- 投稿日:2021-02-25T23:18:16+09:00
GoogleColab での Janome を使用したテキスト解析と頻出単語の可視化
はじめに
- AI について勉強したい、何かきっかけが欲しいなと本屋でブラブラしていたら出会った『人気ブロガーからあげ先生のとにかく楽しいAI自作教室』
- 環境準備が不要で、自分で実際に手を動かせるサンプルのサイズ感がよく、まずは日本語テキストの解析からチャレンジする
- 具体的には前述の書籍の 3 章に基づいて Google Colaboratory 上で青空文庫から取得した文章を Janome で形態素解析して名詞を抽出、 WordCloud で可視化するところまでを実施する
使用したツール類
Google Colaboratory
- Google が無料で提供しているブラウザベースで機械学習が行えるクラウドサービス
- ブラウザ上で全て完結して環境を気にせず簡易に実行できるのが実に良い
- この環境上で Python のコーディングや実行、可視化が行える
- 内容としては Colab がホストする Jupyter ノートブック
- GPU も使用可
- ただし、使用時間に制限があり 12 時間立つと環境がリセットされる
- 自分の Google Drive をマウントしてその上で作業すれば wget したものなどは保持される
- 最初はマウントすることを知らず wget したものなどが揮発してしまい難儀していた
- マウントに関しては下記がとても参考になった
- Google Colaboratory の詳細や操作方法に関しては下記がとても参考になった
Janome
- Python で使用可能な形態素解析ライブラリの一つ
- 日本語テキストを解析して品詞ごとに分かち書きできる (単語を区切って表示する)
WordCloud
- 文章内の単語を検出頻度に応じて大小をつけて表示する Python のライブラリ
やってみた (以降は全て Google Colaboratory 上で実施した)
事前準備1 (テキストファイルのダウンロード)
マウントした作業用ディレクトリに移動し、青空文庫から『吾輩は猫である』を取得して解凍する
%cd /content/drive/MyDrive/textData/ !wget https://github.com/aozorabunko/aozorabunko/raw/master/cards/000148/files/789_ruby_5639.zip !unzip 789_ruby_5639.zip !ls 789_ruby_5639.zip wagahaiwa_nekodearu.txt事前準備2 (テキストファイルの読み込み)
『吾輩は猫である』のテキストファイルを text_list へ全行読み込む
text_list = [] with open('wagahaiwa_nekodearu.txt', encoding='shift_jis') as f: text_list = f.readlines()Janome のセットアップ
インストールと version の確認
!pip install janome!janome --version janome 0.4.1Janome での形態素解析の実施
『吾輩は猫である』のテキストを格納した text_list を形態素解析し、名詞のみを抽出して分かち書きを行う
from janome.tokenizer import Tokenizer t = Tokenizer() words = [] for text in text_list: tokens = t.tokenize(text) for token in tokens: pos = token.part_of_speech.split(',')[0] if pos == '名詞': words.append(token.surface) text = ' '.join(words)解析結果の中身の一部を確認
『吾輩』という単語がみえ、正しく名詞を抽出できている様子
print(text[1000:1100]) 路 邸 しき 先 善 い うち 腹 さ 雨 始末 一刻 猶予 仕方 そう 方 方 今 時 家 内 の ここ 吾輩 彼 書生 以外 人間 機会 遭遇 ぐう の 一 の さん これ 前 書生 乱暴 方 吾WordCloud による可視化
WordCloud と日本語フォントのインストール
!apt -y install fonts-ipafont-gothic !pip install wordcloud及び、 Matplotlib のインポートし
from wordcloud import WordCloud import matplotlib.pyplot as plt実行
fpath = 'usr/share/fonts/opentype/ipafont-gothic/ipagp.ttf' wordcloud = WordCloud(background_color="white", font_path=fpath, width=900, height=500).generate(text) plt.figure(figsize=(15,12)) plt.imshow(wordcloud) plt.axis("off") plt.show()実行結果
- 『それ』『ところ』『これ』『そう』などなど一般的な文章でよく使用される単語が大きく表示されている
- 『猫』という単語が最頻出で最も大きく描画されると想定していた (読んだことがないのだけれど)

フィルタの追加と再実行
- 『吾輩は猫である』特有の頻出単語を検知したいので先述した処理に不要な単語を除外する remove_stopwords メソッドの追加とテキストを読み込むごとに実行するように改修した
- 再度『吾輩は猫である』のテキストファイルを text_list へ全行読み込む
text_list = [] with open('wagahaiwa_nekodearu.txt', encoding='shift_jis') as f: text_list = f.readlines()不要な単語を除外する remove_stopwords メソッドの定義
import re def remove_stopwords(text): text = re.sub(r'それ', "", text) text = re.sub(r'ところ', "", text) text = re.sub(r'これ', "", text) text = re.sub(r'そう', "", text) text = re.sub(r'さん', "", text) text = re.sub(r'あれ', "", text) text = re.sub(r'そこ', "", text) text = re.sub(r'ほか', "", text) text = re.sub(r'どこ', "", text) text = re.sub(r'よう', "", text) text = re.sub(r'もの', "", text) text = re.sub(r'うち', "", text) text = re.sub(r'ため', "", text) text = re.sub(r'いや', "", text) text = re.sub(r'こっち', "", text) text = re.sub(r'ここ', "", text) text.strip() return texttext_list から不要な単語を除外した結果を new_text_list に再度格納する
new_text_list = [] for text in text_list: text = remove_stopwords(text) new_text_list.append(text)『吾輩は猫である』のテキストから不要な単語を除外して改めて格納した new_text_list を形態素解析し、名詞のみを抽出して分かち書きを行う
from janome.tokenizer import Tokenizer t = Tokenizer() words = [] for text in new_text_list: tokens = t.tokenize(text) for token in tokens: pos = token.part_of_speech.split(',')[0] if pos == '名詞': words.append(token.surface) text = ' '.join(words)WordCloud の実行
fpath = 'usr/share/fonts/opentype/ipafont-gothic/ipagp.ttf' wordcloud = WordCloud(background_color="white", font_path=fpath, width=900, height=500).generate(text) plt.figure(figsize=(15,12)) plt.imshow(wordcloud) plt.axis("off") plt.show()再実行結果
- 『主人』が最頻出の名詞で次点が『吾輩』となった
- 結果から想像するに、主役が『主人』で『吾輩』と適宜絡みがあり『細君』『傍点』『迷亭』『先生』『寒月』などが関わっていく物語だと思われる
おわりに
まずはこういったツール類を使用して機械学習がどういったものなのか掴んでいきたい
参考 書籍/URL:

- 投稿日:2021-02-25T22:45:51+09:00
【python3】import, from, as の違いについて
pythonの上に付いてる謎のやつ
importしか使っていなかったがfrom・asって一体なんぞや。ということで記入。
既に同じような記事があるかと思う。。記事内容
- import
- from
- as
import
pipでインストールしたパッケージ導入時に使用。以下の例の様にpythonにそもそもないものを使う時に使用する。
python使ってれば結構使うことになると思われ。てか直ぐ使うことになる。import datetime datetime.datetime.now()from
ここの階層に移動するとソース・ファイルがあるよーってのを教える時に使用する。
※ fromを使用する場合は.py付けない# 同一階層のhage.py を使用(関数aaaを呼び出す) import hage hage.aaa() # aaa/hige.py を使用(関数aaaを呼び出す) from aaa import hige hige.aaa() # 1つ上の階層のhuge.py を使用(関数aaaを呼び出す) from .. import huge huge.aaa()as
import, from で指定した内容を省略・名前変更する時に使用する。
import datetime as dt from ./ import hage as hage_light # 上のimportの例と同じだけど、このように短縮可能 dt.datetime.now()結論
実際使った方が早いと思う。
- 投稿日:2021-02-25T21:52:33+09:00
Nintendo Switchの画像をひとつのディレクトリに集結させたい
おうち時間の増加によってさらなる売上を伸ばしているらしいニンテンドースイッチ。
ゲーム画面のスクリーンショットをワンタッチで撮影することができるボタンを備えていて、撮影した写真をスマホに送ったり、直接SNSに投稿したりすることができます。
前提
画像のディレクトリ構成
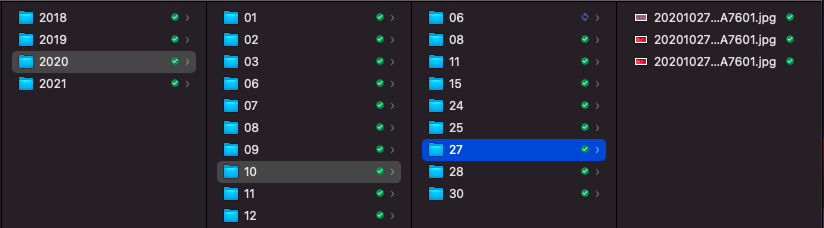
画像は本体またはSDカードに保存されますが、SDカードをPCに差し込んで中を除くと以下のようなディレクトリ構成になっていることがわかります。
年 / 月 / 日 / 年月日時間_xxxxxxxxx.jpgメリット
- 画像が撮影日ごとになっているのは単純にわかりやすい
- 「ああ、この時こんなソフトで遊んでたなあ」と思い出に更けやすい
デメリット
- 探したい画像がある場合に一覧で探せない(探しづらい)
- いちいち日付ディレクトリまでくだるのがめんどくさい
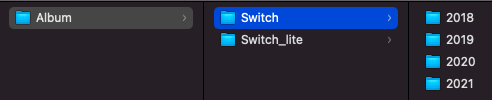
対象はSwitch二台分
僕はSwitchを二台持っているので、今回はそれぞれの画像ルートディレクトリを下記のような構成で配置しておきます。
やりたいこと
下記のように、ひとつのディレクトリに全画像を集結させ、一覧性を高めたい!
方法
たぶんshellでもできるけど、なんとなくPythonを使ってみたい。
(Pythonならでは、じゃないのでPythonサイコー!とはなりません)ソースコード
初心者過ぎてコードを正しく解説できる自信はないし、何より「もっとこう書けるよ?」的な感じのご意見もあると思うのでさっさと結論を貼ります。
import os import glob import shutil from pathlib import Path # ベースディレクトリ base_dir = "/Users/hogehoge/Desktop/Game/Album" # なければ出力ディレクトリを作成 output_dir = "/Users/hogehoge/Desktop/output" Path(output_dir).mkdir(exist_ok=True) # ファイルコピー関数 def func(input_dir): # **/*.jpgにより、サブディレクトリまで探索 for i, img_path in enumerate(Path(input_dir).glob("**/*.jpg")): # 保存ファイルパス <output_dir>/<元のファイル名>.jpg save_path = Path(output_dir) / img_path.name # ファイルをコピー(img_path => save_path) shutil.copyfile(img_path, save_path) # なんとなく枚数カウント cnt =+ i print(cnt + 1) # 最後に枚数出力 if __name__ == '__main__': # ベース配下のディレクトリの絶対パスを取得(recursive = サブディレクトリまで見るかどうか) paths = map(os.path.abspath, glob.glob(base_dir + '/*', recursive=False)) # ディレクトリだけにフィルタリングして、listで返す paths = list(filter(os.path.isdir, paths)) # 1つずつ処理する for i, p in enumerate(paths): print('[%s / %s] Start %s' % (i + 1, len(paths), p)) func(p)ちょこっとだけ解説(備忘録)
Path("hoge/fugafuga")
Path(output_dir).mkdir(exist_ok=True)これにより与えられた文字列をディレクトリパスとして扱うことができるらしいです。
__name__
if __name__ == '__main__':プログラミングでよくある冒頭のおまじない的な感じです。(importされた時の挙動制御みたいな意味合いがあるらしいです)
ディレクトリのリストに対する操作諸々
paths = map(os.path.abspath, glob.glob(base_dir + '/*', recursive=False)) paths = list(filter(os.path.isdir, paths))最初の
map関数で、base_dir/*にあるファイルやディレクトリの絶対パス(abspath)を取得して、次のfilter関数で、pathsの中からディレクトリだけ(isdir)を取得します。(返却はlist型)今回は
base_dir配下に、SwitchとSwitch_liteという二つのフォルダがあるので、最終的なpathsは以下のようになりました(整形済み)。[ '/Users/hogehoge/Desktop/Game/Album/Switch_lite', '/Users/hogehoge/Desktop/Game/Album/Switch' ]enumerate(paths)
forループの中で使うとインデックス番号を取得できるらしいです。(以下の場合、iがインデックス番号)
for i, p in enumerate(paths):glob
glob.glob(base_dir + '/*', recursive=False) Path(input_dir).glob("**/*.jpg")同じ
glob関数ですが、前者はbase_dir/*配下のファイルやディレクトリ、後者はinput_dir配下の*.jpgファイルを再帰的に取得します。ちなみに、前者は後者のような書き方でも大丈夫そうです。ただ、どっちがいいかはわからないです。
Path(base_dir).glob("*")shutil.copyfile
shutil.copyfile(img_path, save_path)
img_pathをsave_pathにコピーするらしいです。shutilは読み方、エスエイチユーティルでいいのかな。
というわけで趣味の延長ですが、Nintendo Switchで撮影した画面キャプチャをもともとのディレクトリ構造からひとつのディレクトリに集結させるPythonを書いてみた話でした。
- 投稿日:2021-02-25T20:51:05+09:00
Python tutorial #1 文字列
文字列の操作
コメント
このコードは何に使っているんだろうかと困ることが将来よくあることであろう。そのことを防ぐためには、コメントという機能を用いることで対処できる。コメントとは実際に書いたものをコード自体に影響を及ぼさなない。つまりシステムになんの影響も与えないもののことである。よって実行しても何も起こらない。コメントのやり方は下のコードのように前に'#'をつけることである。
#これはコメントです。'\'によるエスケープ
特定の文字の前に\を入れるといろいろな処理を行うことができる。例えば\nを用いると改行ができる。
print('Name: Anna\nFrom: Tokyo\nSchool: Stanford') Name: Anna From: Tokyo School: Stanfordprint()を用いて文字列を打つときに、""のなかに文字を入れるのだがその中に""が入っていたら、それを出力するとエラーが発生してしまう。それを防ぐためには、\を用いるか''を使って器用にこなすかである。
print(""I like Pizza!", but,"I don't like Sushi"") #実行結果 print(""I like Pizza!", but,"I don't like Sushi"") ^ SyntaxError: invalid syntax print("\"I like Pizza!\", but,\"I don't like Sushi\"") #実行結果 "I like Pizza!", but,"I don't like Sushi"このようにして利用すると簡易的にコメントのような文字が打てる。
'+'による連結
print('I' + 'am' + 'Chicken') #実行結果 IamChicken'*'による繰り返し
print('Hi '*10) #実行結果 Hi Hi Hi Hi Hi Hi Hi Hi Hi Hi'[]'による文字の抽出
ここでは対話型インタープリタ(ターミナル)を用いて実行していこう。
letters = 'abcdefghijklmnopqrstuvwxyz' letters[0] # 実行結果 'a'文字列はイミュータブル(変更できない)ので変更するにはreplace()を用いることで実行できる。しかしこれは一時的なものなのでその新しく変えたものを新しく変数として考えていく必要がある。またスライスというものを用いることも可能である。
new_letters = letters.replace('a', 'b') print(new_letters) bbcdefghijklmnopqrstuvwxyz print(letters) abcdefghijklmnopqrstuvwxyz new_letters_2 = 'n' + [1:] print(new_letters_2) nbcdefghijklmnopqrstuvwxyzスライスについてスライスは文字列から部分的な文字列を取り出すことができる。
*[:] 先頭から最後まで
*[X:]Xから最後まで
*[:X]最初からXまで
*[X:Y]XからYまで
*[X:Y:N]XからYまでをN文字ずつ順に取り出す。letters = 'abcdefghijklmnopqrstuvwxyz' print(letters[:]) print(letters[3:]) print(letters[:3]) print(letters[3:7]) print(letters[1:20:3]) abcdefghijklmnopqrstuvwxyz defghijklmnopqrstuvwxyz abc defg behknqtそのほかの関数:len(),split(),join()
len():文字列の文字数を確認するものだ。
split():分割(リストを作成)
join():結合(リストから文字列を作成)
これらについてコードから詳しく考えてみよう。len(letters) #実行結果 26 complex_letters = 'abc,def,ghi,jkl,mno,pqr,stu,vwx,yz' simple_letters_with_list = complex_letters.split(',') print(simple_letters_with_list) #実行結果 ['abc', 'def', 'ghi', 'jkl', 'mno', 'pqr', 'stu', 'vwx', 'yz'] new_complex_letters = ', '.join(simple_letters_with_list) print(new_complex_letters) abc, def, ghi, jkl, mno, pqr, stu, vwx, yz文字列の区別と配置
これに関してはコードのみで説明する。
letters_capi = letters.capitalize() #最初だけ大文字 print(letters_capi) 'Abcdefghijklmnopqrstuvwxyz' Greeting_patterns = 'hello, whats up!, wow' Title_Greeting_patterns = Greeting_patterns.title() #各文の最初の文字列を大文字にする。 print(Title_Greeting_patterns) 'Hello, Whats up!, Wow' Upper_Greeting_patterns = Greeting_patterns.upper() print(Upper_Greeting_patterns) #全て大文字にする。 'HELLO, WHATS UP, WOW' Lower_Greeting_patterns = Greeting_patterns.lower() #全て小文字にする 'hello, whats up!, wow' Greeting_patterns_center = Greeting_patterns.center(30) print(Greeting_patterns_center) #指定した数ないで文字を中心に寄せてくれる。 hello, what's up!, wow #左寄せ Greeting_patterns_left = Greeting_patterns.ljust(30) #右寄せ Greeting_patterns_right = Greeting_patterns.rjust(30) print(Greeting_patterns_left) hello, what's up!, wow print(Greeting_patterns_right) hello, what's up!, wow
- 投稿日:2021-02-25T20:27:49+09:00
毎朝LINEで天気を教えてくれるbotを作成した
はじめに
何番煎じだよ、と突っ込まれそうですが、毎朝LINEで天気をお知らせしてくれるbotを作成したいと思います。
BeautifulSoupの使い方とAPIの使い方が学べるので、Pythonが少しわかる程度にはもってこいの教材なんです。
独学なのでコードが汚いのはご了承を...。コード作成
まずはライブラリをインポートします。
BeautifulSoupはHTMLやXMLを解析するためのライブラリです。
データを取ってくるライブラリではないことに注意です。
データを取ってくるのにはrequestsというライブラリが必要です。必要なライブラリのインポートimport requests from bs4 import BeautifulSoup import datetime import schedule import time続いてBeautifulSoupオブジェクトを作成します。
今回スクレイプするサイトはtenki.jpです。
好きな市町村のURLを埋め込んでいただければ大丈夫です。
今回は例として福井市で設定します。
まず初めにhtmlにアクセスし、返された内容をBeautifulSoupの第一引数としてBeautifulSoupオブジェクトを作成します。
第二引数の"html.parser"はhtmlを解析する場合に選択するモードです。
以上の作業は基本的に同じなので、どのサイトにも同じことが書いてあると思います。BeautifulSoupオブジェクトの作成info = requests.get("https://tenki.jp/forecast/4/21/5710/18201/") # 好きな市町村のURLにしてもよいです bs = BeautifulSoup(info.content, "html.parser")取りたい情報の抽出を行います。
BeautifulSoupオブジェクトのfindメソッドを呼ぶと、子クラスのBeautifulSoupオブジェクトが返され、さらにfindメソッドを呼ぶことができます。
そのようにして階層的に目的の場所までたどり着きます。
今回はclassで指定しましたが、class名が同じタグもあるので、idで指定する方法の方が確実にたどり着けるかもです。
.stringでタグの中身を文字列として受け取れます。
今回は天気と最高気温と最低気温のみとしました。
私はそれだけで十分だったので...笑抽出today = bs.find(class_="today-weather") weather = today.find(class_="weather-telop").string high_temp = today.find_all(class_="value")[0].string low_temp = today.find_all(class_="value")[1].string message = "今日の天気は" + weather + "、最高気温は{}℃".format(high_temp) + "、最低気温は{}℃です。".format(low_temp) message'今日の天気は曇、最高気温は10℃、最低気温は-1℃です。'いい感じです!出来上がったメッセージをLINEで送信してみましょう。
"MY TOKEN"にあなたのLINENotifyトークンを入れればよいです。
LINENotifyトークンの取得およびメッセージ送信については、@moriita様の記事を参考にしてください。メッセージの送信headers = {"Authorization": "Bearer " + "MY TOKEN"} payload = {"message": message} r = requests.post("https://notify-api.line.me/api/notify", headers=headers, params=payload,)無事送信完了です。コードからメッセージを送れるとわくわくしますね。
さらに毎朝7時に定期実行をしたいと思います。定期実行を行うにはscheduleモジュールを活用します。
一日単位で指定の時刻で実行したいときは以下のようにします。schedule.every().day.at("時刻").do(起動したい関数f)このように設定しておくと、run_pendingメソッドが呼び出され時刻が条件を満たしている場合関数fが実行されます。
つまり、定期的(60s単位)にrun_pendingメソッドを呼び出す必要があります。定期実行の設定schedule.every().day.at("7:00").do(send) while True: schedule.run_pending() time.sleep(10) print("Running...")以上がコードの基盤です。これを組み合わせてコーディングしていきましょう。
完成コード
weather_notify.pyimport requests from bs4 import BeautifulSoup import datetime import schedule import time class Weather: def __init__(self, weather_url, token, time): self.weather_url = weather_url self.line_url = "https://notify-api.line.me/api/notify" self.token = token self.time = time def parse_make_message(self): info = requests.get(self.weather_url) bs = BeautifulSoup(info.content, "html.parser") today = bs.find(class_="today-weather") weather = today.find(class_="weather-telop").string high_temp = today.find_all(class_="value")[0].string low_temp = today.find_all(class_="value")[1].string message = "今日の天気は" + weather + "、最高気温は{}℃".format(high_temp) + "、最低気温は{}℃です。".format(low_temp) return message def send(self): headers = {"Authorization": "Bearer " + self.token} payload = {"message": self.parse_make_message()} r = requests.post(self.line_url, headers=headers, params=payload,) def set_do(self): schedule.every().day.at(self.time).do(self.send) while True: schedule.run_pending() time.sleep(10) print("Running...") fukui_url = "https://tenki.jp/forecast/4/21/5710/18201/" my_token = "MY TOKEN" weather = Weather(weather_url=fukui_url, token=my_token, time="07:00") weather.set_do()おわりに
たった数行で毎朝を便利にしてくれるのでよいプロダクトではないでしょうか。
問題点としてはずっとプログラムを実行させる必要があるところです。
windowsの定期実行を利用してpythonファイルを開く方がよさそうですね...。
改良版お待ちください...。

- 投稿日:2021-02-25T20:23:03+09:00
nginx・gunicorn・djangoの環境におけるTips
webアプリケーションを開発したものの、インフラ周りが弱いため、Tipsとしてまとめていくつもりです。
適宜、更新はしていくつもりです。間違いだった場合は指摘いただければ幸いです。クラウドには、digital oceanを使用しています。
基本的には、現場で使える Django の教科書《実践編》を模倣しています。
アーキテクチャはこちらから技術スタック
- Django(3.0.8)
- nginx(1.18.0)
- gunicorn(20.0.4)
- ubuntu(20.04)
ファイル構成
/home/webapp/mysite/[django-project]
変更を反映させたい時
nginx、gunicorn、djangoなど色々いじると思います。
開発環境とは異なり、いじったらrestartしないといけないです。gunicorn周りを変更した時
反映させるファイルは、
/etc/systemd/system/mysite.serviceと/etc/systemd/system/mysite.socketです。特に、daemon-reloadも必要らしい。ということで、
sudo systemctl daemon-reload
(↑sudoをつけないと怒られた)
sudo systemctl restart mysite.service
sudo systemcctl restart mysite.socketdjangoの中身(models.pyとかviews.pyとか)を変更したとき
なぜかわかりませんが、ここら辺の変更を適用するためには
sudo systemctl restart mysite.service
が必要でした。もちろん、models.py周りを変更した際は
python manage.py makemigrationsやpython manage.py migrateも忘れずに。nginx周りを変更させたとき
restartをしましよう。
sudo systemctl restart nginx状態を知りたいとき
基本的には、
sudo systemctl statusでOKでした。ex.
sudo systemctl status nginx
sudo systemctl status mysite.service
sudo systemctl status mysite.socket後は、
error_logですね。
/var/log/nginx/error_logです。最終更新日
- 2020.02.25
- 投稿日:2021-02-25T20:06:58+09:00
GCPロギングを使いPython(Flask)のログを管理
GCPロギングを使いPython(Flask)のログを管理
google-cloud-logging をインストール
$ pip install google-cloud-loggingロギング設定
from google.cloud import logging client = logging.Client() logger = client.logger("pronichi")ログ用の関数
severityはログレベル(INFO,NOTICE,ERROR etc...)
ログは環境変数、URI、任意メッセージを保存することにした
ensure_ascii=Falseを設定しないとコンソール表示が文字化けdef log_write(severity: str, uri: str, message: str): tmp = {"env": APP_ENV, "uri": uri, "message": message} tmp_json = json.dumps(tmp, ensure_ascii=False) logger.log_text(tmp_json, severity=severity)スクリプトにログ追加
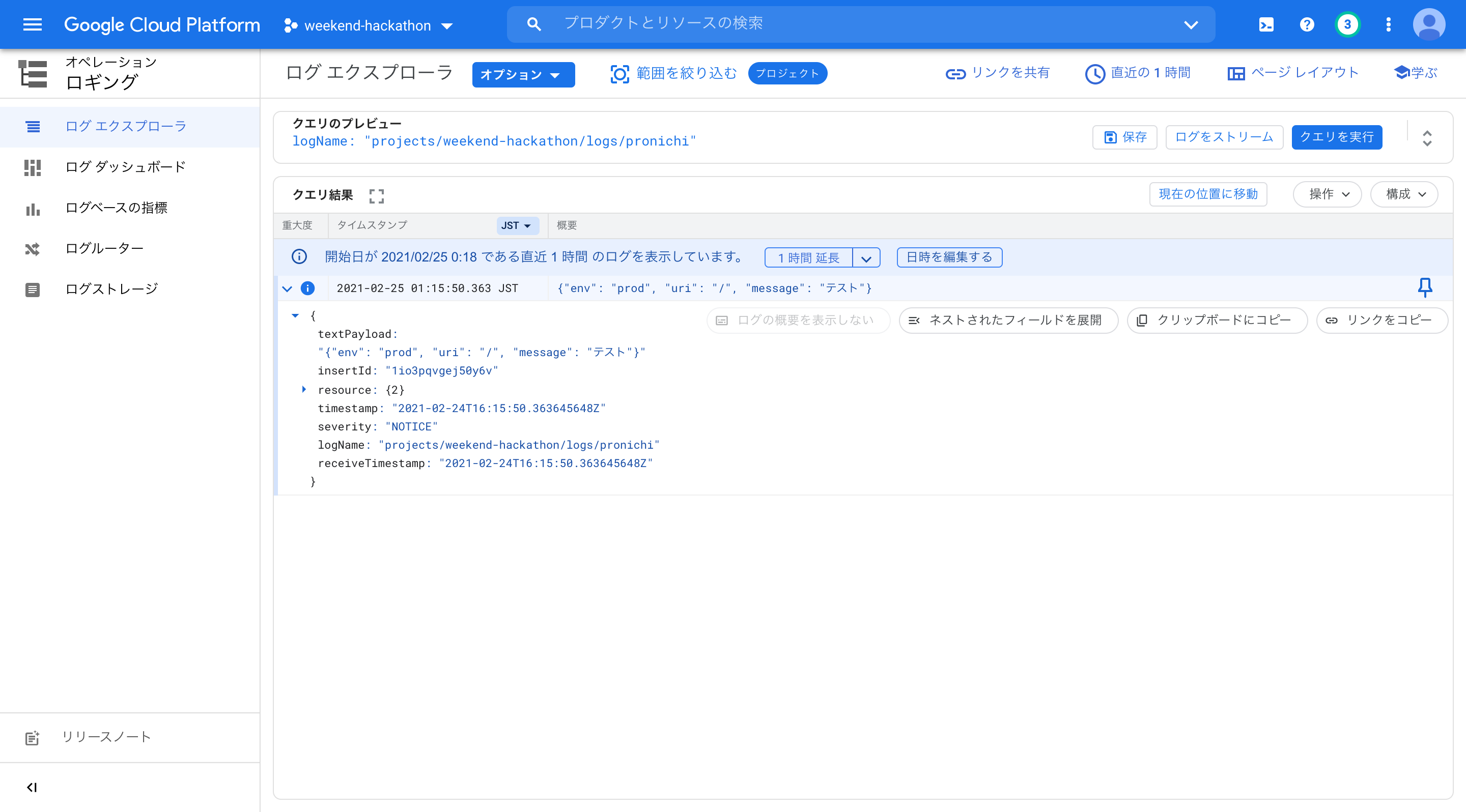
log_write("NOTICE", "/", "テスト")ログ確認
GCPコンソールよりログ出力されたか確認
{ textPayload: "{"env": "prod", "uri": "/", "message": "テスト"}" insertId: "1io3pqvgej50y6v" resource: {2} timestamp: "2021-02-24T16:15:50.363645648Z" severity: "NOTICE" logName: "projects/weekend-hackathon/logs/pronichi" receiveTimestamp: "2021-02-24T16:15:50.363645648Z" }
ログが出力できるようになりました
いいね!と思ったら LGTM お願いします【PR】プログラミング新聞リリースしました! → https://pronichi.com
【PR】週末ハッカソンというイベントやってます! → https://weekend-hackathon.toyscreation.jp/about/
- 投稿日:2021-02-25T19:40:00+09:00
Pythonチュートリアル ノート
概要
Pythonチュートリアルを読みながら手元で実行したコマンドのメモ。
https://docs.python.org/ja/3/tutorial/index.html1. やる気を高めよう
Pythonの特徴
- インタプリタ言語なので、コンパイル・リンクが不要。電卓として使える。
- シェルはファイル操作・テキストデータの操作に向いているけど、GUIアプリ、ゲームには向いていない。単純にシェルより機能が多い。
- GUIのインターフェイスも標準で提供される。(Tk)
- テキスト処理ならAwkとかPerlもあるが、それらより汎用的なデータ型が存在する。それでいて同じくらい簡単。
- C, Javaよりコードが短くなる。より高レベルなデータ型があるのと、実行文のグループ化がインデントなので、括弧だけの行がない。
- Cアプリケーションの拡張言語として利用可能。
- 変数、引数宣言が不要
- モンティパイソンの空飛ぶサーカス「Monty Python's Flying Circus」が元ネタ。
2. Python インタプリタを使う
コマンドを指定したインタプリタの起動
python -c command [arg] ... python3 -c "print(1 + 2)"スクリプト実行後にそのまま対話モードに入れる。-iオプション
# 2-1.py a = 12 $ python3 -i 2-1.py >>> a 12 >>>コマンドライン引数
sysモジュールのargv変数に格納される。
# 2-2.py import sys print(sys.argv) $ python3 2-2.py ['2-2.py'] $ python3 2-2.py asdf ['2-2.py', 'asdf']sys[0]はスクリプトならファイル名、コマンド指定でインタプリタを起動した場合は"-c"
python3 -c "import sys; print(sys.argv)" ['-c']文字コードを指定するにはファイルの先頭にエンコーディングを記述する。
# -*- coding:cp1242 -*-3. 形式ばらない Python の紹介
除算と整数除算
python3から除算と整数除算の演算子が分かれて定義された。
>>> 17 / 3 5.666666666666667 >>> 17 // 3 5冪乗
>>> 2**10 1024対話モードで便利な「_」
対話モードでのみ、前回の計算結果が「_」に毎回代入される。_
>>> 60 * 60 3600 >>> 24 * _ 86400文字列リテラル
# 3-1.py a = """ hello world """ $ python3 -i 3-1.py >>> a '\n\n hello\n\n world\n\n\n' >>>スライス
スライスの場合のみ範囲外のインデックスでもエラーにならない。
>>> a = "abcdefg" >>> a[3:] 'defg' >>> a[-2] 'f' >>> a[2] 'c' >>> a[2:-2] 'cde' >>> a[100] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: string index out of range >>> a[2:100] 'cdefg'リスト
リストの代入は参照が返るので、破壊的な操作が起き得る。
>>> a = [1,2,3] >>> b = a >>> b [1, 2, 3] >>> b[0] = 100 >>> b [100, 2, 3] >>> a [100, 2, 3] >>>[https://docs.python.org/ja/3/library/copy.html#shallow-vs-deep-copy]
浅いコピーで回避可能。
スライスか、copyモジュールのcopy関数で浅いコピーを作れる。>>> import copy as cp >>> a = [1,2,3] >>> b = cp.copy(a) >>> b [1, 2, 3] >>> b[0] = 100 >>> a [1, 2, 3] >>> b [100, 2, 3]浅いコピーは1次元のリストのみ有効。
>>> a = [[1,2], [2,3], [3,4]] >>> b = a[:] >>> b [[1, 2], [2, 3], [3, 4]] >>> b[0][0] = 100 >>> b [[100, 2], [2, 3], [3, 4]] >>> a [[100, 2], [2, 3], [3, 4]] >>>2次元以上のリストをコピーする場合、深いコピーが必要。
copyモジュールのdeepcopy関数で深いコピーが作れる。>>> import copy as cp >>> a = [[1,2],[2,3],[3,4]] >>> b = cp.deepcopy(a) >>> b[0][0] = 100 >>> b [[100, 2], [2, 3], [3, 4]] >>> a [[1, 2], [2, 3], [3, 4]] >>>リストのスライス代入
スライス代入によりサイズの変更、削除が自由。
>>> a = [0,1,2,3,4,5,6,7,8,9] a[2:4] = [] >>> a [0, 1, 4, 5, 6, 7, 8, 9]複数同時代入
スワップにも利用可能
>>> a, b = 1,2 >>> a 1 >>> b 2 >>> a, b = b, a >>> a 2 >>> b 14. その他の制御フローツール
elif
else ifをelifと省略して書ける。switch文が無いので代わりに使う。
for
C言語のforみたいなのは無くて、foreachのようなforがある。
>>> for a in [1,2,3]: ... print(a) ... 1 2 3for (int i = 0; i < 10; i++)
は以下のようにrangeを使う。>>> for i in range(10): ... print(i) ... 0 1 2 3 4 5 6 7 8 9ちなみに、rangeの戻り値がリストになっているかというとそうではない。
rangeクラスのオブジェクトが返る。>>> print( type([0,1,2]) ) <class 'list'> >>> print( type(range(3)) ) <class 'range'>[https://docs.python.org/ja/3/tutorial/controlflow.html]
range() が返すオブジェクトは、いろいろな点でリストであるかのように振る舞いますが、本当はリストではありません。これは、イテレートした時に望んだ数列の連続した要素を返すオブジェクトです。しかし実際にリストを作るわけではないので、スペースの節約になります。
こういうオブジェクトはイテラブル(iterable: 反復可能)と呼ばれる。
sum()はイテラブルも受け取れるようになっている。(リストも受け取れる)>>> sum(range(10)) 45 >>> sum([0,1,2,3,4,5,6,7,8,9]) 45イテラブルからリストへの変換
>>> list(range(10)) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]for文はelse節も持てる。
>>> for i in range(3): ... print(i) ... else: ... print("test") ... 0 1 2 testfor文のelse句は途中でbreakされると呼ばれない。
>>> for i in range(3): ... if i > 1: ... break ... print(i) ... else: ... print("test") ... 0 1pass
pythonはブロックの中を省略できないので、そういう場合はpass文を書いておく。
pass文は何もしない。>>> a = 1 >>> if a > 0: ... File "<stdin>", line 2 ^ IndentationError: expected an indented block >>> >>> if a > 0: ... pass ... >>> >>>関数
def fib(n): """docstringをここに書く""" a, b = 0, 1 for i in range(n): a, b = b, a + b return bNone
return文の無い関数はNoneを返す。意味がないのでインタプリタは通常出力を抑制する。
def test(): pass >>> test() >>> print(test()) None >>> type(test()) <class 'NoneType'>シンボルテーブル
pythonにはブロックスコープがあり、例えば関数内から変数を参照した際には、まず関数内のシンボルテーブルから変数が参照され、次により外側のローカルなシンボルテーブルが参照され、、と続いていく。
ローカルなシンボルテーブルはlocals()で確認可能。>>> def test(): ... aaa = 1 ... for item in locals().items(): ... print(item[0]) ... >>> >>> test() aaa >>>デフォルト引数
>>> def test(a = 50): ... print(a) ... >>> test() 50 >>> test(2) 2デフォルト値は最初の一度しか評価されない。
最初の呼び出しでarrが初期化され、それ以降は同じオブジェクトが使い回されるので注意。>>> def test(arr = []): ... arr.append("aaa") ... return arr ... >>> >>> test() ['aaa'] >>> test() ['aaa', 'aaa'] >>> test() ['aaa', 'aaa', 'aaa']キーワード引数
引数名を指定することで、順番を気にせず引数を渡すことが可能
>>> def test(a = 1, b = 2): ... print(a, b) ... >>> test() 1 2 >>> test(b = 5) 1 5*name形式の仮引数があると、タプル型として扱われて実引数の値がそこに入る。
>>> def test(*a): ... print(type(a), a) ... >>> test() <class 'tuple'> () >>> >>> test(1, 2, 3) <class 'tuple'> (1, 2, 3) >>> >>> test(1, 2, 3, a = 1) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() got an unexpected keyword argument 'a' >>> >>>**name形式の仮引数は辞書型として扱われて、実引数のkey, valueが入る。
>>> def test(**a): ... print(type(a), a) ... >>> test() <class 'dict'> {} >>> >>> test(b = 1, c = 2) <class 'dict'> {'b': 1, 'c': 2} >>> >>> >>> test(1) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() takes 0 positional arguments but 1 was given >>>*name形式、**name形式は混在可能。
>>> def test(*a, **b): ... print(type(a), a, type(b), b) ... >>> test() <class 'tuple'> () <class 'dict'> {} >>> >>> test(1,2,3) <class 'tuple'> (1, 2, 3) <class 'dict'> {} >>> >>> test(a = 1) <class 'tuple'> () <class 'dict'> {'a': 1} >>> >>> test(1,2,3,a = 1) <class 'tuple'> (1, 2, 3) <class 'dict'> {'a': 1} >>>特殊な仮引数「/」「*」
def test(a, /, b, *, c):とした場合、
a: 第一引数としてのみ渡せる。(位置専用引数)
b: 第二引数として渡すか、キーワード引数として渡す。
c: キーワード引数としてのみ渡せる。(キーワード専用引数)
という意味になる。>>> def test(a, /, b, *, c): ... print(a, b, c) ... >>> test(1, 2, 3) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() takes 2 positional arguments but 3 were given >>> >>> test(1, 2, c = 3) 1 2 3 >>> >>> test(1, c = 3, b = 2) 1 2 3 >>> >>> test(c = 3, b = 2, a = 1) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() got some positional-only arguments passed as keyword arguments: 'a'以下のように、キーワード専用のみの引数も定義可能
>>> def test(*, a): ... print(a) ... >>> test() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() missing 1 required keyword-only argument: 'a' >>> >>> test(1) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() takes 0 positional arguments but 1 was given >>> >>> test(a = 1) 1 >>>任意引数リスト
必須パラメータと任意パラメータを以下のように組み合わせることがある。
