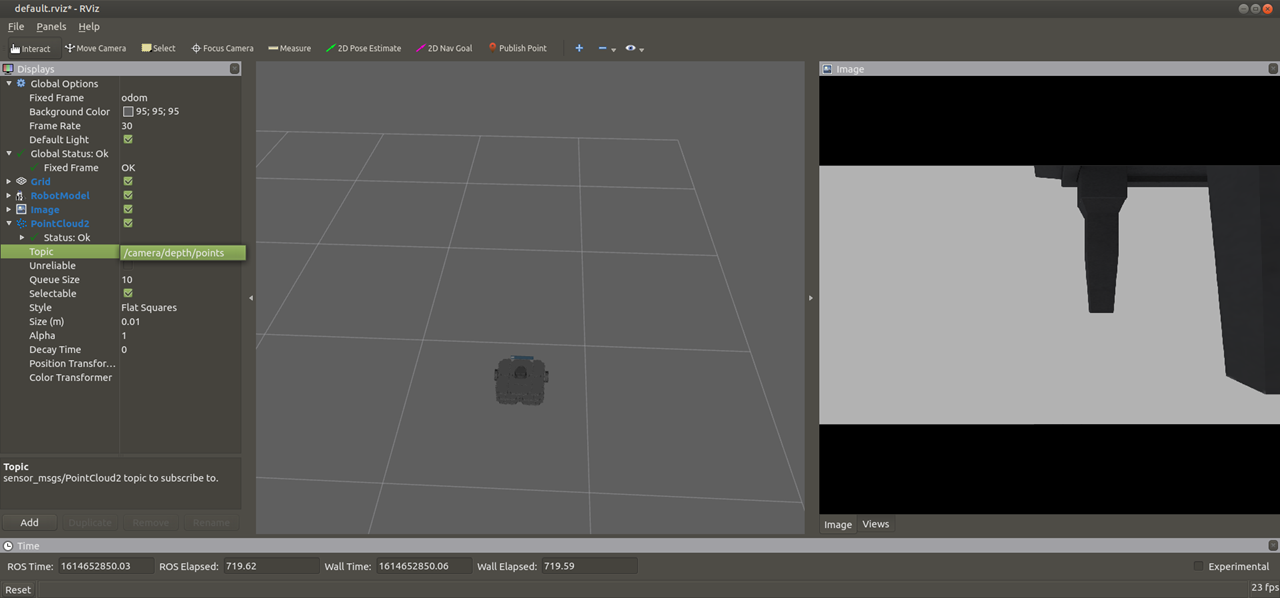
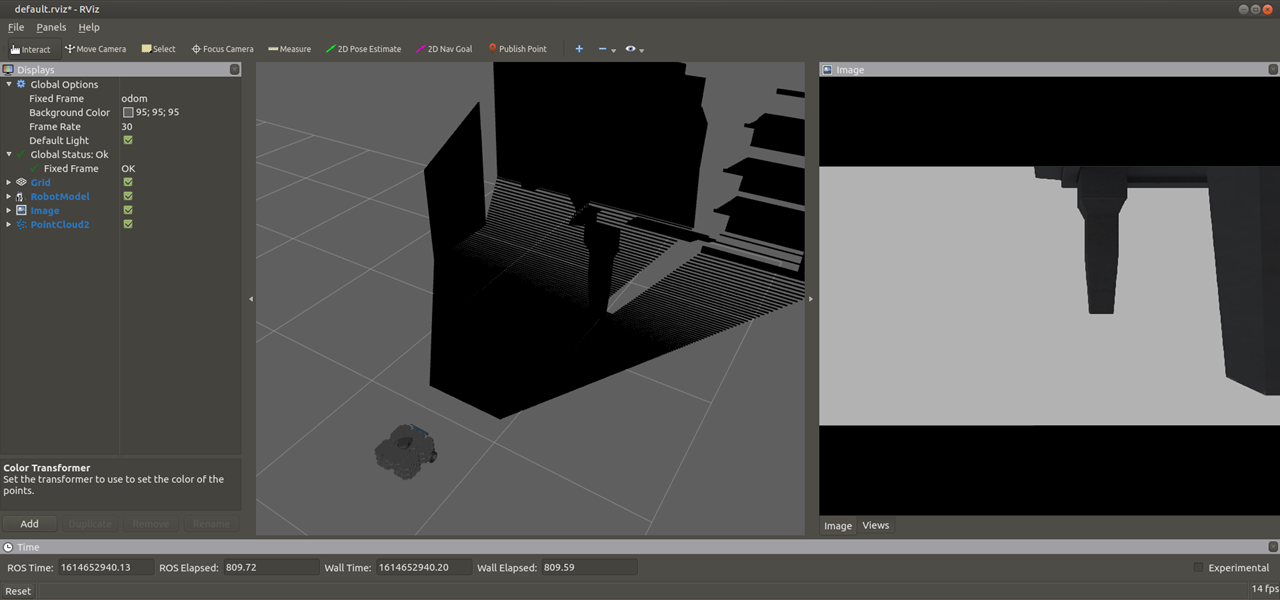
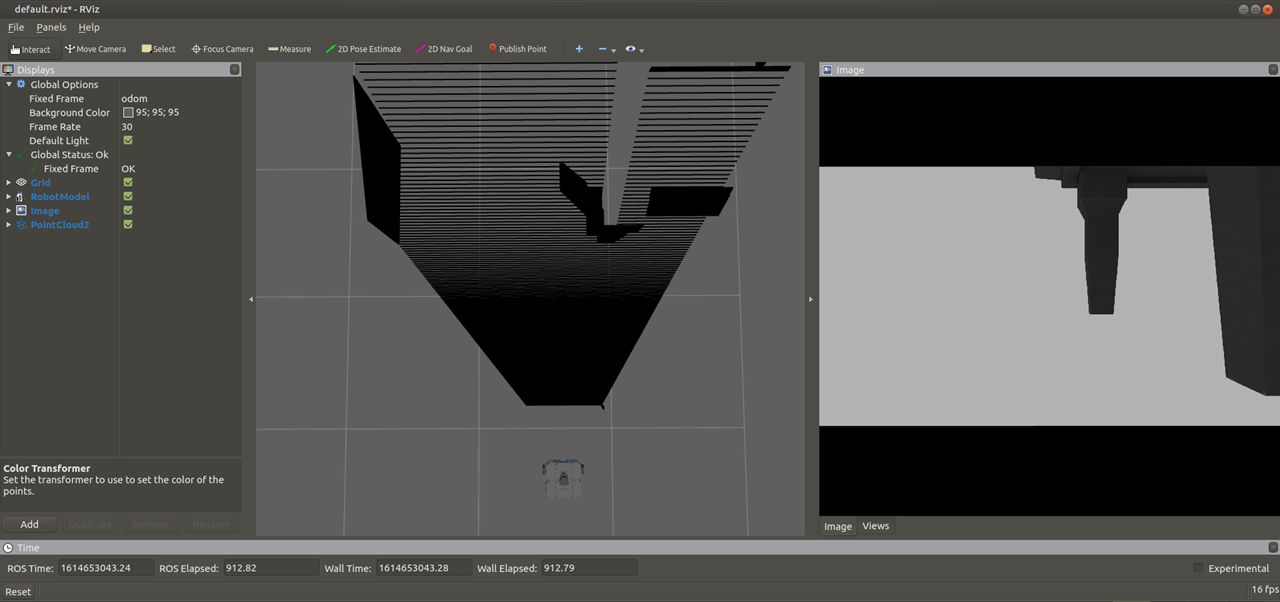
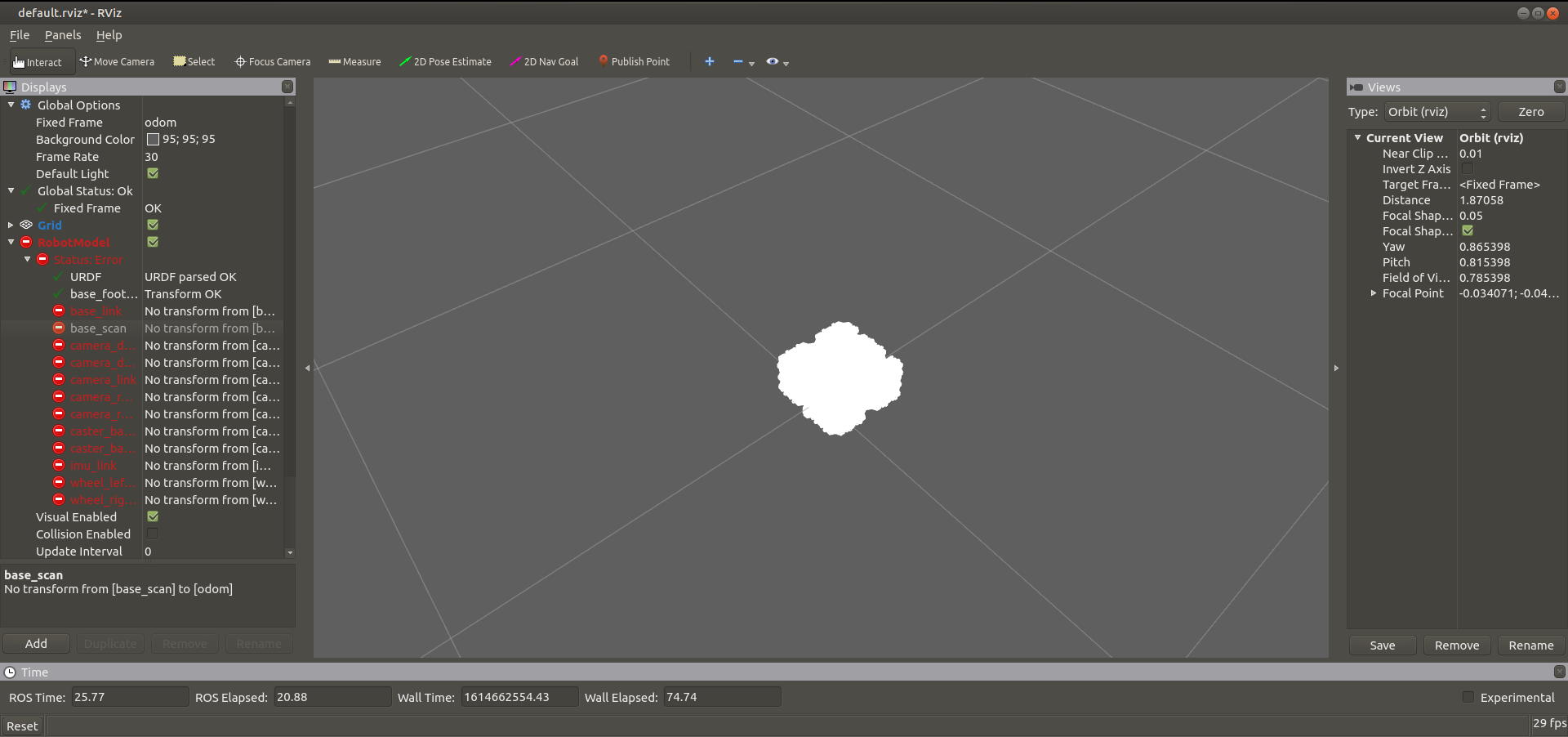
- 投稿日:2021-03-02T14:46:40+09:00
Raspberry Pi Multi-Camera Adapter Module V2.2を使用し、カメラを制御する方法
サークルでロボットに着けるカメラをAruducam製、Raspberry Pi Multi-Camera Adapter Module V2.2で制御しようと思い購入しました。付属している説明書が正しくなかったり(AruducamのGitHubに行くと正しいセットアップやサンプルコードが手に入りました)、ネットにもあまり使い方について書いているページを見かけなかったりして使うのにかなり苦労したため、備忘録として残したいと思います。また、プログラミングや電装は独学で学んだため、かなり怪しいところがあります。あくまで参考程度にしてください。
使用したもの
Raspberry Pi 4B(以下 Raspberry Pi)
Aruducam製、Raspberry Pi Multi-Camera Adapter Module V2.2(以下 カメラモジュール)
Raspberry Pi Camera V2 4個(以下 ラズパイカメラ)初めに
Raspberry Piの設定からカメラとI2Cの設定を有効にしておく。
カメラモジュールにラズパイカメラを接続した後(配線の向きに注意してください)、Raspberry Piのカメラポートにカメラモジュールを接続する。
接続後、カメラモジュールのピンソケットにRaspberry Piのピンを接続する。カメラテスト
AruducamのGitHubを参考にカメラのテストを行います。初めに、カメラモジュールを動かすのに必要なものrをRaspberry Piにインストールします。ターミナルで以下の操作を行ってください。
$ sudo apt-get install wiringpi $ sudo apt-get install libopencv-devインストール後、Raspberry Pi 4Bにカメラモジュールを対応させるため以下の処理を行います。
$ cd /tmp $ wget https://project-downloads.drogon.net/wiringpi-latest.deb $ sudo dpkg -i wiringpi-latest.debAruducamのGitHubからサンプルコードをダウンロードし、カメラテストをします。
$ git clone https://github.com/ArduCAM/RaspberryPi.git $ cd RaspberryPi/Multi_Camera_Adapter/Multi_Adapter_Board_4Channel/Multi_Camera_Adapter_V2.2_python/ $ sudo chmod +x init_camera.sh $ sudo ./init_camera.sGitHubではC++でカメラテストしていますが、私はpythonでカメラテストをしました。
Multi_Camera_Adapter_V2.2_pythonファイルは、print文の"( )"が抜けているのでエラーが入ると思います。(2021/03/02現在)ファイルを開いてすべてのprint文に"( )"を入れてあげてください。
5秒間隔でカメラモジュールに接続されたカメラが順番に起動し、写真を取れたら成功です。応用する
pythonのサンプルコードではプログラムから、ターミナルに"i2cset"と"raspistill"を入力し写真を撮っていることが分かりました。私は、最終的にロボットカメラで得た映像をリアルタイムで操縦者に提供することをしたいので、ターミナルのコマンドから映像を得る方法では少し不便だなと感じました。そこで、"pigpio"、"picamera"、"opencv"のライブラリを使用し、キーボートのアクセスでカメラを順番に切り替えるプログラムを作成しました。
import pigpio import cv2 import picamera import picamera.array pi = pigpio.pi() pi.set_mode(4,pigpio.OUTPUT) pi.set_mode(17,pigpio.OUTPUT) pi.set_mode(18,pigpio.OUTPUT) pi.set_mode(22,pigpio.OUTPUT) pi.set_mode(23,pigpio.OUTPUT) pi.set_mode(9,pigpio.OUTPUT) pi.set_mode(25,pigpio.OUTPUT) pi.write(17,1) pi.write(18,1) pi.write(22,1) pi.write(23,1) pi.write(9,1) pi.write(25,1) width=400 