- 投稿日:2021-02-27T22:44:22+09:00
Railsポートフォリオ #3 herokuにデプロイ
こんにちは
今回はherokuへのデプロイを行いました。(前回記事(#3 DB設計))私は、前職(ホテルの料飲部)における、コミュニケーションの課題を解決するアプリを作っているのですが、今回は、
herokuへのデプロイを行いました
元々はAWSでデプロイするつもりだったのですが(やったことあったので)、難しすぎて、一旦諦め、herokuで手を打つことにしました。。。
感じたこと
- AWSの勉強不足
Qiita記事等を参考にしながら行ったのですが、知識不足でやってるので、どこで間違ったのかわからん、、、、、
もう少し勉強してから出直そうと思いました。
こちらの記事(【画像付きで丁寧に解説】AWS(EC2)にRailsアプリをイチから上げる方法【その1〜ネットワーク,RDS環境設定編〜】)とかを参考に行ったのですが、敗北しました。
非常に悔しいです。さらに
実際にアプリの中身を作っていたら、作っておいたER図が全然的外れだったと言うことにも気づきました。
こちらもやり直さねば。。。次は、ER図を修正し、基本機能を実装していきます
- 投稿日:2021-02-27T22:24:39+09:00
【Rails】JSが読み込まれない時の対処法
- 投稿日:2021-02-27T21:27:00+09:00
[Ruby on Rails] データベースの削除の仕方
色々あってDBを作り直すことになったので、その備忘録を書いていきます。
とても繊細なdatabase.ymlなどを修正する際にも使えるので覚えておこうと思います。
ちなみにシークエルプロと言うデータベースを視覚化できるアプリを使っています。
データベースを削除する方法
database.ymlに記載されている、エンコードの設定やデータベース名を誤った状態でデータベースを作成してしまった場合は、一度データベースを削除してから作り直す必要があります。
手順は以下のとおりです。
データベースを削除する
database.ymlを正しい形に修正する
データベースを再度作成する
①データベースを削除する
データベースを削除するためにはrails db:dropのコマンドを実行します。
% cd ~/projects/データベースを作り直したいアプリケーションのディレクトリディレクトリ移動後にrails db:drop
このコマンドを実行することで、該当するアプリケーションのデータベースを削除することができます。
②database.ymlなどを修正する
データベースを削除できたら、この段階でdatabase.ymlなどを修正します。
③データベースを再度作成する
そして、rails db:createのコマンドでデータベースを再度作成します。% cd ~/projects/データベースを作り直したいアプリケーションのディレクトリデータベースの削除とマイグレーションファイルの適用を一括で行う方法を学ぼう
データベースの設定は間違っていないものの、再度データベースを作り直し、既存のマイグレーションファイルを適用したい場合があります。その場合は、rails db:migrate:resetのコマンドを実行します。
% cd ~/projects/データベースを作り直したいアプリケーションのディレクトリ % rails db:migrate:resetこのコマンドを実行することで、以下の操作を一括で行ってくれます。
データベースを削除する
データベースを再度生成する
既存のマイグレーションファイルをすべて適用する
ただし、データベースを一度削除するため、保存されているデータなどはすべて削除されます。
極力、データベースを消すほどのミスはしたく無いものです。
- 投稿日:2021-02-27T21:24:16+09:00
Ruby/Railsの環境構築
これからRuby/Railsの環境構築を行っていきます。
まずは用語から説明していきます。
ご存知の方は飛ばしてもらって構いません。シェルとは?
ターミナルで実行されたコマンドを読み取ってくれるOSの窓口役です
ターミナルから入力されたコマンドを読み取って、OSに対して指示を渡し、結果をターミナルに返して表示や実行などの動作をさせます。
このシェルがターミナルとOSの間に挟まって、コマンドによる命令と実行結果の橋渡しをしています。シェルにも種類があり、プロンプトやコマンド実行後の出力で挙動が若干異なります。
zsh
zshはシェルの1つでターミナルで
% echo $SHELLとコマンドを実行すると現在使用しているシェルはzshであることがわかります。
.zshrcに設定を記述して、PATHにアプリケーションの場所を示すことでコマンドを使用可能にします。PATH
PATHとは、「環境変数」と呼ばれるOS用の変数のことです。PATHには、複数の絶対パスの情報が保存されており
コマンドが入力されたときに、シェルはPATHに記述されたパスのディレクトリ内のファイルを検索します。
PATHに絶対パスを保存してアプリケーションの場所を示すことでどこからでもアプリケーションのコマンドを打つことができます。
一般的に「PATHを通す」と表現します。echoコマンド
「>>」に続けてファイル名を指定することで、ファイルに文字を追加できるLinuxコマンドで、設定を反映するためのコマンドを記述することで、PATHを通すことができます。
コマンドラインツール
コマンドで操作するアプリケーションのまとまりで
コマンドラインツールを導入することで、OSが初めからコマンドで操作できるアプリケーション以外の物もインストールできます。Command Line Tools
macOS専用のコマンドラインツールのことです。
macOSでは、元々Linuxコマンドで操作できるアプリケーションや機能を標準搭載しています。Linuxコマンド以外で操作するアプリケーションの多くはCommand Line Toolsのインストールによって、まとめてPCに導入できます。パッケージ管理ツール
パッケージとは、プログラムや処理をひとまとめにしたもののことでライブラリとも言えます。
パッケージ管理とは、パッケージやパッケージが持つライブラリなどの依存関係を考慮して
インストールやバージョンアップを行う管理のことです。
あるパッケージを利用したい場合、そのパッケージと依存関係にあるパッケージも一緒にインストールしてくれます。Homebrew
macOSのパッケージ管理ツールでmacOS上で動作するアプリケーションの多くがHomebrewからインストールできます。
依存関係のあるパッケージが正しく動作するよう、複数のパッケージのバージョンをコントロールしてインストールできます。
コマンド 説明 brew -v Homebrewのバージョンを表示する brew install [パッケージ名] パッケージをインストールする brew uninstall [パッケージ名] パッケージをアンインストールする brew search インストール可能なパッケージを表示する brew update インストールしたパッケージを最新へ更新する Node.js
Node.jsは、本来ブラウザ上で動くJavaScriptをサーバーサイドで動作させる「実行環境」です。
インストールされると、サーバーサイドで利用できるJavaScriptのパッケージを活用できます。
パッケージは依存関係を生むため、YarnなどのNode.jsのパッケージ管理ツールもあります。Yarn
Node.jsの環境上で動作するパッケージを管理する、JavaScriptのパッケージ管理ツールです。
バージョン管理
変更したバージョンを記録あるいは外部から保存して、過去のバージョンや最新のバージョンに切り替えることなどをバージョン管理と呼びます。
バージョン管理をすることで、パッケージとの依存関係の問題を解消したり、変更して問題が発生したプロジェクトを過去の安定したバージョンに切り替える、などの対応ができます。
rbenv
Rubyのバージョンを切り替えるためのバージョン管理ツールです。
バージョン管理ツールを使わない場合、RubyのバージョンはすべてPC内で共通となってしまい「あるプロジェクトで使用しているRubyのライブラリが使用できなくなってしまう」などの依存関係の問題が生じます。
複数のバージョンのRubyをダウンロードしておいて、使用するRubyのバージョンをディレクトリごとに指定することも可能になります。
コマンド 説明 rbenv -v rbenvのバージョンを表示 rbenv install [バージョン][パッケージ名] Rubyバージョンを指定してインストールする。 rbenv uninstall [バージョン] Rubyバージョンを指定してアンインストールする。 rbenv versions インストールされているRubyバージョンの一覧を表示する。 rbenv global [バージョン] すべてのディレクトリで使用するRubyバージョンを切り替える。 rbenv local [バージョン] カレントディレクトリで使用するRubyバージョンを切り替える。 rbenv rehash RubyやGemに関するコマンドをバージョン変更後も使用できるようにする。 さてこれから環境構築に取り掛かっていきましょう!
シェルをzshに設定
# zshをデフォルトに設定 % chsh -s /bin/zsh # ログインシェルを表示 % echo $SHELL # 以下のように表示されれば成功 /bin/zshCommand Line Toolsを用意
% xcode-select --installHomebrewをインストール
% cd # ホームディレクトリに移動 % pwd # ホームディレクトリにいるかどうか確認 % /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)" # コマンドを実行Homebrewがインストールされているか確認
% brew -v # 以下のように、Homebrewのバージョン情報が表示されれば無事にインストールされています。 Homebrew 2.5.1 # 数字は異なる場合があります。 % brew update # Homebrewをアップデート % sudo chown -R `whoami`:admin /usr/local/bin # Homebrewの権限を変更rbenv と ruby-buildをインストール
% brew install rbenv ruby-buildrbenvをどこからも使用できるようにパスを通す。
% echo 'eval "$(rbenv init -)"' >> ~/.zshrc設定ファイルであるzshrcを修正したので変更を反映
% source ~/.zshrcターミナルのirb上で日本語入力を可能にするreadlineをinstall
% brew install readlinereadlineをどこからも使用できるようにする
% brew link readline --forcerbenvを利用してRubyをインストール
% RUBY_CONFIGURE_OPTS="--with-readline-dir=$(brew --prefix readline)" % rbenv install 2.6.5利用するRubyのバージョンを指定
% rbenv global 2.6.5rbenvを読み込んで変更を反映
% rbenv rehashRubyのバージョンを確認
% ruby -vMySQLのインストール
% brew install mysql@5.6MySQLの自動起動設定
% mkdir ~/Library/LaunchAgents % ln -sfv /usr/local/opt/mysql\@5.6/*.plist ~/Library/LaunchAgents % launchctl load ~/Library/LaunchAgents/homebrew.mxcl.mysql\@5.6.plistmysqlコマンドをどこからでも実行できるようパスを通す
% echo 'export PATH="/usr/local/opt/mysql@5.6/bin:$PATH"' >> ~/.zshrc # mysqlのコマンドを実行できるようにする設定 % source ~/.zshrc # 設定を読み込むコマンド % which mysql # mysqlのコマンドが打てるか確認する # 以下のように表示されれば成功 /usr/local/opt/mysql@5.6/bin/mysqlMySQLの起動を確認
% mysql.server status # MySQLの状態を確認するコマンド # 以下のように表示されれば成功 SUCCESS! MySQL runningRubyの拡張機能(gem)を管理するためのbundler(バンドラー)をインストール
% gem install bundler --version='2.1.4'Railsをインストール
% gem install rails --version='6.0.0'rbenvを再読み込み
% rbenv rehashNode.jsを用意
% brew install node@14Node.jsへのパスを通す
% echo 'export PATH="/usr/local/opt/node@14/bin:$PATH"' >> ~/.zshrc % source ~/.zshrcNode.jsが導入できたか確認。バージョンが表示されれば、問題なくインストールが完了
% node -v v14.15.3 # 数値は異なる場合がありますyarnをインストール
% brew install yarnyarnが導入できたか確認
% yarn -v以上で環境構築は完了です。お疲れ様でした。
- 投稿日:2021-02-27T21:20:42+09:00
[Rails] CarrierWaveで画像のプレビュー機能の実装方法
前提
RailsでCarrierWaveを使って画像投稿機能が実装されていること。
CarrierWaveの実装方法画像ファイルにidを追加する
Javascriptで処理するときに使うので、画像ファイルにidを追加します。
<%= f.label "ユーザー画像" %> <%= f.file_field :image, id: :user_img %>画像を表示させる
画像を表示させるコードを追記します。こちらも、Javascriptで処理するときに使うので、画像ファイルにidをつけておきましょう。
また、画像を選択している時としていない時の表示をif文で分けます。<% if @user.image.present? %> <%= image_tag @user.image, id: :img_prev %> <% else %> <%= image_tag "user_default.png", id: :img_prev %> <% end %>Javascriptに追記する
jsファイルにJavascriptを追記します。
jQueryを使えるようにするdocument.addEventListener("turbolinks:load", function() { $(function() { function readURL(input) { if (input.files && input.files[0]) { var reader = new FileReader(); reader.onload = function (e) { $('#img_prev').attr('src', e.target.result); } reader.readAsDataURL(input.files[0]); } } $("#user_img").change(function(){ readURL(this); }); }); })
- 投稿日:2021-02-27T21:17:16+09:00
Rails6.0アプリに独自ドメインを付与
始めに
Railsアプリを本番環境にデプロイさせる工程は今回の内容で最後になります。
今まではElastic IPアドレスを使ってブラウザに入力していましたが、ドメインを取得してよりわかりやすいURLに変えていきます。
ドメインは有料ですが,こだわらなければ初年度は数百円程度で取得できます。
この記事では「お名前.com」というサービスを利用してドメインを取得します。用意するもの
- クレジットカード
- AWSのアカウント
- AWSでデプロイ済みのEC2インスタンス
目次
1.ドメインを購入
2.IPアドレスとドメインの関連付け
3.ネームサーバーの設定
4.Nginxの設定1. ドメインを購入
①お名前.com (https://www.onamae.com/) にアクセスします。
②取得したいドメインを検索バーで検索します。
- 注意
- 先に誰かが使用しているドメインは取得できません。
- ドメインに使用できる文字は
「半角英数字」と「ハイフン -」です- また"_"や"!"といった特殊な記号は使用できないことがあります。

③希望のドメインを選択。
こだわりがなければ初年度の安いドメインを取得をおすすめします。
僕自身は.workというドメインを選択し最安値の1円に押さえました。
- 購入処理の際の注意
- 「サーバー」は「利用しない」をチェック
- 「Whois情報公開代行メール転送オプション」などは全てチェック不要
④その後、会員登録を済ませドメインを購入。 会員登録した際に入力したメールアドレスに以下のメールが来たら、取得可能です。

2. IPアドレスとドメインの関連付け
①サービスでRoute53を選択
先ほど購入したドメインをIPアドレスに変換することができます。②一番左のDNS managementを選択。
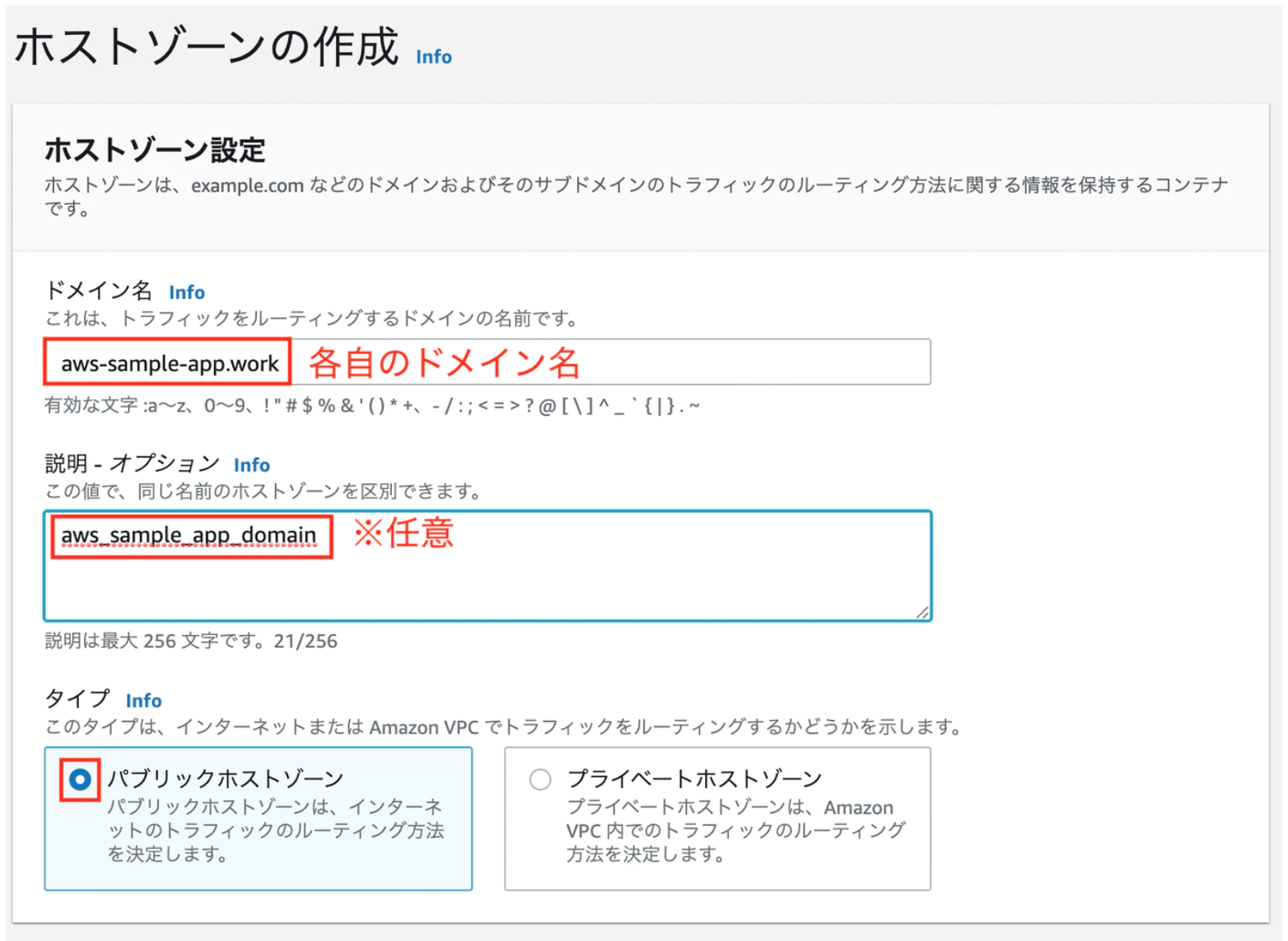
③ホストゾーンの作成。
キー 値 ドメイン名 取得したドメイン名 説明-オプション アプリ名_domein Type Public Hostes Zone
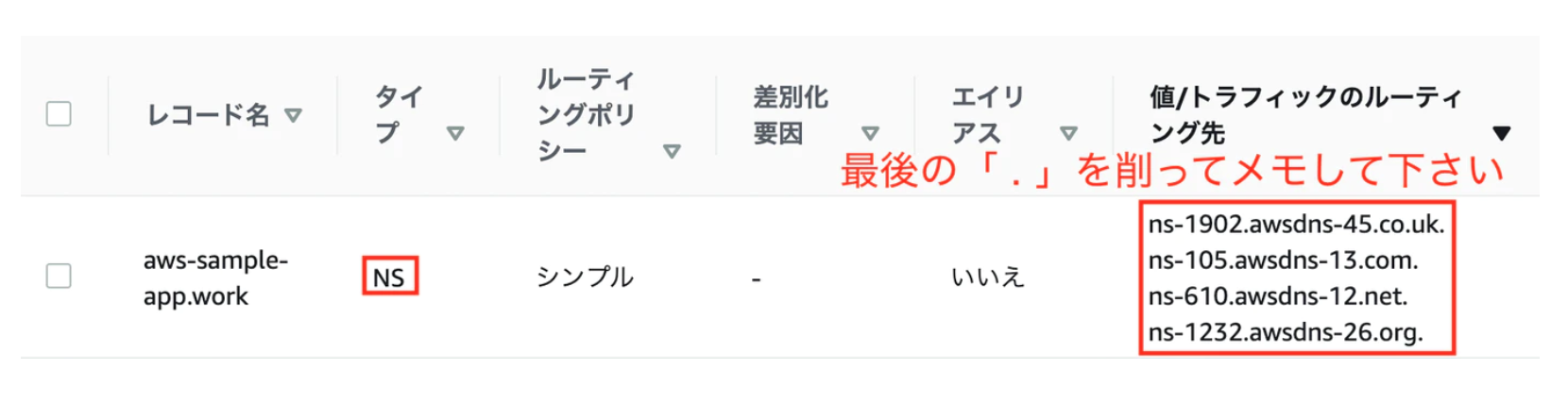
上記を入力したらホストゾーン作成をクリックホストゾーンが作成されると「値/トラフィックのルーティング先」というものが作成されます。
このうちタイプがNSで表示されている4つをネームサーバーとしてメモしておきましょう。
メモする際に,それぞれの最後についている「ドット .」は削除して下さい!