複数の引数を入力した場合は、paramsにタプル型として渡される。>>> def test(a, *params): ... print(a, params) ... >>> test() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() missing 1 required positional argument: 'a' >>> test(1) 1 () >>> test(1, 2) 1 (2,) >>> test(1, 2, 3) 1 (2, 3) >>>任意引数リストの後に定義した仮引数はキーワード専用変数になる。
>>> def test(*params, a): ... print(params, a) ... >>> test() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() missing 1 required keyword-only argument: 'a' >>> test(1) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() missing 1 required keyword-only argument: 'a' >>> test(a = 0) () 0 >>> test(1, a = 0) (1,) 0 >>> test(1, 2, a = 0) (1, 2) 0アンパック
リストをアンパックすることにより、要素を引数として利用可能
>>> def test(a, b, c): ... print(a, b, c) ... >>> l = [1, 2, 3] >>> test(l) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() missing 2 required positional arguments: 'b' and 'c' >>> >>> test(*l) 1 2 3 >>>辞書もアンパックすることでキーワード引数として利用可能
>>> def test(a, b, c): ... print(a, b, c) ... >>> d = {"a": 10, "b": 20, "c": 30} >>> >>> test(d) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() missing 2 required positional arguments: 'b' and 'c' >>> >>> >>> test(**d) 10 20 30引数まとめ
- 引数の名前を知らせる必要がないなら位置専用引数を使う。
- 引数の名前に意味があるなら順番を覚える必要のないキーワード引数が便利。
- APIでは名前を変更した際に動かなくなると困るので位置専用引数を使う。
ラムダ式
>>> a = lambda n: n + 1 >>> a <function <lambda> at 0x104fc3af0> >>> a(1) 2 >>>ドキュメンテーション文字列
>>> def test(n): ... """1行目は簡潔にまとめた説明を書く。 ... ... 2行目は空けて、3行目から呼び出しの規約、副作用について書く。 ... """ ... return n + 1 ... >>> test(1) 2 >>> test.__doc__ '1行目は簡潔にまとめた説明を書く。\n\n\t2行目は空けて、3行目から呼び出しの規約、副作用について書く。\n\t' >>>アノテーション
ドキュメントとして戻り値の型を知らせることが可能。動作には影響しない。
>>> def test()->str: ... print("test") ... >>> test.__annotations__ {'return': <class 'str'>}コーディング規約
基本PEP8に従う。PEPは海外でも「ペップ」と読まれているらしい。
[https://pep8-ja.readthedocs.io/ja/latest/]5. データ構造
List
初期化
>>> a = [] >>> type(a) <class 'list'>要素の追加: append(x)
マージはされない。
>>> a = [] >>> a.append(1) >>> a [1] >>> a.append([2,3,4]) >>> a [1, [2, 3, 4]]要素の拡張: extend(iterable)
>>> a [1, 2, 3] >>> a.extend([4,5,6]) >>> a [1, 2, 3, 4, 5, 6] >>>要素の挿入: insert(i, x)
>>> a = [5, 6, 7] >>> a.insert(2, 100) >>> a [5, 6, 100, 7] >>>要素の削除: remove(x)
値で検索して最初の要素を削除
>>> a = [100, 200, 300] >>> a.remove(200) >>> a [100, 300] >>>要素の取り出し: pop([i])
指定しなければ末尾、指定されればそのインデックスの要素を取り出す。
>>> a = [100, 200, 300, 400] >>> a.pop() 400 >>> a [100, 200, 300] >>> a.pop(1) 200 >>> a [100, 300]要素の全削除: clear()
>>> a = [1, 2, 3, 4, 5] >>> a.clear() >>> a [] >>>要素の検索: index(x, [start, end])
>>> a = [1, 3, 5, 7, 9] >>> a.index(5) 2 >>> a.index(5, 0, 4) 2 >>> a.index(5, 0, 3) 2 >>> a.index(5, 0, 2) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: 5 is not in list >>> >>> a.index(5, 1, 4) 2 >>> a.index(5, 2, 4) 2 >>> a.index(5, 3, 4) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: 5 is not in list要素のカウント: count
>>> a [5, 6, 6, 7, 7, 7, 8] >>> >>> a.count(6) 2 >>> a.count(7) 3 >>>ソート
>>> a [4, 2, 6, 6, 5, 4] >>> a.sort() >>> a [2, 4, 4, 5, 6, 6] >>> a.sort(reverse=True) >>> a [6, 6, 5, 4, 4, 2]キーによるソート
>>> a [(5, 'asdf'), (2, 'zxcv'), (8, 'bbb')] >>> a.sort(key = lambda tpl: tpl[1]) >>> a [(5, 'asdf'), (8, 'bbb'), (2, 'zxcv')]逆順ソート
>>> a [6, 6, 5, 4, 4, 2] >>> a.sort() >>> a [2, 4, 4, 5, 6, 6] >>> a.reverse() >>> >>> a [6, 6, 5, 4, 4, 2]配列のコピー(shallow)
>>> b = a.copy() >>> b [1, 2, 3] >>> b[0] = 100 >>> b [100, 2, 3] >>> a [1, 2, 3] >>>スタック
>>> a = [1,2,3] >>> a.pop() 3 >>> a [1, 2] >>>キュー
リストの終端に対する操作は速いが、先頭に対しての操作は遅い。
例えば、先頭から1つ取り出すと、要素を全てずらす必要がある。
キューを利用したい場合、リストではなくキューの操作に最適化されたdequeを利用するのがよい。double-ended queue (両端キュー)
>>> a = deque([1,2,3]) >>> a deque([1, 2, 3]) >>> a.popleft() 1 >>> a.popleft() 2 >>> a deque([3]) >>> a.append(5) >>> a deque([3, 5])リスト内包表記
>>> a = [ i * 2 for i in range(10) ] >>> a [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]2重ループ
>>> [(i,j) for i in range(3) for j in range(3)] [(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]del
関数ではなく文である理由:
>>> a = [1,2,3] >>> a [1, 2, 3] >>> del a[0] >>> a [2, 3]タプル
>>> a = 1,2,3 >>> a (1, 2, 3) >>> type(a) <class 'tuple'> >>> a[2] 3 >>> a = (1,2,3) >>> a (1, 2, 3) >>> type(a) <class 'tuple'> >>> a = () >>> a () >>> type(a) <class 'tuple'> >>> >>> a = 1, >>> a (1,) >>> type(a) <class 'tuple'> >>> >>> len(a) 1集合
宣言
>>> a = {1,2,3} >>> type(a) <class 'set'> >>> >>> >>> a = {} >>> type(a) <class 'dict'> >>>演算
>>> a = {1,2,3,4,5} >>> b = {4,5,6,7,8} >>> a + b Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'set' and 'set' >>> >>> >>> >>> a - b {1, 2, 3} >>> a | b {1, 2, 3, 4, 5, 6, 7, 8} >>> a &b {4, 5} >>> >>> >>> a ^ b {1, 2, 3, 6, 7, 8} >>>辞書
マップ、連想配列、と同じもの。
>>> a = {'aaa': 10, 'bbb': 20} >>> a {'aaa': 10, 'bbb': 20} >>> a['aaa'] 10items()メソッドにより、key, value両方が取り出せる。
dict_items型として取り出しているらしい。>>> for i in a: ... print(i, a[i]) ... aaa 10 bbb 20 >>> >>> >>> for k, v in a.items(): ... print(k, v) ... aaa 10 bbb 20 >>> a.items() dict_items([('aaa', 10), ('bbb', 20)]) >>> type(a.items()) <class 'dict_items'> >>>zip
>>> for i, j in zip(a, b): ... print(i, j) ... 1 4 2 5 3 6配列の要素をユニークに
>>> a = [1, 2, 2, 3, 3, 4] >>> a [1, 2, 2, 3, 3, 4] >>> set(a) {1, 2, 3, 4} >>>in
要素が存在するか調べる。
>>> a [1, 2, 2, 3, 3, 4] >>> 3 in a True >>> 5 in a Falseセイウチ演算子
「:=」のこと。式中での代入に使う。
>>> f = open("aaa") >>> while line := f.readline(): ... line ... 'aaa\n' 'bbb\n' 'ccc\n' >>> while line = f.readline(): File "<stdin>", line 1 while line = f.readline(): ^ SyntaxError: invalid syntax >>>シーケンスオブジェクト同士の比較
辞書順で先頭から比較していく。
>>> [1,2,3,4,5] < [1,2,4,5,6] True6. モジュール
モジュールの作成
処理をファイルに分割して記述し、別の場所からファイル名 = モジュール名としてimport可能。
$ cat test.py def aaa(): print("test func is called.") >>> import test >>> dir(test) ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'aaa'] >>> test.aaa() test func is called. >>>モジュールの定義を全てimport
読み込み元の名前空間にシンボルが上書きされるので、確認用途以外では使わない。
$ cat aaa.py def asdf(): print("asdf") def zxcv(): print("zxcv") def qwer(): print("qwer") >>> from aaa import * >>> globals() {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'asdf': <function asdf at 0x1015f2d30>, 'zxcv': <function zxcv at 0x1015f2ee0>, 'qwer': <function qwer at 0x1015f2f70>}名前付きでimport
>>> import test as zzzzz >>> zzzzz.aaa() test func is called.モジュールの初期実行
モジュール読み込み時に一度モジュールの中身が実行される。
通常、これを初期化に利用する。$ cat bbb.py print("bbb.py is loaded.") def test(): print("test is called.") >>> import bbb bbb.py is loaded. >>> bbb.test() test is called. >>>コマンドラインから実行した場合の処理
コマンドラインからスクリプトを実行すると、モジュールの「__name__」が「__main__」になる。
$ cat ccc.py cat ccc.py def test(): print("test is called.") print(__name__) >>> import ccc ccc >>> $ python ccc.py __main__これを利用し、コマンドライン実行の場合のみ実行される処理が定義可能。
$ cat ccc.py f = False def action(): print("Initialized." if f else "Not initialized.") if __name__ == "__main__": f = True action() $ python ccc.py Initialized. >>> import ccc >>> ccc.action() Not initialized. >>>モジュールの検索パス
モジュールは以下のパスから検索される。
- ビルトインモジュール
- 実行対象のスクリプトのディレクトリ
- カレントディレクトリ
- PYTHONPATH
モジュールのコンパイル
モジュールの読み込みを高速化するため、コンパイルされているファイルが存在しない場合、読み込み時にモジュールはコンパイルされ、「__pycache__」ディレクトリに出力される。
ls __pycache__ aaa.cpython-39.pyc ccc.cpython-39.pyc test.cpython-39.pyc bbb.cpython-39.pyc fibo.cpython-39.pyc標準モジュール
いくつかのモジュールはインタプリタにビルトインされている。
例えば、sysモジュール等。dir()
引数無し実行。
locals()で得られるリストと同様の模様。>>> dir() ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a'] >>> sorted(list(locals().keys())) ['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'a']モジュール内の変数、関数などのリスト取得
>>> import aaa >>> dir(aaa) ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'asdf', 'qwer', 'zxcv']パッケージ
「__init__.py」が存在するとパッケージとして認識される。
>>> import p.a.aaa p.__init__ is loaded. a.__init__ is loaded. aaa.py is loaded. >>> >>> p.a.aaa.test() aaa.test() is called. >>>読み込まれるモジュールの指定
「__init__.py」内の「__all__」にデフォルトで読み込むモジュールを指定可能
$ ls __init__.py asdf.py qwer.py zxcv.py $ cat __init__.py print("b.__init__ is called.") __all__ = ["qwer", "zxcv"] >>> from p.b import * p.__init__ is loaded. b.__init__ is called. qwer is loaded zxcv is loaded同パッケージ内でのモジュール読み込み
同じパッケージに属するモジュールを読み込む際、
- 絶対パスでimport
- 相対パスでimport
の2パターン存在する。
絶対パスでimportする場合
$ cat p/b/test.py import p.a.aaa def f(): p.a.aaa.test() >>> import p.b.test p.__init__ is loaded. b.__init__ is called. a.__init__ is loaded. aaa.py is loaded. >>> >>> p.b.test.f() aaa.test() is called. >>>相対パスでimportする場合
cat test.py from ..a import aaa def f(): aaa.test() >>> import p.b.test p.__init__ is loaded. b.__init__ is called. a.__init__ is loaded. aaa.py is loaded. >>> >>> p.b.test.f() aaa.test() is called. >>>7. 入力と出力
変数展開
>>> v = 100 >>> s = f'v: {v}' >>> >>> s 'v: 100' >>> >>> f'pi: {math.pi:.3f}' 'pi: 3.142' >>>formatメソッド
>>> import math >>> '{:1.5}'.format(math.pi) '3.1416' >>> '{:1.7}'.format(math.pi) '3.141593'repr()とstr()
reprはデバッグ用途。
>>> str(datetime.date.today()) '2021-02-10' >>> >>> repr(datetime.date.today()) 'datetime.date(2021, 2, 10)' >>>str.format()とvars()の組み合わせ
vars()はローカルな変数の一覧を返す。
以下のように利用すると、format()の引数を入力する手間が省けてデバッグ時に便利。>>> format = 'a = {a}, v = {v}' >>> a = 5 >>> v = 10 >>> >>> fmt.format(**vars()) 'a = 5, v = 10'出力文字列のセンタリング
右寄せはrjust(10), 左寄せはrjust(10)。
引数10は桁数。>>> for i in range(10): ... print(repr(i**5).center(10)) ... 0 1 32 243 1024 3125 7776 16807 32768 59049ゼロ埋め
>>> '5'.zfill(5) '00005'古いフォーマット指定
>>> 'pi: %.3f' % math.pi 'pi: 3.142'ファイル書き込み・読み込み
>>> f = open("a", "w") >>> f.write("hello world.") 12 >>> f.close() >>> >>> >>> f = open("a") >>> f.readline() 'hello world.' >>> >>> f.seek(0) 0 >>> f.readline() 'hello world.' >>>with文によるclose()の省略
>>> with open("a") as f: ... f.readline() ... 'hello world.' >>>読み込む文字数の指定
>>> with open("a") as f: ... f.read(1) ... 'h'1行ずつ高速に読み込む
$ cat aaa aaa bbb ccc >>> f = open("aaa") >>> for line in f: ... line ... 'aaa\n' 'bbb\n' 'ccc\n' >>>全ての行を一度に読み込む
readline()使用
>>> with open("aaa") as f: ... f.readlines() ... ['aaa\n', 'bbb\n', 'ccc\n'] >>>list()使用
>>> with open("aaa") as f: ... list(f) ... ['aaa\n', 'bbb\n', 'ccc\n']jsonの読み込み
$ cat a.json { "aaa": 5, "bbb": [1, 2, 3], "ccc": "test" } >>> with open("a.json") as f: ... json.load(f) ... {'aaa': 5, 'bbb': [1, 2, 3], 'ccc': 'test'}8. エラーと例外
構文エラー
SyntaxError: 構文エラー
>>> if aaa File "<stdin>", line 1 if aaa ^ SyntaxError: invalid syntax >>>例外のtry, catch
>>> try: ... aaa ... except NameError: ... print("Name Error occured.") ... Name Error occured.例外が起きなかった場合の処理 (try, else)
>>> try: ... True ... except NameError: ... print("name error.") ... else: ... print("no problem.") ... True no problem. >>>例外の送出 (raise)
raiseで送出できるのはExceptionクラスを継承した例外クラスのみ。
>>> try: ... raise Exception("aaa") ... except Exception as e: ... e ... type(e) ... e.args ... Exception('aaa') <class 'Exception'> ('aaa',) >>>raiseを再度実行することで、再送出可能
>>> try: ... raise Exception("aaa") ... except Exception as e: ... e ... raise ... Exception('aaa') Traceback (most recent call last): File "<stdin>", line 2, in <module> Exception: aaa例外の連鎖 (raise, from)
>>> try: ... raise IOError ... except Exception as e: ... raise RuntimeError from e ... Traceback (most recent call last): File "<stdin>", line 2, in <module> OSError The above exception was the direct cause of the following exception: Traceback (most recent call last): File "<stdin>", line 4, in <module> RuntimeError >>>例外クラスの自作
Exceptionから派生したクラスを作成可能
>>> class MyError(Exception): ... pass ... >>> >>> raise MyError("test") Traceback (most recent call last): File "<stdin>", line 1, in <module> __main__.MyError: test必ず実行されるクリーンアップ動作 (Finally節)
with文を利用したファイル操作等、問題発生時にファイルがcloseされるようにクリーンアップ動作が設定されているものがある。
例外処理の際、このようなクリーンアップ動作をFinally節により指定可能。>>> try: ... True ... except NameError: ... print("name error.") ... else: ... print("no problem") ... finally: ... print("done.") ... True no problem done. >>>9. クラス
- クラスはデータと機能を組み合わせる方法
- 他の言語より最小限の構文でクラスを作成できる
- オブジェクト指向プログラミングの標準的な機能を提供する。
- 複数の基底クラスを持つことが可能
- 基本的にクラスメンバはpublicで、virtual。よってオーバーライド可能。
- c++と異なり、組み込み型についても拡張可能。
nonlocal
Pythonでは、外側のスコープの変数は基本読み取り専用。
a()の中からvalの読み取りは可能。>>> def test(): ... def a(): ... print(val) ... val = 1 ... a() ... >>> test() 1しかし、val = 3と書き換えようとするとエラー。
>>> def test(): ... def a(): ... print(val) ... val = 3 ... val = 1 ... a() ... >>> test() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 6, in test File "<stdin>", line 3, in a UnboundLocalError: local variable 'val' referenced before assignment >>>これに対し、nonlocal文を使うことで書き込みできるようになる。
def test(): def a(): nonlocal val print(val) val = 3 val = 1 a() >>> test() >>> 1global
ローカル変数のグローバルスコープへの束縛。
def test(): global a a = "asdf" test() aclass
クラス定義はif文内にも記述可能
>>> f = 1 >>> if f == 1: ... class A: ... pass ... else: ... class B: ... pass ... >>> A() <__main__.A object at 0x102fbdb20> >>> B() Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'B' is not definedclass定義の終端を抜けるとクラスオブジェクトが生成される。
別の言語のような宣言ではなくクラスオブジェクトの生成であり、type型のインスタンスが作成される。>>> class A: ... pass ... >>> A <class '__main__.A'>属性参照
クラスのメンバ変数、メンバ関数のことを属性と呼んでいる。
属性には「.」でアクセスする。>>> class A: ... a = 1 ... def asdf(): ... print("asdf is called") ... >>> A.a 1 >>> A.asdf() asdf is calledクラスのインスタンス化
pythonにnew演算子は無く、クラスオブジェクトをcallすることでインスタンスが作成される。
>>> class A: ... pass ... >>> A() <__main__.A object at 0x1013129d0>init
クラスのインスタンス化時に「__init__」メソッドが呼ばれる。
通常、初期化はこの中で行う。>>> class A: ... def __init__(self): ... print("init is called.") ... >>> >>> A() init is called. <__main__.A object at 0x10149d430>メソッドオブジェクト
メソッドの第一引数にはインスタンスオブジェクトが渡される。
>>> class A: ... def test(self): ... print(self) ... >>> a = A() >>> a.test() <__main__.A object at 0x1013d4c40> >>> >>> A.test("aa") aa >>> A.test() Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: test() missing 1 required positional argument: 'self' >>>インスタンスオブジェクトの変数名は別に「self」でなくてもよい。
が、ツール等でこの文字列を当てにしている場合があるので注意。>>> class A: ... def __init__(a): ... print(a) ... >>> a = A() <__main__.A object at 0x1013b9b50>メンバ変数
>>> class A: ... def __init__(self): ... self.val = "default" ... def set(self, val): ... self.val = val ... >>> a = A() >>> a.val 'default' >>> >>> a.set(10) >>> a.val 10 >>>メソッドが参照するスコープ
メソッド内から参照するスコープは基本グローバルスコープ。
データ属性を優先的に参照するなどは無い。>>> a = 1 >>> class A: ... a = 2 ... def f(self): ... print(a) ... print(self.a) >>> b = A() >>> b.f() 1 2プライベート変数について
クラスのメンバ(データ属性)はプライベートにできない。これはPythonにおいてクラスを純粋な抽象データ型として使うことができないことを意味する。
あらゆる属性をプライベートにできないので、クラスの利用者はいくらでも拡張してしまえる。そこで、Pythonではアンダースコア始まりのメンバをプライベートとして扱うことが慣習となっている。>>> class A: ... _val = 1 ... def f(self): ... print(self._val) ... >>> a = A() >>> a.f() 1 >>> >>> a._val 1 >>>あくまで慣習なので、上記の例のように「a._val」とアクセスできるが、推奨はされない。
ネームマングリング (name mangling)
アンダースコア2つで始まる属性はクラス名を頭に付けないと参照できなくなる。
これをネームマングリング機構と呼ぶ。
主に親クラスと名前が衝突しないようにするために利用される。>>> class A: ... __val = 1 ... def f(self): ... print(self.__val) ... >>> >>> a = A() >>> a.__val Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'A' object has no attribute '__val' >>> >>> a._A__val 1 >>> >>> a.f() 1 >>>継承
以下のようにしてクラスを継承する。
>>> class A: ... a = 1 ... >>> >>> class B(A): ... def f(self): ... print(self.a) ... >>> >>> b = B() >>> b.f() 1 >>>属性は全てvirtualなので、派生クラス側で上書きできる。
>>> class A: ... def f(self): ... print(self.val) ... >>> >>> class B(A): ... val = 5 ... >>> b = B() >>> >>> b.f() 5多重継承
以下のようにしてクラスを多重継承する。
メソッドの検索順は、多重継承時に記述した順番に依存する。>>> class A: ... def f(self): ... print("A.f is called.") ... >>> class B: ... def f(self): ... print("B.f is called.") ... >>> class C(A, b): ... pass ... >>> c = C() >>> c.f() A.f is called. >>> >>> class C2(B, A): ... pass ... >>> >>> c2 = C2() >>> c2.f() B.f is called.構造体
Cのような構造体は存在しないが、以下のように空のクラスで代用することがある。
>>> >>> class A: ... pass ... >>> a = A() >>> a.name = "test" >>> a.val = 5 >>>イテレータ
Pythonの各コンテナオブジェクトはイテレータが実装されているため、for文によりループで各要素にアクセス出来て便利。
イテレータは以下のように自作クラスに実装できる。$ cat iterator.py class A: def __init__(self, data): self.data = data self.index = 0 def __iter__(self): return self def __next__(self): if len(self.data) == self.index: raise StopIteration self.index += 1 return self.data[self.index - 1] >>> a = A("asdf") >>> for s in a: ... s ... 'a' 's' 'd' 'f'ジェネレータ (generator)
ジェネレータを利用することでイテレータを自動で作成できる。
これにより「iter」、「next」を実装する手間が省ける。$ cat generator.py class A: def __init__(self, data): self.data = data self.index = 0 def sequence(self): for i in range(len(self.data)): yield self.data[i] >>> a = A("asdf") >>> for s in a.sequence(): ... s ... 'a' 's' 'd' 'f'ジェネレータ式
リスト内包表記を括弧で囲ったものがジェネレータ式。
>>> g = (i * i for i in range(10)) >>> >>> g <generator object <genexpr> at 0x10522d7b0> >>> >>> list(g) [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> >>> list(g) [] >>> >>> g = (i * i for i in range(10)) >>> sum(g) 28510. 標準ライブラリミニツアー
os: OSとの対話
「from os import * 」と読み込むとopen()とos.open()が被るので「import os」と読み込む。
カレントディレクトリ取得 (os.getcwd())
>>> import os >>> os.getcwd() '/private/tmp'ディレクトリの移動 (os.chdir())
>>> os.chdir("/var") >>> os.getcwd() '/private/var' >>>シェルコマンド実行
>>> os.system("date") 2021年 2月22日 月曜日 18時19分04秒 JSTshutil: ファイル操作
ファイルコピー (shutil.copyfile)
>>> shutil.copyfile("aaa", "aaa2") 'aaa2' >>>glob: ファイルリスト取得
特定の拡張子のファイル一覧取得 (glob.glob())
>>> glob.glob("*.py") ['fibo.py', 'ccc.py', 'bbb.py', 'aaa.py', 'test.py', 'generator.py', 'iterator.py', 'sys.py']sys: システムパラメータ取得
コマンドライン引数 (sys.argv)
$ python -i aaa.py >>> import sys >>> sys.argv ['aaa.py']標準エラー出力 (sys.stderr.write())
>>> sys.stderr.write("test") 4 test>>> >>>スクリプトの終了 (sys.exit())
>>> sys.exit() $argparse: コマンドライン引数処理
プログラム名取得 (ArgumentParser.prog)
>>> parser = argparse.ArgumentParser() >>> parser.prog 'aaa.py' >>>re: 文字列のパターンマッチング
正規表現 (re.findall)
>>> import re >>> re.findall('asdf[a-z]*', "1234asdfwer78989") ['asdfwer']random: 乱数に基づいた要素選択
ランダムに要素を選択 (random.choice())
>>> import random >>> random.choice([1,2,3,4,5]) 3乱数の生成 (random.random())
>>> import random >>> random.random() 0.31780501360951163statistics: 統計
平均 (statistics.mean())
>>> import statistics >>> statistics.mean([1,3,5,7,9,11]) 6標本分散 (statistics.pvariance())
>>> import statistics >>> statistics.pvariance([1,3,5,7,9,11]) 11.666666666666666urllib: インターネットアクセス
GETリクエスト (urllib.urlopen)
>>> for line in urlopen("https://example.com"): ... line ... b'<!doctype html>\n' b'<html>\n' b'<head>\n' b' <title>Example Domain</title>\n' b'\n' b' <meta charset="utf-8" />\n' b' <meta http-equiv="Content-type" content="text/html; charset=utf-8" />\n' b' <meta name="viewport" content="width=device-width, initial-scale=1" />\n' b' <style type="text/css">\n' b' body {\n' ... ...datetime: 日時の操作
現在の日時取得
>>> import datetime >>> datetime.date.today() datetime.date(2021, 2, 22)gzip: データ圧縮
文字列の圧縮 (zlib.compress())
import zlib >>> s = b'This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.' >>> len(s) 152 >>> len(zlib.compress(s)) 113timeit: 実行時間計測
実行時間の計測 (timeit.timeit())
>>> timeit.timeit("[i * i for i in range(10)]") 0.4927712500000325 >>> >>> >>> timeit.timeit("[i * i for i in range(100)]") 3.143982625000035 >>>doctest: テスト
docstringに埋め込んだテストをdoctestモジュールで実行することが可能。
$ cat mytest.py def mytest1(a, b): """Calc sum of a and b. >>> print(mytest1(1, 2)) 4 """ return a + b if __name__ == "__main__": import doctest doctest.testmod() $ python mytest.py ********************************************************************** File "/private/tmp/mytest.py", line 4, in __main__.mytest1 Failed example: print(mytest1(1, 2)) Expected: 4 Got: 3 ********************************************************************** 1 items had failures: 1 of 1 in __main__.mytest1 ***Test Failed*** 1 failures.11. 標準ライブラリミニツアー --- その 2
reprlib: オブジェクトの省略表現
オブジェクトの文字列表現 (repr())
eval()によってオブジェクトに戻せるような文字列に変換する。
>>> import datetime >>> a = datetime.datetime.today() >>> str(a) '2021-02-23 23:52:09.178283' >>> repr(a) 'datetime.datetime(2021, 2, 23, 23, 52, 9, 178283)' >>> >>> b = eval( repr(a) ) >>> b datetime.datetime(2021, 2, 23, 23, 52, 9, 178283) >>>オブジェクトの省略表現 (reprlib.repr())
デバッグ用途等のため、オブジェクトをrepr()の短縮版に変換する。
>>> import reprlib >>> a = datetime.datetime.today() >>> repr(a) 'datetime.datetime(2021, 2, 23, 23, 52, 9, 178283)' >>> >>> reprlib.repr(a) 'datetime.date...52, 9, 178283)' >>>pprint: オブジェクトの表示制御
改行表示 (pprint.pprint())
>>> import pprint >>> a = {"a": 1, "b": [1,2,3], "c": "zxcv"} >>> a {'a': 1, 'b': [1, 2, 3], 'c': 'zxcv'} >>> >>> pprint.pprint(a, width=5) {'a': 1, 'b': [1, 2, 3], 'c': 'zxcv'} >>>textwrap: テキストの折り返しと詰め込み
文章の表示幅制限 (textwrap.fill())
>>> a = "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque egestas ex a orci fringilla finibus. " >>> print(textwrap.fill(a, width=20)) Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque egestas ex a orci fringilla finibus.locale: 国際化
通貨の表示 (locale.currency())
>>> locale.setlocale(locale.LC_ALL, '') 'ja_JP.UTF-8' >>> >>> locale.currency(12345678) '¥12345678' >>> >>> locale.currency(12345678, grouping=True) '¥12,345,678'string: 文字列テンプレート
変数展開 (string.substitute())
>>> from string import Template >>> t = Template('a: ${a}, b: ${b}') >>> t.substitute(a = "aaa", b = "bbb") 'a: aaa, b: bbb'struct: バイナリデータ処理
数値 - バイナリ間の変換 (struct.pack(), struct.unpack())
>>> a = struct.pack('b', 127) >>> a b'\x7f' >>> type(a) <class 'bytes'> >>> struct.unpack('b', a) (127,)threading: マルチスレッド
##### スレッド作成 (threding.Thread())
>>> import threading >>> import time >>> >>> class A: ... val = 0 ... def test(self): ... time.sleep(3) ... self.val = 100 >>> >>> th = threading.Thread(target = a.test) >>> th.start() >>> >>> a.val 0 >>> a.val 100logging: ログ
##### 標準エラー出力 (logging.error())
>>> import logging >>> logging.error("test") ERROR:root:testweakref: 弱参照
pythonのGCはリファレンスカウンタ方式なので、delによって削除を行っても参照されている限りメモリが開放されない。
weakrefを利用すると、参照先が削除された際にメモリが開放されるような弱参照の辞書を作成できる。弱参照辞書 (weakref.WeakValueDictionary())
>>> a = User("asdf") >>> a <__main__.User object at 0x103649b20> >>> b = {"user": a} >>> b {'user': <__main__.User object at 0x103649b20>} >>> del a >>> b["user"] <__main__.User object at 0x103649b20> >>> b["user"].name 'asdf' >>> import weakref >>> a = User("asdf") >>> a <__main__.User object at 0x1035db7c0> >>> b = weakref.WeakValueDictionary({"user": a}) >>> b <WeakValueDictionary at 0x10366f4f0> >>> b["user"].name 'asdf' >>> del a >>> >>> b["user"] Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/opt/homebrew/Cellar/python@3.9/3.9.1_6/Frameworks/Python.framework/Versions/3.9/lib/python3.9/weakref.py", line 134, in __getitem__ o = self.data[key]() KeyError: 'user' >>>array: 配列
arrayはlist型と違って指定した型のデータしか受け入れない代わりに、コンパクトな配列を作成できる。
バイト型の配列 (array.array('b', ...))
>>> import sys >>> import array >>> >>> a = [1,2,3] >>> b = array.array('b',[1,2,3]) >>> >>> sys.getsizeof(a) 120 >>> sys.getsizeof(b) 67decimal: 浮動小数演算
浮動小数点誤差が出ると困る場合、decimalモジュールで精度を指定して演算を行う。
>>> 0.1 + 0.2 0.30000000000000004 >>> decimal.Decimal(0.1) + decimal.Decimal(0.2) Decimal('0.3000000000000000166533453694') >>> decimal.getcontext().prec = 2 >>> decimal.Decimal(0.1) + decimal.Decimal(0.2) Decimal('0.30')12. 仮想環境とパッケージ
pip install等でモジュールをインストールする環境を分けたい場合、venvを利用してディレクトリ単位の仮想環境を作成する。
$ py -m venv my-project $ cat my-project/pyvenv.cfg home = /opt/homebrew/bin include-system-site-packages = false version = 3.9.113. さあ何を?
