- 投稿日:2021-02-27T22:52:59+09:00
【Ruby】オブジェクト指向について基礎的なあれこれ
はじめに
今後個人開発でもっと複雑なものや共同開発をしていく上でオブジェクト指向の理解が重要だと考え、勉強のアウトプットとして記事にしました。
この記事でわかること
・オブジェクト指向の概要
・三大要素
・オブジェクト指向での設計のポイント参考にしました→オブジェクト指向でなぜ作るのか
オブジェクト指向の概要
オブジェクト指向という言葉自体はゼロックス社パロアルト研究所の計算機科学者アラン・ケイが70年代生み出した言葉です。その後、自由で曖昧な定義のまま発展を続けたので、どんなものかを説明するのが難しいです。
しかし、ざっくり説明するとソフトウエアの保守や再利用をしやすくすることを目的とした技術です。個々の部品により強く着目し、部品の独立性を高め、それらを組み上げてシステム全体の機能を実現するという考え方にもとづきます。
オブジェクト指向プログラミング言語はとOOP(ObjectOrientedProgramminglanguage)と呼ばれます。【代表的なOOP】
Simula67、Smalltalk、C++、Python、Java、Ruby、JavaScript..などなどまた、オブジェクト指向には三大要素があります。
- クラス(カプセル化)
- ポリモーフィズム
- 継承
また、オブジェクト指向には、抽象的な「汎用の整理術」と、具体的な「プログラミング技術」という2つの側面があります。
三大要素
クラス(カプセル化)
「分類」「種類」といった「同種のものの集まり」と言った意味。関連性の強いメソッドとインスタンス変数を1つにまとめて粒度の大きいソフトウエア部品を作る仕組みです。
この仕組みの特徴は「まとめて、隠して、たくさん作る」ことです。メソッドとは?
プログラムの一連の処理をまとめたパッケージのようなものです。言語によっては関数と呼ばれます。
インスタンスとは?
クラスをもとに生成されたオブジェクトの実体です。
1.まとめる
結びつきの強い(複数の)メソッドと(複数の)インスタンス変数を1つのクラスに「まとめる」ことができます。
これにより次のメリットが得られます。
【利点】
- 部品の数が減る。
- メソッドの名前づけが楽になる。
- メソッドが探しやすくなる。
2.隠す
クラスに定義した変数とメソッドを、他のクラスから「隠す」ことができます。プログラムの保守性悪化の元凶となるグローバル変数を使わずにプログラムを書くことが可能です。
Rubyではprivateを使用します。3.たくさん作る
いったんクラスとして定義すると、実行時にそこからいくつでもインスタンスを作ることができます。これにより、ファイル、文字列、顧客情報など、同種の情報を複数同時に扱う処理であっても、そのクラス内部のロジックをシンプルにできます。
Rubyではインスタンスメソッドを実行する際、下記の様にインスタンスを格納する変数名にピリオドをつけて、その後にメソッド名を書きます。インスタンスを格納する変数名.メソッド名(引数)
【まとめ】
- サブルーチンと変数を「まとめる」
- クラスの内部だけで使う変数やサブルーチンを「隠す」
- 1つのクラスからインスタンスを「たくさん作る」
ポリモーフィズム
類似したクラスに対するメッセージの送り方を共通にする仕組み。また、相手が具体的にどのクラスのインスタンスであるかを意識せずにメッセージを送れる仕組みです。
継承
継承は、クラス定義の共通部分を別クラスにまとめて、コードの重複を排除する仕組みです。
共通部分のクラスのことをスーパークラスと呼び、それを利用するクラスをサブクラス呼びます。
三大要素まとめ
クラス ポリモーフィズム 継承 説明 サブルーチンと変数をまとめてソフトウェア部品を作る メソッドを呼び出す側を共通化する 重複するクラス定義を共通化する 目的 整理整頓 無駄を省く 無駄を省く 三大要素を使ったコーディング
Rubyを使用してオブジェクト指向を意識したコーディングをしていきます。
クラス(カプセル化)
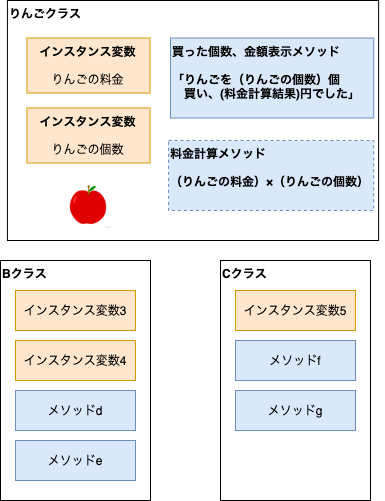
sample.rbclass Apple def initialize(quantity, price) @quantity = quantity @price = price end def buy puts "りんごを#{@quantity}個買い、#{calculation(@quantity, @price)}円でした。" end private def calculation(quantity, price) quantity * price end endAppleクラスを作成しました。
内容は下記図の通りとなります。
irbを走らせ、インスタンスを生成しました。
irb(main):002:0> apple1 = Apple.new(2, 300) => #<Apple:0x00007fc92c82be58 @quantity=2, @price=300> irb(main):003:0> apple1.buy りんごを2個買い、600円でした。 irb(main):002:0> apple2 = Apple.new(3, 300) => #<Apple:0x00007fc92c82be58 @quantity=2, @price=300> irb(main):003:0> apple2.buy りんごを3個買い、900円でした。ポリモーフィズム、継承
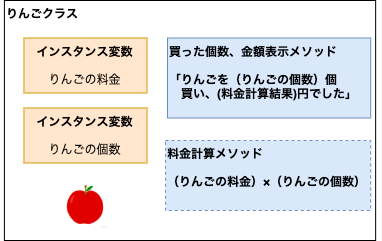
sample.rbclass Shopping def initialize(quantity, price) @quantity = quantity @price = price end def buy(product='') puts "#{product}を#{@quantity}個買い、#{calculation(@quantity, @price)}円でした。" end private def calculation(quantity, price) quantity * price end end class Apple < Shopping def buy(product='りんご') super end end class Orange < Shopping def buy(product='オレンジ') super end end下記図の通り、スーパークラスとしてShoppingクラスを作成しました。Apple、OrangeクラスにはShoppingクラスを継承させました。オーバーライドしているbuyメソッドを
superでよびだしました(ポリモーフィズム)。
irbを走らせ、インスタンスを生成しました。
irb(main):002:0> apple = Apple.new(2, 300) => #<Apple:0x00007fc92c82be58 @quantity=2, @price=300> irb(main):003:0> apple.buy りんごを2個買い、600円でした。 irb(main):002:0> orange = Orange.new(4 ,300) => #<Orange:0x00007fa55e96c5c0 @quantity=4, @price=300> irb(main):003:0> orange.buy オレンジを4個買い、1200円でした。オブジェクト指向での設計のポイントについて
重複を排除する
重複部分が多いと規模が大きくなり、コードが複雑になります。また、変更時の修正漏れが発生する場合があります。
ポリモーフィズムや継承の仕組みを利用し、なるべく重複を排除することが推奨されます。部品の独立性を高める
複雑なシステムを部品ごとに分割することでサブシステムや部品の機能がハッキリするため、変更する場合の修正個所の特定が容易になります。また、独立した部品を別のシステムに再利用することも可能になります。
部品やサブシステムの独立性を高めるための考え方として、「凝集度」と「結合度」と呼ばれる2つの尺度があります。凝集度
個々の部品の機能のまとまり度合いを評価する尺度です。この凝集度が「強い」ほど良い設計といえます。結合度
部品間の結びつき度合いを評価する尺度です。この結合度は凝集度と反対に、「弱い」ほど良い設計といえます。また、部品の独立性を高めるために具体的なコツとして下記3点があります。
ひと言で表現する名前をつける
隠す仕組みを利用し秘密をたくさん作る
小さく作る
依存関係を循環させない
クラス同士の依存関係を循環させると再利用がしづらくなるため、循環しないような設計が必要になります。
まとめ
オブジェクト指向について学ぶために一冊本を読みましたが、メモリ、要件定義、モデリング、アジャイル開発など幅広いところまで波及しており、とてつもなく奥が深いと感じました。まだまだこれからも勉強していきたいと思います。


- 投稿日:2021-02-27T22:44:22+09:00
Railsポートフォリオ #3 herokuにデプロイ
こんにちは
今回はherokuへのデプロイを行いました。(前回記事(#3 DB設計))私は、前職(ホテルの料飲部)における、コミュニケーションの課題を解決するアプリを作っているのですが、今回は、
herokuへのデプロイを行いました
元々はAWSでデプロイするつもりだったのですが(やったことあったので)、難しすぎて、一旦諦め、herokuで手を打つことにしました。。。
感じたこと
- AWSの勉強不足
Qiita記事等を参考にしながら行ったのですが、知識不足でやってるので、どこで間違ったのかわからん、、、、、
もう少し勉強してから出直そうと思いました。
こちらの記事(【画像付きで丁寧に解説】AWS(EC2)にRailsアプリをイチから上げる方法【その1〜ネットワーク,RDS環境設定編〜】)とかを参考に行ったのですが、敗北しました。
非常に悔しいです。さらに
実際にアプリの中身を作っていたら、作っておいたER図が全然的外れだったと言うことにも気づきました。
こちらもやり直さねば。。。次は、ER図を修正し、基本機能を実装していきます
- 投稿日:2021-02-27T22:24:39+09:00
【Rails】JSが読み込まれない時の対処法
- 投稿日:2021-02-27T21:27:00+09:00
[Ruby on Rails] データベースの削除の仕方
色々あってDBを作り直すことになったので、その備忘録を書いていきます。
とても繊細なdatabase.ymlなどを修正する際にも使えるので覚えておこうと思います。
ちなみにシークエルプロと言うデータベースを視覚化できるアプリを使っています。
データベースを削除する方法
database.ymlに記載されている、エンコードの設定やデータベース名を誤った状態でデータベースを作成してしまった場合は、一度データベースを削除してから作り直す必要があります。
手順は以下のとおりです。
データベースを削除する
database.ymlを正しい形に修正する
データベースを再度作成する
①データベースを削除する
データベースを削除するためにはrails db:dropのコマンドを実行します。
% cd ~/projects/データベースを作り直したいアプリケーションのディレクトリディレクトリ移動後にrails db:drop
このコマンドを実行することで、該当するアプリケーションのデータベースを削除することができます。
②database.ymlなどを修正する
データベースを削除できたら、この段階でdatabase.ymlなどを修正します。
③データベースを再度作成する
そして、rails db:createのコマンドでデータベースを再度作成します。% cd ~/projects/データベースを作り直したいアプリケーションのディレクトリデータベースの削除とマイグレーションファイルの適用を一括で行う方法を学ぼう
データベースの設定は間違っていないものの、再度データベースを作り直し、既存のマイグレーションファイルを適用したい場合があります。その場合は、rails db:migrate:resetのコマンドを実行します。
% cd ~/projects/データベースを作り直したいアプリケーションのディレクトリ % rails db:migrate:resetこのコマンドを実行することで、以下の操作を一括で行ってくれます。
データベースを削除する
データベースを再度生成する
既存のマイグレーションファイルをすべて適用する
ただし、データベースを一度削除するため、保存されているデータなどはすべて削除されます。
極力、データベースを消すほどのミスはしたく無いものです。
- 投稿日:2021-02-27T21:24:16+09:00
Ruby/Railsの環境構築
これからRuby/Railsの環境構築を行っていきます。
まずは用語から説明していきます。
ご存知の方は飛ばしてもらって構いません。シェルとは?
ターミナルで実行されたコマンドを読み取ってくれるOSの窓口役です
ターミナルから入力されたコマンドを読み取って、OSに対して指示を渡し、結果をターミナルに返して表示や実行などの動作をさせます。
このシェルがターミナルとOSの間に挟まって、コマンドによる命令と実行結果の橋渡しをしています。シェルにも種類があり、プロンプトやコマンド実行後の出力で挙動が若干異なります。
zsh
zshはシェルの1つでターミナルで
% echo $SHELLとコマンドを実行すると現在使用しているシェルはzshであることがわかります。
.zshrcに設定を記述して、PATHにアプリケーションの場所を示すことでコマンドを使用可能にします。PATH
PATHとは、「環境変数」と呼ばれるOS用の変数のことです。PATHには、複数の絶対パスの情報が保存されており
コマンドが入力されたときに、シェルはPATHに記述されたパスのディレクトリ内のファイルを検索します。
PATHに絶対パスを保存してアプリケーションの場所を示すことでどこからでもアプリケーションのコマンドを打つことができます。
一般的に「PATHを通す」と表現します。echoコマンド
「>>」に続けてファイル名を指定することで、ファイルに文字を追加できるLinuxコマンドで、設定を反映するためのコマンドを記述することで、PATHを通すことができます。
コマンドラインツール
コマンドで操作するアプリケーションのまとまりで
コマンドラインツールを導入することで、OSが初めからコマンドで操作できるアプリケーション以外の物もインストールできます。Command Line Tools
macOS専用のコマンドラインツールのことです。
macOSでは、元々Linuxコマンドで操作できるアプリケーションや機能を標準搭載しています。Linuxコマンド以外で操作するアプリケーションの多くはCommand Line Toolsのインストールによって、まとめてPCに導入できます。パッケージ管理ツール
パッケージとは、プログラムや処理をひとまとめにしたもののことでライブラリとも言えます。
パッケージ管理とは、パッケージやパッケージが持つライブラリなどの依存関係を考慮して
インストールやバージョンアップを行う管理のことです。
あるパッケージを利用したい場合、そのパッケージと依存関係にあるパッケージも一緒にインストールしてくれます。Homebrew
macOSのパッケージ管理ツールでmacOS上で動作するアプリケーションの多くがHomebrewからインストールできます。
依存関係のあるパッケージが正しく動作するよう、複数のパッケージのバージョンをコントロールしてインストールできます。
コマンド 説明 brew -v Homebrewのバージョンを表示する brew install [パッケージ名] パッケージをインストールする brew uninstall [パッケージ名] パッケージをアンインストールする brew search インストール可能なパッケージを表示する brew update インストールしたパッケージを最新へ更新する Node.js
Node.jsは、本来ブラウザ上で動くJavaScriptをサーバーサイドで動作させる「実行環境」です。
インストールされると、サーバーサイドで利用できるJavaScriptのパッケージを活用できます。
パッケージは依存関係を生むため、YarnなどのNode.jsのパッケージ管理ツールもあります。Yarn
Node.jsの環境上で動作するパッケージを管理する、JavaScriptのパッケージ管理ツールです。
バージョン管理
変更したバージョンを記録あるいは外部から保存して、過去のバージョンや最新のバージョンに切り替えることなどをバージョン管理と呼びます。
バージョン管理をすることで、パッケージとの依存関係の問題を解消したり、変更して問題が発生したプロジェクトを過去の安定したバージョンに切り替える、などの対応ができます。
rbenv
Rubyのバージョンを切り替えるためのバージョン管理ツールです。
バージョン管理ツールを使わない場合、RubyのバージョンはすべてPC内で共通となってしまい「あるプロジェクトで使用しているRubyのライブラリが使用できなくなってしまう」などの依存関係の問題が生じます。
複数のバージョンのRubyをダウンロードしておいて、使用するRubyのバージョンをディレクトリごとに指定することも可能になります。
コマンド 説明 rbenv -v rbenvのバージョンを表示 rbenv install [バージョン][パッケージ名] Rubyバージョンを指定してインストールする。 rbenv uninstall [バージョン] Rubyバージョンを指定してアンインストールする。 rbenv versions インストールされているRubyバージョンの一覧を表示する。 rbenv global [バージョン] すべてのディレクトリで使用するRubyバージョンを切り替える。 rbenv local [バージョン] カレントディレクトリで使用するRubyバージョンを切り替える。 rbenv rehash RubyやGemに関するコマンドをバージョン変更後も使用できるようにする。 さてこれから環境構築に取り掛かっていきましょう!