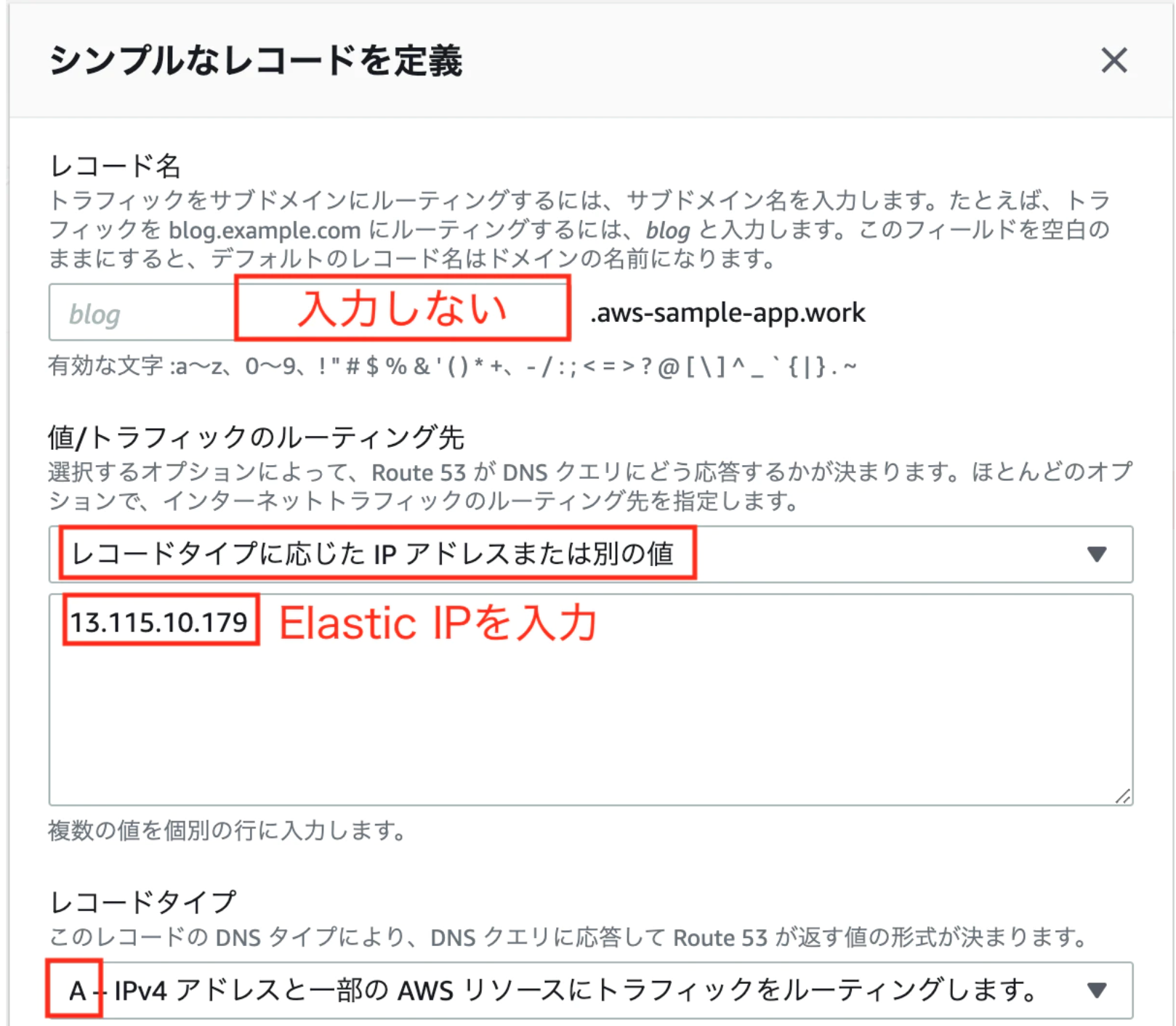
④レコードセットの作成。
Route53の画面から、「レコードを作成」をクリック
キー 値 レコード名 入力しない 値/トラフィックのルーティング先 「レコードタイプに応じた IP アドレス または別の値」をクリックし, Elastic IP を入力 レコードタイプ A
Aタイプのレコードが作成されたら完了です!3. ネームサーバーの設定
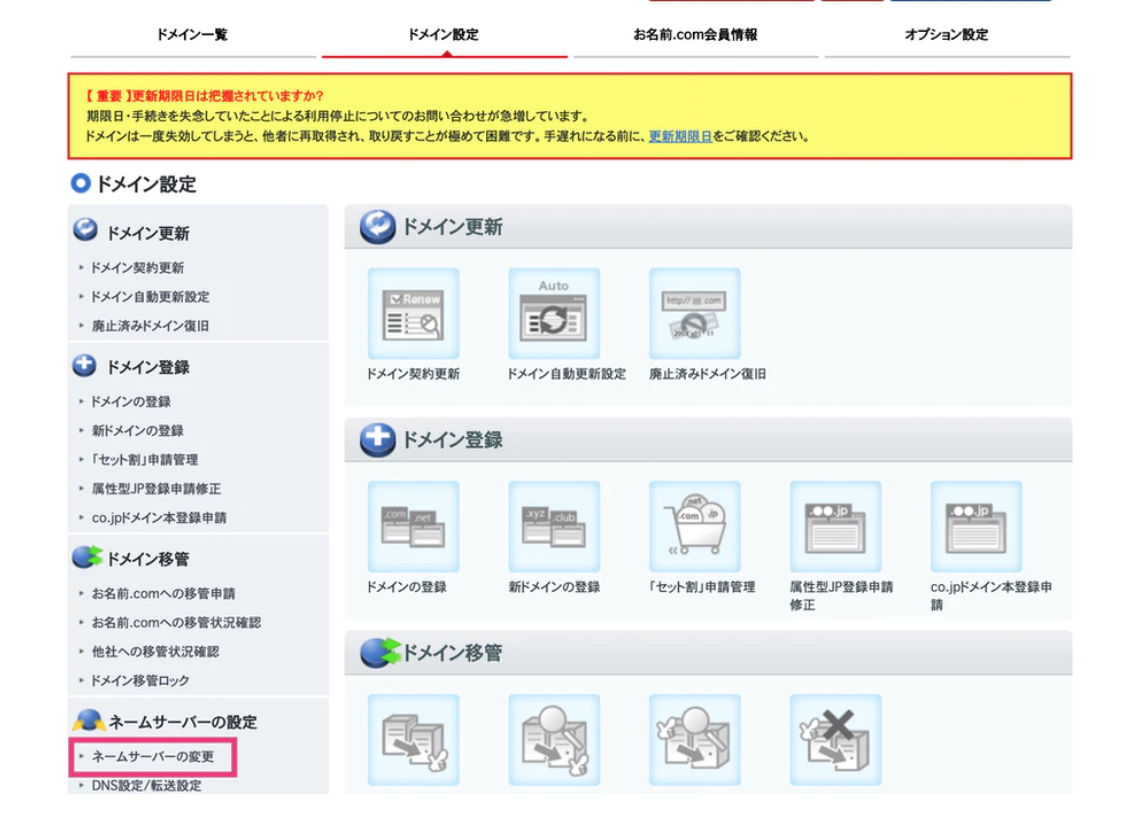
①お名前.comに戻ってログインします。
②ログインしたらドメインの設定から
ネームサーバーの変更を選択してください。
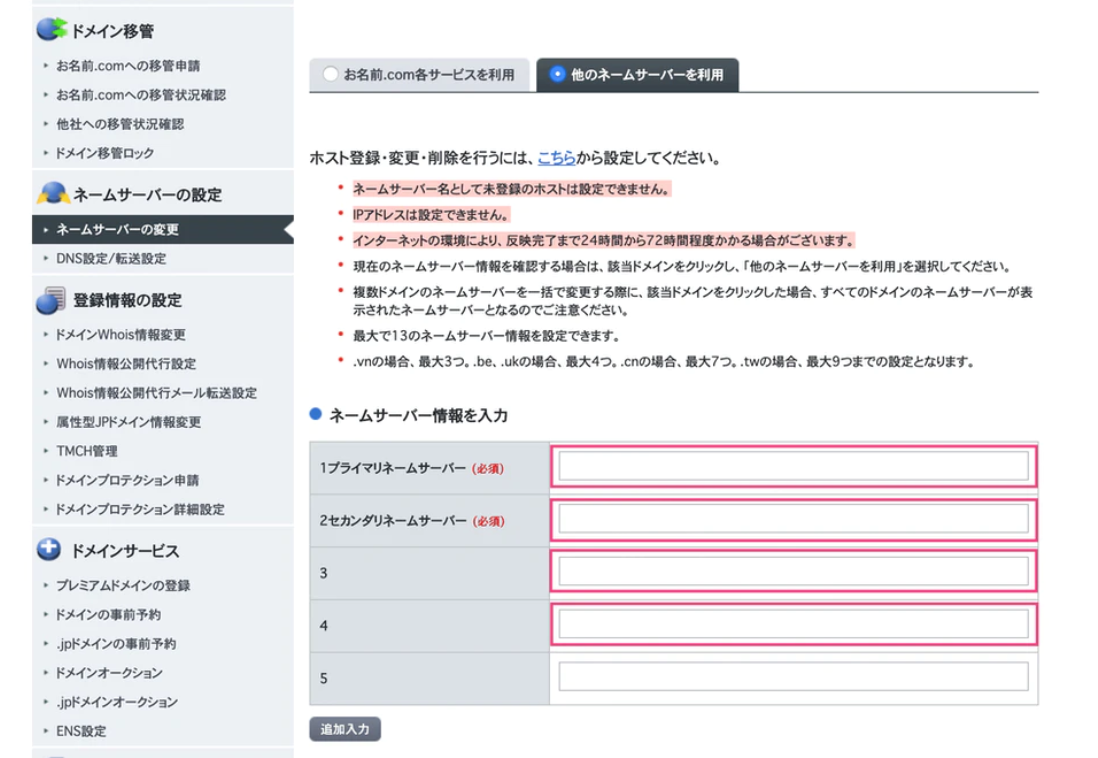
③他のネームサーバーを利用を選択。
ネームサーバー情報を入力する欄に先ほどAWSで取得したNSタイプのレコード(4つ)を入力。
デフォルトでは2つしか枠がないので、追加入力を2回クリックして枠を追加します。
ネームサーバーの確認
ローカル環境のターミナルから以下のコマンドを実行して下さい。
登録した4つのドメインが入っていればOKです。(順番が入れ替わっていてもOK)ターミナル$ dig ドメイン名 NS +shortまた、ターミナルでdig xxxxx.xxx(←自分のドメイン名)と入力してみましょう。
AWSで取得したレコードが表示されていれば成功です!ターミナル$dig xxxxxxx.com ; <<>> DiG 9.10.6 <<>> xxxxxxx.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31076 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;xxxxxx.com. IN A ;; ANSWER SECTION: xxxxxxx.com. 278 IN A xx.xxx.xx.xxxここまででドメインの設定は完了です!
ドメインの浸透には5分~30分ほど時間がかかる場合があるので、しばらくしたらブラウザにIPアドレスではなくドメイン名を入力して確認してみましょう。4. Nginxの設定
本番環境にNginxを採用している場合は設定を変更しないとエラーがおきてしまいます。
nginx.confのserver_nameを変更しましょう。/etc/nginx/conf.d/rails.confupstream app_server { # Unicornと連携させるための設定。 server unix:/var/www/xxxxxx/shared/tmp/sockets/unicorn.sock; } # サーバの設定 server { # このプログラムが接続を受け付けるポート番号 listen 80; # Elastic IPアドレスを独自ドメインに変更 server_name xxxx.com; # 接続が来た際のrootディレクトリ root /var/www/xxxxxx/current/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; root /var/www/xxxxxx/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html;以上で終了です!
ブラウザで確認してみましょう。
- 投稿日:2021-02-27T21:17:16+09:00
【 Ruby on Rails 6.0 】 AWS + Nginx + Unicornでデプロイ⑧
始めに
Railsアプリを本番環境にデプロイさせる工程は今回の内容で最後になります。
今まではElastic IPアドレスを使ってブラウザに入力していましたが、ドメインを取得してよりわかりやすいURLに変えていきます。
ドメインは有料ですが,こだわらなければ初年度は数百円程度で取得できます。
この記事では「お名前.com」というサービスを利用してドメインを取得します。用意するもの
- クレジットカード
- AWSのアカウント
- AWSでデプロイ済みのEC2インスタンス
目次
目次 内容 セクション1 EC2インスタンス作成 セクション2 Linuxサーバー構築 セクション3 データベース設定 セクション4 EC2上でGemをインストールし環境変数を設定 セクション5 Railsアプリを起動 セクション6 Nginxの導入 セクション7 自動デプロイ セクション8 独自ドメイン取得(今回の内容) 1. ドメインを購入
①お名前.com (https://www.onamae.com/) にアクセスします。
②取得したいドメインを検索バーで検索します。
- 注意
- 先に誰かが使用しているドメインは取得できません。
- ドメインに使用できる文字は
「半角英数字」と「ハイフン -」です- また"_"や"!"といった特殊な記号は使用できないことがあります。
③希望のドメインを選択。
こだわりがなければ初年度の安いドメインを取得をおすすめします。
僕自身は.workというドメインを選択し最安値の1円に押さえました。
- 購入処理の際の注意
- 「サーバー」は「利用しない」をチェック
- 「Whois情報公開代行メール転送オプション」などは全てチェック不要
2. IPアドレスとドメインの関連付け
①サービスでRoute53を選択
先ほど購入したドメインをIPアドレスに変換することができます。②一番左のDNS managementを選択。
③ホストゾーンの作成。
キー 値 ドメイン名 取得したドメイン名 説明-オプション アプリ名_domein Type Public Hostes Zone
上記を入力したらホストゾーン作成をクリックホストゾーンが作成されると「値/トラフィックのルーティング先」というものが作成されます。
このうちタイプがNSで表示されている4つをネームサーバーとしてメモしておきましょう。
メモする際に,それぞれの最後についている「ドット .」は削除して下さい!
④レコードセットの作成。
Route53の画面から、「レコードを作成」をクリック
キー 値 レコード名 入力しない 値/トラフィックのルーティング先 「レコードタイプに応じた IP アドレス または別の値」をクリックし, Elastic IP を入力 レコードタイプ A
Aタイプのレコードが作成されたら完了です!3. ネームサーバーの設定
①お名前.comに戻ってログインします。
②ログインしたらドメインの設定から
ネームサーバーの変更を選択してください。
③他のネームサーバーを利用を選択。
ネームサーバー情報を入力する欄に先ほどAWSで取得したNSタイプのレコード(4つ)を入力。
デフォルトでは2つしか枠がないので、追加入力を2回クリックして枠を追加します。
ネームサーバーの確認
ローカル環境のターミナルから以下のコマンドを実行して下さい。
登録した4つのドメインが入っていればOKです。(順番が入れ替わっていてもOK)ターミナル$ dig ドメイン名 NS +shortまた、ターミナルでdig xxxxx.xxx(←自分のドメイン名)と入力してみましょう。
AWSで取得したレコードが表示されていれば成功です!ターミナル$dig xxxxxxx.com ; <<>> DiG 9.10.6 <<>> xxxxxxx.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31076 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;xxxxxx.com. IN A ;; ANSWER SECTION: xxxxxxx.com. 278 IN A xx.xxx.xx.xxxここまででドメインの設定は完了です!
ドメインの浸透には5分~30分ほど時間がかかる場合があるので、しばらくしたらブラウザにIPアドレスではなくドメイン名を入力して確認してみましょう。4. Nginxの設定
本番環境にNginxを採用している場合は設定を変更しないとエラーがおきてしまいます。
nginx.confのserver_nameを変更しましょう。/etc/nginx/conf.d/rails.confupstream app_server { # Unicornと連携させるための設定。 server unix:/var/www/xxxxxx/shared/tmp/sockets/unicorn.sock; } # サーバの設定 server { # このプログラムが接続を受け付けるポート番号 listen 80; # Elastic IPアドレスを独自ドメインに変更 server_name xxxx.com; # 接続が来た際のrootディレクトリ root /var/www/xxxxxx/current/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; root /var/www/xxxxxx/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html;以上で終了です!