リンク集。
14. 対話入力編集と履歴置換
対話シェルの種類
bpython
入力補完とドキュメントの表示が強力な対話シェル。
[https://www.bpython-interpreter.org/]
$ brew install bpython対話シェルでの実行履歴
デフォルトで以下のファイルに保存される。
$ cat ~/.python_history15. 浮動小数点演算、その問題と制限
丸め誤差
浮動小数点の丸め誤差に注意。
round()で適宜計算結果を丸める等の対策が必要。>>> 0.1 + 0.1 == 0.2 True >>> 0.1 + 0.1 + 0.1 == 0.3 False >>> >>> round(0.1 + 0.1 + 0.1, 2) == 0.3 True16. 付録
対話モード起動時に読み込むスクリプト
環境変数「PYTHONSTARTUP」に指定されたパスのスクリプトは対話モードの開始時に読み込まれる。
よく利用するモジュールのimportや自作のちょっとしたモジュールはここに書いておくと便利。# ~/.zshrc ... export PYTHONSTARTUP=~/.python_startup.py ... # ~/.python_startup.py def myfunc(): print("test") $ python Python 3.9.2 (default, Feb 19 2021, 06:54:56) [Clang 12.0.0 (clang-1200.0.32.29)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> >>> myfunc() test >>>実行可能なPythonスクリプト
スクリプトにシバンを書き、実行権限を付与しておくと、直接実行できて便利。
$ cat test.py #!/usr/bin/env python3 def run(): print("run func is called.") if __name__ == "__main__": run() $ chmod a+x test.py $ ./test.py run func is called.
- 投稿日:2021-02-25T19:13:09+09:00
scoop 環境下での python 周りの SSL エラー
scoop で anaconda や python を入れていたら SSL エラーが出るように。具体的には pip や anaconda (conda コマンド) で https につないだ通信でエラーになる。
certificate verify failedとか$ conda update anaconda-navigator Collecting package metadata (current_repodata.json): failed CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.com/pkgs/main/win-64/current_repodata.json> Elapsed: -とかが発生する。
解決法
家の環境では↓で直った。
$ scoop install openssl $ pip install pyopenssl $ conda update conda再発したときに忘れてそうなのでメモ。
- 投稿日:2021-02-25T19:09:37+09:00
初心者が深層学習で小説の文章から感想を生成しようとした話
はじめに
小説の文章から内容を考慮した感想を自動生成したいと思い、ちょうど機会があったので挑戦してみました。半年ぐらいで「ゼロから作るDeepLearning」の1と2を一通り読み、残り半年で実装しました。せっかく頑張ったので記録用に書いてます。
作業の流れ
次のような順番で実装しました。
- データ収集
- データの前処理
- 学習
- 生成
これから順を追って説明していきます。
データ収集
学習するためには大量のデータが必要です。モデルには本文と感想をペアにして入力するので、小説の本文と感想をセットで入手する必要があります。今回は「小説家になろう」と「カクヨム」からスクレイピングして集めました。
小説家になろう
小説家になろうでは最近(2019年ぐらい?)から作品の一話ずつに感想が書き込めるようになりました。そこで本文ページとその感想ページを行き来するクローラーを作成しました。
- 作品ページ
- 本文ページ
- 感想ページ
- 本文ページ
- 感想ページ
簡単に説明すると、上のような構造になっているので、作品ページのURLから一話の本文ページのURLを取得し、本文データと感想ページのURLを集め、感想ページの感想データを収集する。これを本文ページの次の話のリンクがなくなるまで続け、終わったら次の作品ページという様に繰り返す。
なろうは静的なサイトでhtmlの構造もわかりやすかったので簡単に集めることができました。本文データはあとで一文づつに分割したいので改行をすべて「/」に変換して一文にし、本文データと感想データが一対一になるように保存しました。
PythonはBeautifulSoupのようなライブラリが充実しているので、簡単にスクレイピングできます。ヘッダー情報としてユーザエージェントがいるので、忘れないようにしましょう。
データは小説の本文を約2.5GBほど集めました。
カクヨム
小説家になろうの一話ごとに感想が対応するシステムは比較的最近ついた機能なので、データ数が足りなかったのでカクヨムからも集めました。カクヨムは小説家になろうとは違い、動的なサイトであるため、感想の欄(カクヨムでは応援コメント)をクリックして読み込む必要がある。そこでseleniumを用いて感想欄を読み込んでからhtmlを読み込むようにしてデータを集めました。
こちらは約1GBほど集めました。
データの前処理
現在の深層学習モデルではTransformerを用いても小説全文を入力することはできません。そこで入力に使うデータは感想に対応する数文をとってくる必要があります。また、スクレイピングして集めてきた感想データには学習データとして不適切なものも混ざっています。前処理の流れはざっくりと次のようになります。
- 本文から感想に対応する数文を取ってくる
- テキストデータを掃除する
本文から感想に対応する数文を取ってくる
感想は小説全体を指しての感想もあると思いますが、今回は一話の一部分に対しての感想を考えます。感想は小説の一部分を参考にして書くとすると、感想に出てきて小説にも出てくる単語は感想を書く上で重要な単語のはずです。よって、感想で出てくる単語を重みづけして、それを利用して数文取り出すようにします。
そこで使うのがTF-IDFです。TFはTerm Frequencyを表し、これは単語の出現頻度のことです。IDFはInverse Document Frequencyで、これはある単語が含まれる文書の割合の逆数のことです。TF-IDFはTF値とIDF値をかけ合わせて計算します。TF-IDFはその文章で出現回数は多いが、他の文書では出現していない単語のTF-IDFの値は大きくなり,それ以外の単語についてはTF-IDF値は相対的に小さくなります。簡単にいうと、頻度を考慮して単語毎の重要度を算出することができます。つまりは、その文章の中でよく出る人物名などの固有名詞の重要度を上げることができます。ちなみにTF-IDFの計算はsklearnにTfidfVectorizerがあるのでこれを使いました。
単語の分割にはMeCabを使用しました。MeCabはオープンソースの形態素解析エンジンで日本語を形態素に分割するツールです。こちらもmecab-python-windowsを使用するとPython上で利用できます。
さて、TF-IDFで単語の重みづけができたら、本文データを一文づつに分割して学習に使う数文を選びます。今回は三文選ぶことにします。一文づつに分けたものをさらにMeCabで単語に単語に分割して、一文ごとに単語の重みを合計します。このままでは長い文ほど合計が高くなる可能性が高くなってしまうので、長さで正規化します。この数値が大きい三文を用いて学習します。Transformerで学習するとき、複数文をつないでいることがわかるようにタグでつなぎます。
文[タグ]文[タグ]文
これで上のようになります。
テキストデータの掃除
スクレイピングで集めてきた感想データには「更新ありがとうございました」や「次回も楽しみにしています」のような本文の内容には関係のない感想や誤字報告などが混ざっています。これらはどの小説でも一定数存在しているので何もせず学習すると、本文と感想との対応を学習しづらくなり適切に学習できません。
そこで今回は次の2つで掃除しました。
- 感想の文章の長さが短いものを外す
- 本文に関係のない単語が出ている文を外す
まず、感想の文章の長さが短いものを外すのは、短いものはそもそも内容に触れていないものが多いと感じたからです。内容に対する感想を出力したいのでこれは外します。
次に、本文に関係のない単語が出ている文を外すことに関してです。こちらも内容に対する感想を出力するために邪魔になるので排除します。本文に関係のない単語は「更新」、「誤字」、url、「次回」、「著者」、「書籍化」などいくつか実際に感想を見て、いらないと思った単語をリストにしました。MeCabで分割してこの単語を含む文は使わないようにしました。前処理の流れ
最後に前処理流れをもう一度まとめます。
- 感想のTF-IDFを取り、単語に重みづけする
- このとき、データの掃除も行う
- 本文を一文づつに分割し、一文ごとに出てきた単語の重みの合計を求める
- 長さで正規化する
- 数値の大きい三文を取りだし、タグでつなぐ
学習
いよいよ学習です。学習する上での方針は「本文に出現する単語を感想にも出現させたい」ということです。普通の翻訳モデルでは入力と出力の単語は別々にされています。翻訳モデルでは日本語と英語のようにはっきりとわかれているので単語が混ざってはいけないからです。そこで今回は要約モデルを使います。要約モデルを使うことで単語辞書やembeddingを入力と出力で共有することができます。これによって小説に出てきた登場人物や固有名詞を感想に出現させることができるようになることを期待しています。
今回モデルを自分で一から作るのは厳しかったので、オープンソースの機械翻訳エンジンであるopenNMTを用いました。特にpytorchを使ったopenNMT-pyを使用しています。ドキュメントはこちらです。こちらを使うことでモデルを一から作ることなく、手軽に高性能なモデルを使えます。便利ですね。デフォルトでは機械翻訳用なのですが、パラメータを設定することで要約モデルでの学習もできます。モデルは最近ではRNNよりTransformerの方が高性能で主流のようなので、Transformerを使います。Transformerの説明はこちらかこちらあたりがわかやりやすいと思います。
学習データは前処理を行った本文と感想のペアを約18万ペア用います。
さて、ではまずopenNMT-pyの前処理を行っていきます。コマンド一つで簡単にできます。
onmt_preprocess -train_src data/train_body.txt -train_tgt data/train_comment.txt -valid_src data/valid_body.txt -valid_tgt data/valid_comment.txt -save_data naro -src_seq_length 400 -tgt_seq_length 400 -dynamic_dict -share_vocabこれだけで学習用の語彙データが作れます。特徴的なのはdynamic_dictとshare_vocabです。dtnamic_dictは生成時に入力された文も辞書に加えて生成するようにします。これによって、生成時に入力された文から単語を取り出して出力に出現させることが可能になります。share_vocabは入力データと出力データの辞書データを共有します。翻訳モデルの場合では日本語と英語のように混ざってはいけないが、今回は入力と出力が両方日本語で混ざっても大丈夫なので、辞書データを共有することで語彙数を増やしつつ、共通する語を省けるので動作を軽くできます。
次に、作った語彙データを用いて学習していきます。
onmt_train -data naro -save_model naro-model -layers 8 -rnn_size 1024 -word_vec_size 1024 -transformer_ff 4096 -heads 8 -encoder_type transformer -decoder_type transformer -position_encoding -train_steps 300000 -max_generator_batches 2 -dropout 0.1 -batch_size 4096 -batch_type tokens -normalization tokens -accum_count 4 -optim adam -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 -learning_rate 0.01 -max_grad_norm 0 -param_init 0 -param_init_glorot -label_smoothing 0.1 -valid_steps 2500 -save_checkpoint_steps 2500 -world_size 2 -gpu_rank 0 1 -share_embedding -copy_attn今回はGPU2台を用いて学習しました。オプションの詳しい説明はドキュメントを見てください。特徴的なのはshare_embeddingとcopy_attnです。share_embeddingはそのままの意味でencoderとdecoderでembeddingを共有するようにします。これもshare_vocabと狙いは同じで、embeddingを共有することで一つのembeddingで計算できるので動作を軽くできます。copy_attnはdynamic_dictと対応しています。dynamic_dictと合わせることで生成時に入力の単語を出力に出現させることができるようになります。
生成
学習ができれば、実際に生成します。しかし、学習用データと同様に、入力に小説全文を使うことはできないので、生成の入力データ用に適切に数文を選ぶ必要があります。その後、openNMT-pyのtranslateを用いて生成します。
生成用入力データの作成
当然ですが、ここでの入力データは学習に使った入力データとできるだけ近い構造でないとモデルが学習できていても、生成時にうまく生成することができません。そこで、生成用の入力データは学習用の入力データに近づける必要があるのですが、学習用の入力データは出力データである感想に対して取り出しています。生成時には小説データしかないので、これだけで学習用の入力データに近づける必要があります。
ここで、学習用の入力データは感想中の単語を重みにして選んでいるので、小説から選ばれる3文は似たような単語、文章になっていると考えました。そこで、生成用の文章でも三文が似たような単語、文章になるようにします。ここでも前処理で使ったTF-IDFを用います。入力データの作成の流れは次のようになります。
- 一文ずつに分けた小説データに対してTF-IDFを取り、単語に重みづけをする
- その重みを用いて、合計値が最も大きい一文を選ぶ
- 一文ずつに分けた小説データをベクトル化し、コサイン類似度をとる
- TF-IDFの最も大きい文とコサイン類似度が大きい2つはタグでつなぐ
TF-IDFで単語に重みづけをし、まずは一文を決めます。その後、それに似た文を選ぶためコサイン類似度で似たものを探します。コサイン類似度はベクトルがどれだけ同じ方向に向いているかを計算します。自然言語処理では単語をベクトル化することでコンピュータで扱えるようにし、うまくできればベクトルの足し引きで単語を推測できることも知られています。これを用いることで最初に選んだ一文と似ているであろうと思われる二文を選び、生成用の入力データにします。
openNMT-pyによる生成
前処理、学習と同じでコマンド一つで生成できます。
onmt_translate -gpu 0 -batch_size 10 -model data/naro-model_step_62500.pt -src data/test.txt -output pred.txt -min_length 15 -verbose -stepwise_penalty -coverage_penalty summary -beta 5 -length_penalty wu -alpha 0.9 -block_ngram_repeat 2 -ignore_when_blocking "." "[SEN]" "。" -replace_unkいろいろと書いてますが、簡単にいうとビームサーチで生成するということと長さや繰り返しにペナルティを与えていることが書いています。詳しくはドキュメントを見てください。
結果
お待ちかねの結果です。いくつか生成した例を載せます。
test.txt「 しかし 、 あの よう な やり方 で 一方 的 に 公爵 令嬢 が 排除 さ れ た と なる と 、 他 の 貴族 家 も 安泰 で は 無くなり ます 。 すると その 先 に 待つ の は 王 太子 殿下 と 第 二 王子 殿下 の 継承 権 争い です 。 過去 の 歴史 を 振り返っ て も この 争い は 非常 に 危険 で 、 多く の 血 が 流れ 、 国 は 乱れる こと でしょ う 」 [SEN] 「 ですが 、 そんな 決闘 で も 決闘 です 。 あの まま アナスタシア 様 が ご 自身 で 決闘 に 臨ま れ た 場合 、 アナスタシア 様 に 殿下 を 傷つける こと は でき ない でしょ う から 、 おそらく 敗れ た はず です 」 [SEN] 「 さて 、 まず 昨晩 は 娘 の 代理人 として 王 太子 殿下 や クロード 王子 と 決闘 を し て くれ た そう だ な 。 この 点 について は 礼 を 言お う 。 アレン 君 、 ありがとう 」pred.txt王 太子 と 第 二 王子 の 継承 権 争い が 勃発 し そう です なこれは小説の内容を言い換えして、語尾を変換したような感想になっています。
test.txtつまり 、 フロレスクルス 公爵 家 として は 、 ナゼルバート 様 が 王女 の 伴侶 に なっ て も 、 ロビン 様 の 子供 が 次 の 国王 に なっ て も 、 どちら でも 良く て 、 「 できれ ば 、 御し やすい 王女 殿下 と ロビン 様 の 子供 が 王 に なっ て くれ た 方 が いい かも 」 なんて 考え を 持っ て いる という こと だ 。 [SEN] 「 俺 を 正式 な 夫 に 、 ロビン 殿 を 愛人 として 迎え入れる ん だって 。 で 、 ロビン 殿 と ミーア 王女 の 子供 が 男 だっ たら 、 その 子 が 次 の 王 だ 」 [SEN] もともと 、 ナゼルバート 様 と 結婚 する の を 条件 に 、 王女 殿下 は 次期 女王 に なる こと を 認め られ て い た らしい 。 というのも 、 王女 殿下 は 全く 政治 の 勉強 を し て い ない から だ 。pred.txt王 太子 は ロビン を 傀儡 に する つもり だっ た の か な ?これも、小説の内容を言い換えている感想になります。個人的に入力で出てこない傀儡という単語が出てきたのが面白いと思います。しかし、名詞の当てはめで間違っています。
test.txt帝国 と バークレイ 産 の 麦 の 取引 、 及び レナート と マリ アベル の 婚姻 に 際 する 条件 について は 、 予定 さ れ て いる 二 人 の 運命 の 出会い の 前 に 条件 を 詰める こと に なっ て いる 。 [SEN] その間 に 、 マリ アベル は 帝国 独自 の マナー など を 教え て もらっ た 。 [SEN] 帝国 の 皇太子 と も なれ ば 、 その 予定 は びっしり と 詰まっ て いる こと だろ う 。pred.txtマリ アベル と 皇太子 の 仲 が 進展 し そう な 気 が し ます感想でよく出現するテンプレパターンです。
test.txt「 とりあえず この 辺り で 肩 慣らし を し て … … 単純 に リエル が 戦闘 に 慣れる 練習 を しよ う か 。 ファースト スキル の 死ん だ フリ も 何 度 も 使っ て いれ ば ドンドン 精度 や スキル 技能 が 向上 する はず だ 。 まずは 死ん だ フリ を 強化 し て 行こ う 」 [SEN] どこ の 世界 に 死ん だ フリ の 技能 を 向上 する ため に 修練 を する なんて 話 が ある の だろ う か 。 [SEN] 「 リエル 、 今 一 度 君 の 最強 スキル 、 死ん だ フリ と 真剣 に 向き合っ て ほしい 」pred.txt「 とりあえず この 辺り で 肩 慣らし を し て … … 単純 に リエル が 戦闘 中 に 死ん だ フリ を しよ う か 。 ファースト スキル の 死ん だ フリ も 何 度 も 使っ て いれ ば ドンドン 精度 が 向上 する はず だ 。 」 この 部分 の 最強 スキル だ と 思っ たなんと本文を引用して、感想を出力しています。
ここまで見ると、それなりの感想が出力されているように見えますが、これは少数のよさそうなものを取ってきた例です。実際はほとんどのものは日本語がおかしかったり、名詞の当てはめで間違っていたりしています。ダメな例をいくつか載せておきます。
pred.txtロビン が 腕 を 飲む こと は 出来 ない ん じゃ ない か な ? エレイン と エレイン の コンビ は 結構 好き な ん じゃ ない か な 。 シャナル の 「 シャナル さん 、 人質 って こと に なっ て もらっ て いい よ 」 エルフ たち は エルフ の 国 の こと を 知っ て いる の でしょ う か ? 剣 聖 の 剣 と 剣 の 関係 性 が 出 て き まし た 。 犬 人 型 の 犬 、 猫 耳 と 尻尾 を 装着 し て ます アスラ かっこいい ! グンドウ と グンドウ を 回収 し まし た ね !ですので、うまくできたモデルを作れたという結果にはなりませんでした。
簡単な考察
語尾の偏り
生成した感想では語尾に一定のパターンができていた。例えば、「かな?」「気になります」「でしょうか?」「良いのでは?」のようなものです。前者2つは人間が書く感想でもよく見られる語尾なので良いのですが、「気になります」が多すぎる問題があります。「~と~の関係が気になります!」のような文がよく生成されます。これは学習データにある感想にこのような文が多かったのだと思われます。後者2つはおそらく誤字を指摘するコメントから来たものだと考えています。小説家になろうやカクヨムの感想ではそういった感想ではなく誤字を指摘するコメントが見られます。一応「誤字」といったキーワードで排除したのですが、排除できていないものが多そうなので、確実に排除する必要があります。
感想の傾向
出力された感想はいくつかのパターン当てはまってるように感じました。
まず本文の内容を言い換え、語尾を変換したものです。これは「~ですよね?」のような疑問形や確認する形に変換されている例をよく見ます。
次に、「~気になります」、「~が好きです」、「~と~の関係」、「~の今後」のようなテンプレに対して単語を当てはめたものです。これは実際の感想でもよく見られるので単語の当てはめがうまくいけば感想っぽく見えます。しかし、実際に単語の当てはめがうまくいっているものは少ないです。~と~のような並列の単語当てはめでは、まったく関係がない2つを選んだり、2つとも同じ単語が入ったりすることが頻出します。
最後に、本文から引用して一言のパターンです。これは入力データから文を取ってきて最後に何か一文付け加えているものです。引用しているので違和感があれば目立ちます。これは誤字指摘のコメントから来ていると考えています。相当する一文を引用して、ここがこっちのほうがいいと思います、という内容の誤字指摘から一文引用と一言というパターンができたと考えました。これも誤字を指摘するコメントの排除が不十分だったことを表しているので、前処理が課題になっていることがわかります。
たまに出現する変わったものとしてメタ的な感想を出力することがあります。例えば、「ヒロインは~ですね」みたいな内容です。モデルでは実際に内容を理解しているわけではないので、名詞の当てはめに間違う確率が高く、間違っていると目立ちます。でも、合っていると人間が書いた感想のようになります。
課題
今回の課題点をまとめてみました。
- 全体的に日本語がおかしい
- 要モデルの改善
- 名詞の当てはめ
- 特定の語尾に偏り
- 前処理での排除
- 感想に関係がない単語の排除
- 前処理での排除
- データ数
- そもそも学習データが減るため思い切った前処理ができなかった
- 前処理で徹底して排除するにはより多くのデータが必要
まとめ
要約モデルを用いて小説の本文から感想の出力を行いました。全体的な性能としてはよいとは言えませんが、一部でも感想らしいもの生成されたのでよかったです。一番大きな課題は名詞の当てはめです。有識者に聞いた限り、名詞の当てはめ問題はかなり大きなモデルを使っても起こるらしいので難しいそうです。
今後は、データ数を増やし、質のいい学習データを作り、モデルの改善を行っていきたいと考えています。前処理での工夫余地はあって、タグを増やしてネガティブ、ポジティブで分類したり、本文以外の情報、例えば登場人物やあらすじを入力データにくっつけるなども考えています。
うまくできたらTwitterBotや小説の内容を考慮した対話システムも作ってみたい(願望)。
自然言語処理や深層学習に触る体験ができたので自分の中では割と満足しています。
- 投稿日:2021-02-25T19:07:56+09:00
入力待ち(wait for input)のsubprocessにinputを送る
概要
subprocessで起動したプロセスが入力待ちになったタイミングで、外部から入力を送りたい場面があります。
業務の中でPythonでこれを行うときになかなか苦戦したので記しておきます。標準入出力
サブプロセスとして起動する以下のようなプログラムを想定します。
sub.pyimport time if __name__ == "__main__": while True: time.sleep(5) user_input = input("wait for input :") print(f"User Input is {user_input}")五秒ごとにユーザーからの入力を受け付けるいたってシンプルなプログラムです。
これをサブプロセスとしてメインプロセスから起動します。__main__.pyfrom subprocess import Popen import sys import time p = Popen( args=["python", "sub.py"], stdin=sys.stdin, stdout=sys.stdout ) while True: time.sleep(1)コンソールの標準出力と標準入力をサブプロセスに引き渡しているので、当然コンソール画面から入出力ができます。
>> python __main__.py wait for input : abcdefg User Input is abcdefgIOインターフェースの引き渡し
標準入出力が使えれば世話はないですが、それ以外のioインターフェスを利用したい場合はどうすればよいでしょうか。
試しに以下のコードを実行してみます。__main__.pyimport io stdin = io.BytesIO() p = Popen( args=["python", "sub.py"], stdin=stdin, stdout=sys.stdout )すると以下のエラーが発生します。
io.UnsupportedOperation: fileno
ioをプロセス間で共有する場合、file descriptorを利用する必要があります。
mainプロセスで宣言されたBytesIOは、あくまでPythonのメインプロセス内に限定されたioインターフェースで、OSレベルの利用を想定したものではありません。pythonのIOインターフェースの読み込み
pythonでは
IO.read(size=-1)でストリームを読み込むことができます。
sizeを指定しない場合は、EOFまで読み込んでくれますが、
os.fdopenで開けたストリームはブロッキングで開かれているため、
指定したサイズのバッファが来るまで待ち続けます。
つまり普通にstdoutを読み込んでしまうと、サブプロセスが入力待ちになった時点で、ブロックされてしまいます。よって
IO.read(1)として、1 byteずつ読み込むことで、サブプロセスが入力待ちになる直前までのアウトプットを取得することができます。下記のコードはサブプロセスからのoutputを受けて、入力待ちになった段階で別プロセスから入力を送るプログラムです。
以下の二つの処理を別スレッドでwhile loopで回し続けています。
- stdoutの読み込み
- subprocessが入力待ちになった時点で入力の送信
main.pyfrom subprocess import Popen, PIPE import time import sys import io import os import threading from dataclasses import dataclass @dataclass class SubprocessStatus: wait_for_input: bool @property def is_wait(self): pass @is_wait.getter def is_wait(self): return self.wait_for_input @is_wait.setter def is_wait(self, is_wait): self.wait_for_input = is_wait class Threadable: def thread_target(self): pass def start(self): self.t = threading.Thread(target=self.thread_target) self.t.setDaemon(True) self.t.start() class ProcessWatcher(Threadable): """ processがwait for inputになったらcallback """ subprocess_status: SubprocessStatus def __init__(self, subprocess_status, callback): self.subprocess_status = subprocess_status self.callback = callback def wait(self): time.sleep(1) def thread_target(self): while True: self.wait() if not self.subprocess_status.is_wait: continue self.callback() class StdoutLineReader(Threadable): """ stdoutを1 byteずつ読み込んで、行として処理 """ line = b"" def __init__(self, fd_stdout: int, callback): self.fd_stdout = fd_stdout self.callback = callback def thread_target(self): self.stdout = os.fdopen(self.fd_stdout, "rb") linesep = os.linesep.encode() while True: r = self.stdout.read(1) self.line += r self.callback(self.line) if self.line.endswith(linesep): print("line :", self.line) self.line = b"" class MainProcess: count = 0 target_line = b"wait for input" def __init__(self): self.fd_stdin_r, self.fd_stdin_w = os.pipe() self.fd_stdout_r, self.fd_stdout_w = os.pipe() self.stdout_w = os.fdopen(self.fd_stdin_w, "wb") self.subprocess_status = SubprocessStatus(False) self.stdout_line_reader = StdoutLineReader( self.fd_stdout_r, self.handle_line) self.process_watcher = ProcessWatcher( self.subprocess_status, self.when_wait_for_input) def handle_line(self, line: bytes): if not line.startswith(self.target_line): return self.subprocess_status.wait_for_input = True def when_wait_for_input(self): self.subprocess_status.wait_for_input = False self.stdout_w.write(f'Input:{self.count}\n'.encode()) self.stdout_w.flush() self.count += 1 def start(self): self.process = Popen( args=["python", "sub.py"], stdin=self.fd_stdin_r, stdout=self.fd_stdout_w, stderr=sys.stderr ) self.stdout_line_reader.start() self.process_watcher.start() main_process = MainProcess() main_process.start() while True: time.sleep(1)詳細
サブプロセスの状態とstdoutからの出力は当然誤差があるため、
SubprocessStatusを作成して、サブプロセスの状態を仮想的に制御します。StdoutLineReaderはstdoutを一文字ずつ読み続け、改行コードが出現した段階で、リフレッシュします。別スレッドで動かすことで、入力待ち時のブロッキングを回避します。
ProcessWatcherでサブプロセスの状態を監視させ、wait for inputになった時点で
callbackを呼び出します。仕様かやり方が悪いのかわかりませんが、openしたfile descriptorについて、一度closeしててから、同一のfile descriptorを再びopenしようとするとOS errorが出ます。
よって、stdinに使うfile descriptorについては開いたままにしています。※Popen.communicateについて
サブプロセスへの入力が一度きりの場合については、popenのcommunicateが利用できます。ほかの記事を参考にしてみてください。
- 投稿日:2021-02-25T19:07:56+09:00
Python : 入力待ち(wait for input)のsubprocessにinputを送る
概要
subprocessで起動したプロセスが入力待ちになったタイミングで、外部から入力を送りたい場面があります。