シェルをzshに設定
# zshをデフォルトに設定 % chsh -s /bin/zsh # ログインシェルを表示 % echo $SHELL # 以下のように表示されれば成功 /bin/zshCommand Line Toolsを用意
% xcode-select --installHomebrewをインストール
% cd # ホームディレクトリに移動 % pwd # ホームディレクトリにいるかどうか確認 % /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)" # コマンドを実行Homebrewがインストールされているか確認
% brew -v # 以下のように、Homebrewのバージョン情報が表示されれば無事にインストールされています。 Homebrew 2.5.1 # 数字は異なる場合があります。 % brew update # Homebrewをアップデート % sudo chown -R `whoami`:admin /usr/local/bin # Homebrewの権限を変更rbenv と ruby-buildをインストール
% brew install rbenv ruby-buildrbenvをどこからも使用できるようにパスを通す。
% echo 'eval "$(rbenv init -)"' >> ~/.zshrc設定ファイルであるzshrcを修正したので変更を反映
% source ~/.zshrcターミナルのirb上で日本語入力を可能にするreadlineをinstall
% brew install readlinereadlineをどこからも使用できるようにする
% brew link readline --forcerbenvを利用してRubyをインストール
% RUBY_CONFIGURE_OPTS="--with-readline-dir=$(brew --prefix readline)" % rbenv install 2.6.5利用するRubyのバージョンを指定
% rbenv global 2.6.5rbenvを読み込んで変更を反映
% rbenv rehashRubyのバージョンを確認
% ruby -vMySQLのインストール
% brew install mysql@5.6MySQLの自動起動設定
% mkdir ~/Library/LaunchAgents % ln -sfv /usr/local/opt/mysql\@5.6/*.plist ~/Library/LaunchAgents % launchctl load ~/Library/LaunchAgents/homebrew.mxcl.mysql\@5.6.plistmysqlコマンドをどこからでも実行できるようパスを通す
% echo 'export PATH="/usr/local/opt/mysql@5.6/bin:$PATH"' >> ~/.zshrc # mysqlのコマンドを実行できるようにする設定 % source ~/.zshrc # 設定を読み込むコマンド % which mysql # mysqlのコマンドが打てるか確認する # 以下のように表示されれば成功 /usr/local/opt/mysql@5.6/bin/mysqlMySQLの起動を確認
% mysql.server status # MySQLの状態を確認するコマンド # 以下のように表示されれば成功 SUCCESS! MySQL runningRubyの拡張機能(gem)を管理するためのbundler(バンドラー)をインストール
% gem install bundler --version='2.1.4'Railsをインストール
% gem install rails --version='6.0.0'rbenvを再読み込み
% rbenv rehashNode.jsを用意
% brew install node@14Node.jsへのパスを通す
% echo 'export PATH="/usr/local/opt/node@14/bin:$PATH"' >> ~/.zshrc % source ~/.zshrcNode.jsが導入できたか確認。バージョンが表示されれば、問題なくインストールが完了
% node -v v14.15.3 # 数値は異なる場合がありますyarnをインストール
% brew install yarnyarnが導入できたか確認
% yarn -v以上で環境構築は完了です。お疲れ様でした。
- 投稿日:2021-02-27T19:55:31+09:00
銀行振込を忘れないためのwebアプリ
はじめに
今はもう使われていない振込券をベースに作りました。
なぜ作ったか
- 実家の会社で振込忘れや伝達ミスなどが多発していた
- 督促状が届き面倒な手続きに時間を取られることが多かった
- そんな状態を改善・解決できるのではないかと思った
開発環境
- 言語
- ruby
- フレームワーク
- rails
- データベース
- mysql
- その他
- https://bank.teraren.com/
- 銀行名、支店名を入力する際に上記のAPIを利用させていただきました
基本機能
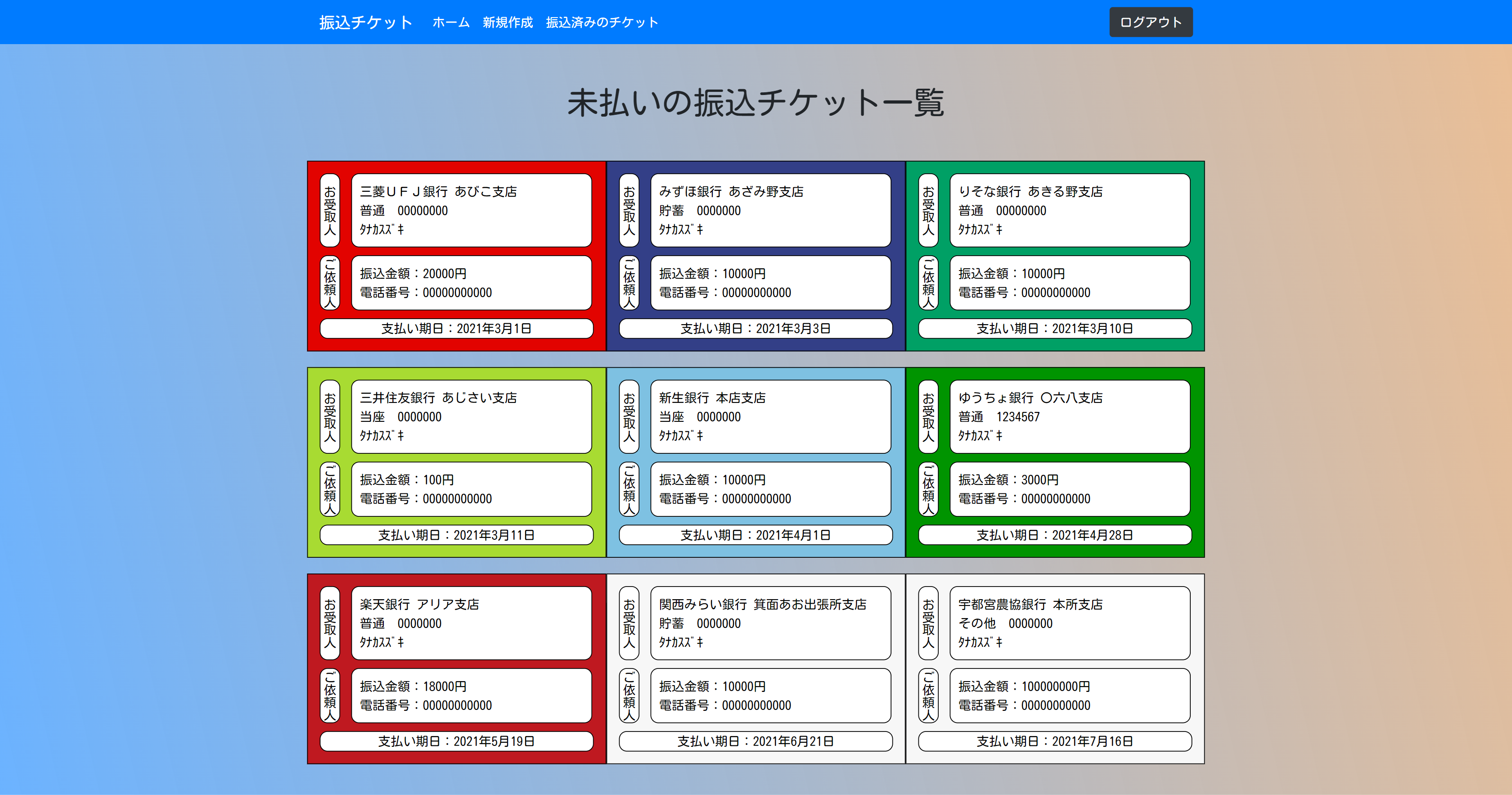
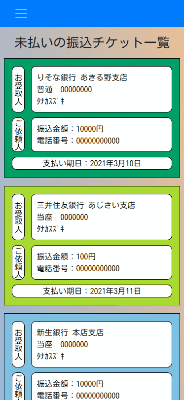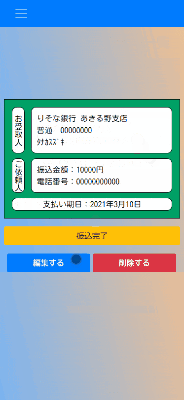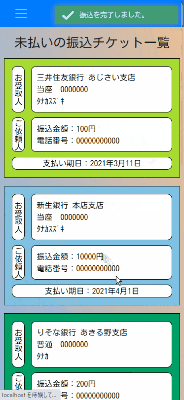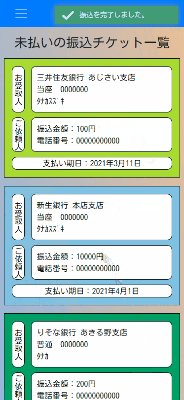
振込チケットの管理
未払いの振込チケットを振込期日順に閲覧することができます。
また、見た目で分かりやすいように、いわゆるメガバンクはロゴの色に合わせてチケットの色を変えています。
振込チケットの作成
チケットの作成の際には、"https://bank.teraren.com/"
上記の銀行名、支店名を取得できるAPIを利用させていただき、自動で候補を取得し選択できるようにしました。
振込チケットの振込完了報告
振込済みのチケットは別画面で閲覧できます。
スマホ画面
検討している追加機能・改善点
- 期日が近づいた際のwebプッシュ通知
- 管理者権限の有無で使える機能の制限


- 投稿日:2021-02-27T19:44:14+09:00
Railsで大量のデータを更新する際はin_batchesを使おう
Ruby on Railsのプロジェクトで、大量のデータを更新しようとしたらメモリ不足でエラーとなったため、解決方法をメモ。
こんな感じで、データを更新しようとしていました。
Hoge.all.map do |hoge| hoge.update(fuga: hoge.foo) endしかしデータが数十万件あり、メモリ不足で余裕で落ちました。
そんなときは in_batchesを使いましょう。
デフォルトでは1000件ずつ読み込んで処理してくれます。Hoge.in_batches do |hoges| hoges.map do |hoge| hoge.update(fuga: hoge.foo) end end無事解決!
どれくらいの量のデータが扱われるかは、常に意識しないといけないですね。
- 投稿日:2021-02-27T19:08:20+09:00
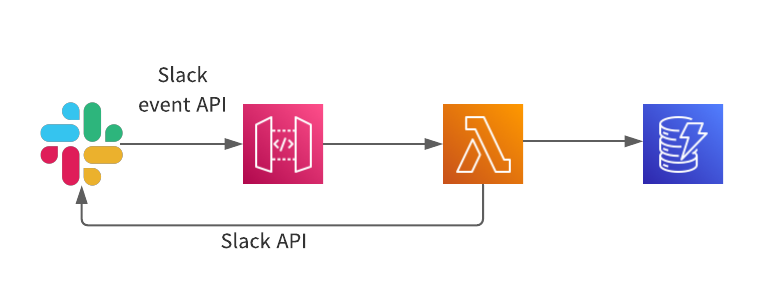
いまさらSlackとLambdaとDynamoを連携させてみた
いまさらですが、LambdaとDynamoを触ってみたのでまとめておきたいと思います。
APIGateway/Lambda/Dynamoなど触ったことのない人の助けになれば幸いです。今回やってみたことは以下です
1. SlackのAppにメッセージを送信
2. Slackのevent apiでAPI Gatewayのエンドポイントにリクエストを送る
3. Lambdaで、飛んできたリクエスト内容をDynamoDBに保存
4. Lambdaで登録した旨をSlackに返信作成手順
以下の順序で作成を行います
- Lambda関数の作成
- API Gatewayでエンドポイントを作成
- Slackのevent APIの設定と、メッセージの送信
- CloudWatchでログを確認する
- Lambdaでのメッセージ処理
- LambdaからDynamoにデータを登録
1. Lambda関数の作成
Lambdaとは
AWS Lambda はサーバーレスコンピューティングサービスで、サーバーのプロビジョニングや管理、ワークロード対応のクラスタースケーリングロジックの作成、イベント統合の維持、ランタイムの管理を行わずにコードを実行できます。Lambda を使用すれば、実質どのようなタイプのアプリケーションやバックエンドサービスでも管理を必要とせずに実行できます。
凄く雑な説明をすれば、Lambda上にスクリプトを置いておくと、
こちらが指定したトリガー(HTTPリクエストなど)のタイミングでそのスクリプトを実行してくれます。
スクリプトを置いておくサーバーは意識する必要はなく、課金は実行回数によって発生します。
月100万リクエストまで無料なので、遊びで使う分には(多分)お金は発生しません。関数の作成
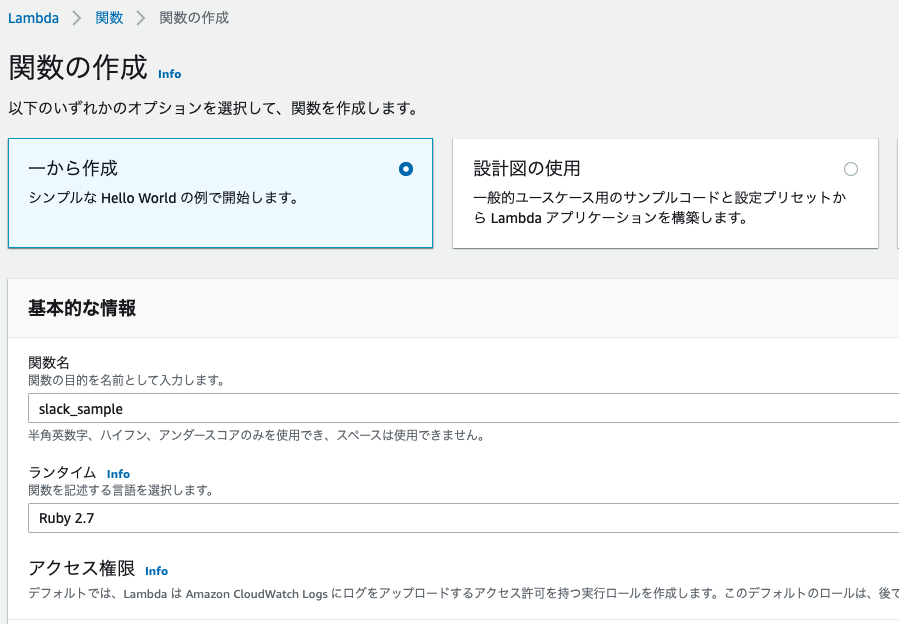
AWSのマネジメントコンソールからLambdaを検索します。
「関数の作成」というボタンがあるはずなので、クリックして作成しましょう。
こういう画面になるので、関数名とランタイムの欄を入れて関数の作成をしましょう。
他に詳細設定などがありますが、今回は大枠を理解するだけなので、パスします。作成後の画面に
関数コードという画面があればOKです。
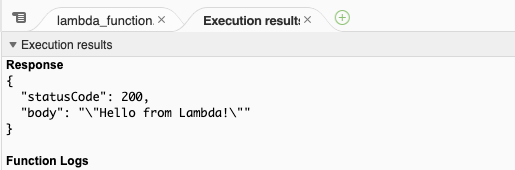
関数のテスト
Testというボタンがあるので、イベント名に適当な名前を入れて作成
再度Testボタンを教えてみましょう。
画面に以下のようなテスト結果が出ればOKです!
2. API Gatewayでエンドポイントを作成
API Gatewayの設定
非常に簡素ですが、Lambdaの関数は作成できました。
次はLambda関数の実行を外からできるように、API Gatewayを設定します。
Lambdaの関数の画面から、
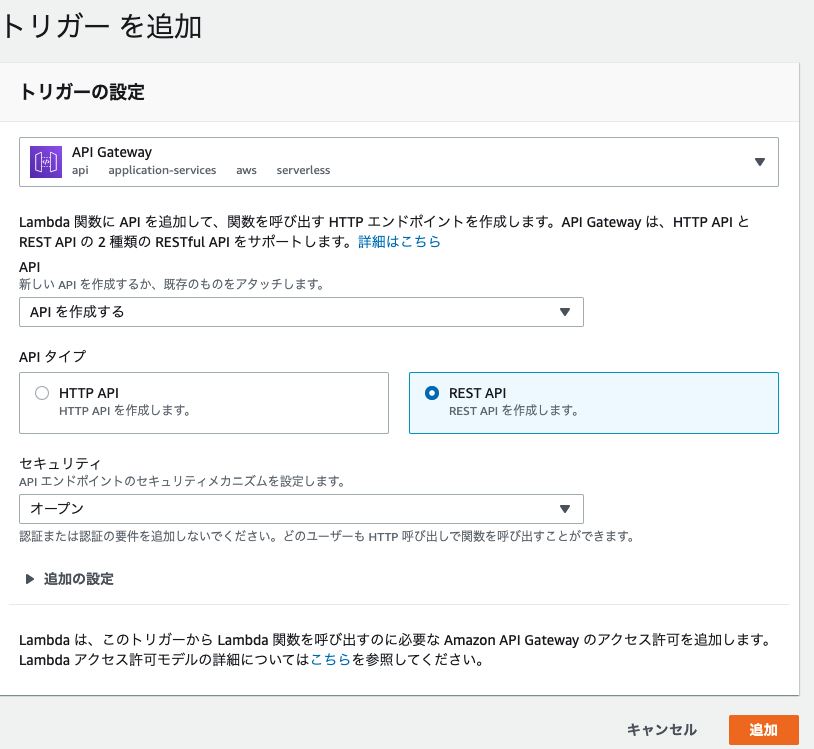
デザイナ>トリガーを追加をクリック
すると、トリガーを追加という画面がでてくるので、以下のように設定してください。
大枠を理解するため、また後で消すのでオープンにしていますが、そうでない場合はきちんと設定してください。
作成後にAPI Gatewayの項目にslack_sample_APIができていればOKです。エンドポイントの作成
API Gatewayのリンクをクリックし、設定画面に行きます。
アクションからメソッドの作成を行います。
POSTを選択した後、以下のように選択して、保存します
作成後、再度
アクションボタンからAPIのデプロイを実行します。
デプロイされるステージをdefaultを選択肢、デプロイします。
このようなURLが表示されていればエンドポイントの作成は完了です。
とりあえず、テストでcurlを叩いてみましょう!