ブラウザで確認してみましょう。
- 投稿日:2021-02-27T19:55:31+09:00
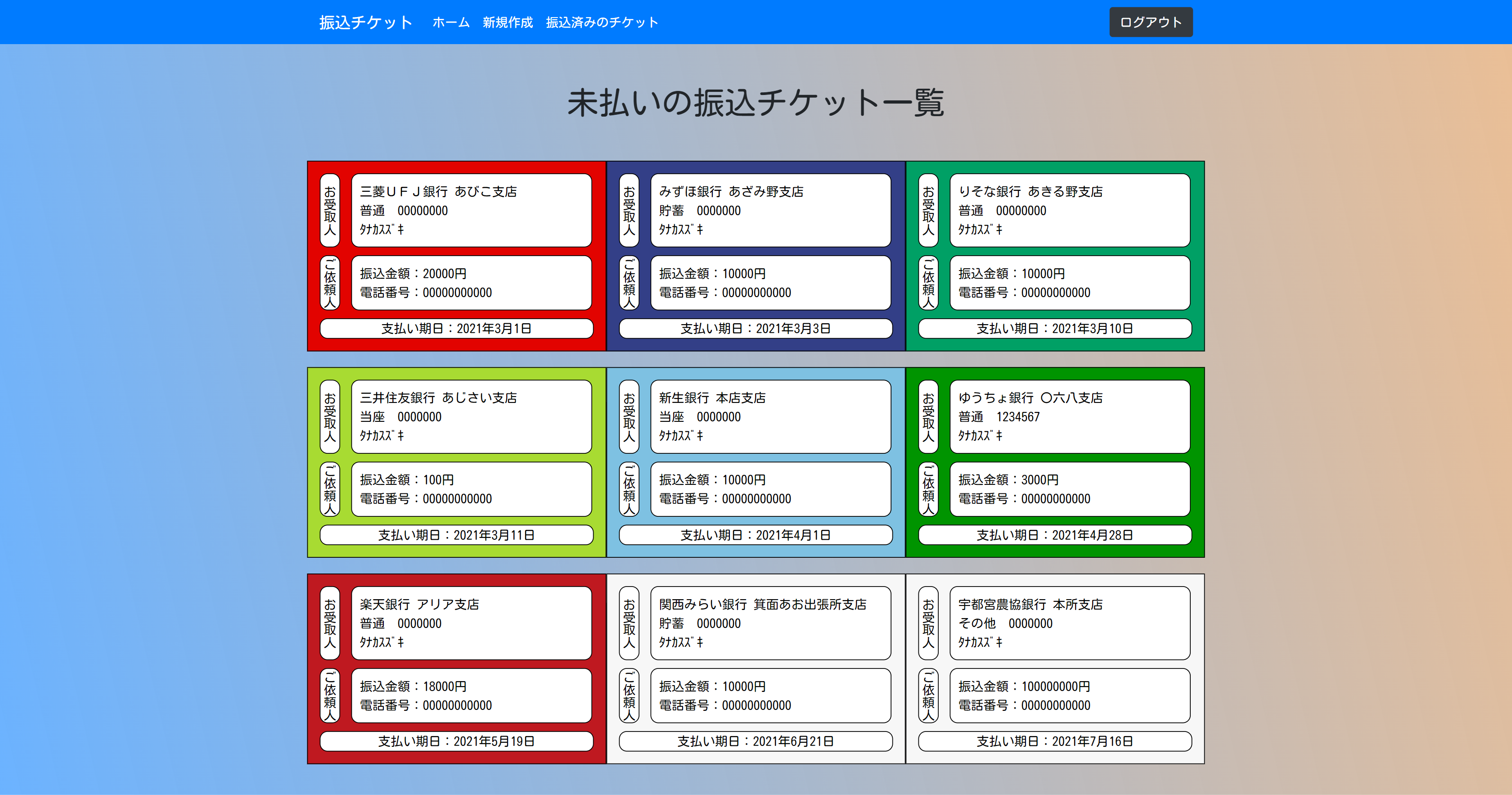
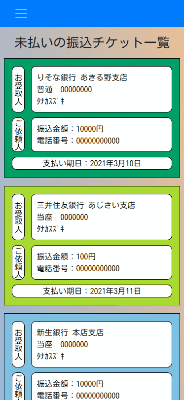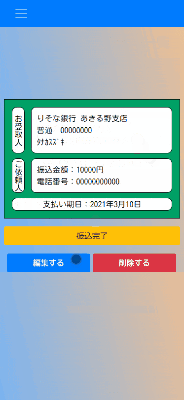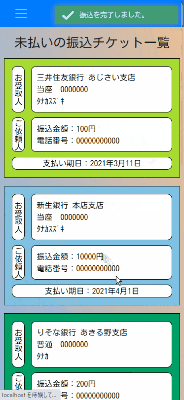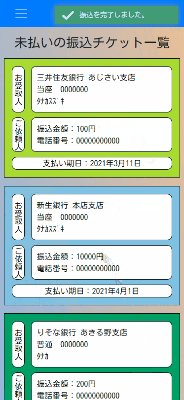
銀行振込を忘れないためのwebアプリ
はじめに
今はもう使われていない振込券をベースに作りました。
なぜ作ったか
- 実家の会社で振込忘れや伝達ミスなどが多発していた
- 督促状が届き面倒な手続きに時間を取られることが多かった
- そんな状態を改善・解決できるのではないかと思った
開発環境
- 言語
- ruby
- フレームワーク
- rails
- データベース
- mysql
- その他
- https://bank.teraren.com/
- 銀行名、支店名を入力する際に上記のAPIを利用させていただきました
基本機能
振込チケットの管理
未払いの振込チケットを振込期日順に閲覧することができます。
また、見た目で分かりやすいように、いわゆるメガバンクはロゴの色に合わせてチケットの色を変えています。
振込チケットの作成
チケットの作成の際には、"https://bank.teraren.com/"
上記の銀行名、支店名を取得できるAPIを利用させていただき、自動で候補を取得し選択できるようにしました。
振込チケットの振込完了報告
振込済みのチケットは別画面で閲覧できます。
スマホ画面
検討している追加機能・改善点
- 期日が近づいた際のwebプッシュ通知
- 管理者権限の有無で使える機能の制限


- 投稿日:2021-02-27T19:44:14+09:00
Railsで大量のデータを更新する際はin_batchesを使おう
Ruby on Railsのプロジェクトで、大量のデータを更新しようとしたらメモリ不足でエラーとなったため、解決方法をメモ。
こんな感じで、データを更新しようとしていました。
Hoge.all.map do |hoge| hoge.update(fuga: hoge.foo) endしかしデータが数十万件あり、メモリ不足で余裕で落ちました。
そんなときは in_batchesを使いましょう。
デフォルトでは1000件ずつ読み込んで処理してくれます。Hoge.in_batches do |hoges| hoges.map do |hoge| hoge.update(fuga: hoge.foo) end end無事解決!
どれくらいの量のデータが扱われるかは、常に意識しないといけないですね。
- 投稿日:2021-02-27T19:05:32+09:00
エラーページを表示させる
HTTPレスポンスのステータスコードとは
クライアントからのリクエストの結果を返す3桁の整数値のことです。
特定のHTTPリクエストが正常に完了したどうかを示します。
通常はリクエストが成功するとステータスコード200を返します。ステータスコードの種類の例
403
アクセス権限がないことを示す。404
リクエスト先が見つからない、またはページが存在していないためにアクセスができないことを示す。「指定されたページは存在しません」などのエラーページが表示されるケース。500
webサーバーで何かしらのエラーが発生したことを示す。503
リクエスト先が一時的にアクセス集中やメンテナンスなどで使用できないことを示す。一時的に、ソースを変更したら再起動しなくてもリロードされるように設定します。
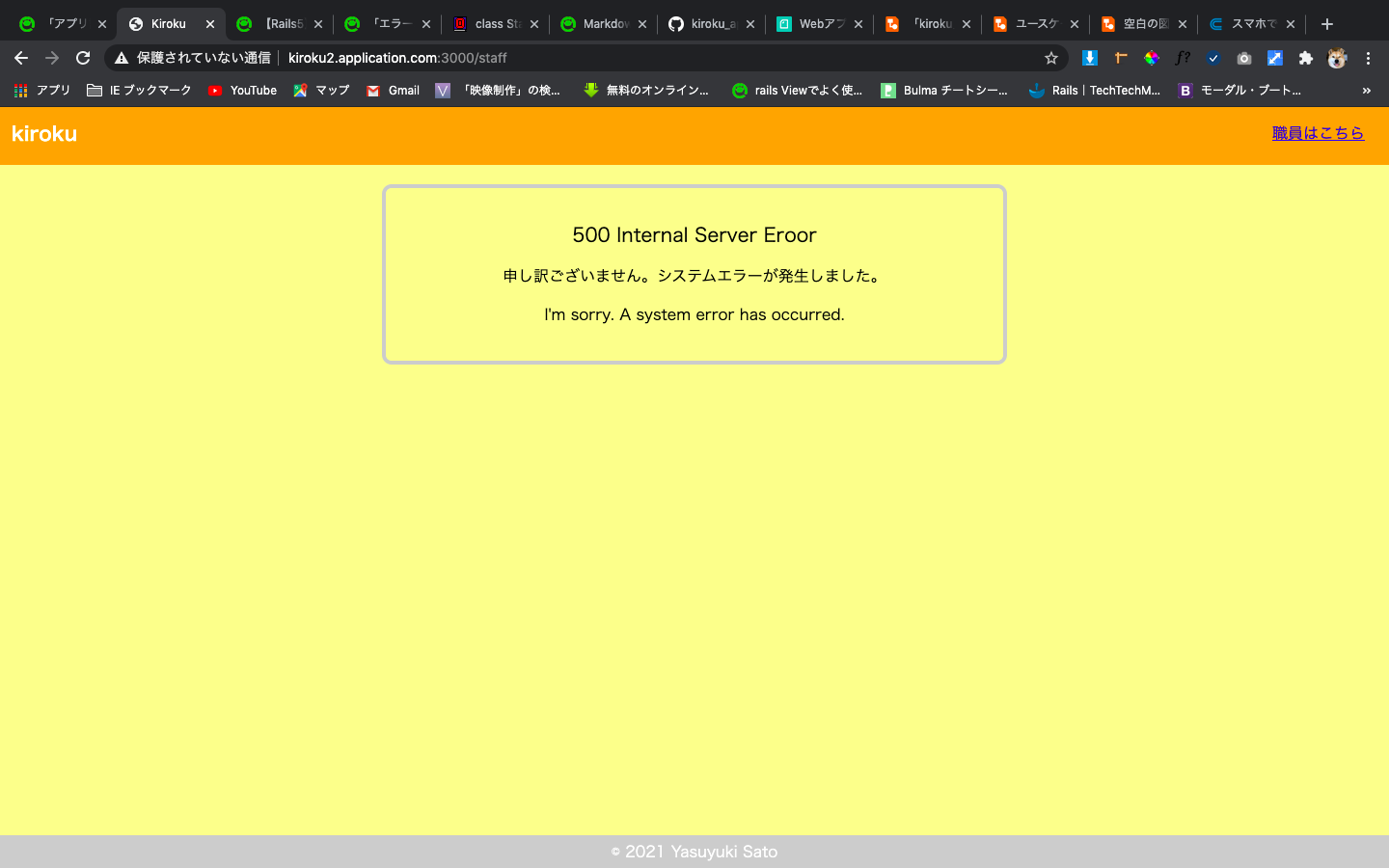
config/environments/production.rbconfig.cache_classes = falseアクションにraiseメソッドを追記してアクセスをすると、強制的に例外の画面が表示されます。
画像はproductionモードでのデフォルトエラー画面です。
ログを出力してみます。
tail -f log/production.log satouyasuyukinoMacBook-Air:kiroku yasuyuki$ tail -f log/production.log [008ffbf8-ca54-443f-927b-90ddff363516] puma (4.3.7) lib/puma/server.rb:472:in `process_client' [008ffbf8-ca54-443f-927b-90ddff363516] puma (4.3.7) lib/puma/server.rb:328:in `block in run' [008ffbf8-ca54-443f-927b-90ddff363516] puma (4.3.7) lib/puma/thread_pool.rb:134:in `block in spawn_thread' I, [2021-02-27T09:10:05.937895 #32132] INFO -- : [32b82d69-ef18-4283-87b3-7655b4b244c7] Started GET "/staff" for 127.0.0.1 at 2021-02-27 09:10:05 +0900 I, [2021-02-27T09:10:05.946757 #32132] INFO -- : [32b82d69-ef18-4283-87b3-7655b4b244c7] Processing by Staff::TopController#index as HTML I, [2021-02-27T09:10:05.951715 #32132] INFO -- : [32b82d69-ef18-4283-87b3-7655b4b244c7] Completed 500 Internal Server Error in 5ms (Allocations: 399) F, [2021-02-27T09:10:05.952131 #32132] FATAL -- : [32b82d69-ef18-4283-87b3-7655b4b244c7] [32b82d69-ef18-4283-87b3-7655b4b244c7] RuntimeError (): [32b82d69-ef18-4283-87b3-7655b4b244c7] [32b82d69-ef18-4283-87b3-7655b4b244c7] app/controllers/staff/top_controller.rb:3:in `index'このエラー画面を任意の画面にカスタマイズします。
app/controllers/application_controller.rb
rescue_from StandardError, with: :rescue500 private def rescue500(e) render "errors/internal_server_error", status: 500 endStandardErrorエラーが発生したら、rescue500のプライベートメソッドの処理が実行されるようにしています。
rescue500メソッドではrenderメソッドでerrorsフォルダのinternal_server_error.html.erbを返しています。
Rubyでは例外を表現するためのExceptionクラスというものが存在します。
StandardErrorはExceptionクラスを継承しています。
サーバーを再起動して以下の画面になってるとokです。
※アクションのraiseメソッドを消すのを忘れずに。
参考:【Rails5】rescue_fromによる例外処理:アプリ固有のエラーハンドリングとエラーページ表示
rails6ガイド
- 投稿日:2021-02-27T18:37:07+09:00
Railsの便利メソッド pluckについて調べてみた
はじめに
Railsでアプリケーションを作成時に、モデルから特定のカラムをリストで抜いてきたい場面が時々あり、なにかいいメソッドはないかと探していたところ、このメソッドにたどり着いた。
idsメソッドなどidカラムのリストを取得するメソッドを知っていたが他のカラムは一々、allで全取得して、mapやselect等を駆使してループ処理を行い、対象のカラムのリストを取得していたので、このメソッドを使用することでかなり簡略化につながるpluckメソッドについて
上記でも簡単に説明したように、対象のカラムのみを指定してリストで取得する事ができる
Railsガイドでは以下のように説明されている。
pluckは、1つのモデルで使用されているテーブルからカラム (1つでも複数でも可) を取得するクエリを送信するのに使用できます。引数としてカラム名のリストを与えると、指定したカラムの値の配列を、対応するデータ型で返します。
実際の使い方について
以下のようなモデルがあると仮定して、サンプルのコードを書いていく
Userモデル
型 カラム名 id integer name string age integer
id name age 1 hoge 21 2 fuga 30 2 hogehoge 34 基本的な使い方
User.pluck(:name) # SELECT name FROM users # => ['hoge', 'fuga', 'hogehoge']その他の使い方
引数を複数のカラムを渡すことで、指定したカラムのリストも取得できます。
戻り値が二次元配列になってかえってくるのでそこだけ注意が必要になります。User.pluck(:name, :age) # SELECT name, age FROM users # => [['hoge', 21], ['fuga', 30], ['hogehoge', 34]]pluckメソッドを使うことのメリット
コードの冗長化を防ぎ、スッキリ書ける
仮に
pluckを使わないで上記と同じような結果が得られるコードを書いてみましょう# pluckを使わない場合 User.select(:name).map{|user|user.name} User.select(:name, :age).map{|user|[user.name, user.age]}発行されるSQLが変わる
mapメソッドを駆使して同じような結果は得られますが、実はRailsが発行するSQL文が変わってきます。
# mapを使用したパターン User.all.map{|user|user.name} => SELECT users.* FROM users # pluckを使用したパターン User.pluck(:name) => SELECT name FROM users上記のSQLを見比べると前者は
SELECT users.* FROM usersでusersテーブルのカラムを一旦すべて取得しているのに対して、後者はSELECT name FROM usersでusersテーブルのnameカラムのみを取得しています。カラムすべてを取得するより、対象を指定してあげて取得する方がパフォーマンスや負荷もこ後者の方が基本的にはよくなるはずです。
ただ便利だから使うのではなく、パフォーマンス等も考慮して最適なメソッドを選べると良さそうです。その他pluckを使う時の注意点について
Railsガイドでは以下のように記載されています
pluckは、selectなどのRelationスコープと異なり、クエリを直接トリガするので、その後ろに他のスコープをチェインすることはできません。ただし、構成済みのスコープをpluckの前に置くことはできます。
つまり、
pluckメソッドの後ろには絞り込みやソートの条件を付ける事ができないということです。
以下のような書き方はエラーとなります。User.pluck(:name).limit(3) User.pluck(:age).order(id: "DESC")ただし、
pluckを使う前に予めスコープを設定しておくことで取得する事ができます。
例えば年齢カラムのリストを降順で取得したい場合は以下のように記述できます。User.order(age: "DESC").pluck(:age) # => [34, 30, 21]
- 投稿日:2021-02-27T17:07:39+09:00
【Rails】deviseで実装したパスワードリセット機能を使って本番環境でメール送信してみた
環境
macOS: Big Sur Ver11.2.1
Rails: 6.1.1
Ruby: 2.6.5
本番環境: Heroku記事の目的
Herokuにデプロイしたアプリケーションでパスワードリセットが正しく動作すること。
パスワードリセット機能はdeviseで導入済み、開発環境で動作確認済みです。
詳しくは、こちらの記事をどうぞ!実装
今回はアプリケーションがHerokuにデプロイされているからHerokuのアドオンであるMailgunを利用して本番環境でのメール送信を試みます。
手順①:アプリの環境設定
Mailgunの公式ドキュメントを参考に、以下のようにファイルを編集。
どちらかというとRailsチュートリアルの11章を参考にしたほうがわかりやすい。config/environmemts/production.rbRails.application.configure do (中略) config.action_mailer.raise_delivery_errors = true config.action_mailer.delivery_method = :smtp host = 'https://furima-34501.herokuapp.com/' config.action_mailer.default_url_options = { host: host } ActionMailer::Base.smtp_settings = { :port => ENV['MAILGUN_SMTP_PORT'], :address => ENV['MAILGUN_SMTP_SERVER'], :user_name => ENV['MAILGUN_SMTP_LOGIN'], :password => ENV['MAILGUN_SMTP_PASSWORD'], :domain => host, :authentication => :plain, } (略)ここで環境変数をいきなり使っていますが、この後にherokuコマンドを打つと自動的にHerokuの本番環境でも環境変数が設定されるようです。なので、あらかじめ先に決められた環境変数名で記述しているだけ。
手順②:Herokuのアドオンを追加
まずはアプリケーションをHerokuにデプロイしましょう。
% git push heroku master % heroku run rails db:migrateデプロイできたら以下のコマンドを実行。
% heroku addons:create mailgun:starter最後のstarterとは、アドオンのプラン名です。今回は無料プランにしています。
ここで、さっきconfig/environmemts/production.rbに記載した環境変数が設定された確認できます。
% heroku config:get MAILGUN_SMTP_LOGIN % heroku config:get MAILGUN_SMTP_PASSWORD実行すると、ちゃんと環境変数が結果に返ってくるはず!