業務の中でPythonでこれを行うときになかなか苦戦したので記しておきます。標準入出力
サブプロセスとして起動する以下のようなプログラムを想定します。
sub.pyimport time if __name__ == "__main__": while True: time.sleep(5) user_input = input("wait for input :") print(f"User Input is {user_input}")五秒ごとにユーザーからの入力を受け付けるいたってシンプルなプログラムです。
これをサブプロセスとしてメインプロセスから起動します。__main__.pyfrom subprocess import Popen import sys import time p = Popen( args=["python", "sub.py"], stdin=sys.stdin, stdout=sys.stdout ) while True: time.sleep(1)コンソールの標準出力と標準入力をサブプロセスに引き渡しているので、当然コンソール画面から入出力ができます。
>> python __main__.py wait for input : abcdefg User Input is abcdefgIOインターフェースの引き渡し
標準入出力を使えれば世話はないですが、それ以外のioインターフェスを利用したい場合はどうすればよいでしょうか。
試しに以下のコードを実行してみます。__main__.pyimport io stdin = io.BytesIO() p = Popen( args=["python", "sub.py"], stdin=stdin, stdout=sys.stdout )すると以下のエラーが発生します。
io.UnsupportedOperation: filenoストリームをプロセス間で共有する場合、file descriptorを利用する必要があります。
mainプロセスで宣言されたBytesIOは、あくまでPythonのメインプロセス内に限定されたioインターフェースで、OSレベルの利用を想定したものではありません。pythonのIOインターフェースの読み込み
そこで、osモジュールのpipeメソッドで作ったfile descriptorを利用して、ストリームの共有を図ります。
pythonでは
IO.read(size=-1)でストリームを読み込むことができます。
sizeを指定しない場合は、EOFまで読み込んでくれますが、
os.fdopenで開けたストリームはブロッキングで開かれているため、
指定したサイズのバッファが来るまで待ち続けます。
つまり普通にstdoutを読み込んでしまうと、サブプロセスが入力待ちになった時点で、ブロックされてしまいます。よって
IO.read(1)として、1 byteずつ別スレッドで読み込むことで、サブプロセスが入力待ちになる直前までのアウトプットを取得するアプローチを取ります。下記のコードはサブプロセスからのoutputを受けて、入力待ちになった段階で別プロセスから入力を送るプログラムです。
以下の二つの処理を別スレッドでwhile loopで回し続けています。
- stdoutの読み込み
- subprocessが入力待ちになった時点で入力の送信
main.pyfrom subprocess import Popen, PIPE import time import sys import io import os import threading from dataclasses import dataclass @dataclass class SubprocessStatus: wait_for_input: bool @property def is_wait(self): pass @is_wait.getter def is_wait(self): return self.wait_for_input @is_wait.setter def is_wait(self, is_wait): self.wait_for_input = is_wait class Threadable: def thread_target(self): pass def start(self): self.t = threading.Thread(target=self.thread_target) self.t.setDaemon(True) self.t.start() class ProcessWatcher(Threadable): """ processがwait for inputになったらcallback """ subprocess_status: SubprocessStatus def __init__(self, subprocess_status, callback): self.subprocess_status = subprocess_status self.callback = callback def wait(self): time.sleep(1) def thread_target(self): while True: self.wait() if not self.subprocess_status.is_wait: continue self.callback() class StdoutLineReader(Threadable): """ stdoutを1 byteずつ読み込んで、行として処理 """ line = b"" def __init__(self, fd_stdout: int, callback): self.fd_stdout = fd_stdout self.callback = callback def thread_target(self): self.stdout = os.fdopen(self.fd_stdout, "rb") linesep = os.linesep.encode() while True: r = self.stdout.read(1) self.line += r self.callback(self.line) if self.line.endswith(linesep): print("line :", self.line) self.line = b"" class MainProcess: count = 0 target_line = b"wait for input" def __init__(self): self.fd_stdin_r, self.fd_stdin_w = os.pipe() self.fd_stdout_r, self.fd_stdout_w = os.pipe() self.stdout_w = os.fdopen(self.fd_stdin_w, "wb") self.subprocess_status = SubprocessStatus(False) self.stdout_line_reader = StdoutLineReader( self.fd_stdout_r, self.handle_line) self.process_watcher = ProcessWatcher( self.subprocess_status, self.when_wait_for_input) def handle_line(self, line: bytes): if not line.startswith(self.target_line): return self.subprocess_status.wait_for_input = True def when_wait_for_input(self): self.subprocess_status.wait_for_input = False self.stdout_w.write(f'Input:{self.count}\n'.encode()) self.stdout_w.flush() self.count += 1 def start(self): self.process = Popen( args=["python", "sub.py"], stdin=self.fd_stdin_r, stdout=self.fd_stdout_w, stderr=sys.stderr ) self.stdout_line_reader.start() self.process_watcher.start() main_process = MainProcess() main_process.start() while True: time.sleep(1)詳細
サブプロセスの状態とstdoutからの出力は当然誤差があるため、
SubprocessStatusを作成して、サブプロセスの状態を仮想的に制御します。StdoutLineReaderはstdoutを一文字ずつ読み続け、改行コードが出現した段階で、リフレッシュします。別スレッドで動かすことで、入力待ち時のブロッキングを回避します。
ProcessWatcherでサブプロセスの状態を監視させ、wait for inputになった時点で
callbackを呼び出します。仕様かやり方が悪いのかわかりませんが、openしたfile descriptorについて、一度closeしててから、
同一のfile descriptorを再びopenしようとするとLinux,windowsそれぞれでOSエラーがでます。Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/lib/python3.8/os.py", line 1023, in fdopen return io.open(fd, *args, **kwargs) OSError: [Errno 9] Bad file descriptorTraceback (most recent call last): File "<stdin>", line 1, in <module> File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.8_3.8.2032.0_x64__qbz5n2kfra8p0\lib\os.py", line 1023, in fdopen return io.open(fd, *args, **kwargs) OSError: [WinError 6] ハンドルが無効です。よって、stdinに使うfile descriptorについては開いたままにしています。
※Popen.communicateについて
サブプロセスへの入力が一度きりの場合については、popenのcommunicateが利用できます。ほかの記事を参考にしてみてください。
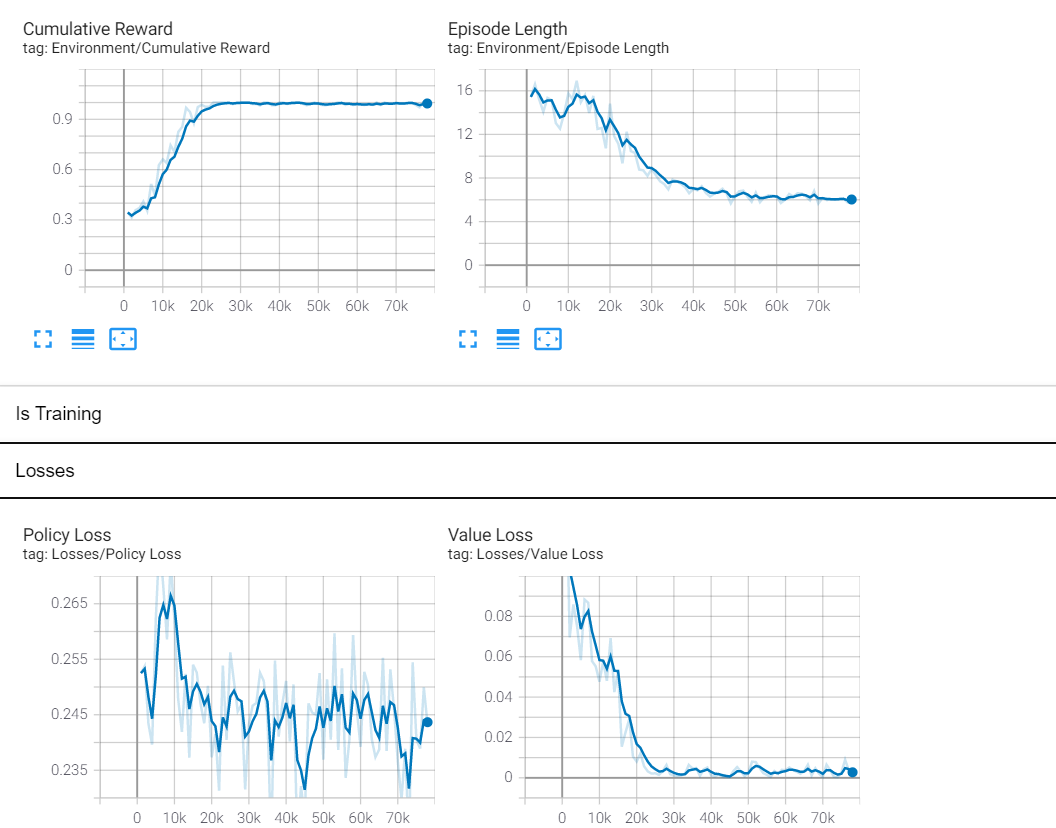
- 投稿日:2021-02-25T17:54:34+09:00
UnityのMLAgentsでPython使って機械学習 2021年最新版
はじめに
こんにちは。陰キャ大学生です。
前置きはさておき、Pythonを使って機械学習していると、「物理エンジン使ってやってみたいなぁ」なんて思う時があります。
ありません
そこで今回は、Unityのために作られた機械学習ライブラリML Agents を使って物理エンジンで機械学習してみました。
実はすでにQiita上には多くのMLAgentsの記事が上がっています。【ML-Agents】UnityとPythonのTensorFlowをつかって機械学習させてみた(v0.11β対応)
しかし、このMLAgents、バージョンアップが頻繁なうえに、バージョン変わると関数やメソッド名も変わるというなんともQiitaライター泣かせな仕様となっています。
そこで今回は、現在(2021年2月25日)最新であるRelease13 について記事を書きます。
おそらく数か月後には古くて使い物にならない記事になると思いますが、今この瞬間にMLAgentsを使いたいんだ!!という人に届いてほしいと思います。MLAgentsについて
こちらの記事が大変わかりやすく参考になりますので、ぜひご覧ください
環境
MLAgentsの推奨環境
- Unity (2018.4以降)
- Python (3.6.1以降)
今回私が使用した環境
- Unity (2019.4.15f1)
- Python (3.7.9) Anaconda
推奨環境を満たしていれば大丈夫だと思いますが、Unityはバージョン等によりUIが変わる可能性があるのでご容赦ください。
前準備
MLAgentsのダウンロード
こちらのサイトから、Release13をダウンロードしてください。
ダウンロードされたZIPファイルを任意の場所に展開してください。PythonとUnityのダウンロード&インストール
参考記事がわかりやすくまとめてくださったので引用します。参照されてください。
【ML-Agents】UnityとPythonのTensorFlowをつかって機械学習させてみた(v0.11β対応)
準備
Pythonの環境構築
Pytorchのインストール
ターミナルで以下を実行します
pip install torch~=1.7.1 -f https://download.pytorch.org/whl/torch_stable.html
完了関連ライブラリのインストール
展開したディレクトリに移動して、以下を実行
pip install -e ./ml-agents-envs pip install -e ./ml-agents実際、
pip install mlagentsでもインストールできますが、この際は常に最新版がインストールされますので、バージョンの整合性をとるためにもダウンロードしたSetup.pyから参照することをお勧めします。0.24.0がインストールされたことを確認してください
Unitでプロジェクト作成
Unity Hubを開いて、プロジェクトの作成をします
上のメニューから、
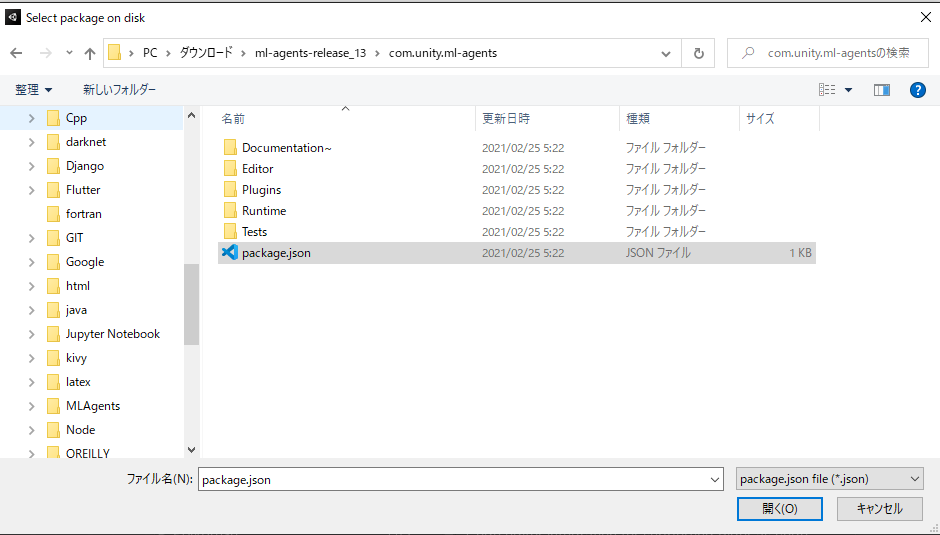
Window>Package Managerの順に進んで、左上の+マークから、Add Package from disk...を選択して、<展開したフォルダ>/com.unity.ml-agents/package.jsonを選択します。
インポートが始まり、
In ProjectにML Agents 1.8.0があれば大丈夫です。
今回は、箱をボールが追いかけるAIを作成します。(詳しくは記事の最後を見てね)
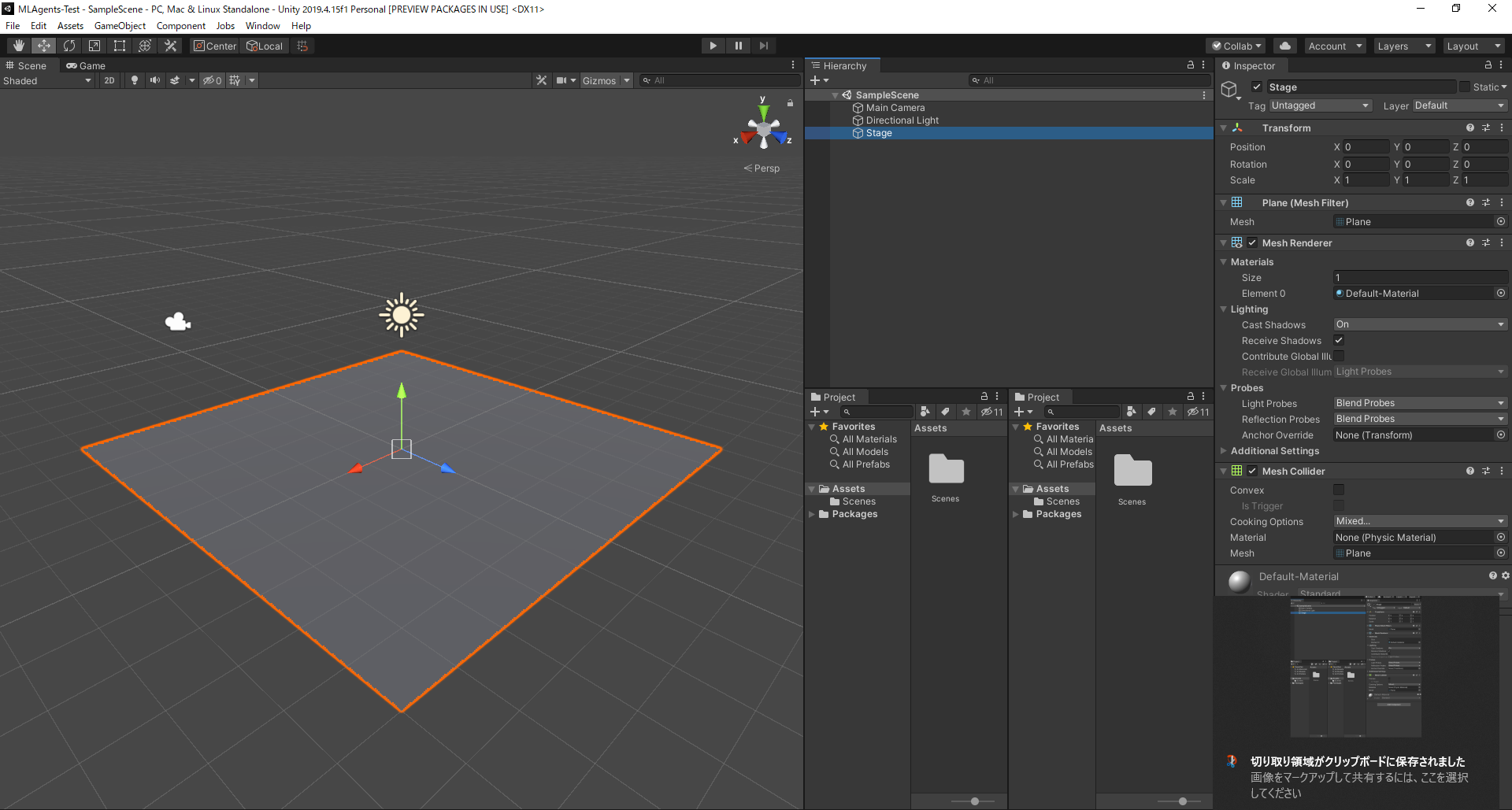
Unityの詳しい説明等はここでは省略します。ステージの作成
GameObject>3D Object>Planeを選択し、Stageに改名、Positionを(0, 0, 0)Scaleを(1, 1, 1)に設定
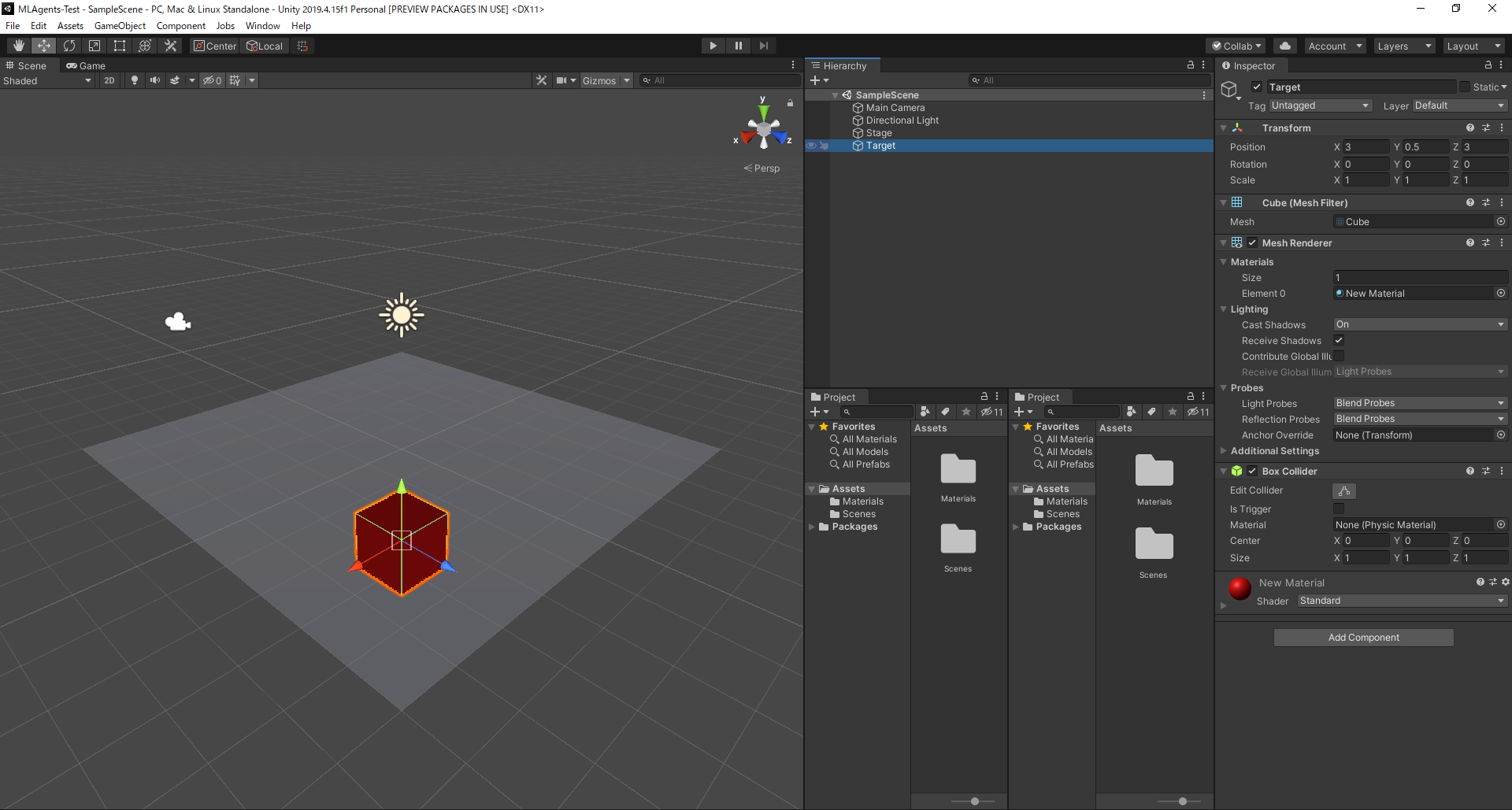
箱の設定
GameObject>3D Object>Cubeを選択し、Targetに改名、Positionを(3, 0.5, 3)Scaleを(1, 1, 1)に設定
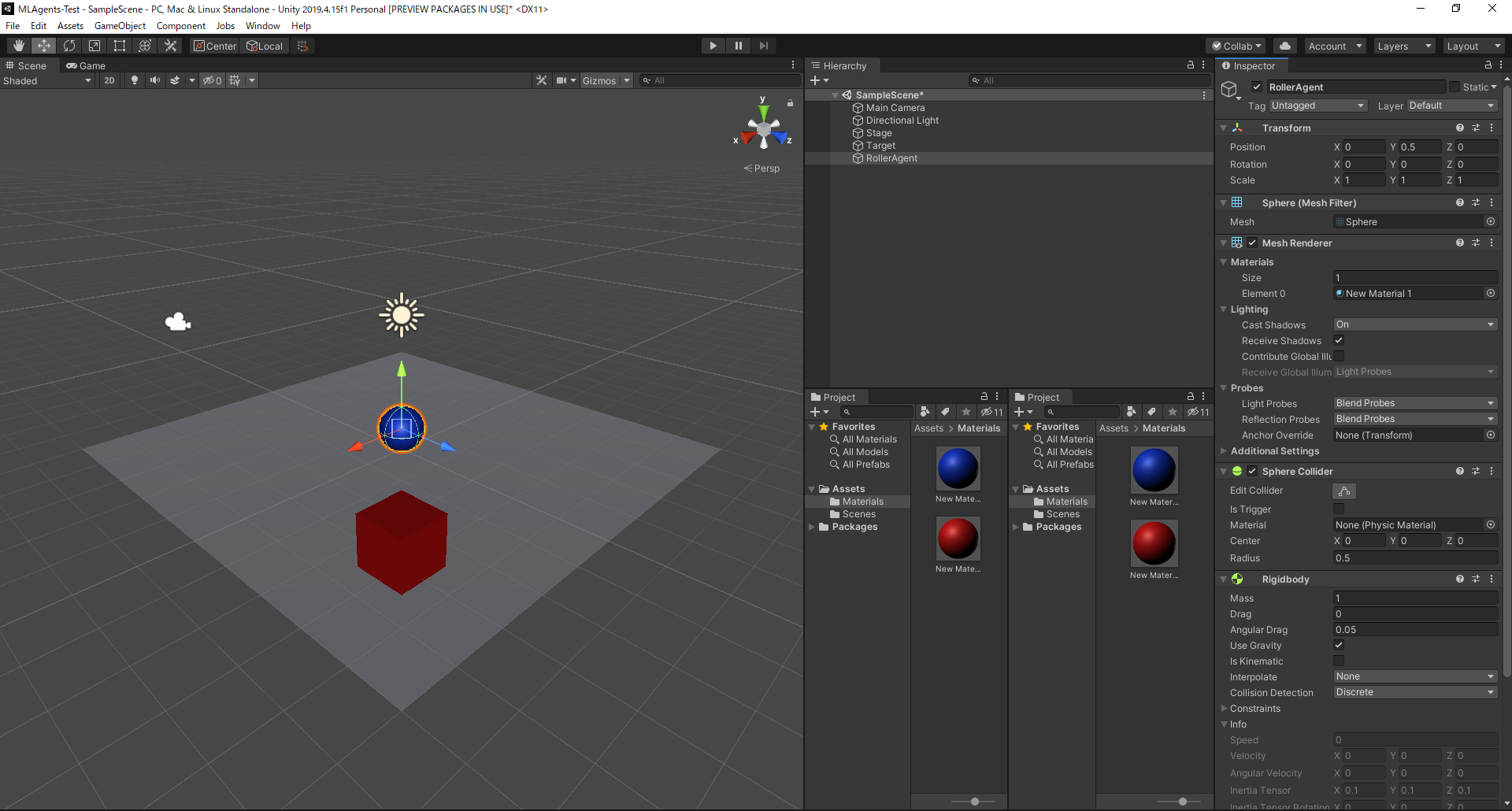
ボールの設定
GameObject>3D Object>Sphereを選択し、RollerAgentに改名、Positionを(0, 0.5, 0)Scaleを(1, 1, 1)に設定Inspector下部の
Add Componentから、Physics>Rigidbodyを追加 ?これめちゃ大事です!!!
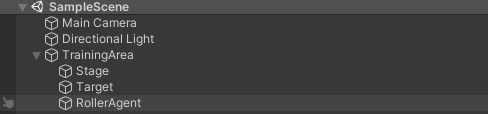
後で複製できるように、グループ化しておきます。
GameObject>Create Emptyを選択し、Stage、Target、RollerAgentをドラッグしてグループ化します名前は何でもいいです。
ボールのスクリプト作成
UnityのProject内に
Scriptsフォルダを作り、その中にRollerAgent.csを作成します
中身をお好きなエディタで以下のように書き換えてください。
解説は適宜コメントで挿入してあるので見てみてくださいね。RollerAgent.cs// 使用ライブラリのインポート using System.Collections.Generic; using UnityEngine; using Unity.MLAgents; using Unity.MLAgents.Sensors; using Unity.MLAgents.Actuators; // Agentクラスを継承し、必要なところだけ書き換えていきます public class RollerAgent:Agent { Rigidbody rBody; // スタートしたときに呼び出される関数 void Start () { // ボールの物体を変数に格納 rBody = GetComponent<Rigidbody>(); } // Targetをグローバルに宣言 public Transform Target; // エピソード(学習のステップ)が始まった時に呼び出される関数 public override void OnEpisodeBegin() { // ボールのY座標が0=落下したとき if (this.transform.localPosition.y < 0) { // 初期化 this.rBody.angularVelocity = Vector3.zero; this.rBody.velocity = Vector3.zero; this.transform.localPosition = new Vector3( 0, 0.5f, 0); } // ターゲットをランダムな位置に Target.localPosition = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4); } // 観測データ(この場合で言うと学習に必要な数値)の取得 public override void CollectObservations(VectorSensor sensor) { // ボールと箱の座標(x, y, z) x 2 sensor.AddObservation(Target.localPosition); sensor.AddObservation(this.transform.localPosition); // ボールのスピード(x, z) sensor.AddObservation(rBody.velocity.x); sensor.AddObservation(rBody.velocity.z); // トータルで入力次元は8次元になる } // 力を加えるときの乗数 public float forceMultiplier = 10; // アクションが起きたときに呼び出される関数 public override void OnActionReceived(ActionBuffers actionBuffers) { // XとZ軸の入力に合わせてボールに力を加える Vector3 controlSignal = Vector3.zero; controlSignal.x = actionBuffers.ContinuousActions[0]; controlSignal.z = actionBuffers.ContinuousActions[1]; rBody.AddForce(controlSignal * forceMultiplier); // 箱とボールの距離 float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition); // 箱にボールが到達したとき if (distanceToTarget < 1.42f) { // 報酬を1に設定 SetReward(1.0f); // エピソードを終了 EndEpisode(); } // ボールが落下したとき else if (this.transform.localPosition.y < 0) { // エピソードを終了 EndEpisode(); } } // 手で動かす際の設定 public override void Heuristic(in ActionBuffers actionsOut) { var continuousActionsOut = actionsOut.ContinuousActions; continuousActionsOut[0] = Input.GetAxis("Horizontal"); continuousActionsOut[1] = Input.GetAxis("Vertical"); } }ファイルのアタッチ
作成したスクリプトを
RollerAgentにドラッグします。
RollerAgent (Script)のTargetに、Target(ゲームオブジェクト)をドラッグ
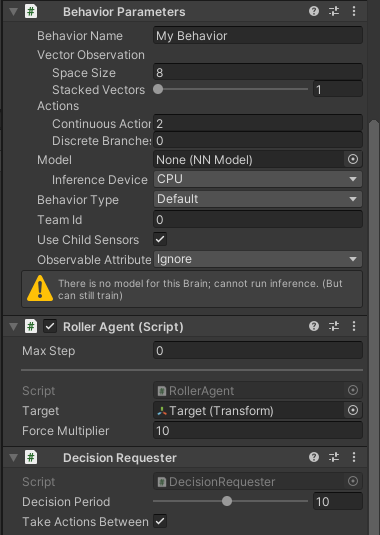
Add Componentから、ML Agents>Behavior Parametersを追加
Vector Observation>Space Sizeを8に変更
Actions>Continuous Actionsを2に変更
Behavior nameをRollerBallに変更
Add Componentから、ML Agents>Decision Requesterを追加
Decision Periodを10に変更最後はこんな感じになります
テスト
Behavior ParametersのBehavior TypeをHeuristic Onlyに変更中央上部のプレイボタンを押して、矢印キーで遊べるか確認してみてください
学習
<展開したディレクトリ>/config/rollerball.yamlを作成して、以下を書き込みますrollerball.yamlbehaviors: RollerBall: trainer_type: ppo hyperparameters: batch_size: 10 buffer_size: 100 learning_rate: 3.0e-4 beta: 5.0e-4 epsilon: 0.2 lambd: 0.99 num_epoch: 3 learning_rate_schedule: linear network_settings: normalize: false hidden_units: 128 num_layers: 2 reward_signals: extrinsic: gamma: 0.99 strength: 1.0 max_steps: 500000 time_horizon: 64 summary_freq: 1000
Behavior ParametersのBehavior TypeをDefaultに変更展開したディレクトリに移動して、以下を実行
mlagents-learn config/rollerball.yaml --run-id=RollerBall
Listening on port 5004. Start training by pressing the Play button in the Unity Editor.この文言がでたら、Unityに戻って、プレイボタンを押すと、学習が始まります。
最初のうちはボールがオロオロ動くのがなかなかに可愛いです笑学習並列化
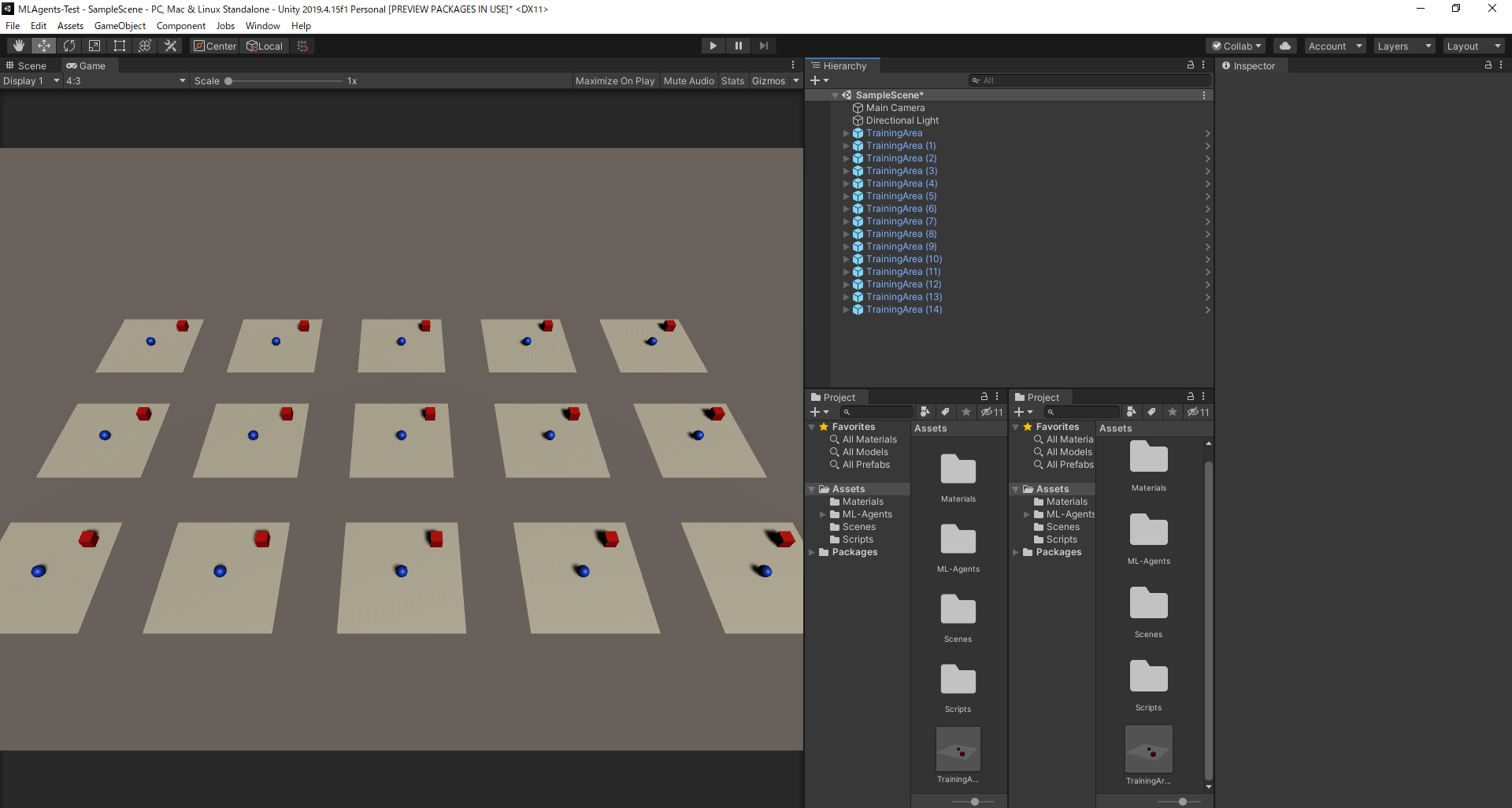
物理エンジンのいいところは、モデルを複製して同時に学習を進められるところです。
先ほどグループ化したものをプレハブ化し、複製してみましょう。(特にコード等変える必要はありません)
さて、改めて学習してみましょう。
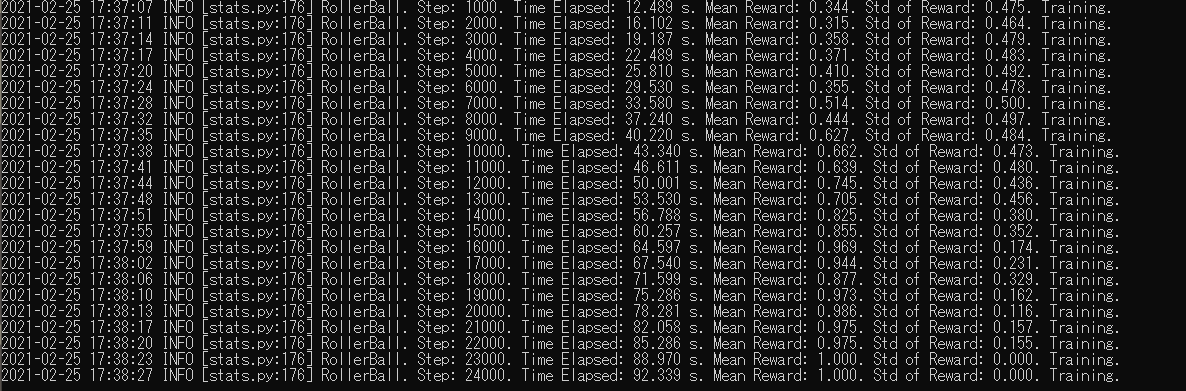
ログはこのようになります。
Mean Rewardが1に近づけばうまく学習が行われています。
終了したいときは、CTRL+Cで止められます。その時のモデルデータを自動的に保存してくれます。
また、バックボーンはTensorFlowなので、別ターミナルでコマンドを実行することで、TensorBoardも確認することができます。
tensorboard --logdir results --port 6006
学習モデルでテスト
<展開したディレクトリ>/results/RollerBall/RollerBall.onnxを、Unityプロジェクト内のAssetsにドロップしたのちに、RollerAgentのInspector内ののBehavior Parameters>Modelにドロップ。プレイボタンを押すと、学習されたモデルでボールが動く様子を見ることができます。
床から落ちることなく箱を一生懸命追っている姿が確認できますね。可愛い。
最後に
たびたびバージョンの変わってしまうMLAgentsですが、使い方によっては機械学習の世界が広がると思います。
僕も早くコマンドラインで学習できるようにならないかなぁ




- 投稿日:2021-02-25T17:27:03+09:00
Pythonで学ぶ制御工学 第7弾:グラフ作成へ向けて
#Pythonで学ぶ制御工学< グラフ作成へ向けて >
はじめに
基本的な制御工学をPythonで実装し,復習も兼ねて制御工学への理解をより深めることが目的である.
その第7弾として「グラフ作成へ向けて」を扱う.グラフ作成へ向けて
ここでは,次回以降必要になってくるグラフ作成において,便利になってくるであろうものを関数化し,以降使えるようにする.関数化することで,毎度細かな設定を行う手間が省ける.なお,ここで記述するのは,参考書にあったものであり,絶対的なものではない.あくまでもその参考書の説明の中で手間を省くために用意されているものである.しかしながら,設定の方法を学ぶことができ,今後自分好みや,ある基準に従った仕様でグラフ作成する際に,役立つ知識となるであろうと思い,ここに記録することとする.
関数の定義
for_plot.py""" 2021/02/25 @Yuya Shimizu 図を整えるための関数定義 """ #グラフをプロットするときの線種を決めるジェネレータ def linestyle_generator(): linestyle = ['-', '--', '-.', ':'] lineID = 0 while True: yield linestyle[lineID] lineID = (lineID + 1) % len(linestyle) #グラフを整える関数 def plot_set(fig_ax, *args): fig_ax.set_xlabel(arg[0]) #x軸のラベルを1つ目の引数で設定 fig_ax.set_ylabel(arg[1]) #y軸のラベルを2つ目の引数で設定 fig_ax.grid(ls=':') #グラフの補助線を点線で設定 if len(args) == 3: fig_ax.legend(loc=args[2]) #凡例の位置を3つ目の引数で設定 #ボード線図を整える関数 def bodeplot_set(): #ゲイン線図のグリッドとy軸ラベルの設定 fig_ax[0].grid(which='both', ls=':') fig_ax[0].set_ylabel('Gain [dB]') #位相線図のグリッドとx軸, y軸ラベルの設定 fig_ax[1].grid(which='both', ls=':') fig_ax[1].set_xlabel('$\omega$ [rad/s]') fig_ax[1].set_ylabel('Phase [deg]') #凡例の表示 if len(args) > 0: fig_ax[1].legend(loc=args[0]) #引数が1つ以上:ゲイン線図に表示 if len(args) > 1: fig_ax[0].legend(loc=args[1]) #引数が2つ以上:位相線図にも表示感想
今回は直接制御工学についての学習ではなかったが,グラフをきれいに整えるものを関数化するというのは,この教材にとどまらず,以降,何かしらグラフを扱っていく中で役立つことにはなってくるはずである.
参考文献
Pyhtonによる制御工学入門 南 祐樹 著 オーム社
- 投稿日:2021-02-25T16:28:28+09:00
VSCodeで、「ターミナルの起動に失敗しました。エラー 1260」でPythonが実行できない。
さて、VSCodeでPythonを使う方法は、色々ウェブ上で紹介されていますが、基本的にインストーラを使えば、パスの設定などは必要ないはずだと思います。
ところが、私の場合、Windows10でVSCodeのインストール → Pythonのインストール → print("Hello world!")を実行、と行けるはずが、print文を実行して、「ターミナルの起動に失敗しました。エラー 1260」で、右下にターミナル・ウィンドウが表示されませんでした。
そこで、VSCodeを一度アンインストールし、再インストールしたのですが、ダメでした。
さらに、設定 → 機能 → ターミナル を確認し、
External: Windows Exec
どのターミナルを Windows で実行するかをカスタマイズします。
C:\WINDOWS\System32\cmd.exe
と正しく設定されていました。そこで、このエラーメッセージ上にあったトラブルシューティングをよく読み、
C:\Users(ユーザ名)\AppData\Roaming\Code\User\ にある settings.json に、
"terminal.integrated.shell.windows": "C:\\WINDOWS\\system32\\cmd.exe"
の1行を手動で追加して、Pythonが無事動きました。何かの参考になれば、幸いです。
以上です。
- 投稿日:2021-02-25T16:22:48+09:00
ポケモンセンターオンラインの入荷情報をLINEbotを使用して通知する
皆様はポケモンカードゲームやってますでしょうか?僕は1月に友人に勧められて始めました.ポケカ初めて1か月くらいたったのですが,分かったことがあります.
ポケモンカードは買えない!
人気すぎるんですね.この間でたばかりの一撃マスター・連撃マスターに加え,誰しもが買いたいであろうシャイニースターV,他にも人気の過去の商品が多数あります.もちろん,転売ヤーから高い値段で買うことはできますがそんなことはしたくない!そう思い,ポケモンセンターオンラインで入荷したらLINEで通知が来るようなbotを作成することにしました.
Pythonの歴はポケカよりも短く,今月始めたばかりなので稚拙なプログラムになっているとは思うのですがアドバイス等あればぜひお願いします.環境
- Raspberry Pi 3(Windows10)
- Raspbian
環境設定
このプログラムでは,Raspberry Pi(以下ラズパイ)を用いて入荷しているかどうかのプログラムを毎分動作させることで目的を達成させています.Windowsでももちろん起動させ続ければ可能ですが,ずっとPCをつけておく必要があります.以下はラズパイで動作させることを前提に話していきますが,基本Windowsでも可能です.
ライブラリのインストール
今回のプログラムで必要なライブラリをインストールします.Windowsの方はPythonの環境構築をまずしてもらい,その後これらのライブラリをインストールしてください.どちらも場合でも,コマンドプロンプトに以下のものを順々に入力するだけです.Winの方は$は>>だと思ってください.
$ pip3 install line-bot-sdk $ pip3 install schedule $ pip3 install requests $ pip3 install beautifulsoup4他にも必要なライブラリがあるかもしれませんが,基本installの後に入れたいライブラリ名(line-bot-sdkとか)を入力するだけです.
LINEの設定
こちらの記事の最初の章を参考にLINEDevelopersに登録し,Messaging API(要はbot)を作成します.そしてそのアクセストークンというものをメモしておいてください.
次に,そのAPIを入手するページから上記画像にあるチャンネルの基本設定というページに飛びます.そこにあるあなたのユーザーIDというのもメモしておきます.これはあなたが普段使用しているLINEのIDで,このIDあてに通知が来るように設定します.
プログラム
pokemon.pyimport requests import re from bs4 import BeautifulSoup from linebot import LineBotApi from linebot.models import TextSendMessage from linebot.exceptions import LineBotApiError import schedule import time import datetime def LINEloop(): LINE_CHANNEL_ACCESS_TOKEN = "チャンネルトークン" line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN) LINE_USER_ID = "LINEユーザーID" # 欲しいものの商品名 card = ["シャイニースターV" , "TAG TEAM GX BOX"] result_str1 = "予約受付中" result_str2 = "在庫あるよ!" # 欲しいもののURL pokemon_url = [ "https://www.pokemoncenter-online.com/?p_cd=4521329313405", "https://www.pokemoncenter-online.com/?p_cd=4521329266541" ] dt_now = datetime.datetime.now() print(dt_now.minute) if 8 < dt_now.hour < 21: if dt_now.minute == 0: line_bot_api.push_message(LINE_USER_ID, TextSendMessage(text="動作確認 at " + str(dt_now.hour) + ":" + str(dt_now.minute) + ":" + str(dt_now.second))) for i in range(len(pokemon_url)): data = requests.get(pokemon_url[i], headers = my_header) data.encoding = data.apparent_encoding data = data.text soup = BeautifulSoup(data, "html.parser") detail = soup.find("table",class_="no_size") detailstr = str(detail) if "soldout" in detailstr: 1 elif "yoyaku" in detailstr: line_bot_api.push_message(LINE_USER_ID, TextSendMessage(text=card[i]+result_str1)) elif "add_cart_btn": line_bot_api.push_message(LINE_USER_ID, TextSendMessage(text=card[i]+result_str2)) def main(): LINEloop() if __name__ == "__main__": schedule.every(1).minutes.do(main) while True: schedule.run_pending()利用方法
まず,LINEのアクセストークンとユーザーIDを所定の箇所に入力します.入力後は""でそれぞれが囲われている状態にしておいてください.