以下のように返ってきたら成功です!!curl -X POST https://それぞれのURL/default/slack_sample => {"statusCode":200,"body":"\"Hello from Lambda!\""}%3. Slackのevent APIの設定と、メッセージの送信
Slackのアプリ作成
こちらからAppの作成
名前を適当に入れ、workspaceを設定します。request urlと、Lambada関数の修正
サイドバーの
Basic Informationから
Add features and functionality>Event Subscriptionsを選択してください。
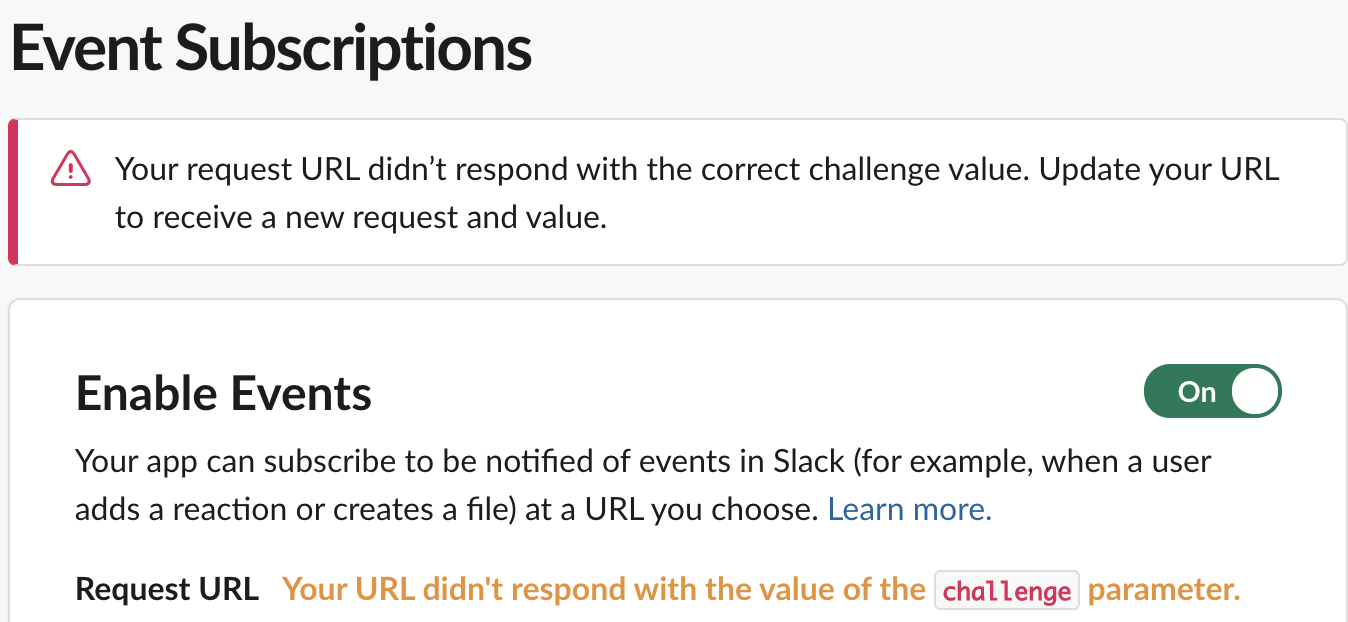
requestを送るURLを求められるので、先程作成したエンドポイントのURLを入れましょう。すると、以下のように怒られます。
どうやらchallengeというパラメータを返す必要があるようです
Lambda関数のメソッドを、以下のように修正した後、
Deployボタンを押しましょう。def lambda_handler(event:, context:) # event["challenge"]がどこから来たかは、後述します { statusCode: 200, body: JSON.generate('Hello from Lambda!'), challenge: event["challenge"] } endデプロイ後にSlack画面の
retryボタンを押すと、Request URL Verified と表示されるはずですSubscribe to bot events
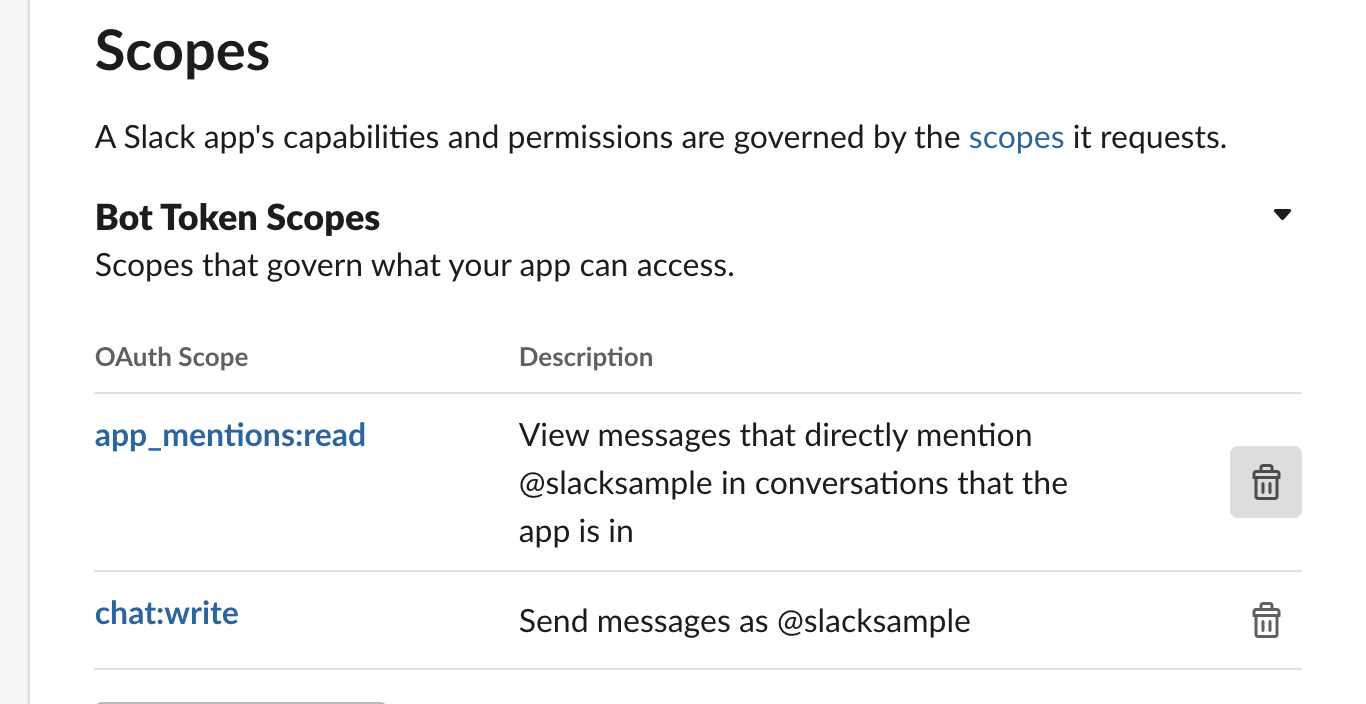
botの権限を設定します。
今回はBotへのメンションをトリガーにrequestを送信。Botぽくそれに返信をしたいので
app_mentions:readとchat:writeを入れておきますworkspaceへのインストール
再び、
Basic Informationに戻り、
今度はInstall your appからworkspaceにアプリをインストールしますSlackでメッセージを送る
Bot的に使いたいので、適当なchannelにbotを入れて、
メンションをつけてメッセージを送ってみましょう4. CloudWatchでログを確認する
実はLambda関数を作成したタイミングで
のロググループが出来ています。
AWSでCloudWatchを検索し、
サイドバーのログ>ロググループ
から/aws/lambda/slack_sampleを見てみましょう。ログストリームの項目に、先程メンションを送った時間のものが増えていれば、
SlackからAPI Gatewayを介してLambda関数が実行出来ています!!5. Lambdaでのメッセージ処理
Botぽく反応させたいのでSlackのスレッドに返信するようにしましょう。
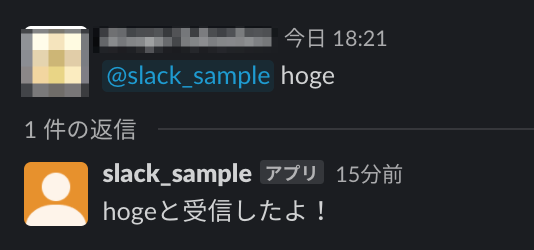
とりあえず、メンション付きで「hoge」と送ったら、
「hogeと受信したよ!」とでも返すようにします。Slackからのeventを見る
slackからのメッセージをLambda上で処理したいので、requestがどんな形か知りたいです。
lambda関数を以下のように修正してdef lambda_handler(event:, context:) puts event { statusCode: 200, body: JSON.generate('Hello from Lambda!'), challenge: event["challenge"] } endデプロイしたあとに、
再度、slackでbotにメンション付きでメッセージを送りましょう。
CloudWatchのログに以下のようなものが出ていればOKです。{ "token"=>"hoge", "team_id"=>"foo", "api_app_id"=>"fuga", "event"=>{ "client_msg_id"=>"1234", "type"=>"app_mention", "text"=>"<@id> hoge", "ts"=>"1614412451.000800", ~~~~~略~~~~ }スレッドに返信する
Token
返信するためにSlackのTokenが必要です。
Slackアプリ画面のサイバーの
Features>OAuth&PermissionsからBot User OAuth Tokenをメモしておきます。コードの修正
Lambda関数を
と、先程のCloudWatchのログを参考に、以下のように書き換えます。
# サンプルなので、ここに書いていますが本当は適切に暗号化する必要があります SLACK_TOKEN = "token" def lambda_handler(event:, context:) event_data = event["event"] # メッセージにメンションがついてしまうため、送信されたテキストからIDを削除 text = event_data.dig("text").delete("<@id>") channel = event_data.dig("channel") params = { token: SLACK_TOKEN, channel: channel, as_user: true, text: "#{text}と受信したよ!", thread_ts: event_data["ts"] } uri = URI.parse("https://slack.com/api/chat.postMessage") Net::HTTP.post_form(uri, params) { statusCode: 200, body: "test", challenge: event["challenge"] } endこれで、Slack API → API Gateway → Lambda →Slackの流れができました!
7. LambdaからDynamoにデータを登録
最後に、なんとなくDynamoにSlackのメッセージを入れてみましょう!
Dynamoとは
KeyValue型のNoSQLです。集計などには向きませんが、1件のデータの登録、抽出に優れています。
テーブルの作成
Dynamoの画面から
テーブルの作成をクリック
テーブル名とプライマリーキーを入れます。
他の設定はデフォルトでOKです。テーブルが作成できたら、
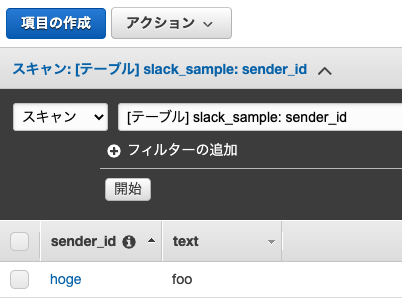
項目の作成から増やしてみます。
今回はtextを増やしてみました。
Lambdaの設定変更
このままだとLambdaからDynamoにまだアクセスできないのでポリシーを追加します
Lambda関数の画面のアクセス権限のタブから実行ロールのロール名をクリック
IAMの画面からポリシーをアタッチします。
Lambda関数の修正
後は、
を参考に、
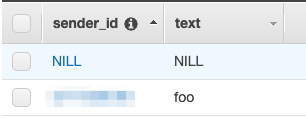
Lambda関数を以下のように修正しますrequire 'json' require "net/http" require 'aws-sdk-dynamodb' SLACK_TOKEN = "token" def lambda_handler(event:, context:) event_data = event["event"] # メッセージにメンションがついてしまうため、送信されたテキストからIDを削除 text = event_data.dig("text").delete("<@id>") # Dynamoへのinput dynamodb = Aws::DynamoDB::Client.new(region: 'ap-northeast-1') item = { text: text, sender_id: event_data["user"], } params = { table_name: 'dynamo_table_name', item: item } dynamodb.put_item(params) # slackへの送信 channel = event_data.dig("channel") params = { token: SLACK_TOKEN, channel: channel, as_user: true, text: "#{text}と受信したよ!", thread_ts: event_data["ts"] } uri = URI.parse("https://slack.com/api/chat.postMessage") Net::HTTP.post_form(uri, params) { statusCode: 200, body: "test", challenge: event["challenge"] } endここまでうまく行っていれば、このように
Dynamoにレコードが登録され、
Slack上でも返信が来ていると思います。
とりあえずしたかったことは出来たので、完了です。
最後に
やっぱり、インフラが分かって無くても、AWSがいい感じにしてくれるのはすごいですね。
工程も簡単で、この記事を書きながらしても3時間ぐらいで終わりました。
多分、作業だけすれば1時間ぐらいで終わると思います。大枠を理解するために雑な紹介でしたが、
IAMの設定や、API Gatewayのアクセス制限、Lambda関数が失敗したときの処理など
本当はしないといけないことが、実はまだまだあります。
今回の記事で興味を持ってくれた人がいたら、ぜひやってみください。
「LambdaやDynamo全然わからないけど、なんか触ってみたい!」という人に役立てばば幸いです。




- 投稿日:2021-02-27T19:05:32+09:00
エラーページを表示させる
HTTPレスポンスのステータスコードとは
クライアントからのリクエストの結果を返す3桁の整数値のことです。
特定のHTTPリクエストが正常に完了したどうかを示します。
通常はリクエストが成功するとステータスコード200を返します。ステータスコードの種類の例
403
アクセス権限がないことを示す。404
リクエスト先が見つからない、またはページが存在していないためにアクセスができないことを示す。「指定されたページは存在しません」などのエラーページが表示されるケース。500
webサーバーで何かしらのエラーが発生したことを示す。503
リクエスト先が一時的にアクセス集中やメンテナンスなどで使用できないことを示す。一時的に、ソースを変更したら再起動しなくてもリロードされるように設定します。
config/environments/production.rbconfig.cache_classes = falseアクションにraiseメソッドを追記してアクセスをすると、強制的に例外の画面が表示されます。
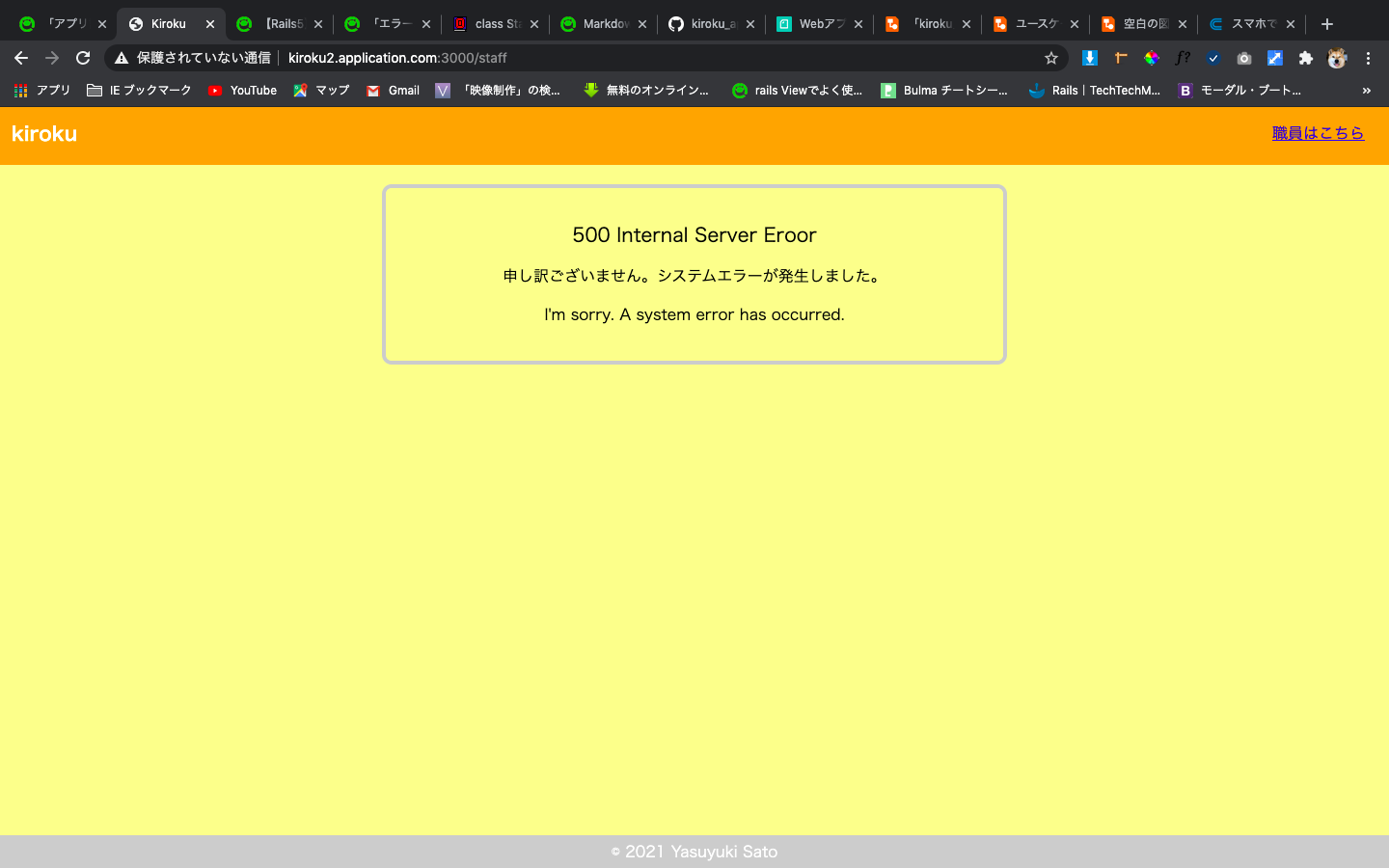
画像はproductionモードでのデフォルトエラー画面です。
ログを出力してみます。
tail -f log/production.log satouyasuyukinoMacBook-Air:kiroku yasuyuki$ tail -f log/production.log [008ffbf8-ca54-443f-927b-90ddff363516] puma (4.3.7) lib/puma/server.rb:472:in `process_client' [008ffbf8-ca54-443f-927b-90ddff363516] puma (4.3.7) lib/puma/server.rb:328:in `block in run' [008ffbf8-ca54-443f-927b-90ddff363516] puma (4.3.7) lib/puma/thread_pool.rb:134:in `block in spawn_thread' I, [2021-02-27T09:10:05.937895 #32132] INFO -- : [32b82d69-ef18-4283-87b3-7655b4b244c7] Started GET "/staff" for 127.0.0.1 at 2021-02-27 09:10:05 +0900 I, [2021-02-27T09:10:05.946757 #32132] INFO -- : [32b82d69-ef18-4283-87b3-7655b4b244c7] Processing by Staff::TopController#index as HTML I, [2021-02-27T09:10:05.951715 #32132] INFO -- : [32b82d69-ef18-4283-87b3-7655b4b244c7] Completed 500 Internal Server Error in 5ms (Allocations: 399) F, [2021-02-27T09:10:05.952131 #32132] FATAL -- : [32b82d69-ef18-4283-87b3-7655b4b244c7] [32b82d69-ef18-4283-87b3-7655b4b244c7] RuntimeError (): [32b82d69-ef18-4283-87b3-7655b4b244c7] [32b82d69-ef18-4283-87b3-7655b4b244c7] app/controllers/staff/top_controller.rb:3:in `index'このエラー画面を任意の画面にカスタマイズします。
app/controllers/application_controller.rb
rescue_from StandardError, with: :rescue500 private def rescue500(e) render "errors/internal_server_error", status: 500 endStandardErrorエラーが発生したら、rescue500のプライベートメソッドの処理が実行されるようにしています。
rescue500メソッドではrenderメソッドでerrorsフォルダのinternal_server_error.html.erbを返しています。
Rubyでは例外を表現するためのExceptionクラスというものが存在します。
StandardErrorはExceptionクラスを継承しています。
サーバーを再起動して以下の画面になってるとokです。
※アクションのraiseメソッドを消すのを忘れずに。
参考:【Rails5】rescue_fromによる例外処理:アプリ固有のエラーハンドリングとエラーページ表示
rails6ガイド
- 投稿日:2021-02-27T18:37:07+09:00
Railsの便利メソッド pluckについて調べてみた
はじめに
Railsでアプリケーションを作成時に、モデルから特定のカラムをリストで抜いてきたい場面が時々あり、なにかいいメソッドはないかと探していたところ、このメソッドにたどり着いた。
idsメソッドなどidカラムのリストを取得するメソッドを知っていたが他のカラムは一々、allで全取得して、mapやselect等を駆使してループ処理を行い、対象のカラムのリストを取得していたので、このメソッドを使用することでかなり簡略化につながるpluckメソッドについて
上記でも簡単に説明したように、対象のカラムのみを指定してリストで取得する事ができる
Railsガイドでは以下のように説明されている。
pluckは、1つのモデルで使用されているテーブルからカラム (1つでも複数でも可) を取得するクエリを送信するのに使用できます。引数としてカラム名のリストを与えると、指定したカラムの値の配列を、対応するデータ型で返します。
実際の使い方について
以下のようなモデルがあると仮定して、サンプルのコードを書いていく
Userモデル
型 カラム名 id integer name string age integer
id name age 1 hoge 21 2 fuga 30 2 hogehoge 34 基本的な使い方
User.pluck(:name) # SELECT name FROM users # => ['hoge', 'fuga', 'hogehoge']その他の使い方
引数を複数のカラムを渡すことで、指定したカラムのリストも取得できます。
戻り値が二次元配列になってかえってくるのでそこだけ注意が必要になります。User.pluck(:name, :age) # SELECT name, age FROM users # => [['hoge', 21], ['fuga', 30], ['hogehoge', 34]]pluckメソッドを使うことのメリット
コードの冗長化を防ぎ、スッキリ書ける
仮に
pluckを使わないで上記と同じような結果が得られるコードを書いてみましょう# pluckを使わない場合 User.select(:name).map{|user|user.name} User.select(:name, :age).map{|user|[user.name, user.age]}発行されるSQLが変わる
mapメソッドを駆使して同じような結果は得られますが、実はRailsが発行するSQL文が変わってきます。
# mapを使用したパターン User.all.map{|user|user.name} => SELECT users.* FROM users # pluckを使用したパターン User.pluck(:name) => SELECT name FROM users上記のSQLを見比べると前者は
SELECT users.* FROM usersでusersテーブルのカラムを一旦すべて取得しているのに対して、後者はSELECT name FROM usersでusersテーブルのnameカラムのみを取得しています。カラムすべてを取得するより、対象を指定してあげて取得する方がパフォーマンスや負荷もこ後者の方が基本的にはよくなるはずです。
ただ便利だから使うのではなく、パフォーマンス等も考慮して最適なメソッドを選べると良さそうです。その他pluckを使う時の注意点について
Railsガイドでは以下のように記載されています
pluckは、selectなどのRelationスコープと異なり、クエリを直接トリガするので、その後ろに他のスコープをチェインすることはできません。ただし、構成済みのスコープをpluckの前に置くことはできます。
つまり、
pluckメソッドの後ろには絞り込みやソートの条件を付ける事ができないということです。
以下のような書き方はエラーとなります。User.pluck(:name).limit(3) User.pluck(:age).order(id: "DESC")ただし、
pluckを使う前に予めスコープを設定しておくことで取得する事ができます。
例えば年齢カラムのリストを降順で取得したい場合は以下のように記述できます。User.order(age: "DESC").pluck(:age) # => [34, 30, 21]
- 投稿日:2021-02-27T16:55:47+09:00
「action_args」のソースから学ぶ「Ruby」② ソース分析1日目
「action_args」ソース分析1日目です。
以前Gem作り方で分かったのは、lib/action_args.rbがこのGemのスタートなのでそこから見てみます。action_argsソース
以下のファイルが「action_args」の全てのソース
$ tree . ├── CONTRIBUTING.md ├── Gemfile ├── MIT-LICENSE ├── README.md ├── Rakefile ├── action_args.gemspec ├── gemfiles │ ├── rails_41.gemfile │ ├── rails_42.gemfile │ ├── rails_50.gemfile │ ├── rails_51.gemfile │ ├── rails_52.gemfile │ ├── rails_60.gemfile │ └── rails_edge.gemfile ├── lib │ ├── action_args │ │ ├── abstract_controller.rb │ │ ├── callbacks.rb │ │ ├── params_handler.rb │ │ └── version.rb │ ├── action_args.rb │ └── generators │ └── rails │ ├── action_args_scaffold_controller_generator.rb │ └── templates │ └── controller.rb └── test ├── controllers │ ├── action_args_controller_test.rb │ ├── hooks_test.rb │ ├── kwargs_controller_test.rb │ ├── kwargs_keyreq_controller_test.rb │ ├── ordinal_controller_test.rb │ └── strong_parameters_test.rb ├── fake_app.rb ├── kwargs_controllers.rb ├── kwargs_keyreq_controllers.rb ├── mailers │ └── action_mailer_test.rb ├── params_handler │ └── params_handler_test.rb └── test_helper.rblib/action_args.rbからスタート
以下の三つのファイルを読み込んでいる。
lib/action_args.rbrequire 'action_args/params_handler' require 'action_args/abstract_controller' require 'action_args/callbacks'本日はparams_handler.rbのextract_method_arguments_from_paramsメソッド分析
extract_method_arguments_from_params
パラメーターにメソッド名を渡すとそのメソッドのパラメーターが一般パラメーターの場合はパラメーターの値配列、キーワードパラメーターの場合は、キーワード名と値のハッシューを返すメソッド。
詳細な処理内容はテストケースを見るとわかりやすいです。学習ポイント1
method関数について知らなかった!