high=260 def camera(): with picamera.PiCamera(0) as camera: with picamera.array.PiRGBArray(camera) as stream: camera.resolution = (width,high) while True: camera.capture(stream,'bgr',use_video_port=True) cv2.imshow('frame',stream.array) if cv2.waitKey(1)&0xFF==ord('q'): cv2.destroyAllWindows() break stream.seek(0) stream.truncate(0) def main(): print("Start test the camera A") h=pi.i2c_open(1,0x70) pi.i2c_write_byte_data(h,0x00,0x04) pi.write(4,0) pi.write(17,0) pi.write(18,1) camera() print("Start test the camera B") pi.i2c_write_byte_data(h,0x00,0x05) pi.write(4,1) pi.write(17,0) pi.write(18,1) camera() print("Start test the camera C") pi.i2c_write_byte_data(h,0x00,0x06) pi.write(4,0) pi.write(17,1) pi.write(18,0) camera() print("Start test the camera D") pi.i2c_write_byte_data(h,0x00,0x07) pi.write(4,1) pi.write(17,1) pi.write(18,0) camera() if __name__ =="__main__": main() gp.write(4,0) gp.write(17,0) gp.write(18,1)せっかく、opencvを使用しているのでカメラ映像を"cv2.VideoCapture(0)"で読み込みたかったのですが、なぜか"cv2.VideoCapture(0)"ではカメラを一つしか認識しませんでした。そのため、"picamera"のライブラリを使用しています。また、サンプルプログラムでは、"RPi.GPIO"のライブラリでGPIOを制御していますが、私は "RPi.GPIO"ライブラリがうまく扱えないので、"pigpio"で制御しています。そのため、サンプルプログラムとピンの番号が違っていますが、やっていることは同じです。
要は、I2C通信でカメラモジュールのアドレス0x07(サンプルも、私も同じアドレスでした)にアクセスし、register(サンプルも、私も0x00でした)に各カメラの[vlue](カメラAなら0x04)を書き込んであげて、各カメラに対応するgpioピンをアクティブにしてあげれば動くと思います。
- 投稿日:2021-03-02T14:28:26+09:00
At Coder ABC 192 コンテストを受けてD問題で解けなかった話
AtCoder で Rating 緑 を Python3 で目指している現在灰色です。
192 では A ~ C 問題までは解けたのですが、D問題につまづいてしまい
解答することができなかったのでどうすればよかったかを纏めますどこで解けなかったか
1回目の解答
計算量を無視して一先ず解答が合うコードを書いた結果TLEを起こした
2回目以降の解答
Python での int 型で n進数を指定してしてみたが、36進数以下までしか対応していないことに気がつかなかった
int(“100”, 37)やるとエラーを起こす
対策
計算量がわからなかった場合
AtCoderでの解説動画で最初に計算量を算出してから、
コードを書くようにする、もし計算量がなんとなくでもわからない場合は
その問題を飛ばして次の問題を確認するABC 192 では E 問題のほうが難易度が低いこともあるので
計算量がなんとなくでもいいから算出できそうな問題を解くようにする
n進数変換でエラーを出していた
Int型 の第2パラメータに数値を入れるとその進数になるのだが、 上限があり 36進数までだったことに気がつかなかった
焦らずちゃんとドキュメントを読み、出来ること出来ないことを確認する
2分探索の過去問を解く
過去問より、どんなケースだと2分探索が必要になるのか解説しているページから、解説をみずに時間(2時間以内)をかけてもいいので解けるまで挑戦する。
時間内に解けなかったら解説を見て、他の2分探索の過去問に挑戦する
まとめ
何故解説動画では、最初に計算量を算出するのかの理由がわかり 前よりかは解けている気がしています(まだまだ足りませんが)
コンテスト中2度ぐらい解答に失敗するとものすごく焦ってしまい思考が停止してしまうので、