次に,欲しいもののURLを取得しておきます.今回はシャイニースターVとTAG TEAM GXのBOXにしています.
取得したら,欲しいもののURLという部分に""で囲って入力し,複数ある場合は,で区切って複数入力していきます.今回は2つですが,何個でも可能です.
そして,欲しいものの商品名の部分も変更します.わかるような名称を""で囲い入力します.ただし,この入力順はURLを入力した順番と一致させてください.
そうしましたら,いよいよ動作確認です.動作確認をする際は,pokemon.pyの最後の部分if __name__ == "__main__": schedule.every(1).minutes.do(main) while True: schedule.run_pending()を
if __name__ == "__main__": main()にすることで,1度のみ動作をさせることが可能になります.ここでエラーをはかず現在の分数がでれば動作確認完了です.エラーは調べてもらうと多分出てくるんでそれを見て対処してください.どうしてもわからなかったらコメントしてくだされば一緒に考えます(対処はできないかも).
ちゃんと動作しているかを確認するために8~21時の毎時0分に動作チェックのLINEが来ますが,『うっせえわ』という方はif 8 < dt_now.hour < 21: if dt_now.minute == 0: line_bot_api.push_message(LINE_USER_ID, TextSendMessage(text="動作確認 at " + str(dt_now.hour) + ":" + str(dt_now.minute) + ":" + str(dt_now.second)))の部分を消せば来なくなります.8,21の部分を変えれば来る時間帯の変化も可能で,0を変えれば来る分数も変更可能です.
解説
解説というほどちゃんと説明する気もないのですが,大まかな流れだけ書いておきます.動作すればいいという方は読まなくていいです.
- 対象のURLからrequests,BeautifulSoup4を用いてカートに入れるとかが書いてある部分のHTMLを取得
- 対象のHTMLは画像データを含むのでその画像データのタイトルで判断する."soldout"が含まれていたら売り切れ,"yoyaku"が含まれていたら予約受付中,"add_cart_btn"と含まれていたら在庫あり.ただし,予約受付中の時も"add_cart_btn"は含まれるのでこの順でなければ判断できない.
- 予約受付中もしくは在庫ありだった場合,line_bot_apiを用いてメッセージを送る
この一連を毎分schedule関数を用いて実行する,といったところです.取得するHTMLをいじればAmazonや他のサイトでも価格を監視したりできると思います,
おわりに
ポケカが欲しすぎて初めてPythonに触れましたが,Cを授業でちょっと触れたことのないプログラミング初心者でもQiitaを参考にしたり既存のライブラリを利用すればある程度できて便利だなと感じました.HTMLの取得部分は正直あまり理解できていないのでそこをどうにかするのと,あとはscheduleで毎分実行するというのはだいぶゴリ押しなんだろうというのはプログラミング初心者の私でもわかるのでそこももっといい手段があれば変えたいです.いい方法あれば教えてください.
なんであれ,達成感だけはあったのでやってみてよかったです.ラズパイもこのためだけに買って,初めて使いました.ラズパイとPCキーボードとマウス1つでどうにか抜き差しなしで共有できないんですかね?教えてください.
ちなみにこれ作ってからずっと動作させてるけど肝心の入荷はまだないです.

- 投稿日:2021-02-25T15:56:03+09:00
データの前処理(教師あり学習)
前処理
データに前処理を行いデータ分析をしやすくする
前提条件
これから使うデータやライブラリーを読み込む
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split cancer=load_breast_cancer() X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=0)MinMaxScaler
-データがちょうど0から1に入るように変換を行う
-from sklearn.prerpocessing import MinMaxScalerStandardScaler
-データを平均0分散1に前処理する
-from sklearn.preprocessing import StandardScalerRobustScaler
-平均値と分散の代わりに中央値と四分範囲を用いる
-外れ値を無視できる
-from sklearn.preprocessing import RobustScalerデータに対して前処理を行う手順
MinMaxScalerを例にして紹介する
from sklearn.prerpocessing import MinMaxScaler#ライブラリーをインポート scaler=MinMaxScaler()#モデルを読み込む X_train_scaled=scaler.fit_transform(X_train)#訓練データ X_test_scaled=scaler.transform(X_test)#テストデータ訓練データに対して行った前処理をテストデータに対して同じ様に前処理を行う必要がある
- 投稿日:2021-02-25T15:49:21+09:00
blenderとpythonと数式を駆使してポテトチップス大量生産系工場長になる
概要
これを作ります。blenderとpythonと数式で。
動機
sachiko15さん(Twitter:@vaguely20)という方が、モデリング文化祭という3DCG作品の展覧会のようなものを開催していらっしゃいます。それに自分も何か出そうと思ったのが事の発端です。私自身つい最近この方を知ったのですが、その作品群は非常に素晴らしいものばかりで、とても尊敬しています。そんな方の企画となると、多少ましなものを作らなければなりません。しかもお題が食べ物と作ったことが一度もないものでした。どうしようかと思案した挙句、ある思い付きと共に奇人枠として振っていこうと決意しました。
ポテトチップスには鞍点がある
伝わる人には伝わるネタかも知れませんが、ポテトチップスってとても身近な鞍点ではないでしょうか。鞍点という概念を知った日から何となくそう思っていましたが、今回はそれを実現していきます。
鞍点とは
wikiの定義では、鞍点は次のようになっています。
鞍点(あんてん、saddle point)は、多変数実関数の変域の中で、ある方向で見れば極大値だが別の方向で見れば極小値となる点である。
鞍部点、峠点とも言う。微分可能な関数については極値を取らない停留点とも言う。これだけ見てもよく分からないと思いますが、図を見れば直感的に理解できると思います。
(この図もwikiより引用)
峠点という名前が一番分かりやすいかも知れません。詳しい数学的な話はここでは飛ばし、数式だけ利用していくことにします。この図の数式が$z=x^2-y^2$であることを覚えておくと、後の話が分かりやすくなるかもしれません。
数学的な補足
$z=f(x,y)$の形式で表される二次曲面は、クロスタームを含まない時、楕円放物面、双曲放物面に大別されます。(例外などは数学書を当たってください) 偏微分をすれば分かることですが、$x^2$の項と$y^2$の項が同符号ならば楕円放物面(つまり鞍点なし)、異符号なら双曲放物面(つまり鞍点あり)となります。無論すべてのポテトチップスに鞍点がある訳ではないので、一部はこの楕円放物面を採用して作成しました。この他言及すべき点は多々ある気はしますが、本記事ではこれくらいでお許しください。もう一つの動機
ポテトチップスを例え数式で表せたとしても、それだけで先程言ったモデリング文化祭に作品を提出できるかと言えば、無論NOです。3DCGソフトで具体的にポテトチップスを作成しなければなりません。では、3DCGソフトであるblenderで数式を具体的に表現できるのか?
ここで鍵となるのがpythonです。
Blednerの拡張機能であるaddonには、Add Mesh Extra Objectsというものが存在します。それのZ Math Surfaceという機能には、先程のような$z=f(x,y)$という数式をポリゴンに変換してくれる機能があります。
これで理論と実装、両者の道が開けてきました。結局何がしたいのか
Blenderという3Dソフトにおいて、鞍点を含む局面を表す$z=x^2-y^2$という式、およびそれをメッシュ化するZ Math Surfaceという機能を活用し、ポテトチップスを大量に生産する。これがゴールとなります。
作業の概要
STEP1 ポテト曲面の作成
鞍点を含む面など、ポテトチップス作成の基となる曲面のことをポテト曲面と呼び、それを大量に生成します。STEP2 型の作成
ポテト曲面からポテトチップスを切り抜くための型を同じ数だけ作成します。STEP3 ポテトの切り抜き
最後にポテト曲面から型をつかって、ポテトチップスを切り抜きます。
それでは具体的に見ていきましょう。
STEP1 ポテト曲面の作成
では早速ポテト曲面を作っていきます。
この記事ではその動機故に、初心者の方でも分かりやすいことを心掛けています。なので、以下ではコード(import なんちゃらから始まる、英語の部分のことです)が出てきますが、出来る限りそれらを読み飛ばしても流れは理解できるように努めました。なので、python分からんという方にも楽しんで頂けたら幸いです。import bpy import random #最初にシーン内のオブジェクトを全て削除します for item in bpy.data.objects: bpy.data.objects.remove(item) for counter in range(101): #以下の処理を100回(都合上101になっていますが)繰り返すことで100枚のポテチを作るということです #今回のメインであるz_function_surfaceを使っていきます #infoの欄からこの関数の引数を確認することは出来ますが、 #https://github.com/sobotka/blender-addons/blob/master/add_mesh_extra_objects/add_mesh_3d_function_surface.py #の113行目辺りからも確認することが出来ます。 x_coefficient=random.uniform(0,0.3) #xの係数を0から0.3までの範囲で選びます y_coefficient=random.uniform(0,0.3) #yの係数を0から0.3までの範囲で選びます sign=random.choice(["+","-","-"]) #符号を決めます 今回は1対2の割合で鞍点を持つもの(-)を採用します myEquation="{0}*x**2{2}{1}*y**2".format(x_coefficient,y_coefficient,sign) #方程式を合成します bpy.ops.mesh.primitive_z_function_surface(equation=myEquation, div_x=32, div_y=32, size_x=10+2, size_y=10+2) #これがz math functiondです。なお、+2は余白です bpy.ops.object.editmode_toggle() bpy.ops.mesh.solidify(thickness=0.1) #編集モードに入って厚み付けをしておしまいです。 bpy.ops.object.editmode_toggle()上では100個のポテト曲面を作成していますが、その内の一つを取り出すとこんな形です。
先ほど見た鞍点を含む曲面が出来ています。これを100個集めたのが以下の画像です。
これをpotato surfaceというcollectionに入れておきます。STEP2 型の作成
ポテト曲面を切り抜くための型を作成していきます。
数式の説明
まず最初に数式の部分だけ軽く説明します。
ポテトを切り抜く型としては楕円が基本的な図形の中で最も近いですが、それではやや機械的すぎます。なので、y軸方向に楕円を非均一に押し潰してやります。
上の図で言えば、青色の閉曲線が押しつぶされた楕円です。
その押し潰す割合(ここではy_scalefactorと名付けました)には二次関数を採用しています。また、上の図では行っていませんが、二次関数の軸を移動させる部分でyの符号をかけてやれば、x軸非対称にすることが出来ます。そうすることでよりポテトらしさが追求できると考えました。
(実を言うとここの実装が一番詰まったところです。Z Math Functionはabs(y)に対しては'NoneType' object is not subscriptableを返すので、非常に困りました。numpyのsignを使えばどうにかなるかと当て勘で変えてみても当然うまく行きませんでした。ただ、1 if y>0 else -1には正常に動作しますので、それをここでは使いました。理由はさっぱり分かりませんが、addon側でyの管理をリストにでもしているのでしょうか?
ただそうだとするとTypyErrorを先に吐くと思うのですが……。
addonのコードを読める方がいれば理由を教えてもらいたいものです。)コードの実行
1/3 局面群の作成
math functionには残念ながら二次曲面を表示する機能がない(あるいは私が見つけられていない)ので、再びz math funcionを用いて上のような局面群を生成し、その後z=1の平面で切り、それをsolidifyすることで型を作っていきます。
import bpy import random for item in bpy.data.objects: bpy.data.objects.remove(item) for counter in range(101): #x**2/a**2+y**2/b**2=1を念頭に置いて書きました a=5 b=random.uniform(3,4.5) y_scalefactor_coefficient=random.uniform(0,0.03) y_scalefactor_shift=random.uniform(0.25,1.75) y_scalefactor_constantterm=random.uniform(0.9,1.1) #y=0は頂点として含まれないことに注意 y_scalefactor_plus ="({0}*(x+{1})**2+{2})".format(y_scalefactor_coefficient,y_scalefactor_shift,y_scalefactor_constantterm) y_scalefactor_minus="({0}*(x-{1})**2+{2})".format(y_scalefactor_coefficient,y_scalefactor_shift,y_scalefactor_constantterm) mySecondEquation_plus ="x**2/{0}**2+(y*{2})**2/{1}**2".format(a,b,y_scalefactor_plus) mySecondEquation_minus="x**2/{0}**2+(y*{2})**2/{1}**2".format(a,b,y_scalefactor_minus) mySecondEquation="{0} if y>0 else {1}".format(mySecondEquation_plus,mySecondEquation_minus) bpy.ops.mesh.primitive_z_function_surface(equation=mySecondEquation, div_x=32, div_y=32, size_x=10+2, size_y=10+2)
2/3 閉曲線の作成
後でも軽く触れますが、私はpythonに躊躇なく手作業を挟み込む派です。
ここではcopy attributesというaddonや、ctrl+Aで出てくるApplyのVisual Geometry to Meshという機能を使って一括にbooleanを設定、適用していきます。後者の機能に関してはややマイナーかも知れませんので、興味のある方は調べてみてください。便利です。
3/3 型の作成
最後にsolidifyで柱体にし、
import bpy for i in range(100): bpy.ops.object.select_all(action='DESELECT') obj=bpy.data.objects['Z Function.{:0=3}'.format(i+1)] bpy.context.view_layer.objects.active = obj bpy.ops.object.editmode_toggle() bpy.ops.mesh.select_all(action='SELECT') bpy.ops.mesh.solidify(thickness=20) bpy.ops.mesh.select_all(action='SELECT') bpy.ops.transform.translate(value=(0, 0, 10)) bpy.ops.object.editmode_toggle()名前を変更して終了です。
import bpy for i,obj in enumerate(bpy.context.selected_objects): obj.name = "mold.{:0=3}".format(i+1)
これでMoldという名前の、型を集めたcollectionが出来ました。STEP3 ポテトの切り抜き
ここまでくればあと一息です。今までに作成したpotato surfaceとMoldの二つのcollectionを新しいblenderファイルにappendし、boolean modifierで切り抜いていきます。
1/2 下準備
potato surface内のオブジェクトを軽く位置をずらしておきます。そうすることで、切り抜きによりランダムさが加わります。
これもややマイナーかも知れませんが、(世間的相場を知らないので何とも言えないのですが……)Randomize Transformでそれを実現します。
2/2 切り抜き
最後の工程です。切り抜いていきます。
import bpy for i in range(100): bpy.ops.object.select_all(action='DESELECT') obj=bpy.data.objects['Z Function.{:0=3}'.format(i+1)] #ポテト曲面を選択し bpy.context.view_layer.objects.active = obj bpy.ops.object.modifier_add(type='BOOLEAN') #boolean modifierをつけて bpy.context.object.modifiers["Boolean"].operation = 'INTERSECT' bpy.context.object.modifiers["Boolean"].object = bpy.data.objects["mold.{:0=3}".format(i+1)] #型を指定し bpy.ops.object.modifier_apply(modifier="Boolean") #適用していきます。これを実行します。
上手く出来たでしょうか?
moldを全て非表示にして、Randomize Transformでポテトを見やすく配置します
すると、おお! ポテチらしきものが!!!
ただ数値設定をミスっていたせいでやや丸まりすぎなので、z方向に0.4倍してやって、、、
今度こそ、揚げたてポテトの完成です。
この中の数枚を取り出してみて見ましょう。
かなりポテチらしき形を有していませんか? 私は満足です。
作品の完成へ
最後に仕上げとして作品にしていきます。
blenderから来た方だけ覗いていただければ結構です。
仕上げの手順
shade smoothを掛けてauto smoothを有効にする。ポテチ100枚だと私のパソコンのスペックではきついので、50枚に減らし、z軸方向にちらす。(この時同時に回転とサイズもランダマイズさせました) 机と皿を適当にモデリングし、それらにはrigid bodyのpassiveを、ポテチにはactiveを付与する。 Meshで物理演算をするとfpsが0.3辺りまで落ちてしまったので(スペックによるとは思いますが)convex hullでcollisionは妥協し、上からポテチを皿に散らす。 いい感じのタイミングで時間を止め、一度fbxで出力し、再度読み込むことで意図しない方向に跳ねたポテチを除く。 最後にマテリアル設定とコンポジット設定を変えて出力。
マテリアルは以下の通り(ColorRampでビミョーに焦げ目をつけたのがこだわりポイントです)
コンポジットは以下の通り(と言ってもただカラーバランスいじっただけですが)
そうして完成したのが、冒頭にもお見せしたこちらになります。
ご覧いただきありがとうございました。
blenderを知らずにpythonからこの記事に来た方がもしいらっしゃれば、pythonってこんなことできるんだなーと楽しんでもらえていれば何よりです。余談
最後に、blenderから来た方に向けて少しだけ。
これはただの偏見ですが、blenderのscriptの機能は、知っているけれど使っていないという方がかなり多いと思いますし、逆に世のサイトを見る限りscriptの機能を使っている人は寧ろそちらをメインに据えて活動している方が多いと私は感じています。私はそういう後者の方々を勝手にロマン派と呼んでいますが(無論馬鹿にしているわけではありません。このような方々のサイトがなければ、blenderでpythonを使うことは到底不可能です。)、私はどちらかと言うとモデリングをメインに据えてpythonはあくまで手段として使用しています。実用主義です。
そのため、全ての工程をscriptでやることには一切拘らず、それこそ躊躇なく手作業を交えていきます。
特に、今回も使用したCopy Attributesなどは非常に強力で、これらを駆使すれば多くの場面でpythonなど知らなくとも、実現したいことを簡潔に実行できます。そしてそういうことを知れば知るほど、「それpythonじゃなくてよくね?」という風になってきます。ただ、それでもpythonを使うメリットがあるなと思うは、本記事の題名にも据えた大量生産の利があるからです。普通にポテチを作るなら恐らくプロシージャル編集を活用するかスカルプトを使うかでしょうか。ただどちらでも大量生産は少しきついです。その点メリットがあります。
二つ目のメリットはコードの書きやすさです。私自身pythonを知ったのはある友人の勧めからで、まだまだ歴は浅いのですが、それでもBlenderのInfo欄を見れば、大体の操作は勝手が分かります。(この点、つまりInfo欄の有用性こそ真にマイナーな点かも知れません。) 実際、python固有の知識としても、高々forとformat、およびrandomモジュールを抑えていればどうにかなります。富士山なみに高いハードルでは決してないと、個人的には感じています。
そして三つ目が楽しさです。これを言葉で尽くすのは無粋でしょう。本記事を通してblender×pythonが面白そうと思う方が一人でも増えてくれれば幸いです。
参考文献
鞍点関連
https://ja.wikipedia.org/wiki/%E9%9E%8D%E7%82%B9#:~:text=%E9%9E%8D%E7%82%B9%EF%BC%88%E3%81%82%E3%82%93%E3%81%A6%E3%82%93%E3%80%81saddle%20point,%E3%81%AA%E3%81%84%E5%81%9C%E7%95%99%E7%82%B9%E3%81%A8%E3%82%82%E8%A8%80%E3%81%86%E3%80%82
https://mathtrain.jp/quadraticform
https://kotobank.jp/word/%E5%9B%BA%E6%9C%89%E4%BA%8C%E6%AC%A1%E6%9B%B2%E9%9D%A2-1320652Z Math Function
https://github.com/sobotka/blender-addons/blob/master/add_mesh_extra_objects/add_mesh_3d_function_surface.pyモデリング文化祭
https://twitter.com/vaguely20/status/1359464831472967683


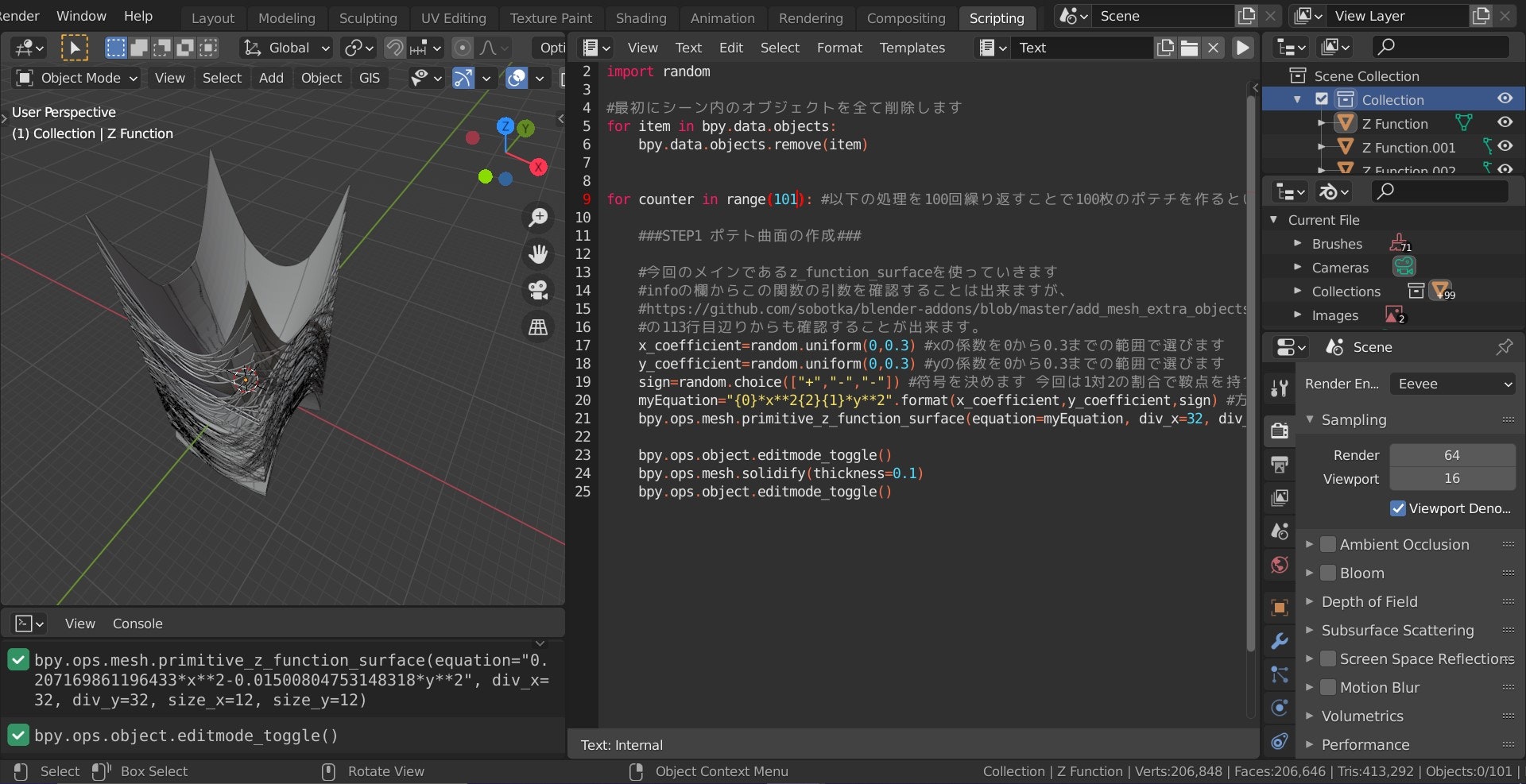
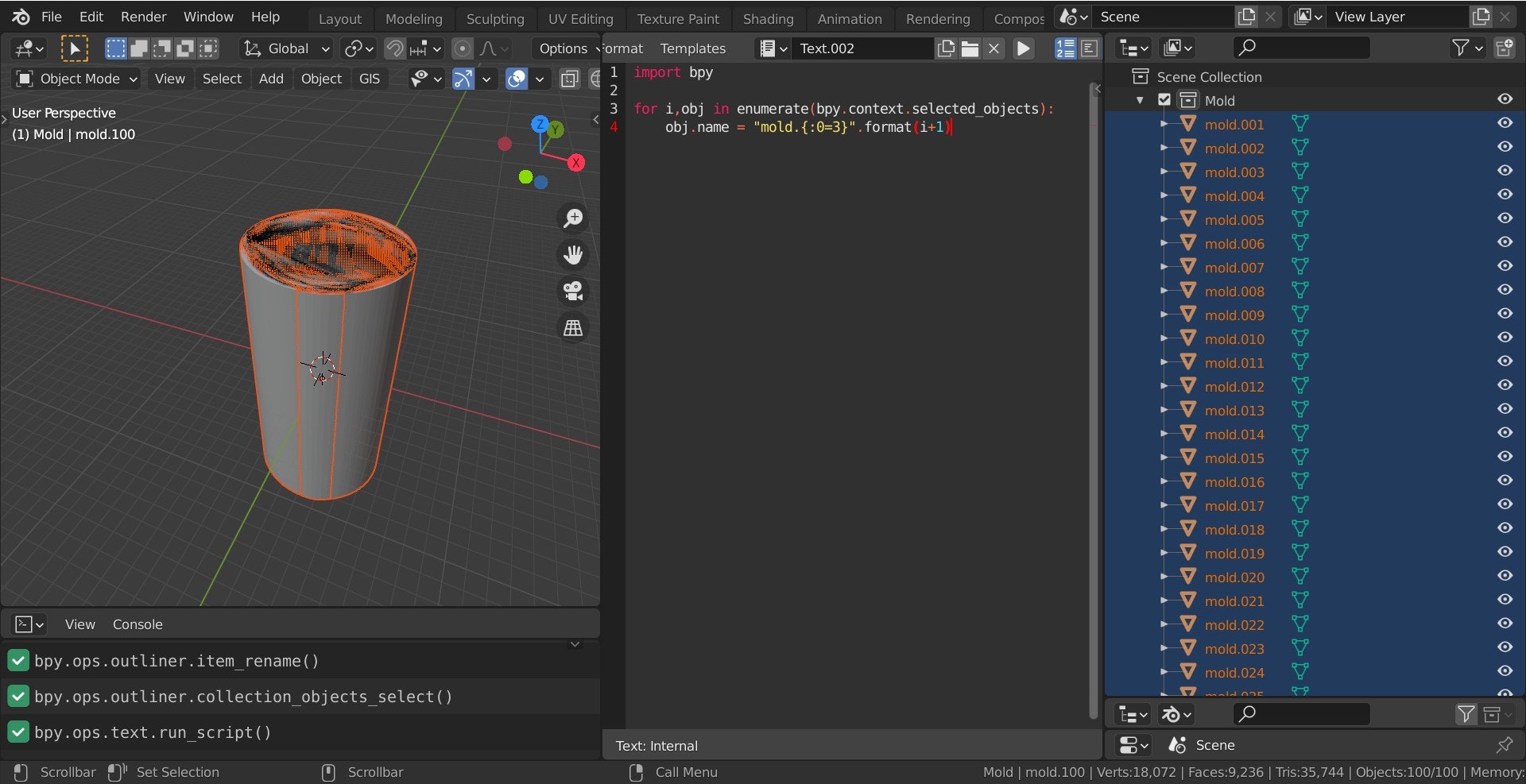
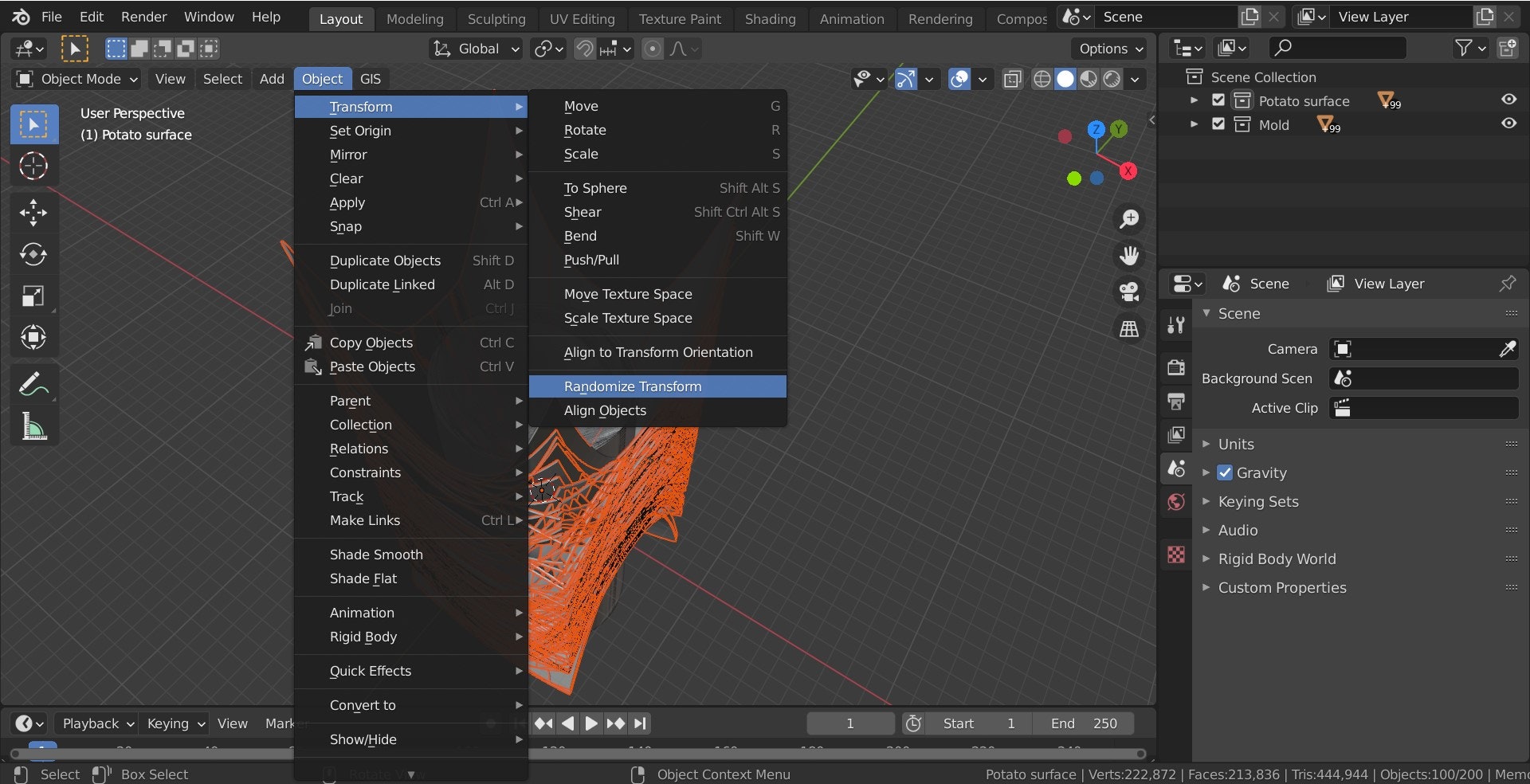
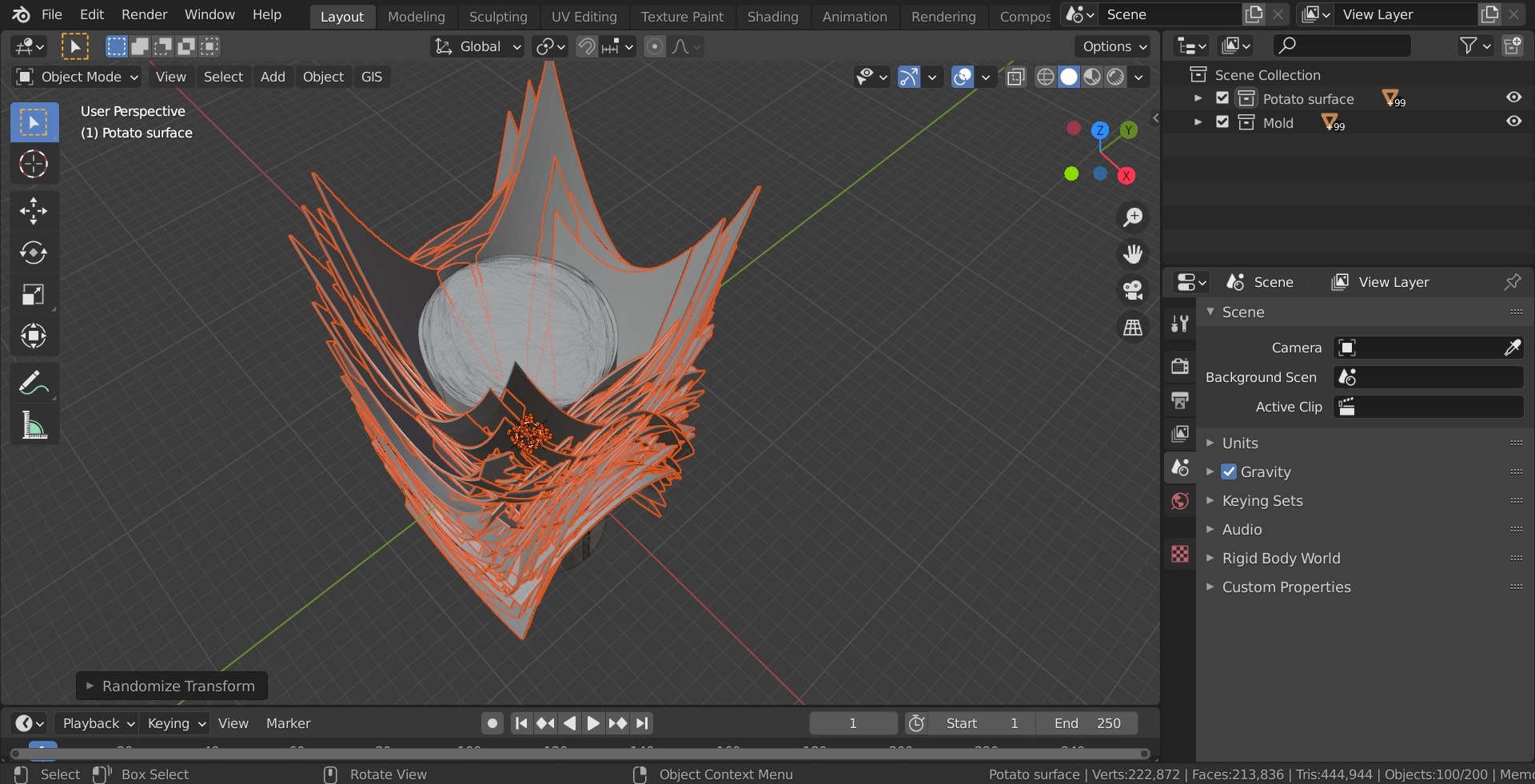
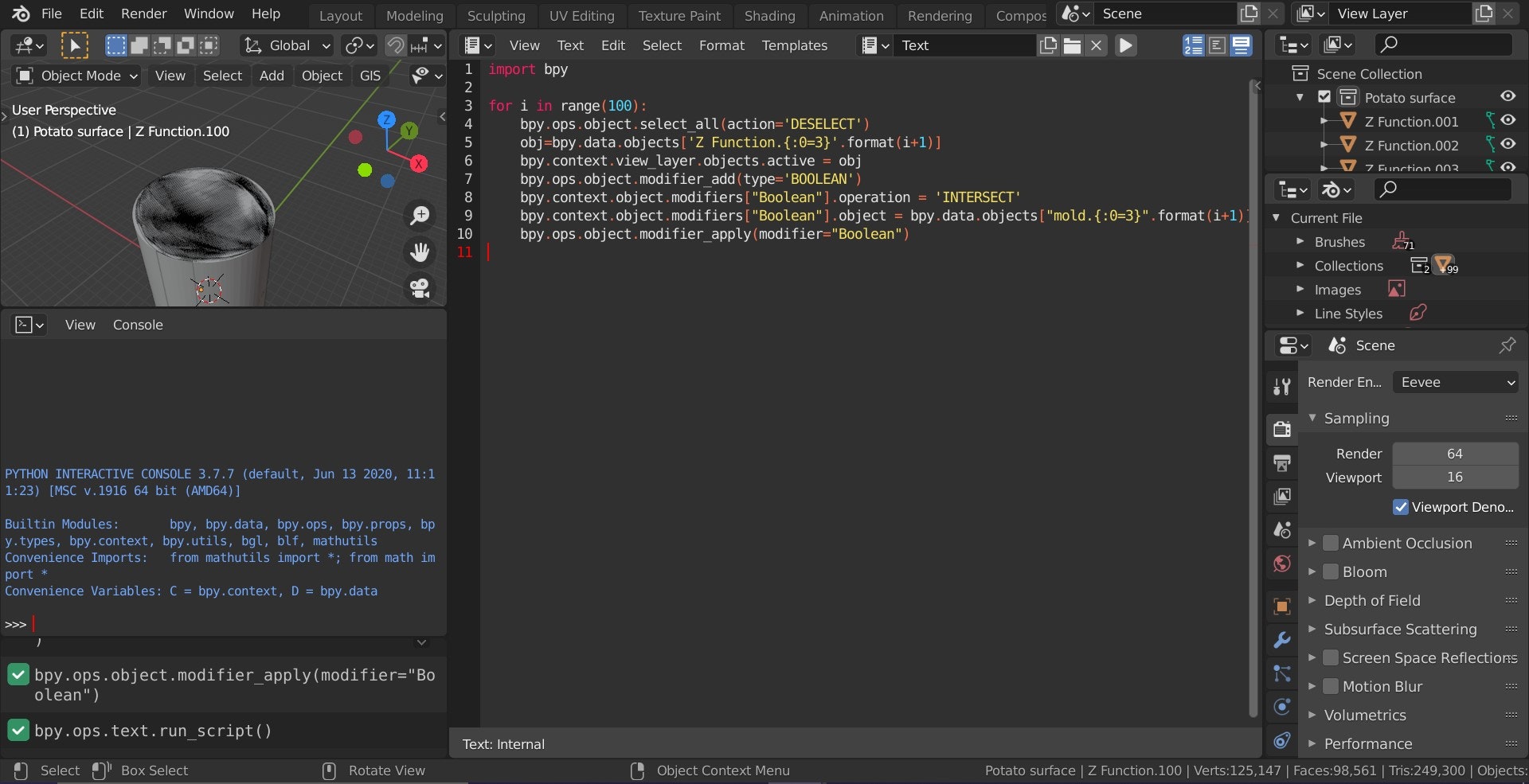
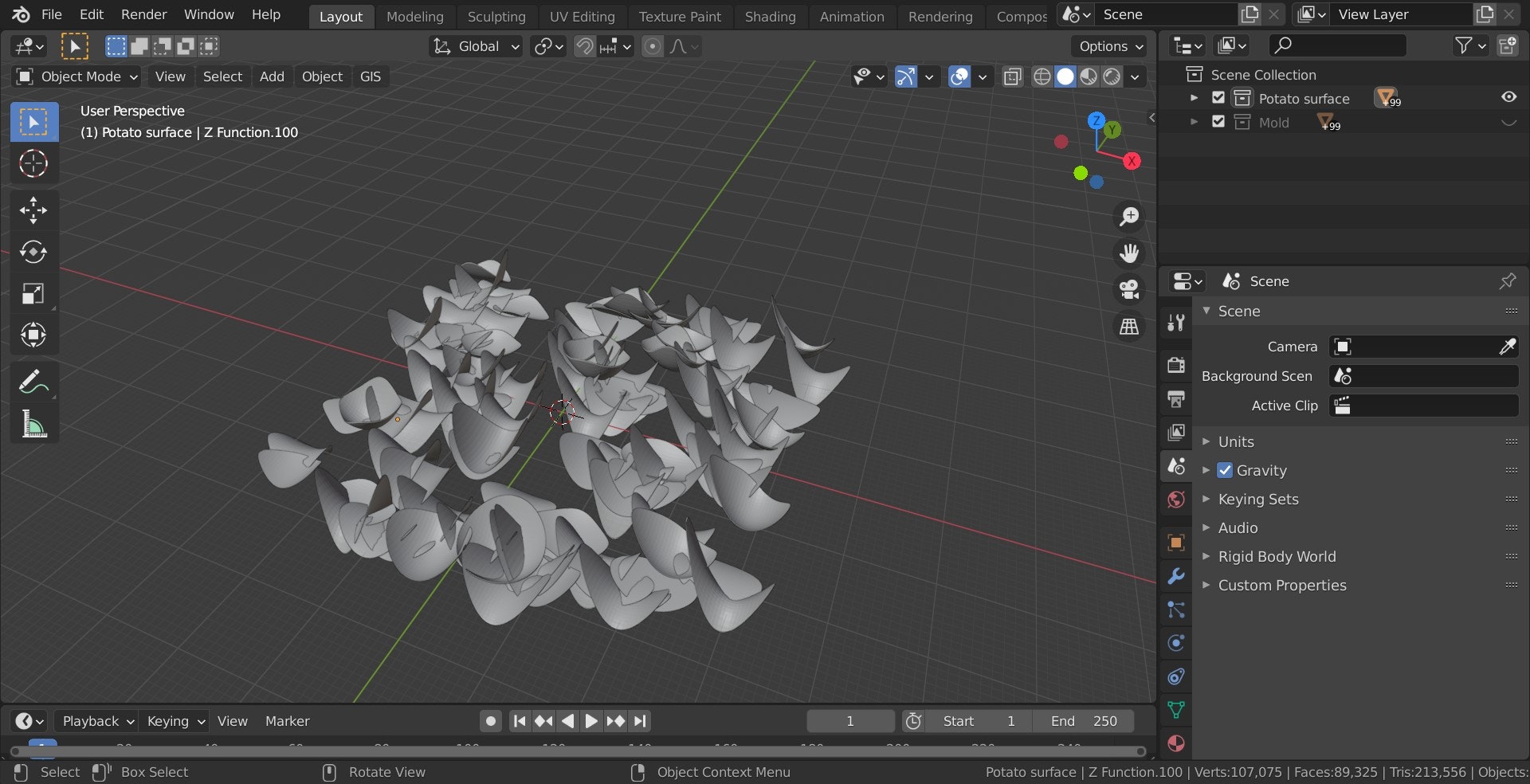
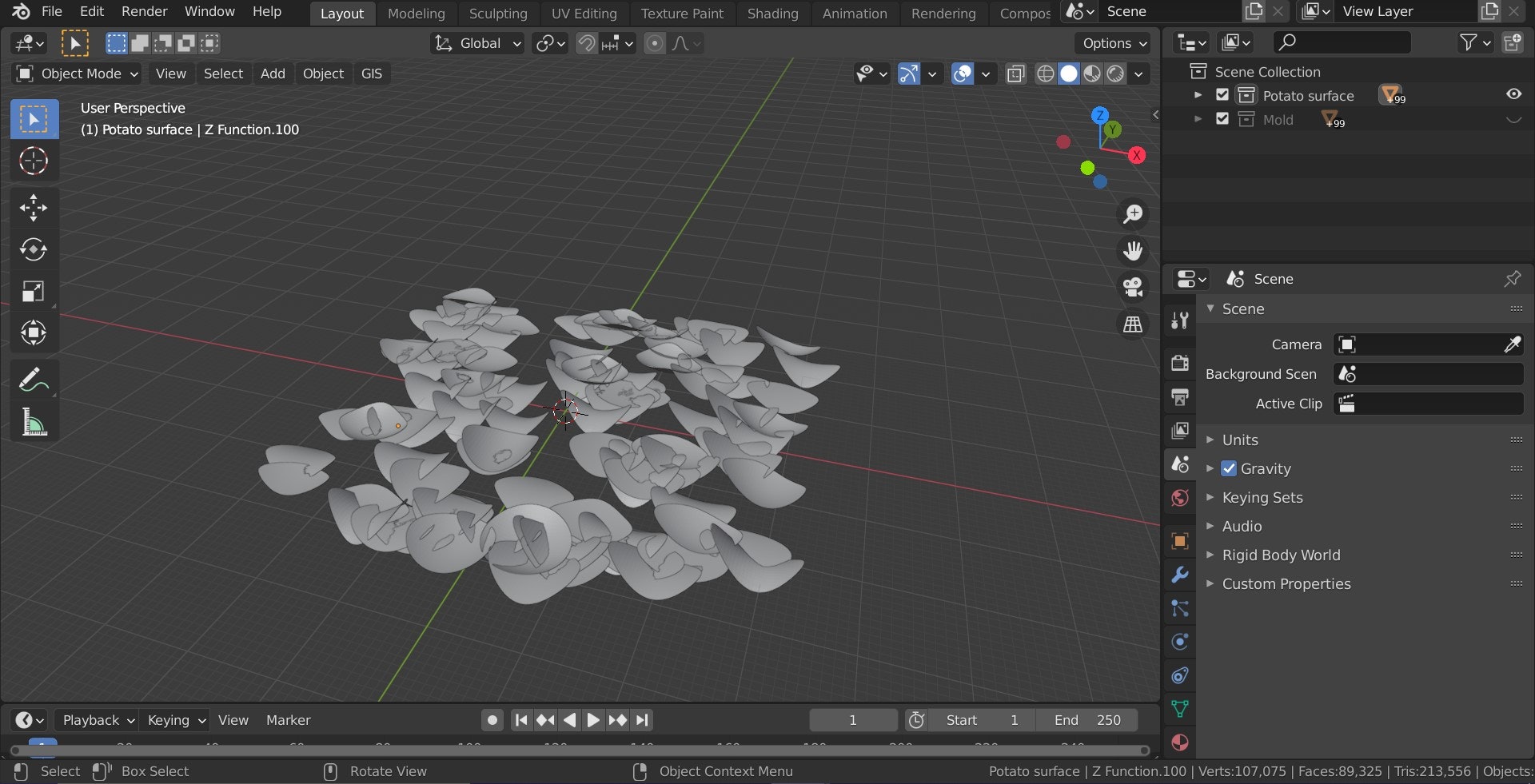
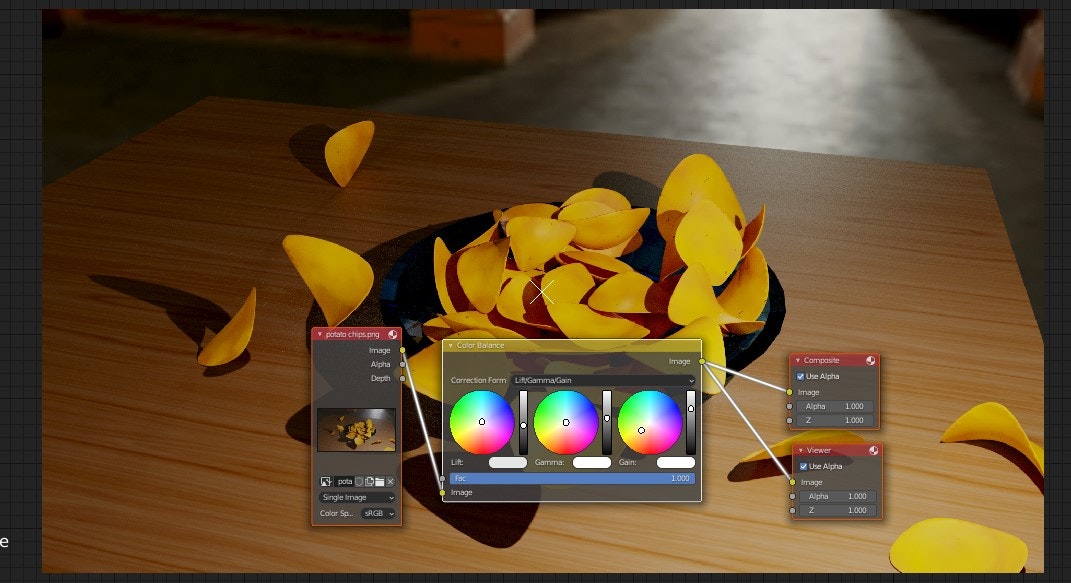
- 投稿日:2021-02-25T15:49:21+09:00