method関数:オブジェクトのメソッドnameをオブジェクト化したMethodオブジェクトを返します。params_handler.rbmethod_parameters = method(method_name).parameters以下のようにmethodにメソッド名を渡せば、Methodオブジェクトを返すのでそのオブジェクトのparametersを取得できる
sampleirb(main):003:0> def hello(name) irb(main):004:1> "hello #{name}" irb(main):005:1> end => :hello irb(main):008:0> method(:hello).parameters => [[:req, :name]]
:reqは必須の引数を意味
その他の説明はparametersを参考parameters_samplem = Class.new{define_method(:m){|x, y=42, *other, k_x:, k_y: 42, **k_other, &b|}}.instance_method(:m) m.parameters #=> [[:req, :x], [:opt, :y], [:rest, :other], [:keyreq, :k_x], [:key, :k_y], [:keyrest, :k_other], [:block, :b]] File.method(:symlink).parameters #=> [[:req], [:req]]学習ポイント2
method(method_name).parametersは配列の配列を返し、各配列の要素は引数の種類に応じたSymbol が入るのでmapを利用してパラメーター名だけを配列に返しているparams_handler.rbparameter_names = method_parameters.map(&:last)学習ポイント3
reverse_eachを使って後ろのパラメーターから処理している。
https://github.com/asakusarb/action_args/blob/e5e4f3e10e410b34cc7dfbf0056b6d3d289ef96d/lib/action_args/params_handler.rb#L11a = [ "a", "b", "c" ] a.reverse_each {|x| print x, " " } # => c b a学習ポイント4
trimmed_key = key.to_s.sub(/_params\z/, '').to_symストロングパラメーターの場合、後ろの
_params文字列を削除している。学習ポイント5
:reqは必須項目を意味するのでparamsにtrimmed_keyが入ってない場合、missing_required_params配列に入れて次の処理を行なっている。
:keyreq,:keyタイプのキーはkwargsハッシュに保存しているmethod_parameters.reverse_each do |type, key| trimmed_key = key.to_s.sub(/_params\z/, '').to_sym case type when :req missing_required_params << key unless params.key? trimmed_key next when :keyreq if params.key? trimmed_key kwargs[key] = params[trimmed_key] else missing_required_params << key end when :key kwargs[key] = params[trimmed_key] if params.key? trimmed_key when :opt break if params.key? trimmed_key end # omitting parameters that are :block, :rest, :opt without a param, and :key without a param parameter_names.delete key endextract_method_arguments_from_paramsメソッドのテストケース
学習ポイント6
@controller = Class.new(ApplicationController).new.tap {|c| c.params = params }Object#tapについて
メソッドチェインの途中で直ちに操作結果を表示するためにメソッドチェインに "入り込む" ことが、このメソッドの主目的です。
以下のような使い方がありそう。生成されるSQLを表示irb(main):010:0> User.where(name:'a').tap{|a| p a.to_sql}.all "SELECT \"users\".* FROM \"users\" WHERE \"users\".\"name\" = 'a'" User Load (0.3ms) SELECT "users".* FROM "users" WHERE "users"."name" = ? LIMIT ? [["name", "a"], ["LIMIT", 11]]余談
1日目の最後に感じたのは、他人が作ったソースから学ぶのって楽しい!
まだ始まったばかりですが、最後まで頑張ります〜
- 投稿日:2021-02-27T16:12:08+09:00
ruby on rails 非同期いいね(編集中)
アプリケーションの立ち上げ
% rails new favorite-app -d mysql % cd favorite-app % rails db:create % rails g scaffold post title:string user_id:integer #postコントローラ作成 % rails g controller likes #likesコントローラ作成 % rails g model Like user_id:integer post_id:integerGemfileの下部に以下を追記
gem 'devise' gem 'font-awesome-sass'Gemfile編集後に実行
% bundle install % rails g devise:install % rails g devise user % rails db:migrate「application.css」を「application.scss」に変更
その後以下のコードを追記。
// application.scssの下部に以下を追記(既存のコードは消さない)
```ruby
/*
* This is a manifest file that'll be compiled into application.css
* vendor/assets/stylesheets directory can be referenced here using a relative path.
* 省略
*= require_tree .
*= require_self
*/------------この部分を追記-----------------
@import "font-awesome-sprockets";
@import "font-awesome";
------------この部分----------------------
```favorite-app/app/javascript/packs/application.jsを編集
require("@rails/ujs").start() // require("turbolinks").start() ⇐この行を削除 require("@rails/activestorage").start() require("channels")
- 投稿日:2021-02-27T16:12:08+09:00
ruby on rails 非同期いいね
アプリケーションの立ち上げ
% rails new favorite-app -d mysql % cd favorite-app % rails db:create % rails g scaffold post title:string user_id:integer #postコントローラ作成 % rails g controller likes #likesコントローラ作成 % rails g model Like user_id:integer post_id:integerGemfileの下部に以下を追記
gem 'devise' gem 'font-awesome-sass'Gemfile編集後に実行
% bundle install % rails g devise:install % rails g devise user % rails db:migrate「application.css」を「application.scss」に変更
その後以下のコードを追記。
// application.scssの下部に以下を追記(既存のコードは消さない)
```ruby
/*
* This is a manifest file that'll be compiled into application.css
* vendor/assets/stylesheets directory can be referenced here using a relative path.
* 省略
*= require_tree .
*= require_self
*/------------この部分を追記-----------------
@import "font-awesome-sprockets";
@import "font-awesome";
------------この部分----------------------
```favorite-app/app/javascript/packs/application.jsを編集
require("@rails/ujs").start() // require("turbolinks").start() ⇐この行を削除 require("@rails/activestorage").start() require("channels")
- 投稿日:2021-02-27T16:12:08+09:00
ruby on rails 非同期いいね (編集中)
アプリケーションの立ち上げ
% rails new favorite-app -d mysql % cd favorite-app % rails db:create % rails g controller home #homeコントローラ作成 % rails g scaffold post title:string user_id:integer #postコントローラ作成 % rails g controller likes #likesコントローラ作成 % rails g model Like user_id:integer post_id:integerGemfileの下部に以下を追記
gem 'devise' gem 'font-awesome-sass'Gemfile編集後に実行
% bundle install % rails g devise:install % rails g devise user % rails db:migrate「application.css」を「application.scss」に変更
その後以下のコードを追記。
// application.scssの下部に以下を追記(既存のコードは消さない)
/* * This is a manifest file that'll be compiled into application.css * vendor/assets/stylesheets directory can be referenced here using a relative path. * 省略 *= require_tree . *= require_self */ ------------この部分を追記----------------- @import "font-awesome-sprockets"; @import "font-awesome"; ------------この部分----------------------favorite-app/app/javascript/packs/application.jsを編集
require("@rails/ujs").start() // require("turbolinks").start() ⇐この行を削除 require("@rails/activestorage").start() require("channels")favorite-app/config/routes.rb
Rails.application.routes.draw do devise_for :users root 'home#index' resources :posts post 'like/:id' => 'likes#create', as: 'create_like' delete 'like/:id' => 'likes#destroy', as: 'destroy_like' endfavorite-app/app/controllers/posts_controller.rb
class PostsController < ApplicationController before_action :authenticate_user! before_action :set_post, only: %i[ show edit update destroy ] def index @posts = Post.all end def show end def new @post = Post.new end def edit end def create @post = Post.new(post_params) @post.user_id = current_user.id respond_to do |format| if @post.save format.html { redirect_to @post, notice: "Post was successfully created." } format.json { render :show, status: :created, location: @post } else format.html { render :new, status: :unprocessable_entity } format.json { render json: @post.errors, status: :unprocessable_entity } end end end def update respond_to do |format| if @post.update(post_params) format.html { redirect_to @post, notice: "Post was successfully updated." } format.json { render :show, status: :ok, location: @post } else format.html { render :edit, status: :unprocessable_entity } format.json { render json: @post.errors, status: :unprocessable_entity } end end end def destroy @post.destroy respond_to do |format| format.html { redirect_to posts_url, notice: "Post was successfully destroyed." } format.json { head :no_content } end end private def set_post @post = Post.find(params[:id]) end def post_params params.require(:post).permit(:title) end end
- 投稿日:2021-02-27T15:10:07+09:00
【超かんたん】Active Hashで投稿ページにプルダウンメニューを作成しよう!
Active Hashを利用して投稿ページにプルダウンメニューを作成します。
超初心者向けにレシピ投稿アプリを例に作成していきます。完成イメージ
Active Hashとは
Active Hashとは、「基本的に変更されないデータ」をモデルファイルに直接記述し取り扱うことができるGem。公式ドキュメント
Active Hashの導入
Active Hashのインストール
Gemfileに下記を記述しbundle installする。
Gemfilegem 'active_hash'Recipeモデルの作成
今回はレシピ投稿アプリなのでRecipeモデルを作成します。
ターミナルrails g model recipeマイグレーションファイルを編集。
今回、Active Hashを利用してカテゴリー(categoty)と所要時間(time_required)を保存するので、integer型の:モデル名_idという形で記述します。
このあと作成するCategoryモデルとTimeRequiredモデルのidを外部キーとして管理するためです。db/migrate/20XXXXXXXXXXXX_create_recipes.rbclass CreateRecipes < ActiveRecord::Migration[6.0] def change create_table :recipes do |t| #ここから t.string :title, null: false t.text :text, null: false t.integer :category_id, null:false t.integer :time_required_id, null: false #ここまで t.timestamps end end endターミナルrails db:migrate先ほど、integer型で指定したカテゴリーと所要時間の中身を作成していきましょう。
Category、TimeRequiredモデルの作成
モデルファイルの作成
ターミナルtouch app/models/categoty.rbActive Hashを用いて作成するモデルはActiveHash::Baseクラスを継承します。
モデルファイルに以下のような形でプルダウンメニューに表示させたいデータをハッシュの中に記述していきましょう。app/models/categoty.rbclass Category < ActiveHash::Base self.data =[ {id: 0 , name: '---'}, {id: 1 , name: 'すし・魚料理'}, {id: 2 , name: '丼もの・揚げ物'}, {id: 3 , name: 'ラーメン・麺類'}, {id: 4 , name: '中華'}, {id: 5 , name: '焼きもの・粉もの'}, {id: 6 , name: '洋食・西洋料理'}, {id: 7 , name: 'イタリアン'}, {id: 8 , name: 'フレンチ'}, {id: 9 , name: 'アジア・エスニック'}, {id: 10 , name: 'お菓子・スイーツ'} ] end同じ要領でTimeRequiredモデルも作成していきます。
ターミナルtouch app/models/time_required.rb※モデル名はアッパーキャメルケースで記述します。
app/models/time_required.rbclass TimeRequired < ActiveHash::Base self.data =[ {id: 0 , name: '---'}, {id: 1 , name: '10分以内'}, {id: 2 , name: '10分〜20分'}, {id: 3 , name: '20分〜30分'}, {id: 4 , name: '30分〜45分'}, {id: 5 , name: '45分〜60分'}, {id: 6 , name: '60分以上'} ] endアソシエーションの設定
Recipeモデルのアソシエーションの設定
投稿するレシピ(Recipe)はひとつのカテゴリー(Category)と所要時間(TimeRequired)に紐づくのでbelongs_toを設定します。
また、Active Hashを用いて、belongs_toを設定するには、extend ActiveHash::Associations::ActiveRecordExtensionsと記述してモジュールを取り込みます。app/models/recipe.rbclass Recipe < ApplicationRecord extend ActiveHash::Associations::ActiveRecordExtensions belongs_to :category belongs_to :time_required endCategory、TimeRequiredモデルのアソシエーションの設定