ブレイクできる何かがほしいと最近思っています。今の目標は 3月中に Rating 緑 を取りたいので
高校数学の勉強と過去問を解くのに時間をあてています
- 投稿日:2021-03-02T14:17:28+09:00
RaspberryPiで作業画像を定期的にTweetする
はじめに
ラズパイで撮影した画像をTwitterに自動投稿するbotを作成したので、その手順を書き記したものです。
OSのインストールから完成まで、なるべく細かく手順を記載しました。
開発の参考になれば幸いです。こんなひとに向けて書いています
- RaspberryPiを初めて触る人
- TwitterAPIを初めて触る人
経緯
在宅勤務になって、死ぬほど作業効率が超落ちました。
そう、私は「誰かに見られていないとサボってしまう意志の弱い人間」なのです。作業風景を自動投稿して全世界に公開したら、そんなゴミクズでもPCの前でスマホを触らなくなるだろうし、
毎日スウェットではなく人に会えるような格好で仕事をするだろうと考え、当botを作成しました。使ったもの
- Raspberry Pi Zero WH (RASPIZWHSC0065)
- Piカメラ Official V2 for 3/2/1/0 (913-2664)
- Raspberry Pi Zero W公式シェル新品、RPI zero ABSカバーシェルシェル(通常、GPIOおよびカメラ用)、2 15 cmカメラFFCフレキシブルケーブル付き
- MacBookPro 2012Mid
- microSD
1. RaspberryPiにOSをインストールする
https://www.raspberrypi.org/software/
上記のページからRaspberry Pi Imagerをインストールしましょう。
書き込みを行いたいSDカードをセットして、「WRITE」をクリックすればあとは勝手に書き込んでくれます。2. ラズパイを無線LANに接続する
そのまま、macbookでSDカードにsshファイルと、wpa_supplicant.confを追加します。
2-1. sshファイルの追加
touch /Volumes/boot/ssh2-2. wpa_supplicant.confファイルの追加
vi /Volumes/boot/wpa_supplicant.confwpa_supplicant.confctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev country=JP update_config=1 network={ ssid="wifiのSSIDを書くところ" psk="wifiのパスワードを書くところ" }※ ssidと、pskは環境によって書き換えてください。
2-3. 接続テストを行う
ラズパイにSDカードをセット後、電源をつないで暫く待つ。
※ デーモンの起動とか色々あるからそのあとMacからpingで疎通確認をしてみる。
$ping raspberrypi.local PING raspberrypi.local (XXX.XXX.XXX.XXX): 56 data bytes 64 bytes from XXX.XXX.XXX.XXX: icmp_seq=0 ttl=64 time=6.344 ms```OKっぽいのでssh接続する
ssh pi@raspberrypi.local※ 初期パスワードは「raspberry」です。
3. Twitterのアプリ作成
3-1. Twitter developerの認証
Twitter Developersページにアクセスして、アプリの作成を行います。
3-1-1. 申請を開始する
「Create an app」をクリックします。
「appを作るのにはdevelopper accountとして認証される必要があるよ〜」 的なことを言っているのでApplyをクリック3-1-2. アプリの作成理由を説明する
「お前はなんのためにTwitter使うねん」的なことを聞かれているので、画像の順番でクリック&クリック3-1-4. メールアドレス認証を行う
※ 本垢がある場合は画像のようにエイリアスを使うと便利です3-1-5. 質問事項に答える
質問事項に答えて、Nextをクリック3-1-6. アプリを作成する理由を英語で説明する
英語が苦手な方は、Google翻訳で日本語文章を打ち込めばいいと思います。
※ アプリ作成時にも英作文があるので、文章残しておくとよいです。
私が作成した文章は下記に記載するので参考程度にどうぞ(コピペで認証通るのかどうかはわからない)
Since September of last year, my work has been working from home.
No one monitors, unlike when I was working in the office.
I'm a weak-willed person, so I skip it.I want someone to monitor me by automatically posting the work status on the Raspberry Pi.