blenderとpythonと数式を駆使してポテトチップス大量生産を実現する
概要
これを作ります。blenderとpythonと数式で。
動機
sachiko15さん(Twitter:@vaguely20)という方が、モデリング文化祭という3DCG作品の展覧会のようなものを開催していらっしゃいます。それに自分も何か出そうと思ったのが事の発端です。私自身つい最近この方を知ったのですが、その作品群は非常に素晴らしいものばかりで、とても尊敬しています。そんな方の企画となると、多少ましなものを作らなければなりません。しかもお題が食べ物と作ったことが一度もないものでした。どうしようかと思案した挙句、ある思い付きと共に奇人枠として振っていこうと決意しました。
ポテトチップスには鞍点がある
伝わる人には伝わるネタかも知れませんが、ポテトチップスってとても身近な鞍点ではないでしょうか。鞍点という概念を知った日から何となくそう思っていましたが、今回はそれを実現していきます。
鞍点とは
wikiの定義では、鞍点は次のようになっています。
鞍点(あんてん、saddle point)は、多変数実関数の変域の中で、ある方向で見れば極大値だが別の方向で見れば極小値となる点である。
鞍部点、峠点とも言う。微分可能な関数については極値を取らない停留点とも言う。これだけ見てもよく分からないと思いますが、図を見れば直感的に理解できると思います。
(この図もwikiより引用)
峠点という名前が一番分かりやすいかも知れません。詳しい数学的な話はここでは飛ばし、数式だけ利用していくことにします。この図の数式が$z=x^2-y^2$であることを覚えておくと、後の話が分かりやすくなるかもしれません。
数学的な補足
$z=f(x,y)$の形式で表される二次曲面は、クロスタームを含まない時、楕円放物面、双曲放物面に大別されます。(例外などは数学書を当たってください) 偏微分をすれば分かることですが、$x^2$の項と$y^2$の項が同符号ならば楕円放物面(つまり鞍点なし)、異符号なら双曲放物面(つまり鞍点あり)となります。無論すべてのポテトチップスに鞍点がある訳ではないので、一部はこの楕円放物面を採用して作成しました。この他言及すべき点は多々ある気はしますが、本記事ではこれくらいでお許しください。もう一つの動機
ポテトチップスを例え数式で表せたとしても、それだけで先程言ったモデリング文化祭に作品を提出できるかと言えば、無論NOです。3DCGソフトで具体的にポテトチップスを作成しなければなりません。では、3DCGソフトであるblenderで数式を具体的に表現できるのか?
ここで鍵となるのがpythonです。
Blednerの拡張機能であるaddonには、Add Mesh Extra Objectsというものが存在します。それのZ Math Surfaceという機能には、先程のような$z=f(x,y)$という数式をポリゴンに変換してくれる機能があります。
これで理論と実装、両者の道が開けてきました。結局何がしたいのか
Blenderという3Dソフトにおいて、鞍点を含む局面を表す$z=x^2-y^2$という式、およびそれをメッシュ化するZ Math Surfaceという機能を活用し、ポテトチップスを大量に生産する。これがゴールとなります。
作業の概要
STEP1 ポテト曲面の作成
鞍点を含む面など、ポテトチップス作成の基となる曲面のことをポテト曲面と呼び、それを大量に生成します。STEP2 型の作成
ポテト曲面からポテトチップスを切り抜くための型を同じ数だけ作成します。STEP3 ポテトの切り抜き
最後にポテト曲面から型をつかって、ポテトチップスを切り抜きます。
それでは具体的に見ていきましょう。
STEP1 ポテト曲面の作成
では早速ポテト曲面を作っていきます。
この記事ではその動機故に、初心者の方でも分かりやすいことを心掛けています。なので、以下ではコード(import なんちゃらから始まる、英語の部分のことです)が出てきますが、出来る限りそれらを読み飛ばしても流れは理解できるように努めました。なので、python分からんという方にも楽しんで頂けたら幸いです。import bpy import random #最初にシーン内のオブジェクトを全て削除します for item in bpy.data.objects: bpy.data.objects.remove(item) for counter in range(101): #以下の処理を100回(都合上101になっていますが)繰り返すことで100枚のポテチを作るということです #今回のメインであるz_function_surfaceを使っていきます #infoの欄からこの関数の引数を確認することは出来ますが、 #https://github.com/sobotka/blender-addons/blob/master/add_mesh_extra_objects/add_mesh_3d_function_surface.py #の113行目辺りからも確認することが出来ます。 x_coefficient=random.uniform(0,0.3) #xの係数を0から0.3までの範囲で選びます y_coefficient=random.uniform(0,0.3) #yの係数を0から0.3までの範囲で選びます sign=random.choice(["+","-","-"]) #符号を決めます 今回は1対2の割合で鞍点を持つもの(-)を採用します myEquation="{0}*x**2{2}{1}*y**2".format(x_coefficient,y_coefficient,sign) #方程式を合成します bpy.ops.mesh.primitive_z_function_surface(equation=myEquation, div_x=32, div_y=32, size_x=10+2, size_y=10+2) #これがz math functiondです。なお、+2は余白です bpy.ops.object.editmode_toggle() bpy.ops.mesh.solidify(thickness=0.1) #編集モードに入って厚み付けをしておしまいです。 bpy.ops.object.editmode_toggle()上では100個のポテト曲面を作成していますが、その内の一つを取り出すとこんな形です。
先ほど見た鞍点を含む曲面が出来ています。これを100個集めたのが以下の画像です。
これをpotato surfaceというcollectionに入れておきます。STEP2 型の作成
ポテト曲面を切り抜くための型を作成していきます。
数式の説明
まず最初に数式の部分だけ軽く説明します。
ポテトを切り抜く型としては楕円が基本的な図形の中で最も近いですが、それではやや機械的すぎます。なので、y軸方向に楕円を非均一に押し潰してやります。
上の図で言えば、青色の閉曲線が押しつぶされた楕円です。
その押し潰す割合(ここではy_scalefactorと名付けました)には二次関数を採用しています。また、上の図では行っていませんが、二次関数の軸を移動させる部分でyの符号をかけてやれば、x軸非対称にすることが出来ます。そうすることでよりポテトらしさが追求できると考えました。
(実を言うとここの実装が一番詰まったところです。Z Math Functionはabs(y)に対しては'NoneType' object is not subscriptableを返すので、非常に困りました。numpyのsignを使えばどうにかなるかと当て勘で変えてみても当然うまく行きませんでした。ただ、1 if y>0 else -1には正常に動作しますので、それをここでは使いました。理由はさっぱり分かりませんが、addon側でyの管理をリストにでもしているのでしょうか?
ただそうだとするとTypyErrorを先に吐くと思うのですが……。
addonのコードを読める方がいれば理由を教えてもらいたいものです。)コードの実行
1/3 局面群の作成
math functionには残念ながら二次曲面を表示する機能がない(あるいは私が見つけられていない)ので、再びz math funcionを用いて上のような局面群を生成し、その後z=1の平面で切り、それをsolidifyすることで型を作っていきます。
import bpy import random for item in bpy.data.objects: bpy.data.objects.remove(item) for counter in range(101): #x**2/a**2+y**2/b**2=1を念頭に置いて書きました a=5 b=random.uniform(3,4.5) y_scalefactor_coefficient=random.uniform(0,0.03) y_scalefactor_shift=random.uniform(0.25,1.75) y_scalefactor_constantterm=random.uniform(0.9,1.1) #y=0は頂点として含まれないことに注意 y_scalefactor_plus ="({0}*(x+{1})**2+{2})".format(y_scalefactor_coefficient,y_scalefactor_shift,y_scalefactor_constantterm) y_scalefactor_minus="({0}*(x-{1})**2+{2})".format(y_scalefactor_coefficient,y_scalefactor_shift,y_scalefactor_constantterm) mySecondEquation_plus ="x**2/{0}**2+(y*{2})**2/{1}**2".format(a,b,y_scalefactor_plus) mySecondEquation_minus="x**2/{0}**2+(y*{2})**2/{1}**2".format(a,b,y_scalefactor_minus) mySecondEquation="{0} if y>0 else {1}".format(mySecondEquation_plus,mySecondEquation_minus) bpy.ops.mesh.primitive_z_function_surface(equation=mySecondEquation, div_x=32, div_y=32, size_x=10+2, size_y=10+2)
2/3 閉曲線の作成
後でも軽く触れますが、私はpythonに躊躇なく手作業を挟み込む派です。
ここではcopy attributesというaddonや、ctrl+Aで出てくるApplyのVisual Geometry to Meshという機能を使って一括にbooleanを設定、適用していきます。後者の機能に関してはややマイナーかも知れませんので、興味のある方は調べてみてください。便利です。
3/3 型の作成
最後にsolidifyで柱体にし、
import bpy for i in range(100): bpy.ops.object.select_all(action='DESELECT') obj=bpy.data.objects['Z Function.{:0=3}'.format(i+1)] bpy.context.view_layer.objects.active = obj bpy.ops.object.editmode_toggle() bpy.ops.mesh.select_all(action='SELECT') bpy.ops.mesh.solidify(thickness=20) bpy.ops.mesh.select_all(action='SELECT') bpy.ops.transform.translate(value=(0, 0, 10)) bpy.ops.object.editmode_toggle()名前を変更して終了です。
import bpy for i,obj in enumerate(bpy.context.selected_objects): obj.name = "mold.{:0=3}".format(i+1)
これでMoldという名前の、型を集めたcollectionが出来ました。STEP3 ポテトの切り抜き
ここまでくればあと一息です。今までに作成したpotato surfaceとMoldの二つのcollectionを新しいblenderファイルにappendし、boolean modifierで切り抜いていきます。
1/2 下準備
potato surface内のオブジェクトを軽く位置をずらしておきます。そうすることで、切り抜きによりランダムさが加わります。
これもややマイナーかも知れませんが、(世間的相場を知らないので何とも言えないのですが……)Randomize Transformでそれを実現します。
2/2 切り抜き
最後の工程です。切り抜いていきます。
import bpy for i in range(100): bpy.ops.object.select_all(action='DESELECT') obj=bpy.data.objects['Z Function.{:0=3}'.format(i+1)] #ポテト曲面を選択し bpy.context.view_layer.objects.active = obj bpy.ops.object.modifier_add(type='BOOLEAN') #boolean modifierをつけて bpy.context.object.modifiers["Boolean"].operation = 'INTERSECT' bpy.context.object.modifiers["Boolean"].object = bpy.data.objects["mold.{:0=3}".format(i+1)] #型を指定し bpy.ops.object.modifier_apply(modifier="Boolean") #適用していきます。これを実行します。
上手く出来たでしょうか?
moldを全て非表示にして、Randomize Transformでポテトを見やすく配置します
すると、おお! ポテチらしきものが!!!
ただ数値設定をミスっていたせいでやや丸まりすぎなので、z方向に0.4倍してやって、、、
今度こそ、揚げたてポテトの完成です。
この中の数枚を取り出してみて見ましょう。
かなりポテチらしき形を有していませんか? 私は満足です。
作品の完成へ
最後に仕上げとして作品にしていきます。
blenderから来た方だけ覗いていただければ結構です。
仕上げの手順
shade smoothを掛けてauto smoothを有効にする。ポテチ100枚だと私のパソコンのスペックではきついので、50枚に減らし、z軸方向にちらす。(この時同時に回転とサイズもランダマイズさせました) 机と皿を適当にモデリングし、それらにはrigid bodyのpassiveを、ポテチにはactiveを付与する。 Meshで物理演算をするとfpsが0.3辺りまで落ちてしまったので(スペックによるとは思いますが)convex hullでcollisionは妥協し、上からポテチを皿に散らす。 いい感じのタイミングで時間を止め、一度fbxで出力し、再度読み込むことで意図しない方向に跳ねたポテチを除く。 最後にマテリアル設定とコンポジット設定を変えて出力。
マテリアルは以下の通り(ColorRampでビミョーに焦げ目をつけたのがこだわりポイントです)
コンポジットは以下の通り(と言ってもただカラーバランスいじっただけですが)
そうして完成したのが、冒頭にもお見せしたこちらになります。
ご覧いただきありがとうございました。
blenderを知らずにpythonからこの記事に来た方がもしいらっしゃれば、pythonってこんなことできるんだなーと楽しんでもらえていれば何よりです。余談
最後に、blenderから来た方に向けて少しだけ。
blenderをpythonで操作する場合、気をつけるべき点の一つは、そうする事で逆に利便性を損いかねないという事でしょう。scriptを利用しない方が早く済む場面というのも当然多く存在します。そのため、もしモデリングを中心に行う人の場合、自動化は確かに魅力的ですが、全ての工程をscriptでやることにはあまり拘らず、手作業を交えた方がいいかも知れません。
特に、今回も使用したCopy Attributesなどは非常に強力で、これらを駆使すれば多くの場面でpythonなど知らなくとも、実現したいことを簡潔に実行できます。そしてそういうことを知れば知るほど、「それpythonじゃなくてよくね?」という風になってきます。ただ、それでもpythonを使うメリットがあるなと思うは、本記事の題名にも据えた大量生産の利があるからです。普通にポテチを作るなら恐らくプロシージャル編集を活用するかスカルプトを使うかでしょうか。ただどちらでも大量生産は少しきついです。その点メリットがあります。
二つ目の良い点はコードの書きやすさです。学習コストの低さとも言えるでしょう。私自身pythonを知ったのはある友人の勧めからで、まだまだ歴は浅いのですが、それでもBlenderのInfo欄を見れば、大体の操作は勝手が分かります。(この点、つまりInfo欄の有用性こそ真にマイナーな点かも知れません。) 実際、python固有の知識としても、高々forとformat、およびrandomモジュールを抑えていればどうにかなります。富士山なみに高いハードルでは決してないと、個人的には感じています。
そして三つ目が楽しさです。これを言葉で尽くすのは無粋でしょう。本記事を通してblender×pythonが面白そうと思う方が一人でも増えてくれれば幸いです。
参考文献
鞍点関連
https://ja.wikipedia.org/wiki/%E9%9E%8D%E7%82%B9#:~:text=%E9%9E%8D%E7%82%B9%EF%BC%88%E3%81%82%E3%82%93%E3%81%A6%E3%82%93%E3%80%81saddle%20point,%E3%81%AA%E3%81%84%E5%81%9C%E7%95%99%E7%82%B9%E3%81%A8%E3%82%82%E8%A8%80%E3%81%86%E3%80%82
https://mathtrain.jp/quadraticform
https://kotobank.jp/word/%E5%9B%BA%E6%9C%89%E4%BA%8C%E6%AC%A1%E6%9B%B2%E9%9D%A2-1320652Z Math Function
https://github.com/sobotka/blender-addons/blob/master/add_mesh_extra_objects/add_mesh_3d_function_surface.pyモデリング文化祭
https://twitter.com/vaguely20/status/1359464831472967683
- 投稿日:2021-02-25T15:42:37+09:00
【Python画像処理】スプライト・アニメーション(Sprite Animation)を試す。
この投稿は最初以下の投稿の再現テストだったのですが…
Pythonで画像のピクセル操作
- 元投稿では画像処理にPillow(PIL)を使ってるが、私の環境ではそのままでは動かないのでOpenCVに置き換える事にした(そもそもJupyter notebookで走らせる用のコーディングではなかった?)。
- そして試行錯誤するうち、気付いたら以下のスプライト・アニメーション(Sprite Animation)が出来上がっていた。
なるほど、どうやらアフィン変換導入によって(どうやら多くの人がつまづくらしい)ROI(Region of Interest=関心領域)からのフレームアウト問題がを自然に回避してしまった様です。こいつは便利だ…
画像の諸元(透過処理なし)
とりあえずの使用画像はこちら。
数学者のイラスト(女性)
import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み image = cv2.imread("desktop/python/suugakusya.jpg",cv2.IMREAD_UNCHANGED)[:,:,::-1] height, width, channels = image.shape[:3] plt.imshow(image) plt.show()諸元を求めてみます。
OpenCVで画像ファイルの読み書きをしよう (Python)
Python + OpenCVでの画像サイズ取得方法import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み image = cv2.imread("desktop/python/suugakusya.jpg",cv2.IMREAD_UNCHANGED)[:,:,::-1] height, width, channels = image.shape[:3] plt.imshow(image) plt.show() # 各チャンネルの表示 height, width, channels = image.shape[:3] print("width: " + str(width)) print("height: " + str(height)) print("channels: " + str(channels)) #出力結果 width: 858 height: 450 channels: 3αチャンネルが存在しない場合は強制追加…
OpenCVを用いて画像をRGBAで読み込みたいimport cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み image = cv2.imread("desktop/python/suugakusya.jpg",cv2.IMREAD_UNCHANGED)[:,:,::-1] height, width, channels = image.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 image = cv2.cvtColor(image, cv2.COLOR_RGB2RGBA) # # 各チャンネルの表示 height, width, channels = image.shape[:3] print("width: " + str(width)) print("height: " + str(height)) print("channels: " + str(channels)) #出力結果 width: 858 height: 450 channels: 4それぞれのチャンネルの表示。
OpenCVで透過画像を扱う ~スプライトを舞わせる~各要素はndim=2すなわち(height, width)のシェイプとなっている。だから各要素を画像として表示させるとグレースケールになる。
そして…
RGBA画像を取り込むにはcv2.imread()でflags = cv2.IMREAD_UNCHANGEDと指定する。実際はそんな呪文を覚える必要はなく、2番目の引数として-1を指定すればよい。引数を1にするもしくは省略するとRGBの3チャンネル画像として取り込まれる。
なるほど、そういう事だったのか(まずはそこから分かってなかった)…アルファ値は0が透明で255が不透明。透明度というより不透明度? 元画像にアルファ値設定がなかったので、このチャンネルはただの真っ黒です。
import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み image = cv2.imread("desktop/python/suugakusya.jpg")[:,:,::-1] height, width, channels = image.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 image = cv2.cvtColor(image, cv2.COLOR_RGB2RGBA) plt.imshow(image) plt.show() # 各チャンネルの表示 b = image[:, :, 0] g = image[:, :, 1] r = image[:, :, 2] a = image[:, :, 3] plt.imshow(b) plt.show() plt.imshow(g) plt.show() plt.imshow(r) plt.show() plt.imshow(a) plt.show()
何故黄ばむ?
画像の諸元(透過処理あり)
ここで元画像を切り替えます。
決めポーズを取る戦隊もののキャラクターたち(集合)import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み image = cv2.imread("desktop/python/sentai_ranger_5colors.jpg")[:,:,::-1] #画像の読み込み plt.imshow(image) plt.show()
ここでこの話が出てくる訳ですね。
OpenCVで透過画像を扱う ~スプライトを舞わせる~この画像をcv2.imshow()で表示したとき背景が黒になる。お絵かきソフトで透明キャンバスの上に絵を描くと、透明の部分は色要素がないために黒として扱われるわけだ。RGB成分がすべてゼロ=(0,0,0)=黒ということ。
なるほど…各チャンネルの画像を生成するとこんな感じ。やはり黄ばむ。そして元画像の表示が…チャンネル順序がRBGAでなくARBGである事と何か関係が?