カテゴリー(Category)と所要時間(TimeRequired)はたくさんのレシピ(Recipe)に紐付いているのでhas_manyを設定します。
また、Active Hashを用いて、has_manyを設定するには、include ActiveHash::Associationsと記述してモジュールを取り込みます。app/models/categoty.rbclass Category < ActiveHash::Base self.data =[ {id: 0 , name: '---'}, {id: 1 , name: 'すし・魚料理'}, {id: 2 , name: '丼もの・揚げ物'}, {id: 3 , name: 'ラーメン・麺類'}, {id: 4 , name: '中華'}, {id: 5 , name: '焼きもの・粉もの'}, {id: 6 , name: '洋食・西洋料理'}, {id: 7 , name: 'イタリアン'}, {id: 8 , name: 'フレンチ'}, {id: 9 , name: 'アジア・エスニック'}, {id: 10 , name: 'お菓子・スイーツ'} ] #以下追記 include ActiveHash::Associations has_many :recipes endapp/models/time_required.rbclass TimeRequired < ActiveHash::Base self.data =[ {id: 0 , name: '---'}, {id: 1 , name: '10分以内'}, {id: 2 , name: '10分〜20分'}, {id: 3 , name: '20分〜30分'}, {id: 4 , name: '30分〜45分'}, {id: 5 , name: '45分〜60分'}, {id: 6 , name: '60分以上'} ] #以下追記 include ActiveHash::Associations has_many :recipes endバリデーションの設定
presence: true 空データは登録できない
numericality 数値のみを許可する
{ other_than: 0 } numericalityのオプション、0以外を保存
先ほど、Active Hashを用いて作成したモデルのid: 0には'---'とデータが入っていないので0以外を保存するということになります。app/models/recipe.rbclass Recipe < ApplicationRecord extend ActiveHash::Associations::ActiveRecordExtensions belongs_to :category belongs_to :time_required #以下追記 validates :title, presence: true validates :text, presence: true validates :category_id, numericality: { other_than: 0 } validates :time_required_id, numericality: { other_than: 0 } endビューの作成
コントローラー、ビューファイルの作成
ターミナルrails g controller recipes newコントローラーに以下を記述。
app/controllers/recipes_controller.rbclass RecipesController < ApplicationController def index end def new @recipe = Recipe.new end def create @recipe = Recipe.new(recipe_params) if @recipe.save redirect_to root_path else render :new end end private def recipe_params params.require(:recipe).permit(:title, :text, :category_id, :time_required_id) end endルーティングの設定
config/routes.rbRails.application.routes.draw do root to: 'recipes#index' resources :recipes, only: [:index, :new, :create] endビューファイルの編集
一部、Bootstrapを使用しております。
Bootstapについての記事も投稿いているのでこちらを参照してくだい
【図解あり】Rails6でBootstrapを導入してトップページを作成するActive Hashで作成したデータを表示させるにはcollection_selectというメソッドを使用します。
collection_selectは、下記のような順番で記述します。例<%= form.collection_select(保存するカラム名, オブジェクトの配列, カラムに保存する項目, 選択肢に表示するカラム名, オプション, htmlオプション) %>先ほど作成したCategoryモデルだと下記のような記述になります。
例<%= f.collection_select(:category_id, Category.all, :id, :name, {}, {class:"category"}) %>第5引数のオプションは先頭に値のない選択肢を表示するinclude_blankなどがあります。
今回はid: 0 に'---'を指定しているので空にしてあります。
第5引数、第6引数についてはRailsドキュメントを参照してください。
それではビューファイルに記述していきましょう。
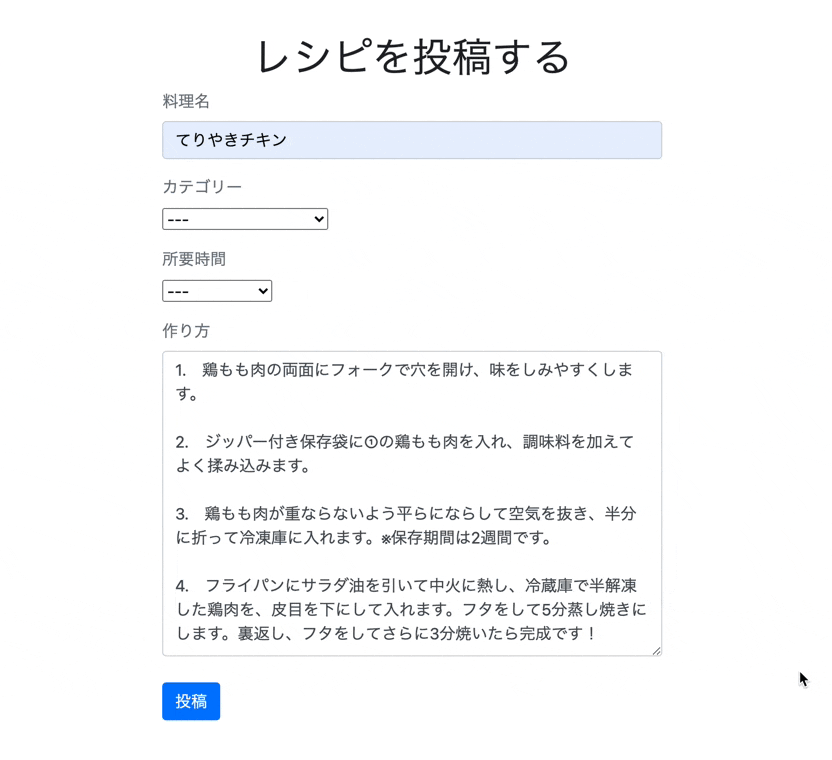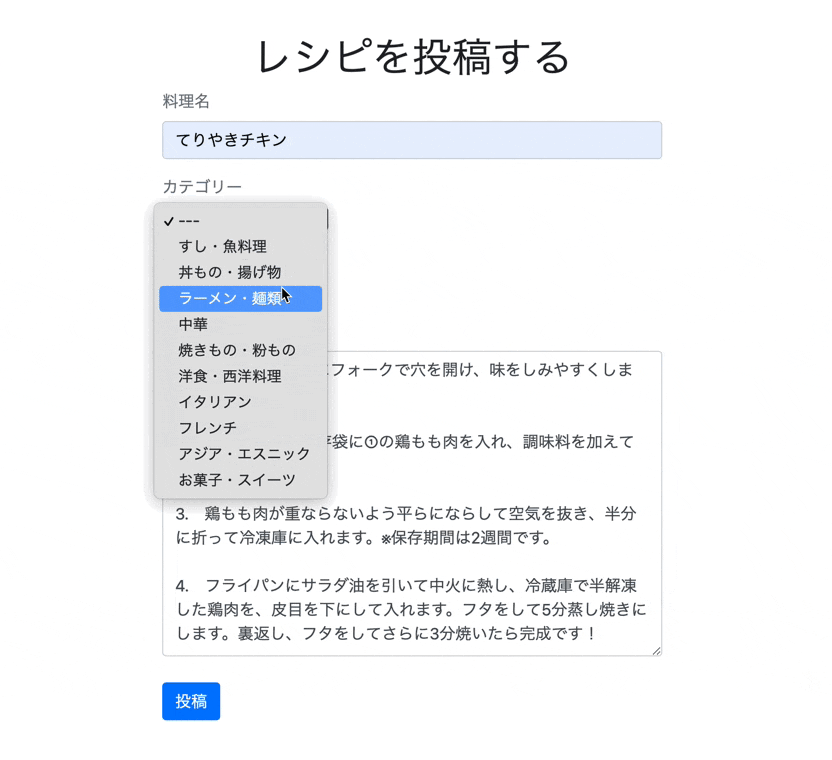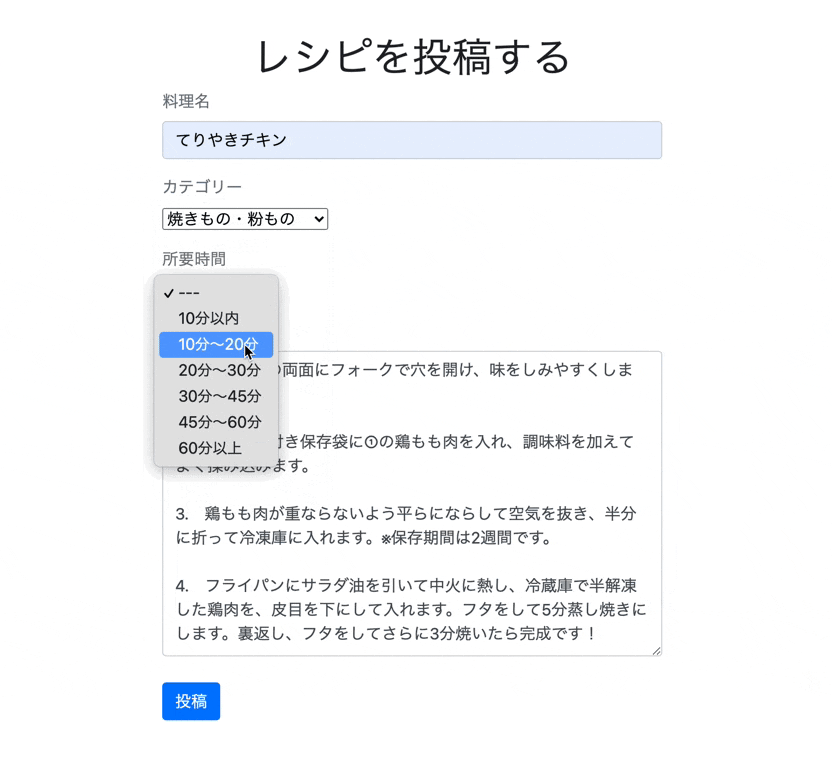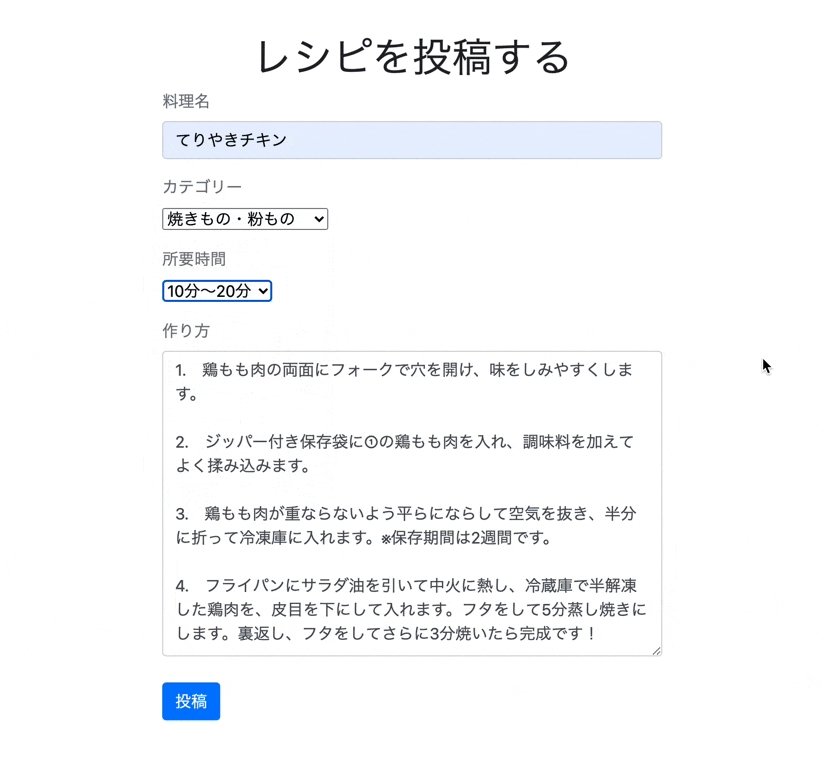
app/views/recipes/index.html.erb<div class="recipe-form "> <h1 class="text-center">レシピを投稿する</h1> <%= form_with model: @recipe, local: true do |f| %> <div class="form-group"> <label class="text-secondary">料理名</label><br /> <%= f.text_field :title, class: "form-control"%> </div> <div class="form-group"> <label class="text-secondary">カテゴリー</label><br /> <%= f.collection_select(:category_id, Category.all, :id, :name, {}, {class:"category"}) %> </div> <div class="form-group"> <label class="text-secondary">所要時間</label><br /> <%= f.collection_select(:time_required_id, TimeRequired.all, :id, :name, {}, {class:"time"}) %> </div> <div class="form-group"> <label class="text-secondary">作り方</label><br /> <%= f.text_area :text, class: "form-control"%> </div> <div class="actions"> <%= f.submit "投稿", class: "btn btn-primary" %> </div> <% end %> </div>最後にCSSを整えます。
.recipe-form{ width: 500px; margin: 0 auto; margin-top: 40px; }これで完成になります。
では、実際に投稿できるか確認してみましょう。
しっかり保存されいています。
- 投稿日:2021-02-27T14:49:24+09:00
初めてのRuby On Rails その2(DB編)
テーブル作成手順
1.データベースに変更を指示するファイルを作成
マイグレーションファイルと呼ばれるデータベースに変更を指示するファイルを作成する
今回はpostsテーブルを作成する例を見てみる
この場合、Postと単数形にするターミナルrails g model Post content:textPost:モデル名
content:カラム名
text:データ型以下の2ファイルが作成される
ツリー構造
├ app/
│ └ models/
│ └ post.rb
├ db/
└ migrate/
└ 20210226224717_create_posts.rbpost.rbclass Post < ApplicationRecord end20210226224717_create_posts.rbclass CreatePosts < ActiveRecord::Migration[5.0] def change create_table :posts do |t| t.text :content t.timestamps end end end2.データベースに変更を反映
ターミナルrails db:migrate自動で生成されるカラム
id,created_at,updated_atrails console
後述するテーブルへのデータ保存で使うので記載しておく
開始する場合
ターミナルrails console対話型でコマンドを実行できるようになる
終了する場合
ターミナルquitテーブルに投稿データを保存しよう
手順
- new メソッドで Post モデルのインスタンスを作成
- posts テーブルに保存
1. インスタンスを作成
ターミナルrails console > post = Post.new(content:"Hello world") > post2 = Post.new(content:"Hello world 2") > post3 = Post.new(content:"Hello world 3")2. 保存
DBに3つのデータが挿入される
ターミナル> post.save > post2.save > post3.saveデータ取得
最初のデータを取り出す
postsテーブルの最初のデータを取得
ターミナル> post = Post.first > post.content => "Hello world"すべてのデータを取り出す
postsテーブルの全データを配列で取得
allメソッドを用いるターミナル> posts = Post.all > posts[1].content => "Hello world 2"特定のデータを取り出す
postsテーブルの条件を指定した特定のデータを取得
find_byメソッドを用いるターミナル> post = Post.find_by(id: 3) > post.content => "Hello world 3"並び替えた状態でデータを取り出す
orderメソッドを用いる
desc:降順、asc:昇順ターミナル> posts = Post.all.order(created_at: :desc)データ更新
①編集したいデータを取得
②そのデータのcontentの値を上書き
③データベースに保存ターミナル> post = Post.find_by(id: 3) > post.content = "Rails" > post.save上記のタイミングで、updated_atカラムの値がデータを更新したときの時刻に更新される
データ削除
ターミナル> post = Post.find_by(id: 3) > post.destroyまとめ
DBの基礎知識があれば、特に難しいことはなかった。
SQLを書かないでデータ挿入、取得するのは少し違和感があった。
- 投稿日:2021-02-27T14:45:20+09:00
railsで投稿できないのを対処しました
構築環境
macOS Big sur
ruby 2.6.5
rails 6.0.0何があったのか
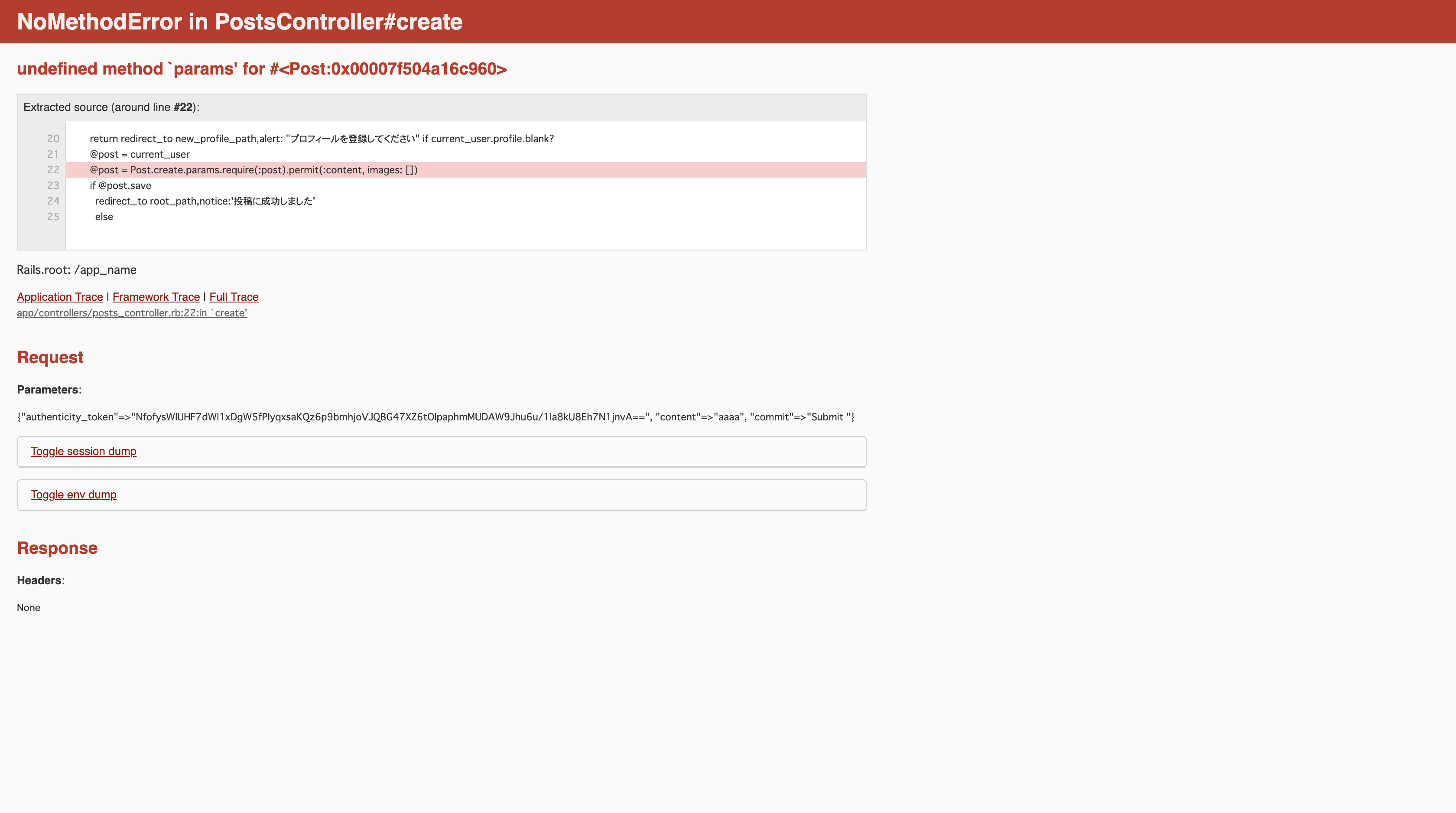
最初は、
こんな感じで、paramsが入っていないっていうエラー。しかしcontrollerを見てみてもおかしいところはなさそう
しかし、おかしいところを見つけましたね。
controllの記述を間違えてしまいました。↓こちらは修正前の、投稿に関するcontroller
posts_controller.rbclass PostsController < ApplicationController before_action :authenticate_user! before_action :find_post, only: [:edit, :update, :show, :destroy] def index @posts = Post.all end def new @post = Post.new end def edit @post = Post.find(post_params) end def create return redirect_to new_profile_path,alert: "プロフィールを登録してください" if current_user.profile.blank? @post = current_user @post = Post.create params.require(:post).permit(:content, images: []) if @post.save redirect_to root_path,notice:'投稿に成功しました' else render :new end end def update if @post.update(post_params) redirect_to root_path else render :edit end end def destroy if @post.destroy redirect_to root_path,alert: '投稿を削除しました' else redirect_to root_path end end private def post_params params.require(:post).permit(:content, images: []) end def find_post @post = Post.find(params[:id]) end def force_redirect_unless_my_post return redirect_to root_path,alert:'権限がありません'if @post.user != current_user end end修正後↓
class PostsController < ApplicationController before_action :authenticate_user! before_action :find_post, only: [:edit, :update, :show, :destroy] def index @posts = Post.all end def new @post = Post.new end def edit @post = Post.find(post_params) end def create return redirect_to new_profile_path,alert: "プロフィールを登録してください" if current_user.profile.blank? @post = current_user @post = Post.create params.require(:post).permit(:content, images: []) if @post.save redirect_to root_path,notice:'投稿に成功しました' else render :new end end def update if @post.update(post_params) redirect_to root_path else render :edit end end def destroy if @post.destroy redirect_to root_path,alert: '投稿を削除しました' else redirect_to root_path end end private def post_params params.require(:post).permit(:content, images: []) end def find_post @post = Post.find(params[:id]) end def force_redirect_unless_my_post return redirect_to root_path,alert:'権限がありません'if @post.user != current_user end end20行目の、
@post = Post.create.params.require(:post).permit(:content, images: [])
の部分を、
@post = Post.create params.require(:post).permit(:content, images: [])に変えました。
上の間違った文章だと、Postのcreateメソドッドのparamsを撮ってこいってなってしまうので、そりゃあparamsなんてないよって上のエラーの画像みたいに怒られるでしょうね。
しかし、したのようにしたことで、Post.createと、paramsのストラロングパラメーターの部分と分離するという本来伝えたかった意味になるので、通ったわけです。もうひとつやったことがありました。
class Post < ApplicationRecord has_many_attached :images belongs_to :user, optional: true endmodelの部分のアソシエーションは、userと結びつけていますなので、userと投稿であるpostは、1対多になります
↓が、userに関するmodelです。deviceを使っているので、それに関する記述がありますがここでは説明しないので気にしないでくださいclass User < ApplicationRecord # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable, :trackable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable, :trackable and :omniauthable has_many :posts has_one :profile, dependent: :destroy end
has_many :postsとしているので、userは、一人でもたくさんの投稿ができるようになっています。下が
post.rbclass Post < ApplicationRecord has_many_attached :images belongs_to :user, optional: true end
optional: trueをuserにつけることで、親クラス(user)の外部キーのnilを許可するようにすることで、投稿機能の中にあるsaveメソッドをきのうさせることができました。

- 投稿日:2021-02-27T14:40:02+09:00
【デイリードリル】解説&知識補完記事 51~60編
目次
51.コールバックの適用について
52.CSRFについて
53.仕様が決められたrailsアプリケーションの作成
54.ぼっち演算子
55.マイグレーションファイルの管理について
56.仕様が決められたrailsアプリケーションの作成
57.CSS、SCSSのインポートについて
58.if,else問題1
59.if,else問題2
60.rubyのAPI問題1コールバックの適用について
問題.1
Railsのコールバックを利用して以下の機能を実装してください。
①Pictweetに機能を追加する。 ②ユーザーが投稿を行ったら、textカラムに保存されるデータの最後に「!!」を自動で追加する。
解答
tweet.rbbefore_create :change_tweet def change_tweet self.text = text + "!!" end end
解説
そもそもコールバックとは何でしょうか?