Someone watching me3-1-7. 用途を入力する
今回の場合はすべてOFFで大丈夫です。3-1-8. 規約に同意する
チェック入れて、「Submit application」をクリックします。
これで申請は完了です。承認をもらえたらメールが届くので気長にまちましょう。3-2. アプリ作成
申請が通ったら、いよいよTwitterAPIアプリを作成していきます。
3-2-1. 届いたメールの「Confirm your email」をクリックします
3-2-2. コンソール画面の「create project」をクリックします
3-2-3. 必要事項を記入する
私の設定を公開するので参考にしてください
※ 前手順で作成した英文をそのまま貼り付ければ良いです
※ App nameは重複が許されないみたいなので、適当に書き換えてください
完了後、上記の画面が表示されます。
アプリ作成に必要な情報が表示されるので、しっかりと控えておきましょう
こちらの情報は再作成するので、控えなくても大丈夫です3−3. token情報を取得する
3-3-1. 権限の変更を行う
Appが作成できたら左のパネルに「App名」の項目が出現するので、「App名」 > 「Edit」の順にクリックして
権限変更画面に移動します。
作成するAppでは書き込みも行うので、「Read and Write」を選択して、「Save」をクリックします
3-3-2. token情報の生成と取得
「Keys and tokens」タブを選択したあと、
「API key & secret」 と 「Access token & secret」のRegenerateをクリックして、token情報を作成します。
※ 作成したtoken情報はアプリに設定する必要があるので控えておいてください
自動投稿スクリプトを作成する
GitHubでリポジトリを公開しているので、cloneしてください。
git clone https://github.com/nekonisi/monitor_me.gitそのあと、const.py.exampleをコピーしてconst.pyを作成、