手順③:受信メールの認証
無料プランを利用している場合は、承認された受信者にのみ送信するように制限がかかっているため、本番環境でメールを送るアドレスを認証する作業が必要となる。
以下のコマンドを実行。% heroku addons:open mailgunすると、MailgunダッシュボードのURLが表示され、勝手にブラウザが起動します。
MailGun公式ドキュメントに従い、受信するメールアドレスを認証します。画面左側の「Sending」→「Domains」のリストにある「sandbox」で始まるサンドボックスドメインを選択します。
画面右側の「Authorized Recipients」にメールを送信するアドレス(とりあえず自分の個人アドレスとか)を入力し、認証します。最後に
今回は無料プランかつHerokuにデプロイしたアプリケーションでの実装でした。
Railsチュートリアル様、ありがとうございました!
- 投稿日:2021-02-27T15:35:52+09:00
Rails+Unicorn+NginxにCapistrano導入
はじめに
EC2にRails+Unicorn+Nginxの環境を構築した状態で自動デプロイツール
Capistranoを導入します。Capistranoを利用するためのGemをインストール
ローカル環境のGemfileを編集。
Gemfilegroup :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano3-unicorn' endGemfileを読み込み。
ローカルのターミナルで以下のコマンド。$ bundle install $ bundle exec cap installいくつかファイルが生成されます。
・Capfile利用するライブラリを指定するファイル
・deploy.rb、production.rb、staging.rbデプロイについての設定を書くファイルCapfileを編集
Capfilerequire "capistrano/setup" require "capistrano/deploy" require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn' Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r }デプロイについての設定ファイルを編集
production.rbを編集。config/deploy/production.rbserver '<Elastic IP>', user: 'ec2-user', roles: %w{app db web}
deploy.rbを編集。
production環境、staging環境どちらにも当てはまる設定を記述します。
下記のような項目があります。・アプリケーション名
・gitのレポジトリ
・利用するSCM
・タスク
・それぞれのタスクで実行するコマンド
config/deploy.rbを以下のように書き換えます。config/deploy.rb# config valid only for current version of Capistrano # capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '<Capistranoのバージョン>' # Capistranoのログの表示に利用する set :application, '<自身のアプリケーション名>' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:<Githubのユーザー名>/<レポジトリ名>.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, '<このアプリで使用しているrubyのバージョン>' # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['<ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス(例:~/.ssh/key_pem.pem)>'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end endCapistranoによる自動デプロイ後のディレクトリ構造が変わるので以下の操作が必要。
unicorn.rbの記述を編集
以下のように書き換え。
config/unicorn.rbapp_path = File.expand_path('../../../', __FILE__) worker_processes 1 # currentを指定 working_directory "#{app_path}/current" # それぞれ、sharedの中を参照するよう変更 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" pid "#{app_path}/shared/tmp/pids/unicorn.pid" stderr_path "#{app_path}/shared/log/unicorn.stderr.log" stdout_path "#{app_path}/shared/log/unicorn.stdout.log"Nginxの設定ファイルの記述を編集
EC2サーバー上で操作。
$ sudo vim /etc/nginx/conf.d/rails.conf自身の設定ファイルを全て書き換え。
<>の中身は自身のものと書き換え必要。rails.confupstream app_server { # sharedの中を参照するよう変更 server unix:/var/www/<アプリケーション名>/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name <Elastic IPを記入>; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }Nginxの設定を変更したら、再読込・再起動。
$ sudo systemctl reload nginx $ sudo systemctl restart nginxデータベースの起動を確認。(サーバー上にDB構築の場合)
$ sudo systemctl restart mariadbunicornのプロセスをkill。
$ ps aux | grep unicorn $ kill <確認したunicorn rails masterのPID>ローカルでの修正を全てmasterにpush。
自動デプロイを実行
ローカルのターミナルで以下のコマンド。
$ bundle exec cap production deploy無事に完了したらブラウザで確認。
うまくいかなかったらログを確認しましょう。
- 投稿日:2021-02-27T15:10:07+09:00
【超かんたん】Active Hashで投稿ページにプルダウンメニューを作成しよう!
Active Hashを利用して投稿ページにプルダウンメニューを作成します。
超初心者向けにレシピ投稿アプリを例に作成していきます。完成イメージ
Active Hashとは
Active Hashとは、「基本的に変更されないデータ」をモデルファイルに直接記述し取り扱うことができるGem。公式ドキュメント
Active Hashの導入
Active Hashのインストール
Gemfileに下記を記述しbundle installする。
Gemfilegem 'active_hash'Recipeモデルの作成
今回はレシピ投稿アプリなのでRecipeモデルを作成します。
ターミナルrails g model recipeマイグレーションファイルを編集。
今回、Active Hashを利用してカテゴリー(categoty)と所要時間(time_required)を保存するので、integer型の:モデル名_idという形で記述します。
このあと作成するCategoryモデルとTimeRequiredモデルのidを外部キーとして管理するためです。db/migrate/20XXXXXXXXXXXX_create_recipes.rbclass CreateRecipes < ActiveRecord::Migration[6.0] def change create_table :recipes do |t| #ここから t.string :title, null: false t.text :text, null: false t.integer :category_id, null:false t.integer :time_required_id, null: false #ここまで t.timestamps end end endターミナルrails db:migrate先ほど、integer型で指定したカテゴリーと所要時間の中身を作成していきましょう。
Category、TimeRequiredモデルの作成
モデルファイルの作成
ターミナルtouch app/models/categoty.rbActive Hashを用いて作成するモデルはActiveHash::Baseクラスを継承します。
モデルファイルに以下のような形でプルダウンメニューに表示させたいデータをハッシュの中に記述していきましょう。app/models/categoty.rbclass Category < ActiveHash::Base self.data =[ {id: 0 , name: '---'}, {id: 1 , name: 'すし・魚料理'}, {id: 2 , name: '丼もの・揚げ物'}, {id: 3 , name: 'ラーメン・麺類'}, {id: 4 , name: '中華'}, {id: 5 , name: '焼きもの・粉もの'}, {id: 6 , name: '洋食・西洋料理'}, {id: 7 , name: 'イタリアン'}, {id: 8 , name: 'フレンチ'}, {id: 9 , name: 'アジア・エスニック'}, {id: 10 , name: 'お菓子・スイーツ'} ] end同じ要領でTimeRequiredモデルも作成していきます。
ターミナルtouch app/models/time_required.rb※モデル名はアッパーキャメルケースで記述します。
app/models/time_required.rbclass TimeRequired < ActiveHash::Base self.data =[ {id: 0 , name: '---'}, {id: 1 , name: '10分以内'}, {id: 2 , name: '10分〜20分'}, {id: 3 , name: '20分〜30分'}, {id: 4 , name: '30分〜45分'}, {id: 5 , name: '45分〜60分'}, {id: 6 , name: '60分以上'} ] endアソシエーションの設定
Recipeモデルのアソシエーションの設定
投稿するレシピ(Recipe)はひとつのカテゴリー(Category)と所要時間(TimeRequired)に紐づくのでbelongs_toを設定します。
また、Active Hashを用いて、belongs_toを設定するには、extend ActiveHash::Associations::ActiveRecordExtensionsと記述してモジュールを取り込みます。app/models/recipe.rbclass Recipe < ApplicationRecord extend ActiveHash::Associations::ActiveRecordExtensions belongs_to :category belongs_to :time_required endCategory、TimeRequiredモデルのアソシエーションの設定
カテゴリー(Category)と所要時間(TimeRequired)はたくさんのレシピ(Recipe)に紐付いているのでhas_manyを設定します。
また、Active Hashを用いて、has_manyを設定するには、include ActiveHash::Associationsと記述してモジュールを取り込みます。app/models/categoty.rbclass Category < ActiveHash::Base self.data =[ {id: 0 , name: '---'}, {id: 1 , name: 'すし・魚料理'}, {id: 2 , name: '丼もの・揚げ物'}, {id: 3 , name: 'ラーメン・麺類'}, {id: 4 , name: '中華'}, {id: 5 , name: '焼きもの・粉もの'}, {id: 6 , name: '洋食・西洋料理'}, {id: 7 , name: 'イタリアン'}, {id: 8 , name: 'フレンチ'}, {id: 9 , name: 'アジア・エスニック'}, {id: 10 , name: 'お菓子・スイーツ'} ] #以下追記 include ActiveHash::Associations has_many :recipes endapp/models/time_required.rbclass TimeRequired < ActiveHash::Base self.data =[ {id: 0 , name: '---'}, {id: 1 , name: '10分以内'}, {id: 2 , name: '10分〜20分'}, {id: 3 , name: '20分〜30分'}, {id: 4 , name: '30分〜45分'}, {id: 5 , name: '45分〜60分'}, {id: 6 , name: '60分以上'} ] #以下追記 include ActiveHash::Associations has_many :recipes endバリデーションの設定
presence: true 空データは登録できない
numericality 数値のみを許可する
{ other_than: 0 } numericalityのオプション、0以外を保存
先ほど、Active Hashを用いて作成したモデルのid: 0には'---'とデータが入っていないので0以外を保存するということになります。app/models/recipe.rbclass Recipe < ApplicationRecord extend ActiveHash::Associations::ActiveRecordExtensions belongs_to :category belongs_to :time_required #以下追記 validates :title, presence: true validates :text, presence: true validates :category_id, numericality: { other_than: 0 } validates :time_required_id, numericality: { other_than: 0 } endビューの作成
コントローラー、ビューファイルの作成
ターミナルrails g controller recipes newコントローラーに以下を記述。
app/controllers/recipes_controller.rbclass RecipesController < ApplicationController def index end def new @recipe = Recipe.new end def create @recipe = Recipe.new(recipe_params) if @recipe.save redirect_to root_path else render :new end end private def recipe_params params.require(:recipe).permit(:title, :text, :category_id, :time_required_id) end endルーティングの設定
config/routes.rbRails.application.routes.draw do root to: 'recipes#index' resources :recipes, only: [:index, :new, :create] endビューファイルの編集
一部、Bootstrapを使用しております。