import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み image = cv2.imread("desktop/python/sentai_ranger_5colors.jpg",-1)[:,:,::-1] height, width, channels = image.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 image = cv2.cvtColor(image, cv2.COLOR_RGB2RGBA) plt.imshow(image) plt.show() # 各チャンネルの表示 a = image[:, :, 0] r = image[:, :, 1] g = image[:, :, 2] b = image[:, :, 3] plt.imshow(a) plt.show() plt.imshow(r) plt.show() plt.imshow(g) plt.show() plt.imshow(b) plt.show()
さらに各色表示を試します。他色成分を0としたRGB画像をあらためて作ってやる場合。
import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み image = cv2.imread("desktop/python/sentai_ranger_5colors.jpg",-1)[:,:,::-1] height, width, channels = image.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 image = cv2.cvtColor(image, cv2.COLOR_RGB2RGBA) # 各チャンネルの合成 a = image[:, :, 0] r = image[:, :, 1] g = image[:, :, 2] b = image[:, :, 3] z = np.full(image.shape[:2], 0, np.uint8) imgR = cv2.merge((r,z,z)) imgG = cv2.merge((z,g,z)) imgB = cv2.merge((z,z,b)) #各チャンネルの表示 plt.imshow(imgR) plt.show() plt.imshow(imgG) plt.show() plt.imshow(imgB) plt.show()
そして元のRGB画像で不必要な色の輝度を0にする場合。
import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み image = cv2.imread("desktop/python/sentai_ranger_5colors.jpg")[:,:,::-1] height, width, channels = image.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 image = cv2.cvtColor(image, cv2.COLOR_RGB2RGBA) # 各チャンネルの合成 imgB = image.copy() imgR[:, :, (0,1)] = 0 # 3ch(BGR)の1番目(G)と2番目(R)を0にする imgG = image.copy() imgG[:, :, (0,2)] = 0 # 3ch(BGR)の0番目(B)と2番目(R)を0にする imgB = image.copy() imgR[:, :, (1,2)] = 0 # 3ch(BGR)の0番目(B)と1番目(G)を0にする #各チャンネルの表示 plt.imshow(imgB) plt.show() plt.imshow(imgG) plt.show() plt.imshow(imgR) plt.show()
もちろん結果は同じ。RGBとGBRが混ざって頭が混乱してきました。
画像合成とスプライト・アニメーション(Sprite Animation)
ここまで来たら引用投稿にある画像合成も試さずにはいられません。まずは以下を背景に選び、前景とサイズを合わせます。
宇宙のイラスト(背景素材)
OpenCVでトリミングする ~覗き動画を作る~OpenCVのタイプはnumpy.ndarray。だからスライスでその一部を取り出すことができる。行列だから行・列の順。行列だから「どの行(列)からどの行(列)まで」を指定する。「左上座標と切り取るサイズ」ではない。要はimg[r1: r2, c1: c2]だが、理屈を理解すれば img[r: r+h, c: c+w] という書き方を暗記するのは容易だ。
サイズが近過ぎてトリミングでは上手くいかないのでリサイズで対応。アスペクト比の狂いはとりあえず黙殺するものとします。
OpenCVで画像サイズの変更をしてみたimport cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み関数 def open_img(file_name): img = cv2.imread(file_name,-1)[:,:,::-1] height, width, channels = img.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 image = cv2.cvtColor(img, cv2.COLOR_RGB2RGBA) return img #前景(サイズのみ利用) img_front = open_img("desktop/python/sentai_ranger_5colors.jpg") height1, width1, channels1 = img_front.shape[:3] #前景(オリジナル) img_back = open_img("desktop/python/bg_uchu_space.jpg") height2, width2, channels2 = img_back.shape[:3] plt.imshow(img_back) plt.show() #前景(リサイズ)チャンネル数が4から3に減ってしまう。 img_resize=cv2.resize(img_back, (width1,height1)) plt.imshow(img_resize) plt.show()
まずは透過色設定を試してみましょう。
OpenCVで透過画像を扱う ~スプライトを舞わせる~前景画像の中に「この色は主たる画像の一部ではなく、背景として使われているだけだ」という色がある場合、numpy.where()を使って透明色を設定できる。クロマキーのようなものだ。前景に透過色が使われていないことを事前に確認しておかないと透明になったガチャピンのような事態になってしまう。
ガチャピン、透明になる放送事故 冷静対応のキャスターに称賛の声import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み関数 def open_img(file_name): img = cv2.imread(file_name)[:,:,::-1] height, width, channels = img.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 img = cv2.cvtColor(img, cv2.COLOR_RGB2RGBA) return img #前景(サイズのみ利用) img_front = open_img("desktop/python/sentai_ranger_5colors.jpg") height1, width1, channels1 = img_front.shape[:3] #背景(オリジナル) img_back = open_img("desktop/python/bg_uchu_space.jpg") height2, width2, channels2 = img_back.shape[:3] #背景(リサイズ) img_resize=cv2.resize(img_back, (width1,height1)) #透過処理 #backとfrontは同じシェイプ/同じチャンネル数である必要がある。 transparence = (0,0,0) result = np.where(img_front==transparence, img_resize, img_front) plt.imshow(result) plt.show()
マスク処理する場合は以下。
【Python】OpenCVでピクセル毎の論理演算 – AND, OR, XOR, NOTimport cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み関数 def open_img(file_name): img = cv2.imread(file_name,-1)[:,:,::-1] height, width, channels = img.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 img = cv2.cvtColor(img, cv2.COLOR_RGB2RGBA) return img #前景(サイズのみ利用) img_front = open_img("desktop/python/sentai_ranger_5colors.jpg") height1, width1, channels1 = img_front.shape[:3] #マスク作成 a = img_front[:, :, 0] r = img_front[:, :, 1] g = img_front[:, :, 2] b = img_front[:, :, 3] img_front1 = cv2.merge((r, g, b)) # RGBAのうちRGB mask3 = cv2.merge((a, a, a)) # 3チャンネルのRGB画像とする mask3r=cv2.bitwise_not(mask3) #背景(オリジナル) img_back = open_img("desktop/python/bg_uchu_space.jpg") height2, width2, channels2 = img_back.shape[:3] #背景(リサイズ) img_resize=cv2.resize(img_back, (width1,height1)) print("Front & reverse mask") result1=cv2.bitwise_and(img_front1,mask3) plt.imshow(result1) plt.show() print("Back & mask") result2=cv2.bitwise_and(img_resize,mask3) plt.imshow(result2) plt.show() print("Back & reverse mask") result3=cv2.bitwise_and(img_resize,mask3r) plt.imshow(result3) plt.show() print("(Front & reverse mask)||(Back & reverse mask)") result4=cv2.bitwise_or(result1,result3) plt.imshow(result4) plt.show()Front & reverse mask
Back & reverse mask
Back & reverse mask
(Front & reverse mask)||(Back & reverse mask)
せっかくなのでこちらのアニメーション処理と組み合わせてみましょう。
【Python画像処理】アフィン変換(Affine Transformation)を試す。
import cv2 import matplotlib.pyplot as plt import numpy as np import matplotlib.animation as animation #画像の準備(img_front,imag_back,) #イメージ読み込み関数 def open_img(file_name): img = cv2.imread(file_name,-1)[:,:,::-1] height, width, channels = img.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 img = cv2.cvtColor(img, cv2.COLOR_RGB2RGBA) return img #前景(サイズのみ利用) img_front_org = open_img("sentai_ranger_5colors.jpg") height1, width1, channels1 = img_front_org.shape[:3] #マスク作成 a = img_front_org[:, :, 0] r = img_front_org[:, :, 1] g = img_front_org[:, :, 2] b = img_front_org[:, :, 3] img_front = cv2.merge((r, g, b)) # RGBAのうちRGB mask3 = cv2.merge((a, a, a)) # 3チャンネルのRGB画像とする #背景(オリジナル) img_back_org = open_img("bg_uchu_space.jpg") height2, width2, channels2 = img_back_org.shape[:3] #背景(リサイズ) img_back=cv2.resize(img_back_org, (width1,height1)) #アニメーション前準備 #画面をデフォルトの640*480と設定した場合。 #fig = plt.figure(figsize = (6.4, 4.8)) fig = plt.figure() #Indx数列を作成。 c0=np.arange(0,width1,3) c1=np.append(c0,[width1]) c2=c0[::-1] indx=np.append(c1,c2) def shift_x(image,shift): h, w = image.shape[:2] src = np.array([[0.0, 0.0],[0.0, 1.0],[1.0, 0.0]], np.float32) dest = src.copy() dest[:,0] += shift # シフトするピクセル値 affine = cv2.getAffineTransform(src, dest) return cv2.warpAffine(image, affine, (w, h)); def update(i): plt.cla() img_front1 = shift_x(img_front,indx[i]) mask_a = shift_x(mask3,indx[i]) mask_r = cv2.bitwise_not(mask_a) result1 = cv2.bitwise_and(img_front1,mask_a) result2 = cv2.bitwise_and(img_back,mask_r) result3 = cv2.bitwise_or(result1,result2) plt.imshow(result3) plt.title("Sift "+'x='+str(indx[i])); ani = animation.FuncAnimation(fig, update, interval=50,frames=len(indx)) ani.save("sprite04.gif", writer="pillow")スプライトを名乗るならば背景画像の範囲外にも描写できなければ話にならない。という解説を書くつもりだったが、すでに前回の記事「OpenCVで日本語フォントを描写する を関数化する を汎用的にする」で実装してしまったので説明は略。
OpenCVで日本語フォントを描写する を関数化する を汎用的にするアフィン変換導入によってROI(Region of Interest=関心領域)からのフレームアウト問題は自然解決。さらにはこんな風に拡大縮小/クルクル回しも思うがまま。
import cv2 import matplotlib.pyplot as plt import numpy as np import matplotlib.animation as animation #画像の準備(img_front,imag_back,) #イメージ読み込み関数 def open_img(file_name): img = cv2.imread(file_name,-1)[:,:,::-1] height, width, channels = img.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 img = cv2.cvtColor(img, cv2.COLOR_RGB2RGBA) return img #前景(サイズのみ利用) img_front_org = open_img("sentai_ranger_5colors.jpg") height1, width1, channels1 = img_front_org.shape[:3] #マスク作成 a = img_front_org[:, :, 0] r = img_front_org[:, :, 1] g = img_front_org[:, :, 2] b = img_front_org[:, :, 3] img_front = cv2.merge((r, g, b)) # RGBAのうちRGB mask3 = cv2.merge((a, a, a)) # 3チャンネルのRGB画像とする #背景(オリジナル) img_back_org = open_img("bg_uchu_space.jpg") height2, width2, channels2 = img_back_org.shape[:3] #背景(リサイズ) img_back=cv2.resize(img_back_org, (width1,height1)) #アニメーション前準備 #画面をデフォルトの640*480と設定した場合。 #fig = plt.figure(figsize = (6.4, 4.8)) fig = plt.figure() #Indx数列を作成。 indx=np.arange(0,360,3) def rotate_fit(image, angle): h, w = image.shape[:2] # 回転後のサイズ radian = np.radians(angle) sine = np.abs(np.sin(radian)) cosine = np.abs(np.cos(radian)) tri_mat = np.array([[cosine, sine],[sine, cosine]], np.float32) old_size = np.array([w,h], np.float32) new_size = np.ravel(np.dot(tri_mat, old_size.reshape(-1,1))) # 回転アフィン affine = cv2.getRotationMatrix2D((w/2.0, h/2.0), angle, 1.0) # 平行移動 affine[:2,2] += (new_size-old_size)/2.0 # リサイズ affine[:2,:] *= (old_size / new_size).reshape(-1,1) return cv2.warpAffine(image, affine, (w, h)) def update(i): plt.cla() img_front1 = rotate_fit(img_front,indx[i]) mask_a = rotate_fit(mask3,indx[i]) mask_r = cv2.bitwise_not(mask_a) result1 = cv2.bitwise_and(img_front1,mask_a) result2 = cv2.bitwise_and(img_back,mask_r) result3 = cv2.bitwise_or(result1,result2) plt.imshow(result3) plt.title("Rotate "+'='+str(indx[i])); ani = animation.FuncAnimation(fig, update, interval=50,frames=len(indx)) ani.save("sprite05.gif", writer="pillow")まさしくアフィン変換は偉大なり…
本題だった筈の「反転表示」と「グレースケール表示」について。
これでやっと画像のピクセル操作の準備が整いました。
Pythonで画像のピクセル操作
Python OpenCVの基礎 画素へのアクセス画像を読み込んで、y座標10, x座標20の画素のBGR値を取得します。x,yではなくy,xでRGBではなくBGRであるところに注意ですね!
ネガへの反転
import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み関数 #coding:utf-8 def open_img(file_name): img = cv2.imread(file_name)[:,:,::-1] height, width, channels = img.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 image = cv2.cvtColor(img, cv2.COLOR_RGB2RGBA) return img #画像の読み込みとサイズ取得 img1 = open_img("sentai_ranger_5colors.jpg") height, width, channels = img1.shape[:3] #取得したサイズと同じ空のイメージを新規に作成 z = np.full(img1.shape[:2], 0, np.uint8) img2 = cv2.merge((z,z,z)) #loop #x for y in range(height): #y for x in range(width): #ピクセルを取得 b,g,r = img1[y,x] #反転処理 b = 255 - b g = 255 - g r = 255 - r #set pixel img2[y,x]=[b,g,r] #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show()上掲のスプライトアニメ制作過程で(遥かに簡単な)別解を見つけてしまいました。
OpenCVで画像の色反転をしてみた
import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み関数 #coding:utf-8 def open_img(file_name): img = cv2.imread(file_name)[:,:,::-1] height, width, channels = img.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 image = cv2.cvtColor(img, cv2.COLOR_RGB2RGBA) return img #画像の読み込みとサイズ取得 img1 = open_img("sentai_ranger_5colors.jpg") img2 = cv2.bitwise_not(img1) #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show()グレースケールは、r,g,bが同じ値を持つことでグレーに見えます。ただ、そのようなルールで同じ値にするかはケースバイケースです。ここではr,g,bの平均値を取得し、その値にしてみます。
グレースケール化
import cv2 import matplotlib.pyplot as plt import numpy as np #イメージ読み込み関数 #coding:utf-8 def open_img(file_name): img = cv2.imread(file_name)[:,:,::-1] height, width, channels = img.shape[:3] if channels == 3: # RGBならアルファチャンネル追加 image = cv2.cvtColor(img, cv2.COLOR_RGB2RGBA) return img #画像の読み込みとサイズ取得 img1 = open_img("sentai_ranger_5colors.jpg") height, width, channels = img1.shape[:3] #取得したサイズと同じ空のイメージを新規に作成 z = np.full(img1.shape[:2], 0, np.uint8) img2 = cv2.merge((z,z,z)) #loop #x for y in range(height): #y for x in range(width): #ピクセルを取得 b,g,r = img1[y,x] #平均化(整数商) gray = (b+g+r)//3 #set pixel img2[y,x]=[gray,gray,gray] #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show() #エラーが出る <ipython-input-1-5ea43bffd6a9>:30: RuntimeWarning: overflow encountered in ubyte_scalars gray = (b+g+r)//3ああ!! 繊細なグラデーションが特徴のモモレンジャーが迷彩レンジャーに!! 上掲のスプライトアニメ制作過程で(遥かに簡単な)別解を見つけましたが、困った事にちゃんと動きません。どうやら上掲の「黄ばみ」と原因は同じ様だ?
OpenCVで画像ファイルの読み書きをしよう (Python)
import cv2 import matplotlib.pyplot as plt import numpy as np #画像の読み込みとサイズ取得 img1 = cv2.imread("suugakusya.jpg",cv2.IMREAD_COLOR) img2 = cv2.imread("suugakusya.jpg",cv2.IMREAD_GRAYSCALE) #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show() #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show()
import cv2 import matplotlib.pyplot as plt import numpy as np #画像の読み込みとサイズ取得 img1 = cv2.imread("sentai_ranger_5colors.jpg",cv2.IMREAD_COLOR) img2 = cv2.imread("sentai_ranger_5colors.jpg",cv2.IMREAD_GRAYSCALE) #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show()バージョンアップに伴う仕様変更の匂いがします。以下も最終解答じゃない…
Python でグレースケール(grayscale)化
import cv2 import matplotlib.pyplot as plt import numpy as np #画像の読み込みとサイズ取得 img1 = cv2.imread("suugakusya.jpg")[:,:,::-1] img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) # RGB2〜 でなく BGR2〜 を指定 #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show()
import cv2 import matplotlib.pyplot as plt import numpy as np #画像の読み込みとサイズ取得 img1 = cv2.imread("sentai_ranger_5colors.jpg")[:,:,::-1] img2 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) # RGB2〜 でなく BGR2〜 を指定 #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show()import cv2 import matplotlib.pyplot as plt import numpy as np #画像の読み込み img1 = cv2.imread("suugakusya.jpg")[:,:,::-1] #グレイスケール化 img2 = 0.299 * img1[:, :, 2] + 0.587 * img1[:, :, 1] + 0.114 * img1[:, :, 0] #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show()
import cv2 import matplotlib.pyplot as plt import numpy as np #画像の読み込み img1 = cv2.imread("sentai_ranger_5colors.jpg")[:,:,::-1] #グレイスケール化 img2 = 0.299 * img1[:, :, 2] + 0.587 * img1[:, :, 1] + 0.114 * img1[:, :, 0] #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.show()どうやらこの辺りが現時点における私の限界の様です。
- (2021.2.25)こんな拙い初学者投稿なのに、コメント欄で一杯アドバイスを頂きました。なるほど
plt.imshow(img2, cmap="gray", vmin=0, vmax=255)ですか。そして…
[matplotlib]グレースケール画像の表示解決策1
import cv2 import matplotlib.pyplot as plt import numpy as np #画像の読み込みとサイズ取得 img1 = cv2.imread("sentai_ranger_5colors.jpg")[:,:,::-1] img2 = cv2.imread("sentai_ranger_5colors.jpg",0) #show plt.imshow(img1) plt.show() plt.imshow(img2,cmap = "gray") plt.show()解決策2
import cv2 import matplotlib.pyplot as plt import numpy as np #画像の読み込みとサイズ取得 img1 = cv2.imread("sentai_ranger_5colors.jpg")[:,:,::-1] img2 = cv2.imread("sentai_ranger_5colors.jpg",0) #show plt.imshow(img1) plt.show() plt.imshow(img2) plt.gray() plt.show()まだ理屈は全然分かってませんが、どうやらこれが正解の模様?
そんな感じで以下続報…














































- 投稿日:2021-02-25T15:01:23+09:00
ハノイの塔のコードを理解してみよう[再帰関数]
はじめに
今回はハノイの塔のコードをざっくり理解しよう。
コード
test.pydef hanoi(disk: int, src:str, dest:str, outer:str): if disk < 1: return hanoi(disk-1, src, outer, dest) #A print(f'move {disk} from {src} to {dest}') #first hanoi(disk-1, outer, dest, src) #B if __name__ == '__main__': hanoi(3,'a','c','b') #move 1 from a to c #Aの中の#A #move 2 from a to b #A(#Ax) #move 1 from c to b #Axの#B #move 3 from a to c #first #move 1 from b to a #Bの#A #move 2 from b to c #Bの#first #move 1 from a to c #Bの#B理解
上のコードのコメントが全てです。
こちらのコードは一番下のhanoi(3,'a','c','b')から、hanoi関数がリカーシブしています。再帰関数と呼ばれる物です。
#Aの中でhanoiのdiskの値が無くなるまで#Aを繰り返し実行します。そのため、printはmove 1からprintされていきます。
再帰関数が分からないと(なんで-1なのにmove 2が最初に描画されないんだ?)となってしまいます。私です。
そして#Aのdiskが1であっても、printが実行された後#Bのhanoiは実行されません。diskが0になるためです。
そのため、printが実行された後にdiskの値が2以上でなければ#Bは起動しない、という事です。
- 投稿日:2021-02-25T13:31:43+09:00
Googleカレンダーの作業記録から出勤簿を作成したい(前編)
はじめに
僕が所属している研究室では,自分の研究以外の活動(企業や他大学との共同研究やプロジェクト)に関わると,その時間分だけアルバイト代をもらえるようになっています.
アルバイト代を申請するためには,毎月末「出勤簿」と呼んでいる用紙を印刷し活動内容と活動日時を手書きで書いて大学に提出します.大した作業ではないのかもしれませんが,怠惰な僕には耐えられなかったのである程度自動化してみようと思います.
どうやるか
まず何らかの形で日々の活動内容を記録しておく必要があります.そのためにGoogle Calendarを利用し,Google Calendar APIでその記録を取り出そうと思います.研究室メンバーはGoogle Calendarで予定を作ったり確認したりするのが習慣づいてるので,Google Calendarを使えば他のメンバーに布教できるし活動を記録するハードルが低くなる気がします.
次にその活動記録から出勤簿を生成します.出勤簿には決められたフォーマット(PDFとExcel)があるので,それに書き込むようにします.本当はExcelファイルに書き込みたかったのですが,なぜかパスワードで保護されていたので諦めてPDFを使うことにしています.(大学に問い合わせれば教えてもらえそうですが,面倒なのでPDFで行きます)
Quick Start
公式のQuick Startを見てみます.
https://developers.google.com/calendar/quickstart/python認証
手順にしたがって
credentials.jsonをダウンロードして作業フォルダに置きます.とりあえずプログラムをコピペして動作を確認してみます.プログラムを実行すると,ブラウザでアカウント選択画面が表示されます.
アカウントを選択して認証すると,カレンダーにある予定が最大10件表示されます.プログラムを実行すると,
token.pickleというファイルが出来上がっています.ここに認証情報が保存されています.これがあればプログラムを実行する度に毎回許可しなくてもGoogle Calendar APIが使えます.試しにtoken.pickleを削除して実行してみると,またアカウント選択画面が表示されると思います.
token.pickleを作成したり更新したりしてるのが,プログラムの次の部分です.creds = None # The file token.pickle stores the user's access and refresh tokens, and is # created automatically when the authorization flow completes for the first # time. if os.path.exists('token.pickle'): with open('token.pickle', 'rb') as token: creds = pickle.load(token) # If there are no (valid) credentials available, let the user log in. if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file( 'credentials.json', SCOPES) creds = flow.run_local_server(port=0) # Save the credentials for the next run with open('token.pickle', 'wb') as token: pickle.dump(creds, token)上のプログラムで認証情報が入った
credsが最終的にできます.そしてcredsをもとにGoogle Calendar APIのサービスオブジェクトserviceを作ります.service = build('calendar', 'v3', credentials=creds)この後は
serviceを使ってGoogle Calendar APIを操作します.なので上のコードは変更を加えずにそのまま使って良さそうです.予定を取得する
公式のQuick Startは次のように続きます.
now = datetime.datetime.utcnow().isoformat() + 'Z' # 'Z' indicates UTC time print('Getting the upcoming 10 events') events_result = service.events().list(calendarId='primary', timeMin=now, maxResults=10, singleEvents=True, orderBy='startTime').execute() events = events_result.get('items', []) if not events: print('No upcoming events found.') for event in events: start = event['start'].get('dateTime', event['start'].get('date')) print(start, event['summary'])
events_result = service.events().list(...).execute()で様々な条件を指定して予定(イベント)を取得できます.
calendarIdにはカレンダーIDを指定します.後で説明しますが,カレンダーIDを取得するにはcalendarList.listメソッドを利用します.またcalendarIdに'primary'を指定することでメインのカレンダーを選択できるみたいです.
singleEvents=Trueとすることで,繰り返しのイベントが個別のイベントとして取得されます.
Event.listメソッドで指定できる条件の一覧はリファレンスに載ってます.
https://developers.google.com/calendar/v3/reference/events/list
events_resultの中身
Event.listメソッドの結果は辞書として返ってきます.中身は次のようになっています.{ "kind": "calendar#events", "etag": etag, "summary": string, "description": string, "updated": datetime, "timeZone": string, "accessRole": string, "defaultReminders": [ { "method": string, "minutes": integer } ], "nextPageToken": string, "nextSyncToken": string, "items": [ events Resource ] }予定(イベント)は
events_result['items']に入っています.上のevents Resourceの部分です.
各イベントの構造は次のようになっています.長いので後半を省略しています.
https://developers.google.com/calendar/v3/reference/events#resource{ "kind": "calendar#event", "etag": etag, "id": string, "status": string, "htmlLink": string, "created": datetime, "updated": datetime, "summary": string, "description": string, "location": string, "colorId": string, "creator": { "id": string, "email": string, "displayName": string, "self": boolean }, "organizer": { "id": string, "email": string, "displayName": string, "self": boolean }, "start": { "date": date, "dateTime": datetime, "timeZone": string }, "end": { "date": date, "dateTime": datetime, "timeZone": string }, . . . }紛らわしいと思ったのがイベントの
summaryとdescriptionです.summaryはイベント(予定)の表示名,そしてdescriptionは説明にあたります.
また紛らわしいことに
Event.listメソッドで返ってくるsummaryとdescriptionはカレンダーの表示名と説明です.イベントのsummaryとdescriptionとは別です.CalendarIdを取得する
活動記録方法として,活動記録用専用のカレンダーを作ることにします.また活動の種類ごとに分けて(A社共同研究,B社共同研究のように)記入したいので,活動種類ごとにカレンダーを作ります.
各カレンダーを指定するために,カレンダーIDが必要になります.そのために
calendarList.listメソッドを利用します.リファレンスにあるサンプルプログラムを見てみます.
https://developers.google.com/calendar/v3/reference/calendarList/listpage_token = None while True: calendar_list = service.calendarList().list(pageToken=page_token).execute() for calendar_list_entry in calendar_list['items']: print calendar_list_entry['summary'] page_token = calendar_list.get('nextPageToken') if not page_token: break難しそうですが,実際にカレンダーのリストを取得しているのは
calendar_list = service.calendarList().list(pageToken=page_token).execute()の部分です.
それ以外の部分では,
page_tokenを使ってすべてのカレンダーを漏れなく取得しようとしています.カレンダーのリストを取得するとき,一回のリクエストで返ってくるカレンダーの数には上限(デフォルトでは100個まで)があります.例えば300個カレンダーがある場合は,1回リクエストを送っても1~100番目のカレンダーしか得ることができません.101~200番目のカレンダーを取得するためにもう一度同じリクエストを送りたくなりますが,返ってくるのは同じ1~100番目のカレンダーです.
101番目以降のカレンダーを取得するために必要なのが
page_tokenです.先ほどの例と同じように1回リクエストを送ると1~100番目のカレンダーが返ってきますが,そのとき同時にnextPageTokenも返ってきます.そして2回目のリクエストのときに'nextPageToken'を一緒に送ると101~200番目のカレンダーが得られ,また新しいnextPageTokenが付いてきます.そして3回目のリクエストで,2個目のnextPageTokenを一緒に送ることで201~300番目のカレンダーが取得できます.これですべてのカレンダーを取得できたので,今度はnextPageTokenは付いてきません.言い換えればnextPageTokenがなければすべてのカレンダーを取りきったと分かります.カレンダーを300個も持ってる人はまずいないとは思いますが...
上のサンプルプログラムがこの処理をしています.
calendar_list.get('nextPageToken')の部分でnextPageTokenがあるか確認しています.calendar_list['nextPageToken']と書かずにgetを使っているので,nextPageTokenが存在しない場合はNoneが返ってきます.
参考:Pythonの辞書のgetメソッドでキーから値を取得(存在しないキーでもOK)ちなみに1回のリクエストで得られるカレンダーの数は
maxResultsで決まっていて,最大250個にまで増やせます.作業記録用カレンダーから記録を取り出す
ここまでわかればやりたいことはできそうです.
import datetime import pickle import os.path from googleapiclient.discovery import build from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request from devtools import debug # If modifying these scopes, delete the file token.pickle. SCOPES = ['https://www.googleapis.com/auth/calendar.readonly'] class GoogleCalendar: def __init__(self): self.creds = self.get_creds() self.service = build('calendar', 'v3', credentials=self.creds) def get_creds(self): creds = None # The file token.pickle stores the user's access and refresh tokens, and is # created automatically when the authorization flow completes for the first # time. if os.path.exists('token.pickle'): with open('token.pickle', 'rb') as token: creds = pickle.load(token) # If there are no (valid) credentials available, let the user log in. if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file( 'credentials.json', SCOPES) creds = flow.run_local_server(port=0) # Save the credentials for the next run with open('token.pickle', 'wb') as token: pickle.dump(creds, token) return creds def get_events_this_month(self, calendarId): """ calendarIdで指定されたカレンダー内にある,今月のイベントを取得する. ※このプログラムではイベントの数が250より多いと,多い分のイベントが取得できない.250より多くのイベントを取得したい場合は,nextPageTokenを利用する. """ # 月の最初の日と最後の日 first_day = datetime.datetime.today().replace(day=1, hour=0, minute=0, second=0, microsecond=0) last_day = datetime.datetime.today().replace(month=first_day.month+1, day=1, hour=0, minute=0, second=0, microsecond=0) - datetime.timedelta(days=1) # 文字列に変換 first_day = first_day.isoformat() + 'Z' last_day = last_day.isoformat() + 'Z' events_result = self.service.events().list(calendarId=calendarId, timeMin=first_day, maxResults=250, singleEvents=True, orderBy='startTime').execute() events = events_result.get('items', []) return events def get_calendar_from_summaries(self, summaries): """ カレンダーの表示名(summary)からカレンダーのIDを取得し,{summary: calendar_id}のような辞書として返す. """ page_token = None all_calendar = [] while True: calendar_list = self.service.calendarList().list(pageToken=page_token).execute() all_calendar += calendar_list['items'] page_token = calendar_list.get('nextPageToken') if not page_token: break # カレンダーIDを探す. calendar_id_dict = {} for cal in all_calendar: if cal['summary'] in summaries: calendar_id_dict[cal['summary']] = cal['id'] return calendar_id_dict if __name__ == '__main__': gcal = GoogleCalendar() debug(calendar_id_dict := gcal.get_calendar_from_summaries(['A社', 'B社'])) for calendar_summary, calendar_id in calendar_id_dict.items(): events = gcal.get_events_this_month(calendar_id) for e in events: start = e['start']['dateTime'] end = e['end']['dateTime'] print(start, end, calendar_summary, e['summary'])実行するとその月の活動記録がプリントされます.
2021-02-23T20:00:00+09:00 2021-02-23T21:00:00+09:00 A社 ミーティング 2021-02-26T13:30:00+09:00 2021-02-26T14:30:00+09:00 A社 実験補助 2021-02-16T02:30:00+09:00 2021-02-16T03:30:00+09:00 B社 実験補助 2021-02-26T14:45:00+09:00 2021-02-26T18:15:00+09:00 B社 ミーティング
Quick Startでインストールしたパッケージに加えて,
python-devtoolsというパッケージをインストールしています.デバッグするときにおわりに
思ったことを書いていたら想像以上に長くなってしまいました.
次はPDFに書き込みます.
- 投稿日:2021-02-25T13:21:26+09:00
'DataFrame' object has no attribute 'ix'の解決法
はじめに
オライリージャパンの「Pythonではじめる機械学習」の4章のp.210の以下のコードを打ち込んだ時,エラーが発生しました.
features = data_dummies.ix[:,"age":"occupation_ Transport-moving"] #NumPy配列を取り出す X = features.values y = data_dummies["income_ >50K"].values print("X.shape: {} y.shape: {}".format(X.shape,y.shape))エラー内容
'DataFrame' object has no attribute 'ix'解決法
調べてみると,2020年2月に導入されたpandas-1.0.0で,以前バージョン0.7.3まで使用できたDataFrameの.ixが廃止されたそうです.
しかし,代わりにlocを用いることで解決できます.features = data_dummies.loc[:,"age":"occupation_ Transport-moving"] #NumPy配列を取り出す X = features.values y = data_dummies["income_ >50K"].values print("X.shape: {} y.shape: {}".format(X.shape,y.shape))loc使用後
X.shape: (32561, 44) y.shape: (32561,)エラーが消えました.