値を前手順で取得した情報に書き換えてくださいcd monitor_me/ cp const.py.example const.py vim const.pyconst.py#!/usr/bin/env python #coding: UTF-8 #設定値の定数化 CONSUMER_KEY = "YOUR_CONSUMER_KEY" CONSUMER_SECRET = "YOUR_CONSUMER_SECRET" ACCESS_TOKEN = "YOUR_ACCESS_TOKEN" ACCESS_SECRET = "YOUR_ACCESS_SECRET"下記コマンドで動作確認をしましょう
python monitor_me.py問題なければ、カメラで撮影された画像がtweetされているはずです。
crontabの登録
定期的に画像投稿をするためにcrontabを登録しましょう。
crontab -e*/1 10,11,13-18 * * 1-5 python /home/pi/monitor_me/monitor_me.py上記のように登録しておけば月〜金の10~19時(12時台はなし)で1分毎に投稿されます。
おわりに
スクリプト作成するのよりも記事を書く方が大変でした。
たくさん記事を書いてくれる人達はすごい。感謝します。
完全に途中で息切れしているので、少しずつ修正します。
作業風景はコチラで投稿しています。
サボってたら怒ってください。参考サイト

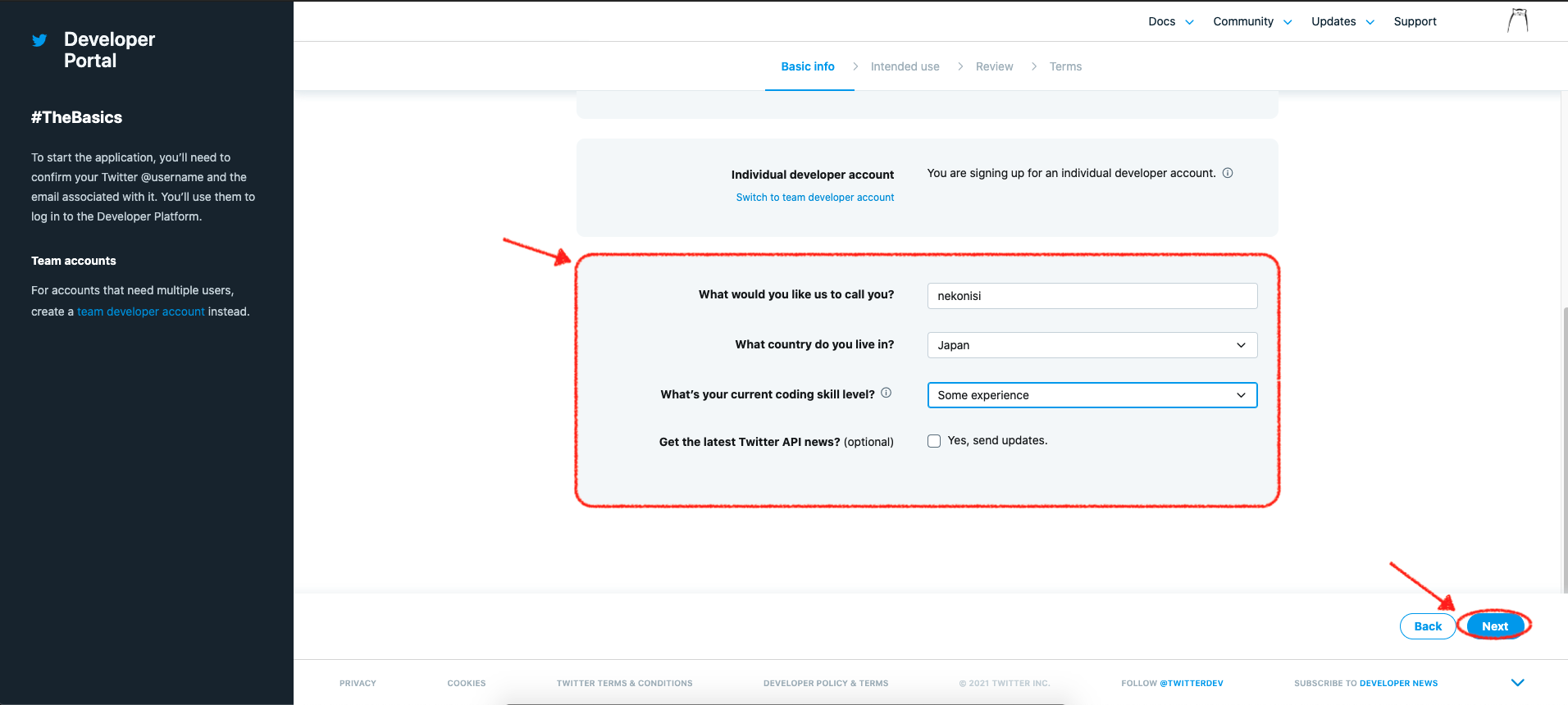


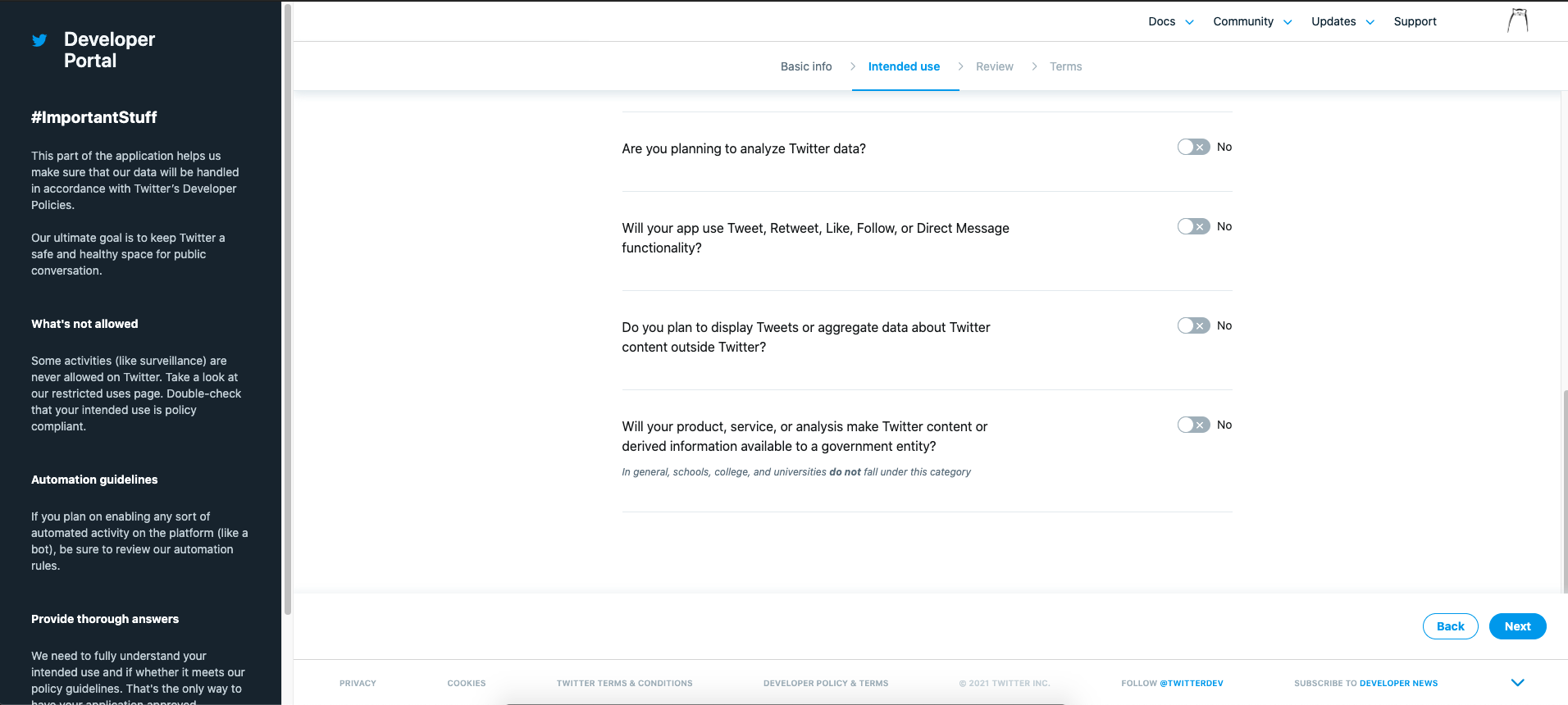
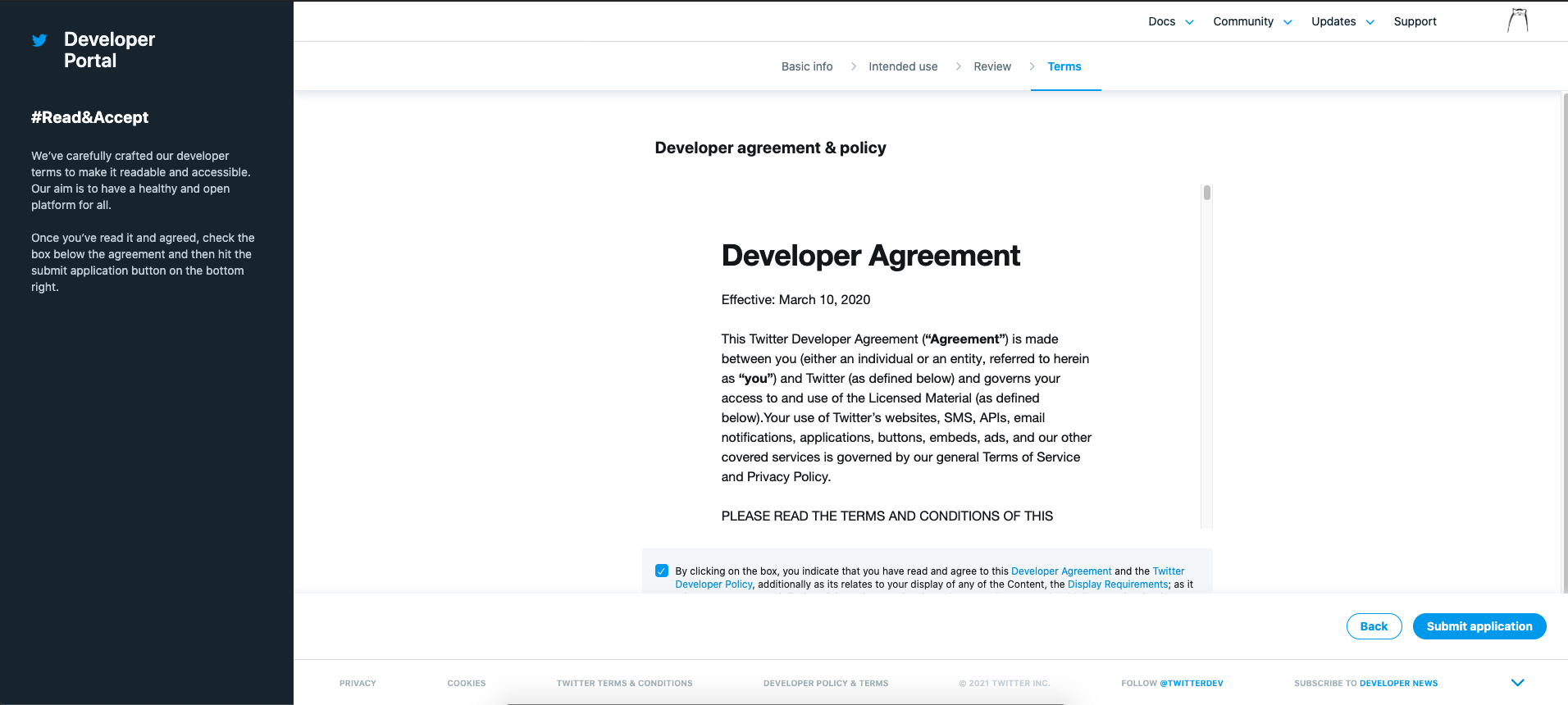
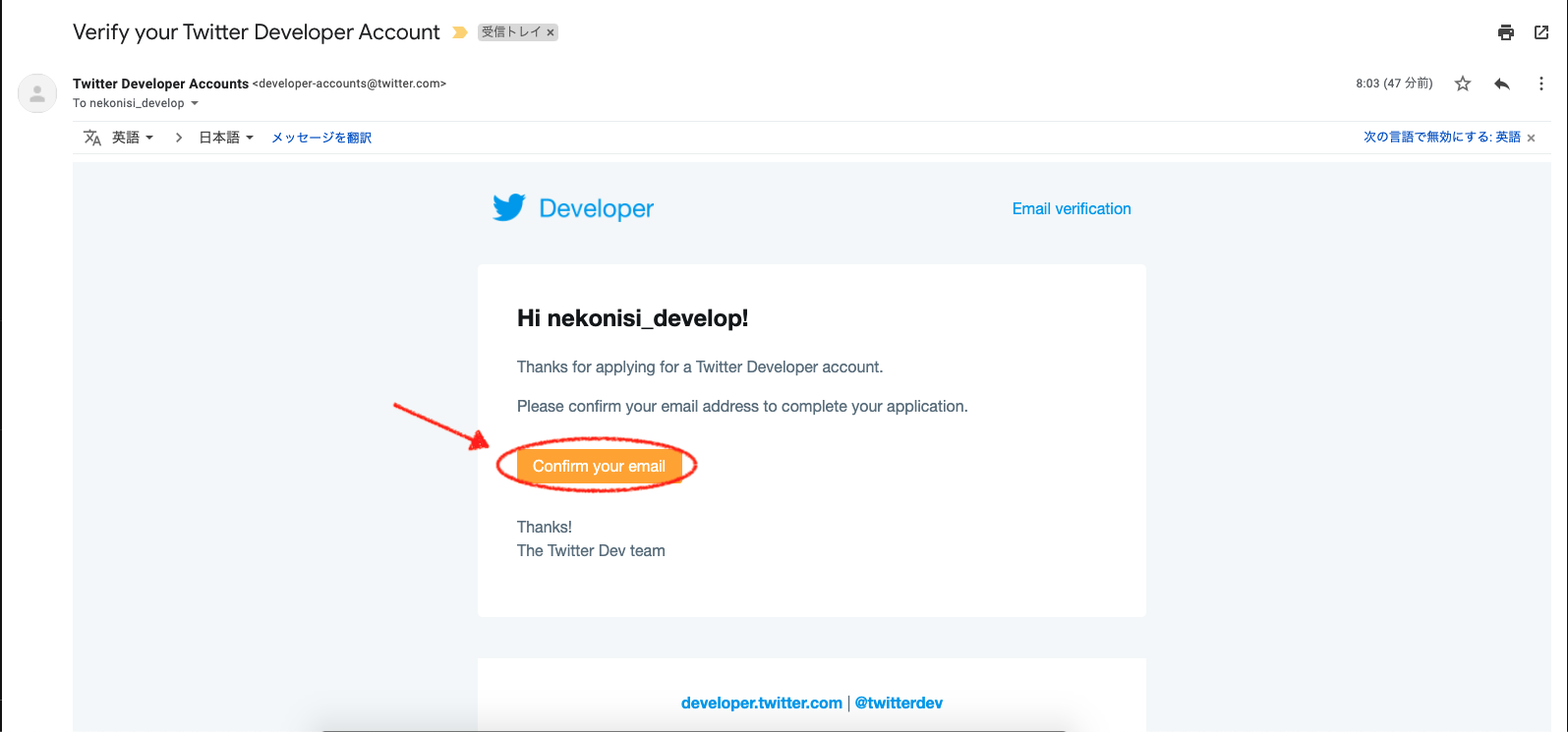
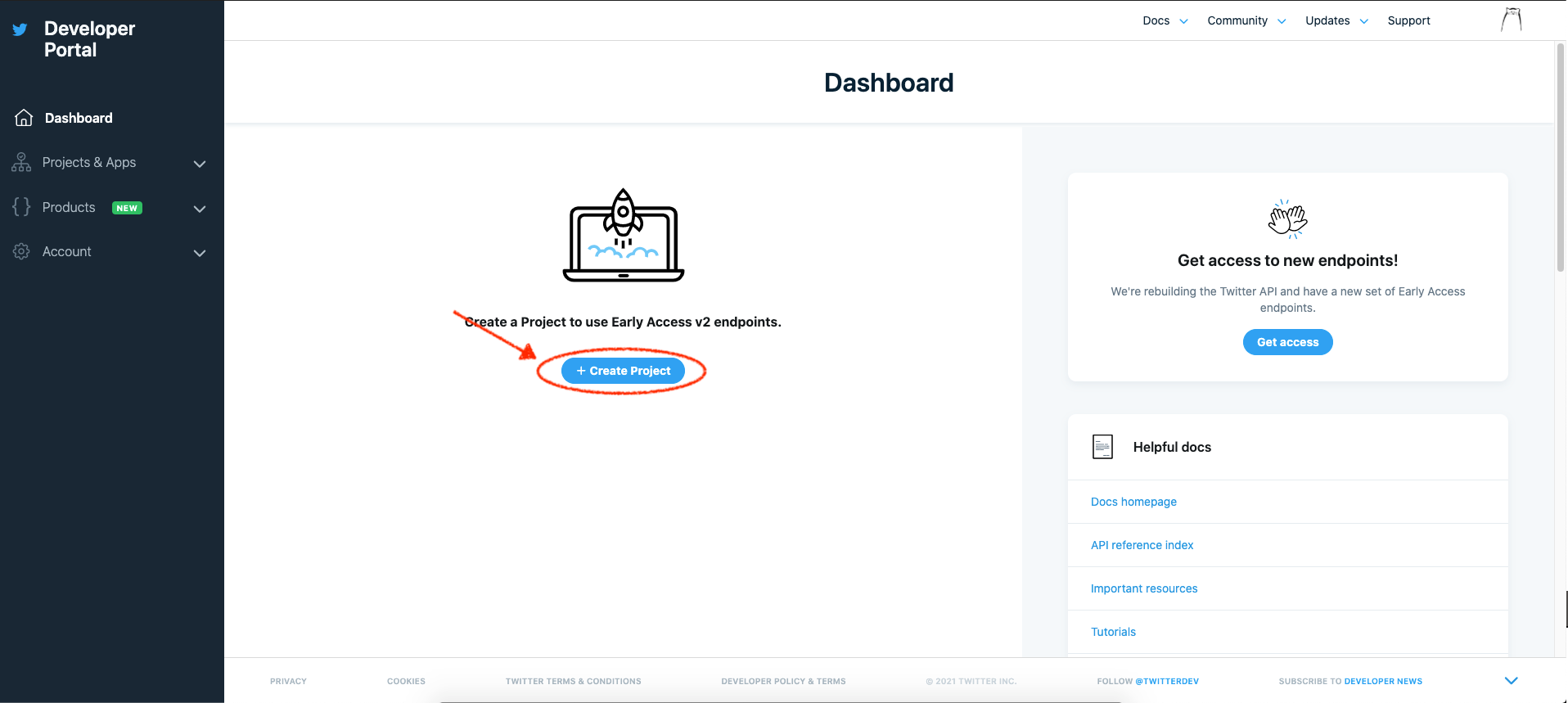

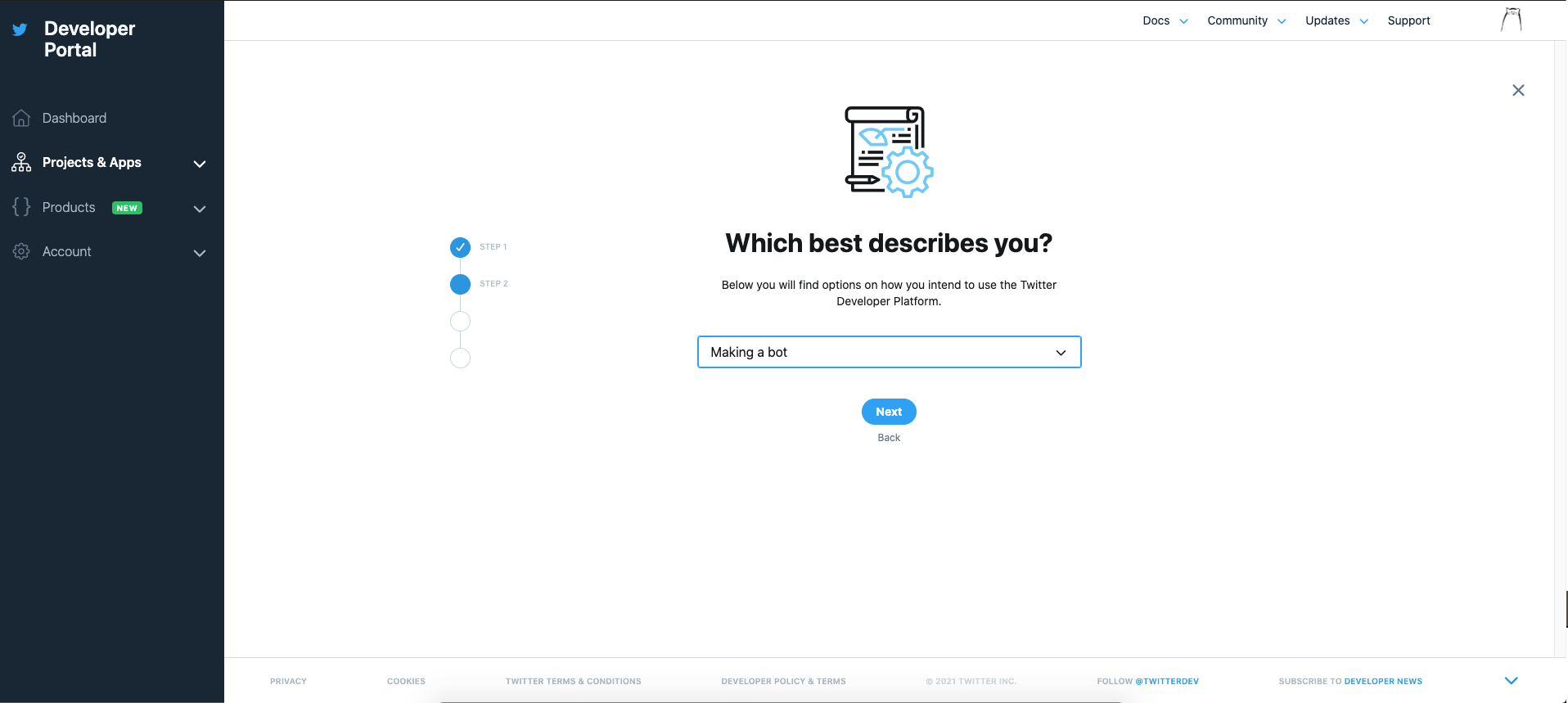
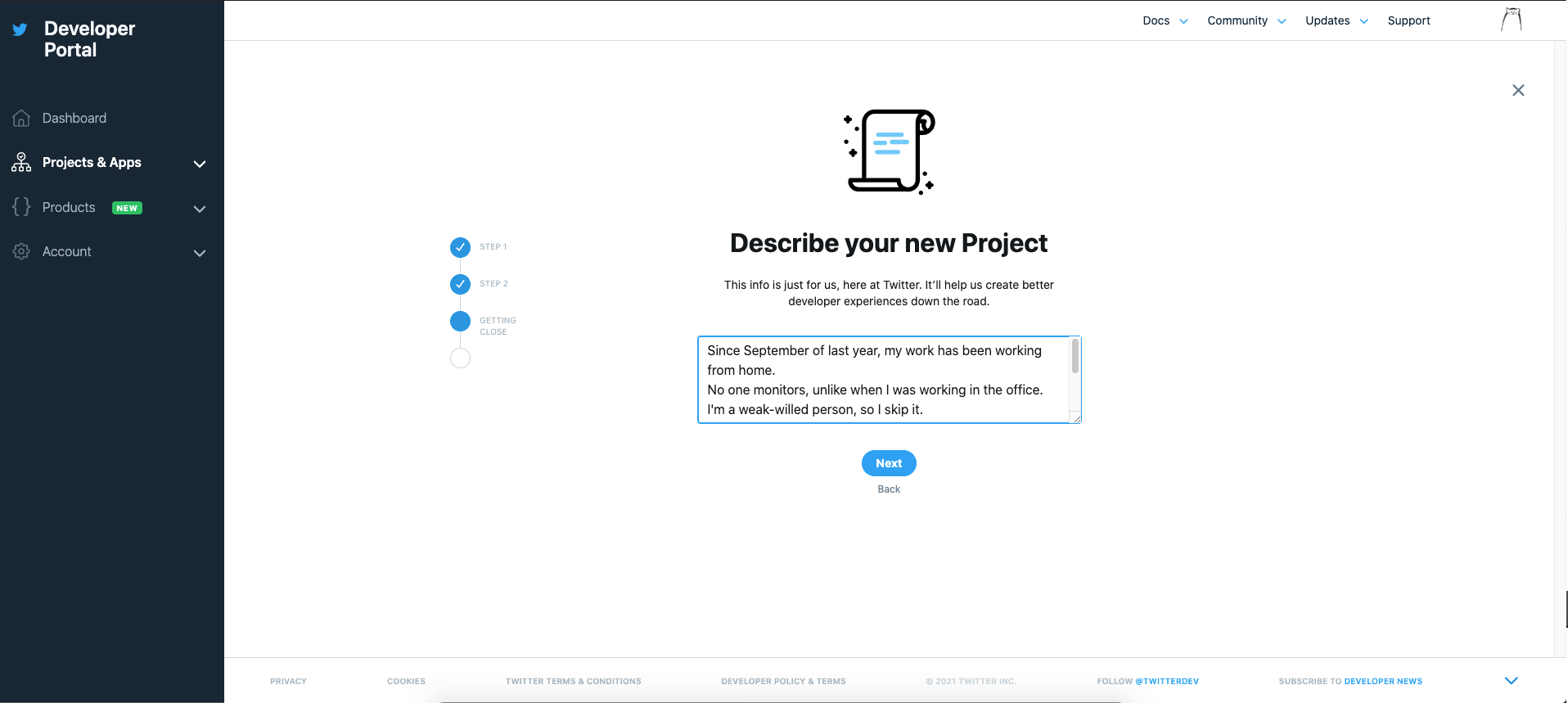