Bootstapについての記事も投稿いているのでこちらを参照してくだい
【図解あり】Rails6でBootstrapを導入してトップページを作成するActive Hashで作成したデータを表示させるにはcollection_selectというメソッドを使用します。
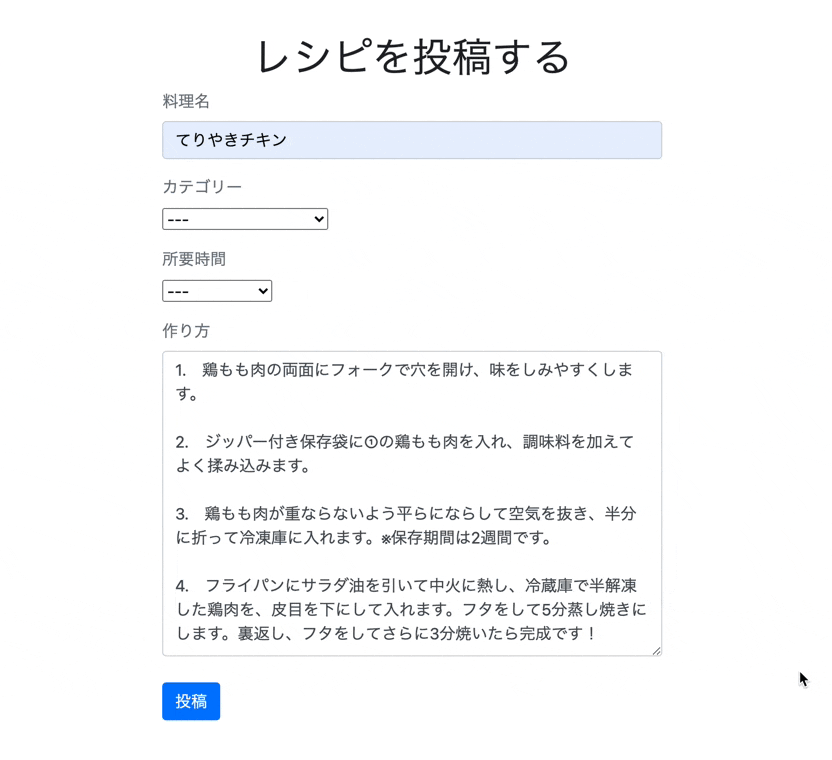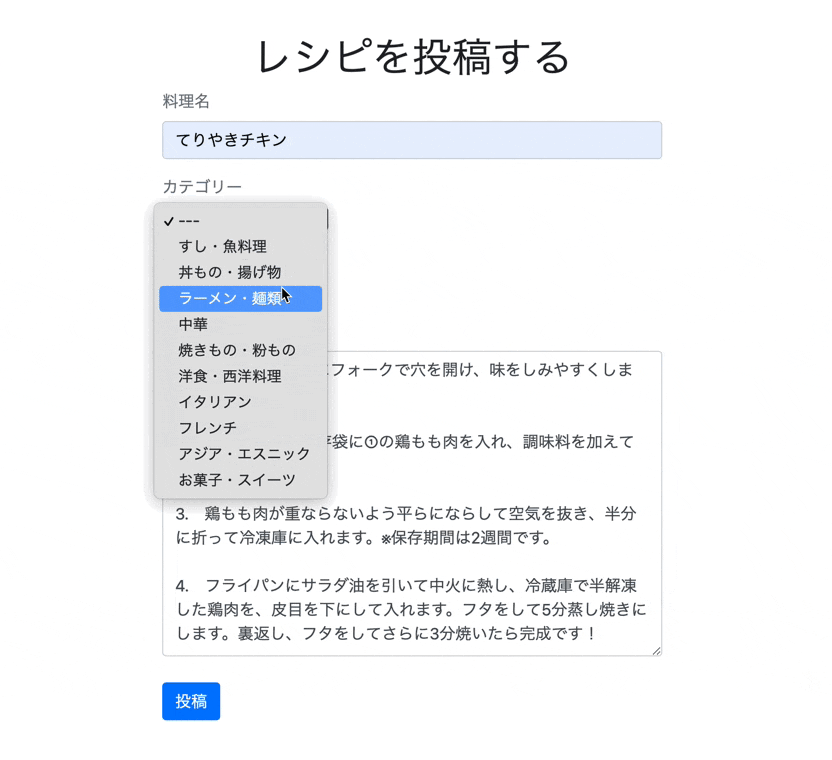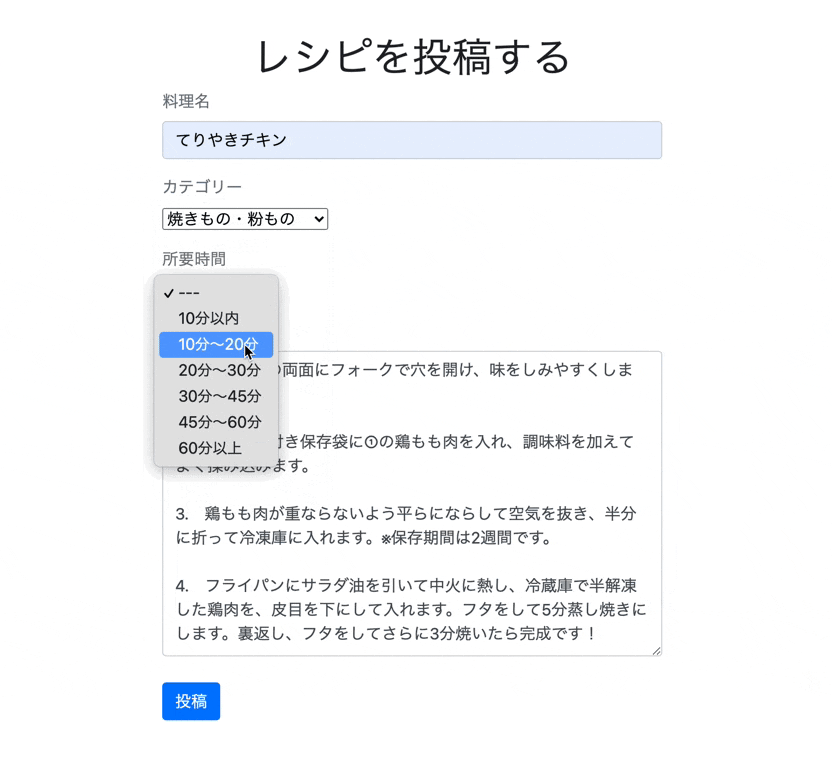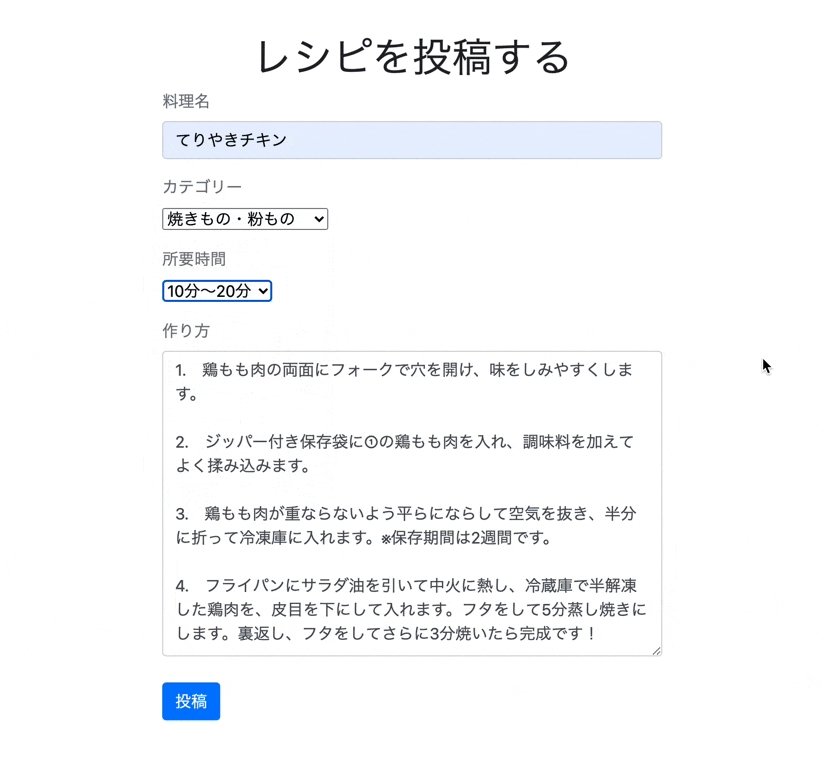
collection_selectは、下記のような順番で記述します。例<%= form.collection_select(保存するカラム名, オブジェクトの配列, カラムに保存する項目, 選択肢に表示するカラム名, オプション, htmlオプション) %>先ほど作成したCategoryモデルだと下記のような記述になります。
例<%= f.collection_select(:category_id, Category.all, :id, :name, {}, {class:"category"}) %>第5引数のオプションは先頭に値のない選択肢を表示するinclude_blankなどがあります。
今回はid: 0 に'---'を指定しているので空にしてあります。
第5引数、第6引数についてはRailsドキュメントを参照してください。
それではビューファイルに記述していきましょう。
app/views/recipes/index.html.erb<div class="recipe-form "> <h1 class="text-center">レシピを投稿する</h1> <%= form_with model: @recipe, local: true do |f| %> <div class="form-group"> <label class="text-secondary">料理名</label><br /> <%= f.text_field :title, class: "form-control"%> </div> <div class="form-group"> <label class="text-secondary">カテゴリー</label><br /> <%= f.collection_select(:category_id, Category.all, :id, :name, {}, {class:"category"}) %> </div> <div class="form-group"> <label class="text-secondary">所要時間</label><br /> <%= f.collection_select(:time_required_id, TimeRequired.all, :id, :name, {}, {class:"time"}) %> </div> <div class="form-group"> <label class="text-secondary">作り方</label><br /> <%= f.text_area :text, class: "form-control"%> </div> <div class="actions"> <%= f.submit "投稿", class: "btn btn-primary" %> </div> <% end %> </div>最後にCSSを整えます。
.recipe-form{ width: 500px; margin: 0 auto; margin-top: 40px; }これで完成になります。
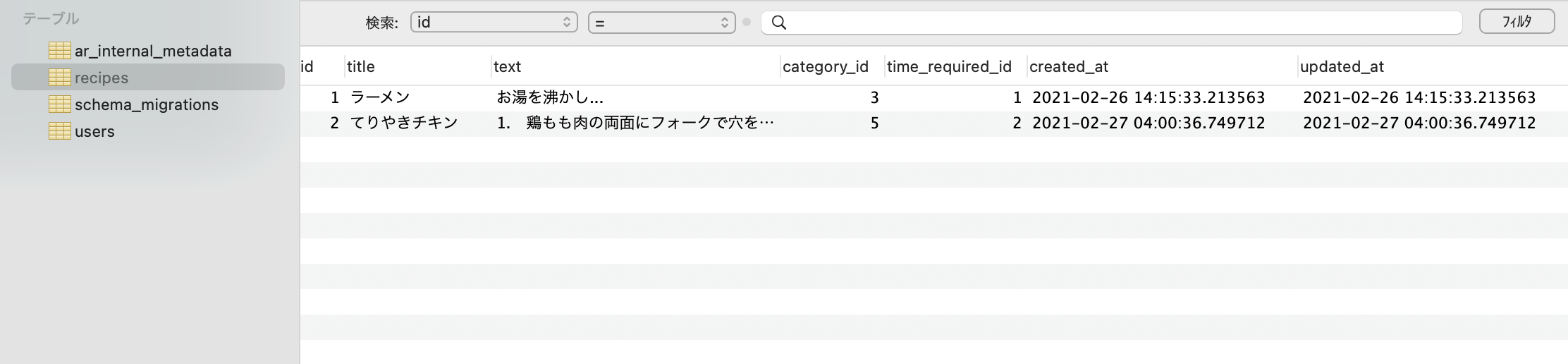
では、実際に投稿できるか確認してみましょう。
しっかり保存されいています。
- 投稿日:2021-02-27T14:49:24+09:00
初めてのRuby On Rails その2(DB編)
テーブル作成手順
1.データベースに変更を指示するファイルを作成
マイグレーションファイルと呼ばれるデータベースに変更を指示するファイルを作成する
今回はpostsテーブルを作成する例を見てみる
この場合、Postと単数形にするターミナルrails g model Post content:textPost:モデル名
content:カラム名
text:データ型以下の2ファイルが作成される
ツリー構造
├ app/
│ └ models/
│ └ post.rb
├ db/
└ migrate/
└ 20210226224717_create_posts.rbpost.rbclass Post < ApplicationRecord end20210226224717_create_posts.rbclass CreatePosts < ActiveRecord::Migration[5.0] def change create_table :posts do |t| t.text :content t.timestamps end end end2.データベースに変更を反映
ターミナルrails db:migrate自動で生成されるカラム
id,created_at,updated_atrails console
後述するテーブルへのデータ保存で使うので記載しておく
開始する場合
ターミナルrails console対話型でコマンドを実行できるようになる
終了する場合
ターミナルquitテーブルに投稿データを保存しよう
手順
- new メソッドで Post モデルのインスタンスを作成
- posts テーブルに保存
1. インスタンスを作成
ターミナルrails console > post = Post.new(content:"Hello world") > post2 = Post.new(content:"Hello world 2") > post3 = Post.new(content:"Hello world 3")2. 保存
DBに3つのデータが挿入される
ターミナル> post.save > post2.save > post3.saveデータ取得
最初のデータを取り出す
postsテーブルの最初のデータを取得
ターミナル> post = Post.first > post.content => "Hello world"すべてのデータを取り出す
postsテーブルの全データを配列で取得
allメソッドを用いるターミナル> posts = Post.all > posts[1].content => "Hello world 2"特定のデータを取り出す
postsテーブルの条件を指定した特定のデータを取得
find_byメソッドを用いるターミナル> post = Post.find_by(id: 3) > post.content => "Hello world 3"並び替えた状態でデータを取り出す
orderメソッドを用いる
desc:降順、asc:昇順ターミナル> posts = Post.all.order(created_at: :desc)データ更新
①編集したいデータを取得
②そのデータのcontentの値を上書き
③データベースに保存ターミナル> post = Post.find_by(id: 3) > post.content = "Rails" > post.save上記のタイミングで、updated_atカラムの値がデータを更新したときの時刻に更新される
データ削除
ターミナル> post = Post.find_by(id: 3) > post.destroyまとめ
DBの基礎知識があれば、特に難しいことはなかった。
SQLを書かないでデータ挿入、取得するのは少し違和感があった。
- 投稿日:2021-02-27T14:44:04+09:00
EC2サーバーにRails + Nginx
はじめに
すでにEC2へ
Railsを導入し、アプリをデプロイした状態(アプリケーションサーバー構築済)からNginxを導入します。
以下にその手順を記載してます。
EC2にRails + MySQL環境構築Nginx導入
Nginx1というバージョンを導入。
EC2サーバー上で以下のコマンド。$ sudo amazon-linux-extras install nginx1Nginxの設定ファイルを編集
$ sudo vim /etc/nginx/conf.d/rails.conf以下のように編集します。
<アプリケーション名>、<Elastic IP>は書き換えてください。rails.confupstream app_server { # Unicornと連携させるための設定。アプリケーション名を自身のアプリ名に書き換えることに注意。 server unix:/var/www/<アプリケーション名>/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name <Elastic IP>; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/<アプリケーション名>/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }nginxの権限を変更
POSTメソッドでもエラーが出ないようにするために権限変更。
$ cd /var/lib $ sudo chmod -R 775 nginxNginxを起動して、設定ファイルを再読み込み
$ cd ~ $ sudo systemctl start nginx $ sudo systemctl reload nginxunicorn.rbを修正
Nginxを介した処理を行うためにunicornの設定を修正します。
unicorn.rblisten 3000 ↓以下のように修正 listen "#{app_path}/tmp/sockets/unicorn.sock"ローカルで編集したファイルをリモートへpushします。
次にサーバー側にクローンします。$ cd /var/www/<アプリ名(任意)> $ git pull origin masterUnicornを再起動
Unicornのプロセスをkillして、再起動する作業を行います。
$ ps aux | grep unicorn $ kill <確認したunicorn rails masterのPID>Unicornを起動します。
$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dブラウザで確認
ブラウザからElastic IPでアクセスすると、アプリケーションにアクセスできます(:3000をつける必要なし)。なお、この時もunicornが起動している必要があります。
エラーが出る場合は、nginxのlogの確認が必要です。
$ less /var/log/nginx/error.logまたは、
$ less /var/www/<レポジトリ名>/log/unicorn.stderr.logで、ログを確認します。
これで、EC2インスタンスにWEBサーバーとアプリケーションサーバーを構築できました。
- 投稿日:2021-02-27T14:40:02+09:00
【デイリードリル】解説&知識補完記事 51~60編
目次
51.コールバックの適用について
52.CSRFについて
53.仕様が決められたrailsアプリケーションの作成
54.ぼっち演算子
55.マイグレーションファイルの管理について
56.仕様が決められたrailsアプリケーションの作成
57.CSS、SCSSのインポートについて
58.if,else問題1
59.if,else問題2
60.rubyのAPI問題1コールバックの適用について
問題.1
Railsのコールバックを利用して以下の機能を実装してください。
①Pictweetに機能を追加する。 ②ユーザーが投稿を行ったら、textカラムに保存されるデータの最後に「!!」を自動で追加する。
解答
tweet.rbbefore_create :change_tweet def change_tweet self.text = text + "!!" end end
解説
そもそもコールバックとは何でしょうか?
コールバックとは、オブジェクトのライフサイクル期間における特定の瞬間に呼び出されるメソッドのことです。
簡単に言うと、必要なタイミングで呼び出せるように、あらかじめ定義しておく関数のことです!つまり、今回の問題では、「ユーザーが投稿を行ったら、textカラムに保存されるデータの最後に「!!」を自動で追加する関数を書け!!!」って問題です。
コールバックはmodelに定義します。詳しくはガイダンスを読みましょう。ガイダンス:Active Record コールバック
次に、解答のコードの解説をしていきます。
tweet.rbbefore_create :change_tweet def change_tweet self.text = text + "!!" end end
change_tweetっていうメソッドを定義し、それをbefore_createで呼び出しています。
before_createについては以下の記事を参照してください。参考:https://morizyun.github.io/ruby/active-record-callback.html
上記コードのselfには、これから保存されるTweetクラスのインスタンスが代入されます。
そのため、self.textとするとユーザーが入力した投稿のtextを取得することができます(@tweet.textみたいな感じで値を取得出来るイメージ!)。
通常、この場合のselfは省略可能です。※例外としてセッターメソッドを使う場合のselfは省略できないため、左辺のselfは必須となります。
よく分かりませんね、そういうものだと思いましょう。
詳しく知りたい方は自分でガイダンスを読んでくださいネ。CSRFについて
問題
Railsには、悪意のある攻撃に対してセキュリティを高める仕組みが様々用意されています。
CSRFと呼ばれるサイトの成りすましによるクラッキングに対して、どのような対策が取られているか述べてください。なお、CSRFがどのようなものか理解に自信がない場合はあらかじめこのことについて調べてからお答えください。
解答
ApplicationControllerにデフォルトで以下の記述がある。protect_from_forgery with: :exceptionこれにより、アプリで作られたフォームに対してトークンが発行され、正しいフォームからの通信なのかを判別することができる。
↓以下のポイントが記述できていればOK!
protect_from_forgeryについて述べられている- トークンの発行によりクラッキングを防いでいることが述べられている
解説
まずは専門用語の解説をしていきましょう。CSRF(クロスサイトリクエストフォージェリ)
Webアプリケーションに存在する脆弱性、もしくはその脆弱性を利用した攻撃方法のことをいいます。
脆弱性とは、コンピュータのOSやソフトウェアにおいて、プログラムの不具合等のミスが原因となって、発生した情報セキュリティ上の欠陥のことをいいます。
これにより、本来拒否すべき他サイトからのリクエストを受信して、処理してしまうという現象が生じる...。..................わからない!!!ムズカシイ!!!(;^ω^)
めっちゃ簡単にまとめると、
悪い人がWebアプリサーバにイタズラする
↓
訪問者がホームページにログインして操作する
↓
被害に遭う
ってことです。悪い人がアプリに細工するんです。いけませんねえ…
クラッキング
コンピュータネットワークに繋がれたシステムへ不正に侵入したり、コンピュータシステムを破壊・改竄するなど、コンピュータを不正に利用することをいう。
IDとパスワードを不正に入手してログインしたり、パスワードを総当たりして特定する悪いやつです。いけないですねえ。困った奴らだ…
対策
では、どのようにして対策しているのか??
実は、railsが対策を考えてくれているのです!!!RailsではCSRF対策として「セキュリティトークンを仕込む」という方法を採用しています。
それをやってくれているのがprotect_from_forgeryメソッドと、Railsが提供するformのヘルパーです。Railsが提供する
form_withなどのヘルパーを使うと、自動でセキュリティトークン(authenticity_token)を仕込んでくれます。すごい!!