コールバックとは、オブジェクトのライフサイクル期間における特定の瞬間に呼び出されるメソッドのことです。
簡単に言うと、必要なタイミングで呼び出せるように、あらかじめ定義しておく関数のことです!つまり、今回の問題では、「ユーザーが投稿を行ったら、textカラムに保存されるデータの最後に「!!」を自動で追加する関数を書け!!!」って問題です。
コールバックはmodelに定義します。詳しくはガイダンスを読みましょう。ガイダンス:Active Record コールバック
次に、解答のコードの解説をしていきます。
tweet.rbbefore_create :change_tweet def change_tweet self.text = text + "!!" end end
change_tweetっていうメソッドを定義し、それをbefore_createで呼び出しています。
before_createについては以下の記事を参照してください。参考:https://morizyun.github.io/ruby/active-record-callback.html
上記コードのselfには、これから保存されるTweetクラスのインスタンスが代入されます。
そのため、self.textとするとユーザーが入力した投稿のtextを取得することができます(@tweet.textみたいな感じで値を取得出来るイメージ!)。
通常、この場合のselfは省略可能です。※例外としてセッターメソッドを使う場合のselfは省略できないため、左辺のselfは必須となります。
よく分かりませんね、そういうものだと思いましょう。
詳しく知りたい方は自分でガイダンスを読んでくださいネ。CSRFについて
問題
Railsには、悪意のある攻撃に対してセキュリティを高める仕組みが様々用意されています。
CSRFと呼ばれるサイトの成りすましによるクラッキングに対して、どのような対策が取られているか述べてください。なお、CSRFがどのようなものか理解に自信がない場合はあらかじめこのことについて調べてからお答えください。
解答
ApplicationControllerにデフォルトで以下の記述がある。protect_from_forgery with: :exceptionこれにより、アプリで作られたフォームに対してトークンが発行され、正しいフォームからの通信なのかを判別することができる。
↓以下のポイントが記述できていればOK!
protect_from_forgeryについて述べられている- トークンの発行によりクラッキングを防いでいることが述べられている
解説
まずは専門用語の解説をしていきましょう。CSRF(クロスサイトリクエストフォージェリ)
Webアプリケーションに存在する脆弱性、もしくはその脆弱性を利用した攻撃方法のことをいいます。
脆弱性とは、コンピュータのOSやソフトウェアにおいて、プログラムの不具合等のミスが原因となって、発生した情報セキュリティ上の欠陥のことをいいます。
これにより、本来拒否すべき他サイトからのリクエストを受信して、処理してしまうという現象が生じる...。..................わからない!!!ムズカシイ!!!(;^ω^)
めっちゃ簡単にまとめると、
悪い人がWebアプリサーバにイタズラする
↓
訪問者がホームページにログインして操作する
↓
被害に遭う
ってことです。悪い人がアプリに細工するんです。いけませんねえ…
クラッキング
コンピュータネットワークに繋がれたシステムへ不正に侵入したり、コンピュータシステムを破壊・改竄するなど、コンピュータを不正に利用することをいう。
IDとパスワードを不正に入手してログインしたり、パスワードを総当たりして特定する悪いやつです。いけないですねえ。困った奴らだ…
対策
では、どのようにして対策しているのか??
実は、railsが対策を考えてくれているのです!!!RailsではCSRF対策として「セキュリティトークンを仕込む」という方法を採用しています。
それをやってくれているのがprotect_from_forgeryメソッドと、Railsが提供するformのヘルパーです。Railsが提供する
form_withなどのヘルパーを使うと、自動でセキュリティトークン(authenticity_token)を仕込んでくれます。すごい!!
protect_from_forgeryメソッドを記述すると、Rails側で正しいauthenticity_tokenがセットされるかどうかをチェックしてくれるので、CSRFを防ぐことができます!参考:
Rails セキュリティガイド:3 クロスサイトリクエストフォージェリ (CSRF)
3分でわかるXSSとCSRFの違い
RailsのCSRF対策について仕様が決められたrailsアプリケーションの作成
問題
以下の仕様を満たすRailsアプリケーションを作成してください。ただし、scaffoldを使用して構いません。
・authorsテーブルがある ・booksテーブルがある ・authorsとbooksは1対多のアソシエーションが組まれている ・authorsテーブルのレコードを削除すると、関連するbooksテーブルのレコードも同時に削除される
解答
(手順例)(ターミナルで以下を実行) > rails new sample-app -d mysql > rails g scaffold author name:string > rails g scaffold book name:string author:referencesauthor.rbclass Author < ApplicationRecord has_many :books ,dependent: :destroy end
解説
アプリケーションを作成するので、ターミナルでコマンドを実行します。ここであんまり馴染みがないのが、
scaffoldだと思います。
scaffoldは、アプリケーションを作成する際に必要なモデルやコントローラー、ビューを作っていき、さらに必要なルーティングを作成していく作業をまとめて行って、簡単にアプリケーションの雛形を作ってくれる機能です。
すごいやつだ。便利〜(・∀・)あとは、実装条件に必要なアソシエーションを記述していきます。
authorsテーブルのレコードを削除すると、関連するbooksテーブルのレコードも同時に削除される
これは、dependentを使用することで実装できます。
dependentは、親モデルを削除する際に、その親モデルに紐づく「子モデル」も一緒に削除できるオプションです。参考:
覚えておくと超便利!Ruby on Railsのscaffoldの使い方【初心者向け】
[Rails] dependent: :destroy についてぼっち演算子
問題
以下のような、Deviseを使ったRailsのコードがあるとします。
これはDeviseを使用したときのcurrent_userに対して、nicknameカラムに
あるデータを取得して@nicknameに代入することを意図したものです。@nickname = current_user.nicknameただし、ログインしないときにこれを実行するとnilに対してメソッドを使おうとしてエラーになってしまいます。
これを回避できる記述がRuby2.3からできるようになりました。
それがどのような記述か、またそれはどのような動きをするのか説明してください。
解答
@nickname = current_user&.nickname
解説
これはぼっち演算子(&)を知ってますか?って問題ですね。
知識があるかどうかの問題なので、ご存じない方はこれを機に頭の片隅に置いとくといいと思います。
&はsafe navigation operator、 lonely operator(ぼっち演算子)などと呼ばれる演算子です。メソッドに続けて記述すると、そのメソッドがnilでなかった場合のみ右辺のメソッドが実行されます。
もしnilだった場合は全ての演算結果としてnilを返します。つまり@nicknameにnilが代入されます。とても使い勝手の良い演算子のため、覚えて活用していきましょう。
なお、ぼっち演算子という命名は、&の記号が一人ぼっちで膝を抱えている人に見えるところからきています。
マイグレーションファイルの管理について
Railsのマイグレートに関して、以下の問いに答えてください。
問題1
Railsのマイグレーションファイルは、ファイルを作成後にマイグレートをして初めてDBに変更が加わります。
今存在している複数のマイグレーションファイルのうち、どのファイルまでマイグレートが終わっているか確認するためにターミナルでどのようなコマンドを打てばよいですか。
解答
rails db:migrate:status問題2
マイグレートを行なった後、その内容に誤りがあることがわかりました。どのように修正すればよいか、手順を述べてください。
解答
例1)
①rails db:rollbackで一度マイグレートされていない状態に戻す
②マイグレーションファイルを修正する
③再びマイグレートを行う例2)
①rails g migrationで新たなマイグレーションファイルを作成する
②修正箇所を正しい内容に変更するためのマイグレーションファイルを作成する
③マイグレートを実行する問題3
一度実行されたマイグレーションファイルは、次のマイグレートに影響は及ぼしません。
そのため、マイグレート後にファイルを変更したり削除したとしても今のDBに悪影響を及ぼすことはありません。ただし、上記の行為は絶対に行なってはいけません。
その理由はいくつかありますが、開発において致命的な不具合が出てしまう理由をお答えください。
解答
アプリケーションのファイルをデプロイ先にpushし、マイグレートを行なった時に、ローカル環境と違ったDBが出来上がったり、エラーになってしまうから。
仕様が決められたrailsアプリケーションの作成
問題
ターミナル> cd ~/projects/ > rails new reverse-app -d mysql > cd reverse-app/ > rails g scaffold item name:string > bundle exec rake db:create > bundle exec rake db:migrate仕様
・登録されたitemのnameが回文(上から読んでも下から読んでも同じになる文)なのかを判定するヘルパーメソッドpalindrome?を作成してください。 ・ヘルパーメソッドは、回文だった時は「回文です」そうでない時は「回文ではありません」という文字列を返すものとします。 ・一覧表示画面で、以下のようにその結果を表示させるようにしてください。
解答
items_helper.rbmodule ItemsHelper def palindrome?(word) word == word.reverse ? "回文です" : "回文ではありません" end endindex.html.erb<p id="notice"><%= notice %></p> <h1>Items</h1> <table> <thead> <tr> <th>Name</th> <th colspan="3"></th> </tr> </thead> <tbody> <% @items.each do |item| %> <tr> <td><%= item.name %></td> <td><%= palindrome?(item.name) %></td> #追加 <td><%= link_to 'Show', item %></td> <td><%= link_to 'Edit', edit_item_path(item) %></td> <td><%= link_to 'Destroy', item, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %> </tbody> </table> <br> <%= link_to 'New Item', new_item_path %> (17行目を追加)
解説
今回のポイントは、palindrome?メソッドを使用できるか?という部分です。
palindrome?メソッドは使用にも書いてあるように回分かどうかを判定するヘルパーメソッドです。Railsにおいては helpersディレクトリにヘルパーメソッドを管理するファイルがあるので、今回はitems_helper.rbに記載します。
items_helper.rbmodule ItemsHelper def palindrome?(word) word == word.reverse ? "回文です" : "回文ではありません" end end
reverseメソッドは、文字列を文字単位で左右逆転した文字列を返します。
そして、三項演算子を使用し、回文です or 回文ではありませんを表示出来るように記載しています。三項演算子とは、
a ? b : cと書くことで、a が真であれば b さもなくば cという結果を返すことができます。ちょいちょい使うので覚えておくと便利です。次に、作ったメソッドをビューで呼び出します。
ヘルパーメソッドはViewではどこからでも呼び出せるため、呼び出したい部分に記載します。index.html.erb#省略 <% @items.each do |item| %> <tr> <td><%= item.name %></td> <td><%= palindrome?(item.name) %></td> #追加 <td><%= link_to 'Show', item %></td> <td><%= link_to 'Edit', edit_item_path(item) %></td> <td><%= link_to 'Destroy', item, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %> #省略先程作ったメソッドを呼び出し、ビューに表示させています。
これで、使用の要件を満たすコードの完成です!!参考:
Ruby 3.0.0 リファレンスマニュアル instance method String#reverse
ヘルパーメソッドをつくろう
Ruby入門 - 演算子css, scssのインポートについて
問題
rails newを実行しアプリケーションを作成した段階では、application.cssに
*= require_tree .という記述があり、これによってCSSファイルを読み込んでいます。SCSSを使用する際は、ファイルの拡張子をscssに変更した上で、@importでファイルを読み込みます。
この時の、requireと@importはどう違うのか、それぞれのインポートの仕組みを踏まえて答えてください。
解答
requireはRailsのアセットパイプラインの仕組みを使ってファイルをインポートする。アセットパイプラインは、cssファイルやJavaScriptのファイルを1つにまとめ、圧縮することで処理速度を早くするための仕組み。sprocketsというgemがこの機能を担っている。
それに対して@importはscssが用意しているメソッド。そのため、application.scssと拡張子を変更しないと使えない。また、application.scssからscssファイルをインポートするために使用する。
if,else問題1
問題
平日でないまたは休日の場合は「True」と返信し、
休日ではない場合は「False」と条件分岐させるメソッドを作りましょう。呼び出し方
sleep_in(weekday, vacation)出力例
sleep_in(false, false) → False sleep_in(true, false) → False sleep_in(false, true) → True
解答
def sleep_in(is_weekday, is_vacation) if (is_weekday != true) || (is_vacation == true) puts "True" else puts "False" end end is_weekday = true is_vacation = false sleep_in(is_weekday,is_vacation)
解説
ポイントは演算子をいくつも使っていることですね。
おそらくコードを見てよくわからない、と感じる方は
sleep_inの中身がよくわからないのではないかと思います。def sleep_in(is_weekday, is_vacation) if (is_weekday != true) || (is_vacation == true) puts "True" else puts "False" end end仮引数(
is_weekday,is_vacation)の結果がtrueかどうかを判別するために、if文と論理演算子(||)、比較演算子(!=、==)を組み合わせて使用しています。理論演算子(
||)は、a または b が true であればという演算子です。
比較演算子は、!=はa と b が等しくないとき、==はa と b が等しいとき、という演算子です。つまり、
is_weekdayがtrueと等しくなかったら(falseだったら)、もしくはis_vacationがtrueだったらputs "True"を実行してね、っていうコードになります。ややこしいコードはいきなり細部から読んでもよくわからないので、if文が使われていて、その条件式の中に演算子が使われていて…と大枠から見ていくと解読しやすくなると思います。
参考:Ruby入門 - 演算子
if,else問題2
問題
あなたは警官です。aとb二人の容疑者の取り調べをしています。
どちらも証言がTrue、またはFalseであればその証言はTrueです。
しかしどちらかがFalseでTrueであればその証言はFalse、と出力するメソッドを作りましょう。呼び出し方
police_trouble(a, b)出力例
police_trouble(true, false) → False police_trouble(false, false) → True police_trouble(true, true) → True
解答
def police_trouble(a, b) if a && b || !a && !b puts "True" else puts "False" end end
解説
こちらは問題58と似ていますね。条件式の中に演算子を用いています。
今回使用しているのは、論理演算子(
!、&&、||)です。
!はa が false であればという意味で、&&はa かつ b が true であれば、という意味です。
||は、問題58でも記述したとおり、a または b が true であればという演算子です。つまり、aとbがどちらもtrueである、もしくはaとbがどちらもfalseであるという条件のときに、
puts "True"を実行してね、というコードになります。参考:Ruby入門 - 演算子
rubyのAPI問題1
問題
任意の文字に対してn番目の文字を消し、
その消した文字を出力するメソッドを作りましょう。※ヒント:APIを利用して問題を解きましょう。
参考URL: https://docs.ruby-lang.org/ja/search/呼び出し方
missing_char(string, num)出力例
missing_char('kitten', 1) → 'itten' missing_char('kitten', 2) → 'ktten' missing_char('kitten', 4) → 'kittn'
解答
def missing_char(array, n) array.slice!(n) puts array end
解説
今回は、任意の文字に対してn番目の文字を消すために必要な処理(メソッド)を使用する必要があるようです。
今回は、
slice!メソッドを使用します。
slice!メソッドは、指定した範囲を文字列から取り除いたうえで取り除いた部分文字列を返します。注意点として、
sliceメソッドとは違うので注意してください。
sliceメソッドは、文字列の任意の部分文字列を取得しますが、元の文字列には影響がありません。
対して、slice!メソッドは破壊的メソッドであるため、戻り値として指定した要素を返しますが、同時に自分自身から戻り値に返した部分を削除してしまいます。コードで見るとわかりやすいかと思います。
#sliceの場合 str = aab puts str.slice(2) #=>b puts str #=>aab #slice!の場合 str = aab puts str.slice!(2) #=>b puts str #=>aa今回は、n番目の文字を消すようなコードを書く問題であるため、
slice!メソッドを使用します。参考:
【Ruby入門説明書】ruby sliceについて解説
Ruby 3.0.0 リファレンスマニュアル instance method String#slice!