- 投稿日:2021-03-02T14:17:28+09:00
リモートワークでサボらないように作業風景投稿botを作ってみた
はじめに
ラズパイで撮影した画像をTwitterに自動投稿するbotを作成したので、その手順を書き記したものです。
終わってから書いたから、抜けてる部分あるかも。経緯
在宅勤務になって、死ぬほど作業効率が超落ちました。
そう、私は「誰かに見られていないとサボってしまう意志の弱い人間」なのです。作業風景を自動投稿して全世界に公開したら、そんなゴミクズでもPCの前でスマホを触らなくなるだろうし、
毎日スウェットではなく人に会えるような格好で仕事をするだろうと考え、当botを作成しました。使ったもの
- Raspberry Pi Zero WH (RASPIZWHSC0065)
- Piカメラ Official V2 for 3/2/1/0 (913-2664)
- Raspberry Pi Zero W公式シェル新品、RPI zero ABSカバーシェルシェル(通常、GPIOおよびカメラ用)、2 15 cmカメラFFCフレキシブルケーブル付き
- MacBookPro 2012Mid
- microSD
OSインストール
https://www.raspberrypi.org/software/
上記のページからRaspberry Pi Imagerをインストールしましょう。
書き込みを行いたいSDカードをセットして、「WRITE」をクリックすればあとは勝手に書き込んでくれます。ラズパイを無線LANに接続する
そのまま、macbookでSDカードにsshファイルと、wpa_supplicant.confを追加します。
sshファイルの追加
touch /Volumes/boot/sshwpa_supplicant.confファイルの追加
vi /Volumes/boot/wpa_supplicant.confwpa_supplicant.confctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev country=JP update_config=1 network={ ssid="wifiのSSIDを書くところ" psk="wifiのパスワードを書くところ" }※ ssidと、pskは環境によって書き換えるんだよ。