protect_from_forgeryメソッドを記述すると、Rails側で正しいauthenticity_tokenがセットされるかどうかをチェックしてくれるので、CSRFを防ぐことができます!参考:
Rails セキュリティガイド:3 クロスサイトリクエストフォージェリ (CSRF)
3分でわかるXSSとCSRFの違い
RailsのCSRF対策について仕様が決められたrailsアプリケーションの作成
問題
以下の仕様を満たすRailsアプリケーションを作成してください。ただし、scaffoldを使用して構いません。
・authorsテーブルがある ・booksテーブルがある ・authorsとbooksは1対多のアソシエーションが組まれている ・authorsテーブルのレコードを削除すると、関連するbooksテーブルのレコードも同時に削除される
解答
(手順例)(ターミナルで以下を実行) > rails new sample-app -d mysql > rails g scaffold author name:string > rails g scaffold book name:string author:referencesauthor.rbclass Author < ApplicationRecord has_many :books ,dependent: :destroy end
解説
アプリケーションを作成するので、ターミナルでコマンドを実行します。ここであんまり馴染みがないのが、
scaffoldだと思います。
scaffoldは、アプリケーションを作成する際に必要なモデルやコントローラー、ビューを作っていき、さらに必要なルーティングを作成していく作業をまとめて行って、簡単にアプリケーションの雛形を作ってくれる機能です。
すごいやつだ。便利〜(・∀・)あとは、実装条件に必要なアソシエーションを記述していきます。
authorsテーブルのレコードを削除すると、関連するbooksテーブルのレコードも同時に削除される
これは、dependentを使用することで実装できます。
dependentは、親モデルを削除する際に、その親モデルに紐づく「子モデル」も一緒に削除できるオプションです。参考:
覚えておくと超便利!Ruby on Railsのscaffoldの使い方【初心者向け】
[Rails] dependent: :destroy についてぼっち演算子
問題
以下のような、Deviseを使ったRailsのコードがあるとします。
これはDeviseを使用したときのcurrent_userに対して、nicknameカラムに
あるデータを取得して@nicknameに代入することを意図したものです。@nickname = current_user.nicknameただし、ログインしないときにこれを実行するとnilに対してメソッドを使おうとしてエラーになってしまいます。
これを回避できる記述がRuby2.3からできるようになりました。
それがどのような記述か、またそれはどのような動きをするのか説明してください。
解答
@nickname = current_user&.nickname
解説
これはぼっち演算子(&)を知ってますか?って問題ですね。
知識があるかどうかの問題なので、ご存じない方はこれを機に頭の片隅に置いとくといいと思います。
&はsafe navigation operator、 lonely operator(ぼっち演算子)などと呼ばれる演算子です。メソッドに続けて記述すると、そのメソッドがnilでなかった場合のみ右辺のメソッドが実行されます。
もしnilだった場合は全ての演算結果としてnilを返します。つまり@nicknameにnilが代入されます。とても使い勝手の良い演算子のため、覚えて活用していきましょう。
なお、ぼっち演算子という命名は、&の記号が一人ぼっちで膝を抱えている人に見えるところからきています。
マイグレーションファイルの管理について
Railsのマイグレートに関して、以下の問いに答えてください。
問題1
Railsのマイグレーションファイルは、ファイルを作成後にマイグレートをして初めてDBに変更が加わります。
今存在している複数のマイグレーションファイルのうち、どのファイルまでマイグレートが終わっているか確認するためにターミナルでどのようなコマンドを打てばよいですか。
解答
rails db:migrate:status問題2
マイグレートを行なった後、その内容に誤りがあることがわかりました。どのように修正すればよいか、手順を述べてください。
解答
例1)
①rails db:rollbackで一度マイグレートされていない状態に戻す
②マイグレーションファイルを修正する
③再びマイグレートを行う例2)
①rails g migrationで新たなマイグレーションファイルを作成する
②修正箇所を正しい内容に変更するためのマイグレーションファイルを作成する
③マイグレートを実行する問題3
一度実行されたマイグレーションファイルは、次のマイグレートに影響は及ぼしません。
そのため、マイグレート後にファイルを変更したり削除したとしても今のDBに悪影響を及ぼすことはありません。ただし、上記の行為は絶対に行なってはいけません。
その理由はいくつかありますが、開発において致命的な不具合が出てしまう理由をお答えください。
解答
アプリケーションのファイルをデプロイ先にpushし、マイグレートを行なった時に、ローカル環境と違ったDBが出来上がったり、エラーになってしまうから。
仕様が決められたrailsアプリケーションの作成
問題
ターミナル> cd ~/projects/ > rails new reverse-app -d mysql > cd reverse-app/ > rails g scaffold item name:string > bundle exec rake db:create > bundle exec rake db:migrate仕様
・登録されたitemのnameが回文(上から読んでも下から読んでも同じになる文)なのかを判定するヘルパーメソッドpalindrome?を作成してください。 ・ヘルパーメソッドは、回文だった時は「回文です」そうでない時は「回文ではありません」という文字列を返すものとします。 ・一覧表示画面で、以下のようにその結果を表示させるようにしてください。
解答
items_helper.rbmodule ItemsHelper def palindrome?(word) word == word.reverse ? "回文です" : "回文ではありません" end endindex.html.erb<p id="notice"><%= notice %></p> <h1>Items</h1> <table> <thead> <tr> <th>Name</th> <th colspan="3"></th> </tr> </thead> <tbody> <% @items.each do |item| %> <tr> <td><%= item.name %></td> <td><%= palindrome?(item.name) %></td> #追加 <td><%= link_to 'Show', item %></td> <td><%= link_to 'Edit', edit_item_path(item) %></td> <td><%= link_to 'Destroy', item, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %> </tbody> </table> <br> <%= link_to 'New Item', new_item_path %> (17行目を追加)
解説
今回のポイントは、palindrome?メソッドを使用できるか?という部分です。
palindrome?メソッドは使用にも書いてあるように回分かどうかを判定するヘルパーメソッドです。Railsにおいては helpersディレクトリにヘルパーメソッドを管理するファイルがあるので、今回はitems_helper.rbに記載します。
items_helper.rbmodule ItemsHelper def palindrome?(word) word == word.reverse ? "回文です" : "回文ではありません" end end
reverseメソッドは、文字列を文字単位で左右逆転した文字列を返します。
そして、三項演算子を使用し、回文です or 回文ではありませんを表示出来るように記載しています。三項演算子とは、
a ? b : cと書くことで、a が真であれば b さもなくば cという結果を返すことができます。ちょいちょい使うので覚えておくと便利です。次に、作ったメソッドをビューで呼び出します。
ヘルパーメソッドはViewではどこからでも呼び出せるため、呼び出したい部分に記載します。index.html.erb#省略 <% @items.each do |item| %> <tr> <td><%= item.name %></td> <td><%= palindrome?(item.name) %></td> #追加 <td><%= link_to 'Show', item %></td> <td><%= link_to 'Edit', edit_item_path(item) %></td> <td><%= link_to 'Destroy', item, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %> #省略先程作ったメソッドを呼び出し、ビューに表示させています。
これで、使用の要件を満たすコードの完成です!!参考:
Ruby 3.0.0 リファレンスマニュアル instance method String#reverse
ヘルパーメソッドをつくろう
Ruby入門 - 演算子css, scssのインポートについて
問題
rails newを実行しアプリケーションを作成した段階では、application.cssに
*= require_tree .という記述があり、これによってCSSファイルを読み込んでいます。SCSSを使用する際は、ファイルの拡張子をscssに変更した上で、@importでファイルを読み込みます。
この時の、requireと@importはどう違うのか、それぞれのインポートの仕組みを踏まえて答えてください。
解答
requireはRailsのアセットパイプラインの仕組みを使ってファイルをインポートする。アセットパイプラインは、cssファイルやJavaScriptのファイルを1つにまとめ、圧縮することで処理速度を早くするための仕組み。sprocketsというgemがこの機能を担っている。
それに対して@importはscssが用意しているメソッド。そのため、application.scssと拡張子を変更しないと使えない。また、application.scssからscssファイルをインポートするために使用する。
if,else問題1
問題
平日でないまたは休日の場合は「True」と返信し、
休日ではない場合は「False」と条件分岐させるメソッドを作りましょう。呼び出し方
sleep_in(weekday, vacation)出力例
sleep_in(false, false) → False sleep_in(true, false) → False sleep_in(false, true) → True
解答
def sleep_in(is_weekday, is_vacation) if (is_weekday != true) || (is_vacation == true) puts "True" else puts "False" end end is_weekday = true is_vacation = false sleep_in(is_weekday,is_vacation)
解説
ポイントは演算子をいくつも使っていることですね。
おそらくコードを見てよくわからない、と感じる方は
sleep_inの中身がよくわからないのではないかと思います。def sleep_in(is_weekday, is_vacation) if (is_weekday != true) || (is_vacation == true) puts "True" else puts "False" end end仮引数(
is_weekday,is_vacation)の結果がtrueかどうかを判別するために、if文と論理演算子(||)、比較演算子(!=、==)を組み合わせて使用しています。理論演算子(
||)は、a または b が true であればという演算子です。
比較演算子は、!=はa と b が等しくないとき、==はa と b が等しいとき、という演算子です。つまり、
is_weekdayがtrueと等しくなかったら(falseだったら)、もしくはis_vacationがtrueだったらputs "True"を実行してね、っていうコードになります。ややこしいコードはいきなり細部から読んでもよくわからないので、if文が使われていて、その条件式の中に演算子が使われていて…と大枠から見ていくと解読しやすくなると思います。
参考:Ruby入門 - 演算子
if,else問題2
問題
あなたは警官です。aとb二人の容疑者の取り調べをしています。
どちらも証言がTrue、またはFalseであればその証言はTrueです。
しかしどちらかがFalseでTrueであればその証言はFalse、と出力するメソッドを作りましょう。呼び出し方
police_trouble(a, b)出力例
police_trouble(true, false) → False police_trouble(false, false) → True police_trouble(true, true) → True
解答
def police_trouble(a, b) if a && b || !a && !b puts "True" else puts "False" end end
解説
こちらは問題58と似ていますね。条件式の中に演算子を用いています。
今回使用しているのは、論理演算子(
!、&&、||)です。
!はa が false であればという意味で、&&はa かつ b が true であれば、という意味です。
||は、問題58でも記述したとおり、a または b が true であればという演算子です。つまり、aとbがどちらもtrueである、もしくはaとbがどちらもfalseであるという条件のときに、
puts "True"を実行してね、というコードになります。参考:Ruby入門 - 演算子
rubyのAPI問題1
問題
任意の文字に対してn番目の文字を消し、
その消した文字を出力するメソッドを作りましょう。※ヒント:APIを利用して問題を解きましょう。
参考URL: https://docs.ruby-lang.org/ja/search/呼び出し方
missing_char(string, num)出力例
missing_char('kitten', 1) → 'itten' missing_char('kitten', 2) → 'ktten' missing_char('kitten', 4) → 'kittn'
解答
def missing_char(array, n) array.slice!(n) puts array end
解説
今回は、任意の文字に対してn番目の文字を消すために必要な処理(メソッド)を使用する必要があるようです。
今回は、
slice!メソッドを使用します。
slice!メソッドは、指定した範囲を文字列から取り除いたうえで取り除いた部分文字列を返します。注意点として、
sliceメソッドとは違うので注意してください。
sliceメソッドは、文字列の任意の部分文字列を取得しますが、元の文字列には影響がありません。
対して、slice!メソッドは破壊的メソッドであるため、戻り値として指定した要素を返しますが、同時に自分自身から戻り値に返した部分を削除してしまいます。コードで見るとわかりやすいかと思います。
#sliceの場合 str = aab puts str.slice(2) #=>b puts str #=>aab #slice!の場合 str = aab puts str.slice!(2) #=>b puts str #=>aa今回は、n番目の文字を消すようなコードを書く問題であるため、
slice!メソッドを使用します。参考:
【Ruby入門説明書】ruby sliceについて解説
Ruby 3.0.0 リファレンスマニュアル instance method String#slice!


- 投稿日:2021-02-27T12:47:44+09:00
アプリ開発実践入門7 Modelとデータベース モデルの基本
今日の教科書
モデルを作る
rails generate model モデル名 設定項目:モデル作成のコマンド
基本モデル名とクラス名とファイル名は大文字小文字の差はあれど一緒である。コマンドで作成されるファイルについて
モデル名.rb:モデルのソースコード
生成日時_create_モデル名の複数形.rb:マイグレーションというデータベースの更新に関する処理のためのファイル
モデル名_test.rb:テストのためのソースコード
モデル名の複数形.yml:テストに関する情報を記述したファイルモデルのソースコード
class モデル名 < ApplicationRecord end最初の記述内容。ApplicationRecordというクラスが継承されている。モデルは全てこれを継承している。ApplicationRecordは最初から組み込まれているものではない。application_record.rbファイルが作成されていて、ここに書かれている。
このクラスはActiveRecord:Baseというクラスを継承している。これはモデルの元になっている機能で含み、これの機能のクラスを使っている。マイグレーションの実行
データベースを使うためにモデルに必要なテーブルをデータベースに用意する作業が必要。
マイグレーションはデータベースのアップデート作業であり、情報を用意しておきこれを元に
最新の状態に更新する。
rails db:migrate:マイグレーションのコマンド。これでなくブラウザのエラーメッセージと一緒に出るボタンを押してもできる。マイグレーションファイルについて
class クラス名 < ActiveRecode::Migration[6.0] def change create_table :テーブル名 do |変数| 処理 end end end自動生成。
シードを作る
ダミーのデータを用意してデータベースの動きを把握する。そのためシードに記述する。
rails db:seed:seeds.rbをシードとして実行するコマンド。データベースにデータが追加される。コントローラーを作成
rails generate controller モデル名複数形 アクション:モデルのコントローラーとアクションとテンプレートが作成される。モデルは単数系、コントローラーは複数系という命名規則に則る。アクションでデータを表示する
class PeopleController < ApplicationController def index @msg = `モデル名 data.` @data = モデル名.all end end
変数 = モデル名.all:allはモデルのデータを全て、配列のようなものにして取り出すメソッド。
得られるものの正確な名称はActiveRecord::Relationというオブジェクト。
Enumerableという機能を使って配列のように値を順番に取り出せるようにしてくれる。テンプレートの作成
繰り返し処理を使って順にデータを取り出していく。
<% @data.each do |obj| %> objを処理 <% end %>@dataから順にデータを取り出して変数objに入れて処理を実行している。
モデルを利用してデータベースから取り出されるデータは全てモデルのインスタンス。
テーブルに用意されている項目で保管されていて、全て取り出せる。<td><%= obj.id %></td> ・・・モデル作成時に自動的に生成される項目がある。
id:データにつけられる番号
created_at:データの作成日時
updated_at:データの最終更新日時ルーティグの設定
ジェネレータコマンドで作ると自動で生成される。
- 投稿日:2021-02-27T12:47:37+09:00
【Rails】deviseを使ってパスワード再設定機能を実装(開発環境ver)
環境
macOS Big Sur Ver11.2.1
Rails6.1.1
Ruby 2.6.5やりたいこと
deviseを導入しているので、パスワードリセット機能を実装してみる。
流れとしては、
①ログイン画面からパスワードリセットメールを送るためのアドレス入力画面に遷移し、
②入力したアドレスにパスワードリセットのためのURLが掲載されたメールが届き、
③URLをクリックするとパスワードリセット画面に遷移する。
④新しいパスワードを入力するとパスワードの変更ができる。
をイメージしてます。モデルの実装
devise導入後、「rails g devise user」コマンドでUserモデルを生成している。
パスワードリセットに使うのは、deviseのモジュールの中の「recoverable」app/models/user.rbclass User < ApplicationRecord (略) devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable (略) endルーティングの確認
デフォルトのルーティングが使えるので、「rails routes」で確認します。
コントローラーとアクション名の組み合わせが、「devise/passwords#アクション名」になっている部分が使用するルーティングです。ビューファイルの生成
「rails g devise:views」コマンドでデフォルトのビューを生成します。今回は、
①パスワードリセットメールの送信先アドレスを入力させるビュー(new.html.erb)
②リセットメール記載のURLをクリックして表示されるパスワード再設定画面のビュー(edit.html.erb)
の2つが必要。
それぞれデフォルトのビューを以下のように変更。app/views/devise/passwords/new.html.erb<%= render "shared/second-header"%> <%= form_with model: @user, url: user_password_path, class: 'registration-main', local: true do |f| %> <div class='form-wrap'> <div class='form-header'> <h1 class='form-header-text'> パスワード再設定 </h1> </div> <%# エラーメッセージの出力 %> <%= render 'shared/error_messages', model: f.object %> <div class="form-group"> <div class='form-text-wrap'> <label class="form-text">メールアドレス</label> <span class="indispensable">必須</span> </div> <%= f.email_field :email, class:"input-default", id:"email", placeholder:"PC・携帯どちらでも可", autofocus: true %> </div> <div class="form-group"> <h2 class='form-bottom-text'> 入力されたメールアドレスにパスワード再設定メールを<br>送信します </h2> </div> <div class='register-btn'> <%= f.submit "会員登録" ,class:"register-red-btn" %> </div> </div> <% end %> <%= render "shared/second-footer"%>こちらは普通の入力フォームを生成すればOK。
app/views/devise/passwords/edit.html.erb<%= render "shared/second-header"%> <%= form_with model: @user, url: user_password_path, method: :patch, class: 'registration-main', local: true do |f| %> <div class='form-wrap'> <div class='form-header'> <h1 class='form-header-text'> パスワード再設定 </h1> </div> <%# エラーメッセージの出力 %> <%= render 'shared/error_messages', model: f.object %> <div class="form-group"> <div class='form-text-wrap'> <label class="form-text">新しいパスワード</label> <span class="indispensable">必須</span> </div> <%= f.password_field :password, class:"input-default", id:"password", placeholder:"6文字以上の半角英数字" %> <p class='info-text'>※英字と数字の両方を含めて設定してください</p> </div> <div class="form-group"> <div class='form-text-wrap'> <label class="form-text">パスワード(確認)</label> <span class="indispensable">必須</span> </div> <%= f.password_field :password_confirmation, class:"input-default", id:"password-confirmation", placeholder:"同じパスワードを入力して下さい" %> </div> <%# 隠しフィールドでトークンもパラメーターで送る。こうすることでDBに保存されているリセットトークンとここから送られたトークンが一致するか確認している。 %> <%= f.hidden_field :reset_password_token %> <div class="form-group"> <h2 class='form-bottom-text'> よろしければ以下のボタンを押してください </h2> </div> <div class='register-btn'> <%= f.submit "パスワードを変更する" ,class:"register-red-btn" %> </div> </div> <% end %> <%= render "shared/second-footer"%>パスワード再設定画面では、「hidden_field」タグがキモ。
この画面のURLに含まれるパスワードリセットトークンの値と、パスワード再設定メールを送信した時にデータベースに保存されている(deviseが自動で保存してくれる)トークンの値が等しいか判断するのに必要。
隠しフィールドでトークンも送信してあげないと、deviseのコントローラーでトークンの一致を確認できず、「トークンを入力してください」というエラーが出てしまう。送信メールの内容変更
実際に送信されるメールの文章を編集する。
※本当はユーザー名を表示したりしたかったが、なぜか文字化けしてしまったのでルーティングのアドレスだけ変更。app/views/devise/mailer/reset_password_instructions.html.erb<p>Hello <%= @resource.email %>!</p> <p>Someone has requested a link to change your password. You can do this through the link below.</p> # この下のルーティングだけ編集した。 <p><%= link_to 'Change my password', edit_user_password_url(@resource, reset_password_token: @token) %></p> <p>If you didn't request this, please ignore this email.</p> <p>Your password won't change until you access the link above and create a new one.</p>環境設定
今回は開発環境でメールが送れるかチェックしたいので、以下のファイルを編集。
ここの記述はRailsチュートリアルの11章「アカウントの有効化」も参考にしました。config/environment/development.rb(略) # Don't care if the mailer can't send. config.action_mailer.raise_delivery_errors = false # 開発環境でメールを送るためのホストの設定(Railsチュートリアル11章) host = 'localhost:3000' config.action_mailer.default_url_options = { host: host, protocol: 'http' } (略)補足
deviseでパスワード再設定を実装するとデフォルトで以下の機能が実装されているので、Railsチュートリアルでイチから実装した内容が結構含まれています。
①パスワード再設定リンクの有効時間(デフォルトは送信されてから6時間)→config/initializers/devise.rb
②リセットトークンの消去(パスワード再設定に成功したら、他人が不正利用できないようトークンを削除)最後に
deviseを使ったパスワード再設定のやり方はほとんど情報がなかったので苦労しました。
今後、本番環境でもパスワードリセットができるよう追加実装していきます。
- 投稿日:2021-02-27T11:50:52+09:00
ローカル 環境開発 Ruby on Railsの環境構築方法
はじめに
ローカル環境でRailsの環境構築ができるようになり、http://localhost:3000/で以下の表示がされるとゴールです。
初めて、ローカル環境で構築しましたので、その方法を記載します。
到達点
以下の1点を達成する
・http://localhost:3000/ で上記の図を表示する仕様
初期仕様
・mac
・Ruby(2.6.3)今回インストールするバージョン
・Ruby on Rails (6.1.1)
・MySQL (8.0.23)
・Homebrew (2.7.6)流れ
① Homebrewインストール
② bundlerインストール
③ MySQLインストール
④ railsインストール
⑤ アプリケーションの新規作成
⑥ サーバー立ち上げ① Homebrewインストール
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"ターミナルで上記のコマンドでHomebrewインストールをします.
brew -vインストールされたか確認します
② bundlerインストール
gem install bundlerターミナルで上記のコマンドでbundlerをインストールします
③ MySQLインストール
brew install mysqlターミナルで上記のコマンドでMySQLをインストールします
brew info mysqlインストールされたか、バージョンも含め確認します
MySQLの自動起動設定
brew services start mysqlこのコマンドでmacが再起動すると、自動的にSQLが再起動されます
MySQLパスワード設定
MySQLはHomebrewでインストールすると、パスワードなしでしようできるため、
パスワードありにしたい場合、下記のコマンドをしますmysql_secure_installation
④ railsインストール
gem install railsターミナルで上記のコマンドでRailsをインストールします
rails -vインストールされたか、バージョンも含め確認します
⑤ アプリケーションの新規作成
rails new app -d mysql rails new app *これでもできるかもrailsはmysqlがデフォルトでないため、
-d mysqlを使いましたが必要ないかもしれません。
このコマンドで、アプリケーションの新規フォルダを作成します。
数分かかります。
⑥ サーバー立ち上げ
cd app rails db:create *データベースがないとエラーになりました rails sappフォルダに移動し,サーバーを立ち上げます。
http://localhost:3000/に以下の画面が表示されれば、成功です!!