- 投稿日:2021-02-27T13:23:07+09:00
機密情報に関わる文字列の比較は == ではなく secure_compare を使おう
はじめに
パスワードハッシュやトークンなどの文字列を比較する際には、
==ではなくRack::Utils.secure_compareを使ったほうが良いということを学んだので、勉強の記録として共有します。
==での文字列比較の危険性
Rack::Utils.secure_compareを知るまでは、まさか==に危険性があるとは思いませんでした1が、パスワードハッシュやトークンなどを比較する際には==は使用しないほうが良いです。その理由は、Timing Attack (タイミング攻撃) と呼ばれる攻撃によって機密情報である文字列を推測されてしまう可能性があるからです。
タイミング攻撃とは、機密情報となる文字列を左から見ていったときに、どこまで合っているかを、文字列比較の処理時間 (
falseが返ってくるまでの時間) を利用して、推測するという攻撃手法です。この説明だけだといまいちわかりづらいと思いますので、もう少し詳しく説明します。
==による文字列の比較は、左から文字を見ていって、異なる文字が出てきた時点ですぐさまfalseを返します。たとえば、
"abcdef"と"abcefg"という文字列を比較する際、左の文字から比較していき、4 文字目でdとeという異なる文字が登場したので、5 文字目以降は見ずにfalseを返します。abcdef abcefg ^ ここで false を返すこの仕様は、処理の高速化のために採用されているものですが、これを攻撃に利用されてしまう可能性があるということです。
たとえば攻撃者が
"xaeteuijft"というトークンを知りたかったとしましょう。まずは適当にありがちな文字列をサーバに投げて比較させます。その際に、処理結果がすぐに返ってきた場合は、文字列の (左から見て) 早い段階で文字が間違っていることになります。
何回か繰り返しているうちに、左側の文字が合ってくると、処理結果が返ってくるまでにわずかに時間がかかるようになります。
処理結果が返ってくるのが若干遅くなれば合っている、速くなれば間違っている、というのを何度も繰り返すと、いずれ本当の文字列がバレてしまう可能性があるということです。短くて単純なものならなおさらです。
これがタイミング攻撃の攻撃手法になります。そして、この攻撃を防ぐための文字列比較のメソッドが
Rack::Utils.secure_compareと呼ばれるものです。
Rack::Utils.secure_compareの実装を見てみるでは、
Rack::Utils.secure_compareはいったいどんな実装になっているのでしょうか。さっそく見てみましょう。# Constant time string comparison. # # NOTE: the values compared should be of fixed length, such as strings # that have already been processed by HMAC. This should not be used # on variable length plaintext strings because it could leak length info # via timing attacks. if defined?(OpenSSL.fixed_length_secure_compare) def secure_compare(a, b) return false unless a.bytesize == b.bytesize OpenSSL.fixed_length_secure_compare(a, b) end else def secure_compare(a, b) return false unless a.bytesize == b.bytesize l = a.unpack("C*") r, i = 0, -1 b.each_byte { |v| r |= v ^ l[i += 1] } r == 0 end end
OpenSSL.fixed_length_secure_compareが定義されている場合はこれを使うようになっているのですが、今回は説明のわかりやすさの観点で、こちらではなく、Rack の実装のほうを見てみます。def secure_compare(a, b) return false unless a.bytesize == b.bytesize l = a.unpack("C*") r, i = 0, -1 b.each_byte { |v| r |= v ^ l[i += 1] } r == 0 end引数
aに本当の文字列 (トークンなど)、引数bに対象となる文字列 (クライアントからやってくる文字列など) が来るものとします。以後、aとbをそれぞれ「本当の文字列」、「対象となる文字列」と呼ぶことにします。バイト長の比較
return false unless a.bytesize == b.bytesizeまず最初の段階で、そもそもバイト長が違っていたら
falseを返します。本当の文字列を 8 bit 符号なし整数の配列に変換
l = a.unpack("C*")本当の文字列をアンパックします。
アンパックというのは、簡単に言うと特定のルールに従って文字列を分解し、配列で返すメソッドです。今回は引数に
"C*"が指定されているので、文字列中の各々の文字を 8 bit 符号なし整数に変換して、配列で返します。
"abcdef".unpack("C*") => [97, 98, 99, 100, 101, 102]
"a"が97、"b"が98、"c"が99、、、とそれぞれ対応しています。変数の初期化
r, i = 0, -1
rに0、iに-1が入ります。文字列の比較
b.each_byte { |v| r |= v ^ l[i += 1] }ここがメインの部分で、少しだけ複雑なので丁寧に解説します。
対象となる文字列を
each_byteでループ処理します。たとえばbが"abcdef"だったら、vには97、98、99、、、が順番に入ってきます。その
vと、先ほど本当の文字列を 8 bit 符号なし整数でアンパックした配列lとを、最初のほうから順番に比較していきます。ぼく自身も最初見たときに少し戸惑ったのですが、
l[i += 1]というのは、先にi += 1が実行されてからlの中身が参照されます。iは最初-1から始まるので、先にiが0になってからl[0]が評価されるので、配列を最初から見ているということです。そして
v ^ l[i += 1]の^は XOR (排他的論理和演算子) です。こういったライブラリではなく、アプリケーションでしか Ruby を書かない人にとっては、あまり馴染みがないかもしれません。
排他的論理和
排他的論理和は、2 つの数値を 2 進数で表記した際に、両者が異なる数字なら
1、同じ数字なら0を返す演算です。01110101 00100010上記の 2 つの 2 進数の排他的論理和を取ると、以下のようになります。
01010111左の 1 文字目は両者とも
0なので0、2 文字目は片方が1で片方が0なので1、3 文字目は両者とも1なので0、、、といった感じです。
1 2 3 4 5 6 7 8 1 つめの 2 進数 0 1 1 1 0 1 0 1 2 つめの 2 進数 0 0 1 0 0 0 1 0 排他的論理和 0 1 0 1 0 1 1 1
01110101は 10 進数で表すなら117、00100010は34、01010111は87となります。つまり、10 進数表記の117と34の排他的論理和を取ると87になる、というわけです。117 ^ 34 => 87
さて、Rack の実装の話に戻ると、
v ^ l[i += 1]なので、対象となる文字列と、本当の文字列の 8 bit 符号なし整数を左から順番に比較しているのでした。ここで、両者が同じ文字 (数字) だったら、何が返ってくるでしょう。たとえば両者とも
"a"だったら97を排他的論理和で比較することになります。両方同じ数字だということは、当然すべての bit が同じなので、0 になります。
1100001 1100001を比較すると、どの bit もすべて同じなので、
0000000となります。
97 ^ 97 => 0つまり、同じ文字 (数字) なら
0になり、そうじゃなければ0じゃない値になるということです。そしてこの結果を
rに代入していますが、ただの代入ではなく、論理和代入になっています。r |= v ^ l[i += 1]これは、以下と同様です。
r = r | v ^ l[i += 1]つまり、
rと、先ほどの文字 (数字) 比較を論理和演算した結果をrに代入しています。論理和演算は、どちらか片方が1なら1で、両者とも0なら0を返す演算です。
1 つめの bit 2 つめの bit 論理和 0 0 0 0 1 1 1 0 1 1 1 1
rは0で初期化されていたので、先ほどの文字 (数字) 比較の結果、すべての bit が0ならrもすべて0が入り、0じゃない値がどこかの bit に入ったら、rもどこかの bit に0じゃない値が入ります。ということは、本当の文字列と、対象となる文字列が完全に一致していれば、
rはずっと0のままなので最終的にも0になり、逆にどこか一箇所でも違う文字になっていれば、つまり一致していなければ、rは0じゃない値になる、というわけです。一度でも
rに0じゃない bit が含まれてしまうと、その bit を再び0に戻すことは、論理和では無理です。なぜなら片方が1なら1になってしまうからです。つまりrは最初から最後までずっと0じゃないと、最終的にも0にはなりえないというわけです。裏を返せば、
b.each_byteで本当の文字列と対象となる文字列を一文字ずつ比較した結果、rが0のままであるなら両者の文字列は一致していることになります。真偽値の返却
r == 0最後に
rが0かどうかを見ていて、0(両者の文字列が一致している) ならこのメソッドはtrueを返し、0じゃなければ (両者が一致していなければ)falseを返すというわけです。
少し長い説明になりましたが、これで
Rack::Utils.secure_compareがどのように文字列を比較しているかがわかりました。
Rack::Utils.secure_compareの安全性文字列比較は
==でもできるわけですから、肝心なのは、冒頭で説明したタイミング攻撃が防げるかどうかです。
==の場合は文字の比較の途中で違う文字が登場したらすぐさまfalseを返す仕様でしたが、Rack::Utils.secure_compareはどうでしょうか。文字列の比較は以下の部分です。
b.each_byte { |v| r |= v ^ l[i += 1] }処理の高速化という意味では、
rが途中で0じゃなくなれば、文字列が一致していないことになるので、falseを返すことができますが、それだと本末転倒です。途中でfalseを返したらタイミング攻撃が成立してしまう可能性があります。しかし
Rack::Utils.secure_compareは、文字列比較の途中でfalseを返すようなことはしていないので、途中で文字が違うことがわかっても最後まで比較し続けます。そのためループ内の処理時間は文字列が合っていようが間違っていようが変わらず、タイミング攻撃 (文字列そのものの推測に限る) は成立しないと言えます。
Rack::Utils.secure_compareの危険性ただし注意点もあります。これは ソースコード内のコメント にも記載されていますが、タイミング攻撃で、本当の文字列の 長さ を推測されてしまう危険性はあります。
これが先ほど「文字列そのものの推測に限る」と書いた理由です。
Rack::Utils.secure_compareはたしかに、タイミング攻撃による「文字列そのものの推測」は防ぐことができます。しかし、「文字列の長さの推測」までは防げない可能性があります。理由はここにあります。
return false unless a.bytesize == b.bytesizeそもそも比較する 2 つの文字列のバイト長が異なっていたら文字列の比較をせずにすぐさま
falseを返しています。もし本当の文字列が 10 文字だったとしたら、10 文字以外の長さの文字列を対象となる文字列として渡すと、すぐさま
falseが返ってくるので、順番に文字列の長さを変えて試していけば、そのうち文字列が長さがバレてしまいます。つまりどういうことかというと、
Rack::Utils.secure_compareは 可変長の平文文字列では安全ではない ということになります。使用用途としては、HMAC のような、文字列長が常に一定になるアルゴリズムを使って、文字列をハッシュ化してから使うことになります。ハッシュ化せずそのままの文字列 (平文文字列) をこのメソッドに渡してしまうと長さが推測されてしまう可能性があります。
さいごに
今回は機密情報に関わる文字列を Ruby で安全に比較する方法として
Rack::Utils.secure_compareをご紹介しました。この記事では Ruby を例に挙げましたが、他の言語でも似たようなライブラリが提供されているかと思いますので、機密情報に関わる文字列を比較する際は一度調べてみることをおすすめします。
参考サイト
一応、誤解のないように書いておくと、機密情報に関わらない文字列の比較に
==を使用することは何も問題はありません。Ruby の==の実装に脆弱性があるというわけではないです。 ↩
- 投稿日:2021-02-27T13:14:58+09:00
「action_args」のソースから学ぶ「Ruby」① Gemの作り方
目的
Gemについて勉強したかったのでRailsで使われている「action_args」ソースから学ぶのが目的
ここで言うGemはRubyGemsが公開しているRubyのパッケージのことですaction_argsについて
action_argsは、コントローラーのアクションメソッドを拡張して、任意のアクションのメソッド定義で対象の引数を指定できるようにしたRailsプラグインです。詳細内容はREADME参考
git clone https://github.com/asakusarb/action_args.gitGemの作り方
aciton_argsのソースを分析する前にGemの作り方から学ぶ
1. bundlerを最新にする
# gemのアップデート $ gem update --system # bundlerのアップデート $ gem update bundler $ bundler -v Bundler version 2.2.112. Hello gemを作る
Gemのベースを作成します。
bundle gem hello_gem -tでRspecが使えると思いましたが、minitestになってたので
公式を参考にして--test=rspecを指定して解決できました。
https://bundler.io/v2.1/bundle_gem.html$bundle gem hello_gem --test=rspec $cd hello_gem $ tree . ├── Gemfile ├── README.md ├── Rakefile ├── bin │ ├── console │ └── setup ├── hello_gem.gemspec ├── lib │ ├── hello_gem │ │ └── version.rb │ └── hello_gem.rb └── spec ├── hello_gem_spec.rb └── spec_helper.rb3. hello_gem.gemspecを修正
hello_gem.gemspecファイルを開くとTODOと書かれているところがあるので自分が作るGemに合わせて修正しないとbundle installできません。
修正が終わったら依存gemをインストールします。$bundle install4. gemの実装
lib/hello_gem.rbに処理を書きます。
bundle gem hello_gemから自動生成された以下のファイルにコードを追加します。lib/hello_gem.rb# frozen_string_literal: true require_relative "hello_gem/version" module HelloGem class Error < StandardError; end # helloを出力 def self.say_hello "hello!!!" end end4. テスト実装
spec/hello_gem_spec.rb# frozen_string_literal: true RSpec.describe HelloGem do it "has a version number" do expect(HelloGem::VERSION).not_to be nil end it "say_hello test" do expect(HelloGem.say_hello).to eq("hello!!!") end end$ bundle exec rake spec5. 実行
$ ./bin/console irb(main):001:0> HelloGem.say_hello => "hello!!!"これでGemの基本的な作り方はわかったので次回からは本格的に「action_args」のソース分析に入ります
- 投稿日:2021-02-27T12:47:44+09:00
アプリ開発実践入門7 Modelとデータベース モデルの基本
今日の教科書
モデルを作る
rails generate model モデル名 設定項目:モデル作成のコマンド
基本モデル名とクラス名とファイル名は大文字小文字の差はあれど一緒である。コマンドで作成されるファイルについて
モデル名.rb:モデルのソースコード
生成日時_create_モデル名の複数形.rb:マイグレーションというデータベースの更新に関する処理のためのファイル
モデル名_test.rb:テストのためのソースコード
モデル名の複数形.yml:テストに関する情報を記述したファイルモデルのソースコード
class モデル名 < ApplicationRecord end最初の記述内容。ApplicationRecordというクラスが継承されている。モデルは全てこれを継承している。ApplicationRecordは最初から組み込まれているものではない。application_record.rbファイルが作成されていて、ここに書かれている。
このクラスはActiveRecord:Baseというクラスを継承している。これはモデルの元になっている機能で含み、これの機能のクラスを使っている。マイグレーションの実行
データベースを使うためにモデルに必要なテーブルをデータベースに用意する作業が必要。
マイグレーションはデータベースのアップデート作業であり、情報を用意しておきこれを元に
最新の状態に更新する。
rails db:migrate:マイグレーションのコマンド。これでなくブラウザのエラーメッセージと一緒に出るボタンを押してもできる。マイグレーションファイルについて
class クラス名 < ActiveRecode::Migration[6.0] def change create_table :テーブル名 do |変数| 処理 end end end自動生成。
シードを作る
ダミーのデータを用意してデータベースの動きを把握する。そのためシードに記述する。
rails db:seed:seeds.rbをシードとして実行するコマンド。データベースにデータが追加される。コントローラーを作成
rails generate controller モデル名複数形 アクション:モデルのコントローラーとアクションとテンプレートが作成される。モデルは単数系、コントローラーは複数系という命名規則に則る。アクションでデータを表示する
class PeopleController < ApplicationController def index @msg = `モデル名 data.` @data = モデル名.all end end
変数 = モデル名.all:allはモデルのデータを全て、配列のようなものにして取り出すメソッド。
得られるものの正確な名称はActiveRecord::Relationというオブジェクト。
Enumerableという機能を使って配列のように値を順番に取り出せるようにしてくれる。テンプレートの作成
繰り返し処理を使って順にデータを取り出していく。
<% @data.each do |obj| %> objを処理 <% end %>@dataから順にデータを取り出して変数objに入れて処理を実行している。
モデルを利用してデータベースから取り出されるデータは全てモデルのインスタンス。
テーブルに用意されている項目で保管されていて、全て取り出せる。<td><%= obj.id %></td> ・・・モデル作成時に自動的に生成される項目がある。
id:データにつけられる番号
created_at:データの作成日時
updated_at:データの最終更新日時ルーティグの設定
ジェネレータコマンドで作ると自動で生成される。
- 投稿日:2021-02-27T11:50:52+09:00
ローカル 環境開発 Ruby on Railsの環境構築方法
はじめに
ローカル環境でRailsの環境構築ができるようになり、http://localhost:3000/で以下の表示がされるとゴールです。
初めて、ローカル環境で構築しましたので、その方法を記載します。
到達点
以下の1点を達成する
・http://localhost:3000/ で上記の図を表示する仕様
初期仕様
・mac
・Ruby(2.6.3)今回インストールするバージョン
・Ruby on Rails (6.1.1)
・MySQL (8.0.23)
・Homebrew (2.7.6)流れ
① Homebrewインストール
② bundlerインストール
③ MySQLインストール
④ railsインストール
⑤ アプリケーションの新規作成
⑥ サーバー立ち上げ① Homebrewインストール
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"ターミナルで上記のコマンドでHomebrewインストールをします.
brew -vインストールされたか確認します
② bundlerインストール
gem install bundlerターミナルで上記のコマンドでbundlerをインストールします
③ MySQLインストール
brew install mysqlターミナルで上記のコマンドでMySQLをインストールします
brew info mysqlインストールされたか、バージョンも含め確認します
MySQLの自動起動設定
brew services start mysqlこのコマンドでmacが再起動すると、自動的にSQLが再起動されます
MySQLパスワード設定
MySQLはHomebrewでインストールすると、パスワードなしでしようできるため、
パスワードありにしたい場合、下記のコマンドをしますmysql_secure_installation
④ railsインストール
gem install railsターミナルで上記のコマンドでRailsをインストールします
rails -vインストールされたか、バージョンも含め確認します
⑤ アプリケーションの新規作成
rails new app -d mysql rails new app *これでもできるかもrailsはmysqlがデフォルトでないため、
-d mysqlを使いましたが必要ないかもしれません。
このコマンドで、アプリケーションの新規フォルダを作成します。
数分かかります。
⑥ サーバー立ち上げ
cd app rails db:create *データベースがないとエラーになりました rails sappフォルダに移動し,サーバーを立ち上げます。
http://localhost:3000/に以下の画面が表示されれば、成功です!!