sshでつないで見る
ラズパイにSDカードをセット後、電源をつないで暫く待つ。
※ デーモンの起動とか色々あるからそのあとMacからpingで疎通確認をしてみる。
$ping raspberrypi.local PING raspberrypi.local (XXX.XXX.XXX.XXX): 56 data bytes 64 bytes from XXX.XXX.XXX.XXX: icmp_seq=0 ttl=64 time=6.344 ms```OKっぽいのでssh接続する
ssh pi@raspberrypi.local初期パスワードは「raspberry」
Twitterのアプリ作成を行う
Twitter developerの認証
Twitter Developersページにアクセスして、アプリの作成を行う。
1. Create an appをクリック
2. 「appを作るのにはdevelopper accountとして認証される必要があるよ〜」 的なことを言っているのでApplyをクリック
3. 「お前はなんのためにTwitter使うねん」的なことを聞かれているので、画像の順番でクリック&クリック
4. メールアドレスの認証が必要なので認証を行う。
※ 本垢がある場合は画像のようにエイリアスを使うと便利ですよ
5. 質問事項に答えて、Nextをクリック
※ 日本人は皆、「What's your current coding skill levels?」に、「Some experience」を選ぶ気がする。
6. 多分一番大変な英作文。
Google翻訳で思いの丈をぶつけよう
- アプリ作成時にも英作文があるので、文章残しておくとよいです。
- 私が作成した文章は下記に記載するので参考程度にどうぞ(コピペで認証通るのかどうかはわからない)
Since September of last year, my work has been working from home.