参考記事
VS codeの初期設定とRuby on Railsの環境設定 環境構築
ActiveRecord::NoDatabaseError: Unknown database 'アプリ名_development' 解決策

- 投稿日:2021-02-27T10:08:12+09:00
Rspecを動かすまでまとめ(簡易版: 単体・統合テスト)
今回はテスト内容などにはあまり触れていません
Rspecを使ってテストするまでをまとめています。Gemfilegroup :test do gem 'capybara' gem 'rspec-rails' gem "factory_bot_rails" gem 'faker' endgroup :test do 〜 endの中を変更し、bundle install します。
ターミナル$ bundle install $ rails g rspec:installspec/rails_helper.rb#最後の方に追加する config.include FactoryBot::Syntax::Methods end記述することでletを使用した際に、FactoryBotが使用できるようになります。
factories/item.spec.rbFactoryBot.define do factory :"モデル名" do "カラム名" { Faker::Lorem.characters(number: 10) } end endFaker::Lorem.characters(number: 10)とは
テスト用の文字列を作成する。今回の場合はカラム名のところに10文字のテストデータを作成してくれます。spec_helper.rbRSpec.configure do |config| #追加します config.before(:each, type: :system) do driven_by :rack_test end #省略 end単体テスト
models/item_spec.rbrequire 'rails_helper' RSpec.describe 'Itemモデルのテスト', type: :model do describe 'バリデーションのテスト' do subject { item.valid? } let(:user) { create(:user) } let(:genre) { create(:genre) } let!(:item) { build(:item, user_id: user.id, genre_id: genre.id) } context 'nameカラム' do it '空でないこと' do item.name = '' is_expected.to eq false end it '2文字以上であること: 2文字は〇' do item.name = Faker::Lorem.characters(number: 2) is_expected.to eq true end it '2文字以上であること: 1文字は×' do item.name = Faker::Lorem.characters(number: 1) is_expected.to eq false end end end endターミナル$ rspec spec/models/item_spec.rb単体テストの実行できます。
今回はItemモデルのテスト実行しています。統合テスト
system/test.spec.rbrequire 'rails_helper' describe 'トップ画面のテスト' do before do visit root_path end context '表示内容の確認' do it 'URLが正しい' do expect(current_path).to eq '/' end end endターミナル$ rspec spec/system/test.spec.rb統合テストの実行できます。
これでテスト環境は出来ましたので
追加したい項目を書いていくだけになります。おまけ
system/test_spec.rblet(:"モデル名") { FactoryBot.create(:"モデル名", "カラム名": "データ") } let(:item) { create(:item, user_id: user.id, genre_id: genre.id) }2個目の記述のようにFactoryBotを省略できます。
letとlet!の違い
item_spec.rblet(:genre) { create(:genre) } let!(:item) { build(:item, user_id: user.id, genre_id: genre.id) }
- letを使用した場合は処理が行われずにitの中で呼ばれたときにcreateが実行されます。
- let!を使用した場合はそのまま処理される。
毎回呼び出す必要のないものは" ! "を外した方がわかりやすくなります。createとbuildの違い
item_spec.rblet(:genre) { create(:genre) } let!(:item) { build(:item, user_id: user.id, genre_id: genre.id) }
- createはにメモリにデータを保存する。
- buildはDBにデータ保存する。
使い分け方
今回はアイテムを登録するためのバリデーションをテストしますので
createで実行すると一回でもテストに通るとメモリに残っているので
アイテムが登録されている状態でバリデーションのテスト行うようになってしまうため、
ちゃんとテストが実行されているかが判断できなくなります。
これから確認したい対象物にはbuildを使うことがいいと思います。
- 投稿日:2021-02-27T08:41:06+09:00
deviseの導入方法について
はじめに
本日は、deviseの導入方法を記事にしたいと思います。
deviseとはログインやサインアップが実装できるGemです。
Gemを導入するだけで簡単にユーザー管理機能が実装できます。手順
1.deviseのインストール
2.テーブル作成
3.viewの作成
4.ストロングパラメーターの設定バージョン
・Ruby 2.6.5
・Rails 6.0.0deviseのインストール
まずは、Gemfileに
Gemfile
gem 'devise'こちらを記述し、
# Gemをインストール % bundle installターミナルよりインストールを行います。
次に、deviseの設定ファイルを作成します。
# deviseの設定ファイルを作成 % rails g devise:installこのコマンドは、追加したdeviseというGemの「設定関連に使用するファイル」
を自動で生成するコマンドです。次にUserモデルを作成します。
# deviseコマンドでUserモデルを作成 % rails g devise userすると、以下のようなログが表示されます
invoke active_record create db/migrate/20200309082300_devise_create_users.rb create app/models/user.rb invoke test_unit create test/models/user_test.rb create test/fixtures/users.yml insert app/models/user.rb route devise_for :usersユーザーに関するモデルやマイグレーションも自動生成してくれます。
また、routes.rbのファイルをみてみると、
routes.rb
Rails.application.routes.draw do devise_for :users #以下省略 endルーティングが自動追記されています。
これで、deviseの導入は完了です。テーブルの作成
次にテーブルを作成します。
2021xxxxxxx_devise_create_user.rb
class DeviseCreateUsers < ActiveRecord::Migration[6.0] def change create_table :users do |t| ## Database authenticatable t.string :nickname, null: false t.string :profile, null: false t.string :email, null: false, default: "" t.string :encrypted_password, null: false, default: "" #以下省略 enddeviseを導入すると、デフォルトでemailとpassword、再passwordの
カラムは設定されています。
それ以外にカラムが必要でしたら、マイグレーションファイルに記述します。
今回は、nicknameとprofileのカラムを追加しました。設計しまいたら、マイグレーションを実行します。
# マイグレーションを実行 % rails db:migrateこれで、テーブル作成は完了です。
マイグレーションを行ったらサーバーを再起動させます。ビューの作成
deviseを導入すると、ログイン、サインアップの画面が自動生成されますが
ビューファイルとしては生成されません。
deviseのビューファイルに変更を加えるためには、deviseのコマンドを利用して、ビューファイルを生成する必要があります。% rails g devise:viewsdeviseのコマンドで、devise用のビューファイルを生成します。
ファイルを生成したら自身でファイルを編集します。
views/devise/registrations/new.html.erb
<div class="main"> <%= render partial: "posts/header"%> <div class="inner_login"> <div class="form__wrapper"> <h2 class="page-heading">新規登録</h2> <%= form_with model: @user, url: user_registration_path, local: true do |f| %> <%= render 'posts/error', model: f.object %> <div class="field"> <%= f.label :email, "メールアドレス", class: :form__text_1 %><br /> <%= f.email_field :email, autofocus: true, autocomplete: "email" %> </div> <div class="field"> <%= f.label :password, "パスワード(半角英数混合6文字以上)", class: :form__text_1 %><br /> <%= f.password_field :password, autocomplete: "new-password" %> </div> <div class="field"> <%= f.label :password_confirmation, "パスワード再入力", class: :form__text_1 %><br /> <%= f.password_field :password_confirmation, autocomplete: "new-password" %> </div> <div class="field"> <%= f.label :image, "プロフィール写真" ,class: :form__text_1 %><br /> <%= f.file_field :image %> </div> <div class="field"> <%= f.label :nickname, "nickname",class: :form__text_1 %><br /> <%= f.text_field :nickname %> </div> <div class="field"> <%= f.label :profile, "プロフィール(自分を一言で表現してください)" ,class: :form__text_1 %><br /> <%= f.text_area :profile, class: :form__text %> </div> <div class="actions"> <%= f.submit "新規登録", class: :form__btn %> </div> <% end %> </div> </div> </div>こちらは、新規登録のビューです。
nickname、profile、email、password、再password
プロフィール写真(Active Storage)の記述を行いました。※プロフィール写真に関してはここでは、無視してください。
ストロングパラメーターの設定
deviseの処理を行うコントローラーはGem内に記述されているため、編集することができない
ため、application_controller.rbのファイルに記述します。
このファイルは全てのコントローラーが継承しているファイルです。application_controller.rb
class ApplicationController < ActionController::Base before_action :configure_permitted_parameters, if: :devise_controller? private def configure_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [:nickname, :profile, :image]) end endbefore_actionの記述は、もしdeviseに関するコントローラーの処理であれば、そのときだけconfigure_permitted_parametersメソッドを実行するように設定したものです。
devise_parameter_sanitizerメソッド
deviseが提供しているメソッドでこれにより、新規登録のパラメーターを取得できます。
permitの引数には、第一引数に処理名、第二引数に許可するキーを記述します。permit(:deviseの処理名, keys: [:許可するキー])今回は新規登録時に、nicknameとprofileとimageを許可する設定をしました。
デフォルトのemailやpassword以外にカラムを設定した場合はこの記述が必要
となります。以上がdeviseの導入と設定の手順です。
deviseを導入すると使えるようになるメソッドなんかもあり
とても便利です。
興味ある方は調べてみてください。まだまだ、初心者なので不備があるかもしれません。
その際は、コメントいただければ幸いです。
- 投稿日:2021-02-27T07:54:25+09:00
【 Ruby on Rails 6.0 】 AWS + Nginx + Unicornでデプロイ⑦
始めに
前回の内容でNginxというWebサーバーを導入しRailsアプリを本番環境で起動出来ました。
しかし、現状だと開発環境で変更したものを本番環境に反映させるのに工数が多く不便です。
そこで、Capistranoという自動デプロイツールを導入しコマンドひとつでデプロイ作業を完了できるように設定していきます。目次
目次 内容 セクション1 EC2インスタンス作成 セクション2 Linuxサーバー構築 セクション3 データベース設定 セクション4 EC2上でGemをインストールし環境変数を設定 セクション5 Railsアプリを起動 セクション6 Nginxの導入 セクション7 自動デプロイ(今回の内容) セクション8 独自ドメイン取得 Capistranoの導入
必要なGemをインストールし、Capistranoを動かすために必要な設定ファイルを生成します。
Gemfile(ローカル)group :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capist endターミナル(ローカル)$ bundle install # gemを読み込めたら、下記のコマンドを打ちます。 $ bundle exec cap installするとデプロイについての設定を書くファイルが自動で生成されます。
Capfileを編集
Capfileは、capistrano全体の設定ファイルです。
Capifilerequire "capistrano/setup" require "capistrano/deploy" require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn' Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r }デプロイについての設定ファイルを編集
cap installコマンドを打つと、config/deploy配下にproduction.rbとstaging.rbの2 種類のファイルが生成されます。production.rbですが2つファイルがあります
❌ config/environment/production.rb
⭕️ config/deploy/production.rb今回作業はするのはconfig/deploy/production.rbです。
production.rbを下記のように編集
config/deploy/production.rb# 最下部に追記 server 'XX.XXX.XX.XXX(Elastic IP)', user: 'ec2-user', roles: %w{app db web}deploy.rbを編集
config/deploy.rb# 全て削除して以下を追記 # config valid only for current version of Capistrano # capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '○.○○.○(Capistranoのバージョン)' # Capistranoのログの表示に利用する set :application, '○○○(自身のアプリケーション名)' set :deploy_to, '/var/www/○○○(アプリ名)' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:○○○(Githubのユーザー名)/○○○(レポジトリ名.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, '○.○.○(rubyのバージョン)' #カリキュラム通りに進めた場合、2.5.1か2.3.1です # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/○○○○○.pem(ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス 例:~/.ssh/key_pem.pem))'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end end以下の5点は書き換えが必須です。
- 3行目のはご自身のバージョンを記述しましょう。
- 6行目の<自身のアプリケーション名>はご自身のものを記述しましょう。
- 9行目の/<レポジトリ名>も同様に、ご自身のもの記述してください。
- 15行目の<このアプリで使用しているrubyのバージョン>はご自身のものを確認して 記述してください。
- 19行目の<ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス>も同様に、ご自 身のもの記述してください。
Capistranoのバージョン確認
capistranoのバージョンは、gemfile.lockに記載されています。
capistrano(3.11.0)ように記載されています。rubyのバージョンの確認
ローカルのターミナルで以下のように確認します。
ターミナル$ ruby -v # 実行結果 ruby2.6.5....unicorn.rbの記述を編集
capistrano導入後はアプリケーションのディレクトリ構造が変化するので以下のように記述を編集します。
config/unicorn.rbapp_path = File.expand_path('../../', __FILE__) worker_processes 1 working_directory app_path pid "#{app_path}/tmp/pids/unicorn.pid" listen "#{app_path}/tmp/sockets/unicorn.sock" stderr_path "#{app_path}/log/unicorn.stderr.log" stdout_path "#{app_path}/log/unicorn.stdout.log" # 以下のように変更↓ # ../が一つ増えている app_path = File.expand_path('../../../', __FILE__) worker_processes 1 # currentを指定 working_directory "#{app_path}/current" # それぞれ、sharedの中を参照するよう変更 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" pid "#{app_path}/shared/tmp/pids/unicorn.pid" stderr_path "#{app_path}/shared/log/unicorn.stderr.log" stdout_path "#{app_path}/shared/log/unicorn.stdout.log"Nginxの設定ファイルの記述を編集
同様に、Nginxの設定ファイルもディレクトリで構造が変化しているので編集します。
ターミナル(EC2)# SSHログインしてから実行 [ec2-user@ip-172-31-25-189 ~]$ $ sudo vim /etc/nginx/conf.d/rails.confrails.confupstream app_server { # sharedの中を参照するよう変更(/shared/tmp/sockets/unicorn.sock;) server unix:/var/www/○○○○○(アプリケーション名)/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name XX.XXX.XX(Elastic IP); # currentの中を参照するよう変更(/current/public;) root /var/www/○○○○○(アプリケーション名)/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更(/current/public;) root /var/www/○○○○○○(アプリケーション名)/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }編集し終わったら、
escキーを押して:wqで保存します。
Nginxの設定を変更したら、忘れずに再読込・再起動をします。ターミナル(EC2)# nginx起動 [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl reload nginx [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart nginx # nginxのステータスを確認(active runningであれば成功) $ sudo systemctl status nginx.service ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset: disabled) Active: active (running) since 水 2021-02-17 11:28:00 UTC; 7h ago # エラーが出た場合はnginxのエラーログを確認 [ec2-user@ip-172-31-45-167 アプリ名]$ sudo cat /var/log/nginx/error.logデータベースの起動を確認
データベースが立ち上がっていないとデプロイが失敗するので起動します。
ターミナル(EC2)[ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart mariadb # ステータスを確認(active runningなら成功) [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl status mariadbunicornのプロセスをkill
自動デプロイを実行する前にunicornのコマンドをkillします。
ターミナル(EC2)# プロセスを確認 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn # 一番上のunicorn_rails masterをkillしたいので、下記を実施 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill 17877ローカルでの修正を全てmasterにpush
ローカルでのコードの変更が、全てmasterにpushされていることを確認しましょう。
自動デプロイ実行
これで、ローカルのターミナルからコマンド一発でデプロイできるようになりました。
ターミナル(ローカル)# アプリケーションのディレクトリで実行する $ bundle exec cap production deployエラーがなく完了したらデプロイ完了です!
ブラウザからElastic IPでアクセスすると、アプリケーションにアクセスできます!
確認してみましょう。もし途中でエラーが出たら
- EC2のターミナルで
less log/unicorn.stderr.logコマンドでエラーログを確認- ローカルでの編集のpushやpullを忘れていないか確認
- mariaDBやNginxを再起動してみる
- EC2インスタンスを再起動してみる
終わりに
ここまででRailsアプリを本番環境にデプロイする工程が終了しました!
ただ、IPアドレスだと覚えにくいので次回で独自ドメインを取得方法をまとめたいと思います。
お疲れさまでした。。。次回
独自ドメイン取得

- 投稿日:2021-02-27T01:51:27+09:00
アセットパイプラインに関わる画像が表示されないエラー
今回のエラー
制作環境は
- Ruby on Rails
- unicorn
- AWS EC2
- Nginx
Nginxを導入して設定をした後から、本番環境でトップページに表示される予定の画像が表示されない状態になっていた。
ログイン画面のアニメーションとして用意してあった音声ファイルが読みこまれていない。
一部では表示されている画像もあった。原因
アセットパイプラインの参照先の記述に問題があった。
問題箇所
今回の不具合箇所は2点
トップページの画像の記述
<%= image_tag("/assets/title_logo.png", class: "header-logo" ) %>ログイン画面の音声ファイル
<%= audio_tag("/assets/submit", autoplay: false, controls: true, id:"audio_sub") %>対処
行ったことは
1. 参照先URLを修正
2. git hubに修正をpush
3. 本番環境でプリコンパイル、プロセス再起動1. コードを以下のように変更
トップページの画像の記述
<%= image_tag "title_logo.png", class: "header-logo" %>ログイン画面の音声ファイル
<%= audio_tag "submit", autoplay: false, controls: true, id:"audio_sub" %>変更箇所
変更したのは参照先のURL部分
/assets/部分を削除した2. git hubに変更をpush
git hubデスクトップ上でpush
ブランチを切っているなら、masterにmarge
※GUI、ブラウザでの操作だったので詳細割愛3. 本番環境でプリコンパイル、プロセス再起動
以下ターミナルで操作
- 今回はAWSのEC2でデプロイしているので、EC2のデプロイ済みのインスタンスにログイン
- git masterをpull
git pull origin master- プリコンパイル
rails assets:precompile RAILS_ENV=production- nginxを再読み込み
sudo systemctl reload nginxsudo systemctl start nginxプロセス再起動
- プロセス確認
ps aux | grep unicorn- プロセス停止
kill (rails masterのプロセス番号)- アプリケーションサーバー起動
RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D以上で改善した
気づいた事
- 開発環境では
image_tag,audio_tagを複数使用しており、URLに/assets/が混同していても問題なかったが、unicorn、nginx(webサーバー)が加わり問題が起きた- コードが改善していても改めてプリコンパイルをしないと表示されなかった
原因の仮説
以下は今回の対処にあたって思ったこと。
調べきれていないので、メモとして書いておく。
- Nginxを利用するとプリコンパイルあたりで違う挙動をする?