参考
https://ebcrpa.jamstec.go.jp/~yyousuke/matplotlib/info.html ,2021/2/25参照
- 投稿日:2021-02-25T13:08:18+09:00
データの分け方
学習データとテストデータの分け方
テストデータと学習データの分け方を紹介する
分け方を間違えると良い結果が得られないことが多い前提条件
import numpy as np from sklearn.datasets import load_iris data=load_iris() from sklearn.linear_model import LogisticRegression model=LogisticRegression()交差検証
-汎化性能を評価する統計的手法
-訓練セットとテストセットに分割する方法と比べて、より安定で徹底した手法
-データの分割を何度も行い複数のモデルを訓練するk分割交差検証(k-fold cross-validation)
-最もよく用いられる交差検証
-データをk分割し1個をテストデータ残りを訓練データにする(これをk回繰り返す)
-5<k<10
-交差検証はscikit-learnではmodel_selectionモジュールのcross_val_score関数で実装from sklearn.model_selection import cross_val_score print(cross_val_score(model,data.data,data.target))結果[0.96666667 1. 0.93333333 0.96666667 1. ]cross_val_scoreは、デフォルトでcv=3
パラメータcvを色々試してみるfor i in range(5): model=LogisticRegression() scores=cross_val_score(model,data.data,data.target,cv=i+2) print(scores) print(scores.mean())結果[0.96 0.96]#cv=2 [0.98 0.96 0.98]cv=3 [0.97368421 0.97368421 0.94594595 1. ]#cv=4 [0.96666667 1. 0.93333333 0.96666667 1. ]#cv=5 [0.96 1. 0.96 0.92 0.96 1. ]#cv=6 0.9666666666666667#平均層化k分割交差検証
-各分割内でのクラスの比率が全体の比率と同じになるように分割する
-k分割交差検証ではなく層化交差検証を使った方が良いfrom sklearn.model_selection import KFold kfold=KFold(n_splits=3,shuffle=True,random_state=0) print(scorr_val_score(model,data.data,data.target,cv=kfold))結果[0.98 0.96 0.96]KFoldの引数
-n_split:分割する数
-Shuffle=True:データをシャッフルしてサンプルがラベル順に並ばないようにするleave-OneOut
-データをここに分割し1つをテストデータ残りを訓練データ
-小さいデータセットに適しているfrom sklearn.model_selection import LeaveOneOut loo=LeaveOneOut() scores=cross_val_score(model,data.data,data.target,cv=loo) print(scores) print(len(scores))結果[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.] 150シャッフル分割交差検証
-毎回train_size個の点を選び出し訓練セットとし、test_size個の点を選び出してテストセットとする
from sklearn.model_selection import ShuffleSplit shuffle_split=ShuffleSplit(test_size=.5,train_size=.5,n_splits=10) scores=cross_val_score(model,data.data,data.target,cv=shuffle_split) print(scores)結果[0.93333333 0.96 0.94666667 0.96 0.96 0.92 1. 0.97333333 0.96 0.97333333]
- 投稿日:2021-02-25T11:49:59+09:00
python pathlibの使い方メモ
1. pathlibとは
ファイルやディレクトリを操作するpython標準パッケージです
https://docs.python.org/ja/3/library/pathlib.htmlos.pathで出来ることは大抵できます
2. os.pathよりも優れている点
2-1. 連続して操作するときに可読性が上がる
os.pathだと入れ子になって読みにくいですが、pathlibだと読みやすいです
os.pathの場合>>> path = '../hoge/fuga/hoo/sample.png' >>> os.path.dirname(os.path.dirname(os.path.dirname(path))) '../hoge'pathlibの場合>>> p = Path('../hoge/fuga/hoo/') >>> p.parent.parent.as_posix() '../hoge'2-2. 末尾の / の有無を意識しなくても良い
os.path.dirname(path)は '/'.join(path.split('/')[:-1]) をやってるだけなので末尾に'/'があるかないかで結果が変わりますが、pathlibはオブジェクト化するときに解釈して末尾の'/'を無視してくれるので意識する必要がなくなります
os.pathの場合>>> path = '../hoge/fuga/hoo/' >>> os.path.dirname(os.path.dirname(os.path.dirname(path))) '../hoge' >>> path = '../hoge/fuga/hoo' >>> os.path.dirname(os.path.dirname(os.path.dirname(path))) '../'pathlibの場合>>> p = Path('../hoge/fuga/hoo/') >>> p.parent.parent.parent '../' >>> p = Path('../hoge/fuga/hoo') >>> p.parent.parent.parent '../'2-3. 拡張子やファイル名の置き換えが簡単
拡張子の置き換え>>> file = Path('../code/hoge.py') >>> file.with_suffix('.txt').as_posix() '../code/hoge.txt'ファイル名の置き換え>>> file = Path('../code/hoge.py') >>> file.with_name('fuga.py').as_posix() '../code/fuga.py'2-4. ワイルドカード検索が出来る
拡張子やファイル名でファイルまたはフォルダを検索することが出来ます
>>> list(p.rglob('*.py')) [WindowsPath('../code/fuga.py'), WindowsPath('../code/hoba.py'), WindowsPath('../code/hoge.py'), WindowsPath('../code2/fugafuga.py'), WindowsPath('../code2/hogehoge.py')]3. 使い方
pathの指定
pathを指定する>>> from pathlib import Path >>> p = Path('..') >>> p WindowsPath('..')ファイル一覧を取得する
>>> list(p.iterdir()) [WindowsPath('../code'), WindowsPath('../code2'), WindowsPath('../data'), WindowsPath('../input')]pathを移動する
フォルダに移動する>>> q = p / 'code' >>> q WindowsPath('../code')親フォルダに移動する>>> q = q.parent >>> q WindowsPath('..')pathを文字列で取得する
posix形式>>> q = p / 'code' >>> q.as_posix() '../code'絶対path>>> q.resolve() WindowsPath('C:/Users/jjaka/google_drive/python/python練習/20210224_pathlib')ファイル名、拡張子を取得する
>>> q = Path('../code/foo.tar.gz') >>> q WindowsPath('../code/foo.tar.gz') >>> q.name 'foo.tar.gz' >>> q.suffix gz >>> q.suffixes ['.tar', '.gz']ファイル名、拡張子を置き換える
>>> q = Path('../code/hoge.py') >>> q.with_suffix('.txt') WindowsPath('../code/hoge.txt') >>> q.with_name('fuga.txt') WindowsPath('../code/fuga.txt')pathにファイル、ディレクトリがあるか確認する
>>> q = Path('../code/hoge.py') >>> q.is_file() True >>> q = Path('../code') >>> q.is_dir() True >>> q.is_reserved() Falseワイルドカードで検索する
rglobはフォルダ以下をすべて検索してくれます
>>> p = Path('..') >>> list(p.rglob('*.py')) [WindowsPath('../code/fuga.py'), WindowsPath('../code/hoba.py'), WindowsPath('../code/hoge.py'), WindowsPath('../code2/fugafuga.py'), WindowsPath('../code2/hogehoge.py')] >>> q = q / 'code' >>> list(q.rglob('*.py')) [WindowsPath('../code/fuga.py'), WindowsPath('../code/hoba.py'), WindowsPath('../code/hoge.py')]
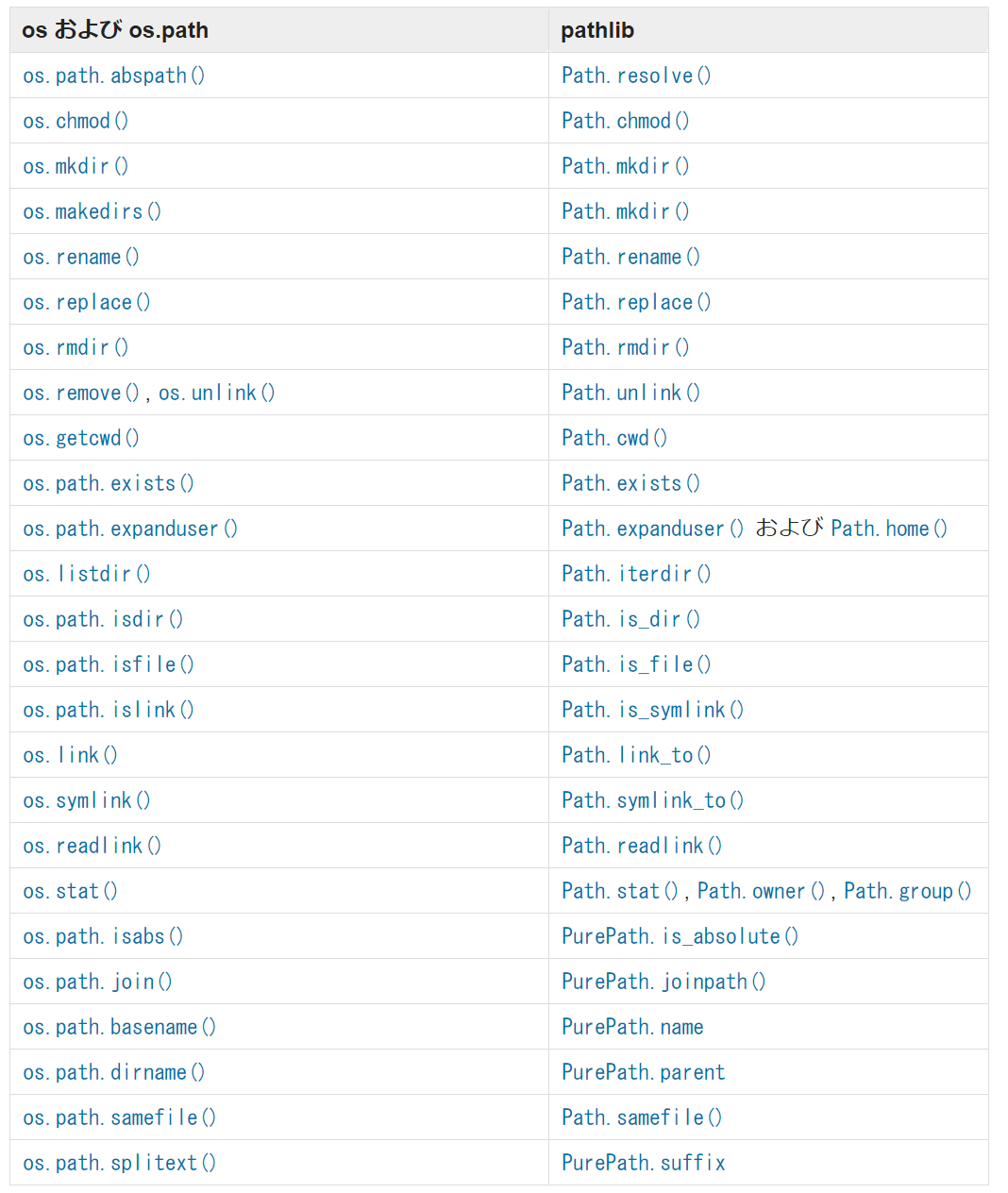
- 投稿日:2021-02-25T11:37:34+09:00
python全角⇔半角文字列変換
ZEN = chr(0x3000) + "".join(chr(0xff01 + i) for i in range(94)) HAN = "".join(chr(0x20 + i) for i in range(95)) # 全角から半角へ変換 def to_hankaku(s, tdic=str.maketrans(ZEN, HAN)): return s.translate(tdic) # 半角から全角へ変換 def to_zenkaku(s, tdic=str.maketrans(HAN, ZEN)): return s.translate(tdic) >>> to_hankaku("12 3") '12 3' >>> to_zenkaku("12 3") '12\u30003'
- 投稿日:2021-02-25T11:05:26+09:00
【Signate】「The 4th Tellus Satellite Challenge:海岸線の抽出」で試した手法
はじめに
2020年8月〜11月に開催された海岸線の抽出コンペに参加しました。結果自体は48位と振るわなかったのですが、色々な手法を試して、自分にとってはとても勉強になったので、こちらで共有したいと思います。
参考
情報公開ポリシー
この記事はSignateの情報公開ポリシーに従って公開しています。
コンペ概要
本コンペの目的は「SAR データを用いた海岸線の抽出」です。海岸線を含む画像に対し、陸地と海の境界となる線を引くことを目的とします。
コンペの意義についてはコンペのサイトに詳しく記載されていますので、そちらを参照してください。
データ
- L バンド SAR 画像
衛星:ALOS2(JAXA) 大きさ:600×600~10000×10000(画像により異なる) 解像度:3m × 3m HH偏波, 波長:約24cm 海岸数:17 画像数:55枚(学習用)25枚、(評価用)30枚※偏波とは電波の性質を表す一つの指標で、電界の振動方向の向きを表します。HH は水平偏波を送信し水平偏波で受信します。
- アノテーション(学習用データに対する海岸線の座標情報) 形式:JSON
試したこと
本コンペでは、まず海と陸を分けるセグメンテーションとして、大津の二値化による海と陸の分離を試してみました。その途中でKSVDによるノイズ除去を試してみたり、グラフカットを試してみましたが、いくつかの理由により断念しました。
次に、海岸線そのものを予測するセグメンテーションを試してみました。こちらもあまりうまくいきませんでしたが、大まかには捉えており、意外な結果となりました。
画像処理による手法 ー海のセグメンテーションー
海のセグメンテーション(二値化)
ある画像の海と陸の画素分布を確認したところ、海と陸が割とはっきりと分離していることが分かりました。
そこで、大津の二値化で海と陸が分類できるのではないかと考えました。大津の二値化は、クラス内分散を最小化し、クラス間分散を最大化するような二値分類をする方法です。
th, ret = cv2.threshold(img, 0, 255, cv2.THRESH_OTSU)大津の二値化を実施すると海と陸をある程度分離できるものの、まだら模様になってしまいます。
ノイズ除去
ノイズを除去するためにフィルタ処理をかけます。中央値フィルタをかけると綺麗になるものの、画像のサイズが画像ごとに異なるため、ノイズの大きさもばらばらで、画像のサイズに依存してフィルターの大きさを決める必要があり、全画像共通のパラメータでフィルタをかけるのは難しいです。
img = cv2.medianBlur(img, 31)
ここで、二値化処理の前にモルフォロジー変換と非局所平均フィルターをかけておくと、画像がなめらかになり、二値化によるノイズが小さくなる傾向があることがわかりました。モルフォロジー変換では膨張処理と収縮処理を行いノイズ除去に有効です。非局所平均フィルターはある画素に対して周囲に小さな小領域を定義し、画像中から似ているパッチを見つけ、似ているパッチの平均値を出力画像の対応する画素の画素値にする手法です。
def morphology_trans(img, trans_num=2, element=None): """モルフォロジー変換. Parameters ---------- img : np.ndarray 画像. trans_num : int, default 2 変換回数. element : np.ndarray 近傍を指定するエレメント. Returns ------- img_ : np.ndarray 変換後の画像. """ if element is None: element = np.ones((3, 3), np.uint8) img_ = np.copy(img) for _ in range(trans_num): img_ = cv2.morphologyEx(img_, cv2.MORPH_OPEN, element) for _ in range(trans_num): img_ = cv2.morphologyEx(img_, cv2.MORPH_CLOSE, element) return img_ def non_local_means_filter(img): """非局所平均フィルター. Parameters ---------- img : np.ndarray 画像. Returns ------- img_ : np.ndarray フィルタ処理後の画像. """ img_ = cv2.fastNlMeansDenoising(img, None, 7, 21, 10) return img_他にも、画像のノイズを低減できないか、Morphological Component Analysis (MCA) 1も試してみました。大域的 MCA では画像を分離するためにフィルターが必要になりますが、DCT の構成法は見つけられましたものの、curvelet のフィルターの構成法がわからず、大域的 MCA は断念しました。局所的 MCA は
spm-image2というライブラリを使用すると実施可能です。KSVDアルゴリズムで画像から辞書を取得します。# ksvdのパラメータ patch_size = (8, 8) n_components = 8*8 transform_n_nonzero_coefs = 3 max_iter = 30
辞書のそれぞれの画像に対しアクティビティと呼ばれる、エッジっぽいかテクスチャっぽいかを表す量を計算します。閾値を決めて、テクスチャの辞書を取り除き、エッジの辞書のみで画像を再構成しました。閾値はk-meansで決定しました。
細かいノイズが除去される一方でブロックノイズが乗ってしまいました。また、スケールが大きいテクスチャを分離できていません。また、画像が大きすぎると計算量が大きくなり、処理に時間がかかるため、MCAは断念しました。
ちなみに画層は疑似カラー化しています。
# 疑似カラー化 img = cv2.applyColorMap(img, cmapy.cmap('ocean'))領域選択
今回の画像は川も写っているため、陸地内にある川も海と同じと分類されてしまいます。
そこで、かなり楽観的なのですが、画像を占める領域で最大の領域が海だと考え、最大面積部分を海として抽出しました。汎用的な手法ではないですが、コンペなので与えられたデータに対して処理できればひとまず良いと考えて試しています。
contours = cv2.findContours( ret, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0] # 一番面積が大きい輪郭を選択する。 max_cnt = max(contours, key=lambda x: cv2.contourArea(x)) # 黒い画像に一番大きい輪郭だけ塗りつぶして描画する。 out = np.zeros_like(ret) out = cv2.drawContours(out, [max_cnt], -1, color=255, thickness=-1) out = cv2.drawContours(out, [max_cnt], -1, color=255, thickness=1)正解の海岸線にかなり近い境界になったと思います。
境界線の取得
二値化に成功したあと、境界線を取得しなければならないのですが、これが意外とよくわからなかったです。初めはCanny法でエッジを取得しました。
# エッジを取得する edges = cv2.Canny(img, 100, 100)ただCanny法では斜めの線の部分の線が連結していない場合があり、線にポツポツと穴が空いてしまうという問題がありました。
そこでエッジ検出ではなく、輪郭検出に変えました。ただし、輪郭検出は白の領域の周囲全体を検出してしまうため、画像の端にも線を引いてしまいます。そこで、輪郭検出後、画像の端を改めて0で埋めています。
def extract_edge(y, h, w): y_ = np.zeros_like(y) contours = cv2.findContours( y, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)[0] # 一番面積が大きい輪郭を選択する。 max_cnt = max(contours, key=lambda x: cv2.contourArea(x)) # 輪郭線画像を生成 img = cv2.drawContours(y_, [max_cnt], 0, 255, 1) # 画像の端の線を削除 img[0, :] = 0 img[h-1, :] = 0 img[:, 0] = 0 img[:, w-1] = 0 return img結論
以上の方法で画像処理を出来ないか模索したのですが、決定的な問題があり、この方向性は断念しました。
- 海と陸の画素分布にほとんど差がない場合は二値化不可能。
- 海側に欠損がある場合は「欠損とその他」の二値分類になってしまう。
例えばフォーラム掲載の画像のtrain19などは、画像全体が白っぽくなり、海と陸の画素の分布が別れておらず、ヒストグラムで可視化すると一つの山になってしまっています。このような画像に対しては大津の二値化が使用できません。
また、train09のように、海側に海側に欠損がある場合、「海と陸」で分布が別れず、「海+陸と欠損部分」で二値化されてしまうこともわかりました。インプレーティングで欠損部分と近接している画素で埋めるといった方法も試したましたが、あまりうまくいきませんでした。
dst = cv2.inpaint(img, mask, 3, cv2.INPAINT_NS)もっと欠損部分の処理を丁寧に行えば回避できたかもしれませんが、全画像に対して共通処理はできそうにありませんでしたので、画像処理による手法は断念しました。
おまけ
ちなみに、海と陸を二値化するにあたってはGrabCutも試してみました。ただしOpenCVに実装されている GrabCut は、前景を囲むように長方形の領域を選択しなければならず、海岸線が画像の対角線上を走るような場合は海だけを囲むようにすることが出来ません。自分で実装3すれば、比較的自由に領域を選択出来るのですが、画像が大きい場合は計算量が莫大になることがわかり、実装はしませんでした。面白そうなアルゴリズムなので、いつか実装してみたいです。
ディープラーニングによる手法
海のセグメンテーション再び
はじめに、セグメンテーションを使用して海をセグメンテーションしました。海のセグメンテーションをするにあたっては
labelmeを使用しました。正解の境界をなぞるように境界線を引き、境界線がないところは自分の感覚で引いてしまいました。海側を1としてアノテーションしています。コンペの参考資料に、過去のコンペでは画像の縮小がキーになっているという話があり、また、解像度が高い状態で海岸線付近をうまくクロップする方法が思いつかなかったため、画像全体を$(224, 224)$にリサイズしてモデリングしました。Augmentationは下記の設定で行いました。モデルはPSPNetです。
smp.PSPNet('resnet34', encoder_weights='imagenet', activation='sigmoid')def get_transforms(is_train=True): list_transforms = [] if is_train: list_transforms.extend( [ A.RandomResizedCrop( 224, 224, scale=(0.4, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=1, always_apply=False, p=1.0), A.Rotate( limit=90, interpolation=1, border_mode=4, value=None, mask_value=None, always_apply=False, p=1.0), A.Flip( p=0.5), A.RandomBrightnessContrast( brightness_limit=0.2, contrast_limit=0.2, brightness_by_max=True, always_apply=False, p=1.0), ]) else: list_transforms.extend([ A.Resize(224, 224, interpolation=1, always_apply=False, p=1.0) ]) list_transforms.extend([ # A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], p=1), A.pytorch.ToTensor(), ]) list_trfms = A.Compose(list_transforms) return list_trfmsこのモデルだと、川も海として検出してしまいました。画像全体に推論をかける以上、川の誤認識は避けられません。
境界線のセグメンテーション
フォーラム で境界線を直接セグメンテーションできないかというスレッドが立っていました。Petr (CZ)さんが、ポジティブな回答をしていたので、線を直接予測できるか試してみました。正直懐疑的でしたが、これを試してみることにしました。
フォーラムにあったアドバイス通り、
BCEWithLogitsLossに重みをかけて学習させました。画像サイズは(448, 448)とし、モデルはUnetを使用しました。重みはピクセルの比だと、重みはおよそ1:400ですが、何度か試して1:1000くらいが良さそうでした。このモデルだと、光のノイズなどが大きい画像だとノイズに対して予測を出してしまいました。なんとかパラメータを微調整して、このモデルで最終提出としました。
class WeightedBCEWithLogitsLoss(nn.Module): def __init__(self, weights=None): super().__init__() assert len(weights) == 2 self.weights = weights def forward(self, output, target): output = torch.clamp(output,min=1e-8,max=1-1e-8) if self.weights is not None: loss = self.weights[1] * (target * torch.log(output)) + \ self.weights[0] * ((1 - target) * torch.log(1 - output)) else: loss = target * torch.log(output) + (1 - target) * torch.log(1 - output) return torch.neg(torch.mean(loss)) criterion = WeightedBCEWithLogitsLoss(weights=torch.Tensor([1, 1000]))
検出した海岸線は太すぎるので細くする必要があります。細線化アルゴリズムはZhang-Suenを使用して、こちらのコードを使用しました。
おまけ
以下は、使用したけど紹介しなかった諸々のコードです。汚いですが(汗)
import datetime import gc import glob import json import math import os import pdb import pickle import random import shutil import time import uuid import warnings from datetime import timedelta from pathlib import Path from typing import Dict, List, Sequence, Tuple, Union import albumentations as A import cmapy import cv2 import matplotlib.pyplot as plt import numpy as np import pandas as pd import segmentation_models_pytorch as smp import skimage import tifffile import torch import torch.backends.cudnn as cudnn import torch.nn as nn import torch.optim as optim import torchvision from catalyst.callbacks.checkpoint import CheckpointCallback from catalyst.callbacks.early_stop import EarlyStoppingCallback from catalyst.dl import SupervisedRunner from catalyst.utils import metrics from labelme.utils import shape_to_mask from skimage.future import graph from sklearn.feature_extraction.image import (extract_patches_2d, reconstruct_from_patches_2d) from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler, StandardScaler from torch.autograd import Variable from torch.nn import functional as F from torch.nn.modules.utils import _pair, _single from torch.optim import lr_scheduler from torch.optim.lr_scheduler import ReduceLROnPlateau from torch.utils.data import DataLoader, Dataset, sampler from torchsummary import summary from tqdm import tqdm_notebook as tqdm from tqdm.auto import tqdm %matplotlib inline warnings.filterwarnings("ignore") def seed_everything(seed): random.seed(seed) os.environ["PYTHONHASHSEED"] = str(seed) np.random.seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True # seed setting seed = 69 seed_everything(seed) pd.set_option('display.max_columns', 50) pd.set_option('display.max_rows', 50)def get_image(idx, is_train=True): """画像読み込み. Parameters ---------- idx : int 画像のインデックス. is_train : bool, default True trainのときはTrue. Returns ------- img : np.ndarray 画像. """ if is_train: img = cv2.imread(str(INPUT_PATH / 'train_images' / f'train_{idx:02d}.png')) else: img = cv2.imread(str(INPUT_PATH / 'test_images' / f'test_{idx:02d}.png')) if img is None: raise ValueError("File path is incorrect.") img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) return img def normalize(img): """min-maxスケーリング. Parameters ---------- img : np.ndarray 画像. Returns ------- img_ : np.ndarray 0-255にスケーリングされた画像. """ img_ = (img - img.min()) / (img.max() - img.min()) img_ = (img_*255).astype(np.uint8) return img_ def get_annotaion(idx): """アノテーション読み込み. Parameters ---------- idx : int 画像のインデックス. train : bool, default True trainのときはTrue. Returns ------- annotation : dict 正解アノテーション. """ with open( INPUT_PATH / 'train_annotations' / f'train_{idx:02d}.json', 'r') as fp: annotation = json.load(fp) return annotation def create_mask2(mask, annotaion): """ 線のアノテーション """ for cols, rows in np.array(annotaion['coastline_points']): mask[rows, cols] = 1 mask_img = mask.astype(np.int) return mask_imgclass CoastlineDataset(Dataset): def __init__(self, df, is_train=True, force=False): self.df = df self.transforms = get_transforms(is_train=is_train) self.is_train = is_train self.force = force def __len__(self): return len(self.df) def __getitem__(self, idx): file = str(self.df.loc[idx]['data']) img = cv2.imread(file) if img is None: raise ValueError("File path is incorrect.") img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) mask = np.zeros(img.shape[0:2]) if self.is_train or self.force: file = str(self.df.loc[idx]['annotation']) with open(file, 'r') as fp: annotation = json.load(fp) mask = create_mask2(mask, annotation) if self.transforms: augmented = self.transforms(image=img, mask=mask) img = augmented['image'] mask = augmented['mask'] return img, mask## データの一覧を作成 def get_resolution(filepath): img = cv2.imread(filepath) # 画像ファイルの読み込みに失敗したらエラー終了 if img is None: print("Failed to load image file.") sys.exit(1) # カラーとグレースケールで場合分け if len(img.shape) == 3: height, width, channels = img.shape[:3] else: height, width = img.shape[:2] channels = 1 return width, height, channels def get_train(): train_files = sorted(list((INPUT_PATH / 'train_images').iterdir())) train_annotations = sorted(list((INPUT_PATH / 'train_annotations').iterdir())) df_train = pd.DataFrame({'data': train_files, 'annotation': train_annotations}) height_list, width_list = [], [] for f in train_files: width, height, channels = get_resolution(str(f)) height_list.append(height) width_list.append(width) df_train['height'] = height_list df_train['width'] = width_list return df_train def get_test(): test_files = sorted(list((INPUT_PATH / 'test_images').iterdir())) df_test = pd.DataFrame({'data': test_files}) height_list, width_list = [], [] for f in test_files: width, height, channels = get_resolution(str(f)) height_list.append(height) width_list.append(width) df_test['height'] = height_list df_test['width'] = width_list return df_testdef get_model(): return smp.Unet('resnet50', encoder_weights='imagenet', activation='sigmoid') def get_data_loader(df_train, df_test, batch_size): train_dataset = CoastlineDataset(df_train) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True) valid_dataset = CoastlineDataset(df_train[16:].reset_index(drop=True)) valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True) return train_loader, valid_loader def get_optimizer(net, epochs): optimizer = optim.Adam(net.parameters(), lr=0.0005, betas=(0.9, 0.999)) # scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[int(epochs/2), int(epochs/4*3)], gamma=0.1) return optimizer, None #schedulerdef get_transforms(is_train=True): list_transforms = [] if is_train: list_transforms.extend([ A.RandomResizedCrop(448, 448, scale=(0.4, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=1, always_apply=False, p=1.0), # A.Rotate(limit=90, interpolation=1, border_mode=4, value=None, mask_value=None, always_apply=False, p=1.0), A.Flip(p=0.5), A.RandomBrightnessContrast(brightness_limit=(-0.2, 0.4), contrast_limit=0.2, brightness_by_max=True, always_apply=False, p=1.0), ]) else: list_transforms.extend([ A.Resize(448, 448, interpolation=1, always_apply=False, p=1.0) ]) list_transforms.extend([ # A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], p=1), A.pytorch.ToTensor(), ]) list_trfms = A.Compose(list_transforms) return list_trfms class DfFactory(): df_train = None df_test = None @classmethod def create(cls, force=False): if force or cls.df_train is None: cls.df_train = get_train() cls.df_test = get_test() return cls.df_train, cls.df_test# Set experiment id exp_id = str(uuid.uuid4())[:8] print(f'Experiment Id: {exp_id}', flush=True) # Config gpu use_cuda = torch.cuda.is_available() device = torch.device("cuda" if use_cuda else "cpu") # Prepare data factory = DfFactory() df_train, df_test = factory.create() train_loader, valid_loader = get_data_loader(df_train, df_test, c.train_batch_size) loaders = {"train": train_loader, "valid": train_loader} model = get_model().to(device) optimizer, _ = get_optimizer(model, c.epochs) # criterion = nn.BCEWithLogitsLoss() criterion = WeightedBCEWithLogitsLoss(weights=torch.Tensor([1, 1000])) runner = SupervisedRunner(device=device)runner.train( model=model, criterion=criterion, optimizer=optimizer, # scheduler=scheduler, loaders=loaders, # model will be saved to {logdir}/checkpoints logdir=os.path.join(c.log_dir, exp_id), callbacks=[ CheckpointCallback(save_n_best=c.n_saved), # EarlyStoppingCallback( # patience=c.es_patience, # metric="loss", # minimize=True, # ) ], num_epochs=c.epochs, main_metric="loss", minimize_metric=True, fp16=None, verbose=True )class Predictor(): def __init__(self, model, threshold, device): self.model = model self.threshold = threshold self.device = device def predict(self, img): self.model.eval() self.model.to(self.device) img = img.to(self.device) with torch.no_grad(): y = self.model(img[None, ...]).cpu().detach().numpy() y = y.reshape(448, 448) y = ((y > self.threshold)*255).astype('uint8') return ydef select_max_area(mask): contours = cv2.findContours( mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0] # 一番面積が大きい輪郭を選択する。 max_cnt = max(contours, key=lambda x: cv2.contourArea(x)) # 黒い画像に一番大きい輪郭だけ塗りつぶして描画する。 out = np.zeros_like(mask) out = cv2.drawContours(out, [max_cnt], -1, color=255, thickness=-1) out = cv2.drawContours(out, [max_cnt], -1, color=255, thickness=1) return outdef predict_1file(df, ds, predictor, idx, debug=False): img, _ = ds[idx] y = predictor.predict(img) # デバッグ if debug: plt.imshow(y, 'gray') # 細線化 y = ZhangSuen(y).astype('uint8')*255 # 元の画像の大きさにリサイズする row = df.iloc[idx] h = row['height'] w = row['width'] y = cv2.resize(y, (w, h), interpolation=cv2.INTER_NEAREST) # 細線化 y = ZhangSuen(y).astype('uint8')*255 # 図示チェック if debug: plt.figure(figsize=(15, 15)) plt.imshow(255-y, 'gray') # 線の点数が30000を超えるとエラー num_point = (y==255).sum() print(idx, ":", num_point) assert num_point < 30_000 ih, iw = np.where(y==255) return list(zip(iw.tolist(), ih.tolist()))predictor = Predictor(model, 0.5, device) ds = CoastlineDataset(df_test, is_train=False) dict_sub = {} for idx in range(30): dict_sub[f'test_{idx:02d}.tif'] = predict_1file(df_test, ds, predictor, idx) with open('submission.json', 'w') as file: file.write(json.dumps(dict_sub))おわりに
以上がThe 4th Tellus Satellite Challenge:海岸線の抽出」で試した手法でした。他の方がやっていたような高解像度でクロップして予測、結合といった手法は上手いなと思いました。海と陸を含むようにどのように画像を取り出すかが鍵だったように思えます。また、解像度が高いと逆に、海と陸の境界がよくわからないように思えたのですが、ディープラーニングだと上手く拾えたということでしょうか。このあたりは上位の方の話を聞いてみたいです。







- 投稿日:2021-02-25T07:46:23+09:00
OpenCVをAWS Lambda + Python + Serverless Frameworkで動かす
OpenCVをAWS Lambda + Python + Serverless Frameworkで動かしてみました。
先日、PillowをLambdaで動かす記事を書きましたが、このときと違って、OpenCVはyumでインストールの必要なshared objectに依存しているのでだいぶ面倒でした。
手順概要
- serverless-python-requirements インストール
- Pythonサンプルコードを記述
- requirements.txt と serverless.yml と Dockerfile にOpenCV動作に必要な事項を記述
- あとはデプロイ
OpenCV特有は3のみです。
手順詳細
serverless-python-requirements インストール
AWS Lambda + Python + Serverless FrameworkにPythonのパッケージをインストールする方法は以前の記事に書きました。
これに従って、まずは
serverless createして、serverless-python-requirementsプラグインをインストールします。$ serverless create --template aws-python3 $ serverless plugin install -n serverless-python-requirementsServerlessFrameworkのバージョンはv2.18.0でした。
Pythonソースコード
handler.pyの内容です。OpenCVを参照できることを確認できる最小限です。import cv2 def hello(event, context): print("Hellow, OpenCV!") print(cv2.__version__)requirements.txt
OpenCVのパッケージ名を記述します。この1行のみです。
opencv-pythonserverless.yml
serverless.ymlの記載がもっとも面倒でした。成功例を書きます。service: sample frameworkVersion: '2' provider: name: aws runtime: python3.8 lambdaHashingVersion: 20201221 region: ap-northeast-1 functions: hello: handler: handler.hello events: - httpApi: "*" plugins: - serverless-python-requirements custom: pythonRequirements: dockerizePip: true dockerFile: Dockerfile dockerExtraFiles: - /usr/lib64/libGL.so.1 - /usr/lib64/libgthread-2.0.so.0 - /usr/lib64/libglib-2.0.so.0 - /usr/lib64/libGLX.so.0 - /usr/lib64/libX11.so.6 - /usr/lib64/libXext.so.6 - /usr/lib64/libGLdispatch.so.0 - /usr/lib64/libxcb.so.1 - /usr/lib64/libXau.so.6Dockerfile
Dockerfileを作成します。serverless.ymlからファイル名で参照しています。FROM lambci/lambda:build-python3.8 RUN yum install -y mesa-libGLデプロイと実行
デプロイ。
$ serverless deploy -vデプロイされたLambdaを実行するとCloudWatch Logsに以下が出力されました。
Hellow, OpenCV! 4.5.1serverless.yml を書くまでの道のり
最初は以下だけで動かそうとしました。
service: sample frameworkVersion: '2' provider: name: aws runtime: python3.8 lambdaHashingVersion: 20201221 region: ap-northeast-1 functions: hello: handler: handler.hello plugins: - serverless-python-requirementsこれでデプロイしてLambdaを実行すると、CloudWatch Logsに以下のエラーが吐かれました。
[ERROR] Runtime.ImportModuleError: Unable to import module 'handler': libGL.so.1: cannot open shared object file: No such file or directory
libGL.so.1というファイルが不足しているので、これを追加すればよいのですが、これは環境に依存していそうなので、手元にある同じファイル名をコピーしただけではたぶん動きません。Lambdaの動くAmazon Linux環境でこのファイルを用意する必要があります。これをするために
serverless.ymlにdockerの記述をします。以下の記述です。custom: pythonRequirements: dockerizePip: true dockerFile: Dockerfile dockerExtraFiles: - ...
Dockerfileも用意します。FROM lambci/lambda:build-python3.8 RUN yum install -y mesa-libGL # OpenCVに必要なパッケージをインストールこれを書くだけでserverlessがデプロイ時にDockerを起動して、Lambdaの動くAmazon Linux環境を再現し、その中でyumインストールしてくれます。
serverless.ymlのdockerExtraFilesに記載したファイルを、yumインストール後に抜き出して、Lambdaデプロイイメージに同梱してくれます。
dockerExtraFilesに書いたリストは、デプロイして実行時のエラーメッセージから1つずつ書き足して、成功するまで繰り返しました。エラーメッセージにはsoファイル名しか表示されませんので、以下のコマンドでLambdaの動くAmazon Linux環境の中に入ってみて、
yum install -y mesa-libGLしてから、soファイルのありかを探しました。$ docker run -it --rm lambci/lambda:build-python3.8 bashAmazon Linux上では
/usr/lib64/libGL.so.1は/usr/lib64/libGL.so.1.7.0へというように、すべてシンボリックリンクになっていますが、serverless.ymlには実態ではなくシンボリックリンクだけ記述すれば動きました。注意事項
ここに書いているsoファイルのリストはサンプルPythonコードを動かすために最小限のものです。エラーメッセージを見て、足りないsoファイルを追加するというのを繰り返しましたのみです。従ってOpenCVのすべての動作がこれだけで足りてるかどうかはわかりません。
ハマりどころ1
.serverless/requirements/の中にLambdaのイメージが展開されるのですが、Dockerで構築されるためか、soファイルがroot権限になり、試行錯誤の過程で serverless.yml の変更が権限不足で反映できないというトラブルがありました。原因がわかればroot権限でそのディレクトリを削除することで解決しましたが、それに気が付くまで時間をだいぶ消耗しました。ハマりどころ2
serverlessが内部でDockerを利用するため、serverless自体をDockerの中で動かしたらデプロイ時にDockerでエラーになりました。Dockerのvolumeも使っていたので、Dockerのsocket共有でもうまくいかず、あきらめました。
ハマりどころ3
最初はLambdaのLayerにOpenCVを入れたかったのですが、
LD_LIBRARY_PATHがLayerには通っていないため、OpenCVを動作させることはできませんでした。
- 投稿日:2021-02-25T06:28:41+09:00
VOSK test_simple.py on GoogleColaboratory [002]
previous article is ' VOSK test_simple.py on GoogleColaboratory [001] '
The Google Colab files for the articles on this page are at the bottom of this article.1
Install VOSK on GoogleColaboratory
GoogleColab!pip install vosk !git clone https://github.com/alphacep/vosk-apiDownload Language Model
- case a: English Language Model ... see previous "VOSK test_simple.py on GoogleColaboratory [001]"
- case b: Chinese Language Model
Download via https://alphacephei.com/vosk/models
a:English ASR testing
GoogleColab%cd vosk-api/python/example #English lang model !wget https://alphacephei.com/kaldi/models/vosk-model-small-en-us-0.15.zip !unzip vosk-model-small-en-us-0.15.zip %mv vosk-model-small-en-us-0.15 modelb:Chinese ASR testing
GoogleColab%cd vosk-api/python/example #Chinese lang model !wget https://alphacephei.com/vosk/models/vosk-model-small-cn-0.3.zip !unzip vosk-model-small-cn-0.3.zip %mv vosk-model-small-cn-0.3 model !rm -rf vosk-model-small-cn-0.3.zipModel structure
Once you trained the model arrange the files according to the following layout (see en-us-aspire for details):
- am/final.mdl - acoustic model
- conf/mfcc.conf - mfcc config file. Make sure you take mfcc_hires.conf version if you are using hires model (most external ones)
- conf/model.conf - provide default decoding beams and silence phones. you have to create this file yourself, it is not present in kaldi model
- ivector/final.dubm - take ivector files from ivector extractor (optional folder if the model is trained with ivectors)
- ivector/final.ie
- ivector/final.mat
- ivector/splice.conf
- ivector/global_cmvn.stats
- ivector/online_cmvn.conf
- graph/phones/word_boundary.int - from the graph
- graph/HCLG.fst - this is the decoding graph, if you are not using lookahead
- graph/HCLr.fst - use Gr.fst and HCLr.fst instead of one big HCLG.fst if you want to run rescoring graph/Gr.fst
- graph/phones.txt - from the graph
- graph/words.txt - from the graph
- rescore/G.carpa - carpa rescoring is optional but helpful in big models. Usually located inside data/lang_test_rescore
- rescore/G.fst - also optional if you want to use rescoring
directory check
GoogleColab!pwdTest Audio sampling
case b: YouTube
GoogleColaburltext ='https://youtu.be/cNSq5RdVf28' # Chinese YouTube Clip with no captionsGoogleColabfrom urllib.parse import urlparse, parse_qs args = [urltext] video_id = '' def extract_video_id(url): query = urlparse(url) if query.hostname == 'youtu.be': return query.path[1:] if query.hostname in {'www.youtube.com', 'youtube.com'}: if query.path == '/watch': return parse_qs(query.query)['v'][0] if query.path[:7] == '/embed/': return query.path.split('/')[2] if query.path[:3] == '/v/': return query.path.split('/')[2] # fail? return None for url in args: video_id = (extract_video_id(url)) print('youtube video_id:',video_id) from IPython.display import YouTubeVideo YouTubeVideo(video_id)GoogleColab!rm -rf e*.wav !pip install -q youtube-dl !youtube-dl --extract-audio --audio-format wav --output "extract.%(ext)s" {urltext}GoogleColab!apt install ffmpeg !ffmpeg -i extract.wav -vn -acodec pcm_s16le -ac 1 -ar 16000 -f wav test1.wavASR test_simple.py ...
Speech to text
GoogleColab#!/usr/bin/env python3 from vosk import Model, KaldiRecognizer, SetLogLevel import sys import os import wave path = '/content/vosk-api/python/example/' SetLogLevel(0) if not os.path.exists("model"): print ("Please download the model from https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.") exit (1) #wf = wave.open(path+'/test.wav',"rb")# a:English test sample wf = wave.open(path+'/test1.wav',"rb")# b:Chinese lang test sample if wf.getnchannels() != 1 or wf.getsampwidth() != 2 or wf.getcomptype() != "NONE": print ("Audio file must be WAV format mono PCM.") exit (1) model = Model("model") rec = KaldiRecognizer(model, wf.getframerate()) while True: data = wf.readframes(4000) if len(data) == 0: break if rec.AcceptWaveform(data): print(rec.Result()) else: print(rec.PartialResult()) print(rec.FinalResult())GoogleColabfrom IPython.display import Audio #Audio(path+'/test.wav') # a:English Audio(path+'/test1.wav') # b:ChineseOriginal 'test_simple.py'
GoogleColab%%bash cat -n /content/vosk-api/python/example/test_simple.pytest_ffmpeg.py
GoogleColab%%bash cat -n /content/vosk-api/python/example/test_ffmpeg.pycheck:
YouTube, Deepspeech, with Google Colaboratory [testing_0003]YoavRamon/awesome-kaldi
https://github.com/YoavRamon/awesome-kaldi
test googlecolab ↩

- 投稿日:2021-02-25T03:00:48+09:00
keyとvalueについて-media_url取得までの流れ
型について
#terminal上で取得している {'data': [{'id': '1234567890', 'media_type': 'IMAGE', 'media_url':'https://test.com/', 'timestamp': '2021********', 'username': 'qiita'}], 'paging': {'cursors': {'before': 'abcd', 'after': 'abcd'}}}このdataは辞書型{}とリスト型[]が存在している。
今回は仮定として変数を profile_data ということにする。最初に'data'を取得してみる
>>>profile_data['data'] [{'id': '1234567890', 'media_type': 'IMAGE', 'media_url':'https://test.com/', 'timestamp': '2021********', 'username': 'qiita'}]commandでprofile_data['data']と入力すると元の情報からdataの部分だけが抽出される。
先頭の辞書型がなくなり、[{}]の型に変化した次に何個目の情報を取得するのかを指定する
>>>profile_data['data'][0] {'id': '1234567890', 'media_type': 'IMAGE', 'media_url':'https://test.com/', 'timestamp': '2021********', 'username': 'qiita'}comandに[0]を追加することにより、何個目の情報を取得するのかを指定できる。今回は1つしかないため[0]を使用した。
最後にmedia_urlを取得する
>>>profile_data['data'][0]['media_url'] 'https://test-qiita.com/''media_url'を追加し取得する。今回は'media_url'だったが、'id'、'media_type'でも同様のことが可能である。