No one monitors, unlike when I was working in the office.
I'm a weak-willed person, so I skip it.I want someone to monitor me by automatically posting the work status on the Raspberry Pi.
Someone watching me
7. 「なんか難しいことに使うん?」と聞かれているので「そんな難しいことしません」と答える
8. チェック入れて、「Submit application」をクリック
9. 「確認しときますわ」と言われるので、しばらく待ちましょうアプリ作成
1. そのうち、上記のようなメールが届くので「Confirm your email」をクリックする
2. コンソール画面に飛ばされるので「create project」をクリック
3. 適当に入力していきましょう
- Describe 〜 のところにはdeveloper認証のところで作成した英文をそのまま貼り付ければ良いです。
- App nameは重複が許されないみたいなので、適当に書き換えてください
4.アプリ作成に必要な情報が表示されるので、しっかりと控えておきましょう
4. こちらの情報はあとで再作成するので、控えなくても大丈夫です
以上tokenとかを取得する
1. Appが作成できたら左のパネルに「App名」の項目が出現するので、App名をクリック
2. 権限を編集するために、Add permissionsのEditをクリック
3. 作成するAppでは書き込みも行うので、「Read and Write」を選択して、「Save」をクリック
4. 「Keys and tokens」を選択
5. 「API key & secret」 と 「Access token & secret」のRegenerateをクリックして、tokenとかを作成しましょう
※ 作成した情報は控えておいてください
以上自動投稿スクリプトを作成する
GitHubでリポジトリを公開しているので、cloneしてください。
git clone https://github.com/nekonisi/monitor_me.gitそのあと、const.py.exampleをコピーしてconst.pyを作成、
値を前手順で取得した情報に書き換えてくださいcd monitor_me/ cp const.py.example const.py vim const.pyconst.py#!/usr/bin/env python #coding: UTF-8 #設定値の定数化 CONSUMER_KEY = "YOUR_CONSUMER_KEY" CONSUMER_SECRET = "YOUR_CONSUMER_SECRET" ACCESS_TOKEN = "YOUR_ACCESS_TOKEN" ACCESS_SECRET = "YOUR_ACCESS_SECRET"下記コマンドで動作確認をしましょう
python monitor_me.py問題なければ、カメラで撮影された画像がtweetされているはずです。
crontabの登録
定期的に画像投稿をするためにcrontabを登録しましょう。
crontab -e*/1 10,11,13-18 * * 1-5 python /home/pi/monitor_me/monitor_me.py上記のように登録しておけば月〜金の10~19時(12時台はなし)で1分毎に投稿されます。
おわりに
スクリプト作成するのよりも記事を書く方が大変でした。
たくさん記事を書いてくれる人達はすごい。感謝します。
完全に途中で息切れしているので、少しずつ修正します。
作業風景はコチラで投稿しています。
サボってたら怒ってください。参考サイト
- 投稿日:2021-03-02T13:56:45+09:00
複数の動画データから大量の画像を取得
はじめに
前回、YouTubeの動画を検索キーワードをもとに一括ダウンロードし、たくさんの動画を手に入れました。
今回は、この動画ファイルを大量の画像ファイルに変換していきたいと思います。
そうすることで大量の画像データセットを作成することができると考えたからです。ディレクトリ構成
ディレクトリ構成を示します。
DataImagesフォルダは今回作成するのですでにある必要はないです。
動画ファイルの拡張子はmp4である必要はありませんが、OpenCVが対応しているファイルのいずれかである必要があります。作業ディレクトリ/ ├ DataMovies/ │ └ title/ │ ├ 動画ファイル.mp4 │ └ 動画ファイル.mp4 └ DataImages/ └ title/ ├ 画像ファイル.png └ 画像ファイル.pngコード作成
まず、DataMovies/titleの動画ファイルをすべて取得する必要があります。
globを用いて取得することができます。
動画ファイル一覧はリストとして取得できます。
私の動画数は48でした。import glob import os title = "title" videos_path = os.path.join("Data_Movies", title, "*") video_files = glob.glob(videos_path) len(videos_files)48OpenCVを用いて動画を解析する場合はcv2.VideoCapture()を用います。
countは動画の総フレーム数、fpsは単位時間当たりのフレーム数を示します。for video_file in video_files: cap = cv2.VideoCapture(video_file) count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) fps = int(cap.get(cv2.CAP_PROP_FPS)) print(count, fps)18659 29 26855 23 6700 23 6700 23 41473 23 2670 29 6101 30 9723 23 13335 29 9362 23 10848 23 10271 23 . . .どうやら、fpsは20~30が多いようです。
5秒に一枚のペースで画像を取得したいので、100フレーム毎に画像に変換するとよさそうです。
続いて画像変換していきたいと思います。
cap.read()をフレーム回数分実行することにより、動画フレームを取得することができます。
動画フレーム数が100で割り切れる場合、画像として保存します。
保存した画像を表示させることができますが、notebookが重くなってしまったのでコメントアウトしておきました。for i, video_file in enumerate(video_files): cap = cv2.VideoCapture(video_file) count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) #fps = int(cap.get(cv2.CAP_PROP_FPS)) for loop in range(count): ret, frame = cap.read() if loop % 100 == 0: try: print("frame:" , loop) #plt.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)) #plt.axis("off") #plt.show() os.chdir(images_path) cv2.imwrite("{}-{}.png".format(i, loop), frame) os.chdir("../..") except: continue完成コード
完成コードです。DataMovies/titleとDataImages/titleのtitleは同じにする必要があります。
何フレーム毎に画像を取得するかを選択することができるので、fpsを見ながら検討するとよいです。video_to_image.pyimport glob import os import cv2 import matplotlib.pyplot as plt class VideoToImage(): def __init__(self, title, n_frame): self.title = title self.n_frame = n_frame self.images_path = os.path.join("Data_Images", self.title) os.makedirs(self.images_path, exist_ok=True) def fetch_video_list(self): videos_path = os.path.join("Data_Movies", self.title, "*") video_files = glob.glob(videos_path) return video_files def convert(self): for i, video_file in enumerate(self.fetch_video_list()): cap = cv2.VideoCapture(video_file) count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) #fps = int(cap.get(cv2.CAP_PROP_FPS)) for loop in range(count): ret, frame = cap.read() if loop % self.n_frame == 0: try: print("frame:" , loop) #表示したい場合 #plt.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)) #plt.axis("off") #plt.show() os.chdir(self.images_path) cv2.imwrite("{}-{}.png".format(i, loop), frame) os.chdir("../..") except: continue video_to_image = VideoToImage("title", 100) video_to_image.convert()おわりに
これで動画ファイルから画像ファイルに変換することができました。
しかし、対象の物体が入っていなかったりラベル付けをしたりする必要があるので、機械学習モデル構築するのにはまだまだ時間がかかりそうです。