参考記事
VS codeの初期設定とRuby on Railsの環境設定 環境構築
ActiveRecord::NoDatabaseError: Unknown database 'アプリ名_development' 解決策

- 投稿日:2021-02-27T10:14:52+09:00
[Ruby]irbが動作しなくなったお話。[エラー]
先日、irbを起動させようと思ったら、、、
~ $ irb /usr/local/Cellar/rbenv/1.1.2/libexec/rbenv-exec: /Users/inouesyo/.rbenv/versions/2.6.6/bin/irb: /Users/inoueshou/.rbenv/versions/2.6.6/bin/ruby: bad interpreter: No such file or directory /usr/local/Cellar/rbenv/1.1.2/libexec/rbenv-exec: line 47: /Users/inouesyo/.rbenv/versions/2.6.6/bin/irb: Undefined error: 0という表示が出て起動できず。
エラーを読むに原因は恐らく、以前にホームディレクトリの名前を変更したのでそれが原因でパスが通ってないのかな?と推測。と言うことで、user/Users/inouesyo/.rbenv/versions/2.6.6/bin/irb:のirbファイルを編集する。
irbファイルはUNIX実行ファイルとなっているため、右クリック→このアプリケーションで開く→からテキストエディタで開く。
するとirb#!/Users/inoueshou/.rbenv/versions/2.6.6/bin/ruby # # This file was generated by RubyGems. # # The application 'irb' is installed as part of a gem, and # this file is here to facilitate running it. # require 'rubygems' version = ">= 0.a" str = ARGV.first if str str = str.b[/\A_(.*)_\z/, 1] if str and Gem::Version.correct?(str) version = str ARGV.shift end end if Gem.respond_to?(:activate_bin_path) load Gem.activate_bin_path('irb', 'irb', version) else gem "irb", version load Gem.bin_path("irb", "irb", version) end一行目のホームディレクトリの部分が以前のホームディレクトリ名になっていたので変更。
~ $ irb irb(main):001:0>無事に動作し一安心。
- 投稿日:2021-02-27T10:08:12+09:00
Rspecを動かすまでまとめ(簡易版: 単体・統合テスト)
今回はテスト内容などにはあまり触れていません
Rspecを使ってテストするまでをまとめています。Gemfilegroup :test do gem 'capybara' gem 'rspec-rails' gem "factory_bot_rails" gem 'faker' endgroup :test do 〜 endの中を変更し、bundle install します。
ターミナル$ bundle install $ rails g rspec:installspec/rails_helper.rb#最後の方に追加する config.include FactoryBot::Syntax::Methods end記述することでletを使用した際に、FactoryBotが使用できるようになります。
factories/item.spec.rbFactoryBot.define do factory :"モデル名" do "カラム名" { Faker::Lorem.characters(number: 10) } end endFaker::Lorem.characters(number: 10)とは
テスト用の文字列を作成する。今回の場合はカラム名のところに10文字のテストデータを作成してくれます。spec_helper.rbRSpec.configure do |config| #追加します config.before(:each, type: :system) do driven_by :rack_test end #省略 end単体テスト
models/item_spec.rbrequire 'rails_helper' RSpec.describe 'Itemモデルのテスト', type: :model do describe 'バリデーションのテスト' do subject { item.valid? } let(:user) { create(:user) } let(:genre) { create(:genre) } let!(:item) { build(:item, user_id: user.id, genre_id: genre.id) } context 'nameカラム' do it '空でないこと' do item.name = '' is_expected.to eq false end it '2文字以上であること: 2文字は〇' do item.name = Faker::Lorem.characters(number: 2) is_expected.to eq true end it '2文字以上であること: 1文字は×' do item.name = Faker::Lorem.characters(number: 1) is_expected.to eq false end end end endターミナル$ rspec spec/models/item_spec.rb単体テストの実行できます。
今回はItemモデルのテスト実行しています。統合テスト
system/test.spec.rbrequire 'rails_helper' describe 'トップ画面のテスト' do before do visit root_path end context '表示内容の確認' do it 'URLが正しい' do expect(current_path).to eq '/' end end endターミナル$ rspec spec/system/test.spec.rb統合テストの実行できます。
これでテスト環境は出来ましたので
追加したい項目を書いていくだけになります。おまけ
system/test_spec.rblet(:"モデル名") { FactoryBot.create(:"モデル名", "カラム名": "データ") } let(:item) { create(:item, user_id: user.id, genre_id: genre.id) }2個目の記述のようにFactoryBotを省略できます。
letとlet!の違い
item_spec.rblet(:genre) { create(:genre) } let!(:item) { build(:item, user_id: user.id, genre_id: genre.id) }
- letを使用した場合は処理が行われずにitの中で呼ばれたときにcreateが実行されます。
- let!を使用した場合はそのまま処理される。
毎回呼び出す必要のないものは" ! "を外した方がわかりやすくなります。createとbuildの違い
item_spec.rblet(:genre) { create(:genre) } let!(:item) { build(:item, user_id: user.id, genre_id: genre.id) }
- createはにメモリにデータを保存する。
- buildはDBにデータ保存する。
使い分け方
今回はアイテムを登録するためのバリデーションをテストしますので
createで実行すると一回でもテストに通るとメモリに残っているので
アイテムが登録されている状態でバリデーションのテスト行うようになってしまうため、
ちゃんとテストが実行されているかが判断できなくなります。
これから確認したい対象物にはbuildを使うことがいいと思います。
- 投稿日:2021-02-27T08:53:51+09:00
if文なしでじゃんけん
if文なしでじゃんけんに触発されました
プログラム
janken.rbHANDS = ["✊", "✌️", "?"] RESULTS = ["あいこ", "かち", "まけ"] me = gets.chomp enemy = gets.chomp p RESULTS[(HANDS.index(me) - HANDS.index(enemy)).abs]
- 投稿日:2021-02-27T07:54:25+09:00
【 Ruby on Rails 6.0 】 AWS + Nginx + Unicornでデプロイ⑦
始めに
前回の内容でNginxというWebサーバーを導入しRailsアプリを本番環境で起動出来ました。
しかし、現状だと開発環境で変更したものを本番環境に反映させるのに工数が多く不便です。
そこで、Capistranoという自動デプロイツールを導入しコマンドひとつでデプロイ作業を完了できるように設定していきます。目次
目次 内容 セクション1 EC2インスタンス作成 セクション2 Linuxサーバー構築 セクション3 データベース設定 セクション4 EC2上でGemをインストールし環境変数を設定 セクション5 Railsアプリを起動 セクション6 Nginxの導入 セクション7 自動デプロイ(今回の内容) セクション8 独自ドメイン取得 Capistranoの導入
必要なGemをインストールし、Capistranoを動かすために必要な設定ファイルを生成します。
Gemfile(ローカル)group :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capist endターミナル(ローカル)$ bundle install # gemを読み込めたら、下記のコマンドを打ちます。 $ bundle exec cap installするとデプロイについての設定を書くファイルが自動で生成されます。
Capfileを編集
Capfileは、capistrano全体の設定ファイルです。
Capifilerequire "capistrano/setup" require "capistrano/deploy" require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn' Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r }デプロイについての設定ファイルを編集
cap installコマンドを打つと、config/deploy配下にproduction.rbとstaging.rbの2 種類のファイルが生成されます。production.rbですが2つファイルがあります
❌ config/environment/production.rb
⭕️ config/deploy/production.rb今回作業はするのはconfig/deploy/production.rbです。
production.rbを下記のように編集
config/deploy/production.rb# 最下部に追記 server 'XX.XXX.XX.XXX(Elastic IP)', user: 'ec2-user', roles: %w{app db web}deploy.rbを編集
config/deploy.rb# 全て削除して以下を追記 # config valid only for current version of Capistrano # capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '○.○○.○(Capistranoのバージョン)' # Capistranoのログの表示に利用する set :application, '○○○(自身のアプリケーション名)' set :deploy_to, '/var/www/○○○(アプリ名)' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:○○○(Githubのユーザー名)/○○○(レポジトリ名.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, '○.○.○(rubyのバージョン)' #カリキュラム通りに進めた場合、2.5.1か2.3.1です # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/○○○○○.pem(ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス 例:~/.ssh/key_pem.pem))'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end end以下の5点は書き換えが必須です。
- 3行目のはご自身のバージョンを記述しましょう。
- 6行目の<自身のアプリケーション名>はご自身のものを記述しましょう。
- 9行目の/<レポジトリ名>も同様に、ご自身のもの記述してください。
- 15行目の<このアプリで使用しているrubyのバージョン>はご自身のものを確認して 記述してください。
- 19行目の<ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス>も同様に、ご自 身のもの記述してください。
Capistranoのバージョン確認
capistranoのバージョンは、gemfile.lockに記載されています。
capistrano(3.11.0)ように記載されています。rubyのバージョンの確認
ローカルのターミナルで以下のように確認します。
ターミナル$ ruby -v # 実行結果 ruby2.6.5....unicorn.rbの記述を編集
capistrano導入後はアプリケーションのディレクトリ構造が変化するので以下のように記述を編集します。
config/unicorn.rbapp_path = File.expand_path('../../', __FILE__) worker_processes 1 working_directory app_path pid "#{app_path}/tmp/pids/unicorn.pid" listen "#{app_path}/tmp/sockets/unicorn.sock" stderr_path "#{app_path}/log/unicorn.stderr.log" stdout_path "#{app_path}/log/unicorn.stdout.log" # 以下のように変更↓ # ../が一つ増えている app_path = File.expand_path('../../../', __FILE__) worker_processes 1 # currentを指定 working_directory "#{app_path}/current" # それぞれ、sharedの中を参照するよう変更 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" pid "#{app_path}/shared/tmp/pids/unicorn.pid" stderr_path "#{app_path}/shared/log/unicorn.stderr.log" stdout_path "#{app_path}/shared/log/unicorn.stdout.log"Nginxの設定ファイルの記述を編集
同様に、Nginxの設定ファイルもディレクトリで構造が変化しているので編集します。
ターミナル(EC2)# SSHログインしてから実行 [ec2-user@ip-172-31-25-189 ~]$ $ sudo vim /etc/nginx/conf.d/rails.confrails.confupstream app_server { # sharedの中を参照するよう変更(/shared/tmp/sockets/unicorn.sock;) server unix:/var/www/○○○○○(アプリケーション名)/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name XX.XXX.XX(Elastic IP); # currentの中を参照するよう変更(/current/public;) root /var/www/○○○○○(アプリケーション名)/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更(/current/public;) root /var/www/○○○○○○(アプリケーション名)/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }編集し終わったら、
escキーを押して:wqで保存します。
Nginxの設定を変更したら、忘れずに再読込・再起動をします。ターミナル(EC2)# nginx起動 [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl reload nginx [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart nginx # nginxのステータスを確認(active runningであれば成功) $ sudo systemctl status nginx.service ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset: disabled) Active: active (running) since 水 2021-02-17 11:28:00 UTC; 7h ago # エラーが出た場合はnginxのエラーログを確認 [ec2-user@ip-172-31-45-167 アプリ名]$ sudo cat /var/log/nginx/error.logデータベースの起動を確認
データベースが立ち上がっていないとデプロイが失敗するので起動します。
ターミナル(EC2)[ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart mariadb # ステータスを確認(active runningなら成功) [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl status mariadbunicornのプロセスをkill
自動デプロイを実行する前にunicornのコマンドをkillします。
ターミナル(EC2)# プロセスを確認 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn # 一番上のunicorn_rails masterをkillしたいので、下記を実施 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill 17877ローカルでの修正を全てmasterにpush
ローカルでのコードの変更が、全てmasterにpushされていることを確認しましょう。
自動デプロイ実行
これで、ローカルのターミナルからコマンド一発でデプロイできるようになりました。
ターミナル(ローカル)# アプリケーションのディレクトリで実行する $ bundle exec cap production deployエラーがなく完了したらデプロイ完了です!
ブラウザからElastic IPでアクセスすると、アプリケーションにアクセスできます!
確認してみましょう。もし途中でエラーが出たら
- EC2のターミナルで
less log/unicorn.stderr.logコマンドでエラーログを確認- ローカルでの編集のpushやpullを忘れていないか確認
- mariaDBやNginxを再起動してみる
- EC2インスタンスを再起動してみる
終わりに
ここまででRailsアプリを本番環境にデプロイする工程が終了しました!
ただ、IPアドレスだと覚えにくいので次回で独自ドメインを取得方法をまとめたいと思います。
お疲れさまでした。。。次回
独自ドメイン取得

- 投稿日:2021-02-27T01:51:27+09:00
アセットパイプラインに関わる画像が表示されないエラー
今回のエラー
制作環境は
- Ruby on Rails
- unicorn
- AWS EC2
- Nginx
Nginxを導入して設定をした後から、本番環境でトップページに表示される予定の画像が表示されない状態になっていた。
ログイン画面のアニメーションとして用意してあった音声ファイルが読みこまれていない。
一部では表示されている画像もあった。原因
アセットパイプラインの参照先の記述に問題があった。
問題箇所
今回の不具合箇所は2点
トップページの画像の記述
<%= image_tag("/assets/title_logo.png", class: "header-logo" ) %>ログイン画面の音声ファイル
<%= audio_tag("/assets/submit", autoplay: false, controls: true, id:"audio_sub") %>対処
行ったことは
1. 参照先URLを修正
2. git hubに修正をpush
3. 本番環境でプリコンパイル、プロセス再起動1. コードを以下のように変更
トップページの画像の記述
<%= image_tag "title_logo.png", class: "header-logo" %>ログイン画面の音声ファイル
<%= audio_tag "submit", autoplay: false, controls: true, id:"audio_sub" %>変更箇所
変更したのは参照先のURL部分
/assets/部分を削除した2. git hubに変更をpush
git hubデスクトップ上でpush
ブランチを切っているなら、masterにmarge
※GUI、ブラウザでの操作だったので詳細割愛3. 本番環境でプリコンパイル、プロセス再起動
以下ターミナルで操作
- 今回はAWSのEC2でデプロイしているので、EC2のデプロイ済みのインスタンスにログイン
- git masterをpull
git pull origin master- プリコンパイル
rails assets:precompile RAILS_ENV=production- nginxを再読み込み
sudo systemctl reload nginxsudo systemctl start nginxプロセス再起動
- プロセス確認
ps aux | grep unicorn- プロセス停止
kill (rails masterのプロセス番号)- アプリケーションサーバー起動
RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D以上で改善した
気づいた事
- 開発環境では
image_tag,audio_tagを複数使用しており、URLに/assets/が混同していても問題なかったが、unicorn、nginx(webサーバー)が加わり問題が起きた- コードが改善していても改めてプリコンパイルをしないと表示されなかった
原因の仮説
以下は今回の対処にあたって思ったこと。
調べきれていないので、メモとして書いておく。
- Nginxを利用するとプリコンパイルあたりで違う挙動をする?
- webサーバー(Nginx)は静的な情報を返すもので、動的な情報はアプリケーションサーバーに割り振るような仕組みだと理解しているが、静的な情報としてプリコンパイルをする際に、アセットパイプラインで参照している? そのため、'''/assets/'''と記述してあるとアセットパイプラインとは別に、個別参照になりプリコンパイルがうまくいかなかった?
- 投稿日:2021-02-27T01:29:56+09:00
AWSのEC2でデプロイ後、背景画像が本番環境で反映されない・・・
初めに
今回初投稿になります。
私は現在プログラミング学習を始めて約4ヶ月一通り簡単なポートフォリオは作成できる技術はついてきましたが、まだまだ初学者でエラーで止まることが多いため、振り返り学習を兼ねてエラーで詰まったことや日々の学習での気付きをその都度投稿します。今回EC2でのデプロイ時、ローカル環境で反映されていたポートフォリオの背景画像が本番環境で反映されないエラー解決に苦戦したので私が行った解決方法をまとめておきます。
今回の問題について
Rubyをベースにポートフォリオを作成して、AWSのEC2を利用し設定して本番環境にデプロイを試みたところ、ブラウザー上で作成したポートフォリオの背景画像のみうまく表示されず、背景がまっさらの状態に・・・・
同じimagesディレクトリ内に一緒に置いているロゴの画像は反映されているので、EC2の設定のせいで画像の読み込みが出来ていないということはない様子。
アプリ自体の他の機能も問題ない状態でした。アプリケーションサーバーはUnicorn
WEBサーバーはNginxを使用しています。考えられる要因
1.背景画像の容量が大きい為、反映されない
2.画像を適用しているCSSの記述のミス
3.デプロイの設定時のミス試みた対処法
まずはロゴ画像は反映されている状況から①の画像容量の問題かと思い、画像容量を落とした背景画像の差し替えて再度デプロイして確認しましたが、相変わらず背景はまっさらなままでした。
そのため画像容量の問題ではないと判断。次に②の背景画像を適用しているCSSの記述の見直しの為、同じ症状のエラーがないか調べて記述を見直ししました。
修正前
・style.css
.big-bg {
background-image: url('main-bg.jpg');
min-height: 95vh;
min-width: 100vw;
}↓
修正後
・index.scss
.big-bg {
background-image: image-url('main-bg.jpg');
min-height: 95vh;
min-width: 100vw;
}
背景画像の記述をstyle.cssからindex.scssへ書き換え、
background-image: url('main-bg.jpeg') → background-image: image-url('main-bg.jpeg')に変更調べた限りではこの方法で解消される可能性が高いようなので、改めてデプロイして確認したところ・・・・・ 背景まっさら・・・・・なぜ????
他の方で同じ症状の方はこの方法で大抵解消されているようでした。③のデプロイの設定もまだ初学者の為、カリキュラムを都度都度確認しながら実装しているし、他の機能は問題ない為、設定は間違ってはいないはずなのでエラーログを確認します。
※最終的にまずエラーログから確認するべきでした・・・EC2内のログをコマンドを入力して確認します
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ less log/production.logエラーログを発見し、内容としてはpublicディレクトリ内のassetsディレクトリ内にmain-bg.jpegが無いとゆうものでした。
?????? 読み込み先がpublicディレクトリのassetsディレクトリ?
普段からassetsディレクトリ内のimagesディレクトリに画像を入れていて問題なかったので、ずっとそうしていましたが、今回はpublicディレクトリを読み込んでいるようです。その為、さらに同じ症状でのエラー解消をした内容を探してpublicディレクトリ内にassetsディレクトリを作成して、その中にimagesディレクトリを移して背景画像ファイルを配置しました。
その後、改めてデプロイして確認したところ・・・・・ 背景画像が反映されています!!!やりました!!!
解決方法
今回はEC2内のエラーログを確認して、エラー内容を確認。
public/assets/images/main-bg.jpeg(画像)と配置することで解消できました。
その前に行ったCSSの記述をSCSSファイルに記述し直したことも必要だったと思います。さらにその後、デプロイ時の設定を見直しておそらくですがアセットファイルのコンパイルのコマンドを設定し忘れていたような気もするので、そこも気をつけて今後EC2の設定をしようと思いました。
- 投稿日:2021-02-27T00:30:16+09:00
【Rails】 初心者向け!gem 'dotenv-rails'の使い方
はじめに
最近当たり前のように使用している'dotenv-rails'のgemと環境変数という言葉ですが、使い始めた頃は何が何だかよく分からなかった覚えがあります。そんな自分自身の復習と、同じような初心者の方の参考になればと思い、なるべく一つ一つ丁寧に、また画像なども掲載しつつ投稿させていただいております。
開発環境
ruby 2.6.3
Rails 5.2.4.4
dotenv-railsとは
環境変数を管理することができるgemです。
自身で作成したアプリケーションの直下に.envファイルを作成することで、パスワードなどネット上に公開させたくない情報を扱い、自動で読み込むことが可能です。
環境変数とは
参考書やネットで当たり前に出てくる「環境変数」という言葉。
私は当初この言葉の意味すら分かりませんでしたので、説明を掲載しておきます。
簡単に言うと、ネット上に公開させたくない情報を入れておく箱になります。この箱自体には、自身で任意の名前をつけることが可能です。つまり、ネット上に公開させたくない情報は、一度この環境変数という箱の中に入れ、コード上で使用することで、情報漏洩を防ぐことができます。
gemを導入
Gemfile.gem 'dotenv-rails'terminal.$ bundle install
.env ファイルを作成
① アプリケーション名のディレクトリにカーソルを合わせ、右クリックします。
② New Fileを選択します。
③ ファイル名を「.env」にします。
画像のような配置でファイルを作成できていれば、完成です!④ 以下のような形で必要な情報を記述してください。
(参考画像)
 .env# Google map用 GOOGLE_API_KEY = "***************" # 問い合わせ機能用 SEND_MAIL = "***************" SEND_MAIL_PASSWORD = "***************" # デプロイ用 DB_USERNAME = "***************" DB_PASSWORD = "***************" DB_HOST = "***************" DB_DATABASE = "***************"
.env# Google map用 GOOGLE_API_KEY = "***************" # 問い合わせ機能用 SEND_MAIL = "***************" SEND_MAIL_PASSWORD = "***************" # デプロイ用 DB_USERNAME = "***************" DB_PASSWORD = "***************" DB_HOST = "***************" DB_DATABASE = "***************"
環境変数の記述の仕方
ENV['設定した名前']
たったこれだけの記述で環境変数を扱うことができます。ENV['GOOGLE_API_KEY'] ENV['SEND_MAIL']
.gitignoreファイルへ追記
アプリケーション直下にある、Gitの管理に含めないファイル名を記述するファイルです。
こちらのファイルの他にも、ファイル名の前に.(ドット)が付いているものは、Gitの管理に含めないファイルとして取り扱われています。
※ こちらに「/.env」の記述をしないと、全ての情報がネット上に公開されてしまうので注意!.gitignore# 最終行に下記の記述を加えてください。 /.env
万が一GitHubにpushしてしまったら...
誤ってGithub上に公開してしまっている方は、下記のコマンドで.envをGitの管理から外してください。
コマンド実行後は、.gitignoreファイルに「/.env」を追記した上で、再度git pushをし直してください。● git rm --cached [ファイル名]
ファイル自体は残したままGitの管理から外すことが可能なコマンドterminal.$ git rm --cached .env
終わり
今回は以上になります。
私自身もプログラミング初心者ですが、同じ様な立場の方に少しでも参考になれば幸いです。
また、もし内容に誤りなどがございましたら、ご指摘いただけますと幸いです。