- webサーバー(Nginx)は静的な情報を返すもので、動的な情報はアプリケーションサーバーに割り振るような仕組みだと理解しているが、静的な情報としてプリコンパイルをする際に、アセットパイプラインで参照している? そのため、'''/assets/'''と記述してあるとアセットパイプラインとは別に、個別参照になりプリコンパイルがうまくいかなかった?
- 投稿日:2021-02-27T00:30:16+09:00
【Rails】 初心者向け!gem 'dotenv-rails'の使い方
はじめに
最近当たり前のように使用している'dotenv-rails'のgemと環境変数という言葉ですが、使い始めた頃は何が何だかよく分からなかった覚えがあります。そんな自分自身の復習と、同じような初心者の方の参考になればと思い、なるべく一つ一つ丁寧に、また画像なども掲載しつつ投稿させていただいております。
開発環境
ruby 2.6.3
Rails 5.2.4.4
dotenv-railsとは
環境変数を管理することができるgemです。
自身で作成したアプリケーションの直下に.envファイルを作成することで、パスワードなどネット上に公開させたくない情報を扱い、自動で読み込むことが可能です。
環境変数とは
参考書やネットで当たり前に出てくる「環境変数」という言葉。
私は当初この言葉の意味すら分かりませんでしたので、説明を掲載しておきます。
簡単に言うと、ネット上に公開させたくない情報を入れておく箱になります。この箱自体には、自身で任意の名前をつけることが可能です。つまり、ネット上に公開させたくない情報は、一度この環境変数という箱の中に入れ、コード上で使用することで、情報漏洩を防ぐことができます。
gemを導入
Gemfile.gem 'dotenv-rails'terminal.$ bundle install
.env ファイルを作成
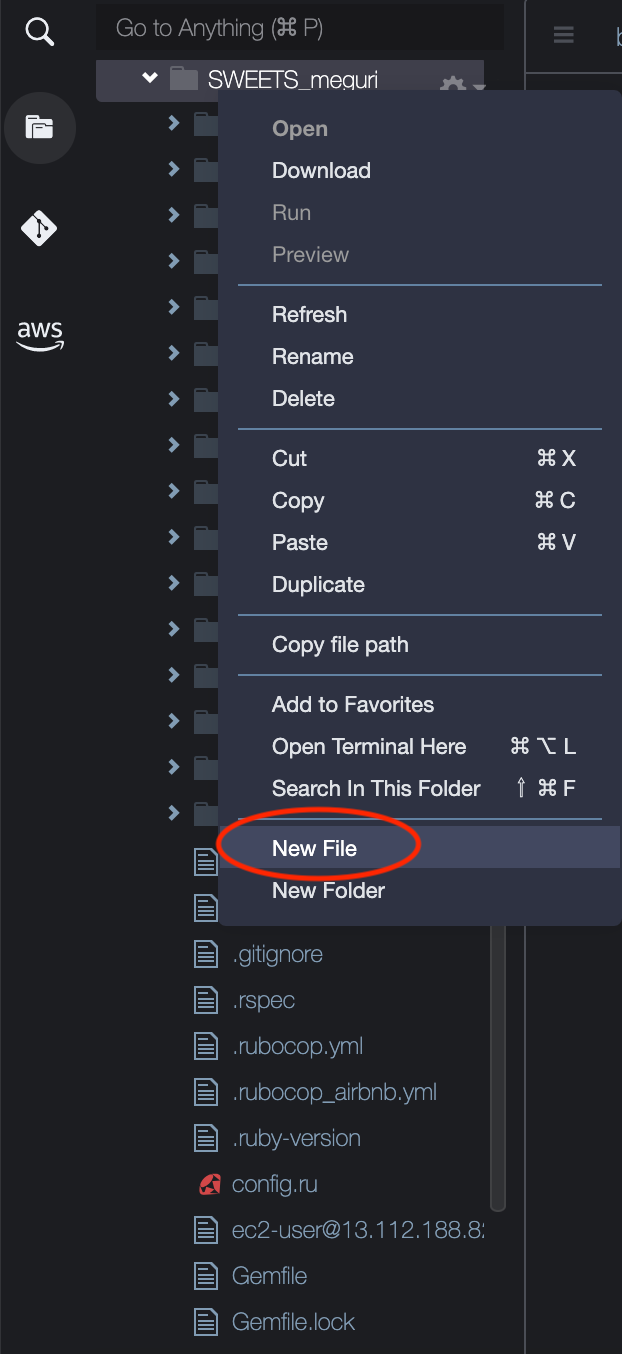
① アプリケーション名のディレクトリにカーソルを合わせ、右クリックします。
② New Fileを選択します。
③ ファイル名を「.env」にします。
画像のような配置でファイルを作成できていれば、完成です!④ 以下のような形で必要な情報を記述してください。
(参考画像)
 .env# Google map用 GOOGLE_API_KEY = "***************" # 問い合わせ機能用 SEND_MAIL = "***************" SEND_MAIL_PASSWORD = "***************" # デプロイ用 DB_USERNAME = "***************" DB_PASSWORD = "***************" DB_HOST = "***************" DB_DATABASE = "***************"
.env# Google map用 GOOGLE_API_KEY = "***************" # 問い合わせ機能用 SEND_MAIL = "***************" SEND_MAIL_PASSWORD = "***************" # デプロイ用 DB_USERNAME = "***************" DB_PASSWORD = "***************" DB_HOST = "***************" DB_DATABASE = "***************"
環境変数の記述の仕方
ENV['設定した名前']
たったこれだけの記述で環境変数を扱うことができます。ENV['GOOGLE_API_KEY'] ENV['SEND_MAIL']
.gitignoreファイルへ追記
アプリケーション直下にある、Gitの管理に含めないファイル名を記述するファイルです。
こちらのファイルの他にも、ファイル名の前に.(ドット)が付いているものは、Gitの管理に含めないファイルとして取り扱われています。
※ こちらに「/.env」の記述をしないと、全ての情報がネット上に公開されてしまうので注意!.gitignore# 最終行に下記の記述を加えてください。 /.env
万が一GitHubにpushしてしまったら...
誤ってGithub上に公開してしまっている方は、下記のコマンドで.envをGitの管理から外してください。
コマンド実行後は、.gitignoreファイルに「/.env」を追記した上で、再度git pushをし直してください。● git rm --cached [ファイル名]
ファイル自体は残したままGitの管理から外すことが可能なコマンドterminal.$ git rm --cached .env
終わり
今回は以上になります。
私自身もプログラミング初心者ですが、同じ様な立場の方に少しでも参考になれば幸いです。
また、もし内容に誤りなどがございましたら、ご指摘いただけますと幸いです。
- 投稿日:2021-02-27T00:24:20+09:00
Railsで通知機能を作る(①基本機能編)
やったこと
Railsでアプリを作っています。
通知機能を作りましょうという課題がありました。
初めて作る&覚えておくと応用が効きそうなので、いかにやり方をまとめます。なお、実行環境は以下の通りです。
- Rails
5.2.3- Ruby
2.6.4仕様
以下のような仕様になっています。
userがフォローされた時userの投稿したpostにコメントがついた時userの投稿に「いいね!」がされた時上記の条件でユーザーに通知を出します。
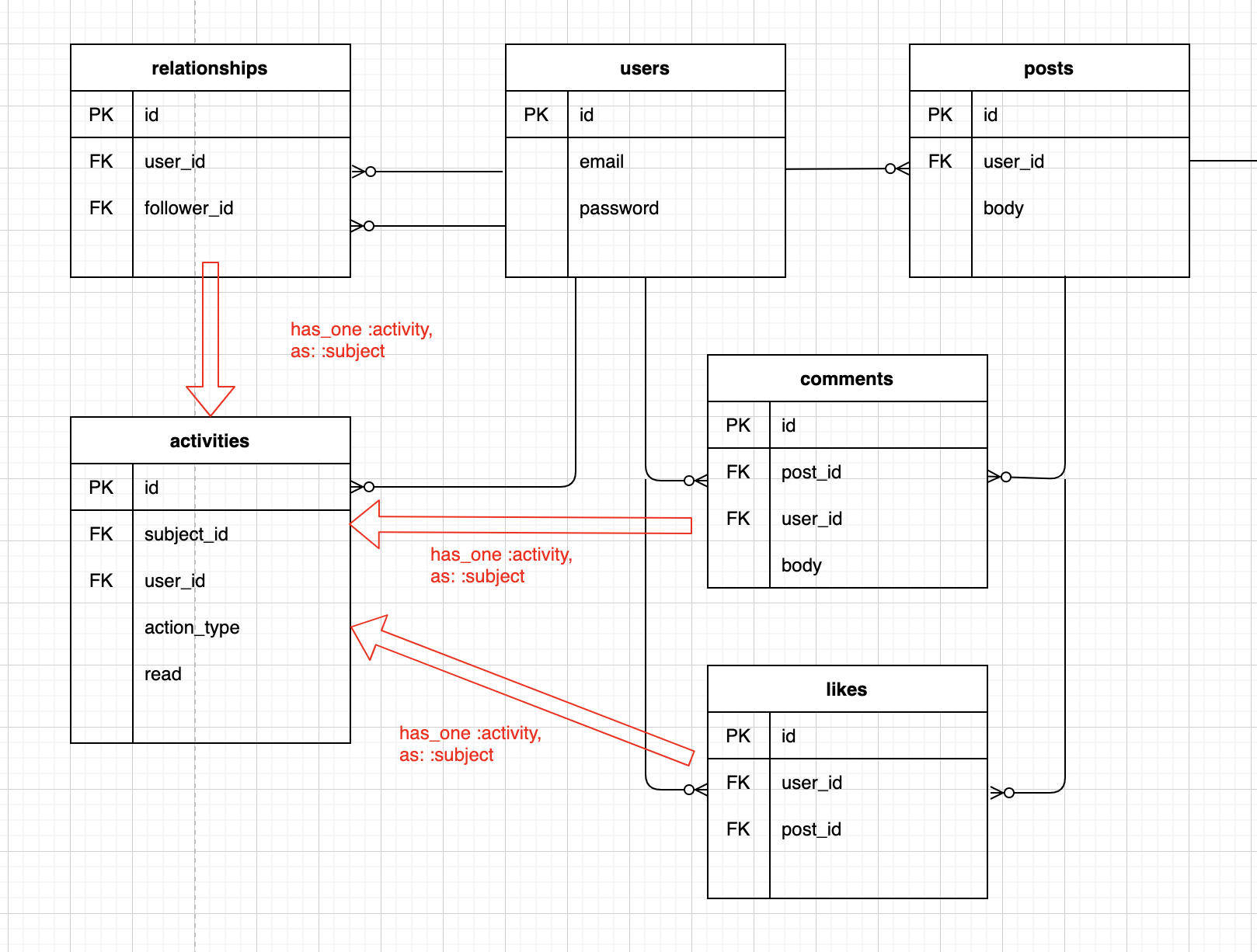
DB設計
こちらのようになっています。
データベース構造の詳細はこちらの記事をご覧ください。
また、
activitiesテーブルのreadカラムも利用して、既読管理も行いますが、これは、本記事ではなく、次回の記事にて紹介します。ゴール
上記のテーブル設計から「
activitiesを作成し、現在のuserのものを集約し、それを一覧表示する」ことが今回のゴールとなりそうです。通知機能
Model
今回は、
userがフォローされた時 =>relationshipsのレコードが作られた時userの投稿したpostにコメントがついた時 =>commentsのレコードが作られた時userの投稿に「いいね!」がされた時 =>likesのレコードが作られたとき↑上記3つのアクションが行われたときに、
activitiesのレコードも同時に作られれば良さそうです。それは、以下の方法で実装しました。モデルメソッドに書いた内容を、3つまとめて紹介します。
class Like < ApplicationRecord # 中略 after_create_commit :create_activities private def create_activities Activity.create!(subject: self, user: post.user, action_type: :liked_to_own_post) end end class Relationship < ApplicationRecord # 中略 after_create_commit :create_activities private def create_activities Activity.create!(subject: self, user: follower, action_type: :followed_me) end end lass Comment < ApplicationRecord # 中略 after_create_commit :create_activities private def create_activities Activity.create!(subject: self, user: post.user, action_type: :commented_to_own_post) end end今思うと、各モデルの
create_activitiesがプライベートメソッドなのは、別々のモデルに同名のメソッドを使っているからなのですね。。。(当初は、お手本のメソッドの写経をしていましたが、今、改めて見直してみて思うです。。。)
そして、
after_create_commitなのですが、動きとしてはafter_saveと似ているコールバックです。ただし、データベース変更のコミットが完了するまで鳥がされない点が異なるそう。詳しい説明はRailsガイドのこちらの記述をどうぞ。
なお、
modelにはそれぞれ、ポリモーフィック関連付けを定義する記述もつけています。こちらは、先に挙げたこちらの記事をご覧ください。さて、これで基本的な通知機能は実装できました。まだ
viewができていないので、console上で実験すると...$ rails c > user = User.first > user.activities #=> Activityのインスタンスたちが取得できる上記のコマンドで
userに紐づく通知一式が取得できます。これをeachで回せば、viewで表示できそうです。実際の表示は、通知機能と同時に実装することになりそうですが、長くなりますので、既読管理は次回の記事に譲ろうと思います。
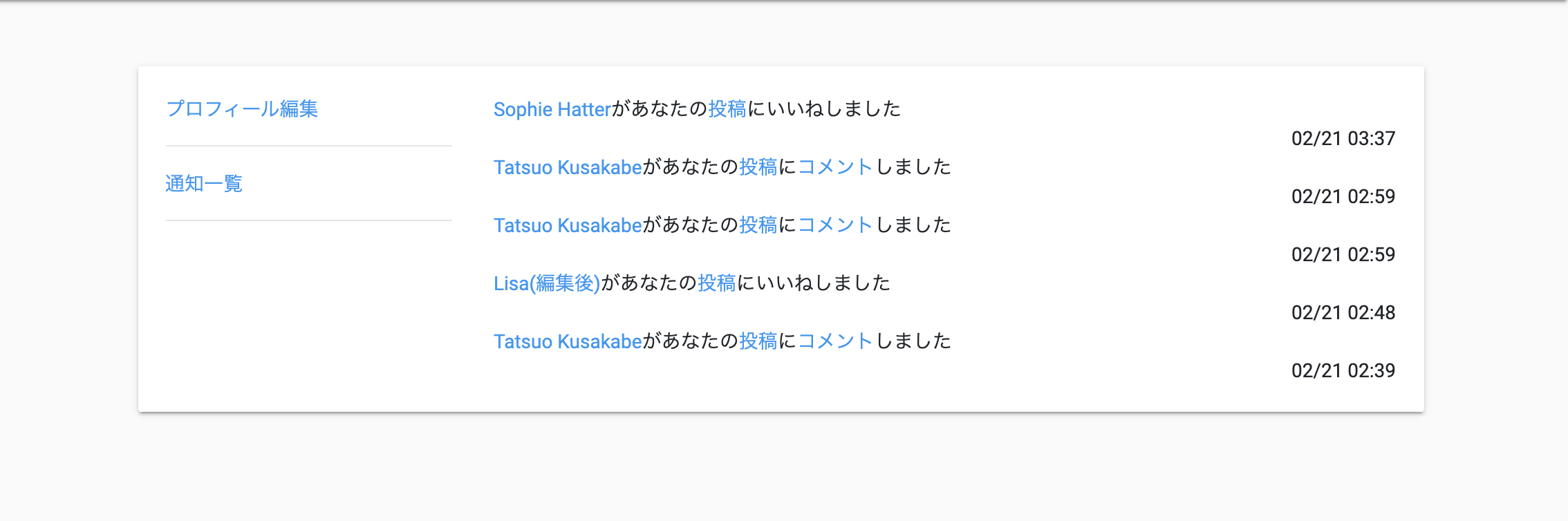
追記)Viewで通知を表示する
とはいえ、Viewで通知を表示しないと既読管理機能は作りにくかったので、Viewを続けて実装することにしました。
仕様は以下の通りです。3種類ある通知をクリックすると、それぞれ以下のページに遷移します。
- 自分がフォローされた時の通知 => フォローしてくれたユーザーの詳細ページ
- 自分の投稿へのコメントの通知 => 該当の投稿
- 自分の投稿へのいいねの通知 => 該当の投稿
それぞれの遷移先は、以下のように設定します。(本当はモデルメソッドとして実装しましたが、記事の範囲内で動作させるために、一時的にヘルパーに記載しています。)
some_helper.rbmodule SomeHelper def transition_path(activity) case activity.action_type.to_sym when :commented_to_own_post post_path(activity.subject.post, anchor: "js-comment-#{activity.subject.id}") when :liked_to_own_post post_path(activity.subject.post) when :followed_me user_path(activity.subject.follower) end end endそして、
action_type(通知のタイプ)と同じ名前のビューを作り...
(ここではサンプルに1例だけ載せます)views/mypage/activities/_liked_to_own_post.html.slim= link_to transition_path(activity) do = link_to activity.subject.user.username, user_path(activity.subject.user) | があなたの =link_to '投稿', post_path(activity.subject.post) | にいいねしました .text-right = l activity.created_at, format: :short
controllerにて、current_userのものだけ集約したactivityをapp/controllers/mypage/activities_controller.rbclass Mypage::ActivitiesController < Mypage::BaseController def index @activities = current_user.activities.order(created_at: :desc) end end
viewでこんな感じに回すのでした。views/mypage/activities/index.html.slim- if @activities.present? - @activities.each do |activity| = render "#{activity.action_type}", activity: activity - else .text-center | お知らせはありません
renderで呼び出す内容って、動的に生成できるのですね^^上記の内容で、以下のようにページが表示できました。
ここから、既読管理を作り込んでいきます。